Аппаратная версия виртуальной машины vCenter оставалась на уровне версии 10 (совместима с VMware ESX 5.5 и более поздними) со времён VMware vSphere 5.5. С выходом vSphere в составе VMware Cloud Foundation 9.1 она обновлена до версии 17.
Примечание: в зависимости от интерфейса, статьи базы знаний или технической документации могут использоваться взаимозаменяемые термины «совместимость виртуальной машины», «совместима с ESX версии» или «версия аппаратного обеспечения виртуальной машины». Для ясности: виртуальное аппаратное обеспечение версии 17 в интерфейсе vSphere Client обозначается как «Compatible with ESXi 7.0 and later».
Об обновлении аппаратной версии виртуальной машины vCenter
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом Reduced Downtime Upgrade аппаратная версия виртуальной машины vCenter обновляется автоматически с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter.
После выполнения in-place обновления vCenter (с 9.0.x до 9.1.0) аппаратную версию ВМ vCenter необходимо обновить вручную. Эта процедура требует выключения виртуальной машины vCenter.
Если виртуальная машина vCenter управляется другим экземпляром vCenter, её необходимо выключить и выполнить обновление аппаратного обеспечения ВМ до версии 17 через vSphere Client. Подробности — в документации Upgrade the Compatibility of a Virtual Machine Manually.
Обновление аппаратного обеспечения ВМ необратимо — откатить версию назад невозможно. Перед обновлением аппаратной версии ВМ vCenter рекомендуется создать снапшот виртуальной машины или выполнить её резервное копирование.
Важно: необходимо выбирать именно Compatible with ESXi 7.0 and later (версия 17). Если выбрана более поздняя версия, vCenter окажется в неподдерживаемом состоянии — потребуется восстановление из снапшота или из более ранней резервной копии vCenter.
Также доступна возможность запланировать обновление аппаратной версии при следующей перезагрузке.
Совет: рекомендуется включить запланированное обновление аппаратной версии до начала in-place обновления vCenter до версии 9.1. Поскольку обновление требует перезагрузки, можно совместить обновление vCenter до 9.1 и обновление аппаратной версии ВМ в рамках одного цикла перезагрузки.
Почему именно версия 17?
Краткий ответ: обратная совместимость. Виртуальное аппаратное обеспечение версии 17 поддерживается на хостах ESX 7.0 и более поздних. Инфраструктурные обновления нередко выполняются постепенно, а устаревшее и даже не поддерживаемое оборудование продолжает использоваться в производственных средах. Возможность запускать vCenter версии 9.1 на более старых хостах ESX предоставляет клиентам гибкость: они могут перейти на vCenter 9.1, не торопясь с миграцией на новые аппаратные платформы. Миграция между управляющими серверами (Cross-vCenter migration) позволит перенести ВМ vCenter на новую инфраструктуру в удобный момент.
Будет ли аппаратная версия vCenter обновляться снова?
Да. Цель — поддерживать аппаратную версию ВМ vCenter по модели N-1 относительно мажорных версий ESX. Например, текущая мажорная версия ESX — 9.x, следовательно, версия N-1 — это 8.x.
Необходимо также учитывать, что vCenter всегда обновляется раньше ESX. Аппаратная версия ВМ vCenter не может быть повышена до уровня, который ещё не обновлённый ESX не в состоянии обеспечить.
Компания «Базис», работающая на российском рынке программных решений для управления динамической инфраструктурой, сообщила о выходе платформы серверной виртуализации Basis Dynamix Enterprise версии 4.5.
В новом релизе расширены возможности экосистемы за счёт более тесной интеграции с системой управления программно-определяемыми сетями Basis SDN, улучшена совместимость с отечественными системами хранения данных, а также добавлены инструменты для повышения производительности и автоматизации управления ИТ-инфраструктурой. Всего версия 4.5 включает более 90 доработок и нововведений.
Расширение поддержки отечественных систем хранения данных
Одним из ключевых направлений развития версии 4.5.0 стало расширение поддержки российских СХД. В частности, добавлена работа с системой хранения uStor, включая полный набор операций: создание и управление дисками, работу с образами и снапшотами, а также презентацию и депрезентацию дисков вычислительным узлам.
Кроме того, реализована поддержка СХД Yadro Tatlin.Unified с версией ПО 3.2, при этом сохранена обратная совместимость с предыдущими версиями прошивки Tatlin. Это даёт заказчикам больше гибкости при выборе оборудования для построения импортонезависимой инфраструктуры и упрощает взаимодействие с ним через платформу.
Эффективное использование дискового пространства
В версии 4.5 внедрена поддержка unmap для дисков виртуальных машин. Теперь при удалении файлов внутри виртуальной машины освобождённое пространство не только помечается как свободное в гостевой системе, но и возвращается обратно в СХД. Это обеспечивает более эффективное использование дисковой ёмкости, что особенно важно при большом количестве виртуальных машин и использовании thin-provisioned дисков.
Развитие интеграции с программно-определяемыми сетями
Релиз 4.5 усиливает нативную интеграцию Basis Dynamix Enterprise с решением для программно-определяемых сетей Basis SDN и расширяет сетевые возможности платформы. Например, при создании виртуальных машин появилась возможность автоматически подключать SDN-сегменты с одновременным созданием логических портов, что сокращает объём ручной настройки и упрощает работу администраторов.
Автоматизация управления узлами
В Basis Dynamix 4.5 появился механизм автоматического перевода физического узла из состояния «На обслуживании» в статус «Работает». Соответствующая настройка доступна на странице «Физические узлы» в интерфейсе системы. При этом вместе с узлом автоматически запускаются виртуальные машины, ранее закреплённые за ним на момент перевода в режим обслуживания. Функция применима как к отдельным узлам, так и к целым зонам, что упрощает эксплуатацию крупных инфраструктур.
Другие улучшения
Помимо этого, версия 4.5.0 включает ряд дополнительных улучшений, повышающих удобство администрирования:
Механизм Watchdog, обеспечивающий автоматическое восстановление зависших виртуальных машин.
Поддержка режима Cache Write Through, повышающего производительность дисковой подсистемы.
Упрощённая начальная установка за счёт минимального конфигурационного файла.
Обновление спецификации API до версии OpenAPI 3.1.0.
Доработка модели физического узла: понятие «вычислительный узел» (stack) было упразднено, а его функциональность перенесена в сущность «физический узел» (node), что позволило упростить как модель данных, так и API платформы.
Возможность при создании виртуальной машины, даже если она разворачивается не из образа, включать дополнительные возможности гипервизора — такие как NUMA, CPU pinning и Huge Pages.
Возможность сделать виртуальную машину доступной только для чтения для всех пользователей.
При создании ВМ можно задавать маску сети для интерфейсов DPDK и VFNIC, а также настраивать MTU для транковых сетей в диапазоне от 1500 до 9216.
Можно ограничивать количество узлов, обрабатываемых одновременно, и при этом сбой на одном узле не прерывает общий процесс.
После первичной установки реализовано автоматическое обновление API-ключа для служебного пользователя.
Комментарий разработчика
«Одной из важнейших задач в рамках развития нашей флагманской платформы Basis Dynamix Enterprise является поддержание её совместимости с актуальным инфраструктурным оборудованием и ПО. Это касается в том числе и нашего собственного решения для организации программно-определяемых сетей Basis SDN, которое успешно работает в тестовых средах заказчиков и быстро развивается с учётом их пожеланий. Нашей целью является не просто поддержка отечественных систем хранения данных, инструментов резервного копирования или других решений. Мы хотим дать заказчику возможность построить на базе Basis Dynamix Enterprise полностью импортонезависимую динамическую ИТ-инфраструктуру, не ограничивая его при этом в выборе поставщиков "железа" или программных продуктов»
— Дмитрий Сорокин, технический директор компании «Базис».
В марте на российском рынке виртуализации серверов заметно усилился акцент на экосистемной совместимости, защищённой инфраструктуре и связке отечественного ПО с локальными аппаратными платформами. Ниже — обзор ключевых событий месяца.
Совместимость zVirt с системой доверенной загрузки «Соболь»
Одной из самых заметных мартовских новостей стало подтверждение совместимости платформы виртуализации zVirt с системой доверенной загрузки «Соболь». Для рынка это не просто технический тест, а важный сигнал о том, что отечественные платформы виртуализации всё активнее встраиваются в контур защищённой ИТ-инфраструктуры.
Практическое значение новости заключается в том, что организации из госсектора, критической инфраструктуры и компаний с повышенными требованиями к безопасности получают более предсказуемый сценарий внедрения виртуализации. Защита на этапе загрузки сервера дополняет архитектуру гипервизора и снижает риски компрометации базового уровня инфраструктуры.
В более широком контексте эта новость показывает зрелость экосистемы вокруг российских платформ виртуализации: заказчику уже недостаточно просто гипервизора, ему нужен связанный стек из виртуализации, средств защиты и поддержки регуляторных требований.
Sharx Base расширяет аппаратную совместимость через интеграцию с серверами Trinity
Другой важный сюжет марта связан с платформой Sharx Base и её совместимостью с серверами Trinity. Подобные новости на первый взгляд могут выглядеть как обычные интеграционные объявления, но для рынка импортозамещения они имеют стратегическое значение.
Сегодня заказчику нужен не отдельный программный продукт, а работоспособный и подтверждённый стек: сервер, слой виртуализации, система хранения и понятная схема поддержки. Именно поэтому новости о сертифицированной или подтверждённой совместимости привлекают внимание значительно сильнее, чем просто функциональные обновления.
Интеграция Sharx Base с серверами Trinity показывает, что российские игроки продолжают выстраивать полноценную инфраструктурную экосистему. Это снижает барьер входа для корпоративных клиентов и делает проекты миграции с зарубежных решений менее рискованными.
Реальные внедрения: использование Helius в крупной корпоративной инфраструктуре
Сильный информационный эффект в марте дали новости о практическом внедрении российских решений виртуализации в крупных инфраструктурных проектах. В этом контексте особое внимание привлекло использование Helius в составе геораспределённого вычислительного кластера у НМТП.
Такие кейсы важны потому, что рынок виртуализации давно вышел из стадии обсуждения возможностей на уровне презентаций. Для корпоративных заказчиков решающим аргументом становится подтверждение того, что отечественная платформа выдерживает промышленную эксплуатацию, масштабирование и работу в распределённой среде.
Появление подобных внедрений усиливает доверие к российским продуктам и служит сигналом для компаний, которые ещё находятся в фазе выбора альтернатив зарубежным платформам. Чем больше примеров работающих production-сценариев, тем быстрее ускоряется принятие решений на рынке.
Новые серверные платформы как фундамент для роста виртуализации
Мартовская повестка была связана не только с самим ПО виртуализации, но и с аппаратной базой, на которой эти решения будут массово разворачиваться. В этом смысле важной стала новость о включении серверов «Гравитон» в реестр Минпромторга.
Для сегмента виртуализации такие новости имеют прикладное значение. Массовое внедрение гипервизоров невозможно без понятной и доступной аппаратной платформы, которая подходит для корпоративных и государственных проектов, закупается по формальным требованиям и имеет прогнозируемый цикл поставки и поддержки.
Чем увереннее развивается российская серверная база, тем устойчивее выглядит вся экосистема виртуализации. Рынок постепенно переходит от точечных проектов к сборке полноценного импортонезависимого контура, где и программная, и аппаратная части развиваются синхронно.
Отраслевые конференции как индикатор зрелости рынка
Отдельным маркером зрелости рынка стала подготовка и проведение отраслевого мероприятия "Платформы виртуализации 2026", посвящённого российским платформам виртуализации, которое пройдет 31 марта 2026 года. Конференции в этой сфере уже выступают не витриной отдельных поставщиков, а пространством для обсуждения миграционных стратегий, реальных кейсов и динамики спроса.
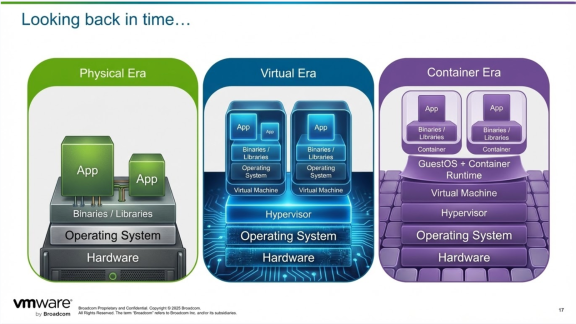
Виртуализация решила основную проблему «один сервер — одно приложение». Контейнеризация опиралась на этот результат и уточнила способ его достижения. Однако виртуализация остаётся основой современной вычислительной среды, и многие из наиболее критически важных рабочих нагрузок в мире продолжают и будут продолжать работать в виртуальных машинах. Помимо своей долговечности, виртуализация улучшает контейнеризацию и Kubernetes, помогая обеспечивать ключевые результаты, которых ожидают пользователи и которые требуются бизнесу.
Администраторы ИТ-инфраструктур и ИТ-менеджеры часто задают вопросы наподобие: «Какое отношение виртуализация имеет к Kubernetes?» Понимание этого крайне важно для ИТ-подразделений и организационных бюджетов. Вычисления революционизировали то, как мы взаимодействуем друг с другом, как работаем, и сформировали рамки возможного в промышленности. ИТ-нагрузки требуют вычислительных ресурсов, таких как CPU, память, хранилище, сеть и т. д., чтобы выполнять нужные функции — например, отправку электронного письма или обновление базы данных. Важная часть бизнес-операций заключается в том, чтобы ИТ-организации оптимизировали стратегию размещения своих нагрузок — будь то на мейнфрейме, в локальном дата-центре или в публичном облаке.
Виртуализация не исчезла с появлением Kubernetes — напротив, она помогает Kubernetes работать лучше в масштабе предприятия.
Виртуализация
С зарождения электронной вычислительной техники в 1940-х годах пользователи взаимодействовали с выделенным физическим оборудованием для выполнения своих задач. Приложения, рабочие нагрузки и оборудование стремительно развивались и расширяли возможности, сложность и охват того, что пользователи могли делать с помощью вычислений. Однако оставалось ключевое ограничение — одна машина, или сервер, выделялась под одно приложение. Например, у организаций были серверы, выделенные под почтовую функциональность, или целый сервер, выделенный под действия, выполнявшиеся лишь несколько раз в месяц, такие как начисление заработной платы.
Виртуализация — использование технологий для имитации ИТ-ресурсов — была впервые реализована в 1960-х годах на мейнфреймах. В ту эпоху виртуализация обеспечивала совместный доступ к ресурсам мейнфрейма и позволяла использовать мейнфреймы для нескольких приложений и сценариев. Это стало прообразом современной виртуализации и облачных вычислений, позволяя нескольким приложениям работать на выделенном оборудовании.
VMware возглавила бум облачных вычислений благодаря виртуализации архитектуры x86 — самого распространённого набора инструкций для персональных компьютеров и серверов. Теперь физическое оборудование могло размещать несколько распределённых приложений, поддерживать многих пользователей и полностью использовать дорогостоящее «железо». Виртуализация — ключевая технология, которая делает возможными публичные облачные вычисления; ниже приведено резюме:
Абстракция: виртуализация абстрагирует физическое оборудование, предоставляющее CPU, RAM и хранилище, в логические разделы, которыми можно управлять независимо.
Гибкость, масштабируемость, эластичность: абстрагированные разделы теперь можно масштабировать под потребности бизнеса, выделять и отключать по требованию, а ресурсы - возвращать по мере необходимости.
Консолидация ресурсов и эффективность: физическое оборудование теперь может запускать несколько логических разделов «правильного размера» с нужным объёмом CPU, RAM и хранилища — максимально используя оборудование и снижая постоянные затраты, такие как недвижимость и электроэнергия.
Изоляция и безопасность: у каждой ВМ есть собственный «мир» с ОС, независимой от той, что запущена на физическом оборудовании, что обеспечивает глубокую безопасность и изоляцию для приложений, использующих общий хост.
