В настройках кластера VMware vSphere High Availability существует параметр Performance degradation VMs tolerate, который определяет допустимый уровень снижения производительности виртуальных машин при отказе одного из хостов кластера.
По умолчанию значение параметра установлено в 100%, что фактически означает отсутствие ограничений по деградации производительности в аварийном сценарии. При таком значении система не будет предупреждать администратора о возможном ухудшении SLA виртуальных машин после отказа узла.
Как работает параметр
Механизм оценивает, смогут ли уже запущенные виртуальные машины сохранить сопоставимый объем вычислительных ресурсов после отказа одного хоста. Логика работы следующая:
Рассматривается сценарий отказа одного узла кластера.
Оценивается суммарная доступная вычислительная емкость после отказа.
С помощью VMware Distributed Resource Scheduler DRS моделируется перераспределение работающих виртуальных машин на другие хосты ESX.
Проверяется, какой уровень снижения ресурсов (CPU / Memory) получат виртуальные машины.
Если ожидаемая деградация превышает заданный порог, генерируется предупреждение.
Важно! Это не блокирующий механизм. Даже при появлении предупреждения запуск новых виртуальных машин остается возможным - параметр выполняет исключительно функцию оповещения.
Требования для работы
Для корректной работы параметра необходим работающий DRS, но включенный Admission Control не требуется. Это частое заблуждение: параметр не использует настройки Admission Control (например, Host failures cluster tolerates). Вместо этого он самостоятельно моделирует отказ одного хоста и анализирует последствия для производительности виртуальных машин.
Практический смысл настройки
Параметр полезен в сценариях, когда:
В кластере высокая консолидация нагрузки.
Виртуальные машины активно используют CPU / RAM выше уровня reservation.
Ресурсы после отказа хоста могут оказаться достаточными для запуска ВМ, но недостаточными для сохранения нужной производительности.
Пример:
Допустим, кластер работает с загрузкой 80–85%. После выхода одного узла из строя оставшиеся хосты смогут принять виртуальные машины, однако фактическая доступность ресурсов для каждой машины снизится.
50% — допускается существенное снижение производительности
100% — предупреждения фактически отключены
Рекомендации по настройке
Практически значение 100% малоинформативно, так как не дает сигналов о потенциальной проблеме.
Часто используются значения:
0–10% — для критичных production-нагрузок
25% — сбалансированный вариант
50% — для сред с менее строгими SLA
Выбор зависит от допустимого уровня деградации сервисов при аварийном восстановлении.
Вывод
Параметр Performance degradation VMs tolerate — это механизм оценки риска снижения производительности ВМ при отказе узла, а не механизм резервирования ресурсов.
Его особенности:
Анализирует сценарий отказа одного хоста
Требует DRS
Не зависит от Admission Control
Не запрещает запуск ВМ
Предупреждает о возможном ухудшении производительности
Настройка позволяет заранее понять, насколько кластер готов к отказу оборудования с точки зрения SLA, а не только с точки зрения возможности перезапуска виртуальных машин.
DVD Store — это инструментарий для тестирования баз данных с открытым исходным кодом, который активно применяется с момента своего первого релиза в 2005 году. Он поддерживает работу с СУБД SQL Server, Oracle, PostgreSQL и MySQL. DVD Store моделирует интернет-магазин, в котором пользователи авторизуются, просматривают каталог, оставляют отзывы, выставляют оценки и покупают DVD. В тесте задействуется большое число типичных возможностей реляционных БД: хранимые процедуры, индексы, внешние ключи, полнотекстовый поиск, сложные запросы с множественными join'ами и транзакции.
Изначально DVD Store разрабатывался как нагрузка, ориентированная преимущественно на CPU. Тем не менее в нём с самого начала были предусмотрены параметры, позволяющие менять этот профиль и переключаться на сценарии, в которых акцент делается на сеть, дисковую подсистему или даже память. Примеры таких профилей теперь добавлены и описаны в основном репозитории DVD Store на GitHub: https://github.com/dvdstore/ds35/tree/main/workload_profiles
VMware провела тестирование тестирование платформы VMware vSphere с помощью этого инструмента для того, чтобы понять, насколько эти профили меняют поведение нагрузки относительно стандартного CPU-ориентированного сценария. Все измерения проводились на одной виртуальной машине, развёрнутой на сервере ESX 9.0 платформы VMware Cloud Foundation (VCF). ВМ работала под управлением Windows Server 2022, в качестве СУБД использовалась SQL Server 2022. Все показатели производительности фиксировались со стороны хоста ESX с помощью утилиты esxtop (аналог linux top, но адаптированный под ESX и собирающий значительно более широкий набор метрик).
CPU Utilization — загрузка процессора на хосте ESX
Disk I/O per second (IOPS) — операции чтения и записи на диск со стороны хоста ESX
Mb received per second (Mb Rec/s) — мегабиты, принятые в секунду по сети
Mb sent per second (Mb Sent/s) — мегабиты, отправленные в секунду по сети
Active Memory (ActiveMem) — объём памяти, к которой недавно было обращение (активная память)
Относительное изменение ключевых метрик в разных профилях нагрузки
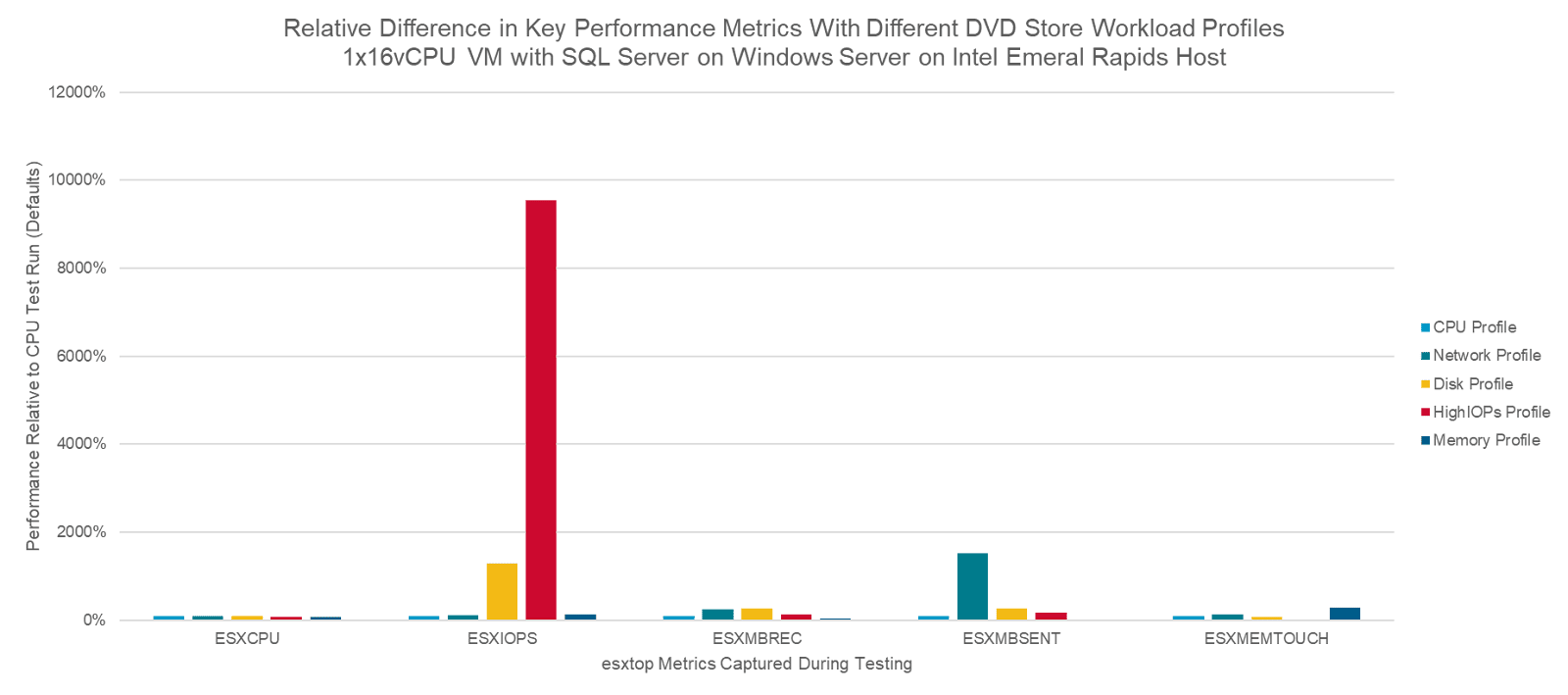
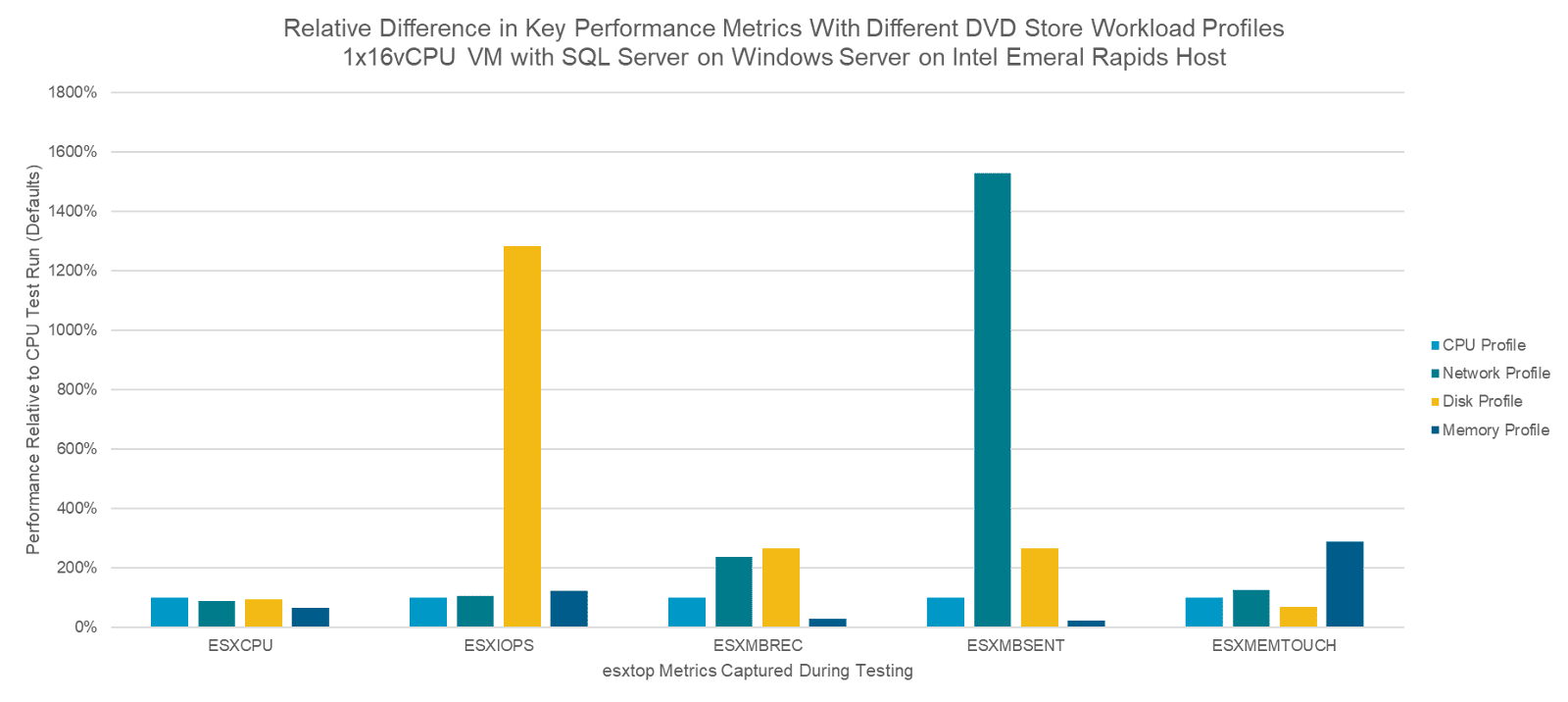
Для построения базовой линии замеры выполнялись на CPU-ориентированном профиле. Затем те же тесты были проведены с профилями, акцентированными на диск, на максимально высокий IOPS, на сеть и на память; полученные значения ключевых метрик сопоставлялись с базовыми. На графиках ниже показаны относительные различия по этим метрикам относительно базового CPU-профиля. На первом графике приведены все профили нагрузки; на втором профиль highIOPS убран, чтобы наглядно увидеть различия между остальными.
