VMware vSAN предоставляет ряд технологий для эффективного использования дискового пространства, что повышает ценность инфраструктуры хранения и снижает затраты. Рассматриваемые ниже возможности актуальны для среды VMware Cloud Foundation 9.0 (на базе vSAN 9.0) и охватывают как классическую архитектуру хранения (Original Storage Architecture, OSA), присутствующую во всех версиях vSAN, так и новую Express Storage Architecture (ESA), впервые представленную в vSAN 8.0.
Технологии экономии места условно делятся на оппортунистические и детерминированные. Оппортунистические методы (например, дедупликация, сжатие, тонкое выделение емкости, TRIM/UNMAP) зависят от характера данных и могут дать разную степень экономии, не гарантируя фиксированный результат. Детерминированные методы основываются на схемах размещения данных с заданной избыточностью (например, RAID 5/6) и обеспечивают предсказуемый уровень экономии емкости. В кластере vSAN можно сочетать оба метода одновременно, добиваясь баланса между экономией пространства и производительностью. Ниже подробно рассмотрены ключевые механизмы экономии места – дедупликация, сжатие, кодирование erasure coding (RAID 5/6), – а также особенности новой архитектуры vSAN ESA, включая преимущества, требования и сценарии использования.
Дедупликация позволяет устранять дублированные блоки данных, храня их единожды и ссылаясь на них через специальные хеш-таблицы, вместо того чтобы записывать каждый дубль отдельно. Это оппортунистическая технология: степень экономии от дедупликации зависит от того, насколько часто в данных встречаются повторяющиеся блоки. В среде vSAN дедупликация тесно связана со сжатием и реализована по-разному в традиционной архитектуре OSA и в новой ESA.
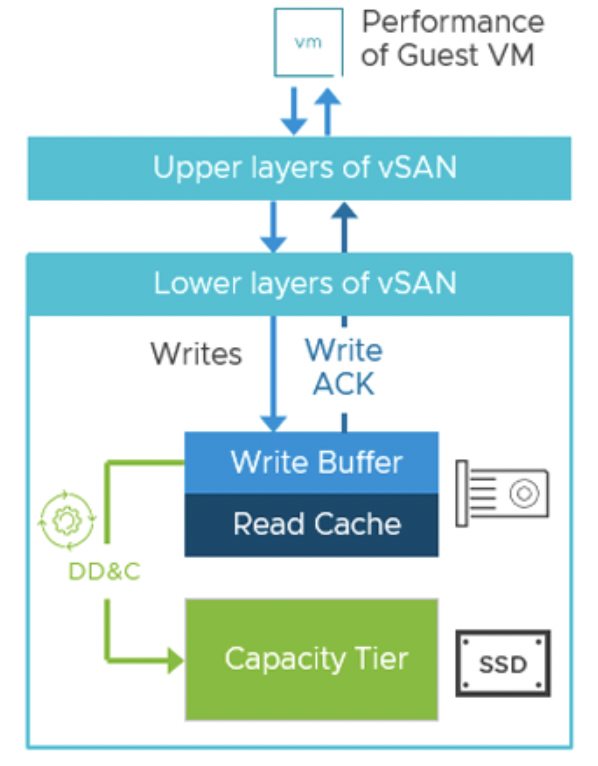
В классической архитектуре vSAN (OSA) дедупликация включается на уровне всего кластера одновременно со сжатием данных – как единая функция "Deduplication & Compression". Требуется, чтобы кластер был all-flash (то есть все носители – твердотельные), так как дедупликация/сжатие поддерживаются только на полностью флеш-конфигурациях (это связано с требованиями к производительности и формату хранилища). При включенной дедупликации и сжатии vSAN применяет эти процессы во время выгрузки данных из кэша на емкостной уровень (capacity tier), уже после подтверждения записи виртуальной машине. Такой отложенный (post-processing) подход минимизирует влияние на задержку записи – гостевая ВМ получает подтверждение быстро, а обработка данных (поиск дубликатов, сжатие) выполняется позже, в фоновом режиме при сбросе данных на SSD-хранилище. На практике это означает, что vSAN сначала записывает данные в кэш-память и подтверждает запись, и лишь затем, при очередном destage, выполняет дедупликацию и сжатие.
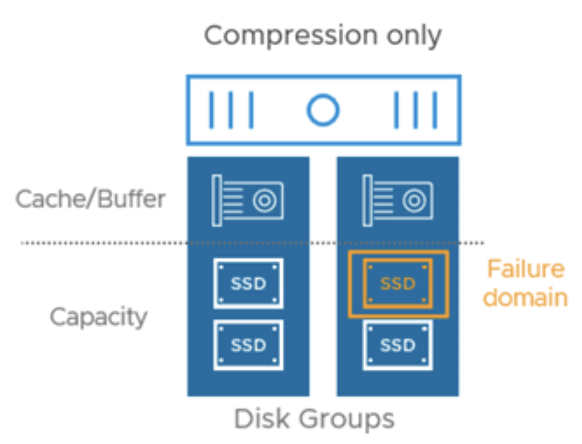
Дедупликация в OSA действует в пределах каждой дисковой группы (disk group) хоста – это и есть "домен дедупликации" в vSAN OSA. Повторяющиеся 4 KB блоки данных обнаруживаются внутри одной дисковой группы и заменяются одним экземпляром с соответствующими указателями (ссылками) вместо дублей. Если одинаковые блоки хранятся на разных хостах (в разных дисковых группах), OSA-дедупликация их не увидит – они будут устранены только в пределах каждого хоста отдельно. Это ограничивает общий эффект экономии, поскольку дубликаты на разных узлах не объединяются. Например, в среде VDI, где много виртуальных машин с идентичными ОС, дубли могут присутствовать на всех узлах кластера; OSA сможет устранить копии только на уровне каждого хоста, поэтому фактически один и тот же блок может храниться по одному разу на каждом хосте, участвующем в хранении этих ВМ.
Алгоритм работы OSA при включенной дедупликации и сжатии можно описать так: когда накопилось достаточно данных для сброса из кэша, vSAN обрабатывает каждый блок (стандартный размер блока – 4 KB). Сначала выполняется вычисление криптографического хэша блока и поиск такого хэша среди уже сохраненных в текущей дисковой группе. Если совпадение найдено (т.е. этот блок уже был ранее сохранен), вместо записи дубликата vSAN помещает в метаданные указатель на существующий блок и освобождает место, которое занял бы дубль. Таким образом, один уникальный экземпляр данных может представлять множество совпадающих блоков от разных ВМ. Если же хэш не найден (блок уникален), данные записываются на диск, а новый хэш добавляется в таблицу для будущих сравнений. После дедупликации (по завершении прохода по блоку или группе блоков) запускается процедура сжатия.
Важно отметить, что OSA применяет условное сжатие: каждый блок 4 KB сжимается, только если сжатие дает выигрыш не менее 50% по размеру. То есть, если алгоритм способен ужать блок хотя бы до 2 KB и меньше, vSAN сохранит сжатую версию; если же после сжатия блок всё равно больше 2 KB (например, 3 KB), то система сохранит его как есть (несжатым). Такой порог введен, чтобы избежать накладных расходов на сжатие там, где экономия пространства незначительна. В результате слабо сжимаемые данные (например, уже сжатые видео или изображения) будут просто записаны без сжатия – это повышает эффективность работы.
Требования и ресурсы
Включение дедупликации и сжатия в OSA предъявляет повышенные требования к ресурсам хоста – в частности, к объему памяти и вычислительным мощностям для обслуживания хэш-таблиц и выполнения компрессии. Каждый дисковой группе для хранения метаданных дедупликации выделяется область в памяти (вплоть до нескольких ГБ на каждую группу в зависимости от емкости), а сами процессы хеширования и сжатия нагружают CPU. Кроме того, при выходе из строя диска в дисковой группе vSAN должен восстанавливать не отдельный объект, а всю группу (т.к. она единица отказа), что при включенной дедупликации означает реконструкцию большого объема данных и хэш-метаданных, что может занять больше времени. По этим причинам использовать дедупликацию/сжатие следует при наличии достаточных ресурсов и на рабочих нагрузках, где выгода от экономии пространства перевешивает возможное влияние на производительность.
Ограничения
Поскольку дедупликация работает с неизмененными (постоянными) данными, наибольший эффект она дает для относительно статичных данных или в сценариях, где много идентичных блоков (например, клоны ОС, шаблоны, базы данных с повторяющимися паттернами). В противоположность этому, для полностью уникальных или часто меняющихся данных (например, зашифрованные данные, случайные наборы) дедупликация не принесет пользы, а будет только расходовать ресурсы. Следует отметить, что использование сквозного шифрования vSAN (Encryption at rest) фактически нейтрализует эффективность дедупликации: зашифрованные блоки выглядят как случайные и не будут совпадать по хэшу. В vSAN OSA формально можно включить дедупликацию вместе с шифрованием, но дедупликационный коэффициент при этом будет близок к нулю. В новой реализации ESA на момент выпуска глобальная дедупликация вообще несовместима с шифрованием – об этом будет сказано ниже.
С точки зрения отказоустойчивости, дедупликация и сжатие не влияют на уровень отказоустойчивости (FTT), заданный политикой – vSAN по-прежнему хранит нужное количество копий или фрагментов данных. Но администратору стоит учитывать, что сочетание дедупликации с определёнными топологиями (например, с растянутым кластером, где данные дублируются между площадками) может быть неоптимальным: в таких случаях дедупликация выполняется отдельно в каждом сайте, а межсайтовый трафик не сокращается.