Для большинства предприятий и организаций критически важные рабочие нагрузки, обеспечивающие их миссию, рассчитаны на работу в виртуальных машинах, и они доверяют Broadcom предоставлять лучшие ВМ и лучшие технологии виртуализации. Доказав, что инфраструктуру можно абстрагировать и управлять ею независимо от физического оборудования, виртуализация заложила основу для следующей эволюции размещения рабочих нагрузок.
Контейнеризация
По мере роста вычислительных потребностей экспоненциально росла и сложность приложений и рабочих нагрузок. Приложения, которые традиционно проектировались и управлялись как монолиты, то есть как единый блок, начали разбиваться на меньшие функциональные единицы, называемые микросервисами. Это позволило разработчикам и администраторам приложений управлять компонентами независимо, упрощая масштабирование, обновления и повышая надёжность. Эти микросервисы запускаются в контейнерах, которые стали популярны в отрасли благодаря Docker.
Контейнеры Docker упаковывают приложения и их зависимости - такие как код, библиотеки и конфигурационные файлы - в единицы, которые могут стабильно работать на любой инфраструктуре: будь то ноутбук разработчика, сервер в датацентре предприятия или сервер в публичном облаке. Контейнеры получили своё название по аналогии с грузовыми контейнерами и дают многие из тех же преимуществ, что и их физические «тёзки», такие как стандартизация, переносимость и инкапсуляция. Ниже — краткий обзор ключевых преимуществ контейнеризации:
Стандартизация: как грузовые контейнеры упаковывают товары в формат, с которым другое оборудование может взаимодействовать единообразно, так и программные контейнеры упаковывают приложения в унифицированную, логически абстрагированную и изолированную среду
Переносимость: грузовые контейнеры перемещаются с кораблей на грузовики и поезда. Программные контейнеры могут запускаться на ноутбуке разработчика, в средах разработки, на продакшн-серверах и между облачными провайдерами
Инкапсуляция: грузовые контейнеры содержат всё необходимое для выполнения заказа. Программные контейнеры содержат код приложения, среду выполнения, системные инструменты, библиотеки и любые другие зависимости, необходимые для запуска приложения.
Изоляция: и грузовые, и программные контейнеры изолируют своё содержимое от других контейнеров. Программные контейнеры используют общую ОС физической машины, но не зависимости приложений.
По мере того как контейнеры стали отраслевым стандартом, команды начали разрабатывать собственные инструменты для оркестрации и управления контейнерами в масштабе. Kubernetes появился из этих проектов в 2015 году, а затем был передан сообществу open source. Продолжая морскую тематику контейнеров, Kubernetes по-гречески означает «рулевой» или «пилот» и выполняет роль мозга инфраструктуры.
Контейнер позволяет легко развёртывать приложения - Kubernetes позволяет масштабировать число экземпляров приложения, он гарантирует, что каждый экземпляр остаётся запущенным, и работает одинаково у любого облачного провайдера или в любом датцентре. Это три «S»-столпа: самовосстановление (Self-Healing), масштабируемость (Scalability) и стандартизация (Standardization). Эти результаты ускорили рост Kubernetes до уровня отраслевого золотого стандарта, и он стал повсеместным в cloud native-вычислениях, обеспечивая операционную согласованность, снижение рисков и повышенную переносимость.
Виртуализация > Контейнеризация
Виртуализация проложила путь разработчикам к размещению и изоляции нескольких приложений на физическом оборудовании, администраторам — к управлению ИТ-ресурсами, отделёнными от базового оборудования, и доказала жизнеспособность абстрагирования нижних частей стека для запуска и масштабирования сложного ПО. Контейнеры развивают эти принципы и абстрагируют уровень приложений, предоставляя следующие преимущества по сравнению с виртуализацией:
Эффективность: благодаря общей ОС контейнеры устраняют накладные расходы (CPU, память, хранилище), связанные с запуском нескольких одинаковых ОС для приложений.
Скорость: меньший «вес» позволяет значительно быстрее запускать и останавливать.
Переносимость: контейнеры лёгкие и могут выполняться на любом совместимом контейнерном рантайме.
Виртуализация улучшает Kubernetes
Виртуализация также стабилизирует и ускоряет Kubernetes. Большинство управляемых Kubernetes-сервисов, включая предложения гиперскейлеров (EKS на AWS, AKS на Azure, GKE на GCP), запускают Kubernetes-слой поверх виртуализованной ОС. Поскольку Kubernetes-среды обычно сложны, виртуализация значительно усиливает изоляцию, безопасность и надёжность, а также упрощает операции управления накладными процессами. Краткий обзор преимуществ:
Изоляция и безопасность: без виртуализации все контейнеры, работающие в кластере Kubernetes на физическом хосте, используют один и тот же Kernel (ядро ОС). Если контейнер взломан, всё, что работает на физическом хосте, потенциально может быть скомпрометировано на уровне оборудования. Гипервизор препятствует распространению злоумышленников на другие узлы Kubernetes и контейнеры.
Надёжность: Kubernetes может перезапускать контейнеры, если те падают, но бессилен, если проблемы возникают на уровне физического хоста. Виртуализация может перезапустить окружение Kubernetes за счёт высокой доступности (High Availability) на другом физическом сервере.
Операции: без виртуализации весь физический хост обычно принадлежит одному Kubernetes-кластеру. Это означает, что среда привязана к одной версии Kubernetes, что снижает скорость развития и делает апгрейды и операции сложными.
Именно поэтому каждый крупный управляемый Kubernetes-сервис работает на виртуальных машинах: виртуализация обеспечивает изоляцию, надёжность и операционную гибкость, необходимые в корпоративном масштабе.
Broadcom предоставляет лучшую платформу для размещения рабочих нагрузок
Инженерные команды Broadcom продолжают активно участвовать в upstream Kubernetes и вносят вклад в такие проекты, как Harbor, Cluster API и etcd.
С выпуском VCF 9 подразделение VCF компании Broadcom принесло в отрасль унифицированные операции, общую инфраструктуру и единые инструменты, независимые от форм-факторов рабочих нагрузок. Клиенты могут запускать ВМ и контейнеры/Kubernetes-нагрузки на одном и том же оборудовании и управлять ими одними и теми же инструментами, на которых миллионы специалистов построили свои навыки и карьеры. Предприятия и организации могут снизить капитальные и операционные расходы, стандартизировать операционную модель и модернизировать приложения и инфраструктуру, чтобы бизнес мог двигаться быстрее, защищать данные и повышать надёжность своих ключевых систем.
В этой статье мы завершаем рассказывать об итогах 2025 года в сферах серверной и настольной виртуализации на базе российских решений. Сегодня мы поговорим о том, как их функционал соотносится с таковым от ведущего мирового производителя - VMware.
Первую часть статьи можно прочитать тут, вторая - доступна здесь.
Сравнение с VMware vSphere
Как же отечественные решения выглядят на фоне VMware vSphere, многолетнего эталона в сфере виртуализации? По набору функций российские платформы стремятся обеспечить полный паритет с VMware – и во многом этого уже достигли. Однако при более глубоком сравнении выявляются отличия в зрелости, экосистеме и опыте эксплуатации.
Функциональность
Почти все базовые возможности VMware теперь доступны и в отечественных продуктах: от управления кластерами, миграции ВМ на лету и снапшотов до сетевой виртуализации и распределения нагрузки. Многие платформы прямо ориентируются на VMware при разработке. Например, SpaceVM позиционирует свои компоненты как аналоги VMware: SDN Flow = NSX, FreeGRID = NVIDIA vGPU (для Horizon), Space Dispatcher = Horizon Connection Server. ZVirt, Red, ROSA, SpaceVM – все поддерживают VMware-совместимые форматы виртуальных дисков (VMDK/OVA) и умеют импортировать ВМ из vSphere.
То есть миграция технически осуществима без кардинальной переделки ВМ. Live Migration, HA, кластеры, резервирование – эти функции стали стандартом де-факто, и российские продукты их предоставляют. Более того, появились и некоторые новые возможности, которых нет в базовом издании vSphere: например, интеграция с Kubernetes (KubeVirt) в решении Deckhouse от Flant позволяет управлять ВМ через Kubernetes API – VMware предлагает нечто подобное (vSphere with Tanzu), но это отдельно лицензируемый модуль.
Другой пример – поддержка облачных сервисов: некоторые отечественные платформы сразу рассчитаны на гибридное облако, тогда как VMware требует vCloud Suite (сейчас это часть платформы VMware Cloud Foundation, VCF). Тем не менее, зрелость функционала различается: если у VMware каждая возможность отполирована годами использования по всему миру, то у новых продуктов возможны баги или ограничения. Эксперты отмечают, что просто сравнить чекбоксы “есть функция X” – недостаточно, важна реализация. У VMware она, как правило, образцовая, а у российского аналога – может требовать ручных доработок. Например, та же миграция ВМ в российских системах работает, но иногда возникают нюансы с live migration при специфических нагрузках (что-то, что VMware давно решила).
Производительность и масштабирование
VMware vSphere славится стабильной работой кластеров до 64 узлов (в v7 – до 96 узлов) и тысяч ВМ. В принципе, и наши решения заявляют сопоставимый масштаб, но проверены они временем меньше. Как упоминалось, некоторые продукты испытывали сложности уже на 50+ хостах. Тем не менее, для 90% типовых инсталляций (до нескольких десятков серверов) разницы в масштабируемости не будет. По производительности ВМ – разница тоже минимальна: KVM и VMware ESXi показывают близкие результаты бенчмарков. А оптимизации вроде vStack с 2% overhead вообще делают накладные расходы незаметными. GPU-виртуализация – здесь VMware имела преимущество (технология vGPU), но сейчас SpaceVM и другие сократили отставание своим FreeGRID. Зато VMware до последнего времени обеспечивала более широкую поддержку оборудования (драйверы для любых RAID, сетевых карт) – российские ОС и гипервизоры поддерживают далеко не все модели железа, особенно новейшие. Однако ситуация улучшается за счет локализации драйверов и использования стандартных интерфейсов (VirtIO, NVMe и пр.).
Совместимость и экосистема
Ключевое различие – в экосистеме смежных решений. Окружение VMware – это огромный пласт интеграций: сотни backup-продуктов, мониторингов, готовых виртуальных апплаенсов, специальных плагинов и т.д. В российской экосистеме такого разнообразия пока нет. Многие специализированные плагины и appliance, рассчитанные на VMware, не будут работать на отечественных платформах.
Например, виртуальные апплаенсы от зарубежных вендоров (сетевые экраны, балансировщики), выпускались в OVF под vSphere – их можно включить и под KVM, но официальной поддержки может не быть. Приходится либо искать аналогичный российский софт, либо убеждаться, что в open-source есть совместимый образ. Интеграция с enterprise-системами – тоже вопрос: у VMware был vCenter API, поддерживаемый многими инструментами. Отечественным гипервизорам приходится писать собственные модули интеграции. Например, не все мониторинговые системы «из коробки» знают про zVirt или SpaceVM – нужно настраивать SNMP/API вручную.
Такая же ситуация с резервным копированием: знакомые всем Veeam и Veritas пока не имеют официальных агентов под наши платформы (хотя Veeam частично работает через стандартный SSH/VIX). В итоге на текущем этапе экосистема поддержки у VMware гораздо более развита, и это объективный минус для новых продуктов. Однако постепенно вокруг популярных российских гипервизоров формируется своё сообщество: появляются модули для Zabbix, адаптеры для Veeam через скрипты, свои решения backup (например, CyberProtect для Cyber Infrastructure, модуль бэкапа в VMmanager и т.п.).
Надёжность и поддержка
VMware десятилетиями оттачивала стабильность: vSphere известна редкими «падениями» и чётким поведением в любых ситуациях. Российским платформам пока ещё не хватает шлифовки – пользователи отмечают, что полностью «скучной» работу с ними назвать нельзя. Периодически инженерам приходится разбираться с нетривиальными багами или особенностями. В пример приводят трудоёмкость настройки сетевой агрегации (линков) – то, что на VMware привычно, на некоторых отечественных системах реализовано иначе и требует дополнительных манипуляций.
При обновлении версий возможны проблемы с обратной совместимостью: участники рынка жалуются, что выход каждого нового релиза иногда «ломает» интеграции, требуя доработки скриптов и настроек. Отсюда повышенные требования к квалификации админов – нужно глубже понимать «под капотом», чем при работе с отлаженной VMware. Но есть и плюс: почти все российские вендоры предоставляют оперативную техподдержку, зачастую напрямую от команд разработчиков. В критических случаях они готовы выпустить патч под конкретного заказчика или дать обходной совет. В VMware же, особенно после перехода на Broadcom, поддержка стала менее клиентоориентированной для средних клиентов. В России же каждый клиент на вес золота, поэтому реакция, как правило, быстрая (хотя, конечно, уровень экспертизы разных команд разнится).
Стоимость и лицензирование
Ранее VMware имела понятную, хоть и недешёвую модель лицензирования (по процессорам, +опции за функции). После покупки Broadcom стоимость выросла в разы, а бессрочные лицензии отменены – только подписка. Это сделало VMware финансово тяжелее для многих. Отечественные же продукты зачастую предлагают более гибкие условия: кто-то лицензирует по ядрам, кто-то по узлам, у кого-то подписка с поддержкой. Но в целом ценовой порог для легального использования ниже, чем у VMware (тем более, что последняя официально недоступна, а «серыми» схемами пользоваться рискованно). Некоторые российские решения и вовсе доступны в рамках господдержки по льготным программам для госучреждений. Таким образом, с точки зрения совокупной стоимости владения (TCO) переход на отечественную виртуализацию может быть выгоден (но может и не быть), особенно с учётом локальной техподдержки и отсутствия валютных рисков.
Подведём коротко плюсы и минусы российских платформ относительно VMware.
Плюсы отечественных решений:
Импортонезависимость и соответствие требованиям. Полное соблюдение требований законодательства РФ для госкомпаний и КИИ (реестр ПО, совместимость с ГОСТ, сертификация ФСТЭК у компонентов).
Локальная поддержка и доработка. Возможность напрямую взаимодействовать с разработчиком, получать кастомные улучшения под свои задачи и быстро исправлять проблемы в сотрудничестве (что практически невозможно с глобальным вендором).
Интеграция с отечественной экосистемой. Совместимость с российскими ОС (Astra, РЕД, ROSA), СУБД, средствами защиты (например, vGate) – упрощает внедрение единого импортозамещённого ландшафта.
Новые технологии под свои нужды. Реализация специфичных возможностей: работа без лицензий NVIDIA (FreeGRID), поддержка гостевых Windows без обращения к зарубежным серверам активации, отсутствие жёсткого вендорлока по железу (любое x86 подходит).
Стоимость и модель владения. Более низкая цена лицензий и поддержки по сравнению с VMware (особенно после удорожания VMware); оплата в рублях, отсутствие риска отключения при санкциях.
Минусы и вызовы:
Меньшая зрелость и удобство. Интерфейсы и процессы менее отточены – администрирование требует больше времени и знаний, некоторые задачи реализованы не так элегантно, больше ручной работы.
Ограниченная экосистема. Не все привычные внешние инструменты совместимы – придется пересматривать решения для бэкапа, мониторинга, а автоматизация требует дополнительных скриптов. Нет огромного сообщества интеграторов по всему миру, как у VMware.
Риски масштабируемости и багов. На больших нагрузках или в сложных сценариях могут всплывать проблемы, которые VMware уже давно решила. Требуется тщательное пилотирование и возможно компромиссы (уменьшить размер кластера, разделить на несколько и др.).
Обучение персонала. ИТ-специалистам, годами работавшим с VMware, нужно переучиваться. Нюансы каждой платформы свои, документация не всегда идеальна, на русском языке материалов меньше, чем англоязычных по VMware.
Отсутствие некоторых enterprise-фишек. Например, у VMware есть многолетние наработки по гибридному облаку, экосистема готовых решений в VMware Marketplace. Российским аналогам предстоит путь создания таких же богатых экосистем.
