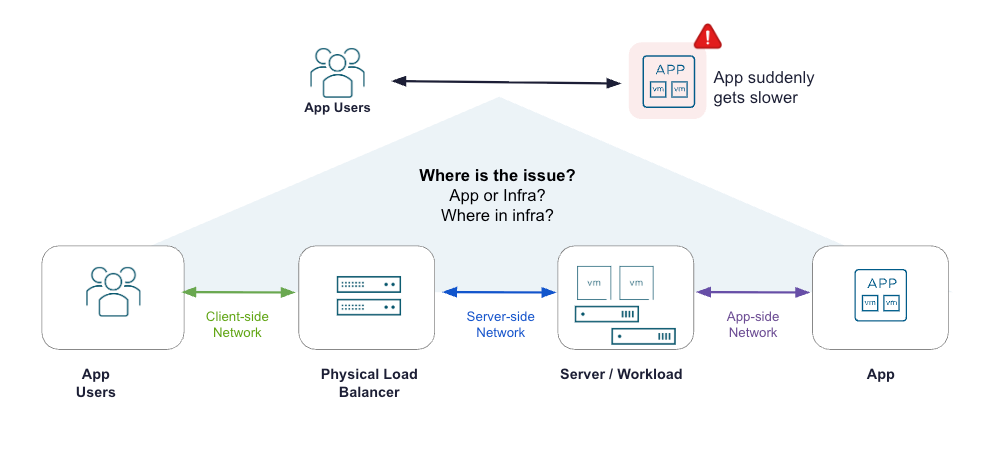
Медленная работа приложений и простои серьезно влияют на удовлетворенность клиентов, вызывают перебои в бизнес-процессах и могут отражаться на выручке. Когда критически важное приложение дает сбой в сложной распределенной среде, главная трудность заключается в том, чтобы быстро определить первопричину. Во время инцидентов высокой важности ИТ-команды оказываются в ситуационных комнатах для диагностики, где снова и снова возникает один и тот же вопрос: проблема находится в базовой инфраструктуре или в самом приложении?
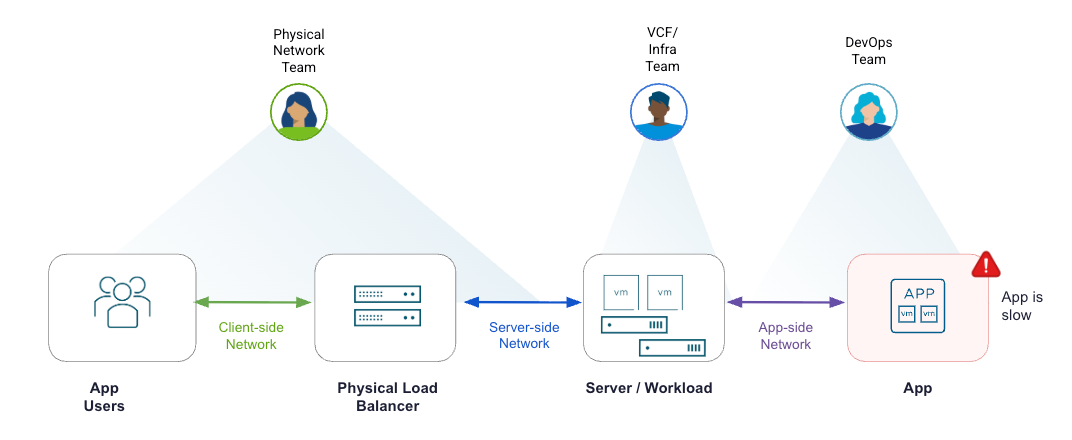
При традиционном подходе сетевые, инфраструктурные и DevOps-команды вынуждены работать изолированно. Они используют разные инструменты и разрозненные наборы данных, не имея сквозной видимости. В результате возникает изматывающий цикл обмена сообщениями туда и обратно. Поиск первопричины превращается в тяжелый и медленный процесс, который занимает дни, а иногда и недели. Устаревшие балансировщики нагрузки, хотя и видят транзакции как со стороны клиента, так и со стороны сервисов, способны предоставлять только фрагментированные метрики.
Как Avi ускоряет диагностику с помощью App Health Score
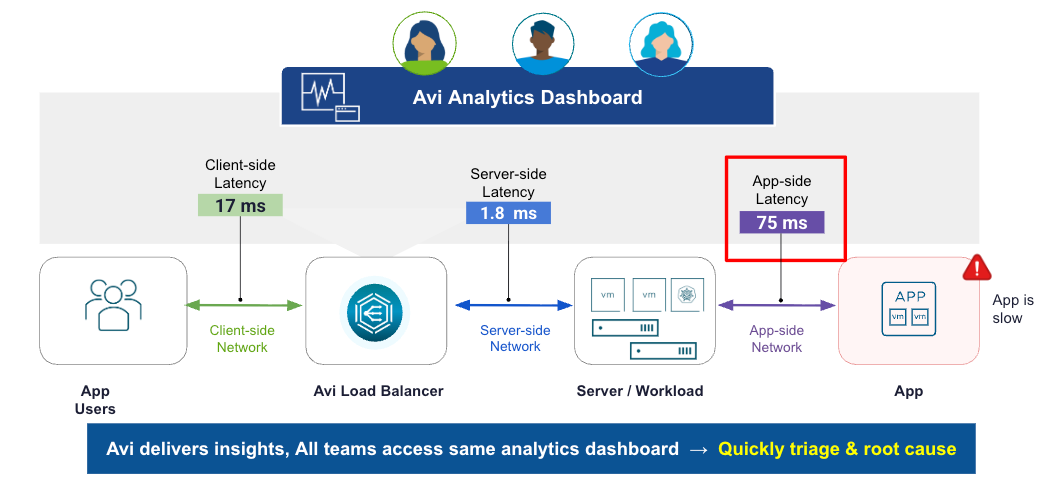
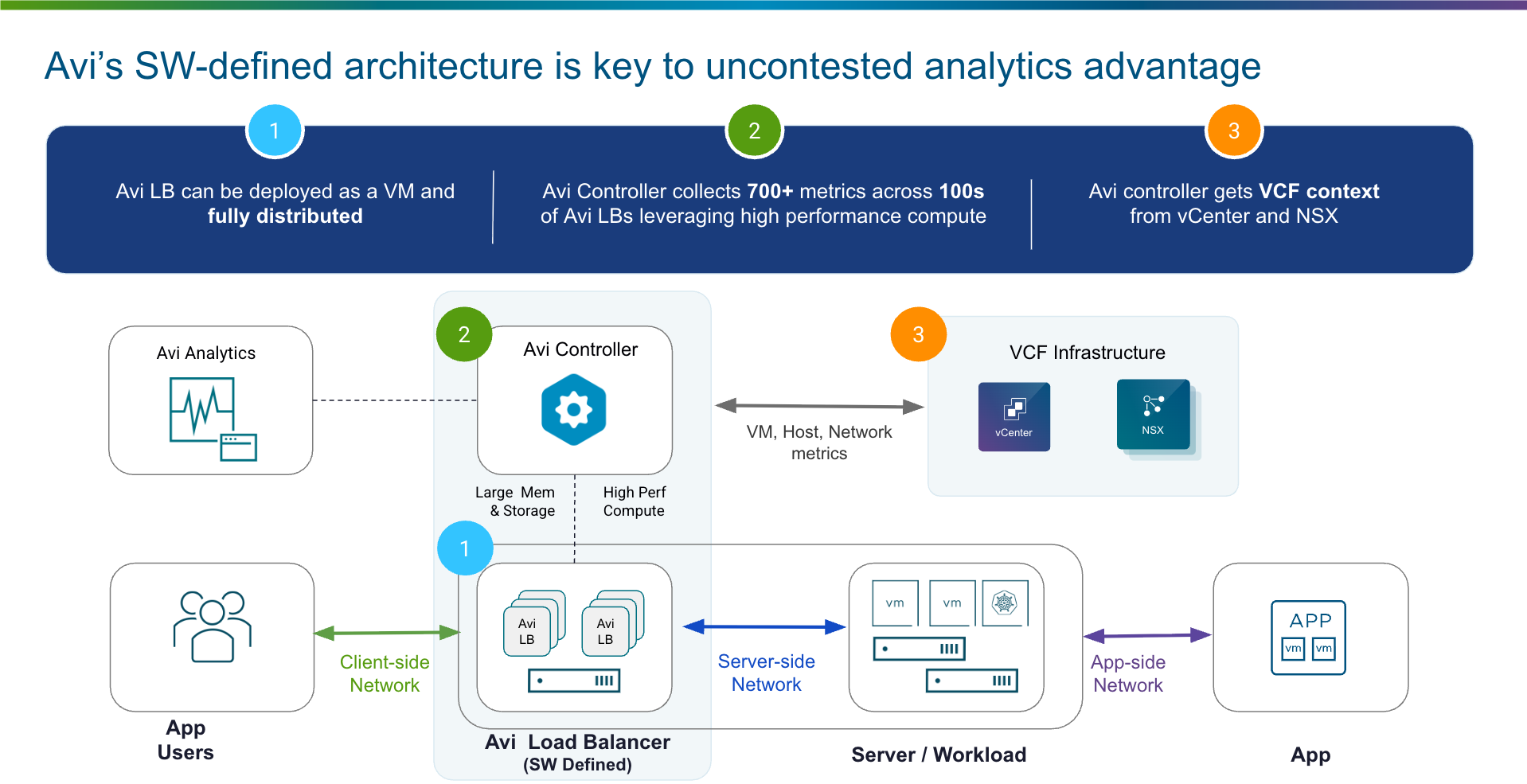
Программно-определяемая архитектура балансировки нагрузки Avi является основой его аналитического преимущества. Avi собирает полную телеметрию на уровне транзакций по каждому потоку и показывает ее в единой панели управления. Благодаря этому разрозненные команды получают доступ к одной и той же сквозной аналитике задержек приложения на стороне клиента, сервера и самого приложения. Все участники могут быстро и точно определить первопричину узких мест производительности или угроз безопасности. Рассмотрим подробнее.
