Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
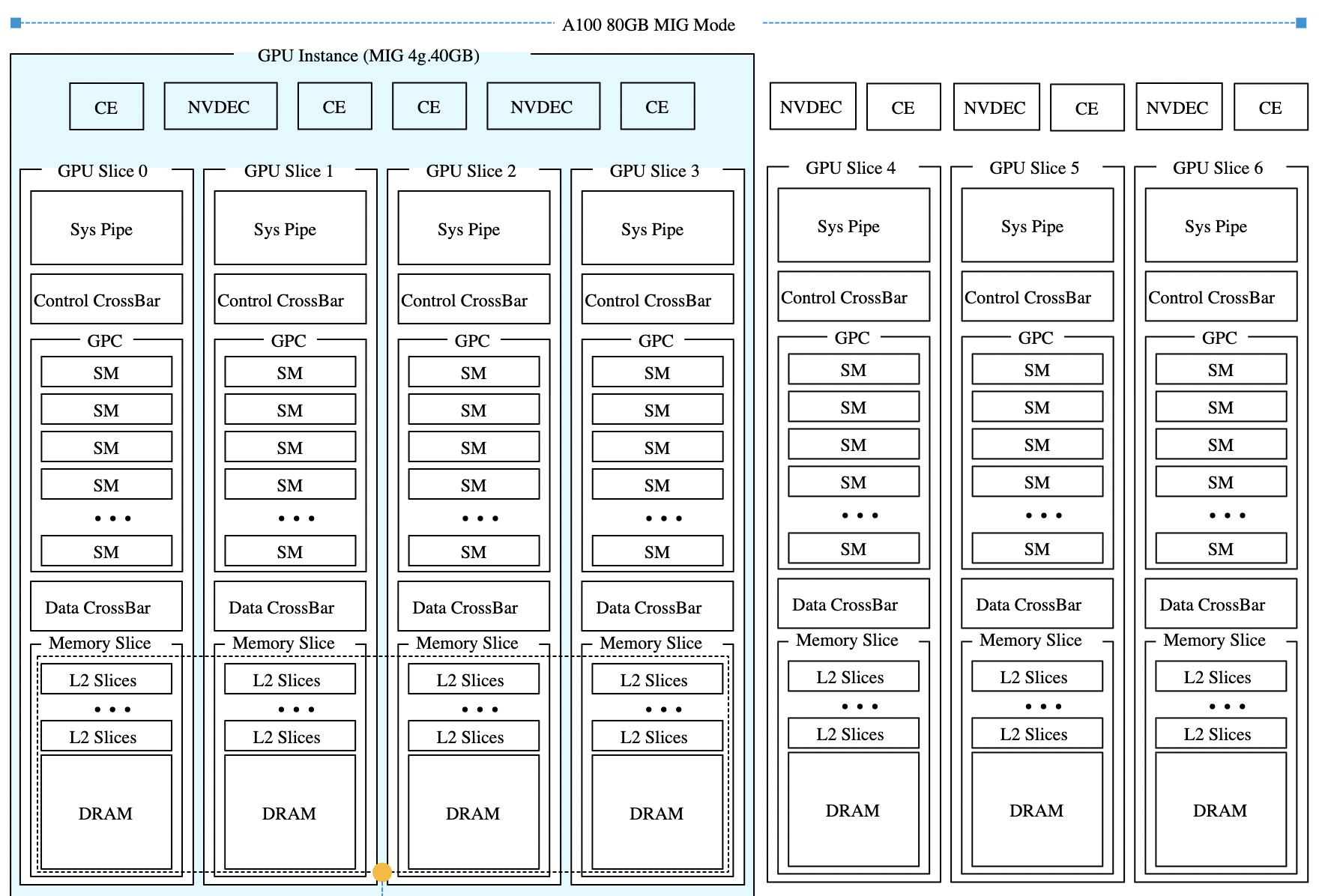
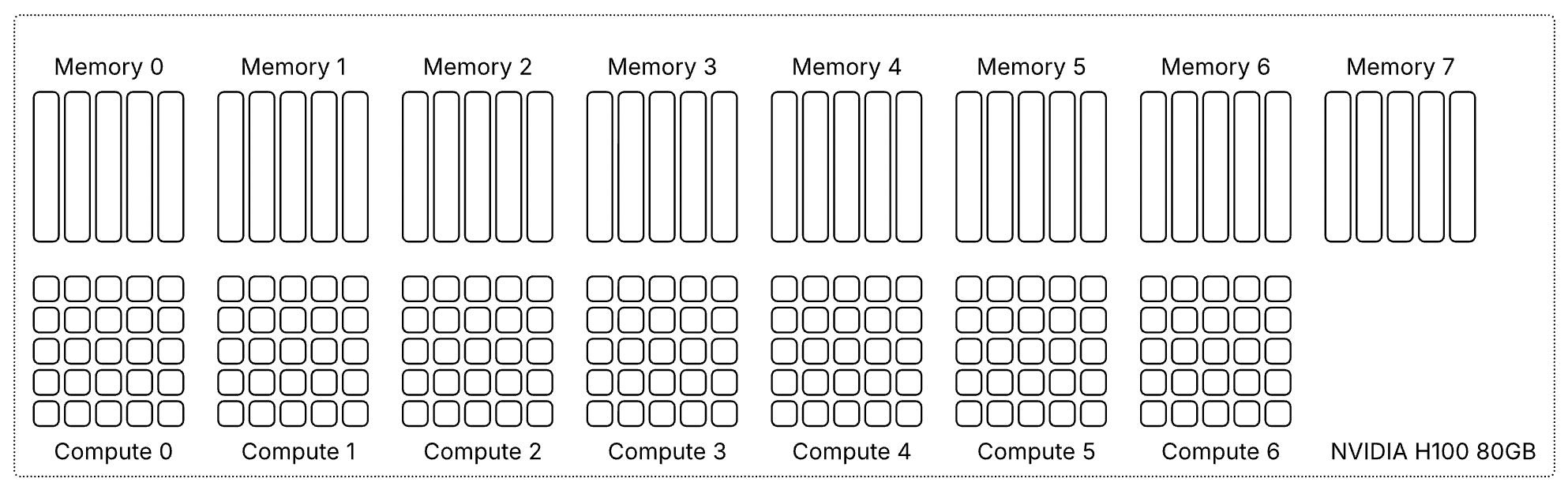
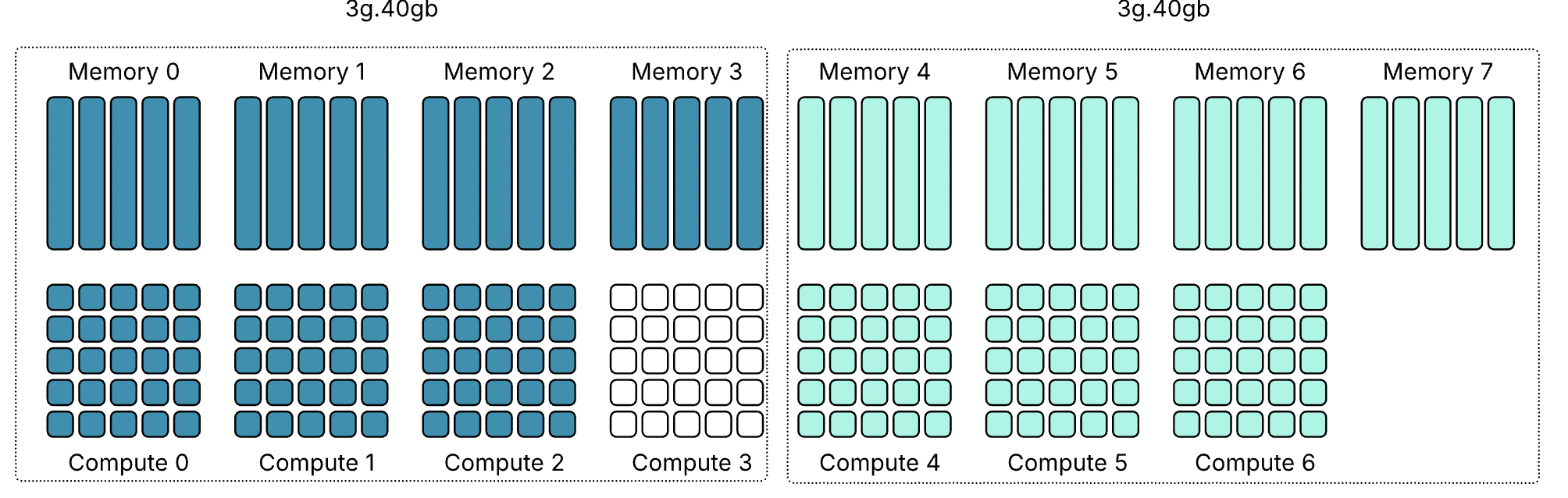
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
Profile
Compute slices
Memory slices
Memory
1g.10gb
1
1
10 GB
1g.20gb
1
2
20 GB
2g.20gb
2
2
20 GB
3g.40gb
3
4
40 GB
4g.40gb
4
4
40 GB
7g.80gb
7
8
80 GB
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
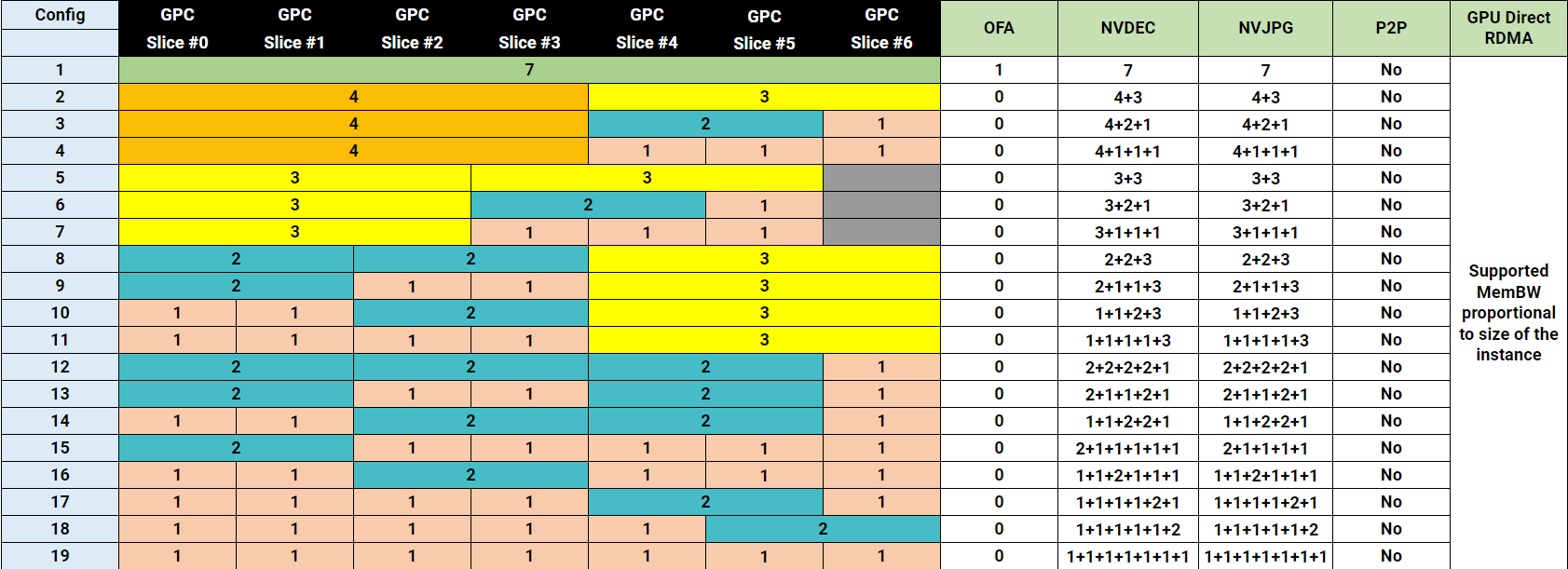
Потерянная ёмкость
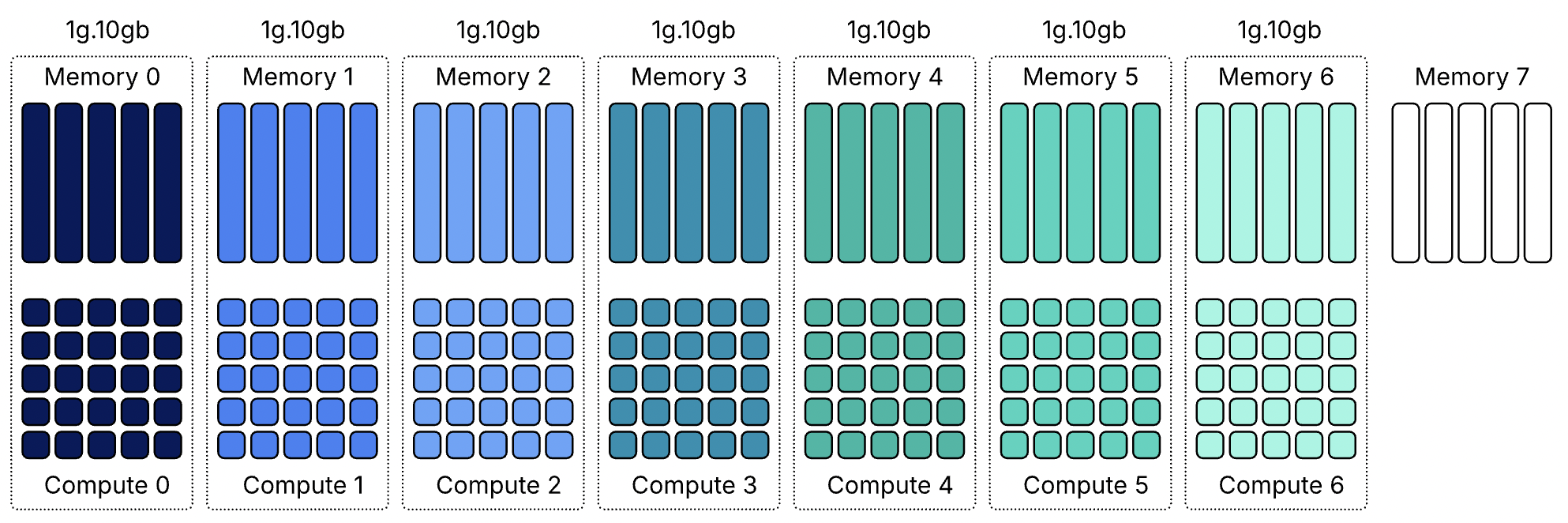
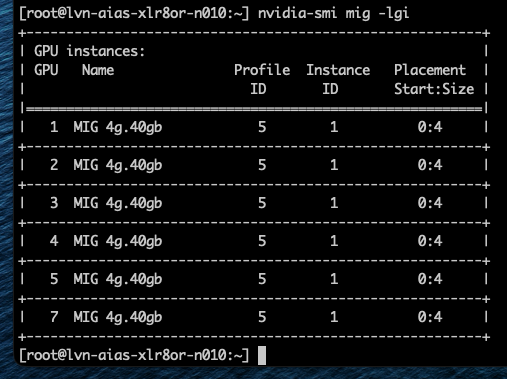
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
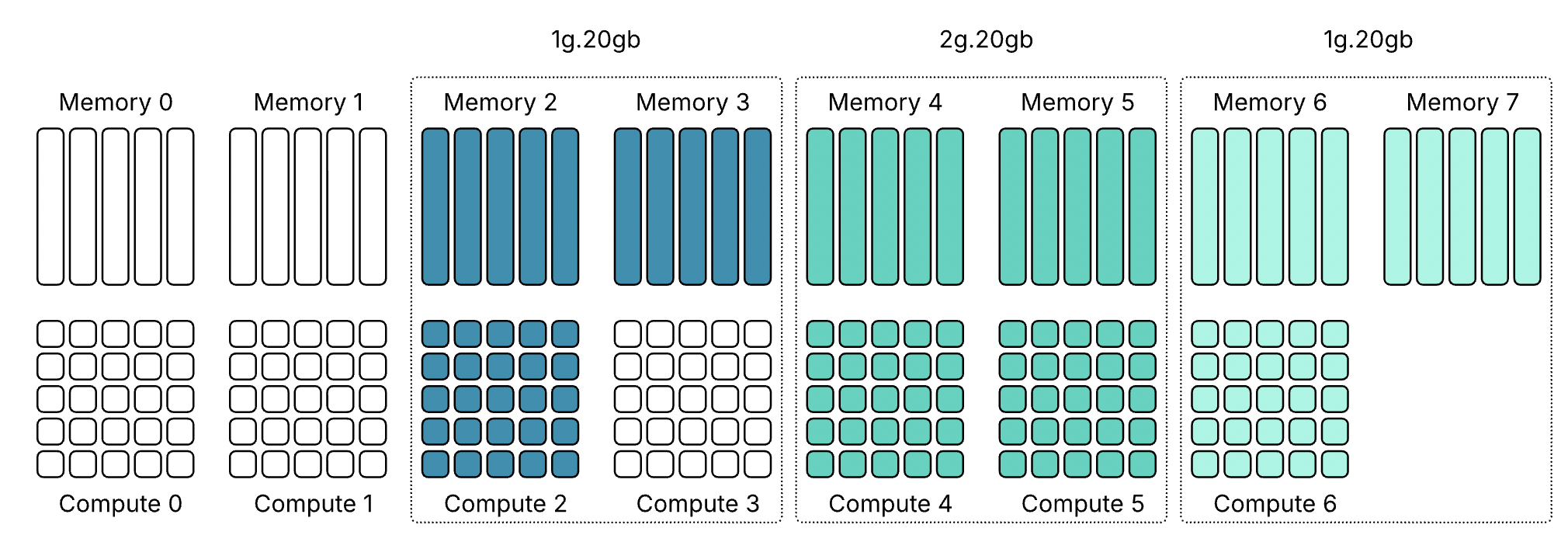
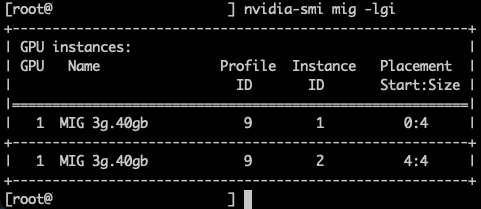
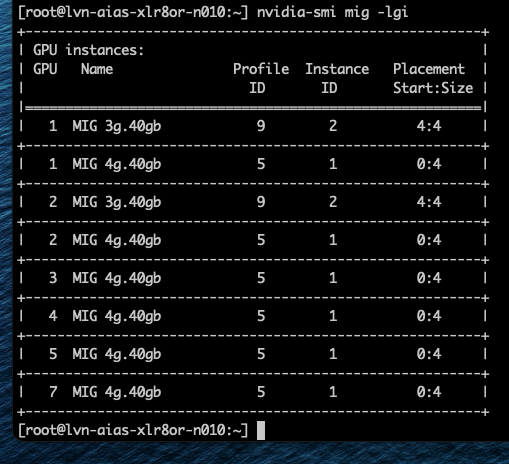
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
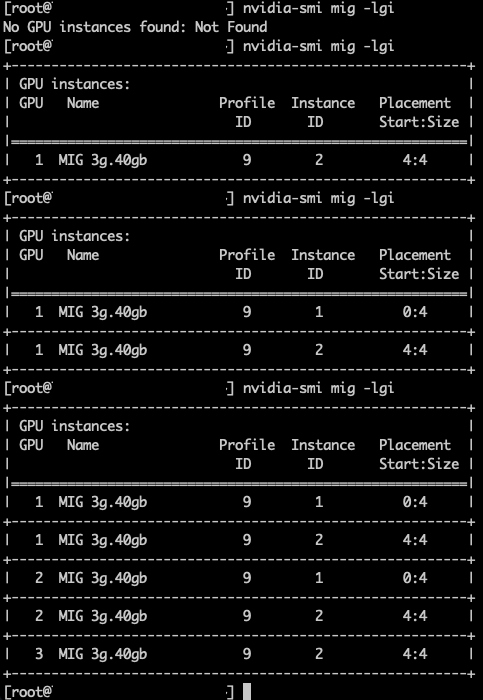
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.
В видеоролике ниже демонстрируется процесс развертывания решения Private AI Foundation с NVIDIA с использованием мастера быстрой настройки.
Автор пошагово показывает, как запустить Foundation Quick Start, выбрать проект и соответствующее пространство имен (namespace), а также вставить клиентский конфигурационный токен, полученный от NVIDIA. В примере используется среда с подключением к интернету, поэтому дополнительные параметры, такие как офлайн-реестр или изменение расположения драйверов, настраивать не требуется.
Далее в видео подробно рассматриваются ключевые параметры развертывания:
Выбор версии Kubernetes (или VKR).
Указание образа виртуальной машины для задач глубокого обучения (Deep Learning VM), заранее загруженного в библиотеку контента.
Выбор класса хранилища (storage class).
Настройка GPU-совместимых классов ВМ (резервирование GPU).
Выбор классов ВМ без поддержки GPU.
Также демонстрируется, что в рамках примера не активируются дополнительные сервисы VCF Data Services и не используется прокси-сервер.
После проверки всех параметров запускается процесс создания ресурсов каталога в выбранном пространстве имен. Через несколько минут новые элементы становятся доступны в разделе Build and Deploy -> Catalog, где можно увидеть созданные позиции Private AI Foundation с NVIDIA и при необходимости запросить их для дальнейшего использования.
Видео будет полезно администраторам и инженерам, занимающимся развертыванием инфраструктуры для задач искусственного интеллекта и машинного обучения в среде Kubernetes с поддержкой GPU.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
На выступлении в рамках конференции Explore 2025 Крис Вулф объявил о поддержке DirectPath для GPU в VMware Private AI, что стало важным шагом в упрощении управления и масштабировании корпоративной AI-инфраструктуры. DirectPath предоставляет виртуальным машинам эксклюзивный высокопроизводительный доступ к GPU NVIDIA, позволяя организациям в полной мере использовать возможности графических ускорителей без дополнительной лицензионной сложности. Это упрощает эксперименты, прототипирование и перевод AI-проектов в производственную среду. Кроме того, VMware Private AI размещает модели ближе к корпоративным данным, обеспечивая безопасные, эффективные и экономичные развертывания. Совместно разработанное Broadcom и NVIDIA решение помогает компаниям ускорять инновации при снижении совокупной стоимости владения (TCO).
