Одно из главных преимуществ VMware Cloud Foundation (VCF) 9.1 — гибкость и широкая поддержка уже существующих клиентских сред, что позволяет встретить заказчиков ровно на той точке, где они находятся на пути к частному облаку. Это охватывает самые разные сценарии: от отдельных развёртываний vSphere с VCF Operations до сред с различными комбинациями vSAN, NSX и Aria Automation, вплоть до полнофункционального развёртывания всего стека VCF.
Благодаря возросшей гибкости VCF 9.1 заказчикам, в зависимости от того, какие компоненты и функции развёрнуты в их среде, может потребоваться учитывать конкретную последовательность обновления компонентов, дополнительные операционные процедуры и требования к ресурсам. Всё это способно превратить понимание общего хода обновления в непростую задачу. Раньше для уверенного планирования и проведения обновления приходилось собирать сведения по частям — из продуктовой документации, статей базы знаний и матриц совместимости.
Чтобы упростить процесс обновления, был предложен иной подход: почему бы не начать с того, где заказчик находится сейчас, опираясь на уже развёрнутые продукты и функции, вместо того чтобы требовать от него разбираться во всём множестве вариантов развёртывания и сценариев обновления? Используя эти данные как исходные, можно затем предложить подходящие целевые сценарии, до которых возможно обновиться, и, что особенно важно, сформировать индивидуальный план обновления именно для его среды.
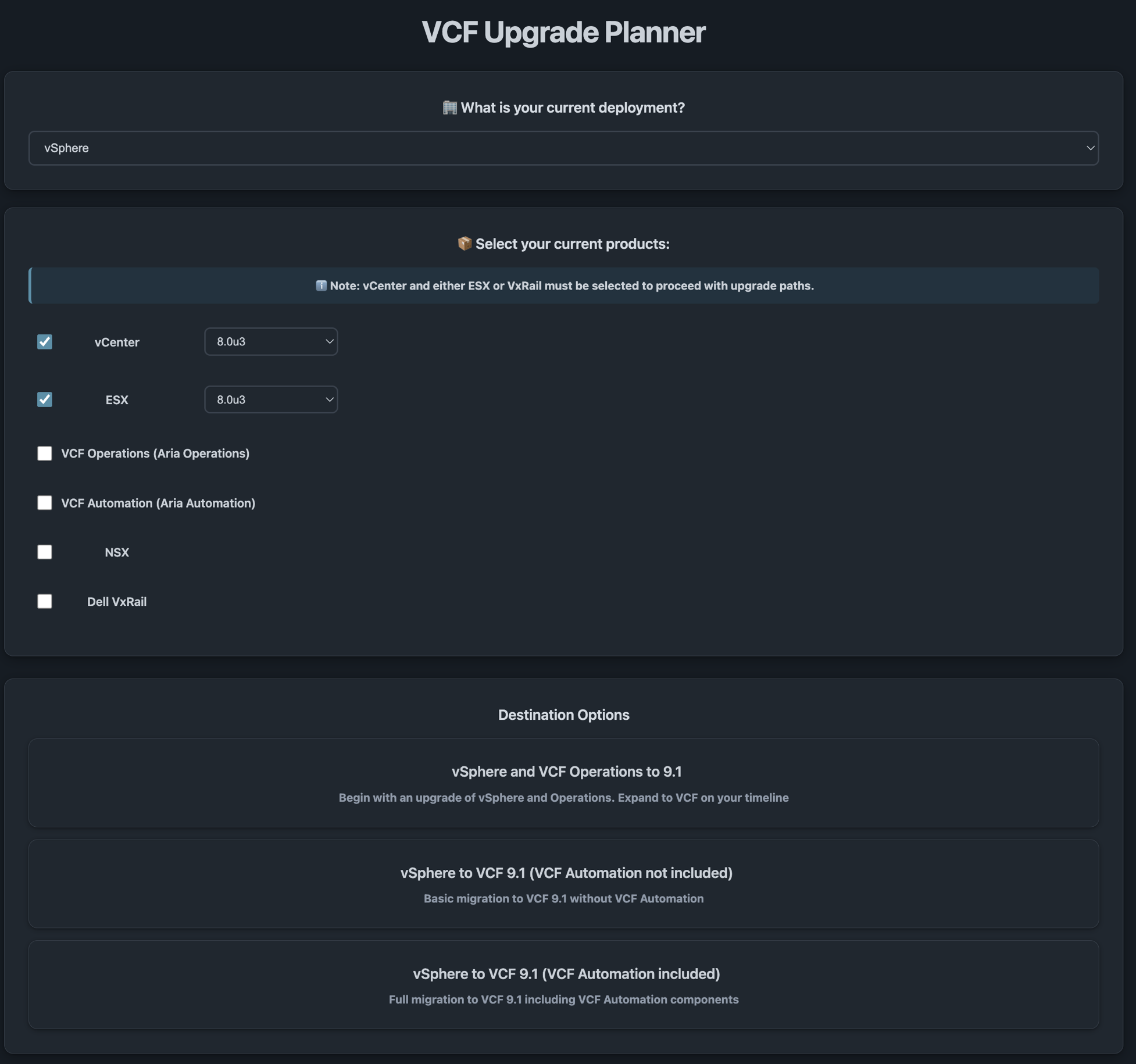
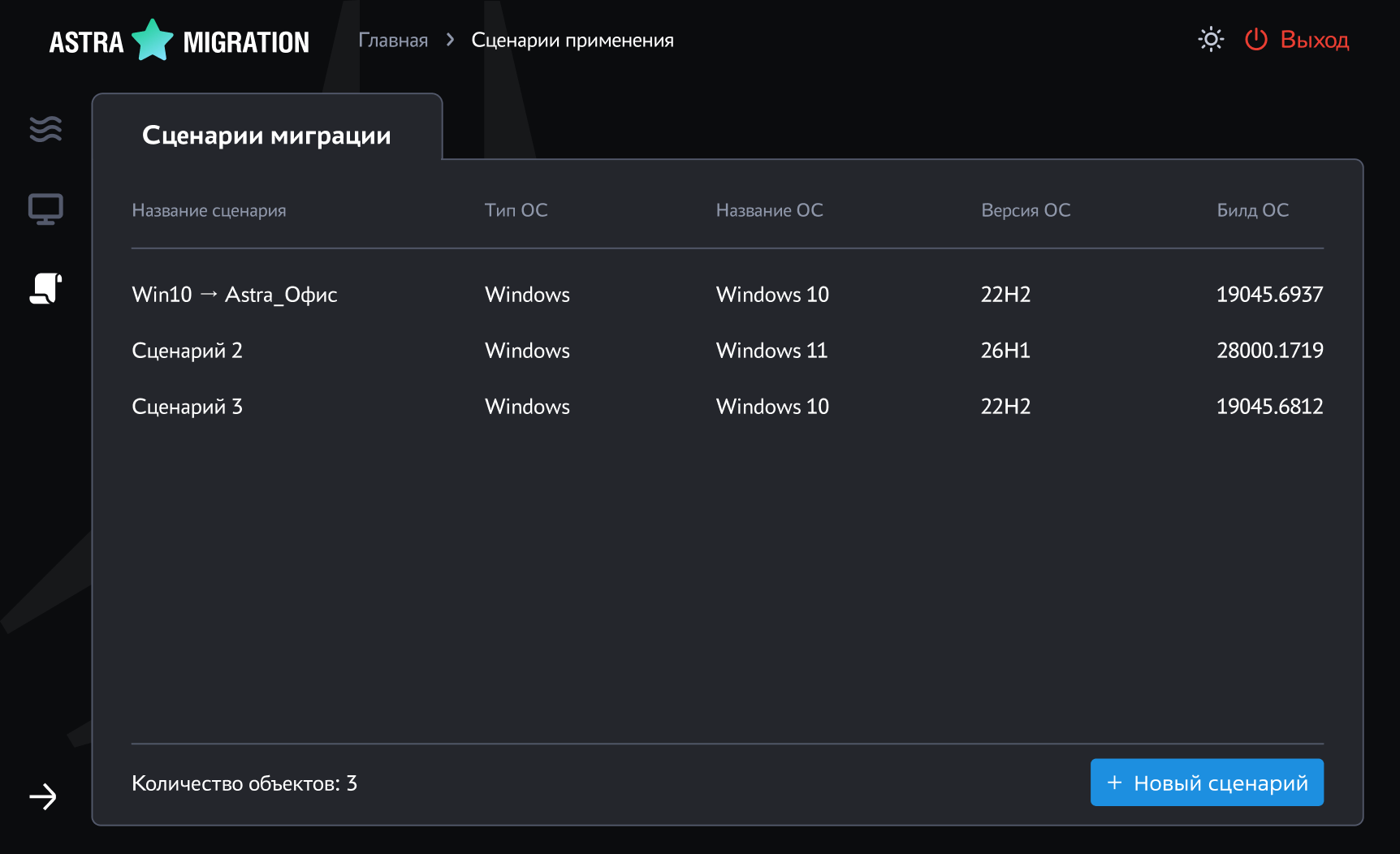
Объявлено о выпуске инструмента планирования обновлений VCF 9.1, который обеспечивает индивидуально подобранный сценарий планирования и помогает заказчикам уверенно пройти путь обновления VCF.
После указания текущего развёртывания — это может быть среда на базе vSphere или VCF — вместе с конкретными версиями, которые используются, пользователю предлагается набор применимых целевых вариантов на выбор.
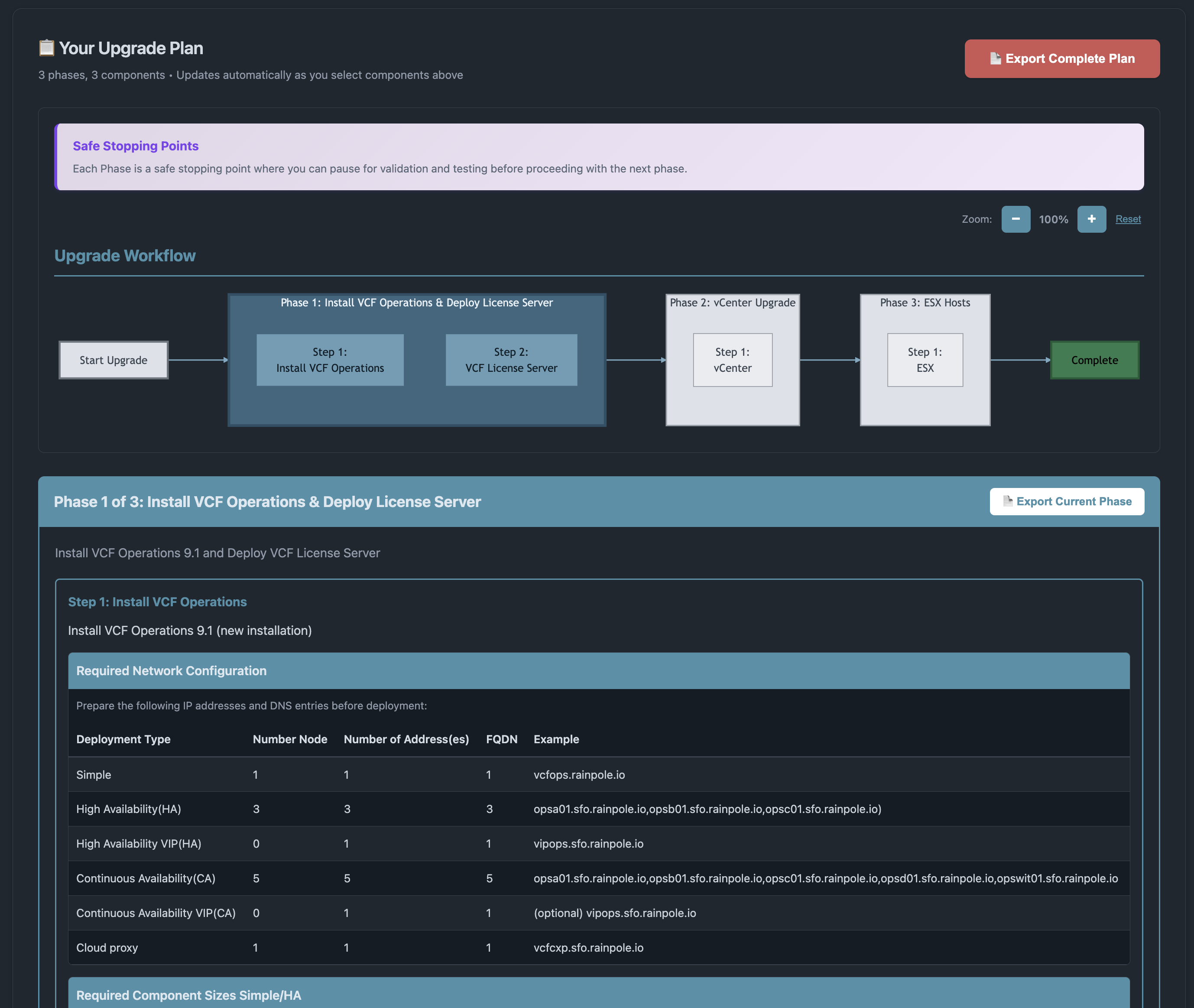
Как только целевой вариант выбран, инструмент планирования обновления VCF формирует исчерпывающий план обновления, который включает:
Общий ход обновления, разбитый на отдельные этапы, что помогает спланировать окна технического обслуживания
Требования к ресурсам и сети
Ключевые соображения и потенциальные подводные камни, которых следует избегать
Соответствующие ссылки на продуктовую документацию VCF
Инструмент планирования обновления VCF можно использовать в интерактивном режиме, а также экспортировать весь ход обновления и (или) отдельные его этапы в PDF для работы офлайн.
Ожидается, что этот инструмент сделает процесс обновления VCF более удобным. При наличии отзывов, замечаний или предложений по улучшению можно создать Issue на GitHub или даже внести собственный вклад в проект.
Один из ключевых сдвигов в развитии VDI-платформы Basis Workplace — постепенный уход от зависимостей: сначала от middleware-слоя при подключении к гипервизорам, теперь от сторонних протоколов доставки. Версия 3.3, вышедшая в конце мая 2026 года, закрепляет эту логику: в состав платформы включён собственный протокол Basis Connect, а интеграция с Basis SDN превращает линейку «Базис» в замкнутый отечественный стек — от гипервизора до сетевого уровня.
Зачем VDI нужен собственный протокол
Протокол доставки — это то, что пользователь ощущает напрямую: задержки, качество картинки, работа веб-камеры и периферии. До версии 3.3 Basis Workplace предлагал два варианта: проприетарные протоколы с отдельными лицензиями (RX, Loudplay) либо open-source-решения, требующие самостоятельной доработки. Оба подхода создают либо финансовую, либо операционную зависимость.
Basis Connect разрабатывался как третий путь — нативный протокол без внешних лицензий, сразу встроенный в платформу. В первом публичном релизе он поддерживает передачу видео и звука, буфер обмена (текст, файлы, папки, изображения), клавиатуру, мышь, принтеры, сканеры и USB-устройства, включая аппаратные токены с сертификатами. Поддержка RX и Loudplay при этом сохраняется.
Замкнутый стек на продуктах «Базис»
Версия 3.2 убрала промежуточный слой vControl при подключении к Basis Dynamix Enterprise и OpenStack. Версия 3.3 идёт дальше: Basis Dynamix Enterprise теперь работает в связке с Basis SDN — собственным решением компании для управления программно-определяемой сетью. Заказчик, использующий эту конфигурацию, получает VDI-инфраструктуру полностью на продуктах одного вендора: серверная виртуализация, сетевой уровень и управление рабочими столами — без иностранных компонентов.
Устойчивость к сбоям в крупных и распределённых инсталляциях
Для организаций с разветвлённой инфраструктурой в версии 3.3 реализован ряд механизмов повышения надёжности. Появился резервный бэкенд с автоматическим переключением при отказе основного. Брокерный слой получил балансировку через Global Server Load Balancing (GSLB). В настройках службы каталогов теперь можно задавать список контроллеров домена — система перебирает их по очереди, если текущий недоступен.
В геораспределённых конфигурациях каждая площадка получает отдельный сертификат, а ключи генерируются прямо в интерфейсе списка площадок. Это упрощает подключение новых ЦОД и разграничивает доверие между узлами. Добавлена также возможность отката сервиса к предыдущей версии — если обновление повело себя непредсказуемо, администратор восстанавливает работоспособное состояние без сложных ручных операций.
Мониторинг, аудит и управление доступом
В версии 3.3 появилась сводная информационная страница (dashboard) с общим состоянием инфраструктуры, обновлены метрики подключений к пулам и суперпулам, а историю загрузки виртуальных машин теперь можно анализировать ретроспективно за любой выбранный период. Ряд операций с ВМ пользователей, ранее выполнявшихся только поодиночке, стал доступен в массовом режиме. Управление сервисами и удаление объектов системы — организаций, проектов, служб каталога, ролей — перенесено в панель управления. Возможности аудита расширились: отчёты теперь охватывают не только действия пользователей и администраторов, но и устройства доступа, за любой выбранный период.
Безопасность и корпоративные интеграции
Список поддерживаемых служб каталогов и SSO-провайдеров расширен: добавлена поддержка Avanpost DS и SSO-аутентификации через Blitz Identity Provider по протоколу OpenID Connect. В логинах для доменов Microsoft Active Directory теперь поддерживается кириллица. Для встраивания в корпоративный контур информационной безопасности реализована передача событий во внешние SIEM-системы в формате CEF.
Усилен и контроль доступа: учётная запись блокируется после нескольких неудачных попыток входа подряд, а пользователи получили возможность отклонять подключение администратора к своей сессии. Настройки буфера обмена для RDP-сессий стали более гибкими.
Периферия и подключение к виртуальным машинам
В версии 3.3 реализован проброс сканеров между клиентом и виртуальным рабочим местом, доработан проброс устройств при работе с протоколом Loudplay. Для отдельных категорий пользователей добавлена возможность подключаться к виртуальным машинам пула напрямую по протоколу RDP — без установки клиентского приложения Basis Workplace, используя любой совместимый RDP-клиент.
«При создании Basis Connect мы ориентировались на запросы заказчиков на нативный протокол передачи данных в составе Basis Workplace. Он позволяет обеспечивать высокое качество работы в виртуальной среде, не требует отдельных лицензий на проприетарные протоколы и упрощает эксплуатацию платформы. Что касается интеграции с Basis SDN, то здесь мы считаем принципиально важным, чтобы возможности нашего программно-определяемого решения были доступны в других продуктах экосистемы. Для заказчиков это означает более удобное управление сетевой частью виртуальной инфраструктуры, более быстрое развёртывание рабочих мест и более высокий уровень контроля над безопасностью и сегментацией среды» — Дмитрий Сорокин, технический директор компании «Базис».
Современные центры обработки данных сталкиваются с беспрецедентными вызовами в области хранения данных: ИТ-командам необходимо обеспечивать производительность, отказоустойчивость и эффективность для постоянно растущих объёмов данных, при этом бюджеты растут значительно медленнее. В прошлом стоимость хранения и памяти со временем снижалась, сглаживая влияние роста данных на бюджет, однако текущий суперцикл памяти ломает эту тенденцию. Методы снижения избыточности данных, уменьшение требований к процессору и памяти, а также новые типы носителей позволяют ИТ-командам нейтрализовать влияние растущих цен на всю инфраструктуру хранения.
Кроме того, ИТ-подразделения испытывают стремительный рост как масштаба приложений, так и их количества в датацентре. Рабочие нагрузки AI требуют огромных объёмов данных, и их распространение вынуждает ИТ осваивать новые интерфейсы хранения — объектное хранилище и высокопроизводительные файловые сервисы. Кроме этого, ИТ необходим более простой способ предоставления командам разработчиков доступа к инфраструктуре хранения. Сегодня администраторы нередко вынуждены работать с тикетными системами для выделения ресурсов: процессы часто выполняются вручную, отнимают много времени и чреваты ошибками. Администраторы хотят предоставлять доступ к ключевым сервисам хранения, не теряя при этом контроля и соответствия требованиям, — чтобы разработчики могли двигаться с темпом, которого требует бизнес.
Но давление на ИТ этим не ограничивается. Угрозы безопасности эволюционируют быстрее, чем когда-либо, а атаки вымогателей вынуждают ИТ-команды переосмыслить фундаментальную устойчивость инфраструктуры хранения. Время восстановления критически важных приложений приобретает всё больший приоритет. Данные должны быть защищены с помощью неизменяемых снимков, зашифрованы при хранении и передаче, а также восстанавливаемы в случае кибератак.
Наконец, ИТ-команды нуждаются в помощи с управлением растущей сложностью датацентра. По мере стремительного увеличения масштабов инфраструктуры ИТ нуждается в том, чтобы поставщики инфраструктуры автоматизировали и упрощали процессы, позволяя администраторам управлять большей инфраструктурой меньшими силами. Инфраструктура хранения должна самоуправляться, самодиагностироваться и предоставлять критическую диагностическую информацию для быстрого устранения проблем.
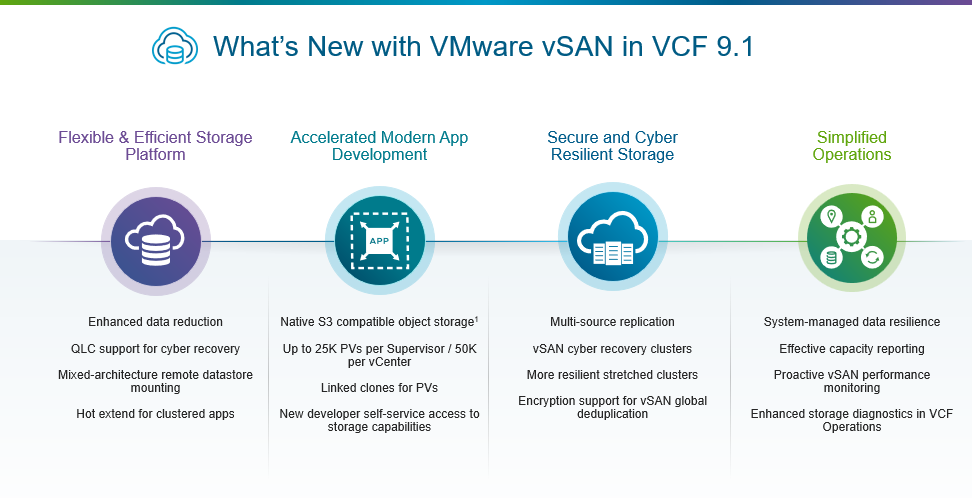
Именно поэтому всё больше клиентов отказываются от устаревших трёхуровневых архитектур в пользу полностью интегрированного частного облака. vSAN является критически важным, встроенным компонентом VMware Cloud Foundation (VCF), обеспечивающим развитие новых и существующих возможностей VCF. В vSAN в составе VCF 9.1 реализованы функции, которые упрощают снижение затрат на инфраструктуру хранения, ускоряют разработку современных приложений, обеспечивают запуск и защиту рабочих нагрузок в частном облаке на базе VCF, а также упрощают операции с хранилищем VCF.
Гибкая и эффективная платформа хранения
Экономическая эффективность всегда была сильной стороной vSAN, а vSAN в VCF 9.1 делает ещё один шаг вперёд благодаря более интеллектуальному сжатию и доступным по цене аппаратным конфигурациям.
Глобальная дедупликация
В VCF 9.1 глобальная дедупликация vSAN переходит в статус общедоступной. Глобальная дедупликация vSAN позволяет сократить используемую ёмкость до 8 раз — это критически важная возможность в условиях быстро растущей стоимости хранения и увеличивающихся сроков поставок оборудования. Дедупликация в vSAN спроектирована с минимальным влиянием на процессор и может применяться ко всем данным в кластере. Это дедупликация с постобработкой: она выполняется в фоновом режиме при низкой нагрузке на процессор. В отличие от традиционных систем хранения, где дедупликация ограничена хранилищем за парой I/O-контроллеров, домен дедупликации vSAN масштабируется вместе с кластером, потенциально обеспечивая более высокую эффективность.
Улучшенное сжатие
В vSAN в составе VCF 9.1 введены новые методы сжатия, обеспечивающие значительно более высокие коэффициенты компрессии. Новый алгоритм одновременно быстр и эффективен: инженерная команда оптимизировала его для баланса между снижением избыточности данных и потреблением ресурсов. VCF 9.1 теперь обеспечивает более высокую степень сжатия при минимальном влиянии на производительность.
Что делает это особенно ценным? Новое сжатие применяется только к новым записям, поэтому оно может внедряться в среду без прерываний и включено по умолчанию.
В сочетании с глобальной дедупликацией это улучшение обеспечивает снижение совокупной стоимости владения на 39% по сравнению с традиционными внешними массивами.
Узлы ReadyNode для киберрезервного копирования с устройствами QLC
Сценарии резервного копирования — аварийное, операционное и киберрезервное — предъявляют к инфраструктуре иные требования, чем основное хранилище: меньше ресурсов процессора и памяти, но более высокая ёмкость. Хотя исторически ИТ при инвестициях в инфраструктуру резервного копирования ориентировались прежде всего на стоимость, изменившийся характер бизнеса потребовал повышенного внимания к производительности и времени восстановления. VCF 9.1 представляет узлы ReadyNode, оптимизированные для киберрезервного копирования с устройствами QLC (Quad-Level Cell), обеспечивающими оптимальный баланс плотности, производительности, выносливости и стоимости для данного сценария.
Эти сертифицированные конфигурации обеспечивают более высокую плотность хранения и консолидацию серверов, снижая стоимость гигабайта для полностью флэш-хранилища при одновременном сокращении потребления электроэнергии, охлаждения и площади стойки по сравнению с решениями на основе HDD. Это практичный ответ на задачу расширения инфраструктуры киберрезервного копирования без увеличения бюджетов.
Расширенная гибкость для кластеров хранения vSAN
Многие пользователи vSAN последовательно развивают свою инфраструктуру хранения, поэтому нередко используют сочетание vSAN Express Storage Architecture (ESA) и Original Storage Architecture (OSA). Клиенты хотят иметь возможность инвестировать в новую инфраструктуру, одновременно эксплуатируя старые кластеры vSAN до конца срока их службы. VCF 9.1 снимает прежние ограничения, позволяя монтировать новые хранилища ESA к кластерам OSA и давая вычислительным кластерам без хранения возможность монтировать как OSA, так и ESA. Клиенты могут расширять инфраструктуру для приложений на кластерах OSA без необходимости инвестировать в технологии предыдущих поколений.
Ещё более значимо следующее: кластеры хранения vSAN теперь могут совместно использоваться через границы vCenter — так же, как традиционные внешние массивы. Это позволяет максимизировать использование ёмкости, консолидировать развёртывания и увеличивать плотность при сохранении низкой совокупной стоимости владения.
Ускорение разработки современных приложений
Современные ИТ-команды поддерживают всё — от традиционных баз данных до контейнерных приложений и современных практик DevOps, — строго соблюдая соглашения об уровне обслуживания. vSAN в VCF 9.1 расширяет гибкость для удовлетворения этих разнообразных требований.
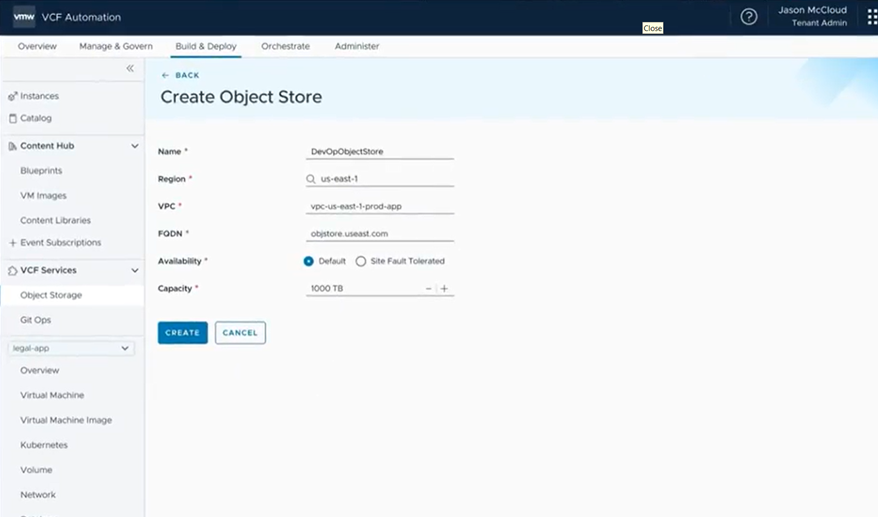
Нативное объектное хранилище S3 в vSAN (Technical Preview)
Впервые vSAN предоставляет нативное объектное хранилище, совместимое с S3, добавляя третий тип хранения — наряду с блочным и файловым — непосредственно в VCF. Данная версия Technical Preview ориентирована на сценарии использования в DevOps и конвейерах CI/CD, где разработчикам необходим быстрый самостоятельный доступ к масштабируемому объектному хранилищу.
Реализация включает мультитенантность, S3-бакеты как услугу и базовые функции безопасности и соответствия требованиям — всё это доступно через VCF Automation. В результате разработчики получают необходимую гибкость, а ИТ сохраняет управление и контроль. При этом решение включено в лицензии VCF, обеспечивая снижение совокупной стоимости владения на 34% по сравнению с автономными локальными продуктами объектного хранения.
Новые возможности самообслуживания разработчиков для работы с хранилищем
Значительное увеличение масштаба для постоянных томов
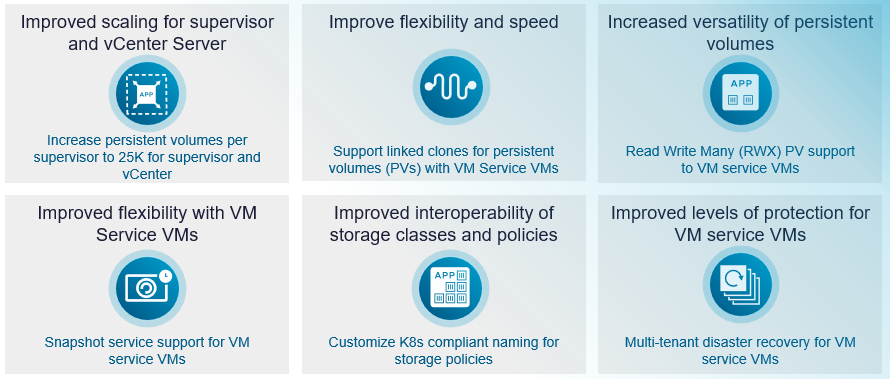
vSAN в VCF 9.1 существенно увеличивает масштаб контейнерных томов для сред VCF. Максимальное количество постоянных томов Read Write Once (RWO) на Supervisor возрастает с 7 500 до 25 000 — рост на 233%. На уровне vCenter лимит увеличивается с 30 000 до 50 000 постоянных томов, что составляет рост на 66%. Расширенные лимиты устраняют ограничения масштабирования для крупных развёртываний Kubernetes и мультитенантных сред.
Эффективное выделение ресурсов с помощью связанных клонов
Полные клоны слишком интенсивно используют хранилище и неэффективны для большинства сценариев. VCF 9.1 вводит поддержку связанных клонов для постоянных томов с First Class Disks, что существенно сокращает время выделения ресурсов и повышает операционную гибкость. Связанные клоны совместно используют общие базовые данные, что делает их идеальными для сред разработки, тестирования и сценариев, где необходимо быстро запустить несколько аналогичных рабочих нагрузок без затрат хранилища на полные клоны.
