Обновление аппаратного обеспечения виртуальной машины vCenter в vSphere с VCF 9.1
Аппаратная версия виртуальной машины vCenter оставалась на уровне версии 10 (совместима с VMware ESX 5.5 и более поздними) со времён VMware vSphere 5.5. С выходом vSphere в составе VMware Cloud Foundation 9.1 она обновлена до версии 17.
Примечание: в зависимости от интерфейса, статьи базы знаний или технической документации могут использоваться взаимозаменяемые термины «совместимость виртуальной машины», «совместима с ESX версии» или «версия аппаратного обеспечения виртуальной машины». Для ясности: виртуальное аппаратное обеспечение версии 17 в интерфейсе vSphere Client обозначается как «Compatible with ESXi 7.0 and later».
Об обновлении аппаратной версии виртуальной машины vCenter
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом Reduced Downtime Upgrade аппаратная версия виртуальной машины vCenter обновляется автоматически с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter.
После выполнения in-place обновления vCenter (с 9.0.x до 9.1.0) аппаратную версию ВМ vCenter необходимо обновить вручную. Эта процедура требует выключения виртуальной машины vCenter.
Если виртуальная машина vCenter является «самоуправляемой», её необходимо выключить и выполнить обновление аппаратного обеспечения ВМ до версии 17 через ESX Host Client. Подробности — в документации Upgrade Virtual Machine Compatibility by Using the VMware Host Client.
Если виртуальная машина vCenter управляется другим экземпляром vCenter, её необходимо выключить и выполнить обновление аппаратного обеспечения ВМ до версии 17 через vSphere Client. Подробности — в документации Upgrade the Compatibility of a Virtual Machine Manually.
Обновление аппаратного обеспечения ВМ необратимо — откатить версию назад невозможно. Перед обновлением аппаратной версии ВМ vCenter рекомендуется создать снапшот виртуальной машины или выполнить её резервное копирование.
Важно: необходимо выбирать именно Compatible with ESXi 7.0 and later (версия 17). Если выбрана более поздняя версия, vCenter окажется в неподдерживаемом состоянии — потребуется восстановление из снапшота или из более ранней резервной копии vCenter.
Также доступна возможность запланировать обновление аппаратной версии при следующей перезагрузке.

Подробности — в документации Schedule a Compatibility Upgrade for a Virtual Machine.
Совет: рекомендуется включить запланированное обновление аппаратной версии до начала in-place обновления vCenter до версии 9.1. Поскольку обновление требует перезагрузки, можно совместить обновление vCenter до 9.1 и обновление аппаратной версии ВМ в рамках одного цикла перезагрузки.
Почему именно версия 17?
Краткий ответ: обратная совместимость. Виртуальное аппаратное обеспечение версии 17 поддерживается на хостах ESX 7.0 и более поздних. Инфраструктурные обновления нередко выполняются постепенно, а устаревшее и даже не поддерживаемое оборудование продолжает использоваться в производственных средах. Возможность запускать vCenter версии 9.1 на более старых хостах ESX предоставляет клиентам гибкость: они могут перейти на vCenter 9.1, не торопясь с миграцией на новые аппаратные платформы. Миграция между управляющими серверами (Cross-vCenter migration) позволит перенести ВМ vCenter на новую инфраструктуру в удобный момент.
Будет ли аппаратная версия vCenter обновляться снова?
Да. Цель — поддерживать аппаратную версию ВМ vCenter по модели N-1 относительно мажорных версий ESX. Например, текущая мажорная версия ESX — 9.x, следовательно, версия N-1 — это 8.x.
Необходимо также учитывать, что vCenter всегда обновляется раньше ESX. Аппаратная версия ВМ vCenter не может быть повышена до уровня, который ещё не обновлённый ESX не в состоянии обеспечить.
Полный список версий аппаратного обеспечения виртуальных машин доступен по ссылке: Virtual Machine Hardware Versions.
Таги: VMware, vCenter, Hardware, Upgrade, VMachines
VMware Cloud on AWS: новый инстанс i7i.metal-24xl
С момента запуска VMware Cloud on AWS компании VMware и AWS совместно расширяли портфель специализированных инстансов на базе bare-metal — от оригинальных i3.metal и i3en.metal до высокоплотного i4i.metal. Теперь для VMware Cloud on AWS объявлен запуск нового типа инстансов — i7i.metal-24xl. Оснащённый процессорами 5 поколения Intel Xeon Scalable (Emerald Rapids), SSD третьего поколения AWS Nitro и высокоскоростной памятью DDR5, новый инстанс обеспечивает значимый скачок в пропускной способности хранилища и вычислительной эффективности — при этом существующая операционная модель VMware не требует каких-либо изменений.
По мере того как всё больше заказчиков переносят в облако наиболее требовательные рабочие нагрузки, новый инстанс i7i обеспечивает наилучшую вычислительную производительность и производительность хранилища среди x86-инстансов Amazon EC2, оптимизированных для хранения данных. Пользователи VMware Cloud on AWS получают заметно более высокую пропускную способность ввода-вывода, меньшую задержку и улучшенное соотношение цены и производительности по сравнению с предыдущим поколением.
Ключевые характеристики
Инстанс i7i.metal-24xl представляет собой универсальный bare-metal-инстанс, разработанный для I/O-интенсивных корпоративных рабочих нагрузок, которым требуется максимально возможная производительность случайного ввода-вывода с предсказуемой субмиллисекундной задержкой.
| Характеристика | i7i.metal-24xl |
|---|
| Процессор | 5th Gen Intel Xeon (Emerald Rapids) |
| vCPU | 96 |
| Физические ядра | 48 |
| Память | 768 ГиБ DDR5 (5600 MT/s) |
| Локальное NVMe-хранилище | 6 x 3,75 ТБ NVMe SSD |
| Используемая ёмкость* |
vSAN OSA ~ 13 ТБ / vSAN ESA ~ 20 ТБ |
| Пропускная способность сети | 56,25 Гбит/с |
Источник: Amazon EC2 I7i Instances — aws.amazon.com. Используемая ёмкость является оценочной. Для конфигураций с оптимизацией vSAN на кластере из 3 узлов фактическая ёмкость будет варьироваться в зависимости от профиля нагрузки, политики FTT/RAID и применяемых параметров сжатия и дедупликации vSAN.
Региональная доступность
Тип инстансов i7i.metal-24xl доступен для приобретения в следующих регионах AWS:
| География | Регионы AWS |
|---|
| Америка | US East (N. Virginia), US East (Ohio), US West (Oregon), US West (N. California), Canada (Central) |
| Европа | Europe (Ireland), Europe (London), Europe (Frankfurt), Europe (Stockholm), Europe (Milan) |
| Ближний Восток | Middle East (Bahrain) |
| Азиатско-Тихоокеанский регион | Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Melbourne), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Osaka), Asia Pacific (Mumbai), Asia Pacific (Hyderabad) |
Подробнее — в разделе о доступных регионах и зонах доступности.
Конфигурация кластера и гибкость
VMware vSAN работает непосредственно поверх локальных NVMe-дисков каждого хоста i7i.metal-24xl. При включённом сжатии vSAN кластер из 3 узлов обеспечивает значительную используемую ёмкость — конкретный результат зависит от характеристик нагрузки, политики FTT/RAID и показателей снижения объёма данных. Размер конфигурации рекомендуется валидировать применительно к конкретному профилю данных.
На i7i.metal-24xl по умолчанию включён гиперпоточный режим, что обеспечивает 96 логических ядер на хост — это хорошо подходит для приложений, выигрывающих от увеличенного параллелизма потоков CPU. Для заказчиков, которым важны показатели производительности приложений или условия программного лицензирования, VMware Cloud on AWS поддерживает опцию Custom CPU Core Count, позволяющую управлять количеством физических ядер, доступных на каждом хосте.
Для вторичных кластеров i7i.metal поддерживаются следующие конфигурации:
- Кластеры от 3 узлов: 8, 16, 24, 30 или 36 физических ядер на хост
- Кластеры из 2 узлов: 16, 24, 30 или 36 физических ядер на хост
Такая гибкость особенно ценна для ПО с лицензированием по числу ядер — например, Oracle Database и Microsoft SQL Server: сокращение числа активных ядер может существенно снизить лицензионные расходы без потери объёма памяти и хранилища хоста.
Кроме того, доступно развёртывание Stretched Cluster с охватом нескольких зон доступности для новых SDDC на базе i7i.metal-24xl — это обеспечивает высокую доступность рабочих нагрузок сразу в двух зонах доступности AWS в пределах одного региона. По умолчанию в Stretched Cluster SDDC используется vSAN OSA.
Приобретение подписок i7i.metal-24xl
За информацией о ценах, доступных регионах и вариантах приобретения следует обращаться к представителю Broadcom. Если контактные данные представителя неизвестны, можно воспользоваться формой на сайте продаж Broadcom.
Важно учитывать, что тип инстансов i7i требует предварительного обновления существующих развёртываний до версии SDDC 1.26v2 — для конвертации кластеров и развёртывания новых вторичных кластеров. Для запроса досрочного обновления необходимо открыть запрос в поддержку с указанием организации, данных SDDC и желаемой даты обновления — команда VMC поддержки скоординирует дальнейшие шаги.
Развёртывание и миграция на i7i.metal-24xl
Существует два сценария: развертывание нового SDDC с инстансами i7i.metal-24xl или миграция рабочих нагрузок с имеющихся узлов i3.metal, i3en.metal и/или i4i.metal на новый i7i.metal-24xl. Тип инстансов i7i доступен только для SDDC версии 1.26v2.
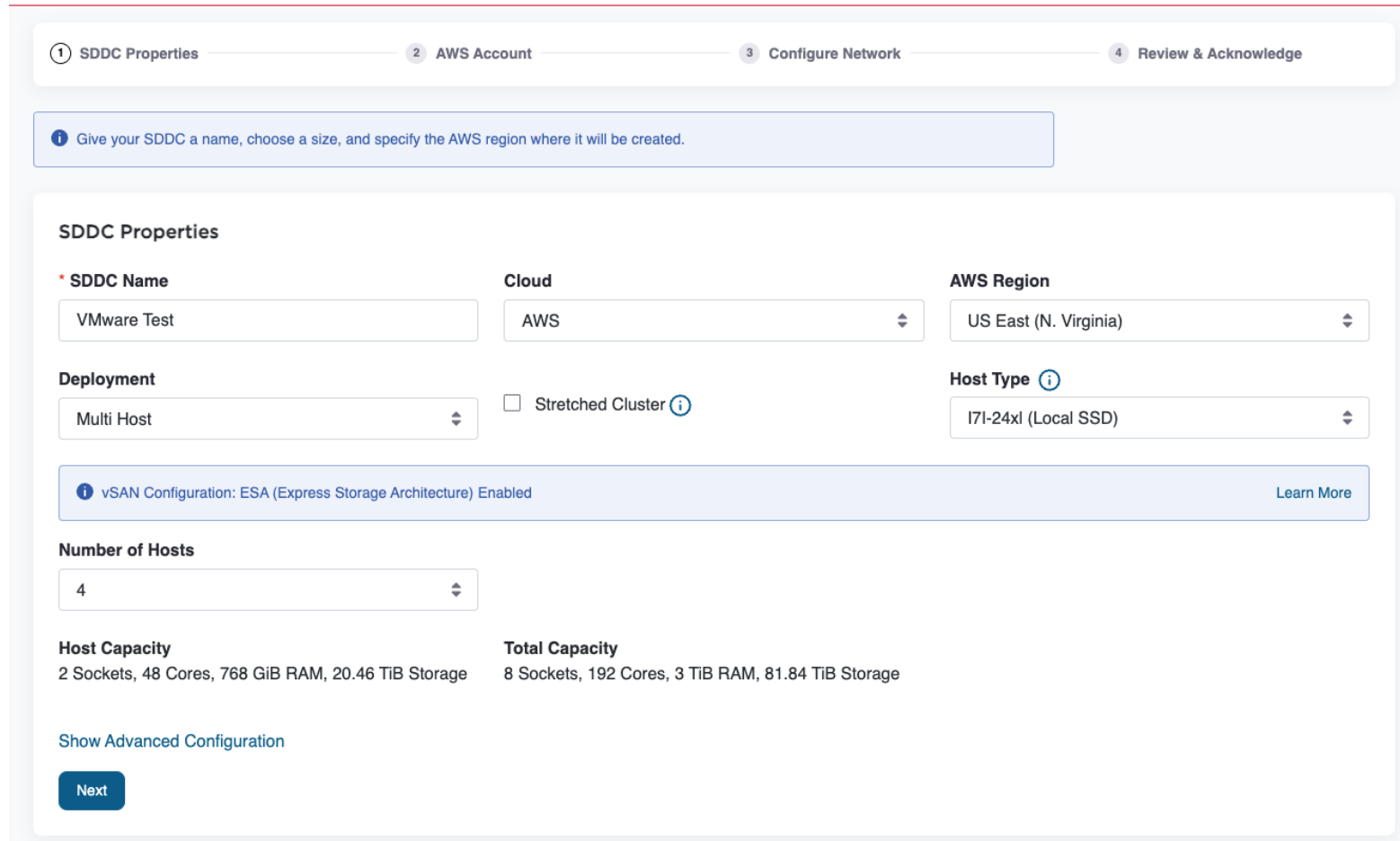
Создание нового SDDC
Все вновь развёртываемые SDDC будут работать на актуальной версии SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции доступны в разделе «Развёртывание SDDC из VMware Cloud Console».
- Войдите в VMware Cloud Console по адресу vmc.broadcom.com.
- Выберите Create SDDC и укажите тип хоста i7i.metal-24xl.
- Задайте размер кластера (минимум 2 хоста) и выполните оставшиеся шаги.
- Завершите развёртывание SDDC. VMware автоматически выполняет настройку ESXi, vSAN, vCenter и NSX.
Добавление вторичного кластера в существующий SDDC
К существующему SDDC (после обновления до версии 1.26v2) можно добавить новый кластер на базе i7i.metal-24xl без прерывания выполняющихся нагрузок. После подготовки кластера vSphere vMotion позволяет перенести виртуальные машины из имеющихся кластеров в новый i7i с минимальным воздействием. Новый кластер будет работать под управлением SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции — в разделе «Добавление кластера».
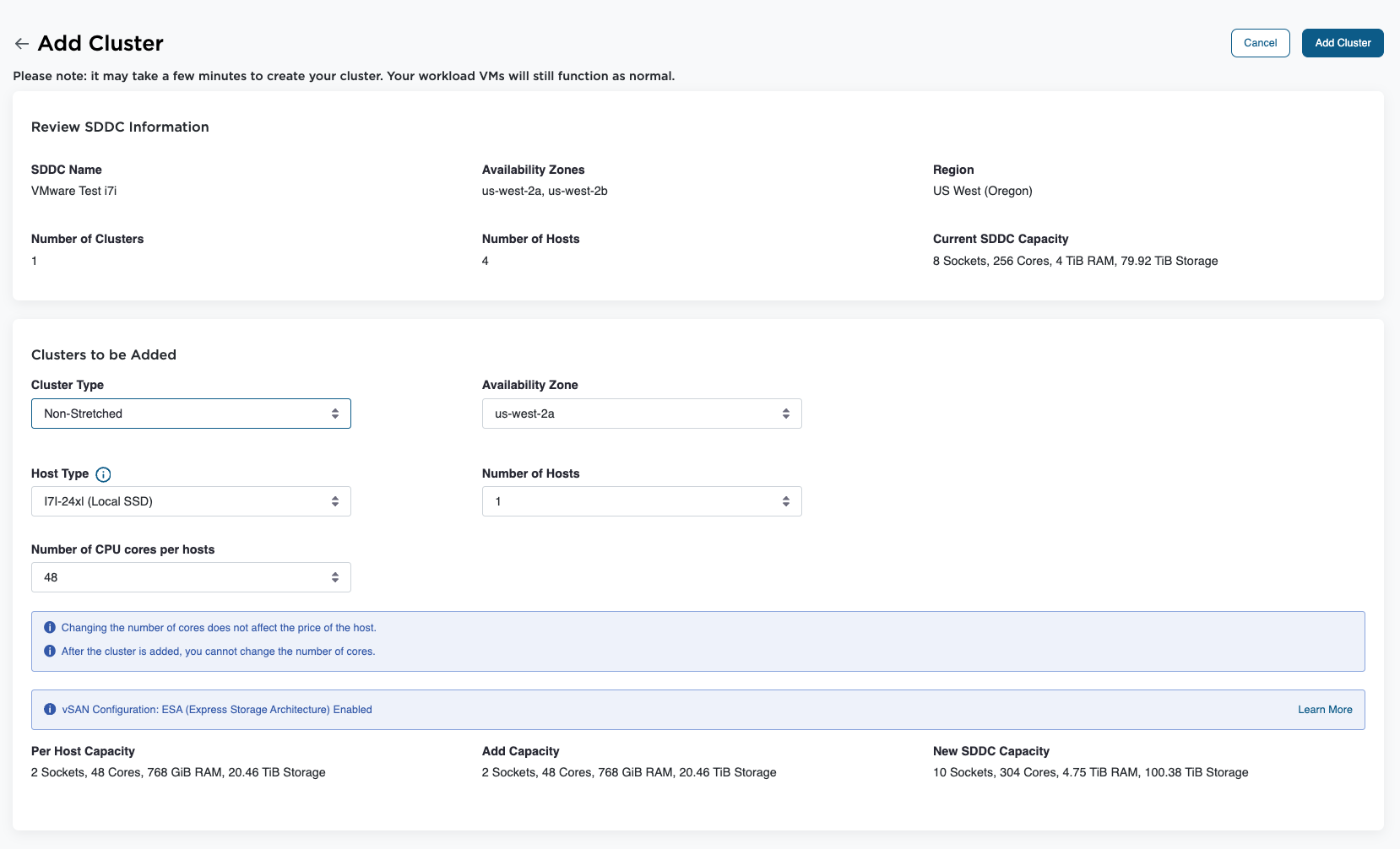
Конвертация кластеров с хостами i3 / i3en / i4i
Миграция с i3.metal, i4i.metal или i3en.metal на i7i.metal-24xl возможна с помощью vSphere vMotion. Для подходящих конфигураций VMware также предоставляет услугу конвертации кластера по запросу. Подробные инструкции — в разделе «Конвертация типов хостов в кластерах».
Следует учитывать, что кластеры, использующие аппаратную версию виртуальных машин 21, не подходят для конвертации с i4i на i7i из-за ограничений совместимости оборудования. Для получения помощи с расчётом размеров и планированием конвертации кластеров следует обращаться к команде Broadcom. Также доступен инструмент VMC Sizer — для оценок на основе хостов, нагрузок или конвертации кластеров.
Начало работы
Для обсуждения того, как i7i.metal-24xl может модернизировать среду VMware Cloud on AWS, рекомендуется связаться с представителем Broadcom. На vmc.broadcom.com доступны настройка нового SDDC, изучение вариантов расчёта размеров и запрос оценки рабочих нагрузок.
Таги: VMware, VMConAWS, AWS, Cloud, Hardware
Требования к памяти и CPU для Witness VM в VMware vSAN ESA и OSA
В какой-то момент требования к ресурсам для Witness VM в vSAN ESA исчезли из официальной документации. Между тем этот вопрос остаётся актуальным: сколько памяти выделяется виртуальной машине и сколько у неё vCPU? Ответ зависит от выбранного профиля — Witness VM доступна в трёх вариантах: M, L и XL.
Выбор профиля определяется количеством виртуальных машин, которые планируется развернуть. При этом рекомендуется закладывать запас на рост. Когда Witness VM разворачивается через мастер развёртывания, нужные цифры там не указаны — однако их можно узнать, заглянув в OVF-дескриптор.
Из OVF-файла vSAN ESA Witness получены следующие данные о ресурсах:
- vSAN ESA Witness XL — 8 vCPU, 64 ГБ памяти
- vSAN ESA Witness L — 4 vCPU, 32 ГБ памяти
- vSAN ESA Witness M — 4 vCPU, 16 ГБ памяти
Для тех, кто использует vSAN OSA, требования к ресурсам следующие:
- vSAN OSA Witness XL — 6 vCPU, 32 ГБ памяти
- vSAN OSA Witness L — 2 vCPU, 32 ГБ памяти
- vSAN OSA Witness Normal — 2 vCPU, 16 ГБ памяти
- vSAN OSA Witness Tiny — 2 vCPU, 8 ГБ памяти
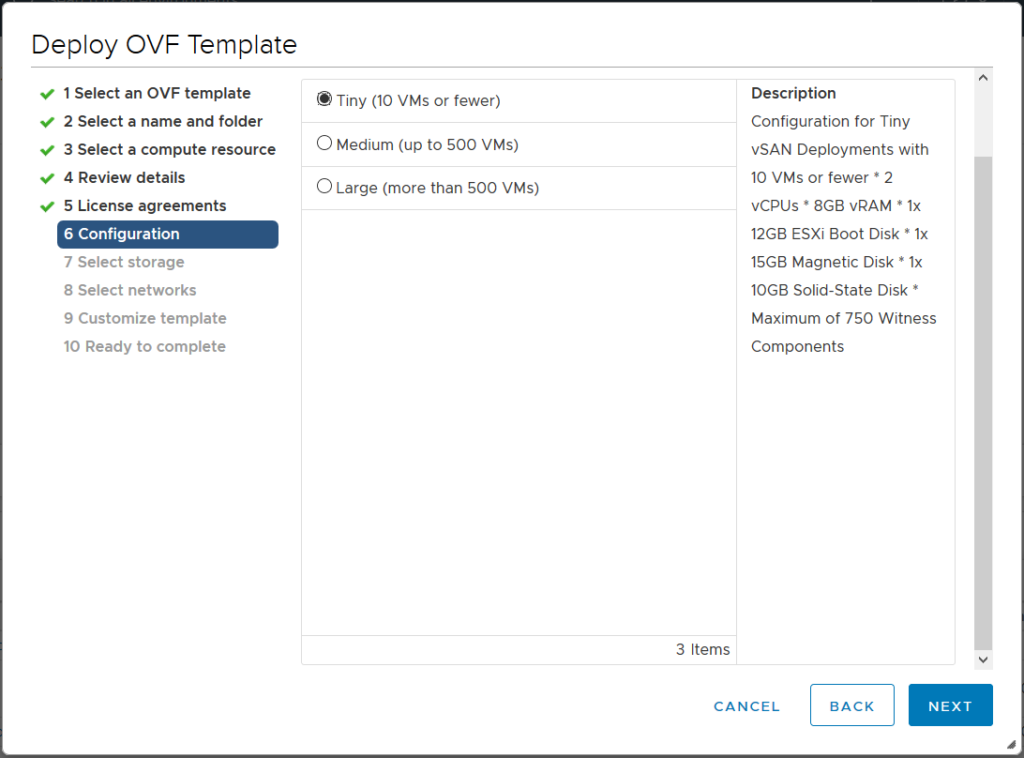
Важно учитывать, что приведённые значения актуальны на момент публикации — с выходом новых версий vSAN требования к ресурсам могут измениться.
Источник.
Таги: VMware, vSAN, Hardware, Witness, Blogs
Новый документ: VMware vSAN Frequently Asked Questions
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.

vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
- Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
- Требования к оборудованию и сети
- Варианты развертывания кластеров
- Масштабирование и отказоустойчивость
- Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
- General Information — общая информация о vSAN
- Express Storage Architecture (ESA)
- Availability — отказоустойчивость
- Cloud-Native Storage
- vSAN File Services
- vSAN Storage Clusters (disaggregated storage)
- Stretched clusters и 2-node clusters
- Networking
- Capacity и Space Efficiency
- Operations
- Performance
- Security
- vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.
Таги: VMware, vSAN, Storage, Hardware, Enterprise, Whitepaper
Разделение NVIDIA MIG, геометрия размещения и потерянная ёмкость
Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
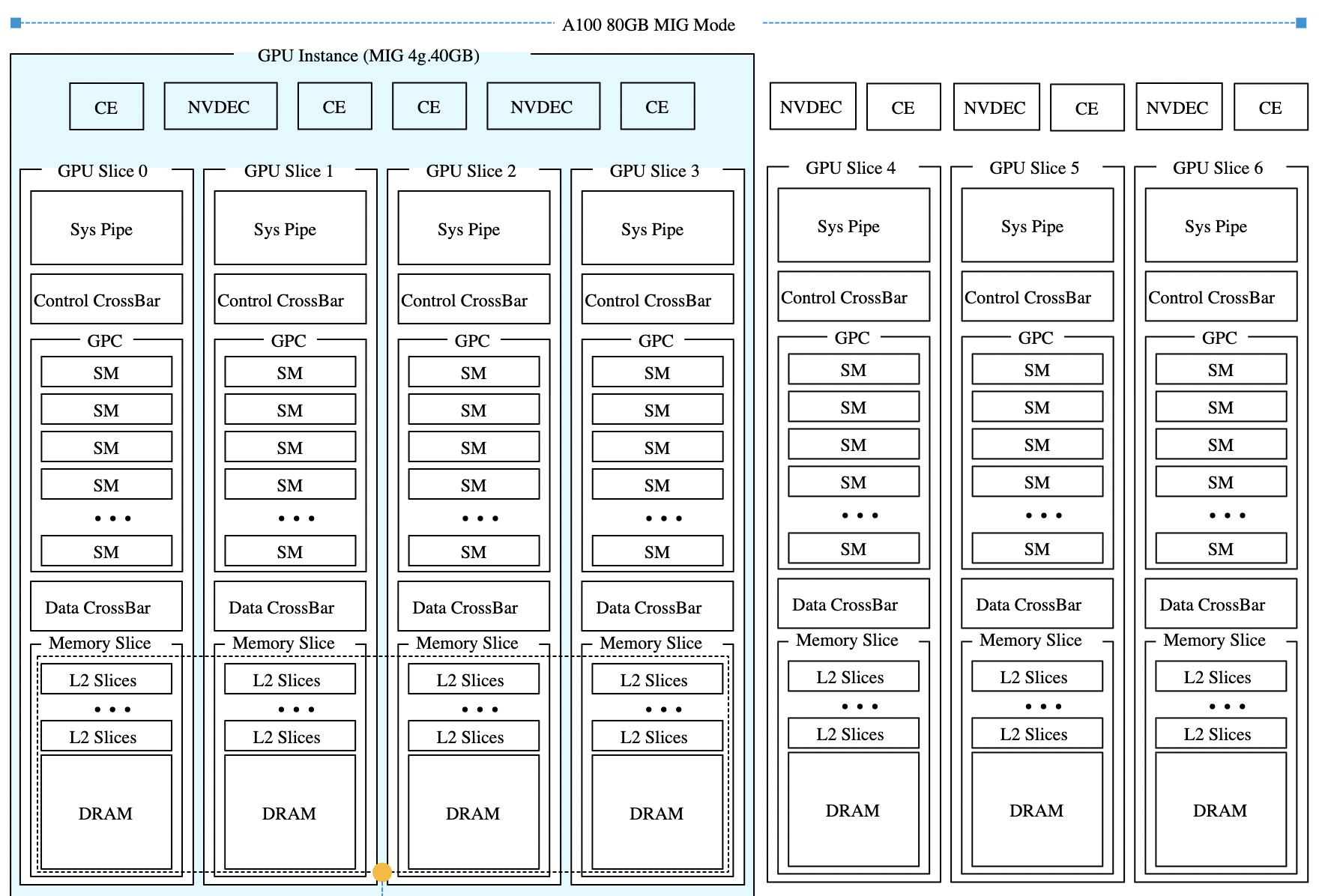
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
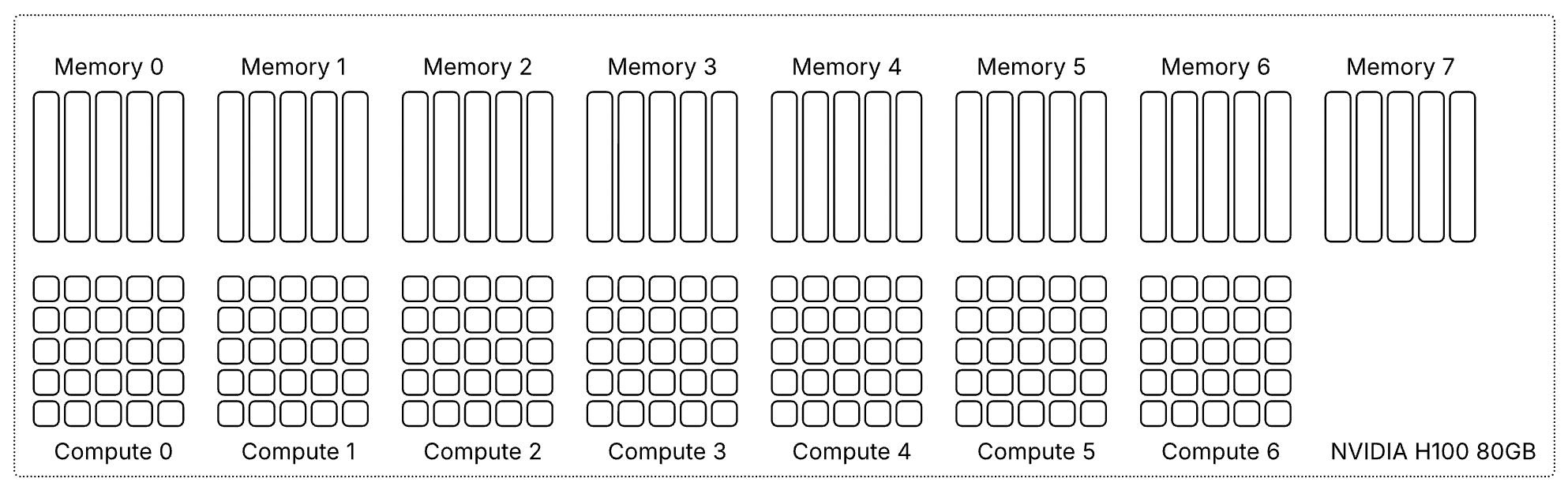
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
| Profile |
Compute slices |
Memory slices |
Memory |
| 1g.10gb |
1 |
1 |
10 GB |
| 1g.20gb |
1 |
2 |
20 GB |
| 2g.20gb |
2 |
2 |
20 GB |
| 3g.40gb |
3 |
4 |
40 GB |
| 4g.40gb |
4 |
4 |
40 GB |
| 7g.80gb |
7 |
8 |
80 GB |
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
Потерянная ёмкость
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
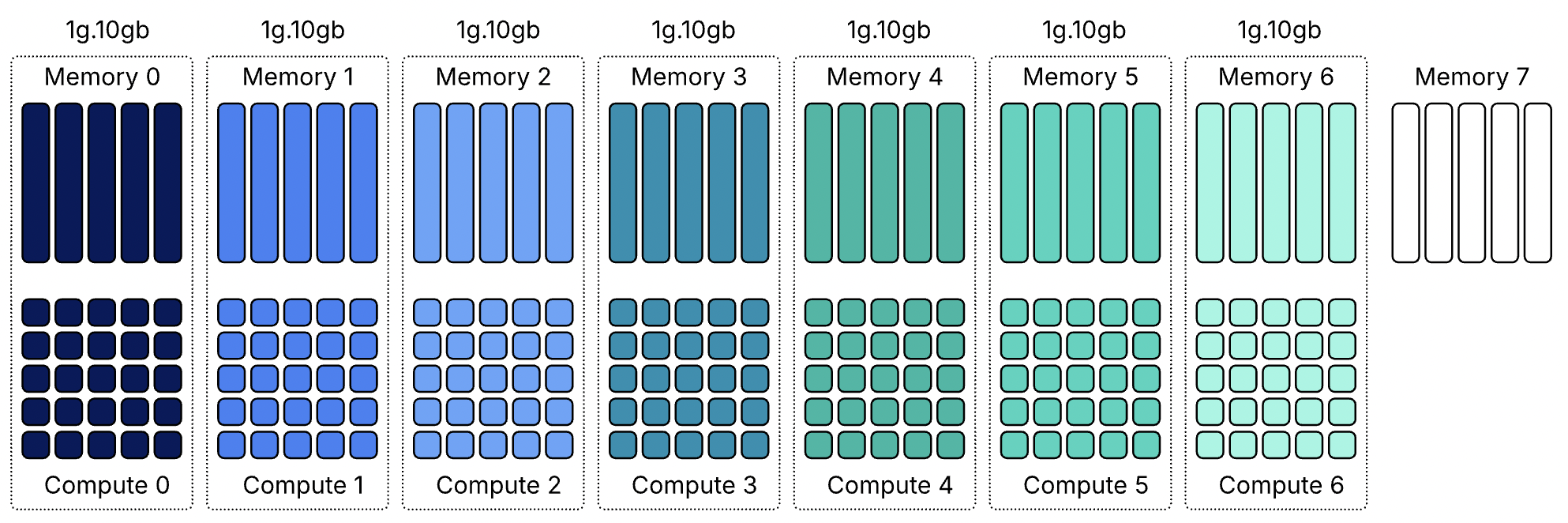
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
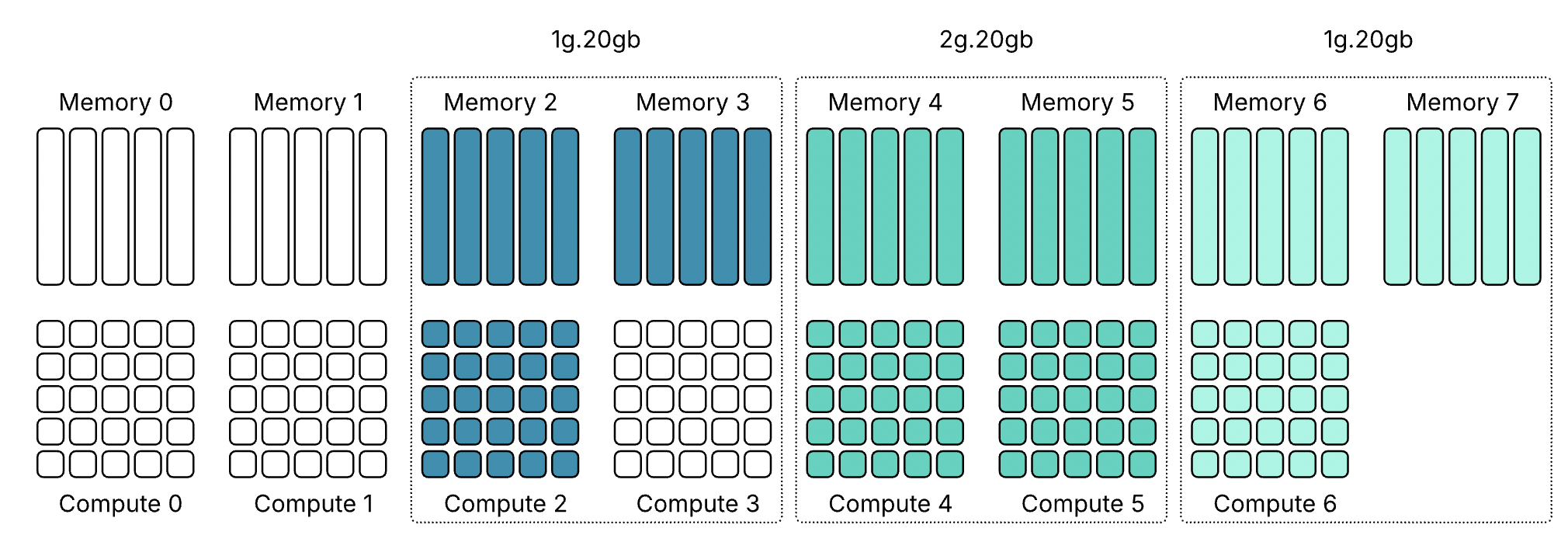
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
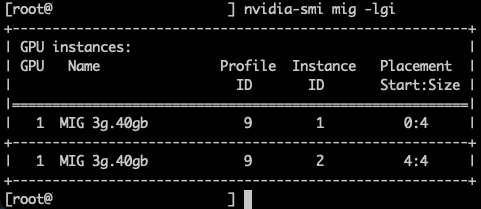
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
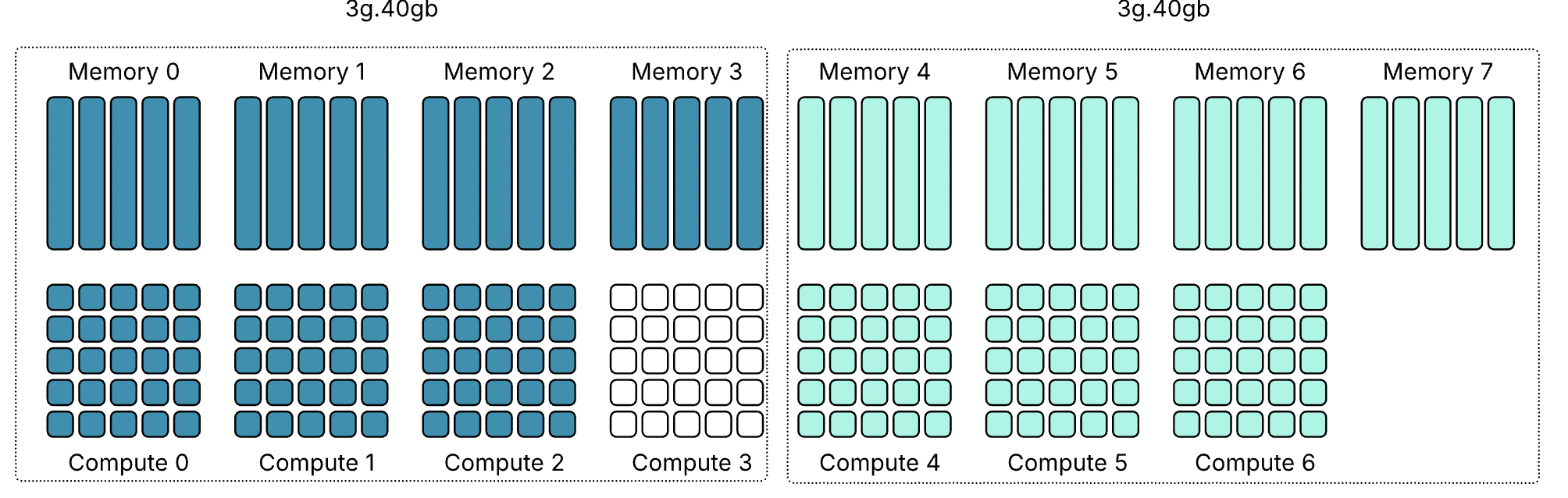
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
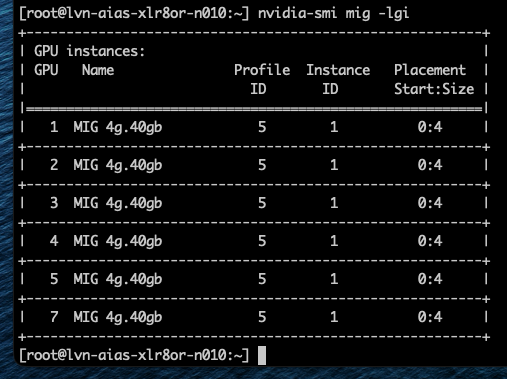
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
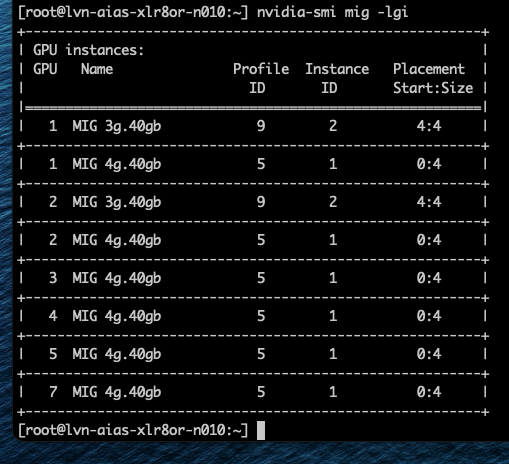
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
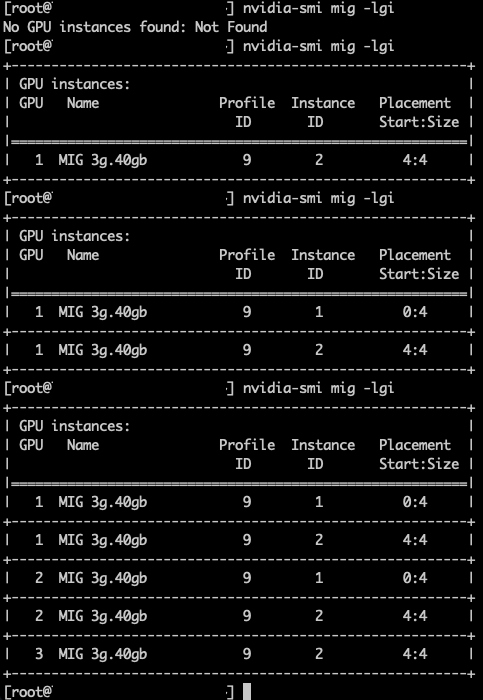
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.
Таги: VMware, NVIDIA, GPU, Hardware, ESX, Blogs
Архитектура NVMe Memory Tiering на платформе VMware Cloud Foundation - настройка
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут, тут и тут) мы поговорим о настройке этой технологии на серверах VMware ESX инфраструктуры VCF.
На протяжении всей этой серии статей мы рассматривали важные аспекты, которые следует учитывать перед настройкой Memory Tiering, такие как проектирование, подбор размеров, совместимость, избыточность, безопасность и многое другое. Теперь пришло время применить то, чему вы научились, и оптимизировать эту функцию для вашей среды, бюджета и стратегии.
Поскольку во многих статьях подробно описаны шаги настройки, этот пост будет сосредоточен на подходе высокого уровня и будет ссылаться на предыдущие посты для конкретных разделов. Всегда полагайтесь на официальную документацию Broadcom для точных шагов настройки — официальное руководство можно найти здесь, ну а основные аспекты развертывания Memory Tiering мы описывали тут.
Шаги настройки
Технически для настройки Memory Tiering в вашей среде требуется всего два шага, но мы добавили задачи до и после настройки, чтобы обеспечить должную тщательность и проверить внедрение.
Предварительные проверки
Плотники живут по правилу «семь раз отмерь — один раз отрежь», потому что после разреза нельзя прокрутить фарш обратно. Чтобы избежать критических ошибок при настройке, мы должны сначала убедиться, что приняли правильные архитектурные решения для нашей среды.
Убедитесь, что вы ознакомились со следующим:
После того как вы приняли все эти важные решения, этап предварительных проверок включает подтверждение того, что устройства корректно отображаются на всех ESX-хостах. Вам понадобится UID каждого устройства, чтобы создать раздел, который будет использоваться Memory Tiering.
Создание разделов
Первый шаг — создание раздела для каждого NVMe-устройства. Независимо от того, разворачиваете ли вы одно устройство на хост или используете аппаратный RAID, раздел требуется на каждом логическом NVMe-устройстве.
Методы:
- ESXCLI: выполните стандартную команду esxcli (подробности тут).
- PowerShell: создайте скрипт для автоматизации процесса. Пример скрипта доступен тут, он может быть изменён под среду вашего кластера.
Частые вопросы
Вопрос: Могу ли я настроить разделы на двух устройствах без RAID на одном и том же хосте для обеспечения избыточности?
Ответ: Нет. Хотя VCF 9.0 позволяет без ошибок создавать разделы Memory Tiering на нескольких устройствах на хост, система не объединяет их и не зеркалирует данные.
Результат: Memory Tiering смонтирует только один диск, выбранный недетерминированным образом в процессе загрузки. Второй диск будет проигнорирован и не даст ни избыточности, ни увеличения ёмкости (см. будущую информацию об обновлении VCF 9.1 - там что-то может поменяться).
Включение Memory Tiering
Этот шаг активирует функцию Memory Tiering. Вы можете выполнить эту настройку через ESXCLI, PowerShell или интерфейс vCenter UI, применяя её к отдельным хостам или ко всему кластеру одновременно.
Вопрос: Требуется ли настраивать Memory Tiering на всех хостах в кластере VCF 9.0?
Ответ: Нет. У вас есть возможность выбрать конкретные хосты для Memory Tiering.
Хотя идеально, чтобы все хосты имели одинаковую конфигурацию, все понимают, что определённые ограничения ВМ могут потребовать исключений (см. тут).
Самый эффективный способ настроить Memory Tiering — использовать профили конфигурации vSphere. Это позволяет включить функцию сразу на всех ваших хостах, одновременно используя переопределения хостов для тех хостов, где вы не хотите включать её. Подробнее — тут.
Финальный шаг
Последний шаг прост: перезагрузите все хосты и выполните проверку. В VCF/VVF 9.0 перезагрузка является обязательной, чтобы эта функция вступила в силу.
Если вы используете профили конфигурации (Configuration Profiles), система автоматизирует поочерёдные перезагрузки (одна за другой), одновременно мигрируя ВМ, чтобы они оставались в сети. И если вам интересно, обеспечивает ли этот метод также доступность данных vSAN - ответ: да.
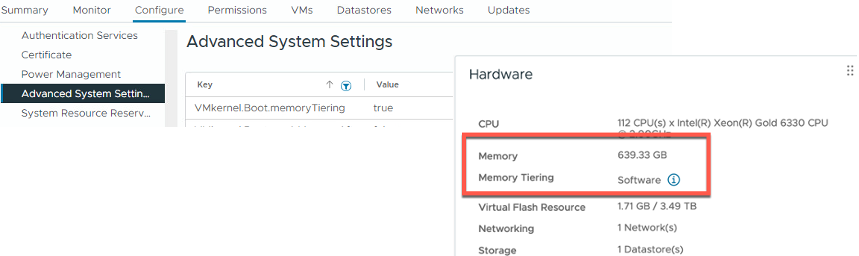
После того как все хосты снова будут онлайн, вы увидите новые элементы в интерфейсе, расположенные в разделах Advanced System Settings, на вкладке Monitor, а также Configure > Hardware > Overview > Memory.
Вы также должны увидеть, что по умолчанию объём доступной памяти увеличился в 2 раза как на уровне хоста, так и на уровне кластера. Вот это простой и недорогой способ удвоить ваш объём памяти!
В заключение: включение Memory Tiering - очень простой и понятный процесс. В качестве бонуса добавляем ссылку на актуальную лабораторную работу (Hands-on Lab), посвящённую Memory Tiering. Там вы можете выполнить настройку «от начала до конца», включая расширенные параметры, которые будут рассмотрены в следующих постах.
Таги: VMware, VCF, Memory, Tiering, Hardware
Результаты тестирования платформы VMware Cloud Foundation 9 с помощью MLPerf 5.1 для AI-нагрузок
