p>Это пошаговое руководство описывает, как развернуть HCX Manager в среде VCF 9.1, а также в устаревшей (legacy) инфраструктуре. Материал содержит полное описание всех этапов процесса и сопровождается видеозаписью, охватывающей каждый шаг. Для администратора эффективная и безопасная миграция рабочих нагрузок внутри центров обработки данных и между ними является фундаментальной частью стратегии частного облака.
В версии VMware Data Services Manager 9.1 поддержка Microsoft SQL Server переведена в статус общей доступности на платформе VCF — продукт полностью поддерживается и готов к промышленным нагрузкам.
В демонстрации, подготовленной Эриком Греем (Eric Gray) из подразделения технического маркетинга VCF, показан полный цикл восстановления базы данных на произвольный момент времени. В стенде уже развёрнут промышленный кластер Always On availability group из трёх узлов, на котором работают базы данных. Задача — восстановить одну из этих баз на конкретный момент времени для отладки, не изменяя и не затрагивая работающий кластер.
Исходное состояние стенда
Работа ведётся в интерфейсе управления DSM под учётной записью администратора DSM. Среда заранее подготовлена: настроена интеграция с Active Directory, сконфигурированы S3-совместимые хранилища для резервных копий баз данных и системных бэкапов, а также уже запущено несколько баз данных.
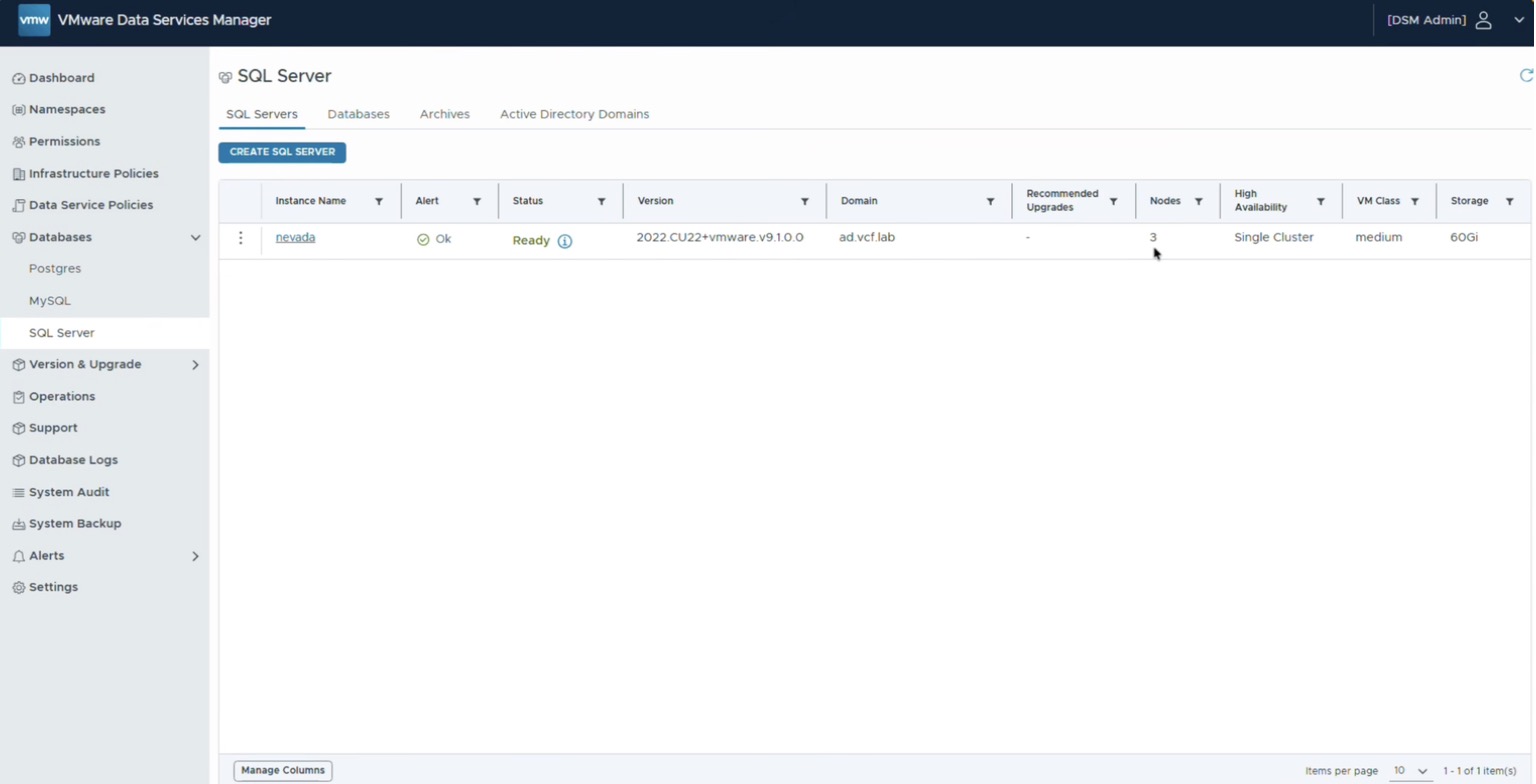
Основное внимание в демонстрации уделяется SQL Server. В окружении уже работает один экземпляр SQL Server, и его можно рассмотреть подробнее.
Одна из особенностей, отличающих SQL Server от СУБД с открытым исходным кодом в DSM, — намеренно проведённое разделение между базовым экземпляром (instance) и пользовательской базой данных. На скриншоте видно, что базовый экземпляр состоит из трёх узлов и представляет собой кластер Always On availability group. Он интегрирован с Active Directory, работает под управлением SQL Server 2022 с накопительным обновлением и находится в использовании.
На этом экземпляре размещены две пользовательские базы данных, названные в честь деревьев — spruce и pine. В рамках операции демонстрируется восстановление базы pine на момент времени с размещением копии на новом базовом экземпляре, предназначенном для отладки.
Создание нового экземпляра SQL Server
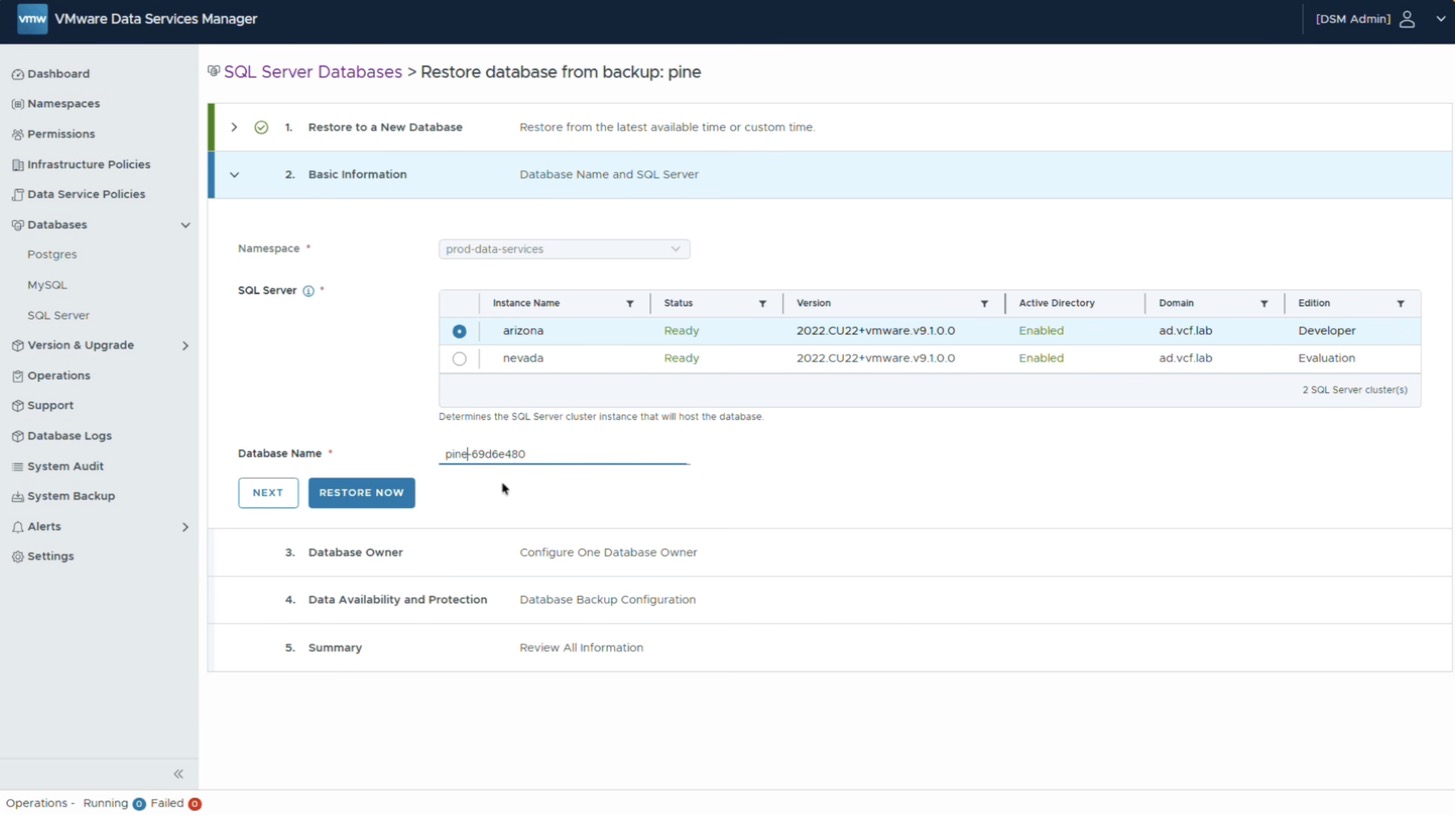
Первым шагом создаётся новый экземпляр SQL Server — так не придётся вмешиваться в существующий трёхузловой HA-кластер. Экземпляру задаётся имя (в демонстрации используются названия штатов), после чего выбирается редакция. Для решаемой задачи достаточно редакции Developer, однако DSM предлагает и другие варианты — на случай, если требуются возможности уровня Enterprise.
Далее можно указать имя и пароль административной учётной записи либо оставить эти поля пустыми: тогда DSM сгенерирует учётные данные автоматически. Второй вариант удобнее — при необходимости их всегда можно посмотреть позже.
Интеграция с Active Directory
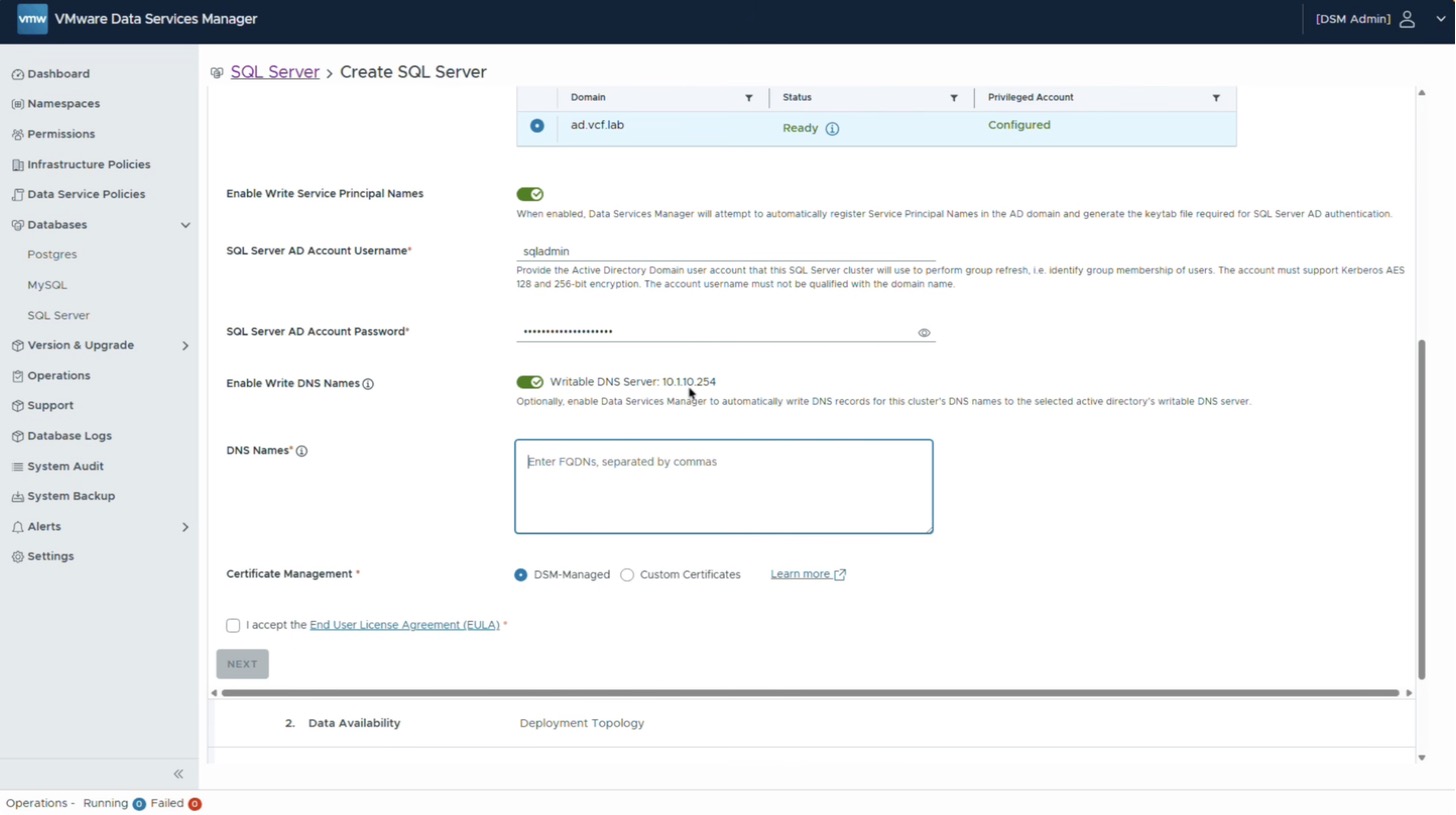
Здесь проявляется одно из ключевых преимуществ связки DSM и Microsoft SQL Server — работа с Active Directory. В качестве подготовительного шага интеграция с AD в DSM уже настроена: указаны имя домена и учётные данные. Поэтому при создании нового экземпляра достаточно выбрать опцию присоединения к домену.
Для этого указывается заранее созданная на стороне AD учётная запись с необходимыми правами и включается запись DNS-имён. Задаётся IP-адрес сервера AD, выполняющего роль DNS-сервера, и вводится полное доменное имя (FQDN). DSM самостоятельно создаст прямую и обратную записи для этого FQDN, благодаря чему к экземпляру можно будет обращаться по имени, а не по IP-адресу.
Чтобы продолжить, необходимо принять лицензионное соглашение Microsoft и перейти к выбору топологии развёртывания.
Топология развёртывания и инфраструктурные политики
Рассмотренный ранее экземпляр использовал трёхузловую конфигурацию Always On availability group — кластер для обеспечения высокой доступности и отработки отказов. Для текущего проекта, связанного только с восстановлением ради отладки, высокая доступность не нужна, поэтому создаётся одиночный виртуальный экземпляр SQL Server.
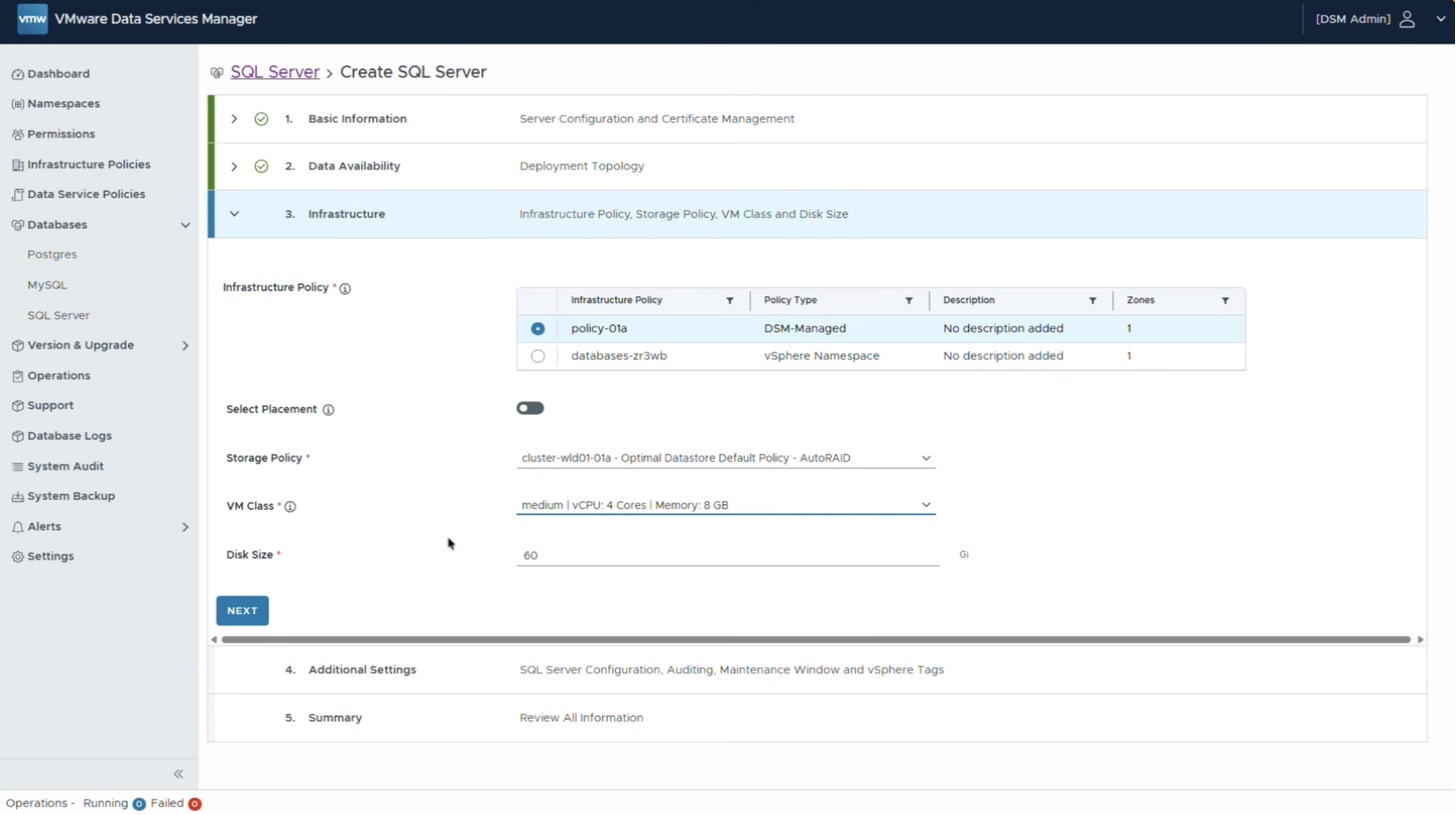
В DSM существует понятие инфраструктурных политик — это ресурсы, на которых выполняются сами базы данных. Доступны два варианта: пространство имён vSphere либо политика, создаваемая в клиенте vSphere, — так называемая DSM managed policy. Она представляет собой набор ресурсов: кластер, пул IP-адресов, набор классов виртуальных машин. Эти ресурсы создаёт администратор vSphere, и они становятся местом размещения базы данных.
Пространство имён vSphere в данном стенде было создано в VCF Automation для другого проекта, поэтому оно не используется — выбор делается в пользу политики DSM. Соответствующая политика хранения подставляется автоматически, остаётся выбрать класс виртуальной машины. Произвольные значения CPU и памяти задать нельзя: выбор ограничен классами, подготовленными администраторами. В данном случае четырёх vCPU и 8 ГБ оперативной памяти более чем достаточно.
Если бы речь шла о промышленной базе данных, с которой будут работать администраторы SQL Server, им наверняка потребовался бы включённый агент SQL Server для планирования регламентных заданий, а также специфические настройки конфигурации SQL Server. Всё это задаётся на данном шаге. Для отладочного проекта достаточно значений по умолчанию.
После итогового просмотра всех параметров запускается создание экземпляра. Процесс занимает несколько минут: в фоновом режиме на инфраструктуре vSphere разворачивается новая виртуальная машина, внутри неё устанавливается Microsoft SQL Server, после чего экземпляр вводится в работу.
