В сфере виртуализации и облачной инфраструктуры системные инженеры регулярно сталкиваются с задачами расчётов, проверки параметров конфигурации и подготовки инфраструктуры к развертыванию. Именно для таких задач создан сайт https://tools.virtualbytes.cloud/ — онлайн-площадка с полезными утилитами для специалистов по VMware-инфраструктуре и облачным платформам.
Что представляет собой сервис
Tools.VirtualBytes.Cloud — это коллекция веб-инструментов, предназначенных для работы с инфраструктурными компонентами VMware-экосистемы и сопутствующих технологий. Сервис позволяет использовать различные утилиты прямо в браузере без установки дополнительного программного обеспечения на локальную машину.
Основная идея платформы — предоставить инженерам быстрый доступ к вспомогательным инструментам, которые упрощают администрирование и проектирование виртуальной инфраструктуры.
Какие инструменты доступны онлайн
Сервис ориентирован на специалистов, работающих с современными датацентрами и программно-определяемыми инфраструктурами. Среди основных направлений инструментов:
Работа с платформой VMware Cloud Foundation (VCF)
Инструменты для VMware NSX и сетевой виртуализации
Вспомогательные утилиты для vSAN
Сетевые и инфраструктурные калькуляторы
Инструменты для анализа и подготовки конфигураций
Благодаря веб-формату инструменты можно использовать с любого устройства — достаточно открыть сайт в браузере.
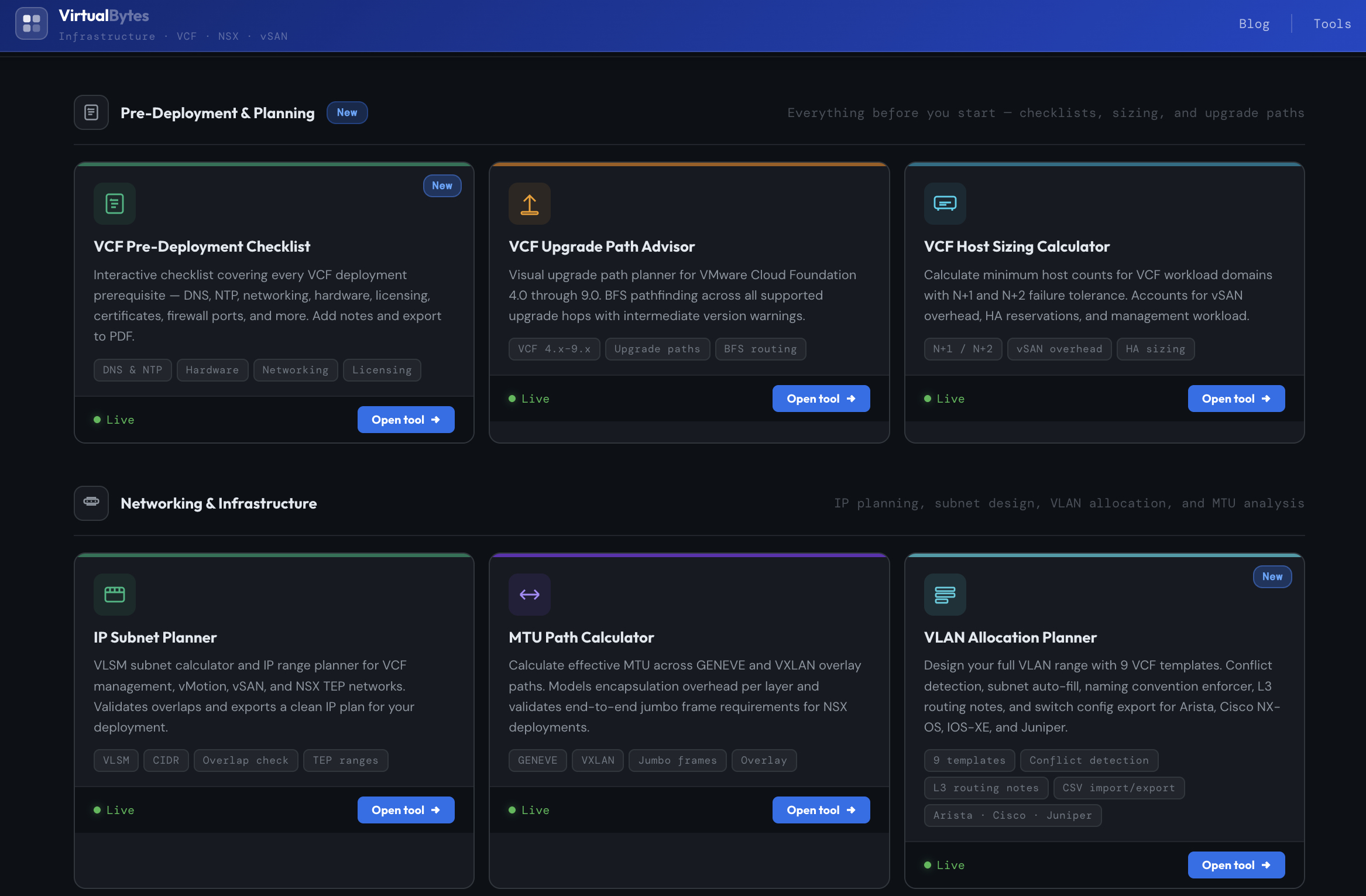
Бесплатные онлайн-утилиты
VCF Pre-Deployment Checklist
Интерактивный чеклист, охватывающий все требования перед развертыванием VCF — DNS, NTP, сетевую инфраструктуру, оборудование, лицензии, сертификаты, порты файрвола и многое другое. Позволяет добавлять заметки и экспортировать результат в PDF.
VCF Upgrade Path Advisor
Визуальный планировщик путей обновления для VMware Cloud Foundation версий 4.0–9.0. Использует поиск оптимального пути (BFS) между поддерживаемыми этапами обновления и предупреждает о промежуточных версиях.
VCF Host Sizing Calculator
Калькулятор минимального количества хостов для доменов нагрузки VCF с учетом отказоустойчивости N+1 и N+2. Учитывает накладные расходы vSAN, резервации HA и нагрузку management-компонентов.
IP Subnet Planner
Калькулятор подсетей VLSM и планировщик диапазонов IP-адресов для сетей VCF: management, vMotion, vSAN и NSX TEP. Проверяет пересечения подсетей и позволяет экспортировать готовый IP-план для развертывания.
MTU Path Calculator
Калькулятор эффективного MTU для overlay-сетей GENEVE и VXLAN. Моделирует накладные расходы инкапсуляции на каждом уровне и проверяет требования к jumbo-фреймам для NSX-инфраструктуры.
VLAN Allocation Planner
Инструмент для проектирования полного диапазона VLAN с использованием 9 шаблонов VCF. Включает обнаружение конфликтов, автоматическое заполнение подсетей, контроль соглашений по именованию, заметки по L3-маршрутизации и экспорт конфигураций коммутаторов для Arista, Cisco NX-OS, IOS-XE и Juniper.
VCF 9 Network Config Generator
Генератор полной сетевой конфигурации для VCF 9, включая назначение VLAN, параметры MTU, политики teaming и конфигурацию пулов NSX TEP для развертываний с несколькими кластерами.
vSAN Capacity Calculator
Калькулятор полезной емкости vSAN для архитектур OSA и ESA с политиками RAID-1, RAID-5 и RAID-6. Учитывает slack space, отказ хостов и приблизительную эффективность дедупликации.
NSX Firewall Rule Planner
Инструмент для планирования и документирования правил распределенного файрвола NSX. Позволяет задавать группы источников и назначений, сервисы и область применения (Applied-To), проверяет логику правил и экспортирует их в структурированную таблицу.
VCF Day 2 Operations Planner
Набор пошаговых runbook-процедур для операций Day-2: расширение кластера, создание доменов нагрузки, ротация сертификатов, обновление компонентов, смена паролей, расширение vSAN и управление сегментами NSX.
Для кого предназначен сайт
Платформа будет полезна:
Системным администраторам и инженерам виртуализации
Архитекторам облачной инфраструктуры
DevOps-специалистам
Инженерам датацентров и лабораторий
Особенно ценным ресурс становится при работе с VMware-экосистемой, где часто требуется быстро рассчитать параметры инфраструктуры или проверить настройки перед развертыванием.
Итог
Tools.VirtualBytes.Cloud — это полезный ресурс для специалистов по виртуализации и облачным технологиям. Он объединяет набор практических инструментов, которые помогают упростить работу с инфраструктурой VMware и ускорить решение повседневных задач администрирования.
Для инженеров, работающих с VCF, NSX и другими компонентами программно-определяемого дата-центра, подобные сервисы позволяют экономить время и повышать эффективность управления инфраструктурой.
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
Отличные новости для сетевых инженеров и архитекторов, работающих в экосистеме VMware. Компания представила новую сертификацию VMware Certified Advanced Professional – VCAP Administrator Networking (3V0-25.25). Этот экзамен продвинутого уровня (VCAP) предназначен для подтверждения глубоких знаний и практических навыков в проектировании, развертывании и администрировании сетевых решений VMware Cloud Foundation (VCF).
Новый стандарт профессиональной экспертизы в VCF Networking
Экзамен 3V0-25.25 ориентирован на опытных ИТ-специалистов, которые работают с современными корпоративными и мультиоблачными инфраструктурами. Получение данной сертификации демонстрирует способность кандидата эффективно решать сложные сетевые задачи в рамках архитектуры VMware Cloud Foundation.
Ключевые параметры экзамена:
Код экзамена: 3V0-25.25
Продолжительность: 135 минут
Количество вопросов: 60
Проходной балл: 300
Стоимость: 250 USD
Язык: английский
Кому подойдет эта сертификация
Экзамен рассчитан на специалистов с уверенным опытом в корпоративных сетях и экспертизой по решению VMware NSX. Рекомендуемый профиль кандидата включает:
1–2 года практического опыта проектирования и администрирования решений NSX
Не менее 2 лет работы с Enterprise-сетями
Уверенное владение UI-, CLI- и API-ориентированными рабочими процессами VCF
Практический опыт работы с VCF Networking и vSphere
Если вы ежедневно сталкиваетесь с проектированием и эксплуатацией сложных сетевых архитектур, этот экзамен станет логичным шагом в развитии карьеры.
Что проверяет экзамен 3V0-25.25
Основной акцент в экзамене сделан на планирование и дизайн сетевых решений VCF, с максимальной ориентацией на реальные архитектурные сценарии. Ключевые области оценки знаний включают:
ИТ-архитектуры, технологии и стандарты - проверяется понимание архитектурных принципов, умение различать бизнес- и технические требования, а также управлять рисками и ограничениями при проектировании.
Планирование и проектирование решений VMware - центральный блок экзамена, оценивающий способность спроектировать полноценное решение VMware Cloud Foundation с учетом доступности, управляемости, производительности, безопасности и восстановляемости.
Несмотря на то что в экзаменационном гайде указано наличие разделов без активных проверяемых целей, глубокое понимание всего жизненного цикла VCF Networking — от установки до устранения неполадок — значительно повышает шансы на успех.
Как подготовиться к экзамену
VMware рекомендует сочетать практический опыт с целенаправленным обучением. Для подготовки к экзамену доступны следующие курсы:
VMware Cloud Foundation Networking Advanced Design
VMware Cloud Foundation Networking Advanced Configuration
VMware Cloud Foundation Networking Advanced Troubleshooting
Также крайне важно изучить официальную документацию VMware Cloud Foundation 9.0, актуальные release notes и технические материалы от Broadcom, чтобы быть в курсе всех возможностей и изменений платформы.
Будьте среди первых сертифицированных специалистов
Выход сертификации VMware Certified Advanced Professional – VCF Networking — значимое событие для профессионалов в области сетевых технологий. Этот статус подтверждает высокий уровень экспертизы и позволяет выделиться на фоне других специалистов, открывая новые карьерные возможности. Если вы хотите быть на передовой в индустрии и официально подтвердить свои знания в области VCF Networking — сейчас самое время сделать этот шаг.
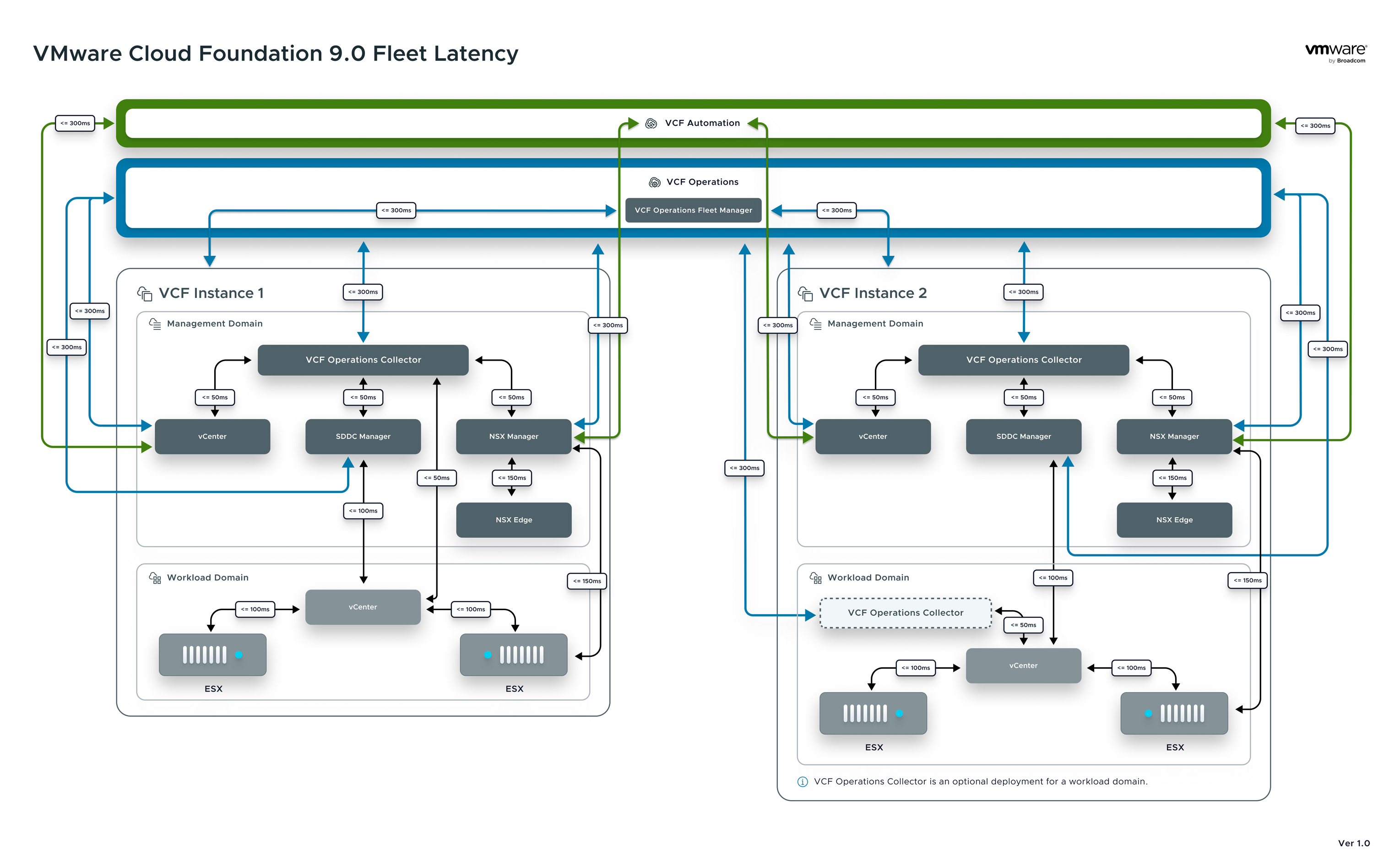
Диаграмма задержек VMware Cloud Foundation 9.0 теперь официально доступна на сайте Ports and Protocols в разделе Network Diagrams > VMware Cloud Foundation. Это официальный и авторитетный источник, который наглядно показывает сетевые взаимодействия и требования к задержкам в VCF 9.0.
Данное руководство настоятельно рекомендуется распечатать и разместить на рабочем месте каждого архитектора и администратора. Оно значительно упрощает проектирование, внедрение и сопровождение инфраструктуры, помогает быстрее выявлять узкие места, а также служит удобной шпаргалкой при обсуждении архитектурных решений, устранении неполадок и проверке соответствия требованиям. Фактически, это must-have материал для всех, кто работает с VMware Cloud Foundation в производственной среде.
Диаграмма демонстрирует, как различные элементы инфраструктуры VCF — управляющие домены, рабочие домены и центральные службы — взаимодействуют друг с другом в рамках распределённой частной облачной платформы, а также какие целевые значения Round-Trip Time (RTT) рекомендованы для стабильной и предсказуемой работы.
Что отражено на диаграмме:
VCF Fleet Components: диаграмма охватывает два отдельных экземпляра VCF (Instance 1 и Instance 2), включая их управляющие домены (Management Domain) и рабочие домены (Workload Domain), а также центральные Fleet-сервисы — VCF Operations и VCF Automation.
Целевые задержки: на диаграмме проставлены ориентировочные максимальные RTT-значения между компонентами, например между коллекторами VCF Operations и такими элементами, как vCenter, SDDC Manager, NSX Manager и ESX-хостами. Это служит практическим ориентиром для сетевых инженеров при планировании WAN- или LAN-связей между локациями.
Линии связи разной направленности: взаимодействия выполняются по разным путям и цветам, отражая направление обмена данными и зависимости между сервисами. Это помогает визуализировать, какие службы должны быть ближе друг к другу с точки зрения сети, а какие могут находиться дальше.
Практическая ценность
Такой сетевой ориентир крайне полезен архитекторам и администраторам, которые проектируют либо оптимизируют VCF-окружения в распределённых инфраструктурах. Он служит чёткой справочной картой, позволяющей:
Определить, какие связи нужно обеспечить минимально короткими с точки зрения задержки.
Согласовать проектные требования к ширине канала и RTT в разных сегментах сети.
Избежать узких мест в межкластерных коммуникациях, которые могут повлиять на производительность, управление или репликацию данных.
