Это заключительная часть серии статей (см. прошлые части тут, тут, тут, тут, тут и тут), посвящённых технологии Memory Tiering. В предыдущих публикациях мы рассмотрели архитектуру, проектирование, расчёт ёмкости и базовую настройку, а также другие темы. Теперь мы переходим к расширенной конфигурации. Эти параметры не являются обязательными для работы функции как таковой, но предоставляют дополнительные возможности - такие как шифрование данных и настройка соотношений памяти, но и не только.
Хотя значения по умолчанию в vSphere в составе VMware Cloud Foundation 9.0 разработаны так, чтобы «просто работать» в большинстве сред, для настоящей оптимизации требуется тонкая настройка. Независимо от того, используете ли вы виртуальные рабочие столы или базы данных, важно понимать, какие рычаги управления стоит задействовать.
Ниже описано, как освоить расширенные параметры для настройки соотношений памяти, шифрования на уровне хоста и отдельных ВМ, а также отключения технологии Memory Tiering на уровне отдельных машин.
Настройка соотношения DRAM:NVMe
По умолчанию при включении Memory Tiering ESX устанавливает соотношение DRAM к NVMe равным 1:1, то есть 100% дополнительной памяти за счёт NVMe. Это означает, что при наличии 512 ГБ DRAM хост получит ещё 512 ГБ NVMe-ёмкости в качестве памяти Tier 1, что в сумме даст 1 ТБ памяти.
Однако в зависимости от типа рабочих нагрузок вы можете захотеть изменить эту плотность. Например, в VDI-среде, где ключевым фактором является стоимость одного рабочего стола, может быть выгодно использовать более высокое соотношение (больше NVMe на каждый гигабайт DRAM). Напротив, для кластеров с высокими требованиями к производительности вы можете захотеть ограничить размер NVMe-яруса.
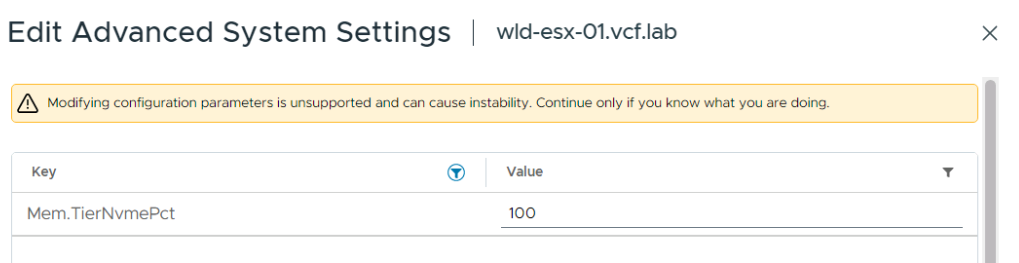
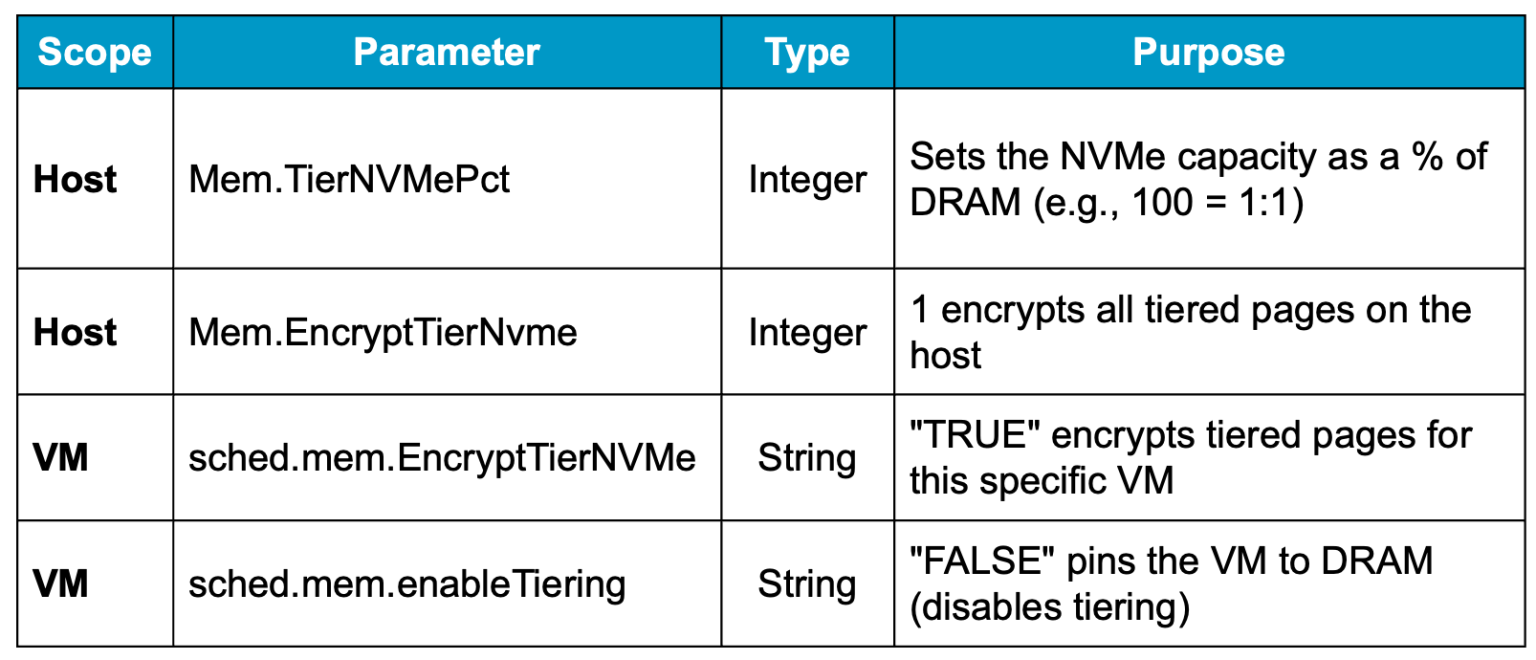
Управление этим параметром осуществляется через расширенную системную настройку хоста: Mem.TierNVMePct.
Параметр
Где настраивается: Host Advanced System Settings
Ключ: Mem.TierNVMePct
Значение: процент DRAM, используемый в качестве NVMe-яруса
Возможные значения:
100 (по умолчанию): 100% от объёма DRAM (соотношение 1:1)
200: 200% от объёма DRAM (соотношение 1:2)
50: 50% от объёма DRAM — очень консервативный вариант (соотношение 2:1)
Примечание. Рекомендации и лучшие практики предполагают сохранение соотношения по умолчанию 1:1, так как оно подходит для большинства рабочих нагрузок. Если вы решите изменить это соотношение, необходимо предварительно тщательно проанализировать свои нагрузки и убедиться, что вся активная память может быть размещена в объёме DRAM хоста. Подробнее о расчёте ёмкости Memory Tiering см. вот тут.
Защита уровня: шифрование
Одним из архитектурных различий между DRAM и NVMe является постоянство хранения данных. В то время как обычная оперативная память теряет данные (практически) мгновенно при отключении питания, NVMe является энергонезависимой. Несмотря на то что VMware выполняет очистку страниц памяти, организации с повышенными требованиями к безопасности (особенно в регулируемых отраслях) часто требуют шифрование данных «на диске» (Data-at-Rest Encryption) для любых данных, записываемых на накопители, даже если эти накопители используются как память. Более подробное описание шифрования NVMe в контексте Memory Tiering приведено вот тут.
Здесь доступны два уровня управления: защита всего NVMe-уровня хоста целиком либо выборочное шифрование данных только для определённых виртуальных машин, вместо шифрования данных всех ВМ на хосте.
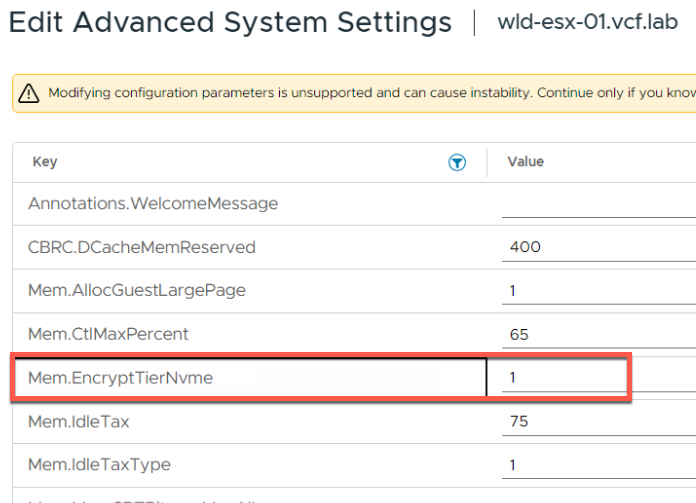
Вариант A: шифрование на уровне хоста
Это «универсальный» подход. Он гарантирует, что любая страница памяти, перемещаемая из DRAM в NVMe-уровень на данном хосте, будет зашифрована с использованием алгоритма AES-XTS.
Параметр
Где настраивается:Host Advanced Configuration Parameters
Ключ: Mem.EncryptTierNvme
Значение: 1 — включено, 0 — отключено
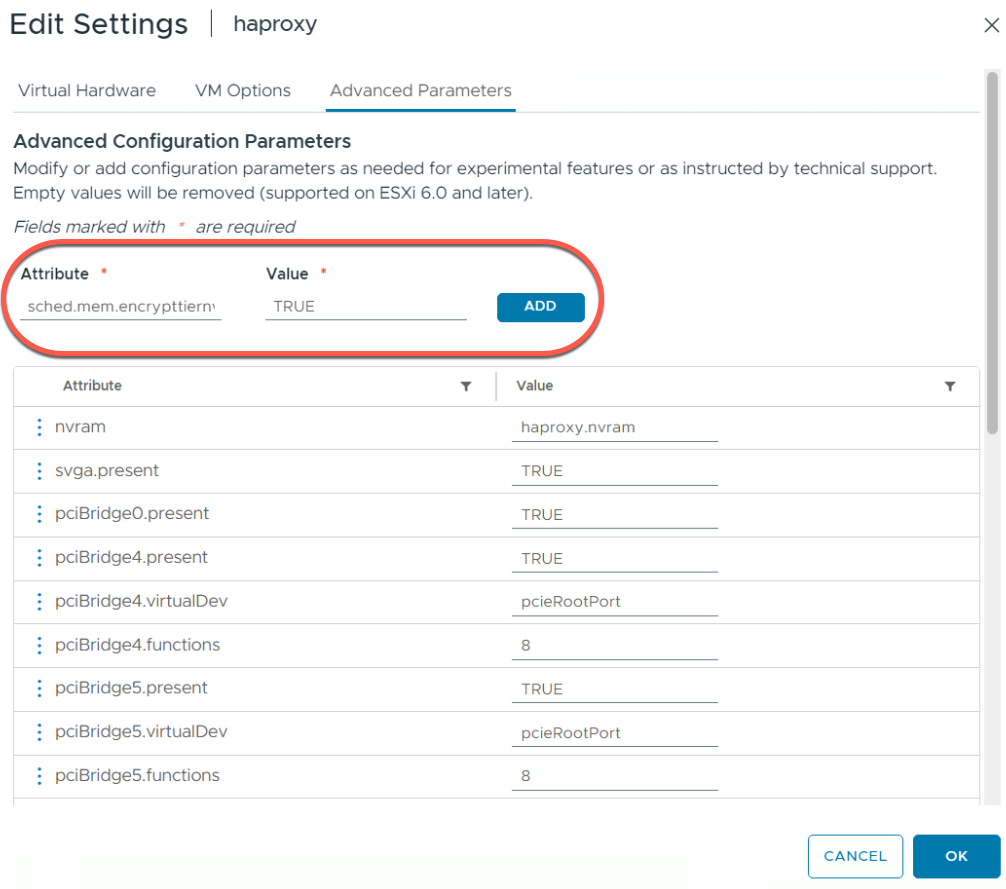
Вариант Б: шифрование на уровне виртуальной машины
Если вы хотите включить шифрование только для отдельных виртуальных машин — то есть шифровать лишь те страницы памяти, которые размещаются на NVMe, — вы можете применить эту настройку только к наиболее критичным рабочим нагрузкам (например, контроллерам домена или финансовым базам данных).