Таким образом, при функциональном паритете с VMware на бумаге, в практической эксплуатации российские продукты могут требовать больше усилий и доставлять больше проблем. Но этот разрыв постепенно сокращается по мере их развития и накопления опыта внедрений.
Выводы и перспективы импортозамещения VMware
За почти четыре года, прошедшие с ухода VMware, российская индустрия виртуализации совершила огромный рывок. Из десятков появившихся решений постепенно выделился костяк наиболее зрелых и универсальных продуктов, способных заменить VMware vSphere в корпоративных ИТ-инфраструктурах. Как показывают кейсы крупных организаций (банков, промышленных предприятий, госструктур), импортозамещение виртуализации в России – задача выполнимая, хотя и сопряжена с определёнными трудностями. Подводя итоги обзора, можно назвать наиболее перспективные платформы и технологии, на которые сегодня стоит обратить внимание ИТ-директорам:
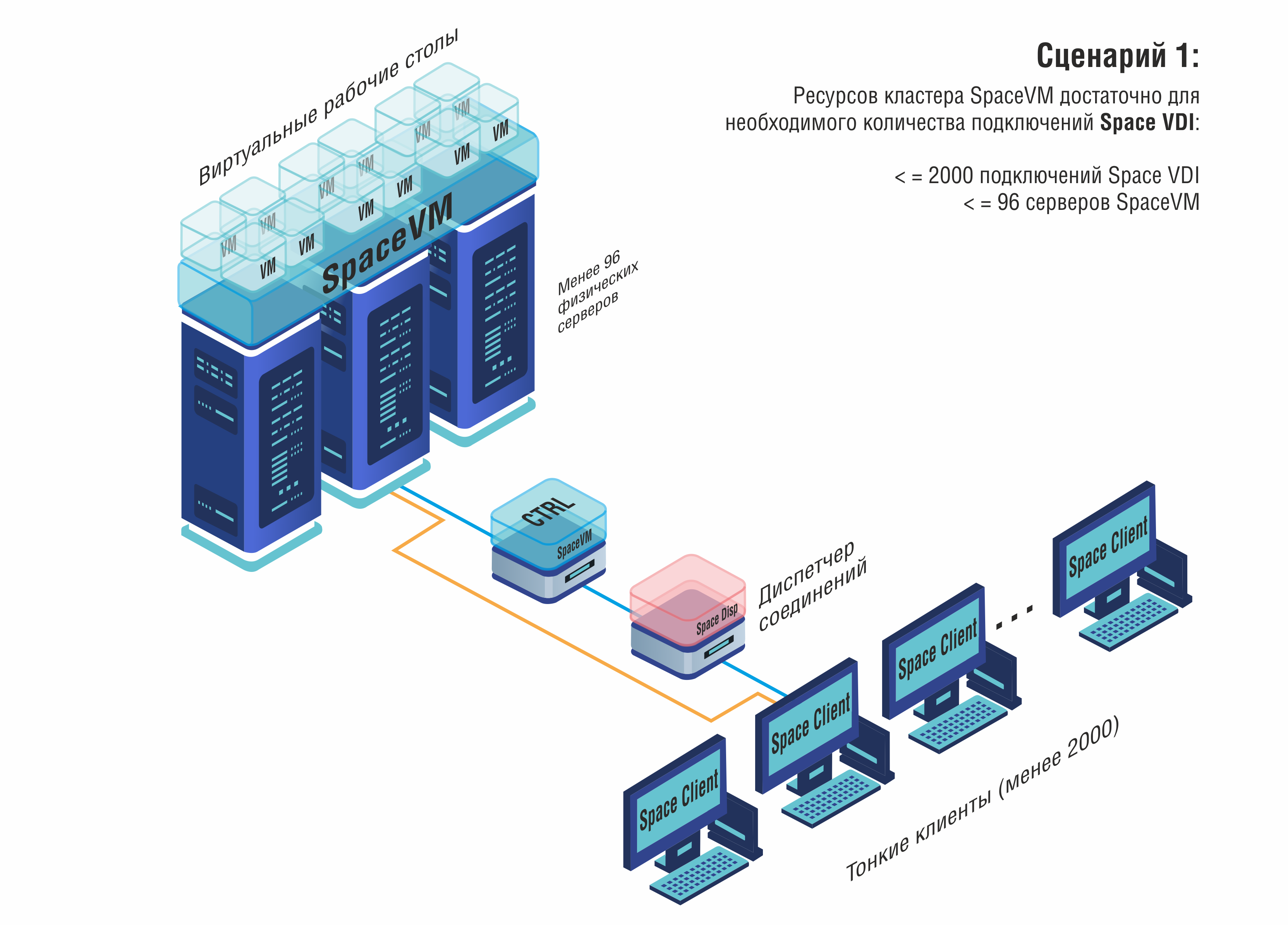
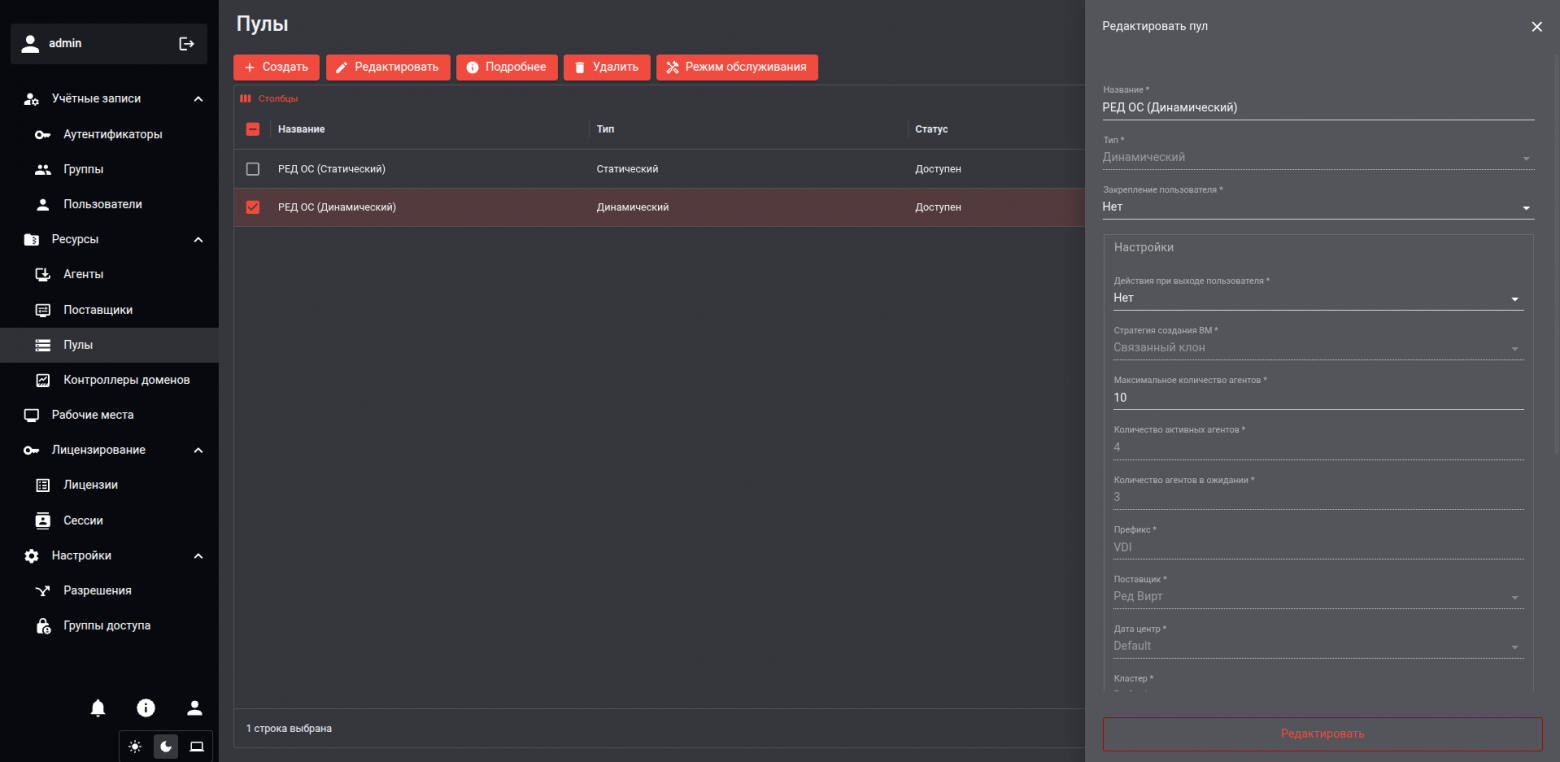
SpaceVM + Space VDI (экоcистема Space) – комплексное решение от компании «ДАКОМ M», которое отличается максимальной полнотой функционала. SpaceVM обеспечивает производительную серверную виртуализацию с собственными технологиями (SDN, FreeGRID), а Space VDI дополняет её средствами виртуализации рабочих мест. Этот тандем особенно хорош для компаний, которым нужны все компоненты "как у VMware" под одним брендом – гипервизор, диспетчеры, клиенты, протоколы. Space активно набирает популярность: 1-е место в рейтингах, успешные внедрения, награды отрасли. Можно ожидать, что он станет одним из столпов корпоративной виртуализации РФ.
Basis Dynamix – продукт компании «Базис», ставший лидером технических рейтингов. Basis привлекает госзаказчиков и большие корпорации, ценящие интегрированный подход: платформа тесно сопряжена с отечественным оборудованием, ОС и имеет собственный центр разработки. Ее козыри – высокая производительность, гибкость (поддержка и классической, и HCI-схем) и готовность к кастомизации под клиента. Basis – хороший выбор для тех, кто строит полностью отечественный программно-аппаратный комплекс, и кому нужна платформа с длительной перспективой развития в России.
zVirt (Orion soft) – одна из самых распространённых на практике платформ, обладающая богатым набором функций и сильным акцентом на безопасность. За счет происхождения от oVirt, zVirt знаком многим по архитектуре, а доработки Orion soft сделали его удобнее и безопаснее (SDN, микросегментация, интеграция с vGate). Крупнейшая инсталляционная база говорит о доверии рынка. Хотя у zVirt есть ограничения по масштабированию, для средних размеров (десятки узлов) он отлично справляется. Это надежный вариант для постепенной миграции с VMware в тех организациях, где ценят проверенные решения и требуются сертификаты ФСТЭК по безопасности.
Red Виртуализация – решение от РЕД СОФТ, важное для госсектора и компаний с экосистемой РЕД ОС. Его выбрал, к примеру, Россельхозбанк для одной из крупнейших миграций в финансовом секторе. Продукт относительно консервативный (форк известного проекта), что можно считать плюсом – меньше сюрпризов, более понятный функционал. Red Virtualization перспективна там, где нужна максимальная совместимость с отечественным ПО (ПО РЕД, СУБД РЕД и пр.) и официальная поддержка на уровне регуляторов.
vStack HCP – хотя и более нишевое решение, но весьма перспективное для тех, кому нужна простота HCI и высочайшая производительность. Отсутствие зависимости от громоздких компонентов (ни Linux, ни Windows – гипервизор на FreeBSD) дает vStack определенные преимущества в легковесности. Его стоит рассматривать в том числе для задач на периферии, в распределенных офисах, где нужна автономная работа без сложной поддержки, или для быстрорастущих облачных сервисов, где горизонтальное масштабирование – ключевой фактор.
HostVM VDI / Veil / Termidesk – в сфере VDI помимо Space VDI, внимания заслуживают и другие разработки. HostVM VDI – как универсальный брокер с множеством протоколов – может подойти интеграторам, строящим сервис VDI для разных платформ. Veil VDI и Termidesk – пока чуть менее известны на рынке, но имеют интересные технологии (например, Termidesk с собственным кодеком TERA). Для компаний, уже использующих решения этих вендоров, логично присмотреться к их VDI для совместимости.
В заключение, можно уверенно сказать: российские продукты виртуализации достигли уровня, при котором ими можно заменить VMware vSphere во многих сценариях. Да, переход потребует усилий – от тестирования до обучения персонала, – но выгоды в виде независимости от внешних факторов, соответствия требованиям законодательства и поддержки со стороны локальных вендоров зачастую перевешивают временные сложности. Российские разработчики продемонстрировали способность быстро закрыть функциональные пробелы и даже внедрить новые инновации под нужды рынка. В ближайшие годы можно ожидать дальнейшего роста качества этих продуктов: уже сейчас виртуализация перестает быть "экзотикой" и становится обыденным, надёжным инструментом в руках отечественных ИТ-специалистов. А значит, корпоративный сектор России получает реальную альтернативу VMware – собственный технологический базис для развития ИТ-инфраструктуры.
В этой части статьи мы продолжаем рассказывать об итогах 2025 года в плане серверной и настольной виртуализации на базе российских решений. Первую часть статьи можно прочитать тут.
Возможности VDI (виртуализации рабочих мест)
Импортозамещение коснулось не только серверной виртуализации, но и инфраструктуры виртуальных рабочих столов (VDI). После ухода VMware Horizon (сейчас это решение Omnissa) и Citrix XenDesktop российские компании начали внедрять отечественные VDI-решения для обеспечения удалённой работы сотрудников и центрального управления рабочими станциями. К 2025 году сформировался пул новых продуктов, позволяющих развернуть полнофункциональную VDI-платформу на базе отечественных технологий.
Лидерами рынка VDI стали решения, созданные в тесной связке с платформами серверной виртуализации. Так, компания «ДАКОМ М» (бренд Space) помимо гипервизора SpaceVM предложила продукт Space VDI – систему управления виртуальными рабочими столами, интегрированную в их экосистему. Space VDI заняла 1-е место в рейтинге российских VDI-решений 2025 г., набрав 228 баллов по совокупности критериев.
Её сильные стороны – полностью собственная разработка брокера и агентов (не опирающаяся на чужие open-source) и наличие всех компонентов, аналогичных VMware Horizon: Space Dispatcher (диспетчер VDI, альтернатива Horizon Connection Server), Space Agent VDI (клиентский агент на виртуальной машине, аналог VMware Horizon Agent), Space Client для подключения с пользовательских устройств, и собственный протокол удалённых рабочих столов GLINT. Протокол GLINT разработан как замена зарубежных (RDP/PCoIP), оптимизирован для работы в российских сетях и обеспечивает сжатие/шифрование трафика. В частности, заявляется поддержка мультимедиа-ускорения и USB-перенаправления через модуль Mediapipe, который служит аналогом Citrix HDX. В результате Space VDI предоставляет высокую производительность графического интерфейса и мультимедиа, сравнимую с мировыми аналогами, при этом полностью вписывается в отечественный контур безопасности.
Вторым крупным игроком стала компания HOSTVM с продуктом HostVM VDI. Этот продукт изначально основыван на открытой платформе UDS (VirtualCable) и веб-интерфейсе на Angular, но адаптирован российским разработчиком. HostVM VDI поддерживает широкий набор протоколов – SPICE, RDP, VNC, NX, PCoIP, X2Go, HTML5 – фактически покрывая все популярные способы удалённого доступа. Такая всеядность упрощает миграцию с иностранных систем: например, если ранее использовался протокол PCoIP (как в VMware Horizon), HostVM VDI тоже его поддерживает. Решение заняло 2-е место в отраслевом рейтинге с 218 баллами, немного уступив Space VDI по глубине интеграции функций.
Своеобразный подход продемонстрировал РЕД СОФТ. Их продукт «РЕД Виртуализация» является, в первую очередь, серверной платформой (форком oVirt на KVM) для развертывания ВМ. Однако благодаря тесной интеграции с РЕД ОС и другим ПО компании, Red Виртуализация может использоваться и для VDI-сценариев. Она заняла 3-е место в рейтинге VDI-платформ. По сути, РЕД предлагает создать инфраструктуру на базе своего гипервизора и доставлять пользователям рабочие столы через стандартные протоколы (для Windows-ВМ – RDP, для Linux – SPICE или VNC). В частности, поддерживаются протоколы VNC, SPICE и RDP, что покрывает базовые потребности. Кроме того, заявлена возможность миграции виртуальных машин в РЕД Виртуализацию прямо из сред VMware vSphere и Microsoft Hyper-V, что упрощает переход на решение.
