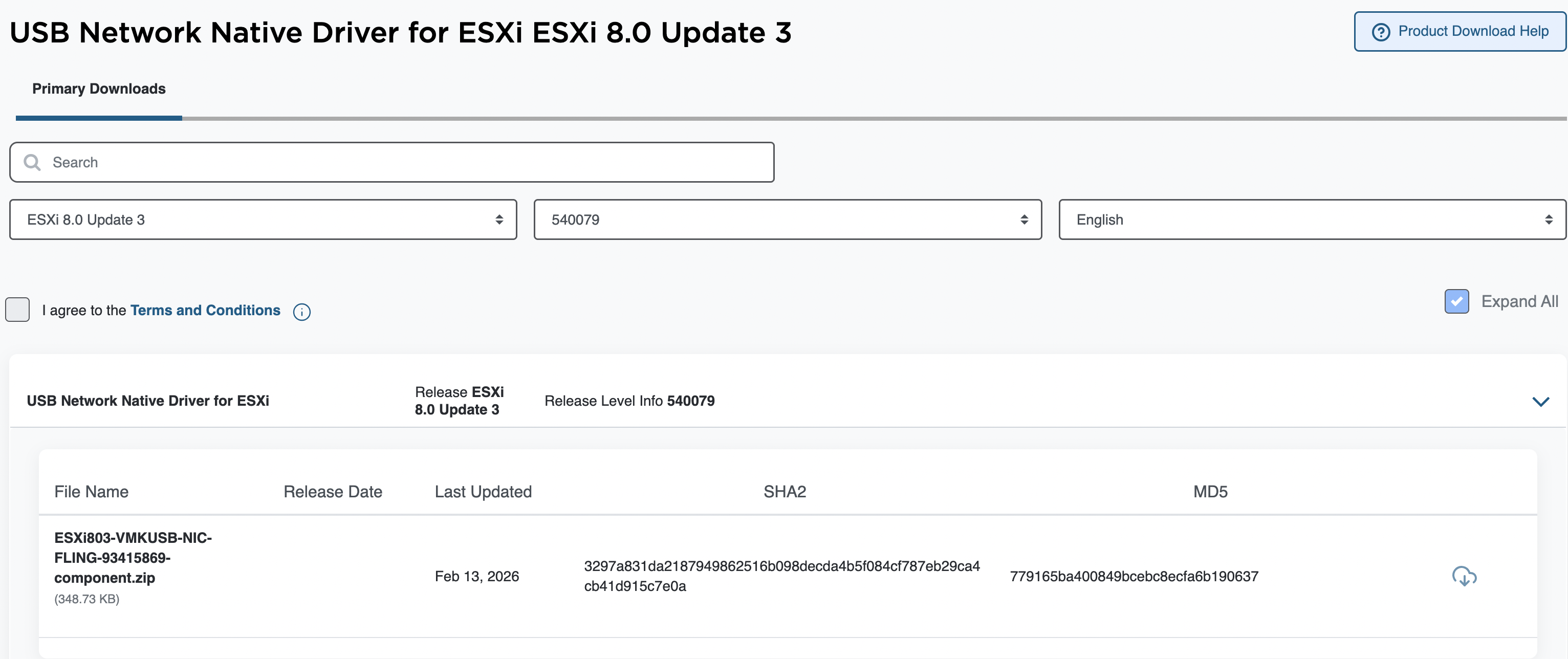
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
В последнее время в индустрии виртуализации наблюдалась тревожная тенденция — крупнейшие игроки начали отказываться от бесплатных версий своих гипервизоров. После покупки VMware компанией Broadcom одной из первых резонансных новостей стало прекращение распространения бесплатного гипервизора VMware ESXi (ранее известного как vSphere Hypervisor). Это решение вызвало волну недовольства в сообществе, особенно среди ИТ-специалистов и малых компаний, использующих ESXi в тестовых или домашних лабораториях.
Ранее: Broadcom, завершив поглощение VMware, прекратила предоставление бесплатной версии vSphere Hypervisor. Это вызвало резкую критику и обеспокоенность среди пользователей, привыкших использовать ESXi в учебных, тестовых или малобюджетных инфраструктурах.
Теперь: В составе релиза ESXi 8.0 Update 3e появилась entry-level редакция гипервизора, которая предоставляется бесплатно, как указано в разделе "What's New" официальной документации Broadcom. Хотя точных технических ограничений этой редакции пока не раскрыто в деталях, уже ясно, что она рассчитана на начальный уровень использования и доступна без подписки.
Почему это важно?
Возвращение бесплатной версии гипервизора от Broadcom означает, что:
Независимые администраторы и энтузиасты снова могут использовать ESXi в личных или образовательных целях.
Организации с ограниченным бюджетом могут рассматривать VMware как вариант для пилотных проектов.
Broadcom, вероятно, отреагировала на давление сообщества и рынка.
Новые возможности VMware 8.0 Update 3e:
1. Поддержка протокола CDC-NCM (Communication Device Class Network Control Model) в USB-драйвере ESXi
Начиная с версии ESXi 8.0 Update 3e, USB-драйвер ESXi поддерживает протокол CDC-NCM для обеспечения совместимости с виртуальным сетевым адаптером HPE Gen12 iLO (iLO Virtual NIC) и взаимодействия с такими инструментами, как HPE Agentless Management (AMS), Integrated Smart Update Tools (iSUT), iLORest (инструмент настройки), Intelligent Provisioning, а также DPU.
2. ESXi 8.0 Update 3e добавляет поддержку технологии vSphere Quick Boot для следующих драйверов:
Intel vRAN Baseband Driver
Intel Platform Monitoring Technology Driver
Intel Data Center Graphics Driver
Драйвер серии AMD Instinct MI
Вывод
Хотя отказ от бесплатной версии ESXi вызвал разочарование и обеспокоенность, возвращение entry-level редакции в составе ESXi 8.0 Update 3e — это шаг в сторону компромисса. Broadcom, похоже, услышала голос сообщества и нашла способ вернуть гипервизор в открытый доступ, пусть и с оговорками. Теперь остаётся дождаться подробностей о лицензировании и технических возможностях этой редакции.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
В индустрии виртуализации в последние годы наметилась заметная тенденция: крупные вендоры сворачивают бесплатные версии своих гипервизоров. Microsoft прекратила выпуск отдельного бесплатного Hyper-V Server, VMware (после поглощения Broadcom) закрыла свободный доступ к ESXi Free (vSphere Hypervisor), а Red Hat объявила о завершении поддержки платформы Red Hat Virtualization (RHV) к 2026 году. Ниже приводится детальный обзор этих новостей...
Таги: VMware, Microsoft, Red Hat, ESXi, Hyper-V, KVM
Компания Broadcom сообщает, что с 24 марта 2025 года произойдёт важное изменение в процессе загрузки бинарных файлов ПО VMware (включая обновления и исправления) для продуктов VMware Cloud Foundation (VCF), vCenter, ESXi и служб vSAN. Это обновление упростит доступ и приведёт его в соответствие с текущими передовыми практиками отрасли.
Ниже представлена вся необходимая информация о грядущих изменениях и их влиянии на вас.
Что именно изменится?
С 24 марта 2025 года текущий процесс загрузки бинарных файлов будет заменён новым методом. Данное изменение предполагает:
Централизация на едином ресурсе: бинарные файлы программного обеспечения будут доступны для загрузки с единого сайта, а не с нескольких различных ресурсов, как ранее. Это будет доступно как для онлайн-сред, так и для изолированных («air-gapped») систем.
Проверка загрузок: загрузка будет авторизована с помощью уникального токена. Новые URL-адреса будут содержать этот токен, подтверждающий, что именно вы являетесь авторизованным пользователем или стороной, осуществляющей загрузку файла.
Примечание: текущие URL-адреса для загрузки будут доступны в течение одного месяца для облегчения переходного периода. С 24 апреля 2025 года текущие URL-адреса перестанут действовать.
Что это значит для вас?
Вам необходимо выполнить следующие действия:
Получите токен загрузки: войдите на сайт support.broadcom.com, чтобы получить уникальный токен.
Изучите техническую документацию: ознакомьтесь с KB-статьями, в которых изложены требования и пошаговые инструкции.
Обновите URL-адреса в продуктах: Broadcom предоставит скрипт, который автоматизирует замену текущих URL-адресов в продуктах ESXi, vCenter и SDDC Manager.
Обновите скрипты автоматизации (если применимо): Если у вас есть собственные скрипты, обновите URL-адреса согласно рекомендациям из KB-статей.
Где получить дополнительную информацию?
Рекомендуемые материалы для успешного перехода на новую систему:
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Иногда у администратора VMware vSphere возникает необходимость отключить физический интерфейс на хосте VMware ESXi, чтобы сделать некоторые операции или протестировать различные сценарии.
Например:
Тестирование сценариев отказоустойчивости сети.
Определение и изоляция сетевых проблем за счет отключения подозрительного неисправного сетевого адаптера (NIC).
Временное отключение сетевого адаптера (NIC), чтобы оценить влияние на производительность сети и проверить эффективность балансировки нагрузки.
Проверка того, как виртуальные машины реагируют на отказ определенного сетевого пути.
Отключение vmnic, который подключен к ненадежному VLAN или неправильно настроенной сети.
Тестирование различных сетевых конфигураций без внесения постоянных изменений в физические соединения.
Итак, чтобы отключить vmnic, нужно зайти на ESXi по SSH и выполнить там следующую команду, чтобы вывести список сетевых адаптеров:
esxcli network nic list
Далее отключаем vmnic командой (X - это номер в имени адаптера):
esxcli network nic down -n vmnicX
В разделе физических адаптеров vSphere Client мы увидим следующую картину (адаптер в статусе "down"):
Чтобы вернуть vmnic в исходное состояние, просто выполняем команду:
Один из клиентов VMware недавно обратился к Вильяму Ламу с вопросом о том, как можно легко провести аудит всей своей инфраструктуры серверов VMware ESXi, чтобы определить, какие хосты всё ещё загружаются с использованием устаревшей прошивки BIOS, которая будет удалена в будущих выпусках vSphere и заменена на стандартную для индустрии прошивку типа UEFI.
В vSphere 8.0 Update 2 было введено новое свойство API vSphere под названием firmwareType, которое было добавлено в объект информации о BIOS оборудования ESXi, что значительно упрощает получение этой информации с помощью следующей однострочной команды PowerCLI:
(Get-VMHost).ExtensionData.Hardware.BiosInfo
Пример ее вывода для сервера ESXi при использовании UEFI выглядит вот так:
Если же используется устаревший BIOS, то вот так:
Поскольку это свойство vSphere API было недавно введено в vSphere 8.0 Update 2, если вы попытаетесь использовать его на хосте ESXi до версии 8.0 Update 2, то это поле будет пустым, если вы используете более новую версию PowerCLI, которая распознаёт это свойство. Или же оно просто не отобразится, если вы используете более старую версию PowerCLI.
В качестве альтернативы, если вам всё же необходимо получить эту информацию, вы можете подключиться напрямую к хосту ESXi через SSH. Это не самый удобный вариант, но вы можете использовать следующую команду VSISH для получения этих данных:
Некоторое время назад Вильям Лам поделился решением, позволяющим установить VIB-пакет в сборке для Nested ESXi при использовании vSAN Express Storage Architecture (ESA) и VMware Cloud Foundation (VCF), чтобы обойти предварительную проверку на соответствие списку совместимого оборудования vSAN ESA (HCL) для дисков vSAN ESA.
Хотя в большинстве случаев Вильям использует Nested ESXi для тестирования, недавно он развернул физическую среду VCF. Из-за ограниченного количества NVMe-устройств он хотел использовать vSAN ESA для домена управления VCF, но, конечно же, столкнулся с той же проверкой сертифицированных дисков vSAN ESA, которая не позволяла установщику продолжить процесс.
Вильям надеялся, что сможет использовать метод эмуляции для физического развертывания. Однако после нескольких попыток и ошибок он столкнулся с нестабильным поведением. Пообщавшись с инженерами, он выяснил, что существующее решение также применимо к физическому развертыванию ESXi, поскольку аппаратные контроллеры хранилища скрываются методом эмуляции. Если в системе есть NVMe-устройства, совместимые с vSAN ESA, предварительная проверка vSAN ESA HCL должна пройти успешно, что позволит продолжить установку.
