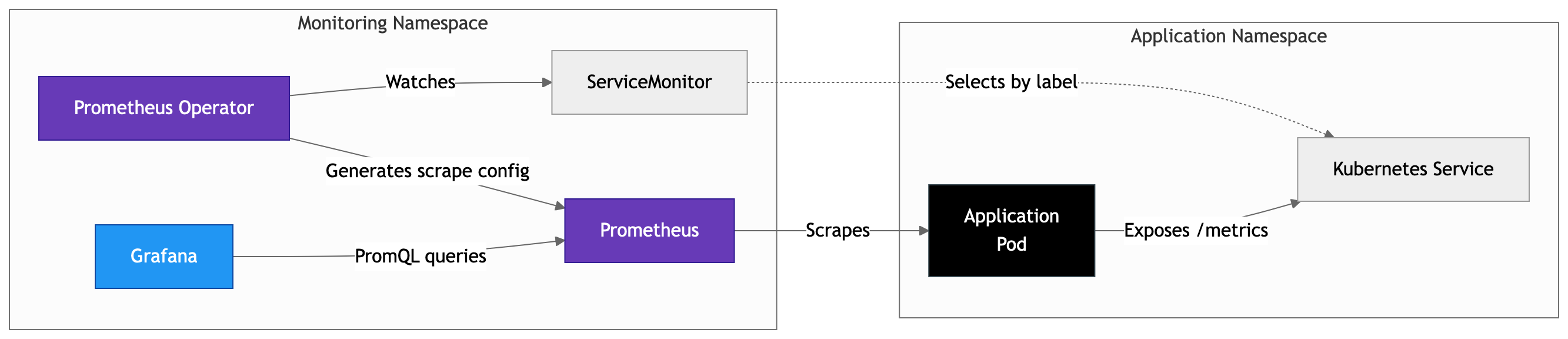
Облачные нативные приложения обеспечивают гибкость, масштабируемость и более быструю доставку сервисов, однако они также вносят новую операционную сложность. В средах Kubernetes рабочие нагрузки являются эфемерными, сервисы распределены, а телеметрия генерируется в больших объёмах на разных уровнях стека. Компания VMware выпустила новый документ "Observability on vSphere Kubernetes Service", в котором рассматривается, как решить эту задачу на платформе VMware Cloud Foundation (VCF) с использованием vSphere Kubernetes Service (VKS).
В документе представлена практическая референсная архитектура, основанная на трёх ключевых компонентах наблюдаемости:
Метрики
Для сбора метрик архитектура использует стек Prometheus Community (kube-prometheus-stack), который включает:
Prometheus Operator для динамического обнаружения целей
Grafana для построения дашбордов
Node Exporter для сбора статистики на уровне узлов
Метрики дополнительно обогащаются телеметрией сервисов Istio и интегрируются с решением VCF Operations для предоставления контекста базовой инфраструктуры.
Логи
Для работы с логами используется Fluent Bit, который собирает и обогащает данные логов Kubernetes. Для хранения и индексации применяется Grafana Loki, обеспечивая нативный для Kubernetes анализ логов через Grafana.
Тот же поток логов также передаётся в VCF Operations for Logs, что позволяет коррелировать события с более широкой инфраструктурной средой.
Трейсы
Для трассировки используется OpenTelemetry для распределённого трейсинга, Jaeger v2 — для приёма и визуализации данных трассировки в формате OTLP, а OpenSearch — в качестве постоянного хранилища трейсов.
Это позволяет отслеживать прохождение запросов через различные сервисы и анализировать их вместе с сопутствующей телеметрией приложений и платформы.
Для команд, использующих vSphere Kubernetes Service на платформе VMware Cloud Foundation, этот документ представляет собой практическую отправную точку для построения модульного, ориентированного на промышленную эксплуатацию стека наблюдаемости. Также репозиторий, на который ссылается документ, размещен по этой ссылке.
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.
vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
Требования к оборудованию и сети
Варианты развертывания кластеров
Масштабирование и отказоустойчивость
Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
General Information — общая информация о vSAN
Express Storage Architecture (ESA)
Availability — отказоустойчивость
Cloud-Native Storage
vSAN File Services
vSAN Storage Clusters (disaggregated storage)
Stretched clusters и 2-node clusters
Networking
Capacity и Space Efficiency
Operations
Performance
Security
vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.
Компания VMware выпустила обновлённое официальное руководство vSAN Stretched Cluster Guide, предназначенное для архитекторов и администраторов, работающих с растянутыми кластерами vSAN в рамках платформы VMware Cloud Foundation (VCF) 9.0. Документ был выпущен 18 февраля 2026 года и отражает актуальные практики проектирования, развертывания и эксплуатации таких инфраструктур.
Руководство подробно описывает ключевые концепции и требования к растянутым кластерам vSAN — типу конфигурации, в которой ресурсы распределены по двум географически разнесённым сайтам с целью обеспечения максимальной отказоустойчивости и непрерывной доступности виртуальных машин.
Что нового в версии для VCF 9.0
Актуализация под VCF 9.0 и vSAN 9
Документ ориентирован на использование растянутых кластеров именно в контексте VCF 9.0, в том числе с учётом последних архитектурных изменений и интеграции с инструментами автоматизации SDDC Manager.
Расширенные рекомендации по сетевым требованиям
В руководстве обновлены требования к сети между площадками — минимальные значения пропускной способности и задержек, оптимальные настройки MTU и рекомендации по сегментации трафика.
Поддержка разных архитектур хранения
Кроме классической архитектуры vSAN (OSA), руководство учитывает и vSAN Express Storage Architecture (ESA) — более современный вариант с улучшенной производительностью и эффективностью хранения.
Процессы установки и конвертации
Обозначены пошаговые процессы установки растянутого кластера, развёртывания и конфигурации vSAN Witness Host, а также инструкция по конвертации существующего кластера vSAN в растянутую конфигурацию без прерывания работы.
Сценарии отказов и восстановление
Отдельный раздел посвящён анализу отказов, поведения кластера в стрессовых ситуациях и практикам восстановления после отказов отдельных компонентов или целых площадок.
Практическая ценность для предприятий
Растянутые кластеры vSAN в VCF 9.0 остаются одним из ключевых решений для компаний с критичными требованиями к доступности (финансовые учреждения, телеком, здравоохранение), обеспечивая непрерывность бизнес-сервисов при отказах на уровне целого дата-центра.
Новый документ vSAN Stretched Cluster Guide служит исчерпывающим справочником для ИТ-специалистов, помогая спланировать архитектуру, соблюсти требования к оборудованию и сети, правильно настроить объектные политики хранения и обеспечить корректное поведение системы в случае сбоев.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
Современная инфраструктура не прощает простоев. Любая потеря доступности данных — это не только бизнес-риск, но и вопрос репутации. VMware vSAN, будучи ядром гиперконвергентной архитектуры VMware Cloud Foundation, всегда стремился обеспечивать высокую доступность и устойчивость хранения. Но с появлением Express Storage Architecture (ESA) подход к отказоустойчивости изменился фундаментально.
Документ vSAN Availability Technologies (часть VCF 9.0) описывает, как именно реализована устойчивость на уровне данных, сетей и устройств. Разберём, какие технологии стоят за доступностью vSAN, и почему переход к ESA меняет правила игры.
Архитектура отказоустойчивости: OSA против ESA
OSA — классика, но с ограничениями
Original Storage Architecture (OSA) — традиционный вариант vSAN, основанный на концепции дисковых групп (disk groups):
Одно кэш-устройство (SSD)
Несколько накопителей ёмкости (HDD/SSD)
Проблема в том, что выход из строя кеш-диска делает всю группу недоступной. Кроме того, классическая зеркальная защита (RAID-1) неэффективна по ёмкости: чтобы выдержать один отказ, приходится хранить копию 1:1.
