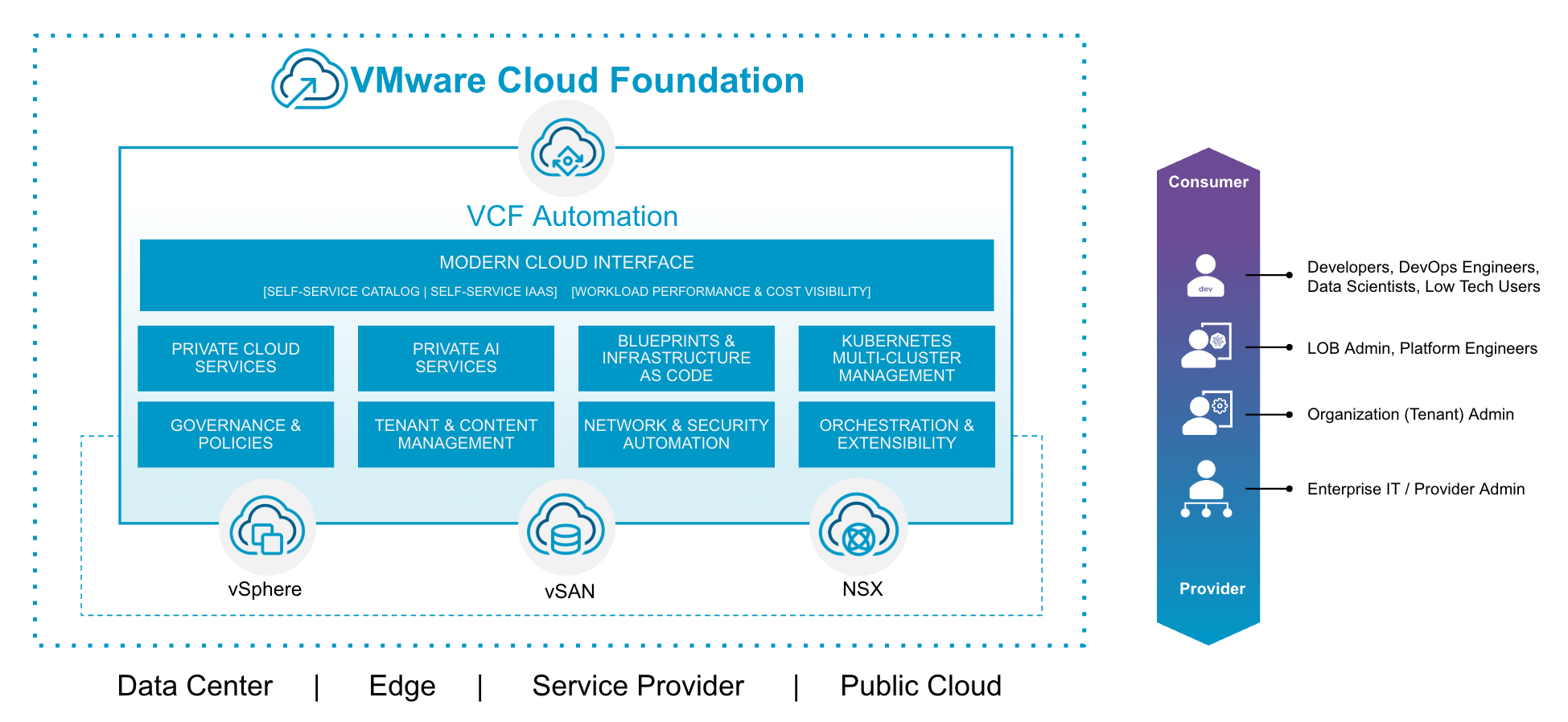
Платформа VMware Cloud Foundation (VCF) заметно прогрессирует от выпуска к выпуску. Версия 9.1 продолжит развитие возможностей, заложенных в VCF 9.0, и предложит более совершенный опыт потребления в рамках модели самообслуживания (self-service) частного облака.
По данным опроса заказчиков Broadcom, проведённого в марте 2026 года и посвящённого оценке VCF 9, компании, применяющие VCF Automation, добились двух существенных результатов. Во-первых, промежуток времени от запроса до готовой к использованию прикладной среды сократился на 49%. Во-вторых, ручные усилия по сопровождению жизненного цикла приложений — от разворачивания и обновления до установки патчей и изменения конфигурации — уменьшились ещё на 49%.
В VCF 9.1 этот фундамент будет расширен новыми возможностями автоматизации, призванными ещё сильнее ускорить выпуск приложений, снизить затраты и масштабировать управляемость и соответствие требованиям в рамках всего предприятия. Далее рассматриваются три ключевых направления, по которым VCF 9.1 преобразит подходы к предоставлению и потреблению сервисов частного облака.
1. Ускоренное развёртывание благодаря расширенным сервисам
Container as a Service
В VCF 9.1 ускорение развёртывания контейнеров достигается за счёт чёткого разделения трёх вариантов исполнения — VM Service, Container Service и VMware vSphere Kubernetes Service (VKS). Такое разграничение позволяет подобрать подходящий runtime под конкретную нагрузку без излишних сложностей.
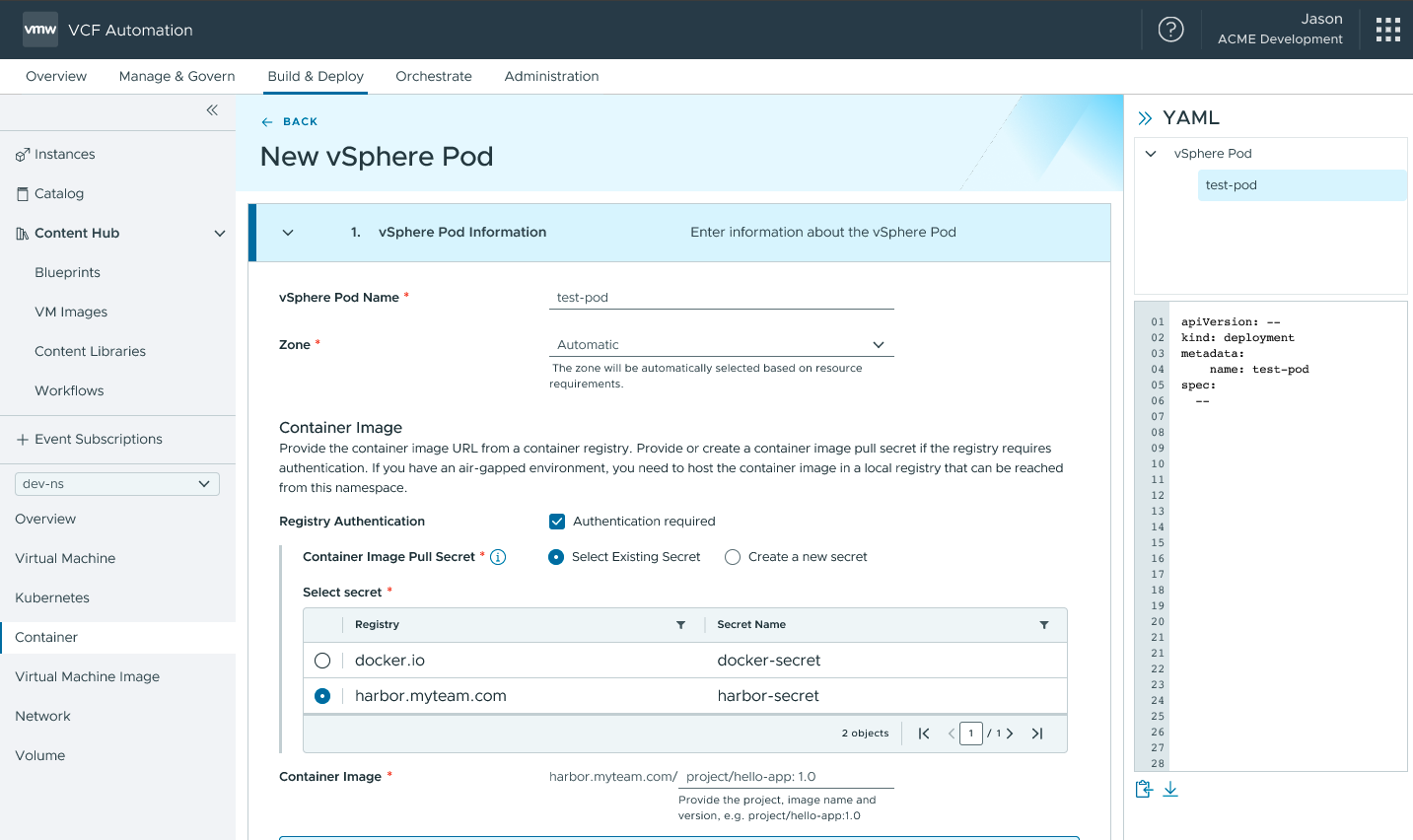
VCF Automation обеспечит доступ к Container Service с полным управлением жизненным циклом. Разворачивать, настраивать, отслеживать, обновлять и удалять контейнеры можно будет прямо через интерфейс — без команд kubectl, без YAML-файлов и без необходимости разбираться в Kubernetes API. Контейнеры станут полноценными runtime-сущностями наряду с виртуальными машинами и кластерами VKS.
Такой упрощённый контейнерный runtime обеспечит высокую гибкость без операционных издержек, связанных с инфраструктурой Kubernetes. Он будет работать непосредственно на ESX без накладных расходов на кластер, предоставляя изоляцию нагрузок и эффективное использование ресурсов в управляемом, по сути serverless-режиме. Платформа VCF полностью автоматизирует планирование, изоляцию, оптимизацию производительности и обновления. Когда архитектура приложения будет развиваться, интерфейс сформирует согласованный YAML, обеспечивающий плавный переход к кластерам VKS — мягкий путь от простых развёртываний контейнеров к полноценным возможностям Kubernetes.
VCF Automation: интерфейс развёртывания Container Service
Fast Deploy для VKS и виртуальных машин
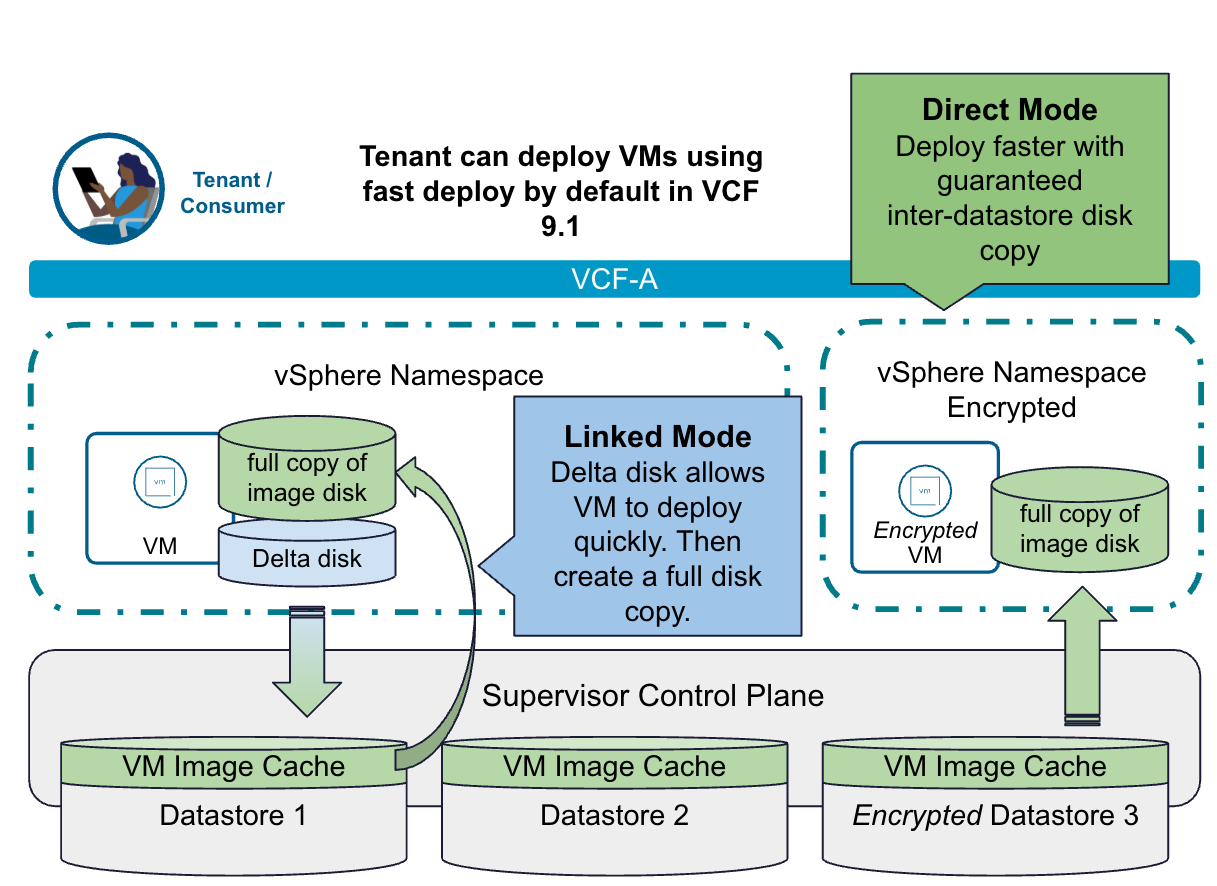
В VCF 9.1 появится механизм Fast Deploy, существенно ускоряющий выделение виртуальных машин и кластеров VKS. После обновления функция автоматически активируется для каждой ВМ, разворачиваемой из blueprint, и не требует настройки в интерфейсе. Работая прозрачно через YAML, она ускорит все жизненные операции на базе виртуальных машин, в том числе развёртывания VM Service и инициализацию кластеров VKS.
Fast Deploy получит два режима под разные сценарии. Linked-Mode использует цепочку связанных клонов с delta-disk и обеспечит мгновенное включение виртуальной машины, при этом полный диск формируется асинхронно в фоне — это сокращает и время развёртывания, и расход хранилища. Direct-Mode ускоряет выделение в зависимости от размера образа ВМ и числа параллельных операций, давая более быстрое развёртывание в масштабе с сохранением полной целостности диска с самого начала.
Развёртывание кластеров VKS заметно ускорится — с 37 минут до 11 минут, то есть на 69%. Обновления кластеров будут выполняться на 75% быстрее: 1,7 часа вместо 6,9 часа, что экономит более 5 часов на каждый цикл обновления. Команды разработки приложений смогут применять Fast Deploy, чтобы по запросу поднимать среды разработки, динамически масштабировать нагрузки, оперативно создавать тестовые окружения, повторяющие промышленные среды, а также быстро разворачивать многоуровневые приложения.
VCF Automation: рабочий процесс Fast Deploy
Централизованное управление сервисами и новые встроенные сервисы
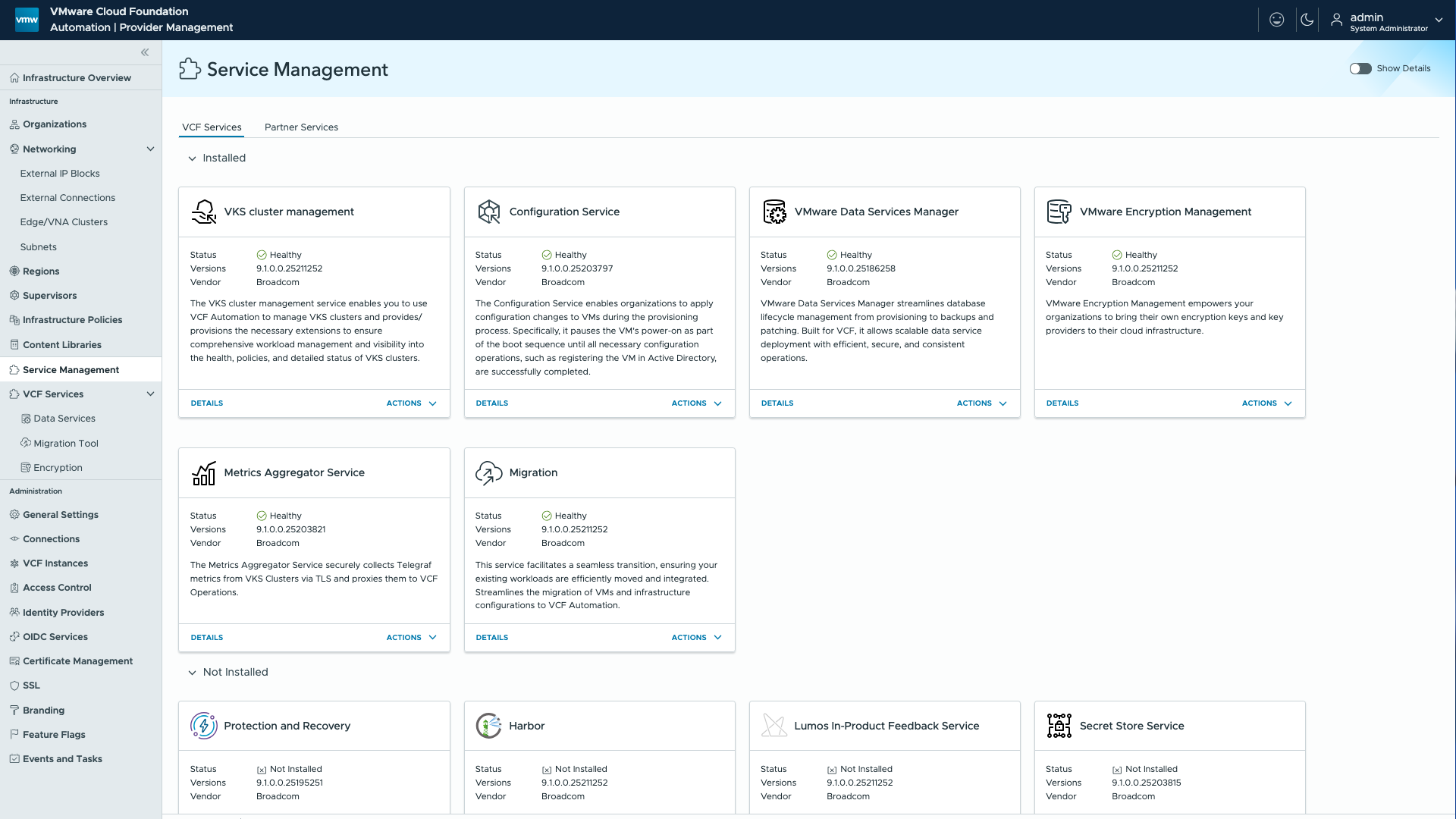
Работа с расширяемыми сервисами в частном облаке станет централизованной и более простой. В VCF 9.1 появится усовершенствованное управление сервисами, опирающееся на региональный экземпляр Harbor для упрощения развёртывания и сопровождения сервисов по всей платформе. Service Manager будет получать и отображать содержимое сервисов непосредственно из этого реестра, благодаря чему расширится круг сервисов, подключаемых и публикуемых для арендаторов.
Вместе с релизом будут поставляться десять предустановленных сервисов, автоматически синхронизируемых в составе базовой конфигурации платформы. Они отображаются в интерфейсе в виде отдельных плиток: Harbor, VMware Data Services Manager, Secret Store Service, сервис автоподключения для управления кластерами VKS (Auto-Attach Service), Encryption Management (BYOK) и другие.
Такой централизованный подход обеспечит более быстрый доступ к возможностям платформы: сервисы доступны по умолчанию и сразу пригодны к использованию через интерфейс. Это позволит ускорить внедрение во всех регионах и упростить эксплуатацию за счёт централизованных обновлений и сокращения ручной административной работы, что приведёт к согласованности окружений.
VCF Automation: интерфейс управления сервисами
Расширенный Day-2 жизненный цикл виртуальных машин
В VCF 9.1 потребители смогут самостоятельно изменять конфигурацию CPU, памяти, хранилища и сети уже после развёртывания. Среди расширенных возможностей — изменяемость сети, снапшоты и VM Groups. Это устранит административные узкие места и сократит циклы обслуживания заявок с дней до минут.
Сетевые улучшения
Расширенное управление IP для провайдеров и арендаторов
Арендаторы смогут самостоятельно резервировать IP-адреса и управлять ими с поддержкой нескольких CIDR и интеграцией с Infoblox. Это позволит реализовывать сложные сетевые конфигурации, например NAT «один к одному», без зависимости от рабочих нагрузок.
Гибкие Transit Gateway для сложных топологий маршрутизации
VCF 9.1 даст возможность создавать множественные внешние подключения и несколько Transit Gateway на одного арендатора с изолированными VPN, статическими маршрутами и пользовательскими настройками NAT. Это позволит гибко выстраивать межсайтовую маршрутизацию и точно управлять трафиком без внешнего маршрутизирующего оборудования.
Самообслуживание по сети и безопасности для арендаторов
В VCF 9.1 будет доступно сетевое самообслуживание, предоставляющее прямой доступ к ЦОД, выведение частных сетей, развертывание VPN и Gateway Firewall. Это расширит возможности арендаторов и позволит им самостоятельно управлять сетевой безопасностью.
Общие подсети и VLAN-расширения
В VCF 9.1 появятся подсети уровня организации и расширения VLAN с прямым подключением на уровне L2. Это откроет путь к сложным сетевым архитектурам, включая виртуальные машины с несколькими сетевыми адаптерами и прямое подключение к физической фабрике на уровне нагрузок арендатора.
Подключение к существующим VLAN через распределённые Transit Gateway
VCF 9.1 представит распределённые Transit Gateway, которые подключают VPC напрямую с хостов ESX с использованием только идентификатора VLAN, без Edge-кластеров и динамической маршрутизации. Это упростит эксплуатацию для унаследованных VLAN-окружений и обеспечит прямую коммуникацию между виртуальными машинами VCF и не-NSX ВМ.
Упрощённые межсетевые экраны и автоматизированная безопасность между VPC
VCF 9.1 позволит реализовать модель Zero Trust с автоматизированной микросегментацией, правилами межсетевого экрана и метками соответствия с использованием vDefend. Это даст автоматизированную безопасность с первого дня, исключая ручную настройку и обеспечивая единообразное применение политик.