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.EncryptTierNVMe
Значение: TRUE
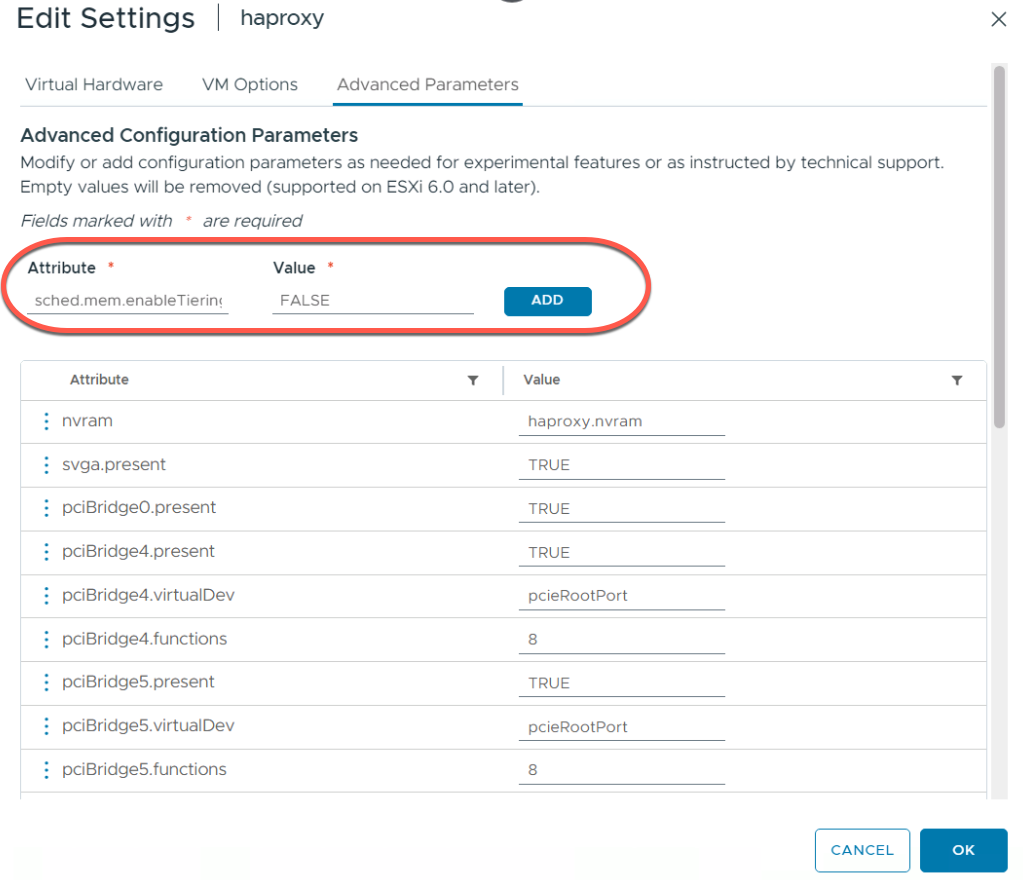
Отказ от использования: отключение Memory Tiering для критичных ВМ
Memory Tiering отлично подходит для «холодных» данных, однако «горячие» данные должны находиться в DRAM. Несмотря на то, что планировщик ESX чрезвычайно интеллектуален в вопросах размещения страниц памяти, некоторые рабочие нагрузки слишком чувствительны, чтобы допускать даже минимальные всплески задержек, связанные с использованием Memory Tiering.
Типичные сценарии использования:
SAP HANA и другие in-memory базы данных
Приложения для высокочастотной торговли (High-Frequency Trading)
Виртуальные машины безопасности
Кроме того, существуют профили виртуальных машин, которые в настоящее время не поддерживают Memory Tiering, такие как ВМ с низкой задержкой, ВМ с Fault Tolerance (FT), ВМ с большими страницами памяти (large memory pages) и др. Для таких профилей Memory Tiering необходимо отключать на уровне виртуальной машины. Это принудительно размещает страницы памяти ВМ исключительно в Tier 0 (DRAM). Полный список профилей ВМ см. в официальной документации VMware.
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.enableTiering
Значение: FALSE
Ну и в заключение - таблица расширенных параметров Memory Tiering:
Memory Tiering в VCF 9.0 представляет собой серьёзный сдвиг в подходе к плотности серверов и интеллектуальному потреблению ресурсов. Эта технология уводит нас от жёсткого «потолка по RAM» и предоставляет гибкий, экономически эффективный буфер памяти. Однако, как и в случае с любым мощным инструментом, значения по умолчанию — лишь отправная точка. Используя описанные выше параметры, вы можете настроить поведение системы в соответствии как с ограничениями бюджета, так и с требованиями SLA.
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут и тут) мы предоставим некоторую информацию о различиях при включении Memory Tiering в разных сценариях. Хотя основной процесс остаётся тем же, есть моменты, которые могут потребовать дополнительного внимания и планирования, чтобы сэкономить время и усилия. Когда мы говорим о сценариях greenfield, мы имеем в виду совершенно новые развертывания VMware Cloud Foundation (VCF), включая новое оборудование и новую конфигурацию для всего стека. Сценарии brownfield будут охватывать настройку Memory Tiering в существующей среде VCF. Наконец, мы рассмотрим и лабораторные сценарии, поскольку встречаются неоднозначные утверждения о том, что это не поддерживается, но мы рассмотрим это в конце данной статьи.
Greenfield-развертывания
Давайте начнём с процесса конфигурации сред greenfield. Ранее мы рассказали о том, как VMware vSAN и Memory Tiering совместимы и могут сосуществовать в одном и том же кластере. Мы также обращали внимание на кое-что важное, о чём вам следует помнить во время greenfield-развертываний VCF. Начиная с VCF 9.0, включение Memory Tiering — это операция «Day 2», то есть сначала вы настраиваете VCF, а затем можете настроить Memory Tiering, но в ходе рабочего процесса развертывания VCF вы заметите, что опции для включения Memory Tiering (пока) нет, зато можно включить vSAN. То, как вы поступите с вашим NVMe-устройством, выделенным для Memory Tiering, будет определять шаги, необходимые для того, чтобы это устройство было представлено для его конфигурации.
Если все NVMe-устройства и для vSAN, и для Memory Tiering присутствуют во время развертывания VCF, есть вероятность, что vSAN может автоматически занять все накопители (включая NVMe-устройство, которое вы выделили для Memory Tiering). В этом случае вам пришлось бы удалить накопитель из vSAN после конфигурации, стереть разделы, а затем начать настройку Memory Tiering. Этот шаг был рассмотрен тут.
Другой подход — извлечь или не устанавливать устройство Memory Tiering в сервер и добавить его обратно в сервер после развертывания VCF. Таким образом вы не будете рисковать тем, что vSAN автоматически займет NVMe для Memory Tiering. Хотя это и не является серьёзным препятствием, всё равно полезно знать, что произойдёт и почему, чтобы вы могли быстро выделить ресурсы, необходимые для настройки Memory Tiering.
Brownfield-развертывания
Сценарии brownfield немного проще, так как VVF/VCF уже настроен; однако vSAN мог быть включён или ещё нет.
Если vSAN не включён, вам нужно будет отключить функцию auto-claim, пройти через конфигурацию vSAN и вручную выбрать ваши устройства (кроме NVMe-устройств для Memory Tiering). Всё выполняется в интерфейсе UI и по процедуре, которая используется уже много лет. Это гарантирует, что NVMe-устройство Memory Tiering будет доступно для настройки. Подробный процесс задокументирован в TechDocs.
Если vSAN уже включён, мы предполагаем, что NVMe-устройство для Memory Tiering только что было приобретено и готово к установке. Значит, всё, что нам нужно сделать, — добавить его в хост и убедиться, что оно корректно отображается как NVMe-устройство и что на нём нет существующих разделов. Это, вероятно, самый простой сценарий и самый распространённый.
Развертывания в тестовой среде
Теперь давайте поговорим о давно ожидаемом лабораторном сценарии. Для лаборатории типа bare metal, где сервер ESX одноуровневый и нет вложенных сред, применяются те же принципы greenfield и brownfield. Что касается вложенной (nested) виртуализации, многие говорят о том, что вложенный Memory Tiering не поддерживается. Ну, это и так, и не так.
Когда мы говорим о вложенных средах, мы имеем в виду два уровня ESX. Внешний уровень — это ESX, установленный на оборудовании (обычная настройка), а внутренний уровень ESX состоит из виртуальных машин, запускающих ESX и выступающих в роли как бы физических хостов. Memory Tiering МОЖЕТ быть включён на внутреннем уровне (вложенном), и все параметры конфигурации работают нормально. Мы делаем следующее: берём datastore и создаём виртуальный Hard Disk типа NVMe, чтобы представить его виртуальной машине, которая выступает в роли вложенного хоста. Хотя мы видим NVMe-устройство на вложенном хосте и можем настроить Memory Tiering, базовое устройство хранения состоит из устройств, формирующих выбранный datastore. Вы можете настроить Memory Tiering, и вложенные хосты смогут видеть hot и active pages, но не ожидайте какого-либо уровня производительности, учитывая, что компоненты базового хранилища построены на традиционных накопителях. Работает ли это? ДА, но только в лабораторных средах.
Тестирование в лабораторной среде очень полезно: оно помогает вам пройти шаги конфигурации и понять, как работает настройка и какие расширенные параметры можно задать. Это отличный вариант использования для подготовки (практики) к развертыванию в производственной среде или даже просто для знакомства с функцией, например, для целей сдачи сертификационного экзамена.
А как насчёт внешнего уровня? Ну, это как раз то, что не поддерживается в VCF 9.0, поскольку внешний уровень ESX не имеет видимости внутреннего уровня и не может видеть активность памяти ВМ, по сути пытаясь «прозреть» сквозь вложенный уровень до виртуальной машины (inception). Это и есть главное отличие (не вдаваясь слишком глубоко в технические детали).
Так что если вам интересно протестировать Memory Tiering, а всё, что у вас есть — это вложенная среда, вы можете настроить Memory Tiering и любые расширенные параметры. Интересно наблюдать, как несколько шагов настройки могут добавить хостам 100% дополнительной памяти.
В ранних статьях мы упоминали, что вы можете настраивать разделы NVMe с помощью команд ESXCLI, PowerCLI и даже скриптов. В более поздних публикациях мы говорили о том, что опубликуем скрипт для настройки разделов, который мы приводим ниже, но с оговоркой и прямым предупреждением: вы можете запускать скрипт на свой страх и риск, и он может не работать в вашей среде в зависимости от вашей конфигурации.
Рассматривайте этот скрипт только как пример того, как это можно автоматизировать, а не как поддерживаемое решение автоматизации. Кроме того, скрипт не стирает разделы за вас, поэтому убедитесь, что вы сделали это до запуска скрипта. Как всегда, сначала протестируйте.