Эти достижения появляются в критически важный момент. Обслуживание передовых LLM-моделей (Large Language Models) — таких как DeepSeek-R1, Meta Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking — на полной длине контекста зачастую превышает возможности одного сервера с 8 GPU и картой H100, что делает распределённый инференс необходимым. Агрегирование ресурсов нескольких GPU-узлов позволяет эффективно запускать такие модели, но при этом создаёт новые вызовы в управлении инфраструктурой, оптимизации межсерверных соединений и планировании рабочих нагрузок.
Именно здесь ключевую роль играет решение VMware Cloud Foundation (VCF). Это первая в отрасли платформа частного облака, которая сочетает масштаб и гибкость публичного облака с безопасностью, отказоустойчивостью и производительностью on-premises — и всё это с меньшей стоимостью владения. Используя такие технологии, как NVIDIA NVLink, NVSwitch и GPUDirect RDMA, VCF обеспечивает высокую пропускную способность и низкую задержку коммуникаций между узлами. Также гарантируется эффективное использование сетевых соединений, таких как InfiniBand (IB) и RoCEv2 (RDMA over Converged Ethernet), снижая издержки на коммуникацию, которые могут ограничивать производительность распределённого инференса. С VCF предприятия могут развернуть продуктивный распределённый инференс, добиваясь стабильной работы даже самых крупных reasoning-моделей с предсказуемыми характеристиками.
Использование серверов HGX для максимальной производительности
Серверы NVIDIA HGX играют центральную роль. Их внутренняя топология — PCIe-коммутаторы, GPU NVIDIA H100/H200 и адаптеры ConnectX-7 IB HCA — подробно описана. Критически важным условием для оптимальной производительности GPUDirect RDMA является соотношение GPU-к-NIC 1:1, что обеспечивает каждому ускорителю выделенный высокоскоростной канал.
Внутриузловая и межузловая коммуникация
NVLink и NVSwitch обеспечивают сверхбыструю связь внутри одного HGX-узла (до 8 GPU), тогда как InfiniBand или RoCEv2 дают необходимую пропускную способность и низкую задержку для масштабирования инференса на несколько серверов HGX.
GPUDirect RDMA в VCF
Включение GPUDirect RDMA в VCF требует особых настроек, таких как активация Access Control Services (ACS) в ESX и Address Translation Services (ATS) на сетевых адаптерах ConnectX-7. ATS позволяет выполнять прямые транзакции DMA между PCIe-устройствами, обходя Root Complex и возвращая производительность, близкую к bare metal, в виртуализированных средах.
Определение требований к серверам
В документ включена практическая методика для расчёта минимального количества серверов HGX, необходимых для инференса LLM. Учитываются такие факторы, как num_attention_heads и длина контекста, а также приведена справочная таблица с требованиями к аппаратному обеспечению для популярных моделей LLM (например, Llama-3.1-405B, DeepSeek-R1, Llama-4-Series, Kimi-K2 и др.). Так, для DeepSeek-R1 и Llama-3.1-405B при полной длине контекста требуется как минимум два сервера H00-HGX.