Поддержка Read Write Many (RWX) для виртуальных машин VM Service
Хотя файловые тома RWX могли использоваться в отдельных сценариях, они были недоступны для рабочих нагрузок — например, vSphere Pods и VM Service VMs — в пространстве имён Supervisor. VCF 9.1 устраняет этот пробел, позволяя виртуальным машинам VM Service монтировать и использовать тома RWX. Это открывает новые возможности для рабочих нагрузок, которым требуется совместный доступ к хранилищу сразу нескольких подов или виртуальных машин.
Единый подход к снимкам и операциям восстановления
Виртуальные машины VM Service теперь могут использовать простые операции восстановления по снимку VM, что приводит их в соответствие с традиционными виртуальными машинами. Такая согласованность упрощает рабочие процессы резервного копирования и восстановления вне зависимости от того, используются ли стандартные ВМ или машины VM Service — единый подход для всех рабочих нагрузок.
Соответствующие требованиям Kubernetes имена политик хранения
VCF 9.1 позволяет администраторам задавать настраиваемые имена политик хранения, совместимые с Kubernetes, при их создании. Это устраняет прежние ограничения именования, усложнявшие сопоставление политик хранения со StorageClass, упрощает согласование политик vSAN с соглашениями Kubernetes и улучшает опыт разработчиков.
Мультитенантное аварийное восстановление для машин VM Service
Облачные среды нередко обслуживают несколько команд или клиентов, каждый из которых требует независимых возможностей защиты и восстановления. VCF 9.1 вводит базовое мультитенантное аварийное восстановление (MTDR) для машин VM Service, предоставляя администраторам провайдеров и арендаторов возможность защищать виртуальные машины на базе Supervisor для сценариев защиты VCF-to-VCF.
Безопасность и киберустойчивость для современных угроз
Программы-вымогатели и утечки данных требуют хранилища, которое не только работает — но и защищает. vSAN в VCF 9.1 расширяет возможности защиты данных для долгосрочного хранения и комплексных сценариев восстановления.
Гибкое расписание снимков
В одном из предыдущих релизов нативные снапшоты vSAN получили возможность неизменяемости, а их производительность при масштабных и глубоких цепочках снапшотов — до 200 на ВМ — всегда оставалась высокой. vSAN в VCF 9.1 вводит гибкое расписание — широко известное как «дед–отец–сын» (GFS), — позволяющее расширить историю снимков для долгосрочного хранения в сценариях киберрезервного копирования.
Вместо того чтобы хранить каждый последовательный снимок, можно удерживать конкретные снимки с течением времени — например, почасовые снимки с сохранением одного за каждые 24 часа. Такой подход эффективно управляет ёмкостью, обеспечивая расширенную временную шкалу защиты, которую требуют нормативные и восстановительные требования.
Репликация из нескольких источников
Ранее репликация в VCF поддерживала только виртуальные машины, работающие с хранилища vSAN, на другое хранилище vSAN. В VCF 9.1 это ограничение снято: теперь можно реплицировать любую ВМ на базе VCF — включая те, что размещены на внешних массивах или других программно-определяемых хранилищах — в хранилище vSAN.
Эта возможность обеспечивает репликацию на основе политик по всей среде VCF, упрощая рабочие процессы восстановления и гарантируя согласованную защиту вне зависимости от текущего расположения ВМ. Репликацию можно совмещать с кластером киберрезервного копирования на базе vSAN для ускорения киберзащиты и восстановления.
Шифрование для глобальной дедупликации vSAN
Безопасность данных теперь распространяется на глобальную дедупликацию vSAN, гарантируя, что данные получают выгоду от экономии места без ущерба для защиты. Независимо от того, хранятся данные или передаются, они защищены шифрованием, валидированным по стандарту FIPS 140-3, от несанкционированного доступа.
Расширенные возможности растянутых кластеров
Растянутые кластеры уже давно обеспечивают устойчивость на уровне площадки для развёртываний vSAN. VCF 9.1 вводит два критически важных улучшения, повышающих операционную гибкость.
Во-первых, теперь можно перевести целый сайт в режим обслуживания с помощью управляемого процесса с расширенными предварительными проверками, обеспечивающими плавный вход и выход без прерывания сервиса. Во-вторых, в сценариях множественных отказов — когда один сайт находится в режиме обслуживания и одновременно происходит отказ второго сайта и свидетеля — теперь можно самостоятельно восстановить работоспособный сайт без обращения в глобальную службу поддержки. Встроенные предварительные проверки направляют процесс восстановления, сокращая время простоя и возвращая контроль в руки администраторов.
Упрощённые операции, масштабируемые с ростом инфраструктуры
Лучшая инфраструктура — та, о которой не нужно думать. VCF 9.1 реализует автоматизацию и интеллект, снижающие операционную нагрузку на ИТ-команды.
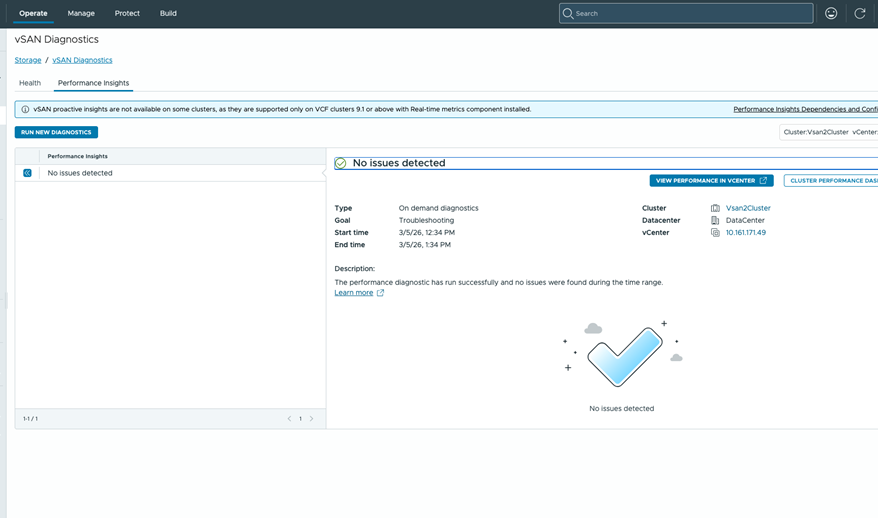
Проактивный мониторинг производительности vSAN
Диагностика проблем производительности в программно-определяемой инфраструктуре может быть непростой задачей. Где узкое место — в хранилище, вычислительных ресурсах или сети? VCF 9.1 применяет проактивный подход: постоянный мониторинг шаблонов производительности хранилища, установка базовых линий и оповещение об отклонениях.
При отклонении производительности от базовой линии VCF Operations использует расширенную аналитику для выявления корневых причин и предоставляет конкретные шаги по устранению — всё это доступно прямо в интерфейсе Performance Service. Алгоритмический подход к диагностике коррелирует точки данных, выявляет закономерности и предоставляет инсайты, поиск которых вручную занял бы часы.
Автоматизированное управление политиками хранения
vSAN в VCF 9.1 автоматически применяет наивысший уровень отказоустойчивости и оптимальный erasure coding с учётом размера кластера. Это устраняет неопределённость при настройке политик хранения и гарантирует максимальную устойчивость и эффективность без ручной настройки. В сочетании с улучшенными отчётами об эффективной ёмкости обеспечивается более чёткая видимость реальной используемой ёмкости, что делает планирование ёмкости более точным и понятным.
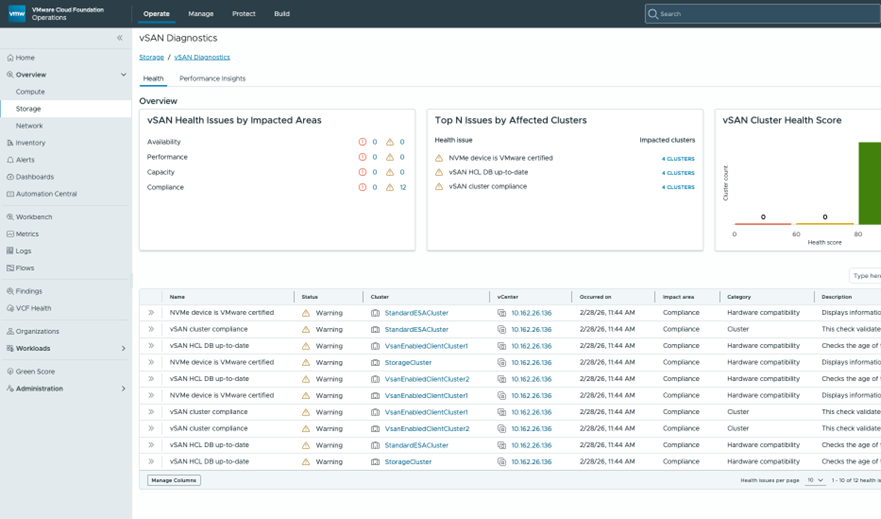
Расширенная диагностика хранилища vSAN
В одном из предыдущих выпусков в VCF Operations была представлена панель хранилища с важными метриками: оценками состояния, использованной ёмкостью и другими показателями. В vSAN в составе VCF 9.1 VCF Operations предоставит значительно расширенный набор информации и возможность принимать меры по диагностическим проблемам vSAN непосредственно из консоли VCF. Администраторам больше не придётся вручную перемещаться по интерфейсу для выявления корневых причин низких оценок состояния или определения способов устранения проблем — количество необходимых кликов сокращается до 60%.
vSAN в VCF 9.1 представляет собой значительный шаг вперёд в направлении более эффективного, гибкого, безопасного и интеллектуального хранилища для частного облака. Независимо от того, оптимизируете ли вы совокупную стоимость владения, поддерживаете разнообразные рабочие нагрузки, укрепляете устойчивость или упрощаете операции, этот релиз предоставляет практические возможности, решающие реальные ИТ-задачи.
Недавно компания VMware объявила о доступности для загрузки новых версий настольных платформ виртуализации - VMware Workstation 26H1 и VMware Fusion 26H1. Эти обновления продолжают эволюцию наших настольных гипервизоров, обеспечивая критически важные архитектурные переходы для пользователей Windows, расширенную видимость для управления виртуальными машинами и расширенную поддержку новейшего оборудования и операционных систем.
Новый релиз развивает фундаментальные изменения, представленные в предыдущем обновлении 25H2, где был осуществлен переход на календарное версионирование и представлены мощные инструменты автоматизации, такие как dictTool. В 2026 году сохраняется фокус на том, чтобы среда виртуализации оставалась современной, эффективной и соответствующей отраслевым стандартам.
Современное архитектурное соответствие: 64-битная VMware Workstation Pro
С релизом 26H1 VMware Workstation Pro для Windows теперь является 64-битным приложением. Этот переход гарантирует, что большинство бинарных файлов, библиотек и компонентов установщика выполняются как 64-битные процессы. Приводя гипервизор в соответствие с современными аппаратными и программными стандартами, VMware предоставляет более стабильную и производительную основу для самых требовательных виртуализированных рабочих нагрузок.
Расширенная видимость и упрощенное управление
Управление сложной библиотекой виртуальных машин требует быстрого доступа к информации. Развивая организационные улучшения, появившиеся в последних релизах, релиз 26H1 представляет новые функции «качества жизни», которые помогут вам поддерживать порядок:
Метки времени жизненного цикла (VMware Workstation и Fusion): мгновенно идентифицируйте виртуальные машины по времени их создания и последнего включения. Это упрощает отслеживание долгосрочных проектов и очистку временных тестовых сред.
Интегрированные заметки к папкам (VMware Workstation): заметки виртуальных машин перенесли непосредственно во вкладки папок в VMware Workstation. Это обеспечивает немедленный доступ к критически важным метаданным и документации без необходимости переходить через отдельные меню настроек.
Повышенная ясность Credential Manager (VMware Workstation): формат сохраненных учетных данных для зашифрованных виртуальных машин и удаленных серверов был модернизирован для VMware Workstation. Это помогает обеспечить простую идентификацию записей, относящихся к VMware, во встроенном менеджере учетных данных вашей хостовой платформы.
Расширение удаленного подключения к серверам ESXi ARM
По мере диверсификации сред разработки кросс-архитектурное подключение становится необходимым. Этот релиз добавляет возможность подключения к удаленным ARM-based ESXi, позволяя пользователям управлять виртуальными машинами на удаленных ARM-серверах напрямую из VMware Workstation или Fusion на любой поддерживаемой платформе. На данный момент ESXi ARM Server находится в режиме Tech Preview.
Поддержка ведущих ОС и оборудования
Поддержание актуальности с новейшими платформами является одной из главных целей для сообщества. Workstation и Fusion 26H1 продолжают лидировать на рынке, поддерживая новейшие гостевые и хостовые операционные системы:
Поддержка новых гостевых ОС (VMware Workstation и Fusion):
Ubuntu 26.04 LTS
Fedora 43 и 44
SUSE Linux Enterprise 16 и openSUSE 16.0
FreeBSD 15.0
Поддержка новых хостовых ОС (VMware Workstation):
Ubuntu 26.04 LTS
Fedora 43 и 44
SUSE Linux Enterprise 16 и openSUSE 16.0
Стабильность и надежность
В дополнение к новым функциям этот релиз включает несколько функциональных улучшений и улучшений безопасности, которые поддерживают стабильную и защищенную работу среды виртуализации. Также устранили проблемы пользовательского интерфейса, чтобы все кнопки Help и ссылки корректно вели на портал Broadcom Technical Documentation для более быстрого доступа к руководствам.
Ресурсы для клиентов и доступность
VMware стремится предоставлять понятную и доступную информацию для глобальной пользовательской базы. Customer FAQ остается единым надежным источником актуальных рекомендаций по лицензированию, конфигурации и вопросам, поднятым сообществом.
Workstation Pro и Fusion Pro 26H1 доступны уже сегодня через Broadcom Support Portal. Напоминаем, что оба продукта остаются бесплатными для коммерческого, образовательного и личного использования, предоставляя каждому профессионалу доступ к ведущему настольному гипервизору в отрасли.
Благодаря стратегии календарного версионирования и фокусу на архитектурной модернизации, VMware Workstation и Fusion остаются отраслевым стандартом настольной виртуализации. Компания планирует продолжать совершенствовать эти продукты и сопутствующие ресурсы с каждым релизом, предоставляя инструменты, необходимые сегодня, и уверенность для масштабирования виртуальной среды завтра.
Вышла новая версия VMware Cloud Foundation 9.1, об этом вы уже знаете. В этой статье рассматриваются многие новые возможности и улучшения платформы vSphere в составе пакета VCF 9.1. Также рекомендуем ознакомиться с примечаниями к выпуску и уведомлениями о поддержке продуктов для получения важной информации.
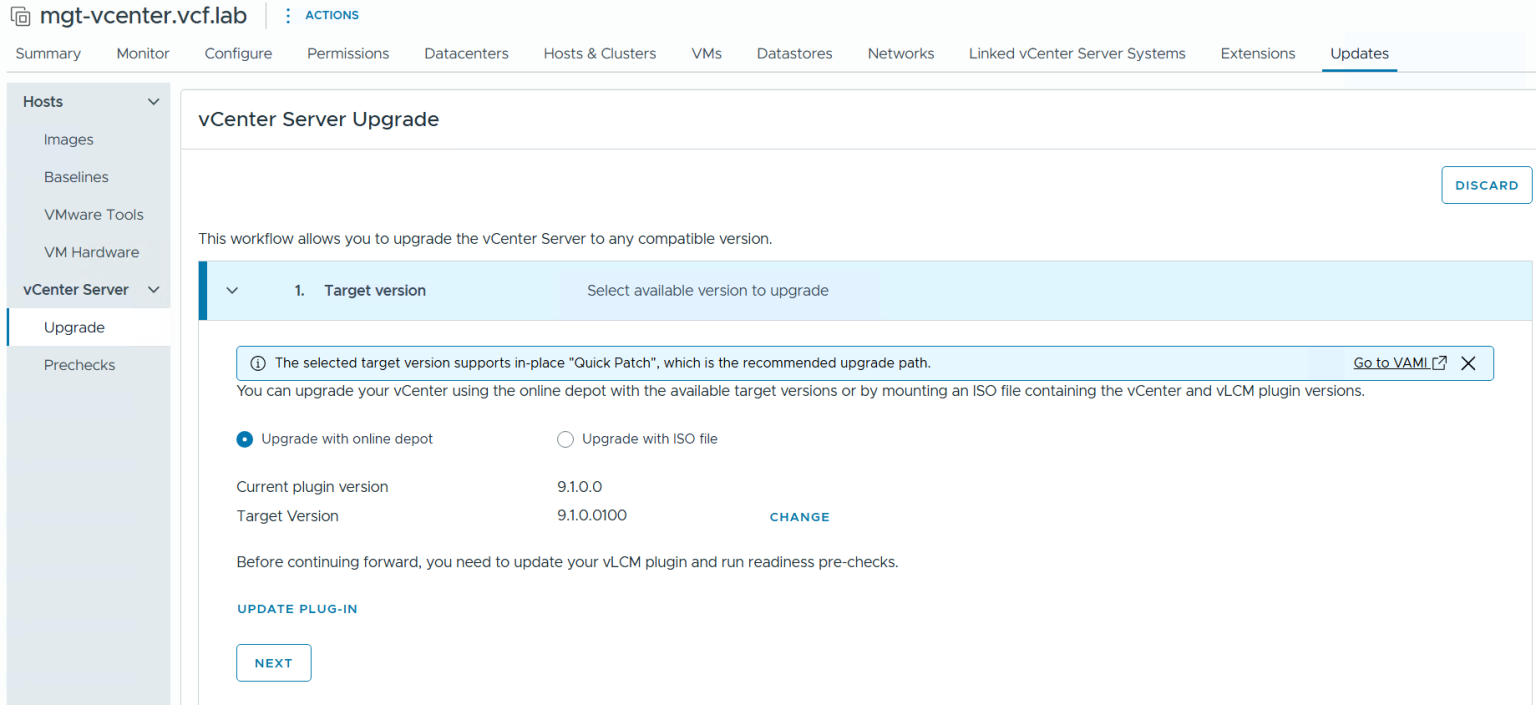
Быстрое развёртывание патчей безопасности vCenter
Функция быстрого патчинга vCenter (vCenter Quick Patch) обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлению. Механизм Quick Patch ориентирован на быстрое устранение критических уязвимостей безопасности в vCenter.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, изменился ли соответствующий сервис или компонент. Quick Patch затрагивает только те RPM или бинарные файлы, которые действительно изменились в составе патча. Такой подход кардинально сокращает общее окно обслуживания и снижает время простоя vCenter до менее чем 1 минуты, а в ряде случаев сводит его к нулю.
Благодаря vCenter Quick Patch критически важные обновления безопасности можно применять без прерывания рабочих процессов: развёртывание виртуальных машин и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются. Меньше времени уходит на планирование окон обслуживания — больше на поддержание актуальности патчей.
Помимо Quick Patch, в версии 9.1 улучшены и другие аспекты обслуживания vCenter.
Обновление vCenter с сокращённым временем простоя (Reduced Downtime Upgrade, RDU) теперь поддерживает работу с онлайн-репозиторием. Это упрощает использование метода RDU для подключённых к интернету экземпляров vCenter. Автономный метод с использованием примонтированного ISO по-прежнему доступен. Последующие патчи, обновления и апгрейды vCenter 9.1.x и более поздних версий также можно применять через RDU с онлайн-репозиторием, что значительно упрощает эксплуатацию для подключённых инсталляций.
В vCenter появился новый API, с помощью которого сторонние компоненты могут получать уведомления о планируемом или текущем техническом обслуживании. Обратный прокси Envoy будет отдавать заголовок 503 с информацией о том, что vCenter находится на обслуживании, и указанием ожидаемого времени завершения.
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом RDU версия аппаратного обеспечения виртуальной машины vCenter автоматически повышается с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter. При выполнении in-place обновления (с 9.0.x до 9.1.0) версию аппаратного обеспечения ВМ vCenter потребуется обновить вручную — эта процедура требует выключения ВМ vCenter.
Изменение ресурсов vCenter через единый API
В VCF 9.1 появился новый API, упрощающий масштабирование ресурсов vCenter. Для увеличения объёма вычислительных ресурсов и дискового пространства vCenter достаточно одного вызова API и перезагрузки.
Вызов API можно инициировать из Developer Center API Explorer в интерфейсе vCenter. API называется deployment/size и использует метод PATCH.
Упрощение обслуживания хостов ESX
Образы, создаваемые и управляемые через vSphere Lifecycle Manager, теперь включают контрольную сумму SHA256. Она позволяет проверять целостность образов при экспорте и импорте в другие экземпляры vCenter: администратор может сравнить контрольные суммы на источнике и целевом сервере. Речь идёт о контрольной сумме именно определения образа, а не VIB-файлов ESX.
В предыдущих версиях vSphere Lifecycle Manager проверял актуальность прошивок и драйверов устройств по HCL только при наличии стороннего Hardware Support Manager (HSM). Начиная с версии 9.1 вывод информации о текущих драйверах и прошивках устройств, а также их валидация по HCL выполняются для кластеров vSAN даже в отсутствие HSM. Некоторые устройства могут не сообщать данные о прошивке без соответствующего HSM. Это обеспечивает базовый уровень проверки устройств в кластере vSAN.
Подготовка кластеров vSphere с образом и конфигурацией
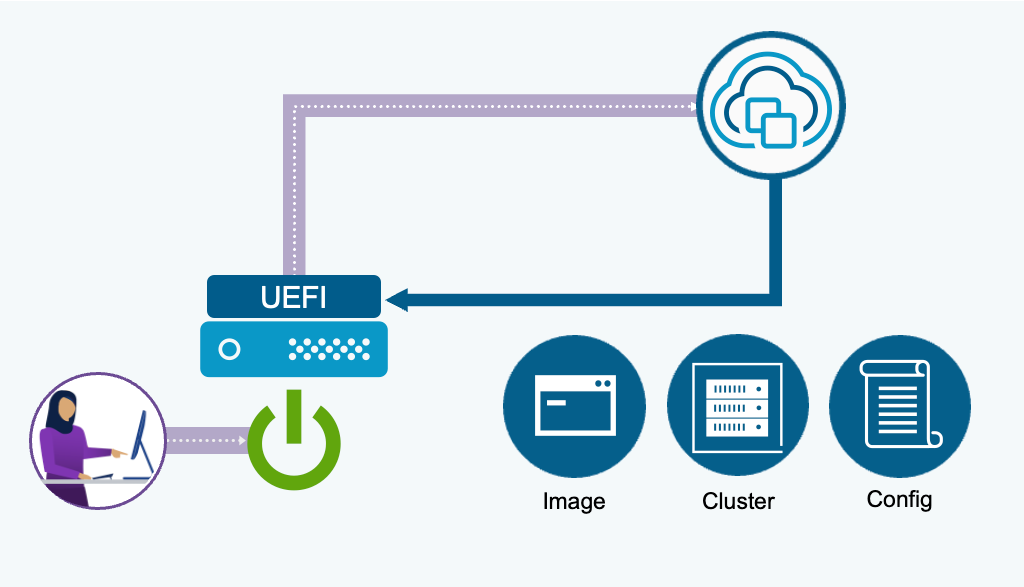
Zero Touch Provisioning (ZTP) строится на базе существующей инфраструктуры vSphere Auto-Deploy. Механизм задействует современные протоколы загрузки — UEFI HTTP/S Boot — и поддерживает актуальные серверные конфигурации, включая Secure Boot и TPM. ZTP не требует внешнего TFTP-сервера: достаточно настроить URL загрузки UEFI, указывающий на vCenter, и загрузить хост по сети. Если UEFI не поддерживает настройку статического IP для загрузки, потребуется DHCP-сервер.
Образ ESX и конфигурация определяются расположением кластера, выбранным при настройке правила развёртывания. Если для целевого кластера не настроен профиль конфигурации vSphere (VCP), хост загрузится и присоединится к кластеру с конфигурацией по умолчанию.
Быстрое и менее затратное обновление кластеров vSphere
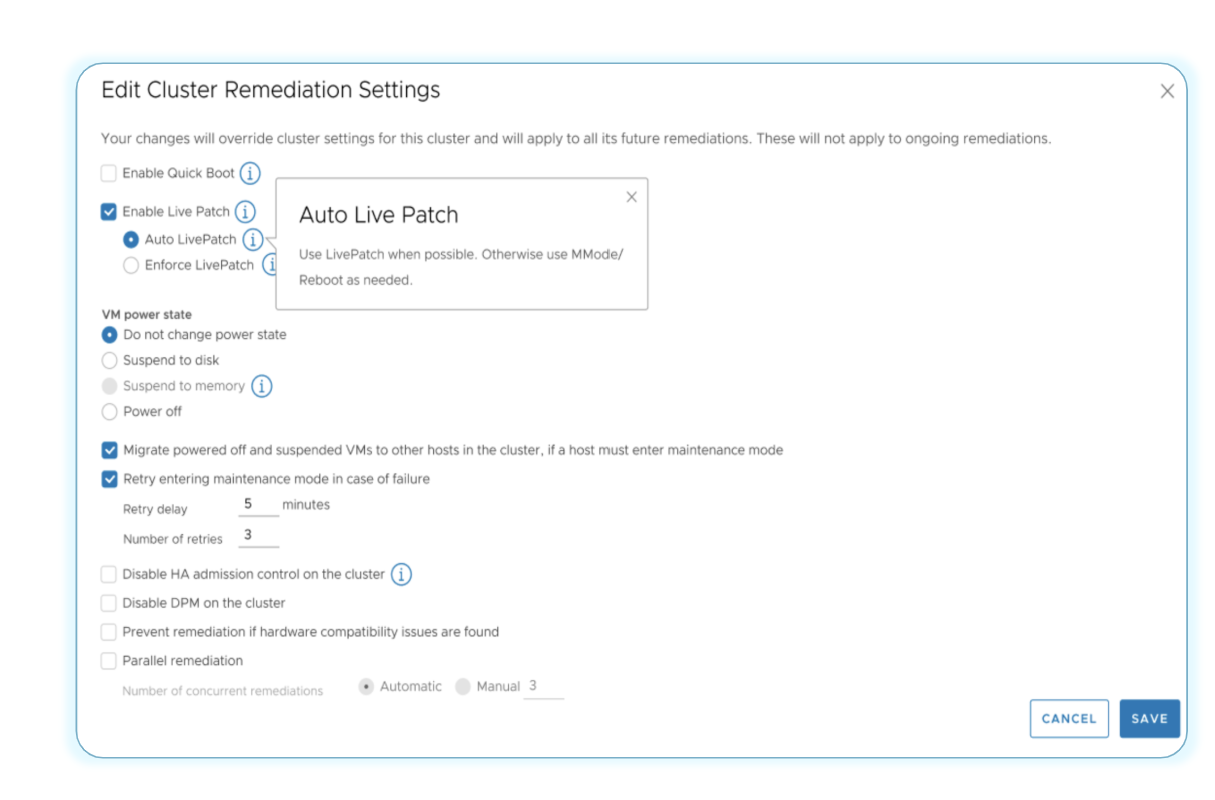
ESX Live Patch включён по умолчанию для всех кластеров и автоматически применяется, если устанавливаемый патч поддерживает этот режим. Если патч несовместим с Live Patch, по умолчанию используется стандартный метод с переходом в режим обслуживания и перезагрузкой хоста.
Параметр можно изменить, включив принудительное применение Live Patch. В этом режиме исправление будет выполняться только через Live Patch, а для хостов, требующих режима обслуживания, процесс патчинга будет заблокирован. Настройки можно задать как на уровне кластера, так и на уровне vCenter — параметры vCenter применяются ко всем кластерам, если они не переопределены на уровне кластера.
ESX Live Patch теперь поддерживает серверы с включённым TPM. Пользователям не нужно отключать TPM или отказываться от Live Patch при использовании ESX 9.1 и более поздних версий.
Поддержка Live Patch расширена: охватывает больше компонентов vmkernel и обеспечивает более высокую производительность при патчинге ядра. Теперь механизм поддерживает дополнительные пользовательские демоны и сервисы, включая демоны vSAN, базовые демоны хранилища и соответствующие библиотеки.
Расширение интеграции с механизмом Desired State Configuration
Профили конфигурации vSphere (vSphere Configuration Profiles) обеспечивают соответствие изменений конфигурации и операций по устранению отклонений требованиям vSAN. Политики режима обслуживания vSAN и политики доступности объектов соблюдаются при исправлении кластеров vSAN. Расширенная конфигурация vSAN может применяться на уровне всего кластера.
Профили конфигурации vSphere используются для настройки memory tiering на хостах кластера. Устройства NVMe могут быть выделены для memory tiering; дополнительное устройство NVMe опционально может быть задействовано в качестве зеркального устройства для программного зеркалирования.
Профили конфигурации vSphere обеспечивают конфигурацию хостов при установке через Zero Touch Provisioning, а также поддерживают начальную настройку vSphere Distributed Switch в процессе развёртывания хоста.
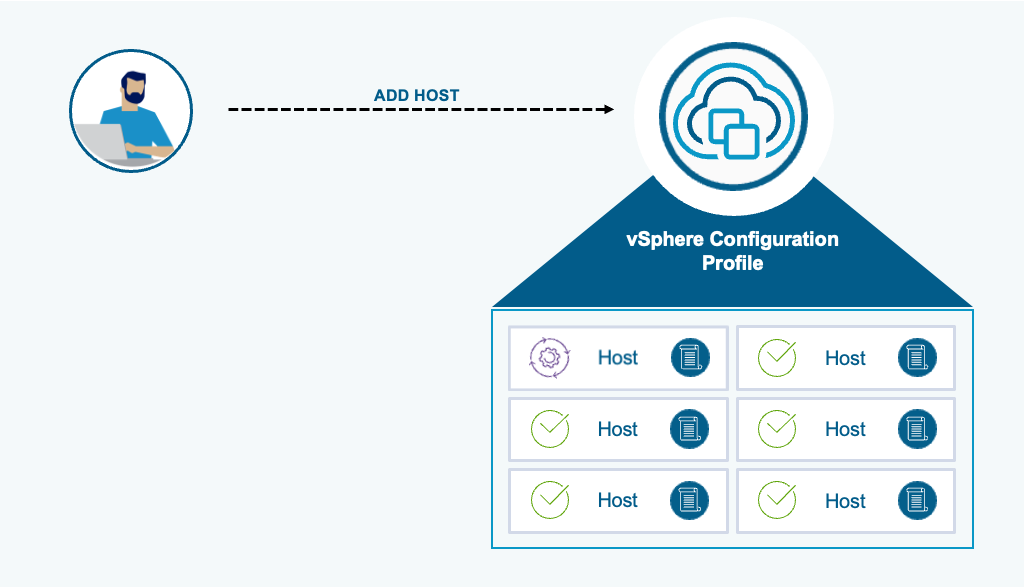
Оптимизация Desired State Configuration
При добавлении новых хостов в кластеры с включёнными профилями конфигурации vSphere желаемая конфигурация автоматически применяется к входящему хосту. Специфичные для хоста атрибуты (например, IP-адреса) извлекаются из него автоматически и добавляются в соответствующий раздел профиля кластера.