Есть некоторые переменные, которые вам нужно изменить, чтобы он работал в вашей среде:
$vCenter = “ваш vCenter FQDN или IP” (строка 27)
$clusterName = “имя вашего кластера” (строка 28)
Вот и сам скрипт:
function Update-NvmeMemoryTier {
param (
[Parameter(Mandatory=$true)]
[VMware.VimAutomation.ViCore.Impl.V1.Inventory.VMHostImpl]$VMHost,
[Parameter(Mandatory=$true)]
[string]$DiskPath
)
try {
# Verify ESXCLI connection
$esxcli = Get-EsxCli -VMHost $VMHost -V2
# Note: Verify the correct ESXCLI command for NVMe memory tiering; this is a placeholder
# Replace with the actual command or API if available
$esxcli.system.tierdevice.create.Invoke(@{ nvmedevice = $DiskPath }) # Hypothetical command
Write-Output "NVMe Memory Tier created successfully on host $($VMHost.Name) with disk $DiskPath"
return $true
}
catch {
Write-Warning "Failed to create NVMe Memory Tier on host $($VMHost.Name) with disk $DiskPath. Error: $_"
return $false
}
}
# Securely prompt for credentials
$credential = Get-Credential -Message "Enter vCenter credentials"
$vCenter = "vcenter FQDN"
$clusterName = "cluster name"
try {
# Connect to vCenter
Connect-VIServer -Server $vCenter -Credential $credential -WarningAction SilentlyContinue
Write-Output "Connected to vCenter Server successfully."
# Get cluster and hosts
$cluster = Get-Cluster -Name $clusterName -ErrorAction Stop
$vmHosts = Get-VMHost -Location $cluster -ErrorAction Stop
foreach ($vmHost in $vmHosts) {
Write-Output "Fetching disks for host: $($vmHost.Name)"
$disks = @($vmHost | Get-ScsiLun -LunType disk |
Where-Object { $_.Model -like "*NVMe*" } | # Filter for NVMe disks
Select-Object CanonicalName, Vendor, Model, MultipathPolicy,
@{N='CapacityGB';E={[math]::Round($_.CapacityMB/1024,2)}} |
Sort-Object CanonicalName) # Explicit sorting
if (-not $disks) {
Write-Warning "No NVMe disks found on host $($vmHost.Name)"
continue
}
# Build disk selection table
$diskWithIndex = @()
$ctr = 1
foreach ($disk in $disks) {
$diskWithIndex += [PSCustomObject]@{
Index = $ctr
CanonicalName = $disk.CanonicalName
Vendor = $disk.Vendor
Model = $disk.Model
MultipathPolicy = $disk.MultipathPolicy
CapacityGB = $disk.CapacityGB
}
$ctr++
}
# Display disk selection table
$diskWithIndex | Format-Table -AutoSize | Out-String | Write-Output
# Get user input with validation
$maxRetries = 3
$retryCount = 0
do {
$diskChoice = Read-Host -Prompt "Select disk for NVMe Memory Tier (1 to $($disks.Count))"
if ($diskChoice -match '^\d+$' -and $diskChoice -ge 1 -and $diskChoice -le $disks.Count) {
break
}
Write-Warning "Invalid input. Enter a number between 1 and $($disks.Count)."
$retryCount++
} while ($retryCount -lt $maxRetries)
if ($retryCount -ge $maxRetries) {
Write-Warning "Maximum retries exceeded. Skipping host $($vmHost.Name)."
continue
}
# Get selected disk
$selectedDisk = $disks[$diskChoice - 1]
$devicePath = "/vmfs/devices/disks/$($selectedDisk.CanonicalName)"
# Confirm action
Write-Output "Selected disk: $($selectedDisk.CanonicalName) on host $($vmHost.Name)"
$confirm = Read-Host -Prompt "Confirm NVMe Memory Tier configuration? This may erase data (Y/N)"
if ($confirm -ne 'Y') {
Write-Output "Configuration cancelled for host $($vmHost.Name)."
continue
}
# Configure NVMe Memory Tier
$result = Update-NvmeMemoryTier -VMHost $vmHost -DiskPath $devicePath
if ($result) {
Write-Output "Successfully configured NVMe Memory Tier on host $($vmHost.Name)."
} else {
Write-Warning "Failed to configure NVMe Memory Tier on host $($vmHost.Name)."
}
}
}
catch {
Write-Warning "An error occurred: $_"
}
finally {
# Disconnect from vCenter
Disconnect-VIServer -Server $vCenter -Confirm:$false -ErrorAction SilentlyContinue
Write-Output "Disconnected from vCenter Server."
}
Решение VMware vSAN довольно часто всплывает в обсуждениях Memory Tiering — как из-за сходства между этими технологиями, так и из-за вопросов совместимости, поэтому давайте разберёмся подробнее.
Когда мы только начали работать с Memory Tiering, сходство между Memory Tiering и vSAN OSA было достаточно очевидным. Обе технологии используют многоуровневый подход, при котором активные данные размещаются на быстрых устройствах, а неактивные — на более дешёвых, что помогает снизить TCO и уменьшить потребность в дорогих устройствах для хранения «холодных» данных. Обе также глубоко интегрированы в vSphere и просты в реализации. Однако, помимо сходств, изначально возникала некоторая путаница относительно совместимости, интеграции и возможности одновременного использования обеих функций. Поэтому давайте попробуем ответить на эти вопросы.
Да, вы можете одновременно использовать vSAN и Memory Tiering в одних и тех же кластерах. Путаница в основном связана с идеей предоставления хранилища vSAN для Memory Tiering — а это категорически не поддерживается. Мы говорили об этом ранее, но ещё раз подчеркнем: хотя обе технологии могут использовать NVMe-устройства, это не означает, что они могут совместно использовать одни и те же ресурсы. Memory Tiering требует собственного физического или логического устройства, предназначенного исключительно для выделения памяти. Мы не хотим делить это физическое/логическое устройство с чем-либо ещё, включая vSAN или другие датасторы. Почему? Потому что в случае совместного использования мы будем конкурировать за пропускную способность, а уж точно не хотим замедлять работу памяти ради того, чтобы «не тратить впустую» NVMe-пространство. Это всё равно что сказать: "У меня бак машины наполовину пуст, поэтому я залью туда воду, чтобы не терять место".
При этом технически вы можете создать несколько разделов для лабораторной среды (на свой страх и риск), но когда речь идёт о продуктивных нагрузках, обязательно используйте выделенное физическое или логическое (HW RAID) устройство исключительно для Memory Tiering.
Подводя итог по vSAN и Memory Tiering: они МОГУТ сосуществовать, но не могут совместно использовать ресурсы (диски/датасторы). Они хорошо работают в одном кластере, но их функции не пересекаются — это независимые решения. Виртуальные машины могут одновременно использовать датастор vSAN и ресурсы Memory Tiering. Вы даже можете иметь ВМ с шифрованием vSAN и шифрованием Memory Tiering — но эти механизмы работают на разных уровнях. Несмотря на кажущееся сходство, решения функционируют независимо друг от друга и при этом отлично дополняют друг друга, обеспечивая более целостную инфраструктуру в рамках VCF.
Соображения по хранению данных
Теперь мы знаем, что нельзя использовать vSAN для предоставления хранилища для Memory Tiering, но тот же принцип применяется и к другим датасторам или решениям NAS/SAN. Для Memory Tiering требуется выделенное устройство, локально подключённое к хосту, на котором не должно быть создано никаких других разделов. Соответственно, не нужно предоставлять датастор на базе NVMe для использования в Memory Tiering.
Говоря о других вариантах хранения, также важно подчеркнуть, что мы не делим устройства между локальным хранилищем и Memory Tiering. Это означает, что одно и то же устройство не может одновременно обслуживать локальное хранилище (локальный датастор) и Memory Tiering. Однако такие устройства всё же можно использовать для Memory Tiering. Поясним.
Предположим, вы действительно хотите внедрить Memory Tiering в своей среде, но у вас нет свободных NVMe-устройств, и запрос на капитальные затраты (CapEx) на покупку новых устройств не был одобрен. В этом случае вы можете изъять NVMe-устройства из локальных датасторов или даже из vSAN и использовать их для Memory Tiering, следуя корректной процедуре:
Убедитесь, что рассматриваемое устройство входит в рекомендуемый список и имеет класс износостойкости D и класс производительности F или G (см. нашу статью тут).
Удалите NVMe-устройство из vSAN или локального датастора.
Удалите все оставшиеся разделы после использования в vSAN или локальном датасторе.
Создайте раздел для Memory Tiering.
Настройте Memory Tiering на хосте или кластере.
Как вы видите, мы можем «позаимствовать» устройства для нужд Memory Tiering, однако крайне важно убедиться, что вы можете позволить себе потерю этих устройств для прежних датасторов, а также что выбранное устройство соответствует требованиям по износостойкости, производительности и наличию «чистых» разделов. Кроме того, при необходимости обязательно защитите или перенесите данные в другое место на время использования устройств.
Это лишь один из шагов, к которому можно прибегнуть в сложной ситуации, когда необходимо получить устройства; однако если данные на этих устройствах должны сохраниться, убедитесь, что у вас есть свободное пространство в другом месте. Выполняйте эти действия на свой страх и риск.
На момент выхода VCF 9 в процессе развёртывания VCF отсутствует отдельный рабочий процесс для выделения устройств под Memory Tiering, а vSAN автоматически захватывает устройства во время развёртывания. Поэтому при развертывании VCF «с нуля» (greenfield) вам может потребоваться использовать описанную процедуру, чтобы вернуть из vSAN устройство, предназначенное для Memory Tiering. VMware работает над улучшением этого процесса и поменяет его в ближайшем будущем.
В постах ранее мы подчеркивали ценность, которую NVMe Memory Tiering приносит клиентам Broadcom, и то, как это стимулирует ее внедрение. Кто же не хочет сократить свои расходы примерно на 40% просто благодаря переходу на VMware Cloud Foundation 9? Мы также затронули предварительные требования и оборудование в части 1, а архитектуру — в Части 2; так что теперь поговорим о правильном масштабировании вашей среды, чтобы вы могли максимально эффективно использовать свои вложения и одновременно снизить затраты.
Правильное масштабирование для NVMe Memory Tiering касается главным образом оборудования, но здесь есть два возможных подхода: развёртывания greenfield и brownfield.
Начнем с brownfield — внедрения Memory Tiering на существующей инфраструктуре. Вы пришли к осознанию, что VCF 9 — действительно интегрированный продукт, и решили развернуть его, но только что узнали о Memory Tiering. Не волнуйтесь, вы всё ещё можете внедрить NVMe Memory Tiering после развертывания VCF 9. Прочитав части 1 и 2, вы узнали о важности классов производительности и выносливости NVMe, а также о требовании 50% активной памяти. Это означает, что нам нужно рассматривать NVMe-устройство как минимум такого же размера, что и DRAM, поскольку мы удвоим объём доступной памяти. То есть, если каждый хост имеет 1 ТБ DRAM, у нас также должно быть минимум 1 ТБ NVMe. Вроде бы просто. Однако мы можем взять NVMe и покрупнее — и всё равно это будет дешевле, чем покупка дополнительных DIMM. Сейчас объясним.
VMware не случайно транслирует мысль: «покупайте NVMe-устройство как минимум такого же размера, что и DRAM», поскольку по умолчанию они используют соотношение DRAM:NVMe равное 1:1 — половина памяти приходится на DRAM, а половина на NVMe. Однако существуют рабочие нагрузки, которые не слишком активны с точки зрения использования памяти — например, некоторые VDI-нагрузки. Если у вас есть рабочие нагрузки с 10% активной памяти на постоянной основе, вы можете действительно воспользоваться расширенными возможностями NVMe Memory Tiering.
Соотношение 1:1 выбрано по следующей причине: большинство нагрузок хорошо укладывается в такие пропорции. Но это отношение DRAM:NVMe является параметром расширенной конфигурации, который можно изменить — вплоть до 1:4, то есть до 400% дополнительной памяти. Поэтому для рабочих нагрузок с очень низкой активностью памяти соотношение 1:4 может максимизировать вашу выгоду. Как это влияет на стратегию масштабирования?
