Современные центры обработки данных сталкиваются с беспрецедентными вызовами в области хранения данных: ИТ-командам необходимо обеспечивать производительность, отказоустойчивость и эффективность для постоянно растущих объёмов данных, при этом бюджеты растут значительно медленнее. В прошлом стоимость хранения и памяти со временем снижалась, сглаживая влияние роста данных на бюджет, однако текущий суперцикл памяти ломает эту тенденцию. Методы снижения избыточности данных, уменьшение требований к процессору и памяти, а также новые типы носителей позволяют ИТ-командам нейтрализовать влияние растущих цен на всю инфраструктуру хранения.
Кроме того, ИТ-подразделения испытывают стремительный рост как масштаба приложений, так и их количества в датацентре. Рабочие нагрузки AI требуют огромных объёмов данных, и их распространение вынуждает ИТ осваивать новые интерфейсы хранения — объектное хранилище и высокопроизводительные файловые сервисы. Кроме этого, ИТ необходим более простой способ предоставления командам разработчиков доступа к инфраструктуре хранения. Сегодня администраторы нередко вынуждены работать с тикетными системами для выделения ресурсов: процессы часто выполняются вручную, отнимают много времени и чреваты ошибками. Администраторы хотят предоставлять доступ к ключевым сервисам хранения, не теряя при этом контроля и соответствия требованиям, — чтобы разработчики могли двигаться с темпом, которого требует бизнес.
Но давление на ИТ этим не ограничивается. Угрозы безопасности эволюционируют быстрее, чем когда-либо, а атаки вымогателей вынуждают ИТ-команды переосмыслить фундаментальную устойчивость инфраструктуры хранения. Время восстановления критически важных приложений приобретает всё больший приоритет. Данные должны быть защищены с помощью неизменяемых снимков, зашифрованы при хранении и передаче, а также восстанавливаемы в случае кибератак.
Наконец, ИТ-команды нуждаются в помощи с управлением растущей сложностью датацентра. По мере стремительного увеличения масштабов инфраструктуры ИТ нуждается в том, чтобы поставщики инфраструктуры автоматизировали и упрощали процессы, позволяя администраторам управлять большей инфраструктурой меньшими силами. Инфраструктура хранения должна самоуправляться, самодиагностироваться и предоставлять критическую диагностическую информацию для быстрого устранения проблем.
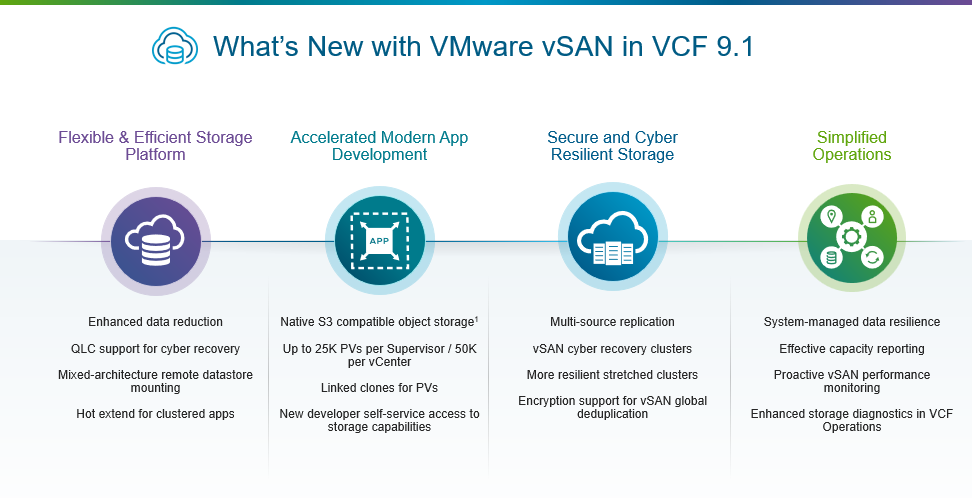
Именно поэтому всё больше клиентов отказываются от устаревших трёхуровневых архитектур в пользу полностью интегрированного частного облака. vSAN является критически важным, встроенным компонентом VMware Cloud Foundation (VCF), обеспечивающим развитие новых и существующих возможностей VCF. В vSAN в составе VCF 9.1 реализованы функции, которые упрощают снижение затрат на инфраструктуру хранения, ускоряют разработку современных приложений, обеспечивают запуск и защиту рабочих нагрузок в частном облаке на базе VCF, а также упрощают операции с хранилищем VCF.
Гибкая и эффективная платформа хранения
Экономическая эффективность всегда была сильной стороной vSAN, а vSAN в VCF 9.1 делает ещё один шаг вперёд благодаря более интеллектуальному сжатию и доступным по цене аппаратным конфигурациям.
Глобальная дедупликация
В VCF 9.1 глобальная дедупликация vSAN переходит в статус общедоступной. Глобальная дедупликация vSAN позволяет сократить используемую ёмкость до 8 раз — это критически важная возможность в условиях быстро растущей стоимости хранения и увеличивающихся сроков поставок оборудования. Дедупликация в vSAN спроектирована с минимальным влиянием на процессор и может применяться ко всем данным в кластере. Это дедупликация с постобработкой: она выполняется в фоновом режиме при низкой нагрузке на процессор. В отличие от традиционных систем хранения, где дедупликация ограничена хранилищем за парой I/O-контроллеров, домен дедупликации vSAN масштабируется вместе с кластером, потенциально обеспечивая более высокую эффективность.
Улучшенное сжатие
В vSAN в составе VCF 9.1 введены новые методы сжатия, обеспечивающие значительно более высокие коэффициенты компрессии. Новый алгоритм одновременно быстр и эффективен: инженерная команда оптимизировала его для баланса между снижением избыточности данных и потреблением ресурсов. VCF 9.1 теперь обеспечивает более высокую степень сжатия при минимальном влиянии на производительность.
Что делает это особенно ценным? Новое сжатие применяется только к новым записям, поэтому оно может внедряться в среду без прерываний и включено по умолчанию.
В сочетании с глобальной дедупликацией это улучшение обеспечивает снижение совокупной стоимости владения на 39% по сравнению с традиционными внешними массивами.
Узлы ReadyNode для киберрезервного копирования с устройствами QLC
Сценарии резервного копирования — аварийное, операционное и киберрезервное — предъявляют к инфраструктуре иные требования, чем основное хранилище: меньше ресурсов процессора и памяти, но более высокая ёмкость. Хотя исторически ИТ при инвестициях в инфраструктуру резервного копирования ориентировались прежде всего на стоимость, изменившийся характер бизнеса потребовал повышенного внимания к производительности и времени восстановления. VCF 9.1 представляет узлы ReadyNode, оптимизированные для киберрезервного копирования с устройствами QLC (Quad-Level Cell), обеспечивающими оптимальный баланс плотности, производительности, выносливости и стоимости для данного сценария.
Эти сертифицированные конфигурации обеспечивают более высокую плотность хранения и консолидацию серверов, снижая стоимость гигабайта для полностью флэш-хранилища при одновременном сокращении потребления электроэнергии, охлаждения и площади стойки по сравнению с решениями на основе HDD. Это практичный ответ на задачу расширения инфраструктуры киберрезервного копирования без увеличения бюджетов.
Расширенная гибкость для кластеров хранения vSAN
Многие пользователи vSAN последовательно развивают свою инфраструктуру хранения, поэтому нередко используют сочетание vSAN Express Storage Architecture (ESA) и Original Storage Architecture (OSA). Клиенты хотят иметь возможность инвестировать в новую инфраструктуру, одновременно эксплуатируя старые кластеры vSAN до конца срока их службы. VCF 9.1 снимает прежние ограничения, позволяя монтировать новые хранилища ESA к кластерам OSA и давая вычислительным кластерам без хранения возможность монтировать как OSA, так и ESA. Клиенты могут расширять инфраструктуру для приложений на кластерах OSA без необходимости инвестировать в технологии предыдущих поколений.
Ещё более значимо следующее: кластеры хранения vSAN теперь могут совместно использоваться через границы vCenter — так же, как традиционные внешние массивы. Это позволяет максимизировать использование ёмкости, консолидировать развёртывания и увеличивать плотность при сохранении низкой совокупной стоимости владения.
Ускорение разработки современных приложений
Современные ИТ-команды поддерживают всё — от традиционных баз данных до контейнерных приложений и современных практик DevOps, — строго соблюдая соглашения об уровне обслуживания. vSAN в VCF 9.1 расширяет гибкость для удовлетворения этих разнообразных требований.
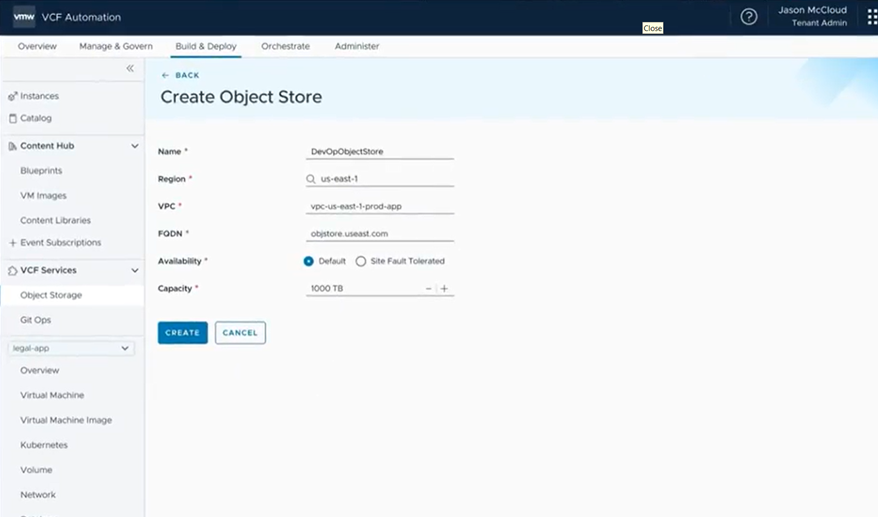
Нативное объектное хранилище S3 в vSAN (Technical Preview)
Впервые vSAN предоставляет нативное объектное хранилище, совместимое с S3, добавляя третий тип хранения — наряду с блочным и файловым — непосредственно в VCF. Данная версия Technical Preview ориентирована на сценарии использования в DevOps и конвейерах CI/CD, где разработчикам необходим быстрый самостоятельный доступ к масштабируемому объектному хранилищу.
Реализация включает мультитенантность, S3-бакеты как услугу и базовые функции безопасности и соответствия требованиям — всё это доступно через VCF Automation. В результате разработчики получают необходимую гибкость, а ИТ сохраняет управление и контроль. При этом решение включено в лицензии VCF, обеспечивая снижение совокупной стоимости владения на 34% по сравнению с автономными локальными продуктами объектного хранения.
Новые возможности самообслуживания разработчиков для работы с хранилищем
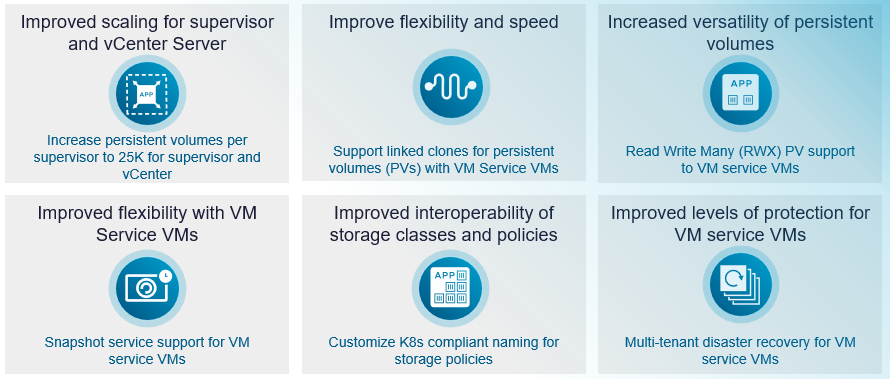
Значительное увеличение масштаба для постоянных томов
vSAN в VCF 9.1 существенно увеличивает масштаб контейнерных томов для сред VCF. Максимальное количество постоянных томов Read Write Once (RWO) на Supervisor возрастает с 7 500 до 25 000 — рост на 233%. На уровне vCenter лимит увеличивается с 30 000 до 50 000 постоянных томов, что составляет рост на 66%. Расширенные лимиты устраняют ограничения масштабирования для крупных развёртываний Kubernetes и мультитенантных сред.
Эффективное выделение ресурсов с помощью связанных клонов
Полные клоны слишком интенсивно используют хранилище и неэффективны для большинства сценариев. VCF 9.1 вводит поддержку связанных клонов для постоянных томов с First Class Disks, что существенно сокращает время выделения ресурсов и повышает операционную гибкость. Связанные клоны совместно используют общие базовые данные, что делает их идеальными для сред разработки, тестирования и сценариев, где необходимо быстро запустить несколько аналогичных рабочих нагрузок без затрат хранилища на полные клоны.
Поддержка Read Write Many (RWX) для виртуальных машин VM Service
Хотя файловые тома RWX могли использоваться в отдельных сценариях, они были недоступны для рабочих нагрузок — например, vSphere Pods и VM Service VMs — в пространстве имён Supervisor. VCF 9.1 устраняет этот пробел, позволяя виртуальным машинам VM Service монтировать и использовать тома RWX. Это открывает новые возможности для рабочих нагрузок, которым требуется совместный доступ к хранилищу сразу нескольких подов или виртуальных машин.
Единый подход к снимкам и операциям восстановления
Виртуальные машины VM Service теперь могут использовать простые операции восстановления по снимку VM, что приводит их в соответствие с традиционными виртуальными машинами. Такая согласованность упрощает рабочие процессы резервного копирования и восстановления вне зависимости от того, используются ли стандартные ВМ или машины VM Service — единый подход для всех рабочих нагрузок.
Соответствующие требованиям Kubernetes имена политик хранения
VCF 9.1 позволяет администраторам задавать настраиваемые имена политик хранения, совместимые с Kubernetes, при их создании. Это устраняет прежние ограничения именования, усложнявшие сопоставление политик хранения со StorageClass, упрощает согласование политик vSAN с соглашениями Kubernetes и улучшает опыт разработчиков.
Мультитенантное аварийное восстановление для машин VM Service
Облачные среды нередко обслуживают несколько команд или клиентов, каждый из которых требует независимых возможностей защиты и восстановления. VCF 9.1 вводит базовое мультитенантное аварийное восстановление (MTDR) для машин VM Service, предоставляя администраторам провайдеров и арендаторов возможность защищать виртуальные машины на базе Supervisor для сценариев защиты VCF-to-VCF.
Безопасность и киберустойчивость для современных угроз
Программы-вымогатели и утечки данных требуют хранилища, которое не только работает — но и защищает. vSAN в VCF 9.1 расширяет возможности защиты данных для долгосрочного хранения и комплексных сценариев восстановления.
Гибкое расписание снимков
В одном из предыдущих релизов нативные снапшоты vSAN получили возможность неизменяемости, а их производительность при масштабных и глубоких цепочках снапшотов — до 200 на ВМ — всегда оставалась высокой. vSAN в VCF 9.1 вводит гибкое расписание — широко известное как «дед–отец–сын» (GFS), — позволяющее расширить историю снимков для долгосрочного хранения в сценариях киберрезервного копирования.
Вместо того чтобы хранить каждый последовательный снимок, можно удерживать конкретные снимки с течением времени — например, почасовые снимки с сохранением одного за каждые 24 часа. Такой подход эффективно управляет ёмкостью, обеспечивая расширенную временную шкалу защиты, которую требуют нормативные и восстановительные требования.
Репликация из нескольких источников
Ранее репликация в VCF поддерживала только виртуальные машины, работающие с хранилища vSAN, на другое хранилище vSAN. В VCF 9.1 это ограничение снято: теперь можно реплицировать любую ВМ на базе VCF — включая те, что размещены на внешних массивах или других программно-определяемых хранилищах — в хранилище vSAN.
Эта возможность обеспечивает репликацию на основе политик по всей среде VCF, упрощая рабочие процессы восстановления и гарантируя согласованную защиту вне зависимости от текущего расположения ВМ. Репликацию можно совмещать с кластером киберрезервного копирования на базе vSAN для ускорения киберзащиты и восстановления.
Шифрование для глобальной дедупликации vSAN
Безопасность данных теперь распространяется на глобальную дедупликацию vSAN, гарантируя, что данные получают выгоду от экономии места без ущерба для защиты. Независимо от того, хранятся данные или передаются, они защищены шифрованием, валидированным по стандарту FIPS 140-3, от несанкционированного доступа.
Расширенные возможности растянутых кластеров
Растянутые кластеры уже давно обеспечивают устойчивость на уровне площадки для развёртываний vSAN. VCF 9.1 вводит два критически важных улучшения, повышающих операционную гибкость.
Во-первых, теперь можно перевести целый сайт в режим обслуживания с помощью управляемого процесса с расширенными предварительными проверками, обеспечивающими плавный вход и выход без прерывания сервиса. Во-вторых, в сценариях множественных отказов — когда один сайт находится в режиме обслуживания и одновременно происходит отказ второго сайта и свидетеля — теперь можно самостоятельно восстановить работоспособный сайт без обращения в глобальную службу поддержки. Встроенные предварительные проверки направляют процесс восстановления, сокращая время простоя и возвращая контроль в руки администраторов.
Упрощённые операции, масштабируемые с ростом инфраструктуры
Лучшая инфраструктура — та, о которой не нужно думать. VCF 9.1 реализует автоматизацию и интеллект, снижающие операционную нагрузку на ИТ-команды.
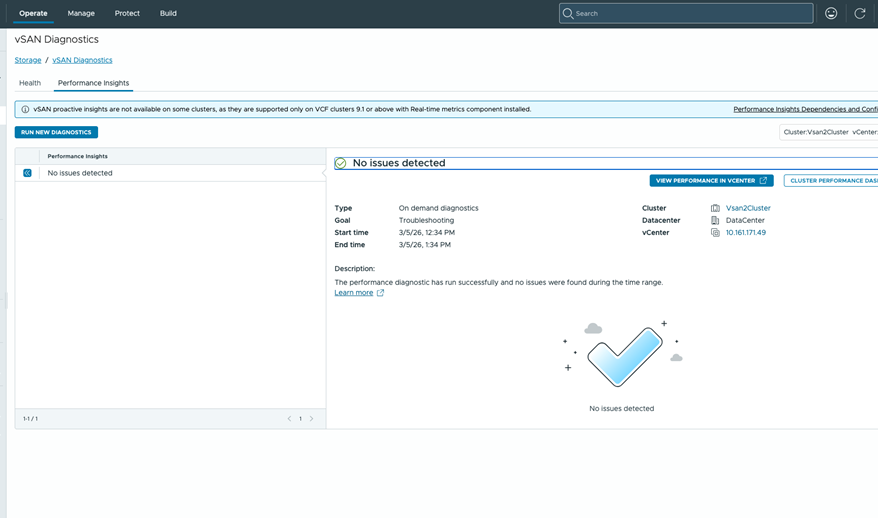
Проактивный мониторинг производительности vSAN
Диагностика проблем производительности в программно-определяемой инфраструктуре может быть непростой задачей. Где узкое место — в хранилище, вычислительных ресурсах или сети? VCF 9.1 применяет проактивный подход: постоянный мониторинг шаблонов производительности хранилища, установка базовых линий и оповещение об отклонениях.
При отклонении производительности от базовой линии VCF Operations использует расширенную аналитику для выявления корневых причин и предоставляет конкретные шаги по устранению — всё это доступно прямо в интерфейсе Performance Service. Алгоритмический подход к диагностике коррелирует точки данных, выявляет закономерности и предоставляет инсайты, поиск которых вручную занял бы часы.
Автоматизированное управление политиками хранения
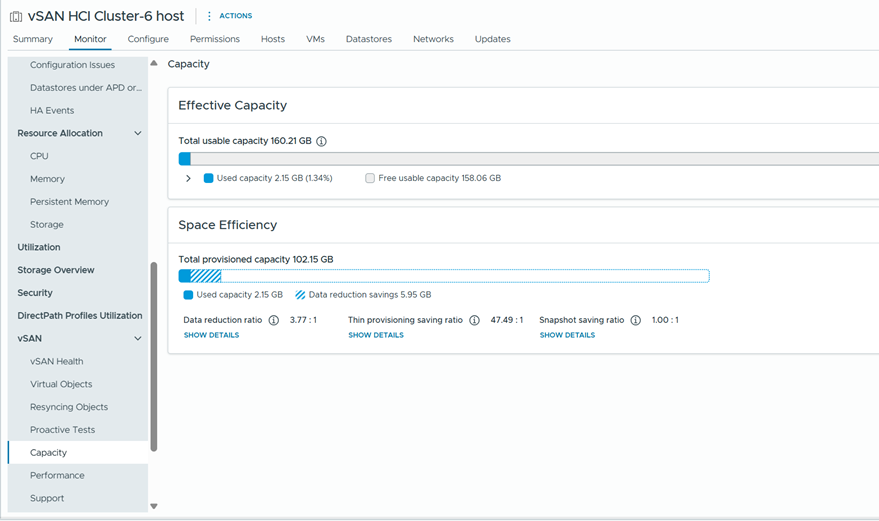
vSAN в VCF 9.1 автоматически применяет наивысший уровень отказоустойчивости и оптимальный erasure coding с учётом размера кластера. Это устраняет неопределённость при настройке политик хранения и гарантирует максимальную устойчивость и эффективность без ручной настройки. В сочетании с улучшенными отчётами об эффективной ёмкости обеспечивается более чёткая видимость реальной используемой ёмкости, что делает планирование ёмкости более точным и понятным.
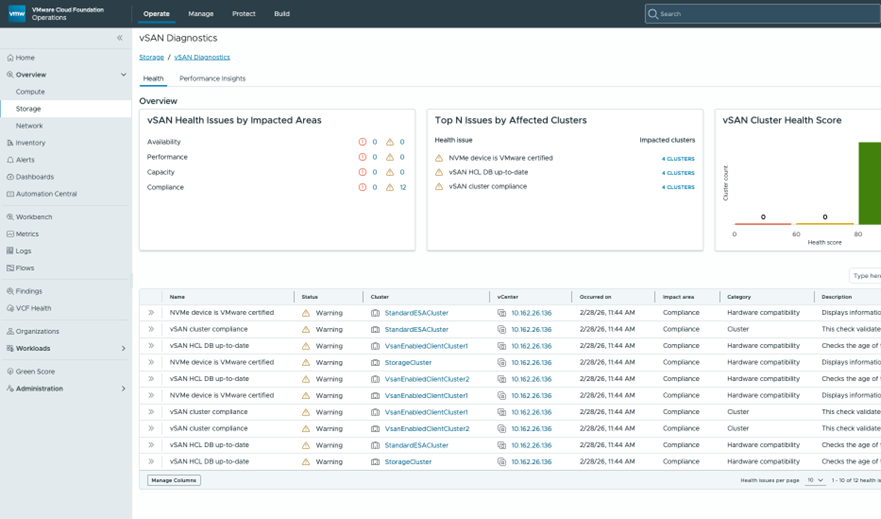
Расширенная диагностика хранилища vSAN
В одном из предыдущих выпусков в VCF Operations была представлена панель хранилища с важными метриками: оценками состояния, использованной ёмкостью и другими показателями. В vSAN в составе VCF 9.1 VCF Operations предоставит значительно расширенный набор информации и возможность принимать меры по диагностическим проблемам vSAN непосредственно из консоли VCF. Администраторам больше не придётся вручную перемещаться по интерфейсу для выявления корневых причин низких оценок состояния или определения способов устранения проблем — количество необходимых кликов сокращается до 60%.
vSAN в VCF 9.1 представляет собой значительный шаг вперёд в направлении более эффективного, гибкого, безопасного и интеллектуального хранилища для частного облака. Независимо от того, оптимизируете ли вы совокупную стоимость владения, поддерживаете разнообразные рабочие нагрузки, укрепляете устойчивость или упрощаете операции, этот релиз предоставляет практические возможности, решающие реальные ИТ-задачи.
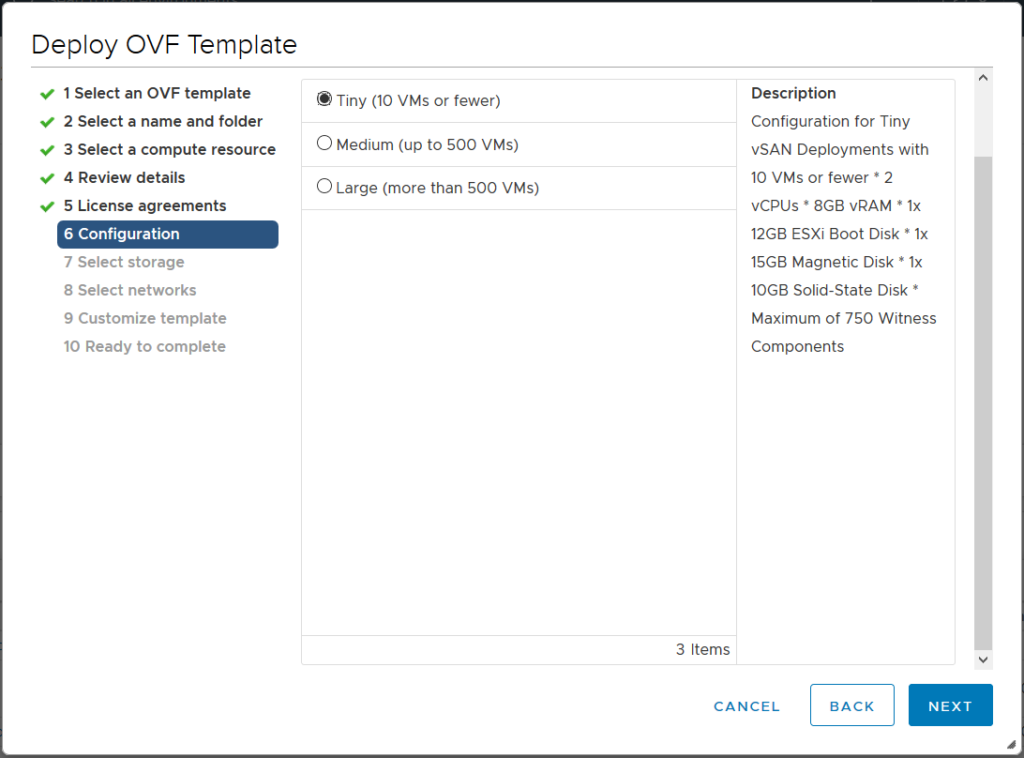
В какой-то момент требования к ресурсам для Witness VM в vSAN ESA исчезли из официальной документации. Между тем этот вопрос остаётся актуальным: сколько памяти выделяется виртуальной машине и сколько у неё vCPU? Ответ зависит от выбранного профиля — Witness VM доступна в трёх вариантах: M, L и XL.
Выбор профиля определяется количеством виртуальных машин, которые планируется развернуть. При этом рекомендуется закладывать запас на рост. Когда Witness VM разворачивается через мастер развёртывания, нужные цифры там не указаны — однако их можно узнать, заглянув в OVF-дескриптор.