ESA — новое поколение хранения
Express Storage Architecture (ESA) ломает эту модель:
Нет больше disk groups — каждый накопитель независим.
Встроен мониторинг NVMe-износа, зеркалирование метаданных и прогноз отказов устройств.
В результате ESA уменьшает "зону взрыва" при сбое и повышает эффективность хранения до 30–50 %, особенно при политике FTT=2.
Как vSAN обеспечивает доступность данных
Всё в vSAN строится вокруг объектов (диски ВМ, swap, конфигурации). Каждый объект состоит из компонентов, которые распределяются по узлам.
Доступность объекта определяется параметром FTT (Failures To Tolerate) — числом отказов, которые система выдержит без потери данных.
Например:
FTT=1 (RAID-1) — один отказ хоста или диска.
FTT=2 (RAID-6) — два отказа одновременно.
RAID-5/6 обеспечивает ту же устойчивость, но с меньшими затратами ёмкости.
Механизм кворума
Каждый компонент имеет "голос". Объект считается доступным, если более 50 % голосов доступны. Это предотвращает split-brain-ситуации, когда две части кластера считают себя активными.
В сценариях 2-Node или stretched-cluster добавляется witness-компонент — виртуальный "свидетель", решающий, какая часть кластера останется активной.
Домены отказов и географическая устойчивость
vSAN позволяет группировать узлы в домены отказов — например, по стойкам, стойкам или площадкам. Данные и компоненты одной ВМ никогда не размещаются в пределах одного домена, что исключает потерю данных при отказе стойки или сайта.
В растянутом кластере (stretched cluster) домены соответствуют сайтам, а witness appliance располагается в третьей зоне для арбитража.
Рекомендация: проектируйте кластер не по минимуму (3–4 узла), а с запасом. Например, для FTT=2 нужно минимум 6 узлов, но VMware рекомендует 7, чтобы система могла восстановить избыточность без потери устойчивости.
Поведение при сбоях: состояния компонентов
vSAN отслеживает каждое состояние компонентов:
Состояние
Описание
Active
Компонент доступен и синхронизирован
Absent
Недоступен (например, временный сбой сети)
Degraded
Компонент повреждён, требуется восстановление
Active-Stale
Компонент доступен, но содержит устаревшие данные
Reconfiguring
Идёт перестройка или изменение политики
Компоненты в состоянии Absent ждут по умолчанию 60 минут перед восстановлением — чтобы избежать лишнего трафика из-за кратковременных сбоев.
Если восстановление невозможно, создаётся новая копия на другом узле.
Сеть как основа устойчивости
vSAN — это распределённое хранилище, и его надёжность напрямую зависит от сети.
Транспорт — TCP/unicast с внутренним протоколом Reliable Datagram Transport (RDT).
Поддерживается RDMA (RoCE v2) для минимизации задержек.
Рекомендуется:
2 NIC на каждый хост;
Подключение к разным коммутаторам;
Active/Standby teaming для vSAN-трафика (предсказуемые пути).
Если часть сети теряет связность, vSAN формирует partition groups и использует кворум, чтобы определить, какая группа "основная". vSAN тесно интегрирован с vSphere HA, что обеспечивает синхронное понимание состояния сети и автоматический рестарт ВМ при отказах.
Ресинхронизация и обслуживание
Resync (восстановление)
Когда хост возвращается в строй или изменяется политика, vSAN ресинхронизирует данные для восстановления FTT-уровня. В ESA ресинхронизация стала интеллектуальной и возобновляемой (resumable) — меньше нагрузка на сеть и диски.
Maintenance Mode
При вводе хоста в обслуживание доступны три режима:
Full Data Migration — полная миграция данных (долго, безопасно).
Ensure Accessibility — минимальный перенос для сохранения доступности (дефолт).
No Data Migration — без переноса (быстро, рискованно).
ESA использует durability components, чтобы временно сохранить данные и ускорить возврат в строй.
Предиктивное обслуживание и мониторинг
VMware внедрила целый ряд механизмов прогнозирования и диагностики:
Degraded Device Handling (DDH) — анализ деградации накопителей по задержкам и ошибкам до фактического отказа.
NVMe Endurance Tracking — контроль износа NVMe с предупреждениями в vCenter.
Low-Level Metadata Resilience — зеркалирование метаданных для защиты от URE-ошибок.
Proactive Hardware Management — интеграция с OEM-телеметрией и предупреждения через Skyline Health.
Эти механизмы в ESA работают точнее и с меньшими ложными срабатываниями по сравнению с OSA.
Disaster Recovery — восстановление после катастрофы (вторая площадка, репликация, резервное копирование).
vSAN отвечает за первое. Для второго используются VMware SRM, vSphere Replication и внешние DR-решения. Однако комбинация vSAN ESA + stretched cluster уже позволяет реализовать site-level resilience без отдельного DR-инструмента.
Практические рекомендации
Используйте ESA при проектировании новых кластеров.
Современные NVMe-узлы и сети 25 GbE позволяют реализовать отказоустойчивость без потери производительности.
Проектируйте с запасом по хостам.
Один дополнительный узел обеспечит восстановление без снижения FTT-уровня.
Настройте отказоустойчивую сеть.
Два интерфейса, разные коммутаторы, Route Based on Port ID — минимальные требования для надёжного vSAN-трафика.
Следите за здоровьем устройств.
Активируйте DDH и NVMe Endurance Monitoring, используйте Skyline Health для предиктивного анализа.
Планируйте обслуживание грамотно.
Режим Ensure Accessibility — оптимальный баланс между безопасностью и скоростью.
Заключение
VMware vSAN уже давно стал стандартом для гиперконвергентных систем, но именно с Express Storage Architecture он сделал шаг от "устойчивости" к "самоисцеляемости". ESA сочетает erasure coding, предиктивную аналитику и глубокую интеграцию с платформой vSphere, обеспечивая устойчивость, производительность и эффективность хранения. Для архитекторов и инженеров это значит одно: устойчивость теперь проектируется не как надстройка, а как неотъемлемая часть самой архитектуры хранения.
Таги: VMware, vSAN, Availability, HA, DR, Storage, Whitepaper
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.
Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.
Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
Конфигурацию ESX для включения GPUDirect RDMA
Развертывание Service VM
Настройку кластера VKS
Установку операторов (NVIDIA Network и GPU Operators)
Процедуры загрузки хранилища и моделей
Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.
Недавно компания VMware опубликовала полезный для администраторов документ «vSphere 9.0 Performance Best Practices» с указанием ключевых рекомендаций по обеспечению максимальной производительности гипервизора ESX и инфраструктуры управления vCenter.
Документ охватывает ряд аспектов, начиная с аппаратных требований и заканчивая тонкой настройкой виртуальной инфраструктуры. Некоторые разделы включают не всем известные аспекты тонкой настройки:
Настройки BIOS: рекомендуется включить AES-NI, правильно сконфигурировать энергосбережение (например, «OS Controlled Mode»), при необходимости отключить некоторые C-states в особо чувствительных к задержкам приложениях.
vCenter и Content Library: советуют минимизировать автоматические скриптовые входы, использовать группировку vCenter для повышения синхронизации, хранить библиотеку контента на хранилищах с VAAI и ограничивать сетевую нагрузку через глобальный throttling.
Тонкое администрирование: правила доступа, лимиты, управление задачами, патчинг и обновления (включая рекомендации по BIOS и live scripts) и прочие глубокие настройки.
