В какой-то момент требования к ресурсам для Witness VM в vSAN ESA исчезли из официальной документации. Между тем этот вопрос остаётся актуальным: сколько памяти выделяется виртуальной машине и сколько у неё vCPU? Ответ зависит от выбранного профиля — Witness VM доступна в трёх вариантах: M, L и XL.
Выбор профиля определяется количеством виртуальных машин, которые планируется развернуть. При этом рекомендуется закладывать запас на рост. Когда Witness VM разворачивается через мастер развёртывания, нужные цифры там не указаны — однако их можно узнать, заглянув в OVF-дескриптор.
Из OVF-файла vSAN ESA Witness получены следующие данные о ресурсах:
vSAN ESA Witness XL — 8 vCPU, 64 ГБ памяти
vSAN ESA Witness L — 4 vCPU, 32 ГБ памяти
vSAN ESA Witness M — 4 vCPU, 16 ГБ памяти
Для тех, кто использует vSAN OSA, требования к ресурсам следующие:
vSAN OSA Witness XL — 6 vCPU, 32 ГБ памяти
vSAN OSA Witness L — 2 vCPU, 32 ГБ памяти
vSAN OSA Witness Normal — 2 vCPU, 16 ГБ памяти
vSAN OSA Witness Tiny — 2 vCPU, 8 ГБ памяти
Важно учитывать, что приведённые значения актуальны на момент публикации — с выходом новых версий vSAN требования к ресурсам могут измениться.
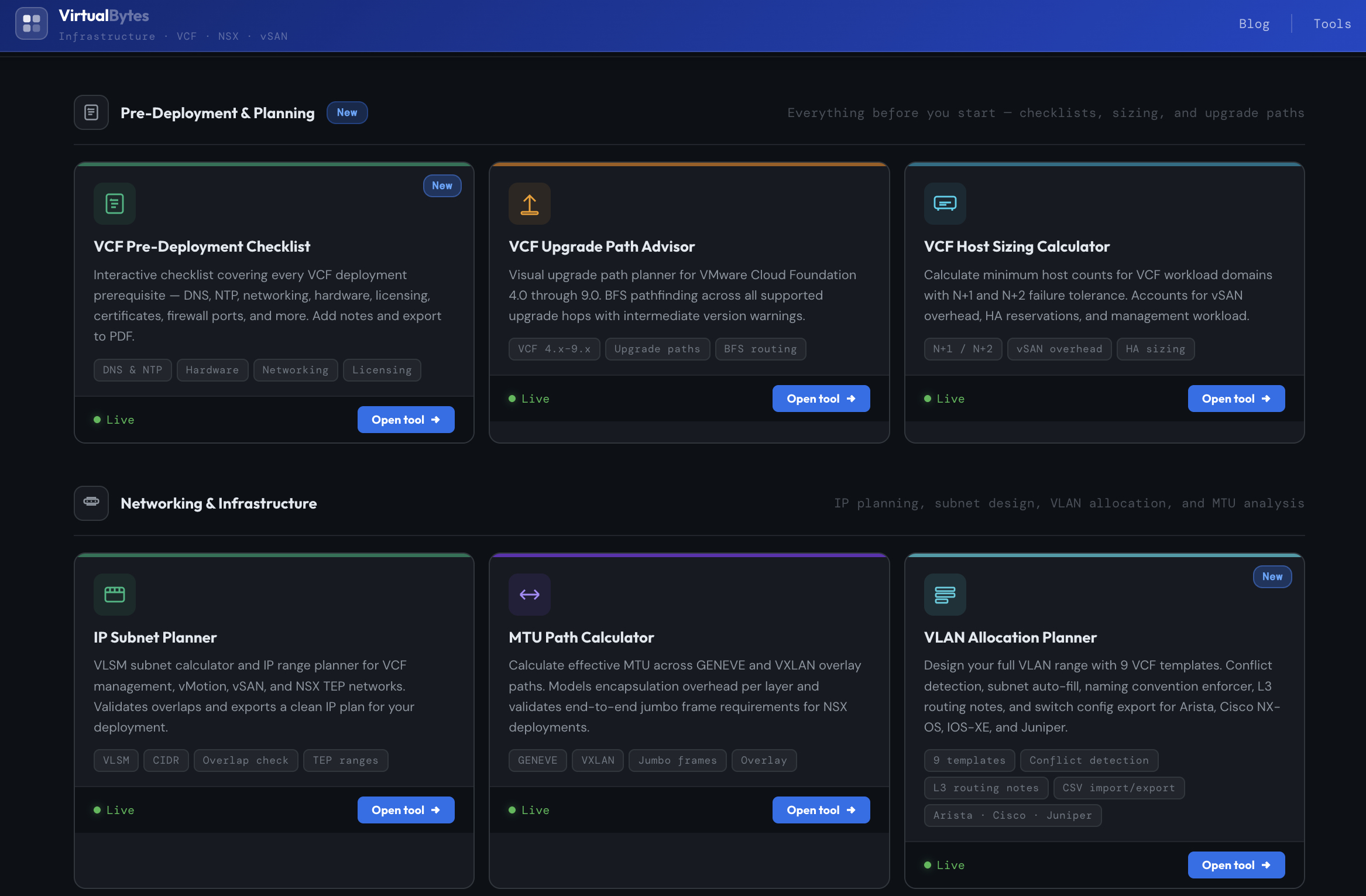
В сфере виртуализации и облачной инфраструктуры системные инженеры регулярно сталкиваются с задачами расчётов, проверки параметров конфигурации и подготовки инфраструктуры к развертыванию. Именно для таких задач создан сайт https://tools.virtualbytes.cloud/ — онлайн-площадка с полезными утилитами для специалистов по VMware-инфраструктуре и облачным платформам.
Что представляет собой сервис
Tools.VirtualBytes.Cloud — это коллекция веб-инструментов, предназначенных для работы с инфраструктурными компонентами VMware-экосистемы и сопутствующих технологий. Сервис позволяет использовать различные утилиты прямо в браузере без установки дополнительного программного обеспечения на локальную машину.
Основная идея платформы — предоставить инженерам быстрый доступ к вспомогательным инструментам, которые упрощают администрирование и проектирование виртуальной инфраструктуры.
Какие инструменты доступны онлайн
Сервис ориентирован на специалистов, работающих с современными датацентрами и программно-определяемыми инфраструктурами. Среди основных направлений инструментов:
Работа с платформой VMware Cloud Foundation (VCF)
Инструменты для VMware NSX и сетевой виртуализации
Вспомогательные утилиты для vSAN
Сетевые и инфраструктурные калькуляторы
Инструменты для анализа и подготовки конфигураций
Благодаря веб-формату инструменты можно использовать с любого устройства — достаточно открыть сайт в браузере.
Бесплатные онлайн-утилиты
VCF Pre-Deployment Checklist
Интерактивный чеклист, охватывающий все требования перед развертыванием VCF — DNS, NTP, сетевую инфраструктуру, оборудование, лицензии, сертификаты, порты файрвола и многое другое. Позволяет добавлять заметки и экспортировать результат в PDF.
VCF Upgrade Path Advisor
Визуальный планировщик путей обновления для VMware Cloud Foundation версий 4.0–9.0. Использует поиск оптимального пути (BFS) между поддерживаемыми этапами обновления и предупреждает о промежуточных версиях.
VCF Host Sizing Calculator
Калькулятор минимального количества хостов для доменов нагрузки VCF с учетом отказоустойчивости N+1 и N+2. Учитывает накладные расходы vSAN, резервации HA и нагрузку management-компонентов.
IP Subnet Planner
Калькулятор подсетей VLSM и планировщик диапазонов IP-адресов для сетей VCF: management, vMotion, vSAN и NSX TEP. Проверяет пересечения подсетей и позволяет экспортировать готовый IP-план для развертывания.
MTU Path Calculator
Калькулятор эффективного MTU для overlay-сетей GENEVE и VXLAN. Моделирует накладные расходы инкапсуляции на каждом уровне и проверяет требования к jumbo-фреймам для NSX-инфраструктуры.
VLAN Allocation Planner
Инструмент для проектирования полного диапазона VLAN с использованием 9 шаблонов VCF. Включает обнаружение конфликтов, автоматическое заполнение подсетей, контроль соглашений по именованию, заметки по L3-маршрутизации и экспорт конфигураций коммутаторов для Arista, Cisco NX-OS, IOS-XE и Juniper.
VCF 9 Network Config Generator
Генератор полной сетевой конфигурации для VCF 9, включая назначение VLAN, параметры MTU, политики teaming и конфигурацию пулов NSX TEP для развертываний с несколькими кластерами.
vSAN Capacity Calculator
Калькулятор полезной емкости vSAN для архитектур OSA и ESA с политиками RAID-1, RAID-5 и RAID-6. Учитывает slack space, отказ хостов и приблизительную эффективность дедупликации.
NSX Firewall Rule Planner
Инструмент для планирования и документирования правил распределенного файрвола NSX. Позволяет задавать группы источников и назначений, сервисы и область применения (Applied-To), проверяет логику правил и экспортирует их в структурированную таблицу.
VCF Day 2 Operations Planner
Набор пошаговых runbook-процедур для операций Day-2: расширение кластера, создание доменов нагрузки, ротация сертификатов, обновление компонентов, смена паролей, расширение vSAN и управление сегментами NSX.
Для кого предназначен сайт
Платформа будет полезна:
Системным администраторам и инженерам виртуализации
Архитекторам облачной инфраструктуры
DevOps-специалистам
Инженерам датацентров и лабораторий
Особенно ценным ресурс становится при работе с VMware-экосистемой, где часто требуется быстро рассчитать параметры инфраструктуры или проверить настройки перед развертыванием.
Итог
Tools.VirtualBytes.Cloud — это полезный ресурс для специалистов по виртуализации и облачным технологиям. Он объединяет набор практических инструментов, которые помогают упростить работу с инфраструктурой VMware и ускорить решение повседневных задач администрирования.
Для инженеров, работающих с VCF, NSX и другими компонентами программно-определяемого дата-центра, подобные сервисы позволяют экономить время и повышать эффективность управления инфраструктурой.
Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
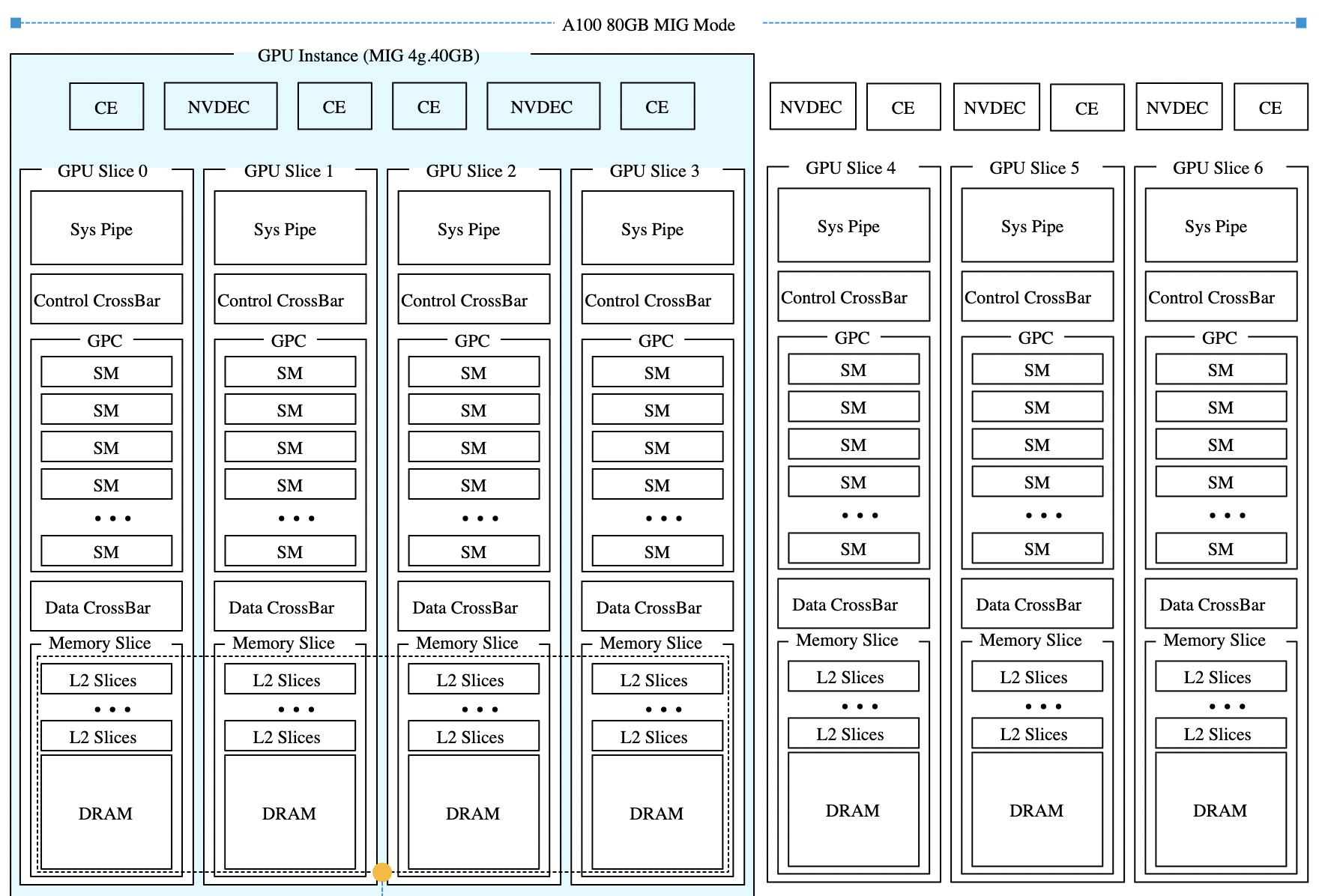
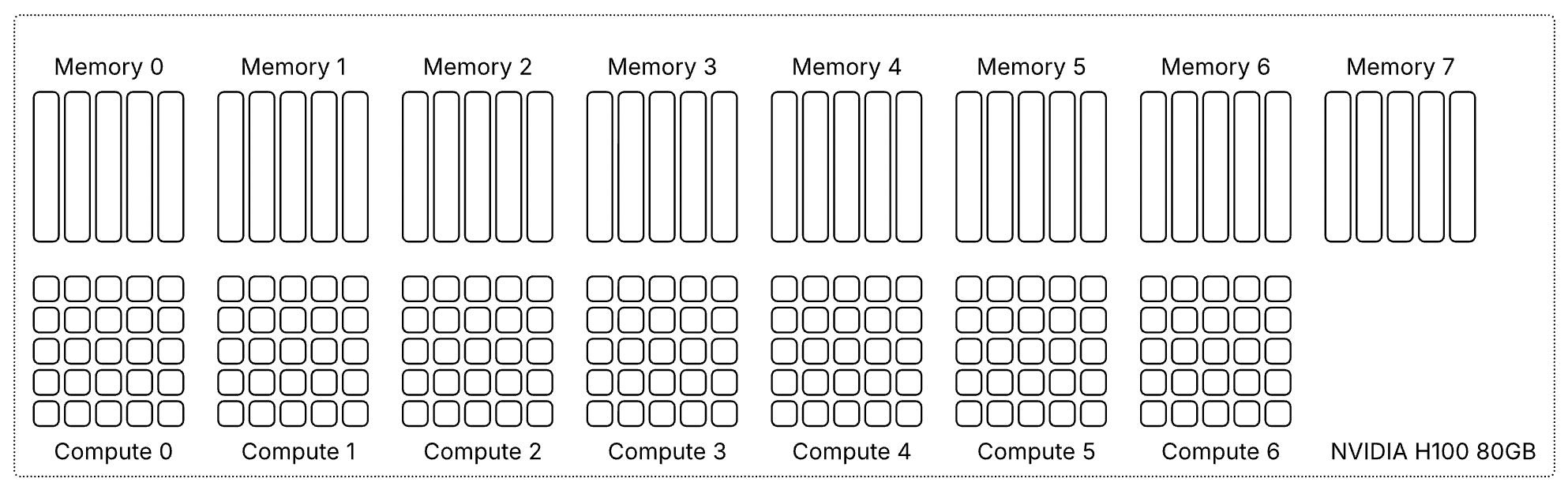
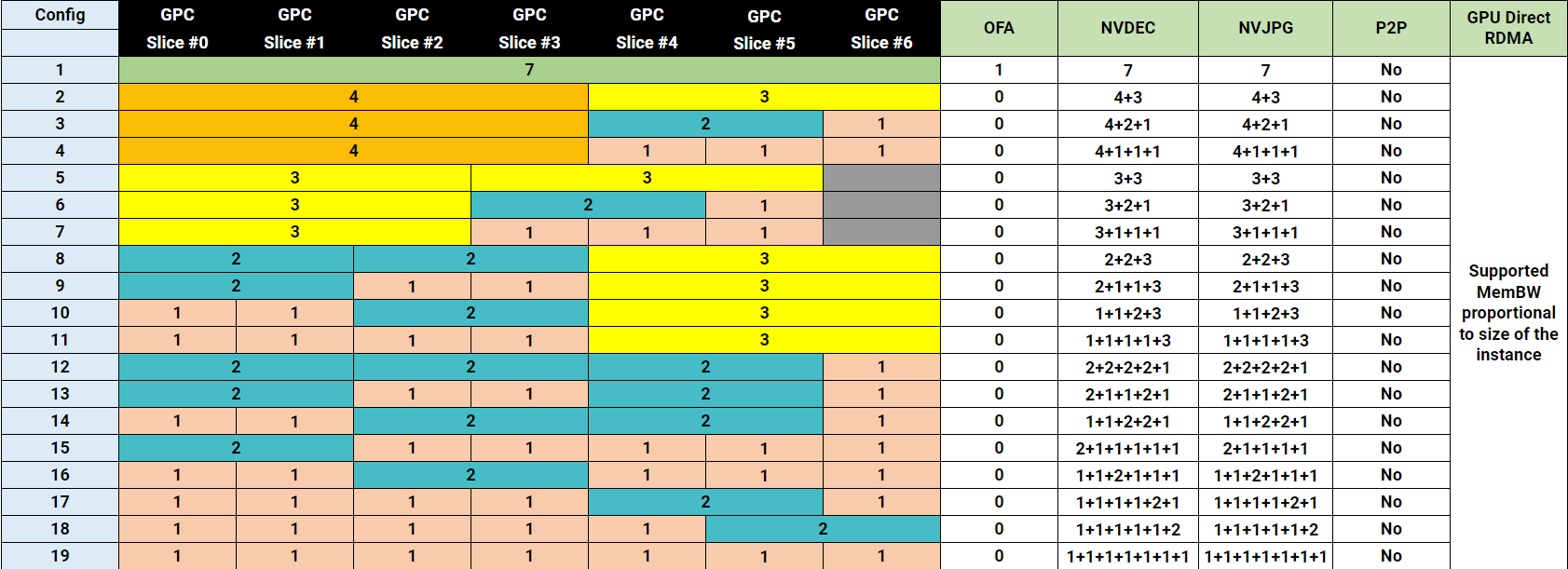
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
Profile
Compute slices
Memory slices
Memory
1g.10gb
1
1
10 GB
1g.20gb
1
2
20 GB
2g.20gb
2
2
20 GB
3g.40gb
3
4
40 GB
4g.40gb
4
4
40 GB
7g.80gb
7
8
80 GB
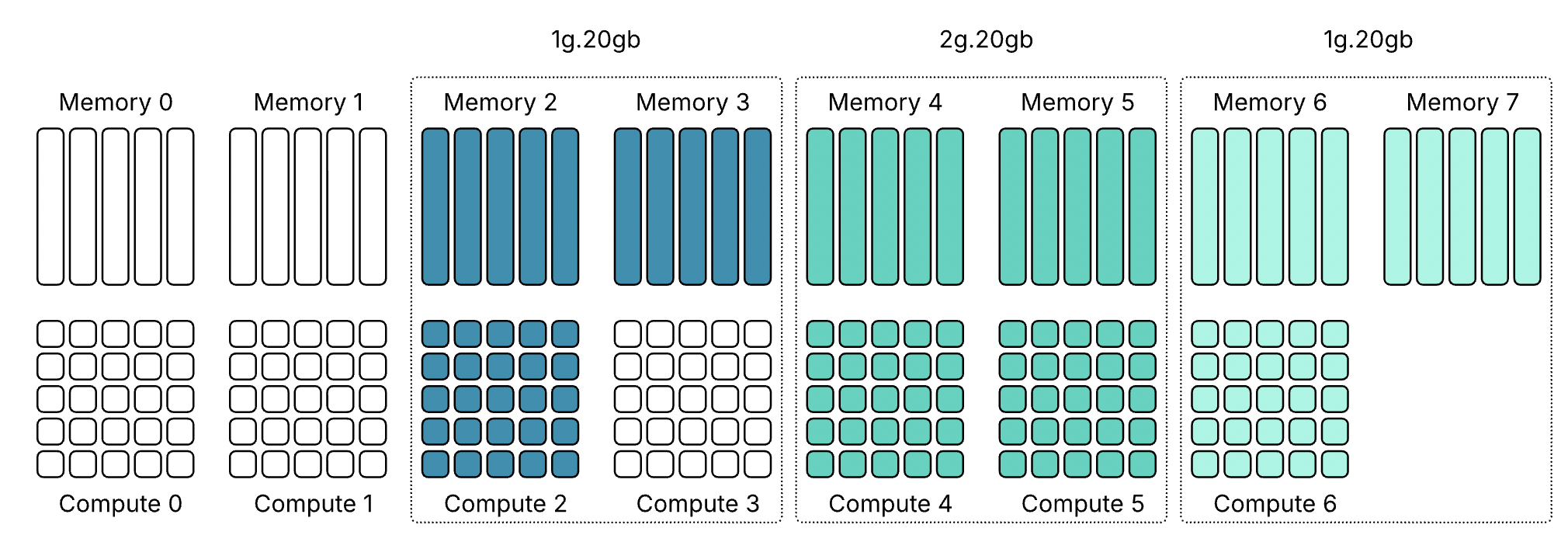
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
Потерянная ёмкость
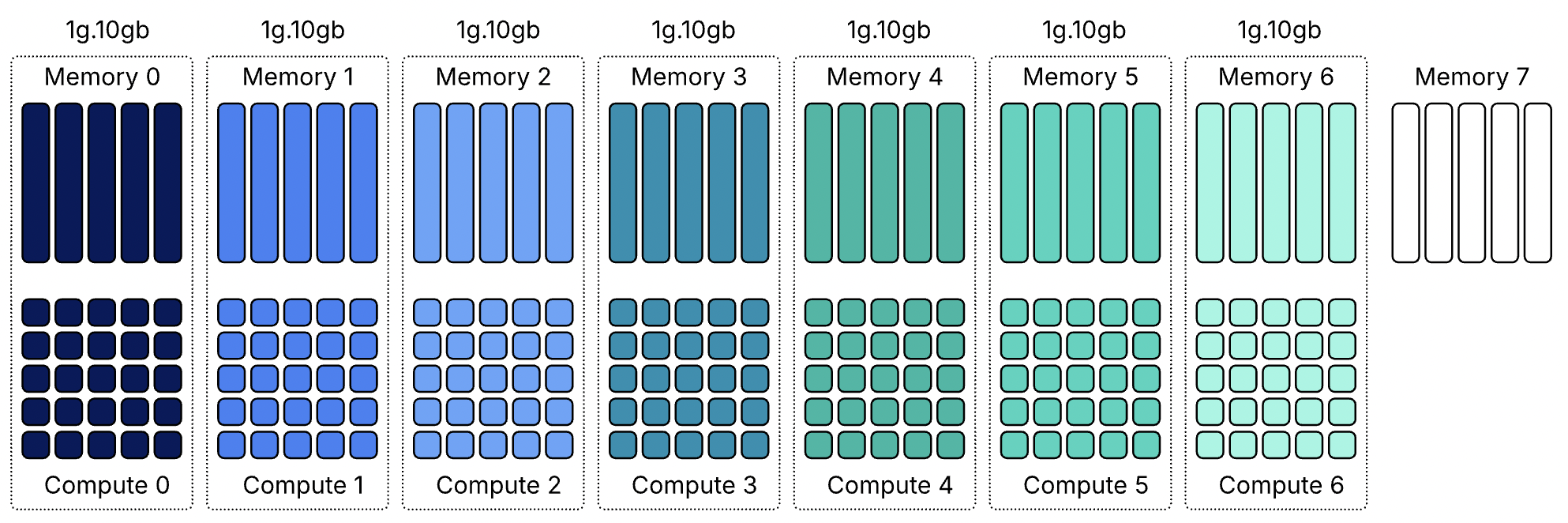
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
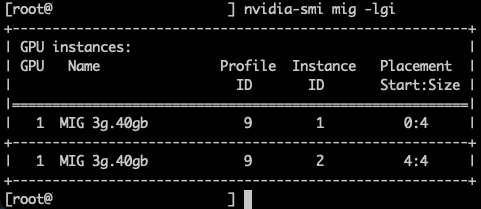
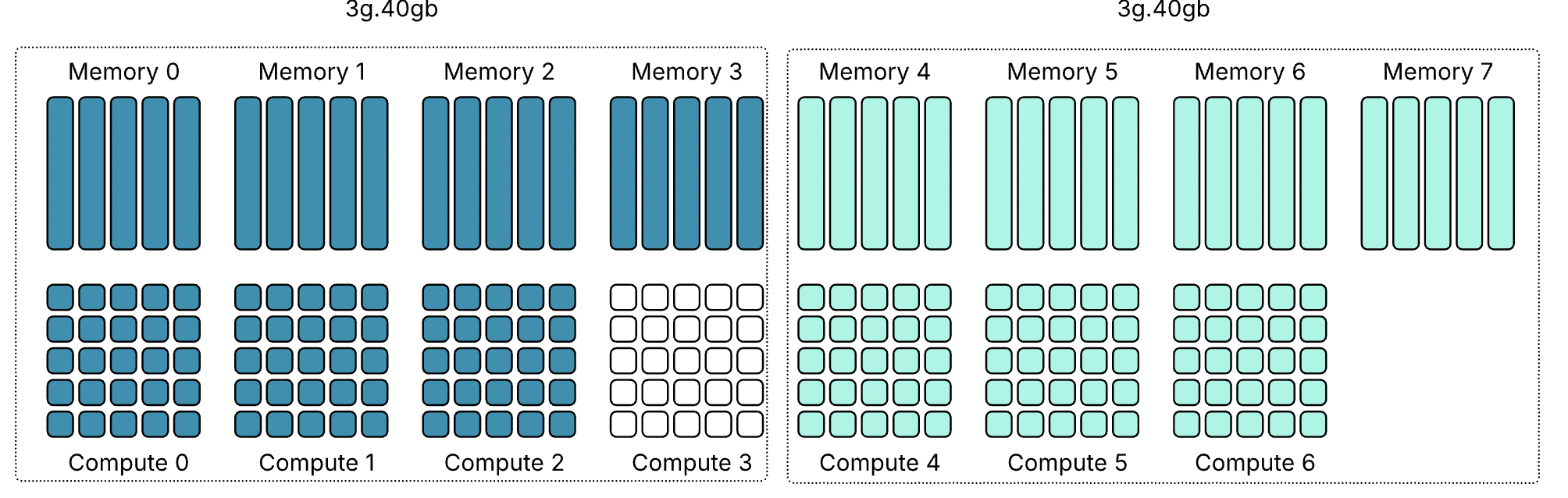
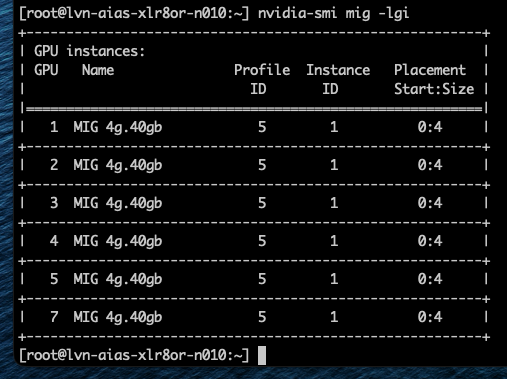
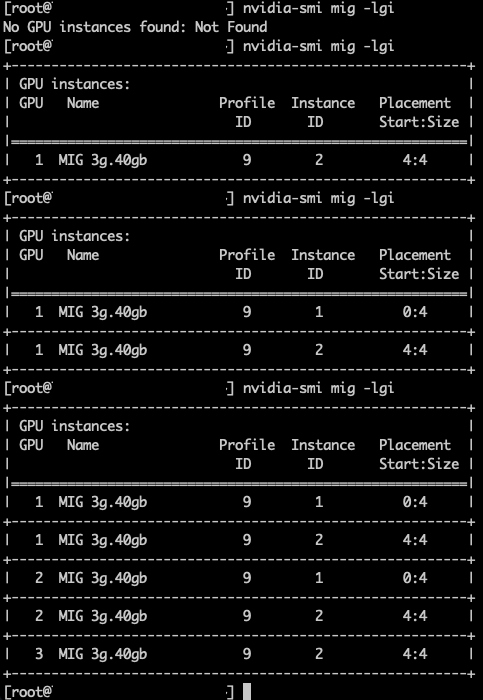
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
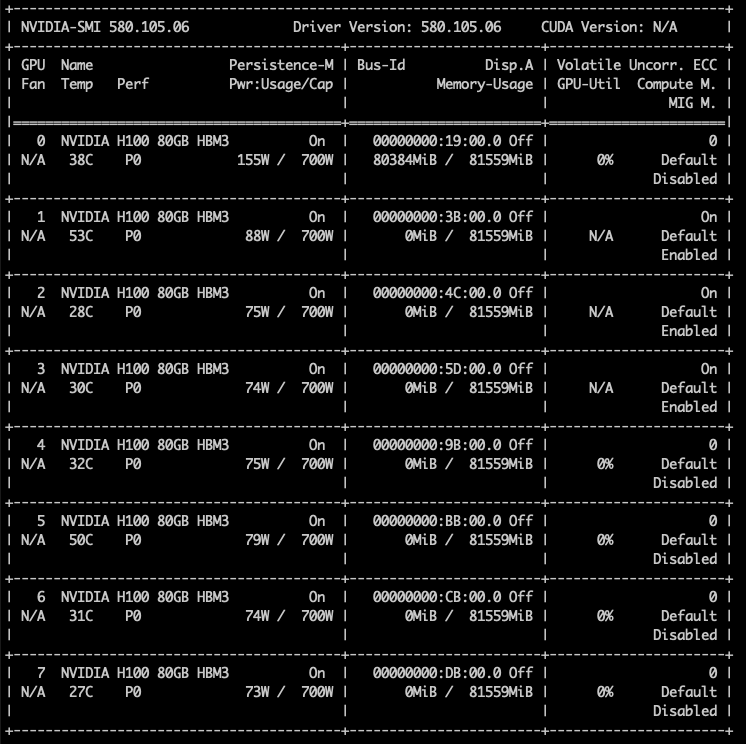
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
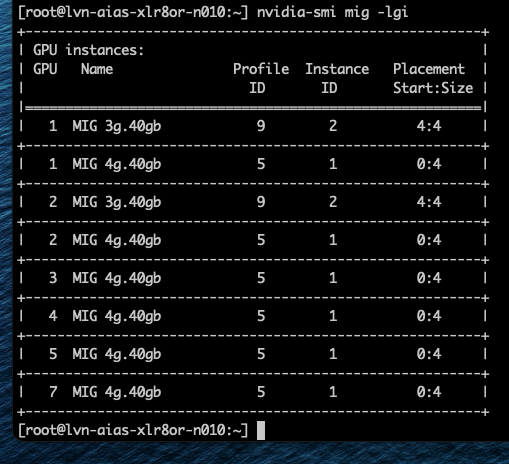
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.
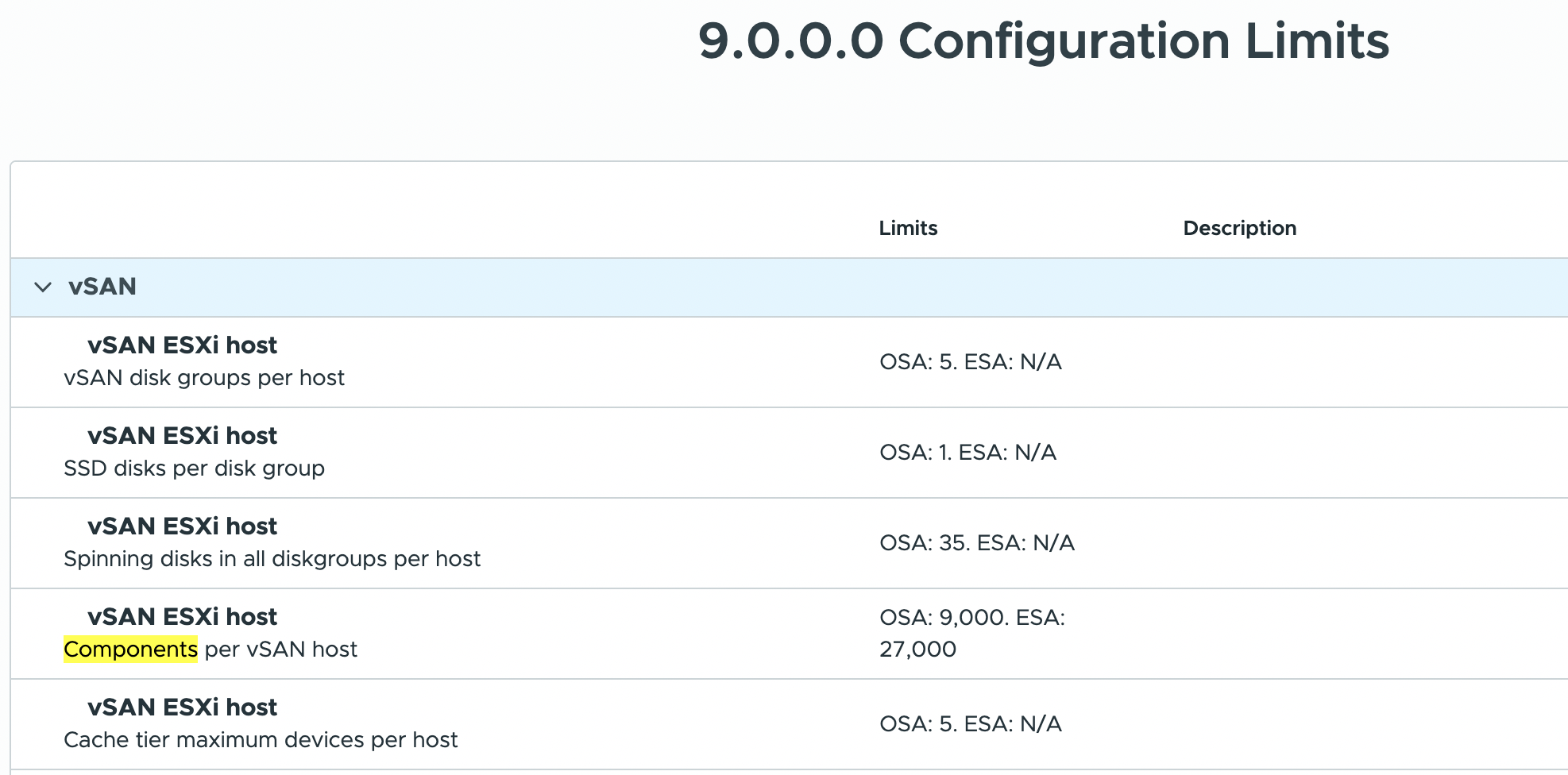
Дункан Эппинг написал интересный пост на тему решения VMware vSAN и допустимых лимитов на компоненты. За последние несколько лет у него было не так много обсуждений по поводу лимитов, но в последнее время такие разговоры почему-то стали возникать всё чаще. Если спросить клиента, каков лимит компонентов у vSAN, кто-то скажет — 9000 на хост (OSA), другие — 27 000 на хост (ESA), а некоторые даже знают ограничение по количеству компонентов на кластер (в документации эти лимиты указаны здесь и здесь). Однако есть один критически важный аспект, о котором большинство обычно не задумывается. В этом посте мы сосредоточимся на vSAN ESA.