Из OVF-файла vSAN ESA Witness получены следующие данные о ресурсах:
vSAN ESA Witness XL — 8 vCPU, 64 ГБ памяти
vSAN ESA Witness L — 4 vCPU, 32 ГБ памяти
vSAN ESA Witness M — 4 vCPU, 16 ГБ памяти
Для тех, кто использует vSAN OSA, требования к ресурсам следующие:
vSAN OSA Witness XL — 6 vCPU, 32 ГБ памяти
vSAN OSA Witness L — 2 vCPU, 32 ГБ памяти
vSAN OSA Witness Normal — 2 vCPU, 16 ГБ памяти
vSAN OSA Witness Tiny — 2 vCPU, 8 ГБ памяти
Важно учитывать, что приведённые значения актуальны на момент публикации — с выходом новых версий vSAN требования к ресурсам могут измениться.
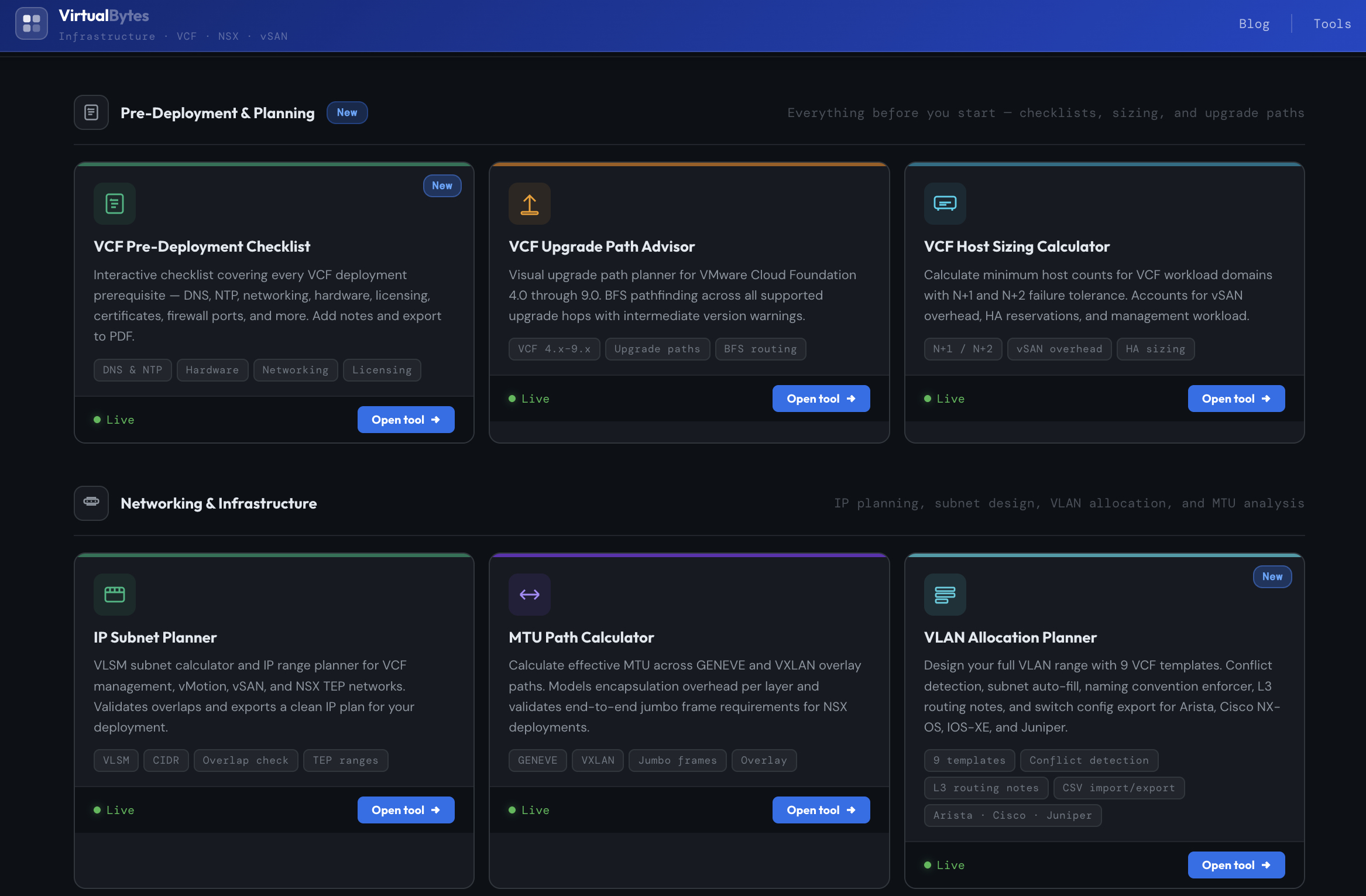
В сфере виртуализации и облачной инфраструктуры системные инженеры регулярно сталкиваются с задачами расчётов, проверки параметров конфигурации и подготовки инфраструктуры к развертыванию. Именно для таких задач создан сайт https://tools.virtualbytes.cloud/ — онлайн-площадка с полезными утилитами для специалистов по VMware-инфраструктуре и облачным платформам.
Что представляет собой сервис
Tools.VirtualBytes.Cloud — это коллекция веб-инструментов, предназначенных для работы с инфраструктурными компонентами VMware-экосистемы и сопутствующих технологий. Сервис позволяет использовать различные утилиты прямо в браузере без установки дополнительного программного обеспечения на локальную машину.
Основная идея платформы — предоставить инженерам быстрый доступ к вспомогательным инструментам, которые упрощают администрирование и проектирование виртуальной инфраструктуры.
Какие инструменты доступны онлайн
Сервис ориентирован на специалистов, работающих с современными датацентрами и программно-определяемыми инфраструктурами. Среди основных направлений инструментов:
Работа с платформой VMware Cloud Foundation (VCF)
Инструменты для VMware NSX и сетевой виртуализации
Вспомогательные утилиты для vSAN
Сетевые и инфраструктурные калькуляторы
Инструменты для анализа и подготовки конфигураций
Благодаря веб-формату инструменты можно использовать с любого устройства — достаточно открыть сайт в браузере.
Бесплатные онлайн-утилиты
VCF Pre-Deployment Checklist
Интерактивный чеклист, охватывающий все требования перед развертыванием VCF — DNS, NTP, сетевую инфраструктуру, оборудование, лицензии, сертификаты, порты файрвола и многое другое. Позволяет добавлять заметки и экспортировать результат в PDF.
VCF Upgrade Path Advisor
Визуальный планировщик путей обновления для VMware Cloud Foundation версий 4.0–9.0. Использует поиск оптимального пути (BFS) между поддерживаемыми этапами обновления и предупреждает о промежуточных версиях.
VCF Host Sizing Calculator
Калькулятор минимального количества хостов для доменов нагрузки VCF с учетом отказоустойчивости N+1 и N+2. Учитывает накладные расходы vSAN, резервации HA и нагрузку management-компонентов.
IP Subnet Planner
Калькулятор подсетей VLSM и планировщик диапазонов IP-адресов для сетей VCF: management, vMotion, vSAN и NSX TEP. Проверяет пересечения подсетей и позволяет экспортировать готовый IP-план для развертывания.
MTU Path Calculator
Калькулятор эффективного MTU для overlay-сетей GENEVE и VXLAN. Моделирует накладные расходы инкапсуляции на каждом уровне и проверяет требования к jumbo-фреймам для NSX-инфраструктуры.
VLAN Allocation Planner
Инструмент для проектирования полного диапазона VLAN с использованием 9 шаблонов VCF. Включает обнаружение конфликтов, автоматическое заполнение подсетей, контроль соглашений по именованию, заметки по L3-маршрутизации и экспорт конфигураций коммутаторов для Arista, Cisco NX-OS, IOS-XE и Juniper.
VCF 9 Network Config Generator
Генератор полной сетевой конфигурации для VCF 9, включая назначение VLAN, параметры MTU, политики teaming и конфигурацию пулов NSX TEP для развертываний с несколькими кластерами.
vSAN Capacity Calculator
Калькулятор полезной емкости vSAN для архитектур OSA и ESA с политиками RAID-1, RAID-5 и RAID-6. Учитывает slack space, отказ хостов и приблизительную эффективность дедупликации.
NSX Firewall Rule Planner
Инструмент для планирования и документирования правил распределенного файрвола NSX. Позволяет задавать группы источников и назначений, сервисы и область применения (Applied-To), проверяет логику правил и экспортирует их в структурированную таблицу.
VCF Day 2 Operations Planner
Набор пошаговых runbook-процедур для операций Day-2: расширение кластера, создание доменов нагрузки, ротация сертификатов, обновление компонентов, смена паролей, расширение vSAN и управление сегментами NSX.
Для кого предназначен сайт
Платформа будет полезна:
Системным администраторам и инженерам виртуализации
Архитекторам облачной инфраструктуры
DevOps-специалистам
Инженерам датацентров и лабораторий
Особенно ценным ресурс становится при работе с VMware-экосистемой, где часто требуется быстро рассчитать параметры инфраструктуры или проверить настройки перед развертыванием.
Итог
Tools.VirtualBytes.Cloud — это полезный ресурс для специалистов по виртуализации и облачным технологиям. Он объединяет набор практических инструментов, которые помогают упростить работу с инфраструктурой VMware и ускорить решение повседневных задач администрирования.
Для инженеров, работающих с VCF, NSX и другими компонентами программно-определяемого дата-центра, подобные сервисы позволяют экономить время и повышать эффективность управления инфраструктурой.
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.
vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
Требования к оборудованию и сети
Варианты развертывания кластеров
Масштабирование и отказоустойчивость
Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
General Information — общая информация о vSAN
Express Storage Architecture (ESA)
Availability — отказоустойчивость
Cloud-Native Storage
vSAN File Services
vSAN Storage Clusters (disaggregated storage)
Stretched clusters и 2-node clusters
Networking
Capacity и Space Efficiency
Operations
Performance
Security
vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.
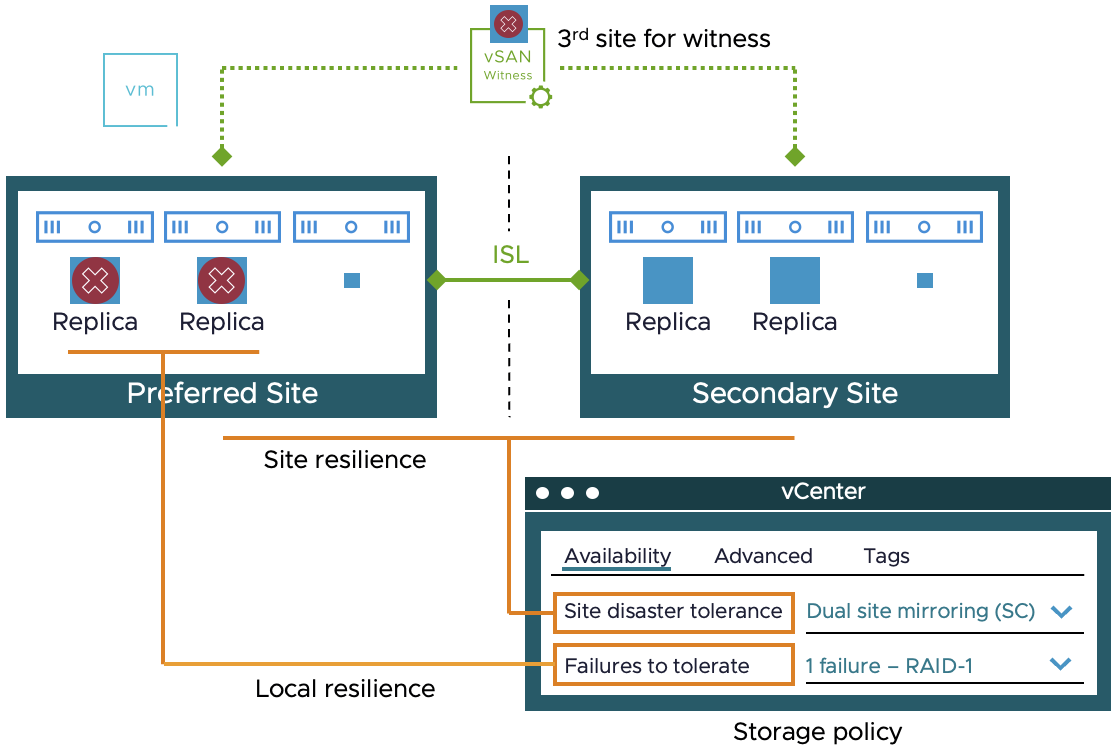
Дункан Эппинг в своей статье ответил на этот вопрос. Он стал замечать, что этот вопрос возникает всё чаще: можно ли реплицировать или создавать снапшот виртуального модуля vSAN Stretched Cluster Witness для быстрого восстановления? Обычно люди задают его потому, что не могут соблюсти требование трёх площадок для vSAN Stretched Cluster. Поэтому, настроив какой-то механизм репликации с низким RPO, они пытаются снизить этот риск.
Возможно, этот вопрос возникает из-за недостаточного понимания того, какую роль выполняет Witness. Он обеспечивает механизм кворума, а этот механизм помогает определить, какая площадка получает доступ к данным в случае сетевого сбоя (ISL) между площадками хранения данных.
Так почему же виртуальное устройство Witness нельзя снапшотить или реплицировать? Дело в том, что для обеспечения механизма кворума Witness Appliance хранит witness-компонент для каждого объекта. Причём не для каждой площадки и не для каждой виртуальной машины, а для каждого объекта! То есть если у вас есть ВМ с несколькими VMDK, то для одной ВМ на Witness Appliance будет храниться несколько witness-объектов.
Этот witness-объект содержит метаданные и с помощью номера последовательности журнала (log sequence number) определяет, какой объект содержит самые актуальные данные. И вот здесь возникает проблема. Если вы откатите Witness Appliance к более раннему моменту времени, то witness-компоненты также откатятся назад и будут иметь другой номер последовательности журнала, чем ожидается. В результате vSAN не сможет сделать объект доступным для выжившей площадки или для той площадки, которая должна обладать кворумом.
Итак, краткий вывод: следует ли реплицировать или создавать снапшот Witness Appliance? Нет!
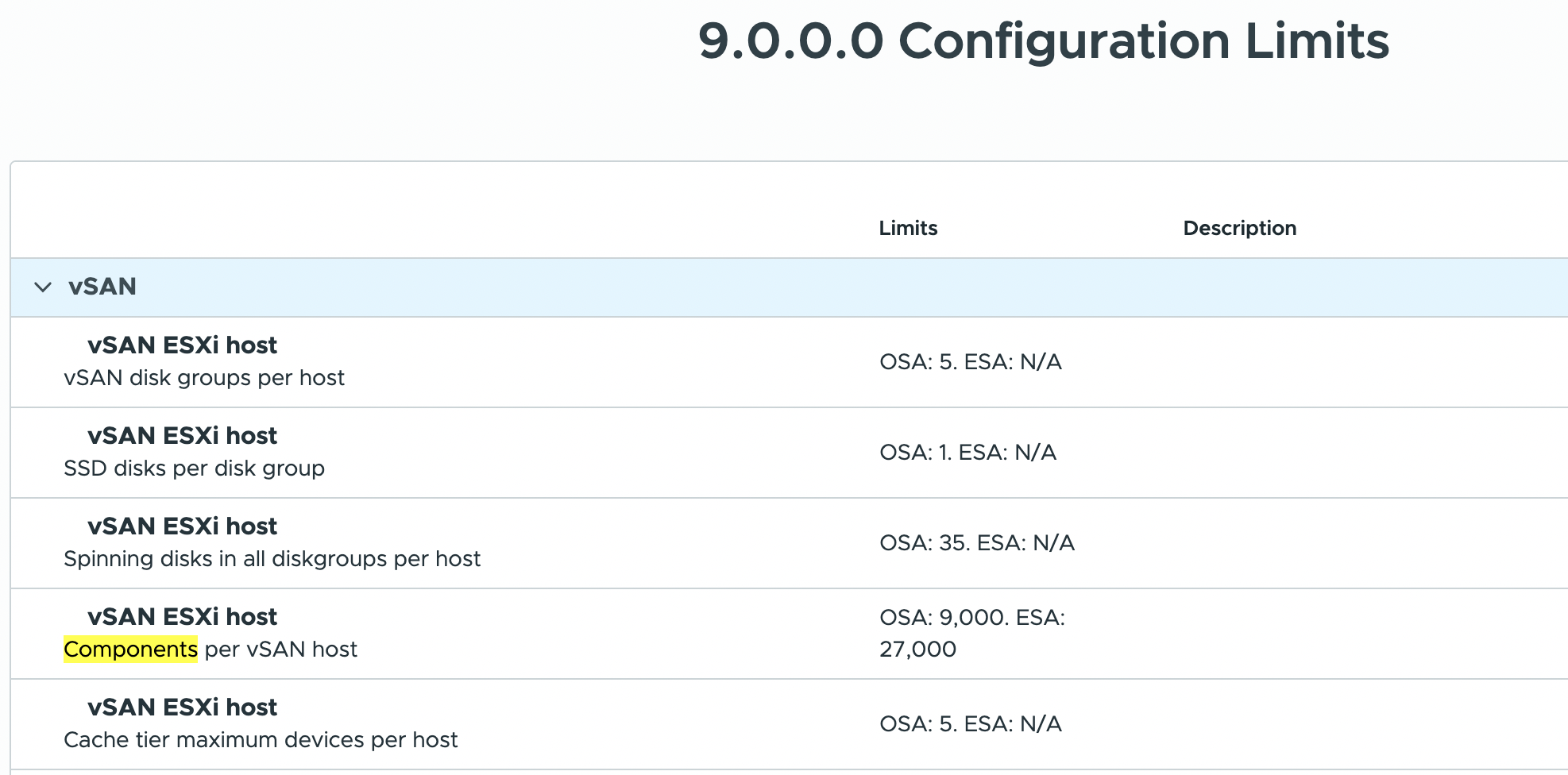
Дункан Эппинг написал интересный пост на тему решения VMware vSAN и допустимых лимитов на компоненты. За последние несколько лет у него было не так много обсуждений по поводу лимитов, но в последнее время такие разговоры почему-то стали возникать всё чаще. Если спросить клиента, каков лимит компонентов у vSAN, кто-то скажет — 9000 на хост (OSA), другие — 27 000 на хост (ESA), а некоторые даже знают ограничение по количеству компонентов на кластер (в документации эти лимиты указаны здесь и здесь). Однако есть один критически важный аспект, о котором большинство обычно не задумывается. В этом посте мы сосредоточимся на vSAN ESA.
Как уже упоминалось, существует лимит на хост и на кластер, но также есть ограничение на устройство (диск). Частая ошибка заключается в том, что люди воспринимают кластерный и хостовый лимиты как самостоятельные и фиксированные значения. Однако здесь есть зависимость. Как было сказано, у устройства тоже есть свой предел. В vSAN ESA одно устройство может содержать максимум 3000 data-компонентов и 3000 metadata-компонентов. Именно такие ограничения поддерживаются в текущей версии (vSAN 9.0). Пока сосредоточимся на data-компонентах (уровень ёмкости).
Это означает, что если в хосте 8 устройств или меньше, то максимальное количество компонентов будет не 27 000, а «количество устройств x 3000». Другими словами, если в хосте один NVMe-накопитель для vSAN ESA, максимальное количество компонентов для этого хоста — 3000. Если два устройства — максимум 6000, и так далее.
Почему об этом стоит писать? Если учесть количество компонентов на один объект и умножить его на типичное количество объектов, быстро становится понятно почему. Предположим, вы используете RAID-5 с ESA в конфигурации 4+1 — это даст как минимум 5 компонентов. Если у виртуальной машины несколько дисков, легко можно получить 35–40 компонентов на одну ВМ. Если взять лимит 3000 и разделить его, скажем, на 40 компонентов, получаем всего 75–80 виртуальных машин. Конечно, у вас будет несколько хостов, и это число масштабируется по их количеству, но пример наглядно показывает, почему важно учитывать этот максимум.
Возникает вопрос: почему эта тема стала подниматься именно сейчас? Дело в том, что по мере того как заказчики всё увереннее используют vSAN ESA, мы видим всё более «экзотические» конфигурации. Всё чаще развёртываются системы с очень ёмкими накопителями, но в небольшом количестве. Если раньше обычно использовали 6–8 устройств на хост по 1–2 ТБ каждое, то теперь всё чаще спрашивают о конфигурациях с одним NVMe-накопителем на 15 ТБ или двумя устройствами по 7.x ТБ. Нетрудно представить, что при таких вводных лимит в 3000 data-компонентов достигается значительно быстрее, чем хостовый лимит в 27 000 компонентов.
Поэтому, если вы планируете новый кластер vSAN, обязательно учитывайте эти ограничения. Не стоит думать только о ёмкости — есть и другие важные факторы, которые необходимо принимать во внимание.
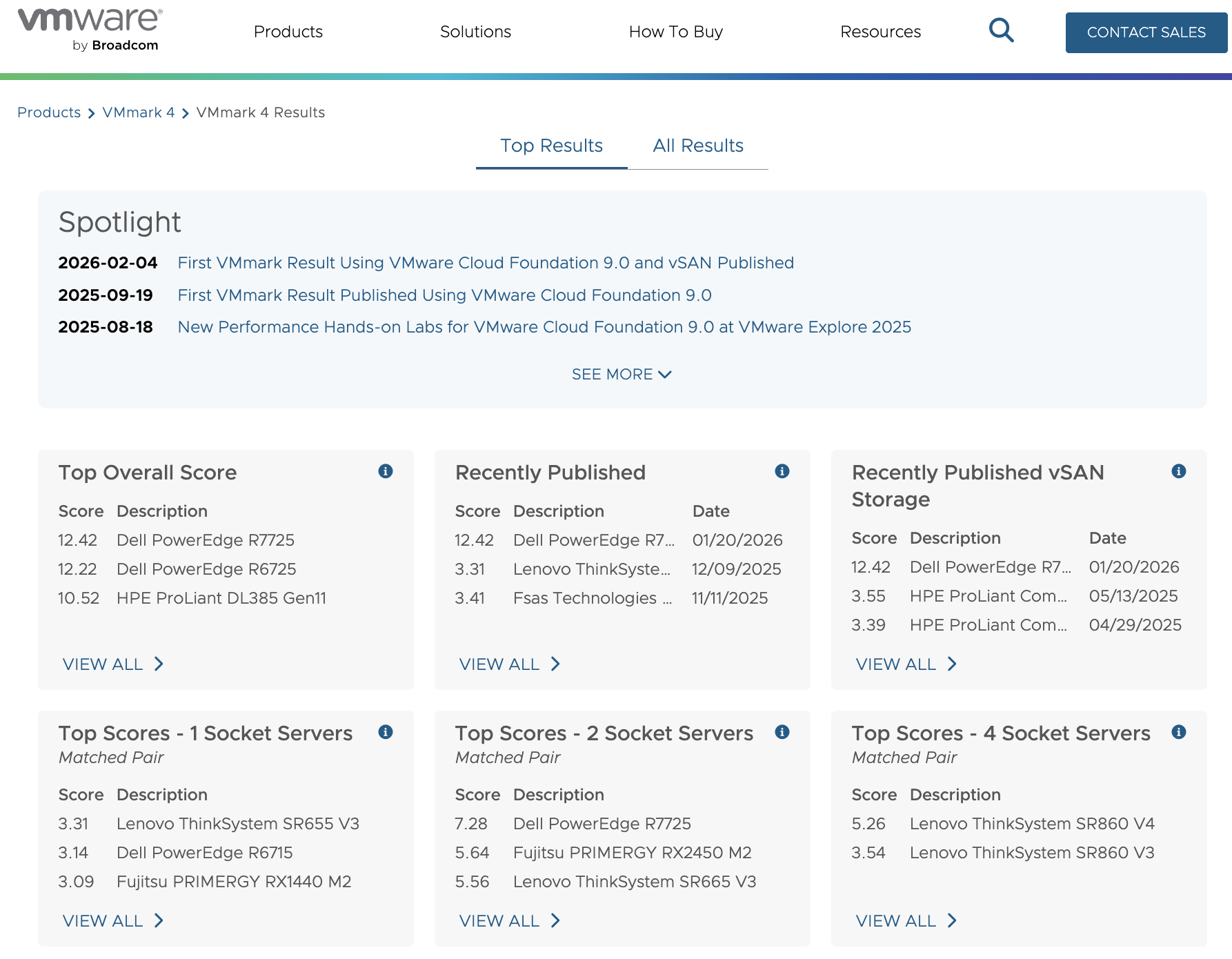
Компания VMware продолжает развитие своей платформы для частных облаков — VMware Cloud Foundation (VCF) 9.0. Недавно опубликованы первые результаты производительности с использованием бенчмарка VMmark 4, выполненные на базе VCF 9.0 с встроенным программно определяемым хранилищем VMware vSAN. Этот результат стал важной вехой для оценки возможностей платформы в реальных условиях нагрузки, демонстрируя, что VCF 9.0 способна эффективно масштабировать инфраструктуру частного облака с помощью современного оборудования и передовых технологий.
Что такое VMmark 4, и зачем он нужен
VMmark 4 — это кластерный бенчмарк VMware, предназначенный для измерения производительности и масштабируемости виртуализированных сред. В отличие от синтетических тестов, VMmark моделирует реальные корпоративные рабочие нагрузки:
базы данных
веб-серверы
почтовые системы
application-серверы
файловые сервисы
Нагрузка масштабируется в единицах tiles — каждый tile представляет собой комплекс виртуальных машин с типовым профилем предприятия. Итоговый показатель (VMmark Score) отражает способность кластера обслуживать увеличивающееся число рабочих нагрузок при сохранении SLA по производительности.
Тестовая конфигурация: ключевые компоненты
Для испытаний использовалась конфигурация, включающая новейшие аппаратные и программные компоненты:
Программное обеспечение: VMware Cloud Foundation 9.0.1.0 .
vSAN 9 ESA: программное хранилище уровня предприятия с оптимизированной архитектурой Express Storage Architecture.
NSX: сетевые сервисы и безопасность для виртуальной инфраструктуры.
Operations: мониторинг, аналитика и автоматизация облачных ресурсов.
Главная цель VCF — упростить развёртывание и управление частными облаками с уровня инфраструктуры до сервисов, при этом обеспечивая масштабируемость, производительность и возможность автоматизации.
Результат тестирования
Для объективного сравнения использовалась идентичная вычислительная платформа (AMD EPYC 9965, суммарно 1536 физических ядер кластера), но две разные подсистемы хранения:
vSAN 9.0 ESA (All-Flash, NVMe)
Классический FC SAN (Dell PowerMax 8000)
Таблица результатов:
Версия VCF
Тип хранилища
Процессор
Всего ядер
VMmark 4 Score
9.0.1.0
vSAN 9.0 ESA (All-Flash)
AMD EPYC 9965
1536
12.42 @ 15.4 tiles
9.0.0.0
FC SAN (Dell PowerMax 8000)
AMD EPYC 9965
1536
12.22 @ 14 tiles
Интерпретация результатов:
Tiles — это масштабируемые блоки нагрузки в VMmark 4. Каждый tile представляет набор типовых корпоративных рабочих нагрузок (Web, DB, Mail, Application Server и др.).
