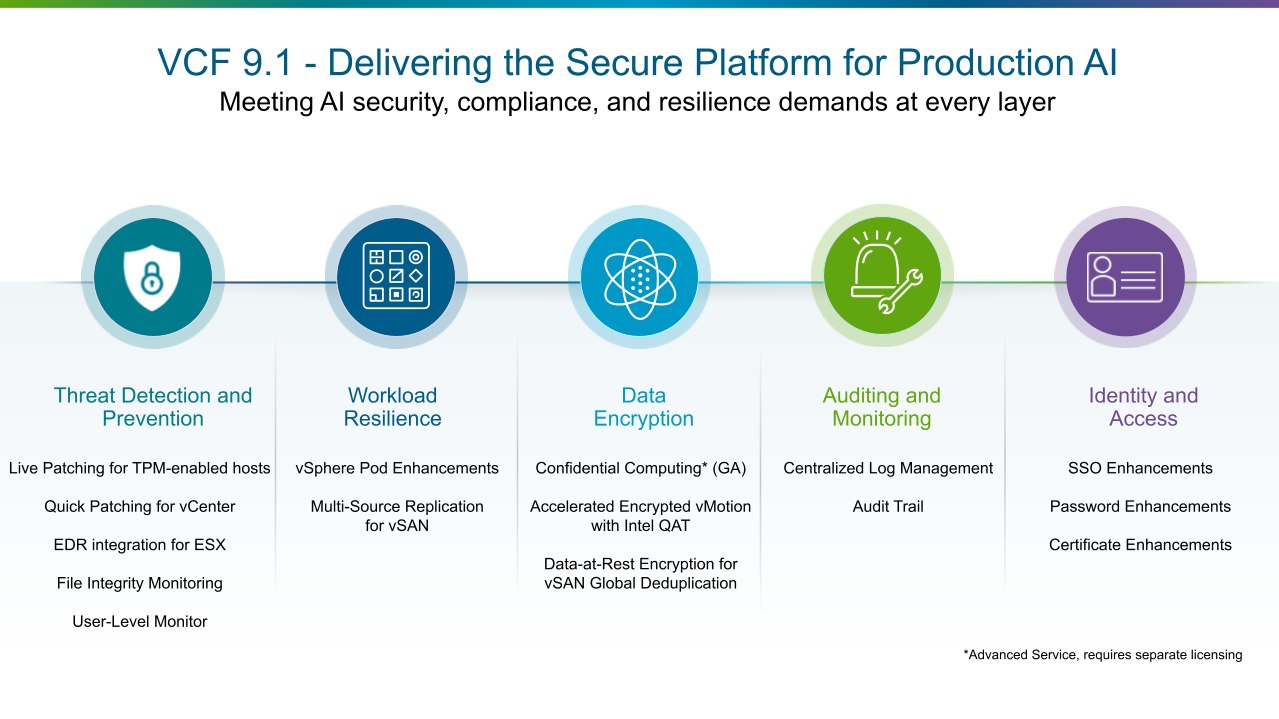
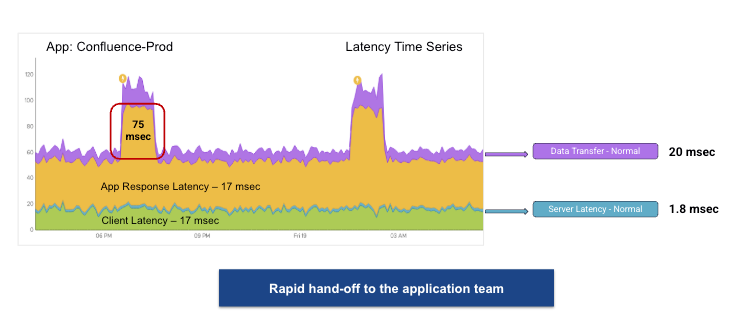
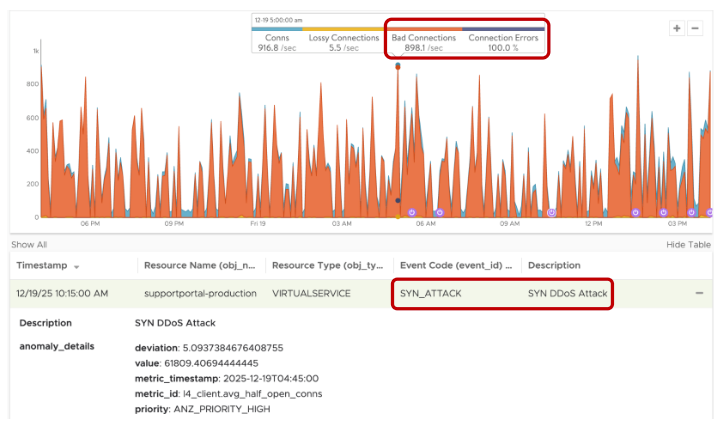
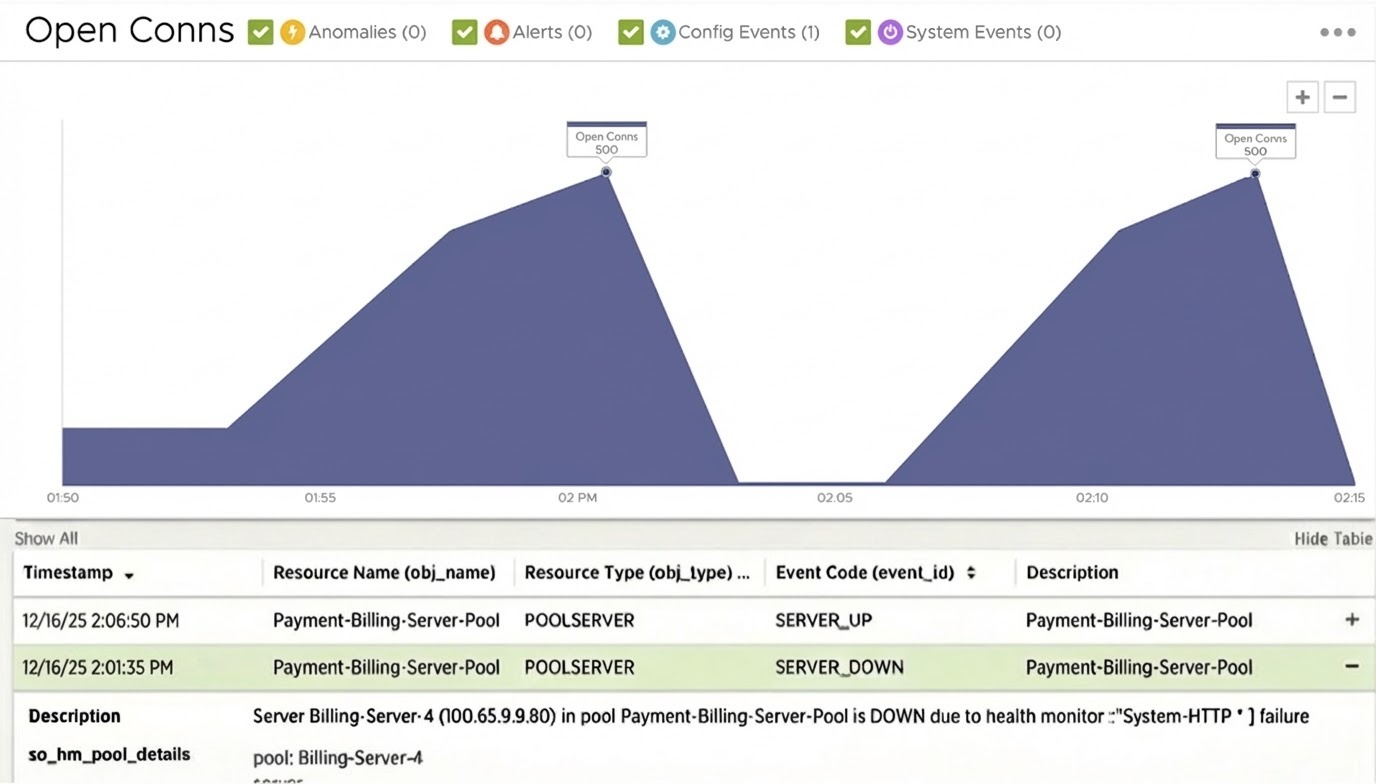
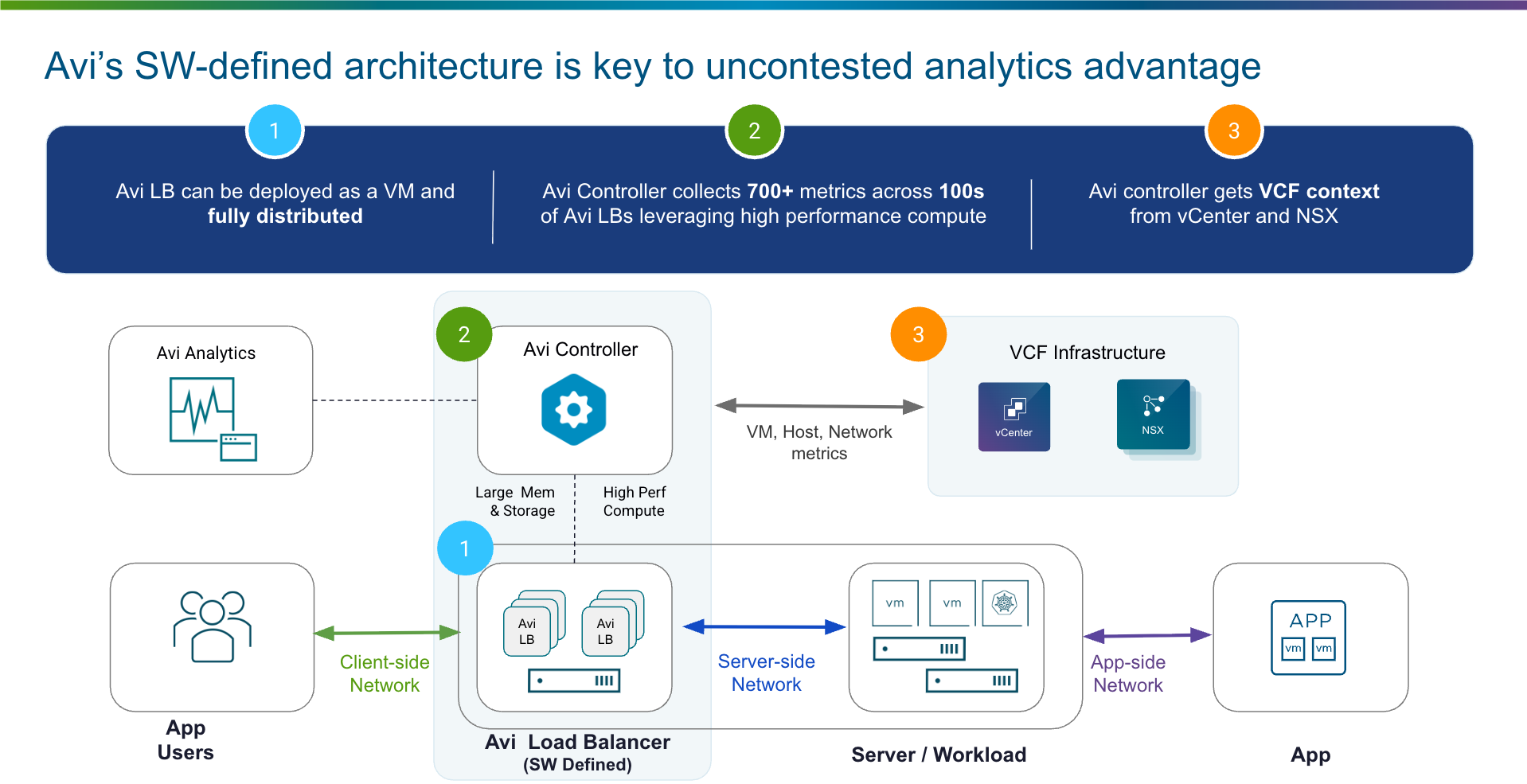
Компания Broadcom не так давно объявила о выпуске VMware Cloud Foundation (VCF) 9.1 — очередном этапе развития самой широко применяемой в отрасли платформы частного облака. Этот релиз имеет ясную и сфокусированную цель: стать наиболее экономичным и защищённым фундаментом для продуктивного искусственного интеллекта, современных приложений и традиционных нагрузок, управляемых из единой плоскости управления, на инфраструктуре, которой предприятие владеет и которую само контролирует.
Одно из главных преимуществ VMware Cloud Foundation (VCF) 9.1 — гибкость и широкая поддержка уже существующих клиентских сред, что позволяет встретить заказчиков ровно на той точке, где они находятся на пути к частному облаку. Это охватывает самые разные сценарии: от отдельных развёртываний vSphere с VCF Operations до сред с различными комбинациями vSAN, NSX и Aria Automation, вплоть до полнофункционального развёртывания всего стека VCF.
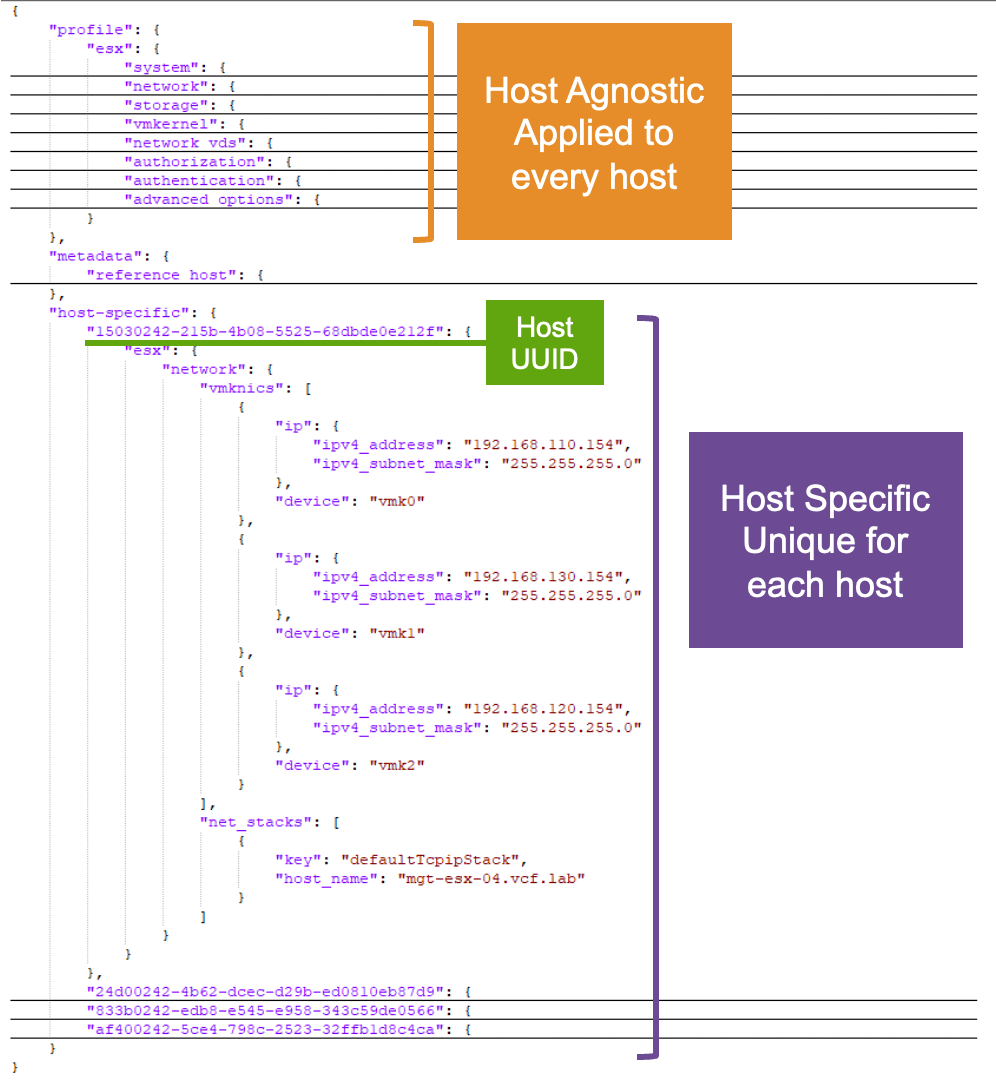
Благодаря возросшей гибкости VCF 9.1 заказчикам, в зависимости от того, какие компоненты и функции развёрнуты в их среде, может потребоваться учитывать конкретную последовательность обновления компонентов, дополнительные операционные процедуры и требования к ресурсам. Всё это способно превратить понимание общего хода обновления в непростую задачу. Раньше для уверенного планирования и проведения обновления приходилось собирать сведения по частям — из продуктовой документации, статей базы знаний и матриц совместимости.
Чтобы упростить процесс обновления, был предложен иной подход: почему бы не начать с того, где заказчик находится сейчас, опираясь на уже развёрнутые продукты и функции, вместо того чтобы требовать от него разбираться во всём множестве вариантов развёртывания и сценариев обновления? Используя эти данные как исходные, можно затем предложить подходящие целевые сценарии, до которых возможно обновиться, и, что особенно важно, сформировать индивидуальный план обновления именно для его среды.
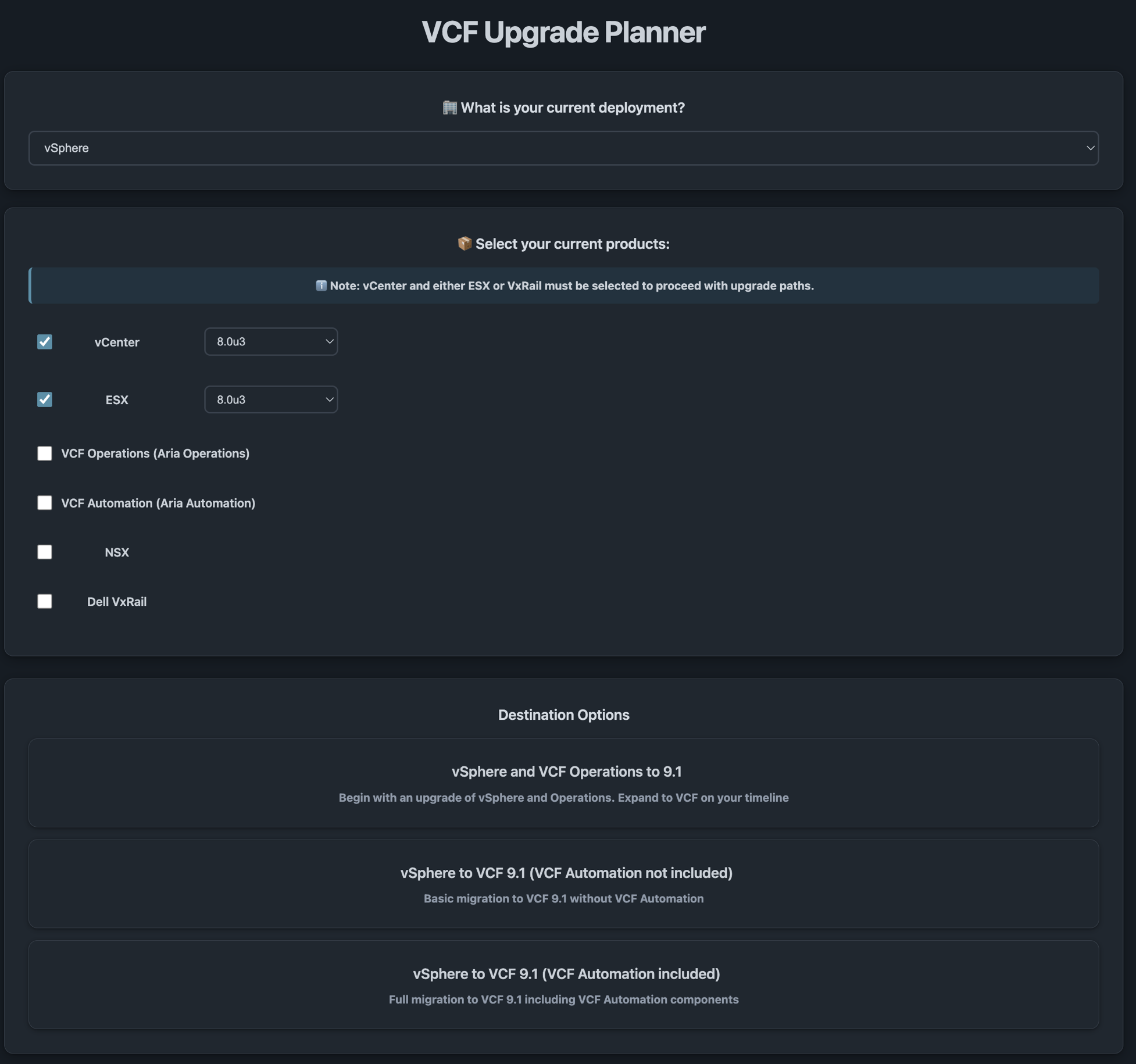
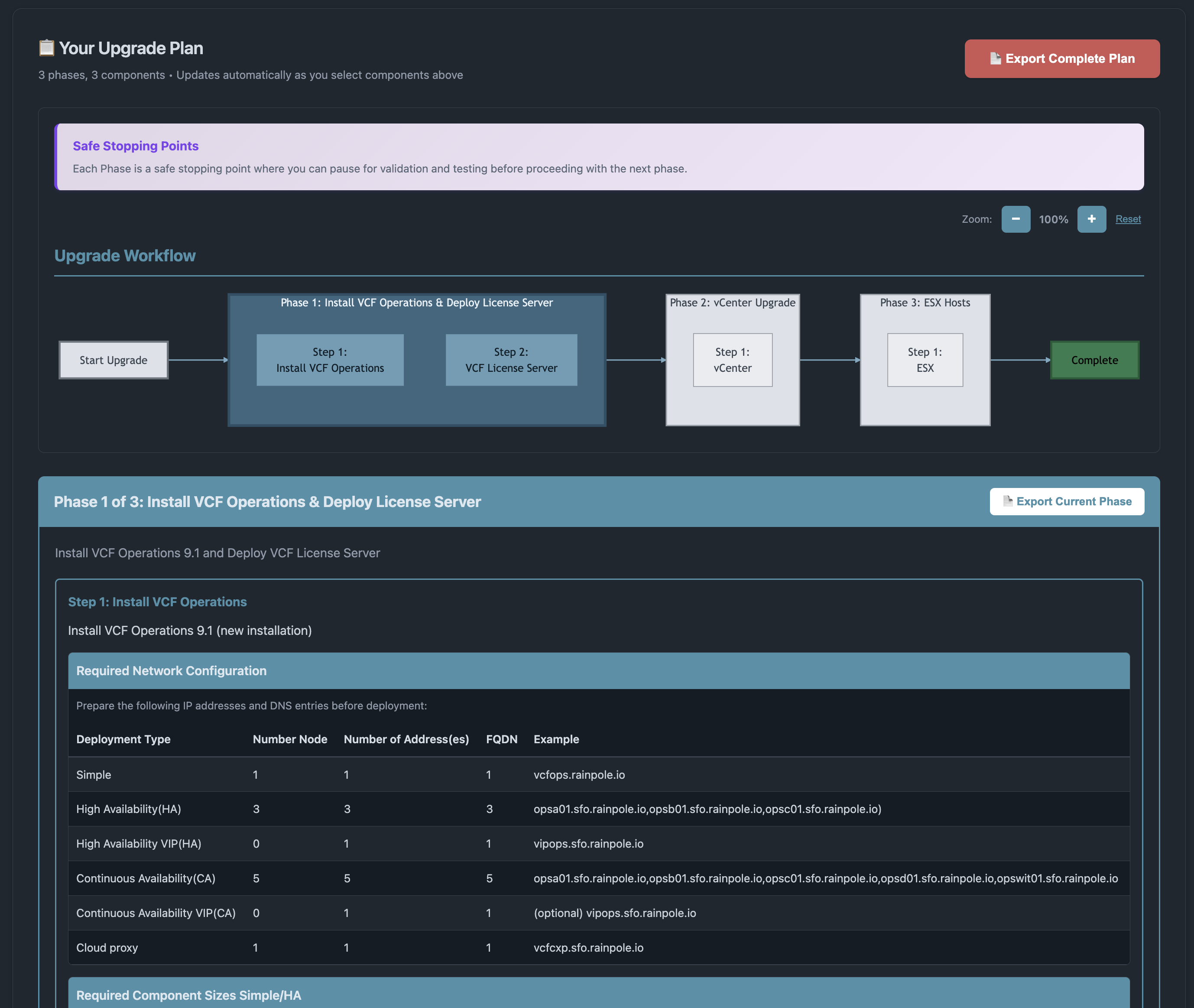
Объявлено о выпуске инструмента планирования обновлений VCF 9.1, который обеспечивает индивидуально подобранный сценарий планирования и помогает заказчикам уверенно пройти путь обновления VCF.
После указания текущего развёртывания — это может быть среда на базе vSphere или VCF — вместе с конкретными версиями, которые используются, пользователю предлагается набор применимых целевых вариантов на выбор.
Как только целевой вариант выбран, инструмент планирования обновления VCF формирует исчерпывающий план обновления, который включает:
Общий ход обновления, разбитый на отдельные этапы, что помогает спланировать окна технического обслуживания
Требования к ресурсам и сети
Ключевые соображения и потенциальные подводные камни, которых следует избегать
Соответствующие ссылки на продуктовую документацию VCF
Инструмент планирования обновления VCF можно использовать в интерактивном режиме, а также экспортировать весь ход обновления и (или) отдельные его этапы в PDF для работы офлайн.
Ожидается, что этот инструмент сделает процесс обновления VCF более удобным. При наличии отзывов, замечаний или предложений по улучшению можно создать Issue на GitHub или даже внести собственный вклад в проект.
Модернизация центров обработки данных сегодня выглядит иначе, чем ещё несколько лет назад. Акцент сместился с простого наращивания мощностей на то, чтобы извлечь максимум из уже имеющейся инфраструктуры. Для большинства команд, отвечающих за инфраструктуру, реальная сложность состоит в том, чтобы совместить требования современных приложений с жёсткими бюджетами на оборудование и при этом не отставать от циклов обслуживания, которые поглощают продуктивное время.
VMware vSphere Foundation 9.1 создавалась, чтобы решать эту задачу напрямую. Объединяя вычисления, хранение и управление в тесно интегрированный стек, выпуск сокращает эксплуатационные простои, раскрывает более высокую производительность рабочих нагрузок и улучшает экономику среды без необходимости полностью перестраивать процессы эксплуатации.
Если это первое знакомство с vSphere Foundation 9.1, начать стоит с обзорной публикации о выпуске VMware vSphere Foundation 9.1 — в ней подробно описана каждая новая возможность. Настоящий материал является продолжением: это краткая ориентация по трём ключевым областям возможностей вместе с подборкой ресурсов, которые помогут команде перейти от первичного знакомства к этапам оценки и планирования.
Что нового: краткий обзор
Рисунок 1: VMware vSphere Foundation 9.1 переосмысливает экономику инфраструктуры, резко сокращая эксплуатационные простои и обеспечивая более высокую производительность рабочих нагрузок.
VMware vSphere Foundation 9.1 приносит усовершенствования по трём стратегическим направлениям. В обзорной публикации каждое из них рассмотрено детально; ниже приводится краткое резюме для ориентации и для указания на наиболее релевантные ресурсы из перечисленных далее.
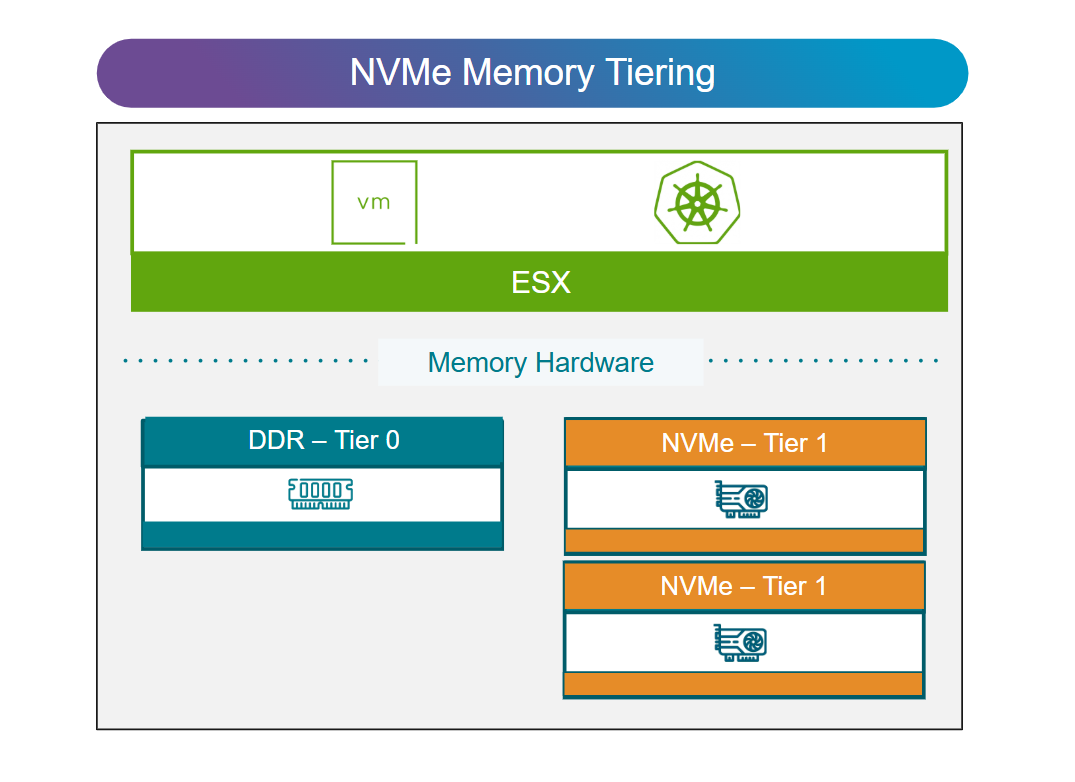
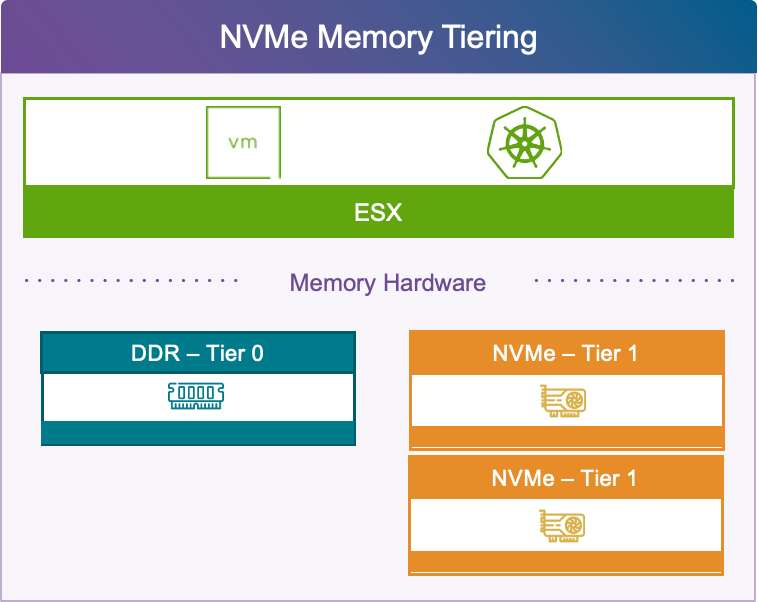
Повышение операционной эффективности и снижение TCO. Встроенная высокоточная наблюдаемость и функция Proactive Diagnostic Insights теперь располагаются непосредственно в основной консоли эксплуатации, объединяя то, что прежде требовало нескольких разрозненных инструментов. Усовершенствованное многоуровневое размещение памяти на NVMe (NVMe Memory Tiering) добавляет высокопроизводительный второй уровень памяти, который интеллектуально берёт на себя от 20 до 25 процентов обращений к памяти, снижая TCO сервера и повышая плотность размещения виртуальных машин без ущерба для отзывчивости приложений.
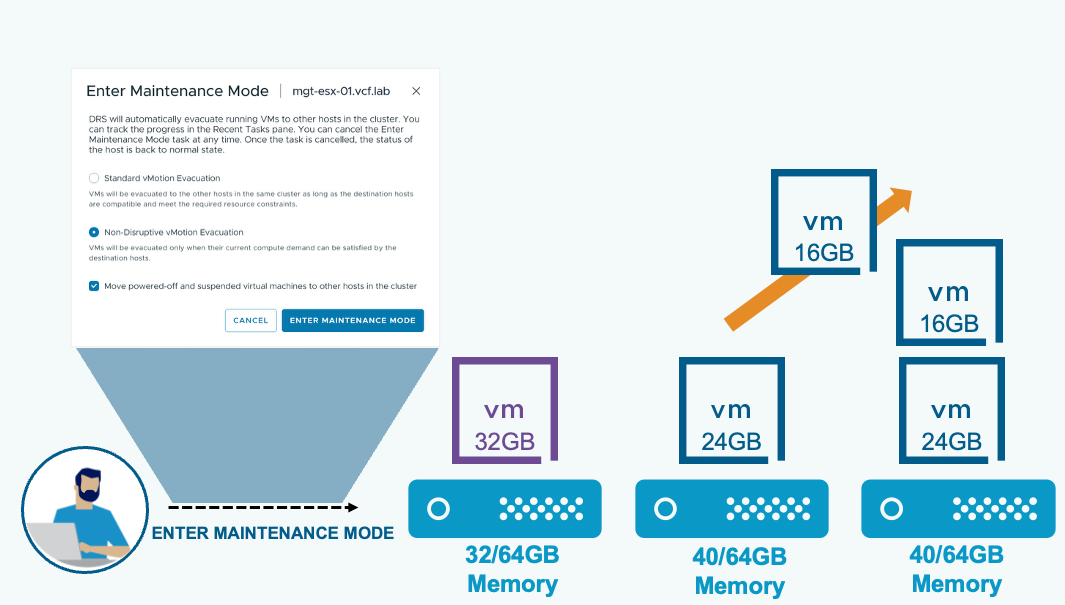
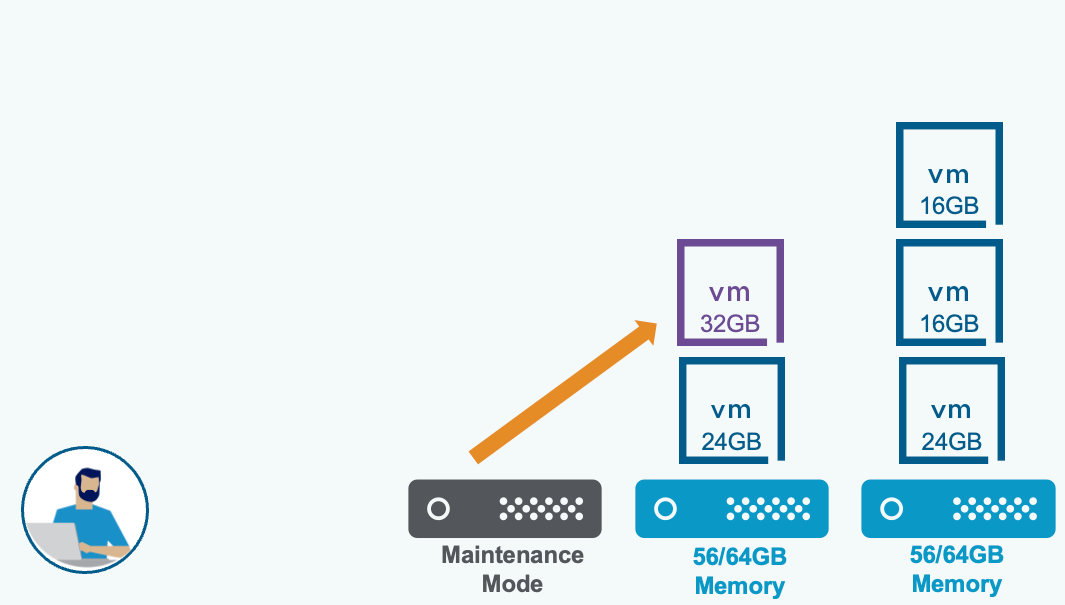
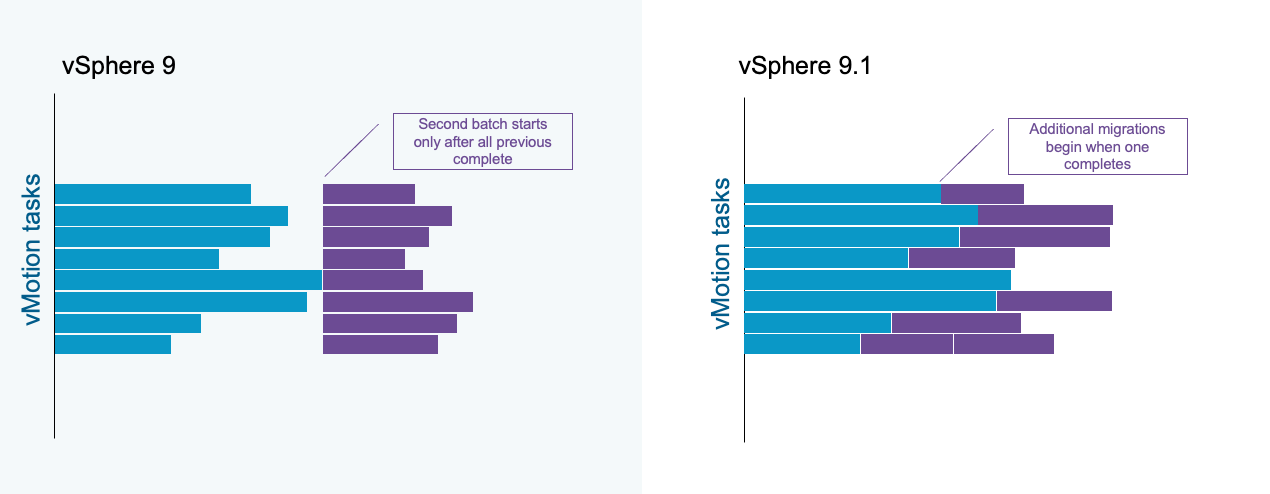
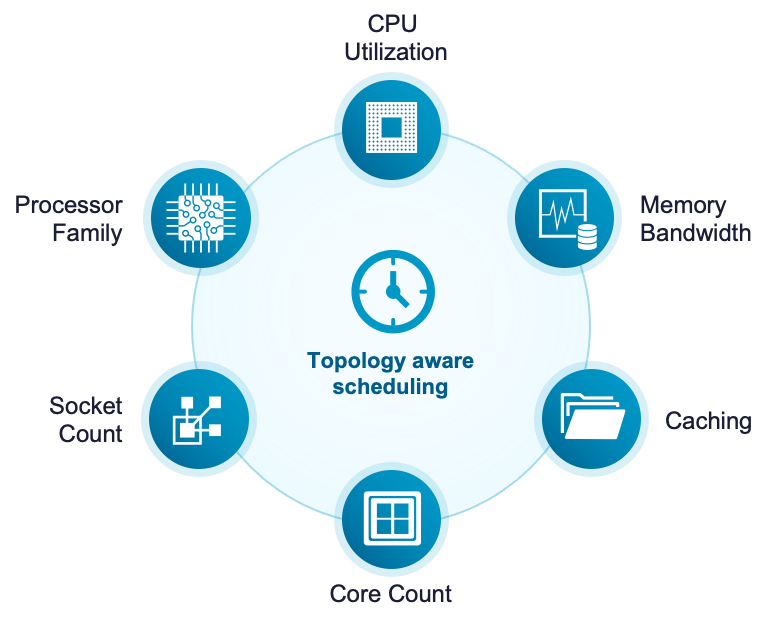
Кардинальный рост производительности рабочих нагрузок. Планирование с учётом топологии (vSphere Topology-Aware Scheduling) применяет логику, учитывающую устройство процессора, для оптимизации размещения NUMA на процессорах высокой плотности, удерживая ресурсоёмкие приложения на пике производительности. Параллельная обработка миграций DRS vMotion устраняет последовательное узкое место при балансировке кластера, обеспечивая более быструю и непрерывную мобильность рабочих нагрузок. Расширенное сокращение данных vSAN (vSAN Data Reduction) даёт снижение TCO хранения до 39 процентов за счёт дедупликации и сжатия, оптимизированных по производительности.
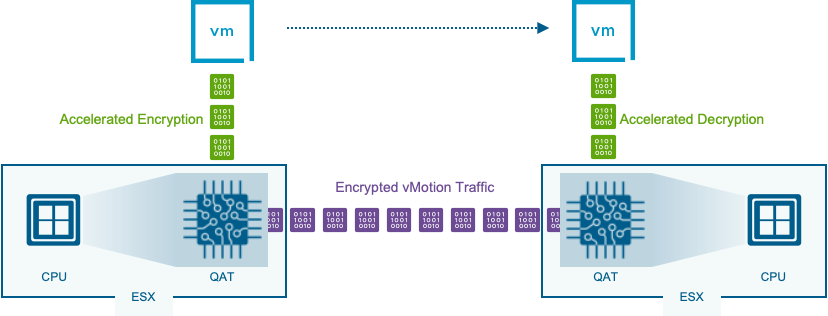
Усиление безопасности, отказоустойчивости и соответствия требованиям. Оперативное применение исправлений (live patching) для хостов с поддержкой TPM позволяет устанавливать до 80 процентов критических обновлений безопасности без простоя, полностью выводя обслуживание безопасности за рамки запланированного окна технических работ. Расширенная репликация виртуальных машин с внешних массивов напрямую в кластер vSAN упрощает архитектуру восстановления и даёт реальную экономию по сравнению с устаревшими конфигурациями.
Ресурсы по VMware vSphere Foundation 9.1
Рисунок 2: Раздел ресурсов и вопросов-ответов по VMware vSphere Foundation 9.1 в нижней части страницы продукта VMware vSphere Foundation.
Читать о выпуске и понимать, как им воспользоваться, — это разные вещи. Материалы ниже созданы именно для второго шага, независимо от того, что сейчас в приоритете: подготовка внутреннего обоснования, сравнение вариантов платформ или подготовка команды к обновлению. Их можно использовать по порядку или сразу перейти к тому, который соответствует текущей ситуации.
Инфографика:VMware vSphere Foundation 9.1 с первого взгляда. С неё стоит начать ради быстрого визуального обзора. Инфографика показывает, как NVMe Memory Tiering снижает TCO сервера, как устраняются узкие места последовательной миграции, и как оперативное применение исправлений выводит обслуживание безопасности за пределы производственного календаря — всё в формате, удобном для распространения среди заинтересованных сторон.
Техническое описание (Datasheet):Возможности и преимущества продукта. Структурированный справочник для ИТ-специалистов, проводящих формальную оценку. Он охватывает возможности платформы, поддерживаемые аппаратные новшества и целевые сценарии использования, давая всё необходимое для оценки того, как vSphere Foundation 9.1 вписывается в стратегию ЦОД.
Краткое описание решения (Solution Brief):Новая экономика инфраструктуры. Подготовлено для руководителей в сфере инфраструктуры и бизнеса, следящих за предсказуемостью бюджета и окупаемостью оборудования. Документ обосновывает, как vSphere Foundation 9.1 справляется с волатильностью цен на DRAM и с постоянными издержками устаревших циклов обслуживания. Это хороший материал для выстраивания внутреннего согласия вокруг модернизации.