Вильям быстро переустановил последнюю версию ESXi 8.0 Update 3b на одном из своих физических серверов, установил vSAN ESA Hardware Mock VIB и, используя последнюю версию VCF 5.2.1 Cloud Builder, успешно прошел предварительную проверку vSAN ESA, после чего развертывание началось без проблем!
Отлично, что теперь это решение работает как для физических, так и для вложенных (nested) ESXi при использовании с VCF, особенно для создания демонстрационных сред (Proof-of-Concept)!
Примечание: В интерфейсе Cloud Builder по-прежнему выполняется предварительная проверка физических сетевых адаптеров, чтобы убедиться, что они поддерживают 10GbE или более. Таким образом, хотя проверка совместимости vSAN ESA HCL пройдет успешно, установка все же завершится с ошибкой при использовании UI.
Обходной путь — развернуть домен управления VCF с помощью Cloud Builder API, где проверка на 10GbE будет отображаться как предупреждение, а не как критическая ошибка, что позволит продолжить развертывание. Вы можете использовать этот короткий PowerShell-скрипт для вызова Cloud Builder API, а затем отслеживать процесс развертывания через UI Cloud Builder.
$cloudBuilderIP = "192.168.30.190"
$cloudBuilderUser = "admin"
$cloudBuilderPass = "VMware123!"
$mgmtDomainJson = "vcf50-management-domain-example.json"
#### DO NOT EDIT BEYOND HERE ####
$inputJson = Get-Content -Raw $mgmtDomainJson
$pwd = ConvertTo-SecureString $cloudBuilderPass -AsPlainText -Force
$cred = New-Object Management.Automation.PSCredential ($cloudBuilderUser,$pwd)
$bringupAPIParms = @{
Uri = "https://${cloudBuilderIP}/v1/sddcs"
Method = 'POST'
Body = $inputJson
ContentType = 'application/json'
Credential = $cred
}
$bringupAPIReturn = Invoke-RestMethod @bringupAPIParms -SkipCertificateCheck
Write-Host "Open browser to the VMware Cloud Builder UI to monitor deployment progress ..."
Вильям Лам написал очень полезную статью, касающуюся развертывания виртуальных хостов (Nested ESXi) в тестовой лаборатории VMware Cloud Foundation.
Независимо от того, настраиваете ли вы vSAN Express Storage Architecture (ESA) напрямую через vCenter Server или через VMware Cloud Foundation (VCF), оборудование ESXi автоматически проверяется на соответствие списку совместимого оборудования vSAN ESA (HCL), чтобы убедиться, что вы используете поддерживаемое железо для vSAN.
В случае использования vCenter Server вы можете проигнорировать предупреждения HCL, принять риски и продолжить настройку. Однако при использовании облачной инфраструктуры VCF и Cloud Builder операция блокируется, чтобы гарантировать пользователям качественный опыт при выборе vSAN ESA для развертывания управляющего или рабочего домена VCF.
С учетом вышеизложенного, существует обходное решение, при котором вы можете создать свой собственный пользовательский JSON-файл HCL для vSAN ESA на основе имеющегося у вас оборудования, а затем загрузить его в Cloud Builder для настройки нового управляющего домена VCF или в SDDC Manager для развертывания нового рабочего домена VCF. Вильям уже писал об этом в своих блогах здесь и здесь.
Использование Nested ESXi (вложенного ESXi) является популярным способом развертывания VCF, особенно если вы новичок в этом решении. Этот подход позволяет легко экспериментировать и изучать платформу. В последнее время Вильям заметил рост интереса к развертыванию VCF с использованием vSAN ESA. Хотя вы можете создать пользовательский JSON-файл HCL для vSAN ESA, как упоминалось ранее, этот процесс требует определенных усилий, а в некоторых случаях HCL для vSAN ESA может быть перезаписан, что приводит к затруднениям при решении проблем.
После того как Вильям помогал нескольким людям устранять проблемы в их средах VCF, он начал задумываться о лучшем подходе и использовании другой техники, которая, возможно, малоизвестна широкой аудитории. Вложенный ESXi также широко используется для внутренних разработок VMware и функционального тестирования. При развертывании vSAN ESA инженеры сталкиваются с такими же предупреждениями HCL, как и пользователи. Одним из способов обхода этой проблемы является "эмуляция" оборудования таким образом, чтобы проверка работоспособности vSAN успешно проходила через HCL для vSAN ESA. Это достигается путем создания файла stress.json, который размещается на каждом Nested ESXi-хосте.
Изначально Вильям не был поклонником этого варианта, так как требовалось создавать файл на каждом хосте. Кроме того, файл не сохраняется после перезагрузки, что добавляло сложности. Хотя можно было бы написать сценарий автозагрузки, нужно было помнить о его добавлении на каждый новый хост.
После анализа обоих обходных решений он обнаружил, что вариант с использованием stress.json имеет свои плюсы: он требует меньше модификаций продукта, а возня с конфигурационными файлами — не самый лучший способ, если можно этого избежать. Учитывая ситуации, с которыми сталкивались пользователи при работе с новыми версиями, он нашел простое решение — создать пользовательский ESXi VIB/Offline Bundle. Это позволяет пользователям просто установить stress.json в правильный путь для их виртуальной машины Nested ESXi, решая вопросы сохранения данных, масштабируемости и удобства использования.
Перейдите в репозиторий Nested vSAN ESA Mock Hardware для загрузки ESXi VIB или ESXi Offline Bundle. После установки (необходимо изменить уровень принятия программного обеспечения на CommunitySupported) просто перезапустите службу управления vSAN, выполнив следующую команду:
/etc/init.d/vsanmgmtd restart
Или вы можете просто интегрировать этот VIB в новый профиль образа/ISO ESXi с помощью vSphere Lifecycle Manager, чтобы VIB всегда был частью вашего окружения для образов ESXi. После того как на хосте ESXi будет содержаться файл stress.json, никаких дополнительных изменений в настройках vCenter Server или VCF не требуется, что является огромным преимуществом.
Примечание: Вильям думал о том, чтобы интегрировать это в виртуальную машину Nested ESXi Virtual Appliance, но из-за необходимости изменения уровня принятия программного обеспечения на CommunitySupported, он решил не вносить это изменение на глобальном уровне. Вместо этого он оставил все как есть, чтобы пользователи, которым требуется использование vSAN ESA, могли просто установить VIB/Offline Bundle как отдельный компонент.
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
В прошлом году Вильям Лам продемонстрировал метод настройки строки железа SMBIOS с использованием Nested ESXi, но решение было далеко от идеала: оно требовало модификации ROM-файла виртуальной машины и ограничивалось использованием BIOS-прошивки для машины Nested ESXi, в то время как поведение с EFI-прошивкой отличалось.
В конце прошлого года Вильям проводил исследования и наткнулся на гораздо более изящное решение, которое работает как для физического, так и для виртуального ESXi. Существует параметр ядра ESXi, который можно переключить, чтобы просто игнорировать стандартный SMBIOS оборудования, а затем эмулировать собственную пользовательскую информацию SMBIOS.
Шаг 1 – Подключитесь по SSH к вашему ESXi-хосту, отредактируйте файл конфигурации /bootbank/boot.cfg и добавьте ignoreHwSMBIOSInfo=TRUE в строку kernelopt, после чего перезагрузите систему.
Шаг 2 – Далее нам нужно выполнить команду vsish, чтобы настроить желаемую информацию SMBIOS. Однако, вместо того чтобы заставлять пользователей вручную создавать команду, Вильям создал простую функцию PowerShell, которая сделает процесс более удобным.
Сохраните или выполните приведенный ниже фрагмент PowerShell-кода, который определяет новую функцию Generate-CustomESXiSMBIOS. Эта функция принимает следующие шесть аргументов:
Uuid – UUID, который будет использоваться в симулированной информации SMBIOS.
Вам потребуется перезапустить службу hostd, чтобы информация стала доступной. Для этого выполните команду:
/etc/init.d/hostd restart
Если вы теперь войдете в ESXi Host Client, vCenter Server или vSphere API (включая PowerCLI), то обнаружите, что производитель оборудования, модель, серийный номер и UUID отображают заданные вами пользовательские значения, а не данные реального физического оборудования!
Пользовательский SMBIOS не сохраняется после перезагрузки, поэтому вам потребуется повторно запускать команду каждый раз после перезагрузки вашего хоста ESXi.
Недавно мы писали о том, что команда ESXi-Arm выпустила новую версию популярной платформы виртуализации ESXi-Arm Fling (v2.0) (ссылка на скачивание тут), которая теперь основана на базе кода ESXi версии 8.x и конкретно использует последний релиз ESXi-x86 8.0 Update 3b.
Вильям Лам рассказал о том, что теперь вы можете запустить экземпляр ESXi-Arm V2 внутри виртуальной машины, что также называется Nested ESXi-Arm. На конференции VMware Explore в США он использовал Nested ESXi-Arm, так как у него есть ноутбук Apple M1, и ему нужно было провести демонстрацию для сессии Tech Deep Dive: Automating VMware ESXi Installation at Scale, посвященной автоматизированной установке ESXi с помощью Kickstart. Поскольку и ESXi-x86, и ESXi-Arm имеют одинаковую реализацию, возможность запуска Nested ESXi-Arm оказалась полезной (хотя он использовал версию, отличающуюся от официального релиза Fling). Такой же подход может быть полезен, если вы хотите запустить несколько виртуальных машин ESXi-Arm для изучения API vSphere и подключить Nested ESXi-Arm к виртуальной машине x86 VCSA (vCenter Server Appliance). Возможно, вы разрабатываете что-то с использованием Ansible или Terraform - это действительно открывает множество вариантов для тех, у кого есть такая потребность.
Arm Hardware
Так же как и при создании Nested ESXi-x86 VM, выберите опцию типа ВМ "Other" (Другое) и затем выберите "VMware ESXi 8.0 or later", настроив как минимум на 2 виртуальных процессора (vCPU) и 8 ГБ оперативной памяти.
Примечание: Текущая версия ESXi-Arm НЕ поддерживает VMware Hardware-Assisted Virtualization (VHV), которая необходима для запуска 64-битных операционных систем в Nested или внутренних виртуальных машинах. Если вы включите эту настройку, запустить Nested ESXi-Arm VM не получится, поэтому убедитесь, что эта настройка процессора отключена (по умолчанию она отключена).
VMware Fusion (M1 и новее)
Еще одна хорошая новость: для пользователей Apple Silicon (M1 и новее) теперь также можно запускать виртуальные машины Nested ESXi-Arm! Просто выберите «Other» (Другое), затем тип машины «Other 64-bit Arm» и настройте ВМ с как минимум 2 виртуальными процессорами (vCPU) и 8 ГБ оперативной памяти. Вильяму как раз потребовалась эта возможность на VMware Explore, когда он демонстрировал вещи, не связанные напрямую с архитектурой Arm. Он попросил команду инженеров предоставить внутреннюю сборку ESXi-Arm, которая могла бы работать на Apple M1, теперь же эта возможность ESXi-Arm доступна для всех.
Примечание: поскольку для работы Nested-ESXi-Arm требуется режим promiscuous mode, при включении виртуальной машины в VMware Fusion вас могут раздражать запросы на ввод пароля администратора. Если вы хотите отключить эти запросы, ознакомьтесь с этой статьей в блоге для получения дополнительной информации.
Вильям Лам сообщает, что команда ESXi-Arm недавно выпустила новую версию популярной платформы виртуализации ESXi-Arm Fling (v2.0) (ссылка на скачивание тут), которая теперь основана на базе кода ESXi версии 8.x и конкретно использует последний релиз ESXi-x86 8.0 Update 3b. Это очень значимое обновление, так как изначальный релиз ESXi-Arm Fling (выпущенный 4 года назад) был основан на ESXi 7.x при начальной адаптации x86-дистрибутива для архитектуры ARM.
После выпуска первого коммерческого продукта ESXi-Arm в составе vSphere Distributed Service Engine (vDSE), ранее известного как Project Monterey, команда ESXi-Arm активно работала над унификацией кодовой базы ESXi-Arm, которая также используется и для работы коммерческой технологии vDSE.