Сокращение Mean Time to Innocence (MTTI) за счет детальной аналитики:
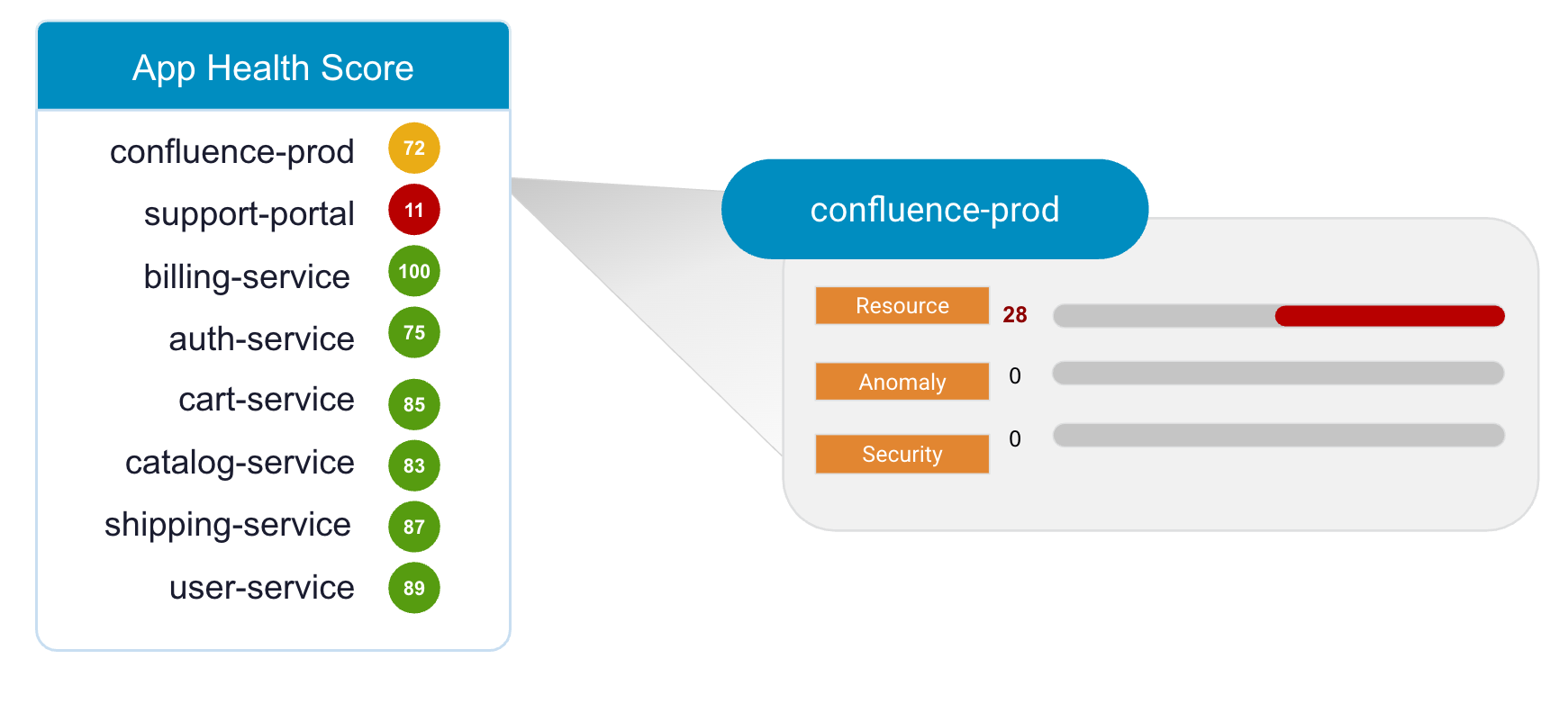
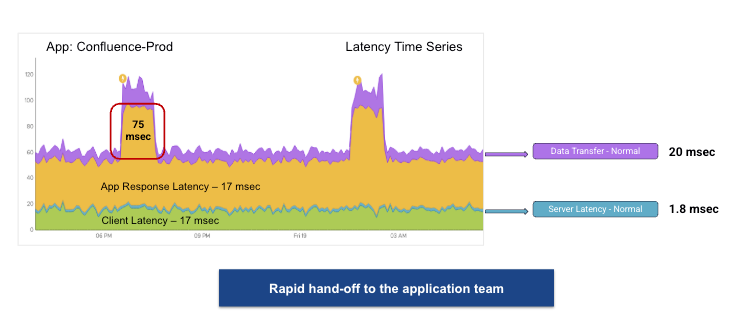
Avi Analytics сводит данные о производительности приложений в понятные оценки здоровья от 0 до 100. Avi App Health Score дает комплексную оценку общего состояния приложения или виртуального сервиса, объединяя показатели производительности, доступности ресурсов, аномального поведения и факторов риска безопасности. Эти оценки дают администраторам практические подсказки и позволяют быстро находить проблемы прямо на панели управления. Например, желтая оценка 72 для «confluence prod» сразу указывает на деградацию сервиса из-за базовых ресурсов и подсвечивает критические проблемы вместе с релевантной диагностической информацией.
Кроме того, Avi Analytics существенно сокращает MTTI, предоставляя детальную видимость каждой транзакции приложения. Централизация этих метрик в единой панели помогает кросс-функциональным командам сразу понять, что задержка 75 мс возникает в приложении, а не в сети или на стороне клиента. Такой подход на основе данных сокращает длительный триаж и позволяет организациям с высокой точностью определить конкретный источник проблем производительности.
Повышение устойчивости приложений благодаря встроенной веб-безопасности:
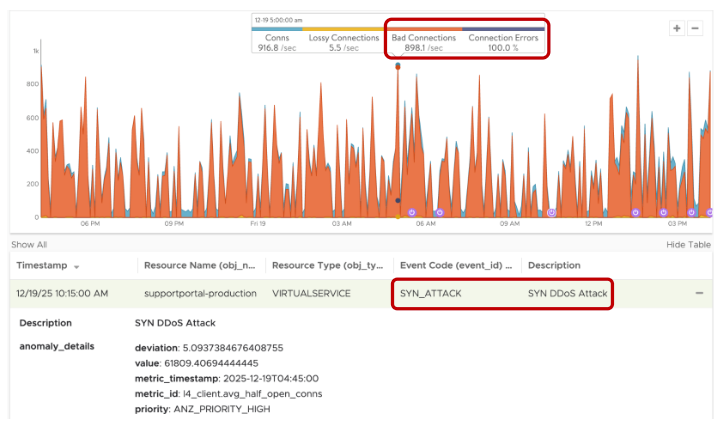
Интегрируя сведения о безопасности непосредственно в App Health Score, Avi улучшает защиту приложений за счет встроенного web application firewall (WAF). Аналитика платформы в реальном времени выявляет частые ошибки соединений и отмечает сложные веб-атаки, включая DDoS-атаки: от обнаружения до автоматического смягчения последствий проходят минуты. В результате устойчивость приложений повышается, а высокая доступность и производительность сохраняются даже при большой нагрузке или целевых веб-угрозах.
Минимизация простоя приложений за счет выявления временных проблем:
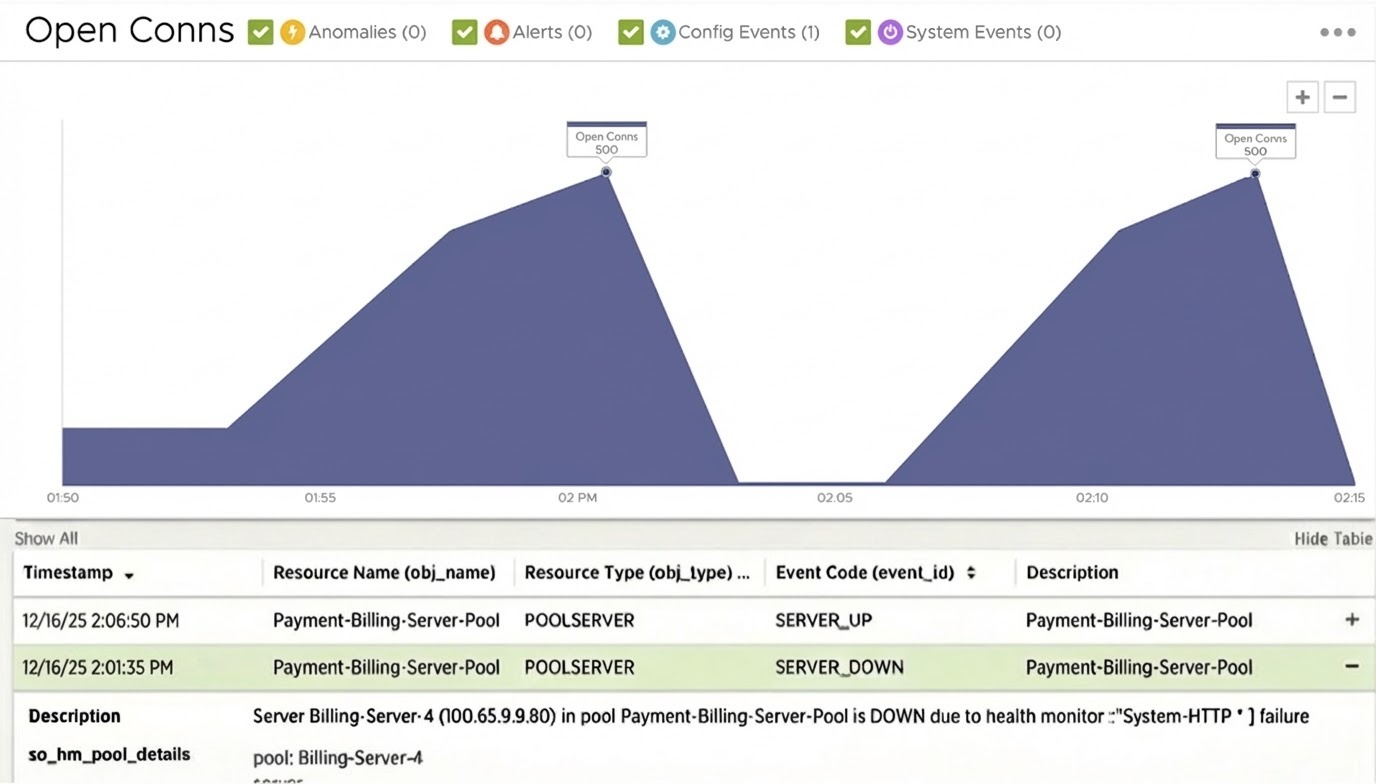
Avi ускоряет анализ первопричин, используя глубокую историческую аналитику и избавляя команды от необходимости ждать, пока периодическая проблема повторится. Традиционным аппаратным балансировщикам нагрузки почти невозможно находить временные аномалии уровня «иголка в стоге сена», тогда как подробные журналы транзакций Avi позволяют инженерам переходить к конкретным IP-адресам серверов пула и выявлять исчерпание ресурсов виртуальных машин, то есть базовую проблему на стороне приложения.
Преимущество Avi Analytics: аналитика задержек приложений
Устаревшие балансировщики нагрузки уже не соответствуют требованиям современных приложений к производительности, гибкости и масштабируемости. Диагностика проблем производительности приложений стала реактивным и утомительным процессом. Avi собирает аналитику прямо из трафика и предоставляет единый «источник истины», который сокращает длительный операционный триаж между сетевыми, безопасностными и прикладными командами.
Программно-определяемая архитектура: Avi обеспечивает глубокую видимость в реальном времени, разделяя централизованную плоскость управления и распределенную плоскость данных. Avi развертывается как виртуальные машины рядом с вычислительной инфраструктурой. Он собирает детальную телеметрию из потока трафика и дает комплексную аналитику со сквозной видимостью из одной консоли, чтобы ускорять диагностику, автоматизировать масштабирование и заранее поддерживать высокую производительность приложений.
Полнота данных и охвата: Avi Controller непрерывно агрегирует более 700 метрик производительности из распределенных балансировщиков нагрузки. Используя высокопроизводительные вычислительные ресурсы, Avi обрабатывает крупное озеро телеметрических данных и применяет расширенные ML/AI-выводы для анализа паттернов и аномалий. Avi Analytics преобразует инфраструктурные данные в практические сведения о приложениях, позволяя ИТ-командам перейти от реактивного устранения неполадок к проактивной оптимизации.
Контекст VCF без сложной настройки: Avi глубоко и нативно интегрируется с частным облаком VCF. Благодаря контексту рабочих нагрузок VCF Avi обеспечивает согласованную видимость для виртуальных машин и контейнеров. Такая контекстная осведомленность связывает доставку и безопасность приложений с инфраструктурой, уменьшает слепые зоны и упрощает балансировку нагрузки в VCF.
Как крупная финансовая организация сократила количество заявок на 90%
Сетевые команды одной очень крупной финансовой организации до внедрения Avi Analytics постоянно были перегружены большим накопившимся объемом заявок на диагностику приложений. Ограниченная видимость, которую давали устаревшие балансировщики нагрузки, приводила к тому, что все проблемы приложений направлялись сетевым командам, даже если сеть не была их причиной. Это создавало серьезное узкое место: операционные специалисты обрабатывали почти все заявки.
После развертывания Avi Analytics организация предоставила более чем 50 DevOps-командам прямой доступ к единой аналитической панели. Команды получили практические сведения по более чем 90 000 виртуальных IP-адресов и смогли самостоятельно диагностировать, находится ли причина проблемы в приложении или в сети.
Переход к современной балансировке нагрузки на основе аналитики привел к резкому сокращению количества заявок, связанных с приложениями, которые попадали в сетевую команду: их стало меньше на 90%. В результате операционные специалисты смогли перераспределить ресурсы с обработки заявок на более ценные стратегические проекты, что показывает явное преимущество такого подхода по сравнению с традиционной балансировкой нагрузки.