Сравнение возможностей:VMware Cloud Foundation и VMware vSphere Foundation 9.1. Понятный разбор двух основных платформ VMware. Если команда выбирает между модернизацией имеющейся инфраструктуры на базе vSphere Foundation и переходом к полнофункциональному частному облаку на VMware Cloud Foundation, этот документ наглядно излагает различия.
FAQ:Ответы на частые вопросы клиентов. Охватывает вопросы, которые обычно возникают вокруг развёртывания, аппаратной совместимости и новых возможностей централизованного управления. Практичный спутник для команд на этапе планирования и подготовки.
Дополнительные материалы
Обновление до VMware vSphere Foundation 9.1 даёт командам, отвечающим за инфраструктуру, не только новое программное обеспечение. Это практический шаг к среде, которая справляется с требованиями современных приложений, удерживает затраты на оборудование под контролем и высвобождает операционные ресурсы, обычно поглощаемые рутинным обслуживанием.
Изучите полную библиотеку ресурсов и начните знакомство с vSphere Foundation 9.1 уже сегодня:
Оговорка: все заявления об улучшении производительности и снижении затрат основаны на внутренних инженерных оценках Broadcom и результатах аппаратного тестирования за 2026 год, если не указано иное. Результаты могут изменяться.
VMware VCF — платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью и производительностью локальной инфраструктуры, повышая продуктивность и снижая совокупную стоимость владения (TCO).
Полнофункциональная платформа Infrastructure as a Service (IaaS), предоставляющая программно-определяемые вычисления, хранение, сеть, Kubernetes, безопасность и средства управления.
Встроенная автоматизация формирует платформу самообслуживания для быстрого развёртывания виртуальных машин и контейнеров и повышения скорости разработки.
Закалённая платформа со встроенной отказоустойчивостью, масштабированием и кластеризацией для непрерывной работы.
Облачная гибкость позволяет наращивать инфраструктуру без увеличения штата, перенося облачную модель потребления в локальную среду.
Автоматизация и оркестрация упрощают задачи нулевого, первого и второго дня.
Поставляется единым SKU, что упрощает развёртывание всего стека.
VMware vSphere Foundation — рабочая платформа корпоративного уровня для современной инфраструктуры. Она даёт преимущества виртуализации, упрощённое управление, экономичность и масштабируемость и служит ядром, на котором строится VMware Cloud Foundation.
Единая платформа для совместного запуска виртуальных машин и контейнеров с нативной средой выполнения Kubernetes.
Интеллектуальное управление эксплуатацией обеспечивает расширенную видимость и оптимизацию инфраструктуры.
Гиперконвергентная инфраструктура объединяет виртуализацию вычислений и хранения для эффективного управления ресурсами.
Упрощённое развёртывание и масштабируемость с единым SKU ускоряют доставку приложений и готовят инфраструктуру к будущему.
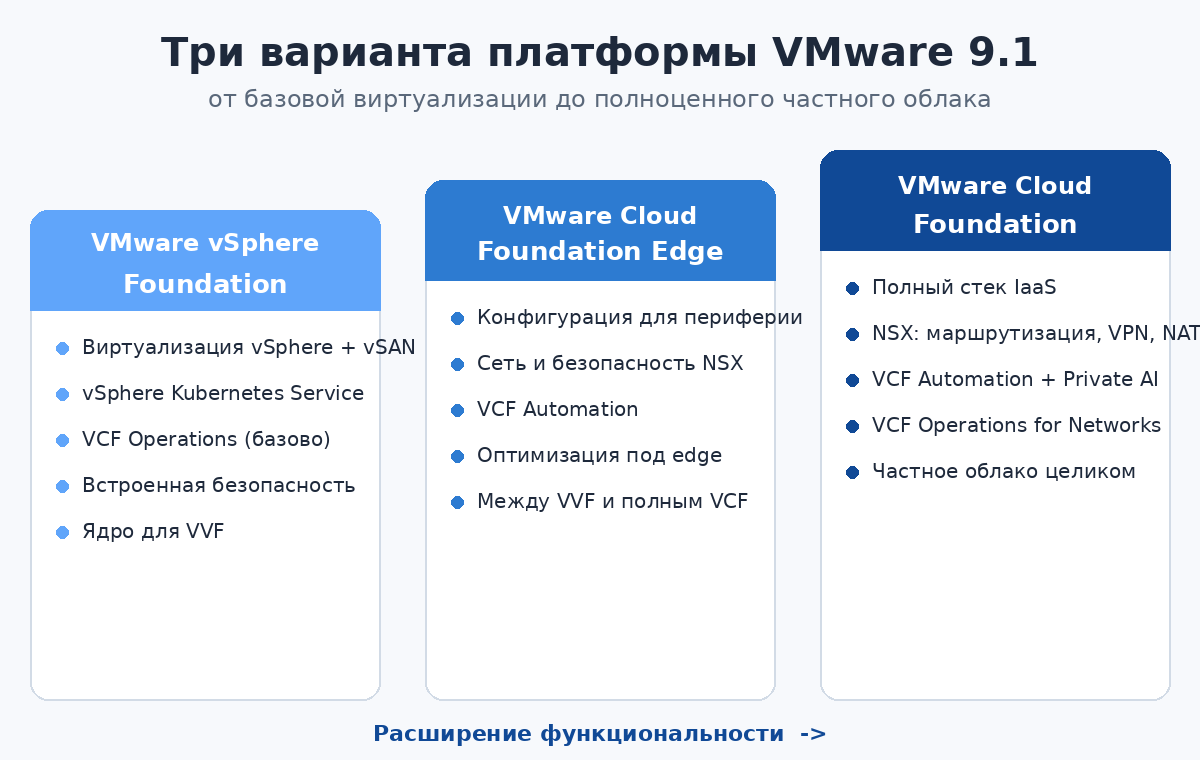
На рисунке ниже показан упрощённый портфель VMware by Broadcom и три варианта поставки.
Детальное сравнение функций
В сравнении участвуют три варианта поставки.
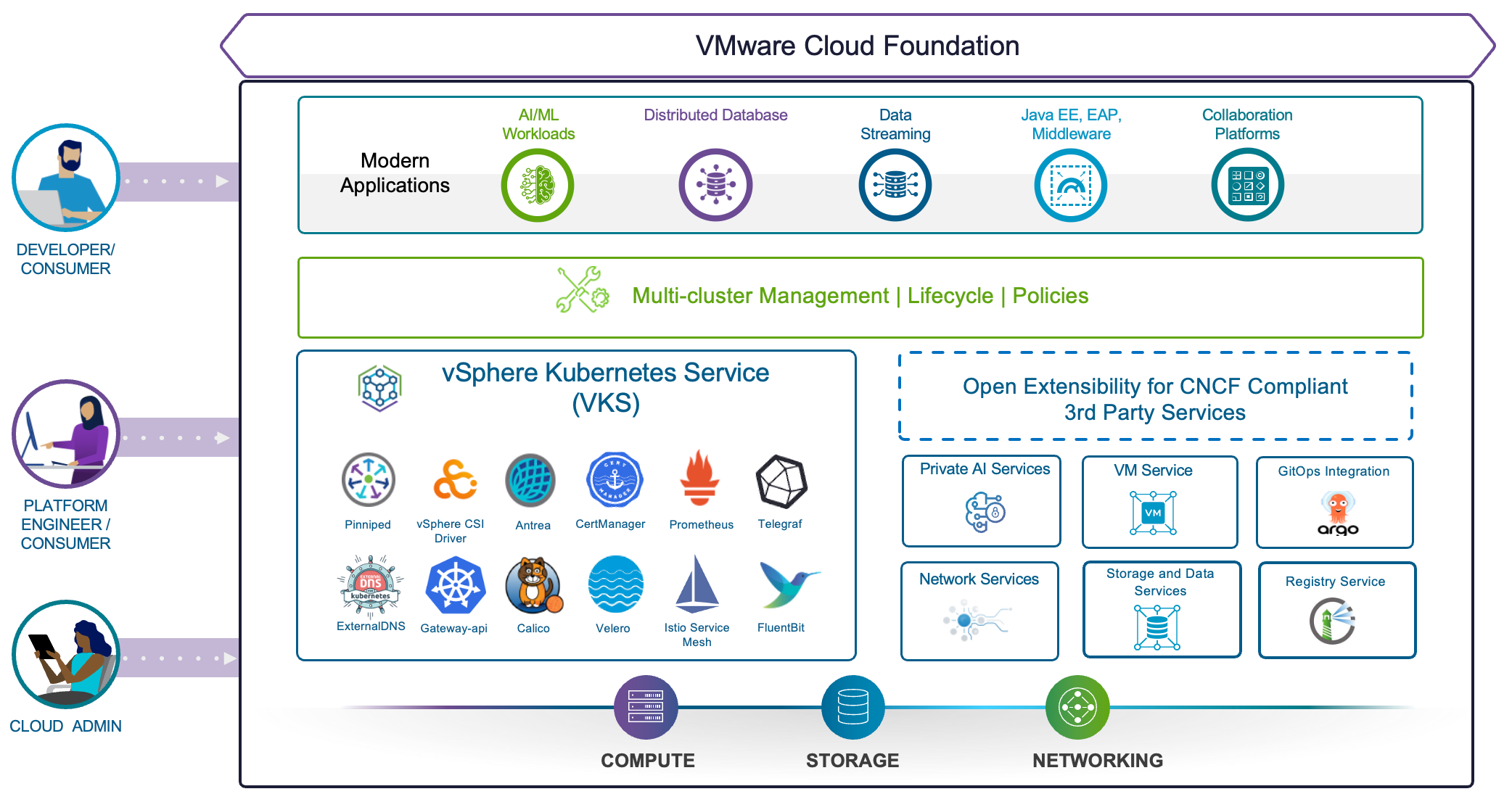
VMware Cloud Foundation — ПО частного облака с интегрированными компонентами: vSphere, vSphere Kubernetes Service, VCF Operations, VCF Operations for Networks, VCF Operations fleet management, VCF Automation, vSAN и NSX.
VMware vSphere Foundation — ПО, предоставляющее часть возможностей VCF или их ограниченные версии: vSphere, vSphere Kubernetes Service, VCF Operations и vSAN.
VMware Cloud Foundation Edge — оптимизированная конфигурация VMware Cloud Foundation для периферийных сценариев.
В таблицах ниже символ • означает, что функция включена в соответствующее издание, прочерк — что функция недоступна. Числа в квадратных скобках отсылают к примечаниям в конце статьи.
Вычисления (Compute)
Включённые сервисы:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Kubernetes Service (VKS)
•
•
•
VM Service
•
•
•
Storage Service
•[2]
•
•
Network Service
•[2]
•
•
Container Registry Service
•
•
•
Harbor Image Registry Service
•
•
•
vSphere Pod Service
•
•
•
VKS Load Balancing
•
•
•
Service Mesh
•
•
•
External DNS
•
•
•
ArgoCD Operator
—
•
•
Secret Store Service
—
•
•
IaaS Policy Service
—
•
•
Data Services
•
•
•
Workload Availability Zones
•
•
•
Упрощённое управление жизненным циклом кластеров VKS
—
•
•
Build Your Own Image (BYOI)
•
•
•
Supervisor Independent Updates
•
•
•
Custom Zone Optimization
•
•
•
Управление эксплуатацией:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Lifecycle Manager
•
•
•
Live Patching for ESX
•
•
•
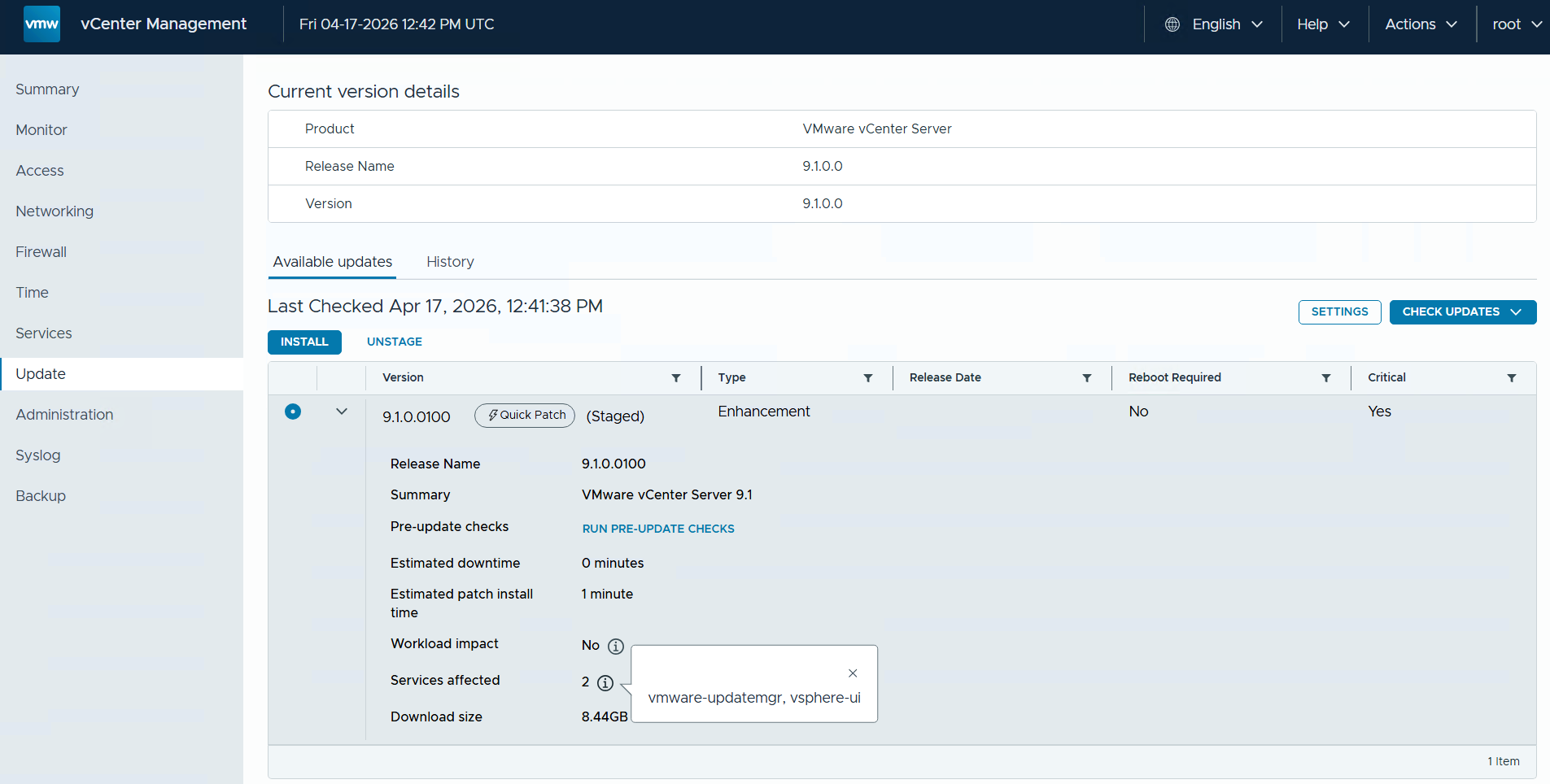
vCenter Quick Patching
•
•
•
vCenter Server Profiles
•
•
•
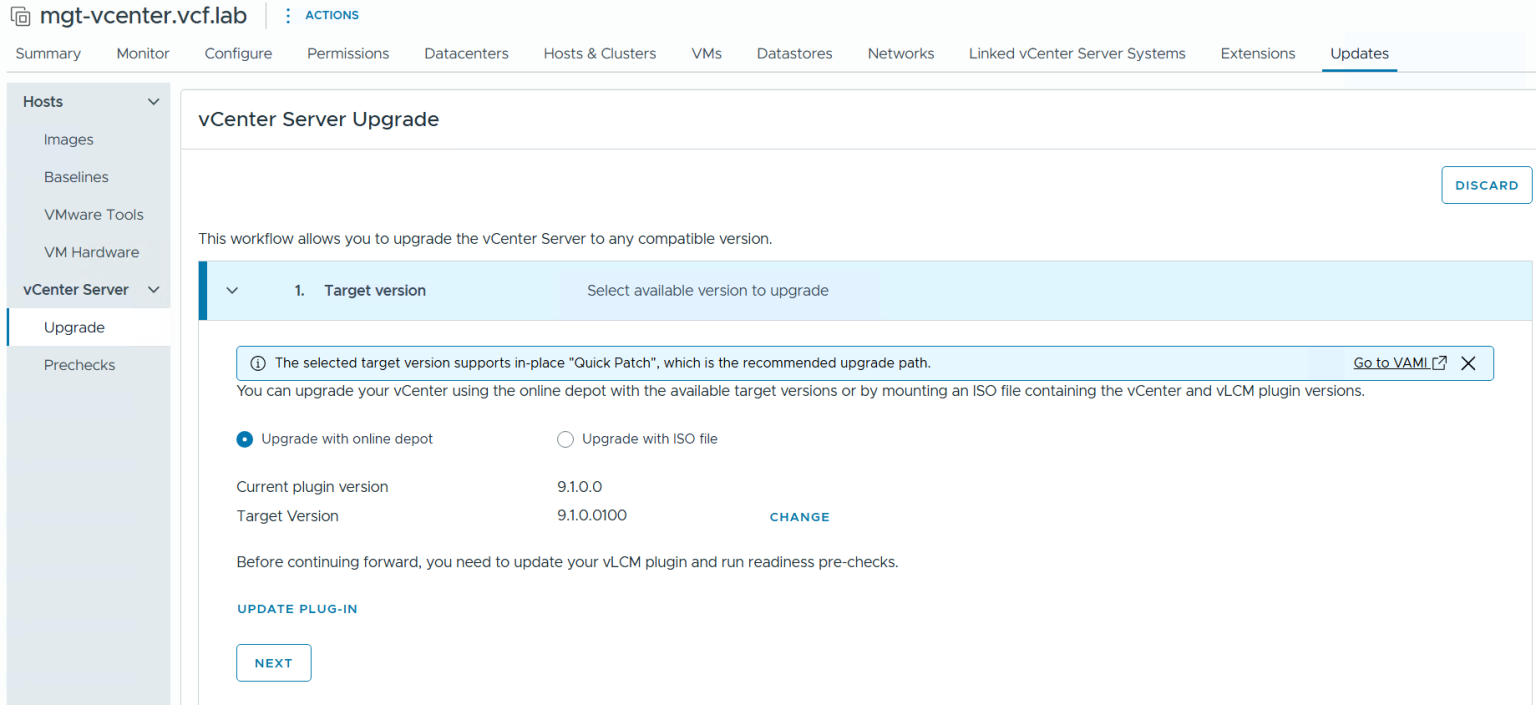
vCenter Update Planner
•
•
•
Content Library
•
•
•
vSphere Configuration Profiles
•
•
•
Host Profiles
•
[3]
[3]
Auto Deploy
•
[3]
[3]
Эластичное предоставление vSphere (ZTP)
•
•
•
Green Metrics
•
•
•
Встроенная безопасность:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
Identity Federation
•
•
•
Аппаратный TPM 2.0
•
•
•
Virtual TPM 2.0
•
•
•
Сертификация FIPS 140-2 и Common Criteria
•
•
•
TLS 1.2
•
•
•
TLS 1.3
•[4]
•[4]
•[4]
Шифрование виртуальных машин
•
•
•
Standard Key Provider (внешний KMS)
•
•
•
Native Key Provider
•
•
•
File Integrity Monitoring
•
•
•
Confidential Computing
[15]
•
•
Интеграция EDR для ESX
•
•
•
Производительность приложений:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
Per-VM Enhanced vMotion Compatibility (EVC)
•
•
•
Instant Clone
•
•
•
Distributed Resource Scheduler (DRS)
•
•
•
Storage DRS
•
•
•
Distributed Power Management (DPM)
•
•
•
Storage Policy-Based Management
•
•
•
I/O Controls (хранилище)
•
•
•
SR-IOV
•
•
•
vSphere Persistent Memory
•
•
•
Memory Tiering
•
•
•
NVIDIA GRID vGPU
•
•
•
Accelerated Graphics for VMs
•
•
•
Dynamic DirectPath IO
•
•
•
Enhanced DirectPath I/O
•
•
•
Vendor Device Group
•
•
•
Разные профили vGPU на одном GPU
•
•
•
Автоматизация DRS для vGPU-нагрузок
•
•
•
Поддержка DPU и Dual DPU
—
•
•
Непрерывность бизнеса:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vMotion
•
•
•
Cross-vCenter vMotion
•
•
•
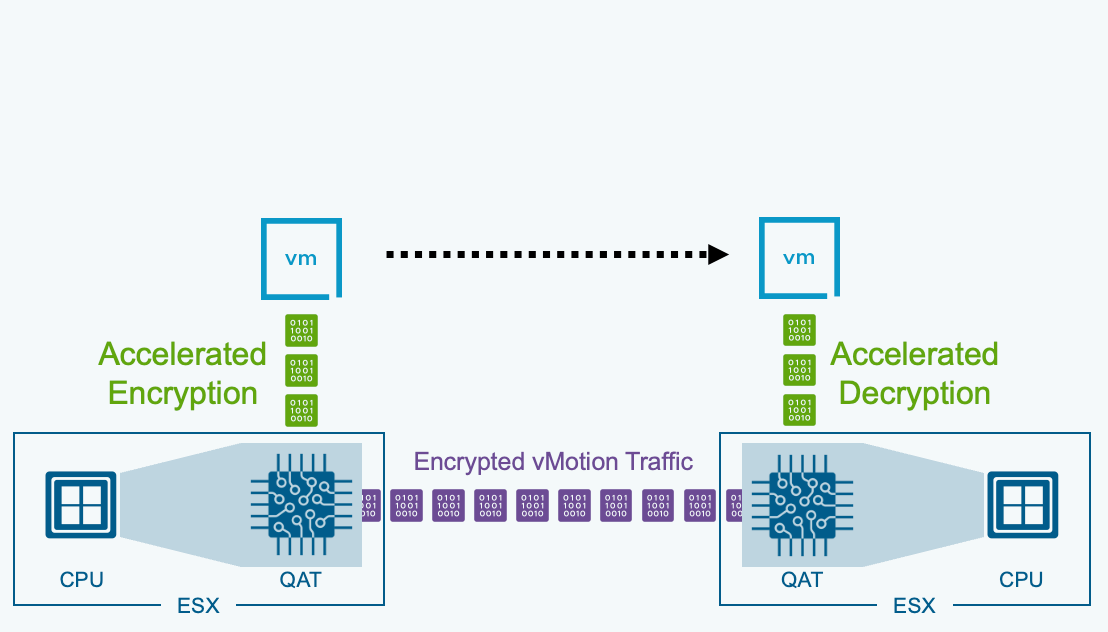
Encrypted vMotion
•
•
•
vCenter Enhanced Linked Mode
•
•
•
vSMP
•
•
•
vSphere High Availability (HA)
•
•
•
Proactive HA
•
•
•
Storage vMotion
•
•
•
Fault Tolerance
•
•
•
vSphere Replication
•
•
•
Поддержка 4k Native Storage
•
•
•
vSphere Quick Boot
•
•
•
Файловое резервное копирование и восстановление vCenter
•
•
•
Cross vCenter Mixed Version Provisioning
•
•
•
Горячая и холодная миграция в облако
•
•
•
Управление на основе политик (Policy-based Governance)
•
•
•
Kubernetes Automation
•
•
•
Workload Lifecycle Management
•
•
•
vCenter Orchestration & Extensibility
•
•
•
Хранение (Storage)
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSAN Express Storage Architecture (ESA)
•
•
•
vSAN Original Storage Architecture (OSA)
•
•
•
All-Flash оборудование
•
•
•
Базовые компрессия и дедупликация
• (только OSA)
• (только OSA)
• (только OSA)
Продвинутое сжатие и глобальная дедупликация
• (только ESA)
• (только ESA)
• (только ESA)
Шифрование данных «в покое»
•
•
•
Шифрование данных «в движении»
•
•[3]
•[3]
Storage Policy-Based Management
•
•
•
Программная контрольная сумма
•
•
•
vSAN over RDMA
•
•[3]
•[3]
QoS — ограничение IOPS
•
•
•
Auto-Managed RAID
•
•
•
Кластеры хранения vSAN
•
•
•
Кластеры кибервосстановления vSAN
—
•[15]
•[15]
Удалённые хранилища (Remote Datastores)
•
•
•
Растянутый кластер (Stretched Cluster)
•
•
•
Двухузловой кластер (2-Node Cluster)
•
•[3]
•[3]
File Services
•
•
•
Object Storage
—
•[17]
•[17]
iSCSI Target Service
•
•[3]
•[3]
Cloud Native Storage (CNS) Control Plane
•
•
•
vSphere Container Storage Interface (CSI) Driver
•
•
•
Rack Awareness (Fault Domains)
•
•[3]
•[3]
Snapshot Manager с гибким расписанием
•
•
•
Неизменяемые снимки (Immutable Snapshots)
•
•
•
Репликация Any-to-vSAN
•[14]
•[14]
•[14]
Внешние хранилища:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
VMFS — Fibre Channel
•
• (Principal, Supplemental)
• (Principal, Supplemental)
VMFS — iSCSI
•
• (Supplemental)
• (Supplemental)
VMFS — FCoE
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/FC
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/TCP
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/RDMA
•
• (Supplemental)
• (Supplemental)
NFS — v3
•
• (Principal, Supplemental)
• (Principal, Supplemental)
NFS — v4.1
•
• (Supplemental)
• (Supplemental)
Storage I/O QoS Controls (SIOC)
•
•
•
VAAI для блочного хранилища
•
•
•
VAAI для NFS-хранилища
•
•
•
Кластеризация нагрузок (VMDK Clustering)
•
•
•
Автонастройка с NFS
•
•
•
Сторонние плагины хранения
•
•
•
Ввод хостов и управление кластером
•
•
•
Сеть (Networking)
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Distributed Switch
•
•
•
Link Aggregation Control Protocol (LACP)
•
•[3]
•[3]
Load-Based Teaming
•
•
•
Network I/O QoS Control (NIOC)
•
•
•
Private VLAN
•
•
•
MAC Learning
•
•
•
BPDU Guard
•
•
•
Guest VLAN Tagging
•
•
•
VLAN Backed Networking
•
•
•
Virtual Networking
—
•
•
Spoofguard
—
•
•
L2 Multicast
•
•
•
L3 Multicast
—
•
•
Enhanced Datapath
—
•
•
Enhanced Datapath для DPU
—
•
•
Маршрутизация IPv4 и IPv6
—
•
•
Динамическая маршрутизация (OSPFv2/BGP/BFD)
—
•
•
VRF
—
•
•
EVPN
—
•
•
NAT
—
•
•
L2 и L3 VPN
—
•
•
Quality of Service (QoS)
• (NIOC)
• (NIOC и NSX)
• (NIOC и NSX)
NSX Edge Bridge для сети
—
•
•
DNS, DHCP и IPAM
—
•
•
Container Networking с NCP
—
•[16]
•[16]
Container Networking с Antrea
•[16]
•[16]
•[16]
Политики, теги и группировка
—
•
•
Мультиарендность через проекты
—
•
•
Virtual Private Cloud (VPC)
—
•
•
Балансировка для компонентов VCF [12]
—
•
•
Балансировка L4 для vSphere Supervisor [11],[12]
•
•
•
Кластеризация менеджеров / контроллеров
—
•
•
Federation
—
•
•
NSX Edge в форм-факторе ВМ и bare-metal
—
•
•
Автоматическое и ручное развёртывание менеджера и Edge
—
•
•
Автоматическая подготовка хостов
—
•
•
Port Mirroring
•
•
•
Netflow/IPFIX
•
•
•
Traceflow
—
•
•
Live Traffic Analysis
—
•
•
Packet Capture
•
•
•
vSphere Kubernetes Services (VKS) и облачные сервисы VCF
Клиентам, которым нужна универсальная или продвинутая балансировка, рекомендуется приобрести Avi Load Balancer. Тем, кому требуется время на миграцию с существующей балансировки VCF на Avi, разрешено продолжать пользоваться полной балансировкой VCF до 30 мая 2027 года при наличии необходимых лицензий Avi. Подробности об лицензировании и вариантах миграции — в статье базы знаний № 439411.
Дополнительные сервисы приобретаются отдельно и не входят в базовые поставки VMware Cloud Foundation и VMware vSphere Foundation.
Требует лицензию VMware Site Recovery Manager (SRM).
Требует VCF Advanced Cyber Compliance (надстройка Advanced Services).
Поддержка Antrea предоставляется только для VMware VKS. Поддержка NCP — только для VMware vSphere Supervisor и Tanzu Elastic Runtime.
Tech Preview.
Функция доступна начиная с VKS 3.5+.
Пути обновления (Upgrade Paths)
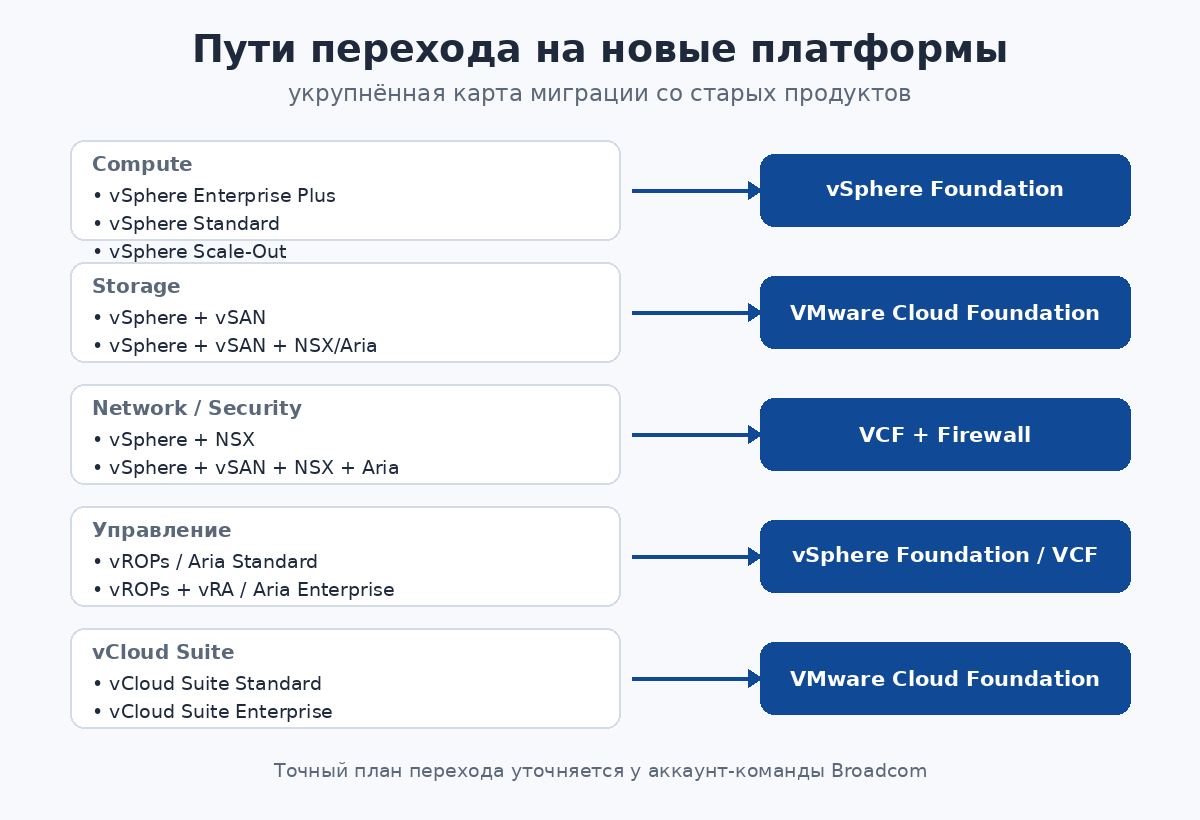
Графики ниже показывают маршруты перехода с прежних продуктов на новые предложения.
Пути для вычислений (Compute). Прежние издания vSphere Foundation, vSphere Enterprise Plus, vSphere Enterprise, vSphere for Desktop, vSphere Scale-Out и vSphere Standard рекомендуется переводить на vSphere Foundation.
Пути для хранения (Storage). Связка vSphere + vSAN + NSX + Aria и vSphere + vSAN + Aria ведут к VMware Cloud Foundation; vSphere + vSAN и vSphere + vSAN + NSX — к vSphere Foundation вместе с надстройкой vSAN.
Пути для сети и безопасности (Networking/Security). Конфигурации vSphere + vSAN + NSX + Aria и vSphere + NSX + Aria переходят на VMware Cloud Foundation с межсетевым экраном Firewall; vSphere + vSAN + NSX и vSphere + NSX — также на VCF с Firewall.
Путь управления (Management). vSphere с Aria Suite Enterprise или vRCU Enterprise переходит на VMware Cloud Foundation; vSphere с vROPs + vRA, Aria Suite Advanced или vRCU Advanced — на vSphere Foundation; vSphere с vROPs, Aria Suite Standard или vRCU Standard — также на vSphere Foundation.
Пути vCloud Suite. vCloud Suite Enterprise консолидируется в VMware Cloud Foundation с Aria Suite Enterprise и vSphere Enterprise Plus; vCloud Suite Advanced — в vSphere Foundation с Aria Suite Advanced и vSphere Enterprise Plus; vCloud Suite Standard — в Aria Suite Standard с vSphere Enterprise Plus.
Пути VCF. VCF Enterprise, VCF Advanced, VCF Standard и VCF Starter переходят на VMware Cloud Foundation с межсетевым экраном Firewall.
За дополнительными деталями Broadcom предлагает обращаться к сотрудникам VMware и официальным партнерам.
Современные центры обработки данных сталкиваются с беспрецедентными вызовами в области хранения данных: ИТ-командам необходимо обеспечивать производительность, отказоустойчивость и эффективность для постоянно растущих объёмов данных, при этом бюджеты растут значительно медленнее. В прошлом стоимость хранения и памяти со временем снижалась, сглаживая влияние роста данных на бюджет, однако текущий суперцикл памяти ломает эту тенденцию. Методы снижения избыточности данных, уменьшение требований к процессору и памяти, а также новые типы носителей позволяют ИТ-командам нейтрализовать влияние растущих цен на всю инфраструктуру хранения.
Кроме того, ИТ-подразделения испытывают стремительный рост как масштаба приложений, так и их количества в датацентре. Рабочие нагрузки AI требуют огромных объёмов данных, и их распространение вынуждает ИТ осваивать новые интерфейсы хранения — объектное хранилище и высокопроизводительные файловые сервисы. Кроме этого, ИТ необходим более простой способ предоставления командам разработчиков доступа к инфраструктуре хранения. Сегодня администраторы нередко вынуждены работать с тикетными системами для выделения ресурсов: процессы часто выполняются вручную, отнимают много времени и чреваты ошибками. Администраторы хотят предоставлять доступ к ключевым сервисам хранения, не теряя при этом контроля и соответствия требованиям, — чтобы разработчики могли двигаться с темпом, которого требует бизнес.
Но давление на ИТ этим не ограничивается. Угрозы безопасности эволюционируют быстрее, чем когда-либо, а атаки вымогателей вынуждают ИТ-команды переосмыслить фундаментальную устойчивость инфраструктуры хранения. Время восстановления критически важных приложений приобретает всё больший приоритет. Данные должны быть защищены с помощью неизменяемых снимков, зашифрованы при хранении и передаче, а также восстанавливаемы в случае кибератак.
Наконец, ИТ-команды нуждаются в помощи с управлением растущей сложностью датацентра. По мере стремительного увеличения масштабов инфраструктуры ИТ нуждается в том, чтобы поставщики инфраструктуры автоматизировали и упрощали процессы, позволяя администраторам управлять большей инфраструктурой меньшими силами. Инфраструктура хранения должна самоуправляться, самодиагностироваться и предоставлять критическую диагностическую информацию для быстрого устранения проблем.
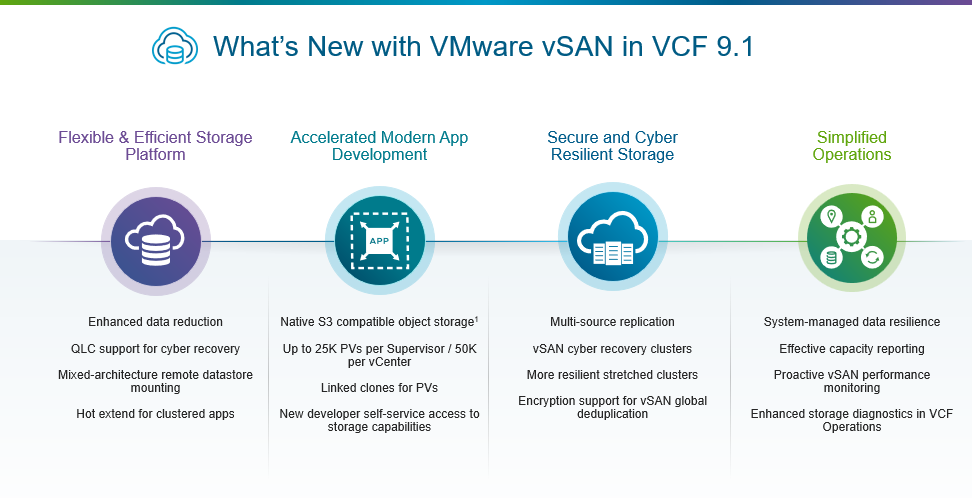
Именно поэтому всё больше клиентов отказываются от устаревших трёхуровневых архитектур в пользу полностью интегрированного частного облака. vSAN является критически важным, встроенным компонентом VMware Cloud Foundation (VCF), обеспечивающим развитие новых и существующих возможностей VCF. В vSAN в составе VCF 9.1 реализованы функции, которые упрощают снижение затрат на инфраструктуру хранения, ускоряют разработку современных приложений, обеспечивают запуск и защиту рабочих нагрузок в частном облаке на базе VCF, а также упрощают операции с хранилищем VCF.
Гибкая и эффективная платформа хранения
Экономическая эффективность всегда была сильной стороной vSAN, а vSAN в VCF 9.1 делает ещё один шаг вперёд благодаря более интеллектуальному сжатию и доступным по цене аппаратным конфигурациям.
Глобальная дедупликация
В VCF 9.1 глобальная дедупликация vSAN переходит в статус общедоступной. Глобальная дедупликация vSAN позволяет сократить используемую ёмкость до 8 раз — это критически важная возможность в условиях быстро растущей стоимости хранения и увеличивающихся сроков поставок оборудования. Дедупликация в vSAN спроектирована с минимальным влиянием на процессор и может применяться ко всем данным в кластере. Это дедупликация с постобработкой: она выполняется в фоновом режиме при низкой нагрузке на процессор. В отличие от традиционных систем хранения, где дедупликация ограничена хранилищем за парой I/O-контроллеров, домен дедупликации vSAN масштабируется вместе с кластером, потенциально обеспечивая более высокую эффективность.
Улучшенное сжатие
В vSAN в составе VCF 9.1 введены новые методы сжатия, обеспечивающие значительно более высокие коэффициенты компрессии. Новый алгоритм одновременно быстр и эффективен: инженерная команда оптимизировала его для баланса между снижением избыточности данных и потреблением ресурсов. VCF 9.1 теперь обеспечивает более высокую степень сжатия при минимальном влиянии на производительность.
Что делает это особенно ценным? Новое сжатие применяется только к новым записям, поэтому оно может внедряться в среду без прерываний и включено по умолчанию.
В сочетании с глобальной дедупликацией это улучшение обеспечивает снижение совокупной стоимости владения на 39% по сравнению с традиционными внешними массивами.
Узлы ReadyNode для киберрезервного копирования с устройствами QLC
Сценарии резервного копирования — аварийное, операционное и киберрезервное — предъявляют к инфраструктуре иные требования, чем основное хранилище: меньше ресурсов процессора и памяти, но более высокая ёмкость. Хотя исторически ИТ при инвестициях в инфраструктуру резервного копирования ориентировались прежде всего на стоимость, изменившийся характер бизнеса потребовал повышенного внимания к производительности и времени восстановления. VCF 9.1 представляет узлы ReadyNode, оптимизированные для киберрезервного копирования с устройствами QLC (Quad-Level Cell), обеспечивающими оптимальный баланс плотности, производительности, выносливости и стоимости для данного сценария.
Эти сертифицированные конфигурации обеспечивают более высокую плотность хранения и консолидацию серверов, снижая стоимость гигабайта для полностью флэш-хранилища при одновременном сокращении потребления электроэнергии, охлаждения и площади стойки по сравнению с решениями на основе HDD. Это практичный ответ на задачу расширения инфраструктуры киберрезервного копирования без увеличения бюджетов.
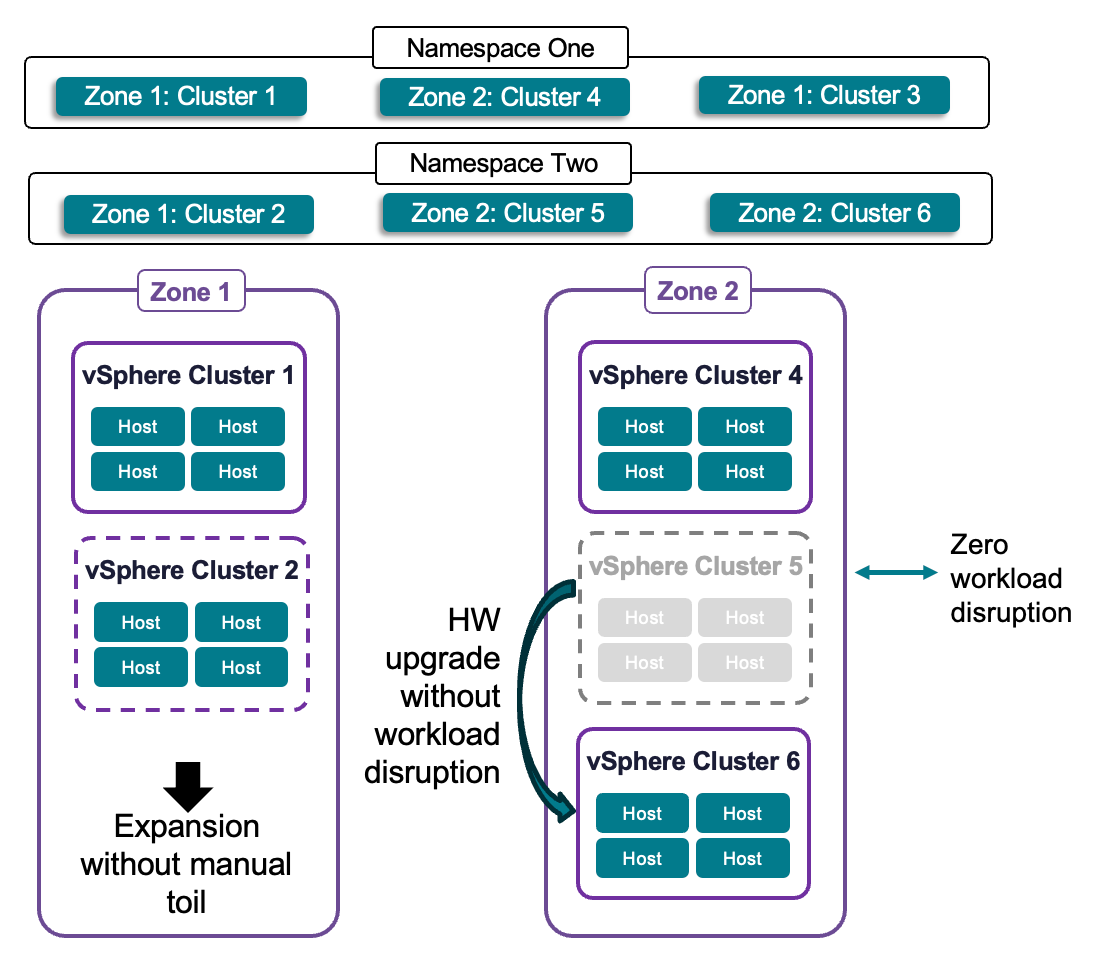
Расширенная гибкость для кластеров хранения vSAN
Многие пользователи vSAN последовательно развивают свою инфраструктуру хранения, поэтому нередко используют сочетание vSAN Express Storage Architecture (ESA) и Original Storage Architecture (OSA). Клиенты хотят иметь возможность инвестировать в новую инфраструктуру, одновременно эксплуатируя старые кластеры vSAN до конца срока их службы. VCF 9.1 снимает прежние ограничения, позволяя монтировать новые хранилища ESA к кластерам OSA и давая вычислительным кластерам без хранения возможность монтировать как OSA, так и ESA. Клиенты могут расширять инфраструктуру для приложений на кластерах OSA без необходимости инвестировать в технологии предыдущих поколений.