Если кратко резюмировать результаты, то в ключевой для каждого профиля метрике заметен значительный прирост:
Disk-профиль выдаёт в 13 раз больше IOPS
HighIOPS-профиль обеспечивает в 95 раз больше IOPS — это в 7 раз выше, чем у Disk-профиля
Network-профиль увеличивает количество отправленных мегабит в секунду в 15 раз
Memory-профиль вызывает в 2,9 раза большее значение активной памяти
Подробное описание всех профилей нагрузки приведено в файле ds35_workload_profiles.txt в репозитории DVD Store на GitHub. Там же указаны конкретные параметры DVD Store, особенности конфигурации БД и краткие пояснения к каждому сценарию.
Компания VMware продолжает развитие своей платформы для частных облаков — VMware Cloud Foundation (VCF) 9.0. Недавно опубликованы первые результаты производительности с использованием бенчмарка VMmark 4, выполненные на базе VCF 9.0 с встроенным программно определяемым хранилищем VMware vSAN. Этот результат стал важной вехой для оценки возможностей платформы в реальных условиях нагрузки, демонстрируя, что VCF 9.0 способна эффективно масштабировать инфраструктуру частного облака с помощью современного оборудования и передовых технологий.
Что такое VMmark 4, и зачем он нужен
VMmark 4 — это кластерный бенчмарк VMware, предназначенный для измерения производительности и масштабируемости виртуализированных сред. В отличие от синтетических тестов, VMmark моделирует реальные корпоративные рабочие нагрузки:
базы данных
веб-серверы
почтовые системы
application-серверы
файловые сервисы
Нагрузка масштабируется в единицах tiles — каждый tile представляет собой комплекс виртуальных машин с типовым профилем предприятия. Итоговый показатель (VMmark Score) отражает способность кластера обслуживать увеличивающееся число рабочих нагрузок при сохранении SLA по производительности.
Тестовая конфигурация: ключевые компоненты
Для испытаний использовалась конфигурация, включающая новейшие аппаратные и программные компоненты:
Программное обеспечение: VMware Cloud Foundation 9.0.1.0 .
vSAN 9 ESA: программное хранилище уровня предприятия с оптимизированной архитектурой Express Storage Architecture.
NSX: сетевые сервисы и безопасность для виртуальной инфраструктуры.
Operations: мониторинг, аналитика и автоматизация облачных ресурсов.
Главная цель VCF — упростить развёртывание и управление частными облаками с уровня инфраструктуры до сервисов, при этом обеспечивая масштабируемость, производительность и возможность автоматизации.
Результат тестирования
Для объективного сравнения использовалась идентичная вычислительная платформа (AMD EPYC 9965, суммарно 1536 физических ядер кластера), но две разные подсистемы хранения:
vSAN 9.0 ESA (All-Flash, NVMe)
Классический FC SAN (Dell PowerMax 8000)
Таблица результатов:
Версия VCF
Тип хранилища
Процессор
Всего ядер
VMmark 4 Score
9.0.1.0
vSAN 9.0 ESA (All-Flash)
AMD EPYC 9965
1536
12.42 @ 15.4 tiles
9.0.0.0
FC SAN (Dell PowerMax 8000)
AMD EPYC 9965
1536
12.22 @ 14 tiles
Интерпретация результатов:
Tiles — это масштабируемые блоки нагрузки в VMmark 4. Каждый tile представляет набор типовых корпоративных рабочих нагрузок (Web, DB, Mail, Application Server и др.).
Значение 15.4 tiles означает более высокий уровень масштабирования кластера.
Итоговый показатель 12.42 — агрегированный производительный балл, учитывающий пропускную способность и latency.
Главный вывод - конфигурация с vSAN 9.0 ESA продемонстрировала:
Большее число поддерживаемых tiles (15.4 против 14 для FC)
Более высокий итоговый Score
Лучшую масштабируемость без использования внешнего SAN-массива.
Это подтверждает, что современная архитектура vSAN ESA в составе VCF 9.0 способна не только конкурировать с традиционными FC-решениями, но и превосходить их при одинаковой вычислительной базе.
Заключение
Новый VMmark 4 результат, полученный на VMware Cloud Foundation 9.0 с vSAN, подтверждает:
Высокую производительность и масштабируемость платформы.
Превосходство программно-определяемого хранения (vSAN) над традиционными SAN в современных конфигурациях.
Готовность VMware VCF 9.0 к использованию в масштабных частных облаках и корпоративных средах.
Для инженеров и архитекторов частных облаков это подтверждение того, что VCF 9.0 + vSAN — это не только удобная абстракция управления, но и мощная вычислительная платформа с высокими показателями эффективности.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
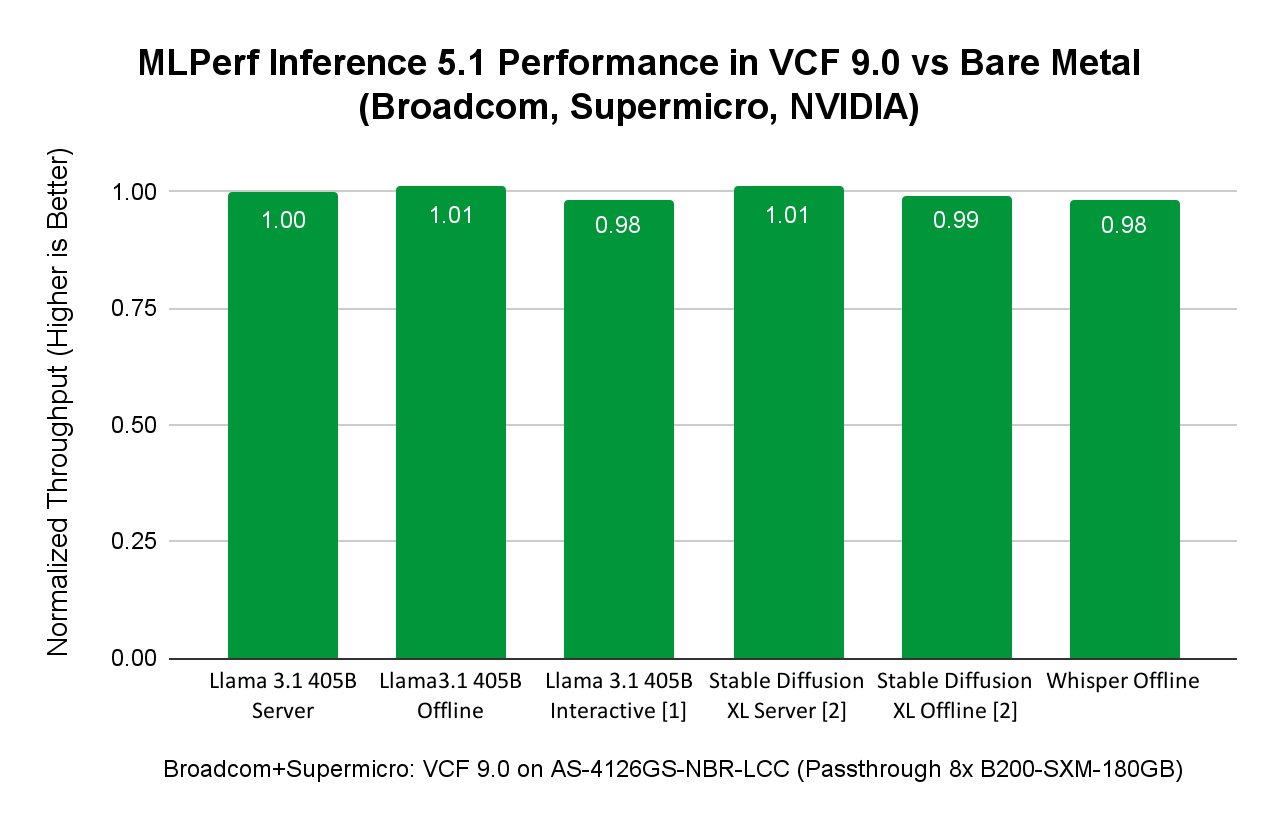
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
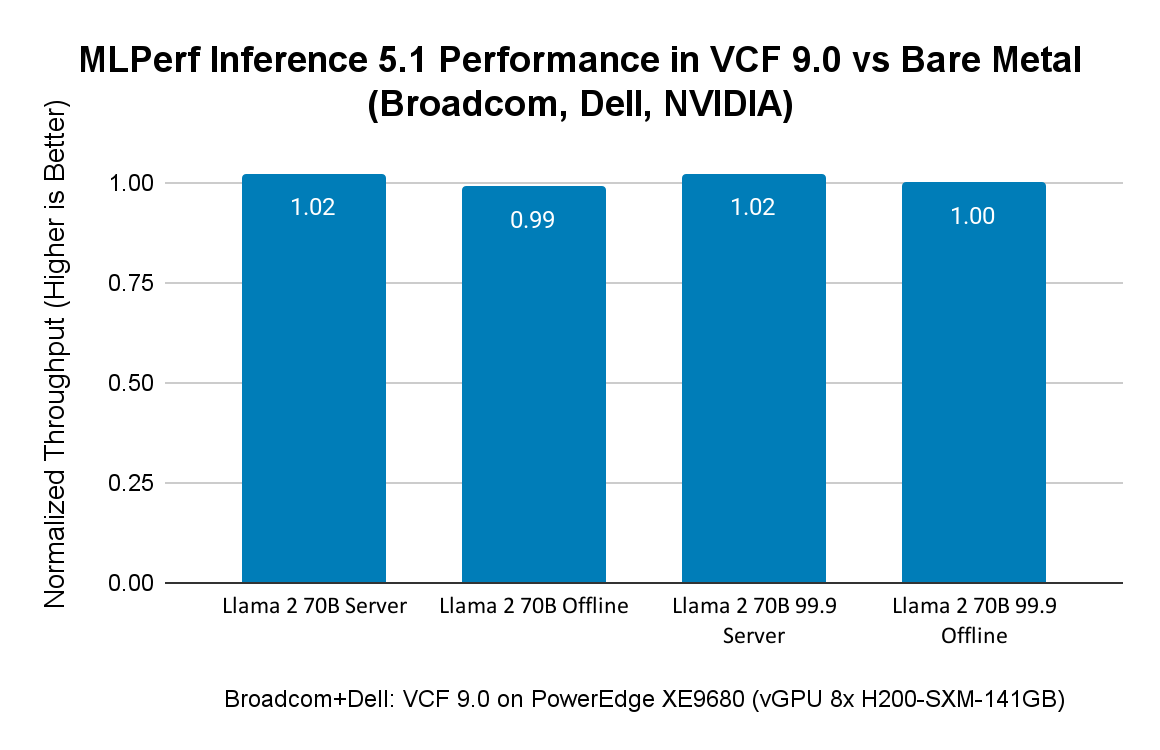
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
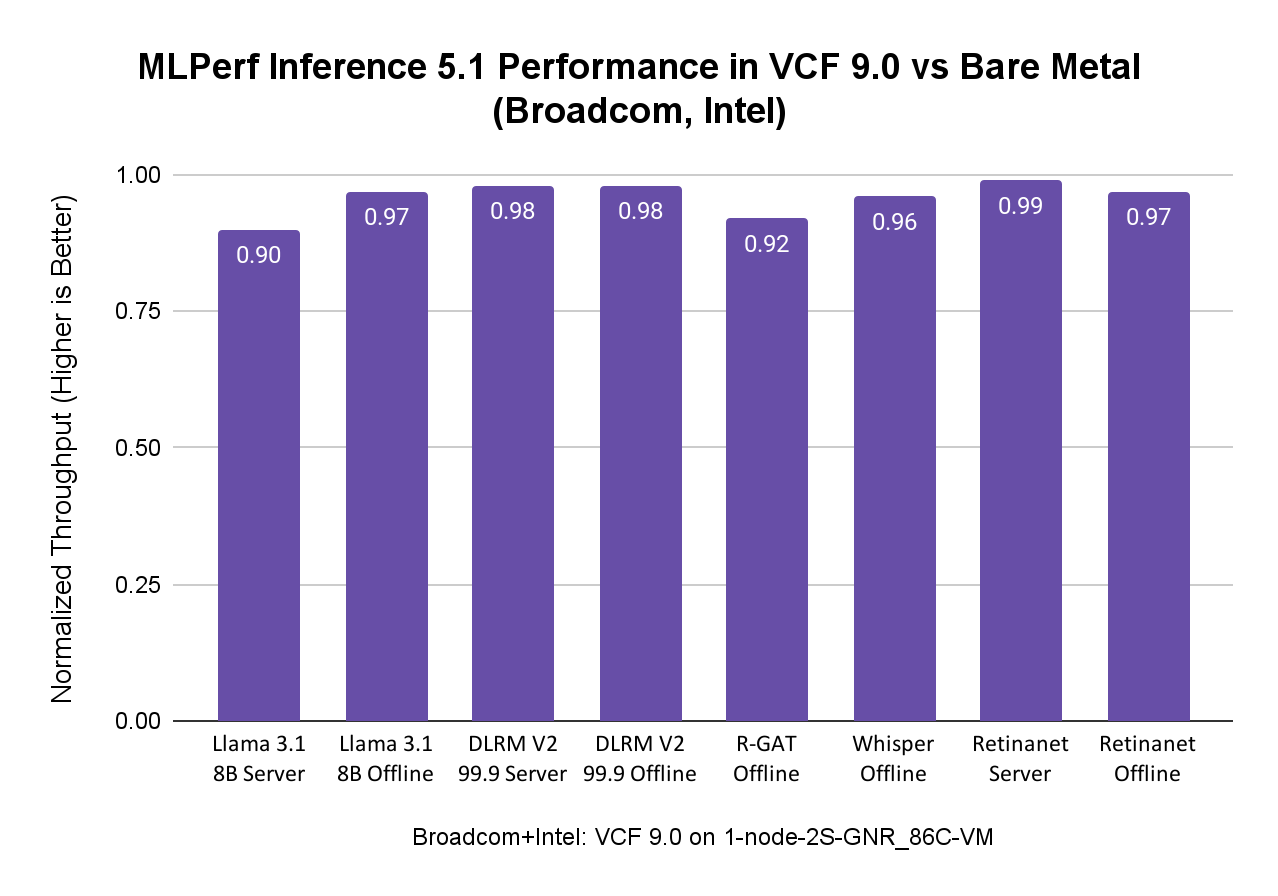
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Компания VMware недавно объявила о первом результате теста VMmark 4 с использованием последнего релиза платформы виртуализации VMware Cloud Foundation (VCF) 9.0. Метрики, показанные системой Lenovo, также стали первым результатом тестирования новейшей 4-сокетной системы на базе процессора Intel Xeon серии 6700 с технологией Performance-cores, который обеспечивает большее количество ядер и более высокую пропускную способность памяти. Итоговый результат доступен на странице VMmark 4 Results.