2. Улучшенное управление жизненным циклом приложений и нагрузок
App Stack Formation
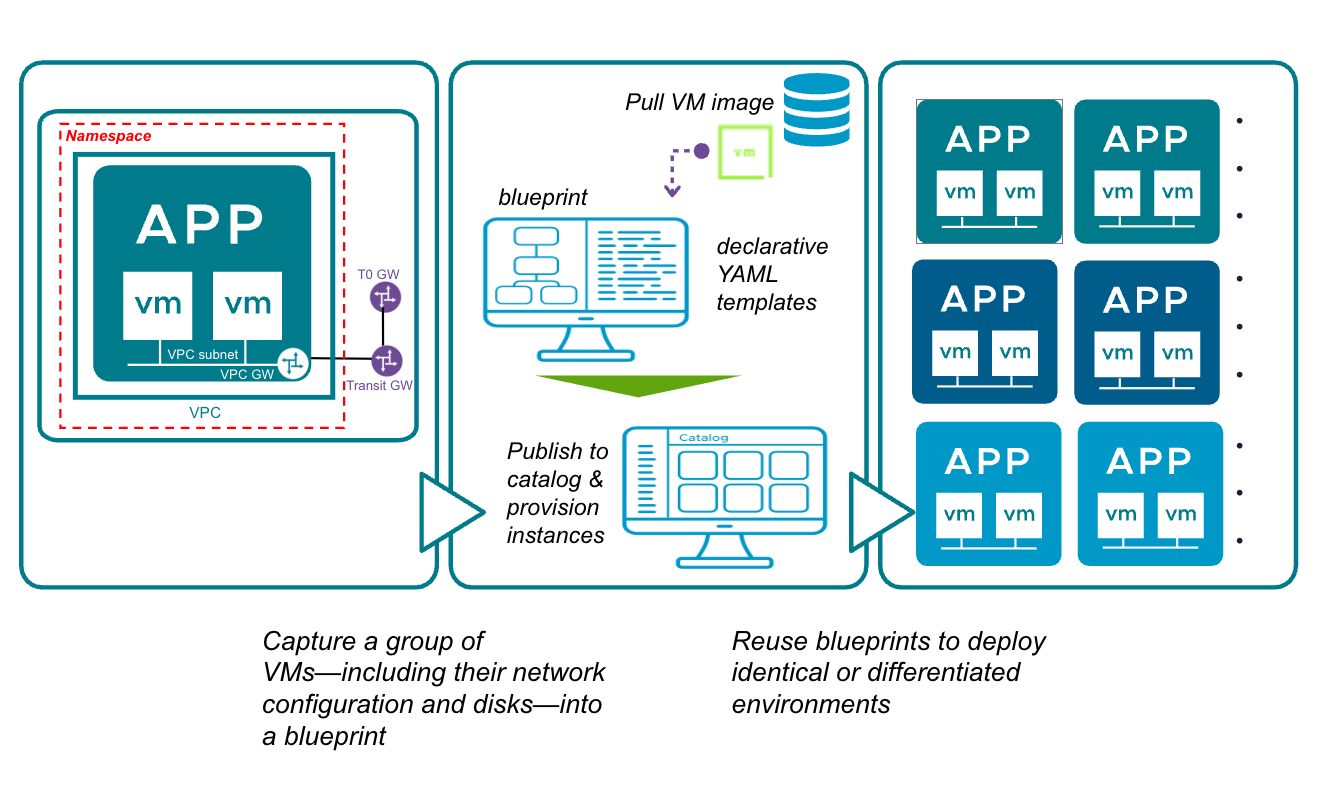
В VCF 9.1 будет реализован сценарий формирования прикладного стека (App Stack Formation) — принципиально новый подход к созданию blueprint. Он позволит пользователям зафиксировать работающую топологию — группу ВМ, их сетевую конфигурацию и диски — в виде единого blueprint. Эта возможность превратит живые среды приложений в переиспользуемые шаблоны, обеспечивая мгновенную, идентичную и масштабируемую доставку сервисов.
Вместо повторной сборки среды с нуля платформенные инженеры смогут фиксировать работающие ВМ вместе с их сетевыми настройками (VPC, подсети), дисками хранения (PVC), параметрами гостевой ОС и зависимостями между ВМ. Также можно будет задать последовательности запуска и остановки виртуальных машин внутри стека, чтобы многоуровневые приложения запускались в правильном порядке. Многоуровневые приложения будут собираться в единый переносимый пакет OVF/OVA, что устранит расхождения между средами Dev, Test и Prod. Управление всем прикладным стеком как одним объектом упростит операции старта/остановки и снапшотов с поддержкой заданного порядка включения. Провайдеры смогут предлагать готовые прикладные стеки через каталоги, развивая самообслуживание для арендаторов и сокращая время вывода новых сервисов на рынок.
VCF Automation: рабочий процесс App Stack Formation
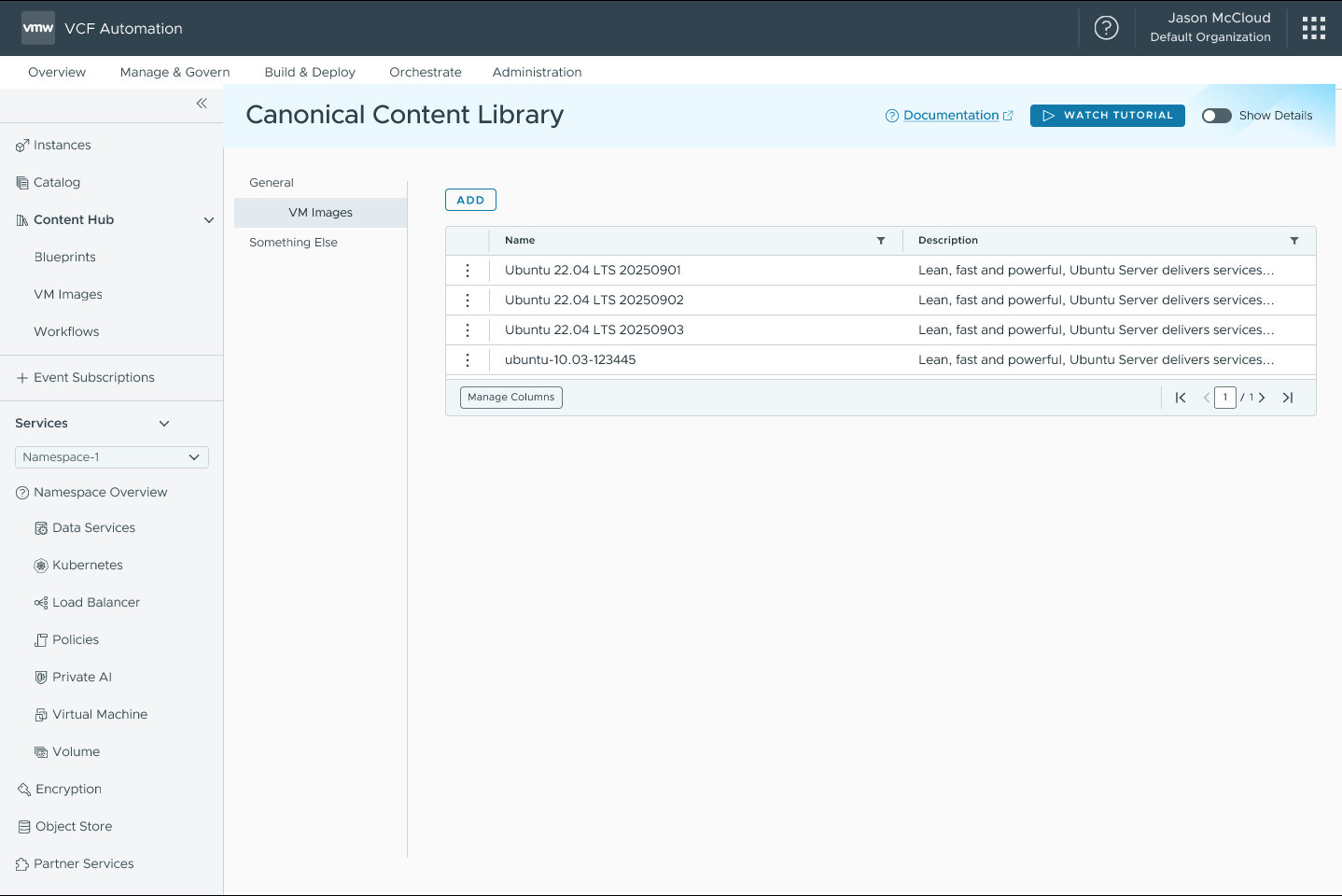
В VCF 9.1 появится встроенная интеграция с библиотеками контента Canonical, обеспечивающая поставку оптимизированных под VCF образов Ubuntu LTS. В эти образы включены пакеты — драйверы ВМ и инструменты, необходимые для успешного развёртывания и работы поверх VCF; они входят в базовую лицензию VCF для клиентов с активной подпиской.
Интерфейс обеспечит удобный поиск и выбор образов Ubuntu непосредственно в VCF Automation, избавляя пользователей от необходимости переходить на внешние сайты для поиска и импорта этих образов. Корпоративные ИТ-администраторы смогут подписаться на сопровождаемые Canonical библиотеки контента и автоматически синхронизировать официальные образы Ubuntu (например, 24.04 LTS) прямо в окружение, пополняя VM Images без ручных загрузок. Это обеспечит стабильность развёртываний, повышенный уровень безопасности и операционную эффективность за счёт эффективного управления патчами для критических уязвимостей и уязвимостей высокого уровня. Broadcom будет включать актуальные патчи в полные образы и размещать их в каталоге решений, гарантируя автоматическую поставку официального и проверенного контента. Клиенты получат упрощённый доступ к доверенным образам Ubuntu через защищённое нативное подключение.
VCF Automation: библиотека контента Canonical
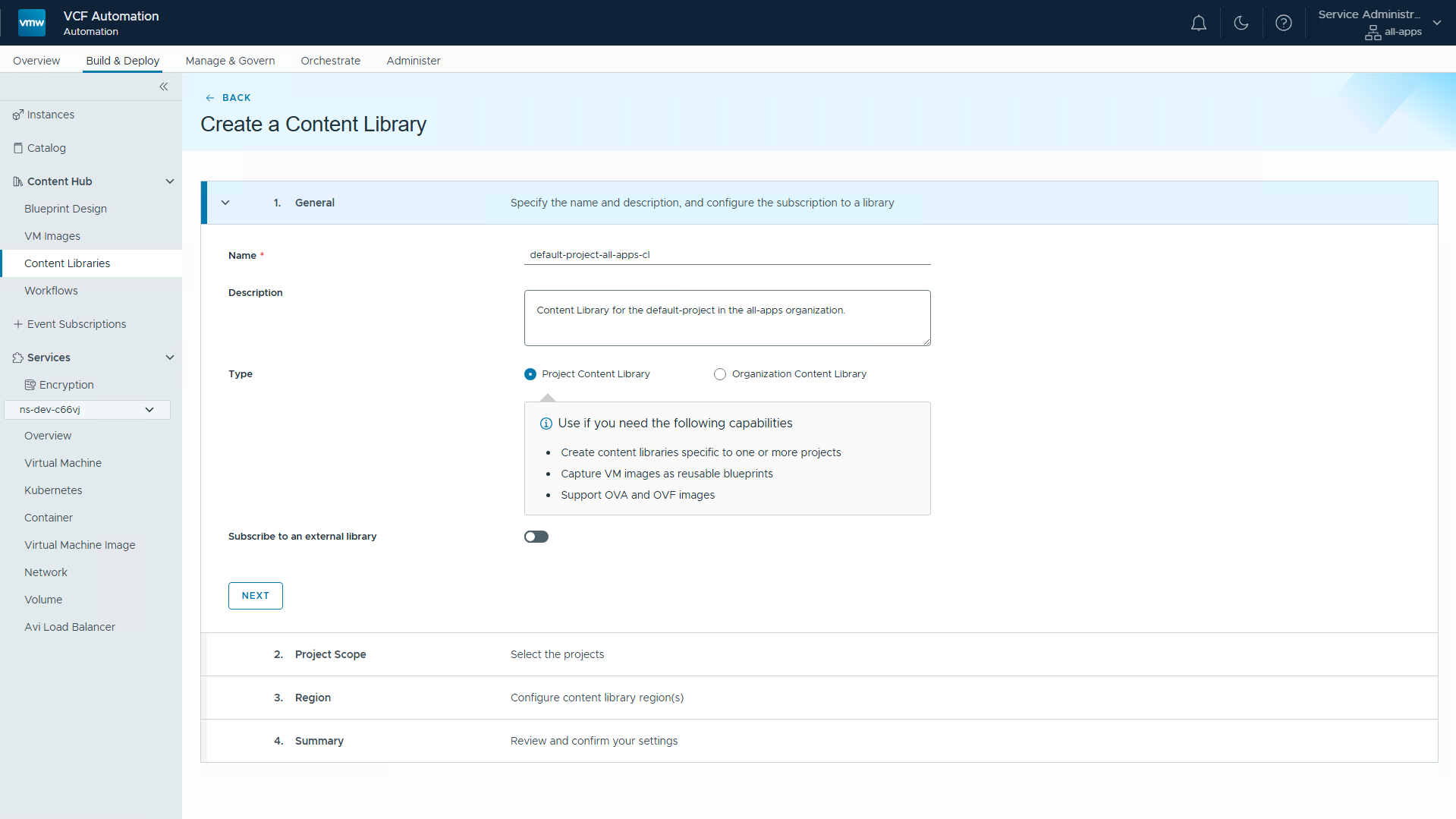
Библиотеки контента на уровне проектов для автономии команд
В VCF 9.1 будут реализованы Project-level Content Libraries: администраторы организации смогут создавать отдельные библиотеки контента и явно привязывать их к одному или нескольким выбранным проектам внутри организации. После создания система предоставит право записи администраторам проектов и продвинутым пользователям проектов, позволяя им непосредственно публиковать, писать и управлять образами (например, ISO и OVA) в рамках выделенной библиотеки.
Это обеспечит автономию, снизив зависимость команд проектов от администраторов организации в части курирования и сопровождения библиотек контента, специфичных для проектов и приложений. Также появится возможность расширения: можно будет применять процессы Packer, в которых участники проектов публикуют собственные образы ВМ. Дополнительно VI-администраторы смогут использовать существующие шаблоны ВМ для построения библиотек контента VCF Automation без необходимости создавать новые образы. Это устранит операционное узкое место, при котором команды проектов прежде не могли управлять собственными библиотеками или напрямую загружать необходимые файлы вроде ISO и OVA, что в итоге шло вразрез с идеей потребительского самообслуживания и тормозило гибкую разработку.
VCF Automation: управление библиотекой контента проекта
Дополнительные возможности
Делегирование пространств имён и управление
VCF 9.1 позволит администраторам организации делегировать создание пространств имён администраторам проектов и платформенным инженерам с заранее определёнными ограничениями. Это устранит заторы, давая прикладным командам возможность самостоятельно управлять пространствами имён при сохранении управляющего контроля.
Расширения Terraform Provider для арендаторов в политике и управлении контентом
В VCF 9.1 будет расширен Terraform Provider с поддержкой полного развёртывания окружений, управления жизненным циклом образов ВМ и реализацией политик как кода, Day-2-операций и IaaS. Это позволит программно применять политики и реализовывать сценарий App Stack Formation через подход infrastructure-as-code.
3. Усиленное управление, безопасность и прозрачность затрат
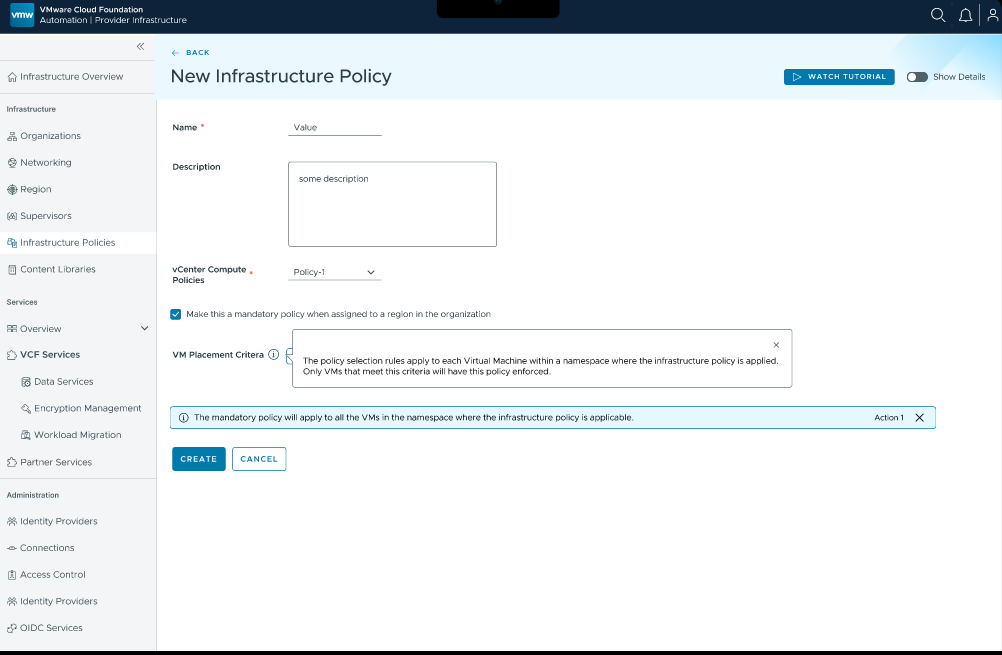
Новые политики размещения инфраструктуры для лучшего контроля над нагрузками
В VCF 9.1 появятся политики размещения инфраструктуры, позволяющие администраторам задавать критерии размещения виртуальных машин с учётом их атрибутов и нацеливаться на конкретные подмножества ВМ. Система поддержит обязательный режим политики, который автоматически применяется при назначении организации и помогает гарантировать исполнение заданных правил размещения без участия арендатора.
Новые политики размещения инфраструктуры позволят оптимизировать лицензирование за счёт размещения по типу ОС и упростят соблюдение требований, давая инструменты для точного контроля того, где именно располагаются нагрузки, что облегчит соответствие нормативным или внутренним стандартам. Дополнительно это поможет облачным администраторам обеспечивать оптимальное размещение нагрузок для соответствия требованиям без ограничения возможностей самообслуживания.
Политики размещения обеспечат автоматическое распределение нагрузок по конкретным хостам на основе атрибутов вроде гостевой ОС или меток, гарантируя, что определённые типы ВМ последовательно попадают на наиболее подходящую или предназначенную для них инфраструктуру. Обязательный режим политики обеспечит строгое исполнение размещения ВМ согласно требованиям рабочих нагрузок в мультиарендных средах при сохранении управляемости через политическое регулирование.
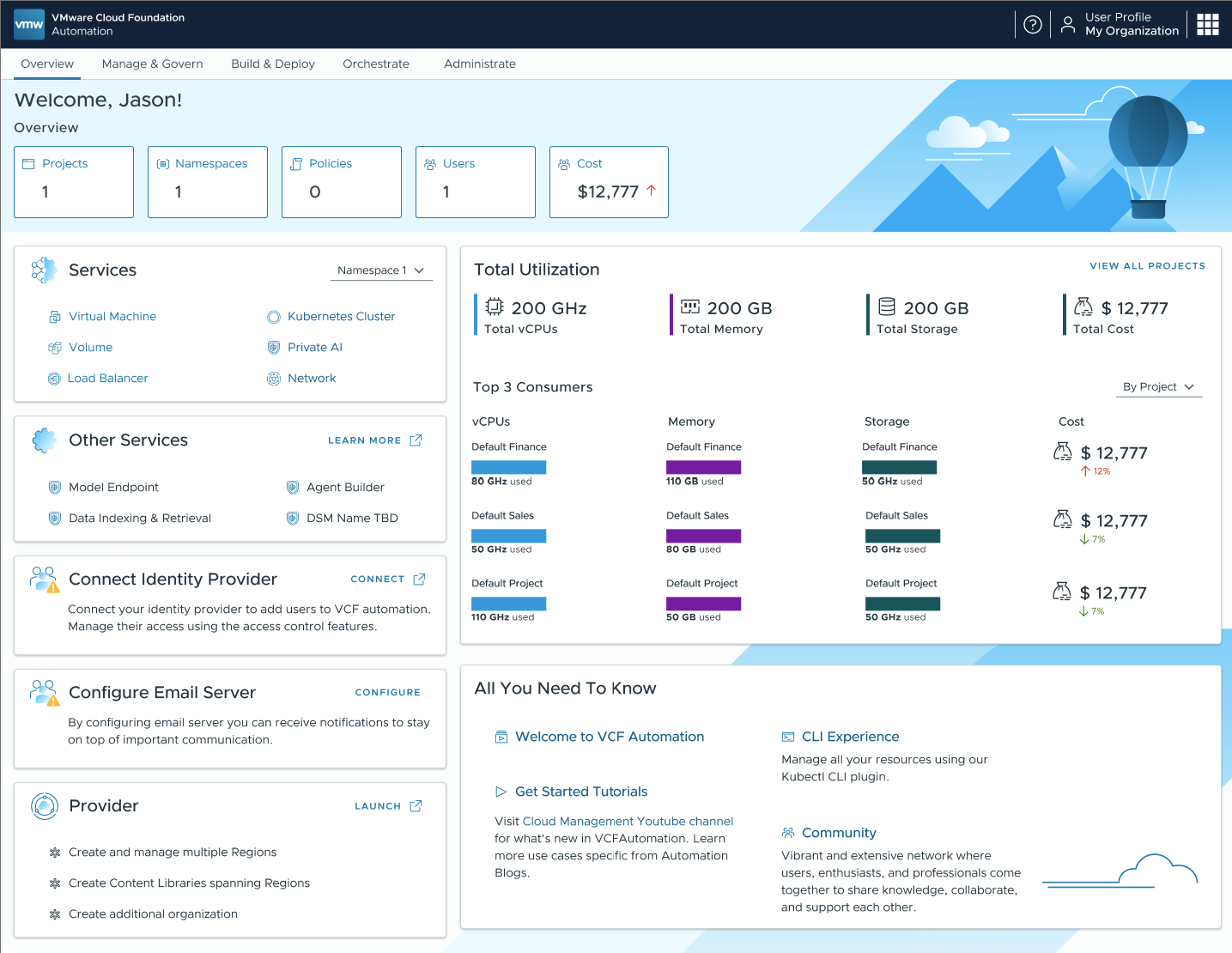
VCF 9.1 будет выводить данные о затратах прямо в панелях управления Org и Project, позволяя администраторам видеть совокупные затраты на этих уровнях и переходить к детализации по конкретным затратам и инвентарю для отдельных проектов и пространств имён. VCF Automation предложит предварительную тарификацию (оценку стоимости по rate card VCF Operations) в рамках процесса развёртывания, давая администраторам возможность назначать цены сервисам частного облака, таким как VM Service и VKS Service. VCF Automation поддержит оповещения и отчёты по электронной почте. Администраторы смогут указывать конкретные адреса для получения уведомлений по биллингу, отчётам о затратах и критическим оповещениям — в частности, по квотам или доступности сервисов — с возможностью формирования и прямой загрузки отчётов и счетов.