Отличия от версии для vSphere 8 (ESX и vCenter)
Аппаратные рекомендации
vSphere 8 предоставляет рекомендации по оборудованию: совместимость, минимальные требования, использование PMem (Optane, NVDIMM-N), vPMEM/vPMEMDisk, VAAI, NVMe, сетевые настройки, BIOS-опции и оптимизации I/O и памяти.
vSphere 9 добавляет новые аппаратные темы: фокус на AES-NI, snoop-режимах, NUMA-настройках, более гибком управлении энергопотреблением и безопасности на уровне BIOS.
vMotion и миграции
vSphere 8: введение «Unified Data Transport» (UDT) для ускорения холодных миграций и клонирования (при поддержке обеих сторон). Также рекомендации для связки encrypted vMotion и vSAN.
vSphere 9: больше внимания уделяется безопасности и производительности на стороне vCenter и BIOS, но UDT остаётся ключевым механизмом. В анонсах vSphere 9 в рамках Cloud Foundation акцент сделан на улучшенном управлении жизненным циклом и live patching.
Управление инфраструктурой
vSphere 8: рекомендации по vSphere Lifecycle Manager, UDT, обновлению vCenter и ESXi, GPU профили (в 8.0 Update 3) — включая поддержку разных vGPU, GPU Media Engine, dual DPU и live patch FSR.
vSphere 9 / VMware Cloud Foundation 9.0: новый подход к управлению жизненным циклом – поддержка live patch для vmkernel, NSX компонентов, более мощные «монстр-ВМ» (до 960 vCPU), direct upgrade с 8-й версии, image-based lifecycle management.
Работа с памятью
vSphere 8: рекомендации для Optane PMem, vPMEM/vPMEMDisk, управление памятью через ESXi.
vSphere 9 (через Cloud Foundation 9.0): внедрён memory tiering, позволяющий увеличить плотность ВМ в 2 раза при минимальной потере производительности (5%) и снижении TCO до 40%, без изменений в гостевой ОС.
Документ vSphere 9.0 Performance Best Practices содержит обновлённые и расширенные рекомендации для платформы vSphere 9, уделяющие внимание аппаратному уровню (BIOS-настройки, безопасность), инфраструктурному управлению, а также новым подходам к памяти (главный из них - memory tiering).
На днях было официально выпущено долгожданное руководство по проектированию VMware Cloud Foundation (VCF) версии 9. Оно предоставляет архитекторам облаков, инженерам платформ и администраторам виртуальной инфраструктуры всестороннюю основу для проектирования надёжных, масштабируемых и эффективных инфраструктур частных облаков с использованием VCF.
Будь то развертывание с нуля или оптимизация существующей среды, это руководство предлагает практические рекомендации, структурированные шаблоны и продуманную систему принятия решений, адаптированную под последнюю версию VCF.
Что внутри VMware Cloud Foundation 9 Design Guide?
Руководство тщательно структурировано по нескольким ключевым разделам, каждый из которых помогает принимать обоснованные решения на каждом этапе проектирования и развертывания VCF.
1. Варианты архитектуры в VMware Cloud Foundation
Изучите обзор на высоком уровне каждого компонента VCF — включая вычисления, хранилище и сеть — а также компромиссы, преимущества и последствия различных архитектурных решений.
2. Проектные шаблоны
Быстро начните реализацию, используя заранее подготовленные шаблоны, адаптированные под конкретные сценарии использования. Эти шаблоны содержат рекомендации по проектированию «от и до» — их можно использовать как в готовом виде, так и как основу для настройки под нужды вашей организации.
Доступные шаблоны включают описания VCF-компонентов в следующих конфигурациях:
На одной площадке с минимальным размером
Полноценно на одной площадке
На нескольких площадках в одном регионе
На нескольких площадках в разных регионах
На нескольких площадках в одном регионе плюс дополнительные регионы
3. Библиотека проектирования
Глубоко погрузитесь в особенности проектирования каждого отдельного компонента VCF. Каждый раздел включает:
Требования к проекту – обязательные конфигурации, необходимые для корректной работы VCF.
Рекомендации по проекту – лучшие практики, основанные на реальном опыте и инженерной проверке.
Варианты проектных решений – точки выбора, где допустимы несколько подходов, с рекомендациями, в каких случаях стоит предпочесть тот или иной.
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
Сегодня искусственный интеллект преобразует бизнес во всех отраслях, однако компании сталкиваются с проблемами, связанными со стоимостью, безопасностью данных и масштабируемостью при запуске задач инференса (производительной нагрузки) в публичных облаках. VMware и NVIDIA предлагают альтернативу — платформу VMware Private AI Foundation with NVIDIA, предназначенную для эффективного и безопасного размещения AI-инфраструктуры непосредственно в частном датацентре. В документе "VMware Private AI Foundation with NVIDIA on HGX Servers" подробно рассматривается работа технологии Private AI на серверном оборудовании HGX.
Зачем бизнесу нужна частная инфраструктура AI?
1. Оптимизация использования GPU
На практике графические ускорители (GPU), размещенные в собственных датацентрах, часто используются неэффективно. Они могут простаивать из-за неправильного распределения или чрезмерного резервирования. Платформа VMware Private AI Foundation решает эту проблему, позволяя динамически распределять ресурсы GPU. Это обеспечивает максимальную загрузку графических процессоров и существенное повышение общей эффективности инфраструктуры.
2. Гибкость и удобство для специалистов по AI
Современные сценарии работы с AI требуют высокой скорости и гибкости в работе специалистов по данным. Платформа VMware обеспечивает привычный облачный опыт работы, позволяя командам специалистов быстро разворачивать AI-среды, при этом сохраняя полный контроль инфраструктуры у ИТ-команд.
3. Конфиденциальность и контроль за данными
Публичные облака вызывают беспокойство в вопросах приватности, особенно когда AI-модели обрабатывают конфиденциальные данные. Решение VMware Private AI Foundation гарантирует полную конфиденциальность, соответствие нормативным требованиям и контроль доступа к проприетарным моделям и наборам данных.
4. Знакомый интерфейс управления VMware
Внедрение нового программного обеспечения обычно требует значительных усилий на изучение и адаптацию. Платформа VMware использует уже знакомые инструменты администрирования (vSphere, vCenter, NSX и другие), что существенно сокращает время и затраты на внедрение и эксплуатацию.
Основные компоненты платформы VMware Private AI Foundation с NVIDIA
VMware Cloud Foundation (VCF)
Это интегрированная платформа, объединяющая ключевые продукты VMware:
vSphere для виртуализации серверов.
vSAN для виртуализации хранилищ.
NSX для программного управления сетью.
Aria Suite (бывшая платформа vRealize) для мониторинга и автоматизации управления инфраструктурой.
NVIDIA AI Enterprise
NVIDIA AI Enterprise является важным элементом платформы и включает:
Технологию виртуализации GPU (NVIDIA vGPU C-Series) для совместного использования GPU несколькими виртуальными машинами.
NIM (NVIDIA Infrastructure Manager) для простого управления инфраструктурой GPU.
NeMo Retriever и AI Blueprints для быстрого развёртывания и масштабирования моделей AI и генеративного AI.
NVIDIA HGX Servers
Серверы HGX специально разработаны NVIDIA для интенсивных задач AI и инференса. Каждый сервер оснащён 8 ускорителями NVIDIA H100 или H200, которые взаимосвязаны через высокоскоростные интерфейсы NVSwitch и NVLink, обеспечивающие высокую пропускную способность и минимальные задержки.
Высокоскоростная сеть
Сетевое взаимодействие в кластере обеспечивается Ethernet-коммутаторами NVIDIA Spectrum-X, которые предлагают скорость передачи данных до 100 GbE, обеспечивая необходимую производительность для требовательных к данным задач AI.
Референсная архитектура для задач инференса
Референсная архитектура предлагает точные рекомендации по конфигурации аппаратного и программного обеспечения:
Физическая архитектура
Серверы инференса: от 4 до 16 серверов NVIDIA HGX с GPU H100/H200.
