Компания Broadcom не так давно объявила о выпуске VMware Cloud Foundation (VCF) 9.1 — очередном этапе развития самой широко применяемой в отрасли платформы частного облака. Этот релиз имеет ясную и сфокусированную цель: стать наиболее экономичным и защищённым фундаментом для продуктивного искусственного интеллекта, современных приложений и традиционных нагрузок, управляемых из единой плоскости управления, на инфраструктуре, которой предприятие владеет и которую само контролирует.
Искусственный интеллект обладает огромным потенциалом для трансформации всех предприятий - IDC прогнозирует, что решения и сервисы AI окажут глобальное влияние на сумму 22,3 трлн долларов к 2030 году.
С учетом такого масштаба неудивительно, что предприятия стремятся использовать AI для повышения производительности во всех областях бизнеса. Однако им нужна комплексная стратегия, которая ускорит интеграцию AI в инфраструктуру дата-центров. С VMware Cloud Foundation Private AI Services компания Broadcom стремится помочь предприятиям раскрыть потенциал AI и повысить продуктивность при более низкой совокупной стоимости владения.
Реальный эффект: что говорят клиенты
Компании из разных отраслей уже развертывают VCF Private AI Services и получают экономию, приватность и безопасность для своих AI-нагрузок:
«Внедрив VCF Private AI Services, мы усилили возможности интеллектуальных сервисов», — говорит Тунг-Лян Чен, вице-президент Chunghwa Post. «Запуск AI в собственной инфраструктуре частного облака на базе VCF позволяет нам существенно снижать затраты и повышать эффективность автоматизированного обнаружения в реальном времени, одновременно обеспечивая бесшовную интеграцию с существующими системами».
«Анализ многолетних архивов новостей в публичном облаке обходится слишком дорого, а непредсказуемое ценообразование затрудняет планирование AI-проектов», — сказал V V Jacob, старший генеральный менеджер по системам Malayala Manorama Co Ltd. «Развернув VCF Private AI Services на существующей инфраструктуре VMware Cloud Foundation, мы сможем запускать AI-суммаризацию контента, генерацию заголовков и редакторскую помощь прямо в частном облаке. Мы считаем, что это даст нам приватность и безопасность, необходимые для защиты редакционных источников, а также предсказуемость затрат, которую обеспечивает локальная инфраструктура частного облака».
На днях был объявлен следующий выпуск VCF Private AI Services вместе с VCF 9.1. В новой версии для предприятий добавляется несколько важных функций.
Новые возможности
1. Приватность и безопасность
Broadcom помогает предприятиям создавать и развертывать приватные и безопасные AI-модели со встроенными возможностями защиты, предоставляемыми через VCF Private AI Services.
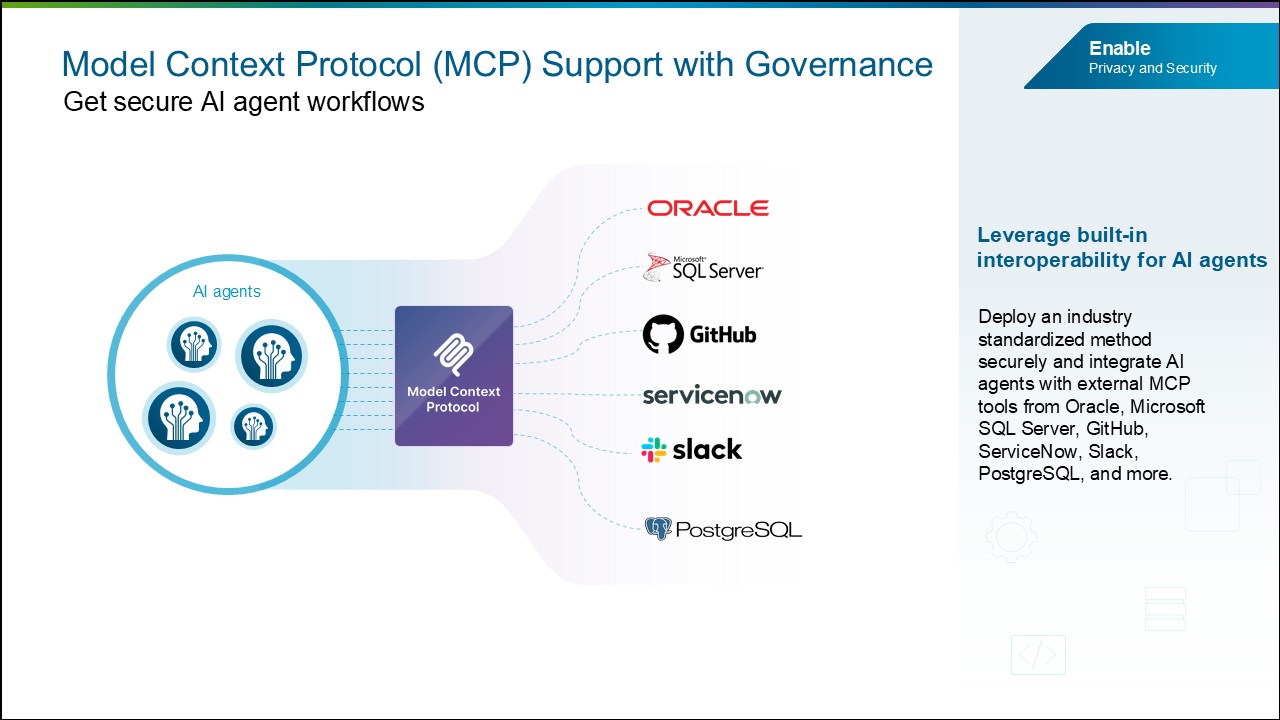
Поддержка Model Context Protocol (MCP) с управлением. Благодаря поддержке MCP предприятия получают безопасный и стандартизированный способ интегрировать AI-ассистентов с внутренними репозиториями контента и внешними MCP-инструментами от Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL и других поставщиков без разработки и сопровождения собственных коннекторов.
2. Упрощение управления инфраструктурой
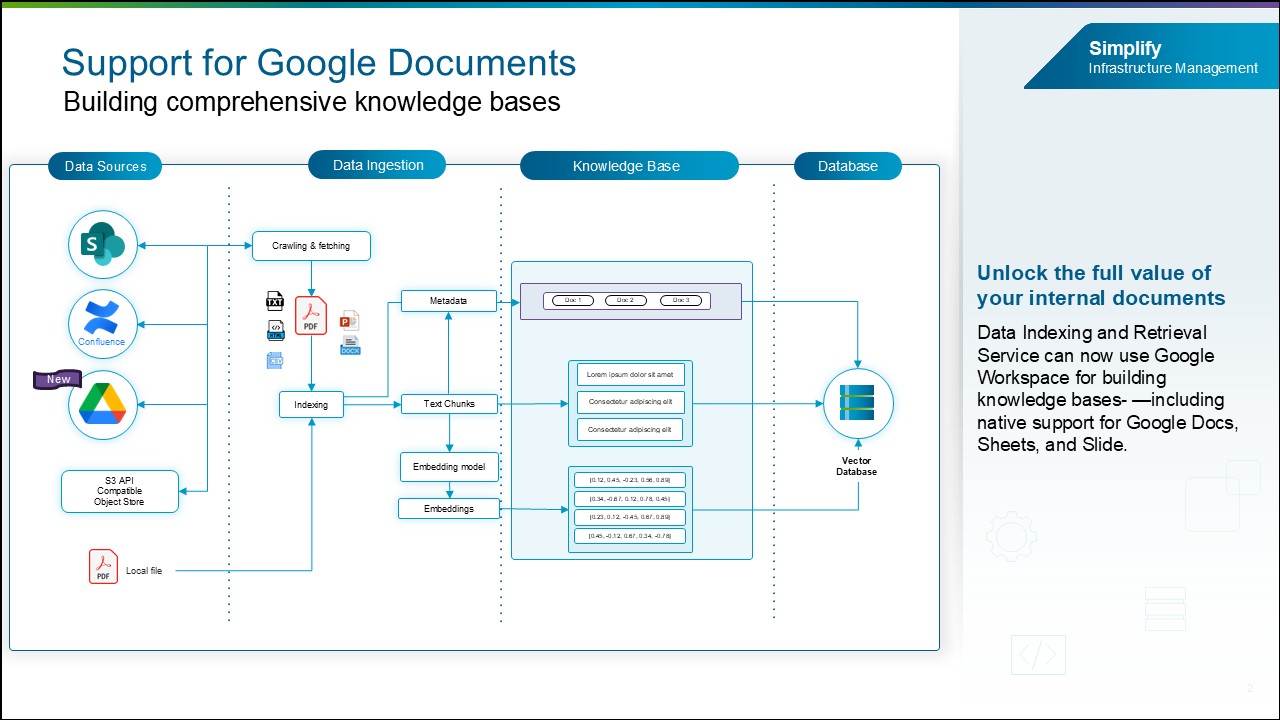
Поддержка Google Documents. VCF Private AI Services теперь предоставит полноценную поддержку Google Workspace, включая Google Docs, Sheets и Slides, без необходимости экспортировать документы в PDF и загружать их в базу знаний. В дополнение к уже существующей поддержке Microsoft Word, Microsoft PowerPoint, PDF, CSV и других форматов предприятия получают доступ к очень широкому набору типов документов и смогут добиваться качественных результатов для AI-нагрузок.
DirectPath Enablement для GPU. В этом выпуске VCF Private AI Services поддерживает DirectPath Enablement для инфраструктуры NVIDIA AI. Это обеспечит высокопроизводительный эксклюзивный доступ к GPU для одной виртуальной машины, которая сможет полностью использовать возможности GPU. С этой новой функцией предприятия смогут развертывать AI-проекты с NVIDIA GPU в режиме DirectPath.
Поддержка последнего поколения NVIDIA Blackwell GPU. VCF теперь поддерживает новейшую серию GPU NVIDIA Blackwell. В дополнение к существующей поддержке NVIDIA RTX PRO 6000 Blackwell Server Edition объявлена поддержка NVIDIA HGX B200 и NVIDIA RTX PRO 4500 Blackwell Server Edition. Поддержка этих новых GPU Blackwell на VCF определяет следующий этап корпоративного AI с беспрецедентной производительностью, эффективностью и масштабом.
Будущая поддержка. В одном из следующих выпусков VCF будет поддерживать NVIDIA HGX B300. VCF на NVIDIA HGX B300 позволит предприятиям без усилий масштабировать самые производительные AI-нагрузки и подготовить инфраструктуру к будущим требованиям.
Поддержка NVIDIA HGX Platform с Blackwell GPU и NVLink Switch. VCF теперь поддерживает NVIDIA HGX platform с Blackwell GPU и NVLink Switch. Благодаря этой возможности предприятия смогут получить преимущества крупномасштабных AI-развертываний с VCF Private AI Services и платформой NVIDIA HGX. NVIDIA HGX объединяет всю мощь инфраструктуры NVIDIA AI, включая NVIDIA GPU, NVIDIA NVLink, NVLink Switch, NVIDIA networking и полностью оптимизированные AI software stacks, чтобы обеспечивать максимальную производительность AI-приложений и ускорять получение инсайтов в каждом дата-центре.
Высокоскоростная сеть с Enhanced DirectPath I/O. VCF теперь поддерживает сетевые адаптеры NVIDIA ConnectX-7 и NVIDIA BlueField-3 с Enhanced DirectPath I/O. С этим улучшением предприятия смогут использовать такие расширенные возможности, как NVIDIA GPUDirect RDMA и GPUDirect Storage, для высокоскоростного обучения AI-моделей на нескольких хостах и передачи данных, что особенно важно для требовательных Gen AI-нагрузок.
3. Упрощение вывода моделей в эксплуатацию
Новые возможности в этой категории помогают предприятиям снижать сложность перевода моделей в production.
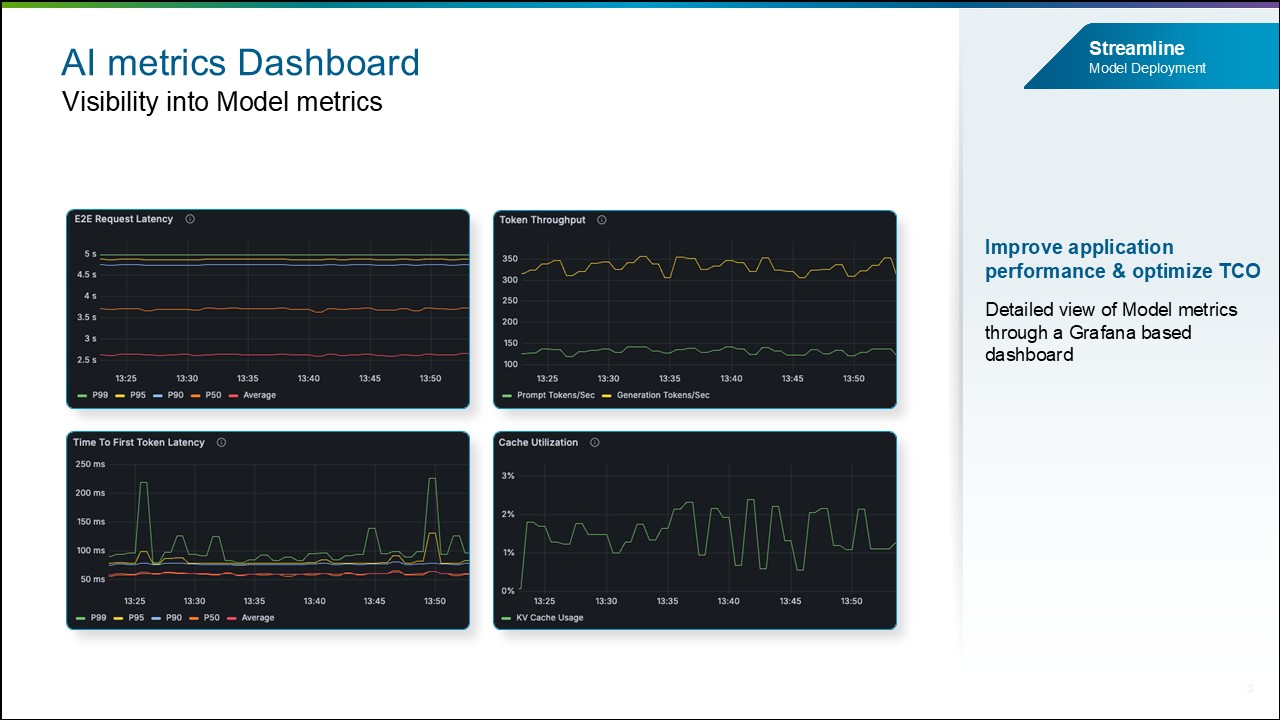
AI Metrics Observability Dashboard.
По мере масштабирования корпоративных AI-сред ограниченная видимость производительности моделей и агентов, а также факторов затрат мешает командам выявлять неэффективность, ведет к росту расходов на инфраструктуру и снижает производительность приложений. Чтобы решить эти проблемы, выпускается AI Metrics Observability Dashboard, который будет показывать важные AI-метрики.
Улучшенная видимость AI-метрик позволит специалистам по data science и MLOps выявлять узкие места, оптимизировать распределение ресурсов, повышать throughput и производительность.
Рассмотрим некоторые AI-метрики, которые будут доступны:
Метрики моделей. Эти метрики помогут предприятиям отслеживать продуктивность, скорость, задержку и другие параметры, предоставляя детальное представление о моделях. Будут доступны такие показатели, как Cache Utilization, Tokens generated per request, Token throughput, Time to first token (TFFT), End-to-end (E2E) request latency и другие.
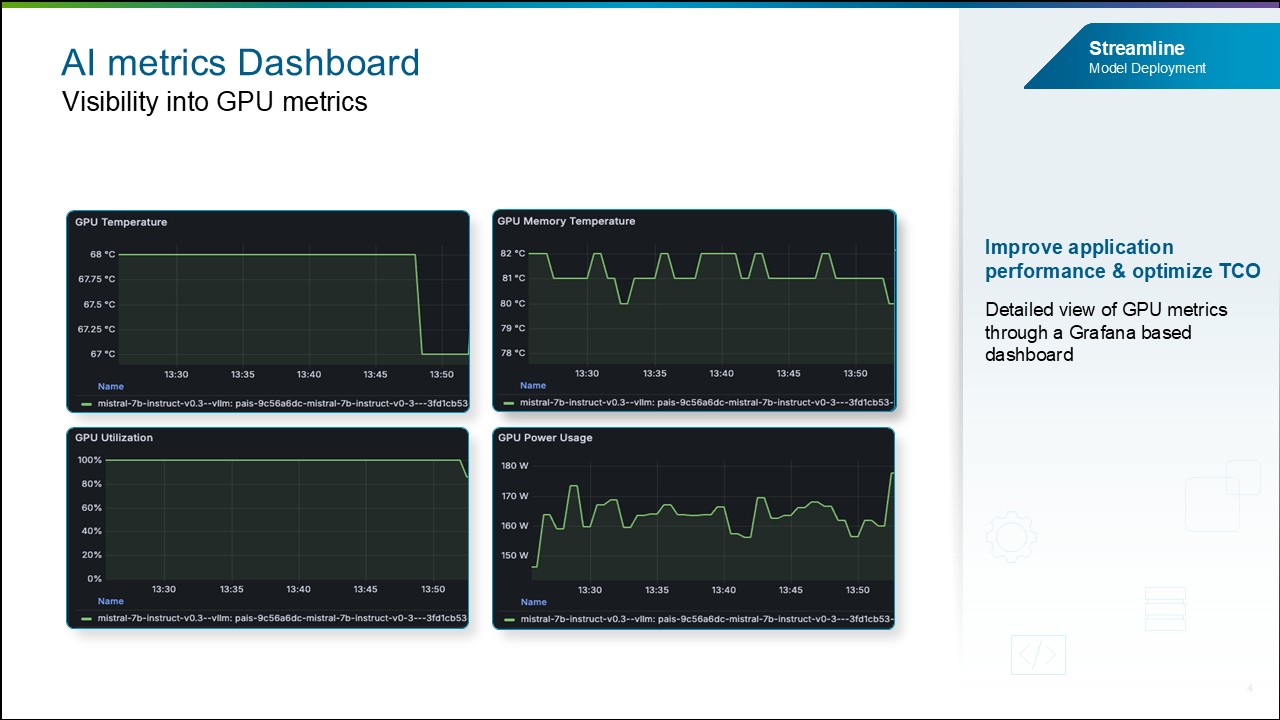
Метрики использования GPU. Также будут доступны GPU-метрики, включая Utilization, Temperature, Power Usage, Memory Temperature, Memory Clock и другие.