Сертификат TLS для vCenter теперь обновляется автоматически за 5 дней до истечения срока действия. Сертификат ESX обновляется за 30 дней до истечения. Порог для ESX настраивается через расширенные параметры vCenter Server с помощью параметра vpxd.certmgmt.certs.autoRenewThreshold.
В обоих случаях автоматическое обновление выполняется для сертификатов, управляемых VMCA. Сертификаты, выданные внешними центрами сертификации, не обновляются автоматически — ответственность за их управление лежит на администраторе.
Если до истечения срока действия корневого сертификата VMCA остаётся менее 1 года, в процессе обновления vCenter автоматически обновляются корневой сертификат VMCA, а также дочерние сертификаты решений. Сертификаты TLS для vCenter и ESX в рамках этой операции не обновляются.
Масштабируемость, стабильность и производительность
В крупных и сверхкрупных развёртываниях vCenter ожидается увеличение числа операций в минуту до 25%. Это касается множества операций с виртуальными машинами и хостами, а также изменений конфигурации. Масштаб одновременных операций резервного копирования ВМ увеличен до 500–1000 в зависимости от размера vCenter. Операции резервного копирования ВМ теперь защищены от бесконтрольного потребления всех ресурсов vCenter. Передача файлов использует выделенные потоки, что исключает влияние на другие операции vCenter. Расширенные параметры vCenter для операций резервного копирования позволяют настраивать масштабируемость под конкретную среду.
Новый API мониторинга утилизации vCenter позволяет отслеживать активные подключения и сравнивать их с максимально допустимыми лимитами. Появилась возможность отслеживать количество запросов ко всем сервисам vCenter и контролировать, чтобы их интенсивность не превышала допустимых порогов.
Введены два новых оповещения — High Session Count и Increased Request Load — для сигнализации о нагрузке на один или несколько сервисов vCenter. Оповещение High Session Count срабатывает, когда число сессий приближается к лимиту (по умолчанию 3000); в сообщении указываются IP-адреса и имена пяти пользователей, создавших наибольшую нагрузку с более чем 100 сессиями каждый. При изменении состава топ-5 пользователей генерируется новое событие. В список могут попасть любые пользователи, включая сервисные аккаунты. Оповещение Increased Request Load срабатывает при достижении лимита активных запросов к конечной точке сервиса (по умолчанию 1024 для большинства конечных точек) и содержит информацию о затронутых сервисах и конечных точках.
Гибкая настройка виртуальных машин
Для поддержки миграции с VMware Cloud Director (vCD) на VMware Cloud Foundation Automation (VCFA) гостевой API настройки ОС (Guest OS Customization, GOSC) дополнен следующими возможностями, обеспечивающими паритет с функциями vCD:
Установка пароля учётной записи root в Linux
Сброс пароля учётной записи root в Linux
Сброс паролей учётных записей группы администраторов в Windows
Выполнение скриптов настройки в Windows
Теперь администраторы могут явно отключить IPv4 и настроить сеть только для IPv6 в гостевой настройке — как через интерфейс, так и через API. Это устраняет прежнее требование сохранять параллельную конфигурацию IPv4.
Появилась возможность выполнять настройку только сетевых параметров виртуальной машины — для выключенных и для работающих ВМ, что позволяет применять изменения сетевой конфигурации в реальном времени.
Сохранение производительности рабочих нагрузок во время обслуживания хоста
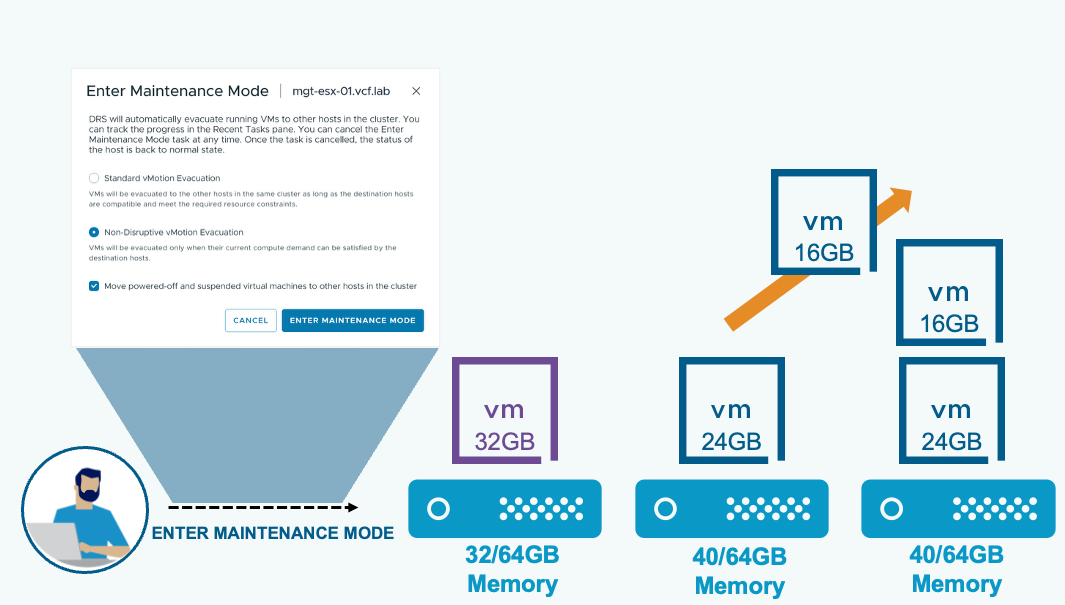
DRS-оптимизированная эвакуация через vMotion (DRS Optimized vMotion Evacuation) гарантирует, что виртуальные машины будут мигрированы с хоста только при наличии достаточной вычислительной ёмкости для их размещения без конкуренции за ресурсы. DRS может предварительно перебалансировать оставшиеся хосты, чтобы создать свободную ёмкость для эвакуируемых ВМ.
При переводе хоста в режим обслуживания для кластеров с включённым DRS доступны два варианта:
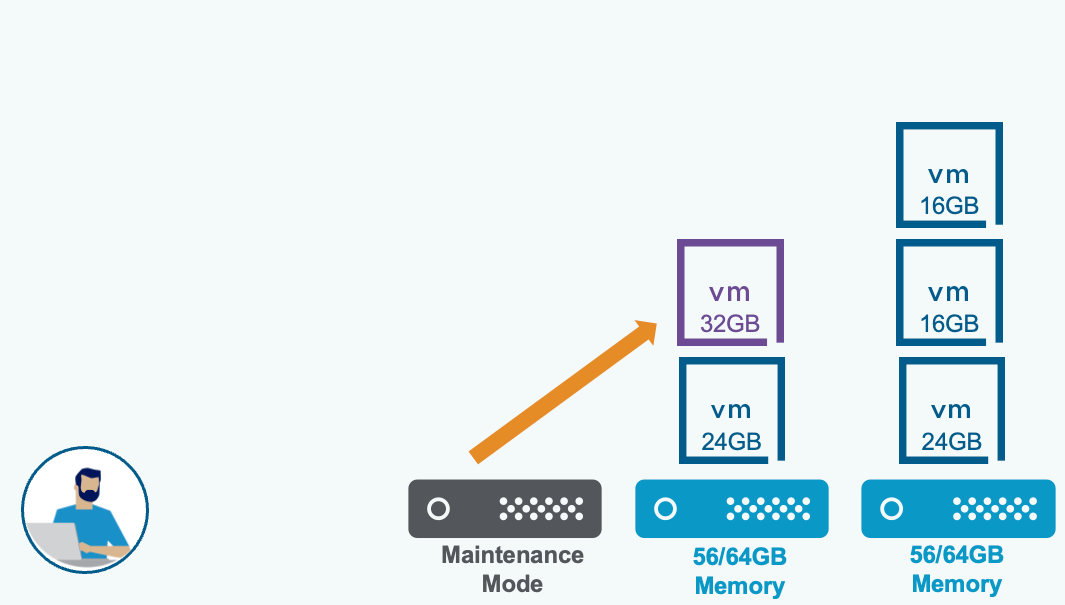
Стандартная эвакуация через vMotion: виртуальные машины переносятся на другие хосты в том же кластере при условии совместимости целевых хостов и соответствия требованиям по ресурсам.
Нон-деструктивная эвакуация через vMotion: виртуальные машины переносятся только в том случае, если их текущие вычислительные потребности могут быть удовлетворены целевыми хостами.
Примечание: термин «нон-деструктивная» применительно к новому режиму эвакуации не означает, что стандартная эвакуация как-либо вредит рабочим нагрузкам. Он лишь указывает на то, что при этом режиме эвакуация выполняется только без создания конкуренции за ресурсы на целевых хостах.
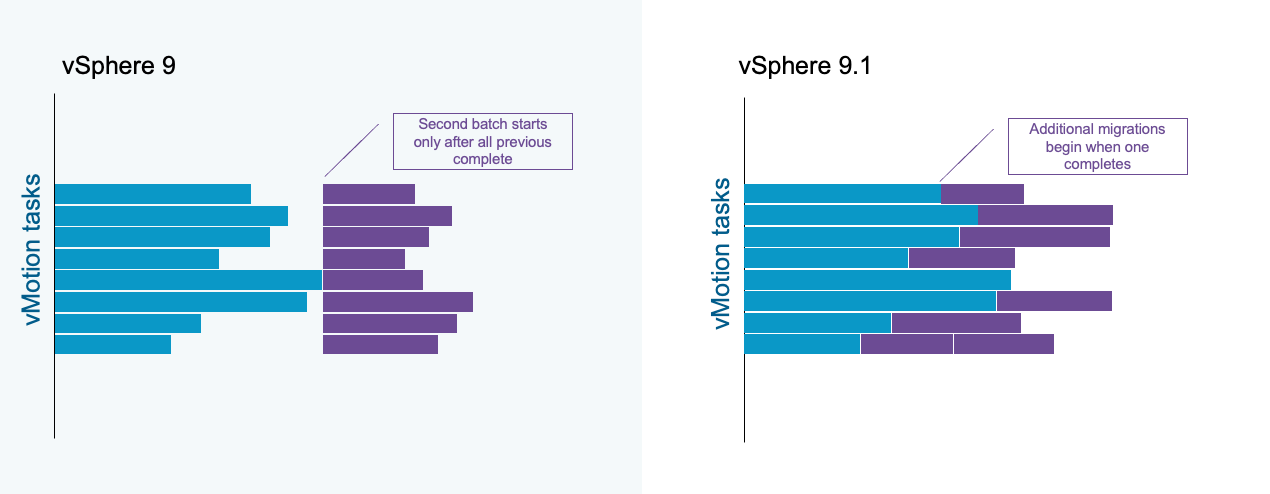
Улучшение утилизации ресурсов vMotion и снижение конкуренции
Максимальное количество одновременных задач vMotion по умолчанию равно 8. В предыдущих версиях, если 8 задач vMotion выполнялись одновременно в рамках пакетной операции, новые задачи не начинались до завершения всех предыдущих. Начиная с vSphere 9.1, как только одна задача vMotion завершается и освобождается слот, следующая задача может немедленно стартовать.
Усовершенствованная обработка задач vMotion обеспечивает более равномерное распределение нагрузки по хостам кластера. Число хостов, испытывающих пиковую одновременную нагрузку vMotion, сокращается, а сетевые ресурсы и ресурсы хранилища используются эффективнее.
Более высокая пропускная способность vMotion и сокращение времени миграции
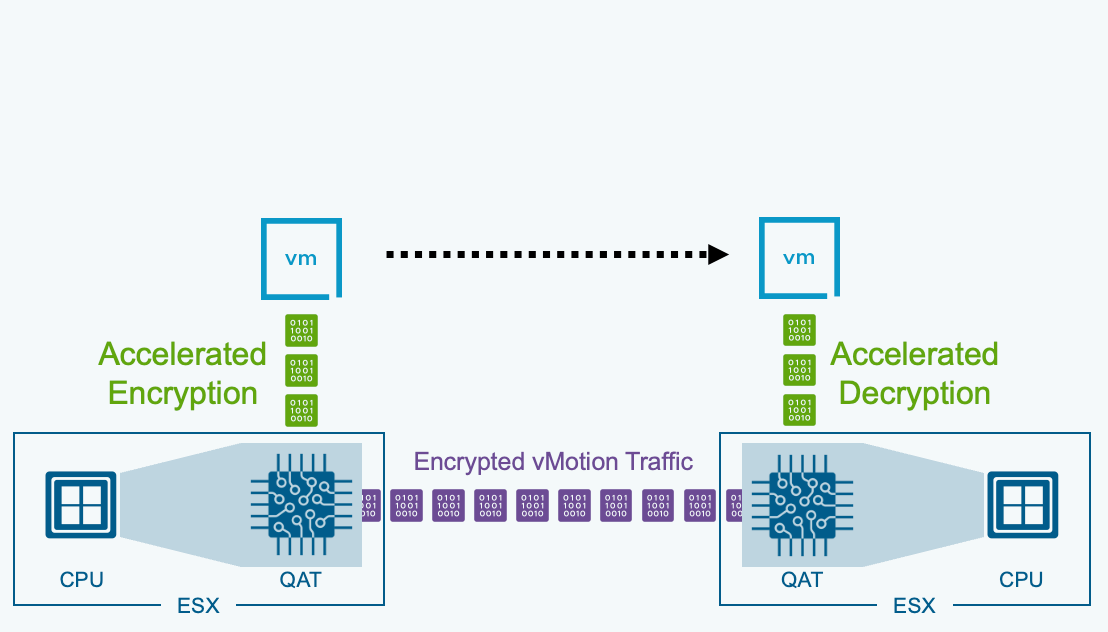
В VCF 9.1 появилась возможность разгрузки операций зашифрованного vMotion на Intel QAT (QuickAssist Technology). Это освобождает ценные ресурсы CPU и возвращает их рабочим нагрузкам.
Для максимально эффективного использования ресурсов в VCF задействована технология Intel QAT (QuickAssist Technology) для ускорения инфраструктурных операций. Перенос «тяжёлой» части задач vMotion на выделенное аппаратное обеспечение позволяет вернуть ценные ядра CPU реальным рабочим нагрузкам. Intel QAT берёт на себя шифрование данных при выполнении операций vMotion.
Оптимизированная масштабируемость и производительность для современных CPU
Планировщик Topology Aware Scheduler перешёл на событийно-ориентированный механизм встроенного обновления, что обеспечивает более согласованное и сбалансированное размещение по NUMA-узлам.
Архитектура NUMA (Non-Uniform Memory Access) используется для повышения масштабируемости и производительности серверов с несколькими процессорными сокетами. Планировщик — компонент ядра ESX, отвечающий за управление размещением виртуальных машин и балансировкой нагрузки по NUMA-узлам с целью минимизации задержек доступа к памяти и оптимального использования ресурсов CPU и памяти рабочими нагрузками.
Topology Aware Scheduler оптимизирован для нового поколения высокоплотных процессоров: улучшена модель оценки эффективности использования CPU и памяти. Существующий планировщик при принятии решений о размещении в основном учитывал конкуренцию за CPU (ready time). Topology Aware Scheduler учитывает не только конкуренцию за CPU, но и конкуренцию за кэш и пропускную способность памяти.
Для систем с асимметричной топологией NUMA, где расстояние между некоторыми парами узлов существенно больше, чем между другими, Topology Aware Scheduler может размещать смежные NUMA-клиенты одной ВМ на подмножестве узлов, расположенных ближе друг к другу.
Готовность к работе с AI-платформами различных производителей
В VCF 9.1 расширена поддержка Enhanced DirectPath I/O.
Речь идёт не просто о «проброске» оборудования, а о его виртуализации — это обеспечивает лучшую утилизацию ресурсов и возможность выполнения операций обслуживания и масштабирования без остановки AI-рабочих нагрузок. Поддержка новых аппаратных устройств в VCF 9.1 открывает доступ ко многим преимуществам виртуализации, включая stun-based операции и быстрое приостановление и возобновление работы. Среди этих преимуществ:
Storage vMotion
Снапшоты (включая снапшоты памяти)
Операции реконфигурации дисков
Горячее добавление и удаление виртуальных устройств
ESX Live Patch
ESX 9.1 расширяет свои возможности, внедряя поддержку виртуализации IOMMU для CPU AMD. Теперь администраторы могут задействовать устройства PCI passthrough на системах на базе AMD, повышая производительность и обеспечивая прямой доступ к оборудованию для виртуальных машин.
AMD vIOMMU (Virtual I/O Memory Management Unit) — аппаратно-ускоренная технология, обеспечивающая безопасный высокопроизводительный прямой доступ к памяти (DMA) для виртуальных машин за счёт прямого доступа гостевых систем к регистрам MMIO.
Flow Processing Offload (FPO) и аппаратное направление трафика (hardware steering) повышают эффективность центра обработки данных, перенося обработку сложных сетевых правил с CPU на выделенное аппаратное обеспечение. Это обеспечивает производительность на уровне линейной скорости и быструю масштабируемость виртуализированных сред, освобождая ресурсы CPU для бизнес-приложений.
Enhanced DirectPath I/O поддерживает прямую связь GPU-to-GPU через RDMA over Converged Ethernet (RoCE). Решение предназначено для организаций, выполняющих массивные AI-рабочие нагрузки или высокоскоростную обработку данных: оно обеспечивает производительность, близкую к нативной (необходимую для AI), без отказа от инструментов управления, которые упрощают эксплуатацию виртуализованных ЦОД.
GPU NVIDIA, используемые для vGPU, теперь можно настроить одновременно для тайм-слайсинга и режима MIG, что обеспечивает ещё более эффективное совместное использование ресурсов и повышение плотности.
VMware vCenter является критически важным компонентом стека VMware Cloud Foundation (VCF), помогая администраторам балансировать между доступностью сервисов и необходимостью проводить регулярное обслуживание и установку патчей. Традиционный in-place патчинг vCenter может приводить к простою продолжительностью до часа и более. VMware Cloud Foundation 9.1 представляет механизм vCenter Quick Patch, выводящий процесс обновлений vCenter на принципиально новый уровень.
vCenter Quick Patch обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлениям. Механизм Quick Patch ориентирован на быстрое развёртывание критических исправлений безопасности для vCenter.
Важно: как и в случае с ESX Live Patch, не каждый патч для vCenter совместим с Quick Patch — это определяется содержимым конкретного патча. Информация о совместимости с Quick Patch указывается в примечаниях к выпуску vCenter и в деталях патча непосредственно в интерфейсе продукта. Главная область применения vCenter Quick Patch — обновления безопасности.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, были ли изменения в соответствующем сервисе или компоненте. vCenter Quick Patch изменяет только те RPM или бинарные файлы, которые действительно претерпели изменения в составе патча. Такой подход кардинально сокращает общее окно обслуживания: время простоя vCenter снижается до менее чем 1 минуты, а в ряде случаев сводится к нулю.
vCenter Quick Patch позволяет применять критически важные патчи безопасности без прерывания рабочих процессов: развёртывание ВМ и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются, а затраты времени на планирование окон обслуживания сокращаются.
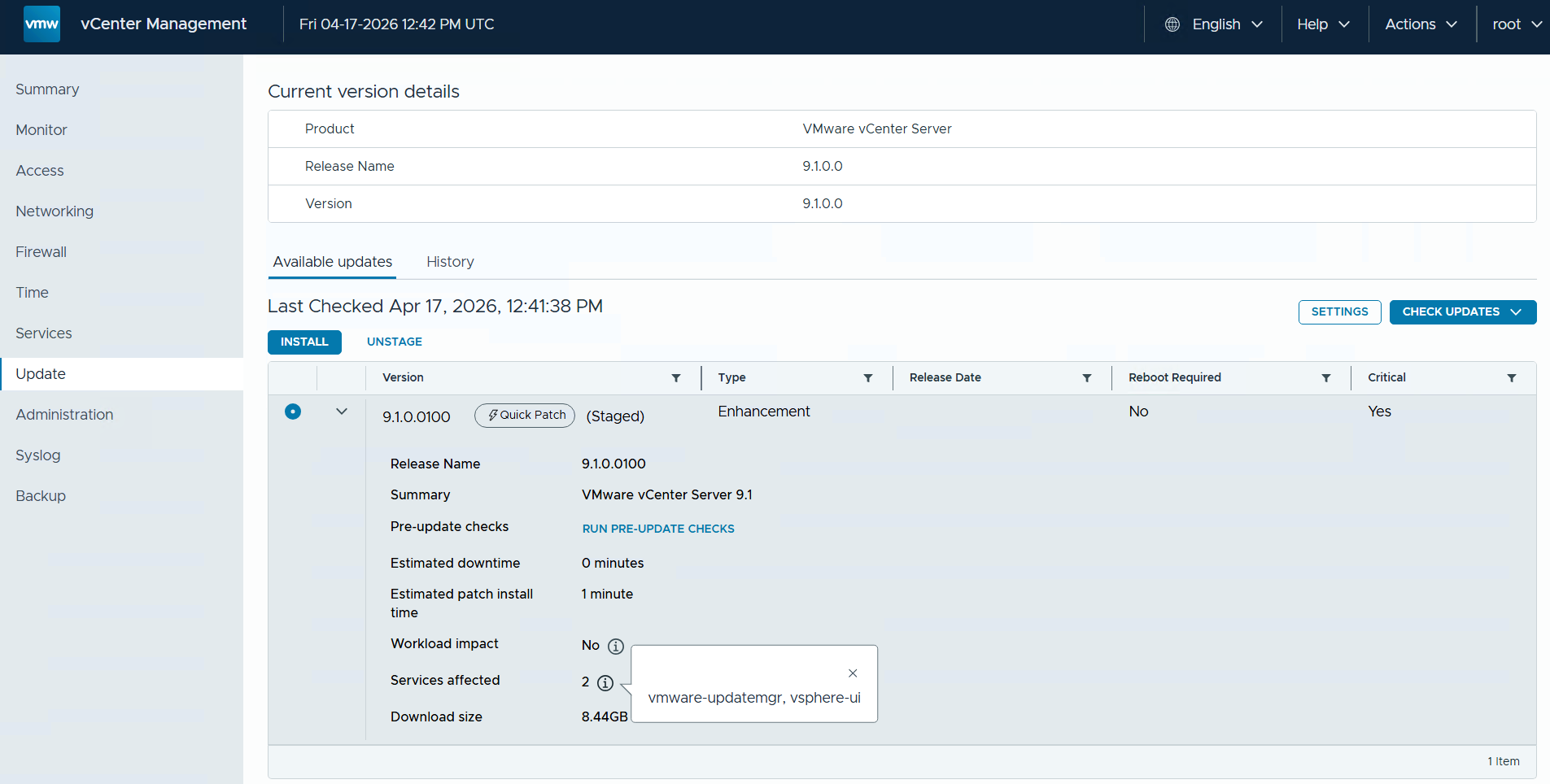
Применение vCenter Quick Patch выполняется через VMware Appliance Management Interface (VAMI) и использует тот же рабочий процесс, что и традиционный in-place патчинг. Патч, совместимый с Quick Patch, отмечается специальным значком Quick Patch. В деталях патча указываются влияние на рабочие нагрузки, затрагиваемые сервисы и ожидаемое время простоя. vCenter Quick Patch также можно применять с помощью CLI-методов. Специально выбирать метод Quick Patch не требуется: если патч поддерживает этот режим, vCenter автоматически использует его.
В представленном ниже примере ожидаемое время простоя составляет 0 минут, влияние на рабочие нагрузки отсутствует, а затрагиваемыми сервисами являются vmware-updatemgr и vsphere-ui.
При переходе на вкладку обновлений vCenter в vSphere Client отображается информация о том, что выбранный патч совместим с Quick Patch, с рекомендацией воспользоваться именно этим методом. Применение Quick Patch-совместимого обновления по-прежнему возможно через метод Reduced Downtime Update, однако это увеличит общее время обслуживания и продолжительность простоя.
Примечание: vCenter Quick Patch рекомендуется использовать для минорных патчей обслуживания, совместимых с Quick Patch (например, обновление vCenter с 9.1.0 до 9.1.1). Метод Reduced Downtime Update рекомендуется для минорных обновлений или мажорных апгрейдов (например, с vCenter 9.0.0 до 9.1.0).
Итог
vCenter Quick Patch обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя определяется тем, какие сервисы задействованы в патче. Механизм Quick Patch ориентирован на быстрое развёртывание критических исправлений безопасности для vCenter.
Классическая инфраструктура изначально не проектировалась для периферийных масштабов. Управление сотнями и тысячами распределённых площадок с использованием разрозненных стеков, изолированных инструментов и ручных процедур порождает операционные риски, неоднородность защиты и высокую стоимость обслуживания каждой точки в отдельности.
Для многих организаций это означает необходимость заходить на сотни площадок для установки обновлений, разбираться с несовпадающими конфигурациями и зависеть от локальных ИТ-специалистов, что замедляет развёртывание и увеличивает риски. По мере того как AI-нагрузки и приложения реального времени смещаются ближе к местам формирования данных, эти проблемы становятся ещё острее.
VMware Cloud Foundation Edge (VCF Edge) меняет эту модель. Продукт представляет собой унифицированную распределённую частную облачную платформу, на которой одновременно работают виртуальные машины, приложения на базе Kubernetes и AI-нагрузки с единой моделью эксплуатации во всех локациях, что устраняет необходимость в отдельной периферийной инфраструктуре.
VCF Edge 9.1 развивает эту концепцию за счёт автономных периферийных операций — автоматизации развёртывания, управления жизненным циклом в масштабе и политик безопасности, в том числе в окружениях без подключения и в полностью изолированных (air-gapped) средах.
Автономные периферийные операции
На больших масштабах задача состоит не в развёртывании отдельной площадки, а в согласованной эксплуатации сотен или тысяч таких площадок.
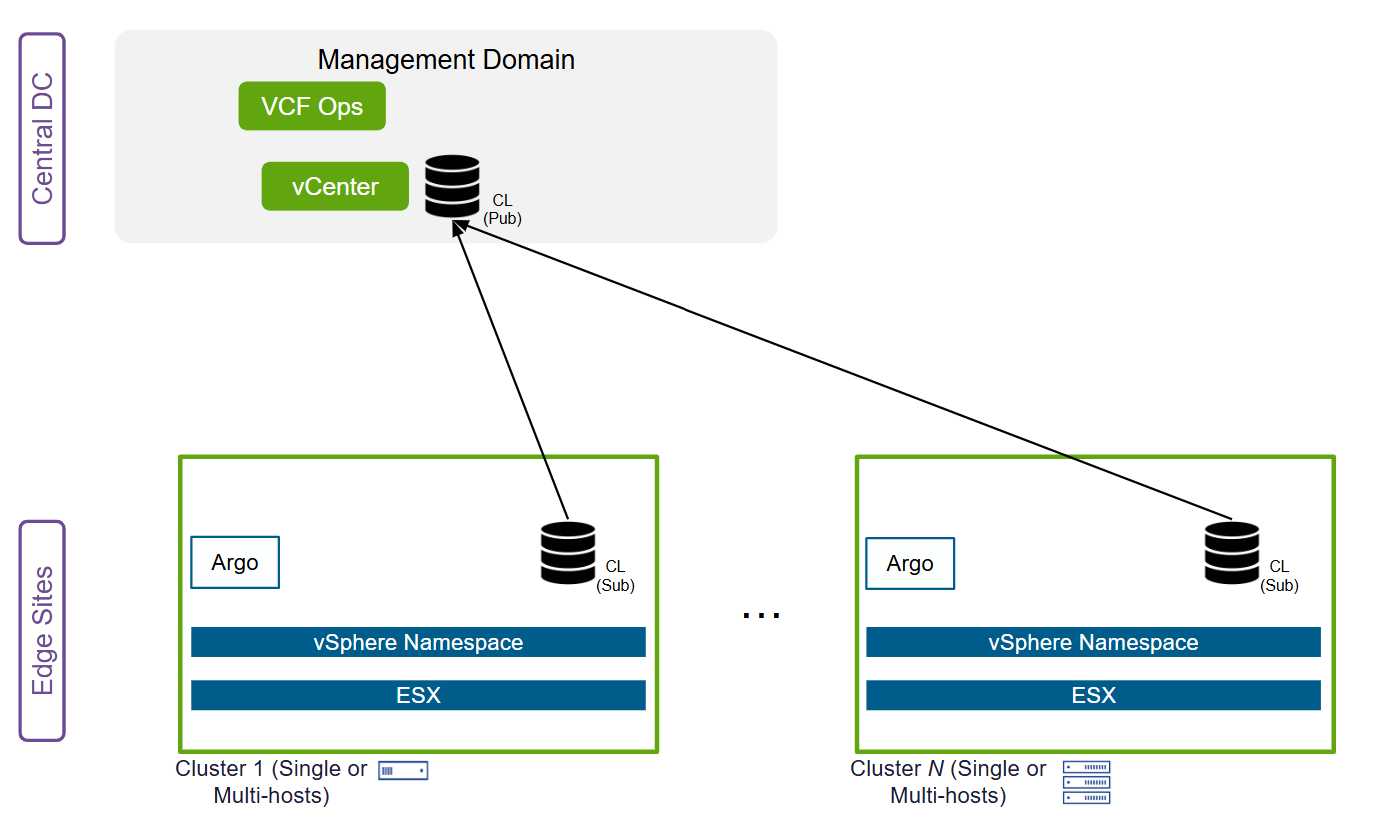
VCF Edge заменяет фрагментированную периферийную инфраструктуру единой платформой для виртуальных машин, контейнеров и AI, стандартизируя операции в распределённых средах и поддерживая разные топологии — от одноузловых конфигураций до мультикластерных схем. Каждая площадка работает локально, обеспечивая отказоустойчивость, а централизованное управление применяет политики, регламент жизненного цикла и правила governance ко всему парку.
Итогом становятся снижение операционных издержек, ускорение развёртывания и возможность масштабировать периферийную инфраструктуру без роста сложности и рисков.
Рисунок: гибкие топологии развёртывания VCF Edge для распределённых сред.