Отлично, что вы спросили) Поскольку DRAM:NVMe может меняться так же, как меняется активность памяти ваших рабочих нагрузок, это нужно учитывать уже на этапе закупки NVMe-устройств. Вернувшись к предыдущему примеру хоста с 1 ТБ DRAM, вы, например, решили, что 1 ТБ NVMe — разумный минимум, но при нагрузках с очень низкой активной памятью этот 1 ТБ может быть недостаточно выгодным. В таком случае NVMe на 4 ТБ позволит использовать соотношение 1:4 и увеличить объём доступной памяти на 400%. Именно поэтому так важно изучить активную память ваших рабочих нагрузок перед покупкой NVMe-устройств.
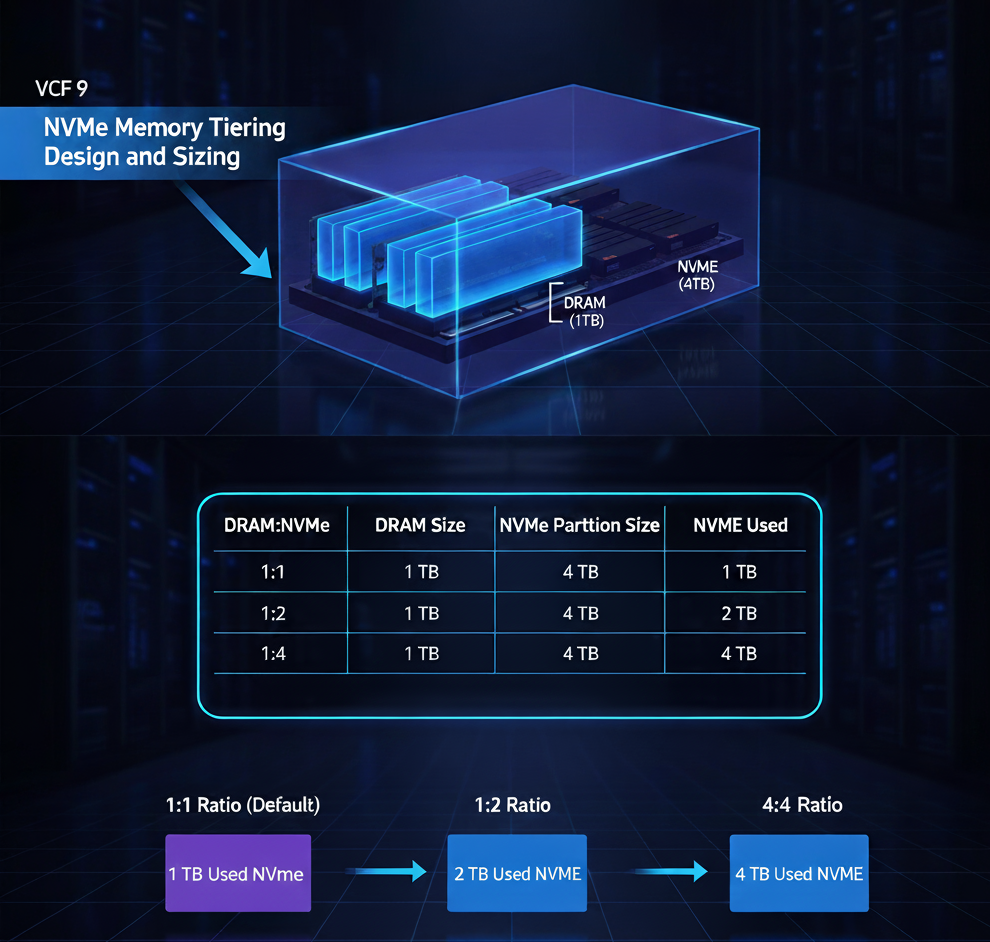
Еще один аспект, влияющий на масштабирование, — размер раздела (partition). Когда мы создаём раздел на NVMe перед настройкой NVMe Memory Tiering, мы вводим команду, но обычно не указываем размер вручную — он автоматически создаётся равным размеру диска, но максимум до 4 ТБ. Объём NVMe, который будет использоваться для Memory Tiering, — это комбинация размера раздела NVMe, объёма DRAM и заданного отношения DRAM:NVMe. Допустим, мы хотим максимизировать выгоду и «застраховать» оборудование на будущее, купив 4 ТБ SED NVMe, хотя на хосте всего 1 ТБ DRAM. После настройки вариантами по умолчанию размер раздела составит 4 ТБ (это максимальный поддерживаемый размер), но для Memory Tiering будет использован лишь 1 ТБ NVMe, поскольку используется соотношение 1:1. Если нагрузка изменится или мы поменяем соотношение на, скажем, 1:2, то размер раздела останется прежним (пересоздавать не требуется), но теперь мы будем использовать 2 ТБ NVMe вместо 1 ТБ — просто изменив коэффициент соотношения. Важно понимать, что не рекомендуется менять это соотношение без надлежащего анализа и уверенности, что активная память рабочих нагрузок вписывается в доступный объём DRAM.
DRAM:NVME
DRAM Size
NVMe Partition Size
NVMe Used
1:1
1 TB
4 TB
1 TB
1:2
1 TB
4 TB
2 TB
1:4
1 TB
4 TB
4 TB
Итак, при определении размера NVMe учитывайте максимальный поддерживаемый размер раздела (4 ТБ) и соотношения, которые можно настроить в зависимости от активной памяти ваших рабочих нагрузок. Это не только вопрос стоимости, но и вопрос масштабируемости. Имейте в виду, что даже при использовании крупных NVMe-устройств вы всё равно сэкономите значительную сумму по сравнению с использованием только DRAM.
Теперь давайте поговорим о вариантах развертывания greenfield, когда вы заранее знаете о Memory Tiering и вам нужно закупить серверы — вы можете сразу учесть эту функцию как параметр в расчете стоимости. Те же принципы, что и для brownfield-развертываний, применимы и здесь, но если вы планируете развернуть VCF, логично тщательно изучить, как NVMe Memory Tiering может существенно снизить стоимость покупки серверов. Как уже говорилось, крайне важно убедиться, что ваши рабочие нагрузки подходят для Memory Tiering (большинство подходят), но проверку провести необходимо.
После исследования вы можете принимать решения по оборудованию на основе квалификации рабочих нагрузок. Допустим, все ваши рабочие нагрузки подходят для Memory Tiering, и большинство из них используют около 30% активной памяти. В таком случае всё ещё рекомендуется придерживаться консервативного подхода и масштабировать систему с использованием стандартного соотношения DRAM:NVMe 1:1. То есть, если вам нужно 1 ТБ памяти на хост, вы можете уменьшить объем DRAM до 512 ГБ и добавить 512 ГБ NVMe — это даст вам требуемый общий объем памяти, и вы уверены (благодаря исследованию), что активная память ваших нагрузок всегда уместится в DRAM. Кроме того, количество NVMe-устройств на хост и RAID-контроллер — это отдельное решение, которое не влияет на доступный объем NVMe, поскольку в любом случае необходимо предоставить одно логическое устройство, будет ли это один независимый NVMe или 2+ устройства в RAID-конфигурации. Однако это решение влияет на стоимость и отказоустойчивость.
С другой стороны, вы можете оставить исходный объем DRAM в 1 ТБ и добавить еще 1 ТБ памяти через Memory Tiering. Это позволит использовать более плотные серверы, сократив общее количество серверов, необходимых для размещения ваших нагрузок. В этом случае экономия достигается за счет меньшего количества оборудования и компонентов, а также сокращения затрат на охлаждение и энергопотребление.
В заключение, при определении размеров необходимо учитывать все переменные: объем DRAM, размер NVMe-устройств, размер раздела и соотношение DRAM:NVMe. Помимо этих параметров, для greenfield-развертываний следует проводить более глубокий анализ — именно здесь можно добиться дополнительной экономии, покупая DRAM только для активной памяти, а не для всего пула, как мы делали годами. Говоря о факторах и планировании, стоит также учитывать совместимость Memory Tiering с vSAN — это будет рассмотрено в следующей части серии.
В первой части статей этой серии мы рассмотрели некоторые предварительные требования для NVMe Memory Tiering, такие как оценка рабочих нагрузок, процент активности памяти, ограничения профилей виртуальных машин, предварительные требования и совместимость устройств NVMe.
Кроме того, мы подчеркнули важность внедрения платформы VMware Cloud Foundation (VCF) 9, которая может обеспечить значительное сокращение затрат на память, лучшее использование CPU и более высокую консолидацию виртуальных машин. Но прежде чем полностью развернуть это решение, важно спроектировать его с учётом безопасности, отказоустойчивости и масштабируемости — именно об этом и пойдёт речь в этой статье.
Безопасность
Безопасность памяти не является особенно популярной темой среди администраторов, и это объясняется тем, что память является энергонезависимой. Однако злоумышленники могут использовать память для хранения вредоносной информации на энергонезависимых носителях, чтобы избежать обнаружения — но это уже скорее тема криминалистики. Как только питание отключается, данные в DRAM (энергозависимой памяти) исчезают в течение нескольких минут. Таким образом, с NVMe Memory Tiering мы переносим страницы из энергозависимой памяти (DRAM) на энергонезависимую (NVMe).
Чтобы устранить любые проблемы безопасности, связанные с хранением страниц памяти на устройствах NVMe, VMware разработала несколько решений, которые клиенты могут легко реализовать после первоначальной настройки.
В этом первом выпуске функции Memory Tiering шифрование уже входит в комплект и готово к использованию «из коробки». Фактически, у вас есть возможность включить шифрование на уровне виртуальной машины (для каждой ВМ) или на уровне хоста (для всех ВМ на данном хосте). По умолчанию эта опция не активирована, но её легко добавить в конфигурацию через интерфейс vCenter.
Для шифрования в NVMe Memory Tiering нам не требуется система управления ключами (KMS) или встроенный поставщик ключей (NKP). Вместо этого ключ случайным образом генерируется на уровне ядра каждым хостом с использованием шифрования AES-XTS. Это избавляет от зависимости от внешних поставщиков ключей, поскольку данные, выгруженные в NVMe, актуальны только в течение времени жизни виртуальной машины.
Случайный 256-битный ключ создаётся при включении виртуальной машины, и данные шифруются в момент их выгрузки из DRAM в NVMe, а при обратной загрузке в DRAM для чтения — расшифровываются. Во время миграции виртуальной машины (vMotion) страницы памяти сначала расшифровываются, затем передаются по зашифрованному каналу vMotion на целевой хост, где генерируется новый ключ (целевым хостом) для последующих выгрузок памяти на NVMe.
Этот процесс одинаков как для «шифрования на уровне виртуальной машины», так и для «шифрования на уровне хоста» — единственное различие заключается в том, где именно применяется конфигурация.
Отказоустойчивость
Цель отказоустойчивости — повысить надёжность, сократить время простоя и, конечно, обеспечить спокойствие администратора. В контексте памяти существует несколько методов, некоторые из которых распространены больше других. В большинстве случаев для обеспечения избыточности памяти используют модули с коррекцией ошибок (ECC) и резервные модули памяти. Однако теперь, с появлением NVMe Memory Tiering, необходимо учитывать как DRAM, так и NVMe. Мы не будем подробно останавливаться на методах избыточности для DRAM, а сосредоточимся на NVMe в контексте памяти.
В VVF/VCF 9.0 функция NVMe Memory Tiering поддерживает аппаратную конфигурацию RAID, три-режимный (tri-mode) контроллер и технологию VROC (Virtual RAID on CPU) для обеспечения отказоустойчивости холодных или неактивных страниц памяти. Что касается RAID, мы не ограничиваемся какой-то одной конфигурацией: например, RAID-1 — это хорошее и поддерживаемое решение для обеспечения отказоустойчивости NVMe, но также поддерживаются RAID-5, RAID-10 и другие схемы. Однако такие конфигурации потребуют больше NVMe-устройств и, соответственно, увеличат стоимость.