Примечание: для этих AI Metrics dashboards предприятиям необходимо развернуть Grafana.
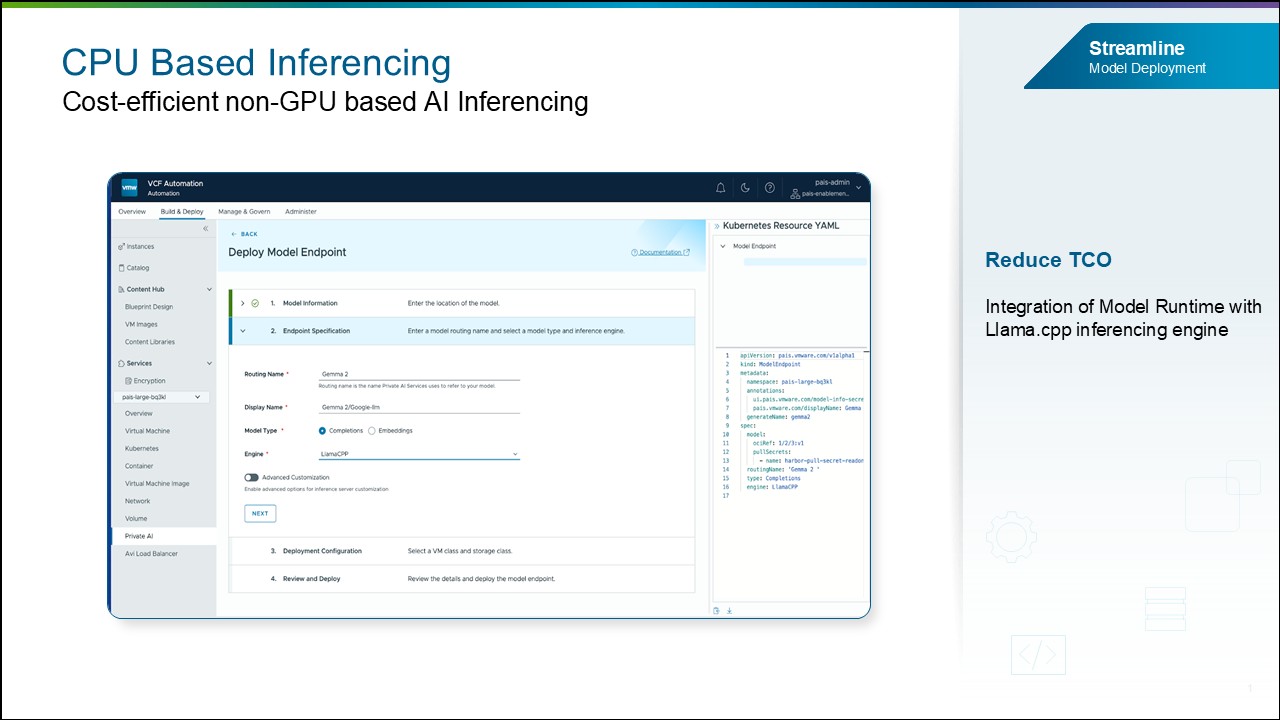
CPU-Based Inferencing. VCF Private AI Services теперь поддерживает CPU-based inferencing в дополнение к GPU-развертываниям благодаря интеграции Model Runtime с inference-движком Llama.cpp. На базе Llama.cpp, одного из ведущих open source inference-движков с широкой поддержкой сообщества, клиенты также получат доступ к большому набору моделей с day-zero-поддержкой от ведущих поставщиков, включая Google, OpenAI и других. Это улучшение снижает TCO, позволяя предприятиям развертывать менее ресурсоемкие среды для тестирования, proof-of-concept-инициатив или AI-приложений с минимальными требованиями к GPU либо без них.
В видеоролике ниже демонстрируется процесс развертывания решения Private AI Foundation с NVIDIA с использованием мастера быстрой настройки.
Автор пошагово показывает, как запустить Foundation Quick Start, выбрать проект и соответствующее пространство имен (namespace), а также вставить клиентский конфигурационный токен, полученный от NVIDIA. В примере используется среда с подключением к интернету, поэтому дополнительные параметры, такие как офлайн-реестр или изменение расположения драйверов, настраивать не требуется.
Далее в видео подробно рассматриваются ключевые параметры развертывания:
Выбор версии Kubernetes (или VKR).
Указание образа виртуальной машины для задач глубокого обучения (Deep Learning VM), заранее загруженного в библиотеку контента.
Выбор класса хранилища (storage class).
Настройка GPU-совместимых классов ВМ (резервирование GPU).
Выбор классов ВМ без поддержки GPU.
Также демонстрируется, что в рамках примера не активируются дополнительные сервисы VCF Data Services и не используется прокси-сервер.
После проверки всех параметров запускается процесс создания ресурсов каталога в выбранном пространстве имен. Через несколько минут новые элементы становятся доступны в разделе Build and Deploy -> Catalog, где можно увидеть созданные позиции Private AI Foundation с NVIDIA и при необходимости запросить их для дальнейшего использования.
Видео будет полезно администраторам и инженерам, занимающимся развертыванием инфраструктуры для задач искусственного интеллекта и машинного обучения в среде Kubernetes с поддержкой GPU.
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
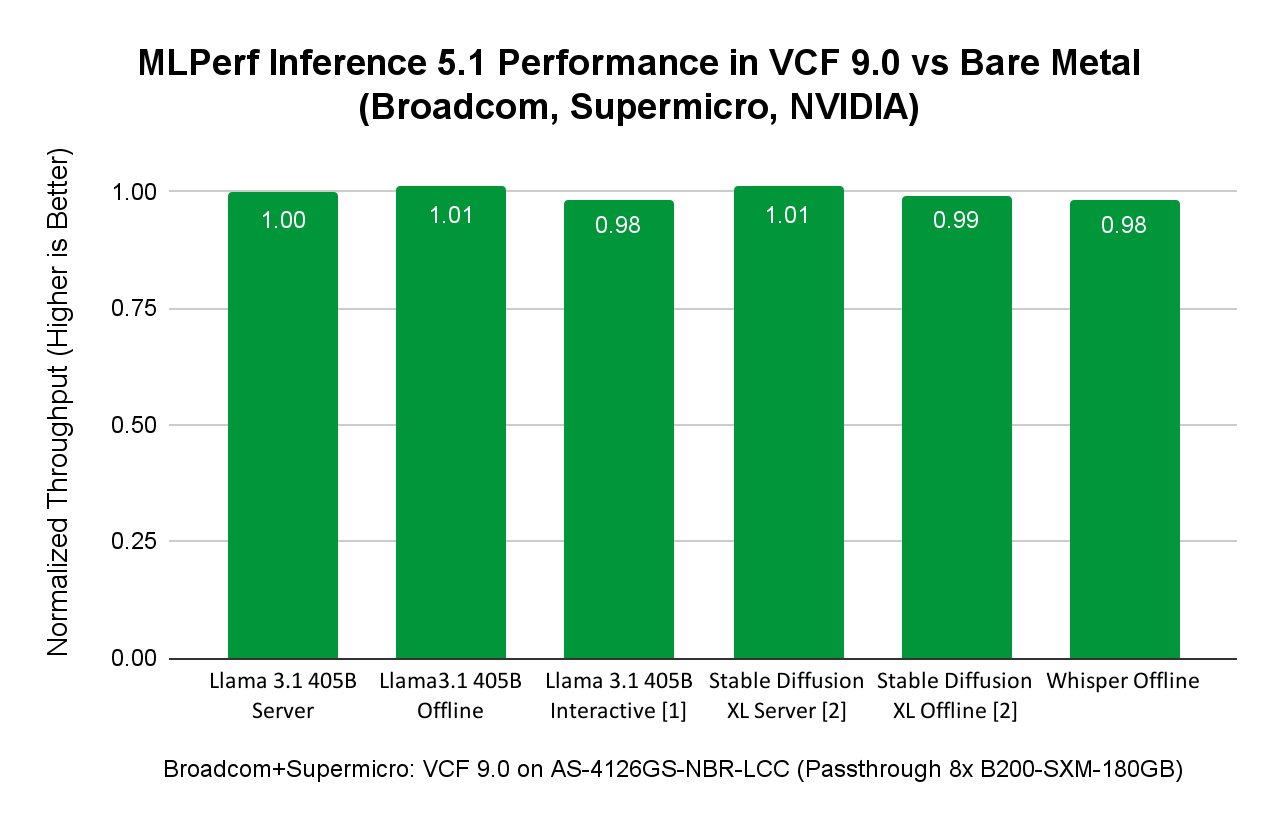
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
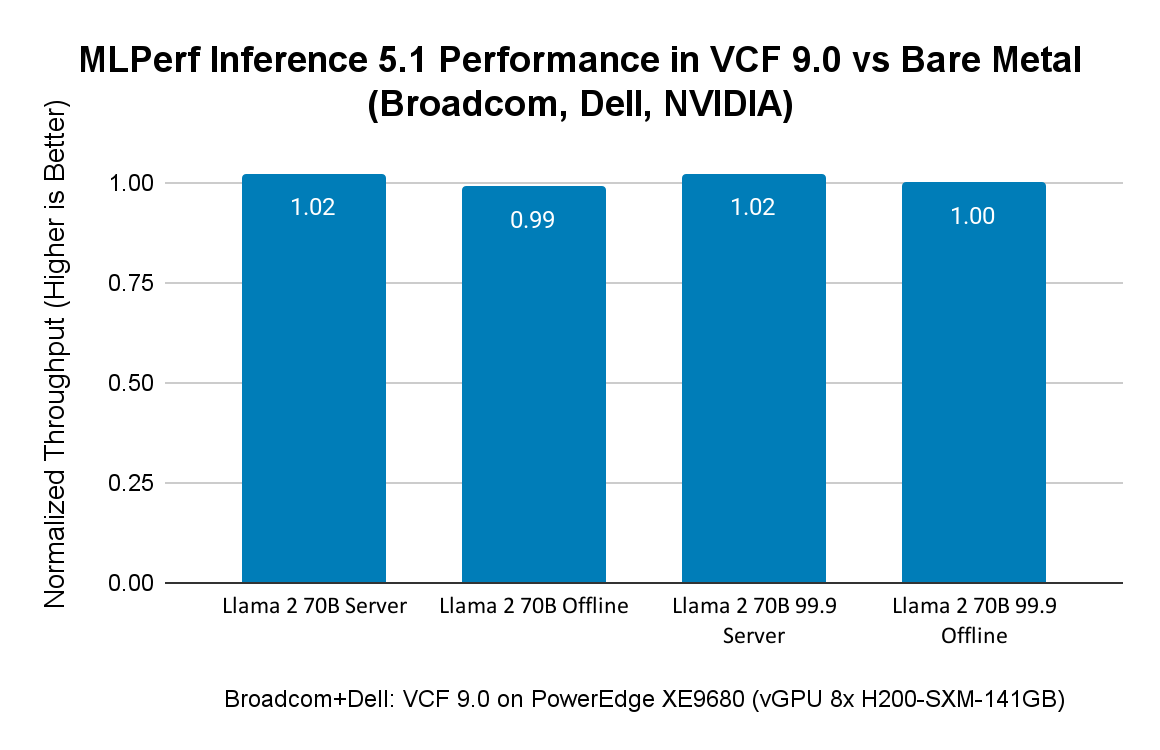
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
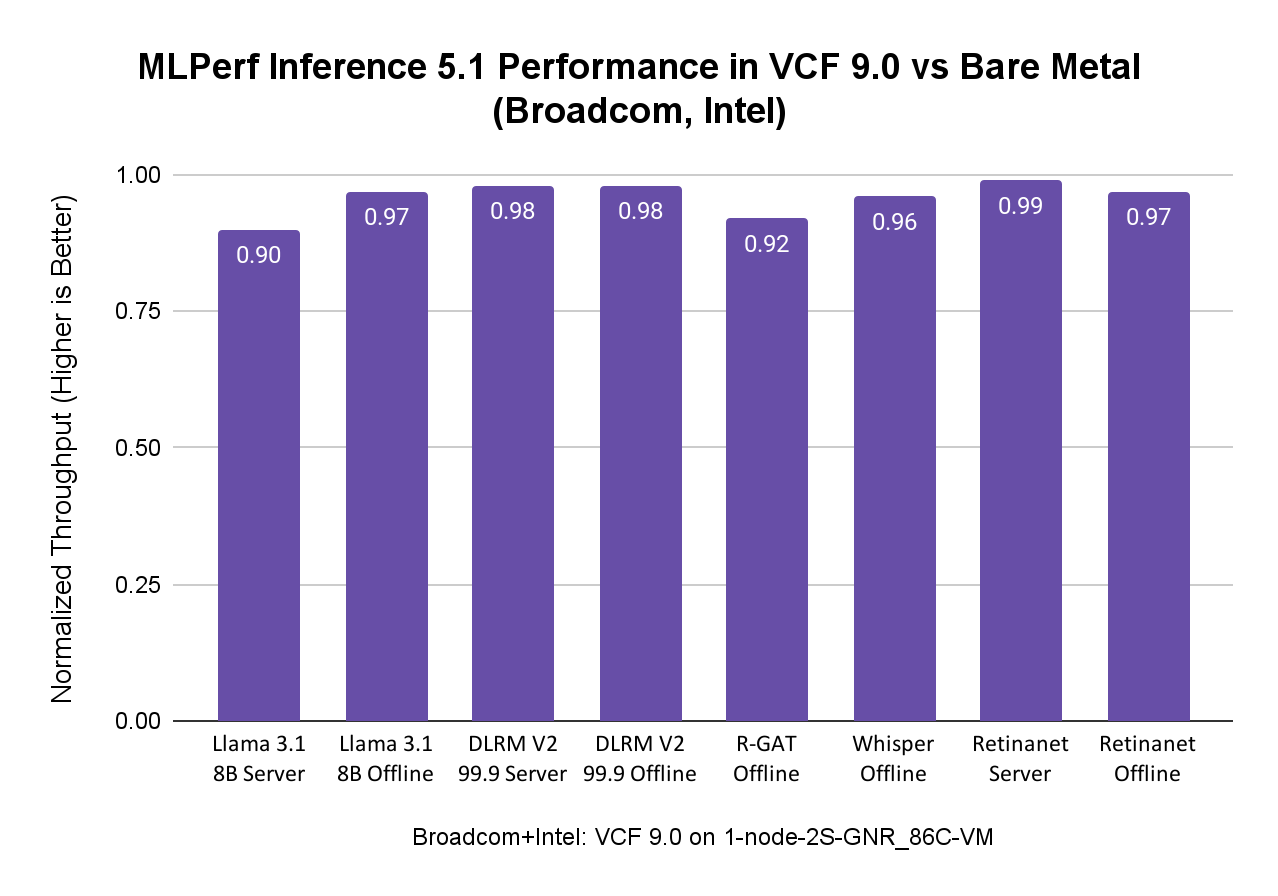
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
Ландшафт корпоративного AI стремительно развивается, и организации сталкиваются с фундаментальными вопросами: как использовать генеративный AI, сохраняя контроль над собственными данными? Что необходимо для построения AI-инфраструктуры, которая масштабируется безопасно? Как перейти от экспериментов к рабочим AI-нагрузкам, готовым к промышленной эксплуатации?
На VMware Explore 2025 лидеры отрасли и технические эксперты напрямую рассмотрели эти критические задачи. От проектирования безопасных основ частного AI до подбора оптимальной инфраструктуры для ресурсоёмких AI-нагрузок — сессии предоставили практические инсайты, выходящие за пределы теоретических рамок и переходящие к стратегиям реальной реализации.
Будь вы инженер платформ, стремящийся внедрить AI во всей организации, специалист по безопасности, сосредоточенный на защите AI-нагрузок, или архитектор инфраструктуры, планирующий следующее AI-развёртывание, эти сессии предлагают проверенные подходы и полученные на практике уроки.
Вот ключевые AI-сессии, которые дают наиболее ясный путь вперёд для успеха при внедрении AI в корпоративной среде.
Building Secure Private AI Deep Dive [INVB1432LV]
С момента запуска VMware Private AI Foundation with NVIDIA это решение развилось и теперь предлагает надёжные сервисы, позволяющие превращать собственную интеллектуальную собственность в уникальные GenAI-приложения с использованием NVIDIA Inference Microservices (NIM), развёрнутых в архитектурах Retrieval Augmented Generation (RAG) в локальной инфраструктуре.
Присоединяйтесь к команде менеджеров продуктов VMware и NVIDIA совместно с UT Systems, чтобы узнать, как решение развивается, чтобы:
Поддерживать передовые GPU и системы HGX, разработанные специально для AI и использующие VMware Cloud Foundation (VCF)
Упростить доставку RAG-приложений с помощью: сервисов Private AI, включая среду исполнения моделей для развертывания LLM как сервиса; сервисов AI-данных, включая NVIDIA NeMo Microservices и сервис индексирования и поиска данных VMware; а также цифровых людей на VCF с использованием блупринтов NVIDIA.
Building Secure Private AI Deep Dive [INVB1432LV]
Узнайте, как безопасно создавать и масштабировать инфраструктуру Private AI с помощью VMware vDefend и VMware Private AI with NVIDIA. Эта сессия проведёт вас через процессы разработки надёжной архитектуры частного AI с встроенной защитой данных, изоляцией рабочих нагрузок и автоматическим применением политик.