Как уже упоминалось, существует лимит на хост и на кластер, но также есть ограничение на устройство (диск). Частая ошибка заключается в том, что люди воспринимают кластерный и хостовый лимиты как самостоятельные и фиксированные значения. Однако здесь есть зависимость. Как было сказано, у устройства тоже есть свой предел. В vSAN ESA одно устройство может содержать максимум 3000 data-компонентов и 3000 metadata-компонентов. Именно такие ограничения поддерживаются в текущей версии (vSAN 9.0). Пока сосредоточимся на data-компонентах (уровень ёмкости).
Это означает, что если в хосте 8 устройств или меньше, то максимальное количество компонентов будет не 27 000, а «количество устройств x 3000». Другими словами, если в хосте один NVMe-накопитель для vSAN ESA, максимальное количество компонентов для этого хоста — 3000. Если два устройства — максимум 6000, и так далее.
Почему об этом стоит писать? Если учесть количество компонентов на один объект и умножить его на типичное количество объектов, быстро становится понятно почему. Предположим, вы используете RAID-5 с ESA в конфигурации 4+1 — это даст как минимум 5 компонентов. Если у виртуальной машины несколько дисков, легко можно получить 35–40 компонентов на одну ВМ. Если взять лимит 3000 и разделить его, скажем, на 40 компонентов, получаем всего 75–80 виртуальных машин. Конечно, у вас будет несколько хостов, и это число масштабируется по их количеству, но пример наглядно показывает, почему важно учитывать этот максимум.
Возникает вопрос: почему эта тема стала подниматься именно сейчас? Дело в том, что по мере того как заказчики всё увереннее используют vSAN ESA, мы видим всё более «экзотические» конфигурации. Всё чаще развёртываются системы с очень ёмкими накопителями, но в небольшом количестве. Если раньше обычно использовали 6–8 устройств на хост по 1–2 ТБ каждое, то теперь всё чаще спрашивают о конфигурациях с одним NVMe-накопителем на 15 ТБ или двумя устройствами по 7.x ТБ. Нетрудно представить, что при таких вводных лимит в 3000 data-компонентов достигается значительно быстрее, чем хостовый лимит в 27 000 компонентов.