В дополнение к переезду ESXi-Arm с версии 7.x на 8.x, команда продолжает поддерживать широкий спектр систем на базе Arm, которые представлены в списке ниже:
Серверы на базе Ampere Computing Altra и AltraMax (системы с одним процессором, такие как HPE ProLiant RL300 Gen 11, или системы с двумя процессорами, как Ampere 2U Mt. Collins)
Платформа mini-ITX SolidRun HoneyComb LX2K на базе NXP LayerScape 2160A
Raspberry Pi 4B (только с 8 ГБ памяти)
Raspberry Pi 5 (только с 8 ГБ памяти)
PINE64 Quartz64 Model A и вычислительный модуль SOQuartz на базе Rockchip RK3566
Firefly ROC-RK3566-PC и StationPC Station M2 на базе Rockchip RK3566
Для тех, кто обновляется с Fling версии 1.x, потребуется небольшое ручное обновление конфигурационных файлов виртуальных машин. Обязательно прочитайте главу 3 "Upgrading from Fling v1" в документации к ESXi. Чтобы загрузить последнюю версию ESXi-Arm ISO/Offline Bundle вместе с обновленной документацией по ESXi-Arm, используйте вашу бесплатную учетную запись или зарегистрируйтесь на Broadcom Community и посетите портал VMware Flings.
Если вы пропустили новость о том, что вышло обновление платформы VMware vSphere 8 Update 3b, то сейчас самое время подумать об обновлении, так как сообщений о каких-то серьезных багах не поступало.
Итак, что нового в VMware ESXi 8.0 Update 3b:
DPU/SmartNIC - появилась поддержка VMware vSphere Distributed Services Engine с DPU NVIDIA Bluefield-3. Устройства DPU NVIDIA Bluefield-3 поддерживаются как в режиме одиночного DPU, так и в dual-DPU конфигурациях.
ESXi 8.0 Update 3b добавляет поддержку vSphere Quick Boot для нескольких серверов, включая:
Улучшения в проектировании переменных cloud-init guestInfo: начиная с ESXi 8.0 Update 3b, попытка обычных пользователей задать переменные cloud-init guestInfo внутри гостевой ОС приводит к ошибке. Для получения дополнительной информации см. KB 377267.
Что нового в VMware vCenter 8.0 Update 3b:
Этот выпуск устраняет уязвимости CVE-2024-38812 и CVE-2024-38813. Для получения дополнительной информации об этих уязвимостях и их влиянии на продукты VMware посмотрите статью VMSA-2024-0019.
VMware vCenter Server 8.0 Update 3b предоставляет исправления ошибок, описанные в разделе Resolved Issues.
Вильям Лам написал наиполезнейшую статью о сбросе/восстановлении пароля консоли сервера VMware ESXi 8 и 7 в составе платформы виртуализации VMware vSphere.
Ранее также было возможно сбросить пароль root ESXi, загрузив систему в Linux и вручную обновив файл /etc/shadow, что похоже на то, как можно сбросить пароль в системе на базе Linux. В сети можно найти множество статей в блогах, описывающих этот процесс. Однако с появлением ESXi Configuration Store данный метод больше не работает для современных версий ESXi, начиная с ESXi 7.0 Update 1 и выше.
Тем не менее, эта тема все еще часто поднимается, особенно в контексте администраторов, которые начинают работать в новой компании, где пароль root ESXi не был должным образом задокументирован, или когда администратору поручено поддерживать набор отдельных ESXi хостов без владельцев. Независимо от сценария, хотя переустановка является самым быстрым способом восстановления, конечно, было бы неплохо сохранить исходную конфигурацию, особенно если нет документации.
Хотя в сети было опубликовано множество фрагментов информации (здесь, здесь и здесь), включая информацию от самого Вильяма, было бы полезно выяснить по шагам актуальный процесс восстановления ESXi 7.x или 8.x хоста без необходимости его переустановки.
Предварительные требования:
Доступ к физическому носителю, на который установлен ESXi (USB или HDD/SSD)
Виртуальная машина Linux (Ubuntu или Photon OS)
Виртуальная машина с вложенным ESXi
Для демонстрации описанного ниже процесса восстановления Вильям установил ESXi 8.0 Update 3c на USB-устройство с базовой конфигурацией (имя хоста, сеть, SSH MOTD), чтобы убедиться в возможности восстановления системы. Затем он изменил пароль root на что-то полностью случайное и удалил этот пароль, чтобы нельзя было войти в систему. Хост ESXi, на котором он "забыл" пароль, будет называться физическим хостом ESXi, а вложенная виртуальная машина с ESXi, которая будет помогать в восстановлении, будет называться вложенным хостом (Nested ESXi).
Шаг 1 — Разверните вложенную виртуальную машину с ESXi (скачать с сайта VMware Flings), версия которой должна соответствовать версии вашего физического хоста ESXi, который вы хотите восстановить.
Шаг 2 — Скопируйте файл state.tgz с физического хоста ESXi, который вы хотите восстановить. Обязательно сделайте резервную копию на случай, если допустите ошибку.
Если ваш хост ESXi установлен на USB, отключите USB-устройство, подключите его к настольной системе и скопируйте файл с тома BOOTBANK1.
Если ваш хост ESXi установлен на HDD/SSD, вам нужно будет загрузить физическую систему с помощью Linux LiveCD (Ubuntu или Knoppix) и смонтировать раздел 5 для доступа к файлу state.tgz.
Шаг 3 — Скопируйте файл state.tgz с вашего физического хоста ESXi на вложенный хост ESXi и поместите его в /tmp/state.tgz, затем выполните следующую команду для извлечения содержимого файла:
tar -zxvf state.tgz
rm -f state.tgz
Шаг 4 — Войдите на ваш вложенный хост ESXi и выполните следующие команды для извлечения его файла state.tgz, который будет помещен в каталог /tmp/a. Затем мы используем утилиту crypto-util для расшифровки файла local.tgz.ve вложенного хоста ESXi, чтобы получить файл local.tgz, и затем просто удаляем зашифрованный файл вместе с файлом encryption.info вложенного хоста ESXi. После этого мы заменим их файлом encryption.info с нашего физического хоста ESXi и создадим модифицированную версию state.tgz, которая будет загружаться в нашей вложенной виртуальной машине ESXi. Мы используем это для расшифровки исходного файла state.tgz с нашего физического хоста ESXi.
mkdir /tmp/a
cd /tmp/a
tar xzf /bootbank/state.tgz
crypto-util envelope extract --aad ESXConfiguration local.tgz.ve local.tgz
rm -f local.tgz.ve encryption.info
cp /tmp/encryption.info /tmp/a/encryption.info
tar -cvf /tmp/state-mod.tgz encryption.info local.tgz
После успешного выполнения последней команды, нам нужно скопировать файл /tmp/state-mod.tgz на ваш рабочий стол, а затем выключить вложенную виртуальную машину ESXi.
Шаг 5 — Смонтируйте первый VMDK диск из вашей вложенной виртуальной машины ESXi на вашу виртуальную машину с Linux. В данном случае Вильм использует Photon OS, который также управляет и DNS-инфраструктурой.
Шаг 6 — Убедитесь, что VMDK вашей вложенной виртуальной машины ESXi виден в вашей системе Linux, выполнив следующую команду. Мы должны увидеть два раздела bootbank (5 и 6), как показано на скриншоте ниже:
fdisk -l
Шаг 7 — Перенесите файл state-mod.tgz, созданный на Шаге 4, на вашу виртуальную машину с Linux, затем смонтируйте оба раздела bootbank и замените файл state.tgz на нашу модифицированную версию.
Примечание: Этот шаг необходим, потому что, если вы просто скопируете модифицированный файл state.tgz напрямую на USB-устройство физического хоста ESXi, вы обнаружите, что система восстановит оригинальный файл state.tgz, даже если на обоих разделах содержится модифицированная версия.
Шаг 8 — Сделайте remove (не удаляйте) VMDK файл вложенной виртуальной машины ESXi с виртуальной машины Linux, затем включите вложенную виртуальную машину ESXi.
После успешной загрузки вложенной виртуальной машины ESXi, она теперь работает с оригинальным файлом encryption.info с нашего физического хоста ESXi, что позволит нам восстановить исходный файл state.tgz.
Шаг 9 — Скопируйте исходный файл state.tgz, созданный на Шаге 2, во вложенную виртуальную машину ESXi, поместите его в каталог /tmp/state.tgz и выполните следующую команду, которая теперь позволит нам расшифровать файл state.tgz с физического хоста ESXi, как показано на скриншоте ниже!
cd /tmp
tar -zxvf state.tgz
rm -f state.tgz
crypto-util envelope extract --aad ESXConfiguration local.tgz.ve local.tgz
rm -f local.tgz.ve
Шаг 10 — После расшифровки исходного файла state.tgz у нас должен появиться файл local.tgz, который мы извлечем локально в каталоге /tmp, выполнив следующую команду:
tar -zxvf local.tgz
Следующие три каталога: .ssh, etc/ и var/ будут размещены в /tmp, а /tmp/var/lib/vmware/configstore/backup/current-store-1 — это хранилище конфигурации ESXi для физического хоста ESXi, которое нам нужно обновить и заменить оригинальный хеш пароля root на желаемый, чтобы мы могли войти в систему.
Для непосредственного изменения хранилища конфигурации ESXi нам необходимо использовать утилиту sqlite3, так как файл хранится в виде базы данных sqlite3. Мы можем выполнить следующую команду на вложенной виртуальной машине ESXi, чтобы проверить текущий хеш пароля root:
/usr/lib/vmware/sqlite/bin/sqlite3 /tmp/var/lib/vmware/configstore/backup/current-store-1 "select * from config where Component='esx' and ConfigGroup = 'authentication' and Name = 'user_accounts' and Identifier = 'root'"
Шаг 11 — Вам потребуется новый хеш пароля в формате SHA512, где вы знаете сам пароль, после чего выполните следующую команду, заменив хеш.
/usr/lib/vmware/sqlite/bin/sqlite3 /tmp/var/lib/vmware/configstore/backup/current-store-1 "update config set UserValue='{\"name\":\"root\",\"password_hash\":\"\$6\$s6ic82Ik\$ER28x38x.1umtnQ99Hx9z0ZBOHBEuPYneedI1ekK2cwe/jIpjDcBNUHWHw0LwuRYJWhL3L2ORX3I5wFxKmyki1\",\"description\":\"Administrator\"}' where Component='esx' and ConfigGroup = 'authentication' and Name = 'user_accounts' and Identifier = 'root'"
Примечание: Вам нужно правильно экранировать любые специальные символы, например, как в приведенном выше примере, где хеш пароля содержит символ "$". Чтобы убедиться, что замена хеша выполнена правильно, вы можете выполнить вышеуказанную команду запроса, чтобы убедиться, что вывод соответствует желаемому хешу пароля, как показано на скриншоте ниже.
Шаг 12 — Теперь, когда мы обновили хранилище конфигурации ESXi с нашим желаемым паролем root, нам нужно заново создать файл state.tgz, который будет содержать наши изменения, выполнив следующие команды:
rm -f local.tgz
tar -cvf /tmp/local.tgz .ssh/ etc/ var/
tar -cvf /tmp/state-recover.tgz encryption.info local.tgz
Скопируйте файл /tmp/state-recover.tgz с вложенной виртуальной машины ESXi на вашу виртуальную машину с Linux, которая затем будет использоваться для монтирования носителя физического хоста ESXi, чтобы заменить файл state.tgz на нашу восстановленную версию.
Шаг 13 — Смонтируйте носитель физического хоста ESXi на вашу виртуальную машину с Linux. Поскольку физический хост ESXi установлен на USB, можно просто подключить USB-устройство напрямую к виртуальной машине с Linux.
Снова мы можем убедиться, что виртуальная машина с Linux видит носитель с установленным физическим хостом ESXi, выполнив команду fdisk -l, и мы должны увидеть два раздела bootbank (5 и 6), как показано на скриншоте ниже.
Шаг 14 — Теперь нам просто нужно смонтировать раздел bootbank и заменить оригинальный файл state.tgz на нашу модифицированную версию (state-recover.tgz).
Примечание: Поскольку физический хост ESXi был только что установлен, на втором разделе bootbank не было ничего для замены, но если вы найдете файл state.tgz, его также следует заменить, используя ту же команду, но указав другой номер раздела.
Шаг 15 — Последний шаг: размонтируйте носитель физического хоста ESXi с виртуальной машины Linux, затем включите ваш физический хост ESXi, и теперь вы сможете войти в систему, используя обновленный пароль root!