Сетевая инфраструктура: 100 GbE для рабочих нагрузок инференса, 25 GbE для управления и хранения данных.
Управляющие серверы: 4 узла, совместимые с VMware vSAN, для запуска сервисов VMware.
Виртуальная архитектура
Домен управления: vCenter, SDDC Manager, NSX, Aria Suite для управления облачной инфраструктурой.
Домен рабочих нагрузок: виртуальные машины с GPU и Supervisor Clusters для запуска Kubernetes-кластеров и виртуальных машин с глубоким обучением (DLVM).
Векторные базы данных: PostgreSQL с расширением pgVector для поддержки Retrieval-Augmented Generation (RAG) в генеративном AI.
Производительность и валидация
VMware и NVIDIA протестировали платформу с помощью набора тестов GenAI-Perf, сравнив производительность виртуализированных и bare-metal сред. Решение VMware Private AI Foundation продемонстрировало высокую пропускную способность и низкую задержку, соответствующие или превосходящие показатели не виртуализированных решений.
Почему компании выбирают VMware Private AI Foundation с NVIDIA?
Эффективное использование GPU: максимизация загрузки GPU, что экономит ресурсы.
Высокий уровень безопасности и защиты данных: конфиденциальность данных и контроль над AI-моделями.
Операционная эффективность: использование привычных инструментов VMware сокращает затраты на внедрение и управление.
Масштабируемость и перспективность: возможность роста и адаптации к новым задачам в области AI.
Итоговые выводы
Платформа VMware Private AI Foundation с NVIDIA является комплексным решением для компаний, стремящихся эффективно и безопасно реализовывать задачи искусственного интеллекта в частных дата-центрах. Она обеспечивает высокую производительность, гибкость и конфиденциальность данных, являясь оптимальным решением для организаций, которым критично важно сохранять контроль над AI-инфраструктурой, не жертвуя при этом удобством и масштабируемостью.
В современной динамично развивающейся сфере информационных технологий автоматизация уже не роскошь, а необходимость. Команды, отвечающие за безопасность, сталкиваются с растущей сложностью управления политиками сетевой безопасности, что требует эффективных и автоматизированных решений. Межсетевой экран vDefend, интегрированный с VMware NSX, предлагает мощные возможности автоматизации с использованием различных инструментов и языков сценариев. Выпущенное недавно руководство "Beginners Guide to Automation with vDefend Firewall" рассматривает стратегии автоматизации, доступные в vDefend, которые помогают ИТ-специалистам упростить рабочие процессы и повысить эффективность обеспечения безопасности.
Понимание операций CRUD в сетевой автоматизации
Операции CRUD (Create, Read, Update, Delete) являются основой рабочих процессов автоматизации. vDefend позволяет выполнять эти операции через RESTful API-методы:
GET — получение информации о ресурсе.
POST — создание нового ресурса.
PUT/PATCH — обновление существующих ресурсов.
DELETE — удаление ресурса.
Используя эти методы REST API, ИТ-команды могут автоматизировать политики межсетевого экрана, создавать группы безопасности и настраивать сетевые параметры без ручного вмешательства.
Стратегии автоматизации для межсетевого экрана vDefend
С vDefend можно использовать несколько инструментов автоматизации, каждый из которых предлагает уникальные преимущества:
Вызовы REST API через NSX Policy API - API политики NSX Manager позволяют напрямую выполнять действия CRUD с сетевыми ресурсами. Разработчики могут использовать языки программирования, такие как Python, GoLang и JavaScript, для написания сценариев взаимодействия с NSX Manager, обеспечивая бесшовную автоматизацию задач безопасности.
Terraform и OpenTofu - эти инструменты «инфраструктура-как-код» (IaC) помогают стандартизировать развертывание сетей и политик безопасности. Используя декларативные манифесты, организации могут определять балансировщики нагрузки, правила межсетевого экрана и политики безопасности, которые могут контролироваться версионно и развертываться через CI/CD-конвейеры.
Ansible - этот инструмент часто применяется для развертывания основных компонентов NSX, включая NSX Manager, Edge и транспортные узлы. ИТ-команды могут интегрировать Ansible с Terraform для полной автоматизации конфигурации сети.
PowerCLI — это модуль PowerShell для VMware, который позволяет администраторам эффективно автоматизировать конфигурации межсетевых экранов и политик сетевой безопасности.
Aria Automation Suite - платформа Aria обеспечивает оркестрацию задач сетевой безопасности корпоративного уровня. Она включает:
Aria Assembler — разработка и развертывание облачных шаблонов для настройки безопасности.
Aria Orchestrator — автоматизация сложных рабочих процессов для управления безопасностью NSX.
Aria Service Broker — портал самообслуживания для автоматизации сетевых и защитных операций.
Ключевые основы работы с API
Для эффективного использования возможностей автоматизации vDefend важно понимать архитектуру его API:
Иерархическая структура API: API NSX построен по древовидной структуре с ресурсами в отношениях родитель-потомок.
Пагинация с курсорами: большие наборы данных разбиваются на страницы с использованием курсоров для повышения эффективности запросов.
Порядковые номера: правила межсетевого экрана выполняются сверху вниз, приоритет отдается правилам с меньшими порядковыми номерами.
Методы аутентификации: вызовы API требуют аутентификации через базовую авторизацию, сеансовые токены или ключи API.
Пример полномасштабной автоматизации
Реальный сценарий автоматизации с использованием vDefend включает:
Сбор информации о виртуальных машинах — идентификацию ВМ и получение тегов безопасности.
Присвоение тегов ВМ — назначение меток для категоризации ресурсов.
Создание групп — динамическое формирование групп безопасности на основе тегов ВМ.
Определение пользовательских служб — создание пользовательских сервисов межсетевого экрана с конкретными требованиями к портам.
Создание политик и правил межсетевого экрана — автоматизация развертывания политик для применения мер безопасности.
Например, автоматизированное правило межсетевого экрана для разрешения HTTPS-трафика от группы веб-серверов к группе приложений будет выглядеть следующим образом в формате JSON:
Документ Network Observability Maturity Model от компании Broadcom представляет собой руководство по достижению высокого уровня наблюдаемости (observability) сетей, что позволяет ИТ-командам эффективно управлять современными сложными сетевыми инфраструктурами.
С развитием облачных технологий, удаленной работы и зависимости от внешних провайдеров, традиционные инструменты мониторинга устарели. В документе описана модель зрелости наблюдаемости сети, которая помогает организациям эволюционировать от базового мониторинга до полностью автоматизированного и самовосстанавливающегося управления сетью.
Основные вызовы в управлении сетями
Растущая сложность – 78% компаний отмечают, что управление сетями стало значительно сложнее из-за многообразия технологий и распределенных архитектур.
Удаленная работа – 95% компаний используют гибридный режим работы, что усложняет контроль за производительностью сетей, зависящих от домашних Wi-Fi и внешних провайдеров.
Облачные технологии – 98% организаций уже используют облачную инфраструктуру, что приводит к недостатку прозрачности в управлении данными и сетевым трафиком.
Зависимость от сторонних сервисов – 65% компаний передают часть сетевого управления сторонним поставщикам, что затрудняет полное наблюдение за сетью.
Рост потребности в пропускной способности – развитие AI и других технологий увеличивает нагрузку на сети, требуя более эффективных стратегий управления трафиком.
Устаревшие инструменты – 80% компаний считают, что традиционные средства мониторинга не обеспечивают должного уровня видимости сети.
Последствия недостаточной наблюдаемости
Проблемы с диагностикой – 76% сетевых команд испытывают задержки из-за недостатка данных.
Реактивный подход – 84% компаний узнают о проблемах от пользователей, а не от систем мониторинга.