Настройка политики сервиса данных
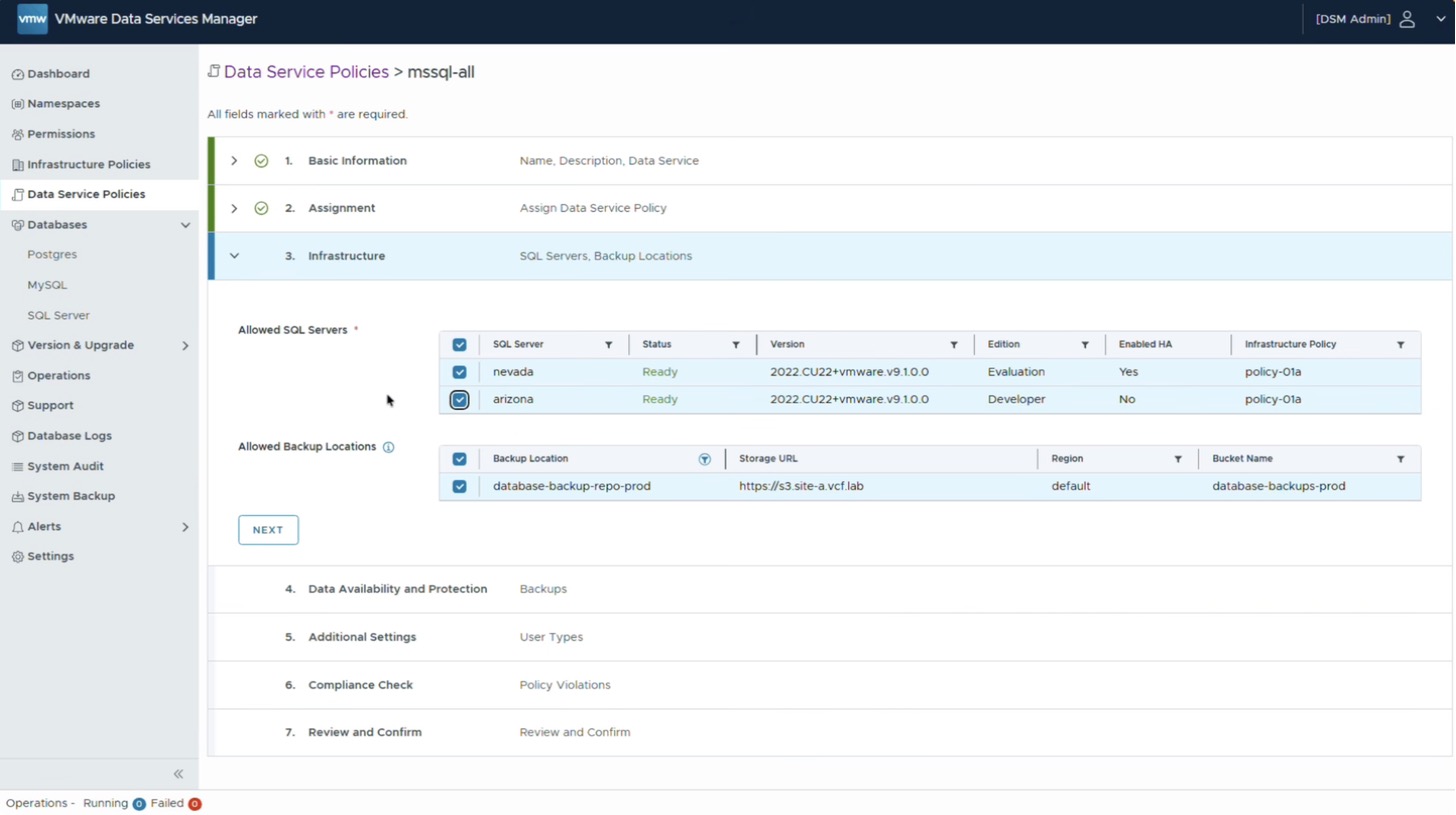
Следующий шаг — получить доступ к новому экземпляру баз данных в DSM. Доступ полностью управляется через концепцию политик сервисов данных (data service policies). В рассматриваемом окружении политика для SQL Server уже существует, поэтому вместо создания новой достаточно отредактировать имеющуюся. Эта политика определяет, кто, что и где может запускать.
Сейчас она настроена на применение ко всем пространствам имён — в тестовой среде это самый простой вариант. Кроме того, политика управляет тем, к каким серверам баз данных имеет доступ пользователь.
До этого момента в списке присутствовал только экземпляр nevada — тот самый трёхузловой HA-кластер. Поскольку в среде появился новый экземпляр arizona, его необходимо отметить, чтобы получить возможность разворачивать на этой инфраструктуре новые пользовательские базы данных.
Новый одноузловой SQL Server будет использоваться временно и, скорее всего, впоследствии удалён, поэтому резервное копирование для него делать необязательно. Политика меняется с режима «требовать резервные копии», который необходим при использовании варианта с HA-кластером, на режим «разрешать резервные копии». В результате базы данных на HA-кластере продолжают резервироваться, а для одиночного экземпляра резервное копирование можно не задействовать.
Типы аутентификации остаются без изменений — разрешены оба: Windows Active Directory и связка «имя пользователя и пароль SQL Server». Второй вариант считается менее безопасным, но зачастую более удобным, поэтому пока допускаются оба. После краткой проверки настроек политика сохраняется и готова к использованию.
Восстановление базы данных на момент времени
Далее выполняется возврат к разделу SQL Server и переход на вкладку баз данных, где видны две работающие пользовательские базы. Из существующей базы данных запускается восстановление на определённый момент времени.
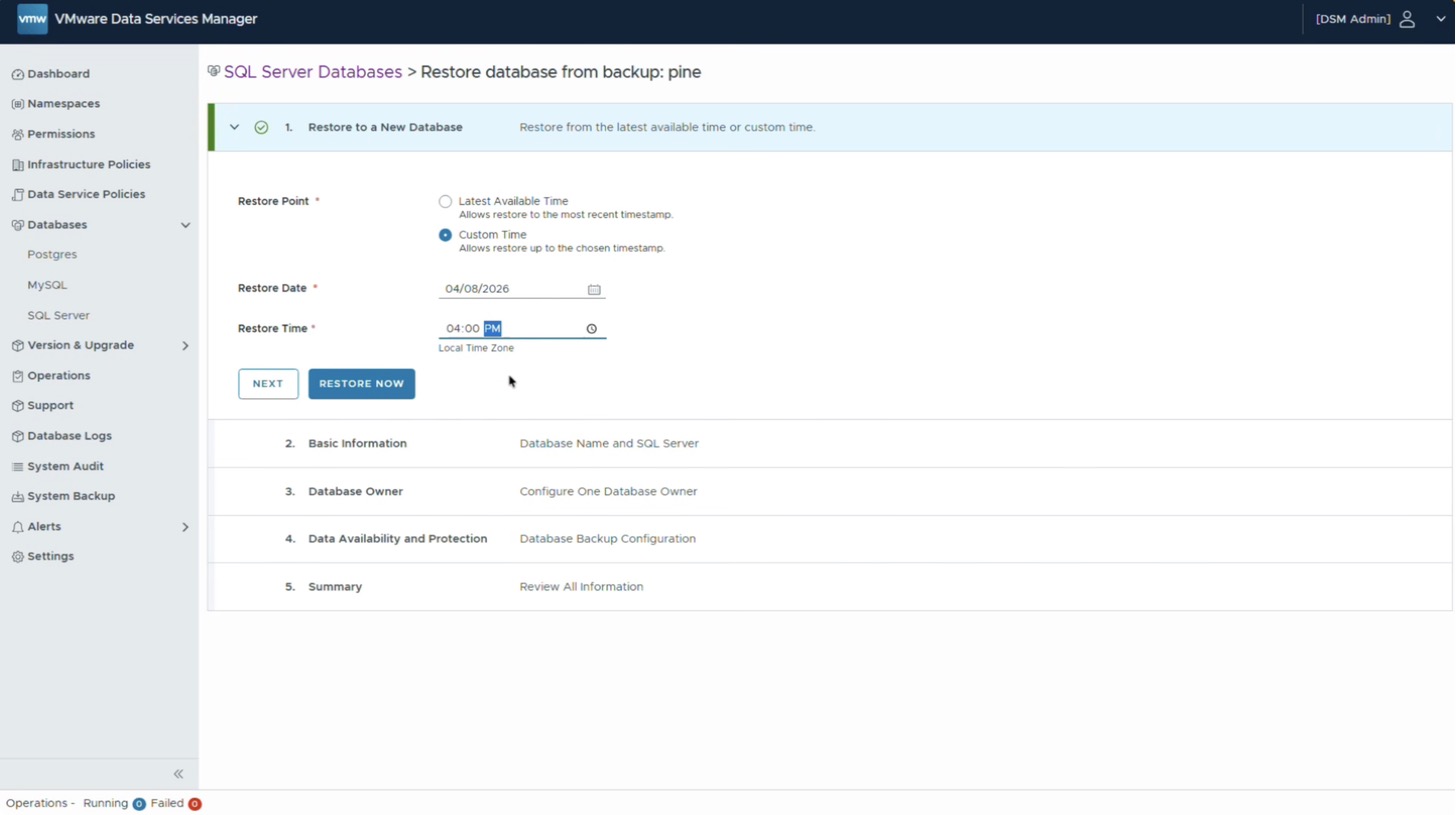
Это востребованная возможность. Например, произошло повреждение данных или кто-то внёс изменения, и требуется вернуться назад, чтобы понять, как база выглядела в определённый момент, — ради отладки. В мастере выбирается вариант Custom Time вместо восстановления на последнюю доступную точку, после чего указываются нужные дата и время.
Копия разворачивается не поверх существующего экземпляра, где работает «живая» база, а на новом экземпляре arizona, созданном ранее. База при этом переименовывается — так её проще запомнить.
Имя пользователя не меняется: используется аутентификация Windows и учётная запись Active Directory с именем DBA. Резервные копии для этой базы отключаются, чтобы не засорять корзину S3, — база всё равно будет удалена через день-два. После итогового просмотра параметров запускается восстановление. В результате в среде появляется третья база данных SQL Server, размещённая на другом сервере SQL Server и готовая к работе.
Подключение через SQL Server Management Studio
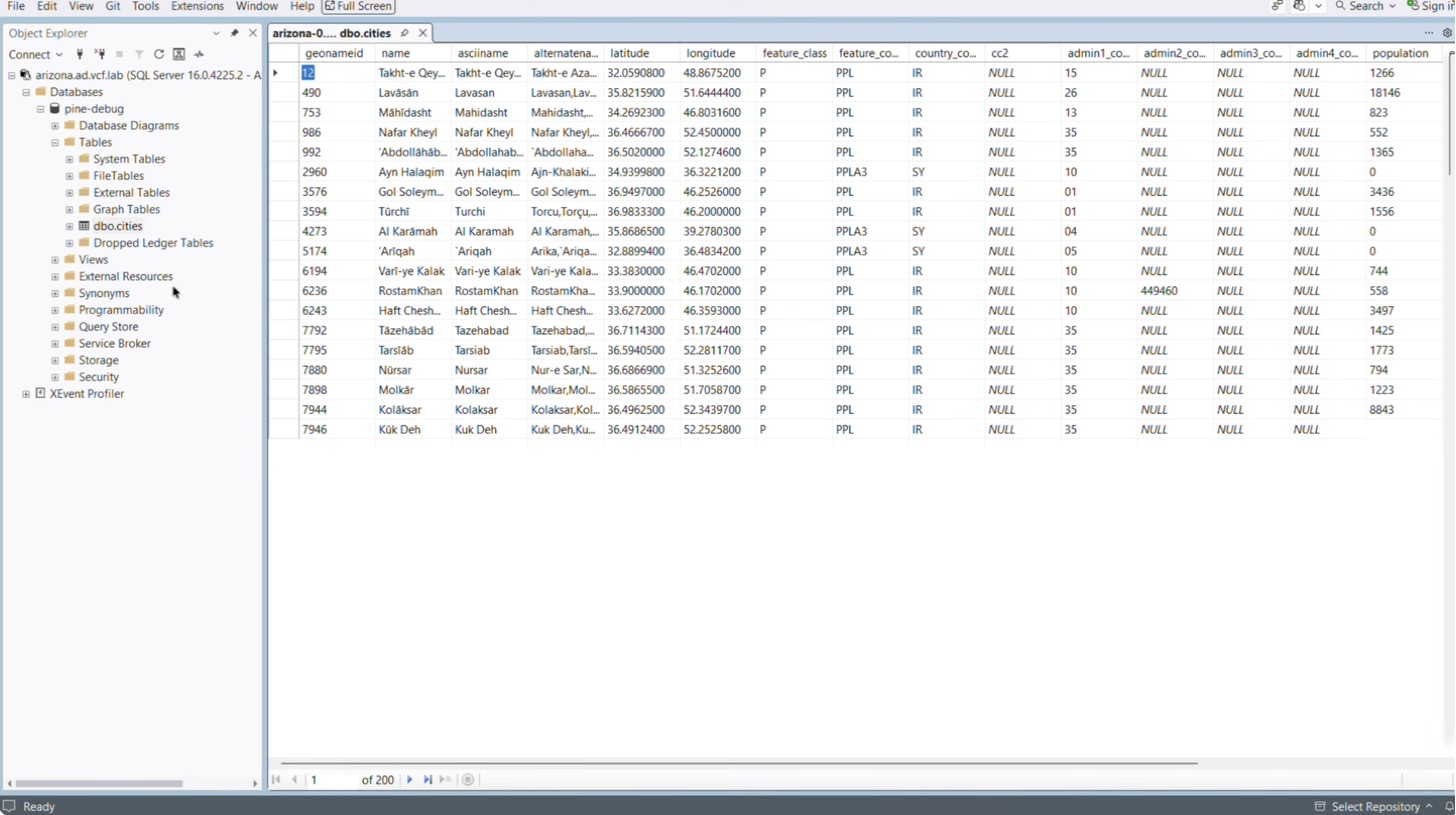
Дальнейшая работа переносится на рабочий стол Windows, где выполнен вход под той самой доменной учётной записью DBA. Заранее открыта SQL Server Management Studio, в которой уже указано полное доменное имя только что созданного экземпляра базы данных. Соответствующая запись в DNS присутствует — её автоматически создал DSM.
Остаётся ввести имя новой базы данных, работающей на этом экземпляре. Шифрование и доверие сертификату сервера также настроены. После нажатия кнопки подключения база открывается так же, как любая другая знакомая база SQL Server.
Видно, что это копия на определённый момент времени: в ней уже присутствует таблица cities — набор данных о городах со всего мира, и данные в ней есть. Начиная с этого момента разработчик или администратор баз данных может выполнять запросы и выяснять состояние тех элементов, которые предположительно вызывают проблемы и требуют расследования путём восстановления на момент времени.
Итог
Показанный сценарий представляет собой восстановление базы данных SQL Server на момент времени с размещением на полностью изолированном экземпляре. Промышленный кластер при этом не был затронут.
DSM самостоятельно подготовил целевой экземпляр, присоединил его к Active Directory, автоматически зарегистрировал DNS-запись и восстановил базу данных на точно указанную метку времени. Администратор базы данных подключился с использованием аутентификации Windows — без необходимости управлять паролями. Ручных операций с инфраструктурой и заявок в поддержку не потребовалось.
Именно так выглядит управление жизненным циклом SQL Server на платформе VCF в DSM 9.1: автоматизированно, управляемо и с готовностью к промышленной эксплуатации.
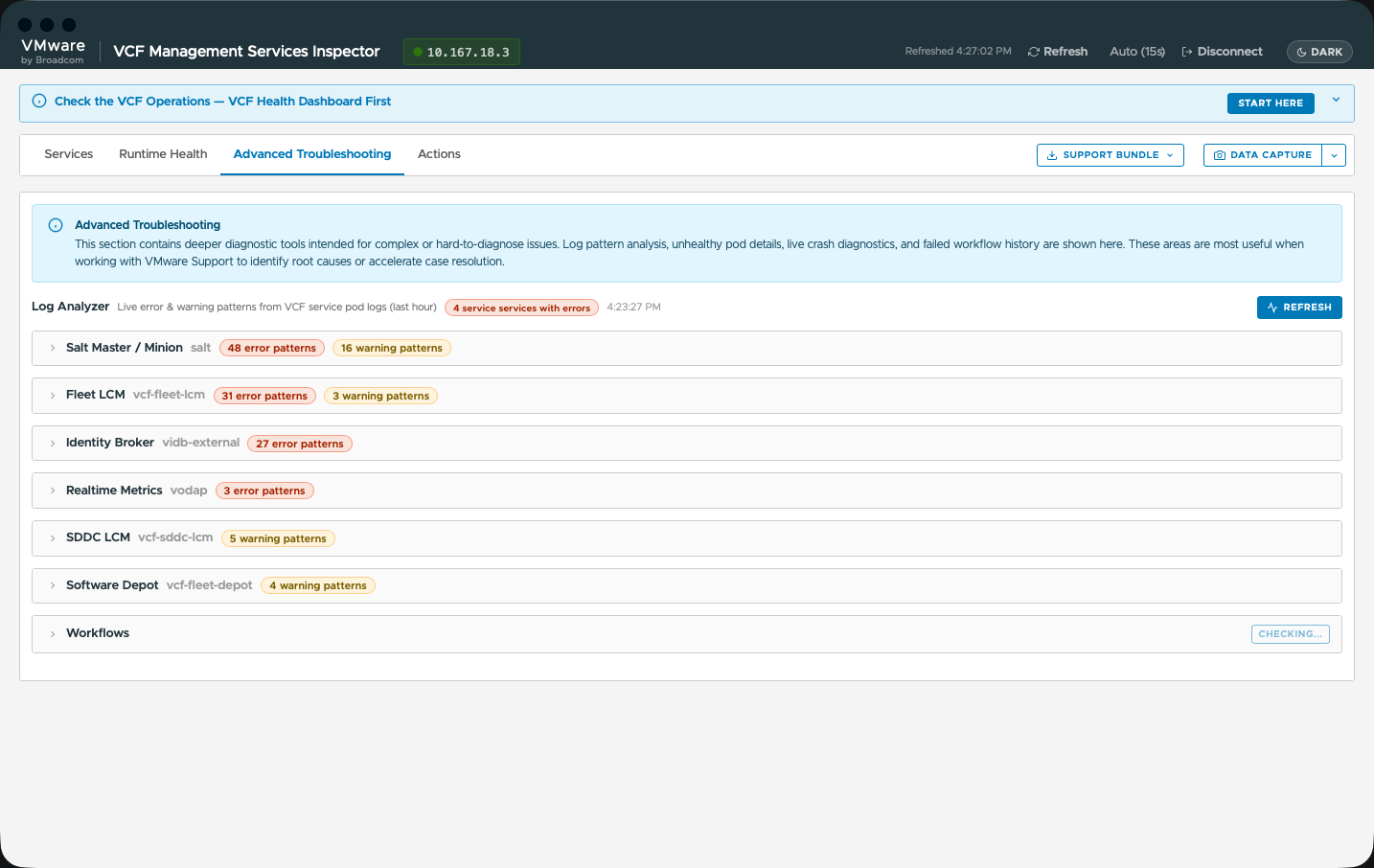
Состоялся анонс средства VMware VCF Inspector — нового автономного средства диагностики, проверки состояния и устранения неполадок, созданного специально для VMware Cloud Foundation (VCF) 9.1 и служб управления VCF (VCF management services).
VCF Inspector предоставляет администраторам инфраструктуры, инженерам поддержки и архитекторам решений мгновенную структурированную картину происходящего в средах VCF 9.1 — без ручной работы в командной строке, без написания собственных SSH-скриптов и без развёртывания тяжеловесных виртуальных модулей.
Модуль VCF Inspector уже доступен для бесплатной загрузки на портале Broadcom Support Portal в разделе VMware Flings.
Зачем понадобился VCF Inspector
Службы управления VCF, появившиеся в версии VCF 9.1, представляют собой единую архитектуру для централизованного управления жизненным циклом и эксплуатацией всего парка VCF. В их состав входят ключевые сервисы уровня флота и отдельных инстансов: службы управления жизненным циклом, VCF SSO, управление журналами, управление конфигурациями Salt и другие.
Такая унифицированная модель даёт упорядоченные операции жизненного цикла и глобальную видимость через VCF Operations, однако управление этими взаимосвязанными службами и поиск неисправностей в них требуют рассматривать состояние компонентов, сертификаты платформы, межкомпонентные соединения и процессы жизненного цикла как единую платформу.