Memory Tiering использует более дешевые устройства в качестве памяти. В Update 3 платформа vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Вильям Лам написал интересный пост о выводе информации для NVMe Tiering в VMware vSphere через API. После успешного включения функции NVMe Tiering, которая была введена в vSphere 8.0 Update 3, вы можете найти полезную информацию о конфигурации NVMe Tiering, перейдя к конкретному хосту ESXi, затем выбрав "Configure" -> "Hardware" и в разделе "Memory", как показано на скриншоте ниже.
Здесь довольно много информации, поэтому давайте разберём отдельные элементы, которые полезны с точки зрения NVMe-тиринга, а также конкретные vSphere API, которые можно использовать для получения этой информации.
Memory Tiering Enabled
Поле Memory Tiering указывает, включён ли тиринг памяти на хосте ESXi, и может иметь три возможных значения: "No Tiering" (без тиринга), "Hardware Memory Tiering via Intel Optane" (аппаратный тиринг памяти с помощью технологии Intel Optane) или "Software Memory Tiering via NVMe Tiering" (программный тиринг памяти через NVMe). Мы можем получить значение этого поля, используя свойство "memoryTieringType" в vSphere API, которое имеет три перечисленных значения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Поле Tier 0 представляет общий объём физической оперативной памяти (DRAM), доступной на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "DRAM"}).Size
Tier 1 Memory
Поле Tier 1 представляет общий объём памяти, предоставляемой NVMe-тирингом, которая доступна на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Примечание: Можно игнорировать термин "Unmappable" — это просто другой способ обозначения памяти, отличной от DRAM.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "NVMe"}).Size
Поле Total представляет общий объём памяти, доступный ESXi при объединении как DRAM, так и памяти NVMe-тиринга, который можно агрегировать, используя размеры Tier 0 и Tier 1 (в байтах).
Устройства NVMe для тиринга
Чтобы понять, какое устройство NVMe настроено для NVMe-тиринга, нужно перейти в раздел "Configure" -> "Storage" -> "Storage Devices", чтобы просмотреть список устройств. В столбце "Datastore" следует искать значение "Consumed for Memory Tiering", как показано на скриншоте ниже. Мы можем получить это поле, используя свойство "usedByMemoryTiering" при энумерации всех устройств хранения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Отношение объёма DRAM к NVMe по умолчанию составляет 25% и настраивается с помощью следующего расширенного параметра ESXi под названием "Mem.TierNvmePct". Мы можем получить значение этого поля, используя либо vSphere API ("OptionManager"), либо через ESXCLI.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Вильям собрал все вышеперечисленные парметры и создал скрипт PowerCLI под названием "get-nvme-tiering-info.ps1", который предоставляет удобное резюме для всех хостов ESXi в рамках конкретного кластера Sphere (вы также можете изменить скрипт, чтобы он запрашивал конкретный хост ESXi). Это может быть полезно для быстрого получения информации о хостах, на которых NVMe-тиринг может быть настроен (или нет).
Вильям Лам написал интересную статью о поддержке технологии Intel Neural Processing Unit (NPU) на платформе VMware ESXi.
Начиная с процессоров Intel Meteor Lake (14 поколения), которые теперь входят в новый бренд Intel Core Ultra Processor (серия 1), встроенный нейронный процессор (Neural Processing Unit, NPU) интегрирован прямо в систему на кристалле (system-on-chip, SoC) и оптимизирован для энергоэффективного выполнения AI-инференса.
Хотя вы уже можете использовать интегрированную графику Intel iGPU на таких платформах, как Intel NUC, с ESXi для инференса рабочих нагрузок, Вильяму стало интересно, сможет ли этот новый нейронный процессор Intel NPU работать с ESXi?
Недавно Вильям получил доступ к ASUS NUC 14 Pro (на который позже он сделает подробный обзор), в котором установлен новый нейронный процессор Intel NPU. После успешной установки последней версии VMware ESXi 8.0 Update 3, он увидел, что акселератор Intel NPU представлен как PCIe-устройство, которое можно включить в режиме passthrough и, видимо, использовать внутри виртуальной машины.
Для тестирования он использовал Ubuntu 22.04 и библиотеку ускорения Intel NPU, чтобы убедиться, что он может получить доступ к NPU.
Шаг 1 - Создайте виртуальную машину с Ubuntu 22.04 и настройте резервирование памяти (memory reservation - это требуется для PCIe passthrough), затем добавьте устройство NPU, которое отобразится как Meteor Lake NPU.
Примечание: вам нужно будет отключить Secure Boot (этот режим включен по умолчанию), так как необходимо установить более новую версию ядра Linux, которая всё ещё находится в разработке. Отредактируйте виртуальную машину и перейдите в VM Options -> Boot Options, чтобы отключить его.
Когда Ubuntu будет запущена, вам потребуется установить необходимый драйвер Intel NPU для доступа к устройству NPU, однако инициализация NPU не удастся, что можно увидеть, выполнив следующую команду:
dmesg | grep vpu
После подачи обращения в поддержку Github по поводу драйвера Intel NPU, было предложено, что можно инициализировать устройство, используя новую опцию ядра, доступную только в версии 6.11 и выше.
Шаг 2 - Используя эту инструкцию, мы можем установить ядро Linux версии 6.11, выполнив следующие команды:
После перезагрузки вашей системы Ubuntu вы можете убедиться, что теперь она использует версию ядра 6.11, выполнив команду:
uname -r
Шаг 3 - Теперь мы можем установить драйвер Intel NPU для Linux, и на момент публикации этой статьи последняя версия — 1.8.0. Для этого выполните следующие команды:
Нам также нужно создать следующий файл, который включит необходимую опцию ядра (force_snoop=1) для инициализации NPU по умолчанию, выполнив следующую команду:
Теперь перезагрузите систему, и NPU должен успешно инициализироваться, как показано на скриншоте ниже.
Наконец, если вы хотите убедиться, что NPU полностью функционален, в библиотеке Intel NPU Acceleration есть несколько примеров, включая примеры малых языковых моделей (SLM), такие как TinyLlama, Phi-2, Phi-3, T5 и другие.
Для настройки вашего окружения Python с использованием conda выполните следующее:
Автор попробовал пример tiny_llama_chat.py (видимо, тренировочные данные для этой модели могли быть основаны на изображениях или художниках).
Независимо от того, используете ли вы новую библиотеку Intel NPU Acceleration или фреймворк OpenVino, теперь у вас есть доступ к ещё одному ускорителю с использованием ESXi, что может быть полезно для периферийных развертываний, особенно для рабочих нагрузок, требующих инференса AI, и теперь с меньшим энергопотреблением.
Следующий пример на Python можно использовать для проверки того, что устройство NPU видно из сред выполнения, таких как OpenVino.
from openvino.runtime import Core
def list_available_devices():
# Initialize the OpenVINO runtime core
core = Core()
# Get the list of available devices
devices = core.available_devices
if not devices:
print("No devices found.")
else:
print("Available devices:")
for device in devices:
print(f"- {device}")
# Optional: Print additional device information
for device in devices:
device_info = core.get_property(device, "FULL_DEVICE_NAME")
print(f"\nDevice: {device}\nFull Device Name: {device_info}")
if __name__ == "__main__":
list_available_devices()
Вильям Лам написал полезную статью о новой фиче вышедшего недавно обновления фреймворка для управления виртуальной инфраструктурой с помощью сценариев - VMware PowerCLI 13.3.
Параметры загрузки ядра (kernel boot options) в VMware ESXi можно добавить во время загрузки ESXi (нажав SHIFT+O) или обновив файл конфигурации boot.cfg, чтобы повлиять на определенные настройки и/или поведение системы.
Раньше было сложно получить полную картину по всем ESXi хостам, чтобы определить, на каких из них используются пользовательские параметры загрузки, особенно в тех случаях, когда они уже не нужны или, что хуже, если кто-то вручную добавил настройку, которую вы не планировали.
В vSphere 8.0 Update 3 добавлено новое свойство bootCommandLine в vSphere API, которое теперь предоставляет полную информацию обо всех параметрах загрузки, используемых для конкретного ESXi хоста.
На днях был выпущен релиз PowerCLI 13.3, который поддерживает последние API, представленные как в vSphere 8.0 Update 3, так и в VMware Cloud Foundation (VCF) 5.2. Вы можете легко получить доступ к этому новому свойству, выполнив следующую команду в сценарии:
Выход платформы VMware vSphere 8 переопределил подход к управлению жизненным циклом и обслуживанием инфраструктуры vSphere. Решение vSphere Lifecycle Manager упрощает управление образами кластеров, обеспечивает полный цикл управления драйверами и прошивками, а также ускоряет полное восстановление кластера. Управление сертификатами происходит без сбоев, а обновления vCenter можно выполнять с гораздо меньшими простоями по сравнению с прошлыми релизами платформы.
vSphere 8 Update 3 продолжает эту тенденцию снижения и устранения простоев с введением функции vSphere Live Patch.
vSphere Live Patch позволяет обновлять кластеры vSphere и накатывать патчи без миграции рабочих нагрузок с целевых хостов и без необходимости перевода хостов в полный режим обслуживания. Патч применяется в реальном времени, пока рабочие нагрузки продолжают выполняться.
Требования данной техники:
vSphere Live Patch является опциональной функцией, которую необходимо активировать перед выполнением задач восстановления.
vCenter должен быть версии 8.0 Update 3 или выше.
Хосты ESXi должны быть версии 8.0 Update 3 или выше.
Настройка Enforce Live Patch должна быть включена в глобальных настройках восстановления vSphere Lifecycle Manager или в настройках восстановления кластера.
DRS должен быть включен на кластере vSphere и работать в полностью автоматическом режиме.
Для виртуальных машин с включенной vGPU необходимо активировать Passthrough VM DRS Automation.
Текущая сборка кластера vSphere должна быть пригодна для применения live-патчинга (подробности ниже).
Как работает Live Patching
Кликните на картинку, чтобы открыть анимацию:
Распишем этот процесс по шагам:
Хост ESXi переходит в режим частичного обслуживания (partial maintenance mode). Частичный режим обслуживания — это автоматическое состояние, в которое переходит каждый хост. В этом особом состоянии существующие виртуальные машины продолжают работать, но создание новых ВМ на хосте или миграция ВМ на этот хост или с него запрещены.
Новая версия компонентов целевого патча монтируется параллельно с текущей версией.
Файлы и процессы обновляются за счет смонтированной версии патча.
Виртуальные машины проходят быструю паузу и запуск (fast-suspend-resume) для использования обновленной версии компонентов.
Не все патчи одинаковы
Механизм vSphere Live Patch изначально доступен только для определенного типа патчей. Патчи для компонента выполнения виртуальных машин ESXi (virtual machine execution component) являются первыми целями для vSphere Live Patch.
Патчи, которые могут изменить другие области ESXi, например патчи VMkernel, изначально не поддерживаются для vSphere Live Patch и пока требуют следования существующему процессу патчинга, который подразумевает перевод хостов в режим обслуживания и эвакуацию ВМ.
Обновления vSphere Live Patches могут быть установлены только на поддерживаемые совместимые версии ESXi. Каждый Live Patch будет указывать, с какой предыдущей сборкой он совместим. vSphere Lifecycle Manager укажет подходящие версии при определении образа кластера. Также вы можете увидеть подходящую версию в репозитории образов vSphere Lifecycle Manager:
Например, patch 8.0 U3a 23658840 может быть применен только к совместимой версии 8.0 U3 23653650. Системы, которые не работают на совместимой версии, все равно могут быть обновлены, но для этого будет использован существующий процесс "холодных" патчей, требующий перевода хостов в режим обслуживания и эвакуации ВМ.
Соответствие образа кластера будет указывать на возможность использования Live Patch.
Быстрое приостановление и возобновление (fast-suspend-resume)
Как упоминалось ранее, патчи для компонента выполнения виртуальных машин в ESXi являются первой целью для vSphere Live Patch. Это означает, что хотя виртуальные машины не нужно эвакуировать с хоста, им нужно выполнить так называемое быстрое приостановление и возобновление (FSR) для использования обновленной среды выполнения виртуальных машин.
FSR виртуальной машины — это ненарушающее работу действие, которое уже используется в операциях с виртуальными машинами при добавлении или удалении виртуальных аппаратных устройств (Hot Add) в работающие виртуальные машины.