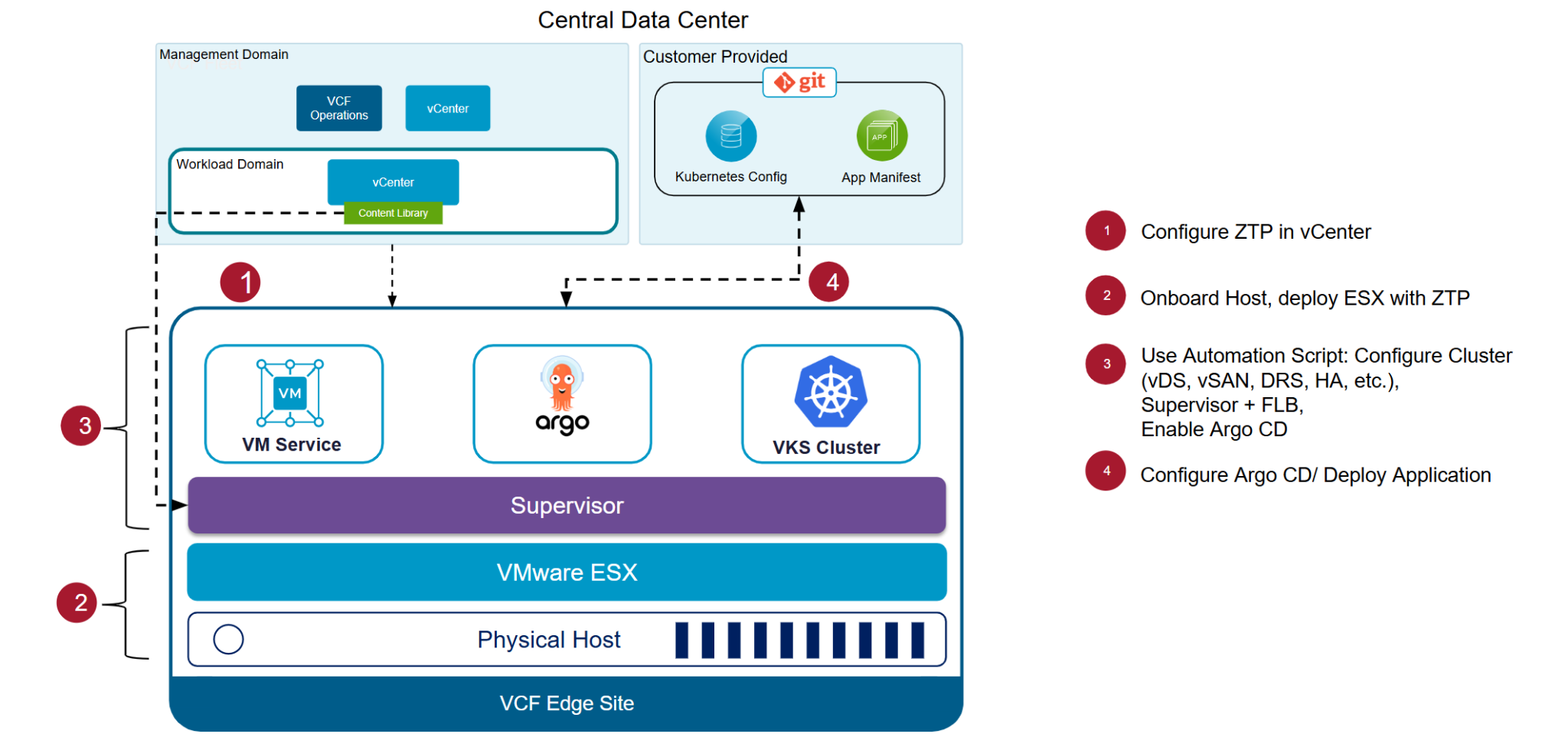
Ускорение развёртывания с помощью Zero-Touch Provisioning
Классические сценарии развёртывания периферии подразумевают ручную настройку, присутствие ИТ-специалистов на площадке и недели координации, из-за чего крупные внедрения идут медленно и дорого. VCF Edge снимает эти барьеры с помощью технологии Zero-Touch Provisioning (ZTP). После включения сервер безопасно загружается, подключается к централизованному управлению и получает полное целевое состояние — образ ОС, конфигурацию кластера и сетевые параметры, — что автоматизирует развёртывание от начала до конца. Скрипт активации Day 0 Activation Script гарантирует готовность каждой площадки к продуктивной работе вместе с платформенными сервисами и интеграцией GitOps.
Результат — ускоренное развёртывание, единообразные конфигурации и возможность вводить периферийную инфраструктуру в строй за часы, без ручной настройки и присутствия ИТ-сотрудников на месте, что заметно сокращает операционные расходы.
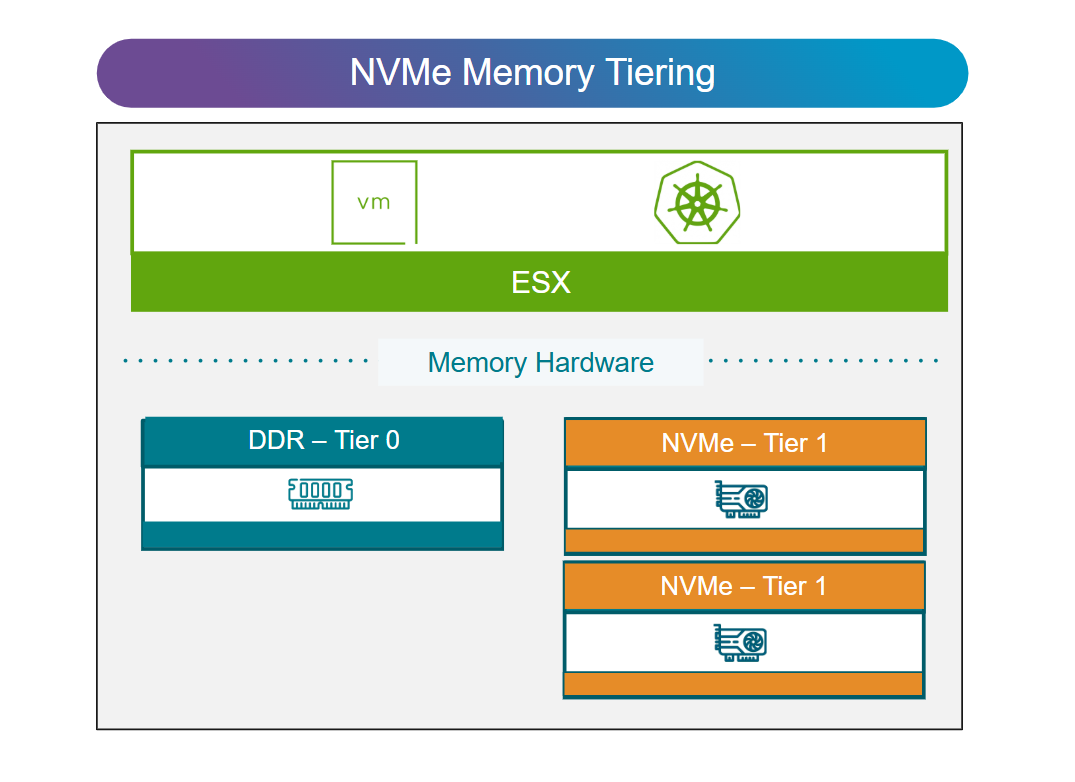
Оптимизация производительности и стоимости через Advanced NVMe Memory Tiering
На периферии масштабирование инфраструктуры часто означает добавление новых серверов, что ведёт к росту стоимости, занимаемого пространства и энергопотребления. В VCF Edge добавлены улучшения в технологии NVMe Memory Tiering, которая расширяет системную память за счёт высокопроизводительных NVMe-устройств без дополнительной установки модулей DRAM. В результате повышается плотность размещения нагрузок, лучше используется имеющееся оборудование и появляется возможность отложить или вовсе отказаться от дорогостоящих обновлений инфраструктуры.
Рисунок: NVMe Memory Tiering для периферийной инфраструктуры (расширение памяти без добавления DRAM).
Единая платформа, готовая к AI-нагрузкам периферии
Управление инфраструктурой, Kubernetes и AI-сервисами в распределённых средах становится крайне сложной задачей. VCF Edge упрощает её за счёт единой платформы для виртуальных машин, Kubernetes и AI, что избавляет от необходимости развёртывать и обслуживать раздельные стеки.
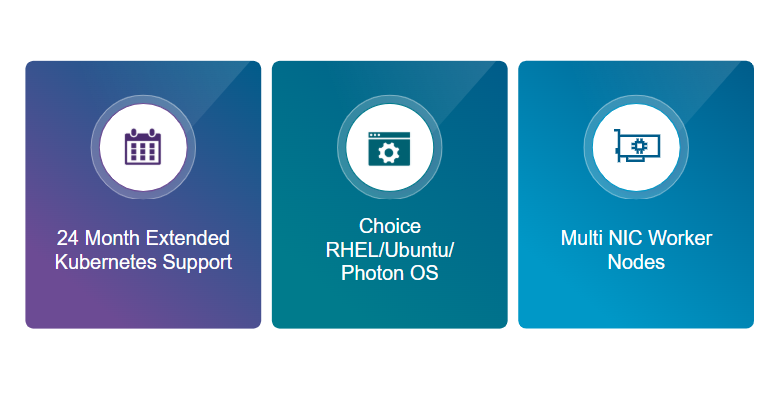
Готовый к производственной среде Kubernetes на периферии
VCF Edge предоставляет Kubernetes-платформу промышленного уровня с расширенной поддержкой жизненного цикла, гибким выбором операционной системы и продвинутыми сетевыми возможностями. Результат — упрощённая эксплуатация, ускоренное развёртывание приложений и согласованные окружения на каждой из площадок.
Рисунок: расширенная поддержка, гибкость ОС и продвинутые сетевые функции для периферийных развёртываний.
Простота без сложности Kubernetes
Не каждой нагрузке требуется полноценный Kubernetes. VCF Edge позволяет запускать контейнеры рядом с виртуальными машинами через механизм vSphere Pods. Это даёт более быстрое развёртывание, меньшие операционные затраты и упрощённый переход к контейнерам без необходимости в экспертизе по Kubernetes.
Рисунок: запуск контейнеров через vSphere Pods (CaaS без сложности Kubernetes).
AI на периферии без инфраструктурных компромиссов
Доступность GPU, их стоимость и ограничения по энергоснабжению нередко лимитируют список мест, где можно развернуть AI. VCF Edge позволяет запускать инференс AI-моделей вместе с уже работающими нагрузками с использованием GPU либо вычислений на CPU (через llama.cpp). Организации получают возможность размещать AI-сервисы ближе к источникам данных, не разворачивая отдельные инфраструктурные стеки. Итог — снижение стоимости инфраструктуры под AI, более быстрое внедрение сценариев применения AI и возможность охватить большее число периферийных площадок без обязательной установки GPU на каждой из них.
Ускорение AI-нагрузок с поддержкой GPU и других ускорителей
Платформа поддерживает высокопроизводительные ускорители для запуска требовательных AI-инференс-задач на периферии, обеспечивая при этом максимальное использование GPU между площадками.
Рисунок: поддержка GPU и ускорителей для AI-нагрузок на периферии.
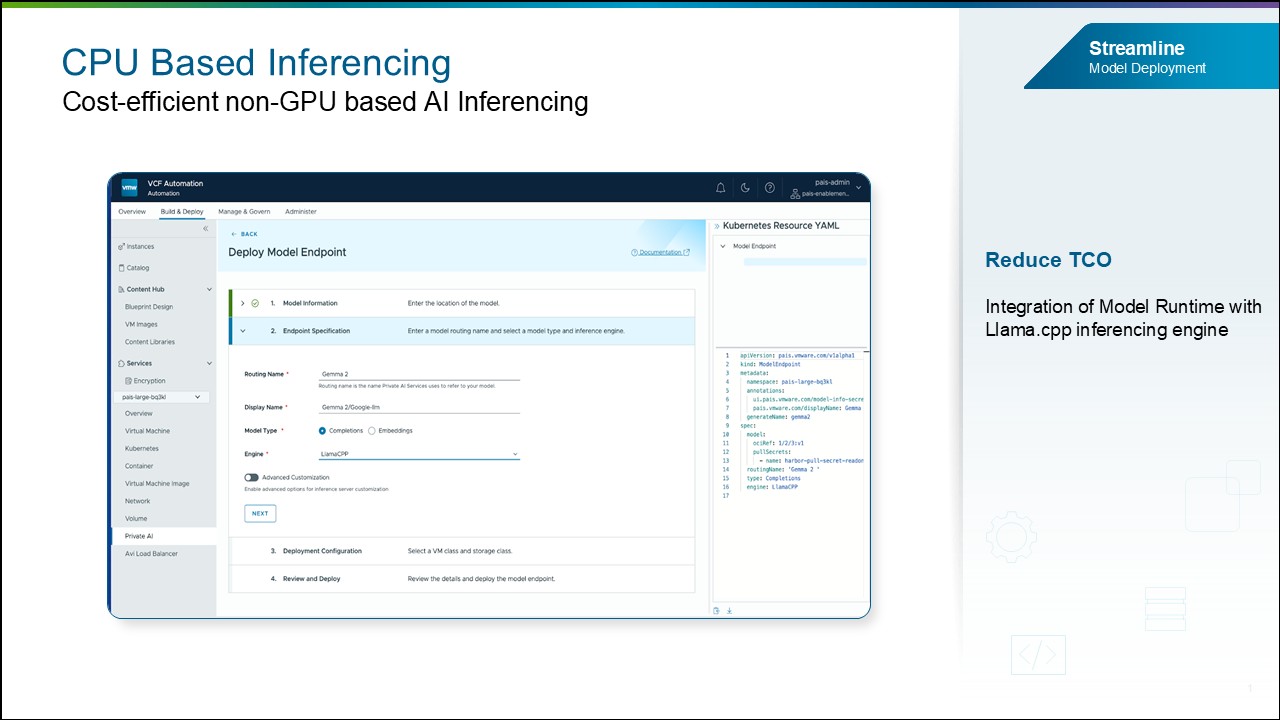
Распространение AI через инференс на CPU
VCF Edge даёт возможность выполнять инференс AI-моделей на стандартной CPU-инфраструктуре с использованием llama.cpp, что снижает зависимость от GPU и открывает применение AI в ограниченных или удалённых периферийных средах, где развёртывание GPU нецелесообразно.
Рисунок: CPU-инференс для периферийных сред (llama.cpp).
Непрерывная поставка через распределённые периферийные площадки
Поддержание согласованности на периферии — это не разовая задача развёртывания, а постоянный операционный вызов.
VCF Edge обеспечивает непрерывность работы благодаря централизованной дистрибуции образов по pull-модели, использующей Content Library для синхронизации образов в рамках всего парка. Эта архитектура целенаправленно спроектирована под надёжную эксплуатацию в средах с низкой связностью, без подключения или полностью изолированных, поскольку позволяет каждой площадке хранить и управлять своим состоянием локально. Благодаря отказу от постоянного канала к управлению уменьшается потребление трафика, и каждая периферийная площадка остаётся отказоустойчивой автономной единицей, способной поддерживать согласованные развёртывания вне зависимости от внешней связи.
Рисунок: централизованная дистрибуция образов в распределённых периферийных средах (pull-модель).
Автоматизация на основе GitOps для непрерывной поставки
После развёртывания инфраструктуры поддержание согласованности между распределёнными периферийными площадками требует непрерывной поставки и автоматизированного управления конфигурацией.
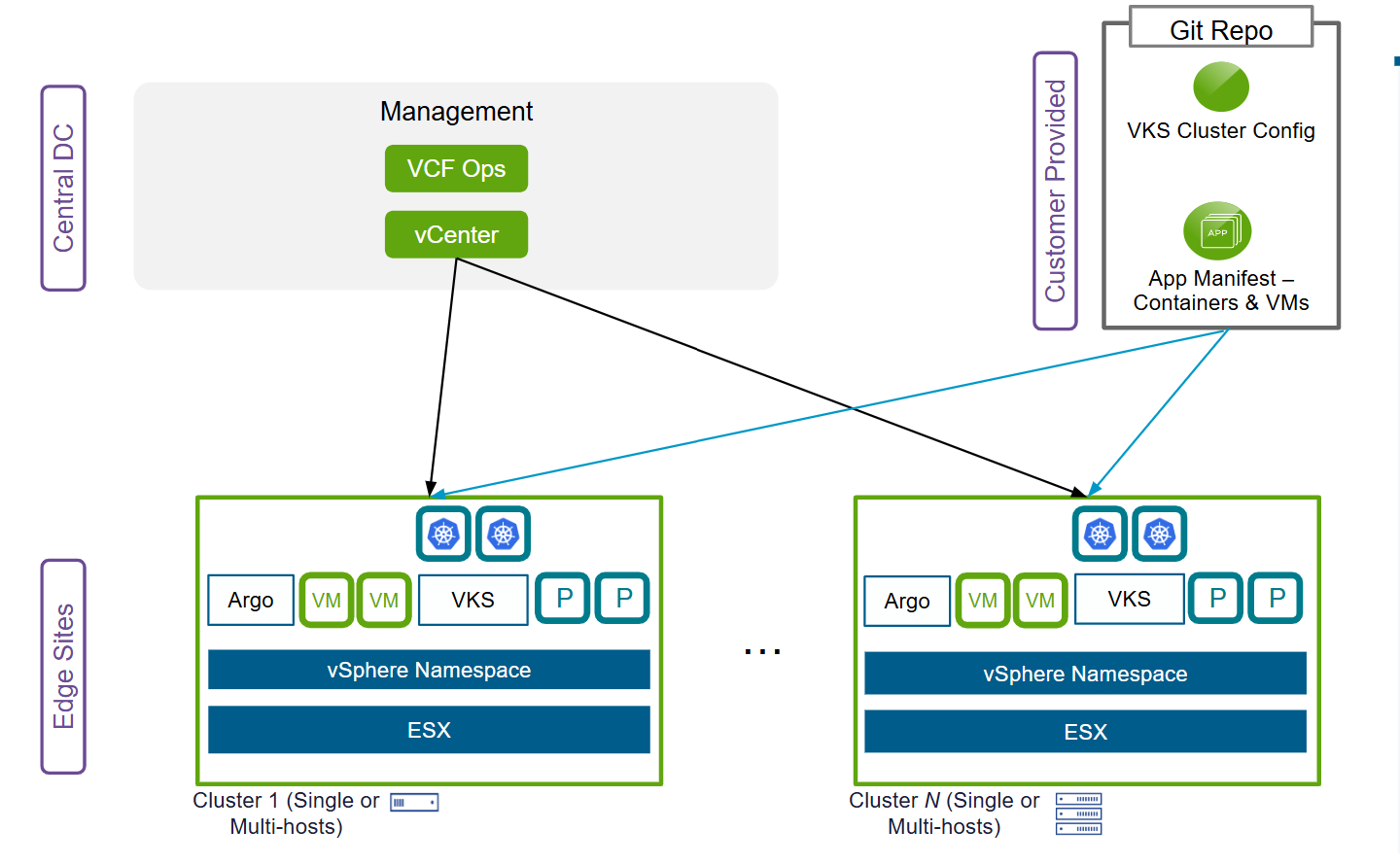
VCF Edge поддерживает автоматизацию по подходу GitOps через интеграцию с инструментами вроде Argo CD, что позволяет описывать конфигурации инфраструктуры и приложений в Git и автоматически выкатывать обновления на все периферийные площадки. Вместо точечного управления изменениями на каждой площадке конфигурации задаются один раз и применяются ко всему парку.
Итог — ускоренная поставка приложений, автоматические обновления, постоянное выявление и устранение расхождений (drift), а также единообразные окружения во всех периферийных локациях.
Рисунок: управление желаемым состоянием по GitOps в распределённых периферийных средах (Argo CD).
Наблюдаемость парка в реальном времени
Без централизованной видимости диагностика периферийных сред идёт медленно и реактивно. VCF Edge обеспечивает наблюдаемость всего парка в реальном времени, открывая возможность для проактивного мониторинга и более быстрого устранения проблем. Это сокращает простои и повышает надёжность эксплуатации.
Рисунок: наблюдаемость и мониторинг распределённых периферийных сред в реальном времени.
Защищённая и устойчивая периферия
Обеспечение безопасности на периферии сопряжено с трудностями: локальные ИТ-ресурсы ограничены, а риски распределены.
Live-патчинг без прерывания работы
VCF Edge поддерживает ESX Live Patching для хостов с TPM, что позволяет устанавливать до 80% патчей безопасности без перезагрузки. Обновления выполняются удалённо, без окон обслуживания, благодаря чему нагрузки остаются доступными непрерывно, а защита поддерживается в нужном масштабе.
Рисунок: ESX Live Patching без прерывания работы для периферийной инфраструктуры (хосты с TPM).
Оптимизировано под масштаб периферии. Создано для реальной эксплуатации.
VCF Edge заменяет фрагментированные периферийные архитектуры единой платформой, рассчитанной на распределённый масштаб. Лицензирование, развёртывание и эксплуатация выстраиваются с учётом особенностей периферийных сред: продукт оптимизирован под ограниченные по ресурсам конфигурации и одновременно избавляет от ручного управления на уровне каждой из площадок.
За счёт стандартизации инфраструктуры, приложений и AI на единой операционной модели VCF Edge обеспечивает эффективные и повторяемые операции в каждой локации. Получается автономная, масштабируемая и подготовленная к ИИ платформа, которая позволяет предприятиям управлять тысячами периферийных площадок с простотой, характерной для одной платформы.
Современные кибератаки перестали быть точечными ударами по приложениям — теперь они нацелены на саму инфраструктуру. Целенаправленные постоянные угрозы, программы-вымогатели и атаки supply chain бьют именно по тем фундаментальным слоям, на которых работают рабочие нагрузки. Защита фундамента — это уже не опция, а обязательное условие для эксплуатации безопасной и устойчивой инфраструктуры частного облака в эпоху, когда кибератаки, ранее опиравшиеся на ручной хакинг, превратились в управляемые AI-кампании, способные к самоэволюции.
По мере масштабирования корпоративных развёртываний AI архитектура безопасности становится стратегическим приоритетом. Чтобы обеспечить доверенное взаимодействие между людьми, данными и системами AI, требуется продуманный подход к защите инфраструктуры; единая платформа частного облака даёт здесь существенное преимущество с точки зрения архитектурного контроля, суверенитета данных и соответствия регуляторным требованиям.
VMware Cloud Foundation (VCF) предоставляет валидированный и проверенный на целостность фундамент инфраструктуры, на который можно опереться при защите чувствительных данных и обеспечении непрерывности бизнеса в условиях изощрённых угроз. Вместо неявного доверия VCF реализует непрерывную верификацию системы, обеспечивая глубокую видимость платформы и мониторинг целостности в реальном времени. Усиленная программно-определяемая инфраструктура VCF со встроенными средствами контроля безопасности даёт предприятиям необходимый запас устойчивости, чтобы опережать угрозы, которые благодаря ИИ движутся быстрее и постоянно адаптируются.
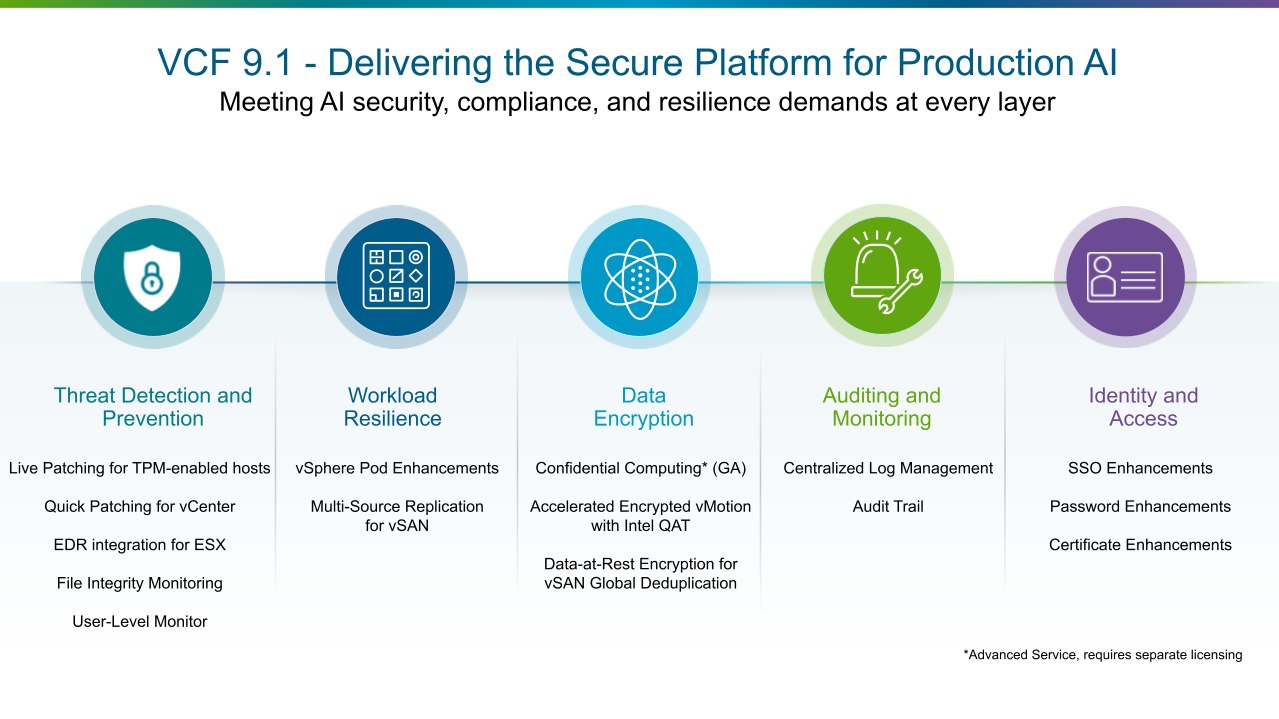
Безопасность платформы в VCF 9.1
Каждый новый выпуск VCF приносит улучшения и расширения возможностей безопасности платформы. В VCF 9.1 представлены свежие функции платформенной безопасности, необходимые для поддержки промышленных развёртываний AI. Новый релиз защищает AI-нагрузки, проприетарные модели и чувствительные данные за счёт интеграции механизмов безопасности на всём стеке инфраструктуры — от гипервизора до уровня приложений.
Ключевые платформенные функции безопасности VCF 9.1 распределены по пяти категориям:
Обнаружение и предотвращение угроз усиливает защиту гипервизора и ускоряет установку патчей без простоев.
Устойчивость рабочих нагрузок обеспечивает непрерывную работу и восстановимость приложений за счёт аппаратной изоляции и кроссплатформенной репликации.
Шифрование данных защищает данные в процессе обработки, при передаче и в покое на всём стеке.
Аудит и мониторинг предоставляют единое управление журналами и централизованный аудиторский след для быстрого форензик-анализа.
Идентификация и доступ обеспечивают принцип Zero Trust за счёт SSO уровня фабрики, политик паролей и управления сертификатами.
В совокупности эти пять направлений формируют эшелонированную оборону, необходимую частному облаку и промышленным AI-нагрузкам в противостоянии всё более способным, адаптивным и автоматизированным противникам.
Обнаружение и предотвращение угроз
VCF 9.1 продолжает добавлять новые возможности в направлении проактивных оповещений и интеллектуального анализа, а также верификации целостности и конфигурации инфраструктуры — всё это улучшает обнаружение и предотвращение угроз. В этом релизе значительно расширены возможности патчинга VCF.
Live Patching для хостов с включённым TPM
В VCF 9.1 функция live patching в vSphere продолжает развиваться: обновления безопасности можно применять к кластерам без миграции рабочих нагрузок с целевых хостов и без перевода хостов в полный режим обслуживания. Релиз также закрывает пробел, который ранее не позволял хостам с включённым TPM на ESX участвовать в рабочем процессе live patching. Установка патчей без простоев особенно выгодна для бизнес-критичных приложений — таких как сервисы AI-инференса и агентные AI-приложения, для которых требуется непрерывная доступность ради соблюдения SLA.
Quick Patching для vCenter
Функция Quick Patch позволяет VMware vCenter получать патчи безопасности, оставаясь в работающем состоянии. Применение обновления vCenter теперь занимает приблизительно 5 минут без прерывания рабочих нагрузок — против примерно 20 минут простоя и до 40 минут общего времени операции в случае обычного патча. Снижение операционной стоимости патчинга vCenter устраняет одну из частых точек трения, из-за которой обновления одного из самых критичных управленческих компонентов инфраструктуры регулярно откладываются.
С возможностями Live Patching и Quick Patching VCF 9.1 расширяет способность применять исправления безопасности в большем масштабе и с большей скоростью — без обновлений всего стека и без прерывания работы нагрузок.
Интеграция EDR для ESX
Хосты ESX теперь могут запускать EDR-агенты от партнёров по безопасности непосредственно на гипервизоре. EDR-агент работает в изолированном контейнере на хосте, отделённом от ядра системы, чтобы не вмешиваться в нормальную работу. Он отслеживает события — например, запуск и завершение процессов, установление сетевых соединений — и передаёт их на платформу управления вендора средств защиты. Поддержка EDR доступна в ESX 9.1 и требует, чтобы вендоры EDR предоставили совместимых агентов. Организациям, заинтересованным в использовании этих возможностей, следует уточнить у своего EDR-вендора, готовы ли его агенты.
Мониторинг целостности файлов
В VCF 9.1 появилась функция мониторинга целостности файлов (File Integrity Monitoring, FIM), соответствующая требованиям NIST и PCI DSS. Она выявляет изменения, внесённые вредоносным ПО или злоумышленниками, в статические файлы и бинарники, установленные vCenter. FIM включён по умолчанию и запускается каждые четыре часа, фиксируя злонамеренные, непреднамеренные изменения или повреждения установленных файлов. Администраторы VCF могут получить FIM-отчёт через API или передавать FIM-логи в VCF Operations for Logs через службу syslog.
User-Level Monitor
User-Level Monitor (ULM) поставляется в VCF 9.1 как монитор по умолчанию для всех виртуальных машин. ULM полностью переписывает виртуальный монитор машин (Virtual Machine Monitor, VMM) ESX — компонент, который управлял исполнением виртуальных машин на физическом железе с 1998 года. Ранее VMM работал с максимальными привилегиями ОС, а значит, любая уязвимость могла скомпрометировать весь хост и все ВМ на нём. ULM переносит монитор в пользовательский режим с пониженными привилегиями, ограничивая потенциальный ущерб от эксплойтов. Переработанный интерфейс ядра трактует все входные данные как недоверенные; адресное пространство исключает секреты хоста и память других ВМ; упрощённая архитектура значительно сокращает поверхность атаки и сложность гипервизора.