Veeam использует интеллектуальный анализ данных во всей своей платформе, чтобы защищать ваши критические данные, обеспечивать их целостность и помогать организациям становиться более эффективными. Veeam предоставляет не только возможности резервного копирования данных, но и видимость вашей системы резервного копирования и виртуальной среды через мониторинг и отчётность в Veeam Data Platform Advanced. Благодаря этому вы можете выявлять проблемы, которые могут снижать производительность виртуальных машин или нарушать операции резервного копирования и препятствовать восстановлению данных.
Veeam Intelligent Diagnostics, функция, входящая в состав Veeam ONE (часть пакета Veeam Data Platform Advanced), позволяет автоматически выявлять известные проблемы в конфигурации и производительности инфраструктуры резервного копирования. Активировав эту функциональность через Veeam ONE, вы получаете уведомления об общих ошибках, что позволяет вам быстрее их устранять с помощью статей из базы знаний и предлагаемых решений, что снижает риски в вашей среде и гарантирует готовность к защите или восстановлению данных в любой момент.
Сигнатуры Veeam Intelligent Diagnostics
У Veeam более 550 000 клиентов, что, если задуматься, является огромным числом. Клиенты Veeam бывают самых разных размеров и работают в различных областях. От технологических компаний до медицинских организаций, нефтегазовых компаний и образовательных учреждений — Veeam защищает огромный объём данных своих клиентов.
Клиенты используют продукты по-разному, и, изучая различные случаи поддержки, Veeam узнает много нового о типичных проблемах, с которыми они сталкиваются. Veeam создает новые сигнатуры Veeam Intelligent Diagnostics на основе того, что наблюдают сотрудники компании, например, общие ошибки конфигурации или проблемы, которые возникают только в очень специфических условиях, о которых клиент даже не мог бы подумать, как, например, проблема с производительностью.
С помощью Veeam Intelligent Diagnostics можно использовать уроки, извлечённые из этих сред, чтобы снизить риски для всех клиентов.
Как VID анализирует виртуальные среды
С помощью простого агента, установленного на сервер Veeam Backup & Replication через Veeam ONE, состояние вашей среды Veeam анализируется безопасно, при этом вы полностью контролируете свои данные. Установка на серверы Veeam выполняется в один клик (если это не было сделано при подключении к среде Veeam ONE).
При этом никакие ваши данные никогда не отправляются на серверы Veeam. Вместо этого Veeam ONE просто загружает новые сигнатуры Veeam Intelligent Diagnostics с серверов Veeam, а агент, установленный на сервере Veeam, выполняет анализ. Клиенты, использующие Veeam Data Platform Advanced и Premium, могут в любое время проверить наличие новых сигнатур через Veeam ONE Data Protection View или загрузить их напрямую с веб-сайта Veeam и импортировать на сервер Veeam ONE.
Анализ логов VID может быть настроен на ежедневный запуск, а также выполняться по запросу в любое время. На самом деле, не существует более простого способа для принятия проактивных мер по защите вашей среды Veeam Backup & Replication.
Исправляйте проблемы до того, как они повлекут последствия
Сигнатуры VID обновляются дважды в месяц и содержат множество улучшений. Помимо новых определений для обнаружения проблем, с которыми могут столкнуться клиенты Veeam, обновления также включают новые возможности и улучшения самого диагностического механизма.
Если обнаружена проблема, клиенты получают уведомления через алармы в Veeam ONE с важной информацией, которая упрощает процесс устранения проблемы. Давайте рассмотрим одну из последних сигнатур VID.
Этот пример касается задач резервного копирования на ленту, он идентифицирует причину срабатывания аларма и предлагает способы её устранения. В этом случае можно увидеть, что обновление до последней версии Veeam Backup and Replication может помочь решить проблему. Если это не помогает, вам предоставляется номер тикета Veeam Intelligent Diagnostics, чтобы упростить процесс поддержки и получить частное исправление.
В данном случае Veeam Intelligent Diagnostics предоставил правильное решение, которое требует обновления. Просто подождите установки обновления 15-20 минут, и вы больше не столкнетесь с этой проблемой. Это отличный пример того, как Veeam помогает своим клиентам действительно понять, что происходит в их среде, и избежать возможных обращений в службу поддержки.
Все клиенты Veeam Data Platform могут снизить риски в своих средах, используя Veeam Intelligent Diagnostics, и в индустрии нет ничего подобного. Veeam безопасно обрабатывает информацию из логов вашей среды непосредственно на ваших серверах Veeam. Ваши данные никогда не отправляются на сервера Veeam или куда-либо ещё.
Опираясь на опыт более чем 550 000 клиентов, Veeam постоянно обновляет определения VID и отправляет их при возникновении новых проблем и рисков, помогая клиентам устранять сложности до того, как они повлекут серьезные последствия.
Если вы уже используете Veeam Data Platform Advanced или Premium, уделите несколько минут, чтобы убедиться, что у вас установлен агент Veeam ONE. Затем вы сможете просмотреть сигнатуры Veeam Intelligent Diagnostics, зайдя в раздел Intelligent Diagnostics в секции Backup & Replication представления Alarm Management.
Если вы ещё не используете Veeam Data Platform Advanced или Premium, вы можете загрузить бесплатную пробную версию на 30 дней, чтобы протестировать функции Veeam Intelligent Diagnostics.
В последнем релизе VMware vSAN 8.0 Update 3, утилита vSAN IO Trip Analyzer была существенно доработана. В чем именно заключается это улучшение? Теперь IO Trip Analyzer может быть включен для нескольких ВМ одновременно. Это особенно полезно при устранении проблем с производительностью комплексного сервиса, состоящего из нескольких ВМ.
Данное улучшение позволяет вам одновременно мониторить несколько ВМ и анализировать, на каком уровне у каждой из выбранных ВМ возникает задержка (latency). Обратите внимание, что это улучшение работает как для vSAN ESA, так и для vSAN OSA.
Дункан Эппинг записал на эту тему интересное обзорное видео:
В VMware Cloud Foundation (VCF) версии 5.2 появилась новая консоль, которая добавляет диагностические возможности в Operations VMware Cloud Foundation (VMware Aria Operations). VMware Cloud Foundation Operations включен в VCF и VMware vSphere Foundation.
Новые функции включают "Общие выводы" и "Рекомендации по безопасности". Кроме того, такие разделы, как "Серверы vCenter", "Хосты ESXi", "Развертывание рабочих нагрузок" и "Кластеры vSAN", которые ранее были доступны в VMware Cloud Foundation Operations, теперь включены для улучшенной видимости. Также улучшена интеграция с VMware Aria Operations for Logs, что предоставляет больше информации о миграциях vMotion и снапшотах. Чтобы включить эту функцию, необходимо подключить Operations к Operations for Logs и хотя бы одному vCenter. При добавлении дополнительных компонентов VMware vSphere Foundation и VCF станут доступны дополнительные наборы данных. Давайте рассмотрим каждый раздел более подробно.
Общие выводы
В новой версии VMware Cloud Foundation Operations объединены диагностические возможности (из Skyline Health Diagnostics, Skyline Advisor и VMware Aria Operations for Logs) в единый интерфейс, представленный в новой консоли. С помощью Skyline можно применять рекомендации по безопасности и эксплуатации на основе версий. Теперь VMware Cloud Foundation Operations и VMware Aria Operations for Logs привязаны к одним и тем же конечным эндпоинтам, что способствует появлению новых диагностических выводов в консоли, уменьшая необходимость в развертывании дополнительного программного обеспечения (сокращает необходимость в Skyline Advisor Collector и виртуальной машине Skyline Health Diagnostics). Эта бесшовная интеграция уменьшает дублирование усилий, о которых упоминалось ранее, и упрощает развертывание и управление средой. В результате получается системный подход к представлению диагностических выводов клиентам.
Вот некоторые распространенные задачи:
Просмотр всех файндингов
Определение общего количества ресурсов
Категоризация выводов по критичности (критические, срочные и предупреждения)
Классификация по типу:
Рекомендации по безопасности
Доступность
Проверки перед обновлением
Диагностика эксплуатации
Производительность
Уточнение их представления с помощью фильтров на основе:
Инвентарь VCF
Компоненты VCF
Тип файндинга
Серьезность
Возможности:
vMotions
Снапшоты
Развертывание рабочих нагрузок
Домены рабочих нагрузок
DRS
HA
Для доступа к диагностической консоли выберите "Diagnostics" в левой панели навигации. На странице Home -> Overview найдите ссылки на "Appliances Health & Management".
Рисунок 1. Дэшборд главной страницы.
Рисунок 2. Дэшборд диагностики из меню слева.
В основном дэшборде «Overall Findings» вы можете быстро просмотреть все файндинги. Вы можете уточнить их количество, выбрав компоненты в левой панели. Кроме того, вы можете искать конкретные файндинги или использовать подстановочные знаки в строке поиска, расположенной выше списка файндингов.
Рисунок 3. Опции фильтрации и поиска на панели «Diagnostic Findings».
Вы можете углубиться в просмотр конкретных деталей, выбрав отдельный файндинг, например, Last Observed, Affected Objects и Recommendations.
Рисунок 4. Просмотр Last Objerved и Affected Objects.
На вкладке «Affected Objects» вы можете найти имя объекта, время его первого наблюдения (Occurrence Time) и время последней проверки (Check Time). Окружение будет сканироваться каждые четыре часа, и детали на этой вкладке будут обновляться соответственно. Не забудьте учитывать следующую информацию:
Рисунок 5. Просмотр деталей «Affected Objects».
В разделе «Recommendations» вы можете найти версию продукта, в которой проблема была решена, а также статью базы знаний (KB), в которой представлены детали о проблеме, исправлении и воркэраунде.
Рисунок 6. Просмотр рекомендаций по исправленным версиям и статьям базы знаний (KB).
Вот некоторые распространенные сценарии использования:
Просмотр VMSA и CVE для определения возможных проблем и обновлений для определенного набора серверов.
Помощь в планировании обновлений vCenter и ESXi для решения нескольких файндингов одновременно.
Разделение списка файндингов по регионам, чтобы распределить работу среди сотрудников, работающих в разных регионах.
Управление сертификатами
Все сертификаты в среде будут отображены здесь. Эти сертификаты существуют во всех приложениях VMware для обеспечения идентификации приложений (с целью уменьшения риска атак типа «man in the middle»). Поскольку каждое приложение может иметь до трех сертификатов, управление сертификатами занимает много времени и является сложным процессом. С учетом даты истечения срока действия и внешнего центра сертификации, управление графиком обновления и импорта сертификатов может вызывать проблемы.
Когда вы настраиваете консоль диагностики, то заполняется и панель управления сертификатами. Вы можете легко увидеть все сертификаты для конкретного сервера, включая информацию о том, являются ли они самоподписанными или сертификатами CA, а также активны ли они. Для активных сертификатов пользователи могут увидеть оставшееся время до истечения срока действия, что помогает начать процесс обновления сертификатов до их истечения, чтобы предотвратить возможные перебои в работе.
Рисунок 7. Обзор дэшборда управления сертификатами.
Вот некоторые распространенные сценарии использования:
Проверка наличия «неактивных» сертификатов и их немедленное исправление.
Просмотр даты истечения срока действия и немедленное исправление самоподписанных сертификатов.
Превентивное предотвращение истечения срока действия сертификатов.
vCenter
В дэшборде диагностики vCenter вы можете легко просмотреть все vCenter, подключенные к VCF Operations. Здесь объединяются все данные из vCenter, а также данные из VCF Operations. Вы можете быстро проверить операционный статус каждого vCenter. Если какой-либо vCenter не работает, вы можете определить количество затронутых хостов ESXi и виртуальных машин. Кроме того, вы можете увидеть все службы, запущенные на конкретном vCenter. В течение нескольких секунд можно определить, какие службы не работают, устранить проблемы и вернуть их в рабочее состояние. Этот процесс занял бы 30 минут или больше, если бы использовались традиционные методы, такие как проверка vCenter через консоль сервера и файлы журналов. При необходимости можно выбрать отдельные vCenter для более детального исследования.
Рисунок 8. Дэшборд vCenter.
Вот некоторые распространенные сценарии использования:
Проверка доступности любого vCenter и определение затронутых серверов и виртуальных машин.
