DVD Store — это инструментарий для тестирования баз данных с открытым исходным кодом, который активно применяется с момента своего первого релиза в 2005 году. Он поддерживает работу с СУБД SQL Server, Oracle, PostgreSQL и MySQL. DVD Store моделирует интернет-магазин, в котором пользователи авторизуются, просматривают каталог, оставляют отзывы, выставляют оценки и покупают DVD. В тесте задействуется большое число типичных возможностей реляционных БД: хранимые процедуры, индексы, внешние ключи, полнотекстовый поиск, сложные запросы с множественными join'ами и транзакции.
Изначально DVD Store разрабатывался как нагрузка, ориентированная преимущественно на CPU. Тем не менее в нём с самого начала были предусмотрены параметры, позволяющие менять этот профиль и переключаться на сценарии, в которых акцент делается на сеть, дисковую подсистему или даже память. Примеры таких профилей теперь добавлены и описаны в основном репозитории DVD Store на GitHub: https://github.com/dvdstore/ds35/tree/main/workload_profiles
VMware провела тестирование тестирование платформы VMware vSphere с помощью этого инструмента для того, чтобы понять, насколько эти профили меняют поведение нагрузки относительно стандартного CPU-ориентированного сценария. Все измерения проводились на одной виртуальной машине, развёрнутой на сервере ESX 9.0 платформы VMware Cloud Foundation (VCF). ВМ работала под управлением Windows Server 2022, в качестве СУБД использовалась SQL Server 2022. Все показатели производительности фиксировались со стороны хоста ESX с помощью утилиты esxtop (аналог linux top, но адаптированный под ESX и собирающий значительно более широкий набор метрик).
CPU Utilization — загрузка процессора на хосте ESX
Disk I/O per second (IOPS) — операции чтения и записи на диск со стороны хоста ESX
Mb received per second (Mb Rec/s) — мегабиты, принятые в секунду по сети
Mb sent per second (Mb Sent/s) — мегабиты, отправленные в секунду по сети
Active Memory (ActiveMem) — объём памяти, к которой недавно было обращение (активная память)
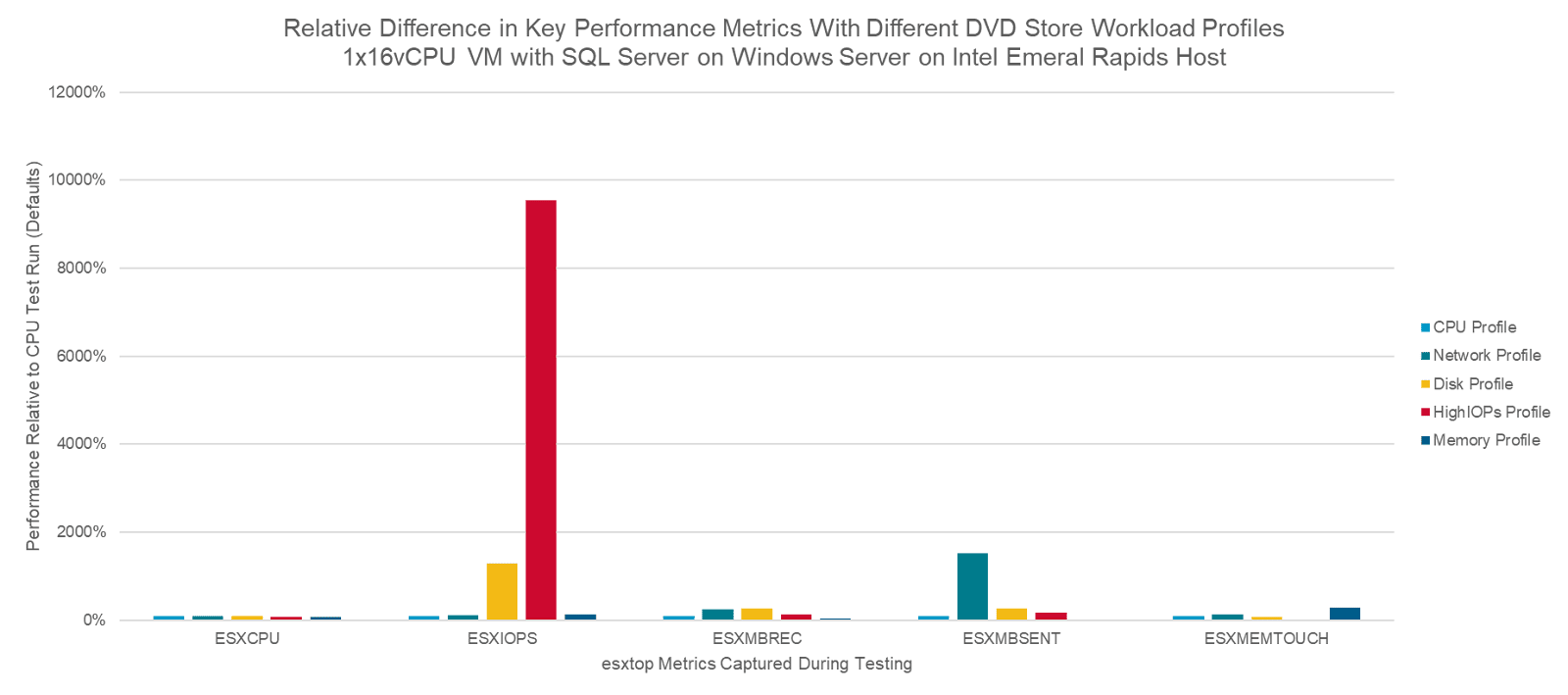
Относительное изменение ключевых метрик в разных профилях нагрузки
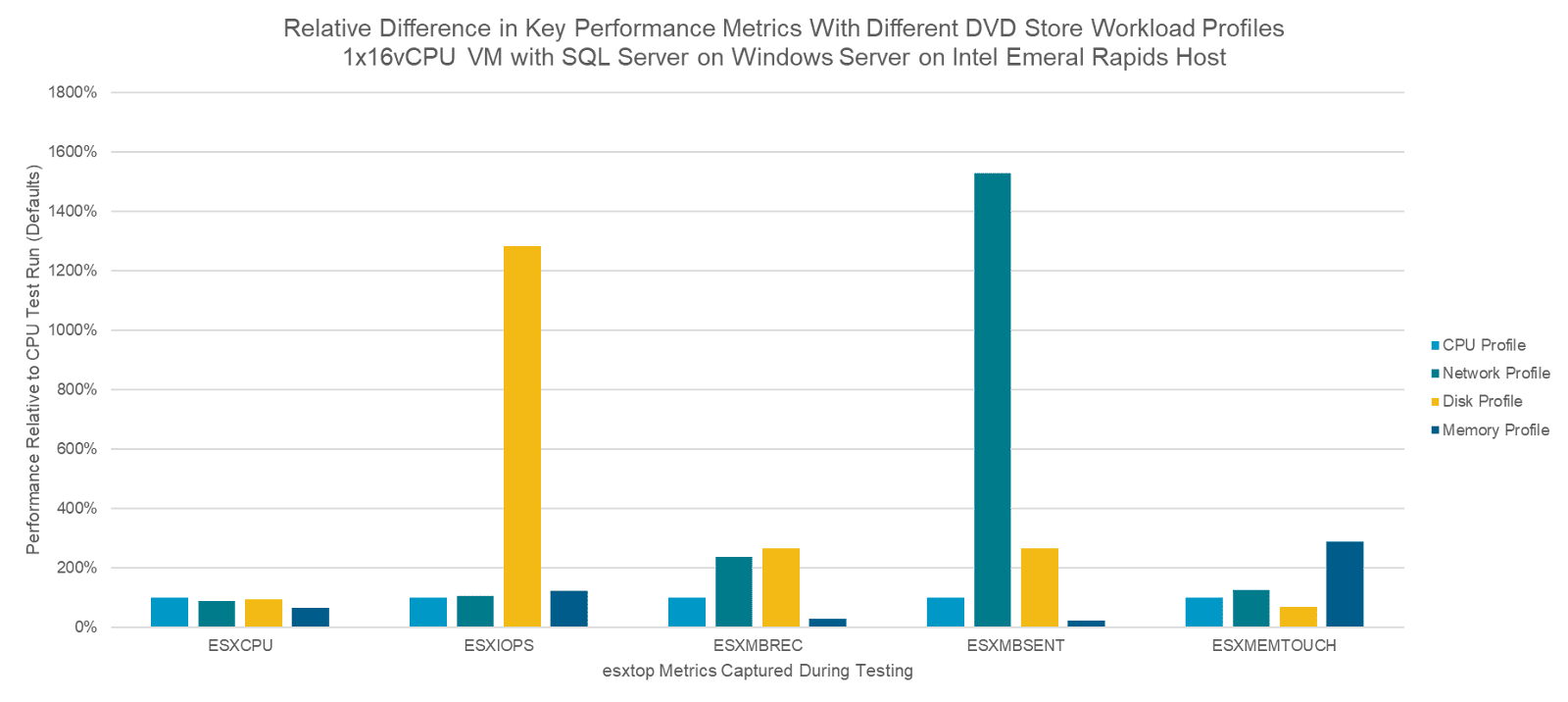
Для построения базовой линии замеры выполнялись на CPU-ориентированном профиле. Затем те же тесты были проведены с профилями, акцентированными на диск, на максимально высокий IOPS, на сеть и на память; полученные значения ключевых метрик сопоставлялись с базовыми. На графиках ниже показаны относительные различия по этим метрикам относительно базового CPU-профиля. На первом графике приведены все профили нагрузки; на втором профиль highIOPS убран, чтобы наглядно увидеть различия между остальными.