Чтобы дать администраторам больше возможностей и укрепить уверенность в эксплуатации, VCF Inspector закрывает три ключевых сценария:
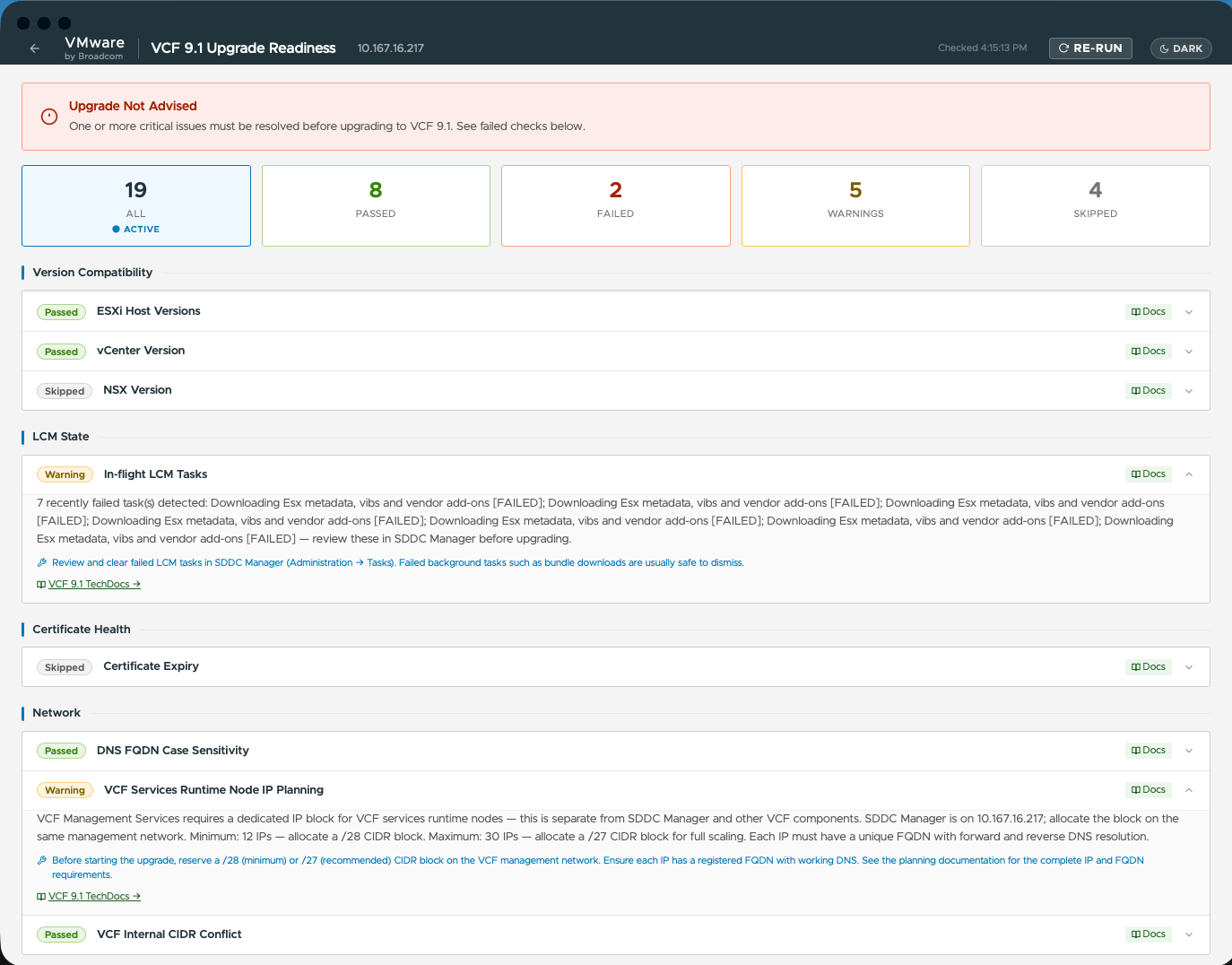
Проактивная проверка готовности к обновлению: автоматизированный способ в один клик убедиться в соответствии парольных политик требованиям, готовности хостов, доступности сети и валидности сертификатов до запуска обновления до VCF 9.1
Прозрачность развёртывания и обновления: сводная временная шкала хода установок и обновлений VCF в реальном времени, дающая командам ясное представление о выполнении подзадач и автоматические подсказки по первопричинам сбоев без ручного поиска по журналам на узлах управляющей плоскости
Мгновенная диагностика режима day-2: структурированная проверка состояния всех служб платформы, позволяющая отслеживать состояния сервисов, динамику перезапусков и релевантные рекомендации из базы знаний в едином интерфейсе
Все три возможности флинг VCF Inspector реализует в одном исполняемом файле, рассчитанном на запуск с рабочей станции администратора или с jumpbox-хоста.
Ключевые возможности и сценарии применения
VCF Inspector поддерживает три основных сценария «из коробки»:
1. Оценка готовности к обновлению VCF 9.1
Теперь не требуется быть экспертом по документации VCF или разбираться в каждой статье базы знаний (KB). Инструмент выполняет набор автоматизированных предварительных проверок в отношении SDDC Manager и vCenter до запуска обновления VCF. Проверяются:
Соответствие парольным политикам и сроки истечения учётных записей
Состояние хостов и готовность кластеров vSphere
Доступность необходимых сетевых портов (SSH 22, HTTPS 443, Platform API 5480, Cluster API 6443)
Статус активных задач управления жизненным циклом и пороговые значения истечения сертификатов
Выдача конкретных рекомендаций по устранению для непройденных проверок
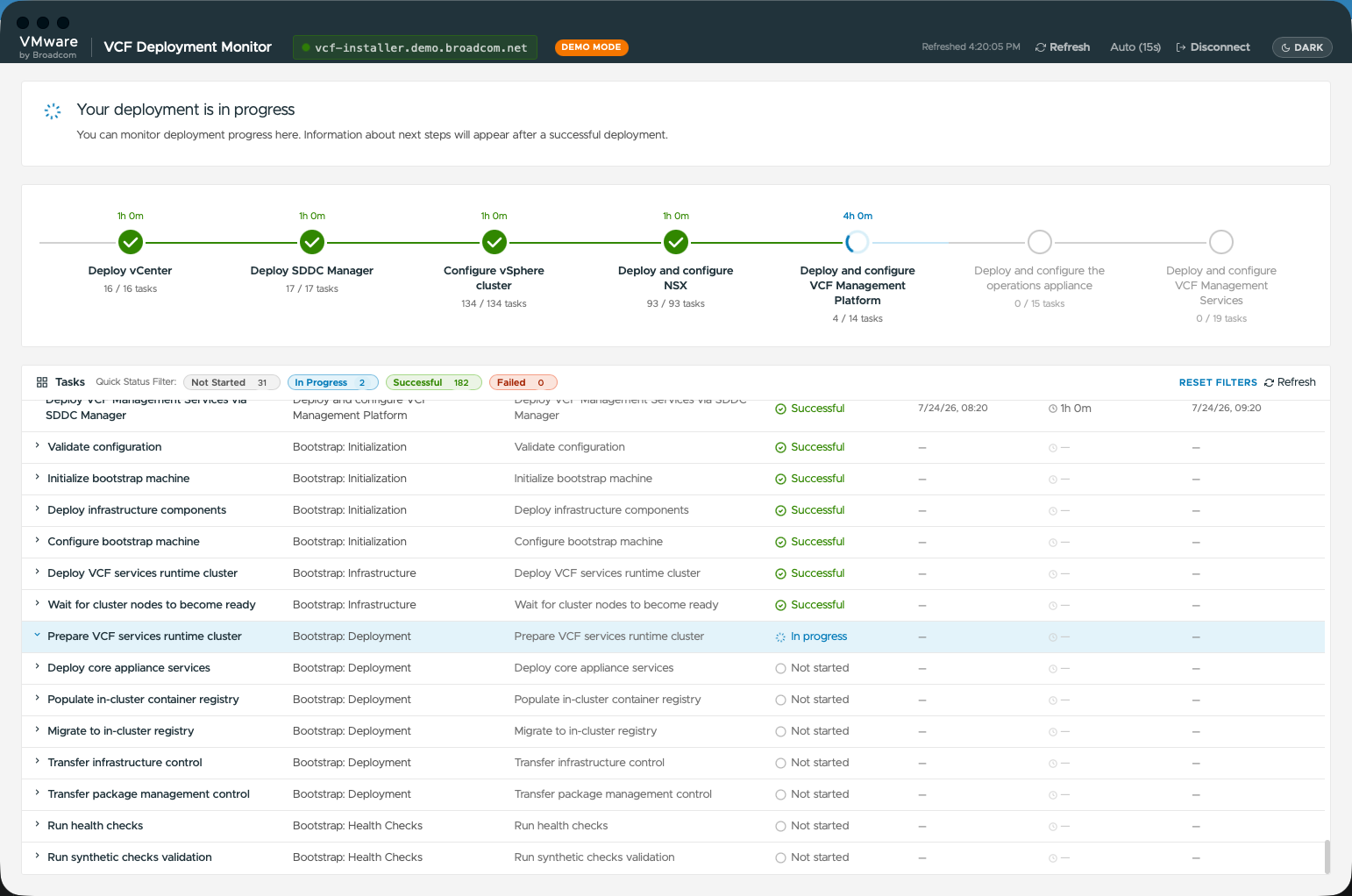
2. Мониторинг развёртывания и обновления в реальном времени
Инструмент позволяет отслеживать ход текущей установки или обновления VCF в реальном времени. В числе функций:
Временная шкала подзадач SDDC Manager и стадий Bootstrap в реальном времени
Автоматическое обнаружение зависших задач и извлечение первопричины ошибок
Прямые ссылки на статьи базы знаний Broadcom по известным проблемам развёртывания
Расчёт длительности стадий и фильтрация по стадиям
Расширенный мониторинг задач развёртывания служб управления VCF
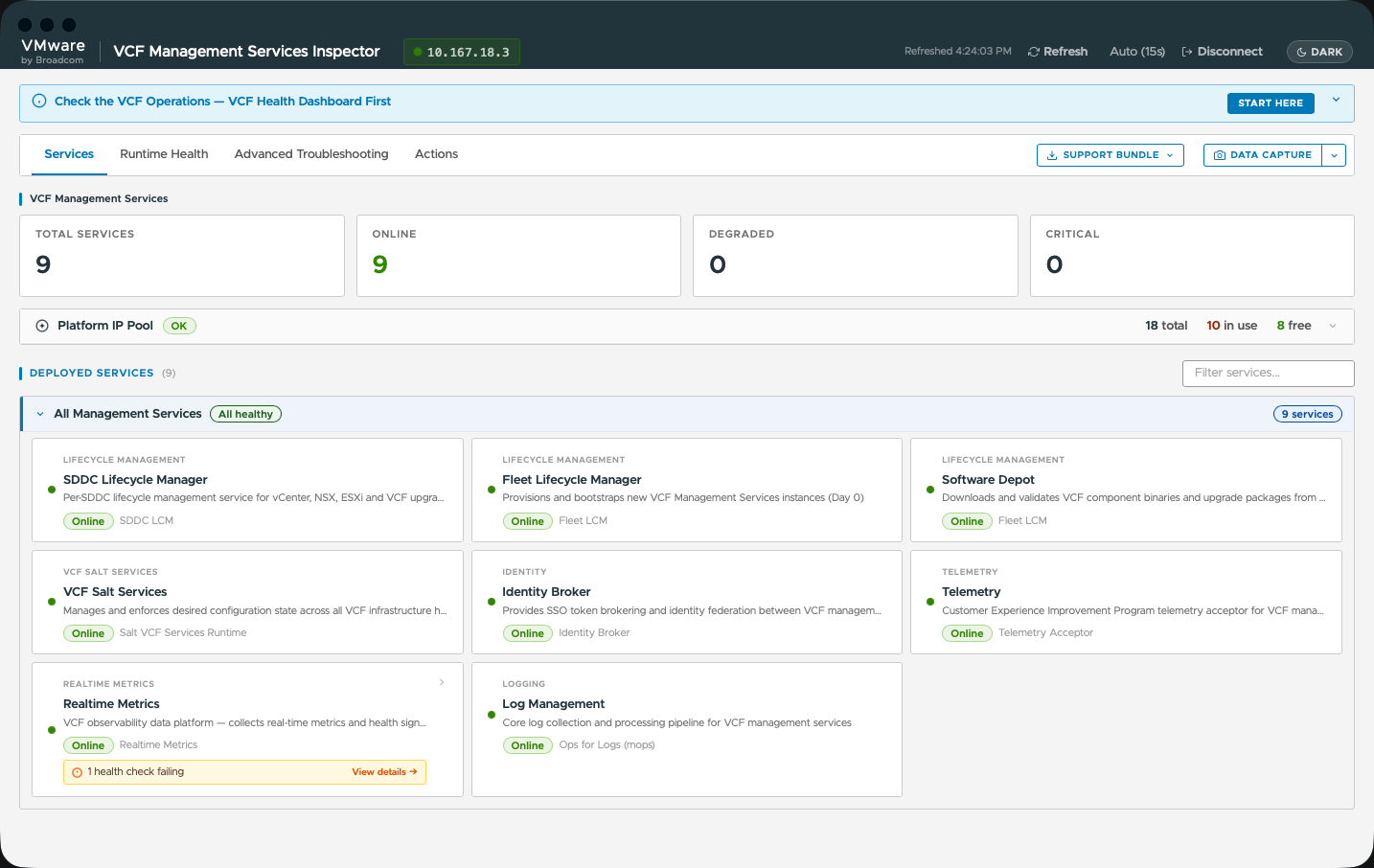
3. Диагностика и контроль состояния служб управления VCF в режиме day-2
Проверка состояния всех работающих служб платформы выполняется без какой-либо настройки:
Мгновенная проверка состояния сервисов: сгруппированное представление служб управления VCF (управление журналами, управление жизненным циклом флота, VCF Automation, брокер идентификации, компоненты VMware Salt for VCF, телеметрия) с индикаторами состояния.
Обнаружение пулов IP и FQDN платформы: развёрнутая таблица соответствий VIP-адресов управляющей плоскости, IP-адресов рабочих узлов, канонических FQDN и служб LoadBalancer.
Схема топологии узлов: визуальная матрица узлов управляющей плоскости и рабочих узлов с отображением размещения компонентов и их статуса.
Анализатор журналов и диагностика компонентов: выявление недавних шаблонов ошибок и предупреждений в журналах служб платформы с мгновенной диагностикой компонентов и журналами выполнения в отдельном окне с деталями.
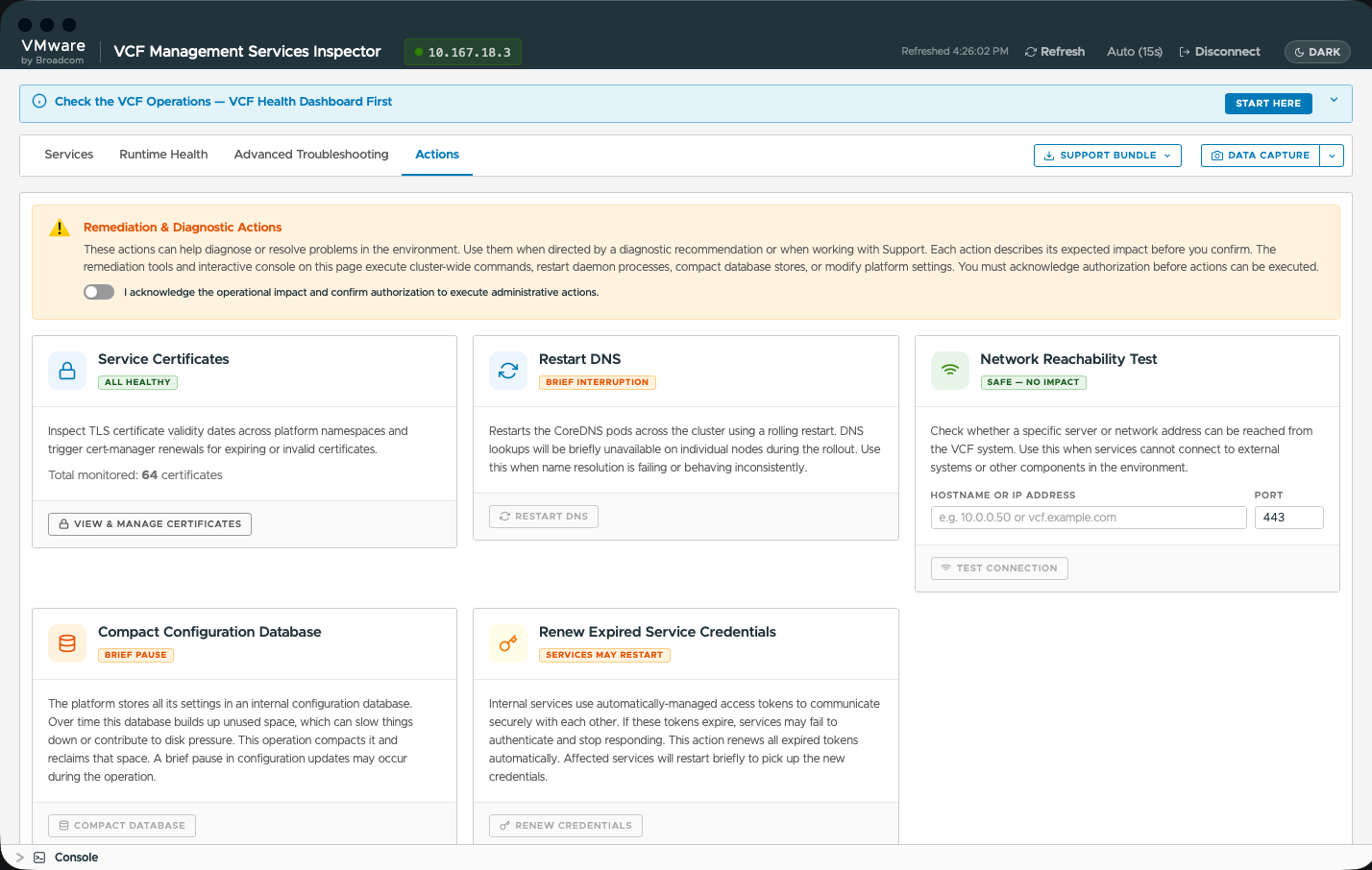
Административные действия по устранению неполадок: обновление сертификатов cert-manager, поочерёдный перезапуск DNS, уплотнение системной базы данных и проверка сетевой доступности — всё в один клик и под защитой интерактивной блокировки с подтверждением.
Безопасная консоль терминала: консоль для продвинутых пользователей со строгой проверкой команд только на чтение, что разрешает безопасные запросы статуса и блокирует деструктивные операции.
Обзор служб управления VCF:
Действия по устранению неполадок и контролируемая консоль:
Расширенное устранение неполадок:
Как начать работу
Запуск VCF Inspector занимает считанные минуты:
Загрузка бинарного файла: нужно перейти на портал Broadcom Support Portal, раздел Free Downloads / VMware Flings и скачать единственный бинарный файл для своей операционной системы (vcf-inspector-darwin-arm64-native, vcf-inspector-windows-amd64-native.exe или vcf-inspector-linux-amd64).
Выдача прав на выполнение и запуск:
macOS/Linux: в терминале выполнить chmod +x ./vcf-inspector-darwin-arm64-native, затем запустить ./vcf-inspector-darwin-arm64-native.
Windows: дважды кликнуть по vcf-inspector-windows-amd64-native.exe.
Подключение к среде:
Ввести IP-адрес или FQDN любого узла управляющей плоскости VCF (либо SDDC Manager).
Указать учётные данные vmware-system-user (или администратора SDDC Manager).
VCF Inspector установит защищённую сессию и автоматически заполнит все панели состояния.
Итоги и обратная связь
VCF Inspector сводит устранение неполадок в VCF 9.1 к работе с одним изящным инструментом, который не требует ни установки, ни какого-либо инфраструктурного следа. Подготовка к обновлению до VCF 9.1, наблюдение за идущим развёртыванием или проверки состояния в режиме day-2 — во всех этих случаях VCF Inspector мгновенно выдаёт нужную информацию. Попробовать VCF Inspector можно уже сегодня, а отзывы, сообщения об ошибках и пожелания по функциональности принимаются через каналы сообщества VMware Flings.