Просмотр служб на каждом vCenter, чтобы убедиться, что все они работают нормально.
Хосты ESXi
Дэшборд ESXi предоставляет важную диагностическую информацию о хостах ESXi. Во-первых, вы можете проверить наличие «неотвечающих ESXi» серверов, так как это вопросы высокого приоритета. Далее, вы можете проверить, находятся ли какие-либо ESXi серверы в режиме обслуживания и определить, должны ли они оставаться в этом режиме или выйти из него. Также важно обратить внимание на серверы ESXi, которые были «отключены» или «не отвечают» в течение длительного времени. При выборе каждого ESXi сервера вы можете получить доступ к настройкам «родительского кластера», что может предоставить ценные сведения о возможных проблемах. В течение нескольких секунд можно выявить проблемы и инициировать необходимые действия по их устранению.
Рисунок 9. Дэшборд ESXi.
Вот некоторые распространенные сценарии использования:
Выявление всех «не отвечающих» серверов ESXi и их восстановление до нормального состояния.
Проверка ESXi режиме обслуживания для уверенности в том, что они действительно должны там находиться. Вывод из режима обслуживания как можно скорее для оптимального использования ресурсов.
Определение «Родительского кластера» конкретного ESXi и проверка правильности всех настроек.
Развертывание рабочих нагрузок
На панели управления развертыванием рабочих нагрузок вы можете просмотреть общие задачи по управлению нагрузкой, такие как «Создать новую виртуальную машину», «Развернуть OVF» и «Клонировать виртуальную машину». Вы можете быстро выявить любые сбои. При просмотре деталей пользователи могут увидеть информацию, такую как «Время запроса», «Имя виртуальной машины», «Инициатор», «vCenter» и «Кластер». С этой информацией вы можете исследовать окружение на наличие потенциальных проблем, выполнить необходимые исправления и уведомить инициаторов о необходимости повторного выполнения их задач.
Рисунок 10. Дэшборд развертывания рабочих нагрузок.
Вот некоторые распространенные сценарии использования:
Определение всех диагностических файндингов, связанных с развертыванием рабочих нагрузок.
Проверка любых сбоев для выявления основной причины проблемы.
Просмотр «инициаторов», чтобы убедиться, что все пользователи правильно назначены.
Миграции vMotion
Технология vMotion существует уже достаточно давно. Вы можете наблюдать за активностью vMotion в списке «recent tasks» в консоли vCenter. Однако ранее не было возможности видеть все события vMotion из одного представления. Теперь у вас есть такая возможность. Вы можете выбрать каждый vCenter, чтобы просмотреть все случаи vMotion, определяя как сбои, так и успешные события. В случае сбоя вы можете просмотреть такие детали, как имя виртуальной машины, источник, назначение и время, что поможет выявить и устранить проблему, предотвращая аналогичные сбои в будущем. Для тех, кто использует HCX (который использует vMotion), также фиксируются все активности HCX vMotion.
Рисунок 11. Дэшборд vMotion.
Вот некоторые распространенные сценарии использования:
Определение всех диагностических файндингов, связанных с vMotion.
Просмотр всех локаций, а также каждого vCenter на основе прошлых проблем.
Проверка исходного и целевого хостов для выявления проблем.
Снапшоты
В диагностической консоли вы можете просмотреть все снапшоты в окружении. Вы сможете определить наиболее проблемные виртуальные машины с проблемами снапшотов, особенно те, которые требуют консолидации. Еще один важный аспект — оценка общего количества снимков для семи наиболее важных виртуальных машин. У вас есть возможность фильтровать успешные и неудачные снимки. Для каждой проблемы, связанной со снимками, вы можете просмотреть такие детали, как виртуальные машины, vCenter, хранилище данных и временная метка. Это должно предоставить достаточно информации, чтобы определить, является ли проблема специфичной для конкретной виртуальной машины или это системная проблема, связанная с vCenter, ESXi или хранилищем данных.
Рисунок 12. Дэшборд снапшотов.
Вот некоторые распространенные сценарии использования:
Определение всех диагностических файндингов, связанных со снапшотами.
Просмотр любых сбоев.
Сопоставление любого сбоя с проблемой ESXi, графиком резервного копирования или другими сбоями (сеть, хранилище и т.д.).
Кластеры vSAN
Раздел «vSAN Health» в диагностической консоли предоставляет обзор состояния инфраструктуры vSAN. Вы можете быстро отфильтровать количество предупреждений «Красного», «Оранжевого» и «Желтого» уровня. При выборе каждого кластера появятся детали о свойствах выбранного кластера, которые помогут убедиться, что все необходимые настройки корректны. Ниже вы можете просмотреть детали каждого предупреждения, что поможет правильно расставить приоритеты и устранить проблемы для обеспечения наилучшей производительности и стабильности кластера vSAN.
Рисунок 13. Панель управления здоровьем vSAN.
Вот некоторые распространенные сценарии использования:
Просмотр всех предупреждений «Красного», «Оранжевого» и «Желтого» уровня.
Проверка всех свойств выбранного кластера на правильность настроек.
Прохождение по всем выводам по отдельности для планирования обновления с целью решения проблем.
После изучения всех функций в диагностической консоли (файндинги, сертификаты, vCenter, ESXi, развертывание рабочих нагрузок, vMotion, снапшоты и кластеры vSAN) вы можете оценить значимость новых дэшбордов. Некоторые из них представляют собой недавно добавленные функции из других продуктов, а другие — это детали существующих панелей, объединенные в этой консоли. Цель заключается в предоставлении ценных сведений с минимальными усилиями по развертыванию и настройке. Это позволит использовать существующие экземпляры Aria Operations и Operations for Logs, что в конечном итоге сэкономит время клиентов на решение проблем и сократит время простоя и обслуживания.
Компания VMware выпустила интересный документ "Troubleshooting vSAN Performance", в котором рассматриваются вопросы решения проблем в области производительности отказоустойчивых хранилищ VMware vSAN.
Статья на VMware Core разделена на несколько ключевых разделов:
1. Определение проблемы: начальный этап, включающий идентификацию проблемы и её масштаба. 2. Обзор конфигурации: анализ текущей конфигурации vSAN, включая параметры хранилища, сеть и оборудование. 3. Анализ рабочих нагрузок: изучение типов нагрузок, которые могут влиять на производительность. 4. Метрики и инструменты: описание ключевых метрик и инструментов для мониторинга и диагностики, таких как vSAN Observer и vRealize Operations. 5. Рекомендации по оптимизации: практические советы по настройке и оптимизации для повышения производительности, включая изменения в программных и аппаратных компонентах.
Каждый из этих этапов направлен на систематическое выявление и устранение узких мест в производительности vSAN. Статья предлагает практические примеры и сценарии для понимания и решения типичных проблем.
Блоггер Yahya Zahedi планирует написать интересную серию постов об утилитах для траблшутинга кластеров VMware vSAN. Сейчас самыми полезными для этих целей являются следующие средства:
vSAN Skyline Health
vSAN Cluster Level Monitoring
vSAN Host Monitoring
vSAN VM Monitoring
В этом посте мы приведем его рассказ о самом функциональном продукте - vSAN Skyline Health.
Skyline Health — это средство самостоятельной диагностики, предназначенное для обнаружения и устранения проблем в средах vSphere и vSAN. Важно отметить, что хотя эта утилита часто ассоциируется с vSAN, она также доступна и для vSphere. Таким образом, она не является эксклюзивной для vSAN, ее можно и нужно использовать для vSphere.
Сегодня мы посмотрим, как использовать Skyline Health для vSAN. Вы можете получить доступ к этому средству, перейдя к кластеру vSAN, затем выбрав вкладку "Monitor" и выбрав Skyline Health в разделе vSAN. Здесь, в разделе "Overview", вы найдете две карточки: "Cluster Health Score", которая работает на основе недавних файндингов по здоровью, и "Health Score Trend", которая показывает тренд оценки здоровья за последние 24 часа. Этот тренд можно настроить, указав конкретный временной промежуток.
В разделе файндингов по здоровью есть четыре категории: Unhealthy, Healthy, Info, Silenced, которые вы можете использовать для диагностики проблем, устранения неполадок и траблшутинга. Давайте начнем с первой категории файндингов.
Находки категории Unhealthy относятся к важным проблемам, которые требуют внимания. Например, в данном случае используется не сертифицированное VMware устройство хранения данных, и если вы посмотрите на зону воздействия этой проблемы, в описании вы увидите Compliance, что означает, что устройства хранения не соответствуют списку совместимости оборудования VMware HCL.
Как вы можете видеть, есть три опции:
Silence Alert - заглушает предупреждение и перемещает карточку в категорию Silenced.
Troubleshoot - показывает новую карточку с инструкциями по решению проблемы.
View History Details - отображает историю проблемы.
Нажмем на View History Details:
Будет показана новая карточка, предоставляющая историческую информацию об этой конкретной проблеме. Вы сможете увидеть, сколько раз она произошла и в какие дни.
Если вы нажмете на "Troubleshoot", появится новая карточка, предоставляющая информацию о проблеме и основной причине для облегчения ее решения. В разделе "Why is the issue occurring?" вы найдете детали о причинах. В разделе "How to troubleshoot and fix" вы узнаете дополнительные сведения, в данном случае - какие устройства испытывают проблемы совместимости оборудования, а также рекомендуемые действия для эффективного решения.
Вторая категория — Healthy, которая относится к файндингам без каких-либо проблем, следовательно, не требующим дополнительного внимания. Все функционирует гладко, что указывает зеленый статус. Наша основная цель — обеспечить, чтобы все файндинги попадали в эту категорию, оставляя другие категории пустыми.
Третья категория — Info, она относится к находкам, которые могут не влиять напрямую на состояние vSAN, но важны для повышения общего здоровья и эффективности кластера vSAN. Эта категория включает в себя некоторые передовые методы и рекомендации, направленные на оптимизацию производительности и стабильности кластера vSAN.
Четвертая категория — Silenced. Если вы заглушите любые файндинги из других категорий, они появятся здесь. Если у вас есть проблемы, которые вы активно решаете в течение длительного времени, или по какой-либо другой причине предпочитаете не отображать их в категории Unhealthy или других категориях, вы можете нажать на Silence Alert, чтобы переместить их в эту категорию.
В следующем посте автор рассмотрит утилиту vSAN Cluster Monitoring.
В продукт VMware Skyline Advisor Pro, предназначенный для генерации умных проактивных рекомендаций (Findings), новые фичи добавляются каждый месяц (правда, в последний раз мы писали несколько месяцев назад об этом тут). Результаты приоритезируются на основе актуальных проблем при обращениях в техническую поддержку VMware, особенностей, выявленных в процессе обзора работы с тикетами, уязвимостей безопасности, проблем, выявленных инжиниринговой командой VMware, а также улучшений предлагаемых клиентами.
В январе было выпущено 60 новых рекомендаций. Из них 37 основаны на текущих проблемах, 9 - на обзорах после работы с тикетами, 1 - на основе рекомендаций безопасности VMSA и 12 - на основе предложений пользователей. В VMware выбрали несколько из этих результатов, которые наиболее ценны в этом релизе - приведем их ниже.
Уязвимости безопасности
В критическом патче VMSA-2024-0001 обновления VMware Aria Automation (ранее известного как vRealize Automation) решают проблему отсутствия контроля доступа (CVE-2023-34063). Аутентифицированный злоумышленник может использовать уязвимость так, что это приведет к несанкционированному доступу к удаленным организациям и рабочим процессам. Эта проблема была устранена в Aria Automation 8.16. Также доступны постпатчи для Aria Automation 8.11.2, 8.12.2, 8.13.1 и 8.14.1, которые будут добавлены в VMware Skyline Advisor Pro в будущем.
Обзор после эскалации тикетов
Техническая поддержка VMware разработала процесс ревью после эскалации. Инженеры анализируют критические тикеты, поступающие команде управления эскалациями, для которых определяются шаги для предотвращения таких эскалаций в будущем с другими клиентами. Одним из результатов этого является создание рекомендаций Skyline. Техническая поддержка VMware разработала строгий процесс обзора после эскалации для анализа критических ситуаций. Основная цель - всесторонний анализ этих эскалаций, выявление корневых причин и формулировка мер предотвращения.