Узнайте, как vDefend повышает безопасность AI-моделей с помощью сегментации и обнаружения угроз в реальном времени, а Private AI with NVIDIA предоставляет платформу для развертывания и управления AI-нагрузками с полным контролем.
Идеально подходит для архитекторов и команд безопасности: эта сессия предлагает практические инсайты для безопасного внедрения AI в среде частного облака.
Sizing AI Workloads in VMware Private AI Foundation [INVB1801LV]
По мере роста внедрения AI обеспечение оптимальной производительности и масштабируемости AI-нагрузок становится критически важным для получения точных результатов и своевременных инсайтов. В этой сессии мы разберём несколько типовых сценариев и покажем инструменты, которые помогут вам правильно рассчитать размеры ваших AI-нагрузок.
Tanzu AI Solutions Essentials: What You Need to Know to Get Up and Running [MODB1496LV]
Планируете запускать AI-нагрузки на своей платформе, но не знаете, с чего начать? Интересуетесь практической работой с AI с использованием VMware Tanzu Platform? Эта сессия предназначена для инженеров платформ, которым нужен практичный старт.
В ходе сессии рассмотриваются ключевые компоненты решений Tanzu AI — от готовности инфраструктуры до моделей развертывания, — чтобы вы могли включать, масштабировать и операционализировать AI в своих средах. Вы узнаете, как интегрировать AI-модели в новые или существующие платформы, обеспечивать управление и масштабируемость, а также предоставлять самообслуживание для команд данных и разработчиков.
Основные выводы включают архитектурные лучшие практики, ключевые шаги конфигурации и рекомендации по обеспечению быстрого и безопасного эксперимента с AI — чтобы вы были готовы поддерживать инновации с первого дня.
10 Big Benefits of Private AI That Make Your Decision Easy [CLOB1707LV]
В этой сессии мы поговорим о том, что такое Private AI, и рассмотрим 10 ключевых причин, по которым он является правильным подходом для использования генеративного AI на предприятии. Эта сессия поможет вам лучше разобраться в вопросе, принимать верные решения для своей организации и раскрыть потенциал частного AI в её масштабах.
Unlock Innovation with VMware Private AI Foundation with NVIDIA [INVB1446LV]
Узнайте, как предприятия трансформируют свои стратегии в области AI с помощью совместной платформы GenAI от Broadcom и NVIDIA — VMware Private AI Foundation with NVIDIA. В этой сессии основное внимание уделяется сервисам Private AI, включая среду выполнения моделей, индексирование и поиск данных, сервисы создания агентов и многое другое.
Real-World Lessons in Rightsizing VMware Cloud Foundation for On-Premises AI Workloads [INVB1300LV]
Нагрузки AI — особенно основанные на больших языковых моделях (LLM) — меняют то, как мы проектируем, масштабируем и эксплуатируем инфраструктуру. Речь уже не только о вычислениях и хранилищах. Размер модели, задержка при инференсе, параллельность и распределение GPU — всё это оказывает существенное влияние.
В этой сессии Фрэнк Деннеман и Йохан ван Амерсфорт делятся практическими уроками, полученными при проектировании и развертывании платформ VMware Cloud Foundation, готовых к AI, в различных средах заказчиков. Вы узнаете практические стратегии правильного подбора размеров инфраструктуры, балансировки компромиссов между резервным копированием и конвейерами MLOps, а также проектирования инфраструктуры для локальных AI-нагрузок.
Используя практический инструмент для расчёта размеров AI-инфраструктуры, они продемонстрируют, как согласовать инфраструктуру с реальными требованиями и вести предметный диалог со стейкхолдерами и поставщиками AI-решений, чтобы принимать более разумные и экономически эффективные решения по платформе.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.
Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.
Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
Конфигурацию ESX для включения GPUDirect RDMA
Развертывание Service VM
Настройку кластера VKS
Установку операторов (NVIDIA Network и GPU Operators)
Процедуры загрузки хранилища и моделей
Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.
AI и генеративный AI (Gen AI) требуют значительной инфраструктуры, а задачи, такие как тонкая настройка, кастомизация, развертывание и выполнение запросов, могут сильно нагружать ресурсы. Масштабирование этих операций становится проблематичным без достаточной инфраструктуры. Кроме того, необходимо соответствовать различным требованиям в области комплаенса и законодательства в разных отраслях и странах. Решения на базе Gen AI должны обеспечивать контроль доступа, правильное размещение рабочих нагрузок и готовность к аудиту для соблюдения этих стандартов. Чтобы решить эти задачи, Broadcom представила VMware Private AI, которая помогает клиентам запускать модели рядом с их собственными данными. Объединяя инновации обеих компаний, Broadcom и NVIDIA стремятся раскрыть потенциал AI и повысить производительность при более низкой совокупной стоимости владения (TCO).
Технический документ «Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking» подробно описывает сквозное развертывание и конфигурацию, с акцентом на DirectPath I/O (passthrough) для GPU, а также сетевые адаптеры Thor 2 с Ethernet-коммутатором Tomahawk 5. Это руководство необходимо архитекторам инфраструктуры, администраторам VCF и специалистам по data science, которые стремятся достичь оптимальной производительности своих AI-моделей в среде VCF.
Что охватывает этот документ?
Документ предоставляет детальные рекомендации по следующим направлениям:
Адаптеры Broadcom Thor 2 и GPU NVIDIA: как эффективно интегрировать сетевые карты Broadcom и GPU NVIDIA в виртуальные машины глубокого обучения (DLVM) на базе Ubuntu в среде VMware Cloud Foundation (VCF).
Сетевая конфигурация: пошаговые инструкции по настройке Ethernet-адаптеров Thor 2 и коммутаторов Tomahawk 5 для включения RoCE (RDMA over Converged Ethernet) с GPU NVIDIA, что обеспечивает низкую задержку и высокую пропускную способность, критически важные для AI-нагрузок.
Тестирование производительности: процедуры запуска тестов с использованием ключевых библиотек коллективных коммуникаций, таких как NCCL, для проверки эффективности многопроцессорных GPU-операций.
Инференс LLM: рекомендации по запуску и тестированию инференса больших языковых моделей (LLM) с помощью NVIDIA Inference Microservices (NIM) и vLLM, демонстрирующие реальный прирост производительности.
Ключевые особенности решения
Решение, описанное в документе, ориентировано на сертифицированные системы VMware Private AI на базе HGX, которые обычно оснащены 4 или 8 GPU H100/H200 с интерконнектом NVSwitch и NVLink. Целевая среда — это приватное облако на базе VCF, использующее сетевые адаптеры Broadcom 400G BCM957608 NICs и кластеризированные GPU NVIDIA H100, соединённые через Ethernet.
Ключевой аспект данного развертывания — использование DirectPath I/O для GPU и адаптеров Thor2, что обеспечивает выделенный доступ к аппаратным ресурсам и максимальную производительность. В руководстве также подробно рассматриваются следующие важные элементы:
BIOS и прошивки: рекомендуемые конфигурации для серверов HGX, позволяющие раскрыть максимальную производительность.
Настройки ESX: оптимизация ESX для passthrough GPU и сетевых устройств, включая корректную разметку оборудования и конфигурацию ACS (Access Control Services).
Настройки виртуальных машин: кастомизация Deep Learning VM (DLVM) для DirectPath I/O, включая назначение статических IP и важные расширенные параметры ВМ для ускоренного запуска и повышения производительности.
Валидация производительности
Подробные инструкции по запуску RDMA, GPUDirect RDMA с Perftest и тестов NCCL на нескольких узлах с разъяснением ожидаемой пропускной способности и задержек.
Бенчмаркинг виртуальной и bare-metal производительности Llama-3.1-70b NIM с помощью genai-perf, позволяющий достичь результатов, близких к bare-metal.
Использование evalscope для оценки точности и стресс-тестирования производительности передовой модели рассуждений gpt-oss-120b.
Вот интересный результат из исследования, доказывающий, что работа GPU в виртуальной среде ничем не хуже, чем в физической:
Это комплексное руководство является ценным ресурсом для всех, кто стремится развернуть и оптимизировать AI-инференс на надежной виртуальной инфраструктуре с использованием серверов NVIDIA HGX и сетевых решений Broadcom Ethernet. Следуя описанным в документе лучшим практикам, организации могут создавать масштабируемые и высокопроизводительные AI-платформы, соответствующие требованиям современных приложений глубокого обучения.
На конференции VMware Explore 2025 компания Broadcom объявила, что службы VMware Private AI Services теперь входят в стандартную поставку VMware Cloud Foundation 9.0 (VCF 9.0). То есть VCF превращается в полноценную AI-native платформу частного облака: из коробки доступны (или будут доступны) сервисы для работы с моделями, наблюдаемость за GPU, среда исполнения для моделей и агент-фреймворк, плюс дорожная карта с MCP, multi-accelerator и AI-ассистентом для VCF.
Платформа VCF 9.0 уже находится в статусе General Availability и доступна с июня 2025, а выход служб Private AI Services в составе подписки планируется к началу первого квартала 2026 финансового года Broadcom.
Давайте посмотрим на состав и функции VMware Private AI Services:
Слой AI-сервисов в VCF 9.0
Что «входит по умолчанию» в Private AI Services (становится частью подписки VCF 9.0):
GPU Monitoring — телеметрия и наблюдаемость графических карт.
Model Store — репозиторий и версионирование моделей.
Model Runtime — сервисный слой для развертывания/экспонирования моделей (endpoints).
Vector Database & Data Indexing/Retrieval — индексация корпоративных данных и RAG-потоки.
Эти возможности поставляются как native services платформы, а не «надстройка» — и это важная архитектурная деталь: AI становится частью инфраструктуры, живущей в тех же сущностных/безопасностных доменах, что и виртуальные машины и контейнеры.
Также были анонсированы следуюие продукты и технологии в рамках дорожной карты:
Intelligent Assist for VCF — LLM-ассистент для диагностики и самопомощи в VCF (пока как tech preview для on-prem/air-gapped и cloud-моделей).
Model Context Protocol (MCP) — стандартная, управляемая интеграция ассистентов с инструментами и БД (Oracle, MSSQL, ServiceNow, GitHub, Slack, PostgreSQL и др.).
Multi-accelerator Model Runtime — единая среда исполнения для AMD и NVIDIA GPU без переработки приложений; поддержка NVIDIA Blackwell, B200, ConnectX-7/BlueField-3 с технологией Enhanced DirectPath I/O.
Multi-tenant Models-as-a-Service — безопасное шаринг-использование моделей между пространствами имен/линиями бизнеса.
Ядро VCF 9.0: что поменялось в самой платформе
Единая операционная плоскость
VCF 9.0 переносит фокус на «One interface to operate» (VCF Operations) и «One interface to consume» (VCF Automation): единая модель политик, API и общий движок жизненного цикла. Это снижает расхождение инструментов и обучаемость. На практике это дает унифицированное управление инфраструктурой, health/patch/compliance из одной консоли, централизованные функции IAM/SSO/сертификатов, анализ корреляции логов и другие возможности.
Примеры экранов и функций, доступных в VCF Operations: обзор по всем инстансам, геокарта, статус сертификатов с автообновлением, NetOps-дэшборды (NSX health, VPC, flows), интеграция Live Recovery и LogAssist.
Слой потребления (для разработчиков/проектных команд)
GitOps (Argo CD) как встроенная модель доставки, Istio Service Mesh для zero-trust/observability трафика, единый контроль политик по проектам.
vSphere Kubernetes Service (VKS) — функции enterprise-K8s, доступные прямо из VCF.
Native vSAN S3 Object Store — S3-совместимый API хранилища объектов на vSAN, без внешних лицензий/модулей.
Все это — официальные «новые в 9.0» элементы, влияющие на скорость доставки сервисов и безопасность.
Производительность и эффективность
NVMe Memory Tiering — расширение оперативной памяти за счет NVMe для высокочастотных/in-memory нагрузок.
Встроенные chargeback/showback и cost dashboards (TCO-прозрачность, прогнозирование, возврат/reclaim неиспользуемых ресурсов).
Аппаратные улучшения/сетевой стек для AI
VCF 9.0 выравнивает работу «больших» AI-нагрузок на частной инфраструктуре:
Поддержка NVIDIA Blackwell (включая RTX PRO 6000 Blackwell Server Edition, B200, HGX с NVSwitch), GPUDirect RDMA/Storage, Enhanced DirectPath I/O - при этом сохраняются «классические» возможности vSphere (vMotion, HA, DRS, Live Patching).
Совместная работа с AMD: ROCm Enterprise AI и Instinct MI350 для задач fine-tuning/RAG/inference. Это не «плагин», а интегрированная часть VCF и экосистемы VMware Private AI Foundation with NVIDIA.
Как это интегрируется в вашм бизнес-процессы
Типовые сценарии, которые теперь проще закрывать «из коробки»:
Агенты поверх LLM: ускоренный старт с Agent Builder + подключение к корпоративным данным через индексирование/вектора.
RAG-потоки с политиками и аудитом: источники данных под управлением VCF, контроль доступа на уровне платформы, видимость (observability).
Доставка сервисов K8s: GitOps (Argo CD), сервис-меш (Istio), S3-объекты на vSAN для артефактов/данных.
Лицензирование/доставка и пути обновления
GA: VCF 9.0 доступен с 17 июня 2025.
Службы Private AI Services обещаны как часть подписки VCF 9.0 в Q1 FY26 от Broadcom.
Официальный документ с фичами и путями миграции VCF <-> VVF 9.0 доступен тут.
Вывод
VCF 9.0 — это не просто «еще одна» версия с оптимизациями. За счет включения Private AI Services в базовую платформу и сдвига на «one interface to operate/consume», VCF превращает AI-нагрузки в основу частного облака, сохраняя корпоративные политики, комплаенс и привычные SRE-процессы — от GPU до GitOps.
Агентный ИИ (Agentic AI) больше не футуристическая мечта — он уже здесь и стремительно становится необходимостью для компаний, стремящихся ускорить инновации, повысить эффективность и обогнать конкурентов. Согласно исследованию IDC, более 50% корпоративного рынка приложений уже используют AI-ассистентов или советников, а около 20% — полноценных AI-агентов.
Компании, ранее воспользовавшиеся возможностями генеративного AI (GenAI) по обработке запросов, теперь переключают внимание на агентный AI — системы, которые автономно выполняют задачи в заданных рамках, повышая эффективность и снижая издержки. Однако реализация таких решений пока остаётся сложной. Один из опросов показал, что 46% проектов на стадии концепции так и не доходят до промышленного внедрения. Причина? Корпоративный AI требует интеграции с трудносовместимыми компонентами: разрозненными источниками данных и устоявшимися бизнес-процессами. Создание действительно полезных инструментов, таких как виртуальные помощники корпоративного уровня, требует координации этой сложной экосистемы данных, инструментов, моделей и систем управления — непростая задача для компаний, только начинающих осваивать AI.
Платформа Tanzu решает эту задачу, упрощая разработку и развёртывание приложений за счёт встроенного доступа и контроля к ключевым сервисам данных, инструментам для разработчиков, системам управления и брокерам моделей. Эта платформа как услуга (PaaS), оптимизированная под частные облака, позволяет предприятиям использовать возможности GenAI и агентного AI. С Tanzu предприятия могут дополнять критически важные бизнес-приложения информированными, обоснованными ответами на естественном языке или быстро создавать новые приложения и агентов, безопасно интегрируя собственные данные и системы. Это стало возможным благодаря продвинутым AI-функциям Tanzu, таким как планирование, использование инструментов, память и цепочки действий, позволяющим превращать идеи в готовый к развёртыванию код за считанные минуты.
В результате предприятия получают простой способ создать более безопасные и масштабируемые решения на базе GenAI и агентного AI, соответствующие корпоративным требованиям и стандартам комплаенса. На недавнем мероприятии Racing Toward AI App Delivery with Tanzu: Navigating the Fast Lane with Intelligence сотрудники VMware обсудили последние тренды в сфере AI:
Перспективы агентного AI
Начнём с определения агентного AI. Это тип искусственного интеллекта, который не просто отвечает на запросы, но и способен автономно выполнять задачи и предпринимать действия на основе пользовательского ввода или условий окружающей среды. В то время как традиционный генеративный AI работает по модели «только для чтения» — то есть выдаёт ответы, предложения или прогнозы — агентный AI поднимает взаимодействие на новый уровень, выполняя задачи самостоятельно.
Агентный AI становится возможным благодаря добавлению к генеративному AI дополнительного уровня интеллекта. Когда поступает запрос, агентный AI проходит многоэтапный процесс, используя доступные знания и инструменты. Сначала система анализирует запрос и разбивает его на мелкие, выполнимые задачи; затем она самостоятельно выполняет эти задачи — вызывая API, обращаясь к микросервисам или исполняя код; в завершение AI оценивает результаты своих действий (часто с участием человека в процессе) и при необходимости вносит корректировки, чтобы добиться нужного результата.
Например, представим сценарий с использованием агентного AI при обработке страхового случая: при подаче заявления агент координирует работу нескольких AI-модулей — один использует компьютерное зрение для анализа фотографий повреждений, другой применяет обработку естественного языка (NLP) для извлечения данных из форм и отчётов об аварии.
Инновационность этого подхода заключается в способности агента самостоятельно решать, к каким корпоративным системам обратиться для получения информации о полисе, как интерпретировать сложные правила покрытия и когда применять определённую бизнес-логику. Система активирует движок принятия решений, который сопоставляет параметры полиса с данными о происшествии, а также задействует AI для выявления мошенничества, сравнивая случай с тысячами исторических паттернов. В простых, стандартных случаях агент сам принимает решение об одобрении, рассчитывает выплаты с использованием предиктивных моделей и инициирует процесс оплаты — при этом на каждом этапе сохраняется возможность участия человека для проверки или вмешательства. Такой подход с участием человека в процессе («human-in-the-loop») обеспечивает контроль, при этом позволяя AI эффективно обрабатывать рутинные случаи от начала до конца.