Влияние на производительность
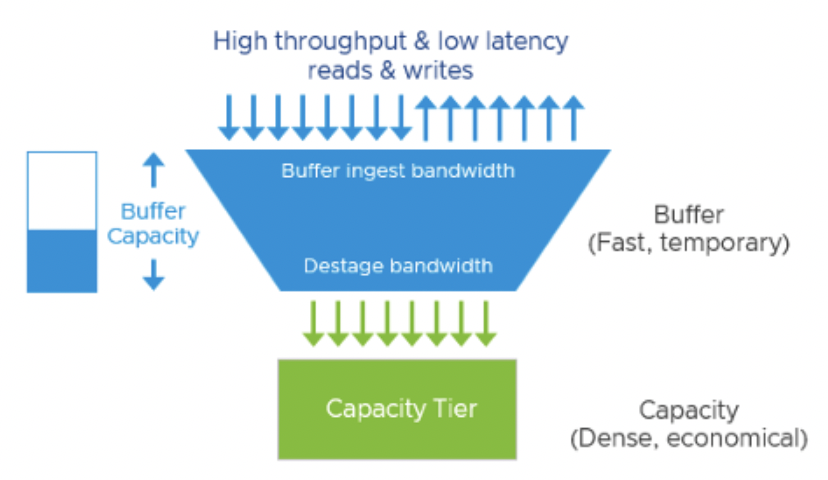
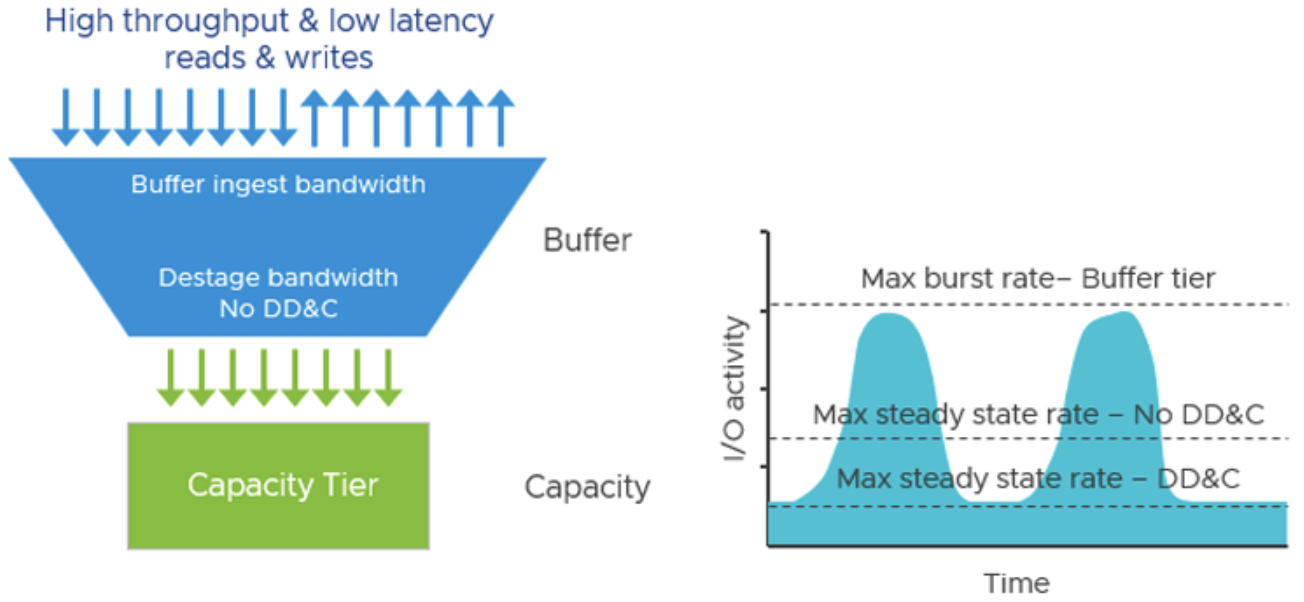
Реализация дедупликации/сжатия после подтверждения записи (asynchronous destaging) в OSA специально выбрана, чтобы минимизировать влияние на обычные операции ввода-вывода. Тем не менее, полностью исключить влияние невозможно: при интенсивной нагрузке на запись включенная дедупликация и сжатие могут снизить пропускную способность постоянного уровня хранения. Проще говоря, максимум устойчивой производительности (steady-state throughput) у кластера с дедупликацией будет ниже, чем у аналогичного без дедупликации.
Это проявляется в том, что:
Буфер записи заполнится быстрее (поскольку емкостной уровень сбрасывает данные медленнее)
Выгрузка из буфера идет медленнее
Время отклика на запись для ВМ может увеличиваться, когда буфер переполнен и начинает ждать освобождения места.
В нормально спроектированной системе с запасом ресурсов этот эффект может быть незначительным, но в нагруженной среде нужно быть готовым к некоторому снижению производительности при активной дедупликации. Практически, VMware рекомендует трезво оценивать нагрузки: если приложение чрезвычайно чувствительно к задержкам и выполняет массу мелких случайных операций записи (например, высоконагруженная OLTP база данных), возможно, стоит отключить дедупликацию/сжатие для этого кластера либо использовать режим только сжатия, описанный ниже. С другой стороны, для сценариев, где преобладают повторяемые шаблоны данных (VDI, тестовые и девелоперские среды с множеством одинаковых ВМ) выгода в экономии места оправдывает незначительное падение производительности.
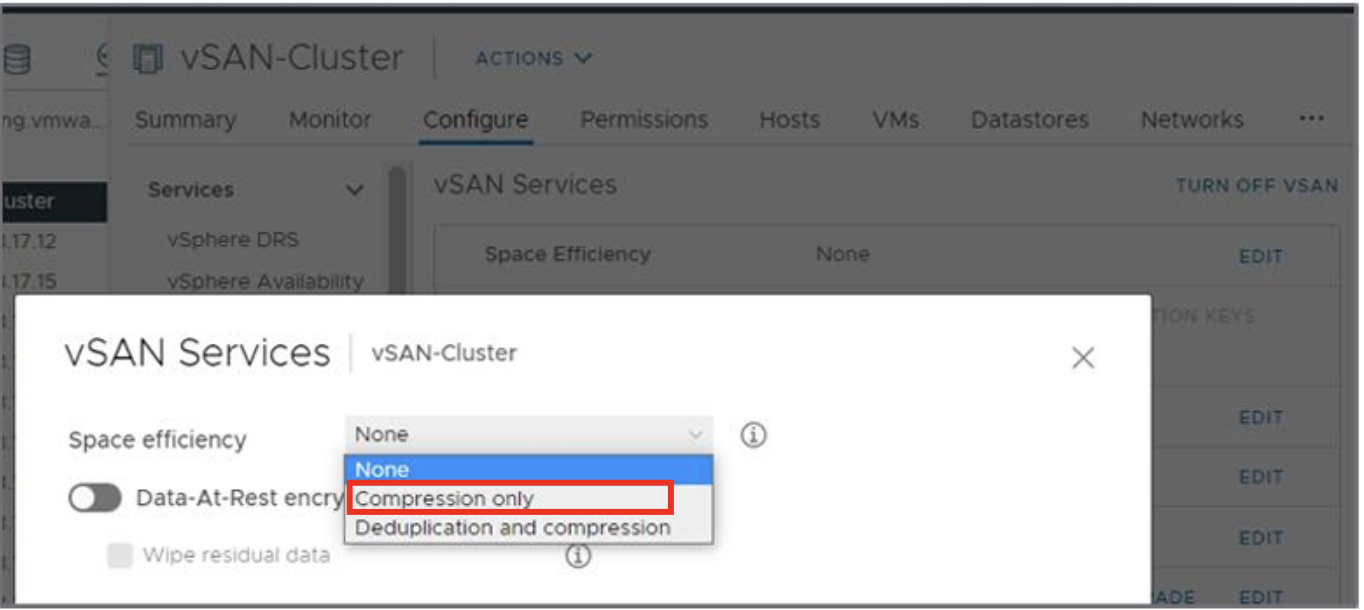
Начиная с vSAN 7 Update 1, была введена возможность включать только сжатие данных без дедупликации в традиционной архитектуре. Такой режим призван дать некоторую экономию места там, где дедупликация малоэффективна или нежелательна. Compression onlyтакже доступно только на all-flash кластерах и так же включается на уровне всего кластера (через меню Services vSAN). При его активации vSAN пропускает шаг хэширования/сравнения блоков, выполняя лишь компрессию 4 KB блоков при сбросе на емкостной уровень. В остальном механизм идентичен описанному выше: блок сжимается, если уменьшился как минимум вдвое; если нет – сохраняется в исходном размере.
Преимущество режима Compression only – снижение накладных расходов: не требуется вычислять и хранить хэши, поддерживать большие таблицы в памяти, и выполнять сравнение блоков. Это экономит CPU и RAM на каждом узле, а также ускоряет операции восстановления (ребилда) после отказа диска, поскольку данные не перемешаны дедупликацией. Сжатие само по себе существенно менее требовательно, чем дедупликация, но всё же дает ощутимую экономию для данных, которые хорошо компрессируются (текст, лог-файлы, базы, многие офисные данные). Если же данные уже в сжатом формате (медиа-файлы, архивы) или уникальны, то и компрессия не принесет выгоды, но и потребление ресурсов на этот процесс будет небольшим. Поэтому режим только сжатие часто рекомендуют, когда:
Характер данных не обещает высокой dedup-экономии (нет большого числа дублей), но сжать их можно
В кластере недостаточно ресурсов (CPU/RAM) для полной дедупликации, либо производительность системы уже на пределе
Используются приложения, которые сами выполняют дедупликацию на уровне контента (например, некоторые резервные системы) – тогда повторная дедупликация vSAN бесполезна.
В таких случаях можно ограничиться компрессией, чтобы достичь компромисса между экономией емкости и быстродействием.