Устойчивость рабочих нагрузок
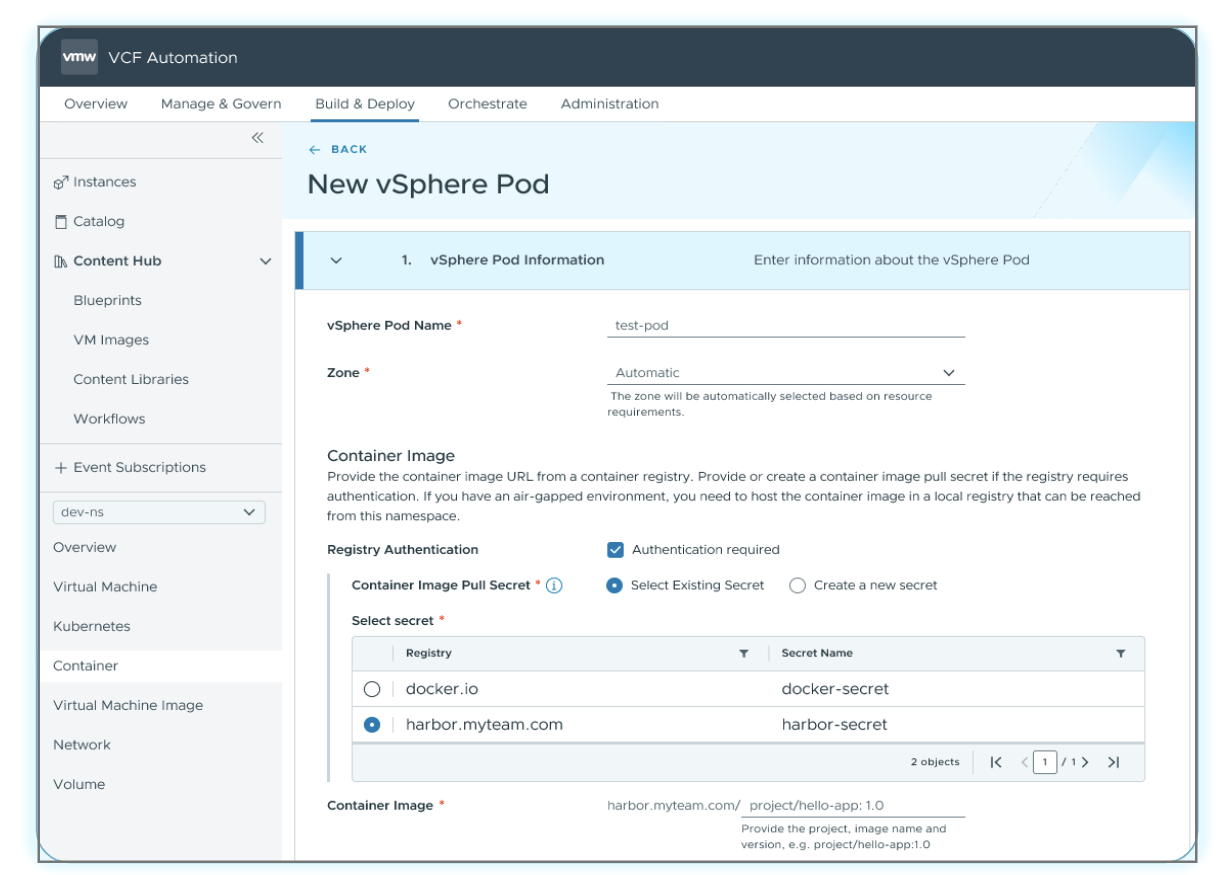
Усовершенствование vSphere Pod
Один из способов, которыми VCF обеспечивает изоляцию контейнерных нагрузок, — это vSphere Pods: контейнеры запускаются напрямую внутри управляемых ESX виртуальных машин, что сочетает скорость и плотность контейнеров с аппаратной изоляцией гипервизора. PodVM (vSphere Pods) используются для запуска одного или нескольких контейнерных инстансов без необходимости разворачивать кластер Kubernetes. На vSphere Pods построены сервисы Supervisor, и теперь они доступны через новый UI Container Service.
vSphere Pods используют Container Runtime Executive (CRX), обеспечивающий лёгкую и высокопроизводительную среду, которая загружается за секунды. Это делает их идеальным выбором для нагрузок с повышенными требованиями к безопасности, где необходима строгая изоляция ядер между приложениями, либо для ресурсоёмких микросервисов, которым нужны продвинутое планирование и предиктивные возможности DRS в ESX.
По мере увеличения числа сервисов Supervisor накладные расходы памяти PodVM могут стать узким местом. Благодаря оптимизации памяти PodVM внутренние тесты показывают, что накладные расходы памяти снижаются примерно на 75% по сравнению со стандартной ВМ — за счёт совместного использования образа загрузки между инстансами PodVM на одном хосте. Кроме того, внутренние тесты подтверждают, что PodVM загружается до 70% быстрее, чем типичная ВМ.
Новый сервис Container Service позволяет разворачивать отдельные контейнеры без необходимости управлять полноценным кластером Kubernetes. Используя изолированные runtime-среды внутри vSphere Pods, он даёт возможность запускать отдельные контейнеры, не разворачивая и не обслуживая Kubernetes-кластер целиком.
В этом релизе также добавлен потоковый вывод STDOUT/STDERR в реальном времени со всех контейнеров внутри PodVM на внешние syslog-серверы. Это применимо только к vSphere Pods и не распространяется на гостевые кластерные нагрузки VMware vSphere Kubernetes Service (VKS).
Multi-Source Replication для кластеров vSAN
В VCF 9.0 в vSAN была представлена репликация vSAN-to-vSAN, обеспечивающая защиту ВМ из одного vSAN-кластера в другой. В нынешнем релизе эта возможность расширена дальше. Теперь можно реплицировать или защищать ВМ из любого источника — например, из хранилища VMFS или NFS — на vSAN-цель. Это даёт большую гибкость в защите существующих сред VCF, где может присутствовать смешанный набор платформ хранения. Теперь возможно защищать все ВМ среды через единую цель репликации и единый рабочий процесс — независимо от того, на какой платформе хранения они в данный момент находятся, — с политиками снапшотов и репликацией, действующими на всю инфраструктуру.
Возможности репликации доступны через VMware Site Recovery Manager (SRM) или решение VMware Advanced Cyber Compliance.
Шифрование данных
VCF 9.1 добавляет и расширяет возможности шифрования по всему стеку, включая улучшения для данных в покое, данных в движении и нагрузок confidential computing.
Confidential Computing — теперь в общедоступной версии
Confidential Computing запускает чувствительные нагрузки внутри аппаратно зашифрованных областей памяти, которые остаются недоступными даже для гипервизора, защищая данные в процессе использования на разделяемой инфраструктуре частного облака. VCF поддерживал более ранние поколения этой технологии уже несколько лет; VCF 9.1 завершает работу над поддержкой текущих реализаций — Intel TDX и AMD SEV-SNP, — переводя их в категорию общедоступных (general availability). Одно из практических улучшений — повторное включение Quick Boot на хостах, где активен Confidential Computing: раньше хосты, использующие Intel TDX или AMD SEV-SNP, не могли воспользоваться Quick Boot — функцией, позволяющей ESX перезапускаться без полного цикла аппаратной инициализации и тем самым сокращающей окна обслуживания.
Дополнительно VCF Operations теперь автоматически профилирует ESX-хосты и определяет, какие из них способны выполнять конфиденциальные ВМ и контейнеры. Это снимает с архитекторов гадания при размещении чувствительных нагрузок на защищённом оборудовании. Операторы также могут видеть, активирован ли Confidential Computing на подходящем хосте.
Confidential Computing в VCF доступен через решение VMware Advanced Cyber Compliance.
Ускоренный шифрованный vMotion с технологией Intel QuickAssist (QAT)
vMotion сам по себе может быть ресурсоёмким процессом, и эта нагрузка возрастает, когда включено шифрование. По мере того как рабочие нагрузки становятся крупнее, а частота операций vMotion растёт, потребление ресурсов на эту задачу заметно увеличивается. Перенос функции шифрования на аппаратное ускорение требует меньше критически важных ресурсов, которые освобождаются для других приложений, что в итоге сокращает затраты.
QAT включён по умолчанию на поддерживаемом оборудовании, обеспечивая более плавный пользовательский опыт и упрощённое управление жизненным циклом.
Шифрование данных в покое для vSAN Global Deduplication
В связке с переводом vSAN Global Deduplication в общедоступную версию в VCF 9.1 кластеры vSAN, использующие глобальную дедупликацию, теперь поддерживают шифрование данных в покое (Data-at-Rest Encryption). Включить Data-at-Rest Encryption можно на уровне отдельного кластера, одновременно используя на том же кластере vSAN Global Deduplication — без каких-либо компромиссов между этими двумя функциями. Дедупликация работает как фоновая постобработка и совместима с шифрованием данных в покое; включение шифрования не влияет на коэффициенты дедупликации.
Аудит и мониторинг
Централизованное управление журналами
VCF 9.1 улучшает управление логами, полностью интегрируя возможности отдельного UI VCF Operations for Logs внутрь VCF Operations и предоставляя администраторам и операторам VCF единый интерфейс для всех задач управления журналами. В интеграцию входят правила обработки логов, администрирование логов, публичные API для логов, глобальные настройки управления кластером логов, а также улучшения страницы анализа логов.
Отдельный UI больше не требуется, поскольку все возможности встроены непосредственно в VCF Operations.
Аудиторский след (Audit Trail)
Форматы лог-записей и аудиторских записей теперь стандартизированы между компонентами VCF.
Новый Audit Trail в VCF Operations идёт дальше и предоставляет централизованное представление пользовательской активности с временными срезами по всем компонентам (включая VKS), упрощая разбор для форензики, выявление ключевых событий и сокращая время аудита. Когда меняются правила межсетевого экрана или фиксируются неудачные попытки входа, операторы могут проследить всю цепочку событий через весь стек.
Идентификация и доступ
VCF 9.1 расширяет возможности единого SSO, управления паролями и сертификатами, представленные в предыдущем релизе, — добавляя более широкое покрытие компонентов, средства управления на уровне фабрики и новые интеграции с хранилищами секретов и центрами сертификации.
Усовершенствование Identity Broker
VCF Identity Broker (VIDB) получил расширенные параметры конфигурации и улучшения развёртывания. VIDB обеспечивает SSO-связь между компонентами VCF и внешним поставщиком идентификации (Identity Provider, IDP) или службой каталогов. Identity Broker теперь устанавливается в момент развёртывания или обновления VCF и больше не требует отдельной загрузки в качестве предусловия для настройки единого входа.
Identity Broker можно настраивать в embedded-режиме или режиме appliance — через VCF Operations или API. Развёртывание Identity Broker в виде кластера из трёх узлов обеспечивает более высокую производительность, масштабируемость и высокую доступность; такой вариант рекомендован для промышленной эксплуатации. Узлы Identity Broker теперь могут разворачиваться за пределами management-кластера.
VCF 9.x также предоставляет скриптовый рабочий процесс для организаций, обновившихся с VCF 5.x, — позволяющий без прерывания работы мигрировать пользователей и группы из VMware Identity Manager (VIDM) в Identity Broker. В процессе обновления Identity Broker разворачивается автоматически. Скрипт запускается уже после завершения обновления. Далее Identity Broker можно интегрировать с выбранным поставщиком идентификации; существующие пользователи и группы при этом не затрагиваются.
Усовершенствование управления паролями
VCF Operations 9.1 расширяет управление паролями, добавляя политики уровня фабрики, интеграцию с хранилищами секретов и покрытие дополнительных компонентов.
Теперь возможно задавать единые политики паролей между компонентами VCF и проводить проверки соответствия паролей с последующей коррекцией. Созданные политики применяются на уровне фабрики VCF или для отдельных компонентов VCF. Кроме того, администраторы могут управлять паролями для VCF Operations workload mobility (ранее известного как HCX) и балансировщиков Avi, развёрнутых или обновлённых до VCF 9.1.
Пароли break-glass-учётных записей больше не сохраняются — что устраняет одну из распространённых причин для процедур принудительной смены паролей. Дополнительно новые API для интеграции с корпоративными хранилищами паролей поддерживают сторонние инструменты — в частности, CyberArk. Корпоративные парольные хранилища, управляемые через API, потребуют плагина для VCF.
Усовершенствование управления сертификатами
В VCF 9.1 добавлены конфигурация центров сертификации на уровне фабрики, расширенная поддержка Microsoft CA и OpenSSL, а также массовые операции с сертификатами. Центр сертификации (Certificate Authority, CA) теперь настраивается на уровне фабрики VCF, а не отдельного инстанса, что позволяет управлять сертификатами на уровне всей фабрики.
Поддержка Microsoft CA и OpenSSL расширена и теперь охватывает как компоненты VCF instance, так и компоненты управления VCF. В предыдущем релизе Microsoft CA и OpenSSL поддерживались только для компонентов VCF instance (vCenter, NSX и ESX), тогда как компоненты управления можно было настраивать исключительно с использованием Microsoft CA.
В UI VCF Operations операторы теперь могут выполнять массовые операции с сертификатами. Запросы на подпись сертификатов, их обновление и импорт — всё это выполняется пакетно, сокращая время и дополнительно упрощая операции по управлению сертификатами. API VCF Operations можно использовать для интеграции со сторонними решениями и автоматизации управления сертификатами для всех компонентов VCF.
Дополнительные материалы
VCF 9.1 содержит последние достижения технологии виртуализации VMware. Релиз объединяет Zero Trust-безопасность и устойчивость на каждом уровне: vSphere, NSX, vSAN, VMware vSphere Kubernetes Service, VCF Private AI Services, VCF Operations и VCF Automation, помогая организациям защитить инфраструктуру частного облака от продвинутых, ускоренных AI-угроз.
Также материалы по усилению безопасности, соответствию требованиям и часто задаваемые вопросы по конкретным функциям доступны в репозитории GitHub: https://brcm.tech/vcf-security.
Искусственный интеллект обладает огромным потенциалом для трансформации всех предприятий - IDC прогнозирует, что решения и сервисы AI окажут глобальное влияние на сумму 22,3 трлн долларов к 2030 году.
С учетом такого масштаба неудивительно, что предприятия стремятся использовать AI для повышения производительности во всех областях бизнеса. Однако им нужна комплексная стратегия, которая ускорит интеграцию AI в инфраструктуру дата-центров. С VMware Cloud Foundation Private AI Services компания Broadcom стремится помочь предприятиям раскрыть потенциал AI и повысить продуктивность при более низкой совокупной стоимости владения.
Реальный эффект: что говорят клиенты
Компании из разных отраслей уже развертывают VCF Private AI Services и получают экономию, приватность и безопасность для своих AI-нагрузок:
«Внедрив VCF Private AI Services, мы усилили возможности интеллектуальных сервисов», — говорит Тунг-Лян Чен, вице-президент Chunghwa Post. «Запуск AI в собственной инфраструктуре частного облака на базе VCF позволяет нам существенно снижать затраты и повышать эффективность автоматизированного обнаружения в реальном времени, одновременно обеспечивая бесшовную интеграцию с существующими системами».
«Анализ многолетних архивов новостей в публичном облаке обходится слишком дорого, а непредсказуемое ценообразование затрудняет планирование AI-проектов», — сказал V V Jacob, старший генеральный менеджер по системам Malayala Manorama Co Ltd. «Развернув VCF Private AI Services на существующей инфраструктуре VMware Cloud Foundation, мы сможем запускать AI-суммаризацию контента, генерацию заголовков и редакторскую помощь прямо в частном облаке. Мы считаем, что это даст нам приватность и безопасность, необходимые для защиты редакционных источников, а также предсказуемость затрат, которую обеспечивает локальная инфраструктура частного облака».
На днях был объявлен следующий выпуск VCF Private AI Services вместе с VCF 9.1. В новой версии для предприятий добавляется несколько важных функций.
Новые возможности
1. Приватность и безопасность
Broadcom помогает предприятиям создавать и развертывать приватные и безопасные AI-модели со встроенными возможностями защиты, предоставляемыми через VCF Private AI Services.
Поддержка Model Context Protocol (MCP) с управлением. Благодаря поддержке MCP предприятия получают безопасный и стандартизированный способ интегрировать AI-ассистентов с внутренними репозиториями контента и внешними MCP-инструментами от Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL и других поставщиков без разработки и сопровождения собственных коннекторов.
2. Упрощение управления инфраструктурой
Поддержка Google Documents. VCF Private AI Services теперь предоставит полноценную поддержку Google Workspace, включая Google Docs, Sheets и Slides, без необходимости экспортировать документы в PDF и загружать их в базу знаний. В дополнение к уже существующей поддержке Microsoft Word, Microsoft PowerPoint, PDF, CSV и других форматов предприятия получают доступ к очень широкому набору типов документов и смогут добиваться качественных результатов для AI-нагрузок.
DirectPath Enablement для GPU. В этом выпуске VCF Private AI Services поддерживает DirectPath Enablement для инфраструктуры NVIDIA AI. Это обеспечит высокопроизводительный эксклюзивный доступ к GPU для одной виртуальной машины, которая сможет полностью использовать возможности GPU. С этой новой функцией предприятия смогут развертывать AI-проекты с NVIDIA GPU в режиме DirectPath.
Поддержка последнего поколения NVIDIA Blackwell GPU. VCF теперь поддерживает новейшую серию GPU NVIDIA Blackwell. В дополнение к существующей поддержке NVIDIA RTX PRO 6000 Blackwell Server Edition объявлена поддержка NVIDIA HGX B200 и NVIDIA RTX PRO 4500 Blackwell Server Edition. Поддержка этих новых GPU Blackwell на VCF определяет следующий этап корпоративного AI с беспрецедентной производительностью, эффективностью и масштабом.
Будущая поддержка. В одном из следующих выпусков VCF будет поддерживать NVIDIA HGX B300. VCF на NVIDIA HGX B300 позволит предприятиям без усилий масштабировать самые производительные AI-нагрузки и подготовить инфраструктуру к будущим требованиям.
Поддержка NVIDIA HGX Platform с Blackwell GPU и NVLink Switch. VCF теперь поддерживает NVIDIA HGX platform с Blackwell GPU и NVLink Switch. Благодаря этой возможности предприятия смогут получить преимущества крупномасштабных AI-развертываний с VCF Private AI Services и платформой NVIDIA HGX. NVIDIA HGX объединяет всю мощь инфраструктуры NVIDIA AI, включая NVIDIA GPU, NVIDIA NVLink, NVLink Switch, NVIDIA networking и полностью оптимизированные AI software stacks, чтобы обеспечивать максимальную производительность AI-приложений и ускорять получение инсайтов в каждом дата-центре.
Высокоскоростная сеть с Enhanced DirectPath I/O. VCF теперь поддерживает сетевые адаптеры NVIDIA ConnectX-7 и NVIDIA BlueField-3 с Enhanced DirectPath I/O. С этим улучшением предприятия смогут использовать такие расширенные возможности, как NVIDIA GPUDirect RDMA и GPUDirect Storage, для высокоскоростного обучения AI-моделей на нескольких хостах и передачи данных, что особенно важно для требовательных Gen AI-нагрузок.
3. Упрощение вывода моделей в эксплуатацию
Новые возможности в этой категории помогают предприятиям снижать сложность перевода моделей в production.
AI Metrics Observability Dashboard.
По мере масштабирования корпоративных AI-сред ограниченная видимость производительности моделей и агентов, а также факторов затрат мешает командам выявлять неэффективность, ведет к росту расходов на инфраструктуру и снижает производительность приложений. Чтобы решить эти проблемы, выпускается AI Metrics Observability Dashboard, который будет показывать важные AI-метрики.
Улучшенная видимость AI-метрик позволит специалистам по data science и MLOps выявлять узкие места, оптимизировать распределение ресурсов, повышать throughput и производительность.
Рассмотрим некоторые AI-метрики, которые будут доступны:
Метрики моделей. Эти метрики помогут предприятиям отслеживать продуктивность, скорость, задержку и другие параметры, предоставляя детальное представление о моделях. Будут доступны такие показатели, как Cache Utilization, Tokens generated per request, Token throughput, Time to first token (TFFT), End-to-end (E2E) request latency и другие.
Метрики использования GPU. Также будут доступны GPU-метрики, включая Utilization, Temperature, Power Usage, Memory Temperature, Memory Clock и другие.
Примечание: для этих AI Metrics dashboards предприятиям необходимо развернуть Grafana.
CPU-Based Inferencing. VCF Private AI Services теперь поддерживает CPU-based inferencing в дополнение к GPU-развертываниям благодаря интеграции Model Runtime с inference-движком Llama.cpp. На базе Llama.cpp, одного из ведущих open source inference-движков с широкой поддержкой сообщества, клиенты также получат доступ к большому набору моделей с day-zero-поддержкой от ведущих поставщиков, включая Google, OpenAI и других. Это улучшение снижает TCO, позволяя предприятиям развертывать менее ресурсоемкие среды для тестирования, proof-of-concept-инициатив или AI-приложений с минимальными требованиями к GPU либо без них.
Инфраструктурные команды сталкиваются с парадоксом: среды становятся все сложнее, а бюджеты и численность персонала остаются прежними. VMware Cloud Foundation (VCF) 9.1 призвана ответить на эту проблему инновациями, которые повышают эффективность, ускоряют доставку приложений и усиливают киберустойчивость, сохраняя при этом простоту эксплуатации. За последние несколько лет разговор об инфраструктуре изменился. Вопрос уже не только в том, где выполняются рабочие нагрузки, но и в том...
«Группа Астра» объявила о коммерческом релизе продукта Astra Migration — инструмента для автоматизированного и управляемого переноса рабочих станций с Windows на российскую платформу Astra Linux. Решение уже доступно для заказа и нацелено на решение одной из ключевых задач отечественного ИТ-рынка — массового и контролируемого перевода организаций на отечественное программное обеспечение. Компания занимает 76% российского рынка ОС для ПК и серверов и выпускает инструмент, который призван сделать переход на её платформу максимально быстрым и безболезненным.
Зачем нужен Astra Migration
На практике миграция с Windows сопряжена с серьёзными операционными трудностями: ручные сценарии плохо масштабируются, требуют значительного участия ИТ-специалистов и не дают прозрачной картины процесса. Без централизованного инструмента контролировать сроки, статусы и качество перехода крайне сложно. Именно эти барьеры призван устранить новый продукт «Группы Астра».
Актуальность задачи подтверждается рыночными прогнозами. По оценкам аналитиков Strategy Partners, объём российского рынка операционных систем для ПК и серверов к 2030 году вырастет до 55 млрд рублей при среднегодовых темпах роста в 23%. В государственном секторе уровень проникновения отечественных ОС к тому же сроку приблизится к 100%, тогда как корпоративный сегмент сохранит значительный потенциал для дальнейшего роста.
Клиент-серверная архитектура
Astra Migration построен по клиент-серверной модели с чётким разделением функций между двумя компонентами.
Astra Migration App — клиентский модуль, устанавливаемый централизованно на исходные рабочие станции под управлением Windows. Он автоматически выполняет инвентаризацию конфигурации АРМ: полный сбор сведений об аппаратном обеспечении и установленном ПО занимает не более 30 секунд. На всех этапах перехода приложение информирует пользователя о ходе миграции через интерактивные уведомления, прогресс-бар и подсказки — всё это обеспечивает вовлечённость сотрудника при минимальных требованиях к его участию.
Astra Migration Server — серверная часть, предоставляющая IT-администратору единую панель управления. Через неё выполняется полная настройка сценариев и волн миграции, мониторинг состояния устройств в реальном времени и контроль блокеров, препятствующих переходу.
Что настраивает администратор
Работа с продуктом со стороны IT-специалиста включает несколько уровней конфигурации. На уровне сценария задаются параметры целевой ОС, сетевые настройки и параметры установки Astra Linux. На уровне волн миграции — их состав (группы АРМов), статусы и перечень блокеров, при наличии которых переход конкретной станции откладывается. Предусмотрен запуск проверки совместимости программного обеспечения и оборудования до фактического начала переноса, а также формирование отчётов о динамике перехода пользователей на новую ОС.
Что происходит на рабочем месте пользователя
Процесс перехода со стороны конечного пользователя организован следующим образом:
На рабочий стол поступает уведомление о включении АРМ в волну миграции.
Пользователь самостоятельно выбирает удобную ему дату из перечня, предоставленного администратором.
Накануне миграции пользователь получает уведомление о запланированной процедуре, её этапах, а также рекомендации по подготовке и приветственный баннер с инструкциями по работе в Astra Linux.
В выбранную дату миграция запускается и завершается в автоматическом режиме без дальнейшего участия сотрудника.
Такой подход обеспечивает плавную адаптацию персонала: сотрудники заблаговременно осведомлены о предстоящих изменениях и чувствуют себя участниками процесса, а не его объектами.
Что переносится и что сохраняется
В ходе миграции Astra Migration обеспечивает перенос пользовательских данных и персональных настроек операционной системы. Отдельно выполняется проверка совместимости установленного ПО и подключённого оборудования с новой ОС. При возникновении проблем предусмотрен откат: образ исходной ОС сохраняется, что позволяет вернуться к Windows при необходимости.
Текущие возможности и планы
В выпущенной версии реализован режим Dualboot — Windows и Astra Linux устанавливаются параллельно на одном устройстве с переносом данных в рамках поддерживаемого сценария. Режим полной замены ОС с переносом данных (clean install) запланирован к добавлению в следующих обновлениях продукта.
По заявлению разработчиков, Astra Migration ускоряет процесс перевода рабочих мест в десятки раз по сравнению с ручным подходом, обеспечивая параллельную обработку более 100 АРМов одновременно. Все этапы — от инвентаризации исходной системы до финального перехода — полностью прозрачны для IT-администратора.
Для кого предназначено решение
Продукт ориентирован на широкий круг заказчиков: государственные структуры, крупный бизнес, а также средние и малые предприятия, которые решают задачу импортозамещения Windows и стремятся провести переход без потери эффективности работы сотрудников.
Зрелость платформы определяется не только качеством ядра, но и тем, насколько легко на неё перейти. Тысячи компаний переходят на Astra Linux прямо сейчас, и качество этого процесса формирует их отношение к нашему продукту на годы вперёд. Именно поэтому мы создали Astra Migration — инструмент, который позволяет перевести тысячи рабочих мест на Astra Linux без остановки бизнеса и перегрузки ИТ-службы, превращая миграцию из необходимости в управляемый и предсказуемый процесс. — Михаил Геллерман, директор управления операционных систем «Группы Астра»
Первая публичная демонстрация Astra Migration состоялась 20 апреля 2026 года на стенде «Группы Астра» в рамках конференции АКПО-Конф. 23 апреля 2026 года компания проводит онлайн-вебинар «Astra Migration: автоматизированная миграция с Windows без боли», на котором будет показана практическая работа продукта и разобраны сценарии внедрения.
С момента запуска VMware Cloud on AWS компании VMware и AWS совместно расширяли портфель специализированных инстансов на базе bare-metal — от оригинальных i3.metal и i3en.metal до высокоплотного i4i.metal. Теперь для VMware Cloud on AWS объявлен запуск нового типа инстансов — i7i.metal-24xl. Оснащённый процессорами 5 поколения Intel Xeon Scalable (Emerald Rapids), SSD третьего поколения AWS Nitro и высокоскоростной памятью DDR5, новый инстанс обеспечивает значимый скачок в пропускной способности хранилища и вычислительной эффективности — при этом существующая операционная модель VMware не требует каких-либо изменений.
По мере того как всё больше заказчиков переносят в облако наиболее требовательные рабочие нагрузки, новый инстанс i7i обеспечивает наилучшую вычислительную производительность и производительность хранилища среди x86-инстансов Amazon EC2, оптимизированных для хранения данных. Пользователи VMware Cloud on AWS получают заметно более высокую пропускную способность ввода-вывода, меньшую задержку и улучшенное соотношение цены и производительности по сравнению с предыдущим поколением.
Ключевые характеристики
Инстанс i7i.metal-24xl представляет собой универсальный bare-metal-инстанс, разработанный для I/O-интенсивных корпоративных рабочих нагрузок, которым требуется максимально возможная производительность случайного ввода-вывода с предсказуемой субмиллисекундной задержкой.
Характеристика
i7i.metal-24xl
Процессор
5th Gen Intel Xeon (Emerald Rapids)
vCPU
96
Физические ядра
48
Память
768 ГиБ DDR5 (5600 MT/s)
Локальное NVMe-хранилище
6 x 3,75 ТБ NVMe SSD
Используемая ёмкость*
vSAN OSA ~ 13 ТБ / vSAN ESA ~ 20 ТБ
Пропускная способность сети
56,25 Гбит/с
Источник: Amazon EC2 I7i Instances — aws.amazon.com. Используемая ёмкость является оценочной. Для конфигураций с оптимизацией vSAN на кластере из 3 узлов фактическая ёмкость будет варьироваться в зависимости от профиля нагрузки, политики FTT/RAID и применяемых параметров сжатия и дедупликации vSAN.
Региональная доступность
Тип инстансов i7i.metal-24xl доступен для приобретения в следующих регионах AWS:
География
Регионы AWS
Америка
US East (N. Virginia), US East (Ohio), US West (Oregon), US West (N. California), Canada (Central)
Европа
Europe (Ireland), Europe (London), Europe (Frankfurt), Europe (Stockholm), Europe (Milan)
Ближний Восток
Middle East (Bahrain)
Азиатско-Тихоокеанский регион
Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Melbourne), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Osaka), Asia Pacific (Mumbai), Asia Pacific (Hyderabad)
VMware vSAN работает непосредственно поверх локальных NVMe-дисков каждого хоста i7i.metal-24xl. При включённом сжатии vSAN кластер из 3 узлов обеспечивает значительную используемую ёмкость — конкретный результат зависит от характеристик нагрузки, политики FTT/RAID и показателей снижения объёма данных. Размер конфигурации рекомендуется валидировать применительно к конкретному профилю данных.
На i7i.metal-24xl по умолчанию включён гиперпоточный режим, что обеспечивает 96 логических ядер на хост — это хорошо подходит для приложений, выигрывающих от увеличенного параллелизма потоков CPU. Для заказчиков, которым важны показатели производительности приложений или условия программного лицензирования, VMware Cloud on AWS поддерживает опцию Custom CPU Core Count, позволяющую управлять количеством физических ядер, доступных на каждом хосте.
Для вторичных кластеров i7i.metal поддерживаются следующие конфигурации:
Кластеры от 3 узлов: 8, 16, 24, 30 или 36 физических ядер на хост
Кластеры из 2 узлов: 16, 24, 30 или 36 физических ядер на хост
Такая гибкость особенно ценна для ПО с лицензированием по числу ядер — например, Oracle Database и Microsoft SQL Server: сокращение числа активных ядер может существенно снизить лицензионные расходы без потери объёма памяти и хранилища хоста.
Кроме того, доступно развёртывание Stretched Cluster с охватом нескольких зон доступности для новых SDDC на базе i7i.metal-24xl — это обеспечивает высокую доступность рабочих нагрузок сразу в двух зонах доступности AWS в пределах одного региона. По умолчанию в Stretched Cluster SDDC используется vSAN OSA.
Приобретение подписок i7i.metal-24xl
За информацией о ценах, доступных регионах и вариантах приобретения следует обращаться к представителю Broadcom. Если контактные данные представителя неизвестны, можно воспользоваться формой на сайте продаж Broadcom.
Важно учитывать, что тип инстансов i7i требует предварительного обновления существующих развёртываний до версии SDDC 1.26v2 — для конвертации кластеров и развёртывания новых вторичных кластеров. Для запроса досрочного обновления необходимо открыть запрос в поддержку с указанием организации, данных SDDC и желаемой даты обновления — команда VMC поддержки скоординирует дальнейшие шаги.
Развёртывание и миграция на i7i.metal-24xl
Существует два сценария: развертывание нового SDDC с инстансами i7i.metal-24xl или миграция рабочих нагрузок с имеющихся узлов i3.metal, i3en.metal и/или i4i.metal на новый i7i.metal-24xl. Тип инстансов i7i доступен только для SDDC версии 1.26v2.
Создание нового SDDC
Все вновь развёртываемые SDDC будут работать на актуальной версии SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции доступны в разделе «Развёртывание SDDC из VMware Cloud Console».
Выберите Create SDDC и укажите тип хоста i7i.metal-24xl.
Задайте размер кластера (минимум 2 хоста) и выполните оставшиеся шаги.
Завершите развёртывание SDDC. VMware автоматически выполняет настройку ESXi, vSAN, vCenter и NSX.
Добавление вторичного кластера в существующий SDDC
К существующему SDDC (после обновления до версии 1.26v2) можно добавить новый кластер на базе i7i.metal-24xl без прерывания выполняющихся нагрузок. После подготовки кластера vSphere vMotion позволяет перенести виртуальные машины из имеющихся кластеров в новый i7i с минимальным воздействием. Новый кластер будет работать под управлением SDDC 1.26v2 и по умолчанию использовать vSAN ESA. Подробные инструкции — в разделе «Добавление кластера».
Конвертация кластеров с хостами i3 / i3en / i4i
Миграция с i3.metal, i4i.metal или i3en.metal на i7i.metal-24xl возможна с помощью vSphere vMotion. Для подходящих конфигураций VMware также предоставляет услугу конвертации кластера по запросу. Подробные инструкции — в разделе «Конвертация типов хостов в кластерах».