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
- SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
- Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
- Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
| Параметр |
Bare Metal |
Виртуальная среда |
| Система |
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC |
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC |
| Процессоры |
2x Intel Xeon 6960P, 72 ядра |
2x AMD EPYC 9965, 192 ядра |
| Логические процессоры |
144 |
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации |
| GPU |
8x NVIDIA B200, 180 ГБ HBM3e |
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e |
| Межсоединение ускорителей |
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с |
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с |
| Память |
2,3 ТБ |
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса |
| Хранилище |
4x NVMe SSD по 15,36 ТБ |
4x NVMe SSD по 13,97 ТБ |
| ОС |
Ubuntu 24.04 |
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229 |
| CUDA |
CUDA 12.9 и драйвер 575.57.08 |
CUDA 12.8 и драйвер 570.158.01 |
| TensorRT |
TensorRT 10.11 |
TensorRT 10.11 |
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
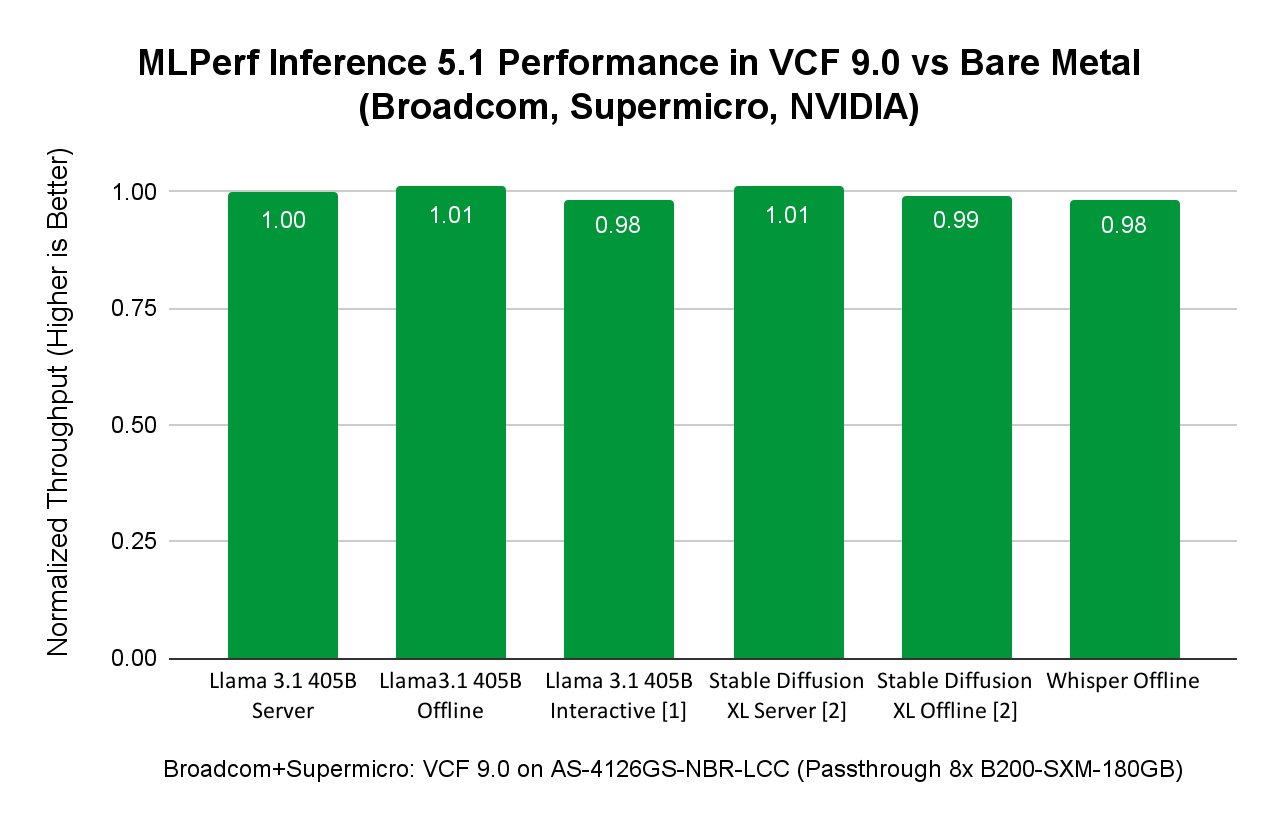
Некоторые моменты:
- Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
- Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
| Параметр |
Bare Metal |
Виртуальная среда |
| Система |
Dell PowerEdge XE9680 |
Dell PowerEdge XE9680 |
| Процессоры |
Intel Xeon Platinum 8568Y+, 96 ядер |
Intel Xeon Platinum 8568Y+, 96 ядер |
| Логические процессоры |
192 |
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации |
| GPU |
8x NVIDIA H200, 141 ГБ HBM3e |
8x виртуализированных NVIDIA H200-SXM-141GB (vGPU) |
| Межсоединение ускорителей |
18x NVLink 4-го поколения, 900 ГБ/с |
18x NVLink 4-го поколения, 900 ГБ/с |
| Память |
3 ТБ |
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса |
| Хранилище |
2 ТБ SSD, 5 ТБ CIFS |
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ |
| ОС |
Ubuntu 24.04 |
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229 |
| CUDA |
CUDA 12.8 и драйвер 570.133 |
CUDA 12.8 и драйвер Linux 570.158.01 |
| TensorRT |
TensorRT 10.11 |
TensorRT 10.11 |
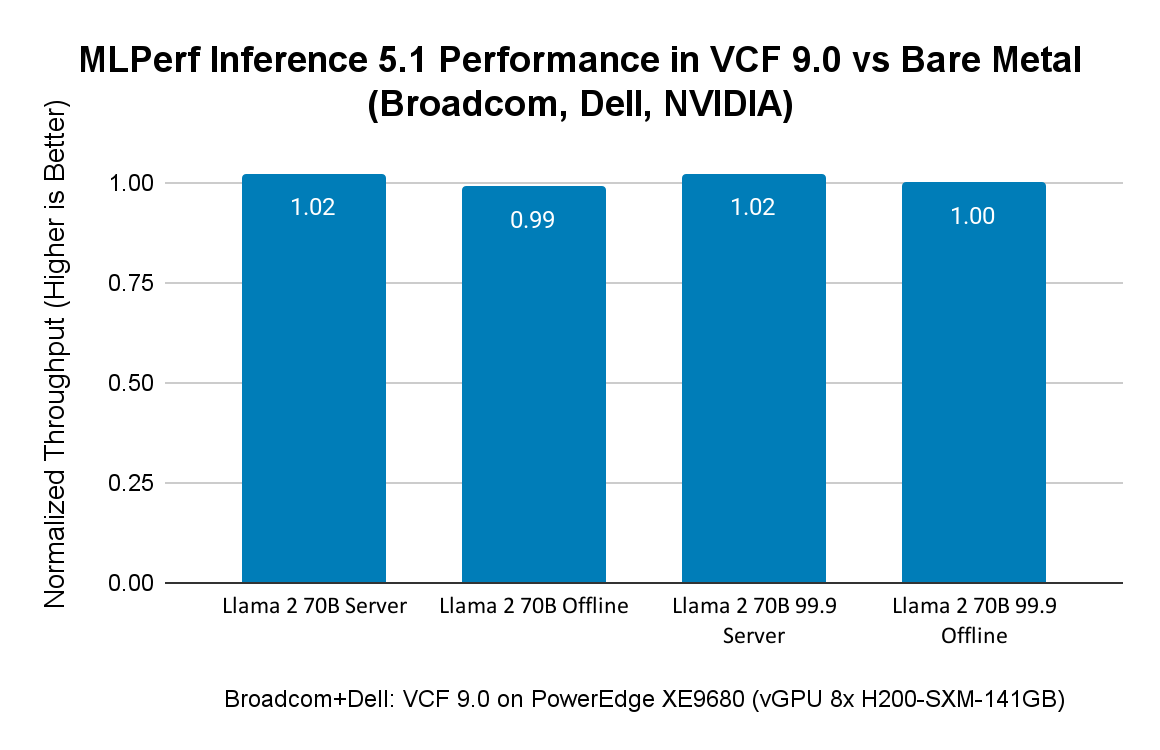
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
| Бенчмарки |
Пропускная способность |
| Llama 3.1 405B Server (токенов/с) |
277 |
| Llama 3.1 405B Offline (токенов/с) |
547 |
| Llama 2 70B Server (токенов/с) |
33 385 |
| Llama 2 70B Offline (токенов/с) |
34 301 |
| Llama 2 70B — высокая точность — Server (токенов/с) |
33 371 |
| Llama 2 70B — высокая точность — Offline (токенов/с) |
34 486 |
| SDXL Server (сэмплов/с) |
17,95 |
| SDXL Offline (сэмплов/с) |
18,64 |
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
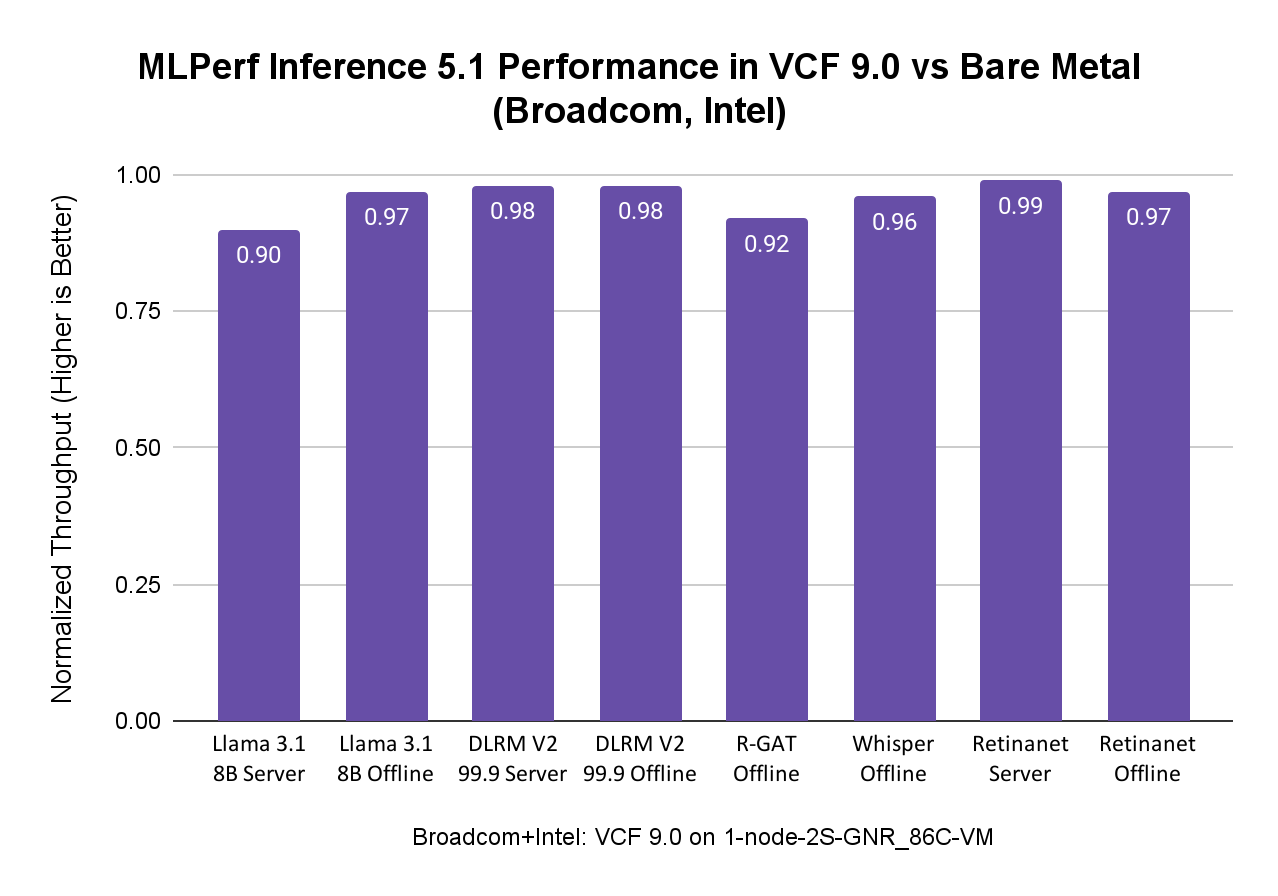
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
| Параметр |
Bare Metal |
Виртуальная среда |
| Система |
1-node-2S-GNR_86C_BareMetal |
1-node-2S-GNR_86C_ESXi_172VCPU-VM |
| Процессоры |
Intel Xeon 6787P, 86 ядер |
Intel Xeon 6787P, 86 ядер |
| Логические процессоры |
172 |
172 vCPU (43 vCPU на NUMA-узел) |
| Память |
1 ТБ (16x64 ГБ DDR5, 1 286 400 MT/s [8000 MT/s]) |
921 ГБ |
| Хранилище |
1x SSD 1,7 ТБ |
1x SSD 1,7 ТБ |
| ОС |
CentOS Stream 9 |
CentOS Stream 9 |
| Прочее ПО |
6.6.0-gnr.bkc.6.6.31.1.45.x86_64 |
6.6.0-gnr.bkc.6.6.31.1.45.x86_64VMware ESXi 9.0.0.0.24755229 |
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
| Область |
Задача |
Модель |
Набор данных |
Размер QSL |
| LLM |
LLM — вопросы и ответы |
Llama 2 70B |
OpenOrca |
24 576 |
| LLM |
Суммаризация |
Llama 3.1 8B |
CNN Dailymail (v3.00, max_seq_len = 2048) |
13 368 |
| LLM |
Генерация текста |
Llama 3.1 405B |
Подмножество LongBench, LongDataCollections, Ruler, GovReport |
8 313 |
| Зрение |
Обнаружение объектов |
RetinaNet |
OpenImages (800x800) |
64 |
| Речь |
Распознавание речи |
Whisper |
LibriSpeech |
1 633 |
| Изображения |
Генерация изображений |
SDXL 1.0 |
COCO-2014 |
5 000 |
| R-GAT |
Классификация узлов |
R-GAT |
IGBH |
788 379 |
| Commerce |
Рекомендательные системы |
DLRM-DCNv2 |
Criteo 4TB Multi-hot |
204 800 |
| Commerce |
Рекомендательные системы |
DLRM |
1TB Click Logs |
204 800 |
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
| Сценарий |
Генерация запросов |
Длительность |
Сэмплов на запрос |
Ограничение по задержке |
Tail
latency |
Метрика производительности |
| Server |
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона |
270 336 запросов и 60 секунд |
1 |
Зависит от бенчмарка |
99% |
Максимально поддерживаемый параметр пропускной способности Пуассона |
| Offline |
LoadGen отправляет все запросы в SUT в начале |
1 запрос и 60 секунд |
Не менее 24 576 |
Нет |
Н/Д |
Измеренная пропускная способность |
Источник: MLPerf Inference: Datacenter Benchmark Suite Results, раздел «Scenarios and Metrics».
Заключение
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
Таги: VMware, AI, Hardware, VCF, Performance
Проектирование и масштабирование технологии NVMe Memory Tiering в VMware Cloud Foundation 9 с учётом безопасности и отказоустойчивости
В первой части статей этой серии мы рассмотрели некоторые предварительные требования для NVMe Memory Tiering, такие как оценка рабочих нагрузок, процент активности памяти, ограничения профилей виртуальных машин, предварительные требования и совместимость устройств NVMe.
Кроме того, мы подчеркнули важность внедрения платформы VMware Cloud Foundation (VCF) 9, которая может обеспечить значительное сокращение затрат на память, лучшее использование CPU и более высокую консолидацию виртуальных машин. Но прежде чем полностью развернуть это решение, важно спроектировать его с учётом безопасности, отказоустойчивости и масштабируемости — именно об этом и пойдёт речь в этой статье.
Безопасность
Безопасность памяти не является особенно популярной темой среди администраторов, и это объясняется тем, что память является энергонезависимой. Однако злоумышленники могут использовать память для хранения вредоносной информации на энергонезависимых носителях, чтобы избежать обнаружения — но это уже скорее тема криминалистики. Как только питание отключается, данные в DRAM (энергозависимой памяти) исчезают в течение нескольких минут. Таким образом, с NVMe Memory Tiering мы переносим страницы из энергозависимой памяти (DRAM) на энергонезависимую (NVMe).
Чтобы устранить любые проблемы безопасности, связанные с хранением страниц памяти на устройствах NVMe, VMware разработала несколько решений, которые клиенты могут легко реализовать после первоначальной настройки.
В этом первом выпуске функции Memory Tiering шифрование уже входит в комплект и готово к использованию «из коробки». Фактически, у вас есть возможность включить шифрование на уровне виртуальной машины (для каждой ВМ) или на уровне хоста (для всех ВМ на данном хосте). По умолчанию эта опция не активирована, но её легко добавить в конфигурацию через интерфейс vCenter.