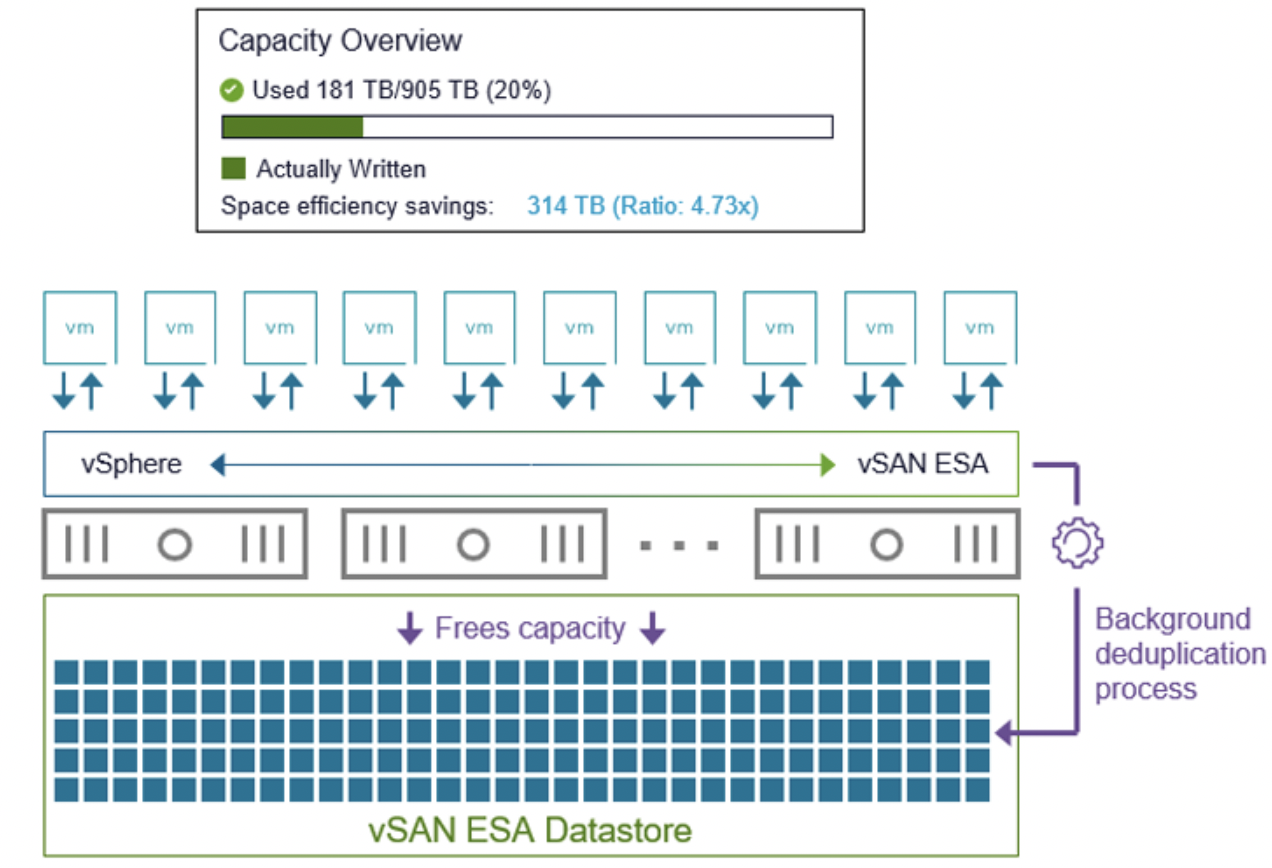
Новая экспресс-архитектура хранения (ESA) изначально (в vSAN 8.0) предлагала только сжатие данных, но не имела функции дедупликации. В релизе VMware Cloud Foundation 9.0 (vSAN 9.0) представлена глобальная дедупликация специально для ESA-кластеров. В отличие от OSA, где дедупликация ограничена дисковой группой, в ESA область дедупликации охватывает весь кластер. Это означает, что поиск и устранение дублей происходит среди всех данных кластера: если идентичные блоки находятся на разных хостах, ESA сможет объединить их в один, хранящийся единожды (с учетом отказоустойчивости). Дедупликационный домен динамически расширяется с ростом числа узлов – чем больше хостов и данных, тем выше шанс найти повторяющиеся блоки и тем значительнее потенциальная экономия. Это существенный шаг вперед по сравнению с OSA, где дедупликация была локальной и во многом ограничивала коэффициент экономии.
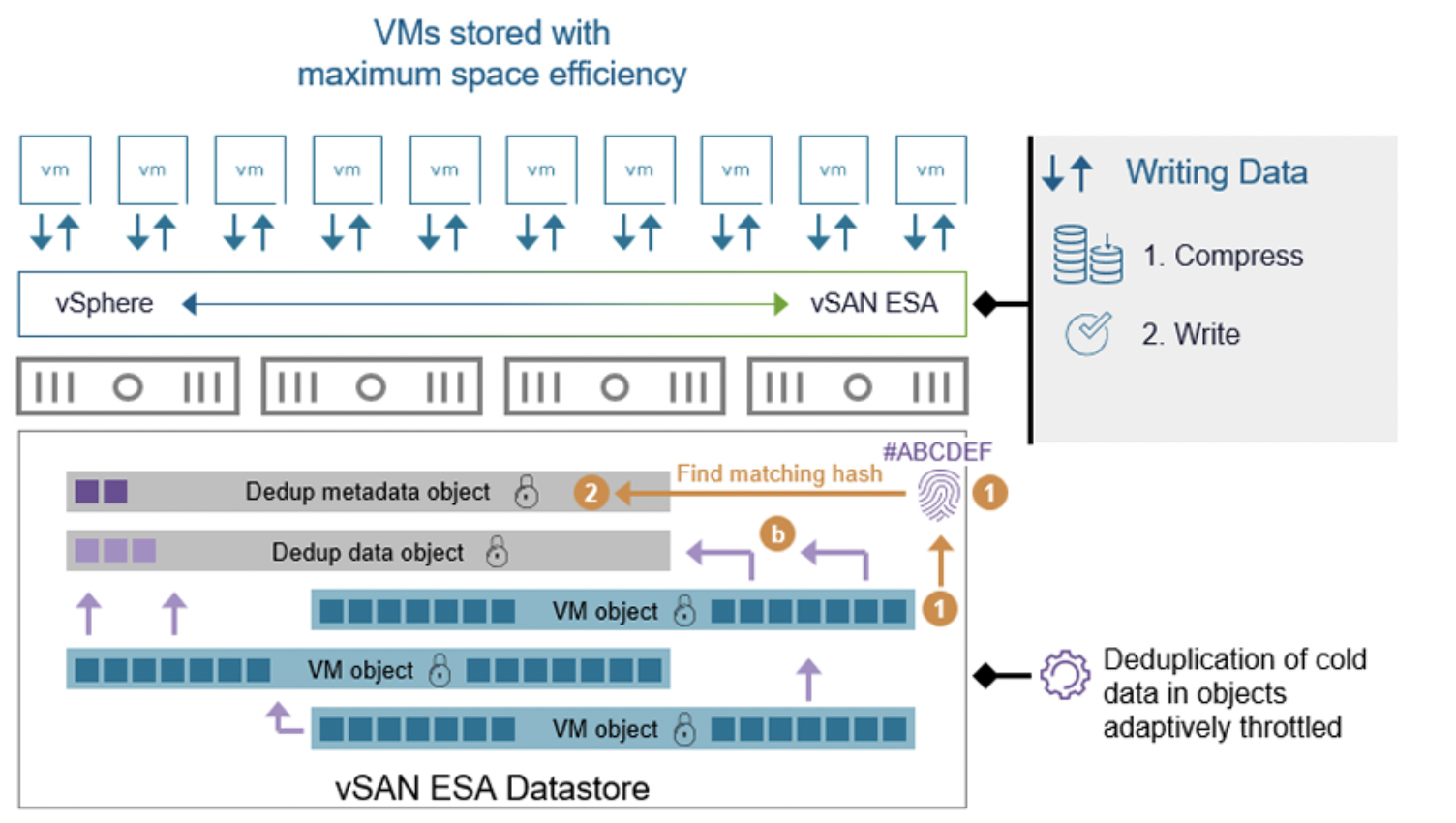
Глобальная дедупликация в ESA реализована как постпроцесс – она работает асинхронно, вне пути основного потока записи. vSAN сначала записывает данные (сжимает их – об этом далее) и подтверждает запись, а дедупликация выполняется позже, не вмешиваясь в операцию ack-write. Такой подход, наряду с интеллектуальным управлением ресурсами, означает, что влияние дедупликации на производительность минимально. vSAN ESA умеет адаптивно дозировать ресурсы на дедупликацию в зависимости от загрузки: во время пиковых нагрузок процесс замедляется до минимального, чтобы не влиять на активные ВМ, а в периоды простоя ускоряется, перерабатывая накопившиеся данные.
Все это происходит автоматически, без необходимости ручной настройки – администратор не управляет нюансами дедупликации, система сама оптимизирует выполнение. Благодаря новой архитектуре метаданных ESA распознает, какие данные недавно записаны (горячие) и какие давно не изменялись (холодные), и прежде всего выполняет дедупликацию на холодных блоках. Это логично: нет смысла тратить ресурсы на дедупликацию блока, который активно перезаписывается – велика вероятность, что вскоре он изменится и дедупликация того старого варианта окажется бесполезной. Вместо этого ESA фокусируется сначала на устоявшихся данных, максимально повышая эффективность.
Технически глобальная дедупликация в ESA основана на специальных объектах vSAN, создаваемых при включении этой функции. Выделяется объект метаданных дедупликации (хранилище хэш-индексов для всех блоков) и один или несколько объектов данных дедупликации (хранилища уникальных блоков). Когда обнаружен дубль, система обновляет метаданные, указывая на уже существующий блок в объекте данных, и освобождает место, ранее занимаемое дублирующим блоком. При этом уникальные блоки "перекочевывают" из исходных объектов ВМ в специальное хранилище дедупликации – такой дизайн нужен, чтобы избежать ситуации, когда множество ВМ начинают ссылаться на блок, лежащий в одном файле какой-то одной машины (что затруднило бы управление). Вместо этого общие блоки выносятся в отдельный пул, к которому затем привязаны все ссылки. Эта архитектура повышает отказоустойчивость и упрощает обслуживание, хотя и является сложнее внутренне.ё
По заявлениям VMware, глобальная дедупликация ESA обеспечивает гораздо более высокий коэффициент сокращения данных без ощутимых компромиссов по производительности. В сочетании со сжатием (которое всегда активно в ESA) совокупная экономия может сравняться или даже превысить показатели, наблюдаемые на традиционных хранилищах высокого класса. Таким образом, администратор ESA-кластера получает "лучшее из обоих миров": максимум экономии места и почти нулевое влияние на работу ВМ.
Пример сценария
Если в кластере много однотипных ВМ (тот же VDI или облачные шаблоны), ESA с глобальной дедупликацией сможет хранить их общий контент в одном экземпляре на весь кластер (с нужными копиями для отказоустойчивости), а не по одному экземпляру на хост, как было в OSA. Это резко снижает суммарный объем занятых данных. При этом, в отличие от OSA, такая экономия не "наказывается" падением производительности – система нивелирует традиционные проблемы дедупликации (дополнительные операции при записи, при чтении, при восстановлении и т.п.).