Далее, существуют специализированные отечественные VDI-продукты: ROSA VDI, Veil VDI, Termidesk и др.
ROSA VDI (разработка НТЦ ИТ РОСА) базируется на том же oVirt и ориентирована на интеграцию с российскими ОС РОСА.
Veil VDI – решение компаний «НИИ Масштаб»/Uveon – представляет собственную разработку брокера виртуальных рабочих столов; оно также попало в топ-5 рейтинга.
Termidesk – ещё одна проприетарная система, замыкающая первую шестёрку лидеров. Каждая из них предлагает конкурентоспособные функции, хотя по некоторым пунктам уступает лидерам. Например, Veil VDI и Termidesk пока набрали меньше баллов (182 и 174 соответственно) и, вероятно, имеют более узкую специализацию или меньшую базу внедрений.
Общей чертой российских VDI-платформ является ориентация на безопасность и импортозамещение. Все они зарегистрированы как отечественное ПО и могут применяться вместо VMware Horizon, Citrix или Microsoft RDS. С точки зрения пользовательского опыта, основные функции реализованы: пользователи могут подключаться к своим виртуальным рабочим столам с любых устройств (ПК, тонкие клиенты, планшеты) через удобные клиенты или даже браузер. Администраторы получают централизованную консоль для создания образов ВМ, массового обновления ПО на виртуальных рабочих столах и мониторинга активности пользователей. Многие решения интегрируются с инфраструктурой виртуализации серверов – например, Space VDI напрямую работает поверх гипервизора SpaceVM, ROSA VDI – поверх ROSA Virtualization, что упрощает установку.
Отдельно стоит отметить поддержку мультимедийных протоколов и оптимизацию трафика. Поскольку качество работы VDI сильно зависит от протокола передачи картинки, разработчики добавляют собственные улучшения. Мы уже упомянули GLINT (Space) и широкий набор протоколов в HostVM. Также используется протокол Loudplay – это отечественная разработка в области облачного гейминга, адаптированная под VDI.
Некоторые платформы (например, Space VDI, ROSA VDI, Termidesk) заявляют поддержку Loudplay наряду со SPICE/RDP, чтобы обеспечить плавную передачу видео и 3D-графики даже в сетях с высокой задержкой. Терминальные протоколы оптимизированы под российские условия: так, Termidesk применяет собственный кодек TERA для сжатия видео и звука. В результате пользователи могут комфортно работать с графическими приложениями, CAD-системами и видео в своих виртуальных десктопах.
С точки зрения масштабируемости VDI, российские решения способны обслуживать от десятков до нескольких тысяч одновременных пользователей. Лабораторные испытания показывают, что Space VDI и HostVM VDI могут управлять тысячами виртуальных рабочих столов в распределенной инфраструктуре (с добавлением необходимых серверных мощностей). Важным моментом остаётся интеграция со средствами обеспечения безопасности: многие платформы поддерживают подключение СЗИ для контроля за пользователями (DLP-системы, антивирусы на виртуальных рабочих местах) и могут работать в замкнутых контурах без доступа в интернет.
Таким образом, к концу 2025 года отечественные VDI-платформы покрывают основные потребности удалённой работы. Они позволяют централизованно развертывать и обновлять рабочие места, сохранять данные в защищённом контуре датацентра и предоставлять сотрудникам доступ к нужным приложениям из любой точки. При этом особый акцент сделан на совместимость с российским стеком (ОС, ПО, требования регуляторов) и на возможность миграции с западных систем с минимальными затратами (поддержка разных протоколов, перенос ВМ из VMware/Hyper-V). Конечно, каждой организации предстоит выбрать оптимальный продукт под свои задачи – лидеры рынка (Space VDI, HostVM, Red/ROSA) уже имеют успешные внедрения, тогда как нишевые решения могут подойти под специальные сценарии.
Кластеризация, отказоустойчивость и управление ресурсами
Функциональность, связанная с обеспечением высокой доступности (HA) и отказоустойчивости, а также удобством управления ресурсами, является критичной при сравнении платформ виртуализации. Рассмотрим, как обстоят дела с этими возможностями у российских продуктов по сравнению с VMware vSphere.
Кластеризация и высокая доступность (HA)
Почти все отечественные системы поддерживают объединение хостов в кластеры и автоматический перезапуск ВМ на доступных узлах в случае сбоя одного из серверов – аналог функции VMware HA. Например, SpaceVM имеет встроенную поддержку High Availability для кластеров: при падении хоста его виртуальные машины автоматически запускаются на других узлах кластера.
Basis Dynamix, VMmanager, Red Virtualization – все они также включают механизмы мониторинга узлов и перезапуска ВМ при отказе, что отражено в их спецификациях (наличие HA подтверждалось анкетами рейтингов). По сути, обеспечение базовой отказоустойчивости сейчас является стандартной функцией для любых платформ виртуализации. Важно отметить, что для корректной работы HA требуется резерв мощности в кластере (чтобы были свободные ресурсы для поднятия упавших нагрузок), поэтому администраторы должны планировать кластеры с некоторым запасом хостов, аналогично VMware.
Fault Tolerance (FT)
Более продвинутый режим отказоустойчивости – Fault Tolerance, при котором одна ВМ дублируется на другом хосте в режиме реального времени (две копии работают синхронно, и при сбое одной – вторая продолжает работать без прерывания сервиса). В VMware FT реализован для критичных нагрузок, но накладывает ограничения (например, количество vCPU). В российских решениях прямая аналогия FT практически не встречается. Тем не менее, некоторые разработчики заявляют поддержку подобных механизмов. В частности, Basis Dynamix Enterprise в материалах указывал наличие функции Fault Tolerance. Однако широкого распространения FT не получила – эта технология сложна в реализации, а также требовательна к каналам связи. Обычно достаточен более простой подход (HA с быстрым перезапуском, кластерные приложения на уровне ОС и т.п.). В критических сценариях (банковские системы реального времени и др.) могут быть построены решения с FT на базе метрокластеров, но это скорее штучные проекты.
Снапшоты и резервное копирование
Снимки состояния ВМ (snapshots) – необходимая функция для безопасных изменений и откатов. Все современные платформы (zVirt, SpaceVM, Red и прочие) поддерживают создание мгновенных снапшотов ВМ в рабочем состоянии. Как правило, доступны возможности делать цепочки снимков, однако требования к хранению диктуют, что постоянно держать много снапшотов нежелательно (как и в VMware, где они влияют на производительность). Для резервного копирования обычно предлагается интеграция с внешними системами бэкапа либо встроенные средства экспорта ВМ.
Например, SpaceVM имеет встроенное резервное копирование ВМ с возможностью сохранения бэкапов на удалённое хранилище. VMmanager от ISPsystem также предоставляет модуль бэкапа. Тем не менее, организации часто используют сторонние системы резервирования – здесь важно, что у российских гипервизоров обычно открыт API для интеграции. Почти все продукты предоставляют REST API или SDK, позволяющий автоматизировать задачи бэкапа, мониторинга и пр. Отдельные вендоры (например, Basis) декларируют принцип API-first, что упрощает связку с оркестраторами резервного копирования и мониторинга.
Управление ресурсами и балансировка
Мы уже упоминали наличие аналогов DRS в некоторых платформах (автоматическое перераспределение ВМ). Кроме этого, важно, как реализовано ручное управление ресурсами: пулы CPU/памяти, приоритеты, квоты. В VMware vSphere есть ресурсные пулы и shares-приоритеты. В российских системах подобные механизмы тоже появляются. zVirt, например, позволяет объединять хосты в логические группы и задавать политику размещения ВМ, что помогает распределять нагрузку. Red Virtualization (oVirt) исторически поддерживает задание весов и ограничений на ЦП и ОЗУ для групп виртуальных машин. В Basis Dynamix управление ресурсами интегрировано с IaC-инструментами – можно через Terraform описывать необходимые ресурсы, а платформа сама их выделит.
Такое тесное сочетание с DevOps-подходами – одно из преимуществ новых продуктов: Basis и SpaceVM интегрируются с Ansible, Terraform для автоматического развертывания инфраструктуры как кода. Это позволяет компаниям гибко управлять ИТ-ресурсами и быстро масштабировать кластеры или развертывать новые ВМ по шаблонам.
Управление кластерами
Центральная консоль управления кластером – обязательный компонент. Аналог VMware vCenter в отечественных решениях присутствует везде, хотя может называться по-разному. Например, у Space – SpaceVM Controller (он же выполняет роль менеджера кластера, аналог vCenter). У zVirt – собственная веб-консоль, у Red Virtualization – знакомый интерфейс oVirt Engine, у VMmanager – веб-панель от ISPsystem. То есть любой выбранный продукт предоставляет единый интерфейс для управления всеми узлами, ВМ и ресурсами. Многие консоли русифицированы и достаточно дружелюбны. Однако по отзывам специалистов, удобство администрирования ещё требует улучшений: отмечается, что ряд операций в отечественных платформах более трудоёмкие или требуют «танцев с бубном» по сравнению с отлаженным UI VMware. Например, на Хабре приводился пример, что создание простой ВМ в некоторых системах превращается в квест с редактированием конфигурационных файлов и чтением документации, тогда как в VMware это несколько кликов мастера создания ВМ. Это как раз то направление, где нашим решениям ещё есть куда расти – UX и простота администрирования.
В плане кластеризации и отказоустойчивости можно заключить, что функционально российские платформы предоставляют почти весь минимально необходимый набор возможностей. Кластеры, миграция ВМ, HA, снапшоты, бэкап, распределенная сеть, интеграция со сториджами – всё это реализовано (см. сводную таблицу ниже). Тем не менее, зрелость реализации зачастую ниже: возможны нюансы при очень крупных масштабах, не все функции могут быть такими же «отполированными» как у VMware, а администрирование требует большей квалификации.
Платформа
Разработчик
Технологическая основа
Особенности архитектуры
Ключевые сильные стороны
Известные ограничения
Basis Dynamix
БАЗИС
Собственная разработка (KVM-совместима)
Классическая и гибридная архитектура (есть Standard и Enterprise варианты)
Высокая производительность, интеграция с Ansible/Terraform, единая экосистема (репозиторий, поддержка); востребован в госсекторе.
Мало публичной информации о тонкостях; относительно новый продукт, требует настройки под задачу.
SpaceVM
ДАКОМ M (Space)
Проприетарная (собственный стек гипервизора)
Классическая архитектура, интеграция с внешними СХД + проприетарные HCI-компоненты (FreeGRID, SDN Flow)
Максимально функциональная платформа: GPU-виртуализация (FreeGRID), своя SDN (аналог NSX), полный VDI-комплекс (Space VDI) и собственные протоколы; высокое быстродействие.
Более сложное администрирование (богатство функций = сложность настроек).
zVirt
Orion soft
Форк oVirt (KVM) + собственный бэкенд
Классическая модель, SDN-сеть внутри (distributed vSwitch)
Богатый набор функций: микросегментация сети SDN, Storage Live Migration, авто-балансировка ресурсов (DRS-аналог), совместим с открытой экосистемой oVirt; крупнейшая инсталляционная база (21k+ хостов ожидается).
Проблемы масштабируемости на очень больших кластерах (>50 узлов); интерфейс менее удобен, чем VMware (выше порог входа).
Red Виртуализация
РЕД СОФТ
Форк oVirt (KVM)
Классическая схема, тесная интеграция с РЕД OS и ПО РЕД СОФТ
Знакомая VMware-подобная архитектура; из коробки многие функции (SAN, HA и др.); сертификация ФСТЭК РЕД ОС дает базу для безопасности; успешные кейсы миграции (Росельхозбанк, др.).
Более ограниченная экосистема поддержки (сильно завязана на продукты РЕД); обновления зависят от развития форка oVirt (нужны ресурсы на самостоятельную разработку).
vStack HCP
vStack (Россия)
FreeBSD + bhyve (HCI-платформа)
Гиперконвергентная архитектура, собственный легковесный гипервизор
Минимальные накладные расходы (2–5% CPU), масштабируемость «без ограничений» (нет фикс. лимитов на узлы/ВМ), единый веб-интерфейс; независим от Linux.
Относительно новая/экзотичная технология (FreeBSD), сообщество меньше; возможно меньше совместимых сторонних инструментов (бэкап, драйверы).
Cyber Infrastructure
Киберпротект
OpenStack + собственные улучшения (HCI)
Гиперконвергенция (Ceph-хранилище), поддержка внешних СХД
Глубокая интеграция с резервным копированием (наследие Acronis), сертификация ФСТЭК AccentOS (OpenStack), масштабируемость для облаков; работает на отечественном оборудовании.
Менее подходит для нагрузок, требующих стабильности отдельной ВМ (особенности OpenStack); сложнее в установке и сопровождении без экспертизы OpenStack.
Другие (ROSA, Numa, HostVM)
НТЦ ИТ РОСА, Нума Техн., HostVM
KVM (oVirt), Xen (xcp-ng), KVM+UDS и др.
В основном классические, частично HCI
Закрывают узкие ниши или предлагают привычный функционал для своих аудиторий (например, Xen для любителей XenServer, ROSA для Linux-инфраструктур). Часто совместимы с специфическими отечественными ОС (ROSA, ALT).
Как правило, менее функционально богаты (ниже баллы рейтингов); меньшая команда разработки = более медленное развитие.
«Альт Виртуализация» — это российское решение для построения и управления виртуальной инфраструктурой. Недавно вышедший релиз Альт Виртуализации версии 11.0 базируется на Proxmox VE 8.4 и предлагает унифицированный способ работы с виртуальными машинами (KVM/QEMU) и контейнерами (LXC) через веб-интерфейс, CLI и API. Поддерживаются архитектуры x86_64 и AArch64. Продукт включён в Реестр отечественного ПО Минцифры (рег.№ 6487) и выпускается в редакционном формате: сейчас доступна только PVE-версия, облачная готовится.
Основная функциональность продукта
1. Виртуализация серверов:
Полноценная аппаратная виртуализация под KVM/QEMU.
Лёгкие контейнеры LXC с поддержкой cgroups/namespaces.
2. Кластеризация и HA – обновлённая кластерная файловая система (pmxcfs), живая миграция, механизмы высокой доступности.
3. Сетевая инфраструктура – Linux bridge, Open vSwitch, VLAN, bonding, а теперь SDN с поддержкой VXLAN, QinQ и виртуальных сетей (VNets).
4. Хранилища – поддержка локальных (LVM, ZFS) и сетевых хранилищ (NFS, iSCSI, Ceph, GlusterFS и др.).
5. Резервное копирование – встроенные средства + интеграция с Proxmox Backup Server 3.3.
6. Безопасность и аутентификация – механизм ролевого доступа RBAC, поддержка PAM, LDAP, MS AD/Samba DC, OpenID Connect; OpenSSL 3.3 обеспечивает повышенную безопасность.
7. Поддержка GPU/PCI passthrough – возможность напрямую передавать устройства в ВМ.
8. Интеграция и API – единый Web GUI, CLI (с автодополнением), RESTful API на JSON для внешних интеграций.
Новшества в версии Альт Виртуализация 11.0
1. Улучшенный установщик
Быстрая установка с выбором файловых систем Ext4 или Btrfs (RAID 0/1/10), автоматическим созданием LVM-thin.
Интегрированный сетевой раздел с поддержкой VLAN, автоматическим мостом vmbr0, DNS и доменами.
2. SDN-подсистема
Полная поддержка SDN: создание виртуальных сетевых зон, сегментаций, изоляции, VNets и управление трафиком.