Для шифрования в NVMe Memory Tiering нам не требуется система управления ключами (KMS) или встроенный поставщик ключей (NKP). Вместо этого ключ случайным образом генерируется на уровне ядра каждым хостом с использованием шифрования AES-XTS. Это избавляет от зависимости от внешних поставщиков ключей, поскольку данные, выгруженные в NVMe, актуальны только в течение времени жизни виртуальной машины.
Случайный 256-битный ключ создаётся при включении виртуальной машины, и данные шифруются в момент их выгрузки из DRAM в NVMe, а при обратной загрузке в DRAM для чтения — расшифровываются. Во время миграции виртуальной машины (vMotion) страницы памяти сначала расшифровываются, затем передаются по зашифрованному каналу vMotion на целевой хост, где генерируется новый ключ (целевым хостом) для последующих выгрузок памяти на NVMe.
Этот процесс одинаков как для «шифрования на уровне виртуальной машины», так и для «шифрования на уровне хоста» — единственное различие заключается в том, где именно применяется конфигурация.

Отказоустойчивость
Цель отказоустойчивости — повысить надёжность, сократить время простоя и, конечно, обеспечить спокойствие администратора. В контексте памяти существует несколько методов, некоторые из которых распространены больше других. В большинстве случаев для обеспечения избыточности памяти используют модули с коррекцией ошибок (ECC) и резервные модули памяти. Однако теперь, с появлением NVMe Memory Tiering, необходимо учитывать как DRAM, так и NVMe. Мы не будем подробно останавливаться на методах избыточности для DRAM, а сосредоточимся на NVMe в контексте памяти.
В VVF/VCF 9.0 функция NVMe Memory Tiering поддерживает аппаратную конфигурацию RAID, три-режимный (tri-mode) контроллер и технологию VROC (Virtual RAID on CPU) для обеспечения отказоустойчивости холодных или неактивных страниц памяти. Что касается RAID, мы не ограничиваемся какой-то одной конфигурацией: например, RAID-1 — это хорошее и поддерживаемое решение для обеспечения отказоустойчивости NVMe, но также поддерживаются RAID-5, RAID-10 и другие схемы. Однако такие конфигурации потребуют больше NVMe-устройств и, соответственно, увеличат стоимость.
Говоря о стоимости, стоит учитывать и наличие RAID-контроллеров, если вы планируете использовать RAID для отказоустойчивости. Обеспечение резервирования для холодных страниц — это архитектурное решение, которое должно приниматься с учётом баланса между затратами и операционными издержками. Что для вас важнее — надёжность, стоимость или простота эксплуатации? Также необходимо учитывать совместимость RAID-контроллера с vSAN: vSAN ESA не поддерживает RAID-контроллеры, в то время как vSAN OSA поддерживает, но они должны использоваться раздельно.

Преимущества RAID:
- Обеспечивает избыточность для NVMe как устройства памяти
- Повышает надёжность
- Возможное сокращение времени простоя
Недостатки RAID:
- Необходимость RAID-контроллера
- Дополнительные расходы
- Операционные издержки (настройка, обновление прошивок и драйверов)
- Усложнение инфраструктуры
- Появление новой точки отказа
- Возможные проблемы совместимости с vSAN, если все накопители подключены к одной общей плате (backplane)
Как видно, у аппаратной избыточности есть как плюсы, так и минусы. Следите за обновлениями — в будущем могут появиться новые поддерживаемые методы отказоустойчивости.
Теперь предположим, что вы решили не использовать RAID-контроллер. Что произойдёт, если у вас есть один выделенный накопитель NVMe для Memory Tiering, и он выйдет из строя?
Ранее мы обсуждали, что на NVMe переносятся только «холодные» страницы памяти виртуальных машин по мере необходимости. Это означает, что страницы памяти самого хоста не находятся на NVMe, а также что на накопителе может быть как много, так и мало холодных страниц — всё зависит от нагрузки на DRAM. VMware не выгружает страницы (даже холодные), если в этом нет нужды — зачем расходовать вычислительные ресурсы?
Таким образом, если часть холодных страниц была выгружена на NVMe и накопитель вышел из строя, виртуальные машины, чьи страницы находились там, могут попасть в ситуацию высокой доступности (HA). Мы говорим "могут", потому что это произойдёт только если и когда ВМ запросит эти холодные страницы обратно из NVMe, которые теперь недоступны. Если же ВМ никогда не обратится к этим страницам, она продолжит работать без сбоев.
Иными словами, сценарий отказа зависит от активности в момент сбоя NVMe:
- Если на NVMe нет холодных страниц — ничего не произойдёт.
- Если есть немного холодных страниц — возможно, несколько ВМ войдут в HA-событие и перейдут на другой хост;
- Если все холодные страницы хранились на NVMe — возможно, большинство ВМ окажутся в HA-режиме по мере запроса страниц.
Это не обязательно приведёт к полному отказу всех систем. Некоторые ВМ могут выйти из строя сразу, другие — позже, а третьи — вообще не пострадают. Всё зависит от их активности. Главное — хост ESX продолжит работу, а поведение виртуальных машин будет различаться в зависимости от текущих нагрузок.

Масштабируемость
Масштабируемость памяти — это, пожалуй, один из тех неожиданных факторов, который может обойтись очень дорого. Как известно, память составляет значительную часть (до 80%) общей стоимости нового сервера. В зависимости от подхода к закупке серверов, вы могли выбрать меньшие по объёму модули DIMM, установив их во все слоты — в этом случае у вас нет возможности увеличить объём памяти без полной замены всех модулей, а иногда даже самого сервера.
В также могли выбрать высокоплотные модули DIMM, оставив несколько слотов свободными для будущего роста — это позволяет масштабировать память, но тоже дорого, так как позже придётся докупать совместимые модули (если они ещё доступны). В обоих случаях масштабирование получается дорогим и медленным, особенно учитывая длительные процедуры утверждения бюджета и заказов в компаниях.
Именно здесь NVMe Memory Tiering показывает себя с лучшей стороны — снижая затраты и позволяя быстро увеличить объём памяти. В данном случае масштабирование памяти сводится к покупке хотя бы одного устройства NVMe и включению функции Memory Tiering — и вот у вас уже на 100% больше памяти для ваших хостов. Отличная выгода.
Можно даже «позаимствовать» накопитель из вашего хранилища vSAN, если есть возможность выделить его под Memory Tiering… но об этом чуть позже (делайте это с осторожностью).
В этой части важно понимать ограничения и возможности, чтобы обеспечить надёжность инвестиций в будущем. Мы уже говорили о требованиях к устройствам NVMe по показателям производительности и износостойкости, но что насчёт объёма NVMe-устройств? Об этом мы напишем в следующей части.
Таги: VMware, NVMe, Memory, Tiering, Hardware, Security, HA
Расширение открытой экосистемы для VMware Cloud Foundation (VCF)
Компания Broadcom объявила о продвижении «открытой, расширяемой экосистемы» для VMware Cloud Foundation (VCF), с тем чтобы пользователи могли строить, подключать, защищать и расширять свои приватные облака. Цель — дать заказчикам большую свободу выбора оборудования, сетевых архитектур и софтверных компонентов при развертывании приватного облака или облачной инфраструктуры на базе VCF.
Ключевые направления:
- Расширение аппаратной сертификации (OEM/ODM)
- Внедрение открытых сетевых конструкций (EVPN, BGP, SONiC)
- Вклад в open-source проекты (например, Kubernetes и связанные)
- Усиленные партнёрства с такими игроками как Cisco Systems, Intel Corporation, OVHcloud, Supermicro Inc., SNUC.

Архитектура и аппаратная сертификация
VCF AI ReadyNodes и ODM self-certification
Одной из ключевых инициатив является расширение программы сертификации аппаратных узлов для VCF:
- Появляются новые «VCF AI ReadyNodes» — предсертифицированные серверные конфигурации с CPU, GPU и другими ускорителями, пригодные для AI-обучения и вывода (inference).
- В программе сертификации ReadyNode для ODM-партнёров теперь предусмотрена самосертификация (ODM Partner Self-Certification) через технологическую альянс-программу Broadcom Technology Alliance Program (TAP). Вся сертифицированная система обеспечена полной совместимостью с VCF и единым жизненным циклом управления VCF.
- Поддержка edge-узлов: расширена поддержка компактных, «прочностных» (rugged) серверов для индустриальных, оборонных, розничных и удалённых площадок, что позволяет разворачивать современное приватное облако ближе к точкам генерации данных.
Технические следствия:
- Возможность применять новейшие аппаратные ускорители (GPU, FPGA и др.) под VCF, с гарантией совместимости.
- Упрощение цепочки выбора оборудования: благодаря self-certification ODM могут быстрее вывезти сертифицированные узлы, заказчик — выбрать из более широкого набора.
- Edge-варианты означают, что приватные облака не ограничены классическими ЦОД-конфигурациями, а могут быть размещены ближе к источнику данных (IoT, фабрики, розница), что важно для задержки, пропускной способности, регулирования данных.
- В совокупности это снижает TCO (Total Cost of Ownership) и ускоряет модернизацию инфраструктуры. Broadcom отмечает, что Intel, OVHcloud и др. подтверждают, что это даёт меньшее время time-to-market.
Почему это важно
Для организаций, которые строят приватные облака, часто возникает проблема «запертой» инфраструктуры: если узел не сертифицирован, риск несовместимости — обновления, жизненный цикл, поддержка. Открытая сертификация даёт больший выбор и снижает зависимость от одного производителя. При этом, с учётом AI-нагрузок и edge-инфраструктуры, требования к аппаратуре растут, и важна гарантия, что выбранный сервер будет работать под VCF без сюрпризов.
Сетевые инициативы: открытые сети и EVPN
Стратегия Broadcom в отношении сети
Broadcom объявляет стратегию объединения сетевых фабрик (network fabrics) и упрощения сетевых операций в приватном облаке через стандарты EVPN и BGP. Основные моменты:
- Поддержка сетевой интероперабельности между средами приложений и сетью: применение стандарта EVPN/BGP позволяет гибче и масштабируемее организовать сетевые фабрики.
- Цель — ускорить развертывание, дать мультивендорную гибкость, сохранить существующие сетевые инвестиции.
- Совместимость с продуктом NSX (в составе VCF) и сторонними сетевыми решениями на уровне VPC-защиты, единой сетевой операционной модели, маршрутизации и видимости.
- В рамках партнёрства с Cisco: VCF переходит к поддержке EVPN и совместимости с решением Cisco Nexus One fabric, что даёт клиентам архитектурную гибкость.
- VCF Networking (NSX) поддерживает открытый NOS (network operating system) SONiC — операционную систему для сетевых коммутаторов, основанную на Linux, на многосоставном и мультивендорном оборудовании.
Технические особенности EVPN / BGP в контексте VCF
- EVPN (Ethernet VPN) обеспечивает слой 2/3 виртуализации по IP/MPLS сетям, поддерживает VXLAN, MPLS-Over-EVPN и даёт нативную мультидоменную сегментацию.
- BGP служит как протокол контрольной плоскости для EVPN, позволяет сетям в разных локациях или доменах обмениваться маршрутами VXLAN/EVPN.
- В контексте VCF нужно, чтобы сеть поддерживала мультивендорность, работу с NSX, автоматизацию и процессы жизненного цикла. С открытым стандартом EVPN/BGP графику управления можно встроить в операции DevOps, IaC (Infrastructure as Code).
- Поддержка SONiC позволяет использовать коммутаторы «commodity» с открытым NOS, снижая затраты как CAPEX, так и OPEX: модульная архитектура, контейнеризация, возможность обновлений без простоя.
Значение для заказчика
- Возможность построить приватное облако, где сеть не является узким местом или «чёрным ящиком» вендора, а открытa и гибка по архитектуре.
- Снижение риска vendor-lock-in: можно выбирать разное сетевое оборудование, переключаться между вендорами и сохранять совместимость.
- Повышенная скорость развертывания: сертифицированные интеграции, открытые стандарты, меньше ручной настройки.
- Поддержка edge-сценариев и распределённых облаков: сетевые фабрики могут распространяться по ЦОД, филиалам, edge-узлам с единым контролем и видимостью.
Вклад в открытое программное обеспечение (Open Source)
Broadcom подчёркивает свою активность как участника сообщества облачных нативных технологий. Основные пункты:
- Компания является одним из пяти крупнейших долгосрочных контрибьюторов в Cloud Native Computing Foundation (CNCF) и вносит изменения/улучшения в проекты: Antrea, Cluster API, containerd, Contour, etcd, Harbor и другие.
- Важная веха: решение vSphere Kubernetes Service (VKS) от VMware теперь является Certified Kubernetes AI Conformant Platform — это означает, что платформа соответствует требованиям для AI-нагрузок и встроена в стандарты Kubernetes.
Техническое значение
- Совместимость с Kubernetes-экосистемой означает, что приватные облака на VCF могут использовать облачно-нативные модели: контейнеры, микро-сервисы, CI/CD, GitOps.
- AI Conformant сертификация даёт уверенность, что платформа поддерживает стандартизированную среду для AI-нагрузок (модели, фреймворки, инфраструктура).
- Работа с такими компонентами как containerd, etcd, Harbor облегчает создание, хранение, оркестрацию контейнеров и сбор образов, что важно для DevOps/DevSecOps практик.
- Интеграция с открытым стеком упрощает автоматизацию, ускоряет выход новых функций, увеличивает портируемость и мобильность рабочих нагрузок.
Пользовательские выгоды
- Организации получают возможность не просто виртуализировать нагрузки, но и расширяться в направлении «контейнеров + AI + edge».
- Более лёгкий перенос рабочих нагрузок между средами, снижение необходимости в проприетарных решениях.
- Возможность быстро реагировать на изменение требований бизнеса: добавление AI-сервиса, изменение инфраструктуры, использование микросервисов.
Практические сценарии применения
Приватное облако с AI-нагрузками
С сертифицированными AI ReadyNodes и поддержкой Kubernetes + AI Conformant платформой, заказчики могут:
- Развернуть приватное облако для обучения моделей машинного обучения/AI (CPU + GPU + ускорители) на базе VCF.
- Вывести inference-нагрузки ближе к источнику данных — например, на edge-узле в фабрике или розничном магазине.
- Использовать унифицированный стек: виртуальные машины + контейнеры + Kubernetes на одной платформе.
- Выполнить модернизацию инфраструктуры с меньшими затратами, за счёт сертификации и ПО с открытыми стандартами.
Развёртывание edge-инфраструктуры
С расширением поддержки edge-оптимизированных узлов:
- Приватное облако может распространяться за пределы ЦОД — например, на фабрики, сеть розничных точек, удалённые площадки.
- Сеть EVPN/BGP + SONiC позволяет обеспечить единое управление и видимость сетевой фабрики, даже если часть инфраструктуры находится далеко от центра.
- Заказчики в индустрии, госсекторе, рознице могут использовать эту архитектуру для низкой задержки, автономной работы, гибкой интеграции в основной ЦОД или облако.
Гетерогенная инфраструктура и мультивендорные сети
- Благодаря открытым стандартам и сертификации, заказчики не ограничены выбором одного поставщика оборудования или сети.
- Можно комбинировать разные серверные узлы (от разных OEM/ODM), разные коммутаторы и сетевой софт, и быть уверенным в интеграции с VCF.
- Это помогает снизить зависимость от единственного вендора, сделать инфраструктуру более гибкой и адаптивной к будущим изменениям.
Последствия и рекомендации
Последствия для рынка и архитектуры приватных облаков
- Увеличится конкуренция среди аппаратных и сетевых поставщиков, так как сертификация и сами архитектуры становятся более открытыми.
- Уменьшается риск «запирания» заказчиков в единой экосистеме производителя. Это способствует более быстрому внедрению инноваций: ускорители, AI-узлы, edge.
- Открытые сети и стандарты означают повышение скорости развертывания, уменьшение сложности и затрат.
- Часто частные облака превращаются в гибридные либо распределённые модели, где части инфраструктуры находятся в ЦОД, на edge, в филиалах — и такие архитектуры становятся проще благодаря инициативам Broadcom/VCF.
Что стоит учесть пользователям
- При выборе инфраструктуры приватного облака важно проверять сертифицированные конфигурации VCF ReadyNodes, чтобы быть уверенным в поддержке жизненного цикла, обновлений и совместимости.
- Если планируется AI-нагрузка — уделите внимание использованию AI ReadyNodes, поддержке GPU/ускорителей, сертификации.
- Если сеть критична (например, распределённые локации, филиалы, edge) — рассмотрите архитектуры EVPN/BGP, совместимые с NSX и мультивендорными решениями, а также возможности SONiC.
- Не забывайте об автоматизации и интеграции с облачно-нативными технологиями (Kubernetes, контейнеры, CI/CD): наличие поддержки этих технологий позволяет быстрее развивать платформу.
- Оцените TCO не только с точки зрения CAPEX (серверы, оборудование) но и OPEX (обслуживание, обновления, гибкость). Использование открытых стандартов и сертифицированных решений может снизить оба.
Заключение
Объявление Broadcom о «открытой экосистеме» для VMware Cloud Foundation — это важный шаг к тому, чтобы приватные облака стали более гибкими, адаптивными и ориентированными на будущее. Сертификация аппаратуры (в том числе для AI и edge), открытые сетевые стандарты и активный вклад в open-source проекты – всё это создаёт технологическую платформу, на которой организации могут строить современные инфраструктуры.
При этом важно помнить: открытость сама по себе не решает все проблемы — требуется грамотная архитектура, планирование жизненного цикла, взаимодействие с партнёрами и понимание, как компоненты сочетаются. Тем не менее, такие инициативы создают условия для более лёгкой и менее рисковой модернизации облачной инфраструктуры.
Таги: VMware, VCF, Hardware
Предварительные требования и совместимость оборудования для многоуровневой памяти VMware vSphere NVMe Memory Tiering
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).

Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.

Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
- Высокопроизводительные ВМ (High-performance VMs)
- Защищённые ВМ, использующие SEV / SGX / TDX
- ВМ с включенным механизмом непрерывной доступности Fault Tolerance
- Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
- На уровне хоста или кластера
- Через интерфейс vCenter UI
- С помощью ESXCLI или PowerCLI
- А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
- Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
- Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.

Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
- Устройства формата 2.5", если в сервере есть свободные слоты.
- Вставляемые модули E3.S.
- Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Таги: VMware, vSphere, Memory, Tiering, Performance, Hardware, NVMe
Broadcom представила инфраструктуру на базе Wi-Fi 8
В эпоху, когда AI всё чаще «уходит к краю сети» — то есть — выполняется непосредственно на устройстве или на близкой инфраструктуре, требования к беспроводным сетям меняются. Вместо гонки за пиковыми скоростями становится важнее низкая задержка, высокая надёжность, предсказуемость и адаптивность. Именно в этом контексте появляется новое поколение — Wi-Fi 8 (также обозначаемое как IEEE 802.11bn), задача которого — стать «основой» для беспроводного AI edge. Компания Broadcom представила своё семейство чипсетов Wi-Fi 8, позиционируя их как фундаментальную платформу для сетей с AI-устройствами.

Почему Wi-Fi 8 — это не про максимальную скорость?
В предыдущих поколениях Wi-Fi (например, Wi-Fi 6, Wi-Fi 6E, Wi-Fi 7) основной акцент делался на увеличение пропускной способности: больше GHz, больше антенн, более мощная модуляция. Однако в блоге Broadcom подчёркивается, что Wi-Fi 8 сменяет приоритеты: теперь главное — надёжность, предсказуемость, контроль задержки и способность работать в сложных, насыщенных средах. Другими словами: устройство может не показывать «в идеале» наибольшую скорость, но важно, чтобы оно доставляло данные вовремя, без провалов, даже если сеть нагружена.
Это особенно актуально для оконечных AI-устройств: камеры, датчики, автономные роботы, автомобили, «умный дом», промышленная автоматизация — там требуется мгновенная реакция, и беспроводная сеть не может быть слабым звеном.

Технические особенности Wi-Fi 8
Ниже — основные архитектурные и технологические моменты, которые Broadcom выделяет как отличительные черты Wi-Fi 8.
1. Телеметрия и адаптивность
Семейство чипов Wi-Fi 8 от Broadcom включает встроенные механизмы телеметрии, которые постоянно измеряют поведение сети: условия канала, загруженность, помехи, мобильность устройств. Эта информация используется в реальном времени для адаптации: например, переключение каналов, корректировка мощности, приоритизация трафика, динамическое управление потоком данных — всё с целью обеспечить низкую задержку и стабильное соединение.
2. Архитектура «краевого AI» (Edge AI)
Wi-Fi 8 позиционируется именно как платформа для Edge AI — то есть инфраструктуры, где модель, обработка данных или рекомендации выполняются ближе к устройству, а не в облаке. Broadcom подчёркивает: устройства и сети должны быть «AI-ready» — готовыми к работе с интенсивными задачами AI в режиме реального времени.
Это требует:
- Очень низкой задержки (чтобы не было «запаздывания» отклика)
- Высокой надёжности (чтобы результат был предсказуемым)
- Способности одновременно обслуживать множество устройств (IoT, сенсоры, камеры и др.)
3. Поддержка различных классов устройств и сценариев
Broadcom указывает, что Wi-Fi 8 охватывает не только домашние маршрутизаторы, но и корпоративные точки доступа, а также клиентские устройства: смартфоны, ноутбуки, автомобильные системы.
Такая универсальность важна: сеть на краю должна обслуживать разные типы устройств с разными требованиями.
4. Лицензирование стратегии и экосистема
Интересный аспект: Broadcom открывает свою платформу Wi-Fi 8 через лицензирование IP и продуктов, особенно для рынков IoT и automotive. Это позволяет партнёрам быстрее внедрять Wi-Fi 8 в новые устройства и экосистемы.

5. Стандарт IEEE 802.11bn — ориентиры
Хотя Wi-Fi 8 ещё находится в разработке (стандарт IEEE 802.11bn), уже видны ориентиры: фокус на «Ultra High Reliability» (UHR) — чрезвычайно высокая надёжность, низкая задержка, устойчивость к помехам и плотной среде.
Например, даже если физические изменения по сравнению с Wi-Fi 7 не столь радикальны, акцент смещается на качество соединения, а не просто на максимальную скорость.

Зачем Wi-Fi 8 нужен именно для Wireless AI Edge
Рассмотрим ключевые сценарии, где преимущества Wi-Fi 8 раскрываются наиболее ярко.
Сценарий: автономные системы и роботы
Представьте завод с роботами-манипуляторами, дронами, транспортными средствами на базе AI. Они генерируют, обрабатывают и обмениваются данными на месте: карты, сенсоры, объекты, навигация. Здесь задержка, потеря пакетов или нестабильность соединения — недопустимы. Wi-Fi 8 помогает обеспечить:
- Постоянное качество соединения даже при движении устройств
- Адаптацию к изменяющимся условиям канала
- Высокую плотность устройств в ограниченном пространстве
Сценарий: IP-камеры, видеоаналитика и умный дом
Камеры с AI-аналитикой могут находиться где-то между облаком и Edge. Wi-Fi 8 обеспечивает непрерывную передачу потока, реагирование на события и автономную работу без нарушения связи.
Сценарий: автомобильная и транспортная инфраструктура
Wi-Fi 8 встроен в автомобильные системы и мобильные устройства. При движении, смене точек доступа, большом количестве подключённых устройств важно, чтобы сеть была непрерывной, с минимальной задержкой, автоматически адаптировалась при смене сценария.

Так появится экосистема решений Wi-Fi 8 для домашних (BCM6718), корпоративных (BCM43840, BCM43820) и клиентских устройств (BCM43109).
Вызовы и что ещё предстоит
Хотя Wi-Fi 8 выглядит многообещающе, есть несколько моментов, на которые стоит обратить внимание.
- Стандартизация и сроки - стандарт IEEE 802.11bn ещё не окончательно утверждён; коммерческая доступность устройств и сертификация могут занять несколько лет.
Это значит, что внедрение Wi-Fi 8-решений в промышленном масштабе может состояться не сразу.
- Экосистема и совместимость - чтобы Wi-Fi 8 стал по-настоящему успешным, требуется: устройства-клиенты (смартфоны, ноутбуки, IoT-устройства), точки доступа, маршрутизаторы, инфраструктура поддержки, программные платформы. Переход всей экосистемы — задача небыстрая.
- Цена и обоснование обновлений - поскольку пиковые скорости могут не сильно отличаться от Wi-Fi 7, организациям и пользователям придётся оценивать: стоит ли обновлять оборудование сейчас ради большей надёжности и «готовности к AI Edge». Некоторые аналитики отмечают, что без заметного прироста скорости маркетинг может быть слабее.
- Безопасность и управление - с большим количеством устройств, большим количеством трафика «на краю», а также AI-нагрузками возрастает важность безопасности как на уровне устройства, так и на уровне сети. Wi-Fi 8 должен преодолеть этот вызов.
Заключение
Wi-Fi 8 от Broadcom — это не просто новое поколение беспроводного стандарта ради скорости — это полноценная платформа, ориентированная на эпоху Edge AI. Она призвана обеспечить надежную, предсказуемую, гибкую сеть, способную поддерживать устройства с AI-нагрузкой в самых требовательных сценариях.
Для организаций, которые планируют развивать инфраструктуру Edge AI, промышленный IoT, автономные системы, «умный город», Wi-Fi 8 может стать ключевым технологическим элементом. Однако, как и с любой новой технологией, важно учитывать сроки стандартизации, экосистему, реальную выгоду от обновления и стратегию внедрения.
Таги: Broadcom, Hardware, Update
Broadcom представила сетевой адаптер Thor Ultra со скоростью 800 Гбит/с
Компания Broadcom на днях объявила о выпуске Thor Ultra — первой в отрасли 800G AI Ethernet сетевой карты (NIC), способной объединять сотни тысяч XPU (eXtreme Processing Units) для выполнения AI-нагрузок с триллионами параметров. Приняв открытую спецификацию Ultra Ethernet Consortium (UEC), Thor Ultra предоставляет клиентам возможность масштабировать AI-нагрузки с экстремальной производительностью и эффективностью в открытой экосистеме.

«Thor Ultra воплощает видение Ultra Ethernet Consortium по модернизации RDMA для крупных AI-кластеров», — сказал Рам Велага, старший вице-президент и генеральный директор подразделения Core Switching Group компании Broadcom. — «Разработанная с нуля, Thor Ultra — это первый в отрасли 800G Ethernet NIC, полностью соответствующий спецификации UEC. Мы благодарны нашим клиентам за сотрудничество и нашей выдающейся инженерной команде за инновации продукта».
Традиционная RDMA не поддерживает multipathing-передачу, out-of-order доставку пакетов, выборочную повторную передачу и масштабируемый контроль перегрузок. Thor Ultra представляет революционный набор инноваций RDMA, соответствующих UEC, включая:
- Multipathing-передачу на уровне пакетов для эффективной балансировки нагрузки.
- Доставку пакетов out-of-order напрямую в память XPU для максимального использования сетевой фабрики.
- Выборочную повторную передачу для эффективной передачи данных.
- Программируемые алгоритмы контроля перегрузок на стороне приёмника и отправителя.
Thor Ultra обеспечивает высокопроизводительные расширенные возможности RDMA в открытой экосистеме. Это даёт клиентам свободу подключения любых XPU, оптики или коммутаторов и снижает зависимость от проприетарных, вертикально интегрированных решений.
Дополнительные особенности Broadcom Thor Ultra включают:
- Доступность в стандартных форм-факторах PCIe CEM и OCP 3.0.
- 200G или 100G PAM4 SerDes с поддержкой длинных пассивных медных соединений.
- Самый низкий в отрасли уровень битовых ошибок (BER) SerDes, что уменьшает разрывы соединений и ускоряет время завершения заданий (JCT).
- Интерфейс PCI Express Gen6 x16 для хоста.
- Шифрование и дешифрование на скорости линии с разгрузкой PSP, снимая с хоста/XPU вычислительно-интенсивные задачи.
- Безопасная загрузка с подписанным микропрограммным обеспечением и аттестацией устройства.
- Программируемый конвейер контроля перегрузок.
- Поддержка обрезки пакетов и сигнализации перегрузок (CSIG) с Tomahawk 5, Tomahawk 6 или любым коммутатором, совместимым с UEC.
Будучи передовой сетевой картой, Thor Ultra является ключевым дополнением к портфолио Broadcom по Ethernet-сетям для AI. В сочетании с Tomahawk 6, Tomahawk 6-Davisson, Tomahawk Ultra, Jericho 4 и Scale-Up Ethernet (SUE) Thor Ultra обеспечивает открытую экосистему для масштабных высокопроизводительных внедрений XPU.
Более подробно о сетевой карте Thor Ultra можно узнать вот тут.
Таги: Broadcom, Hardware, Networking
Новый документ: "Deploy Distributed LLM Inference with GPUDirect RDMA over InfiniBand in VMware Private AI"
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Этот пост о новом документе «Deploy Distributed LLM inference with GPUDirect RDMA over Infiniband in VMware Private AI», где приведены архитектурные рекомендации, детальные шаги развертывания и технические best practices для распределённого инференса LLM на нескольких GPU-узлах с использованием VCF и серверов NVIDIA HGX с GPUDirect RDMA по InfiniBand.
Основные моменты и технические детали
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.

Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.

Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
- Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
- Конфигурацию ESX для включения GPUDirect RDMA
- Развертывание Service VM
- Настройку кластера VKS
- Установку операторов (NVIDIA Network и GPU Operators)
- Процедуры загрузки хранилища и моделей
- Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
- Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
- YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
- Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
- Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.


Больше подробностей вы можете узнать из документа «Deploy Distributed LLM inference with GPUDirect RDMA over Infiniband in VMware Private AI».
Таги: VMware, VCF, AI, Hardware, NVIDIA, LLM, Performance, Whitepaper
Оборудование для домашней лаборатории от Вильяма Лама для развертывания VMware Cloud Foundation 9
Во время конференции VMware Explore 2025 к блогеру Вильяму Ламу, много пишущему о технологиях виртуализации по существу, обратился один из участников, которого заинтересовала его физическая сетевая инфраструктура и то, как всё подключено в его лабораторной среде VMware Cloud Foundation (VCF) 9.0. Сетевая схема ниже основана на вот этой спецификации оборудования (Hardware BOM — Build-of-Material) для VCF 9.0:

В самой лаборатории используется следующая сетевая конфигурация с дополнительными комментариями к каждому подключению в описании ниже:

Примечание: все зелёные линии на схеме выше обозначают сетевые подключения 10 GbE, а все синие линии обозначают подключения 2.5 GbE.
Порты:
- Роутер MikroTik (слева направо): порты 1–5
- Роутер Sodola (слева направо): порты 1–6
Подключения портов:
- Порт 1 на MikroTik подключен к интернет-аплинку
Это необходимо, если вам требуется исходящее подключение для установки/загрузки пакетов в вашу среду.
- Порты 2–4 на MikroTik подключены к 3 x MS-A2 через первый порт 10GbE SFP+
ESXi определит первый SFP+ порт как vmnic1.
- Порт 5 на MikroTik подключен к порту 6 (10GbE SFP+) на коммутаторе Sodola
Настроен как транковый VLAN (802.1Q), который будет передавать все VLAN’ы, определённые на MikroTik.
- Порт 1 на Sodola подключен к настольному iMac
Настроен как нетегированный VLAN, и конкретно для сети Management, чтобы можно было получить доступ ко всем системам.
- Порт 2 на Sodola подключен к ASUS NUC 14
Настроен как транковый VLAN (802.1Q) для дополнительного хоста с рабочими нагрузками VCF Workload Domain.
- Порт 5 на Sodola подключен к Synology NAS
Настроен как тегированный VLAN для доступа к VCF Offline Depot.
- Порты 3–4 на Sodola не используются и доступны для расширения системы.
Более подробно о тестовой лаборатории Вильяма можно почитать вот тут.
Таги: VMware, VCF, Hardware
Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking
AI и генеративный AI (Gen AI) требуют значительной инфраструктуры, а задачи, такие как тонкая настройка, кастомизация, развертывание и выполнение запросов, могут сильно нагружать ресурсы. Масштабирование этих операций становится проблематичным без достаточной инфраструктуры. Кроме того, необходимо соответствовать различным требованиям в области комплаенса и законодательства в разных отраслях и странах. Решения на базе Gen AI должны обеспечивать контроль доступа, правильное размещение рабочих нагрузок и готовность к аудиту для соблюдения этих стандартов. Чтобы решить эти задачи, Broadcom представила VMware Private AI, которая помогает клиентам запускать модели рядом с их собственными данными. Объединяя инновации обеих компаний, Broadcom и NVIDIA стремятся раскрыть потенциал AI и повысить производительность при более низкой совокупной стоимости владения (TCO).
Технический документ «Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking» подробно описывает сквозное развертывание и конфигурацию, с акцентом на DirectPath I/O (passthrough) для GPU, а также сетевые адаптеры Thor 2 с Ethernet-коммутатором Tomahawk 5. Это руководство необходимо архитекторам инфраструктуры, администраторам VCF и специалистам по data science, которые стремятся достичь оптимальной производительности своих AI-моделей в среде VCF.
Что охватывает этот документ?
Документ предоставляет детальные рекомендации по следующим направлениям:
- Адаптеры Broadcom Thor 2 и GPU NVIDIA: как эффективно интегрировать сетевые карты Broadcom и GPU NVIDIA в виртуальные машины глубокого обучения (DLVM) на базе Ubuntu в среде VMware Cloud Foundation (VCF).
- Сетевая конфигурация: пошаговые инструкции по настройке Ethernet-адаптеров Thor 2 и коммутаторов Tomahawk 5 для включения RoCE (RDMA over Converged Ethernet) с GPU NVIDIA, что обеспечивает низкую задержку и высокую пропускную способность, критически важные для AI-нагрузок.
- Тестирование производительности: процедуры запуска тестов с использованием ключевых библиотек коллективных коммуникаций, таких как NCCL, для проверки эффективности многопроцессорных GPU-операций.
- Инференс LLM: рекомендации по запуску и тестированию инференса больших языковых моделей (LLM) с помощью NVIDIA Inference Microservices (NIM) и vLLM, демонстрирующие реальный прирост производительности.