Говоря о стоимости, стоит учитывать и наличие RAID-контроллеров, если вы планируете использовать RAID для отказоустойчивости. Обеспечение резервирования для холодных страниц — это архитектурное решение, которое должно приниматься с учётом баланса между затратами и операционными издержками. Что для вас важнее — надёжность, стоимость или простота эксплуатации? Также необходимо учитывать совместимость RAID-контроллера с vSAN: vSAN ESA не поддерживает RAID-контроллеры, в то время как vSAN OSA поддерживает, но они должны использоваться раздельно.
Преимущества RAID:
Обеспечивает избыточность для NVMe как устройства памяти
Повышает надёжность
Возможное сокращение времени простоя
Недостатки RAID:
Необходимость RAID-контроллера
Дополнительные расходы
Операционные издержки (настройка, обновление прошивок и драйверов)
Усложнение инфраструктуры
Появление новой точки отказа
Возможные проблемы совместимости с vSAN, если все накопители подключены к одной общей плате (backplane)
Как видно, у аппаратной избыточности есть как плюсы, так и минусы. Следите за обновлениями — в будущем могут появиться новые поддерживаемые методы отказоустойчивости.
Теперь предположим, что вы решили не использовать RAID-контроллер. Что произойдёт, если у вас есть один выделенный накопитель NVMe для Memory Tiering, и он выйдет из строя?
Ранее мы обсуждали, что на NVMe переносятся только «холодные» страницы памяти виртуальных машин по мере необходимости. Это означает, что страницы памяти самого хоста не находятся на NVMe, а также что на накопителе может быть как много, так и мало холодных страниц — всё зависит от нагрузки на DRAM. VMware не выгружает страницы (даже холодные), если в этом нет нужды — зачем расходовать вычислительные ресурсы?
Таким образом, если часть холодных страниц была выгружена на NVMe и накопитель вышел из строя, виртуальные машины, чьи страницы находились там, могут попасть в ситуацию высокой доступности (HA). Мы говорим "могут", потому что это произойдёт только если и когда ВМ запросит эти холодные страницы обратно из NVMe, которые теперь недоступны. Если же ВМ никогда не обратится к этим страницам, она продолжит работать без сбоев.
Иными словами, сценарий отказа зависит от активности в момент сбоя NVMe:
Если на NVMe нет холодных страниц — ничего не произойдёт.
Если есть немного холодных страниц — возможно, несколько ВМ войдут в HA-событие и перейдут на другой хост;
Если все холодные страницы хранились на NVMe — возможно, большинство ВМ окажутся в HA-режиме по мере запроса страниц.
Это не обязательно приведёт к полному отказу всех систем. Некоторые ВМ могут выйти из строя сразу, другие — позже, а третьи — вообще не пострадают. Всё зависит от их активности. Главное — хост ESX продолжит работу, а поведение виртуальных машин будет различаться в зависимости от текущих нагрузок.
Масштабируемость
Масштабируемость памяти — это, пожалуй, один из тех неожиданных факторов, который может обойтись очень дорого. Как известно, память составляет значительную часть (до 80%) общей стоимости нового сервера. В зависимости от подхода к закупке серверов, вы могли выбрать меньшие по объёму модули DIMM, установив их во все слоты — в этом случае у вас нет возможности увеличить объём памяти без полной замены всех модулей, а иногда даже самого сервера.
В также могли выбрать высокоплотные модули DIMM, оставив несколько слотов свободными для будущего роста — это позволяет масштабировать память, но тоже дорого, так как позже придётся докупать совместимые модули (если они ещё доступны). В обоих случаях масштабирование получается дорогим и медленным, особенно учитывая длительные процедуры утверждения бюджета и заказов в компаниях.
Именно здесь NVMe Memory Tiering показывает себя с лучшей стороны — снижая затраты и позволяя быстро увеличить объём памяти. В данном случае масштабирование памяти сводится к покупке хотя бы одного устройства NVMe и включению функции Memory Tiering — и вот у вас уже на 100% больше памяти для ваших хостов. Отличная выгода.
Можно даже «позаимствовать» накопитель из вашего хранилища vSAN, если есть возможность выделить его под Memory Tiering… но об этом чуть позже (делайте это с осторожностью).
В этой части важно понимать ограничения и возможности, чтобы обеспечить надёжность инвестиций в будущем. Мы уже говорили о требованиях к устройствам NVMe по показателям производительности и износостойкости, но что насчёт объёма NVMe-устройств? Об этом мы напишем в следующей части.
Таги: VMware, NVMe, Memory, Tiering, Hardware, Security, HA
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Многоуровневая память (Memory Tiering) снижает затраты и повышает эффективность использования ресурсов. Эта функция была впервые представлена в виде технологического превью в vSphere 8.0 Update 3 и получила очень положительные отзывы от клиентов. Обратная связь от пользователей касалась в основном устойчивости данных, безопасности и гибкости в конфигурациях хостов и виртуальных машин. С выходом платформы VCF 9.0 все эти вопросы были решены.
Теперь многоуровневая память — это готовое к использованию в производственной среде решение, включающее поддержку DRS и vMotion, повышенную производительность, улучшенное соотношение DRAM:NVMe по умолчанию (1:1), а также множество других улучшений, направленных на повышение надёжности этой функции.
В компании Broadcom было проведено масштабное внутреннее тестирование, которое показало, что использование многоуровневой памяти позволяет сократить совокупную стоимость владения (TCO) до 40% для большинства рабочих нагрузок, а также обеспечивает рост загрузки CPU, позволяя использовать на 25–30% больше ядер под задачи. Меньше затрат — больше ресурсов. Кроме того, лучшая консолидация ВМ может означать меньше серверов или больше ВМ на каждом сервере.
Многоуровневая память обеспечивает все эти и многие другие преимущества, используя NVMe-устройства в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогих устройств, таких как NVMe. Между предварительной технической версией и готовым к промышленному использованию выпуском с VCF 9.0 существует множество важных отличий. Давайте рассмотрим эти улучшения.
Новые возможности Advanced Memory Tiering
Смешанный кластер
Многоуровневая память (Memory Tiering) может быть настроена на всех хостах в кластере, либо вы можете включить эту функцию только для части хостов. Причины для этого могут быть разными: например, вы хотите протестировать технологию на одном хосте и нескольких ВМ, возможно, только несколько хостов имеют свободные слоты для NVMe-устройств, или вам разрешили приобрести лишь ограниченное количество накопителей. Хорошая новость в том, что поддерживаются все эти и многие другие сценарии — чтобы соответствовать текущим возможностям заказчиков. Вы можете выбрать только часть хостов или активировать эту функцию на всех.
Резервирование
Резервирование всегда является приоритетом при проектировании архитектуры. Как вы знаете, не бывает серьезной производственной среды с одной единственной сетевой картой на сервер. Что касается накопителей, то обеспечить отказоустойчивость можно с помощью конфигурации RAID — именно это и было реализовано. Многоуровневая память может использовать два и более NVMe-устройств в аппаратной RAID-конфигурации для защиты от отказов устройств.
Поддержка DRS
Технология DRS (Distributed Resource Scheduler) существует уже довольно давно, это одна из функций, без которой большинство клиентов уже не могут обходиться. VMware вложила много усилий в то, чтобы сделать алгоритм Memory Tiering «умным» — чтобы он не только анализировал состояние страниц памяти, но и эффективно управлял ими в пределах кластера.
DRAM:NVMe — новое соотношение
В vSphere 8.0 U3 функция Memory Tiering была представлена как технологическое превью. Тогда использовалось соотношение 4:1, то есть на 4 части DRAM приходилась 1 часть NVMe. Это дало увеличение объёма памяти на 25%. Хотя это может показаться незначительным, при сравнении стоимости увеличения объёма памяти на 25% с использованием DRAM и NVMe становится очевидно, насколько это выгодно.
В VCF 9.0, после всех улучшений производительности, изменили соотношение по умолчанию: теперь оно 1:1 — то есть увеличение объема памяти в 2 раза по умолчанию. И это значение можно настраивать в зависимости от нагрузки и потребностей. То есть, если у вас есть хост ESX с 1 ТБ DRAM и вы включаете Memory Tiering, вы можете получить 2 ТБ доступной памяти. Для некоторых сценариев, таких как VDI, возможно соотношение до 1:4 — это позволяет вчетверо увеличить объём памяти при минимальных затратах.
Другие улучшения
В VCF 9.0 было реализовано множество других улучшений функции Memory Tiering. Общие улучшения производительности сделали решение более надёжным, гибким, отказоустойчивым и безопасным. С точки зрения безопасности добавлено шифрование: как на уровне виртуальных машин, так и на уровне хоста. Страницы памяти ВМ теперь могут быть зашифрованы индивидуально для каждой ВМ или сразу для всех машин на хосте — с помощью простой и удобной настройки.
Как начать использовать Advanced Memory Tiering
С чего начать? Как понять, подходят ли ваши рабочие нагрузки для Memory Tiering? Клиентам стоит учитывать следующие факторы при принятии решения о внедрении Memory Tiering:
Активная память
Memory Tiering особенно подходит для клиентов с высоким потреблением (выделено под ВМ более 50%) и низким уровнем активного использования памяти (фактически используемая нагрузками — менее 50% от общего объема DRAM).
Скриншот ниже показывает, как можно отслеживать активную память и объём DRAM с помощью vCenter:
NVMe-устройства
Существуют рекомендации по производительности и ресурсу для поддерживаемых накопителей — в руководстве по совместимости Broadcom (VMware) указано более 1500 одобренных моделей. NVMe-накопители, такие как E3.S, являются модульными и зачастую могут быть установлены в свободные слоты серверов, например, как в Dell PowerEdge, показанном ниже. VMware настоятельно рекомендует клиентам обращаться к руководству по совместимости Broadcom, чтобы обеспечить нужный уровень производительности своих рабочих нагрузок за счёт выбора рекомендованных устройств.
Многоуровневая память Advanced Memory Tiering снижает затраты и одновременно повышает эффективность использования ресурсов, и её будущее выглядит многообещающим. Уже ведётся работа над рядом улучшений, которые обеспечат ещё больший комфорт и дополнительные преимущества. В ближайшие месяцы будет доступно больше информации о технологии Memory Tiering.
Продолжаем рассказывать о технологии ярусной памяти Memory Tiering, которая появилась в VMware vSphere 8 Update 3 (пока в статусе Tech Preview). Вильям Лам написал об интересной возможности использования одного устройства как для NVMe Tiering, так и для датасторов VMFS на платформе VMware vSphere.
На данный момент включение NVMe Tiering требует выделенного устройства NVMe. Для производственных систем это, вероятно, не проблема, так как важно избежать конкуренции за ресурсы ввода-вывода на одном устройстве NVMe. Однако для среды разработки или домашней лаборатории это может быть проблемой из-за ограниченного количества доступных NVMe-устройств.
Оказывается, можно использовать одно устройство NVMe для NVMe Tiering!
Для владельцев систем малого форм-фактора, таких как ASUS NUC, с ограниченным количеством NVMe-устройств, есть такой вариант: вы можете запустить ESXi с USB-устройства, сохранив возможность использовать локальный VMFS-датастор и NVMe Tiering. Таким образом, у вас даже останется свободный слот или два для vSAN OSA или ESA!
Важно: Это решение не поддерживается официально со стороны VMware. Используйте его на свой страх и риск.
Шаг 1 - Убедитесь, что у вас есть пустое устройство NVMe, так как нельзя использовать устройство с существующими разделами. Для идентификации и получения имени SSD-устройства используйте команду vdq -q.
Затем запустите его, как показано на скриншоте ниже:
Примечание: скрипт только генерирует необходимые команды, но вам нужно будет выполнить их вручную. Сохраните их — это избавит вас от необходимости вручную рассчитывать начальные и конечные сектора хранилища.
Пример выполнения сгенерированных команд для конкретной настройки: есть NVMe-устройство объёмом 1 ТБ (913,15 ГБ), из которого выделяется 256 ГБ для NVMe Tiering, а оставшееся пространство будет использовано для VMFS-датастора.