3. Графический апдейт
Из веб-интерфейса можно подключать и отключать репозитории, обновлять систему и пакеты без CLI.
4. Упрощённая архитектура
Контейнеризация на базе Kubernetes, Docker, CRI-O, Podman вынесена в «Альт Сервер 11.0», что позволило повысить стабильность и упрощённость PVE-системы.
Для виртуализации остался только LXC.
5. Импорт из VMware ESXi
Новый инструмент упрощает миграцию: импортирует VMDK + конфигурации сети и дисков напрямую из ESXi.
6. Обновление компонентов
Основные версии: PVE 8.4, LXC 6.0, QEMU 9.2, Ceph 19.2, Open vSwitch 3.3, Corosync 3.1, ZFS 2.3, OpenSSL 3.3.
Зачем всё это нужно
Быстрая и простая установка снижает порог входа и риски ошибок.
SDN-поддержка позволяет строить сложную и безопасную сетевую инфраструктуру без стороннего ПО.
Гибкое обновление через GUI упрощает эксплуатацию.
Упрощённая среда без лишних контейнерных инструментов — более надёжна и менее уязвима.
Прямая миграция с VMware облегчает переход на отечественные решения.
Современные компоненты поднимают производительность, безопасность и совместимость.
Заключение
«Альт Виртуализация 11.0» — важный шаг вперёд для российской виртуализации. Упрощённая установка, расширенные сетевые возможности, интеграция с системами резервного копирования и удобное обновление делают платформу достойным решением для корпоративного уровня. Первоначальный фокус на PVE-редакции с дальнейшим выходом облачной версии обеспечит гибкость и масштабируемость.
В условиях ухода западных вендоров с российского рынка и активного импортозамещения, спрос на отечественные платформы виртуализации значительно вырос. Одним из наиболее ярких и амбициозных проектов в этой области является «Иридиум», решение компании РТ-Иридиум, предназначенное для построения отказоустойчивой и масштабируемой виртуальной инфраструктуры. В июле 2025 года был представлен релиз «Иридиум» 2.0, вобравший в себя широкий набор корпоративных функций.
Архитектура и технологическая база
Платформа «Иридиум» построена на базе гипервизора KVM/QEMU — проверенного временем решения с открытым исходным кодом, которое активно используется и в других коммерческих продуктах (в том числе в ROSA Virtualization и Proxmox). Использование KVM обеспечивает высокую производительность, гибкость, поддержку современных функций виртуализации, а также совместимость с отечественным оборудованием.
Компоненты архитектуры «Иридиум»:
Гипервизор: KVM (работает на Linux, взаимодействует с аппаратной виртуализацией через Intel VT-x/AMD-V).
Управляющая панель: web-интерфейс с ролью диспетчера и оркестратора (аналог vCenter).
VSAN-подобное хранилище: поддержка отказоустойчивого кластера хранения.
Система управления пользователями и политиками безопасности (в том числе LDAP, SSO).
Интеграция с Docker-контейнерами — что делает платформу применимой не только для ВМ, но и для микросервисных архитектур.
Кластеры высокой доступности — объединение до 64 физических узлов с горячей миграцией и автоматическим восстановлением ВМ.
Новые возможности в версии 2.0
Релиз «Иридиум» 2.0 вывел продукт на уровень зрелого корпоративного решения. В числе ключевых новшеств:
HA-кластеры (High Availability) — автоматическое восстановление ВМ при сбое узла.
Горячая и холодная миграция виртуальных машин между узлами.
Встроенное резервное копирование и восстановление.
Поддержка VDI-сценариев (виртуальных рабочих столов).
Контроль доступа и кросс-доменная авторизация.
Новая панель мониторинга с метриками и журналами аудита.
Совместимость с российскими серверами (например, RDW Computers), включая проверку отказоустойчивости.
Сравнение с конкурентами
Характеристика
Иридиум 2.0
ROSA Virtualization
VMware vSphere
Основа гипервизора
KVM/QEMU
KVM/QEMU
Собственный гипервизор ESXi
Интерфейс управления
Web UI, REST API
Web UI (на базе Cockpit)
vCenter
Горячая миграция ВМ
Да
Да
Да
Кластеры высокой доступности
Да
Ограниченно (в Enterprise)
Да (через vSphere HA)
Поддержка VDI
Да
Нет (только через сторонние решения)
Да (через Omnissa)
Репликация и бэкапы
Встроенные
Через сторонние решения
Через Veeam, vSphere Replication
Сертификация ФСТЭК
В процессе получения
Есть (у отдельных сборок)
Нет (нерелевантно для РФ после ухода)
Docker/контейнеры
Да (встроено)
Частично (в экспериментальных сборках)
Через Tanzu (Kubernetes)
Импортозамещение/локализация
Отечественная сборка на базе Open Source
Отечественная сборка на базе Open Source
Нет (не поддерживается в РФ)
Заключение
С выходом версии 2.0 платформа «Иридиум» совершила качественный скачок, превратившись в конкурентоспособную альтернативу западным решениям уровня VMware. Поддержка кластеров высокой доступности, встроенное резервное копирование, интерфейс управления и интеграция с VDI делают продукт особенно привлекательным для корпоративных клиентов, органов власти и критически важных объектов инфраструктуры.
Благодаря открытому гипервизору KVM, российской разработке, масштабируемости и активной интеграции с отечественным «железом», «Иридиум» становится не просто ответом на уход VMware, но полноценным участником новой экосистемы российских ИТ-решений.
ROSA Virtualization — это отечественная платформа для управления виртуальной серверной инфраструктурой, разработанная АО «НТЦ ИТ РОСА». Она построена на базе открытого программного обеспечения (KVM, libvirt и др.) и предназначена для развёртывания отказоустойчивых, масштабируемых и защищённых виртуализованных сред.
Основные функции платформы:
Создание и управление виртуальными машинами
Настройка виртуальных сетей и хранилищ
Кластеры высокой доступности (HA)
Живая миграция ВМ между хостами
Резервное копирование и восстановление
Централизованное управление через веб-интерфейс
Поддержка требований по безопасности и соответствие ГОСТ
Сертификация для использования в госорганах
Главные изменения ROSA Virtualization 3.1 (релиз 27 мая 2025 года)
1. Отказ от CLI — весь функционал в GUI
Теперь все операции, включая настройку LDAP, шифрование дисков и управление пользователями, доступны через единый графический интерфейс. CLI используется только в самых экстренных случаях.
2. Поддержка Ceph
Включение интеграции с распределённым хранилищем Ceph позволило значительно повысить отказоустойчивость, масштабируемость и надёжность платформы.
3. Живая миграция ВМ и автозапуск
Поддерживается безостановочная миграция виртуальных машин между кластерами. Кроме того, при корректной перезагрузке хоста ВМ теперь автоматически запускаются после восстановления.
4. Сеть, визуализация и резервное копирование
Добавлена визуализация сетевой схемы, мастер настройки NFS, улучшен интерфейс бэкапов (включительно поддержка СУСВ через веб), а также адаптация событий под требования ГОСТ.
5. Интеграция с Loudplay и безопасность
Нововведения включают поддержку Loudplay (протокол для передачи консольных данных) и адаптацию событийной логики в соответствии с ГОСТ-стандартами.
6. Лицензирование и сертификация
Платформа доступна по одной из двух моделей лицензирования: либо по числу виртуальных машин, либо по числу хостов. В комплект входит год технической поддержки, включая версию сертифицированную ФСТЭК.
Почему это важно
Упрощение управления: привычные интерфейсы GUI значительно снижают порог входа для операторов и системных администраторов.
Надёжность и масштабируемость: интеграция с Ceph обеспечивает отказоустойчивую, распределённую архитектуру хранения.
Бесшовность и доступность: живая миграция и автозапуск ВМ минимизируют время простоя.
Безопасность и соответствие: ГОСТ-адаптация и сертификация ФСТЭК делают решение готовым к внедрению в государственных структурах и критически важной инфраструктуре.
Кому подойдёт ROSA Virtualization 3.1
Организациям госсектора и тем, кто выполняет требования по импортозамещению и ГОСТ-сертификации.
Компаниям, нуждающимся в простом и визуальном администрировании виртуальной инфраструктуры.
Телеком-операторам, дата-центрам и частным компаниям, которым важна отказоустойчивость и масштабируемость.
ROSA Virtualization 3.1 — зрелое отечественное решение для виртуализации, сочетающее:
Простоту и удобство графического интерфейса
Корпоративную надёжность благодаря Ceph и живой миграции
Соответствие государственным стандартам безопасности.
Платформа отлично подходит для предприятий и госструктур, где нужна надёжная, масштабируемая и управляемая виртуальная инфраструктура отечественного производства.
По умолчанию скорость соединения (link speed) адаптера vmxnet3 виртуальной машины устанавливается как 10 Гбит/с. Это применяемое по умолчанию отображаемое значение в гостевой ОС для соединений с любой скоростью. Реальная скорость будет зависеть от используемого вами оборудования (сетевой карты).
VMXNET 3 — это паравиртуализированный сетевой адаптер, разработанный для обеспечения высокой производительности. Он включает в себя все функции, доступные в VMXNET 2, и добавляет несколько новых возможностей, таких как поддержка нескольких очередей (также известная как Receive Side Scaling в Windows), аппаратное ускорение IPv6 и доставка прерываний с использованием MSI/MSI-X. VMXNET 3 не связан с VMXNET или VMXNET 2.
Если вы выведите свойства соединения на адаптере, то получите вот такую картину:
В статье Broadcom KB 368812 рассказывается о том, как с помощью расширенных настроек виртуальной машины можно установить корректную скорость соединения. Для этого выключаем ВМ, идем в Edit Settings и на вкладке Advanced Parameters добавляем нужное значение:
ethernet0.linkspeed 20000
Также вы можете сделать то же самое, просто добавив в vmx-файл виртуальной машины строчку ethernetX.linkspeed = "ХХХ".
При этом учитывайте следующие моменты:
Начиная с vSphere 8.0.2 и выше, vmxnet3 поддерживает скорость соединения в диапазоне от 10 Гбит/с до 65 Гбит/с.
Значение скорости по умолчанию — 10 Гбит/с.
Если вами указано значение скорости меньше 10000, то оно автоматически устанавливается в 10 Гбит/с.
Если вами указано значение больше 65000, скорость также будет установлена по умолчанию — 10 Гбит/с.
Важно отметить, что это изменение касается виртуального сетевого адаптера внутри гостевой операционной системы виртуальной машины и не влияет на фактическую скорость сети, которая всё равно будет ограничена физическим оборудованием (процессором хоста, физическими сетевыми картами и т.д.).
Это изменение предназначено для обхода ограничений на уровне операционной системы или приложений, которые могут возникать из-за того, что адаптер vmxnet3 по умолчанию определяется со скоростью 10 Гбит/с.
В видеоролике ниже рассматривается то, как включить Virtualization-Based Security (VBS) в гостевых операционных системах Windows, работающих в среде VMware Cloud Foundation и vSphere:
Что такое Virtualization-Based Security (VBS)?
VBS — это технология безопасности от Microsoft, использующая возможности аппаратной виртуализации и изоляции для создания защищённой области памяти. Она используется для защиты критически важных компонентов операционной системы, таких как Credential Guard и Device Guard.
Предварительные требования
Перед тем как включить VBS, необходимо убедиться в выполнении следующих условий:
Active Directory Domain Controller
Необходим для настройки групповой политики. В демонстрации он уже создан, но пока выключен.
Загрузка через UEFI (EFI)
Виртуальная машина должна использовать загрузку через UEFI, а не через BIOS (legacy mode).
Secure Boot
Желательно включить Secure Boot — это обеспечивает дополнительную защиту от вредоносных программ на стадии загрузки.
Модуль TPM (Trusted Platform Module)
Не обязателен, но настоятельно рекомендуется. Большинство руководств по безопасности требуют его наличия.
Настройка VBS в VMware
Перейдите к параметрам виртуальной машины в Edit Settings.
Убедитесь, что:
Используется UEFI и включен Secure Boot.
Включена опция "Virtualization-based security" в VM Options.
Виртуализация ввода-вывода (IO MMU) и аппаратная виртуализация будут активированы после перезагрузки.
Важно: Если переключаться с legacy BIOS на EFI, ОС может перестать загружаться — будьте осторожны.
Настройка VBS внутри Windows
После включения параметров на уровне гипервизора нужно активировать VBS в самой Windows:
Turn on Virtualization Based Security – активировать.
Secure Boot and DMA Protection – да.
Virtualization-based protection of Code Integrity – включить с UEFI Lock.
Credential Guard – включить.
Secure Launch Configuration – включить.
Примечание: Если вы настраиваете контроллер домена, обратите внимание, что Credential Guard не защищает базу данных AD, но защищает остальную ОС.
Перезагрузите виртуальную машину.
Проверка работоспособности VBS
После перезагрузки:
Откройте System Information и убедитесь, что:
Virtualization Based Security включена.
MA Protection работает.
redential Guard активен.
В Windows Security проверьте:
Включена ли Memory Integrity.
Активна ли защита от вмешательства (Tamper Protection).
Заключение
Теперь у вас есть полностью защищённая Windows-гостевая ОС с включённой Virtualization-Based Security, Credential Guard и другими функциями. Это отличный способ повысить уровень безопасности в вашей инфраструктуре VMware.
Для получения дополнительной информации смотрите ссылки под видео.
Таги: VMware, vSphere, Security, VMachines, Windows
Пару лет назад Дункан Эппинг писал о функции Witness Resilience - это функция повышения устойчивости к сбоям свидетеля (Witness Failure Resilience) в конфигурациях растянутых кластеров vSAN 7.0 Update 3 (stretched clusters). Эта функция направлена на обеспечение доступности виртуальных машин даже при одновременном выходе из строя одного из дата-центров и узла-свидетеля (Witness). Мы ее детально описывали вот тут.
В традиционной конфигурации растянутого кластера данные реплицируются между двумя сайтами, а узел-свидетель размещается в третьей локации для обеспечения кворума. При отказе одного из сайтов кворум сохраняется за счет оставшегося сайта и узла-свидетеля. Однако, если после этого выходит из строя узел-свидетель, оставшийся сайт терял кворум, что приводило к недоступности машин.
С введением функции устойчивости к сбоям свидетеля в vSAN 7.0 Update 3, при отказе одного из сайтов система автоматически перераспределяет голоса (votes) компонентов данных. Компоненты на оставшемся сайте получают дополнительные голоса, а голоса компонентов на узле-свидетеле — уменьшаются. Это означает, что если после отказа сайта выходит из строя и узел-свидетель, оставшийся сайт все еще имеет достаточное количество голосов для поддержания кворума и обеспечения доступности ВМ.
Важно отметить, что процесс перераспределения голосов занимает некоторое время (обычно около 3 минут), в течение которого система адаптируется к новой конфигурации. После восстановления отказавшего сайта и узла-свидетеля система возвращает исходное распределение голосов для нормальной работы.
Таким образом, функция устойчивости к сбоям свидетеля значительно повышает надежность и отказоустойчивость растянутых кластеров, позволяя ВМ оставаться доступными даже при одновременном отказе одного из сайтов и узла-свидетеля.
Недавно Дункан снова поднял тонкий вопрос на эту тему. Он провёл несколько тестов и решил написать продолжение прошлой статьи. В данном случае мы говорим о конфигурации с двумя узлами, но это также применимо и к растянутому кластеру (stretched cluster).
В случае растянутого кластера или конфигурации с двумя узлами, когда сайт с данными выходит из строя (или переводится в режим обслуживания), автоматически выполняется перерасчёт голосов для каждого объекта/компонента. Это необходимо для того, чтобы при последующем выходе из строя Witness объекты/виртуальные машины оставались доступными.
А что если сначала выйдет из строя Witness, а только потом сайт с данными?