Избыточные тревоги – 41% организаций сталкиваются с ложными срабатываниями, что увеличивает время поиска неисправностей.
Сложности с наймом специалистов – 48% компаний не могут найти специалистов с нужными навыками.
Ключевые требования для построения наблюдаемости сети
Видимость внешних сред – важна мониторинговая прозрачность не только для внутренних сетей, но и для облаков и провайдеров.
Интеллектуальный анализ данных – использование алгоритмов для корреляции событий, подавления ложных тревог и прогнозирования отказов.
Активный мониторинг – симуляция сетевого трафика позволяет выявлять узкие места в режиме реального времени.
Автоматизация и интеграция – объединение разрозненных инструментов в единую систему с автоматическими рекомендациями по устранению неполадок.
Модель зрелости наблюдаемости сети
Модель зрелости состоит из пяти уровней:
Ручной уровень – разрозненные инструменты, долгие поиски неисправностей.
Традиционный уровень – базовое объединение инструментов, но с разрывами между данными.
Современный уровень – использование активного мониторинга и потоковой телеметрии.
Следующее поколение – автоматизированные решения на основе AI/ML, минимизация ложных тревог.
Самообслуживание и самовосстановление – автоматическая коррекция сетевых аномалий без вмешательства человека.
Практическая реализация модели
Для внедрения зрелой системы наблюдаемости компании должны:
Создать единую модель данных для многовендорных сетей.
Инвестировать в решения с AI-аналитикой.
Использовать активное и потоковое наблюдение за сетью.
Интегрировать мониторинг как внутренних, так и внешних сетей.
Документ Network Observability Maturity Model подчеркивает важность перехода от традиционного мониторинга к интеллектуальной наблюдаемости сети. Автоматизация, AI-аналитика и активный мониторинг позволяют существенно сократить время диагностики проблем, снизить издержки и повысить надежность сетевых сервисов. В документе даны полезные рекомендации по развитию мониторинговых систем, обеспечивающих полную прозрачность работы сети и снижение нагрузки на ИТ-отделы.
В январе 2025 года компания VMware опубликовала технический документ под названием «Performance Tuning for Latency-Sensitive Workloads: VMware vSphere 8». Этот документ предоставляет рекомендации по оптимизации производительности для рабочих нагрузок, критичных к задержкам, в среде VMware vSphere 8.
Документ охватывает различные аспекты конфигурации, включая требования к базовой инфраструктуре, настройки хоста, виртуальных машин, сетевые аспекты, а также оптимизацию операционной системы и приложений. В разделе «Host considerations» обсуждаются такие темы, как изменение настроек BIOS на физическом сервере, отключение EVC, управление vMotion и DRS, а также настройка продвинутых параметров, таких как отключение action affinity и открытие кольцевых буферов.
В разделе «VM considerations» рассматриваются рекомендации по оптимальному выделению ресурсов виртуальным машинам, использованию актуальных версий виртуального оборудования, настройке vTopology, отключению функции hot-add, активации параметра чувствительности к задержкам для каждой ВМ, а также использовании сетевого адаптера VMXNET3. Кроме того, обсуждается балансировка потоков передачи и приема данных, привязка потоков передачи к определенным ядрам, ассоциация ВМ с конкретными NUMA-нодами и использование технологий SR-IOV или DirectPath I/O при необходимости.
Раздел о сетевых настройках акцентирует внимание на использовании улучшенного пути передачи данных для NFV-нагрузок и разгрузке сервисов vSphere на DPU (Data Processing Units), также известных как SmartNICs.
Наконец, в разделе, посвященном настройке гостевой ОС и приложений, приводятся рекомендации по оптимизации производительности на уровне операционной системы и приложений, работающих внутри виртуальных машин.
Он представляет собой презентацию, в которой подробно рассматриваются три основных способа упрощения управления хранилищами данных с помощью VMware vSAN:
Упрощение операций с помощью управления на основе политик хранения: VMware vSAN позволяет администраторам задавать политики хранения, которые автоматически применяются к виртуальным машинам. Это устраняет необходимость в ручной настройке и снижает вероятность ошибок, обеспечивая согласованность и эффективность управления хранилищем.
Упрощение управления жизненным циклом хранилища: традиционные системы хранения часто требуют сложного и трудоемкого обслуживания. VMware vSAN интегрируется непосредственно в гипервизор vSphere, что позволяет автоматизировать многие процессы, такие как обновление и масштабирование, значительно снижая операционные затраты и облегчая сопровождение инфраструктуры.
Упрощение хранения за пределами центра обработки данных: с ростом объемов данных и необходимостью их обработки на периферийных устройствах и в облаке, VMware vSAN предлагает решения для консистентного и эффективного управления хранилищем в распределенных средах. Это обеспечивает единообразие операций и политики безопасности независимо от местоположения данных.
Этот документ предназначен для ИТ-специалистов и руководителей, стремящихся оптимизировать свою инфраструктуру хранения данных, снизить сложность управления и подготовить свою организацию к будущим вызовам.
В документе описаны улучшения производительности различных API тегирования, которые доступны для vCenter в VMware vSphere Automation SDK. Он содержит примеры кода и обновленные данные о производительности.
По сравнению с выпуском vCenter 7.0 U3, версия 8.0 U3 демонстрирует значительное ускорение работы API привязки тегов:
attach() – увеличение скорости на 40%.
attachTagToMultipleObjects() – увеличение скорости на 200%.
attachMultipleTagsToObject() – увеличение скорости на 31%–36%.
Помимо привязки тегов, в документе представлены данные о запросах виртуальных машин, связанных с тегами, а также об улучшениях работы режима связи нескольких vCenter - Enhanced Linked Mode. vCenter 8.0 U3 поддерживает те же лимиты, что и 7.0 U3, в отношении количества тегов, категорий и привязок тегов, но при этом обеспечивает повышенную производительность.
Ниже представлена диаграмма, демонстрирующая некоторые из достигнутых улучшений. В частности, attachTagToMultipleObjects() показывает увеличение производительности на 200% при привязке 15 тегов к 5000 виртуальным машинам в vCenter 8.0 U3 по сравнению с 7.0 U3.
Летом 2024 года Фрэнк Даннеман написал интересный аналитический документ «VMware Private AI Foundation – Privacy and Security Best Practices», который раскрывает основные концепции безопасности для инфраструктуры частного AI (в собственном датацентре и на базе самостоятельно развернутых моделей, которые работают в среде виртуализации).
Как многие из вас знают, мир искусственного интеллекта стремительно развивается, и с этим появляются новые вызовы, особенно в области конфиденциальности и безопасности. Этот документ не ограничивается теорией. Это практическое руководство, в котором представлены базовые концепции, структуры и модели, лежащие в основе безопасности приватного AI. В нем подробно рассматриваются ключевые аспекты конфиденциальности и безопасности в контексте ИИ, а также предоставляются инструменты, которые помогут вам внедрить эти принципы в своей работе. Вы узнаете о принципе совместной ответственности, моделировании угроз для приложений с генеративным AI, а также о триаде CIA — конфиденциальность, целостность и доступность, которая используется как основная модель информационной безопасности.
Основные моменты документа:
Преимущества Private AI в корпоративных датацентрах:
Контроль и безопасность: организации получают полный контроль над своими данными и моделями, что позволяет минимизировать риски, связанные с конфиденциальностью, и избегать зависимости от сторонних поставщиков.
Экономическая эффективность: Private AI позволяет управлять расходами на AI, избегая неожиданных затрат от сторонних сервисов и оптимизируя ИТ-бюджет.
Гибкость и инновации: быстрое тестирование и настройка AI-моделей на внутренних данных без задержек, связанных с внешними сервисами, что способствует повышению производительности и точности моделей.
Принцип совместной ответственности в Private AI:
Документ подчеркивает важность распределения обязанностей между поставщиком инфраструктуры и организацией для обеспечения безопасности и соответствия требованиям.