Обзор архитектуры
Архитектура решения разделена на кластер VKS, кластер Supervisor и критически важные Service VM, на которых работает NVIDIA Fabric Manager. Подчёркивается использование Dynamic DirectPath I/O, которое обеспечивает прямой доступ GPU и сетевых адаптеров (NIC) к рабочим узлам кластера VKS, в то время как NVSwitch передаётся в режиме passthrough к Service VM.
Рабочий процесс развертывания и лучшие практики
В документе рассмотрен 8-шаговый рабочий процесс развертывания, включающий:
Подготовку аппаратного обеспечения и прошивок (включая обновления BIOS и firmware)
Конфигурацию ESX для включения GPUDirect RDMA
Развертывание Service VM
Настройку кластера VKS
Установку операторов (NVIDIA Network и GPU Operators)
Процедуры загрузки хранилища и моделей
Развертывание LLM с использованием SGLang и Leader-Worker Sets (LWS)
Проверку после развертывания
Практические примеры и конфигурации
Приведены конкретные примеры, такие как:
YAML-манифесты для развертывания кластера VKS с узлами-воркерами, поддерживающими GPU.
Конфигурация LeaderWorkerSet для запуска моделей DeepSeek-R1-0528, Llama-3.1-405B-Instruct и Qwen3-235B-A22B-thinking на двух узлах HGX
Индивидуально настроенные файлы топологии NCCL для максимизации производительности в виртуализированных средах
Проверка производительности
Приведены шаги для проверки работы RDMA, GPUDirect RDMA и NCCL в многосерверных конфигурациях. Также включены результаты тестов производительности для моделей DeepSeek-R1-0528 и Llama-3.1-405B-Instruct на 2 узлах HGX с использованием стресс-тестового инструмента GenAI-Perf.
AI и генеративный AI (Gen AI) требуют значительной инфраструктуры, а задачи, такие как тонкая настройка, кастомизация, развертывание и выполнение запросов, могут сильно нагружать ресурсы. Масштабирование этих операций становится проблематичным без достаточной инфраструктуры. Кроме того, необходимо соответствовать различным требованиям в области комплаенса и законодательства в разных отраслях и странах. Решения на базе Gen AI должны обеспечивать контроль доступа, правильное размещение рабочих нагрузок и готовность к аудиту для соблюдения этих стандартов. Чтобы решить эти задачи, Broadcom представила VMware Private AI, которая помогает клиентам запускать модели рядом с их собственными данными. Объединяя инновации обеих компаний, Broadcom и NVIDIA стремятся раскрыть потенциал AI и повысить производительность при более низкой совокупной стоимости владения (TCO).
Технический документ «Развертывание VMware Private AI на серверах HGX с использованием Broadcom Ethernet Networking» подробно описывает сквозное развертывание и конфигурацию, с акцентом на DirectPath I/O (passthrough) для GPU, а также сетевые адаптеры Thor 2 с Ethernet-коммутатором Tomahawk 5. Это руководство необходимо архитекторам инфраструктуры, администраторам VCF и специалистам по data science, которые стремятся достичь оптимальной производительности своих AI-моделей в среде VCF.
Что охватывает этот документ?
Документ предоставляет детальные рекомендации по следующим направлениям:
Адаптеры Broadcom Thor 2 и GPU NVIDIA: как эффективно интегрировать сетевые карты Broadcom и GPU NVIDIA в виртуальные машины глубокого обучения (DLVM) на базе Ubuntu в среде VMware Cloud Foundation (VCF).
Сетевая конфигурация: пошаговые инструкции по настройке Ethernet-адаптеров Thor 2 и коммутаторов Tomahawk 5 для включения RoCE (RDMA over Converged Ethernet) с GPU NVIDIA, что обеспечивает низкую задержку и высокую пропускную способность, критически важные для AI-нагрузок.
Тестирование производительности: процедуры запуска тестов с использованием ключевых библиотек коллективных коммуникаций, таких как NCCL, для проверки эффективности многопроцессорных GPU-операций.
Инференс LLM: рекомендации по запуску и тестированию инференса больших языковых моделей (LLM) с помощью NVIDIA Inference Microservices (NIM) и vLLM, демонстрирующие реальный прирост производительности.
Ключевые особенности решения
Решение, описанное в документе, ориентировано на сертифицированные системы VMware Private AI на базе HGX, которые обычно оснащены 4 или 8 GPU H100/H200 с интерконнектом NVSwitch и NVLink. Целевая среда — это приватное облако на базе VCF, использующее сетевые адаптеры Broadcom 400G BCM957608 NICs и кластеризированные GPU NVIDIA H100, соединённые через Ethernet.
Ключевой аспект данного развертывания — использование DirectPath I/O для GPU и адаптеров Thor2, что обеспечивает выделенный доступ к аппаратным ресурсам и максимальную производительность. В руководстве также подробно рассматриваются следующие важные элементы:
BIOS и прошивки: рекомендуемые конфигурации для серверов HGX, позволяющие раскрыть максимальную производительность.
Настройки ESX: оптимизация ESX для passthrough GPU и сетевых устройств, включая корректную разметку оборудования и конфигурацию ACS (Access Control Services).
Настройки виртуальных машин: кастомизация Deep Learning VM (DLVM) для DirectPath I/O, включая назначение статических IP и важные расширенные параметры ВМ для ускоренного запуска и повышения производительности.
Валидация производительности
Подробные инструкции по запуску RDMA, GPUDirect RDMA с Perftest и тестов NCCL на нескольких узлах с разъяснением ожидаемой пропускной способности и задержек.
Бенчмаркинг виртуальной и bare-metal производительности Llama-3.1-70b NIM с помощью genai-perf, позволяющий достичь результатов, близких к bare-metal.
Использование evalscope для оценки точности и стресс-тестирования производительности передовой модели рассуждений gpt-oss-120b.
Вот интересный результат из исследования, доказывающий, что работа GPU в виртуальной среде ничем не хуже, чем в физической:
Это комплексное руководство является ценным ресурсом для всех, кто стремится развернуть и оптимизировать AI-инференс на надежной виртуальной инфраструктуре с использованием серверов NVIDIA HGX и сетевых решений Broadcom Ethernet. Следуя описанным в документе лучшим практикам, организации могут создавать масштабируемые и высокопроизводительные AI-платформы, соответствующие требованиям современных приложений глубокого обучения.
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:
Конфигурация оборудования Dell PowerEdge XE9680:
Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:
Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.
Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.
Сегодня искусственный интеллект преобразует бизнес во всех отраслях, однако компании сталкиваются с проблемами, связанными со стоимостью, безопасностью данных и масштабируемостью при запуске задач инференса (производительной нагрузки) в публичных облаках. VMware и NVIDIA предлагают альтернативу — платформу VMware Private AI Foundation with NVIDIA, предназначенную для эффективного и безопасного размещения AI-инфраструктуры непосредственно в частном датацентре. В документе "VMware Private AI Foundation with NVIDIA on HGX Servers" подробно рассматривается работа технологии Private AI на серверном оборудовании HGX.
Зачем бизнесу нужна частная инфраструктура AI?
1. Оптимизация использования GPU
На практике графические ускорители (GPU), размещенные в собственных датацентрах, часто используются неэффективно. Они могут простаивать из-за неправильного распределения или чрезмерного резервирования. Платформа VMware Private AI Foundation решает эту проблему, позволяя динамически распределять ресурсы GPU. Это обеспечивает максимальную загрузку графических процессоров и существенное повышение общей эффективности инфраструктуры.
2. Гибкость и удобство для специалистов по AI
Современные сценарии работы с AI требуют высокой скорости и гибкости в работе специалистов по данным. Платформа VMware обеспечивает привычный облачный опыт работы, позволяя командам специалистов быстро разворачивать AI-среды, при этом сохраняя полный контроль инфраструктуры у ИТ-команд.
3. Конфиденциальность и контроль за данными
Публичные облака вызывают беспокойство в вопросах приватности, особенно когда AI-модели обрабатывают конфиденциальные данные. Решение VMware Private AI Foundation гарантирует полную конфиденциальность, соответствие нормативным требованиям и контроль доступа к проприетарным моделям и наборам данных.
4. Знакомый интерфейс управления VMware
Внедрение нового программного обеспечения обычно требует значительных усилий на изучение и адаптацию. Платформа VMware использует уже знакомые инструменты администрирования (vSphere, vCenter, NSX и другие), что существенно сокращает время и затраты на внедрение и эксплуатацию.
Основные компоненты платформы VMware Private AI Foundation с NVIDIA
VMware Cloud Foundation (VCF)
Это интегрированная платформа, объединяющая ключевые продукты VMware:
vSphere для виртуализации серверов.
vSAN для виртуализации хранилищ.
NSX для программного управления сетью.
Aria Suite (бывшая платформа vRealize) для мониторинга и автоматизации управления инфраструктурой.
NVIDIA AI Enterprise
NVIDIA AI Enterprise является важным элементом платформы и включает:
Технологию виртуализации GPU (NVIDIA vGPU C-Series) для совместного использования GPU несколькими виртуальными машинами.
NIM (NVIDIA Infrastructure Manager) для простого управления инфраструктурой GPU.
NeMo Retriever и AI Blueprints для быстрого развёртывания и масштабирования моделей AI и генеративного AI.
NVIDIA HGX Servers
Серверы HGX специально разработаны NVIDIA для интенсивных задач AI и инференса. Каждый сервер оснащён 8 ускорителями NVIDIA H100 или H200, которые взаимосвязаны через высокоскоростные интерфейсы NVSwitch и NVLink, обеспечивающие высокую пропускную способность и минимальные задержки.
Высокоскоростная сеть
Сетевое взаимодействие в кластере обеспечивается Ethernet-коммутаторами NVIDIA Spectrum-X, которые предлагают скорость передачи данных до 100 GbE, обеспечивая необходимую производительность для требовательных к данным задач AI.
Референсная архитектура для задач инференса
Референсная архитектура предлагает точные рекомендации по конфигурации аппаратного и программного обеспечения:
Физическая архитектура
Серверы инференса: от 4 до 16 серверов NVIDIA HGX с GPU H100/H200.
Сетевая инфраструктура: 100 GbE для рабочих нагрузок инференса, 25 GbE для управления и хранения данных.
Управляющие серверы: 4 узла, совместимые с VMware vSAN, для запуска сервисов VMware.
Виртуальная архитектура
Домен управления: vCenter, SDDC Manager, NSX, Aria Suite для управления облачной инфраструктурой.
Домен рабочих нагрузок: виртуальные машины с GPU и Supervisor Clusters для запуска Kubernetes-кластеров и виртуальных машин с глубоким обучением (DLVM).
Векторные базы данных: PostgreSQL с расширением pgVector для поддержки Retrieval-Augmented Generation (RAG) в генеративном AI.
Производительность и валидация
VMware и NVIDIA протестировали платформу с помощью набора тестов GenAI-Perf, сравнив производительность виртуализированных и bare-metal сред. Решение VMware Private AI Foundation продемонстрировало высокую пропускную способность и низкую задержку, соответствующие или превосходящие показатели не виртуализированных решений.
Почему компании выбирают VMware Private AI Foundation с NVIDIA?
Эффективное использование GPU: максимизация загрузки GPU, что экономит ресурсы.
Высокий уровень безопасности и защиты данных: конфиденциальность данных и контроль над AI-моделями.
Операционная эффективность: использование привычных инструментов VMware сокращает затраты на внедрение и управление.
Масштабируемость и перспективность: возможность роста и адаптации к новым задачам в области AI.
Итоговые выводы
Платформа VMware Private AI Foundation с NVIDIA является комплексным решением для компаний, стремящихся эффективно и безопасно реализовывать задачи искусственного интеллекта в частных дата-центрах. Она обеспечивает высокую производительность, гибкость и конфиденциальность данных, являясь оптимальным решением для организаций, которым критично важно сохранять контроль над AI-инфраструктурой, не жертвуя при этом удобством и масштабируемостью.
Что означает "реализовать Private AI" для одного или нескольких сценариев использования на платформе VMware Cloud Foundation (VCF)?
VMware недавно представила примеры того, что значит "реализовать Private AI". Эти сценарии использования уже внедрены внутри компании Broadcom в рамках частного применения. Они доказали свою ценность для бизнеса Broadcom, что дает вам больше уверенности в том, что аналогичные сценарии могут быть реализованы и в вашей инсталляции VCF на собственных серверах.
Описанные ниже сценарии были выбраны, чтобы показать, как происходит увеличение эффективности бизнеса за счет:
Повышения эффективности сотрудников, работающих с клиентами с помощью чат-ботов, использующих данные компании.
Помощи разработчикам в создании более качественного кода с помощью ассистентов.
Сценарий использования 1: создание чат-бота, понимающего приватные данные компании
Этот тип приложения является наиболее распространенным стартовым вариантом для тех, кто начинает изучение Generative AI. Основная ценность, отличающая его от чат-ботов в публичных облаках, заключается в использовании приватных данных для ответа на вопросы, касающиеся внутренних вопросов компании. Этот чат-бот предназначен исключительно для внутреннего использования, что снижает возможные риски и служит возможностью для обучения перед созданием приложений, ориентированных на внешнюю аудиторию.