Ключевые особенности решения
Решение, описанное в документе, ориентировано на сертифицированные системы VMware Private AI на базе HGX, которые обычно оснащены 4 или 8 GPU H100/H200 с интерконнектом NVSwitch и NVLink. Целевая среда — это приватное облако на базе VCF, использующее сетевые адаптеры Broadcom 400G BCM957608 NICs и кластеризированные GPU NVIDIA H100, соединённые через Ethernet.
Ключевой аспект данного развертывания — использование DirectPath I/O для GPU и адаптеров Thor2, что обеспечивает выделенный доступ к аппаратным ресурсам и максимальную производительность. В руководстве также подробно рассматриваются следующие важные элементы:
- BIOS и прошивки: рекомендуемые конфигурации для серверов HGX, позволяющие раскрыть максимальную производительность.
- Настройки ESX: оптимизация ESX для passthrough GPU и сетевых устройств, включая корректную разметку оборудования и конфигурацию ACS (Access Control Services).
- Настройки виртуальных машин: кастомизация Deep Learning VM (DLVM) для DirectPath I/O, включая назначение статических IP и важные расширенные параметры ВМ для ускоренного запуска и повышения производительности.
Валидация производительности
- Подробные инструкции по запуску RDMA, GPUDirect RDMA с Perftest и тестов NCCL на нескольких узлах с разъяснением ожидаемой пропускной способности и задержек.
- Бенчмаркинг виртуальной и bare-metal производительности Llama-3.1-70b NIM с помощью genai-perf, позволяющий достичь результатов, близких к bare-metal.
- Использование evalscope для оценки точности и стресс-тестирования производительности передовой модели рассуждений gpt-oss-120b.
Вот интересный результат из исследования, доказывающий, что работа GPU в виртуальной среде ничем не хуже, чем в физической:

Это комплексное руководство является ценным ресурсом для всех, кто стремится развернуть и оптимизировать AI-инференс на надежной виртуальной инфраструктуре с использованием серверов NVIDIA HGX и сетевых решений Broadcom Ethernet. Следуя описанным в документе лучшим практикам, организации могут создавать масштабируемые и высокопроизводительные AI-платформы, соответствующие требованиям современных приложений глубокого обучения.
Чтобы подробнее ознакомиться с техническими деталями и процедурами развертывания, рекомендуем прочитать полный документ:
https://www.vmware.com/docs/paif-hgx-brcm-eth.
Таги: VMware, Private AI, GenAI, Performance, NVIDIA, Hardware
VMware представила Industrial vSwitch (IvS) в платформе VMware Cloud Foundation 9.0
Мир промышленной автоматизации переживает глубокую трансформацию, вызванную необходимостью повышения гибкости, эффективности и надёжности. Традиционные среды операционных технологий (OT), часто характеризующиеся жёстким, проприетарным оборудованием, эволюционируют в сторону более гибких, программно-определяемых архитектур. Broadcom находится в авангарде этой трансформации. В продолжение предыдущего анонса о поддержке Broadcom компании Audi в создании автоматизации заводов нового поколения с использованием VMware Cloud Foundation (VCF), VMware подчеркивает ключевую роль, которую играет VCF Networking в процессе модернизации Audi.
В рамках инициативы Audi Edge Cloud for Production, одним из ключевых кейсов является виртуализация физических PLC (программируемых логических контроллеров), управляющих критически важными операциями на производстве, такими как сборка автомобилей роботами. Цель — виртуализировать PLC и запускать их как виртуальные машины или контейнеры, управляемые как современные ИТ-нагрузки из частного облака Audi. Эту трансформацию поддерживает Industrial vSwitch (IvS), представленный в VCF 9.0. Разработанный в сотрудничестве с экспертами в области промышленной автоматизации, IvS приносит виртуализацию на завод, обеспечивая связь почти в реальном времени между виртуальными PLC и устройствами ввода/вывода.
Что такое Industrial vSwitch?
Industrial vSwitch (IvS) — это специализированная функция в составе NSX, работающая как распределённый сетевой коммутатор для промышленных сетей. Его основная задача — обеспечить передачу PROFINET-трафика в реальном времени на уровне 2 (L2) между устройствами с требуемой задержкой менее миллисекунды. Это обеспечивает бесшовную маршрутизацию критически важного PROFINET-трафика между виртуальными PLC (vPLC), развернутыми в VCF, и физическими устройствами ввода/вывода на производстве.
IvS основан на технологии NSX Enhanced Datapath (EDP) и разработан с учётом строгих требований промышленных систем управления: низкая задержка, минимальный джиттер и детерминированные сетевые характеристики. Производственная среда требует задержки на уровне сотен микросекунд для соответствия требованиям систем реального времени.
Основные функции
Поддержка PROFINET:
- Поддерживает протокол PROFINET DCP (обнаружение и конфигурация устройств), необходимый для настройки и управления vPLC и I/O-устройствами.
- Обрабатывает VLAN-тегирование и удаление тегов в Ethernet-кадрах PROFINET, поддерживает классы обслуживания для RT и NRT-трафика.
- Использует режим Dedicated в EDP для обработки пакетов с высоким уровнем производительности и минимальной задержкой.
Поддержка PRP (Parallel Redundancy Protocol):
- Поддерживает режим PRP RedBox, позволяющий подключать vPLC к двум независимым сетям для обеспечения отказоустойчивости.
- Отправляет управляющие кадры PRP от имени vPLC и следит за состоянием обеих сетей.
- Поддерживает взаимодействие с другими PRP-устройствами и управляет таблицами PRP Node и VDAN.
Измерение задержек:
Почему сейчас? Переход к программно-определяемому производству
Мотивация внедрения IvS очевидна: производители стремятся виртуализировать OT-среду и модернизировать цеха ради гибкости и конкурентоспособности. Ядром этой среды являются PLC. С помощью IvS возможно:
- Повысить гибкость и адаптивность производственных процессов
- Оперативно внедрять новые функции через обновления ПО
- Существенно сократить время восстановления при сбоях, повысив надёжность
- Централизованно управлять инфраструктурой
- Стандартизировать стеки приложений и обеспечить безопасность и управляемость как локально, так и удалённо
- Объединить несколько PLC на одном хосте — до 12 vPLC на систему
- Обеспечить полную отказоустойчивость с нулевым временем переключения
Архитектура и требования
ПО:
- VMware Cloud Foundation 9.0 с обновлённым NSX
- Хосты в домене нагрузки с Industrial vSwitch
Сетевые интерфейсы (NIC):
- Должны поддерживать NSX Enhanced Datapath — Dedicated
- Поддержка устройств: NVIDIA Mellanox ConnectX-6
Совместимость с ПО:
Совместимость с PRP:
Архитектура развертывания
vPLC и IvS развертываются в рамках VCF workload domain, образуя кластер управления для производственной среды. Решение интегрируется с существующими промышленными шинами (fieldbus) и заменяет традиционные аппаратные PLC. Взаимодействие с устройствами в цехе происходит через Industrial Ethernet (PROFINET). Для отказоустойчивости используется PRP, подключённый к двум сетям: LAN-A и LAN-B.
Пример развертывания
- vPLC VM размещаются в домене нагрузки VCF 9 и получают выделенные NSX VLAN-сегменты для подключения к своим ячейкам на производстве.
- IvS подключается к LAN-A и LAN-B через встроенный PRP-интерфейс и формирует PRP-каналы с коммутаторами в каждой ячейке.
- Трафик между vPLC и I/O реплицируется по обеим сетям для высокой надёжности и соответствия таймаутам.
- Коммутаторы на производстве конфигурируются как PRP RedBox, обеспечивая безотказную связь между устройствами fieldbus и vPLC.
- Основные инфраструктурные сервисы (NSX Manager, vCenter и пр.) размещаются в VCF Management domain.

Как это работает?
Industrial vSwitch (IvS) специально разработан для удовлетворения уникальных требований сценария использования vPLC, который требует:
- Платформы виртуализации с поддержкой работы в реальном времени и детерминированным поведением управления.
- Виртуального коммутатора с минимальной задержкой и предсказуемым джиттером.
- Устойчивости к сбоям в сети.
- Интеграции с PROFISAFE для обеспечения безопасности персонала.
В этой архитектуре задачи виртуализации и вычислений в реальном времени решаются за счёт продвинутых возможностей платформы ESX, а сетевые требования обеспечиваются Industrial vSwitch с встроенной поддержкой PRP (Parallel Redundancy Protocol). Интеграция с PROFISAFE была реализована в тесном сотрудничестве с производителями PLC в рамках общего проектирования решения.
Как настроить Industrial vSwitch в VCF 9
Шаг 1: Создание IvS в vCenter
Первым шагом активации Industrial vSwitch является его создание в vCenter.

Шаг 2: Добавление vSwitch в NSX
Добавьте vSwitch в NSX в составе профиля транспортного узла (Transport Node Profile) и настройте параметры PROFINET, PRP и другие конфигурации, необходимые для работы в режиме реального времени.

Шаг 3: Создание профиля сегмента IvS и VLAN-сегментов
Создайте профиль сегмента IvS, который будет использоваться для всех сегментов, предназначенных для развертывания vPLC. Настройте параметры PRP и активируйте измерение задержки (Latency Measurement) в соответствии с требованиями.

Далее настройте VLAN-сегменты в NSX в соответствии с VLAN’ами, используемыми vPLC и устройствами ввода/вывода. Затем назначьте профиль сегмента IvS на соответствующий сегмент, чтобы применить конфигурации для каждого VLAN отдельно.

Шаг 4: Развертывание виртуальной машины vPLC
Разверните виртуальную машину vPLC с сетевым интерфейсом, подключённым к IvS. Параметры vNIC — Strict Latency и Latency Measurement — автоматически настроят соответствующие параметры интерфейса. В частности, конфигурация Latency Measurement должна соответствовать выбранному профилю сегмента. Это позволит включить измерение задержки при передаче (TX) и приёме (RX) пакетов между vNIC и uplink-интерфейсами хоста.

После завершения настройки IvS непрерывно отслеживает задержку пакетов для каждого vNIC виртуального vPLC, чтобы обеспечить детерминированную производительность и контролируемый джиттер. Система фиксирует максимальную задержку по каждому vNIC и генерирует оповещение, если значение превышает заданный порог. Ниже приведён пример вывода для одного интерфейса, где максимальная задержка при передаче (TX) составила 108 микросекунд, а при приёме (RX) — 67 микросекунд.

С завершением основной настройки Industrial vSwitch вы можете приступить к вводу в эксплуатацию и программированию дополнительных vPLC, подключённых к IvS, через инженерную среду разработки (IDE). Для достижения оптимальной производительности рекомендуется обратиться к официальной документации, где приведены рекомендации по тонкой настройке — включая оптимизацию параметров BIOS хоста и обеспечение корректного выравнивания по NUMA.
Взгляд в будущее
Выход Industrial vSwitch в составе VCF 9 — это важный шаг вперёд в направлении расширения программно-определяемой инфраструктуры на среду промышленной автоматизации, где критически важна работа в реальном времени. Обеспечивая высокопроизводительную и отказоустойчивую сетевую связь для виртуализированных контроллеров, IvS создаёт прочную основу для построения более гибких, эффективных и надёжных производств будущего.
В дальнейшем VMware планирует добавить поддержку дополнительных протоколов шины fieldbus, расширить сотрудничество с технологическими партнёрами и продолжить развитие платформы под задачи операционных технологий (OT).
Таги: VMware, IvS, Enterprise, Hardware, Networking
Сетевая архитектура VMware vSAN - нужен ли вам RDMA?
В предыдущей статье мы рассмотрели, что производительность vSAN зависит не только от физической пропускной способности сети, соединяющей хосты vSAN, но и от архитектуры самого решения. При использовании vSAN ESA более высокоскоростные сети в сочетании с эффективным сетевым дизайном позволяют рабочим нагрузкам в полной мере использовать возможности современного серверного оборудования. Стремясь обеспечить наилучшие сетевые условия для вашей среды vSAN, вы, возможно, задаётесь вопросом: можно ли ещё как-то улучшить производительность vSAN за счёт сети? В этом посте мы обсудим использование vSAN поверх RDMA и разберёмся, подойдёт ли это решение вам и вашей инфраструктуре.
Обзор vSAN поверх RDMA
vSAN использует IP-сети на базе Ethernet для обмена данными между хостами. Ethernet-кадры (уровень 2) представляют собой логический транспортный слой, обеспечивающий TCP-соединение между хостами и передачу соответствующих данных. Полезная нагрузка vSAN размещается внутри этих пакетов так же, как и другие типы данных. На протяжении многих лет TCP поверх Ethernet обеспечивал исключительно надёжный и стабильный способ сетевого взаимодействия для широкого спектра типов трафика. Его надёжность не имеет аналогов — он может функционировать даже в условиях крайне неудачного проектирования сети и плохой связности.
Однако такая гибкость и надёжность имеют свою цену. Дополнительные уровни логики, используемые для подтверждения получения пакетов, повторной передачи потерянных данных и обработки нестабильных соединений, создают дополнительную нагрузку на ресурсы и увеличивают вариативность доставки пакетов по сравнению с протоколами без потерь, такими как Fibre Channel. Это может снижать пропускную способность и увеличивать задержки — особенно в плохо спроектированных сетях. В правильно организованных средах это влияние, как правило, незначительно.
Чтобы компенсировать особенности TCP-сетей на базе Ethernet, можно использовать vSAN поверх RDMA через конвергентный Ethernet (в частности, RoCE v2). Эта технология всё ещё использует Ethernet, но избавляется от части избыточной сложности TCP, переносит сетевые операции с CPU на аппаратный уровень и обеспечивает прямой доступ к памяти для процессов. Более простая сетевая модель высвобождает ресурсы CPU для гостевых рабочих нагрузок и снижает задержку при передаче данных. В случае с vSAN это улучшает не только абсолютную производительность, но и стабильность этой производительности.

RDMA можно включить в кластере vSAN через интерфейс vSphere Client, активировав соответствующую опцию в настройках кластера. Это предполагает, что вы уже выполнили все предварительные действия, необходимые для подготовки сетевых адаптеров хостов и коммутаторов к работе с RDMA. Обратитесь к документации производителей ваших NIC и коммутаторов для получения информации о необходимых шагах по активации RDMA.
Если в конфигурации RDMA возникает хотя бы одна проблема — например, один из хостов кластера теряет возможность связи по RDMA — весь кластер автоматически переключается обратно на TCP поверх Ethernet.
Рекомендация. Рассматривайте использование RDMA только в случае, если вы используете vSAN ESA. Хотя поддержка vSAN поверх RDMA появилась ещё в vSAN 7 U2, наибольшую пользу эта технология приносит в сочетании с высокой производительностью архитектуры ESA, начиная с vSAN 8 и выше.
Как указано в статье «Проектирование сети vSAN», использование RDMA с vSAN влечёт за собой дополнительные требования, ограничения и особенности. К ним относятся:
- ReadyNodes для vSAN должны использовать сетевые адаптеры, сертифицированные для RDMA.
- Коммутаторы должны быть совместимы с RDMA и настроены соответствующим образом (включая такие параметры, как DCB — Data Center Bridging и PFC — Priority Flow Control).
- Размер кластера не должен превышать 32 хоста.
- Поддерживаются только следующие политики объединения интерфейсов:
- Route based on originating virtual port
- Route based on source MAC hash
Использование LACP или IP Hash не поддерживается с RDMA.
- Предпочтительно использовать отдельные порты сетевых адаптеров для RDMA, а не совмещать RDMA и TCP на одном uplink.
- RDMA не совместим со следующими конфигурациями:
- 2-узловые кластеры (2-Node)
- Растянутые кластеры (stretched clusters)
- Совместное использование хранилища vSAN
- Кластеры хранения vSAN (vSAN storage clusters)
- В VCF 5.2 использование vSAN поверх RDMA не поддерживается. Эта возможность не интегрирована в процессы SDDC Manager, и не предусмотрено никаких способов настройки RDMA для кластеров vSAN. Любые попытки настроить RDMA через vCenter в рамках VCF 5.2 также не поддерживаются.
Дополнительную информацию о настройке RDMA для vSAN можно найти в базе знаний KB 382163: Configuring RDMA for vSAN.
Прирост производительности при использовании vSAN поверх RDMA
При сравнении двух кластеров с одинаковым аппаратным обеспечением, vSAN с RDMA может показывать лучшую производительность по сравнению с vSAN, использующим TCP поверх Ethernet. В публикации Intel «Make the Move to 100GbE with RDMA on VMware vSAN with 4th Gen Intel Xeon Scalable Processors» были зафиксированы значительные улучшения производительности в зависимости от условий среды.
Рекомендация: используйте RDTBench для тестирования соединений RDMA и TCP между хостами. Это также отличный инструмент для проверки конфигурации перед развёртыванием производительного кластера в продакшене.
Fibre Channel — действительно ли это «золотой стандарт»?
Fibre Channel заслуженно считается надёжным решением в глазах администраторов хранилищ. Протокол Fibre Channel изначально разрабатывался с одной целью — передача трафика хранения данных. Он использует «тонкий стек» (thin stack), специально созданный для обеспечения стабильной и низколатентной передачи данных. Детеминированная сеть на базе Fibre Channel работает как единый механизм, где все компоненты заранее определены и согласованы.
Однако Fibre Channel и другие протоколы, рассчитанные на сети без потерь, тоже имеют свою цену — как в прямом, так и в переносном смысле. Это дорогая технология, и её внедрение часто «съедает» большую часть бюджета, уменьшая возможности инвестирования в другие сетевые направления. Кроме того, инфраструктуры на Fibre Channel менее гибкие по сравнению с Ethernet, особенно при необходимости поддержки разнообразных топологий.
Хотя Fibre Channel изначально ориентирован на физическую передачу данных без потерь, сбои в сети могут привести к непредвиденным последствиям. В спецификации 32GFC был добавлен механизм FEC (Forward Error Correction) для борьбы с кратковременными сбоями, но по мере роста масштаба фабрики растёт и её сложность, что делает реализацию сети без потерь всё более трудной задачей.
Преимущество Fibre Channel — не в абсолютной скорости, а в предсказуемости передачи данных от точки к точке. Как видно из сравнения, даже с учётом примерно 10% накладных расходов при передаче трафика vSAN через TCP поверх Ethernet, стандартный Ethernet легко может соответствовать или даже превосходить Fibre Channel по пропускной способности.