Поэтому, если вы планируете новый кластер vSAN, обязательно учитывайте эти ограничения. Не стоит думать только о ёмкости — есть и другие важные факторы, которые необходимо принимать во внимание.
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
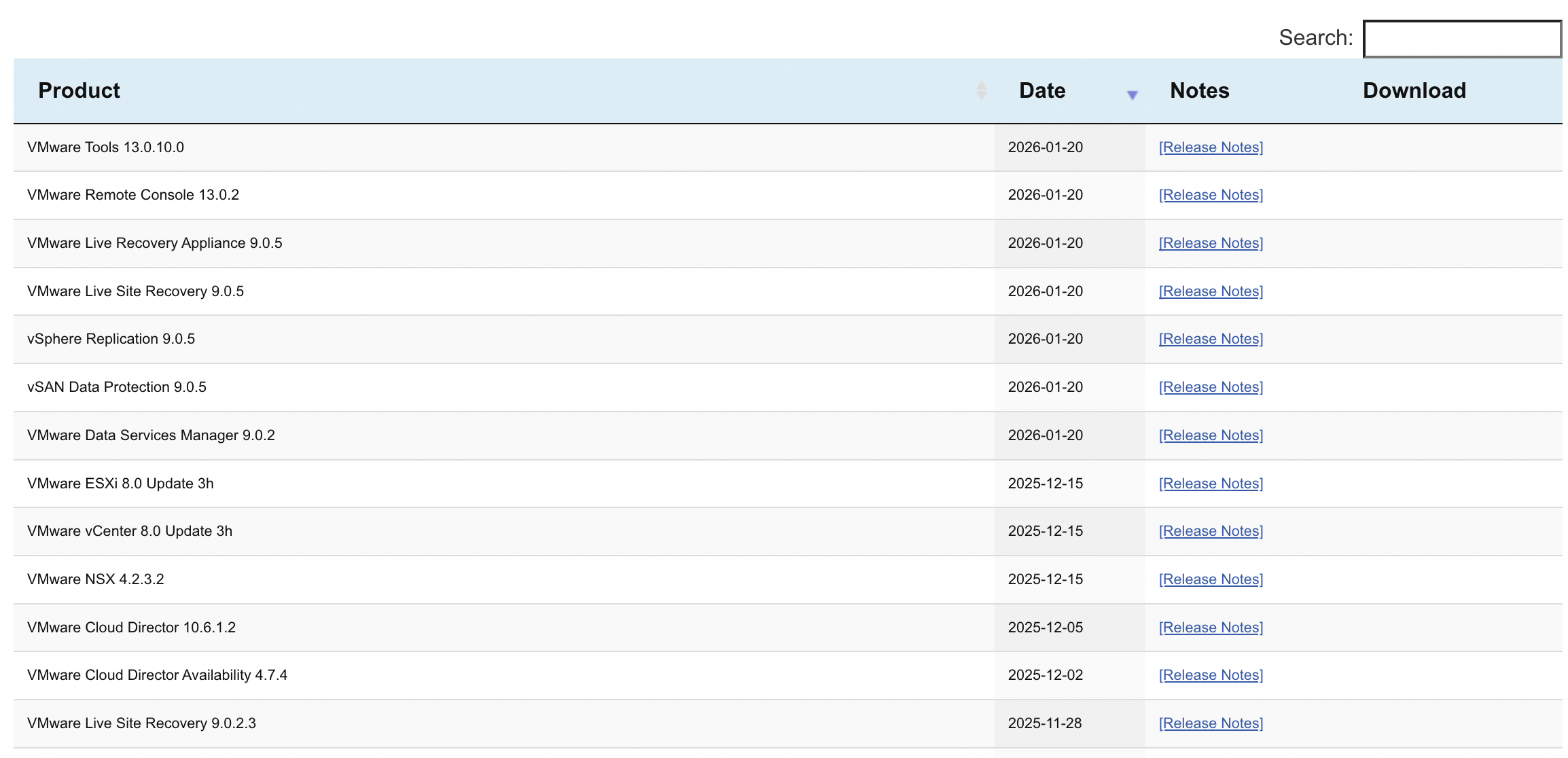
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут и тут) мы предоставим некоторую информацию о различиях при включении Memory Tiering в разных сценариях. Хотя основной процесс остаётся тем же, есть моменты, которые могут потребовать дополнительного внимания и планирования, чтобы сэкономить время и усилия. Когда мы говорим о сценариях greenfield, мы имеем в виду совершенно новые развертывания VMware Cloud Foundation (VCF), включая новое оборудование и новую конфигурацию для всего стека. Сценарии brownfield будут охватывать настройку Memory Tiering в существующей среде VCF. Наконец, мы рассмотрим и лабораторные сценарии, поскольку встречаются неоднозначные утверждения о том, что это не поддерживается, но мы рассмотрим это в конце данной статьи.
Greenfield-развертывания
Давайте начнём с процесса конфигурации сред greenfield. Ранее мы рассказали о том, как VMware vSAN и Memory Tiering совместимы и могут сосуществовать в одном и том же кластере. Мы также обращали внимание на кое-что важное, о чём вам следует помнить во время greenfield-развертываний VCF. Начиная с VCF 9.0, включение Memory Tiering — это операция «Day 2», то есть сначала вы настраиваете VCF, а затем можете настроить Memory Tiering, но в ходе рабочего процесса развертывания VCF вы заметите, что опции для включения Memory Tiering (пока) нет, зато можно включить vSAN. То, как вы поступите с вашим NVMe-устройством, выделенным для Memory Tiering, будет определять шаги, необходимые для того, чтобы это устройство было представлено для его конфигурации.
Если все NVMe-устройства и для vSAN, и для Memory Tiering присутствуют во время развертывания VCF, есть вероятность, что vSAN может автоматически занять все накопители (включая NVMe-устройство, которое вы выделили для Memory Tiering). В этом случае вам пришлось бы удалить накопитель из vSAN после конфигурации, стереть разделы, а затем начать настройку Memory Tiering. Этот шаг был рассмотрен тут.
Другой подход — извлечь или не устанавливать устройство Memory Tiering в сервер и добавить его обратно в сервер после развертывания VCF. Таким образом вы не будете рисковать тем, что vSAN автоматически займет NVMe для Memory Tiering. Хотя это и не является серьёзным препятствием, всё равно полезно знать, что произойдёт и почему, чтобы вы могли быстро выделить ресурсы, необходимые для настройки Memory Tiering.
Brownfield-развертывания
Сценарии brownfield немного проще, так как VVF/VCF уже настроен; однако vSAN мог быть включён или ещё нет.
Если vSAN не включён, вам нужно будет отключить функцию auto-claim, пройти через конфигурацию vSAN и вручную выбрать ваши устройства (кроме NVMe-устройств для Memory Tiering). Всё выполняется в интерфейсе UI и по процедуре, которая используется уже много лет. Это гарантирует, что NVMe-устройство Memory Tiering будет доступно для настройки. Подробный процесс задокументирован в TechDocs.
Если vSAN уже включён, мы предполагаем, что NVMe-устройство для Memory Tiering только что было приобретено и готово к установке. Значит, всё, что нам нужно сделать, — добавить его в хост и убедиться, что оно корректно отображается как NVMe-устройство и что на нём нет существующих разделов. Это, вероятно, самый простой сценарий и самый распространённый.
Развертывания в тестовой среде
Теперь давайте поговорим о давно ожидаемом лабораторном сценарии. Для лаборатории типа bare metal, где сервер ESX одноуровневый и нет вложенных сред, применяются те же принципы greenfield и brownfield. Что касается вложенной (nested) виртуализации, многие говорят о том, что вложенный Memory Tiering не поддерживается. Ну, это и так, и не так.
Когда мы говорим о вложенных средах, мы имеем в виду два уровня ESX. Внешний уровень — это ESX, установленный на оборудовании (обычная настройка), а внутренний уровень ESX состоит из виртуальных машин, запускающих ESX и выступающих в роли как бы физических хостов. Memory Tiering МОЖЕТ быть включён на внутреннем уровне (вложенном), и все параметры конфигурации работают нормально. Мы делаем следующее: берём datastore и создаём виртуальный Hard Disk типа NVMe, чтобы представить его виртуальной машине, которая выступает в роли вложенного хоста. Хотя мы видим NVMe-устройство на вложенном хосте и можем настроить Memory Tiering, базовое устройство хранения состоит из устройств, формирующих выбранный datastore. Вы можете настроить Memory Tiering, и вложенные хосты смогут видеть hot и active pages, но не ожидайте какого-либо уровня производительности, учитывая, что компоненты базового хранилища построены на традиционных накопителях. Работает ли это? ДА, но только в лабораторных средах.
Тестирование в лабораторной среде очень полезно: оно помогает вам пройти шаги конфигурации и понять, как работает настройка и какие расширенные параметры можно задать. Это отличный вариант использования для подготовки (практики) к развертыванию в производственной среде или даже просто для знакомства с функцией, например, для целей сдачи сертификационного экзамена.
А как насчёт внешнего уровня? Ну, это как раз то, что не поддерживается в VCF 9.0, поскольку внешний уровень ESX не имеет видимости внутреннего уровня и не может видеть активность памяти ВМ, по сути пытаясь «прозреть» сквозь вложенный уровень до виртуальной машины (inception). Это и есть главное отличие (не вдаваясь слишком глубоко в технические детали).
Так что если вам интересно протестировать Memory Tiering, а всё, что у вас есть — это вложенная среда, вы можете настроить Memory Tiering и любые расширенные параметры. Интересно наблюдать, как несколько шагов настройки могут добавить хостам 100% дополнительной памяти.
В ранних статьях мы упоминали, что вы можете настраивать разделы NVMe с помощью команд ESXCLI, PowerCLI и даже скриптов. В более поздних публикациях мы говорили о том, что опубликуем скрипт для настройки разделов, который мы приводим ниже, но с оговоркой и прямым предупреждением: вы можете запускать скрипт на свой страх и риск, и он может не работать в вашей среде в зависимости от вашей конфигурации.
Рассматривайте этот скрипт только как пример того, как это можно автоматизировать, а не как поддерживаемое решение автоматизации. Кроме того, скрипт не стирает разделы за вас, поэтому убедитесь, что вы сделали это до запуска скрипта. Как всегда, сначала протестируйте.
Есть некоторые переменные, которые вам нужно изменить, чтобы он работал в вашей среде:
$vCenter = “ваш vCenter FQDN или IP” (строка 27)
$clusterName = “имя вашего кластера” (строка 28)
Вот и сам скрипт:
function Update-NvmeMemoryTier {
param (
[Parameter(Mandatory=$true)]
[VMware.VimAutomation.ViCore.Impl.V1.Inventory.VMHostImpl]$VMHost,
[Parameter(Mandatory=$true)]
[string]$DiskPath
)
try {
# Verify ESXCLI connection
$esxcli = Get-EsxCli -VMHost $VMHost -V2
# Note: Verify the correct ESXCLI command for NVMe memory tiering; this is a placeholder
# Replace with the actual command or API if available
$esxcli.system.tierdevice.create.Invoke(@{ nvmedevice = $DiskPath }) # Hypothetical command
Write-Output "NVMe Memory Tier created successfully on host $($VMHost.Name) with disk $DiskPath"
return $true
}
catch {
Write-Warning "Failed to create NVMe Memory Tier on host $($VMHost.Name) with disk $DiskPath. Error: $_"
return $false
}
}
# Securely prompt for credentials
$credential = Get-Credential -Message "Enter vCenter credentials"
$vCenter = "vcenter FQDN"
$clusterName = "cluster name"
try {
# Connect to vCenter
Connect-VIServer -Server $vCenter -Credential $credential -WarningAction SilentlyContinue
Write-Output "Connected to vCenter Server successfully."