Вот пример пользовательского интерфейса простого стартового чат-бота из NVIDIA AI Enterprise Suite, входящего в состав продукта. Существует множество различных примеров чат-ботов для начинающих в этой области. Вы можете ознакомиться с техническим описанием от NVIDIA для чат-ботов здесь.
Современные чат-боты с поддержкой AI проектируются с использованием векторной базы данных, которая содержит приватные данные вашей компании. Эти данные разделяются на блоки, индексируются и загружаются в векторную базу данных офлайн, без связи с основной моделью чат-бота. Когда пользователь задает вопрос в приложении чат-бота, сначала извлекаются все релевантные данные из векторной базы данных. Затем эти данные, вместе с исходным запросом, передаются в большую языковую модель (LLM) для обработки. LLM обрабатывает и суммирует извлеченные данные вместе с исходным запросом, представляя их пользователю в удобном для восприятия виде. Этот подход к проектированию называется Retrieval Augmented Generation (RAG).
RAG стал общепринятым способом структурирования приложений Generative AI, чтобы дополнить знания LLM приватными данными вашей компании, что позволяет предоставлять более точные ответы. Обновление приватных данных теперь сводится к обновлению базы данных, что гораздо проще, чем повторное обучение или настройка модели.
Пример использования чат-бота
Представим ситуацию: клиент разговаривает с сотрудником компании и спрашивает о функции, которую хотел бы видеть в следующей версии программного продукта компании. Сотрудник не знает точного ответа, поэтому обращается к чат-боту и взаимодействует с ним в диалоговом стиле, используя естественный язык. Логика на стороне сервера в приложении чат-бота извлекает релевантные данные из приватного источника, обрабатывает их в LLM и представляет сотруднику в виде сводки. Теперь сотрудник может дать клиенту более точный ответ.
Пример из Broadcom
В Broadcom специалисты по данным разработали производственный чат-бот для внутреннего использования под названием vAQA (или “VMware’s Automated Question Answering Service”). Этот чат-бот обладает мощными функциями для интерактивного чата или поиска данных, собранных как внутри компании, так и извне.
На панели навигации справа есть возможность фильтровать источники данных. Пример простого использования системы демонстрирует её способность отвечать на вопросы на естественном языке. Например, сотрудник спросил чат-бота о блогах с информацией о виртуальных графических процессорах (vGPU) на VMware Cloud Foundation, указав, чтобы он предоставил URL-адреса этих статей. Система ответила списком релевантных URL-адресов и, что важно, указала свои источники.
Здесь имеется гораздо больше функциональности, чем просто поиск и обработка данных, но это выходит за рамки текущего обсуждения.
Данная система чат-бота использует эмбеддинги, хранящиеся в базе данных, для поиска, связанного с вопросами, а также одну или несколько больших языковых моделей (LLM) для обработки результатов. Кроме того, она использует драйверы GPU на уровне общей инфраструктуры для поддержки этого процесса.
Как VMware Private AI Foundation с NVIDIA позволяет создать чат-бота для работы с приватными данными
Для реализации приложения чат-бота можно использовать несколько компонентов из представленной выше архитектуры для проектирования и доставки рабочего приложения (начиная с синего уровня от VMware).
Система управления моделями (Model Governance) используется для тестирования, оценки и хранения предварительно обученных больших языковых моделей, которые считаются безопасными и подходящими для бизнес-использования. Эти модели сохраняются в библиотеке (называемой "галерея моделей", основанной на Harbor). Процесс оценки моделей уникален для каждой компании.
Функционал векторной базы данных применяется через развертывание этой базы данных с помощью дружественного интерфейса с использованием автоматизации VCF. Затем база данных заполняется очищенными и организованными приватными данными компании.
Инструменты "автоматизации самообслуживания", основанные на автоматизации VCF, используются для предоставления наборов виртуальных машин глубокого обучения для тестирования моделей, а затем для создания кластеров Kubernetes для развертывания и масштабирования приложения.
Средства мониторинга GPU в VCF Operations используются для оценки влияния приложения на производительность GPU и системы в целом.
Вы можете получить лучшие практики и технические советы от авторов VMware о развертывании собственного чат-бота, основанного на RAG, прочитав статью VMware RAG Starter Pack вместе с упомянутыми техническими документами.
Сценарий использования 2: ассистента кода для помощи инженерам в процессе разработки
Предоставление ассистента разработки кода для ускорения процессов разработки программного обеспечения является одним из наиболее значимых сценариев для любой организации, занимающейся разработкой ПО. Это включает подсказки по коду, автозаполнение, рефакторинг, обзоры кода и различные интеграции с IDE.
Инженеры и специалисты по данным VMware изучили множество инструментов, управляемых AI, в области ассистентов кода и, после тщательного анализа, остановились на двух сторонних поставщиках: Codeium и Tabnine, которые интегрированы с VMware Private AI Foundation with NVIDIA. Ниже кратко описан первый из них.
Основная идея состоит в том, чтобы помочь разработчику в процессе написания кода, позволяя общаться с AI-"советником" без прерывания рабочего потока. Советник предлагает подсказки по коду прямо в редакторе, которые можно принять простым нажатием клавиши "Tab". По данным компании Codeium, более 44% нового кода, добавляемого клиентами, создается с использованием их инструментов. Для получения дополнительной информации о советнике можно ознакомиться с этой статьей.
Особенности ассистентов
кода
Одной из интересных функций ассистентов кода является их способность предугадывать, какие действия вы собираетесь выполнить в программировании, помимо вставки следующего фрагмента кода. Ассистент анализирует контекст до и после текущей позиции курсора и предлагает вставку кода с учетом этого контекста. Кроме того, кодовые ассистенты помогают не только с написанием кода, но и с его обзором, тестированием, документированием и рефакторингом. Они также улучшают командное сотрудничество через функции индексирования нескольких репозиториев, управления рабочими местами и другие технологии.
Как VMware Private AI Foundation с NVIDIA помогает развернуть ассистенты
кода
Сторонний ассистент от Codeium разворачивается локально — либо в виртуальной машине с Docker, либо в кластере Kubernetes, созданном, например, с помощью службы vSphere Kubernetes Service (VKS). Код пользователя, независимо от того, написан он вручную или сгенерирован инструментом, не покидает компанию, что защищает интеллектуальную собственность. Целевой кластер Kubernetes создается с помощью инструмента автоматизации VCF и поддерживает работу с GPU благодаря функции VMware Private AI Foundation с NVIDIA — GPU Operator. Этот оператор устанавливает необходимые драйверы vGPU в поды, работающие на кластере Kubernetes, чтобы поддерживать функциональность виртуальных GPU. После этого функциональность Codeium разворачивается в Kubernetes с использованием Helm charts.
Инфраструктура Codeium включает серверы Inference Server, Personalization Server, а также аналитическую базу данных, как показано на рисунке ниже:
Вы можете получить больше информации об использовании Codeium с VMware Private AI Foundation с NVIDIA в этом кратком описании решения.
Ниже приведены простые примеры использования Codeium для генерации функции на Python на основе текстового описания.
Затем в Broadcom попросили ассистента кода написать и включить тестовые сценарии использования для ранее созданной функции.
В первой части этой серии мы рассмотрели два примера использования Private AI на платформе VCF: чат-бот для бэк-офиса, который улучшает взаимодействие с клиентами в контактных центрах, и ассистента кода, помогающего инженерам работать более эффективно.
VCF позволяет предприятиям легко развертывать эти два сценария, используя передовые технологии и быстро выполняя сложные задачи через автоматизацию, при этом обеспечивая безопасность данных на ваших локальных серверах.
На второй день конференции VMware Explore в Барселоне обсуждались передовые технологии, включая решения VMware Private AI Foundation и их интеграцию с решениями от NVIDIA. В видео ниже ведущие эксперты делятся опытом применения Retrieval Augmented Generation (RAG) и другими ключевыми возможностями Private AI для повышения эффективности работы корпоративных систем и оптимизации использования AI.
Основные темы видео:
Что такое VMware Private AI?
VMware Private AI — это платформа, которая позволяет использовать возможности искусственного интеллекта, сохраняя конфиденциальность данных.
RAG (Retrieval Augmented Generation) — технология, интегрирующая базу данных с частными данными в модели AI, что обеспечивает точные ответы и минимизирует "галлюцинации" модели.
Ключевые сценарии использования Private AI:
Внутренние чат-боты: помощь сотрудникам, например, операторам колл-центров, в быстром получении ответов с использованием внутренних данных компании.
Генерация кода: создание инструментов для разработчиков на основе частных данных, таких как внутренний исходный код.
Работа с внутренними базами знаний: быстрый доступ к информации, хранящейся в документации или системах управления знаниями, таких как Confluence.
RAG: Что это и как работает?
Использует внутренние базы данных (векторные базы данных) для поиска информации, релевантной запросу.
Пример: при запросе информация сначала ищется в базе знаний, а затем контекст передается модели AI для создания точного и краткого ответа.
Интеграция с NVIDIA:
Использование NVIDIA NGC для адаптации моделей под ресурсы, такие как GPU, с возможностью значительного повышения производительности (в 2–8 раз).
Поддержка различных уровней точности вычислений (FP32, FP16 и другие) для оптимального баланса скорости и качества.
Модельное управление и тестирование:
Встроенные инструменты для проверки моделей AI на наличие ошибок, галлюцинаций и других проблем до их использования.
Гибкая интеграция любых моделей, включая те, что загружаются из Hugging Face, NVIDIA или создаются внутри компании.
Преимущества подхода Private AI:
Сохранение конфиденциальности данных в онпремизных средах.
Повышение точности работы моделей за счет использования внутренних данных.
Улучшение взаимодействия сотрудников с клиентами и внутри команды.
Для кого это видео:
Системных администраторов, DevOps-инженеров, специалистов по AI.
Компаний, стремящихся внедрить передовые технологии AI, сохраняя конфиденциальность данных.
Тех, кто хочет углубить знания в области RAG и Private AI.
Посмотрите это видео, чтобы узнать больше о том, как VMware и NVIDIA трансформируют корпоративные системы с помощью искусственного интеллекта.
Современные задачи искусственного интеллекта (AI) и машинного обучения (ML) требуют высокопроизводительных решений при минимизации затрат на инфраструктуру, поскольку оборудование для таких нагрузок стоит дорого. Использование графических процессоров NVIDIA в сочетании с технологией NVIDIA AI Enterprise и платформой VMware Cloud Foundation (VCF) позволяет компаниям...
Компания Broadcom выпустила интересное видео, где Mark Achtemichuk и Uday Kulkurne обсуждают оптимизацию AI/ML нагрузок с использованием аппаратной платформы NVIDIA GPU и решения VMware Cloud Foundation:
Производительность и эффективность виртуализации графических процессоров (GPU) является одним из ключевых направлений для разработки решений в области искусственного интеллекта (AI) и машинного обучения (ML).
Виртуализация AI/ML задач, работающих на GPU, представляет собой вызов, так как традиционно считается, что виртуализация может значительно снижать производительность по сравнению с «чистой» конфигурацией на физическом оборудовании (bare metal). Однако VMware Cloud Foundation демонстрирует почти аналогичную производительность с минимальными потерями за счет умной виртуализации и использования технологий NVIDIA.
Рассматриваемые в данном видо графические процессоры от NVIDIA включают модели H100, A100 и L4, каждая из которых имеет уникальные характеристики для обработки AI/ML задач. Например, H100 оснащен 80 миллиардами транзисторов и способен ускорять работу трансформеров (на основе архитектуры GPT) в шесть раз. Особенностью H100 является возможность разделения GPU на несколько независимых сегментов, что позволяет обрабатывать задачи параллельно без взаимного влияния. A100 и L4 также обладают мощными возможностями для AI/ML, с небольшими различиями в спецификациях и применимости для графических задач и машинного обучения.
VMware Cloud Foundation (VCF) позволяет использовать все преимущества виртуализации, обеспечивая при этом производительность, близкую к физическому оборудованию. Одна из ключевых возможностей — это поддержка дробных виртуальных GPU (vGPU) с изоляцией, что позволяет безопасно распределять ресурсы GPU между несколькими виртуальными машинами.
Используя виртуализированные конфигурации на базе VCF и NVIDIA GPU, компании могут значительно снизить общие затраты на владение инфраструктурой (TCO). VMware Cloud Foundation позволяет консолидировать несколько виртуальных машин и задач на одном физическом хосте без существенной потери производительности. Это особенно важно в условиях современных датацентров, где необходимо максимизировать эффективность использования ресурсов.