Если кратко резюмировать результаты, то в ключевой для каждого профиля метрике заметен значительный прирост:
Disk-профиль выдаёт в 13 раз больше IOPS
HighIOPS-профиль обеспечивает в 95 раз больше IOPS — это в 7 раз выше, чем у Disk-профиля
Network-профиль увеличивает количество отправленных мегабит в секунду в 15 раз
Memory-профиль вызывает в 2,9 раза большее значение активной памяти
Подробное описание всех профилей нагрузки приведено в файле ds35_workload_profiles.txt в репозитории DVD Store на GitHub. Там же указаны конкретные параметры DVD Store, особенности конфигурации БД и краткие пояснения к каждому сценарию.
Есть вопрос, который администраторы платформы виртуализации VMware vSphere задают регулярно:
Какие идеальные соотношения vCPU к pCPU я должен планировать и поддерживать для максимальной производительности? Как учитывать многопоточность Hyper-Threading и Simultaneous Multithreading в этом соотношении?
Ответ?
Он прост - общего, универсального соотношения не существует — и, более того, сам такой подход может привести к операционным проблемам. Сейчас объясним почему.
Раньше мы пользовались рекомендациями вроде 4 vCPU на 1 pCPU (4:1) или даже 10:1, но этот подход основывался на негласной предпосылке — рабочие нагрузки в основном были в простое. Многие организации начинали свою виртуализацию с консолидации наименее нагруженных систем, и в таких случаях высокое соотношение vCPU:pCPU было вполне обычным явлением.
Так появилась концепция коэффициента консолидации, ставшая основой для планирования ресурсов в виртуальных средах. Даже возникала конкуренция: кто сможет добиться более высокого уровня консолидации. Позже появились технологии вроде Intel Hyper-Threading и AMD SMT (Simultaneous Multithreading), которые позволяли достичь ещё большей консолидации. Тогда расчёт стал сложнее: нужно было учитывать не только физические ядра, но и логические потоки. Огромные Excel-таблицы превратились в операционные панели мониторинга ресурсов.
Но этот подход к планированию и эксплуатации устарел. Высокая динамика изменений в инфраструктуре заказчиков и рост потребления ресурсов со стороны виртуальных машин сделали модель статического соотношения нежизнеспособной. К тому же, с переходом к политике virtual-first, многие компании больше не тестируют приложения на "голом железе" до виртуализации.
А если мы не можем заранее предсказать, что будет виртуализовано, какие ресурсы ему нужны и как долго оно будет работать — мы не можем зафиксировать статическое соотношение ресурсов (процессор, память, сеть, хранилище).
Вместо этого нужно "управлять по конкуренции" (drive by contention)
То есть — инвестировать в пулы ресурсов для владельцев приложений и мониторить эти пулы на предмет высокой загруженности ресурсов и конкуренции (contention). Если возникает конфликт — значит, пул достиг предела, и его нужно расширять. Это требует нового подхода к работе команд, особенно с учётом того, что современные процессоры могут иметь огромное количество ядер.
Именно под такие задачи была спроектирована платформа VMware Cloud Foundation (VCF) и ее инструменты управления — и не только для CPU. На уровне платформы vSphere поддерживает крупные кластеры, автоматически балансируемые такими сервисами, как DRS, которые минимизируют влияние конфликтов на протяжении всего жизненного цикла приложений.
Операционный пакет VCF (Aria) следит за состоянием приложений и пулов ресурсов, сообщает о проблемах с производительностью или нехваткой ёмкости. Такая модель позволяет использовать оборудование эффективно, добиваясь лучшего уровня консолидации без ущерба для KPI приложений. Этого нельзя достичь при помощи фиксированного соотношения vCPU:pCPU.
Поэтому — чтобы не быть в рамках ограничений статических коэффициентов, повысить эффективность использования "железа" и адаптироваться к быстро меняющимся бизнес-реалиям, необходимо переосмыслить операционные модели и инструменты. В них нужно учитывать такие вещи, как:
Логические CPU не равно физические CPU/ядра (в случае гиперпоточности)
Важность точного подбора размеров виртуальных машин (right-sizing)
Ключевым фактором снижения рисков становится время вашей реакции на проблемы с производительностью или ёмкостью.
Если обеспечить быструю реакцию пока невозможно — начните с консервативного соотношения 1:1 vCPU:pCPU, не учитывая гиперпоточность. Это безопасный старт. По мере роста зрелости вашей инфраструктуры, процессов и инструментов, соотношение будет естественно улучшаться.
Идеальное финальное соотношение будет уникально для каждой организации, в зависимости от приложений, стека технологий и зрелости эксплуатации.
Вкратце:
Соотношение 1:1 даёт максимальную производительность, но по максимальной цене. Но в мире, где нужно делать больше с меньшими затратами, умение "управлять по конкуренции"— это путь к эффективной работе и инвестициям. VCF и был создан для того, чтобы справляться с этими задачами.
Intel недавно представила новое поколение серверных процессоров — Intel Xeon 6 с производительными ядрами (Performance-cores), которые отличаются увеличенным числом ядер и более высокой пропускной способностью памяти. Чтобы продемонстрировать производительность и масштабируемость этих процессоров, VMware опубликовала новые результаты тестов VMmark 4, полученных при участии двух ключевых партнёров — Dell Technologies и Hewlett Packard Enterprise. Конфигурация Dell представляет собой пару узлов в режиме «Matched Pair», а результат HPE получен на четырёхузловом кластере VMware vSAN. Оба результата основаны на VMware ESXi 8.0 Update 3e — первой версии, поддерживающей эти процессоры. Новые данные уже доступны на странице результатов VMmark 4.
Сравнение производительности: «Granite Rapids» и «Emerald Rapids»
В качестве примера, иллюстрирующего высокую производительность и масштабируемость, ниже приводится таблица с двумя результатами VMmark 4, позволяющая сравнить процессоры предыдущего поколения “Emerald Rapids” с новыми “Granite Rapids” серии 6700.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
Интересную статью написал Tom Fojta в своем блоге, касающуюся возможного повреждения данных на платформе VMware vSAN 8.0 (включая пакеты обновлений Update 1 и 2). Согласно статье базы знаний KB 367589, такое повреждение может случиться, если в вашей виртуальной машине некоторые приложения используют набор инструкций AVX-512.
Пока известно, что эти инструкции используются СУБД IBM Db2 и
SAP HANA (однако и другие приложения могут их потенциально использовать).
Чтобы проверить, есть ли поддержка AVX-512 у вашего процессора, нужно выполнить следующую команду:
Чтобы решить проблему на уровне процессора (виртуальной машины), нужно отмаскировать некоторые флаги в наборе инструкций CPU. Вы также можете решить проблему и на уровне приложений (для этого обратитесь к KB, указанной выше).
Итак, нужно добавить в Advanced Configuration Parameters виртуальной машины следующие строчки для проблемных инструкций AVX-512:
Сделать это можно и через интерфейс vSphere Client или Cloud Director - там нужно создать политику Compute Policy для виртуальных машин (в интерфейсе она называется VM Sizing Policy) с расширенными параметрами:
На днях на сайте virten.net появилась информация об уязвимости CVE-2022-40982 Gather Data Sampling (GDS/Downfall) хостов VMware ESXi 8 инфраструктуры vSphere, которая может быть полезна для администраторов.
8 августа этого года компания Intel рассказала о проблеме "transient execution side-channel vulnerability" (уязвимость побочного канала при переходном выполнении), которая затрагивает определенные процессоры. В особых микроархитектурных состояниях CPU возможно раскрытие информации после transient-исполнения команд в некоторых векторных модулях исполнения, что может привести к ситуации, когда аутентифицированный пользователь может получить неавторизованный доступ к информации через механику локального доступа. Подробнее об уязвимости CVE-2022-40982 можно почитать тут.
Также вам могут быть полезны следующие ресурсы:
Описание уязвимости Intel Security Advisory - INTEL-SA-00828
Чтобы понять, имеет ли ваш процессор данную дыру в безопасности, вам нужно получить о нем следующую информацию: CPU Family, Model и Stepping. Сделать это можно через PowerShell с помощью скрипта Get-CPUid, который вы можете скачать здесь.
Если вы посмотрели на вывод колонок и узнали там свой процессор из таблицы, а в колонке на сайте Intel увидели значение "MCU", то вам нужно накатывать обновление микрокода вашего сервера для защиты от угроз данного типа. Для получения обновления вам нужно связаться с вендором вашего серверного оборудования (например, ссылки для HP и Dell приведены выше).