С помощью клиента ESXi Host Client мы можем увидеть два раздела, которые мы только что создали:
Шаг 3 – Включите функцию NVMe Tiering, если она еще не активирована, выполнив следующую команду ESXCLI:
esxcli system settings kernel set -s MemoryTiering -v TRUE
Шаг 4 – Настройте желаемый процент использования NVMe Tiering (от 25 до 400), исходя из конфигурации вашей физической оперативной памяти (DRAM), выполнив следующую команду:
esxcli system settings advanced set -o /Mem/TierNvmePct -i 400
Шаг 5 – Наконец, перезагрузите хост ESXi, чтобы настройки NVMe Tiering вступили в силу. После перезагрузки ваш хост ESXi будет поддерживать использование одного NVMe-устройства как для NVMe Tiering, так и для локального VMFS-датастора, готового для размещения виртуальных машин.
Компания VMware недавно выпустила интересное видео в рамках серии Extreme Performance, где рассматривается, как технологии Memory Tiering могут оптимизировать серверную инфраструктуру, улучшить консолидацию серверов и снизить общую стоимость владения (TCO). Ведущие эксперты, работающие в сфере производительности платформ VMware, делятся новейшими разработками и результатами тестов, которые помогут сделать работу администраторов с серверами более эффективной.
Основные моменты видео:
Что такое Memory Tiering? Memory Tiering — это технология, реализованная в ядре ESXi, которая прозрачно для приложений и гостевых ОС разделяет память на два уровня:
Tier 1: Быстрая память DRAM.
Tier 2: Бюджетные и емкие устройства памяти, такие как NVMe SSD и CXL.
Преимущества Memory Tiering:
Увеличение доступной памяти за счет использования NVMe в качестве памяти второго уровня.
Снижение затрат на память до 50%.
Исключение таких проблем, как ballooning и случайный обмен страницами.
Реальные результаты:
Удвоение плотности виртуальных машин (VMs): на одной хост-машине можно разместить вдвое больше ВМ без заметной потери производительности (<3%).
Оптимизация работы баз данных: для SQL Server и Oracle наблюдалось почти линейное масштабирование с минимальными потерями производительности.
Стабильный пользовательский опыт (VDI): эталонный тест Login VSI показал, что даже при удвоении числа ВМ пользовательский опыт остается на высоком уровне.
Ключевые метрики и рекомендации:
Active memory: один из основных параметров для мониторинга. Оптимальный уровень — около 50% от объема Tier 1 (DRAM).
Использование NVMe: рекомендации по чтению и записи (до 200 мс latency для чтения и 500 мс для записи).
Практические примеры и кейсы:
Клиенты из финансового и медицинского секторов, такие как SS&C Cloud, уже успешно применяют Memory Tiering, чтобы уменьшить затраты на серверы и улучшить их производительность.
Советы по настройке и мониторингу:
Как отслеживать активность NVMe-устройств и состояние памяти через vCenter.
Какие показатели важны для анализа производительности.
Кому будет полезно:
Системным администраторам, DevOps-инженерам и специалистам по виртуализации.
Организациям, которые стремятся сократить затраты на ИТ-инфраструктуру и повысить плотность виртуализации.
Любителям передовых технологий, которые хотят понять, как современные подходы меняют управление памятью в дата-центрах.
Memory Tiering — это прорывная технология, которая уже сегодня позволяет добиться больших результатов в консолидации серверов. Узнайте, как её применить в вашем окружении, и станьте частью следующего поколения производительности серверов.
Таги: VMware, vSphere, Memory, Performance, NVMe, Video
Memory Tiering использует более дешевые устройства в качестве памяти. В Update 3 платформа vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Вильям Лам написал интересный пост о выводе информации для NVMe Tiering в VMware vSphere через API. После успешного включения функции NVMe Tiering, которая была введена в vSphere 8.0 Update 3, вы можете найти полезную информацию о конфигурации NVMe Tiering, перейдя к конкретному хосту ESXi, затем выбрав "Configure" -> "Hardware" и в разделе "Memory", как показано на скриншоте ниже.
Здесь довольно много информации, поэтому давайте разберём отдельные элементы, которые полезны с точки зрения NVMe-тиринга, а также конкретные vSphere API, которые можно использовать для получения этой информации.
Memory Tiering Enabled
Поле Memory Tiering указывает, включён ли тиринг памяти на хосте ESXi, и может иметь три возможных значения: "No Tiering" (без тиринга), "Hardware Memory Tiering via Intel Optane" (аппаратный тиринг памяти с помощью технологии Intel Optane) или "Software Memory Tiering via NVMe Tiering" (программный тиринг памяти через NVMe). Мы можем получить значение этого поля, используя свойство "memoryTieringType" в vSphere API, которое имеет три перечисленных значения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Поле Tier 0 представляет общий объём физической оперативной памяти (DRAM), доступной на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "DRAM"}).Size
Tier 1 Memory
Поле Tier 1 представляет общий объём памяти, предоставляемой NVMe-тирингом, которая доступна на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Примечание: Можно игнорировать термин "Unmappable" — это просто другой способ обозначения памяти, отличной от DRAM.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "NVMe"}).Size
Поле Total представляет общий объём памяти, доступный ESXi при объединении как DRAM, так и памяти NVMe-тиринга, который можно агрегировать, используя размеры Tier 0 и Tier 1 (в байтах).
Устройства NVMe для тиринга
Чтобы понять, какое устройство NVMe настроено для NVMe-тиринга, нужно перейти в раздел "Configure" -> "Storage" -> "Storage Devices", чтобы просмотреть список устройств. В столбце "Datastore" следует искать значение "Consumed for Memory Tiering", как показано на скриншоте ниже. Мы можем получить это поле, используя свойство "usedByMemoryTiering" при энумерации всех устройств хранения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Отношение объёма DRAM к NVMe по умолчанию составляет 25% и настраивается с помощью следующего расширенного параметра ESXi под названием "Mem.TierNvmePct". Мы можем получить значение этого поля, используя либо vSphere API ("OptionManager"), либо через ESXCLI.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Вильям собрал все вышеперечисленные парметры и создал скрипт PowerCLI под названием "get-nvme-tiering-info.ps1", который предоставляет удобное резюме для всех хостов ESXi в рамках конкретного кластера Sphere (вы также можете изменить скрипт, чтобы он запрашивал конкретный хост ESXi). Это может быть полезно для быстрого получения информации о хостах, на которых NVMe-тиринг может быть настроен (или нет).
vSphere Memory Tiering - это очень интересная функция, которую VMware выпустила в качестве технического превью в составе vSphere 8.0 Update 3, чтобы дать своим клиентам возможность оценить механику ранжирования памяти в их тестовых средах. Об этом мы уже немного рассказывали, а сегодня дополним.
По сути, Memory Tiering использует более дешевые устройства в качестве памяти. В vSphere 8.0 Update 3 vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Memory Tiering также решает проблемы несоответствия между ядрами процессора и объемом памяти и способствует лучшей консолидации рабочих нагрузок и виртуальных машин.
Memory Tiering настраивается на каждом ESXi в кластере, и все хосты должны работать на vSphere 8.0 U3. По умолчанию соотношение DRAM к NVMe составляет 4:1, но его можно изменить для использования большего количества ресурсов NVMe в качестве памяти.
Для изменения этого соотношения нужно зайти в Host > Manage > System > Advanced settings и поменять там настройку Mem.TierNvmePct. По умолчанию это 25, то есть NVMe занимает 25% от общей оперативной памяти хоста ESXi. Максимальное значение составляет 400, минимальное - 1.
Технические подробности настройки vSphere Memory Tiering описаны в статье базы знаний KB 95944. Там можно скачать документ "Memory Tiering over NVMe Tech Preview", где описываются все аспекты использования данной технологии:
Если же вы хотите посмотреть на работу этой штуки в действии, то можете почитать интересные посты Вильяма Лама:
На конференции Explore 2022 компания VMware объявила о выпуске новой версии платформы VMware vSphere 8, о возможностях которой мы уже писали. Сегодня мы посмотрим, что нового появилось в механизме работы томов vVols, которые позволяют более гибко подходить к хранению объектов виртуальных машин за счет передачи некоторых функций работы с их данными на сторону хранилищ.
Сегодня мы поговорим о нововведениях, которые появились в технологии vVols для восьмой версии платформы.
1. Поддержка технологии NVMe-oF
Это большое нововведение означает поддержку томами vVols на платформе vSphere 8 технологии NVMe-oF. В новой спецификации vVols появились определения vSphere API для механики работы с хранилищами VASA (vSphere Storage APIs for Storage Awareness) 4.0.
Напомним, что NVMe-oF - это реализация технологии RDMA, которая позволяет не использовать CPU для удаленного доступа к памяти и пропускать к хранилищу основной поток управляющих команд и команд доступа к данным напрямую, минуя процессоры серверов и ядро операционной системы. Еще один его плюс - это то, что он обратно совместим с такими технологиями, как InfiniBand, RoCE и iWARP. Для всего этого нужна поддержка RDMA со стороны HBA-адаптера хоста ESXi.
NVMe-oF имеет преимущество в виде меньших задержек (latency) над традиционным интерфейсом SCSI. Эта технология изначально предназначена для флэш-памяти и позволяет подключать all-flash NVMe дисковые массивы с очень высокой производительностью.
В рамках технологии NVMe-oF vVols каждый объект vVol становится пространством имен NVMe Namespace. Эти пространства имен группируются в ANA group (Asymmetrical Namespace Access). Многие команды проходят как In-Band для более эффективной коммуникации между хостами ESXi и дисковыми массивами.
Также упростилась настройка томов, в том числе NVMe с технологией vVols. При развертывании NVMe в vCenter, когда зарегистрирован VASA-провайдер, оставшаяся установка происходит в фоновом режиме, а обнаружение NVMe-контроллеров происходит автоматически. Как только создается датастор, объекты vPE (virtual Protocol Endpoints) и само соединение подхватываются и обрабатываются автоматически.
2. Дополнительные улучшения vVols NVMe-oF
Они включают в себя следующее:
Поддержка до 256 пространств имен и 2000 путей
Расширенная поддержка механизма резерваций для устройств NVMe - это позволит поддерживать функцию Clustered VMDK для кластеризованных приложений, таких как Microsoft WSFC на базе хранилищ NVMe-oF
Функции автообнаружения в механизме NVMe Discovery Services для ESXi при использовании NVMe-TCP для обнаружения контроллеров NVMe
3. Прочие улучшения
Улучшение VM swap - уменьшенное время при включении и выключении для обеспечения лучшего быстродействия vMotion
Улучшенная производительность компонента config-vVol - убраны задержки при обращения виртуальных машин к платформе ESXi
В середине июня компания VMware представила сообществу Open Source свою новую разработку - нереляционную базу данных типа key-value SplinterDB. Базы данных с механиками "ключ-значение" работают очень быстро и в данный момент применяются для решения широкого круга задач. VMware сделала тут вот какую вещь - эта СУБД работает еще быстрее остальных (иногда в разы), поэтому она позиционируется как "ultra fast"-решение для высокопроизводительных нагрузок.
Платформа SplinterDB была разработана VMware Research Group в плотном сотрудничестве с группой разработки решений линейки vSAN. Ключевой особенностью этой базы данных является возможность быстро работать как с запросами на вставку/обновление данных, так и с запросами на чтение пар ключ-значение из хранилища. Вот так это выглядит в сравнении с СУБД RocksDB (она была разработана в Facebook), которая работает в той же нише, что и SplinterDB, на примере бенчмарка Yahoo Cloud Services Benchmark (YCSB):
SplinterDB максимально использует возможности ядер процессоров, легко масштабируется и использует все преимущества технологии организации хранилищ NVMe. Поэтому SplinterDB можно использовать поверх существующих key-value хранилищ, а также традиционных реляционных баз данных, NoSQL-СУБД, микросервисов, обработчиков потоков, архитектуры edge/IoT, хранилищ метаданных и графовых баз данных.