Ещё более значимо следующее: кластеры хранения vSAN теперь могут совместно использоваться через границы vCenter — так же, как традиционные внешние массивы. Это позволяет максимизировать использование ёмкости, консолидировать развёртывания и увеличивать плотность при сохранении низкой совокупной стоимости владения.
Ускорение разработки современных приложений
Современные ИТ-команды поддерживают всё — от традиционных баз данных до контейнерных приложений и современных практик DevOps, — строго соблюдая соглашения об уровне обслуживания. vSAN в VCF 9.1 расширяет гибкость для удовлетворения этих разнообразных требований.
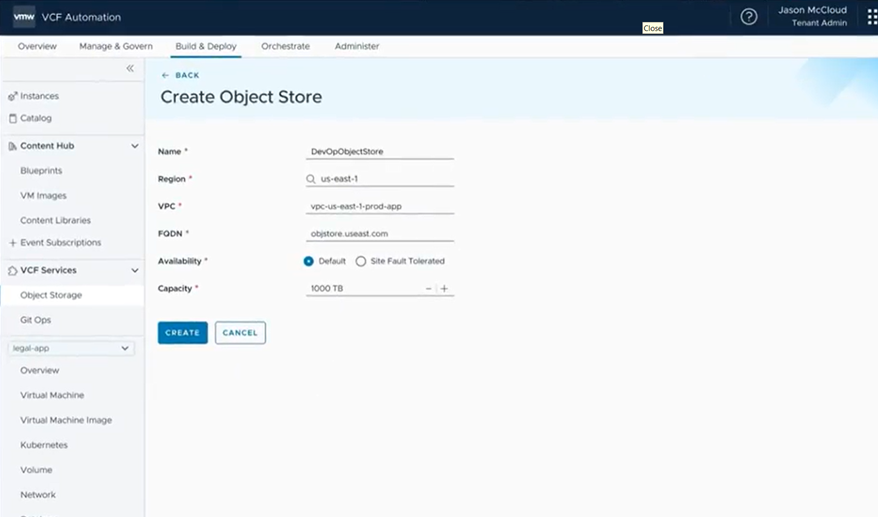
Нативное объектное хранилище S3 в vSAN (Technical Preview)
Впервые vSAN предоставляет нативное объектное хранилище, совместимое с S3, добавляя третий тип хранения — наряду с блочным и файловым — непосредственно в VCF. Данная версия Technical Preview ориентирована на сценарии использования в DevOps и конвейерах CI/CD, где разработчикам необходим быстрый самостоятельный доступ к масштабируемому объектному хранилищу.
Реализация включает мультитенантность, S3-бакеты как услугу и базовые функции безопасности и соответствия требованиям — всё это доступно через VCF Automation. В результате разработчики получают необходимую гибкость, а ИТ сохраняет управление и контроль. При этом решение включено в лицензии VCF, обеспечивая снижение совокупной стоимости владения на 34% по сравнению с автономными локальными продуктами объектного хранения.
Новые возможности самообслуживания разработчиков для работы с хранилищем
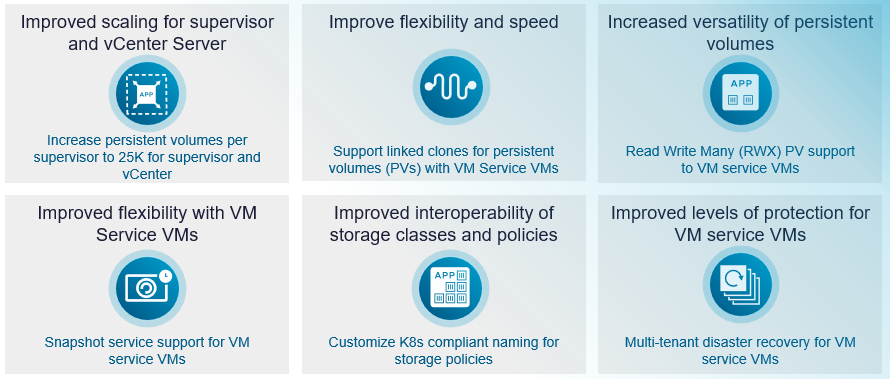
Значительное увеличение масштаба для постоянных томов
vSAN в VCF 9.1 существенно увеличивает масштаб контейнерных томов для сред VCF. Максимальное количество постоянных томов Read Write Once (RWO) на Supervisor возрастает с 7 500 до 25 000 — рост на 233%. На уровне vCenter лимит увеличивается с 30 000 до 50 000 постоянных томов, что составляет рост на 66%. Расширенные лимиты устраняют ограничения масштабирования для крупных развёртываний Kubernetes и мультитенантных сред.
Эффективное выделение ресурсов с помощью связанных клонов
Полные клоны слишком интенсивно используют хранилище и неэффективны для большинства сценариев. VCF 9.1 вводит поддержку связанных клонов для постоянных томов с First Class Disks, что существенно сокращает время выделения ресурсов и повышает операционную гибкость. Связанные клоны совместно используют общие базовые данные, что делает их идеальными для сред разработки, тестирования и сценариев, где необходимо быстро запустить несколько аналогичных рабочих нагрузок без затрат хранилища на полные клоны.
Поддержка Read Write Many (RWX) для виртуальных машин VM Service
Хотя файловые тома RWX могли использоваться в отдельных сценариях, они были недоступны для рабочих нагрузок — например, vSphere Pods и VM Service VMs — в пространстве имён Supervisor. VCF 9.1 устраняет этот пробел, позволяя виртуальным машинам VM Service монтировать и использовать тома RWX. Это открывает новые возможности для рабочих нагрузок, которым требуется совместный доступ к хранилищу сразу нескольких подов или виртуальных машин.
Единый подход к снимкам и операциям восстановления
Виртуальные машины VM Service теперь могут использовать простые операции восстановления по снимку VM, что приводит их в соответствие с традиционными виртуальными машинами. Такая согласованность упрощает рабочие процессы резервного копирования и восстановления вне зависимости от того, используются ли стандартные ВМ или машины VM Service — единый подход для всех рабочих нагрузок.
Соответствующие требованиям Kubernetes имена политик хранения
VCF 9.1 позволяет администраторам задавать настраиваемые имена политик хранения, совместимые с Kubernetes, при их создании. Это устраняет прежние ограничения именования, усложнявшие сопоставление политик хранения со StorageClass, упрощает согласование политик vSAN с соглашениями Kubernetes и улучшает опыт разработчиков.
Мультитенантное аварийное восстановление для машин VM Service
Облачные среды нередко обслуживают несколько команд или клиентов, каждый из которых требует независимых возможностей защиты и восстановления. VCF 9.1 вводит базовое мультитенантное аварийное восстановление (MTDR) для машин VM Service, предоставляя администраторам провайдеров и арендаторов возможность защищать виртуальные машины на базе Supervisor для сценариев защиты VCF-to-VCF.
Безопасность и киберустойчивость для современных угроз
Программы-вымогатели и утечки данных требуют хранилища, которое не только работает — но и защищает. vSAN в VCF 9.1 расширяет возможности защиты данных для долгосрочного хранения и комплексных сценариев восстановления.
Гибкое расписание снимков
В одном из предыдущих релизов нативные снапшоты vSAN получили возможность неизменяемости, а их производительность при масштабных и глубоких цепочках снапшотов — до 200 на ВМ — всегда оставалась высокой. vSAN в VCF 9.1 вводит гибкое расписание — широко известное как «дед–отец–сын» (GFS), — позволяющее расширить историю снимков для долгосрочного хранения в сценариях киберрезервного копирования.
Вместо того чтобы хранить каждый последовательный снимок, можно удерживать конкретные снимки с течением времени — например, почасовые снимки с сохранением одного за каждые 24 часа. Такой подход эффективно управляет ёмкостью, обеспечивая расширенную временную шкалу защиты, которую требуют нормативные и восстановительные требования.
Репликация из нескольких источников
Ранее репликация в VCF поддерживала только виртуальные машины, работающие с хранилища vSAN, на другое хранилище vSAN. В VCF 9.1 это ограничение снято: теперь можно реплицировать любую ВМ на базе VCF — включая те, что размещены на внешних массивах или других программно-определяемых хранилищах — в хранилище vSAN.
Эта возможность обеспечивает репликацию на основе политик по всей среде VCF, упрощая рабочие процессы восстановления и гарантируя согласованную защиту вне зависимости от текущего расположения ВМ. Репликацию можно совмещать с кластером киберрезервного копирования на базе vSAN для ускорения киберзащиты и восстановления.
Шифрование для глобальной дедупликации vSAN
Безопасность данных теперь распространяется на глобальную дедупликацию vSAN, гарантируя, что данные получают выгоду от экономии места без ущерба для защиты. Независимо от того, хранятся данные или передаются, они защищены шифрованием, валидированным по стандарту FIPS 140-3, от несанкционированного доступа.
Расширенные возможности растянутых кластеров
Растянутые кластеры уже давно обеспечивают устойчивость на уровне площадки для развёртываний vSAN. VCF 9.1 вводит два критически важных улучшения, повышающих операционную гибкость.
Во-первых, теперь можно перевести целый сайт в режим обслуживания с помощью управляемого процесса с расширенными предварительными проверками, обеспечивающими плавный вход и выход без прерывания сервиса. Во-вторых, в сценариях множественных отказов — когда один сайт находится в режиме обслуживания и одновременно происходит отказ второго сайта и свидетеля — теперь можно самостоятельно восстановить работоспособный сайт без обращения в глобальную службу поддержки. Встроенные предварительные проверки направляют процесс восстановления, сокращая время простоя и возвращая контроль в руки администраторов.
Упрощённые операции, масштабируемые с ростом инфраструктуры
Лучшая инфраструктура — та, о которой не нужно думать. VCF 9.1 реализует автоматизацию и интеллект, снижающие операционную нагрузку на ИТ-команды.
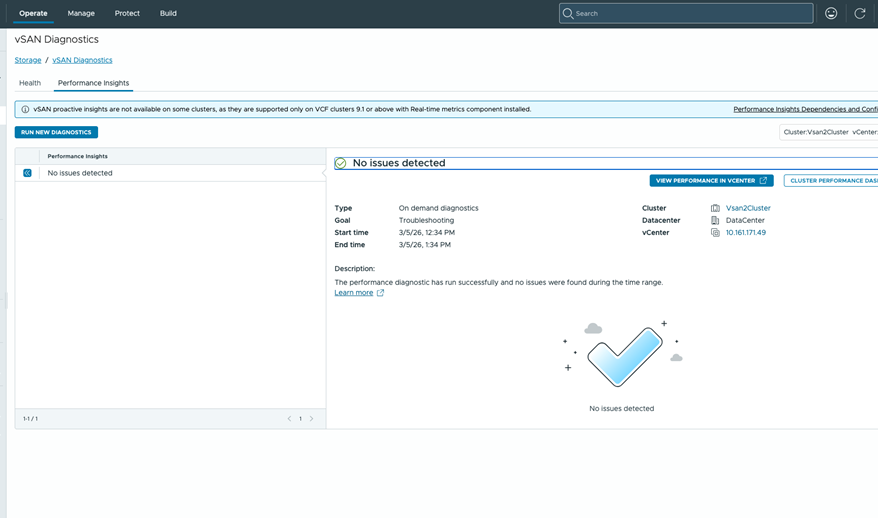
Проактивный мониторинг производительности vSAN
Диагностика проблем производительности в программно-определяемой инфраструктуре может быть непростой задачей. Где узкое место — в хранилище, вычислительных ресурсах или сети? VCF 9.1 применяет проактивный подход: постоянный мониторинг шаблонов производительности хранилища, установка базовых линий и оповещение об отклонениях.
При отклонении производительности от базовой линии VCF Operations использует расширенную аналитику для выявления корневых причин и предоставляет конкретные шаги по устранению — всё это доступно прямо в интерфейсе Performance Service. Алгоритмический подход к диагностике коррелирует точки данных, выявляет закономерности и предоставляет инсайты, поиск которых вручную занял бы часы.
Автоматизированное управление политиками хранения
vSAN в VCF 9.1 автоматически применяет наивысший уровень отказоустойчивости и оптимальный erasure coding с учётом размера кластера. Это устраняет неопределённость при настройке политик хранения и гарантирует максимальную устойчивость и эффективность без ручной настройки. В сочетании с улучшенными отчётами об эффективной ёмкости обеспечивается более чёткая видимость реальной используемой ёмкости, что делает планирование ёмкости более точным и понятным.
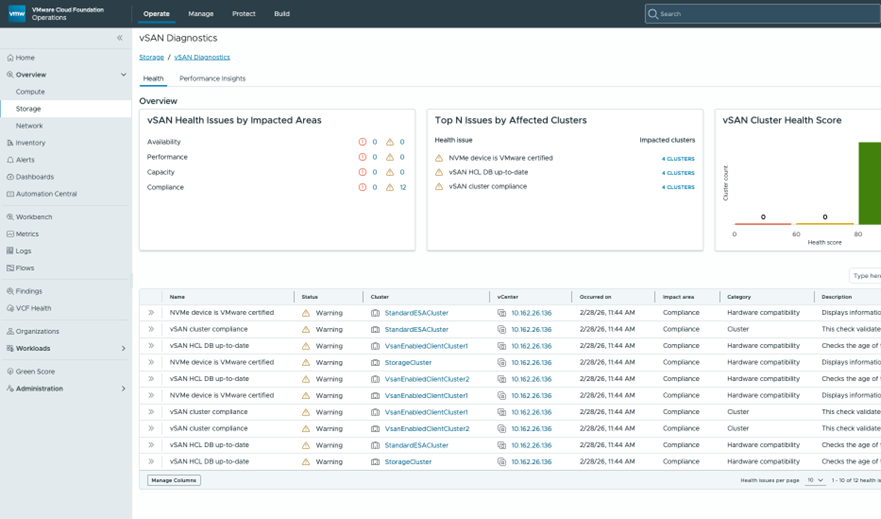
Расширенная диагностика хранилища vSAN
В одном из предыдущих выпусков в VCF Operations была представлена панель хранилища с важными метриками: оценками состояния, использованной ёмкостью и другими показателями. В vSAN в составе VCF 9.1 VCF Operations предоставит значительно расширенный набор информации и возможность принимать меры по диагностическим проблемам vSAN непосредственно из консоли VCF. Администраторам больше не придётся вручную перемещаться по интерфейсу для выявления корневых причин низких оценок состояния или определения способов устранения проблем — количество необходимых кликов сокращается до 60%.
vSAN в VCF 9.1 представляет собой значительный шаг вперёд в направлении более эффективного, гибкого, безопасного и интеллектуального хранилища для частного облака. Независимо от того, оптимизируете ли вы совокупную стоимость владения, поддерживаете разнообразные рабочие нагрузки, укрепляете устойчивость или упрощаете операции, этот релиз предоставляет практические возможности, решающие реальные ИТ-задачи.
Рабочие AI-нагрузки меняют экономику инфраструктуры. Из-за резкого роста спроса стоимость процессоров и памяти существенно возросла, что делает серверы дороже. Дополнительные расходы на оборудование затрудняют для ИТ-руководителей решение проблем производительности и ограничений ёмкости за счёт простого наращивания инфраструктуры. Успешные организации будут применять программно-определяемые стратегии, позволяющие извлечь максимальную ценность из уже имеющейся инфраструктуры. В новой реальности ИТ-специалисты, способные оптимизировать развёртывание инфраструктуры и операции второго дня, станут незаменимыми для обеспечения экономичной работы бизнеса.
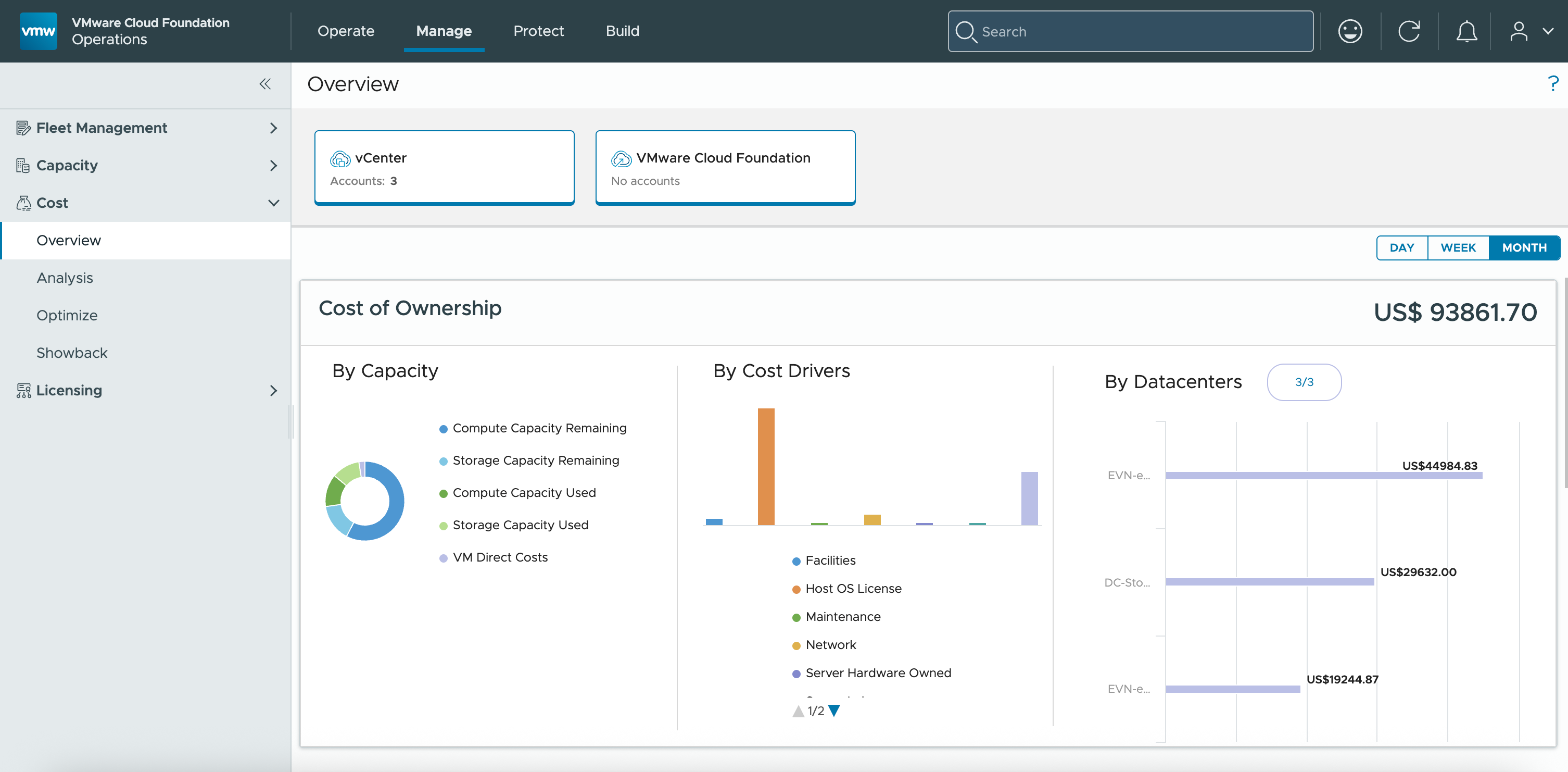
С выходом VMware Cloud Foundation (VCF) 9.1 компания Broadcom обеспечивает организациям эффективное управление крупномасштабными средами частного облака. VCF Operations поможет снизить корпоративные риски за счёт упрощения процессов усиления защиты — благодаря более простым рабочим процессам исправлений. Предоставляя данные о состоянии и диагностике с централизованной видимостью VMware Security Advisories (VMSAs) и Common Vulnerabilities and Exposures (CVEs), VCF 9.1 обеспечит оперативное устранение уязвимостей, упростит управление жизненным циклом и предоставит ИТ-командам возможность проактивно укреплять общий уровень безопасности.
VCF Operations предоставит панели мониторинга с расширенной аналитикой ёмкости и конкретными рекомендациями по распределению памяти NVMe для оптимизации производительности. Кроме того, платформа предложит комплексный учёт затрат для VMware vSphere Kubernetes Service (VKS) и проактивное управление флотом для бесперебойной работы. VCF обеспечит единое представление, которое превратит реактивное управление инфраструктурой в высокооптимизированное и экономически эффективное преимущество.
VCF Operations создаёт бизнес-ценность, трансформируя управление инфраструктурой из реактивной нагрузки в стратегическое преимущество — для построения, управления, эксплуатации и защиты инфраструктуры частного облака. Операционные процессы второго дня будут улучшены: исправление, обновление, определение стоимости инфраструктуры, диагностика и многое другое.
Опираясь на унифицированное управление флотом для контроля в масштабе, упрощённые Day-2 операции для наблюдения и диагностики проблем в режиме реального времени, а также на расширенный уровень безопасности для непрерывного соответствия требованиям, организации превратят инфраструктуру из центра затрат в отказоустойчивый высокопроизводительный механизм. Расширенный уровень безопасности потребует дополнения VMware Advanced Cyber Compliance.
Рисунок 1 - Новое в VCF 9.1 для VCF Operations. VCF Operations обеспечивает эффективную инфраструктуру и операции в масштабе.
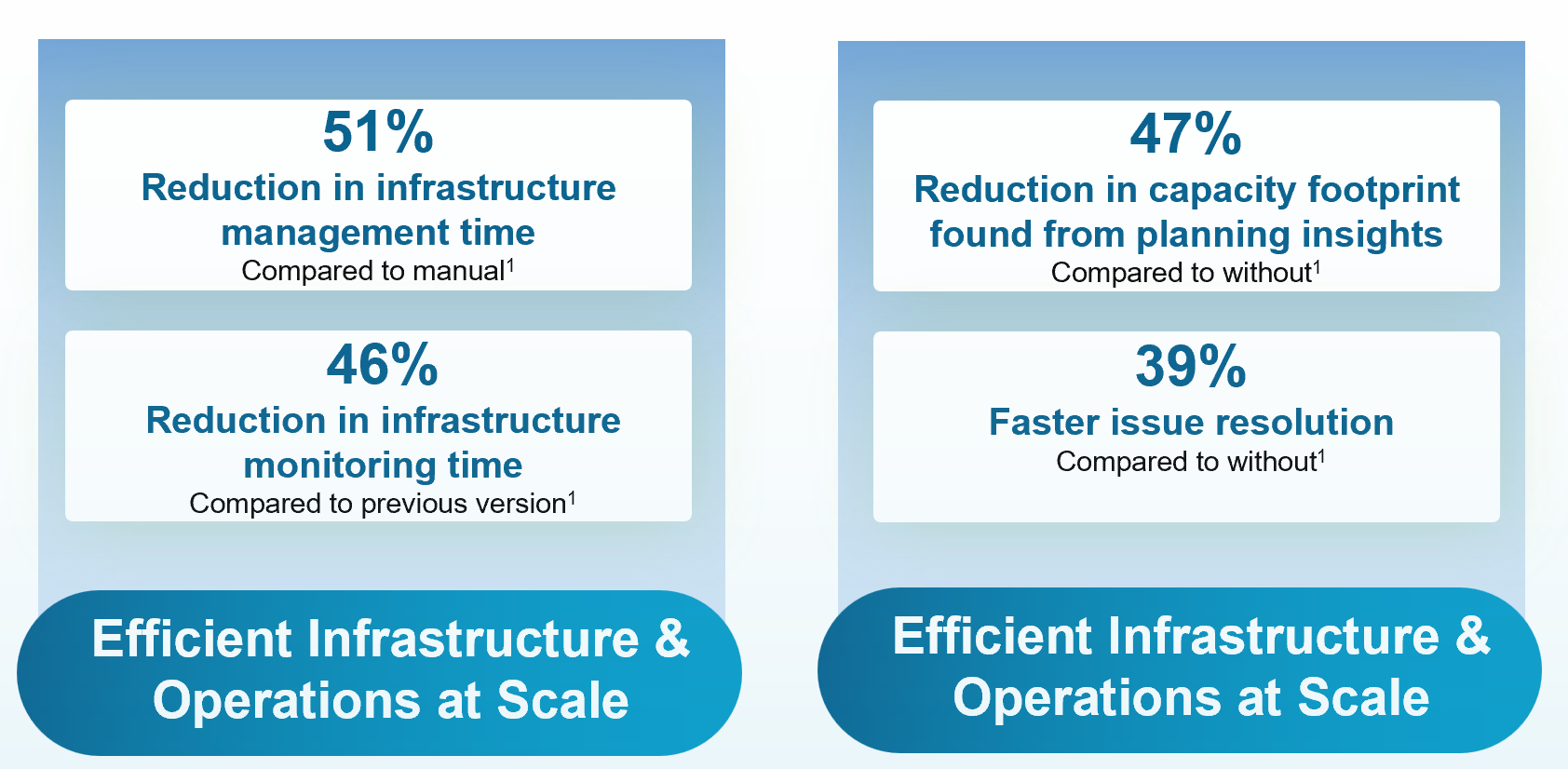
Данные опроса клиентов
Опрос Broadcom среди клиентов VCF 9 (n=44), проведённый в марте 2026 года, показывает, что модернизация частного облака связана с возвращением наиболее ценного ресурса команды — времени. Данные опроса свидетельствуют о том, что клиенты могут достичь следующих результатов в среднем:
Рисунок 2 - Средние результаты по данным опроса Broadcom среди клиентов VCF 9 (n=44) в марте 2026 года.
Опрос показал, что клиенты достигают в среднем 51% сокращения времени на управление инфраструктурой при использовании VCF 9, что позволяет командам переключиться с ручного обслуживания на эффективные операции. Объединив метрики, журналы и потоки в единой консоли, платформа сокращает среднее время мониторинга на 46%. Расширенная видимость обеспечивает среднее сокращение требуемой ёмкости на 47% по сравнению с предыдущими прогнозами. Даже при возникновении инцидентов VCF 9 ускоряет их устранение на 39% по показателям MTTR/MTTI благодаря интегрированным диагностическим панелям и возможностям анализа первопричин.
Быстрое развёртывание и масштабирование
С помощью VCF Installer клиенты смогут объединить существующую среду vCenter/ESX vSphere 8.0 Update 3 и выше с доменом управления VCF. С помощью VCF Operations клиенты смогут импортировать среды VMware vCenter 8.0 Update 3a (и выше) или VMware ESX 8.0 Update 3 (и выше) в рабочий домен VCF (VI). Оба подхода позволяют использовать существующую инфраструктуру и не требуют простоя или миграции приложений и данных.
Используя VCF Operations, организации с vSphere 8.0 Update 3 или выше смогут легко интегрировать существующий vCenter в качестве рабочего домена в VCF 9.1, обеспечивая непрерывность бизнеса и получая возможности корпоративного управления. Среда VCF будет работать под управлением VCF 9.1, а VCF Operations сможет управлять более старой средой vSphere 8.0 Update 3 или выше для управления жизненным циклом, обеспечивая бесперебойную работу бизнес-приложений.
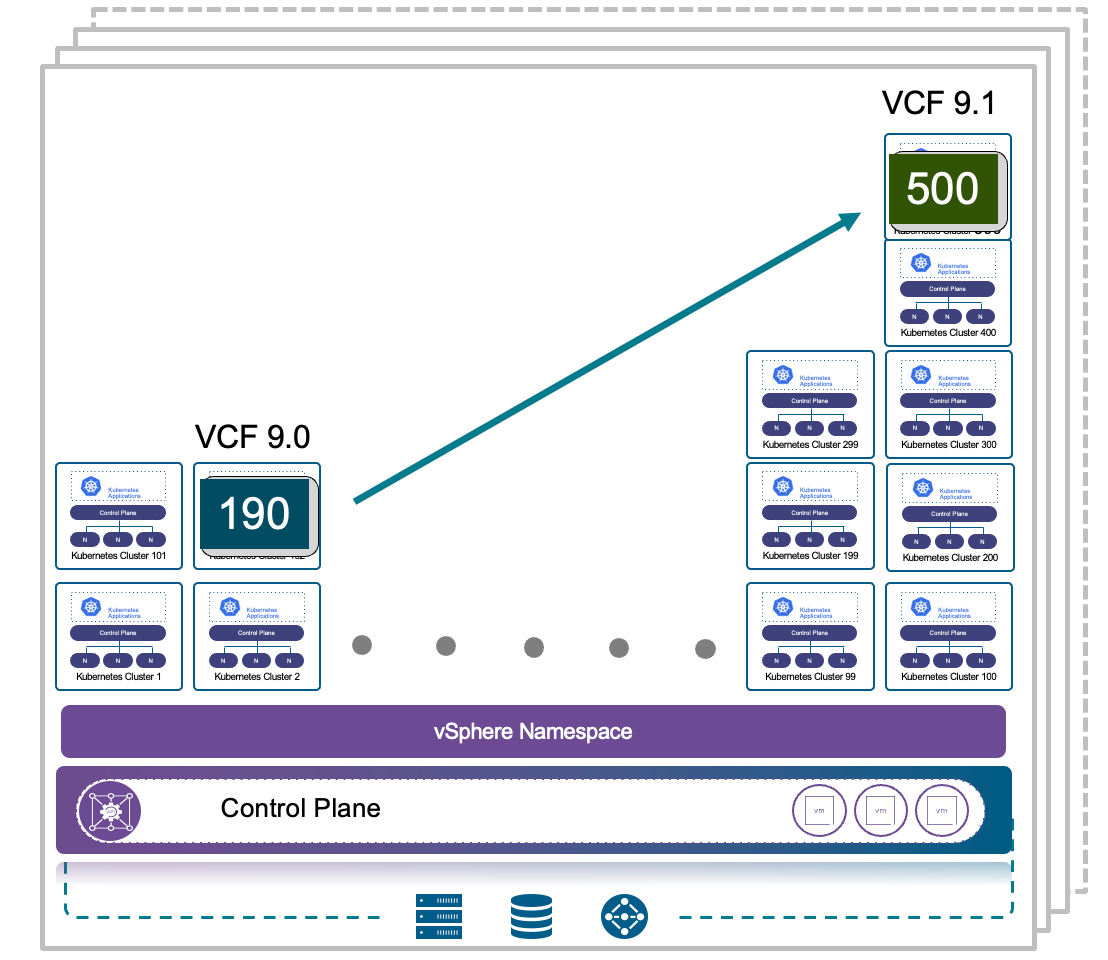
Расширенный масштаб управления позволит одному экземпляру поддерживать до 5 000 хостов ESX, что в 2 раза больше по сравнению с предыдущим релизом.
VCF 9.1 предложит 4-кратное увеличение параллельной ёмкости обновлений с поддержкой до 256 кластеров одновременно. Это существенно сократит время простоя и позволит операторам выполнять задачи обслуживания значительно быстрее в рамках запланированных окон.
VCF Operations объединит исправление и обновление всех компонентов в единый интерфейс управления жизненным циклом. С этой централизованной панели можно будет комплексно планировать устранение критических CVE, планировать и выполнять обновления как для глобальных компонентов флота VCF, так и для рабочих доменов. VCF Operations предоставит планы обновлений с указанием количества шагов и точной последовательности их выполнения, устраняя необходимость угадывать при планировании окон обслуживания. Поскольку VCF полностью интегрирует последние инновации в области исправлений vSphere и ESX, эти комплексные рабочие процессы можно выполнять с полной уверенностью в минимальном или нулевом операционном воздействии на работающие нагрузки.
В VCF 9.1 модуль диагностики работоспособности VCF Operations введёт публичные API, позволяющие настраивать данные из результатов проверок. Это обеспечит бесшовную интеграцию диагностических данных в режиме реального времени с существующими процессами, например, с системами управления заявками и платформами управления рисками.
В данном выпуске представлены сервисы управления VCF — централизованный набор инфраструктурных компонентов, размещённых в выделенной среде выполнения сервисов. Это обеспечит унифицированное управление жизненным циклом, идентификацией и операциями для VCF. Каждый экземпляр VCF будет включать сервисы управления: управление жизненным циклом, программное хранилище, управление журналами и данные в режиме реального времени. Вместо работы в виде отдельных устройств эти сервисы будут распределены на общей среде выполнения. Среда выполнения сервисов VCF служит общей архитектурной основой для сервисов управления и развёртываний VCF Automation.
VCF 9.1 представит унифицированный сервис программного хранилища, использующий токены OAuth для безопасного управления обновлениями как в подключённых, так и в изолированных средах.
Управление флотом в масштабе
Рисунок 4 - Панель VCF Operations в VCF 9.1 обеспечивает глобальный обзор.
VCF 9.1 представит ряд ключевых улучшений для упрощения внедрения. Управление распределённой инфраструктурой не будет умножать рабочую нагрузку. VCF 9.1 централизует контроль над всем флотом частного облака, превращая десятки отдельных задач в единые операции.
Для лицензирования VCF 9.1 в режиме подключения не потребуется ручных действий. В подключённом режиме администраторы VCF 9.0 ранее должны были вручную подтверждать обновлённые файлы лицензий каждые 180 дней или менее. VCF 9.1 реализует автоматическую загрузку файлов лицензий каждые 24 часа в подключённом режиме. После выбора подключённого режима автоматизация становится поведением по умолчанию. Данные об использовании лицензий передаются в Broadcom, а обновлённый файл лицензии загружается и применяется автоматически — без вмешательства администратора.
Оптимизированное управление идентификацией и доступом предоставит назначение ролей на уровне VCF с интегрированными конфигурациями SSO и поставщика удостоверений. Управлять доступом ко всему флоту можно будет из единой точки контроля.
Управление жизненным циклом и конфигурацией обеспечит применение политик на уровне всего флота с детальной видимостью изменений конфигурации и отклонений в экземплярах VCF, vCenter и отдельных кластерах. Для проверки готовности среды к обновлению будут выполняться предварительные проверки. VCF запустит их для выявления проблем, которые могут привести к сбою обновления. Комплексные проверки оценивают общее состояние системы, достаточность ресурсов и другие параметры.
Для сред VxRail ключевые возможности Days 0, 1 и 2, ранее обрабатывавшиеся Dell VxRail Manager, теперь можно будет управлять с помощью VCF Operations на узлах vSAN ReadyNodes.
Массовые операции устранят повторяющуюся ручную работу. Операции с сертификатами, импорт и продление выполняются одновременно для всех компонентов VCF. То, что раньше занимало часы, теперь займёт минуты.
Интеграция с хранилищем паролей обеспечит управление паролями на основе политик через стандартные публичные API, а также новую интеграцию с хранилищем паролей CyberArk, гарантируя согласованность политики паролей в VCF и остальной инфраструктуре. Это упростит ротацию паролей и обслуживание в среде VCF.
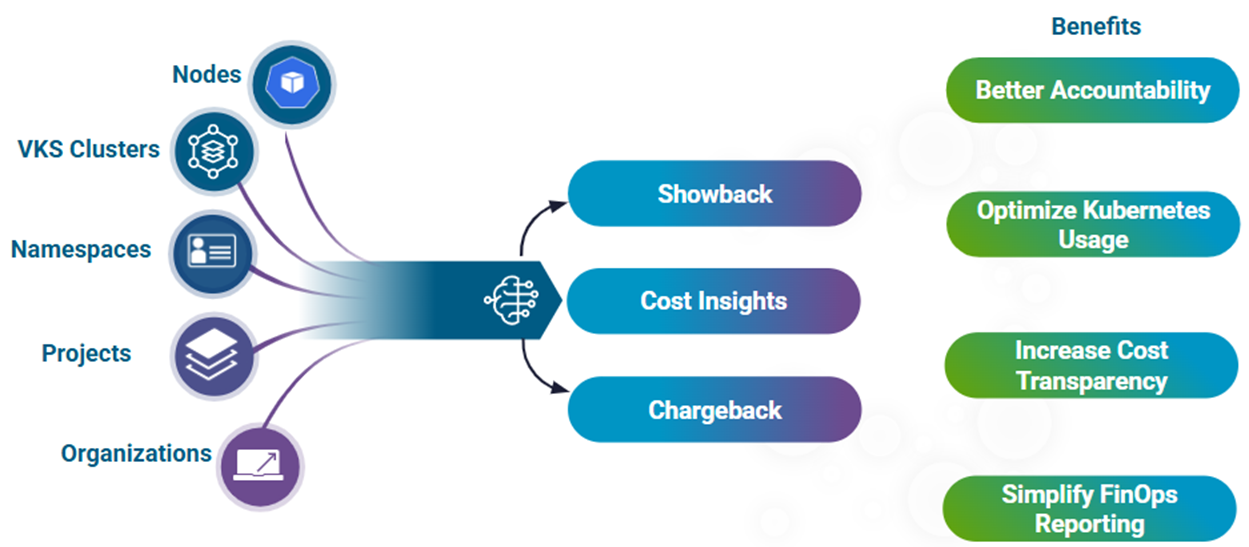
Рисунок 5 - VCF 9.1 предоставит детализацию затрат VMware vSphere Kubernetes Service (VKS), что улучшит возможности анализа, выставления счетов, учёта расходов и распределения затрат для современных рабочих нагрузок.
Интеллектуальная оптимизация ёмкости и затрат предоставит практические рекомендации. Рекомендации по распределению памяти на кластерах NVMe позволят количественно оценить экономию и повышение плотности виртуальных машин. В этом выпуске также появится поддержка анализа What-If для распределения памяти NVMe. Расширенное управление затратами VKS предоставит учёт расходов, распределение затрат и оценку цен в режиме реального времени — финансовую видимость, которую требует современная ИТ-служба. VCF следует операционной методологии FinOps Open Cost and Usage Specification (FOCUS) для частного облака, обеспечивающей стандартизированный формат данных о счетах для улучшенного распределения затрат и ускоренного анализа.
Упрощение операций второго дня
Глубокая наблюдаемость станет основой надёжных операций. VCF 9.1 обеспечит ИТ-команды видимостью в режиме реального времени и интеграциями, готовыми к использованию с AI, необходимыми для более быстрого устранения неполадок и поддержания работоспособности критически важных приложений.
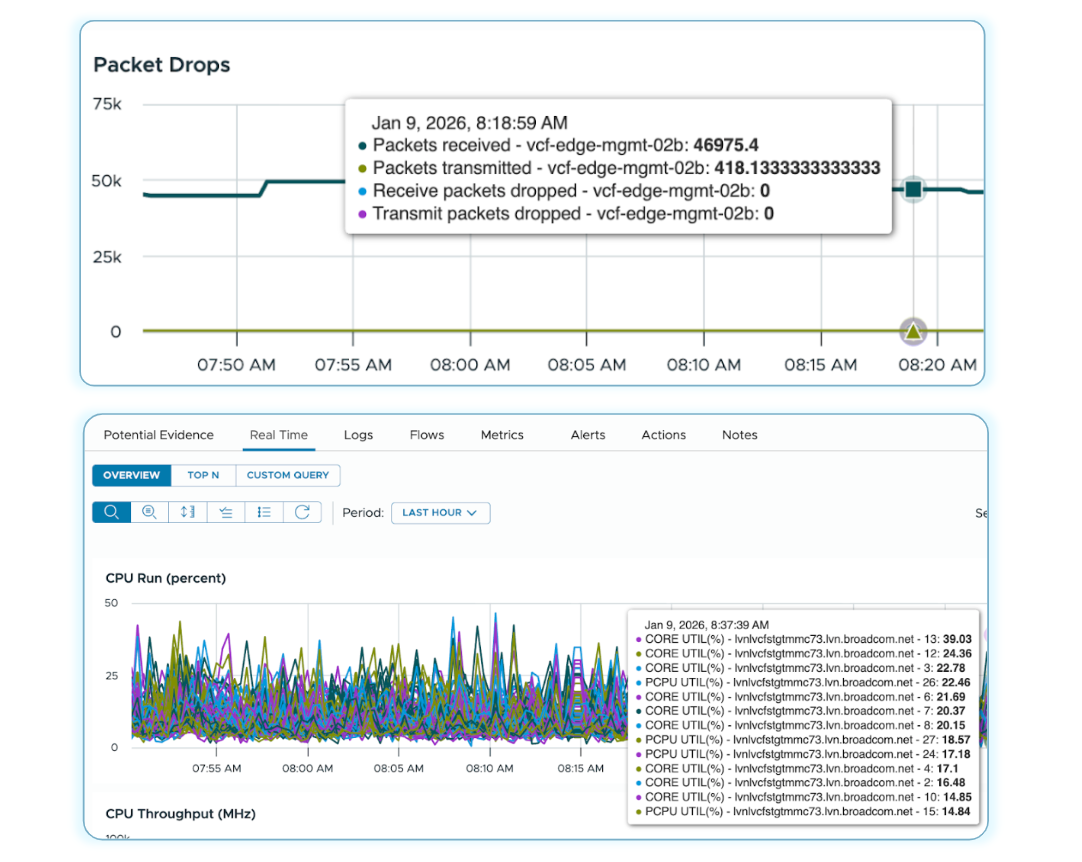
Наблюдаемость в реальном времени теперь будет собирать метрики в секундах с настраиваемым интервалом сбора до 2 секунд для хостов ESX. Для критических рабочих нагрузок своевременные данные позволят проактивно улучшить работу бизнес-приложений.
Централизованное управление журналами объединит агрегацию журналов с расширенными панелями и бесшовной пересылкой в сторонние решения. Интерфейс журналов будет полностью интегрирован в VCF Operations. Поиск проблем в разных интерфейсах станет ненужным — всё будет доступно в одном месте для всех компонентов VCF.
Проактивная диагностика поможет предупреждать проблемы вместо реагирования на сбои. VCF 9.1 позволит использовать улучшенные панели работоспособности VCF и расширенную диагностику vSAN для выявления потенциальных проблем производительности. Диагностика будет выделять ключевые проблемы для vCenter, хостов ESX, vSAN и VCF Networking в NSX Manager и узлах Edge: проблемы с подключением, работоспособностью сервисов, использованием ресурсов и другие.