Диаграмма — это не просто техническая схема, а полноценный план качества сети, который должен учитываться при разворачивании VCF 9.0 на уровне предприятия.
Компания Broadcom на днях объявила о выпуске Thor Ultra — первой в отрасли 800G AI Ethernet сетевой карты (NIC), способной объединять сотни тысяч XPU (eXtreme Processing Units) для выполнения AI-нагрузок с триллионами параметров. Приняв открытую спецификацию Ultra Ethernet Consortium (UEC), Thor Ultra предоставляет клиентам возможность масштабировать AI-нагрузки с экстремальной производительностью и эффективностью в открытой экосистеме.
«Thor Ultra воплощает видение Ultra Ethernet Consortium по модернизации RDMA для крупных AI-кластеров», — сказал Рам Велага, старший вице-президент и генеральный директор подразделения Core Switching Group компании Broadcom. — «Разработанная с нуля, Thor Ultra — это первый в отрасли 800G Ethernet NIC, полностью соответствующий спецификации UEC. Мы благодарны нашим клиентам за сотрудничество и нашей выдающейся инженерной команде за инновации продукта».
Традиционная RDMA не поддерживает multipathing-передачу, out-of-order доставку пакетов, выборочную повторную передачу и масштабируемый контроль перегрузок. Thor Ultra представляет революционный набор инноваций RDMA, соответствующих UEC, включая:
Multipathing-передачу на уровне пакетов для эффективной балансировки нагрузки.
Доставку пакетов out-of-order напрямую в память XPU для максимального использования сетевой фабрики.
Выборочную повторную передачу для эффективной передачи данных.
Программируемые алгоритмы контроля перегрузок на стороне приёмника и отправителя.
Thor Ultra обеспечивает высокопроизводительные расширенные возможности RDMA в открытой экосистеме. Это даёт клиентам свободу подключения любых XPU, оптики или коммутаторов и снижает зависимость от проприетарных, вертикально интегрированных решений.
Дополнительные особенности Broadcom Thor Ultra включают:
Доступность в стандартных форм-факторах PCIe CEM и OCP 3.0.
200G или 100G PAM4 SerDes с поддержкой длинных пассивных медных соединений.
Самый низкий в отрасли уровень битовых ошибок (BER) SerDes, что уменьшает разрывы соединений и ускоряет время завершения заданий (JCT).
Интерфейс PCI Express Gen6 x16 для хоста.
Шифрование и дешифрование на скорости линии с разгрузкой PSP, снимая с хоста/XPU вычислительно-интенсивные задачи.
Безопасная загрузка с подписанным микропрограммным обеспечением и аттестацией устройства.
Программируемый конвейер контроля перегрузок.
Поддержка обрезки пакетов и сигнализации перегрузок (CSIG) с Tomahawk 5, Tomahawk 6 или любым коммутатором, совместимым с UEC.
Будучи передовой сетевой картой, Thor Ultra является ключевым дополнением к портфолио Broadcom по Ethernet-сетям для AI. В сочетании с Tomahawk 6, Tomahawk 6-Davisson, Tomahawk Ultra, Jericho 4 и Scale-Up Ethernet (SUE) Thor Ultra обеспечивает открытую экосистему для масштабных высокопроизводительных внедрений XPU.
Более подробно о сетевой карте Thor Ultra можно узнать вот тут.
Мир промышленной автоматизации переживает глубокую трансформацию, вызванную необходимостью повышения гибкости, эффективности и надёжности. Традиционные среды операционных технологий (OT), часто характеризующиеся жёстким, проприетарным оборудованием, эволюционируют в сторону более гибких, программно-определяемых архитектур. Broadcom находится в авангарде этой трансформации. В продолжение предыдущего анонса о поддержке Broadcom компании Audi в создании автоматизации заводов нового поколения с использованием VMware Cloud Foundation (VCF), VMware подчеркивает ключевую роль, которую играет VCF Networking в процессе модернизации Audi.
В рамках инициативы Audi Edge Cloud for Production, одним из ключевых кейсов является виртуализация физических PLC (программируемых логических контроллеров), управляющих критически важными операциями на производстве, такими как сборка автомобилей роботами. Цель — виртуализировать PLC и запускать их как виртуальные машины или контейнеры, управляемые как современные ИТ-нагрузки из частного облака Audi. Эту трансформацию поддерживает Industrial vSwitch (IvS), представленный в VCF 9.0. Разработанный в сотрудничестве с экспертами в области промышленной автоматизации, IvS приносит виртуализацию на завод, обеспечивая связь почти в реальном времени между виртуальными PLC и устройствами ввода/вывода.
Что такое Industrial vSwitch?
Industrial vSwitch (IvS) — это специализированная функция в составе NSX, работающая как распределённый сетевой коммутатор для промышленных сетей. Его основная задача — обеспечить передачу PROFINET-трафика в реальном времени на уровне 2 (L2) между устройствами с требуемой задержкой менее миллисекунды. Это обеспечивает бесшовную маршрутизацию критически важного PROFINET-трафика между виртуальными PLC (vPLC), развернутыми в VCF, и физическими устройствами ввода/вывода на производстве.
IvS основан на технологии NSX Enhanced Datapath (EDP) и разработан с учётом строгих требований промышленных систем управления: низкая задержка, минимальный джиттер и детерминированные сетевые характеристики. Производственная среда требует задержки на уровне сотен микросекунд для соответствия требованиям систем реального времени.
Основные функции
Поддержка PROFINET:
Поддерживает протокол PROFINET DCP (обнаружение и конфигурация устройств), необходимый для настройки и управления vPLC и I/O-устройствами.
Обрабатывает VLAN-тегирование и удаление тегов в Ethernet-кадрах PROFINET, поддерживает классы обслуживания для RT и NRT-трафика.
Использует режим Dedicated в EDP для обработки пакетов с высоким уровнем производительности и минимальной задержкой.
Поддержка PRP (Parallel Redundancy Protocol):
Поддерживает режим PRP RedBox, позволяющий подключать vPLC к двум независимым сетям для обеспечения отказоустойчивости.
Отправляет управляющие кадры PRP от имени vPLC и следит за состоянием обеих сетей.
Поддерживает взаимодействие с другими PRP-устройствами и управляет таблицами PRP Node и VDAN.
Измерение задержек:
IvS отслеживает задержки на уровне пакетов внутри хоста ESX, включая одностороннюю задержку между vNIC каждой ВМ и uplink-интерфейсом, с возможностью оповещений при превышении порогов.
Почему сейчас? Переход к программно-определяемому производству
Мотивация внедрения IvS очевидна: производители стремятся виртуализировать OT-среду и модернизировать цеха ради гибкости и конкурентоспособности. Ядром этой среды являются PLC. С помощью IvS возможно:
Повысить гибкость и адаптивность производственных процессов
Оперативно внедрять новые функции через обновления ПО
Существенно сократить время восстановления при сбоях, повысив надёжность
Централизованно управлять инфраструктурой
Стандартизировать стеки приложений и обеспечить безопасность и управляемость как локально, так и удалённо
Объединить несколько PLC на одном хосте — до 12 vPLC на систему
Обеспечить полную отказоустойчивость с нулевым временем переключения
Архитектура и требования
ПО:
VMware Cloud Foundation 9.0 с обновлённым NSX
Хосты в домене нагрузки с Industrial vSwitch
Сетевые интерфейсы (NIC):
Должны поддерживать NSX Enhanced Datapath — Dedicated
Поддержка устройств: NVIDIA Mellanox ConnectX-6
Совместимость с ПО:
Протестировано с Siemens TIA Portal v20, SIMATIC S7-1500V, CodeSys IDE, Control VM
Совместимость с PRP:
Проверено с Cisco IE3400 и Siemens Scalance
Архитектура развертывания
vPLC и IvS развертываются в рамках VCF workload domain, образуя кластер управления для производственной среды. Решение интегрируется с существующими промышленными шинами (fieldbus) и заменяет традиционные аппаратные PLC. Взаимодействие с устройствами в цехе происходит через Industrial Ethernet (PROFINET). Для отказоустойчивости используется PRP, подключённый к двум сетям: LAN-A и LAN-B.
Пример развертывания
vPLC VM размещаются в домене нагрузки VCF 9 и получают выделенные NSX VLAN-сегменты для подключения к своим ячейкам на производстве.
IvS подключается к LAN-A и LAN-B через встроенный PRP-интерфейс и формирует PRP-каналы с коммутаторами в каждой ячейке.
Трафик между vPLC и I/O реплицируется по обеим сетям для высокой надёжности и соответствия таймаутам.
Коммутаторы на производстве конфигурируются как PRP RedBox, обеспечивая безотказную связь между устройствами fieldbus и vPLC.
Основные инфраструктурные сервисы (NSX Manager, vCenter и пр.) размещаются в VCF Management domain.
Как это работает?
Industrial vSwitch (IvS) специально разработан для удовлетворения уникальных требований сценария использования vPLC, который требует:
Платформы виртуализации с поддержкой работы в реальном времени и детерминированным поведением управления.
Виртуального коммутатора с минимальной задержкой и предсказуемым джиттером.
Устойчивости к сбоям в сети.
Интеграции с PROFISAFE для обеспечения безопасности персонала.
В этой архитектуре задачи виртуализации и вычислений в реальном времени решаются за счёт продвинутых возможностей платформы ESX, а сетевые требования обеспечиваются Industrial vSwitch с встроенной поддержкой PRP (Parallel Redundancy Protocol). Интеграция с PROFISAFE была реализована в тесном сотрудничестве с производителями PLC в рамках общего проектирования решения.
Как настроить Industrial vSwitch в VCF 9
Шаг 1: Создание IvS в vCenter
Первым шагом активации Industrial vSwitch является его создание в vCenter.
Шаг 2: Добавление vSwitch в NSX
Добавьте vSwitch в NSX в составе профиля транспортного узла (Transport Node Profile) и настройте параметры PROFINET, PRP и другие конфигурации, необходимые для работы в режиме реального времени.
Шаг 3: Создание профиля сегмента IvS и VLAN-сегментов
Создайте профиль сегмента IvS, который будет использоваться для всех сегментов, предназначенных для развертывания vPLC. Настройте параметры PRP и активируйте измерение задержки (Latency Measurement) в соответствии с требованиями.
Далее настройте VLAN-сегменты в NSX в соответствии с VLAN’ами, используемыми vPLC и устройствами ввода/вывода. Затем назначьте профиль сегмента IvS на соответствующий сегмент, чтобы применить конфигурации для каждого VLAN отдельно.
Шаг 4: Развертывание виртуальной машины vPLC
Разверните виртуальную машину vPLC с сетевым интерфейсом, подключённым к IvS. Параметры vNIC — Strict Latency и Latency Measurement — автоматически настроят соответствующие параметры интерфейса. В частности, конфигурация Latency Measurement должна соответствовать выбранному профилю сегмента. Это позволит включить измерение задержки при передаче (TX) и приёме (RX) пакетов между vNIC и uplink-интерфейсами хоста.
После завершения настройки IvS непрерывно отслеживает задержку пакетов для каждого vNIC виртуального vPLC, чтобы обеспечить детерминированную производительность и контролируемый джиттер. Система фиксирует максимальную задержку по каждому vNIC и генерирует оповещение, если значение превышает заданный порог. Ниже приведён пример вывода для одного интерфейса, где максимальная задержка при передаче (TX) составила 108 микросекунд, а при приёме (RX) — 67 микросекунд.
С завершением основной настройки Industrial vSwitch вы можете приступить к вводу в эксплуатацию и программированию дополнительных vPLC, подключённых к IvS, через инженерную среду разработки (IDE). Для достижения оптимальной производительности рекомендуется обратиться к официальной документации, где приведены рекомендации по тонкой настройке — включая оптимизацию параметров BIOS хоста и обеспечение корректного выравнивания по NUMA.
Взгляд в будущее
Выход Industrial vSwitch в составе VCF 9 — это важный шаг вперёд в направлении расширения программно-определяемой инфраструктуры на среду промышленной автоматизации, где критически важна работа в реальном времени. Обеспечивая высокопроизводительную и отказоустойчивую сетевую связь для виртуализированных контроллеров, IvS создаёт прочную основу для построения более гибких, эффективных и надёжных производств будущего.
В дальнейшем VMware планирует добавить поддержку дополнительных протоколов шины fieldbus, расширить сотрудничество с технологическими партнёрами и продолжить развитие платформы под задачи операционных технологий (OT).
VMware Ports and Protocols — это веб-приложение от Broadcom, предоставляющее в одном месте информацию о сетевых портах и протоколах, необходимых для работы различных продуктов VMware.
Основные возможности
Удобный выбор продуктов: доступен список таких решений, как vSphere, NSX, vSAN, Horizon, VMware Cloud Foundation, Workspace ONE и другие.
Гибкая фильтрация: можно выбрать один или несколько продуктов, чтобы сформировать кастомный перечень необходимых портов.
Удобство совместительного использования: ссылка динамически меняется с учётом выбранных продуктов, что облегчает обмен URL между коллегами или клиентами.
Выгрузка данных: возможна загрузка в формате PDF или Excel — удобно для офлайн-использования или передачи техническим командам.
Почему это полезно
Сокращает время на настройку фаерволлов и сетевых правил — нет необходимости искать порты в разных документах.
Минимизирует риск ошибок — информация всегда актуальна и обновляется при выходе новых версий продуктов VMware .
Удобно для мультипродуктовых решений — независимо от сложности вашей инфраструктуры, всё можно настроить системно.
Выберите нужные продукты из боковой панели (например, NSX и vSphere).
Просмотрите отображаемый список с указанием портов, типов протоколов, исходных/назначения и описания служб.
Скачайте результат в формате PDF или Excel — через соответствующую кнопку.
Скопируйте сгенерированный URL и используйте его в документации или отправьте коллегам.
Ограничения и рекомендации
На момент написания доступна информация лишь по продуктам VMware (включая Aria, Network Insight и другие).
Если интересует не-VMware направление (например, порты для Symantec, CA или других продуктов Broadcom), нужно искать отдельные страницы на сайте techdocs.broadcom.com.
Само приложение требует включенного JavaScript — функциональность без него ограничена.
Заключение
Ресурс VMware Ports and Protocols от Broadcom — это мощный инструмент для администраторов и инженеров, который упрощает управление сетевыми требованиями для продуктов VMware. Он позволяет быстро собрать актуальную информацию, экспортировать её и делиться с командой — всё это делает процесс настройки безопасной и надёжной инфраструктуры более удобным и структурированным.
Для успешного предоставления современных цифровых решений необходима частная облачная среда, построенная на современной инфраструктуре, но при этом поддерживающая облачную модель эксплуатации.
С выходом обновленной платформы VMware Cloud Foundation (VCF) 9.0, ИТ-команды получили возможность объединить скорость и гибкость облачного опыта с производительностью, управляемостью и контролем затрат, необходимыми для корпоративной инфраструктуры на собственных серверах. Успешная реализация частного облака также требует интегрированных сетевых облачных сервисов, которые обеспечивают преимущества облака за счёт модернизации способов подключения и защиты ИТ-ресурсов, приложений и сервисов.
С VCF 9.0 стали доступны расширенные возможности самообслуживания в части сетевых сервисов, приближенные к опыту публичного облака, более простое развёртывание и гибкие варианты подключения, а также повышенная операционная эффективность и экономия за счёт интеграции полной автоматизации и управления на всех уровнях. Настройка и эксплуатация сетей стала проще благодаря глубокой интеграции со стеком VCF, прямому подключению к коммутаторным фабрикам и расширенной конфигурируемости и доступности виртуальных частных облаков (VPC). Благодаря улучшениям в VCF Automation, VCF Operations и vCenter компания VMware помогает компаниям запускать критически важные рабочие нагрузки — быстрее, надёжнее и эффективнее.
Основные сетевые новшества в VCF 9.0
1. Самообслуживание для подключения рабочих нагрузок и обеспечения безопасности через VPC
VCF 9.0 представляет серьёзный прогресс в области сетевого самообслуживания, делая развёртывания VCF готовыми к использованию Virtual Private Cloud (VPC) "из коробки". Это позволяет разным командам легко использовать изолированные виртуальные сети, управляемые политиками, аналогично опыту в публичных облаках.
Изначально представленные как упрощённая модель потребления сетевых сервисов, VPC в VMware Cloud Foundation создают изолированные облачные окружения, позволяющие различным арендаторам, проектам или отделам безопасно и независимо работать, предоставляя им доступ в модели самообслуживания к подсетям, сетевым сервисам (таким как NAT), правилам межсетевого экрана и балансировке нагрузки.
Улучшения, представленные в VCF 5.2.1, добавили отображение VPC в vCenter, что ускоряет развертывание рабочих нагрузок при помощи единообразных сетевых политик и упрощает реализацию правил безопасности. Теперь же, с выходом VCF 9.0, жизненный цикл VPC полностью интегрирован в автоматизационные процессы VCF и vCenter, что ещё больше упрощает развёртывание и потребление ресурсов.
Новый интерфейс потребления ресурсов предоставляет приложениям прямой и упрощённый доступ к настройке сетевого подключения, правил межсетевого экрана и других сервисов, таких как балансировка нагрузки и NAT, необходимых для развёртывания приложений в рамках VPC.
Команды, отвечающие за инфраструктуру и платформу, теперь могут предоставлять сеть как услугу, что значительно снижает необходимость в тикетах и ускоряет работу разработчиков. Это также способствует лучшему управлению за счёт последовательного применения политик распределения ресурсов, сетевых правил и стандартов именования.
2. Более простое развёртывание и гибкие варианты подключения
VCF 9.0 представляет ряд улучшений, направленных на упрощение развёртывания виртуальных сетевых функций с более гибкими опциями подключения.
Упрощённое развёртывание
VMware продолжает оптимизировать процессы развертывания сетей с новым установщиком в VCF 9.0, который теперь включает возможность развертывания виртуальных сетевых компонентов.
Предустановленные сетевые модули устраняют необходимость в сложной ручной настройке и сокращают время получения ценности от новых облачных сред. Ядро ESX теперь по умолчанию включает модули виртуальной сети (VIB), что снижает сложность и время установки и обновления сетевых функций. Эти улучшенные процессы позволяют использовать виртуальные сетевые возможности «из коробки», следуя рекомендованным архитектурным подходам и лучшим практикам — это позволяет быстро создавать новые домены рабочих нагрузок без отдельного развёртывания и настройки NSX.