Расширенная прозрачность с подробной детализацией затрат по проектам и пространствам имён поможет организациям управлять потреблением и снижать неэффективные капитальные расходы. Платформа будет формировать культуру осознанного отношения к затратам и финансовую подотчётность, позволяя потребителям и арендаторам видеть стоимость развёрнутых ими ресурсов, а администраторы получат проактивные уведомления по электронной почте без необходимости вручную следить за системой.
VCF Automation: панель прозрачности затрат
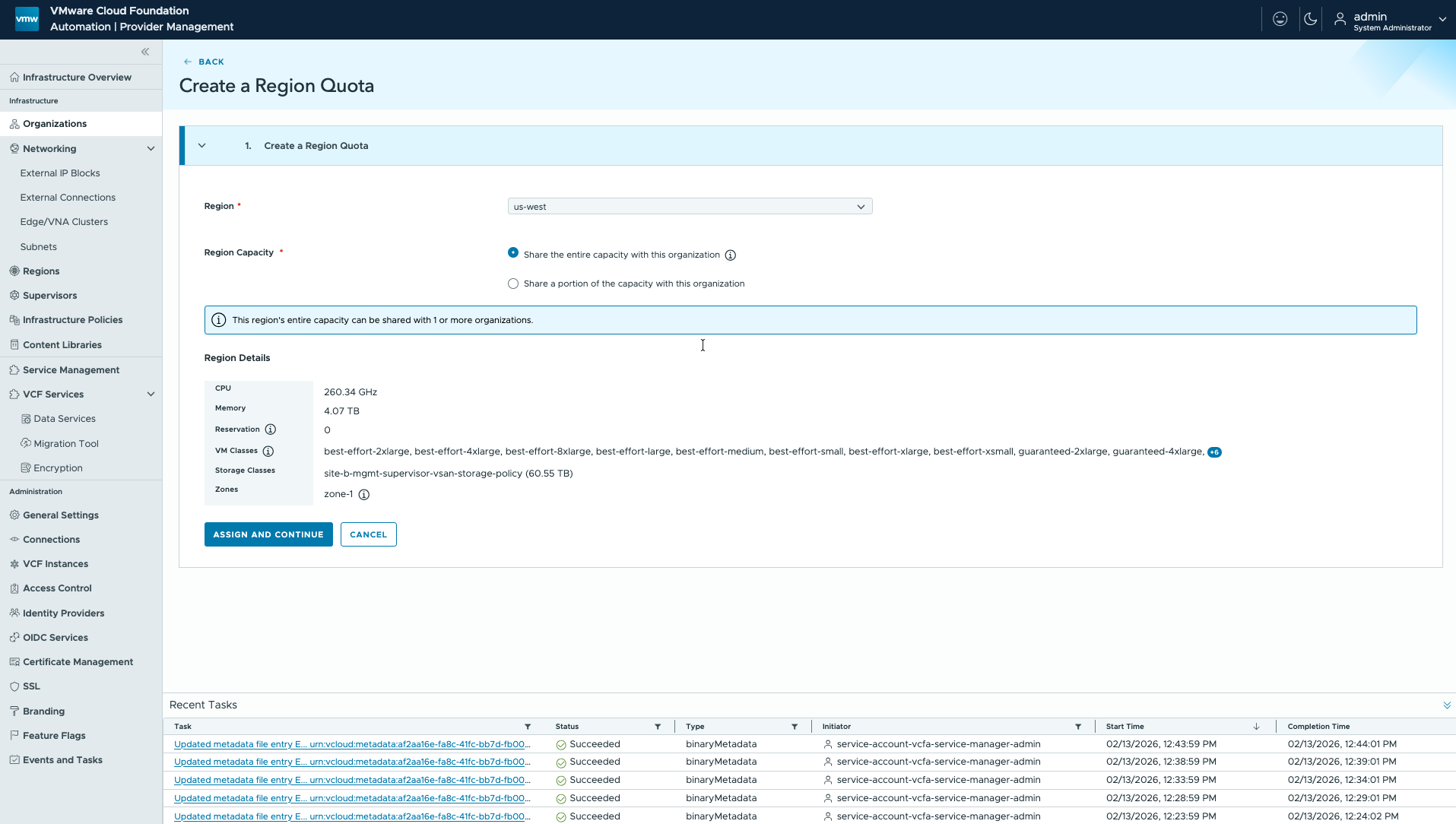
Полностью выделенные региональные квоты для организаций-арендаторов
В VCF 9.1 появится механизм полностью выделенной региональной квоты, позволяющий корпоративным ИТ-администраторам выделять всю ёмкость региона (квоту 100%) одной организации-арендатору без привязки к конкретным зонам. Администраторы смогут применять одинаковые лимиты и резервации CPU и памяти ко всем доступным зонам, отвязывая регион от единственного Supervisor и допуская наличие нескольких Supervisor и vCenter в рамках одной региональной квоты. Эти возможности упростят выделение ресурсов и облегчат управление инфраструктурой для предприятий, которым не требуется строгое исполнение квот.
В режиме Day 2 администраторы смогут изменять выделения, добавляя резервации или уменьшая квоту с полного региона до конкретных лимитов. Это превратит регион в единый пул ресурсов, позволяя организациям потреблять инфраструктуру в нескольких Supervisor вместо ограничения одним. Организации получат совместный доступ к инфраструктурной ёмкости по принципу первой очереди, что повысит гибкость и эффективность использования ресурсов в рамках окружения.
VCF Automation: распределение региональных квот
Единый API управления кластерами VKS
VCF 9.1 стандартизирует API управления кластерами VKS, приведя его к шаблону VCF API и объединив управление ВМ, контейнерами и VKS. Это обеспечит согласованное взаимодействие со всеми сервисами и упростит управление ресурсами через VCF CLI, Terraform или kubectl.
VCF 9.1 переопределит возможности инфраструктуры частного облака. Благодаря VCF Automation, VMware Cloud Foundation поможет запустить и масштабировать мультиарендное частное облако, в котором прикладные команды смогут собирать рабочие нагрузки быстрее, безопаснее и с меньшими затратами. Будь то воспроизведение масштабируемости и гибкости публичного облака в собственном ЦОД, внедрение единого интерфейса потребления для виртуальных машин и контейнеров либо повышение гибкости бизнеса и ИТ за счёт самообслуживания — VCF 9.1 предоставит необходимые инновации.
Будущее корпоративных ИТ уже здесь: настоящий облачный опыт в сочетании с безопасностью, производительностью и контролем частного облака. VCF 9.1 предоставит платформу, возможности и автоматизацию для превращения ЦОД в современное самообслуживаемое частное облако, расширяющее возможности прикладных команд при сохранении управления и соответствия требованиям, необходимых корпоративному ИТ.
Для многих организаций внедрение Kubernetes начиналось как технологическая инициатива, однако превращение его в надёжную корпоративную платформу нередко оказывалось значительно сложнее, чем предполагалось. То, что задумывалось как инновация, быстро становилось источником сложностей:
Растущие операционные издержки
Фрагментированные среды
Пробелы в безопасности, нормативном соответствии и компетенциях
Замедление вывода продуктов на рынок
В то же время ставки повышаются. Инициативы в области искусственного интеллекта, приложения, работающие с большими объёмами данных, и цифровой клиентский опыт сегодня зависят от инфраструктуры, которая должна быть не только масштабируемой, но и предсказуемой, безопасной и эффективной. Согласно последнему отчёту State of Platform Engineering Report, 64% специалистов по платформенной инженерии называют Kubernetes одним из ключевых направлений для достижения автоматизированного, надёжного и стандартизованного развёртывания приложений.
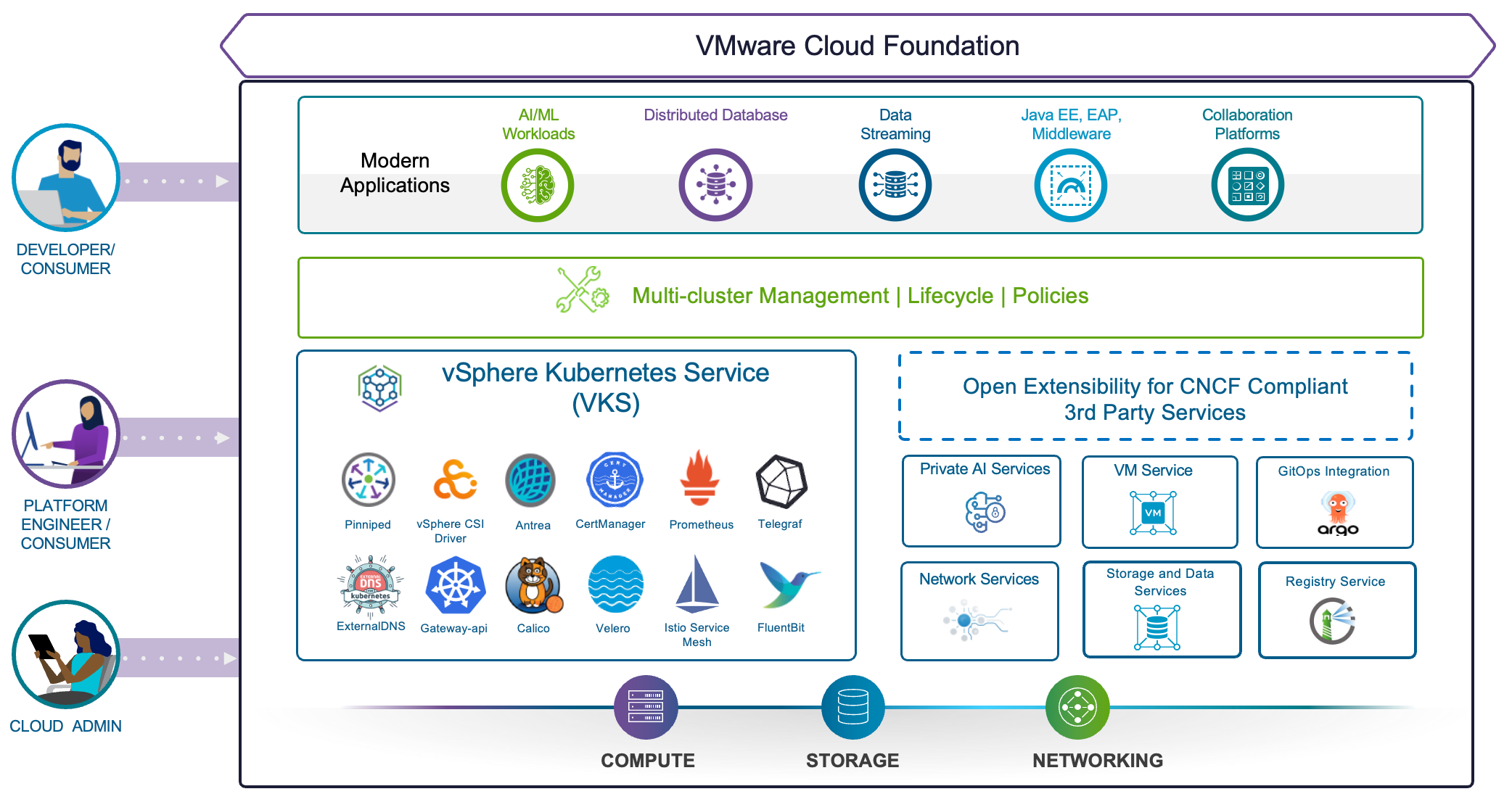
С появлением VMware Cloud Foundation (VCF) и развитием её компонента VMware vSphere Kubernetes Service (VKS) фокус сместился с управления инфраструктурой как такового на достижение конкретных бизнес-результатов.
VCF закрывает ключевые приоритеты, предоставляя единую платформу для контейнеров и виртуальных машин со встроенной сертифицированной CNCF средой выполнения Kubernetes, реализованной через компонент VKS. VMware VKS даёт инженерам платформ возможность развёртывать и обслуживать кластеры Kubernetes, опираясь на богатый набор облачных сервисов, входящих в VCF, а также на сторонние CNCF-совместимые сервисы (рис. 1). VKS — одна из первых Kubernetes-платформ, получивших сертификацию AI conformant, которая к тому же упрощает управление множеством кластеров, позволяя предприятиям уверенно запускать ИИ и другие современные рабочие нагрузки.
Рис. 1. VKS предлагает комплексный набор облачных сервисов вместе со всеми сторонними CNCF-совместимыми сервисами.
Императив CIO: меньше сложности, больше скорости
Сегодня перед ИТ-директорами стоит двойная задача — обеспечить безопасность, управляемость, контроль и нормативное соответствие, одновременно ускоряя инновации, и всё это при неизменном или сокращающемся бюджете.
Исторически эти цели вступали в противоречие. Однако благодаря снижению совокупной стоимости владения (TCO), более быстрому выходу на ценность, повышенной безопасности и упрощённой операционной модели VKS быстро становится предпочтительной средой выполнения Kubernetes для современных приложений. Чтобы помочь клиентам максимизировать отдачу от инвестиций, VKS в составе VCF 9.1 предоставит три ключевых преимущества:
1. Повышенный масштаб и производительность для поддержки критически важных бизнес-задач.
2.
Более высокую операционную эффективность, снижающую затраты и сложность.
3.
Встроенную по умолчанию безопасность и соответствие требованиям.
VCF 9.1: краткий обзор улучшений Kubernetes
VMware VKS в VCF 9.1 принесёт улучшения сразу по трём важнейшим направлениям:
Масштаб и производительность: 500 кластеров на один control plane, ускорение развёртывания кластеров до 70%, ускорение обновлений до 75%, поддержка нескольких сетей.
Операционная эффективность: интеллектуальное размещение пулов узлов, несколько кластеров в одной зоне, распределённый transit gateway.
Безопасность и соответствие требованиям: автоматизированное внедрение секретов и тонкое управление доступом.
Повышенный масштаб и производительность для критически важных бизнес-задач
Будь то пиковые нагрузки в розничной торговле, глобальные сервисы или крупномасштабные AI-задачи — инфраструктура должна реагировать мгновенно и при этом не терять стабильности.
В VCF 9.1 возможности VKS позволят:
Быстро выделять ресурсы — время развёртывания сократится до 70%.
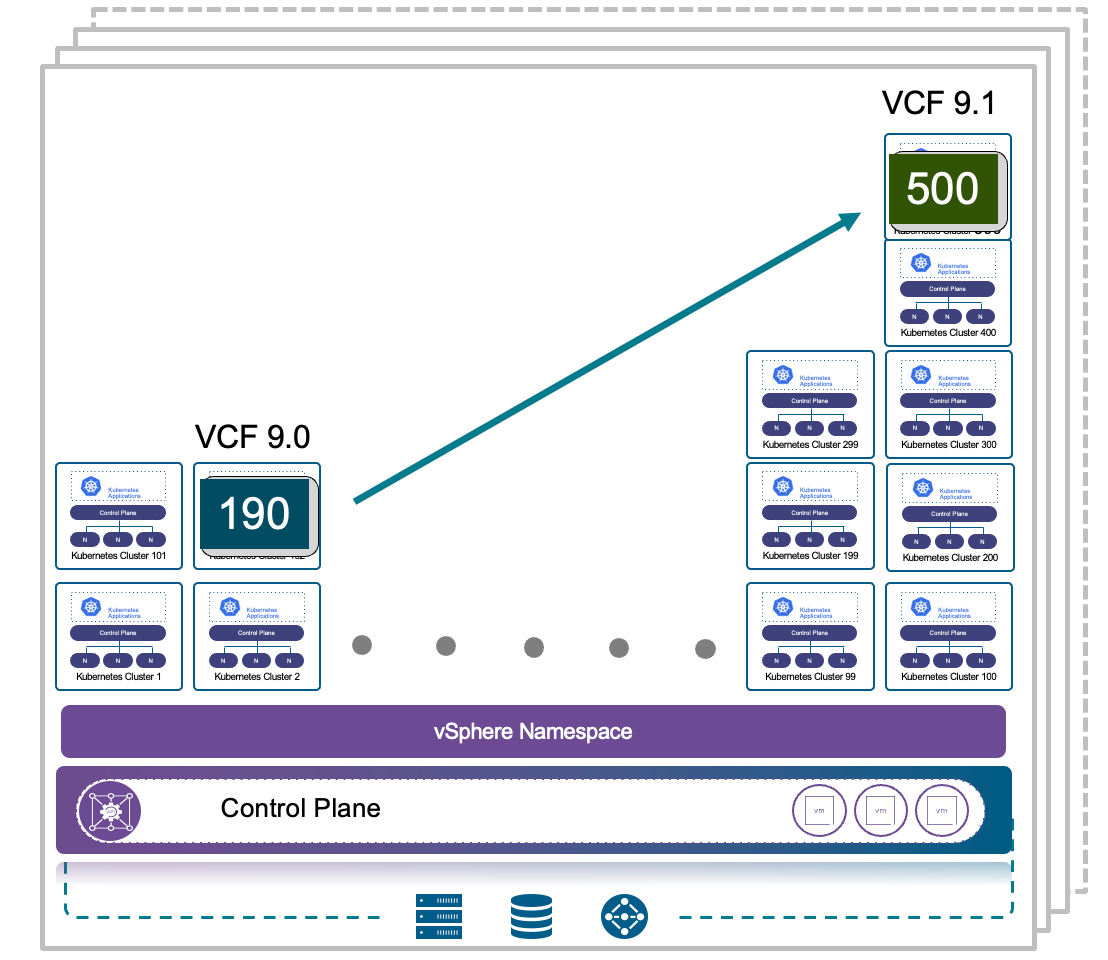
Достигать огромного масштаба — до 500 кластеров в рамках одного control plane.
Повышать производительность — изолировать критически важные приложения для лучшего качества обслуживания.
Выгоды для бизнеса:
Более быстрый запуск новых сервисов, улучшенный клиентский опыт во время пиковых нагрузок и возможность поддерживать требования современных рабочих нагрузок без перепроектирования инфраструктуры.
Выгоды для платформенной инженерии:
Современный ландшафт приложений охватывает широкий спектр требований к производительности — от высокопроизводительных и чувствительных к задержкам приложений до интенсивных по GPU AI-нагрузок. Организации стремятся к более сильной изоляции, уменьшению зоны поражения при сбоях и кастомизированным требованиям к кластерам, что увеличивает потребность в большем количестве кластеров.
Рис. 2. VKS поддержит до 500 рабочих кластеров на один control plane для лучшей изоляции рабочих нагрузок и значительно меньшей площади атаки.
Для более крупных инфраструктур можно развернуть несколько экземпляров control plane и централизованно управлять ими через VCF Automation (VCFA). Это обеспечивает горизонтальное масштабирование при сохранении единообразия операций.
Внезапные всплески спроса, типичные для электронной коммерции в сезон распродаж, потокового видео или финансовых приложений во время рыночной волатильности, требуют инфраструктуры, способной реагировать в реальном времени. Кроме того, организациям часто сложно оперативно подготавливать зеркальные среды для тестирования перед выводом в производственную среду. Чтобы ответить на эти потребности, VKS повысит операционную скорость: развёртывание новых кластеров ускорится до 70%, а окна обновлений сократятся до 75%.
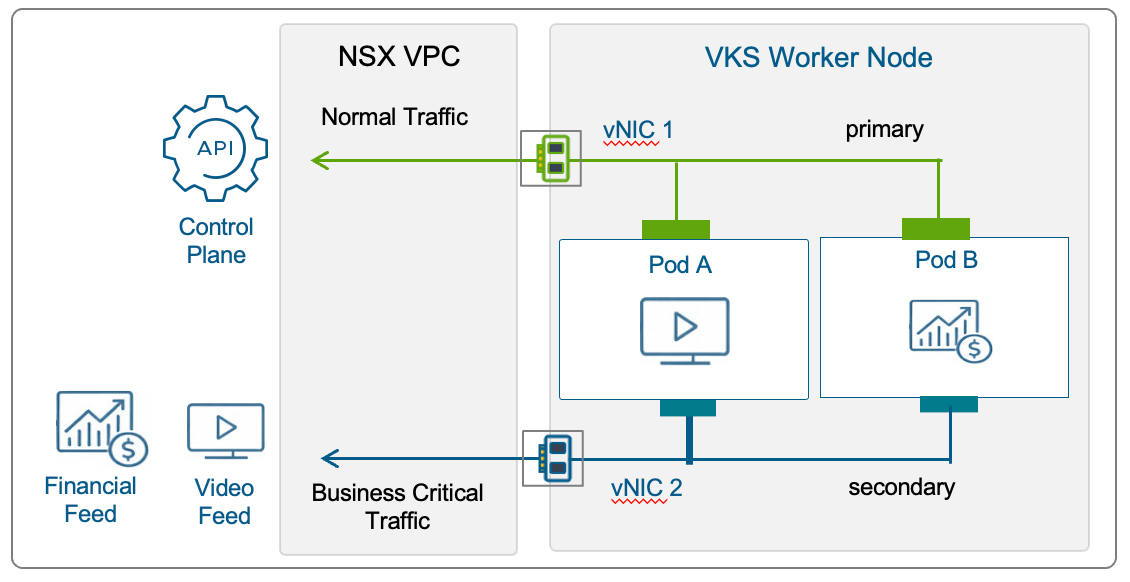
Чтобы обеспечить лучшее качество обслуживания для трафикоёмких потоковых приложений, чувствительных к задержкам финансовых сервисов или регулируемых приложений с требованиями к классифицированному доступу, VKS в VCF 9.1 представит расширенные сетевые возможности. Узлы кластера смогут разворачиваться с несколькими vNIC, что позволит изолировать трафик на уровне узла (рис. 3). Это даёт возможность разделять трафик приложений, систем хранения и управления, а также выделять отдельные сетевые маршруты для нагрузок, чувствительных к задержкам или требующих высокой пропускной способности, повышая производительность, стабильность и операционный контроль.
