Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
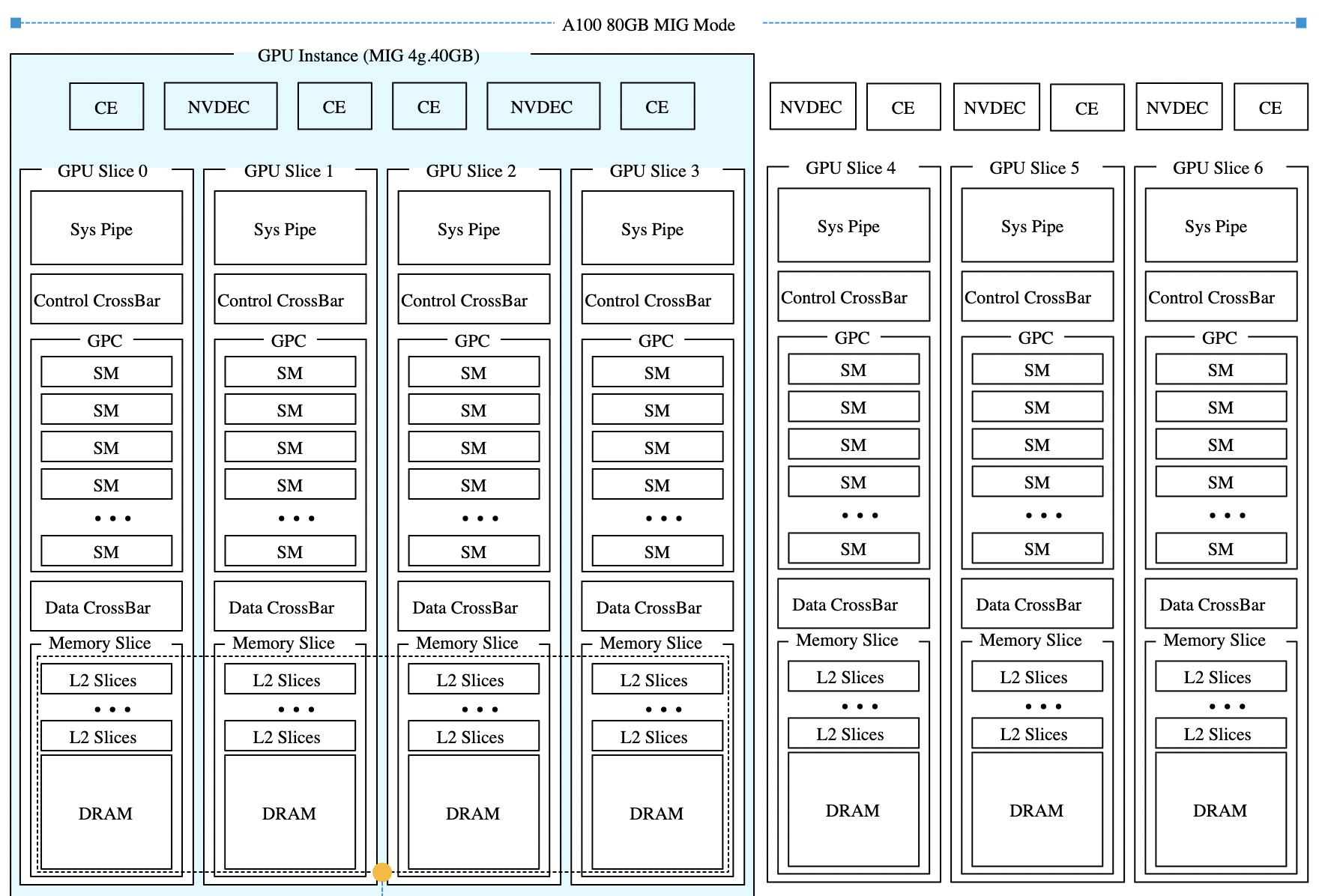
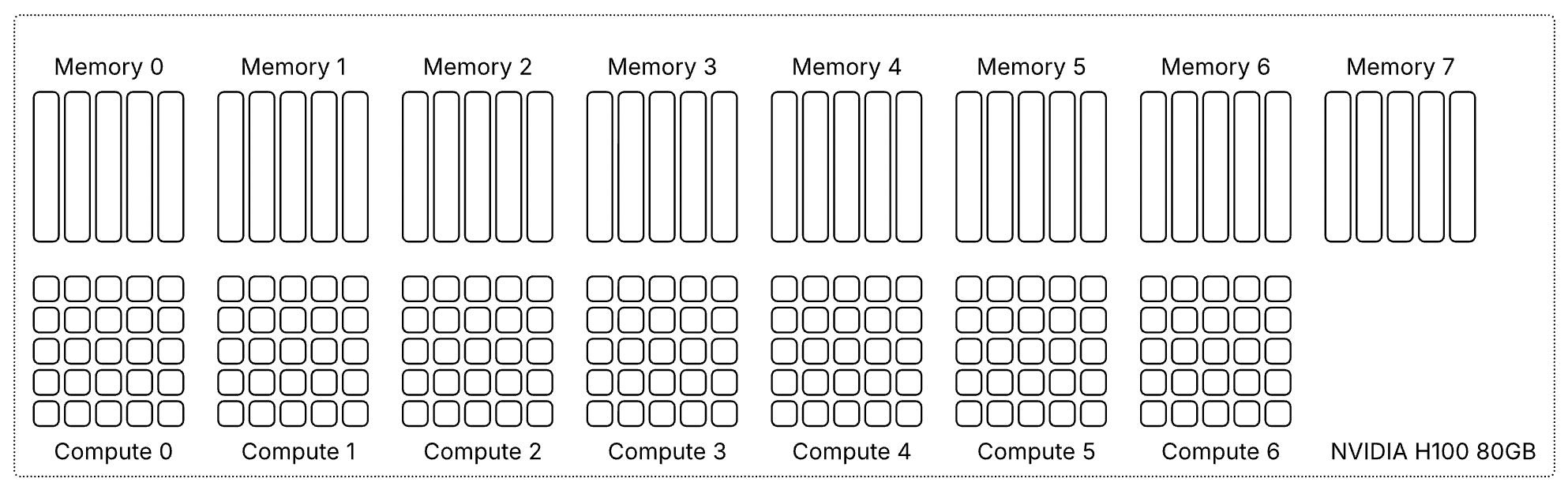
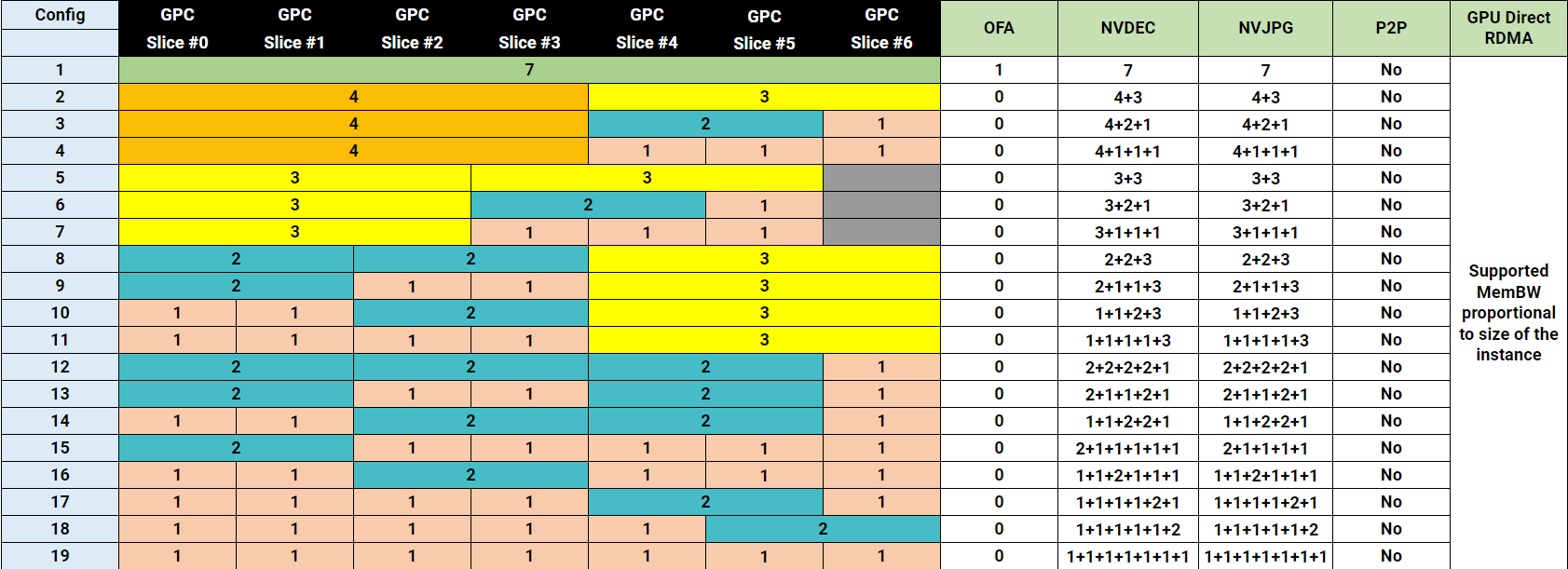
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