Значение 15.4 tiles означает более высокий уровень масштабирования кластера.
Итоговый показатель 12.42 — агрегированный производительный балл, учитывающий пропускную способность и latency.
Главный вывод - конфигурация с vSAN 9.0 ESA продемонстрировала:
Большее число поддерживаемых tiles (15.4 против 14 для FC)
Более высокий итоговый Score
Лучшую масштабируемость без использования внешнего SAN-массива.
Это подтверждает, что современная архитектура vSAN ESA в составе VCF 9.0 способна не только конкурировать с традиционными FC-решениями, но и превосходить их при одинаковой вычислительной базе.
Заключение
Новый VMmark 4 результат, полученный на VMware Cloud Foundation 9.0 с vSAN, подтверждает:
Высокую производительность и масштабируемость платформы.
Превосходство программно-определяемого хранения (vSAN) над традиционными SAN в современных конфигурациях.
Готовность VMware VCF 9.0 к использованию в масштабных частных облаках и корпоративных средах.
Для инженеров и архитекторов частных облаков это подтверждение того, что VCF 9.0 + vSAN — это не только удобная абстракция управления, но и мощная вычислительная платформа с высокими показателями эффективности.
Компания VMware выпустила обновлённое официальное руководство vSAN Stretched Cluster Guide, предназначенное для архитекторов и администраторов, работающих с растянутыми кластерами vSAN в рамках платформы VMware Cloud Foundation (VCF) 9.0. Документ был выпущен 18 февраля 2026 года и отражает актуальные практики проектирования, развертывания и эксплуатации таких инфраструктур.
Руководство подробно описывает ключевые концепции и требования к растянутым кластерам vSAN — типу конфигурации, в которой ресурсы распределены по двум географически разнесённым сайтам с целью обеспечения максимальной отказоустойчивости и непрерывной доступности виртуальных машин.
Что нового в версии для VCF 9.0
Актуализация под VCF 9.0 и vSAN 9
Документ ориентирован на использование растянутых кластеров именно в контексте VCF 9.0, в том числе с учётом последних архитектурных изменений и интеграции с инструментами автоматизации SDDC Manager.
Расширенные рекомендации по сетевым требованиям
В руководстве обновлены требования к сети между площадками — минимальные значения пропускной способности и задержек, оптимальные настройки MTU и рекомендации по сегментации трафика.
Поддержка разных архитектур хранения
Кроме классической архитектуры vSAN (OSA), руководство учитывает и vSAN Express Storage Architecture (ESA) — более современный вариант с улучшенной производительностью и эффективностью хранения.
Процессы установки и конвертации
Обозначены пошаговые процессы установки растянутого кластера, развёртывания и конфигурации vSAN Witness Host, а также инструкция по конвертации существующего кластера vSAN в растянутую конфигурацию без прерывания работы.
Сценарии отказов и восстановление
Отдельный раздел посвящён анализу отказов, поведения кластера в стрессовых ситуациях и практикам восстановления после отказов отдельных компонентов или целых площадок.
Практическая ценность для предприятий
Растянутые кластеры vSAN в VCF 9.0 остаются одним из ключевых решений для компаний с критичными требованиями к доступности (финансовые учреждения, телеком, здравоохранение), обеспечивая непрерывность бизнес-сервисов при отказах на уровне целого дата-центра.
Новый документ vSAN Stretched Cluster Guide служит исчерпывающим справочником для ИТ-специалистов, помогая спланировать архитектуру, соблюсти требования к оборудованию и сети, правильно настроить объектные политики хранения и обеспечить корректное поведение системы в случае сбоев.
Решение VMware vSAN довольно часто всплывает в обсуждениях Memory Tiering — как из-за сходства между этими технологиями, так и из-за вопросов совместимости, поэтому давайте разберёмся подробнее.
Когда мы только начали работать с Memory Tiering, сходство между Memory Tiering и vSAN OSA было достаточно очевидным. Обе технологии используют многоуровневый подход, при котором активные данные размещаются на быстрых устройствах, а неактивные — на более дешёвых, что помогает снизить TCO и уменьшить потребность в дорогих устройствах для хранения «холодных» данных. Обе также глубоко интегрированы в vSphere и просты в реализации. Однако, помимо сходств, изначально возникала некоторая путаница относительно совместимости, интеграции и возможности одновременного использования обеих функций. Поэтому давайте попробуем ответить на эти вопросы.
Да, вы можете одновременно использовать vSAN и Memory Tiering в одних и тех же кластерах. Путаница в основном связана с идеей предоставления хранилища vSAN для Memory Tiering — а это категорически не поддерживается. Мы говорили об этом ранее, но ещё раз подчеркнем: хотя обе технологии могут использовать NVMe-устройства, это не означает, что они могут совместно использовать одни и те же ресурсы. Memory Tiering требует собственного физического или логического устройства, предназначенного исключительно для выделения памяти. Мы не хотим делить это физическое/логическое устройство с чем-либо ещё, включая vSAN или другие датасторы. Почему? Потому что в случае совместного использования мы будем конкурировать за пропускную способность, а уж точно не хотим замедлять работу памяти ради того, чтобы «не тратить впустую» NVMe-пространство. Это всё равно что сказать: "У меня бак машины наполовину пуст, поэтому я залью туда воду, чтобы не терять место".
При этом технически вы можете создать несколько разделов для лабораторной среды (на свой страх и риск), но когда речь идёт о продуктивных нагрузках, обязательно используйте выделенное физическое или логическое (HW RAID) устройство исключительно для Memory Tiering.
Подводя итог по vSAN и Memory Tiering: они МОГУТ сосуществовать, но не могут совместно использовать ресурсы (диски/датасторы). Они хорошо работают в одном кластере, но их функции не пересекаются — это независимые решения. Виртуальные машины могут одновременно использовать датастор vSAN и ресурсы Memory Tiering. Вы даже можете иметь ВМ с шифрованием vSAN и шифрованием Memory Tiering — но эти механизмы работают на разных уровнях. Несмотря на кажущееся сходство, решения функционируют независимо друг от друга и при этом отлично дополняют друг друга, обеспечивая более целостную инфраструктуру в рамках VCF.
Соображения по хранению данных
Теперь мы знаем, что нельзя использовать vSAN для предоставления хранилища для Memory Tiering, но тот же принцип применяется и к другим датасторам или решениям NAS/SAN. Для Memory Tiering требуется выделенное устройство, локально подключённое к хосту, на котором не должно быть создано никаких других разделов. Соответственно, не нужно предоставлять датастор на базе NVMe для использования в Memory Tiering.
Говоря о других вариантах хранения, также важно подчеркнуть, что мы не делим устройства между локальным хранилищем и Memory Tiering. Это означает, что одно и то же устройство не может одновременно обслуживать локальное хранилище (локальный датастор) и Memory Tiering. Однако такие устройства всё же можно использовать для Memory Tiering. Поясним.
Предположим, вы действительно хотите внедрить Memory Tiering в своей среде, но у вас нет свободных NVMe-устройств, и запрос на капитальные затраты (CapEx) на покупку новых устройств не был одобрен. В этом случае вы можете изъять NVMe-устройства из локальных датасторов или даже из vSAN и использовать их для Memory Tiering, следуя корректной процедуре:
Убедитесь, что рассматриваемое устройство входит в рекомендуемый список и имеет класс износостойкости D и класс производительности F или G (см. нашу статью тут).
Удалите NVMe-устройство из vSAN или локального датастора.
Удалите все оставшиеся разделы после использования в vSAN или локальном датасторе.
Создайте раздел для Memory Tiering.
Настройте Memory Tiering на хосте или кластере.
Как вы видите, мы можем «позаимствовать» устройства для нужд Memory Tiering, однако крайне важно убедиться, что вы можете позволить себе потерю этих устройств для прежних датасторов, а также что выбранное устройство соответствует требованиям по износостойкости, производительности и наличию «чистых» разделов. Кроме того, при необходимости обязательно защитите или перенесите данные в другое место на время использования устройств.
Это лишь один из шагов, к которому можно прибегнуть в сложной ситуации, когда необходимо получить устройства; однако если данные на этих устройствах должны сохраниться, убедитесь, что у вас есть свободное пространство в другом месте. Выполняйте эти действия на свой страх и риск.
На момент выхода VCF 9 в процессе развёртывания VCF отсутствует отдельный рабочий процесс для выделения устройств под Memory Tiering, а vSAN автоматически захватывает устройства во время развёртывания. Поэтому при развертывании VCF «с нуля» (greenfield) вам может потребоваться использовать описанную процедуру, чтобы вернуть из vSAN устройство, предназначенное для Memory Tiering. VMware работает над улучшением этого процесса и поменяет его в ближайшем будущем.
Доступность данных — ключевая компетенция корпоративных систем хранения. На протяжении десятилетий такие системы стремились обеспечить высокий уровень доступности данных при одновременном соблюдении ожиданий по производительности и эффективности использования пространства. Достичь всего этого одновременно непросто.
Кодирование с восстановлением (erasure coding) играет важную роль в хранении данных устойчивым, но при этом эффективным с точки зрения занимаемого пространства способом. Этот пост поможет лучше понять, как erasure coding реализовано в VMware vSAN, чем оно отличается от подходов, применяемых в традиционных системах хранения, и как корректно интерпретировать возможности erasure code в контексте доступности данных.
Назначение Erasure Coding
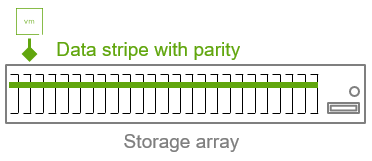
Основная ответственность любой системы хранения — вернуть запрошенный бит данных. Чтобы делать это надежно, системе хранения необходимо сохранять данные устойчивым способом. Простейшая форма устойчивости данных достигается посредством нескольких копий или «зеркал», которые позволяют поддерживать доступность при возникновении отказа в системе хранения, например при выходе из строя диска в массиве хранения или хоста в распределённой системе хранения, такой как vSAN. Одна из проблем этого подхода — высокая стоимость хранения: полные копии данных занимают много места. Одна дополнительная копия удваивает объём, две — утраивают.
Erasure codes позволяют хранить данные устойчиво, но гораздо более эффективно с точки зрения пространства, чем традиционное зеркалирование. Вместо хранения копий данные распределяются по нескольким локациям — каждая из которых может считаться точкой отказа (например, диск или хост в распределённой системе, такой как vSAN). Фрагменты данных формируют «полосу» (stripe), к которой добавляются фрагменты четности, создаваемые при записи данных. Данные четности получаются в результате математических вычислений. Если какой-либо фрагмент данных отсутствует, система может прочитать доступные части полосы и вычислить недостающий фрагмент, используя четность. Таким образом, она может либо выполнить исходный запрос чтения «на лету», либо реконструировать отсутствующие данные в новое место. Тип erasure code определяет, может ли он выдержать потерю одного, двух или более фрагментов при сохранении доступности данных.
Erasure codes обеспечивают существенную экономию пространства по сравнению с традиционным зеркальным хранением. Экономия зависит от характеристик конкретного типа erasure code — например, сколько отказов он способен выдержать и по скольким локациям распределяются данные.
Erasure codes бывают разных типов. Их обычно обозначают количеством фрагментов данных и количеством фрагментов четности. Например, обозначение 6+3 или 6,3 означает, что полоса состоит из 6 (k) фрагментов данных и 3 (m) фрагментов четности, всего 9 (n) фрагментов. Такой тип erasure code может выдержать отказ любых трёх фрагментов, сохранив доступность данных. Он обеспечивает такую устойчивость при всего лишь 50% дополнительного расхода пространства.
Но erasure codes не лишены недостатков. Операции ввода-вывода становятся более сложными: одна операция записи может преобразовываться в несколько операций чтения и записи, что называют «усилением ввода-вывода» (I/O amplification). Это может замедлять обработку в системе хранения, а также увеличивать нагрузку на CPU и требовать больше полосы пропускания. Однако при правильной реализации erasure codes могут сочетать устойчивость с высокой производительностью. Например, инновационная архитектура vSAN ESA устраняет типичные проблемы производительности erasure codes, и RAID-6 в ESA может обеспечивать такую же или даже лучшую производительность, чем RAID-1.
Хранение данных в vSAN и в традиционном массиве хранения
Прежде чем сравнивать erasure codes в vSAN и традиционных системах хранения, рассмотрим, как vSAN хранит данные по сравнению с классическим массивом.
Хранилища часто предоставляют большой пул ресурсов в виде LUN. В контексте vSphere он форматируется как datastore с VMware VMFS, где располагаются несколько виртуальных машин. Команды SCSI передаются от ВМ через хосты vSphere в систему хранения. Такой datastore на массиве охватывает большое количество устройств хранения в его корпусе, что означает не только широкую логическую границу (кластерная файловая система с множеством ВМ), но и большую физическую границу (несколько дисков). Как и многие другие файловые системы, такая кластерная ФС должна оставаться целостной, со всеми метаданными и данными, доступными в полном объёме.
vSAN использует совершенно иной подход. Вместо классической файловой системы с большой логической областью данных, распределённой по всем хостам, vSAN оперирует малой логической областью данных для каждого объекта. Примерами могут служить диски VMDK виртуальной машины, постоянный том для контейнера или файловый ресурс, предоставленный службами файлов vSAN. Именно это делает vSAN аналогичным объектному хранилищу, даже несмотря на то, что фактически это блочное хранилище с использованием SCSI-семантики или файловой семантики в случае файловых сервисов. Для дополнительной информации об объектах и компонентах vSAN см. пост «vSAN Objects and Components Revisited».
Такой подход обеспечивает vSAN целый ряд технических преимуществ по сравнению с монолитной кластерной файловой системой в традиционном массиве хранения. Erasure codes применяются к объектам независимо и более гранулярно. Это позволяет заказчикам проектировать кластеры vSAN так, как они считают нужным — будь то стандартный односайтовый кластер, кластер с доменами отказа для отказоустойчивости на уровне стоек или растянутый кластер (stretched cluster). Кроме того, такой подход позволяет vSAN масштабироваться способами, недоступными при традиционных архитектурных решениях.
Сравнение erasure coding в vSAN и традиционных системах хранения
Имея базовое понимание того, как традиционные массивы и vSAN предоставляют ресурсы хранения, рассмотрим, чем их подходы к erasure coding отличаются. В этих сравнениях предполагается наличие одновременных отказов, поскольку многие системы хранения способны справляться с единичными отказами в течение некоторого времени.
Массив хранения (Storage Array)
В данном примере традиционный массив использует erasure code конфигурации 22+3 для одного LUN (k=22, m=3, n=25).
Преимущества:
Относительно низкие накладные расходы по ёмкости. Дополнительная ёмкость, потребляемая данными четности для поддержания доступности при сбоях в доменах отказа (устройствах хранения), составляет около 14%. Такого низкого уровня удаётся достичь благодаря распределению данных по очень большому числу устройств хранения.
Относительно высокий уровень отказоустойчивости (3). Любые три устройства хранения могут выйти из строя, и том останется доступным. Но, как отмечено ниже, это только часть картины.
Компромиссы:
Относительно большой «радиус поражения». Если число отказов превысит то, на которое рассчитан массив, зона воздействия будет очень большой. В некоторых случаях может пострадать весь массив.
Защита только от отказов устройств хранения. Erasure coding в массивах защищает только от отказов самих накопителей. Массивы могут испытывать серьёзную деградацию производительности и доступности при других типах отказов, например, межсоединений (interconnects), контроллеров хранения и некорректных обновлениях прошивок. Ни один erasure code не может обеспечить доступность данных, если выйдёт из строя больше контроллеров, чем массив способен выдержать.
Относительно высокий эффект на производительность во время или после отказов. Отказы при больших значениях k и m могут требовать очень много ресурсов на восстановление и быть более подвержены высоким значениям tail latency.
Относительно большое количество потенциальных точек отказа на одну четность. Соотношение 8,33:1 отражает высокий показатель потенциальных точек отказа относительно количества битов четности, обеспечивающих доступность. Высокое соотношение указывает на более высокую хрупкость.
Последний пункт является чрезвычайно важным. Erasure codes нельзя оценивать только по заявленному уровню устойчивости (m), но необходимо учитывать сопоставление заявленной устойчивости с количеством потенциальных точек отказа, которые она прикрывает (n). Это обеспечивает более корректный подход к пониманию вероятностной надёжности системы хранения.
vSAN
В этом примере предположим, что у нас есть кластер vSAN из 24 хостов, и объект данных ВМ настроен на использование RAID-6 erasure code ы (k=4, m=2, n=6).
Важно отметить, что компоненты, формирующие объект vSAN при использовании RAID-6, будут содержать как фрагменты данных, так и фрагменты четности. Как описывает Христос Караманолис в статье "The Use of Erasure Coding in vSAN" (vSAN OSA, примерно 2018 год), vSAN не создаёт отдельные компоненты четности.
Преимущества:
Относительно небольшой «радиус поражения». Если кластер переживает более двух одновременных отказов хостов, это затронет лишь некоторые объекты, но не выведет из строя весь datastore.
Защита от широкого спектра типов отказов. Erasure coding в vSAN учитывает отказы отдельных устройств хранения, хостов и отказы заранее определённых доменов (например, стоек).
Относительно низкое влияние на производительность во время или после отказа. Небольшие значения k уменьшают вычислительные затраты при восстановлении.
Относительно малое число потенциальных точек отказа на единицу четности. Соотношение 3:1 указывает на малое количество возможных точек отказа по сравнению с числом битов четности, обеспечивающих доступность.
Компромиссы:
Низкая абсолютная устойчивость объекта к отказам (2). У vSAN RAID-6 (4+2) заявленная устойчивость меньше. Однако важно помнить:
граница отказа — это объект, а не весь кластер, количество потенциальных точек отказа на четность существенно ниже.
Относительно более высокие накладные расходы. Дополнительная ёмкость, потребляемая битами четности для поддержания доступности при отказе домена (хоста), составляет 50%.
Несмотря на то, что RAID-6 в vSAN защищает от 2 отказов (в отличие от 3), он остаётся чрезвычайно надёжным благодаря небольшому количеству потенциальных точек отказа: всего 6 против 25. Это обеспечивает vSAN RAID-6 (4+2) техническое преимущество перед схемой хранения массива 22+3, если сравнивать надёжность с точки зрения вероятностей отказов.
Для vSAN использование erasure code с малым значением n обеспечивает гораздо большую гибкость в построении кластеров под самые разные сценарии. Например, RAID-6 (4+2) можно использовать минимум на 6 хостах. Для erasure code 22+3 теоретически потребовалось бы не менее 25 хостов в одном кластере.
Развязка размера кластера и доступности
RAID-6 в vSAN всегда остаётся схемой 4+2, независимо от размера кластера. Когда к объекту применяется политика хранения FTT=2 с RAID-6, это означает, что объект может выдержать два одновременных отказа хостов, на которых находятся его компоненты.
Это свойство относится к состоянию объекта, а не всего кластера. Отказы на других хостах не влияют на доступность данного объекта, за исключением того, что эти хосты могут быть использованы для восстановления недостающей части полосы с помощью четности.
vSAN рассматривает такие уцелевшие хосты как кандидатов для размещения реконструируемых компонентов, чтобы вернуть объекту заданный уровень устойчивости.
Такой подход позволяет vSAN разорвать зависимость между размером кластера и уровнем доступности. В то время как многие масштабируемые системы хранения становятся более хрупкими по мере увеличения числа узлов, подход vSAN, напротив, снижает риски по мере масштабирования кластера.
Для дополнительной информации о доступности и механизмах обработки отказов в vSAN см. документ "vSAN Availability Technologies" на VMware Resource Center.
Итог
Erasure coding — это мощная технология, позволяющая хранить данные очень устойчиво и при этом эффективно использовать пространство. Но не все erasure codes одинаково полезны.
vSAN использует такие схемы erasure coding, которые обеспечивают оптимальный баланс устойчивости, гибкости и эффективности использования пространства в распределённой среде. В сочетании с дополнительными механизмами оптимизации пространства — такими как сжатие данных в vSAN и глобальная дедупликация в ESA (в составе VCF 9.0), хранилище vSAN становится ещё более производительным, ёмким и надёжным, чем когда-либо.
Дункан Эппинг выпустил обзорное видео, где он отвечает на вопрос одного из читателей, который касается поведения VMware vSAN после восстановления отказавших площадок. Речь идёт о сценарии, когда производится Site Takeover и два сайта выходят из строя, а позже снова становятся доступными. Что же происходит с виртуальными машинами и их компонентами в такой ситуации?
Автор решил смоделировать следующий сценарий:
Отключить preferred-локацию и witness-узел.
Выполнить Site Takeover, чтобы виртуальная машина Photon-1 стала снова доступна после ее перезапуска, но уже только на оставшейся рабочей площадке.
После восстановления всех узлов проверить, как vSAN автоматически перераспределит компоненты виртуальной машины.
Поведение виртуальной машины после отказа
Когда preferred-локация и witness отключены, виртуальная машина Photon-1 продолжает работу благодаря механизму vSphere HA. Компоненты ВМ в этот момент существуют только на вторичном домене отказа (fault domain), то есть на той площадке, которая осталась доступной.
Автор пропускает часть сценария с перезапуском ВМ, поскольку этот процесс уже подробно освещался ранее.
Что происходит при восстановлении сайтов
После того как preferred-локация и witness возвращаются в строй, начинается полностью автоматический процесс:
vSAN анализирует политику хранения, назначенную виртуальной машине.
Поскольку политика предусматривает растяжение ВМ между двумя площадками, система автоматически начинает перераспределение компонентов.
Компоненты виртуальной машины снова создаются и на preferred-локации, и на secondary-локации.
При этом администратору не нужно предпринимать никаких действий — все операции происходят автоматически.
Важный момент: полная ресинхронизация
Дункан подчёркивает, что восстановление не является частичным, а выполняется полный ресинк данных:
Компоненты, которые находились на preferred-локации до сбоя, vSAN считает недействительными и отбрасывает.
Данные перезапущенной ВМ полностью синхронизируются с рабочей площадки (теперь это secondary FD) на вновь доступную preferred-локацию.
Это необходимо для исключения расхождений и гарантии целостности данных.
Итоги
Демонстрация показывает, что vSAN при восстановлении площадок:
Автоматически перераспределяет компоненты виртуальных машин согласно политике хранения.
Выполняет полную ресинхронизацию данных.
Не требует ручного вмешательства администратора.
Таким образом, механизм stretched-кластеров vSAN обеспечивает предсказуемое и безопасное восстановление после крупных сбоев.
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
Если вы уже знакомы с преимуществами локальных снапшотов для защиты данных в vSAN ESA, значит у вас есть опыт работы с одной из служб в составе объединённого виртуального модуля защиты и восстановления, являющегося частью решения ACC (Advanced Cyber Compliance).
Расширение защиты и восстановления ВМ
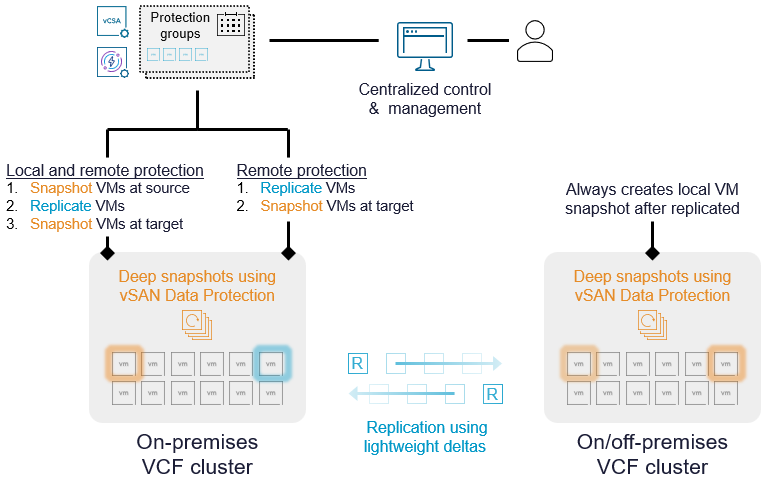
Давайте рассмотрим объединённую ценность защиты данных vSAN и VMware Advanced Cyber Compliance, позволяющую обеспечить надёжное, уверенное восстановление после кибератак и других катастроф. Виртуальный модуль защиты и восстановления, включённый в возможности аварийного восстановления решения Advanced Cyber Compliance, содержит три службы — все объединены в один простой в развертывании и управлении модуль (Virtual Appliance):
Служба снимков vSAN ESA
Расширенная репликация vSphere
Группы защиты и оркестрация восстановления
Сочетание этих служб модуля вместе с возможностями хранения vSAN ESA расширяет возможности для более широкой мультисайтовой защиты и восстановления ваших рабочих нагрузок в VCF.
Настройка вторичного сайта восстановления
В рамках вашей топологии развертывания VCF просто включите ещё один кластер vSAN ESA на втором сайте или в другой локации. Второй сайт подразумевает дополнительную среду vCenter в домене рабочих нагрузок VCF. Для простоты и удобства ссылки назовём эти два сайта «Site A» и «Site B» и развернём их в одном экземпляре VCF, как показано ниже.
Чтобы максимизировать ценность всех трёх упомянутых выше служб и расширить защиту данных vSAN между этими сайтами, вам потребуется лицензировать возможность оркестрации. Возможность оркестрации защиты и восстановления необходима для управления параметрами защиты данных vSAN для групп защиты, которым требуется включать функции репликации.
Имейте в виду, что расширенная репликация vSphere и возможности службы снапшотов vSAN уже включены в лицензирование VCF.
На новом вторичном сайте разверните кластер vSAN ESA для соответствующего vCenter вместе с ещё одним экземпляром объединённого виртуального модуля. Во многих случаях как модули vCenter, так и эти устройства защиты и восстановления устанавливаются в домен управления VCF.
После настройки двух сайтов процесс установления расширенной репликации vSphere между хостами ESX на каждом сайте довольно прост.
Расширение охвата политики защиты
VMware Advanced Cyber Compliance включает полностью оркестрированное аварийное восстановление между локальными сайтами VCF, и благодаря хранилищам данных vSAN ESA на этих нескольких сайтах теперь можно построить более надёжное решение по защите данных и аварийному восстановлению на уровне всего предприятия.
При наличии многосайтовой, объединённой конфигурации Advanced Cyber Compliance и vSAN ESA, группы защиты, которые вы определяете в рамках защиты данных vSAN для локального восстановления, теперь могут воспользоваться двумя дополнительными вариантами (2 и 3 пункты ниже), включающими репликацию и координацию защиты между двумя сайтами:
Локальная защита — защита с помощью снапшотов в пределах одного сайта.
Репликация — репликация данных ВМ на вторичный сайт.
Локальная защита и репликация — репликация данных ВМ между сайтами плюс локальные снапшоты и хранение удалённых снапшотов.
