Одно из главных преимуществ VMware Cloud Foundation (VCF) 9.1 — гибкость и широкая поддержка уже существующих клиентских сред, что позволяет встретить заказчиков ровно на той точке, где они находятся на пути к частному облаку. Это охватывает самые разные сценарии: от отдельных развёртываний vSphere с VCF Operations до сред с различными комбинациями vSAN, NSX и Aria Automation, вплоть до полнофункционального развёртывания всего стека VCF.
Благодаря возросшей гибкости VCF 9.1 заказчикам, в зависимости от того, какие компоненты и функции развёрнуты в их среде, может потребоваться учитывать конкретную последовательность обновления компонентов, дополнительные операционные процедуры и требования к ресурсам. Всё это способно превратить понимание общего хода обновления в непростую задачу. Раньше для уверенного планирования и проведения обновления приходилось собирать сведения по частям — из продуктовой документации, статей базы знаний и матриц совместимости.
Чтобы упростить процесс обновления, был предложен иной подход: почему бы не начать с того, где заказчик находится сейчас, опираясь на уже развёрнутые продукты и функции, вместо того чтобы требовать от него разбираться во всём множестве вариантов развёртывания и сценариев обновления? Используя эти данные как исходные, можно затем предложить подходящие целевые сценарии, до которых возможно обновиться, и, что особенно важно, сформировать индивидуальный план обновления именно для его среды.
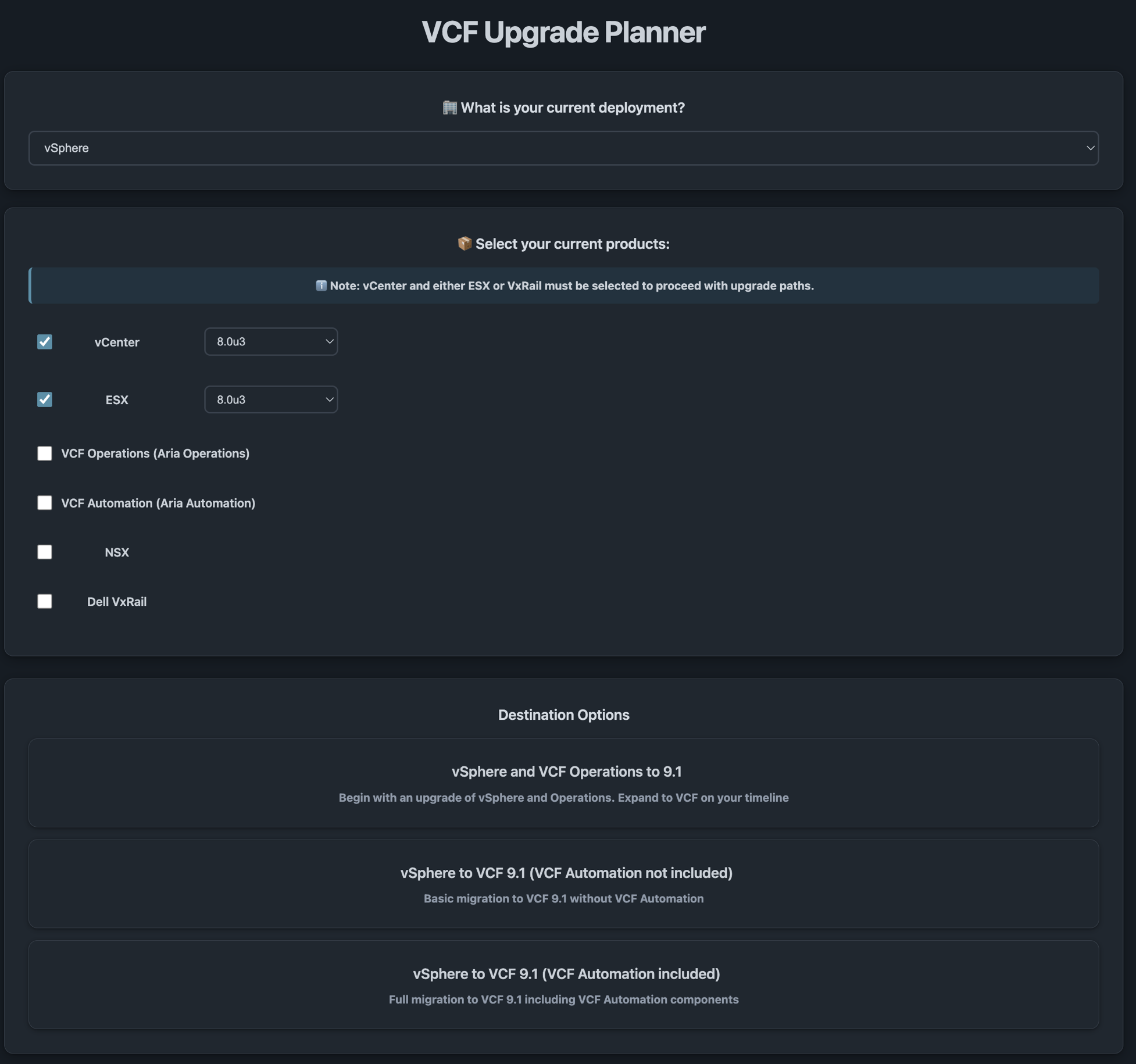
Объявлено о выпуске инструмента планирования обновлений VCF 9.1, который обеспечивает индивидуально подобранный сценарий планирования и помогает заказчикам уверенно пройти путь обновления VCF.
После указания текущего развёртывания — это может быть среда на базе vSphere или VCF — вместе с конкретными версиями, которые используются, пользователю предлагается набор применимых целевых вариантов на выбор.
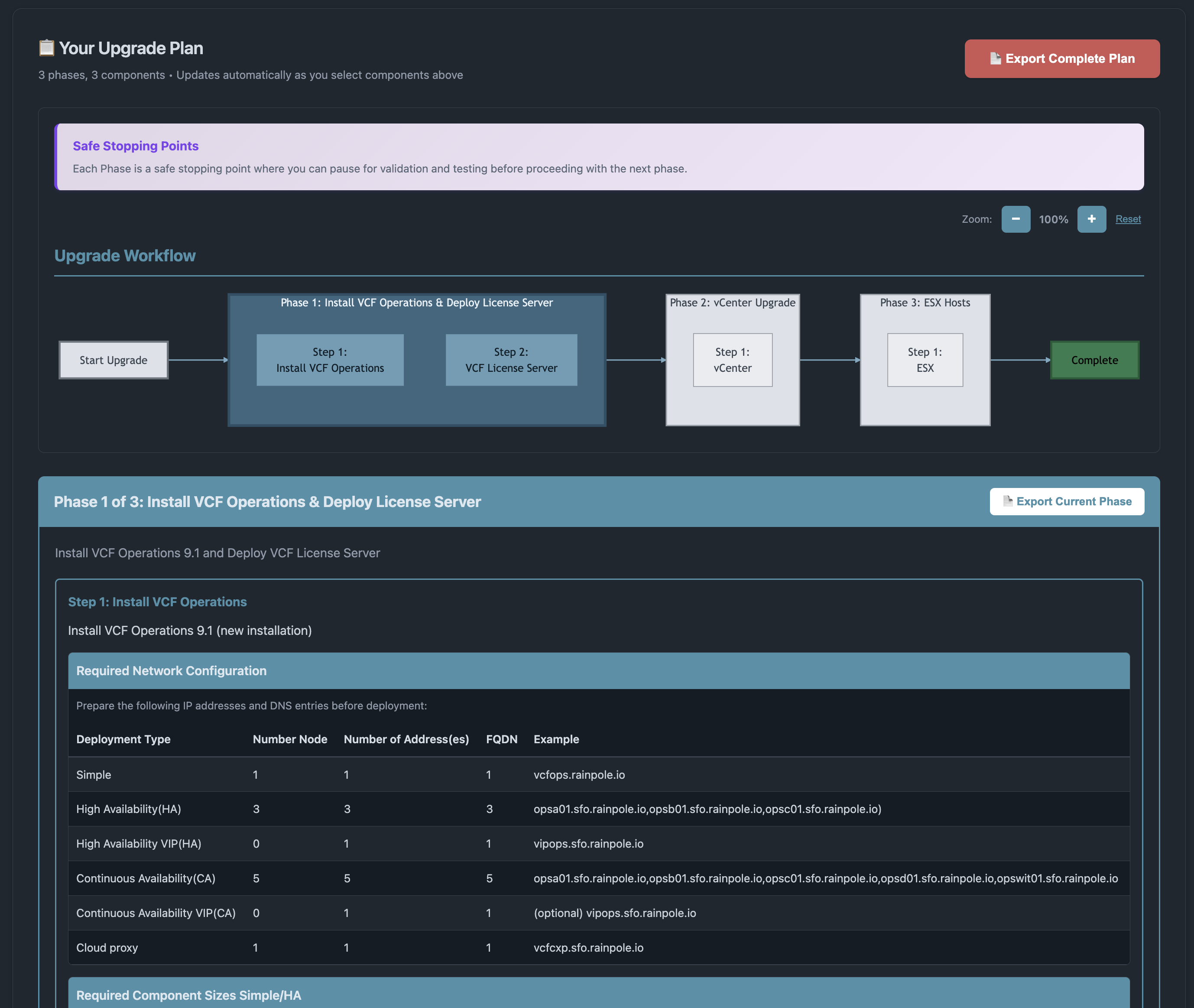
Как только целевой вариант выбран, инструмент планирования обновления VCF формирует исчерпывающий план обновления, который включает:
Общий ход обновления, разбитый на отдельные этапы, что помогает спланировать окна технического обслуживания
Требования к ресурсам и сети
Ключевые соображения и потенциальные подводные камни, которых следует избегать
Соответствующие ссылки на продуктовую документацию VCF
Инструмент планирования обновления VCF можно использовать в интерактивном режиме, а также экспортировать весь ход обновления и (или) отдельные его этапы в PDF для работы офлайн.
Ожидается, что этот инструмент сделает процесс обновления VCF более удобным. При наличии отзывов, замечаний или предложений по улучшению можно создать Issue на GitHub или даже внести собственный вклад в проект.
Модернизация центров обработки данных сегодня выглядит иначе, чем ещё несколько лет назад. Акцент сместился с простого наращивания мощностей на то, чтобы извлечь максимум из уже имеющейся инфраструктуры. Для большинства команд, отвечающих за инфраструктуру, реальная сложность состоит в том, чтобы совместить требования современных приложений с жёсткими бюджетами на оборудование и при этом не отставать от циклов обслуживания, которые поглощают продуктивное время.
VMware vSphere Foundation 9.1 создавалась, чтобы решать эту задачу напрямую. Объединяя вычисления, хранение и управление в тесно интегрированный стек, выпуск сокращает эксплуатационные простои, раскрывает более высокую производительность рабочих нагрузок и улучшает экономику среды без необходимости полностью перестраивать процессы эксплуатации.
Если это первое знакомство с vSphere Foundation 9.1, начать стоит с обзорной публикации о выпуске VMware vSphere Foundation 9.1 — в ней подробно описана каждая новая возможность. Настоящий материал является продолжением: это краткая ориентация по трём ключевым областям возможностей вместе с подборкой ресурсов, которые помогут команде перейти от первичного знакомства к этапам оценки и планирования.
Что нового: краткий обзор
Рисунок 1: VMware vSphere Foundation 9.1 переосмысливает экономику инфраструктуры, резко сокращая эксплуатационные простои и обеспечивая более высокую производительность рабочих нагрузок.
VMware vSphere Foundation 9.1 приносит усовершенствования по трём стратегическим направлениям. В обзорной публикации каждое из них рассмотрено детально; ниже приводится краткое резюме для ориентации и для указания на наиболее релевантные ресурсы из перечисленных далее.
Повышение операционной эффективности и снижение TCO. Встроенная высокоточная наблюдаемость и функция Proactive Diagnostic Insights теперь располагаются непосредственно в основной консоли эксплуатации, объединяя то, что прежде требовало нескольких разрозненных инструментов. Усовершенствованное многоуровневое размещение памяти на NVMe (NVMe Memory Tiering) добавляет высокопроизводительный второй уровень памяти, который интеллектуально берёт на себя от 20 до 25 процентов обращений к памяти, снижая TCO сервера и повышая плотность размещения виртуальных машин без ущерба для отзывчивости приложений.
Кардинальный рост производительности рабочих нагрузок. Планирование с учётом топологии (vSphere Topology-Aware Scheduling) применяет логику, учитывающую устройство процессора, для оптимизации размещения NUMA на процессорах высокой плотности, удерживая ресурсоёмкие приложения на пике производительности. Параллельная обработка миграций DRS vMotion устраняет последовательное узкое место при балансировке кластера, обеспечивая более быструю и непрерывную мобильность рабочих нагрузок. Расширенное сокращение данных vSAN (vSAN Data Reduction) даёт снижение TCO хранения до 39 процентов за счёт дедупликации и сжатия, оптимизированных по производительности.
Усиление безопасности, отказоустойчивости и соответствия требованиям. Оперативное применение исправлений (live patching) для хостов с поддержкой TPM позволяет устанавливать до 80 процентов критических обновлений безопасности без простоя, полностью выводя обслуживание безопасности за рамки запланированного окна технических работ. Расширенная репликация виртуальных машин с внешних массивов напрямую в кластер vSAN упрощает архитектуру восстановления и даёт реальную экономию по сравнению с устаревшими конфигурациями.
Ресурсы по VMware vSphere Foundation 9.1
Рисунок 2: Раздел ресурсов и вопросов-ответов по VMware vSphere Foundation 9.1 в нижней части страницы продукта VMware vSphere Foundation.
Читать о выпуске и понимать, как им воспользоваться, — это разные вещи. Материалы ниже созданы именно для второго шага, независимо от того, что сейчас в приоритете: подготовка внутреннего обоснования, сравнение вариантов платформ или подготовка команды к обновлению. Их можно использовать по порядку или сразу перейти к тому, который соответствует текущей ситуации.
Инфографика:VMware vSphere Foundation 9.1 с первого взгляда. С неё стоит начать ради быстрого визуального обзора. Инфографика показывает, как NVMe Memory Tiering снижает TCO сервера, как устраняются узкие места последовательной миграции, и как оперативное применение исправлений выводит обслуживание безопасности за пределы производственного календаря — всё в формате, удобном для распространения среди заинтересованных сторон.
Техническое описание (Datasheet):Возможности и преимущества продукта. Структурированный справочник для ИТ-специалистов, проводящих формальную оценку. Он охватывает возможности платформы, поддерживаемые аппаратные новшества и целевые сценарии использования, давая всё необходимое для оценки того, как vSphere Foundation 9.1 вписывается в стратегию ЦОД.
Краткое описание решения (Solution Brief):Новая экономика инфраструктуры. Подготовлено для руководителей в сфере инфраструктуры и бизнеса, следящих за предсказуемостью бюджета и окупаемостью оборудования. Документ обосновывает, как vSphere Foundation 9.1 справляется с волатильностью цен на DRAM и с постоянными издержками устаревших циклов обслуживания. Это хороший материал для выстраивания внутреннего согласия вокруг модернизации.
Сравнение возможностей:VMware Cloud Foundation и VMware vSphere Foundation 9.1. Понятный разбор двух основных платформ VMware. Если команда выбирает между модернизацией имеющейся инфраструктуры на базе vSphere Foundation и переходом к полнофункциональному частному облаку на VMware Cloud Foundation, этот документ наглядно излагает различия.
FAQ:Ответы на частые вопросы клиентов. Охватывает вопросы, которые обычно возникают вокруг развёртывания, аппаратной совместимости и новых возможностей централизованного управления. Практичный спутник для команд на этапе планирования и подготовки.
Дополнительные материалы
Обновление до VMware vSphere Foundation 9.1 даёт командам, отвечающим за инфраструктуру, не только новое программное обеспечение. Это практический шаг к среде, которая справляется с требованиями современных приложений, удерживает затраты на оборудование под контролем и высвобождает операционные ресурсы, обычно поглощаемые рутинным обслуживанием.
Изучите полную библиотеку ресурсов и начните знакомство с vSphere Foundation 9.1 уже сегодня:
Оговорка: все заявления об улучшении производительности и снижении затрат основаны на внутренних инженерных оценках Broadcom и результатах аппаратного тестирования за 2026 год, если не указано иное. Результаты могут изменяться.
VMware VCF — платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью и производительностью локальной инфраструктуры, повышая продуктивность и снижая совокупную стоимость владения (TCO).
Полнофункциональная платформа Infrastructure as a Service (IaaS), предоставляющая программно-определяемые вычисления, хранение, сеть, Kubernetes, безопасность и средства управления.
Встроенная автоматизация формирует платформу самообслуживания для быстрого развёртывания виртуальных машин и контейнеров и повышения скорости разработки.
Закалённая платформа со встроенной отказоустойчивостью, масштабированием и кластеризацией для непрерывной работы.
Облачная гибкость позволяет наращивать инфраструктуру без увеличения штата, перенося облачную модель потребления в локальную среду.
Автоматизация и оркестрация упрощают задачи нулевого, первого и второго дня.
Поставляется единым SKU, что упрощает развёртывание всего стека.
VMware vSphere Foundation — рабочая платформа корпоративного уровня для современной инфраструктуры. Она даёт преимущества виртуализации, упрощённое управление, экономичность и масштабируемость и служит ядром, на котором строится VMware Cloud Foundation.
Единая платформа для совместного запуска виртуальных машин и контейнеров с нативной средой выполнения Kubernetes.
Интеллектуальное управление эксплуатацией обеспечивает расширенную видимость и оптимизацию инфраструктуры.
Гиперконвергентная инфраструктура объединяет виртуализацию вычислений и хранения для эффективного управления ресурсами.
Упрощённое развёртывание и масштабируемость с единым SKU ускоряют доставку приложений и готовят инфраструктуру к будущему.
На рисунке ниже показан упрощённый портфель VMware by Broadcom и три варианта поставки.
Детальное сравнение функций
В сравнении участвуют три варианта поставки.
VMware Cloud Foundation — ПО частного облака с интегрированными компонентами: vSphere, vSphere Kubernetes Service, VCF Operations, VCF Operations for Networks, VCF Operations fleet management, VCF Automation, vSAN и NSX.
VMware vSphere Foundation — ПО, предоставляющее часть возможностей VCF или их ограниченные версии: vSphere, vSphere Kubernetes Service, VCF Operations и vSAN.
VMware Cloud Foundation Edge — оптимизированная конфигурация VMware Cloud Foundation для периферийных сценариев.
В таблицах ниже символ • означает, что функция включена в соответствующее издание, прочерк — что функция недоступна. Числа в квадратных скобках отсылают к примечаниям в конце статьи.
Вычисления (Compute)
Включённые сервисы:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Kubernetes Service (VKS)
•
•
•
VM Service
•
•
•
Storage Service
•[2]
•
•
Network Service
•[2]
•
•
Container Registry Service
•
•
•
Harbor Image Registry Service
•
•
•
vSphere Pod Service
•
•
•
VKS Load Balancing
•
•
•
Service Mesh
•
•
•
External DNS
•
•
•
ArgoCD Operator
—
•
•
Secret Store Service
—
•
•
IaaS Policy Service
—
•
•
Data Services
•
•
•
Workload Availability Zones
•
•
•
Упрощённое управление жизненным циклом кластеров VKS
—
•
•
Build Your Own Image (BYOI)
•
•
•
Supervisor Independent Updates
•
•
•
Custom Zone Optimization
•
•
•
Управление эксплуатацией:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Lifecycle Manager
•
•
•
Live Patching for ESX
•
•
•
vCenter Quick Patching
•
•
•
vCenter Server Profiles
•
•
•
vCenter Update Planner
•
•
•
Content Library
•
•
•
vSphere Configuration Profiles
•
•
•
Host Profiles
•
[3]
[3]
Auto Deploy
•
[3]
[3]
Эластичное предоставление vSphere (ZTP)
•
•
•
Green Metrics
•
•
•
Встроенная безопасность:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
Identity Federation
•
•
•
Аппаратный TPM 2.0
•
•
•
Virtual TPM 2.0
•
•
•
Сертификация FIPS 140-2 и Common Criteria
•
•
•
TLS 1.2
•
•
•
TLS 1.3
•[4]
•[4]
•[4]
Шифрование виртуальных машин
•
•
•
Standard Key Provider (внешний KMS)
•
•
•
Native Key Provider
•
•
•
File Integrity Monitoring
•
•
•
Confidential Computing
[15]
•
•
Интеграция EDR для ESX
•
•
•
Производительность приложений:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
Per-VM Enhanced vMotion Compatibility (EVC)
•
•
•
Instant Clone
•
•
•
Distributed Resource Scheduler (DRS)
•
•
•
Storage DRS
•
•
•
Distributed Power Management (DPM)
•
•
•
Storage Policy-Based Management
•
•
•
I/O Controls (хранилище)
•
•
•
SR-IOV
•
•
•
vSphere Persistent Memory
•
•
•
Memory Tiering
•
•
•
NVIDIA GRID vGPU
•
•
•
Accelerated Graphics for VMs
•
•
•
Dynamic DirectPath IO
•
•
•
Enhanced DirectPath I/O
•
•
•
Vendor Device Group
•
•
•
Разные профили vGPU на одном GPU
•
•
•
Автоматизация DRS для vGPU-нагрузок
•
•
•
Поддержка DPU и Dual DPU
—
•
•
Непрерывность бизнеса:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vMotion
•
•
•
Cross-vCenter vMotion
•
•
•
Encrypted vMotion
•
•
•
vCenter Enhanced Linked Mode
•
•
•
vSMP
•
•
•
vSphere High Availability (HA)
•
•
•
Proactive HA
•
•
•
Storage vMotion
•
•
•
Fault Tolerance
•
•
•
vSphere Replication
•
•
•
Поддержка 4k Native Storage
•
•
•
vSphere Quick Boot
•
•
•
Файловое резервное копирование и восстановление vCenter
•
•
•
Cross vCenter Mixed Version Provisioning
•
•
•
Горячая и холодная миграция в облако
•
•
•
Управление на основе политик (Policy-based Governance)
•
•
•
Kubernetes Automation
•
•
•
Workload Lifecycle Management
•
•
•
vCenter Orchestration & Extensibility
•
•
•
Хранение (Storage)
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSAN Express Storage Architecture (ESA)
•
•
•
vSAN Original Storage Architecture (OSA)
•
•
•
All-Flash оборудование
•
•
•
Базовые компрессия и дедупликация
• (только OSA)
• (только OSA)
• (только OSA)
Продвинутое сжатие и глобальная дедупликация
• (только ESA)
• (только ESA)
• (только ESA)
Шифрование данных «в покое»
•
•
•
Шифрование данных «в движении»
•
•[3]
•[3]
Storage Policy-Based Management
•
•
•
Программная контрольная сумма
•
•
•
vSAN over RDMA
•
•[3]
•[3]
QoS — ограничение IOPS
•
•
•
Auto-Managed RAID
•
•
•
Кластеры хранения vSAN
•
•
•
Кластеры кибервосстановления vSAN
—
•[15]
•[15]
Удалённые хранилища (Remote Datastores)
•
•
•
Растянутый кластер (Stretched Cluster)
•
•
•
Двухузловой кластер (2-Node Cluster)
•
•[3]
•[3]
File Services
•
•
•
Object Storage
—
•[17]
•[17]
iSCSI Target Service
•
•[3]
•[3]
Cloud Native Storage (CNS) Control Plane
•
•
•
vSphere Container Storage Interface (CSI) Driver
•
•
•
Rack Awareness (Fault Domains)
•
•[3]
•[3]
Snapshot Manager с гибким расписанием
•
•
•
Неизменяемые снимки (Immutable Snapshots)
•
•
•
Репликация Any-to-vSAN
•[14]
•[14]
•[14]
Внешние хранилища:
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
VMFS — Fibre Channel
•
• (Principal, Supplemental)
• (Principal, Supplemental)
VMFS — iSCSI
•
• (Supplemental)
• (Supplemental)
VMFS — FCoE
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/FC
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/TCP
•
• (Supplemental)
• (Supplemental)
VMFS — NVMe/RDMA
•
• (Supplemental)
• (Supplemental)
NFS — v3
•
• (Principal, Supplemental)
• (Principal, Supplemental)
NFS — v4.1
•
• (Supplemental)
• (Supplemental)
Storage I/O QoS Controls (SIOC)
•
•
•
VAAI для блочного хранилища
•
•
•
VAAI для NFS-хранилища
•
•
•
Кластеризация нагрузок (VMDK Clustering)
•
•
•
Автонастройка с NFS
•
•
•
Сторонние плагины хранения
•
•
•
Ввод хостов и управление кластером
•
•
•
Сеть (Networking)
Функция
vSphere Foundation
VCF Edge
VMware Cloud Foundation
vSphere Distributed Switch
•
•
•
Link Aggregation Control Protocol (LACP)
•
•[3]
•[3]
Load-Based Teaming
•
•
•
Network I/O QoS Control (NIOC)
•
•
•
Private VLAN
•
•
•
MAC Learning
•
•
•
BPDU Guard
•
•
•
Guest VLAN Tagging
•
•
•
VLAN Backed Networking
•
•
•
Virtual Networking
—
•
•
Spoofguard
—
•
•
L2 Multicast
•
•
•
L3 Multicast
—
•
•
Enhanced Datapath
—
•
•
Enhanced Datapath для DPU
—
•
•
Маршрутизация IPv4 и IPv6
—
•
•
Динамическая маршрутизация (OSPFv2/BGP/BFD)
—
•
•
VRF
—
•
•
EVPN
—
•
•
NAT
—
•
•
L2 и L3 VPN
—
•
•
Quality of Service (QoS)
• (NIOC)
• (NIOC и NSX)
• (NIOC и NSX)
NSX Edge Bridge для сети
—
•
•
DNS, DHCP и IPAM
—
•
•
Container Networking с NCP
—
•[16]
•[16]
Container Networking с Antrea
•[16]
•[16]
•[16]
Политики, теги и группировка
—
•
•
Мультиарендность через проекты
—
•
•
Virtual Private Cloud (VPC)
—
•
•
Балансировка для компонентов VCF [12]
—
•
•
Балансировка L4 для vSphere Supervisor [11],[12]
•
•
•
Кластеризация менеджеров / контроллеров
—
•
•
Federation
—
•
•
NSX Edge в форм-факторе ВМ и bare-metal
—
•
•
Автоматическое и ручное развёртывание менеджера и Edge
—
•
•
Автоматическая подготовка хостов
—
•
•
Port Mirroring
•
•
•
Netflow/IPFIX
•
•
•
Traceflow
—
•
•
Live Traffic Analysis
—
•
•
Packet Capture
•
•
•
vSphere Kubernetes Services (VKS) и облачные сервисы VCF
Клиентам, которым нужна универсальная или продвинутая балансировка, рекомендуется приобрести Avi Load Balancer. Тем, кому требуется время на миграцию с существующей балансировки VCF на Avi, разрешено продолжать пользоваться полной балансировкой VCF до 30 мая 2027 года при наличии необходимых лицензий Avi. Подробности об лицензировании и вариантах миграции — в статье базы знаний № 439411.