Как написали коллеги с сайта virten.net, при установке платформы VMware ESXi 7 или 8 на сервер с процессорами Intel Core 12 поколения возникает розовый экран смерти (PSOD), содержащий следующие сообщения:
HW feature incompatibility detected; cannot start
Fatal CPU mismatch on feature "Hyperthreads per core" Fatal CPU mismatch on feature "Cores per package" Fatal CPU mismatch on feature "Cores per die"
Проблема здесь заключается в том, что новая архитектура процессоров Intel идет с ядрами двух типов - Performance-cores и Efficient-cores. Начиная с vSphere 7.0 Update 2, в ядро гипервизора был добавлен параметр cpuUniformityHardCheckPanic для того, чтобы избежать подобной проблемы, которая проявляется в следующих версиях платформы виртуализации:
vSphere / ESXi 8.0 или более поздние
vSphere / ESXi 7.0 Update 2 или более поздние
1. Итак, в самом начале установки ESXi нажимаете SHIFT+O, чтобы изменить параметры загрузки. Далее в появившейся строке вводите:
cpuUniformityHardCheckPanic=FALSE
2. После этого нажимаете Enter и дожидаетесь окончания установки.
3. Затем во время первой загрузки опять нажимаете SHIFT+O и вводите ту же самую строчку.
4. А уже когда гипервизор загрузится, нужно добавить следующую строчку в параметры ядра, чтобы отключить проверку, а ESXi не вылетал в розовый экран при каждой загрузке:
# esxcli system settings kernel set -s cpuUniformityHardCheckPanic -v FALSE
Также есть метод, описанный для установки через механизм автоматизированного развертывания Kickstart:
1. Создаем флэшку USB с ISO-образом ESXi, как написано здесь.
2. Открываем файл /efi/boot/boot.cfg в редакторе и добавляем следующую опцию в строчку kernelopt= параметров ядра:
ks=usb:/KS.CFG cpuUniformityHardCheckPanic=FALSE
3. Далее вам надо создать файл /KS.CFG для конфигурации Kickstart и в секциях %post (пост-параметры установки, но до первой загрузки) и %firstboot (первая загрузка) добавить следующее:
# NTP
esxcli system ntp set -s pool.ntp.org
esxcli system ntp set -e 1
4. Далее можете провести установку с USB-флэшки, а через пару минут вы уже сможете получить доступ к ESXi через консоль или по SSH.
5. Если вы используете механизм Secure Boot, то обычно секция %firstboot не применяется (так работает по умолчанию на большинстве систем). Поэтому вам потребоваться ввести команды этой секции вручную или отключить Secure Boot. С командами раздела %post все будет в порядке.
6. По окончании установки через Kickstart все будет работать:
Как вы знаете, главным релизом этого года стала новая версия платформы VMware vSphere 8, где появилось множество новых возможностей и улучшений уже существующих технологий. Одной из интересных функций стала vSphere Virtual Topology.
Для виртуальных машин с Hardware version 20 теперь доступно простое конфигурирование vNUMA-топологии для виртуальных машин:
Для виртуальных машин теперь доступна информационная панелька CPU Topology с конфигурацией vNUMA:
Недавно компания VMware выпустила документ "vSphere 8.0 Virtual Topology Performance Study", где рассматриваются аспекты производительности новой технологии, которую назвали vTopology. Виртуальная топология CPU включает в себя такие техники, как virtual sockets, узлы virtual non-uniform memory access (vNUMA), а также механизм кэширования virtual last-level caches (LLC).
До vSphere 8.0 дефолтной конфигурацией виртуальных машин было одно виртуальное ядро на сокет - это в некоторых случаях создавало затыки в производительности и неэффективность использования ресурсов. Теперь же ESXi автоматически подстраивает число виртуальных ядер на сокет для заданного числа vCPU.
На картинке ниже показана высокоуровневая архитектура компонентов двухсокетной системы. Каждый сокет соединен с локальным узлом памяти (memory bank) и образует с ним NUMA-узел. Каждый сокет имеет 4 ядра (он имеет кэши L1 и L2), а ядра шарят между собой общий кэш last-level cache (LLC).
Когда создается виртуальная машина с четырьмя vCPU, в vSphere она конфигурируется на одном сокете, вместо четырех, как это было ранее:
Так это выглядит в выводе команды CoreInfo для двух рассмотренных топологий:
Слева - это старая конфигурация, где был один vCPU на сокет, а справа - 4 vCPU (виртуальных ядер ВМ) на один сокет.
В указанном документе VMware проводит различных конфигураций (от 8 до 51 vCPU на машину) для разных нагрузок с помощью бенчмарков и утилит DVD Store 3.5, Login VSI, VMmark, Iometer, Fio и Netperf в операционных системах Windows и Linux. Забегая вперед, скажем, что для нагрузок Oracle прирост производительности составил 14%, а для Microsoft SQL server - 17%.
Итак, результаты теста DVD Store для БД Oracle:
Статистики NUMA hits NUMA misses для гостевой ОС Linux:
Результаты тестов для Microsoft SQL server:
Результаты тестирования хранилищ с помощью IOmeter:
Производительность в разрезе метрики CPU cycles per I/O (CPIO):
Компания VMware недавно выпустила пару интересных материалов о Project Monterey. Напомним, что продолжение развития технологии Project Pacific для контейнеров на базе виртуальной инфраструктуры, только с аппаратной точки зрения для инфраструктуры VMware Cloud Foundation (VCF).
Вендоры аппаратного обеспечения пытаются сделать высвобождение некоторых функций CPU, передав их соответствующим компонентам сервера (модуль vGPU, сетевая карта с поддержкой offload-функций и т.п.), максимально изолировав их в рамках необходимостей. Но вся эта новая аппаратная архитектура не будет хорошо работать без изменений в программной платформе.
Project Monterey - это и есть переработка архитектуры VCF таким образом, чтобы появилась родная интеграция новых аппаратных возможностей и программных компонентов. Например, новая аппаратная технология SmartNIC позволяет обеспечить высокую производительность, безопасность по модели zero-trust и простую эксплуатацию в среде VCF. За счет технологии SmartNIC инфраструктура VCF будет поддерживать операционные системы и приложения, исполняемые на "голом железе" (то есть без гипервизора).
Вот что нового в последнее время появилось о Project Monterey:
На сайте проекта VMware Labs появилось еще одно интересное средство Virtual Machine Desired State Configuration (VMDSC). Администраторам виртуальной инфраструктуры часто приходится менять параметры виртуальной машины, такие как CPU и память, чтобы проводить разного рода тюнинг и оптимизации. Для таких действий требуется перезагрузка виртуальной машины, что вызывает сложности в планировании.
Раньше подход был таким - к нужной дате/времени, согласованному с владельцами систем, происходила перезагрузка машин, которые за некоторое время уже поднимались в желаемой конфигурации (Desired State). Но это рождает довольно сложный административный процесс такого согласования.
Утилита VMDSC использует другой подход - виртуальные машины окажутся в Desired State при следующей перезагрузке гостевой ОС. Это позволяет не договариваться о простое ВМ в определенные периоды, а просто встраивать процесс реконфигурации процессора и памяти в жизненный цикл систем, когда им и так требуется перезагрузка (например, при накатывании обновлений).
Также в VMDSC встроена интеграция с vRealize Operations (vROPs), которая позволяет настраивать параметры ВМ на базе рекомендаций vROPs прямо из консоли этого решения:
Также массовую реконфигурацию ВМ можно проводить для отдельной папки, кластера или пула ресурсов.
Установка и развертывание утилиты состоит из нескольких несложных шагов:
Создаем служебный аккаунт VMDSC vCenter Service Account
Развертываем виртуальный модуль VMDSC в формате OVA
Используем Postman для настройки желаемых конфигураций ВМ (для этого нужно скачать и установить VMDSC Postman Collection)
Настроить интеграцию с vRealize Orchestrator и vRealize Operations
Для работы продукта понадобится vCenter 7 и новее, а также следующие разрешения сервисного аккаунта:
System.Read
System.View
VirtualMachine.Interact.PowerOff
VirtualMachine.Interact.PowerOn
VirtualMachine.Interact.Reset
VirtualMachine.Config.CPUCount
VirtualMachine.Config.Memory
VirtualMachine.Config.AdvancedConfig
VirtualMachine.Config.Settings
Sessions.ValidateSession
Ну и небольшое обзорное видео решения VMDSC:
Скачать Virtual Machine Desired State Configuration можно по этой ссылке.
Очередная интересная штука появилась на сайте проекта VMware Labs - утилита NUMA Observer, которая позволяет обнаружить виртуальные машины с перекрытием использования NUMA-узлов на хостах ESXi. При работе с тяжелыми нагрузками, требовательными к Latency, администраторы часто создают affinity-правила по привязке виртуальных машин к NUMA-узлам и ядрам CPU, чтобы они работали быстрее, с наименьшими задержками.
Но после сбоев и неполадок механизм VMware HA, восстанавливающий виртуальные машины на других хостах, может нарушить эту конфигурацию - там могут быть ВМ с уже привязанными NUMA-узлами, в результате чего возникнет перекрытие (overlap), которое полезно своевременно обнаружить.