Рис. 3. Рабочий узел VKS изолирует высокопроизводительный трафик за счёт поддержки нескольких vNIC.
Повышение операционной эффективности для снижения стоимости инноваций
Одна из самых существенных скрытых статей расходов в корпоративной ИТ-инфраструктуре — операционное трение. VKS в VCF 9.1 получит как улучшения, специфичные для Kubernetes, так и более широкие платформенные возможности, появившиеся в VCF:
Интеллектуальное размещение пулов узлов — на основе алгоритма vSphere Distributed Resource Scheduler, что устраняет инфраструктурные узкие места, замедляющие развёртывание.
Несколько кластеров в одной зоне — для неразрушающего управления жизненным циклом оборудования и масштабирования без ручной работы.
Организации добиваются более быстрого выхода на ценность за счёт ускорения пути инноваций от концепции к продуктивной эксплуатации. Кроме того, приложения остаются доступными и прибыльными во время миграции сервисов и текущих работ по обслуживанию оборудования, что снижает потери от простоев.
Выгоды для платформенной инженерии:
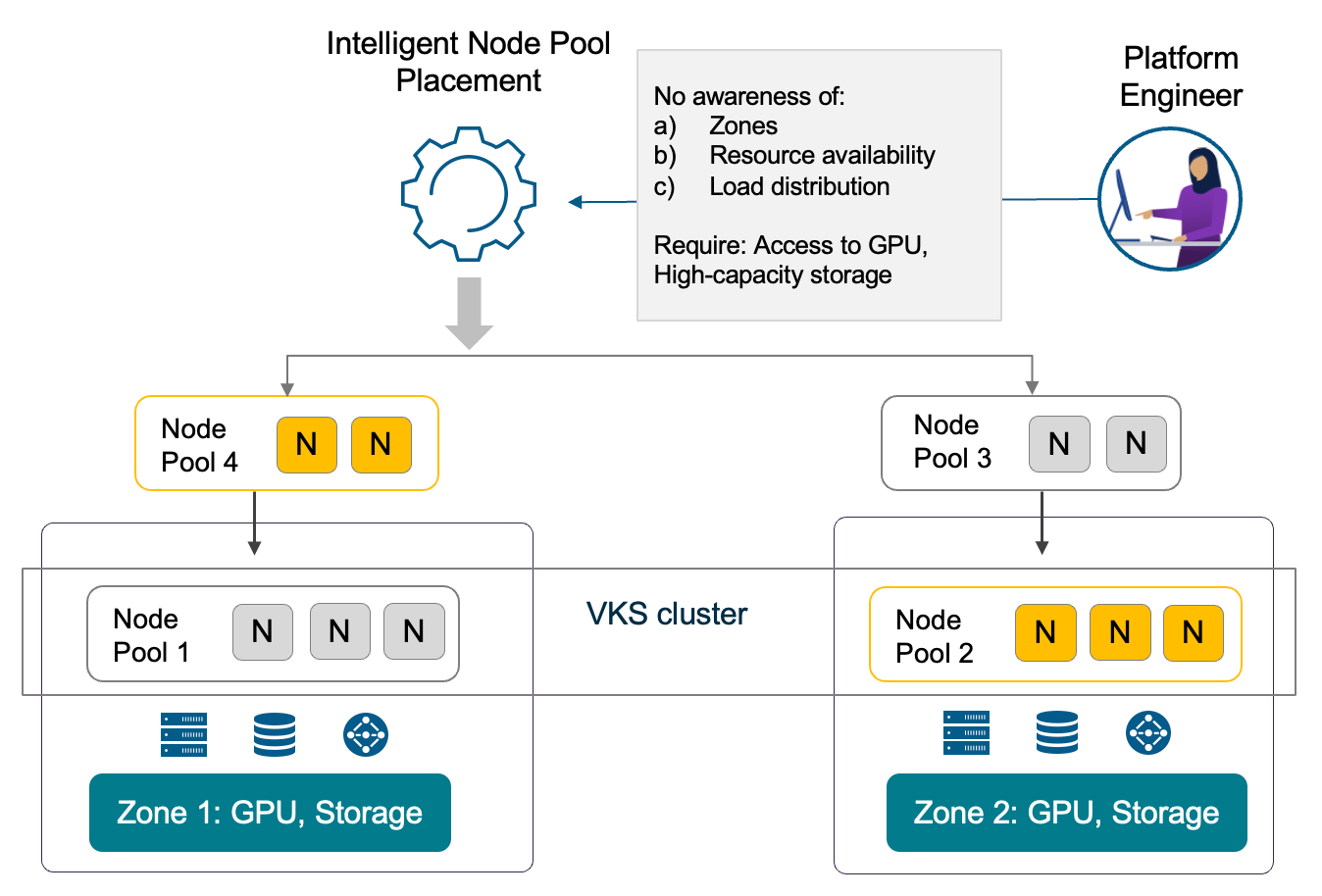
При развёртывании рабочих нагрузок размещение пулов узлов является критически важной, но зачастую сложной задачей. Инженерам платформ приходится учитывать широкий спектр приложений: AI-приложениям нужен доступ к GPU, потоковым — высокопроизводительное хранилище, e-commerce — высокая доступность. При этом инженеры платформ не должны быть обременены глубокой инфраструктурной экспертизой, необходимой для работы со специализированными ресурсами — таких как доступ к GPU, требования к высокоёмкому хранению, осведомлённость о зонах, доступность ресурсов между зонами, распределение нагрузки и ограничения, связанные с отказоустойчивостью (HA), которые предъявляют современные рабочие нагрузки.
Благодаря интеллектуальному размещению пулов узлов VKS снизит требования к глубокой инфраструктурной экспертизе инженеров платформ (рис. 4 ниже). Такая автоматизация обеспечит гибкость без фрагментации развёртываний и даст инженерам платформ согласованный, предсказуемый и надёжный опыт работы. Эти улучшения существенно сокращают трение при развёртывании рабочих нагрузок, исключая сбои при размещении и трудноотлаживаемые проблемы с распределением ресурсов.
Рис. 4. Снижение трения при развёртывании благодаря интеллектуальному размещению пулов узлов.
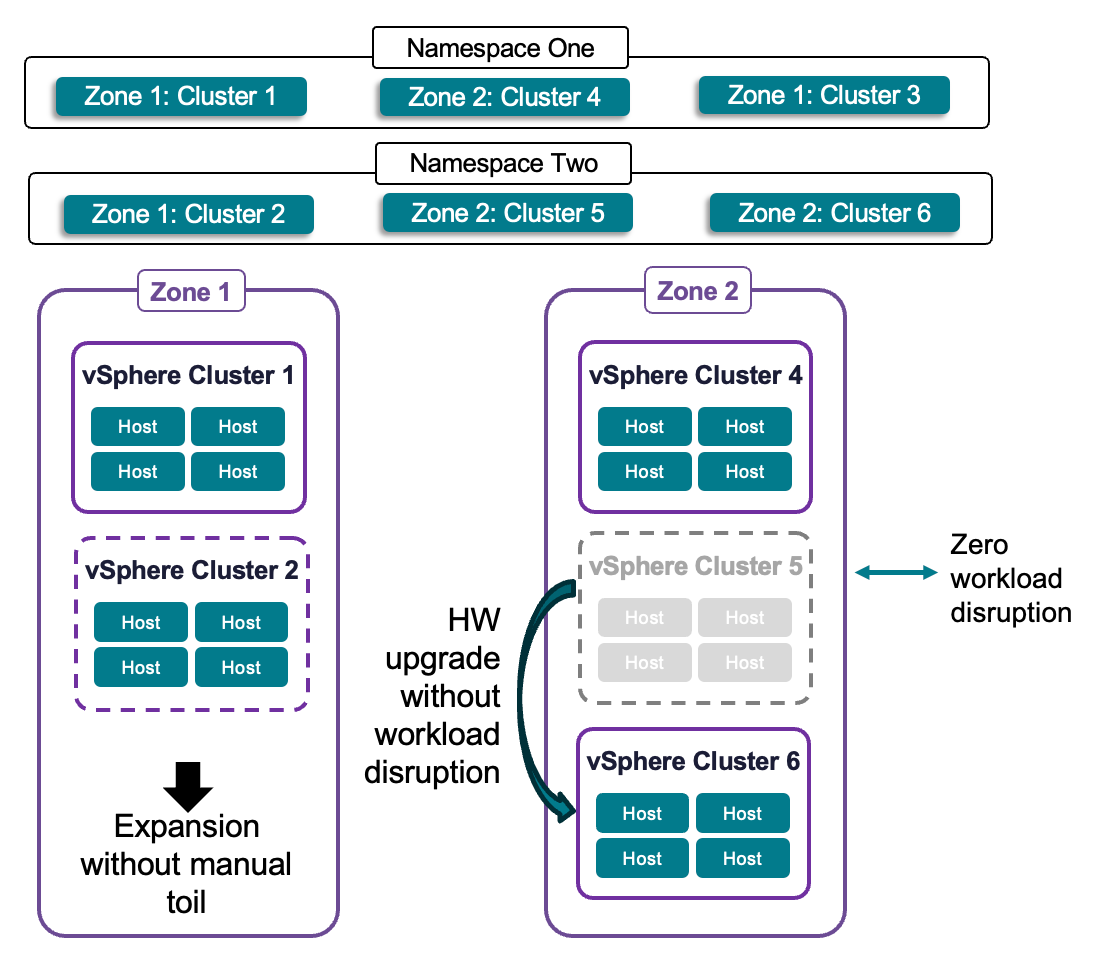
С поддержкой нескольких кластеров в одной зоне администраторы облака смогут заменять, выводить из эксплуатации или обновлять оборудование без влияния на доступность приложений и без нарушения «желаемого состояния», что даёт инженерам платформ спокойствие (рис. 5). Такая абстракция также позволит инфраструктуре динамически реагировать на растущие потребности в вычислительных и дисковых ресурсах: масштабирование больше не требует сложной переработки среды.
Рис. 5. Несколько кластеров в одной зоне с нулевым простоем при обслуживании жизненного цикла и улучшенным масштабированием.
Инженеры платформ смогут быстрее подключать новые рабочие нагрузки и получать лучшую производительность сети благодаря Distributed Transit Gateway (DTGW), который обеспечивает более простой и согласованный способ подключения нагрузок к коммутирующей фабрике. DTGW также улучшает задержки и масштабирование: хост ESX подключается напрямую к коммутирующей фабрике, без необходимости использовать полный edge-кластер NSX.
Усиленная безопасность и соответствие требованиям, встроенные, а не «прикрученные сверху»
После того как вопросы производительности и масштаба решены, следующий важный рубеж — безопасность и соответствие требованиям. Безопасность в Kubernetes-средах часто фрагментирована: для управления секретами и применения политик доступа требуется множество инструментов и ручных процессов.
VKS в VCF 9.1 упростит эту задачу, встраивая средства контроля безопасности в саму платформу:
Интегрированные процессы управления секретами уменьшают объём ручной настройки.
Детальное управление доступом обеспечивает соблюдение принципа минимальных привилегий.
Единообразное применение политик улучшает аудируемость и готовность к соответствию.
Это позволит командам платформ автоматизировать работу с секретами и согласованно применять границы доступа во всех кластерах, снижая операционные риски и повышая готовность к проверкам на соответствие.
Выгоды для бизнеса:
Организации получат сокращённую площадь атаки и сниженный риск утечек данных, что обеспечит защиту критической инфраструктуры от современных угроз. Такой единый подход естественным образом формирует более прочный профиль соответствия за счёт согласованного применения политик и повышает уверенность при развёртывании регулируемых и чувствительных рабочих нагрузок.
Выгоды для платформенной инженерии:
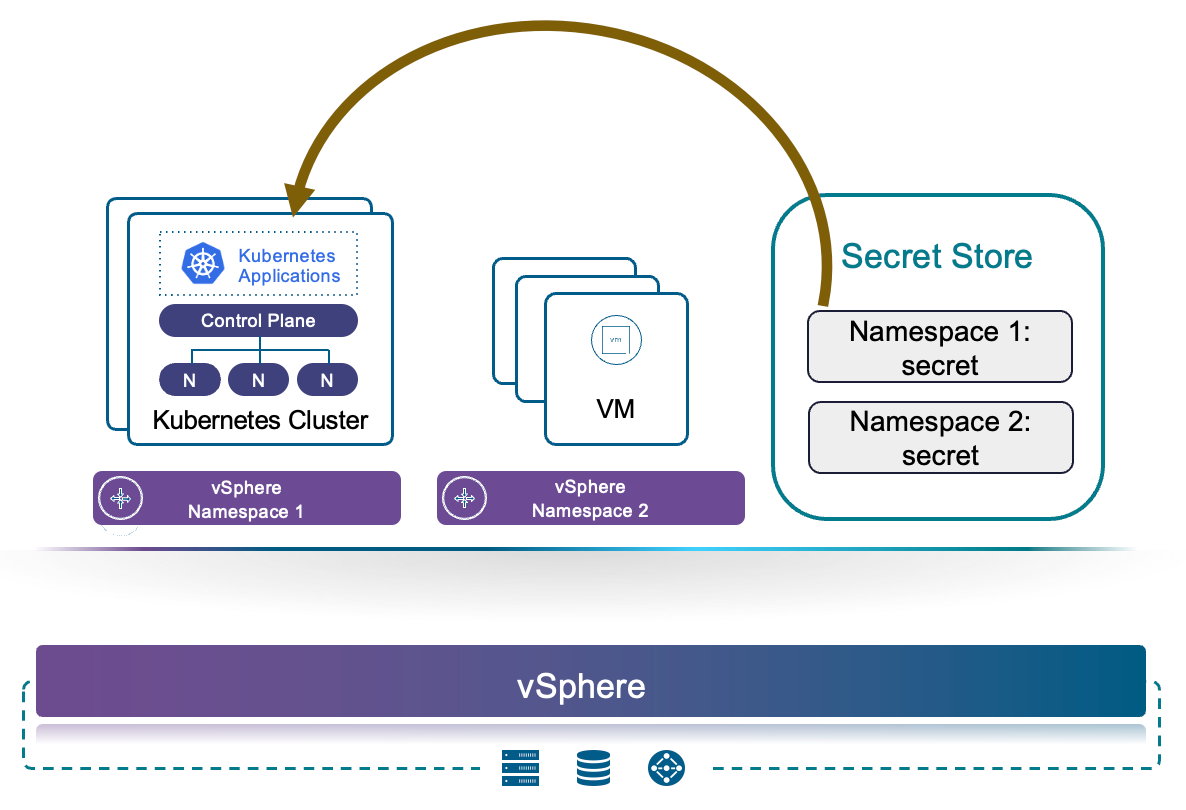
Клиенты смогут достичь более устойчивого профиля безопасности благодаря упрощённому автоматизированному способу внедрения секретов в процесс развёртывания (рис. 6 ниже). Гарантируя безопасную обработку чувствительных данных без ручной настройки, это улучшение усилит общую безопасность, повысит аудируемость и предоставит единый механизм управления секретами для всех рабочих нагрузок.
Рис. 6. Упрощённое и автоматизированное внедрение секретов.
Инженеры платформ также смогут настраивать гранулированные политики доступа рабочих нагрузок к секретам, сокращая площадь атаки и гарантируя, что секреты получают только авторизованные нагрузки. Это поможет заказчикам соответствовать требованиям комплаенса и регуляторов.
Container-as-a-Service в VCF 9.1
VCF 9.1 представит среду исполнения Container Service, поставляемую через VCF Automation, с полным управлением жизненным циклом. Эта упрощённая контейнерная среда исполнения будет работать непосредственно на ESX без накладных расходов на кластер, обеспечивая изоляцию рабочих нагрузок и эффективность использования ресурсов. Платформа VCF полностью автоматизирует планирование, изоляцию, оптимизацию производительности и обновления. Когда архитектура приложения эволюционирует, пользовательский интерфейс сгенерирует согласованный YAML для плавного перехода к кластерам VKS — обеспечивая мягкий переход от простых развёртываний контейнеров к полноценным возможностям Kubernetes.
О релизе VKS 3.6
Хотя VKS входит в единую интегрированную программную платформу облака, циклы выпуска компонента VKS отделены от графика релизов VCF: для VKS предусмотрено три обновления в год. Такое отдельное расписание было разработано специально, чтобы обеспечить плавную синхронизацию с релизами upstream-проекта CNCF Kubernetes. С выходом в феврале VKS 3.6 заказчики могут разворачивать полностью соответствующие требованиям кластеры на актуальной версии Kubernetes 1.35. Для удобства планирования VKS 3.6 также позволяет одновременно развёртывать и обслуживать кластеры Kubernetes версий 1.33 и 1.34 наряду с последним релизом.
Функционал vSphere Configuration Profiles помогает администраторам VMware Cloud Foundation управлять настройками ESX-хостов не по отдельности, а на уровне всего кластера. Такой подход удобен, когда нужно не только поддерживать единый стандарт внутри одного кластера, но и переносить уже проверенную конфигурацию в другие кластеры.
Примечание: описанные шаги и интерфейсные элементы относятся к VMware vSphere 9.0.2. В других версиях названия пунктов меню и формулировки могут отличаться.
Что такое vSphere Configuration Profiles
vSphere Configuration Profiles появилась в vSphere 8.0 как развитие идеи Host Profiles для масштабного управления конфигурацией ESX-хостов. В Host Profiles администратору приходилось описывать конфигурацию целиком, что усложняло работу: часто известны только конкретные изменения, которые нужно внести, а не весь полный набор настроек.
В vSphere Configuration Profiles требуется зафиксировать только отличия от конфигурации по умолчанию. Благодаря этому профиль получается более понятным для человека, проще читается и легче поддерживается.
Перенос конфигурации в новые кластеры
Один из типовых сценариев управления конфигурацией — обеспечить одинаковые настройки сразу в нескольких кластерах vSphere. vSphere Configuration Profiles делает такой перенос достаточно прямолинейным: желаемое состояние можно экспортировать из существующего кластера, скорректировать уникальные параметры хостов и затем импортировать в новый кластер.
Совет: конфигурацию можно подготовить для кластера еще до добавления в него ESX-хостов. Для этого нужно заранее знать Host BIOS UUID будущих хостов.
Ниже приведен рабочий процесс копирования конфигурации из одного кластера в другой.
Экспорт конфигурации из существующего кластера
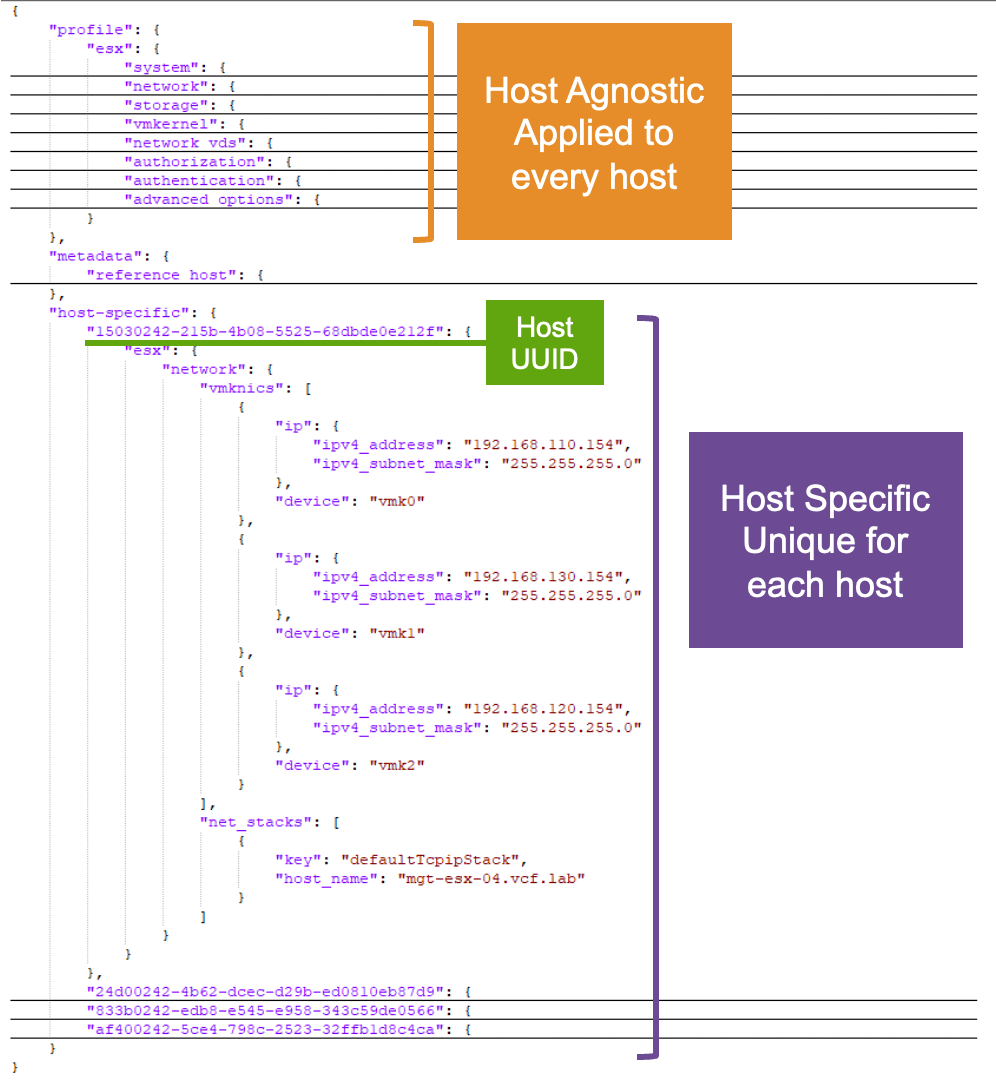
Сначала нужно выгрузить желаемую конфигурацию из уже настроенного кластера. В интерфейсе vSphere следует открыть Cluster, затем Configure, затем Configuration в разделе Desired State. Экспортированный файл будет сохранен в формате JSON.