Некоторые виртуальные машины несовместимы с FSR. Виртуальные машины, настроенные с включенной функцией Fault Tolerance, машины, использующие Direct Path I/O, и vSphere Pods не могут использовать FSR и нуждаются в участии администратора. Это может быть выполнено либо путем миграции виртуальной машины, либо путем перезагрузки виртуальной машины.
Сканирование на соответствие в vSphere Lifecycle Manager укажет виртуальные машины, несовместимые с FSR, и причину несовместимости:
После успешного восстановления кластера любые хосты, на которых работают виртуальные машины, не поддерживающие FSR, будут продолжать сообщать о несоответствии требованиям. Виртуальные машины необходимо вручную переместить с помощью vMotion или перезагрузить. Только тогда кластер будет полностью соответствовать требованиям (compliant).
Отметим, что
vSphere Live Patch несовместим с системами, работающими с устройствами TPM или DPU, использующими vSphere Distributed Services Engine.
Если у вас нет полноценного способа резервирования конфигураций серверов ESXi, но вы задумались о том, что будет если, то вот тут есть простой и свежий сценарий, который позволить вам сделать бэкап конфигурации и восстановить конфигурацию хостов ESXi.
Автор не хотел вручную создавать резервные копии каждого ESXi хоста, так как это не масштабируется. Вместо этого он создал PowerShell скрипт под названием vCenter ESXi Config Backup, который выполняет в автоматическом режиме.
Скрипт vCenter ESXi config backup подключается к VMware vCenter, далее использует его для подключения к каждому ESXi хосту и последовательно создает резервную копию каждой конфигурации. Поскольку скрипт использует vCenter, вам не нужно включать SSH на каких-либо ESXi хостах для выполнения резервного копирования.
По умолчанию, скрипт предполагает, что вы не подключены к vCenter, и запросит вас подключиться к vCenter. Вы можете изменить это поведение, если вы уже подключены к vCenter, установив опциональный параметр connected со значением Yes.
Скрипт проверяет, существует ли указанная вами папка для резервного копирования. Если папка не существует, скрипт создаст ее.
Затем скрипт получает все ESXi хосты в vCenter, подключается к каждому из них и создает резервную копию конфигурации. Скрипт сохраняет резервную копию в указанную вами папку.
После завершения резервного копирования скрипт переименовывает файл резервной копии, добавляя к имени хоста установленную версию ESXi, номер сборки и дату резервного копирования.
Для использования скрипта необходимо предоставить несколько параметров. Первый параметр — vcenter, за которым следует FQDN-имя вашего vCenter. Второй параметр — folder, за которым следует расположение, куда вы хотите сохранить резервные копии конфигурации ESXi.
Вчера мы писали о новых возможностях последнего пакета обновлений VMware vSphere 8.0 Update 3, а сегодня расскажем что нового появилось в плане основных функций хранилищ (Core Storage).
Каждое обновление vSphere 8 добавляет множество возможностей для повышения масштабируемости, устойчивости и производительности. В vSphere 8 Update 3 продолжили улучшать и дорабатывать технологию vVols, добавляя новые функции.
Продолжая основной инженерный фокус на vVols и NVMe-oF, VMware также обеспечивает их поддержку в VMware Cloud Foundation. Некоторые функции включают дополнительную поддержку кластеризации MS WSFC на vVols и NVMe-oF, улучшения по возврату свободного пространства (Space Reclamation), а также оптимизации для VMFS и NFS.
Ключевые улучшения
Поддержка растянутых кластеров хранилищ (Stretched Clusters) для vVols
Новая спецификация vVols VASA 6
Кластеризация VMDK для NVMe/TCP
Ограничение максимального количества хостов, выполняющих Unmap
Поддержка NFS 4.1 Port Binding и nConnect
Дополнительная поддержка CNS/CSI для vSAN
vVols
Поддержка растянутого кластера хранилища vVols на SCSI
Растянутый кластер хранения vVols (vVols-SSC) был одной из самых запрашиваемых функций для vVols в течение многих лет, особенно в Европе. В vSphere 8 U3 добавлена поддержка растянутого хранилища vVols только на SCSI (FC или iSCSI). Первоначально Pure Storage, который был партнером по дизайну этой функции, будет поддерживать vVols-SSC, но многие из партнеров VMware по хранению также активно работают над добавлением данной поддержки.
Почему это заняло так много времени?
Одна из причин, почему реализация vVols-SSC заняла столько времени, заключается в дополнительных улучшениях, необходимых для защиты компонентов виртуальных машин (VMCP). Когда используется растянутое хранилище, необходимо наличие процесса для обработки событий хранения, таких как Permanent Device Loss (PDL) или All Paths Down (APD). VMCP — это функция высокой доступности (HA) vSphere, которая обнаруживает сбои хранения виртуальных машин и обеспечивает автоматическое восстановление затронутых виртуальных машин.
Сценарии отказа и восстановления
Контейнер/datastore vVols становится недоступным. Контейнер/datastore vVols становится недоступным, если либо все пути данных (к PE), либо все пути управления (доступ к VP, предоставляющим этот контейнер) становятся недоступными, либо если все пути VASA Provider, сообщающие о растянутом контейнере, отмечают его как UNAVAILABLE (новое состояние, которое VP может сообщить для растянутых контейнеров).
PE контейнера vVols может стать недоступным. Если PE для контейнера переходит в состояние PDL, то контейнер также переходит в состояние PDL. В этот момент VMCP будет отвечать за остановку виртуальных машин на затронутых хостах и их перезапуск на других хостах, где контейнер доступен.
Контейнер или PE vVols становится доступным снова или восстанавливается подключение к VP. Контейнер вернется в доступное состояние из состояния APD, как только хотя бы один VP и один PE станут доступны снова. Контейнер вернется в доступное состояние из состояния PDL только после того, как все виртуальные машины, использующие контейнеры, будут выключены, и все клиенты, имеющие открытые файловые дескрипторы к хранилищу данных vVols, закроют их.
Поведение растянутого контейнера/хранилища данных довольно похоже на VMFS, и выход из состояния PDL требует уничтожения PE, что может произойти только после освобождения всех vVols, связанных с PE. Точно так же, как VMFS (или устройство PSA) не может выйти из состояния PDL, пока все клиенты тома VMFS (или устройства PSA) не закроют свои дескрипторы.
Требования
Хранилище SCSI (FC или iSCSI)
Макс. время отклика между хостами vSphere — 11 мс
Макс. время отклика массива хранения — 11 мс
Выделенная пропускная способность сети vSphere vMotion — 250 Мбит/с
Один vCenter (vCenter HA не поддерживается с vVols)
Контроль ввода-вывода хранения не поддерживается на datastore с включенным vVol-SSC
Дополнительная поддержка UNMAP
Начиная с vSphere 8.0 U1, config-vvol теперь создается с 255 ГБ VMFS vVol вместо 4 ГБ. Это добавило необходимость в возврате свободного пространства в config-vvol. В 8.0 U3 VMware добавила поддержку как ручного (CLI), так и автоматического UNMAP для config-vvol для SCSI и NVMe.
Это гарантирует, что при записи и удалении данных в config-vvol обеспечивается оптимизация пространства для новых записей. Начиная с vSphere 8.0 U3, также поддерживается команда Unmap для хранилищ данных NVMe-oF, а поддержка UNMAP для томов SCSI была добавлена в предыдущем релизе.
Возврат пространства в хранилищах виртуальных томов vSphere описан тут.
Кликните на картинку, чтобы посмотреть анимацию:
Поддержка кластеризации приложений на NVMe-oF vVols
В vSphere 8.0 U3 VMware расширила поддержку общих дисков MS WSFC до NVMe/TCP и NVMe/FC на основе vVols. Также добавили поддержку виртуального NVMe (vNVME) контроллера для гостевых кластерных решений, таких как MS WSFC.
Эти функции были ограничены SCSI на vVols для MS WSFC, но Oracle RAC multi-writer поддерживал как SCSI, так и NVMe-oF. В vSphere 8.0 U3 расширили поддержку общих дисков MS WSFC до vVols на базе NVMe/TCP и NVMe/FC. Также была добавлена поддержка виртуального NVMe (vNVME) контроллера виртуальной машины в качестве фронтенда для кластерных решений, таких как MS WSFC. Обратите внимание, что контроллер vNVMe в качестве фронтенда для MS WSFC в настоящее время поддерживается только с NVMe в качестве бэкенда.
Обновление отчетности по аутентификации хостов для VASA Provider
Иногда при настройке Storage Provider для vVols некоторые хосты могут не пройти аутентификацию, и это может быть сложно диагностировать. В версии 8.0 U3 VMware добавила возможность для vCenter уведомлять пользователей о сбоях аутентификации конкретных хостов с VASA провайдером и предоставили механизм для повторной аутентификации хостов в интерфейсе vCenter. Это упрощает обнаружение и решение проблем аутентификации Storage Provider.
Гранулярность хостов Storage Provider для vVols
С выходом vSphere 8 U3 была добавлена дополнительная информация о хостах для Storage Provider vVols и сертификатах. Это предоставляет клиентам и службе поддержки дополнительные детали о vVols при устранении неполадок.
NVMe-oF
Поддержка NVMe резервирования для кластерного VMDK с NVMe/TCP
В vSphere 8.0 U3 была расширена поддержка гостевой кластеризации до NVMe/TCP (первоначально поддерживалась только NVMe/FC). Это предоставляет клиентам больше возможностей при использовании NVMe-oF и желании перенести приложения для гостевой кластеризации, такие как MS WSFC и Oracle RAC, на хранилища данных NVMe-oF.
Поддержка NVMe Cross Namespace Copy
В предыдущих версиях функция VAAI, аппаратно ускоренное копирование (XCOPY), поддерживалась для SCSI, но не для NVMe-oF. Это означало, что копирование между пространствами имен NVMe использовало ресурсы хоста для передачи данных. С выпуском vSphere 8.0 U3 теперь доступна функция Cross Namespace Copy для NVMe-oF для поддерживаемых массивов. Применение здесь такое же, как и для SCSI XCOPY между логическими единицами/пространствами имен. Передачи данных, такие как копирование/клонирование дисков или виртуальных машин, теперь могут работать значительно быстрее. Эта возможность переносит функции передачи данных на массив, что, в свою очередь, снижает нагрузку на хост.
Кликните на картинку, чтобы посмотреть анимацию:
VMFS
Сокращение времени на расширение EZT дисков на VMFS
В vSphere 8.0 U3 был реализован новый API для VMFS, чтобы ускорить расширение блоков на диске VMFS, пока диск используется. Этот API может работать до 10 раз быстрее, чем существующие методы, при использовании горячего расширения диска EZT на VMFS.
Виртуальные диски на VMFS имеют тип аллокации, который определяет, как резервируется основное хранилище: Thin (тонкое), Lazy Zeroed Thick (толстое с занулением по мере обращения) или Eager Zeroed Thick (толстое с предварительным занулением). EZT обычно выбирается на VMFS для повышения производительности во время выполнения, поскольку все блоки полностью выделяются и зануляются при создании диска. Если пользователь ранее выбрал тонкое выделение диска и хотел преобразовать его в EZT, этот процесс был медленным. Новый API позволяет значительно это ускорить.
Кликните на картинку для просмотра анимации:
Ограничение количества хостов vSphere, отправляющих UNMAP на VMFS datastore
В vSphere 8.0 U2 VMware добавила возможность ограничить скорость UNMAP до 10 МБ/с с 25 МБ/с. Это предназначено для клиентов с высоким уровнем изменений или массовыми отключениями питания, чтобы помочь уменьшить влияние возврата пространства на массив.
Кликните на картинку для просмотра анимации:
По умолчанию все хосты в кластере, до 128 хостов, могут отправлять UNMAP. В версии 8.0 U3 добавлен новый параметр для расширенного возврата пространства, называемый Reclaim Max Hosts. Этот параметр может быть установлен в значение от 1 до 128 и является настройкой для каждого хранилища данных. Чтобы изменить эту настройку, используйте ESXCLI. Алгоритм работает таким образом, что после установки нового значения количество хостов, отправляющих UNMAP одновременно, ограничивается этим числом. Например, если установить максимальное значение 10, в кластере из 50 хостов только 10 будут отправлять UNMAP на хранилище данных одновременно. Если другие хосты нуждаются в возврате пространства, то, как только один из 10 завершит операцию, слот освободится для следующего хоста.