С помощью NUMA Observer можно не только обнаруживать перекрытия по использованию ядер CPU и NUMA-узлов со стороны виртуальных машин, но и собирать статистики по использованию памяти дальнего узла и недостатке CPU-ресурсов (метрика CPU Ready). После анализа конфигураций и использования ресурсов, утилита генерирует алерты, которые администратор может использовать как исходные данные при настройке новой конфигурации NUMA-узлов.
Скачать NUMA Observer
можно по этой ссылке. После установки сервис доступен через веб-консоль по адресу localhost:8443. Для его работы потребуется Java 8.
Когда вышло обновление VMware vSphere 7 Update 2, мы рассказывали о новых оптимизациях для процессоров AMD EPYC, которые были сделаны в платформе виртуализации на базе гипервизора ESXi. Реализация поддержки новых функций CPU идет в соответствии с развитием технологий аппаратной виртуализации AMD, которую VMware поддерживает наравне с таковой от Intel.
В документе есть много интересных тестов (большинство из них сделано с помощью утилиты VMmark3), приведем ниже результаты некоторых из них:
Увеличение производительности одной ВМ для БД Microsoft SQL Server под нагрузкой HammerDB (тут и далее нормировано к показателям vSphere 7 Update 1):
Несколько виртуальных машин с 8 vCPU на борту и нагрузкой HammerDB - производительность при увеличении числа виртуальных машин на хосте:
Использование базы данных CockroachDB на 6-узловом кластере, прирост производительности до 50%:
Тестирование кластера Kubernetes c узлами по 64 воркера с помощью бенчмарка Weathervane (на 16 инстансах приложений прирост производительности - более 40%):
На сайте проекта VMware Labs появилась новая версия утилиты Virtual Machine Compute Optimizer 3.0, о которой в последний раз мы писали летом 2019 года. С тех пор вышло несколько обновлений этого средства. Напомним, что VMCO - это PowerShell-сценарий для модуля PowerCLI VMware.VimAutomation.Core, который собирает информацию о хостах ESXi и виртуальных машинах в вашем виртуальном окружении и выдает отчет о том, правильно ли они сконфигурированы с точки зрения процессоров и памяти.
В третьей версии сценария появился рабочий процесс установки/апгрейда всех необходимых модулей - VMCO и PowerCLI. Теперь это единый сценарий, в котором есть мастер, проходящий по всем шагам установки модулей, соединения с vCenter и экспорта результатов.
Также в последних версиях была добавлена опция -simple, которая позволяет отобразить только информацию о виртуальных машинах (без серверов vCenter, кластеров и хостов ESXi), обновлена документация и исправлено много ошибок.
Скачивайте Virtual Machine Compute Optimizer 3.0 и выясняйте, правильно ли у вас настроены vCPU и Memory для виртуальных машин. Надо понимать, что VMCO анализирует вашу инфраструктуру только на базе рекомендаций для оптимальной конфигурации виртуальных машин без учета реальной нагрузки, которая исполняется внутри.
Некоторое время назад мы писали о технологии Remote Direct Memory Access (RDMA) которая позволяет не использовать CPU сервера для удаленного доступа приложения к памяти другого хоста. RDMA позволяет приложению обратиться (в режиме чтение-запись) к данным памяти другого приложения на таргете, минуя CPU и операционную систему за счет использования аппаратных возможностей, которые предоставляют сетевые карты с поддержкой этой технологии - называются они Host Channel Adaptor (HCA).
Устройства HCA могут коммуницировать с памятью приложений на сервере напрямую. Грубо говоря, если в обычном режиме (TCP) коммуникация по сети происходит так:
То при наличии на обоих хостах HCA, обмен данными будет происходить вот так:
Очевидно, что такая схема не только снижает нагрузку на CPU систем, но и существенно уменьшает задержки (latency) ввиду обхода некоторых компонентов, для прохождения которых данными требуется время.
Поддержка RDMA появилась еще в VMware vSphere 6.5, когда для сетевых адаптеров PCIe с поддержкой этой технологии появилась возможность обмениваться данными памяти для виртуальных машин напрямую через RDMA API. Эта возможность получила название Paravirtual RDMA (PVRDMA).
Работает она только в окружениях, где есть хосты ESXi с сетевыми картами с соответствующей поддержкой, а также где виртуальные машины подключены к распределенному коммутатору vSphere Distributed Switch (VDS). Метод коммуникации между виртуальными машинами в таком случае выбирается по следующему сценарию:
Если две машины общаются между собой на одном ESXi, то используется техника memory copy для PVRDMA, что не требует наличия HCA-карточки на хосте, но сама коммуникация между ВМ идет напрямую.
Если машины находятся на хостах с HCA-адаптерами, которые подключены как аплинки к VDS, то коммуникация идет через PVRDMA-канал, минуя обработку на CPU хостов, что существенно повышает быстродействие.
Если в коммуникации есть хоть одна ВМ на хосте, где поддержки RDMA на уровне HCA нет, то коммуникация идет через стандартный TCP-туннель.
Начиная с VMware vSphere 7 Update 1, для PVRDMA была добавлена поддержка оконечных устройств с поддержкой RDMA (Native Endpoints), в частности хранилищ. Это позволяет передать хранилищу основной поток управляющих команд и команд доступа к данным от виртуальных машин напрямую, минуя процессоры серверов и ядро операционной системы. К сожалению для таких коммуникаций пока не поддерживается vMotion, но работа в этом направлении идет.
Чтобы у вас работала технология PVRDMA для Native Endpoints:
ESXi должен поддерживать пространство имен PVRDMA. Это значит, что аппаратная платформа должна гарантировать, что физический сетевой ресурс для виртуальной машины может быть выделен с тем же публичным идентификатором, что и был для нее на другом хосте (например, она поменяла размещение за счет vMotion или холодной миграции). Для этого обработка идентификаторов происходит на сетевых карточках, чтобы не было конфликтов в сети.
Гостевая ОС должна поддерживать RDMA namespaces
на уровне ядра (Linux kernel 5.5 и более поздние).
Виртуальная машина должна иметь версию VM Hardware 18
или более позднюю.
За счет PVRDMA для Native Endpoints виртуальные машины могут быстрее налаживать коммуникацию с хранилищами и снижать задержки в сети, что положительно сказывается на производительности как отдельных приложений и виртуальных машин, так и на работе виртуального датацентра в целом.
Недавно на сайте проекта VMware Labs появилось обновление этой платформы до версии 1.1. Эту версию нужно обязательно ставить заново, потому что обновление с версии 1.0 не поддерживется.
Давайте посмотрим, что там появилось нового:
Исправлена критическая ошибка, вызывавшая розовый экран смерти (PSOD) при добавлении к коммутатору VDS (см. тут)
Поддержка аппаратной платформы Arm N1 SDP
Поддержка виртуальных машин на процессорах Neoverse N1 CPU
Улучшения стабильности работы на платформах LS1046A и LX2160A
Исправления ошибок для отображения некорректного использования CPU на vCenter/DRS
Исправление ошибки с аварийным завершением виртуальной машины при полной заполненности хранилища
Исправление ошибки с поддержка устройств non-coherent DMA
Теперь можно ставить гипервизор имея в распоряжении 4% от 4 ГБ памяти вместо 3.125 (критично для некоторых аппаратных платформ)
Улучшения работы с последовательным портом
Обновление документации (больше информации об iSCSI, документы по платформам LS1046ARDB и Arm N1SDP, обновлен список поддерживаемых гостевых ОС)
Скачать VMware ESXi Arm Edition 1.1 можно по этой ссылке. Ну и бонусом несколько видео от Вильяма Лама по использованию этой платформы:
Многие администраторы платформы VMware vSphere после выхода седьмой версии продукта обнаружили, что ESXi 7.0 больше не хочет устанавливаться на старом оборудовании. Так происходит с каждой версией VMware vSphere - старые драйверы убирают, новые добавляют - это нормальный цикл жизни и развития продуктов. Например, больше не поддерживаются следующие процессоры:
Intel Family 6, Model = 2C (Westmere-EP)
Intel Family 6, Model = 2F (Westmere-EX)
Однако для тех, кому очень надо, компания VMware оставила небольшую возможность все-таки установить ESXi 7.0 на старом железе со старыми процессорами, но без каких-либо гарантий по работоспособности и поддержке (то есть, статус у этого режима - unsupported). В частности, коллеги написали статью об установке vSphere 7 на сервер IBM M3 X3550 Series.
Для начала решили ставить ESXi на USB-диск, так как RAID-контроллер сервера больше не поддерживается со стороны ESXi 7:
Далее при загрузке установщика ESXi с CD-ROM или ISO нужно нажать комбинацию клавиш Shift + <O> (это буква, а не ноль), после чего появится приглашение ко вводу. Надо ввести вот такую строчку в дополняемую строку:
allowLegacyCPU=true
Далее для установки выбрали USB-диск и начали установку ESXi на него:
После того, как ESXi установится на ваш сервер, вам нужно будет снова нажать Shift + <O> и повторно вбить указанный выше параметр при первом запуске:
Теперь нужно сделать так, чтобы данный параметр добавлялся при каждой загрузке ESXi. Сначала включим сервисы командной строки ESXi и удаленного доступа по SSH. Для этого нужно запустить службы TSM и TSM-SSH на хосте ESXi:
Далее подключаемся к ESXi по SSH и с помощью следующей команды находим файл конфигурации загрузки:
find / -name "boot.cfg
Далее добавляем в него параметр allowLegacyCPU=true в разделе kernelopt:
Два загрузочных модуля ESXi находятся в директориях /bootbank и /altbootbank. На всякий случай надо поменять boot.cfg в обеих директориях.