Следует учитывать, что кластеры, использующие аппаратную версию виртуальных машин 21, не подходят для конвертации с i4i на i7i из-за ограничений совместимости оборудования. Для получения помощи с расчётом размеров и планированием конвертации кластеров следует обращаться к команде Broadcom. Также доступен инструмент VMC Sizer — для оценок на основе хостов, нагрузок или конвертации кластеров.
Начало работы
Для обсуждения того, как i7i.metal-24xl может модернизировать среду VMware Cloud on AWS, рекомендуется связаться с представителем Broadcom. На vmc.broadcom.com доступны настройка нового SDDC, изучение вариантов расчёта размеров и запрос оценки рабочих нагрузок.
Компания «Базис», работающая на российском рынке программных решений для управления динамической инфраструктурой, сообщила о выходе платформы серверной виртуализации Basis Dynamix Enterprise версии 4.5.
В новом релизе расширены возможности экосистемы за счёт более тесной интеграции с системой управления программно-определяемыми сетями Basis SDN, улучшена совместимость с отечественными системами хранения данных, а также добавлены инструменты для повышения производительности и автоматизации управления ИТ-инфраструктурой. Всего версия 4.5 включает более 90 доработок и нововведений.
Расширение поддержки отечественных систем хранения данных
Одним из ключевых направлений развития версии 4.5.0 стало расширение поддержки российских СХД. В частности, добавлена работа с системой хранения uStor, включая полный набор операций: создание и управление дисками, работу с образами и снапшотами, а также презентацию и депрезентацию дисков вычислительным узлам.
Кроме того, реализована поддержка СХД Yadro Tatlin.Unified с версией ПО 3.2, при этом сохранена обратная совместимость с предыдущими версиями прошивки Tatlin. Это даёт заказчикам больше гибкости при выборе оборудования для построения импортонезависимой инфраструктуры и упрощает взаимодействие с ним через платформу.
Эффективное использование дискового пространства
В версии 4.5 внедрена поддержка unmap для дисков виртуальных машин. Теперь при удалении файлов внутри виртуальной машины освобождённое пространство не только помечается как свободное в гостевой системе, но и возвращается обратно в СХД. Это обеспечивает более эффективное использование дисковой ёмкости, что особенно важно при большом количестве виртуальных машин и использовании thin-provisioned дисков.
Развитие интеграции с программно-определяемыми сетями
Релиз 4.5 усиливает нативную интеграцию Basis Dynamix Enterprise с решением для программно-определяемых сетей Basis SDN и расширяет сетевые возможности платформы. Например, при создании виртуальных машин появилась возможность автоматически подключать SDN-сегменты с одновременным созданием логических портов, что сокращает объём ручной настройки и упрощает работу администраторов.
Автоматизация управления узлами
В Basis Dynamix 4.5 появился механизм автоматического перевода физического узла из состояния «На обслуживании» в статус «Работает». Соответствующая настройка доступна на странице «Физические узлы» в интерфейсе системы. При этом вместе с узлом автоматически запускаются виртуальные машины, ранее закреплённые за ним на момент перевода в режим обслуживания. Функция применима как к отдельным узлам, так и к целым зонам, что упрощает эксплуатацию крупных инфраструктур.
Другие улучшения
Помимо этого, версия 4.5.0 включает ряд дополнительных улучшений, повышающих удобство администрирования:
Механизм Watchdog, обеспечивающий автоматическое восстановление зависших виртуальных машин.
Поддержка режима Cache Write Through, повышающего производительность дисковой подсистемы.
Упрощённая начальная установка за счёт минимального конфигурационного файла.
Обновление спецификации API до версии OpenAPI 3.1.0.
Доработка модели физического узла: понятие «вычислительный узел» (stack) было упразднено, а его функциональность перенесена в сущность «физический узел» (node), что позволило упростить как модель данных, так и API платформы.
Возможность при создании виртуальной машины, даже если она разворачивается не из образа, включать дополнительные возможности гипервизора — такие как NUMA, CPU pinning и Huge Pages.
Возможность сделать виртуальную машину доступной только для чтения для всех пользователей.
При создании ВМ можно задавать маску сети для интерфейсов DPDK и VFNIC, а также настраивать MTU для транковых сетей в диапазоне от 1500 до 9216.
Можно ограничивать количество узлов, обрабатываемых одновременно, и при этом сбой на одном узле не прерывает общий процесс.
После первичной установки реализовано автоматическое обновление API-ключа для служебного пользователя.
Комментарий разработчика
«Одной из важнейших задач в рамках развития нашей флагманской платформы Basis Dynamix Enterprise является поддержание её совместимости с актуальным инфраструктурным оборудованием и ПО. Это касается в том числе и нашего собственного решения для организации программно-определяемых сетей Basis SDN, которое успешно работает в тестовых средах заказчиков и быстро развивается с учётом их пожеланий. Нашей целью является не просто поддержка отечественных систем хранения данных, инструментов резервного копирования или других решений. Мы хотим дать заказчику возможность построить на базе Basis Dynamix Enterprise полностью импортонезависимую динамическую ИТ-инфраструктуру, не ограничивая его при этом в выборе поставщиков "железа" или программных продуктов»
— Дмитрий Сорокин, технический директор компании «Базис».
В сфере виртуализации и облачной инфраструктуры системные инженеры регулярно сталкиваются с задачами расчётов, проверки параметров конфигурации и подготовки инфраструктуры к развертыванию. Именно для таких задач создан сайт https://tools.virtualbytes.cloud/ — онлайн-площадка с полезными утилитами для специалистов по VMware-инфраструктуре и облачным платформам.
Что представляет собой сервис
Tools.VirtualBytes.Cloud — это коллекция веб-инструментов, предназначенных для работы с инфраструктурными компонентами VMware-экосистемы и сопутствующих технологий. Сервис позволяет использовать различные утилиты прямо в браузере без установки дополнительного программного обеспечения на локальную машину.
Основная идея платформы — предоставить инженерам быстрый доступ к вспомогательным инструментам, которые упрощают администрирование и проектирование виртуальной инфраструктуры.
Какие инструменты доступны онлайн
Сервис ориентирован на специалистов, работающих с современными датацентрами и программно-определяемыми инфраструктурами. Среди основных направлений инструментов:
Работа с платформой VMware Cloud Foundation (VCF)
Инструменты для VMware NSX и сетевой виртуализации
Вспомогательные утилиты для vSAN
Сетевые и инфраструктурные калькуляторы
Инструменты для анализа и подготовки конфигураций
Благодаря веб-формату инструменты можно использовать с любого устройства — достаточно открыть сайт в браузере.
Бесплатные онлайн-утилиты
VCF Pre-Deployment Checklist
Интерактивный чеклист, охватывающий все требования перед развертыванием VCF — DNS, NTP, сетевую инфраструктуру, оборудование, лицензии, сертификаты, порты файрвола и многое другое. Позволяет добавлять заметки и экспортировать результат в PDF.
VCF Upgrade Path Advisor
Визуальный планировщик путей обновления для VMware Cloud Foundation версий 4.0–9.0. Использует поиск оптимального пути (BFS) между поддерживаемыми этапами обновления и предупреждает о промежуточных версиях.
VCF Host Sizing Calculator
Калькулятор минимального количества хостов для доменов нагрузки VCF с учетом отказоустойчивости N+1 и N+2. Учитывает накладные расходы vSAN, резервации HA и нагрузку management-компонентов.
IP Subnet Planner
Калькулятор подсетей VLSM и планировщик диапазонов IP-адресов для сетей VCF: management, vMotion, vSAN и NSX TEP. Проверяет пересечения подсетей и позволяет экспортировать готовый IP-план для развертывания.
MTU Path Calculator
Калькулятор эффективного MTU для overlay-сетей GENEVE и VXLAN. Моделирует накладные расходы инкапсуляции на каждом уровне и проверяет требования к jumbo-фреймам для NSX-инфраструктуры.
VLAN Allocation Planner
Инструмент для проектирования полного диапазона VLAN с использованием 9 шаблонов VCF. Включает обнаружение конфликтов, автоматическое заполнение подсетей, контроль соглашений по именованию, заметки по L3-маршрутизации и экспорт конфигураций коммутаторов для Arista, Cisco NX-OS, IOS-XE и Juniper.
VCF 9 Network Config Generator
Генератор полной сетевой конфигурации для VCF 9, включая назначение VLAN, параметры MTU, политики teaming и конфигурацию пулов NSX TEP для развертываний с несколькими кластерами.
vSAN Capacity Calculator
Калькулятор полезной емкости vSAN для архитектур OSA и ESA с политиками RAID-1, RAID-5 и RAID-6. Учитывает slack space, отказ хостов и приблизительную эффективность дедупликации.
NSX Firewall Rule Planner
Инструмент для планирования и документирования правил распределенного файрвола NSX. Позволяет задавать группы источников и назначений, сервисы и область применения (Applied-To), проверяет логику правил и экспортирует их в структурированную таблицу.
VCF Day 2 Operations Planner
Набор пошаговых runbook-процедур для операций Day-2: расширение кластера, создание доменов нагрузки, ротация сертификатов, обновление компонентов, смена паролей, расширение vSAN и управление сегментами NSX.
Для кого предназначен сайт
Платформа будет полезна:
Системным администраторам и инженерам виртуализации
Архитекторам облачной инфраструктуры
DevOps-специалистам
Инженерам датацентров и лабораторий
Особенно ценным ресурс становится при работе с VMware-экосистемой, где часто требуется быстро рассчитать параметры инфраструктуры или проверить настройки перед развертыванием.
Итог
Tools.VirtualBytes.Cloud — это полезный ресурс для специалистов по виртуализации и облачным технологиям. Он объединяет набор практических инструментов, которые помогают упростить работу с инфраструктурой VMware и ускорить решение повседневных задач администрирования.
Для инженеров, работающих с VCF, NSX и другими компонентами программно-определяемого дата-центра, подобные сервисы позволяют экономить время и повышать эффективность управления инфраструктурой.
В марте на российском рынке виртуализации серверов заметно усилился акцент на экосистемной совместимости, защищённой инфраструктуре и связке отечественного ПО с локальными аппаратными платформами. Ниже — обзор ключевых событий месяца.
Совместимость zVirt с системой доверенной загрузки «Соболь»
Одной из самых заметных мартовских новостей стало подтверждение совместимости платформы виртуализации zVirt с системой доверенной загрузки «Соболь». Для рынка это не просто технический тест, а важный сигнал о том, что отечественные платформы виртуализации всё активнее встраиваются в контур защищённой ИТ-инфраструктуры.
Практическое значение новости заключается в том, что организации из госсектора, критической инфраструктуры и компаний с повышенными требованиями к безопасности получают более предсказуемый сценарий внедрения виртуализации. Защита на этапе загрузки сервера дополняет архитектуру гипервизора и снижает риски компрометации базового уровня инфраструктуры.
В более широком контексте эта новость показывает зрелость экосистемы вокруг российских платформ виртуализации: заказчику уже недостаточно просто гипервизора, ему нужен связанный стек из виртуализации, средств защиты и поддержки регуляторных требований.
Sharx Base расширяет аппаратную совместимость через интеграцию с серверами Trinity
Другой важный сюжет марта связан с платформой Sharx Base и её совместимостью с серверами Trinity. Подобные новости на первый взгляд могут выглядеть как обычные интеграционные объявления, но для рынка импортозамещения они имеют стратегическое значение.
Сегодня заказчику нужен не отдельный программный продукт, а работоспособный и подтверждённый стек: сервер, слой виртуализации, система хранения и понятная схема поддержки. Именно поэтому новости о сертифицированной или подтверждённой совместимости привлекают внимание значительно сильнее, чем просто функциональные обновления.
Интеграция Sharx Base с серверами Trinity показывает, что российские игроки продолжают выстраивать полноценную инфраструктурную экосистему. Это снижает барьер входа для корпоративных клиентов и делает проекты миграции с зарубежных решений менее рискованными.
Реальные внедрения: использование Helius в крупной корпоративной инфраструктуре
Сильный информационный эффект в марте дали новости о практическом внедрении российских решений виртуализации в крупных инфраструктурных проектах. В этом контексте особое внимание привлекло использование Helius в составе геораспределённого вычислительного кластера у НМТП.
Такие кейсы важны потому, что рынок виртуализации давно вышел из стадии обсуждения возможностей на уровне презентаций. Для корпоративных заказчиков решающим аргументом становится подтверждение того, что отечественная платформа выдерживает промышленную эксплуатацию, масштабирование и работу в распределённой среде.
Появление подобных внедрений усиливает доверие к российским продуктам и служит сигналом для компаний, которые ещё находятся в фазе выбора альтернатив зарубежным платформам. Чем больше примеров работающих production-сценариев, тем быстрее ускоряется принятие решений на рынке.
Новые серверные платформы как фундамент для роста виртуализации
Мартовская повестка была связана не только с самим ПО виртуализации, но и с аппаратной базой, на которой эти решения будут массово разворачиваться. В этом смысле важной стала новость о включении серверов «Гравитон» в реестр Минпромторга.
Для сегмента виртуализации такие новости имеют прикладное значение. Массовое внедрение гипервизоров невозможно без понятной и доступной аппаратной платформы, которая подходит для корпоративных и государственных проектов, закупается по формальным требованиям и имеет прогнозируемый цикл поставки и поддержки.
Чем увереннее развивается российская серверная база, тем устойчивее выглядит вся экосистема виртуализации. Рынок постепенно переходит от точечных проектов к сборке полноценного импортонезависимого контура, где и программная, и аппаратная части развиваются синхронно.
Отраслевые конференции как индикатор зрелости рынка
Отдельным маркером зрелости рынка стала подготовка и проведение отраслевого мероприятия "Платформы виртуализации 2026", посвящённого российским платформам виртуализации, которое пройдет 31 марта 2026 года. Конференции в этой сфере уже выступают не витриной отдельных поставщиков, а пространством для обсуждения миграционных стратегий, реальных кейсов и динамики спроса.
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.
vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
Требования к оборудованию и сети
Варианты развертывания кластеров
Масштабирование и отказоустойчивость
Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
General Information — общая информация о vSAN
Express Storage Architecture (ESA)
Availability — отказоустойчивость
Cloud-Native Storage
vSAN File Services
vSAN Storage Clusters (disaggregated storage)
Stretched clusters и 2-node clusters
Networking
Capacity и Space Efficiency
Operations
Performance
Security
vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.
Компания VMware продолжает развитие своей платформы для частных облаков — VMware Cloud Foundation (VCF) 9.0. Недавно опубликованы первые результаты производительности с использованием бенчмарка VMmark 4, выполненные на базе VCF 9.0 с встроенным программно определяемым хранилищем VMware vSAN. Этот результат стал важной вехой для оценки возможностей платформы в реальных условиях нагрузки, демонстрируя, что VCF 9.0 способна эффективно масштабировать инфраструктуру частного облака с помощью современного оборудования и передовых технологий.
Что такое VMmark 4, и зачем он нужен
VMmark 4 — это кластерный бенчмарк VMware, предназначенный для измерения производительности и масштабируемости виртуализированных сред. В отличие от синтетических тестов, VMmark моделирует реальные корпоративные рабочие нагрузки:
базы данных
веб-серверы
почтовые системы
application-серверы
файловые сервисы
Нагрузка масштабируется в единицах tiles — каждый tile представляет собой комплекс виртуальных машин с типовым профилем предприятия. Итоговый показатель (VMmark Score) отражает способность кластера обслуживать увеличивающееся число рабочих нагрузок при сохранении SLA по производительности.
Тестовая конфигурация: ключевые компоненты
Для испытаний использовалась конфигурация, включающая новейшие аппаратные и программные компоненты:
Программное обеспечение: VMware Cloud Foundation 9.0.1.0 .
vSAN 9 ESA: программное хранилище уровня предприятия с оптимизированной архитектурой Express Storage Architecture.
NSX: сетевые сервисы и безопасность для виртуальной инфраструктуры.
Operations: мониторинг, аналитика и автоматизация облачных ресурсов.
Главная цель VCF — упростить развёртывание и управление частными облаками с уровня инфраструктуры до сервисов, при этом обеспечивая масштабируемость, производительность и возможность автоматизации.
Результат тестирования
Для объективного сравнения использовалась идентичная вычислительная платформа (AMD EPYC 9965, суммарно 1536 физических ядер кластера), но две разные подсистемы хранения:
vSAN 9.0 ESA (All-Flash, NVMe)
Классический FC SAN (Dell PowerMax 8000)
Таблица результатов:
Версия VCF
Тип хранилища
Процессор
Всего ядер
VMmark 4 Score
9.0.1.0
vSAN 9.0 ESA (All-Flash)
AMD EPYC 9965
1536
12.42 @ 15.4 tiles
9.0.0.0
FC SAN (Dell PowerMax 8000)
AMD EPYC 9965
1536
12.22 @ 14 tiles
Интерпретация результатов:
Tiles — это масштабируемые блоки нагрузки в VMmark 4. Каждый tile представляет набор типовых корпоративных рабочих нагрузок (Web, DB, Mail, Application Server и др.).
Значение 15.4 tiles означает более высокий уровень масштабирования кластера.
Итоговый показатель 12.42 — агрегированный производительный балл, учитывающий пропускную способность и latency.
Главный вывод - конфигурация с vSAN 9.0 ESA продемонстрировала:
Большее число поддерживаемых tiles (15.4 против 14 для FC)
Более высокий итоговый Score
Лучшую масштабируемость без использования внешнего SAN-массива.
Это подтверждает, что современная архитектура vSAN ESA в составе VCF 9.0 способна не только конкурировать с традиционными FC-решениями, но и превосходить их при одинаковой вычислительной базе.
Заключение
Новый VMmark 4 результат, полученный на VMware Cloud Foundation 9.0 с vSAN, подтверждает:
Высокую производительность и масштабируемость платформы.
Превосходство программно-определяемого хранения (vSAN) над традиционными SAN в современных конфигурациях.
Готовность VMware VCF 9.0 к использованию в масштабных частных облаках и корпоративных средах.
Для инженеров и архитекторов частных облаков это подтверждение того, что VCF 9.0 + vSAN — это не только удобная абстракция управления, но и мощная вычислительная платформа с высокими показателями эффективности.
По мере того как внедрение Kubernetes в корпоративной среде становится более зрелым, задачи, с которыми сталкиваются команды платформ, изменились. Развертывание кластеров больше не является основной проблемой. Настоящая работа начинается после первого дня: безопасное обновление кластеров, предсказуемая эксплуатация и поддержка нагрузок, таких как базы данных и регулируемые приложения, без хрупких скриптов или разовых исключений.
В последнем выпуске VMware vSphere Kubernetes Service (VKS) 3.6 в команде VMware сосредоточились именно на этих аспектах. Вместо того чтобы представлять длинный список несвязанных функций, этот релиз развивает платформу по нескольким ключевым операционным направлениям, которые действительно важны для платформенных инженеров и администраторов, запускающих Kubernetes в промышленной эксплуатации в крупном масштабе.
Кратко: что нового в VKS 3.6
VKS 3.6 включает улучшения в области корпоративной эксплуатации, производительности и гибкости экосистемы:
Открытая и расширяемая сетевая экосистема – поддерживаемый путь для партнерских сетевых дополнений позволяет плагинам Container Network Interface (CNI) нативно интегрироваться с VKS, оставаясь в рамках жизненного цикла и поддержки.
Настройка производительности для ресурсоемких по данным и чувствительных к задержкам нагрузок – декларативные профили TuneD позволяют безопасно настраивать параметры ядра и sysctl для баз данных и высокопроизводительных приложений без неподдерживаемых изменений на хостах.
Выбор корпоративной ОС с поддержкой RHEL – узлы на базе Red Hat Enterprise Linux (RHEL), включая кластеры со смешанными операционными системами.
Kubernetes 1.35, созданный для корпоративной эксплуатации
VKS 3.6 добавляет поддержку Kubernetes версии 1.35, продолжая обязательство Broadcom по предоставлению Kubernetes с сертификацией CNCF, предназначенного для корпоративного использования. Как и в предыдущих релизах, Broadcom предоставляет расширенную поддержку на 24 месяца для каждой версии Kubernetes с перекрывающейся поддержкой версий. Это позволяет крупным организациям переводить команды на новые версии в собственном темпе, не вынуждая выполнять массовые обновления всего парка или проводить сжатые окна обслуживания.
Некоторые заметные нововведения в выпуске Kubernetes 1.35 включают:
Настраиваемая параллельность для поэтапных обновлений StatefulSet с параметром maxUnavailable – теперь платформенные команды могут одновременно выводить из работы несколько Pod’ов во время обновлений StatefulSet, контролируя уровень нарушения работы для stateful-нагрузок и сокращая время развертывания.
Улучшенная осведомленность о топологии для нагрузок – приложения могут безопасно использовать информацию о топологии узлов, повышая понимание своего расположения в инфраструктуре, что полезно для чувствительных к задержкам и ресурсоемких по данным приложений.
Модернизированные основы хранения данных – такие усовершенствования, как тома на основе OCI, делают потребление хранилища в Kubernetes более согласованным с контейнерно-ориентированными моделями поставки.
В то же время Kubernetes продолжает удалять или объявлять устаревшими некоторые функции. VKS следует срокам устаревания upstream-версии, при этом предоставляя расширенную поддержку и четкие пути миграции, давая платформенным командам время на адаптацию без внезапных сбоев. Такой баланс сохраняет соответствие upstream-версии, избегая при этом разрушительных и массовых неожиданностей.
Более плавные обновления и более безопасные операции второго дня
Именно в процессе обновлений платформы Kubernetes чаще всего испытывают наибольшую нагрузку. На практике сбои при обновлении редко вызваны самим Kubernetes, а чаще конфигурацией и интеграциями. Политики, admission webhooks, а также инструменты безопасности или управления могут непреднамеренно блокировать операции жизненного цикла.
Развивая ранее внедренные предварительные проверки PodDisruptionBudget, VKS 3.6 расширяет проверки готовности к обновлению, чтобы выявлять распространенные конфликты конфигурации до начала обновления. Вместо обнаружения блокирующих факторов в середине процесса обновления платформенные команды могут заранее выявить и устранить проблемы до окна обслуживания, снижая количество неудачных обновлений и незапланированных сбоев. Эти проверки выполняются непрерывно, выявляя риски обновления через условие SystemCheckSucceeded, а не только во время выполнения обновления.
В результате — меньше неожиданностей при обновлении, более ранние предупреждения и более надежные операции второго дня без риска непредвиденной потери данных.
Производительность и ресурсоемкие по данным нагрузки
Запуск баз данных и других stateful-платформ в Kubernetes часто требует настройки ядра и параметров узлов, выходящих за пределы стандартных значений. Во многих средах команды полагались на ручные изменения узлов или специально собранные образы для удовлетворения этих требований. В моделях управляемого Kubernetes такие изменения, как правило, должны быть выражены декларативно (например, через утвержденные механизмы конфигурации, привилегированные DaemonSet’ы или стандартизированные образы), чтобы сохраняться при обновлениях и замене узлов.
VKS 3.6 вводит поддерживаемые профили TuneD, позволяя разработчикам декларативно настраивать ядро Linux (включая параметры sysctl и sysfs) через ресурсы Kubernetes. Профили могут быть привязаны к определенным пулам узлов, обеспечивая оптимизацию под конкретные нагрузки в рамках одного кластера.
Это делает распространенные сценарии простыми и поддерживаемыми, например:
Оптимизация узлов для высокопроизводительных сетевых нагрузок
Настройка поведения памяти для баз данных и систем кэширования
Корректировка параметров ядра для нагрузок, чувствительных к задержкам
Встроенный профиль обеспечивает безопасную отправную точку конфигурации, готовую для корпоративного использования, а пользовательские профили позволяют при необходимости сделать более глубокую специализацию. Результат — согласованная, безопасная при обновлениях настройка производительности, применяемая через стандартные рабочие процессы Kubernetes, без ручной конфигурации узлов и без дрейфа конфигурации.
Безопасность, соответствие требованиям и управление
VKS 3.6 упрощает поддержку нормативных и требований безопасности без жесткой фиксации кластеров в универсальных схемах усиленной защиты. Расширенная конфигурация компонентов Kubernetes позволяет платформенным командам настраивать уровень соответствия требованиям для каждой нагрузки и среды. Команды могут применять более строгие меры там, где это требуется, ослаблять их при необходимости и постепенно развивать конфигурации вместо пересоздания кластеров для изменения политики.
В этом выпуске также упрощено управление профилями AppArmor. Администраторы теперь могут определять профили AppArmor как Custom Resources и автоматически загружать их и поддерживать синхронизацию на всех рабочих узлах кластера или в отдельных пулах узлов. Это позволяет настраивать каждый workload с требуемым профилем AppArmor без сложности конфигурации на уровне узлов.
VKS 3.6 также повышает операционную автономность. Владельцы workload-кластеров теперь могут генерировать пакеты поддержки VKS без учетных данных vCenter, устраняя необходимость повышенного инфраструктурного доступа при устранении неполадок. Это снижает трения между командами Kubernetes и инфраструктуры, сохраняя принцип наименьших привилегий.
Пользовательский опыт платформы и развитие экосистемы
Корпоративные платформы Kubernetes требуют как сильных настроек по умолчанию, так и реального выбора в экосистеме. Чрезмерная жесткость замедляет внедрение; избыточная свобода создает операционные риски. Этот релиз продвигает баланс вперед, открывая платформу для партнерских инноваций и поддерживая возможность использования собственных инструментов заказчика.
Ваша сеть — ваш выбор
Теперь доступна поддерживаемая точка интеграции для сетевых партнеров и ISV. Платформенные команды могут использовать проверенные партнерами сетевые дополнения, оставаясь в рамках стандартных процессов жизненного цикла, обновления и поддержки. Это открывает возможности для нативной интеграции сторонних сетевых и сетевых защитных решений.
Команды могут сохранить сетевой стек, которому уже доверяют, а партнеры получают стабильную и поддерживаемую основу для разработки. Это снижает трения при миграции существующих сред Kubernetes на VKS и со временем расширяет набор доступных сетевых возможностей.
Ваш фаервол — ваш выбор
VKS 3.6 вводит централизованное управление правилами сетевого экрана на уровне узлов через API для всех поддерживаемых операционных систем. Теперь платформенные команды могут открывать необходимые порты для HostPorts и сервисов NodePort через конфигурацию кластера, вместо использования привилегированных init-контейнеров или DaemonSet’ов на каждом узле.
Перенос управления файрволом с отдельных нагрузок на уровень кластера упрощает конфигурацию, повышает аудируемость и снижает риски безопасности, связанные с привилегированными компонентами. Для Linux-узлов VKS 3.6 также добавляет поддержку backend nftables для kube-proxy, обеспечивая лучшую производительность и масштабируемость по сравнению с реализацией по умолчанию на основе iptables.
Ваша ОС — ваш выбор
Red Hat Enterprise Linux (RHEL) 9 присоединяется к Photon OS 5, Ubuntu 22.04 и 24.04, а также Windows Server 2022 в качестве поддерживаемых операционных систем для узлов кластера VKS. RHEL может использоваться как для узлов control plane, так и для рабочих узлов.
Для поддержки разнообразных требований приложений в рамках одного кластера VKS продолжает позволять различным пулам узлов работать на разных операционных системах. Пулы узлов RHEL могут существовать наряду с узлами Windows, Ubuntu и Photon, обеспечивая гетерогенные кластеры и постепенную миграцию ОС со временем.
VKS 3.6 также включает улучшенные инструменты для сборки пользовательских образов узлов для всех поддерживаемых операционных систем. Image Baker предназначен для сред с ограниченной сетевой связностью, работает независимо от vCenter для снижения инфраструктурных зависимостей и поставляется как плагин CLI VMware Cloud Foundation (VCF). Broadcom продолжает предоставлять готовые образы для Photon и Ubuntu.
Kubernetes — с меньшим количеством неожиданностей
Этот релиз сосредоточен на тех аспектах Kubernetes, которые наиболее важны после первого дня. Обновления становятся более предсказуемыми, настройка производительности для ресурсоемких нагрузок упрощается, среды на базе RHEL получают четкий путь миграции, а сетевая подсистема открывается для растущей экосистемы проверенных партнеров.
В совокупности эти изменения приводят Kubernetes в соответствие с тем, как заказчики реально используют его в промышленной эксплуатации: стандартизированно, с управлением на базе политик и с интеграцией с существующими инструментами и платформами.
Для платформенных команд, работающих в масштабе, результат прост: меньше неожиданностей, ниже операционные риски и более надежная основа для дальнейшего развития.
Более подробно о VMware vSphere Kubernetes Service 3.6 можно узнать на странице продукта.
В 2026 году сообщество ESX получило сразу два важнейших обновления, которые расширяют возможности использования популярных сетевых устройств Realtek RTL8157 и RTL8156BG в виртуальной инфраструктуре VMware. Эти обновления особенно актуальны для лабораторных сред, мини-ПК и других систем с оборудованием, не поддерживаемым «из коробки» стандартным инсталлятором ESX.
Интеграция Realtek Network Driver Fling в бесплатный установочный ISO ESXi
Одной из ключевых проблем при установке ESXi 8 Update 3 на ПК с сетевыми адаптерами Realtek является отсутствие драйверов для этих сетевых контроллеров в стандартном установщике. Чтобы обойти это ограничение, было разработано решение для сообщества пользователей - Realtek Network Driver Fling (пока еще недоступно для ESX 9, но скоро будет).
Этот драйвер не является официальным продуктом Realtek, а представляет собой компонент Fling (экспериментальный инструмент для расширения ESXi), который обеспечивает базовую поддержку PCIe-сетевых адаптеров Realtek. Об этом недавно написал Вильям Лам.
Драйвер поддерживает ряд популярных моделей Realtek:
RTL8111 — 1 GbE
RTL8125 — 2,5 GbE
RTL8126 — 5 GbE
RTL8127 — 10 GbE
Проблема в том, что в бесплатных ISO-образах ESXi отсутствует пакет offline bundle (который можно было бы включить стандартным способом). Однако, как показано в одной из публикаций Вильяма Лама, можно вручную интегрировать драйвер в ISO-установщик ESXi 8.0 Update 3e.
Процесс включает:
Загрузку ISO-образа ESXi и архива драйвера Realtek Network Driver Fling.
Извлечение модуля драйвера и переименование в специальный файл (например, ifre.v00).
Добавление этого модуля в загрузочный конфигурационный файл ISO (boot.cfg) для автоматической загрузки при старте установщика.
Установку ESXi с загрузочного носителя и копирование модуля драйвера на установленную систему для постоянного использования.
Этот метод позволяет запускать ESXi даже там, где стандартный инсталлятор не видит сетевой адаптер — например, на небольших ПК или системах без Intel-сетевых контроллеров.
Расширение USB-сетевого драйвера — поддержка новых чипов Realtek
Другая важная новость касается USB Native Network Driver для ESXi, ещё одного модуля Fling, который добавляет поддержку USB-сетевых адаптеров. Сегодня этот драйвер поддерживает уже более 25 различных чипсетов, а в свежем обновлении разработчики добавили поддержку USB-адаптеров Realtek RTL8157 (5 GbE) и RTL8156BG (2,5 GbE).
Это означает, что пользователи могут подключать к ESXi внешние USB-сетевые адаптеры и использовать их для сетевого трафика без необходимости установки PCIe-карты. Такие адаптеры, особенно в формате USB-C или USB-A, часто используются в компактных рабочих станциях и ноутбуках.