Для достижения такой продвиной функциональности агентному AI необходимо больше, чем просто базовый генеративный инструментарий. Приложения с агентным AI требуют фреймворка для управления контекстом и памятью между сессиями, а также системы для управления API-запросами и интеграции различных сервисов — всё это предоставляет платформа VMware Tanzu.
Чтобы повысить доступность и масштабируемость разработки агентных решений для корпоративных клиентов, осенью 2024 года компания Anthropic, один из лидеров в области AI, опубликовала Model Context Protocol (MCP) — стандарт, описывающий, как AI-модели могут взаимодействовать с внешними инструментами и источниками данных. Вскоре после этого команда Tanzu Spring создала MCP Java SDK — реализацию MCP на Java. Этот SDK стал официальной реализацией MCP на Java.
В результате разработчики на Java теперь могут создавать или использовать существующие сторонние MCP-серверы, с которыми смогут взаимодействовать агентные системы. Это устраняет необходимость в сложных, кастомных и жёстко прописанных связях между системами, которые могли бы добавлять месяцы к срокам разработки.
Начинайте уже сейчас c теми разработчиками, что есть
Многие руководители обеспокоены нехваткой навыков программирования AI в своих организациях. VMware старается решать эту вполне реальную проблему, не требуя от корпоративных разработчиков переобучения, а приходя к ним на том уровне, где они уже находятся.
В течение последнего года в VMware внедряли новейшие технологии AI для корпоративных Java-разработчиков с помощью Spring AI — неотъемлемой части платформы Tanzu. Поскольку многие Java-разработчики используют Spring, Spring AI играет ключевую роль в реализации бизнес-ценности: разработчики могут добавлять AI-возможности в свои приложения, не изучая новые языки или инструменты. Можно сказать, что VMware превращает Java-разработчиков в разработчиков агентных систем. Компания предоставляет все возможности проверенной и зрелой PaaS-платформы, помогая быстро переходить от идеи к коду и далее — к продакшену, при этом инструменты для обеспечения безопасности, соответствия требованиям и масштабируемости уже встроены. Это означает более быстрые итерации, меньше доработок и более быструю окупаемость.
Разработка AI-приложений — это глубоко итеративный процесс, поэтому те, кто начинает раньше, быстрее получают важные инсайты, могут добавлять продвинутые AI-функции в приложения и сохранять лидерство за счёт постоянных инноваций.
Но для инноваций нужна прочная основа. Без платформы, которая берёт на себя AI-операции второго уровня — такие как безопасность, контроль и масштабируемость — разработчики вынуждены тратить время на рутинные задачи. Tanzu Platform помогает снять это бремя, чтобы разработчики могли сосредоточиться на главном: превращении идей в код и доставке этого кода в продакшен.
Платформа Tanzu помогает бизнесу идти в ногу с эволюцией AI
Агентный AI стремительно развивается и преобразует как бизнес, так и клиентский опыт. Средствами платформы Tanzu компания VMware предлагает клиентам способ быстро начать работу, чтобы они могли экспериментировать, учиться и развивать свою стратегию создания AI-приложений. Ключ к успеху — это быстрая доставка и обучение через практику. Такой подход не только помогает находить ценные инсайты, но и способствует перестройке организационных процессов для более глубокой и эффективной интеграции AI.
Многие клиенты VMware уже имеют доступ к этим возможностям — через Spring AI или GenAI Tile, в зависимости от текущих условий их подписки. Загляните на сайт Tanzu AI Solutions, чтобы узнать больше.
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:
Конфигурация оборудования Dell PowerEdge XE9680:
Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:
Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.
Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.
Сегодня искусственный интеллект преобразует бизнес во всех отраслях, однако компании сталкиваются с проблемами, связанными со стоимостью, безопасностью данных и масштабируемостью при запуске задач инференса (производительной нагрузки) в публичных облаках. VMware и NVIDIA предлагают альтернативу — платформу VMware Private AI Foundation with NVIDIA, предназначенную для эффективного и безопасного размещения AI-инфраструктуры непосредственно в частном датацентре. В документе "VMware Private AI Foundation with NVIDIA on HGX Servers" подробно рассматривается работа технологии Private AI на серверном оборудовании HGX.
Зачем бизнесу нужна частная инфраструктура AI?
1. Оптимизация использования GPU
На практике графические ускорители (GPU), размещенные в собственных датацентрах, часто используются неэффективно. Они могут простаивать из-за неправильного распределения или чрезмерного резервирования. Платформа VMware Private AI Foundation решает эту проблему, позволяя динамически распределять ресурсы GPU. Это обеспечивает максимальную загрузку графических процессоров и существенное повышение общей эффективности инфраструктуры.
2. Гибкость и удобство для специалистов по AI
Современные сценарии работы с AI требуют высокой скорости и гибкости в работе специалистов по данным. Платформа VMware обеспечивает привычный облачный опыт работы, позволяя командам специалистов быстро разворачивать AI-среды, при этом сохраняя полный контроль инфраструктуры у ИТ-команд.
3. Конфиденциальность и контроль за данными
Публичные облака вызывают беспокойство в вопросах приватности, особенно когда AI-модели обрабатывают конфиденциальные данные. Решение VMware Private AI Foundation гарантирует полную конфиденциальность, соответствие нормативным требованиям и контроль доступа к проприетарным моделям и наборам данных.
4. Знакомый интерфейс управления VMware
Внедрение нового программного обеспечения обычно требует значительных усилий на изучение и адаптацию. Платформа VMware использует уже знакомые инструменты администрирования (vSphere, vCenter, NSX и другие), что существенно сокращает время и затраты на внедрение и эксплуатацию.
Основные компоненты платформы VMware Private AI Foundation с NVIDIA
VMware Cloud Foundation (VCF)
Это интегрированная платформа, объединяющая ключевые продукты VMware:
vSphere для виртуализации серверов.
vSAN для виртуализации хранилищ.
NSX для программного управления сетью.
Aria Suite (бывшая платформа vRealize) для мониторинга и автоматизации управления инфраструктурой.
NVIDIA AI Enterprise
NVIDIA AI Enterprise является важным элементом платформы и включает:
Технологию виртуализации GPU (NVIDIA vGPU C-Series) для совместного использования GPU несколькими виртуальными машинами.
NIM (NVIDIA Infrastructure Manager) для простого управления инфраструктурой GPU.
NeMo Retriever и AI Blueprints для быстрого развёртывания и масштабирования моделей AI и генеративного AI.
NVIDIA HGX Servers
Серверы HGX специально разработаны NVIDIA для интенсивных задач AI и инференса. Каждый сервер оснащён 8 ускорителями NVIDIA H100 или H200, которые взаимосвязаны через высокоскоростные интерфейсы NVSwitch и NVLink, обеспечивающие высокую пропускную способность и минимальные задержки.
Высокоскоростная сеть
Сетевое взаимодействие в кластере обеспечивается Ethernet-коммутаторами NVIDIA Spectrum-X, которые предлагают скорость передачи данных до 100 GbE, обеспечивая необходимую производительность для требовательных к данным задач AI.
Референсная архитектура для задач инференса
Референсная архитектура предлагает точные рекомендации по конфигурации аппаратного и программного обеспечения:
Физическая архитектура
Серверы инференса: от 4 до 16 серверов NVIDIA HGX с GPU H100/H200.
Сетевая инфраструктура: 100 GbE для рабочих нагрузок инференса, 25 GbE для управления и хранения данных.
Управляющие серверы: 4 узла, совместимые с VMware vSAN, для запуска сервисов VMware.
Виртуальная архитектура
Домен управления: vCenter, SDDC Manager, NSX, Aria Suite для управления облачной инфраструктурой.
Домен рабочих нагрузок: виртуальные машины с GPU и Supervisor Clusters для запуска Kubernetes-кластеров и виртуальных машин с глубоким обучением (DLVM).
Векторные базы данных: PostgreSQL с расширением pgVector для поддержки Retrieval-Augmented Generation (RAG) в генеративном AI.
Производительность и валидация
VMware и NVIDIA протестировали платформу с помощью набора тестов GenAI-Perf, сравнив производительность виртуализированных и bare-metal сред. Решение VMware Private AI Foundation продемонстрировало высокую пропускную способность и низкую задержку, соответствующие или превосходящие показатели не виртуализированных решений.
Почему компании выбирают VMware Private AI Foundation с NVIDIA?
Эффективное использование GPU: максимизация загрузки GPU, что экономит ресурсы.
Высокий уровень безопасности и защиты данных: конфиденциальность данных и контроль над AI-моделями.
Операционная эффективность: использование привычных инструментов VMware сокращает затраты на внедрение и управление.
Масштабируемость и перспективность: возможность роста и адаптации к новым задачам в области AI.
Итоговые выводы
Платформа VMware Private AI Foundation с NVIDIA является комплексным решением для компаний, стремящихся эффективно и безопасно реализовывать задачи искусственного интеллекта в частных дата-центрах. Она обеспечивает высокую производительность, гибкость и конфиденциальность данных, являясь оптимальным решением для организаций, которым критично важно сохранять контроль над AI-инфраструктурой, не жертвуя при этом удобством и масштабируемостью.
Генеративный AI продолжает уверенно завоевывать позиции в корпоративной среде. И хотя большинство организаций находятся на этапах экспериментов, происходит постепенный переход к внедрению технологий в полномасштабные производственные среды. По мере роста зрелости рынка и компаний, сбалансированный подход к сильным и слабым сторонам генеративного AI помогает организациям снижать риски, уделяя приоритетное внимание безопасности и конфиденциальности данных, что прокладывает путь к созданию таких кейсов использования, которые одновременно безопасны и трансформируют бизнес.
Эволюция кейсов применения генеративного AI
По мере того как подходы и среды для работы с GenAI становятся более сложными и безопасными, расширяются и направления его применения в компаниях. На ранних этапах организации использовали генеративный AI для таких задач, как визуализация данных и резюмирование информации — это были задачи более низкого порядка, не требующие глубоких знаний в предметной области.
Однако в течение следующих 12 месяцев, по данным опросов, наибольший прирост ценности ожидается в областях, требующих большего учета специфики рабочих процессов и внутреннего контекста компании, таких как генерация кода, улучшение клиентского опыта, продвинутый поиск информации и безопасная генерация контента. Еще одной быстро развивающейся сферой является агентный AI (Agentic AI), который, как ожидается, приведет к улучшению процессов оптимизации и автоматизации задач.
Фокус на безопасной генерации контента
Создание контента — одно из ключевых применений генеративного AI и принципиально новая возможность, открытая благодаря уникальным возможностям генеративных моделей. Эта область стремительно набирает популярность в корпоративной среде благодаря способности повышать продуктивность и автоматизировать типовые задачи по производству контента. В частности, генерация текстов привлекла особое внимание пользователей из-за широкой области применения и остается наиболее востребованной модальностью генеративного AI.
Все чаще бизнес также экспериментирует с другими типами контента, такими как изображения, 3D-рендеры, аудио и видео, часто нацеливаясь на кросс-модальные рабочие процессы. Например, маркетинговые сценарии, где создание изображений продукции сочетается с разработкой текстов рекламных кампаний, или клиентские сервисы, где аудио интегрируется с текстом.
В рамках исследования Voice of the Enterprise: AI & Machine Learning, Use Cases 2025 компании 451 Research (опрошено 1006 компаний) был задан следующий вопрос: "Вашей организацией была приобретена или разработана технология генеративного AI, используемая для создания любого из следующих типов контента?". Вопрос касался исключительно технологий, которые были приобретены или разработаны.
После обработки ответов текущие и планируемые модальности контента GenAI были представлены так:
Одной из распространенных проблем при использовании сотрудниками публичных инструментов генеративного AI или базовых моделей является отсутствие учета специфики организации. Эффективным решением для создания контента, соответствующего корпоративным стилевым требованиям и отражающего идентичность бренда, является тонкая настройка моделей (fine-tuning) в защищенной среде. В сочетании с генерацией, дополненной поиском (retrieval-augmented generation), которая позволяет LLM-моделям использовать и перерабатывать существующие материалы, это помогает компаниям создавать высокорелевантный контент с большей скоростью и частотой, что ведет к росту продуктивности.
Взгляд в будущее
По мере перехода организаций к более сложным и дающим большую ценность сценариям применения GenAI, особое внимание к вопросам конфиденциальности и безопасности становится критически важным для раскрытия трансформационного потенциала технологии. Особенно это актуально для кейсов генерации контента, где зачастую задействуются объекты интеллектуальной собственности и чувствительные данные. Использование публичных AI-сервисов может привести к утечкам данных и краже интеллектуальной собственности, так как вводимые запросы и генерируемые ответы могут сохраняться, анализироваться и становиться доступными третьим лицам. Работа в собственной защищенной среде позволяет компаниям лучше контролировать протоколы безопасности и управление данными, получая максимальную выгоду от генеративного AI без ущерба для стандартов безопасности и защиты информации.
Летом 2024 года Фрэнк Даннеман написал интересный аналитический документ «VMware Private AI Foundation – Privacy and Security Best Practices», который раскрывает основные концепции безопасности для инфраструктуры частного AI (в собственном датацентре и на базе самостоятельно развернутых моделей, которые работают в среде виртуализации).
Как многие из вас знают, мир искусственного интеллекта стремительно развивается, и с этим появляются новые вызовы, особенно в области конфиденциальности и безопасности. Этот документ не ограничивается теорией. Это практическое руководство, в котором представлены базовые концепции, структуры и модели, лежащие в основе безопасности приватного AI. В нем подробно рассматриваются ключевые аспекты конфиденциальности и безопасности в контексте ИИ, а также предоставляются инструменты, которые помогут вам внедрить эти принципы в своей работе. Вы узнаете о принципе совместной ответственности, моделировании угроз для приложений с генеративным AI, а также о триаде CIA — конфиденциальность, целостность и доступность, которая используется как основная модель информационной безопасности.
Основные моменты документа:
Преимущества Private AI в корпоративных датацентрах:
Контроль и безопасность: организации получают полный контроль над своими данными и моделями, что позволяет минимизировать риски, связанные с конфиденциальностью, и избегать зависимости от сторонних поставщиков.
Экономическая эффективность: Private AI позволяет управлять расходами на AI, избегая неожиданных затрат от сторонних сервисов и оптимизируя ИТ-бюджет.
Гибкость и инновации: быстрое тестирование и настройка AI-моделей на внутренних данных без задержек, связанных с внешними сервисами, что способствует повышению производительности и точности моделей.
Принцип совместной ответственности в Private AI:
Документ подчеркивает важность распределения обязанностей между поставщиком инфраструктуры и организацией для обеспечения безопасности и соответствия требованиям.
Моделирование угроз для Gen-AI приложений:
Рассматриваются потенциальные угрозы для генеративных AI-приложений и предлагаются стратегии их смягчения, включая анализ угроз и разработку соответствующих мер безопасности.
Модель CIA (Конфиденциальность, Целостность, Доступность):
Конфиденциальность: обсуждаются методы защиты данных, включая контроль доступа, шифрование и обеспечение конфиденциальности пользователей.
Целостность: рассматриваются механизмы обеспечения точности и согласованности данных и моделей, а также защита от несанкционированных изменений.
Доступность: подчеркивается необходимость обеспечения постоянного и надежного доступа к данным и моделям для авторизованных пользователей.
Защита Gen-AI приложений:
Предлагаются лучшие практики для обеспечения безопасности генеративных AI-приложений, включая разработку безопасной архитектуры, управление доступом и постоянный мониторинг.
Архитектура Retrieval-Augmented Generation (RAG):
Документ подробно описывает процесс индексирования, подготовки данных и обеспечения безопасности в архитектурах RAG, а также методы эффективного поиска и извлечения релевантной информации для улучшения работы AI-моделей.
В заключение, документ предоставляет всестороннее руководство по созданию и поддержке приватных AI-решений, акцентируя внимание на критически важных аспектах конфиденциальности и безопасности, что позволяет организациям уверенно внедрять AI-технологии в своих инфраструктурах.
И это еще не все. В ближайшем будущем VMware продолжает развивать эти концепции в другом аналитическом документе, посвященном настройкам VMware Cloud Foundation (VCF). Этот документ станет вашим основным ресурсом для получения подробных рекомендаций по конфигурации и оптимизации VCF, чтобы создать надежную и безопасную среду для Private AI.
Что означает "реализовать Private AI" для одного или нескольких сценариев использования на платформе VMware Cloud Foundation (VCF)?
VMware недавно представила примеры того, что значит "реализовать Private AI". Эти сценарии использования уже внедрены внутри компании Broadcom в рамках частного применения. Они доказали свою ценность для бизнеса Broadcom, что дает вам больше уверенности в том, что аналогичные сценарии могут быть реализованы и в вашей инсталляции VCF на собственных серверах.
Описанные ниже сценарии были выбраны, чтобы показать, как происходит увеличение эффективности бизнеса за счет:
Повышения эффективности сотрудников, работающих с клиентами с помощью чат-ботов, использующих данные компании.
Помощи разработчикам в создании более качественного кода с помощью ассистентов.
Сценарий использования 1: создание чат-бота, понимающего приватные данные компании
Этот тип приложения является наиболее распространенным стартовым вариантом для тех, кто начинает изучение Generative AI. Основная ценность, отличающая его от чат-ботов в публичных облаках, заключается в использовании приватных данных для ответа на вопросы, касающиеся внутренних вопросов компании. Этот чат-бот предназначен исключительно для внутреннего использования, что снижает возможные риски и служит возможностью для обучения перед созданием приложений, ориентированных на внешнюю аудиторию.
Вот пример пользовательского интерфейса простого стартового чат-бота из NVIDIA AI Enterprise Suite, входящего в состав продукта. Существует множество различных примеров чат-ботов для начинающих в этой области. Вы можете ознакомиться с техническим описанием от NVIDIA для чат-ботов здесь.