Дополнительные сервисы приобретаются отдельно и не входят в базовые поставки VMware Cloud Foundation и VMware vSphere Foundation.
Требует лицензию VMware Site Recovery Manager (SRM).
Требует VCF Advanced Cyber Compliance (надстройка Advanced Services).
Поддержка Antrea предоставляется только для VMware VKS. Поддержка NCP — только для VMware vSphere Supervisor и Tanzu Elastic Runtime.
Tech Preview.
Функция доступна начиная с VKS 3.5+.
Пути обновления (Upgrade Paths)
Графики ниже показывают маршруты перехода с прежних продуктов на новые предложения.
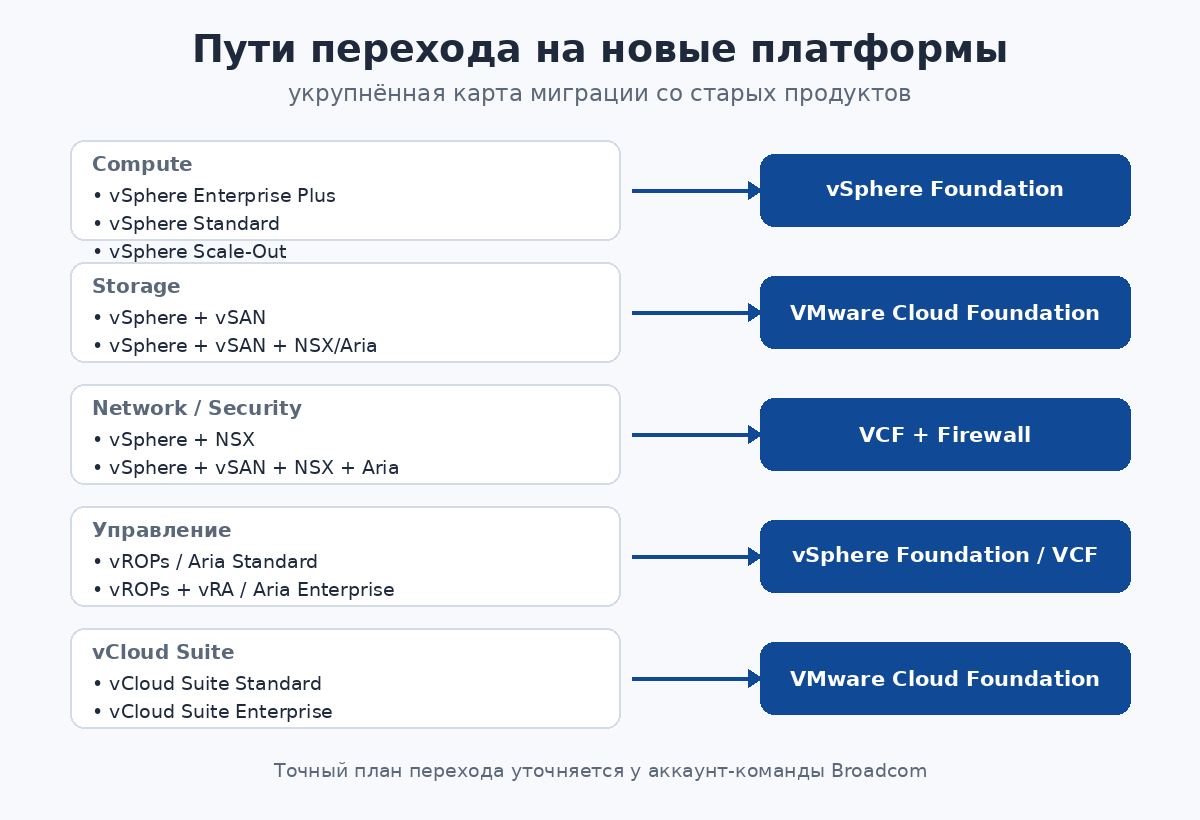
Пути для вычислений (Compute). Прежние издания vSphere Foundation, vSphere Enterprise Plus, vSphere Enterprise, vSphere for Desktop, vSphere Scale-Out и vSphere Standard рекомендуется переводить на vSphere Foundation.
Пути для хранения (Storage). Связка vSphere + vSAN + NSX + Aria и vSphere + vSAN + Aria ведут к VMware Cloud Foundation; vSphere + vSAN и vSphere + vSAN + NSX — к vSphere Foundation вместе с надстройкой vSAN.
Пути для сети и безопасности (Networking/Security). Конфигурации vSphere + vSAN + NSX + Aria и vSphere + NSX + Aria переходят на VMware Cloud Foundation с межсетевым экраном Firewall; vSphere + vSAN + NSX и vSphere + NSX — также на VCF с Firewall.
Путь управления (Management). vSphere с Aria Suite Enterprise или vRCU Enterprise переходит на VMware Cloud Foundation; vSphere с vROPs + vRA, Aria Suite Advanced или vRCU Advanced — на vSphere Foundation; vSphere с vROPs, Aria Suite Standard или vRCU Standard — также на vSphere Foundation.
Пути vCloud Suite. vCloud Suite Enterprise консолидируется в VMware Cloud Foundation с Aria Suite Enterprise и vSphere Enterprise Plus; vCloud Suite Advanced — в vSphere Foundation с Aria Suite Advanced и vSphere Enterprise Plus; vCloud Suite Standard — в Aria Suite Standard с vSphere Enterprise Plus.
Пути VCF. VCF Enterprise, VCF Advanced, VCF Standard и VCF Starter переходят на VMware Cloud Foundation с межсетевым экраном Firewall.
За дополнительными деталями Broadcom предлагает обращаться к сотрудникам VMware и официальным партнерам.
Вышла новая версия VMware Cloud Foundation 9.1, об этом вы уже знаете. В этой статье рассматриваются многие новые возможности и улучшения платформы vSphere в составе пакета VCF 9.1. Также рекомендуем ознакомиться с примечаниями к выпуску и уведомлениями о поддержке продуктов для получения важной информации.
Быстрое развёртывание патчей безопасности vCenter
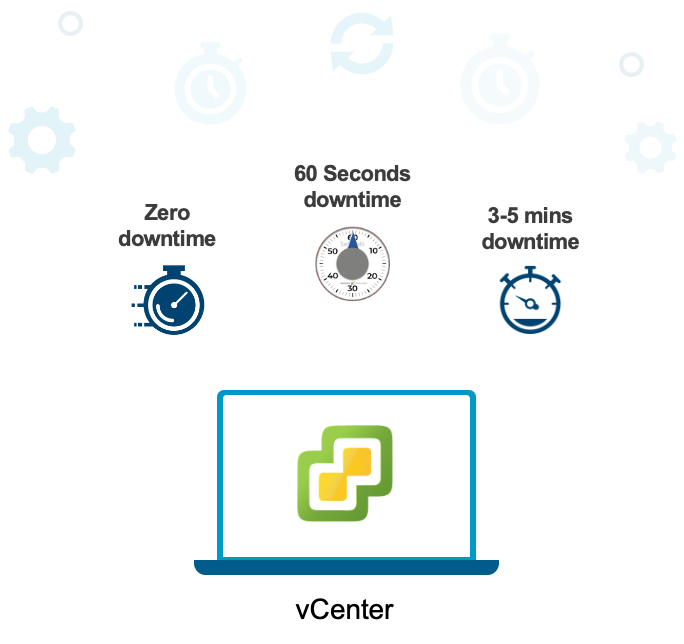
Функция быстрого патчинга vCenter (vCenter Quick Patch) обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлению. Механизм Quick Patch ориентирован на быстрое устранение критических уязвимостей безопасности в vCenter.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, изменился ли соответствующий сервис или компонент. Quick Patch затрагивает только те RPM или бинарные файлы, которые действительно изменились в составе патча. Такой подход кардинально сокращает общее окно обслуживания и снижает время простоя vCenter до менее чем 1 минуты, а в ряде случаев сводит его к нулю.
Благодаря vCenter Quick Patch критически важные обновления безопасности можно применять без прерывания рабочих процессов: развёртывание виртуальных машин и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются. Меньше времени уходит на планирование окон обслуживания — больше на поддержание актуальности патчей.
Помимо Quick Patch, в версии 9.1 улучшены и другие аспекты обслуживания vCenter.
Обновление vCenter с сокращённым временем простоя (Reduced Downtime Upgrade, RDU) теперь поддерживает работу с онлайн-репозиторием. Это упрощает использование метода RDU для подключённых к интернету экземпляров vCenter. Автономный метод с использованием примонтированного ISO по-прежнему доступен. Последующие патчи, обновления и апгрейды vCenter 9.1.x и более поздних версий также можно применять через RDU с онлайн-репозиторием, что значительно упрощает эксплуатацию для подключённых инсталляций.
В vCenter появился новый API, с помощью которого сторонние компоненты могут получать уведомления о планируемом или текущем техническом обслуживании. Обратный прокси Envoy будет отдавать заголовок 503 с информацией о том, что vCenter находится на обслуживании, и указанием ожидаемого времени завершения.
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом RDU версия аппаратного обеспечения виртуальной машины vCenter автоматически повышается с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter. При выполнении in-place обновления (с 9.0.x до 9.1.0) версию аппаратного обеспечения ВМ vCenter потребуется обновить вручную — эта процедура требует выключения ВМ vCenter.
Изменение ресурсов vCenter через единый API
В VCF 9.1 появился новый API, упрощающий масштабирование ресурсов vCenter. Для увеличения объёма вычислительных ресурсов и дискового пространства vCenter достаточно одного вызова API и перезагрузки.
Вызов API можно инициировать из Developer Center API Explorer в интерфейсе vCenter. API называется deployment/size и использует метод PATCH.
Упрощение обслуживания хостов ESX
Образы, создаваемые и управляемые через vSphere Lifecycle Manager, теперь включают контрольную сумму SHA256. Она позволяет проверять целостность образов при экспорте и импорте в другие экземпляры vCenter: администратор может сравнить контрольные суммы на источнике и целевом сервере. Речь идёт о контрольной сумме именно определения образа, а не VIB-файлов ESX.
В предыдущих версиях vSphere Lifecycle Manager проверял актуальность прошивок и драйверов устройств по HCL только при наличии стороннего Hardware Support Manager (HSM). Начиная с версии 9.1 вывод информации о текущих драйверах и прошивках устройств, а также их валидация по HCL выполняются для кластеров vSAN даже в отсутствие HSM. Некоторые устройства могут не сообщать данные о прошивке без соответствующего HSM. Это обеспечивает базовый уровень проверки устройств в кластере vSAN.
Подготовка кластеров vSphere с образом и конфигурацией
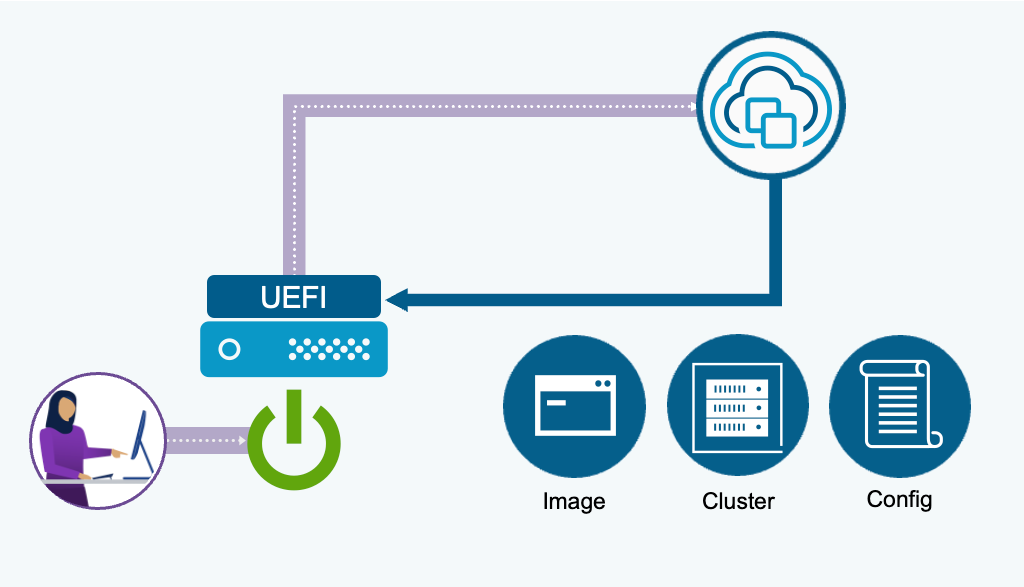
Zero Touch Provisioning (ZTP) строится на базе существующей инфраструктуры vSphere Auto-Deploy. Механизм задействует современные протоколы загрузки — UEFI HTTP/S Boot — и поддерживает актуальные серверные конфигурации, включая Secure Boot и TPM. ZTP не требует внешнего TFTP-сервера: достаточно настроить URL загрузки UEFI, указывающий на vCenter, и загрузить хост по сети. Если UEFI не поддерживает настройку статического IP для загрузки, потребуется DHCP-сервер.
Образ ESX и конфигурация определяются расположением кластера, выбранным при настройке правила развёртывания. Если для целевого кластера не настроен профиль конфигурации vSphere (VCP), хост загрузится и присоединится к кластеру с конфигурацией по умолчанию.
Быстрое и менее затратное обновление кластеров vSphere
ESX Live Patch включён по умолчанию для всех кластеров и автоматически применяется, если устанавливаемый патч поддерживает этот режим. Если патч несовместим с Live Patch, по умолчанию используется стандартный метод с переходом в режим обслуживания и перезагрузкой хоста.
Параметр можно изменить, включив принудительное применение Live Patch. В этом режиме исправление будет выполняться только через Live Patch, а для хостов, требующих режима обслуживания, процесс патчинга будет заблокирован. Настройки можно задать как на уровне кластера, так и на уровне vCenter — параметры vCenter применяются ко всем кластерам, если они не переопределены на уровне кластера.
ESX Live Patch теперь поддерживает серверы с включённым TPM. Пользователям не нужно отключать TPM или отказываться от Live Patch при использовании ESX 9.1 и более поздних версий.
Поддержка Live Patch расширена: охватывает больше компонентов vmkernel и обеспечивает более высокую производительность при патчинге ядра. Теперь механизм поддерживает дополнительные пользовательские демоны и сервисы, включая демоны vSAN, базовые демоны хранилища и соответствующие библиотеки.
Расширение интеграции с механизмом Desired State Configuration
Профили конфигурации vSphere (vSphere Configuration Profiles) обеспечивают соответствие изменений конфигурации и операций по устранению отклонений требованиям vSAN. Политики режима обслуживания vSAN и политики доступности объектов соблюдаются при исправлении кластеров vSAN. Расширенная конфигурация vSAN может применяться на уровне всего кластера.
Профили конфигурации vSphere используются для настройки memory tiering на хостах кластера. Устройства NVMe могут быть выделены для memory tiering; дополнительное устройство NVMe опционально может быть задействовано в качестве зеркального устройства для программного зеркалирования.
Профили конфигурации vSphere обеспечивают конфигурацию хостов при установке через Zero Touch Provisioning, а также поддерживают начальную настройку vSphere Distributed Switch в процессе развёртывания хоста.
Оптимизация Desired State Configuration
При добавлении новых хостов в кластеры с включёнными профилями конфигурации vSphere желаемая конфигурация автоматически применяется к входящему хосту. Специфичные для хоста атрибуты (например, IP-адреса) извлекаются из него автоматически и добавляются в соответствующий раздел профиля кластера.
Сертификат TLS для vCenter теперь обновляется автоматически за 5 дней до истечения срока действия. Сертификат ESX обновляется за 30 дней до истечения. Порог для ESX настраивается через расширенные параметры vCenter Server с помощью параметра vpxd.certmgmt.certs.autoRenewThreshold.
В обоих случаях автоматическое обновление выполняется для сертификатов, управляемых VMCA. Сертификаты, выданные внешними центрами сертификации, не обновляются автоматически — ответственность за их управление лежит на администраторе.
Если до истечения срока действия корневого сертификата VMCA остаётся менее 1 года, в процессе обновления vCenter автоматически обновляются корневой сертификат VMCA, а также дочерние сертификаты решений. Сертификаты TLS для vCenter и ESX в рамках этой операции не обновляются.
Масштабируемость, стабильность и производительность
В крупных и сверхкрупных развёртываниях vCenter ожидается увеличение числа операций в минуту до 25%. Это касается множества операций с виртуальными машинами и хостами, а также изменений конфигурации. Масштаб одновременных операций резервного копирования ВМ увеличен до 500–1000 в зависимости от размера vCenter. Операции резервного копирования ВМ теперь защищены от бесконтрольного потребления всех ресурсов vCenter. Передача файлов использует выделенные потоки, что исключает влияние на другие операции vCenter. Расширенные параметры vCenter для операций резервного копирования позволяют настраивать масштабируемость под конкретную среду.
Новый API мониторинга утилизации vCenter позволяет отслеживать активные подключения и сравнивать их с максимально допустимыми лимитами. Появилась возможность отслеживать количество запросов ко всем сервисам vCenter и контролировать, чтобы их интенсивность не превышала допустимых порогов.
Введены два новых оповещения — High Session Count и Increased Request Load — для сигнализации о нагрузке на один или несколько сервисов vCenter. Оповещение High Session Count срабатывает, когда число сессий приближается к лимиту (по умолчанию 3000); в сообщении указываются IP-адреса и имена пяти пользователей, создавших наибольшую нагрузку с более чем 100 сессиями каждый. При изменении состава топ-5 пользователей генерируется новое событие. В список могут попасть любые пользователи, включая сервисные аккаунты. Оповещение Increased Request Load срабатывает при достижении лимита активных запросов к конечной точке сервиса (по умолчанию 1024 для большинства конечных точек) и содержит информацию о затронутых сервисах и конечных точках.
Гибкая настройка виртуальных машин
Для поддержки миграции с VMware Cloud Director (vCD) на VMware Cloud Foundation Automation (VCFA) гостевой API настройки ОС (Guest OS Customization, GOSC) дополнен следующими возможностями, обеспечивающими паритет с функциями vCD:
Установка пароля учётной записи root в Linux
Сброс пароля учётной записи root в Linux
Сброс паролей учётных записей группы администраторов в Windows
Выполнение скриптов настройки в Windows
Теперь администраторы могут явно отключить IPv4 и настроить сеть только для IPv6 в гостевой настройке — как через интерфейс, так и через API. Это устраняет прежнее требование сохранять параллельную конфигурацию IPv4.
Появилась возможность выполнять настройку только сетевых параметров виртуальной машины — для выключенных и для работающих ВМ, что позволяет применять изменения сетевой конфигурации в реальном времени.
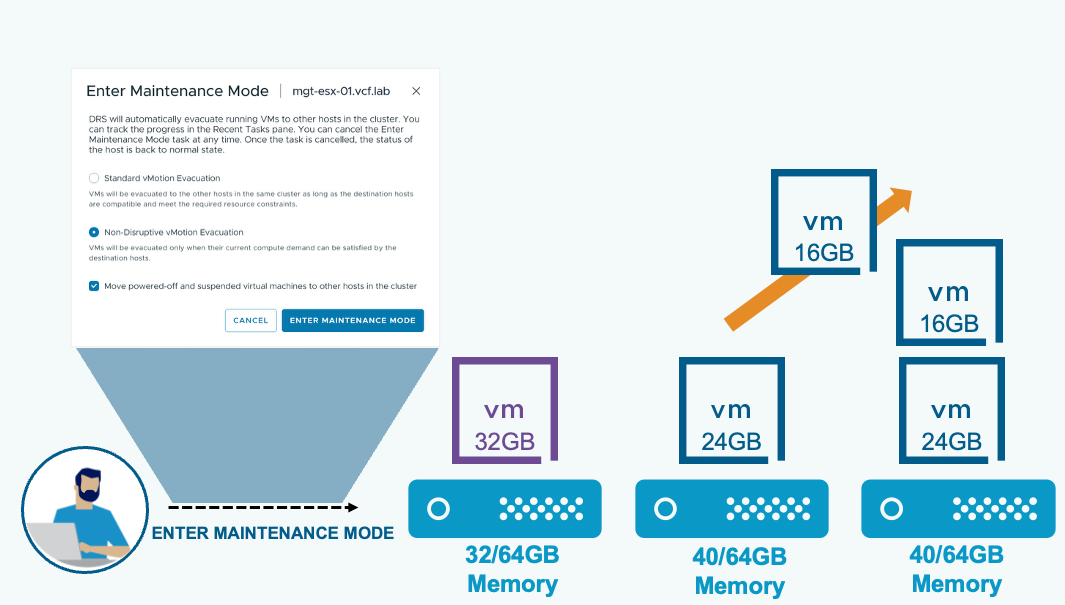
Сохранение производительности рабочих нагрузок во время обслуживания хоста
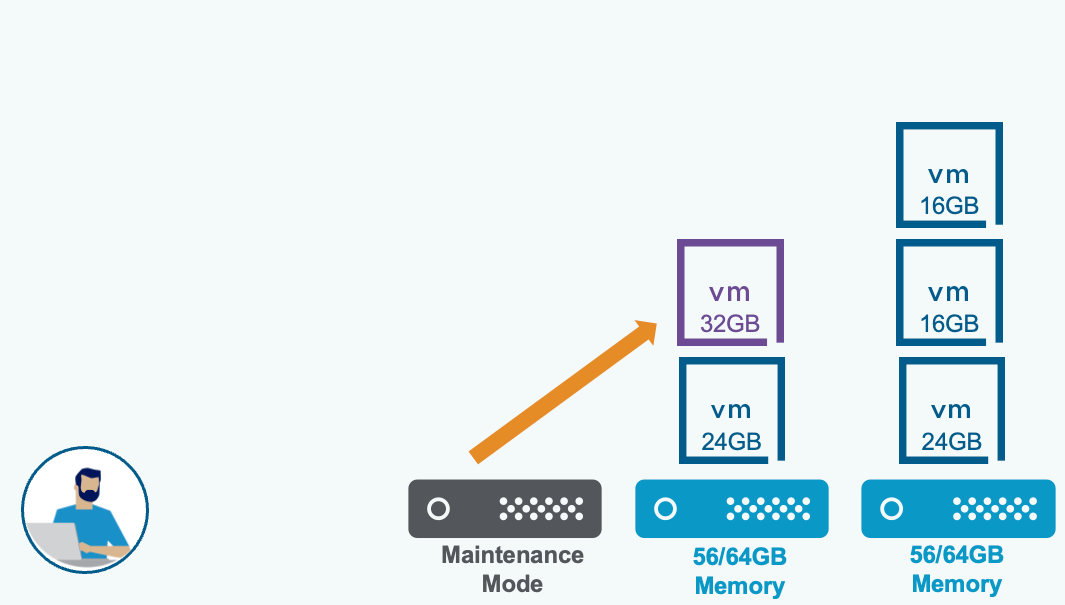
DRS-оптимизированная эвакуация через vMotion (DRS Optimized vMotion Evacuation) гарантирует, что виртуальные машины будут мигрированы с хоста только при наличии достаточной вычислительной ёмкости для их размещения без конкуренции за ресурсы. DRS может предварительно перебалансировать оставшиеся хосты, чтобы создать свободную ёмкость для эвакуируемых ВМ.