Пример использования : esxcli storage vmfs reclaim config set -l <Datastore> -n <number_of_hosts>
Вот пример изменения максимального числа хостов, отправляющих UNMAP одновременно:
PSA
Поддержка уведомлений о производительности Fabric (FPIN, ошибки связи, перегрузка)
VMware добавила поддержку Fabric Performance Impact Notification (FPIN) в vSphere 8.0 U3. С помощью FPIN слой инфраструктуры vSphere теперь может обрабатывать уведомления от SAN-коммутаторов или целевых хранилищ о падении производительности каналов SAN, чтобы использовать исправные пути к устройствам хранения. Он может уведомлять хосты о перегрузке каналов и ошибках. FPIN — это отраслевой стандарт, который предоставляет средства для уведомления устройств о проблемах с соединением.
Вы можете использовать команду esxcli storage FPIN info set -e= <true/false>, чтобы активировать или деактивировать уведомления FPIN.
Кликните на картинку, чтобы посмотреть анимацию:
NFS
Привязка порта NFS v4.1 к vmk
Эта функция добавляет возможность байндинга соединения NFS v4.1 к определенному vmknic для обеспечения изоляции пути. При использовании многопутевой конфигурации можно задать несколько vmknic. Это обеспечивает изоляцию пути и помогает повысить безопасность, направляя трафик NFS через указанную подсеть/VLAN и гарантируя, что трафик NFS не использует сеть управления или другие vmknic. Поддержка NFS v3 была добавлена еще в vSphere 8.0 U1. В настоящее время эта функция поддерживается только с использованием интерфейса esxcli и может использоваться совместно с nConnect.
Начиная с версии 8.0 U3, добавлена поддержка nConnect для хранилищ данных NFS v4.1. nConnect предоставляет несколько соединений, используя один IP-адрес в сессии, таким образом расширяя функциональность агрегации сессий для этого IP. С этой функцией многопутевая конфигурация и nConnect могут сосуществовать. Клиенты могут настроить хранилища данных с несколькими IP-адресами для одного сервера, а также с несколькими соединениями с одним IP-адресом. В настоящее время максимальное количество соединений ограничено 8, значение по умолчанию — 1. Текущие версии реализаций vSphere NFSv4.1 создают одно соединение TCP/IP от каждого хоста к каждому хранилищу данных. Возможность добавления нескольких соединений на IP может значительно увеличить производительность.
При добавлении нового хранилища данных NFSv4.1, количество соединений можно указать во время монтирования, используя команду:
Общее количество соединений, используемых для всех смонтированных хранилищ данных NFSv4.1, ограничено 256.
Для существующего хранилища данных NFSv4.1, количество соединений можно увеличить или уменьшить во время выполнения, используя следующую команду:
esxcli storage nfs41 param set -v <volume-label> -c <number_of_connections>
Это не влияет на многопутевую конфигурацию. NFSv4.1 nConnect и многопутевые соединения могут сосуществовать. Количество соединений создается для каждого из многопутевых IP.
В настоящее время CNS поддерживает только 100 файловых томов. В vSphere 8.0 U3 этот лимит увеличен до 250 томов. Это поможет масштабированию для клиентов, которым требуется больше файловых хранилищ для постоянных томов (PVs) или постоянных запросов томов (PVCs) в Kubernetes (K8s).
Поддержка файловых томов в топологии HCI Mesh в одном vCenter
Добавлена поддержка файловых томов в топологии HCI Mesh в пределах одного vCenter.
Поддержка CNS на TKGs на растянутом кластере vSAN
Появилась поддержка растянутого кластера vSAN для TKGs для обеспечения высокой доступности.
Миграция PV между несвязанными datastore в одном VC
Возможность перемещать постоянный том (PV), как присоединённый, так и отсоединённый, с одного vSAN на другой vSAN, где нет общего хоста. Примером этого может быть перемещение рабочей нагрузки Kubernetes (K8s) из кластера vSAN OSA в кластер vSAN ESA.
Поддержка CNS на vSAN Max
Появилась поддержка развертывания CSI томов для vSAN Max при использовании vSphere Container Storage Plug-in.
VMware VMmark 4.0 - это бесплатный кластерный бенчмарк, который измеряет производительность и масштабируемость виртуальных корпоративных сред.
VMmark 4 продолжает использовать дизайн и архитектуру предыдущих версий VMmark, предоставляя улучшенную автоматизацию и отчетность. Он использует модульный дизайн нагрузки с разнородными приложениями, включающий обновленные версии нескольких нагрузок из VMmark 3, также в нем появились и новые современные приложения, которые более точно соответствуют современным корпоративным виртуальным средам.
VMmark 4 также включает инфраструктурные нагрузки, такие как vMotion, Storage vMotion, Cross vMotion и Clone & Deploy. В дополнение к ним, VMware vSphere DRS также работает в тестируемом кластере для балансировки нагрузок. В VMmark 4.0 было сделано улучшение полностью автоматизированного процесса развертывания, который появился в VMmark 3 - это сокращает время, необходимое пользователям для получения ценных результатов. Большинство пользователей теперь смогут перейти от загружаемого шаблона VMmark до результатов VMmark 4 примерно за два часа для "турбо" запуска.
Бенчмарк VMmark 4:
Позволяет точно и повторяемо оценивать производительность виртуальных датацентров на основе vSphere.
Использует разнообразные традиционные, устаревшие и современные нагрузки приложений в разнородном модульном подходе.
Облегчает анализ и сравнение изменений в оборудовании, программном обеспечении и конфигурациях виртуальных сред VMware.
Уровни создаваемой нагрузки теперь значительно выше, чем в предыдущих версиях VMmark, чтобы лучше отражать современные реалии.
Обновления удобства использования VMmark 4:
Новый режим "Быстрый старт" для развертывания, запуска и получения результатов бенчмарка с помощью одной команды.
Новые режимы развертывания, которые позволяют большую гибкость в распределении виртуальных машин по более разнообразным хранилищам.
Функциональность частичных модулей (Partial Tile) для увеличения гранулярности бенчмарка через предписанное включение рабочих нагрузок приложений в конечный модуль.
Дизайн "Автоматизация в первую очередь" - многие основные операции администрирования vSphere теперь доступны пользователям. Операции, такие как deleting_all_vmmark4, manual_xvmotion и power_vmmark4_tiles, помогают пользователям в полной автоматизации VMmark 4. Посмотрите вывод команды vmmark4service для получения списка из более чем 20 новых доступных операций.
Улучшенная HTML-отчетность - пользователи теперь автоматически получают улучшенный HTML-вывод для пропускной способности, качества обслуживания и операций инфраструктуры для каждого запуска.
Новое приложение "disclosure creator", которое упрощает и автоматизирует создание HTML файлов.
Сбор данных о потреблении энергии - новый подход VMmark 4 к пониманию потребления энергопотребления. Этот режим собирает метрики энергопотребления на тестируемых системах и генерирует улучшенный HTML-отчет, чтобы помочь пользователям посчитать потребление энергии как хостами, так и виртуальными машинами.
Интеграция оповещений - оповещения в Slack и Google Chat легко встраиваются в VMmark 4 и включаются одним параметром.
Рабочие нагрузки приложений VMmark 4:
NoSQLBench - это новая рабочая нагрузка приложения в VMmark 4, используемая для анализа производительности новой распределенной NoSQL базы данных Apache Cassandra на 3 узлах.
SocialNetwork - эта новая рабочая нагрузка приложения в VMmark использует Docker-контейнеры для моделирования социальной сети с операциями, такими как создание постов, подписка на пользователей и т.д.
DVDstore (обновлено до версии 3.5) - включает PostgreSQL и параллельную загрузку базы данных, сокращая время на развертывание первого модуля.
Weathervane (обновлено до версии 2.0) - это масштабируемое веб-приложение, имитирующее онлайн-аукцион, теперь работает в Kubernetes контейнерах и в виртуальных машинах.
Standby - сервер Standby имитирует heartbeat-сервер, который периодически пингуется, чтобы убедиться, что он все еще работает и подключен.
Инфраструктурные нагрузки VMmark 4:
vMotion - эта операция инфраструктуры выполняет живую миграцию одной из Standby ВМ по круговой схеме, чтобы смоделировать современные операции системного администратора.
Storage vMotion - для этой операции одна из ВМ AuctionWebF мигрируется на указанное пользователем хранилище для обслуживания, а затем через некоторое время возвращается в исходное место.
Cross vMotion (XvMotion) - эта операция одновременно перемещает одну из ВМ DS3WebA на альтернативный хост и хранилище для обслуживания. Аналогично операции Storage vMotion, через некоторое время ВМ возвращается в исходное место.
Автоматическое балансирование нагрузки (DRS) - VMmark требует, чтобы DRS был включен и работал, чтобы гарантировать типичные операции ребалансировки в тестируемой среде.
Также на днях стали доступны первые результаты тестирования производительности различного оборудования с помощью VMmark 4.0. Их можно посмотреть вот тут.
В блоге Angry Admin появилась интересная статья, посвященная новому варианту основанного на Linux ПО, которое использует пакет TargetCompany Ransomware для атаки серверов VMware ESXi.
Важное событие в сфере кибербезопасности: исследователи Trend Micro выявили новый вариант Linux из печально известного семейства программ-вымогателей TargetCompany.
Этот вариант специально нацелен на среды VMware ESXi, используя сложный пользовательский shell-скрипт для доставки и выполнения вредоносных программ. Известный под несколькими псевдонимами, включая Mallox, FARGO и Tohnichi, ветка TargetCompany представляет собой постоянную угрозу с момента ее появления в июне 2021 года, в основном сосредотачиваясь на атаках на базы данных в Тайване, Южной Корее, Таиланде и Индии.
Эволюция вымогателя TargetCompany
Вымогатель TargetCompany первоначально привлек внимание своими агрессивными атаками на различные системы баз данных, такие как MySQL, Oracle и SQL Server. В феврале 2022 года антивирусная компания Avast сделала значительный прорыв, выпустив бесплатный инструмент для расшифровки, который мог противодействовать известным на тот момент вариантам вымогателя. Однако к сентябрю 2022 года группа вымогателей восстановила свои позиции, переключив внимание на уязвимые серверы Microsoft SQL и используя Telegram в качестве платформы для угроз жертвам утечками данных.
Новый Linux-вариант вымогателя: подробный обзор
Недавно компания Trend Micro сообщила о новом варианте вымогателя TargetCompany для Linux, что является заметным изменением в стратегии выбора целей вымогателя. Этот новый вариант убеждается в наличии административных привилегий перед началом своих вредоносных действий. Пользовательский скрипт используется для загрузки и выполнения вредоносного кода, который также способен извлекать данные на два отдельных сервера. Эта избыточность гарантирует, что данные остаются доступными, даже если один сервер столкнется с техническими проблемами или будет скомпрометирован.
После проникновения в целевую систему, вымогатель проверяет наличие среды VMware ESXi, выполняя команду uname и ища строчку "vmkernel". Затем создается файл "TargetInfo.txt", который отправляется на сервер управления и контроля (C2). Этот файл содержит важную информацию о жертве, такую как имя хоста, IP-адрес, сведения об операционной системе, зарегистрированные пользователи и их привилегии, уникальные идентификаторы и подробности о зашифрованных файлах и каталогах.
Скрытные операции и атрибуция
Операции вымогателя разработаны так, чтобы оставлять минимальные следы. После завершения своих задач, shell-скрипт удаляет полезную нагрузку с помощью команды ‘rm -f x’, эффективно уничтожая любые доказательства, которые могли бы помочь в расследованиях после инцидента. Аналитики Trend Micro приписали эти атаки актору по имени «vampire», который также был упомянут в отчете Sekoia в прошлом месяце. IP-адреса, связанные с доставкой полезной нагрузки и получением информации о жертве, были отслежены до интернет-провайдера в Китае, хотя этого недостаточно для точного определения происхождения атакующего.
Влияние и рекомендации
Исторически вымогатель TargetCompany в основном нацеливался на машины под управлением Windows. Появление варианта для Linux и акцент на средах VMware ESXi подчеркивают эволюционирующую тактику и расширяющийся вектор угроз этой заразы. В отчете Trend Micro подчеркивается важность надежных мер кибербезопасности для противодействия этой растущей угрозе. Основные рекомендации включают включение многофакторной аутентификации (MFA), регулярное резервное копирование (в том числе на immutable хранилища) и поддержание обновленными всех систем. Кроме того, исследователи предоставили список индикаторов компрометации, включая хэши для версии вымогателя для Linux, пользовательского shell-скрипта и образцы, связанные с актором «vampire».