Гибкие подключения
VCF 9.0 представляет новый сетевой элемент — Transit Gateway. Он настраивается во время создания рабочего домена VCF и обеспечивает лёгкое развертывание и масштабируемое подключение рабочих нагрузок с высокой доступностью. Вы можете подключать VPC к Transit Gateway, чтобы упростить взаимодействие между VPC, а также с внешними сервисами.
Transit Gateway полностью совместим с существующими сетевыми архитектурами на базе vSphere VDS и VLAN, что упрощает интеграцию с физической сетевой инфраструктурой. Вы можете подключаться напрямую от хоста к коммутаторной фабрике, используя упрощённую модель внешнего подключения, которая не требует развёртывания пограничных (edge) узлов или сложной маршрутизации. Это уменьшает количество промежуточных переходов, увеличивает пропускную способность, снижает задержки и облегчает устранение неполадок за счёт согласованности между физической и виртуальной топологиями.
Сокращение
компонентов
VMware Cloud Foundation 9.0 теперь поддерживает развертывание одного NSX Manager — для клиентов, которым не требуется высокая доступность, обеспечиваемая кластером NSX Manager, и которые хотят сократить потребление ресурсов. Хотя наивысший уровень доступности по-прежнему требует кластера из трёх NSX Manager, новая топология с одним экземпляром позволяет более лёгкое управление в небольших окружениях, тестовых лабораториях или на периферийных площадках, где особенно важно экономить ресурсы.
3. Гибкая эксплуатация и мониторинг
Масштабная эксплуатация требует не только гибкости при развёртывании, но и высокой наблюдаемости, надёжности и упрощённых процедур повседневной работы. VCF 9.0 включает несколько улучшений, упрощающих текущее управление сетевой инфраструктурой:
NSX теперь глубже интегрирован с автоматизацией VCF, включая управление жизненным циклом сертификатов, учётных данных и обновлений. Это снижает операционные издержки и риски для безопасности.
Обновлённая панель мониторинга состояния системы (System Health Dashboard) предоставляет унифицированное представление ключевых данных по сетевым, защитным и платформенным сервисам. Это ускоряет поиск причин неисправностей и отслеживание трендов.
Поддержка "живых" обновлений через vLCM (vSphere Lifecycle Manager) и синхронизация с циклами обновления vSphere делает обновления NSX более эффективными. Операторы могут применять патчи безопасности и функциональные улучшения без полного простоя, минимизируя влияние на сервисы.
В совокупности эти улучшения уменьшают нагрузку на команды инфраструктуры, повышая отказоустойчивость и производительность частного облака. Мониторинг становится более проактивным, а обновления — быстрее и безопаснее.
Резюме
С выпуском VCF 9.0 VMware предлагает более мощную сетевую основу для частных облаков — такую, которая сочетает гибкость и простоту публичных облаков с контролем и эффективностью локальной инфраструктуры.
От самообслуживаемых VPC-сетей до автоматизированного развёртывания и упрощённой эксплуатации — сетевая составляющая продолжает играть ключевую роль в реализации облачной модели работы в VMware Cloud Foundation.
Будь то развёртывание новых приложений, гибридная интеграция или управление жизненным циклом в масштабах предприятия — сеть в VCF 9.0 помогает вам действовать быстрее, быть устойчивее и работать умнее.
В предыдущей статье мы рассмотрели, что производительность vSAN зависит не только от физической пропускной способности сети, соединяющей хосты vSAN, но и от архитектуры самого решения. При использовании vSAN ESA более высокоскоростные сети в сочетании с эффективным сетевым дизайном позволяют рабочим нагрузкам в полной мере использовать возможности современного серверного оборудования. Стремясь обеспечить наилучшие сетевые условия для вашей среды vSAN, вы, возможно, задаётесь вопросом: можно ли ещё как-то улучшить производительность vSAN за счёт сети? В этом посте мы обсудим использование vSAN поверх RDMA и разберёмся, подойдёт ли это решение вам и вашей инфраструктуре.
Обзор vSAN поверх RDMA
vSAN использует IP-сети на базе Ethernet для обмена данными между хостами. Ethernet-кадры (уровень 2) представляют собой логический транспортный слой, обеспечивающий TCP-соединение между хостами и передачу соответствующих данных. Полезная нагрузка vSAN размещается внутри этих пакетов так же, как и другие типы данных. На протяжении многих лет TCP поверх Ethernet обеспечивал исключительно надёжный и стабильный способ сетевого взаимодействия для широкого спектра типов трафика. Его надёжность не имеет аналогов — он может функционировать даже в условиях крайне неудачного проектирования сети и плохой связности.
Однако такая гибкость и надёжность имеют свою цену. Дополнительные уровни логики, используемые для подтверждения получения пакетов, повторной передачи потерянных данных и обработки нестабильных соединений, создают дополнительную нагрузку на ресурсы и увеличивают вариативность доставки пакетов по сравнению с протоколами без потерь, такими как Fibre Channel. Это может снижать пропускную способность и увеличивать задержки — особенно в плохо спроектированных сетях. В правильно организованных средах это влияние, как правило, незначительно.
Чтобы компенсировать особенности TCP-сетей на базе Ethernet, можно использовать vSAN поверх RDMA через конвергентный Ethernet (в частности, RoCE v2). Эта технология всё ещё использует Ethernet, но избавляется от части избыточной сложности TCP, переносит сетевые операции с CPU на аппаратный уровень и обеспечивает прямой доступ к памяти для процессов. Более простая сетевая модель высвобождает ресурсы CPU для гостевых рабочих нагрузок и снижает задержку при передаче данных. В случае с vSAN это улучшает не только абсолютную производительность, но и стабильность этой производительности.
RDMA можно включить в кластере vSAN через интерфейс vSphere Client, активировав соответствующую опцию в настройках кластера. Это предполагает, что вы уже выполнили все предварительные действия, необходимые для подготовки сетевых адаптеров хостов и коммутаторов к работе с RDMA. Обратитесь к документации производителей ваших NIC и коммутаторов для получения информации о необходимых шагах по активации RDMA.
Если в конфигурации RDMA возникает хотя бы одна проблема — например, один из хостов кластера теряет возможность связи по RDMA — весь кластер автоматически переключается обратно на TCP поверх Ethernet.
Рекомендация. Рассматривайте использование RDMA только в случае, если вы используете vSAN ESA. Хотя поддержка vSAN поверх RDMA появилась ещё в vSAN 7 U2, наибольшую пользу эта технология приносит в сочетании с высокой производительностью архитектуры ESA, начиная с vSAN 8 и выше.
Как указано в статье «Проектирование сети vSAN», использование RDMA с vSAN влечёт за собой дополнительные требования, ограничения и особенности. К ним относятся:
Коммутаторы должны быть совместимы с RDMA и настроены соответствующим образом (включая такие параметры, как DCB — Data Center Bridging и PFC — Priority Flow Control).
Размер кластера не должен превышать 32 хоста.
Поддерживаются только следующие политики объединения интерфейсов:
Route based on originating virtual port
Route based on source MAC hash
Использование LACP или IP Hash не поддерживается с RDMA.
Предпочтительно использовать отдельные порты сетевых адаптеров для RDMA, а не совмещать RDMA и TCP на одном uplink.
RDMA не совместим со следующими конфигурациями:
2-узловые кластеры (2-Node)
Растянутые кластеры (stretched clusters)
Совместное использование хранилища vSAN
Кластеры хранения vSAN (vSAN storage clusters)
В VCF 5.2 использование vSAN поверх RDMA не поддерживается. Эта возможность не интегрирована в процессы SDDC Manager, и не предусмотрено никаких способов настройки RDMA для кластеров vSAN. Любые попытки настроить RDMA через vCenter в рамках VCF 5.2 также не поддерживаются.
Прирост производительности при использовании vSAN поверх RDMA
При сравнении двух кластеров с одинаковым аппаратным обеспечением, vSAN с RDMA может показывать лучшую производительность по сравнению с vSAN, использующим TCP поверх Ethernet. В публикации Intel «Make the Move to 100GbE with RDMA on VMware vSAN with 4th Gen Intel Xeon Scalable Processors» были зафиксированы значительные улучшения производительности в зависимости от условий среды.
Рекомендация: используйте RDTBench для тестирования соединений RDMA и TCP между хостами. Это также отличный инструмент для проверки конфигурации перед развёртыванием производительного кластера в продакшене.
Fibre Channel — действительно ли это «золотой стандарт»?
Fibre Channel заслуженно считается надёжным решением в глазах администраторов хранилищ. Протокол Fibre Channel изначально разрабатывался с одной целью — передача трафика хранения данных. Он использует «тонкий стек» (thin stack), специально созданный для обеспечения стабильной и низколатентной передачи данных. Детеминированная сеть на базе Fibre Channel работает как единый механизм, где все компоненты заранее определены и согласованы.
Однако Fibre Channel и другие протоколы, рассчитанные на сети без потерь, тоже имеют свою цену — как в прямом, так и в переносном смысле. Это дорогая технология, и её внедрение часто «съедает» большую часть бюджета, уменьшая возможности инвестирования в другие сетевые направления. Кроме того, инфраструктуры на Fibre Channel менее гибкие по сравнению с Ethernet, особенно при необходимости поддержки разнообразных топологий.
Хотя Fibre Channel изначально ориентирован на физическую передачу данных без потерь, сбои в сети могут привести к непредвиденным последствиям. В спецификации 32GFC был добавлен механизм FEC (Forward Error Correction) для борьбы с кратковременными сбоями, но по мере роста масштаба фабрики растёт и её сложность, что делает реализацию сети без потерь всё более трудной задачей.
Преимущество Fibre Channel — не в абсолютной скорости, а в предсказуемости передачи данных от точки к точке. Как видно из сравнения, даже с учётом примерно 10% накладных расходов при передаче трафика vSAN через TCP поверх Ethernet, стандартный Ethernet легко может соответствовать или даже превосходить Fibre Channel по пропускной способности.
Обратите внимание, что такие обозначения, как «32GFC» и Ethernet 25 GbE, являются коммерческими названиями, а не точным отражением фактической пропускной способности. Каждый стандарт использует завышенную скорость передачи на уровне символов (baud rate), чтобы компенсировать накладные расходы протокола. В случае с Ethernet фактическая пропускная способность зависит от типа передаваемого трафика. Стандарт 40 GbE не упоминается, так как с 2017 года он считается в значительной степени устаревшим.
Тем временем Ethernet переживает новый виток развития благодаря инфраструктурам, ориентированным на AI, которым требуется высокая производительность без уязвимости традиционных «безубыточных» сетей. Ethernet изначально проектировался с учётом практических реалий дата-центров, где неизбежны изменения в условиях эксплуатации и отказы оборудования.
Благодаря доступным ценам на оборудование 100 GbE и появлению 400 GbE (а также приближению 800 GbE) Ethernet становится чрезвычайно привлекательным решением. Даже традиционные поставщики систем хранения данных в последнее время отмечают, что всё больше клиентов, ранее серьёзно инвестировавших в Fibre Channel, теперь рассматривают Ethernet как основу своей следующей сетевой архитектуры хранения. Объявление Broadcom о выпуске чипа Tomahawk 6, обеспечивающего 102,4 Тбит/с внутри одного кристалла, — яркий индикатор того, что будущее высокопроизводительных сетей связано с Ethernet.
С vSAN ESA большинство издержек TCP поверх Ethernet можно компенсировать за счёт грамотной архитектуры — без переподписки и с использованием сетевого оборудования, поддерживающего высокую пропускную способность. Это подтверждается в статье «vSAN ESA превосходит по производительности топовое хранилище у крупной финансовой компании», где vSAN ESA с TCP по Ethernet с лёгкостью обошёл по скорости систему хранения, использующую Fibre Channel.
Насколько хорош TCP поверх Ethernet?
Если у вас качественно спроектированная сеть с высокой пропускной способностью и без переподписки, то vSAN на TCP поверх Ethernet будет достаточно хорош для большинства сценариев и является наилучшей отправной точкой для развёртывания новых кластеров vSAN. Эта рекомендация особенно актуальна для клиентов, использующих vSAN в составе VMware Cloud Foundation 5.2, где на данный момент не поддерживается RDMA.
Хотя RDMA может обеспечить более высокую производительность, его требования и ограничения могут не подойти для вашей среды. Тем не менее, можно добиться от vSAN такой производительности и стабильности, которая будет приближена к детерминированной модели Fibre Channel. Для этого нужно:
Грамотно спроектированная сеть. Хорошая архитектура Ethernet-сети обеспечит высокую пропускную способность и низкие задержки. Использование топологии spine-leaf без блокировки (non-blocking), которая обеспечивает линейную скорость передачи от хоста к хосту без переподписки, снижает потери пакетов и задержки. Также важно оптимально размещать хосты vSAN внутри кластера — это повышает сетевую эффективность и производительность.
Повышенная пропускная способность. Устаревшие коммутаторы должны быть выведены из эксплуатации — им больше нет места в современных ЦОДах. Использование сетевых адаптеров и коммутаторов с высокой пропускной способностью позволяет рабочим нагрузкам свободно передавать команды на чтение/запись и данные без узких мест. Ключ к стабильной передаче данных по Ethernet — исключить ситуации, при которых кадры или пакеты TCP нуждаются в повторной отправке из-за нехватки ресурсов или ненадёжных каналов.
Настройка NIC и коммутаторов. Сетевые адаптеры и коммутаторы часто имеют настройки по умолчанию, которые не оптимизированы для высокой производительности. Это может быть подходящим шагом, если вы хотите улучшить производительность без использования RDMA, и уже реализовали два предыдущих пункта. В документе «Рекомендации по производительности для VMware vSphere 8.0 U1» приведены примеры таких возможных настроек.
По умолчанию скорость соединения (link speed) адаптера vmxnet3 виртуальной машины устанавливается как 10 Гбит/с. Это применяемое по умолчанию отображаемое значение в гостевой ОС для соединений с любой скоростью. Реальная скорость будет зависеть от используемого вами оборудования (сетевой карты).
VMXNET 3 — это паравиртуализированный сетевой адаптер, разработанный для обеспечения высокой производительности. Он включает в себя все функции, доступные в VMXNET 2, и добавляет несколько новых возможностей, таких как поддержка нескольких очередей (также известная как Receive Side Scaling в Windows), аппаратное ускорение IPv6 и доставка прерываний с использованием MSI/MSI-X. VMXNET 3 не связан с VMXNET или VMXNET 2.
Если вы выведите свойства соединения на адаптере, то получите вот такую картину:
В статье Broadcom KB 368812 рассказывается о том, как с помощью расширенных настроек виртуальной машины можно установить корректную скорость соединения. Для этого выключаем ВМ, идем в Edit Settings и на вкладке Advanced Parameters добавляем нужное значение:
ethernet0.linkspeed 20000
Также вы можете сделать то же самое, просто добавив в vmx-файл виртуальной машины строчку ethernetX.linkspeed = "ХХХ".
При этом учитывайте следующие моменты:
Начиная с vSphere 8.0.2 и выше, vmxnet3 поддерживает скорость соединения в диапазоне от 10 Гбит/с до 65 Гбит/с.
Значение скорости по умолчанию — 10 Гбит/с.
Если вами указано значение скорости меньше 10000, то оно автоматически устанавливается в 10 Гбит/с.
Если вами указано значение больше 65000, скорость также будет установлена по умолчанию — 10 Гбит/с.
Важно отметить, что это изменение касается виртуального сетевого адаптера внутри гостевой операционной системы виртуальной машины и не влияет на фактическую скорость сети, которая всё равно будет ограничена физическим оборудованием (процессором хоста, физическими сетевыми картами и т.д.).
Это изменение предназначено для обхода ограничений на уровне операционной системы или приложений, которые могут возникать из-за того, что адаптер vmxnet3 по умолчанию определяется со скоростью 10 Гбит/с.
Платформа vSphere всегда предоставляла несколько способов использовать несколько сетевых карт (NIC) совместно, но какой из них лучший для vSAN? Давайте рассмотрим ключевые моменты, важные для конфигураций vSAN в сетевой топологии. Этот материал не является исчерпывающим анализом всех возможных вариантов объединения сетевых интерфейсов, а представляет собой справочную информацию для понимания наилучших вариантов использования техники teaming в среде VMware Cloud Foundation (VCF).
Описанные здесь концепции основаны на предыдущих публикациях:
Объединение сетевых портов NIC — это конфигурация vSphere, при которой используется более одного сетевого порта для выполнения одной или нескольких задач, таких как трафик ВМ или трафик VMkernel (например, vMotion или vSAN). Teaming позволяет достичь одной или обеих следующих целей:
Резервирование: обеспечение отказоустойчивости в случае сбоя сетевого порта на хосте или коммутатора, подключенного к этому порту.
Производительность: распределение одного и того же трафика по нескольким соединениям может обеспечить агрегацию полосы пропускания и повысить производительность при нормальной работе.
В этой статье мы сосредоточимся на объединении ради повышения производительности.
Распространённые варианты объединения
Выбор варианта teaming для vSAN зависит от среды и предпочтений, но есть важные компромиссы, особенно актуальные для vSAN. Начиная с vSAN 8 U3, платформа поддерживает один порт VMkernel на хост, помеченный для трафика vSAN. Вот три наиболее распространённые подхода при использовании одного порта VMkernel:
1. Один порт VMkernel для vSAN с конфигурацией Active/Standby
Используются два и более аплинков (uplinks), один из которых активен, а остальные — в режиме ожидания.
Это наиболее распространённая и рекомендуемая конфигурация для всех кластеров vSAN.
Простая, надёжная, идеально подходит для трафика VMkernel (например, vSAN), так как обеспечивает предсказуемый маршрут, что особенно важно в топологиях spine-leaf (Clos).
Такой подход обеспечивает надежную и стабильную передачу трафика, но не предоставляет агрегации полосы пропускания — трафик проходит только по одному активному интерфейсу.
Обычно Standby-интерфейс используется для другого типа трафика, например, vMotion, для эффективной загрузки каналов.