Внутри JSON находятся как общие для кластера настройки, так и уникальные атрибуты отдельных хостов, например IP-адреса и имена хостов. Минимальная обязательная правка перед переносом — заменить host-specific секцию vSphere Configuration Profile на значения, соответствующие целевому кластеру.
Перед импортом полезно понимать структуру JSON-файла профиля. В секции profile > esx находятся настройки, не зависящие от конкретного хоста. Такие параметры можно применить ко всем хостам кластера, поскольку они не содержат уникальных значений для отдельного сервера.
Настройки vSphere Distributed Switch, Port Groups или Datastores могут отличаться от кластера к кластеру, поэтому при необходимости их нужно менять в соответствующих разделах JSON. В демонстрационном сценарии используются те же vSphere Distributed Switch, Port Groups и Datastores, что и в исходном кластере.
Основное внимание при переносе нужно уделить секции host-specific. В показанном примере уникальными значениями для хостов являются IP-адреса трех vmkernel-интерфейсов и имя хоста.
Каждый ESX-хост в host-specific разделе идентифицируется через Host UUID. Этот идентификатор также называют BIOS UUID, поскольку он уникален на уровне аппаратной платформы. В актуальных версиях vSphere и VCF проще всего получить Host UUID через PowerCLI, подключившись к vCenter или напрямую к ESX-хосту.
После этого в JSON-файле нужно заменить Host UUID, IP-адреса, маски подсети и имена хостов для каждого сервера целевого кластера. При необходимости хосты можно добавлять или удалять, но важно следить за корректным синтаксисом JSON, особенно за запятыми между элементами.
Импорт обновленной конфигурации в новый кластер
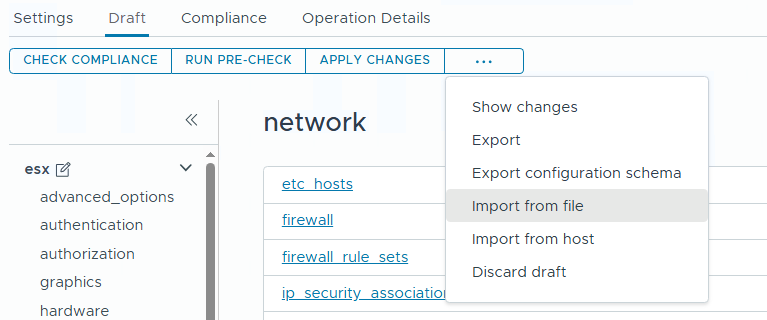
Если целевой кластер еще не создан с включенными vSphere Configuration Profiles или пока не переведен на них, обновленный JSON можно импортировать через workflow перехода на vSphere Configuration Profiles.
Если кластер уже использует vSphere Configuration Profiles, нужно открыть вкладку Draft, выбрать Import From File и загрузить подготовленный JSON-файл.
Затем на вкладке Draft нужно выбрать Apply Changes, чтобы выполнить remediation и применить импортированную конфигурацию. Перед фактическим применением стоит внимательно пройти окна Pre-check, Remediation Settings и Review Impact.
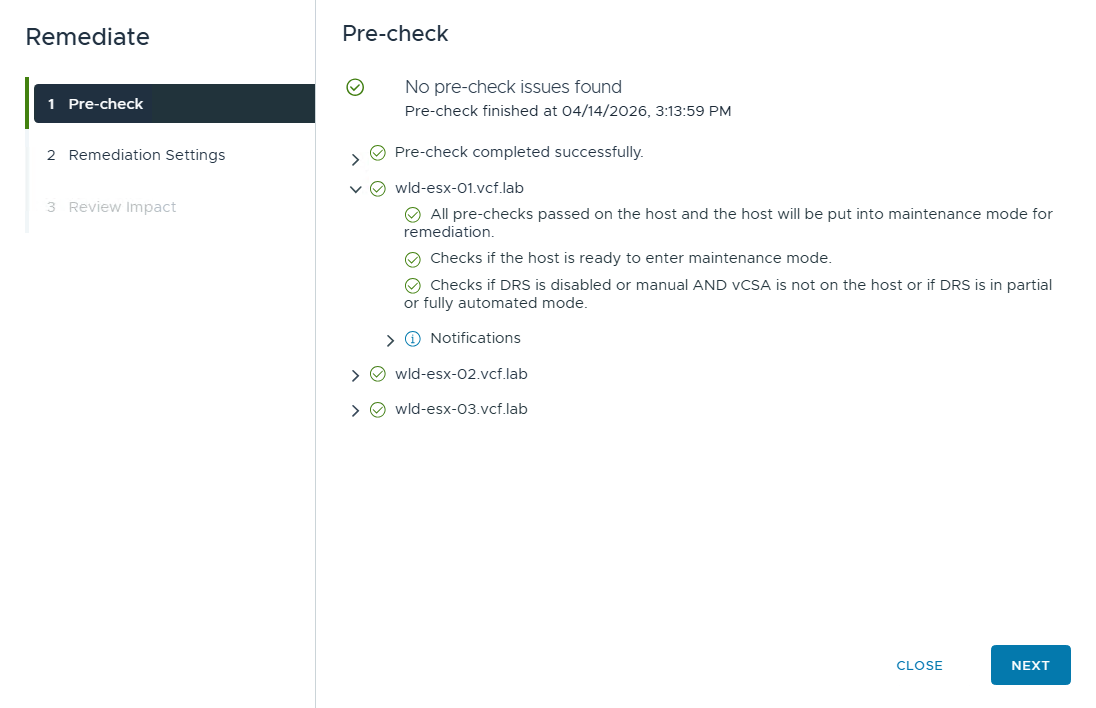
Pre-check проверяет готовность хоста к remediation, включая возможность перевести его в maintenance mode. Также учитывается, включен ли DRS, чтобы при необходимости автоматически эвакуировать виртуальные машины с хоста. Окно Remediation Settings показывает текущие параметры remediation, унаследованные от vSphere Lifecycle Manager.
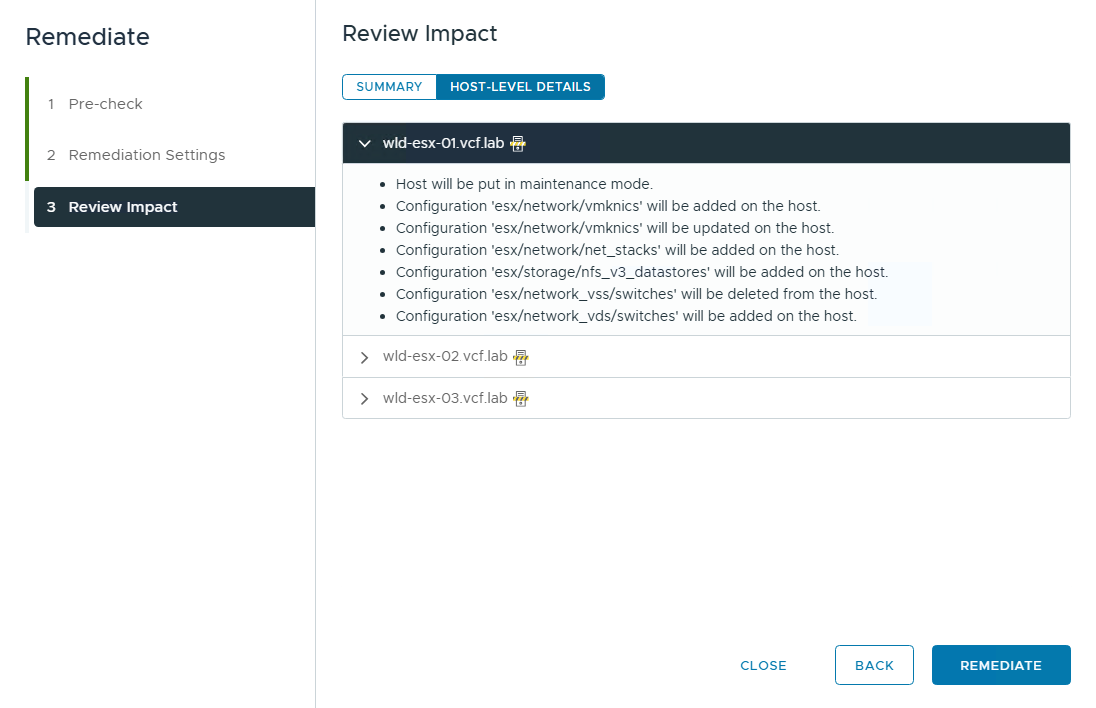
В окне Review Impact на вкладке Host-Level Details можно раскрыть каждый хост и увидеть, какие именно изменения будут применены. Там же отображается, потребуется ли конкретному хосту переход в maintenance mode.
После проверки влияния изменений остается нажать Remediate, чтобы применить конфигурацию к кластеру.
Итог
vSphere Configuration Profiles позволяет переносить стандартную конфигурацию из одного кластера в другой без ручного повторения всех настроек. Это помогает поддерживать единое желаемое состояние как внутри отдельного кластера, так и между несколькими кластерами vSphere.
Технология Advanced Memory Tiering в VMware Cloud Foundation 9 позволяет существенно расширить эффективный объём памяти хоста за счёт NVMe-накопителей — без изменения рабочих процессов и без влияния на привычные инструменты управления. Ниже собраны практические рекомендации, которые помогут правильно оценить среду, корректно настроить платформу и избежать типичных ошибок при развёртывании.
Как работает двухуровневая память
Архитектура Advanced Memory Tiering строится на двух уровнях.
Tier 0 — это DRAM: быстрая оперативная память, которая обслуживает активные страницы виртуальных машин.
Tier 1 — NVMe-накопитель, куда перемещаются холодные, редко используемые страницы. При этом память гипервизора (vmkernel) никогда не попадает в NVMe: ESX всегда работает исключительно в DRAM.
Когда виртуальная машина обращается к странице, находящейся в Tier 1, гипервизор возвращает её в DRAM — прозрачно и без участия гостевой ОС. Такая схема идеально подходит для рабочих нагрузок с выраженным разделением горячих и холодных страниц памяти.
Оценка готовности среды
Прежде чем включать Memory Tiering, необходимо проанализировать текущее потребление памяти. Ключевой показатель — активная память (active memory): объём страниц, к которым виртуальные машины реально обращаются в единицу времени. Технология оптимально работает, когда потреблённая (allocated) память превышает 50% от установленного объёма DRAM, а активная остаётся ниже этого порога.
Проверить активную память можно несколькими способами. В интерфейсе vCenter откройте VM > Monitor > Performance > Advanced, переключитесь в режим отображения памяти и выберите режим реального времени — показатель active memory доступен только в нём, поскольку относится к статистике уровня 1.
Для более широкого охвата подойдёт VCF Operations — если он уже развёрнут в инфраструктуре, он обеспечит сквозную видимость по всем хостам и кластерам. Ещё один вариант — RVTools: утилита собирает статистику памяти в реальном времени и позволяет быстро оценить картину по всей среде.
Порог активной памяти: правило 50%
Главное эксплуатационное правило Memory Tiering звучит просто: активная память должна оставаться на уровне 50% или ниже от объёма DRAM. Это гарантирует, что горячий рабочий набор данных комфортно размещается в быстрой памяти и при этом остаётся достаточный запас.
Если активная память стабильно превышает 70% от объёма DRAM, часть горячих страниц неизбежно окажется в Tier 1, и производительность виртуальных машин может заметно снизиться. В такой ситуации следует либо добавить DRAM на хост, либо перераспределить нагрузку между узлами кластера, прежде чем включать тиринг.
Настройка соотношения DRAM:NVMe
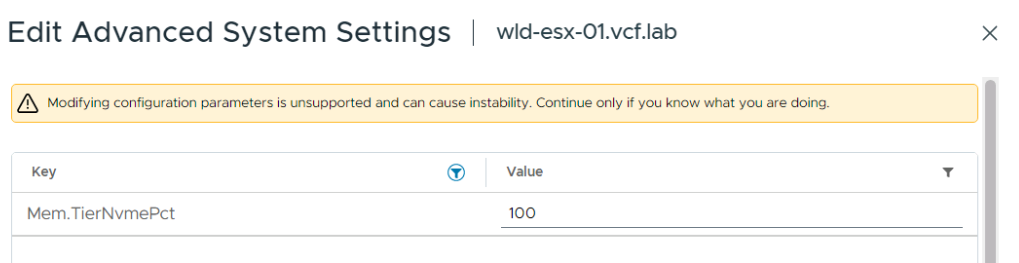
При включении Memory Tiering ESXi устанавливает соотношение DRAM к NVMe равным 1:1 по умолчанию. Это означает, что при наличии 512 ГБ DRAM хост получит дополнительные 512 ГБ ёмкости Tier 1. Параметр контролируется через расширенную настройку хоста: Mem.TierNVMePct со значением по умолчанию 100 (100% от объёма DRAM).
Рекомендуется сохранять соотношение 1:1 для большинства рабочих нагрузок — оно охватывает типичные сценарии использования. Изменять его стоит только после тщательного анализа профиля активной памяти конкретных ВМ. При выборе размера NVMe-накопителей разумно ориентироваться с запасом: более ёмкие устройства замедляют износ ячеек, дают пространство для будущего изменения соотношения и позволяют безболезненно справляться с неожиданным ростом нагрузки.
Подходящие рабочие нагрузки
Memory Tiering наиболее эффективна для рабочих нагрузок с естественным разделением горячих и холодных страниц. В их числе:
Общая серверная виртуализация — разнородный парк ВМ с умеренной и переменной активностью памяти.
VDI-среды — виртуальные рабочие столы с большим количеством ВМ, каждая из которых использует лишь часть выделенной памяти одновременно.
Среды разработки и тестирования — временные ВМ, которые редко используют всю выделенную память одновременно.
Веб-серверы и серверы приложений — нагрузки с предсказуемым рабочим набором в памяти.
Базы данных с умеренной активностью — СУБД, у которых значительная часть данных в памяти остаётся холодной
Неподходящие рабочие нагрузки
Ряд профилей виртуальных машин в настоящее время не поддерживает работу с Memory Tiering. Для таких ВМ тиринг следует отключить на уровне виртуальной машины — это принудительно размещает все её страницы в Tier 0 (DRAM).
Высокопроизводительные и latency-sensitive ВМ — приложения, требующие предсказуемых ультранизких задержек доступа к памяти
ВМ с аппаратной защитой памяти — виртуальные машины, использующие технологии шифрования AMD SEV, Intel SGX или Intel TDX
ВМ с Fault Tolerance (FT) — непрерывная синхронизация состояния несовместима с тирингом
«Монстроидальные» ВМ — машины с объёмом памяти от 1 ТБ и более 128 vCPU
ВМ с большими страницами памяти (large memory pages)
Вложенная виртуализация (nested VMs)
Если в кластере присутствуют такие нагрузки, оптимальная стратегия — выделить для них отдельные хосты и включить Memory Tiering только на оставшихся узлах кластера, либо управлять исключениями на уровне отдельных ВМ.
Интеграция с vSphere
Advanced Memory Tiering полностью интегрирована в стандартные механизмы управления vSphere — никаких специальных процедур не требуется:
vMotion — миграция ВМ между хостами работает прозрачно; оба уровня памяти учитываются при переносе.
DRS — балансировщик нагрузки осведомлён об обоих уровнях и учитывает их при принятии решений о размещении ВМ.
High Availability (HA) — при отказе хоста ВМ перезапускаются на оставшихся узлах по стандартным правилам HA.
Рекомендации по развёртыванию
Для успешного внедрения рекомендуется придерживаться следующих принципов. Во-первых, поддерживайте единую конфигурацию хостов в кластере с помощью vSphere Configuration Profiles — это исключает расхождения между узлами и упрощает масштабирование. Во-вторых, применяйте поэтапный подход: включайте тиринг последовательно, начиная с одного-двух хостов, оценивайте результаты и только потом распространяйте изменение на весь кластер. В-третьих, фиксируйте исключения: документируйте все ВМ, для которых Memory Tiering отключена на уровне виртуальной машины, чтобы не потерять контроль над конфигурацией при росте инфраструктуры.
Мониторинг после включения
После включения Memory Tiering следует регулярно отслеживать ключевые показатели:
Процент активной памяти на уровне хостов и кластера
Паттерны доступа к страницам (горячие/холодные)
Тренды утилизации памяти по кластеру в целом
Потребление памяти на уровне отдельных ВМ
Задержки чтения и записи NVMe-накопителей Tier 1
Рост задержек NVMe или увеличение активной памяти выше порога 50% DRAM — сигнал для пересмотра распределения нагрузки или конфигурации тиринга. Регулярный мониторинг позволяет выявлять изменения в профиле нагрузки на ранней стадии и реагировать проактивно.
Функция vSphere Configuration Profiles, впервые представленная в VMware vSphere 8.0, позволяет администраторам VMware Cloud Foundation управлять конфигурацией хостов ESX на уровне кластера. В данном материале рассматривается, чем эта функция отличается от Host Profiles, и как выполнить переход с Host Profiles на vSphere Configuration Profiles в vSphere 9.
Примечание: скриншоты и описанные шаги основаны на vSphere 9.0.2. В более ранних или более поздних версиях отдельные элементы интерфейса или формулировки могут отличаться.
О vSphere Configuration Profiles
vSphere Configuration Profiles — новая функция, впервые появившаяся в vSphere 8.0. Она является преемником Host Profiles в части управления конфигурацией хостов ESX в масштабе. Host Profiles неудобны тем, что требуют полного описания конфигурации хоста целиком. Это создаёт избыточную нагрузку на администраторов, которым, как правило, достаточно указать лишь те изменения, которые необходимо внести в конфигурацию.
vSphere Configuration Profiles, напротив, требует от администратора только определить отклонения от конфигурации по умолчанию. Это делает конфигурационный документ удобочитаемым и значительно более управляемым.
Переход с Host Profiles
Администраторы, управляющие конфигурацией хостов ESX с помощью Host Profiles в кластере, жизненный цикл которого управляется образами vSphere Lifecycle Manager, могут перевести кластеры на использование vSphere Configuration Profiles.
Примечание: использование vSphere Configuration Profiles с кластерами под управлением базовых уровней (baselines) поддерживается в vSphere 8 U3. Однако в vSphere 9 такие кластеры больше не поддерживаются, а Host Profiles считаются устаревшими, хотя и продолжают поддерживаться. Рекомендуется использовать кластеры под управлением образов vSphere Lifecycle Manager.
Перед переходом рекомендуется убедиться, что хосты ESX соответствуют текущему Host Profile. Ниже описан процесс перехода.
Управление конфигурацией на уровне кластера
Первый шаг — включить vSphere Configuration Profiles в кластере. Для этого перейдите в Cluster > Configure > Configuration в разделе Desired State и нажмите Create Configuration. Будут запущены проверки совместимости, чтобы убедиться, что кластер может быть переведён на vSphere Configuration Profiles. На рисунке 1 показан вариант запуска vSphere Configuration Profiles в существующем кластере.
Примечание: если к кластеру прикреплён Host Profile, появится предупреждение о необходимости удалить его после завершения перехода. После перехода Host Profiles не могут быть прикреплены ни к кластеру, ни к хостам внутри него. Этот процесс можно использовать и в том случае, если Host Profiles в данный момент не применяются.
Создание конфигурации
Далее необходимо указать, каким образом конфигурация хоста ESX для vSphere Configuration Profiles должна быть импортирована. Доступны два варианта:
Импорт с эталонного хоста.
Импорт JSON-файла с желаемой конфигурацией кластера.
Поскольку выполняется переход кластера, управляемого с помощью Host Profiles, предпочтительным вариантом является IMPORT FROM REFERENCE HOST. В качестве эталонного хоста можно выбрать любой хост ESX в кластере — все хосты уже должны соответствовать используемому Host Profile.
Примечание: при импорте с эталонного хоста любые отклонения от его конфигурации будут зафиксированы как переопределения хоста. Возможно, потребуется вручную проверить конфигурацию и удалить эти переопределения, если необходима единая конфигурация для всех хостов кластера.
На рисунке 2 показаны варианты импорта. Нажмите Import.
На рисунке 3 показан выбор эталонного хоста.
После импорта нажмите Next. Процесс импорта проверяет сгенерированный документ относительно всех хостов ESX в кластере. После успешной проверки нажмите Next. На рисунке 4 показан этап проверки конфигурации.
Предварительная проверка и применение
На последнем шаге vSphere Configuration Profiles проверяет хосты ESX в кластере на соответствие желаемой конфигурации и устраняет любые отклонения, обнаруженные в ходе проверки.
Примечание: поскольку выполняется переход с кластера под управлением Host Profile, исправлений не ожидается. Ознакомьтесь с влиянием изменений конфигурации на хосты. Нажмите Finish and Apply. На рисунке 5 показан предварительный просмотр эффекта применения. Нажмите Continue.
После этого сгенерированный vSphere Configuration Profile будет установлен в качестве желаемой конфигурации кластера, а все несоответствующие хосты ESX будут приведены в соответствие. На рисунке 6 показан диалог подтверждения завершения и применения.
Функция vSphere Configuration Profiles теперь включена, и доступен просмотр заданных конфигураций. На рисунке 7 показано, что конфигурация на уровне кластера включена.
На рисунке 8 показано соответствие хостов конфигурации кластера.
На завершающем шаге необходимо отсоединить Host Profile от хостов ESX.
Итог
Управление конфигурациями ESX остаётся непростой задачей в корпоративных средах. vSphere Configuration Profiles — новая возможность, впервые представленная в vSphere 8.0, которая решает эту задачу в масштабе большой инфраструктуры.
Многие VMware-инфраструктуры сегодня находятся в переходной стадии: организации продолжают использовать
vSphere-кластеры, но постепенно переходят к модели Software-Defined Data Center и частного облака на базе VMware Cloud Foundation (VCF).