В KB 95965 для vSphere 8.0 Update 2 файлы Changed Block Tracking (CBT) могут стать несогласованными, что может привести к неправильной записи резервных копий. Эта проблема проявляется только при создании резервных копий после расширения диска ВМ в горячем режиме. Простое изменение размера диска выключенной машины не вызовет этой проблемы. Ситуация может возникнуть с дисками всех типов хранилищ (VVOL, VMFS, NFS, vSAN). Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление о выходе исправления.
Также в KB 96065 для vCenter Server 8.0 Update 2 при попытке выполнения операций с виртуальными машинами операция висит и завершается после долгого времени или не завершается вовсе. Из-за нечувствительности к регистру символов в полном имени хоста vCenter Server в URL-адресе назначения умных прокси (Envoy sidecar proxy), при использовании верхнего регистра символов в именах хостов vCenter Server получаются висячие вызовы к службе VSM. Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление о выходе исправления.
Ну и в KB 96049 для vCenter Server 8.0U2 описана проблема, проявляющася при попытке выполнения операций с виртуальными машинами - операция висит и завершается, либо не завершается вовсе. Корневой причиной является отсутствие файлов jar в пакете службы VSM. Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление, когда будет доступно исправление.
Ну а полный список новых рекомендаций для релиза Skyline Advisor Pro Proactive Findings – January 2024 Edition вы можете посмотреть тут.
При использовании VMware SDDC Manager иногда вам нужно перезапустить неудачно выполненную задачу. Для этого вам просто нужно нажать кнопку "Retry Task" в панели задач. Однако иногда вам нужно изменить входные данные для этой задачи, например, у вас есть опечатка в IP-адресе. Также материалы этой статьи помогут вам понять глубже о том, как устроено исполнение задач в SDDC Manager.
Для начала вам нужно включить доступ к SDDC Manager по API, который, начиная с VCF 5.0, отключен по умолчанию по соображениям безопасности. Вам необходимо его включить, чтобы иметь возможность использовать команду curl.
Войдите в консоль виртуального модуля SDDC Manager по SSH с учетной записью "vcf" и переключитесь на "root‘, используя команду su -
Откройте файл application-prod.conf, который находится в директории /etc/vmware/vcf/domainmanager/
Добавьте следующую строку в конец файла: vcf.vault.http-access=true
Сохраните файл
Перезапустите службу доменного менеджера следующей командой: # systemctl restart domainmanager и подождите несколько минут
Далее переходим к редактированию самой задачи:
1. Войдите в пользовательский интерфейс SDDC Manager, перейдите к неудачно выполненной задаче и скопируйте ID задачи из URL. Смотрите пример на скриншоте ниже. Убедитесь, что вы не скопировали скобку в конце URL.
2. Затем войдите в SDDC Manager по SSH и переключитесь на пользователя "root", используя команду su -.
3. Чтобы изменить параметры входных данных задачи, вам нужно получить спецификацию задачи, выполнив следующую команду:
Для TASK_ID используйте ID, который вы скопировали в самом начале
Для FILENAME выберите имя нового файла, который будет содержать спецификацию JSON для задачи
4. Откройте JSON-файл в папке tmp в текстовом редакторе, внесите необходимые корректировки (например, поменяйте IP-адрес) и сохраните его.
5. Перезапустите задачу с измененным JSON-файлом, используя следующую команду:
# curl -H 'Content-Type:text/plain' -X PUT http://localhost/domainmanager/internal/vault/<TASK_ID> -d @/tmp/<MODIFIED_JSON_FILE>.json
Для ‘TASK_ID‘ используйте тот же ваш ID, а для MODIFIED_JSON_FILE - имя файла, который вы создали.
6. Вернитесь в пользовательский интерфейс SDDC Manager и перезапустите неудачно выполненную задачу, нажав кнопку "Retry Task". Теперь задача должна перезапуститься с новыми значениями.
Не забудьте изменить свойства файла application-prod.conf обратно на исходные, удалив строку vcf.vault.http-access=true и перезапустив службу domainmanager в SDDC Manager.
На сайте проекта VMware Labs вышло очередное обновление утилиты vSphere Diagnostic Tool 1.1.6. Напомним, что это python-скрипт, который запускает диагностические команды на виртуальном модуле Photon OS (на его базе построен, например, vCenter Server Appliance), а также в перспективе это будет работать и в среде VMware ESXi. О последнем обновлении vSphere Diagnostic Tool (VDT) мы писали вот тут.
Давайте посмотрим на новые возможности vSphere Diagnostic Tool 1.1.5:
Общие улучшения:
Увеличен таймаут проверок с 10 до 20 секунд
Исправлена проблема, когда версия/топология идентифицировались некорректно
Проверка VC VMDIR:
Была добавлена проверки Domain Functional Level (DFL) для обнаружения дополнительных возможных проблем
Проверка сертификатов vCenter:
Проверка идентификатора ключа на предмет того, что он не заполнен
Новая проверка для подсчета объектов CRL в разделе TRUSTED_ROOT_CRLS
Скачать VMware vSphere Diagnostic Tool 1.1.6 можно скачать по этой ссылке.
На днях компания VMware анонсировала новую версию решения Skyline Health Diagnostics 4.0 (SHD). Напомним, что это решение является полноценной платформой для самодиагностики, позволяющей обнаруживать проблемы, используя журналы, анализ конфигураций и другую информацию. Она предоставляет рекомендации в виде статьи базы знаний с процедурами для устранения проблем в продуктах vSphere, vSAN, VMware Cloud Foundation SDDC Manager и VMware Horizon. Этот инструмент также может помочь выявлять проблемы до того, как они усугубятся и приведут к дорогостоящим простоям.
SHD теперь преобразовался в объединенный диагностический инструмент, который обеспечивает как проактивную, так и реактивную проверку состояния и диагностику для различных продуктов VMware. Это решение является совместной инициативой отделов разработки и глобальной поддержки VMware с целью улучшения опыта взаимодействия с поддержкой VMware. SHD сокращает время простоя за счет управления операциями Day-2 и обеспечивает бесшовные обновления.
Вот новые функции SHD 4.0, анонсированные на этой неделе:
Включено более 2000+ сигнатур для быстрого определения блокировок и проблем в виртуальной среде во время Day-2 операций. Эти сигнатуры основаны на наиболее важных обращениях в службу поддержки в прошлом, связанных как с продуктовыми трудностями, так и с проблемами окружения.
Диагностика и проверка состояния на основе профилей.
Поддержка продуктов VMware Horizon и SD-WAN, начиная с SHD 4.0.
Оценка возможности обновления VMware Cloud Foundation.
Полностью поддерживаемые API для выполнения задач в SHD.
Опция апгрейда для SHD 4.0.
Развертывание и управление SHD через единую консоль.
1. Диагностика и проверка состояния на основе профилей
Здесь появились следующие новые функции:
Улучшения пользовательского интерфейса для обеспечения лучшего пользовательского опыта. Теперь доступны создание и запуск диагностики и предварительных проверок на определенном сайте (vCenter, VSAN, VCF, Horizon и хосты ESXi) и в определенной среде.
Теперь можно сохранять выполненные проверки в виде профилей для последующего использования и автоматически назначать профили для еженедельного, ежемесячного и ежегодного выполнения.
SHD 4.0 способен в ручном режиме исполнять сохраненные профили, так что пользователь может выполнить любой профиль в будущем.
Созданные профили могут быть скопированы, отредактированы в рамках рабочего процесса и выполнены.
2. Поддержка продуктов VMware Horizon и SD-WAN в SHD 4.0
Здесь следующие улучшения:
Добавлено более 60 плагинов для VMware Horizon.
SD-WAN теперь находится в режиме технического превью с функциями офлайн-аналитики.
Добавлено более 80 подписей для SD-WAN с офлайн-анализом.
3. Оценка возможности обновления VMware Cloud Foundation
Вот что нового в этой категории:
SHD 4.0 теперь имеет отдельную диагностику SDDC Manager, которая может быть выполнена в среде VCF.
SHD 4.0 теперь может запускать оценку возможности обновления для сред VMware Cloud Foundation, начиная с VCF 4.5 и для более поздних версий.
Интегрированный с SHD механизм оценки теперь способен валидировать и отмечать текущие проблемы (с продуктом или средой), чтобы пользователи могли исправить их до обновления VCF.
4. Полностью поддерживаемые API, доступные начиная с SHD 4.0
Что интересного появилось для работы через API:
API теперь категоризированы по продуктам.
Загрузка офлайн-анализа журналов из удаленных и локальных мест через API.
Редактирование и создание профилей через API.
Обновления на основе API в базе данных совместимости VMware
5. Варианты апгрейда с SHD 4.0
Для апгрейда с предыдущих версий SHD к SHD 4.0 нужно загрузить виртуальный модуль в формате OVA.
Обновления на предыдущие версии теперь не поддерживаются, так как SHD 4.0 - это мажорный релиз.
6. Развертывание и управление SHD через единую консоль
Начиная с vSphere 8 U1, достаточно просто войти в клиент vSphere, чтобы развернуть SHD и выбрать конкретный vCenter в режиме ELM для развертывания.
Клиент vSphere теперь полностью позволяет управлять и развертывать SHD из единой консоли.
Release Notes по продукту доступны тут, документация здесь, а скачать VMware Skyline Health Diagnostics 4.0 можно по этой ссылке.
Таги: VMware, Skyline, Update, Troubleshooting, Support
На сайте проекта VMware Labs обновилась утилита vSphere Diagnostic Tool
до версии 1.1.5. Напомним, что она представляет собой python-скрипт, который запускает диагностические команды на виртуальном модуле Photon OS (на его базе построен, например, vCenter Server Appliance), а также в перспективе это будет работать и в среде VMware ESXi. О последнем обновлении vSphere Diagnostic Tool (VDT) мы писали вот тут.
Давайте посмотрим на новые возможности vSphere Diagnostic Tool 1.1.5.
VDT 1.1.5 больше не поддерживает vCenter 6.7, хотя многие проверки все еще будут работать. 1.1.4 останется доступной для тех, кто все еще нуждается в ней для продуктовой линейки 6.x.
Учетные данные теперь проверяются в самом начале. Пользователю сообщается, что проверки, требующие аутентификации, не будут запускаться, если проверка пароля трижды не удастся.
Поведение при тайм-ауте изменилось. Теперь он предлагает пользователю пропустить проверку или позволить ей выполниться, вместо того чтобы требовать флаг --force.
Проверка базы данных vCenter:
Проверка VCDB теперь показывает уровни статистики, а также политики хранения задач и событий.
Выходные данные проверки VCDB теперь соответствуют результатам из KB 1028356.
Проверка vCenter VMDIR:
Проверка vmdir теперь включает информацию о партнерах ELM и тестирует подключение к портам через 389, 443, 2012 и 2020 к ним.
Старая проверка портов была удалена в пользу описанной выше.
Проверка vmdir теперь ищет устаревшую (нативную) конфигурацию PSC HA в реестре likewise.
Проверка сертификата vCenter:
Срок действия сертификата теперь отображается с каждым сообщением о сертификате.
Сертификат vmdir от 6.0 больше не включен в список проверок сертификатов.
Исправление ошибок:
VDT теперь декодирует в utf-8, а не в ascii, чтобы избежать ошибок парсинга.
Обновлены ссылки на KB.
Скачать vSphere Diagnostic Tool 1.1.5 можно по этой ссылке.
Дункан Эппинг опубликовал интересную статью, касающуюся проблем, возникающих в растянутом кластере VMware vSAN при различных сценариях отказов в нем.
В некоторых из приведенных ниже сценариев Дункан обсуждает сценарии разделения кластера. Под разделением подразумевается ситуация, когда и L3-соединение с компонентом Witness, и ISL-соединение с другим сайтом недоступны для одного из сайтов. Так, на примере приведенной выше диаграммы, если говорится, что сайт B изолирован - это означает, что сайт A все еще может общаться со свидетелем, но сайт B не может общаться ни со свидетелем, ни с сайтом A.