# Get cluster and hosts
$cluster = Get-Cluster -Name $clusterName -ErrorAction Stop
$vmHosts = Get-VMHost -Location $cluster -ErrorAction Stop
foreach ($vmHost in $vmHosts) {
Write-Output "Fetching disks for host: $($vmHost.Name)"
$disks = @($vmHost | Get-ScsiLun -LunType disk |
Where-Object { $_.Model -like "*NVMe*" } | # Filter for NVMe disks
Select-Object CanonicalName, Vendor, Model, MultipathPolicy,
@{N='CapacityGB';E={[math]::Round($_.CapacityMB/1024,2)}} |
Sort-Object CanonicalName) # Explicit sorting
if (-not $disks) {
Write-Warning "No NVMe disks found on host $($vmHost.Name)"
continue
}
# Build disk selection table
$diskWithIndex = @()
$ctr = 1
foreach ($disk in $disks) {
$diskWithIndex += [PSCustomObject]@{
Index = $ctr
CanonicalName = $disk.CanonicalName
Vendor = $disk.Vendor
Model = $disk.Model
MultipathPolicy = $disk.MultipathPolicy
CapacityGB = $disk.CapacityGB
}
$ctr++
}
# Display disk selection table
$diskWithIndex | Format-Table -AutoSize | Out-String | Write-Output
# Get user input with validation
$maxRetries = 3
$retryCount = 0
do {
$diskChoice = Read-Host -Prompt "Select disk for NVMe Memory Tier (1 to $($disks.Count))"
if ($diskChoice -match '^\d+$' -and $diskChoice -ge 1 -and $diskChoice -le $disks.Count) {
break
}
Write-Warning "Invalid input. Enter a number between 1 and $($disks.Count)."
$retryCount++
} while ($retryCount -lt $maxRetries)
if ($retryCount -ge $maxRetries) {
Write-Warning "Maximum retries exceeded. Skipping host $($vmHost.Name)."
continue
}
# Get selected disk
$selectedDisk = $disks[$diskChoice - 1]
$devicePath = "/vmfs/devices/disks/$($selectedDisk.CanonicalName)"
# Confirm action
Write-Output "Selected disk: $($selectedDisk.CanonicalName) on host $($vmHost.Name)"
$confirm = Read-Host -Prompt "Confirm NVMe Memory Tier configuration? This may erase data (Y/N)"
if ($confirm -ne 'Y') {
Write-Output "Configuration cancelled for host $($vmHost.Name)."
continue
}
# Configure NVMe Memory Tier
$result = Update-NvmeMemoryTier -VMHost $vmHost -DiskPath $devicePath
if ($result) {
Write-Output "Successfully configured NVMe Memory Tier on host $($vmHost.Name)."
} else {
Write-Warning "Failed to configure NVMe Memory Tier on host $($vmHost.Name)."
}
}
}
catch {
Write-Warning "An error occurred: $_"
}
finally {
# Disconnect from vCenter
Disconnect-VIServer -Server $vCenter -Confirm:$false -ErrorAction SilentlyContinue
Write-Output "Disconnected from vCenter Server."
}
VMware Cloud Foundation (VCF) 9.0 предоставляет быстрый и простой способ развертывания частного облака. Хотя обновление с VCF 5.x спроектировано как максимально упрощённое, оно вносит обязательные изменения в методы управления и требует аккуратного, поэтапного выполнения.
Недавно Джонатан Макдональд провёл насыщенный вебинар вместе с Брентом Дугласом, где они подробно разобрали процесс обновления с VCF 5.2 до VCF 9.0. Сотни участников и шквал вопросов ясно показали, что этот переход сейчас волнует многих клиентов VMware.
Джонатан отфильтровал повторяющиеся вопросы, объединив похожие в единые, комплексные темы. Ниже представлены 10 ключевых вопросов («must-know»), заданных аудиторией, вместе с подробными ответами, которые помогут вам уверенно пройти путь к VCF 9.0.
Вопрос 1: Как VMware SDDC Manager выполняет обновления? Есть ли значительные изменения в обновлениях версии 9.0?
Было много вопросов, связанных с SDDC Manager и процессом обновлений. Существенных изменений в том, как выполняются обновления, нет. Если вы знакомы с VCF 5.2, то асинхронный механизм патчинга встроен в консоль точно так же и в версии 9.0. Это позволяет планировать обновления и патчи по необходимости. Главное отличие заключается в том, что интерфейс SDDC Manager был интегрирован в консоль VCF Operations и теперь находится в разделе управления парком (Fleet Management). Многие рабочие процессы также были перенесены, что позволило консолидировать интерфейсы.
Вопрос 2: Есть ли особенности обновления кластеров VMware vSAN Original Storage Architecture (OSA)?
vSAN OSA не «уходит» и не объявлен устаревшим в VCF 9.0. Аппаратные требования для vSAN Express Storage Architecture (ESA) существенно отличаются и могут быть несовместимы с существующим оборудованием. vSAN OSA — отличный способ продолжать эффективно использовать имеющееся оборудование без необходимости покупать новое. Для самого обновления важно проверить совместимость аппаратного обеспечения и прошивок с версией 9.0. Если они поддерживаются, обновление пройдёт так же, как и в предыдущих релизах.
Вопрос 3: Как выполняется обновление VMware NSX?
При обновлении VCF все компоненты, включая NSX, обновляются последовательно. Обычно процесс начинается с компонентов VCF Operations. После этого управление передаётся рабочим процессам SDDC Manager: сначала обновляется сам SDDC Manager, затем NSX, потом VMware vCenter и в конце — хосты VMware ESX.
Вопрос 4: Если VMware Aria Suite развернут в режиме VCF-aware в версии 5.2, нужно ли отвязывать Aria Suite перед обновлением?
Нет. Вы можете сначала обновить компоненты Aria Suite до версии, совместимой с VCF 9, а затем продолжить обновление остальных компонентов.
Вопрос 5: Можно ли обновиться с VCF 5.2 без настроенных LCM и Aria Suite?
Да. Наличие компонентов Aria Suite до обновления на VCF 9.0 не требуется. Однако в рамках обновления будут развернуты Aria Lifecycle (в версии 9.0 — VCF Fleet Management) и VCF Operations, так как они являются обязательными компонентами в 9.0.
Вопрос 6: Сколько хостов допускается в консолидированном дизайне VCF 9.0?
Для нового консолидированного дизайна рекомендуется минимум четыре хоста. При конвергенции инфраструктуры с использованием vSAN требуется минимум три ESX-хоста (четыре рекомендуются для отказоустойчивости). При использовании внешних систем хранения достаточно минимум двух хостов. Что касается максимальных значений, документированных ограничений нет, кроме ограничений VMware vSphere: 96 хостов на кластер и 2500 хостов на один vCenter. В целом рекомендуется по мере роста добавлять дополнительные домены рабочих нагрузок или кластеры для логического разделения среды с точки зрения производительности, доступности и восстановления.
Вопрос 7: Как перейти с VMware Identity Manager (vIDM) на VCF Identity Broker (VIDB) в VCF 9?
Прямого пути обновления или миграции с vIDM на VIDB не существует. Требуется «чистое» (greenfield) развертывание VIDB. Это особенно актуально, если используется VCF Automation, так как в этом случае новое развертывание VIDB является обязательным.
Вопрос 8: Нужно ли загружать дистрибутивы для VCF Operations и куда их помещать?
Это зависит от используемого сценария. В общем случае, если вы выполняете обновление и компоненты Aria ещё не установлены, потребуется загрузить и развернуть виртуальные машины VCF Operations и VCF Operations Fleet Management. После их развертывания бинарные файлы загружаются в репозиторий (depot) VCF Operations Fleet Management для установки дополнительных компонентов. Если вы конвергируете vSphere в VCF, все недостающие компоненты будут развернуты установщиком VCF, и, соответственно, должны быть загружены в него заранее.
Вопрос 9: Существует ли путь отката (rollback), если во время обновления возникла ошибка?
В целом не существует «кнопки отката» для всего VCF сразу. Лучше рассматривать каждое последовательное обновление как контрольную точку. Например, перед обновлением SDDC Manager с 5.2 до 9.0 нужно всегда делать резервную копию. Если во время обновления возникает сбой, можно откатиться к состоянию до ошибки и продолжить диагностику. То же самое относится к другим компонентам. При сбоях в обновлении NSX, vCenter или ESX-хостов нужно оценить ситуацию и либо выполнить откат, либо обратиться в поддержку, если время окна обслуживания истекает и необходимо срочно восстановить работоспособность среды. Именно поэтому тщательное планирование имеет решающее значение при любом обновлении VCF.
Вопрос 10: Существует ли путь миграции с VMware Cloud Director (VCD) на VCF Automation?
На данный момент VCD не поддерживается в VCF 9.0, и официальных путей миграции не существует. Если у вас есть вопросы по этому поводу, обратитесь к вашему Account Director.
Дункан Эппинг выпустил обзорное видео, где он отвечает на вопрос одного из читателей, который касается поведения VMware vSAN после восстановления отказавших площадок. Речь идёт о сценарии, когда производится Site Takeover и два сайта выходят из строя, а позже снова становятся доступными. Что же происходит с виртуальными машинами и их компонентами в такой ситуации?
Автор решил смоделировать следующий сценарий:
Отключить preferred-локацию и witness-узел.
Выполнить Site Takeover, чтобы виртуальная машина Photon-1 стала снова доступна после ее перезапуска, но уже только на оставшейся рабочей площадке.
После восстановления всех узлов проверить, как vSAN автоматически перераспределит компоненты виртуальной машины.
Поведение виртуальной машины после отказа
Когда preferred-локация и witness отключены, виртуальная машина Photon-1 продолжает работу благодаря механизму vSphere HA. Компоненты ВМ в этот момент существуют только на вторичном домене отказа (fault domain), то есть на той площадке, которая осталась доступной.
Автор пропускает часть сценария с перезапуском ВМ, поскольку этот процесс уже подробно освещался ранее.
Что происходит при восстановлении сайтов
После того как preferred-локация и witness возвращаются в строй, начинается полностью автоматический процесс:
vSAN анализирует политику хранения, назначенную виртуальной машине.
Поскольку политика предусматривает растяжение ВМ между двумя площадками, система автоматически начинает перераспределение компонентов.
Компоненты виртуальной машины снова создаются и на preferred-локации, и на secondary-локации.
При этом администратору не нужно предпринимать никаких действий — все операции происходят автоматически.
Важный момент: полная ресинхронизация
Дункан подчёркивает, что восстановление не является частичным, а выполняется полный ресинк данных:
Компоненты, которые находились на preferred-локации до сбоя, vSAN считает недействительными и отбрасывает.
Данные перезапущенной ВМ полностью синхронизируются с рабочей площадки (теперь это secondary FD) на вновь доступную preferred-локацию.
Это необходимо для исключения расхождений и гарантии целостности данных.
Итоги
Демонстрация показывает, что vSAN при восстановлении площадок:
Автоматически перераспределяет компоненты виртуальных машин согласно политике хранения.
Выполняет полную ресинхронизацию данных.
Не требует ручного вмешательства администратора.
Таким образом, механизм stretched-кластеров vSAN обеспечивает предсказуемое и безопасное восстановление после крупных сбоев.
Вильям Лам описал способ развертывания виртуального модуля OVF/OVA напрямую с сервера с Basic Authentication.
Он делал эксперименты с использованием OVFTool и доработал свой скрипт deploy_data_services_manager.sh, чтобы он ссылался на URL, где был размещён Data Services Manager (DSM) в формате OVA. В этом случае базовую аутентификацию (имя пользователя и пароль) можно включить прямым текстом в URL. Хотя это не самый безопасный способ, он позволяет удобно использовать этот метод развертывания.
Thomas Kopton написал интересный пост о получении паролей из VCF Fleet Manager на примере для прокси VMware VCF Operations Cloud.
Одно из преимуществ всеобъемлющего решения частного облака, такого как VMware Cloud Foundation (VCF), заключается в уровне автоматизации, который оно предоставляет. VCF стремится упростить ваши операции - от автоматической установки или обновления прокси-серверов VCF Operations Cloud до управления критически важными паролями, такими как пароль пользователя root в VCF Fleet Manager. Но что делать, если вам всё же нужен этот пароль root? Как его получить?
В этом посте рассказывается, как получить доступ к паролям, хранящимся в защищённом хранилище VCF Fleet Manager, на примере пользователя root для прокси-сервера VCF Operations Cloud.
Пароли VCF Fleet Manager
В VCF Fleet Manager раздел Fleet Management Passwords представляет собой решение VCF для автоматизированного и безопасного управления учётными данными. Он централизует, генерирует и управляет критически важными паролями (например, для прокси-серверов VCF Operations Cloud) в защищённом хранилище, снижая количество ручных операций и повышая безопасность в частном облаке.
Хотя Fleet Manager управляет паролями для критически важных компонентов в фоновом режиме, обычно вы не сможете напрямую «извлечь» существующие пароли в открытом виде через его интерфейс. Вместо этого функция Fleet Management Passwords предназначена для проактивного управления этими учётными данными. Это означает, что вы можете обновлять или восстанавливать пароли при необходимости. Если вам нужно восстановить доступ к системе, пароль которой управляется VCF, для этого используется определённый процесс на основе REST API — а не простое извлечение данных из хранилища.
Fleet Management API
За пределами ручных действий в пользовательском интерфейсе API управления флотом VCF предоставляет возможности для максимальной автоматизации. Он открывает функции Fleet Manager через набор программных эндпоинтов, позволяя создавать скрипты для сложных рабочих процессов и интегрировать управление VCF в существующие фреймворки автоматизации.