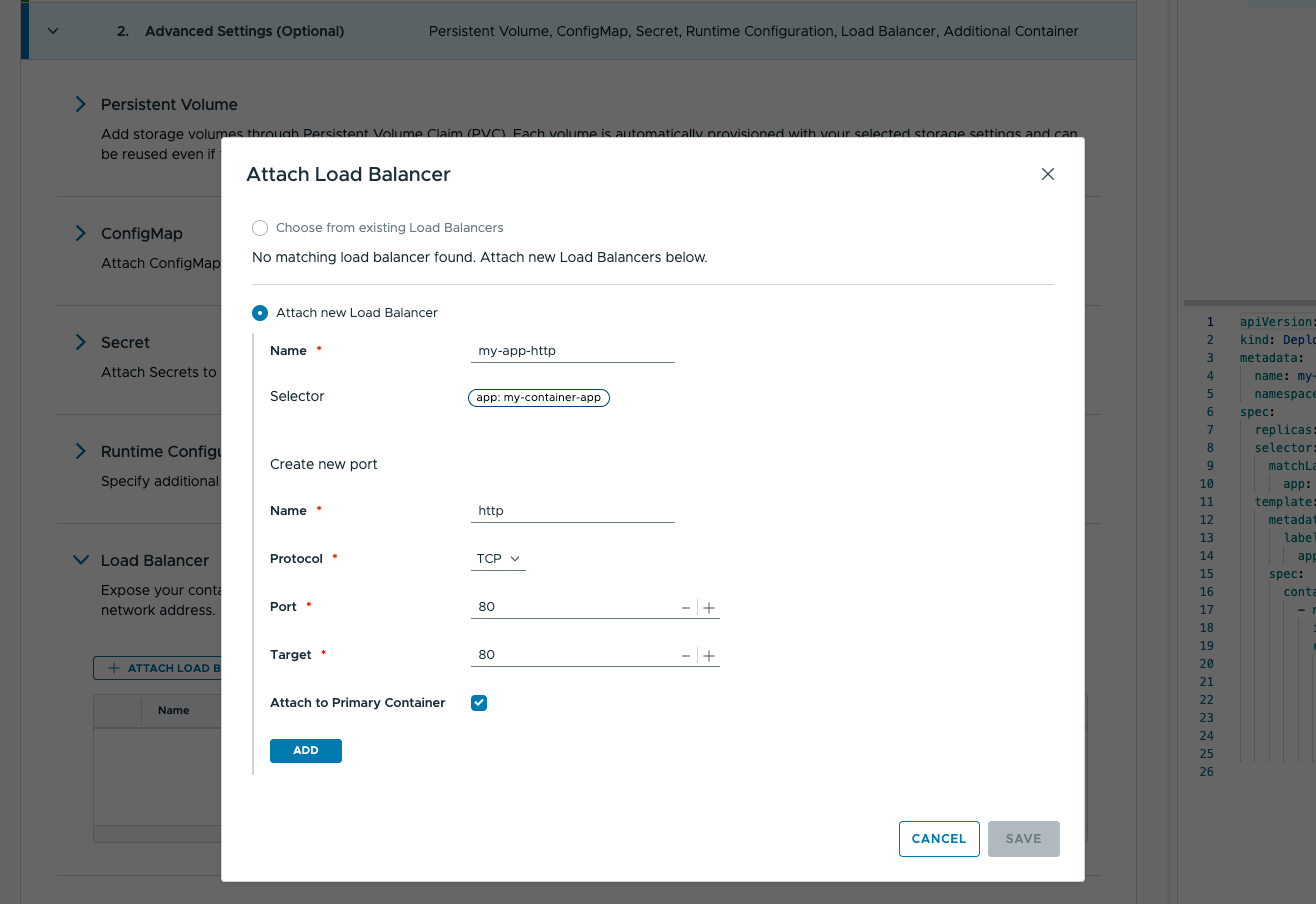
Решение VMware Cloud Foundation Operations HCX 9.1 включено в состав платформы VCF 9.1 и развивает линейку инструментов мобильности рабочих нагрузок. В новой версии переработана архитектура транспортных устройств, управление жизненным циклом полностью переведено в VCF Operations, усилены механизмы безопасности и соответствия требованиям, а также расширены возможности миграции и поддержка гостевых операционных систем. Ниже разобраны основные нововведения. Полное описание доступно в официальной документации по мобильности рабочих нагрузок.
Оптимизированная архитектура устройств IX и NE
Ключевое нововведение версии — новая оптимизированная (enhanced) архитектура устройств HCX Interconnect (IX) и Network Extension (NE), обеспечивающая более высокую производительность передачи данных между площадками.
Начиная с версии 9.1, все вновь создаваемые сервисные сети (Service Mesh) автоматически разворачиваются на базе оптимизированной архитектуры. Устройства, развёрнутые в предыдущих версиях, продолжают работать на прежней (legacy) архитектуре до тех пор, пока не будут переведены на новую через процедуру миграции расширений сети (Migrating Network Extensions).
Дополнительно версия отказывается от самоуправляемых устройств на базе PhotonOS в пользу стека NSX Edge, который обеспечивает более высокую производительность и устраняет избыточность поддержки двух функционально эквивалентных сетевых стеков. Для перевода устройств PhotonOS на архитектуру NSX Edge в HCX 9.1 предусмотрен автоматизированный сценарий миграции. Поддержка PhotonOS-устройств объявлена устаревшей, полное удаление запланировано на VCF 10.0.0.
Развёртывание и управление жизненным циклом через VCF Operations
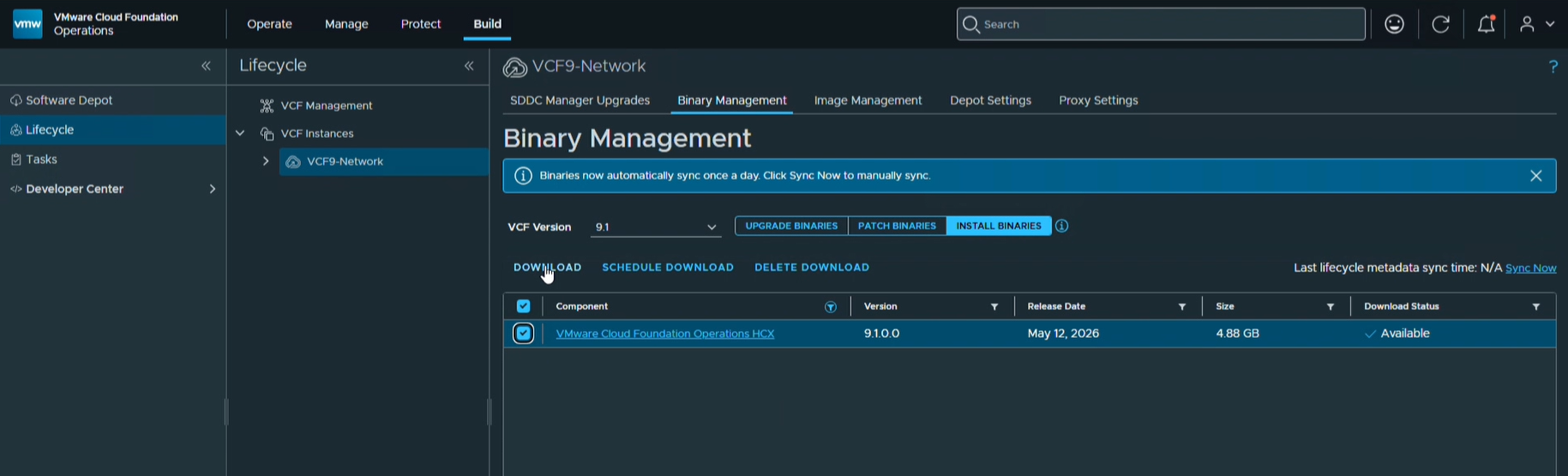
HCX 9.1 становится неотъемлемой частью платформы VCF: развёртывание, управление и обновление HCX Manager теперь выполняются непосредственно из VCF Operations. Установочные дистрибутивы загружаются в экземпляр VCF, после чего устройство разворачивается через централизованный интерфейс без ручных операций с OVA на целевой стороне.
Загрузка дистрибутивов VMware Cloud Foundation Operations HCX из консоли VCF Operations:
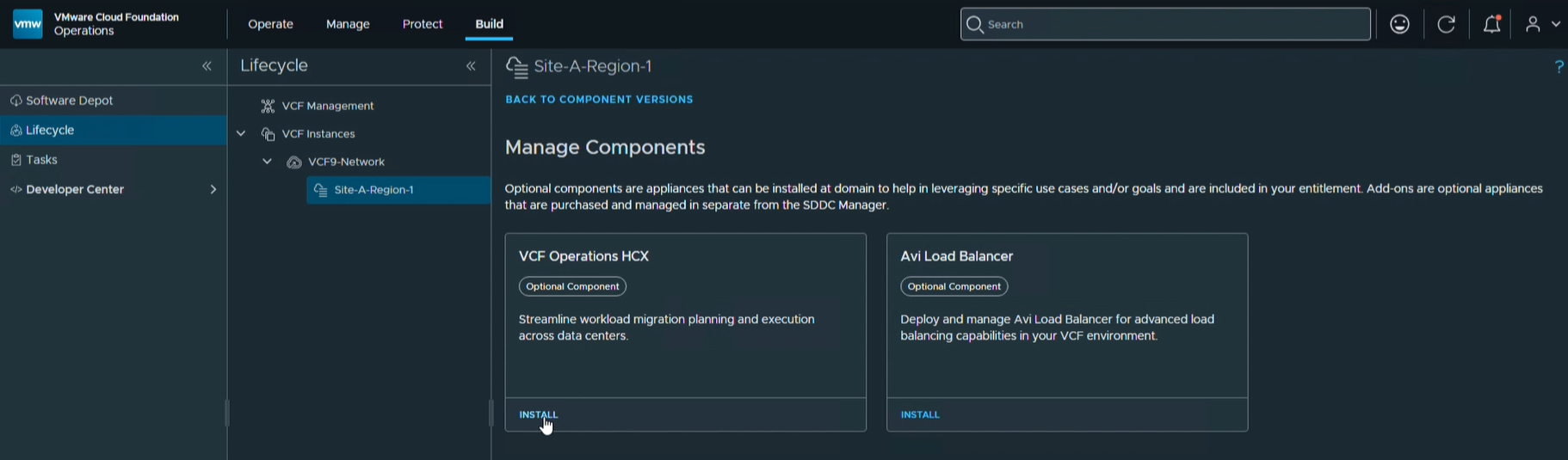
Установка HCX Manager как дополнительного компонента домена прямо из интерфейса VCF Operations:
Экземпляры HCX Manager, развёрнутые вручную (например, в устаревшей исходной среде за пределами VCF), можно подключить (onboard) и в дальнейшем управлять ими из VCF Operations. Основные возможности блока управления жизненным циклом:
Управление жизненным циклом (LCM): развёртывание, обслуживание и обновление HCX Manager выполняются через VCF Operations.
Пакет управления VCF Operations HCX Management Pack: новый пакет для установки в VCF Operations, обеспечивающий критически важные сервисы — ротацию паролей локальных пользователей, ротацию сертификатов и сбор диагностических журналов. Пакет несовместим с прежним пакетом управления HCX для vRealize Operations.
Идентификация и доступ: поддержка единого входа VCF Single Sign-On (SSO) и ролей VCF для унифицированной аутентификации и авторизации в веб-интерфейсе и API HCX Manager.
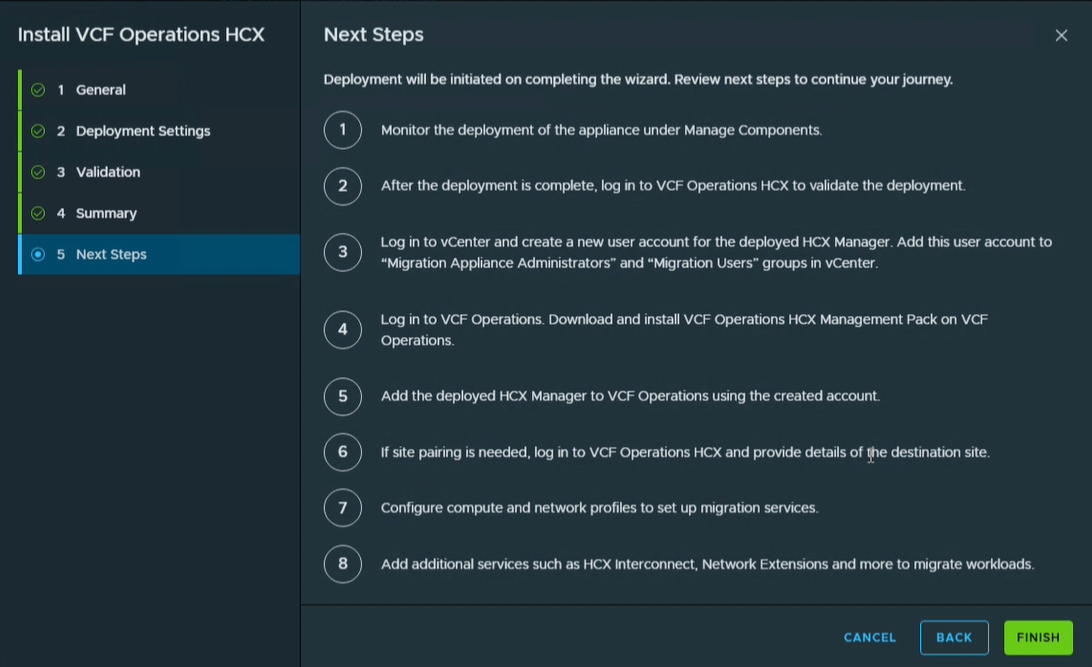
Завершение мастера развёртывания HCX Manager, запускающего автоматизированную установку:
Безопасность и соответствие требованиям
Сертификация FIPS 140-3: HCX теперь сертифицирован по стандарту FIPS 140-3, что соответствует строгим требованиям к безопасности.
Неразрывное управление сертификатами (NDC): новые REST API HCX Manager позволяют управлять сертификатами HCX без нарушения доверия со стороны клиентов.
Сетевая безопасность: порты HCX добавлены в список исключений распределённого межсетевого экрана (DFW); между оптимизированными устройствами IX и NE используется стандартный трафик IPsec.
Улучшения миграции и Interconnect
Оптимизация WAN: возвращена функция эффективной оптимизации WAN, встроенная непосредственно в конфигурацию сервисной сети HCX Interconnect. Возможность доступна исключительно для оптимизированных сервисных сетей и не поддерживается для миграций OSAM и HAV.
Локальные миграции в пределах площадки: поддержка миграций без развёртывания устройств внутри одного экземпляра vCenter с помощью HCX Assisted vMotion (HAV) — источник и приёмник могут быть одним и тем же экземпляром.
Расширенная поддержка хранилищ и правил: поддержка нестандартных политик хранения при «холодных» (Cold) миграциях, а также возможность выбирать несколько целевых хранилищ данных для одной виртуальной машины (кроме OSAM).
Расширения VLAN-сетей: поддержка расширения VLAN-сетей на нативные распределённые группы портов (DVPG) на целевой площадке.
Обновлённый веб-интерфейс: переработанный и дополненный пользовательский интерфейс.
Расширенная поддержка гостевых ОС
Список поддерживаемых операционных систем для кастомизации гостевой ОС и миграции с помощью агента (OS Assisted Migration, OSAM) расширен:
Кастомизация гостевой ОС и массовая (Bulk) миграция теперь поддерживают Windows Server 2022.
Миграция OSAM теперь поддерживает Windows Server 2022 и Windows Server 2025.
Устаревшие функции
В рамках упрощения продукта в версии 9.1 объявлен отказ от ряда возможностей:
Устройства на базе PhotonOS: поддержка самоуправляемых устройств PhotonOS объявлена устаревшей с версии 9.1.0, полное удаление намечено на VCF 10.0.0. Предусмотрен автоматизированный переход на архитектуру NSX Edge.
VMware Cloud Director (VCD): поддержка VCD в VCF Operations HCX объявлена устаревшей с версии 9.1.0. Поскольку VCD не поддерживается в VCF 9, для переноса рабочих нагрузок в VCF Automation 9 внедряется новый инструмент импорта. Полное удаление запланировано на VCF 9.2.0.
Совокупность нововведений делает VCF Operations HCX 9.1 более производительным, безопасным и глубоко интегрированным в платформу VCF решением для мобильности рабочих нагрузок. Подробности приведены в официальных заметках о выпуске VCF 9.1.
Прежний подход к установке патчей устарел. Ежеквартальные окна обслуживания, тщательно спланированные периоды заморозки изменений и растянутые на недели графики устранения уязвимостей создавались под ту среду угроз, которой больше не существует. Сегодня исследования безопасности с помощью AI, автоматизированные средства сканирования и расширившиеся программы bug bounty радикально сократили промежуток между раскрытием уязвимости и началом её активной эксплуатации. Инфраструктурные команды, у которых прежде были недели на реакцию, теперь располагают днями, а иногда и часами. Каждый час задержки — это уже не просто операционное неудобство, а накапливающийся риск с вполне реальными последствиями.
Broadcom непрерывно совершенствует процесс обновления VMware Cloud Foundation (VCF), чтобы корпоративные заказчики могли опережать развивающиеся угрозы безопасности. Версия VCF 9.1 отвечает новой реальности напрямую. В этом релизе реализована многоуровневая оркестрируемая архитектура установки патчей, которая позволяет операторам оперативно применять исправления безопасности на всех уровнях стека — с минимальным или вовсе нулевым влиянием на рабочие нагрузки.
Трёхуровневая архитектура, рассчитанная на скорость и стабильность
VCF управляет инфраструктурой на трёх отдельных уровнях, у каждого из которых свои особенности обновления и свой профиль рисков:
Уровень управления — VCF Management Services, VCF Operations, VCF Automation, Cloud Proxy, VCF Operations for Networks.
Уровень плоскости управления — vCenter, NSX Manager, vSphere Supervisor и VMware vSphere Kubernetes Service (VKS).
Уровень плоскости данных — ESX, vSAN, NSX Edge и прочее.
Вместо единого монолитного сценария обновления для всех трёх уровней в VCF 9.1 предусмотрены специализированные механизмы, соответствующие профилю потенциальных нарушений работы каждого из них. Ключевая мысль проста: скорость и стабильность не противоречат друг другу. При правильном инструментарии организации могут устанавливать патчи агрессивно, не соглашаясь на тот простой, который прежде делал быстрое обновление операционно неприемлемым.
Стратегия обновления под каждый уровень
Трёхуровневая архитектура VCF служит и основой того, как платформа сама себя обновляет. У каждого уровня свой профиль возможных нарушений работы, поэтому для каждого выбран подход, настроенный под собственную задачу, при общей цели: применять исправления быстро, сохраняя доступность.
Уровень управления обновляется предсказуемо и без риска для рабочих нагрузок. Архитектурно он отделён от плоскости нагрузок, поэтому окна его обновления не несут для них никакой угрозы. Декларативная модель жизненного цикла позволяет администраторам задать целевую версию, а сервис Fleet Lifecycle оркестрирует всё остальное в масштабе всего парка систем, заменяя ручные операции, из-за которых обновление уровня управления было подвержено ошибкам.
Уровень плоскости управления остаётся доступным во время обновлений, так что vCenter, NSX и управление Kubernetes продолжают работать. Поскольку от этого уровня зависит каждая операция, простой сводится к минимуму механизмами, подобранными под тип патча: vCenter Quick Patch для исправлений безопасности и мелких доработок, Reduced Downtime Upgrade для перехода между версиями, а также плавающие обновления для кластеров vSphere Supervisor и VKS. Управление NSX сохраняет доступность на всём протяжении процесса за счёт того, что как минимум два узла остаются активными.
Уровень плоскости данных — это среда исполнения рабочих нагрузок, и к нему предъявляются самые жёсткие требования. Задача состоит в том, чтобы обновить хосты, не нарушив работу этих нагрузок. Технология ESX Live Patch применяет исправления непосредственно в памяти — без окна обслуживания, без эвакуации виртуальных машин и без перезагрузки, а в VCF 9.1 её действие распространено и на хосты с включённым TPM. Когда перезагрузки избежать не удаётся, влияние минимизируют Quick Boot, предварительная подготовка образов и эвакуация нагрузок через живую миграцию vMotion.
На всех уровнях действует один и тот же принцип: предварительные проверки подтверждают вероятный успех патча до его фиксации, а восстанавливаемые схемы на базе миграции обеспечивают путь отката, если что-то пойдёт не так.
В основе всех перечисленных возможностей лежит переход к декларативному управлению жизненным циклом. Вместо выполнения последовательности отдельных команд обновления администраторы задают целевую версию для среды VCF, а оркестрацию всего процесса берёт на себя VCF Operations. Такая модель снижает вероятность человеческой ошибки, ускоряет выполнение и удерживает среду в известном и согласованном состоянии.