Современные чат-боты с поддержкой AI проектируются с использованием векторной базы данных, которая содержит приватные данные вашей компании. Эти данные разделяются на блоки, индексируются и загружаются в векторную базу данных офлайн, без связи с основной моделью чат-бота. Когда пользователь задает вопрос в приложении чат-бота, сначала извлекаются все релевантные данные из векторной базы данных. Затем эти данные, вместе с исходным запросом, передаются в большую языковую модель (LLM) для обработки. LLM обрабатывает и суммирует извлеченные данные вместе с исходным запросом, представляя их пользователю в удобном для восприятия виде. Этот подход к проектированию называется Retrieval Augmented Generation (RAG).
RAG стал общепринятым способом структурирования приложений Generative AI, чтобы дополнить знания LLM приватными данными вашей компании, что позволяет предоставлять более точные ответы. Обновление приватных данных теперь сводится к обновлению базы данных, что гораздо проще, чем повторное обучение или настройка модели.
Пример использования чат-бота
Представим ситуацию: клиент разговаривает с сотрудником компании и спрашивает о функции, которую хотел бы видеть в следующей версии программного продукта компании. Сотрудник не знает точного ответа, поэтому обращается к чат-боту и взаимодействует с ним в диалоговом стиле, используя естественный язык. Логика на стороне сервера в приложении чат-бота извлекает релевантные данные из приватного источника, обрабатывает их в LLM и представляет сотруднику в виде сводки. Теперь сотрудник может дать клиенту более точный ответ.
Пример из Broadcom
В Broadcom специалисты по данным разработали производственный чат-бот для внутреннего использования под названием vAQA (или “VMware’s Automated Question Answering Service”). Этот чат-бот обладает мощными функциями для интерактивного чата или поиска данных, собранных как внутри компании, так и извне.
На панели навигации справа есть возможность фильтровать источники данных. Пример простого использования системы демонстрирует её способность отвечать на вопросы на естественном языке. Например, сотрудник спросил чат-бота о блогах с информацией о виртуальных графических процессорах (vGPU) на VMware Cloud Foundation, указав, чтобы он предоставил URL-адреса этих статей. Система ответила списком релевантных URL-адресов и, что важно, указала свои источники.
Здесь имеется гораздо больше функциональности, чем просто поиск и обработка данных, но это выходит за рамки текущего обсуждения.
Данная система чат-бота использует эмбеддинги, хранящиеся в базе данных, для поиска, связанного с вопросами, а также одну или несколько больших языковых моделей (LLM) для обработки результатов. Кроме того, она использует драйверы GPU на уровне общей инфраструктуры для поддержки этого процесса.
Как VMware Private AI Foundation с NVIDIA позволяет создать чат-бота для работы с приватными данными
Для реализации приложения чат-бота можно использовать несколько компонентов из представленной выше архитектуры для проектирования и доставки рабочего приложения (начиная с синего уровня от VMware).
Система управления моделями (Model Governance) используется для тестирования, оценки и хранения предварительно обученных больших языковых моделей, которые считаются безопасными и подходящими для бизнес-использования. Эти модели сохраняются в библиотеке (называемой "галерея моделей", основанной на Harbor). Процесс оценки моделей уникален для каждой компании.
Функционал векторной базы данных применяется через развертывание этой базы данных с помощью дружественного интерфейса с использованием автоматизации VCF. Затем база данных заполняется очищенными и организованными приватными данными компании.
Инструменты "автоматизации самообслуживания", основанные на автоматизации VCF, используются для предоставления наборов виртуальных машин глубокого обучения для тестирования моделей, а затем для создания кластеров Kubernetes для развертывания и масштабирования приложения.
Средства мониторинга GPU в VCF Operations используются для оценки влияния приложения на производительность GPU и системы в целом.
Вы можете получить лучшие практики и технические советы от авторов VMware о развертывании собственного чат-бота, основанного на RAG, прочитав статью VMware RAG Starter Pack вместе с упомянутыми техническими документами.
Сценарий использования 2: ассистента кода для помощи инженерам в процессе разработки
Предоставление ассистента разработки кода для ускорения процессов разработки программного обеспечения является одним из наиболее значимых сценариев для любой организации, занимающейся разработкой ПО. Это включает подсказки по коду, автозаполнение, рефакторинг, обзоры кода и различные интеграции с IDE.
Инженеры и специалисты по данным VMware изучили множество инструментов, управляемых AI, в области ассистентов кода и, после тщательного анализа, остановились на двух сторонних поставщиках: Codeium и Tabnine, которые интегрированы с VMware Private AI Foundation with NVIDIA. Ниже кратко описан первый из них.
Основная идея состоит в том, чтобы помочь разработчику в процессе написания кода, позволяя общаться с AI-"советником" без прерывания рабочего потока. Советник предлагает подсказки по коду прямо в редакторе, которые можно принять простым нажатием клавиши "Tab". По данным компании Codeium, более 44% нового кода, добавляемого клиентами, создается с использованием их инструментов. Для получения дополнительной информации о советнике можно ознакомиться с этой статьей.
Особенности ассистентов
кода
Одной из интересных функций ассистентов кода является их способность предугадывать, какие действия вы собираетесь выполнить в программировании, помимо вставки следующего фрагмента кода. Ассистент анализирует контекст до и после текущей позиции курсора и предлагает вставку кода с учетом этого контекста. Кроме того, кодовые ассистенты помогают не только с написанием кода, но и с его обзором, тестированием, документированием и рефакторингом. Они также улучшают командное сотрудничество через функции индексирования нескольких репозиториев, управления рабочими местами и другие технологии.
Как VMware Private AI Foundation с NVIDIA помогает развернуть ассистенты
кода
Сторонний ассистент от Codeium разворачивается локально — либо в виртуальной машине с Docker, либо в кластере Kubernetes, созданном, например, с помощью службы vSphere Kubernetes Service (VKS). Код пользователя, независимо от того, написан он вручную или сгенерирован инструментом, не покидает компанию, что защищает интеллектуальную собственность. Целевой кластер Kubernetes создается с помощью инструмента автоматизации VCF и поддерживает работу с GPU благодаря функции VMware Private AI Foundation с NVIDIA — GPU Operator. Этот оператор устанавливает необходимые драйверы vGPU в поды, работающие на кластере Kubernetes, чтобы поддерживать функциональность виртуальных GPU. После этого функциональность Codeium разворачивается в Kubernetes с использованием Helm charts.
Инфраструктура Codeium включает серверы Inference Server, Personalization Server, а также аналитическую базу данных, как показано на рисунке ниже:
Вы можете получить больше информации об использовании Codeium с VMware Private AI Foundation с NVIDIA в этом кратком описании решения.
Ниже приведены простые примеры использования Codeium для генерации функции на Python на основе текстового описания.
Затем в Broadcom попросили ассистента кода написать и включить тестовые сценарии использования для ранее созданной функции.
В первой части этой серии мы рассмотрели два примера использования Private AI на платформе VCF: чат-бот для бэк-офиса, который улучшает взаимодействие с клиентами в контактных центрах, и ассистента кода, помогающего инженерам работать более эффективно.
VCF позволяет предприятиям легко развертывать эти два сценария, используя передовые технологии и быстро выполняя сложные задачи через автоматизацию, при этом обеспечивая безопасность данных на ваших локальных серверах.
На второй день конференции VMware Explore в Барселоне обсуждались передовые технологии, включая решения VMware Private AI Foundation и их интеграцию с решениями от NVIDIA. В видео ниже ведущие эксперты делятся опытом применения Retrieval Augmented Generation (RAG) и другими ключевыми возможностями Private AI для повышения эффективности работы корпоративных систем и оптимизации использования AI.
Основные темы видео:
Что такое VMware Private AI?
VMware Private AI — это платформа, которая позволяет использовать возможности искусственного интеллекта, сохраняя конфиденциальность данных.
RAG (Retrieval Augmented Generation) — технология, интегрирующая базу данных с частными данными в модели AI, что обеспечивает точные ответы и минимизирует "галлюцинации" модели.
Ключевые сценарии использования Private AI:
Внутренние чат-боты: помощь сотрудникам, например, операторам колл-центров, в быстром получении ответов с использованием внутренних данных компании.
Генерация кода: создание инструментов для разработчиков на основе частных данных, таких как внутренний исходный код.
Работа с внутренними базами знаний: быстрый доступ к информации, хранящейся в документации или системах управления знаниями, таких как Confluence.
RAG: Что это и как работает?
Использует внутренние базы данных (векторные базы данных) для поиска информации, релевантной запросу.
Пример: при запросе информация сначала ищется в базе знаний, а затем контекст передается модели AI для создания точного и краткого ответа.
Интеграция с NVIDIA:
Использование NVIDIA NGC для адаптации моделей под ресурсы, такие как GPU, с возможностью значительного повышения производительности (в 2–8 раз).
Поддержка различных уровней точности вычислений (FP32, FP16 и другие) для оптимального баланса скорости и качества.
Модельное управление и тестирование:
Встроенные инструменты для проверки моделей AI на наличие ошибок, галлюцинаций и других проблем до их использования.
Гибкая интеграция любых моделей, включая те, что загружаются из Hugging Face, NVIDIA или создаются внутри компании.
Преимущества подхода Private AI:
Сохранение конфиденциальности данных в онпремизных средах.
Повышение точности работы моделей за счет использования внутренних данных.
Улучшение взаимодействия сотрудников с клиентами и внутри команды.
Для кого это видео:
Системных администраторов, DevOps-инженеров, специалистов по AI.
Компаний, стремящихся внедрить передовые технологии AI, сохраняя конфиденциальность данных.
Тех, кто хочет углубить знания в области RAG и Private AI.
Посмотрите это видео, чтобы узнать больше о том, как VMware и NVIDIA трансформируют корпоративные системы с помощью искусственного интеллекта.
С момента основания VMware ее цель заключалась в том, чтобы обеспечить клиентам и партнёрам широкий выбор типов приложений и сервисов, которые они могут запускать в облачной инфраструктуре. Этот основной принцип также лежит в основе подхода к экосистеме Private AI.
Сегодня среди множества поддерживаемых коммерческих и открытых моделей и сервисов AI, клиенты теперь могут запускать Azure AI Video Indexer, поддерживаемый технологией Azure Arc, на платформе VMware Cloud Foundation на локальных серверах или в облаке Azure VMware Solution.
Клиенты и партнёры VMware просили более тесно сотрудничать с Microsoft для интеграции сервисов Azure в инфраструктуру VMware на локальных серверах. Включение Azure Video Indexer on Arc в VMware Cloud Foundation является важным первым шагом в этом направлении.
Возможности VMware Private AI и Azure Video Indexer
VMware Private AI представляет собой архитектурный подход, позволяющий предприятиям использовать потенциал генеративного AI, сохраняя при этом конфиденциальность данных, контроль и соответствие нормативным требованиям. Этот подход позволяет организациям запускать сервисы AI там, где они работают.
Azure Video Indexer — это сервис видеоаналитики в облаке и на периферии, использующий AI для извлечения полезных данных из аудио- и видеофайлов. При развертывании в виде расширения Arc на Kubernetes-кластерах он предоставляет мощные возможности видеоанализа для локальных сред.
Зачем интегрировать VMware Private AI с Azure Video Indexer on Arc?
Интеграция этих двух технологий даёт несколько важных преимуществ:
Конфиденциальность данных и контроль: обработка чувствительного видеоконтента на локальных серверах при сохранении полного контроля над данными.
Экономичность: использование существующей инфраструктуры VMware для AI-нагрузок, что потенциально снижает затраты на облако.
Улучшенное обнаружение контента: возможность поиска с автоматическим извлечением метаданных из видеоконтента.
Интеллектуальная оптимизация инфраструктуры: динамическое объединение и распределение ресурсов AI, включая вычислительные мощности, сеть и данные.
Соответствие требованиям: соблюдение регуляторных требований с размещением данных и средств их обработки в контролируемой среде.
Упрощённое управление: управление как инфраструктурой, так и AI-нагрузками через привычные инструменты VMware.
Примеры использования
Существует ряд примеров, в которых можно получить дополнительную ценность, запуская этот сервис на периферийных сайтах или внутри собственных центров обработки данных, включая такие возможности, как:
Локализация: быстро добавляйте локализацию в видеоконтент и обучающие материалы для внутренних пользователей или клиентов из разных географических регионов.
Предварительная фильтрация и локальные предсказания: снижайте нагрузку на WAN-сети, локализуя обработку AI/ML, что особенно ценно для приложений сегмента computer vision.
Медиа и развлечения: анализируйте и размечайте большие видеотеки, улучшая возможность обнаружения контента и повышая вовлечённость пользователей. Локальное развертывание обеспечивает защиту авторских прав и конфиденциальных данных.
Корпоративное обучение: крупные предприятия могут использовать эту интеграцию для автоматической индексации и анализа обучающих видеоматериалов, делая их более доступными и удобными для поиска сотрудниками, сохраняя при этом конфиденциальную информацию внутри инфраструктуры компании.
Интеграция VMware Private AI с Azure Video Indexer on Arc, работающего на кластерах Tanzu Kubernetes внутри VCF, представляет собой отличное решение для организаций, стремящихся использовать AI для анализа видео, сохраняя контроль над данными и инфраструктурой. Эта комбинация предлагает улучшенную конфиденциальность, масштабируемость и производительность, открывая новые возможности для AI-инсайтов в различных отраслях.
На конференции VMware Explore 2024 в Барселоне компания Broadcom представила революционную сетевую архитектуру VeloRAIN, предназначенную для поддержки и оптимизации рабочих нагрузок, связанных с искусственным интеллектом (AI), в рамках больших предприятий. VeloRAIN (RAIN - это Robust AI Networking) создана для улучшения производительности и безопасности AI-нагрузок в распределенных средах, что делает её важным инструментом для современных предприятий, сталкивающихся с растущими потребностями в передаче данных и выполнении AI-задач.
Основные Преимущества VeloRAIN
Выявление AI-приложений с помощью AI и машинного обучения (ML)
Одной из ключевых особенностей VeloRAIN является способность обнаруживать зашифрованный трафик приложений, который ранее было невозможно анализировать стандартными решениями для оптимизации сети. Это дает компаниям возможность более точно определять и выделять приоритеты для AI-приложений, что, в свою очередь, позволяет повысить качество обслуживания (QoS) и улучшить пользовательский опыт.
Повышение эффективности сети и оптимизация трафика
VeloRAIN предлагает инновационные методы оценки качества каналов связи, которые помогают улучшить обслуживание пользователей при работе с беспроводными каналами, включая 5G и спутниковые соединения. Это позволяет достичь качества, сравнимого с проводной связью, даже при изменяющихся условиях сети. Кроме того, архитектура ускоряет настройку сетей в удаленных офисах или филиалах, делая запуск инфраструктуры более быстрым и менее трудоемким.
Динамическая система управления приоритетами на основе AI
Новая динамическая платформа управления политиками автоматизирует присвоение приоритетов для приложений, что упрощает управление сетью. С помощью функции Dynamic Application-Based Slicing (DABS) платформа VeloRAIN обеспечивает высокое качество обслуживания для каждого приложения, даже если сети, по которым передаются данные, не поддерживают послойную сегментацию. DABS также использует профили пользователей, чтобы предоставлять приоритетный трафик ключевым сотрудникам, улучшая их опыт и общую производительность сети.
Автоматизация и мониторинг сети с использованием AI
VeloRAIN позволяет компаниям получить глубокую видимость работы сети, автоматизировать процессы приоритезации и мониторинга, а также сократить вмешательство со стороны IT-специалистов. Это особенно важно для AI-нагрузок, которые являются автономными и требуют оркестрации, а не ручного администрирования. Используя VeloRAIN, предприятия могут более эффективно и оперативно настраивать свои сети под потребности бизнес-нагрузок, что улучшает адаптивность к изменениям в рабочем процессе и инфраструктуре.
Стратегическая Значимость VeloRAIN для современного бизнеса
VeloRAIN представляет собой значительный шаг вперед в управлении распределенными рабочими нагрузками AI, так как позволяет предприятиям быстро адаптироваться к изменениям и обеспечивать безопасность и производительность своих AI-нагрузок. С помощью этой архитектуры компании смогут не только улучшить качество взаимодействия с клиентами, но и оптимизировать расходы, так как система автономно распределяет приоритеты и адаптируется под изменения в сети.
Цель Broadcom в развитии сетевой инфраструктуры на базе AI
Как отметил Санжай Аппал, вице-президент и генеральный директор подразделения VeloCloud компании Broadcom, VeloRAIN станет основой инноваций компании в AI-сетях, предоставляя компаниям инструменты для оптимизации их AI-нагрузок. Broadcom планирует активно развивать свою экосистему партнеров, чтобы предоставить компаниям инфраструктуру нового поколения для поддержки AI и облачных рабочих нагрузок в будущем.
Прочие анонсы VeloCloud
VeloCloud Edge 4100 и 5100: высокопроизводительные устройства для крупных предприятий
Broadcom представила устройства VeloCloud Edge 4100 и 5100, которые обеспечивают повышенную пропускную способность и масштабируемость. Устройство Edge 4100 поддерживает до 30 Гбит/с и до 12 000 туннелей, а Edge 5100 — до 100 Гбит/с и до 20 000 туннелей. Эти решения упрощают сетевую архитектуру и обеспечивают высокую надежность для AI и других рабочих нагрузок.
Titan: Новая партнерская программа для поддержки MSP
Программа Titan предлагает партнерам Managed Service Providers (MSP) эксклюзивные преимущества, такие как стабильный рост бизнеса, доступ к передовым технологиям, новую модель лицензирования и улучшенные возможности по предоставлению управляемых услуг для клиентов.
Особенности новой программы:
Вознаграждение на основе показателей, включая совместную разработку решений, признание на рынке и стабильный и предсказуемый рост бизнеса.
Эксклюзивный доступ к инновационным технологиям и каналам выхода на рынок.
Новая модель лицензирования, обеспечивающая переносимость лицензий, простоту управления и стабильность цен.
Программа создания услуг, ориентированная на ключевые ценностные драйверы, вертикальное выравнивание и более высокие маржинальные показатели.
Новое предложение «White label», позволяющее партнерам высшего уровня расширять базу VeloCloud через региональных и специализированных партнеров канала.