В серии тестов было проверено, как виртуализированные GPU справляются с различными AI/ML задачами по сравнению с физическим оборудованием. Используя стандартные бенчмарки, такие как ML Commons, было показано, что виртуализированные GPU демонстрируют производительность от 95% до 104% по сравнению с bare metal конфигурациями в режиме инференса (вычисления запросов) и около 92-98% в режиме обучения. Это означает, что даже в виртуализированной среде можно добиться почти той же скорости, что и при использовании физического оборудования, а в некоторых случаях — даже превзойти её.
Основное преимущество использования VMware Cloud Foundation с NVIDIA GPU заключается в гибкости и экономии ресурсов. Виртуализированные среды позволяют разделять ресурсы GPU между множеством задач, что позволяет более эффективно использовать доступные мощности. Это особенно важно для компаний, стремящихся к оптимизации капитальных затрат на инфраструктуру и повышению эффективности использования серверных мощностей.
В рамках анонсов конференции Explore 2024, касающихся VMware Private AI Foundation с NVIDIA (PAIF-N), в компании VMware решили обновить Improved RAG Starter Pack v2.0, чтобы помочь клиентам воспользоваться новейшими микросервисами для инференса NVIDIA (модули NIM), которые обеспечивают атрибуты промышленного уровня (надёжность, масштабируемость и безопасность) для языковых моделей, используемых в системах Retrieval Augmented Generation (RAG).
Следуя духу оригинального Improved RAG Starter Pack (v1.0), Broadcom предлагает серию Jupyter-блокнотов, реализующих улучшенные методы поиска. Эти методы обогащают большие языковые модели (LLMs) актуальными и достоверными контекстами, помогая им генерировать более точные и надёжные ответы на вопросы, связанные с специализированными знаниями, которые могут не быть частью их предобученного датасета. Благодаря этому можно эффективно снизить "галлюцинации" LLM и повысить надёжность приложений, управляемых AI.
Новые функции обновлённого Improved RAG Starter Pack:
Используются NVIDIA NIMs для LLM, текстовых встраиваний и ранжирования текстов — трёх основных языковых моделей, которые питают RAG-пайплайны.
Обновили LlamaIndex до версии v0.11.1.
Используются Meta-Llama3-8b-Instruct в качестве генератора LLM, который управляет RAG-пайплайном.
Заменили OpenAI GPT-4 на Meta-Llama-3-70b-Instruct как движок для DeepEval для выполнения двух ключевых задач, связанных с оценкой RAG-пайплайнов:
Для оценки ("судейства") RAG-пайплайнов путём оценки ответов пайплайна на запросы, извлечённые из набора для оценки. Каждый ответ оценивается по нескольким метрикам DeepEval.
Анатомия улучшенного RAG Starter Pack
Каталог репозитория GitHub, содержащий этот стартовый пакет, предоставляет пошаговое руководство по внедрению различных элементов стандартных систем RAG.
Помимо NVIDIA NIM, системы RAG используют такие популярные технологии, как LlamaIndex (фреймворк для разработки приложений на основе LLM), vLLM (сервис для инференса LLM) и PostgreSQL с PGVector (масштабируемая и надёжная векторная база данных, которую можно развернуть с помощью VMware Data Services Manager).
Все начинается с реализации стандартного RAG-пайплайна. Далее используется база знаний RAG для синтеза оценочного набора данных для оценки системы RAG. Затем улучшается стандартная система RAG за счет добавления более сложных методов поиска, которые будут подробно описаны далее. Наконец, различные подходы RAG оцениваются с помощью DeepEval и сравниваются для выявления их плюсов и минусов.
Структура каталога организована следующим образом.
Теперь давайте обсудим содержание каждой секции.
Настройка сервисов NIM и vLLM (00)
Эта секция содержит инструкции и скрипты для Linux shell, которые необходимы для развертывания сервисов NVIDIA NIM и vLLM, требуемых для реализации RAG-пайплайнов и их оценки.
Инициализация PGVector (01)
Эта секция предлагает несколько альтернатив для развертывания PostgreSQL с PGVector. PGVector — это векторное хранилище, которое будет использоваться LlamaIndex для хранения базы знаний (текстов, встраиваний и метаданных), что позволит расширить знания LLM и обеспечить более точные ответы на запросы пользователей.
Загрузка документов базы знаний (02)
Каждый демо-пример RAG и введение в RAG используют базу знаний для расширения возможностей генерации LLM при вопросах, касающихся областей знаний, которые могут не входить в предобученные данные моделей. Для этого стартового пакета VMware выбрала десять документов из коллекции электронных книг по истории от NASA, предлагая таким образом вариант типичных документов, часто используемых в туториалах по RAG.
Загрузка документов в систему (03)
Эта секция содержит начальный Jupyter-блокнот, где используется LlamaIndex для обработки электронных книг (формат PDF), их разбиения на части (узлы LlamaIndex), кодирования каждого узла в виде длинного вектора (встраивания) и хранения этих векторов в PostgreSQL с PGVector, который действует как наш векторный индекс и движок запросов. На следующем изображении показан процесс загрузки документов в систему.
После того как PGVector загрузит узлы, содержащие метаданные, текстовые фрагменты и их соответствующие встраивания, он сможет предоставить базу знаний для LLM, которая будет генерировать ответы на основе этой базы знаний (в нашем случае это книги по истории от NASA).
Генерация оценочного набора данных (04)
Jupyter-блокнот в этой папке демонстрирует использование Synthesizer из DeepEval для создания набора данных вопросов и ответов, который впоследствии будет использоваться метриками DeepEval для оценки качества RAG-пайплайнов. Это позволит определить, как изменения ключевых компонентов пайплайна RAG, таких как LLM, модели встраиваний, модели повторного ранжирования, векторные хранилища и алгоритмы поиска, влияют на качество генерации. Для синтетической генерации оценочного набора данных используется модель Meta-Llama-3-70b-Instruct.
Реализация вариантов RAG (05)
В этом каталоге содержатся три подкаталога, каждый из которых включает Jupyter-блокнот, исследующий один из следующих вариантов реализации RAG-пайплайна на основе LlamaIndex и открытых LLM, обслуживаемых через vLLM:
Стандартный RAG-пайплайн + повторное ранжирование: этот блокнот реализует стандартный RAG-пайплайн с использованием LlamaIndex, включая финальный этап повторного ранжирования, который управляется моделью ранжирования. В отличие от модели встраиваний, повторное ранжирование использует вопросы и документы в качестве входных данных и напрямую выдаёт степень схожести, а не встраивание. Вы можете получить оценку релевантности, вводя запрос и отрывок в модель повторного ранжирования. VMware использует следующие микросервисы NVIDIA (NIM) для работы RAG-системы:
Генератор LLM для RAG: Meta-Llama-3-8b-Instruct
Модель встраиваний для RAG: nvidia/nv-embedqa-e5-v5
Модель повторного ранжирования для RAG: nvidia/nv-rerankqa-mistral-4b-v3
Следующая картинка иллюстрирует, как работает эта RAG-система.
Извлечение с использованием окон предложений:
Метод извлечения с использованием окон фраз (Sentence Window Retrieval, SWR) улучшает точность и релевантность извлечения информации в RAG-пайплайнах, фокусируясь на определённом окне фраз вокруг целевой фразы. Такой подход повышает точность за счёт фильтрации нерелевантной информации и повышает эффективность, сокращая объём текста, обрабатываемого во время поиска.
Разработчики могут регулировать размер этого окна, чтобы адаптировать поиск к своим конкретным задачам. Однако у метода есть потенциальные недостатки: узкая фокусировка может привести к упущению важной информации в соседнем тексте, что делает выбор подходящего размера окна контекста критически важным для оптимизации как точности, так и полноты процесса поиска. Jupyter-блокнот в этой директории использует реализацию SWR от LlamaIndex через модуль Sentence Window Node Parsing, который разбивает документ на узлы, каждый из которых представляет собой фразу. Каждый узел содержит окно из соседних фраз в метаданных узлов. Этот список узлов повторно ранжируется перед передачей LLM для генерации ответа на запрос на основе данных из узлов.
Автоматическое слияние при извлечении:
Метод автоматического слияния при извлечении — это подход RAG, разработанный для решения проблемы фрагментации контекста в языковых моделях, особенно когда традиционные процессы поиска создают разрозненные фрагменты текста. Этот метод вводит иерархическую структуру, где меньшие текстовые фрагменты связаны с более крупными родительскими блоками. В процессе извлечения, если определённый порог меньших фрагментов из одного родительского блока достигнут, они автоматически сливаются. Такой подход гарантирует, что система собирает более крупные, связные родительские блоки, вместо извлечения разрозненных фрагментов. Ноутбук в этой директории использует AutoMergingRetriever от LlamaIndex для реализации этого варианта RAG.
Оценка RAG-пайплайна (06)
Эта папка содержит Jupyter-блокнот, который использует DeepEval для оценки ранее реализованных RAG-пайплайнов. Для этой цели DeepEval использует оценочный набор данных, сгенерированный на предыдущем шаге. Вот краткое описание метрик DeepEval, используемых для сравнения различных реализаций RAG-пайплайнов. Обратите внимание, что алгоритмы метрик DeepEval могут объяснить, почему LLM присвоил каждую оценку. В нашем случае эта функция включена, и вы сможете увидеть её работу.
Contextual Precision оценивает ретривер вашего RAG-пайплайна, проверяя, расположены ли узлы в вашем контексте поиска, которые релевантны данному запросу, выше, чем нерелевантные узлы.
Faithfulness оценивает качество генератора вашего RAG-пайплайна, проверяя, соответствует ли фактический вывод содержимому вашего контекста поиска.
Contextual Recall оценивает качество ретривера вашего RAG-пайплайна, проверяя, насколько контекст поиска соответствует ожидаемому результату.
Answer Relevancy измеряет, насколько релевантен фактический вывод вашего RAG-пайплайна по отношению к данному запросу.
Hallucination — эта метрика определяет, генерирует ли ваш LLM фактически корректную информацию, сравнивая фактический вывод с предоставленным контекстом. Это фундаментальная метрика, так как одной из главных целей RAG-пайплайнов является помощь LLM в генерации точных, актуальных и фактических ответов на запросы пользователей.
Оценки DeepEval были выполнены с использованием следующей конфигурации:
LLM-оценщик, оценивающий метрики DeepEval: Meta-Llama-3-70b-Instruct, работающая на vLLM в режиме guided-JSON.
Следующая таблица показывает результаты оценки из одного из экспериментов VMware, который включал более 40 пар вопросов и ответов.
Следующая диаграмма представляет другой ракурс взгляда на предыдущий результат:
Как показывает таблица, конкретная реализация RAG может показывать лучшие результаты по определённым метрикам, что указывает на их применимость к различным сценариям использования. Кроме того, метрики оценки помогают определить, какие компоненты ваших RAG-пайплайнов нуждаются в корректировке для повышения общей производительности системы.
Заключение
Обновлённый RAG Starter Pack предоставляет ценный инструментарий для тех, кто внедряет системы RAG, включая серию хорошо документированных Python-блокнотов, предназначенных для улучшения LLM за счёт углубления контекстного понимания. В этот пакет включены передовые методы поиска и такие инструменты, как DeepEval, для оценки системы, которые помогают снизить такие проблемы, как "галлюцинации" LLM, и повысить надёжность ответов AI. Репозиторий на GitHub хорошо структурирован и предлагает пользователям понятное пошаговое руководство, которому легко следовать, даже если вы не являетесь специалистом в области данных. Клиенты и партнёры Broadcom, использующие PAIF-N, найдут этот пакет полезным для запуска приложений на базе генеративного AI в инфраструктурах VMware Cloud Foundation. Ожидайте новых статей, в которых VMware рассмотрит ключевые аспекты безопасности и защиты в производственных RAG-пайплайнах.
Недавно на конференции NVIDIA GTC 2024 было объявлено о начальной доступности VMware Private AI Foundation with NVIDIA, что знаменует начало эпохи AI в датацентрах крупных заказчиков. VMware Private AI Foundation with NVIDIA позволяет пользователям запускать AI-нагрузки на собственной инфраструктуре, используя VMware Cloud Foundation (VCF) и экосистему программного обеспечения и графических процессоров NVIDIA.
Эта совместная платформа не только поддерживает более безопасные AI-нагрузки, но также добавляет гибкость и операционную эффективность при сохранении максимальной производительности. Кроме того, VCF добавляет уровень автоматизации, упрощающий развертывание виртуальных машин дата-сайентистами для глубокого обучения. Подробнее о данной процедуре написано здесь.
Хотя Broadcom и NVIDIA обеспечивают основные потребности в программном обеспечении, выбор лучшего оборудования для выполнения рабочих нагрузок Private AI также является ключевым элементом успешной реализации проектов в области AI. VMware сотрудничает с такими производителями серверов, как Dell, Fujitsu, Hitachi, HPE, Lenovo и Supermicro, чтобы составить исчерпывающий список поддерживаемых платформ, оптимизированных для работы с графическими процессорами NVIDIA и VMware Cloud Foundation. Хотя некоторые AI-задачи могут выполняться и на более старых графических процессорах NVIDIA A100, в настоящее время рекомендуется использовать NVIDIA L40 и H100 для современных AI-нагрузок, чтобы достичь оптимальной производительности и эффективности.