Заключение
Появление нового варианта вымогателя TargetCompany для Linux подчеркивает неустанную эволюцию киберугроз и необходимость бдительных и проактивных мер кибербезопасности. Организации должны оставаться информированными и подготовленными к защите от этих сложных атак, обеспечивая реализацию комплексных мер безопасности для защиты своих систем и данных. По мере того, как угрозы вымогателей, такие как TargetCompany, продолжают развиваться, организациям и частным лицам необходимо предпринимать проактивные меры для защиты своих систем и данных. Вот несколько основных советов и рекомендаций для предотвращения атак вымогателей:
1. Включите многофакторную аутентификацию (MFA)
Внедрите MFA для всех учетных записей и систем. Это добавляет дополнительный уровень безопасности, затрудняя злоумышленникам несанкционированный доступ даже при компрометации паролей.
2. Отключите доступ по SSH
Отключите доступ по SSH на системах, где он не требуется. Это уменьшает поверхность атаки, предотвращая несанкционированный удаленный доступ.
3. Используйте режим блокировки (lockdown mode)
Включите режим блокировки на критически важных системах, таких как VMware ESXi, чтобы ограничить административные операции и дополнительно защитить среду от потенциальных угроз.
4. Регулярное резервное копирование
Регулярно выполняйте резервное копирование всех критически важных данных и храните резервные копии оффлайн или в безопасной облачной среде. Это гарантирует возможность восстановления данных в случае атаки вымогателя без уплаты выкупа.
5. Обновляйте системы
Убедитесь, что все программное обеспечение, включая операционные системы, приложения и антивирусные программы, регулярно обновляются для защиты от известных уязвимостей и эксплойтов.
6. Сегментация сети
Сегментируйте сети, чтобы ограничить распространение вымогателей. Изолируя критические системы и данные, вы можете сдержать инфекцию и предотвратить ее влияние на всю сеть.
7. Обучение сотрудников
Проводите регулярные тренинги по кибербезопасности для сотрудников, чтобы информировать их о опасностях вымогателей, фишинговых атак и безопасных практиках в интернете.
8. Внедрите сильные политики безопасности
Разработайте и соблюдайте надежные политики безопасности, включая использование сложных уникальных паролей, ограниченный контроль доступа и регулярные аудиты для обеспечения соблюдения требований.
9. Развертывание передовых решений безопасности
Используйте передовые решения безопасности, такие как обнаружение и реагирование на конечных точках (Endpoint Detection and Response, EDR), системы обнаружения вторжений (IDS) и системы предотвращения вторжений (IPS), чтобы обнаруживать и смягчать угрозы в режиме реального времени.
10. Мониторинг сетевого трафика
Постоянно контролируйте сетевой трафик на предмет необычной активности, которая может указывать на атаку вымогателя. Раннее обнаружение может помочь смягчить последствия атаки.
11. План реагирования на инциденты
Разработайте и регулярно обновляйте план реагирования на инциденты. Убедитесь, что все члены команды знают свои роли и обязанности в случае атаки вымогателя.
12. Ограничение привилегий пользователей
Ограничьте привилегии пользователей только теми, которые необходимы для выполнения их ролей. Ограничение административных привилегий может предотвратить распространение вымогателей по сети.
Следуя этим советам и оставаясь бдительными, организации могут значительно снизить риск стать жертвой атак вымогателей и защитить свои критически важные системы и данные.
Вильям Лам написал интересную статью о том, как можно редактировать настройки SMBIOS для вложенного/виртуального (Nested) VMware ESXi в части hardware manufacturer и vendor.
Nested ESXi продолжает оставаться полезным ресурсом, который часто используется администраторами: от прототипирования решений, воспроизведения проблем клиентов до автоматизированных развертываний лабораторий, поддерживающих как VMware Cloud Foundation (VCF), так и VMware vSphere Foundation (VVF).
Хотя с помощью Nested ESXi можно сделать почти все, но имитировать или симулировать конкретные аппаратные свойства, такие как производитель или поставщик (hardware manufacturer и vendor), не совсем возможно или, по крайней мере, очень сложно. Коллега Вильяма Люк Хакаба нашел хитрый трюк, играя с настройками загрузочных ROM виртуальной машины по умолчанию, которые поставляются с ESXi и VMware Desktop Hypervisors (платформы Workstation/Fusion).
Виртуальная машина vSphere может загружаться, используя либо BIOS, либо EFI прошивку, поэтому в зависимости от желаемого типа прошивки вам нужно будет изменить либо файл BIOS.440.ROM, либо EFI64.ROM. Эти файлы ROM можно найти в следующих каталогах для соответствующих гипервизоров VMware:
Примечание: не редактируйте файлы ROM по умолчанию, которые поставляются с гипервизором VMware, сделайте их копию и используйте измененную версию, которую могут использовать виртуальные машины в VMware vSphere, Fusion или Workstation. Кроме того, хотя эта статья посвящена виртуальной машине Nested ESXi, это также должно работать и на других гостевых операционных системах для отображения информации SMBIOS.
Редактирование BIOS
Шаг 1 - Скачайте и установите Phoenix BIOS Editor. Установщик Phoenix BIOS Editor имеет проблемы при запуске на системе Windows Server 2019, и единственным способом завершить установку - это изменить совместимость приложения на Windows 8, что позволит успешно завершить установку.
Шаг 2 - Скачайте и откройте файл BIOS.440.ROM с помощью Phoenix BIOS Editor, затем перейдите на панель DMI Strings для изменения нужных полей.
Когда вы закончите вносить все изменения, перейдите в меню "Файл" и нажмите "Собрать BIOS" (Build BIOS), чтобы создать новый файл ROM. В данном примере это файл BIOS.440.CUSTOM.ROM.
Шаг 3 - Скопируйте новый файл ROM в хранилище вашего физического хоста ESXi. Вы можете сохранить его в общей папке, чтобы использовать с несколькими виртуальными машинами Nested ESXi, ИЛИ вы можете сохранить его непосредственно в папке отдельной виртуальной машины Nested ESXi. Второй вариант позволит вам повторно использовать один и тот же кастомный файл ROM в нескольких виртуальных машинах, поэтому, с точки зрения тестирования, возможно, вам захочется создать несколько файлов ROM в зависимости от ваших нужд и просто перенастроить виртуальную машину для использования нужного файла ROM.
Шаг 4 - Чтобы кастомный файл ROM мог быть использован нашей виртуальной машиной Nested ESXi, нам нужно добавить следующую дополнительную настройку (Advanced Setting) виртуальной машины, которая указывает путь к нашему кастомному файлу ROM:
bios440.filename = "BIOS.440.CUSTOM.ROM"
Шаг 5 - Наконец, мы можем включить нашу виртуальную машину Nested ESXi, и теперь мы должны увидеть кастомную информацию SMBIOS, как показано на скриншоте ниже.
Редактирование EFI
Шаг 1 - Скачайте и установите HEX-редактор, который может редактировать файл EFI ROM. Например, ImHex - довольно удобный с точки зрения редактирования, но поиск определенных строк с помощью этого инструмента является нетривиальной задачей.
Шаг 2 - Скачайте и откройте файл EFI64.ROM с помощью редактора ImHex и найдите строку "VMware7,1". Как только вы найдете расположение этой строки, вам нужно аккуратно отредактировать значения hex, чтобы получить желаемые ASCII строки.
Кроме того, вы можете использовать UEFITool (версия 28 позволяет модифицировать ROM), который имеет гораздо более удобный и функциональный поиск, а также позволяет извлекать часть файла ROM для редактирования с помощью HEX-редактора. В этой утилите можно использовать поиск (CTRL+F), и как только он находит нужный раздел, двойным щелчком по результату переходите к точному месту в файле ROM. Чтобы извлечь раздел для редактирования, щелкните правой кнопкой мыши и выберите "Extract as is" и сохраните файл на рабочий стол.
Затем вы можете открыть конкретный раздел с помощью ImHex, чтобы внести свои изменения.
После того как вы сохранили свои изменения, не теряйте указатель в UEFITool. Теперь мы просто заменим раздел нашим измененным файлом, щелкнув правой кнопкой мыши и выбрав "Replace as is", указав измененный раздел. Вы можете подтвердить, что изменения были успешными, просто найдя строку, которую вы заменили. Затем перейдите в меню "Файл" и выберите "Сохранить образ файла" (Save image file), чтобы создать новый файл ROM. В данном случае - это файл EFI64.CUSTOM.ROM.
Шаг 3 - Скопируйте новый файл ROM в хранилище вашего физического хоста ESXi. Вы можете сохранить его в общей папке, чтобы использовать с несколькими виртуальными машинами Nested ESXi, ИЛИ вы можете сохранить его непосредственно в папке отдельной виртуальной машины Nested ESXi.
Шаг 4 - Чтобы наш кастомный файл ROM мог быть использован виртуальной машиной Nested ESXi, нам нужно добавить следующую дополнительную настройку ВМ в файл vmx, которая указывает путь к нашему кастомному файлу ROM:
efi64.filename = "EFI64.CUSTOM.ROM"
Шаг 5 - Наконец, мы можем включить виртуальную машину Nested ESXi, и теперь мы должны увидеть кастомную информацию SMBIOS.
Как видно на скриншоте, Вильяму удалось изменить только модель оборудования, но не значение вендора.
Примечание: хотя автору и удалось найти строку "VMware, Inc." для вендора, изменение значения не оказало никакого эффекта, как показано на скриншоте выше, что, вероятно, указывает на то, что эта информация может храниться в другом месте или содержаться в каком-то встроенном файле.
Многие администраторы часто добавляют новые хосты ESXi, но довольно редко обсуждается вопрос о том, как правильно выводить из эксплуатации хост VMware ESXi. Об этом интересную статью написал Stephen Wagner.
Многих может удивить, что нельзя просто выключить хост ESXi и удалить его из окружения сервера vCenter, так как необходимо выполнить ряд шагов заранее, чтобы обеспечить успешный вывод из эксплуатации (decomission). Правильное списание хоста ESXi предотвращает появление изолированных объектов в базе данных vCenter, которые иногда могут вызывать проблемы в будущем.
Итак, процесс: как списать хост ESXi
Предполагается, что вы уже перенесли все ваши виртуальные машины, шаблоны и файлы с хоста, и он не содержит данных, которые требуют резервного копирования или миграции. Если вы этого не сделали - проверьте все еще раз, на хосте могут оказаться, например, кастомные скрипты, которые вы не сохраняли в другом месте.
Вкратце процесс выглядит так:
Перевод ESXi в режим обслуживания (Maintenance Mode)
Удаление хоста из распределенного коммутатора vSphere Distributed Switch (vDS)
Отключение и размонтирование томов iSCSI LUN
Перемещение хоста из кластера в датацентр как отдельного хоста
Удаление хоста из инвентаря (Inventory)
Выполнение расширенных процедур
Вход в режим обслуживания
Мы переходим в режим обслуживания, чтобы убедиться, что на хосте не запущены виртуальные машины. Вы можете просто щелкнуть правой кнопкой мыши по хосту и войти в режим обслуживания (Enter Maintenance Mode):
Если хост ESXi входит в состав кластера VMware vSAN, то вам будут предложены опции того, что нужно сделать с данными на нем хранящимися:
Удаление хоста из окружения vSphere Distributed Switch (vDS)
Необходимо аккуратно удалить хост из любых распределенных коммутаторов vDS (VMware Distributed Switches) перед удалением хоста из сервера vCenter.
Вы можете создать стандартный vSwitch и мигрировать адаптеры vmk (VMware Kernel) с vDS на обычный vSwitch, чтобы поддерживать связь с сервером vCenter и другими сетями.
Обратите внимание, что если вы используете коммутаторы vDS для подключений iSCSI, необходимо заранее разработать план по этому поводу, либо размонтировать/отключить iSCSI LUN на vDS перед удалением хоста, либо аккуратно мигрировать адаптеры vmk на стандартный vSwitch, используя MPIO для предотвращения потери связи во время выполнения процесса.