При переводе хоста в режим обслуживания для кластеров с включённым DRS доступны два варианта:
Стандартная эвакуация через vMotion: виртуальные машины переносятся на другие хосты в том же кластере при условии совместимости целевых хостов и соответствия требованиям по ресурсам.
Нон-деструктивная эвакуация через vMotion: виртуальные машины переносятся только в том случае, если их текущие вычислительные потребности могут быть удовлетворены целевыми хостами.
Примечание: термин «нон-деструктивная» применительно к новому режиму эвакуации не означает, что стандартная эвакуация как-либо вредит рабочим нагрузкам. Он лишь указывает на то, что при этом режиме эвакуация выполняется только без создания конкуренции за ресурсы на целевых хостах.
Улучшение утилизации ресурсов vMotion и снижение конкуренции
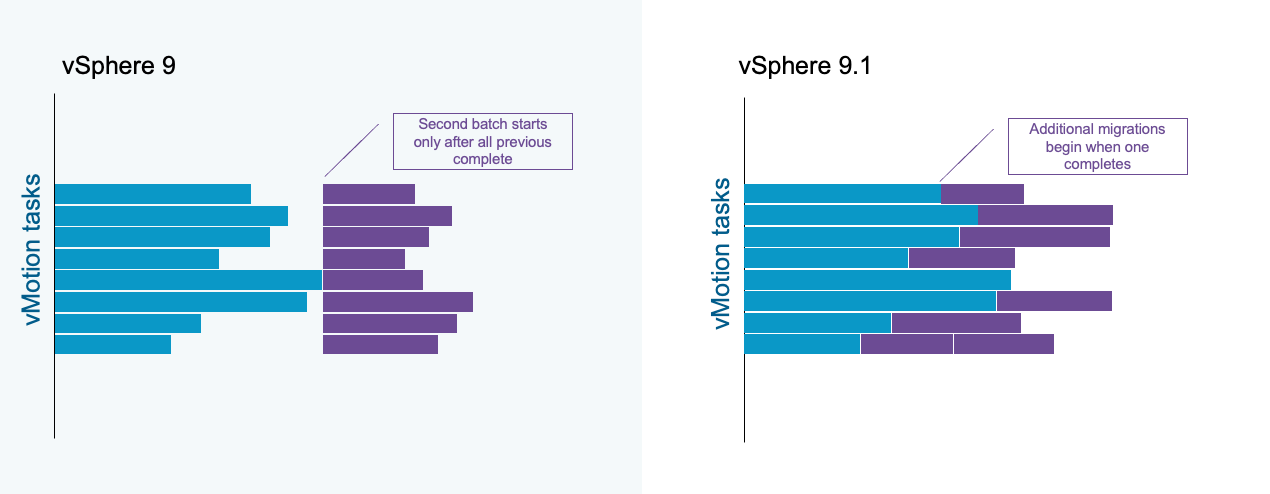
Максимальное количество одновременных задач vMotion по умолчанию равно 8. В предыдущих версиях, если 8 задач vMotion выполнялись одновременно в рамках пакетной операции, новые задачи не начинались до завершения всех предыдущих. Начиная с vSphere 9.1, как только одна задача vMotion завершается и освобождается слот, следующая задача может немедленно стартовать.
Усовершенствованная обработка задач vMotion обеспечивает более равномерное распределение нагрузки по хостам кластера. Число хостов, испытывающих пиковую одновременную нагрузку vMotion, сокращается, а сетевые ресурсы и ресурсы хранилища используются эффективнее.
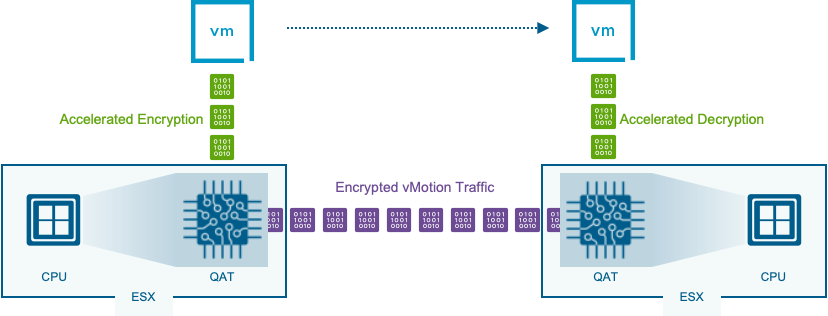
Более высокая пропускная способность vMotion и сокращение времени миграции
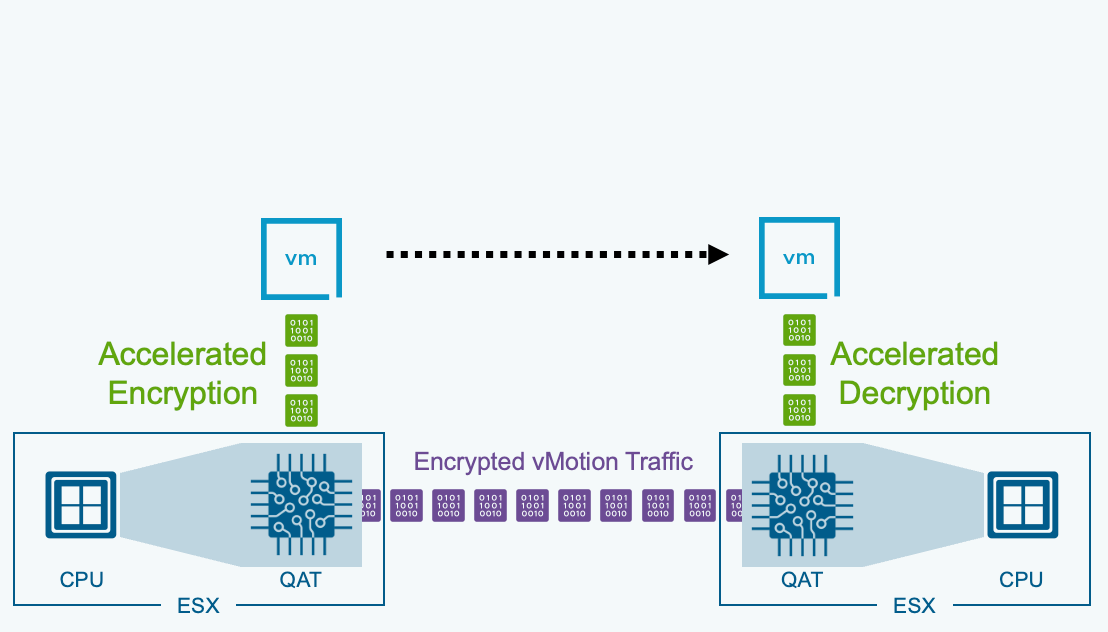
В VCF 9.1 появилась возможность разгрузки операций зашифрованного vMotion на Intel QAT (QuickAssist Technology). Это освобождает ценные ресурсы CPU и возвращает их рабочим нагрузкам.
Для максимально эффективного использования ресурсов в VCF задействована технология Intel QAT (QuickAssist Technology) для ускорения инфраструктурных операций. Перенос «тяжёлой» части задач vMotion на выделенное аппаратное обеспечение позволяет вернуть ценные ядра CPU реальным рабочим нагрузкам. Intel QAT берёт на себя шифрование данных при выполнении операций vMotion.
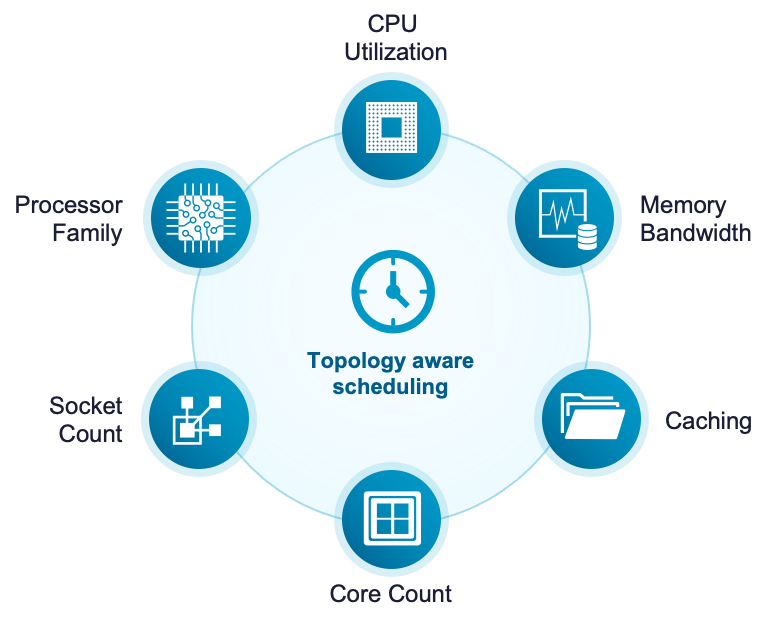
Оптимизированная масштабируемость и производительность для современных CPU
Планировщик Topology Aware Scheduler перешёл на событийно-ориентированный механизм встроенного обновления, что обеспечивает более согласованное и сбалансированное размещение по NUMA-узлам.
Архитектура NUMA (Non-Uniform Memory Access) используется для повышения масштабируемости и производительности серверов с несколькими процессорными сокетами. Планировщик — компонент ядра ESX, отвечающий за управление размещением виртуальных машин и балансировкой нагрузки по NUMA-узлам с целью минимизации задержек доступа к памяти и оптимального использования ресурсов CPU и памяти рабочими нагрузками.
Topology Aware Scheduler оптимизирован для нового поколения высокоплотных процессоров: улучшена модель оценки эффективности использования CPU и памяти. Существующий планировщик при принятии решений о размещении в основном учитывал конкуренцию за CPU (ready time). Topology Aware Scheduler учитывает не только конкуренцию за CPU, но и конкуренцию за кэш и пропускную способность памяти.
Для систем с асимметричной топологией NUMA, где расстояние между некоторыми парами узлов существенно больше, чем между другими, Topology Aware Scheduler может размещать смежные NUMA-клиенты одной ВМ на подмножестве узлов, расположенных ближе друг к другу.
Готовность к работе с AI-платформами различных производителей
В VCF 9.1 расширена поддержка Enhanced DirectPath I/O.
Речь идёт не просто о «проброске» оборудования, а о его виртуализации — это обеспечивает лучшую утилизацию ресурсов и возможность выполнения операций обслуживания и масштабирования без остановки AI-рабочих нагрузок. Поддержка новых аппаратных устройств в VCF 9.1 открывает доступ ко многим преимуществам виртуализации, включая stun-based операции и быстрое приостановление и возобновление работы. Среди этих преимуществ:
Storage vMotion
Снапшоты (включая снапшоты памяти)
Операции реконфигурации дисков
Горячее добавление и удаление виртуальных устройств
ESX Live Patch
ESX 9.1 расширяет свои возможности, внедряя поддержку виртуализации IOMMU для CPU AMD. Теперь администраторы могут задействовать устройства PCI passthrough на системах на базе AMD, повышая производительность и обеспечивая прямой доступ к оборудованию для виртуальных машин.
AMD vIOMMU (Virtual I/O Memory Management Unit) — аппаратно-ускоренная технология, обеспечивающая безопасный высокопроизводительный прямой доступ к памяти (DMA) для виртуальных машин за счёт прямого доступа гостевых систем к регистрам MMIO.
Flow Processing Offload (FPO) и аппаратное направление трафика (hardware steering) повышают эффективность центра обработки данных, перенося обработку сложных сетевых правил с CPU на выделенное аппаратное обеспечение. Это обеспечивает производительность на уровне линейной скорости и быструю масштабируемость виртуализированных сред, освобождая ресурсы CPU для бизнес-приложений.
Enhanced DirectPath I/O поддерживает прямую связь GPU-to-GPU через RDMA over Converged Ethernet (RoCE). Решение предназначено для организаций, выполняющих массивные AI-рабочие нагрузки или высокоскоростную обработку данных: оно обеспечивает производительность, близкую к нативной (необходимую для AI), без отказа от инструментов управления, которые упрощают эксплуатацию виртуализованных ЦОД.
GPU NVIDIA, используемые для vGPU, теперь можно настроить одновременно для тайм-слайсинга и режима MIG, что обеспечивает ещё более эффективное совместное использование ресурсов и повышение плотности.
Во времена, когда на счету каждый доллар или сотня рублей, а каждая минута простоя стоит дорого, команды, отвечающие за инфраструктуру, оказались в "идеальном шторме" вызовов: дефицит оборудования, который прогнозируется вплоть до 2027 года, изолированные среды, возникающие из-за сосуществования старых и современных архитектур, постоянно меняющиеся требования к компетенциям и нарастающая сложность управления установками, обновлениями и обслуживанием в разнородных системах. Параллельно с этим эволюция угроз и рост числа и изощрённости кибератак требуют детальной и точной видимости поведения гостевой ОС и активности рабочих нагрузок. Традиционные подходы перестают быть жизнеспособными: организации испытывают сильное давление, заставляющее минимизировать совокупную стоимость владения (TCO) и одновременно добиваться измеримой отдачи от каждой инвестиции. Нужна не просто большая инфраструктура — нужна более умная инфраструктура, которая по максимуму использует уже имеющиеся ресурсы за счёт инновационных подходов. Именно здесь vSphere в составе VMware Cloud Foundation (VCF) 9.1 меняет правила игры, привнося прорывные нововведения, которые фундаментально переопределяют экономику инфраструктуры, её производительность и безопасность.
Экономика модернизации без замены оборудования
В vSphere внедрён набор возможностей, нацеленных на то, чтобы выжать максимум из уже сделанных инфраструктурных инвестиций и снизить TCO. vSphere в VCF 9.1 также включает функции, существенно сокращающие накладные расходы и повышающие операционную эффективность. Речь идёт не о точечных улучшениях, а о фундаментальных сдвигах в том, как инфраструктура создаёт ценность.
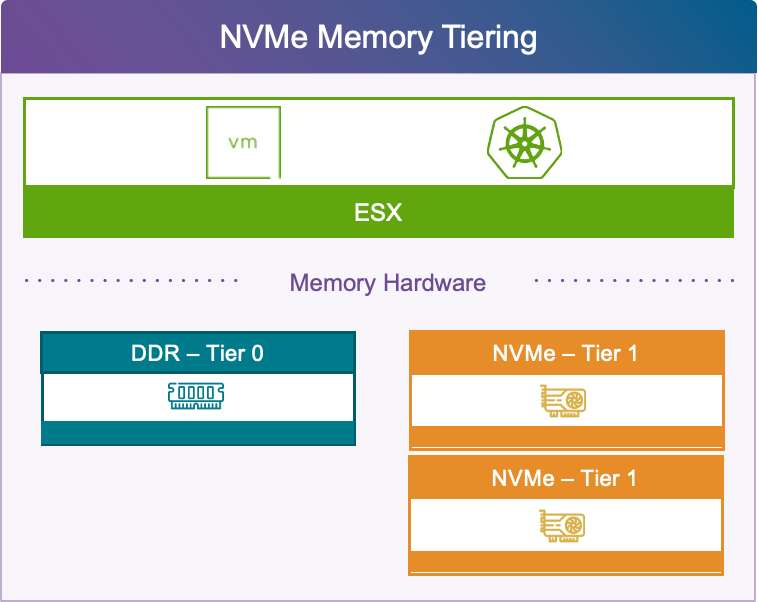
Память по-новому: интеллектуальный NVMe-тиринг
Стоимость памяти долгое время оставалась ограничителем при масштабировании инфраструктуры, а сегодня этот фактор стал ещё острее из-за стремительно растущих цен на память на фоне всплеска интереса к AI. vSphere полностью меняет это уравнение. Усовершенствованная функция тиринга памяти на NVMe позволяет снизить TCO сервера до 40% и одновременно убирает операционные неудобства.
Что делает версию 9.1 по-настоящему трансформирующей — это устранение барьеров для внедрения. Например, отменяется требование перезагрузки для включения тиринга памяти. Уведомления в интерфейсе позволят без усилий определять подходящие кластеры и рабочие нагрузки, а проактивный мониторинг состояния устройств обеспечит их замену ещё до того, как они выйдут из строя.
Появление зеркалирования RAID 1 для тиринга памяти обеспечивает критически важную отказоустойчивость, не позволяя сбоям отдельных устройств перерастать в масштабные простои виртуальных машин. Для нагрузок, активно работающих с данными, — аналитики больших данных, e-commerce-платформ и сервисов видеостриминга — это означает резкое расширение доступной памяти без пропорционального наращивания «железа». При улучшенном соотношении ядер и памяти организации добиваются более плотной консолидации ВМ и более высокой загрузки CPU, что усиливает экономический эффект от снижения TCO.
Время — деньги: Quick Patching для vCenter
Требования к безопасности и соответствию нормативам диктуют необходимость регулярного патчинга, однако традиционные окна обслуживания дорого обходятся: они нарушают работу и истощают ресурсы ИТ-команд. Функция Quick Patching для vCenter сокращает общее время операции примерно на 80% — окно патчинга уменьшается приблизительно с 30 минут до менее чем 5 минут.
Это резкое сокращение — не только про экономию времени. Quick Patching интеллектуально классифицирует сервисы vCenter по степени их влияния и оптимизирует процедуру обновления под каждый тип. В итоге улучшается соблюдение требований по критическим патчам, снижается риск ручных ошибок и заметно уменьшается административная нагрузка. В то время как у конкурентов на ручной патчинг уходят значительные человеко-часы, автоматизированный подход vSphere превращается в конкурентное преимущество, которое со временем только усиливается.
Эластичное развертывание в любых масштабах
Развёртывание инфраструктуры исторически было медленным ручным процессом, что затрудняло быстрое масштабирование. Технология vSphere Elastic Provisioning (Zero-Touch Provisioning) превращает это узкое место в отлаженную операцию. Используя UEFI HTTP для безопасной загрузки и vSphere Configuration Profiles для настройки среды в желаемом состоянии, организации могут быстро разворачивать инфраструктуру в масштабе при минимальном ручном вмешательстве.
Оптимизация производительности для требовательных нагрузок
По мере того как рабочие нагрузки становятся всё более ресурсоёмкими, а архитектуры процессоров эволюционируют, традиционные подходы к оптимизации производительности создают узкие места, ограничивающие масштабируемость и эффективность. vSphere в VCF 9.1 решает эти задачи в лоб с помощью интеллектуальных улучшений производительности, которые устраняют накладные расходы, не жертвуя при этом ни безопасностью, ни непрерывностью операций.
Производительность без накладных расходов: ускорение шифрованного vMotion
Для ресурсоёмких нагрузок с большими буферами кадров традиционный зашифрованный vMotion способен создавать существенные узкие места по производительности во время живой миграции. vSphere в VCF 9.1 задействует технологию Intel Quick Assist Technology (QAT), чтобы выгружать на сторону железа задачи шифрования, дешифрования и сжатия с CPU хоста в процессе vMotion.
Какой эффект? Значительно ускоряется этап переключения vMotion — и при этом не страдает безопасность. Организации сохраняют непрерывность работы даже для самых требовательных нагрузок, безопасно передавая данные без потерь в производительности. В средах, где каждая секунда миграции имеет значение — будь то окна обслуживания, балансировка нагрузки или восстановление после сбоев, — такая оптимизация даёт ощутимую бизнес-ценность и операционную гибкость.
Максимум производительности: планирование с учётом топологии
Процессоры с большим числом ядер раздвигают границы прежних NUMA-архитектур, создавая такие проблемы, как переполнение узлов, лишние миграции и неоптимальная производительность на системах AMD и системах с включённым SNC. Планирование с учётом топологии в vSphere меняет то, как платформа работает с этими процессорами высокой плотности нового поколения.
Обновлённый NUMA-планировщик теперь работает скорее по принципу DRS: используется та же модель справедливости с пулами ресурсов и параметрами min/max shares, а для эффективности применяется многоресурсная модель «качества», учитывающая стоимость миграции страниц памяти. Такой интеллектуальный подход принимает во внимание архитектурные особенности процессоров нового поколения и оптимизирует алгоритмы планирования, обеспечивая лучшую производительность, более эффективное использование ресурсов и более предсказуемое поведение нагрузок на самых разных аппаратных конфигурациях.
Безопасность: встроенная защита на всех уровнях стека
vSphere представляет собой по-настоящему защищённую платформу, расширяющую защиту до данных в обработке (data-in-use), детектирующую угрозы в реальном времени и обеспечивающую соблюдение нормативных требований и отраслевых рекомендаций по конфигурации безопасности «из коробки».
Безопасность без простоев: расширенный Live Patching
По мере того как организации переходят на серверы с TPM (а такие машины составляют почти 90% нового железа), vSphere в VCF 9.1 распространяет поддержку Live Patching на хосты с TPM и включает эту функцию по умолчанию. Возможность позволяет применять важные патчи к инфраструктуре платформы ESX без перевода хостов в офлайн и без эвакуации виртуальных машин, доставляя критические обновления безопасности быстро в рамках фиксированных SLA и поддерживая надёжные обновления без ошибок.
Confidential Computing: защита данных в обработке
Защита данных не ограничивается хранением и передачей: следующий рубеж — это защита данных непосредственно в процессе их обработки. vSphere в VCF 9.1 переводит в общую доступность Confidential Computing с поддержкой Intel TDX и AMD SEV-SNP. Эти аппаратные средства шифрования памяти и контроля её целостности изолируют рабочие нагрузки от инфраструктурного стека, формируя защищённые Trust Domains (у Intel) и Confidential VMs (у AMD), благодаря чему безопасность становится неотъемлемым свойством платформы.
Глубокая видимость: интеграция с EDR
Традиционные средства Endpoint Detection and Response (EDR) хорошо справляются с мониторингом гостевых операционных систем, однако часто не имеют видимости в сам хост ESX. vSphere в VCF 9.1 позволяет агентам EDR от сторонних производителей интегрироваться непосредственно в гипервизор ESX и анализировать события на уровне процессов, файлов и сети на предмет подозрительной активности. Такая глубокая интеграция средств обнаружения угроз прямо в гипервизор крайне важна для выявления горизонтального перемещения злоумышленников, бесфайлового вредоносного ПО и эксплойтов нулевого дня — и всё это без появления узких мест по производительности.
Инфраструктура, которая окупает себя
vSphere в VCF 9.1 — это фундаментальный сдвиг в экономике инфраструктуры. Максимально используя уже установленное оборудование через тиринг памяти на NVMe, сокращая операционные накладные расходы за счёт быстрого патчинга и эластичного провижининга, устраняя узкие места по производительности через интеллектуальную выгрузку задач и обеспечивая непрерывность работы благодаря Live Patching, организации превращают инфраструктуру из статьи затрат в стратегическое преимущество.
В условиях, когда дефицит оборудования сохраняется и каждая инвестиция должна приносить измеримую отдачу, vSphere в VCF 9.1 предлагает понятный путь вперёд: использовать то, что уже есть, оптимизировать то, как выстроены операции, и масштабироваться без пропорционального роста затрат.
Инфраструктурные команды сталкиваются с парадоксом: среды становятся все сложнее, а бюджеты и численность персонала остаются прежними. VMware Cloud Foundation (VCF) 9.1 призвана ответить на эту проблему инновациями, которые повышают эффективность, ускоряют доставку приложений и усиливают киберустойчивость, сохраняя при этом простоту эксплуатации. За последние несколько лет разговор об инфраструктуре изменился. Вопрос уже не только в том, где выполняются рабочие нагрузки, но и в том...