Это объяснить довольно просто — в таком случае виртуальные машины станут недоступными. Почему? Потому что в этом сценарии перерасчёт голосов уже не выполняется. Конечно же, он протестировал это, и ниже представлены скриншоты, которые это подтверждают.
На этом скриншоте показано, что Witness отсутствует (Absent), и оба компонента с данными имеют по одному голосу. Это значит, что если один из хостов выйдет из строя, соответствующий компонент станет недоступным. Давайте теперь отключим один из хостов и посмотрим, что покажет интерфейс.
Как видно на скриншоте ниже, виртуальная машина теперь недоступна. Это произошло из-за того, что больше нет кворума — 2 из 3 голосов недействительны:
Это говорит нам о том, что нужно обязательно следить за доступностью хоста Witness, который очень важен для контроля кворума кластера.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
В прошлом году Вильям Лам продемонстрировал метод настройки строки железа SMBIOS с использованием Nested ESXi, но решение было далеко от идеала: оно требовало модификации ROM-файла виртуальной машины и ограничивалось использованием BIOS-прошивки для машины Nested ESXi, в то время как поведение с EFI-прошивкой отличалось.
В конце прошлого года Вильям проводил исследования и наткнулся на гораздо более изящное решение, которое работает как для физического, так и для виртуального ESXi. Существует параметр ядра ESXi, который можно переключить, чтобы просто игнорировать стандартный SMBIOS оборудования, а затем эмулировать собственную пользовательскую информацию SMBIOS.
Шаг 1 – Подключитесь по SSH к вашему ESXi-хосту, отредактируйте файл конфигурации /bootbank/boot.cfg и добавьте ignoreHwSMBIOSInfo=TRUE в строку kernelopt, после чего перезагрузите систему.
Шаг 2 – Далее нам нужно выполнить команду vsish, чтобы настроить желаемую информацию SMBIOS. Однако, вместо того чтобы заставлять пользователей вручную создавать команду, Вильям создал простую функцию PowerShell, которая сделает процесс более удобным.
Сохраните или выполните приведенный ниже фрагмент PowerShell-кода, который определяет новую функцию Generate-CustomESXiSMBIOS. Эта функция принимает следующие шесть аргументов:
Uuid – UUID, который будет использоваться в симулированной информации SMBIOS.
Вам потребуется перезапустить службу hostd, чтобы информация стала доступной. Для этого выполните команду:
/etc/init.d/hostd restart
Если вы теперь войдете в ESXi Host Client, vCenter Server или vSphere API (включая PowerCLI), то обнаружите, что производитель оборудования, модель, серийный номер и UUID отображают заданные вами пользовательские значения, а не данные реального физического оборудования!
Пользовательский SMBIOS не сохраняется после перезагрузки, поэтому вам потребуется повторно запускать команду каждый раз после перезагрузки вашего хоста ESXi.
Не все виртуальные машины на базе vSphere одинаковы, Вильям Лам написал интересный пост об обнаружении ВМ разного типа с помощью PowerCLI. Это особенно актуально с введением vSphere IaaS (ранее известного как vSphere Supervisor, vSphere with Tanzu или Project Pacific), который включает современный способ развертывания традиционных/классических виртуальных машин, а также новый тип виртуальной машины, основанный на контейнерах, известный как vSphere Pod VM.
vSphere Pod - это эквивалент Kubernetes pod в среде VMware Tanzu / vSphere IaaS. Это легковесная виртуальная машина, которая запускает один или несколько контейнеров на базе Linux. Каждый vSphere Pod точно настроен для работы с конкретной нагрузкой и имеет явно указанные reservations для ресурсов этой нагрузки. Он выделяет точное количество хранилища, памяти и процессорных ресурсов, необходимых для работы нагрузки внутри ВМ. vSphere Pods поддерживаются только в случаях, когда компонент Supervisor настроен с использованием NSX в качестве сетевого стека.
Недавно возник вопрос о том, как можно различать традиционные/классические виртуальные машины, созданные через пользовательский интерфейс или API vSphere, и виртуальные машины vSphere Pod средствами PowerCLI, в частности с использованием стандартной команды Get-VM.
Как видно на приведенном выше скриншоте, vSphere может создавать и управлять несколькими типами виртуальных машин, от традиционных/классических, которые мы все знаем последние два десятилетия, специализированных "Сервисных/Агентских" виртуальных машин, управляемых различными решениями VMware или сторонних разработчиков, и до новых виртуальных машин vSphere IaaS и виртуальных машин рабочих нагрузок контейнеров vSphere Pod (которые можно назвать Supervisor VM и Supervisor Pod VM).
Хотя команда Get-VM не различает эти типы виртуальных машин, существует несколько свойств, которые можно использовать в vSphere API для различения этих типов виртуальных машин. Ниже приведен фрагмент кода PowerCLI, который Вильям написал для того, чтобы различать типы виртуальных машин, что может быть полезно для автоматизации и/или отчетности.
Вот пример вывода скрипта для той же среды, что и на скриншоте из пользовательского интерфейса vSphere, но теперь у вас есть способ различать различные типы виртуальных машин, управляемых платформой vSphere.
В обеих версиях Microsoft Windows 10 и 11 безопасность на основе виртуализации (Virtualization Based Security, VBS) включена по умолчанию, и эта функция использует платформу Hyper-V, которая реализует технологию вложенной виртуализации (Nested Virtualization). Недавно Вильям Лам написал о том, что в связи с этим платформа VMware Workstation может выдавать ошибку.
Если вы попытаетесь запустить вложенную виртуальную машину с гипервизором ESXi в рамках Workstation под Windows, вы, скорее всего, увидите одно из следующих сообщений об ошибке в зависимости от производителя процессора:
Virtualized Intel VT-x/EPT is not supported on this platform
Virtualized AMD-V/RVI is not supported on this platform
Выглядит это так:
В то же время VMware Workstation была улучшена для совместной работы с Hyper-V благодаря новому режиму Host VBS Mode, представленному в VMware Workstation версии 17.x:
Workstation Pro uses a set of newly introduced Windows 10 features (Windows Hypervisor Platform) that permits the use of VT/AMD-V features, which enables Workstation Pro and Hyper-V to coexist. And because VBS is built on Hyper-V, Windows hosts with VBS enabled can now power on VM in Workstation Pro successfully
В документации VMware Workstation упоминаются несколько ограничений данной возможности. Тем не менее, если вам необходимо запустить вложенный ESXi под VMware Workstation, вам просто нужно отключить VBS в Windows, при условии, что у вас есть права администратора на вашем компьютере.
Шаг 1. Перейдите в раздел «Безопасность устройства» и в разделе «Основная изоляция» (Core isolation) отключите параметр «Целостность памяти» (Memory integrity), как показано на скриншоте ниже.
Шаг 2. Перезагрузите компьютер, чтобы изменения вступили в силу.
Шаг 3. Чтобы убедиться, что VBS действительно отключен, откройте Microsoft System Information (Системную информацию) и найдите запись «Безопасность на основе виртуализации» (Virtualization-based security). Убедитесь, что там указано «Не включено» (Not enabled). На устройствах, управляемых корпоративными системами, эта настройка может автоматически включаться снова. Таким образом, это поможет подтвердить, включена ли настройка или отключена.
Шаг 4. Как видно на скриншоте ниже, Вильяму удалось успешно запустить вложенный ESXi 6.0 Update 3 на последней версии VMware Workstation 17.6.2 под управлением Windows 11 22H2.
На портале технических ресурсов Broadcom появилась полезная статья, посвященная производительности облачных приложений и причинам их земедления в производственной среде.
Часто бывает, что приложение, работающее на физическом сервере, демонстрирует хорошую производительность. Однако после упаковки приложения в образ, тестирования в Docker/Podman и последующей миграции в окружение Kubernetes производительность резко падает. По мере увеличения числа запросов к базе данных, выполняемых приложением, время отклика приложения возрастает.
Эта распространённая ситуация часто вызвана задержками ввода-вывода, связанными с передачей данных. Представьте, что это же приложение снова запускается на физическом сервере, но в следующем сценарии: устройство хранения базы данных создаётся на удалённом хранилище с Network File System (NFS).
Это означает, что необходимо учитывать следующие факторы:
Количество приложений, обращающихся к конечной точке хранилища (предполагается, что оно быстрое по своему устройству).
Это будет влиять на общую производительность отклика из-за производительности подсистемы ввода-вывода хранилища.
Способ, которым приложение извлекает данные из базы данных.
Кэширует ли оно данные, или просто отправляет очередной запрос? Являются ли запросы небольшими или крупными?
Задержка, вызванная сетевым доступом к хранилищу, и общая скорость работы хранилища.
При доступе к сетевому устройству несколько ключевых факторов влияют на скорость передачи данных:
Доступная скорость соединения
Используемое максимальное время передачи (MTU) / максимальный размер сегмента (MSS)
Размер передаваемой полезной нагрузки
Настройки TCP окна (скользящее окно)
Среднее время задержки при прохождении маршрута (RTT) от точки A до точки B в мс.
В датацентре скорость соединения обычно не является проблемой, поскольку все узлы соединены с пропускной способностью не менее 1 Гбит/с, иногда 10 Гбит/с, и подключены к одному коммутатору. MTU/MSS будет оптимальным для настроенного соединения. Остаются размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT. Наибольшее влияние окажут размер полезной нагрузки, задержка соединения и его качество, которые будут влиять на параметры скользящего окна.
Вот пример задержек между узлами в текущей настройке Kubernetes:
При увеличении размера полезной нагрузки пакета в пинге, как только он превышает текущий MTU, время отклика начинает увеличиваться. Например, для node2 размер полезной нагрузки составляет 64k — это экстремальный случай, который наглядно демонстрирует рост задержки.
Учитывая эти три момента (размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT), если разработчик создаёт приложение без использования встроенных возможностей кэширования, то запросы к базе данных начнут накапливаться, вызывая нагрузку на ввод-вывод. Такое упущение направляет все запросы через сетевое соединение, что приводит к увеличению времени отклика всего приложения.
На локальном хранилище или в среде с низкой задержкой (как сети, так и хранилища) можно ожидать, что приложение будет работать хорошо. Это типичная ситуация, когда команды разработки тестируют все в локальной среде. Однако при переходе на сетевое хранилище задержка, вызванная сетью, будет влиять на возможный максимальный уровень запросов. При проведении тех же тестов в производственной среде команды, вероятно, обнаружат, что система, способная обрабатывать, скажем, 1000 запросов к базе данных в секунду, теперь справляется только с 50 запросами в секунду. В таком случае стоит обратить внимание на три вероятные причины:
Переменные размеры пакетов, средний размер которых превышает настроенный MTU.
Сетевая задержка из-за того, что база данных размещена на отдельном узле, вдали от приложения.
Уменьшенное скользящее окно, так как все связанные системы подключаются к узлу базы данных. Это создаёт нагрузку на ввод-вывод файловой системы, из-за чего база данных не может обрабатывать запросы достаточно быстро.
Тесты показали, что алгоритм скользящего окна привёл к снижению скорости передачи данных (для справки: это механизм, используемый удалённым хранилищем на основе NFS). При среднем размере полезной нагрузки 4 Кб скорость передачи данных упала с 12 МБ/с на быстром соединении 1 Гбит/с (8 мс задержки) до ~15 Кбит/с, когда задержка соединения достигла 180 мс. Скользящее окно может вынудить каждую передачу данных возвращать пакет подтверждения (ACK) отправителю перед отправкой следующего пакета на соединениях с низкой задержкой.
Эту ситуацию можно протестировать локально с помощью утилиты tc на системе Linux. С её помощью можно вручную задать задержку для каждого устройства. Например, интерфейс можно настроить так, чтобы он отвечал с задержкой в 150 мс.
На Kubernetes, например, вы можете развернуть приложение с фронтендом, сервером приложений и бэкендом базы данных. Если сервер приложений и бэкенд базы данных развернуты на разных узлах, даже если эти узлы быстрые, они будут создавать сетевые задержки для каждого пакета, отправленного с сервера приложений в базу данных и обратно. Эти задержки суммируются и значительно ухудшают производительность!
Ниже приведён реальный пример, показывающий время отклика приложения. База данных развернута на node2.
В этом случае выполнение приложения требует большого количества запросов к базе данных, что значительно влияет на среднее время отклика затронутых компонентов. В данном случае среднее время отклика составляет 3,9 секунды.
Для этого теста функция graph_dyn запрашивает из базы данных 80 тысяч строк данных, где каждая строка содержит метаданные для построения различных точек графика.
Переместив базу данных на ту же машину, где размещена часть приложения, удалось снизить среднее время отклика до 0,998 секунды!
Это значительное улучшение производительности было достигнуто за счёт сокращения задержек сетевых запросов (round trip), то есть перемещения контейнера базы данных на тот же узел.
Ещё одним распространённым фактором, влияющим на производительность Kubernetes, являются ESXi-среды, где узлы кластера имеют избыточную нагрузку на ввод-вывод сети, а узлы Kubernetes развёрнуты в виде виртуальных машин. Узел Kubernetes не может увидеть, что CPU, память, ввод-вывод диска и/или подключённое удалённое хранилище уже находятся под нагрузкой. В результате пользователи сталкиваются с ухудшением времени отклика приложений.
Как оптимизировать производительность приложения
Учтите кэширование в дизайне приложения.
Убедитесь, что приложение учитывает кэширование (общих запросов, запросов к базе данных и так далее) и не выполняет лишних запросов.
Отключите переподписку ресурсов (oversubscription) в средах ESXi.
Если Kubernetes/OpenShift работают поверх ESXi, убедитесь, что переподписка ресурсов отключена для всех доступных CPU и памяти. Учтите, что даже небольшие задержки могут быстро накопиться и привести к эластичному поведению времени отклика приложения. Кроме того, если хост ESXi уже находится под нагрузкой, запущенные на нём образы не будут осведомлены об этом, и оркестратор Kubernetes может развернуть дополнительные поды на этом узле, считая ресурсы (CPU, память, хранилище) всё ещё доступными. Поэтому, если вы используете Kubernetes/OpenShift, а у вас есть возможность запустить их на физическом сервере, сделайте это! Вы получите прямую и полную видимость ресурсов хоста.
Минимизируйте сетевые задержки ввода-вывода в Kubernetes.
Сократите сетевые задержки ввода-вывода при развёртывании подов. Упакуйте контейнеры в один под, чтобы они развертывались на одном узле. Это значительно снизит сетевые задержки ввода-вывода между сервером приложений и базой данных.
Размещайте контейнеры с высокими требованиями к базе данных на узлах с быстрым хранилищем.
Развёртывайте контейнеры, которым требуется быстрый доступ к базе данных, на узлах с быстрым хранилищем. Учитывайте требования к высокой доступности и балансировке нагрузки. Если хранилище NFS недостаточно быстрое, рассмотрите возможность создания PV (Persistent Volume) на определённом узле с локальным RAID 10 диском. Учтите, что в этом случае резервирование придётся настраивать вручную, так как оркестратор Kubernetes не сможет управлять этим при отказе оборудования конкретного узла.
Как мониторить задержки между компонентами
Для Kubernetes, OpenShift и Docker (Swarm) можно использовать Universal Monitoring Agent (UMA), входящий в решения AIOps and Observability от Broadcom, для мониторинга взаимодействия всего окружения. Этот агент способен извлекать все релевантные метрики кластера. Если UMA обнаруживает поддерживаемую технологию, такую как Java, .Net, PHP или Node.js, он автоматически внедряет пробу (probe) и предоставляет детализированную информацию о выполнении приложения по запросу. Эти данные включают запросы ввода-вывода (I/O) от компонента к базе данных, удалённые вызовы и другие внутренние метрики приложения.
Если приложение работает некорректно, встроенное обнаружение аномалий UMA запускает трассировку транзакций (это не требует дополнительной настройки). UMA собирает подробные метрики с агентов, связанных с компонентами, по пути выполнения конкретного приложения. Эти возможности позволяют получить детализированное представление выполнения приложения вплоть до строки кода, вызывающей замедление. Администраторы могут настроить полный сквозной мониторинг, который предоставляет детали выполнения, включая производительность фронтенда (браузера).