Management Pack Builder позволит создавать интеграции со сторонними системами без написания кода для расширения видимости инфраструктуры. VCF 9.1 также обеспечит прямую интеграцию с Prometheus Server Management Pack для расширения набора метрик и данных, доступных для мониторинга.
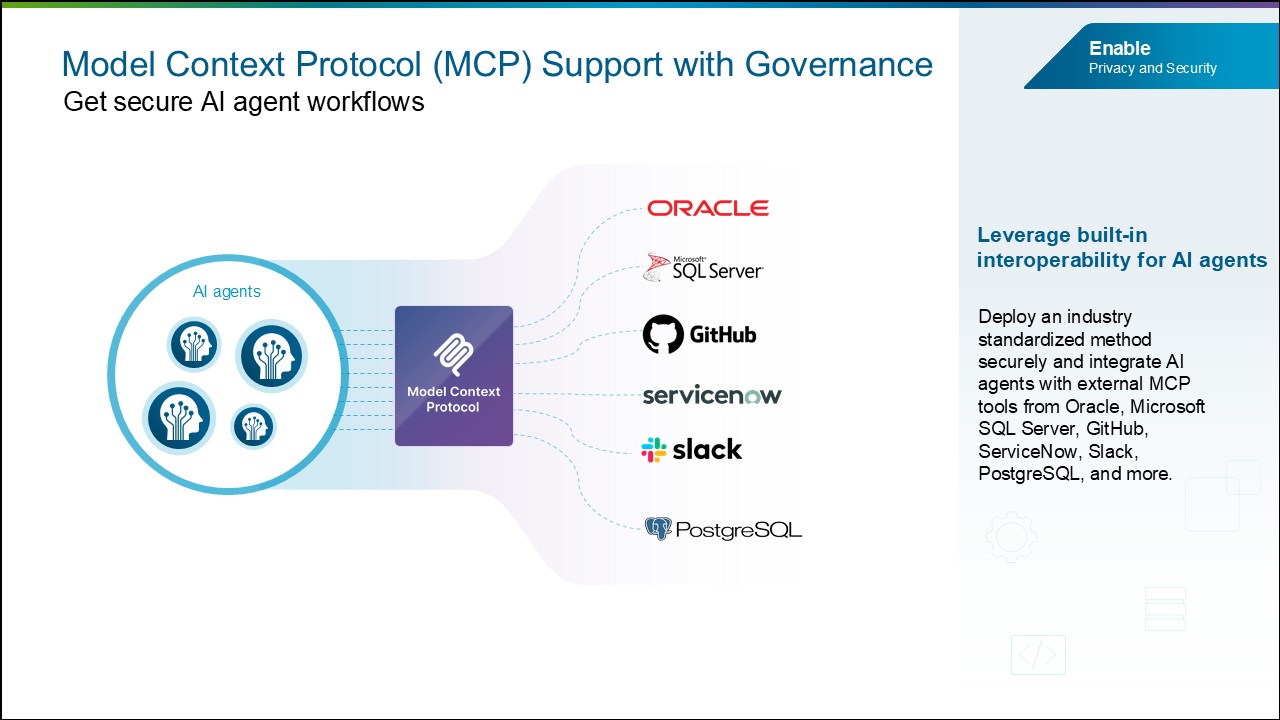
В VCF 9.1 Operations представляет собой платформу, готовую к интеграции с AI, через API для подключения к пайплайнам Retrieval-Augmented Generation (RAG) и фреймворкам Model Context Protocol (MCP). Это позволит клиентам экспортировать аналитику из дата-лейка инфраструктуры в другие AI-системы, например, в AIOps-движки для прогностического анализа. Встроенный мониторинг и управление журналами для кластеров VMware vSphere Kubernetes Service (VKS) обеспечат операционную видимость современных Kubernetes-рабочих нагрузок на том же уровне, что и существующие виртуальные машины.
Безопасные операции
Управление уровнем безопасности выполнит комплексные оценки соответствия по всему флоту VCF с простыми средствами устранения несоответствий для приведения инфраструктуры к требуемым эталонным показателям. Поддерживается соответствие стандартам Payment Card Industry (PCI) и Security Baseline. Управление уровнем безопасности потребует дополнительной услуги Advanced Service надстройки VMware Advanced Cyber Compliance.
Распределённые рабочие нагрузки и расширение ИИ-инициатив создают растущую поверхность атаки. VCF 9.1 интегрирует расширенную услугу надстройки VMware Advanced Cyber Compliance в пользовательский интерфейс VCF Operations. С её помощью автоматическое отслеживание соответствия требованиям станет частью операционных рабочих процессов.
VCF обеспечит аудиторские следы для ускорения расследования инцидентов на основе стандартизированных архитектур журналов и централизованных исторических данных. При возникновении событий безопасности будут доступны криминалистические данные для понимания произошедшего. Аудиторскую запись можно развернуть по временным интервалам и экспортировать в виде CSV-файла.
Расширенная панель SecOps предоставит обзор проблем безопасности: предупреждения, статус шифрования рабочих нагрузок, состояние функций конфиденциальных вычислений на подходящих хостах и другие параметры.
От реактивных задач к проактивным операциям
VCF 9.1 выходит за рамки инкрементальных обновлений. Через VCF 9.1 Broadcom предоставляет консолидированное управление, глубокую наблюдаемость и простое устранение несоответствий требованиям — чтобы ИТ-команда тратила меньше времени на обслуживание и больше на то, что действительно важно.
Управление облачными расходами исторически представляло собой фрагментированный процесс: каждый провайдер использует собственный формат, схему и терминологию. Это создаёт своеобразный «налог на перевод» — организации тратят значительную часть времени на очистку и нормализацию данных вместо их анализа и оптимизации. FinOps-командам приходится вручную согласовывать данные из публичных облаков, SaaS-сервисов и внутренних систем, прежде чем возможен какой-либо полноценный анализ. Для решения этой проблемы был разработан стандарт FOCUS — единая спецификация учёта затрат и потребления.
В Broadcom убеждены, что финансовая прозрачность должна быть стратегическим преимуществом, а не источником ручной работы. Именно поэтому VCF 9.1 реализует поддержку FinOps Open Cost & Usage Specification (FOCUS) — глобального стандарта, позволяющего привести разрозненные данные о затратах к единому виду для сопоставимого анализа.
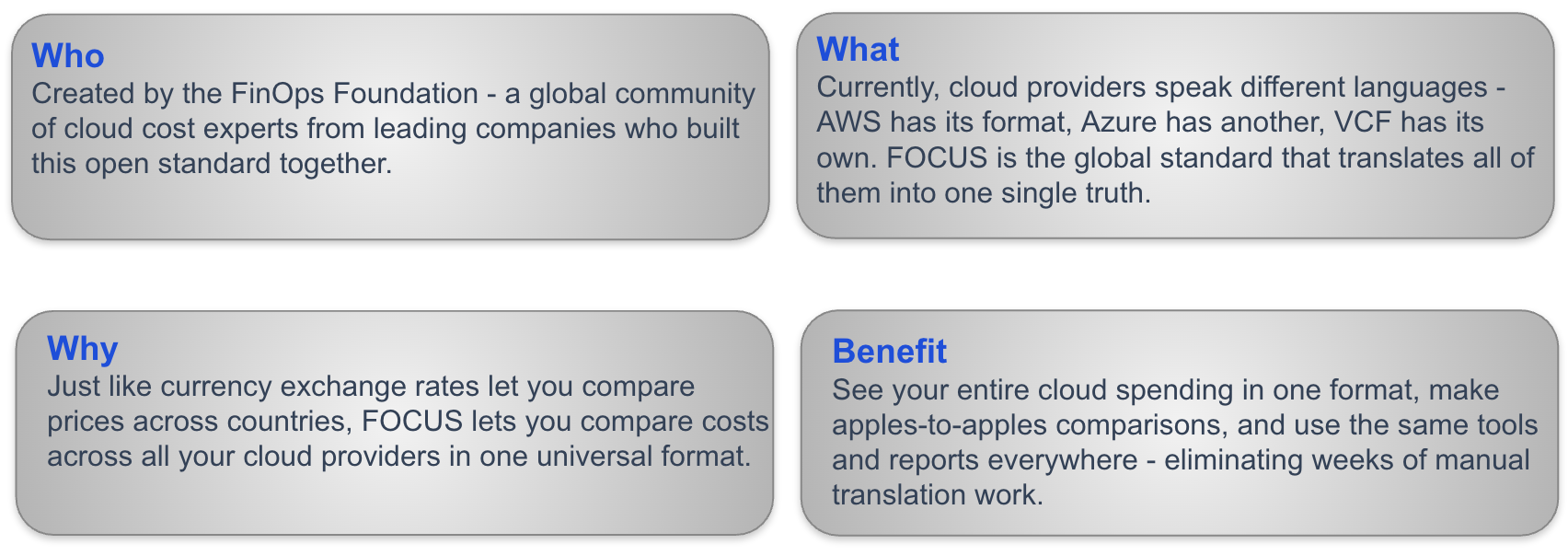
Что такое FOCUS?
FOCUS можно сравнить с универсальным обменником валют для управления облачными расходами. Подобно тому как обменные курсы позволяют сравнивать цены в разных странах, FOCUS даёт возможность сопоставлять затраты у всех облачных провайдеров в едином формате. Разработанный FinOps Foundation, этот открытый стандарт устраняет необходимость в многонедельном ручном переводе данных, позволяя командам видеть все облачные расходы в единой сопоставимой форме.
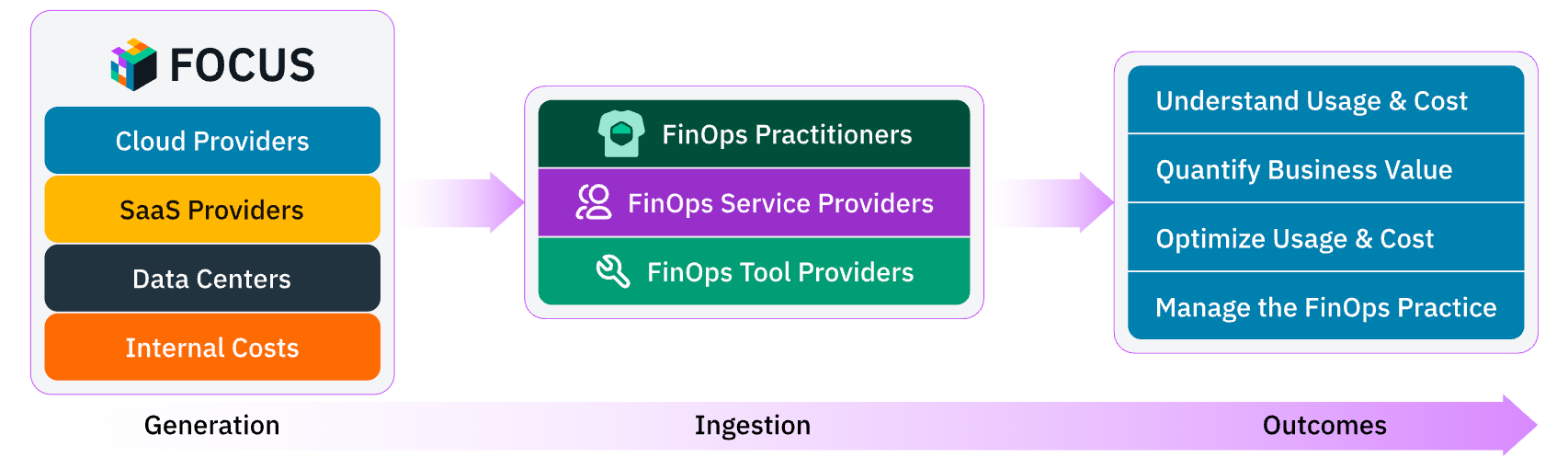
Как работает FOCUS
FOCUS нормализует биллинговые данные из различных источников, сокращая объём работы, необходимой для начала FinOps-анализа, и позволяя переключить усилия на более стратегические задачи. Стандарт упрощает FinOps-цикл, приводя разрозненные данные о выставлении счетов из облачных, SaaS- и внутренних источников к согласованному, удобному для работы формату — как для генераторов данных, так и для их потребителей. Упрощение процесса получения данных позволяет организациям перейти от ручной обработки к стратегическим результатам: оптимизации затрат и оценке бизнес-ценности.
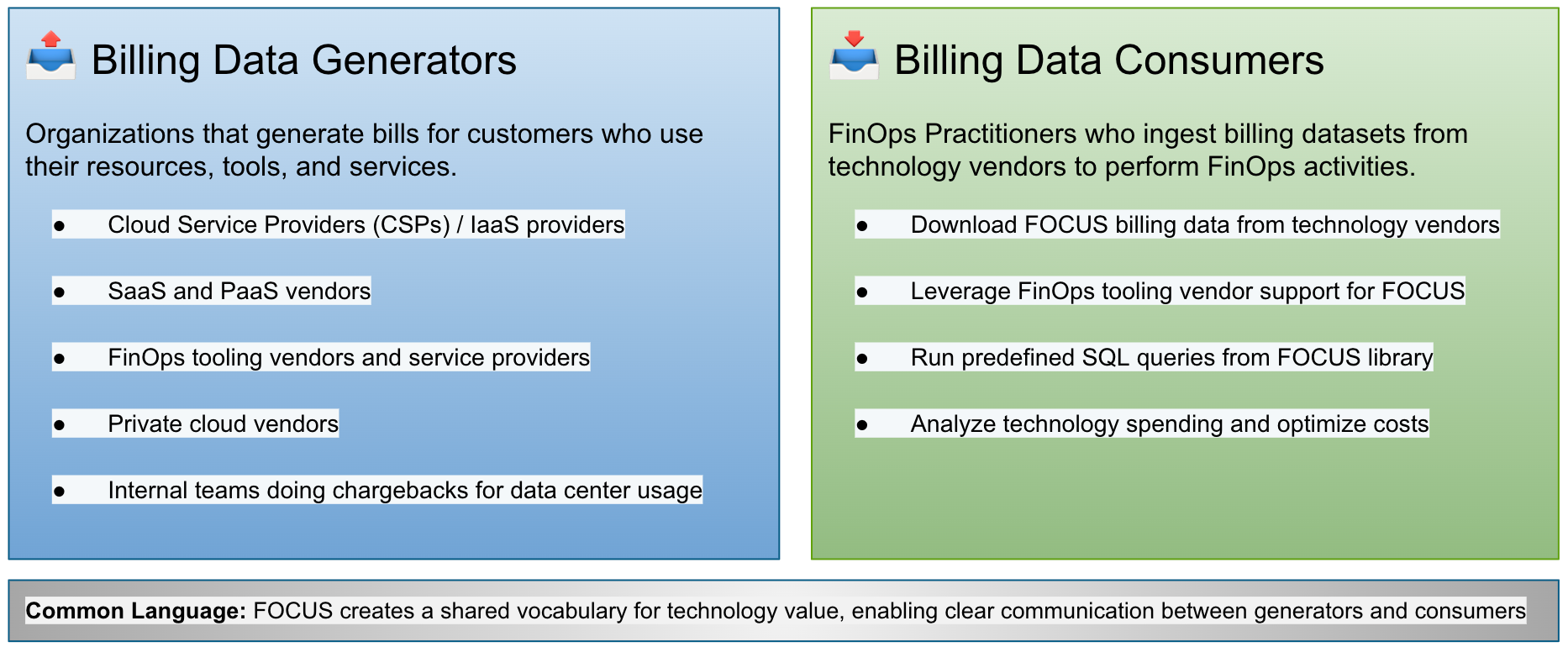
Кто использует FOCUS
FOCUS формирует общий словарь, устраняющий разрыв между генераторами биллинговых данных (облачными и SaaS-провайдерами) и их потребителями (FinOps-специалистами).
Этот общий язык позволяет командам эффективно обрабатывать и анализировать сложные наборы биллинговых данных, обеспечивая прозрачность коммуникации и более результативную оптимизацию технологических расходов.
Преимущества FOCUS
FOCUS повышает эффективность всей FinOps-экосистемы за счёт стандартизации биллинговых данных, позволяя специалистам и поставщикам инструментов переключиться с ручной нормализации на стратегические задачи.
Организации получают возможность принимать комплексные решения на основе данных при меньших операционных затратах, а технологические провайдеры — ускорить внедрение продуктов благодаря общей прозрачной терминологии.
Актуальность в 2026 году
Финансовая прозрачность перестала быть опцией — наступила точка перелома. По данным исследования The Linux Foundation, конкурентная среда к 2026 году кардинально изменилась:
98% команд теперь управляют расходами на AI - резкий рост по сравнению с 31% в 2024 году.
78% FinOps-специалистов подчиняются напрямую CTO или CIO, что свидетельствует о стратегическом повышении роли управления затратами.
Более $83 млрд облачных расходов отслеживается с использованием стандартизированных практик.
Бизнес-ценность FOCUS
FOCUS создаёт значительную бизнес-ценность, обеспечивая отслеживание затрат на AI и GPU-нагрузки в реальном времени, автоматизированное устранение избыточных расходов и формирование стратегических дашбордов для руководства в рамках VMware Cloud Foundation.
Консолидация финансовых функций и управления мощностями позволяет даже небольшим командам масштабировать операции и устранять неожиданные расходы посредством упреждающего анализа. Этот подход обеспечивает основанную на данных базу для достижения полной видимости и контроля над гибридными облачными инвестициями.
VCF + FOCUS = 100% покрытие сценариев использования
VCF Operations обеспечивает 100-процентное покрытие стандартных FinOps-сценариев, определённых спецификацией FOCUS. Восемь возможностей доступны «из коробки», ещё четыре легко настраиваются — таким образом, инфраструктура частного облака на базе VCF Operations полностью соответствует глобальным стандартам.
Заключение: финансовая ясность как конкурентное преимущество
VMware Cloud Foundation в связке с глобальным стандартом FOCUS устраняет разрыв в видимости между частным и публичным облаком. Нормализация телеметрии VCF в соответствии со схемой FOCUS позволяет организациям впервые проводить прямое, сопоставимое сравнение затрат по всему гибридному ландшафту. VCF выступает прозрачным движком данных, позволяя сравнивать стоимость локальных рабочих нагрузок с альтернативами у гиперскейлеров с высокой точностью. При стопроцентном покрытии сценариев использования и отслеживании в реальном времени организации получают финансовую ясность, необходимую для стратегического выбора наиболее экономичного размещения каждой рабочей нагрузки и уверенного управления корпоративными инвестициями.
Дункан Эппинг записал новое демо-видео для решения VMware VCF 9.1 Protection and Recovery, ранее известного как VMware Live Recovery. В этом демо он показывет процесс восстановления после атаки ransomware. Дункан в деталях делится тем, насколько просто это делается на этой платформе, а также то, что она включает интеграцию как с Carbon Black, так и с CrowdStrike.
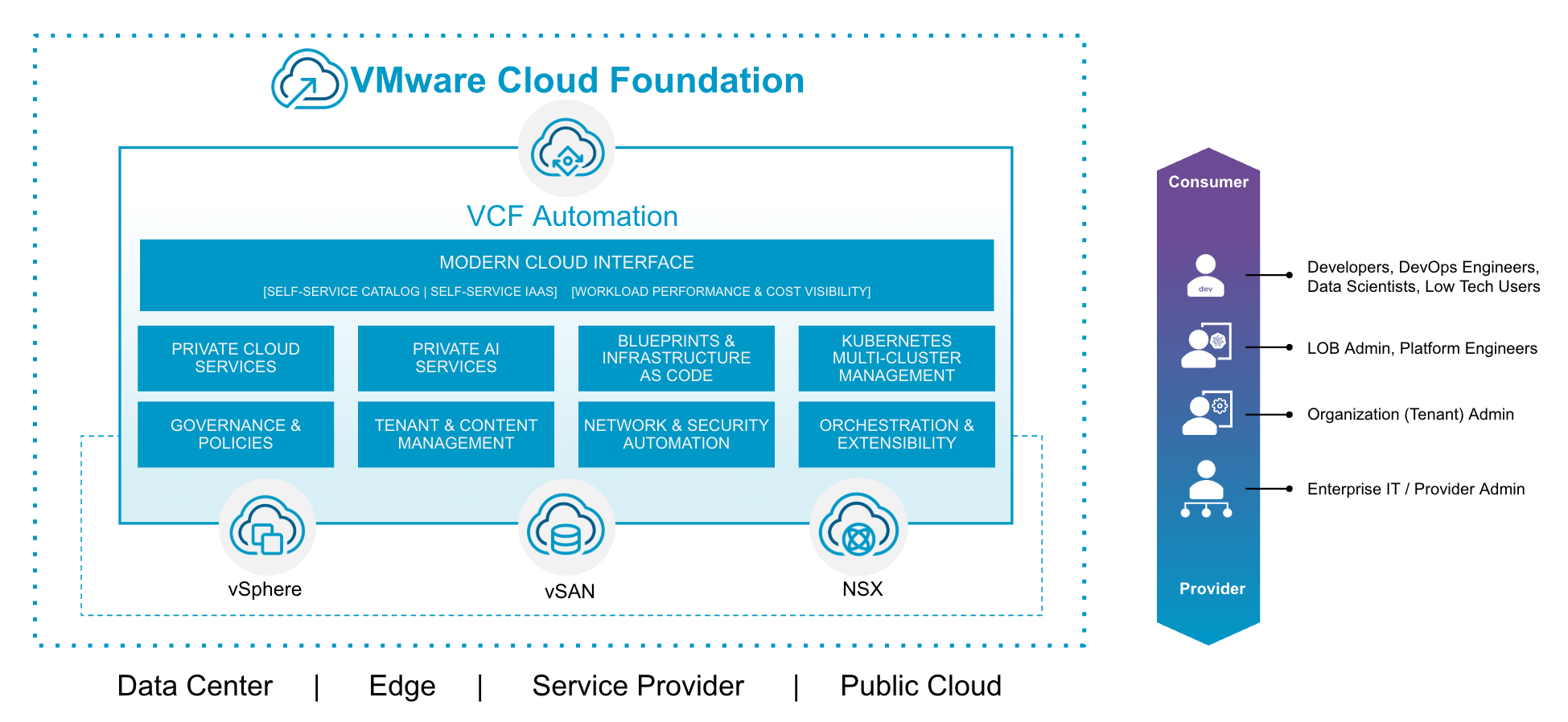
Платформа VMware Cloud Foundation (VCF) заметно прогрессирует от выпуска к выпуску. Версия 9.1 продолжит развитие возможностей, заложенных в VCF 9.0, и предложит более совершенный опыт потребления в рамках модели самообслуживания (self-service) частного облака.
По данным опроса заказчиков Broadcom, проведённого в марте 2026 года и посвящённого оценке VCF 9, компании, применяющие VCF Automation, добились двух существенных результатов. Во-первых, промежуток времени от запроса до готовой к использованию прикладной среды сократился на 49%. Во-вторых, ручные усилия по сопровождению жизненного цикла приложений — от разворачивания и обновления до установки патчей и изменения конфигурации — уменьшились ещё на 49%.
В VCF 9.1 этот фундамент будет расширен новыми возможностями автоматизации, призванными ещё сильнее ускорить выпуск приложений, снизить затраты и масштабировать управляемость и соответствие требованиям в рамках всего предприятия. Далее рассматриваются три ключевых направления, по которым VCF 9.1 преобразит подходы к предоставлению и потреблению сервисов частного облака.
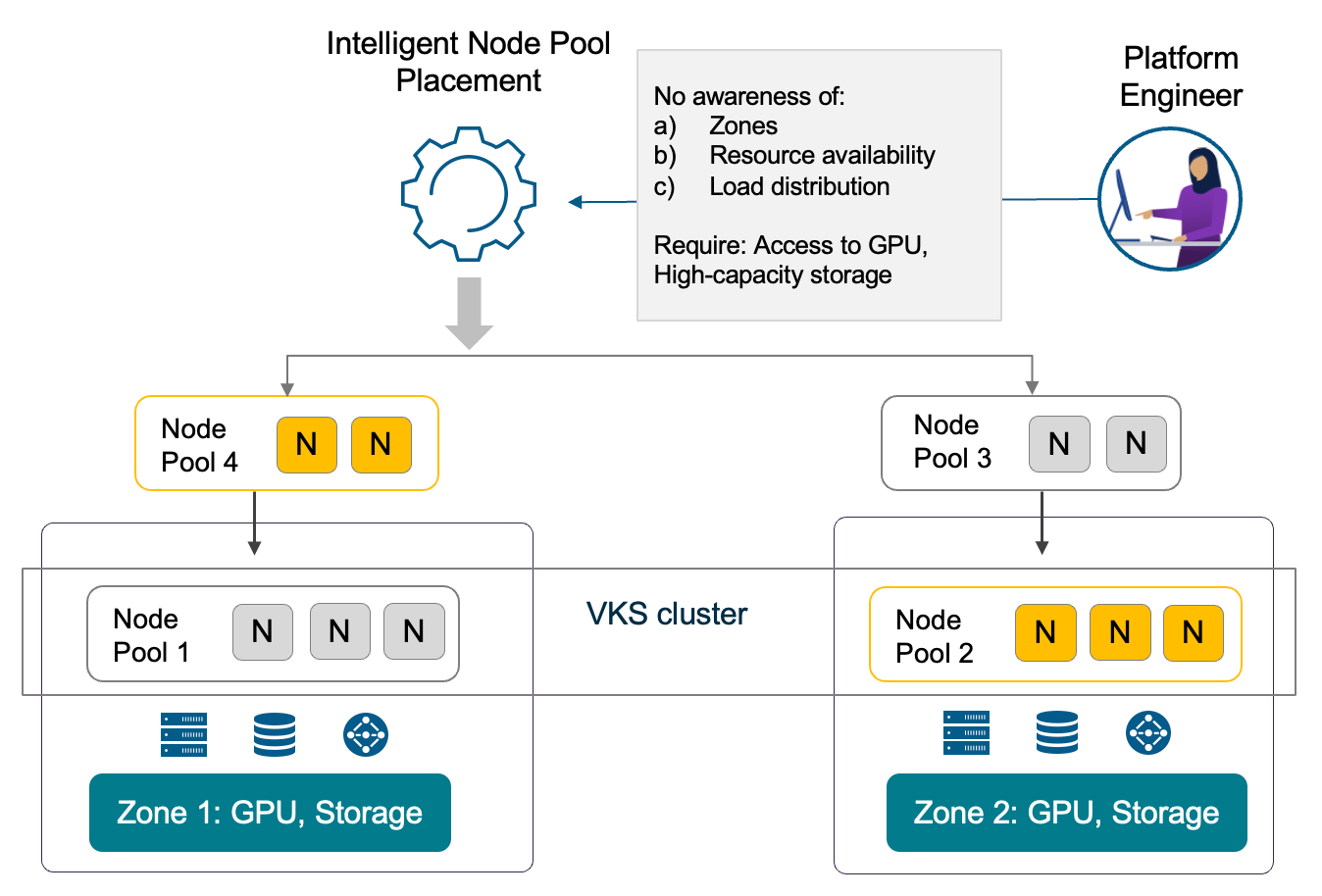
1. Ускоренное развёртывание благодаря расширенным сервисам
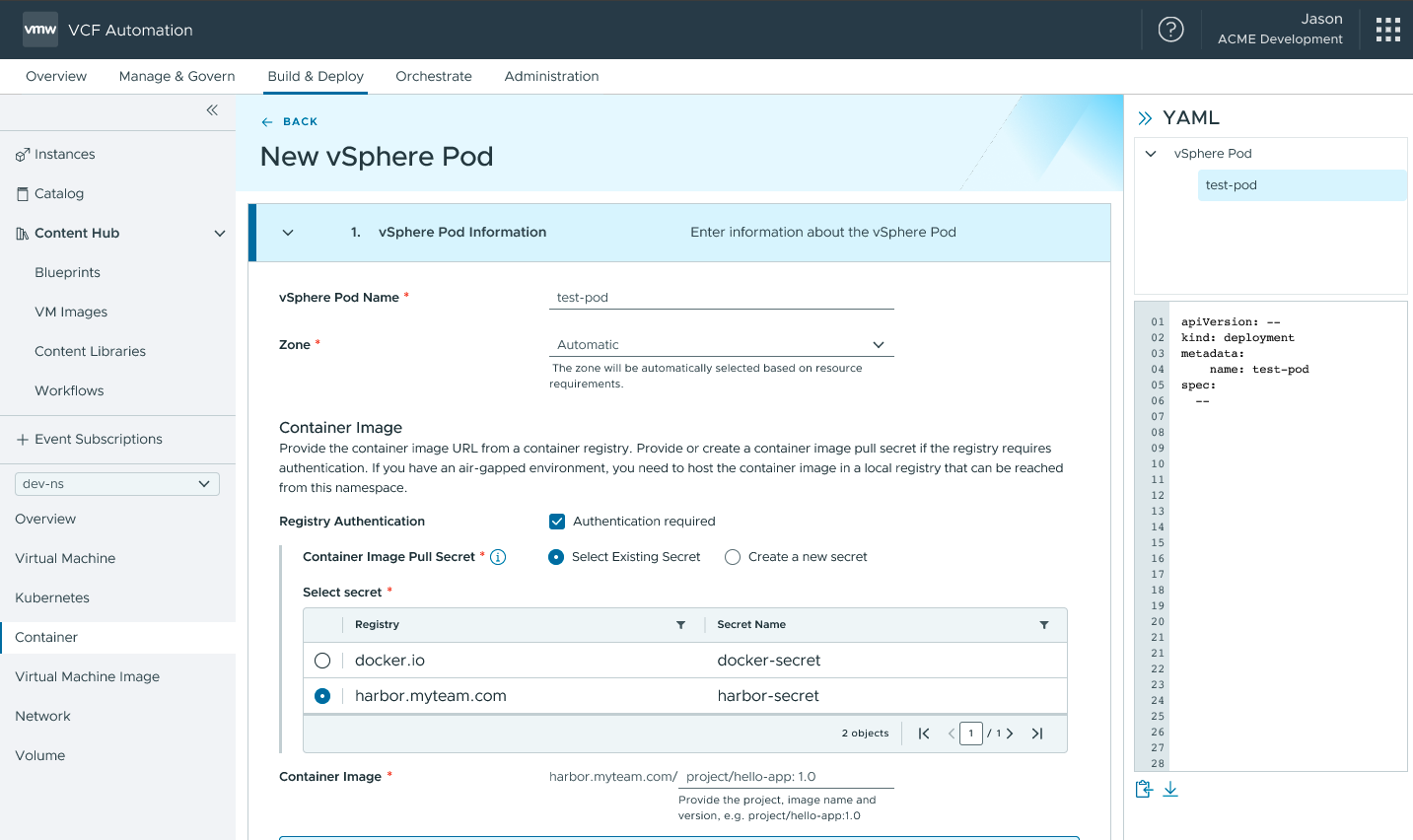
Container as a Service
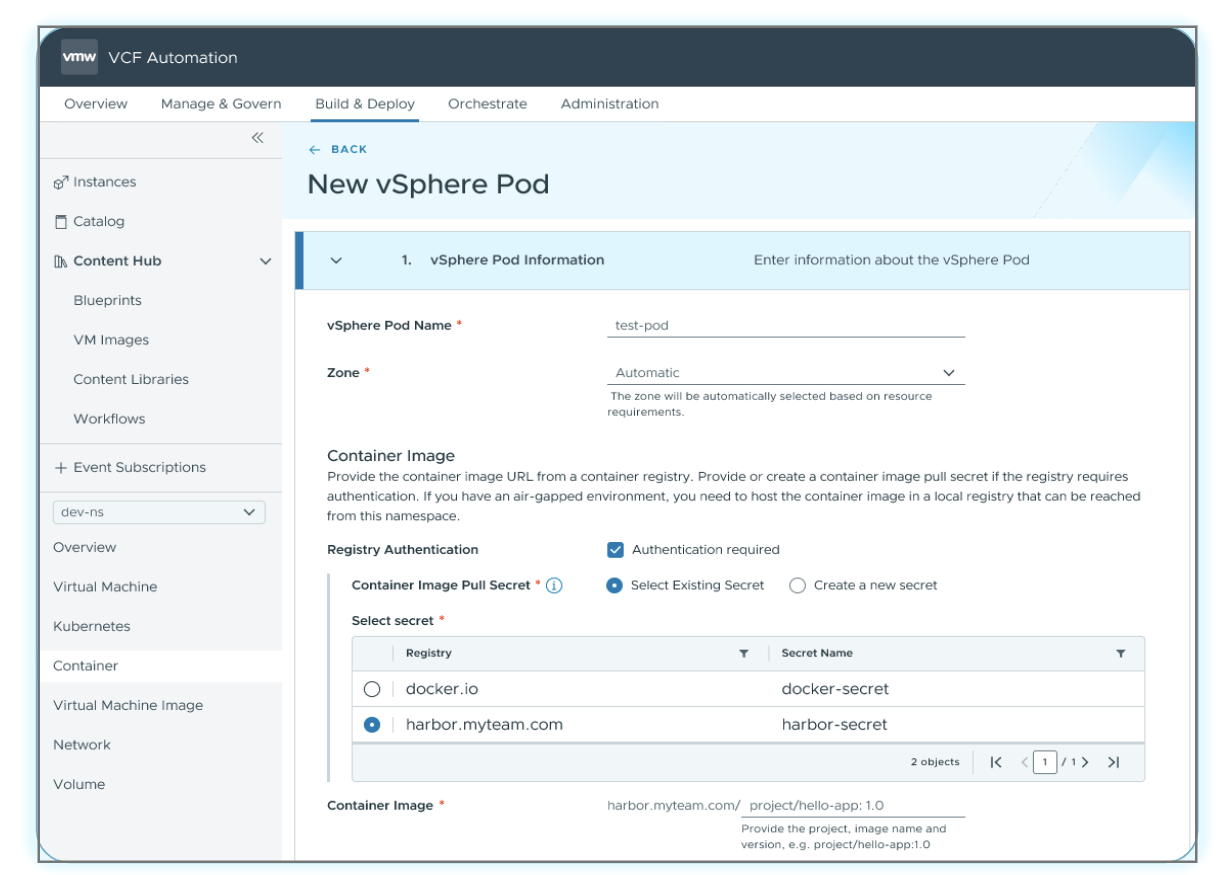
В VCF 9.1 ускорение развёртывания контейнеров достигается за счёт чёткого разделения трёх вариантов исполнения — VM Service, Container Service и VMware vSphere Kubernetes Service (VKS). Такое разграничение позволяет подобрать подходящий runtime под конкретную нагрузку без излишних сложностей.
VCF Automation обеспечит доступ к Container Service с полным управлением жизненным циклом. Разворачивать, настраивать, отслеживать, обновлять и удалять контейнеры можно будет прямо через интерфейс — без команд kubectl, без YAML-файлов и без необходимости разбираться в Kubernetes API. Контейнеры станут полноценными runtime-сущностями наряду с виртуальными машинами и кластерами VKS.
Такой упрощённый контейнерный runtime обеспечит высокую гибкость без операционных издержек, связанных с инфраструктурой Kubernetes. Он будет работать непосредственно на ESX без накладных расходов на кластер, предоставляя изоляцию нагрузок и эффективное использование ресурсов в управляемом, по сути serverless-режиме. Платформа VCF полностью автоматизирует планирование, изоляцию, оптимизацию производительности и обновления. Когда архитектура приложения будет развиваться, интерфейс сформирует согласованный YAML, обеспечивающий плавный переход к кластерам VKS — мягкий путь от простых развёртываний контейнеров к полноценным возможностям Kubernetes.
VCF Automation: интерфейс развёртывания Container Service
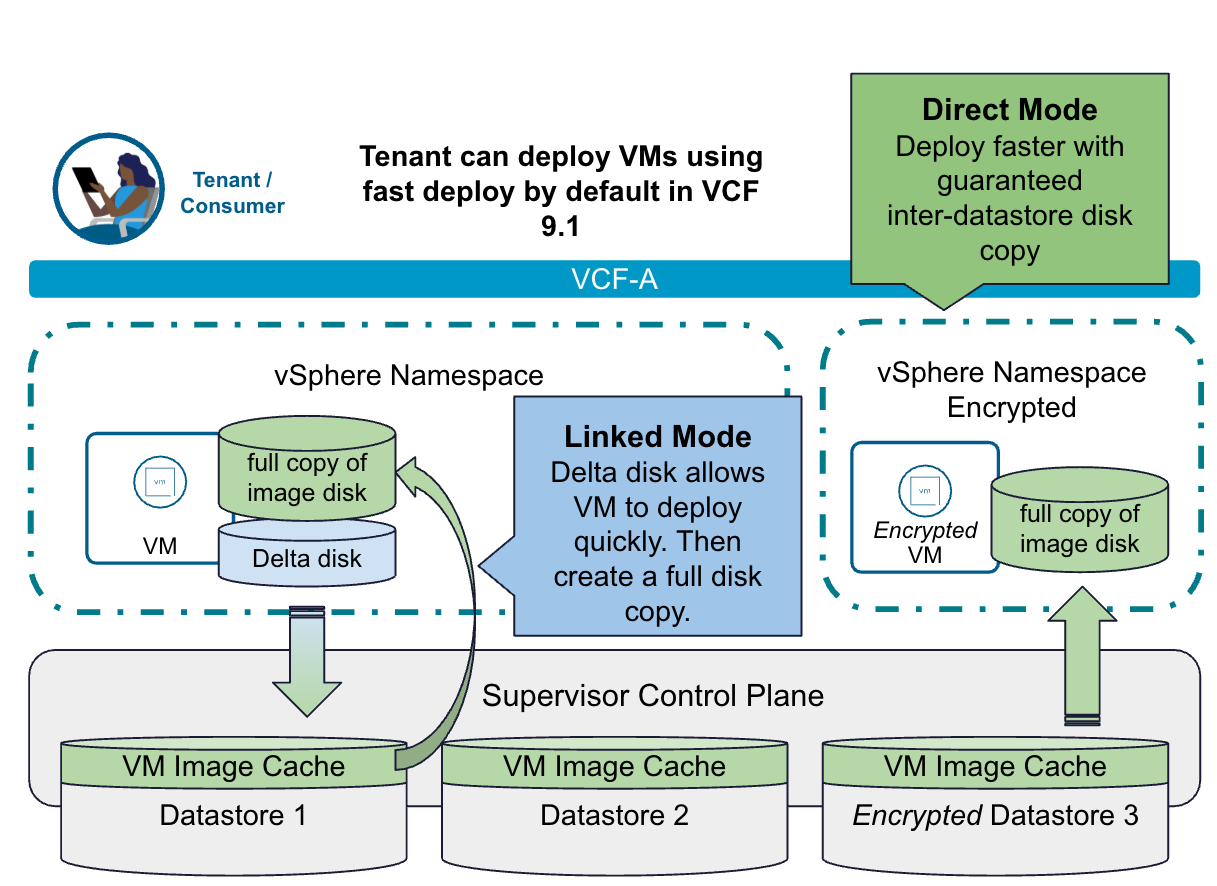
Fast Deploy для VKS и виртуальных машин
В VCF 9.1 появится механизм Fast Deploy, существенно ускоряющий выделение виртуальных машин и кластеров VKS. После обновления функция автоматически активируется для каждой ВМ, разворачиваемой из blueprint, и не требует настройки в интерфейсе. Работая прозрачно через YAML, она ускорит все жизненные операции на базе виртуальных машин, в том числе развёртывания VM Service и инициализацию кластеров VKS.
Fast Deploy получит два режима под разные сценарии. Linked-Mode использует цепочку связанных клонов с delta-disk и обеспечит мгновенное включение виртуальной машины, при этом полный диск формируется асинхронно в фоне — это сокращает и время развёртывания, и расход хранилища. Direct-Mode ускоряет выделение в зависимости от размера образа ВМ и числа параллельных операций, давая более быстрое развёртывание в масштабе с сохранением полной целостности диска с самого начала.
Развёртывание кластеров VKS заметно ускорится — с 37 минут до 11 минут, то есть на 69%. Обновления кластеров будут выполняться на 75% быстрее: 1,7 часа вместо 6,9 часа, что экономит более 5 часов на каждый цикл обновления. Команды разработки приложений смогут применять Fast Deploy, чтобы по запросу поднимать среды разработки, динамически масштабировать нагрузки, оперативно создавать тестовые окружения, повторяющие промышленные среды, а также быстро разворачивать многоуровневые приложения.