Итог
Необновлённая инфраструктура — это обязательство, объём которого теперь растёт с каждым часом. VCF 9.1 помогает снять многие операционные препятствия, которые прежде вынуждали выбирать между реакцией на угрозу и доступностью рабочих нагрузок. Благодаря специализированному инструментарию для плоскостей управления, контроля и данных программное обеспечение VMware предлагает целостную интегрированную архитектуру обновления всего программно-определяемого центра обработки данных — быстро, единообразно и без прерывания работы.
Недавно VMware сделала доступным каталог контента VMware Explore 2026 - пора приступать к формированию персональной программы конференции. Мероприятие пройдет с 31 августа по 3 сентября 2026 года в Лас-Вегасе, в конференц-центре The Venetian. Независимо от того, интересует ли вас тематика частного AI или модернизация инфраструктуры частного облака, в каталоге найдется контент для любого ИТ-специалиста — и его действительно много.
Четыре трека — одна облачная стратегия
В этом году программа разбита на четыре учебных трека, охватывающих ключевые направления для профессионального развития:
Cloud Infrastructure - модернизация инфраструктуры, операционных моделей и приложений.
Security - безопасная работа приложений за счет интеллектуальной автоматизации сети.
Innovation - свежие идеи для инноваций и карьерного роста.
Как эффективно работать с каталогом
Каталог устроен так, чтобы собрать нужную программу можно было без маркерной доски и стикеров. Для поиска сессий предусмотрены фильтры по следующим критериям:
Трек — Cloud Infrastructure, Modern Apps, Innovation или объединенный Networking, Security & Load Balancing.
Тип сессии — доклады (Breakouts), туториалы, короткие выступления (Quick Talks) и другие форматы.
Технический уровень — от вводного бизнес-уровня (Business 100) до экспертного (Technical 300).
Продукты — как хорошо знакомые, так и новые решения.
Полезное: у любой сессии в каталоге можно нажать значок сердечка и добавить ее в избранное, собрав собственную программу (потребуется вход в учетную запись). Когда 21 июля откроется запись на сессии, ваш план уже будет готов.
Разобраться в навигации по каталогу поможет специальное руководство.
Дополнительные возможности
Параллельно с открытием каталога проходило голосование People's Choice Awards: участники выбирали по одной сессии в каждом треке, помогая организаторам заполнить оставшиеся слоты программы с учетом интересов аудитории. Прием голосов завершился 10 июля 2026 года.
Наконец, открытый каталог с техническими сессиями — весомый аргумент для согласования поездки с руководством. Набор материалов Convince Your Manager поможет связать контент Explore с бизнес-целями команды и получить одобрение на участие.
Компания VMware объявила о доступности документа Performance Best Practices for VMware vSphere 9.1. Это подробное руководство, призванное помочь системным администраторам добиться максимальной производительности своих развёртываний платформы vSphere 9.1.
В документе (а лучше сказать - книге) рассматриваются новые возможности платформы, а также обновляются и расширяются темы, освещавшиеся в предыдущих версиях Performance Best Practices for VMware vSphere.
Основные темы документа
Расширенные рекомендации по управлению питанием, включая C-states и технологию Intel Hardware P-States (HWP)
Расширенные рекомендации для конкретных семейств процессоров, включая Intel Granite Rapids и AMD EPYC
Новый раздел об использовании Intel QAT для снижения нагрузки на CPU при шифрованном vMotion
Новое обсуждение аппаратной локальности в NUMA-системах
Расширенное описание многоуровневой памяти (memory tiering)
Расширенные рекомендации по производительности NVMe
Дополнительные подробности о технологии Receive Side Scaling (RSS)
Расширенные рекомендации по vSAN Express Storage Architecture (ESA)
Расширенное описание VCF Single Sign-On
Рекомендации по выбору оборудования для хранилищ
Рекомендации по выбору сетевого оборудования
Технология Hyper-Threading
NUMA и vNUMA
Определение объёма памяти, переподписка (overcommit), разделение страниц (page sharing) и оптимизации свопинга
Производительность хранилищ VMware vSAN, SAN, iSCSI, NFS, NVMe и NVMe over Fabrics
Рекомендации по шифрованию виртуальных машин
Производительность сети
Работа с нагрузками, чувствительными к задержкам хранилища
Работа с нагрузками, чувствительными к сетевым задержкам
Network I/O Control (NetIOC)
DirectPath I/O
Microsoft Virtualization-Based Security (VBS)
Выбор виртуальных сетевых адаптеров
Производительность базы данных vCenter
Производительность vSphere Client
vMotion, Storage vMotion и Cross-Host Storage vMotion
Distributed Resource Scheduler (DRS) и Distributed Power Management (DPM)
Если вы управляете Kubernetes вместе с традиционными виртуальными машинами, vSphere Supervisor в vSphere 9.0 и VMware Cloud Foundation (VCF) 9.0 служит единой плоскостью управления. Но когда дело доходит до настройки инфраструктуры, у команд, проектирующих такие среды, всегда возникает один и тот же вопрос:
«Какие балансировщики нагрузки поддерживаются и как выбрать правильный для моего vSphere Supervisor?»
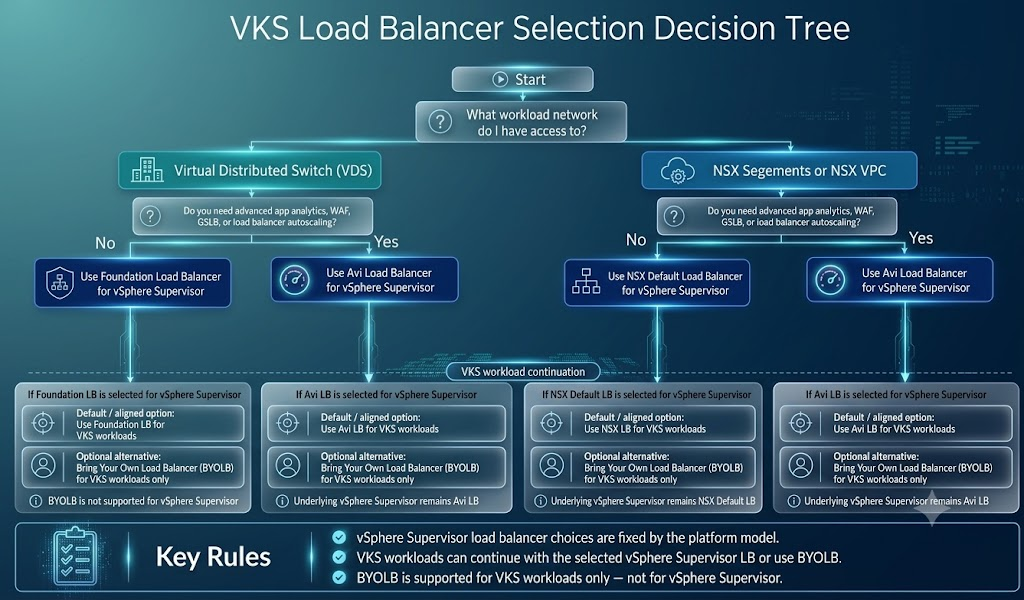
Ответ полностью зависит от вашей существующей сетевой архитектуры, лицензирования и того, какой объём контроля над управлением трафиком вы хотите передать платформе, а какой — командам разработки. Разберём поддерживаемые платформенные балансировщики нагрузки в vSphere 9 и VCF 9, посмотрим, как они соотносятся с топологией сети, и выясним, где остаётся гибкость на уровне приложений.
Основные варианты организации платформенного балансировщика нагрузки
vSphere Supervisor поддерживает несколько вариантов платформенного балансировщика нагрузки. Ваш выбор определяет, как ключевые инфраструктурные сервисы — включая виртуальные машины VM Service, нативные vSphere Pods и управляющие плоскости кластеров VMware vSphere Kubernetes Service (VKS) — получают связность на уровне L4. Каждый вариант рассчитан на свою сетевую архитектуру и операционную модель.
1. Foundation Load Balancer и NSX Load Balancer: связность L4 из коробки
Если вам нужна интегрированная балансировка нагрузки на уровне Layer 4 (IP:порт) сразу после установки, основными вариантами платформенного балансировщика являются Foundation Load Balancer (FLB) и NSX Load Balancer (NSX-LB). Оба обеспечивают нативную связность L4 для рабочих нагрузок, управляемых Supervisor.
Какой из них использовать — зависит от вашего окружения:
FLB: включён из коробки и доступен как с лицензией VMware vSphere Foundation (VVF), так и с VCF.
NSX-LB: включён в состав VCF для сред, использующих сети NSX.
Оба платформенных балансировщика обеспечивают связность L4 для рабочих нагрузок под управлением Supervisor, включая:
Виртуальные машины VM Service: ВМ, развёрнутые через VM Service в пространство имён vSphere Namespace.
vSphere Pods: контейнерные нагрузки, работающие непосредственно на гипервизоре ESX.
Кластеры vSphere Kubernetes Service (VKS): CNCF-совместимые кластеры Kubernetes и приложения, работающие внутри них.
А что насчёт маршрутизации Layer 7 (уровень приложений)?
FLB и NSX-LB предоставляют сервисы L4 на уровне платформы, но команды приложений по-прежнему могут использовать Kubernetes-нативные решения для ingress и управления трафиком, такие как Contour, Istio и Gateway API, внутри кластеров VKS. Это открывает возможности Layer 7, включая маршрутизацию HTTP, маршрутизацию по путям и терминацию TLS с помощью привычных инструментов Kubernetes.
2. Avi Load Balancer: продвинутое управление трафиком корпоративного класса
Для организаций, которым нужны развитые контроллеры доставки приложений (ADC) во всей облачной инфраструктуре, Avi Load Balancer (Enterprise Edition) расширяет платформу возможностями управления трафиком на уровне L7, безопасности и аналитики.
Когда Avi Enterprise выбран в качестве платформенного балансировщика для vSphere Supervisor, он добавляет продвинутые сервисы доставки приложений на уровне платформы, включая:
Управление трафиком Layer 7: продвинутая маршрутизация HTTP/HTTPS, переключение контента и управление трафиком на основе политик.
Web Application Firewall (WAF): интеллектуальная распределённая защита от уязвимостей и веб-эксплойтов на границе.
Расширенный мониторинг и аналитика: видимость производительности приложений, сквозных задержек и паттернов пользовательского трафика в реальном времени.
Интегрированный DNS и Global Server Load Balancing (GSLB): доступность на нескольких площадках и распределение трафика между географически разнесёнными локациями.
Если ваша операционная модель требует централизованного управления безопасностью, глубокой аналитики или единообразия между облаками, Avi предоставляет продвинутые сервисы доставки приложений, безопасности и управления трафиком сразу в нескольких средах.
Выбор платформенного балансировщика по типу сети рабочих нагрузок
Архитектура сети рабочих нагрузок определяет, какие варианты платформенного балансировщика доступны при развёртывании vSphere Supervisor. Сетевые модели соотносятся с поддерживаемыми балансировщиками следующим образом:
vSphere Distributed Switch (VDS): поддерживает Foundation Load Balancer (FLB) или Avi Load Balancer — для сред с традиционными сетями vSphere.
Сегмент NSX: поддерживает NSX Load Balancer или Avi Load Balancer — для сред с сетями NSX.
NSX Virtual Private Cloud (VPC): поддерживает Avi Load Balancer и предназначен для cloud-native сред, использующих сети NSX VPC.
Гибкость на уровне кластеров VKS
Одна из сильных сторон VKS заключается в том, что выбор платформенного балансировщика для Supervisor не ограничивает варианты балансировки, доступные рабочим нагрузкам внутри кластеров VKS.
Поскольку кластеры VKS — это upstream-совместимые кластеры Kubernetes, они поддерживают стандартные ingress-контроллеры Kubernetes, реализации балансировщиков и другие Kubernetes-нативные решения доставки приложений.
Это позволяет инфраструктурным командам стандартизироваться на FLB, NSX-LB или Avi на уровне платформы, оставляя командам приложений свободу выбирать решение доставки приложений, которое лучше всего подходит их нагрузкам.
Краткое сравнение платформенных балансировщиков
В таблице ниже сведены ключевые различия между поддерживаемыми платформенными балансировщиками:
Функция / возможность
Foundation Load Balancer (FLB)
NSX Load Balancer (NSX-LB)
Avi Load Balancer (Enterprise)
Поддерживаемые типы сетей
VDS
Сегмент NSX или NSX VPC
VDS, сегмент NSX или NSX VPC
Основной уровень маршрутизации
Layer 4 (IP:порт)
Layer 4 (IP:порт)
Layer 4 и Layer 7
Требуемая лицензия
VVF или VCF
VCF
Лицензия Avi Enterprise
Ingress / WAF из коробки
Нет (используется VKS Ingress)
Нет (используется VKS Ingress)
Да (нативные функции платформы)
Расширенная аналитика и GSLB
Нет
Нет
Да
Переопределение на уровне VKS
Да
Да
Да
Заключение
Выбор правильного платформенного балансировщика в конечном счёте сводится к архитектуре сети рабочих нагрузок и операционным требованиям. Нужна ли вам интегрированная связность L4 с FLB или NSX-LB, либо продвинутая доставка приложений на уровне L7 с Avi — vSphere Supervisor предлагает поддерживаемый путь для каждой модели развёртывания.
Дерево решений ниже служит быстрой памяткой, помогающей выбрать платформенный балансировщик, который лучше всего подходит вашему окружению.
Те, кто уже настраивает VMware Memory Tiering или только присматривается к этой технологии, наверняка задавались вопросом: что происходит с большими страницами памяти (Memory Large Pages)? Вопрос действительно важный, поскольку ответ на него влияет на планирование ёмкости и настройку виртуальных машин. Разберём эту тему подробно.
Немного контекста
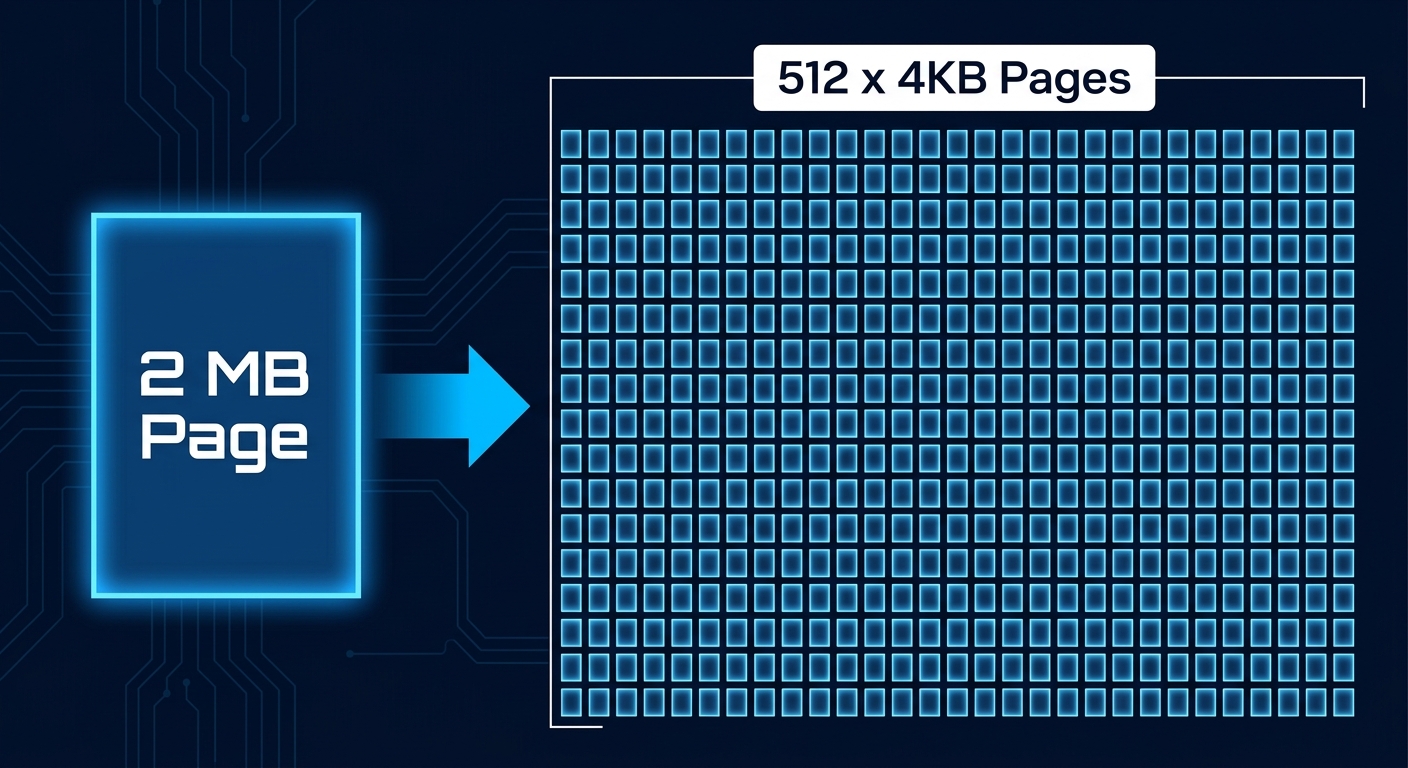
Прежде чем переходить к особенностям поведения при многоуровневом хранении памяти, стоит кратко вспомнить, что такое большие страницы (Large Pages) и почему они важны. Архитектура x86 поддерживает три размера страниц: 4 КБ (малые страницы), 2 МБ и 1 ГБ. Два последних размера в совокупности называют «большими страницами». Размер страницы можно сравнить с номиналом купюр в кошельке: крупные купюры удобнее носить с собой, но с них сложнее давать сдачу. Большие страницы работают так же: они снижают нагрузку на TLB (Translation Lookaside Buffer) и уменьшают стоимость обхода таблиц страниц, что даёт потенциальный прирост производительности для нагрузок, интенсивно работающих с памятью. По умолчанию ESX использует страницы размером 2 МБ для виртуальной оперативной памяти гостевых систем, и не случайно: выигрыш в производительности хорошо подтверждён.
Поэтому логично было бы предположить, что при включении Memory Tiering большие страницы остаются активными. Но именно здесь начинается самое интересное.
Memory Tiering меняет правила игры
При включении Memory Tiering на хосте виртуальные машины по умолчанию настраиваются так, что большие страницы исключены из механизма тиринга. На первый взгляд это выглядит нелогично, но на самом деле такое решение вполне обоснованно.
Алгоритм тиринга, встроенный в уровень управления памятью ESX, отслеживает «горячесть» и «холодность» каждой страницы. Активные страницы — рабочий набор виртуальной машины — остаются в Tier 0 (DRAM) для максимальной производительности. Холодные страницы при росте давления на память мигрируют в Tier 1 (NVMe). Всё это происходит интеллектуально, автоматически и не требует ручного вмешательства. Но есть нюанс: для качественной работы алгоритму необходим детальный контроль на уровне мелких блоков.
Как это влияет на большие страницы? Большая страница размером 2 МБ является атомарной единицей — переместить её половину на NVMe невозможно. Весь блок в 2 МБ перемещается целиком либо не перемещается вовсе. Это как пытаться точно регулировать температуру термостатом, который меняет её только с шагом в 10 градусов: работать будет, но без точности. При гранулярности 4 КБ движок тиринга способен принимать хирургически точные решения о том, какие именно страницы горячие, а какие холодные. Именно эта точность обеспечивает высокую эффективность Memory Tiering, поэтому по умолчанию используются малые страницы.
Три сценария размеров страниц
Сравним три размера страниц памяти и их поведение при работе Memory Tiering. Когда все варианты разложены по полочкам, понять их достаточно просто. Вот как ведёт себя каждый размер страницы.
Малые страницы 4 КБ: полная оптимизация
Это оптимальный вариант. Производительность специально оптимизирована для страниц 4 КБ при активном Memory Tiering. Алгоритм тиринга работает с максимальной точностью: горячие страницы остаются в DRAM, а холодные плавно выгружаются на NVMe. ESX намеренно отключает большие страницы на уровне хоста, когда настроен Memory Tiering. Чтобы точно отслеживать и перемещать память без огромных накладных расходов на производительность, ESX возвращается к использованию стандартных базовых страниц 4 КБ для гостевой памяти. Работая на уровне 4 КБ с самого начала, движок тиринга ESX избавлен от необходимости постоянно разбивать крупные страницы, чтобы выяснить, какие данные реально используются.
Большие страницы 2 МБ: включение вручную, с оговоркой
Стандартная конфигурация vSphere предполагает включённые большие страницы 2 МБ (параметр Mem.AllocGuestLargePage установлен в 1), однако при активном Memory Tiering страницы 2 МБ по умолчанию не участвуют в тиринге.