На следующем скриншоте показано, как получить доступ к интерфейсу Swagger UI для VCF Fleet Management.
В API Explorer мы можем выбрать между публичным и приватным API, как показано на следующем скриншоте:
Получение пароля
Процесс извлечения пароля, хранящегося в защищённом хранилище VCF (в данном примере пароля пользователя root для прокси VCF Operations Cloud) включает три этапа:
Авторизация
Получение vmid сохранённых учётных данных
Извлечение расшифрованного пароля
Авторизация
Авторизация в Swagger UI выполняется быстро. При нажатии соответствующей кнопки открывается диалоговое окно, ожидающее ввода строки Basic Auth, закодированной в Base64. Необходимо закодировать комбинацию User:Password и ввести её в виде строки "Basic xxxxxxx", как показано в примере ниже.
На следующем скриншоте показан процесс авторизации в интерфейсе Swagger UI:
Получение списка паролей
Далее нам нужно получить список доступных учётных данных и найти в нём наш Cloud Proxy, чтобы получить vmid. Этот идентификатор необходим для завершающего шага.
Для тестов в рамках этой статьи используется инфраструктура VCF 9.0.1. REST-запрос, который мы будем использовать, находится в разделе v3 контроллера Locker Password Controller. На следующем изображении показан вызов типа GET.
Разумеется, для этого мы можем использовать Postman или просто curl, как показано здесь:
Заключительный шаг — выполнить запрос к эндпоинту /lcm/locker/api/v2/passwords/{vmid}/decrypted. Это POST-запрос, в котором параметр vmid передаётся в URL, а в теле JSON указывается root-пароль Fleet Manager. На следующем скриншоте показан этот запрос в интерфейсе Swagger.
Решение с вызовом vSphere MOB и ручной генерацией XML-запроса для добавления хоста ESXi в нужный кластер vSphere в vCenter Server было, мягко говоря, неидеальным, но задачу оно выполняло. Сейчас это решение можно значительно улучшить, используя более современные подходы, при этом сохранив исходное требование: возможность добавить хост в кластер vSphere прямо из ESXi 8.x/9.x Kickstart без внешних зависимостей.
Шаг 1. Предполагаем, что у вас уже есть инфраструктура ESX Kickstart, готовая к работе.
Примечание: Для разработки Вильям настоятельно рекомендует использовать Nested ESXi и HTTP Boot через Virtual EFI — так вы сможете быстро протестировать автоматизацию ESX Kickstart перед тем, как развернуть её на реальном железе. Это позволит без особых усилий быстро создать рабочий прототип решения, которое вы увидите здесь.
Шаг 2. С помощью ChatGPT Вильяму удалось создать современную версию скрипта на основе Pyvmomi (vSphere SDK для Python), который использует тот же самый API vSphere для добавления хоста ESX в vCenter Server и его подключения к нужному кластеру vSphere. Скачайте скрипт add_host_to_cluster.py и разместите его на веб-сервере, с которого вы отдаёте конфигурацию ESX Kickstart, либо внедрите прямо в kickstart-файл.
Скрипт можно запускать локально на системе с установленным Pyvmomi или прямо на ESXi 8.x/9.x со следующим синтаксисом:
Шаг 3. Обновите ваш ESX Kickstart так, чтобы он запускал скрипт add_host_to_cluster.py с нужными параметрами. В данном примере и kickstart ESX, и скрипт add_host_to_cluster.py размещены на веб-сервере Вильяма, поэтому kickstart сначала загружает скрипт на хост ESX в рамках секции %firstboot, а затем запускает его с учётными данными для vCenter Server и хоста ESX, которые необходимы для вызова vSphere API.
Примечание: Скорее всего, вам НЕ следует использовать учётную запись администратора для добавления ESX-хоста. Вместо этого создайте сервисную учётную запись, у которой есть только права на добавление хостов в кластер vSphere и никакие другие роли, так как учётные данные придётся указывать в открытом виде (plain text).
Вот скриншот итогового решения, где Вильям смог быстро продемонстрировать это с помощью виртуальной машины Nested ESXi и загрузки по HTTP через Virtual EFI (см. ссылку в Шаге 1). ESX устанавливается автоматически, так же как и на физической машине, а затем, в рамках пост-настройки, загружается наш скрипт на Pyvmomi и хост присоединяется к нужному кластеру vSphere:
Дункан Эппинг рассказал о том, как можно убедиться, что ваши диски VMware vSAN зашифрованы.
Если у вас включена техника шифрования "vSAN Encryption – Data At Rest", то вы можете проверить, что действительно данные на этих дисках зашифрованы в разделе настроек vSAN в клиенте vSphere Client. Однако вы можете сделать это и на уровне хоста ESXi, выполнив команду:
esxcli vsan storage list
Как вы можете увидеть из вывода команды, для шифрования указан параметр Encryption: true.
Второй момент - вам надо убедиться, что служба управления ключами шифрования Key Management System доступна и работает как положено. Это вы можете увидеть в разделе vSAN Skyline Health клиента vSphere:
Дункан также обращает внимание, что если вы используете Native Key Server и получаете ошибку "not available on host", проверьте, опцию "Use key provider only with TPM". Если она включена, то вы должны иметь модуль TPM для корректной работы механизмов шифрования. Если у вас модуля такого нет - просто снимите эту галочку.
Broadcom Compatibility Guide (ранее VMware Compatibility Guide) — это ресурс, где пользователи могут проверить совместимость оборудования (нового или уже используемого) с программным обеспечением VMware. Вильям Лам написал интересную статью о доступе к BCG через программный интерфейс VMware PowerCLI.
Существует несколько различных руководств по совместимости, которые можно использовать для поиска информации, начиная от процессоров и серверов и заканчивая разнообразными устройствами ввода-вывода, такими как ускорители и видеокарты. Если у вас небольшое количество оборудования, поиск будет достаточно простым. Однако, если необходимо проверить разнообразное оборудование, веб-интерфейс может оказаться не самым быстрым и удобным вариантом.
Хорошая новость в том, что Broadcom Compatibility Guide (BCG) может легко использоваться программно, в отличие от предыдущего VMware Compatibility Guide (VCG), у которого была другая система бэкенда.
Хотя официального API с документацией, поддержкой и обратной совместимостью для BCG нет, пользователи могут взаимодействовать с BCG, используя тот же API, который применяется веб-интерфейсом BCG.
Обе функции предполагают поиск на основе комбинации идентификаторов поставщика (Vendor ID, VID), идентификатора устройства (Device ID, DID) и идентификатора поставщика подсистемы (SubSystem Vendor ID, SVID).
Примечание: BCG предоставляет разнообразные возможности поиска и фильтрации; ниже приведены лишь примеры одного из способов работы с API BCG. Если вам интересны другие методы поиска, ознакомьтесь со справочной информацией в конце документа, где описаны иные опции фильтрации и руководства по совместимости BCG.
Шаг 1 – Загрузите скрипт queryHostPCIInfo.ps1 (который Вильям также обновил, чтобы можно было легко исключить неприменимые устройства с помощью строк исключений), и запишите идентификаторы устройств (VID, DID, SVID), которые вы хотите проверить.
По умолчанию функция возвращает четыре последние поддерживаемые версии ESXi, однако вы можете изменить это, указав параметр ShowNumberOfSupportedReleases:
При проверке SSD-накопителей vSAN через BCG вы также можете указать конкретный поддерживаемый уровень vSAN (Hybrid Cache, All-Flash Cache, All-Flash Capacity или ESA), используя следующие параметры:
Если вы хотите автоматизировать работу с другими руководствами по совместимости в рамках BCG, вы можете определить формат запроса (payload), используя режим разработчика в браузере. Например, в браузере Chrome, перед выполнением поиска в конкретном руководстве по совместимости, нажмите на три точки в правом верхнем углу браузера и выберите "More Tools->Developer Tools", после чего откроется консоль разработчика Chrome. Далее вы можете использовать скриншот, чтобы разобраться, как выглядит JSON-запрос для вызова API "viewResults".
Разбор сложного HTML — это, безусловно, непростая задача, даже с PowerShell. Вильям Лам недавно пытался использовать бесплатную версию ChatGPT и новую модель 4o, чтобы сделать функцию на PowerShell для парсинга HTML, но он постоянно сталкивался с системными ограничениями, а AI часто неправильно понимал, чего от него хотят.
По запросу одного из пользователей он пытался расширить свою статью в блоге за 2017 год об автоматизации глобальных прав vSphere и добавить поддержку их вывода через PowerCLI.
Оказалось, что получить список всех текущих глобальных прав окружения VMware vSphere через приватный API vSphere Global Permissions с помощью vSphere MOB крайне трудно из-за сложного HTML, который рендерит этот интерфейс. На самом деле, Вильяму понадобилось 25 итераций, прежде чем он нашёл рабочее решение с помощью модели ChatGPT 4o. В нескольких попытках прогресс даже откатывался назад — и это было довольно раздражающе.
В итоге, теперь есть файл GlobalPermissions.ps1, который содержит новую функцию Get-GlobalPermission. Эта функция извлекает все глобальные права vSphere, включая имя субъекта (principal), назначенную роль vSphere и то, где именно эта роль определена (глобальное право или право в рамках inventory сервера vCenter).
Ниже приведён пример использования новой функции — перед этим потребуется выполнить Connect-VIServer, чтобы можно было сопоставить ID роли vSphere, полученный из функции, с её реальным именем, которое возвращается встроенным командлетом PowerCLI.
Пару лет назад Дункан Эппинг писал о функции Witness Resilience - это функция повышения устойчивости к сбоям свидетеля (Witness Failure Resilience) в конфигурациях растянутых кластеров vSAN 7.0 Update 3 (stretched clusters). Эта функция направлена на обеспечение доступности виртуальных машин даже при одновременном выходе из строя одного из дата-центров и узла-свидетеля (Witness). Мы ее детально описывали вот тут.
В традиционной конфигурации растянутого кластера данные реплицируются между двумя сайтами, а узел-свидетель размещается в третьей локации для обеспечения кворума. При отказе одного из сайтов кворум сохраняется за счет оставшегося сайта и узла-свидетеля. Однако, если после этого выходит из строя узел-свидетель, оставшийся сайт терял кворум, что приводило к недоступности машин.
С введением функции устойчивости к сбоям свидетеля в vSAN 7.0 Update 3, при отказе одного из сайтов система автоматически перераспределяет голоса (votes) компонентов данных. Компоненты на оставшемся сайте получают дополнительные голоса, а голоса компонентов на узле-свидетеле — уменьшаются. Это означает, что если после отказа сайта выходит из строя и узел-свидетель, оставшийся сайт все еще имеет достаточное количество голосов для поддержания кворума и обеспечения доступности ВМ.
Важно отметить, что процесс перераспределения голосов занимает некоторое время (обычно около 3 минут), в течение которого система адаптируется к новой конфигурации. После восстановления отказавшего сайта и узла-свидетеля система возвращает исходное распределение голосов для нормальной работы.
Таким образом, функция устойчивости к сбоям свидетеля значительно повышает надежность и отказоустойчивость растянутых кластеров, позволяя ВМ оставаться доступными даже при одновременном отказе одного из сайтов и узла-свидетеля.
Недавно Дункан снова поднял тонкий вопрос на эту тему. Он провёл несколько тестов и решил написать продолжение прошлой статьи. В данном случае мы говорим о конфигурации с двумя узлами, но это также применимо и к растянутому кластеру (stretched cluster).
В случае растянутого кластера или конфигурации с двумя узлами, когда сайт с данными выходит из строя (или переводится в режим обслуживания), автоматически выполняется перерасчёт голосов для каждого объекта/компонента. Это необходимо для того, чтобы при последующем выходе из строя Witness объекты/виртуальные машины оставались доступными.
А что если сначала выйдет из строя Witness, а только потом сайт с данными?
Это объяснить довольно просто — в таком случае виртуальные машины станут недоступными. Почему? Потому что в этом сценарии перерасчёт голосов уже не выполняется. Конечно же, он протестировал это, и ниже представлены скриншоты, которые это подтверждают.
На этом скриншоте показано, что Witness отсутствует (Absent), и оба компонента с данными имеют по одному голосу. Это значит, что если один из хостов выйдет из строя, соответствующий компонент станет недоступным. Давайте теперь отключим один из хостов и посмотрим, что покажет интерфейс.
Как видно на скриншоте ниже, виртуальная машина теперь недоступна. Это произошло из-за того, что больше нет кворума — 2 из 3 голосов недействительны:
Это говорит нам о том, что нужно обязательно следить за доступностью хоста Witness, который очень важен для контроля кворума кластера.
В течение последнего года Broadcom проводила сокращения персонала, включая увольнения в отделе продаж VMware в октябе и в команде профессиональных услуг на прошлой неделе, по данным нынешних и бывших сотрудников, а также публикаций в LinkedIn. Кроме того, за последние несколько месяцев Broadcom сократила штат и в других подразделениях или офисах.