С помощью команды cat выведите содержимое отредактированных файлов, чтобы убедиться, что параметры загрузки у вас будут сохраняться:
Ну и, собственно, сам сервер ESXi 7.0.0, нормально работающий на сервере IBM x3550 M3:
Бонусом шутка про редактор vi, которым редактировался файл boot.cfg:
Те из вас, кто следит за анонсами Apple, наверняка знают, что компания решила отказаться от процессоров Intel в новом поколении компьютеров Mac, включая MacBook. Процессоры, разработанные компанией Apple, будут созданы на базе ARM-архитектуры, которая откроет возможности по увеличению производительности, уменьшению использования батареи и перспективы совместимости приложений между устройствами Apple других форм-факторов (телефоны и планшеты) без каких-либо изменений со стороны разработчиков. С точки зрения ОС, это все будет имплементировано в следующем поколении операционных систем, начиная с macOS Big Sur.
Но для нас в этой новости главное вот что - из-за смены архитектуры Intel на собственную ARM-платформу Apple перестанут работать решения для виртуализации настольных ПК VMware Fusion и Parallels Desktop, обеспечивающие работу виртуальных машин с гостевыми ОС Windows.
Не секрет, что пользователи Mac и MacBook все меньше и меньше пользуются Windows в ежедневной работе, ну а такой переход, возможно, и вовсе принудительно отменит ставшую уже небольшой необходимость.
В новой ОС для маков будет присутствовать решение по трансляции кода Rosetta 2, которое будет обеспечивать работоспособность x86/x64-приложений на базе архитектуры Apple. Но - за исключением платформ виртуализации VMware и Parallels, которые используют довольно много расширенных возможностей процессоров Intel.
Кроме того, не будет работать и механизм двойной загрузки операционной системы Boot Camp.
Понятное дело, что ситуация эта, скорее всего, временная - VMware и Parallels наверняка уже работают над решением этой проблемы и разработкой собственных платформ для новой архитектуры. Но очевидно, что дело это довольно долгое, а Apple, скорее всего, прорабатывает этот вопрос уже давно и выкатит собственное решение довольно быстро.
Таги: VMware, Apple, Fusion, Parallels, Desktop, CPU
При развертывании новой версии платформы VMware vSphere 7 в виртуальной машине (вложенные/nested ESXi) на серверах со старыми процессорами вы можете столкнуться с тем, что ваш CPU не поддерживается со стороны платформы:
В этом случае вы все равно можете установить гипервизор ESXi седьмой версии. Для этого вам надо открыть настройки виртуальной машины:
В разделе CPUID Mask нажать ссылку Advanced и далее вбить в регистре eax для Level 1 следующие значения:
Для процессоров Intel CPU: 0000:0000:0000:0011:0000:0110:1100:0011
Для процессоров AMD CPU: 0000:0000:0110:0000:0000:1111:0001:0000
После этого включайте ВМ, где будет установлен ESXi 7, и проходите до конца установки:
После этого ваш ESXi 7 спокойно загрузится. Затем нужно откатить маскирование функций CPU к исходной чистой конфигурации, удалив значение регистра eax:
Обратите внимание, что такая конфигурация не поддерживается в производственной среде! Поэтому используйте такие виртуальные ESXi 7 только для тестирования и других некритичных задач.
На днях компания VMware сделала анонс о грядущих изменениях в лицензировании платформы виртуализации VMware vSphere. Теперь понятие "лицензия на CPU" будет включать в себя процессоры, которые содержат до 32 физических ядер.
Если в процессоре больше ядер, то квантоваться они будут по 32 штуки - то есть, если в физическом CPU 64 ядра, то вам потребуется 2 лицензии VMware vSphere (2x32). Надо понимать, что речь идет о физических ядрах процессоров, а не о логических, доступных через Hyper-threading.
Процессоры с таким количеством ядер уже не за горами - например, AMD анонсировала процессор Ryzen 9 3990X с 64 ядрами, который будет стоить $4 000 (его обещают выпустить уже 7 февраля). Intel уже продает процессор Xeon Platinum 8280 с 28 ядрами на борту, но скоро в соревновании с AMD неизбежно надо будет делать больше ядер - так что изменения в лицензировании vSphere уже скоро станут вполне актуальны.
Наглядно новую схему лицензирования процессоров можно представить так:
Данные изменения вступят в силу 2 апреля 2020 года, но до 30 апреля действует grace period - то есть до этой даты вы сможете купить и лицензировать хосты VMware ESXi по старым правилам (очевидно, что VMware потребует доказательства приобретения и самих серверов до этой даты). Поэтому если до этого времени вдруг у ваших процессоров окажется очень много ядер - самое время будет приобрести лицензии VMware vSphere впрок.
На днях компания Intel опубликовала руководство по безопасности Security Advisory INTEL-SA-00329, в котором описаны новые обнаруженные уязвимости в CPU, названные L1D Eviction Sampling (она же "CacheOut") и Vector Register Sampling. Прежде всего, надо отметить, что обе этих уязвимости свежие, а значит исправления для них пока не выпущено.
Соответственно, VMware также не может выпустить апдейт, пока нет обновления микрокода CPU от Intel. Когда Intel сделает это, VMware сразу выпустит патч, накатив который на VMware vSphere вы избавитесь от этих потенциальных уязвимостей.
Vector Register Sampling (CVE-2020-0548). Эта уязвимость является пережитком бага, найденного в подсистеме безопасности в ноябре прошлого года. Она связана с атаками типа side-channel, о которых мы писали вот тут. В рамках данной атаки можно использовать механизм Transactional Synchronization Extensions (TSX), представленный в процессорах Cascade Lake. О прошлой подобной уязвимости можно почитать вот тут. А список подверженных уязвимости процессоров Intel можно найти тут.
L1D Eviction Sampling (CVE-2020-0549). Эта уязвимость (ее также называют CacheOut) позволяет злоумышленнику, имеющему доступ к гостевой ОС, получить доступ к данным из памяти других виртуальных машин. Более подробно об уязвимостях данного типа можно почитать на специальном веб-сайте. Также вот тут находится список уязвимых процессоров.
Следите за обновлениями VMware, патчи будут доступны сразу, как только Intel обновит микрокод процессоров. Достаточно будет просто накатить обновления vSphere - и они пофиксят уязвимости CPU.
Таги: VMware, Intel, Security, VMachines, vSphere, CPU
Для большинства ИТ-специалистов виртуализация ассоциируется с накладными расходами на ее содержание. Виртуальная машина имеет такие-то потери по CPU и столько-то издержки по оперативной памяти. Но иногда бывает и обратная ситуация - например, в статье про производительность контейнеров на платформе Project Pacific утверждается, что в виртуальных машинах они работают на 8% быстрее, чем на голом железе с Linux на борту.
Давайте посмотрим, почему это может быть так.
Сначала для тестирования взяли 2 идентичных аппаратных конфигурации (кластер из двух узлов), на одной из которых развернули гипервизор ESXi на платформе Project Pacific (там Kubernetes pods работают в виртуальных машинах), а на второй поставили Linux с Kubernetes pods (видимо, подразумевается Red Hat) с настройками из коробки, которые работают нативно:
VMware объясняет высокую производительность Project Pacific тем, что гипервизор воспринимает Pods как изолированные сущности, которые можно адресовать на CPU для наиболее подходящих локальных NUMA-узлов. Планировщик ESXi уже давно умеет эффективно работать с NUMA-узлами для vCPU ВМ, поэтому вполне логично ожидать здесь хороших результатов.
При настройке Kubernetes на Linux пользователь, с точки зрения выделения ресурсов CPU, оперирует логическими ядрами, которые дает технология hyperthreading, а при настройке виртуальных машин - физическими pCPU, то есть физическими ядрами процессора. Поэтому для чистоты эксперимента в тестах производительности VMware отключала hyperthreading.
Конфигурация каждого Pod выглядела так:
Всего было развернуто 10 Kubernetes pods, каждый из которых имел лимит по ресурсам 8 CPU и 42 ГБ RAM. Далее там был запущен один из Java-бенчмарков, целевым показателем которого была полоса пропускания (maximum throughput).
Результат оказался следующим:
Из графика видно, что кластер vSphere дал на 8% лучше результаты, чем нативный кластер Kubernetes на Linux.
Чтобы понять механику процесса, VMware замерила число попаданий в local DRAM (на уровне локального NUMA-домена) по сравнению с remote DRAM при условии промаха кэша в L3 процессора.
Для ESXi число таких попаданий составило 99,2%:
Это означает, что планировщик ESXi умеет размещать процессы ВМ таким образом, чтобы они могли получать более быстрый доступ к local DRAM.