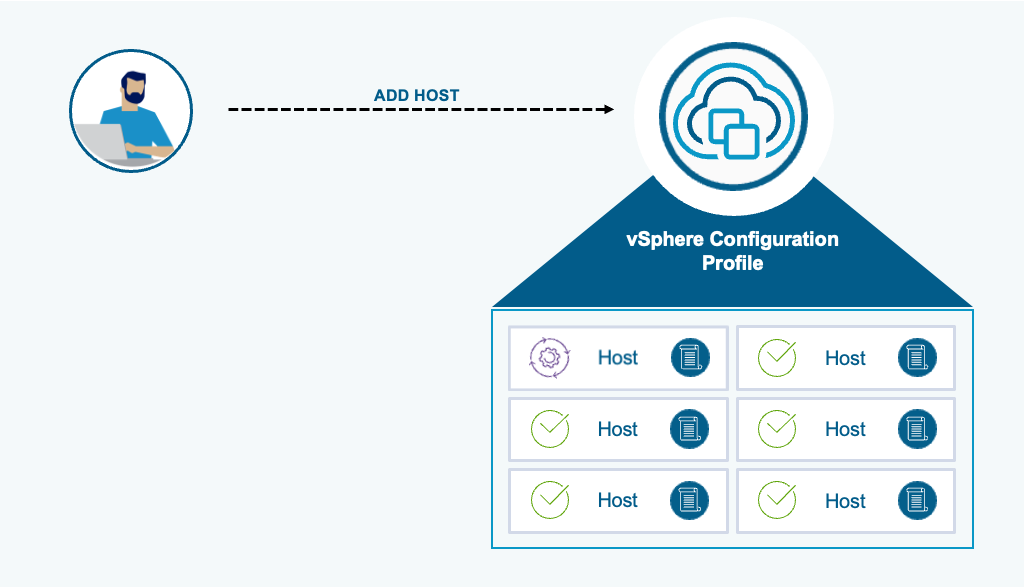
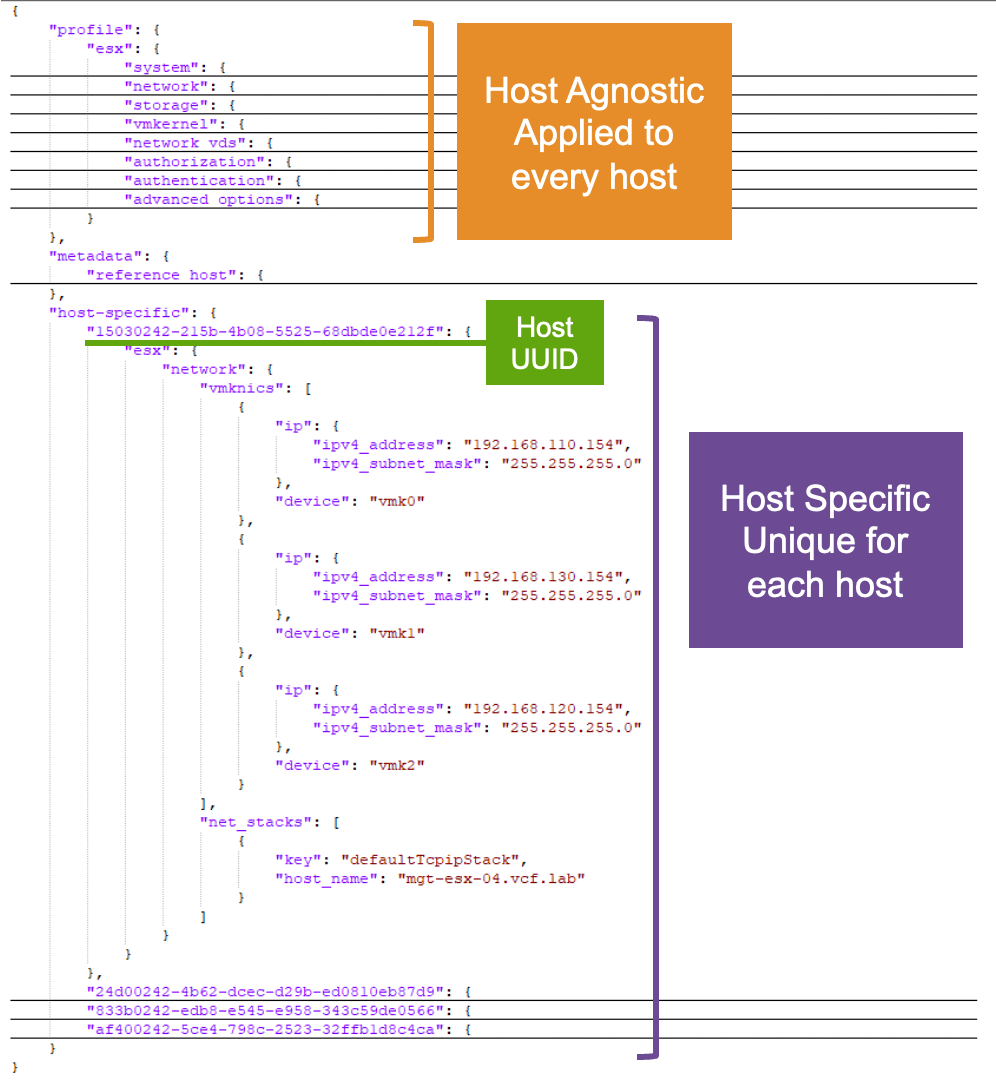
Функционал vSphere Configuration Profiles помогает администраторам VMware Cloud Foundation управлять настройками ESX-хостов не по отдельности, а на уровне всего кластера. Такой подход удобен, когда нужно не только поддерживать единый стандарт внутри одного кластера, но и переносить уже проверенную конфигурацию в другие кластеры.
Примечание: описанные шаги и интерфейсные элементы относятся к VMware vSphere 9.0.2. В других версиях названия пунктов меню и формулировки могут отличаться.
Что такое vSphere Configuration Profiles
vSphere Configuration Profiles появилась в vSphere 8.0 как развитие идеи Host Profiles для масштабного управления конфигурацией ESX-хостов. В Host Profiles администратору приходилось описывать конфигурацию целиком, что усложняло работу: часто известны только конкретные изменения, которые нужно внести, а не весь полный набор настроек.
В vSphere Configuration Profiles требуется зафиксировать только отличия от конфигурации по умолчанию. Благодаря этому профиль получается более понятным для человека, проще читается и легче поддерживается.
Перенос конфигурации в новые кластеры
Один из типовых сценариев управления конфигурацией — обеспечить одинаковые настройки сразу в нескольких кластерах vSphere. vSphere Configuration Profiles делает такой перенос достаточно прямолинейным: желаемое состояние можно экспортировать из существующего кластера, скорректировать уникальные параметры хостов и затем импортировать в новый кластер.
Совет: конфигурацию можно подготовить для кластера еще до добавления в него ESX-хостов. Для этого нужно заранее знать Host BIOS UUID будущих хостов.
Ниже приведен рабочий процесс копирования конфигурации из одного кластера в другой.
Экспорт конфигурации из существующего кластера
Сначала нужно выгрузить желаемую конфигурацию из уже настроенного кластера. В интерфейсе vSphere следует открыть Cluster, затем Configure, затем Configuration в разделе Desired State. Экспортированный файл будет сохранен в формате JSON.
Внутри JSON находятся как общие для кластера настройки, так и уникальные атрибуты отдельных хостов, например IP-адреса и имена хостов. Минимальная обязательная правка перед переносом — заменить host-specific секцию vSphere Configuration Profile на значения, соответствующие целевому кластеру.
Перед импортом полезно понимать структуру JSON-файла профиля. В секции profile > esx находятся настройки, не зависящие от конкретного хоста. Такие параметры можно применить ко всем хостам кластера, поскольку они не содержат уникальных значений для отдельного сервера.
Настройки vSphere Distributed Switch, Port Groups или Datastores могут отличаться от кластера к кластеру, поэтому при необходимости их нужно менять в соответствующих разделах JSON. В демонстрационном сценарии используются те же vSphere Distributed Switch, Port Groups и Datastores, что и в исходном кластере.
Основное внимание при переносе нужно уделить секции host-specific. В показанном примере уникальными значениями для хостов являются IP-адреса трех vmkernel-интерфейсов и имя хоста.
Каждый ESX-хост в host-specific разделе идентифицируется через Host UUID. Этот идентификатор также называют BIOS UUID, поскольку он уникален на уровне аппаратной платформы. В актуальных версиях vSphere и VCF проще всего получить Host UUID через PowerCLI, подключившись к vCenter или напрямую к ESX-хосту.
После этого в JSON-файле нужно заменить Host UUID, IP-адреса, маски подсети и имена хостов для каждого сервера целевого кластера. При необходимости хосты можно добавлять или удалять, но важно следить за корректным синтаксисом JSON, особенно за запятыми между элементами.
Импорт обновленной конфигурации в новый кластер
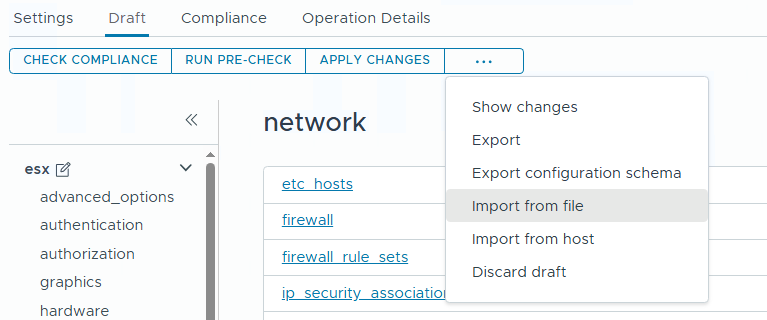
Если целевой кластер еще не создан с включенными vSphere Configuration Profiles или пока не переведен на них, обновленный JSON можно импортировать через workflow перехода на vSphere Configuration Profiles.
Если кластер уже использует vSphere Configuration Profiles, нужно открыть вкладку Draft, выбрать Import From File и загрузить подготовленный JSON-файл.
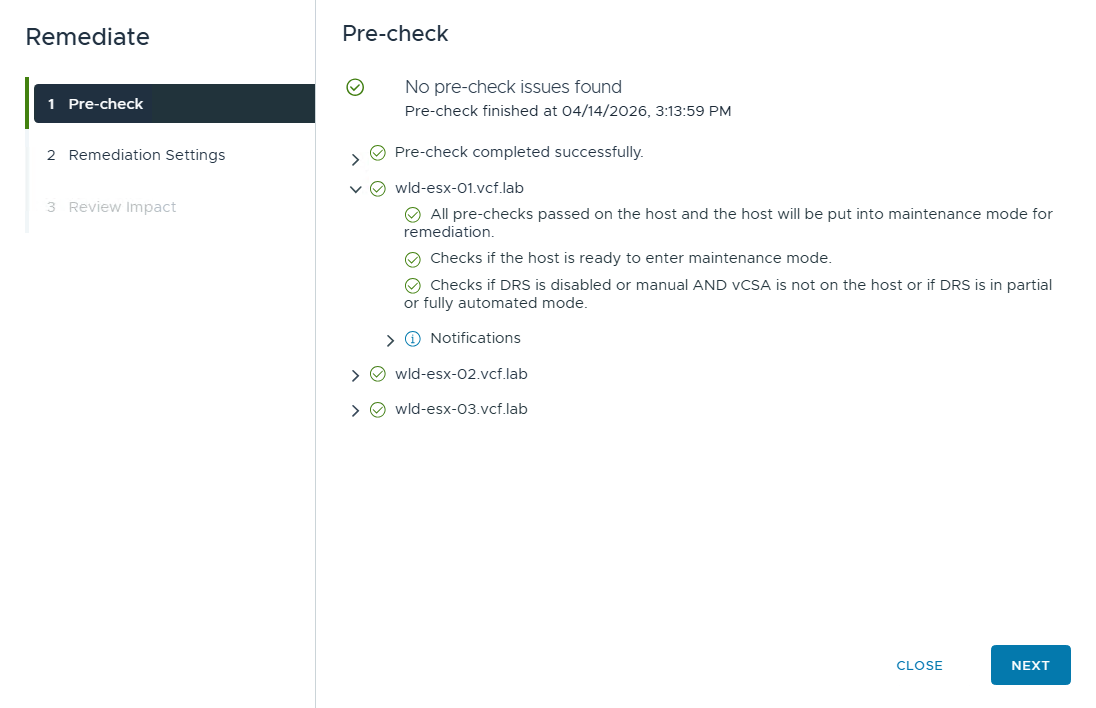
Затем на вкладке Draft нужно выбрать Apply Changes, чтобы выполнить remediation и применить импортированную конфигурацию. Перед фактическим применением стоит внимательно пройти окна Pre-check, Remediation Settings и Review Impact.
Pre-check проверяет готовность хоста к remediation, включая возможность перевести его в maintenance mode. Также учитывается, включен ли DRS, чтобы при необходимости автоматически эвакуировать виртуальные машины с хоста. Окно Remediation Settings показывает текущие параметры remediation, унаследованные от vSphere Lifecycle Manager.
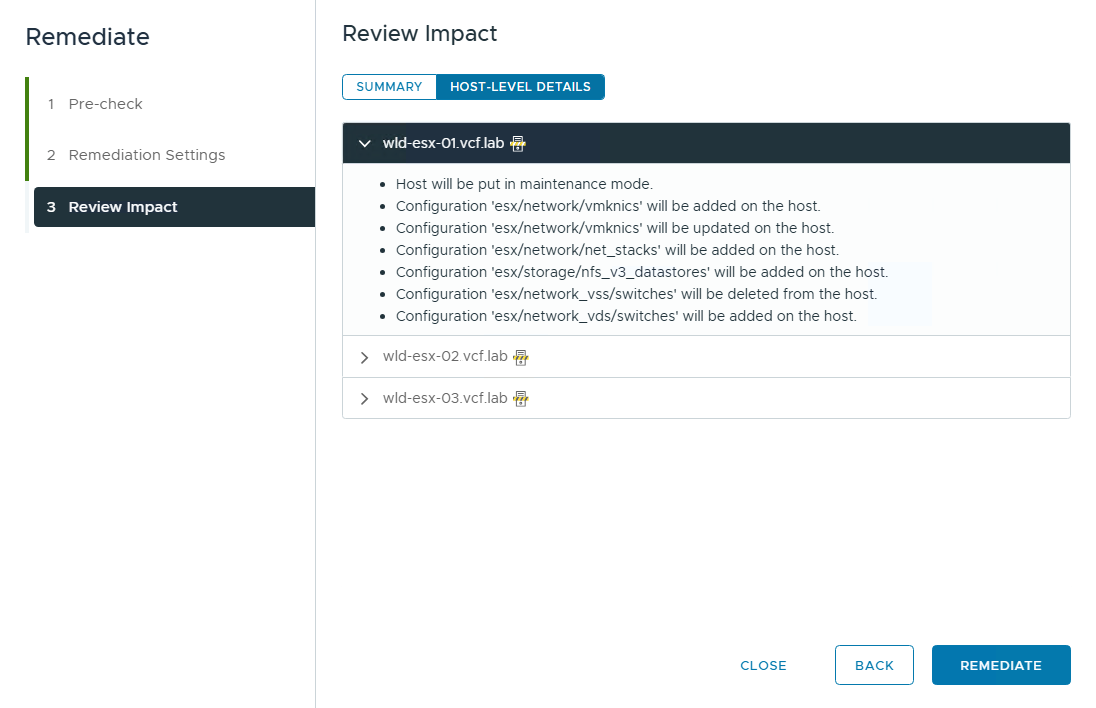
В окне Review Impact на вкладке Host-Level Details можно раскрыть каждый хост и увидеть, какие именно изменения будут применены. Там же отображается, потребуется ли конкретному хосту переход в maintenance mode.
После проверки влияния изменений остается нажать Remediate, чтобы применить конфигурацию к кластеру.
Итог
vSphere Configuration Profiles позволяет переносить стандартную конфигурацию из одного кластера в другой без ручного повторения всех настроек. Это помогает поддерживать единое желаемое состояние как внутри отдельного кластера, так и между несколькими кластерами vSphere.
В настройках кластера VMware vSphere High Availability существует параметр Performance degradation VMs tolerate, который определяет допустимый уровень снижения производительности виртуальных машин при отказе одного из хостов кластера.
По умолчанию значение параметра установлено в 100%, что фактически означает отсутствие ограничений по деградации производительности в аварийном сценарии. При таком значении система не будет предупреждать администратора о возможном ухудшении SLA виртуальных машин после отказа узла.
Как работает параметр
Механизм оценивает, смогут ли уже запущенные виртуальные машины сохранить сопоставимый объем вычислительных ресурсов после отказа одного хоста. Логика работы следующая:
Рассматривается сценарий отказа одного узла кластера.
Оценивается суммарная доступная вычислительная емкость после отказа.
С помощью VMware Distributed Resource Scheduler DRS моделируется перераспределение работающих виртуальных машин на другие хосты ESX.
Проверяется, какой уровень снижения ресурсов (CPU / Memory) получат виртуальные машины.
Если ожидаемая деградация превышает заданный порог, генерируется предупреждение.
Важно! Это не блокирующий механизм. Даже при появлении предупреждения запуск новых виртуальных машин остается возможным - параметр выполняет исключительно функцию оповещения.
Требования для работы
Для корректной работы параметра необходим работающий DRS, но включенный Admission Control не требуется. Это частое заблуждение: параметр не использует настройки Admission Control (например, Host failures cluster tolerates). Вместо этого он самостоятельно моделирует отказ одного хоста и анализирует последствия для производительности виртуальных машин.
Практический смысл настройки
Параметр полезен в сценариях, когда:
В кластере высокая консолидация нагрузки.
Виртуальные машины активно используют CPU / RAM выше уровня reservation.
Ресурсы после отказа хоста могут оказаться достаточными для запуска ВМ, но недостаточными для сохранения нужной производительности.
Пример:
Допустим, кластер работает с загрузкой 80–85%. После выхода одного узла из строя оставшиеся хосты смогут принять виртуальные машины, однако фактическая доступность ресурсов для каждой машины снизится.
50% — допускается существенное снижение производительности
100% — предупреждения фактически отключены
Рекомендации по настройке
Практически значение 100% малоинформативно, так как не дает сигналов о потенциальной проблеме.
Часто используются значения:
0–10% — для критичных production-нагрузок
25% — сбалансированный вариант
50% — для сред с менее строгими SLA
Выбор зависит от допустимого уровня деградации сервисов при аварийном восстановлении.
Вывод
Параметр Performance degradation VMs tolerate — это механизм оценки риска снижения производительности ВМ при отказе узла, а не механизм резервирования ресурсов.
Его особенности:
Анализирует сценарий отказа одного хоста
Требует DRS
Не зависит от Admission Control
Не запрещает запуск ВМ
Предупреждает о возможном ухудшении производительности
Настройка позволяет заранее понять, насколько кластер готов к отказу оборудования с точки зрения SLA, а не только с точки зрения возможности перезапуска виртуальных машин.
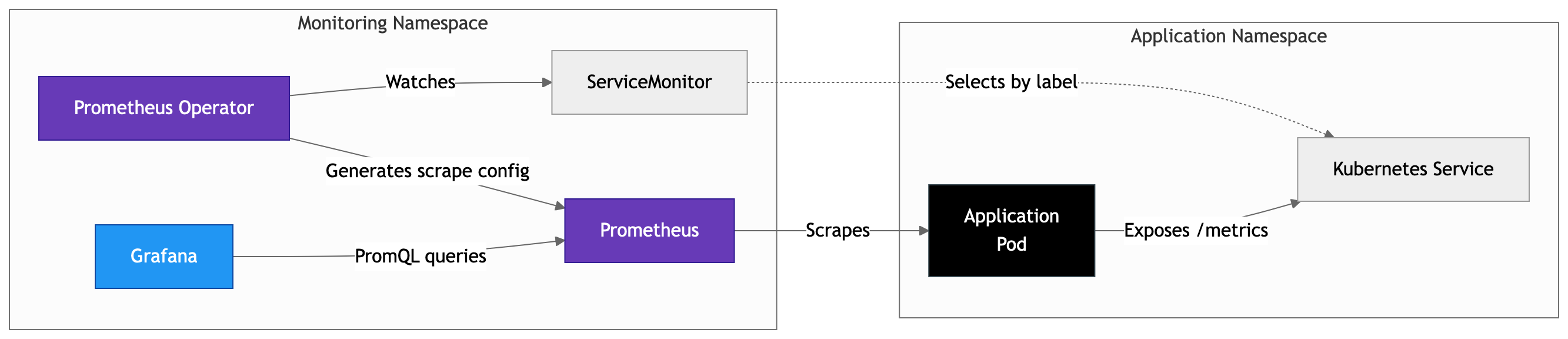
Облачные нативные приложения обеспечивают гибкость, масштабируемость и более быструю доставку сервисов, однако они также вносят новую операционную сложность. В средах Kubernetes рабочие нагрузки являются эфемерными, сервисы распределены, а телеметрия генерируется в больших объёмах на разных уровнях стека. Компания VMware выпустила новый документ "Observability on vSphere Kubernetes Service", в котором рассматривается, как решить эту задачу на платформе VMware Cloud Foundation (VCF) с использованием vSphere Kubernetes Service (VKS).
В документе представлена практическая референсная архитектура, основанная на трёх ключевых компонентах наблюдаемости:
Метрики
Для сбора метрик архитектура использует стек Prometheus Community (kube-prometheus-stack), который включает:
Prometheus Operator для динамического обнаружения целей
Grafana для построения дашбордов
Node Exporter для сбора статистики на уровне узлов
Метрики дополнительно обогащаются телеметрией сервисов Istio и интегрируются с решением VCF Operations для предоставления контекста базовой инфраструктуры.
Логи
Для работы с логами используется Fluent Bit, который собирает и обогащает данные логов Kubernetes. Для хранения и индексации применяется Grafana Loki, обеспечивая нативный для Kubernetes анализ логов через Grafana.
Тот же поток логов также передаётся в VCF Operations for Logs, что позволяет коррелировать события с более широкой инфраструктурной средой.
Трейсы
Для трассировки используется OpenTelemetry для распределённого трейсинга, Jaeger v2 — для приёма и визуализации данных трассировки в формате OTLP, а OpenSearch — в качестве постоянного хранилища трейсов.
Это позволяет отслеживать прохождение запросов через различные сервисы и анализировать их вместе с сопутствующей телеметрией приложений и платформы.
Для команд, использующих vSphere Kubernetes Service на платформе VMware Cloud Foundation, этот документ представляет собой практическую отправную точку для построения модульного, ориентированного на промышленную эксплуатацию стека наблюдаемости. Также репозиторий, на который ссылается документ, размещен по этой ссылке.
Развёртывание Kubernetes в производственной среде требует не просто установки кластера — необходимо с самого начала принять правильные архитектурные решения, от которых будут зависеть масштабируемость, доступность и управляемость платформы. Вебинар специалистов Broadcom Professional Services и MomentumAI посвящён ключевым принципам проектирования VMware vSphere Kubernetes Service (VKS) поверх VMware Cloud Foundation (VCF). Докладчики — Vijay Appani, Solution Architect компании Broadcom, и Caleb Washburn, CTO и основатель MomentumAI — рассматривают проверенные шаблоны проектирования, которые их команды применяют в реальных enterprise-проектах.
Что такое VKS и зачем запускать Kubernetes на VCF
VMware vSphere Kubernetes Service (VKS) — это встроенный механизм запуска Kubernetes на платформе vSphere, интегрированный непосредственно в VMware Cloud Foundation. В отличие от сторонних дистрибутивов, VKS использует подтверждённую CNCF версию Kubernetes и глубоко интегрирован с инфраструктурными компонентами VCF: вычислительным слоем (vSphere), сетью (NSX) и хранилищем (vSAN). Это позволяет организациям строить современную private cloud-платформу, избегая «лоскутных» решений и накапливаемого технического долга.
Ключевая идея заключается в том, что VCF предоставляет единую платформу, объединяющую ресурсы compute, network и storage в согласованный операционный слой. Kubernetes в таком окружении получает доступ к корпоративным политикам хранения, сетевой изоляции на уровне неймспейсов и интеграции с порталом самообслуживания VCF Automation — всё это без необходимости разворачивать и поддерживать внешние инструменты.
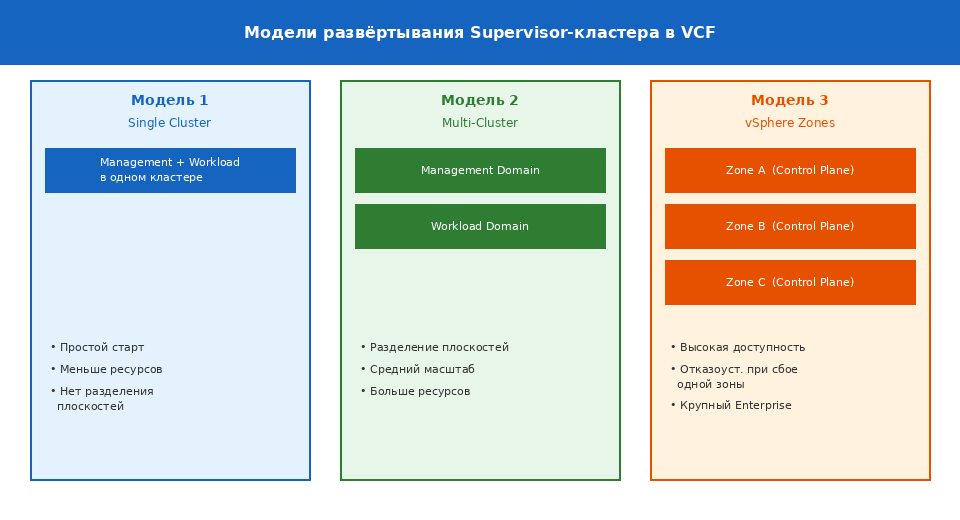
Три модели развёртывания Supervisor-кластера
Центральным компонентом VKS является Supervisor-кластер — уровень управления Kubernetes, развёртываемый поверх рабочего домена VCF. Существует три основные топологии его размещения, и выбор между ними определяет поведение платформы при сбоях, требования к ресурсам и сложность эксплуатации.