Современные задачи искусственного интеллекта (AI) и машинного обучения (ML) требуют высокопроизводительных решений при минимизации затрат на инфраструктуру, поскольку оборудование для таких нагрузок стоит дорого. Использование графических процессоров NVIDIA в сочетании с технологией NVIDIA AI Enterprise и платформой VMware Cloud Foundation (VCF) позволяет компаниям...
Вильям Лам написал интересную статью о поддержке технологии Intel Neural Processing Unit (NPU) на платформе VMware ESXi.
Начиная с процессоров Intel Meteor Lake (14 поколения), которые теперь входят в новый бренд Intel Core Ultra Processor (серия 1), встроенный нейронный процессор (Neural Processing Unit, NPU) интегрирован прямо в систему на кристалле (system-on-chip, SoC) и оптимизирован для энергоэффективного выполнения AI-инференса.
Хотя вы уже можете использовать интегрированную графику Intel iGPU на таких платформах, как Intel NUC, с ESXi для инференса рабочих нагрузок, Вильяму стало интересно, сможет ли этот новый нейронный процессор Intel NPU работать с ESXi?
Недавно Вильям получил доступ к ASUS NUC 14 Pro (на который позже он сделает подробный обзор), в котором установлен новый нейронный процессор Intel NPU. После успешной установки последней версии VMware ESXi 8.0 Update 3, он увидел, что акселератор Intel NPU представлен как PCIe-устройство, которое можно включить в режиме passthrough и, видимо, использовать внутри виртуальной машины.
Для тестирования он использовал Ubuntu 22.04 и библиотеку ускорения Intel NPU, чтобы убедиться, что он может получить доступ к NPU.
Шаг 1 - Создайте виртуальную машину с Ubuntu 22.04 и настройте резервирование памяти (memory reservation - это требуется для PCIe passthrough), затем добавьте устройство NPU, которое отобразится как Meteor Lake NPU.
Примечание: вам нужно будет отключить Secure Boot (этот режим включен по умолчанию), так как необходимо установить более новую версию ядра Linux, которая всё ещё находится в разработке. Отредактируйте виртуальную машину и перейдите в VM Options -> Boot Options, чтобы отключить его.
Когда Ubuntu будет запущена, вам потребуется установить необходимый драйвер Intel NPU для доступа к устройству NPU, однако инициализация NPU не удастся, что можно увидеть, выполнив следующую команду:
dmesg | grep vpu
После подачи обращения в поддержку Github по поводу драйвера Intel NPU, было предложено, что можно инициализировать устройство, используя новую опцию ядра, доступную только в версии 6.11 и выше.
Шаг 2 - Используя эту инструкцию, мы можем установить ядро Linux версии 6.11, выполнив следующие команды:
После перезагрузки вашей системы Ubuntu вы можете убедиться, что теперь она использует версию ядра 6.11, выполнив команду:
uname -r
Шаг 3 - Теперь мы можем установить драйвер Intel NPU для Linux, и на момент публикации этой статьи последняя версия — 1.8.0. Для этого выполните следующие команды:
Нам также нужно создать следующий файл, который включит необходимую опцию ядра (force_snoop=1) для инициализации NPU по умолчанию, выполнив следующую команду:
Теперь перезагрузите систему, и NPU должен успешно инициализироваться, как показано на скриншоте ниже.
Наконец, если вы хотите убедиться, что NPU полностью функционален, в библиотеке Intel NPU Acceleration есть несколько примеров, включая примеры малых языковых моделей (SLM), такие как TinyLlama, Phi-2, Phi-3, T5 и другие.
Для настройки вашего окружения Python с использованием conda выполните следующее:
Автор попробовал пример tiny_llama_chat.py (видимо, тренировочные данные для этой модели могли быть основаны на изображениях или художниках).
Независимо от того, используете ли вы новую библиотеку Intel NPU Acceleration или фреймворк OpenVino, теперь у вас есть доступ к ещё одному ускорителю с использованием ESXi, что может быть полезно для периферийных развертываний, особенно для рабочих нагрузок, требующих инференса AI, и теперь с меньшим энергопотреблением.
Следующий пример на Python можно использовать для проверки того, что устройство NPU видно из сред выполнения, таких как OpenVino.
from openvino.runtime import Core
def list_available_devices():
# Initialize the OpenVINO runtime core
core = Core()
# Get the list of available devices
devices = core.available_devices
if not devices:
print("No devices found.")
else:
print("Available devices:")
for device in devices:
print(f"- {device}")
# Optional: Print additional device information
for device in devices:
device_info = core.get_property(device, "FULL_DEVICE_NAME")
print(f"\nDevice: {device}\nFull Device Name: {device_info}")
if __name__ == "__main__":
list_available_devices()
Компания Broadcom выпустила интересное видео, где Mark Achtemichuk и Uday Kulkurne обсуждают оптимизацию AI/ML нагрузок с использованием аппаратной платформы NVIDIA GPU и решения VMware Cloud Foundation:
Производительность и эффективность виртуализации графических процессоров (GPU) является одним из ключевых направлений для разработки решений в области искусственного интеллекта (AI) и машинного обучения (ML).
Виртуализация AI/ML задач, работающих на GPU, представляет собой вызов, так как традиционно считается, что виртуализация может значительно снижать производительность по сравнению с «чистой» конфигурацией на физическом оборудовании (bare metal). Однако VMware Cloud Foundation демонстрирует почти аналогичную производительность с минимальными потерями за счет умной виртуализации и использования технологий NVIDIA.
Рассматриваемые в данном видо графические процессоры от NVIDIA включают модели H100, A100 и L4, каждая из которых имеет уникальные характеристики для обработки AI/ML задач. Например, H100 оснащен 80 миллиардами транзисторов и способен ускорять работу трансформеров (на основе архитектуры GPT) в шесть раз. Особенностью H100 является возможность разделения GPU на несколько независимых сегментов, что позволяет обрабатывать задачи параллельно без взаимного влияния. A100 и L4 также обладают мощными возможностями для AI/ML, с небольшими различиями в спецификациях и применимости для графических задач и машинного обучения.
VMware Cloud Foundation (VCF) позволяет использовать все преимущества виртуализации, обеспечивая при этом производительность, близкую к физическому оборудованию. Одна из ключевых возможностей — это поддержка дробных виртуальных GPU (vGPU) с изоляцией, что позволяет безопасно распределять ресурсы GPU между несколькими виртуальными машинами.
Используя виртуализированные конфигурации на базе VCF и NVIDIA GPU, компании могут значительно снизить общие затраты на владение инфраструктурой (TCO). VMware Cloud Foundation позволяет консолидировать несколько виртуальных машин и задач на одном физическом хосте без существенной потери производительности. Это особенно важно в условиях современных датацентров, где необходимо максимизировать эффективность использования ресурсов.
В серии тестов было проверено, как виртуализированные GPU справляются с различными AI/ML задачами по сравнению с физическим оборудованием. Используя стандартные бенчмарки, такие как ML Commons, было показано, что виртуализированные GPU демонстрируют производительность от 95% до 104% по сравнению с bare metal конфигурациями в режиме инференса (вычисления запросов) и около 92-98% в режиме обучения. Это означает, что даже в виртуализированной среде можно добиться почти той же скорости, что и при использовании физического оборудования, а в некоторых случаях — даже превзойти её.
Основное преимущество использования VMware Cloud Foundation с NVIDIA GPU заключается в гибкости и экономии ресурсов. Виртуализированные среды позволяют разделять ресурсы GPU между множеством задач, что позволяет более эффективно использовать доступные мощности. Это особенно важно для компаний, стремящихся к оптимизации капитальных затрат на инфраструктуру и повышению эффективности использования серверных мощностей.
Текстовая генерация и суммаризация с использованием GenAI становятся мейнстримом благодаря своей способности быстро создавать точные и связные резюме нужной информации. Хотя есть общедоступные инструменты для суммаризации, компании могут предпочесть внутренние решения по причинам конфиденциальности данных, безопасности и соблюдения регулятивных норм. Поэтому возникает потребность в локальных продуктах, которые могут адаптироваться к требованиям организации и ее правилам управления данными.
Команды часто сталкиваются с серьезными препятствиями при создании собственных решений на основе машинного обучения. Какую технику суммаризации следует использовать для больших документов, которые превышают размер контекстного окна моделей LLM? Какие библиотеки лучше всего подходят для парсинга больших документов, таких как PDF, с их сложными структурами (например, таблицы, графики и изображения)? Какая LLM подходит для суммаризации длинных расшифровок встреч, где есть множество смен диалогов, что затрудняет понимание ценной контекстной информации? Какие эффективные подсказки (prompts) следует использовать для выбранных моделей?
Сервис Summarize-and-Chat
Summarize-and-Chat — это проект с открытым исходным кодом для VMware Private AI, который решает вышеуказанные задачи и помогает командам начать работу с их кейсами. Этот проект может быть развернут на VMware Private AI Foundation с NVIDIA, чтобы клиенты могли начать использовать GenAI на своих приватных данных. Данная возможность предоставляет универсальный и масштабируемый подход для типичных задач суммаризации, обеспечивая взаимодействие на естественном языке через чат-интерфейсы. Интеграция суммаризации документов и общения через чат в единой системе имеет несколько преимуществ. Во-первых, это позволяет пользователям получать краткие резюме различного контента, включая статьи, отзывы клиентов, баги/проблемы или пропущенные встречи.
Во-вторых, благодаря использованию LLM для чатов, данная возможность обеспечивает более вовлекающие и контекстно-осведомленные разговоры, повышая удовлетворенность пользователей.
Ключевые особенности
Summarize-and-Chat предоставляет следующие возможности:
Поддержка различных типов и форматов документов (PDF, DOCX, PPTX, TXT, VTT и популярных аудиофайлов - mp3, mp4, mpeg, mpga, m4a, wav и webm).
Поддержка открытых LLM на движке вывода, совместимого с OpenAI.
Интуитивно понятный пользовательский интерфейс для загрузки файлов, генерации резюме и чатов.
Суммаризация:
Вставляйте, копируйте или загружайте файлы и просматривайте их.
Выбирайте способ суммаризации (пользовательские подсказки, размер фрагмента, диапазон страниц для документов или временной диапазон для аудио).
Регулируйте длину резюмирующего вывода.
Получайте резюме за считанные секунды и загружайте его.
Чат с вашим документом:
Автоматически сгенерированные вопросы по документу.
Получайте ответ с указанием источника за считанные секунды.
Анализ инсайтов:
Выбирайте два или более документа.
Пишите запрос для сравнения или определения инсайтов из выбранных документов.
Преобразование речи в текст.
Поддержка различных PDF-парсеров: PyPDF, PDFMiner, PyMUPDF.
API.
Шаги развертывания
Настройка Summarize-and-Chat проста и включает несколько конфигурационных шагов для каждого компонента.
Summarize-and-Chat включает три компонента:
1. Summarization-client: веб-приложение на Angular/Clarity. 2. Summarization-server: сервер-шлюз на FastAPI для управления основными функциями приложения, включая:
Контроль доступа.
Пайплайн обработки документов: обработка документов, извлечение метаданных для заполнения векторного индекса (текстовые эмбеддинги).
Суммаризация с использованием LangChain Map Reduce. Этот подход позволяет суммаризовать большие документы, которые превышают лимит токенов на входе модели.
Улучшенное извлечение с помощью Retrieval Augmented Generation (RAG), используя возможности ранжирования LlamaIndex и pgvector для повышения производительности в системах вопрос-ответ.
3. Speed-to-text (STT): преобразование аудио в текст с использованием OpenAI's faster-whisper.
Следуйте инструкциям по быстрой установке и настройке в файле README, и вы сможете начать работу через несколько минут.
Использование Summarize-and-Chat
Теперь давайте посмотрим, как можно использовать Summarize-and-Chat для суммаризации длинного PDF-документа и полноценного взаимодействия с ним.
Для начала войдите в клиент суммаризации, используя ваши учетные данные Okta.
1. Загрузите файл и добавьте метаданные (дату, версию).
2. Выберите опцию QUICK для краткого резюме или DETAILED для детальной суммаризации.
3. Нажмите кнопку SUMMARIZE, и резюме будет сгенерировано мгновенно. Для длинного документа вы увидите оценку времени и получите уведомление, когда резюме будет готово к загрузке.
Чат с вашим документом
Вы можете нажать на иконку "чат" в верхнем меню, чтобы начать общение с вашим документом. Вы можете выбрать один из автоматически сгенерированных вопросов или ввести свой собственный вопрос и получить ответ с указанием источника за несколько секунд.
Что дальше
Broadcom представила Summarize-and-Chat с открытым исходным кодом, чтобы поддержать проекты по работе с данными и машинному обучению на платформе VMware Private AI.
Если вы хотите принять участие в проекте, пожалуйста, ознакомьтесь с этим руководством.
В рамках анонсов конференции Explore 2024, касающихся VMware Private AI Foundation с NVIDIA (PAIF-N), в компании VMware решили обновить Improved RAG Starter Pack v2.0, чтобы помочь клиентам воспользоваться новейшими микросервисами для инференса NVIDIA (модули NIM), которые обеспечивают атрибуты промышленного уровня (надёжность, масштабируемость и безопасность) для языковых моделей, используемых в системах Retrieval Augmented Generation (RAG).
Следуя духу оригинального Improved RAG Starter Pack (v1.0), Broadcom предлагает серию Jupyter-блокнотов, реализующих улучшенные методы поиска. Эти методы обогащают большие языковые модели (LLMs) актуальными и достоверными контекстами, помогая им генерировать более точные и надёжные ответы на вопросы, связанные с специализированными знаниями, которые могут не быть частью их предобученного датасета. Благодаря этому можно эффективно снизить "галлюцинации" LLM и повысить надёжность приложений, управляемых AI.
Новые функции обновлённого Improved RAG Starter Pack:
Используются NVIDIA NIMs для LLM, текстовых встраиваний и ранжирования текстов — трёх основных языковых моделей, которые питают RAG-пайплайны.
Обновили LlamaIndex до версии v0.11.1.
Используются Meta-Llama3-8b-Instruct в качестве генератора LLM, который управляет RAG-пайплайном.
Заменили OpenAI GPT-4 на Meta-Llama-3-70b-Instruct как движок для DeepEval для выполнения двух ключевых задач, связанных с оценкой RAG-пайплайнов:
Для оценки ("судейства") RAG-пайплайнов путём оценки ответов пайплайна на запросы, извлечённые из набора для оценки. Каждый ответ оценивается по нескольким метрикам DeepEval.
Анатомия улучшенного RAG Starter Pack
Каталог репозитория GitHub, содержащий этот стартовый пакет, предоставляет пошаговое руководство по внедрению различных элементов стандартных систем RAG.
Помимо NVIDIA NIM, системы RAG используют такие популярные технологии, как LlamaIndex (фреймворк для разработки приложений на основе LLM), vLLM (сервис для инференса LLM) и PostgreSQL с PGVector (масштабируемая и надёжная векторная база данных, которую можно развернуть с помощью VMware Data Services Manager).
Все начинается с реализации стандартного RAG-пайплайна. Далее используется база знаний RAG для синтеза оценочного набора данных для оценки системы RAG. Затем улучшается стандартная система RAG за счет добавления более сложных методов поиска, которые будут подробно описаны далее. Наконец, различные подходы RAG оцениваются с помощью DeepEval и сравниваются для выявления их плюсов и минусов.
Структура каталога организована следующим образом.
Теперь давайте обсудим содержание каждой секции.
Настройка сервисов NIM и vLLM (00)
Эта секция содержит инструкции и скрипты для Linux shell, которые необходимы для развертывания сервисов NVIDIA NIM и vLLM, требуемых для реализации RAG-пайплайнов и их оценки.
Инициализация PGVector (01)
Эта секция предлагает несколько альтернатив для развертывания PostgreSQL с PGVector. PGVector — это векторное хранилище, которое будет использоваться LlamaIndex для хранения базы знаний (текстов, встраиваний и метаданных), что позволит расширить знания LLM и обеспечить более точные ответы на запросы пользователей.
Загрузка документов базы знаний (02)
Каждый демо-пример RAG и введение в RAG используют базу знаний для расширения возможностей генерации LLM при вопросах, касающихся областей знаний, которые могут не входить в предобученные данные моделей. Для этого стартового пакета VMware выбрала десять документов из коллекции электронных книг по истории от NASA, предлагая таким образом вариант типичных документов, часто используемых в туториалах по RAG.
Загрузка документов в систему (03)
Эта секция содержит начальный Jupyter-блокнот, где используется LlamaIndex для обработки электронных книг (формат PDF), их разбиения на части (узлы LlamaIndex), кодирования каждого узла в виде длинного вектора (встраивания) и хранения этих векторов в PostgreSQL с PGVector, который действует как наш векторный индекс и движок запросов. На следующем изображении показан процесс загрузки документов в систему.
После того как PGVector загрузит узлы, содержащие метаданные, текстовые фрагменты и их соответствующие встраивания, он сможет предоставить базу знаний для LLM, которая будет генерировать ответы на основе этой базы знаний (в нашем случае это книги по истории от NASA).
Генерация оценочного набора данных (04)
Jupyter-блокнот в этой папке демонстрирует использование Synthesizer из DeepEval для создания набора данных вопросов и ответов, который впоследствии будет использоваться метриками DeepEval для оценки качества RAG-пайплайнов. Это позволит определить, как изменения ключевых компонентов пайплайна RAG, таких как LLM, модели встраиваний, модели повторного ранжирования, векторные хранилища и алгоритмы поиска, влияют на качество генерации. Для синтетической генерации оценочного набора данных используется модель Meta-Llama-3-70b-Instruct.