Во всех следующих сценариях действуют следующие условия: сайт A является предпочтительным местоположением, а сайт B - второстепенным. Что касается таблицы ниже, то первые два столбца относятся к настройке политики для виртуальной машины, как показано на скриншоте:
Третий столбец относится к местоположению, откуда виртуальная машина работает с точки зрения вычислительных ресурсов (хоста ESXi). Четвертый описывает тип сбоя, а пятый и шестой столбцы детализируют наблюдаемое в этом случае поведение.
Site Disaster Tolerance
Failures to Tolerate
VM Location
Failure
vSAN behavior
HA behavior
None Preferred
No data redundancy
Site A or B
Host failure Site A
Objects are inaccessible if failed host contained one or more components of objects
VM cannot be restarted as object is inaccessible
None Preferred
RAID-1/5/6
Site A or B
Host failure Site A
Objects are accessible as there's site local resiliency
VM does not need to be restarted, unless VM was running on failed host
None Preferred
No data redundancy / RAID-1/5/6
Site A
Full failure Site A
Objects are inaccessible as full site failed
VM cannot be restarted in Site B, as all objects reside in Site A
None Preferred
No data redundancy / RAID-1/5/6
Site B
Full failure Site B
Objects are accessible, as only Site A contains objects
VM can be restarted in Site A, as that is where all objects reside
None Preferred
No data redundancy / RAID-1/5/6
Site A
Partition Site A
Objects are accessible as all objects reside in Site A
VM does not need to be restarted
None Preferred
No data redundancy / RAID-1/5/6
Site B
Partition Site B
Objects are accessible in Site A, objects are not accessible in Site B as network is down
VM is restarted in Site A, and killed by vSAN in Site B
None Secondary
No data redundancy / RAID-1/5/6
Site B
Partition Site B
Objects are accessible in Site B
VM resides in Site B, does not need to be restarted
None Preferred
No data redundancy / RAID-1/5/6
Site A
Witness Host Failure
No impact, witness host is not used as data is not replicated
No impact
None Secondary
No data redundancy / RAID-1/5/6
Site B
Witness Host Failure
No impact, witness host is not used as data is not replicated
No impact
Site Mirroring
No data redundancy
Site A or B
Host failure Site A or B
Components on failed hosts inaccessible, read and write IO across ISL as no redundancy locally, rebuild across ISL
VM does not need to be restarted, unless VM was running on failed host
Site Mirroring
RAID-1/5/6
Site A or B
Host failure Site A or B
Components on failed hosts inaccessible, read IO locally due to RAID, rebuild locally
VM does not need to be restarted, unless VM was running on failed host
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A
Objects are inaccessible in Site A as full site failed
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Partition Site A
Objects are inaccessible in Site A as full site is partitioned and quorum is lost
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Witness Host Failure
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Full failure Site A
Objects are inaccessible in Site A as full site failed
VM does not need to be restarted as it resides in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Partition Site A
Objects are inaccessible in Site A as full site is partitioned and quorum is lost
VM does not need to be restarted as it resides in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Witness Host Failure
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Network failure between Site A and B (ISL down)
Site A binds with witness, objects in Site B becomes inaccessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Network failure between Site A and B (ISL down)
Site A binds with witness, objects in Site B becomes inaccessible
VM restarted in Site A
Site Mirroring
No data redundancy / RAID-1/5/6
Site A or Site B
Network failure between Witness and Site A/B
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, and simultaneous Witness Host Failure
Objects are inaccessible in Site A and Site B due to quorum being lost
VM cannot be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, followed by Witness Host Failure a few minutes later
Pre vSAN 7.0 U3: Objects are inaccessible in Site A and Site B due to quorum being lost
VM cannot be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, followed by Witness Host Failure a few minutes later
Post vSAN 7.0 U3: Objects are inaccessible in Site A, but accessible in Site B as votes have been recounted
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Full failure Site B, followed by Witness Host Failure a few minutes later
Post vSAN 7.0 U3: Objects are inaccessible in Site B, but accessible in Site A as votes have been recounted
VM restarted in Site A
Site Mirroring
No data redundancy
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, if components reside on failed host then object is inaccessible in Site B
VM cannot be restarted
Site Mirroring
No data redundancy
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, if components do not reside on failed host then object is accessible in Site B
VM restarted in Site B
Site Mirroring
RAID-1/5/6
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, accessible in Site B as there's site local resiliency
VM restarted in Site B
Таги: VMware, vSAN, Troubleshooting, HA, DR, Blogs
Это средство представляет собой "проверяльщик" предварительных требований для установки решения Horizon и позволяет администраторам проверить совместимость инфраструктуры, необходимой для установки Horizon Connection Server.
Важным аспектом успешного развертывания среды VDI Horizon является предварительная проверка готовности инфраструктуры. Администраторы Horizon могут использовать Pre-req Checker, чтобы валидировть инфраструктуру и создать отчет о проверке требований.
Pre-req Checker предназначен для использования перед планируемой установкой и настройкой Connection Server, чтобы выявить возможные проблемы, которые могут потребовать времени для решения. Например, изменения в службах Active Directory или DNS.
Среда Horizon зависит от компонентов и инфраструктуры, таких как контроллеры домена Active Directory, группы портов сети, сервер баз данных, подключение к vCenter и ESXi, доступность компонентов и готовность операционной системы Windows Server.
Цель Pre-req Checker - дать зеленый свет администратору, что свидетельствует о готовности виртуальной машины для продолжения установки и настройки Connection Server, либо выявить проблемы с предварительными требованиями, указать причину сбоя и дать рекомендации по их устранению.
Итоговый отчет выглядит следующим образом:
Скачать Horizon Installation Pre-req Checker можно по этой ссылке.
В начале года компания VMware выпустила решение Aria Operations for Applications, предназначенное для облачных провайдеров, которое позволяет их клиентам наблюдать за инфраструктурой контейнеризованных приложений на платформе Tanzu. Ранее этот продукт назывался Tanzu Observability.
Решение позиционируется как платформа cloud-native observability, доступная для партнеров через портал Cloud Partner Navigator (CPN), которые участвуют в программе VMware Managed Service Providers (MSP). Aria Operations for Applications дает партнерам инструменты для команд DevOps, SecOps и SRE в части получения данных телеметрии, которые помогают планированию стратегии управления приложениями, API, базами данных, очередями сообщений для публичных, частных и гибридных облаков.
Сегодня мы поговорим о функциональности Query Analyzer, которая появилась в последней версии продукта. Она позволяет анализировать запросы и подзапросы в ситуациях, когда в результате запроса на графике не отображаются данные с пометкой No Data:
Query Analyzer позволяет найти проблему в ваших запросах и понять причину отсутствующих данных, начать процедуру решения проблем, а также получить статистики производительности запросов и подзапросов.
Если вы используете переменные в ваших запросах, Query Analyzer заменяет переменные их актуальными на данный момент значениями. Например, если вы хотите проанализировать max(${latency}), где переменная latency равна ts(requests.latency, source="app-1*" or source="app2*", env="dev"), то в Query Analyzer вы увидите такой запрос:
max(ts(requests.latency, source="app-1*" or source="app2*", env="dev"))
Итак, как проанализировать запрос:
Нажимаем на имя графика, который показывает No Data для открытия режима правки.
Если у вас несколько запросов, то найдите тот, который хотите проанализировать.
Нажмите на иконку рядом с запросом и выберите пункт Query Analyzer, после чего он откроется.
Сам анализатор выглядит так:
Нажимаем кнопку Analyze, чтобы найти проблемный запрос. В результате подзапрос, который вызывает проблему, будет подсвечен:
Здесь можно увидеть информацию о найденных проблемах:
У ситуации No Data может быть несколько причин, например:
Опечатка в запросе
В Aria Operations for Applications действительно нет данных для этого запроса
Запрос содержит один или несколько подзапросов, результат которых не содержит данных
Также на скриншоте выше вы видите, что Query Analyzer показывает статистики производительности на уровне подзапросов, содержащие 3 параметра:
Cardinality - число уникальных снятий данных в рамках временного интервала запроса (unique time series).
Points Scanned - число датапоинтов, которое использовалось для вывода графика на экран.
Duration - время между началом исполнения запроса и получением результата.
Если запрос содержит более одного подзапроса, который содержит No Data, то когда вы анализируете запрос, то первый подзапрос с пустыми данными будет отображен в разделе Detected Issues. Остальные подзапросы с No Data будут подчеркнуты пунктиром - их также можно развернуть для просмотра обнаруженных проблем.
Более подробно о функционале Query Analyze можно почитать в документации.
На днях компания VMware объявила о выходе новой версии облачного решения Aria Operations for Logs February 2023, которое предназначено для агрегации данных логов, их глубокой аналитики и визуализации различных метрик в рамках дэшбордов.
О возможностях прошлой онпремизной версии Aria Operations for Logs 8.10 мы писали в октябре прошлого года вот тут (напомним, что раньше этот продукт назывался Log Insight).
Основная возможность февральского релиза - это доступность контент-пака инфраструктуры Tanzu Kubernetes Grid для лог-процессора FluentBit. Как знают администраторы контейнерных сред, FluentBit - это один из самых популярных движков для логов, а теперь с помощью TKG content pack вы можете перенаправлять логи Tanzu в Aria Operations for Logs, просматривать там различные события и выполнять операции по решению проблем в инфраструктуре контейнеров.
Вот пример списка дэшбордов, которые становятся доступными при интеграции контент-пака:
В рамках API обрабатываются события сервера, среды управления, консоли управления, подов и планировщика. Также посмотрим на некоторые предсозданные дэшборды из TKG content pack. Вот, например, события API Server, разбитые также по кластерам и подам:
А вот отчет о событиях TKG events, которые решение FluentBit отправляет в продукт Aria Operations for Logs. Множество типов передаваемых данных позволят вам гибко построить полезные дэшборды и запросы:
Так что если вы используете Tanzu Kubernetes Grid и решение Aria Operations for Logs, то обязательно установите новый контент-пак, чтобы обрабатывать Таги: VMware, Aria, Logs, Operations, Troubleshooting, Kubernetes, TKG, Update, Cloud
На сайте проекта VMware Labs появилась первая новая утилита этого года - Horizon Cloud Service next-gen Edge Subnet URL Checker. Она предназначена для автоматизированной проверки доменов VMware/Azure, описанных в документации VMware pre-onboarding documentation, на их валидность.
Продолжаем рассказывать об интересных новых утилитах, появившихся в последнее время на сайте проекта VMware Labs. Сегодня мы посмотрим на средство End User Computing - Diagnostic Tool версии 1.0 (EDT), которое появилось недавно. С помощью него можно получить диагностические данные в реальном времени об окружении инфраструктуры виртуальных десктопов и ее состоянии, что позволяет исполнять процессы по обнаружению проблем и их исправлению в VDI-среде.
EDT - это Windows-приложение, которое содержит в себе лучшие практики по решению проблем, которые на данный момент доступны для продукта VMware Workspace ONE UEM, но скоро будут работать и для других решений. EDT использует SQL и PowerShell, исполнение которых происходит в окружении Python, чтобы собрать информацию о конфигурациях и выполнить проверки типа Pass/Fail при обнаружении часто встречающихся проблем.
Важно, что EDT предоставляет дополнительную диагностическую информацию в виде отчета, чтобы оценить требуемые действия по исправлению ситуации. Также для пользователей есть статья VMware KB 88683, в которой есть руководство по самостоятельному исправлению некоторых проблем при неуспешных результатах тестов:
Кроме того, EDT позволяет построить профиль окружения, которое можно отправить в техническую поддержку (Global Support), чтобы минимизировать объем коммуникаций с ее сотрудниками.
Для работы поддерживается комбинация любых из следующих компонентов Workspace ONE UEM:
WorkspaceOne UEM Console
WorkspaceOne UEM Device Services
WorkspaceOne UEM API
WorkspaceOne UEM ACC
WorkspaceOne UEM AWCM
Сама утилита End User Computing - Diagnostic Tool может работать в ОС Windows Server 2012 R2, Windows Server 2016 или Windows Server 2019. Скачать ее можно по этой ссылке.