Profile
Compute slices
Memory slices
Memory
1g.10gb
1
1
10 GB
1g.20gb
1
2
20 GB
2g.20gb
2
2
20 GB
3g.40gb
3
4
40 GB
4g.40gb
4
4
40 GB
7g.80gb
7
8
80 GB
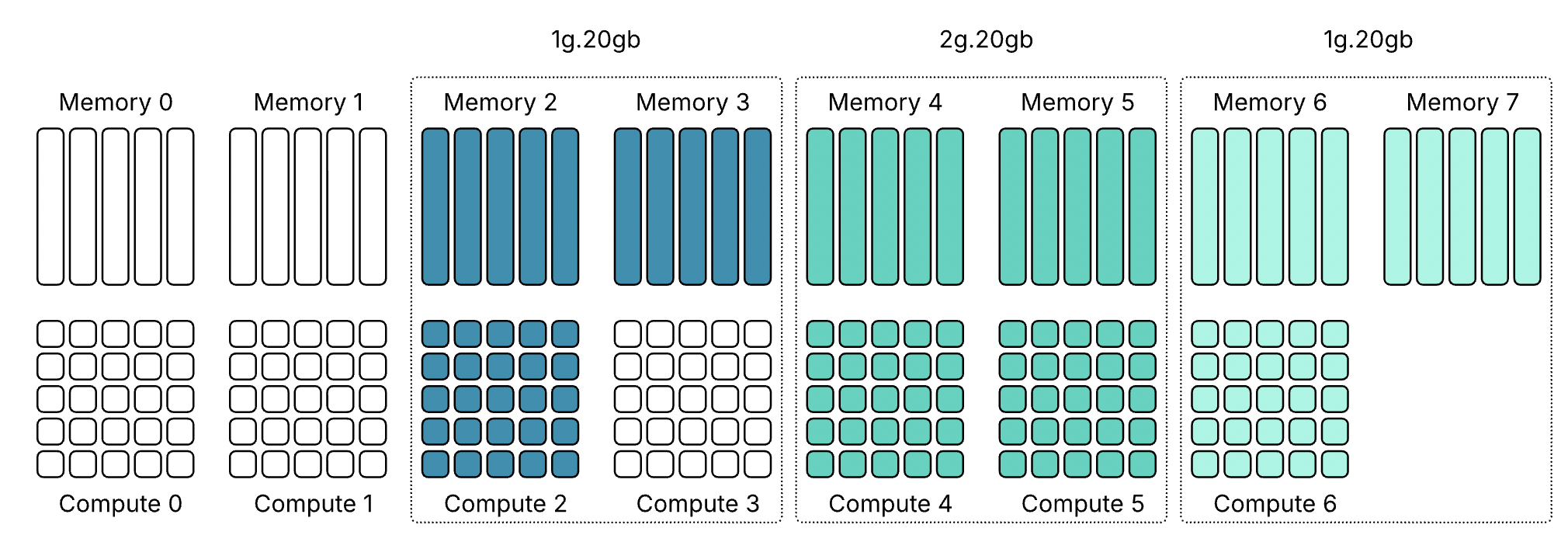
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