Ограничения
На момент выпуска (vSAN 9.0) глобальная дедупликация ESA имеет некоторые ограничения по совместимости. В частности, ее нельзя использовать параллельно с шифрованием данных в vSAN – эти функции пока несовместимы. Ожидается, что в будущих обновлениях совместимость появится, но пока администраторы должны выбирать: либо глобальная дедупликация, либо vSAN Encryption. В сценариях с распределенными топологиями (растянутые кластеры) стоит учесть, что дедупликация, хотя и глобальная, не выполняется между сайтами – каждый сайт (fault domain) дедуплицируется по отдельности, ведь копии данных хранятся раздельно на площадках. Тем не менее, внутри каждого сайта выгода сохраняется.
Еще один нюанс – включение/выключение дедупликации. В OSA переключение дедупликации/сжатия требует переформатирования дисковых групп (операция, требующая либо наличия свободного места для перемещения данных, либо полной перезагрузки хранилища). В ESA же, дедупликация включается достаточно прозрачно (создаются новые объекты метаданных), однако отключение ее потребует реинтеграции уникальных данных обратно – потенциально тоже непростая операция. Поэтому решение о включении глобальной дедупликации следует принимать перед вводом кластера в эксплуатацию или после тщательного планирования.
Выводы по дедупликации
Для кластеров на OSA дедупликация + сжатие остается полезным инструментом экономии места, но требующим осторожности: не на всех нагрузках и не во всех средах она оправдана. Если система уже испытывает дефицит ресурсов или хранилище работает на пределе, возможно, лучше отключить дедупликацию или ограничиться компрессией. В новых же кластерах ESA глобальная дедупликация – желательная опция в тех случаях, когда ожидается существенная повторяемость данных. Если оборудование и лицензии позволяют перейти на ESA, VMware рекомендует делать это, поскольку ESA-оптимизации более эффективны и проще в эксплуатации, чем прежние механизмы. Информация о дедупликации в OSA, по сути, адресована тем, кто пока остается на классической архитектуре (например, из-за старого оборудования), тогда как стратегически целесообразно планировать миграцию на ESA для максимальной эффективности.
Сжатие данных (compression) – это алгоритмическое уплотнение данных, позволяющее хранить тот же набор информации в меньшем объеме за счет удаления избыточности в пределах блока или файла. В контексте vSAN сжатие всегда работает совместно с дедупликацией в OSA (или отдельно в режиме compression-only), а в ESA – является базовой функцией, применяемой ко всем данным. Рассмотрим реализацию сжатия в обеих архитектурах.
В оригинальной архитектуре vSAN сжатие, как отмечалось, включается вместе с дедупликацией (либо отдельно как compression-only) на уровне всего кластера. Технически, в OSA сжатие происходит после дедупликации при сбросе данных на емкостной уровень. Алгоритм и условие мы уже описали: блок сжимается, если достигнуто >=50% экономии, иначе сохраняется несжатым. Используется стандартный алгоритм без потерь (для обычных данных – вариант LZ4). Размер несжатого блока – 4096 байт (4 KB). Если компрессия проходит порог, блок сохраняется в виде сжатого фрагмента, обычно меньшего размера (например, 2 KB или еще меньше). Несжатые же блоки хранятся как есть (4 KB).
Эффективность сжатия зависит исключительно от природы данных. Скажем, текстовые или табличные файлы могут сжиматься в разы, тогда как уже сжатые форматы (ZIP-архивы, JPEG-изображения, видео H.264) дополнительно ужать почти невозможно. Поэтому итоговый коэффициент сжатия данных на vSAN будет разным для разных нагрузок. VMware рекомендует консервативно оценивать ожидаемую экономию от сжатия, опираясь на понимание своих данных. Например, если в хранилище много медиа-контента, не стоит рассчитывать на значительное снижение объема – можно считать, что они займут почти столько же, сколько и в исходном виде.
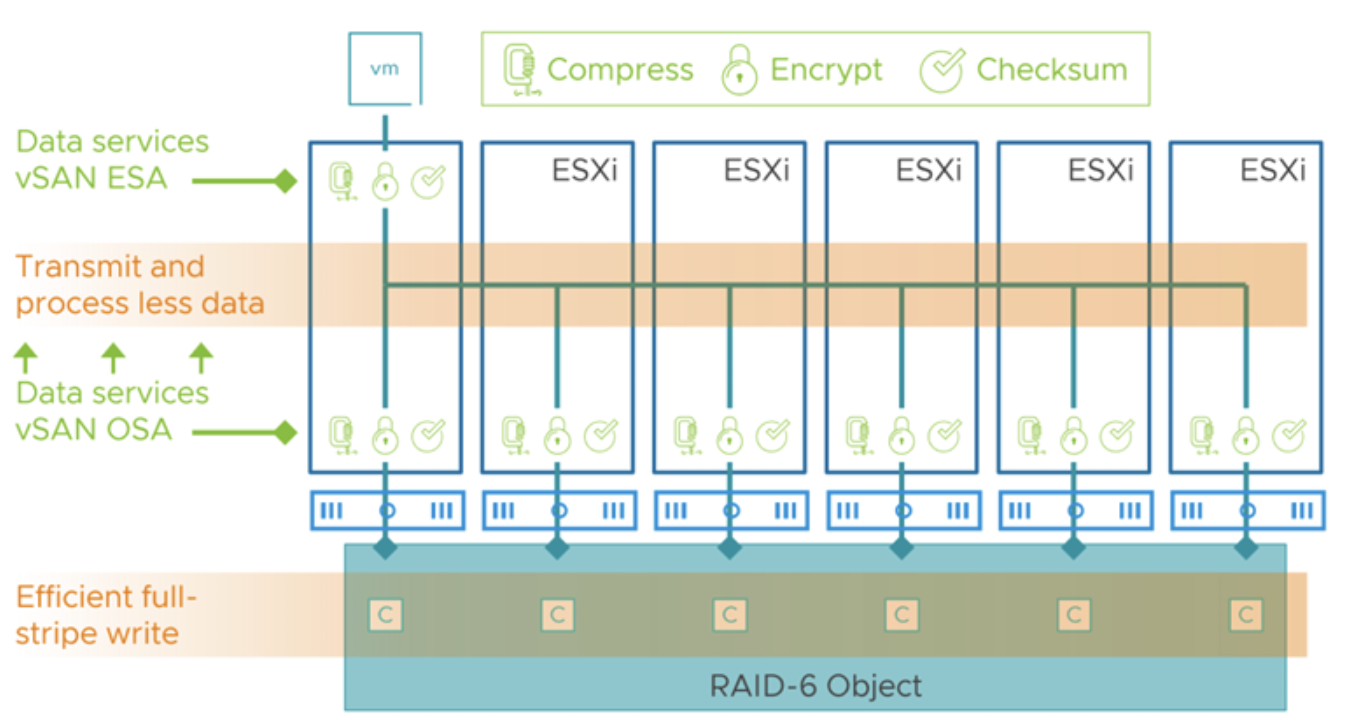
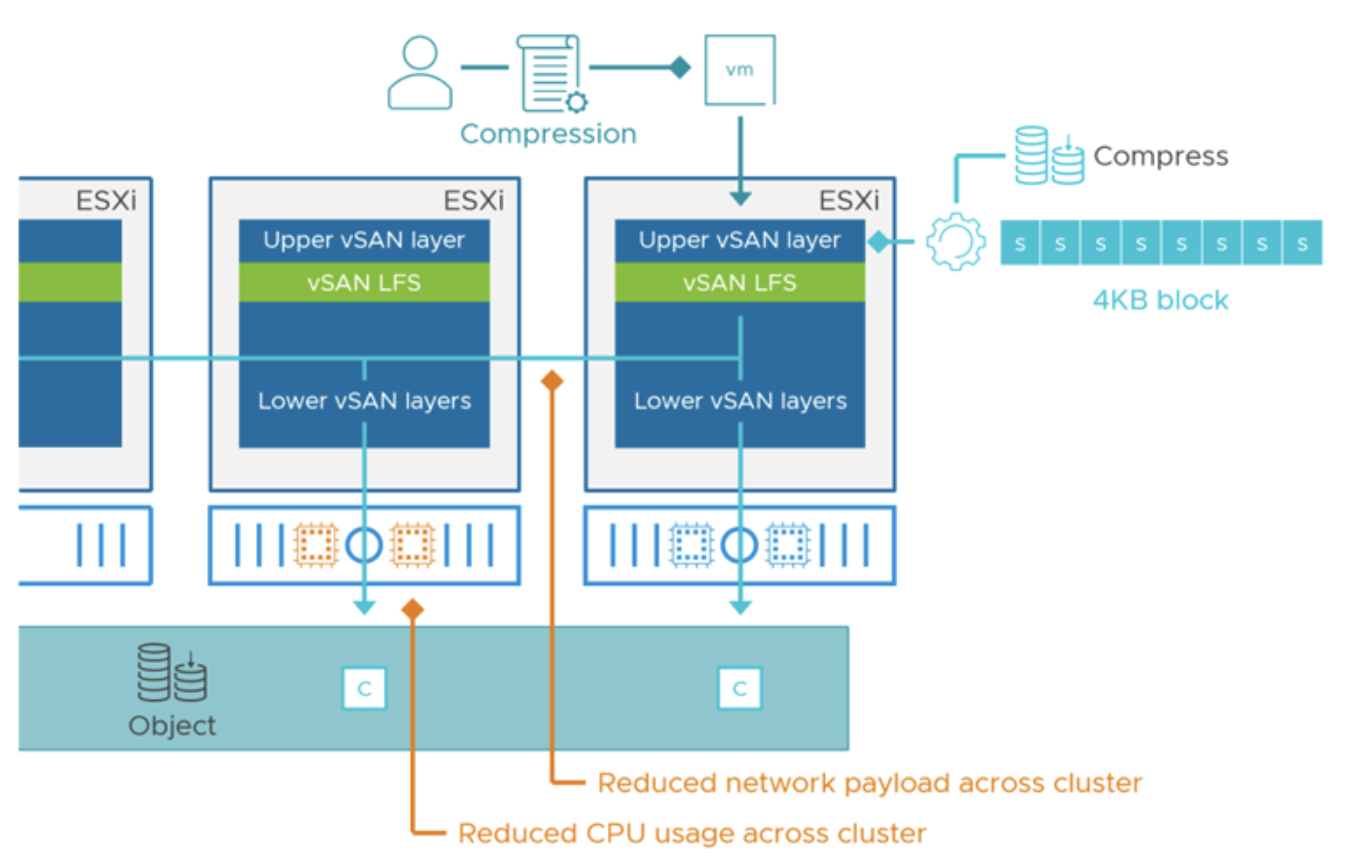
Важной особенностью vSAN OSA является то, что сжатие выполняется на каждом узле отдельно, после того как данные были реплицированы на другие узлы (в соответствии с политикой FTT). То есть, один и тот же блок данных, отправленный на два хоста (для зеркала), будет независимо сжат на каждом из них. Это лишняя работа, которая увеличивает совокупные затраты CPU по кластеру, а также означает передачу по сети “сырых” данных полного размера (они же сжимаются только после передачи, уже при записи на диск). Таким образом, OSA-схема ведет к тому, что данные по сети и в кэше перемещаются в несжатом виде, а сжимаются только при окончательном сохранении. Это историческое решение упрощает реализацию (не нужно сжимать “на лету” при передаче), но не оптимально с точки зрения сетевых и CPU ресурсов.