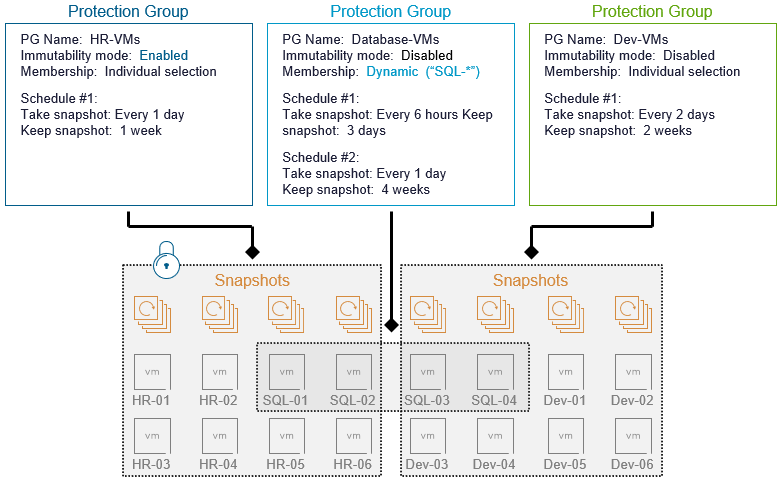
Давайте более подробно рассмотрим пример настройки защиты данных vSAN между двумя сайтами, которую можно использовать для аварийного восстановления, если исходный сайт станет недоступным или выйдет из строя. Для этого примера мы создадим новую группу защиты и пройдём процесс настройки политики, как показано ниже. Процесс настройки состоит всего из нескольких шагов, включая:
Задание свойств политики защиты.
Определение инвентаря защищаемых ВМ.
Настройку расписаний локальных снапшотов.
Настройку параметров репликации и хранения данных между сайтами.
Для типа защиты мы выбрали вариант «Локальная защита и репликация» (Local protection and replication). Это добавляет шаги 4 и 5 (показанные ниже) в определение политики группы защиты соответственно.
Расписания локальных снапшотов (шаг 4) определяют точки восстановления, которые будут доступны для выбранных виртуальных машин на локальном хранилище данных vSAN ESA. Каждая политика группы защиты может включать несколько расписаний, определяющих частоту создания снапшотов и период их хранения.
Примечание: это определение политики группы защиты также использует критерии выбора ВМ, основанные как на шаблонах имён (шаг 2), так и на индивидуальном выборе (шаг 3), показанных на скриншоте выше. Это обеспечивает высокую гибкость при определении состава ВМ, подлежащих защите.
Снапшоты и репликация имеют отдельные параметры конфигурации политики. Данные между сайтами Site A и Site B в данном примере будут реплицироваться независимо от локальных снапшотов, создаваемых по расписанию. Это также означает, что процесс репликации выполняется отдельно от процессов локального создания снапшотов.
С VMware Advanced Cyber Compliance для аварийного восстановления частота репликации vSphere replication — или первичная цель точки восстановления (RPO) — для каждой ВМ может быть минимальной, вплоть до 1 минуты.
При настройке параметров репликации вы также указываете хранение снапшотов на удалённом сайте, определяя глубину восстановления на вашем вторичном сайте. После завершения определения политики группы защиты в интерфейсе защиты данных vSAN вы можете увидеть различные параметры расписаний, хранения и частоты репликации, как показано на скриншоте ниже:
Примечание: группы защиты, определённые с использованием методов защиты данных vSAN, которые включают параметры репликации, будут обнаружены механизмом оркестрации защиты и восстановления и добавлены как записи групп репликации и защиты в инвентарь оркестрации, как указано в информационном блоке на скриншоте выше.
Интеграция с оркестрацией восстановления
Если переключиться на этот интерфейс, вы увидите, что наша политика "Example-Multi-Site-Protection-Group" отображается ниже — она была импортирована в инвентарь групп защиты вместе с существующими группами защиты, определёнными в пользовательском интерфейсе оркестрации защиты и восстановления.
Кроме того, любые виртуальные машины, включённые в группу защиты, определённую с использованием методов защиты данных vSAN, также отображаются в инвентаре Replications и помечаются соответствующим типом, как показано ниже:
В интерфейсе оркестрации, если вам нужно изменить группу защиты, созданную с использованием vSAN data protection, легко перейти обратно в соответствующий интерфейс управления этой группой. Контекстная ссылка для этого отображается на изображении ниже (сразу над выделенной областью Virtual Machines):
Используя совместно защиту данных vSAN и возможности аварийного восстановления VMware Advanced Cyber Compliance в вашем развертывании VCF, вы получаете улучшенную локальную защиту ВМ для оперативного восстановления, а также удалённую защиту ВМ, полезную для целей аварийного восстановления.
В VMware Cloud Foundation (VCF) 9.0 легко упустить из виду относительно новые функции, находящиеся прямо перед глазами. Защита данных в частном облаке в последнее время стала особенно актуальной темой, выходящей далеко за рамки обычных задач восстановления данных. Клиенты ищут практичные стратегии защиты от атак вымогателей и аварийного восстановления с помощью решений, которыми легко управлять в масштабах всей инфраструктуры.
vSAN Data Protection впервые появилась в vSAN 8 U3 как часть VMware Cloud Foundation 5.2. Наиболее часто упускаемый момент — это то, что vSAN Data Protection входит в лицензию VCF!
Почему это важно? Если вы используете vSAN ESA в своей среде VCF, у вас уже есть всё необходимое для локальной защиты рабочих нагрузок с помощью vSAN Data Protection. Это отличный способ дополнить существующие стратегии защиты или создать основу для более комплексной.
Рассмотрим кратко, что может предложить эта локальная защита и как просто и масштабируемо её внедрить.
Простая локальная защита
Как часть лицензии VCF, vSAN Data Protection позволяет использовать снапшоты именно так, как вы всегда хотели. Благодаря встроенному механизму создания снапшотов vSAN ESA, вы можете:
Легко определять группы ВМ и их расписание защиты и хранения — до 200 снапшотов на ВМ.
Создавать согласованные по сбоям снапшоты ВМ с минимальным влиянием на производительность.
Быстро восстанавливать одну или несколько ВМ прямо в vCenter Server через vSphere Client, даже если они были удалены из инвентаря.
Поскольку vSAN Data Protection работает на уровне ВМ, защита и восстановление отдельных VMDK-дисков внутри виртуальной машины пока не поддерживается.
Простое и гибкое восстановление
Причины восстановления данных могут быть разными, и vSAN Data Protection даёт администраторам платформ виртуализации возможность выполнять типовые задачи восстановления без привлечения других команд.
Например, обновление ОС виртуальной машины не удалось или произошла ошибка конфигурации — vSAN Data Protection готова обеспечить быстрое и простое восстановление. Или, допустим, виртуальная машина была случайно удалена из инвентаря. Ранее ни один тип снимков VMware не позволял восстановить снимок удалённой ВМ, но vSAN Data Protection справится и с этим.
Обратите внимание, что восстановление виртуальных машин в демонстрации выше выполняется напрямую в vSphere Client, подключённом к vCenter Server. Не нужно использовать дополнительные приложения, и поскольку процесс основан на уровне ВМ, восстановление интуитивно понятное и безопасное — без сложностей, связанных с восстановлением на основе снимков хранилища (array-based snapshots).
Для клиентов, уже внедривших vSAN Data Protection, такая простота восстановления стала одной из наиболее ценных возможностей решения.
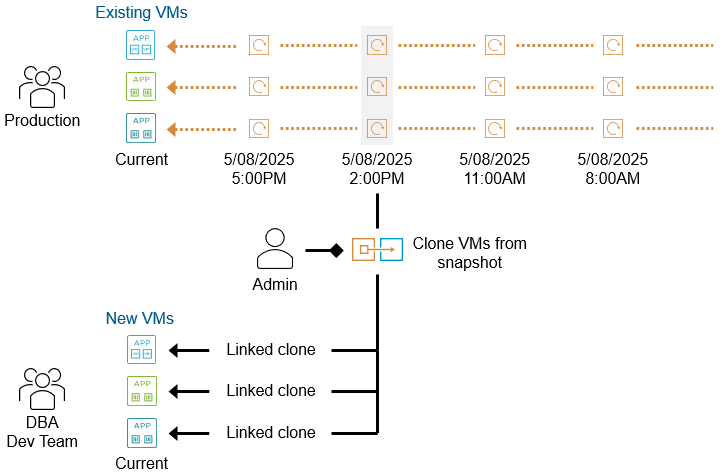
Быстрое и гибкое клонирование
Преимущества автоматизированных снапшотов, создаваемых с помощью vSAN Data Protection, выходят далеко за рамки восстановления данных. С помощью vSAN Data Protection можно легко создавать клоны виртуальных машин из существующих снапшотов. Это чрезвычайно простой и эффективный по использованию пространства способ получить несколько ВМ для различных задач.
Клонирование из снапшотов можно использовать для разработки и тестирования программного обеспечения, а также для администрирования и тестирования приложений. Администраторы платформ виртуализации могут без труда интегрировать эту функцию в повседневные IT-операции и процессы управления жизненным циклом.
Давайте посмотрим, как выглядит такое быстрое клонирование большой базы данных в пользовательском интерфейсе.
Обратите внимание, что клонированная виртуальная машина, созданная из снапшота в vSAN Data Protection, представляет собой связанную копию (linked clone). Такой клон не может быть впоследствии защищён с помощью групп защиты и снапшотов в рамках vSAN Data Protection. Клон можно добавить в группу защиты, однако при следующем цикле защиты для этой группы появится предупреждение «Protection Group Health», указывающее, что создание снапшота для клонированной ВМ не удалось.
Ручные снапшоты таких связанных клонов можно создавать вне vSAN Data Protection (через интерфейс или с помощью VADP), что позволяет решениям резервного копирования, основанным на VADP, защищать эти клоны.
С чего начать
Так как функции защиты данных уже включены в вашу лицензию VCF, как приступить к работе? Рассмотрим краткий план.
Установка виртуального модуля для vSAN Data Protection
Для реализации описанных возможностей требуется установка виртуального модуля (Virtual Appliance) — обычно одного на каждый vCenter Server. Этот виртуальный модуль VMware Live Recovery (VLR) обеспечивает работу службы vSAN Data Protection, входящей в состав VCF, и предоставляет локальную защиту данных. Оно управляет процессом создания и координации снимков, но не участвует в передаче данных и не является единой точкой отказа.
Базовые шаги для развертывания и настройки модуля:
Загрузите виртуальный модуль для защиты данных с портала Broadcom.
Войдите в vSphere Client, подключённый к нужному vCenter Server, и разверните модуль как обычный OVF-шаблон.
Защита виртуальных машин осуществляется с помощью групп защиты (protection groups), которые определяют желаемую стратегию защиты ВМ. Вы можете управлять тем, какие ВМ будут защищены, как часто выполняется защита, а также настройками хранения снапшотов.
Группы защиты также позволяют указать, должны ли снапшоты быть неизменяемыми (immutable) — всё это настраивается с помощью простого флажка в интерфейсе.
Неизменяемость гарантирует, что снапшоты не могут быть каким-либо образом изменены или удалены. Эта опция обеспечивает базовую защиту от вредоносных действий и служит основой для более продвинутых механизмов киберустойчивости (cyber resilience).
Давайте посмотрим, насколько просто это реализуется в интерфейсе. Сначала рассмотрим настройку группы защиты в vSphere Client.
Группы защиты начинают выполнять заданные параметры сразу после создания первого снапшота. Это отличный пример принципа «настроил и забыл» (set it and forget it), реализованного в vSAN Data Protection, который обеспечивает простое и интуитивное восстановление одной или нескольких виртуальных машин при необходимости.
Рекомендация: если вы используете динамические шаблоны имен ВМ в группах защиты, убедитесь, что виртуальные машины, созданные из снапшотов в vSAN Data Protection, не попадают под этот шаблон. В противном случае будет сгенерировано предупреждение о состоянии группы защиты (Health Alert), указывающее, что связанный клон не может быть защищён в рамках этой группы.
Расширенные возможности в VCF 9.0
В версии VCF 9.0 vSAN Data Protection получила ряд улучшений, которые сделали её ещё более удобной и функциональной.
Единый виртуальный модуль
Независимо от того, используете ли вы только локальную защиту данных через vSAN Data Protection или расширенные возможности репликации и аварийного восстановления (DR), теперь для этого используется единый виртуальный модуль, доступный для загрузки по ссылке.
Он сокращает потребление ресурсов, упрощает управление и позволяет расширять функциональность для DR и защиты от программ-вымогателей путём простого добавления лицензионного ключа.
Защита ВМ на других кластерах vSAN
Хотя vSAN Data Protection обеспечивает простой способ локальной защиты рабочих нагрузок, новая технология, представленная в VCF 9.0, позволяет реплицировать данные на другой кластер vSAN — механизм, известный как vSAN-to-vSAN replication.
Для использования vSAN-to-vSAN репликации требуется дополнительная лицензия (add-on license). Если она отсутствует, вы по-прежнему можете использовать локальную защиту данных с помощью vSAN Data Protection. Однако эта лицензия предоставляет не только возможность удалённой репликации — она также добавляет инструменты для комплексной защиты данных и оркестрации, помогая выполнять требования по аварийному восстановлению (DR) и кибербезопасности.
Иными словами, все базовые возможности локальной защиты вы можете реализовать с помощью vSAN Data Protection. А когда придёт время расширить защиту для сценариев аварийного восстановления (DR) и восстановления после киберинцидентов (cyber recovery), это можно сделать просто — активировав дополнительные возможности с помощью add-on лицензии.
Для ответов на часто задаваемые вопросы о vSAN Data Protection см. раздел «vSAN Data Protection» в актуальной версии vSAN FAQs.
Итоги
Клиенты VCF, использующие vSAN ESA в составе VCF 5.2 или 9.0, уже обладают невероятно мощным инструментом, встроенным в их решение. vSAN Data Protection обеспечивает возможность локальной защиты рабочих нагрузок без необходимости приобретения дополнительных лицензий.
Таги: VMware, vSAN, Storage, Data Protection, Update, Enterprise, Licensing
Поддержание доступности данных и приложений, которые эти данные создают или используют, может быть одной из самых важных задач администраторов центров обработки данных. Такие возможности, как высокая производительность или специализированные службы данных, мало что значат, если приложения и данные, которые они создают или используют, недоступны. Обеспечение доступности — это сложная тема, поскольку доступность приложений и доступность данных достигаются разными методами. Иногда требования к доступности реализуются с помощью механизмов на уровне инфраструктуры, а иногда — с использованием решений, ориентированных на приложения. Оптимальный вариант для вашей среды во многом зависит от требований и возможностей инфраструктуры.
Хотя VMware Cloud Foundation (VCF) может обеспечивать высокий уровень доступности данных и приложений простым способом, в этой статье рассматриваются различия между обеспечением высокой доступности приложений и данных с использованием технологий на уровне приложений и встроенных механизмов на уровне инфраструктуры в VCF. Мы также рассмотрим, как VMware Data Services Manager (DSM) может помочь упростить принятие подобных решений.
Учёт отказов
Защита приложений и данных требует понимания того, как выглядят типичные сбои, и что система может сделать для их компенсации. Например, сбои в физической инфраструктуре могут затрагивать:
Централизованные решения для хранения, такие как дисковые массивы
Отдельные устройства хранения в распределённых системах
Такие сбои могут затронуть данные, приложения, или и то, и другое. Сбои могут проявляться по-разному — некоторые явно, другие лишь по отсутствию отклика. Часть из них временные, другие — постоянные. Решения должны быть достаточно интеллектуальными, чтобы автоматически справляться с такими ситуациями отказа и восстановления.
Доступность и восстановление приложений и данных
Доступность приложений и их наборов данных кажется интуитивно понятной, но требует краткого пояснения.
Доступность приложения
Это состояние приложения, например базы данных или веб-приложения. Независимо от того, установлено ли оно в виртуальной машине или запущено в контейнере, приложение заранее настроено на работу с данными определённым образом. Некоторые приложения могут работать в нескольких экземплярах для повышения доступности при сбоях и использовать собственные механизмы синхронной репликации, чтобы данные сохранялись в нескольких местах. Технологии, такие как vSphere HA, могут повысить доступность приложения и его данных, перезапуская виртуальную машину на другом хосте кластера vSphere в случае сбоя.
Доступность данных
Это способность данных быть доступными для приложения или пользователей в любое время, даже при сбое. Высокодоступные данные хранятся с использованием устойчивых механизмов, обеспечивающих хранение в нескольких местах — в зависимости от возможных границ сбоя: устройства, хоста, массива хранения или целого сайта.
Надёжность данных
Хранить данные в нескольких местах недостаточно — они должны записываться синхронно и последовательно во все копии, чтобы при сбое данные из одного места совпадали с данными из другого. Корпоративные системы хранения данных реализуют принципы ACID (атомарность, согласованность, изолированность, долговечность) и протоколы, обеспечивающие надёжность данных.
Описанные выше концепции вводят два термина, которые помогают количественно определить возможности восстановления в случае сбоя:
RPO (Recovery Point Objective) — целевая точка восстановления. Показывает, с каким интервалом данные защищаются устойчивым образом. RPO=0 означает, что система всегда выполняет запись в синхронном, согласованном состоянии. Как будет отмечено далее, не все решения способны обеспечивать настоящий RPO=0.
RTO (Recovery Time Objective) — целевое время восстановления. Показывает минимальное время, необходимое для восстановления систем и/или данных до рабочего состояния. Например, RTO=10m означает, что восстановление займёт не менее 10 минут. RTO может относиться к восстановлению доступности данных или комбинации данных и приложения.
Эволюция решений для высокой доступности
Подходы к обеспечению доступности данных и приложений эволюционировали с развитием технологий и ростом требований. Некоторые приложения, такие как Microsoft SQL Server, MySQL, PostgreSQL и другие, включают собственные механизмы репликации, обеспечивающие избыточность данных и состояния приложения. Виртуализация, совместно с общим хранилищем, предоставляет простые способы обеспечения высокой доступности приложений и хранимых ими данных.
В зависимости от ваших требований может подойти один из подходов или их комбинация. Рассмотрим, как каждый из них обеспечивает высокий уровень доступности.
Высокая доступность на уровне приложений (Application-Level HA)
Этот подход основан на запуске нескольких экземпляров приложения в разных местах. Синхронное и устойчивое хранилище, а также механизмы отказоустойчивости обеспечиваются самим приложением для гарантии высокой доступности приложения и его данных.
Высокая доступность на уровне инфраструктуры (Infrastructure-Level HA)
Этот подход использует vSphere HA для перезапуска одного экземпляра приложения на другом хосте кластера. Синхронное и устойчивое хранение данных обеспечивает VMware vSAN (в контексте данного сравнения). Такая комбинация гарантирует высокую доступность приложения и его данных.
Оба подхода достигают схожих целей, но имеют определённые компромиссы. Рассмотрим два простых примера, чтобы лучше понять различия.
В приведённых примерах предполагается, что данные должны сохраняться в нескольких местах (например, на уровне сайта или зоны), чтобы обеспечить доступность при сбое площадки. Также предполагается, что приложение может работать в тех же местах. Оба варианта обеспечивают автоматический отказоустойчивый переход и RPO=0, поскольку данные записываются синхронно в несколько мест.
Высокая доступность на уровне приложений для приложений и данных
Высокая доступность на уровне приложений, как в случае MS SQL Always On Availability Groups (AG), использует два или более работающих экземпляра базы данных и дополнительное местоположение для определения кворума при различных сценариях отказа.
Этот подход полностью опирается на технологии, встроенные в само приложение, чтобы синхронно реплицировать данные в другое место и обеспечить механизм отказоустойчивого переключения состояния приложения.
Высокая доступность на уровне инфраструктуры для приложений и данных
Высокая доступность на уровне инфраструктуры использует приложение базы данных, работающее на одной виртуальной машине. vSphere HA обеспечивает автоматическое восстановление приложения, обращающегося к данным, в то время как vSAN гарантирует надёжность и доступность данных при различных типах сбоев инфраструктуры.
vSAN может выдерживать отказы отдельных устройств хранения, сетевых карт (NIC), сетевых коммутаторов, хостов и даже целых географических площадок или зон, которые определяются как «домен отказа» (fault domain).
В приведённом ниже примере кластер vSAN растянут между двумя площадками, чтобы обеспечить устойчивое хранение данных на обеих. Растянутые кластеры vSAN (vSAN Stretched Clusters) также используют третью площадку, на которой размещается небольшой виртуальный модуль — witness host appliance (хост-свидетель), помогающий определить кворум при различных возможных сценариях отказа.
Одним из самых убедительных преимуществ высокой доступности на уровне инфраструктуры является то, что в VCF она является встроенной частью платформы. vSAN интегрирован прямо в гипервизор и обеспечивает отказоустойчивость данных в соответствии с вашими требованиями, всего лишь посредством настройки простой политики хранения (storage policy). Экземпляры приложений становятся высокодоступными благодаря проверенной технологии vSphere HA, которая позволяет перезапускать виртуальные машины на любом хосте в пределах кластера vSphere. Такой подход также отлично работает, когда приложения баз данных развертываются и управляются в вашей среде VCF с помощью DSM.
Разные подходы к обеспечению согласованности данных
Хотя оба подхода могут обеспечивать цель восстановления точки (RPO), равную нулю (RPO=0), за счёт синхронной репликации, способы достижения этого различаются. Оба используют специальные протоколы, помогающие обеспечить согласованность данных, записываемых в нескольких местах — что на практике значительно сложнее, чем кажется.
В случае MS SQL Server Always On Availability Groups согласованность достигается на уровне приложения, тогда как vSAN обеспечивает синхронную запись данных по своей сути — как часть распределённой архитектуры, изначально разработанной для обеспечения отказоустойчивости.
При репликации данных на уровне приложения такой высокий уровень доступности ограничен только этим конкретным приложением и его данными. Однако возможности на уровне приложений реализованы не одинаково. Например, MS SQL Server Always On AG могут обеспечивать RPO=0 при множестве сценариев отказа, тогда как MySQL InnoDB Cluster использует подход, при котором RPO=0 возможно только при отказе одного узла. Хотя данные при этом остаются согласованными, в некоторых сценариях отказа — например, при полном сбое кластера или незапланированной перезагрузке — могут быть потеряны последние зафиксированные транзакции. Это означает, что при определённых обстоятельствах обеспечить истинный RPO=0 невозможно.
В случае vSAN в составе VCF, высокая доступность является универсальной характеристикой, которая применяется ко всем рабочим нагрузкам, записывающим данные в хранилище vSAN datastore.
Различия во времени восстановления (RTO)
Одной из основных причин различий между возможностями RTO при доступности на уровне приложения и на уровне инфраструктуры является то, как приложение возвращается в рабочее состояние после сбоя.
Например, некоторые приложения, такие как SQL Server AG, используют лицензированные «резервные» виртуальные машины (standby VMs) в вашей инфраструктуре, чтобы обеспечить использование другого состояния приложения при отказе. Это позволяет достичь низкого RTO, но приводит к увеличению затрат из-за необходимости дополнительных лицензий и потребляемых ресурсов. Высокая доступность на уровне приложения — это специализированное решение, требующее экспертизы в конкретном приложении для достижения нужного результата. Однако DSM может значительно снизить сложность таких сценариев, поскольку автоматизирует эти процессы и снимает значительную часть административной нагрузки.
Высокая доступность на уровне инфраструктуры работает иначе. Используя механизмы виртуализации, такие как vSphere High Availability (HA), она обеспечивает перезапуск приложения в другом месте при сбое виртуальной машины. Перезапуск ВМ и самого приложения, а также процесс восстановления журналов обычно занимают больше времени, чем подход с резервной ВМ, используемый при высокой доступности на уровне приложений.
Приведённые выше значения времени восстановления являются оценочными. Фактическое время восстановления может значительно различаться в зависимости от условий среды, размера и активности экземпляра MS SQL.
Что выбрать именно вам?
Наилучший выбор зависит от ваших требований, ограничений и того, насколько решение подходит вашей организации. Например:
Требования к доступности
Возможно, ваши требования предполагают, что приложение и его данные должны быть доступны за пределами определённой границы отказа — например, уровня сайта или зоны. Это поможет определить, нужна ли вообще доступность на уровне сайта или зоны.
Требования к RTO
Если требуемое время восстановления (RTO) допускает 2–5 минут, то высокая доступность на уровне инфраструктуры — отличный вариант, поскольку она встроена в платформу и работает для всех ваших нагрузок. Если же есть несколько отдельных приложений, для которых требуется меньшее RTO, и вас не смущают дополнительные затраты и сложность, связанные с этим решением, то подход на уровне приложения может быть оправдан.
Технические ограничения
В вашей организации могут быть инициативы по упрощению инструментов и рабочих процессов, что может ограничивать возможность или желание использовать дополнительные технологии, такие как высокая доступность на уровне приложений. Обычно предпочтение отдаётся универсальным инструментам, применимым ко всем системам, а не узкоспециализированным решениям. Другие технические факторы, например задержки (latency) между сайтами или зонами, также могут сделать тот или иной подход непрактичным.
Финансовые ограничения
Возможно, на вас оказывают давление с целью сократить постоянные расходы на программное обеспечение — например, на дополнительные лицензии или более дорогие уровни лицензирования, необходимые для обеспечения высокой доступности на уровне приложений. В этом случае более выгодным решением могут оказаться уже имеющиеся технологии.
Можно также использовать комбинацию обоих подходов.
Например, на первом рисунке в начале статьи показано, как высокая доступность на уровне приложений реализуется между сайтами или зонами с помощью MS SQL Always On Availability Groups, а высокая доступность на уровне инфраструктуры обеспечивается vSAN и vSphere HA внутри каждого сайта или зоны.
Этот вариант также может быть отличным примером использования VMware Data Services Manager (DSM). Вместо запуска и управления отдельными виртуальными машинами можно использовать базы данных, развёрнутые DSM, для обеспечения доступности приложений между сайтами или зонами. Такой подход обеспечивает низкое RTO, устраняет административную сложность, связанную с репликацией на уровне приложений, и при этом позволяет vSAN обеспечивать доступность данных внутри сайтов или зон.
Современная инфраструктура не прощает простоев. Любая потеря доступности данных — это не только бизнес-риск, но и вопрос репутации. VMware vSAN, будучи ядром гиперконвергентной архитектуры VMware Cloud Foundation, всегда стремился обеспечивать высокую доступность и устойчивость хранения. Но с появлением Express Storage Architecture (ESA) подход к отказоустойчивости изменился фундаментально.
Документ vSAN Availability Technologies (часть VCF 9.0) описывает, как именно реализована устойчивость на уровне данных, сетей и устройств. Разберём, какие технологии стоят за доступностью vSAN, и почему переход к ESA меняет правила игры.
Архитектура отказоустойчивости: OSA против ESA
OSA — классика, но с ограничениями
Original Storage Architecture (OSA) — традиционный вариант vSAN, основанный на концепции дисковых групп (disk groups):
Одно кэш-устройство (SSD)
Несколько накопителей ёмкости (HDD/SSD)
Проблема в том, что выход из строя кеш-диска делает всю группу недоступной. Кроме того, классическая зеркальная защита (RAID-1) неэффективна по ёмкости: чтобы выдержать один отказ, приходится хранить копию 1:1.
ESA — новое поколение хранения
Express Storage Architecture (ESA) ломает эту модель:
Нет больше disk groups — каждый накопитель независим.
Встроен мониторинг NVMe-износа, зеркалирование метаданных и прогноз отказов устройств.