Страница 2 МБ состоит из 512 отдельных страниц по 4 КБ. Допустим, 400 из них горячие и активно используются. В идеале такая большая страница должна целиком остаться в DRAM. Но это означает, что оставшиеся 112 холодных страниц тоже застревают в DRAM, хотя могли бы быть выгружены на NVMe. Эти 112 страниц представляют собой заблокированную ёмкость — и это лишь одна большая страница. Умножьте это на любое количество, и станет ясно, что тысячи холодных страниц могут остаться в DRAM вместо выгрузки на NVMe. При гранулярности 4 КБ движок тиринга освободил бы их, а при гранулярности 2 МБ — не может, поскольку перемещение половины большой страницы невозможно.
Чтобы использовать большие страницы 2 МБ вместе с Memory Tiering, необходимо явно задать VMX-параметр виртуальной машины: monitor_control.disable_mmu_largepages = "FALSE". После установки параметра машина попадает в общий пул многоуровневой памяти, и здесь начинается самое любопытное. Когда большие страницы включены, алгоритм тиринга проактивно разбивает часть больших страниц на основе определённых эвристик и либо выгружает холодные страницы из 2-мегабайтного региона, либо собирает его обратно в большую страницу.
В этом и заключается ключевое противоречие: большие страницы и тиринг тянут в противоположные стороны. Тиринг наиболее эффективен, когда может освобождать память с максимально мелкой гранулярностью, то есть 4 КБ. Большие страницы сознательно снижают эту гранулярность ради эффективности TLB. Эти два механизма фундаментально противоречат друг другу, и этот компромисс важно понимать до того, как включать большие страницы.
Страницы 1 ГБ: только DRAM, без исключений
Здесь действует жёсткое правило. Виртуальные машины, настроенные на использование страниц 1 ГБ, автоматически закрепляются за Tier 0 (DRAM) и никогда не будут использовать ёмкость NVMe Tier 1. Memory Tiering применяет это ограничение автоматически, поэтому никакой специальной настройки не требуется. Однако это необходимо учитывать при планировании ёмкости: такие машины следует рассчитывать исходя из доступного объёма DRAM, а не из общей ёмкости многоуровневой памяти. Их стоит выявить заранее.
Аспект TPS
Есть и вторичный эффект, который стоит понимать, особенно если для экономии памяти используется механизм Transparent Page Sharing (TPS). Как включение больших страниц в среде с тирингом влияет на TPS? Как выясняется, плохо.
TPS не дедуплицирует большие страницы напрямую. На современном оборудовании с Intel EPT или AMD RVI, использующем страницы 2 МБ, TPS и так малоэффективен: вероятность найти два идентичных региона по 2 МБ крайне низка, а их сравнение несёт существенные накладные расходы. Прежде чем TPS сможет дедуплицировать большие страницы, их нужно разбить на малые страницы 4 КБ, а это происходит только при определённых состояниях давления на память.
На практике это означает, что включение больших страниц в среде с тирингом снижает как эффективность алгоритма тиринга, так и экономию от TPS, на которую можно было рассчитывать. Эти две техники движутся в противоположных направлениях в вопросе размера страниц. Поэтому для нагрузок вроде VDI или сред с высокой плотностью виртуальных машин, где TPS исторически приносил пользу, стоит взвесить, готовы ли вы пожертвовать этой экономией.
Итог
Memory Tiering идёт на осознанный компромисс: жертвует эффективностью TLB, которую дают большие страницы, в обмен на операционную точность, необходимую для интеллектуального размещения данных по уровням. Для большинства нагрузок этот обмен оправдан, тем более что задержки NVMe в Tier 1 продолжают снижаться.
Вот как подходить к планированию среды с многоуровневой памятью:
Используйте страницы 4 КБ по умолчанию для виртуальных машин, которые должны получать выгоду от тиринга.
Выявляйте машины со страницами 1 ГБ на раннем этапе планирования ёмкости — они потребляют только DRAM.
Тщательно оценивайте машины с большими страницами 2 МБ: сначала тестируйте и не рассчитывайте на те же характеристики производительности, что в среде без тиринга.
Проработка вопроса больших страниц до включения Memory Tiering избавит от многих сложностей в будущем. При этом беспокоиться не о чем: как только правила понятны, система обрабатывает большую часть этих ситуаций автоматически.
Новый сервис Container Service в VMware Cloud Foundation (VCF) представляет собой простую отправную точку для использования Kubernetes (K8s) в компании, не требующую экспертизы в этой области. Многие организации сообщают, что им порой «просто нужно запустить контейнер», что они не могут нанять специалистов для работы с нагрузками в Kubernetes или что они только начинают путь модернизации приложений — берут старые приложения на .Net Framework, рефакторят их на .Net Core и приступают к контейнеризации.
Обычно, когда требуется запустить простые контейнерные приложения, рабочий процесс выглядит так:
Подготовить хостовую ОС
Установить и настроить среду выполнения контейнеров
Настроить аутентификацию в реестре образов
Загрузить и запустить образ контейнера
И это не считая управления жизненным циклом, установки патчей ОС, обновления среды выполнения, усиления безопасности и прочих задач, необходимых для эксплуатации такой системы в долгосрочной перспективе.
Какова бы ни была причина, заказчики ясно дали понять, что им нужен простой управляемый сервис, позволяющий получить преимущества Kubernetes без рутины и внутренней экспертизы. Поэтому новый Container Service был встроен в VCF Automation (а также в Local Consumption Interface, если VCF Automation не используется), чтобы можно было легко запускать готовые контейнеры. Рассмотрим, как это работает, что умеет сервис и как его можно применять уже сегодня.
Демонстрация
Технический обзор
VCF Container Service — это удобная обёртка вокруг концепции vSphere Pods в кластере Supervisor. vSphere Pods позволяют запускать контейнеры как виртуальные машины, что полезно в целом ряде случаев: когда требуется жёсткая граница ядра между контейнерами, когда не хочется нести накладные расходы на выделенные управляющие плоскости K8s или когда нет желания управлять кластерами K8s и их жизненным циклом.
Эта обёртка открывает практически всё, что можно ожидать от работы с контейнерной нагрузкой в K8s. Платформа даже принимает интеллектуальные решения на основе указанных спецификаций нагрузки — например, следует ли запускать приложение как Deployment или как StatefulSet в терминах Kubernetes.
Развернуть контейнер ещё никогда не было так просто
Начать работу очень легко: достаточно передать Container Service образ, совместимый с OCI, и сервис запустит его самостоятельно. При этом конфигурацию можно усложнять по мере необходимости: определять, в какие зоны (Zones) должна быть развёрнута нагрузка, какие ресурсы требуются для её эффективного планирования, а также сколько реплик нужно для этой нагрузки. Сервис даже берёт на себя аутентификацию в OCI-реестре. В результате пользователь получает конечную точку (endpoint), по которой доступно работающее приложение.
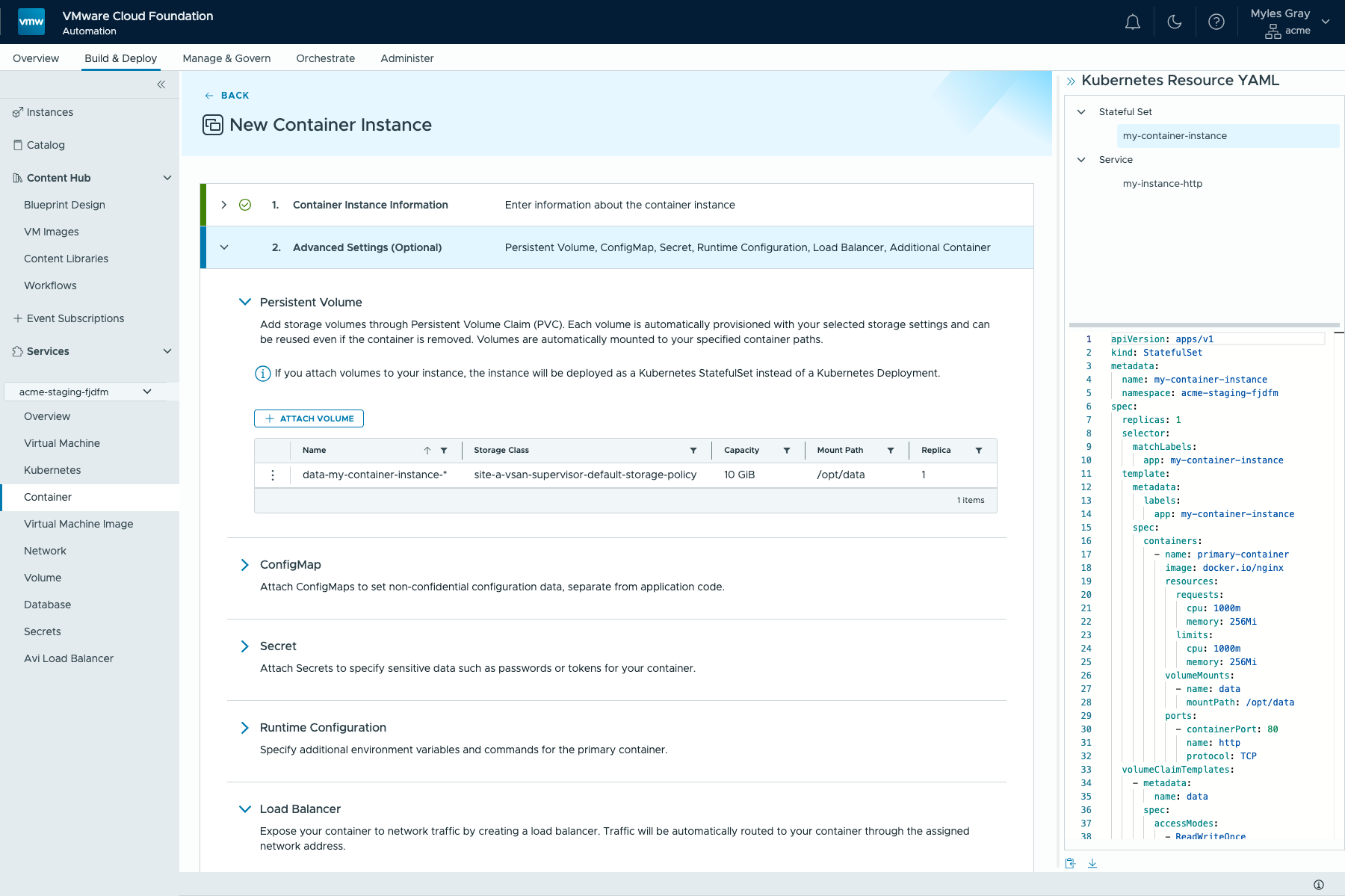
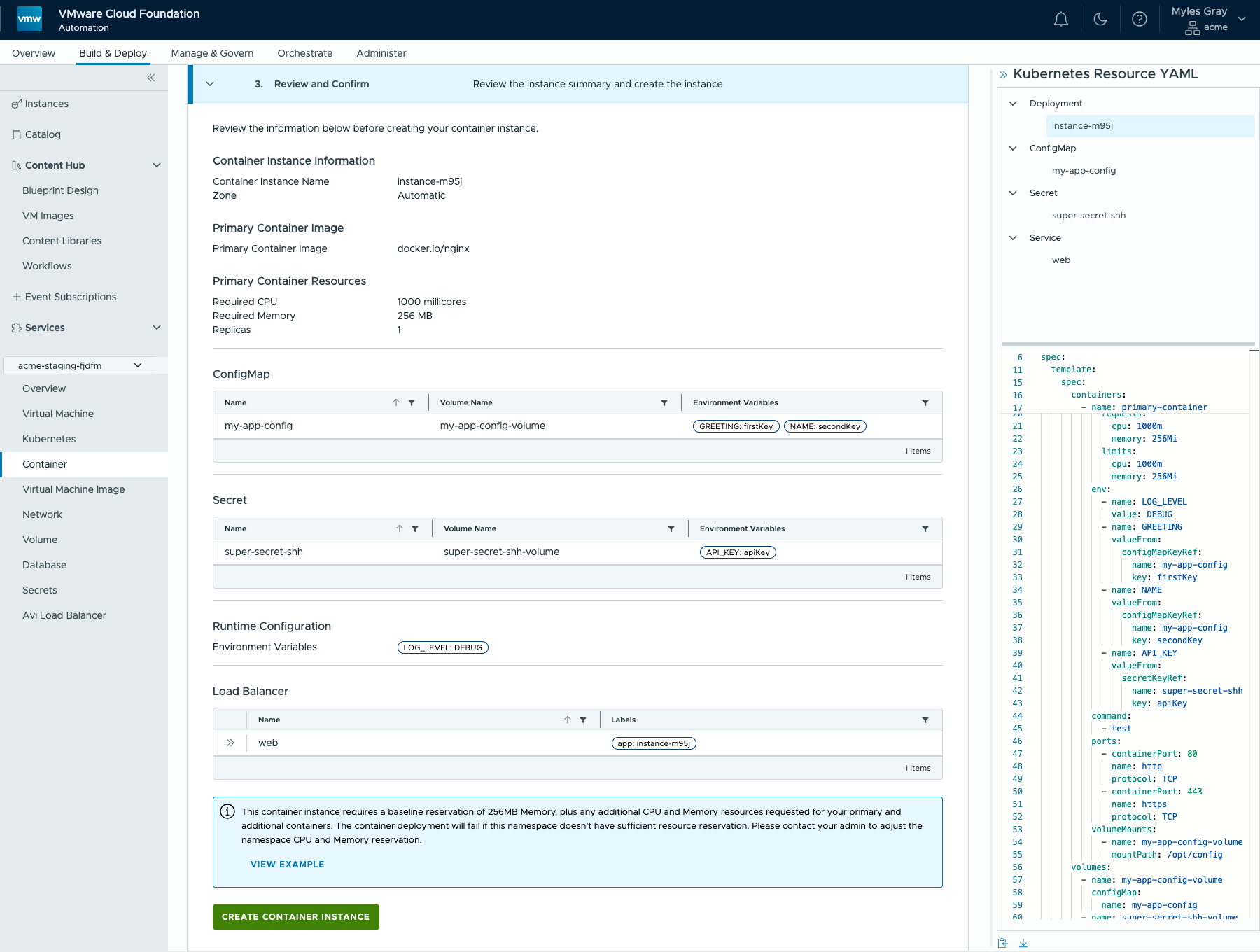
Обратите внимание на скриншот ниже: любые настройки, сделанные через UI, автоматически преобразуются в валидный K8s YAML в правой части экрана. Его можно скачать или скопировать и добавить в любую другую систему для воспроизводимых развёртываний. Так же устроены и другие сервисы в интерфейсе VCF, например «Виртуальные машины» или «Кластеры Kubernetes».
Заданные запросы CPU и памяти (значения по умолчанию уже установлены)
Всё остальное, описанное ниже, опционально и предназначено для более специфических сценариев.
Расширенные настройки
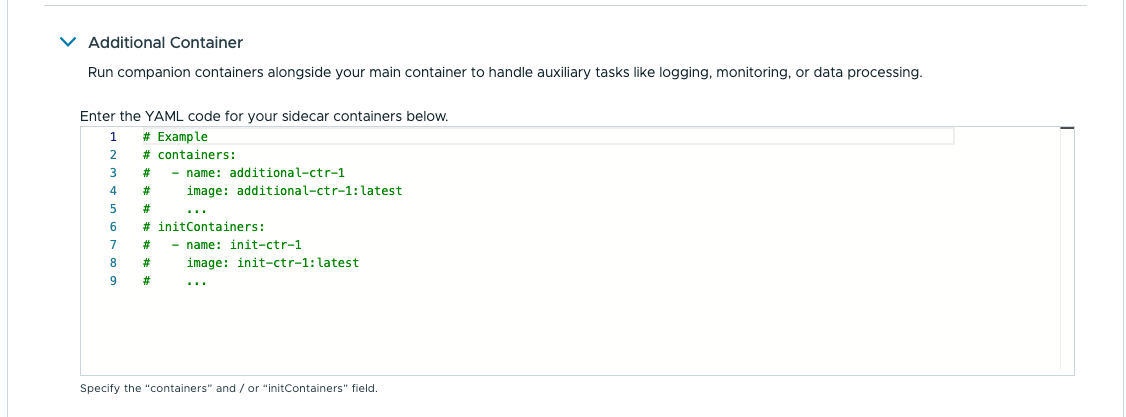
Если к работе приложения предъявляются особые требования — это не проблема: Container Service отнюдь не ограничен базовыми сценариями. Через сервис доступно практически всё, что может понадобиться контейнерной нагрузке: хранилище, балансировка нагрузки, управление конфигурациями и секретами, настройки среды выполнения вроде переменных окружения и даже sidecar-контейнеры для более продвинутых случаев.
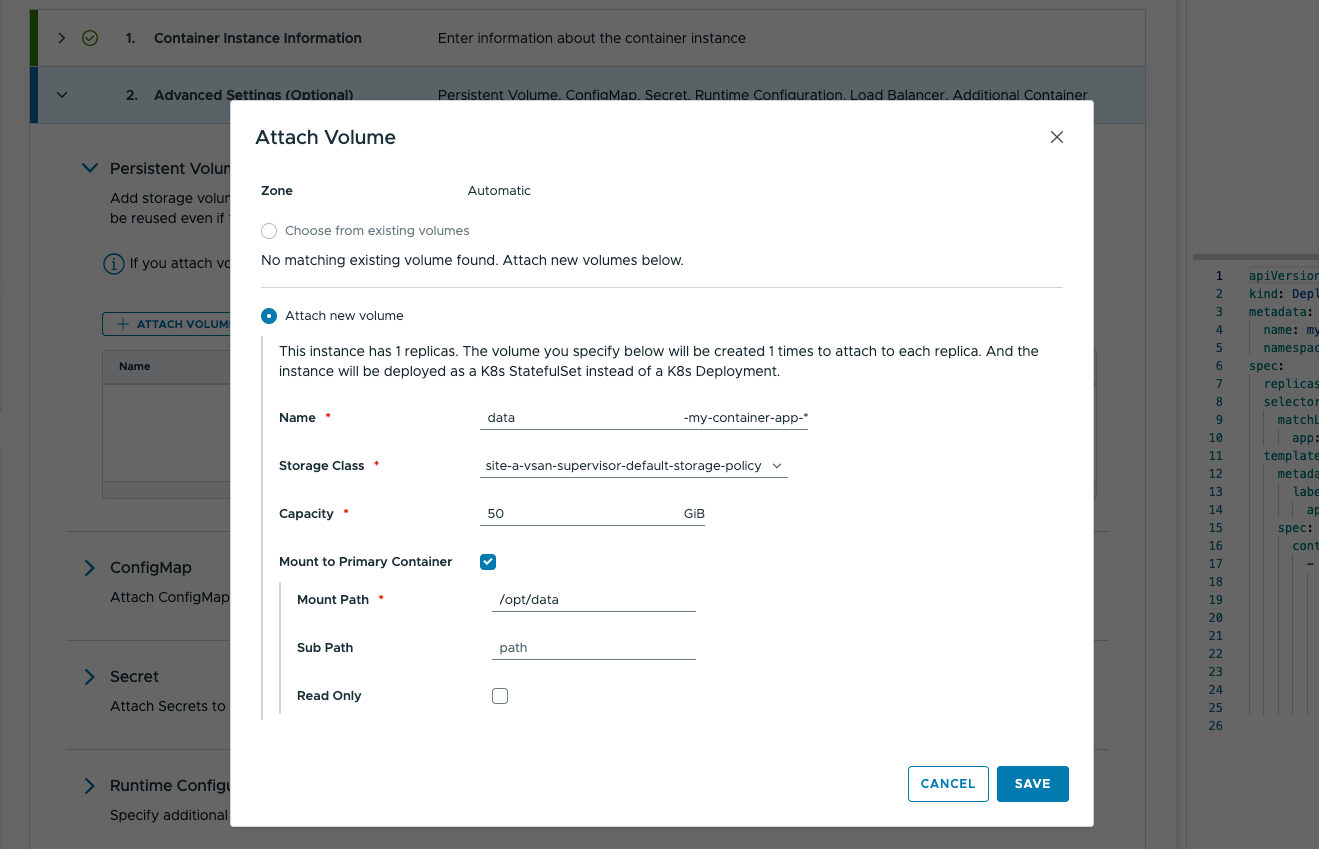
Хранилище
Большинство (полезных) приложений так или иначе хранят состояние. Это не значит, что не бывает полезных приложений без него, но почти каждое приложение как минимум обрабатывает данные, если не хранит их. Поэтому одной из фундаментальных возможностей, которую нужно было представить в понятной форме, стали тома PersistentVolume. В Kubernetes тома PersistentVolume могут вести себя не так, как ожидают пользователи, в зависимости от их политики reclaimPolicy: по умолчанию том удаляется.