2. Один порт VMkernel для vSAN с двумя активными аплинками (uplinks) и балансировкой Load Based Teaming (LBT)
Используются два и более аплинков в режиме «Route based on physical NIC load».
Это можно рассматривать как агрегацию на уровне гипервизора.
Изначально предназначен для VM-портов, а не для трафика VMkernel.
Преимущества для трафика хранилища невелики, могут вызывать проблемы из-за отсутствия предсказуемости маршрута.
Несмотря на то, что это конфигурация по умолчанию в VCF, она не рекомендуется для портов VMkernel, помеченных как vSAN.
В VCF можно вручную изменить эту конфигурацию на Active/Standby без проблем.
3. Один порт VMkernel для vSAN с использованием Link Aggregation (LACP)
Использует два и более аплинков с расширенным хешированием для балансировки сетевых сессий.
Может немного повысить пропускную способность, но требует дополнительной настройки на коммутаторах и хосте.
Эффективность зависит от топологии и может увеличить нагрузку на spine-коммутаторы.
Используется реже и ограниченно поддерживается в среде VCF.
Версия VCF по умолчанию может использовать Active/Active с LBT для трафика vSAN. Это универсальный режим, поддерживающий различные типы трафика, но неоптимален для VMkernel, особенно для vSAN.
Рекомендуемая конфигурация:
Active/Standby с маршрутизацией на основе виртуального порта (Route based on originating virtual port ID). Это поддерживается в VCF и может быть выбрано при использовании настраиваемого развертывания коммутатора VDS. Подробнее см. в «VMware Cloud Foundation Design Guide».
Можно ли использовать несколько портов VMkernel на хосте для трафика vSAN?
Теоретически да, но только в редком случае, когда пара коммутаторов полностью изолирована (подобно Fibre Channel fabric). Это не рекомендуемый и редко используемый вариант, даже в vSAN 8 U3.
Влияние объединения на spine-leaf-сети
Выбор конфигурации teaming на хостах vSAN может показаться несущественным, но на деле сильно влияет на производительность сети и vSAN. В топологии spine-leaf (Clos), как правило, нет прямой связи между leaf-коммутаторами. При использовании Active/Active LBT половина трафика может пойти через spine, вместо того чтобы оставаться на уровне leaf, что увеличивает задержки и снижает стабильность.
Аналогичная проблема у LACP — он предполагает наличие прямой связи между ToR-коммутаторами. Если её нет, трафик может либо пойти через spine, либо LACP-связь может полностью нарушиться.
На практике в некоторых конфигурациях spine-leaf коммутаторы уровня ToR (Top-of-Rack) соединены между собой через межкоммутаторное соединение, такое как MLAG (Multi-Chassis Link Aggregation) или VLTi (Virtual Link Trunking interconnect). Однако не стоит считать это обязательным или даже желательным в архитектуре spine-leaf, так как такие соединения часто требуют механизмов блокировки, например Spanning Tree (STP).
Стоимость и производительность: нативная скорость соединения против агрегации каналов
Агрегация каналов (link aggregation) может быть полезной для повышения производительности при правильной реализации и в подходящих условиях. Но её преимущества часто переоцениваются или неправильно применяются, что в итоге может приводить к большим затратам. Ниже — четыре аспекта, которые часто упускаются при сравнении link aggregation с использованием более быстрых нативных сетевых соединений.
1. Высокое потребление портов
Агрегация нескольких соединений требует большего количества портов и каналов, что снижает общую портовую ёмкость коммутатора и ограничивает количество возможных хостов в стойке. Это увеличивает расходы на оборудование.
2. Ограниченный прирост производительности
Агрегация каналов, основанная на алгоритмическом балансировании нагрузки (например, LACP), не дает линейного увеличения пропускной способности.
То есть 1+1 не равно 2. Такие механизмы лучше работают при большом количестве параллельных потоков данных, но малоэффективны для отдельных (дискретных) рабочих нагрузок.
3. Ошибочные представления об экономичности
Существует мнение, что старые 10GbE-коммутаторы более экономичны. На деле — это миф.
Более объективный показатель — это пропускная способность коммутатора, измеряемая в Гбит/с или Тбит/с. Хотя сам по себе 10Gb-коммутатор может стоить дешевле, более быстрые модели обеспечивают в 2–10 раз больше пропускной способности, что делает стоимость за 1 Гбит/с ниже. Кроме того, установка более быстрых сетевых адаптеров (NIC) на серверы обычно увеличивает стоимость менее чем на 1%, при этом может дать 2,5–10-кратный прирост производительности.
4. Нереализованные ресурсы
Современные серверы обладают огромными возможностями по процессору, памяти и хранилищу, но не могут раскрыть свой потенциал из-за сетевых ограничений.
Балансировка между вычислительными ресурсами и сетевой пропускной способностью позволяет:
сократить общее количество серверов;
снизить капитальные затраты;
уменьшить занимаемое пространство;
снизить нагрузку на систему охлаждения;
уменьшить потребление портов в сети.
Именно по этим причинам VMware рекомендует выбирать более высокие нативные скорости соединения (25Gb или 100Gb), а не полагаться на агрегацию каналов — особенно в случае с 10GbE. Напомним, что когда 10GbE появился 23 года назад, серверные процессоры имели всего одно ядро, а объём оперативной памяти составлял в 20–40 раз меньше, чем сегодня. С учётом того, что 25GbE доступен уже почти десятилетие, актуальность 10GbE для дата-центров практически исчерпана.
Объединение для повышения производительности и отказоустойчивости обычно предполагает использование нескольких физических сетевых карт (NIC), каждая из которых может иметь 2–4 порта. Сколько всего портов следует иметь на хостах vSAN? Это зависит от следующих факторов:
Степень рабочих нагрузок: среда с относительно пассивными виртуальными машинами предъявляет гораздо меньшие требования, чем среда с тяжёлыми и ресурсоёмкими приложениями.
Нативная пропускная способность uplink-соединений: более высокая скорость снижает вероятность конкуренции между сервисами (vMotion, порты ВМ и т.д.), работающими через одни и те же аплинки.
Используемые сервисы хранения данных: выделение пары портов для хранения (например, vSAN) почти всегда даёт наилучшие результаты — это давно устоявшаяся практика, независимо от хранилища.
Требования безопасности и изоляции: в некоторых средах может потребоваться, чтобы аплинки, используемые для хранения или других задач, были изолированы от остального трафика.
Количество портов на ToR-коммутаторах: количество аплинков может быть ограничено самими коммутаторами ToR. Пример: пара ToR-коммутаторов с 2?32 портами даст 64 порта на стойку. Если в стойке размещено максимум 16 хостов по 2U, каждый хост может получить максимум 4 uplink-порта. А если коммутаторы имеют по 48 портов, то на 16 хостов можно выделить по 6 uplink-портов на каждый хост. Меньшее количество хостов в стойке также позволяет увеличить количество портов на один хост.
Рекомендация:
Даже если вы не используете все аплинки на хосте, рекомендуется собирать vSAN ReadyNode с двумя NIC, каждая из которых имеет по 4 uplink-порта. Это позволит без проблем выделить отдельную команду (team) портов только под vSAN, что настоятельно рекомендуется. Такой подход обеспечит гораздо большую гибкость как сейчас, так и в будущем, по сравнению с конфигурацией 2 NIC по 2 порта.
Итог
Выбор оптимального варианта объединения (teaming) и скорости сетевых соединений для ваших хостов vSAN — это важный шаг к тому, чтобы обеспечить максимальную производительность ваших рабочих нагрузок.
В современной динамично развивающейся сфере информационных технологий автоматизация уже не роскошь, а необходимость. Команды, отвечающие за безопасность, сталкиваются с растущей сложностью управления политиками сетевой безопасности, что требует эффективных и автоматизированных решений. Межсетевой экран vDefend, интегрированный с VMware NSX, предлагает мощные возможности автоматизации с использованием различных инструментов и языков сценариев. Выпущенное недавно руководство "Beginners Guide to Automation with vDefend Firewall" рассматривает стратегии автоматизации, доступные в vDefend, которые помогают ИТ-специалистам упростить рабочие процессы и повысить эффективность обеспечения безопасности.
Понимание операций CRUD в сетевой автоматизации
Операции CRUD (Create, Read, Update, Delete) являются основой рабочих процессов автоматизации. vDefend позволяет выполнять эти операции через RESTful API-методы:
GET — получение информации о ресурсе.
POST — создание нового ресурса.
PUT/PATCH — обновление существующих ресурсов.
DELETE — удаление ресурса.
Используя эти методы REST API, ИТ-команды могут автоматизировать политики межсетевого экрана, создавать группы безопасности и настраивать сетевые параметры без ручного вмешательства.
Стратегии автоматизации для межсетевого экрана vDefend
С vDefend можно использовать несколько инструментов автоматизации, каждый из которых предлагает уникальные преимущества:
Вызовы REST API через NSX Policy API - API политики NSX Manager позволяют напрямую выполнять действия CRUD с сетевыми ресурсами. Разработчики могут использовать языки программирования, такие как Python, GoLang и JavaScript, для написания сценариев взаимодействия с NSX Manager, обеспечивая бесшовную автоматизацию задач безопасности.
Terraform и OpenTofu - эти инструменты «инфраструктура-как-код» (IaC) помогают стандартизировать развертывание сетей и политик безопасности. Используя декларативные манифесты, организации могут определять балансировщики нагрузки, правила межсетевого экрана и политики безопасности, которые могут контролироваться версионно и развертываться через CI/CD-конвейеры.
Ansible - этот инструмент часто применяется для развертывания основных компонентов NSX, включая NSX Manager, Edge и транспортные узлы. ИТ-команды могут интегрировать Ansible с Terraform для полной автоматизации конфигурации сети.
PowerCLI — это модуль PowerShell для VMware, который позволяет администраторам эффективно автоматизировать конфигурации межсетевых экранов и политик сетевой безопасности.
Aria Automation Suite - платформа Aria обеспечивает оркестрацию задач сетевой безопасности корпоративного уровня. Она включает:
Aria Assembler — разработка и развертывание облачных шаблонов для настройки безопасности.
Aria Orchestrator — автоматизация сложных рабочих процессов для управления безопасностью NSX.
Aria Service Broker — портал самообслуживания для автоматизации сетевых и защитных операций.
Ключевые основы работы с API
Для эффективного использования возможностей автоматизации vDefend важно понимать архитектуру его API:
Иерархическая структура API: API NSX построен по древовидной структуре с ресурсами в отношениях родитель-потомок.
Пагинация с курсорами: большие наборы данных разбиваются на страницы с использованием курсоров для повышения эффективности запросов.
Порядковые номера: правила межсетевого экрана выполняются сверху вниз, приоритет отдается правилам с меньшими порядковыми номерами.
Методы аутентификации: вызовы API требуют аутентификации через базовую авторизацию, сеансовые токены или ключи API.
Пример полномасштабной автоматизации
Реальный сценарий автоматизации с использованием vDefend включает:
Сбор информации о виртуальных машинах — идентификацию ВМ и получение тегов безопасности.
Присвоение тегов ВМ — назначение меток для категоризации ресурсов.
Создание групп — динамическое формирование групп безопасности на основе тегов ВМ.
Определение пользовательских служб — создание пользовательских сервисов межсетевого экрана с конкретными требованиями к портам.
Создание политик и правил межсетевого экрана — автоматизация развертывания политик для применения мер безопасности.
Например, автоматизированное правило межсетевого экрана для разрешения HTTPS-трафика от группы веб-серверов к группе приложений будет выглядеть следующим образом в формате JSON:
Документ Network Observability Maturity Model от компании Broadcom представляет собой руководство по достижению высокого уровня наблюдаемости (observability) сетей, что позволяет ИТ-командам эффективно управлять современными сложными сетевыми инфраструктурами.
С развитием облачных технологий, удаленной работы и зависимости от внешних провайдеров, традиционные инструменты мониторинга устарели. В документе описана модель зрелости наблюдаемости сети, которая помогает организациям эволюционировать от базового мониторинга до полностью автоматизированного и самовосстанавливающегося управления сетью.
Основные вызовы в управлении сетями
Растущая сложность – 78% компаний отмечают, что управление сетями стало значительно сложнее из-за многообразия технологий и распределенных архитектур.
Удаленная работа – 95% компаний используют гибридный режим работы, что усложняет контроль за производительностью сетей, зависящих от домашних Wi-Fi и внешних провайдеров.
Облачные технологии – 98% организаций уже используют облачную инфраструктуру, что приводит к недостатку прозрачности в управлении данными и сетевым трафиком.
Зависимость от сторонних сервисов – 65% компаний передают часть сетевого управления сторонним поставщикам, что затрудняет полное наблюдение за сетью.
Рост потребности в пропускной способности – развитие AI и других технологий увеличивает нагрузку на сети, требуя более эффективных стратегий управления трафиком.
Устаревшие инструменты – 80% компаний считают, что традиционные средства мониторинга не обеспечивают должного уровня видимости сети.
Последствия недостаточной наблюдаемости
Проблемы с диагностикой – 76% сетевых команд испытывают задержки из-за недостатка данных.
Реактивный подход – 84% компаний узнают о проблемах от пользователей, а не от систем мониторинга.
Избыточные тревоги – 41% организаций сталкиваются с ложными срабатываниями, что увеличивает время поиска неисправностей.
Сложности с наймом специалистов – 48% компаний не могут найти специалистов с нужными навыками.
Ключевые требования для построения наблюдаемости сети
Видимость внешних сред – важна мониторинговая прозрачность не только для внутренних сетей, но и для облаков и провайдеров.
Интеллектуальный анализ данных – использование алгоритмов для корреляции событий, подавления ложных тревог и прогнозирования отказов.
Активный мониторинг – симуляция сетевого трафика позволяет выявлять узкие места в режиме реального времени.
Автоматизация и интеграция – объединение разрозненных инструментов в единую систему с автоматическими рекомендациями по устранению неполадок.
Модель зрелости наблюдаемости сети
Модель зрелости состоит из пяти уровней:
Ручной уровень – разрозненные инструменты, долгие поиски неисправностей.
Традиционный уровень – базовое объединение инструментов, но с разрывами между данными.
Современный уровень – использование активного мониторинга и потоковой телеметрии.
Следующее поколение – автоматизированные решения на основе AI/ML, минимизация ложных тревог.
Самообслуживание и самовосстановление – автоматическая коррекция сетевых аномалий без вмешательства человека.
Практическая реализация модели
Для внедрения зрелой системы наблюдаемости компании должны:
Создать единую модель данных для многовендорных сетей.
Инвестировать в решения с AI-аналитикой.
Использовать активное и потоковое наблюдение за сетью.
Интегрировать мониторинг как внутренних, так и внешних сетей.
Документ Network Observability Maturity Model подчеркивает важность перехода от традиционного мониторинга к интеллектуальной наблюдаемости сети. Автоматизация, AI-аналитика и активный мониторинг позволяют существенно сократить время диагностики проблем, снизить издержки и повысить надежность сетевых сервисов. В документе даны полезные рекомендации по развитию мониторинговых систем, обеспечивающих полную прозрачность работы сети и снижение нагрузки на ИТ-отделы.
Иногда у администратора VMware vSphere возникает необходимость отключить физический интерфейс на хосте VMware ESXi, чтобы сделать некоторые операции или протестировать различные сценарии.
Например:
Тестирование сценариев отказоустойчивости сети.
Определение и изоляция сетевых проблем за счет отключения подозрительного неисправного сетевого адаптера (NIC).
Временное отключение сетевого адаптера (NIC), чтобы оценить влияние на производительность сети и проверить эффективность балансировки нагрузки.
Проверка того, как виртуальные машины реагируют на отказ определенного сетевого пути.
Отключение vmnic, который подключен к ненадежному VLAN или неправильно настроенной сети.
Тестирование различных сетевых конфигураций без внесения постоянных изменений в физические соединения.
Итак, чтобы отключить vmnic, нужно зайти на ESXi по SSH и выполнить там следующую команду, чтобы вывести список сетевых адаптеров:
esxcli network nic list
Далее отключаем vmnic командой (X - это номер в имени адаптера):
esxcli network nic down -n vmnicX
В разделе физических адаптеров vSphere Client мы увидим следующую картину (адаптер в статусе "down"):
Чтобы вернуть vmnic в исходное состояние, просто выполняем команду:
Pete Del Vecchio, Data Center Switch Product Line Manager в компании Broadcom, выпустил интересное видео, в котором он высказывает свои предположения касательно развития сетевой инфраструктуры в 2025 году:
Краткое содержание предсказаний Broadcom на 2025 год:
Переход от InfiniBand к Ethernet для крупных GPU-кластеров:
Broadcom прогнозирует, что в 2025 году все крупные гипермасштабируемые GPU-кластеры окончательно перейдут с технологии InfiniBand на Ethernet. Уже сейчас большинство объявленных продуктов и кластеров для GPU используют Ethernet, и эта тенденция продолжится.
Ethernet станет стандартом для масштабируемых сетей (Scale-Up):
Ethernet не только заменит InfiniBand в сетях Scale-Out (соединения между GPU-узлами), но и станет основой для сетей Scale-Up, обеспечивая связи внутри отдельных GPU-систем. В 2025 году ожидаются новые продукты и системы GPU на основе Ethernet для этих задач.
Демократизация искусственного интеллекта (AI):
Broadcom считает, что AI станет доступнее для компаний разного масштаба, а не только для крупных гипермасштабируемых компаний. Основой для этого будет использование более эффективных процессоров и сетевых технологий от различных производителей. Broadcom видит свою роль в создании высокоэффективных сетевых решений, поддерживающих распределённые системы для обучения и работы AI.
Роль Broadcom заключается в активном участии в переходе на Ethernet, разработке решений для масштабируемых сетей и создании технологий, способствующих демократизации AI.
В статье ниже рассказано о том, как можно использовать API платформы VMware Cloud Foundation (VCF) для расширения кластера между стойками без расширения уровня L2 в физической сети. Расширение кластера на хосты в разных стойках служит двум ключевым целям: увеличению емкости вычислительных мощностей и ...