В результате ESA уменьшает "зону взрыва" при сбое и повышает эффективность хранения до 30–50 %, особенно при политике FTT=2.
Как vSAN обеспечивает доступность данных
Всё в vSAN строится вокруг объектов (диски ВМ, swap, конфигурации). Каждый объект состоит из компонентов, которые распределяются по узлам.
Доступность объекта определяется параметром FTT (Failures To Tolerate) — числом отказов, которые система выдержит без потери данных.
Например:
FTT=1 (RAID-1) — один отказ хоста или диска.
FTT=2 (RAID-6) — два отказа одновременно.
RAID-5/6 обеспечивает ту же устойчивость, но с меньшими затратами ёмкости.
Механизм кворума
Каждый компонент имеет "голос". Объект считается доступным, если более 50 % голосов доступны. Это предотвращает split-brain-ситуации, когда две части кластера считают себя активными.
В сценариях 2-Node или stretched-cluster добавляется witness-компонент — виртуальный "свидетель", решающий, какая часть кластера останется активной.
Домены отказов и географическая устойчивость
vSAN позволяет группировать узлы в домены отказов — например, по стойкам, стойкам или площадкам. Данные и компоненты одной ВМ никогда не размещаются в пределах одного домена, что исключает потерю данных при отказе стойки или сайта.
В растянутом кластере (stretched cluster) домены соответствуют сайтам, а witness appliance располагается в третьей зоне для арбитража.
Рекомендация: проектируйте кластер не по минимуму (3–4 узла), а с запасом. Например, для FTT=2 нужно минимум 6 узлов, но VMware рекомендует 7, чтобы система могла восстановить избыточность без потери устойчивости.
Поведение при сбоях: состояния компонентов
vSAN отслеживает каждое состояние компонентов:
Состояние
Описание
Active
Компонент доступен и синхронизирован
Absent
Недоступен (например, временный сбой сети)
Degraded
Компонент повреждён, требуется восстановление
Active-Stale
Компонент доступен, но содержит устаревшие данные
Reconfiguring
Идёт перестройка или изменение политики
Компоненты в состоянии Absent ждут по умолчанию 60 минут перед восстановлением — чтобы избежать лишнего трафика из-за кратковременных сбоев.
Если восстановление невозможно, создаётся новая копия на другом узле.
Сеть как основа устойчивости
vSAN — это распределённое хранилище, и его надёжность напрямую зависит от сети.
Транспорт — TCP/unicast с внутренним протоколом Reliable Datagram Transport (RDT).
Поддерживается RDMA (RoCE v2) для минимизации задержек.
Рекомендуется:
2 NIC на каждый хост;
Подключение к разным коммутаторам;
Active/Standby teaming для vSAN-трафика (предсказуемые пути).
Если часть сети теряет связность, vSAN формирует partition groups и использует кворум, чтобы определить, какая группа "основная". vSAN тесно интегрирован с vSphere HA, что обеспечивает синхронное понимание состояния сети и автоматический рестарт ВМ при отказах.
Ресинхронизация и обслуживание
Resync (восстановление)
Когда хост возвращается в строй или изменяется политика, vSAN ресинхронизирует данные для восстановления FTT-уровня. В ESA ресинхронизация стала интеллектуальной и возобновляемой (resumable) — меньше нагрузка на сеть и диски.
Maintenance Mode
При вводе хоста в обслуживание доступны три режима:
Full Data Migration — полная миграция данных (долго, безопасно).
Ensure Accessibility — минимальный перенос для сохранения доступности (дефолт).
No Data Migration — без переноса (быстро, рискованно).
ESA использует durability components, чтобы временно сохранить данные и ускорить возврат в строй.
Предиктивное обслуживание и мониторинг
VMware внедрила целый ряд механизмов прогнозирования и диагностики:
Degraded Device Handling (DDH) — анализ деградации накопителей по задержкам и ошибкам до фактического отказа.
NVMe Endurance Tracking — контроль износа NVMe с предупреждениями в vCenter.
Low-Level Metadata Resilience — зеркалирование метаданных для защиты от URE-ошибок.
Proactive Hardware Management — интеграция с OEM-телеметрией и предупреждения через Skyline Health.
Эти механизмы в ESA работают точнее и с меньшими ложными срабатываниями по сравнению с OSA.
Disaster Recovery — восстановление после катастрофы (вторая площадка, репликация, резервное копирование).
vSAN отвечает за первое. Для второго используются VMware SRM, vSphere Replication и внешние DR-решения. Однако комбинация vSAN ESA + stretched cluster уже позволяет реализовать site-level resilience без отдельного DR-инструмента.
Практические рекомендации
Используйте ESA при проектировании новых кластеров.
Современные NVMe-узлы и сети 25 GbE позволяют реализовать отказоустойчивость без потери производительности.
Проектируйте с запасом по хостам.
Один дополнительный узел обеспечит восстановление без снижения FTT-уровня.
Настройте отказоустойчивую сеть.
Два интерфейса, разные коммутаторы, Route Based on Port ID — минимальные требования для надёжного vSAN-трафика.
Следите за здоровьем устройств.
Активируйте DDH и NVMe Endurance Monitoring, используйте Skyline Health для предиктивного анализа.
Планируйте обслуживание грамотно.
Режим Ensure Accessibility — оптимальный баланс между безопасностью и скоростью.
Заключение
VMware vSAN уже давно стал стандартом для гиперконвергентных систем, но именно с Express Storage Architecture он сделал шаг от "устойчивости" к "самоисцеляемости". ESA сочетает erasure coding, предиктивную аналитику и глубокую интеграцию с платформой vSphere, обеспечивая устойчивость, производительность и эффективность хранения. Для архитекторов и инженеров это значит одно: устойчивость теперь проектируется не как надстройка, а как неотъемлемая часть самой архитектуры хранения.
Таги: VMware, vSAN, Availability, HA, DR, Storage, Whitepaper
VMware vSAN предоставляет ряд технологий для эффективного использования дискового пространства, что повышает ценность инфраструктуры хранения и снижает затраты. Рассматриваемые ниже возможности актуальны для среды VMware Cloud Foundation 9.0 (на базе vSAN 9.0) и охватывают как классическую архитектуру хранения (Original Storage Architecture, OSA), присутствующую во всех версиях vSAN, так и новую Express Storage Architecture (ESA), впервые представленную в vSAN 8.0.
В современных ИТ-системах шифрование данных стало обязательным элементом защиты информации. Цель шифрования — гарантировать, что данные могут прочитать только системы, обладающие нужными криптографическими ключами. Любой, не имеющий ключей доступа, увидит лишь бессмысленный набор символов, поскольку информация надёжно зашифрована устойчивым алгоритмом AES-256. VMware vSAN поддерживает два уровня шифрования для повышения безопасности кластерного хранения данных: шифрование данных на носителях (Data-at-Rest Encryption) и шифрование данных при передаче (Data-in-Transit Encryption). Эти механизмы позволяют защитить данные как в состоянии покоя (на дисках), так и в движении (между узлами кластера). В результате vSAN помогает организациям соответствовать требованиям регуляторов и предотвращать несанкционированный доступ к данным, например, при краже носителей или перехвате сетевого трафика.
Архитектура шифрования vSAN включает несколько ключевых элементов: внешний или встроенный сервер управления ключами (KMS), сервер VMware vCenter, гипервизоры ESXi в составе vSAN-кластера и собственно криптографические модули в ядре гипервизора. Внешний KMS-сервер (совместимый с протоколом KMIP), либо встроенный поставщик ключей vSphere NKP, обеспечивает генерацию и хранение мастер-ключей шифрования. vCenter Server отвечает за интеграцию с KMS: именно vCenter устанавливает доверенные отношения (обмен сертификатами) с сервером ключей и координирует выдачу ключей хостам ESXi. Каждый узел ESXi, входящий в шифрованный кластер vSAN, содержит встроенный криптомодуль VMkernel (сертифицированный по требованиям FIPS), который выполняет операции шифрования и дешифрования данных на стороне гипервизора.
Распределение ключей
При включении шифрования vSAN на кластере vCenter запрашивает у KMS два ключа для данного кластера: ключ шифрования ключей (Key Encryption Key, KEK) и ключ хоста (Host Key). KEK играет роль мастер-ключа: с его помощью будут шифроваться все остальные ключи (например, ключи данных). Host Key предназначен для защиты дампов памяти (core dumps) и других служебных данных хоста. После получения этих ключей vCenter передаёт информацию о KMS и идентификаторы ключей (ID) всем хостам кластера. Каждый узел ESXi устанавливает прямое соединение с KMS (по протоколу KMIP) и получает актуальные копии KEK и Host Key, помещая их в защищённый кэш памяти.
Важно: сами ключи не сохраняются на диске хоста, они хранятся только в оперативной памяти или, при наличии, в аппаратном модуле TPM на узле. Это означает, что при перезагрузке хоста ключи стираются из памяти и в общем случае должны быть вновь запрошены у KMS, прежде чем хост сможет монтировать зашифрованное хранилище.
Ключи данных (DEK)
Помимо вышеупомянутых кластерных ключей, каждый диск или объект данных получает свой собственный ключ шифрования данных (Data Encryption Key, DEK). В оригинальной архитектуре хранения vSAN (OSA) гипервизор генерирует уникальный DEK (алгоритм XTS-AES-256) для каждого физического диска в дисковой группе. Эти ключи оборачиваются (wrap) с помощью кластерного KEK и сохраняются в метаданных, что позволяет безопасно хранить ключи на дисках: получить «сырой» DEK можно только расшифровав его при помощи KEK. В более новой архитектуре vSAN ESA подход несколько отличается: используется единый ключ шифрования кластера, но при этом для различных объектов данных применяются уникальные производные ключи. Благодаря этому данные каждой виртуальной машины шифруются своим ключом, даже если в основе лежит общий кластерный ключ. В обоих случаях vSAN обеспечивает надёжную защиту: компрометация одного ключа не даст злоумышленнику доступа ко всему массиву данных.
Роль гипервизора и производительность
Шифрование в vSAN реализовано на уровне ядра ESXi, то есть прозрачно для виртуальных машин. Гипервизор использует сертифицированный криптографический модуль VMkernel, прошедший все необходимые проверки по стандарту FIPS 140-2 (а в новых версиях — и FIPS 140-3). Все операции шифрования выполняются с использованием аппаратного ускорения AES-NI, что минимизирует влияние на производительность системы. Опыт показывает, что нагрузка на CPU и задержки ввода-вывода при включении шифрования vSAN обычно незначительны и хорошо масштабируются с ростом числа ядер и современных процессоров. В свежей архитектуре ESA эффективность ещё выше: благодаря более оптимальному расположению слоя шифрования в стеке vSAN, для той же нагрузки требуется меньше CPU-циклов и операций, чем в классической архитектуре OSA.
Управление доступом
Стоит упомянуть, что управление шифрованием в vSAN встроено в систему ролей и привилегий vCenter. Только пользователи с особыми правами (Cryptographic administrator) могут настраивать KMS и включать/отключать шифрование на кластере. Это добавляет дополнительный уровень безопасности: случайный администратор без соответствующих привилегий даже не увидит опцию включения шифрования в интерфейсе. Разграничение доступа гарантирует, что ключи шифрования и связанные операции контролируются ограниченным кругом доверенных администраторов.
Шифрование данных на носителях (vSAN Data-at-Rest Encryption)
Этот тип шифрования обеспечивает защиту всех данных, хранящихся в vSAN-датасторе. Включение функции означает, что вся информация, записываемая на диски кластера, автоматически шифруется на последнем этапе ввода-вывода перед сохранением на устройство. При чтении данные расшифровываются гипервизором прозрачно для виртуальных машин – приложения и ОС внутри ВМ не осведомлены о том, что данные шифруются. Главное назначение Data-at-Rest Encryption – обезопасить данные на случай, если накопитель будет изъят из системы (например, при краже или некорректной утилизации дисков).
Без соответствующих ключей злоумышленник не сможет прочитать информацию с отключенного от кластера диска. Шифрование «на покое» не требует специальных самошифрующихся дисков – vSAN осуществляет его программно, используя собственные криптомодули, и совместимо как с гибридными, так и полностью флэш-конфигурациями хранилища.
Принцип работы: в оригинальной реализации OSA шифрование данных происходит после всех операций дедупликации и сжатия, то есть уже на «выходе» перед записью на носитель. Такой подход позволяет сохранить эффективность экономии места: данные сначала сжимаются и устраняются дубликаты, и лишь затем шифруются, благодаря чему коэффициенты дедупликации/сжатия не страдают. В архитектуре ESA шифрование интегрировано выше по стеку – на уровне кэша – но всё равно после выполнения компрессии данных.
То есть в ESA шифрование также не препятствует сжатию. Однако особенностью ESA является то, что все данные, покидающие узел, уже зашифрованы высокоуровневым ключом кластера (что частично перекрывает и трафик между узлами – см. ниже). Тем не менее для обеспечения максимальной криптостойкости vSAN ESA по-прежнему поддерживает отдельный механизм Data-in-Transit Encryption для уникального шифрования каждого сетевого пакета.
Включение и поддержка: шифрование данных на носителях включается на уровне всего кластера vSAN – достаточно установить флажок «Data-at-Rest Encryption» в настройках служб vSAN для выбранного кластера. Данная возможность доступна только при наличии лицензии vSAN Enterprise или выше.
В традиционной архитектуре OSA шифрование можно включать как при создании нового кластера, так и на уже работающем кластере. В последнем случае vSAN выполнит поочерёдное перевоспроизведение данных с каждого диска (evacuation) и форматирование дисковых групп в зашифрованном виде, что потребует определённых затрат ресурсов и времени. В архитектуре ESA, напротив, решение о шифровании принимается только на этапе создания кластера и не может быть изменено позднее без полной перестройки хранилища. Это связано с тем, что в ESA шифрование глубоко интегрировано в работу кластера, обеспечивая максимальную производительность, но и требуя фиксации режима на старте. В обоих случаях, после включения, сервис шифрования прозрачно работает со всеми остальными функциями vSAN (в том числе со снапшотами, клонированием, vMotion и т.д.) и практически не влияет на операционную деятельность кластера.
Шифрование данных при передаче (vSAN Data-in-Transit Encryption)
Второй компонент системы безопасности vSAN – это шифрование сетевого трафика между узлами хранения. Функция Data-in-Transit Encryption гарантирует, что все данные, пересылаемые по сети между хостами vSAN, будут зашифрованы средствами гипервизора.
Это особенно важно, если сеть хранения не полностью изолирована или если требуется соответствовать строгим стандартам по защите данных в транзите. Механизм шифрования трафика не требует KMS: при включении этой опции хосты vSAN самостоятельно генерируют и обмениваются симметричными ключами для установления защищённых каналов. Процесс полностью автоматизирован и не требует участия администратора – достаточно активировать настройку в параметрах кластера.
Data-in-Transit Encryption впервые появилась в vSAN 7 Update 1 и доступна для кластеров как с OSA, так и с ESA. В случае OSA администратор может независимо включить шифрование трафика (оно не зависит от шифрования на дисках, но для полноты защиты желательно задействовать оба механизма). В случае ESA отдельного переключателя может не потребоваться: при создании кластера с шифрованием данные «на лету» фактически уже будут выходить из узлов зашифрованными единым высокоуровневым ключом. Однако, чтобы каждый сетевой пакет имел уникальный криптографический отпечаток, ESA по-прежнему предусматривает опцию Data-in-Transit (она остаётся активной в интерфейсе и при включении обеспечит дополнительную уникализацию шифрования каждого пакета). Следует учесть, что на момент выпуска vSAN 9.0 в составе VCF 9.0 шифрование трафика поддерживается только для обычных (HCI) кластеров vSAN и недоступно для т. н. disaggregated (выделенных storage-only) кластеров.
С технической точки зрения, Data-in-Transit Encryption использует те же проверенные криптомодули, сертифицированные по FIPS 140-2/3, что и шифрование данных на дисках. При активации этой функции vSAN автоматически выполняет взаимную аутентификацию хостов и устанавливает между ними защищённые сессии с помощью динамически создаваемых ключей. Когда новый узел присоединяется к шифрованному кластеру, для него генерируются необходимые ключи и он аутентифицируется существующими участниками; при исключении узла его ключи отзываются, и трафик больше не шифруется для него. Всё это происходит «под капотом», не требуя ручной настройки. В результате даже при потенциальном перехвате пакетов vSAN-трафика на уровне сети, извлечь из них полезные данные не представляется возможным.
Для использования шифрования данных на vSAN необходим сервер управления ключами (Key Management Server, KMS), совместимый со стандартом KMIP 1.1+. Исключение составляет вариант применения встроенного поставщика ключей vSphere (Native Key Provider, NKP), который появился начиная с vSphere 7.0 U2. Внешний KMS может быть программным или аппаратным (множество сторонних решений сертифицировано для работы с vSAN), но в любом случае требуется лицензия не ниже vSAN Enterprise.
Перед включением шифрования администратор должен зарегистрировать KMS в настройках vCenter: добавить информацию о сервере и установить доверие между vCenter и KMS. Обычно настройка доверия реализуется через обмен сертификатами: vCenter либо получает от KMS корневой сертификат (Root CA) для проверки подлинности, либо отправляет на KMS сгенерированный им запрос на сертификат (CSR) для подписи. В результате KMS и vCenter обмениваются удостоверяющими сертификатами и устанавливают защищённый канал. После этого vCenter может выступать клиентом KMS и запрашивать ключи.
В конфигурации с Native Key Provider процесс ещё проще: NKP разворачивается непосредственно в vCenter, генерируя мастер-ключ локально, поэтому внешний сервер не нужен. Однако даже в этом случае рекомендуется экспортировать (зарезервировать) копию ключа NKP во внешнее безопасное место, чтобы избежать потери ключей в случае сбоя vCenter.
Запрос и кэширование ключей
Как только доверие (trust) между vCenter и KMS установлено, можно активировать шифрование vSAN на уровне кластера. При этом vCenter от имени кластера делает запрос в KMS на выдачу необходимых ключей (KEK и Host Key) и распределяет их идентификаторы хостам, как описано выше. Каждый ESXi узел соединяется с KMS напрямую для получения своих ключей. На период нормальной работы vSAN-хосты обмениваются ключами с KMS напрямую, без участия vCenter.
Это означает, что после первоначальной настройки для ежедневной работы кластера шифрования доступность vCenter не критична – даже если vCenter временно выключен, хосты будут продолжать шифровать/расшифровывать данные, используя ранее полученные ключи. Однако vCenter нужен для проведения операций управления ключами (например, генерации новых ключей, смены KMS и пр.). Полученные ключи хранятся на хостах в памяти, а при наличии TPM-модуля – ещё и в его защищённом хранилище, что позволяет пережить перезагрузку хоста без немедленного запроса к KMS.
VMware настоятельно рекомендует оснащать все узлы vSAN доверенными платформенными модулями TPM 2.0, чтобы обеспечить устойчивость к отказу KMS: если KMS временно недоступен, хосты с TPM смогут перезапускаться и монтировать зашифрованное хранилище, используя кешированные в TPM ключи.
Лучшие практики KMS
В контексте vSAN есть важное правило: не размещать сам KMS на том же зашифрованном vSAN-хранилище, которое он обслуживает. Иначе возникает круговая зависимость: при отключении кластера или перезагрузке узлов KMS сам окажется недоступен (ведь он работал как ВМ на этом хранилище), и хосты не смогут получить ключи для расшифровки датасторов.
Лучше всего развернуть кластер KMS вне шифруемого кластера (например, на отдельной инфраструктуре или как облачный сервис) либо воспользоваться внешним NKP от другого vCenter. Также желательно настроить кластер из нескольких узлов KMS (для отказоустойчивости) либо, в случае NKP, надёжно сохранить резервную копию ключа (через функцию экспорта в UI vCenter).
При интеграции с KMS крайне важна корректная сетевая настройка: все хосты vSAN-кластера должны иметь прямой доступ к серверу KMS (обычно по протоколу TLS на порт 5696). В связке с KMS задействуйте DNS-имя для обращения (вместо IP) – это упростит перенастройку в случае смены адресов KMS и снизит риск проблем с подключением.
vSphere Native Key Provider
Этот встроенный механизм управления ключами в vCenter заслуживает отдельного упоминания. NKP позволяет обойтись без развертывания отдельного KMS-сервера, что особенно привлекательно для небольших компаний или филиалов. VMware поддерживает использование NKP для шифрования vSAN начиная с версии 7.0 U2. По сути, NKP хранит мастер-ключ в базе данных vCenter (в зашифрованном виде) и обеспечивает необходимые функции выдачи ключей гипервизорам. При включении шифрования vSAN с NKP процесс выдачи ключей аналогичен: vCenter генерирует KEK и распределяет его на хосты. Разница в том, что здесь нет внешнего сервера – все операции выполняются средствами самого vCenter.
Несмотря на удобство, у NKP есть ограничения (например, отсутствие поддержки внешних интерфейсов KMIP для сторонних приложений), поэтому для крупных сред на долгосрочной основе часто выбирают полноценный внешний KMS. Тем не менее, NKP – это простой способ быстро задействовать шифрование без дополнительных затрат, и он идеально подходит для многих случаев использования.
После того как кластер vSAN сконфигурирован для шифрования и получены необходимые ключи, каждая операция записи данных проходит через этап шифрования в гипервизоре. Рассмотрим упрощённо этот процесс на примере OSA (Original Storage Architecture):
Получение блока данных. Виртуальная машина записывает данные на диск vSAN, которые через виртуальный контроллер поступают на слой vSAN внутри ESXi. Там данные сначала обрабатываются сервисами оптимизации – например, вычисляются хеши для дедупликации и выполняется сжатие (если эти функции включены на кластере).
Шифрование блока. Когда очередь дошла до фактической записи блока на устройство, гипервизор обращается к ключу данных (DEK), связанному с целевым диском, и шифрует блок по алгоритму AES-256 (режим XTS) с помощью этого DEK. Как упоминалось, в OSA у каждого диска свой DEK, поэтому даже два диска одного узла шифруют данные разными ключами. Шифрование происходит на уровне VMkernel, используя AES-NI, и добавляет минимальную задержку.
Запись на устройство. Зашифрованный блок записывается в кеш или напрямую на SSD в составе дисковой группы. На носитель попадают только зашифрованные данные; никакой незашифрованной копии информации на диске не сохраняется. Метаданные vSAN также могут быть зашифрованы или содержать ссылки на ключ (например, KEK_ID), но без владения самим ключом извлечь полезную информацию из зашифрованного блока невозможно.
В архитектуре ESA процесс схож, с тем отличием, что шифрование происходит сразу после сжатия, ещё на высокоуровневом слое ввода-вывода. Это означает, что данные выходят из узла уже шифрованными кластерным ключом. При наличии Data-in-Transit Encryption vSAN накладывает дополнительное пакетное шифрование: каждый сетевой пакет между хостами шифруется с использованием симметрических ключей сеанса, которые регулярно обновляются. Таким образом, данные остаются зашифрованы как при хранении, так и при передаче по сети, что создаёт многослойную защиту (end-to-end encryption).
Чтение данных (дешифрование)
Обратный процесс столь же прозрачен. Когда виртуальная машина запрашивает данные из vSAN, гипервизор на каждом затронутом хосте находит нужные зашифрованные блоки на дисках и считывает их. Прежде чем передать данные наверх VM, гипервизор с помощью соответствующего DEK выполняет расшифровку каждого блока в памяти. Расшифрованная информация проходит через механизмы пост-обработки (восстановление сжатых данных, сборка из дедуплицированных сегментов) и отправляется виртуальной машине. Для ВМ этот процесс невидим – она получает привычный для себя блок данных, не зная, что на физическом носителе он хранится в зашифрованном виде. Если задействовано шифрование трафика, то данные могут передаваться между узлами в зашифрованном виде и расшифровываются только на том хосте, который читает их для виртуальной машины-потребителя.
Устойчивость к сбоям
При нормальной работе все операции шифрования/дешифрования происходят мгновенно для пользователя. Но стоит рассмотреть ситуацию с потенциальным сбоем KMS или перезагрузкой узла. Как отмечалось ранее, хосты кэшируют полученные ключи (KEK, Host Key и необходимые DEK) в памяти или TPM, поэтому кратковременное отключение KMS не влияет на работающий кластер.
Виртуальные машины продолжат и читать, и записывать данные, пользуясь уже загруженными ключами. Проблемы могут возникнуть, если перезагрузить хост при недоступном KMS: после перезапуска узел не сможет получить свои ключи для монтирования дисковых групп, и его локальные компоненты хранилища останутся офлайн до восстановления связи с KMS. Именно поэтому, как уже упоминалось, рекомендуется иметь резервный KMS (или NKP) и TPM-модули на узлах, чтобы повысить отказоустойчивость системы шифрования.
Безопасность криптосистемы во многом зависит от регулярной смены ключей. VMware vSAN предоставляет администраторам возможность проводить плановую ротацию ключей шифрования без простоя и с минимальным влиянием на работу кластера. Поддерживаются два режима: «мелкая» ротация (Shallow Rekey) и «глубокая» ротация (Deep Rekey). При shallow rekey генерируется новый мастер-ключ KEK, после чего все ключи данных (DEK) перешифровываются этим новым KEK (старый KEK уничтожается). Важно, что сами DEK при этом не меняются, поэтому операция выполняется относительно быстро: vSAN просто обновляет ключи в памяти хостов и в метаданных, не перестраивая все данные на дисках. Shallow rekey обычно используют для регулярной смены ключей в целях комплаенса (например, раз в квартал или при смене ответственного администратора).
Deep rekey, напротив, предполагает полную замену всех ключей: генерируются новые DEK для каждого объекта/диска, и все данные кластера постепенно перераспределяются и шифруются уже под новыми ключами. Такая операция более ресурсоёмка, фактически аналогична повторному шифрованию всего объёма данных, и может занять продолжительное время на крупных массивах. Глубокую ротацию имеет смысл выполнять редко – например, при подозрении на компрометацию старых ключей или после аварийного восстановления системы, когда есть риск утечки ключевой информации. Оба типа рекея можно инициировать через интерфейс vCenter (в настройках кластера vSAN есть опция «Generate new encryption keys») или с помощью PowerCLI-скриптов. При этом для shallow rekey виртуальные машины могут продолжать работать без простоев, а deep rekey обычно тоже выполняется онлайн, хотя и создаёт повышенную нагрузку на подсистему хранения.
Смена KMS и экспорт ключей
Если возникает необходимость поменять используемый KMS (например, миграция на другого вендора или переход от внешнего KMS к встроенному NKP), vSAN упрощает эту процедуру. Администратор добавляет новый KMS в vCenter и обозначает его активным для данного кластера. vSAN автоматически выполнит shallow rekey: запросит новый KEK у уже доверенного нового KMS и переведёт кластер на использование этого ключа, перешифровав им все старые DEK. Благодаря этому переключение ключевого сервиса происходит прозрачно, без остановки работы хранилища. Тем не менее, после замены KMS настоятельно рекомендуется удостовериться, что старый KMS более недоступен хостам (во избежание путаницы) и сделать резервную копию конфигурации нового KMS/NKP.