Потерянная ёмкость
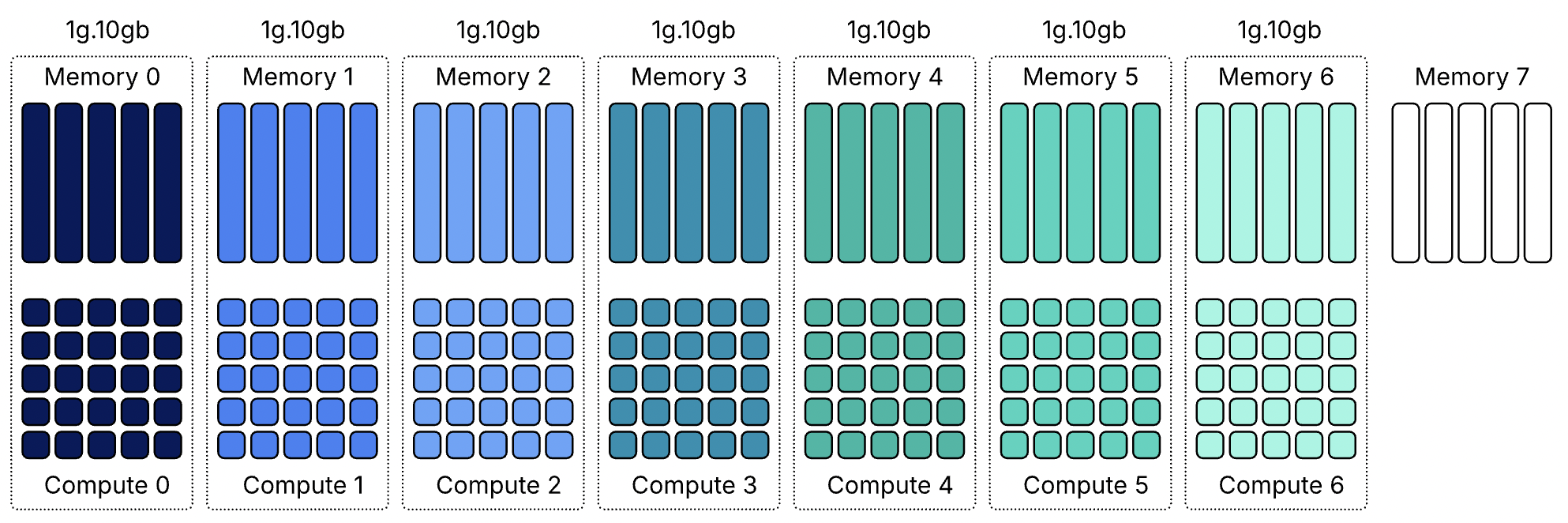
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
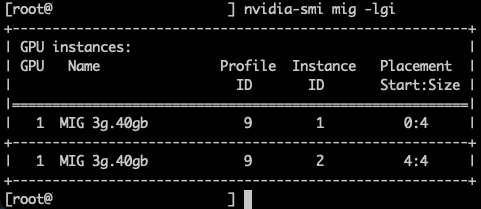
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