Реализация вариантов RAG (05)
В этом каталоге содержатся три подкаталога, каждый из которых включает Jupyter-блокнот, исследующий один из следующих вариантов реализации RAG-пайплайна на основе LlamaIndex и открытых LLM, обслуживаемых через vLLM:
Стандартный RAG-пайплайн + повторное ранжирование: этот блокнот реализует стандартный RAG-пайплайн с использованием LlamaIndex, включая финальный этап повторного ранжирования, который управляется моделью ранжирования. В отличие от модели встраиваний, повторное ранжирование использует вопросы и документы в качестве входных данных и напрямую выдаёт степень схожести, а не встраивание. Вы можете получить оценку релевантности, вводя запрос и отрывок в модель повторного ранжирования. VMware использует следующие микросервисы NVIDIA (NIM) для работы RAG-системы:
Генератор LLM для RAG: Meta-Llama-3-8b-Instruct
Модель встраиваний для RAG: nvidia/nv-embedqa-e5-v5
Модель повторного ранжирования для RAG: nvidia/nv-rerankqa-mistral-4b-v3
Следующая картинка иллюстрирует, как работает эта RAG-система.
Извлечение с использованием окон предложений:
Метод извлечения с использованием окон фраз (Sentence Window Retrieval, SWR) улучшает точность и релевантность извлечения информации в RAG-пайплайнах, фокусируясь на определённом окне фраз вокруг целевой фразы. Такой подход повышает точность за счёт фильтрации нерелевантной информации и повышает эффективность, сокращая объём текста, обрабатываемого во время поиска.
Разработчики могут регулировать размер этого окна, чтобы адаптировать поиск к своим конкретным задачам. Однако у метода есть потенциальные недостатки: узкая фокусировка может привести к упущению важной информации в соседнем тексте, что делает выбор подходящего размера окна контекста критически важным для оптимизации как точности, так и полноты процесса поиска. Jupyter-блокнот в этой директории использует реализацию SWR от LlamaIndex через модуль Sentence Window Node Parsing, который разбивает документ на узлы, каждый из которых представляет собой фразу. Каждый узел содержит окно из соседних фраз в метаданных узлов. Этот список узлов повторно ранжируется перед передачей LLM для генерации ответа на запрос на основе данных из узлов.
Автоматическое слияние при извлечении:
Метод автоматического слияния при извлечении — это подход RAG, разработанный для решения проблемы фрагментации контекста в языковых моделях, особенно когда традиционные процессы поиска создают разрозненные фрагменты текста. Этот метод вводит иерархическую структуру, где меньшие текстовые фрагменты связаны с более крупными родительскими блоками. В процессе извлечения, если определённый порог меньших фрагментов из одного родительского блока достигнут, они автоматически сливаются. Такой подход гарантирует, что система собирает более крупные, связные родительские блоки, вместо извлечения разрозненных фрагментов. Ноутбук в этой директории использует AutoMergingRetriever от LlamaIndex для реализации этого варианта RAG.
Оценка RAG-пайплайна (06)
Эта папка содержит Jupyter-блокнот, который использует DeepEval для оценки ранее реализованных RAG-пайплайнов. Для этой цели DeepEval использует оценочный набор данных, сгенерированный на предыдущем шаге. Вот краткое описание метрик DeepEval, используемых для сравнения различных реализаций RAG-пайплайнов. Обратите внимание, что алгоритмы метрик DeepEval могут объяснить, почему LLM присвоил каждую оценку. В нашем случае эта функция включена, и вы сможете увидеть её работу.
Contextual Precision оценивает ретривер вашего RAG-пайплайна, проверяя, расположены ли узлы в вашем контексте поиска, которые релевантны данному запросу, выше, чем нерелевантные узлы.
Faithfulness оценивает качество генератора вашего RAG-пайплайна, проверяя, соответствует ли фактический вывод содержимому вашего контекста поиска.
Contextual Recall оценивает качество ретривера вашего RAG-пайплайна, проверяя, насколько контекст поиска соответствует ожидаемому результату.
Answer Relevancy измеряет, насколько релевантен фактический вывод вашего RAG-пайплайна по отношению к данному запросу.
Hallucination — эта метрика определяет, генерирует ли ваш LLM фактически корректную информацию, сравнивая фактический вывод с предоставленным контекстом. Это фундаментальная метрика, так как одной из главных целей RAG-пайплайнов является помощь LLM в генерации точных, актуальных и фактических ответов на запросы пользователей.
Оценки DeepEval были выполнены с использованием следующей конфигурации:
LLM-оценщик, оценивающий метрики DeepEval: Meta-Llama-3-70b-Instruct, работающая на vLLM в режиме guided-JSON.
Следующая таблица показывает результаты оценки из одного из экспериментов VMware, который включал более 40 пар вопросов и ответов.
Следующая диаграмма представляет другой ракурс взгляда на предыдущий результат:
Как показывает таблица, конкретная реализация RAG может показывать лучшие результаты по определённым метрикам, что указывает на их применимость к различным сценариям использования. Кроме того, метрики оценки помогают определить, какие компоненты ваших RAG-пайплайнов нуждаются в корректировке для повышения общей производительности системы.
Заключение
Обновлённый RAG Starter Pack предоставляет ценный инструментарий для тех, кто внедряет системы RAG, включая серию хорошо документированных Python-блокнотов, предназначенных для улучшения LLM за счёт углубления контекстного понимания. В этот пакет включены передовые методы поиска и такие инструменты, как DeepEval, для оценки системы, которые помогают снизить такие проблемы, как "галлюцинации" LLM, и повысить надёжность ответов AI. Репозиторий на GitHub хорошо структурирован и предлагает пользователям понятное пошаговое руководство, которому легко следовать, даже если вы не являетесь специалистом в области данных. Клиенты и партнёры Broadcom, использующие PAIF-N, найдут этот пакет полезным для запуска приложений на базе генеративного AI в инфраструктурах VMware Cloud Foundation. Ожидайте новых статей, в которых VMware рассмотрит ключевые аспекты безопасности и защиты в производственных RAG-пайплайнах.
С ростом числа сценариев использования генеративного AI, а также с существующими рабочими нагрузками AI и машинного обучения, все хотят получить больше мощностей GPU и стремятся максимально эффективно использовать те, которые у них уже есть. В настоящее время метрики использования GPU доступны только на уровне хоста в vSphere, а с помощью модуля vSphere GPU Monitoring вы теперь можете видеть их на уровне кластера. Эта информация имеет большое значение для таких задач, как планирование ёмкости, что оказывает значительное стратегическое влияние на организации, стремящиеся увеличить использование AI.
vSphere GPU Monitoring Fling предоставляет метрики GPU на уровне кластера в VMware vSphere, что позволяет максимально эффективно использовать дорогостоящее оборудование. Он совместим с vSphere версий 7 и 8. Также функционал утилиты также доступен в виде основного патча vCenter 8.0 Update 2 для тех, кто использует более новые версии платформы (то есть, Fling не требуется!). Скачайте плагин здесь и поделитесь своим мнением в разделе Threads на портале community.broadcom.com или по электронной почте vspheregpu.monitoring@broadcom.com.
Пользователям нужно провести установку плагина для объекта Datacenter, после чего они смогут видеть сводные метрики своих GPU для кластеров в этом датацентре. В представлении датацентра пользователь может нажать на «View Details», чтобы увидеть более подробную информацию о распределении и потреблении GPU, а также о типе совместного использования GPU.
Наконец, температура также является важной метрикой для отслеживания, так как долговечность и производительность GPU значительно снижаются, если они слишком долго работают при высокой температуре. Этот Fling также включает и мониторинг температуры:
Недавно на конференции NVIDIA GTC 2024 было объявлено о начальной доступности VMware Private AI Foundation with NVIDIA, что знаменует начало эпохи AI в датацентрах крупных заказчиков. VMware Private AI Foundation with NVIDIA позволяет пользователям запускать AI-нагрузки на собственной инфраструктуре, используя VMware Cloud Foundation (VCF) и экосистему программного обеспечения и графических процессоров NVIDIA.
Эта совместная платформа не только поддерживает более безопасные AI-нагрузки, но также добавляет гибкость и операционную эффективность при сохранении максимальной производительности. Кроме того, VCF добавляет уровень автоматизации, упрощающий развертывание виртуальных машин дата-сайентистами для глубокого обучения. Подробнее о данной процедуре написано здесь.
Хотя Broadcom и NVIDIA обеспечивают основные потребности в программном обеспечении, выбор лучшего оборудования для выполнения рабочих нагрузок Private AI также является ключевым элементом успешной реализации проектов в области AI. VMware сотрудничает с такими производителями серверов, как Dell, Fujitsu, Hitachi, HPE, Lenovo и Supermicro, чтобы составить исчерпывающий список поддерживаемых платформ, оптимизированных для работы с графическими процессорами NVIDIA и VMware Cloud Foundation. Хотя некоторые AI-задачи могут выполняться и на более старых графических процессорах NVIDIA A100, в настоящее время рекомендуется использовать NVIDIA L40 и H100 для современных AI-нагрузок, чтобы достичь оптимальной производительности и эффективности.
Серверы, перечисленные ниже, сертифицированы специально для VMware Private AI Foundation с NVIDIA. Процесс сертификации включает сертификацию партнера по графическим процессорам с аппаратной платформой, а также поддержку общего назначения графических процессоров с помощью VMware VM DirectPath IO. Обратите внимание, что дополнительные производители и графические процессоры будут добавлены позже, поэтому не забывайте проверять обновления.
Private AI Ready Infrastructure – это уже готовое модульное решение, которое предлагает руководство по проектированию, внедрению и эксплуатации для развертывания AI-нагрузок на стеке VMware Cloud Foundation. Используя GPU-ускоренные VCF Workload Domains, vSphere with Tanzu, NSX и vSAN, это решение обеспечивает прочную основу для современных инициатив в области AI.
Разбор сложностей инфраструктуры, связанных с GPU, и оптимизация AI-нагрузок может быть трудной задачей для администраторов без специальной экспертизы. Трудности, связанные с конфигурацией и управлением средами с GPU, значительны и часто требуют глубоких знаний характеристик оборудования, совместимости драйверов и оптимизации производительности. Однако с решением Private AI Ready Infrastructure VMware Validated Solution, организации могут обойти эти проблемы и уверенно развертывать свои AI нагрузки с проверенными валидированными конфигурациями и лучшими практиками.
Инфраструктура Private AI Foundation with NVIDIA также включена в состав решения VMware Validated Solution, предлагая клиентам возможность поднять свою AI инфраструктуру на новый уровень совместно с решением от NVIDIA.
Что входит в состав решения?
Детальный документ по проектированию архитектуры, охватывающий высокоскоростные сети, вычислительные мощности, хранилища и Accelerators для AI, а также компоненты VMware Private AI Foundation с NVIDIA.
Руководство по сайзингу
Руководство по внедрению
Руководство по эксплуатации и управлению жизненным циклом, включая проверку работоспособности с помощью VMware Starter Pack на основе vLLM RAG
Руководство по совместимости
Начало работы
Ели вы готовы раскрыть весь потенциал вашей Private AI инфраструктуры, получите доступ к этому решению VMware Validated Solution по этой ссылке.
Построенный и запущенный на ведущей в отрасли платформе для частного облака, VMware Cloud Foundation, VMware Private AI Foundation with NVIDIA включает в себя новые микросервисы NVIDIA NIM, модели искусственного интеллекта от NVIDIA и других участников сообщества (таких как Hugging Face), а также инструменты и фреймворки искусственного интеллекта от NVIDIA, доступные с лицензиями NVIDIA AI Enterprise.
VMware Private AI Foundation с NVIDIA — это дополнительный SKU на базе VMware Cloud Foundation. Лицензии программного обеспечения NVIDIA AI Enterprise необходимо приобретать отдельно. Это решение использует NVIDIA NIM — часть NVIDIA AI Enterprise, набор простых в использовании микросервисов, предназначенных для ускорения развертывания генеративных моделей AI в облаке, центрах обработки данных и на рабочих станциях.
С момента GA-релиза VMware Private AI Foundation с NVIDIA были также добавлены дополнительные возможности к этой платформе.
1. Мониторинг GPU
Панели мониторинга — это новые представления для GPU, которые позволяют администраторам легко отслеживать метрики GPU по кластерам. Эта панель предоставляет данные в реальном времени о температуре GPU, использовании памяти и вычислительных мощностях, что позволяет администраторам улучшить время решения проблем с инфраструктурой и операционную эффективность.
Мониторинг температуры — с мониторингом температуры GPU администраторы теперь могут максимизировать производительность GPU, получая ранние предупреждения о перегреве. Это позволяет предпринимать проактивные меры для предотвращения снижения производительности и обеспечения оптимальной работы GPU.
2. Скрипты PowerCLI
Была представлена коллекция из четырёх мощных настраиваемых скриптов PowerCLI, предназначенных для повышения эффективности развёртывания и минимизации ручных усилий для администраторов. Эти скрипты служат ценными инструментами для автоматизации развёртывания необходимой инфраструктуры при внедрении рабочих нагрузок AI в среде VCF. Давайте рассмотрим детали.
Развертывание домена рабочих нагрузок VCF - этот скрипт размещает хосты ESXi в SDDC Manager и разворачивает домен рабочих нагрузок VCF. Этот домен служит основой для настройки VMware Private AI Foundation с NVIDIA для развёртывания рабочих нагрузок AI/ML.
Конфигурация хостов ESXi - используя возможности VMware vSphere Lifecycle Manager, этот скрипт упрощает конфигурацию хостов ESXi, плавно устанавливая компоненты программного обеспечения NVIDIA, входящие в состав NVIDIA AI Enterprise, такие как драйвер NVIDIA vGPU и сервис управления GPU NVIDIA.
Развертывание кластера NSX Edge - этот скрипт облегчает развертывание кластера NSX Edge в домене рабочих нагрузок VCF, обеспечивая внешнюю сетевую связность для рабочих нагрузок AI/ML.
Конфигурация кластера Supervisor и библиотеки содержимого образов ВМ глубокого обучения - этот сценарий настраивает кластер Supervisor в домене рабочих нагрузок VCF. Также он создаёт новую библиотеку содержимого образов VM для глубокого обучения, позволяя пользователям легко развертывать рабочие нагрузки ИИ/ML с предварительно настроенными средами выполнения.
Больше технических деталей о возможностях этого релизы вы можете узнать здесь и здесь.
В современном быстро развивающемся цифровом ландшафте организациям необходимо при релизовывать инициативы по модернизации инфраструктуры, чтобы оставаться актуальными. Новая волна приложений с поддержкой искусственного интеллекта обещает значительно увеличить производительность работников и ускорить экономическое развитие на глобальном уровне, подобно тому как революция мобильных приложений трансформировала бизнес и технологии на протяжении многих лет. Цель компаний Broadcom и VMware состоит в том, чтобы сделать эту мощную и новую технологию более доступной, надежной и доступной по цене. Однако управление разнообразными технологиями, преодоление человеческого сопротивления изменениям и обеспечение прибыльности могут стать сложными препятствиями для любой комплексной ИТ-стратегии.
В связи с объявлением о начальной доступности VMware Private AI Foundation с NVIDIA, в компании Broadcom рады объявить о новой возможности Private AI Automation Services, работающей на базе решения VMware Aria Automation. С помощью служб Private AI Automation Services, встроенных в VMware Cloud Foundation, клиенты могут автоматизировать настройку и предоставление частных AI-услуг и аллокацию машин с поддержкой GPU для ML-нагрузок.
Существует растущая потребность предприятий в решениях для AI, но их реализация может быть сложной и затратной по времени. Чтобы удовлетворить эту потребность, новая интеграция "из коробки" VMware Private AI Foundation с NVIDIA позволит организациям предоставлять возможности автоматизации на базе платформы VMware Cloud Foundation. Интеграция будет сопровождаться новым мастером настройки каталога, который обеспечит быстрый старт, автоматическую настройку частных AI-услуг и самостоятельное предоставление машин с поддержкой GPU, включая ML-нагрузки и TKG GPU на базе кластеров Kubernetes.
Платформа VMware Cloud Foundation (VCF) представляет собой комплексное решение для частной облачной инфраструктуры, которое обеспечивает всеобъемлющую, безопасную и масштабируемую платформу для создания и эксплуатации генеративных AI-нагрузок. Оно предоставляет организациям гибкость, адаптивность и масштабируемость для удовлетворения их меняющихся бизнес-потребностей. С помощью VMware Cloud Foundation ИТ-администраторы могут управлять дорогостоящими и востребованными ресурсами, такими как GPU, с помощью политик использования, шаблонов и ролей пользователей.
Это позволяет членам команд более эффективно использовать инфраструктурные услуги для своих AI/ML-проектов, в то время как ИТ-администраторы обеспечивают оптимальное и безопасное использование ресурсов. Время развертывания AI-инфраструктуры будет сокращено за счет использования Supervisor VM и сервисов TKG в рамках пространства имен супервизора и предоставления через интерфейс потребления облака.
Этот интерфейс теперь доступен локально для клиентов VMware Cloud Foundation через Aria Automation, позволяя им использовать преимущества VMware Private AI Foundation with NVIDIA. Кроме того, Cloud Consumption Interface предлагает простое и безопасное самостоятельное потребление всех Kubernetes-ориентированных desired state IaaS API, доступных на платформе vSphere. Это позволяет предприятиям легко внедрять опыт DevOps и разрабатывать приложения с большей гибкостью, адаптивностью и современными методами в среде vSphere, сохраняя контроль над своей инфраструктурой.
VMware Cloud Foundation помогает клиентам интегрировать гибкость и контроль, необходимые для поддержки нового поколения приложений с AI, что значительно увеличивает производительность работников, способствует трансформации основных бизнес-функций и оказывает положительное экономическое воздействие.
Частные AI-среды VMware служат отличной основой для нового класса приложений на основе AI, что облегчает использование приватных, но широко распределенных данных. Кроме того, возможности Automation Services обеспечивают более быстрый выход на рынок за счет ускоренной итерации изменений AI/ML-инфраструктуры, управляемой через шаблоны. Они также удобны в использовании за счет сокращения времени доступа к средам разработки с поддержкой GPU через каталоги самообслуживания. Кроме того, они дают разработчикам и командам DevOps подход, соответствующий Kubernetes (desired state), для управления изменениями Day-2. Наконец, они помогут снизить затраты на дорогостоящие ресурсы GPU за счет улучшенного управления и использования мощностей AI/ML-инфраструктуры с встроенными политиками и управлением через опции самообслуживания.