При использовании vSphere Native Key Provider важно регулярно экспортировать зашифрованную копию ключа NKP (через интерфейс vCenter) и хранить её в безопасном месте. Это позволит восстановить доступ к зашифрованному vSAN, если vCenter выйдет из строя и потребуется его переустановка. В случае же аппаратного KMS, как правило, достаточно держать под рукой актуальные резервные копии самого сервера KMS (или использовать кластер KMS из нескольких узлов для отказоустойчивости).
Безопасное удаление данных
Одним из побочных преимуществ внедрения шифрования является упрощение процедуры безопасной утилизации носителей. vSAN предлагает опцию Secure Disk Wipe для случаев, когда необходимо вывести диск из эксплуатации или изъять узел из кластера. При включенной функции шифрования проще всего выполнить «очистку» диска путем сброса ключей: как только DEK данного носителя уничтожен (либо кластерный KEK перегенерирован), все данные на диске навсегда остаются в зашифрованном виде, то есть фактически считаются стёртыми (так называемая криптографическая санация).
Кроме того, начиная с vSAN 8.0, доступна встроенная функция стирания данных в соответствии со стандартами NIST (например, перезапись нулями или генерация случайных шаблонов). Администратор может запустить безопасное стирание при выведении диска из кластера – vSAN приведёт накопитель в состояние, удовлетворяющее требованиям безопасной утилизации, удалив все остаточные данные. Комбинация шифрования и корректного удаления обеспечивает максимальную степень защиты: даже физически завладев снятым накопителем, злоумышленник не сможет извлечь конфиденциальные данные.
VMware vSAN Encryption Services были разработаны с учётом строгих требований отраслевых стандартов безопасности. Криптографический модуль VMkernel, на котором основано шифрование vSAN, прошёл валидацию FIPS 140-2 (Cryptographic Module Validation Program) ещё в 2017 году. Это означает, что реализация шифрования в гипервизоре проверена независимыми экспертами и отвечает критериям, предъявляемым правительственными организациями США и Канады.
Более того, в 2024 году VMware успешно завершила сертификацию модуля по новому стандарту FIPS 140-3, обеспечив преемственность соответствия более современным требованиям. Для заказчиков из сфер, где необходима сертификация (государственный сектор, финансы, медицина и т.д.), это даёт уверенность, что vSAN может использоваться для хранения чувствительных данных. Отдельно отметим, что vSAN включена в руководства по безопасности DISA STIG для Министерства обороны США, а также поддерживает механизмы двухфакторной аутентификации администраторов (RSA SecurID, CAC) при работе с vCenter — всё это подчёркивает серьёзное внимание VMware к безопасности решения.
Совместимость с функционалом vSAN
Шифрование в vSAN спроектировано так, чтобы быть максимально прозрачным для остальных возможностей хранения. Дедупликация и сжатие полностью совместимы с Data-at-Rest Encryption: благодаря порядку выполнения (сначала дедупликация/сжатие, потом шифрование) эффективность экономии места практически не снижается. Исключение составляет экспериментальная функция глобальной дедупликации в новой архитектуре ESA — на момент запуска vSAN 9.0 одновременное включение глобальной дедупликации и шифрования не поддерживается (ожидается снятие этого ограничения в будущих обновлениях).
Снапшоты и клоны виртуальных машин на зашифрованном vSAN работают штатно: все мгновенные копии хранятся в том же шифрованном виде, и при чтении/записи гипервизор так же прозрачно шифрует их содержимое. vMotion и другие механизмы миграции ВМ также поддерживаются – сама ВМ при миграции может передаваться с шифрованием (функция Encrypted vMotion, независимая от vSAN) или без него, но это не влияет на состояние ее дисков, которые на принимающей стороне всё равно будут записаны на vSAN уже в зашифрованном виде.
Резервное копирование и репликация
vSAN Encryption не накладывает ограничений на работу средств резервного копирования, использующих стандартные API vSphere (такие как VMware VADP) или репликации на уровне ВМ. Данные читаются гипервизором в расшифрованном виде выше уровня хранения, поэтому бэкап-приложения получают их так же, как и с обычного хранилища. При восстановлении или репликации на целевой кластер vSAN, естественно, данные будут записаны с повторным шифрованием под ключи того кластера. Таким образом, процессы защиты и восстановления данных (VDP, SRM, vSphere Replication и пр.) полностью совместимы с зашифрованными датасторами vSAN.
Ограничения и особенности
Поскольку vSAN реализует программное шифрование, аппаратные самошифрующиеся диски (SED) не требуются и официально не поддерживаются в роли средства шифрования на уровне vSAN. Если в серверы установлены SED-накопители, они могут использоваться, но без включения режимов аппаратного шифрования – vSAN в любом случае выполнит шифрование средствами гипервизора. Ещё один момент: при включении vSAN Encryption отключается возможность рентген-просмотра (в веб-клиенте vSAN) содержимого дисков, так как данные на них хранятся в зашифрованном виде. Однако на функциональность управления размещением объектов (Storage Policy) это не влияет. Наконец, стоит учитывать, что шифрование данных несколько повышает требования к процессорным ресурсам на хостах. Практика показывает, что современные CPU справляются с этим отлично, но при проектировании больших нагрузок (вроде VDI или баз данных на all-flash) закладывать небольшой запас по CPU будет не лишним.
VMware vSAN Encryption Services предоставляют мощные средства защиты данных для гиперконвергентной инфраструктуры. Реализовав сквозное шифрование (от диска до сети) на уровне хранения, vSAN позволяет организациям выполнить требования по безопасности без сложных доработок приложений. Среди ключевых преимуществ решения можно отметить:
Всесторонняя защита данных. Даже если злоумышленник получит физический доступ к носителям или перехватит трафик, конфиденциальная информация останется недоступной благодаря сильному шифрованию (AES-256) и раздельным ключам для разных объектов. Это особенно важно для соблюдения стандартов GDPR, PCI-DSS, HIPAA и других.
Прозрачность и совместимость. Шифрование vSAN работает под управлением гипервизора и не требует изменений в виртуальных машинах. Все основные функции vSphere (кластеризация, миграция, бэкап) полностью поддерживаются. Решение не привязано к специфическому оборудованию, а опирается на открытые стандарты (KMIP, TLS), что облегчает интеграцию.
Удобство централизованного управления. Администратор может включить шифрование для всего кластера несколькими кликами – без необходимости настраивать каждую ВМ по отдельности (в отличие от VMcrypt). vCenter предоставляет единый интерфейс для управления ключами, а встроенный NKP ещё больше упрощает старт. При этом разграничение прав доступа гарантирует, что только уполномоченные лица смогут внести изменения в политику шифрования.
Минимальное влияние на производительность. Благодаря оптимизациям (использование AES-NI, эффективные алгоритмы) накладные расходы на шифрование невелики. Особенно в архитектуре ESA шифрование реализовано с учётом высокопроизводительных сценариев и практически не сказывается на IOPS и задержках. Отсутствуют и накладные расходы по ёмкости: включение шифрования не уменьшает полезный объём хранилища и не создаёт дублирования данных.
Гибкость в выборе подхода. vSAN поддерживает как внешние KMS от разных поставщиков (для предприятий с уже выстроенными процессами управления ключами), так и встроенный vSphere Native Key Provider (для простоты и экономии). Администраторы могут ротировать ключи по своему графику, комбинировать или отключать сервисы при необходимости (например, включить только шифрование трафика для удалённого филиала с общим хранилищем).
При внедрении шифрования в vSAN следует учесть несколько моментов: обеспечить высокую доступность сервера KMS (или надёжно сохранить ключ NKP), активировать TPM на хостах для хранения ключей, а также не сочетать шифрование vSAN с шифрованием на уровне ВМ (VM Encryption) без крайней необходимости. Двойное шифрование не повышает безопасность, зато усложняет управление и снижает эффективность дедупликации и сжатия.
В целом же шифрование vSAN значительно повышает уровень безопасности инфраструктуры с минимальными усилиями. Оно даёт организациям уверенность, что данные всегда под надёжной защитой – будь то на дисках или в пути между узлами, сегодня и в будущем, благодаря следованию современным стандартам криптографии FIPS.
Введение глобальной дедупликации в vSAN для VMware Cloud Foundation (VCF) 9.0 открывает новую эру эффективности использования пространства в vSAN. Применение современных технологий оптимизации хранения позволяет разместить больше данных, чем это физически возможно при традиционных способах хранения, помогая извлечь максимум из уже имеющихся ресурсов.
Однако дедупликация в vSAN для VCF 9.0 — это не просто долгожданная функция в поиске идеального решения для хранения данных. Новый подход использует распределённую архитектуру vSAN и повышает её способность к дедупликации данных по мере роста размера кластера. Кроме того, эта технология отлично сочетается с моделью лицензирования VCF, которая включает хранилище vSAN в состав вашей лицензии.
Благодаря этому глобальная дедупликация vSAN становится более эффективной с точки зрения экономии пространства и значительно доступнее, чем использование VCF с другими решениями для хранения данных. Если рассматривать совокупную стоимость владения (TCO), как описано далее, то использование VCF с vSAN обходится до 34% дешевле, чем VCF с конкурирующим хранилищем в инфраструктуре с 10 000 ядрами. По внутренним оценкам VMware, в этой же модели одна только глобальная дедупликация vSAN может снизить общую стоимость VCF до 4% — что примерно соответствует 10 миллионам долларов! Давайте посмотрим, как особенности глобальной дедупликации vSAN могут помочь сократить расходы на ваше виртуальное частное облако с использованием VCF.
Измерение эффективности
Чтобы правильно понять преимущества дедупликации, необходимо иметь метод оценки её эффективности. Эффективность дедупликации обычно выражается в виде коэффициента, показывающего объём данных до дедупликации и после неё. Чем выше коэффициент, тем больше экономия ёмкости. Такой коэффициент также может отображаться без «:1» — например, вместо «4:1» будет показано «4x».
Хотя коэффициент дедупликации легко понять, к сожалению, системы хранения могут измерять его по-разному. Некоторые показывают эффективность дедупликации только как общий коэффициент «сжатия данных», включая в него такие методы, как сжатие данных, клонирование и выделение пространства под тонкие (thin) тома. Другие могут отображать коэффициенты дедупликации, исключая метаданные и другие накладные расходы, которые не учитываются в измерении. Это важно понимать, если вы сравниваете эффективность дедупликации между системами хранения.
На эффективность дедупликации в системе хранения влияет несколько факторов, включая, но не ограничиваясь:
Архитектурой системы дедупликации. Системы хранения часто проектируются с учётом компромиссов между эффективностью и затратами, что и определяет разные подходы к дедупликации.
Размером/гранулярностью дедупликации. Это единица данных, по которой осуществляется поиск дубликатов. Чем меньше гранулярность, тем выше вероятность нахождения совпадений.
Объёмом данных в пределах домена дедупликации. Обычно, чем больше объём данных, тем выше вероятность, что они будут дедуплицированы с другими данными.
Сходством данных. Единица данных должна полностью совпадать с другой единицей, прежде чем дедупликация принесёт пользу. Иногда приложения могут использовать шифрование или другие методы, которые снижают возможность дедупликации данных.
Характеристиками данных и рабочих нагрузок. Данные, создаваемые приложением, могут быть более или менее благоприятны для дедупликации. Например, структурированные данные, такие как OLTP-базы, обычно содержат меньше потенциальных дубликатов, чем неструктурированные данные.
Последние два пункта относятся к рабочим нагрузкам и наборам данных, уникальным для клиента. Именно они часто объясняют, почему одни данные лучше поддаются дедупликации, чем другие. Но при этом архитектура системы хранения играет ключевую роль в эффективности дедупликации. Может ли она выполнять дедупликацию с минимальным вмешательством в рабочие нагрузки? Может ли выполнять её с высокой степенью детализации и в широком домене дедупликации для максимальной эффективности? Глобальная дедупликация vSAN была разработана для обеспечения лучших результатов при минимальном влиянии на рабочие процессы.
Простой внутренний тест продемонстрировал превосходство архитектуры vSAN. На массиве конкурента было создано 50 полных клонов, и столько же — на vSAN. С учётом возможностей дедупликации и сжатия массив показал общий коэффициент сжатия данных 41.3 к 1. vSAN достиг коэффициента 45.27 к 1. Это наглядно демонстрирует впечатляющую эффективность дедупликации vSAN, усиленную сжатием данных для ещё большей экономии. Хотя этот пример не является репрезентативным для показателей дедупликации на произвольных наборах данных, он демонстрирует эффективность дедупликации в vSAN.
Масштабирование ради повышения эффективности
Архитектура системы дедупликации в хранилище играет значительную, но не единственную роль в общей эффективности технологии. Например, домен дедупликации определяет границы данных, в пределах которых система ищет дубликаты блоков. Чем шире домен дедупликации, тем выше вероятность нахождения повторяющихся данных, а значит — тем эффективнее система в плане экономии пространства.
Традиционные модульные массивы хранения, как правило, не были изначально спроектированы как распределённые масштабируемые решения. Их домен дедупликации обычно ограничен одним массивом. Когда клиенту необходимо масштабироваться путём добавления ещё одного массива, домен дедупликации разделяется. Это означает, что идентичные данные могут находиться на двух разных массивах, но не могут быть дедуплицированы между ними, поскольку домен дедупликации не увеличивается при добавлении нового хранилища.
Глобальная дедупликация vSAN работает иначе. Она использует преимущества распределённой архитектуры масштабирования vSAN. В кластере vSAN весь кластер является доменом дедупликации, что означает, что по мере добавления новых хостов домен дедупликации автоматически расширяется. Это увеличивает вероятность нахождения повторяющихся данных и обеспечивает рост коэффициента дедупликации.
На рисунке ниже показан этот пример:
Слева изображён традиционный модульный массив хранения, обеспечивающий коэффициент дедупликации 6:1. Если добавить ещё один массив, каждый из них по отдельности может обеспечить тот же коэффициент 6:1, но система теряет возможность дедуплицировать данные между массивами.
Справа показан кластер vSAN из 6 хостов, обеспечивающий коэффициент дедупликации 6:1. По мере добавления новых хостов любые данные, размещённые на этих хостах, входят в тот же домен дедупликации, что и исходные 6 хостов. Это означает, что коэффициент дедупликации будет увеличиваться по мере добавления хостов и роста общего объёма данных.
Использование того, что уже есть
Снижение затрат напрямую связано с увеличением использования уже имеющихся аппаратных и программных ресурсов. Чем выше степень их использования, тем меньше они простаивают и тем дольше можно откладывать будущие расходы.
Модель лицензирования vSAN в составе VCF в сочетании с глобальной дедупликацией vSAN образует выигрышную комбинацию. Каждая лицензия на ядро VCF включает 1 TiB «сырой» ёмкости vSAN. Но благодаря глобальной дедупликации весь объём, который удалось освободить, напрямую работает в вашу пользу!
Например, кластер vSAN из 6 хостов, каждый из которых содержит по 32 ядра, предоставит 192 TiB хранилища vSAN в рамках лицензирования VCF. Если этот кластер обеспечивает коэффициент дедупликации 6:1, то можно хранить почти 1.2 PiB данных, используя только имеющуюся лицензию.
Реальная экономия затрат
Когда хранилище предоставляется как часть лицензии VCF, логично, что затраты на хранение снижаются, поскольку требуется меньше дополнительных покупок. В примере ниже мы сравниваем эффективную цену за 1 ТБ при использовании VCF с конкурентным массивом хранения с дедупликацией для обслуживания рабочих нагрузок уровня Tier-1 и при использовании vSAN с VCF 9.0.
Так как наборы данных представляли собой структурированные данные (SQL), коэффициенты сжатия были весьма скромными. Однако, исходя из модели с 10 000 ядер VCF при предполагаемом уровне загрузки CPU и стоимости лицензирования:
Эффективная цена за ТБ уже на 14% ниже при использовании только сжатия данных в vSAN.
А при использовании дедупликации и сжатия в vSAN стоимость хранения (цена за ТБ) становится ниже на 29%.
По собственным оценкам VMware, совокупная стоимость владения (TCO) для VCF может быть снижена до 34%.
А как насчёт вторичного хранилища? Даже когда vSAN использует накопители Read-Intensive TLC и работает в паре с распространённым сторонним поставщиком решений для резервного копирования, итоговая стоимость за 1 ТБ может оказаться ниже, чем при использовании внешнего устройства вторичного хранения.
Для этого сравнения также рассматривалась среда с 10 000 ядер VCF при предполагаемом уровне загрузки CPU и стоимости лицензирования. Даже с учётом дополнительных расходов на стороннее решение для резервного копирования, стоимость хранения в vSAN оказалась на 13% ниже за каждый терабайт.
Если вы заинтересованы попробовать эту функцию в релизе P01 VCF 9.0, вы можете связаться с Broadcom для получения подробной информации через эту форму. В первую очередь внимание будет уделяться клиентам, которые хотят включить её на односайтовых vSAN HCI или кластерах хранения vSAN размером от 3 до 16 хостов с использованием сетей 25GbE или быстрее. На начальном этапе некоторые топологии, такие как растянутые кластеры, а также некоторые сервисы данных, например, шифрование данных at rest, не будут поддерживаться при использовании этой функции.
Итоги
VMware считает, что глобальная дедупликация для vSAN в VCF 9.0 будет не хуже, а скорее всего лучше, чем решения по дедупликации у других поставщиков систем хранения. Учитывая, что клиенты VCF получают 1 TiB сырой ёмкости vSAN на каждое лицензированное ядро VCF, это открывает огромный потенциал: вы можете обеспечить всю необходимую ёмкость хранения, используя только существующее лицензирование, и при этом снизить затраты до минимума.
Растянутые кластеры vSAN Stretched Clusters — это чрезвычайно популярная топология, используемая большим процентом клиентов VMware. Они зарекомендовали себя как простой и надежный способ достижения устойчивости на уровне площадки без той сложности, которая присуща метрокластерам на базе систем хранения. В версии VCF 9.0 vSAN представляет новые функции, которые повышают гибкость, доступность и упрощают операционные задачи для растянутых кластеров.
Во-первых, теперь поддерживаются растянутые вычислительные кластеры, которые могут монтировать хранилище растянутого кластера vSAN, что упрощает использование растянутых кластеров в среде vSphere.
Во-вторых, новая функция обслуживания на уровне площадки расширяет понятие "режим обслуживания" до уровня всей площадки в растянутом кластере.
И, в-третьих, функция ручного захвата управления площадкой предоставляет администратору возможность самостоятельно восстановить одну площадку в случае серьезного двойного отказа площадок в растянутом кластере.
Лучший способ растянуть кластеры vSphere между площадками
vSAN 8 Update 2 поддерживал кластеры хранения vSAN в топологии растянутого кластера, но имел определённые ограничения. Единственным типом клиентского кластера, который мог монтировать целевое хранилище, был также растянутый кластер vSAN. Любой кластер vSphere, которому требовалось монтировать хранилище, мог располагаться только на одной из двух площадок. Это означало, что для обычных кластеров vSphere можно было обеспечить устойчивость данных между двумя площадками, но нельзя было обеспечить устойчивость и высокую доступность рабочих нагрузок виртуальных машин на обеих площадках одновременно. Причина такого ограничения заключалась в том, что хосты, входящие в кластер vSphere, не имели представления о доменах отказа, как это реализовано в растянутом кластере vSAN.
vSAN в VCF 9.0 устраняет этот пробел и позволяет использовать кластер хранения vSAN, растянутый между двумя площадками, с кластером vSphere. В топологии растянутого кластера это означает, что кластер хранения vSAN может быть растянут между двумя площадками (как и ранее), и один или несколько кластеров vSphere, также растянутых между этими двумя географическими площадками, могут монтировать это хранилище (что ранее не поддерживалось). Это фактически создаёт гораздо более простой аналог «метрокластера хранения», устраняя сложность традиционных метрокластеров на базе систем хранения за счёт простой и надёжной архитектуры vSAN.
Упрощённое обслуживание площадки для растянутых кластеров vSAN
Ранее в vSAN переход в режим обслуживания происходил на уровне отдельного хоста. Для клиентов, использующих vSAN в среде растянутого кластера, не существовало простого или автоматизированного способа перевести в режим обслуживания все хосты, составляющие одну площадку. Задача обслуживания на «уровне площадки» была одной из самых частых просьб со стороны клиентов. Хотя ранее это можно было выполнить вручную, процесс включал в себя множество шагов, был подвержен ошибкам и, в зависимости от условий, мог не обеспечить требуемую согласованность данных.
В VCF 9.0 обслуживание площадки в растянутом кластере vSAN стало значительно проще.
Теперь действия, необходимые от администратора, сводятся практически к одному клику в пользовательском интерфейсе или вызову API. Этот процесс обеспечивает безопасный перевод всех хостов одной площадки в режим обслуживания при сохранении согласованности данных. Новый рабочий процесс предлагает не только надёжный способ перевода всей площадки в режим обслуживания, но и простой механизм возврата из него.
Самостоятельное восстановление при длительном отказе двух площадок
Растянутый кластер vSAN позволяет выдержать отказ любой из трёх площадок, при этом данные остаются доступными. Ранее, при одновременном отказе основной площадки с данными и площадки-свидетеля, кластер vSAN блокировал доступ к данным из-за механизма кворума. Система кворума обеспечивает согласованность данных, предотвращая сценарии разделения кластера (split-brain). В случае длительного одновременного отказа основной площадки и площадки-свидетеля, данные на оставшейся площадке становились недоступными. Чтобы восстановить доступ к этим данным, требовалось обращаться в службу поддержки (GS), и процесс восстановления вручную был трудоёмким и подверженным ошибкам.
Функция ручного захвата управления площадкой (manual site takeover) в vSAN для VCF 9.0 предоставляет возможность самостоятельного восстановления в ситуации, когда одна из площадок находится в режиме обслуживания, а затем происходит одновременный отказ двух других площадок. В этом случае площадку, находящуюся в обслуживании, можно вернуть в рабочее состояние, запустить виртуальные машины и предоставить им доступ к хранилищу.
Изначально эта функция будет доступна в ограниченном виде через программу Broadcom “Technical Qualification Request” (TQR), которая пришла на смену процессу “Request for Product Qualification” (RPQ) от VMware для функциональности, ещё не выпущенной в общем доступе. Для подачи TQR, пожалуйста, свяжитесь с вашим поставщиком, чтобы обратиться в отдел управления продуктом vSAN.
Растянутые кластеры vSAN — это мощное решение для сред, где требуется максимальная устойчивость данных и максимальное время доступности виртуальных машин. Упрощение задач обслуживания и улучшение сценариев восстановления значительно усиливают самый простой способ развертывания VMware Cloud Foundation в мультисайтовой конфигурации.
Таги: VMware, vSAN, Stretched, Update, DR, HA, Enterprise
Недавно мы рассказали об улучшениях и нововведениях платформы VMware Cloud Foundation 9.0, включающей в себя платформу виртуализации VMware vSphere 9.0 и средство создания отказоустойчивой инфраструктуры хранения VMware vSAN 9.0. Посмотрим теперь, что нового эти продукты включают с точки зрения сервисов хранилищ (Core Storage).
Улучшения поддержки хранилищ VCF
Для новых (greenfield) развёртываний VCF теперь поддерживаются хранилища VMFS, Fibre Channel и NFSv3 в качестве основных вариантов хранилища для домена управления. Полную информацию о поддержке хранилищ см. в технической документации VCF 9.
Улучшения NFS
Поддержка TRIM для NFS v3
Существующая поддержка команд TRIM и UNMAP позволяет блочным хранилищам, таким как vSAN и хранилища на базе VMFS, освобождать место после удаления файлов в виртуальной машине или при многократной записи в один и тот же файл. В типичных средах это позволяет освободить до 30% пространства, обеспечивая более эффективное использование ёмкости. С использованием плагина VAAI NFS системы NAS, подключённые через NFSv3, теперь могут выполнять освобождение пространства в VCF 9.
Шифрование данных в процессе передачи для NFS 4.1
Krb5p шифрует трафик NFS при передаче. Шифрование данных «на лету» защищает данные при передаче между хостами и NAS, предотвращая несанкционированный доступ и обеспечивая конфиденциальность информации организации, особенно в случае атак типа «man-in-the-middle». Также будет доступен режим Krb5i, который не выполняет шифрование, но обеспечивает проверку целостности данных, исключая их подмену.
Улучшения базовой подсистемы хранения
Сквозная (End-to-End, E2E) поддержка 4Kn
В версии 9.0 реализована поддержка E2E 4Kn, включающая:
Фронтэнд — представление виртуальных дисков (VMDK) с сектором 4K для виртуальных машин.
Бэкэнд — использование SSD-накопителей NVMe с 4Kn для vSAN ESA. OSA не поддерживает 4Kn SSD.
ESXi также получает поддержку 4Kn SSD с интерфейсом SCSI для локального VMFS и внешних хранилищ.
SEsparse по умолчанию для снимков с NFS и VMFS-5
Исторически, создание снимков (snapshots) имело значительное влияние на производительность ввода-вывода.
Формат Space Efficient Sparse Virtual Disks (SEsparse) был разработан для устранения двух основных проблем формата vmfsSparse:
Освобождение пространства при использовании снимков — SEsparse позволяет выполнять более точную и настраиваемую очистку места, что особенно актуально для VDI-сценариев.
Задержки чтения и снижение производительности из-за множественных операций чтения при работе со снимками.
Производительность была повышена благодаря использованию вероятностной структуры данных, такой как Bloom Filter, особенно для снимков первого уровня. Также появилась возможность настраивать размер блока (grain size) в SEsparse для соответствия типу используемого хранилища.
SEsparse по умолчанию применяется к VMDK объёмом более 2 ТБ на VMFS5, начиная с vSphere 7 Update 2. В vSphere 9 SEsparse становится форматом по умолчанию для всех VMDK на NFS и VMFS-5, независимо от размера. Это уменьшит задержки и увеличит пропускную способность чтения при работе со снимками. Формат SEsparse теперь также будет использоваться с NFS, если не используется VAAI snapshot offload plugin.
Поддержка спецификации vNVMe 1.4 — команда Write Zeroes
С выходом версии 9.0 поддержка NVMe 1.4 в виртуальном NVMe (vNVMe) позволяет гостевой ОС использовать команду NVMe Write Zeroes — она устанавливает заданный диапазон логических блоков в ноль. Эта команда аналогична SCSI WRITE_SAME, но ограничена только установкой значений в ноль.
Поддержка нескольких соединений на сессию iSCSI (Multiple Connections per Session)
Рекомендуется использовать iSCSI с Multi-path I/O (MPIO) для отказоустойчивого подключения к хостам. Это требует отдельных физических путей для каждого порта VMkernel и отказа от использования failover на базе состояния соединения или агрегацию сетевых интерфейсов (NIC teaming) или Link Aggregation Group (LAG), поскольку такие методы не обеспечивают детерминированный выбор пути.
Проблема: iSCSI традиционно использует одиночное соединение, что делает невозможным распределение трафика при использовании NIC teaming или LAG.
Решение — iSCSI с несколькими соединениями в рамках одной сессии, что позволяет:
Использовать несколько каналов, если один порт VMkernel работает в составе LAG с продвинутыми алгоритмами хеширования.