На конференции VMware Explore 2024 в Барселоне компания Broadcom представила революционную сетевую архитектуру VeloRAIN, предназначенную для поддержки и оптимизации рабочих нагрузок, связанных с искусственным интеллектом (AI), в рамках больших предприятий. VeloRAIN (RAIN - это Robust AI Networking) создана для улучшения производительности и безопасности AI-нагрузок в распределенных средах, что делает её важным инструментом для современных предприятий, сталкивающихся с растущими потребностями в передаче данных и выполнении AI-задач.
Основные Преимущества VeloRAIN
Выявление AI-приложений с помощью AI и машинного обучения (ML)
Одной из ключевых особенностей VeloRAIN является способность обнаруживать зашифрованный трафик приложений, который ранее было невозможно анализировать стандартными решениями для оптимизации сети. Это дает компаниям возможность более точно определять и выделять приоритеты для AI-приложений, что, в свою очередь, позволяет повысить качество обслуживания (QoS) и улучшить пользовательский опыт.
Повышение эффективности сети и оптимизация трафика
VeloRAIN предлагает инновационные методы оценки качества каналов связи, которые помогают улучшить обслуживание пользователей при работе с беспроводными каналами, включая 5G и спутниковые соединения. Это позволяет достичь качества, сравнимого с проводной связью, даже при изменяющихся условиях сети. Кроме того, архитектура ускоряет настройку сетей в удаленных офисах или филиалах, делая запуск инфраструктуры более быстрым и менее трудоемким.
Динамическая система управления приоритетами на основе AI
Новая динамическая платформа управления политиками автоматизирует присвоение приоритетов для приложений, что упрощает управление сетью. С помощью функции Dynamic Application-Based Slicing (DABS) платформа VeloRAIN обеспечивает высокое качество обслуживания для каждого приложения, даже если сети, по которым передаются данные, не поддерживают послойную сегментацию. DABS также использует профили пользователей, чтобы предоставлять приоритетный трафик ключевым сотрудникам, улучшая их опыт и общую производительность сети.
Автоматизация и мониторинг сети с использованием AI
VeloRAIN позволяет компаниям получить глубокую видимость работы сети, автоматизировать процессы приоритезации и мониторинга, а также сократить вмешательство со стороны IT-специалистов. Это особенно важно для AI-нагрузок, которые являются автономными и требуют оркестрации, а не ручного администрирования. Используя VeloRAIN, предприятия могут более эффективно и оперативно настраивать свои сети под потребности бизнес-нагрузок, что улучшает адаптивность к изменениям в рабочем процессе и инфраструктуре.
Стратегическая Значимость VeloRAIN для современного бизнеса
VeloRAIN представляет собой значительный шаг вперед в управлении распределенными рабочими нагрузками AI, так как позволяет предприятиям быстро адаптироваться к изменениям и обеспечивать безопасность и производительность своих AI-нагрузок. С помощью этой архитектуры компании смогут не только улучшить качество взаимодействия с клиентами, но и оптимизировать расходы, так как система автономно распределяет приоритеты и адаптируется под изменения в сети.
Цель Broadcom в развитии сетевой инфраструктуры на базе AI
Как отметил Санжай Аппал, вице-президент и генеральный директор подразделения VeloCloud компании Broadcom, VeloRAIN станет основой инноваций компании в AI-сетях, предоставляя компаниям инструменты для оптимизации их AI-нагрузок. Broadcom планирует активно развивать свою экосистему партнеров, чтобы предоставить компаниям инфраструктуру нового поколения для поддержки AI и облачных рабочих нагрузок в будущем.
Прочие анонсы VeloCloud
VeloCloud Edge 4100 и 5100: высокопроизводительные устройства для крупных предприятий
Broadcom представила устройства VeloCloud Edge 4100 и 5100, которые обеспечивают повышенную пропускную способность и масштабируемость. Устройство Edge 4100 поддерживает до 30 Гбит/с и до 12 000 туннелей, а Edge 5100 — до 100 Гбит/с и до 20 000 туннелей. Эти решения упрощают сетевую архитектуру и обеспечивают высокую надежность для AI и других рабочих нагрузок.
Titan: Новая партнерская программа для поддержки MSP
Программа Titan предлагает партнерам Managed Service Providers (MSP) эксклюзивные преимущества, такие как стабильный рост бизнеса, доступ к передовым технологиям, новую модель лицензирования и улучшенные возможности по предоставлению управляемых услуг для клиентов.
Особенности новой программы:
Вознаграждение на основе показателей, включая совместную разработку решений, признание на рынке и стабильный и предсказуемый рост бизнеса.
Эксклюзивный доступ к инновационным технологиям и каналам выхода на рынок.
Новая модель лицензирования, обеспечивающая переносимость лицензий, простоту управления и стабильность цен.
Программа создания услуг, ориентированная на ключевые ценностные драйверы, вертикальное выравнивание и более высокие маржинальные показатели.
Новое предложение «White label», позволяющее партнерам высшего уровня расширять базу VeloCloud через региональных и специализированных партнеров канала.
Вместе с релизом основной платформы VMware Cloud Foundation 5.2 в самом конце июля компания Broadcom представила обновленную версию решения NSX 4.2, предназначенного для виртуализации и агрегации сетей виртуального датацентра. Напомним, что о возможностях прошлой версии VMware NSX 4.1 мы писали вот тут.
Релиз NSX 4.2.0 предоставляет множество новых функций, предлагая новые возможности для виртуализованных сетей и безопасности для частных, публичных и мультиоблачных инфраструктур. Основные новшества:
Простота внедрения виртуальных сетей для виртуальных машин, подключенных к VLAN-топологиям.
Поддержка IPv6 для доступа к NSX Manager и Edge Nodes.
Повышенная доступность сетевого подключения с поддержкой двойных DPU, группировкой TEP, улучшенным обнаружением сбоев и приоритизацией пакетов, обнаруживающих сбои.
Дополнительная поддержка событий, алармов и других эксплуатационных функций.
Улучшения в области многопользовательского доступа и виртуальных частных облаков (VPC).
Увеличение масштаба правил и групп для брандмауэра как в Local Manager, так и в Global Manager.
Доступность функции IDS/IPS на T0 для Gateway Firewall.
Распределенная защита от вредоносных программ на растянутых кластерах VSAN.
Добавлен захват пакетов для анализа угроз и экспертизы в NDR для событий IDS/IPS.
Сетевые возможности
Сетевой уровень 2
Группы TEP более эффективно используют несколько TEP на узел Edge Node, выполняя балансировку трафика на основе потоков, что обеспечивает больше двунаправленной пропускной способности для Tier-0 шлюза.
Поддержка MPLS и DFS трафика улучшает пропускную способность трафика для данных протоколов.
Инструмент для легкого внедрения виртуальных сетей помогает плавно перейти на использование оверлейных сетей.
Совмещенные VIB для безопасности и сетей позволяют настроить распределенный брандмауэр на DVPG и виртуализацию сети на одном хосте ESXi.
Улучшения в области видимости путей данных включают новые возможности мониторинга путей данных через API и UI.
Поддержка неизвестных типов Ethertypes обеспечивает пересылку трафика любого типа, гарантируя пересылку двойных VLAN-меток.
Поддержка неприоритетной active-standby политики тиминга для обеспечения отсутствия сбоев трафика при возврате активного соединения.
Улучшения в области производительности и гибкости коммутаторов включают изменения режима VDS без необходимости удаления конфигурации.
Ускорение на базе DPU
Поддержка Dual DPU для обеспечения высокой доступности, где отказ одного DPU не влияет на серверный хост.
Поддержка двух активных DPU без высокой доступности, при отказе одного DPU трафик на нем не защищен и не будет перенаправлен на второй DPU.
Сетевой уровень 3
Поддержка IPv6 для NSX Managers и Edge Nodes позволяет развертывать NSX без необходимости в IPv4 адресах.
Поддержка уникального идентификатора маршрута EVPN на каждом Tier-0 SR и VRF для active/active шлюзов Tier-0.
Усовершенствованные возможности отладки и журналирования для неудачных сеансов BGP и BFD.
Платформа Edge
Алармы для платформы Edge улучшают ее видимость и служб, работающих на ней.
Аларм при долгом захвате пакетов на Edge.
Функция "Edge Agent Down" помогает определить работоспособность агента Edge.
Аларм "Tunnels down" помогает быстрее идентифицировать проблемы с туннелями на Edge.
Обнаружение событий петли моста при обнаружении петли в сети между мостовыми сетями и сетью NSX.
Поддержка High Security Cipher для NSX Load Balancer.
VPN
Улучшения управления сертификатами VPN с изоляцией между проектами и поддержка VPN на Tier-1 шлюзах проекта.
Сетевые возможности для контейнеров
Поддержка NSX Child Segment для Antrea Egress позволяет использовать сеть в конфигурации Egress IP Pool отличную от сети узлов.
Безопасность
Шлюз брандмауэра
Функция IDS/IPS на T0 Gateway позволяет создавать правила IDS/IPS на шлюзе Tier-0.
Увеличение масштабируемости для vDefend Gateway Firewall.
Увеличение масштабируемости для правил и групп распределенного фаервола.
Распределенный фаервол
Повышение видимости сетевых политик Kubernetes.
Улучшения UI для отображения соответствующих критериям группировок членов.
Network Detection and Response (NDR)
Поддержка корреляции всех кампаний NDR на сайте клиента.
Ведение журналов событий обнаружения и кампаний в SIEM.
Возможность экспорта и загрузки захваченных пакетов (PCAP) для событий IDPS.
Включение событий вредоносных программ из распределенного брандмауэра в корреляцию кампаний NDR.
Система обнаружения и предотвращения вторжений (IDPS)
Обновленный движок для IDPS на NSX Edge для лучшей производительности и улучшенного обнаружения.
Поддержка IDPS на Tier-0 для NSX Edge.
Распределенное обнаружение и защита от вредоносных программ
Поддержка ATP в VCF для конфигурации с растянутым кластером vSAN.
Упрощение развертывания SVM.
Поддержка файлов OneNote для обнаружения и предотвращения распространения вредоносного ПО.
Платформа и операции
Автоматизация
Поддержка Terraform для управления установкой и обновлением NSX Fabric.
Поддержка Terraform для настройки GRE туннелей.
Многопользовательский доступ
Возможность создания проекта и VPC без правил брандмауэра по умолчанию.
Возможность создания VPN в проекте.
Установка и обновление
Прямое обновление с NSX 3.2.x до NSX 4.2.0.
Дополнительные проверки памяти перед обновлением NSX.
Управление сертификатами NSX.
Операции и мониторинг
Доступность NSX Manager в конфигурации XL.
Введение динамических онлайн-руководств по диагностике системы.
Дополнительные метрики в API NSX.
Захват пакетов с трассировкой в Enhanced Datapath Host Switch.
Сокращение размера пакетов поддержки.
Платформенная безопасность
Поддержка TLS 1.3 для внутренних коммуникаций между компонентами NSX.
Масштабируемость
Несколько обновлений максимальной поддерживаемой масштабируемости NSX.
Федерация
Размер XL для Global Manager.
Интеллектуальная безопасность
Расширенные аналитические панели для оперативной безопасности фаервола.
NSX Application Platform (NAPP)
Поддержка развертывания NSX Application Platform за прокси-сервером.
Для получения более подробной информации о новых возможностях NSX 4.2.0 и руководствах по установке и эксплуатации, обращайтесь к официальной документации и ресурсам VMware.
После переезда ресурсов компании VMware на портал Broadcom было опубликовано несколько полезных материалов, касающихся решения для виртуализации и агрегации сетей виртуального датацентра VMware NSX. Основные из них мы приводим ниже: 1. NSX Certificate Management Cookbook...
VMware Avi Load Balancer является первым в отрасли программно-определяемым балансировщиком нагрузки (Load Balancer, LB) для гибридных облаков, который предлагает распределенную архитектуру с встроенной автоматизацией и глубокую видимость приложений. Инновационные решения Avi позволяют ИТ-командам предоставлять балансировку нагрузки с той же скоростью, что и приложения, обеспечивая эластичность (горизонтальное и вертикальное масштабирование) и единообразную модель эксплуатации в гибридных мультиоблачных средах, включая VMware Cloud Foundation (VCF), традиционные центры обработки данных, а также публичные облака для виртуализированных сред, окружений Kubernetes и физических рабочих нагрузок.
Avi Load Balancer реализует новые возможности по следующим направлениям:
1. Приложения для VCF Private Cloud
Avi является предпочтительным балансировщиком нагрузки благодаря своей модели plug-and-play для VCF, предоставляя следующие уникальные преимущества:
Быстрое развертывание балансировщика благодаря встроенным интеграциям с vSphere и NSX.
Автоматизированный рабочий процесс LB с Aria Operations (ранее vRealize Operations, vROPs).
Новое - самообслуживание LB через интеграцию с Aria Automation (ранее vRealize Automation, vRA).
Расширенная видимость приложений для администраторов VCF, что позволяет быстро решать проблемы, связанные с приложениями, до обращения к команде сетевых администраторов.
2. Приложения для Kubernetes
В качестве ingress-балансировщика программно-определяемая и эластичная архитектура Avi идеально подходит для распределенной и динамичной природы контейнерных рабочих нагрузок. Преимущества Avi:
Встроенная автоматизация с Avi Kubernetes Operator (AKO).
Новое - Gateway API – это следующее поколение Kubernetes ingress, значительно уменьшающее потребность в настройках через аннотации и определения пользовательских ресурсов (CRD), а также обеспечивающее защиту клиентов для Kubernetes и бессерверных рабочих нагрузок.
Встроенная безопасность ingress – включая Web Application Firewall (WAF) – для защиты контейнерных рабочих нагрузок.
Дополнительная лицензия на эти функции не требуется.
3. Мобильные и 5G приложения
Avi предоставляет гибкое и последовательное решение для балансировки нагрузки для широкого набора телекоммуникационных и мобильных сценариев использования.
Новое - нативная многопользовательская поддержка, теперь обеспечивающая в 3 раза большую многопользовательскую поддержку с VCF и Telco Cloud Platforms (TCP).
Новое - полная поддержка недавно выпущенного TCP 4.0.
Новое - дальнейшие улучшения программно-определяемого IPv6 балансировщика нагрузки (с разделенными слоями управления IPv6 и распределенными слоями данных) для локальных и облачных решений.
4. Инструмент конвертации старых LB в Avi
Для упрощения и ускорения развертывания Avi в существующих инфраструктурах, VMware представила инструмент конвертации Avi. Этот инструмент:
Обнаруживает старые LB.
Извлекает конфигурации.
Конвертирует конфигурации и пользовательские правила старых LB (например, iRules) в Avi.
Развертывает конфигурации на Avi.
Этот инструмент ускорит миграцию старых LB на Avi, в том числе выполняемую командой профессиональных услуг VMware.
Самообслуживание балансировки нагрузки для VCF Private Cloud
Avi Load Balancer является предпочтительным балансировщиком нагрузки для VCF, полностью интегрированным и поддерживаемым, с функциями plug-and-play. Avi предоставляет беспрецедентную видимость приложений, что помогает администратору VCF быстро выявлять и устранять причины проблем с производительностью приложений в течение нескольких минут.
Клиенты, которые хотят предоставить возможности самообслуживания командам DevOps, считают старые балансировщики нагрузки тяжелыми в эксплуатации, так как их развертывание занимает недели, требуя множества ручных шагов и создания нескольких тикетов.
Интеграция Avi с Aria Automation предлагает командам приложений доступ в форме самообслуживания к услугам балансировки нагрузки уровней L4-L7 (см. Включение балансировки нагрузки как услуги для частного облака на основе VCF). Это позволяет командам приложений и инфраструктуры немедленно развертывать балансировку нагрузки при предоставлении приложений, с минимальными знаниями технологий балансировки нагрузки и без необходимости создания ручных тикетов. Интеграция помогает клиентам снизить операционные затраты, упростить и автоматизировать развертывание и управление емкостью балансировки нагрузки. Смотрите это короткое демонстрационное видео, чтобы увидеть, как легко включить балансировку нагрузки как услугу с использованием Aria Automation.
Увеличение многопользовательской поддержки Avi Load Balancer примерно в 3 раза
Предприятия развертывают крупномасштабные приложения, которые требуют эластичной и надежной балансировки нагрузки. Несколько команд и арендаторов должны иметь доступ к инфраструктуре частного облака. Avi Load Balancer значительно улучшил производительность и масштабируемость, увеличив поддержку многопользовательского режима почти в 3 раза. Теперь клиенты могут управлять большим количеством Avi Service Engines (балансировщиков нагрузки) для каждого развернутого Avi Controller.
Каждый контроллер может поддерживать до 800 маршрутизаторов уровня Tier-1 для VMware NSX-T Cloud. Клиенты не только имеют меньшее количество контроллеров для управления, но и значительно снижают операционные расходы по сравнению с устаревшими балансировщиками нагрузки. В результате, та же команда может управлять большим количеством арендаторов, что повышает производительность. Провайдеры облачных услуг VMware, ранее известные как VMware Cloud Provider Program (VCPP), используют Avi Load Balancer для оптимизации облачных операций и повышения качества предоставляемых услуг. Подробнее см. в этом вебинаре Feature Friday на YouTube.
Avi для Ingress-балансировки нагрузки Kubernetes и бессерверных рабочих нагрузок
Контейнеры по своей природе являются эфемерными и эластичными, постоянно запускаются и останавливаются, что делает устаревшие аппаратные балансировщики нагрузки с традиционными архитектурами неактуальными для облачных и контейнерных сред. В условиях, когда все больше рабочих нагрузок в производственной среде развертываются на платформах Kubernetes, открытые решения становятся нецелесообразными для требований предприятий. Чтобы идти в ногу со скоростью развертывания приложений и предоставлять решения по балансировке нагрузки и ingress корпоративного уровня, Avi Load Balancer предлагает идеальную архитектуру для контейнерных рабочих нагрузок со встроенной безопасностью.