С учётом ожиданий заказчиков поведение по умолчанию было сделано разумным и осторожным: при удалении нагрузки тома сохраняются, чтобы позже их можно было примонтировать к другой нагрузке. Разумеется, тома по-прежнему можно удалить, чтобы освободить место. Кроме того, сервис упрощает идентификацию и повторное монтирование нескольких томов к нескольким экземплярам.
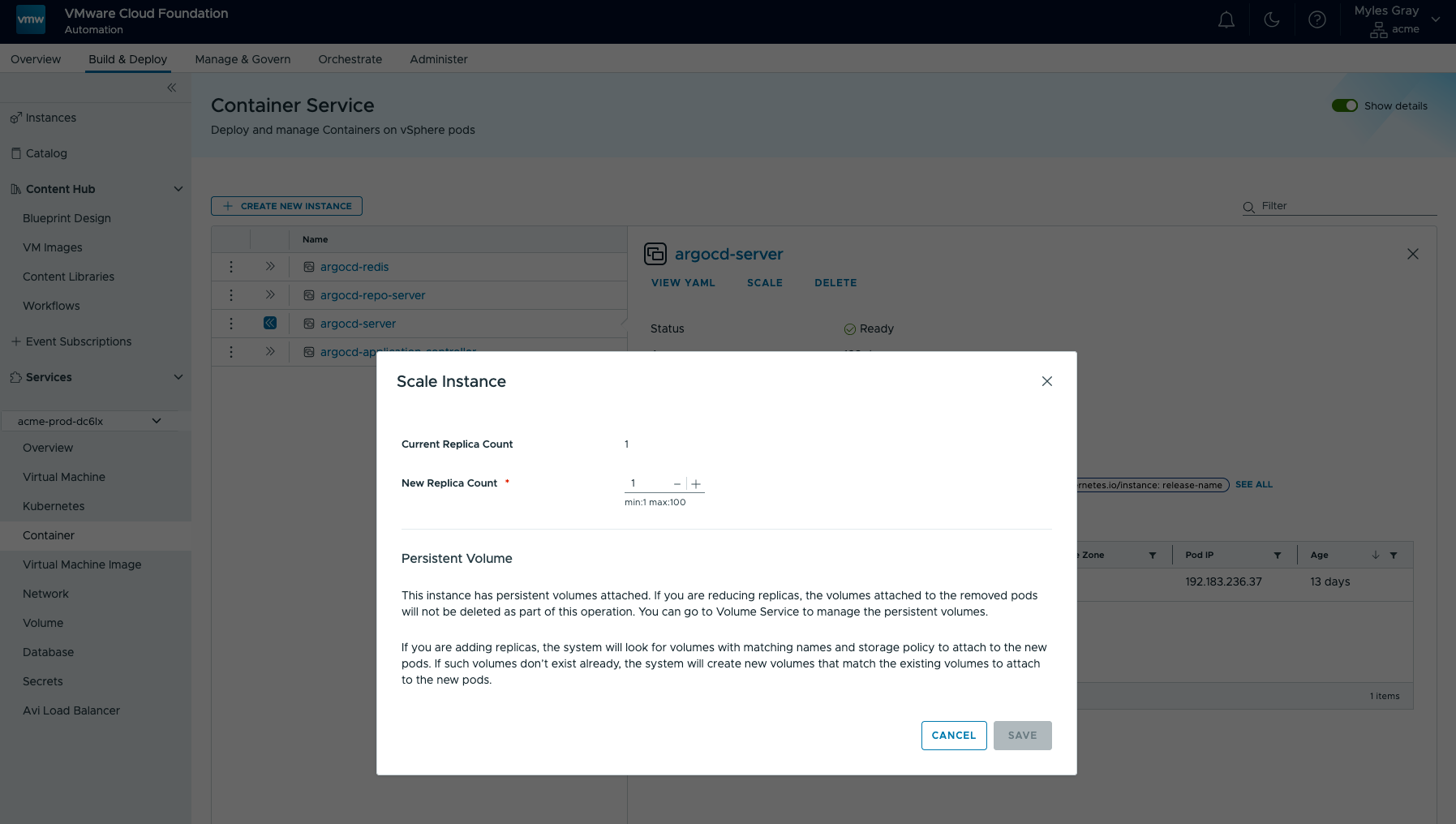
Возьмём пример StatefulSet с двумя репликами. Если удалить этот StatefulSet, тома сохранятся, и впоследствии, когда пользователь создаст другой экземпляр Container Service с двумя репликами и томами PersistentVolume, ему будет предложен выбор: создать новые тома или примонтировать существующие. Аналогично при уменьшении масштаба тома сохраняются и повторно монтируются при последующем увеличении.
Балансировка нагрузки
Следующий важный компонент любого приложения — то, как оно открывается сети, другим приложениям и пользователям. В K8s это делается с помощью объектов Service и Ingress/Gateway, при этом самый распространённый способ публикации нагрузки — LoadBalancer. Container Service позволяет создать LoadBalancer, выбрать протокол (TCP/UDP), внешний порт и внутренний порт контейнера, если выполняется трансляция портов. Такой Service распределяется по всем репликам данного экземпляра Container Service, обеспечивая доступность и отказоустойчивость при сбое экземпляра или нижележащего узла.
Конфигурация
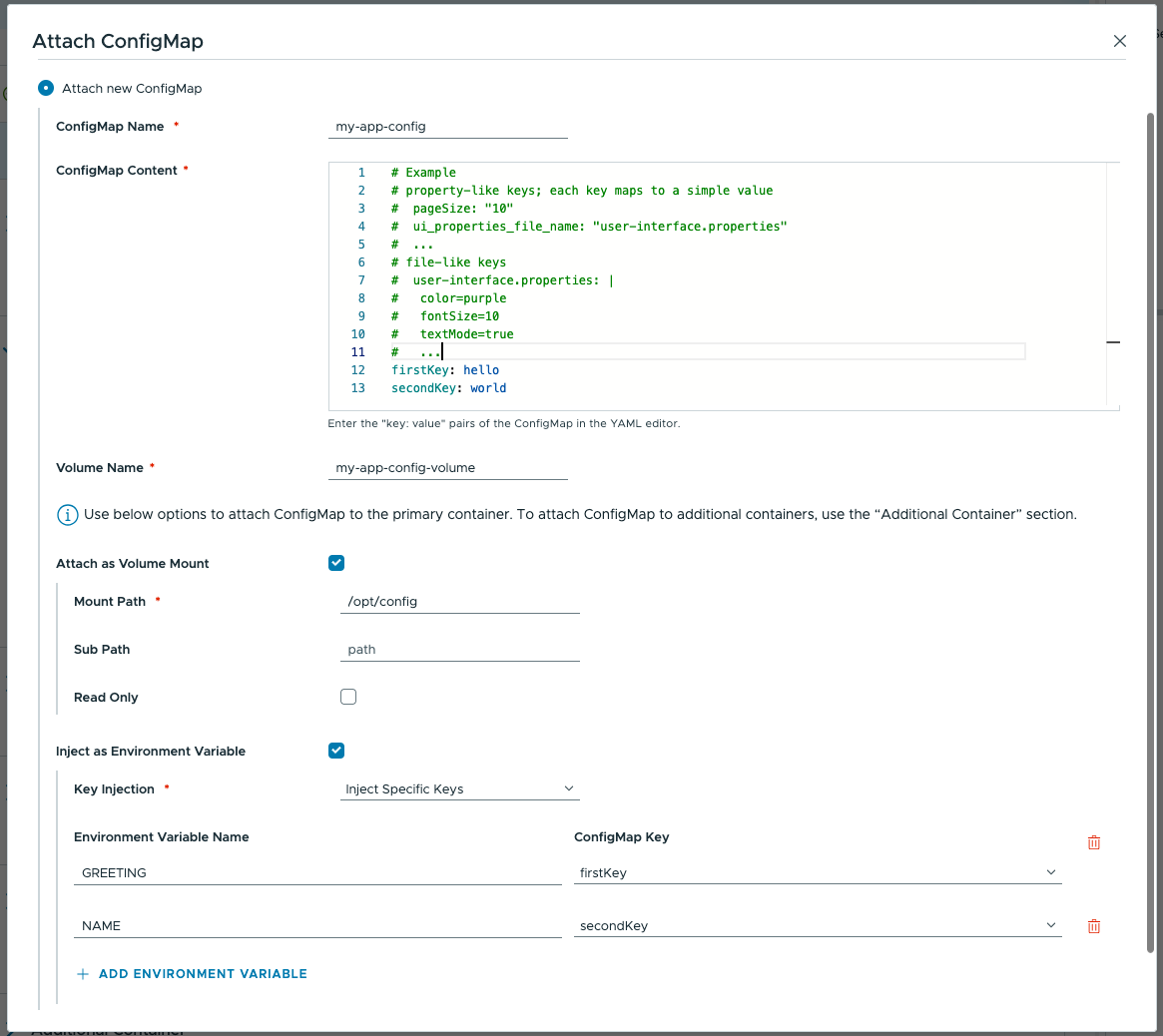
Контейнеры принимают аргументы и настройки самыми разными способами. Распространённый паттерн — конфигурационные файлы, содержимое которых полностью зависит от конкретного приложения. Поэтому в сервисе реализована возможность создавать и монтировать объекты ConfigMap в контейнер, причём очень гранулярно.
Можно выбрать один из существующих в окружении объектов ConfigMap или создать новый. При создании нового достаточно вставить конфигурационный файл как текст через UI и выбрать способ монтирования — как том (Volume) или как переменные окружения.
Кроме того, при инъекции в виде переменных окружения предоставляется дополнительная гибкость: можно выбрать, инжектировать все ключи из конфигурационного файла или только отдельные, а также указать, как именно они будут отображены внутри контейнера.
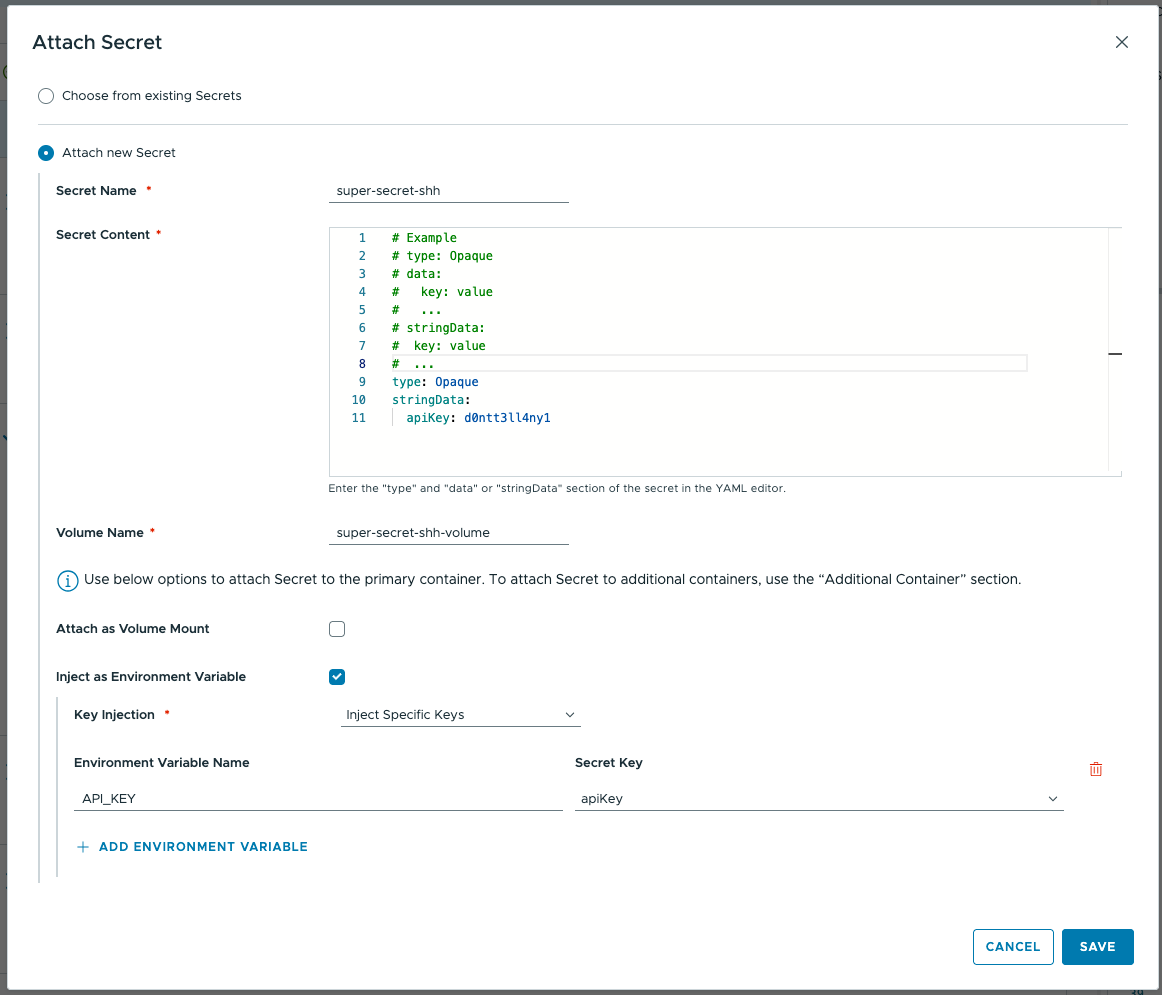
Секреты
Секреты — API-ключи, токены, пароли и т.п. — критичны для многих приложений. Как и объекты ConfigMap, они передаются в контейнер практически теми же способами: как том или как переменные окружения, причём второй вариант наиболее распространён, поскольку данные никогда не оказываются «на диске» внутри контейнера. Отличие от раздела ConfigMap в том, что под капотом эти данные хранятся как объекты Kubernetes Secret.
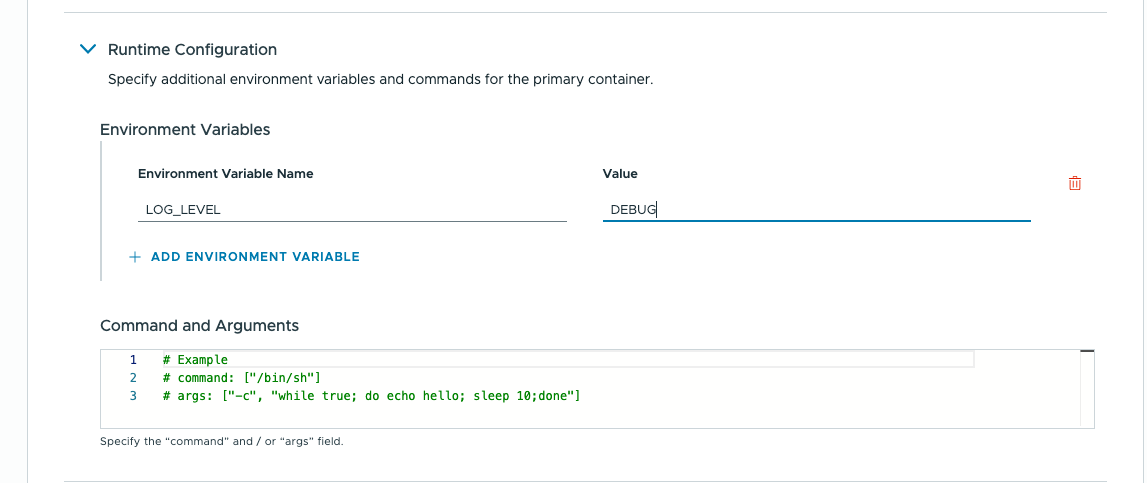
Конфигурация среды выполнения
В этом разделе собраны параметры, определяющие, как контейнер должен работать в рамках конкретного экземпляра. Например, если нужно повысить уровень логирования или детализацию именно этого экземпляра, не затрагивая другие контейнеры, использующие тот же ConfigMap, можно добавить переменную окружения вроде LOG_LEVEL и установить желаемое значение, чтобы приложение отреагировало на него.
Кроме того, если контейнеру или приложению требуется указание, какую команду выполнить при запуске или какие аргументы передать приложению на старте, их можно задать в разделе Command and Arguments, следуя приведённому примеру.
Во всём интерфейсе Container Service выполняется встроенная проверка (линтинг) вводимых команд и конфигураций — это гарантирует их корректность и наличие всех обязательных аргументов, обеспечивая пользователям комфортную работу и избавляя от копания в логах при выяснении, почему контейнеры не развернулись.
Дополнительные контейнеры
Значительно более продвинутая опция — использование sidecar-контейнеров, которые работают рядом с основной нагрузкой в том же поде Kubernetes. Это означает, что под капотом они разделяют некоторые технические характеристики (например, сетевое пространство имён), что позволяет им получать доступ к информации друг друга. Типичные сценарии применения sidecar-контейнеров — сбор логов или метрик, добавление контейнера в сервисную сетку (service mesh) и т.д.
Ещё один пример sidecar-контейнера — InitContainers. Допустим, стек приложения включает базу данных, и при первом запуске нужно выполнить скрипт, который наполнит пустую базу схемой, чтобы приложение могло использовать её при старте. Полезная особенность InitContainers — последовательность выполнения (они блокируют запуск основного контейнера до своего успешного завершения), что помогает гарантировать, например, что база данных запустится раньше основного контейнера.
В конце пользователь получает наглядную сводку всей собранной конфигурации контейнера и возможность скачать описывающий её манифест перед развёртыванием.
Масштабирование рабочих нагрузок
Разумеется, после развёртывания приложение можно масштабировать в большую или меньшую сторону через тот же интерфейс, который использовался при его создании. Как всегда, с подробными подсказками, чтобы было понятно, что именно сделает платформа при использовании этих опций.
Заключение
Чтобы начать работу с новым Container Service в VCF, попробуйте VCF 9.1, доступный на сайте Broadcom. Техническая документация доступна здесь.
Риски безопасности, которые создают передовые AI-модели, делают оперативное реагирование на новые угрозы крайне важным. Broadcom предпринимает шаги, чтобы обеспечить готовность VMware Cloud Foundation (VCF) к немедленному патчингу, позволяя организациям быстро реагировать на возникающие угрозы. Это означает, что для VCF 9.1 будут выпускаться более частые ежемесячные Express Patches. В этой статье описывается, как выглядит процесс их накатывания, и показано, как убедиться, что установлены самые последние патчи.
Прежде чем начать, необходимо обновиться до VCF 9.1, поскольку Express-патчи выпускаются именно для этой версии.
Шаг 1: Проверка наличия и загрузка патчей
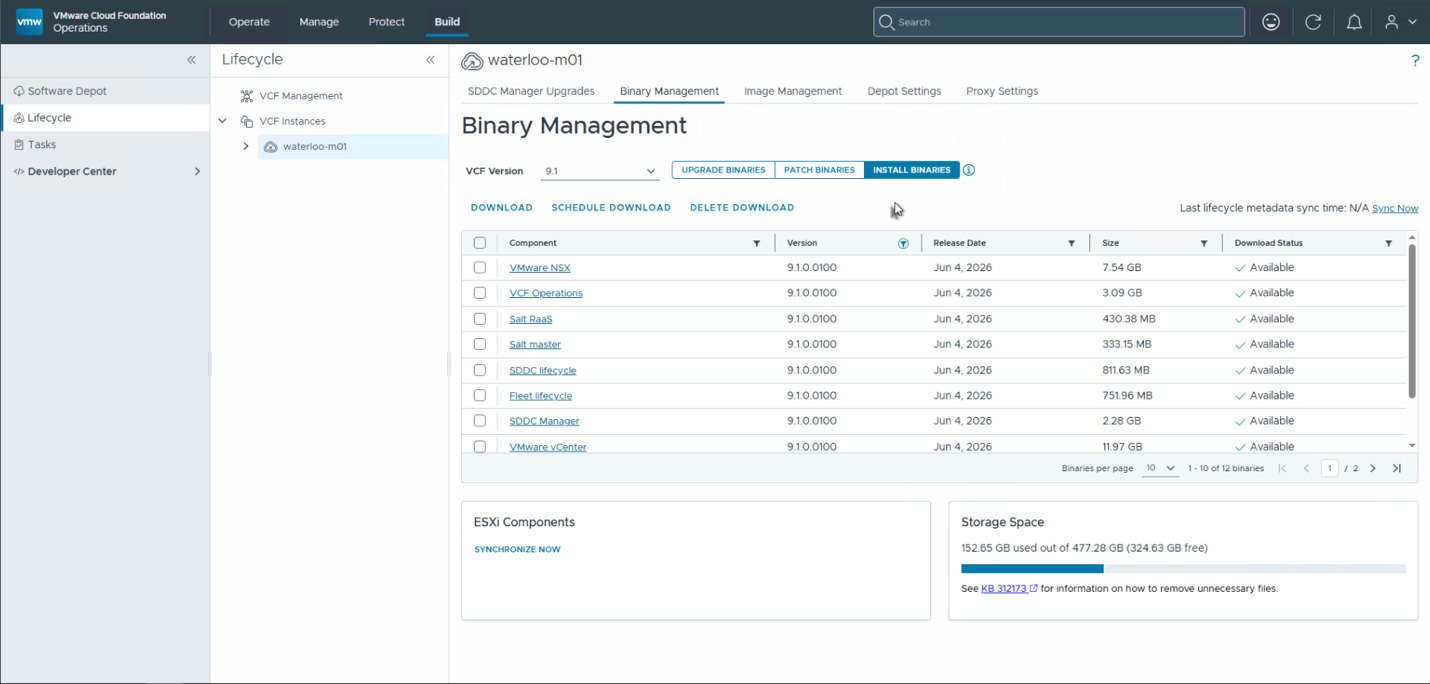
Первый шаг — проверить наличие новых доступных патчей. Это можно сделать, перейдя в раздел Build > Lifecycle в VMware Cloud Foundation Operations.