Повысить пропускную способность, когда скорость сети превышает возможности массива обрабатывать TCP через один поток соединения.
Важно: проконсультируйтесь с производителем хранилища, поддерживает ли он такую конфигурацию.
Выведенные из эксплуатации технологии
Устаревание NPIV
Как VMware предупреждала ранее, технология N-Port ID Virtualization (NPIV) была признана устаревшей и в версии 9.0 больше не поддерживается.
Устаревание гибридной конфигурации в оригинальной архитектуре хранения vSAN (OSA)
Гибридная конфигурация в vSAN Original Storage Architecture будет удалена в одном из будущих выпусков платформы VCF.
Устаревание поддержки vSAN over RDMA
Поддержка vSAN поверх RDMA для архитектуры vSAN OSA также будет прекращена в будущем выпуске VCF.
Устаревание поддержки RVC и зависимых Ruby-компонентов
Начиная с версии VCF 9.0, Ruby vSphere Console (RVC) и её компоненты на базе Ruby (такие как Rbvmomi) в составе vCenter считаются устаревшими. RVC, ранее использовавшаяся технической поддержкой для тестирования и мониторинга систем, уже была признана устаревшей, начиная с vSAN 7.0.
Для задач мониторинга и сопровождения Broadcom рекомендует использовать PowerCLI, DCLI или веб-интерфейс vCenter (UI), поскольку они теперь предоставляют весь функционал, ранее доступный в RVC. RVC и все связанные с ней Ruby-компоненты будут окончательно удалены в одном из будущих выпусков VCF.
В стремительно меняющемся ИТ-ландшафте современности организации сталкиваются с совокупностью тенденций, которые меняют их подход к инфраструктуре — особенно к хранилищам данных. VMware Cloud Foundation (VCF) 9.0 предлагает серьёзные усовершенствования в VMware vSAN 9, соответствующие этим тенденциям и позволяющие предприятиям эффективно, производительно и надёжно удовлетворять современные потребности в хранении данных.
Тенденции отрасли и вызовы для клиентов
Предприятия сталкиваются с быстрыми изменениями как в датацентрах, так и на рынке, и всё чаще становится ясно, что существующие подходы не справляются с новыми задачами — цифровая трансформация становится необходимостью.
Первая ключевая тенденция — рост объёма данных. Данные давно называют «цифровым золотом», ведь они дают конкурентное преимущество за счёт аналитики, новых продуктов и услуг. В дата-центрах особенно быстро растёт объём неструктурированных данных, и общий рост объёма информации остаётся высоким. Стоимость хранения и удержания этих данных — одна из главных проблем. ИТ-отделам необходимы технологии повышения эффективности хранения, такие как дедупликация и сжатие, чтобы снизить совокупную стоимость владения (TCO). Также им нужны хранилища большой ёмкости с низкой задержкой, которые сочетают в себе экономичность и производительность, необходимую для приложений, работающих с этими данными.
Меняется и способ доступа приложений к данным. В организациях стремительно внедряются новые интерфейсы хранения, с помощью которых данные превращаются в источники дохода. Для удовлетворения этих требований предприятия обращаются к объектному хранилищу и высокопроизводительным файловым системам как к основным интерфейсам, особенно для AI-нагрузок. Такие задачи требуют также гибкого управления данными, чтобы обеспечить точность моделей AI и снизить задержки. Сегодня ИТ-отделы используют точечные решения под каждый тип данных, но им гораздо удобнее было бы иметь унифицированную платформу, обеспечивающую простое управление и быструю работу.
Инфраструктурная фрагментация и гибридное облако
Рост объёма данных и внедрение новых интерфейсов усугубляется фрагментацией инфраструктуры, вызванной активным переходом к гибридным облачным стратегиям. По недавнему исследованию компании Broadcom, 92% организаций используют смесь частных и публичных облаков. Это означает, что данные и рабочие нагрузки распределены между локальными датацентрами, периферийными (edge) точками и публичными облаками. В результате появляется множество уникальных архитектур на базе точечных решений, которые трудно масштабировать и поддерживать. ИТ-отделам нужен единый подход к хранению данных и операциям с ними во всех средах, чтобы снизить сложность.
Какие рабочие нагрузки вызывают этот рост данных и требуют новых интерфейсов?
AI-задачи предъявляют совершенно новые требования к инфраструктуре хранения. Как прогнозирующий AI (уже широко используемый), так и генеративный AI (стремительно набирающий популярность) зависят от быстрого и надёжного доступа к огромным объёмам данных. Даже такие специфические рабочие нагрузки, как RAG (Retrieval Augmented Generation), нуждаются в хранилищах с высокой производительностью и низкой задержкой — гораздо выше, чем у традиционных систем на жёстких дисках, где сейчас хранятся многие AI-данные. Более того, AI-среды требуют прямого, высокоскоростного доступа к хранилищам с GPU, в обход узких мест, связанных с CPU, чтобы обрабатывать данные с минимальной задержкой.
Контейнеры, хранилище и скорость разработки
Хотя многие приложения по-прежнему работают в виртуальных машинах, использование контейнеров растёт, особенно в AI-сценариях. Контейнеры по своей природе эфемерны, но используемое ими хранилище должно быть постоянным и отделённым от жизненного цикла контейнера. По мере роста количества контейнеров, управление хранилищем должно происходить на более детализированном уровне — часто на уровне отдельного тома — и быть тесно интегрировано с системой оркестрации контейнеров для быстрой разработки.
В итоге ИТ-отделам необходимы программно-определяемые хранилища, которые масштабируются так же быстро, как контейнеры, и которые можно управлять теми же инструментами и с той же точностью, что и виртуальными машинами. Плюс, они должны предоставлять разработчикам быстрый доступ к инфраструктуре через привычные им инструменты, чтобы ускорить вывод продуктов на рынок.
Устойчивость к киберугрозам
Наконец, киберустойчивость остаётся в приоритете. Программы-вымогатели (ransomware) по-прежнему представляют серьёзную угрозу: в 2023 году две трети организаций подверглись атакам, и более 75% таких случаев сопровождались шифрованием данных. Кибербезопасность регулярно занимает первые места среди главных проблем CIO.
Стратегия хранения данных VMware и современные решения
Видение VMware в области хранения данных в рамках VMware Cloud Foundation заключается в предоставлении полностью интегрированных, унифицированных возможностей хранения в составе программно-определяемого частного облака, охватывающего локальные, периферийные (edge), публичные и суверенные облачные среды. Cтратегия VMware направлена на создание единой, универсальной платформы хранения, поддерживающей как первичные, так и вторичные сценарии использования для различных типов данных и рабочих нагрузок. Эта платформа создаётся с целью упростить операции, повысить безопасность, сократить затраты и ускорить инновации.
Снижение стоимости хранения
VMware уделяет особое внимание снижению затрат, что особенно важно для клиентов. VMware Cloud Foundation включает 1 TiB хранилища vSAN на одно ядро в своей лицензионной модели, что позволило клиентам сократить среднюю стоимость хранения на 30%, а в отдельных случаях — снизить TCO более чем на 40% по сравнению с традиционными массивами с контроллерами.
Дополнительно, VMware снижает расходы за счёт поддержки сертифицированных стандартных серверов: более 500 конфигураций vSAN ReadyNode от 15 OEM-производителей. Это в среднем снижает стоимость хранения на 46% за терабайт. Масштабируемая гиперконвергентная архитектура устраняет неиспользуемую ёмкость, типичную для масштабируемых систем (scale-up), а серверный подход позволяет существенно сократить затраты на поддержку и управление. В итоге заказчики получают высокопроизводительное, устойчивое хранилище для критически важных задач — без высокой стоимости устаревших решений.
С выпуском VCF 9.0 VMware представила глобальную дедупликацию на программном уровне, которая позволяет дополнительно сократить объём хранимых данных вплоть до 8 раз, что особенно актуально при росте объёма информации.
Новая дедупликация vSAN:
Имеет минимальную нагрузку на CPU
Работает в фоновом режиме, когда системные ресурсы не загружены
Охватывает все данные в кластере, а не только данные за одним контроллером, как в традиционных системах
Масштабируется вместе с кластером, что даёт более высокую эффективность
В будущем VMware планирует дополнительно снижать стоимость хранения за счёт более плотных носителей, соответствующих жёстким требованиям по производительности и задержкам. Совместно с гибкой лицензионной моделью это откроет новые сценарии использования vSAN, включая вторичное хранилище для резервного копирования.
Хранилище с низкой задержкой для AI-нагрузок
AI-задачи предъявляют повышенные требования к инфраструктуре, и vSAN соответствует этим требованиям благодаря архитектуре Express Storage Architecture (ESA) нового поколения. На сегодняшний день vSAN ESA обеспечивает:
До 300 000 IOPS на узел.
Постоянную задержку менее 1 мс, даже при пиковых нагрузках.
Линейный рост производительности и ёмкости по мере масштабирования кластера — в отличие от традиционного хранилища, где масштабируется только ёмкость.
Гибкость при сбоях: недавние тесты показали на 60% меньшую задержку в аварийных сценариях по сравнению с классическими системами.
В текущем релизе VMware повысила производительность кластеров vSAN до 25% за счёт разделения трафика — теперь можно использовать отдельные сети для вычислений и хранилища. Это не только освобождает пропускную способность для хранилища, но и позволяет использовать существующие инвестиции. Клиенты могут выбрать более дешёвую, низкоскоростную сеть для вычислений, не тратясь на дорогостоящую высокоскоростную сеть для совместного использования вычислительных и хранилищных задач.
В будущем VMware планирует расширить хранилище vSAN с низкими задержками на вторичные сценарии, включая предиктивные и генеративные AI-нагрузки. vSAN будет обладать оптимальным сочетанием высокой ёмкости, низкой задержки и масштабируемости, чтобы точно соответствовать требованиям этих задач.
Программно-определяемое хранилище для любых рабочих нагрузок
VMware vSAN предлагает гибкую, программно-определяемую, масштабируемую архитектуру, позволяющую организациям оптимизировать и расширять объём хранилища по мере необходимости. Клиенты могут масштабироваться линейно или раздельно, начиная с малого и доходя до петабайтового уровня.
С помощью драйвера CSI vSAN поддерживает постоянные тома для контейнерных нагрузок, позволяя разработчикам работать с инфраструктурой VMware через привычные инструменты. Администраторы получают гранулированный контроль и видимость томов контейнеров, воспринимая их как полноправные элементы инфраструктуры. Поскольку vSAN полностью интегрирован с CSI-драйвером, контейнеры могут использовать управление на основе политик хранения, обеспечивая быстрое и масштабируемое развертывание.
Автоматизация VCF
VCF Automation (VCF-A) в VCF 9.0 предоставляет простой способ предоставления томов для различных арендаторов, использующих хранилище как для ВМ, так и для постоянных томов в Kubernetes-среде VMware (VKS).
В будущем VMware планирует развивать многопользовательские сценарии и инфраструктуру как услугу (IaaS), чтобы дать разработчикам быстрый доступ к ресурсам при сохранении корпоративного контроля.
Единая модель управления хранилищем для локальных, периферийных и облачных сред
Для обеспечения последовательности в операциях VMware Cloud Foundation предлагает унифицированную программно-определяемую инфраструктуру во всех средах VMware — в датацентрах, на периферии и в облаках.
VMware сотрудничает с широчайшим кругом облачных партнёров (все крупные гиперскейлеры и сотни региональных провайдеров), чтобы обеспечить единообразный пользовательский опыт, включая управление хранилищем, во всех типах облаков.
VCF 9.0 включает важные инновации в управлении хранилищем:
Автоматическое развертывание, масштабирование и обновление инфраструктуры на базе vSAN
Единая консоль для всей VCF-инфраструктуры (vSAN, VMFS, NFS)
Уведомления о состоянии, рекомендации и пошаговое устранение проблем
Поддержка мультисайтовых сред для единого мониторинга.
В ближайшее время облачные партнёры внедрят vSAN ESA (Express Storage Architecture) в свои стеки VCF: VMware Cloud Foundation на AWS, Google Cloud VMware Engine и Azure VMware Solution добавят поддержку ESA.
В рамках этой стратегии технология vVols будет выведена из эксплуатации, начиная с VCF/VVF 9.0, и полностью отключена в будущих релизах. vVols не обеспечивают единый операционный подход между локальными, edge и облачными средами, так как не были внедрены большинством публичных и суверенных облачных партнёров.
Их распространённость остаётся низкой (единицы процентов), и они остаются нишевым решением. VMware по-прежнему будет поддерживать внешние хранилища через VMFS и NFS.
Безопасность и киберустойчивость для частного облака
Безопасность и устойчивость — основа vSAN, особенно важная для пользователей VCF. С выпуском vSAN 8.0 появилась новая система моментальных снимков (снапшотов), а в vSAN 8 Update 3 — встроенная защита данных, позволяющая администраторам легко защищать ВМ от случайных или вредоносных действий (например, удаления или атак программ-вымогателей).
Это реализуется через группы защиты, где можно задать, что защищать, как часто и как долго, с поддержкой неизменяемых снапшотов и шифрованием (FIPS 140-3) как для хранимых, так и передаваемых данных.
В VCF 9.0 добавлена репликация vSAN-to-vSAN, основанная на защите данных vSAN. Она позволяет удалённо реплицировать снапшоты на любое хранилище vSAN ESA — как гиперконвергентное, так и разнесённое.
Эта асинхронная репликация:
Дешевле и быстрее традиционной массивной репликации
Позволяет восстанавливать отдельные ВМ, а не целые LUN
Требует меньше места и меньше трафика
Значительно упрощает восстановление, переключение и возврат свободного места
Также репликация интегрирована с VMware Live Recovery (VLR) для восстановления после кибератак и аварий. VCF 9.0 поддерживает кибервосстановление в изолированную зону внутри локального VCF, что важно для соблюдения требований суверенитета и конфиденциальности данных.
Интеграция vSAN и VLR позволяет хранить длинную историю снапшотов, что критично при атаке с шифрованием, когда приходится откатываться назад до "чистых" копий. Управление и кибервосстановление, и аварийным восстановлением возможно через один VLR-апплаенс, с масштабированием восстановления с помощью кластеров vSAN.
В перспективе будет реализована функция Intelligent Threat Detection — AI/ML-алгоритмы для превентивной защиты, раннего обнаружения и анализа зашифрованных копий.
Унифицированное хранилище для всех типов данных
Клиенты давно хотят единую платформу хранения для всех задач, а не отдельные решения для блочного, файлового и объектного хранилища, что создаёт избыточную сложность. vSAN изначально предлагает блочное хранилище, а с 2019 года — встроенные файловые сервисы. VCF 9.0 расширяет их масштабируемость: теперь до 500 файловых ресурсов на кластер.
В будущем планируется добавление новых встроенных протоколов, ориентированных на высокую пропускную способность и низкую задержку, необходимых для AI-задач.
Взгляд в будущее
VMware vSAN — это интегрированное хранилище для частных облаков, на которое предприятия полагаются при работе с критически важными приложениями. Оно помогает сократить капитальные и операционные издержки, обеспечивая при этом производительность, масштаб и устойчивость, необходимые для современных нагрузок — от облачных приложений до AI-аналитики.
Благодаря единым операциям во всех средах (edge, core, облако) и ведущим в отрасли возможностям киберустойчивости, vSAN становится фундаментом современного частного облака.
VMware продолжает инвестировать в инновации, чтобы:
В предыдущей статье мы рассмотрели, что производительность vSAN зависит не только от физической пропускной способности сети, соединяющей хосты vSAN, но и от архитектуры самого решения. При использовании vSAN ESA более высокоскоростные сети в сочетании с эффективным сетевым дизайном позволяют рабочим нагрузкам в полной мере использовать возможности современного серверного оборудования. Стремясь обеспечить наилучшие сетевые условия для вашей среды vSAN, вы, возможно, задаётесь вопросом: можно ли ещё как-то улучшить производительность vSAN за счёт сети? В этом посте мы обсудим использование vSAN поверх RDMA и разберёмся, подойдёт ли это решение вам и вашей инфраструктуре.
Обзор vSAN поверх RDMA
vSAN использует IP-сети на базе Ethernet для обмена данными между хостами. Ethernet-кадры (уровень 2) представляют собой логический транспортный слой, обеспечивающий TCP-соединение между хостами и передачу соответствующих данных. Полезная нагрузка vSAN размещается внутри этих пакетов так же, как и другие типы данных. На протяжении многих лет TCP поверх Ethernet обеспечивал исключительно надёжный и стабильный способ сетевого взаимодействия для широкого спектра типов трафика. Его надёжность не имеет аналогов — он может функционировать даже в условиях крайне неудачного проектирования сети и плохой связности.
Однако такая гибкость и надёжность имеют свою цену. Дополнительные уровни логики, используемые для подтверждения получения пакетов, повторной передачи потерянных данных и обработки нестабильных соединений, создают дополнительную нагрузку на ресурсы и увеличивают вариативность доставки пакетов по сравнению с протоколами без потерь, такими как Fibre Channel. Это может снижать пропускную способность и увеличивать задержки — особенно в плохо спроектированных сетях. В правильно организованных средах это влияние, как правило, незначительно.
Чтобы компенсировать особенности TCP-сетей на базе Ethernet, можно использовать vSAN поверх RDMA через конвергентный Ethernet (в частности, RoCE v2). Эта технология всё ещё использует Ethernet, но избавляется от части избыточной сложности TCP, переносит сетевые операции с CPU на аппаратный уровень и обеспечивает прямой доступ к памяти для процессов. Более простая сетевая модель высвобождает ресурсы CPU для гостевых рабочих нагрузок и снижает задержку при передаче данных. В случае с vSAN это улучшает не только абсолютную производительность, но и стабильность этой производительности.
RDMA можно включить в кластере vSAN через интерфейс vSphere Client, активировав соответствующую опцию в настройках кластера. Это предполагает, что вы уже выполнили все предварительные действия, необходимые для подготовки сетевых адаптеров хостов и коммутаторов к работе с RDMA. Обратитесь к документации производителей ваших NIC и коммутаторов для получения информации о необходимых шагах по активации RDMA.
Если в конфигурации RDMA возникает хотя бы одна проблема — например, один из хостов кластера теряет возможность связи по RDMA — весь кластер автоматически переключается обратно на TCP поверх Ethernet.
Рекомендация. Рассматривайте использование RDMA только в случае, если вы используете vSAN ESA. Хотя поддержка vSAN поверх RDMA появилась ещё в vSAN 7 U2, наибольшую пользу эта технология приносит в сочетании с высокой производительностью архитектуры ESA, начиная с vSAN 8 и выше.
Как указано в статье «Проектирование сети vSAN», использование RDMA с vSAN влечёт за собой дополнительные требования, ограничения и особенности. К ним относятся:
Коммутаторы должны быть совместимы с RDMA и настроены соответствующим образом (включая такие параметры, как DCB — Data Center Bridging и PFC — Priority Flow Control).
Размер кластера не должен превышать 32 хоста.
Поддерживаются только следующие политики объединения интерфейсов:
Route based on originating virtual port
Route based on source MAC hash
Использование LACP или IP Hash не поддерживается с RDMA.
Предпочтительно использовать отдельные порты сетевых адаптеров для RDMA, а не совмещать RDMA и TCP на одном uplink.
RDMA не совместим со следующими конфигурациями:
2-узловые кластеры (2-Node)
Растянутые кластеры (stretched clusters)
Совместное использование хранилища vSAN
Кластеры хранения vSAN (vSAN storage clusters)
В VCF 5.2 использование vSAN поверх RDMA не поддерживается. Эта возможность не интегрирована в процессы SDDC Manager, и не предусмотрено никаких способов настройки RDMA для кластеров vSAN. Любые попытки настроить RDMA через vCenter в рамках VCF 5.2 также не поддерживаются.
Прирост производительности при использовании vSAN поверх RDMA
При сравнении двух кластеров с одинаковым аппаратным обеспечением, vSAN с RDMA может показывать лучшую производительность по сравнению с vSAN, использующим TCP поверх Ethernet. В публикации Intel «Make the Move to 100GbE with RDMA on VMware vSAN with 4th Gen Intel Xeon Scalable Processors» были зафиксированы значительные улучшения производительности в зависимости от условий среды.
Рекомендация: используйте RDTBench для тестирования соединений RDMA и TCP между хостами. Это также отличный инструмент для проверки конфигурации перед развёртыванием производительного кластера в продакшене.
Fibre Channel — действительно ли это «золотой стандарт»?
Fibre Channel заслуженно считается надёжным решением в глазах администраторов хранилищ. Протокол Fibre Channel изначально разрабатывался с одной целью — передача трафика хранения данных. Он использует «тонкий стек» (thin stack), специально созданный для обеспечения стабильной и низколатентной передачи данных. Детеминированная сеть на базе Fibre Channel работает как единый механизм, где все компоненты заранее определены и согласованы.
Однако Fibre Channel и другие протоколы, рассчитанные на сети без потерь, тоже имеют свою цену — как в прямом, так и в переносном смысле. Это дорогая технология, и её внедрение часто «съедает» большую часть бюджета, уменьшая возможности инвестирования в другие сетевые направления. Кроме того, инфраструктуры на Fibre Channel менее гибкие по сравнению с Ethernet, особенно при необходимости поддержки разнообразных топологий.
Хотя Fibre Channel изначально ориентирован на физическую передачу данных без потерь, сбои в сети могут привести к непредвиденным последствиям. В спецификации 32GFC был добавлен механизм FEC (Forward Error Correction) для борьбы с кратковременными сбоями, но по мере роста масштаба фабрики растёт и её сложность, что делает реализацию сети без потерь всё более трудной задачей.
Преимущество Fibre Channel — не в абсолютной скорости, а в предсказуемости передачи данных от точки к точке. Как видно из сравнения, даже с учётом примерно 10% накладных расходов при передаче трафика vSAN через TCP поверх Ethernet, стандартный Ethernet легко может соответствовать или даже превосходить Fibre Channel по пропускной способности.
Обратите внимание, что такие обозначения, как «32GFC» и Ethernet 25 GbE, являются коммерческими названиями, а не точным отражением фактической пропускной способности. Каждый стандарт использует завышенную скорость передачи на уровне символов (baud rate), чтобы компенсировать накладные расходы протокола. В случае с Ethernet фактическая пропускная способность зависит от типа передаваемого трафика. Стандарт 40 GbE не упоминается, так как с 2017 года он считается в значительной степени устаревшим.
Тем временем Ethernet переживает новый виток развития благодаря инфраструктурам, ориентированным на AI, которым требуется высокая производительность без уязвимости традиционных «безубыточных» сетей. Ethernet изначально проектировался с учётом практических реалий дата-центров, где неизбежны изменения в условиях эксплуатации и отказы оборудования.
Благодаря доступным ценам на оборудование 100 GbE и появлению 400 GbE (а также приближению 800 GbE) Ethernet становится чрезвычайно привлекательным решением. Даже традиционные поставщики систем хранения данных в последнее время отмечают, что всё больше клиентов, ранее серьёзно инвестировавших в Fibre Channel, теперь рассматривают Ethernet как основу своей следующей сетевой архитектуры хранения. Объявление Broadcom о выпуске чипа Tomahawk 6, обеспечивающего 102,4 Тбит/с внутри одного кристалла, — яркий индикатор того, что будущее высокопроизводительных сетей связано с Ethernet.
С vSAN ESA большинство издержек TCP поверх Ethernet можно компенсировать за счёт грамотной архитектуры — без переподписки и с использованием сетевого оборудования, поддерживающего высокую пропускную способность. Это подтверждается в статье «vSAN ESA превосходит по производительности топовое хранилище у крупной финансовой компании», где vSAN ESA с TCP по Ethernet с лёгкостью обошёл по скорости систему хранения, использующую Fibre Channel.
Насколько хорош TCP поверх Ethernet?
Если у вас качественно спроектированная сеть с высокой пропускной способностью и без переподписки, то vSAN на TCP поверх Ethernet будет достаточно хорош для большинства сценариев и является наилучшей отправной точкой для развёртывания новых кластеров vSAN. Эта рекомендация особенно актуальна для клиентов, использующих vSAN в составе VMware Cloud Foundation 5.2, где на данный момент не поддерживается RDMA.
Хотя RDMA может обеспечить более высокую производительность, его требования и ограничения могут не подойти для вашей среды. Тем не менее, можно добиться от vSAN такой производительности и стабильности, которая будет приближена к детерминированной модели Fibre Channel. Для этого нужно:
Грамотно спроектированная сеть. Хорошая архитектура Ethernet-сети обеспечит высокую пропускную способность и низкие задержки. Использование топологии spine-leaf без блокировки (non-blocking), которая обеспечивает линейную скорость передачи от хоста к хосту без переподписки, снижает потери пакетов и задержки. Также важно оптимально размещать хосты vSAN внутри кластера — это повышает сетевую эффективность и производительность.
Повышенная пропускная способность. Устаревшие коммутаторы должны быть выведены из эксплуатации — им больше нет места в современных ЦОДах. Использование сетевых адаптеров и коммутаторов с высокой пропускной способностью позволяет рабочим нагрузкам свободно передавать команды на чтение/запись и данные без узких мест. Ключ к стабильной передаче данных по Ethernet — исключить ситуации, при которых кадры или пакеты TCP нуждаются в повторной отправке из-за нехватки ресурсов или ненадёжных каналов.
Настройка NIC и коммутаторов. Сетевые адаптеры и коммутаторы часто имеют настройки по умолчанию, которые не оптимизированы для высокой производительности. Это может быть подходящим шагом, если вы хотите улучшить производительность без использования RDMA, и уже реализовали два предыдущих пункта. В документе «Рекомендации по производительности для VMware vSphere 8.0 U1» приведены примеры таких возможных настроек.
Платформа vSphere всегда предоставляла несколько способов использовать несколько сетевых карт (NIC) совместно, но какой из них лучший для vSAN? Давайте рассмотрим ключевые моменты, важные для конфигураций vSAN в сетевой топологии. Этот материал не является исчерпывающим анализом всех возможных вариантов объединения сетевых интерфейсов, а представляет собой справочную информацию для понимания наилучших вариантов использования техники teaming в среде VMware Cloud Foundation (VCF).
Описанные здесь концепции основаны на предыдущих публикациях:
Объединение сетевых портов NIC — это конфигурация vSphere, при которой используется более одного сетевого порта для выполнения одной или нескольких задач, таких как трафик ВМ или трафик VMkernel (например, vMotion или vSAN). Teaming позволяет достичь одной или обеих следующих целей:
Резервирование: обеспечение отказоустойчивости в случае сбоя сетевого порта на хосте или коммутатора, подключенного к этому порту.
Производительность: распределение одного и того же трафика по нескольким соединениям может обеспечить агрегацию полосы пропускания и повысить производительность при нормальной работе.
В этой статье мы сосредоточимся на объединении ради повышения производительности.
Распространённые варианты объединения
Выбор варианта teaming для vSAN зависит от среды и предпочтений, но есть важные компромиссы, особенно актуальные для vSAN. Начиная с vSAN 8 U3, платформа поддерживает один порт VMkernel на хост, помеченный для трафика vSAN. Вот три наиболее распространённые подхода при использовании одного порта VMkernel:
1. Один порт VMkernel для vSAN с конфигурацией Active/Standby
Используются два и более аплинков (uplinks), один из которых активен, а остальные — в режиме ожидания.