Модель 1: Single Cluster. Supervisor-кластер и рабочие нагрузки размещаются в одном vSphere-кластере. Это наиболее простой с точки зрения конфигурации вариант. Он подходит для начального знакомства с платформой или сред разработчиков, однако не обеспечивает разделения плоскости управления и плоскости данных. При сбое кластера теряется и управление, и рабочие нагрузки.
Модель 2: Multi-Cluster с разделёнными зонами. Supervisor-контрольная плоскость развёртывается в отдельном управляющем домене, а рабочие нагрузки — в выделенных рабочих доменах. Такое разделение обеспечивает независимость управляющего слоя от прикладного, что принципиально важно для инфраструктуры среднего масштаба. Недостатком является необходимость большего числа хостов и более сложная настройка сети и зон.
Модель 3: vSphere Zones (рекомендуется для enterprise). Виртуальные машины управляющей плоскости Supervisor-кластера распределяются по трём vSphere Zones — логическим группам, каждая из которых соответствует отдельному физическому кластеру. Рабочие нагрузки могут совместно использовать те же три зоны или размещаться в выделенных. Платформа выдерживает полный отказ одной зоны без потери доступности — ни управляющий слой, ни приложения не затрагиваются. Данная модель рекомендуется для крупных enterprise-развёртываний, требующих гарантий высокой доступности на уровне инфраструктуры.
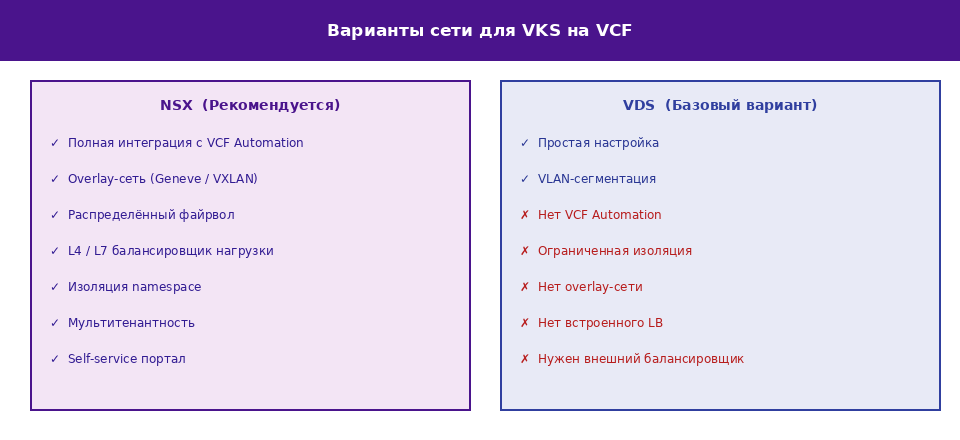
Сетевые опции: NSX или VDS
При настройке сети для VKS на VCF доступны два варианта: NSX и vSphere Distributed Switch (VDS). Выбор между ними оказывает существенное влияние на функциональность платформы и возможности автоматизации.
NSX является рекомендованным выбором для любого нового (greenfield) развёртывания VCF. Overlay-сеть на основе Geneve/VXLAN обеспечивает полную изоляцию на уровне неймспейсов, встроенный распределённый файрвол, встроенный балансировщик нагрузки уровней L4 и L7 (NSX Advanced Load Balancer / AVI), а также глубокую интеграцию с VCF Automation. Именно NSX позволяет реализовать портал самообслуживания, где разработчики и команды самостоятельно запрашивают ресурсы, не взаимодействуя напрямую с vSphere-администраторами.
VDS применяется в случаях, когда NSX не может быть развёрнут — например, при модернизации существующей инфраструктуры или при строгих ограничениях лицензирования. VDS поддерживает базовые возможности VKS, однако не поддерживает VCF Automation, overlay-сети и встроенный балансировщик нагрузки. При использовании VDS в производственной среде потребуется внешний балансировщик, что добавляет операционную сложность.
Отдельно подчёркивается, что если требования к приложению предполагают L4 или L7 балансировку, использование выделенного балансировщика нагрузки является обязательным — независимо от выбранного сетевого варианта.
Хранилище: vSAN, политики и управление томами
Хранилище в архитектуре VKS разделяется на два типа: эфемерное (ephemeral) и постоянное (persistent). Эфемерное хранилище используется для дисков самих узлов Kubernetes (Control Plane VMs и Worker Nodes) и временных томов Pod'ов. Оно берётся из основного или дополнительного хранилища рабочего домена и настраивается при активации Supervisor-кластера.
Постоянные тома (Persistent Volumes, PV) предназначены для stateful-приложений — баз данных, очередей сообщений, систем хранения состояния. Доступ к постоянному хранилищу управляется через Storage Policies — политики хранения vSAN, которые администратор создаёт в vCenter. Политики описывают параметры производительности, доступности (RAID-1, RAID-5/6) и шифрования. Каждый арендатор (tenant) в мультитенантной конфигурации получает доступ только к тем политикам хранения, которые ему явно назначены.
Если арендатору не назначена ни одна storage policy, он не сможет создавать Persistent Volume Claims (PVC) — это удобный механизм ограничения: организации могут предоставлять namespace без прав на stateful-хранение там, где это нежелательно. Поддерживаются режимы доступа RWO (ReadWriteOnce) и RWX (ReadWriteMany) — последний обычно требует дополнительных компонентов типа vSAN File Services или внешних NFS-решений.
Мультитенантность и интеграция с VCF Automation
Одним из ключевых преимуществ VKS на VCF является встроенная поддержка мультитенантности через механизм namespace и интеграцию с VCF Automation. Каждый неймспейс представляет собой изолированную рабочую область, которой могут быть назначены: квоты на CPU и RAM, доступные storage policies, сетевые профили NSX, а также права доступа пользователей или групп из Active Directory / LDAP.
VCF Automation предоставляет портал самообслуживания, через который подразделения и команды разработчиков могут самостоятельно запрашивать Kubernetes namespace, инициировать развёртывание приложений и управлять ресурсами — без участия администратора vSphere. Платформа автоматически создаёт необходимые ресурсы: сетевые сегменты NSX, политики хранения, RBAC-права. Это, по словам авторов вебинара, является «новейшим и наиболее зрелым способом организации современного private cloud».
Рекомендуется начинать с NSX в качестве сетевого стека при любом новом greenfield-развёртывании VCF именно потому, что VCF Automation поддерживает только NSX, и без него модель самообслуживания недоступна.
Рекомендации по проектированию production-платформы
По итогам вебинара сформулированы следующие практические рекомендации для команд, проектирующих VKS на VCF в производственной среде:
Используйте топологию vSphere Zones для любого развёртывания с требованиями к высокой доступности — она обеспечивает автоматический failover при отказе целого кластера без вмешательства администратора.
Выбирайте NSX как сетевой стек при greenfield-развёртывании — только с NSX доступна полная интеграция с VCF Automation и портал самообслуживания.
Планируйте storage policies заранее: определите требования к производительности и отказоустойчивости для разных классов рабочих нагрузок ещё до запуска первых неймспейсов.
Разграничивайте доступ к хранилищу на уровне арендаторов — не назначайте storage policies тем неймспейсам, которым stateful-хранение не нужно.
Если среда требует L4/L7 балансировки, включайте NSX Advanced Load Balancer (AVI) в архитектуру с самого начала — добавить его позднее значительно сложнее.
Не смешивайте управляющую и рабочую плоскости в одном кластере для производственной среды: выделяйте отдельный рабочий домен для приложений, даже если это требует дополнительных хостов.
Вопросы и ответы: ключевые моменты
В ходе сессии вопросов и ответов слушателей интересовали несколько практических аспектов. На вопрос о поддержке собственных сервисов поверх VKS ответ был однозначным: технически это возможно, однако рекомендуется использовать интегрированный стек — vSAN, NSX и VCF Automation — поскольку именно на нём строится поддержка и будущее развитие платформы.
На вопрос об источниках эфемерного хранилища пояснялось, что при активации Supervisor-кластера администратор указывает datastore, из которого берётся эфемерное хранилище для узлов Kubernetes и временных томов Pod'ов. Это может быть как vSAN, так и дополнительное (supplemental) хранилище рабочего домена.
Относительно нестандартных конфигураций — в частности, развёртывания VKS поверх существующей vSphere-среды без полного стека VCF — авторы отметили, что такие варианты существуют, но лишены ключевых преимуществ интегрированной платформы: автоматизации, самообслуживания и единого управления жизненным циклом.
Итог
VMware vSphere Kubernetes Service на VMware Cloud Foundation представляет собой зрелую enterprise-платформу для запуска production-Kubernetes с полной интеграцией в корпоративную инфраструктуру. Правильный выбор топологии Supervisor-кластера, сетевого стека и модели хранения на этапе проектирования определяет, насколько легко платформа будет масштабироваться и насколько просто её будет эксплуатировать в долгосрочной перспективе. Ознакомиться с предстоящими вебинарами серии VCF можно по ссылке go-vmware.broadcom.com/VCFWebinars.
Технология Advanced Memory Tiering в VMware Cloud Foundation 9 позволяет существенно расширить эффективный объём памяти хоста за счёт NVMe-накопителей — без изменения рабочих процессов и без влияния на привычные инструменты управления. Ниже собраны практические рекомендации, которые помогут правильно оценить среду, корректно настроить платформу и избежать типичных ошибок при развёртывании.
Как работает двухуровневая память
Архитектура Advanced Memory Tiering строится на двух уровнях.
Tier 0 — это DRAM: быстрая оперативная память, которая обслуживает активные страницы виртуальных машин.
Tier 1 — NVMe-накопитель, куда перемещаются холодные, редко используемые страницы. При этом память гипервизора (vmkernel) никогда не попадает в NVMe: ESX всегда работает исключительно в DRAM.
Когда виртуальная машина обращается к странице, находящейся в Tier 1, гипервизор возвращает её в DRAM — прозрачно и без участия гостевой ОС. Такая схема идеально подходит для рабочих нагрузок с выраженным разделением горячих и холодных страниц памяти.
Оценка готовности среды
Прежде чем включать Memory Tiering, необходимо проанализировать текущее потребление памяти. Ключевой показатель — активная память (active memory): объём страниц, к которым виртуальные машины реально обращаются в единицу времени. Технология оптимально работает, когда потреблённая (allocated) память превышает 50% от установленного объёма DRAM, а активная остаётся ниже этого порога.
Проверить активную память можно несколькими способами. В интерфейсе vCenter откройте VM > Monitor > Performance > Advanced, переключитесь в режим отображения памяти и выберите режим реального времени — показатель active memory доступен только в нём, поскольку относится к статистике уровня 1.
Для более широкого охвата подойдёт VCF Operations — если он уже развёрнут в инфраструктуре, он обеспечит сквозную видимость по всем хостам и кластерам. Ещё один вариант — RVTools: утилита собирает статистику памяти в реальном времени и позволяет быстро оценить картину по всей среде.
Порог активной памяти: правило 50%
Главное эксплуатационное правило Memory Tiering звучит просто: активная память должна оставаться на уровне 50% или ниже от объёма DRAM. Это гарантирует, что горячий рабочий набор данных комфортно размещается в быстрой памяти и при этом остаётся достаточный запас.
Если активная память стабильно превышает 70% от объёма DRAM, часть горячих страниц неизбежно окажется в Tier 1, и производительность виртуальных машин может заметно снизиться. В такой ситуации следует либо добавить DRAM на хост, либо перераспределить нагрузку между узлами кластера, прежде чем включать тиринг.
Настройка соотношения DRAM:NVMe
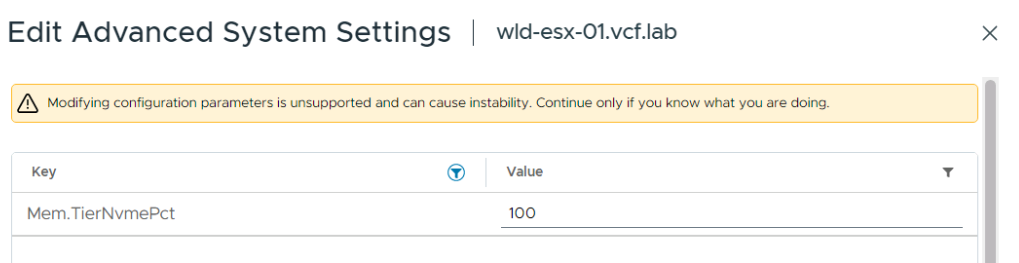
При включении Memory Tiering ESXi устанавливает соотношение DRAM к NVMe равным 1:1 по умолчанию. Это означает, что при наличии 512 ГБ DRAM хост получит дополнительные 512 ГБ ёмкости Tier 1. Параметр контролируется через расширенную настройку хоста: Mem.TierNVMePct со значением по умолчанию 100 (100% от объёма DRAM).
Рекомендуется сохранять соотношение 1:1 для большинства рабочих нагрузок — оно охватывает типичные сценарии использования. Изменять его стоит только после тщательного анализа профиля активной памяти конкретных ВМ. При выборе размера NVMe-накопителей разумно ориентироваться с запасом: более ёмкие устройства замедляют износ ячеек, дают пространство для будущего изменения соотношения и позволяют безболезненно справляться с неожиданным ростом нагрузки.
Подходящие рабочие нагрузки
Memory Tiering наиболее эффективна для рабочих нагрузок с естественным разделением горячих и холодных страниц. В их числе:
Общая серверная виртуализация — разнородный парк ВМ с умеренной и переменной активностью памяти.
VDI-среды — виртуальные рабочие столы с большим количеством ВМ, каждая из которых использует лишь часть выделенной памяти одновременно.
Среды разработки и тестирования — временные ВМ, которые редко используют всю выделенную память одновременно.
Веб-серверы и серверы приложений — нагрузки с предсказуемым рабочим набором в памяти.
Базы данных с умеренной активностью — СУБД, у которых значительная часть данных в памяти остаётся холодной
Неподходящие рабочие нагрузки
Ряд профилей виртуальных машин в настоящее время не поддерживает работу с Memory Tiering. Для таких ВМ тиринг следует отключить на уровне виртуальной машины — это принудительно размещает все её страницы в Tier 0 (DRAM).
Высокопроизводительные и latency-sensitive ВМ — приложения, требующие предсказуемых ультранизких задержек доступа к памяти
ВМ с аппаратной защитой памяти — виртуальные машины, использующие технологии шифрования AMD SEV, Intel SGX или Intel TDX
ВМ с Fault Tolerance (FT) — непрерывная синхронизация состояния несовместима с тирингом
«Монстроидальные» ВМ — машины с объёмом памяти от 1 ТБ и более 128 vCPU
ВМ с большими страницами памяти (large memory pages)
Вложенная виртуализация (nested VMs)
Если в кластере присутствуют такие нагрузки, оптимальная стратегия — выделить для них отдельные хосты и включить Memory Tiering только на оставшихся узлах кластера, либо управлять исключениями на уровне отдельных ВМ.
Интеграция с vSphere
Advanced Memory Tiering полностью интегрирована в стандартные механизмы управления vSphere — никаких специальных процедур не требуется:
vMotion — миграция ВМ между хостами работает прозрачно; оба уровня памяти учитываются при переносе.
DRS — балансировщик нагрузки осведомлён об обоих уровнях и учитывает их при принятии решений о размещении ВМ.
High Availability (HA) — при отказе хоста ВМ перезапускаются на оставшихся узлах по стандартным правилам HA.
Рекомендации по развёртыванию
Для успешного внедрения рекомендуется придерживаться следующих принципов. Во-первых, поддерживайте единую конфигурацию хостов в кластере с помощью vSphere Configuration Profiles — это исключает расхождения между узлами и упрощает масштабирование. Во-вторых, применяйте поэтапный подход: включайте тиринг последовательно, начиная с одного-двух хостов, оценивайте результаты и только потом распространяйте изменение на весь кластер. В-третьих, фиксируйте исключения: документируйте все ВМ, для которых Memory Tiering отключена на уровне виртуальной машины, чтобы не потерять контроль над конфигурацией при росте инфраструктуры.
Мониторинг после включения
После включения Memory Tiering следует регулярно отслеживать ключевые показатели:
Процент активной памяти на уровне хостов и кластера
Паттерны доступа к страницам (горячие/холодные)
Тренды утилизации памяти по кластеру в целом
Потребление памяти на уровне отдельных ВМ
Задержки чтения и записи NVMe-накопителей Tier 1
Рост задержек NVMe или увеличение активной памяти выше порога 50% DRAM — сигнал для пересмотра распределения нагрузки или конфигурации тиринга. Регулярный мониторинг позволяет выявлять изменения в профиле нагрузки на ранней стадии и реагировать проактивно.
Функция vSphere Configuration Profiles, впервые представленная в VMware vSphere 8.0, позволяет администраторам VMware Cloud Foundation управлять конфигурацией хостов ESX на уровне кластера. В данном материале рассматривается, чем эта функция отличается от Host Profiles, и как выполнить переход с Host Profiles на vSphere Configuration Profiles в vSphere 9.
Примечание: скриншоты и описанные шаги основаны на vSphere 9.0.2. В более ранних или более поздних версиях отдельные элементы интерфейса или формулировки могут отличаться.
О vSphere Configuration Profiles
vSphere Configuration Profiles — новая функция, впервые появившаяся в vSphere 8.0. Она является преемником Host Profiles в части управления конфигурацией хостов ESX в масштабе. Host Profiles неудобны тем, что требуют полного описания конфигурации хоста целиком. Это создаёт избыточную нагрузку на администраторов, которым, как правило, достаточно указать лишь те изменения, которые необходимо внести в конфигурацию.
vSphere Configuration Profiles, напротив, требует от администратора только определить отклонения от конфигурации по умолчанию. Это делает конфигурационный документ удобочитаемым и значительно более управляемым.
Переход с Host Profiles
Администраторы, управляющие конфигурацией хостов ESX с помощью Host Profiles в кластере, жизненный цикл которого управляется образами vSphere Lifecycle Manager, могут перевести кластеры на использование vSphere Configuration Profiles.
Примечание: использование vSphere Configuration Profiles с кластерами под управлением базовых уровней (baselines) поддерживается в vSphere 8 U3. Однако в vSphere 9 такие кластеры больше не поддерживаются, а Host Profiles считаются устаревшими, хотя и продолжают поддерживаться. Рекомендуется использовать кластеры под управлением образов vSphere Lifecycle Manager.
Перед переходом рекомендуется убедиться, что хосты ESX соответствуют текущему Host Profile. Ниже описан процесс перехода.
Управление конфигурацией на уровне кластера
Первый шаг — включить vSphere Configuration Profiles в кластере. Для этого перейдите в Cluster > Configure > Configuration в разделе Desired State и нажмите Create Configuration. Будут запущены проверки совместимости, чтобы убедиться, что кластер может быть переведён на vSphere Configuration Profiles. На рисунке 1 показан вариант запуска vSphere Configuration Profiles в существующем кластере.
Примечание: если к кластеру прикреплён Host Profile, появится предупреждение о необходимости удалить его после завершения перехода. После перехода Host Profiles не могут быть прикреплены ни к кластеру, ни к хостам внутри него. Этот процесс можно использовать и в том случае, если Host Profiles в данный момент не применяются.
Создание конфигурации
Далее необходимо указать, каким образом конфигурация хоста ESX для vSphere Configuration Profiles должна быть импортирована. Доступны два варианта:
Импорт с эталонного хоста.
Импорт JSON-файла с желаемой конфигурацией кластера.
Поскольку выполняется переход кластера, управляемого с помощью Host Profiles, предпочтительным вариантом является IMPORT FROM REFERENCE HOST. В качестве эталонного хоста можно выбрать любой хост ESX в кластере — все хосты уже должны соответствовать используемому Host Profile.
Примечание: при импорте с эталонного хоста любые отклонения от его конфигурации будут зафиксированы как переопределения хоста. Возможно, потребуется вручную проверить конфигурацию и удалить эти переопределения, если необходима единая конфигурация для всех хостов кластера.
На рисунке 2 показаны варианты импорта. Нажмите Import.
На рисунке 3 показан выбор эталонного хоста.
После импорта нажмите Next. Процесс импорта проверяет сгенерированный документ относительно всех хостов ESX в кластере. После успешной проверки нажмите Next. На рисунке 4 показан этап проверки конфигурации.
Предварительная проверка и применение
На последнем шаге vSphere Configuration Profiles проверяет хосты ESX в кластере на соответствие желаемой конфигурации и устраняет любые отклонения, обнаруженные в ходе проверки.
Примечание: поскольку выполняется переход с кластера под управлением Host Profile, исправлений не ожидается. Ознакомьтесь с влиянием изменений конфигурации на хосты. Нажмите Finish and Apply. На рисунке 5 показан предварительный просмотр эффекта применения. Нажмите Continue.
После этого сгенерированный vSphere Configuration Profile будет установлен в качестве желаемой конфигурации кластера, а все несоответствующие хосты ESX будут приведены в соответствие. На рисунке 6 показан диалог подтверждения завершения и применения.
Функция vSphere Configuration Profiles теперь включена, и доступен просмотр заданных конфигураций. На рисунке 7 показано, что конфигурация на уровне кластера включена.
На рисунке 8 показано соответствие хостов конфигурации кластера.
На завершающем шаге необходимо отсоединить Host Profile от хостов ESX.
Итог
Управление конфигурациями ESX остаётся непростой задачей в корпоративных средах. vSphere Configuration Profiles — новая возможность, впервые представленная в vSphere 8.0, которая решает эту задачу в масштабе большой инфраструктуры.
Многие VMware-инфраструктуры сегодня находятся в переходной стадии: организации продолжают использовать
vSphere-кластеры, но постепенно переходят к модели Software-Defined Data Center и частного облака на базе VMware Cloud Foundation (VCF).
Полностью перестраивать инфраструктуру с нуля в производственной среде обычно невозможно. Там уже работают
десятки или сотни виртуальных машин, поэтому перенос на новую платформу должен происходить максимально
аккуратно. Именно для таких сценариев VMware предлагает механизм Brownfield-интеграции.
Этот подход позволяет смигрировать существующую инфраструктуру vSphere на VMware Cloud Foundation без
переустановки среды и без миграции виртуальных машин. Подробно этот процесс рассмотрел Tarsio Moraes в своем видео:
Что такое Brownfield-апгрейд
Brownfield-подход означает интеграцию уже существующей инфраструктуры в новую платформу без полного
развертывания новой среды.
В VMware-экосистеме это означает, что существующий vCenter Server,
кластеры ESX и запущенные виртуальные машины могут быть импортированы
в VCF как отдельный Workload Domain.
Таким образом инфраструктура сохраняет текущие рабочие нагрузки, но получает централизованное управление,
автоматизированное lifecycle-обновление и интеграцию сетевой платформы NSX.
Архитектура до и после интеграции
Исходная инфраструктура
Типичная среда включает vSphere 8, один или несколько кластеров ESXi,
vCenter Server и систему хранения — например vSAN или внешние датасторы.
Сетевая конфигурация обычно построена на распределенном коммутаторе Distributed Switch.
В такой архитектуре управление вычислениями, сетью и мониторингом может
осуществляться через разные инструменты.
После интеграции в VCF
После импорта инфраструктура становится частью платформы VMware Cloud Foundation.
Появляется централизованное управление через компоненты VCF, а инфраструктура
разделяется на management domain и workload domains.
Также стоит учитывать изменения в продуктовой линейке VMware:
многие функции бывшей линейки Aria теперь встроены непосредственно в VMware Cloud Foundation (как функционал модуля Operations).
Подготовка инфраструктуры
Перед запуском Brownfield-апгрейда необходимо убедиться,
что инфраструктура соответствует требованиям совместимости.
В первую очередь проверяются версии компонентов:
vSphere, vCenter Server и ESXi (теперь он снова называется ESX). Кроме того,
важно убедиться в совместимости оборудования через VMware Compatibility Guide.
Также необходимо проверить базовые инфраструктурные сервисы:
DNS, NTP, доступность сетей управления и состояние датасторов.