Обратите внимание, что такие обозначения, как «32GFC» и Ethernet 25 GbE, являются коммерческими названиями, а не точным отражением фактической пропускной способности. Каждый стандарт использует завышенную скорость передачи на уровне символов (baud rate), чтобы компенсировать накладные расходы протокола. В случае с Ethernet фактическая пропускная способность зависит от типа передаваемого трафика. Стандарт 40 GbE не упоминается, так как с 2017 года он считается в значительной степени устаревшим.
Тем временем Ethernet переживает новый виток развития благодаря инфраструктурам, ориентированным на AI, которым требуется высокая производительность без уязвимости традиционных «безубыточных» сетей. Ethernet изначально проектировался с учётом практических реалий дата-центров, где неизбежны изменения в условиях эксплуатации и отказы оборудования.
Благодаря доступным ценам на оборудование 100 GbE и появлению 400 GbE (а также приближению 800 GbE) Ethernet становится чрезвычайно привлекательным решением. Даже традиционные поставщики систем хранения данных в последнее время отмечают, что всё больше клиентов, ранее серьёзно инвестировавших в Fibre Channel, теперь рассматривают Ethernet как основу своей следующей сетевой архитектуры хранения. Объявление Broadcom о выпуске чипа Tomahawk 6, обеспечивающего 102,4 Тбит/с внутри одного кристалла, — яркий индикатор того, что будущее высокопроизводительных сетей связано с Ethernet.
С vSAN ESA большинство издержек TCP поверх Ethernet можно компенсировать за счёт грамотной архитектуры — без переподписки и с использованием сетевого оборудования, поддерживающего высокую пропускную способность. Это подтверждается в статье «vSAN ESA превосходит по производительности топовое хранилище у крупной финансовой компании», где vSAN ESA с TCP по Ethernet с лёгкостью обошёл по скорости систему хранения, использующую Fibre Channel.
Насколько хорош TCP поверх Ethernet?
Если у вас качественно спроектированная сеть с высокой пропускной способностью и без переподписки, то vSAN на TCP поверх Ethernet будет достаточно хорош для большинства сценариев и является наилучшей отправной точкой для развёртывания новых кластеров vSAN. Эта рекомендация особенно актуальна для клиентов, использующих vSAN в составе VMware Cloud Foundation 5.2, где на данный момент не поддерживается RDMA.
Хотя RDMA может обеспечить более высокую производительность, его требования и ограничения могут не подойти для вашей среды. Тем не менее, можно добиться от vSAN такой производительности и стабильности, которая будет приближена к детерминированной модели Fibre Channel. Для этого нужно:
-
Грамотно спроектированная сеть. Хорошая архитектура Ethernet-сети обеспечит высокую пропускную способность и низкие задержки. Использование топологии spine-leaf без блокировки (non-blocking), которая обеспечивает линейную скорость передачи от хоста к хосту без переподписки, снижает потери пакетов и задержки. Также важно оптимально размещать хосты vSAN внутри кластера — это повышает сетевую эффективность и производительность.
-
Повышенная пропускная способность. Устаревшие коммутаторы должны быть выведены из эксплуатации — им больше нет места в современных ЦОДах. Использование сетевых адаптеров и коммутаторов с высокой пропускной способностью позволяет рабочим нагрузкам свободно передавать команды на чтение/запись и данные без узких мест. Ключ к стабильной передаче данных по Ethernet — исключить ситуации, при которых кадры или пакеты TCP нуждаются в повторной отправке из-за нехватки ресурсов или ненадёжных каналов.
-
Настройка NIC и коммутаторов. Сетевые адаптеры и коммутаторы часто имеют настройки по умолчанию, которые не оптимизированы для высокой производительности. Это может быть подходящим шагом, если вы хотите улучшить производительность без использования RDMA, и уже реализовали два предыдущих пункта. В документе «Рекомендации по производительности для VMware vSphere 8.0 U1» приведены примеры таких возможных настроек.
Дополнительную информацию по проектированию сетей для vSAN можно найти в vSAN Network Design Guide. Для сред на базе VMware Cloud Foundation см. «Network Design for vSAN for VMware Cloud Foundation».
Таги: VMware, vSAN, RDMA, Networking, Hardware
Соотношение виртуальных (vCPU) и физических (pCPU) процессоров на платформе VMware vSphere больше не актуально
Есть вопрос, который администраторы платформы виртуализации VMware vSphere задают регулярно:
Какие идеальные соотношения vCPU к pCPU я должен планировать и поддерживать для максимальной производительности? Как учитывать многопоточность Hyper-Threading и Simultaneous Multithreading в этом соотношении?

Ответ?
Он прост - общего, универсального соотношения не существует — и, более того, сам такой подход может привести к операционным проблемам. Сейчас объясним почему.
Раньше мы пользовались рекомендациями вроде 4 vCPU на 1 pCPU (4:1) или даже 10:1, но этот подход основывался на негласной предпосылке — рабочие нагрузки в основном были в простое. Многие организации начинали свою виртуализацию с консолидации наименее нагруженных систем, и в таких случаях высокое соотношение vCPU:pCPU было вполне обычным явлением.
Так появилась концепция коэффициента консолидации, ставшая основой для планирования ресурсов в виртуальных средах. Даже возникала конкуренция: кто сможет добиться более высокого уровня консолидации. Позже появились технологии вроде Intel Hyper-Threading и AMD SMT (Simultaneous Multithreading), которые позволяли достичь ещё большей консолидации. Тогда расчёт стал сложнее: нужно было учитывать не только физические ядра, но и логические потоки. Огромные Excel-таблицы превратились в операционные панели мониторинга ресурсов.
Но этот подход к планированию и эксплуатации устарел. Высокая динамика изменений в инфраструктуре заказчиков и рост потребления ресурсов со стороны виртуальных машин сделали модель статического соотношения нежизнеспособной. К тому же, с переходом к политике virtual-first, многие компании больше не тестируют приложения на "голом железе" до виртуализации.
А если мы не можем заранее предсказать, что будет виртуализовано, какие ресурсы ему нужны и как долго оно будет работать — мы не можем зафиксировать статическое соотношение ресурсов (процессор, память, сеть, хранилище).
Вместо этого нужно "управлять по конкуренции" (drive by contention)
То есть — инвестировать в пулы ресурсов для владельцев приложений и мониторить эти пулы на предмет высокой загруженности ресурсов и конкуренции (contention). Если возникает конфликт — значит, пул достиг предела, и его нужно расширять. Это требует нового подхода к работе команд, особенно с учётом того, что современные процессоры могут иметь огромное количество ядер.
Именно под такие задачи была спроектирована платформа VMware Cloud Foundation (VCF) и ее инструменты управления — и не только для CPU. На уровне платформы vSphere поддерживает крупные кластеры, автоматически балансируемые такими сервисами, как DRS, которые минимизируют влияние конфликтов на протяжении всего жизненного цикла приложений.
Операционный пакет VCF (Aria) следит за состоянием приложений и пулов ресурсов, сообщает о проблемах с производительностью или нехваткой ёмкости. Такая модель позволяет использовать оборудование эффективно, добиваясь лучшего уровня консолидации без ущерба для KPI приложений. Этого нельзя достичь при помощи фиксированного соотношения vCPU:pCPU.
Поэтому — чтобы не быть в рамках ограничений статических коэффициентов, повысить эффективность использования "железа" и адаптироваться к быстро меняющимся бизнес-реалиям, необходимо переосмыслить операционные модели и инструменты. В них нужно учитывать такие вещи, как:
- Логические CPU не равно физические CPU/ядра (в случае гиперпоточности)
- Важность точного подбора размеров виртуальных машин (right-sizing)
Ключевым фактором снижения рисков становится время вашей реакции на проблемы с производительностью или ёмкостью.
Если обеспечить быструю реакцию пока невозможно — начните с консервативного соотношения 1:1 vCPU:pCPU, не учитывая гиперпоточность. Это безопасный старт. По мере роста зрелости вашей инфраструктуры, процессов и инструментов, соотношение будет естественно улучшаться.
Идеальное финальное соотношение будет уникально для каждой организации, в зависимости от приложений, стека технологий и зрелости эксплуатации.
Вкратце:
Соотношение 1:1 даёт максимальную производительность, но по максимальной цене. Но в мире, где нужно делать больше с меньшими затратами, умение "управлять по конкуренции"— это путь к эффективной работе и инвестициям. VCF и был создан для того, чтобы справляться с этими задачами.
Таги: VMware, vSphere, CPU, Hardware
Как настроить корректное отображение скорости соединения сетевого адаптера vmxnet3 виртуальной машины в VMware vSphere 8?
По умолчанию скорость соединения (link speed) адаптера vmxnet3 виртуальной машины устанавливается как 10 Гбит/с. Это применяемое по умолчанию отображаемое значение в гостевой ОС для соединений с любой скоростью. Реальная скорость будет зависеть от используемого вами оборудования (сетевой карты).
VMXNET 3 — это паравиртуализированный сетевой адаптер, разработанный для обеспечения высокой производительности. Он включает в себя все функции, доступные в VMXNET 2, и добавляет несколько новых возможностей, таких как поддержка нескольких очередей (также известная как Receive Side Scaling в Windows), аппаратное ускорение IPv6 и доставка прерываний с использованием MSI/MSI-X. VMXNET 3 не связан с VMXNET или VMXNET 2.
Если вы выведите свойства соединения на адаптере, то получите вот такую картину:

В статье Broadcom KB 368812 рассказывается о том, как с помощью расширенных настроек виртуальной машины можно установить корректную скорость соединения. Для этого выключаем ВМ, идем в Edit Settings и на вкладке Advanced Parameters добавляем нужное значение:
ethernet0.linkspeed 20000

Также вы можете сделать то же самое, просто добавив в vmx-файл виртуальной машины строчку ethernetX.linkspeed = "ХХХ".
При этом учитывайте следующие моменты:
- Начиная с vSphere 8.0.2 и выше, vmxnet3 поддерживает скорость соединения в диапазоне от 10 Гбит/с до 65 Гбит/с.
- Значение скорости по умолчанию — 10 Гбит/с.
- Если вами указано значение скорости меньше 10000, то оно автоматически устанавливается в 10 Гбит/с.
- Если вами указано значение больше 65000, скорость также будет установлена по умолчанию — 10 Гбит/с.
Важно отметить, что это изменение касается виртуального сетевого адаптера внутри гостевой операционной системы виртуальной машины и не влияет на фактическую скорость сети, которая всё равно будет ограничена физическим оборудованием (процессором хоста, физическими сетевыми картами и т.д.).
Это изменение предназначено для обхода ограничений на уровне операционной системы или приложений, которые могут возникать из-за того, что адаптер vmxnet3 по умолчанию определяется со скоростью 10 Гбит/с.
Таги: VMware, vSphere, VMachines, Networking, Hardware
Сетевые подключения VMware vSAN — объединение подключений (teaming) для повышения производительности
Платформа vSphere всегда предоставляла несколько способов использовать несколько сетевых карт (NIC) совместно, но какой из них лучший для vSAN? Давайте рассмотрим ключевые моменты, важные для конфигураций vSAN в сетевой топологии. Этот материал не является исчерпывающим анализом всех возможных вариантов объединения сетевых интерфейсов, а представляет собой справочную информацию для понимания наилучших вариантов использования техники teaming в среде VMware Cloud Foundation (VCF).
Описанные здесь концепции основаны на предыдущих публикациях:
Назначение объединения (Teaming)
Объединение сетевых портов NIC — это конфигурация vSphere, при которой используется более одного сетевого порта для выполнения одной или нескольких задач, таких как трафик ВМ или трафик VMkernel (например, vMotion или vSAN). Teaming позволяет достичь одной или обеих следующих целей:
-
Резервирование: обеспечение отказоустойчивости в случае сбоя сетевого порта на хосте или коммутатора, подключенного к этому порту.
-
Производительность: распределение одного и того же трафика по нескольким соединениям может обеспечить агрегацию полосы пропускания и повысить производительность при нормальной работе.
В этой статье мы сосредоточимся на объединении ради повышения производительности.
Распространённые варианты объединения
Выбор варианта teaming для vSAN зависит от среды и предпочтений, но есть важные компромиссы, особенно актуальные для vSAN. Начиная с vSAN 8 U3, платформа поддерживает один порт VMkernel на хост, помеченный для трафика vSAN. Вот три наиболее распространённые подхода при использовании одного порта VMkernel:
1. Один порт VMkernel для vSAN с конфигурацией Active/Standby
- Используются два и более аплинков (uplinks), один из которых активен, а остальные — в режиме ожидания.
- Это наиболее распространённая и рекомендуемая конфигурация для всех кластеров vSAN.
- Простая, надёжная, идеально подходит для трафика VMkernel (например, vSAN), так как обеспечивает предсказуемый маршрут, что особенно важно в топологиях spine-leaf (Clos).
- Такой подход обеспечивает надежную и стабильную передачу трафика, но не предоставляет агрегации полосы пропускания — трафик проходит только по одному активному интерфейсу.
- Обычно Standby-интерфейс используется для другого типа трафика, например, vMotion, для эффективной загрузки каналов.
2. Один порт VMkernel для vSAN с двумя активными аплинками (uplinks) и балансировкой Load Based Teaming (LBT)
- Используются два и более аплинков в режиме «Route based on physical NIC load».
- Это можно рассматривать как агрегацию на уровне гипервизора.
- Изначально предназначен для VM-портов, а не для трафика VMkernel.
- Преимущества для трафика хранилища невелики, могут вызывать проблемы из-за отсутствия предсказуемости маршрута.
- Несмотря на то, что это конфигурация по умолчанию в VCF, она не рекомендуется для портов VMkernel, помеченных как vSAN.
- В VCF можно вручную изменить эту конфигурацию на Active/Standby без проблем.
3. Один порт VMkernel для vSAN с использованием Link Aggregation (LACP)
- Использует два и более аплинков с расширенным хешированием для балансировки сетевых сессий.
- Может немного повысить пропускную способность, но требует дополнительной настройки на коммутаторах и хосте.
- Эффективность зависит от топологии и может увеличить нагрузку на spine-коммутаторы.
- Используется реже и ограниченно поддерживается в среде VCF.
Версия VCF по умолчанию может использовать Active/Active с LBT для трафика vSAN. Это универсальный режим, поддерживающий различные типы трафика, но неоптимален для VMkernel, особенно для vSAN.
Рекомендуемая конфигурация:
Active/Standby с маршрутизацией на основе виртуального порта (Route based on originating virtual port ID). Это поддерживается в VCF и может быть выбрано при использовании настраиваемого развертывания коммутатора VDS. Подробнее см. в «VMware Cloud Foundation Design Guide».
Можно ли использовать несколько портов VMkernel на хосте для трафика vSAN?
Теоретически да, но только в редком случае, когда пара коммутаторов полностью изолирована (подобно Fibre Channel fabric). Это не рекомендуемый и редко используемый вариант, даже в vSAN 8 U3.
Влияние объединения на spine-leaf-сети
Выбор конфигурации teaming на хостах vSAN может показаться несущественным, но на деле сильно влияет на производительность сети и vSAN. В топологии spine-leaf (Clos), как правило, нет прямой связи между leaf-коммутаторами. При использовании Active/Active LBT половина трафика может пойти через spine, вместо того чтобы оставаться на уровне leaf, что увеличивает задержки и снижает стабильность.
Аналогичная проблема у LACP — он предполагает наличие прямой связи между ToR-коммутаторами. Если её нет, трафик может либо пойти через spine, либо LACP-связь может полностью нарушиться.

На практике в некоторых конфигурациях spine-leaf коммутаторы уровня ToR (Top-of-Rack) соединены между собой через межкоммутаторное соединение, такое как MLAG (Multi-Chassis Link Aggregation) или VLTi (Virtual Link Trunking interconnect). Однако не стоит считать это обязательным или даже желательным в архитектуре spine-leaf, так как такие соединения часто требуют механизмов блокировки, например Spanning Tree (STP).
Стоимость и производительность: нативная скорость соединения против агрегации каналов
Агрегация каналов (link aggregation) может быть полезной для повышения производительности при правильной реализации и в подходящих условиях. Но её преимущества часто переоцениваются или неправильно применяются, что в итоге может приводить к большим затратам. Ниже — четыре аспекта, которые часто упускаются при сравнении link aggregation с использованием более быстрых нативных сетевых соединений.
1. Высокое потребление портов
Агрегация нескольких соединений требует большего количества портов и каналов, что снижает общую портовую ёмкость коммутатора и ограничивает количество возможных хостов в стойке. Это увеличивает расходы на оборудование.
2. Ограниченный прирост производительности
Агрегация каналов, основанная на алгоритмическом балансировании нагрузки (например, LACP), не дает линейного увеличения пропускной способности.
То есть 1+1 не равно 2. Такие механизмы лучше работают при большом количестве параллельных потоков данных, но малоэффективны для отдельных (дискретных) рабочих нагрузок.
3. Ошибочные представления об экономичности
Существует мнение, что старые 10GbE-коммутаторы более экономичны. На деле — это миф.
Более объективный показатель — это пропускная способность коммутатора, измеряемая в Гбит/с или Тбит/с. Хотя сам по себе 10Gb-коммутатор может стоить дешевле, более быстрые модели обеспечивают в 2–10 раз больше пропускной способности, что делает стоимость за 1 Гбит/с ниже. Кроме того, установка более быстрых сетевых адаптеров (NIC) на серверы обычно увеличивает стоимость менее чем на 1%, при этом может дать 2,5–10-кратный прирост производительности.
4. Нереализованные ресурсы
Современные серверы обладают огромными возможностями по процессору, памяти и хранилищу, но не могут раскрыть свой потенциал из-за сетевых ограничений.
Балансировка между вычислительными ресурсами и сетевой пропускной способностью позволяет:
- сократить общее количество серверов;
- снизить капитальные затраты;
- уменьшить занимаемое пространство;
- снизить нагрузку на систему охлаждения;
- уменьшить потребление портов в сети.

Именно по этим причинам VMware рекомендует выбирать более высокие нативные скорости соединения (25Gb или 100Gb), а не полагаться на агрегацию каналов — особенно в случае с 10GbE. Напомним, что когда 10GbE появился 23 года назад, серверные процессоры имели всего одно ядро, а объём оперативной памяти составлял в 20–40 раз меньше, чем сегодня. С учётом того, что 25GbE доступен уже почти десятилетие, актуальность 10GbE для дата-центров практически исчерпана.
Дополнительную информацию о сетевой архитектуре для vSAN можно найти в vSAN Network Design Guide. Для среды VMware Cloud Foundation (VCF) см. документ “Network Design for vSAN for VMware Cloud Foundation”.
Количество uplink-портов на хост
Объединение для повышения производительности и отказоустойчивости обычно предполагает использование нескольких физических сетевых карт (NIC), каждая из которых может иметь 2–4 порта. Сколько всего портов следует иметь на хостах vSAN? Это зависит от следующих факторов:
- Степень рабочих нагрузок: среда с относительно пассивными виртуальными машинами предъявляет гораздо меньшие требования, чем среда с тяжёлыми и ресурсоёмкими приложениями.
- Нативная пропускная способность uplink-соединений: более высокая скорость снижает вероятность конкуренции между сервисами (vMotion, порты ВМ и т.д.), работающими через одни и те же аплинки.
- Используемые сервисы хранения данных: выделение пары портов для хранения (например, vSAN) почти всегда даёт наилучшие результаты — это давно устоявшаяся практика, независимо от хранилища.
- Требования безопасности и изоляции: в некоторых средах может потребоваться, чтобы аплинки, используемые для хранения или других задач, были изолированы от остального трафика.
- Количество портов на ToR-коммутаторах: количество аплинков может быть ограничено самими коммутаторами ToR. Пример: пара ToR-коммутаторов с 2?32 портами даст 64 порта на стойку. Если в стойке размещено максимум 16 хостов по 2U, каждый хост может получить максимум 4 uplink-порта. А если коммутаторы имеют по 48 портов, то на 16 хостов можно выделить по 6 uplink-портов на каждый хост. Меньшее количество хостов в стойке также позволяет увеличить количество портов на один хост.
Рекомендация:
Даже если вы не используете все аплинки на хосте, рекомендуется собирать vSAN ReadyNode с двумя NIC, каждая из которых имеет по 4 uplink-порта. Это позволит без проблем выделить отдельную команду (team) портов только под vSAN, что настоятельно рекомендуется. Такой подход обеспечит гораздо большую гибкость как сейчас, так и в будущем, по сравнению с конфигурацией 2 NIC по 2 порта.
Итог
Выбор оптимального варианта объединения (teaming) и скорости сетевых соединений для ваших хостов vSAN — это важный шаг к тому, чтобы обеспечить максимальную производительность ваших рабочих нагрузок.
Таги: VMware, vSAN, Networking, Performance, vNetwork, Enterprise, Hardware
Object First: новое слово в хранении резервных копий для Veeam Backup (от основателя Veeam)
Object First — это компания, основанная Ратмиром Тимашевым, одним из легендарных сооснователей Veeam Software. После того как Veeam был продан инвестиционной компании Insight Partners за $5 млрд в 2020 году, Тимашев отошел от операционного управления компанией, но остался в ИТ-индустрии. Его новым проектом стала Object First, цель которой — предложить максимально простое, защищенное и производительное решение для хранения резервных копий, оптимизированное под решения Veeam.
Цели и философия Object First
Object First была создана с четким пониманием болевых точек ИТ-отделов: сложность настройки хранилищ, высокая стоимость масштабируемых решений и растущие угрозы кибератак, в том числе программ-вымогателей. Команда Object First стремится решить эти проблемы с помощью подхода "Secure by Design" и глубокой интеграции с Veeam Backup and Replication.