В следующей таблице приведено сравнение нового результата Lenovo с системой предыдущего поколения ThinkSystem под управлением vSphere 8.0 Update 3:
График показывает рост общего количества ядер на 43% между этими двумя результатами:
С точки зрения очков производительности, показатель VMmark 4 вырос на 49%:
Ключевые моменты:
Сочетание VCF 9.0 и нового серверного оборудования позволило запустить на 50% больше виртуальных машин / рабочих нагрузок (132) по сравнению с результатом предыдущего поколения (88 ВМ).
Процессоры Intel Xeon 6788P в Lenovo ThinkSystem SR860 V4 имеют на 43% больше ядер, чем процессоры предыдущего поколения Intel Xeon Platinum 8490H в ThinkSystem SR860 V3
Показатель VMmark на 49% выше, чем результат VMmark 4 для предыдущего поколения.
VMmark — это бесплатный инструмент тестирования, который используется партнёрами и клиентами для оценки производительности, масштабируемости и энергопотребления платформ виртуализации. Посетите страницу продукта VMmark и сообщество VMmark Community, чтобы узнать больше. Также вы можете попробовать VMmark 4 прямо сейчас через VMware Hands-on Labs Catalog, выполнив поиск по запросу «VMmark».
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.
Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.
Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
Конфигурацию ESX для включения GPUDirect RDMA
Развертывание Service VM
Настройку кластера VKS
Установку операторов (NVIDIA Network и GPU Operators)
Процедуры загрузки хранилища и моделей
Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.
AI и генеративный AI (Gen AI) требуют значительной инфраструктуры, а задачи, такие как тонкая настройка, кастомизация, развертывание и выполнение запросов, могут сильно нагружать ресурсы. Масштабирование этих операций становится проблематичным без достаточной инфраструктуры. Кроме того, необходимо соответствовать различным требованиям в области комплаенса и законодательства в разных отраслях и странах. Решения на базе Gen AI должны обеспечивать контроль доступа, правильное размещение рабочих нагрузок и готовность к аудиту для соблюдения этих стандартов. Чтобы решить эти задачи, Broadcom представила VMware Private AI, которая помогает клиентам запускать модели рядом с их собственными данными. Объединяя инновации обеих компаний, Broadcom и NVIDIA стремятся раскрыть потенциал AI и повысить производительность при более низкой совокупной стоимости владения (TCO).
Технический документ «Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking» подробно описывает сквозное развертывание и конфигурацию, с акцентом на DirectPath I/O (passthrough) для GPU, а также сетевые адаптеры Thor 2 с Ethernet-коммутатором Tomahawk 5. Это руководство необходимо архитекторам инфраструктуры, администраторам VCF и специалистам по data science, которые стремятся достичь оптимальной производительности своих AI-моделей в среде VCF.
Что охватывает этот документ?
Документ предоставляет детальные рекомендации по следующим направлениям:
Адаптеры Broadcom Thor 2 и GPU NVIDIA: как эффективно интегрировать сетевые карты Broadcom и GPU NVIDIA в виртуальные машины глубокого обучения (DLVM) на базе Ubuntu в среде VMware Cloud Foundation (VCF).
Сетевая конфигурация: пошаговые инструкции по настройке Ethernet-адаптеров Thor 2 и коммутаторов Tomahawk 5 для включения RoCE (RDMA over Converged Ethernet) с GPU NVIDIA, что обеспечивает низкую задержку и высокую пропускную способность, критически важные для AI-нагрузок.
Тестирование производительности: процедуры запуска тестов с использованием ключевых библиотек коллективных коммуникаций, таких как NCCL, для проверки эффективности многопроцессорных GPU-операций.
Инференс LLM: рекомендации по запуску и тестированию инференса больших языковых моделей (LLM) с помощью NVIDIA Inference Microservices (NIM) и vLLM, демонстрирующие реальный прирост производительности.
Ключевые особенности решения
Решение, описанное в документе, ориентировано на сертифицированные системы VMware Private AI на базе HGX, которые обычно оснащены 4 или 8 GPU H100/H200 с интерконнектом NVSwitch и NVLink. Целевая среда — это приватное облако на базе VCF, использующее сетевые адаптеры Broadcom 400G BCM957608 NICs и кластеризированные GPU NVIDIA H100, соединённые через Ethernet.
Ключевой аспект данного развертывания — использование DirectPath I/O для GPU и адаптеров Thor2, что обеспечивает выделенный доступ к аппаратным ресурсам и максимальную производительность. В руководстве также подробно рассматриваются следующие важные элементы:
BIOS и прошивки: рекомендуемые конфигурации для серверов HGX, позволяющие раскрыть максимальную производительность.