Серверы, перечисленные ниже, сертифицированы специально для VMware Private AI Foundation с NVIDIA. Процесс сертификации включает сертификацию партнера по графическим процессорам с аппаратной платформой, а также поддержку общего назначения графических процессоров с помощью VMware VM DirectPath IO. Обратите внимание, что дополнительные производители и графические процессоры будут добавлены позже, поэтому не забывайте проверять обновления.
Все из нас знакомы с понятием центрального процессора (CPU), в последнее время мы также наблюдаем рост использования графических процессоров (GPU) в самых разных областях. GPU набирают популярность в таких направлениях, как машинное обучение, глубокое обучение, анализ данных и, конечно же, игры. Но существует новая технология, которая быстро набирает обороты в датацентрах — это Data Processing Unit (DPU), или процессор обработки данных.
Что же такое DPU?
Проще говоря, DPU — это программируемое устройство с аппаратным ускорением, имеющее также комплекс ARM-процессоров, способных обрабатывать данные. Сегодня DPU доступен в виде SmartNIC (форм-фактор PCIe), который можно установить в сервер и использовать для выполнения различных функций (см. также нашу статью о Project Monterey здесь).
Если взглянуть глубже, SmartNIC содержит ARM-процессор, а также программируемый ускоритель с высокоскоростным интерфейсом между ними. SmartNIC также имеет 2 порта (или больше) с пропускной способностью от 10 Гбит/с до 100 Гбит/с в зависимости от производителя и отдельный Ethernet-порт для управления. У SmartNIC имеется локальное хранилище, что позволяет пользователям устанавливать программное обеспечение, например, гипервизор, такой как ESXi.
В настоящее время в этой технологии участвуют такие производители, как NVIDIA и AMD/Pensando (среди прочих), и вскоре эти устройства станут мейнстримными в датацентрах, поскольку они становятся более доступными для клиентов. Сейчас пока такое устройство от NVIDIA, например, стоит более 2.2 тысяч долларов. Модули от Pensando также начинаются от 2.5 тысяч
По сути, DPU представляет собой систему на чипе (system on a chip, SoC), обеспечивающую высокопроизводительные сетевые интерфейсы, способные обрабатывать данные с гораздо большей скоростью. Но два ключевых аспекта DPU, связанных с портфелем продуктов VMware, включают возможность переноса рабочих нагрузок с хоста x86 на DPU, а также предоставление дополнительного уровня безопасности за счет создания изолированной среды для выполнения некоторых процессов. Эта работа в настоящее время ведется в VMware в рамках проекта Monterey.
В имплементации Monterey сетевые процессы, такие как сетевой трафик, распределенный брандмауэр и другие, будут переданы на обработку SmartNIC. Это означает, что не только ресурсы будут освобождены от сервера x86, но и сам трафик будет обработан DPU. Проект Monterey также упростит установку ESXi и NSX на сам DPU, таким образом, перенос необходимых ресурсов CPU с x86 на DPU не только освободит ресурсы на x86 для использования виртуальными машинами, но и обеспечит дополнительный уровень безопасности.
Недавно мы писали о новых возможностях пакета обновлений платформы виртуализации VMware vSphere 8 Update 3. Сегодня мы более детально рассмотрим, что нового там появилось в плане поддержки карт GPU.
Новые функции охватывают несколько областей, начиная с использования vGPU-профилей разных типов и размеров вместе и заканчивая внесением изменений в расширенные параметры DRS, которые определяют, как ВМ с поддержкой vGPU будет обрабатываться со стороны vMotion, например. Все эти улучшения направлены на упрощение жизни системных администраторов, дата-сайентистов и других пользователей, чтобы они могли использовать свои рабочие нагрузки на платформах vSphere и VCF.
Гетерогенные типы vGPU-профилей с разными размерами
В VMware vSphere мы можем назначить машине vGPU-профиль из набора заранее определенных профилей, чтобы предоставить ей определенную функциональность. Набор доступных vGPU-профилей появляется после установки NVIDIA vGPU менеджера/драйвера на уровне хоста в ESXi посредством vSphere Installation Bundle (VIB).
Эти vGPU-профили называются профилями типа C в случае, если профиль предназначен для интенсивной вычислительной работы, такой как обучение моделей машинного обучения. Существуют и несколько других типов vGPU-профилей, среди которых Q (Quadro) для графических рабочих нагрузок являются одними из самых популярных. Буквы «c» и «q» стоят в конце названия vGPU-профиля, отсюда и название этого типа.
В предыдущем обновлении vSphere 8 Update 2 мы могли назначать машине vGPU-профили, которые предоставляли поддержку различных видов функциональности, используя при этом одно и то же устройство GPU. Ограничением в этой версии vSphere было то, что они должны были быть vGPU-профилями одного и того же размера, например, те, которые заканчиваются на 8q и 8c. Здесь «8» представляет количество гигабайт памяти на самом GPU (иногда называемой framebuffer-памятью), которая назначена ВМ, использующей этот vGPU-профиль. Это значение может изменяться в зависимости от модели основного GPU.
При использовании GPU A40 или L40s мы можем иметь vGPU-профиль типа C, предназначенный для вычислительно интенсивной работы, такой как машинное обучение, и vGPU-профиль типа Q (предназначенный для графической работы), назначенные разным ВМ, которые делят один и тот же физический GPU на хосте.
Теперь в vSphere 8 Update 3 можно продолжать смешивать эти разные типы vGPU-профилей на одном физическом GPU, а также иметь vGPU-профили разного размера памяти, которые делят один и тот же GPU.
В качестве примера новой функциональности vSphere 8 Update 3: ВМ1 с vGPU-профилем l40-16c (для вычислительных нагрузок) и ВМ2 с vGPU-профилем l40-12q (для графических нагрузок) делят одно и то же устройство L40 GPU внутри хоста. Фактически, все вышеупомянутые виртуальные машины делят одно и то же физическое устройство L40 GPU.
Это позволяет лучше консолидировать рабочие нагрузки на меньшее количество GPU, когда рабочие нагрузки не потребляют весь GPU целиком. Возможность размещения гетерогенных типов и размеров vGPU-профилей на одном устройстве GPU применяется к GPU L40, L40s и A40 в частности, так как эти GPU имеют двойное назначение. То есть они могут обрабатывать как графические, так и вычислительно интенсивные задачи, в то время как GPU H100 предназначен исключительно для вычислительно интенсивных задач.
Включение настроек кластера для DRS и мобильности ВМ с vGPU
В vSphere Client версии 8.0 U3 появились новые настройки кластера, которые предоставляют более удобный метод настройки расширенных параметров для кластера DRS. Вы можете установить ограничение по времени приостановки ВМ, которое будет допускаться для машин с vGPU-профилями, которым может потребоваться больше времени, чем по умолчанию, для выполнения vMotion. Время приостановки по умолчанию для vMotion составляет 100 секунд, но этого может быть недостаточно для некоторых ВМ с большими vGPU-профилями. Дополнительное время требуется для копирования памяти GPU на целевой хост. Вы также можете узнать оценочное время приостановки для вашей конкретной ВМ с поддержкой vGPU в vSphere Client. Для получения дополнительной информации о времени приостановки, пожалуйста, ознакомьтесь с этой статьей.
В vSphere 8 Update 3 появился более удобный пользовательский интерфейс для настройки расширенных параметров для кластера DRS, связанных с vMotion виртуальных машин.
Прежде чем мы рассмотрим второй выделенный элемент на экране редактирования настроек кластера ниже, важно понять, что vGPU как механизм доступа к GPU является одной из множества техник, которые находятся в "спектре проброса устройств" (Passthrough spectrum). То есть, vGPU на самом деле является одной из форм прямого доступа. Возможно, вы считали, что подходы прямого проброса и vGPU сильно отличаются друг от друга до настоящего времени, так как они действительно разделены в vSphere Client при выборе добавления нового PCIe-устройства к ВМ. Однако, они тесно связаны друг с другом. Фактически, vGPU ранее назывался "опосредованным пробросом" (mediated passthrough). Этот спектр использования прямого доступа различными способами показан здесь.
Именно поэтому в vSphere Client на выделенном участке экрана ниже используются термины «Passthrough VM» и «Passthrough Devices». Эти термины на самом деле относятся к виртуальным машинам с поддержкой vGPU – и таким образом, обсуждение касается включения DRS и vMotion для виртуальных машин с поддержкой vGPU на этом экране. vMotion не разрешен для виртуальных машин, использующих фиксированный прямой доступ, как показано на левой стороне диаграммы выше.
Новая функция интерфейса позволяет пользователю включить расширенную настройку vSphere под названием «PassthroughDrsAutomation». С включенной этой настройкой, при соблюдении правил по времени приостановки, виртуальные машины в этом кластере могут быть перемещены vMotion на другой хост по решению DRS. Для получения дополнительной информации об этих расширенных настройках DRS, пожалуйста, ознакомьтесь с этой статьей.
Доступ к медиа-движку GPU
Единый медиа-движок на GPU может использоваться виртуальной машиной, которая хостит приложение, которому требуется выполнять транскодирование (кодирование/декодирование) на GPU, а не на более медленном CPU, например, для видео-приложений.
В vSphere 8 Update 3 поддерживается новый vGPU-профиль для виртуальных машин, которым требуется доступ к медиа-движку внутри GPU. Только одна виртуальная машина может использовать этот медиа-движок. Примеры таких vGPU-профилей («me» означает media engine):
a100-1-5cme (один срез)
h100-1-10cme (два среза)
Более высокая скорость vMotion виртуальных машин с большими vGPU-профилями
Новые улучшения в vMotion позволяют нам увеличивать пропускную способность для сети vMotion со скоростью 100 Гбит/с до 60 Гбит/с для vMotion виртуальной машины, к которой подключен современный GPU (H100, L40S), что сокращает время vMotion. Это не относится к GPU A100 и A30, которые относятся к более старой архитектуре (GA100).
Новые технические документы и рекомендации по проектированию GPU с VMware Private AI Foundation with NVIDIA
Недавно были выпущены два важных публикации авторами VMware. Агустин Маланко Лейва и команда опубликовали решение VMware Validation Solution для инфраструктуры Private AI Ready Infrastructure, доступное здесь.
Этот документ предоставляет подробное руководство по настройке GPU/vGPU на VMware Cloud Foundation и многим другим факторам для организации вашей инфраструктуры для развертывания VMware Private AI.
Одним из ключевых приложений, которое будут развертывать в первую очередь в инфраструктуре VMware Private AI Foundation с NVIDIA, является генерация с дополненным извлечением или RAG. Фрэнк Деннеман и Крис МакКейн подробно рассматривают требования к безопасности и конфиденциальности и детали реализации этого в новом техническом документе под названием VMware Private AI – Privacy and Security Best Practices.
Private AI Ready Infrastructure – это уже готовое модульное решение, которое предлагает руководство по проектированию, внедрению и эксплуатации для развертывания AI-нагрузок на стеке VMware Cloud Foundation. Используя GPU-ускоренные VCF Workload Domains, vSphere with Tanzu, NSX и vSAN, это решение обеспечивает прочную основу для современных инициатив в области AI.
Разбор сложностей инфраструктуры, связанных с GPU, и оптимизация AI-нагрузок может быть трудной задачей для администраторов без специальной экспертизы. Трудности, связанные с конфигурацией и управлением средами с GPU, значительны и часто требуют глубоких знаний характеристик оборудования, совместимости драйверов и оптимизации производительности. Однако с решением Private AI Ready Infrastructure VMware Validated Solution, организации могут обойти эти проблемы и уверенно развертывать свои AI нагрузки с проверенными валидированными конфигурациями и лучшими практиками.
Инфраструктура Private AI Foundation with NVIDIA также включена в состав решения VMware Validated Solution, предлагая клиентам возможность поднять свою AI инфраструктуру на новый уровень совместно с решением от NVIDIA.
Что входит в состав решения?
Детальный документ по проектированию архитектуры, охватывающий высокоскоростные сети, вычислительные мощности, хранилища и Accelerators для AI, а также компоненты VMware Private AI Foundation с NVIDIA.
Руководство по сайзингу
Руководство по внедрению
Руководство по эксплуатации и управлению жизненным циклом, включая проверку работоспособности с помощью VMware Starter Pack на основе vLLM RAG
Руководство по совместимости
Начало работы
Ели вы готовы раскрыть весь потенциал вашей Private AI инфраструктуры, получите доступ к этому решению VMware Validated Solution по этой ссылке.
