Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
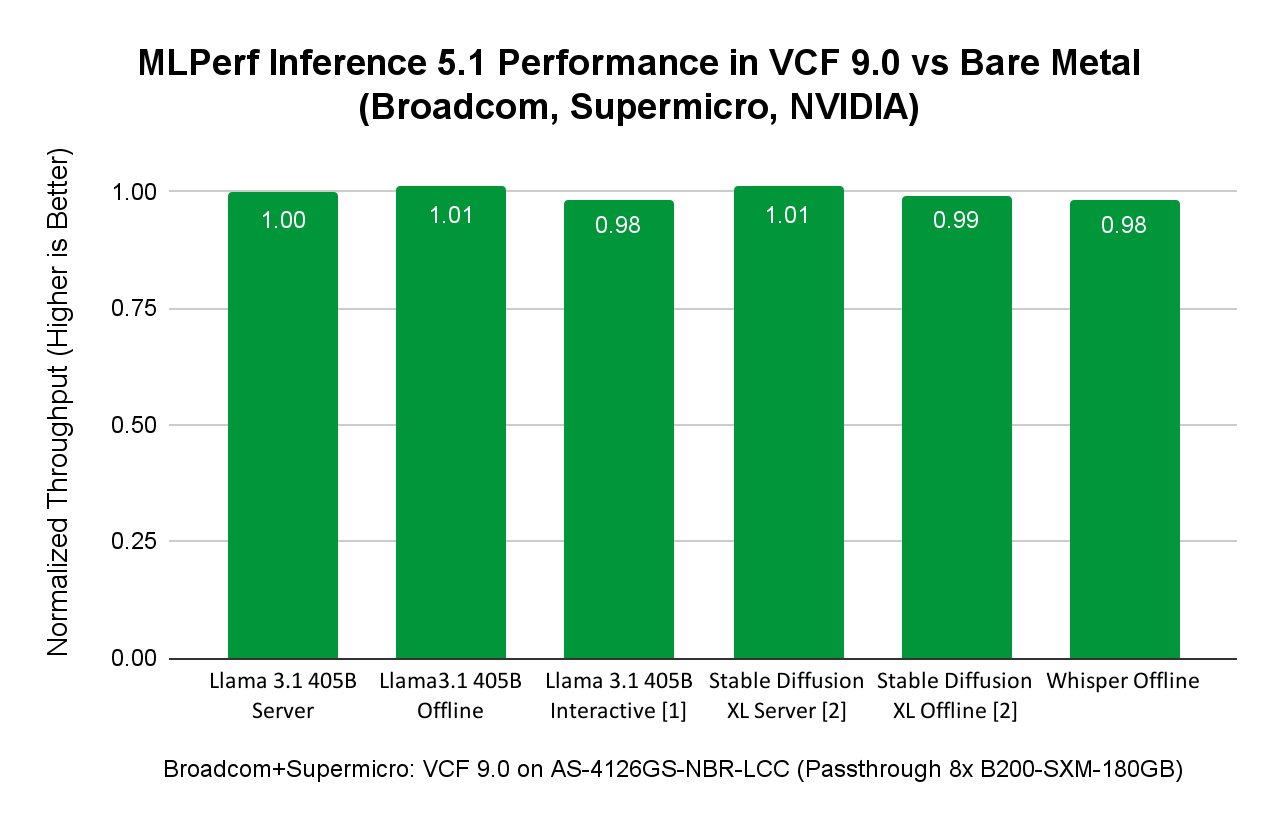
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
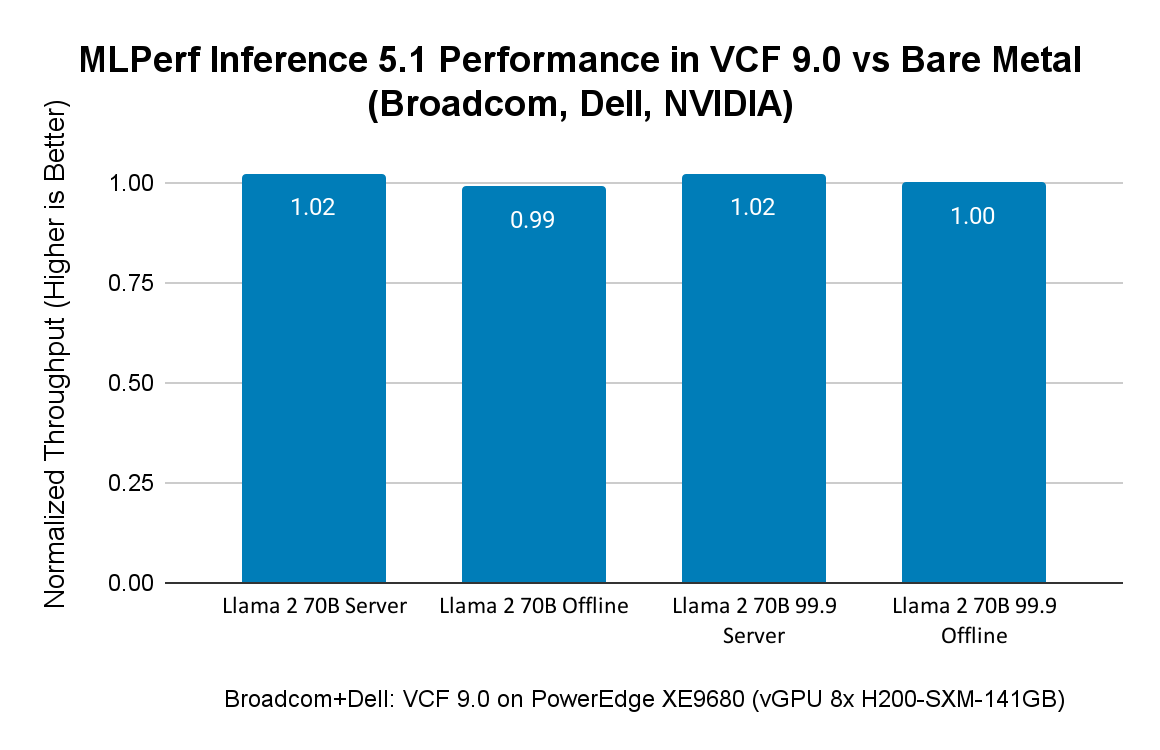