Настройки ESX: оптимизация ESX для passthrough GPU и сетевых устройств, включая корректную разметку оборудования и конфигурацию ACS (Access Control Services).
Настройки виртуальных машин: кастомизация Deep Learning VM (DLVM) для DirectPath I/O, включая назначение статических IP и важные расширенные параметры ВМ для ускоренного запуска и повышения производительности.
Валидация производительности
Подробные инструкции по запуску RDMA, GPUDirect RDMA с Perftest и тестов NCCL на нескольких узлах с разъяснением ожидаемой пропускной способности и задержек.
Бенчмаркинг виртуальной и bare-metal производительности Llama-3.1-70b NIM с помощью genai-perf, позволяющий достичь результатов, близких к bare-metal.
Использование evalscope для оценки точности и стресс-тестирования производительности передовой модели рассуждений gpt-oss-120b.
Вот интересный результат из исследования, доказывающий, что работа GPU в виртуальной среде ничем не хуже, чем в физической:
Это комплексное руководство является ценным ресурсом для всех, кто стремится развернуть и оптимизировать AI-инференс на надежной виртуальной инфраструктуре с использованием серверов NVIDIA HGX и сетевых решений Broadcom Ethernet. Следуя описанным в документе лучшим практикам, организации могут создавать масштабируемые и высокопроизводительные AI-платформы, соответствующие требованиям современных приложений глубокого обучения.
Недавно компания VMware опубликовала полезный для администраторов документ «vSphere 9.0 Performance Best Practices» с указанием ключевых рекомендаций по обеспечению максимальной производительности гипервизора ESX и инфраструктуры управления vCenter.
Документ охватывает ряд аспектов, начиная с аппаратных требований и заканчивая тонкой настройкой виртуальной инфраструктуры. Некоторые разделы включают не всем известные аспекты тонкой настройки:
Настройки BIOS: рекомендуется включить AES-NI, правильно сконфигурировать энергосбережение (например, «OS Controlled Mode»), при необходимости отключить некоторые C-states в особо чувствительных к задержкам приложениях.
vCenter и Content Library: советуют минимизировать автоматические скриптовые входы, использовать группировку vCenter для повышения синхронизации, хранить библиотеку контента на хранилищах с VAAI и ограничивать сетевую нагрузку через глобальный throttling.
Тонкое администрирование: правила доступа, лимиты, управление задачами, патчинг и обновления (включая рекомендации по BIOS и live scripts) и прочие глубокие настройки.
Отличия от версии для vSphere 8 (ESX и vCenter)
Аппаратные рекомендации
vSphere 8 предоставляет рекомендации по оборудованию: совместимость, минимальные требования, использование PMem (Optane, NVDIMM-N), vPMEM/vPMEMDisk, VAAI, NVMe, сетевые настройки, BIOS-опции и оптимизации I/O и памяти.
vSphere 9 добавляет новые аппаратные темы: фокус на AES-NI, snoop-режимах, NUMA-настройках, более гибком управлении энергопотреблением и безопасности на уровне BIOS.
vMotion и миграции
vSphere 8: введение «Unified Data Transport» (UDT) для ускорения холодных миграций и клонирования (при поддержке обеих сторон). Также рекомендации для связки encrypted vMotion и vSAN.
vSphere 9: больше внимания уделяется безопасности и производительности на стороне vCenter и BIOS, но UDT остаётся ключевым механизмом. В анонсах vSphere 9 в рамках Cloud Foundation акцент сделан на улучшенном управлении жизненным циклом и live patching.
Управление инфраструктурой
vSphere 8: рекомендации по vSphere Lifecycle Manager, UDT, обновлению vCenter и ESXi, GPU профили (в 8.0 Update 3) — включая поддержку разных vGPU, GPU Media Engine, dual DPU и live patch FSR.
vSphere 9 / VMware Cloud Foundation 9.0: новый подход к управлению жизненным циклом – поддержка live patch для vmkernel, NSX компонентов, более мощные «монстр-ВМ» (до 960 vCPU), direct upgrade с 8-й версии, image-based lifecycle management.
Работа с памятью
vSphere 8: рекомендации для Optane PMem, vPMEM/vPMEMDisk, управление памятью через ESXi.
vSphere 9 (через Cloud Foundation 9.0): внедрён memory tiering, позволяющий увеличить плотность ВМ в 2 раза при минимальной потере производительности (5%) и снижении TCO до 40%, без изменений в гостевой ОС.
Документ vSphere 9.0 Performance Best Practices содержит обновлённые и расширенные рекомендации для платформы vSphere 9, уделяющие внимание аппаратному уровню (BIOS-настройки, безопасность), инфраструктурному управлению, а также новым подходам к памяти (главный из них - memory tiering).
Затраты на память по-прежнему остаются одной из самых крупных статей расходов на серверную инфраструктуру, и при этом большая часть дорогой оперативной памяти (DRAM) используется неэффективно. А что, если вы могли бы удвоить плотность виртуальных машин и сократить совокупную стоимость владения до 40%?
С выходом VMware Cloud Foundation 9.0 технология Memory Tiering (многоуровневая организация памяти) делает это возможным. Команда инженеров VMware недавно представила результаты тестирования производительности, которые демонстрируют, как эта технология меняет экономику датацентров. Подробности — в новом исследовании: Memory Tiering Performance in VMware Cloud Foundation 9.0.
Ниже мы расскажем об основных результатах исследования, которые показывают, что Memory Tiering позволила увеличить плотность виртуальных машин в 2 раза при незначительном снижении производительности. Для получения полной информации о принципах работы Memory Tiering и более подробных данных о производительности, ознакомьтесь с полным текстом исследования.
Как Memory Tiering улучшает производительность датацентров и снижает затраты
В VMware Cloud Foundation 9.0 технология Memory Tiering предоставляет виртуальным машинам единое логическое адресное пространство памяти. Однако «под капотом» она управляет двумя уровнями памяти: Tier 0 (DRAM) и Tier 1 (Memory Tiering), в зависимости от активности памяти виртуальной машины. Фактически, система старается держать «горячую» (активную) память в DRAM, а «холодную» (неактивную) — на NVMe.
Со стороны виртуальной машины это выглядит как единое, увеличенное пространство памяти. В фоновом режиме гипервизор ESX динамически управляет размещением страниц памяти между двумя уровнями — DRAM и NVMe — обеспечивая при этом оптимальную производительность.
VMware провела тестирование на различных корпоративных нагрузках, чтобы подтвердить эффективность Memory Tiering. Были использованы серверы на базе процессоров Intel и AMD с различными конфигурациями DRAM. В VMware Cloud Foundation 9.0 по умолчанию используется соотношение DRAM к NVMe 1:1, и во всех тестах применялось именно оно.
Увеличение плотности ВМ в 2 раза, потеря производительности - 5-10% (MySQL, SQL)
Login Enterprise: Производительность виртуальных рабочих столов
Команда VMware использовала Login Enterprise для тестирования производительности VDI (виртуальных рабочих столов) в различных сценариях. Во всех тестах удалось удвоить количество виртуальных машин на хосте ESX при минимальном снижении производительности. Например, в конфигурации из трёх узлов vSAN:
Удвоили количество VDI-сессий, которые могли выполняться на трёхузловом кластере vSAN — с 300 (только DRAM) до 600 (с использованием Memory Tiering).
При этом не было зафиксировано потери производительности по сравнению с аналогичной конфигурацией, использующей только DRAM.
Тест VMmark 3.1, включающий несколько нагрузок, имитирующих работу корпоративных приложений, показал отличные результаты:
Конфигурация с Memory Tiering достигла 6 тайлов против 3 тайлов в конфигурации, использующей только DRAM. Это в 2 раза лучше.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering, снижение производительности составило всего 5%, несмотря на использование более медленной памяти NVMe в режиме Memory Tiering.
HammerDB и DVD Store: производительность баз данных
Производительность баз данных — один из самых ресурсоёмких тестов для любой инфраструктуры. VMware использовала HammerDB и DVD Store в качестве нагрузок для тестирования SQL Server, Oracle Database и MySQL. С помощью Memory Tiering удалось удвоить количество виртуальных машин при минимальном влиянии на производительность. Например, в тесте Oracle Database с нагрузкой DVD Store были получены следующие результаты:
На хосте ESX с Memory Tiering удалось запустить 8 виртуальных машин против 4 в конфигурации, использующей только DRAM — плотность удвоилась.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering снижение производительности составило менее 5%.
Мониторинг Memory Tiering на хостах ESX
Для обеспечения высокой производительности при использовании Memory Tiering следует отслеживать два ключевых показателя:
Поддерживайте активную память на уровне 50% или меньше от объёма DRAM — это обеспечит оптимальную производительность.
Следите за задержкой чтения с NVMe-устройства. Наилучшая производительность достигается при задержке менее 200 микросекунд.
Преобразите экономику вашего датацентра
Memory Tiering предлагает новый подход к организации памяти:
До 40% экономии совокупной стоимости владения (TCO) за счёт снижения требований к DRAM.
Прозрачная работа — не требует изменений в приложениях или гостевых операционных системах.
До 2-кратного увеличения плотности виртуальных машин для различных типов нагрузок.
Гибкая инфраструктура, адаптирующаяся к изменяющимся требованиям рабочих нагрузок.
Memory Tiering уже доступна в VMware Cloud Foundation 9. Скачайте полное исследование производительности, чтобы подробнее ознакомиться с методологией тестирования, результатами и рекомендациями по внедрению.
Хотите попробовать Memory Tiering на практике?
Полноценный практический лабораторный курс предоставляет живую среду vSphere 9.0, где вы сможете изучить Memory Tiering и узнать, как использование NVMe-накопителей позволяет расширить и оптимизировать доступную память для хостов ESX.
Платформа vSphere всегда предоставляла несколько способов использовать несколько сетевых карт (NIC) совместно, но какой из них лучший для vSAN? Давайте рассмотрим ключевые моменты, важные для конфигураций vSAN в сетевой топологии. Этот материал не является исчерпывающим анализом всех возможных вариантов объединения сетевых интерфейсов, а представляет собой справочную информацию для понимания наилучших вариантов использования техники teaming в среде VMware Cloud Foundation (VCF).
Описанные здесь концепции основаны на предыдущих публикациях:
Объединение сетевых портов NIC — это конфигурация vSphere, при которой используется более одного сетевого порта для выполнения одной или нескольких задач, таких как трафик ВМ или трафик VMkernel (например, vMotion или vSAN). Teaming позволяет достичь одной или обеих следующих целей:
Резервирование: обеспечение отказоустойчивости в случае сбоя сетевого порта на хосте или коммутатора, подключенного к этому порту.