Это наиболее распространённая и рекомендуемая конфигурация для всех кластеров vSAN.
Простая, надёжная, идеально подходит для трафика VMkernel (например, vSAN), так как обеспечивает предсказуемый маршрут, что особенно важно в топологиях spine-leaf (Clos).
Такой подход обеспечивает надежную и стабильную передачу трафика, но не предоставляет агрегации полосы пропускания — трафик проходит только по одному активному интерфейсу.
Обычно Standby-интерфейс используется для другого типа трафика, например, vMotion, для эффективной загрузки каналов.
2. Один порт VMkernel для vSAN с двумя активными аплинками (uplinks) и балансировкой Load Based Teaming (LBT)
Используются два и более аплинков в режиме «Route based on physical NIC load».
Это можно рассматривать как агрегацию на уровне гипервизора.
Изначально предназначен для VM-портов, а не для трафика VMkernel.
Преимущества для трафика хранилища невелики, могут вызывать проблемы из-за отсутствия предсказуемости маршрута.
Несмотря на то, что это конфигурация по умолчанию в VCF, она не рекомендуется для портов VMkernel, помеченных как vSAN.
В VCF можно вручную изменить эту конфигурацию на Active/Standby без проблем.
3. Один порт VMkernel для vSAN с использованием Link Aggregation (LACP)
Использует два и более аплинков с расширенным хешированием для балансировки сетевых сессий.
Может немного повысить пропускную способность, но требует дополнительной настройки на коммутаторах и хосте.
Эффективность зависит от топологии и может увеличить нагрузку на spine-коммутаторы.
Используется реже и ограниченно поддерживается в среде VCF.
Версия VCF по умолчанию может использовать Active/Active с LBT для трафика vSAN. Это универсальный режим, поддерживающий различные типы трафика, но неоптимален для VMkernel, особенно для vSAN.
Рекомендуемая конфигурация:
Active/Standby с маршрутизацией на основе виртуального порта (Route based on originating virtual port ID). Это поддерживается в VCF и может быть выбрано при использовании настраиваемого развертывания коммутатора VDS. Подробнее см. в «VMware Cloud Foundation Design Guide».
Можно ли использовать несколько портов VMkernel на хосте для трафика vSAN?
Теоретически да, но только в редком случае, когда пара коммутаторов полностью изолирована (подобно Fibre Channel fabric). Это не рекомендуемый и редко используемый вариант, даже в vSAN 8 U3.
Влияние объединения на spine-leaf-сети
Выбор конфигурации teaming на хостах vSAN может показаться несущественным, но на деле сильно влияет на производительность сети и vSAN. В топологии spine-leaf (Clos), как правило, нет прямой связи между leaf-коммутаторами. При использовании Active/Active LBT половина трафика может пойти через spine, вместо того чтобы оставаться на уровне leaf, что увеличивает задержки и снижает стабильность.
Аналогичная проблема у LACP — он предполагает наличие прямой связи между ToR-коммутаторами. Если её нет, трафик может либо пойти через spine, либо LACP-связь может полностью нарушиться.
На практике в некоторых конфигурациях spine-leaf коммутаторы уровня ToR (Top-of-Rack) соединены между собой через межкоммутаторное соединение, такое как MLAG (Multi-Chassis Link Aggregation) или VLTi (Virtual Link Trunking interconnect). Однако не стоит считать это обязательным или даже желательным в архитектуре spine-leaf, так как такие соединения часто требуют механизмов блокировки, например Spanning Tree (STP).
Стоимость и производительность: нативная скорость соединения против агрегации каналов
Агрегация каналов (link aggregation) может быть полезной для повышения производительности при правильной реализации и в подходящих условиях. Но её преимущества часто переоцениваются или неправильно применяются, что в итоге может приводить к большим затратам. Ниже — четыре аспекта, которые часто упускаются при сравнении link aggregation с использованием более быстрых нативных сетевых соединений.
1. Высокое потребление портов
Агрегация нескольких соединений требует большего количества портов и каналов, что снижает общую портовую ёмкость коммутатора и ограничивает количество возможных хостов в стойке. Это увеличивает расходы на оборудование.
2. Ограниченный прирост производительности
Агрегация каналов, основанная на алгоритмическом балансировании нагрузки (например, LACP), не дает линейного увеличения пропускной способности.
То есть 1+1 не равно 2. Такие механизмы лучше работают при большом количестве параллельных потоков данных, но малоэффективны для отдельных (дискретных) рабочих нагрузок.
3. Ошибочные представления об экономичности
Существует мнение, что старые 10GbE-коммутаторы более экономичны. На деле — это миф.
Более объективный показатель — это пропускная способность коммутатора, измеряемая в Гбит/с или Тбит/с. Хотя сам по себе 10Gb-коммутатор может стоить дешевле, более быстрые модели обеспечивают в 2–10 раз больше пропускной способности, что делает стоимость за 1 Гбит/с ниже. Кроме того, установка более быстрых сетевых адаптеров (NIC) на серверы обычно увеличивает стоимость менее чем на 1%, при этом может дать 2,5–10-кратный прирост производительности.
4. Нереализованные ресурсы
Современные серверы обладают огромными возможностями по процессору, памяти и хранилищу, но не могут раскрыть свой потенциал из-за сетевых ограничений.
Балансировка между вычислительными ресурсами и сетевой пропускной способностью позволяет:
сократить общее количество серверов;
снизить капитальные затраты;
уменьшить занимаемое пространство;
снизить нагрузку на систему охлаждения;
уменьшить потребление портов в сети.
Именно по этим причинам VMware рекомендует выбирать более высокие нативные скорости соединения (25Gb или 100Gb), а не полагаться на агрегацию каналов — особенно в случае с 10GbE. Напомним, что когда 10GbE появился 23 года назад, серверные процессоры имели всего одно ядро, а объём оперативной памяти составлял в 20–40 раз меньше, чем сегодня. С учётом того, что 25GbE доступен уже почти десятилетие, актуальность 10GbE для дата-центров практически исчерпана.
Объединение для повышения производительности и отказоустойчивости обычно предполагает использование нескольких физических сетевых карт (NIC), каждая из которых может иметь 2–4 порта. Сколько всего портов следует иметь на хостах vSAN? Это зависит от следующих факторов:
Степень рабочих нагрузок: среда с относительно пассивными виртуальными машинами предъявляет гораздо меньшие требования, чем среда с тяжёлыми и ресурсоёмкими приложениями.
Нативная пропускная способность uplink-соединений: более высокая скорость снижает вероятность конкуренции между сервисами (vMotion, порты ВМ и т.д.), работающими через одни и те же аплинки.
Используемые сервисы хранения данных: выделение пары портов для хранения (например, vSAN) почти всегда даёт наилучшие результаты — это давно устоявшаяся практика, независимо от хранилища.
Требования безопасности и изоляции: в некоторых средах может потребоваться, чтобы аплинки, используемые для хранения или других задач, были изолированы от остального трафика.
Количество портов на ToR-коммутаторах: количество аплинков может быть ограничено самими коммутаторами ToR. Пример: пара ToR-коммутаторов с 2?32 портами даст 64 порта на стойку. Если в стойке размещено максимум 16 хостов по 2U, каждый хост может получить максимум 4 uplink-порта. А если коммутаторы имеют по 48 портов, то на 16 хостов можно выделить по 6 uplink-портов на каждый хост. Меньшее количество хостов в стойке также позволяет увеличить количество портов на один хост.
Рекомендация:
Даже если вы не используете все аплинки на хосте, рекомендуется собирать vSAN ReadyNode с двумя NIC, каждая из которых имеет по 4 uplink-порта. Это позволит без проблем выделить отдельную команду (team) портов только под vSAN, что настоятельно рекомендуется. Такой подход обеспечит гораздо большую гибкость как сейчас, так и в будущем, по сравнению с конфигурацией 2 NIC по 2 порта.
Итог
Выбор оптимального варианта объединения (teaming) и скорости сетевых соединений для ваших хостов vSAN — это важный шаг к тому, чтобы обеспечить максимальную производительность ваших рабочих нагрузок.
Начиная с ноября 2024 года, VMware vSphere Foundation (VVF) начала включать 0,25 ТиБ ёмкости vSAN на одно ядро для всех новых лицензий VVF. С выходом обновления vSphere 8.0 U3e это преимущество распространяется и на существующих клиентов — теперь им также доступна ёмкость vSAN из расчёта 0,25 ТиБ (аналог терабайта) на ядро. Это новое право на использование включает дополнительные преимущества, которые повышают ценность vSAN в составе VVF.
Вот как это работает:
Ёмкость vSAN агрегируется по всей инфраструктуре, что позволяет перераспределять неиспользованные ресурсы с кластеров, содержащих только вычислительные узлы, на кластеры с включённым vSAN. Это помогает оптимизировать использование ресурсов в рамках всей инфраструктуры.
Новые преимущества для текущих клиентов:
Больше никаких ограничений пробной версии: включённые 0,25 ТиБ на ядро теперь полностью предоставлены по лицензии, а не в рамках пробного периода.
Агрегация ёмкости: объединяйте хранилище между кластерами и используйте его там, где это нужнее всего.
Упрощённое масштабирование: если требуется больше хранилища, чем предусмотрено по включённой норме — достаточно просто докупить нужный объём сверх этой квоты.
Почему это важно
Благодаря этому обновлению VMware vSphere Foundation становится ещё более привлекательным решением для организаций, стремящихся модернизировать и унифицировать свою ИТ-инфраструктуру. Поддерживая как виртуальные машины, так и контейнеры, vSAN добавляет возможности гиперконвергентной инфраструктуры (HCI) корпоративного уровня. Интеграция вычислений, хранения и управления в единую платформу упрощает операционные процессы, снижает сложность и обеспечивает комплексное решение с встроенной безопасностью и масштабируемостью.
Дополнительная ёмкость vSAN в составе VMware vSphere Foundation значительно повышает ценность платформы — будь то оптимизация частного облака, повышение гибкости разработки или упрощение ИТ-операций. Это даёт больше контроля и гибкости над инфраструктурой, снижая совокупную стоимость владения и минимизируя операционные издержки.
Чтобы начать пользоваться бесплатной лицензией VMware vSAN загрузите патч vSphere 8.0 Update 3e по этой ссылке.
Компания Broadcom сообщает, что с 24 марта 2025 года произойдёт важное изменение в процессе загрузки бинарных файлов ПО VMware (включая обновления и исправления) для продуктов VMware Cloud Foundation (VCF), vCenter, ESXi и служб vSAN. Это обновление упростит доступ и приведёт его в соответствие с текущими передовыми практиками отрасли.
Ниже представлена вся необходимая информация о грядущих изменениях и их влиянии на вас.
Что именно изменится?
С 24 марта 2025 года текущий процесс загрузки бинарных файлов будет заменён новым методом. Данное изменение предполагает:
Централизация на едином ресурсе: бинарные файлы программного обеспечения будут доступны для загрузки с единого сайта, а не с нескольких различных ресурсов, как ранее. Это будет доступно как для онлайн-сред, так и для изолированных («air-gapped») систем.
Проверка загрузок: загрузка будет авторизована с помощью уникального токена. Новые URL-адреса будут содержать этот токен, подтверждающий, что именно вы являетесь авторизованным пользователем или стороной, осуществляющей загрузку файла.
Примечание: текущие URL-адреса для загрузки будут доступны в течение одного месяца для облегчения переходного периода. С 24 апреля 2025 года текущие URL-адреса перестанут действовать.
Что это значит для вас?
Вам необходимо выполнить следующие действия:
Получите токен загрузки: войдите на сайт support.broadcom.com, чтобы получить уникальный токен.
Изучите техническую документацию: ознакомьтесь с KB-статьями, в которых изложены требования и пошаговые инструкции.
Обновите URL-адреса в продуктах: Broadcom предоставит скрипт, который автоматизирует замену текущих URL-адресов в продуктах ESXi, vCenter и SDDC Manager.
Обновите скрипты автоматизации (если применимо): Если у вас есть собственные скрипты, обновите URL-адреса согласно рекомендациям из KB-статей.
Где получить дополнительную информацию?
Рекомендуемые материалы для успешного перехода на новую систему:
Недавно Дункану Эппингу задали вопрос о том, сколько памяти должна иметь конфигурация AF-4 ReadyNode, чтобы она поддерживалась. Понтяно, откуда возник этот вопрос, но большинство людей не осознают, что существует набор минимальных требований, а профили ReadyNode, как указано в базе знаний (KB), являются лишь рекомендациями. Перечисленные конфигурации – это ориентир. Эти рекомендации основаны на предполагаемом потреблении ресурсов для определенного набора виртуальных машин. Конечно, для вашей нагрузки требования могут быть совершенно другими. Именно поэтому в статье, описывающей аппаратные рекомендации, теперь четко указано следующее:
Чтобы конфигурация поддерживалась службой глобальной поддержки VMware Global Services (GS), все сертифицированные для vSAN ESA ReadyNode должны соответствовать или превышать ресурсы самой минимальной конфигурации (vSAN-ESA-AF-0 для vSAN HCI или vSAN-Max-XS для vSAN Max).
Это относится не только к объему памяти, но и к другим компонентам, при условии соблюдения минимальных требований, перечисленных в таблице ниже (учтите, что это требования для архитектуры ESA, для OSA они другие):
Он представляет собой презентацию, в которой подробно рассматриваются три основных способа упрощения управления хранилищами данных с помощью VMware vSAN:
Упрощение операций с помощью управления на основе политик хранения: VMware vSAN позволяет администраторам задавать политики хранения, которые автоматически применяются к виртуальным машинам. Это устраняет необходимость в ручной настройке и снижает вероятность ошибок, обеспечивая согласованность и эффективность управления хранилищем.
Упрощение управления жизненным циклом хранилища: традиционные системы хранения часто требуют сложного и трудоемкого обслуживания. VMware vSAN интегрируется непосредственно в гипервизор vSphere, что позволяет автоматизировать многие процессы, такие как обновление и масштабирование, значительно снижая операционные затраты и облегчая сопровождение инфраструктуры.
Упрощение хранения за пределами центра обработки данных: с ростом объемов данных и необходимостью их обработки на периферийных устройствах и в облаке, VMware vSAN предлагает решения для консистентного и эффективного управления хранилищем в распределенных средах. Это обеспечивает единообразие операций и политики безопасности независимо от местоположения данных.
Этот документ предназначен для ИТ-специалистов и руководителей, стремящихся оптимизировать свою инфраструктуру хранения данных, снизить сложность управления и подготовить свою организацию к будущим вызовам.
Некоторое время назад Вильям Лам поделился решением, позволяющим установить VIB-пакет в сборке для Nested ESXi при использовании vSAN Express Storage Architecture (ESA) и VMware Cloud Foundation (VCF), чтобы обойти предварительную проверку на соответствие списку совместимого оборудования vSAN ESA (HCL) для дисков vSAN ESA.
Хотя в большинстве случаев Вильям использует Nested ESXi для тестирования, недавно он развернул физическую среду VCF. Из-за ограниченного количества NVMe-устройств он хотел использовать vSAN ESA для домена управления VCF, но, конечно же, столкнулся с той же проверкой сертифицированных дисков vSAN ESA, которая не позволяла установщику продолжить процесс.
Вильям надеялся, что сможет использовать метод эмуляции для физического развертывания. Однако после нескольких попыток и ошибок он столкнулся с нестабильным поведением. Пообщавшись с инженерами, он выяснил, что существующее решение также применимо к физическому развертыванию ESXi, поскольку аппаратные контроллеры хранилища скрываются методом эмуляции. Если в системе есть NVMe-устройства, совместимые с vSAN ESA, предварительная проверка vSAN ESA HCL должна пройти успешно, что позволит продолжить установку.
Вильям быстро переустановил последнюю версию ESXi 8.0 Update 3b на одном из своих физических серверов, установил vSAN ESA Hardware Mock VIB и, используя последнюю версию VCF 5.2.1 Cloud Builder, успешно прошел предварительную проверку vSAN ESA, после чего развертывание началось без проблем!
Отлично, что теперь это решение работает как для физических, так и для вложенных (nested) ESXi при использовании с VCF, особенно для создания демонстрационных сред (Proof-of-Concept)!
Примечание: В интерфейсе Cloud Builder по-прежнему выполняется предварительная проверка физических сетевых адаптеров, чтобы убедиться, что они поддерживают 10GbE или более. Таким образом, хотя проверка совместимости vSAN ESA HCL пройдет успешно, установка все же завершится с ошибкой при использовании UI.
Обходной путь — развернуть домен управления VCF с помощью Cloud Builder API, где проверка на 10GbE будет отображаться как предупреждение, а не как критическая ошибка, что позволит продолжить развертывание. Вы можете использовать этот короткий PowerShell-скрипт для вызова Cloud Builder API, а затем отслеживать процесс развертывания через UI Cloud Builder.
$cloudBuilderIP = "192.168.30.190"
$cloudBuilderUser = "admin"
$cloudBuilderPass = "VMware123!"
$mgmtDomainJson = "vcf50-management-domain-example.json"
#### DO NOT EDIT BEYOND HERE ####
$inputJson = Get-Content -Raw $mgmtDomainJson
$pwd = ConvertTo-SecureString $cloudBuilderPass -AsPlainText -Force
$cred = New-Object Management.Automation.PSCredential ($cloudBuilderUser,$pwd)
$bringupAPIParms = @{
Uri = "https://${cloudBuilderIP}/v1/sddcs"
Method = 'POST'
Body = $inputJson
ContentType = 'application/json'
Credential = $cred
}
$bringupAPIReturn = Invoke-RestMethod @bringupAPIParms -SkipCertificateCheck
Write-Host "Open browser to the VMware Cloud Builder UI to monitor deployment progress ..."
В этой статье мы обобщим лучшие практики использования платформы VMware vSAN, которые нужно применять для первоначального планирования инфраструктуры отказоустойчивых хранилищ. VMware vSAN имеет некоторые минимальные требования для создания кластера, но этих требований достаточно только при создании кластера для малого бизнеса, когда там не требуется высокая степень доступности данных и сервисов. Давайте рассмотрим требования и лучшие практики платформы vSAN, охватывающие диапазон от малого до корпоративного уровня.
Количество хостов в кластере
Количество хостов в кластере VMware vSAN напрямую влияет на масштабируемость, производительность и отказоустойчивость. Минимальные требования тут такие:
Кластер из 2 хостов — минимальная конфигурация, поддерживаемая внешней witness-машиной для обеспечения кворума. Такая настройка является экономичной, но не обладает продвинутыми функциями и масштабируемостью.
Кластер из 3 хостов — устраняет необходимость в выделенном witness-узле и обеспечивает базовую избыточность с использованием RAID 1.
Несмотря на эти минимальные требования, VMware рекомендует использовать не менее 4 хостов для производственных сред. Кластер из 4 и более хостов позволяет использовать конфигурации RAID 5 и RAID 6, обеспечивая защиту до двух отказов одновременно (в этом случае потребуется больше 4 хостов ESXi) и поддерживая операции обслуживания отдельных хостов ESXi без потери доступности машин кластера.
Лучшие практики:
Используйте не менее 4-х хостов для производственной среды, чтобы обеспечить отказоустойчивость и надежность.
Для критически важных нагрузок добавляйте дополнительные хосты ESXi при росте инфраструктуры и обеспечивайте дополнительную резервную емкость на случай отказов.
Числов хостов ESXi в кластере
Возможности
Отказоустойчивость
Уровни RAID
Когда использовать
2
Базовые, нужен компонент Witness
Один отказ хоста
RAID 1
Малый бизнес или маленький филиал
3
Полная функциональность vSAN
Один отказ хоста
RAID 1
Небольшие компании и удаленные офисы
4+
Дополнительно доступен RAID 5/6
Один или два отказа хостов
RAID 1, 5, 6
От средних до больших производственных окружений
Если вы хотите использовать RAID 5/6 в кластере vSAN, то вам нужно принять во внимание требования к количеству хостов ESXi, которые минимально (и рекомендуемо) вам потребуются, чтобы удовлетворять политике FTT (Failures to tolerate):
Домены отказов (Fault Domains)
Домены отказов являются ключевым элементом повышения отказоустойчивости в vSAN, так как они позволяют интеллектуально распределять данные между хостами, чтобы выдерживать отказы, затрагивающие несколько компонентов (например, стойки или источники питания).
Домен отказов — это логическая группа хостов в кластере vSAN. По умолчанию vSAN рассматривает каждый хост как отдельный домен отказов. Однако в крупных развертываниях администраторы могут вручную настроить домены отказов, чтобы защитить данные от отказов, связанных со стойками или электропитанием.
В больших кластерах сбой всей стойки (или группы хостов) может привести к потере данных, если домены отказов не настроены. Например:
Без доменов отказов: vSAN может сохранить все реплики объекта на хостах внутри одной стойки, что приведет к риску потери данных в случае выхода стойки из строя.
С доменами отказов: vSAN распределяет реплики данных между разными стойками, значительно повышая защиту данных.
Лучшие практики для доменов отказов
Соответствие физической инфраструктуре: создавайте домены отказов на основе стоек, подключений источников питания или сетевого сегментирования.
Минимальные требования: для обеспечения производственной отказоустойчивости доменов требуется как минимум 3 домена отказов.
Размер кластера:
Для 6-8 хостов — настройте как минимум 3 домена отказов.
Для кластеров с 9 и более хостами — используйте 4 и более домена отказов для оптимальной защиты.
Тестирование и валидация: регулярно проверяйте конфигурацию доменов отказов, чтобы убедиться, что она соответствует политикам vSAN.
Число хостов ESXi в кластере
Сколько нужно Fault Domains
Назначение
3-5
Опционально или не нужны
Исполнение производственной нагрузки в рамках стойки
6-8
Минимум 3 домена отказов
Отказоустойчивость на уровне стойки или источника питания
9+
4 или более fault domains
Улучшенная защита на уровне стоек или датацентра
Архитектура дисковых групп vSAN OSA
Группы дисков (disk groups) являются строительными блоками хранилища VMware vSAN в архитектуре vSAN OSA. В архитектуре vSAN ESA дисковых групп больше нет (вместо них появился объект Storage Pool).
Дисковые группы vSAN OSA состоят из:
Яруса кэширования (Caching Tier): нужны для ускорения операций ввода-вывода.
Яруса емкости (Capacity Tier): хранит постоянные данные виртуальных машин.
Ярус кэширования (Caching Tier)
Ярус кэширования улучшает производительность чтения и записи. Для кэширования рекомендуется использовать диски NVMe или SSD, особенно в полностью флэш-конфигурациях (All-Flash).
Лучшие практики:
Выделяйте примерно 10% от общего объема VMDK-дисков машин для яруса кэширования в гибридных конфигурациях vSAN, однако при этом нужно учесть параметр политики FTT. Более подробно об этом написано тут. Для All-Flash конфигураций такой рекомендации нет, размер кэша на запись определяется профилем нагрузки (кэша на чтение там нет).
Используйте NVMe-диски корпоративного класса для высокопроизводительных нагрузок.
Ярус емкости (Capacity Tier)
Ярус емкости содержит основную часть данных и критически важен для масштабируемости. Полностью флэш-конфигурации (All-Flash) обеспечивают максимальную производительность, тогда как гибридные конфигурации (hybrid) являются более экономичным решением для менее требовательных нагрузок.
Лучшие практики:
Используйте полностью флэш-конфигурации для приложений, чувствительных к задержкам (latency).
Включайте дедупликацию и сжатие данных для оптимизации дискового пространства. При этом учтите требования и характер нагрузки - если у вас write-intensive нагрузка, то включение дедупликации может привести к замедлению работы системы.
Несколько групп дисков (Multiple Disk Groups)
Добавление нескольких групп дисков на каждом хосте улучшает отказоустойчивость и производительность.
Лучшие практики:
Настройте не менее двух групп дисков на хост.
Равномерно распределяйте рабочие нагрузки между группами дисков, чтобы избежать узких мест.
Конфигурация
Преимущества
Ограничения
Одна дисковая группа
Простая настройка для малых окружений
Ограниченная отказоустойчивость и производительность
Несколько дисковых групп
Улучшенная производительность и отказоустойчивость
Нужно больше аппаратных ресурсов для емкостей
VMware vSAN и блочные хранилища
Решения для организации блочных хранилищ, такие как Dell PowerStore и Unity, остаются популярными для традиционных ИТ-нагрузок. Вот как они выглядят в сравнении с vSAN:
Возможность
vSAN
Блочное хранилище (PowerStore/Unity)
Архитектура
Программно-определяемое хранилище в гиперконвергентной среде
На базе аппаратного комплекса системы хранения
Высокая доступность
Встроенная избыточность RAID 5/6
Расширенные функции отказоустойчивости (HA) с репликацией на уровне массива
Цена
Ниже для окружений VCF (VMware Cloud Foundation)
Высокая входная цена
Масштабируемость
Горизонтальная (путем добавления хостов ESXi)
Вертикальная (добавление новых массивов)
Рабочие нагрузки
Виртуальная инфраструктура
Физическая и виртуальная инфраструктура
Производительность
Оптимизирована для виртуальных машин
Оптимизирована для высокопроизводительных баз данных
Сильные и слабые стороны
Преимущества vSAN:
Глубокая интеграция с vSphere упрощает развертывание и управление.
Гибкость масштабирования за счет добавления хостов, а не выделенных массивов хранения.
Поддержка снапшотов и репликации для архитектуры vSAN ESA.
Экономически выгоден для организаций, уже использующих VMware.
Недостатки vSAN:
Зависимость от аппаратных ресурсов на уровне отдельных хостов, что может ограничивать масштабируемость.
Производительность может снижаться при некорректной конфигурации.
Преимущества блочного хранилища:
Высокая производительность для нагрузок с высокими IOPS, таких как транзакционные базы данных. При этом надо учесть, что vSAN также может обеспечивать высокую производительность при использовании соответствующего оборудования на правильно подобранном количестве хостов кластера.
Развитые функции, такие как снапшоты и репликация (с поддержкой на аппаратном уровне).
Недостатки блочного хранилища:
Меньшая гибкость по сравнению с гиперконвергентными решениями.
Более высокая стоимость и сложность при первоначальном развертывании. Однако также нужно учитывать и политику лицензирования Broadcom/VMware, где цена входа также может оказаться высокой (см. комментарий к этой статье).
Развертывание баз данных на VMware vSAN
Базы данных создают сложные паттерны ввода-вывода, требующие низкой задержки (latency) и высокой пропускной способности (throughput). vSAN удовлетворяет этим требованиям за счет кэширования и конфигураций RAID.
Политики хранения (Storage Policies)
Политики хранения vSAN позволяют точно контролировать производительность и доступность баз данных.
Лучшие практики:
Настройте параметр FTT (Failures to Tolerate) = 2 для критически важных баз данных.
Используйте RAID 5 или RAID 6 для экономии емкостей при защите данных, если вас устраивает производительность и latency.
Мониторинг и оптимизация
Регулярный мониторинг помогает поддерживать оптимальную производительность баз данных. Используйте продукт vRealize Operations для отслеживания таких метрик, как IOPS и latency.

 RSS
RSS