Если же использовать привязку узлов к NUMA-доменам (Numactl-based pinning) в Linux, то результат работы нативных контейнеров выглядит лучше, чем таковой в виртуальных машинах:
Между тем, такая жесткая привязка узлов Kubernetes к NUMA-узлам оказывается непрактичной, когда требуется развертывать большое количество контейнеров, и возникает большая вероятность ошибок в конфигурациях.
Поэтому из коробки получается, что контейнеры Project Pacific работают лучше, чем на Linux-платформе в контексте использования ресурсов CPU.
Таги: VMware, Kubernetes, Performance, ESXi, vSphere, CPU
На сайте проекта VMware Labs очередное обновление - вышла новая версия продукта Virtual Machine Compute Optimizer 2.0. Это средство представляет собой PowerShell-сценарий для модуля PowerCLI VMware.VimAutomation.Core, который собирает информацию о хостах ESXi и виртуальных машинах в вашем виртуальном окружении и выдает отчет о том, правильно ли они сконфигурированы с точки зрения процессоров и памяти.
Напомним, что о первой версии данной утилиты мы писали летом этого года вот тут. Давайте посмотрим, что нового появилось в Virtual Machine Compute Optimizer 2.0:
Собираются приоритеты найденных несоответствий.
Вывод деталей найденных несоответствий.
Собирается информация о кластере, чтобы определить совместимость оборудования хостов на уровне кластера.
В отчет добавляется информация, если виртуальная машина использует разные физические pNUMA узлы, которые транслируются в гостевую ОС.
Добавляется информация об измененных расширенных настройках на уровне ВМ или хоста ESXi, касающихся представления pNUMA-узлов в гостевую ОС.
В отчет попадают ВМ, если у них число vCPU (с использованием гипертрэдов как vCPU) превышает число физических ядер CPU на хосте ESXi.
Возможность использовать отдельную функцию Get-OptimalvCPU для получения еще большей гибкости.
Скачать VM Compute Optimizer 2.0 можно по этой ссылке. Данный сценарий PowerCLI можно запустить различными способами, смотрите сопровождающий PDF (можно выбрать в комбобоксе при загрузке) для получения более детальной информации.
Большинство из вас, конечно же, слышало о серии уязвимостей в процессорах Intel (например, Meltdown и Spectre), которые потенциально могли приводить к получению контроля над исполнением систем (в том числе виртуальных машин), работающих на базе определенных CPU. Об этом можно прочитать у нас, например, тут и тут.
При обнаружении таких уязвимостей Intel выпускает обновления микрокода (firmware) для своих процессоров, которые нужно применить как к серверам ESXi, так и к виртуальным машинам. Например, для устранения уязвимости типа MDS была добавлена инструкция MD_CLEAR, которую гостевая ОС может обнаружить и использовать для защиты от определенных уязвимостей.
В виртуальной среде виртуальная машина - это VMX-процесс на сервере ESXi, который обеспечивает исполнение гостевой операционной системы. При этом ВМ может перемещаться между серверами ESXi средствами vMotion, поэтому она может иметь довольно большой аптайм (больше самих хостов, где она работает) и, как следствие, долго не обновлять виртуальное аппаратное обеспечение.
В то же время, для патчинга некоторых уязвимостей нужно обновить микрокод CPU и пересоздать VMX-процесс виртуальной машины, чтобы она могла инициализировать и подхватить обновления микрокода (что происходит только при первой загрузке). Простая перезагрузка тут не поможет, так как в этом случае пересоздания VMX не происходит, а лишь идет ребут гостевой системы. Кстати, это вам на заметку - если хотите "почистить" виртуальную машину, то лучше выключить и включить ее, а не перезагружать.
Чтобы выполнить процедуру выключения и включения, начиная с vSphere 6.5 Update 3 и vSphere 6.7 Update 3, компания VMware ввела инструкцию vmx.reboot.PowerCycle, которая выполняет цикл питания виртуальной машины. Этот параметр, который можно добавить в VMX-файл, считывается со стороны VMware Tools, которые уже совместно с хостом ESXi обеспечивают исполнение этого цикла.
Чтобы добавить этот параметр в VMX-файл через PowerCLI, вы можете использовать следующую команду:
Эти команды можно сопроводить принудительным флагом исполнения -Force и контролировать поведение в случае ошибки с помощью -ErrorAction.
После того, как параметр PowerCycle будет выставлен, VMware Tools (вы же помните, что они должны быть установлены) смогут совершить цикл сброса питания для виртуальной машины, а затем сам параметр будет удален из VMX-файла. Также он будет удален автоматически, если вы вручную завершите и снова запустите виртуальную машину.
Для контроля того, что параметр установлен, вы можете посмотреть в vSphere Client, в разделе Configuration Parameters (в самом низу):
Также использование данного параметра может вам помочь в случае кластеров Enhanced vMotion Compatibility (EVC). Такие кластеры требуют от виртуальных машин поддержки единого базового уровня инструкций CPU для обеспечения vMotion между хостами с разным аппаратным обеспечением.
В случае, если у вас где-то поменялось железо на хостах, то нужно выполнить перезапуск цикла питания виртуальных машин, что приведет кластер EVC к единому базовому уровню и позволит избавиться от потенциальных проблем.
Это гостевой пост нашего спонсора - облачного провайдера ИТ-ГРАД, предоставляющего услугу аренды виртуальных машин из облака. Говорим о балансировщике нагрузки от инженеров MIT, который планируют использовать в ЦОД. В статье — о принципах работы и возможностях решения.
Цель разработки
Аналитики одного из крупных облачных провайдеров говорят, что мировые ЦОД используют треть имеющихся у них вычислительных ресурсов. В исключительных случаях этот показатель может вырастать до 60%. Из-за неэффективного расходования мощностей в машинных залах появляются так называемые серверы-зомби. Они не выполняют полезную работу (находятся в состоянии «комы») и лишь впустую расходуют электричество. По данным Uptime Institute, без работы стоит около 10 млн серверов (это 30% всех машин). На поддержание их работоспособности ежегодно уходит 30 млрд долларов.
Инженеры из Массачусетского технологического института (MIT) решили исправить ситуацию. Они разработали балансировщик нагрузки, который в теории повысит эффективность использования ресурсов процессоров до 100%. Система получила название Shenango.
Как работает балансировщик
Shenango — это Linux-библиотека на языке программирования C (есть биндинги на Rust и C++). Она мониторит буфер задач CPU и распределяет процессы между свободными ядрами.
В основе системы лежит алгоритм IOKernel. Он запускается на отдельном ядре процессора и управляет запросами к CPU, которые поступают по сетевому интерфейсу NIC. Для этих целей IOKernel использует фреймворк DPDK (Data Plane Development Kit). Фреймворк дает приложениям возможность «общаться» с сетевыми картами напрямую.
Когда процессору поступает новая задача, IOKernel самостоятельно выбирает, какому ядру (или ядрам) ее передать. При этом для каждого процесса выделяются основные ядра (guaranteed) и вспомогательные (burstable) — последние подключаются только в том случае, если количество запросов резко возрастает.
Алгоритм проверяет буфер задач с интервалом в 5 мкс. Он ищет «застрявшие» процессы, которые CPU уже долгое время не может обработать. Если таковые обнаруживаются, они сразу же назначаются свободным ядрам (или другим серверам в дата-центре). Приоритет отдается ядрам, на которых уже выполнялся аналогичный процесс и часть информации о котором осталась в кэше.
Чтобы повысить эффективность балансировки, Shenango также использует метод work stealing. Ядра, работающие с одним приложением, автоматически снимают друг с друга часть нагрузки, если выполняют свои задачи раньше остальных.
Общую схему работы алгоритма IOKernel и системы Shenango можно представить следующим образом:
Код проекта и примеры приложений вы можете найти в официальном репозитории на GitHub.
Возможности
Разработчики говорят, что Shenango способен обрабатывать 5 млн запросов в секунду. Среднее время реакции при этом составляет 37 мкс. Эксперты ИТ-индустрии отмечают, что система поможет оптимизировать работу веб-приложений, например онлайн-магазинов. По статистике, секундная задержка при загрузке страницы снижает количество просмотров на 11%, что в дни распродаж может быть критично. Эффективное распределение нагрузки поможет обслужить большее количество клиентов.
Сейчас инженеры из MIT работают над устранением недостатков и расширением функциональности своего решения. Пока что Shenango не умеет работать с многопроцессорными NUMA-системами. В них чипы подключены к различным модулям памяти и не могут взаимодействовать друг с другом напрямую. Такой подход усложняет распределение нагрузки: IOKernel может контролировать работу отдельного кластера процессоров, но не все устройства сервера.
Кто еще разрабатывает балансировщики нагрузки на CPU
Не только в MIT занимаются разработкой систем распределения нагрузки на процессоры. В качестве еще одного примера можно привести систему Arachne — это библиотека C++ для Linux (код есть на GitHub, документацию по API можно найти на официальном сайте). Arachne рассчитывает, сколько ядер понадобится конкретному приложению, и выделяет необходимое количество при запуске соответствующего процесса.
Еще одним примером балансировщика может служить ZygOS — специализированная операционная система, которая использует структуры данных с общей памятью, NIC с несколькими очередями и межпроцессорные прерывания для распределения нагрузки между ядрами. Как и Shenango (в отличие от Arachne), решение также использует подход work stealing. Код проекта можно найти на GitHub.