Производительность: распределение одного и того же трафика по нескольким соединениям может обеспечить агрегацию полосы пропускания и повысить производительность при нормальной работе.
В этой статье мы сосредоточимся на объединении ради повышения производительности.
Распространённые варианты объединения
Выбор варианта teaming для vSAN зависит от среды и предпочтений, но есть важные компромиссы, особенно актуальные для vSAN. Начиная с vSAN 8 U3, платформа поддерживает один порт VMkernel на хост, помеченный для трафика vSAN. Вот три наиболее распространённые подхода при использовании одного порта VMkernel:
1. Один порт VMkernel для vSAN с конфигурацией Active/Standby
Используются два и более аплинков (uplinks), один из которых активен, а остальные — в режиме ожидания.
Это наиболее распространённая и рекомендуемая конфигурация для всех кластеров vSAN.
Простая, надёжная, идеально подходит для трафика VMkernel (например, vSAN), так как обеспечивает предсказуемый маршрут, что особенно важно в топологиях spine-leaf (Clos).
Такой подход обеспечивает надежную и стабильную передачу трафика, но не предоставляет агрегации полосы пропускания — трафик проходит только по одному активному интерфейсу.
Обычно Standby-интерфейс используется для другого типа трафика, например, vMotion, для эффективной загрузки каналов.
2. Один порт VMkernel для vSAN с двумя активными аплинками (uplinks) и балансировкой Load Based Teaming (LBT)
Используются два и более аплинков в режиме «Route based on physical NIC load».
Это можно рассматривать как агрегацию на уровне гипервизора.
Изначально предназначен для VM-портов, а не для трафика VMkernel.
Преимущества для трафика хранилища невелики, могут вызывать проблемы из-за отсутствия предсказуемости маршрута.
Несмотря на то, что это конфигурация по умолчанию в VCF, она не рекомендуется для портов VMkernel, помеченных как vSAN.
В VCF можно вручную изменить эту конфигурацию на Active/Standby без проблем.
3. Один порт VMkernel для vSAN с использованием Link Aggregation (LACP)
Использует два и более аплинков с расширенным хешированием для балансировки сетевых сессий.
Может немного повысить пропускную способность, но требует дополнительной настройки на коммутаторах и хосте.
Эффективность зависит от топологии и может увеличить нагрузку на spine-коммутаторы.
Используется реже и ограниченно поддерживается в среде VCF.
Версия VCF по умолчанию может использовать Active/Active с LBT для трафика vSAN. Это универсальный режим, поддерживающий различные типы трафика, но неоптимален для VMkernel, особенно для vSAN.
Рекомендуемая конфигурация:
Active/Standby с маршрутизацией на основе виртуального порта (Route based on originating virtual port ID). Это поддерживается в VCF и может быть выбрано при использовании настраиваемого развертывания коммутатора VDS. Подробнее см. в «VMware Cloud Foundation Design Guide».
Можно ли использовать несколько портов VMkernel на хосте для трафика vSAN?
Теоретически да, но только в редком случае, когда пара коммутаторов полностью изолирована (подобно Fibre Channel fabric). Это не рекомендуемый и редко используемый вариант, даже в vSAN 8 U3.
Влияние объединения на spine-leaf-сети
Выбор конфигурации teaming на хостах vSAN может показаться несущественным, но на деле сильно влияет на производительность сети и vSAN. В топологии spine-leaf (Clos), как правило, нет прямой связи между leaf-коммутаторами. При использовании Active/Active LBT половина трафика может пойти через spine, вместо того чтобы оставаться на уровне leaf, что увеличивает задержки и снижает стабильность.
Аналогичная проблема у LACP — он предполагает наличие прямой связи между ToR-коммутаторами. Если её нет, трафик может либо пойти через spine, либо LACP-связь может полностью нарушиться.
На практике в некоторых конфигурациях spine-leaf коммутаторы уровня ToR (Top-of-Rack) соединены между собой через межкоммутаторное соединение, такое как MLAG (Multi-Chassis Link Aggregation) или VLTi (Virtual Link Trunking interconnect). Однако не стоит считать это обязательным или даже желательным в архитектуре spine-leaf, так как такие соединения часто требуют механизмов блокировки, например Spanning Tree (STP).
Стоимость и производительность: нативная скорость соединения против агрегации каналов
Агрегация каналов (link aggregation) может быть полезной для повышения производительности при правильной реализации и в подходящих условиях. Но её преимущества часто переоцениваются или неправильно применяются, что в итоге может приводить к большим затратам. Ниже — четыре аспекта, которые часто упускаются при сравнении link aggregation с использованием более быстрых нативных сетевых соединений.
1. Высокое потребление портов
Агрегация нескольких соединений требует большего количества портов и каналов, что снижает общую портовую ёмкость коммутатора и ограничивает количество возможных хостов в стойке. Это увеличивает расходы на оборудование.
2. Ограниченный прирост производительности
Агрегация каналов, основанная на алгоритмическом балансировании нагрузки (например, LACP), не дает линейного увеличения пропускной способности.
То есть 1+1 не равно 2. Такие механизмы лучше работают при большом количестве параллельных потоков данных, но малоэффективны для отдельных (дискретных) рабочих нагрузок.
3. Ошибочные представления об экономичности
Существует мнение, что старые 10GbE-коммутаторы более экономичны. На деле — это миф.
Более объективный показатель — это пропускная способность коммутатора, измеряемая в Гбит/с или Тбит/с. Хотя сам по себе 10Gb-коммутатор может стоить дешевле, более быстрые модели обеспечивают в 2–10 раз больше пропускной способности, что делает стоимость за 1 Гбит/с ниже. Кроме того, установка более быстрых сетевых адаптеров (NIC) на серверы обычно увеличивает стоимость менее чем на 1%, при этом может дать 2,5–10-кратный прирост производительности.
4. Нереализованные ресурсы
Современные серверы обладают огромными возможностями по процессору, памяти и хранилищу, но не могут раскрыть свой потенциал из-за сетевых ограничений.
Балансировка между вычислительными ресурсами и сетевой пропускной способностью позволяет:
сократить общее количество серверов;
снизить капитальные затраты;
уменьшить занимаемое пространство;
снизить нагрузку на систему охлаждения;
уменьшить потребление портов в сети.
Именно по этим причинам VMware рекомендует выбирать более высокие нативные скорости соединения (25Gb или 100Gb), а не полагаться на агрегацию каналов — особенно в случае с 10GbE. Напомним, что когда 10GbE появился 23 года назад, серверные процессоры имели всего одно ядро, а объём оперативной памяти составлял в 20–40 раз меньше, чем сегодня. С учётом того, что 25GbE доступен уже почти десятилетие, актуальность 10GbE для дата-центров практически исчерпана.
Объединение для повышения производительности и отказоустойчивости обычно предполагает использование нескольких физических сетевых карт (NIC), каждая из которых может иметь 2–4 порта. Сколько всего портов следует иметь на хостах vSAN? Это зависит от следующих факторов:
Степень рабочих нагрузок: среда с относительно пассивными виртуальными машинами предъявляет гораздо меньшие требования, чем среда с тяжёлыми и ресурсоёмкими приложениями.
Нативная пропускная способность uplink-соединений: более высокая скорость снижает вероятность конкуренции между сервисами (vMotion, порты ВМ и т.д.), работающими через одни и те же аплинки.
Используемые сервисы хранения данных: выделение пары портов для хранения (например, vSAN) почти всегда даёт наилучшие результаты — это давно устоявшаяся практика, независимо от хранилища.
Требования безопасности и изоляции: в некоторых средах может потребоваться, чтобы аплинки, используемые для хранения или других задач, были изолированы от остального трафика.
Количество портов на ToR-коммутаторах: количество аплинков может быть ограничено самими коммутаторами ToR. Пример: пара ToR-коммутаторов с 2?32 портами даст 64 порта на стойку. Если в стойке размещено максимум 16 хостов по 2U, каждый хост может получить максимум 4 uplink-порта. А если коммутаторы имеют по 48 портов, то на 16 хостов можно выделить по 6 uplink-портов на каждый хост. Меньшее количество хостов в стойке также позволяет увеличить количество портов на один хост.
Рекомендация:
Даже если вы не используете все аплинки на хосте, рекомендуется собирать vSAN ReadyNode с двумя NIC, каждая из которых имеет по 4 uplink-порта. Это позволит без проблем выделить отдельную команду (team) портов только под vSAN, что настоятельно рекомендуется. Такой подход обеспечит гораздо большую гибкость как сейчас, так и в будущем, по сравнению с конфигурацией 2 NIC по 2 порта.
Итог
Выбор оптимального варианта объединения (teaming) и скорости сетевых соединений для ваших хостов vSAN — это важный шаг к тому, чтобы обеспечить максимальную производительность ваших рабочих нагрузок.
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:
Конфигурация оборудования Dell PowerEdge XE9680:
Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:
Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.
Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.
Intel недавно представила новое поколение серверных процессоров — Intel Xeon 6 с производительными ядрами (Performance-cores), которые отличаются увеличенным числом ядер и более высокой пропускной способностью памяти. Чтобы продемонстрировать производительность и масштабируемость этих процессоров, VMware опубликовала новые результаты тестов VMmark 4, полученных при участии двух ключевых партнёров — Dell Technologies и Hewlett Packard Enterprise. Конфигурация Dell представляет собой пару узлов в режиме «Matched Pair», а результат HPE получен на четырёхузловом кластере VMware vSAN. Оба результата основаны на VMware ESXi 8.0 Update 3e — первой версии, поддерживающей эти процессоры. Новые данные уже доступны на странице результатов VMmark 4.
Сравнение производительности: «Granite Rapids» и «Emerald Rapids»
В качестве примера, иллюстрирующего высокую производительность и масштабируемость, ниже приводится таблица с двумя результатами VMmark 4, позволяющая сравнить процессоры предыдущего поколения “Emerald Rapids” с новыми “Granite Rapids” серии 6700.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
В январе 2025 года компания VMware опубликовала технический документ под названием «Performance Tuning for Latency-Sensitive Workloads: VMware vSphere 8». Этот документ предоставляет рекомендации по оптимизации производительности для рабочих нагрузок, критичных к задержкам, в среде VMware vSphere 8.
Документ охватывает различные аспекты конфигурации, включая требования к базовой инфраструктуре, настройки хоста, виртуальных машин, сетевые аспекты, а также оптимизацию операционной системы и приложений. В разделе «Host considerations» обсуждаются такие темы, как изменение настроек BIOS на физическом сервере, отключение EVC, управление vMotion и DRS, а также настройка продвинутых параметров, таких как отключение action affinity и открытие кольцевых буферов.