VCF Automation: рабочий процесс Fast Deploy
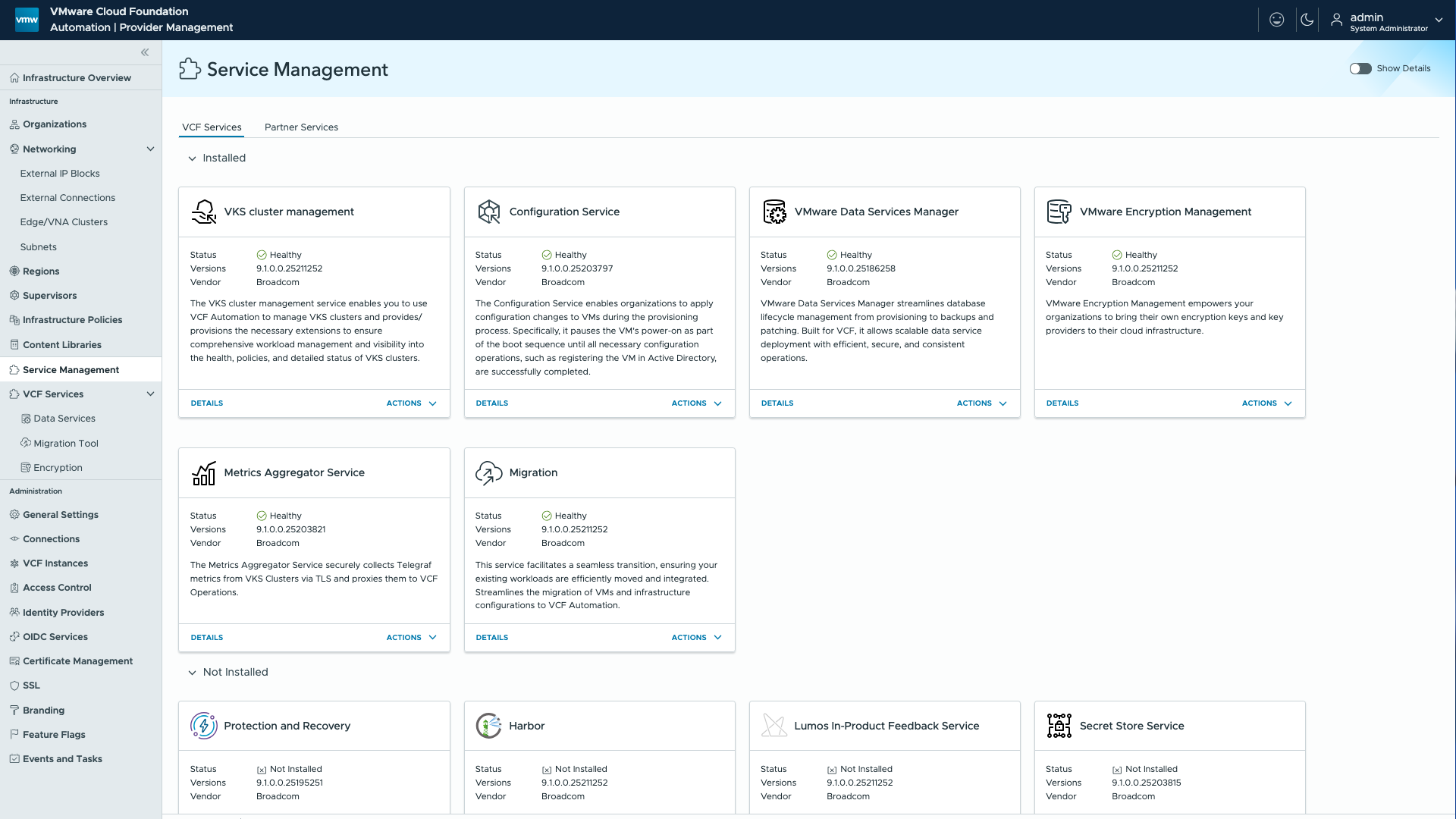
Централизованное управление сервисами и новые встроенные сервисы
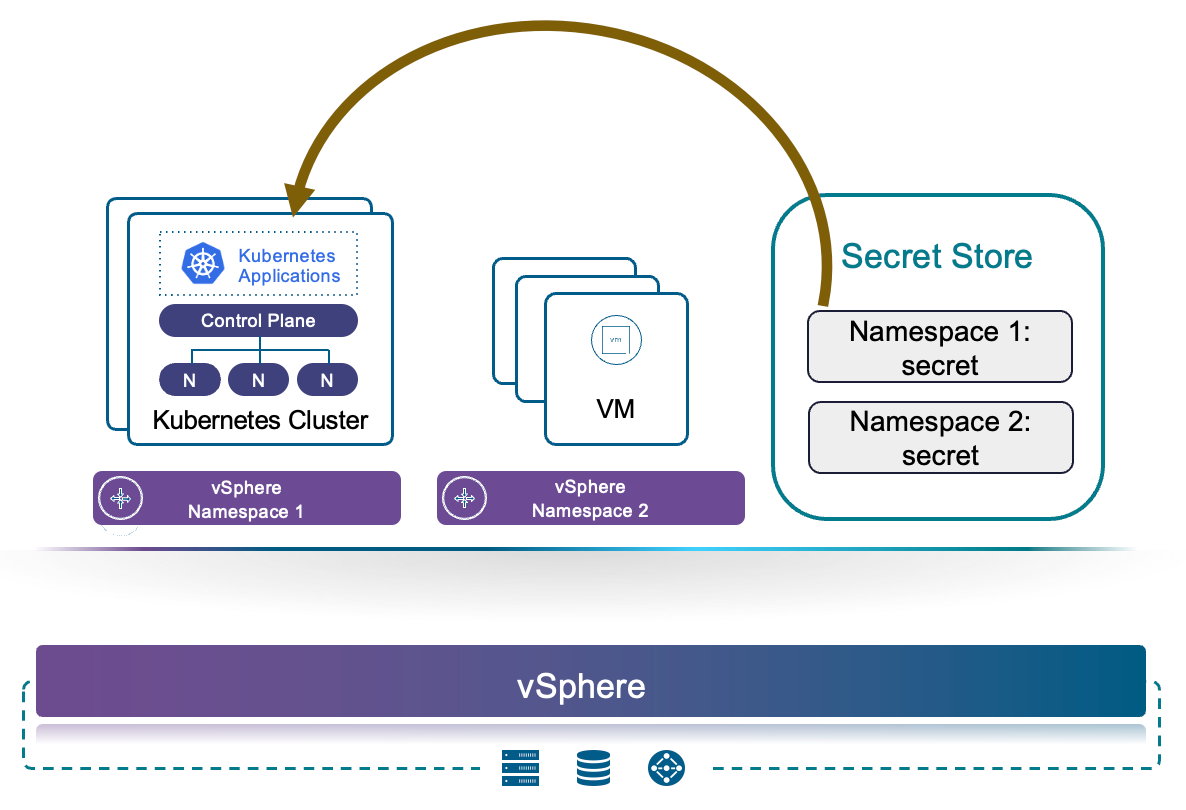
Работа с расширяемыми сервисами в частном облаке станет централизованной и более простой. В VCF 9.1 появится усовершенствованное управление сервисами, опирающееся на региональный экземпляр Harbor для упрощения развёртывания и сопровождения сервисов по всей платформе. Service Manager будет получать и отображать содержимое сервисов непосредственно из этого реестра, благодаря чему расширится круг сервисов, подключаемых и публикуемых для арендаторов.
Вместе с релизом будут поставляться десять предустановленных сервисов, автоматически синхронизируемых в составе базовой конфигурации платформы. Они отображаются в интерфейсе в виде отдельных плиток: Harbor, VMware Data Services Manager, Secret Store Service, сервис автоподключения для управления кластерами VKS (Auto-Attach Service), Encryption Management (BYOK) и другие.
Такой централизованный подход обеспечит более быстрый доступ к возможностям платформы: сервисы доступны по умолчанию и сразу пригодны к использованию через интерфейс. Это позволит ускорить внедрение во всех регионах и упростить эксплуатацию за счёт централизованных обновлений и сокращения ручной административной работы, что приведёт к согласованности окружений.
VCF Automation: интерфейс управления сервисами
Расширенный Day-2 жизненный цикл виртуальных машин
В VCF 9.1 потребители смогут самостоятельно изменять конфигурацию CPU, памяти, хранилища и сети уже после развёртывания. Среди расширенных возможностей — изменяемость сети, снапшоты и VM Groups. Это устранит административные узкие места и сократит циклы обслуживания заявок с дней до минут.
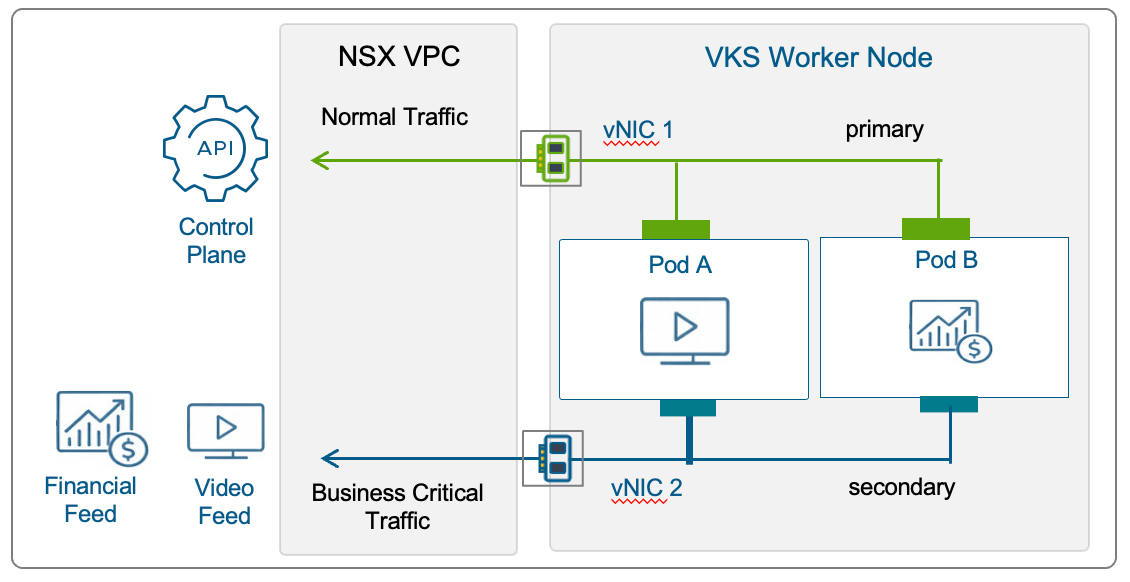
Сетевые улучшения
Расширенное управление IP для провайдеров и арендаторов
Арендаторы смогут самостоятельно резервировать IP-адреса и управлять ими с поддержкой нескольких CIDR и интеграцией с Infoblox. Это позволит реализовывать сложные сетевые конфигурации, например NAT «один к одному», без зависимости от рабочих нагрузок.
Гибкие Transit Gateway для сложных топологий маршрутизации
VCF 9.1 даст возможность создавать множественные внешние подключения и несколько Transit Gateway на одного арендатора с изолированными VPN, статическими маршрутами и пользовательскими настройками NAT. Это позволит гибко выстраивать межсайтовую маршрутизацию и точно управлять трафиком без внешнего маршрутизирующего оборудования.
Самообслуживание по сети и безопасности для арендаторов
В VCF 9.1 будет доступно сетевое самообслуживание, предоставляющее прямой доступ к ЦОД, выведение частных сетей, развертывание VPN и Gateway Firewall. Это расширит возможности арендаторов и позволит им самостоятельно управлять сетевой безопасностью.
Общие подсети и VLAN-расширения
В VCF 9.1 появятся подсети уровня организации и расширения VLAN с прямым подключением на уровне L2. Это откроет путь к сложным сетевым архитектурам, включая виртуальные машины с несколькими сетевыми адаптерами и прямое подключение к физической фабрике на уровне нагрузок арендатора.
Подключение к существующим VLAN через распределённые Transit Gateway
VCF 9.1 представит распределённые Transit Gateway, которые подключают VPC напрямую с хостов ESX с использованием только идентификатора VLAN, без Edge-кластеров и динамической маршрутизации. Это упростит эксплуатацию для унаследованных VLAN-окружений и обеспечит прямую коммуникацию между виртуальными машинами VCF и не-NSX ВМ.
Упрощённые межсетевые экраны и автоматизированная безопасность между VPC
VCF 9.1 позволит реализовать модель Zero Trust с автоматизированной микросегментацией, правилами межсетевого экрана и метками соответствия с использованием vDefend. Это даст автоматизированную безопасность с первого дня, исключая ручную настройку и обеспечивая единообразное применение политик.
2. Улучшенное управление жизненным циклом приложений и нагрузок
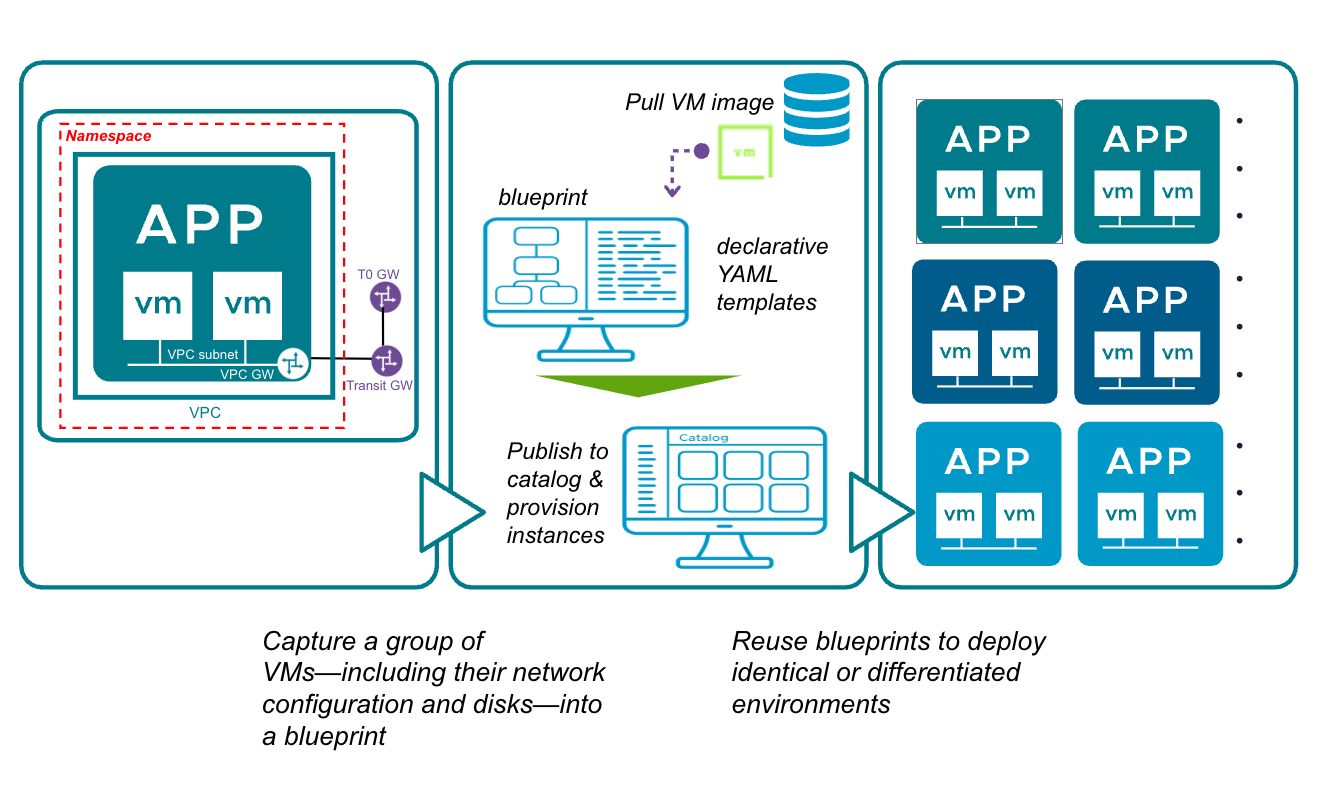
App Stack Formation
В VCF 9.1 будет реализован сценарий формирования прикладного стека (App Stack Formation) — принципиально новый подход к созданию blueprint. Он позволит пользователям зафиксировать работающую топологию — группу ВМ, их сетевую конфигурацию и диски — в виде единого blueprint. Эта возможность превратит живые среды приложений в переиспользуемые шаблоны, обеспечивая мгновенную, идентичную и масштабируемую доставку сервисов.
Вместо повторной сборки среды с нуля платформенные инженеры смогут фиксировать работающие ВМ вместе с их сетевыми настройками (VPC, подсети), дисками хранения (PVC), параметрами гостевой ОС и зависимостями между ВМ. Также можно будет задать последовательности запуска и остановки виртуальных машин внутри стека, чтобы многоуровневые приложения запускались в правильном порядке. Многоуровневые приложения будут собираться в единый переносимый пакет OVF/OVA, что устранит расхождения между средами Dev, Test и Prod. Управление всем прикладным стеком как одним объектом упростит операции старта/остановки и снапшотов с поддержкой заданного порядка включения. Провайдеры смогут предлагать готовые прикладные стеки через каталоги, развивая самообслуживание для арендаторов и сокращая время вывода новых сервисов на рынок.
VCF Automation: рабочий процесс App Stack Formation
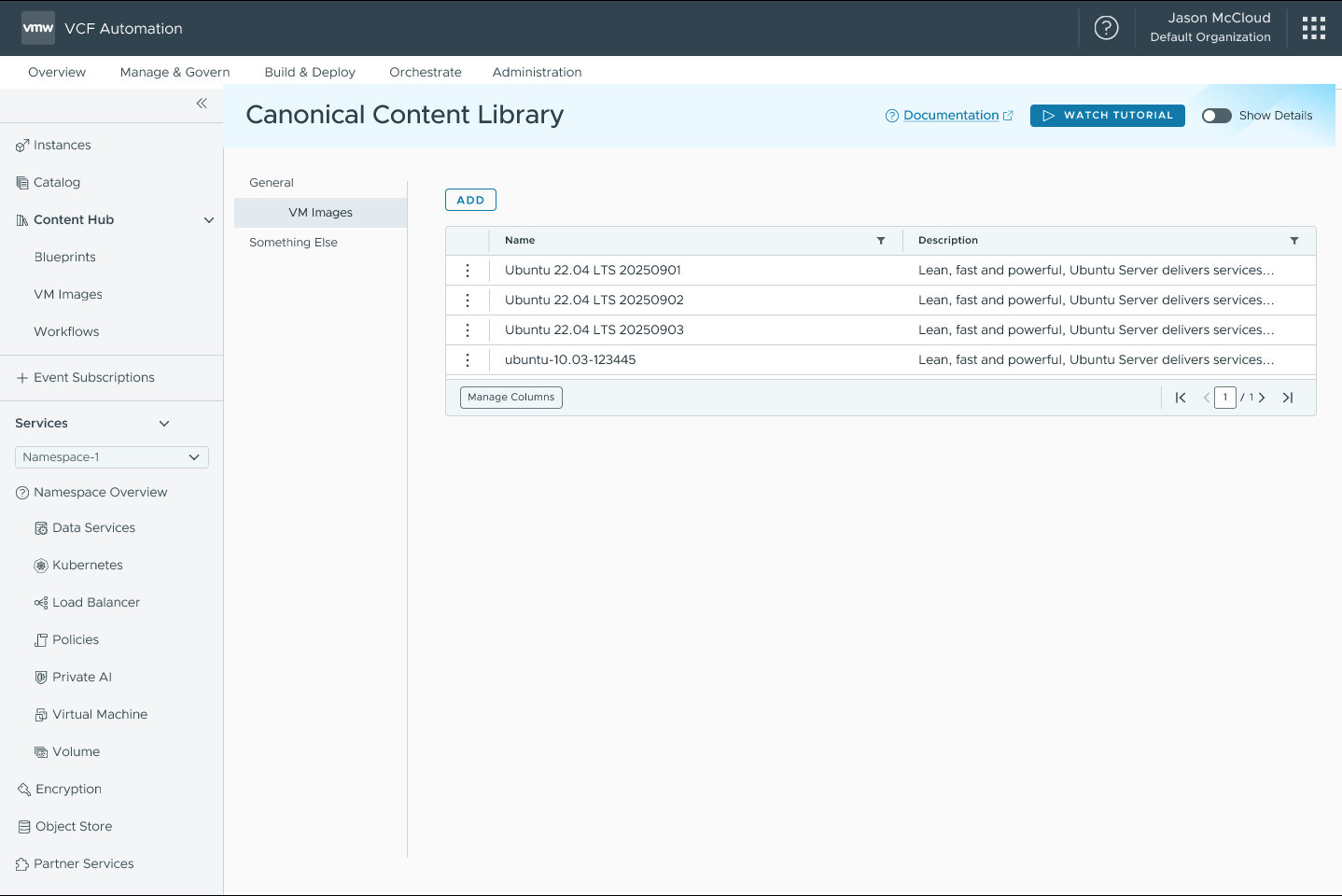
В VCF 9.1 появится встроенная интеграция с библиотеками контента Canonical, обеспечивающая поставку оптимизированных под VCF образов Ubuntu LTS. В эти образы включены пакеты — драйверы ВМ и инструменты, необходимые для успешного развёртывания и работы поверх VCF; они входят в базовую лицензию VCF для клиентов с активной подпиской.
Интерфейс обеспечит удобный поиск и выбор образов Ubuntu непосредственно в VCF Automation, избавляя пользователей от необходимости переходить на внешние сайты для поиска и импорта этих образов. Корпоративные ИТ-администраторы смогут подписаться на сопровождаемые Canonical библиотеки контента и автоматически синхронизировать официальные образы Ubuntu (например, 24.04 LTS) прямо в окружение, пополняя VM Images без ручных загрузок. Это обеспечит стабильность развёртываний, повышенный уровень безопасности и операционную эффективность за счёт эффективного управления патчами для критических уязвимостей и уязвимостей высокого уровня. Broadcom будет включать актуальные патчи в полные образы и размещать их в каталоге решений, гарантируя автоматическую поставку официального и проверенного контента. Клиенты получат упрощённый доступ к доверенным образам Ubuntu через защищённое нативное подключение.
VCF Automation: библиотека контента Canonical
Библиотеки контента на уровне проектов для автономии команд
В VCF 9.1 будут реализованы Project-level Content Libraries: администраторы организации смогут создавать отдельные библиотеки контента и явно привязывать их к одному или нескольким выбранным проектам внутри организации. После создания система предоставит право записи администраторам проектов и продвинутым пользователям проектов, позволяя им непосредственно публиковать, писать и управлять образами (например, ISO и OVA) в рамках выделенной библиотеки.
Это обеспечит автономию, снизив зависимость команд проектов от администраторов организации в части курирования и сопровождения библиотек контента, специфичных для проектов и приложений. Также появится возможность расширения: можно будет применять процессы Packer, в которых участники проектов публикуют собственные образы ВМ. Дополнительно VI-администраторы смогут использовать существующие шаблоны ВМ для построения библиотек контента VCF Automation без необходимости создавать новые образы. Это устранит операционное узкое место, при котором команды проектов прежде не могли управлять собственными библиотеками или напрямую загружать необходимые файлы вроде ISO и OVA, что в итоге шло вразрез с идеей потребительского самообслуживания и тормозило гибкую разработку.
VCF Automation: управление библиотекой контента проекта
Дополнительные возможности
Делегирование пространств имён и управление
VCF 9.1 позволит администраторам организации делегировать создание пространств имён администраторам проектов и платформенным инженерам с заранее определёнными ограничениями. Это устранит заторы, давая прикладным командам возможность самостоятельно управлять пространствами имён при сохранении управляющего контроля.
Расширения Terraform Provider для арендаторов в политике и управлении контентом
В VCF 9.1 будет расширен Terraform Provider с поддержкой полного развёртывания окружений, управления жизненным циклом образов ВМ и реализацией политик как кода, Day-2-операций и IaaS. Это позволит программно применять политики и реализовывать сценарий App Stack Formation через подход infrastructure-as-code.
3. Усиленное управление, безопасность и прозрачность затрат
Новые политики размещения инфраструктуры для лучшего контроля над нагрузками
В VCF 9.1 появятся политики размещения инфраструктуры, позволяющие администраторам задавать критерии размещения виртуальных машин с учётом их атрибутов и нацеливаться на конкретные подмножества ВМ. Система поддержит обязательный режим политики, который автоматически применяется при назначении организации и помогает гарантировать исполнение заданных правил размещения без участия арендатора.
Новые политики размещения инфраструктуры позволят оптимизировать лицензирование за счёт размещения по типу ОС и упростят соблюдение требований, давая инструменты для точного контроля того, где именно располагаются нагрузки, что облегчит соответствие нормативным или внутренним стандартам. Дополнительно это поможет облачным администраторам обеспечивать оптимальное размещение нагрузок для соответствия требованиям без ограничения возможностей самообслуживания.
Политики размещения обеспечат автоматическое распределение нагрузок по конкретным хостам на основе атрибутов вроде гостевой ОС или меток, гарантируя, что определённые типы ВМ последовательно попадают на наиболее подходящую или предназначенную для них инфраструктуру. Обязательный режим политики обеспечит строгое исполнение размещения ВМ согласно требованиям рабочих нагрузок в мультиарендных средах при сохранении управляемости через политическое регулирование.
VCF 9.1 будет выводить данные о затратах прямо в панелях управления Org и Project, позволяя администраторам видеть совокупные затраты на этих уровнях и переходить к детализации по конкретным затратам и инвентарю для отдельных проектов и пространств имён. VCF Automation предложит предварительную тарификацию (оценку стоимости по rate card VCF Operations) в рамках процесса развёртывания, давая администраторам возможность назначать цены сервисам частного облака, таким как VM Service и VKS Service. VCF Automation поддержит оповещения и отчёты по электронной почте. Администраторы смогут указывать конкретные адреса для получения уведомлений по биллингу, отчётам о затратах и критическим оповещениям — в частности, по квотам или доступности сервисов — с возможностью формирования и прямой загрузки отчётов и счетов.
Расширенная прозрачность с подробной детализацией затрат по проектам и пространствам имён поможет организациям управлять потреблением и снижать неэффективные капитальные расходы. Платформа будет формировать культуру осознанного отношения к затратам и финансовую подотчётность, позволяя потребителям и арендаторам видеть стоимость развёрнутых ими ресурсов, а администраторы получат проактивные уведомления по электронной почте без необходимости вручную следить за системой.
VCF Automation: панель прозрачности затрат
Полностью выделенные региональные квоты для организаций-арендаторов
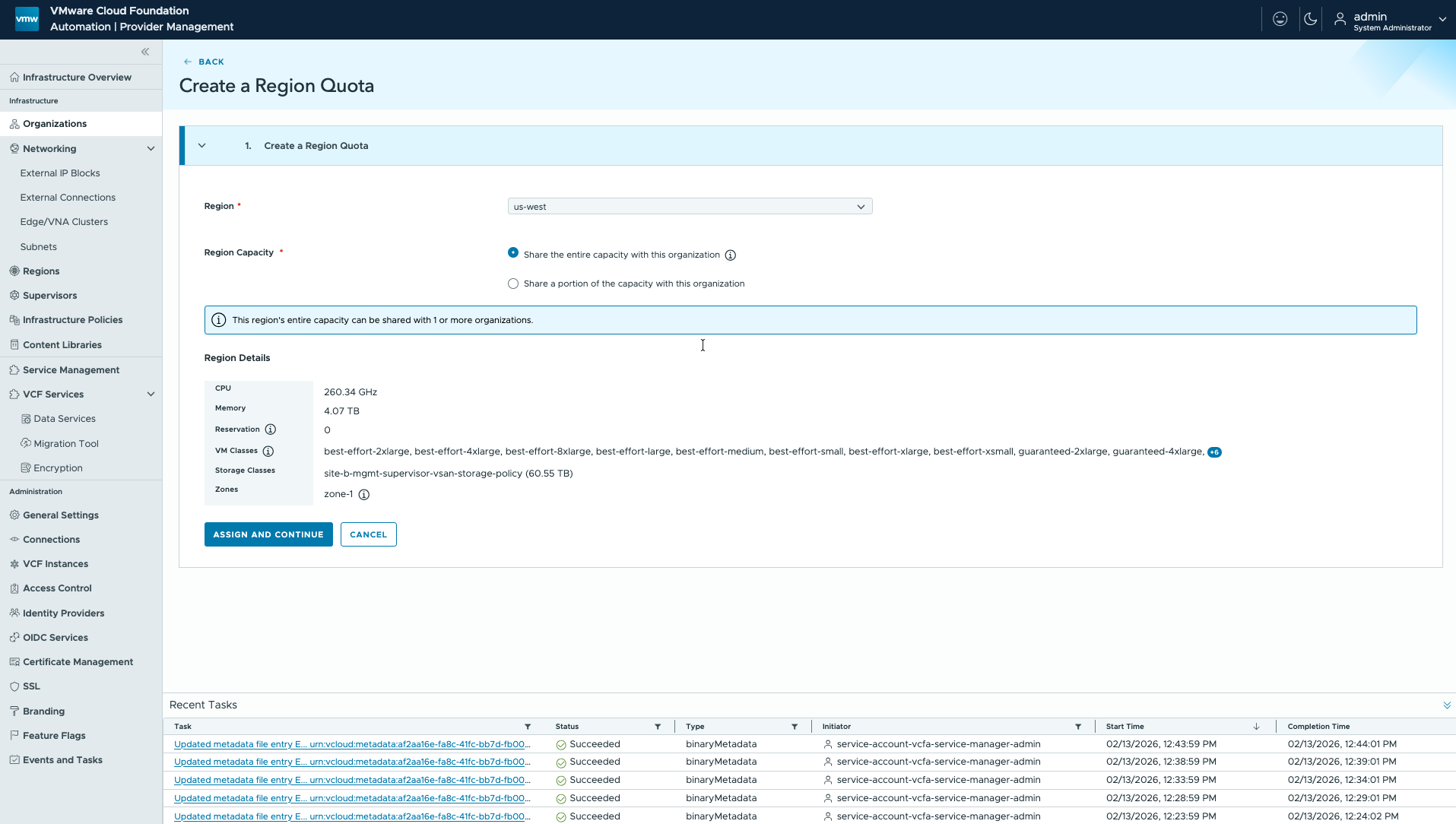
В VCF 9.1 появится механизм полностью выделенной региональной квоты, позволяющий корпоративным ИТ-администраторам выделять всю ёмкость региона (квоту 100%) одной организации-арендатору без привязки к конкретным зонам. Администраторы смогут применять одинаковые лимиты и резервации CPU и памяти ко всем доступным зонам, отвязывая регион от единственного Supervisor и допуская наличие нескольких Supervisor и vCenter в рамках одной региональной квоты. Эти возможности упростят выделение ресурсов и облегчат управление инфраструктурой для предприятий, которым не требуется строгое исполнение квот.
В режиме Day 2 администраторы смогут изменять выделения, добавляя резервации или уменьшая квоту с полного региона до конкретных лимитов. Это превратит регион в единый пул ресурсов, позволяя организациям потреблять инфраструктуру в нескольких Supervisor вместо ограничения одним. Организации получат совместный доступ к инфраструктурной ёмкости по принципу первой очереди, что повысит гибкость и эффективность использования ресурсов в рамках окружения.
VCF Automation: распределение региональных квот
Единый API управления кластерами VKS
VCF 9.1 стандартизирует API управления кластерами VKS, приведя его к шаблону VCF API и объединив управление ВМ, контейнерами и VKS. Это обеспечит согласованное взаимодействие со всеми сервисами и упростит управление ресурсами через VCF CLI, Terraform или kubectl.
VCF 9.1 переопределит возможности инфраструктуры частного облака. Благодаря VCF Automation, VMware Cloud Foundation поможет запустить и масштабировать мультиарендное частное облако, в котором прикладные команды смогут собирать рабочие нагрузки быстрее, безопаснее и с меньшими затратами. Будь то воспроизведение масштабируемости и гибкости публичного облака в собственном ЦОД, внедрение единого интерфейса потребления для виртуальных машин и контейнеров либо повышение гибкости бизнеса и ИТ за счёт самообслуживания — VCF 9.1 предоставит необходимые инновации.
Будущее корпоративных ИТ уже здесь: настоящий облачный опыт в сочетании с безопасностью, производительностью и контролем частного облака. VCF 9.1 предоставит платформу, возможности и автоматизацию для превращения ЦОД в современное самообслуживаемое частное облако, расширяющее возможности прикладных команд при сохранении управления и соответствия требованиям, необходимых корпоративному ИТ.
Недавно компания VMware объявила о доступности для загрузки новых версий настольных платформ виртуализации - VMware Workstation 26H1 и VMware Fusion 26H1. Эти обновления продолжают эволюцию наших настольных гипервизоров, обеспечивая критически важные архитектурные переходы для пользователей Windows, расширенную видимость для управления виртуальными машинами и расширенную поддержку новейшего оборудования и операционных систем.
Новый релиз развивает фундаментальные изменения, представленные в предыдущем обновлении 25H2, где был осуществлен переход на календарное версионирование и представлены мощные инструменты автоматизации, такие как dictTool. В 2026 году сохраняется фокус на том, чтобы среда виртуализации оставалась современной, эффективной и соответствующей отраслевым стандартам.
Современное архитектурное соответствие: 64-битная VMware Workstation Pro
С релизом 26H1 VMware Workstation Pro для Windows теперь является 64-битным приложением. Этот переход гарантирует, что большинство бинарных файлов, библиотек и компонентов установщика выполняются как 64-битные процессы. Приводя гипервизор в соответствие с современными аппаратными и программными стандартами, VMware предоставляет более стабильную и производительную основу для самых требовательных виртуализированных рабочих нагрузок.
Расширенная видимость и упрощенное управление
Управление сложной библиотекой виртуальных машин требует быстрого доступа к информации. Развивая организационные улучшения, появившиеся в последних релизах, релиз 26H1 представляет новые функции «качества жизни», которые помогут вам поддерживать порядок:
Метки времени жизненного цикла (VMware Workstation и Fusion): мгновенно идентифицируйте виртуальные машины по времени их создания и последнего включения. Это упрощает отслеживание долгосрочных проектов и очистку временных тестовых сред.
Интегрированные заметки к папкам (VMware Workstation): заметки виртуальных машин перенесли непосредственно во вкладки папок в VMware Workstation. Это обеспечивает немедленный доступ к критически важным метаданным и документации без необходимости переходить через отдельные меню настроек.
Повышенная ясность Credential Manager (VMware Workstation): формат сохраненных учетных данных для зашифрованных виртуальных машин и удаленных серверов был модернизирован для VMware Workstation. Это помогает обеспечить простую идентификацию записей, относящихся к VMware, во встроенном менеджере учетных данных вашей хостовой платформы.
Расширение удаленного подключения к серверам ESXi ARM
По мере диверсификации сред разработки кросс-архитектурное подключение становится необходимым. Этот релиз добавляет возможность подключения к удаленным ARM-based ESXi, позволяя пользователям управлять виртуальными машинами на удаленных ARM-серверах напрямую из VMware Workstation или Fusion на любой поддерживаемой платформе. На данный момент ESXi ARM Server находится в режиме Tech Preview.
Поддержка ведущих ОС и оборудования
Поддержание актуальности с новейшими платформами является одной из главных целей для сообщества. Workstation и Fusion 26H1 продолжают лидировать на рынке, поддерживая новейшие гостевые и хостовые операционные системы:
Поддержка новых гостевых ОС (VMware Workstation и Fusion):
Ubuntu 26.04 LTS
Fedora 43 и 44
SUSE Linux Enterprise 16 и openSUSE 16.0
FreeBSD 15.0
Поддержка новых хостовых ОС (VMware Workstation):
Ubuntu 26.04 LTS
Fedora 43 и 44
SUSE Linux Enterprise 16 и openSUSE 16.0
Стабильность и надежность
В дополнение к новым функциям этот релиз включает несколько функциональных улучшений и улучшений безопасности, которые поддерживают стабильную и защищенную работу среды виртуализации. Также устранили проблемы пользовательского интерфейса, чтобы все кнопки Help и ссылки корректно вели на портал Broadcom Technical Documentation для более быстрого доступа к руководствам.
Ресурсы для клиентов и доступность
VMware стремится предоставлять понятную и доступную информацию для глобальной пользовательской базы. Customer FAQ остается единым надежным источником актуальных рекомендаций по лицензированию, конфигурации и вопросам, поднятым сообществом.
Workstation Pro и Fusion Pro 26H1 доступны уже сегодня через Broadcom Support Portal. Напоминаем, что оба продукта остаются бесплатными для коммерческого, образовательного и личного использования, предоставляя каждому профессионалу доступ к ведущему настольному гипервизору в отрасли.
Благодаря стратегии календарного версионирования и фокусу на архитектурной модернизации, VMware Workstation и Fusion остаются отраслевым стандартом настольной виртуализации. Компания планирует продолжать совершенствовать эти продукты и сопутствующие ресурсы с каждым релизом, предоставляя инструменты, необходимые сегодня, и уверенность для масштабирования виртуальной среды завтра.
Аппаратная версия виртуальной машины vCenter оставалась на уровне версии 10 (совместима с VMware ESX 5.5 и более поздними) со времён VMware vSphere 5.5. С выходом vSphere в составе VMware Cloud Foundation 9.1 она обновлена до версии 17.
Примечание: в зависимости от интерфейса, статьи базы знаний или технической документации могут использоваться взаимозаменяемые термины «совместимость виртуальной машины», «совместима с ESX версии» или «версия аппаратного обеспечения виртуальной машины». Для ясности: виртуальное аппаратное обеспечение версии 17 в интерфейсе vSphere Client обозначается как «Compatible with ESXi 7.0 and later».
Об обновлении аппаратной версии виртуальной машины vCenter
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом Reduced Downtime Upgrade аппаратная версия виртуальной машины vCenter обновляется автоматически с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter.
После выполнения in-place обновления vCenter (с 9.0.x до 9.1.0) аппаратную версию ВМ vCenter необходимо обновить вручную. Эта процедура требует выключения виртуальной машины vCenter.
Если виртуальная машина vCenter управляется другим экземпляром vCenter, её необходимо выключить и выполнить обновление аппаратного обеспечения ВМ до версии 17 через vSphere Client. Подробности — в документации Upgrade the Compatibility of a Virtual Machine Manually.
Обновление аппаратного обеспечения ВМ необратимо — откатить версию назад невозможно. Перед обновлением аппаратной версии ВМ vCenter рекомендуется создать снапшот виртуальной машины или выполнить её резервное копирование.
Важно: необходимо выбирать именно Compatible with ESXi 7.0 and later (версия 17). Если выбрана более поздняя версия, vCenter окажется в неподдерживаемом состоянии — потребуется восстановление из снапшота или из более ранней резервной копии vCenter.
Также доступна возможность запланировать обновление аппаратной версии при следующей перезагрузке.
Совет: рекомендуется включить запланированное обновление аппаратной версии до начала in-place обновления vCenter до версии 9.1. Поскольку обновление требует перезагрузки, можно совместить обновление vCenter до 9.1 и обновление аппаратной версии ВМ в рамках одного цикла перезагрузки.
Почему именно версия 17?
Краткий ответ: обратная совместимость. Виртуальное аппаратное обеспечение версии 17 поддерживается на хостах ESX 7.0 и более поздних. Инфраструктурные обновления нередко выполняются постепенно, а устаревшее и даже не поддерживаемое оборудование продолжает использоваться в производственных средах. Возможность запускать vCenter версии 9.1 на более старых хостах ESX предоставляет клиентам гибкость: они могут перейти на vCenter 9.1, не торопясь с миграцией на новые аппаратные платформы. Миграция между управляющими серверами (Cross-vCenter migration) позволит перенести ВМ vCenter на новую инфраструктуру в удобный момент.
Будет ли аппаратная версия vCenter обновляться снова?
Да. Цель — поддерживать аппаратную версию ВМ vCenter по модели N-1 относительно мажорных версий ESX. Например, текущая мажорная версия ESX — 9.x, следовательно, версия N-1 — это 8.x.
Необходимо также учитывать, что vCenter всегда обновляется раньше ESX. Аппаратная версия ВМ vCenter не может быть повышена до уровня, который ещё не обновлённый ESX не в состоянии обеспечить.
Вышла новая версия VMware Cloud Foundation 9.1, об этом вы уже знаете. В этой статье рассматриваются многие новые возможности и улучшения платформы vSphere в составе пакета VCF 9.1. Также рекомендуем ознакомиться с примечаниями к выпуску и уведомлениями о поддержке продуктов для получения важной информации.
Быстрое развёртывание патчей безопасности vCenter
Функция быстрого патчинга vCenter (vCenter Quick Patch) обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлению. Механизм Quick Patch ориентирован на быстрое устранение критических уязвимостей безопасности в vCenter.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, изменился ли соответствующий сервис или компонент. Quick Patch затрагивает только те RPM или бинарные файлы, которые действительно изменились в составе патча. Такой подход кардинально сокращает общее окно обслуживания и снижает время простоя vCenter до менее чем 1 минуты, а в ряде случаев сводит его к нулю.
Благодаря vCenter Quick Patch критически важные обновления безопасности можно применять без прерывания рабочих процессов: развёртывание виртуальных машин и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются. Меньше времени уходит на планирование окон обслуживания — больше на поддержание актуальности патчей.
Помимо Quick Patch, в версии 9.1 улучшены и другие аспекты обслуживания vCenter.
Обновление vCenter с сокращённым временем простоя (Reduced Downtime Upgrade, RDU) теперь поддерживает работу с онлайн-репозиторием. Это упрощает использование метода RDU для подключённых к интернету экземпляров vCenter. Автономный метод с использованием примонтированного ISO по-прежнему доступен. Последующие патчи, обновления и апгрейды vCenter 9.1.x и более поздних версий также можно применять через RDU с онлайн-репозиторием, что значительно упрощает эксплуатацию для подключённых инсталляций.
В vCenter появился новый API, с помощью которого сторонние компоненты могут получать уведомления о планируемом или текущем техническом обслуживании. Обратный прокси Envoy будет отдавать заголовок 503 с информацией о том, что vCenter находится на обслуживании, и указанием ожидаемого времени завершения.
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом RDU версия аппаратного обеспечения виртуальной машины vCenter автоматически повышается с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter. При выполнении in-place обновления (с 9.0.x до 9.1.0) версию аппаратного обеспечения ВМ vCenter потребуется обновить вручную — эта процедура требует выключения ВМ vCenter.
Изменение ресурсов vCenter через единый API
В VCF 9.1 появился новый API, упрощающий масштабирование ресурсов vCenter. Для увеличения объёма вычислительных ресурсов и дискового пространства vCenter достаточно одного вызова API и перезагрузки.
Вызов API можно инициировать из Developer Center API Explorer в интерфейсе vCenter. API называется deployment/size и использует метод PATCH.
Упрощение обслуживания хостов ESX
Образы, создаваемые и управляемые через vSphere Lifecycle Manager, теперь включают контрольную сумму SHA256. Она позволяет проверять целостность образов при экспорте и импорте в другие экземпляры vCenter: администратор может сравнить контрольные суммы на источнике и целевом сервере. Речь идёт о контрольной сумме именно определения образа, а не VIB-файлов ESX.
В предыдущих версиях vSphere Lifecycle Manager проверял актуальность прошивок и драйверов устройств по HCL только при наличии стороннего Hardware Support Manager (HSM). Начиная с версии 9.1 вывод информации о текущих драйверах и прошивках устройств, а также их валидация по HCL выполняются для кластеров vSAN даже в отсутствие HSM. Некоторые устройства могут не сообщать данные о прошивке без соответствующего HSM. Это обеспечивает базовый уровень проверки устройств в кластере vSAN.
Подготовка кластеров vSphere с образом и конфигурацией
Zero Touch Provisioning (ZTP) строится на базе существующей инфраструктуры vSphere Auto-Deploy. Механизм задействует современные протоколы загрузки — UEFI HTTP/S Boot — и поддерживает актуальные серверные конфигурации, включая Secure Boot и TPM. ZTP не требует внешнего TFTP-сервера: достаточно настроить URL загрузки UEFI, указывающий на vCenter, и загрузить хост по сети. Если UEFI не поддерживает настройку статического IP для загрузки, потребуется DHCP-сервер.
Образ ESX и конфигурация определяются расположением кластера, выбранным при настройке правила развёртывания. Если для целевого кластера не настроен профиль конфигурации vSphere (VCP), хост загрузится и присоединится к кластеру с конфигурацией по умолчанию.
Быстрое и менее затратное обновление кластеров vSphere
ESX Live Patch включён по умолчанию для всех кластеров и автоматически применяется, если устанавливаемый патч поддерживает этот режим. Если патч несовместим с Live Patch, по умолчанию используется стандартный метод с переходом в режим обслуживания и перезагрузкой хоста.
Параметр можно изменить, включив принудительное применение Live Patch. В этом режиме исправление будет выполняться только через Live Patch, а для хостов, требующих режима обслуживания, процесс патчинга будет заблокирован. Настройки можно задать как на уровне кластера, так и на уровне vCenter — параметры vCenter применяются ко всем кластерам, если они не переопределены на уровне кластера.
ESX Live Patch теперь поддерживает серверы с включённым TPM. Пользователям не нужно отключать TPM или отказываться от Live Patch при использовании ESX 9.1 и более поздних версий.
Поддержка Live Patch расширена: охватывает больше компонентов vmkernel и обеспечивает более высокую производительность при патчинге ядра. Теперь механизм поддерживает дополнительные пользовательские демоны и сервисы, включая демоны vSAN, базовые демоны хранилища и соответствующие библиотеки.
Расширение интеграции с механизмом Desired State Configuration
Профили конфигурации vSphere (vSphere Configuration Profiles) обеспечивают соответствие изменений конфигурации и операций по устранению отклонений требованиям vSAN. Политики режима обслуживания vSAN и политики доступности объектов соблюдаются при исправлении кластеров vSAN. Расширенная конфигурация vSAN может применяться на уровне всего кластера.