Размонтирование и отключение iSCSI LUN
Теперь вы можете приступить к размонтированию и отключению iSCSI LUN с выбранного хоста ESXi:
Размонтируйте тома iSCSI LUN с хоста
Отключите эти iSCSI LUN
Нужно размонтировать LUN только на выводимом из эксплуатации хосте, а затем отключить LUN также только на списываемом хосте.
Перемещение хоста из кластера в датацентр как отдельного хоста
Хотя это может быть необязательным, это полезно, чтобы позволить службам кластера vSphere (HA/DRS) адаптироваться к удалению хоста, а также обработать реконфигурацию агента HA на хосте ESXi. Для этого вы можете просто переместить хост из кластера на уровень родительского дата-центра.
Удаление хоста из инвентаря
После перемещения хоста и прошествия некоторого времени, вы теперь можете приступить к его удалению из Inventory. Пока хост включен и все еще подключен к vCenter, щелкните правой кнопкой мыши по хосту и выберите «Remove from Inventory». Это позволит аккуратно удалить объекты из vCenter, а также удалить агент HA с хоста ESXi.
Повторное использование хоста
Начиная с этого момента, вы можете войти напрямую на хост ESXi с помощью локального пароля root и выключить хост. Сделать этого можно также с помощью обновленного VMware Host Client.
На днях VMware от Broadcom представила бета-версию нового издания продукта для управления отдельными хостами ESXi - VMware Host Client. Все пользователи, зарегистрированные в программе бета-тестирования vSphere, могут получить доступ к новой бета-версии Host Client и загрузить обновленный графический интерфейс для работы с серверами ESXi.
Устаревший VMware Host Client сталкивался с технологическими трудностями и проблемами удобства использования, поэтому был переведен в режим поддержки без значимых обновлений. Для устаревшего клиента решались только критические проблемы, связанные с безопасностью или доступностью графического интерфейса. VMware уже давно обещала выпустить новое издание Host Client - и вот теперь оно доступно, но в рамках бета-программы.
Поскольку это первая версия нового пользовательского интерфейса для управления ESXi, она охватывает только базовые процессы управления самим хостом и виртуальными машинами и лишь некоторые операции. VMware будет постепенно расширять функциональность самыми важными рабочими операциями, чтобы предоставить пользователям vSphere мощный инструмент для управления хостом, охватывающий критические сценарии устранения неполадок на уровне ESXi (а также в случае недоступности vCenter).
Бета-версия нового Host Client — это веб-приложение, которое может быть использовано в macOS, Windows или Linux. Оно не связано с конкретной версией ESXi и, таким образом, может подключаться как к самым последним версиям гипервизора, так и к более старым. При подключении к ESXi можно сохранить данные подключения, чтобы обеспечить легкое переключение между серверами.
Внешний вид нового графического пользовательского интерфейса аналогичен пользовательскому опыту клиента vSphere. Представления данных поддерживают как список, так и вид карточек, а также имеют быструю фильтрацию по строкам:
В качестве отправной точки бета-версия охватывает следующий набор функций:
Просмотр общей информации о ESXi – емкость ресурсов, оборудование, конфигурация, история производительности.
Просмотр списка виртуальных машин, расположенных на хосте ESXi.
Управление виртуальной машиной – операции c питанием, снапшоты, изменение настроек ВМ и открытие ее консоли.
Просмотр алармов, событий и предупреждений, связанных с хостом ESXi.
Живой мониторинг задач, связанных с хостом ESXi.
Управление хранилищем – просмотр деталей и увеличение емкости.
В рамках бета-версии пользователям предоставляется возможность принять участие в программе улучшения пользовательского опыта, позволяя команде VMware собирать телеметрию. Вы также можете поделиться отзывом, используя специальную форму, доступную из консоли Host Client.
Имейте в виду, что устаревший Host Client входит в состояние снятия с производства. Он все еще будет доступен и поддерживаться в общедоступной версии следующего крупного выпуска vSphere и будет сосуществовать с новым пользовательским интерфейсом ESXi. Однако в ходе обновлений следующего мажорного релиза поддержка устаревшего Host Client будет прекращена, и он не будет доступен версии +1.
Скачать бета-версию нового VMware Host Client можно по этой ссылке, заполнив там соответствующую форму.
Для многих продуктов VMware (в том числе vSphere) есть бесплатная пробная лицензия на 60 дней, которую вы можете получить самостоятельно. Тут есть 2 ограничения:
Если вы и ваша компания находитесь в России или Беларуси, то легально получить такую лицензию не получится.
Не все продукты VMware имеют пробные версии на 60 дней, некоторые решения нужно запрашивать через партнеров или в отделе продаж VMware (как правило, это специфические Enterprise-решения).
Итак, рассмотрим этот процесс на примере VMware vSphere. Идем по этой ссылке:
В поиске вбиваем интересующий нас продукт, например, vSphere. Там будет несколько результатов (например, лабораторные работы), находим нужный нам Trial и кликаем по ссылке.
Если у вас уже есть аккаунт VMware Connect, то вы можете зайти под ним в разделе справа. Если же нет, то его можно создать (Create an Account):
Если вы уже использовали пробную версию vSphere на 60 дней в прошлом, то второй раз попробовать продукт уже не получится. Если же вы делаете это впервые, то у вас будет кнопка Register, которая позволит вам зарегистрироваться в программе пробного использования:
Далее нужно будет заполнить анкету, где указывается информация о вас и вашей организации:
После этого в разделе License&Download вам будет доступна лицензия на полнофункциональную версию vSphere Cloud Foundation (VCF) на 60 дней, а также ссылки на скачивание компонентов VMware vSphere.
Также вы можете скачать VMware vSphere и ее компоненты в любой момент по следующей ссылке (для этого не нужно регистрироваться в программе пробного периода):
Продолжаем рассказывать о производительности решения vSAN Express Storage Architecture (ESA), где реализовано высокопроизводительное кодирование RAID 5/6 с исправлением ошибок. Клиенты могут ожидать, что RAID-5/6 будет работать наравне с RAID-1 при использовании vSAN ESA. Новая архитектура обеспечит оптимальные уровни устойчивости, которые также эффективны с точки зрения использования пространства, при этом соблюдается высокий уровень производительности. Все это достигается с использованием технологии RAID-6 на базе новой журналируемой файловой системы и формата объектов.
VMware ESXi 8.0.2, сборка 22380479 с vSAN ESA (все хранилища - NVMe)
Oracle 21.13 Grid Infrastructure, ASM Storage и Linux udev (размер блока базы данных 8k)
OEL UEK 8.9
Детали кластера vSAN Express Storage Architecture (ESA) "env175" показаны ниже. Кластер ESA состоит из 8 серверов Lenovo ThinkAgile VX7531, как показано на картинке:
Каждый сервер Lenovo ThinkAgile VX7531 имеет 2 сокета, 28 ядер на сокет, Intel Xeon Gold 6348 CPU на частоте 2.60GHz и 1TB RAM:
Каждый сервер Lenovo ThinkAgile VX7531 имеет 6 внутренних накопителей NVMe, таким образом каждый сервер дает 6 внутренних устройств NVMe в качестве емкости датастора vSAN ESA:
Информация о сервере ThinkAgile VX7531 "env175-node1.pse.lab" в части деталей HBA и внутренних устройств NVMe:
Политики хранения кластера vSAN Express Storage Architecture (ESA) показаны на картинке ниже.
Базовая политика Oracle "Oracle ESA – FTT0 – NoRAID" была создана только для получения эталонных метрик для сравнения, кроме того, настоящая производственная нагрузка никогда не настраивается с FTT=0 (количество допустимых отказов) и без RAID (то есть без защиты).
Oracle ESA – FTT0 – NoRAID
Oracle ESA – FTT1 – R5
Oracle ESA – FTT2 – R6
Детали виртуальной машины "Oracle21C-OL8-DB_ESA" показаны на картинке ниже.
Виртуальная машина имеет 28 vCPU, 256 ГБ RAM. Один экземпляр базы данных "ORA21C" был создан с опцией multi-tenant на базе инфраструктуры Oracle Grid (ASM). Версия базы данных - 21.13 на операционной системе OEL UEK 8.9.
Oracle ASM использовалась как платформа хранения данных с Linux udev для обеспечения персистентности устройств. Oracle SGA и PGA были установлены на 64G и 10G соответственно. Также были соблюдены все лучшие практики платформы Oracle на VMware.
Виртуальная машина "Oracle21C-OL8-DB_ESA" имеет 4 контроллера vNVMe для дополнительной производительности:
58 устройств хранения привязаны к ВМ "Oracle21C-OL8-DB_ESA", они показаны ниже:
Детали тестов разных политик хранения vmdk для ВМ "Oracle21C-OL8-Customer" показаны ниже:
Тест 1 – Прогон теста со всеми vmdk с политикой хранения "Oracle ESA – FTT0 – NoRAID"
Тест 2 – Прогон теста со всеми vmdk с политикой хранения "Oracle ESA – FTT1 – R5"
Тест 3 – Прогон теста со всеми vmdk с политикой хранения "Oracle ESA – FTT2 – R6"
Детали группы дисков Oracle ASM показаны ниже:
Тестовый сценарий
Результаты ниже являются тестовым сценарием, демонстрирующим преимущества производительности использования vSAN 8 vSAN Express Storage Architecture (ESA) для бизнес-критичных производственных нагрузок Oracle.
Генератор нагрузки SLOB был запущен против 2 TB табличного пространства SLOB с 3 различными политиками хранения.
Oracle ESA – FTT0 – NoRAID
Oracle ESA – FTT1 – R5
Oracle ESA – FTT2 – R6
В качестве генератора нагрузки для этого эксперимента был выбран SLOB 2.5.4.0 с следующими установленными параметрами SLOB:
Для имитации модели нагрузки с многосхемной работой использовались несколько схем SLOB, и количество потоков на схему было установлено в 20.
Размер рабочего блока был установлен в 1024 для максимизации объема ввода-вывода без перегрузки REDO для изучения различий в показателях производительности между 3 различными политиками хранения на vSAN ESA.
В VMware провели несколько прогонов SLOB для вышеупомянутого кейса и сравнили метрики Oracle, как показано в таблице ниже.
Напомним, что базовая политика Oracle "Oracle ESA – FTT0 – NoRAID" была создана ИСКЛЮЧИТЕЛЬНО для получения базовых метрик для сравнения, так как настоящая производственная нагрузка никогда не настраивается с FTT=0 и без RAID.
Мы видим, что метрики базы данных с новым высокопроизводительным кодированием RAID 5/6 архитектуры vSAN Express Storage Architecture (ESA) сопоставимы с базовыми показателями при использовании без RAID.
Как было сказано ранее, клиенты могут ожидать, что RAID-5/6 будет работать наравне с RAID-1 при использовании vSAN ESA. Новая архитектура обеспечит оптимальные уровни устойчивости, а также эффективность с точки зрения использования пространства.
Углубляясь в профили нагрузки основных баз данных, мы видим схожие метрики баз данных для исполнений запросов (SQL), транзакций, чтения/записи в IOPS и чтения/записи в МБ/сек как для прогонов политик хранения "Oracle ESA – FTT1 – R5", так и для "Oracle ESA – FTT2 – R6", а именно:
Выполнение запросов (SQL) в секунду и транзакции в секунду сопоставимы для всех трех прогонов
Запросы на чтение IO в секунду и запросы на запись IO в секунду сопоставимы для всех трех прогонов
Чтение IO (МБ) в секунду и запись IO (МБ) в секунду сопоставимы для всех трех прогонов
Углубляясь в изучение основных событий ожидания (wait events) базы данных, мы видим схожие события ожидания базы данных с похожими временами ожидания (wait times) для прогонов политик хранения "Oracle ESA – FTT1 – R5" и "Oracle ESA – FTT2 – R6".
Рассматривая статистику GOS, мы также можем видеть сопоставимые показатели производительности для запусков политик хранения "Oracle ESA – FTT1 – R5" и "Oracle ESA – FTT2 – R6":
В итоге нам удалось получить сопоставимые показатели производительности как с общей точки зрения базы данных, так и с точки зрения GOS для прогонов политик хранения "Oracle ESA – FTT1 – R5" и "Oracle ESA – FTT2 – R6".
Таги: VMware, vSAN, Oracle, Performance, ESXi, Storage, VMDK, ESA

 RSS
RSS