Особенно важно убедиться, что DNS корректно разрешает имена
хостов ESX, vCenter и будущих узлов NSX Manager.
Подготовка среды управления
Перед импортом vSphere-среды необходимо подготовить управляющие компоненты VMware Cloud Foundation.
К ним относятся VCF Fleet Management и VCF Operations.
Эти сервисы отвечают за централизованное управление инфраструктурой,
мониторинг и lifecycle-операции.
На этом этапе стоит проверить доступность management-компонентов,
валидность сертификатов и сетевую связность между сервисами управления и vCenter.
Использование VCF Import Tool
Для интеграции существующей среды используется специальный инструмент —
VCF Import Tool.
Он анализирует конфигурацию vSphere,
выполняет проверку совместимости и подготавливает инфраструктуру к импорту.
Перед запуском процесса выполняется серия pre-check проверок,
которые анализируют сеть, лицензии, сертификаты, конфигурацию кластеров
и параметры хранения.
Если обнаружены ошибки или предупреждения, их необходимо устранить
до начала импорта.
Импорт vCenter как Workload Domain
После завершения подготовительных этапов можно приступать к импорту
существующего vCenter.
В интерфейсе VCF создаётся новый workload domain,
после чего указываются параметры подключения к существующему vCenter.
После проверки параметров запускается автоматический рабочий процесс (workflow),
который выполняет регистрацию vCenter в инфраструктуре VCF.
С этого момента среда становится частью VMware Cloud Foundation.
Развертывание NSX
Следующий этап — интеграция сетевой платформы NSX.
Если NSX ранее не использовался, VMware Cloud Foundation может автоматически
развернуть NSX Manager cluster и подготовить хосты ESX.
Если NSX уже установлен в инфраструктуре,
он может быть импортирован вместе с workload domain.
Пост-апгрейд проверки
После завершения интеграции необходимо провести проверку состояния среды.
Стоит убедиться, что workload domain корректно отображается
в интерфейсе VCF, хосты ESX подключены,
датасторы доступны, а виртуальные машины работают без ошибок.
Дополнительно рекомендуется протестировать ключевые операции виртуализации:
vMotion, создание снапшота и сетевую связность между виртуальными машинами.
Итог
Brownfield-апгрейд позволяет перевести существующую инфраструктуру
vSphere 8 в модель VMware Cloud Foundation 9 без полного
перестроения среды.
Этот подход сохраняет текущие рабочие нагрузки,
централизует управление инфраструктурой
и позволяет постепенно перейти к архитектуре частного облака.
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Вильям Лам описал способ развертывания виртуального модуля OVF/OVA напрямую с сервера с Basic Authentication.
Он делал эксперименты с использованием OVFTool и доработал свой скрипт deploy_data_services_manager.sh, чтобы он ссылался на URL, где был размещён Data Services Manager (DSM) в формате OVA. В этом случае базовую аутентификацию (имя пользователя и пароль) можно включить прямым текстом в URL. Хотя это не самый безопасный способ, он позволяет удобно использовать этот метод развертывания.
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
В современных ИТ-системах шифрование данных стало обязательным элементом защиты информации. Цель шифрования — гарантировать, что данные могут прочитать только системы, обладающие нужными криптографическими ключами. Любой, не имеющий ключей доступа, увидит лишь бессмысленный набор символов, поскольку информация надёжно зашифрована устойчивым алгоритмом AES-256. VMware vSAN поддерживает два уровня шифрования для повышения безопасности кластерного хранения данных: шифрование данных на носителях (Data-at-Rest Encryption) и шифрование данных при передаче (Data-in-Transit Encryption). Эти механизмы позволяют защитить данные как в состоянии покоя (на дисках), так и в движении (между узлами кластера). В результате vSAN помогает организациям соответствовать требованиям регуляторов и предотвращать несанкционированный доступ к данным, например, при краже носителей или перехвате сетевого трафика.
Архитектура шифрования vSAN включает несколько ключевых элементов: внешний или встроенный сервер управления ключами (KMS), сервер VMware vCenter, гипервизоры ESXi в составе vSAN-кластера и собственно криптографические модули в ядре гипервизора. Внешний KMS-сервер (совместимый с протоколом KMIP), либо встроенный поставщик ключей vSphere NKP, обеспечивает генерацию и хранение мастер-ключей шифрования. vCenter Server отвечает за интеграцию с KMS: именно vCenter устанавливает доверенные отношения (обмен сертификатами) с сервером ключей и координирует выдачу ключей хостам ESXi. Каждый узел ESXi, входящий в шифрованный кластер vSAN, содержит встроенный криптомодуль VMkernel (сертифицированный по требованиям FIPS), который выполняет операции шифрования и дешифрования данных на стороне гипервизора.
Распределение ключей
При включении шифрования vSAN на кластере vCenter запрашивает у KMS два ключа для данного кластера: ключ шифрования ключей (Key Encryption Key, KEK) и ключ хоста (Host Key). KEK играет роль мастер-ключа: с его помощью будут шифроваться все остальные ключи (например, ключи данных). Host Key предназначен для защиты дампов памяти (core dumps) и других служебных данных хоста. После получения этих ключей vCenter передаёт информацию о KMS и идентификаторы ключей (ID) всем хостам кластера. Каждый узел ESXi устанавливает прямое соединение с KMS (по протоколу KMIP) и получает актуальные копии KEK и Host Key, помещая их в защищённый кэш памяти.
Важно: сами ключи не сохраняются на диске хоста, они хранятся только в оперативной памяти или, при наличии, в аппаратном модуле TPM на узле. Это означает, что при перезагрузке хоста ключи стираются из памяти и в общем случае должны быть вновь запрошены у KMS, прежде чем хост сможет монтировать зашифрованное хранилище.
Ключи данных (DEK)
Помимо вышеупомянутых кластерных ключей, каждый диск или объект данных получает свой собственный ключ шифрования данных (Data Encryption Key, DEK). В оригинальной архитектуре хранения vSAN (OSA) гипервизор генерирует уникальный DEK (алгоритм XTS-AES-256) для каждого физического диска в дисковой группе. Эти ключи оборачиваются (wrap) с помощью кластерного KEK и сохраняются в метаданных, что позволяет безопасно хранить ключи на дисках: получить «сырой» DEK можно только расшифровав его при помощи KEK. В более новой архитектуре vSAN ESA подход несколько отличается: используется единый ключ шифрования кластера, но при этом для различных объектов данных применяются уникальные производные ключи. Благодаря этому данные каждой виртуальной машины шифруются своим ключом, даже если в основе лежит общий кластерный ключ. В обоих случаях vSAN обеспечивает надёжную защиту: компрометация одного ключа не даст злоумышленнику доступа ко всему массиву данных.
Роль гипервизора и производительность
Шифрование в vSAN реализовано на уровне ядра ESXi, то есть прозрачно для виртуальных машин. Гипервизор использует сертифицированный криптографический модуль VMkernel, прошедший все необходимые проверки по стандарту FIPS 140-2 (а в новых версиях — и FIPS 140-3). Все операции шифрования выполняются с использованием аппаратного ускорения AES-NI, что минимизирует влияние на производительность системы. Опыт показывает, что нагрузка на CPU и задержки ввода-вывода при включении шифрования vSAN обычно незначительны и хорошо масштабируются с ростом числа ядер и современных процессоров. В свежей архитектуре ESA эффективность ещё выше: благодаря более оптимальному расположению слоя шифрования в стеке vSAN, для той же нагрузки требуется меньше CPU-циклов и операций, чем в классической архитектуре OSA.
Управление доступом
Стоит упомянуть, что управление шифрованием в vSAN встроено в систему ролей и привилегий vCenter. Только пользователи с особыми правами (Cryptographic administrator) могут настраивать KMS и включать/отключать шифрование на кластере. Это добавляет дополнительный уровень безопасности: случайный администратор без соответствующих привилегий даже не увидит опцию включения шифрования в интерфейсе. Разграничение доступа гарантирует, что ключи шифрования и связанные операции контролируются ограниченным кругом доверенных администраторов.
Шифрование данных на носителях (vSAN Data-at-Rest Encryption)
Этот тип шифрования обеспечивает защиту всех данных, хранящихся в vSAN-датасторе. Включение функции означает, что вся информация, записываемая на диски кластера, автоматически шифруется на последнем этапе ввода-вывода перед сохранением на устройство. При чтении данные расшифровываются гипервизором прозрачно для виртуальных машин – приложения и ОС внутри ВМ не осведомлены о том, что данные шифруются. Главное назначение Data-at-Rest Encryption – обезопасить данные на случай, если накопитель будет изъят из системы (например, при краже или некорректной утилизации дисков).
Без соответствующих ключей злоумышленник не сможет прочитать информацию с отключенного от кластера диска. Шифрование «на покое» не требует специальных самошифрующихся дисков – vSAN осуществляет его программно, используя собственные криптомодули, и совместимо как с гибридными, так и полностью флэш-конфигурациями хранилища.
Принцип работы: в оригинальной реализации OSA шифрование данных происходит после всех операций дедупликации и сжатия, то есть уже на «выходе» перед записью на носитель. Такой подход позволяет сохранить эффективность экономии места: данные сначала сжимаются и устраняются дубликаты, и лишь затем шифруются, благодаря чему коэффициенты дедупликации/сжатия не страдают. В архитектуре ESA шифрование интегрировано выше по стеку – на уровне кэша – но всё равно после выполнения компрессии данных.
То есть в ESA шифрование также не препятствует сжатию. Однако особенностью ESA является то, что все данные, покидающие узел, уже зашифрованы высокоуровневым ключом кластера (что частично перекрывает и трафик между узлами – см. ниже). Тем не менее для обеспечения максимальной криптостойкости vSAN ESA по-прежнему поддерживает отдельный механизм Data-in-Transit Encryption для уникального шифрования каждого сетевого пакета.
Включение и поддержка: шифрование данных на носителях включается на уровне всего кластера vSAN – достаточно установить флажок «Data-at-Rest Encryption» в настройках служб vSAN для выбранного кластера. Данная возможность доступна только при наличии лицензии vSAN Enterprise или выше.
В традиционной архитектуре OSA шифрование можно включать как при создании нового кластера, так и на уже работающем кластере. В последнем случае vSAN выполнит поочерёдное перевоспроизведение данных с каждого диска (evacuation) и форматирование дисковых групп в зашифрованном виде, что потребует определённых затрат ресурсов и времени. В архитектуре ESA, напротив, решение о шифровании принимается только на этапе создания кластера и не может быть изменено позднее без полной перестройки хранилища. Это связано с тем, что в ESA шифрование глубоко интегрировано в работу кластера, обеспечивая максимальную производительность, но и требуя фиксации режима на старте. В обоих случаях, после включения, сервис шифрования прозрачно работает со всеми остальными функциями vSAN (в том числе со снапшотами, клонированием, vMotion и т.д.) и практически не влияет на операционную деятельность кластера.
Шифрование данных при передаче (vSAN Data-in-Transit Encryption)
Второй компонент системы безопасности vSAN – это шифрование сетевого трафика между узлами хранения. Функция Data-in-Transit Encryption гарантирует, что все данные, пересылаемые по сети между хостами vSAN, будут зашифрованы средствами гипервизора.
Это особенно важно, если сеть хранения не полностью изолирована или если требуется соответствовать строгим стандартам по защите данных в транзите. Механизм шифрования трафика не требует KMS: при включении этой опции хосты vSAN самостоятельно генерируют и обмениваются симметричными ключами для установления защищённых каналов. Процесс полностью автоматизирован и не требует участия администратора – достаточно активировать настройку в параметрах кластера.
Data-in-Transit Encryption впервые появилась в vSAN 7 Update 1 и доступна для кластеров как с OSA, так и с ESA. В случае OSA администратор может независимо включить шифрование трафика (оно не зависит от шифрования на дисках, но для полноты защиты желательно задействовать оба механизма). В случае ESA отдельного переключателя может не потребоваться: при создании кластера с шифрованием данные «на лету» фактически уже будут выходить из узлов зашифрованными единым высокоуровневым ключом. Однако, чтобы каждый сетевой пакет имел уникальный криптографический отпечаток, ESA по-прежнему предусматривает опцию Data-in-Transit (она остаётся активной в интерфейсе и при включении обеспечит дополнительную уникализацию шифрования каждого пакета). Следует учесть, что на момент выпуска vSAN 9.0 в составе VCF 9.0 шифрование трафика поддерживается только для обычных (HCI) кластеров vSAN и недоступно для т. н. disaggregated (выделенных storage-only) кластеров.
С технической точки зрения, Data-in-Transit Encryption использует те же проверенные криптомодули, сертифицированные по FIPS 140-2/3, что и шифрование данных на дисках. При активации этой функции vSAN автоматически выполняет взаимную аутентификацию хостов и устанавливает между ними защищённые сессии с помощью динамически создаваемых ключей. Когда новый узел присоединяется к шифрованному кластеру, для него генерируются необходимые ключи и он аутентифицируется существующими участниками; при исключении узла его ключи отзываются, и трафик больше не шифруется для него. Всё это происходит «под капотом», не требуя ручной настройки. В результате даже при потенциальном перехвате пакетов vSAN-трафика на уровне сети, извлечь из них полезные данные не представляется возможным.
Для использования шифрования данных на vSAN необходим сервер управления ключами (Key Management Server, KMS), совместимый со стандартом KMIP 1.1+. Исключение составляет вариант применения встроенного поставщика ключей vSphere (Native Key Provider, NKP), который появился начиная с vSphere 7.0 U2. Внешний KMS может быть программным или аппаратным (множество сторонних решений сертифицировано для работы с vSAN), но в любом случае требуется лицензия не ниже vSAN Enterprise.
Перед включением шифрования администратор должен зарегистрировать KMS в настройках vCenter: добавить информацию о сервере и установить доверие между vCenter и KMS. Обычно настройка доверия реализуется через обмен сертификатами: vCenter либо получает от KMS корневой сертификат (Root CA) для проверки подлинности, либо отправляет на KMS сгенерированный им запрос на сертификат (CSR) для подписи. В результате KMS и vCenter обмениваются удостоверяющими сертификатами и устанавливают защищённый канал. После этого vCenter может выступать клиентом KMS и запрашивать ключи.
В конфигурации с Native Key Provider процесс ещё проще: NKP разворачивается непосредственно в vCenter, генерируя мастер-ключ локально, поэтому внешний сервер не нужен. Однако даже в этом случае рекомендуется экспортировать (зарезервировать) копию ключа NKP во внешнее безопасное место, чтобы избежать потери ключей в случае сбоя vCenter.
Запрос и кэширование ключей
Как только доверие (trust) между vCenter и KMS установлено, можно активировать шифрование vSAN на уровне кластера. При этом vCenter от имени кластера делает запрос в KMS на выдачу необходимых ключей (KEK и Host Key) и распределяет их идентификаторы хостам, как описано выше. Каждый ESXi узел соединяется с KMS напрямую для получения своих ключей. На период нормальной работы vSAN-хосты обмениваются ключами с KMS напрямую, без участия vCenter.
Это означает, что после первоначальной настройки для ежедневной работы кластера шифрования доступность vCenter не критична – даже если vCenter временно выключен, хосты будут продолжать шифровать/расшифровывать данные, используя ранее полученные ключи. Однако vCenter нужен для проведения операций управления ключами (например, генерации новых ключей, смены KMS и пр.). Полученные ключи хранятся на хостах в памяти, а при наличии TPM-модуля – ещё и в его защищённом хранилище, что позволяет пережить перезагрузку хоста без немедленного запроса к KMS.
VMware настоятельно рекомендует оснащать все узлы vSAN доверенными платформенными модулями TPM 2.0, чтобы обеспечить устойчивость к отказу KMS: если KMS временно недоступен, хосты с TPM смогут перезапускаться и монтировать зашифрованное хранилище, используя кешированные в TPM ключи.
Лучшие практики KMS
В контексте vSAN есть важное правило: не размещать сам KMS на том же зашифрованном vSAN-хранилище, которое он обслуживает. Иначе возникает круговая зависимость: при отключении кластера или перезагрузке узлов KMS сам окажется недоступен (ведь он работал как ВМ на этом хранилище), и хосты не смогут получить ключи для расшифровки датасторов.
Лучше всего развернуть кластер KMS вне шифруемого кластера (например, на отдельной инфраструктуре или как облачный сервис) либо воспользоваться внешним NKP от другого vCenter. Также желательно настроить кластер из нескольких узлов KMS (для отказоустойчивости) либо, в случае NKP, надёжно сохранить резервную копию ключа (через функцию экспорта в UI vCenter).
При интеграции с KMS крайне важна корректная сетевая настройка: все хосты vSAN-кластера должны иметь прямой доступ к серверу KMS (обычно по протоколу TLS на порт 5696). В связке с KMS задействуйте DNS-имя для обращения (вместо IP) – это упростит перенастройку в случае смены адресов KMS и снизит риск проблем с подключением.
vSphere Native Key Provider
Этот встроенный механизм управления ключами в vCenter заслуживает отдельного упоминания. NKP позволяет обойтись без развертывания отдельного KMS-сервера, что особенно привлекательно для небольших компаний или филиалов. VMware поддерживает использование NKP для шифрования vSAN начиная с версии 7.0 U2. По сути, NKP хранит мастер-ключ в базе данных vCenter (в зашифрованном виде) и обеспечивает необходимые функции выдачи ключей гипервизорам. При включении шифрования vSAN с NKP процесс выдачи ключей аналогичен: vCenter генерирует KEK и распределяет его на хосты. Разница в том, что здесь нет внешнего сервера – все операции выполняются средствами самого vCenter.
Несмотря на удобство, у NKP есть ограничения (например, отсутствие поддержки внешних интерфейсов KMIP для сторонних приложений), поэтому для крупных сред на долгосрочной основе часто выбирают полноценный внешний KMS. Тем не менее, NKP – это простой способ быстро задействовать шифрование без дополнительных затрат, и он идеально подходит для многих случаев использования.
После того как кластер vSAN сконфигурирован для шифрования и получены необходимые ключи, каждая операция записи данных проходит через этап шифрования в гипервизоре. Рассмотрим упрощённо этот процесс на примере OSA (Original Storage Architecture):
Получение блока данных. Виртуальная машина записывает данные на диск vSAN, которые через виртуальный контроллер поступают на слой vSAN внутри ESXi. Там данные сначала обрабатываются сервисами оптимизации – например, вычисляются хеши для дедупликации и выполняется сжатие (если эти функции включены на кластере).
Шифрование блока. Когда очередь дошла до фактической записи блока на устройство, гипервизор обращается к ключу данных (DEK), связанному с целевым диском, и шифрует блок по алгоритму AES-256 (режим XTS) с помощью этого DEK. Как упоминалось, в OSA у каждого диска свой DEK, поэтому даже два диска одного узла шифруют данные разными ключами. Шифрование происходит на уровне VMkernel, используя AES-NI, и добавляет минимальную задержку.
Запись на устройство. Зашифрованный блок записывается в кеш или напрямую на SSD в составе дисковой группы. На носитель попадают только зашифрованные данные; никакой незашифрованной копии информации на диске не сохраняется. Метаданные vSAN также могут быть зашифрованы или содержать ссылки на ключ (например, KEK_ID), но без владения самим ключом извлечь полезную информацию из зашифрованного блока невозможно.
В архитектуре ESA процесс схож, с тем отличием, что шифрование происходит сразу после сжатия, ещё на высокоуровневом слое ввода-вывода. Это означает, что данные выходят из узла уже шифрованными кластерным ключом. При наличии Data-in-Transit Encryption vSAN накладывает дополнительное пакетное шифрование: каждый сетевой пакет между хостами шифруется с использованием симметрических ключей сеанса, которые регулярно обновляются. Таким образом, данные остаются зашифрованы как при хранении, так и при передаче по сети, что создаёт многослойную защиту (end-to-end encryption).
Чтение данных (дешифрование)
Обратный процесс столь же прозрачен. Когда виртуальная машина запрашивает данные из vSAN, гипервизор на каждом затронутом хосте находит нужные зашифрованные блоки на дисках и считывает их. Прежде чем передать данные наверх VM, гипервизор с помощью соответствующего DEK выполняет расшифровку каждого блока в памяти. Расшифрованная информация проходит через механизмы пост-обработки (восстановление сжатых данных, сборка из дедуплицированных сегментов) и отправляется виртуальной машине. Для ВМ этот процесс невидим – она получает привычный для себя блок данных, не зная, что на физическом носителе он хранится в зашифрованном виде. Если задействовано шифрование трафика, то данные могут передаваться между узлами в зашифрованном виде и расшифровываются только на том хосте, который читает их для виртуальной машины-потребителя.
Устойчивость к сбоям
При нормальной работе все операции шифрования/дешифрования происходят мгновенно для пользователя. Но стоит рассмотреть ситуацию с потенциальным сбоем KMS или перезагрузкой узла. Как отмечалось ранее, хосты кэшируют полученные ключи (KEK, Host Key и необходимые DEK) в памяти или TPM, поэтому кратковременное отключение KMS не влияет на работающий кластер.
Виртуальные машины продолжат и читать, и записывать данные, пользуясь уже загруженными ключами. Проблемы могут возникнуть, если перезагрузить хост при недоступном KMS: после перезапуска узел не сможет получить свои ключи для монтирования дисковых групп, и его локальные компоненты хранилища останутся офлайн до восстановления связи с KMS. Именно поэтому, как уже упоминалось, рекомендуется иметь резервный KMS (или NKP) и TPM-модули на узлах, чтобы повысить отказоустойчивость системы шифрования.
Безопасность криптосистемы во многом зависит от регулярной смены ключей. VMware vSAN предоставляет администраторам возможность проводить плановую ротацию ключей шифрования без простоя и с минимальным влиянием на работу кластера. Поддерживаются два режима: «мелкая» ротация (Shallow Rekey) и «глубокая» ротация (Deep Rekey). При shallow rekey генерируется новый мастер-ключ KEK, после чего все ключи данных (DEK) перешифровываются этим новым KEK (старый KEK уничтожается). Важно, что сами DEK при этом не меняются, поэтому операция выполняется относительно быстро: vSAN просто обновляет ключи в памяти хостов и в метаданных, не перестраивая все данные на дисках. Shallow rekey обычно используют для регулярной смены ключей в целях комплаенса (например, раз в квартал или при смене ответственного администратора).
Deep rekey, напротив, предполагает полную замену всех ключей: генерируются новые DEK для каждого объекта/диска, и все данные кластера постепенно перераспределяются и шифруются уже под новыми ключами. Такая операция более ресурсоёмка, фактически аналогична повторному шифрованию всего объёма данных, и может занять продолжительное время на крупных массивах. Глубокую ротацию имеет смысл выполнять редко – например, при подозрении на компрометацию старых ключей или после аварийного восстановления системы, когда есть риск утечки ключевой информации. Оба типа рекея можно инициировать через интерфейс vCenter (в настройках кластера vSAN есть опция «Generate new encryption keys») или с помощью PowerCLI-скриптов. При этом для shallow rekey виртуальные машины могут продолжать работать без простоев, а deep rekey обычно тоже выполняется онлайн, хотя и создаёт повышенную нагрузку на подсистему хранения.
Смена KMS и экспорт ключей
Если возникает необходимость поменять используемый KMS (например, миграция на другого вендора или переход от внешнего KMS к встроенному NKP), vSAN упрощает эту процедуру. Администратор добавляет новый KMS в vCenter и обозначает его активным для данного кластера. vSAN автоматически выполнит shallow rekey: запросит новый KEK у уже доверенного нового KMS и переведёт кластер на использование этого ключа, перешифровав им все старые DEK. Благодаря этому переключение ключевого сервиса происходит прозрачно, без остановки работы хранилища. Тем не менее, после замены KMS настоятельно рекомендуется удостовериться, что старый KMS более недоступен хостам (во избежание путаницы) и сделать резервную копию конфигурации нового KMS/NKP.
При использовании vSphere Native Key Provider важно регулярно экспортировать зашифрованную копию ключа NKP (через интерфейс vCenter) и хранить её в безопасном месте. Это позволит восстановить доступ к зашифрованному vSAN, если vCenter выйдет из строя и потребуется его переустановка. В случае же аппаратного KMS, как правило, достаточно держать под рукой актуальные резервные копии самого сервера KMS (или использовать кластер KMS из нескольких узлов для отказоустойчивости).
Безопасное удаление данных
Одним из побочных преимуществ внедрения шифрования является упрощение процедуры безопасной утилизации носителей. vSAN предлагает опцию Secure Disk Wipe для случаев, когда необходимо вывести диск из эксплуатации или изъять узел из кластера. При включенной функции шифрования проще всего выполнить «очистку» диска путем сброса ключей: как только DEK данного носителя уничтожен (либо кластерный KEK перегенерирован), все данные на диске навсегда остаются в зашифрованном виде, то есть фактически считаются стёртыми (так называемая криптографическая санация).