Подход Private AI становится популярным, потому что он удовлетворяет возникающие потребности бизнеса в использовании AI, соблюдая строгие стандарты управления данными и конфиденциальности. Открытые модели GenAI могут представлять потенциальные риски, такие как проблемы конфиденциальности, что заставляет организации быть все более осторожными. Частный AI предлагает убедительную альтернативу, позволяя предприятиям запускать модели AI рядом с источником данных, повышая безопасность и соответствие требованиям. VMware Private AI прокладывает путь к новой парадигме, где трансформационный потенциал AI реализуется без ущерба для конфиденциальности данных клиентов и собственных корпоративных данных. Это экономически выгодное решение станет более важным в 2024 году, поскольку организации сталкиваются с растущими регуляторными препятствиями.
Ожидается, что Automation Services для VMware Private AI
станут доступны во втором фискальном квартале Broadcom.
Команда VMware Cloud объявила о публичной доступности платформы VMware Cloud Foundation 5.1.1, поддерживающей первоначальный доступ (initial availability, IA) к инфраструктуре VMware Private AI Foundation with NVIDIA в дополнение к новой модели лицензирования решений VCF, что является первым этапом многоэтапной программы по предоставлению полного стека VCF как единого продукта. Ниже представлен обзор этих важных новых возможностей VCF 5.1.1, а также дополнительные ресурсы и ссылки.
Спецификация версий компонентов VMware Cloud Foundation 5.1.1:
VMware Private AI Foundation with NVIDIA
Как было объявлено на конференции GTC AI Conference 2024, Broadcom предоставила первоначальный доступ (initial availability) к VMware Private AI Foundation with NVIDIA в качестве продвинутого аддона к VMware Cloud Foundation. VMware Private AI Foundation открывает новую эру решений инфраструктуры, поддерживаемых VMware Cloud Foundation для широкого спектра случаев использования генеративного AI. Читайте больше о решениях VMware Cloud Foundation для AI и машинного обучения здесь.
VMware Cloud Foundation является основной инфраструктурной платформой для VMware Private AI Foundation with NVIDIA, предоставляющей современное частное облако, которое позволяет организациям динамически масштабировать рабочие нагрузки GenAI по требованию. VMware Cloud Foundation предлагает автоматизированный процесс самообслуживания в облаке, который ускоряет продуктивность для разработчиков, аналитиков и ученых, обеспечивая при этом комплексную безопасность и устойчивость для защиты и восстановления самой чувствительной интеллектуальной собственности организации.
VMware Cloud Foundation решает многие проблемы, возникающие при развертывании инфраструктуры для поддержки рабочих нагрузок GenAI, за счет архитектуры платформы с полным программно-определяемым стеком, объединяя лучшие в своем классе ресурсы GPU, тесно интегрированные с вычислениями, хранением данных, сетями, безопасностью и управлением.
В VMware Cloud Foundation 5.1.1 существуют хорошо задокументированные рабочие процессы в SDDC Manager для настройки и конфигурации домена рабочих нагрузок Private AI. Также имеется мастер настройки каталога автоматизации VCF, который упрощает конфигурацию этих систем. Зв счет интеграции последних релизов Aria с VMware Cloud Foundation 5.1.1, появляются новые возможности управления, которые можно использовать в решениях Aria Operations и Aria Automation.
Aria Operations включает новые свойства и метрики мониторинга GPU, предоставляющие метрики на уровне кластера и хоста для управления здоровьем и использованием ресурсов GPU. Aria Automation предоставляет новые сервисы автоматизации для VMware Private AI, предлагая модель развертывания частного облака самообслуживания, которая позволяет разработчикам и аналитикам настраивать и перестраивать блоки инфраструктуры для поддержки широкого спектра вариантов использования. Эта новая возможность повышает не только производительность, но и эффективность этих решений на основе GPU, снижая общую стоимость владения (TCO). Гибкость, предлагаемая этой архитектурой, позволяет администраторам облака использовать различные домены рабочих нагрузок, каждый из которых может быть настроен для поддержки конкретных типов виртуальных машин, оптимизируя производительность рабочих нагрузок и использование ресурсов GPU.
Поддержка новой модели лицензирования VMware Cloud Foundation
Для дальнейшего упрощения развертывания, VMware Cloud Foundation 5.1.1 предлагает опцию развертывания единого лицензионного ключа решения, которая теперь включает 60-дневный пробный период. Дополнительные продукты и аддоны к VMware Cloud Foundation теперь также могут быть подключены на основе единого ключа (отметим, что лицензия vSAN на TiB является исключением на данный момент и все еще должна применяться отдельно). Поддержка отдельных компонентных лицензионных ключей продолжается, но новая функция единого ключа должна упростить лицензирование решений на базе развертываний VMware Cloud Foundation.
VMware Cloud Foundation 5.1.1 доступен для загрузки и развертывания уже сейчас. Доступ к VMware Private AI Foundation with NVIDIA можно запросить здесь.
На конференции Explore 2023 компания VMware объявила о новой инициативе в области поддержки систем генеративного AI - VMware Private AI. Сейчас, когда технологии генеративного AI выходят на первый план, особенно важно организовать инфраструктуру для них - то есть подготовить программное и аппаратное обеспечение таким образом, чтобы расходовать ресурсы, необходимые для AI и ML, наиболее эффективно, так как уже сейчас в сфере Corporate AI требуются совершенно другие мощности, чтобы обслуживать эти задачи.
Генеративный искусственный интеллект (Gen AI) - одно из важнейших восходящих направлений, которые изменят ландшафт компаний в течение следующих 5-10 лет. В основе этой волны инноваций находятся большие языковые модели (LLM), обрабатывающие обширные и разнообразные наборы данных. LLM позволяют людям взаимодействовать с моделями искусственного интеллекта через естественный язык как в текстовой форме, так и через речь или изображения.
Инвестиции и активность в области исследований и разработок LLM заметно возросли, что привело к обновлению текущих моделей и выпуску новых, таких как Gemini (ранее Bard), Llama 2, PaLM 2, DALL-E и другие. Некоторые из них являются открытыми для общественности, в то время как другие являются собственностью компаний, таких как Google, Meta и OpenAI. В ближайшие несколько лет ценность GenAI будет определяться доработкой и настройкой моделей, адаптированных к конкретным областям бизнеса и отраслям. Еще одним важным развитием в использовании LLM является Retrieval Augmented Generation (RAG), при котором LLM привязываются к большим и разнообразным наборам данных, чтобы предприятия могли взаимодействовать с LLM по вопросам данных.
VMware предоставляет программное обеспечение, которое модернизирует, оптимизирует и защищает рабочие нагрузки самых сложных организаций в области обработки данных, на всех облачных платформах и в любом приложении. Платформа VMware Cloud Foundation помогает предприятиям внедрять инновации и трансформировать свой бизнес, а также развертывать широкий спектр приложений и услуг искусственного интеллекта. VMware Cloud Foundation обеспечивает единый платформенный подход к управлению всеми рабочими нагрузками, включая виртуальные машины, контейнеры и технологии искусственного интеллекта, через среду самообслуживания и автоматизированного ИТ-окружения.
На днях, на конференции NVIDIA GTC, VMware объявила о начальной доступности (Initial Availability) решения VMware Private AI Foundation with NVIDIA.
VMware Private AI Foundation with NVIDIA
VMware/Broadcom и NVIDIA стремятся раскрыть потенциал Gen AI и максимально использовать производительность совместной платформы.
Построенный и запущенный на ведущей в отрасли платформе для частного облака, VMware Cloud Foundation, VMware Private AI Foundation with NVIDIA включает в себя новые микросервисы NVIDIA NIM, модели искусственного интеллекта от NVIDIA и других участников сообщества (таких как Hugging Face), а также инструменты и фреймворки искусственного интеллекта от NVIDIA, доступные с лицензиями NVIDIA AI Enterprise.
Эта интегрированная платформа GenAI позволяет предприятиям запускать рабочие процессы RAG, внедрять и настраивать модели LLM и выполнять эти нагрузки в их центрах обработки данных, решая проблемы конфиденциальности, выбора, стоимости, производительности и комплаенса. Она упрощает развертывание GenAI для предприятий, предлагая интуитивный инструмент автоматизации, образы глубокого обучения виртуальных машин, векторную базу данных и возможности мониторинга GPU. Эта платформа представляет собой дополнительный SKU в дополнение к VMware Cloud Foundation. Обратите внимание, что лицензии NVIDIA AI Enterprise должны быть приобретены отдельно у NVIDIA.
Ключевые преимущества
Давайте разберем ключевые преимущества VMware Private AI Foundation с участием NVIDIA:
Обеспечение конфиденциальности, безопасности и соблюдения нормативов моделей искусственного интеллекта
VMware Private AI Foundation with NVIDIA предлагает архитектурный подход к обслуживанию искусственного интеллекта, обеспечивающий конфиденциальность, безопасность и контроль над корпоративными данными, а также более интегрированную систему безопасности и управления.
VMware Cloud Foundation обеспечивает продвинутые функции безопасности, такие как защита загрузки, виртуальный TPM, шифрование виртуальных машин и многое другое. В рамках услуг NVIDIA AI Enterprise включено программное обеспечение управления для использования рабочей нагрузки и инфраструктуры для масштабирования разработки и развертывания моделей искусственного интеллекта. Стек программного обеспечения для искусственного интеллекта включает более 4500 пакетов программного обеспечения с открытым исходным кодом, включая программное обеспечение сторонних производителей и программное обеспечение NVIDIA.
Часть услуг NVIDIA AI Enterprise включает патчи для критических и опасных уязвимостей (CVE) с производственными и долгосрочными ветвями поддержки и обеспечения совместимости API по всему стеку. VMware Private AI Foundation with NVIDIA обеспечивает средства развертывания, которые предоставляют предприятиям контроль над множеством регуляторных задач с минимальными изменениями в их текущей среде.
Ускоренная производительность моделей GenAI независимо от выбранных LLM
Broadcom и NVIDIA предоставляют программные и аппаратные средства для достижения максимальной производительности моделей GenAI. Эти интегрированные возможности, встроенные в платформу VMware Cloud Foundation, включают мониторинг GPU, горячую миграцию и балансировку нагрузки, мгновенное клонирование (возможность развертывания кластеров с несколькими узлами с предварительной загрузкой моделей за несколько секунд), виртуализацию и пулы GPU, а также масштабирование ввода/вывода GPU с помощью NVIDIA NVLink и NVIDIA NVSwitch.
Недавнее исследование сравнивало рабочие нагрузки искусственного интеллекта на платформе VMware + NVIDIA AI-Ready Enterprise с bare metal. Результаты показывают производительность, сравнимую или даже лучшую, чем на bare metal. Таким образом, размещение рабочих нагрузок искусственного интеллекта на виртуализированных решениях сохраняет производительность и приносит преимущества виртуализации, такие как упрощенное управление и улучшенная безопасность. NVIDIA NIM позволяет предприятиям выполнять операции на широком диапазоне оптимизированных LLM, от моделей NVIDIA до моделей сообщества, таких как Llama-2, и до LLM с открытым исходным кодом, таких как Hugging Face, с высокой производительностью.
Упрощение развертывания GenAI и оптимизация затрат
VMware Private AI Foundation with NVIDIA помогает предприятиям упростить развертывание и достичь экономичного решения для своих моделей GenAI. Он предлагает такие возможности, как векторная база данных для выполнения рабочих процессов RAG, виртуальные машины глубокого обучения и мастер автоматического запуска для упрощения развертывания. Эта платформа реализует единые инструменты и процессы управления, обеспечивая значительное снижение затрат. Этот подход позволяет виртуализировать и использовать общие ресурсы инфраструктуры, такие как GPU, CPU, память и сети, что приводит к существенному снижению затрат, особенно для случаев использования, где полноценные GPU могут быть необязательными.
Архитектура
VMware Cloud Foundation, полноценное решение для частного облачного инфраструктуры, и NVIDIA AI Enterprise, полнофункциональная облачная платформа, образуют основу платформы VMware Private AI Foundation with NVIDIA. Вместе они предоставляют предприятиям возможность запуска частных и безопасных моделей GenAI.
Основные возможности, которые следует выделить:
1. Специальные возможности, разработанные VMware
Давайте подробнее рассмотрим каждую из них.
Шаблоны виртуальных машин для глубокого обучения
Настройка виртуальной машины для глубокого обучения может быть сложным и затратным процессом. Ручное создание может привести к недостатку согласованности и, следовательно, к недостаточной оптимизации в различных средах разработки. VMware Private AI Foundation with NVIDIA предоставляет виртуальные машины для глубокого обучения, которые поставляются предварительно настроенными с необходимыми программными средствами, такими как NVIDIA NGC, библиотеками и драйверами, что освобождает пользователей от необходимости настраивать каждый компонент.
Векторные базы данных для выполнения рабочих процессов RAG
Векторные базы данных стали очень важным компонентом для рабочих процессов RAG. Они обеспечивают быстрый запрос данных и обновление в реальном времени для улучшения результатов LLM без необходимости повторного обучения этих моделей, что может быть очень затратным и долгим. Они стали стандартом для рабочих процессов GenAI и RAG. VMware применяет векторные базы данных, используя pgvector на PostgreSQL. Эта возможность управляется с помощью автоматизации в рамках инфраструктуры служб данных в VMware Cloud Foundation. Сервис управления данными упрощает развертывание и управление базами данных с открытым исходным кодом и коммерческими базами данных из одного интерфейса.
Мастер настройки каталога
Создание инфраструктуры для проектов искусственного интеллекта включает несколько сложных шагов. Эти шаги выполняются администраторами, специализирующимися на выборе и развертывании соответствующих классов виртуальных машин, кластеров Kubernetes, виртуальных графических процессоров (vGPU) и программного обеспечения для искусственного интеллекта/машинного обучения, такого как контейнеры в каталоге NGC.
В большинстве предприятий исследователи данных и DevOps тратят значительное количество времени на сборку необходимой им инфраструктуры для разработки и производства моделей искусственного интеллекта/машинного обучения. Полученная инфраструктура может не соответствовать требованиям безопасности и масштабируемости для разных команд и проектов. Даже при оптимизированных развертываниях инфраструктуры для искусственного интеллекта/машинного обучения исследователи данных и DevOps могут тратить значительное количество времени на ожидание, когда администраторы создадут, составят и предоставят необходимые объекты каталога инфраструктуры для задач искусственного интеллекта/машинного обучения.
Для решения этих проблем VMware Cloud Foundation представляет мастер настройки каталога (Catalog Setup Wizard) - новую возможность Private AI Automation Services. На начальном этапе LOB-администраторы могут эффективно создавать, составлять и предоставлять оптимизированные объекты каталога инфраструктуры искусственного интеллекта через портал самообслуживания VMware Cloud Foundation. После публикации DevOps исследователи данных могут легко получить доступ к элементам каталога машинного обучения и развернуть их с минимальными усилиями. Мастер настройки каталога снижает ручную нагрузку для администраторов и сокращает время ожидания, упрощая процесс создания масштабируемой инфраструктуры.
Мониторинг GPU
Получая видимость использования и метрик производительности GPU, организации могут принимать обоснованные решения для оптимизации производительности, обеспечения надежности и управления затратами в средах с ускорением на GPU. С запуском VMware Private Foundation with NVIDIA сразу доступны возможности мониторинга GPU в VMware Cloud Foundation. Это дает администраторам дэшборды с информацией об использовании GPU в рамках кластеров и хостов, в дополнение к существующим метрикам мониторинга.
2. Возможности NVIDIA AI Enterprise
NVIDIA NIM
NVIDIA NIM - это набор простых в использовании микросервисов, разработанных для ускорения развертывания GenAI на предприятиях. Этот универсальный микросервис поддерживает модели NVIDIA AI Foundation Models - широкий спектр моделей - от ведущих моделей сообщества до моделей, созданных NVIDIA, а также индивидуальные пользовательские модели искусственного интеллекта, оптимизированные для стека NVIDIA. Созданный на основе фундаментальных компонентов NVIDIA Triton Inference Server, NVIDIA TensorRT, TensorRT-LLM и PyTorch, NVIDIA NIM предназначен для обеспечения масштабируемых и гибких моделей AI.
NVIDIA Nemo Retriever
NVIDIA NeMo Retriever - это часть платформы NVIDIA NeMo, которая представляет собой набор микросервисов NVIDIA CUDA-X GenAI, позволяющих организациям без проблем подключать пользовательские модели к разнообразным бизнес-данным и предоставлять высокоточные ответы. NeMo Retriever обеспечивает поиск информации самого высокого уровня с минимальной задержкой, максимальной пропускной способностью и максимальной конфиденциальностью данных, позволяя организациям эффективно использовать свои данные и генерировать бизнес-инсайты в реальном времени. NeMo Retriever дополняет приложения GenAI расширенными возможностями RAG, которые могут быть подключены к бизнес-данным в любом месте их хранения.
NVIDIA RAG LLM Operator
Оператор NVIDIA RAG LLM упрощает запуск приложений RAG в производственную среду. Он оптимизирует развертывание конвейеров RAG, разработанных с использованием примеров рабочих процессов искусственного интеллекта NVIDIA, в производственной среде без переписывания кода.
NVIDIA GPU Operator
Оператор NVIDIA GPU автоматизирует управление жизненным циклом программного обеспечения, необходимого для использования GPU с Kubernetes. Он обеспечивает расширенные функциональные возможности, включая повышенную производительность GPU, эффективное использование ресурсов и телеметрию. Оператор GPU позволяет организациям сосредотачиваться на создании приложений, а не на управлении инфраструктурой Kubernetes.
Поддержка ведущих производителей серверного оборудования
Платформа от VMware и NVIDIA поддерживается ведущими производителями серверного оборудования, такими как Dell, HPE и Lenovo.
Более подробно о VMware Private AI Foundation with NVIDIA можно узнать тут и тут.

 RSS
RSS