Профили конфигурации vSphere используются для настройки memory tiering на хостах кластера. Устройства NVMe могут быть выделены для memory tiering; дополнительное устройство NVMe опционально может быть задействовано в качестве зеркального устройства для программного зеркалирования.
Профили конфигурации vSphere обеспечивают конфигурацию хостов при установке через Zero Touch Provisioning, а также поддерживают начальную настройку vSphere Distributed Switch в процессе развёртывания хоста.
Оптимизация Desired State Configuration
При добавлении новых хостов в кластеры с включёнными профилями конфигурации vSphere желаемая конфигурация автоматически применяется к входящему хосту. Специфичные для хоста атрибуты (например, IP-адреса) извлекаются из него автоматически и добавляются в соответствующий раздел профиля кластера.
Сертификат TLS для vCenter теперь обновляется автоматически за 5 дней до истечения срока действия. Сертификат ESX обновляется за 30 дней до истечения. Порог для ESX настраивается через расширенные параметры vCenter Server с помощью параметра vpxd.certmgmt.certs.autoRenewThreshold.
В обоих случаях автоматическое обновление выполняется для сертификатов, управляемых VMCA. Сертификаты, выданные внешними центрами сертификации, не обновляются автоматически — ответственность за их управление лежит на администраторе.
Если до истечения срока действия корневого сертификата VMCA остаётся менее 1 года, в процессе обновления vCenter автоматически обновляются корневой сертификат VMCA, а также дочерние сертификаты решений. Сертификаты TLS для vCenter и ESX в рамках этой операции не обновляются.
Масштабируемость, стабильность и производительность
В крупных и сверхкрупных развёртываниях vCenter ожидается увеличение числа операций в минуту до 25%. Это касается множества операций с виртуальными машинами и хостами, а также изменений конфигурации. Масштаб одновременных операций резервного копирования ВМ увеличен до 500–1000 в зависимости от размера vCenter. Операции резервного копирования ВМ теперь защищены от бесконтрольного потребления всех ресурсов vCenter. Передача файлов использует выделенные потоки, что исключает влияние на другие операции vCenter. Расширенные параметры vCenter для операций резервного копирования позволяют настраивать масштабируемость под конкретную среду.
Новый API мониторинга утилизации vCenter позволяет отслеживать активные подключения и сравнивать их с максимально допустимыми лимитами. Появилась возможность отслеживать количество запросов ко всем сервисам vCenter и контролировать, чтобы их интенсивность не превышала допустимых порогов.
Введены два новых оповещения — High Session Count и Increased Request Load — для сигнализации о нагрузке на один или несколько сервисов vCenter. Оповещение High Session Count срабатывает, когда число сессий приближается к лимиту (по умолчанию 3000); в сообщении указываются IP-адреса и имена пяти пользователей, создавших наибольшую нагрузку с более чем 100 сессиями каждый. При изменении состава топ-5 пользователей генерируется новое событие. В список могут попасть любые пользователи, включая сервисные аккаунты. Оповещение Increased Request Load срабатывает при достижении лимита активных запросов к конечной точке сервиса (по умолчанию 1024 для большинства конечных точек) и содержит информацию о затронутых сервисах и конечных точках.
Гибкая настройка виртуальных машин
Для поддержки миграции с VMware Cloud Director (vCD) на VMware Cloud Foundation Automation (VCFA) гостевой API настройки ОС (Guest OS Customization, GOSC) дополнен следующими возможностями, обеспечивающими паритет с функциями vCD:
Установка пароля учётной записи root в Linux
Сброс пароля учётной записи root в Linux
Сброс паролей учётных записей группы администраторов в Windows
Выполнение скриптов настройки в Windows
Теперь администраторы могут явно отключить IPv4 и настроить сеть только для IPv6 в гостевой настройке — как через интерфейс, так и через API. Это устраняет прежнее требование сохранять параллельную конфигурацию IPv4.
Появилась возможность выполнять настройку только сетевых параметров виртуальной машины — для выключенных и для работающих ВМ, что позволяет применять изменения сетевой конфигурации в реальном времени.
Сохранение производительности рабочих нагрузок во время обслуживания хоста
DRS-оптимизированная эвакуация через vMotion (DRS Optimized vMotion Evacuation) гарантирует, что виртуальные машины будут мигрированы с хоста только при наличии достаточной вычислительной ёмкости для их размещения без конкуренции за ресурсы. DRS может предварительно перебалансировать оставшиеся хосты, чтобы создать свободную ёмкость для эвакуируемых ВМ.
При переводе хоста в режим обслуживания для кластеров с включённым DRS доступны два варианта:
Стандартная эвакуация через vMotion: виртуальные машины переносятся на другие хосты в том же кластере при условии совместимости целевых хостов и соответствия требованиям по ресурсам.
Нон-деструктивная эвакуация через vMotion: виртуальные машины переносятся только в том случае, если их текущие вычислительные потребности могут быть удовлетворены целевыми хостами.
Примечание: термин «нон-деструктивная» применительно к новому режиму эвакуации не означает, что стандартная эвакуация как-либо вредит рабочим нагрузкам. Он лишь указывает на то, что при этом режиме эвакуация выполняется только без создания конкуренции за ресурсы на целевых хостах.
Улучшение утилизации ресурсов vMotion и снижение конкуренции
Максимальное количество одновременных задач vMotion по умолчанию равно 8. В предыдущих версиях, если 8 задач vMotion выполнялись одновременно в рамках пакетной операции, новые задачи не начинались до завершения всех предыдущих. Начиная с vSphere 9.1, как только одна задача vMotion завершается и освобождается слот, следующая задача может немедленно стартовать.
Усовершенствованная обработка задач vMotion обеспечивает более равномерное распределение нагрузки по хостам кластера. Число хостов, испытывающих пиковую одновременную нагрузку vMotion, сокращается, а сетевые ресурсы и ресурсы хранилища используются эффективнее.
Более высокая пропускная способность vMotion и сокращение времени миграции
В VCF 9.1 появилась возможность разгрузки операций зашифрованного vMotion на Intel QAT (QuickAssist Technology). Это освобождает ценные ресурсы CPU и возвращает их рабочим нагрузкам.
Для максимально эффективного использования ресурсов в VCF задействована технология Intel QAT (QuickAssist Technology) для ускорения инфраструктурных операций. Перенос «тяжёлой» части задач vMotion на выделенное аппаратное обеспечение позволяет вернуть ценные ядра CPU реальным рабочим нагрузкам. Intel QAT берёт на себя шифрование данных при выполнении операций vMotion.
Оптимизированная масштабируемость и производительность для современных CPU
Планировщик Topology Aware Scheduler перешёл на событийно-ориентированный механизм встроенного обновления, что обеспечивает более согласованное и сбалансированное размещение по NUMA-узлам.
Архитектура NUMA (Non-Uniform Memory Access) используется для повышения масштабируемости и производительности серверов с несколькими процессорными сокетами. Планировщик — компонент ядра ESX, отвечающий за управление размещением виртуальных машин и балансировкой нагрузки по NUMA-узлам с целью минимизации задержек доступа к памяти и оптимального использования ресурсов CPU и памяти рабочими нагрузками.
Topology Aware Scheduler оптимизирован для нового поколения высокоплотных процессоров: улучшена модель оценки эффективности использования CPU и памяти. Существующий планировщик при принятии решений о размещении в основном учитывал конкуренцию за CPU (ready time). Topology Aware Scheduler учитывает не только конкуренцию за CPU, но и конкуренцию за кэш и пропускную способность памяти.
Для систем с асимметричной топологией NUMA, где расстояние между некоторыми парами узлов существенно больше, чем между другими, Topology Aware Scheduler может размещать смежные NUMA-клиенты одной ВМ на подмножестве узлов, расположенных ближе друг к другу.
Готовность к работе с AI-платформами различных производителей
В VCF 9.1 расширена поддержка Enhanced DirectPath I/O.
Речь идёт не просто о «проброске» оборудования, а о его виртуализации — это обеспечивает лучшую утилизацию ресурсов и возможность выполнения операций обслуживания и масштабирования без остановки AI-рабочих нагрузок. Поддержка новых аппаратных устройств в VCF 9.1 открывает доступ ко многим преимуществам виртуализации, включая stun-based операции и быстрое приостановление и возобновление работы. Среди этих преимуществ:
Storage vMotion
Снапшоты (включая снапшоты памяти)
Операции реконфигурации дисков
Горячее добавление и удаление виртуальных устройств
ESX Live Patch
ESX 9.1 расширяет свои возможности, внедряя поддержку виртуализации IOMMU для CPU AMD. Теперь администраторы могут задействовать устройства PCI passthrough на системах на базе AMD, повышая производительность и обеспечивая прямой доступ к оборудованию для виртуальных машин.
AMD vIOMMU (Virtual I/O Memory Management Unit) — аппаратно-ускоренная технология, обеспечивающая безопасный высокопроизводительный прямой доступ к памяти (DMA) для виртуальных машин за счёт прямого доступа гостевых систем к регистрам MMIO.
Flow Processing Offload (FPO) и аппаратное направление трафика (hardware steering) повышают эффективность центра обработки данных, перенося обработку сложных сетевых правил с CPU на выделенное аппаратное обеспечение. Это обеспечивает производительность на уровне линейной скорости и быструю масштабируемость виртуализированных сред, освобождая ресурсы CPU для бизнес-приложений.
Enhanced DirectPath I/O поддерживает прямую связь GPU-to-GPU через RDMA over Converged Ethernet (RoCE). Решение предназначено для организаций, выполняющих массивные AI-рабочие нагрузки или высокоскоростную обработку данных: оно обеспечивает производительность, близкую к нативной (необходимую для AI), без отказа от инструментов управления, которые упрощают эксплуатацию виртуализованных ЦОД.
GPU NVIDIA, используемые для vGPU, теперь можно настроить одновременно для тайм-слайсинга и режима MIG, что обеспечивает ещё более эффективное совместное использование ресурсов и повышение плотности.
VMware vCenter является критически важным компонентом стека VMware Cloud Foundation (VCF), помогая администраторам балансировать между доступностью сервисов и необходимостью проводить регулярное обслуживание и установку патчей. Традиционный in-place патчинг vCenter может приводить к простою продолжительностью до часа и более. VMware Cloud Foundation 9.1 представляет механизм vCenter Quick Patch, выводящий процесс обновлений vCenter на принципиально новый уровень.
vCenter Quick Patch обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлениям. Механизм Quick Patch ориентирован на быстрое развёртывание критических исправлений безопасности для vCenter.
Важно: как и в случае с ESX Live Patch, не каждый патч для vCenter совместим с Quick Patch — это определяется содержимым конкретного патча. Информация о совместимости с Quick Patch указывается в примечаниях к выпуску vCenter и в деталях патча непосредственно в интерфейсе продукта. Главная область применения vCenter Quick Patch — обновления безопасности.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, были ли изменения в соответствующем сервисе или компоненте. vCenter Quick Patch изменяет только те RPM или бинарные файлы, которые действительно претерпели изменения в составе патча. Такой подход кардинально сокращает общее окно обслуживания: время простоя vCenter снижается до менее чем 1 минуты, а в ряде случаев сводится к нулю.
vCenter Quick Patch позволяет применять критически важные патчи безопасности без прерывания рабочих процессов: развёртывание ВМ и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются, а затраты времени на планирование окон обслуживания сокращаются.
Применение vCenter Quick Patch выполняется через VMware Appliance Management Interface (VAMI) и использует тот же рабочий процесс, что и традиционный in-place патчинг. Патч, совместимый с Quick Patch, отмечается специальным значком Quick Patch. В деталях патча указываются влияние на рабочие нагрузки, затрагиваемые сервисы и ожидаемое время простоя. vCenter Quick Patch также можно применять с помощью CLI-методов. Специально выбирать метод Quick Patch не требуется: если патч поддерживает этот режим, vCenter автоматически использует его.
В представленном ниже примере ожидаемое время простоя составляет 0 минут, влияние на рабочие нагрузки отсутствует, а затрагиваемыми сервисами являются vmware-updatemgr и vsphere-ui.
При переходе на вкладку обновлений vCenter в vSphere Client отображается информация о том, что выбранный патч совместим с Quick Patch, с рекомендацией воспользоваться именно этим методом. Применение Quick Patch-совместимого обновления по-прежнему возможно через метод Reduced Downtime Update, однако это увеличит общее время обслуживания и продолжительность простоя.
Примечание: vCenter Quick Patch рекомендуется использовать для минорных патчей обслуживания, совместимых с Quick Patch (например, обновление vCenter с 9.1.0 до 9.1.1). Метод Reduced Downtime Update рекомендуется для минорных обновлений или мажорных апгрейдов (например, с vCenter 9.0.0 до 9.1.0).
Итог
vCenter Quick Patch обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя определяется тем, какие сервисы задействованы в патче. Механизм Quick Patch ориентирован на быстрое развёртывание критических исправлений безопасности для vCenter.
Классическая инфраструктура изначально не проектировалась для периферийных масштабов. Управление сотнями и тысячами распределённых площадок с использованием разрозненных стеков, изолированных инструментов и ручных процедур порождает операционные риски, неоднородность защиты и высокую стоимость обслуживания каждой точки в отдельности.
Для многих организаций это означает необходимость заходить на сотни площадок для установки обновлений, разбираться с несовпадающими конфигурациями и зависеть от локальных ИТ-специалистов, что замедляет развёртывание и увеличивает риски. По мере того как AI-нагрузки и приложения реального времени смещаются ближе к местам формирования данных, эти проблемы становятся ещё острее.
VMware Cloud Foundation Edge (VCF Edge) меняет эту модель. Продукт представляет собой унифицированную распределённую частную облачную платформу, на которой одновременно работают виртуальные машины, приложения на базе Kubernetes и AI-нагрузки с единой моделью эксплуатации во всех локациях, что устраняет необходимость в отдельной периферийной инфраструктуре.
VCF Edge 9.1 развивает эту концепцию за счёт автономных периферийных операций — автоматизации развёртывания, управления жизненным циклом в масштабе и политик безопасности, в том числе в окружениях без подключения и в полностью изолированных (air-gapped) средах.
Автономные периферийные операции
На больших масштабах задача состоит не в развёртывании отдельной площадки, а в согласованной эксплуатации сотен или тысяч таких площадок.
VCF Edge заменяет фрагментированную периферийную инфраструктуру единой платформой для виртуальных машин, контейнеров и AI, стандартизируя операции в распределённых средах и поддерживая разные топологии — от одноузловых конфигураций до мультикластерных схем. Каждая площадка работает локально, обеспечивая отказоустойчивость, а централизованное управление применяет политики, регламент жизненного цикла и правила governance ко всему парку.
Итогом становятся снижение операционных издержек, ускорение развёртывания и возможность масштабировать периферийную инфраструктуру без роста сложности и рисков.
Рисунок: гибкие топологии развёртывания VCF Edge для распределённых сред.
Ускорение развёртывания с помощью Zero-Touch Provisioning
Классические сценарии развёртывания периферии подразумевают ручную настройку, присутствие ИТ-специалистов на площадке и недели координации, из-за чего крупные внедрения идут медленно и дорого. VCF Edge снимает эти барьеры с помощью технологии Zero-Touch Provisioning (ZTP). После включения сервер безопасно загружается, подключается к централизованному управлению и получает полное целевое состояние — образ ОС, конфигурацию кластера и сетевые параметры, — что автоматизирует развёртывание от начала до конца. Скрипт активации Day 0 Activation Script гарантирует готовность каждой площадки к продуктивной работе вместе с платформенными сервисами и интеграцией GitOps.
Результат — ускоренное развёртывание, единообразные конфигурации и возможность вводить периферийную инфраструктуру в строй за часы, без ручной настройки и присутствия ИТ-сотрудников на месте, что заметно сокращает операционные расходы.
Оптимизация производительности и стоимости через Advanced NVMe Memory Tiering
На периферии масштабирование инфраструктуры часто означает добавление новых серверов, что ведёт к росту стоимости, занимаемого пространства и энергопотребления. В VCF Edge добавлены улучшения в технологии NVMe Memory Tiering, которая расширяет системную память за счёт высокопроизводительных NVMe-устройств без дополнительной установки модулей DRAM. В результате повышается плотность размещения нагрузок, лучше используется имеющееся оборудование и появляется возможность отложить или вовсе отказаться от дорогостоящих обновлений инфраструктуры.
Рисунок: NVMe Memory Tiering для периферийной инфраструктуры (расширение памяти без добавления DRAM).
Единая платформа, готовая к AI-нагрузкам периферии
Управление инфраструктурой, Kubernetes и AI-сервисами в распределённых средах становится крайне сложной задачей. VCF Edge упрощает её за счёт единой платформы для виртуальных машин, Kubernetes и AI, что избавляет от необходимости развёртывать и обслуживать раздельные стеки.
Готовый к производственной среде Kubernetes на периферии
VCF Edge предоставляет Kubernetes-платформу промышленного уровня с расширенной поддержкой жизненного цикла, гибким выбором операционной системы и продвинутыми сетевыми возможностями. Результат — упрощённая эксплуатация, ускоренное развёртывание приложений и согласованные окружения на каждой из площадок.
Рисунок: расширенная поддержка, гибкость ОС и продвинутые сетевые функции для периферийных развёртываний.
Простота без сложности Kubernetes
Не каждой нагрузке требуется полноценный Kubernetes. VCF Edge позволяет запускать контейнеры рядом с виртуальными машинами через механизм vSphere Pods. Это даёт более быстрое развёртывание, меньшие операционные затраты и упрощённый переход к контейнерам без необходимости в экспертизе по Kubernetes.
Рисунок: запуск контейнеров через vSphere Pods (CaaS без сложности Kubernetes).
AI на периферии без инфраструктурных компромиссов
Доступность GPU, их стоимость и ограничения по энергоснабжению нередко лимитируют список мест, где можно развернуть AI. VCF Edge позволяет запускать инференс AI-моделей вместе с уже работающими нагрузками с использованием GPU либо вычислений на CPU (через llama.cpp). Организации получают возможность размещать AI-сервисы ближе к источникам данных, не разворачивая отдельные инфраструктурные стеки. Итог — снижение стоимости инфраструктуры под AI, более быстрое внедрение сценариев применения AI и возможность охватить большее число периферийных площадок без обязательной установки GPU на каждой из них.
Ускорение AI-нагрузок с поддержкой GPU и других ускорителей
Платформа поддерживает высокопроизводительные ускорители для запуска требовательных AI-инференс-задач на периферии, обеспечивая при этом максимальное использование GPU между площадками.
Рисунок: поддержка GPU и ускорителей для AI-нагрузок на периферии.
Распространение AI через инференс на CPU
VCF Edge даёт возможность выполнять инференс AI-моделей на стандартной CPU-инфраструктуре с использованием llama.cpp, что снижает зависимость от GPU и открывает применение AI в ограниченных или удалённых периферийных средах, где развёртывание GPU нецелесообразно.
Рисунок: CPU-инференс для периферийных сред (llama.cpp).
Непрерывная поставка через распределённые периферийные площадки
Поддержание согласованности на периферии — это не разовая задача развёртывания, а постоянный операционный вызов.
VCF Edge обеспечивает непрерывность работы благодаря централизованной дистрибуции образов по pull-модели, использующей Content Library для синхронизации образов в рамках всего парка. Эта архитектура целенаправленно спроектирована под надёжную эксплуатацию в средах с низкой связностью, без подключения или полностью изолированных, поскольку позволяет каждой площадке хранить и управлять своим состоянием локально. Благодаря отказу от постоянного канала к управлению уменьшается потребление трафика, и каждая периферийная площадка остаётся отказоустойчивой автономной единицей, способной поддерживать согласованные развёртывания вне зависимости от внешней связи.
Рисунок: централизованная дистрибуция образов в распределённых периферийных средах (pull-модель).
Автоматизация на основе GitOps для непрерывной поставки
После развёртывания инфраструктуры поддержание согласованности между распределёнными периферийными площадками требует непрерывной поставки и автоматизированного управления конфигурацией.
VCF Edge поддерживает автоматизацию по подходу GitOps через интеграцию с инструментами вроде Argo CD, что позволяет описывать конфигурации инфраструктуры и приложений в Git и автоматически выкатывать обновления на все периферийные площадки. Вместо точечного управления изменениями на каждой площадке конфигурации задаются один раз и применяются ко всему парку.
Итог — ускоренная поставка приложений, автоматические обновления, постоянное выявление и устранение расхождений (drift), а также единообразные окружения во всех периферийных локациях.
Рисунок: управление желаемым состоянием по GitOps в распределённых периферийных средах (Argo CD).
Наблюдаемость парка в реальном времени
Без централизованной видимости диагностика периферийных сред идёт медленно и реактивно. VCF Edge обеспечивает наблюдаемость всего парка в реальном времени, открывая возможность для проактивного мониторинга и более быстрого устранения проблем. Это сокращает простои и повышает надёжность эксплуатации.
Рисунок: наблюдаемость и мониторинг распределённых периферийных сред в реальном времени.
Защищённая и устойчивая периферия
Обеспечение безопасности на периферии сопряжено с трудностями: локальные ИТ-ресурсы ограничены, а риски распределены.
Live-патчинг без прерывания работы
VCF Edge поддерживает ESX Live Patching для хостов с TPM, что позволяет устанавливать до 80% патчей безопасности без перезагрузки. Обновления выполняются удалённо, без окон обслуживания, благодаря чему нагрузки остаются доступными непрерывно, а защита поддерживается в нужном масштабе.
Рисунок: ESX Live Patching без прерывания работы для периферийной инфраструктуры (хосты с TPM).
Оптимизировано под масштаб периферии. Создано для реальной эксплуатации.
VCF Edge заменяет фрагментированные периферийные архитектуры единой платформой, рассчитанной на распределённый масштаб. Лицензирование, развёртывание и эксплуатация выстраиваются с учётом особенностей периферийных сред: продукт оптимизирован под ограниченные по ресурсам конфигурации и одновременно избавляет от ручного управления на уровне каждой из площадок.
За счёт стандартизации инфраструктуры, приложений и AI на единой операционной модели VCF Edge обеспечивает эффективные и повторяемые операции в каждой локации. Получается автономная, масштабируемая и подготовленная к ИИ платформа, которая позволяет предприятиям управлять тысячами периферийных площадок с простотой, характерной для одной платформы.
Современные кибератаки перестали быть точечными ударами по приложениям — теперь они нацелены на саму инфраструктуру. Целенаправленные постоянные угрозы, программы-вымогатели и атаки supply chain бьют именно по тем фундаментальным слоям, на которых работают рабочие нагрузки. Защита фундамента — это уже не опция, а обязательное условие для эксплуатации безопасной и устойчивой инфраструктуры частного облака в эпоху, когда кибератаки, ранее опиравшиеся на ручной хакинг, превратились в управляемые AI-кампании, способные к самоэволюции.
По мере масштабирования корпоративных развёртываний AI архитектура безопасности становится стратегическим приоритетом. Чтобы обеспечить доверенное взаимодействие между людьми, данными и системами AI, требуется продуманный подход к защите инфраструктуры; единая платформа частного облака даёт здесь существенное преимущество с точки зрения архитектурного контроля, суверенитета данных и соответствия регуляторным требованиям.
VMware Cloud Foundation (VCF) предоставляет валидированный и проверенный на целостность фундамент инфраструктуры, на который можно опереться при защите чувствительных данных и обеспечении непрерывности бизнеса в условиях изощрённых угроз. Вместо неявного доверия VCF реализует непрерывную верификацию системы, обеспечивая глубокую видимость платформы и мониторинг целостности в реальном времени. Усиленная программно-определяемая инфраструктура VCF со встроенными средствами контроля безопасности даёт предприятиям необходимый запас устойчивости, чтобы опережать угрозы, которые благодаря ИИ движутся быстрее и постоянно адаптируются.
Безопасность платформы в VCF 9.1
Каждый новый выпуск VCF приносит улучшения и расширения возможностей безопасности платформы. В VCF 9.1 представлены свежие функции платформенной безопасности, необходимые для поддержки промышленных развёртываний AI. Новый релиз защищает AI-нагрузки, проприетарные модели и чувствительные данные за счёт интеграции механизмов безопасности на всём стеке инфраструктуры — от гипервизора до уровня приложений.
Ключевые платформенные функции безопасности VCF 9.1 распределены по пяти категориям:
Обнаружение и предотвращение угроз усиливает защиту гипервизора и ускоряет установку патчей без простоев.
Устойчивость рабочих нагрузок обеспечивает непрерывную работу и восстановимость приложений за счёт аппаратной изоляции и кроссплатформенной репликации.
Шифрование данных защищает данные в процессе обработки, при передаче и в покое на всём стеке.
Аудит и мониторинг предоставляют единое управление журналами и централизованный аудиторский след для быстрого форензик-анализа.
Идентификация и доступ обеспечивают принцип Zero Trust за счёт SSO уровня фабрики, политик паролей и управления сертификатами.
В совокупности эти пять направлений формируют эшелонированную оборону, необходимую частному облаку и промышленным AI-нагрузкам в противостоянии всё более способным, адаптивным и автоматизированным противникам.
Обнаружение и предотвращение угроз
VCF 9.1 продолжает добавлять новые возможности в направлении проактивных оповещений и интеллектуального анализа, а также верификации целостности и конфигурации инфраструктуры — всё это улучшает обнаружение и предотвращение угроз. В этом релизе значительно расширены возможности патчинга VCF.
Live Patching для хостов с включённым TPM
В VCF 9.1 функция live patching в vSphere продолжает развиваться: обновления безопасности можно применять к кластерам без миграции рабочих нагрузок с целевых хостов и без перевода хостов в полный режим обслуживания. Релиз также закрывает пробел, который ранее не позволял хостам с включённым TPM на ESX участвовать в рабочем процессе live patching. Установка патчей без простоев особенно выгодна для бизнес-критичных приложений — таких как сервисы AI-инференса и агентные AI-приложения, для которых требуется непрерывная доступность ради соблюдения SLA.
Quick Patching для vCenter
Функция Quick Patch позволяет VMware vCenter получать патчи безопасности, оставаясь в работающем состоянии. Применение обновления vCenter теперь занимает приблизительно 5 минут без прерывания рабочих нагрузок — против примерно 20 минут простоя и до 40 минут общего времени операции в случае обычного патча. Снижение операционной стоимости патчинга vCenter устраняет одну из частых точек трения, из-за которой обновления одного из самых критичных управленческих компонентов инфраструктуры регулярно откладываются.
С возможностями Live Patching и Quick Patching VCF 9.1 расширяет способность применять исправления безопасности в большем масштабе и с большей скоростью — без обновлений всего стека и без прерывания работы нагрузок.
Интеграция EDR для ESX
Хосты ESX теперь могут запускать EDR-агенты от партнёров по безопасности непосредственно на гипервизоре. EDR-агент работает в изолированном контейнере на хосте, отделённом от ядра системы, чтобы не вмешиваться в нормальную работу. Он отслеживает события — например, запуск и завершение процессов, установление сетевых соединений — и передаёт их на платформу управления вендора средств защиты. Поддержка EDR доступна в ESX 9.1 и требует, чтобы вендоры EDR предоставили совместимых агентов. Организациям, заинтересованным в использовании этих возможностей, следует уточнить у своего EDR-вендора, готовы ли его агенты.
Мониторинг целостности файлов
В VCF 9.1 появилась функция мониторинга целостности файлов (File Integrity Monitoring, FIM), соответствующая требованиям NIST и PCI DSS. Она выявляет изменения, внесённые вредоносным ПО или злоумышленниками, в статические файлы и бинарники, установленные vCenter. FIM включён по умолчанию и запускается каждые четыре часа, фиксируя злонамеренные, непреднамеренные изменения или повреждения установленных файлов. Администраторы VCF могут получить FIM-отчёт через API или передавать FIM-логи в VCF Operations for Logs через службу syslog.
User-Level Monitor
User-Level Monitor (ULM) поставляется в VCF 9.1 как монитор по умолчанию для всех виртуальных машин. ULM полностью переписывает виртуальный монитор машин (Virtual Machine Monitor, VMM) ESX — компонент, который управлял исполнением виртуальных машин на физическом железе с 1998 года. Ранее VMM работал с максимальными привилегиями ОС, а значит, любая уязвимость могла скомпрометировать весь хост и все ВМ на нём. ULM переносит монитор в пользовательский режим с пониженными привилегиями, ограничивая потенциальный ущерб от эксплойтов. Переработанный интерфейс ядра трактует все входные данные как недоверенные; адресное пространство исключает секреты хоста и память других ВМ; упрощённая архитектура значительно сокращает поверхность атаки и сложность гипервизора.
Устойчивость рабочих нагрузок
Усовершенствование vSphere Pod
Один из способов, которыми VCF обеспечивает изоляцию контейнерных нагрузок, — это vSphere Pods: контейнеры запускаются напрямую внутри управляемых ESX виртуальных машин, что сочетает скорость и плотность контейнеров с аппаратной изоляцией гипервизора. PodVM (vSphere Pods) используются для запуска одного или нескольких контейнерных инстансов без необходимости разворачивать кластер Kubernetes. На vSphere Pods построены сервисы Supervisor, и теперь они доступны через новый UI Container Service.
vSphere Pods используют Container Runtime Executive (CRX), обеспечивающий лёгкую и высокопроизводительную среду, которая загружается за секунды. Это делает их идеальным выбором для нагрузок с повышенными требованиями к безопасности, где необходима строгая изоляция ядер между приложениями, либо для ресурсоёмких микросервисов, которым нужны продвинутое планирование и предиктивные возможности DRS в ESX.
По мере увеличения числа сервисов Supervisor накладные расходы памяти PodVM могут стать узким местом. Благодаря оптимизации памяти PodVM внутренние тесты показывают, что накладные расходы памяти снижаются примерно на 75% по сравнению со стандартной ВМ — за счёт совместного использования образа загрузки между инстансами PodVM на одном хосте. Кроме того, внутренние тесты подтверждают, что PodVM загружается до 70% быстрее, чем типичная ВМ.
Новый сервис Container Service позволяет разворачивать отдельные контейнеры без необходимости управлять полноценным кластером Kubernetes. Используя изолированные runtime-среды внутри vSphere Pods, он даёт возможность запускать отдельные контейнеры, не разворачивая и не обслуживая Kubernetes-кластер целиком.
В этом релизе также добавлен потоковый вывод STDOUT/STDERR в реальном времени со всех контейнеров внутри PodVM на внешние syslog-серверы. Это применимо только к vSphere Pods и не распространяется на гостевые кластерные нагрузки VMware vSphere Kubernetes Service (VKS).
Multi-Source Replication для кластеров vSAN
В VCF 9.0 в vSAN была представлена репликация vSAN-to-vSAN, обеспечивающая защиту ВМ из одного vSAN-кластера в другой. В нынешнем релизе эта возможность расширена дальше. Теперь можно реплицировать или защищать ВМ из любого источника — например, из хранилища VMFS или NFS — на vSAN-цель. Это даёт большую гибкость в защите существующих сред VCF, где может присутствовать смешанный набор платформ хранения. Теперь возможно защищать все ВМ среды через единую цель репликации и единый рабочий процесс — независимо от того, на какой платформе хранения они в данный момент находятся, — с политиками снапшотов и репликацией, действующими на всю инфраструктуру.
Возможности репликации доступны через VMware Site Recovery Manager (SRM) или решение VMware Advanced Cyber Compliance.
Шифрование данных
VCF 9.1 добавляет и расширяет возможности шифрования по всему стеку, включая улучшения для данных в покое, данных в движении и нагрузок confidential computing.
Confidential Computing — теперь в общедоступной версии
Confidential Computing запускает чувствительные нагрузки внутри аппаратно зашифрованных областей памяти, которые остаются недоступными даже для гипервизора, защищая данные в процессе использования на разделяемой инфраструктуре частного облака. VCF поддерживал более ранние поколения этой технологии уже несколько лет; VCF 9.1 завершает работу над поддержкой текущих реализаций — Intel TDX и AMD SEV-SNP, — переводя их в категорию общедоступных (general availability). Одно из практических улучшений — повторное включение Quick Boot на хостах, где активен Confidential Computing: раньше хосты, использующие Intel TDX или AMD SEV-SNP, не могли воспользоваться Quick Boot — функцией, позволяющей ESX перезапускаться без полного цикла аппаратной инициализации и тем самым сокращающей окна обслуживания.
Дополнительно VCF Operations теперь автоматически профилирует ESX-хосты и определяет, какие из них способны выполнять конфиденциальные ВМ и контейнеры. Это снимает с архитекторов гадания при размещении чувствительных нагрузок на защищённом оборудовании. Операторы также могут видеть, активирован ли Confidential Computing на подходящем хосте.
Confidential Computing в VCF доступен через решение VMware Advanced Cyber Compliance.
Ускоренный шифрованный vMotion с технологией Intel QuickAssist (QAT)
vMotion сам по себе может быть ресурсоёмким процессом, и эта нагрузка возрастает, когда включено шифрование. По мере того как рабочие нагрузки становятся крупнее, а частота операций vMotion растёт, потребление ресурсов на эту задачу заметно увеличивается. Перенос функции шифрования на аппаратное ускорение требует меньше критически важных ресурсов, которые освобождаются для других приложений, что в итоге сокращает затраты.
QAT включён по умолчанию на поддерживаемом оборудовании, обеспечивая более плавный пользовательский опыт и упрощённое управление жизненным циклом.
Шифрование данных в покое для vSAN Global Deduplication
В связке с переводом vSAN Global Deduplication в общедоступную версию в VCF 9.1 кластеры vSAN, использующие глобальную дедупликацию, теперь поддерживают шифрование данных в покое (Data-at-Rest Encryption). Включить Data-at-Rest Encryption можно на уровне отдельного кластера, одновременно используя на том же кластере vSAN Global Deduplication — без каких-либо компромиссов между этими двумя функциями. Дедупликация работает как фоновая постобработка и совместима с шифрованием данных в покое; включение шифрования не влияет на коэффициенты дедупликации.
Аудит и мониторинг
Централизованное управление журналами
VCF 9.1 улучшает управление логами, полностью интегрируя возможности отдельного UI VCF Operations for Logs внутрь VCF Operations и предоставляя администраторам и операторам VCF единый интерфейс для всех задач управления журналами. В интеграцию входят правила обработки логов, администрирование логов, публичные API для логов, глобальные настройки управления кластером логов, а также улучшения страницы анализа логов.
Отдельный UI больше не требуется, поскольку все возможности встроены непосредственно в VCF Operations.
Аудиторский след (Audit Trail)
Форматы лог-записей и аудиторских записей теперь стандартизированы между компонентами VCF.
Новый Audit Trail в VCF Operations идёт дальше и предоставляет централизованное представление пользовательской активности с временными срезами по всем компонентам (включая VKS), упрощая разбор для форензики, выявление ключевых событий и сокращая время аудита. Когда меняются правила межсетевого экрана или фиксируются неудачные попытки входа, операторы могут проследить всю цепочку событий через весь стек.
Идентификация и доступ
VCF 9.1 расширяет возможности единого SSO, управления паролями и сертификатами, представленные в предыдущем релизе, — добавляя более широкое покрытие компонентов, средства управления на уровне фабрики и новые интеграции с хранилищами секретов и центрами сертификации.
Усовершенствование Identity Broker
VCF Identity Broker (VIDB) получил расширенные параметры конфигурации и улучшения развёртывания. VIDB обеспечивает SSO-связь между компонентами VCF и внешним поставщиком идентификации (Identity Provider, IDP) или службой каталогов. Identity Broker теперь устанавливается в момент развёртывания или обновления VCF и больше не требует отдельной загрузки в качестве предусловия для настройки единого входа.
Identity Broker можно настраивать в embedded-режиме или режиме appliance — через VCF Operations или API. Развёртывание Identity Broker в виде кластера из трёх узлов обеспечивает более высокую производительность, масштабируемость и высокую доступность; такой вариант рекомендован для промышленной эксплуатации. Узлы Identity Broker теперь могут разворачиваться за пределами management-кластера.
VCF 9.x также предоставляет скриптовый рабочий процесс для организаций, обновившихся с VCF 5.x, — позволяющий без прерывания работы мигрировать пользователей и группы из VMware Identity Manager (VIDM) в Identity Broker. В процессе обновления Identity Broker разворачивается автоматически. Скрипт запускается уже после завершения обновления. Далее Identity Broker можно интегрировать с выбранным поставщиком идентификации; существующие пользователи и группы при этом не затрагиваются.
Усовершенствование управления паролями
VCF Operations 9.1 расширяет управление паролями, добавляя политики уровня фабрики, интеграцию с хранилищами секретов и покрытие дополнительных компонентов.
Теперь возможно задавать единые политики паролей между компонентами VCF и проводить проверки соответствия паролей с последующей коррекцией. Созданные политики применяются на уровне фабрики VCF или для отдельных компонентов VCF. Кроме того, администраторы могут управлять паролями для VCF Operations workload mobility (ранее известного как HCX) и балансировщиков Avi, развёрнутых или обновлённых до VCF 9.1.
Пароли break-glass-учётных записей больше не сохраняются — что устраняет одну из распространённых причин для процедур принудительной смены паролей. Дополнительно новые API для интеграции с корпоративными хранилищами паролей поддерживают сторонние инструменты — в частности, CyberArk. Корпоративные парольные хранилища, управляемые через API, потребуют плагина для VCF.
Усовершенствование управления сертификатами
В VCF 9.1 добавлены конфигурация центров сертификации на уровне фабрики, расширенная поддержка Microsoft CA и OpenSSL, а также массовые операции с сертификатами. Центр сертификации (Certificate Authority, CA) теперь настраивается на уровне фабрики VCF, а не отдельного инстанса, что позволяет управлять сертификатами на уровне всей фабрики.
Поддержка Microsoft CA и OpenSSL расширена и теперь охватывает как компоненты VCF instance, так и компоненты управления VCF. В предыдущем релизе Microsoft CA и OpenSSL поддерживались только для компонентов VCF instance (vCenter, NSX и ESX), тогда как компоненты управления можно было настраивать исключительно с использованием Microsoft CA.
В UI VCF Operations операторы теперь могут выполнять массовые операции с сертификатами. Запросы на подпись сертификатов, их обновление и импорт — всё это выполняется пакетно, сокращая время и дополнительно упрощая операции по управлению сертификатами. API VCF Operations можно использовать для интеграции со сторонними решениями и автоматизации управления сертификатами для всех компонентов VCF.
Дополнительные материалы
VCF 9.1 содержит последние достижения технологии виртуализации VMware. Релиз объединяет Zero Trust-безопасность и устойчивость на каждом уровне: vSphere, NSX, vSAN, VMware vSphere Kubernetes Service, VCF Private AI Services, VCF Operations и VCF Automation, помогая организациям защитить инфраструктуру частного облака от продвинутых, ускоренных AI-угроз.
Также материалы по усилению безопасности, соответствию требованиям и часто задаваемые вопросы по конкретным функциям доступны в репозитории GitHub: https://brcm.tech/vcf-security.
Во времена, когда на счету каждый доллар или сотня рублей, а каждая минута простоя стоит дорого, команды, отвечающие за инфраструктуру, оказались в "идеальном шторме" вызовов: дефицит оборудования, который прогнозируется вплоть до 2027 года, изолированные среды, возникающие из-за сосуществования старых и современных архитектур, постоянно меняющиеся требования к компетенциям и нарастающая сложность управления установками, обновлениями и обслуживанием в разнородных системах. Параллельно с этим эволюция угроз и рост числа и изощрённости кибератак требуют детальной и точной видимости поведения гостевой ОС и активности рабочих нагрузок. Традиционные подходы перестают быть жизнеспособными: организации испытывают сильное давление, заставляющее минимизировать совокупную стоимость владения (TCO) и одновременно добиваться измеримой отдачи от каждой инвестиции. Нужна не просто большая инфраструктура — нужна более умная инфраструктура, которая по максимуму использует уже имеющиеся ресурсы за счёт инновационных подходов. Именно здесь vSphere в составе VMware Cloud Foundation (VCF) 9.1 меняет правила игры, привнося прорывные нововведения, которые фундаментально переопределяют экономику инфраструктуры, её производительность и безопасность.
Экономика модернизации без замены оборудования
В vSphere внедрён набор возможностей, нацеленных на то, чтобы выжать максимум из уже сделанных инфраструктурных инвестиций и снизить TCO. vSphere в VCF 9.1 также включает функции, существенно сокращающие накладные расходы и повышающие операционную эффективность. Речь идёт не о точечных улучшениях, а о фундаментальных сдвигах в том, как инфраструктура создаёт ценность.
Память по-новому: интеллектуальный NVMe-тиринг
Стоимость памяти долгое время оставалась ограничителем при масштабировании инфраструктуры, а сегодня этот фактор стал ещё острее из-за стремительно растущих цен на память на фоне всплеска интереса к AI. vSphere полностью меняет это уравнение. Усовершенствованная функция тиринга памяти на NVMe позволяет снизить TCO сервера до 40% и одновременно убирает операционные неудобства.
Что делает версию 9.1 по-настоящему трансформирующей — это устранение барьеров для внедрения. Например, отменяется требование перезагрузки для включения тиринга памяти. Уведомления в интерфейсе позволят без усилий определять подходящие кластеры и рабочие нагрузки, а проактивный мониторинг состояния устройств обеспечит их замену ещё до того, как они выйдут из строя.
Появление зеркалирования RAID 1 для тиринга памяти обеспечивает критически важную отказоустойчивость, не позволяя сбоям отдельных устройств перерастать в масштабные простои виртуальных машин. Для нагрузок, активно работающих с данными, — аналитики больших данных, e-commerce-платформ и сервисов видеостриминга — это означает резкое расширение доступной памяти без пропорционального наращивания «железа». При улучшенном соотношении ядер и памяти организации добиваются более плотной консолидации ВМ и более высокой загрузки CPU, что усиливает экономический эффект от снижения TCO.
Время — деньги: Quick Patching для vCenter
Требования к безопасности и соответствию нормативам диктуют необходимость регулярного патчинга, однако традиционные окна обслуживания дорого обходятся: они нарушают работу и истощают ресурсы ИТ-команд. Функция Quick Patching для vCenter сокращает общее время операции примерно на 80% — окно патчинга уменьшается приблизительно с 30 минут до менее чем 5 минут.
Это резкое сокращение — не только про экономию времени. Quick Patching интеллектуально классифицирует сервисы vCenter по степени их влияния и оптимизирует процедуру обновления под каждый тип. В итоге улучшается соблюдение требований по критическим патчам, снижается риск ручных ошибок и заметно уменьшается административная нагрузка. В то время как у конкурентов на ручной патчинг уходят значительные человеко-часы, автоматизированный подход vSphere превращается в конкурентное преимущество, которое со временем только усиливается.
Эластичное развертывание в любых масштабах
Развёртывание инфраструктуры исторически было медленным ручным процессом, что затрудняло быстрое масштабирование. Технология vSphere Elastic Provisioning (Zero-Touch Provisioning) превращает это узкое место в отлаженную операцию. Используя UEFI HTTP для безопасной загрузки и vSphere Configuration Profiles для настройки среды в желаемом состоянии, организации могут быстро разворачивать инфраструктуру в масштабе при минимальном ручном вмешательстве.