SplinterDB - это внедренное key-value хранилище во внешней памяти, что означает, что приложения используют SplinterDB путем линковки библиотеки SplinterDB в свой исполняемый файл. SplinterDB хранит данные на высокопроизводительных дисках SSD NVMe и может масштабироваться до огромных датасетов, которые значительно превышают объемы доступной памяти RAM.
На картинке выше показан пример, где SplinterDB и RocksDB хранили датасет 80 GiB в системе, имеющей 4 GiB RAM. Так как лишь малая часть базы данных помещалась в кэш оперативной памяти, то эффективность работы подсистемы ввода-вывода была ключевым фактором оценки производительности. Для теста использовались диски Intel Optane SSD, которые поддерживают 2 GiB/sec на чтение и запись. При этом RocksDB использовала только 30% доступного канала обмена с хранилищем (для операций записи), а SplinterDB использовала до 90% канала. При чтении SplinterDB также показала себя в полтора раза лучше, чем RocksDB, за счет более эффективного использования CPU и техник кэширования.
В чем же секрет такого высокого уровня производительности? Дело в том, что современные key-value хранилища (включая SplinterDB, RocksDB, LevelDB, Apache Cassandra и другие) хранят данные в больших сортируемых таблицах. Запросы ищут значения в каждой таблице, спускаясь от новых данных к старым. Таким образом, запросы замедляют систему, накапливая все больше и больше таблиц с данными. Чтобы избежать замедления работы, эти системы время от времени объединяют несколько отсортированных таблиц в одну (это называется compaction). Это и создает дисбаланс между скоростью на чтение и скоростью на запись. За счет этого запросы исполняются быстро, но вот вставка данных замедляется. Если compaction делать реже, то вставка будет работать быстрее, но и чтение замедлится.
SplinterDB делает compaction более чем в 8 раз реже, чем RocksDB, поэтому вставка данных и работает в первой примерно в 7 раз быстрее, чем во второй. Но что со скоростью на чтение? Чтобы поддерживать высокую скорость чтения, SplinterDB работает иначе, чем современные хранилища. Большинство из них используют фильтры Bloom (или их еще называют cuckoo), чтобы ускорять запросы.
Фильтр - это маленькая структура данных, которая представляет некое множество из таблицы. RocksDB и аналоги используют один фильтр для каждой таблицы, и запросы прежде всего проверяют фильтр перед тем, как искать во всей таблице, чтобы большинство запросов могли искать только в небольшой структуре. Задумка здесь в том, что фильтры будут хранится в памяти, поэтому I/O операции с хранилищами будут вызываться нечасто.
На быстрых хранилищах этот подход работает не так эффективно, особенно когда набор данных в БД значительно превышает размер доступной оперативной памяти. На быстрых хранилищах затраты на CPU при поиске в фильтрах могут быть высокими ввиду большого числа фильтров. При этом может произойти ситуация, когда фильтры не помещаются в память, поэтому они отбрасываются на диск, что делает их использование в этом случае бесполезным.
SplinterDB использует новый вид фильтра, называемый routing filter. Один такой фильтр может заменить несколько фильтров типа Bloom, cuckoo или ribbon и может покрыть сразу несколько таблиц. Обычные фильтры могут сказать только, есть ли соответствующий ключ в доступности в данный момент или нет, а вот routing filter может не только сказать, что ключ есть, но и указать на то, какая конкретно из отсортированных таблиц его содержит. Поэтому запросам нужно делать гораздо меньше работы по поиску в фильтрах, а значит снижается нагрузка на CPU.
Кроме того, поиск в одном фильтре может сильно сэкономить на запросах ко многим таблицам, даже если этот фильтр занимает много места в RAM. Этот механизм работы с данными и был придуман в VMware. Все это позволяет существенно экономить на вычислительных мощностях для очень тяжелых и интенсивных нагрузок.
Многие из вас знают компанию StarWind Software, лидера в сфере поставки программных и программно-аппаратных решений для создания отказоустойчивых хранилищ. Помимо решений непосредственно для организации хранилищ, у компании есть и виртуальный модуль StarWind Backup Appliance, который предназначен для резервного копирования виртуальных машин на хранилищах StarWind. Это программно-аппаратный комплекс на базе оборудования NVMe, который позволяет избавиться от проблемы производительности хранилищ резервных копий и забыть о задаче планирования окна резервного копирования.
Модуль StarWind Backup Appliance поставляется в виде настроенного и готового к работе сервера резервного копирования, построенного на базе StarWind HyperConverged Appliance (HCA). Работа с продуктом происходит через удобный веб-интерфейс StraWind Web UI, есть также плагин StarWind для vCenter.
В апреле компания StarWind объявила, что StarWind Backup Appliance теперь включает в себя оборудование GRAID SupremeRAID - первую в мире карточку NVMe-oF RAID, которая обеспечивает высочайший уровень защиты данных в рамках технологии NVMe RAID на рынке.
Диски NVMe SSD постепенно становятся стандартом индустрии хранения данных, а решение для резервного копирования StarWind BA уже использует полностью только NVMe-хранилища. В этих системах была только одна проблема - с надежной реализацией RAID, и вот теперь она решена с помощью GRAID.
Традиционные RAID-контроллеры не были разработаны изначально для технологии NVMe, а программные RAID работают недостаточно эффективно, потребляя при этом большое число циклов CPU, что мешает рабочим нагрузкам сервера. Поэтому с теперь помощью карточек GRAID комплексы StarWind Backup Appliance обеспечат максимальную производительность и защиту данных на базе дисков NVMe SSD.
Вот так выглядят результаты тестов технологии GRAID по сравнению с текущими реализациями аппаратных RAID для NVMe:
Более подробно об этом нововведении можно узнать из пресс-релиза StarWind. Скачать пробную версию StarWind Backup Appliance можно по этой ссылке.
Недавно мы писали об обновлении на сайте проекта VMware Labs пакета Community Networking Driver for ESXi до версии 1.2.2, который представляет собой комплект нативных драйверов под ESXi для сетевых адаптеров, подключаемых в разъем PCIe. На днях на сайте Labs вышли обновления еще двух пакетов драйверов.
1. NVMe Driver for ESXi версии 1.2
Это набор драйверов для ESXi, которые позволяют поддерживать различные хранилища на базе технологии NVMe. Надо понимать, что community-драйверы не входят в официальный список поддержки VMware HCL, поэтому использовать их можно только в тестовых средах. О прошлой версии мы писали вот тут, а в новой версии нововведение только одно - поддержка ESXi 7.0 и более новых версий гипервизора для устройств Apple NVMe (это Apple 2018 Intel Mac Mini 8.1 или Apple 2019 Intel Mac Pro 7.1).
Скачать пакет драйверов Community NVMe Driver for ESXi 1.2 можно по этой ссылке.
2. USB Network Native Driver for ESXi версии 1.9
Это нативный USB-драйвер для ESXi, который необходим для сетевых адаптеров серверов, подключаемых через USB-порт. Такой адаптер, например, можно использовать, когда вам нужно подключить дополнительные Ethernet-порты к серверу, а у него больше не осталось свободных PCI/PCIe-слотов. О прошлой версии этих драйверов мы писали вот тут.
В версии пакета драйверов 1.9 появились следующие нововведения:
Добавлена поддержка ESXi 7.0 Update 3
Добавлена поддержка VID: 0x0b05/PID: 0x1976 и VID: 0x1A56/PID: 0x3100 (VID=VendorID, PID = ProductID)
Исправлена проблема с функциями управления питанием для xHCI
По умолчанию функция USB bus scanning отключается (настройка usbBusFullScanOnBootEnabled=0), чтобы не вызывать розовый экран смерти (PSOD) для пользователей, которые используют несколько карточек USB NIC.
Таблица поддерживаемых устройств теперь выглядит так:
Скачать USB Network Native Driver for ESXi версии 1.9 можно по этой ссылке (не забудьте корректно указать вашу версию ESXi при загрузке).
На прошедшей онлайн-конференции VMworld 2021 компания VMware представила много новых интересных инициатив, продуктов и технологий. О некоторых из них мы уже рассказали в наших статьях:
Сегодня же мы поговорим о новом начинании VMware - Project Capitola. На рынке серверной виртуализации уже довольно давно развивается экосистема оперативной памяти различных уровней - стандартная DRAM, технология SCM (Optane и Z-SSD), модули памяти CXL, память PMEM, а также NVMe. По аналогии с сетевой инфраструктурой, где есть решение NSX для виртуализации и агрегации сетей, серверной инфраструктурой (где виртуализацией CPU занимается платформа vSphere) и инфраструктурой виртуализации хранилищ vSAN, компания VMware представила среду агрегации и виртуализации оперативной памяти - Project Capitola.
Это - так называемая Software-Defined Memory, определяемая в облаке (неважно - публичном или онпремизном) на уровне кластеров VMware vSphere под управлением vCenter:
Вся доступная память серверов виртуализации в кластере агрегируется в единый пул памяти архитектуры non-uniform memory architecture (NUMA) и разбивается на ярусы (tiers), в зависимости от характеристик производительности, которые определяются категорией железа (price /performance points), предоставляющей ресурсы RAM.
Все это позволяет динамически выделять память виртуальным машинам в рамках политик, созданных для соответствующих ярусов. Для Capitola обеспечивается поддержка большинства механизмов динамической оптимизации виртуального датацентра, таких как Distributed Resource Scheduler (DRS).
Вводить в эксплуатацию свои решения в рамках проекта Capitola компания VMware будет поэтапно: сначала появится управление памятью на уровне отдельных серверов ESXi, а потом уже на уровне кластера.
Очевидно, что такая технология требует поддержки на аппаратном уровне - и VMware уже заручилась поддержкой некоторых вендоров. В плане производителей памяти будет развиваться сотрудничество с Intel, Micron, Samsung, также будут интеграции с производителями серверов (например, Dell, HPE, Lenovo, Cisco), а также сервис-провайдерами (такими как Equinix).
Главная часть сотрудничества VMware - это взаимодействие с компанией Intel, которая предоставляет такие технологии, как Intel Optane PMem на платформах Intel Xeon.
Для получения подробностей смотрите следующие сессии с прошедшего VMworld 2021 (найти их можно тут):
[MCL2384] Big Memory – An Industry Perspective on Customer Pain Points and Potential Solutions
[MCL1453] Introducing VMware’s Project Capitola: Unbounding the "Memory Bound"
Ну а если вам хочется узнать больше о работе с памятью платформы vSphere в принципе, то есть еще и вот такие сессии:
How vSphere Will Redefine Infrastructure to Run Future Apps in the Multi-Cloud Era [MCL2500]
The Big Memory Transformation [VI2342]
Prepared for the New Memory Technology in Next Year’s Enterprise Servers? [VI2334]
Bring Intel PMem into the Mainstream with Memory Monitoring and Remediation [MCL3014S]
60 Minutes of Non-Uniform Memory Access (NUMA) 3rd Edition [MCL1853]
Chasing Down the Next Bottleneck – Accelerating Your Hybrid Cloud [MCL2857S]
Implementing HA for SAP HANA with PMem on vSphere 7.0U2 [VI2331]
5 Key Elements of an Effective Multi-Cloud Platform for Data and Analytics [MCL1594]
Будем держать вас в курсе о дальнейших анонсах инициативы Project Capitola компании VMware.
Данный Fling представляет собой пакет нативных драйверов для ESXi, которые позволяют поддерживать различные хранилища на базе технологии NVMe. Надо понимать, что community-драйверы не входят в официальный список поддержки VMware HCL, поэтому использовать их можно только в тестовых средах.