Современные дата-центры становятся все крупнее. В мире уже построено более четырехсот гипермасштабируемых ЦОД. В ближайшее время их число вырастет еще на 30%. Технологии балансировки нагрузки позволят эффективнее расходовать вычислительные ресурсы. Поэтому решения подобные Shenango, ZygOS и Arachne будут становиться все более востребованными — уже сейчас их внедряют крупные корпорации.
Как знают почти все администраторы платформы VMware vSphere, для кластеров VMware HA/DRS есть такой режим работы, как Enhanced vMotion Compatibility (EVC). Нужен он для того, чтобы настроить презентацию инструкций процессора (CPU) хостами ESXi так, чтобы они в рамках кластера соответствовали одному базовому уровню (то есть все функции процессоров приводятся к минимальному уровню с набором инструкций, которые гарантированно есть на всех хостах).
Ввели режим EVC еще очень давно, чтобы поддерживать кластеры VMware vSphere, где стоят хосты с процессорами разных поколений. Эта ситуация случается довольно часто, так как клиенты VMware строят, например, кластер из 8 хостов, а потом докупают еще 4 через год-два. Понятно, что процессоры уже получаются другие, что дает mixed-окружение, где по-прежнему надо перемещать машины между хостами средствами vMotion. И если набор презентуемых инструкций CPU будет разный - двигать машины между хостами будет проблематично.
EVC маскирует инструкции CPU, которые есть не на всех хостах, от гостевых ОС виртуальных машин средствами интерфейса CPUID, который можно назвать "API для CPU". В статье VMware KB 1005764 можно почитать о том, как в кластере EVC происходит работа с базовыми уровнями CPU, а также о том, какие режимы для каких процессоров используются.
Надо отметить, что согласно опросам VMware, режим кластера EVC используют более 80% пользователей:
В VMware vSphere 6.7 появились механизмы Cross-Cloud Cold и Hot Migration, которые позволяют переносить нагрузки в онлайн и офлайн режиме между облаками и онпремизной инфраструктурой.
Когда это происходит, виртуальной машине приходится перемещаться между хостами с разными наборами инструкций процессора. Поэтому, в связи с распространением распределенных облачных инфраструктур, в vSphere появилась технология Per-VM EVC, которая позволяет подготовить виртуальную машину к миграции на совершенно другое оборудование.
По умолчанию, при перемещении машины между кластерами она теряет свою конфигурацию EVC, но в конфигурации ВМ можно настроить необходимый базовый уровень EVC, чтобы он был привязан к машине и переезжал вместе с ней между кластерами:
Обратите внимание, что Per-VM EVC доступна только, начиная с vSphere 6.7 и версии виртуального железа Hardware Version 14. Эта конфигурация сохраняется в vmx-файле (потому и переезжает вместе с машиной) и выглядит следующим образом:
Некоторые пользователи не включают EVC, так как покупают унифицированное оборудование, но VMware рекомендует включать EVC в кластерах со старта, так как, во-первых, никто не знает, какое оборудование будет докупаться в будущем, а, во-вторых, так будет легче обеспечивать миграцию виртуальных машин между облачными инфраструктурами.
Основная причина, по которой не включают EVC - это боязнь того, что поскольку машины не будут использовать весь набор инструкций CPU (особенно самых последних), то это даст снижение производительности. Поэтому VMware написала целый документ "Impact of Enhanced vMotion Compatibility on Application Performance", где пытается доказать, что это не сильно влияет на производительность. Вот, например, производительность Oracle на выставленных базовых уровнях для разных поколений процессоров (в документе есть еще много интересных графиков):
Чтобы включить EVC на базе виртуальной машины, нужно ее выключить, после чего настроить нужный базовый уровень. Для автоматизации этого процесса лучше использовать PowerCLI, а сама процедура отлично описана в статье "Configuring Per-VM EVC with PowerCLI".
Для того, чтобы выяснить, какие базовые уровни EVC выставлены для виртуальных машин в кластере, можно использовать следующий сценарий PowerCLI:
Get-VM | Select Name,HardwareVersion,
@{Name='VM_EVC_Mode';Expression={$_.ExtensionData.Runtime.MinRequiredEVCModeKey}},
@{Name='Cluster_Name';Expression={$_.VMHost.Parent}},
@{Name='Cluster_EVC_Mode';Expression={$_.VMHost.Parent.EVCMode}} | ft
Это даст примерно следующий результат (надо помнить, что отчет будет сгенерирован только для VM hardware version 14 и позднее):
В примере выше одна машина отличается от базового уровня хостов, но в данном случае это поддерживаемая конфигурация. Проблемы начинаются, когда машина использует более высокий базовый уровень CPU, чем его поддерживает хост ESXi. В этом случае при миграции vMotion пользователь получит ошибку:
Понять максимально поддерживаемый режим EVC на хосте можно с помощью команды:
В целом тут совет такой - включайте режим Enhanced vMotion Compatibility (EVC) в кластерах и для виртуальных машин VMware vSphere сейчас, чтобы не столкнуться с неожиданными проблемами в будущем.
В догонку к найденным и, вроде бы, поборенным уязвимостям Meltdown и Spectre, в процессорах Intel нашли еще одну потенциальную дыру - L1 Terminal Fault Vulnerability, которая затрагивает современные процессоры (2009-2018 годов выпуска) и гипервизор VMware ESXi (а также и все остальные гипервизоры).
Для начала надо сказать, что на днях стали доступны вот такие патчи для платформы виртуализации VMware vSphere, которые настоятельно рекомендуется установить:
Суть уязвимости, описанной в CVE-2018-3646 заключается в том, что виртуальная машина, исполняемая на конкретном ядре, может получить доступ к данным других машин, использующих это ядро, или самого гипервизора через L1 Data Cache, который совместно используется машинами, выполняющими команды на данном ядре.
Для такой уязвимости возможны 2 типа векторов атаки:
Sequential-context - вредоносная машина получает доступ к данным другой ВМ, которая исполнялась на этом ядре ранее и получала доступ к кэшу L1.
Concurrent-context - вредоносная машина прямо сейчас получает доступ к данным ВМ или гипервизора, которые исполняются планировщиком на этом ядре.
Решение вопроса уровня Sequential-context заключается просто в накатывании патчей, которые не должны приводить к падению производительности (как это было с Meltdown и Spectre). А вот для избавления от риска применения вектора атаки Concurrent-context нужно включить фичу, которая называется ESXi Side-Channel-Aware Scheduler. И вот в этом случае влияние на производительность может уже быть существенным, поэтому нужно либо принять риск Concurrent-context, либо следить за производительностью систем.
Таким образом, процесс обновления инфраструктуры VMware vSphere должен выглядеть так:
Обновляете сначала серверы vCenter, потом хосты ESXi.
Смотрите, есть ли на хостах запас по CPU на случай возникновения проблем с производительностью.
Если запас есть - включаете функцию ESXi Side-Channel-Aware Scheduler и наблюдаете за производительностью систем по CPU.
Детальные инструкции по включению ESXi Side-Channel-Aware Scheduler вы найдете здесь. Действовать нужно по следующей схеме:
Ну и в заключение, вот список процессоров, которые подвержены атакам типа L1 Terminal Fault:
Кодовое имя процессора Intel
FMS
Товарное наименование Intel
Nehalem-EP
0x106a5
Intel Xeon 35xx Series;
Intel Xeon 55xx Series
Lynnfield
0x106e5
Intel Xeon 34xx Lynnfield Series
Clarkdale
0x20652
Intel i3/i5 Clarkdale Series;
Intel Xeon 34xx Clarkdale Series
Автор известного технического блога о платформе VMware vSphere, Frank Denneman, совместно с одним из коллег выпустил весьма интересную книгу "vSphere 6.5 Host Resources Deep Dive".
В рамках 570-страничного талмуда авторы рассказывают все технические детали управления ресурсами на уровне хоста ESXi, такими как память, процессор, стек работы с хранилищами и сетевая архитектура. Довольно много содержимого книги посвящено архитектуре NUMA-узлов и оперативной памяти, механикам работы CPU и ядра VMkernel, а также прочим самым глубоким моментам программных и аппаратных компонентов хоста ESXi.
По уверению авторов книга покрывает, например, следующие технические вопросы:
Оптимизация рабочих нагрузок для систем Non-Uniform Memory Access (NUMA).
Объяснение того, как именно работает механика vSphere Balanced Power Management, чтобы получить преимущества функциональности CPU Turbo Boost.
Как настроить компоненты VMkernel для оптимизации производительности трафика VXLAN и окружений NFV.
В общем, книга очень крутая и мудрая. Скачать ее можно по этой ссылке.