Что такое Ootbi?
Флагманский продукт Object First называется Ootbi ("Out-of-the-box immutability") — это on-premise объектное хранилище, специально созданное для Veeam. Основные технические особенности Ootbi:
- Готовность к работе "из коробки": решение поставляется в виде готового устройства, не требующего глубокой предварительной настройки.
- Поддержка объектного хранилища S3: Ootbi работает по протоколу S3 и полностью совместим с Veeam Backup & Replication.
- Неизменяемость данных (immutability): встроенная защита от программ-вымогателей (Ransomware). Используются политики WORM (Write Once, Read Many), гарантирующие, что резервные копии не могут быть удалены или изменены в течение заданного периода (даже с административными привилегиями).
- Интеграция с Veeam через Scale-Out Backup Repository (SOBR): Ootbi можно использовать как capacity tier, обеспечивая гибкое и масштабируемое резервное копирование.
- Безопасность и упрощенное администрирование: не требуется root-доступ или отдельные операционные системы. Решение изолировано и минимизирует человеческий фактор.
Аппаратная архитектура
На данный момент Ootbi представляет собой масштабируемую кластерную систему из 2-4 узлов:
- Каждый узел содержит вычислительные ресурсы и локальное хранилище (HDD и SSD для кэширования).
- Используется распределённая файловая система, обеспечивающая отказоустойчивость и высокую доступность.
- Производительность: до 4 ГБ/сек совокупной пропускной способности, до 1 ПБ эффективного объема хранения с учетом дедупликации и компрессии на стороне Veeam.
Преимущества для клиентов
- Минимизация риска потери данных благодаря immutability и встроенной защите.
- Снижение TCO (total cost of ownership) за счет простоты управления и отказа от сложных инфраструктур.
- Быстрое развёртывание: установка и настройка возможна за считанные часы.
- Отсутствие необходимости в публичном облаке, что важно для компаний с повышенными требованиями к безопасности и локализации данных.
Object First предлагает уникальное, строго специализированное решение для клиентов Veeam, закрывающее потребности в безопасном и удобном хранении резервных копий. Подход компании отражает философию ее основателя — создавать простые и эффективные продукты, фокусируясь на ключевых болевых точках рынка. Ootbi становится привлекательным выбором для компаний, стремящихся к максимальной защищенности своих данных без лишней сложности и затрат.
Таги: Veeam, Object First, Ootbi, Backup, Storage, Hardware
VMware vSphere 9 уже в списках Broadcom Compatibility Guide
Недавно мы писали о программном доступе к спискам совместимости Broadcom Compatibility Guide (BCG), а на днях стало известно, что ключевой компонент платформы VMware Cloud Foundation 9 - платформа VMware vSphere 9 - уже присутствует в BCG, так что можно проверять свои серверы и хранилища на предмет совместимости с VMware ESXi 9.0 и VMware vSAN 9.0:

Кстати в списках совместимости с vVols не указан VMware ESXi 9, так как эта технология будет признана deprecated в следующей версии платформы (и окончательно перестанет поддерживаться в vSphere 9.1).
Имейте в виду, что список совместимости еще может поменяться к моменту финального релиза VMware vSphere 9, но ориентироваться на это для планирования закупок можно уже сейчас.
Таги: VMware, vSphere, Hardware, Upgrade
Программный доступ к Broadcom Compatibility Guide (BCG) / VMware Compatibility Guide
Broadcom Compatibility Guide (ранее VMware Compatibility Guide) — это ресурс, где пользователи могут проверить совместимость оборудования (нового или уже используемого) с программным обеспечением VMware. Вильям Лам написал интересную статью о доступе к BCG через программный интерфейс VMware PowerCLI.

Существует несколько различных руководств по совместимости, которые можно использовать для поиска информации, начиная от процессоров и серверов и заканчивая разнообразными устройствами ввода-вывода, такими как ускорители и видеокарты. Если у вас небольшое количество оборудования, поиск будет достаточно простым. Однако, если необходимо проверить разнообразное оборудование, веб-интерфейс может оказаться не самым быстрым и удобным вариантом.
Хорошая новость в том, что Broadcom Compatibility Guide (BCG) может легко использоваться программно, в отличие от предыдущего VMware Compatibility Guide (VCG), у которого была другая система бэкенда.
Хотя официального API с документацией, поддержкой и обратной совместимостью для BCG нет, пользователи могут взаимодействовать с BCG, используя тот же API, который применяется веб-интерфейсом BCG.
Чтобы продемонстрировать работу с API BCG, Вильям взял в качестве примера руководство по совместимости устройств ввода-вывода и SSD-накопителей vSAN. Он создал PowerShell-скрипт broadcom-compatibility-guide-api.ps1, который содержит следующие функции:
- Check-BroadcomCompatIoDevice
- Check-BroadcomCompatVsanSsdDevice
Обе функции предполагают поиск на основе комбинации идентификаторов поставщика (Vendor ID, VID), идентификатора устройства (Device ID, DID) и идентификатора поставщика подсистемы (SubSystem Vendor ID, SVID).
Примечание: BCG предоставляет разнообразные возможности поиска и фильтрации; ниже приведены лишь примеры одного из способов работы с API BCG. Если вам интересны другие методы поиска, ознакомьтесь со справочной информацией в конце документа, где описаны иные опции фильтрации и руководства по совместимости BCG.
Шаг 1 – Загрузите скрипт queryHostPCIInfo.ps1 (который Вильям также обновил, чтобы можно было легко исключить неприменимые устройства с помощью строк исключений), и запишите идентификаторы устройств (VID, DID, SVID), которые вы хотите проверить.

Шаг 2 – Скачайте файл broadcom-compatibility-guide-api.ps1 и подключите его, чтобы получить доступ к двум функциям PowerShell:
. ./broadcom-compatibility-guide-api.ps1
Вот пример проверки устройства ввода-вывода с помощью BCG:
Check-BroadcomCompatIoDevice -VID "14e4" -DID "1751" -SVID "14e4"

Вот пример проверки SSD-накопителя vSAN с помощью BCG:
Check-BroadcomCompatVsanSsdDevice -VID "8086" -DID "0b60" -SVID "1028"

По умолчанию функция возвращает четыре последние поддерживаемые версии ESXi, однако вы можете изменить это, указав параметр ShowNumberOfSupportedReleases:
Check-BroadcomCompatIoDevice -VID "14e4" -DID "1751" -SVID "14e4" -ShowNumberOfSupportedReleases 2

При проверке SSD-накопителей vSAN через BCG вы также можете указать конкретный поддерживаемый уровень vSAN (Hybrid Cache, All-Flash Cache, All-Flash Capacity или ESA), используя следующие параметры:
- -ShowHybridCacheTier
- -ShowAFCacheTier
- -ShowAFCapacityTier
- -ShowESATier
Check-BroadcomCompatVsanSsdDevice -VID "8086" -DID "0b60" -SVID "1028" -ShowNumberOfSupportedReleases 2 -ShowESATier

Check-BroadcomCompatVsanSsdDevice -VID "8086" -DID "0b60" -SVID "1028" -ShowNumberOfSupportedReleases 2 -ShowAFCacheTier -ShowESATier

Если вы хотите автоматизировать работу с другими руководствами по совместимости в рамках BCG, вы можете определить формат запроса (payload), используя режим разработчика в браузере. Например, в браузере Chrome, перед выполнением поиска в конкретном руководстве по совместимости, нажмите на три точки в правом верхнем углу браузера и выберите "More Tools->Developer Tools", после чего откроется консоль разработчика Chrome. Далее вы можете использовать скриншот, чтобы разобраться, как выглядит JSON-запрос для вызова API "viewResults".

Таги: VMware, Broadcom, Hardware, PowerCLI, Blogs
Производительность виртуализованных нагрузок на платформе VMware Cloud Foundation для целей генеративного AI
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
- SuperMicro SuperServer SYS-821GE-TNRT с 8 виртуализированными NVIDIA SXM H100 80GB GPU
- Dell PowerEdge XE9680 с 8 виртуализированными NVIDIA SXM H100 80GB GPU
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:

Конфигурация оборудования Dell PowerEdge XE9680:

Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:

В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:

Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.

Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.
Таги: VMware, AI, ML, Performance, NVIDIA, Private AI, Hardware
Тесты VMmark демонстрируют масштабируемость процессоров Intel Xeon 6 на платформе VMware vSphere 8.
Тесты VMmark демонстрируют масштабируемость процессоров Intel Xeon 6 на платформе VMware vSphere 8.
Intel недавно представила новое поколение серверных процессоров — Intel Xeon 6 с производительными ядрами (Performance-cores), которые отличаются увеличенным числом ядер и более высокой пропускной способностью памяти. Чтобы продемонстрировать производительность и масштабируемость этих процессоров, VMware опубликовала новые результаты тестов VMmark 4, полученных при участии двух ключевых партнёров — Dell Technologies и Hewlett Packard Enterprise. Конфигурация Dell представляет собой пару узлов в режиме «Matched Pair», а результат HPE получен на четырёхузловом кластере VMware vSAN. Оба результата основаны на VMware ESXi 8.0 Update 3e — первой версии, поддерживающей эти процессоры. Новые данные уже доступны на странице результатов VMmark 4.
Сравнение производительности: «Granite Rapids» и «Emerald Rapids»
В качестве примера, иллюстрирующего высокую производительность и масштабируемость, ниже приводится таблица с двумя результатами VMmark 4, позволяющая сравнить процессоры предыдущего поколения “Emerald Rapids” с новыми “Granite Rapids” серии 6700.
| Сервер и модель
| Модель процессора |
Версия VMware ESXi |
Всего хостов |
Всего сокетов |
Всего ядер |
Результат VMmark 4 |
| Dell PowerEdge R760 |
Intel Xeon Platinum 8592+ |
8.0 Update 3 |
2 |
4 |
256 |
2.50 @ 3 tiles |
| Dell PowerEdge R770 |
Intel Xeon 6787P |
8.0 Update 3e |
2 |
4 |
344 |
3.34 @ 4.2 tiles |
Диаграмма ниже показывает увеличение общего количества ядер на 34% между поколениями процессоров:

Что касается производительности по тесту VMmark, результат также увеличивается ровно на 34%:

Основные моменты:
- Количество ядер: на 34% больше ядер у Intel Xeon 6787P по сравнению с процессором предыдущего поколения Intel Xeon Platinum 8592+.
- Результат VMmark: на 34% выше по сравнению с предыдущим поколением.
- Поддерживаемая нагрузка: на 35% больше виртуальных машин с рабочей нагрузкой (89 против 66).
Узнать больше о процессорах Intel Xeon 6 с производительными ядрами (P-Cores) можно здесь.
Таги: VMware, Intel, Performance, CPU, Hardware, VMmark
VMware vSphere 8.0 Virtual Topology - Performance Study
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
-
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.

-
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
-
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
-
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
Таги: VMware, vSphere, Performance, VMachines, ESXi, CPU, Hardware, Whitepaper
Новый документ: VMware Private AI Foundation with NVIDIA on HGX Servers
Сегодня искусственный интеллект преобразует бизнес во всех отраслях, однако компании сталкиваются с проблемами, связанными со стоимостью, безопасностью данных и масштабируемостью при запуске задач инференса (производительной нагрузки) в публичных облаках. VMware и NVIDIA предлагают альтернативу — платформу VMware Private AI Foundation with NVIDIA, предназначенную для эффективного и безопасного размещения AI-инфраструктуры непосредственно в частном датацентре. В документе "VMware Private AI Foundation with NVIDIA on HGX Servers" подробно рассматривается работа технологии Private AI на серверном оборудовании HGX.

Зачем бизнесу нужна частная инфраструктура AI?
1. Оптимизация использования GPU
На практике графические ускорители (GPU), размещенные в собственных датацентрах, часто используются неэффективно. Они могут простаивать из-за неправильного распределения или чрезмерного резервирования. Платформа VMware Private AI Foundation решает эту проблему, позволяя динамически распределять ресурсы GPU. Это обеспечивает максимальную загрузку графических процессоров и существенное повышение общей эффективности инфраструктуры.
2. Гибкость и удобство для специалистов по AI
Современные сценарии работы с AI требуют высокой скорости и гибкости в работе специалистов по данным. Платформа VMware обеспечивает привычный облачный опыт работы, позволяя командам специалистов быстро разворачивать AI-среды, при этом сохраняя полный контроль инфраструктуры у ИТ-команд.
3. Конфиденциальность и контроль за данными
Публичные облака вызывают беспокойство в вопросах приватности, особенно когда AI-модели обрабатывают конфиденциальные данные. Решение VMware Private AI Foundation гарантирует полную конфиденциальность, соответствие нормативным требованиям и контроль доступа к проприетарным моделям и наборам данных.
4. Знакомый интерфейс управления VMware
Внедрение нового программного обеспечения обычно требует значительных усилий на изучение и адаптацию. Платформа VMware использует уже знакомые инструменты администрирования (vSphere, vCenter, NSX и другие), что существенно сокращает время и затраты на внедрение и эксплуатацию.
Основные компоненты платформы VMware Private AI Foundation с NVIDIA
VMware Cloud Foundation (VCF)
Это интегрированная платформа, объединяющая ключевые продукты VMware:
- vSphere для виртуализации серверов.
- vSAN для виртуализации хранилищ.
- NSX для программного управления сетью.
- Aria Suite (бывшая платформа vRealize) для мониторинга и автоматизации управления инфраструктурой.
NVIDIA AI Enterprise
NVIDIA AI Enterprise является важным элементом платформы и включает:
- Технологию виртуализации GPU (NVIDIA vGPU C-Series) для совместного использования GPU несколькими виртуальными машинами.
- NIM (NVIDIA Infrastructure Manager) для простого управления инфраструктурой GPU.
- NeMo Retriever и AI Blueprints для быстрого развёртывания и масштабирования моделей AI и генеративного AI.
NVIDIA HGX Servers
Серверы HGX специально разработаны NVIDIA для интенсивных задач AI и инференса. Каждый сервер оснащён 8 ускорителями NVIDIA H100 или H200, которые взаимосвязаны через высокоскоростные интерфейсы NVSwitch и NVLink, обеспечивающие высокую пропускную способность и минимальные задержки.
Высокоскоростная сеть
Сетевое взаимодействие в кластере обеспечивается Ethernet-коммутаторами NVIDIA Spectrum-X, которые предлагают скорость передачи данных до 100 GbE, обеспечивая необходимую производительность для требовательных к данным задач AI.
Референсная архитектура для задач инференса
Референсная архитектура предлагает точные рекомендации по конфигурации аппаратного и программного обеспечения:
Физическая архитектура
- Серверы инференса: от 4 до 16 серверов NVIDIA HGX с GPU H100/H200.
- Сетевая инфраструктура: 100 GbE для рабочих нагрузок инференса, 25 GbE для управления и хранения данных.
- Управляющие серверы: 4 узла, совместимые с VMware vSAN, для запуска сервисов VMware.
Виртуальная архитектура
- Домен управления: vCenter, SDDC Manager, NSX, Aria Suite для управления облачной инфраструктурой.
- Домен рабочих нагрузок: виртуальные машины с GPU и Supervisor Clusters для запуска Kubernetes-кластеров и виртуальных машин с глубоким обучением (DLVM).
- Векторные базы данных: PostgreSQL с расширением pgVector для поддержки Retrieval-Augmented Generation (RAG) в генеративном AI.
Производительность и валидация
VMware и NVIDIA протестировали платформу с помощью набора тестов GenAI-Perf, сравнив производительность виртуализированных и bare-metal сред. Решение VMware Private AI Foundation продемонстрировало высокую пропускную способность и низкую задержку, соответствующие или превосходящие показатели не виртуализированных решений.
Почему компании выбирают VMware Private AI Foundation с NVIDIA?
- Эффективное использование GPU: максимизация загрузки GPU, что экономит ресурсы.
- Высокий уровень безопасности и защиты данных: конфиденциальность данных и контроль над AI-моделями.
- Операционная эффективность: использование привычных инструментов VMware сокращает затраты на внедрение и управление.
- Масштабируемость и перспективность: возможность роста и адаптации к новым задачам в области AI.
Итоговые выводы
Платформа VMware Private AI Foundation с NVIDIA является комплексным решением для компаний, стремящихся эффективно и безопасно реализовывать задачи искусственного интеллекта в частных дата-центрах. Она обеспечивает высокую производительность, гибкость и конфиденциальность данных, являясь оптимальным решением для организаций, которым критично важно сохранять контроль над AI-инфраструктурой, не жертвуя при этом удобством и масштабируемостью.
Таги: VMware, Private AI, NVIDIA, Update, Hardware, AI, LLM, Whitepaper
Создание виртуальной тестовой лаборатории VMware Cloud Foundation (VCF) на одном сервере
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Таги: VMware, VCF, Hardware, Labs, ESXi, vCenter, vSphere, SDDC, NSX
Минимальные требования к узлам VMware vSAN для профилей конфигурации AF-0/2/4/6/8 ReadyNode и других
Недавно Дункану Эппингу задали вопрос о том, сколько памяти должна иметь конфигурация AF-4 ReadyNode, чтобы она поддерживалась. Понтяно, откуда возник этот вопрос, но большинство людей не осознают, что существует набор минимальных требований, а профили ReadyNode, как указано в базе знаний (KB), являются лишь рекомендациями. Перечисленные конфигурации – это ориентир. Эти рекомендации основаны на предполагаемом потреблении ресурсов для определенного набора виртуальных машин. Конечно, для вашей нагрузки требования могут быть совершенно другими. Именно поэтому в статье, описывающей аппаратные рекомендации, теперь четко указано следующее:

Чтобы конфигурация поддерживалась службой глобальной поддержки VMware Global Services (GS), все сертифицированные для vSAN ESA ReadyNode должны соответствовать или превышать ресурсы самой минимальной конфигурации (vSAN-ESA-AF-0 для vSAN HCI или vSAN-Max-XS для vSAN Max).
Это относится не только к объему памяти, но и к другим компонентам, при условии соблюдения минимальных требований, перечисленных в таблице ниже (учтите, что это требования для архитектуры ESA, для OSA они другие):

Таги: VMware, vSAN, ReadyNode, Hardware
Проверка типа микрокода (firmware) для хостов ESXi на платформе VMware vSphere
Один из клиентов VMware недавно обратился к Вильяму Ламу с вопросом о том, как можно легко провести аудит всей своей инфраструктуры серверов VMware ESXi, чтобы определить, какие хосты всё ещё загружаются с использованием устаревшей прошивки BIOS, которая будет удалена в будущих выпусках vSphere и заменена на стандартную для индустрии прошивку типа UEFI.
В vSphere 8.0 Update 2 было введено новое свойство API vSphere под названием firmwareType, которое было добавлено в объект информации о BIOS оборудования ESXi, что значительно упрощает получение этой информации с помощью следующей однострочной команды PowerCLI:
(Get-VMHost).ExtensionData.Hardware.BiosInfo
Пример ее вывода для сервера ESXi при использовании UEFI выглядит вот так:

Если же используется устаревший BIOS, то вот так:

Поскольку это свойство vSphere API было недавно введено в vSphere 8.0 Update 2, если вы попытаетесь использовать его на хосте ESXi до версии 8.0 Update 2, то это поле будет пустым, если вы используете более новую версию PowerCLI, которая распознаёт это свойство. Или же оно просто не отобразится, если вы используете более старую версию PowerCLI.

В качестве альтернативы, если вам всё же необходимо получить эту информацию, вы можете подключиться напрямую к хосту ESXi через SSH. Это не самый удобный вариант, но вы можете использовать следующую команду VSISH для получения этих данных:
vsish -e get /hardware/firmwareType
Таги: VMware, ESXi, Hardware, Blogs
|
|  |
|

 RSS
RSS

