На сайте проекта VMware Labs вышло обновление средства Horizon Peripherals Intelligence версии 4.0, предназначенного для самодиагностики периферийных устройств пользователями решения VMware Horizon (о прошлой версии этого решения мы писали вот тут). C помощью данного продукта можно проверить работоспособность и поддержку устройств как со стороны конечных пользователей, так и администраторов платформы Horizon.
Напомним, что утилита Horizon Peripherals Intelligence служит для решения следующих задач:
Публикация отчета о диагностике устройств по запросу конечных пользователей
Обслуживание спектра пользовательских устройств в рамках поддерживаемых со стороны официального списка совместимости device compatibility matrix
Возможность получения администратором доступа к метаданным устройств в каждой категории, где он может загружать, изменять и удалять метаданные, таким образом обслуживая матрицу поддерживаемых устройств на машинах пользователей
Посмотрим, что нового появилось в Horizon Peripherals Intelligence 4.0:
Переработанное представление диагностического отчета для лучшего отображения устройств и их проблем.
Добавлена поддержка Mac-клиента на платформах M1/M2, а также Intel Mac. Кроме того, сделан универсальный установщик Mac-плагинов.
Добавлена поддержка следующих устройств в диагностическом отчете на Mac-клиенте: USB-диск, сканер, принтер, камера, а также USB клавиатура и мышь.
Добавлены возможности плагина по совместимости с анти-кейлоггерами на Windows и Mac.
Текстовый формат диагностического отчета для того, чтобы можно было им поделиться с IT-администраторами для исправления проблем.
СкачатьVMware Horizon Peripherals Intelligence 4.0 можно по этой ссылке.
В августе этого года компания VMware обновила свои решения для проактивного получения рекомендаций по технической поддержке продуктов линейки VMware vSphere - Skyline Advisor Pro
и Skyline Collector 3.2. Напомним, что с помощью этих продуктов пользователи и инженеры технической поддержки VMware (Technical Support Engineers, TSEs) могут просматривать информацию об инфраструктуре клиента и предоставлять информацию о текущем состоянии инфраструктуры, а также выдавать полезные рекомендации по ее улучшению.
Если у вы применяете автоматический апгрейд со Skyline версии 3.1, то имейте в виду, что есть некоторые проблемы с таким типом обновления, описанные в KB 89230. В ручном режиме апгрейд проходит нормально.
В Skyline Collector версии 3.2 исправлена проблема с решением NSX-T. При обновлении NSX-T с версии 3.x на 4.0.x компонент Collector версии 3.1 падал. Подробнее вы можете почитать об этом в KB89303. В версии Collector 3.2 эта проблема решена.
Итак, что нового появилось в Skyline Advisor Pro
и Skyline Collector 3.2:
1. Улучшения дэшбордов
Теперь можно кликнуть на один из элементов Active Findings, Findings Type, Findings Category, Support Requests и Active Log Assists для перехода в детальное представление каждой из этих секций прямо из главного дэшборда.
Также фильтры теперь интегрированы напрямую в дэшборд (gif-картинка откроется в новом окне по клику):
2. Самостоятельные отчеты для пользователей VMware Success 360 и Premier Services
Если вы пользователь VMware Success 360 или Premier Services, то у вас теперь есть доступ к разделу самообслуживания Proactive Insights Reports. Эти отчеты заменят Operational Summary Reports (OSR), которые есть у клиентов Premier Services (новые OSR больше не будут создаваться и придут в статус End of Life 17 октября этого года).
Gif-картинка откроется в новом окне по клику:
3. Ускоренная доставка email-нотификаций
Если пользователь подписался на email-оповещения для критических объектов Findings, то теперь они будут получены в течение 24 часов вместо 48 в прошлых версиях.
Gif-картинка откроется в новом окне по клику:
4. Новые объекты Proactive Findings
В новой версии Skyline было добавлено несколько объектов Findings, включая новые уязвимости и наиболее часто возникающие и просматриваемые пользователями проблемы. Подробнее о добавленных Findings можно почитать вот тут.
Gif-картинка откроется в новом окне по клику:
Более подробно о нововведениях Skyline Advisor Pro
и Skyline Collector 3.2 можно почитать в материалах сообщества по продукту Skyline.
Пользователи облачной инфраструктуры VMware Cloud в части гибридных облаков (то есть комбинации онпремизных ресурсов и инфраструктуры публичного облака) имеют в своем распоряжении такой инструмент, как CloudHealth. С помощью него можно получить информацию о доступности и состоянии всех облачных ресурсов различных вендоров в единой консоли администратора.
Сегодня мы рассмотрим пример поиска причины проблем (Root Cause Analysis), которые возникают в виртуальной инфраструктуре. Метод RCA основан на обнаружении и исследовании аномалий, которые администратор может изучить путем анализа основных показателей виртуальной облачной среды.
CloudHealth позволяет не только обнаружить саму аномалию, но и посмотреть дополнительную информацию о ней, например, вот что мы можем увидеть в аналитике инстанса Amazon EC2:
Как мы видим, в какой-то момент произошло увеличение затрат на содержание инфраструктуры. Далее мы можем "провалиться" в детальный RCA-анализ аномалии, нажав на кнопку View Root Cause в правом верхнем углу:
На картинке выше мы видим, что в какой-то момент существенно увеличился объем передаваемых данных. Чтобы увидеть, когда именно больше всего выросли затраты, можно отсортировать колонку Unblended Cost по убыванию - это даст нам возможность понять, что произошло:
Теперь рассмотрим пример для службы AmazonS3 Service. Также перейдем к конкретному ресурсу, который вызвал данную аномалию:
Здесь мы видим, что 14 апреля произошел всплеск запросов Tier-2, что и привело к увеличению затрат на сервис (то есть проблема не заключается, например, в изменении стоимости услуг со стороны Amazon/VMware).
За последние пару месяцев на сайте проекта VMware Labs вышло несколько обновлений утилиты vSphere Diagnostic Tool. Напомним, что это средство представляет собой python-скрипт, который запускает диагностические команды на виртуальном модуле Photon OS (на его базе построен, например, vCenter Server Appliance), а также в перспективе это будет работать и в среде VMware ESXi. О первой версии vSphere Diagnostic Tool мы писали вот тут.
Основное назначение данной утилиты - дать администраторам быстрое средство траблшутинга, которое они могут использовать для первичной идентификации наиболее распространенных проблем. Если все проверки пройдут успешно, то дальше уже можно более глубоко изучать логи и проводить дополнительные тесты.
Давайте посмотрим, что нового появилось в vSphere Diagnostic Tool (сейчас актуальная версия 1.1.4) с момента ее последнего релиза:
Исправлены проблемы со спецсимволами в паролях
Тесты имеют таймаут 10 секунд, а ключ -f используется для пропуска таймаутов
Название проверки выводится еще до ее запуска
Проверка VC Disk Space Check теперь игнорирует раздел proc
Проверка VC Info Check теперь имеет приятный вывод и возможность вывода во внешний канал PSC
Улучшены проверки VC Core Check
Исправлено множество ошибок, связанных с обработкой паролей и сертификатов
Скорее всего, данное средство включат в будущем в состав инфраструктурных продуктов линейки VMware vSphere для проверки виртуальных модулей на базе Photon OS (а это уже почти все продукты, построенные на базе хостовой ОС Linux, вроде vCSA).
Скачать утилиту vSphere Diagnostic Tool можно по этой ссылке.
Таги: VMware, Labs, Troubleshooting, Update, vSphere, vCSA, vCenter, Photon OS
Многие пользователи продукта VMware Skyline используют функциональность Log Assist для быстрой генерации бандла поддержки (support bundle), который используется при поиске проблем в инфраструктуре с помощью команды технической поддержки VMware Technical Support Engineers (TSEs).
Средствами Log Assist можно автоматизировать процесс отправки серверных логов в техподдержку VMware через виртуальный модуль Skyline Collector Appliance. Теперь такие возможности есть и для компонента SDDC Manager, предназначенного для управления составляющими виртуального датацентра.
Последний релиз Log Assist поддерживает консоль SDDC Manager, ключевой компонент инфраструктуры VMware Cloud Foundation. Вот как это выглядит:
Для работы этой возможности вам понадобится Skyline Collector версии 3.1 или выше, а также VMware Cloud Foundation 4.3.1 или новее.
Ну а вот как подключить ваш компонент Collector к эндпоинтам инфраструктуры VCF:
Вводим имя FQDN или IP-адрес компонента SDDC Manager.
Вводим Account Username для соединения с SDDC Manager (этот аккаунт должен иметь роль ADMIN или OPERATOR для использования с Log Assist).
Вводим пароль и после этого добавляем SDDC Manager в Skyline Collector, нажав Add.
Более подробно обо всем этом можно почитать в документации по VMware Skyline.
Таги: VMware, Skyline, Log Assist, Troubleshooting, Support
Компания VMware в конце января объявила о том, что ее сервис Skyline доступен через партнерскую сеть облачных сервис-провайдеров (Cloud Providers, они же участники программы VCPP), которые предоставляют свои услуги, используя платформу Cloud Partner Navigator (CPN). Напомним, что это решение предназначено для проактивного получения рекомендаций по технической поддержке продуктов линейки VMware vSphere, включая vSAN. В частности, с помощью VMware Skyline пользователи и инженеры технической поддержки VMware (Technical Support Engineers, TSEs) могут делать заключения о правильности работы виртуальной инфраструктуры и вырабатывать основные рекомендации по ее улучшению.
С помощью Skyline Advisor пользователи могут получать проактивную аналитику для своей виртуальной инфраструктуры в целях идентификации текущих и будущих проблем. Он поддерживает не только продукты vSphere, vSAN, NSX, vROps и Horizon, но и среды Cloud Foundation и Dell EMC VxRail.
Все партенры, имеющие доступ к VMware Partner Connect с действующим соглашением VMware Cloud Provider Program agreement, могут получить доступ к поддержке уровня Production. А начиная с 27 января, у них уже есть доступ к сервисам VMware Skyline.
Для сервис-провайдеров тут будет 2 больших плюса:
Получение инструмента, который позволяет обозначать проблемы пользователей еще до их появления и проактивно действовать в этом направлении.
Быстро и удобно взаимодействовать с поддержкой VMware через единый портал для ускорения решения проблем пользователей.
На данный момент сервисы Skyline доступны для следующих продуктов:
VMware vSphere
VMware NSX
VMware vSAN
VMware vRealize Operations
VMware vRealize Automation
VMware Cloud Foundation.
Также сервис распознает Skyline инфраструктуру VxRail и инсталляции типа VMware Validated Design.
Если вы являетесь сервис-провайдером VCPP и уже имеете доступ к Cloud Partner Navigator, то сервис доступен в разделе "Services Available for Provisioning".
Таги: VMware, Skyline, VCPP, Cloud, Update, Troubleshooting, Support
Мы часто пишем о продукте VMware vReazlie Log Insight, который бывает в двух вариантах - облачном (Log Insight Cloud) и онпремизном. Он предназначен для аналитики лог-файлов и мониторинга инфраструктуры в облаке. Решение очень удобно для администраторов, сотрудников технической поддержки и системных инженеров, которые ищут причины проблем различного характера в виртуальной инфраструктуре и решают их...
На днях компания VMware обновила свое облачное решение VMware vRealize Log Insight Cloud. Напомним, что это решение предназначено для аналитики лог-файлов и мониторинга инфраструктуры в облаке. О прошлой версии этого продукта мы писали вот тут.
Давайте посмотрим, что появилось нового в декабрьском обновлении vRLI Cloud:
1. Расширение локаций, где доступен продукт
Теперь Log Insight Cloud можно получить в регионе Asia Pacific (Tokyo, Japan).