Примеры совместимых устройств (которые можно использовать для тестов и сборок лабораторных систем):
USB-A - 2,5 GbE адаптер на базе RTL8156BG
USB-C - 5 GbE адаптер на базе RTL8157
Установка обновлённого USB-сетевого драйвера производится как с помощью offline bundle (через команду esxcli software component apply), так и путём интеграции в ISO-образ ESXi аналогично описанному в статье Вильяма процессу.
Почему это важно
До появления этих драйверов ESXi мог не видеть сетевые устройства Realtek, что делало невозможной установку гипервизора на недорогие системы или платформы с USB-адаптерами. Решения Fling активно развиваются сообществом и дают пользователям гибкие способы расширения функциональности ESXi без официальной поддержки от производителя.
Теперь вы можете:
Интегрировать новейший Realtek PCIe-драйвер прямо в установщик ESXi.
Использовать современные USB-сетевые адаптеры с высокими скоростями передачи (2,5 GbE и 5 GbE).
Поддерживать широкий спектр оборудования в лабораторных или домашних средах.
Отличные новости для сетевых инженеров и архитекторов, работающих в экосистеме VMware. Компания представила новую сертификацию VMware Certified Advanced Professional – VCAP Administrator Networking (3V0-25.25). Этот экзамен продвинутого уровня (VCAP) предназначен для подтверждения глубоких знаний и практических навыков в проектировании, развертывании и администрировании сетевых решений VMware Cloud Foundation (VCF).
Новый стандарт профессиональной экспертизы в VCF Networking
Экзамен 3V0-25.25 ориентирован на опытных ИТ-специалистов, которые работают с современными корпоративными и мультиоблачными инфраструктурами. Получение данной сертификации демонстрирует способность кандидата эффективно решать сложные сетевые задачи в рамках архитектуры VMware Cloud Foundation.
Ключевые параметры экзамена:
Код экзамена: 3V0-25.25
Продолжительность: 135 минут
Количество вопросов: 60
Проходной балл: 300
Стоимость: 250 USD
Язык: английский
Кому подойдет эта сертификация
Экзамен рассчитан на специалистов с уверенным опытом в корпоративных сетях и экспертизой по решению VMware NSX. Рекомендуемый профиль кандидата включает:
1–2 года практического опыта проектирования и администрирования решений NSX
Не менее 2 лет работы с Enterprise-сетями
Уверенное владение UI-, CLI- и API-ориентированными рабочими процессами VCF
Практический опыт работы с VCF Networking и vSphere
Если вы ежедневно сталкиваетесь с проектированием и эксплуатацией сложных сетевых архитектур, этот экзамен станет логичным шагом в развитии карьеры.
Что проверяет экзамен 3V0-25.25
Основной акцент в экзамене сделан на планирование и дизайн сетевых решений VCF, с максимальной ориентацией на реальные архитектурные сценарии. Ключевые области оценки знаний включают:
ИТ-архитектуры, технологии и стандарты - проверяется понимание архитектурных принципов, умение различать бизнес- и технические требования, а также управлять рисками и ограничениями при проектировании.
Планирование и проектирование решений VMware - центральный блок экзамена, оценивающий способность спроектировать полноценное решение VMware Cloud Foundation с учетом доступности, управляемости, производительности, безопасности и восстановляемости.
Несмотря на то что в экзаменационном гайде указано наличие разделов без активных проверяемых целей, глубокое понимание всего жизненного цикла VCF Networking — от установки до устранения неполадок — значительно повышает шансы на успех.
Как подготовиться к экзамену
VMware рекомендует сочетать практический опыт с целенаправленным обучением. Для подготовки к экзамену доступны следующие курсы:
VMware Cloud Foundation Networking Advanced Design
VMware Cloud Foundation Networking Advanced Configuration
VMware Cloud Foundation Networking Advanced Troubleshooting
Также крайне важно изучить официальную документацию VMware Cloud Foundation 9.0, актуальные release notes и технические материалы от Broadcom, чтобы быть в курсе всех возможностей и изменений платформы.
Будьте среди первых сертифицированных специалистов
Выход сертификации VMware Certified Advanced Professional – VCF Networking — значимое событие для профессионалов в области сетевых технологий. Этот статус подтверждает высокий уровень экспертизы и позволяет выделиться на фоне других специалистов, открывая новые карьерные возможности. Если вы хотите быть на передовой в индустрии и официально подтвердить свои знания в области VCF Networking — сейчас самое время сделать этот шаг.
Диаграмма задержек VMware Cloud Foundation 9.0 теперь официально доступна на сайте Ports and Protocols в разделе Network Diagrams > VMware Cloud Foundation. Это официальный и авторитетный источник, который наглядно показывает сетевые взаимодействия и требования к задержкам в VCF 9.0.
Данное руководство настоятельно рекомендуется распечатать и разместить на рабочем месте каждого архитектора и администратора. Оно значительно упрощает проектирование, внедрение и сопровождение инфраструктуры, помогает быстрее выявлять узкие места, а также служит удобной шпаргалкой при обсуждении архитектурных решений, устранении неполадок и проверке соответствия требованиям. Фактически, это must-have материал для всех, кто работает с VMware Cloud Foundation в производственной среде.
Диаграмма демонстрирует, как различные элементы инфраструктуры VCF — управляющие домены, рабочие домены и центральные службы — взаимодействуют друг с другом в рамках распределённой частной облачной платформы, а также какие целевые значения Round-Trip Time (RTT) рекомендованы для стабильной и предсказуемой работы.
Что отражено на диаграмме:
VCF Fleet Components: диаграмма охватывает два отдельных экземпляра VCF (Instance 1 и Instance 2), включая их управляющие домены (Management Domain) и рабочие домены (Workload Domain), а также центральные Fleet-сервисы — VCF Operations и VCF Automation.
Целевые задержки: на диаграмме проставлены ориентировочные максимальные RTT-значения между компонентами, например между коллекторами VCF Operations и такими элементами, как vCenter, SDDC Manager, NSX Manager и ESX-хостами. Это служит практическим ориентиром для сетевых инженеров при планировании WAN- или LAN-связей между локациями.
Линии связи разной направленности: взаимодействия выполняются по разным путям и цветам, отражая направление обмена данными и зависимости между сервисами. Это помогает визуализировать, какие службы должны быть ближе друг к другу с точки зрения сети, а какие могут находиться дальше.
Практическая ценность
Такой сетевой ориентир крайне полезен архитекторам и администраторам, которые проектируют либо оптимизируют VCF-окружения в распределённых инфраструктурах. Он служит чёткой справочной картой, позволяющей:
Определить, какие связи нужно обеспечить минимально короткими с точки зрения задержки.
Согласовать проектные требования к ширине канала и RTT в разных сегментах сети.
Избежать узких мест в межкластерных коммуникациях, которые могут повлиять на производительность, управление или репликацию данных.
Диаграмма — это не просто техническая схема, а полноценный план качества сети, который должен учитываться при разворачивании VCF 9.0 на уровне предприятия.
В Broadcom сосредоточены на том, чтобы помочь клиентам модернизировать инфраструктуру, повысить устойчивость и упростить операции — без добавления сложности для команд, которые всем этим управляют. За последние несколько месяцев было выпущено несколько обновлений, делающих облако VMware Cloud on AWS (VMC) более гибким и простым в использовании. Легко пропустить последние обновления в последних примечаниях к релизам, поэтому мы хотим рассказать о некоторых из самых свежих функций.
Последние обновления предоставляют корпоративным клиентам более экономичную устойчивость благодаря нестандартным вторичным кластерам (non-stretched secondary clusters) и улучшенным возможностям масштабирования вниз, более прозрачную операционную информацию благодаря обновлённому пользовательскому интерфейсу, улучшенный VMC Sizer, новые Host Usage API, а также продолжающиеся улучшения продукта HCX 4.11.3.
Оптимизация развертываний SDDC: улучшения для stretched-кластеров
Когда вы развертываете Software Defined Datacenter (SDDC) в VMC, вам предоставляется выбор между стандартным развертыванием и stretched-развертыванием. Стандартный кластер развертывается в одной зоне доступности AWS (AZ), тогда как stretched-кластер обеспечивает повышенную доступность, развертывая SDDC в трёх зонах доступности AWS. Две зоны используются для размещения экземпляров, а третья — для компонента vSAN Witness.
Поскольку SDDC в stretched-кластерах размещает хосты в двух зонах доступности AWS, клиентам необходимо планировать ресурсы по схеме два к одному, что может быть слишком дорого для рабочих нагрузок, которые не требуют высокой доступности. Кроме того, если stretched-кластер масштабируется более чем до шести хостов, ранее его нельзя было уменьшить обратно. Чтобы улучшить обе эти ситуации, команда VMC внедрила нестандартные вторичные кластеры (Non-Stretched Secondary Clusters) в stretched-SDDC, а также улучшенные возможности масштабирования вниз для stretched-кластеров.
Нестандартные вторичные кластеры в stretched-SDDC
Ранее все кластеры в stretched-SDDC были растянуты между двумя зонами доступности. В этом обновлении только первичный кластер должен быть stretched, в то время как вторичные кластеры теперь могут развертываться в одной зоне доступности.
В stretched-кластере хосты должны развертываться равномерно, поэтому минимальный шаг масштабирования — два хоста.
Но в нестандартном вторичном кластере можно добавлять хосты по одному, что позволяет увеличивать количество развернутых хостов только в той зоне доступности AWS, где они действительно нужны.
Некоторые ключевые преимущества:
Обеспечивает преимущества как stretched-, так и non-stretched-кластеров в одном и том же SDDC.
Позволяет расширять кластер в одной AZ по одному хосту в non-stretched-кластерах.
Снижает стоимость для рабочих нагрузок, которым не требуется доступность stretched-кластера, включая тестовые и/или девелоперские окружения, где высокая доступность не обязательна.
Поддерживает архитектуры приложений с нативной репликацией на уровне приложения — их можно развертывать в двух независимых нестандартных вторичных кластерах (Non-Stretched Secondary Clusters).
VMC поддерживает stretched-кластеры для приложений, которым требуется отказоустойчивость между AZ. Начиная с версии SDDC 1.24 v5, клиенты получают большую гибкость в том, как их кластеры развертываются и масштабируются. Non-stretched-кластеры могут быть развернуты только в одной из двух AWS AZ, в которых находятся stretched-хосты, и эта функция доступна только для SDDC версии 1.24v5 и выше. Кроме того, SLA для non-stretched-кластера отличается от SLA для stretched-кластера, так как non-stretched не предоставляет повышенную доступность.
При планировании новых развертываний SDDC рассмотрите возможность использования Stretched Cluster SDDC, чтобы получить преимущества и высокой доступности, и оптимизированного размещения рабочих нагрузок.
Улучшенные возможности масштабирования вниз (Scale-Down) для stretched-кластеров
Ранее stretched-кластеры нельзя было уменьшить ниже шести хостов (три в каждой AZ). Теперь вы можете уменьшить кластер с шести или более хостов до четырёх хостов (два в каждой AZ) или даже до двух хостов (по одному в каждой AZ), в зависимости от доступных ресурсов и других факторов. Это даёт вам больший контроль над инфраструктурой и помогает оптимизировать расходы.
Ключевые сценарии использования:
Если использование ресурсов рабочей нагрузки снижалось со временем, и теперь вам необходимо уменьшить stretched-кластер, ориентируясь на текущие потребности.
Если ранее вы увеличивали stretched-кластер до шести или более хостов в период пикового спроса, но сейчас такие мощности больше не нужны.
Если вы недавно перевели свои кластеры с i3.metal на i4i.metal или i3en.metal и больше не нуждаетесь в прежнем количестве хостов. Новые типы инстансов обеспечивают такую же или лучшую производительность с меньшим набором хостов, что позволяет экономично уменьшить кластер.
Однако перед уменьшением stretched-кластера необходимо учитывать несколько важных моментов:
Если в вашем первичном кластере используются крупные управляющие модули (large appliances), необходимо поддерживать минимум шесть хостов (три в каждой AZ).
Для кластеров с кастомной конфигурацией 8 CPU минимальный размер — четыре хоста (два в каждой AZ).
Масштабирование вниз невозможно, если кластер уже на пределе ресурсов или если уменьшение нарушило бы пользовательские политики.
Изучите текущую конфигурацию, сравните её с рекомендациями выше — и вы сможете эффективно адаптировать свой stretched-кластер под текущие потребности.
Контролируйте свои данные: новый Host Usage Report API
VMware представила новый Host Usage Report API, который обеспечивает программный доступ к данным о потреблении хостов. Теперь вы можете получать ежедневные отчёты об использовании хостов за любой период и фильтровать их по региону, типу инстанса, SKU и другим параметрам — всё через простой API.
Используйте эти данные, чтобы анализировать тенденции использования хостов, оптимизировать расходы и интегрировать метрики напрямую в существующие инструменты отчётности и дашборды. Host Usage Report API поддерживает стандартные параметры запросов, включая сортировку и фильтрацию, что даёт вам гибкость в получении именно тех данных, которые вам нужны.
Изображение выше — это пример вывода API. Вы можете автоматизировать этот процесс, чтобы передавать данные в любой аналитический инструмент по вашему выбору.
Улучшения продукта: HCX версии 4.11.3 теперь доступен для VMC
Теперь VMware HCX версии 4.11.3 доступен для VMware Cloud on AWS, и он включает важные обновления, о которых вам стоит знать.
Что нового в HCX 4.11.3?
Этот сервисный релиз содержит ключевые исправления и улучшения в областях datapath, системных обновлений и общей эксплуатационной стабильности, чтобы обеспечить более плавную работу. Полный перечень всех улучшений можно найти в официальных HCX Release Notes. Версия HCX 4.11.3 продлевает поддержку до 11 октября 2027 года, обеспечивая долгосрочную стабильность и спокойствие. VMware настоятельно рекомендует всем клиентам обновиться до версии 4.11.3 как можно скорее, так как более старые версии больше не поддерживаются.
Если вы настраиваете HCX впервые, VMware Cloud on AWS автоматически развернёт версию 4.11.3. Для существующих развертываний 4.11.3 теперь является единственной доступной версией для обновления. Нужна помощь, чтобы начать? Ознакомьтесь с инструкциями по активации HCX и по обновлению HCX в VMware Cloud on AWS.
Улучшенный интерфейс: обновлённый VMware Cloud on AWS UI
VMware Cloud on AWS теперь оснащён обновлённым пользовательским интерфейсом с более упрощённой компоновкой, более быстрой навигацией и улучшенной согласованностью на всей платформе. Новый интерфейс уже доступен по адресу https://vmc.broadcom.com.
Улучшенные рекомендации по сайзингу среды: обновления VMC Sizer и Cluster Conversion
VMware представила серьёзные улучшения в процессе конвертации кластеров VMC (VMC Cluster Conversion) в инструменте VMware Cloud Sizer. Эти обновления обеспечивают более точные рекомендации по сайзингу, большую прозрачность и улучшенный пользовательский опыт при планировании перехода с хостов i3.metal на i3en.metal или i4i.metal.
Что нового в оценках VMC Cluster Conversion?
Обновлённый алгоритм оценки в VMC Sizer теперь позволяет получить более полное представление о ваших потребностях в ресурсах перед переходом с i3.metal на более новые типы инстансов.
Рекомендация по количеству хостов в обновлённом выводе VMC Sizer формируется на основе шести ресурсных измерений, и итоговая рекомендация определяется наибольшим из них.
В отчёт включены следующие параметры:
Вычислительные ресурсы (compute)
Память (memory)
Использование хранилища (storage utilization) — с консервативным и агрессивным вариантами оценки
Политики хранения vSAN (vSAN storage policies)
NSX Edge
Другие критически важные параметры
Все эти данные объединены в ясный и практичный отчёт VMC Sizer с рекомендациями, адаптированными под ваш сценарий миграции на новые типы инстансов.
Этот результат оценки является моментальным снимком текущего использования ресурсов и не учитывает будущий рост рабочих нагрузок. При планировании конвертации кластеров следует учитывать и несколько других важных моментов:
Итоговое количество хостов и параметры сайзинга будут подтверждены уже в ходе фактической конвертации кластера.
Клиентам рекомендуется повторно выполнять оценку сайзинга после любых существенных изменений конфигурации, ресурсов или других параметров.
В ходе конвертации политики RAID не изменяются.
Предоставляемые в рамках этого процесса оценки подписки VMware служат исключительно для планирования и не являются гарантированными финальными требованиями.
Фактические потребности в подписке могут оказаться выше предварительных оценок, что может потребовать покупки дополнительных подписок после конвертации.
Возвраты средств или уменьшение объёма подписки не предусмотрены, если предварительная оценка превысит фактические потребности.
VMware повторно представила свои сертификации продвинутого уровня с выпуском трёх новых экзаменов VMware Certified Advanced Professional (VCAP) для VMware Cloud Foundation 9.0. Эти сертификации предназначены для опытных IT-специалистов, которые хотят подтвердить свою экспертизу в проектировании, построении и управлении сложными средами частного облака. Возвращение экзаменов VCAP является важной вехой для специалистов VMware, предлагая чёткий путь для карьерного роста и признания их продвинутых навыков.
Понимание сертификации VCAP
Сертификация VMware Certified Advanced Professional (VCAP) — это престижный квалификационный уровень, который означает глубокое понимание технологий VMware и способность применять эти знания в реальных сценариях. Размещённая выше уровня VMware Certified Professional (VCP), сертификация VCAP предназначена для опытных специалистов, которые уже продемонстрировали прочные базовые знания продуктов и решений VMware. Получение сертификации VCAP демонстрирует приверженность к совершенству и высокий уровень профессионализма в специализированной области технологий VMware.
Новые экзамены VCAP для VMware Cloud Foundation 9.0
С выпуском VMware Cloud Foundation 9.0 VMware представила три новых экзамена VCAP, каждый из которых сосредоточен на критически важном аспекте платформы VCF. Эти экзамены ориентированы на конкретные рабочие роли и наборы навыков, позволяя специалистам специализироваться в областях, которые соответствуют их карьерным целям.
1. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 vSphere Kubernetes Service (3V0-24.25)
Эта сертификация предназначена для специалистов, работающих с контейнеризированными рабочими нагрузками и современными приложениями. Экзамен подтверждает навыки, необходимые для развертывания, управления и обеспечения безопасности vSphere with Tanzu, что позволяет предоставлять Kubernetes-as-a-Service на платформе VCF. Кандидаты на получение этой сертификации должны иметь практический опыт работы с Kubernetes, контейнерными сетями и хранилищами.
2. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Automation (3V0-21.25)
Эта сертификация сосредоточена на возможностях автоматизации и оркестрации VMware Cloud Foundation. Экзамен оценивает способность кандидата проектировать, внедрять и управлять рабочими процессами автоматизации с помощью VMware Aria Automation (ранее vRealize Automation). Эта сертификация идеально подходит для специалистов, которые отвечают за автоматизацию предоставления инфраструктуры и сервисов приложений.
3. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Operations (3V0-22.25)
Эта сертификация ориентирована на специалистов, отвечающих за ежедневные операции и управление средой VMware Cloud Foundation. Экзамен охватывает такие темы, как мониторинг производительности, управление ёмкостью, устранение неполадок и управление жизненным циклом. Эта сертификация хорошо подходит для системных администраторов, операторов облака и инженеров по надёжности.
Все три новых экзамена VCAP для VMware Cloud Foundation 9.0 имеют схожий формат и структуру. Экзамены проводятся под наблюдением и доступны через Pearson VUE. Они состоят из 60 вопросов и имеют длительность 135 минут. Типы вопросов разнообразны и могут включать множественный выбор, drag-and-drop и практические лабораторные симуляции, обеспечивая комплексную оценку знаний и навыков кандидата.
Заключение
Возвращение экзаменов VCAP для VMware Cloud Foundation 9.0 предоставляет ценную возможность для специалистов VMware подтвердить свои продвинутые навыки и экспертизу. Эти сертификации являются свидетельством способности работать с новейшими технологиями VMware и являются признанным эталоном качества в отрасли. Получив сертификацию VCAP, специалисты могут улучшить свои карьерные перспективы и продемонстрировать свою приверженность к тому, чтобы оставаться на переднем крае постоянно развивающегося мира облачных вычислений.
Компания Broadcom объявила о продвижении «открытой, расширяемой экосистемы» для VMware Cloud Foundation (VCF), с тем чтобы пользователи могли строить, подключать, защищать и расширять свои приватные облака. Цель — дать заказчикам большую свободу выбора оборудования, сетевых архитектур и софтверных компонентов при развертывании приватного облака или облачной инфраструктуры на базе VCF.
Ключевые направления:
Расширение аппаратной сертификации (OEM/ODM)
Внедрение открытых сетевых конструкций (EVPN, BGP, SONiC)
Вклад в open-source проекты (например, Kubernetes и связанные)
Усиленные партнёрства с такими игроками как Cisco Systems, Intel Corporation, OVHcloud, Supermicro Inc., SNUC.
Архитектура и аппаратная сертификация
VCF AI ReadyNodes и ODM self-certification
Одной из ключевых инициатив является расширение программы сертификации аппаратных узлов для VCF:
Появляются новые «VCF AI ReadyNodes» — предсертифицированные серверные конфигурации с CPU, GPU и другими ускорителями, пригодные для AI-обучения и вывода (inference).
В программе сертификации ReadyNode для ODM-партнёров теперь предусмотрена самосертификация (ODM Partner Self-Certification) через технологическую альянс-программу Broadcom Technology Alliance Program (TAP). Вся сертифицированная система обеспечена полной совместимостью с VCF и единым жизненным циклом управления VCF.
Поддержка edge-узлов: расширена поддержка компактных, «прочностных» (rugged) серверов для индустриальных, оборонных, розничных и удалённых площадок, что позволяет разворачивать современное приватное облако ближе к точкам генерации данных.
Технические следствия:
Возможность применять новейшие аппаратные ускорители (GPU, FPGA и др.) под VCF, с гарантией совместимости.
Упрощение цепочки выбора оборудования: благодаря self-certification ODM могут быстрее вывезти сертифицированные узлы, заказчик — выбрать из более широкого набора.
Edge-варианты означают, что приватные облака не ограничены классическими ЦОД-конфигурациями, а могут быть размещены ближе к источнику данных (IoT, фабрики, розница), что важно для задержки, пропускной способности, регулирования данных.
В совокупности это снижает TCO (Total Cost of Ownership) и ускоряет модернизацию инфраструктуры. Broadcom отмечает, что Intel, OVHcloud и др. подтверждают, что это даёт меньшее время time-to-market.
Почему это важно
Для организаций, которые строят приватные облака, часто возникает проблема «запертой» инфраструктуры: если узел не сертифицирован, риск несовместимости — обновления, жизненный цикл, поддержка. Открытая сертификация даёт больший выбор и снижает зависимость от одного производителя. При этом, с учётом AI-нагрузок и edge-инфраструктуры, требования к аппаратуре растут, и важна гарантия, что выбранный сервер будет работать под VCF без сюрпризов.
Сетевые инициативы: открытые сети и EVPN
Стратегия Broadcom в отношении сети
Broadcom объявляет стратегию объединения сетевых фабрик (network fabrics) и упрощения сетевых операций в приватном облаке через стандарты EVPN и BGP. Основные моменты:
Поддержка сетевой интероперабельности между средами приложений и сетью: применение стандарта EVPN/BGP позволяет гибче и масштабируемее организовать сетевые фабрики.
Цель — ускорить развертывание, дать мультивендорную гибкость, сохранить существующие сетевые инвестиции.
Совместимость с продуктом NSX (в составе VCF) и сторонними сетевыми решениями на уровне VPC-защиты, единой сетевой операционной модели, маршрутизации и видимости.
В рамках партнёрства с Cisco: VCF переходит к поддержке EVPN и совместимости с решением Cisco Nexus One fabric, что даёт клиентам архитектурную гибкость.
VCF Networking (NSX) поддерживает открытый NOS (network operating system) SONiC — операционную систему для сетевых коммутаторов, основанную на Linux, на многосоставном и мультивендорном оборудовании.
Технические особенности EVPN / BGP в контексте VCF
EVPN (Ethernet VPN) обеспечивает слой 2/3 виртуализации по IP/MPLS сетям, поддерживает VXLAN, MPLS-Over-EVPN и даёт нативную мультидоменную сегментацию.
BGP служит как протокол контрольной плоскости для EVPN, позволяет сетям в разных локациях или доменах обмениваться маршрутами VXLAN/EVPN.
В контексте VCF нужно, чтобы сеть поддерживала мультивендорность, работу с NSX, автоматизацию и процессы жизненного цикла. С открытым стандартом EVPN/BGP графику управления можно встроить в операции DevOps, IaC (Infrastructure as Code).
Поддержка SONiC позволяет использовать коммутаторы «commodity» с открытым NOS, снижая затраты как CAPEX, так и OPEX: модульная архитектура, контейнеризация, возможность обновлений без простоя.
Значение для заказчика
Возможность построить приватное облако, где сеть не является узким местом или «чёрным ящиком» вендора, а открытa и гибка по архитектуре.
Снижение риска vendor-lock-in: можно выбирать разное сетевое оборудование, переключаться между вендорами и сохранять совместимость.
Повышенная скорость развертывания: сертифицированные интеграции, открытые стандарты, меньше ручной настройки.
Поддержка edge-сценариев и распределённых облаков: сетевые фабрики могут распространяться по ЦОД, филиалам, edge-узлам с единым контролем и видимостью.
Вклад в открытое программное обеспечение (Open Source)
Broadcom подчёркивает свою активность как участника сообщества облачных нативных технологий. Основные пункты:
Компания является одним из пяти крупнейших долгосрочных контрибьюторов в Cloud Native Computing Foundation (CNCF) и вносит изменения/улучшения в проекты: Antrea, Cluster API, containerd, Contour, etcd, Harbor и другие.
Важная веха: решение vSphere Kubernetes Service (VKS) от VMware теперь является Certified Kubernetes AI Conformant Platform — это означает, что платформа соответствует требованиям для AI-нагрузок и встроена в стандарты Kubernetes.
Техническое значение
Совместимость с Kubernetes-экосистемой означает, что приватные облака на VCF могут использовать облачно-нативные модели: контейнеры, микро-сервисы, CI/CD, GitOps.
AI Conformant сертификация даёт уверенность, что платформа поддерживает стандартизированную среду для AI-нагрузок (модели, фреймворки, инфраструктура).
Работа с такими компонентами как containerd, etcd, Harbor облегчает создание, хранение, оркестрацию контейнеров и сбор образов, что важно для DevOps/DevSecOps практик.
Интеграция с открытым стеком упрощает автоматизацию, ускоряет выход новых функций, увеличивает портируемость и мобильность рабочих нагрузок.
Пользовательские выгоды
Организации получают возможность не просто виртуализировать нагрузки, но и расширяться в направлении «контейнеров + AI + edge».
Более лёгкий перенос рабочих нагрузок между средами, снижение необходимости в проприетарных решениях.
Возможность быстро реагировать на изменение требований бизнеса: добавление AI-сервиса, изменение инфраструктуры, использование микросервисов.
Практические сценарии применения
Приватное облако с AI-нагрузками
С сертифицированными AI ReadyNodes и поддержкой Kubernetes + AI Conformant платформой, заказчики могут:
Развернуть приватное облако для обучения моделей машинного обучения/AI (CPU + GPU + ускорители) на базе VCF.
Вывести inference-нагрузки ближе к источнику данных — например, на edge-узле в фабрике или розничном магазине.
Использовать унифицированный стек: виртуальные машины + контейнеры + Kubernetes на одной платформе.
Выполнить модернизацию инфраструктуры с меньшими затратами, за счёт сертификации и ПО с открытыми стандартами.
Развёртывание edge-инфраструктуры
С расширением поддержки edge-оптимизированных узлов:
Приватное облако может распространяться за пределы ЦОД — например, на фабрики, сеть розничных точек, удалённые площадки.
Сеть EVPN/BGP + SONiC позволяет обеспечить единое управление и видимость сетевой фабрики, даже если часть инфраструктуры находится далеко от центра.
Заказчики в индустрии, госсекторе, рознице могут использовать эту архитектуру для низкой задержки, автономной работы, гибкой интеграции в основной ЦОД или облако.
Гетерогенная инфраструктура и мультивендорные сети
Благодаря открытым стандартам и сертификации, заказчики не ограничены выбором одного поставщика оборудования или сети.
Можно комбинировать разные серверные узлы (от разных OEM/ODM), разные коммутаторы и сетевой софт, и быть уверенным в интеграции с VCF.
Это помогает снизить зависимость от единственного вендора, сделать инфраструктуру более гибкой и адаптивной к будущим изменениям.
Последствия и рекомендации
Последствия для рынка и архитектуры приватных облаков
Увеличится конкуренция среди аппаратных и сетевых поставщиков, так как сертификация и сами архитектуры становятся более открытыми.
Уменьшается риск «запирания» заказчиков в единой экосистеме производителя. Это способствует более быстрому внедрению инноваций: ускорители, AI-узлы, edge.
Открытые сети и стандарты означают повышение скорости развертывания, уменьшение сложности и затрат.
Часто частные облака превращаются в гибридные либо распределённые модели, где части инфраструктуры находятся в ЦОД, на edge, в филиалах — и такие архитектуры становятся проще благодаря инициативам Broadcom/VCF.
Что стоит учесть пользователям
При выборе инфраструктуры приватного облака важно проверять сертифицированные конфигурации VCF ReadyNodes, чтобы быть уверенным в поддержке жизненного цикла, обновлений и совместимости.
Если планируется AI-нагрузка — уделите внимание использованию AI ReadyNodes, поддержке GPU/ускорителей, сертификации.
Если сеть критична (например, распределённые локации, филиалы, edge) — рассмотрите архитектуры EVPN/BGP, совместимые с NSX и мультивендорными решениями, а также возможности SONiC.
Не забывайте об автоматизации и интеграции с облачно-нативными технологиями (Kubernetes, контейнеры, CI/CD): наличие поддержки этих технологий позволяет быстрее развивать платформу.
Оцените TCO не только с точки зрения CAPEX (серверы, оборудование) но и OPEX (обслуживание, обновления, гибкость). Использование открытых стандартов и сертифицированных решений может снизить оба.
Заключение
Объявление Broadcom о «открытой экосистеме» для VMware Cloud Foundation — это важный шаг к тому, чтобы приватные облака стали более гибкими, адаптивными и ориентированными на будущее. Сертификация аппаратуры (в том числе для AI и edge), открытые сетевые стандарты и активный вклад в open-source проекты – всё это создаёт технологическую платформу, на которой организации могут строить современные инфраструктуры.
При этом важно помнить: открытость сама по себе не решает все проблемы — требуется грамотная архитектура, планирование жизненного цикла, взаимодействие с партнёрами и понимание, как компоненты сочетаются. Тем не менее, такие инициативы создают условия для более лёгкой и менее рисковой модернизации облачной инфраструктуры.
В течение почти двух десятилетий сертификация VMware Certified Design Expert (VCDX) оставалась высшей мерой мастерства для архитекторов, работающих с решениями VMware — глобально признанным достижением экспертного уровня. Но по мере того как развитие частных облаков ускоряется и потребности нашего сообщества эволюционируют, мы не просто адаптируемся — мы совершаем революцию.