Полностью перестраивать инфраструктуру с нуля в производственной среде обычно невозможно. Там уже работают
десятки или сотни виртуальных машин, поэтому перенос на новую платформу должен происходить максимально
аккуратно. Именно для таких сценариев VMware предлагает механизм Brownfield-интеграции.
Этот подход позволяет смигрировать существующую инфраструктуру vSphere на VMware Cloud Foundation без
переустановки среды и без миграции виртуальных машин. Подробно этот процесс рассмотрел Tarsio Moraes в своем видео:
Что такое Brownfield-апгрейд
Brownfield-подход означает интеграцию уже существующей инфраструктуры в новую платформу без полного
развертывания новой среды.
В VMware-экосистеме это означает, что существующий vCenter Server,
кластеры ESX и запущенные виртуальные машины могут быть импортированы
в VCF как отдельный Workload Domain.
Таким образом инфраструктура сохраняет текущие рабочие нагрузки, но получает централизованное управление,
автоматизированное lifecycle-обновление и интеграцию сетевой платформы NSX.
Архитектура до и после интеграции
Исходная инфраструктура
Типичная среда включает vSphere 8, один или несколько кластеров ESXi,
vCenter Server и систему хранения — например vSAN или внешние датасторы.
Сетевая конфигурация обычно построена на распределенном коммутаторе Distributed Switch.
В такой архитектуре управление вычислениями, сетью и мониторингом может
осуществляться через разные инструменты.
После интеграции в VCF
После импорта инфраструктура становится частью платформы VMware Cloud Foundation.
Появляется централизованное управление через компоненты VCF, а инфраструктура
разделяется на management domain и workload domains.
Также стоит учитывать изменения в продуктовой линейке VMware:
многие функции бывшей линейки Aria теперь встроены непосредственно в VMware Cloud Foundation (как функционал модуля Operations).
Подготовка инфраструктуры
Перед запуском Brownfield-апгрейда необходимо убедиться,
что инфраструктура соответствует требованиям совместимости.
В первую очередь проверяются версии компонентов:
vSphere, vCenter Server и ESXi (теперь он снова называется ESX). Кроме того,
важно убедиться в совместимости оборудования через VMware Compatibility Guide.
Также необходимо проверить базовые инфраструктурные сервисы:
DNS, NTP, доступность сетей управления и состояние датасторов.
Особенно важно убедиться, что DNS корректно разрешает имена
хостов ESX, vCenter и будущих узлов NSX Manager.
Подготовка среды управления
Перед импортом vSphere-среды необходимо подготовить управляющие компоненты VMware Cloud Foundation.
К ним относятся VCF Fleet Management и VCF Operations.
Эти сервисы отвечают за централизованное управление инфраструктурой,
мониторинг и lifecycle-операции.
На этом этапе стоит проверить доступность management-компонентов,
валидность сертификатов и сетевую связность между сервисами управления и vCenter.
Использование VCF Import Tool
Для интеграции существующей среды используется специальный инструмент —
VCF Import Tool.
Он анализирует конфигурацию vSphere,
выполняет проверку совместимости и подготавливает инфраструктуру к импорту.
Перед запуском процесса выполняется серия pre-check проверок,
которые анализируют сеть, лицензии, сертификаты, конфигурацию кластеров
и параметры хранения.
Если обнаружены ошибки или предупреждения, их необходимо устранить
до начала импорта.
Импорт vCenter как Workload Domain
После завершения подготовительных этапов можно приступать к импорту
существующего vCenter.
В интерфейсе VCF создаётся новый workload domain,
после чего указываются параметры подключения к существующему vCenter.
После проверки параметров запускается автоматический рабочий процесс (workflow),
который выполняет регистрацию vCenter в инфраструктуре VCF.
С этого момента среда становится частью VMware Cloud Foundation.
Развертывание NSX
Следующий этап — интеграция сетевой платформы NSX.
Если NSX ранее не использовался, VMware Cloud Foundation может автоматически
развернуть NSX Manager cluster и подготовить хосты ESX.
Если NSX уже установлен в инфраструктуре,
он может быть импортирован вместе с workload domain.
Пост-апгрейд проверки
После завершения интеграции необходимо провести проверку состояния среды.
Стоит убедиться, что workload domain корректно отображается
в интерфейсе VCF, хосты ESX подключены,
датасторы доступны, а виртуальные машины работают без ошибок.
Дополнительно рекомендуется протестировать ключевые операции виртуализации:
vMotion, создание снапшота и сетевую связность между виртуальными машинами.
Итог
Brownfield-апгрейд позволяет перевести существующую инфраструктуру
vSphere 8 в модель VMware Cloud Foundation 9 без полного
перестроения среды.
Этот подход сохраняет текущие рабочие нагрузки,
централизует управление инфраструктурой
и позволяет постепенно перейти к архитектуре частного облака.
Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
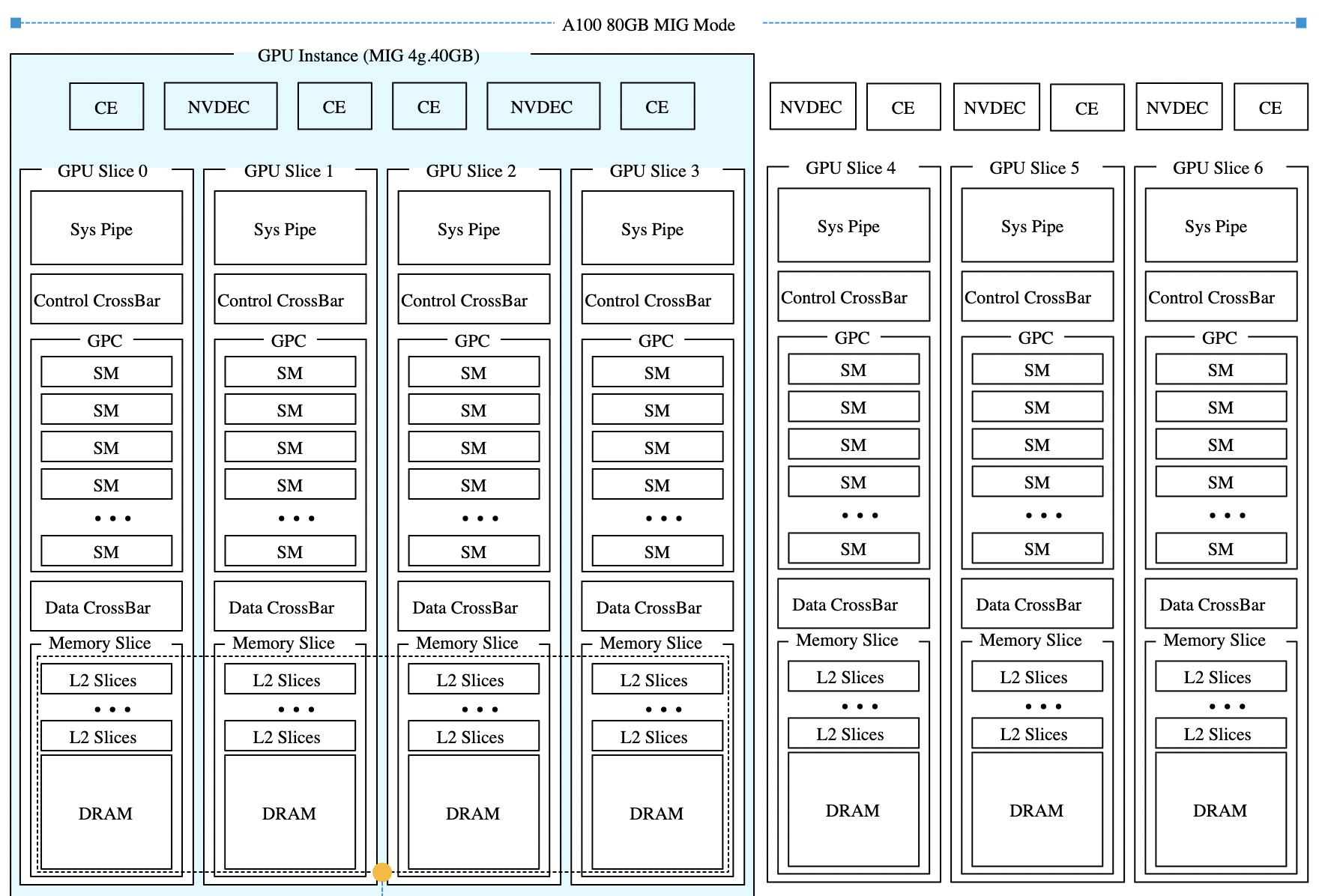
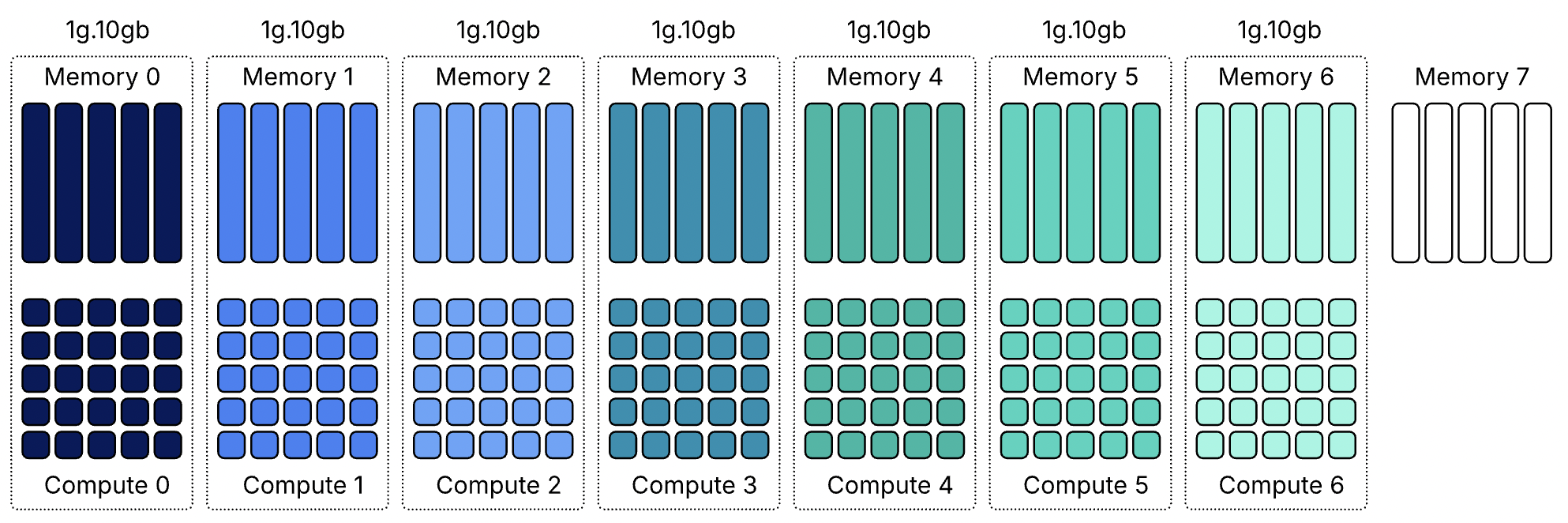
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
Profile
Compute slices
Memory slices
Memory
1g.10gb
1
1
10 GB
1g.20gb
1
2
20 GB
2g.20gb
2
2
20 GB
3g.40gb
3
4
40 GB
4g.40gb
4
4
40 GB
7g.80gb
7
8
80 GB
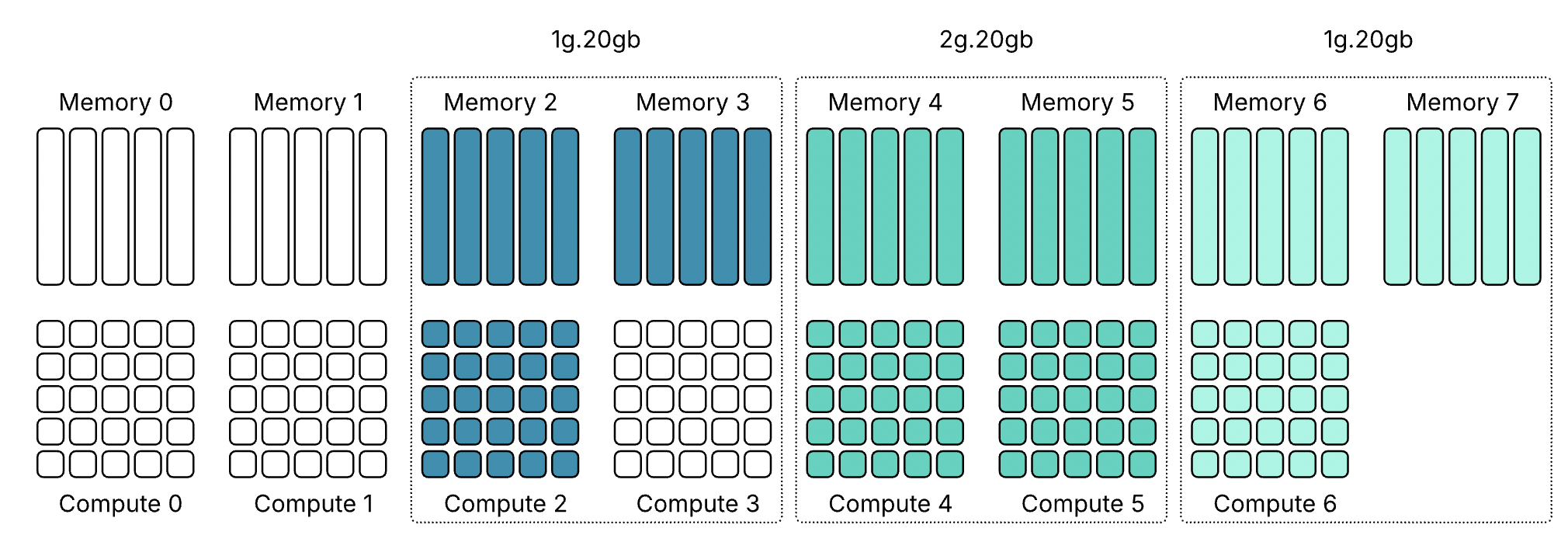
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
Потерянная ёмкость
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
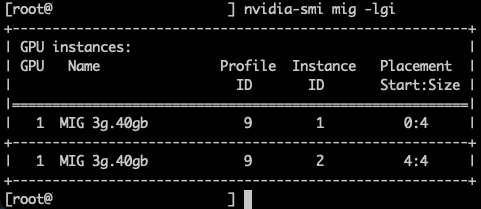
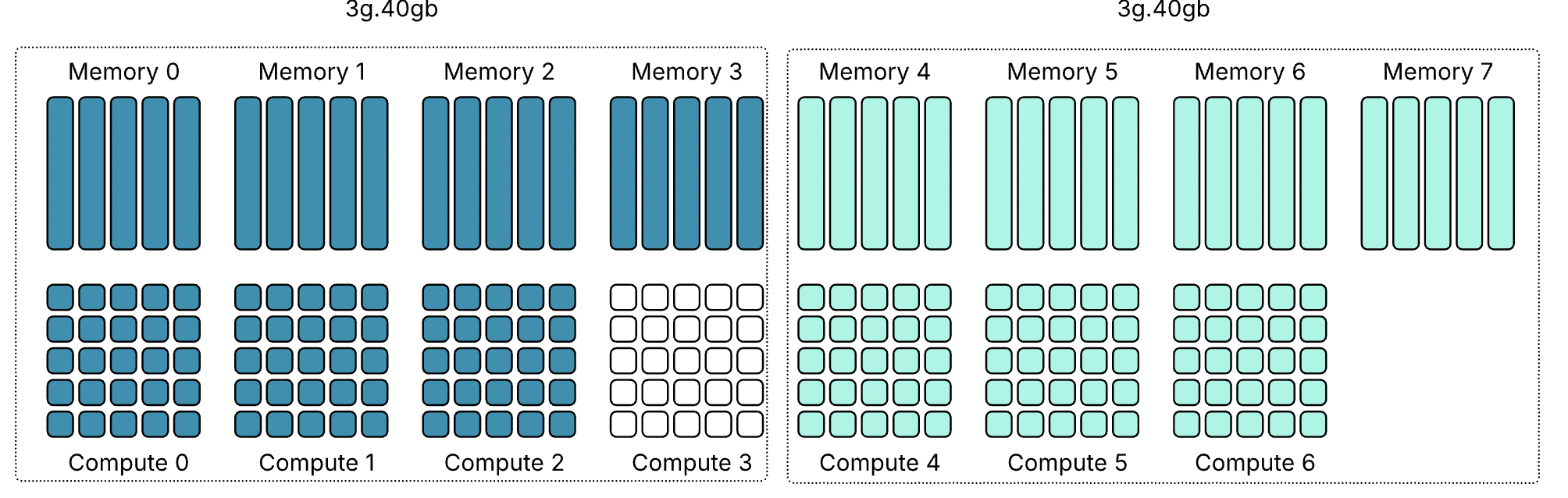
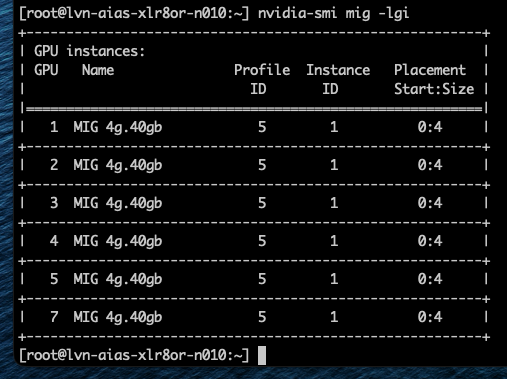
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
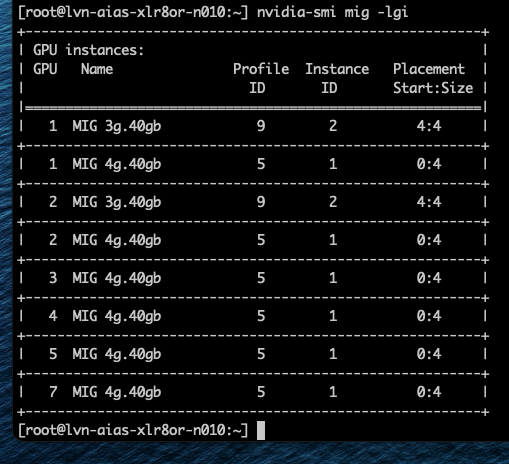
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
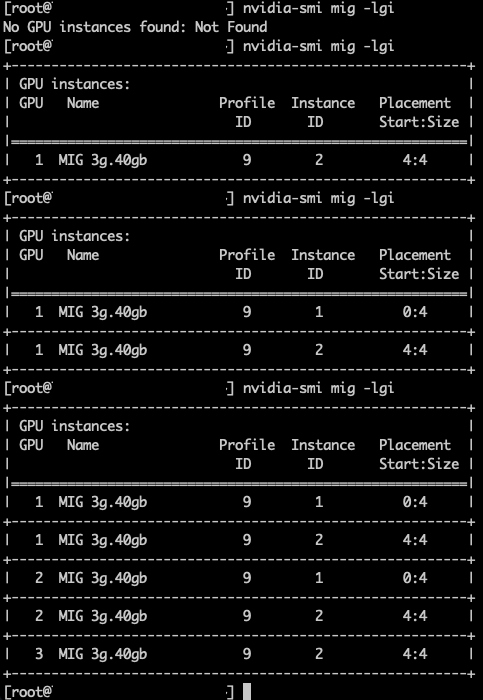
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.
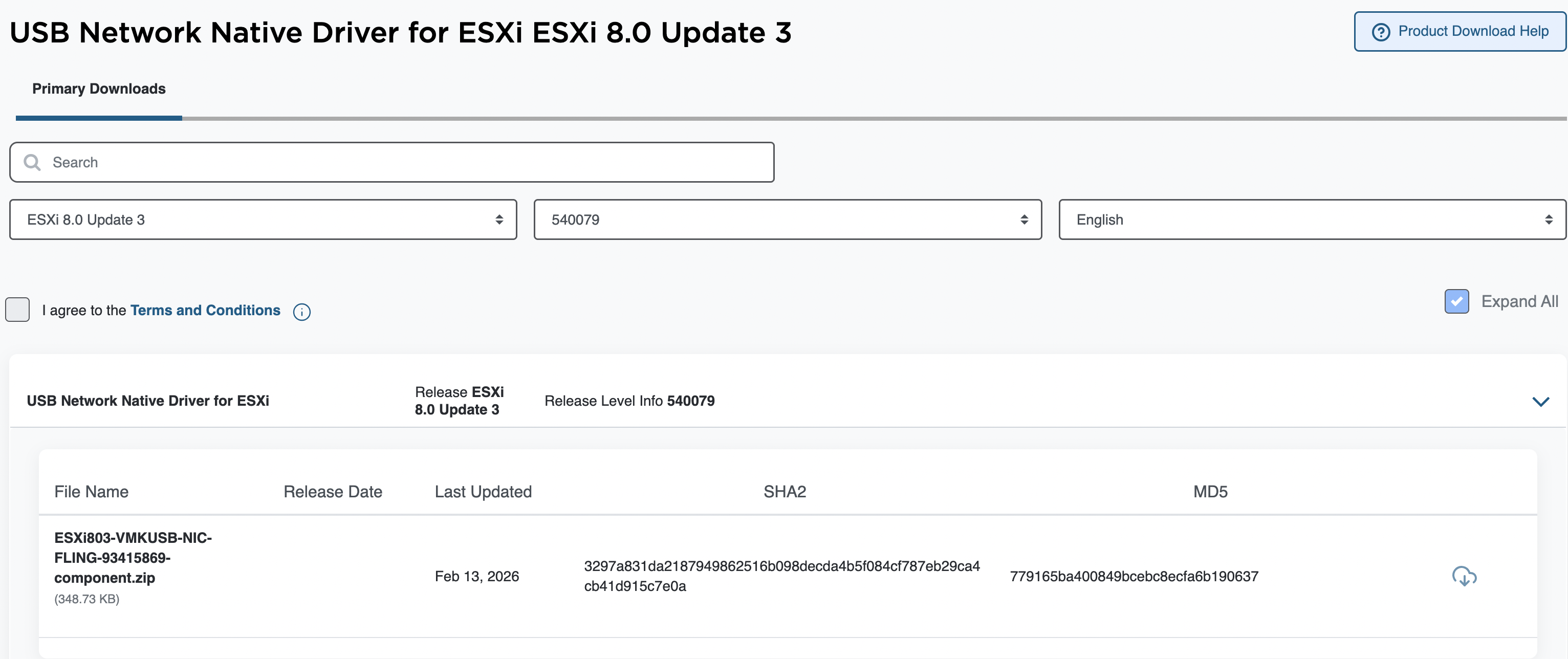
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
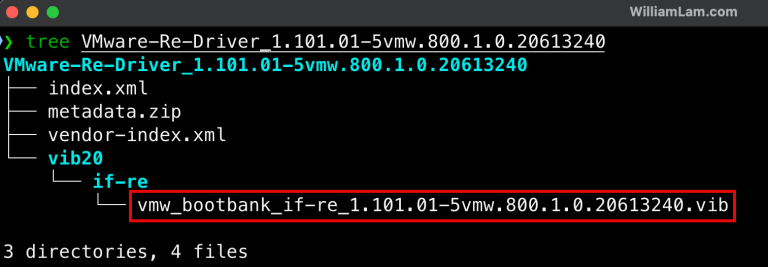
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
Решение с вызовом vSphere MOB и ручной генерацией XML-запроса для добавления хоста ESXi в нужный кластер vSphere в vCenter Server было, мягко говоря, неидеальным, но задачу оно выполняло. Сейчас это решение можно значительно улучшить, используя более современные подходы, при этом сохранив исходное требование: возможность добавить хост в кластер vSphere прямо из ESXi 8.x/9.x Kickstart без внешних зависимостей.