Построенный и запущенный на ведущей в отрасли платформе для частного облака, VMware Cloud Foundation, VMware Private AI Foundation with NVIDIA включает в себя новые микросервисы NVIDIA NIM, модели искусственного интеллекта от NVIDIA и других участников сообщества (таких как Hugging Face), а также инструменты и фреймворки искусственного интеллекта от NVIDIA, доступные с лицензиями NVIDIA AI Enterprise.
VMware Private AI Foundation с NVIDIA — это дополнительный SKU на базе VMware Cloud Foundation. Лицензии программного обеспечения NVIDIA AI Enterprise необходимо приобретать отдельно. Это решение использует NVIDIA NIM — часть NVIDIA AI Enterprise, набор простых в использовании микросервисов, предназначенных для ускорения развертывания генеративных моделей AI в облаке, центрах обработки данных и на рабочих станциях.
С момента GA-релиза VMware Private AI Foundation с NVIDIA были также добавлены дополнительные возможности к этой платформе.
1. Мониторинг GPU
Панели мониторинга — это новые представления для GPU, которые позволяют администраторам легко отслеживать метрики GPU по кластерам. Эта панель предоставляет данные в реальном времени о температуре GPU, использовании памяти и вычислительных мощностях, что позволяет администраторам улучшить время решения проблем с инфраструктурой и операционную эффективность.
Мониторинг температуры — с мониторингом температуры GPU администраторы теперь могут максимизировать производительность GPU, получая ранние предупреждения о перегреве. Это позволяет предпринимать проактивные меры для предотвращения снижения производительности и обеспечения оптимальной работы GPU.
2. Скрипты PowerCLI
Была представлена коллекция из четырёх мощных настраиваемых скриптов PowerCLI, предназначенных для повышения эффективности развёртывания и минимизации ручных усилий для администраторов. Эти скрипты служат ценными инструментами для автоматизации развёртывания необходимой инфраструктуры при внедрении рабочих нагрузок AI в среде VCF. Давайте рассмотрим детали.
Развертывание домена рабочих нагрузок VCF - этот скрипт размещает хосты ESXi в SDDC Manager и разворачивает домен рабочих нагрузок VCF. Этот домен служит основой для настройки VMware Private AI Foundation с NVIDIA для развёртывания рабочих нагрузок AI/ML.
Конфигурация хостов ESXi - используя возможности VMware vSphere Lifecycle Manager, этот скрипт упрощает конфигурацию хостов ESXi, плавно устанавливая компоненты программного обеспечения NVIDIA, входящие в состав NVIDIA AI Enterprise, такие как драйвер NVIDIA vGPU и сервис управления GPU NVIDIA.
Развертывание кластера NSX Edge - этот скрипт облегчает развертывание кластера NSX Edge в домене рабочих нагрузок VCF, обеспечивая внешнюю сетевую связность для рабочих нагрузок AI/ML.
Конфигурация кластера Supervisor и библиотеки содержимого образов ВМ глубокого обучения - этот сценарий настраивает кластер Supervisor в домене рабочих нагрузок VCF. Также он создаёт новую библиотеку содержимого образов VM для глубокого обучения, позволяя пользователям легко развертывать рабочие нагрузки ИИ/ML с предварительно настроенными средами выполнения.
Больше технических деталей о возможностях этого релизы вы можете узнать здесь и здесь.
В видеоблоге, посвященном платформе VMware vSphere, появилось интересное видео о технологии DPU (data processing units). Напомним, что мы писали о ней вот тут и тут.
В данном подкасте "Vare break room chats", ведущий - Shobhit Bhutani, менеджер по продуктовому маркетингу в VMware, а гость - Motti Beck из NVIDIA, обсуждают вызовы, с которыми сталкиваются современные дата-центры, особенно в контексте сложности инфраструктуры. Основная проблема заключается в необходимости обработки больших объемов данных для задач машинного обучения, что требует параллельной обработки и высокопроизводительных сетевых решений.
Они говорят о роли технологий VMware и Nvidia в упрощении управления дата-центрами за счет использования решений на основе DPU, которые позволяют перенести часть задач с CPU на DPU, улучшая тем самым производительность и безопасность. Также обсуждаются достижения новой архитектуры данных, которая позволяет снизить задержки и увеличить пропускную способность, а также повысить энергоэффективность системы.
Примеры улучшений включают возможность работы с большим количеством правил безопасности и эффективное использование ресурсов, что подтверждается бенчмарками. Также поднимается тема удобства интеграции и управления такими системами - установка и настройка не отличаются от традиционных методов, что делает новую технологию доступной без дополнительных усилий со стороны ИТ-специалистов.
В современном быстро развивающемся цифровом ландшафте организациям необходимо при релизовывать инициативы по модернизации инфраструктуры, чтобы оставаться актуальными. Новая волна приложений с поддержкой искусственного интеллекта обещает значительно увеличить производительность работников и ускорить экономическое развитие на глобальном уровне, подобно тому как революция мобильных приложений трансформировала бизнес и технологии на протяжении многих лет. Цель компаний Broadcom и VMware состоит в том, чтобы сделать эту мощную и новую технологию более доступной, надежной и доступной по цене. Однако управление разнообразными технологиями, преодоление человеческого сопротивления изменениям и обеспечение прибыльности могут стать сложными препятствиями для любой комплексной ИТ-стратегии.
В связи с объявлением о начальной доступности VMware Private AI Foundation с NVIDIA, в компании Broadcom рады объявить о новой возможности Private AI Automation Services, работающей на базе решения VMware Aria Automation. С помощью служб Private AI Automation Services, встроенных в VMware Cloud Foundation, клиенты могут автоматизировать настройку и предоставление частных AI-услуг и аллокацию машин с поддержкой GPU для ML-нагрузок.
Существует растущая потребность предприятий в решениях для AI, но их реализация может быть сложной и затратной по времени. Чтобы удовлетворить эту потребность, новая интеграция "из коробки" VMware Private AI Foundation с NVIDIA позволит организациям предоставлять возможности автоматизации на базе платформы VMware Cloud Foundation. Интеграция будет сопровождаться новым мастером настройки каталога, который обеспечит быстрый старт, автоматическую настройку частных AI-услуг и самостоятельное предоставление машин с поддержкой GPU, включая ML-нагрузки и TKG GPU на базе кластеров Kubernetes.
Платформа VMware Cloud Foundation (VCF) представляет собой комплексное решение для частной облачной инфраструктуры, которое обеспечивает всеобъемлющую, безопасную и масштабируемую платформу для создания и эксплуатации генеративных AI-нагрузок. Оно предоставляет организациям гибкость, адаптивность и масштабируемость для удовлетворения их меняющихся бизнес-потребностей. С помощью VMware Cloud Foundation ИТ-администраторы могут управлять дорогостоящими и востребованными ресурсами, такими как GPU, с помощью политик использования, шаблонов и ролей пользователей.
Это позволяет членам команд более эффективно использовать инфраструктурные услуги для своих AI/ML-проектов, в то время как ИТ-администраторы обеспечивают оптимальное и безопасное использование ресурсов. Время развертывания AI-инфраструктуры будет сокращено за счет использования Supervisor VM и сервисов TKG в рамках пространства имен супервизора и предоставления через интерфейс потребления облака.
Этот интерфейс теперь доступен локально для клиентов VMware Cloud Foundation через Aria Automation, позволяя им использовать преимущества VMware Private AI Foundation with NVIDIA. Кроме того, Cloud Consumption Interface предлагает простое и безопасное самостоятельное потребление всех Kubernetes-ориентированных desired state IaaS API, доступных на платформе vSphere. Это позволяет предприятиям легко внедрять опыт DevOps и разрабатывать приложения с большей гибкостью, адаптивностью и современными методами в среде vSphere, сохраняя контроль над своей инфраструктурой.
VMware Cloud Foundation помогает клиентам интегрировать гибкость и контроль, необходимые для поддержки нового поколения приложений с AI, что значительно увеличивает производительность работников, способствует трансформации основных бизнес-функций и оказывает положительное экономическое воздействие.
Частные AI-среды VMware служат отличной основой для нового класса приложений на основе AI, что облегчает использование приватных, но широко распределенных данных. Кроме того, возможности Automation Services обеспечивают более быстрый выход на рынок за счет ускоренной итерации изменений AI/ML-инфраструктуры, управляемой через шаблоны. Они также удобны в использовании за счет сокращения времени доступа к средам разработки с поддержкой GPU через каталоги самообслуживания. Кроме того, они дают разработчикам и командам DevOps подход, соответствующий Kubernetes (desired state), для управления изменениями Day-2. Наконец, они помогут снизить затраты на дорогостоящие ресурсы GPU за счет улучшенного управления и использования мощностей AI/ML-инфраструктуры с встроенными политиками и управлением через опции самообслуживания.
Подход Private AI становится популярным, потому что он удовлетворяет возникающие потребности бизнеса в использовании AI, соблюдая строгие стандарты управления данными и конфиденциальности. Открытые модели GenAI могут представлять потенциальные риски, такие как проблемы конфиденциальности, что заставляет организации быть все более осторожными. Частный AI предлагает убедительную альтернативу, позволяя предприятиям запускать модели AI рядом с источником данных, повышая безопасность и соответствие требованиям. VMware Private AI прокладывает путь к новой парадигме, где трансформационный потенциал AI реализуется без ущерба для конфиденциальности данных клиентов и собственных корпоративных данных. Это экономически выгодное решение станет более важным в 2024 году, поскольку организации сталкиваются с растущими регуляторными препятствиями.
Ожидается, что Automation Services для VMware Private AI
станут доступны во втором фискальном квартале Broadcom.
Команда VMware Cloud объявила о публичной доступности платформы VMware Cloud Foundation 5.1.1, поддерживающей первоначальный доступ (initial availability, IA) к инфраструктуре VMware Private AI Foundation with NVIDIA в дополнение к новой модели лицензирования решений VCF, что является первым этапом многоэтапной программы по предоставлению полного стека VCF как единого продукта. Ниже представлен обзор этих важных новых возможностей VCF 5.1.1, а также дополнительные ресурсы и ссылки.
Спецификация версий компонентов VMware Cloud Foundation 5.1.1:
VMware Private AI Foundation with NVIDIA
Как было объявлено на конференции GTC AI Conference 2024, Broadcom предоставила первоначальный доступ (initial availability) к VMware Private AI Foundation with NVIDIA в качестве продвинутого аддона к VMware Cloud Foundation. VMware Private AI Foundation открывает новую эру решений инфраструктуры, поддерживаемых VMware Cloud Foundation для широкого спектра случаев использования генеративного AI. Читайте больше о решениях VMware Cloud Foundation для AI и машинного обучения здесь.
VMware Cloud Foundation является основной инфраструктурной платформой для VMware Private AI Foundation with NVIDIA, предоставляющей современное частное облако, которое позволяет организациям динамически масштабировать рабочие нагрузки GenAI по требованию. VMware Cloud Foundation предлагает автоматизированный процесс самообслуживания в облаке, который ускоряет продуктивность для разработчиков, аналитиков и ученых, обеспечивая при этом комплексную безопасность и устойчивость для защиты и восстановления самой чувствительной интеллектуальной собственности организации.
VMware Cloud Foundation решает многие проблемы, возникающие при развертывании инфраструктуры для поддержки рабочих нагрузок GenAI, за счет архитектуры платформы с полным программно-определяемым стеком, объединяя лучшие в своем классе ресурсы GPU, тесно интегрированные с вычислениями, хранением данных, сетями, безопасностью и управлением.
В VMware Cloud Foundation 5.1.1 существуют хорошо задокументированные рабочие процессы в SDDC Manager для настройки и конфигурации домена рабочих нагрузок Private AI. Также имеется мастер настройки каталога автоматизации VCF, который упрощает конфигурацию этих систем. Зв счет интеграции последних релизов Aria с VMware Cloud Foundation 5.1.1, появляются новые возможности управления, которые можно использовать в решениях Aria Operations и Aria Automation.
Aria Operations включает новые свойства и метрики мониторинга GPU, предоставляющие метрики на уровне кластера и хоста для управления здоровьем и использованием ресурсов GPU. Aria Automation предоставляет новые сервисы автоматизации для VMware Private AI, предлагая модель развертывания частного облака самообслуживания, которая позволяет разработчикам и аналитикам настраивать и перестраивать блоки инфраструктуры для поддержки широкого спектра вариантов использования. Эта новая возможность повышает не только производительность, но и эффективность этих решений на основе GPU, снижая общую стоимость владения (TCO). Гибкость, предлагаемая этой архитектурой, позволяет администраторам облака использовать различные домены рабочих нагрузок, каждый из которых может быть настроен для поддержки конкретных типов виртуальных машин, оптимизируя производительность рабочих нагрузок и использование ресурсов GPU.