Avi предлагает интегрированные ingress-услуги, которые включают ingress-контроллер, балансировку нагрузки, глобальную балансировку нагрузки серверов в нескольких кластерах (GSLB), WAF и аналитику приложений на одной платформе. Для клиентов, которые развернули Avi для своих виртуализированных рабочих нагрузок, это простое расширение на Kubernetes с использованием того же пользовательского интерфейса, последовательных рабочих процессов и политик. Avi является независимым от контейнерных платформ и поддерживает VMware Tanzu, RedHat OpenShift, Tanzu Application Service (TAS, ранее Pivotal Cloud Foundry) и другие.
Avi Load Balancer вводит общую доступность (GA) поддержки Gateway API в выпуске AKO 1.12.1. Avi добавляет продвинутые функции маршрутизации уровня L7, включая поддержку безсерверного Kubernetes, модификацию заголовков, вставку cookie и ключевой набор функциональных возможностей HTTProute. Avi предлагает продвинутую маршрутизацию трафика, лучшую масштабируемость и мониторинг на основе каждого маршрута, без необходимости в CustomResourceDefinition (CRD) или аннотациях.
Расширение программно-определяемого подхода для мобильных и 5G-приложений
С поддержкой распределенного IPv6, обеспеченной уникальной программно-определяемой архитектурой Avi и поддержкой Telco Cloud Platform 4.0, VMware Avi Load Balancer продолжает предлагать широкий набор сценариев использования: от 4G рабочих нагрузок в ВМ и виртуальных сетевых функций (VNF) до 5G контейнерных рабочих нагрузок и контейнерных сетевых функций (CNF).
Крупный телекоммуникационный клиент VMware сначала развернул Avi в своей корпоративной сети в качестве пилотного проекта. Впечатленная его простотой использования и аналитикой приложений, команда сетевых администраторов представила Avi своей основной телекоммуникационной команде, которая решила расширить использование Avi в Telco Cloud Platform, обеспечивающую 5G сеть для рабочих нагрузок Kubernetes.
С операционной точки зрения это точно такая же платформа для обеих сред, что делает простым обучение персонала и совместную работу по решению проблем с приложениями, которые могут затрагивать несколько команд. Многопользовательская поддержка была ключевым требованием для телекоммуникационных сценариев, поэтому масштабируемость была значительно улучшена с выпуском новой версии. Также Avi предоставляет гранулярный доступ на основе правил (RBAC) для различных арендаторов и команд.
Инструмент конвертации старых балансировщиков нагрузки в Avi
Чтобы еще больше упростить миграцию с устаревших аппаратных балансировщиков нагрузки и ускорить переход на частное облако VCF, Avi Load Balancer объявляет о начальной доступности (Initial Availability) инструмента конвертации на базе UI, который берет старые правила политик, преобразует конфигурации в встроенные функции Avi, а также в Avi DataScript (скриптовый язык на базе Lua). Клиенты разрывают цепь старых балансировщиков нагрузки, переходя от сложных конфигураций для каждого устройства к простому управлению политиками из центральной панели управления.
Больше деталей о последней версии VMware Avi Load Balancer вы можете узнать по этим ссылкам:
Администраторам приложений и сети необходимо иметь возможность идентифицировать, понимать и реагировать на изменения в операционных условиях своих облачных приложений и структуре операций в центрах обработки данных. Любые изменения в операционных процедурах могут быть критическими, поскольку они могут нести бизнес-риски. С другой стороны, некоторые из этих отклонений могут быть предвестниками позитивного роста.
Поэтому обнаружение аномалий является важным и может дать интересные инсайты. Рассмотрим следующие сценарии:
Поставщик облачных услуг хочет знать о любых изменениях в инфраструктуре, таких как отказы ресурсов или избыточный входящий/исходящий сетевой трафик.
Команда информационной безопасности хочет знать о необычных шаблонах поведения пользователей.
Компания управления розничными продажами хочет знать о событиях/скидках, которые действительно вызывают всплески покупок товаров.
Выявление аномалий во всех этих случаях требует создания моделей поведения, которые могут автоматически выявлять и корректировать критерии различия между нормальным и аномальным. Поведенческая модель опирается на поведение данных. Хорошо построенная модель может не только помочь идентифицировать и квалифицировать всплески, но и облегчить прогнозирование. Обратите внимание, что простой подход с использованием статических порогов и предупреждений непрактичен по следующим причинам:
Масштаб операционных параметров: существует более тысячи сетевых, инфраструктурных и прикладных метрик, необходимых для анализа операций облачного приложения.
Слишком много ложных срабатываний или ложных пропусков: если пороги слишком жесткие, может быть слишком много ложных срабатываний. Если они слишком расслаблены, реальные аномалии могут быть упущены.
Чтобы учитывать операционные ограничения в вышеуказанных сценариях, VMware добавила еще одну технику поведенческого обучения в свой арсенал - алгоритм для выявления аномалий в сезонных временных рядах.
Алгоритм Хольта-Винтерса
Алгоритм Holt-Winters (HW), разработанный Хольтом и Винтерсом, помогает построить модель для сезонного временного ряда (например, с учетом суточной сезонности). Эта техника улучшает существующие средства обнаружения аномалий Avi Load Balancer, которое использует алгоритм экспоненциально взвешенного скользящего среднего (EWMA). Если EWMA звучит непонятно, то для быстрого освежения памяти хорошо подходит учебник "Прогнозирование: принципы и практика". По сути, EWMA тесно следует за кривой данных, однако он работает так, что периодические компоненты данных просто игнорируются. Этот момент учитывается при декомпозиции сигнала алгоритмом Хольта-Винтерса. Для сравнения прогностических моделей двух алгоритмов рассмотрим интервалы прогнозирования 80% и 95% EWMA и HW при применении к одним и тем же данным.
Для повышения точности не должно быть игнорирования сезонности входного ряда данных. Алгоритм Хольта-Винтерса работает путем разбиения указанного временного ряда на три компоненты:
Уровень: Можно представить как усреднение входного сигнала.
Тренд: Представляет собой наклон или общее направление движения данных.
Сезонность: Отражает периодичность данных.
На рисунке ниже представлены три составляющие временного ряда (под основным сигналом), который мы прогнозировали выше:
Временной ряд может иметь аддитивную/мультипликативную тенденцию/сезонность. Для простоты в данной статье мы предполагаем применение алгоритма Хольта-Винтерса к временному ряду с аддитивной тенденцией и аддитивной сезонностью (additive-trend-additive-seasonality, HW-AA), так как это ближе к факторам в реальной жизни. Для такого ряда компоненты тренда и сезонности увеличиваются линейно и суммируются, чтобы составить точки данных на прогрессирующих временных срезах. Временной ряд представлен следующим образом:
Где отдельные компоненты вычисляются следующим образом:
Обратите внимание, что каждое уравнение компоненты по сути представляет собой расчет в стиле EWMA. Для дальнейшего понимания обратитесь к книге "Прогнозирование: принципы и практика".
Несколько слов о параметрах сглаживания alpha, beta, gamma. Как общее руководство, инженеры используют уравнение для определения параметров сглаживания, как это рекомендуется в статье "Обнаружение аномалий во временных рядах для мониторинга сети".
Это уравнение подчеркивает, какую важность мы хотим придать историческим данным. Например, в Avi, когда применяется алгоритм HW к метрике, представляющей пропускную способность приложения, вес 95% придается сэмплам (с интервалам 5 минут) за последний час. Подставим эти значения в уравнение выше:
Эта схема применима и к другим параметрам сглаживания. Обратите внимание, что, как видно из уравнений выше, объем памяти, потребляемый алгоритмом HW, пропорционален сезонному периоду. В контексте аналитического движка Avi это означает занимаемый объем памяти размером 96 КБ на метрику. Поэтому из тысячи метрик, анализируемых Avi, VMware внимательно балансирует применение алгоритма HW только к наиболее значимым сезонным метрикам, не перегружая операции.
Для оценки нашего выбора параметров для встраиваемой реализации алгоритма HW мы сравниваем прогнозные значения с уже известным временным рядом. Вот результат:
По оси X отложено время t, а по оси Y - соответствующее значение выборки данных. График представляет собой сравнение исходных и прогнозируемых значений, а также обозначает интервалы прогнозирования с доверительной вероятностью 95%. Легко заметить, что исходные и прогнозируемые данные довольно хорошо совпадают.
Аналитический движок Avi применяет несколько методов обнаружения аномалий к одному временному ряду. Как описано выше, эти методы обнаружения используют варианты EWMA и HW. Таким образом, результаты каждой модели подвергаются режиму консолидации ALL или ANY, где либо все результаты должны согласиться с решением (о маркировке точки данных как аномальной) или же достаточно и одного. Выбор режима консолидации зависит от баланса между ложноположительными и истинными результатами. В режиме ALL ожидаются более частые ложноположительные результаты с более точными истинными, так как диагностика хотя бы одной моделью достаточна для пометки выборки данных как аномальной. В отличие от этого, режим ALL требует единогласного решения алгоритмов, что требует большей уверенности в маркировке выборки данных. Следовательно, это делает более сложным пометку правильных данных как аномальных (соответственно, меньше ложноположительных, но и меньше истинных результатов). В рамках этого подхода VMware предустанавливает режимы в зависимости от конкретной метрики, основываясь на опыте наблюдений.
Вот преимущества подхода Avi:
Inline - это встроенная функция контроллера доставки приложений (Application Delivery Controller, ADC), она не требует дополнительных настроек или использования стороннего программного обеспечения.
Быстрый и действенный - обнаружение аномалий выполняется в реальном времени, а администраторам предоставляются средства по автоматизации их обработки (например, добавление ресурсов). Администраторам не нужно вручную блокировать клиентов, запускать новый сервер или увеличивать ёмкость на основе прогнозов использования ресурсов и т. д.
Интеллектуальный - машинное обучение операционным шаблонам и поведению позволяет аналитическому движку Avi принимать лучшие решения по обнаружению аномалий, прогнозированию нагрузки, планированию эластичной ёмкости и т. д.
Как отмечалось ранее, вы можете использовать модель не только для идентификации аномалий, но и для прогнозирования результатов в будущем. Фактически, прогностические модели используются аналитическим движком Avi для автомасштабирования ресурсов. Это требует оценки метрик, которые могут иметь суточный или другой сезонный характер. Таким образом, прогнозируемую ёмкость теперь можно использовать для масштабирования ресурсов приложений вверх/вниз, что значительно оптимизирует затраты.
В Avi постоянно улучшают эту технологию, разрабатывая и интегрируя все более интеллектуальные методы. Помимо интеграции Хольта-Винтерса в систему обнаружения аномалий, также разрабатываются модели, использующие теории машинного и глубокого обучения. Входные данные от таких новых концепций и технологий продолжают обеспечивать высокое качество моделирования.
Продолжаем рассказывать о решении VMware Avi Load Balancer, которое недавно стало доступно в качестве балансировщика как услуги (Load Balancer as a Service, LBaaS) для решения Aria Automation 8.16.1.
Часто менеджеров датацентров мучает простой вопрос – как администраторы знают, что приложения находятся в "хорошем" состоянии? В VMware провели огромное количество встреч и дебатов по теме, касающейся "здоровья приложений" - приведем ниже основные моменты статьи сотрудников Avi, касающейся здоровья приложений.
В команде были люди с разным опытом, им всем задали один и тот же вопрос – "что для вас значит здоровье приложения?". Вот некоторые из ответов, которые были получены:
"Здоровье" – это пропускная способность (throughput), которую может обеспечивать приложение. Если она составляет 10 Гбит/с, это значит, что оно в хорошем состоянии.
Здоровье плохое, когда CPU и память загружены более чем на 100%.
Здоровье хорошее, когда задержка (latency) ниже 100 мс.
Здоровье хорошее, если приложение работает и отвечает на проверки (health checks).
В реальном мире, если спросить вас - "вы считаете, что у меня хорошее здоровье, если я пробежал сегодня 3 мили?", в зависимости от того, кто вы, вы, скорее всего, ответите: "это зависит от разных факторов", "конечно!", "ты пробежал только сегодня или бегаешь каждый день?" или "каков был твой пульс и жизненные показатели после бега?". У вас будет много дополнительных вопросов, чтобы углубиться в детали. С этой точки зрения, теннисист Роджер Федерер, скорее всего, выиграл бы по этому показателю у большинства людей, даже если бы бегал с гриппом. Сделало бы это его здоровым? Конечно нет!
Как вы видите, простой факт возможности пробежки на 3 мили недостаточен для врача, чтобы выдать заключение о хорошем здоровье. Аналогично, если вы думаете, что можете определить здоровье сервера, исходя из простого факта, что он может обрабатывать пропускную способность 10 Гбит/с, вы, вероятно, ошибаетесь. Автору было трудно с этим смириться, особенно учитывая, что большую часть своей карьеры до Avi он провел в компании по производству оборудования, где было нормально считать, что сетевое оборудование в отличном состоянии, когда соединение работает и передает данные с пропускной способностью 10 Гбит/с.
Аналогии со здоровьем человека
В VMware обнаружили, что в ответах всех было много убежденности и субъективности, но это просто не имело смысла. Тогда авторы решили обратиться к аналогиям со здоровьем человека.
На секунду давайте представим команду Golden State Warriors как веб-приложение. Тогда звездный баскетболист Стефен Карри, вероятно, был бы важным микросервисом в этом приложении. Как бы мы измеряли его здоровье? Конечно, когда Карри здоров, мы ожидаем, что он будет набирать около 30 очков за игру в среднем. Мы также не ожидаем, что он устанет во время игры. В хорошем состоянии здоровья (измеряемом с помощью таких показателей, как пульс, кровяное давление и т. д.) от Карри ожидают, что он будет последовательно и ровно выступать.
Автор применил аналогичную философию к измерению здоровья приложений. Вот определение здоровья от Merriam-Webster, которое он счел релевантным:
"состояние организма в отношении выполнения его жизненно важных функций, особенно оцениваемое субъективно или непрофессионально"
Автор немного улучшил это определение для "оценки здоровья" приложений в Avi:
"Avi Health (Score) – это мера производительности приложения и его постоянства, которая отражает любые риски для приложения в контексте различных факторов, таких как ресурсы и безопасность."
Пока все хорошо. Авторы определили оценку здоровья Avi. Однако оставался "слон в комнате" — как определять термины "производительность", "риски" и т. д. Вот как дальше было конкретизировано определение оценки здоровья:
Performance Score: оценка производительности приложения отражает способность приложения соответствовать и превосходить SLA (соглашения об уровне обслуживания). Метрики производительности должны однозначно показывать хорошее состояние против плохого и указывать на соответствие приложения SLA. В этом случае метрики, такие как максимальное количество одновременных подключений или транзакций в секунду, стали неприемлемы, поскольку эти метрики не могли быть выражены как хорошие или плохие транзакции. Поэтому в VMware построили платформу, использующую множество метрик производительности, таких как качество ответа, качество соединения и качество опыта клиентов, для представления производительности приложения.
Resources Risk (Penalty): следующим важным набором метрик было определение, достаточно ли у приложений ресурсов (или выносливости, энергии и т.д.) для постоянного соответствия требованиям производительности. Оценка здоровья Avi комбинирует несколько метрик, таких как использование CPU, использование памяти, использование программной очереди, использование лицензий и т.д. Вместо прямой шкалы были применены человеческие принципы к ресурсам, которые накладывают штрафы только тогда, когда использование ресурсов превышает пороговое значение (скажем, 80%).
Security Risk (Penalty): так же, как люди лучше работают, когда они находятся в безопасной умственной, физической и социальной среде, в VMware пришли к выводу, что уязвимости приложения должны приводить к снижению его здоровья. Например, использование слабых шифров для SSL приводит к снижению оценки здоровья Avi.
Application Performance Consistency (Anomaly penalty): тут считается, что согласованность производительности является очень важной мерой здоровья приложения. Неважно, если производительность достаточна в периоды низкой нагрузки, если она снижается в периоды пиковой нагрузки.
Теперь, когда определена оценка здоровья Avi, все еще нужно проработать детали того, как комбинировать качество сети с качеством HTTP-ответа, как рассчитывать оценку, когда и память, и CPU используются более чем на 80% и т.д.
Уточнение алгоритма
Пока спор о том, как определить оценку здоровья Avi, еще не был урегулирован, у авторов возник еще один горячий спор о том, как должны работать числа. Аналитическая команда Avi создала два правила, которые должны служить руководящими принципами для объединения информации, связанной со здоровьем приложений:
1. Когда есть две метрики или факторы здоровья различного рода, то используется наименее здоровый фактор для представления Health Score. Например, у человека может быть очень крепкое сердце, но опухоль в головном мозге. Нет смысла вычислять "среднее здоровье" между этими органами, но важно подчеркнуть, что тело не в очень хорошем состоянии из-за опухоли в мозге. Для программного обеспечения выразили эти ситуации как здоровье = min(здоровье_A, здоровье_B), когда необходимо объединить здоровье двух факторов A и B.
2. Когда две метрики или факторы здоровья подобны, то здоровье усредняется по всем подобным факторам. Например, если виртуальная служба имеет 100 серверов, то здоровье пула определяется через среднее здоровье всех 100 серверов, учитывая, что все серверы должны быть схожей природы.
Еще одним важным моментом было, должно ли здоровье приложения основываться на мгновенных метриках или должно включать историю производительности. Большинство пользователей и сотрудников разделились на две группы: 1) команда с опытом в индустрии аппаратного обеспечения, которая отвечала, что здоровье приложения должно основываться на мгновенной информации и 2) команда с программным/операционным опытом, которая склонялась к анализу тенденций и истории. Опять же, в VMware использовали стратегии принятия решений в области здоровья человека, чтобы разрешить спор – считается, что человек еще не в хорошем здоровье, если он все еще восстанавливается после недавней болезни.
Поэтому было принято решение смотреть на метрики последних 6 часов, чтобы определить оценку здоровья приложения. На платформе Avi Vantage, когда администратор приложения видит идеальную оценку здоровья (100), он может с уверенностью сказать, что за предыдущие 6 часов здоровье приложения было идеальным и приложение соответствовало его ожиданиям по производительности.
Avi Health Score - это основа
Процесс получения объективной оценки путем объединения серии субъективных метрик не был простым. Оценка здоровья Avi и метрики и компоненты, определяющие эту оценку, являются темой, над которой очень долго работали в Avi. Как только авторы справились с этим, создание программного обеспечения для имплементации принципов в коде было более простой частью.