Моделирование угроз для Gen-AI приложений:
Рассматриваются потенциальные угрозы для генеративных AI-приложений и предлагаются стратегии их смягчения, включая анализ угроз и разработку соответствующих мер безопасности.
Модель CIA (Конфиденциальность, Целостность, Доступность):
Конфиденциальность: обсуждаются методы защиты данных, включая контроль доступа, шифрование и обеспечение конфиденциальности пользователей.
Целостность: рассматриваются механизмы обеспечения точности и согласованности данных и моделей, а также защита от несанкционированных изменений.
Доступность: подчеркивается необходимость обеспечения постоянного и надежного доступа к данным и моделям для авторизованных пользователей.
Защита Gen-AI приложений:
Предлагаются лучшие практики для обеспечения безопасности генеративных AI-приложений, включая разработку безопасной архитектуры, управление доступом и постоянный мониторинг.
Архитектура Retrieval-Augmented Generation (RAG):
Документ подробно описывает процесс индексирования, подготовки данных и обеспечения безопасности в архитектурах RAG, а также методы эффективного поиска и извлечения релевантной информации для улучшения работы AI-моделей.
В заключение, документ предоставляет всестороннее руководство по созданию и поддержке приватных AI-решений, акцентируя внимание на критически важных аспектах конфиденциальности и безопасности, что позволяет организациям уверенно внедрять AI-технологии в своих инфраструктурах.
И это еще не все. В ближайшем будущем VMware продолжает развивать эти концепции в другом аналитическом документе, посвященном настройкам VMware Cloud Foundation (VCF). Этот документ станет вашим основным ресурсом для получения подробных рекомендаций по конфигурации и оптимизации VCF, чтобы создать надежную и безопасную среду для Private AI.
Документ подробно описывает, как предприятия могут использовать VMware Live Site Recovery для автоматизации и упрощения планов обеспечения непрерывности бизнеса и восстановления после катастроф (BCDR) для критически важных приложений, таких как контроллеры домена Windows Active Directory и Microsoft SQL Server.
Руководство охватывает ключевые аспекты, включая настройку репликации виртуальных машин между защищаемым и резервным сайтами, создание групп защиты и планов восстановления, а также использование встроенных сценариев для автоматизации процессов восстановления. Особое внимание уделяется тестированию планов восстановления без нарушения работы производственной среды, что позволяет организациям убедиться в надежности своих стратегий BCDR.
VMware Live Site Recovery предлагает унифицированное управление возможностями восстановления после катастроф и защиты от программ-вымогателей через облачный интерфейс, обеспечивая защиту VMware vSphere виртуальных машин путем их репликации в облачную файловую систему с возможностью быстрого восстановления при необходимости.
Это руководство является ценным ресурсом для организаций, стремящихся усилить свои стратегии защиты данных и обеспечить бесперебойную работу критически важных приложений в гибридных облачных средах.
Таги: VMware, vSphere, Live Recovery, Whitepaper, DR
Компания VMware выпустила интересный документ "Troubleshooting vSAN Performance", в котором рассматриваются вопросы решения проблем в области производительности отказоустойчивых хранилищ VMware vSAN.
Статья на VMware Core разделена на несколько ключевых разделов:
1. Определение проблемы: начальный этап, включающий идентификацию проблемы и её масштаба. 2. Обзор конфигурации: анализ текущей конфигурации vSAN, включая параметры хранилища, сеть и оборудование. 3. Анализ рабочих нагрузок: изучение типов нагрузок, которые могут влиять на производительность. 4. Метрики и инструменты: описание ключевых метрик и инструментов для мониторинга и диагностики, таких как vSAN Observer и vRealize Operations. 5. Рекомендации по оптимизации: практические советы по настройке и оптимизации для повышения производительности, включая изменения в программных и аппаратных компонентах.
Каждый из этих этапов направлен на систематическое выявление и устранение узких мест в производительности vSAN. Статья предлагает практические примеры и сценарии для понимания и решения типичных проблем.
В руководство добавили различные рекомендации и новые максимальные значения инфраструктуры, касающиеся именно vSphere 8 Update 2 и vSAN 8 Update 2.
Как и всегда, документ разбит на 4 больших блока, касающихся оборудования, самой платформы vSphere и серверов ESXi, виртуальных машин, их гостевых систем и средств управления виртуальной инфраструктурой:
Hardware for Use with VMware vSphere (страница 11)
ESXi and Virtual Machines (страница 25)
Guest Operating Systems (страница 55)
Virtual Infrastructure Management (страница 67)
Предполагается, что читатель уже в достаточной степени осведомлен о методах управления виртуальной инфраструктурой и ее основных компонентах.
Скачать Performance Best Practices for VMware vSphere 8.0 Update 2 можно по этой ссылке.
У компании NAKIVO обнаружился интересный и полезнейший документ - VCP-DCV Community Study Guide, который может помочь вам в подготовке к экзамену на сертификацию VMware Certified Professional Data Center Virtualization (VCP-DCV).
Руководство, в создании которого принимал участие известный блоггер Vladan Seget, содержит 372 страницы, где вы узнаете о многих практических моментах, которые обязательно пригодятся во время сдачи экзамена.
Надо отметить, что данное руководство является неофициальным, но содержит вполне актуальную информацию о платформе VMware vSphere 8.0. Если вам нужно обратиться к официальной информации от VMware, то есть два следующих ресурса:
На конференции VMworld 2020 Online ковидного года компания VMware представила одну из самых интересных своих инициатив по сотрудничеству с вендорами оборудования - Project Monterey. Тогда была представлена технология SmartNIC/DPU, которая позволяет обеспечить высокую производительность, безопасность по модели zero-trust и простую эксплуатацию в среде VCF.
SmartNIC - это специальный сетевой адаптер (NIC) c модулем CPU на борту, который берет на себя offload основных функций управляющих сервисов (а именно, работу с хранилищами и сетями, а также управление самим хостом).
В данном решении есть три основных момента:
Поддержка перенесения сложных сетевых функций на аппаратный уровень, что увеличивает пропускную способность и уменьшает задержки (latency).
Унифицированные операции для всех приложений, включая bare-metal операционные системы.
Модель безопасности Zero-trust security - обеспечение изоляции приложений без падения производительности. Ведь если основной ESXi для исполнения рабочих нагрузок будет скомпрометирован, то управляющий DPU сможет обнаружить ее и устранить уязвимость.
В статье об аппаратных нововведениях платформы VMware vSphere 8 Update 2, представленных на конференции Explore 2023, мы писали о том, что VMware еще в vSphere 8 представила поддержку DPU, позволяя клиентам переносить инфраструктурные рабочие нагрузки с CPU на специализированный модуль DPU, тем самым повышая производительность бизнес-нагрузок. Ну а в vSphere 8 U2 клиенты, использующие серверы Lenovo или Fujitsu, теперь смогут использовать новые функции интеграции vSphere DPU и его преимущества в производительности.
Теперь в платформах vSphere 8 и NSX есть полноценная поддержка устройств SmartNIC или так называемых устройств обработки данных (DPU). Реализация DPU в vSphere называется vSphere Distributed Service Engine.
DPU (SmartNIC) — это сетевые карты с встроенным интеллектом, которые могут выполнять различные сетевые функции непосредственно на адаптере через свои собственные программируемые процессоры. В дополнение к сетевым ускорителям, такие DPU, как NVIDIA BlueField, также имеют ядра общего назначения на базе процессора Arm, которые могут запускать полноценную систему ESXi (вот для чего и пригодился гипервизор VMware ESXi Arm Edition).