Если мы запустим утилиту esxtop, то увидим следующие столбцы (интересующее нас выделено красным):
Нас интересует 5 счетчиков, касающиеся процессоров виртуальных машин, с помощью которых мы сможем сделать выводы об их производительности. Рассмотрим их подробнее:
Счетчик %RUN
Этот счетчик отображает процент времени, в течение которого виртуальная машина исполнялась в системе. Когда этот счетчик для ВМ около нуля или принимает небольшие значение - то с производительностью процессора все в порядке (при большом его значении для idle). Однако бывает так, что он небольшой, а виртуальная машина тормозит. Это значит, что она заблокирована планировщиком ESXi или ей не выделяется процессорного времени в связи с острой нехваткой процессорных ресурсов на сервере ESXi. В этом случае надо смотреть на другие счетчики (%WAIT, %RDY и %CSTP).
Если значение данного счетчика равно <Число vCPU машины> x 100%, это значит, что в гостевой ОС виртуальной машины процессы загрузили все доступные процессорные ресурсы ее vCPU. То есть необходимо зайти внутрь ВМ и исследовать проблему.
Счетчики %WAIT и %VMWAIT
Счетчик %WAIT отображает процент времени, которое виртуальная машина ждала, пока ядро ESXi (VMkernel) выполняло какие-то операции, перед тем, как она смогла продолжить выполнение операций. Если значение этого счетчика значительно больше значений %RUN, %RDY и %CSTP, это значит, что виртуальная машина дожидается окончания какой-то операции в VMkernel, например, ввода-вывода с хранилищем. В этом случае значение счетчика %SYS, показывающего загрузку системных ресурсов хоста ESXi, будет значительно выше значения %RUN.
Когда вы видите высокое значение данного счетчика, это значит, что нужно посмотреть на производительность хранилища виртуальной машины, а также на остальные периферийные устройства виртуального "железа". Зачастую, примонтированный ISO-образ, которого больше нет на хранилище, вызывает высокое значение счетчика. Это же касается примонтированных USB-флешек и других устройств ВМ.
Не надо пугаться высокого значения %WAIT, так как оно включает в себя счетчик %IDLE, который отображает простой виртуальной машины. А вот значение счетчика %VMWAIT - уже более реальная метрика, так как не включает в себя %IDLE, но включает счетчик %SWPWT (виртуальная машина ждет, пока засвопированные таблицы будут прочитаны с диска; возможная причина - memory overcommitment). Таким образом, нужно обращать внимание на счетчик %VMWAIT. К тому же, счетчик %WAIT представляет собой сумму метрик различных сущностей процесса виртуальной машины:
Счетчик %RDY
Главный счетчик производительности процессора. Означает, что виртуальная машина (гостевая ОС) готова исполнять команды на процессоре (ready to run), но ожидает в очереди, пока процессоры сервера ESXi заняты другой задачей (например, другой ВМ). Является суммой значений %RDY для всех отдельных виртуальных процессоров ВМ (vCPU). Обращать внимание на него надо, когда он превышает пороговое значение 10%.
По сути, есть две причины, по которым данный счетчик может зашкаливать приведенное пороговое значение:
сильная нагрузка на физические процессоры из-за большого количества виртуальных машин и нагрузок в них (здесь просто надо уменьшать нагрузку)
большое количество vCPU у конкретной машины. Ведь виртуальные процессоры машин на VMware ESX работают так: если у виртуальной машины 4 vCPU, а на хосте всего 2 физических pCPU, то одна распараллеленная операция (средствами ОС) будет исполняться за в два раза дольший срок. Естественно, 4 и более vCPU для виртуальной машины может привести к существенным задержкам в гостевой ОС и высокому значению CPU Ready. Кроме того, в некоторых случаях нужен co-sheduling нескольких виртуальных vCPU (см. комментарии к статье), когда должны быть свободны столько же pCPU, это, соответственно, тоже вызывает задержки (с каждым vCPU ассоциирован pCPU). В этом случае необходимо смотреть значение счетчика %CSTP
Кроме того, значение счетчика %RDY может быть высоким при установленном значении CPU Limit в настройках виртуальной машины или пула ресурсов (в этом случае посмотрите счетчик %MLMTD, который при значении больше 0, скорее всего, говорит о достижении лимита). Также посмотрите вот этот документ VMware.
Счетчик %CSTP
Этот счетчик отображает процент времени, когда виртуальная машина готова исполнять команды, одна вынуждена ждать освобождения нескольких vCPU при использовании vSMP для одновременного исполнения операций. Например, когда на хосте ESXi много виртуальных машин с четырьмя vCPU, а на самом хосте всего 4 pCPU могут возникать такие ситуации с простоем виртуальных машин для ожидания освобождения процессоров. В этом случае надо либо перенести машины на другие хосты ESXi, либо уменьшить у них число vCPU.
В итоге мы получаем следующую формулу (она верна для одного из World ID одной виртуальной машины)
%WAIT + %RDY + %CSTP + %RUN = 100%
То есть, виртуальная машина либо простаивает и ждет сервер ESXi (%WAIT), либо готова исполнять команды, но процессор занят (%RDY), либо ожидает освобождения нескольких процессоров одновременно (%CSTP), либо, собственно, исполняется (%RUN).
Таги: VMware, vSphere, esxtop, ESXi, VMachines, Performance, CPU
Ben Armstrong, занимающий позицию Virtualization Program Manager в компании Microsoft, опубликовал несколько статей о том, как работает распределение ресурсов процессора в платформе виртуализации Microsoft Hyper-V R2 (кстати, не так давно вышел RTM-билд SP1 для Windows Server 2008 R2).
Приводим краткую выжимку. В настройках виртуальной машины на сервере Hyper-V вы можете увидеть вот такие опции:
Virtual machine reserve
Эта настройка определяет процентную долю процессорных ресурсов хост-сервера, которые должны быть гарантированы виртуальной машине. Если хост на момент запуска виртуальной машины не может гарантировать эти ресусры - виртуальная машина не запустится. То есть вы можете запустить 5 машин с Virtual machine reserve в 20%, а 6-я уже не запустится. При этом неважно, используют ли эти 5 машин какие-либо ресурсы, или они вовсе простаивают.
Однако, данная настройка имеет значение только когда ощущается нехватка процессорных ресурсов. Если 4 из этих 5 машин используют по 4% процента CPU хост-сервера, а пятая хочет 70% - она их получит, но до того момента, пока остальным не потребуются ресурсы процессора. То есть, настройка Virtual machine reserve гарантирует, что машина будет иметь в своем распоряжении ресурсов не меньше, чем заданный процент ресурсов CPU - в условиях борьбы за ресурсы процессора между машинами хоста.
По умолчанию в качестве Virtual machine reserve стоит настройка 0. Это означает, что вы можете запускать виртуальных машин столько, сколько позволяют физически доступные ресурсы хост-сервера Hyper-V.
Virtual machine limit
Эта настройка также задается в процентах. Она показывает какой максимально возможный процент процессорных ресурсов виртуальная машина может использовать от мощности своих виртуальных процессоров (в зависимости от их количества). Используется эта настройка в двух случаях - когда на хосте запущены тестовые виртуальные машины, которые могут при определенных условиях "съесть" все ресурсы, а также, когда приложение в виртуальной машине написано криво и может вызвать нагрузку на процессор, затормозив таким образом остальные машины.
Эта настройка активна всегда, что означает, что машина никогда не возьмет ресурсов больше чем Virtual machine limit, даже если свободных ресурсов очень много. Поэтому выставлять ее нужно в исключительных случаях, а для контроля ресурсов лучше использовать Virtual machine reserve. Кроме того, надо помнить, что Virtual machine limit применяется сразу к нескольким виртуальным CPU - поэтому, если приложение в виртуальной будет давать нагрузку только на один виртуальный процессор - он будет ограничен 50% доступных для него ресурсов, в то время как остальные будут простаивать.
CPU relative weight
Эта настройка позволяет выставить относительный вес виртуальных процессоров машины относительно других виртуальных машин. CPU relative weight - это просто число в диапазоне от 1 до 10000, которое определяет пропорциональный вес машины относительно других (по умолчанию выставлено 100 для всех). Если для одной из машин поставить значение 200 - то в случае нехватки процессорных ресурсов на хосте Hyper-V она получит в два раза больше ресурсов CPU, чем какая-либо из других. Обратите внимание - настройка начинает работать только в случае нехватки процессорных ресурсов на хосте и не раньше.
Смысл этой настройки - разделение виртуальных машин по категориям приоритета использования ресурсов в случае их нехватки (например, 300 - высокий приоритет, 200 - обычный, 100 - низкий). Так как это все относительные величины - имейте в виду, что здесь нет гарантий точного количества ресурсов CPU, получаемых машиной. И еще один момент - если в вашей виртуальной инфраструктуре Hyper-V работают несколько администраторов, то каждый из них может пользоваться своей классификацией весов. Например, у одного это 100, 200 и 300, а у другого - 500, 1000 и 2000. Если каждый из них для своего хоста установит эти значения, а потом за счет Live Migration какая-либо из машин динамически переместится на другой хост - распределение весов сильно изменится, что может повлиять на работу систем в условиях ограниченности ресурсов CPU хост-сервера.
В четвертой части заметок Бен рассматривает вопрос - почему эти значения задаются в процентах, а не в мегагерцах как у VMware. Ответ таков - 1 GHz обладает разной производительностью на разных поколениях CPU, а также хосты могут обладать разной мощностью процессоров, что делает предпочтительным использование относительных значений вместо абсолютных.

 RSS
RSS