Шаг 1. Предполагаем, что у вас уже есть инфраструктура ESX Kickstart, готовая к работе.
Примечание: Для разработки Вильям настоятельно рекомендует использовать Nested ESXi и HTTP Boot через Virtual EFI — так вы сможете быстро протестировать автоматизацию ESX Kickstart перед тем, как развернуть её на реальном железе. Это позволит без особых усилий быстро создать рабочий прототип решения, которое вы увидите здесь.
Шаг 2. С помощью ChatGPT Вильяму удалось создать современную версию скрипта на основе Pyvmomi (vSphere SDK для Python), который использует тот же самый API vSphere для добавления хоста ESX в vCenter Server и его подключения к нужному кластеру vSphere. Скачайте скрипт add_host_to_cluster.py и разместите его на веб-сервере, с которого вы отдаёте конфигурацию ESX Kickstart, либо внедрите прямо в kickstart-файл.
Скрипт можно запускать локально на системе с установленным Pyvmomi или прямо на ESXi 8.x/9.x со следующим синтаксисом:
Шаг 3. Обновите ваш ESX Kickstart так, чтобы он запускал скрипт add_host_to_cluster.py с нужными параметрами. В данном примере и kickstart ESX, и скрипт add_host_to_cluster.py размещены на веб-сервере Вильяма, поэтому kickstart сначала загружает скрипт на хост ESX в рамках секции %firstboot, а затем запускает его с учётными данными для vCenter Server и хоста ESX, которые необходимы для вызова vSphere API.
Примечание: Скорее всего, вам НЕ следует использовать учётную запись администратора для добавления ESX-хоста. Вместо этого создайте сервисную учётную запись, у которой есть только права на добавление хостов в кластер vSphere и никакие другие роли, так как учётные данные придётся указывать в открытом виде (plain text).
Вот скриншот итогового решения, где Вильям смог быстро продемонстрировать это с помощью виртуальной машины Nested ESXi и загрузки по HTTP через Virtual EFI (см. ссылку в Шаге 1). ESX устанавливается автоматически, так же как и на физической машине, а затем, в рамках пост-настройки, загружается наш скрипт на Pyvmomi и хост присоединяется к нужному кластеру vSphere:
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.
В последнее время в индустрии виртуализации наблюдалась тревожная тенденция — крупнейшие игроки начали отказываться от бесплатных версий своих гипервизоров. После покупки VMware компанией Broadcom одной из первых резонансных новостей стало прекращение распространения бесплатного гипервизора VMware ESXi (ранее известного как vSphere Hypervisor). Это решение вызвало волну недовольства в сообществе, особенно среди ИТ-специалистов и малых компаний, использующих ESXi в тестовых или домашних лабораториях.
Ранее: Broadcom, завершив поглощение VMware, прекратила предоставление бесплатной версии vSphere Hypervisor. Это вызвало резкую критику и обеспокоенность среди пользователей, привыкших использовать ESXi в учебных, тестовых или малобюджетных инфраструктурах.
Теперь: В составе релиза ESXi 8.0 Update 3e появилась entry-level редакция гипервизора, которая предоставляется бесплатно, как указано в разделе "What's New" официальной документации Broadcom. Хотя точных технических ограничений этой редакции пока не раскрыто в деталях, уже ясно, что она рассчитана на начальный уровень использования и доступна без подписки.
Почему это важно?
Возвращение бесплатной версии гипервизора от Broadcom означает, что:
Независимые администраторы и энтузиасты снова могут использовать ESXi в личных или образовательных целях.
Организации с ограниченным бюджетом могут рассматривать VMware как вариант для пилотных проектов.
Broadcom, вероятно, отреагировала на давление сообщества и рынка.
Новые возможности VMware 8.0 Update 3e:
1. Поддержка протокола CDC-NCM (Communication Device Class Network Control Model) в USB-драйвере ESXi
Начиная с версии ESXi 8.0 Update 3e, USB-драйвер ESXi поддерживает протокол CDC-NCM для обеспечения совместимости с виртуальным сетевым адаптером HPE Gen12 iLO (iLO Virtual NIC) и взаимодействия с такими инструментами, как HPE Agentless Management (AMS), Integrated Smart Update Tools (iSUT), iLORest (инструмент настройки), Intelligent Provisioning, а также DPU.
2. ESXi 8.0 Update 3e добавляет поддержку технологии vSphere Quick Boot для следующих драйверов:
Intel vRAN Baseband Driver
Intel Platform Monitoring Technology Driver
Intel Data Center Graphics Driver
Драйвер серии AMD Instinct MI
Вывод
Хотя отказ от бесплатной версии ESXi вызвал разочарование и обеспокоенность, возвращение entry-level редакции в составе ESXi 8.0 Update 3e — это шаг в сторону компромисса. Broadcom, похоже, услышала голос сообщества и нашла способ вернуть гипервизор в открытый доступ, пусть и с оговорками. Теперь остаётся дождаться подробностей о лицензировании и технических возможностях этой редакции.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
В индустрии виртуализации в последние годы наметилась заметная тенденция: крупные вендоры сворачивают бесплатные версии своих гипервизоров. Microsoft прекратила выпуск отдельного бесплатного Hyper-V Server, VMware (после поглощения Broadcom) закрыла свободный доступ к ESXi Free (vSphere Hypervisor), а Red Hat объявила о завершении поддержки платформы Red Hat Virtualization (RHV) к 2026 году. Ниже приводится детальный обзор этих новостей...
Таги: VMware, Microsoft, Red Hat, ESXi, Hyper-V, KVM
Компания Broadcom сообщает, что с 24 марта 2025 года произойдёт важное изменение в процессе загрузки бинарных файлов ПО VMware (включая обновления и исправления) для продуктов VMware Cloud Foundation (VCF), vCenter, ESXi и служб vSAN. Это обновление упростит доступ и приведёт его в соответствие с текущими передовыми практиками отрасли.
Ниже представлена вся необходимая информация о грядущих изменениях и их влиянии на вас.
Что именно изменится?
С 24 марта 2025 года текущий процесс загрузки бинарных файлов будет заменён новым методом. Данное изменение предполагает:
Централизация на едином ресурсе: бинарные файлы программного обеспечения будут доступны для загрузки с единого сайта, а не с нескольких различных ресурсов, как ранее. Это будет доступно как для онлайн-сред, так и для изолированных («air-gapped») систем.
Проверка загрузок: загрузка будет авторизована с помощью уникального токена. Новые URL-адреса будут содержать этот токен, подтверждающий, что именно вы являетесь авторизованным пользователем или стороной, осуществляющей загрузку файла.
Примечание: текущие URL-адреса для загрузки будут доступны в течение одного месяца для облегчения переходного периода. С 24 апреля 2025 года текущие URL-адреса перестанут действовать.
Что это значит для вас?
Вам необходимо выполнить следующие действия:
Получите токен загрузки: войдите на сайт support.broadcom.com, чтобы получить уникальный токен.
Изучите техническую документацию: ознакомьтесь с KB-статьями, в которых изложены требования и пошаговые инструкции.
Обновите URL-адреса в продуктах: Broadcom предоставит скрипт, который автоматизирует замену текущих URL-адресов в продуктах ESXi, vCenter и SDDC Manager.
Обновите скрипты автоматизации (если применимо): Если у вас есть собственные скрипты, обновите URL-адреса согласно рекомендациям из KB-статей.
Где получить дополнительную информацию?
Рекомендуемые материалы для успешного перехода на новую систему:
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Иногда у администратора VMware vSphere возникает необходимость отключить физический интерфейс на хосте VMware ESXi, чтобы сделать некоторые операции или протестировать различные сценарии.
Например:
Тестирование сценариев отказоустойчивости сети.
Определение и изоляция сетевых проблем за счет отключения подозрительного неисправного сетевого адаптера (NIC).
Временное отключение сетевого адаптера (NIC), чтобы оценить влияние на производительность сети и проверить эффективность балансировки нагрузки.
Проверка того, как виртуальные машины реагируют на отказ определенного сетевого пути.
Отключение vmnic, который подключен к ненадежному VLAN или неправильно настроенной сети.
Тестирование различных сетевых конфигураций без внесения постоянных изменений в физические соединения.
Итак, чтобы отключить vmnic, нужно зайти на ESXi по SSH и выполнить там следующую команду, чтобы вывести список сетевых адаптеров:
esxcli network nic list
Далее отключаем vmnic командой (X - это номер в имени адаптера):
esxcli network nic down -n vmnicX
В разделе физических адаптеров vSphere Client мы увидим следующую картину (адаптер в статусе "down"):
Чтобы вернуть vmnic в исходное состояние, просто выполняем команду:
Один из клиентов VMware недавно обратился к Вильяму Ламу с вопросом о том, как можно легко провести аудит всей своей инфраструктуры серверов VMware ESXi, чтобы определить, какие хосты всё ещё загружаются с использованием устаревшей прошивки BIOS, которая будет удалена в будущих выпусках vSphere и заменена на стандартную для индустрии прошивку типа UEFI.
В vSphere 8.0 Update 2 было введено новое свойство API vSphere под названием firmwareType, которое было добавлено в объект информации о BIOS оборудования ESXi, что значительно упрощает получение этой информации с помощью следующей однострочной команды PowerCLI:
(Get-VMHost).ExtensionData.Hardware.BiosInfo
Пример ее вывода для сервера ESXi при использовании UEFI выглядит вот так:
Если же используется устаревший BIOS, то вот так:
Поскольку это свойство vSphere API было недавно введено в vSphere 8.0 Update 2, если вы попытаетесь использовать его на хосте ESXi до версии 8.0 Update 2, то это поле будет пустым, если вы используете более новую версию PowerCLI, которая распознаёт это свойство. Или же оно просто не отобразится, если вы используете более старую версию PowerCLI.
В качестве альтернативы, если вам всё же необходимо получить эту информацию, вы можете подключиться напрямую к хосту ESXi через SSH. Это не самый удобный вариант, но вы можете использовать следующую команду VSISH для получения этих данных:
Некоторое время назад Вильям Лам поделился решением, позволяющим установить VIB-пакет в сборке для Nested ESXi при использовании vSAN Express Storage Architecture (ESA) и VMware Cloud Foundation (VCF), чтобы обойти предварительную проверку на соответствие списку совместимого оборудования vSAN ESA (HCL) для дисков vSAN ESA.
Хотя в большинстве случаев Вильям использует Nested ESXi для тестирования, недавно он развернул физическую среду VCF. Из-за ограниченного количества NVMe-устройств он хотел использовать vSAN ESA для домена управления VCF, но, конечно же, столкнулся с той же проверкой сертифицированных дисков vSAN ESA, которая не позволяла установщику продолжить процесс.
Вильям надеялся, что сможет использовать метод эмуляции для физического развертывания. Однако после нескольких попыток и ошибок он столкнулся с нестабильным поведением. Пообщавшись с инженерами, он выяснил, что существующее решение также применимо к физическому развертыванию ESXi, поскольку аппаратные контроллеры хранилища скрываются методом эмуляции. Если в системе есть NVMe-устройства, совместимые с vSAN ESA, предварительная проверка vSAN ESA HCL должна пройти успешно, что позволит продолжить установку.
Вильям быстро переустановил последнюю версию ESXi 8.0 Update 3b на одном из своих физических серверов, установил vSAN ESA Hardware Mock VIB и, используя последнюю версию VCF 5.2.1 Cloud Builder, успешно прошел предварительную проверку vSAN ESA, после чего развертывание началось без проблем!
Отлично, что теперь это решение работает как для физических, так и для вложенных (nested) ESXi при использовании с VCF, особенно для создания демонстрационных сред (Proof-of-Concept)!
Примечание: В интерфейсе Cloud Builder по-прежнему выполняется предварительная проверка физических сетевых адаптеров, чтобы убедиться, что они поддерживают 10GbE или более. Таким образом, хотя проверка совместимости vSAN ESA HCL пройдет успешно, установка все же завершится с ошибкой при использовании UI.
Обходной путь — развернуть домен управления VCF с помощью Cloud Builder API, где проверка на 10GbE будет отображаться как предупреждение, а не как критическая ошибка, что позволит продолжить развертывание. Вы можете использовать этот короткий PowerShell-скрипт для вызова Cloud Builder API, а затем отслеживать процесс развертывания через UI Cloud Builder.
$cloudBuilderIP = "192.168.30.190"
$cloudBuilderUser = "admin"
$cloudBuilderPass = "VMware123!"
$mgmtDomainJson = "vcf50-management-domain-example.json"
#### DO NOT EDIT BEYOND HERE ####
$inputJson = Get-Content -Raw $mgmtDomainJson
$pwd = ConvertTo-SecureString $cloudBuilderPass -AsPlainText -Force
$cred = New-Object Management.Automation.PSCredential ($cloudBuilderUser,$pwd)
$bringupAPIParms = @{
Uri = "https://${cloudBuilderIP}/v1/sddcs"
Method = 'POST'
Body = $inputJson
ContentType = 'application/json'
Credential = $cred
}
$bringupAPIReturn = Invoke-RestMethod @bringupAPIParms -SkipCertificateCheck
Write-Host "Open browser to the VMware Cloud Builder UI to monitor deployment progress ..."
Вильям Лам написал очень полезную статью, касающуюся развертывания виртуальных хостов (Nested ESXi) в тестовой лаборатории VMware Cloud Foundation.
Независимо от того, настраиваете ли вы vSAN Express Storage Architecture (ESA) напрямую через vCenter Server или через VMware Cloud Foundation (VCF), оборудование ESXi автоматически проверяется на соответствие списку совместимого оборудования vSAN ESA (HCL), чтобы убедиться, что вы используете поддерживаемое железо для vSAN.
В случае использования vCenter Server вы можете проигнорировать предупреждения HCL, принять риски и продолжить настройку. Однако при использовании облачной инфраструктуры VCF и Cloud Builder операция блокируется, чтобы гарантировать пользователям качественный опыт при выборе vSAN ESA для развертывания управляющего или рабочего домена VCF.
С учетом вышеизложенного, существует обходное решение, при котором вы можете создать свой собственный пользовательский JSON-файл HCL для vSAN ESA на основе имеющегося у вас оборудования, а затем загрузить его в Cloud Builder для настройки нового управляющего домена VCF или в SDDC Manager для развертывания нового рабочего домена VCF. Вильям уже писал об этом в своих блогах здесь и здесь.
Использование Nested ESXi (вложенного ESXi) является популярным способом развертывания VCF, особенно если вы новичок в этом решении. Этот подход позволяет легко экспериментировать и изучать платформу. В последнее время Вильям заметил рост интереса к развертыванию VCF с использованием vSAN ESA. Хотя вы можете создать пользовательский JSON-файл HCL для vSAN ESA, как упоминалось ранее, этот процесс требует определенных усилий, а в некоторых случаях HCL для vSAN ESA может быть перезаписан, что приводит к затруднениям при решении проблем.
После того как Вильям помогал нескольким людям устранять проблемы в их средах VCF, он начал задумываться о лучшем подходе и использовании другой техники, которая, возможно, малоизвестна широкой аудитории. Вложенный ESXi также широко используется для внутренних разработок VMware и функционального тестирования. При развертывании vSAN ESA инженеры сталкиваются с такими же предупреждениями HCL, как и пользователи. Одним из способов обхода этой проблемы является "эмуляция" оборудования таким образом, чтобы проверка работоспособности vSAN успешно проходила через HCL для vSAN ESA. Это достигается путем создания файла stress.json, который размещается на каждом Nested ESXi-хосте.
Изначально Вильям не был поклонником этого варианта, так как требовалось создавать файл на каждом хосте. Кроме того, файл не сохраняется после перезагрузки, что добавляло сложности. Хотя можно было бы написать сценарий автозагрузки, нужно было помнить о его добавлении на каждый новый хост.
После анализа обоих обходных решений он обнаружил, что вариант с использованием stress.json имеет свои плюсы: он требует меньше модификаций продукта, а возня с конфигурационными файлами — не самый лучший способ, если можно этого избежать. Учитывая ситуации, с которыми сталкивались пользователи при работе с новыми версиями, он нашел простое решение — создать пользовательский ESXi VIB/Offline Bundle. Это позволяет пользователям просто установить stress.json в правильный путь для их виртуальной машины Nested ESXi, решая вопросы сохранения данных, масштабируемости и удобства использования.
Перейдите в репозиторий Nested vSAN ESA Mock Hardware для загрузки ESXi VIB или ESXi Offline Bundle. После установки (необходимо изменить уровень принятия программного обеспечения на CommunitySupported) просто перезапустите службу управления vSAN, выполнив следующую команду:
/etc/init.d/vsanmgmtd restart
Или вы можете просто интегрировать этот VIB в новый профиль образа/ISO ESXi с помощью vSphere Lifecycle Manager, чтобы VIB всегда был частью вашего окружения для образов ESXi. После того как на хосте ESXi будет содержаться файл stress.json, никаких дополнительных изменений в настройках vCenter Server или VCF не требуется, что является огромным преимуществом.
Примечание: Вильям думал о том, чтобы интегрировать это в виртуальную машину Nested ESXi Virtual Appliance, но из-за необходимости изменения уровня принятия программного обеспечения на CommunitySupported, он решил не вносить это изменение на глобальном уровне. Вместо этого он оставил все как есть, чтобы пользователи, которым требуется использование vSAN ESA, могли просто установить VIB/Offline Bundle как отдельный компонент.
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
В прошлом году Вильям Лам продемонстрировал метод настройки строки железа SMBIOS с использованием Nested ESXi, но решение было далеко от идеала: оно требовало модификации ROM-файла виртуальной машины и ограничивалось использованием BIOS-прошивки для машины Nested ESXi, в то время как поведение с EFI-прошивкой отличалось.
В конце прошлого года Вильям проводил исследования и наткнулся на гораздо более изящное решение, которое работает как для физического, так и для виртуального ESXi. Существует параметр ядра ESXi, который можно переключить, чтобы просто игнорировать стандартный SMBIOS оборудования, а затем эмулировать собственную пользовательскую информацию SMBIOS.
Шаг 1 – Подключитесь по SSH к вашему ESXi-хосту, отредактируйте файл конфигурации /bootbank/boot.cfg и добавьте ignoreHwSMBIOSInfo=TRUE в строку kernelopt, после чего перезагрузите систему.
Шаг 2 – Далее нам нужно выполнить команду vsish, чтобы настроить желаемую информацию SMBIOS. Однако, вместо того чтобы заставлять пользователей вручную создавать команду, Вильям создал простую функцию PowerShell, которая сделает процесс более удобным.
Сохраните или выполните приведенный ниже фрагмент PowerShell-кода, который определяет новую функцию Generate-CustomESXiSMBIOS. Эта функция принимает следующие шесть аргументов:
Uuid – UUID, который будет использоваться в симулированной информации SMBIOS.
Вам потребуется перезапустить службу hostd, чтобы информация стала доступной. Для этого выполните команду:
/etc/init.d/hostd restart
Если вы теперь войдете в ESXi Host Client, vCenter Server или vSphere API (включая PowerCLI), то обнаружите, что производитель оборудования, модель, серийный номер и UUID отображают заданные вами пользовательские значения, а не данные реального физического оборудования!
Пользовательский SMBIOS не сохраняется после перезагрузки, поэтому вам потребуется повторно запускать команду каждый раз после перезагрузки вашего хоста ESXi.
Недавно мы писали о том, что команда ESXi-Arm выпустила новую версию популярной платформы виртуализации ESXi-Arm Fling (v2.0) (ссылка на скачивание тут), которая теперь основана на базе кода ESXi версии 8.x и конкретно использует последний релиз ESXi-x86 8.0 Update 3b.
Вильям Лам рассказал о том, что теперь вы можете запустить экземпляр ESXi-Arm V2 внутри виртуальной машины, что также называется Nested ESXi-Arm. На конференции VMware Explore в США он использовал Nested ESXi-Arm, так как у него есть ноутбук Apple M1, и ему нужно было провести демонстрацию для сессии Tech Deep Dive: Automating VMware ESXi Installation at Scale, посвященной автоматизированной установке ESXi с помощью Kickstart. Поскольку и ESXi-x86, и ESXi-Arm имеют одинаковую реализацию, возможность запуска Nested ESXi-Arm оказалась полезной (хотя он использовал версию, отличающуюся от официального релиза Fling). Такой же подход может быть полезен, если вы хотите запустить несколько виртуальных машин ESXi-Arm для изучения API vSphere и подключить Nested ESXi-Arm к виртуальной машине x86 VCSA (vCenter Server Appliance). Возможно, вы разрабатываете что-то с использованием Ansible или Terraform - это действительно открывает множество вариантов для тех, у кого есть такая потребность.