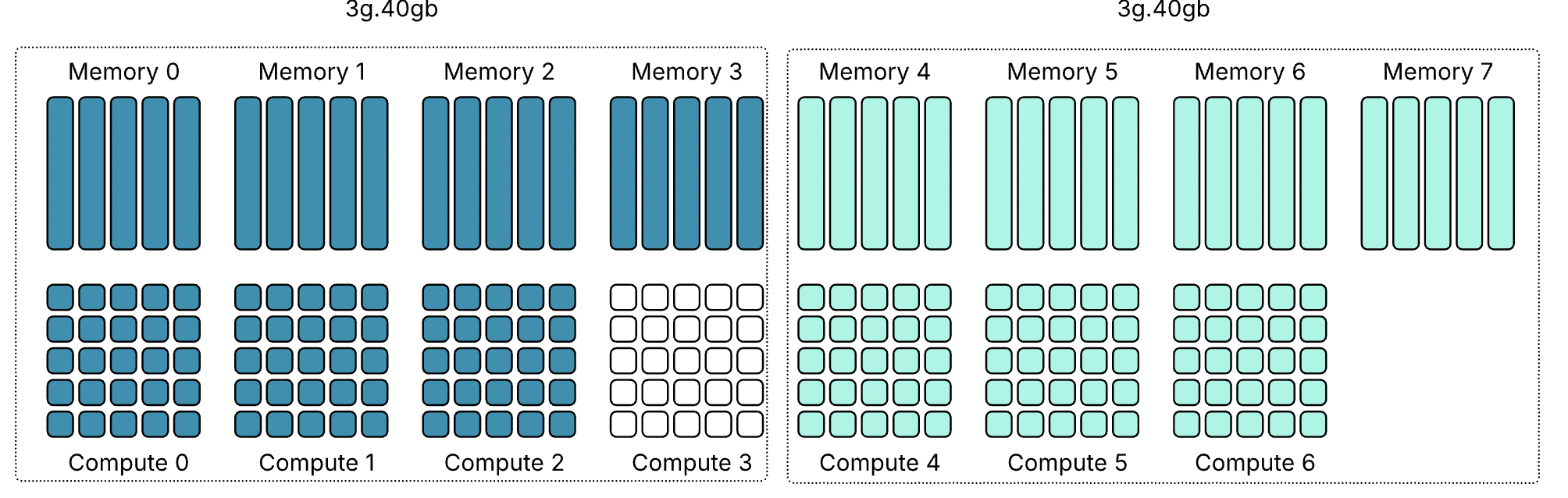
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
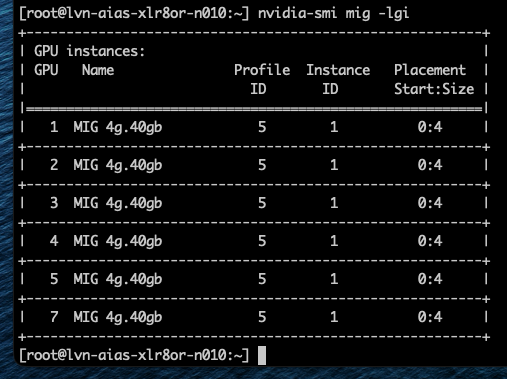
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
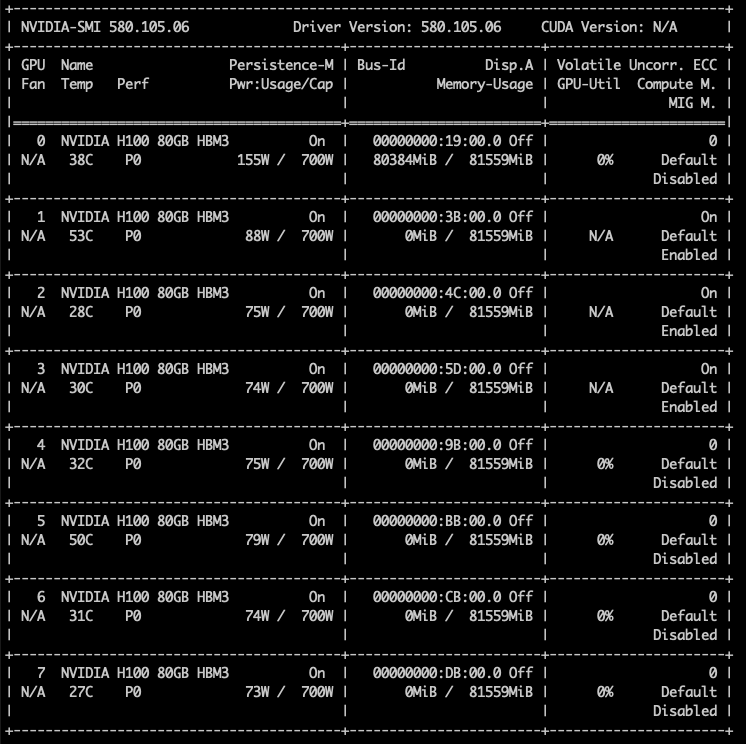