Согласно документам для регулирующих органов, в феврале 2023 года штат VMware насчитывал более 38 тысяч сотрудников, однако многие работники и руководители покинули компанию еще до завершения сделки. Дополнительным фактором сокращения численности персонала стала естественная текучесть кадров.
По данным двух источников, к январю текущего года в VMware осталось примерно 16 тысяч сотрудников. За последние несколько месяцев были сокращены сотрудники в отделах маркетинга, партнерств, а также подразделения VMware Cloud Foundation, согласно информации бывших сотрудников и публикациям в LinkedIn.
Помимо этого, Broadcom внедрила в VMware другие изменения, включая требование о возвращении сотрудников в офис. Один бывший сотрудник сообщил, что в случаях, когда недостаточное количество работников регулярно отмечалось в определенных офисах, Broadcom закрывала эти офисы и сокращала сотрудников, которые там работали.
Также Хок Тан сосредоточился на крупнейших клиентах VMware и перевел бизнес-модель компании с продажи бессрочных лицензий на подписную модель. Недавно во время телефонной конференции по финансовым результатам он заявил, что к настоящему времени на новую модель перешли 60% клиентов.
Компания также повысила цены. Клиенты VMware сообщили, что столкнулись со значительным ростом затрат из-за пакетных предложений, когда несколько продуктов объединяются в один комплект, вынуждая клиентов платить за них все сразу.
При этом
акции Broadcom выросли примерно на 40% за последний год. В декабре рыночная капитализация Broadcom достигла 1 триллиона долларов. Аналитики в основном положительно оценивают подход Broadcom к интеграции VMware после слияния.
«Фактор VMware продолжает оправдывать себя, что неудивительно, учитывая опыт Хока Тана и его проверенную стратегию многократного успешного повторения сделок по слияниям и поглощениям», — заявил Дэйв Вагнер, управляющий портфелем в Aptus Capital Advisors, накануне публикации впечатляющих квартальных результатов компании.
Аналитики компании William Blair назвали VMware «звездой на рынке программного обеспечения», подчеркнув, что это «возможность для Broadcom добиться устойчивого роста в софте и потенциально снизить негативные последствия усиленной текучести клиентов к 2027 году».
Если логи вашего vCenter переполнены сообщениями ApiGwServicePrincipal об истечении срока действия токенов, вы не одиноки. Частые записи уровня «info» в файле apigw.log могут засорять вашу систему, затрудняя выявление реальных проблем. К счастью, есть простое решение: измените уровень логирования с «info» на «error». Автор блога cosmin.us подробно рассказал, как именно можно эффективно уменьшить количество этих лишних записей в журнале.
Со стороны сервера VMware vCenter в логе вы можете увидеть записи следующего вида:
The token with id '_9eb499f7-5f0e-4b83-9149-e64ae5bbf202' for domain vsphere.local(9d121150-d80b-4dbe-8f8a-0254435cf32a) is unusable (EXPIRED). Will acquire a fresh one.
Эти сообщения появляются потому, что по умолчанию для файла apigw.log установлен уровень логирования «info». В результате регистрируется каждое истечение срока действия и обновление токена — обычный процесс, который не требует постоянного внимания. Итог — перегруженные журналы и возможное снижение производительности. Изменив уровень логирования на «error», вы сможете ограничить записи в журналах только критически важными проблемами.
Внимательно следуйте данным инструкциям, чтобы изменить уровень логирования для apigw.log. Этот процесс применим как к отдельным серверам vCenter, так и к серверам в режиме Enhanced Linked Mode.
Создание снапшота сервера vCenter
Перед внесением изменений защитите свою среду, создав снапшот vCenter. Если ваши серверы vCenter работают в режиме Enhanced Linked Mode, используйте оффлайн-снапшоты для обеспечения согласованности всех узлов. Этот снимок послужит вариантом отката, если что-то пойдёт не так.
Войдите на устройство vCenter Server Appliance (VCSA) по SSH с правами root. Выполните следующую команду для резервного копирования файла vmware-services-vsphere-ui.conf:
Перезапуск этих служб активирует новые настройки логирования.
Проверка результата
После перезапуска сервисов убедитесь, что избыточные сообщения об истечении срока действия токенов прекратились. Теперь при уровне логирования «error» будут появляться только критические проблемы, делая ваши журналы более понятными и полезными.
VMware vCenter Server поставляется с рядом системных и пользовательских ролей, которые можно использовать, а также пользователи могут создавать собственные роли с необходимыми привилегиями. Если вам нужно понять, какие роли активно используются, следующий фрагмент кода PowerCLI, который сделал Дункан Эппинг, поможет получить информацию о назначенных ролях. Кроме того, скрипт также создаст файл, содержащий все привилегии, определенные для активно используемых ролей vCenter.
Один из клиентов VMware недавно обратился к Вильяму Ламу с вопросом о том, как можно легко провести аудит всей своей инфраструктуры серверов VMware ESXi, чтобы определить, какие хосты всё ещё загружаются с использованием устаревшей прошивки BIOS, которая будет удалена в будущих выпусках vSphere и заменена на стандартную для индустрии прошивку типа UEFI.
В vSphere 8.0 Update 2 было введено новое свойство API vSphere под названием firmwareType, которое было добавлено в объект информации о BIOS оборудования ESXi, что значительно упрощает получение этой информации с помощью следующей однострочной команды PowerCLI:
(Get-VMHost).ExtensionData.Hardware.BiosInfo
Пример ее вывода для сервера ESXi при использовании UEFI выглядит вот так:
Если же используется устаревший BIOS, то вот так:
Поскольку это свойство vSphere API было недавно введено в vSphere 8.0 Update 2, если вы попытаетесь использовать его на хосте ESXi до версии 8.0 Update 2, то это поле будет пустым, если вы используете более новую версию PowerCLI, которая распознаёт это свойство. Или же оно просто не отобразится, если вы используете более старую версию PowerCLI.
В качестве альтернативы, если вам всё же необходимо получить эту информацию, вы можете подключиться напрямую к хосту ESXi через SSH. Это не самый удобный вариант, но вы можете использовать следующую команду VSISH для получения этих данных:
Некоторое время назад Вильям Лам поделился решением, позволяющим установить VIB-пакет в сборке для Nested ESXi при использовании vSAN Express Storage Architecture (ESA) и VMware Cloud Foundation (VCF), чтобы обойти предварительную проверку на соответствие списку совместимого оборудования vSAN ESA (HCL) для дисков vSAN ESA.
Хотя в большинстве случаев Вильям использует Nested ESXi для тестирования, недавно он развернул физическую среду VCF. Из-за ограниченного количества NVMe-устройств он хотел использовать vSAN ESA для домена управления VCF, но, конечно же, столкнулся с той же проверкой сертифицированных дисков vSAN ESA, которая не позволяла установщику продолжить процесс.
Вильям надеялся, что сможет использовать метод эмуляции для физического развертывания. Однако после нескольких попыток и ошибок он столкнулся с нестабильным поведением. Пообщавшись с инженерами, он выяснил, что существующее решение также применимо к физическому развертыванию ESXi, поскольку аппаратные контроллеры хранилища скрываются методом эмуляции. Если в системе есть NVMe-устройства, совместимые с vSAN ESA, предварительная проверка vSAN ESA HCL должна пройти успешно, что позволит продолжить установку.
Вильям быстро переустановил последнюю версию ESXi 8.0 Update 3b на одном из своих физических серверов, установил vSAN ESA Hardware Mock VIB и, используя последнюю версию VCF 5.2.1 Cloud Builder, успешно прошел предварительную проверку vSAN ESA, после чего развертывание началось без проблем!
Отлично, что теперь это решение работает как для физических, так и для вложенных (nested) ESXi при использовании с VCF, особенно для создания демонстрационных сред (Proof-of-Concept)!
Примечание: В интерфейсе Cloud Builder по-прежнему выполняется предварительная проверка физических сетевых адаптеров, чтобы убедиться, что они поддерживают 10GbE или более. Таким образом, хотя проверка совместимости vSAN ESA HCL пройдет успешно, установка все же завершится с ошибкой при использовании UI.
Обходной путь — развернуть домен управления VCF с помощью Cloud Builder API, где проверка на 10GbE будет отображаться как предупреждение, а не как критическая ошибка, что позволит продолжить развертывание. Вы можете использовать этот короткий PowerShell-скрипт для вызова Cloud Builder API, а затем отслеживать процесс развертывания через UI Cloud Builder.
$cloudBuilderIP = "192.168.30.190"
$cloudBuilderUser = "admin"
$cloudBuilderPass = "VMware123!"
$mgmtDomainJson = "vcf50-management-domain-example.json"
#### DO NOT EDIT BEYOND HERE ####
$inputJson = Get-Content -Raw $mgmtDomainJson
$pwd = ConvertTo-SecureString $cloudBuilderPass -AsPlainText -Force
$cred = New-Object Management.Automation.PSCredential ($cloudBuilderUser,$pwd)
$bringupAPIParms = @{
Uri = "https://${cloudBuilderIP}/v1/sddcs"
Method = 'POST'
Body = $inputJson
ContentType = 'application/json'
Credential = $cred
}
$bringupAPIReturn = Invoke-RestMethod @bringupAPIParms -SkipCertificateCheck
Write-Host "Open browser to the VMware Cloud Builder UI to monitor deployment progress ..."
Дункану Эппингу задали интересный вопрос: учитываются ли файлы, хранящиеся на общих хранилищах vSAN с включенным vSAN File Services, в максимальном количестве объектов (max object count)? Поскольку Дункан не обсуждал это в последние несколько лет, он решил сделать краткое напоминание.
С vSAN File Services файлы, которые пользователи хранят в своем файловом хранилище, размещаются внутри объекта vSAN. Сам объект учитывается при подсчёте максимального количества компонентов в кластере, но отдельные файлы в нем - конечно же, нет.
Что касается vSAN File Services, то для каждого созданного файлового хранилища необходимо выбрать политику. Эта политика будет применяться к объекту, который создаётся для файлового хранилища. Каждый объект, как и для дисков виртуальных машин, состоит из одного или нескольких компонентов. Именно эти компоненты и будут учитываться при подсчёте максимального количества компонентов, которое может быть в кластере vSAN.
Для одного узла vSAN ESA максимальное количество компонентов составляет 27 000, а для vSAN OSA – 9 000 компонентов на хост. Имейте в виду, что, например, RAID-1 и RAID-6 используют разное количество компонентов. Однако, как правило, это не должно быть большой проблемой для большинства клиентов, если только у вас не очень большая инфраструктура (или наоборот, небольшая, но вы на пределе возможностей по количеству хранилищ и т. д.).
В видео ниже показана демонстрация, которую Дункан проводил несколько лет назад, где исследуются эти компоненты в интерфейсе vSphere Client и с помощью CLI:
Вильям Лам написал очень полезную статью, касающуюся развертывания виртуальных хостов (Nested ESXi) в тестовой лаборатории VMware Cloud Foundation.
Независимо от того, настраиваете ли вы vSAN Express Storage Architecture (ESA) напрямую через vCenter Server или через VMware Cloud Foundation (VCF), оборудование ESXi автоматически проверяется на соответствие списку совместимого оборудования vSAN ESA (HCL), чтобы убедиться, что вы используете поддерживаемое железо для vSAN.
В случае использования vCenter Server вы можете проигнорировать предупреждения HCL, принять риски и продолжить настройку. Однако при использовании облачной инфраструктуры VCF и Cloud Builder операция блокируется, чтобы гарантировать пользователям качественный опыт при выборе vSAN ESA для развертывания управляющего или рабочего домена VCF.
С учетом вышеизложенного, существует обходное решение, при котором вы можете создать свой собственный пользовательский JSON-файл HCL для vSAN ESA на основе имеющегося у вас оборудования, а затем загрузить его в Cloud Builder для настройки нового управляющего домена VCF или в SDDC Manager для развертывания нового рабочего домена VCF. Вильям уже писал об этом в своих блогах здесь и здесь.
Использование Nested ESXi (вложенного ESXi) является популярным способом развертывания VCF, особенно если вы новичок в этом решении. Этот подход позволяет легко экспериментировать и изучать платформу. В последнее время Вильям заметил рост интереса к развертыванию VCF с использованием vSAN ESA. Хотя вы можете создать пользовательский JSON-файл HCL для vSAN ESA, как упоминалось ранее, этот процесс требует определенных усилий, а в некоторых случаях HCL для vSAN ESA может быть перезаписан, что приводит к затруднениям при решении проблем.