Драйверы теперь поддерживают VMware ESXi 7.0 или более поздние версии гипервизора для NVMe-хранилищ не от Apple. Пока список поддерживаемых устройств такой:
Для хранилищ Apple SSD пока поддерживается только ESXi 6.7 до версии Patch 03 (Build 16713306). Более новые версии гипервизора с NVMe-устройствами Apple, к сожалению, не работают. Пока драйверы поддерживают Apple 2018 Intel Mac Mini 8.1 и Apple 2019 Intel Mac Pro 7.1, причем подключение портов Thunderbolt 3 не поддерживется (ESXi может выпасть в PSOD).
Драйверы поставляются в виде VIB-пакета, установить который можно командой:
esxcli software vib install -d /path/to/the offline bundle zip
Скачать Community NVMe Driver for ESXi 1.1 можно по этой ссылке.
Напомним, что NVMe-oF - это реализация технологии RDMA, которая позволяет не использовать CPU для удаленного доступа к памяти и пропускать к хранилищу основной поток управляющих команд и команд доступа к данным напрямую, минуя процессоры серверов и ядро операционной системы. Еще один его плюс - это то, что он обратно совместим с такими технологиями, как InfiniBand, RoCE и iWARP. Для всего этого нужна поддержка RDMA со стороны HBA-адаптера хоста ESXi.
Поддержка NVMe-oF для доступа к хранилищам появилась еще в VMware vSphere 7, а в обновлении Update 1 была улучшена и оптимизирована. В указанном выше документе рассматривается сравнение производительности традиционного протокола Fibre Channel Protocol (SCSI FCP) с реализацией FC-NVMe в vSphere 7.0 U1.
Для всех бенчмарков использовался тот же HBA-адаптер и инфраструктура сети хранения данных SAN. Для генерации нагрузки использовались утилиты fio (для создания разных по размеру операций ввода-вывода I/O, а также паттернов нагрузки) и Microsoft CDB (бенчмарк для генерации OLTP-нагрузки в SQL Server).
Результат оказался весьма интересным. С точки зрения IOPS протокол NVMe-oF смог выжать почти в два раза больше операций ввода-вывода практически для IO любого размера:
Задержка (Latency) также снизилась практически в два раза:
На картинке ниже приведены результаты теста Microsoft CDB для базы данных в числе транзакций в секунду:
Здесь также виден значительный прирост для NVMe-oF, а для двух виртуальных машин производительность выше почти в раза!
Остальные интересные детали тестирования - в документе.
Многие администраторы виртуальных инфраструктур в курсе про технологию NVMe (интерфейс Non-volatile Memory дисков SSD), которая была разработана для получения низких задержек и эффективного использования высокого параллелизма твердотельных накопителей. Такие устройства хоть и стоят дороже, но уже показывают свою эффективность за счет использования десятков тысяч очередей команд, что дает очень низкие задержки, требующиеся в таких сферах, как системы аналитики реального времени, онлайн-трейдинг и т.п.
К сожалению, протокол iSCSI (да и Fibre Channel тоже) разрабатывался тогда, когда инженеры еще не думали об архитектуре NVMe и высоком параллелизме, что привело к тому, что если использовать iSCSI для NVMe, использование таких хранилищ происходит неэффективно.
Главная причина - это одна очередь команд на одно устройство NVMe, которую может обслуживать iSCSI-протокол, весь смысл параллелизма теряется:
Вторая проблема - это то, что iSCSI использует процессор для диспетчеризации операций ввода-вывода, создавая дополнительную нагрузку на серверы, а также имеет некоторые сложности по перенаправлению потоков операций для нескольких контроллеров NVMe и устройств хранения на них.
Для этого и был придуман протокол NVMe over Fabrics (NVMe-oF), который не имеет таких ограничений, как iSCSI. Еще один его плюс - это то, что он обратно совместим с такими технологиями, как InfiniBand, RoCE и iWARP.
Компания StarWind сделала свою реализацию данного протокола для продукта StarWind Virtual SAN, чтобы организовать максимально эффективное использование пространства хранения, организованного с помощью технологии NVMe. Об этом было объявлено еще осенью прошлого года. Он поддерживает 64 тысячи очередей, в каждой из которых, в свою очередь, может быть до 64 тысяч команд (в реальной жизни в одной очереди встречается до 512 команд).
Важный момент в реализации NVMe-oF - это применение технологии RDMA, которая позволяет не использовать CPU для удаленного доступа к памяти и пропускать к хранилищу основной поток управляющих команд и команд доступа к данным напрямую, минуя процессоры серверов и ядро операционной системы.
Также RDMA позволяет маппить несколько регионов памяти на одном NVMe-контроллере одновременно и организовать прямое общение типа точка-точка между инициаторами разных хостов (несколько Name Space IDs для одного региона) и этими регионами без нагрузки на CPU.
Такой подход, реализованный в продуктах StarWind, дает потрясающие результаты в плане производительности, о которых мы писали вот в этой статье. К этой статье можно еще добавить то, что реализация инициатора NVMe-oF на базе Windows-систем и таргета на базе Linux (который можно использовать в программно-аппаратных комплексах StarWind Hyperconverged Appliances, HCA) дала накладные издержки на реализацию всего 10 микросекунд по сравнению с цифрами, заявленными в даташитах производителя NVMe-устройств. Знающие люди поймут, насколько это мало.
Еще надо отметить, что бесплатный продукт StarWind NVMe-oF initiator - это единственная программная реализация инициатора NVMe-oF на сегодняшний день. В качестве таргета можно использовать решения Intel SPDK NVMe-oF Target и Linux NVMe-oF Target, что позволяет не зависеть жестко от решений StarWind.
Подробнее о StarWind NVMe-oF initiator можно узнать вот в этой статье. А загрузить его можно по этой ссылке.
Год назад компания StarWind Software анонсировала собственный таргет и инициатор NVMe-oF для Hyper-V, с помощью которых можно организовать высокопроизводительный доступ к хранилищам на базе дисков NVMe (подключенных через шину PCI Express) из виртуальных машин. За прошедший год StarWind достаточно сильно улучшила и оптимизировала этот продукт и представила публично результаты его тестирования.
Для проведения теста в StarWind собрали стенд из 12 программно-апаратных модулей (Hyperconverged Appliances, HCA) на базе оборудования Intel, Mellanox и SuperMicro, составляющий высокопроизводительный вычислительный кластер и кластер хранилищ, где подсистема хранения реализована с помощью продукта Virtual SAN, а доступ к дискам происходит средствами инициатора NVMe-oF от StarWind. Между хостами был настроен 100 Гбит Ethernet, а диски SSD были на базе технологии NVMe (P4800X). Более подробно о конфигурации и сценарии тестирования с технологией NVMe-oF написано тут.
Аппаратная спецификация кластера выглядела так:
Platform: Supermicro SuperServer 2029UZ-TR4+
CPU: 2x Intel® Xeon® Platinum 8268 Processor 2.90 GHz. Intel® Turbo Boost ON, Intel® Hyper-Threading ON
RAM: 96GB
Boot Storage: 2x Intel® SSD D3-S4510 Series (240GB, M.2 80mm SATA 6Gb/s, 3D2, TLC)
Storage Capacity: 2x Intel® Optane™ SSD DC P4800X Series (375GB, 1/2 Height PCIe x4, 3D XPoint™). The latest available firmware installed.
RAW capacity: 9TB
Usable capacity: 8.38TB
Working set capacity: 4.08TB
Networking: 2x Mellanox ConnectX-5 MCX516A-CCAT 100GbE Dual-Port NIC
Для оптимизации потока ввода-вывода и балансировки с точки зрения CPU использовался StarWind iSCSI Accelerator, для уменьшения latency применялся StarWind Loopback Accelerator (часть решения Virtual SAN), для синхронизации данных и метаданных - StarWind iSER initiator.
Как итог, ввод-вывод оптимизировался такими технологиями, как RDMA, DMA in loopback и TCP Acceleration.
С точки зрения размещения узлов NUMA было также сделано немало оптимизаций (кликните для увеличения):
Более подробно о механике самого теста, а также программных и аппаратных компонентах и технологиях, рассказано здесь. Сначала тест проводился на чистом HCA-кластере без кэширования.
Результаты для 4К Random reads были такими - 6,709,997 IOPS при теоретически достижимом значении 13,200,000 IOPS (подробнее вот в этом видео).
Далее результаты по IOPS были следующими:
90% random reads и 10% writes = 5,139,741 IOPS
70% random reads и 30% writes = 3,434,870 IOPS
Полная табличка выглядит так:
Потом на каждом хосте Hyper-V установили еще по 2 диска Optane NVMe SSD и запустили 100% random reads, что дало еще большую пропускную способность - 108.38 GBps (это 96% от теоретической в 112.5 GBps.
Для 100% sequential 2M block writes получили 100.29 GBps.
Полные результаты с учетом добавления двух дисков:
А потом на этой же конфигурации включили Write-Back cache на уровне дисков Intel Optane NVMe SSD для каждой из ВМ и для 100% reads получили 26,834,060 IOPS.
Полная таблица результатов со включенным кэшированием выглядит так:
Да-да, 26.8 миллионов IOPS в кластере из 12 хостов - это уже реальность (10 лет назад выжимали что-то около 1-2 миллионов в подобных тестах). Это, кстати, 101.5% от теоретического максимального значения в 26.4М IOPS (12 хостов, в каждом из которых 4 диска по 550 тысяч IOPS).
Для тестов, когда хранилища были презентованы посредством технологии NVMe-oF (Linux SPDK NVMe-oF Target + StarWind NVMe-oF Initiator), было получено значение 22,239,158 IOPS для 100% reads (что составляет 84% от теоретически расчетной производительности 26,400,000 IOPS). Более подробно об этом тестировании рассказано в отдельной статье.
Полные результаты этого теста:
Все остальное можно посмотреть на этой странице компании StarWind, которая ведет учет результатов. Зал славы сейчас выглядит так :)
Компания StarWind Software, известная своим решением номер 1 для создания отказоустойчивых хранилищ Virtual SAN, на мероприятии Storage Field Day, где она является спонсором, анонсирует программное решение NVMe over Fabrics Target and Initiator для платформ Microsoft Hyper-V и VMware vSphere.
В рамках мероприятия спикеры StarWind:
Объяснят сценарии использования NVM Express over Fabrics (NVMf) и расскажут, как облачные провайдеры могут использовать хранилища NVMe flash.
Наглядно покажут, как небольшой бизнес сможет увеличить отдачу от ИТ-инфраструктуры с использованием NVMf.
Объяснят, как существующие пользователи StarWind смогут получить обновление инфраструктуры за счет нового продукта.
Продемонстрируют решение NVMf в действии (таргет и инициатор).
Расскажут об аспектах производительности хранилищ и особенностях архитектуры решений.
Многие администраторы больших виртуальных инфраструктур VMware vSphere, в которых работают кластеры отказоустойчивых хранилищ VMware vSAN, часто задаются вопросом, какой дисковый контроллер выбрать для организации хранения на хостах ESXi.
Дункан Эппинг дает простую рекомендацию - надо брать один из самых недорогих поддерживаемых контроллеров, который имеет большую глубину очереди (Queue Depth). Например, часто в рекомендациях для vSAN можно встретить контроллер Dell H730, который является весьма дорогим устройством, если брать его на каждый сервер.
Но его не обязательно покупать, достаточно будет дискового контроллера Dell HBA 330, который и стоит дешевле, и глубину очереди имеет в 10 раз больше, чем H730 (хотя оба они соответствуют требованиям vSAN). Да, у H730 есть кэш на контроллере, но он в данном случае не требуется. Лучше использовать интерфейс NVMe для подключения отдельного SSD-кэша, не затрагивающего RAID-контроллеры (его нужно размещать как можно ближе к CPU).
Поэтому итоговая рекомендация по выбору дискового контроллера для кластеров vSAN проста - берите любое недорогое устройство из списка совместимости vSAN Compatibility Guide, но с хорошей глубиной очереди (например, HP H240), а на сэкономленные деньги отдельно организуйте кэш на базе NVMe.

 RSS
RSS