При работе компрессии с данными, не прошедшими дедупликацию, OSA полагается на фиксированный порог. Поэтому умеренно сжимаемые данные не получают никакой выгоды: например, если блок 4 KB ужимается до 3 KB (что формально ~25% экономии), vSAN OSA его не сожмет и сохранит 4 KB, фактически теряя потенциальный выигрыш. Много таких случаев суммарно означают упущенную экономию места. Это был известный компромисс архитектуры OSA.
Express Storage Architecture значительно меняет подход к сжатию данных. В ESA сжатие встроено в верхний уровень I/O стека: данные сжимаются до того, как они начинают распространяться по узлам кластера. Когда виртуальная машина выполняет запись, ее данные, попадая в vSAN, сразу подвергаются сжатию на лету, еще на том хосте, где работает ВМ, и до передачи по сети. В результате блок поступает на остальные узлы (которые хранят копии или фрагменты) уже в сжатом виде, и нет необходимости сжимать его повторно на каждом из хостов. Это имеет два ключевых эффекта:
Уменьшается объем сетевого трафика между узлами (vSAN отправляет меньше данных, так как они ужаты).
Снижается общая нагрузка на CPU по кластеру (т.к. работа выполняется один раз вместо многократного дублирования).
Фактически, ESA ликвидирует один из значимых источников накладных расходов, присущих OSA. Более того, сжатие в ESA может даже улучшать производительность – парадоксально, но уменьшение передаваемых объемов данных ускоряет репликацию и освобождает ресурсы, что особенно заметно в геораспределенных конфигурациях (stretched cluster). Например, в растянутом кластере (две площадки + узел-свидетель) данные между сайтами пересылаются уже сжатые, тем самым эффективная пропускная способность канала используется лучше.
Алгоритм сжатия в ESA также стал более гибким. Если в OSA блок либо сжимается до 2 KB, либо вообще не сжимается, то в ESA реализована компрессия с гранулярностью 512 байт. Входной 4 KB блок разбивается на восемь секторов по 512 байт, и алгоритм оценивает, сколько таких секторов можно “выкинуть” за счет компрессии данных. В итоге блок может быть уменьшен на любой величину кратно 512B: например, до 3.5 KB (7/8 исходного), до 3 KB, 2.5 KB и т.д., вплоть до минимально возможных ~0.5 KB (1/8 исходного размера).
Это означает, что даже частично сжимаемые данные дадут пропорциональный выигрыш. Пример: если блок на 20–25% состоит из повторяющихся или легко кодируемых паттернов, OSA бы его не сжала вовсе, а ESA сократит его примерно до ~3 KB, сохранив ~1 KB пространства. На больших массивах данных такие “по чуть-чуть” выигрыши складываются в существенную экономию. Конечно, предельные случаи – когда блок можно ужать до 1/8 (на 87.5% экономии) – встречаются редко и только на данных типа текстовых, но сама возможность более тонкой настройки дает лучшие коэффициенты сжатия в среднем.
Сжатие в ESA выполняется всегда (по умолчанию включено) для всех объектов, однако администратор может управлять этой опцией через политики хранения. То есть, vSAN ESA позволяет на уровне Storage Policy указать, применять ли компрессию для конкретного объекта (виртуального диска). По умолчанию политика включает сжатие, и VMware рекомендует его не отключать без веской причины. Возможной причиной может быть разве что приложение, которое уже шифрует или сжимает данные внутри себя – двойное сжатие смысла не имеет. Но даже в таких случаях стоит тщательно оценить: встроенные алгоритмы vSAN довольно эффективны и не создают заметного оверхеда, так что оставлять их включенными зачастую все равно выгодно.
Как и дедупликация, сжатие в ESA спроектировано с учетом производительности: оно работает на скоростных NVMe накопителях, используя современный многоядерный CPU – ресурсы, заложенные в дизайн ESA Ready Nodes. Поэтому накладные расходы на сжатие практически не влияют на пользовательские нагрузки. Более того, сжатие, как упомянуто, снижает сетевую нагрузку. В сумме в ESA нет тех сценариев, при которых администратор получил бы значительное проседание производительности из-за включенного сжатия (в отличие от OSA, где при высокой интенсивности записи наблюдалось снижение throughput с включенным сжатием). В stretched-кластерах сжатие в ESA – однозначно благо, повышающее эффективную пропускную способность межсайтового канала (ISL). Так что отключать сжатие в ESA рекомендуется лишь в исключительных случаях.
В заключение отметим: сжатие и дедупликация в ESA работают рука об руку. Данные сжимаются сразу, а дедупликация потом анализирует уже сжатые блоки. Однако, поскольку дедупликация глобальная, даже сжатые блоки сравниваются по хэшу (выполненному от несжатых данных) – то есть ESA "знает", что сжатый блок А и сжатый блок Б идентичны по исходному содержимому, и хранит их как один. Уровень сжатия не мешает дедупликации и наоборот. Благодаря этому ESA дает максимум возможной экономии: сперва устраняя внутреннюю избыточность блоков (compression), а затем внешнюю – повторяемость блоков (deduplication).
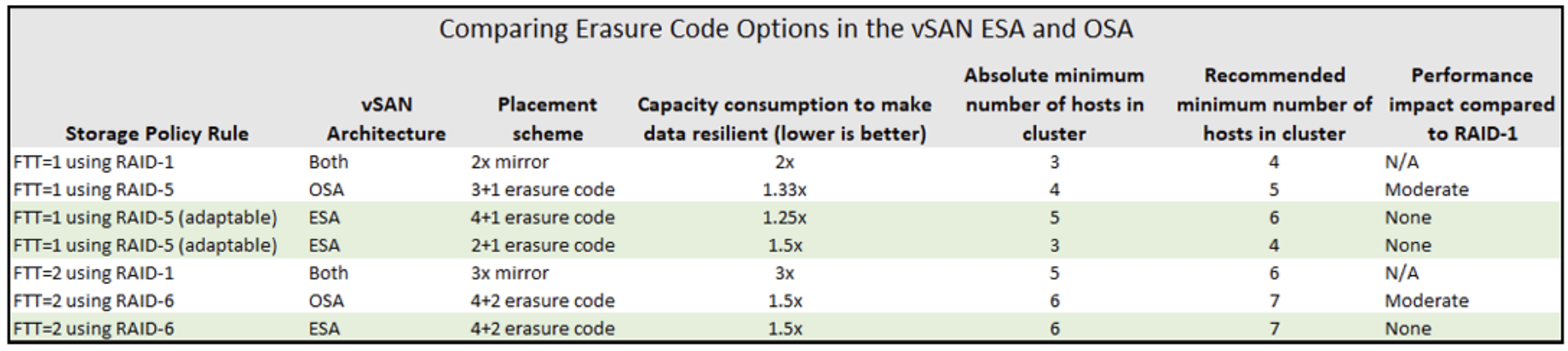
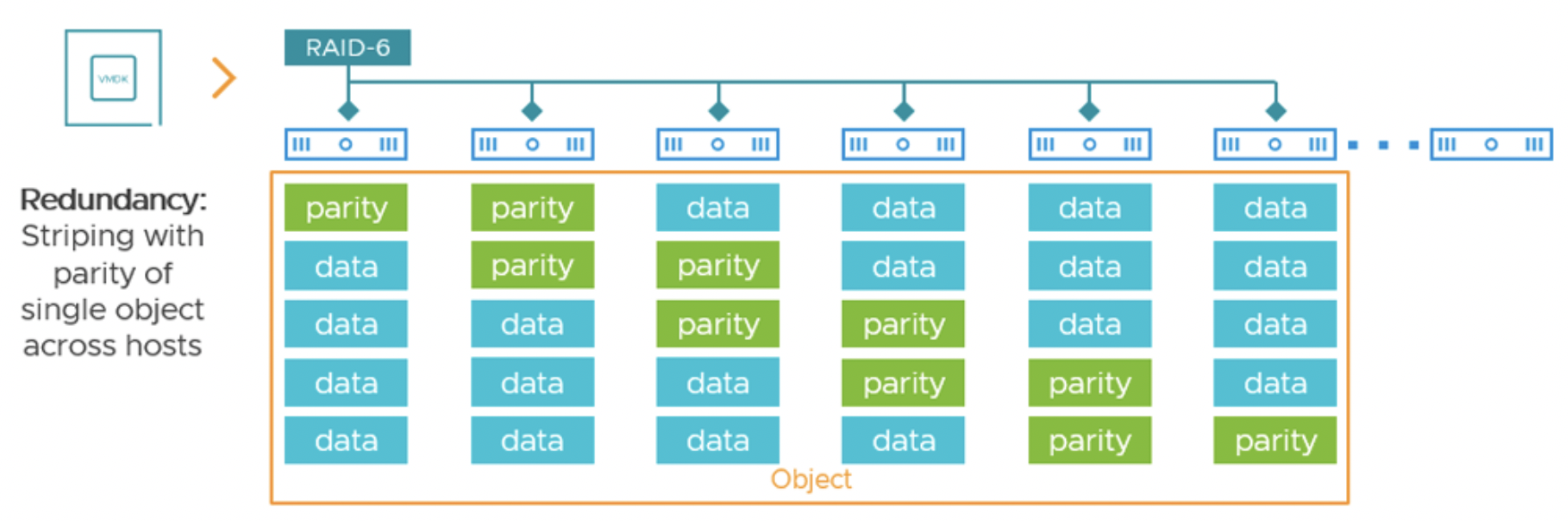
Кодирование erasure coding – это технология хранения, при которой для набора данных вычисляются контрольные фрагменты (паритеты) и данные распределяются по нескольким носителям таким образом, чтобы при потере одного или двух носителей данные можно было восстановить по оставшимся блокам. В традиционных RAID это известные уровни RAID-5 (один блок паритета на несколько блоков данных) и RAID-6 (два паритетных блока). В контексте vSAN под RAID-5/6 понимают создание объектов хранения с отказоустойчивостью за счет схемы N+P (N – число фрагментов данных, P – число фрагментов паритета). Erasure coding является детерминированным методом экономии места, поскольку точно известно, какой процент емкости экономится по сравнению с зеркалированием: RAID-5 с одним паритетом дает экономию примерно 33%, RAID-6 – 50% относительно зеркала (mirroring).