Кроме того, начиная с vSAN 8.0, доступна встроенная функция стирания данных в соответствии со стандартами NIST (например, перезапись нулями или генерация случайных шаблонов). Администратор может запустить безопасное стирание при выведении диска из кластера – vSAN приведёт накопитель в состояние, удовлетворяющее требованиям безопасной утилизации, удалив все остаточные данные. Комбинация шифрования и корректного удаления обеспечивает максимальную степень защиты: даже физически завладев снятым накопителем, злоумышленник не сможет извлечь конфиденциальные данные.
VMware vSAN Encryption Services были разработаны с учётом строгих требований отраслевых стандартов безопасности. Криптографический модуль VMkernel, на котором основано шифрование vSAN, прошёл валидацию FIPS 140-2 (Cryptographic Module Validation Program) ещё в 2017 году. Это означает, что реализация шифрования в гипервизоре проверена независимыми экспертами и отвечает критериям, предъявляемым правительственными организациями США и Канады.
Более того, в 2024 году VMware успешно завершила сертификацию модуля по новому стандарту FIPS 140-3, обеспечив преемственность соответствия более современным требованиям. Для заказчиков из сфер, где необходима сертификация (государственный сектор, финансы, медицина и т.д.), это даёт уверенность, что vSAN может использоваться для хранения чувствительных данных. Отдельно отметим, что vSAN включена в руководства по безопасности DISA STIG для Министерства обороны США, а также поддерживает механизмы двухфакторной аутентификации администраторов (RSA SecurID, CAC) при работе с vCenter — всё это подчёркивает серьёзное внимание VMware к безопасности решения.
Совместимость с функционалом vSAN
Шифрование в vSAN спроектировано так, чтобы быть максимально прозрачным для остальных возможностей хранения. Дедупликация и сжатие полностью совместимы с Data-at-Rest Encryption: благодаря порядку выполнения (сначала дедупликация/сжатие, потом шифрование) эффективность экономии места практически не снижается. Исключение составляет экспериментальная функция глобальной дедупликации в новой архитектуре ESA — на момент запуска vSAN 9.0 одновременное включение глобальной дедупликации и шифрования не поддерживается (ожидается снятие этого ограничения в будущих обновлениях).
Снапшоты и клоны виртуальных машин на зашифрованном vSAN работают штатно: все мгновенные копии хранятся в том же шифрованном виде, и при чтении/записи гипервизор так же прозрачно шифрует их содержимое. vMotion и другие механизмы миграции ВМ также поддерживаются – сама ВМ при миграции может передаваться с шифрованием (функция Encrypted vMotion, независимая от vSAN) или без него, но это не влияет на состояние ее дисков, которые на принимающей стороне всё равно будут записаны на vSAN уже в зашифрованном виде.
Резервное копирование и репликация
vSAN Encryption не накладывает ограничений на работу средств резервного копирования, использующих стандартные API vSphere (такие как VMware VADP) или репликации на уровне ВМ. Данные читаются гипервизором в расшифрованном виде выше уровня хранения, поэтому бэкап-приложения получают их так же, как и с обычного хранилища. При восстановлении или репликации на целевой кластер vSAN, естественно, данные будут записаны с повторным шифрованием под ключи того кластера. Таким образом, процессы защиты и восстановления данных (VDP, SRM, vSphere Replication и пр.) полностью совместимы с зашифрованными датасторами vSAN.
Ограничения и особенности
Поскольку vSAN реализует программное шифрование, аппаратные самошифрующиеся диски (SED) не требуются и официально не поддерживаются в роли средства шифрования на уровне vSAN. Если в серверы установлены SED-накопители, они могут использоваться, но без включения режимов аппаратного шифрования – vSAN в любом случае выполнит шифрование средствами гипервизора. Ещё один момент: при включении vSAN Encryption отключается возможность рентген-просмотра (в веб-клиенте vSAN) содержимого дисков, так как данные на них хранятся в зашифрованном виде. Однако на функциональность управления размещением объектов (Storage Policy) это не влияет. Наконец, стоит учитывать, что шифрование данных несколько повышает требования к процессорным ресурсам на хостах. Практика показывает, что современные CPU справляются с этим отлично, но при проектировании больших нагрузок (вроде VDI или баз данных на all-flash) закладывать небольшой запас по CPU будет не лишним.
VMware vSAN Encryption Services предоставляют мощные средства защиты данных для гиперконвергентной инфраструктуры. Реализовав сквозное шифрование (от диска до сети) на уровне хранения, vSAN позволяет организациям выполнить требования по безопасности без сложных доработок приложений. Среди ключевых преимуществ решения можно отметить:
Всесторонняя защита данных. Даже если злоумышленник получит физический доступ к носителям или перехватит трафик, конфиденциальная информация останется недоступной благодаря сильному шифрованию (AES-256) и раздельным ключам для разных объектов. Это особенно важно для соблюдения стандартов GDPR, PCI-DSS, HIPAA и других.
Прозрачность и совместимость. Шифрование vSAN работает под управлением гипервизора и не требует изменений в виртуальных машинах. Все основные функции vSphere (кластеризация, миграция, бэкап) полностью поддерживаются. Решение не привязано к специфическому оборудованию, а опирается на открытые стандарты (KMIP, TLS), что облегчает интеграцию.
Удобство централизованного управления. Администратор может включить шифрование для всего кластера несколькими кликами – без необходимости настраивать каждую ВМ по отдельности (в отличие от VMcrypt). vCenter предоставляет единый интерфейс для управления ключами, а встроенный NKP ещё больше упрощает старт. При этом разграничение прав доступа гарантирует, что только уполномоченные лица смогут внести изменения в политику шифрования.
Минимальное влияние на производительность. Благодаря оптимизациям (использование AES-NI, эффективные алгоритмы) накладные расходы на шифрование невелики. Особенно в архитектуре ESA шифрование реализовано с учётом высокопроизводительных сценариев и практически не сказывается на IOPS и задержках. Отсутствуют и накладные расходы по ёмкости: включение шифрования не уменьшает полезный объём хранилища и не создаёт дублирования данных.
Гибкость в выборе подхода. vSAN поддерживает как внешние KMS от разных поставщиков (для предприятий с уже выстроенными процессами управления ключами), так и встроенный vSphere Native Key Provider (для простоты и экономии). Администраторы могут ротировать ключи по своему графику, комбинировать или отключать сервисы при необходимости (например, включить только шифрование трафика для удалённого филиала с общим хранилищем).
При внедрении шифрования в vSAN следует учесть несколько моментов: обеспечить высокую доступность сервера KMS (или надёжно сохранить ключ NKP), активировать TPM на хостах для хранения ключей, а также не сочетать шифрование vSAN с шифрованием на уровне ВМ (VM Encryption) без крайней необходимости. Двойное шифрование не повышает безопасность, зато усложняет управление и снижает эффективность дедупликации и сжатия.
В целом же шифрование vSAN значительно повышает уровень безопасности инфраструктуры с минимальными усилиями. Оно даёт организациям уверенность, что данные всегда под надёжной защитой – будь то на дисках или в пути между узлами, сегодня и в будущем, благодаря следованию современным стандартам криптографии FIPS.
Supervisor Control Plane — это управляющий уровень встроенного Kubernetes (Supervisor Cluster) в решении VMware vSphere with Tanzu (ранее vSphere with Kubernetes). Он развёрнут как три виртуальные машины (Supervisor Control Plane VMs), которые выполняют контроль над кластером Kubernetes, включая etcd, API-сервер, контроллеры и планировщик. Важнейшие функции этих виртуальных машин:
Интеграция с инфраструктурой vSphere: Supervisor Control Plane взаимодействует с ресурсами ESX-хостов — CPU, память, сеть, хранилище — и позволяет запускать контейнеры напрямую на гипервизоре (vSphere Pods).
API-доступ: администраторы управляют кластерами через интерфейс vSphere Client и API vSphere with Tanzu, а разработчики — через kubectl.
Высокая доступность: обеспечивается трёхкомпонентной архитектурой. Если один узел выходит из строя, другие продолжают работу.
Полезный трюк — как получить SSH-пароль для Supervisor Control Plane VM
Есть простой способ получить доступ по SSH для виртуальных машин, входящих в состав Supervisor Control Plane:
Подключитесь по SSH к виртуальному модулю сервера vCenter под пользователем root.
Выполните скрипт:
/usr/lib/vmware-wcp/decryptK8Pwd.py
Скрипт выведет IP-адрес (обычно FIP, то есть "floating IP") и автоматически сгенерированный пароль. После этого вы можете подключиться по SSH к Supervisor Control Plane VM как root@<FIP> с полученным паролем.
Важно! Доступ к этим ВМ следует использовать только для диагностики и устранения проблем — любые изменения в них (особенно без одобрения от поддержки VMware) могут привести к нарушению работоспособности Supervisor-кластера, и поддержка может потребовать его полного развертывания заново.
Полезные рекомендации и предосторожения
Скрипт /usr/lib/vmware-wcp/decryptK8Pwd.py извлекает пароль из базы данных vCenter. Он удобен для быстрого доступа, особенно при отладке сетевых или других проблем с Supervisor VM.
Убедитесь, что FIP действительно доступен и корректно маршрутизируется. При сбое etcd FIP не назначится, и придётся использовать реальный IP-адрес интерфейса (например, eth0). Также при смене FIP удалите старую запись из known_hosts — сертификаты могут изменяться при «плавании» IP.
Используйте доступ только для анализа, чтения логов и выполнения команд kubectl logs/get/describe.
Весной этого года вышел новый релиз бесплатной утилиты SexiGraf (Overwatch Nexus), предназначенной для мониторинга виртуальной инфраструктуры VMware vSphere. В последний раз мы писали об этом средстве в октябре прошлого года. Этот продукт был сделан энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным решениям для мониторинга серверов ESX и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Что нового
VMware vSAN Inventory — расширенная инвентаризация объектов vSAN.
PowerShell Core 7.4.6 LTS — обновление среды скриптов.
Ubuntu 22.04.5 LTS — современная версия операционной системы.
Apache 2.4.63 — обновлённый веб-сервер.
Улучшения и исправления
Возможность добавления SSH-ключа при деплое — повышает безопасность и удобство разграничения доступа.
Добавлен сбор события DrsSoftRuleViolationEvent в event-коллектор — расширение мониторинга нарушений правил DRS.
Исправлено неконсистентное значение GuestId в инвентаре VM (различие между vmx и vmtools) — повышение точности данных.
Различные багфиксы — общее улучшение стабильности и надежности.
Миграция и формат поставки
SexiGraf с этой версии доступен исключительно в виде нового OVA-образа, обновления в виде патчей больше не выпускаются (за исключением экстренных случаев). Чтобы обновиться, пользователи должны:
Экспортировать данные из текущего SexiGraf-модуля.
Импортировать данные в новый OVA-модуль через функционал Export/Import.
Виртуальный модуль SexiGraf 0.99l уже доступен для загрузки и развёртывания. Установка происходит стандартным способом через OVA (например, через vSphere, OVF Tool и т.п.).
Версия поддерживает переопределение root-пароля и SSH-ключа на этапе деплоя, что упрощает настройку и повышает безопасность.
Недавно компания VMware опубликовала полезный для администраторов документ «vSphere 9.0 Performance Best Practices» с указанием ключевых рекомендаций по обеспечению максимальной производительности гипервизора ESX и инфраструктуры управления vCenter.
Документ охватывает ряд аспектов, начиная с аппаратных требований и заканчивая тонкой настройкой виртуальной инфраструктуры. Некоторые разделы включают не всем известные аспекты тонкой настройки:
Настройки BIOS: рекомендуется включить AES-NI, правильно сконфигурировать энергосбережение (например, «OS Controlled Mode»), при необходимости отключить некоторые C-states в особо чувствительных к задержкам приложениях.
vCenter и Content Library: советуют минимизировать автоматические скриптовые входы, использовать группировку vCenter для повышения синхронизации, хранить библиотеку контента на хранилищах с VAAI и ограничивать сетевую нагрузку через глобальный throttling.
Тонкое администрирование: правила доступа, лимиты, управление задачами, патчинг и обновления (включая рекомендации по BIOS и live scripts) и прочие глубокие настройки.
Отличия от версии для vSphere 8 (ESX и vCenter)
Аппаратные рекомендации
vSphere 8 предоставляет рекомендации по оборудованию: совместимость, минимальные требования, использование PMem (Optane, NVDIMM-N), vPMEM/vPMEMDisk, VAAI, NVMe, сетевые настройки, BIOS-опции и оптимизации I/O и памяти.
vSphere 9 добавляет новые аппаратные темы: фокус на AES-NI, snoop-режимах, NUMA-настройках, более гибком управлении энергопотреблением и безопасности на уровне BIOS.
vMotion и миграции
vSphere 8: введение «Unified Data Transport» (UDT) для ускорения холодных миграций и клонирования (при поддержке обеих сторон). Также рекомендации для связки encrypted vMotion и vSAN.
vSphere 9: больше внимания уделяется безопасности и производительности на стороне vCenter и BIOS, но UDT остаётся ключевым механизмом. В анонсах vSphere 9 в рамках Cloud Foundation акцент сделан на улучшенном управлении жизненным циклом и live patching.
Управление инфраструктурой
vSphere 8: рекомендации по vSphere Lifecycle Manager, UDT, обновлению vCenter и ESXi, GPU профили (в 8.0 Update 3) — включая поддержку разных vGPU, GPU Media Engine, dual DPU и live patch FSR.
vSphere 9 / VMware Cloud Foundation 9.0: новый подход к управлению жизненным циклом – поддержка live patch для vmkernel, NSX компонентов, более мощные «монстр-ВМ» (до 960 vCPU), direct upgrade с 8-й версии, image-based lifecycle management.
Работа с памятью
vSphere 8: рекомендации для Optane PMem, vPMEM/vPMEMDisk, управление памятью через ESXi.
vSphere 9 (через Cloud Foundation 9.0): внедрён memory tiering, позволяющий увеличить плотность ВМ в 2 раза при минимальной потере производительности (5%) и снижении TCO до 40%, без изменений в гостевой ОС.
Документ vSphere 9.0 Performance Best Practices содержит обновлённые и расширенные рекомендации для платформы vSphere 9, уделяющие внимание аппаратному уровню (BIOS-настройки, безопасность), инфраструктурному управлению, а также новым подходам к памяти (главный из них - memory tiering).
VMware vSphere 7 достигнет конца основного срока поддержки (End of General Support) 2 октября 2025 года. Если вы в настоящее время используете vSphere 7, вам необходимо перейти на vSphere 8, чтобы продолжать получать поддержку продукта, обновления безопасности и патчи. Это также подготовит вас к переходу на VCF 9, когда вы будете к этому готовы.
Существует два варианта обновления:
Вы можете напрямую обновить vSphere 7 до vSphere 8
Либо можно импортировать vSphere 7 в VMware Cloud Foundation (VCF) версии 5.2 и выполнить обновление домена рабочих нагрузок до версии 8 через VMware SDDC Manager.
Выбор подходящего пути зависит от ряда факторов, таких как готовность бизнеса, поддержка сторонних продуктов и конфигурация среды. Ниже описано, как команда VCF Professional Services подходит к каждому из этих вариантов.
Вариант 1: Обновление с использованием vSphere Lifecycle Manager
Этот вариант представляет собой традиционный способ обновления vSphere. Вы можете использовать vSphere Lifecycle Manager Images или vSphere Lifecycle Manager Baselines для выполнения задачи обновления.
Преимущества этого подхода:
Используются уже существующие операционные процессы обновления.
В большинстве случаев требуется минимальное изменение текущей среды.
Нет необходимости в дополнительных виртуальных модулях (appliances).
Недостатки этого подхода:
Вам необходимо вручную выполнять проверки совместимости и валидации между компонентами, что может занять много времени.
Каждая среда проектируется отдельно, что может привести к задержкам из-за различных архитектурных решений между экземплярами VMware vCenter.
Шаги по обновлению с использованием vSphere Lifecycle Manager
Многие организации сначала выполняют обновление на тестовой (staging) среде перед тем, как переходить к рабочей (production). Шаги, как правило, одинаковы для любых сред.
Шаг 1: Планирование, предварительная проверка и подготовка среды к обновлению.
На этом этапе необходимо вручную подтвердить, что ваша среда поддерживает новые версии. Начните с изучения Release Notes для vSphere 8 и проверьте, поддерживают ли ваши интеграции с другими продуктами VMware или сторонними приложениями vSphere 8. Также потребуется подготовка к обновлению vCenter и понимание изменений, связанных с обновлением хостов VMware ESX.
После планирования нужно загрузить необходимые бинарные файлы. Это можно сделать на сайте поддержки Broadcom.
Шаг 3: Обновление vCenter.
Обновление vCenter можно выполнить несколькими способами, в зависимости от требований пользователя. Существует три основных метода:
Обновление с сокращённым временем простоя (Reduced Downtime Upgrade) - при этом способе разворачивается вторичный виртуальный модуль, и конфигурационные данные переносятся на него. Это наиболее предпочтительный метод, поскольку он обеспечивает минимальные простои по сравнению с другими способами обновления.
Установщик vCenter (vCenter Installer) – установщик vCenter включает опцию обновления, которая позволяет обновить существующий виртуальный модуль. Этот метод может быть использован в случае, если недостаточно ресурсов для развертывания второго модуля.
Обновление через интерфейс управления виртуальным модулем (Virtual Appliance Management Interface Upgrade) – этот метод позволяет автоматически загрузить и установить бинарные файлы напрямую из интерфейса управления виртуальным модулем vCenter. Мы также можем использовать этот способ, если недостаточно ресурсов для развертывания второго модуля.
Шаг 4: Обновление хостов ESX.
После обновления vCenter можно переходить к обновлению хостов ESX. Существует несколько способов обновления хостов ESX. VMware использует два основных подхода:
vSphere Lifecycle Manager - это предпочтительный метод, так как он позволяет обновлять целые кластеры одновременно, вместо обновления каждого хоста по отдельности. Это самый простой способ выполнения обновлений.
Сценарные обновления (Scripted Upgrades) – этот метод рекомендуется, когда необходимо обновить большое количество хостов. Существует несколько способов автоматизации обновления с помощью сценариев, что позволяет адаптировать процесс под конкретные операционные процедуры и используемые языки скриптов.
Шаг 5: Обновление VMware vSAN.
После обновления хостов следующим шагом является обновление формата дисков vSAN. Этот шаг рекомендуется, но не является обязательным. Обновление vSAN позволяет воспользоваться новыми функциями.
Шаг 6: Обновление версии vSphere Distributed Switch.
Версию vSphere Distributed Switch также можно обновить. Этот шаг также является необязательным, однако рекомендуется его выполнить, чтобы получить доступ к новым возможностям.
Шаг 7: Проверка после обновления (Post-Upgrade Validation).
Этот шаг зависит от конкретной среды и может включать дополнительные обновления других компонентов для поддержки новой версии. Кроме того, вам потребуется ввести новые лицензии и выполнить все необходимые проверки.
На этом процесс обновления среды vSphere с использованием vSphere Lifecycle Manager завершается.
Вариант 2: Импорт vSphere в экземпляр VCF и обновление через SDDC Manager
Второй вариант — это импорт среды vSphere в VCF 5.2 с последующим обновлением через консоль SDDC Manager. Для этого у вас уже должен быть развернут экземпляр VCF.
Преимущества импорта vSphere в VCF и обновления через SDDC Manager:
VCF включает в себя мощный механизм проверки предварительных условий, что упрощает процесс обновления.
При импорте vSphere в VCF ваша среда проверяется, и определяются необходимые исправления, чтобы привести её в соответствие со стандартной архитектурой VCF.
Вы можете воспользоваться другими возможностями VCF, такими как встроенное управление сертификатами и паролями. Эти функции ускоряют процесс обновления, позволяя легко изменять пароли и сертификаты.
Недостатки:
Требуются дополнительные виртуальные модули. VCF представляет собой полноценный программно-определяемый датацентр, и такие компоненты, как VMware NSX, являются обязательными. Это требует выделения дополнительных ресурсов.
Как упомянуто в разделе с преимуществами, приведение среды к стандарту VCF может потребовать выполнения определённых исправлений.
Шаги по импорту vSphere в VCF и обновлению через SDDC Manager
Шаг 1: Импорт существующей среды vSphere в конфигурацию VCF.
Используйте VCF Import Tool для проверки предварительных условий и выполнения импорта в уже существующий экземпляр VCF.
Шаг 2: Обновление vSphere через SDDC Manager.
После того как в среде доступен SDDC Manager, вы можете использовать его для выполнения следующих задач:
Загрузка пакетов обновлений (Download Update Bundles) – скачайте необходимые пакеты, чтобы иметь возможность выполнить обновление.
Выполнение предварительных проверок (prechecks) – выполните проверку предварительных условий, чтобы выявить проблемы, которые могут привести к сбою обновления. Если будут обнаружены какие-либо ошибки или проблемы, их необходимо устранить перед продолжением процесса.
Обновление компонентов (Upgrade Components) – обновите все компоненты vSphere (vCenter и ESX). SDDC Manager выполнит обновление в правильной последовательности, чтобы обеспечить совместимость с перечнем компонентов (Bill of Materials) VCF 5.2.
Шаг 3: Проверка после обновления (Post-Upgrade Validation).
Этот шаг зависит от конкретной среды и может потребовать дополнительных обновлений других компонентов для поддержки новой версии. Кроме того, потребуется ввести новые лицензии и выполнить все необходимые проверки.
Как уже упоминалось, данный вариант требует наличия развернутого экземпляра VCF. Если его нет, вы можете сначала обновить хотя бы один экземпляр vCenter 7 до vSphere 8, используя Вариант 1, а затем преобразовать этот экземпляр vSphere в VCF.
VMware представила унифицированный фреймворк разработки VCF SDK 9.0 для Python и Java.
Улучшение опыта разработчиков (Developer Experience) — один из главных приоритетов в дальнейшем развитии платформы VMware Cloud Foundation (VCF). Если рассматривать автоматизацию в целом, то можно выделить две чёткие категории пользователей: администраторы и разработчики.
Администраторы в основном сосредоточены на операционной автоматизации, включая развертывание, конфигурацию и управление жизненным циклом среды VCF. Их потребности в автоматизации обычно реализуются через написание скриптов и рабочих процессов, которые управляют инфраструктурой в масштабах всей организации.
Разработчики, напротив, ориентированы на интеграцию возможностей VCF в пользовательские приложения и решения. Им необходимы API и SDK, обеспечивающие программный доступ к сервисам и данным VCF, позволяя разрабатывать собственные инструменты, сервисы и расширения. Потребности в автоматизации у этих двух групп значительно различаются и соответствуют их уникальным ролям в экосистеме VCF. Понимая эти различия, Broadcom предлагает набор интерфейсов прикладного программирования (API), средств разработки (SDK) и разнообразных инструментов автоматизации, таких как PowerCLI, Terraform и Ansible.
Оглядываясь назад, можно сказать, что VMware хорошо обслуживала сообщество администраторов, предоставляя им различные инструменты. Однако API и SDK требовали улучшения в области документации, лучшей интеграции с VCF-стеком в целом и упрощения процесса для разработчиков. До выхода VCF 9.0 разработчики использовали отдельные SDK решений, сталкиваясь с трудностями, связанными с их интеграцией — такими как совместимость, аутентификация и сложность API. С выходом VCF 9.0 VMware рада объявить о доступности Unified VCF SDK 9.0. Давайте подробнее рассмотрим, что это такое.
Unified VCF SDK
Unified VCF SDK доступен с привязками к двум языкам — Java и Python. Это объединённый SDK, который включает в себя все основные SDK решений VCF в единый, упрощённый пакет. В своей первой версии Unified VCF SDK объединяет существующие SDK и добавляет новые библиотеки для установщика VCF и менеджера SDDC.
Список компонентов VCF, включённых в первую версию Unified VCF SDK:
VMware vSphere
VMware vSAN
VMware Cloud Foundation SDDC Manager (новый)
VMware Cloud Foundation Installer (новый)
VMware vSAN Data Protection
Несмотря на то, что Unified VCF SDK поставляется как единый пакет, пользователи могут устанавливать и использовать только те библиотеки, которые необходимы для конкретных задач.
Для краткости в этом тексте Unified VCF SDK будет обозначаться как VCF SDK.
Преимущества
VCF SDK обеспечивает простой, расширяемый и единообразный опыт для разработчиков на протяжении всего жизненного цикла разработки.
Упрощённый жизненный цикл разработчика
С этим релизом были стандартизированы методы доставки и распространения, чтобы поддерживать различные сценарии развертывания:
Онлайн-установка через PyPI (Python) и Maven (Java) — для прямого доступа и лёгкой установки/обновлений.