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
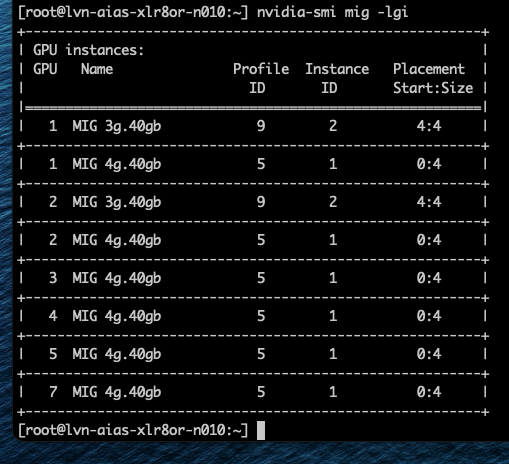
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
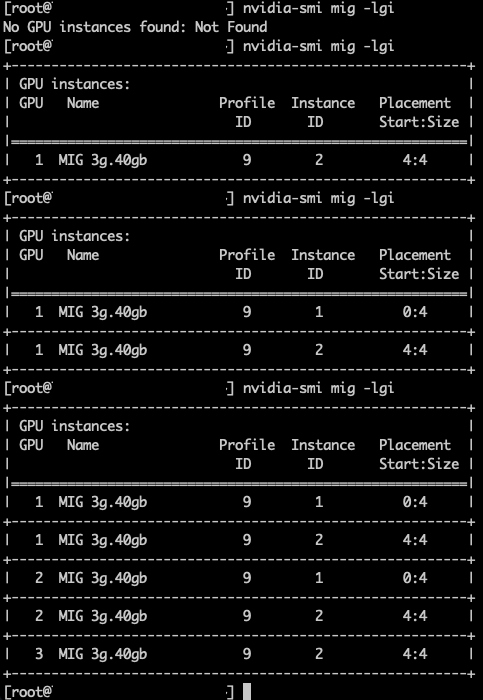
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.

 RSS
RSS