Иными словами, при уровне отказоустойчивости FTT=1 (один отказоустойчивый элемент) зеркирование хранит 2 копии данных (100% избыточность), а RAID-5 хранит 1 паритет на 3 данных (~33% избыточность). При FTT=2 зеркало хранит 3 копии (200% избыточность), а RAID-6 хранит 2 паритета на 4 данных (50% избыточность). Для примера: 100 GB полезных данных займут ~200 GB при зеркировании с FTT=1, ~133 GB при RAID-5 FTT=1, ~300 GB при зеркале FTT=2, и ~150 GB при RAID-6 FTT=2. Таким образом, выигрыш в экономии пространства очевиден – особенно на больших объемах данных.
В VMware vSAN RAID-5/6 реализуются как политики хранения, применяемые к объектам (виртуальным дискам). Администратор может гибко задать, какие именно ВМ или даже конкретные VMDK должны храниться с тем или иным методом – зеркированием (RAID-1) или с кодированием (RAID-5/6). Это означает, что внутри одного и того же кластера могут сосуществовать объекты с разными схемами: например, критически важные базы данных могут быть на зеркале для максимальной скорости, а файловый архив – на RAID-5 для экономии места. Такой подход повышает эффективность использования хранилища – RAID-5/6 не обязательно включать для всего кластера, а достаточно для тех данных, где это оправдано.
В классической реализации (OSA) vSAN поддерживает RAID-5 и RAID-6 на all-flash кластерах начиная с версии 6.2. Они недоступны на гибридных (с HDD) конфигурациях, поскольку использование медленных дисков с кодированием приводило бы к неприемлемому падению производительности. Требуется минимальное число узлов в кластере: для RAID-5 – 4 хоста (схема 3+1), для RAID-6 – 6 хостов (схема 4+2). Рекомендуется иметь на один узел больше минимального, чтобы в случае выхода узла из строя была возможность автоматически восстановить недостающие компоненты (rebalance) на свободном узле, не дожидаясь починки отказавшего.
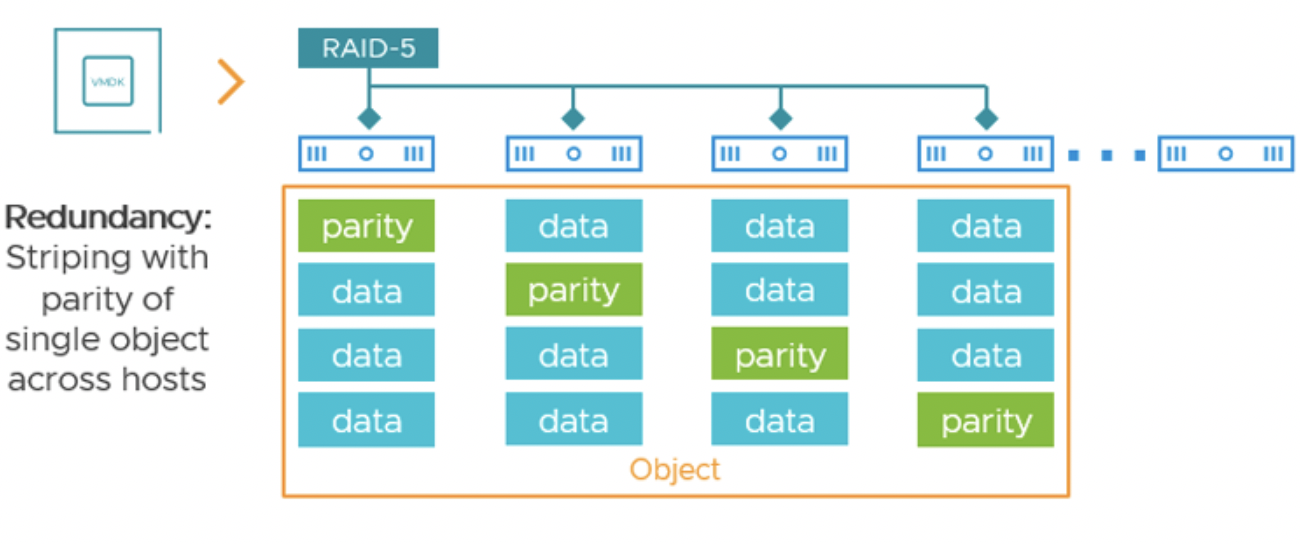
При политике RAID-5 (FTT=1, метод RAID-5) vSAN размещает каждый объект в виде 4 компонентов на разных хостах: 3 фрагмента данных и 1 фрагмент паритета. Любой один хост (или устройство) из этих четырех может выйти из строя – данные восстанавливаются из оставшихся 3 фрагментов.
При политике RAID-6 (FTT=2) объект разбивается на 6 компонентов: 4 данных + 2 паритета, выдерживая отказ двух узлов из шести. Каждый фрагмент (данный или паритет) хранится как отдельный компонент на своем хосте.
Таким образом, для RAID-5 в кластере минимум 4 узла, для RAID-6 – минимум 6, иначе такую политику применить нельзя (vCenter просто не предложит ее, если узлов недостаточно).
Экономия емкости
Как уже указано, RAID-5 экономит ~33% места относительно зеркала (2 копий), а RAID-6 экономит ~50% относительно зеркала с 3 копиями. При больших объемах это позволяет существенно увеличить полезную емкость хранилища. Пример: 10 TB данных при зеркале FTT=1 заняли бы 20 TB, а при RAID-5 – около 13.3 TB, "вернув" ~6.7 TB емкости. Однако плата за это – усложнение операций записи, что влияет на скорость.
Особенности производительности
Кодирование, применяемое в vSAN OSA, связано с вычислением паритетов и записью нескольких фрагментов, поэтому оно более ресурсоемкое, чем простое дублирование. При каждой записи данных RAID-5 должен обновить блок паритета: если запись частично обновляет существующие данные, vSAN вынужден прочитать связанные блоки данных и старый паритет, пересчитать новый паритет, и записать его – это так называемая операция Read-Modify-Write. RAID-6 еще сложнее – там два паритета (например, алгоритм Рида-Соломона), требующие дополнительных вычислений. В результате нагрузка на CPU и дисковую подсистему при RAID-5/6 выше, а скорость записи ниже, особенно для случайных мелких операций. В сравнении, зеркалирование просто записывает копию данных на другой узел, без вычислений, что быстрее на запись (но и трафика требует в 2 раза больше).
Практические эффекты включения RAID-5/6 в OSA могут быть следующими:
Увеличение задержки записи. При интенсивной записи (например, поток мелких транзакций) дополнительные шаги с паритетами могут увеличить задержки. В лучшем случае разница небольшая, но под нагрузкой она становится заметной.
Падение пропускной способности при долгой последовательной записи. Если, например, кластер выполняет продолжительную запись больших данных (архив, бэкап), то с RAID-5/6 он, как правило, даст меньший throughput, чем с зеркалом, из-за вычислительных накладных расходов и большего объема внутренних операций.
Повышенная нагрузка на сеть. Хотя RAID-5 экономнее с точки зрения хранения, он не сокращает сетевой трафик: наоборот, запись полосы RAID-5 все равно требует отправить данные на несколько узлов (каждый фрагмент на свой узел). При зеркале FTT=1 мы отсылаем копию на 1 другой узел; при RAID-5 3+1 мы отсылаем фрагменты на 3 других узла (данные и паритет). Однако объем отправляемых данных суммарно равен 4 KB (3 данных + 1 паритет на каждые 3 данных), что аналогично 2 копиям по 4 KB.
Тут нужно пояснить: в RAID-5 на 4 узлах для записи 4 KB блока мы фактически записываем 4 KB данных и вычисляем 4 KB паритета – итого 8 KB трафика, что аналогично зеркалу (тоже 4 KB х 2 = 8 KB). Но если кластер имеет высокую долю неполных полос (un-strided writes), трафик может возрастать. В общем, минимальная рекомендуемая сеть для RAID-5/6 – 10 Гбит/с, а лучше 25 Гбит/с, чтобы компенсировать нагрузку.
Рекомендации по использованию (OSA)
VMware подчеркивает, что RAID-5/6 в OSA следует применять осмотрительно и не обязательно для всех данных. Целесообразно:
Выбирать на уровне ВМ. Используйте RAID-5/6 для тех виртуальных дисков, где важнее экономия места, и приемлемо небольшое снижение производительности (например, файловые серверы, архивы, резервные копии). Для "горячих" данных (с высокой нагрузкой) оставьте зеркалирование. Поскольку политики можно задавать индивидуально, нет нужды делать выбор "все или ничего".
Учитывать возможности оборудования. Если у кластера слабые CPU или медленная сеть, не стоит переводить всю нагрузку на RAID-5/6 – сначала оцените, справится ли инфраструктура. Возможно, лучше обновить сеть до 25 Гбит или убедиться, что у узлов достаточно свободных CPU-ресурсов, прежде чем широко использовать RAID-5/6.
Избегать RAID-5/6 как второй уровень в растянутом кластере. VMware не запрещает сочетание: можно сделать, например, primary level mirroring между сайтами, а внутри каждого сайта secondary level RAID-5. Однако были замечены сложности с производительностью и восстановлением в таких случаях. Лучше в stretched-средах использовать зеркала, либо тщательно протестировать комбинированные политики.
Мониторить состояние. При активном использовании RAID-5/6 следите за задержками, заполненностью write buffer, нагрузкой на сеть. vSAN Health и Performance сервисы помогут понять, нет ли узких мест. При необходимости можно динамически сменить политику конкретной ВМ на RAID-1, если она испытывает проблемы.