В разделе «VM considerations» рассматриваются рекомендации по оптимальному выделению ресурсов виртуальным машинам, использованию актуальных версий виртуального оборудования, настройке vTopology, отключению функции hot-add, активации параметра чувствительности к задержкам для каждой ВМ, а также использовании сетевого адаптера VMXNET3. Кроме того, обсуждается балансировка потоков передачи и приема данных, привязка потоков передачи к определенным ядрам, ассоциация ВМ с конкретными NUMA-нодами и использование технологий SR-IOV или DirectPath I/O при необходимости.
Раздел о сетевых настройках акцентирует внимание на использовании улучшенного пути передачи данных для NFV-нагрузок и разгрузке сервисов vSphere на DPU (Data Processing Units), также известных как SmartNICs.
Наконец, в разделе, посвященном настройке гостевой ОС и приложений, приводятся рекомендации по оптимизации производительности на уровне операционной системы и приложений, работающих внутри виртуальных машин.
В документе описаны улучшения производительности различных API тегирования, которые доступны для vCenter в VMware vSphere Automation SDK. Он содержит примеры кода и обновленные данные о производительности.
По сравнению с выпуском vCenter 7.0 U3, версия 8.0 U3 демонстрирует значительное ускорение работы API привязки тегов:
attach() – увеличение скорости на 40%.
attachTagToMultipleObjects() – увеличение скорости на 200%.
attachMultipleTagsToObject() – увеличение скорости на 31%–36%.
Помимо привязки тегов, в документе представлены данные о запросах виртуальных машин, связанных с тегами, а также об улучшениях работы режима связи нескольких vCenter - Enhanced Linked Mode. vCenter 8.0 U3 поддерживает те же лимиты, что и 7.0 U3, в отношении количества тегов, категорий и привязок тегов, но при этом обеспечивает повышенную производительность.
Ниже представлена диаграмма, демонстрирующая некоторые из достигнутых улучшений. В частности, attachTagToMultipleObjects() показывает увеличение производительности на 200% при привязке 15 тегов к 5000 виртуальным машинам в vCenter 8.0 U3 по сравнению с 7.0 U3.
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
Последнее независимое исследование, проведенное компанией Principled Technologies, показало, что по сравнению с Red Hat OpenShift Virtualization 4.16.2, платформа VMware vSphere поддерживает на 62% больше транзакций баз данных и сохраняет их стабильную производительность при увеличении количества виртуальных машин. Кроме того, vSphere поддерживает в 1.5 раза больше виртуальных машин на хост, чем OpenShift, без необходимости дополнительной настройки для переподписки памяти (memory overcommitment).
VMware vSphere — это корпоративная платформа виртуализации вычислительных ресурсов, разработанная для предоставления преимуществ облачных технологий в рамках локальных рабочих нагрузок. Она объединяет передовые облачные инфраструктурные технологии с ускорением, основанным на процессорах для обработки данных (DPU) и графических процессорах (GPU), чтобы повысить производительность машин. Сегодня более 300 000 компаний используют vSphere для обеспечения цифровой трансформации. vSphere позволяет ИТ-командам повысить операционную эффективность, ускорить внедрение DevOps-решений и усилить безопасность.
Последнее обновление VMware vSphere 8 Update 3 включает специальную функцию управления памятью для технологии memory overcommitment, которая помогает балансировать производительность виртуальных машин и их плотность. Но как управление памятью в vSphere соотносится с конкурирующими решениями? Компания Principled Technologies провела детальное исследование производительности и плотности виртуальных машин для VMware vSphere 8 Update 3 в сравнении с Red Hat OpenShift Virtualization версии 4.16.2.
Обзор протестированных сценариев
Исследование Principled Technologies началось с тестирования 10 виртуальных машин с установленной СУБД SQL Server c использованием нагрузки TPROC-C для оценки производительности OLTP-транзакций (измеряемой в операциях в минуту, NOPM) для каждой платформы. Начальная конфигурация предполагала memory overcommitment без фактического перераспределения памяти или стрессового использования других ресурсов сервера. Затем плотность виртуальных машин постепенно увеличивалась: сначала до 12 ВМ, создавая сценарий с небольшой переподпиской по памяти, после чего добавлялись ВМ до тех пор, пока производительность платформы не снизилась на 10% или более. Как только платформа показывала значительное ухудшение производительности, тестирование масштабирования для него прекращалось.
Оба сценария использовали один и тот же сервер Dell PowerEdge R650, отличалась только используемая платформа виртуализации.
Ключевые результаты исследования от Principled Technologies
vSphere 8 обеспечивает лучшую производительность OLTP-транзакций и масштабирование до большего количества виртуальных машин без снижения производительности.
В базовом тесте каждое окружение было настроено с 10 виртуальными машинами по 28 ГБ виртуальной памяти (vRAM) каждая, что составило 280 ГБ выделенной памяти без необходимости переподписки. VMware vSphere 8 Update 3 обеспечила на 27,6% больше NOPM (новых операций в минуту), чем OpenShift, при этих условиях.
На следующем этапе тестирования на обех платформах виртуальное окружение масштабировалось до 12 виртуальных машин, что превысило физическую память сервера и потребовало переподписки. vSphere 8 Update 3 успешно справилась с этим увеличением без дополнительных настроек, обеспечив рост NOPM на 6% относительно базового уровня. Напротив, OpenShift потребовала ручной настройки переподписки памяти, что привело к снижению NOPM на 6,9% относительно базового уровня.
Эти результаты показывают, что vSphere 8 Update 3 не только эффективно поддерживает переподписку памяти на производственном уровне, но и увеличивает плотность виртуальных машин и производительность транзакций с минимальным вмешательством в конфигурацию.
vSphere 8 достигает более высоких пределов плотности виртуальных машин с минимальным падением производительности
Когда оба решения были доведены до предела их возможностей для определения порога плотности виртуальных машин, была зафиксирована значительная деградация (снижение NOPM более чем на 10%). VMware vSphere 8 Update 3 достигла значительной деградации при 20 виртуальных машинах, показав снижение NOPM на 14,31% по сравнению с конфигурацией из 12 виртуальных машин с небольшой переподпиской памяти. В то же время OpenShift Virtualization 4.16.2 столкнулась с деградацией уже при 13 виртуальных машинах, продемонстрировав снижение NOPM на 23,19% по сравнению с конфигурацией из 12 виртуальных машин. Это указывает на более низкий порог плотности для оптимальной производительности в случае OpenShift.
При запуске 20 виртуальных машин решение vSphere 8 Update 3 достигло пикового уровня загрузки процессора в 94,4%. При 12 виртуальных машинах загрузка процессора у vSphere составила 91,7%, а при 10 виртуальных машинах — 80,1%. В то же время решение OpenShift Virtualization 4.16.2 показало загрузку процессора в 58,3% при 13 виртуальных машинах, 61,5% при 12 виртуальных машинах и 52,1% при 10 виртуальных машинах. Этот тест демонстрирует, что vSphere 8 Update 3 может справляться с более высокой плотностью виртуальных машин, обеспечивая лучшую стабильность производительности при переподписке выделенной памяти по сравнению с OpenShift.
Таги: VMware, vSphere, Red Hat, OpenShift, Performance
Недавно компания VMware сделала важный анонс относительно компонента балансировщика нагрузки ввода-вывода Storage DRS (SDRS), который включает в себя механизм балансировки нагрузки на основе reservations для SDRS I/O и контроля ввода-вывода Storage I/O Control (SIOC). Все они будут устаревшими в будущих выпусках vSphere. Анонс был сделан в рамках релиза платформы VMware vSphere 8.0 Update 3. Об этом рассказал Дункан Эппинг.
Текущие версии ESXi 8.x и 7.x продолжат поддерживать эту функциональность. Устаревание затронет балансировку нагрузки на основе задержек (latency) для ввода-вывода и балансировку на основе reservations для ввода-вывода между хранилищами в кластере хранилищ Storage DRS. Кроме того, включение SIOC на хранилище и установка reservations и приоритетов с помощью политик хранения SPBM также будут устаревшими. Начальное размещение и балансировка нагрузки Storage DRS на основе хранилищ и настроек политик хранения SPBM для лимитов не будут затронуты.
Для Storage DRS (SDRS) это означает, что функциональность «балансировки по емкости» (capacity balancing) останется доступной, но все, что связано с производительностью, будет недоступно в следующем крупном выпуске платформы. Кроме того, обработка «шумных соседей» (noisy neighbor) через SIOC с использованием приоритетов или, например, reservations ввода-вывода также больше не будет доступна.
Некоторые из вас, возможно, уже заметили, что в интерфейсе на уровне отдельных ВМ исчезла возможность указывать лимит IOPS. Что это значит для лимитов IOPS в целом? Эта функциональность останется доступной через управление на основе политик (SPBM), как и сейчас. Таким образом, если вы задавали лимиты IOPS для каждой ВМ в vSphere 7 отдельно, после обновления до vSphere 8 вам нужно будет использовать настройку через политику SPBM. Опция задания лимитов IOPS через SPBM останется доступной. Несмотря на то, что в интерфейсе она отображается в разделе «SIOC», на самом деле эта настройка применяется через планировщик дисков на уровне каждого хоста.
На портале технических ресурсов Broadcom появилась полезная статья, посвященная производительности облачных приложений и причинам их земедления в производственной среде.
Часто бывает, что приложение, работающее на физическом сервере, демонстрирует хорошую производительность. Однако после упаковки приложения в образ, тестирования в Docker/Podman и последующей миграции в окружение Kubernetes производительность резко падает. По мере увеличения числа запросов к базе данных, выполняемых приложением, время отклика приложения возрастает.
Эта распространённая ситуация часто вызвана задержками ввода-вывода, связанными с передачей данных. Представьте, что это же приложение снова запускается на физическом сервере, но в следующем сценарии: устройство хранения базы данных создаётся на удалённом хранилище с Network File System (NFS).
Это означает, что необходимо учитывать следующие факторы:
Количество приложений, обращающихся к конечной точке хранилища (предполагается, что оно быстрое по своему устройству).
Это будет влиять на общую производительность отклика из-за производительности подсистемы ввода-вывода хранилища.
Способ, которым приложение извлекает данные из базы данных.
Кэширует ли оно данные, или просто отправляет очередной запрос? Являются ли запросы небольшими или крупными?
Задержка, вызванная сетевым доступом к хранилищу, и общая скорость работы хранилища.
При доступе к сетевому устройству несколько ключевых факторов влияют на скорость передачи данных:
Доступная скорость соединения
Используемое максимальное время передачи (MTU) / максимальный размер сегмента (MSS)
Размер передаваемой полезной нагрузки
Настройки TCP окна (скользящее окно)
Среднее время задержки при прохождении маршрута (RTT) от точки A до точки B в мс.