Оптимизация производительности для требовательных нагрузок
По мере того как рабочие нагрузки становятся всё более ресурсоёмкими, а архитектуры процессоров эволюционируют, традиционные подходы к оптимизации производительности создают узкие места, ограничивающие масштабируемость и эффективность. vSphere в VCF 9.1 решает эти задачи в лоб с помощью интеллектуальных улучшений производительности, которые устраняют накладные расходы, не жертвуя при этом ни безопасностью, ни непрерывностью операций.
Производительность без накладных расходов: ускорение шифрованного vMotion
Для ресурсоёмких нагрузок с большими буферами кадров традиционный зашифрованный vMotion способен создавать существенные узкие места по производительности во время живой миграции. vSphere в VCF 9.1 задействует технологию Intel Quick Assist Technology (QAT), чтобы выгружать на сторону железа задачи шифрования, дешифрования и сжатия с CPU хоста в процессе vMotion.
Какой эффект? Значительно ускоряется этап переключения vMotion — и при этом не страдает безопасность. Организации сохраняют непрерывность работы даже для самых требовательных нагрузок, безопасно передавая данные без потерь в производительности. В средах, где каждая секунда миграции имеет значение — будь то окна обслуживания, балансировка нагрузки или восстановление после сбоев, — такая оптимизация даёт ощутимую бизнес-ценность и операционную гибкость.
Максимум производительности: планирование с учётом топологии
Процессоры с большим числом ядер раздвигают границы прежних NUMA-архитектур, создавая такие проблемы, как переполнение узлов, лишние миграции и неоптимальная производительность на системах AMD и системах с включённым SNC. Планирование с учётом топологии в vSphere меняет то, как платформа работает с этими процессорами высокой плотности нового поколения.
Обновлённый NUMA-планировщик теперь работает скорее по принципу DRS: используется та же модель справедливости с пулами ресурсов и параметрами min/max shares, а для эффективности применяется многоресурсная модель «качества», учитывающая стоимость миграции страниц памяти. Такой интеллектуальный подход принимает во внимание архитектурные особенности процессоров нового поколения и оптимизирует алгоритмы планирования, обеспечивая лучшую производительность, более эффективное использование ресурсов и более предсказуемое поведение нагрузок на самых разных аппаратных конфигурациях.
Безопасность: встроенная защита на всех уровнях стека
vSphere представляет собой по-настоящему защищённую платформу, расширяющую защиту до данных в обработке (data-in-use), детектирующую угрозы в реальном времени и обеспечивающую соблюдение нормативных требований и отраслевых рекомендаций по конфигурации безопасности «из коробки».
Безопасность без простоев: расширенный Live Patching
По мере того как организации переходят на серверы с TPM (а такие машины составляют почти 90% нового железа), vSphere в VCF 9.1 распространяет поддержку Live Patching на хосты с TPM и включает эту функцию по умолчанию. Возможность позволяет применять важные патчи к инфраструктуре платформы ESX без перевода хостов в офлайн и без эвакуации виртуальных машин, доставляя критические обновления безопасности быстро в рамках фиксированных SLA и поддерживая надёжные обновления без ошибок.
Confidential Computing: защита данных в обработке
Защита данных не ограничивается хранением и передачей: следующий рубеж — это защита данных непосредственно в процессе их обработки. vSphere в VCF 9.1 переводит в общую доступность Confidential Computing с поддержкой Intel TDX и AMD SEV-SNP. Эти аппаратные средства шифрования памяти и контроля её целостности изолируют рабочие нагрузки от инфраструктурного стека, формируя защищённые Trust Domains (у Intel) и Confidential VMs (у AMD), благодаря чему безопасность становится неотъемлемым свойством платформы.
Глубокая видимость: интеграция с EDR
Традиционные средства Endpoint Detection and Response (EDR) хорошо справляются с мониторингом гостевых операционных систем, однако часто не имеют видимости в сам хост ESX. vSphere в VCF 9.1 позволяет агентам EDR от сторонних производителей интегрироваться непосредственно в гипервизор ESX и анализировать события на уровне процессов, файлов и сети на предмет подозрительной активности. Такая глубокая интеграция средств обнаружения угроз прямо в гипервизор крайне важна для выявления горизонтального перемещения злоумышленников, бесфайлового вредоносного ПО и эксплойтов нулевого дня — и всё это без появления узких мест по производительности.
Инфраструктура, которая окупает себя
vSphere в VCF 9.1 — это фундаментальный сдвиг в экономике инфраструктуры. Максимально используя уже установленное оборудование через тиринг памяти на NVMe, сокращая операционные накладные расходы за счёт быстрого патчинга и эластичного провижининга, устраняя узкие места по производительности через интеллектуальную выгрузку задач и обеспечивая непрерывность работы благодаря Live Patching, организации превращают инфраструктуру из статьи затрат в стратегическое преимущество.
В условиях, когда дефицит оборудования сохраняется и каждая инвестиция должна приносить измеримую отдачу, vSphere в VCF 9.1 предлагает понятный путь вперёд: использовать то, что уже есть, оптимизировать то, как выстроены операции, и масштабироваться без пропорционального роста затрат.
Для многих организаций внедрение Kubernetes начиналось как технологическая инициатива, однако превращение его в надёжную корпоративную платформу нередко оказывалось значительно сложнее, чем предполагалось. То, что задумывалось как инновация, быстро становилось источником сложностей:
Растущие операционные издержки
Фрагментированные среды
Пробелы в безопасности, нормативном соответствии и компетенциях
Замедление вывода продуктов на рынок
В то же время ставки повышаются. Инициативы в области искусственного интеллекта, приложения, работающие с большими объёмами данных, и цифровой клиентский опыт сегодня зависят от инфраструктуры, которая должна быть не только масштабируемой, но и предсказуемой, безопасной и эффективной. Согласно последнему отчёту State of Platform Engineering Report, 64% специалистов по платформенной инженерии называют Kubernetes одним из ключевых направлений для достижения автоматизированного, надёжного и стандартизованного развёртывания приложений.
С появлением VMware Cloud Foundation (VCF) и развитием её компонента VMware vSphere Kubernetes Service (VKS) фокус сместился с управления инфраструктурой как такового на достижение конкретных бизнес-результатов.
VCF закрывает ключевые приоритеты, предоставляя единую платформу для контейнеров и виртуальных машин со встроенной сертифицированной CNCF средой выполнения Kubernetes, реализованной через компонент VKS. VMware VKS даёт инженерам платформ возможность развёртывать и обслуживать кластеры Kubernetes, опираясь на богатый набор облачных сервисов, входящих в VCF, а также на сторонние CNCF-совместимые сервисы (рис. 1). VKS — одна из первых Kubernetes-платформ, получивших сертификацию AI conformant, которая к тому же упрощает управление множеством кластеров, позволяя предприятиям уверенно запускать ИИ и другие современные рабочие нагрузки.
Рис. 1. VKS предлагает комплексный набор облачных сервисов вместе со всеми сторонними CNCF-совместимыми сервисами.
Императив CIO: меньше сложности, больше скорости
Сегодня перед ИТ-директорами стоит двойная задача — обеспечить безопасность, управляемость, контроль и нормативное соответствие, одновременно ускоряя инновации, и всё это при неизменном или сокращающемся бюджете.
Исторически эти цели вступали в противоречие. Однако благодаря снижению совокупной стоимости владения (TCO), более быстрому выходу на ценность, повышенной безопасности и упрощённой операционной модели VKS быстро становится предпочтительной средой выполнения Kubernetes для современных приложений. Чтобы помочь клиентам максимизировать отдачу от инвестиций, VKS в составе VCF 9.1 предоставит три ключевых преимущества:
1. Повышенный масштаб и производительность для поддержки критически важных бизнес-задач.
2.
Более высокую операционную эффективность, снижающую затраты и сложность.
3.
Встроенную по умолчанию безопасность и соответствие требованиям.
VCF 9.1: краткий обзор улучшений Kubernetes
VMware VKS в VCF 9.1 принесёт улучшения сразу по трём важнейшим направлениям:
Масштаб и производительность: 500 кластеров на один control plane, ускорение развёртывания кластеров до 70%, ускорение обновлений до 75%, поддержка нескольких сетей.
Операционная эффективность: интеллектуальное размещение пулов узлов, несколько кластеров в одной зоне, распределённый transit gateway.
Безопасность и соответствие требованиям: автоматизированное внедрение секретов и тонкое управление доступом.
Повышенный масштаб и производительность для критически важных бизнес-задач
Будь то пиковые нагрузки в розничной торговле, глобальные сервисы или крупномасштабные AI-задачи — инфраструктура должна реагировать мгновенно и при этом не терять стабильности.
В VCF 9.1 возможности VKS позволят:
Быстро выделять ресурсы — время развёртывания сократится до 70%.
Достигать огромного масштаба — до 500 кластеров в рамках одного control plane.
Повышать производительность — изолировать критически важные приложения для лучшего качества обслуживания.
Выгоды для бизнеса:
Более быстрый запуск новых сервисов, улучшенный клиентский опыт во время пиковых нагрузок и возможность поддерживать требования современных рабочих нагрузок без перепроектирования инфраструктуры.
Выгоды для платформенной инженерии:
Современный ландшафт приложений охватывает широкий спектр требований к производительности — от высокопроизводительных и чувствительных к задержкам приложений до интенсивных по GPU AI-нагрузок. Организации стремятся к более сильной изоляции, уменьшению зоны поражения при сбоях и кастомизированным требованиям к кластерам, что увеличивает потребность в большем количестве кластеров.
Рис. 2. VKS поддержит до 500 рабочих кластеров на один control plane для лучшей изоляции рабочих нагрузок и значительно меньшей площади атаки.
Для более крупных инфраструктур можно развернуть несколько экземпляров control plane и централизованно управлять ими через VCF Automation (VCFA). Это обеспечивает горизонтальное масштабирование при сохранении единообразия операций.
Внезапные всплески спроса, типичные для электронной коммерции в сезон распродаж, потокового видео или финансовых приложений во время рыночной волатильности, требуют инфраструктуры, способной реагировать в реальном времени. Кроме того, организациям часто сложно оперативно подготавливать зеркальные среды для тестирования перед выводом в производственную среду. Чтобы ответить на эти потребности, VKS повысит операционную скорость: развёртывание новых кластеров ускорится до 70%, а окна обновлений сократятся до 75%.
Чтобы обеспечить лучшее качество обслуживания для трафикоёмких потоковых приложений, чувствительных к задержкам финансовых сервисов или регулируемых приложений с требованиями к классифицированному доступу, VKS в VCF 9.1 представит расширенные сетевые возможности. Узлы кластера смогут разворачиваться с несколькими vNIC, что позволит изолировать трафик на уровне узла (рис. 3). Это даёт возможность разделять трафик приложений, систем хранения и управления, а также выделять отдельные сетевые маршруты для нагрузок, чувствительных к задержкам или требующих высокой пропускной способности, повышая производительность, стабильность и операционный контроль.
Рис. 3. Рабочий узел VKS изолирует высокопроизводительный трафик за счёт поддержки нескольких vNIC.
Повышение операционной эффективности для снижения стоимости инноваций
Одна из самых существенных скрытых статей расходов в корпоративной ИТ-инфраструктуре — операционное трение. VKS в VCF 9.1 получит как улучшения, специфичные для Kubernetes, так и более широкие платформенные возможности, появившиеся в VCF:
Интеллектуальное размещение пулов узлов — на основе алгоритма vSphere Distributed Resource Scheduler, что устраняет инфраструктурные узкие места, замедляющие развёртывание.
Несколько кластеров в одной зоне — для неразрушающего управления жизненным циклом оборудования и масштабирования без ручной работы.
Организации добиваются более быстрого выхода на ценность за счёт ускорения пути инноваций от концепции к продуктивной эксплуатации. Кроме того, приложения остаются доступными и прибыльными во время миграции сервисов и текущих работ по обслуживанию оборудования, что снижает потери от простоев.
Выгоды для платформенной инженерии:
При развёртывании рабочих нагрузок размещение пулов узлов является критически важной, но зачастую сложной задачей. Инженерам платформ приходится учитывать широкий спектр приложений: AI-приложениям нужен доступ к GPU, потоковым — высокопроизводительное хранилище, e-commerce — высокая доступность. При этом инженеры платформ не должны быть обременены глубокой инфраструктурной экспертизой, необходимой для работы со специализированными ресурсами — таких как доступ к GPU, требования к высокоёмкому хранению, осведомлённость о зонах, доступность ресурсов между зонами, распределение нагрузки и ограничения, связанные с отказоустойчивостью (HA), которые предъявляют современные рабочие нагрузки.
Благодаря интеллектуальному размещению пулов узлов VKS снизит требования к глубокой инфраструктурной экспертизе инженеров платформ (рис. 4 ниже). Такая автоматизация обеспечит гибкость без фрагментации развёртываний и даст инженерам платформ согласованный, предсказуемый и надёжный опыт работы. Эти улучшения существенно сокращают трение при развёртывании рабочих нагрузок, исключая сбои при размещении и трудноотлаживаемые проблемы с распределением ресурсов.
Рис. 4. Снижение трения при развёртывании благодаря интеллектуальному размещению пулов узлов.
С поддержкой нескольких кластеров в одной зоне администраторы облака смогут заменять, выводить из эксплуатации или обновлять оборудование без влияния на доступность приложений и без нарушения «желаемого состояния», что даёт инженерам платформ спокойствие (рис. 5). Такая абстракция также позволит инфраструктуре динамически реагировать на растущие потребности в вычислительных и дисковых ресурсах: масштабирование больше не требует сложной переработки среды.
Рис. 5. Несколько кластеров в одной зоне с нулевым простоем при обслуживании жизненного цикла и улучшенным масштабированием.
Инженеры платформ смогут быстрее подключать новые рабочие нагрузки и получать лучшую производительность сети благодаря Distributed Transit Gateway (DTGW), который обеспечивает более простой и согласованный способ подключения нагрузок к коммутирующей фабрике. DTGW также улучшает задержки и масштабирование: хост ESX подключается напрямую к коммутирующей фабрике, без необходимости использовать полный edge-кластер NSX.
Усиленная безопасность и соответствие требованиям, встроенные, а не «прикрученные сверху»
После того как вопросы производительности и масштаба решены, следующий важный рубеж — безопасность и соответствие требованиям. Безопасность в Kubernetes-средах часто фрагментирована: для управления секретами и применения политик доступа требуется множество инструментов и ручных процессов.
VKS в VCF 9.1 упростит эту задачу, встраивая средства контроля безопасности в саму платформу:
Интегрированные процессы управления секретами уменьшают объём ручной настройки.
Детальное управление доступом обеспечивает соблюдение принципа минимальных привилегий.
Единообразное применение политик улучшает аудируемость и готовность к соответствию.
Это позволит командам платформ автоматизировать работу с секретами и согласованно применять границы доступа во всех кластерах, снижая операционные риски и повышая готовность к проверкам на соответствие.
Выгоды для бизнеса:
Организации получат сокращённую площадь атаки и сниженный риск утечек данных, что обеспечит защиту критической инфраструктуры от современных угроз. Такой единый подход естественным образом формирует более прочный профиль соответствия за счёт согласованного применения политик и повышает уверенность при развёртывании регулируемых и чувствительных рабочих нагрузок.
Выгоды для платформенной инженерии:
Клиенты смогут достичь более устойчивого профиля безопасности благодаря упрощённому автоматизированному способу внедрения секретов в процесс развёртывания (рис. 6 ниже). Гарантируя безопасную обработку чувствительных данных без ручной настройки, это улучшение усилит общую безопасность, повысит аудируемость и предоставит единый механизм управления секретами для всех рабочих нагрузок.
Рис. 6. Упрощённое и автоматизированное внедрение секретов.
Инженеры платформ также смогут настраивать гранулированные политики доступа рабочих нагрузок к секретам, сокращая площадь атаки и гарантируя, что секреты получают только авторизованные нагрузки. Это поможет заказчикам соответствовать требованиям комплаенса и регуляторов.
Container-as-a-Service в VCF 9.1
VCF 9.1 представит среду исполнения Container Service, поставляемую через VCF Automation, с полным управлением жизненным циклом. Эта упрощённая контейнерная среда исполнения будет работать непосредственно на ESX без накладных расходов на кластер, обеспечивая изоляцию рабочих нагрузок и эффективность использования ресурсов. Платформа VCF полностью автоматизирует планирование, изоляцию, оптимизацию производительности и обновления. Когда архитектура приложения эволюционирует, пользовательский интерфейс сгенерирует согласованный YAML для плавного перехода к кластерам VKS — обеспечивая мягкий переход от простых развёртываний контейнеров к полноценным возможностям Kubernetes.
О релизе VKS 3.6
Хотя VKS входит в единую интегрированную программную платформу облака, циклы выпуска компонента VKS отделены от графика релизов VCF: для VKS предусмотрено три обновления в год. Такое отдельное расписание было разработано специально, чтобы обеспечить плавную синхронизацию с релизами upstream-проекта CNCF Kubernetes. С выходом в феврале VKS 3.6 заказчики могут разворачивать полностью соответствующие требованиям кластеры на актуальной версии Kubernetes 1.35. Для удобства планирования VKS 3.6 также позволяет одновременно развёртывать и обслуживать кластеры Kubernetes версий 1.33 и 1.34 наряду с последним релизом.
Искусственный интеллект обладает огромным потенциалом для трансформации всех предприятий - IDC прогнозирует, что решения и сервисы AI окажут глобальное влияние на сумму 22,3 трлн долларов к 2030 году.
С учетом такого масштаба неудивительно, что предприятия стремятся использовать AI для повышения производительности во всех областях бизнеса. Однако им нужна комплексная стратегия, которая ускорит интеграцию AI в инфраструктуру дата-центров. С VMware Cloud Foundation Private AI Services компания Broadcom стремится помочь предприятиям раскрыть потенциал AI и повысить продуктивность при более низкой совокупной стоимости владения.
Реальный эффект: что говорят клиенты
Компании из разных отраслей уже развертывают VCF Private AI Services и получают экономию, приватность и безопасность для своих AI-нагрузок:
«Внедрив VCF Private AI Services, мы усилили возможности интеллектуальных сервисов», — говорит Тунг-Лян Чен, вице-президент Chunghwa Post. «Запуск AI в собственной инфраструктуре частного облака на базе VCF позволяет нам существенно снижать затраты и повышать эффективность автоматизированного обнаружения в реальном времени, одновременно обеспечивая бесшовную интеграцию с существующими системами».
«Анализ многолетних архивов новостей в публичном облаке обходится слишком дорого, а непредсказуемое ценообразование затрудняет планирование AI-проектов», — сказал V V Jacob, старший генеральный менеджер по системам Malayala Manorama Co Ltd. «Развернув VCF Private AI Services на существующей инфраструктуре VMware Cloud Foundation, мы сможем запускать AI-суммаризацию контента, генерацию заголовков и редакторскую помощь прямо в частном облаке. Мы считаем, что это даст нам приватность и безопасность, необходимые для защиты редакционных источников, а также предсказуемость затрат, которую обеспечивает локальная инфраструктура частного облака».
На днях был объявлен следующий выпуск VCF Private AI Services вместе с VCF 9.1. В новой версии для предприятий добавляется несколько важных функций.
Новые возможности
1. Приватность и безопасность
Broadcom помогает предприятиям создавать и развертывать приватные и безопасные AI-модели со встроенными возможностями защиты, предоставляемыми через VCF Private AI Services.
Поддержка Model Context Protocol (MCP) с управлением. Благодаря поддержке MCP предприятия получают безопасный и стандартизированный способ интегрировать AI-ассистентов с внутренними репозиториями контента и внешними MCP-инструментами от Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL и других поставщиков без разработки и сопровождения собственных коннекторов.
2. Упрощение управления инфраструктурой
Поддержка Google Documents. VCF Private AI Services теперь предоставит полноценную поддержку Google Workspace, включая Google Docs, Sheets и Slides, без необходимости экспортировать документы в PDF и загружать их в базу знаний. В дополнение к уже существующей поддержке Microsoft Word, Microsoft PowerPoint, PDF, CSV и других форматов предприятия получают доступ к очень широкому набору типов документов и смогут добиваться качественных результатов для AI-нагрузок.
DirectPath Enablement для GPU. В этом выпуске VCF Private AI Services поддерживает DirectPath Enablement для инфраструктуры NVIDIA AI. Это обеспечит высокопроизводительный эксклюзивный доступ к GPU для одной виртуальной машины, которая сможет полностью использовать возможности GPU. С этой новой функцией предприятия смогут развертывать AI-проекты с NVIDIA GPU в режиме DirectPath.
Поддержка последнего поколения NVIDIA Blackwell GPU. VCF теперь поддерживает новейшую серию GPU NVIDIA Blackwell. В дополнение к существующей поддержке NVIDIA RTX PRO 6000 Blackwell Server Edition объявлена поддержка NVIDIA HGX B200 и NVIDIA RTX PRO 4500 Blackwell Server Edition. Поддержка этих новых GPU Blackwell на VCF определяет следующий этап корпоративного AI с беспрецедентной производительностью, эффективностью и масштабом.
Будущая поддержка. В одном из следующих выпусков VCF будет поддерживать NVIDIA HGX B300. VCF на NVIDIA HGX B300 позволит предприятиям без усилий масштабировать самые производительные AI-нагрузки и подготовить инфраструктуру к будущим требованиям.
Поддержка NVIDIA HGX Platform с Blackwell GPU и NVLink Switch. VCF теперь поддерживает NVIDIA HGX platform с Blackwell GPU и NVLink Switch. Благодаря этой возможности предприятия смогут получить преимущества крупномасштабных AI-развертываний с VCF Private AI Services и платформой NVIDIA HGX. NVIDIA HGX объединяет всю мощь инфраструктуры NVIDIA AI, включая NVIDIA GPU, NVIDIA NVLink, NVLink Switch, NVIDIA networking и полностью оптимизированные AI software stacks, чтобы обеспечивать максимальную производительность AI-приложений и ускорять получение инсайтов в каждом дата-центре.
Высокоскоростная сеть с Enhanced DirectPath I/O. VCF теперь поддерживает сетевые адаптеры NVIDIA ConnectX-7 и NVIDIA BlueField-3 с Enhanced DirectPath I/O. С этим улучшением предприятия смогут использовать такие расширенные возможности, как NVIDIA GPUDirect RDMA и GPUDirect Storage, для высокоскоростного обучения AI-моделей на нескольких хостах и передачи данных, что особенно важно для требовательных Gen AI-нагрузок.
3. Упрощение вывода моделей в эксплуатацию
Новые возможности в этой категории помогают предприятиям снижать сложность перевода моделей в production.
AI Metrics Observability Dashboard.
По мере масштабирования корпоративных AI-сред ограниченная видимость производительности моделей и агентов, а также факторов затрат мешает командам выявлять неэффективность, ведет к росту расходов на инфраструктуру и снижает производительность приложений. Чтобы решить эти проблемы, выпускается AI Metrics Observability Dashboard, который будет показывать важные AI-метрики.
Улучшенная видимость AI-метрик позволит специалистам по data science и MLOps выявлять узкие места, оптимизировать распределение ресурсов, повышать throughput и производительность.
Рассмотрим некоторые AI-метрики, которые будут доступны:
Метрики моделей. Эти метрики помогут предприятиям отслеживать продуктивность, скорость, задержку и другие параметры, предоставляя детальное представление о моделях. Будут доступны такие показатели, как Cache Utilization, Tokens generated per request, Token throughput, Time to first token (TFFT), End-to-end (E2E) request latency и другие.
Метрики использования GPU. Также будут доступны GPU-метрики, включая Utilization, Temperature, Power Usage, Memory Temperature, Memory Clock и другие.
Примечание: для этих AI Metrics dashboards предприятиям необходимо развернуть Grafana.
CPU-Based Inferencing. VCF Private AI Services теперь поддерживает CPU-based inferencing в дополнение к GPU-развертываниям благодаря интеграции Model Runtime с inference-движком Llama.cpp. На базе Llama.cpp, одного из ведущих open source inference-движков с широкой поддержкой сообщества, клиенты также получат доступ к большому набору моделей с day-zero-поддержкой от ведущих поставщиков, включая Google, OpenAI и других. Это улучшение снижает TCO, позволяя предприятиям развертывать менее ресурсоемкие среды для тестирования, proof-of-concept-инициатив или AI-приложений с минимальными требованиями к GPU либо без них.
Инфраструктурные команды сталкиваются с парадоксом: среды становятся все сложнее, а бюджеты и численность персонала остаются прежними. VMware Cloud Foundation (VCF) 9.1 призвана ответить на эту проблему инновациями, которые повышают эффективность, ускоряют доставку приложений и усиливают киберустойчивость, сохраняя при этом простоту эксплуатации. За последние несколько лет разговор об инфраструктуре изменился. Вопрос уже не только в том, где выполняются рабочие нагрузки, но и в том...
Медленная работа приложений и простои серьезно влияют на удовлетворенность клиентов, вызывают перебои в бизнес-процессах и могут отражаться на выручке. Когда критически важное приложение дает сбой в сложной распределенной среде, главная трудность заключается в том, чтобы быстро определить первопричину. Во время инцидентов высокой важности ИТ-команды оказываются в ситуационных комнатах для диагностики, где снова и снова возникает один и тот же вопрос: проблема находится в базовой инфраструктуре или в самом приложении?
При традиционном подходе сетевые, инфраструктурные и DevOps-команды вынуждены работать изолированно. Они используют разные инструменты и разрозненные наборы данных, не имея сквозной видимости. В результате возникает изматывающий цикл обмена сообщениями туда и обратно. Поиск первопричины превращается в тяжелый и медленный процесс, который занимает дни, а иногда и недели. Устаревшие балансировщики нагрузки, хотя и видят транзакции как со стороны клиента, так и со стороны сервисов, способны предоставлять только фрагментированные метрики.
Как Avi ускоряет диагностику с помощью App Health Score
Программно-определяемая архитектура балансировки нагрузки Avi является основой его аналитического преимущества. Avi собирает полную телеметрию на уровне транзакций по каждому потоку и показывает ее в единой панели управления. Благодаря этому разрозненные команды получают доступ к одной и той же сквозной аналитике задержек приложения на стороне клиента, сервера и самого приложения. Все участники могут быстро и точно определить первопричину узких мест производительности или угроз безопасности. Рассмотрим подробнее.
Сокращение Mean Time to Innocence (MTTI) за счет детальной аналитики:
Avi Analytics сводит данные о производительности приложений в понятные оценки здоровья от 0 до 100. Avi App Health Score дает комплексную оценку общего состояния приложения или виртуального сервиса, объединяя показатели производительности, доступности ресурсов, аномального поведения и факторов риска безопасности. Эти оценки дают администраторам практические подсказки и позволяют быстро находить проблемы прямо на панели управления. Например, желтая оценка 72 для «confluence prod» сразу указывает на деградацию сервиса из-за базовых ресурсов и подсвечивает критические проблемы вместе с релевантной диагностической информацией.
Кроме того, Avi Analytics существенно сокращает MTTI, предоставляя детальную видимость каждой транзакции приложения. Централизация этих метрик в единой панели помогает кросс-функциональным командам сразу понять, что задержка 75 мс возникает в приложении, а не в сети или на стороне клиента. Такой подход на основе данных сокращает длительный триаж и позволяет организациям с высокой точностью определить конкретный источник проблем производительности.
Повышение устойчивости приложений благодаря встроенной веб-безопасности:
Интегрируя сведения о безопасности непосредственно в App Health Score, Avi улучшает защиту приложений за счет встроенного web application firewall (WAF). Аналитика платформы в реальном времени выявляет частые ошибки соединений и отмечает сложные веб-атаки, включая DDoS-атаки: от обнаружения до автоматического смягчения последствий проходят минуты. В результате устойчивость приложений повышается, а высокая доступность и производительность сохраняются даже при большой нагрузке или целевых веб-угрозах.
Минимизация простоя приложений за счет выявления временных проблем:
Avi ускоряет анализ первопричин, используя глубокую историческую аналитику и избавляя команды от необходимости ждать, пока периодическая проблема повторится. Традиционным аппаратным балансировщикам нагрузки почти невозможно находить временные аномалии уровня «иголка в стоге сена», тогда как подробные журналы транзакций Avi позволяют инженерам переходить к конкретным IP-адресам серверов пула и выявлять исчерпание ресурсов виртуальных машин, то есть базовую проблему на стороне приложения.
Преимущество Avi Analytics: аналитика задержек приложений
Устаревшие балансировщики нагрузки уже не соответствуют требованиям современных приложений к производительности, гибкости и масштабируемости. Диагностика проблем производительности приложений стала реактивным и утомительным процессом. Avi собирает аналитику прямо из трафика и предоставляет единый «источник истины», который сокращает длительный операционный триаж между сетевыми, безопасностными и прикладными командами.
Программно-определяемая архитектура: Avi обеспечивает глубокую видимость в реальном времени, разделяя централизованную плоскость управления и распределенную плоскость данных. Avi развертывается как виртуальные машины рядом с вычислительной инфраструктурой. Он собирает детальную телеметрию из потока трафика и дает комплексную аналитику со сквозной видимостью из одной консоли, чтобы ускорять диагностику, автоматизировать масштабирование и заранее поддерживать высокую производительность приложений.
Полнота данных и охвата: Avi Controller непрерывно агрегирует более 700 метрик производительности из распределенных балансировщиков нагрузки. Используя высокопроизводительные вычислительные ресурсы, Avi обрабатывает крупное озеро телеметрических данных и применяет расширенные ML/AI-выводы для анализа паттернов и аномалий. Avi Analytics преобразует инфраструктурные данные в практические сведения о приложениях, позволяя ИТ-командам перейти от реактивного устранения неполадок к проактивной оптимизации.
Контекст VCF без сложной настройки: Avi глубоко и нативно интегрируется с частным облаком VCF. Благодаря контексту рабочих нагрузок VCF Avi обеспечивает согласованную видимость для виртуальных машин и контейнеров. Такая контекстная осведомленность связывает доставку и безопасность приложений с инфраструктурой, уменьшает слепые зоны и упрощает балансировку нагрузки в VCF.
Как крупная финансовая организация сократила количество заявок на 90%
Сетевые команды одной очень крупной финансовой организации до внедрения Avi Analytics постоянно были перегружены большим накопившимся объемом заявок на диагностику приложений. Ограниченная видимость, которую давали устаревшие балансировщики нагрузки, приводила к тому, что все проблемы приложений направлялись сетевым командам, даже если сеть не была их причиной. Это создавало серьезное узкое место: операционные специалисты обрабатывали почти все заявки.
После развертывания Avi Analytics организация предоставила более чем 50 DevOps-командам прямой доступ к единой аналитической панели. Команды получили практические сведения по более чем 90 000 виртуальных IP-адресов и смогли самостоятельно диагностировать, находится ли причина проблемы в приложении или в сети.
Переход к современной балансировке нагрузки на основе аналитики привел к резкому сокращению количества заявок, связанных с приложениями, которые попадали в сетевую команду: их стало меньше на 90%. В результате операционные специалисты смогли перераспределить ресурсы с обработки заявок на более ценные стратегические проекты, что показывает явное преимущество такого подхода по сравнению с традиционной балансировкой нагрузки.
Функционал vSphere Configuration Profiles помогает администраторам VMware Cloud Foundation управлять настройками ESX-хостов не по отдельности, а на уровне всего кластера. Такой подход удобен, когда нужно не только поддерживать единый стандарт внутри одного кластера, но и переносить уже проверенную конфигурацию в другие кластеры.
Примечание: описанные шаги и интерфейсные элементы относятся к VMware vSphere 9.0.2. В других версиях названия пунктов меню и формулировки могут отличаться.
Что такое vSphere Configuration Profiles
vSphere Configuration Profiles появилась в vSphere 8.0 как развитие идеи Host Profiles для масштабного управления конфигурацией ESX-хостов. В Host Profiles администратору приходилось описывать конфигурацию целиком, что усложняло работу: часто известны только конкретные изменения, которые нужно внести, а не весь полный набор настроек.
В vSphere Configuration Profiles требуется зафиксировать только отличия от конфигурации по умолчанию. Благодаря этому профиль получается более понятным для человека, проще читается и легче поддерживается.
Перенос конфигурации в новые кластеры
Один из типовых сценариев управления конфигурацией — обеспечить одинаковые настройки сразу в нескольких кластерах vSphere. vSphere Configuration Profiles делает такой перенос достаточно прямолинейным: желаемое состояние можно экспортировать из существующего кластера, скорректировать уникальные параметры хостов и затем импортировать в новый кластер.
Совет: конфигурацию можно подготовить для кластера еще до добавления в него ESX-хостов. Для этого нужно заранее знать Host BIOS UUID будущих хостов.
Ниже приведен рабочий процесс копирования конфигурации из одного кластера в другой.
Экспорт конфигурации из существующего кластера
Сначала нужно выгрузить желаемую конфигурацию из уже настроенного кластера. В интерфейсе vSphere следует открыть Cluster, затем Configure, затем Configuration в разделе Desired State. Экспортированный файл будет сохранен в формате JSON.
Внутри JSON находятся как общие для кластера настройки, так и уникальные атрибуты отдельных хостов, например IP-адреса и имена хостов. Минимальная обязательная правка перед переносом — заменить host-specific секцию vSphere Configuration Profile на значения, соответствующие целевому кластеру.
Перед импортом полезно понимать структуру JSON-файла профиля. В секции profile > esx находятся настройки, не зависящие от конкретного хоста. Такие параметры можно применить ко всем хостам кластера, поскольку они не содержат уникальных значений для отдельного сервера.
Настройки vSphere Distributed Switch, Port Groups или Datastores могут отличаться от кластера к кластеру, поэтому при необходимости их нужно менять в соответствующих разделах JSON. В демонстрационном сценарии используются те же vSphere Distributed Switch, Port Groups и Datastores, что и в исходном кластере.
Основное внимание при переносе нужно уделить секции host-specific. В показанном примере уникальными значениями для хостов являются IP-адреса трех vmkernel-интерфейсов и имя хоста.
Каждый ESX-хост в host-specific разделе идентифицируется через Host UUID. Этот идентификатор также называют BIOS UUID, поскольку он уникален на уровне аппаратной платформы. В актуальных версиях vSphere и VCF проще всего получить Host UUID через PowerCLI, подключившись к vCenter или напрямую к ESX-хосту.
После этого в JSON-файле нужно заменить Host UUID, IP-адреса, маски подсети и имена хостов для каждого сервера целевого кластера. При необходимости хосты можно добавлять или удалять, но важно следить за корректным синтаксисом JSON, особенно за запятыми между элементами.
Импорт обновленной конфигурации в новый кластер
Если целевой кластер еще не создан с включенными vSphere Configuration Profiles или пока не переведен на них, обновленный JSON можно импортировать через workflow перехода на vSphere Configuration Profiles.
Если кластер уже использует vSphere Configuration Profiles, нужно открыть вкладку Draft, выбрать Import From File и загрузить подготовленный JSON-файл.
Затем на вкладке Draft нужно выбрать Apply Changes, чтобы выполнить remediation и применить импортированную конфигурацию. Перед фактическим применением стоит внимательно пройти окна Pre-check, Remediation Settings и Review Impact.
Pre-check проверяет готовность хоста к remediation, включая возможность перевести его в maintenance mode. Также учитывается, включен ли DRS, чтобы при необходимости автоматически эвакуировать виртуальные машины с хоста. Окно Remediation Settings показывает текущие параметры remediation, унаследованные от vSphere Lifecycle Manager.
В окне Review Impact на вкладке Host-Level Details можно раскрыть каждый хост и увидеть, какие именно изменения будут применены. Там же отображается, потребуется ли конкретному хосту переход в maintenance mode.
После проверки влияния изменений остается нажать Remediate, чтобы применить конфигурацию к кластеру.
Итог
vSphere Configuration Profiles позволяет переносить стандартную конфигурацию из одного кластера в другой без ручного повторения всех настроек. Это помогает поддерживать единое желаемое состояние как внутри отдельного кластера, так и между несколькими кластерами vSphere.
В настройках кластера VMware vSphere High Availability существует параметр Performance degradation VMs tolerate, который определяет допустимый уровень снижения производительности виртуальных машин при отказе одного из хостов кластера.
По умолчанию значение параметра установлено в 100%, что фактически означает отсутствие ограничений по деградации производительности в аварийном сценарии. При таком значении система не будет предупреждать администратора о возможном ухудшении SLA виртуальных машин после отказа узла.
Как работает параметр
Механизм оценивает, смогут ли уже запущенные виртуальные машины сохранить сопоставимый объем вычислительных ресурсов после отказа одного хоста. Логика работы следующая:
Рассматривается сценарий отказа одного узла кластера.
Оценивается суммарная доступная вычислительная емкость после отказа.
С помощью VMware Distributed Resource Scheduler DRS моделируется перераспределение работающих виртуальных машин на другие хосты ESX.
Проверяется, какой уровень снижения ресурсов (CPU / Memory) получат виртуальные машины.
Если ожидаемая деградация превышает заданный порог, генерируется предупреждение.
Важно! Это не блокирующий механизм. Даже при появлении предупреждения запуск новых виртуальных машин остается возможным - параметр выполняет исключительно функцию оповещения.
Требования для работы
Для корректной работы параметра необходим работающий DRS, но включенный Admission Control не требуется. Это частое заблуждение: параметр не использует настройки Admission Control (например, Host failures cluster tolerates). Вместо этого он самостоятельно моделирует отказ одного хоста и анализирует последствия для производительности виртуальных машин.
Практический смысл настройки
Параметр полезен в сценариях, когда:
В кластере высокая консолидация нагрузки.
Виртуальные машины активно используют CPU / RAM выше уровня reservation.
Ресурсы после отказа хоста могут оказаться достаточными для запуска ВМ, но недостаточными для сохранения нужной производительности.
Пример:
Допустим, кластер работает с загрузкой 80–85%. После выхода одного узла из строя оставшиеся хосты смогут принять виртуальные машины, однако фактическая доступность ресурсов для каждой машины снизится.
50% — допускается существенное снижение производительности
100% — предупреждения фактически отключены
Рекомендации по настройке
Практически значение 100% малоинформативно, так как не дает сигналов о потенциальной проблеме.
Часто используются значения:
0–10% — для критичных production-нагрузок
25% — сбалансированный вариант
50% — для сред с менее строгими SLA
Выбор зависит от допустимого уровня деградации сервисов при аварийном восстановлении.
Вывод
Параметр Performance degradation VMs tolerate — это механизм оценки риска снижения производительности ВМ при отказе узла, а не механизм резервирования ресурсов.
Его особенности:
Анализирует сценарий отказа одного хоста
Требует DRS
Не зависит от Admission Control
Не запрещает запуск ВМ
Предупреждает о возможном ухудшении производительности
Настройка позволяет заранее понять, насколько кластер готов к отказу оборудования с точки зрения SLA, а не только с точки зрения возможности перезапуска виртуальных машин.
DVD Store — это инструментарий для тестирования баз данных с открытым исходным кодом, который активно применяется с момента своего первого релиза в 2005 году. Он поддерживает работу с СУБД SQL Server, Oracle, PostgreSQL и MySQL. DVD Store моделирует интернет-магазин, в котором пользователи авторизуются, просматривают каталог, оставляют отзывы, выставляют оценки и покупают DVD. В тесте задействуется большое число типичных возможностей реляционных БД: хранимые процедуры, индексы, внешние ключи, полнотекстовый поиск, сложные запросы с множественными join'ами и транзакции.
Изначально DVD Store разрабатывался как нагрузка, ориентированная преимущественно на CPU. Тем не менее в нём с самого начала были предусмотрены параметры, позволяющие менять этот профиль и переключаться на сценарии, в которых акцент делается на сеть, дисковую подсистему или даже память. Примеры таких профилей теперь добавлены и описаны в основном репозитории DVD Store на GitHub: https://github.com/dvdstore/ds35/tree/main/workload_profiles
VMware провела тестирование тестирование платформы VMware vSphere с помощью этого инструмента для того, чтобы понять, насколько эти профили меняют поведение нагрузки относительно стандартного CPU-ориентированного сценария. Все измерения проводились на одной виртуальной машине, развёрнутой на сервере ESX 9.0 платформы VMware Cloud Foundation (VCF). ВМ работала под управлением Windows Server 2022, в качестве СУБД использовалась SQL Server 2022. Все показатели производительности фиксировались со стороны хоста ESX с помощью утилиты esxtop (аналог linux top, но адаптированный под ESX и собирающий значительно более широкий набор метрик).
CPU Utilization — загрузка процессора на хосте ESX
Disk I/O per second (IOPS) — операции чтения и записи на диск со стороны хоста ESX
Mb received per second (Mb Rec/s) — мегабиты, принятые в секунду по сети
Mb sent per second (Mb Sent/s) — мегабиты, отправленные в секунду по сети
Active Memory (ActiveMem) — объём памяти, к которой недавно было обращение (активная память)
Относительное изменение ключевых метрик в разных профилях нагрузки
Для построения базовой линии замеры выполнялись на CPU-ориентированном профиле. Затем те же тесты были проведены с профилями, акцентированными на диск, на максимально высокий IOPS, на сеть и на память; полученные значения ключевых метрик сопоставлялись с базовыми. На графиках ниже показаны относительные различия по этим метрикам относительно базового CPU-профиля. На первом графике приведены все профили нагрузки; на втором профиль highIOPS убран, чтобы наглядно увидеть различия между остальными.
Если кратко резюмировать результаты, то в ключевой для каждого профиля метрике заметен значительный прирост:
Disk-профиль выдаёт в 13 раз больше IOPS
HighIOPS-профиль обеспечивает в 95 раз больше IOPS — это в 7 раз выше, чем у Disk-профиля
Network-профиль увеличивает количество отправленных мегабит в секунду в 15 раз
Memory-профиль вызывает в 2,9 раза большее значение активной памяти
Подробное описание всех профилей нагрузки приведено в файле ds35_workload_profiles.txt в репозитории DVD Store на GitHub. Там же указаны конкретные параметры DVD Store, особенности конфигурации БД и краткие пояснения к каждому сценарию.
Облачные нативные приложения обеспечивают гибкость, масштабируемость и более быструю доставку сервисов, однако они также вносят новую операционную сложность. В средах Kubernetes рабочие нагрузки являются эфемерными, сервисы распределены, а телеметрия генерируется в больших объёмах на разных уровнях стека. Компания VMware выпустила новый документ "Observability on vSphere Kubernetes Service", в котором рассматривается, как решить эту задачу на платформе VMware Cloud Foundation (VCF) с использованием vSphere Kubernetes Service (VKS).
В документе представлена практическая референсная архитектура, основанная на трёх ключевых компонентах наблюдаемости:
Метрики
Для сбора метрик архитектура использует стек Prometheus Community (kube-prometheus-stack), который включает:
Prometheus Operator для динамического обнаружения целей
Grafana для построения дашбордов
Node Exporter для сбора статистики на уровне узлов
Метрики дополнительно обогащаются телеметрией сервисов Istio и интегрируются с решением VCF Operations для предоставления контекста базовой инфраструктуры.
Логи
Для работы с логами используется Fluent Bit, который собирает и обогащает данные логов Kubernetes. Для хранения и индексации применяется Grafana Loki, обеспечивая нативный для Kubernetes анализ логов через Grafana.
Тот же поток логов также передаётся в VCF Operations for Logs, что позволяет коррелировать события с более широкой инфраструктурной средой.