Arm Hardware
Так же как и при создании Nested ESXi-x86 VM, выберите опцию типа ВМ "Other" (Другое) и затем выберите "VMware ESXi 8.0 or later", настроив как минимум на 2 виртуальных процессора (vCPU) и 8 ГБ оперативной памяти.
Примечание: Текущая версия ESXi-Arm НЕ поддерживает VMware Hardware-Assisted Virtualization (VHV), которая необходима для запуска 64-битных операционных систем в Nested или внутренних виртуальных машинах. Если вы включите эту настройку, запустить Nested ESXi-Arm VM не получится, поэтому убедитесь, что эта настройка процессора отключена (по умолчанию она отключена).
VMware Fusion (M1 и новее)
Еще одна хорошая новость: для пользователей Apple Silicon (M1 и новее) теперь также можно запускать виртуальные машины Nested ESXi-Arm! Просто выберите «Other» (Другое), затем тип машины «Other 64-bit Arm» и настройте ВМ с как минимум 2 виртуальными процессорами (vCPU) и 8 ГБ оперативной памяти. Вильяму как раз потребовалась эта возможность на VMware Explore, когда он демонстрировал вещи, не связанные напрямую с архитектурой Arm. Он попросил команду инженеров предоставить внутреннюю сборку ESXi-Arm, которая могла бы работать на Apple M1, теперь же эта возможность ESXi-Arm доступна для всех.
Примечание: поскольку для работы Nested-ESXi-Arm требуется режим promiscuous mode, при включении виртуальной машины в VMware Fusion вас могут раздражать запросы на ввод пароля администратора. Если вы хотите отключить эти запросы, ознакомьтесь с этой статьей в блоге для получения дополнительной информации.
Вильям Лам сообщает, что команда ESXi-Arm недавно выпустила новую версию популярной платформы виртуализации ESXi-Arm Fling (v2.0) (ссылка на скачивание тут), которая теперь основана на базе кода ESXi версии 8.x и конкретно использует последний релиз ESXi-x86 8.0 Update 3b. Это очень значимое обновление, так как изначальный релиз ESXi-Arm Fling (выпущенный 4 года назад) был основан на ESXi 7.x при начальной адаптации x86-дистрибутива для архитектуры ARM.
После выпуска первого коммерческого продукта ESXi-Arm в составе vSphere Distributed Service Engine (vDSE), ранее известного как Project Monterey, команда ESXi-Arm активно работала над унификацией кодовой базы ESXi-Arm, которая также используется и для работы коммерческой технологии vDSE.
В дополнение к переезду ESXi-Arm с версии 7.x на 8.x, команда продолжает поддерживать широкий спектр систем на базе Arm, которые представлены в списке ниже:
Серверы на базе Ampere Computing Altra и AltraMax (системы с одним процессором, такие как HPE ProLiant RL300 Gen 11, или системы с двумя процессорами, как Ampere 2U Mt. Collins)
Платформа mini-ITX SolidRun HoneyComb LX2K на базе NXP LayerScape 2160A
Raspberry Pi 4B (только с 8 ГБ памяти)
Raspberry Pi 5 (только с 8 ГБ памяти)
PINE64 Quartz64 Model A и вычислительный модуль SOQuartz на базе Rockchip RK3566
Firefly ROC-RK3566-PC и StationPC Station M2 на базе Rockchip RK3566
Для тех, кто обновляется с Fling версии 1.x, потребуется небольшое ручное обновление конфигурационных файлов виртуальных машин. Обязательно прочитайте главу 3 "Upgrading from Fling v1" в документации к ESXi. Чтобы загрузить последнюю версию ESXi-Arm ISO/Offline Bundle вместе с обновленной документацией по ESXi-Arm, используйте вашу бесплатную учетную запись или зарегистрируйтесь на Broadcom Community и посетите портал VMware Flings.
Если вы пропустили новость о том, что вышло обновление платформы VMware vSphere 8 Update 3b, то сейчас самое время подумать об обновлении, так как сообщений о каких-то серьезных багах не поступало.
Итак, что нового в VMware ESXi 8.0 Update 3b:
DPU/SmartNIC - появилась поддержка VMware vSphere Distributed Services Engine с DPU NVIDIA Bluefield-3. Устройства DPU NVIDIA Bluefield-3 поддерживаются как в режиме одиночного DPU, так и в dual-DPU конфигурациях.
ESXi 8.0 Update 3b добавляет поддержку vSphere Quick Boot для нескольких серверов, включая:
Улучшения в проектировании переменных cloud-init guestInfo: начиная с ESXi 8.0 Update 3b, попытка обычных пользователей задать переменные cloud-init guestInfo внутри гостевой ОС приводит к ошибке. Для получения дополнительной информации см. KB 377267.
Что нового в VMware vCenter 8.0 Update 3b:
Этот выпуск устраняет уязвимости CVE-2024-38812 и CVE-2024-38813. Для получения дополнительной информации об этих уязвимостях и их влиянии на продукты VMware посмотрите статью VMSA-2024-0019.
VMware vCenter Server 8.0 Update 3b предоставляет исправления ошибок, описанные в разделе Resolved Issues.
Вильям Лам написал наиполезнейшую статью о сбросе/восстановлении пароля консоли сервера VMware ESXi 8 и 7 в составе платформы виртуализации VMware vSphere.
Ранее также было возможно сбросить пароль root ESXi, загрузив систему в Linux и вручную обновив файл /etc/shadow, что похоже на то, как можно сбросить пароль в системе на базе Linux. В сети можно найти множество статей в блогах, описывающих этот процесс. Однако с появлением ESXi Configuration Store данный метод больше не работает для современных версий ESXi, начиная с ESXi 7.0 Update 1 и выше.
Тем не менее, эта тема все еще часто поднимается, особенно в контексте администраторов, которые начинают работать в новой компании, где пароль root ESXi не был должным образом задокументирован, или когда администратору поручено поддерживать набор отдельных ESXi хостов без владельцев. Независимо от сценария, хотя переустановка является самым быстрым способом восстановления, конечно, было бы неплохо сохранить исходную конфигурацию, особенно если нет документации.
Хотя в сети было опубликовано множество фрагментов информации (здесь, здесь и здесь), включая информацию от самого Вильяма, было бы полезно выяснить по шагам актуальный процесс восстановления ESXi 7.x или 8.x хоста без необходимости его переустановки.
Предварительные требования:
Доступ к физическому носителю, на который установлен ESXi (USB или HDD/SSD)
Виртуальная машина Linux (Ubuntu или Photon OS)
Виртуальная машина с вложенным ESXi
Для демонстрации описанного ниже процесса восстановления Вильям установил ESXi 8.0 Update 3c на USB-устройство с базовой конфигурацией (имя хоста, сеть, SSH MOTD), чтобы убедиться в возможности восстановления системы. Затем он изменил пароль root на что-то полностью случайное и удалил этот пароль, чтобы нельзя было войти в систему. Хост ESXi, на котором он "забыл" пароль, будет называться физическим хостом ESXi, а вложенная виртуальная машина с ESXi, которая будет помогать в восстановлении, будет называться вложенным хостом (Nested ESXi).
Шаг 1 — Разверните вложенную виртуальную машину с ESXi (скачать с сайта VMware Flings), версия которой должна соответствовать версии вашего физического хоста ESXi, который вы хотите восстановить.
Шаг 2 — Скопируйте файл state.tgz с физического хоста ESXi, который вы хотите восстановить. Обязательно сделайте резервную копию на случай, если допустите ошибку.
Если ваш хост ESXi установлен на USB, отключите USB-устройство, подключите его к настольной системе и скопируйте файл с тома BOOTBANK1.
Если ваш хост ESXi установлен на HDD/SSD, вам нужно будет загрузить физическую систему с помощью Linux LiveCD (Ubuntu или Knoppix) и смонтировать раздел 5 для доступа к файлу state.tgz.
Шаг 3 — Скопируйте файл state.tgz с вашего физического хоста ESXi на вложенный хост ESXi и поместите его в /tmp/state.tgz, затем выполните следующую команду для извлечения содержимого файла:
tar -zxvf state.tgz
rm -f state.tgz
Шаг 4 — Войдите на ваш вложенный хост ESXi и выполните следующие команды для извлечения его файла state.tgz, который будет помещен в каталог /tmp/a. Затем мы используем утилиту crypto-util для расшифровки файла local.tgz.ve вложенного хоста ESXi, чтобы получить файл local.tgz, и затем просто удаляем зашифрованный файл вместе с файлом encryption.info вложенного хоста ESXi. После этого мы заменим их файлом encryption.info с нашего физического хоста ESXi и создадим модифицированную версию state.tgz, которая будет загружаться в нашей вложенной виртуальной машине ESXi. Мы используем это для расшифровки исходного файла state.tgz с нашего физического хоста ESXi.
mkdir /tmp/a
cd /tmp/a
tar xzf /bootbank/state.tgz
crypto-util envelope extract --aad ESXConfiguration local.tgz.ve local.tgz
rm -f local.tgz.ve encryption.info
cp /tmp/encryption.info /tmp/a/encryption.info
tar -cvf /tmp/state-mod.tgz encryption.info local.tgz
После успешного выполнения последней команды, нам нужно скопировать файл /tmp/state-mod.tgz на ваш рабочий стол, а затем выключить вложенную виртуальную машину ESXi.
Шаг 5 — Смонтируйте первый VMDK диск из вашей вложенной виртуальной машины ESXi на вашу виртуальную машину с Linux. В данном случае Вильм использует Photon OS, который также управляет и DNS-инфраструктурой.
Шаг 6 — Убедитесь, что VMDK вашей вложенной виртуальной машины ESXi виден в вашей системе Linux, выполнив следующую команду. Мы должны увидеть два раздела bootbank (5 и 6), как показано на скриншоте ниже:
fdisk -l
Шаг 7 — Перенесите файл state-mod.tgz, созданный на Шаге 4, на вашу виртуальную машину с Linux, затем смонтируйте оба раздела bootbank и замените файл state.tgz на нашу модифицированную версию.
Примечание: Этот шаг необходим, потому что, если вы просто скопируете модифицированный файл state.tgz напрямую на USB-устройство физического хоста ESXi, вы обнаружите, что система восстановит оригинальный файл state.tgz, даже если на обоих разделах содержится модифицированная версия.
Шаг 8 — Сделайте remove (не удаляйте) VMDK файл вложенной виртуальной машины ESXi с виртуальной машины Linux, затем включите вложенную виртуальную машину ESXi.
После успешной загрузки вложенной виртуальной машины ESXi, она теперь работает с оригинальным файлом encryption.info с нашего физического хоста ESXi, что позволит нам восстановить исходный файл state.tgz.
Шаг 9 — Скопируйте исходный файл state.tgz, созданный на Шаге 2, во вложенную виртуальную машину ESXi, поместите его в каталог /tmp/state.tgz и выполните следующую команду, которая теперь позволит нам расшифровать файл state.tgz с физического хоста ESXi, как показано на скриншоте ниже!
cd /tmp
tar -zxvf state.tgz
rm -f state.tgz
crypto-util envelope extract --aad ESXConfiguration local.tgz.ve local.tgz
rm -f local.tgz.ve
Шаг 10 — После расшифровки исходного файла state.tgz у нас должен появиться файл local.tgz, который мы извлечем локально в каталоге /tmp, выполнив следующую команду:
tar -zxvf local.tgz
Следующие три каталога: .ssh, etc/ и var/ будут размещены в /tmp, а /tmp/var/lib/vmware/configstore/backup/current-store-1 — это хранилище конфигурации ESXi для физического хоста ESXi, которое нам нужно обновить и заменить оригинальный хеш пароля root на желаемый, чтобы мы могли войти в систему.
Для непосредственного изменения хранилища конфигурации ESXi нам необходимо использовать утилиту sqlite3, так как файл хранится в виде базы данных sqlite3. Мы можем выполнить следующую команду на вложенной виртуальной машине ESXi, чтобы проверить текущий хеш пароля root:
/usr/lib/vmware/sqlite/bin/sqlite3 /tmp/var/lib/vmware/configstore/backup/current-store-1 "select * from config where Component='esx' and ConfigGroup = 'authentication' and Name = 'user_accounts' and Identifier = 'root'"
Шаг 11 — Вам потребуется новый хеш пароля в формате SHA512, где вы знаете сам пароль, после чего выполните следующую команду, заменив хеш.
/usr/lib/vmware/sqlite/bin/sqlite3 /tmp/var/lib/vmware/configstore/backup/current-store-1 "update config set UserValue='{\"name\":\"root\",\"password_hash\":\"\$6\$s6ic82Ik\$ER28x38x.1umtnQ99Hx9z0ZBOHBEuPYneedI1ekK2cwe/jIpjDcBNUHWHw0LwuRYJWhL3L2ORX3I5wFxKmyki1\",\"description\":\"Administrator\"}' where Component='esx' and ConfigGroup = 'authentication' and Name = 'user_accounts' and Identifier = 'root'"
Примечание: Вам нужно правильно экранировать любые специальные символы, например, как в приведенном выше примере, где хеш пароля содержит символ "$". Чтобы убедиться, что замена хеша выполнена правильно, вы можете выполнить вышеуказанную команду запроса, чтобы убедиться, что вывод соответствует желаемому хешу пароля, как показано на скриншоте ниже.
Шаг 12 — Теперь, когда мы обновили хранилище конфигурации ESXi с нашим желаемым паролем root, нам нужно заново создать файл state.tgz, который будет содержать наши изменения, выполнив следующие команды:
rm -f local.tgz
tar -cvf /tmp/local.tgz .ssh/ etc/ var/
tar -cvf /tmp/state-recover.tgz encryption.info local.tgz
Скопируйте файл /tmp/state-recover.tgz с вложенной виртуальной машины ESXi на вашу виртуальную машину с Linux, которая затем будет использоваться для монтирования носителя физического хоста ESXi, чтобы заменить файл state.tgz на нашу восстановленную версию.
Шаг 13 — Смонтируйте носитель физического хоста ESXi на вашу виртуальную машину с Linux. Поскольку физический хост ESXi установлен на USB, можно просто подключить USB-устройство напрямую к виртуальной машине с Linux.
Снова мы можем убедиться, что виртуальная машина с Linux видит носитель с установленным физическим хостом ESXi, выполнив команду fdisk -l, и мы должны увидеть два раздела bootbank (5 и 6), как показано на скриншоте ниже.
Шаг 14 — Теперь нам просто нужно смонтировать раздел bootbank и заменить оригинальный файл state.tgz на нашу модифицированную версию (state-recover.tgz).
Примечание: Поскольку физический хост ESXi был только что установлен, на втором разделе bootbank не было ничего для замены, но если вы найдете файл state.tgz, его также следует заменить, используя ту же команду, но указав другой номер раздела.
Шаг 15 — Последний шаг: размонтируйте носитель физического хоста ESXi с виртуальной машины Linux, затем включите ваш физический хост ESXi, и теперь вы сможете войти в систему, используя обновленный пароль root!
Memory Tiering использует более дешевые устройства в качестве памяти. В Update 3 платформа vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Вильям Лам написал интересный пост о выводе информации для NVMe Tiering в VMware vSphere через API. После успешного включения функции NVMe Tiering, которая была введена в vSphere 8.0 Update 3, вы можете найти полезную информацию о конфигурации NVMe Tiering, перейдя к конкретному хосту ESXi, затем выбрав "Configure" -> "Hardware" и в разделе "Memory", как показано на скриншоте ниже.
Здесь довольно много информации, поэтому давайте разберём отдельные элементы, которые полезны с точки зрения NVMe-тиринга, а также конкретные vSphere API, которые можно использовать для получения этой информации.
Memory Tiering Enabled
Поле Memory Tiering указывает, включён ли тиринг памяти на хосте ESXi, и может иметь три возможных значения: "No Tiering" (без тиринга), "Hardware Memory Tiering via Intel Optane" (аппаратный тиринг памяти с помощью технологии Intel Optane) или "Software Memory Tiering via NVMe Tiering" (программный тиринг памяти через NVMe). Мы можем получить значение этого поля, используя свойство "memoryTieringType" в vSphere API, которое имеет три перечисленных значения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Поле Tier 0 представляет общий объём физической оперативной памяти (DRAM), доступной на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "DRAM"}).Size
Tier 1 Memory
Поле Tier 1 представляет общий объём памяти, предоставляемой NVMe-тирингом, которая доступна на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Примечание: Можно игнорировать термин "Unmappable" — это просто другой способ обозначения памяти, отличной от DRAM.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "NVMe"}).Size
Поле Total представляет общий объём памяти, доступный ESXi при объединении как DRAM, так и памяти NVMe-тиринга, который можно агрегировать, используя размеры Tier 0 и Tier 1 (в байтах).
Устройства NVMe для тиринга
Чтобы понять, какое устройство NVMe настроено для NVMe-тиринга, нужно перейти в раздел "Configure" -> "Storage" -> "Storage Devices", чтобы просмотреть список устройств. В столбце "Datastore" следует искать значение "Consumed for Memory Tiering", как показано на скриншоте ниже. Мы можем получить это поле, используя свойство "usedByMemoryTiering" при энумерации всех устройств хранения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Отношение объёма DRAM к NVMe по умолчанию составляет 25% и настраивается с помощью следующего расширенного параметра ESXi под названием "Mem.TierNvmePct". Мы можем получить значение этого поля, используя либо vSphere API ("OptionManager"), либо через ESXCLI.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Вильям собрал все вышеперечисленные парметры и создал скрипт PowerCLI под названием "get-nvme-tiering-info.ps1", который предоставляет удобное резюме для всех хостов ESXi в рамках конкретного кластера Sphere (вы также можете изменить скрипт, чтобы он запрашивал конкретный хост ESXi). Это может быть полезно для быстрого получения информации о хостах, на которых NVMe-тиринг может быть настроен (или нет).
Вильям Лам написал интересную статью о поддержке технологии Intel Neural Processing Unit (NPU) на платформе VMware ESXi.
Начиная с процессоров Intel Meteor Lake (14 поколения), которые теперь входят в новый бренд Intel Core Ultra Processor (серия 1), встроенный нейронный процессор (Neural Processing Unit, NPU) интегрирован прямо в систему на кристалле (system-on-chip, SoC) и оптимизирован для энергоэффективного выполнения AI-инференса.
Хотя вы уже можете использовать интегрированную графику Intel iGPU на таких платформах, как Intel NUC, с ESXi для инференса рабочих нагрузок, Вильяму стало интересно, сможет ли этот новый нейронный процессор Intel NPU работать с ESXi?
Недавно Вильям получил доступ к ASUS NUC 14 Pro (на который позже он сделает подробный обзор), в котором установлен новый нейронный процессор Intel NPU. После успешной установки последней версии VMware ESXi 8.0 Update 3, он увидел, что акселератор Intel NPU представлен как PCIe-устройство, которое можно включить в режиме passthrough и, видимо, использовать внутри виртуальной машины.
Для тестирования он использовал Ubuntu 22.04 и библиотеку ускорения Intel NPU, чтобы убедиться, что он может получить доступ к NPU.
Шаг 1 - Создайте виртуальную машину с Ubuntu 22.04 и настройте резервирование памяти (memory reservation - это требуется для PCIe passthrough), затем добавьте устройство NPU, которое отобразится как Meteor Lake NPU.
Примечание: вам нужно будет отключить Secure Boot (этот режим включен по умолчанию), так как необходимо установить более новую версию ядра Linux, которая всё ещё находится в разработке. Отредактируйте виртуальную машину и перейдите в VM Options -> Boot Options, чтобы отключить его.
Когда Ubuntu будет запущена, вам потребуется установить необходимый драйвер Intel NPU для доступа к устройству NPU, однако инициализация NPU не удастся, что можно увидеть, выполнив следующую команду:
dmesg | grep vpu
После подачи обращения в поддержку Github по поводу драйвера Intel NPU, было предложено, что можно инициализировать устройство, используя новую опцию ядра, доступную только в версии 6.11 и выше.
Шаг 2 - Используя эту инструкцию, мы можем установить ядро Linux версии 6.11, выполнив следующие команды:
После перезагрузки вашей системы Ubuntu вы можете убедиться, что теперь она использует версию ядра 6.11, выполнив команду:
uname -r
Шаг 3 - Теперь мы можем установить драйвер Intel NPU для Linux, и на момент публикации этой статьи последняя версия — 1.8.0. Для этого выполните следующие команды:
Нам также нужно создать следующий файл, который включит необходимую опцию ядра (force_snoop=1) для инициализации NPU по умолчанию, выполнив следующую команду:
Теперь перезагрузите систему, и NPU должен успешно инициализироваться, как показано на скриншоте ниже.
Наконец, если вы хотите убедиться, что NPU полностью функционален, в библиотеке Intel NPU Acceleration есть несколько примеров, включая примеры малых языковых моделей (SLM), такие как TinyLlama, Phi-2, Phi-3, T5 и другие.
Для настройки вашего окружения Python с использованием conda выполните следующее:
Автор попробовал пример tiny_llama_chat.py (видимо, тренировочные данные для этой модели могли быть основаны на изображениях или художниках).
Независимо от того, используете ли вы новую библиотеку Intel NPU Acceleration или фреймворк OpenVino, теперь у вас есть доступ к ещё одному ускорителю с использованием ESXi, что может быть полезно для периферийных развертываний, особенно для рабочих нагрузок, требующих инференса AI, и теперь с меньшим энергопотреблением.
Следующий пример на Python можно использовать для проверки того, что устройство NPU видно из сред выполнения, таких как OpenVino.
from openvino.runtime import Core
def list_available_devices():
# Initialize the OpenVINO runtime core
core = Core()
# Get the list of available devices
devices = core.available_devices
if not devices:
print("No devices found.")
else:
print("Available devices:")
for device in devices:
print(f"- {device}")
# Optional: Print additional device information
for device in devices:
device_info = core.get_property(device, "FULL_DEVICE_NAME")
print(f"\nDevice: {device}\nFull Device Name: {device_info}")
if __name__ == "__main__":
list_available_devices()

 RSS
RSS