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
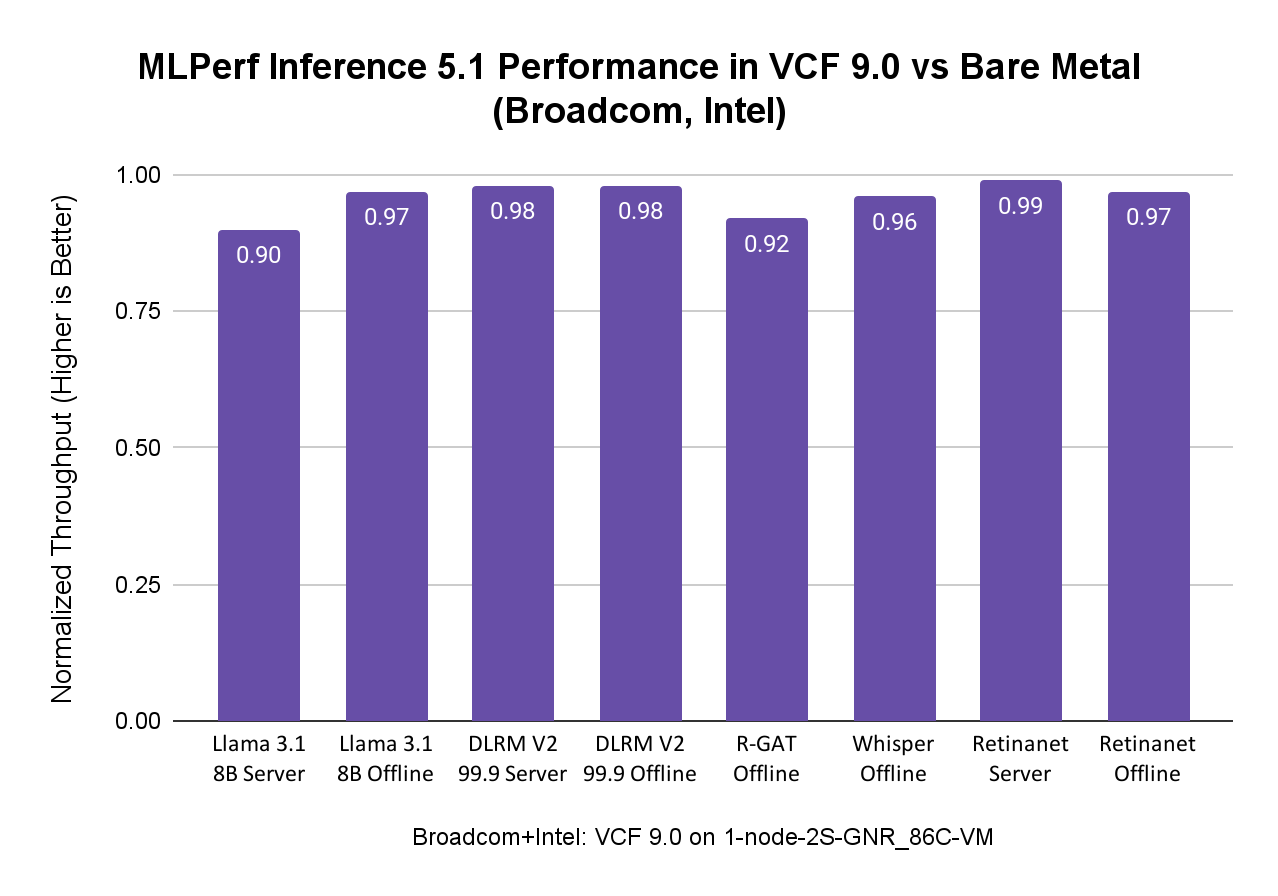
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.

 RSS
RSS