Ниже приведен пример сбора полных сквозных метрик, чтобы команда администраторов могла проанализировать, что пошло не так, и при необходимости принять корректирующие меры:
Одним из преимуществ этого решения для мониторинга является то, что оно показывает среднее время выполнения компонентов внутри кластера. Со временем решение может начать считать плохие средние значения нормой в среде ESXi с избыточной загрузкой. Тем не менее, оператор может оценить реальные значения и сравнить их с показателями других приложений, работающих на том же узле.
Broadcom сообщила, что ОС Windows Server 2025 официально сертифицирована для работы на платформе VMware vSphere версий 7.0 U3, 8.0, 8.0 U1, 8.0 U2 и 8.0 U3. Эти версии прошли тестирование и валидацию, обеспечивая стабильную и высокопроизводительную платформу для запуска Windows Server 2025 в качестве гостевой операционной системы в виртуальных машинах. Для получения подробной информации о поддерживаемых версиях обратитесь к Broadcom Compatibility Guide.
Что нового?
Сертификация VMware vSphere в рамках программы Microsoft SVVP
VMware vSphere 7.0 U3, 8.0, 8.0 U1, 8.0 U2 и 8.0 U3 входят в число первых гипервизоров, сертифицированных в рамках программы Microsoft Windows Server Virtualization Validation Program (SVVP). Эта сертификация подтверждает официальную поддержку Microsoft и VMware для работы Windows Server 2025 в средах VMware vSphere. Подробнее ознакомиться с сертификацией можно на странице сертификации VMware vSphere SVVP.
Поддержка VMware Tools с первого дня для Windows Server 2025
Драйверы VMware PVSCSI и VMXNET3 включены в Windows Server 2025
Начиная с Windows Server 2022, а теперь и для Windows Server 2025, драйверы VMware Paravirtual SCSI (PVSCSI) и сетевого адаптера VMXNET3 предустановлены в ОС от Microsoft. Это упрощает процесс настройки и обеспечивает эффективное развертывание виртуальных машин Windows Server с высокопроизводительными виртуальными устройствами без необходимости ручной установки драйверов.
Новый плагин VMXNET3 KDNET для отладки сетевого ядра
В Windows Server 2025 включён плагин расширения VMXNET3 KDNET для отладки сетевого ядра. Это позволяет выполнять отладку напрямую в виртуальной среде, предоставляя разработчикам удобный и эффективный процесс отладки. Дополнительную информацию о настройке сетевой отладки ядра можно найти в документации Microsoft.
Установка Windows Server 2025 в VMware vSphere
Перед развертыванием виртуальных машин с Windows Server 2025 в VMware vSphere рекомендуется ознакомиться с Руководством по совместимости Broadcom, чтобы убедиться в совместимости вашего оборудования и продуктов VMware. Это руководство содержит важную информацию о поддерживаемых серверах, устройствах хранения, сетевых адаптерах и других компонентах.
Для устранения неисправностей и оптимизации развертывания виртуальных машин Windows Server 2025 на VMware vSphere ознакомьтесь с приведёнными ниже статьями базы знаний (KB). Эти статьи охватывают вопросы совместимости VMware Tools, а также решения известных проблем.
В то время, как организации по всему миру стремятся преобразовать свою инфраструктуру, чтобы соответствовать требованиям цифровой эпохи, гиперконвергентное хранилище стало ключевым инструментом для модернизации ИТ. Решение VMware vSAN находится на переднем плане этой революции, предлагая гибкое, масштабируемое и экономически эффективное решение для управления критически важными рабочими нагрузками.
Однако, когда ИТ-служба принимает решение о внедрении новой технологии, такой как гиперконвергентное хранилище, первый шаг может казаться сложным. Есть очевидные моменты для начала, такие как обновление инфраструктуры или новое развертывание ИТ в периферийной локации. Что касается рабочих нагрузок, то кривая внедрения — какие нагрузки выбрать для старта и как продвигаться дальше — может представлять собой некоторую загадку.
VMware недавно заказала исследование Key Workloads and Use Cases for Virtualized Storage у компании Enterprise Strategy Group, чтобы изучить роль гиперконвергентного хранилища, его преимущества и ключевые случаи применения, где оно оказывает значительное влияние. Рекомендации основаны на опросах сотен пользователей гиперконвергентных хранилищ, а также на тысячах реальных внедрений.
Почему хранилище является проблемой
В стремительно меняющемся цифровом мире управление хранилищем становится сложной задачей. Объемы данных растут экспоненциально из-за таких факторов, как искусственный интеллект, интернет вещей (IoT) и облачные приложения. Сложность и фрагментация хранилищ также увеличиваются, поскольку данные распределены между локальными, облачными и периферийными локациями. Традиционные архитектуры хранилищ на основе трехуровневых систем становятся дорогостоящими, трудными для масштабирования и требуют специальных навыков. Это создает острую необходимость в новом подходе, который упрощает хранение данных, одновременно удовлетворяя растущие потребности современных приложений.
Роль гиперконвергентного хранилища
VMware vSAN устраняет ограничения традиционного хранилища с помощью гиперконвергентного подхода, который объединяет ресурсы хранилища нескольких серверов в единую общую базу данных. Это упрощает управление, улучшает производительность и обеспечивает постепенное масштабирование. В отличие от традиционного хранилища, которое является жестким и дорогим, гиперконвергентное хранилище предлагает гибкую модель, позволяющую организациям масштабироваться вверх или вниз по мере необходимости и работать на серверах промышленного стандарта, снижая капитальные затраты. Гиперконвергентное хранилище позволяет организациям использовать единую программно-определяемую инфраструктуру и единый операционный подход для основного датацентра, периферийной инфраструктуры и публичного облака, что значительно упрощает управление в крупных масштабах. VMware имеет обширный список совместимого оборудования, сертифицированного для работы vSAN как в периферийных системах, так и в основных датацентрах.
Кроме того, vSAN ускоряет рутинные операции с хранилищем, такие как предоставление хранилища за минуты, а не за часы или дни, что делает его идеальным решением для быстро меняющихся условий. Тесная интеграция с облачной инфраструктурой VMware позволяет без проблем управлять как виртуальными машинами, так и контейнерами, что делает его универсальным решением для частных и гибридных облачных сред.
Ключевые рабочие нагрузки для гиперконвергентного хранилища
VMware vSAN подходит для различных сценариев использования, демонстрируя в них свою гибкость и масштабируемость:
1. Виртуальная инфраструктура рабочих столов (VDI): с увеличением числа удаленных сотрудников виртуальные рабочие столы стали критически важными. Однако VDI требует высокой производительности, линейного масштабирования и технологий для сокращения объема данных, чтобы оптимизировать затраты на хранение. vSAN решает эту задачу, предлагая масштабируемое решение. Его архитектура поддерживает высокую производительность и различные технологии сокращения данных для минимизации требований к объему хранения.
2. Бизнес-критичные приложения: для требовательных приложений баз данных, таких как Oracle, SQL Server и SAP HANA, vSAN обеспечивает высокую производительность и масштабируемость. Архитектура vSAN Express Storage Architecture предоставляет высокую производительность и устойчивость, даже с использованием кодирования ошибок RAID 5/6 для эффективности. vSAN также позволяет независимо масштабировать вычислительные ресурсы и ресурсы хранения, что полезно для рабочих нагрузок OTLP, которые часто растут быстрее по объему хранения, чем по вычислительным требованиям.
3. «Мейнстримные» рабочие нагрузки: веб-серверы, аварийное восстановление и защита данных. Это зрелые и широко используемые приложения, для которых требуется простое в управлении и недорогое хранилище. vSAN упрощает работу с этим хранилищем для разных рабочих нагрузок за счет управления на основе политик и снижает затраты, используя серверы промышленного стандарта для достижения необходимой производительности. Он также упрощает аварийное восстановление, позволяя реплицировать данные между сайтами без дорогостоящего специального оборудования.
4. Рабочие нагрузки на периферии (edge workloads): гиперконвергентные решения для хранилищ обеспечивают масштабируемость, гибкость и повышенную производительность на периферии с меньшими затратами, в компактном формате и, что особенно важно, в упрощенном форм-факторе серверов. Ключевые возможности vSAN включают:
возможность экономного масштабирования
поддержку нативного файлового и блочного хранения для уменьшения физического объема
высокую производительность благодаря поддержке NVMe-based TLC NAND flash для приложений с высокой чувствительностью к задержкам
централизованное управление всеми удаленными сайтами из одного инструмента
5. Облачные (cloud-native) рабочие нагрузки: гиперконвергентные решения для хранилищ также являются идеальным подходом, поскольку они поддерживают облачные хранилища и автоматизируют выделение хранилища для контейнерных рабочих нагрузок, что позволяет разработчикам получать доступ к необходимому хранилищу по мере необходимости, одновременно позволяя ИТ-администраторам управлять хранилищем как для контейнеров, так и для виртуальных машин на одной платформе.
Заключение
VMware vSAN — это не просто решение для хранения, это краеугольный камень ИТ-модернизации. Благодаря использованию виртуализации vSAN позволяет организациям создать гибкую, масштабируемую и эффективную инфраструктуру хранения, способную справиться с текущими и будущими нагрузками. Независимо от того, хотите ли вы оптимизировать рабочие столы VDI, улучшить производительность баз данных или модернизировать стратегию аварийного восстановления, VMware vSAN предоставляет комплексное решение для удовлетворения потребностей пользователей.
VMware vSphere давно зарекомендовала себя как одна из ведущих платформ для виртуализации, обеспечивая мощные инструменты для управления виртуальными машинами (VM) и инфраструктурой центров обработки данных (ЦОД). В версии VMware vSphere 8 Update 3 была введена новая важная функция — Live Patch. Это нововведение позволяет администраторам вносить критические исправления и обновления безопасности в ядро гипервизора ESXi без необходимости перезагрузки системы или отключения виртуальных машин. В данной статье мы рассмотрим, что такое Live Patching, его преимущества, технические аспекты работы и потенциальные ограничения.
Выход платформы VMware vSphere 8 переопределил подход к управлению жизненным циклом и обслуживанием инфраструктуры vSphere. Решение vSphere Lifecycle Manager упрощает управление образами кластеров, обеспечивает полный цикл управления драйверами и прошивками, а также ускоряет полное восстановление кластера. Управление сертификатами происходит без сбоев, а обновления vCenter можно выполнять с гораздо меньшими простоями по сравнению с прошлыми релизами платформы.
vSphere 8 Update 3 продолжает эту тенденцию снижения и устранения простоев с введением функции vSphere Live Patch.
vSphere Live Patch позволяет обновлять кластеры vSphere и накатывать патчи без миграции рабочих нагрузок с целевых хостов и без необходимости перевода хостов в полный режим обслуживания. Патч применяется в реальном времени, пока рабочие нагрузки продолжают выполняться.
Требования данной техники:
vSphere Live Patch является опциональной функцией, которую необходимо активировать перед выполнением задач восстановления.
vCenter должен быть версии 8.0 Update 3 или выше.
Хосты ESXi должны быть версии 8.0 Update 3 или выше.
Настройка Enforce Live Patch должна быть включена в глобальных настройках восстановления vSphere Lifecycle Manager или в настройках восстановления кластера.
DRS должен быть включен на кластере vSphere и работать в полностью автоматическом режиме.
Для виртуальных машин с включенной vGPU необходимо активировать Passthrough VM DRS Automation.
Текущая сборка кластера vSphere должна быть пригодна для применения live-патчинга (подробности ниже).
Как работает Live Patching
Кликните на картинку, чтобы открыть анимацию:
Распишем этот процесс по шагам:
Хост ESXi переходит в режим частичного обслуживания (partial maintenance mode). Частичный режим обслуживания — это автоматическое состояние, в которое переходит каждый хост. В этом особом состоянии существующие виртуальные машины продолжают работать, но создание новых ВМ на хосте или миграция ВМ на этот хост или с него запрещены.
Новая версия компонентов целевого патча монтируется параллельно с текущей версией.
Файлы и процессы обновляются за счет смонтированной версии патча.
Виртуальные машины проходят быструю паузу и запуск (fast-suspend-resume) для использования обновленной версии компонентов.
Не все патчи одинаковы
Механизм vSphere Live Patch изначально доступен только для определенного типа патчей. Патчи для компонента выполнения виртуальных машин ESXi (virtual machine execution component) являются первыми целями для vSphere Live Patch.
Патчи, которые могут изменить другие области ESXi, например патчи VMkernel, изначально не поддерживаются для vSphere Live Patch и пока требуют следования существующему процессу патчинга, который подразумевает перевод хостов в режим обслуживания и эвакуацию ВМ.
Обновления vSphere Live Patches могут быть установлены только на поддерживаемые совместимые версии ESXi. Каждый Live Patch будет указывать, с какой предыдущей сборкой он совместим. vSphere Lifecycle Manager укажет подходящие версии при определении образа кластера. Также вы можете увидеть подходящую версию в репозитории образов vSphere Lifecycle Manager:
Например, patch 8.0 U3a 23658840 может быть применен только к совместимой версии 8.0 U3 23653650. Системы, которые не работают на совместимой версии, все равно могут быть обновлены, но для этого будет использован существующий процесс "холодных" патчей, требующий перевода хостов в режим обслуживания и эвакуации ВМ.
Соответствие образа кластера будет указывать на возможность использования Live Patch.
Быстрое приостановление и возобновление (fast-suspend-resume)
Как упоминалось ранее, патчи для компонента выполнения виртуальных машин в ESXi являются первой целью для vSphere Live Patch. Это означает, что хотя виртуальные машины не нужно эвакуировать с хоста, им нужно выполнить так называемое быстрое приостановление и возобновление (FSR) для использования обновленной среды выполнения виртуальных машин.
FSR виртуальной машины — это ненарушающее работу действие, которое уже используется в операциях с виртуальными машинами при добавлении или удалении виртуальных аппаратных устройств (Hot Add) в работающие виртуальные машины.
Некоторые виртуальные машины несовместимы с FSR. Виртуальные машины, настроенные с включенной функцией Fault Tolerance, машины, использующие Direct Path I/O, и vSphere Pods не могут использовать FSR и нуждаются в участии администратора. Это может быть выполнено либо путем миграции виртуальной машины, либо путем перезагрузки виртуальной машины.
Сканирование на соответствие в vSphere Lifecycle Manager укажет виртуальные машины, несовместимые с FSR, и причину несовместимости:
После успешного восстановления кластера любые хосты, на которых работают виртуальные машины, не поддерживающие FSR, будут продолжать сообщать о несоответствии требованиям. Виртуальные машины необходимо вручную переместить с помощью vMotion или перезагрузить. Только тогда кластер будет полностью соответствовать требованиям (compliant).
Отметим, что
vSphere Live Patch несовместим с системами, работающими с устройствами TPM или DPU, использующими vSphere Distributed Services Engine.
Вильям Лам написал интересную статью о том, как можно редактировать настройки SMBIOS для вложенного/виртуального (Nested) VMware ESXi в части hardware manufacturer и vendor.
Nested ESXi продолжает оставаться полезным ресурсом, который часто используется администраторами: от прототипирования решений, воспроизведения проблем клиентов до автоматизированных развертываний лабораторий, поддерживающих как VMware Cloud Foundation (VCF), так и VMware vSphere Foundation (VVF).
Хотя с помощью Nested ESXi можно сделать почти все, но имитировать или симулировать конкретные аппаратные свойства, такие как производитель или поставщик (hardware manufacturer и vendor), не совсем возможно или, по крайней мере, очень сложно. Коллега Вильяма Люк Хакаба нашел хитрый трюк, играя с настройками загрузочных ROM виртуальной машины по умолчанию, которые поставляются с ESXi и VMware Desktop Hypervisors (платформы Workstation/Fusion).