В датацентре скорость соединения обычно не является проблемой, поскольку все узлы соединены с пропускной способностью не менее 1 Гбит/с, иногда 10 Гбит/с, и подключены к одному коммутатору. MTU/MSS будет оптимальным для настроенного соединения. Остаются размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT. Наибольшее влияние окажут размер полезной нагрузки, задержка соединения и его качество, которые будут влиять на параметры скользящего окна.
Вот пример задержек между узлами в текущей настройке Kubernetes:
При увеличении размера полезной нагрузки пакета в пинге, как только он превышает текущий MTU, время отклика начинает увеличиваться. Например, для node2 размер полезной нагрузки составляет 64k — это экстремальный случай, который наглядно демонстрирует рост задержки.
Учитывая эти три момента (размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT), если разработчик создаёт приложение без использования встроенных возможностей кэширования, то запросы к базе данных начнут накапливаться, вызывая нагрузку на ввод-вывод. Такое упущение направляет все запросы через сетевое соединение, что приводит к увеличению времени отклика всего приложения.
На локальном хранилище или в среде с низкой задержкой (как сети, так и хранилища) можно ожидать, что приложение будет работать хорошо. Это типичная ситуация, когда команды разработки тестируют все в локальной среде. Однако при переходе на сетевое хранилище задержка, вызванная сетью, будет влиять на возможный максимальный уровень запросов. При проведении тех же тестов в производственной среде команды, вероятно, обнаружат, что система, способная обрабатывать, скажем, 1000 запросов к базе данных в секунду, теперь справляется только с 50 запросами в секунду. В таком случае стоит обратить внимание на три вероятные причины:
Переменные размеры пакетов, средний размер которых превышает настроенный MTU.
Сетевая задержка из-за того, что база данных размещена на отдельном узле, вдали от приложения.
Уменьшенное скользящее окно, так как все связанные системы подключаются к узлу базы данных. Это создаёт нагрузку на ввод-вывод файловой системы, из-за чего база данных не может обрабатывать запросы достаточно быстро.
Тесты показали, что алгоритм скользящего окна привёл к снижению скорости передачи данных (для справки: это механизм, используемый удалённым хранилищем на основе NFS). При среднем размере полезной нагрузки 4 Кб скорость передачи данных упала с 12 МБ/с на быстром соединении 1 Гбит/с (8 мс задержки) до ~15 Кбит/с, когда задержка соединения достигла 180 мс. Скользящее окно может вынудить каждую передачу данных возвращать пакет подтверждения (ACK) отправителю перед отправкой следующего пакета на соединениях с низкой задержкой.
Эту ситуацию можно протестировать локально с помощью утилиты tc на системе Linux. С её помощью можно вручную задать задержку для каждого устройства. Например, интерфейс можно настроить так, чтобы он отвечал с задержкой в 150 мс.
На Kubernetes, например, вы можете развернуть приложение с фронтендом, сервером приложений и бэкендом базы данных. Если сервер приложений и бэкенд базы данных развернуты на разных узлах, даже если эти узлы быстрые, они будут создавать сетевые задержки для каждого пакета, отправленного с сервера приложений в базу данных и обратно. Эти задержки суммируются и значительно ухудшают производительность!
Ниже приведён реальный пример, показывающий время отклика приложения. База данных развернута на node2.
В этом случае выполнение приложения требует большого количества запросов к базе данных, что значительно влияет на среднее время отклика затронутых компонентов. В данном случае среднее время отклика составляет 3,9 секунды.
Для этого теста функция graph_dyn запрашивает из базы данных 80 тысяч строк данных, где каждая строка содержит метаданные для построения различных точек графика.
Переместив базу данных на ту же машину, где размещена часть приложения, удалось снизить среднее время отклика до 0,998 секунды!
Это значительное улучшение производительности было достигнуто за счёт сокращения задержек сетевых запросов (round trip), то есть перемещения контейнера базы данных на тот же узел.
Ещё одним распространённым фактором, влияющим на производительность Kubernetes, являются ESXi-среды, где узлы кластера имеют избыточную нагрузку на ввод-вывод сети, а узлы Kubernetes развёрнуты в виде виртуальных машин. Узел Kubernetes не может увидеть, что CPU, память, ввод-вывод диска и/или подключённое удалённое хранилище уже находятся под нагрузкой. В результате пользователи сталкиваются с ухудшением времени отклика приложений.
Как оптимизировать производительность приложения
Учтите кэширование в дизайне приложения.
Убедитесь, что приложение учитывает кэширование (общих запросов, запросов к базе данных и так далее) и не выполняет лишних запросов.
Отключите переподписку ресурсов (oversubscription) в средах ESXi.
Если Kubernetes/OpenShift работают поверх ESXi, убедитесь, что переподписка ресурсов отключена для всех доступных CPU и памяти. Учтите, что даже небольшие задержки могут быстро накопиться и привести к эластичному поведению времени отклика приложения. Кроме того, если хост ESXi уже находится под нагрузкой, запущенные на нём образы не будут осведомлены об этом, и оркестратор Kubernetes может развернуть дополнительные поды на этом узле, считая ресурсы (CPU, память, хранилище) всё ещё доступными. Поэтому, если вы используете Kubernetes/OpenShift, а у вас есть возможность запустить их на физическом сервере, сделайте это! Вы получите прямую и полную видимость ресурсов хоста.
Минимизируйте сетевые задержки ввода-вывода в Kubernetes.
Сократите сетевые задержки ввода-вывода при развёртывании подов. Упакуйте контейнеры в один под, чтобы они развертывались на одном узле. Это значительно снизит сетевые задержки ввода-вывода между сервером приложений и базой данных.
Размещайте контейнеры с высокими требованиями к базе данных на узлах с быстрым хранилищем.
Развёртывайте контейнеры, которым требуется быстрый доступ к базе данных, на узлах с быстрым хранилищем. Учитывайте требования к высокой доступности и балансировке нагрузки. Если хранилище NFS недостаточно быстрое, рассмотрите возможность создания PV (Persistent Volume) на определённом узле с локальным RAID 10 диском. Учтите, что в этом случае резервирование придётся настраивать вручную, так как оркестратор Kubernetes не сможет управлять этим при отказе оборудования конкретного узла.
Как мониторить задержки между компонентами
Для Kubernetes, OpenShift и Docker (Swarm) можно использовать Universal Monitoring Agent (UMA), входящий в решения AIOps and Observability от Broadcom, для мониторинга взаимодействия всего окружения. Этот агент способен извлекать все релевантные метрики кластера. Если UMA обнаруживает поддерживаемую технологию, такую как Java, .Net, PHP или Node.js, он автоматически внедряет пробу (probe) и предоставляет детализированную информацию о выполнении приложения по запросу. Эти данные включают запросы ввода-вывода (I/O) от компонента к базе данных, удалённые вызовы и другие внутренние метрики приложения.
Если приложение работает некорректно, встроенное обнаружение аномалий UMA запускает трассировку транзакций (это не требует дополнительной настройки). UMA собирает подробные метрики с агентов, связанных с компонентами, по пути выполнения конкретного приложения. Эти возможности позволяют получить детализированное представление выполнения приложения вплоть до строки кода, вызывающей замедление. Администраторы могут настроить полный сквозной мониторинг, который предоставляет детали выполнения, включая производительность фронтенда (браузера).
Ниже приведен пример сбора полных сквозных метрик, чтобы команда администраторов могла проанализировать, что пошло не так, и при необходимости принять корректирующие меры:
Одним из преимуществ этого решения для мониторинга является то, что оно показывает среднее время выполнения компонентов внутри кластера. Со временем решение может начать считать плохие средние значения нормой в среде ESXi с избыточной загрузкой. Тем не менее, оператор может оценить реальные значения и сравнить их с показателями других приложений, работающих на том же узле.
Компания VMware недавно выпустила интересное видео в рамках серии Extreme Performance, где рассматривается, как технологии Memory Tiering могут оптимизировать серверную инфраструктуру, улучшить консолидацию серверов и снизить общую стоимость владения (TCO). Ведущие эксперты, работающие в сфере производительности платформ VMware, делятся новейшими разработками и результатами тестов, которые помогут сделать работу администраторов с серверами более эффективной.
Основные моменты видео:
Что такое Memory Tiering? Memory Tiering — это технология, реализованная в ядре ESXi, которая прозрачно для приложений и гостевых ОС разделяет память на два уровня:
Tier 1: Быстрая память DRAM.
Tier 2: Бюджетные и емкие устройства памяти, такие как NVMe SSD и CXL.
Преимущества Memory Tiering:
Увеличение доступной памяти за счет использования NVMe в качестве памяти второго уровня.
Снижение затрат на память до 50%.
Исключение таких проблем, как ballooning и случайный обмен страницами.
Реальные результаты:
Удвоение плотности виртуальных машин (VMs): на одной хост-машине можно разместить вдвое больше ВМ без заметной потери производительности (<3%).
Оптимизация работы баз данных: для SQL Server и Oracle наблюдалось почти линейное масштабирование с минимальными потерями производительности.
Стабильный пользовательский опыт (VDI): эталонный тест Login VSI показал, что даже при удвоении числа ВМ пользовательский опыт остается на высоком уровне.
Ключевые метрики и рекомендации:
Active memory: один из основных параметров для мониторинга. Оптимальный уровень — около 50% от объема Tier 1 (DRAM).
Использование NVMe: рекомендации по чтению и записи (до 200 мс latency для чтения и 500 мс для записи).
Практические примеры и кейсы:
Клиенты из финансового и медицинского секторов, такие как SS&C Cloud, уже успешно применяют Memory Tiering, чтобы уменьшить затраты на серверы и улучшить их производительность.
Советы по настройке и мониторингу:
Как отслеживать активность NVMe-устройств и состояние памяти через vCenter.
Какие показатели важны для анализа производительности.
Кому будет полезно:
Системным администраторам, DevOps-инженерам и специалистам по виртуализации.
Организациям, которые стремятся сократить затраты на ИТ-инфраструктуру и повысить плотность виртуализации.
Любителям передовых технологий, которые хотят понять, как современные подходы меняют управление памятью в дата-центрах.
Memory Tiering — это прорывная технология, которая уже сегодня позволяет добиться больших результатов в консолидации серверов. Узнайте, как её применить в вашем окружении, и станьте частью следующего поколения производительности серверов.