VMware рада объявить о развитии этой знаковой программы, расширяя её рамки за пределы традиционной роли дизайнеров виртуальной среды, чтобы приветствовать более широкий круг высококвалифицированных специалистов VMware: архитекторов, администраторов и специалистов поддержки. Чтобы отразить это расширенное видение, VMware переименовала программу в VMware Certified Distinguished Expert (VCDX).
Это не просто обновление — это стратегическое переосмысление программы VCDX, созданное специально для специалистов, стремящихся активно формировать будущее частных облаков. Это также приглашение развивать свои глубокие знания VMware, выходить за привычные рамки и прокладывать путь для нового поколения частных облачных сред, помогая формировать их будущее.
Критически важная потребность в современной облачной экспертизе
Необходимость в специализированных знаниях по современным облачным технологиям сегодня как никогда высока. Согласно отчёту Flexera 2024 State of the Cloud, 76% предприятий планируют расширять облачные сервисы через частные облака, и спрос на глубокую облачную экспертизу стремительно растёт. Тем не менее сохраняется серьёзная проблема — повсеместный дефицит облачных навыков. Аж 95% ИТ-руководителей заявили, что нехватка облачных компетенций негативно сказывается на их командах, приводя к снижению темпов инноваций и росту операционных затрат. Ещё более тревожный факт: почти треть организаций ставят под угрозу свою прибыль, не достигнув финансовых целей из-за этого критического дефицита облачных навыков.
В условиях столь стремительно меняющегося ландшафта постоянное обучение и высокоуровневая сертификация перестали быть опцией — они стали необходимостью для развития ключевых навыков, требуемых современными облачными средами. Программа VMware Certified Distinguished Expert предоставляет уникальную возможность не только преодолеть этот дефицит, но и стать тем ценнейшим специалистом, которого компании отчаянно ищут в области современных облачных технологий.
Преимущество VCDX: открывая путь к эксклюзивным возможностям
Сертификация VMware Certified Distinguished Expert — это высший уровень навыков и лидерства, необходимый для проектирования, разработки концепции и валидации самых надёжных, масштабируемых и безопасных сред VMware Cloud Foundation. Достижение этого престижного статуса предоставляет уникальную возможность использовать свои глубокие знания, активно влиять на развитие облачных сред и вести индустрию к следующему поколению облачной архитектуры.
Помимо формального признания, статус VCDX погружает вас в самую передовую часть развития решений для частных облаков, соединяя с глобальной сетью элитных технических специалистов. Представьте себе: ранний доступ к будущим бета-версиям продуктов, эксклюзивный первый взгляд на предстоящие обновления платформы VCF, позволяющие всегда оставаться впереди.
Вы также получите расширенные возможности напрямую влиять на стратегию, участвуя в ключевых форумах, таких как Product Technical Advisory Boards (PTAB) и Customer Technical Advisory Boards (CTAB). Кроме того, вы сможете усилить свою роль лидера мнений, участвуя в публичных мероприятиях, таких как собрания VMUG и конференции VMware Explore.
Быть частью глобальной сети — значит взаимодействовать с коллегами по всему миру и непосредственно влиять на направление развития продуктов VMware. Ваши востребованные, расширенные технические навыки обеспечат вам лидерские позиции в инновациях частных облаков, значительно расширив как карьерный, так и финансовый потенциал.
Ускорьте карьеру в области частных облаков
Получение сертификации VCDX выделяет вас как специалиста высшего уровня в сфере частных облаков, обладающего конкурентоспособным вознаграждением — согласно данным Glassdoor, средняя зарплата старших облачных специалистов составляет $200 000. Эта элитная квалификация прочно закрепляет вас на передовой частных облачных технологий, готовя к руководству самыми сложными инициативами VMware Cloud Foundation.
Вы не только продемонстрируете экспертное владение ключевыми ролями — Администратора, Архитектора и Специалиста поддержки, — но и утвердитесь как технический лидер-визионер. Представьте, какой вклад вы сможете внести в свою компанию, какие инновации продвинуть и какого ускорения в карьере добиться, достигнув высшего уровня экспертизы в частных облаках. Это не только укрепит ваше профессиональное развитие, но и обеспечит вам статус лидера в динамично развивающемся ландшафте частных облаков.
Ваш путь к достижению облачной экспертизы
Путь к получению статуса VCDX тщательно продуман, чтобы поднять ваш уровень лидерства и экспертизы. Для действующих и будущих специалистов по VCF путь VCDX начинается с формирования комплексной базы знаний о платформе VCF через базовую сертификацию VCP (VMware Certified Professional). Затем он углубляет экспертизу в ключевых технологиях VCF, таких как Kubernetes, с помощью продвинутых сертификаций VCAP (VMware Certified Advanced Professional). Этот строгий путь завершается защитой среди подтвержденных экспертов в рамках офлайн-сессии, подтверждающей глубокие архитектурные знания, продвинутые навыки решения проблем и непревзойдённую экспертизу, соответствующую вашей специализированной роли. Это ваш чёткий путь к элитному лидерству в области частных облаков.
Как профессионал VCDX, вы играете ключевую роль в продвижении следующего поколения облачной архитектуры. Готовы ли вы начать это невероятно перспективное путешествие? Начните путь к VMware Certified Distinguished Expert уже сегодня и определите своё место в будущем частных облаков заново.
Пожалуйста, скачайте руководствo по обучению VCF 9 для различных ролей, чтобы получить доступ к новейшим курсам с инструктором, обучению по запросу, а также ключевым ресурсам для подготовки к экзаменам. Если вы являетесь клиентом VCF Full Platform или партнером, отвечающим требованиям, посетите раздел Learning@Broadcom на Broadcom Support Portal для доступа к обучающим материалам.
Наблюдаемость (Observability) — это призма, через которую команды платформ получают понимание происходящего во всём ландшафте приложений. Она охватывает всё: от производительности, оповещений и устранения неполадок до развертывания и операций второго дня, таких как планирование ресурсов.
В VMware Tanzu Platform 10.3 компания Broadcom представила набор обновлений наблюдаемости в Tanzu Hub, которые углубляют видимость, ускоряют адаптацию команд и помогают сократить время решения проблем. Независимо от того, отвечаете ли вы за надежность, инженерные аспекты платформы или опыт разработчиков, новые функции позволяют автоматически получать и видеть релевантные данные, чтобы действовать быстрее и с большим доверием к своей платформе. Эти усовершенствования обеспечивают централизованный, целостный опыт наблюдаемости в Tanzu Hub.
Ключевые новые улучшения наблюдаемости в Tanzu Hub
В этом выпуске представлены усовершенствованные топологии и наложения оповещений, значительно повышающие видимость взаимосвязей инфраструктуры и зависимостей между сущностями. Теперь оверлей оповещений предоставляет более богатый контекст, включая возможность прямой связи с инфраструктурными системами или событиями в слое VCF, что упрощает процесс устранения неполадок. Контекстные оповещения автоматически сопоставляются с соответствующей сущностью, а в Tanzu Platform 10.3 эта функциональность распространяется также на сервисы и приложения. Эти оповещения будут отображаться в различных представлениях, включая Home, Alerts, Foundations, Applications, Service Instance и Topology.
Этот выпуск также предлагает новый уровень наблюдаемости и включает значительные улучшения тщательно настроенных панелей мониторинга и оповещений, основанных на ключевых показателях (KPI), а также runbook-ов для сервисов Tanzu Data Tile. Это позволяет различным командам сосредоточиться на формализации операционной экспертизы, делая её более доступной и практичной как для инженеров платформ, так и для команд разработчиков любого уровня опыта.
Ключевым аспектом этих улучшений является бесшовная интеграция runbook-ов с потоками наблюдаемости. Это означает, что оповещения и процессы их устранения больше не существуют изолированно; теперь runbook-и являются частью более широкой системы и содержат встроенные действия по следующему шагу прямо внутри оповещений, направляя инженеров через процесс диагностики и решения проблемы шаг за шагом. Runbook-и можно полностью настраивать, отображая контекстные данные, такие как соответствующие журналы ошибок во время и до возникновения оповещения, что делает рабочий процесс более плавным и сокращает время решения проблем. Такой интегрированный подход дает командам, особенно недавно присоединившимся инженерам, возможность действовать быстрее и эффективнее, снижая среднее время устранения проблем и повышая общую операционную эффективность.
Объединение метрик уровня приложений и уровня инфраструктуры в интерфейсе обеспечивает по-настоящему целостное понимание производительности системы. Этот интегрированный подход позволяет легко сопоставлять поведение приложения с состоянием базовой инфраструктуры, предоставляя детализированный обзор связанных сервисов или инфраструктурных изменений, которые могут повлиять на стабильность критически важных приложений. Объединив ранее разрозненные представления и благодаря удобной навигации Tanzu Hub, организации могут гораздо быстрее выявлять первопричины проблем, выходя за рамки поверхностных симптомов и устраняя коренные причины более эффективно.
Эти усовершенствованные представления приносят значительные бизнес-преимущества и могут быть настроены под нужды разных команд, включая инженеров платформы и команды разработчиков. Возможность создавать и управлять пользовательскими панелями мониторинга, а также гибко контролировать данные с помощью фильтров на уровне панели, позволяет командам точно адаптировать свой опыт наблюдения под свои задачи. Кроме того, настройка макетов, диаграмм и виджетов гарантирует, что критически важные данные всегда представлены в наиболее удобной и действенной форме. Это объединение направлено на покрытие большинства сценариев использования Healthwatch, обеспечивая действия на основе разрешений и расширенные возможности анализа метрик. Бесшовная миграция всех панелей Healthwatch, помеченных тегом “healthwatch”, обеспечивает преемственность и простоту поиска. В конечном итоге эти возможности приводят к снижению простоев, повышению операционной эффективности и более проактивному подходу к поддержанию оптимальной производительности приложений, напрямую влияя на удовлетворенность клиентов и непрерывность бизнеса.
Почему эти улучшения важны
Эти усовершенствования приносят значительные бизнес-преимущества, делая работу вашей платформы более эффективной, надежной и устойчивой к будущим изменениям. Наблюдаемость становится более прикладной и контекстной, обеспечивая полноценный анализ на всех уровнях стека. Вы получаете комплексное понимание не только поведения приложений, но и их прямой связи с платформой и базовой инфраструктурой. Это обеспечивает видимость на нескольких уровнях, планирование емкости и контроль соответствия требованиям. Runbook-и и встроенные рекомендации существенно снижают зависимость от индивидуального опыта и «внутренних знаний» команды, повышая эффективность операций на уровне всей организации. И наконец, по мере роста сложности сред, эти улучшения наблюдаемости масштабируются вместе с вами, обеспечивая стабильную производительность и прозрачность.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
Службы VMware vSphere Kubernetes Service (VKS) версии 3.5 появились в общем доступе. Этот новый выпуск обеспечивает 24-месячную поддержку для каждой минорной версии Kubernetes, начиная с vSphere Kubernetes release (VKr) 1.34. Ранее, в июне 2025 года, VMware объявила о 24-месячной поддержке выпуска vSphere Kubernetes (VKr) 1.33. Это изменение обеспечивает командам, управляющим платформой, большую стабильность и гибкость при планировании обновлений.
VKS 3.5 также включает ряд улучшений, направленных на повышение операционной согласованности и улучшение управления жизненным циклом, включая детализированные средства конфигурации основных компонентов Kubernetes, декларативную модель управления надстройками и встроенную генерацию пакетов поддержки напрямую из интерфейса командной строки VCF CLI. Кроме того, новые защитные механизмы при обновлениях — такие как проверка PodDisruptionBudget и проверки совместимости — помогают обеспечить более безопасные и предсказуемые обновления кластеров.
В совокупности эти усовершенствования повышают надежность, операционную эффективность и качество управления Kubernetes-средами на этапе эксплуатации (Day-2) в масштабах предприятия.
Выпуск vSphere Kubernetes (VKr) 1.34
VKS 3.5 добавляет поддержку VKr 1.34. Каждая минорная версия vSphere Kubernetes теперь поддерживается в течение 24 месяцев с момента выпуска. Это снижает давление, связанное с обновлениями, стабилизирует рабочие среды и позволяет командам сосредоточиться на создании ценности, а не на постоянном планировании апгрейдов. Команды, которым нужен быстрый доступ к последним возможностям Kubernetes, могут оперативно переходить на новые версии. Те, кто предпочитает стабильную среду на длительный срок, теперь могут работать в этом режиме с уверенностью. VKS 3.5 поддерживает оба подхода к эксплуатации.
Динамическое распределение ресурсов (Dynamic Resource Allocation, DRA)
Функция DRA получила статус «стабильной» в основной ветке Kubernetes 1.34. Эта возможность позволяет администраторам централизованно классифицировать аппаратные ресурсы, такие как GPU, с помощью объекта DeviceClass. Это обеспечивает надежное и предсказуемое размещение Pod'ов на узлах с требуемым классом оборудования.
DRA повышает эффективность использования устройств, позволяя делить ресурсы между приложениями по декларативному принципу, аналогично динамическому выделению томов (Dynamic Volume Provisioning). Механизм DRA решает проблемы случайного распределения и неполного использования ресурсов. Пользователи могут выполнять точную фильтрацию, запрашивая конкретные устройства с помощью ResourceClaimsTemplates и ResourceClaims при развертывании рабочих нагрузок.
DRA также позволяет совместно использовать GPU между несколькими Pod'ами или контейнерами. Рабочие нагрузки можно настроить так, чтобы выбирать GPU-устройство с помощью Common Expression Language (CEL) и запросов ResourceSlice, что обеспечивает более эффективное использование по сравнению с count-based запросами.
Расширенные возможности конфигурации компонентов кластера Kubernetes
VKS 3.5 предоставляет гибкость для управления более чем 35 параметрами конфигурации компонентов Kubernetes, таких как kubelet, apiserver и etcd. Эти настройки позволяют командам платформ оптимизировать различные аспекты работы кластеров в соответствии с требованиями их рабочих нагрузок. Полный список доступных параметров конфигурации приведён в документации к продукту. Ниже приведён краткий обзор областей конфигурации, которые предлагает VKS 3.5:
Конфигурация
Настраиваемые компоненты
Описание
Журналирование и наблюдаемость (Logging & Observability)
Kubelet, API Server
Настройка поведения журналирования для API-сервера и kubelet, включая частоту сброса логов, формат (text/json) и уровни детализации. Управление хранением логов контейнеров с указанием максимального количества и размера файлов. Это позволяет эффективно управлять использованием диска, устранять неполадки с нужным уровнем детализации логов и интегрироваться с системами агрегирования логов с помощью структурированного JSON-журналирования.
Управление событиями (Event Management)
Kubelet
Управление генерацией событий Kubernetes с настройкой лимитов скорости создания событий (eventRecordQPS) и всплесков (eventBurst), чтобы предотвратить перегрузку API-сервера. Это позволяет контролировать частоту запросов kubelet к API-серверу, обеспечивая стабильность кластера в периоды высокой активности при сохранении видимости важных событий.
Производительность и масштабируемость (Performance & Scalability)
API Server
Управление производительностью API-сервера с помощью настройки пределов на максимальное количество одновременных изменяющих (mutating) и неизменяющих (non-mutating) запросов, а также минимальной продолжительности тайм-аута запроса. Возможность включения или отключения профилирования. Это позволяет адаптировать кластер под высоконагруженные рабочие процессы, предотвращать перегрузку API-сервера и оптимизировать отзывчивость под конкретные сценарии использования.
Конфигурации etcd
etcd
Настройка максимального размера базы данных etcd (в диапазоне 2–8 ГБ). Том создаётся с дополнительными 25 % ёмкости для учёта операций уплотнения, дефрагментации и временных всплесков использования. Это позволяет правильно подобрать объём хранилища etcd в зависимости от масштаба кластера и количества объектов, предотвращая ситуации нехватки места, которые могут перевести кластер в режим только для чтения.
Управление образами (Image Management)
Kubelet
Настройка жизненного цикла образов контейнеров, включая пороги очистки (в процентах использования диска — высокий/низкий), минимальный и максимальный возраст образов до удаления, лимиты скорости загрузки образов (registryPullQPS и registryBurst), максимальное количество параллельных загрузок и политики проверки учётных данных при загрузке. Это помогает оптимизировать использование дискового пространства узлов, контролировать потребление сетевых ресурсов, ускорять запуск Pod’ов за счёт параллельных загрузок и обеспечивать безопасность доступа к образам.
Безопасность на уровне ОС (OS-level Security)
OS
Включение защиты загрузчика GRUB паролем с использованием хэширования PBKDF2 SHA-512. Настройка обязательной повторной аутентификации при использовании sudo. Это позволяет соответствовать требованиям безопасности при загрузке системы и управлении привилегированным доступом, предотвращая несанкционированные изменения системы и обеспечивая соблюдение политик безопасности во всей инфраструктуре кластера.
Cluster API v1beta2 для улучшенного управления кластерами Kubernetes
VKS 3.5 включает Cluster API v1beta2 (CAPI v1.11.1), который вносит ряд изменений и улучшений в версии API для ресурсов по сравнению с v1beta1. Полный список улучшений можно найти в Release Notes для CAPI.
Для обеспечения плавного перехода все новые и существующие кластеры, созданные с использованием прежнего API v1beta1, будут автоматически преобразованы в API v1beta2 обновлёнными контроллерами Cluster API. В дальнейшем рекомендуется использовать API v1beta2 для управления жизненным циклом (LCM) кластеров Kubernetes.
Версия API v1beta2 является важным шагом на пути к выпуску стабильной версии v1. Основные улучшения включают:
Расширенные возможности отслеживания состояния ресурсов, обеспечивающие лучшую наблюдаемость.
Исправления на основе отзывов клиентов и инженеров с реальных внедрений.
Предотвращение сбоев обновлений из-за неверно настроенного PodDisruptionBudget
Pod Disruption Budget (PDB) — это объект Kubernetes, который помогает поддерживать доступность приложения во время плановых операций (например, обслуживания узлов, обновлений или масштабирования). Он гарантирует, что минимальное количество Pod’ов останется активным во время таких событий. Однако неправильно настроенные PDB могут блокировать обновления кластера.
VKS 3.5 вводит механизмы защиты (guardrails) для выявления ошибок конфигурации PDB, которые могут привести к зависанию обновлений или других операций жизненного цикла. Система блокирует обновление кластера, если обнаруживает, что PDB не допускает никаких прерываний.
Для повышения надёжности и успешности обновлений введено новое условие SystemChecksSucceeded в объект Cluster. Оно позволяет пользователям видеть готовность кластера к обновлению, в частности относительно конфигураций PDB.
Ключевые преимущества новой проверки:
Проактивная блокировка обновлений — система обнаруживает PDB, препятствующие выселению Pod’ов, и останавливает обновление до его начала.
Более чёткая диагностика проблем — параметр SystemChecksSucceeded устанавливается в false, если у любого PDB значение allowedDisruptions меньше или равно 0, что указывает на риск простоев.
Планирование обновлений — позволяет заранее устранить ошибки конфигурации PDB до начала обновления.
Примечание: любой PDB, не связанный с Pod’ами (например, из-за неправильного селектора), также будет иметь allowedDisruptions = 0 и, следовательно, заблокирует обновление.
Упрощённые операции: CLI, управление надстройками и инструменты поддержки
Управление надстройками (Add-On Management)
VKS 3.5 упрощает эксплуатационные операции, включая управление жизненным циклом надстроек (add-ons) и создание пакетов поддержки. Новая функция VKS Add-On Management объединяет установку, обновление и настройку стандартных пакетов, предлагая:
Единый метод для всех операций с пакетами, декларативный API и предварительные проверки совместимости.
Возможность управления стандартными пакетами VKS через Supervisor Namespace (установка, обновления, конфигурации) — доступно через VKS-M 9.0.1 или новый плагин ‘addon’ в VCF CLI.
Упрощённую установку Cluster Autoscaler с возможностью автоматического обновления при апгрейде кластера.
Управление установками и обновлениями через декларативные API (AddonInstall, AddonConfig) с помощью Argo CD или других GitOps-контроллеров. Это обеспечивает версионируемое и повторяемое развертывание надстроек с улучшенной трассируемостью и согласованностью.
Возможность настройки Addon Repository во всех кластерах VKS с помощью API AddonRepository / AddonRepositoryInstall, включая случаи с приватными регистрами.
По умолчанию встроенный репозиторий VKS Standard Package устанавливается из пакета VKS (версия v2025.10.22 для релиза VKS 3.5.0).
Во время обновлений кластеров VKS выполняет предварительные проверки совместимости надстроек и обновляет их до последних поддерживаемых версий. Если проверка не пройдена — обновление блокируется. При установке или обновлении надстроек выполняются дополнительные проверки, включая проверку на дублирование пакетов и анализ зависимостей.
Упрощённое обнаружение новых версий и метаданных совместимости для Add-on Releases.
Интегрированный сборщик пакетов поддержки (Support Bundler) в VCF CLI
VKS 3.5 включает VKS Cluster Support Bundler непосредственно в VCF CLI, что значительно упрощает процесс сбора диагностической информации о кластерах. Теперь пользователи могут собирать всю необходимую информацию с помощью команды vcf cluster support-bundle, без необходимости загружать отдельный инструмент.
Основные улучшения здесь:
Существенное уменьшение размера выходного файла.
Селективный сбор логов — только с узлов control plane, для более быстрой и точной диагностики.
Интегрированный сбор сетевых логов, что помогает анализировать сетевые проблемы и получить целостную картину состояния кластера.
В эпоху, когда AI всё чаще «уходит к краю сети» — то есть — выполняется непосредственно на устройстве или на близкой инфраструктуре, требования к беспроводным сетям меняются. Вместо гонки за пиковыми скоростями становится важнее низкая задержка, высокая надёжность, предсказуемость и адаптивность. Именно в этом контексте появляется новое поколение — Wi-Fi 8 (также обозначаемое как IEEE 802.11bn), задача которого — стать «основой» для беспроводного AI edge. Компания Broadcom представила своё семейство чипсетов Wi-Fi 8, позиционируя их как фундаментальную платформу для сетей с AI-устройствами.
Почему Wi-Fi 8 — это не про максимальную скорость?
В предыдущих поколениях Wi-Fi (например, Wi-Fi 6, Wi-Fi 6E, Wi-Fi 7) основной акцент делался на увеличение пропускной способности: больше GHz, больше антенн, более мощная модуляция. Однако в блоге Broadcom подчёркивается, что Wi-Fi 8 сменяет приоритеты: теперь главное — надёжность, предсказуемость, контроль задержки и способность работать в сложных, насыщенных средах. Другими словами: устройство может не показывать «в идеале» наибольшую скорость, но важно, чтобы оно доставляло данные вовремя, без провалов, даже если сеть нагружена.
Это особенно актуально для оконечных AI-устройств: камеры, датчики, автономные роботы, автомобили, «умный дом», промышленная автоматизация — там требуется мгновенная реакция, и беспроводная сеть не может быть слабым звеном.
Технические особенности Wi-Fi 8
Ниже — основные архитектурные и технологические моменты, которые Broadcom выделяет как отличительные черты Wi-Fi 8.
1. Телеметрия и адаптивность
Семейство чипов Wi-Fi 8 от Broadcom включает встроенные механизмы телеметрии, которые постоянно измеряют поведение сети: условия канала, загруженность, помехи, мобильность устройств. Эта информация используется в реальном времени для адаптации: например, переключение каналов, корректировка мощности, приоритизация трафика, динамическое управление потоком данных — всё с целью обеспечить низкую задержку и стабильное соединение.
2. Архитектура «краевого AI» (Edge AI)
Wi-Fi 8 позиционируется именно как платформа для Edge AI — то есть инфраструктуры, где модель, обработка данных или рекомендации выполняются ближе к устройству, а не в облаке. Broadcom подчёркивает: устройства и сети должны быть «AI-ready» — готовыми к работе с интенсивными задачами AI в режиме реального времени.
Это требует:
Очень низкой задержки (чтобы не было «запаздывания» отклика)
Высокой надёжности (чтобы результат был предсказуемым)
Способности одновременно обслуживать множество устройств (IoT, сенсоры, камеры и др.)
3. Поддержка различных классов устройств и сценариев
Broadcom указывает, что Wi-Fi 8 охватывает не только домашние маршрутизаторы, но и корпоративные точки доступа, а также клиентские устройства: смартфоны, ноутбуки, автомобильные системы.
Такая универсальность важна: сеть на краю должна обслуживать разные типы устройств с разными требованиями.
4. Лицензирование стратегии и экосистема
Интересный аспект: Broadcom открывает свою платформу Wi-Fi 8 через лицензирование IP и продуктов, особенно для рынков IoT и automotive. Это позволяет партнёрам быстрее внедрять Wi-Fi 8 в новые устройства и экосистемы.
5. Стандарт IEEE 802.11bn — ориентиры
Хотя Wi-Fi 8 ещё находится в разработке (стандарт IEEE 802.11bn), уже видны ориентиры: фокус на «Ultra High Reliability» (UHR) — чрезвычайно высокая надёжность, низкая задержка, устойчивость к помехам и плотной среде.
Например, даже если физические изменения по сравнению с Wi-Fi 7 не столь радикальны, акцент смещается на качество соединения, а не просто на максимальную скорость.
Зачем Wi-Fi 8 нужен именно для Wireless AI Edge
Рассмотрим ключевые сценарии, где преимущества Wi-Fi 8 раскрываются наиболее ярко.
Сценарий: автономные системы и роботы
Представьте завод с роботами-манипуляторами, дронами, транспортными средствами на базе AI. Они генерируют, обрабатывают и обмениваются данными на месте: карты, сенсоры, объекты, навигация. Здесь задержка, потеря пакетов или нестабильность соединения — недопустимы. Wi-Fi 8 помогает обеспечить:
Постоянное качество соединения даже при движении устройств
Адаптацию к изменяющимся условиям канала
Высокую плотность устройств в ограниченном пространстве
Сценарий: IP-камеры, видеоаналитика и умный дом
Камеры с AI-аналитикой могут находиться где-то между облаком и Edge. Wi-Fi 8 обеспечивает непрерывную передачу потока, реагирование на события и автономную работу без нарушения связи.
Сценарий: автомобильная и транспортная инфраструктура
Wi-Fi 8 встроен в автомобильные системы и мобильные устройства. При движении, смене точек доступа, большом количестве подключённых устройств важно, чтобы сеть была непрерывной, с минимальной задержкой, автоматически адаптировалась при смене сценария.
Так появится экосистема решений Wi-Fi 8 для домашних (BCM6718), корпоративных (BCM43840, BCM43820) и клиентских устройств (BCM43109).
Вызовы и что ещё предстоит
Хотя Wi-Fi 8 выглядит многообещающе, есть несколько моментов, на которые стоит обратить внимание.
Стандартизация и сроки - стандарт IEEE 802.11bn ещё не окончательно утверждён; коммерческая доступность устройств и сертификация могут занять несколько лет.
Это значит, что внедрение Wi-Fi 8-решений в промышленном масштабе может состояться не сразу.
Экосистема и совместимость - чтобы Wi-Fi 8 стал по-настоящему успешным, требуется: устройства-клиенты (смартфоны, ноутбуки, IoT-устройства), точки доступа, маршрутизаторы, инфраструктура поддержки, программные платформы. Переход всей экосистемы — задача небыстрая.
Цена и обоснование обновлений - поскольку пиковые скорости могут не сильно отличаться от Wi-Fi 7, организациям и пользователям придётся оценивать: стоит ли обновлять оборудование сейчас ради большей надёжности и «готовности к AI Edge». Некоторые аналитики отмечают, что без заметного прироста скорости маркетинг может быть слабее.
Безопасность и управление - с большим количеством устройств, большим количеством трафика «на краю», а также AI-нагрузками возрастает важность безопасности как на уровне устройства, так и на уровне сети. Wi-Fi 8 должен преодолеть этот вызов.
Заключение
Wi-Fi 8 от Broadcom — это не просто новое поколение беспроводного стандарта ради скорости — это полноценная платформа, ориентированная на эпоху Edge AI. Она призвана обеспечить надежную, предсказуемую, гибкую сеть, способную поддерживать устройства с AI-нагрузкой в самых требовательных сценариях.
Для организаций, которые планируют развивать инфраструктуру Edge AI, промышленный IoT, автономные системы, «умный город», Wi-Fi 8 может стать ключевым технологическим элементом. Однако, как и с любой новой технологией, важно учитывать сроки стандартизации, экосистему, реальную выгоду от обновления и стратегию внедрения.
Компания Broadcom на днях объявила о выпуске Thor Ultra — первой в отрасли 800G AI Ethernet сетевой карты (NIC), способной объединять сотни тысяч XPU (eXtreme Processing Units) для выполнения AI-нагрузок с триллионами параметров. Приняв открытую спецификацию Ultra Ethernet Consortium (UEC), Thor Ultra предоставляет клиентам возможность масштабировать AI-нагрузки с экстремальной производительностью и эффективностью в открытой экосистеме.
«Thor Ultra воплощает видение Ultra Ethernet Consortium по модернизации RDMA для крупных AI-кластеров», — сказал Рам Велага, старший вице-президент и генеральный директор подразделения Core Switching Group компании Broadcom. — «Разработанная с нуля, Thor Ultra — это первый в отрасли 800G Ethernet NIC, полностью соответствующий спецификации UEC. Мы благодарны нашим клиентам за сотрудничество и нашей выдающейся инженерной команде за инновации продукта».
Традиционная RDMA не поддерживает multipathing-передачу, out-of-order доставку пакетов, выборочную повторную передачу и масштабируемый контроль перегрузок. Thor Ultra представляет революционный набор инноваций RDMA, соответствующих UEC, включая:
Multipathing-передачу на уровне пакетов для эффективной балансировки нагрузки.
Доставку пакетов out-of-order напрямую в память XPU для максимального использования сетевой фабрики.
Выборочную повторную передачу для эффективной передачи данных.
Программируемые алгоритмы контроля перегрузок на стороне приёмника и отправителя.
Thor Ultra обеспечивает высокопроизводительные расширенные возможности RDMA в открытой экосистеме. Это даёт клиентам свободу подключения любых XPU, оптики или коммутаторов и снижает зависимость от проприетарных, вертикально интегрированных решений.
Дополнительные особенности Broadcom Thor Ultra включают:
Доступность в стандартных форм-факторах PCIe CEM и OCP 3.0.
200G или 100G PAM4 SerDes с поддержкой длинных пассивных медных соединений.
Самый низкий в отрасли уровень битовых ошибок (BER) SerDes, что уменьшает разрывы соединений и ускоряет время завершения заданий (JCT).
Интерфейс PCI Express Gen6 x16 для хоста.
Шифрование и дешифрование на скорости линии с разгрузкой PSP, снимая с хоста/XPU вычислительно-интенсивные задачи.
Безопасная загрузка с подписанным микропрограммным обеспечением и аттестацией устройства.
Программируемый конвейер контроля перегрузок.
Поддержка обрезки пакетов и сигнализации перегрузок (CSIG) с Tomahawk 5, Tomahawk 6 или любым коммутатором, совместимым с UEC.
Будучи передовой сетевой картой, Thor Ultra является ключевым дополнением к портфолио Broadcom по Ethernet-сетям для AI. В сочетании с Tomahawk 6, Tomahawk 6-Davisson, Tomahawk Ultra, Jericho 4 и Scale-Up Ethernet (SUE) Thor Ultra обеспечивает открытую экосистему для масштабных высокопроизводительных внедрений XPU.
Более подробно о сетевой карте Thor Ultra можно узнать вот тут.

 RSS
RSS