В итоге, erasure coding в OSA – мощный инструмент снижения накладных затрат емкости, но требующий от администратора понимания компромиссов. В обмен на +33–50% емкости вы можете получить 10–30% производительности (условно) в определенных сценариях. Многие организации соглашаются на это ради экономии, особенно там, где хранится много данных "второго" уровня важности.
Новая архитектура ESA устраняет большинство недостатков, связанных с производительностью RAID-5/6. Главная идея состоит в том, что vSAN ESA благодаря обновленному механизму записи (журналируемая файловая система LFS и пр.) достигает производительности RAID-1 при использовании RAID-5/6. Проще говоря, теперь можно иметь экономию емкости, но без традиционных штрафов на скорость.
Ключевые отличия реализации RAID-5/6 в ESA:
Отсутствие дисковых групп и двухуровневого кеша. ESA использует единый пул NVMe-накопителей с лог-структурированной файловой системой. Запись данных происходит в виде последовательного журнала, и параллельно могут вычисляться паритеты, не влияя на быстрый прием записи. Например, vSAN ESA может сразу записывать данные в performance leg (быстрый слой) с применением RAID-6, что дает одновременно подтверждение записи ВМ и расчет паритета без задержек. Отсутствие этапа "destaging" с Read-Modify-Write снижает накладные операции.
Оптимизированный расчет паритета. Алгоритмы в ESA и задействование современных CPU позволяют вычислять паритеты очень быстро. Кроме того, LFS объединяет мелкие записи в большие блоки ("логические группы записей"), что делает операции кодирования более эффективными – меньше случаев частичного обновления страйпа. Благодаря этому ESA практически избавилась от эффекта I/O amplification, ранее характерного для RAID-5/6. VMware заявляет, что при работе RAID-5/6 в ESA нет дополнительной нагрузки на CPU/IO по сравнению с зеркалом.
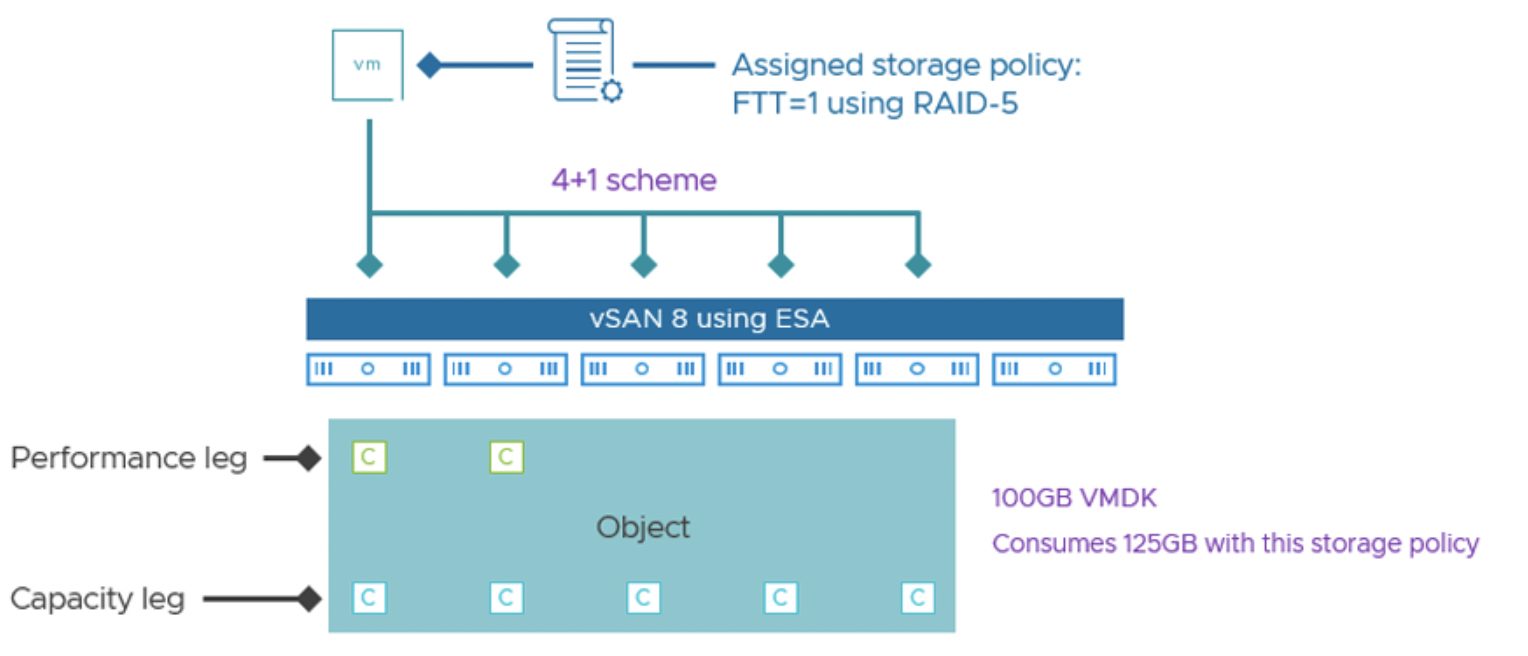
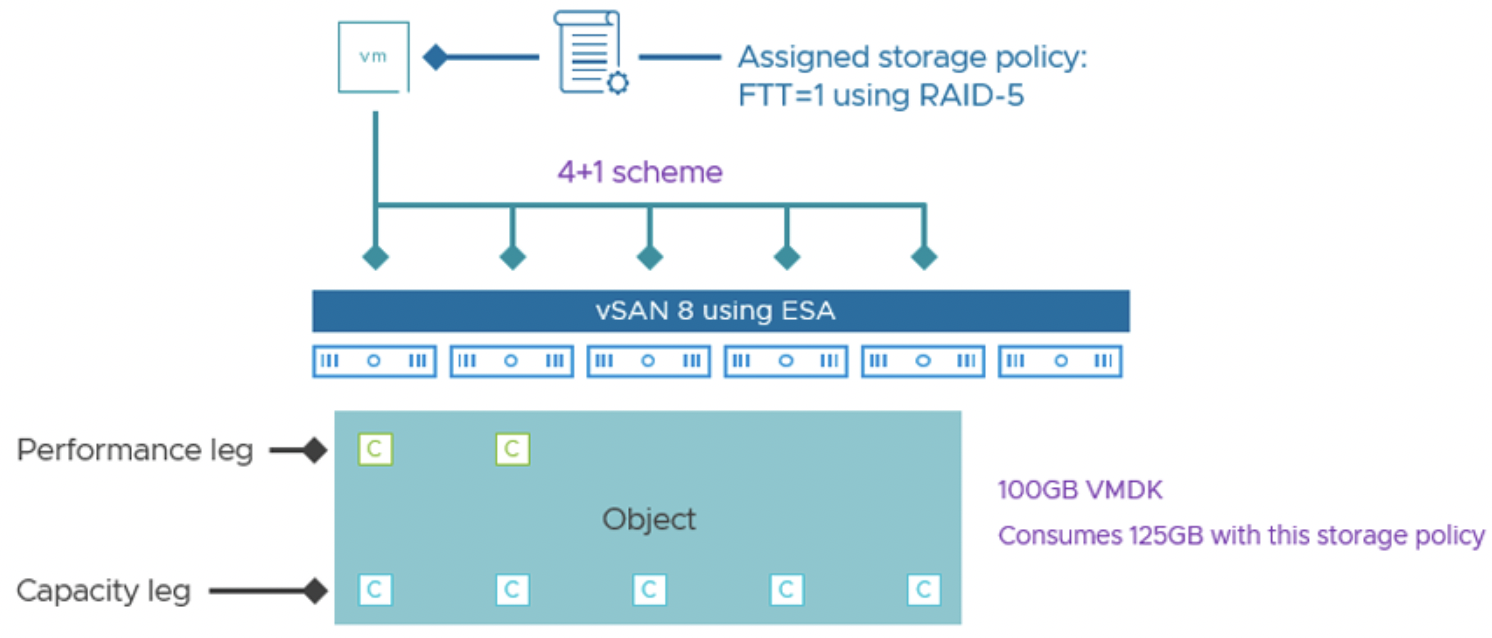
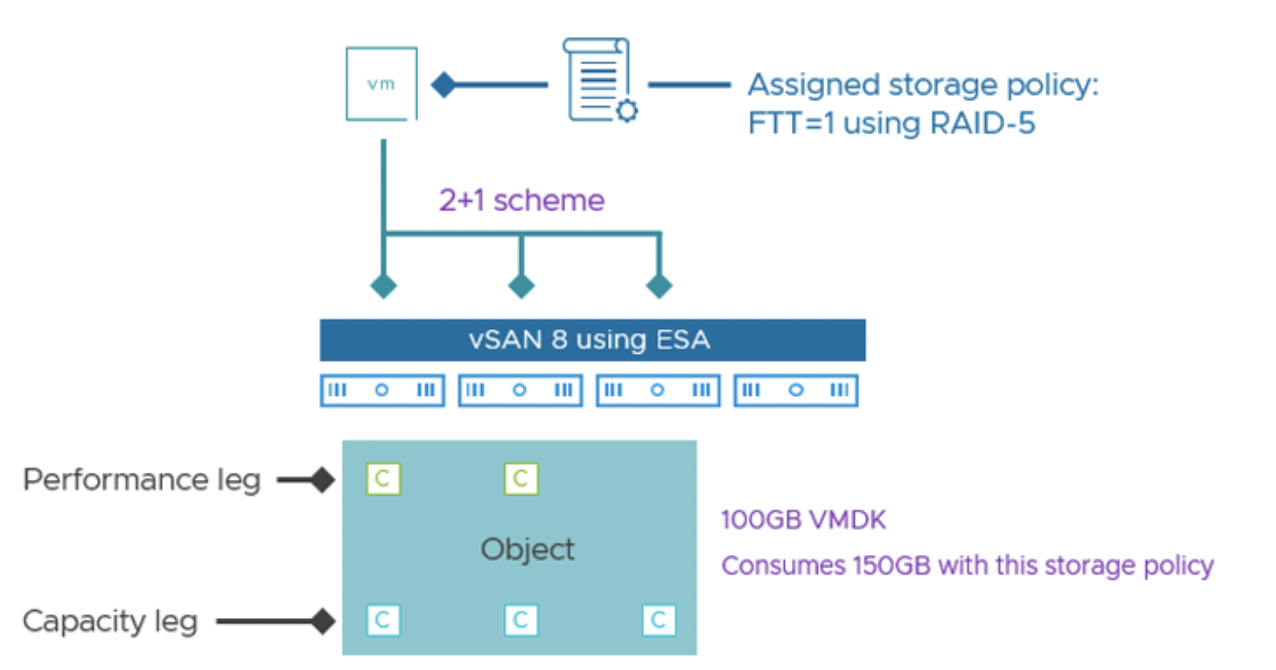
Адаптивная полоса RAID-5. В ESA реализованы две конфигурации RAID-5 и система автоматически выбирает нужную в зависимости от размера кластера. Если в кластере 6 или более узлов, используется схема 4+1 – то есть 4 данных + 1 паритет, размещенные минимум на 5 узлах. Это дает коэффициент использования ~1.25x от объема данных (что даже лучше, чем 1.33x в OSA). Если же в кластере меньше 6 узлов (но не меньше 3), vSAN автоматически применит схему 2+1 – 2 данных + 1 паритет на 3 узлах. Такая полоса менее емкостно эффективна (1.5x от данных, т.е. экономия ~25%), но зато позволяет задействовать RAID-5 даже на минимальном кворуме из 3 хостов. Ранее (в OSA) это было невозможно – требовалось минимум 4. Теперь же небольшой кластер (3-5 узлов) может использовать RAID-5 2+1, получая экономию места ~33% по сравнению с зеркалом (зеркало 2x, RAID-5 1.5x – разница в четверть). При добавлении хостов vSAN автоматически перейдет на 4+1, повышая эффективность хранения. Администратору не нужно выбирать страйп вручную – в интерфейсе есть одна опция "RAID-5 (Erasure Coding)", а остальное система решит сама.