Таги: VMware, vSphere, Memory, Performance, NVMe, Video
В этом месяце VMware опубликовала девять новых результатов тестов VMmark 4 от компаний Dell Technologies, Hewlett Packard Enterprise и Supermicro, которые демонстрируют производительность и масштабируемость новых серверных процессоров AMD EPYC серии 9005, поддерживающихся в хостах VMware vSphere 8. Результаты можно посмотреть на странице результатов VMmark 4, но основные моменты освещены в статье ниже.
Важная особенность: одна плитка (tile) VMmark включает 23 виртуальных машины, выполняющих разнообразные рабочие нагрузки — от традиционных Java- и баз данных до Kubernetes, Docker-контейнеров, NoSQL и нагрузок социальных сетей, характерных для современных корпоративных дата-центров.
Результаты тестирования Supermicro
Первое сравнение демонстрирует, как хорошо масштабируются эти новые процессоры при использовании VMmark 4 и последнего гипервизора VMware ESXi при удвоении общего числа ядер с 128 до 256 (результаты - для двух плиток и для четырех).
Как видно из таблицы и графика выше, результат с 256 ядрами в 1,9 раза выше, чем результат с 128 ядрами, при этом в течение 3 часов теста VMmark работало в два раза больше виртуальных машин (разные плитки).
Результаты тестирования Dell Technologies
На данный момент у Dell есть три результата тестирования VMmark 4 на базе процессоров EPYC 9005 с разным количеством ядер (1, 2, 3).
Одна плитка VMmark 4 состоит из 23 виртуальных машин, однако два из этих результатов содержат дробное количество плиток. Что это значит? Ответ заключается в том, что в VMmark 4 была добавлена функция частичных плиток. Частичные плитки запускают подмножество рабочих нагрузок для более точной детализации, что позволяет тестировщикам максимально использовать производительность их решений для виртуализации. Например, 4.6 плитки включают 99 активных виртуальных машин, тогда как 5 плиток — 115 виртуальных машин, что на 16% больше.
Результаты Dell также являются первыми результатами VMmark, использующими NVMe over TCP с подключением к внешнему хранилищу через двухпортовые сетевые карты Broadcom BCM957508-P2100G со скоростью 100 Гбит/с, вместо традиционных адаптеров шины.
Результаты тестирования Hewlett Packard Enterprise
У HPE есть три результата тестирования VMmark 4 (1, 2, 3).
Первый результат использует процессоры предыдущего поколения EPYC 4-го поколения (обозначенные номером "4" в конце модели процессора). Несмотря на одинаковое количество ядер в первых двух результатах, процессоры 5-го поколения показывают производительность выше более чем на 10%.
Если сравнить результат предыдущего поколения с результатом на 1280 ядрах, он оказывается на впечатляющие 45% выше!
В последнем релизе VMware vSAN 8.0 Update 3, утилита vSAN IO Trip Analyzer была существенно доработана. В чем именно заключается это улучшение? Теперь IO Trip Analyzer может быть включен для нескольких ВМ одновременно. Это особенно полезно при устранении проблем с производительностью комплексного сервиса, состоящего из нескольких ВМ.
Данное улучшение позволяет вам одновременно мониторить несколько ВМ и анализировать, на каком уровне у каждой из выбранных ВМ возникает задержка (latency). Обратите внимание, что это улучшение работает как для vSAN ESA, так и для vSAN OSA.
Дункан Эппинг записал на эту тему интересное обзорное видео:
Современные задачи искусственного интеллекта (AI) и машинного обучения (ML) требуют высокопроизводительных решений при минимизации затрат на инфраструктуру, поскольку оборудование для таких нагрузок стоит дорого. Использование графических процессоров NVIDIA в сочетании с технологией NVIDIA AI Enterprise и платформой VMware Cloud Foundation (VCF) позволяет компаниям...
Компания Broadcom выпустила интересное видео, где Mark Achtemichuk и Uday Kulkurne обсуждают оптимизацию AI/ML нагрузок с использованием аппаратной платформы NVIDIA GPU и решения VMware Cloud Foundation:
Производительность и эффективность виртуализации графических процессоров (GPU) является одним из ключевых направлений для разработки решений в области искусственного интеллекта (AI) и машинного обучения (ML).
Виртуализация AI/ML задач, работающих на GPU, представляет собой вызов, так как традиционно считается, что виртуализация может значительно снижать производительность по сравнению с «чистой» конфигурацией на физическом оборудовании (bare metal). Однако VMware Cloud Foundation демонстрирует почти аналогичную производительность с минимальными потерями за счет умной виртуализации и использования технологий NVIDIA.
Рассматриваемые в данном видо графические процессоры от NVIDIA включают модели H100, A100 и L4, каждая из которых имеет уникальные характеристики для обработки AI/ML задач. Например, H100 оснащен 80 миллиардами транзисторов и способен ускорять работу трансформеров (на основе архитектуры GPT) в шесть раз. Особенностью H100 является возможность разделения GPU на несколько независимых сегментов, что позволяет обрабатывать задачи параллельно без взаимного влияния. A100 и L4 также обладают мощными возможностями для AI/ML, с небольшими различиями в спецификациях и применимости для графических задач и машинного обучения.
VMware Cloud Foundation (VCF) позволяет использовать все преимущества виртуализации, обеспечивая при этом производительность, близкую к физическому оборудованию. Одна из ключевых возможностей — это поддержка дробных виртуальных GPU (vGPU) с изоляцией, что позволяет безопасно распределять ресурсы GPU между несколькими виртуальными машинами.
Используя виртуализированные конфигурации на базе VCF и NVIDIA GPU, компании могут значительно снизить общие затраты на владение инфраструктурой (TCO). VMware Cloud Foundation позволяет консолидировать несколько виртуальных машин и задач на одном физическом хосте без существенной потери производительности. Это особенно важно в условиях современных датацентров, где необходимо максимизировать эффективность использования ресурсов.
В серии тестов было проверено, как виртуализированные GPU справляются с различными AI/ML задачами по сравнению с физическим оборудованием. Используя стандартные бенчмарки, такие как ML Commons, было показано, что виртуализированные GPU демонстрируют производительность от 95% до 104% по сравнению с bare metal конфигурациями в режиме инференса (вычисления запросов) и около 92-98% в режиме обучения. Это означает, что даже в виртуализированной среде можно добиться почти той же скорости, что и при использовании физического оборудования, а в некоторых случаях — даже превзойти её.
Основное преимущество использования VMware Cloud Foundation с NVIDIA GPU заключается в гибкости и экономии ресурсов. Виртуализированные среды позволяют разделять ресурсы GPU между множеством задач, что позволяет более эффективно использовать доступные мощности. Это особенно важно для компаний, стремящихся к оптимизации капитальных затрат на инфраструктуру и повышению эффективности использования серверных мощностей.
Компания VMware представила обновленную версию документа "Best Practices for VMware vSphere 8.0 Update 3", описывающего лучшие практики повышения производительности для последней версии платформы VMware vSphere 8.0 Update 3 — ценный ресурс, наполненный экспертными советами по оптимизации быстродействия. Хотя это и не является всеобъемлющим руководством по планированию и настройке ваших развертываний, он предоставляет важные рекомендации по улучшению производительности в ключевых областях.
Краткий обзор содержания:
Глава 1: Оборудование для использования с VMware vSphere (Стр. 11) — узнайте важные советы по выбору правильного оборудования, чтобы максимально эффективно использовать вашу среду vSphere.
Глава 2: ESXi и виртуальные машины (Стр. 25) — ознакомьтесь с лучшими практиками для платформы VMware ESXi и тонкими настройками виртуальных машин, работающих в этой среде.
Глава 3: Гостевые операционные системы (Стр. 57) — узнайте, как правильно оптимизировать гостевые ОС, работающие в ваших виртуальных машинах vSphere.
Глава 4: Управление виртуальной инфраструктурой (Стр. 69) — получите советы по эффективному управлению для поддержания высокопроизводительной виртуальной инфраструктуры.
Независимо от того, хотите ли вы грамотно настроить свою систему или просто ищете способы повышения эффективности, этот документ является отличным справочником для обеспечения максимальной производительности вашей среды VMware vSphere.
Платформа VMware vSAN 8 Express Storage Architecture (ESA), работающая на процессорах Intel Xeon Scalable 4-го поколения, представляет собой современное решение для гиперконвергентной инфраструктуры (HCI), способствующее консолидации серверов и поддержке высокопроизводительных рабочих нагрузок, включая ИИ.
Преимущества работы vSAN 8 ESA на Intel Xeon 4 поколения
Оптимизация хранения: в отличие от двухуровневой архитектуры предыдущих версий, ESA использует одноуровневую систему с NVMe-накопителями на базе TLC флэш-памяти, что позволяет увеличить емкость и производительность хранилища. Это снижает расходы на хранение данных, благодаря более эффективной компрессии данных и встроенной системе снапшотов.
Скорость и производительность: VMware vSAN 8 ESA, в сочетании с Intel Xeon 4, значительно ускоряет работу как традиционных, так и современных приложений. Интеграция с новейшими технологиями Intel, такими как AMX (Advanced Matrix Extensions) и AVX-512 (Advanced Vector Extensions), увеличивает количество транзакций и снижает время отклика при обработке больших данных.
Снижение задержек и повышение производительности: в тестах ESA показала до 6.2-кратного роста производительности и до 7.1-кратного снижения задержек по сравнению с предыдущими поколениями vSAN и Intel Xeon. Это позволяет консолидировать критически важные рабочие нагрузки, такие как базы данных SQL и VDI, без снижения производительности.
Поддержка AI и современных рабочих нагрузок
Для обеспечения поддержки AI-приложений, vSAN 8 ESA, благодаря новейшим процессорам Intel Xeon, справляется с обработкой больших объемов данных, необходимых для глубокого обучения и инференса, особенно в задачах классификации изображений и обработки естественного языка. Тесты показали до 9-кратного увеличения производительности при использовании INT8 в задачах машинного обучения.
Снижение затрат и повышение эффективности
За счет высокой плотности виртуальных машин и оптимизированного использования ресурсов, VMware vSAN 8 ESA позволяет сократить инфраструктурные расходы, связанные с оборудованием и энергопотреблением. Использование RAID-6 на уровне кластера с производительностью RAID-1 повышает надежность и безопасность данных без ущерба для производительности.
Заключение
VMware vSAN 8 ESA, в сочетании с процессорами Intel Xeon четвертого поколения, представляет собой мощное и экономичное решение для поддержки как традиционных, так и современных рабочих нагрузок, включая AI-приложения. Это позволяет компаниям модернизировать свою инфраструктуру, улучшить производительность и оптимизировать использование ресурсов, что особенно важно в условиях сокращающихся ИТ-бюджетов и растущих требований к производительности приложений.

 RSS
RSS