С технологией DPU, службы NSX, такие как маршрутизация, коммутация, брандмауэр и мониторинг, снимаются с хост-гипервизора и переносятся на DPU. С помощью этих возможностей возможно улучшить производительность, освободить ресурсы на хосте и изолировать рабочую нагрузку и инфраструктурные домены.
Ну и несколько картинок по результатам тестирования хостов ESXi с модулями SmartNIC/DPU на борту, которые показывают, какой прирост производительности дает новая технология:
Недавно опубликованный компанией VMware технический документ "Troubleshooting TCP Unidirectional Data Transfer Throughput" описывает, как устранить проблемы с пропускной способностью однонаправленной (Unidirectional) передачи данных по протоколу TCP. Решение этих проблем, возникающих на хосте vSphere/ESXi, может привести к улучшению производительности. Документ предназначен для разработчиков, опытных администраторов и специалистов технической поддержки.
Передача данных по протоколу TCP очень распространена в средах vSphere. Примеры включают в себя трафик хранения между хостом VMware ESXi и хранилищем данных NFS или iSCSI, а также различные формы трафика vMotion между хранилищами данных vSphere.
В компании VMware обратили внимание на то, что даже крайне редкие проблемы с TCP могут оказывать несоразмерно большое влияние на общую пропускную способность передачи данных. Например, в некоторых экспериментах с чтением NFS из хранилища данных NFS на ESXi, кажущаяся незначительной потеря пакетов (packet loss) в 0,02% привела к неожиданному снижению пропускной способности чтения NFS на 35%.
В документе описывается методология для выявления общих проблем с TCP, которые часто являются причиной низкой пропускной способности передачи данных. Для этого производится захват сетевого трафика передачи данных в файл трассировки пакетов для офлайн-анализа. Эта трассировка пакетов анализируется на предмет сигнатур общих проблем с TCP, которые могут оказать значительное влияние на пропускную способность передачи данных.
Рассматриваемые проблемы с TCP включают в себя потерю пакетов и их переотправку (retransmission), длительные паузы из-за таймеров TCP, а также проблемы с Bandwidth Delay Product (BDP). Для проведения анализа используется решение Wireshark и описывается профиль для упрощения рабочего процесса анализа. VMware описывает системный подход к выявлению общих проблем с протоколом TCP, оказывающих значительное влияние на пропускную способность канала передачи данных - поэтому инженерам, занимающимся устранением проблем с производительностью сети, рекомендуется включить эту методологию в стандартную часть своих рутинных проверок.
В документе рассмотрены рабочие процессы для устранения проблем, справочные таблицы и шаги, которые помогут вам в этом нелегком деле. Также в документе есть пример создания профиля Wireshark с предустановленными фильтрами отображения и графиками ввода-вывода, чтобы упростить администраторам процедуру анализа.
Скачать whitepaper "Troubleshooting TCP Unidirectional Data Transfer Throughput" можно по этой ссылке.
Как и всегда, документ разбит на 4 больших блока, касающихся оборудования, самой платформы vSphere и серверов ESXi, виртуальных машин, их гостевых систем и средств управления виртуальной инфраструктурой:
Hardware for Use with VMware vSphere
ESXi and Virtual Machines
Guest Operating Systems
Virtual Infrastructure Management
Все рекомендации, который были даны для vSphere 8, по-прежнему, в силе, мы не нашли новых моментов, касающихся именно Update 1. Но некоторые косметические и уточняющие правки в документе все-таки есть.
Администраторам настоятельно рекомендуется заглядывать в это руководство, хоть оно и состоит из ста страниц. Там просто огромное количество полезной информации, которую можно использовать ежедневно для поддержания высокого уровня производительности виртуальной среды.
Скачать Performance Best Practices for VMware vSphere 8.0 можно по этой ссылке.
Там приведены результаты тестирования производительности рабочих нагрузок обучения AI/ML на платформе виртуализации VMware vSphere с использованием нескольких графических процессоров NVIDIA A100-80GB с поддержкой технологии NVIDIA NVLink. Результаты попадают в так называемую "зону Голдилокс", что означает область хорошей производительности инфраструктуры, но с преимуществами виртуализации.
Результаты показывают, что время обучения для нескольких тестов MLPerf v3.0 Training1 увеличивается всего от 6% до 8% относительно времени тех же рабочих нагрузок на аналогичной физической системе.
Кроме того, в документе показаны результаты теста MLPerf Inference v3.0 для платформы vSphere с графическими процессорами NVIDIA H100 и A100 Tensor Core. Тесты показывают, что при использовании NVIDIA vGPU в vSphere производительность рабочей нагрузки, измеренная в запросах в секунду (QPS), составляет от 94% до 105% производительности на физической системе.
vSphere 8 и высокопроизводительная виртуализация с графическими процессорами NVIDIA и NVLink.
Партнерство между VMware и NVIDIA позволяет внедрить виртуализированные графические процессоры в vSphere благодаря программному слою NVIDIA AI Enterprise. Это дает возможность не только достигать наименьшего времени обработки для виртуализированных рабочих нагрузок машинного обучения и искусственного интеллекта, но и использовать многие преимущества vSphere, такие как клонирование, vMotion, распределенное планирование ресурсов, а также приостановка и возобновление работы виртуальных машин.
VMware, Dell и NVIDIA достигли производительности, близкой или превышающей аналогичную конфигурацию на физическом оборудовании со следующими настройками:
Dell PowerEdge R750xa с 2-мя виртуализированными графическими процессорами NVIDIA H100-PCIE-80GB
Для вывода в обеих конфигурациях требовалось всего 16 из 128 логических ядер ЦП. Оставшиеся 112 логических ядер ЦП в дата-центре могут быть использованы для других задач. Для достижения наилучшей производительности виртуальных машин во время обучения требовалось 88 логических ядер CPU из 128. Оставшиеся 40 логических ядер в дата-центре могут быть использованы для других активностей.
Производительность обучения AI/ML в vSphere 8 с NVIDIA vGPU
На картинке ниже показано сравнительное время обучения на основе тестов MLPerf v3.0 Training, с использованием vSphere 8.0.1 с NVIDIA vGPU 4x HA100-80c против конфигурации на физическом оборудовании с 4x A100-80GB GPU. Базовое значение для физического оборудования установлено как 1.00, и результат виртуализации представлен в виде относительного процента от базового значения. vSphere с NVIDIA vGPUs показывает производительность близкую к производительности на физическом оборудовании, где накладные расходы на виртуализацию составляют 6-8% при обучении с использованием BERT и RNN-T.
Таблица ниже показывает время обучения в минутах для тестов MLPerf v3.0 Training:
Результаты на физическом оборудовании были получены Dell и опубликованы в разделе закрытых тестов MLPerf v3.0 Training с ID 3.0-2050.2.
Основные моменты из документа:
VMware vSphere с NVIDIA vGPU и технологией AI работает в "зоне Голдилокс" — это область производительности для хорошей виртуализации рабочих нагрузок AI/ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPUs и программное обеспечение NVIDIA AI, показывает от 106% до 108% от главной метрики физического оборудования (100%), измеренной как время обучения для тестов MLPerf v3.0 Training.
vSphere достигла пиковой производительности, используя всего 88 логических ядер CPU из 128 доступных ядер, оставив тем самым 40 логических ядер для других задач в дата-центре.
VMware использовала NVIDIA NVLinks и гибкие группы устройств, чтобы использовать ту же аппаратную конфигурацию для обучения ML и вывода ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPU и программное обеспечение NVIDIA AI, показывает от 94% до 105% производительности физического оборудования, измеренной как количество обслуживаемых запросов в секунду для тестов MLPerf Inference v3.0.
vSphere достигла максимальной производительности вывода, используя всего 16 логических ядер CPU из 128 доступных, оставив тем самым 112 логических ядер CPU для других задач в дата-центре.
vSphere сочетает в себе мощь NVIDIA vGPU и программное обеспечение NVIDIA AI с преимуществами управления дата-центром виртуализации.