При переходе в разделы Patch Binaries или Install Binaries отображаются патчи для всех продуктов, в которых были устранены уязвимости безопасности. В приведённом примере это патч от 4 июня версии 9.1.0.0100.
Первая задача — загрузить патчи для развёртываемого релиза. Это может занять некоторое время в зависимости от количества выпущенных патчей, но после завершения загрузки они становятся доступны для развёртывания.
Шаг 2: Обновление управляющих компонентов VCF
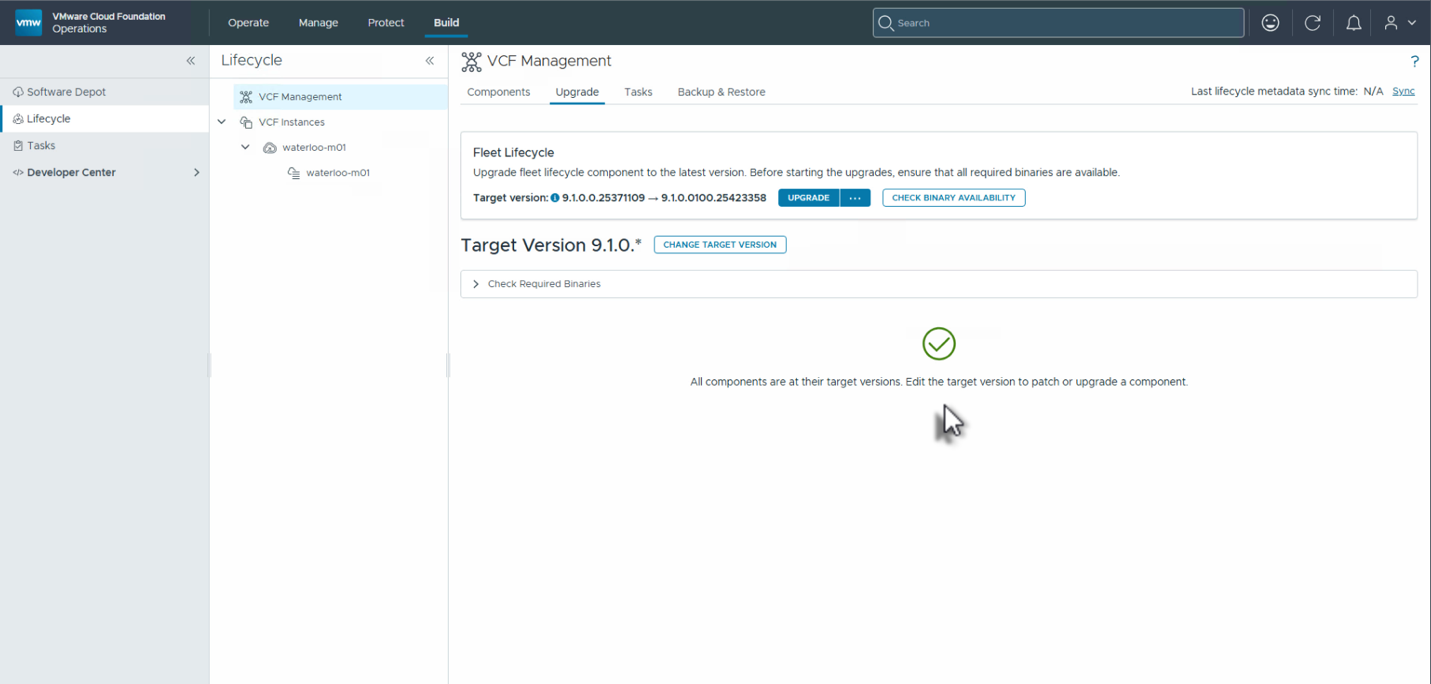
После загрузки патчей их можно развернуть сначала для управляющих компонентов VCF, начиная с Fleet Lifecycle. Перейдите в VCF Operations и выберите Build > Lifecycle > VCF Management > Upgrade — на этой странице можно выбрать целевую версию для обновления.
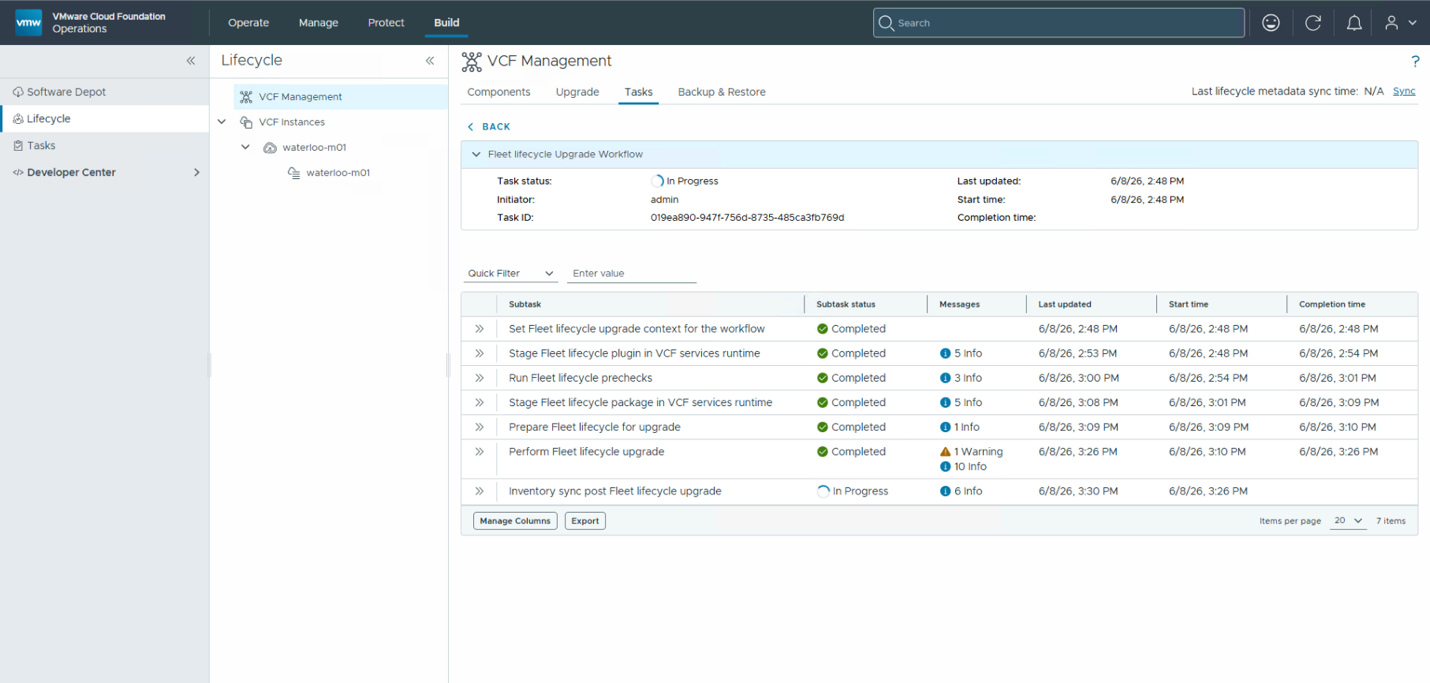
Затем нужно нажать кнопку Upgrade, что запустит обновление этого компонента. Процесс обновления займёт некоторое время, но можно открыть подробности хода выполнения.
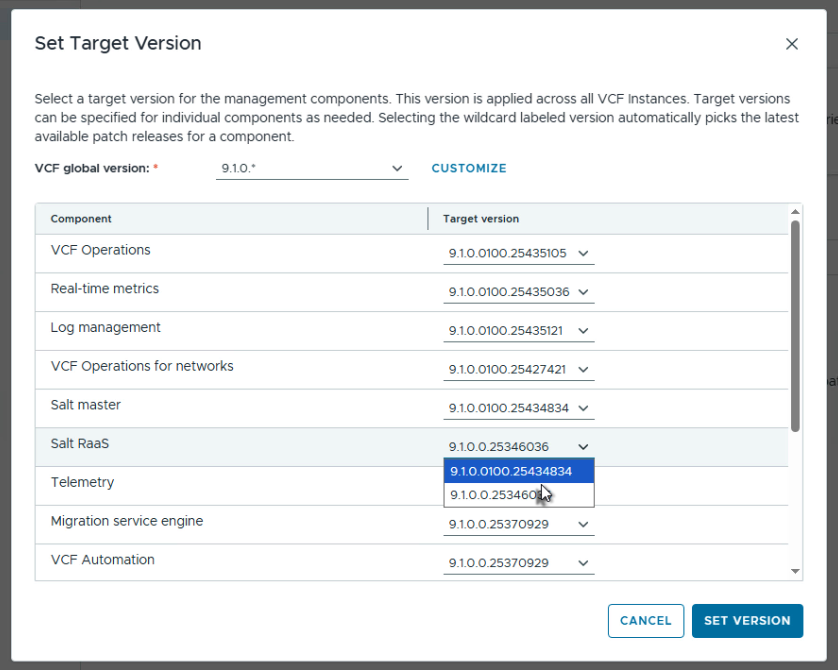
После завершения появится возможность задать целевую версию для каждого из компонентов, входящих в состав управляющих сервисов VCF, для которых доступно обновление.
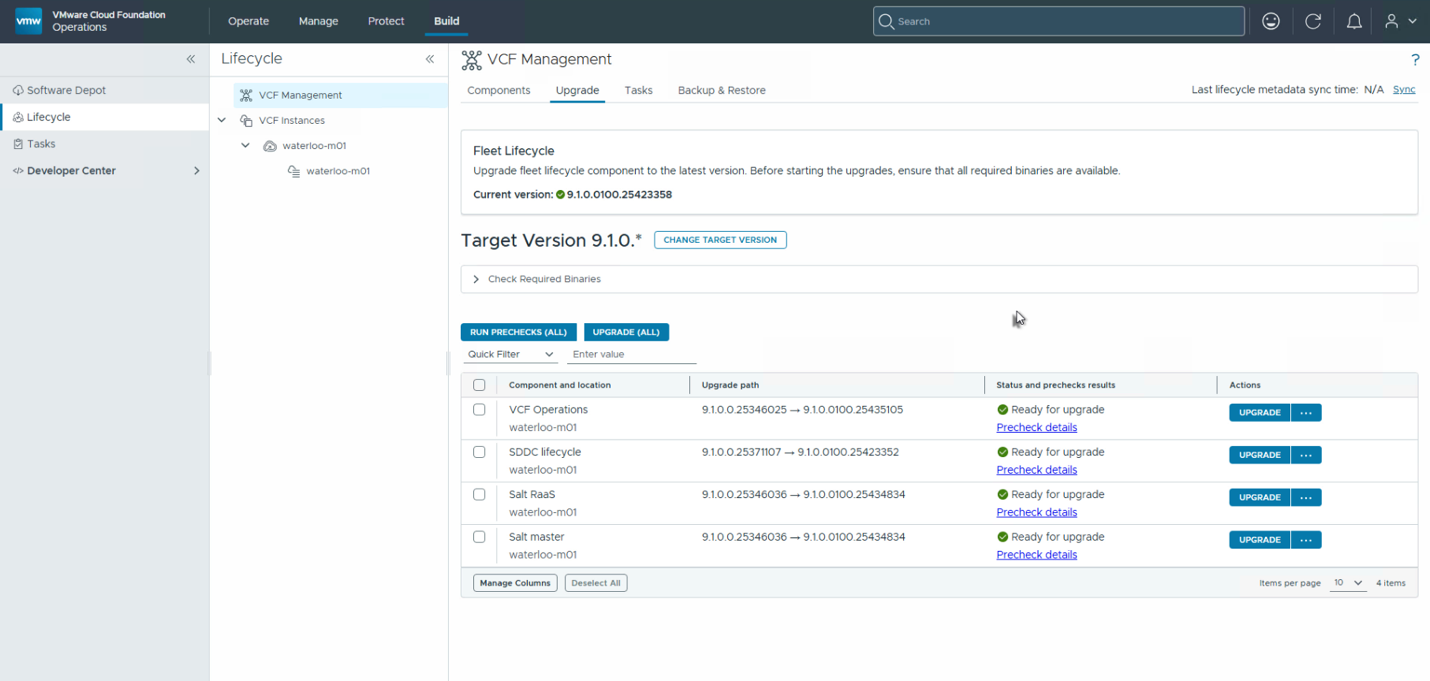
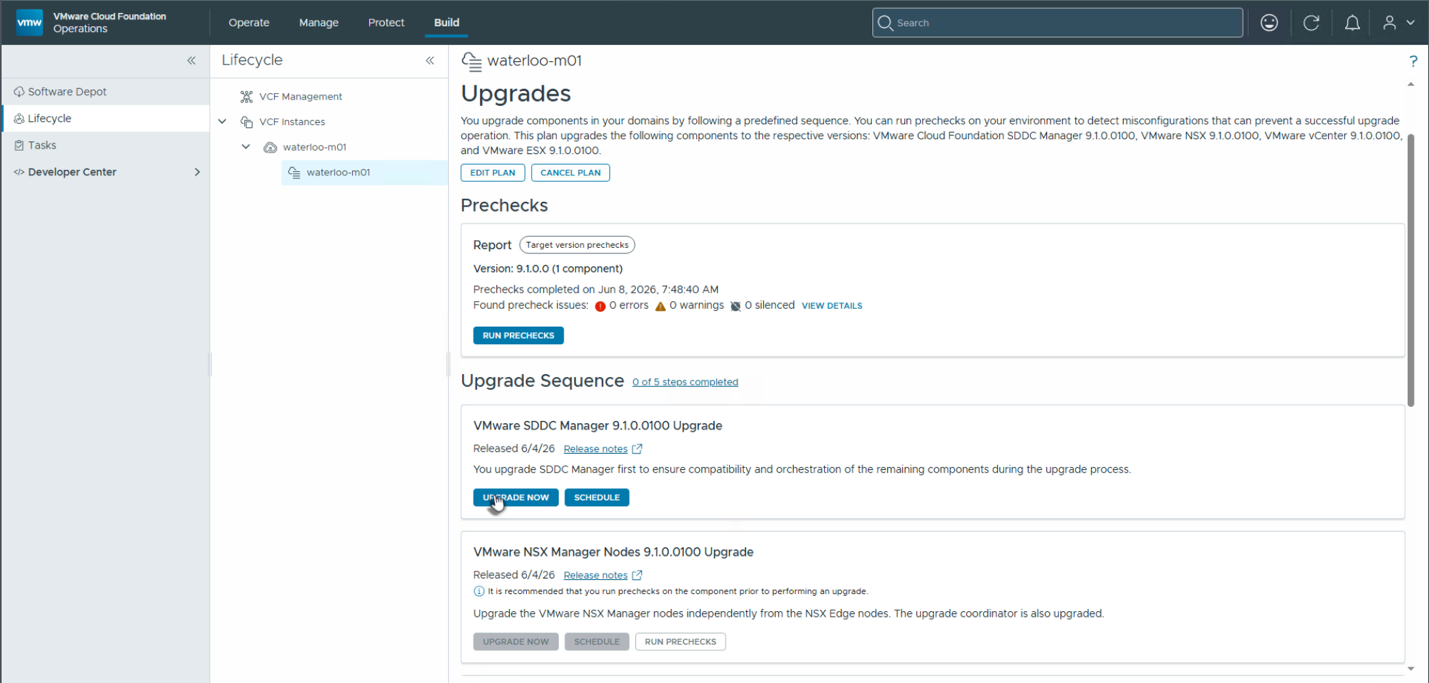
После выбора версии можно применить патчи. Рекомендуется сначала запустить предварительную проверку (precheck) для всех компонентов, нажав Run Prechecks. Обычно проверка запускается сразу для всех компонентов, после чего исправляются найденные проблемы. Когда все предварительные проверки пройдены успешно, можно нажать Upgrade для обновления компонентов. Обычно выбираются все компоненты сразу, чтобы обновление завершилось максимально быстро.
Этот процесс также может занять некоторое время в зависимости от обновляемых компонентов. После завершения обновления управляющих компонентов можно переходить к основным компонентам VCF.
Шаг 3: Обновление основных компонентов VCF
Как и в предыдущих релизах, обновление VMware SDDC Manager, VMware vSphere и VMware NSX происходит по схожему с прошлыми версиями сценарию. В VCF для ускорения развёртывания патчей безопасности используются Live Patching для хостов VMware ESX и Quick Patching для VMware vCenter.
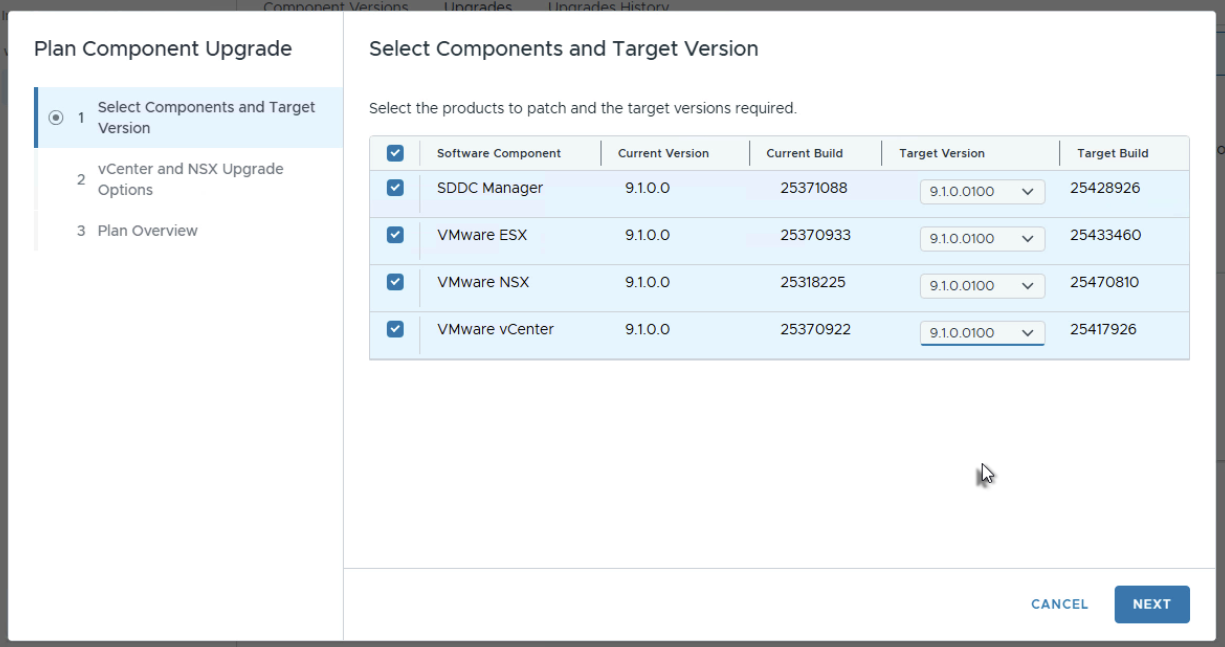
Чтобы применить патчи 9.1.0.0100, снова перейдите в VCF Operations и выберите Build > Lifecycle Management > VCF Instance > Upgrades. Здесь можно нажать кнопку Plan Component Upgrade, чтобы выбрать целевую версию патча и сформировать план обновления.
После того как план создан, можно приступать к обновлению каждого из компонентов.
В зависимости от обновляемых компонентов план может включать один или несколько шагов выполнения. Пройдите все этапы обновления. По завершении патчи 9.1.0.0100 будут успешно применены.

 RSS
RSS