Позже определение, которое предложил один из технических советников по здоровью приложений (должно отражать, как приложение функционирует, что оно не должно испытывать нехватку ресурсов и не должно быть аномалий), точно совпало с предложением авторов, о котором он не знал.
Так что теперь вы знаете, как работает метрика Health Score в Avi, и что означают все эти пункты:
В последнем релизе Aria Operations for Networks 6.12 представлено много новых возможностей для обеспечения видимости сети, чтобы помочь пользователям решения VMware Cloud Foundation улучшить производительность сети приложений и устранять проблемы с сетью.
1. Функция Network Map Scope - область видимости сети
Корпоративные сети обширны и сложны, поэтому важно сузить круг устройств, которые могут быть отображены в топологии, когда пользователи устраняют конкретные проблемы с сетевым взаимодействием приложений. Видимость масштаба сети позволяет пользователям создавать визуальную карту области сети для конкретных типов устройств, чтобы лучше понять, где могут возникать проблемы. К типам устройств, которые могут быть включены в область, относятся как физические, так и виртуальные объекты, такие как узлы NSX Host Transport Nodes и NSX Edge Transport Nodes, хосты vCenter, коммутаторы, маршрутизаторы, брандмауэры, балансировщики нагрузки, блейд-серверы и расширители фабрик.
2. Тэги для устройств
Эта новая возможность позволит пользователям создавать теги на основе города, местоположения, дата-центра, отдела, инвентарного номера или пользовательского свойства. Теги помогут пользователям при составлении отчетов или создании панелей мониторинга на основе этих тегов. Пользователи могут добавлять теги к виртуальным машинам, коммутаторам, маршрутизаторам, брандмауэрам и другим физическим и виртуальным устройствам. Теги упрощают идентификацию устройств в сетевой инфраструктуре в рамках повседневной работы.
3. API и Databus
Для качественного устранения неполадок и анализа их причин в средах NSX были представлены несколько API NSX и vCenter для databus, которые будут извлекать метрики через NSX Edge, хост vCenter и кластер хостов vCenter. Примерами улучшенной видимости сети являются метрики хоста vCenter, такие как usage, transmission и drop rate.
4. Сохранение изменений в таблицах и виджетах
Вы долго настраивали таблицу или представление, но эти изменения исчезли, когда возникла другая проблема? В релизе 6.12 пользователям стало легче устранять неполадки, поскольку любые сортировки таблиц, фильтрации, упорядочивание столбцов и предпочтения таблиц, сделанные пользователем - запоминаются. Кроме того, когда пользователь изменяет размер окна или переставляет виджеты, платформа запоминает измененные настройки в различных экранах и пользовательских панелях мониторинга.
5. Уведомления по почте о закрытии алертов
Теперь в релизе 6.12 есть механизм закрытия алертов, который генерирует сообщение SNMP для инструментов вроде ServiceNow и IBM Netcool. В этом случае пользователям может быть отправлено письмо о закрытом алерте. Эта возможность обеспечивает лучшую видимость для ИТ-команд, делая проблемы более доступными для отслеживания со стороны службы поддержки. Новая функция оповещения о закрытом алерте упростит сотрудничество пользователей, позволив им сосредоточить внимание на текущих открытых и актуальных оповещениях.
Более подробно о VMware Aria Operations for Networks 6.12 можно прочитать в Release Notes, а также на странице продукта.
В прошлом году мы много писали о технологии SmartNIC/DPU (data processing unit). На конференции VMworld 2020 Online ковидного года компания VMware представила одну из самых интересных своих инициатив по сотрудничеству с вендорами оборудования - Project Monterey. Тогда же и была представлена технология SmartNIC, которая позволяет обеспечить высокую производительность, безопасность по модели zero-trust и простую эксплуатацию в среде VCF.
SmartNIC - это специальный сетевой адаптер (NIC) c модулем CPU на борту, который берет на себя offload основных функций управляющих сервисов (а именно, работу с хранилищами и сетями, а также управление самим хостом).
DPU (data processing unit) - это эволюционное развитие технологии SmartNIC. Этот модуль включает в себя функции оффлоадинга, гибкого программируемого конвейера, обработки данных и CPU, характерные для SmartNIC. Однако DPU является эндпоинтом сетевой инфраструктуры, а не сервером, в котором он находится. DPU содержат специализированные чипы и, в некоторых случаях, настраиваемые программируемые вентильные массивы или специальные интегральные схемы под конкретный сценарий использования.
DPU может поддерживать гораздо больше функций, чем SmartNIC, включая сетевые возможности на основе программируемых конвейеров P4, состояний брандмауэров четвертого уровня, сетевого взаимодействия L2/L3, балансировки нагрузки L4, маршрутизации хранения данных, аналитики хранения и VPN. Функциональность DPU варьируется в зависимости от производителя. Некоторые из крупнейших игроков на рынке в 2022-2023 годах - это Fungible, AMD Pensando и Marvell.
Недавно компания VMware выпустила интересное видео, в котором рассказывается о производительности и безопасности DPU-модулей, которые существенно улучшают быстродействие сетевой инфраструктуры, при этом повышая уровень безопасности коммуникаций (но, само собой, это стоит дополнительных денег):
Приведем немного интересных скриншотов из видео. Результаты теста iperf по сравнению с обычными сетевыми картами:
Результаты теста под нагрузкой на CPU (здесь очевидно результаты лучше, так как DPU берет на себя функции CPU в части обработки сетевых функций):
Нормализованное использование ядер хостовых процессоров на 1 Гбит/сек при обработке сетевых задач (CPU почти не используется, когда есть DPU):
Таги: VMware, Networking, Performance, Hardware, DPU, SmartNIC, Video
Сегодня мы расскажем о том, как определить пропускную способность сети между площадками при использовании кластеров vSAN HCI и кластеров vSAN Max в конфигурации Stretched Cluster.
В растянутом кластере два домена отказоустойчивости данных содержат один или несколько хостов, а третий домен отказоустойчивости содержит виртуальный модуль Witness для определения доступности сайтов данных. Далее каждый домен отказоустойчивости данных мы будем называть сайтом. Конфигурации растянутого кластера vSAN могут распространяться на разные расстояния, при условии что соблюдаются требования по пропускной способности (bandwidth) и задержке (latency).
Минимально поддерживаемая пропускная способность и latency между сайтами
Пропускная способность, которая требуется между сайтами, в большой степени зависит от объема операций ввода-вывода (I/O), который генерируют рабочие нагрузки, но будут влиять и другие факторы, такие как используемая архитектура (vSAN ESA или OSA), размер кластера и сценарии обработки сбоев. Ниже указаны минимально поддерживаемые значения, но рассчитанные оценки для конкретной инфраструктуры могут привести к требованиям по пропускной способности, превышающим указанные минимумы.
Приведенные ниже формулы помогут оценить необходимую пропускную способность сети между сайтами. Предполагается, что два сайта данных географически расположены достаточно близко друг к другу, чтобы соответствовать требованиям по задержке.
Понимание активности I/O, соотношения чтения и записи и размеров I/O
Рабочие нагрузки состоят из нескольких характеристик. Не только количество активности I/O значительно различается от нагрузки к нагрузке, но чтения и записи часто происходят с разными скоростями и разными размерами I/O. С целью предоставления простой формулы для расчета мы будем использовать следующие переменные для расчета оценочной пропускной способности связи между сайтами для растянутого кластера (ISL):
Скорость I/O всех команд чтения и записи, измеряемая в IOPS
Соотношение чтения/записи (например, 70/30)
Средний размер I/O, измеряемый в KB
Пропускная способность - это измерение на основе скорости, что означает, как много данных передается за определенный период времени. В отличие от измерения неактивных данных, где оно принимает форму байтов, килобайтов и т. д., измерение данных в процессе передачи по сети выражается в битах (b), килобитах (Kb), мегабитах (Mb) или гигабитах (Gb), и период времени - "в секунду" (ps). Обсуждая скорости, мы должны помнить о конвертации байтов в биты.
Давайте используем простой пример, где общий профиль I/O требует 100 000 I/O в секунду (IOPS), в среднем 8 KB каждый, где 70% IOPS - это чтение, и 30% - запись, в растянутой конфигурации. В этом сценарии запись I/O (30 000 IOPS в среднем 8 KB каждый) будет равна 240 000 Kbps или 240 Mbps. Это будет оценкой пропускной способности ISL, необходимой для этого профиля.
Простейший, но потенциально менее точный способ оценки требований к пропускной способности - это просто использовать входные данные, представляющие общие потребности кластера. Если кто-то использует формулу для расчета отдельных рабочих нагрузок в кластере, сумма этих расчетов предоставит результирующие требования к пропускной способности. Возможно, вы захотите выделить гораздо больше минимального рассчитанного количества, так как рабочие нагрузки со временем неизбежно становятся более ресурсоемкими.
Формулы для расчета оценок пропускной способности указаны ниже, они привязаны к используемой архитектуре: vSAN OSA или vSAN ESA. С введением архитектуры vSAN Express Storage (ESA) появляются все новые возможности по обеспечению производительности хранилища на совершенно новом уровне. Поэтому при использовании ESA рекомендуется тщательно отслеживать использование ISL, чтобы убедиться, что есть достаточная пропускная способность, необходимая для того, чтобы рабочие нагрузки не были ограничены со стороны ISL. Для дополнительной информации см. статью: "Использование vSAN ESA в топологии растянутого кластера".
Формулы расчета пропускной способности для vSAN ESA
Трафик репликации от I/O гостевой ВМ - это доминирующий тип трафика, который мы должны учесть при оценке необходимой пропускной способности для трафика межсайтовой связи (ISL). У растянутых кластеров vSAN ESA трафик чтения по умолчанию обслуживается сайтом, на котором находится ВМ. Требуемая пропускная способность между двумя сайтами данных (B) равна пропускной способности записи (Wb) * множитель данных (md) * множитель ресинхронизации (mr) * коэффициент сжатия (CR).
Расчет пропускной способности для ISL, обслуживающего растянутый кластер vSAN с использованием ESA, отличается от формулы, используемой для OSA. vSAN ESA сжимает данные до их репликации между сайтами. В результате ESA уменьшает использование пропускной способности ISL, эффективно увеличивая его возможности для передачи большего количества данных.
Чтобы учесть это в расчете в топологии, использующей ESA, формула учитывает оценочное соотношение сжатия сохраненных данных. Давайте рассмотрим следующий пример, где мы оцениваем экономию в 2 раза благодаря использованию сжатия в vSAN ESA. Мы используем простое значение "2x" (также называемое 2:1 или 50%) для простоты. Фактические коэффициенты сжатия будут зависеть от данных, хранящихся в вашей среде. Пример 2:1 - это не предположение о том, что вы на самом деле можете увидеть в своей среде.
Преобразуйте это в процент от исходного размера, разделив конечный размер на начальный размер. Это даст, например, результат ".50".
Умножьте окончательное рассчитанное значение из описанной в этой статье формулы на ".50".
В результате формула будет выглядеть так:
B = Wb * md * CR * mr * CR
Как отмечалось выше, коэффициенты сжатия часто могут быть представлены разными способами, чтобы выразить экономию места.
Например:
Сжатие, выраженное в соотношении. [начальный размер]:[конечный размер]. Соотношение сжатия 2:1 указывает на то, что данные будут сжаты до половины своего исходного размера.
Сжатие, выраженное в виде множителя экономии. Соотношение сжатия 2x указывает на то, что данные будут сжаты до половины своего исходного размера. Это то, что отображается в представлении ёмкости кластера vSAN.
Сжатие, выраженное в процентах от исходного размера. Значение сжатия 50% (или, .50) указывает на то, что данные будут сжаты до половины своего исходного размера.
Примеры между сайтами (для vSAN ESA)
Рабочая нагрузка 1
С примером рабочей нагрузки в 10 000 записей в секунду на рабочую нагрузку vSAN со средним размером записи 8 KB потребуется 80 МБ/с или 640 Мбит/с пропускной способности. Предположим, что данные имеют коэффициент сжатия 2x.
B = 640 Мбит/с * 1.4 * 1.25 * .50 = 560 Мбит/с.
Учитывая требования к сети vSAN, требуемая пропускная способность составляет 560 Мбит/с.
Рабочая нагрузка 2
В другом примере, 30 000 записей в секунду, 8KB записи, потребуется 240 MB/s или 1 920 Мбит/с пропускной способности. Предположим, что данные имеют коэффициент сжатия 2x.
B = 1,920 Мбит/с * 1.4 * 1.25 * .50 = 1,680 Мбит/с или примерно 1,7 Гбит/с.
Требуемая пропускная способность составляет примерно 1,7 Гбит/с.
Рабочие нагрузки редко состоят только из чтений или записей, и обычно включают общее соотношение чтения к записи для каждого варианта использования. Используя общую ситуацию, когда общий профиль I/O требует 100 000 IOPS, из которых 70% являются записью, а 30% чтением, в растянутой конфигурации, IO записи - это то, на что рассчитана пропускная способность межсайтовой связи. С растянутыми кластерами vSAN, трафик чтения по умолчанию обслуживается сайтом, на котором находится ВМ.
Формулы расчета пропускной способности для vSAN OSA
Как и в растянутых кластерах с использованием ESA, трафик репликации от I/O гостевой ВМ в растянутом кластере с использованием OSA является доминирующим типом трафика, который мы должны учитывать при оценке необходимой пропускной способности для трафика межсайтовой связи (ISL). В растянутых кластерах vSAN OSA трафик чтения по умолчанию обслуживается сайтом, на котором размещена ВМ. Требуемая пропускная способность между двумя данными сайтами (B) равна пропускной способности записи (Wb) * множитель данных (md) * множитель ресинхронизации (mr), или:
B = Wb * md * mr
Множитель данных состоит из накладных расходов на трафик метаданных vSAN и различных связанных операций. VMware рекомендует использовать множитель данных 1.4. Множитель ресинхронизации включен для учета событий ресинхронизации. Рекомендуется выделять пропускную способность по верхней границе требуемой пропускной способности для событий ресинхронизации. Для учета трафика ресинхронизации рекомендуются дополнительные 25%.
Планируйте использование vSAN ESA для всех новых кластеров vSAN. Эта архитектура быстрее и эффективнее, чем vSAN OSA, и, зачастую, уменьшает количество хостов, необходимых для того же объема рабочих нагрузок. Формула для vSAN OSA остается актуальной для тех, у кого уже есть установки vSAN OSA.
Требования к пропускной способности между Witness и сайтом данных
В топологии растянутого кластера хост-машина Witness просто хранит компоненты, состоящие из небольшого объема метаданных, которые помогают определить доступность объектов, хранящихся на сайтах с данными. В результате сетевой трафик, отправляемый на сайт для этой машины, довольно мал по сравнению с трафиком между двумя сайтами с данными через ISL.
Одной из наиболее важных переменных является объем данных, хранящихся на каждом сайте. vSAN хранит данные в виде объектов и компонентов. Она определяет, сколько компонентов нужно для данного объекта, и где они должны быть размещены по всему кластеру, чтобы поддерживать устойчивость данных в соответствии с назначенной политикой хранения.
Архитектура vSAN ESA обычно использует больше компонентов, чем OSA. Это следует учитывать при расчете потенциально необходимой пропускной способности для машины Witness.
Обязательно выберите правильный размер хоста vSAN Witness. При развертывании предлагается четыре размера машины (Tiny, Medium, Large и Extra Large), каждый из которых предназначен для размещения разных размеров сред. Посмотрите статью "Deploying a vSAN Witness Appliance" для получения дополнительной информации.
Формулы расчета пропускной способности Witness для vSAN ESA и OSA
Сетевое взаимодействие сайтов с Witnessn состоит исключительно из метаданных, что делает запросы к сетевым ресурсам Witness гораздо более легковесными, что отражается в поддерживаемых минимальных требованиях к пропускной способности и задержке.
Поскольку формула для оценки необходимой пропускной способности Witness основана на количестве компонентов, ее можно использовать для расчета растянутых кластеров, использующих OSA или ESA. Поскольку ESA обычно использует больше компонентов на объект (возможно, в 2-3 раза больше) по сравнению с OSA, следует учитывать большее количество компонентов на ВМ при использовании архитектуры на базе ESA.
Базовая формула
Требуемая пропускная способность между Witness и каждым сайтом равна ~1138 Б x Количество компонентов / 5с
1138 Б x Кол-во компонентов / 5 секунд
Значение 1138 Б происходит от операций, которые выполняются, когда предпочтительный сайт выходит из строя, и второстепенный сайт берет на себя владение всеми компонентами. Когда основной сайт выходит из строя, второстепенный сайт становится лидером. Witness отправляет обновления новому лидеру, после чего новый лидер отвечает Witness, по мере обновления владения. Требование в 1138 Б для каждого компонента происходит из сочетания полезной нагрузки от Witness к резервному агенту, за которым следуют метаданные, указывающие, что предпочтительный сайт не работает. В случае отказа предпочтительного сайта, связь должна быть достаточно хорошей, чтобы позволить изменение владения кластером, а также владение всеми компонентами в течение 5 секунд.
Примеры пропускной способности Witness к сайту (OSA)
Нагрузка 1
Если ВМ состоит из:
3 объектов
Параметр допустимого числа отказов (FTT=1)
Приблизительно 166 ВМ с этой конфигурацией потребовало бы, чтобы Witness содержал 996 компонентов (166 ВМ * 3 компонента/ВМ * 2 (FTT+1) * 1 (Ширина полосы)). Чтобы успешно удовлетворить требования пропускной способности Witness для общего числа 1 000 компонентов на vSAN, можно использовать следующий расчет:
Преобразование байтов (Б) в биты (б), умножьте на 8:
В = 1138 Б * 8 * 1 000 / 5с = 1 820 800 бит в секунду = 1.82 Мбит/с
VMware рекомендует добавить безопасный запас в 10% и округлить вверх.
B + 10% = 1.82 Мбит/с + 182 Кбит/с = 2.00 Мбит/с
Таким образом, с учетом безопасного запаса в 10%, можно утверждать, что для каждых 1 000 компонентов подходит канал 2 Мбит/с.