RAID-6 в ESA. Для RAID-6 ESA использует схему 4+2 (6 узлов) так же, как OSA. По состоянию на vSAN 9.0, альтернативных (адаптивных) схем для RAID-6 не заявлено – требуется минимум 6 хостов. Страйп 4+2 дает коэффициент ~1.5x, аналогично OSA. Однако, как упомянуто, производительность при этом остается на уровне зеркала FTT=2, то есть отсутствуют узкие места CPU/IO, характерные для OSA. RAID-6 ESA допускает отказ любых двух узлов из участвующих шести без потери данных и с минимальным влиянием на рабочую нагрузку.
Нет штрафа на производительность. Повторим ключевой тезис: в ESA RAID-5/6 работают практически без компромиссов по скорости, обеспечивая ту же производительность, что и RAID-1 (с учетом одинакового уровня отказоустойчивости). Это означает, что для большинства рабочих нагрузок нет смысла не использовать RAID-5/6 там, где требуется экономия места – вы получаете выигрыш в емкости "бесплатно". Внутренние тесты VMware показали сопоставимые показатели throughput и latency при RAID-5/6 ESA и зеркале. Таким образом, рекомендуется применять RAID-5/6 на ESA-кластерах везде, где топология это позволяет (достаточно узлов).
Пример: возьмем кластер из 4 узлов на ESA. В OSA такой кластер не мог бы использовать RAID-5, а только зеркала (или 2-node схему). В ESA же 4 узла позволяют RAID-5 в режиме 2+1. Предположим, у нас 100 GB данных с FTT=1. При зеркале они займут 200 GB, а при RAID-5 ESA 2+1 – 150 GB. Мы экономим 50 GB (25%) без заметной разницы в быстродействии. Если затем кластер расширить до 6 узлов, vSAN “переключит” объекты на RAID-5 4+1, и те же 100 GB будут занимать уже ~125 GB (экономия 37.5% против зеркала) – емкость высвободится автоматически, а производительность останется высокой. Для FTT=2 (двойная отказоустойчивость) ESA предоставляет RAID-6 4+2 на 6 узлах, где 100 GB займут 150 GB, тогда как зеркало FTT=2 занял бы 300 GB – экономия ровно 50%, и опять же практически без потери производительности.
Особенности и рекомендации (ESA)
В среде ESA администратор может смело выбирать RAID-5/6 для экономии пространства, не опасаясь типичных для OSA проблем. Однако есть некоторые ограничения:
Минимальные размеры. Как и ранее, RAID-5/6 требуют определенного числа хостов. Хотя ESA снижает минимумы (RAID-5 из 3 узлов вместо 4), все же на кластере из 2 узлов или stretched-кластере между 2 сайтами использование чистого RAID-5/6 невозможно из-за нехватки узлов для полосы. В таких конфигурациях основным методом защиты остается зеркалирование.
Stretched-кластеры. Для распределенных (метро) кластеров по-прежнему основная защита между сайтами – зеркалирование (RAID-1). Однако на вторичном уровне (внутри каждого сайта) ESA позволяет применять RAID-5/6. Например, можно создать политику: Primary FTT=1 (синхронное зеркало между сайтами) + Secondary FTT=1 RAID-5 (в пределах каждого сайта). Таким образом, данные на каждом сайте экономично хранятся с паритетом, но при этом между сайтами поддерживается копия. Это дает экономию пространства внутри каждого датацентра, хотя суммарно данные все равно дублируются между площадками. В OSA такая комбинация тоже возможна, но из-за накладных расходов ее старались избегать; в ESA же она выглядит более оправданной. Важно: конфигурации stretched + RAID-5/6 стоит тщательно тестировать на предмет возможности и времени ресинхронизации после потери связи и т.п., хотя VMware заявляет об их поддержке.
Аппаратные требования. Чтобы достичь декларированной производительности, ESA-кластер должен основываться на одобренном оборудовании (ESA Ready Nodes): высокопроизводительные NVMe SSD, современные CPU, сеть 25 GbE и лицензия не ниже vSAN Advanced. В противном случае, если, условно, запустить ESA на “минималках”, эффекта “RAID-6 со скоростью RAID-1” может не получиться. Но такие ситуации редки, так как ESA завязан на современное железо.
В целом, в ESA рационально максимально применять RAID-5/6 для всех рабочих нагрузок, которые требуют отказоустойчивости FTT=1 или FTT=2. Исключение можно сделать разве что для самых критичных к задержкам систем, где администратор психологически предпочитает зеркало (но тесты показывают, что разницы почти нет). Зато выигрыш в емкости очевиден – особенно на крупных хранилищах.
Выбор режима хранения: зеркирование или erasure coding
В заключение стоит обобщить рекомендации по выбору технологий экономии пространства в vSAN:
vSAN OSA (традиционная архитектура): используйте дедупликацию и сжатие на all-flash кластерах, где ожидается высокая степень повторяемости данных (VDI, шаблоны, однородные нагрузки) – это существенно сократит требуемую емкость, но помните о влиянии на производительность при интенсивных записях. Если дедупликация не дает выигрыша (данные уникальные или уже сжатые), рассмотрите вариант отключить дедупликацию, оставив только компрессию – так вы сэкономите ресурсы и упростите восстановление, получив все еще некоторую экономию места. Erasure coding (RAID-5/6) в OSA применяйте точечно, для тех данных, где важнее емкость, а не максимальная скорость. Обеспечьте достаточную инфраструктуру (скоростная сеть, резерв CPU) и следуйте рекомендациям VMware, чтобы нивелировать риск падения производительности. Помните, что RAID-5/6 требуют определенного числа хостов (4 и 6 соответственно) и все устройства должны быть SSD. В среде, где нагрузка не постоянна и есть периоды простоя, vSAN OSA может успешно выполнять дедупликацию/сжатие и кодирование стиранием, экономя место без заметного влияния на пользователей.
vSAN ESA (новая архитектура): стремитесь использовать ESA при наличии соответствующего оборудования и лицензий – выгоды очевидны. Сжатие в ESA включено всегда и почти не требует внимания – оставьте его активным для всех данных (по умолчанию). Глобальную дедупликацию включайте, если ваш сценарий предполагает дублирование данных (а большинство сценариев в той или иной мере предполагают). Она даст дополнительную экономию без ручной работы, особенно в крупных кластерах. Следите за обновлениями VMware – возможно, вскоре дедупликация станет совместима с шифрованием, что снимет последние ограничения. Что касается RAID-5/6, то в ESA их следует рассматривать как предпочтительный вариант, если нет специфических противопоказаний. Фактически, в кластере ESA можно по умолчанию применять RAID-5 (FTT=1) вместо зеркала для любых данных, получая ~1.25x емкости от данных вместо 2x, – и не переживать о производительности. Для максимальной отказоустойчивости (FTT=2) можно смело использовать RAID-6 – вы получите надежность на уровне переноса 2 отказов с половинным расходом емкости против тройного зеркала, тоже без снижения скорости. Конечно, следуйте минимальным требованиям по числу хостов. Например, кластер на 5 узлов не сможет использовать RAID-6 (нужно 6), а кластер на 3 узлах сможет только RAID-5 2+1, но не 4+1 – это автоматом учтется системой. В остальном же ESA снимает дилемму "емкость vs производительность": вы больше не жертвуете одним ради другого, и поэтому новые функции стоит активировать по максимуму.
Заключение
Технологии экономии пространства в vSAN – мощный арсенал в руках администратора, позволяющий оптимизировать затраты на хранение и повысить эффективность инфраструктуры. В данной статье мы рассмотрели дедупликацию и сжатие, которые уменьшают объем хранимых данных за счет устранения избыточности, а также RAID-5/6 кодирование, которое сокращает требуемую избыточность для обеспечения отказоустойчивости. Мы также подчеркнули различия между оригинальной архитектурой vSAN OSA и новой ESA: Express Storage Architecture выводит эти технологии на новый уровень, делая их более эффективными и малозатратными в плане производительности.
При проектировании и эксплуатации vSAN-кластера важно принимать во внимание характер данных и требований приложений, чтобы правильно подобрать и настроить механизмы экономии пространства. Например, для VDI-кластера логичным выбором будет включение дедупликации/сжатия (OSA или глобальной в ESA) и использование RAID-5, что даст наибольшую плотность хранения виртуальных рабочих столов. Для кластера баз данных, напротив, может иметь смысл ограничиться зеркалированием и, возможно, только сжатием, чтобы обеспечить минимальную задержку. Универсального рецепта нет – но, зная технические особенности описанных функций, инженер сможет выработать оптимальную стратегию.
Для получения более подробной информации о технологиях экономии дискового пространства вы можете прочитать в документе "vSAN Space Efficiency Technologies".

 RSS
RSS