Виртуальная машина vSphere может загружаться, используя либо BIOS, либо EFI прошивку, поэтому в зависимости от желаемого типа прошивки вам нужно будет изменить либо файл BIOS.440.ROM, либо EFI64.ROM. Эти файлы ROM можно найти в следующих каталогах для соответствующих гипервизоров VMware:
Примечание: не редактируйте файлы ROM по умолчанию, которые поставляются с гипервизором VMware, сделайте их копию и используйте измененную версию, которую могут использовать виртуальные машины в VMware vSphere, Fusion или Workstation. Кроме того, хотя эта статья посвящена виртуальной машине Nested ESXi, это также должно работать и на других гостевых операционных системах для отображения информации SMBIOS.
Редактирование BIOS
Шаг 1 - Скачайте и установите Phoenix BIOS Editor. Установщик Phoenix BIOS Editor имеет проблемы при запуске на системе Windows Server 2019, и единственным способом завершить установку - это изменить совместимость приложения на Windows 8, что позволит успешно завершить установку.
Шаг 2 - Скачайте и откройте файл BIOS.440.ROM с помощью Phoenix BIOS Editor, затем перейдите на панель DMI Strings для изменения нужных полей.
Когда вы закончите вносить все изменения, перейдите в меню "Файл" и нажмите "Собрать BIOS" (Build BIOS), чтобы создать новый файл ROM. В данном примере это файл BIOS.440.CUSTOM.ROM.
Шаг 3 - Скопируйте новый файл ROM в хранилище вашего физического хоста ESXi. Вы можете сохранить его в общей папке, чтобы использовать с несколькими виртуальными машинами Nested ESXi, ИЛИ вы можете сохранить его непосредственно в папке отдельной виртуальной машины Nested ESXi. Второй вариант позволит вам повторно использовать один и тот же кастомный файл ROM в нескольких виртуальных машинах, поэтому, с точки зрения тестирования, возможно, вам захочется создать несколько файлов ROM в зависимости от ваших нужд и просто перенастроить виртуальную машину для использования нужного файла ROM.
Шаг 4 - Чтобы кастомный файл ROM мог быть использован нашей виртуальной машиной Nested ESXi, нам нужно добавить следующую дополнительную настройку (Advanced Setting) виртуальной машины, которая указывает путь к нашему кастомному файлу ROM:
bios440.filename = "BIOS.440.CUSTOM.ROM"
Шаг 5 - Наконец, мы можем включить нашу виртуальную машину Nested ESXi, и теперь мы должны увидеть кастомную информацию SMBIOS, как показано на скриншоте ниже.
Редактирование EFI
Шаг 1 - Скачайте и установите HEX-редактор, который может редактировать файл EFI ROM. Например, ImHex - довольно удобный с точки зрения редактирования, но поиск определенных строк с помощью этого инструмента является нетривиальной задачей.
Шаг 2 - Скачайте и откройте файл EFI64.ROM с помощью редактора ImHex и найдите строку "VMware7,1". Как только вы найдете расположение этой строки, вам нужно аккуратно отредактировать значения hex, чтобы получить желаемые ASCII строки.
Кроме того, вы можете использовать UEFITool (версия 28 позволяет модифицировать ROM), который имеет гораздо более удобный и функциональный поиск, а также позволяет извлекать часть файла ROM для редактирования с помощью HEX-редактора. В этой утилите можно использовать поиск (CTRL+F), и как только он находит нужный раздел, двойным щелчком по результату переходите к точному месту в файле ROM. Чтобы извлечь раздел для редактирования, щелкните правой кнопкой мыши и выберите "Extract as is" и сохраните файл на рабочий стол.
Затем вы можете открыть конкретный раздел с помощью ImHex, чтобы внести свои изменения.
После того как вы сохранили свои изменения, не теряйте указатель в UEFITool. Теперь мы просто заменим раздел нашим измененным файлом, щелкнув правой кнопкой мыши и выбрав "Replace as is", указав измененный раздел. Вы можете подтвердить, что изменения были успешными, просто найдя строку, которую вы заменили. Затем перейдите в меню "Файл" и выберите "Сохранить образ файла" (Save image file), чтобы создать новый файл ROM. В данном случае - это файл EFI64.CUSTOM.ROM.
Шаг 3 - Скопируйте новый файл ROM в хранилище вашего физического хоста ESXi. Вы можете сохранить его в общей папке, чтобы использовать с несколькими виртуальными машинами Nested ESXi, ИЛИ вы можете сохранить его непосредственно в папке отдельной виртуальной машины Nested ESXi.
Шаг 4 - Чтобы наш кастомный файл ROM мог быть использован виртуальной машиной Nested ESXi, нам нужно добавить следующую дополнительную настройку ВМ в файл vmx, которая указывает путь к нашему кастомному файлу ROM:
efi64.filename = "EFI64.CUSTOM.ROM"
Шаг 5 - Наконец, мы можем включить виртуальную машину Nested ESXi, и теперь мы должны увидеть кастомную информацию SMBIOS.
Как видно на скриншоте, Вильяму удалось изменить только модель оборудования, но не значение вендора.
Примечание: хотя автору и удалось найти строку "VMware, Inc." для вендора, изменение значения не оказало никакого эффекта, как показано на скриншоте выше, что, вероятно, указывает на то, что эта информация может храниться в другом месте или содержаться в каком-то встроенном файле.
Оказывается у сетевого адаптера виртуальной машины vmnic есть свойство, определяющее, будет ли он автоматически присоединяться к виртуальной машине при ее запуске. Свойство это называется StartConnected, оно может быть не установлено по каким-то причинам, что может привести к проблемам.
Как написал Farnky, проверить это свойство у всех виртуальных машин в окружении vCenter можно следующей командой:
Те из вас, кто работает на компьютерах Apple Mac, часто используют виртуальные машины Windows, которые запускаются в виртуальных средах VMware Fusion и Parallels Desktop.
UTM предназначен для создания и запуска виртуальных машин на устройствах Apple. Это комплексный системный эмулятор и хост виртуальных машин, специально разработанный для iOS и macOS. Созданный на мощной платформе QEMU, UTM позволяет пользователям быстро запускать различные операционные системы, такие как Windows и Linux, на устройствах Mac, iPhone и iPad.
UTM является настоящим открытием для пользователей Apple Silicon (процессоры M1/M2). Он использует фреймворк виртуализации Hypervisor от Apple, позволяя операционным системам ARM64 работать на скоростях, почти идентичных скорости нативной работы.
Для владельцев Mac на Intel доступна возможность виртуализации операционных систем x86/x64. Но на этом возможности UTM не заканчиваются - он также предлагает менее производительную эмуляцию для запуска x86/x64 на Apple Silicon и ARM64 на Intel. Эта универсальность расширяется за счет поддержки ряда других эмулируемых процессоров, включая ARM32, MIPS, PPC и RISC-V, делая ваш Mac по-настоящему универсальной платформой.
UTM не только про современные ОС - он также способен вдохнуть жизнь и в классические операционные системы. Будь то старая система PowerPC, SPARC или x86_64, UTM позволяет запускать их на разных платформах в виде виртуальных машин. Любопытные пользователи могут посмотреть галерею, где представлены различные системы, которые может эмулировать UTM.
Вот, например, эмуляция MacOS 9.2.1:
Пользователи Mac на Apple Silicon могут вывести виртуализацию на новый уровень с помощью UTM. Он позволяет запускать несколько экземпляров macOS, что особенно полезно для разработчиков и пользователей, ориентированных на безопасность. Однако эта функция доступна исключительно на Mac на базе ARM с установленной macOS Monterey или более новой версией.
UTM выделяется среди другого ПО для виртуализации благодаря своему дизайну, который создан исключительно для macOS и платформ Apple. Он гармонично сочетается со стилем Big Sur, предлагая пользовательский опыт, который действительно напоминает Mac, включая все ожидаемые функции конфиденциальности и безопасности.
В своей основе UTM использует QEMU - хорошо известного, бесплатного и открытого программного обеспечения для эмуляции. Сам QEMU достаточно сложен в использовании, что часто отпугивает пользователей большим количеством параметров командной строки. UTM устраняет этот барьер, предлагая надежные функции QEMU без сложности, делая его доступным для более широкого круга пользователей.
Скачать UTM для ваших Apple-устройств можно по этой ссылке.
Дункан Эппинг опубликовал интересный пост о том, как предотвратить исполнение виртуальных машин vCLS на VMware vSphere HA Failover Host. Напомним, что vSphere Clustering Service (vCLS) - это служба, которая позволяет организовать мониторинг доступности хостов кластера vSphere, без необходимости зависеть от служб vCenter. Она реализуется тремя агентскими виртуальными машинами в кластере, где 3 или более хостов, и двумя, если в кластере два хоста ESXi. Три машины нужны, чтобы обеспечивать кворум (2 против 1) в случае принятия решения о разделении кластера.
Для тех, кто не знает, сервер vSphere HA Failover Host — это хост, который используется, когда происходит сбой и vSphere HA должен перезапустить виртуальные машины. В некоторых случаях клиенты (обычно партнеры в облачных решениях) хотят предотвратить использование этих хостов для любых рабочих нагрузок, поскольку это может повлиять на стоимость использования платформы.
К сожалению, в пользовательском интерфейсе вы не можете указать, что машины vCLS не могут работать на определенных хостах, вы можете ограничить работу ВМ vCLS рядом с другими виртуальными машинами, но не хостами. Однако есть возможность указать, на каких хранилищах данных могут находиться виртуальные машины, и это может быть потенциальным способом ограничения хостов, на которых могут работать эти ВМ. Как?
Если вы создадите хранилище данных, которое недоступно назначенному Failover-хосту vSphere HA, то машины vCLS не смогут работать на этом хосте, так как хост не сможет получить доступ к датастору. Это обходной путь для решения проблемы, вы можете узнать больше о механизме размещения хранилищ данных для vCLS в этом документе. Обратите внимание, что если остальная часть кластера выйдет из строя и останется только Failover-хост, виртуальные машины vCLS не будут включены. Это означает, что механизм балансировки нагрузки VMware DRS также не будет функционировать, пока эти ВМ недоступны.
Таги: VMware, vSphere, HA, vCLS, VMachines, DRS, Blogs
Мы помним, что некоторые из вас просили рассказать о российских альтернативах платформам виртуализации от ведущих мировых вендоров. Оказывается, еще в 2022 году компании TAdviser и Softline подготовили подробное описание и сравнение российских платформ виртуализации по разным критериям, которое является хорошей отправной точкой для тех, кто больше не имеет возможности использовать продукты VMware.
Вот основные ссылки на информацию о российских производителях ПО для серверной виртуализации:
Обратите внимание, что данное исследование и сравнение сделано в декабре 2022 года, с тех пор многое могло измениться (в зависимости от активности разработчиков).
Полную версию этого отчета на 47 страницах можно скачать по этой ссылке (нужно заполнить форму внизу страницы):
На сайте VMware Developer появился полезный сценарий PowerCLI, который позволяет администратору изменить текущий контроллер SCSI на новый тип для виртуальной машины на платформе VMware vSphere.
Некоторые особенности работы этого сценария:
Не проверяет, настроена ли виртуальная машина для 64-битной гостевой ОС (адаптер BusLogic не поддерживается)
Ппроверяет, работают ли VMware Tools и выключает виртуальную машину с помощью функции выключения гостевой ОС
Возвращает виртуальную машину в предыдущее рабочее состояние
Проверяет, было ли уже установлено новое значение контроллера SCSI
Функция Modify-ScsiController вызывается в самом конце скрипта. Вот различные примеры того, как функция может быть использована:
Администраторы виртуальной инфраструктуры VMware vSphere время от времени сталкиваются с проблемой завершения зависших виртуальных машин. Если в клиенте vSphere Client сделать этого не удаются, приходится заходить в сервисную консоль ESXi или в командную строку PowerCLI/PowerShell и проводить там операции по завершению процесса этой ВМ. Сегодня мы расскажем о 5 способах, которыми это можно сделать.
1. С использованием PowerCLI
Stop-VM - это командлет, используемый для завершения работы виртуальной машины. На самом деле он используется для выключения ВМ, но добавление параметра kill приведет к завершению соответствующих процессов ВМ на ESXi, фактически уничтожая ее. Делается это так:
Stop-VM -kill <отображаемое имя ВМ> -Confirm:$false
2. С использованием esxcli
Esxcli - это интерфейс командной строки (CLI), который предоставляет доступ к ряду пространств имен, таких как vm, vsan, network и software, позволяя выполнять задачи, изменять настройки и так далее. Таким образом, если вам нужно завершить работу неотвечающей виртуальной машины с использованием esxcli, можно действовать следующим образом:
Получить список виртуальных машин, размещенных на ESXi:
esxcli vm process list
Красным выделен идентификатор World ID виртуальной машины.
Скопируйте значение World ID и выполните команду:
esxcli vm process kill --type=soft -w=796791
Команда не выдает никакой обратной связи, кроме случаев, когда она не сможет найти виртуальную машину или вы укажете неверный параметр.
Параметр type принимает три значения:
Soft – позволяет процессу VMX завершиться корректно, аналогично команде kill -SIGTERM
Hard – немедленно завершает процесс VMX, аналогично команде kill -9 или kill -SIGKILL
Force – останавливает процесс VMX, когда не работают варианты Soft или Hard
3. С использованием утилиты vim-cmd
Vim-cmd - это еще одна утилита командной строки, очень похожая на esxcli, но с несколько иным синтаксисом. Также она может использоваться для управления ВМ и другими ресурсами. Соответственно, вот как используется vim-cmd для завершения работы ВМ:
1. Выведите все ВМ на текущем подключенном хосте ESXi и запишите vmid (первый столбец) неотвечающей ВМ:
vim-cmd vmsvc/getallvms
2. Получите состояние питания ВМ, используя ее vmid. Этот шаг необязателен, так как вы уже знаете, что с ВМ что-то не так:
vim-cmd vmsvc/power.getstate 36
3. Сначала попробуйте вариант power.shutdown:
vim-cmd vmsvc/power.shutdown 36
4. Если по какой-то причине ВМ не удается выключить, попробуйте использовать вместо этого power.off:
vim-cmd vmsvc/power.off 36
Следующий скриншот демонстрирует пример использования указанных выше команд для завершения работы ВМ.
4. С использованием esxtop
Esxtop - это отличная утилита, которая предоставляет информацию о том, как ESXi использует системные ресурсы. Она может использоваться для устранения неполадок, сбора статистики производительности и многого другого.
Вот как это делается:
Нажмите Shift+v, чтобы изменить представление на виртуальные машины:
Нажмите <f>, чтобы отобразить список полей, затем нажмите <c>. Это добавит столбец с идентификатором Leader World ID (LWID) в представление. Нажмите любую клавишу, чтобы вернуться в главное меню.
Найдите зависшую виртуальную машину в столбце Name и запишите ее LWID.
Нажмите k и введите значение LWID в строке запроса World to kill (WID). Нажмите Enter:
Чтобы быть полностью уверенным, подождите 30 секунд перед тем, как проверить, что виртуальная машина больше не отображается в списке. Если она все еще там, попробуйте снова. В случае неудачи, скорее всего, вам придется перезагрузить хост ESXi.
5. С помощью традиционной команды kill
Это самый грубый метод завершения работы виртуальной машины. Но он документирован на сайте VMware, хотя и немного по-другому. Виртуальная машина представляет собой серию процессов, выполняемых на ESXi. Используя команду ps ниже, можно вывести процессы, связанные, например, с виртуальной машиной под названием Web Server.
ps | grep "Web Server"
Если вы внимательно посмотрите, вы увидите, что значение во втором столбце одинаково для всех процессов. Это значение идентификатора VMX Cartel, которое, хотя и отличается от значения World ID, все же может быть использовано для завершения работы виртуальной машины следующим образом:
kill 797300
Если процессы продолжают работать, попробуйте kill -9 <идентификатор процесса>:

 RSS
RSS