Более подробно о тестировании и его результатах вы можете узнать из документа.
Он раскрывает аспекты производительности виртуальных машин, работающих в инфраструктуре решений вендоров VMware, Oracle, AMD и Deloitte:
В этом документе рассматривается, как именно Oracle Cloud VMware Solution (OCVS) отличается от публичных облачных сред IaaS. Там также приводится описание следующих процессов:
Перенос виртуальных машин Oracle и SQL Server из локального датацентра в облако OCVS без перенастройки с обеспечением того же уровня производительности.
Демонстрация, как облако OCVS, работающее на оборудовании с процессорами AMD EPYC, достигает повышения производительности баз данных.
Наглядно показывается, что NSX Data Center может ускорить работу с нагрузками Oracle со ссылками на исследования VMware и Deloitte Consulting.
Обоснование экономических и технических преимуществ управления хостами со стороны клиентов.
Об облаке OCVS
OCVS включает следующие продукты VMware: vSphere, vSAN, NSX Data Center и vCenter Server. Эта унифицированная облачная инфраструктура и платформа для операций позволяет ИТ-специалистам предприятий быстро переносить и модернизировать приложения, бесшовно перемещая рабочие нагрузки между локальными средами и инфраструктурой Oracle Cloud Infrastructure (OCI) в больших масштабах. Кроме того, ИТ-команды могут легко использовать такие сервисы, как Oracle Autonomous Database, Oracle Exadata Cloud и Oracle Database Cloud, имея постоянный доступ к облачному порталу и современные API.
Производительность OCVS
VMware vSphere - это проверенная корпоративная платформа виртуализации, которая успешно работает с виртуальными машинами Oracle более 12 лет. Как показано на рисунке ниже, виртуальная машина Oracle Database, выполняющая сложную корпоративную нагрузку в OCVS, работает почти так же хорошо, как и в локальном датацентре. Когда мы масштабируем виртуальные машины Oracle Database до 8, виртуальные машины на OCVS работают даже немного лучше, чем виртуальные машины в локальных средах.
Также, используя эталонный тест VMware для измерения производительности базы данных DVD Store, компания Deloitte в независимом исследовании показывает, что виртуальные машины Oracle Database работают до 4-8 раз быстрее с VMware NSX, как показано на рисунке:
На днях компания VMware выпустила полезный для администраторов инфраструктуры виртуальных десктопов документ App Volumes 4 Evaluation Guide. Напомним, что решение App Volumes предназначено для быстрой доставки приложений в виртуальные среды VMware Horizon без необходимости их установки с широкими возможностями по управлению ими (в том числе, для legacy-приложений).
Данный документ представляет собой подробное руководство по первичному развертыванию продукта App Volumes с подробным объяснением работы данной технологии, составляющих компонентов и взаимосвязей между ними, описанием процесса упаковки приложений, а также реальными примерами использования различных функций.
Основные разделы документа:
Architecture and Components
App Volumes Manager Installation and Initial Configuration
Setup of Packaging VMs and Endpoint VMs
Simplified Application Management with App Volumes (Exercises)
Скачать VMware App Volumes 4 Evaluation Guide можно по этой ссылке, обновляемая онлайн-версия находится тут.
Традиционно документ разбит на 4 больших блока, касающихся оборудования, самой платформы vSphere и серверов ESXi, виртуальных машин, их гостевых систем и средств управления виртуальной инфраструктурой:
Hardware for Use with VMware vSphere
ESXi and Virtual Machines
Guest Operating Systems
Virtual Infrastructure Management
Подразделы этих глав содержат очень много конкретных пунктов про различные аспекты оптимизации виртуальных датацентров и объектов, работающих в их рамках. В основном, документ повторяет рекомендации, которые приводились для прошлых версий платформы, но есть и пункты, касающиеся непосредственно vSphere 8 и ESXi 8:
Документ очень полезный, состоит ровно из ста страниц и дает просто огромное количество полезной информации для администраторов, одной из главных задач которых является поддержание требуемого уровня производительности виртуальной среды.
Скачать Performance Best Practices for VMware vSphere 8.0 можно по этой ссылке.
Как вы знаете, главным релизом этого года стала новая версия платформы VMware vSphere 8, где появилось множество новых возможностей и улучшений уже существующих технологий. Одной из интересных функций стала vSphere Virtual Topology.
Для виртуальных машин с Hardware version 20 теперь доступно простое конфигурирование vNUMA-топологии для виртуальных машин:
Для виртуальных машин теперь доступна информационная панелька CPU Topology с конфигурацией vNUMA:
Недавно компания VMware выпустила документ "vSphere 8.0 Virtual Topology Performance Study", где рассматриваются аспекты производительности новой технологии, которую назвали vTopology. Виртуальная топология CPU включает в себя такие техники, как virtual sockets, узлы virtual non-uniform memory access (vNUMA), а также механизм кэширования virtual last-level caches (LLC).
До vSphere 8.0 дефолтной конфигурацией виртуальных машин было одно виртуальное ядро на сокет - это в некоторых случаях создавало затыки в производительности и неэффективность использования ресурсов. Теперь же ESXi автоматически подстраивает число виртуальных ядер на сокет для заданного числа vCPU.
На картинке ниже показана высокоуровневая архитектура компонентов двухсокетной системы. Каждый сокет соединен с локальным узлом памяти (memory bank) и образует с ним NUMA-узел. Каждый сокет имеет 4 ядра (он имеет кэши L1 и L2), а ядра шарят между собой общий кэш last-level cache (LLC).
Когда создается виртуальная машина с четырьмя vCPU, в vSphere она конфигурируется на одном сокете, вместо четырех, как это было ранее:
Так это выглядит в выводе команды CoreInfo для двух рассмотренных топологий:
Слева - это старая конфигурация, где был один vCPU на сокет, а справа - 4 vCPU (виртуальных ядер ВМ) на один сокет.
В указанном документе VMware проводит различных конфигураций (от 8 до 51 vCPU на машину) для разных нагрузок с помощью бенчмарков и утилит DVD Store 3.5, Login VSI, VMmark, Iometer, Fio и Netperf в операционных системах Windows и Linux. Забегая вперед, скажем, что для нагрузок Oracle прирост производительности составил 14%, а для Microsoft SQL server - 17%.
Итак, результаты теста DVD Store для БД Oracle:
Статистики NUMA hits NUMA misses для гостевой ОС Linux:
Результаты тестов для Microsoft SQL server:
Результаты тестирования хранилищ с помощью IOmeter:
Производительность в разрезе метрики CPU cycles per I/O (CPIO):
Компания VMware выпустила большое руководство и серию обучающих видео, посвященных инфраструктуре доставки облачных пользовательских окружений - Evaluation Guide: Setting Up Cloud-Based VMware Workspace ONE. Эта версия материалов по различным практическим аспектам семейства продуктов для поддержки пользовательских сред построена на базе большой статьи Quick-Start Tutorial for Cloud-Based Workspace ONE, выпущенной еще в 2018 году.
Данный обучающий курс построен в виде готовых «рецептов», практических задач и руководств, которые позволят быстро построить инфраструктуру Workspace ONE в соответствии с лучшими практиками и использовать ее на ежедневной основе. Этот документ занимает всего 32 страницы вместо прошлых 100, поэтому информация подается более лаконично и концентрированно.
Плейлист со всеми обучающими видео доступен по этой ссылке.
Скоро также выйдет и вторая часть руководства, посвященная задачам развертывания и управления приложениями, подключению новых устройств и пользователей, а также всем тем Day-2 операциям, которые приходится выполнять администраторам решения VMware Workspace ONE.

 RSS
RSS