Офлайн-установка через портал разработчиков Broadcom — идеально для сред с ограниченным доступом в интернет.
Готовность к CI/CD — интеграции через пакеты и инструкции, размещённые на GitHub, для бесшовного включения в автоматизированные пайплайны при установке и обновлении.
Улучшенная документация и онбординг
VMware переработала документацию, чтобы упростить старт:
OpenAPI-спецификация описывает API в стандартизированном машинно-читаемом формате (YAML/JSON). С выходом VCF SDK были также публикованы OpenAPI-спецификации для API-эндпоинтов. Это не просто документация — это шаг к философии API-first и ориентированности на разработчиков.
С помощью OpenAPI-спецификаций разработчики могут:
Автоматически генерировать клиентские библиотеки на предпочитаемых языках с помощью инструментов вроде Swagger Codegen, Kiota или OpenAPI Generator.
Загружать спецификации в такие инструменты, как Swagger UI, Redoc или Postman, чтобы визуально исследовать доступные эндпоинты, параметры, схемы ответов и сообщения об ошибках.
pyVmomi — это Python SDK для API управления VMware vSphere, который позволяет быстро создавать решения, интегрированные с VMware ESX и vCenter Server.
vCenter Server
Библиотека VMware vCenter Server содержит клиентские привязки для автоматизационных API VMware vCenter Server.
VMware vSAN Data Protection
Библиотека VMware vSAN Data Protection содержит клиентские привязки для управления встроенными снапшотами, хранящимися локально в кластере vSAN, восстановления ВМ после сбоев или атак вымогателей и т.д.
Библиотека VMware SDDC Manager содержит клиентские привязки к автоматизационным API для управления компонентами инфраструктуры программно-определяемого датацентра (SDDC).
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer в составе VCF SDK содержит библиотеки для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Unified VCF SDK доступен через различные каналы распространения. Это сделано для того, чтобы удовлетворить потребности разных типов сред и разработчиков — каждый может получить доступ к SDK в наиболее удобном для него месте. Ниже перечислены доступные каналы, откуда можно загрузить VCF SDK.
Портал разработчиков Broadcom
VCF Python SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-python-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами. Однако сторонние зависимости не входят в состав архива — они перечислены в файле requirements-third-party.txt, находящемся внутри vcf-python-sdk-9.0.0.0-24798170.zip.
Файлы .whl компонентов VCF SDK находятся в папках ../pypi/*, а примеры кода для компонентов расположены в директориях вида /<имя_компонента>-samples/.
PyPI
VCF SDK доступен в PyPI, что позволяет разработчикам устанавливать и обновлять модуль онлайн. Это самый быстрый способ начать работу с VCF SDK.
Чтобы установить VCF SDK, выполните следующую команду:
$ pip install vcf-sdk
Пакеты, установленные через pip, можно автоматически обновлять. Чтобы обновить VCF SDK, используйте команду:
$ pip install --upgrade vcf-sdk
Чтобы установить конкретную библиотеку из состава VCF SDK, выполните:
Модуль vCenter в составе VCF SDK предоставляет операции, связанные с контент-библиотеками, развертыванием ресурсов, тегированием, а также управлением внутренними и внешними сертификатами безопасности.
Управление виртуальной инфраструктурой (VIM)
Модуль VIM (Virtual Infrastructure Management) предоставляет операции для управления вычислительными, сетевыми и хранилищными ресурсами. Эти ресурсы включают виртуальные машины, хосты ESXi, кластеры, хранилища данных, сети и системные абстракции, такие как события, тревоги, авторизация и расширения через плагины.
SSOCLIENT
Модуль единого входа (Single Sign-On) взаимодействует с сервисом Security Token Service (STS) для выдачи SAML-токенов, необходимых для аутентификации операций с API vCenter.
VMware vSAN Data Protection (vSAN DP)
С помощью встроенных снимков, локально хранящихся в кластере vSAN, модуль защиты данных vSAN обеспечивает быстрое восстановление ВМ после сбоев или атак вымогателей. API защиты данных vSAN управляет группами защиты и обнаруживает снимки виртуальных машин.
Управление жизненным циклом виртуального хранилища (VSLM)
Модуль VSLM (Virtual Storage Lifecycle Management) предоставляет операции, связанные с First Class Disks (FCD) — виртуальными дисками, не привязанными к конкретной виртуальной машине.
Служба мониторинга хранилища (SMS)
Модуль SMS (Storage Monitoring Service) предоставляет методы для получения информации о доступной топологии хранилищ, их возможностях и текущем состоянии. API Storage Awareness (VASA) позволяет хранилищам интегрироваться с vCenter для расширенного управления. Провайдеры VASA предоставляют данные о состоянии, конфигурации и емкости физических устройств хранения. SMS устанавливает и поддерживает соединения с провайдерами VASA и извлекает из них информацию о доступности хранилищ.
Управление на основе политик хранения (SPBM)
Модуль SPBM (Storage Policy Based Management) предоставляет операции для работы с политиками хранения. Эти политики описывают требования к хранению для виртуальных машин и возможности провайдеров хранения.
vSAN
Модуль vSAN предоставляет средства конфигурации и мониторинга vSAN-кластеров хранения и связанных сервисов на хостах ESXi и экземплярах vCenter Server. Включает функции работы с виртуальными дисками, такие как монтирование, разметка, безопасное удаление и создание снимков.
Менеджер агентов ESX (EAM)
Менеджер агентов ESX (ESX Agent Manager) позволяет разработчикам расширять функциональность среды vSphere путём регистрации пользовательских программ как расширений vCenter Server. EAM действует как посредник между vCenter и такими решениями, управляя развертыванием и мониторингом агентских ВМ и установочных пакетов VIB.
SDDC Manager
Модуль SDDC Manager предоставляет операции для управления и мониторинга физической и виртуальной инфраструктуры, развернутой в рамках VMware Cloud Foundation.
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer предоставляет операции для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Аналогично Python SDK, JAVA SDK также доступен через различные каналы распространения, что позволяет использовать его в самых разных средах.
Портал разработчиков Broadcom
VCF Java SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-java-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами.
Файлы привязок SDK .jar, утилит .jar, а также BOM-файлы находятся в папке:
../maven/com/vmware/*
Maven
Артефакты VCF SDK доступны в Maven Central под groupId: com.vmware.sdk. В таблице ниже указаны данные об артефактах VCF SDK для версии 9.0.0.0.
Чтобы начать работу с VCF SDK, добавьте зависимость в файл pom.xml вашего проекта:
С выходом VCF 9.0 VMware начала публиковать журнал изменений API. В нём отражаются все изменения: новые API, обновления существующих и уведомления об устаревании. Ознакомиться с журналом изменений можно здесь.
С выпуском VMware Cloud Foundation 9.0 объединение различных библиотек в один SDK с улучшенной документацией, примерами кода и спецификацией OpenAPI — это важный шаг к простому, расширяемому и согласованному опыту для разработчиков.
Следующий шаг за вами — попробуйте Unified VCF SDK 9.0 и поделитесь с нами своими отзывами.
В платформе VMware vSphere 9 в рамках инфраструктуры VMware Cloud Foundation (VCF) 9.0 была значительно расширена область компонентов ESX, которые можно обновлять с помощью технологии Live Patch. Теперь это включает в себя vmkernel, пользовательские демоны, компоненты NSX, а также уже ранее поддерживаемое выполнение виртуальных машин (vmx), которое было адаптировано к Live Patch.
Используйте Live Patch уже сегодня
Недавно выпущенное обновление ESX 9.0.0.0100 уже полноценно поддерживает Live Patch (см. Release Notes). Вы можете применить это обновление к кластерам ESX 9.0.0 (24755229) с помощью Live Patch, заодно и протестируете работу этой технологии.
Если коротко: Live Patch позволяет применять некоторые обновления ESX без прерывания работы, то есть без необходимости эвакуации виртуальных машин с хоста.
Это означает, что в будущем, вероятно, появится больше обновлений, которые можно будет устанавливать с помощью Live Patch — быстро и без простоев. В первую очередь Live Patch ориентирован на важные обновления безопасности, поскольку критически важно, чтобы организации внедряли их как можно быстрее. Однако не каждое обновление будет поддерживать Live Patch.
Напоминание: чтобы определить, поддерживает ли обновление Live Patch, проверьте Release Notes — в них будет указано, если такая возможность есть. Интерфейсы консолей VCF и vSphere Lifecycle Manager также будут отображать эту информацию:
При обновлении пользовательских демонов (user-space daemons) с помощью Live Patch может потребоваться перезапуск соответствующего демона. В зависимости от того, какой демон обновляется и перезапускается, ESX-хост может на короткое время потерять связь с vCenter. Например, обновление демона hostd может потребовать его перезапуска. Это может привести к кратковременному отображению хоста как отключённого от vCenter — это ожидаемое поведение и не влияет на работу виртуальных машин.
Если Live Patch затрагивает среду исполнения виртуальных машин (vmx), то в процессе обновления выполняется операция быстрой приостановки и возобновления (Fast Suspend-Resume, FSR) виртуальных машин. Не каждое обновление требует выполнения FSR. Подробнее об FSR можно прочитать вот тут. В vSphere с VCF 9.0 операция FSR выполняется значительно быстрее для виртуальных машин с включённым vGPU, что позволяет выполнять Live Patch на кластерах с такими ВМ без прерывания работы AI/ML-приложений.
Перед выполнением задачи Live Patch, vSphere Lifecycle Manager проводит предварительную проверку (precheck), чтобы убедиться, что на хостах достаточно доступных ресурсов. Если ресурсов недостаточно, может потребоваться снизить нагрузку на хосты перед тем, как приступить к обновлению.
Ограничения Live Patch, имевшиеся в vSphere 8, сохраняются и в VCF 9.0. Среди них:
Отсутствие поддержки Live Patch на системах с включёнными устройствами TPM 2.0
Использование DPU в составе vSphere Distributed Services Engine
Невозможность совмещать параллельный апдейт (parallel remediation) с Live Patch.
Aria Operations Enterprise + VCF Operations: full-stack наблюдение и SecOps
Хранилище
vSAN до 1 TiB/core, базовая дедупликация
Расширенные возможности ESA, global dedupe, QoS, снапшоты, растянутый кластер
Доп. сервисы / SaaS
-
Private AI, Data Services, Load Balancing, Network & Security Addons
Пути обновления (Upgrade Paths)
В документе VMware четко описывает возможности перехода с предыдущих продуктов:
Старые версии: vSphere Enterprise Plus, vSphere Standard, vCloud Suite, Aria Suite и другие можно мигрировать либо в vSphere Foundation 9.0 (если нужны базовые функции), либо сразу в VCF 9.0 для полной автоматизации и сетевых возможностей.
Лицензирование:
Подписка VCF 9 или VVF 9 включает лицензию версии 9.0, а также ключи для версий 8.x, которые можно использовать или понижать (downgrade) при необходимости.
Это означает гибкость в выборе развертывания и возможность отката к предыдущим версиям в пределах лицензии.
Последовательность обновления при переходе на VCF 9.0
Broadcom рекомендует следующую схему для обновления компонентов в среде с несколькими доменами нагрузки (workload domains):
Важно: компонент Aria Operations for Logs 8.x не обновляется напрямую — миграция исторических данных происходит через Day-N операции в новом VCF Operations Logs.
Что выбрать?
vSphere Foundation 9.0 — если нужна стабильная виртуализация с контейнерами и vSAN, но без сложной сетевой и автоматизационной логики.
Cloud Foundation 9.0 — если требуется:
Автоматическая настройка облака (IaaS) под клиентов
Полнофункциональные сети и безопасность
Глобальное управление через единую платформу
Поддержка Kubernetes, AI, Data services
Полная интеграция Operations / Automation
Выводы
VMware предложила две SKU-конфигурации, одна — мощная, полностью автоматизированная платформа IaaS (VCF), другая — компактная и эффективная инфраструктурная база ( vSphere Foundation).
Лицензирование и upgrade гибкие — подписка VCF/VVF 9 позволяет использовать версию 9.0 или откатиться на 8.x в рамках лицензии.
Обновление требует чёткого порядка, особенно при переходе с существующих систем – важна последовательность компонентов, миграция логов и identity.
Выбор зависит от ваших нужд: простота и контейнеризация или полный спектр управления частным облаком с IaaS, безопасностью и DevOps-интерфейсами.
В числе множества новых возможностей, представленных в VMware Cloud Foundation 9.0, функция многоуровневой памяти (Memory Tiering) стала одной из ключевых в составе VMware vSphere для VCF 9.0. Как и многие другие функции vSphere, Memory Tiering с использованием NVMe снижает совокупную стоимость владения, полностью интегрируется с ESX (да, гипервизор называется снова ESX), а также с VMware vCenter. Она поддерживает гибкие варианты развертывания, предоставляя клиентам множество опций при настройке.
Memory Tiering с NVMe была представлена в составе VCF 9.0, и важно подчеркнуть её ценность для компаний, стремящихся сократить расходы, особенно при закупке оборудования, так как стоимость оперативной памяти составляет значительную часть спецификации аппаратного обеспечения (Bill of Materials, BOM). Функция, позволяющая масштабировать память за счёт использования недорогого оборудования, может существенно повлиять на распределение ИТ-бюджета и приоритетность проектов.
Memory Tiering с NVMe можно настроить через привычный вам интерфейс vCenter UI, с помощью командной строки через ESXCLI, а также через скрипты в PowerCLI. Можно использовать любую из этих опций или их комбинацию для настройки многоуровневой памяти как на уровне хоста, так и на уровне кластера.
Аппаратное обеспечение имеет значение
Перед настройкой функции Memory Tiering крайне важно обратить внимание на рекомендуемое оборудование. И это не просто совет, а настоятельная рекомендация. Поскольку в роли памяти будут использоваться устройства NVMe, важно, чтобы они были не только надёжными, но и демонстрировали высокую производительность при интенсивной нагрузке. Аналогично тому, как вы определяли рекомендуемые устройства для vSAN, здесь также есть требования: NVMe-устройства должны соответствовать классу выносливости D (не менее 7300 TBW) и классу производительности F или выше (не менее 100 000 операций записи в секунду) для использования в составе многоуровневой памяти. VMware рекомендует воспользоваться руководством по совместимости с vSAN, чтобы убедиться, что выбранные устройства соответствуют этим требованиям.
Также важно отметить, что поддерживается множество форм-факторов. Так что если в вашем сервере нет свободных слотов для 2.5-дюймовых накопителей, но есть, например, свободный слот M.2, вы вполне можете использовать его для Memory Tiering.
Создание раздела на NVMe
После того как вы тщательно выбрали рекомендованные NVMe-устройства (кстати, их можно объединить в RAID-конфигурацию для обеспечения отказоустойчивости), следующим шагом будет создание раздела для NVMe-уровня памяти. Если на выбранном устройстве уже существуют какие-либо разделы, их необходимо удалить перед конфигурацией.
Максимальный размер раздела в текущей версии составляет 4 ТБ, однако вы можете использовать и более ёмкое устройство — это позволит «циклически использовать ячейки» и потенциально продлить срок службы NVMe-накопителя. Хотя размер раздела зависит от ёмкости устройства (до 4 ТБ), фактический объём NVMe, задействованный в качестве памяти, рассчитывается на основе объёма DRAM на хосте и заданного соотношения. По умолчанию в VCF 9.0 применяется соотношение DRAM:NVMe как 1:1 — это в четыре раза больше, чем в технологическом превью на vSphere 8.0 Update 3.
Например, если у вас есть хост с 1 ТБ DRAM и NVMe-устройство на 4 ТБ, то будет создан раздел размером 4 ТБ, но использоваться в рамках Memory Tiering будет только 1 ТБ — если, конечно, вы не измените соотношение. Это соотношение настраивается пользователем, однако стоит проявить осторожность: изменение параметра может негативно повлиять на производительность и сильно зависит от характера и активности рабочих нагрузок. Подробнее об этом — далее.
В текущей версии создание раздела выполняется через командную строку ESXCLI на хосте с помощью следующей команды:
esxcli system tierdevice create -d /vmfs/devices/disks/<UID NVMe-устройства>
Пример:
Конфигурация хоста или кластера
После создания раздела tierdevice остаётся последний шаг — настроить хост или кластер. Да, вы можете гибко подойти к конфигурации: настроить один, несколько хостов или весь кластер целиком. В идеале рекомендуется настраивать кластер гомогенно; однако стоит учитывать, что некоторые типы виртуальных машин пока не поддерживаются в режиме NVMe Memory Tiering. К ним относятся:
ВМ с высокими требованиями к производительности и низкой задержке
Защищённые ВМ (SEV, SGX, TDX),
ВМ с непрерывной доступностью (FT)
"Монстр-машины" (1 ТБ памяти, 128 vCPU)
Вложенные ВМ (nested VMs).
Если в одном кластере у вас сочетаются такие ВМ с обычными рабочими нагрузками, которые могут использовать Memory Tiering, вы можете либо выделить отдельные хосты для «особых» ВМ, либо отключить Memory Tiering на уровне конкретных виртуальных машин.
Для включения Memory Tiering на хосте вы можете воспользоваться ESXCLI, PowerCLI или интерфейсом vCenter UI. В ESXCLI команда очень простая:
esxcli system settings kernel set -s MemoryTiering -v TRUE
В vCenter UI это делается путём изменения параметра VMkernel.Boot.memoryTiering на значение TRUE. Обратите внимание на слово BOOT — для применения параметра хост необходимо перезагрузить. Также перед внесением изменений хост нужно перевести в режим обслуживания.
А если вы хотите настроить весь кластер? Что ж, это даже проще. Вы можете воспользоваться функцией Desired State Configuration в vCenter. Всё, что нужно — создать новый черновик с включённой настройкой memory_tiering в разделе vmkernel > options, установив её в значение true. После этого остаётся просто применить этот драфт ко всем хостам в кластере (или только к выбранным хостам).
После применения конфигурации хосты автоматически будут переведены в режим обслуживания и перезагружены поочерёдно, по мере необходимости. И всё — на этом настройка завершена. Теперь вы можете воспользоваться преимуществами:
Лучшего коэффициента консолидации ВМ
Сниженной совокупной стоимости владения
Простой масштабируемости памяти — по значительно более низкой цене
После завершения настройки вы увидите как минимум двукратное увеличение доступной памяти, а также визуальное отображение уровней памяти (memory tiers) в интерфейсе vCenter UI.
Затраты на память по-прежнему остаются одной из самых крупных статей расходов на серверную инфраструктуру, и при этом большая часть дорогой оперативной памяти (DRAM) используется неэффективно. А что, если вы могли бы удвоить плотность виртуальных машин и сократить совокупную стоимость владения до 40%?
С выходом VMware Cloud Foundation 9.0 технология Memory Tiering (многоуровневая организация памяти) делает это возможным. Команда инженеров VMware недавно представила результаты тестирования производительности, которые демонстрируют, как эта технология меняет экономику датацентров. Подробности — в новом исследовании: Memory Tiering Performance in VMware Cloud Foundation 9.0.
Ниже мы расскажем об основных результатах исследования, которые показывают, что Memory Tiering позволила увеличить плотность виртуальных машин в 2 раза при незначительном снижении производительности. Для получения полной информации о принципах работы Memory Tiering и более подробных данных о производительности, ознакомьтесь с полным текстом исследования.
Как Memory Tiering улучшает производительность датацентров и снижает затраты
В VMware Cloud Foundation 9.0 технология Memory Tiering предоставляет виртуальным машинам единое логическое адресное пространство памяти. Однако «под капотом» она управляет двумя уровнями памяти: Tier 0 (DRAM) и Tier 1 (Memory Tiering), в зависимости от активности памяти виртуальной машины. Фактически, система старается держать «горячую» (активную) память в DRAM, а «холодную» (неактивную) — на NVMe.
Со стороны виртуальной машины это выглядит как единое, увеличенное пространство памяти. В фоновом режиме гипервизор ESX динамически управляет размещением страниц памяти между двумя уровнями — DRAM и NVMe — обеспечивая при этом оптимальную производительность.
VMware провела тестирование на различных корпоративных нагрузках, чтобы подтвердить эффективность Memory Tiering. Были использованы серверы на базе процессоров Intel и AMD с различными конфигурациями DRAM. В VMware Cloud Foundation 9.0 по умолчанию используется соотношение DRAM к NVMe 1:1, и во всех тестах применялось именно оно.
Увеличение плотности ВМ в 2 раза, потеря производительности - 5-10% (MySQL, SQL)
Login Enterprise: Производительность виртуальных рабочих столов
Команда VMware использовала Login Enterprise для тестирования производительности VDI (виртуальных рабочих столов) в различных сценариях. Во всех тестах удалось удвоить количество виртуальных машин на хосте ESX при минимальном снижении производительности. Например, в конфигурации из трёх узлов vSAN:
Удвоили количество VDI-сессий, которые могли выполняться на трёхузловом кластере vSAN — с 300 (только DRAM) до 600 (с использованием Memory Tiering).
При этом не было зафиксировано потери производительности по сравнению с аналогичной конфигурацией, использующей только DRAM.
Тест VMmark 3.1, включающий несколько нагрузок, имитирующих работу корпоративных приложений, показал отличные результаты:
Конфигурация с Memory Tiering достигла 6 тайлов против 3 тайлов в конфигурации, использующей только DRAM. Это в 2 раза лучше.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering, снижение производительности составило всего 5%, несмотря на использование более медленной памяти NVMe в режиме Memory Tiering.
HammerDB и DVD Store: производительность баз данных
Производительность баз данных — один из самых ресурсоёмких тестов для любой инфраструктуры. VMware использовала HammerDB и DVD Store в качестве нагрузок для тестирования SQL Server, Oracle Database и MySQL. С помощью Memory Tiering удалось удвоить количество виртуальных машин при минимальном влиянии на производительность. Например, в тесте Oracle Database с нагрузкой DVD Store были получены следующие результаты:
На хосте ESX с Memory Tiering удалось запустить 8 виртуальных машин против 4 в конфигурации, использующей только DRAM — плотность удвоилась.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering снижение производительности составило менее 5%.
Мониторинг Memory Tiering на хостах ESX
Для обеспечения высокой производительности при использовании Memory Tiering следует отслеживать два ключевых показателя:
Поддерживайте активную память на уровне 50% или меньше от объёма DRAM — это обеспечит оптимальную производительность.
Следите за задержкой чтения с NVMe-устройства. Наилучшая производительность достигается при задержке менее 200 микросекунд.
Преобразите экономику вашего датацентра
Memory Tiering предлагает новый подход к организации памяти:
До 40% экономии совокупной стоимости владения (TCO) за счёт снижения требований к DRAM.
Прозрачная работа — не требует изменений в приложениях или гостевых операционных системах.
До 2-кратного увеличения плотности виртуальных машин для различных типов нагрузок.
Гибкая инфраструктура, адаптирующаяся к изменяющимся требованиям рабочих нагрузок.
Memory Tiering уже доступна в VMware Cloud Foundation 9. Скачайте полное исследование производительности, чтобы подробнее ознакомиться с методологией тестирования, результатами и рекомендациями по внедрению.
Хотите попробовать Memory Tiering на практике?
Полноценный практический лабораторный курс предоставляет живую среду vSphere 9.0, где вы сможете изучить Memory Tiering и узнать, как использование NVMe-накопителей позволяет расширить и оптимизировать доступную память для хостов ESX.
В условиях жесткой конкуренции современным ИТ-инфраструктурам необходимо быть мощными, гибкими и экономичными. Однако многие компании сталкиваются с проблемой разрозненной инфраструктуры, что затрудняет масштабирование, повышает издержки и тормозит инновации.
VMware предлагает решение — vSphere Foundation 9, современную платформу для рабочих нагрузок, которая предоставляет инфраструктуру корпоративного уровня на базе гиперконвергентной архитектуры (HCI).
Платформа объединяет:
vSphere — проверенный гипервизор для запуска виртуальных машин
Встроенную инфраструктуру Kubernetes для запуска контейнеризованных приложений
VSAN — хранилище корпоративного уровня
Интегрированные средства управления и безопасности
С помощью vSphere Foundation 9 вы можете:
Управлять виртуальными машинами, Kubernetes-кластерами и AI-нагрузками средствами единой платформы
Повысить эффективность операций до 77%
Увеличить плотность серверов до 40% благодаря NVMe-кешированию
Ускорить миграцию AI-нагрузок с GPU до 6 раз
Сократить простои в 5 раз и уменьшить время решения проблем на 20%
Усилить защиту с помощью Live-патчинга ESX и репликации между VSAN-кластерами для восстановления после сбоев
Платформа легко масштабируется: можно начать с малого и наращивать мощность по мере роста бизнеса. Это делает vSphere Foundation 9 идеальным решением для компаний, стремящихся модернизировать ИТ-инфраструктуру, ускорить инновации и обеспечить безопасность критичных нагрузок.
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.

 RSS
RSS