Трейсы
Для трассировки используется OpenTelemetry для распределённого трейсинга, Jaeger v2 — для приёма и визуализации данных трассировки в формате OTLP, а OpenSearch — в качестве постоянного хранилища трейсов.
Это позволяет отслеживать прохождение запросов через различные сервисы и анализировать их вместе с сопутствующей телеметрией приложений и платформы.
Для команд, использующих vSphere Kubernetes Service на платформе VMware Cloud Foundation, этот документ представляет собой практическую отправную точку для построения модульного, ориентированного на промышленную эксплуатацию стека наблюдаемости. Также репозиторий, на который ссылается документ, размещен по этой ссылке.
Развёртывание Kubernetes в производственной среде требует не просто установки кластера — необходимо с самого начала принять правильные архитектурные решения, от которых будут зависеть масштабируемость, доступность и управляемость платформы. Вебинар специалистов Broadcom Professional Services и MomentumAI посвящён ключевым принципам проектирования VMware vSphere Kubernetes Service (VKS) поверх VMware Cloud Foundation (VCF). Докладчики — Vijay Appani, Solution Architect компании Broadcom, и Caleb Washburn, CTO и основатель MomentumAI — рассматривают проверенные шаблоны проектирования, которые их команды применяют в реальных enterprise-проектах.
Что такое VKS и зачем запускать Kubernetes на VCF
VMware vSphere Kubernetes Service (VKS) — это встроенный механизм запуска Kubernetes на платформе vSphere, интегрированный непосредственно в VMware Cloud Foundation. В отличие от сторонних дистрибутивов, VKS использует подтверждённую CNCF версию Kubernetes и глубоко интегрирован с инфраструктурными компонентами VCF: вычислительным слоем (vSphere), сетью (NSX) и хранилищем (vSAN). Это позволяет организациям строить современную private cloud-платформу, избегая «лоскутных» решений и накапливаемого технического долга.
Ключевая идея заключается в том, что VCF предоставляет единую платформу, объединяющую ресурсы compute, network и storage в согласованный операционный слой. Kubernetes в таком окружении получает доступ к корпоративным политикам хранения, сетевой изоляции на уровне неймспейсов и интеграции с порталом самообслуживания VCF Automation — всё это без необходимости разворачивать и поддерживать внешние инструменты.
Три модели развёртывания Supervisor-кластера
Центральным компонентом VKS является Supervisor-кластер — уровень управления Kubernetes, развёртываемый поверх рабочего домена VCF. Существует три основные топологии его размещения, и выбор между ними определяет поведение платформы при сбоях, требования к ресурсам и сложность эксплуатации.
Модель 1: Single Cluster. Supervisor-кластер и рабочие нагрузки размещаются в одном vSphere-кластере. Это наиболее простой с точки зрения конфигурации вариант. Он подходит для начального знакомства с платформой или сред разработчиков, однако не обеспечивает разделения плоскости управления и плоскости данных. При сбое кластера теряется и управление, и рабочие нагрузки.
Модель 2: Multi-Cluster с разделёнными зонами. Supervisor-контрольная плоскость развёртывается в отдельном управляющем домене, а рабочие нагрузки — в выделенных рабочих доменах. Такое разделение обеспечивает независимость управляющего слоя от прикладного, что принципиально важно для инфраструктуры среднего масштаба. Недостатком является необходимость большего числа хостов и более сложная настройка сети и зон.
Модель 3: vSphere Zones (рекомендуется для enterprise). Виртуальные машины управляющей плоскости Supervisor-кластера распределяются по трём vSphere Zones — логическим группам, каждая из которых соответствует отдельному физическому кластеру. Рабочие нагрузки могут совместно использовать те же три зоны или размещаться в выделенных. Платформа выдерживает полный отказ одной зоны без потери доступности — ни управляющий слой, ни приложения не затрагиваются. Данная модель рекомендуется для крупных enterprise-развёртываний, требующих гарантий высокой доступности на уровне инфраструктуры.
Сетевые опции: NSX или VDS
При настройке сети для VKS на VCF доступны два варианта: NSX и vSphere Distributed Switch (VDS). Выбор между ними оказывает существенное влияние на функциональность платформы и возможности автоматизации.
NSX является рекомендованным выбором для любого нового (greenfield) развёртывания VCF. Overlay-сеть на основе Geneve/VXLAN обеспечивает полную изоляцию на уровне неймспейсов, встроенный распределённый файрвол, встроенный балансировщик нагрузки уровней L4 и L7 (NSX Advanced Load Balancer / AVI), а также глубокую интеграцию с VCF Automation. Именно NSX позволяет реализовать портал самообслуживания, где разработчики и команды самостоятельно запрашивают ресурсы, не взаимодействуя напрямую с vSphere-администраторами.
VDS применяется в случаях, когда NSX не может быть развёрнут — например, при модернизации существующей инфраструктуры или при строгих ограничениях лицензирования. VDS поддерживает базовые возможности VKS, однако не поддерживает VCF Automation, overlay-сети и встроенный балансировщик нагрузки. При использовании VDS в производственной среде потребуется внешний балансировщик, что добавляет операционную сложность.
Отдельно подчёркивается, что если требования к приложению предполагают L4 или L7 балансировку, использование выделенного балансировщика нагрузки является обязательным — независимо от выбранного сетевого варианта.
Хранилище: vSAN, политики и управление томами
Хранилище в архитектуре VKS разделяется на два типа: эфемерное (ephemeral) и постоянное (persistent). Эфемерное хранилище используется для дисков самих узлов Kubernetes (Control Plane VMs и Worker Nodes) и временных томов Pod'ов. Оно берётся из основного или дополнительного хранилища рабочего домена и настраивается при активации Supervisor-кластера.
Постоянные тома (Persistent Volumes, PV) предназначены для stateful-приложений — баз данных, очередей сообщений, систем хранения состояния. Доступ к постоянному хранилищу управляется через Storage Policies — политики хранения vSAN, которые администратор создаёт в vCenter. Политики описывают параметры производительности, доступности (RAID-1, RAID-5/6) и шифрования. Каждый арендатор (tenant) в мультитенантной конфигурации получает доступ только к тем политикам хранения, которые ему явно назначены.
Если арендатору не назначена ни одна storage policy, он не сможет создавать Persistent Volume Claims (PVC) — это удобный механизм ограничения: организации могут предоставлять namespace без прав на stateful-хранение там, где это нежелательно. Поддерживаются режимы доступа RWO (ReadWriteOnce) и RWX (ReadWriteMany) — последний обычно требует дополнительных компонентов типа vSAN File Services или внешних NFS-решений.
Мультитенантность и интеграция с VCF Automation
Одним из ключевых преимуществ VKS на VCF является встроенная поддержка мультитенантности через механизм namespace и интеграцию с VCF Automation. Каждый неймспейс представляет собой изолированную рабочую область, которой могут быть назначены: квоты на CPU и RAM, доступные storage policies, сетевые профили NSX, а также права доступа пользователей или групп из Active Directory / LDAP.
VCF Automation предоставляет портал самообслуживания, через который подразделения и команды разработчиков могут самостоятельно запрашивать Kubernetes namespace, инициировать развёртывание приложений и управлять ресурсами — без участия администратора vSphere. Платформа автоматически создаёт необходимые ресурсы: сетевые сегменты NSX, политики хранения, RBAC-права. Это, по словам авторов вебинара, является «новейшим и наиболее зрелым способом организации современного private cloud».
Рекомендуется начинать с NSX в качестве сетевого стека при любом новом greenfield-развёртывании VCF именно потому, что VCF Automation поддерживает только NSX, и без него модель самообслуживания недоступна.
Рекомендации по проектированию production-платформы
По итогам вебинара сформулированы следующие практические рекомендации для команд, проектирующих VKS на VCF в производственной среде:
Используйте топологию vSphere Zones для любого развёртывания с требованиями к высокой доступности — она обеспечивает автоматический failover при отказе целого кластера без вмешательства администратора.
Выбирайте NSX как сетевой стек при greenfield-развёртывании — только с NSX доступна полная интеграция с VCF Automation и портал самообслуживания.
Планируйте storage policies заранее: определите требования к производительности и отказоустойчивости для разных классов рабочих нагрузок ещё до запуска первых неймспейсов.
Разграничивайте доступ к хранилищу на уровне арендаторов — не назначайте storage policies тем неймспейсам, которым stateful-хранение не нужно.
Если среда требует L4/L7 балансировки, включайте NSX Advanced Load Balancer (AVI) в архитектуру с самого начала — добавить его позднее значительно сложнее.
Не смешивайте управляющую и рабочую плоскости в одном кластере для производственной среды: выделяйте отдельный рабочий домен для приложений, даже если это требует дополнительных хостов.
Вопросы и ответы: ключевые моменты
В ходе сессии вопросов и ответов слушателей интересовали несколько практических аспектов. На вопрос о поддержке собственных сервисов поверх VKS ответ был однозначным: технически это возможно, однако рекомендуется использовать интегрированный стек — vSAN, NSX и VCF Automation — поскольку именно на нём строится поддержка и будущее развитие платформы.
На вопрос об источниках эфемерного хранилища пояснялось, что при активации Supervisor-кластера администратор указывает datastore, из которого берётся эфемерное хранилище для узлов Kubernetes и временных томов Pod'ов. Это может быть как vSAN, так и дополнительное (supplemental) хранилище рабочего домена.
Относительно нестандартных конфигураций — в частности, развёртывания VKS поверх существующей vSphere-среды без полного стека VCF — авторы отметили, что такие варианты существуют, но лишены ключевых преимуществ интегрированной платформы: автоматизации, самообслуживания и единого управления жизненным циклом.
Итог
VMware vSphere Kubernetes Service на VMware Cloud Foundation представляет собой зрелую enterprise-платформу для запуска production-Kubernetes с полной интеграцией в корпоративную инфраструктуру. Правильный выбор топологии Supervisor-кластера, сетевого стека и модели хранения на этапе проектирования определяет, насколько легко платформа будет масштабироваться и насколько просто её будет эксплуатировать в долгосрочной перспективе. Ознакомиться с предстоящими вебинарами серии VCF можно по ссылке go-vmware.broadcom.com/VCFWebinars.
Современный разработчик привык к беспрепятственному доступу к инфраструктуре. В публичном облаке достаточно нажать кнопку или вызвать API — и через несколько минут кластер Kubernetes, виртуальная машина или база данных готовы к работе. Но что происходит, когда требования к суверенитету данных, соответствию нормативным требованиям или прогнозируемости затрат обязывают развёртывать нагрузки на собственной инфраструктуре?
Исторически онпрем-инфраструктура означала создание заявок в IT-систему и ожидание ресурсов в течение дней или даже недель. Такие задержки превращались в серьёзное препятствие для вывода продуктов на рынок. Разработчики, уставшие от очередей, нередко поднимали собственные «теневые» базы данных на неуправляемых виртуальных машинах — только чтобы двигаться быстрее. Результатом становились бесконтрольное разрастание баз данных, дрейф конфигураций, отсутствие управления и серьёзные угрозы безопасности.
Платформенная инженерия на базе VMware Cloud Foundation (VCF) изменила эту картину. Используя платформу частного облака VCF, организации могут устранить разрыв между IT-операциями и командами разработчиков. VCF обеспечивает настоящее «от платформы до данных» самообслуживание, сравнимое с возможностями публичного облака: разработчики получают нужную им скорость, а платформенные инженеры — централизованное управление всем парком ресурсов.
Соответствие публичному облаку: эквиваленты на on-prem VCF
Чтобы оценить возможности VCF как платформы частного облака, полезно сопоставить её функциональность с сервисами публичного облака, которые разработчики уже хорошо знают. Для тех, кто работал с AWS, on-prem-эквиваленты в VCF выглядят следующим образом:
Amazon EC2 > VCF VM Service: позволяет разработчикам декларативно развёртывать традиционные виртуальные машины и управлять ими совместно с контейнерами.
Amazon EKS > VCF VKS (vSphere Kubernetes Service): предоставляет конформные Kubernetes-кластеры с самообслуживанием, нативно встроенные в VCF.
Amazon RDS > VCF DSM (Data Services Manager): реализует инструмент управления парком баз данных в режиме Database-as-a-Service (DBaaS) по запросу.
Совместное использование этих трёх компонентов позволяет платформенным командам предлагать разработчикам комплексный каталог сервисов, управляемый через API, непосредственно из собственного датацентра.
Рабочий процесс платформенного инженера: установка границ
Архитектурный принцип этого решения — управление через персоны. Системный администратор или платформенный инженер определяет «правила игры» и сохраняет контроль, а разработчик потребляет ресурсы строго в заданных рамках. Рабочий процесс устроен следующим образом.
1. Создание границ. Администратор инфраструктуры создаёт vSphere namespace в VCF. Этот namespace выступает границей tenancy: к конкретному проекту или команде разработчиков привязываются лимиты вычислительных ресурсов, памяти и хранилища.
2. Определение инфраструктуры и политик. В рамках namespace платформенный инженер задаёт правила взаимодействия:
Вычислительные ресурсы: размеры кластеров, пулы ресурсов и классы ВМ (размеры: small, medium, large) — чтобы разработчики не превышали допустимое потребление.
Хранилище и сеть: конкретные политики хранения (vSAN или NFS) и привязка нагрузок к нужным VLAN и VPC-подсетям.
Сервисы данных в DSM: разрешённые движки баз данных и их версии, предварительно проверенные командой DBA.
Опыт разработчика: развёртывание в режиме самообслуживания
После того как администратор задал политики, платформенный инженер открывает доступ команде разработки через защищённый API-токен. С этого момента разработчики полностью самостоятельны — никакого ожидания в очереди задач и утверждений. Используя стандартный инструментарий Kubernetes (kubectl), портал или API DSM либо собственные Terraform-пайплайны, они могут:
поднять новый Kubernetes-кластер (VKS) для тестирования микросервисов;
выбрать движок базы данных — PostgreSQL, MySQL или Microsoft SQL Server (появится в версии 9.1).
При этом все самостоятельно подготовленные ресурсы автоматически соответствуют корпоративным политикам резервного копирования, сети и безопасности, установленным администратором.
Автоматизация и интеграция с Infrastructure-as-Code
Всю описанную среду можно полностью автоматизировать с помощью подхода Infrastructure as Code. Платформенная команда может управлять пространствами имен и конфигурациями сервисов через различные инструменты в зависимости от предпочтений: Kubernetes CRD, Terraform-манифест или корпоративный блупринт, охватывающий целый комплекс ресурсов — VKS-кластер с набором виртуальных машин, сервисы данных DSM и даже ArgoCD для доставки приложений в VKS-кластеры — всё в рамках единого набора API-вызовов.
Ниже — пример CRD для декларативного развёртывания базы данных в namespace, демонстрирующий простоту этого подхода. CRD можно использовать как часть GitOps-процесса:
День второй: операционное управление после запуска
Одно из наиболее значимых преимуществ платформенного подхода, особенно с Data Services Manager, состоит в том, что он не заканчивается на первоначальном «нажатии кнопки». Платформа автоматизирует критически важные операции второго дня жизненного цикла — когда приложению предстоит выйти в продуктив. Задачи, которые традиционно поглощали ресурсы DBA, теперь решаются простым изменением декларативного параметра в CRD:
Высокая доступность: автоматическое развёртывание кластеров для немедленной отказоустойчивости.
Масштабируемость: возможность легко добавлять read-реплики по мере роста нагрузки на приложение.
Защита данных: автоматическое резервное копирование и восстановление до точки во времени (PITR) — «из коробки».
Управление: централизованная видимость для платформенной команды с контролем использования и устранением разрастания баз данных по всем рабочим доменам.
Поддержка OSS-баз данных корпоративного уровня: DSM предоставляет возможности и поддержку коммерческого класса, недоступные в бесплатных open-source версиях PostgreSQL или MySQL.
Заключение
Создание каталога самообслуживания — от платформы до данных — не требует переноса всего в публичное облако. Используя VCF, VKS и DSM, организации получают гибкость публичного облака в сочетании с безопасностью и контролем собственной частной инфраструктуры. Платформенные инженеры при этом трансформируются из ИТ-привратников в enabler'ов — обеспечивая разработчиков API-эндпоинтами, Kubernetes-кластерами и управляемыми базами данных, необходимыми для более быстрой и безопасной разработки ПО, готового к производственному окружению.
Технология Advanced Memory Tiering в VMware Cloud Foundation 9 позволяет существенно расширить эффективный объём памяти хоста за счёт NVMe-накопителей — без изменения рабочих процессов и без влияния на привычные инструменты управления. Ниже собраны практические рекомендации, которые помогут правильно оценить среду, корректно настроить платформу и избежать типичных ошибок при развёртывании.
Как работает двухуровневая память
Архитектура Advanced Memory Tiering строится на двух уровнях.
Tier 0 — это DRAM: быстрая оперативная память, которая обслуживает активные страницы виртуальных машин.
Tier 1 — NVMe-накопитель, куда перемещаются холодные, редко используемые страницы. При этом память гипервизора (vmkernel) никогда не попадает в NVMe: ESX всегда работает исключительно в DRAM.
Когда виртуальная машина обращается к странице, находящейся в Tier 1, гипервизор возвращает её в DRAM — прозрачно и без участия гостевой ОС. Такая схема идеально подходит для рабочих нагрузок с выраженным разделением горячих и холодных страниц памяти.
Оценка готовности среды
Прежде чем включать Memory Tiering, необходимо проанализировать текущее потребление памяти. Ключевой показатель — активная память (active memory): объём страниц, к которым виртуальные машины реально обращаются в единицу времени. Технология оптимально работает, когда потреблённая (allocated) память превышает 50% от установленного объёма DRAM, а активная остаётся ниже этого порога.
Проверить активную память можно несколькими способами. В интерфейсе vCenter откройте VM > Monitor > Performance > Advanced, переключитесь в режим отображения памяти и выберите режим реального времени — показатель active memory доступен только в нём, поскольку относится к статистике уровня 1.
Для более широкого охвата подойдёт VCF Operations — если он уже развёрнут в инфраструктуре, он обеспечит сквозную видимость по всем хостам и кластерам. Ещё один вариант — RVTools: утилита собирает статистику памяти в реальном времени и позволяет быстро оценить картину по всей среде.
Порог активной памяти: правило 50%
Главное эксплуатационное правило Memory Tiering звучит просто: активная память должна оставаться на уровне 50% или ниже от объёма DRAM. Это гарантирует, что горячий рабочий набор данных комфортно размещается в быстрой памяти и при этом остаётся достаточный запас.
Если активная память стабильно превышает 70% от объёма DRAM, часть горячих страниц неизбежно окажется в Tier 1, и производительность виртуальных машин может заметно снизиться. В такой ситуации следует либо добавить DRAM на хост, либо перераспределить нагрузку между узлами кластера, прежде чем включать тиринг.
Настройка соотношения DRAM:NVMe
При включении Memory Tiering ESXi устанавливает соотношение DRAM к NVMe равным 1:1 по умолчанию. Это означает, что при наличии 512 ГБ DRAM хост получит дополнительные 512 ГБ ёмкости Tier 1. Параметр контролируется через расширенную настройку хоста: Mem.TierNVMePct со значением по умолчанию 100 (100% от объёма DRAM).
Рекомендуется сохранять соотношение 1:1 для большинства рабочих нагрузок — оно охватывает типичные сценарии использования. Изменять его стоит только после тщательного анализа профиля активной памяти конкретных ВМ. При выборе размера NVMe-накопителей разумно ориентироваться с запасом: более ёмкие устройства замедляют износ ячеек, дают пространство для будущего изменения соотношения и позволяют безболезненно справляться с неожиданным ростом нагрузки.
Подходящие рабочие нагрузки
Memory Tiering наиболее эффективна для рабочих нагрузок с естественным разделением горячих и холодных страниц. В их числе:
Общая серверная виртуализация — разнородный парк ВМ с умеренной и переменной активностью памяти.
VDI-среды — виртуальные рабочие столы с большим количеством ВМ, каждая из которых использует лишь часть выделенной памяти одновременно.
Среды разработки и тестирования — временные ВМ, которые редко используют всю выделенную память одновременно.
Веб-серверы и серверы приложений — нагрузки с предсказуемым рабочим набором в памяти.
Базы данных с умеренной активностью — СУБД, у которых значительная часть данных в памяти остаётся холодной
Неподходящие рабочие нагрузки
Ряд профилей виртуальных машин в настоящее время не поддерживает работу с Memory Tiering. Для таких ВМ тиринг следует отключить на уровне виртуальной машины — это принудительно размещает все её страницы в Tier 0 (DRAM).
Высокопроизводительные и latency-sensitive ВМ — приложения, требующие предсказуемых ультранизких задержек доступа к памяти
ВМ с аппаратной защитой памяти — виртуальные машины, использующие технологии шифрования AMD SEV, Intel SGX или Intel TDX
ВМ с Fault Tolerance (FT) — непрерывная синхронизация состояния несовместима с тирингом
«Монстроидальные» ВМ — машины с объёмом памяти от 1 ТБ и более 128 vCPU
ВМ с большими страницами памяти (large memory pages)
Вложенная виртуализация (nested VMs)
Если в кластере присутствуют такие нагрузки, оптимальная стратегия — выделить для них отдельные хосты и включить Memory Tiering только на оставшихся узлах кластера, либо управлять исключениями на уровне отдельных ВМ.
Интеграция с vSphere
Advanced Memory Tiering полностью интегрирована в стандартные механизмы управления vSphere — никаких специальных процедур не требуется:
vMotion — миграция ВМ между хостами работает прозрачно; оба уровня памяти учитываются при переносе.
DRS — балансировщик нагрузки осведомлён об обоих уровнях и учитывает их при принятии решений о размещении ВМ.
High Availability (HA) — при отказе хоста ВМ перезапускаются на оставшихся узлах по стандартным правилам HA.
Рекомендации по развёртыванию
Для успешного внедрения рекомендуется придерживаться следующих принципов. Во-первых, поддерживайте единую конфигурацию хостов в кластере с помощью vSphere Configuration Profiles — это исключает расхождения между узлами и упрощает масштабирование. Во-вторых, применяйте поэтапный подход: включайте тиринг последовательно, начиная с одного-двух хостов, оценивайте результаты и только потом распространяйте изменение на весь кластер. В-третьих, фиксируйте исключения: документируйте все ВМ, для которых Memory Tiering отключена на уровне виртуальной машины, чтобы не потерять контроль над конфигурацией при росте инфраструктуры.
Мониторинг после включения
После включения Memory Tiering следует регулярно отслеживать ключевые показатели:
Процент активной памяти на уровне хостов и кластера
Паттерны доступа к страницам (горячие/холодные)
Тренды утилизации памяти по кластеру в целом
Потребление памяти на уровне отдельных ВМ
Задержки чтения и записи NVMe-накопителей Tier 1
Рост задержек NVMe или увеличение активной памяти выше порога 50% DRAM — сигнал для пересмотра распределения нагрузки или конфигурации тиринга. Регулярный мониторинг позволяет выявлять изменения в профиле нагрузки на ранней стадии и реагировать проактивно.
С момента запуска VMware Cloud on AWS компании VMware и AWS совместно расширяли портфель специализированных инстансов на базе bare-metal — от оригинальных i3.metal и i3en.metal до высокоплотного i4i.metal. Теперь для VMware Cloud on AWS объявлен запуск нового типа инстансов — i7i.metal-24xl. Оснащённый процессорами 5 поколения Intel Xeon Scalable (Emerald Rapids), SSD третьего поколения AWS Nitro и высокоскоростной памятью DDR5, новый инстанс обеспечивает значимый скачок в пропускной способности хранилища и вычислительной эффективности — при этом существующая операционная модель VMware не требует каких-либо изменений.
По мере того как всё больше заказчиков переносят в облако наиболее требовательные рабочие нагрузки, новый инстанс i7i обеспечивает наилучшую вычислительную производительность и производительность хранилища среди x86-инстансов Amazon EC2, оптимизированных для хранения данных. Пользователи VMware Cloud on AWS получают заметно более высокую пропускную способность ввода-вывода, меньшую задержку и улучшенное соотношение цены и производительности по сравнению с предыдущим поколением.
Ключевые характеристики
Инстанс i7i.metal-24xl представляет собой универсальный bare-metal-инстанс, разработанный для I/O-интенсивных корпоративных рабочих нагрузок, которым требуется максимально возможная производительность случайного ввода-вывода с предсказуемой субмиллисекундной задержкой.
Характеристика
i7i.metal-24xl
Процессор
5th Gen Intel Xeon (Emerald Rapids)
vCPU
96
Физические ядра
48
Память
768 ГиБ DDR5 (5600 MT/s)
Локальное NVMe-хранилище
6 x 3,75 ТБ NVMe SSD
Используемая ёмкость*
vSAN OSA ~ 13 ТБ / vSAN ESA ~ 20 ТБ
Пропускная способность сети
56,25 Гбит/с
Источник: Amazon EC2 I7i Instances — aws.amazon.com. Используемая ёмкость является оценочной. Для конфигураций с оптимизацией vSAN на кластере из 3 узлов фактическая ёмкость будет варьироваться в зависимости от профиля нагрузки, политики FTT/RAID и применяемых параметров сжатия и дедупликации vSAN.
Региональная доступность
Тип инстансов i7i.metal-24xl доступен для приобретения в следующих регионах AWS:
География
Регионы AWS
Америка
US East (N. Virginia), US East (Ohio), US West (Oregon), US West (N. California), Canada (Central)
Европа
Europe (Ireland), Europe (London), Europe (Frankfurt), Europe (Stockholm), Europe (Milan)
Ближний Восток
Middle East (Bahrain)
Азиатско-Тихоокеанский регион
Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Melbourne), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Osaka), Asia Pacific (Mumbai), Asia Pacific (Hyderabad)
VMware vSAN работает непосредственно поверх локальных NVMe-дисков каждого хоста i7i.metal-24xl. При включённом сжатии vSAN кластер из 3 узлов обеспечивает значительную используемую ёмкость — конкретный результат зависит от характеристик нагрузки, политики FTT/RAID и показателей снижения объёма данных. Размер конфигурации рекомендуется валидировать применительно к конкретному профилю данных.
На i7i.metal-24xl по умолчанию включён гиперпоточный режим, что обеспечивает 96 логических ядер на хост — это хорошо подходит для приложений, выигрывающих от увеличенного параллелизма потоков CPU. Для заказчиков, которым важны показатели производительности приложений или условия программного лицензирования, VMware Cloud on AWS поддерживает опцию Custom CPU Core Count, позволяющую управлять количеством физических ядер, доступных на каждом хосте.
Для вторичных кластеров i7i.metal поддерживаются следующие конфигурации:
Кластеры от 3 узлов: 8, 16, 24, 30 или 36 физических ядер на хост
Кластеры из 2 узлов: 16, 24, 30 или 36 физических ядер на хост
Такая гибкость особенно ценна для ПО с лицензированием по числу ядер — например, Oracle Database и Microsoft SQL Server: сокращение числа активных ядер может существенно снизить лицензионные расходы без потери объёма памяти и хранилища хоста.
Кроме того, доступно развёртывание Stretched Cluster с охватом нескольких зон доступности для новых SDDC на базе i7i.metal-24xl — это обеспечивает высокую доступность рабочих нагрузок сразу в двух зонах доступности AWS в пределах одного региона. По умолчанию в Stretched Cluster SDDC используется vSAN OSA.
Приобретение подписок i7i.metal-24xl
За информацией о ценах, доступных регионах и вариантах приобретения следует обращаться к представителю Broadcom. Если контактные данные представителя неизвестны, можно воспользоваться формой на сайте продаж Broadcom.
Важно учитывать, что тип инстансов i7i требует предварительного обновления существующих развёртываний до версии SDDC 1.26v2 — для конвертации кластеров и развёртывания новых вторичных кластеров. Для запроса досрочного обновления необходимо открыть запрос в поддержку с указанием организации, данных SDDC и желаемой даты обновления — команда VMC поддержки скоординирует дальнейшие шаги.
Развёртывание и миграция на i7i.metal-24xl
Существует два сценария: развертывание нового SDDC с инстансами i7i.metal-24xl или миграция рабочих нагрузок с имеющихся узлов i3.metal, i3en.metal и/или i4i.metal на новый i7i.metal-24xl. Тип инстансов i7i доступен только для SDDC версии 1.26v2.
Создание нового SDDC
Все вновь развёртываемые SDDC будут работать на актуальной версии SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции доступны в разделе «Развёртывание SDDC из VMware Cloud Console».
Выберите Create SDDC и укажите тип хоста i7i.metal-24xl.
Задайте размер кластера (минимум 2 хоста) и выполните оставшиеся шаги.
Завершите развёртывание SDDC. VMware автоматически выполняет настройку ESXi, vSAN, vCenter и NSX.
Добавление вторичного кластера в существующий SDDC
К существующему SDDC (после обновления до версии 1.26v2) можно добавить новый кластер на базе i7i.metal-24xl без прерывания выполняющихся нагрузок. После подготовки кластера vSphere vMotion позволяет перенести виртуальные машины из имеющихся кластеров в новый i7i с минимальным воздействием. Новый кластер будет работать под управлением SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции — в разделе «Добавление кластера».
Конвертация кластеров с хостами i3 / i3en / i4i
Миграция с i3.metal, i4i.metal или i3en.metal на i7i.metal-24xl возможна с помощью vSphere vMotion. Для подходящих конфигураций VMware также предоставляет услугу конвертации кластера по запросу. Подробные инструкции — в разделе «Конвертация типов хостов в кластерах».
Следует учитывать, что кластеры, использующие аппаратную версию виртуальных машин 21, не подходят для конвертации с i4i на i7i из-за ограничений совместимости оборудования. Для получения помощи с расчётом размеров и планированием конвертации кластеров следует обращаться к команде Broadcom. Также доступен инструмент VMC Sizer — для оценок на основе хостов, нагрузок или конвертации кластеров.
Начало работы
Для обсуждения того, как i7i.metal-24xl может модернизировать среду VMware Cloud on AWS, рекомендуется связаться с представителем Broadcom. На vmc.broadcom.com доступны настройка нового SDDC, изучение вариантов расчёта размеров и запрос оценки рабочих нагрузок.
Azure VMware Solution управляет глобальным парком производственных приватных облаков, каждое из которых работает в полноценной управляющей плоскости (control plane) VMware NSX и vCenter Server. Когда, например, кластер VMware NSX Manager теряет кворум, NSX может генерировать множество связанных алармов, однако наблюдаемое воздействие выглядит как одновременный каскадный сбой: обновления плоскости управления и конфигурации прекращаются, работоспособность кластера может деградировать, а некоторые симптомы Edge-узлов или транспортных узлов могут проявляться следом — при этом существующая динамическая маршрутизация Tier-0, как правило, остаётся работоспособной. Иными словами, несколько симптомов могут иметь один общий корневой сбой, который необходимо верифицировать с учётом состояния кластера, работоспособности сервисов, хранилища, состояния Compute Manager и связности транспортных узлов. Без модели, кодирующей направленные зависимости между этими уровнями, набор тревог структурно неотличим от множества независимых одновременных сбоев.
Оператор, обрабатывающий каждую тревогу независимо, продлевает инцидент, повторно проходя один и тот же путь распространения сбоя с каждым действием. В условиях производственных масштабов распространение сбоев NSX стабильно опережает ручную сортировку инцидентов. Система автономного самовосстановления приватного облака Azure VMware Solution — это архитектура управления с замкнутым контуром, созданная для устранения именно этого класса сбоев. Система коррелирует сигналы плоскости управления причинно-следственным образом с использованием динамического графа зависимостей в реальном времени, применяет полный стек политик-шлюзов перед любым автоматическим действием, захватывает ограниченное взаимное исключение перед началом выполнения и независимо верифицирует восстановление прежде, чем закрыть инцидент. В данной статье описываются архитектура системы и принятые проектные решения.
Архитектурные компоненты
Azure VMware Solution — это VMware-валидированный сервис Azure первой стороны от Microsoft, предоставляющий приватные облака с кластерами VMware vSphere на базе выделенной bare-metal инфраструктуры Azure. Это позволяет заказчикам использовать существующие инвестиции в навыки и инструменты VMware, сосредоточившись на разработке и запуске своих VMware-нагрузок в Azure.
Каждый архитектурный компонент Azure VMware Solution выполняет следующие функции:
Azure Subscription — управление доступом, бюджетом и квотами для Azure VMware Solution.
Azure Region — физические местоположения по всему миру, объединяющие центры обработки данных в зоны доступности (AZ), а зоны доступности — в регионы.
Azure Resource Group — контейнер для группировки сервисов и ресурсов Azure в логические группы.
Azure VMware Solution Private Cloud — использует программное обеспечение VMware, включая vCenter Server, программно-определяемые сети NSX, программно-определяемое хранилище vSAN и bare-metal хосты ESXi Azure для предоставления вычислительных ресурсов, сетевых ресурсов и хранилища. Поддерживаются также Azure NetApp Files, Azure Elastic SAN и Pure Cloud Block Store.
Azure VMware Solution Resource Cluster — масштабирует приватное облако за счёт дополнительных bare-metal хостов ESXi и программного обеспечения vSAN.
VMware HCX — обеспечивает мобильность, миграцию и расширение сети.
VMware Site Recovery — обеспечивает автоматизацию аварийного восстановления и репликацию хранилища через vSphere Replication. Также поддерживаются сторонние решения DR — Zerto DR и JetStream DR.
Dedicated Microsoft Enterprise Edge (D-MSEE) — маршрутизатор, обеспечивающий связность между Azure и приватным облаком Azure VMware Solution.
Azure Virtual Network (VNet) — частная сеть для соединения сервисов и ресурсов Azure.
Azure Route Server — позволяет сетевым устройствам обмениваться динамической информацией о маршрутизации с сетями Azure.
Azure Virtual Network Gateway — кросс-облачный шлюз для подключения через IPSec VPN, ExpressRoute и VNet-to-VNet.
Azure ExpressRoute — высокоскоростные приватные подключения между центрами обработки данных Azure и локальной или колокационной инфраструктурой.
Azure Virtual WAN (vWAN) — объединяет функции сетевого взаимодействия, безопасности и маршрутизации в единую глобальную сеть.
Что обеспечивает автономное самовосстановление
Система автономного самовосстановления вводит пять гарантированных на системном уровне свойств корректности, ни одно из которых ранее не существовало как системно-принудительное поведение в пути реагирования на инциденты плоскости управления Azure VMware Solution:
Возможность
Что делает Autonomous Self-Heal
Предыдущее состояние
Ограниченное, верифицируемое время восстановления
Измеряет время от первого скоррелированного сигнала до верифицированного стабильного восстановления.
Инциденты закрывались по завершении действия, а не восстановления.
Целостность сигнала при поступлении
Нормализует события, дедуплицирует источники и подавляет флаппинг перед корреляцией.
Конвейера нормализации не существовало. Инженеры получали необработанный поток тревог.
Выполнение с политикой-шлюзом
Атомарно проверяет окна заморозки, бюджеты риска, радиус проблемы, ограничения скорости и согласования перед выполнением.
Единого атомарного стека шлюзов для ограничений и согласований не существовало.
Доказательная база инцидента с возможностью только дополнения
Сохраняет сигналы, топологию, решения, трассировку workflow и верификацию в структурированной записи.
Доказательства находились в отдельных журналах и с трудом воспроизводились.
Прогрессивная модель доверия
Поддерживает режим только-уведомления, чтобы операторы могли проверить обнаружения и предлагаемые действия перед включением.
Автоматизация была бинарной — не было механизма наблюдения за поведением системы до предоставления полномочий на выполнение.
Принципы проектирования
Автономное самовосстановление вводит семь проектных элементов в операции плоскости управления приватным облаком Azure VMware Solution:
Разделение трёх плоскостей (обнаружение, принятие решений, выполнение) с изоляцией поверхностей сбоя по всему управляющему контуру.
Динамический граф зависимостей реального времени, непрерывно обновляемый из потоков событий VMware NSX и vCenter Server, заменяющий статические наборы правил, которые расходятся с реальной топологией.
Трёхвходная модель причинно-следственной корреляции (сила доказательств, временной порядок, направленность зависимости), отличающая причинно-следственные цепочки от совпадающих событий.
Вычисление радиуса проблемы перед выполнением - входной параметр шлюза, обеспечивающий пропорциональное применение политик до совершения любого действия.
Модель фазовых границ (стабилизация, выполнение, верификация), преобразующая событийные осцилляции в демпфированную петлю обратной связи с гистерезисом.
Структура контракта выполнения (триггер, объявление шлюза, спецификация шагов, контракт верификации), принудительно обеспечивающая допустимость области действия и актуальность топологии как системных ограничений.
Единый журнал с возможностью только дополнения, формирующий идентичные записи для автоматизированных и управляемых людьми путей разрешения инцидентов — для целей управления и воспроизведения после инцидента.
Для сбоев в охватываемой области результат — это ограниченное, воспроизводимое время восстановления в любое время суток без участия оператора. Для сбоев в охватываемой области, где автоматическое устранение не может быть санкционировано, результат — детерминированный пакет доказательств, заменяющий воспоминания инженера структурированной, воспроизводимой передачей дел.
Архитектура: обнаружение, принятие решений и выполнение
Автономное самовосстановление разделяет обнаружение, принятие решений и выполнение на отдельные плоскости с единственными, тестируемыми контрактами между ними. Объединение этих функций — более простой подход — разделяет поверхность сбоя между всеми тремя: ошибка в движке выполнения может повредить доказательства, от которых зависит модель корреляции; всплеск объёма тревог может лишить ресурсов оценщика шлюзов; неправильно настроенный шлюз может заблокировать нормализацию сигналов. Разделение устраняет эти режимы взаимозаражения сбоев.
Плоскость обнаружения преобразует необработанные потоки тревог VMware NSX и vCenter Server в стабильные, дискретные кандидаты на инцидент. Конвейер нормализует форматы событий из разных источников, сворачивает избыточные сигналы и применяет окно задержки для фильтрации переходных изменений состояния. Кандидаты, пересекающие границу плоскости, — это подтверждённые, стабильные единицы, единственная форма, которую модель корреляции способна корректно обработать.
Плоскость принятия решений выполняет причинно-следственную корреляцию по динамическому графу зависимостей приватного облака перед оценкой шлюза, формируя ранжированную гипотезу первопричины с оценками уверенности и вычисленной оценкой радиуса проблемы. Плоскость выдаёт ровно один из двух результатов: санкционированное шлюзом разрешение на выполнение или эскалацию с полным пакетом доказательств.
Плоскость выполнения получает токен, ограниченный минимально жизнеспособной областью сбоя, запускает версионированный идемпотентный контрольно-точечный плейбук и закрывает инцидент только после того, как независимая верификация постусловий подтверждает стабильное восстановление в течение окна стабильности. Каждый переход состояния дополняет журнал инцидента.
Журнал инцидентов
Автономное самовосстановление формирует структурированный журнал с возможностью только дополнения для каждого инцидента вне зависимости от пути разрешения. Последовательно фиксируются пять категорий: необработанные и нормализованные сигналы с результатами подавления; снимок топологии на момент обнаружения; полная запись решений, включая результаты корреляции, ранжирование первопричин, оценку радиуса проблемы и трассировку оценки шлюза; трассировка workflow с метаданными шагов и идентификаторами аренды; и результат верификации с результатами постусловий и диспозицией окна стабильности.
Автоматизированные и управляемые людьми пути формируют одинаковую структуру записи — это требование управляемости, а не предпочтение проектирования. Воспроизведение детерминировано: по одному и тому же журналу два рецензента реконструируют одинаковую временную шкалу инцидента.
Итог
Автономное самовосстановление обрабатывает определённое подмножество сбоев плоскости управления NSX и vCenter в приватном облаке Azure VMware Solution. Система не обрабатывает сбои плоскости данных, сбои хранилища, сбои гипервизора, аппаратные сбои или сбои плоскости управления вне смоделированного графа зависимостей. Она не запускает произвольные скрипты, не обходит управление доступом на основе ролей и не переопределяет границы изоляции тенантов. Ограниченная область является источником надёжности системы — система, пытающаяся устранять всё подряд, несёт режимы сбоя, пропорциональные её охвату.
Когда автономное самовосстановление не может предпринять действий, формируемый им пакет доказательств обеспечивает полную структурированную передачу для ответа оператора.
Несмотря на своё название, VCF Installer способен разворачивать как VMware Cloud Foundation (VCF), так и VMware vSphere Foundation (VVF). Многие ошибочно полагают, что установщик жёстко привязан к конкретному продукту в зависимости от имеющихся лицензий: VVF — для VVF-лицензий, VCF — для VCF-лицензий. На самом деле это не так.
VCF Installer не проверяет и не учитывает имеющиеся лицензии в момент развёртывания. Как VVF-, так и VCF-установки по умолчанию запускаются в режиме 90-дневного пробного периода. Лицензирование компонентов выполняется пользователем уже после завершения развёртывания — через VCF Operations, который обращается к Broadcom Business Service Console (BSC) для получения и применения соответствующих прав.
Гибкое развёртывание под разные сценарии
В зависимости от требований может возникнуть необходимость развернуть полный VCF-стек в основном дата-центре, а в региональном или граничном узле — только подмножество инфраструктурных компонентов. Один из типичных сценариев — развёртывание только компонентов VVF (VCF Operations, vCenter и ESX) с последующим лицензированием через VCF-права. Это полностью поддерживаемый вариант использования.
Конечно, отдельные компоненты можно развернуть вручную — через OVA VCF Operations и ISO-установщик vCenter. Однако VCF Installer предоставляет единый сквозной рабочий процесс: он разворачивает все компоненты VVF и автоматически их связывает. Весь процесс можно полностью автоматизировать, передав готовую JSON-конфигурацию.
Лицензирование через Broadcom BSC
После завершения развёртывания VCF Operations регистрируется в Broadcom Business Service Console (BSC), откуда получает и применяет соответствующие права — будь то VVF или VCF. Таким образом, выбор продукта при установке и применение лицензий — это два независимых этапа, которые не следует путать.
Отложенное развёртывание VCF Operations и VCF Automation
VCF Installer предоставляет дополнительную возможность — отложить развёртывание VCF Operations и/или VCF Automation. Это полезно, если требуется подключить их к альтернативным сетям (DVPGs или NSX-сегментам), отличным от Management Network, выбранной при начальной установке.
Часть организаций предпочитает отложить внедрение VCF Automation до того момента, когда они будут готовы перейти к современным методам доставки рабочих нагрузок через портал самообслуживания. В таком случае можно развернуть VCF-стек без VCF Automation, а позже добавить его как операцию Day-N через VCF Operations Fleet Manager.
Ключевой вывод
VCF Installer — крайне гибкий инструмент. Главное — не смешивать два разных понятия: тип развёртывания (VCF или VVF) и имеющиеся лицензионные права. Это две независимые вещи.
VCF Installer разворачивает как VCF, так и VVF вне зависимости от типа лицензий
Оба варианта запускаются с 90-дневным пробным периодом — до применения лицензий
Лицензии применяются через VCF Operations после развёртывания, через подключение к Broadcom BSC
Развёртывание VVF-компонентов с VCF-правами является полностью поддерживаемым сценарием
VCF Automation можно отложить и добавить позже как операцию Day-N
Полная автоматизация возможна через JSON-конфигурацию

 RSS
RSS