Нагрузка 2
Если ВМ состоит из:
3 объектов
FTT=1
Stripe с параметром 2
Приблизительно 1 500 ВМ с этой конфигурацией потребовало бы хранения 18 000 компонентов на Witness. Чтобы успешно удовлетворить требования пропускной способности Witness для 18 000 компонентов на vSAN расчет будет таким:
B = 1138 Б * 8 * 18 000 / 5с = 32 774 400 бит в секунду = 32.78 Мбит/с
B + 10% = 32.78 Мбит/с + 3.28 Мбит/с = 36.05 Мбит/с
Используя общее уравнение 2 Мбит/с на каждые 1 000 компонентов, (NumComp/1000) X 2 Мбит/с, можно увидеть, что 18 000 компонентов действительно требует 36 Мбит/с.
Пропускная способность Witness для конфигураций с 2 узлами (OSA)
Пример удаленного сайта 1
Рассмотрим пример 25 ВМ в конфигурации с 2 узлами, каждая с виртуальным диском 1 ТБ, защищенные при FTT=1 и Stripe Width=1. Каждый vmdk будет состоять из 8 компонентов (vmdk и реплика) и 2 компонентов для пространства имен ВМ и swap-файла. Общее количество компонентов составляет 300 (12/ВМx25ВМ). С 300 компонентами, используя правило (300/1000 x 2 Мбит/с), требуется пропускная способность 600 кбит/с.
Пример удаленного сайта 2
Рассмотрим другой пример 100 ВМ на каждом хосте, с таким же ВМ выше, с виртуальным диском 1 ТБ, FTT=1 и SW=1. Общее количество компонентов составляет 2 400. Используя правило (2 400/1000 x 2 Мбит/с), требуется пропускная способность 4.8 Мбит/с.
Вот так и рассчитывается пропускная способность для разных рабочих нагрузок и конфигураций в среде vSAN. Понимание этих метрик и формул поможет в проектировании и развертывании решений vSAN, которые обеспечивают оптимальную производительность и надежность.
Недавно опубликованный компанией VMware технический документ "Troubleshooting TCP Unidirectional Data Transfer Throughput" описывает, как устранить проблемы с пропускной способностью однонаправленной (Unidirectional) передачи данных по протоколу TCP. Решение этих проблем, возникающих на хосте vSphere/ESXi, может привести к улучшению производительности. Документ предназначен для разработчиков, опытных администраторов и специалистов технической поддержки.
Передача данных по протоколу TCP очень распространена в средах vSphere. Примеры включают в себя трафик хранения между хостом VMware ESXi и хранилищем данных NFS или iSCSI, а также различные формы трафика vMotion между хранилищами данных vSphere.
В компании VMware обратили внимание на то, что даже крайне редкие проблемы с TCP могут оказывать несоразмерно большое влияние на общую пропускную способность передачи данных. Например, в некоторых экспериментах с чтением NFS из хранилища данных NFS на ESXi, кажущаяся незначительной потеря пакетов (packet loss) в 0,02% привела к неожиданному снижению пропускной способности чтения NFS на 35%.
В документе описывается методология для выявления общих проблем с TCP, которые часто являются причиной низкой пропускной способности передачи данных. Для этого производится захват сетевого трафика передачи данных в файл трассировки пакетов для офлайн-анализа. Эта трассировка пакетов анализируется на предмет сигнатур общих проблем с TCP, которые могут оказать значительное влияние на пропускную способность передачи данных.
Рассматриваемые проблемы с TCP включают в себя потерю пакетов и их переотправку (retransmission), длительные паузы из-за таймеров TCP, а также проблемы с Bandwidth Delay Product (BDP). Для проведения анализа используется решение Wireshark и описывается профиль для упрощения рабочего процесса анализа. VMware описывает системный подход к выявлению общих проблем с протоколом TCP, оказывающих значительное влияние на пропускную способность канала передачи данных - поэтому инженерам, занимающимся устранением проблем с производительностью сети, рекомендуется включить эту методологию в стандартную часть своих рутинных проверок.
В документе рассмотрены рабочие процессы для устранения проблем, справочные таблицы и шаги, которые помогут вам в этом нелегком деле. Также в документе есть пример создания профиля Wireshark с предустановленными фильтрами отображения и графиками ввода-вывода, чтобы упростить администраторам процедуру анализа.
Скачать whitepaper "Troubleshooting TCP Unidirectional Data Transfer Throughput" можно по этой ссылке.
Прошлой осенью мы писали о версии 6.8 этого продукта, а сегодня посмотрим на нововведения версии 6.11:
Улучшения в обнаружении приложений на основе потоков - теперь пользователи могут загружать дополнительные данные приложений через файлы .csv или из CMDB (например, ServiceNow).
Улучшения траблшутинга VMware HCX в плане идентификации потоков и виртуальных машин с включенным MON (Mobility Optimized Networking).
Улучшения Network Assurance and Verification для поддержки карты сети (Network Map): массовый выбор объектов, сброс группы, перетаскивание и прочие улучшения группировки.
Улучшения в оповещениях SNMP для Problem entity и Entity manager (поля IBM Netcool).
Поддержка Ubuntu 20.04.
Поддержка TLS 1.3.
Возможность изменения имени хоста для узлов Platform и Collector.
Допускается смешивание лицензий на процессор и ядра на одной платформе (универсальное лицензирование).
Обнаружение устройств Fortinet для облегчения интеграции с существующей инфраструктурой безопасности.
В целом, с учетом всех новых возможностей в версии 6.11, VMware Aria Operations for Networks становится все более мощным инструментом для предприятий, которые хотят гарантировать, что их приложения и сеть работают на максимальной производительности.
Более подробная информация о продукте доступна по этой ссылке.
Недавно мы писали о большом релизе облачной архитектуры VMware Cloud Foundation 5.0 (VCF), неотъемлемой частью которой является решение VMware NSX, предназначенное для для виртуализации, агрегации и централизованного управления сетями виртуального датацентра.
Напомним, что VCF - это главное программное комплексное инфраструктурное решение VMware, которое включает в себя компоненты VMware vRealize Suite, VMware vSphere Integrated Containers, VMware Integrated OpenStack, VMware Horizon, NSX и другие, работающие в онпремизной, облачной или гибридной инфраструктуре предприятия под управлением SDDC Manager.
Давайте взглянем на основную новую функциональность NSX:
Если кратко, то вот основные моменты, которые заслуживают внимания:
VMware Cloud Foundation 5.0 с поддержкой NSX 4.1 предлагает усовершенствования платформы, такие как многопользовательский доступ к ресурсам сети и NAPP 4.0.1.1.
Antrea - это проект, совместимый с платформой Kubernetes, который реализует CNI и политики сетей Kubernetes для обеспечения сетевой связности и безопасности рабочих нагрузок в подах (pods). NSX 4.1 представляет новые усовершенствования сетевого взаимодействия и безопасности контейнеров, которые позволяют создавать правила сетевого экрана с комбинацией виртуальных машин и ingress/egress объектов Kubernetes.
Дополнительные службы сетевой маршрутизации уровня 3 становятся доступными для фабрики VMware Cloud Foundation Fabric за счет развертывания маршрутизации между VRF.
Улучшенная онлайн-система диагностики, которая содержит шаги для отладки и устранения конкретных проблем.
Теперь рассмотрим все это подробнее:
Улучшения в области сетевого взаимодействия и безопасности
VMware Container Networking with Antrea предлагает пользователям подписанные образы и бинарные файлы, а также полную корпоративную поддержку для проекта Antrea. VMware Container Networking интегрируется с управляемыми сервисами Kubernetes для дальнейшего улучшения сетевых политик Kubernetes. Также поддерживаются рабочие нагрузки Windows и Linux на Kubernetes в нескольких облаках.
NSX 4.1 имеет новые улучшения в области сетевого взаимодействия и безопасности контейнеров, которые позволяют создавать правила сетевого экрана с комбинацией виртуальных машин и объектов Kubernetes. Кроме того, можно создавать динамические группы на основе тегов NSX и меток Kubernetes. Это улучшает удобство использования и функциональность управления кластерами Antrea с помощью NSX.
Пользователи имеют возможность создания политик сетевого экрана, которые разрешают и/или блокируют трафик между различными виртуальными машинами и модулями Kubernetes в одном правиле. Также вводится новая точка принудительного выполнения, которая включает все эндпоинты, а эффективное применение (apply-to) определяется на основе исходных и целевых групп участников.
Более эффективная защита от кибератак с функциональностью NDR
По мере того как сетевые атаки становятся все более распространенными, возрастает важность использования новейших функций в области безопасности. Развертывание NSX 4.1.0 как части VMware Cloud Foundation 5.0 с новыми возможностями распределенного сетевого экрана в сочетании с новыми функциями NDR улучшает защиту.
Технология обнаружения и реагирования на сетевые угрозы (Network Detection and Response, NDR) позволяет команде безопасности визуализировать цепочки атак, преобразуя огромное количество сетевых данных в несколько "кампаний вторжения". NDR строит такие визуализации, объединяя и сопоставляя события безопасности, такие как обнаруженные вторжения, подозрительные объекты и аномальные сетевые потоки.
Усовершенствованная система онлайн-диагностики
Онлайн-диагностика предлагает предопределенные руководства (runbooks), которые содержат шаги отладки для устранения конкретной проблемы. Руководства по устранению неполадок или runbooks - это серия шагов или процедур, которые следует выполнять для диагностики и устранения проблем в системе или приложении. Они разработаны для структурированного подхода к устранению неполадок и помогают быстро и эффективно решать проблемы.
Эти руководства можно вызвать через API, и они запустят шаги отладки с использованием CLI, API и скриптов. После отладки будут предложены рекомендуемые действия для исправления проблемы, а сгенерированные в ходе отладки артефакты можно загрузить для дальнейшего анализа.
Больше технических ресурсов и руководств для архитектуры VMware Cloud Foundation 5.0 вы можете найти на этой странице.
Архитектура SD-WAN является отличным инструментом для организаций, стремящихся оптимизировать производительность сети и улучшить связность между географически разбросанными локациями. Однако, чтобы получить полную выгоду от SD-WAN, вам необходимы эффективные операционные средства и утилиты для мониторинга. Это становится всё более важным из-за операционных сложностей и проблем с безопасностью, которые возникают по мере того как SaaS-приложения становятся более популярными, а пользователи могут работать из любого места.
VMware SD-WAN имеет мощные возможности, включая технологию VMware Edge Network Intelligence, которые помогут вам идентифицировать и решить проблемы с сетью прежде, чем они станут большими проблемами, использовать ресурсы на полную мощность, и обеспечить качественный пользовательский опыт. В видео ниже показаны некоторые из лучших практик для оперирования и мониторинга сети SD-WAN, с акцентом на мониторинг производительности в реальном времени, мониторинг безопасности и видимость приложений.
Мониторинг производительности в реальном времени
Возможность видеть поведение сети в реальном времени необходима для обеспечения оптимальной производительности сети и своевременного определения и решения потенциальных проблем. Вот некоторые лучшие практики эксплуатации сетей SD-WAN:
Мониторьте состояние сети - VMware SASE Orchestrator предоставляет детальное отображение показателей производительности сети, таких как latency, jitter и потери пакетов для каждого доступного WAN-соединения. В то время как функция Dynamic Multipath Optimization (DMPO) автоматически с миллисекундной задержкой принимает меры по устранению проблем со статусом соединения, она также может мониторить состояние сети и использование пропускной способности в реальном времени, чтобы своевременно выявить и решить любые проблемы с производительностью.
Включите механизмы оповещения - настройте алерты для платформ управления производительностью сети для сетевых параметров для метрик, таких как использование связи, потеря пакетов или отклонения в производительности приложения. Это позволяет получать своевременные уведомления, когда производительность отклоняется от ожидаемых уровней, давая возможность проактивно устранять неполадки. Потоковые метрики, которые предоставляются Webhooks и NetFlow, могут быть проанализированы для формирования почти в реальном времени представления о состоянии сети и производительности. Механизмы по запросу, такие как SNMP и API-вызовы, также могут быть использованы для периодического получения автоматизированных снимков состояния сети.
Используйте AI/ML аналитику - продвинутые платформы сетевой аналитики предоставляют ценные, пригодные для использования инсайты в среде SD-WAN для сетевого окружения на периферии. VMware Edge Network Intelligence использует техники искусственного интеллекта (AI) и машинного обучения (ML) для сбора, анализа и обработки данных о телеметрии сети в реальном времени от устройств на периферии. VMware Edge Network Intelligence позволяет пользователям выполнять мониторинг в реальном времени, обнаружение аномалий, прогнозирование, анализ безопасности, визуализацию, отчетность, интеграцию и автоматизацию. Он постоянно отслеживает сетевой трафик и показатели производительности на периферии, и может обнаруживать аномалии и ненормальные паттерны в поведении сети.
Применяйте непрерывный бенчмаркинг - используйте инструменты для непрерывного мониторинга, чтобы собирать и анализировать данные о производительности на постоянной основе. Это позволяет выявлять паттерны и тенденции, помогая администраторам сети принимать обоснованные решения для планирования емкости и оптимизации. Также фиксируйте ценные исторические базовые показатели производительности, которые могут быть использованы для определения, привели ли изменения в сети к улучшению или ухудшению производительности. Периодические автоматизированные отчеты также могут быть использованы для предоставления ценных исторических инсайтов и точек сравнения.
Хотя все эти механизмы рекомендуется использовать, большинство организаций могут сосредоточиться на некотором их подмножестве, которое наилучшим образом соответствует операционным требованиям и целям производительности. Возможности интеграции любых существующих платформ для логирования и алертинга также могут играть роль в выборе наилучших механизмов оповещения.
Кроме того, интегрированное решение на базе AI/ML, такое как VMware Edge Network Intelligence, может сократить необходимость передачи метрик для анализа стороннему решению и сократить среднее время до устранения проблем (mean-time-to-resolution).
Видимость приложений
Для обеспечения оптимальной производительности и пользовательского опыта критически важно иметь широкую видимость трафика приложений. Здесь можно рассмотреть следующие практики:
Используйте маршрутизацию соединений на базе приложений - осведомленность о приложениях предоставляет дополнительный способ контролировать трафик, соответствовать бизнес-целям организации и более эффективно использовать доступные сетевые каналы. Например, трафик критически важных или чувствительных приложений с более высоким приоритетом может быть настроен на использование более безопасных частных соединений, в то время как приложения с более низким приоритетом могут оставаться на более дешевых интернет-соединениях. VMware SD-WAN позволяет осуществлять маршрутизацию, основанную на приложениях, позволяя вам отдавать приоритет критически важным приложениям по сравнению с менее важным трафиком, и имеет возможность динамически перемещать трафик приложений с одного соединения на другое при необходимости.
Используйте инструменты мониторинга производительности приложений (Application Performance Monitoring, APM) - инструменты APM предоставляют глубокие инсайты о метриках производительности приложений, включая время отклика, пропускную способность и успешность транзакций. Эти инструменты помогают администраторам определять проблемы, связанные с приложениями, и эффективно их устранять.
Отслеживайте пользовательский опыт - реализуйте мониторинг пользовательского опыта end-to-end, включая время отклика и доступность приложений. VMware Edge Network Intelligence обеспечивает видимость пользовательского опыта, позволяя администраторам заблаговременно решать проблемы производительности. VMware Edge Network Intelligence обеспечивает динамический бенчмаркинг для приложений в реальном времени, таких как Zoom, и предупреждает о любых значительных отклонениях от этого бенчмарка. Он также отслеживает связанные индикаторы и предоставляет предложения по устранению основной причины проблем, сокращая среднее время до их устранения и, во многих случаях, позволяя ИТ-команде заранее решить проблему, прежде чем она затронет конечных пользователей.
Мониторинг безопасности
Обеспечение безопасности вашей SD-WAN сети является первоочередной задачей. Поскольку SD-WAN становится частью более крупного интегрированного решения SASE, важно, чтобы команды, отвечающие за транспорт и безопасность, также интегрировали свои операционные политики для обеспечения координации мониторинга, логирования, оповещений и отчетности, их согласованности и совместного управления. Вместо двух отдельных действий единый подход обеспечивает обеим командам полное представление о состоянии сети.
Вот ключевые практики для реализации лучших практик SD-WAN по безопасности:
Использовать безопасные соединения - для защиты конфиденциальности и подлинности трафика, проходящего через сетевой оверлей SD-WAN, следует использовать безопасные протоколы, такие как IPsec. SD-WAN от VMware использует шифрованный оверлей на основе IPsec для обеспечения подлинности и конфиденциальности трафика, использующего сети транспорта WAN. Также поддерживаются туннели на основе IPSec и GRE для подключения к не-SD-WAN назначениям.
Реализовать фаерволы нового поколения (next-generation firewalls, NGFW) - организации имеют возможность использовать интегрированный файрвол на основе приложений, размещенный на периферии, IDS и IPS, а также VMware Cloud Web Security для проверки и фильтрации трафика на предмет потенциальных угроз. Также поддерживается интеграция с решениями NGFW от сторонних производителей. Это обеспечивает многоуровневый подход к безопасности против вредоносных действий, а также детальную видимость для попыток вредоносной активности. Эта видимость критически важна для быстрого анализа угрозы и принятия мер по ее устранению, если это необходимо.
Мониторинг событий безопасности - используйте решения по управлению информацией и событиями безопасности (security information and event management, SIEM) для мониторинга и определения корреляции событий безопасности в сети SD-WAN. Анализируя логи и генерируя предупреждения, администраторы могут быстро реагировать на инциденты безопасности.
События безопасности могут быть записаны и проанализированы через логи файрвола, а также интеграцию с платформами SIEM. Orchestrator SASE от VMware также имеет обновляемый в реальном времени дэшборд обнаруженных угроз, включая информацию о затронутых локациях, распределение угроз и их источники.
На сайте проекта VMware Labs обновился пакет драйверов USB Network Native Driver for ESXi до версии 1.12. Напомним, с помощью данных драйверов пользователи могут подключать различные сетевые устройства к ESXi через USB-порт, например дополнительные сетевые адаптеры хостов, если у них больше не осталось свободных PCI/PCIe-слотов. О прошлой версии этого комплекта драйверов мы рассказывали тут.

 RSS
RSS