После того как Вильям помогал нескольким людям устранять проблемы в их средах VCF, он начал задумываться о лучшем подходе и использовании другой техники, которая, возможно, малоизвестна широкой аудитории. Вложенный ESXi также широко используется для внутренних разработок VMware и функционального тестирования. При развертывании vSAN ESA инженеры сталкиваются с такими же предупреждениями HCL, как и пользователи. Одним из способов обхода этой проблемы является "эмуляция" оборудования таким образом, чтобы проверка работоспособности vSAN успешно проходила через HCL для vSAN ESA. Это достигается путем создания файла stress.json, который размещается на каждом Nested ESXi-хосте.
Изначально Вильям не был поклонником этого варианта, так как требовалось создавать файл на каждом хосте. Кроме того, файл не сохраняется после перезагрузки, что добавляло сложности. Хотя можно было бы написать сценарий автозагрузки, нужно было помнить о его добавлении на каждый новый хост.
После анализа обоих обходных решений он обнаружил, что вариант с использованием stress.json имеет свои плюсы: он требует меньше модификаций продукта, а возня с конфигурационными файлами — не самый лучший способ, если можно этого избежать. Учитывая ситуации, с которыми сталкивались пользователи при работе с новыми версиями, он нашел простое решение — создать пользовательский ESXi VIB/Offline Bundle. Это позволяет пользователям просто установить stress.json в правильный путь для их виртуальной машины Nested ESXi, решая вопросы сохранения данных, масштабируемости и удобства использования.
Перейдите в репозиторий Nested vSAN ESA Mock Hardware для загрузки ESXi VIB или ESXi Offline Bundle. После установки (необходимо изменить уровень принятия программного обеспечения на CommunitySupported) просто перезапустите службу управления vSAN, выполнив следующую команду:
/etc/init.d/vsanmgmtd restart
Или вы можете просто интегрировать этот VIB в новый профиль образа/ISO ESXi с помощью vSphere Lifecycle Manager, чтобы VIB всегда был частью вашего окружения для образов ESXi. После того как на хосте ESXi будет содержаться файл stress.json, никаких дополнительных изменений в настройках vCenter Server или VCF не требуется, что является огромным преимуществом.
Примечание: Вильям думал о том, чтобы интегрировать это в виртуальную машину Nested ESXi Virtual Appliance, но из-за необходимости изменения уровня принятия программного обеспечения на CommunitySupported, он решил не вносить это изменение на глобальном уровне. Вместо этого он оставил все как есть, чтобы пользователи, которым требуется использование vSAN ESA, могли просто установить VIB/Offline Bundle как отдельный компонент.
Обратите внимание, что в будущей версии vSAN в интерфейсе появится опция, которая поможет с операциями, описанными ниже.
Прежде всего, вам нужно проверить, реплицированы ли все данные. В некоторых случаях мы видим, что клиенты фиксируют данные (виртуальные машины) в одном месте без репликации, и эти виртуальные машины будут напрямую затронуты, если весь сайт будет переведен в режим обслуживания. Такие виртуальные машины необходимо выключить, либо нужно убедиться, что они перемещены на работающий узел, если требуется их дальнейшая работа. Обратите внимание, что если вы переключаете режимы "Preferred / Secondary", а множество ВМ привязаны к одному сайту, это может привести к значительному объему трафика синхронизации. Если эти виртуальные машины должны продолжать работать, возможно, стоит пересмотреть решение реплицировать их.
Вот шаги, которые Дункан рекомендует предпринять при переводе сайта в режим обслуживания:
Убедитесь, что vSAN Witness работает и находится в здоровом состоянии (проверьте соответствующие health checks).
Проверьте комплаенс виртуальных машин, которые реплицированы.
Настройте DRS (распределённый планировщик ресурсов) в режим "partially automated" или "manual" вместо "fully automated".
Вручную выполните vMotion всех виртуальных машин с сайта X на сайт Y.
Переведите каждый хост ESXi на сайте X в режим обслуживания с опцией "no data migration".
Выключите все хосты ESXi на сайте X.
Включите DRS снова в режиме "fully automated", чтобы среда на сайте Y оставалась сбалансированной.
Выполните все необходимые работы по обслуживанию.
Включите все хосты ESXi на сайте X.
Выведите каждый хост из режима обслуживания.
Обратите внимание, что виртуальные машины не будут автоматически возвращаться обратно, пока не завершится синхронизация для каждой конкретной виртуальной машины. DRS и vSAN учитывают состояние репликации! Кроме того, если виртуальные машины активно выполняют операции ввода-вывода во время перевода хостов сайта X в режим обслуживания, состояние данных, хранящихся на хостах сайта X, будет различаться. Эта проблема будет решена в будущем с помощью функции "site maintenance", как упоминалось в начале статьи.
Также для информации об обслуживании сети и ISL-соединения растянутого кластера vSAN прочитайте вот эту статью.
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
В прошлом году Вильям Лам продемонстрировал метод настройки строки железа SMBIOS с использованием Nested ESXi, но решение было далеко от идеала: оно требовало модификации ROM-файла виртуальной машины и ограничивалось использованием BIOS-прошивки для машины Nested ESXi, в то время как поведение с EFI-прошивкой отличалось.
В конце прошлого года Вильям проводил исследования и наткнулся на гораздо более изящное решение, которое работает как для физического, так и для виртуального ESXi. Существует параметр ядра ESXi, который можно переключить, чтобы просто игнорировать стандартный SMBIOS оборудования, а затем эмулировать собственную пользовательскую информацию SMBIOS.
Шаг 1 – Подключитесь по SSH к вашему ESXi-хосту, отредактируйте файл конфигурации /bootbank/boot.cfg и добавьте ignoreHwSMBIOSInfo=TRUE в строку kernelopt, после чего перезагрузите систему.
Шаг 2 – Далее нам нужно выполнить команду vsish, чтобы настроить желаемую информацию SMBIOS. Однако, вместо того чтобы заставлять пользователей вручную создавать команду, Вильям создал простую функцию PowerShell, которая сделает процесс более удобным.
Сохраните или выполните приведенный ниже фрагмент PowerShell-кода, который определяет новую функцию Generate-CustomESXiSMBIOS. Эта функция принимает следующие шесть аргументов:
Uuid – UUID, который будет использоваться в симулированной информации SMBIOS.
Вам потребуется перезапустить службу hostd, чтобы информация стала доступной. Для этого выполните команду:
/etc/init.d/hostd restart
Если вы теперь войдете в ESXi Host Client, vCenter Server или vSphere API (включая PowerCLI), то обнаружите, что производитель оборудования, модель, серийный номер и UUID отображают заданные вами пользовательские значения, а не данные реального физического оборудования!
Пользовательский SMBIOS не сохраняется после перезагрузки, поэтому вам потребуется повторно запускать команду каждый раз после перезагрузки вашего хоста ESXi.
Не все виртуальные машины на базе vSphere одинаковы, Вильям Лам написал интересный пост об обнаружении ВМ разного типа с помощью PowerCLI. Это особенно актуально с введением vSphere IaaS (ранее известного как vSphere Supervisor, vSphere with Tanzu или Project Pacific), который включает современный способ развертывания традиционных/классических виртуальных машин, а также новый тип виртуальной машины, основанный на контейнерах, известный как vSphere Pod VM.
vSphere Pod - это эквивалент Kubernetes pod в среде VMware Tanzu / vSphere IaaS. Это легковесная виртуальная машина, которая запускает один или несколько контейнеров на базе Linux. Каждый vSphere Pod точно настроен для работы с конкретной нагрузкой и имеет явно указанные reservations для ресурсов этой нагрузки. Он выделяет точное количество хранилища, памяти и процессорных ресурсов, необходимых для работы нагрузки внутри ВМ. vSphere Pods поддерживаются только в случаях, когда компонент Supervisor настроен с использованием NSX в качестве сетевого стека.
Недавно возник вопрос о том, как можно различать традиционные/классические виртуальные машины, созданные через пользовательский интерфейс или API vSphere, и виртуальные машины vSphere Pod средствами PowerCLI, в частности с использованием стандартной команды Get-VM.
Как видно на приведенном выше скриншоте, vSphere может создавать и управлять несколькими типами виртуальных машин, от традиционных/классических, которые мы все знаем последние два десятилетия, специализированных "Сервисных/Агентских" виртуальных машин, управляемых различными решениями VMware или сторонних разработчиков, и до новых виртуальных машин vSphere IaaS и виртуальных машин рабочих нагрузок контейнеров vSphere Pod (которые можно назвать Supervisor VM и Supervisor Pod VM).
Хотя команда Get-VM не различает эти типы виртуальных машин, существует несколько свойств, которые можно использовать в vSphere API для различения этих типов виртуальных машин. Ниже приведен фрагмент кода PowerCLI, который Вильям написал для того, чтобы различать типы виртуальных машин, что может быть полезно для автоматизации и/или отчетности.
Вот пример вывода скрипта для той же среды, что и на скриншоте из пользовательского интерфейса vSphere, но теперь у вас есть способ различать различные типы виртуальных машин, управляемых платформой vSphere.
В обеих версиях Microsoft Windows 10 и 11 безопасность на основе виртуализации (Virtualization Based Security, VBS) включена по умолчанию, и эта функция использует платформу Hyper-V, которая реализует технологию вложенной виртуализации (Nested Virtualization). Недавно Вильям Лам написал о том, что в связи с этим платформа VMware Workstation может выдавать ошибку.
Если вы попытаетесь запустить вложенную виртуальную машину с гипервизором ESXi в рамках Workstation под Windows, вы, скорее всего, увидите одно из следующих сообщений об ошибке в зависимости от производителя процессора:
Virtualized Intel VT-x/EPT is not supported on this platform
Virtualized AMD-V/RVI is not supported on this platform
Выглядит это так:
В то же время VMware Workstation была улучшена для совместной работы с Hyper-V благодаря новому режиму Host VBS Mode, представленному в VMware Workstation версии 17.x:
Workstation Pro uses a set of newly introduced Windows 10 features (Windows Hypervisor Platform) that permits the use of VT/AMD-V features, which enables Workstation Pro and Hyper-V to coexist. And because VBS is built on Hyper-V, Windows hosts with VBS enabled can now power on VM in Workstation Pro successfully
В документации VMware Workstation упоминаются несколько ограничений данной возможности. Тем не менее, если вам необходимо запустить вложенный ESXi под VMware Workstation, вам просто нужно отключить VBS в Windows, при условии, что у вас есть права администратора на вашем компьютере.
Шаг 1. Перейдите в раздел «Безопасность устройства» и в разделе «Основная изоляция» (Core isolation) отключите параметр «Целостность памяти» (Memory integrity), как показано на скриншоте ниже.
Шаг 2. Перезагрузите компьютер, чтобы изменения вступили в силу.
Шаг 3. Чтобы убедиться, что VBS действительно отключен, откройте Microsoft System Information (Системную информацию) и найдите запись «Безопасность на основе виртуализации» (Virtualization-based security). Убедитесь, что там указано «Не включено» (Not enabled). На устройствах, управляемых корпоративными системами, эта настройка может автоматически включаться снова. Таким образом, это поможет подтвердить, включена ли настройка или отключена.
Шаг 4. Как видно на скриншоте ниже, Вильяму удалось успешно запустить вложенный ESXi 6.0 Update 3 на последней версии VMware Workstation 17.6.2 под управлением Windows 11 22H2.
Вильям Лам выложил интересный сценарий PowerCLI, который поможет вам получить информацию об использовании хранилищ и накладных расходах vSAN с использованием API.
В интерфейсе vSphere Client вы можете увидеть подробный анализ использования хранилища vSAN, включая различные системные накладные расходы, выбрав конкретный кластер vSAN, а затем перейдя в раздел Monitor->vSAN->Capacity, как показано на скриншоте ниже:
Различные конфигурации vSAN, такие как использование традиционной архитектуры хранения vSAN OSA или новой архитектуры vSAN Express Storage Architecture (ESA), а также активация функций, таких как дедупликация и сжатие vSAN, приводят к различным метрикам использования дискового пространства, которые отображаются в разделе информации.
Недавно у Вильяма спросили - а как получить информацию о накладных расходах, связанных с дедупликацией и сжатием vSAN, с использованием PowerCLI?
Хотя командлет PowerCLI vSAN Get-VsanSpaceUsage предоставляет множество метрик использования, отображаемых в интерфейсе vSphere, он не раскрывает все свойства.
Тем не менее, мы можем использовать PowerCLI для получения этой информации, используя базовый метод vSAN API, который предоставляет эти данные, в частности querySpaceUsage(). Как видно из документации по API, этот метод возвращает массив объектов типов использования vSAN, которые соответствуют данным, отображаемым в интерфейсе vSphere, с расшифровкой свойства ObjType.
Чтобы продемонстрировать использование этого API, Вильям создал пример PowerCLI-скрипта под названием vsanUsageAndOverheadInfo.ps1, в котором вам нужно просто обновить переменную $vsanCluster, указав имя нужного кластера vSAN.
После подключения к серверу vCenter вы можете просто выполнить этот скрипт, как показано ниже:

 RSS
RSS