Таким образом, полный список доступных регионов выглядит так:
US West (Oregon)
Europe (London, Frankfurt)
Canada (Central)
Asia Pacific (Sydney, Singapore)
South America (Sao Paulo)
Asia Pacific (Tokyo, Japan)
2. Загрузка локальных логов в облако
Часто администраторы загружают лог-файлы своей онпремизной инфраструктуры в облако во время пробного периода, для этого и предусмотрели данную возможность. Можно загружать файлы в формате .log и .txt и 10 файлов одновременно (до 10 МБ каждый).
3. Интеграция с AWS Lamba и HashiCorp Vault
Новая возможность интеграции с функциями платформы AWS Lambda теперь позволяет перенаправить логи CloudWatch, CloudTrail и многих других сервисов в Log Insight Cloud. Если вам нужна дополнительная безопасность по хранению учетных данных, то можно использовать функции интеграции с защищенным хранилищем учетных данных HashiCorp Vault.
4. Новые функции аудита событий через VMware Cloud Services Content Pack 2.0
Дополнительные аудируемые события контент-пака были добавлены для того, чтобы соблюсти регуляторные требования платформы VMware Cloud Service Portal (CSP). Теперь в VMware Cloud Services Content Pack 2.0 есть следующие новые события:
Access Request Raised by Org Members
Access Request Raised by Non Org Members
Entitlement Request for Org Member Cancelled
Entitlement Request for Non Org Member Cancelled
Entitlement Request Actions
Entitlement Request Approval Actions
Violation Policies Updated
Entity Violations Count Update OAuth App
Entity Violations Count Update API Token
Advance Features Toggled
5. Поддержка SSL для Cloud Proxy
Cloud Proxy получает логи и информацию о событиях из разных источников мониторинга и отправляет эти данные в vRealize Log Insight Cloud, которые уже дальше запрашиваются и анализируются. Теперь эти логи могут пересылаться по защищенному каналу SSL.
6. Алерты об изменении статуса форвардинга логов
Теперь по почте можно получать оповещения о следующих событиях:
Log Forwarding Disabled Temporarily – перенаправление логов отключено на несколько следующих минут, ввиду обнаружения слишком большого количества ошибок на источнике.
Log Forwarding Disabled – перенаправление логов отключено постоянно из-за невозможности установить соединение.
Попробовать vRealize Log Insight Cloud в виртуальной тестовой лаборатории и запросить пробную версию в облаке VMware Cloud on AWS можно по этой ссылке.
На сайте проекта VMware Labs обновилась полезная для администраторов VMware vSphere утилита VMware DRS Sump Insight до версии 2.1. Напомним, что это портал самообслуживания, куда пользователи могут загружать файлы дампов DRS. После этого будет выведена информация об операциях по перемещению виртуальных машин, которые рекомендует выполнить механизм балансировки нагрузки DRS. О прошлых версиях этой утилиты мы писали тут и тут.
В новой верси не так много нововведений:
Добавлена поддержка дампов VMware vSphere 7.0 Update 2 и Update 3
Минорные улучшение интерфейса и бэкенда
Исправления ошибок
Напомним также о специальном плагине на базе HTML5 к vSphere Client для данного сервиса. Он добавляет функции утилиты DRS Dump Insight в интерфейс vSphere Client, работающего с сервером vCenter Server Appliance (vCSA).
Скачать VMware DRS Sump Insight 2.1 можно по этой ссылке.
Некоторые Enterprise-администраторы знают, что у VMware есть такой сервис Skyline, предназначенный для проактивного получения рекомендаций по технической поддержке продуктов линейки VMware vSphere, включая vSAN. В частности, с помощью VMware Skyline пользователи и инженеры технической поддержки VMware (Technical Support Engineers, TSEs) могут просматривать некоторые заключения о работе виртуальной инфраструктуры и основные рекомендации по ее улучшению.
Skyline Advisor Pro построен на базе ранее существовавшего продукта Skyline Advisor, который доступен пользователям подписок Production и Premier, vRealize Cloud Universal, а также Success 360. С помощью этого решения пользователи могут получать проактивную аналитику для своей виртуальной инфраструктуры в целях идентификации текущих и будущих проблем. Оно поддерживает не только продукты vSphere, vSAN, NSX, vROps и Horizon, но и среды Cloud Foundation и Dell EMC VxRail.
Давайте взглянем на новые возможности этого продукта.
1. Теперь Skyline Advisor Pro работает быстрее.
В Skyline Advisor Pro реализован движок ускоренного анализа инфраструктуры, понимания необходимости обновлений и отслеживания изменений. Теперь вместо 48 часов в прошлой версии, сбор проблемных моментов и изменений inventory занимает 4 часа, что позволяет быстрее реагировать на инциденты и удобнее планировать активности администраторов по решению проблем (картинка - кликабельный gif):
2. Улучшения движка аналитики
Теперь Skyline Advisor Pro дает больше инсайтов об окружении, например, появился новый раздел End of Life Insights. В нем показывается, когда ваши развернутые решения больше не будут поддерживаться (окончание фаз General Support и Technical Guidance) в плане выпуска патчей, апдейтов и багофиксов. Эта возможность часто запрашивалась пользователями, чтобы дать возможность планирования своевременных апгрейдов виртуальных сред.
Кликните на картинку, чтобы открыть gif:
3. Функция Historical Insights
С помощью исторических данных Historical Insights администраторы могут ассоциировать некоторые ключевые события в своем окружении (например, изменения конфигурации) с рекомендациями, которые были сгенерированы в этот отрезок времени. Это позволяет в ретроспективе оценить полезный эффект от применения рекомендаций.
Посмотрите, как это работает (картинка кликабельна):
4. Функция Proactive Insights Report for Success 360
Она доступна только пользователям подписки Success 360 и предоставляется отдельной командой ИТ-специалистов VMware. Отчеты Proactive Insights генерируются при ее участии и могут быть использованы для регулярных проверок состояния виртуальной среды (там указаны конкретные действия по улучшению, которые были предприняты, а также еще имеющиеся рекомендации).
Также в этих отчетах доступно поле Resolution Type, которое определяет примерный объем усилий, которые нужно приложить для исправления проблемы. Например, применение некоторых рекомендаций не требует перезагрузки и их можно сгруппировать в единый пакет, применив который можно уже переходить к более "тяжелым" рекомендациям.
Ну и полезной также является возможность оставлять комментарии и пожелания о том, что планируется или хотелось бы сделать, чтобы совместно корректировать траекторию по оптимизации инфраструктуры (картинка кликабельна):
5. Новый Insights API
Теперь Skyline Advisor Pro предоставляет Insights API, который предоставляет данные Findings и Recommendations через программный интерфейс для любых сторонних решений в вашей инфраструктуре. Например, данные Findings можно отправить в Slack или создать тикет в ITSM-системе на базе информации, предоставленной Skyline Advisor Pro. Вот как это работает (кликните на картинку):
Также о работе Insights API есть отдельное видео:
Более подробно о продукте и сервисах VMware Skyline Advisor Pro можно узнать на этой странице.
На сайте проекта VMware Labs появилось еще одно полезное средство для администраторов виртуальной инфраструктуры - vSphere Diagnostic Tool. Оно представляет собой python-скрипт, который запускает диагностические команды на виртуальном модуле Photon OS (на его базе построен, например, vCenter Server Appliance), а также в перспективе это будет работать и в среде VMware ESXi.
Основное назначение данной утилиты - дать администраторам быстрое средство траблшутинга, которое они могут использовать для первичной идентификации наиболее распространенных проблем. Если все проверки пройдут успешно, то дальше уже можно более глубоко изучать логи и проводить дополнительные тесты.
Интересно, что данный продукт уже был протестирован во внутренней команде поддержки VMware, которая опробовала его на реальных пользователях.
Для vCenter Server Appliance 6.5 или более поздней версии можно выполнить следующие тесты:
Базовая информация о vCenter
Проверка Lookup Service
Проверка AD
Проверка сертификатов vCenter
Проверка основных файлов (Core File)
Проверка диска
Проверка vCenter DNS
Проверка vCenter NTP
Проверка портов vCenter
Проверка аккаунта Root
Проверка служб vCenter
Проверка механизма VCHA
В качестве результатов будет выдан один из статусов Pass/Warning/Fail, а также для статусов Warning и Fail выводятся ссылки на статьи KB, которые могут пригодиться для решения проблем в данной категории.
Команда заявляет, что в бэклоге проекта еще более 100 планируемых фич, поэтому следите за обновлениями скриптов. Скорее всего, данное средство включат в будущем в состав инфраструктурных продуктов линейки VMware vSphere для проверки виртуальных модулей на базе Photon OS (а это уже почти все продукты, построенные на базе хостовой ОС Linux, вроде vCSA).
Скачать vSphere Diagnostic Tool можно по этой ссылке.
Таги: VMware, vSphere, vCSA, Labs, Troubleshooting, ESXi, Support
Многим Enterprise-администраторам VMware vSphere знаком сервис VMware Skyline, который позволяет проактивно получать рекомендации по технической поддержке продуктов линейки VMware vSphere, включая vSAN.
С помощью технологии VMware Skyline пользователи и инженеры технической поддержки VMware (Technical Support Engineers, TSEs) могут просматривать некоторые заключения о работе виртуальной инфраструктуры и основные рекомендации по ее улучшению, которые содержатся в специальном отчете Skyline Operational Summary Report (OSR).
Если вы хотите спрятать некоторые советы и рекомендации, которые не требуют применения в вашей инфраструктуре, вы можете использовать специальные фильтры для вывода ненужных объектов. Например, можно спрятать Trivial Findings, которые не очень важны и только мешают увидеть серьезные проблемы.
Просто в левой панели выбираете нужный фильтр и нажимаете Hide Findings в разделе Active Findings:
Эти рекомендации не удаляются - их всегда можно увидеть на вкладке Hidden Findings (см. скриншот выше).
Далее спрятанные рекомендации можно экспортировать в CSV-файл, чтобы, например, обсудить их с командой техподдержки VMware или собственной командой:
Вторая полезная функция по сокрытию рекомендаций - это возможность исключить выбранные объекты из Inventory. Для этого в левой панели нужно раскрыть дерево объектов и снять галки с ненужных. Например, это могут быть давно списанные хосты ESXi или компоненты окружения разработки и тестирования:
Ну и чтобы посмотреть описанное в действии, можете взглянуть на это видео:
Компания VMware имеет очень долгую историю разработки продукта Horizon, который вырос на базе решения для виртуализации настольных ПК VMware View. Теперь это не только доставка виртуальных рабочих столов, но и виртуализация и доставка приложений, а также специальные средства для виртуализации пользовательских окружений и пользовательских профилей (настольных и мобильных), реализуемые с помощью еще одного решения VMware Workspace ONE Dynamic Environment Manager (DEM).
Сам же Workspace ONE - это большая экосистема продуктов для управления конфигурациями пользователей и их устройствами, которая включает в себя множество различных приложений и утилит. На днях VMware выпустила еще одну из них - Workspace ONE Assist for Horizon.
Это средство позволяет осуществлять удаленную поддержку пользователей (в облаке и собственном датацентре) с помощью встроенного в решение инструментария для совместной работы - утилиты для запроса прав у пользователя, выделения областей экрана, записи сессии и многого другого.
Основные возможности продукта:
Просмотр экрана и контроль средств управления в реальном времени
Запуск напрямую из Horizon Universal Console
Оповещение пользователей Horizon, когда их экран видит администратор, а также возможность остановить сессию со стороны пользователя
Подсветка экрана, средства рисования и выделения курсора мыши - Screen Draw
Возможность работы с различными клавиатурами, в том числе поддержка множества языков и раскладок
Исполнение команд PowerShell из командной строки
Доступ к хранилищу сертификатов
Автоматическое переподключение к сессии при перезагрузке десктопа пользователя или неполадках в сети
Возможность пригласить еще пользователей для просмотра сессии
Запись сессий для передачи проблемы другим лицам или в целях обучения
Также о главных функциях данного средства можно узнать из видео:
Более подробно узнать о VMware Workspace ONE Assist for Horizon можно на странице продукта. Он входит в состав решения Workspace ONE.

 RSS
RSS