Поддержка новой модели лицензирования VMware Cloud Foundation
Для дальнейшего упрощения развертывания, VMware Cloud Foundation 5.1.1 предлагает опцию развертывания единого лицензионного ключа решения, которая теперь включает 60-дневный пробный период. Дополнительные продукты и аддоны к VMware Cloud Foundation теперь также могут быть подключены на основе единого ключа (отметим, что лицензия vSAN на TiB является исключением на данный момент и все еще должна применяться отдельно). Поддержка отдельных компонентных лицензионных ключей продолжается, но новая функция единого ключа должна упростить лицензирование решений на базе развертываний VMware Cloud Foundation.
VMware Cloud Foundation 5.1.1 доступен для загрузки и развертывания уже сейчас. Доступ к VMware Private AI Foundation with NVIDIA можно запросить здесь.
На конференции Explore 2023 компания VMware объявила о новой инициативе в области поддержки систем генеративного AI - VMware Private AI. Сейчас, когда технологии генеративного AI выходят на первый план, особенно важно организовать инфраструктуру для них - то есть подготовить программное и аппаратное обеспечение таким образом, чтобы расходовать ресурсы, необходимые для AI и ML, наиболее эффективно, так как уже сейчас в сфере Corporate AI требуются совершенно другие мощности, чтобы обслуживать эти задачи.
Генеративный искусственный интеллект (Gen AI) - одно из важнейших восходящих направлений, которые изменят ландшафт компаний в течение следующих 5-10 лет. В основе этой волны инноваций находятся большие языковые модели (LLM), обрабатывающие обширные и разнообразные наборы данных. LLM позволяют людям взаимодействовать с моделями искусственного интеллекта через естественный язык как в текстовой форме, так и через речь или изображения.
Инвестиции и активность в области исследований и разработок LLM заметно возросли, что привело к обновлению текущих моделей и выпуску новых, таких как Gemini (ранее Bard), Llama 2, PaLM 2, DALL-E и другие. Некоторые из них являются открытыми для общественности, в то время как другие являются собственностью компаний, таких как Google, Meta и OpenAI. В ближайшие несколько лет ценность GenAI будет определяться доработкой и настройкой моделей, адаптированных к конкретным областям бизнеса и отраслям. Еще одним важным развитием в использовании LLM является Retrieval Augmented Generation (RAG), при котором LLM привязываются к большим и разнообразным наборам данных, чтобы предприятия могли взаимодействовать с LLM по вопросам данных.
VMware предоставляет программное обеспечение, которое модернизирует, оптимизирует и защищает рабочие нагрузки самых сложных организаций в области обработки данных, на всех облачных платформах и в любом приложении. Платформа VMware Cloud Foundation помогает предприятиям внедрять инновации и трансформировать свой бизнес, а также развертывать широкий спектр приложений и услуг искусственного интеллекта. VMware Cloud Foundation обеспечивает единый платформенный подход к управлению всеми рабочими нагрузками, включая виртуальные машины, контейнеры и технологии искусственного интеллекта, через среду самообслуживания и автоматизированного ИТ-окружения.
На днях, на конференции NVIDIA GTC, VMware объявила о начальной доступности (Initial Availability) решения VMware Private AI Foundation with NVIDIA.
VMware Private AI Foundation with NVIDIA
VMware/Broadcom и NVIDIA стремятся раскрыть потенциал Gen AI и максимально использовать производительность совместной платформы.
Построенный и запущенный на ведущей в отрасли платформе для частного облака, VMware Cloud Foundation, VMware Private AI Foundation with NVIDIA включает в себя новые микросервисы NVIDIA NIM, модели искусственного интеллекта от NVIDIA и других участников сообщества (таких как Hugging Face), а также инструменты и фреймворки искусственного интеллекта от NVIDIA, доступные с лицензиями NVIDIA AI Enterprise.
Эта интегрированная платформа GenAI позволяет предприятиям запускать рабочие процессы RAG, внедрять и настраивать модели LLM и выполнять эти нагрузки в их центрах обработки данных, решая проблемы конфиденциальности, выбора, стоимости, производительности и комплаенса. Она упрощает развертывание GenAI для предприятий, предлагая интуитивный инструмент автоматизации, образы глубокого обучения виртуальных машин, векторную базу данных и возможности мониторинга GPU. Эта платформа представляет собой дополнительный SKU в дополнение к VMware Cloud Foundation. Обратите внимание, что лицензии NVIDIA AI Enterprise должны быть приобретены отдельно у NVIDIA.
Ключевые преимущества
Давайте разберем ключевые преимущества VMware Private AI Foundation с участием NVIDIA:
Обеспечение конфиденциальности, безопасности и соблюдения нормативов моделей искусственного интеллекта
VMware Private AI Foundation with NVIDIA предлагает архитектурный подход к обслуживанию искусственного интеллекта, обеспечивающий конфиденциальность, безопасность и контроль над корпоративными данными, а также более интегрированную систему безопасности и управления.
VMware Cloud Foundation обеспечивает продвинутые функции безопасности, такие как защита загрузки, виртуальный TPM, шифрование виртуальных машин и многое другое. В рамках услуг NVIDIA AI Enterprise включено программное обеспечение управления для использования рабочей нагрузки и инфраструктуры для масштабирования разработки и развертывания моделей искусственного интеллекта. Стек программного обеспечения для искусственного интеллекта включает более 4500 пакетов программного обеспечения с открытым исходным кодом, включая программное обеспечение сторонних производителей и программное обеспечение NVIDIA.
Часть услуг NVIDIA AI Enterprise включает патчи для критических и опасных уязвимостей (CVE) с производственными и долгосрочными ветвями поддержки и обеспечения совместимости API по всему стеку. VMware Private AI Foundation with NVIDIA обеспечивает средства развертывания, которые предоставляют предприятиям контроль над множеством регуляторных задач с минимальными изменениями в их текущей среде.
Ускоренная производительность моделей GenAI независимо от выбранных LLM
Broadcom и NVIDIA предоставляют программные и аппаратные средства для достижения максимальной производительности моделей GenAI. Эти интегрированные возможности, встроенные в платформу VMware Cloud Foundation, включают мониторинг GPU, горячую миграцию и балансировку нагрузки, мгновенное клонирование (возможность развертывания кластеров с несколькими узлами с предварительной загрузкой моделей за несколько секунд), виртуализацию и пулы GPU, а также масштабирование ввода/вывода GPU с помощью NVIDIA NVLink и NVIDIA NVSwitch.
Недавнее исследование сравнивало рабочие нагрузки искусственного интеллекта на платформе VMware + NVIDIA AI-Ready Enterprise с bare metal. Результаты показывают производительность, сравнимую или даже лучшую, чем на bare metal. Таким образом, размещение рабочих нагрузок искусственного интеллекта на виртуализированных решениях сохраняет производительность и приносит преимущества виртуализации, такие как упрощенное управление и улучшенная безопасность. NVIDIA NIM позволяет предприятиям выполнять операции на широком диапазоне оптимизированных LLM, от моделей NVIDIA до моделей сообщества, таких как Llama-2, и до LLM с открытым исходным кодом, таких как Hugging Face, с высокой производительностью.
Упрощение развертывания GenAI и оптимизация затрат
VMware Private AI Foundation with NVIDIA помогает предприятиям упростить развертывание и достичь экономичного решения для своих моделей GenAI. Он предлагает такие возможности, как векторная база данных для выполнения рабочих процессов RAG, виртуальные машины глубокого обучения и мастер автоматического запуска для упрощения развертывания. Эта платформа реализует единые инструменты и процессы управления, обеспечивая значительное снижение затрат. Этот подход позволяет виртуализировать и использовать общие ресурсы инфраструктуры, такие как GPU, CPU, память и сети, что приводит к существенному снижению затрат, особенно для случаев использования, где полноценные GPU могут быть необязательными.
Архитектура
VMware Cloud Foundation, полноценное решение для частного облачного инфраструктуры, и NVIDIA AI Enterprise, полнофункциональная облачная платформа, образуют основу платформы VMware Private AI Foundation with NVIDIA. Вместе они предоставляют предприятиям возможность запуска частных и безопасных моделей GenAI.
Основные возможности, которые следует выделить:
1. Специальные возможности, разработанные VMware
Давайте подробнее рассмотрим каждую из них.
Шаблоны виртуальных машин для глубокого обучения
Настройка виртуальной машины для глубокого обучения может быть сложным и затратным процессом. Ручное создание может привести к недостатку согласованности и, следовательно, к недостаточной оптимизации в различных средах разработки. VMware Private AI Foundation with NVIDIA предоставляет виртуальные машины для глубокого обучения, которые поставляются предварительно настроенными с необходимыми программными средствами, такими как NVIDIA NGC, библиотеками и драйверами, что освобождает пользователей от необходимости настраивать каждый компонент.
Векторные базы данных для выполнения рабочих процессов RAG
Векторные базы данных стали очень важным компонентом для рабочих процессов RAG. Они обеспечивают быстрый запрос данных и обновление в реальном времени для улучшения результатов LLM без необходимости повторного обучения этих моделей, что может быть очень затратным и долгим. Они стали стандартом для рабочих процессов GenAI и RAG. VMware применяет векторные базы данных, используя pgvector на PostgreSQL. Эта возможность управляется с помощью автоматизации в рамках инфраструктуры служб данных в VMware Cloud Foundation. Сервис управления данными упрощает развертывание и управление базами данных с открытым исходным кодом и коммерческими базами данных из одного интерфейса.
Мастер настройки каталога
Создание инфраструктуры для проектов искусственного интеллекта включает несколько сложных шагов. Эти шаги выполняются администраторами, специализирующимися на выборе и развертывании соответствующих классов виртуальных машин, кластеров Kubernetes, виртуальных графических процессоров (vGPU) и программного обеспечения для искусственного интеллекта/машинного обучения, такого как контейнеры в каталоге NGC.
В большинстве предприятий исследователи данных и DevOps тратят значительное количество времени на сборку необходимой им инфраструктуры для разработки и производства моделей искусственного интеллекта/машинного обучения. Полученная инфраструктура может не соответствовать требованиям безопасности и масштабируемости для разных команд и проектов. Даже при оптимизированных развертываниях инфраструктуры для искусственного интеллекта/машинного обучения исследователи данных и DevOps могут тратить значительное количество времени на ожидание, когда администраторы создадут, составят и предоставят необходимые объекты каталога инфраструктуры для задач искусственного интеллекта/машинного обучения.
Для решения этих проблем VMware Cloud Foundation представляет мастер настройки каталога (Catalog Setup Wizard) - новую возможность Private AI Automation Services. На начальном этапе LOB-администраторы могут эффективно создавать, составлять и предоставлять оптимизированные объекты каталога инфраструктуры искусственного интеллекта через портал самообслуживания VMware Cloud Foundation. После публикации DevOps исследователи данных могут легко получить доступ к элементам каталога машинного обучения и развернуть их с минимальными усилиями. Мастер настройки каталога снижает ручную нагрузку для администраторов и сокращает время ожидания, упрощая процесс создания масштабируемой инфраструктуры.
Мониторинг GPU
Получая видимость использования и метрик производительности GPU, организации могут принимать обоснованные решения для оптимизации производительности, обеспечения надежности и управления затратами в средах с ускорением на GPU. С запуском VMware Private Foundation with NVIDIA сразу доступны возможности мониторинга GPU в VMware Cloud Foundation. Это дает администраторам дэшборды с информацией об использовании GPU в рамках кластеров и хостов, в дополнение к существующим метрикам мониторинга.
2. Возможности NVIDIA AI Enterprise
NVIDIA NIM
NVIDIA NIM - это набор простых в использовании микросервисов, разработанных для ускорения развертывания GenAI на предприятиях. Этот универсальный микросервис поддерживает модели NVIDIA AI Foundation Models - широкий спектр моделей - от ведущих моделей сообщества до моделей, созданных NVIDIA, а также индивидуальные пользовательские модели искусственного интеллекта, оптимизированные для стека NVIDIA. Созданный на основе фундаментальных компонентов NVIDIA Triton Inference Server, NVIDIA TensorRT, TensorRT-LLM и PyTorch, NVIDIA NIM предназначен для обеспечения масштабируемых и гибких моделей AI.
NVIDIA Nemo Retriever
NVIDIA NeMo Retriever - это часть платформы NVIDIA NeMo, которая представляет собой набор микросервисов NVIDIA CUDA-X GenAI, позволяющих организациям без проблем подключать пользовательские модели к разнообразным бизнес-данным и предоставлять высокоточные ответы. NeMo Retriever обеспечивает поиск информации самого высокого уровня с минимальной задержкой, максимальной пропускной способностью и максимальной конфиденциальностью данных, позволяя организациям эффективно использовать свои данные и генерировать бизнес-инсайты в реальном времени. NeMo Retriever дополняет приложения GenAI расширенными возможностями RAG, которые могут быть подключены к бизнес-данным в любом месте их хранения.
NVIDIA RAG LLM Operator
Оператор NVIDIA RAG LLM упрощает запуск приложений RAG в производственную среду. Он оптимизирует развертывание конвейеров RAG, разработанных с использованием примеров рабочих процессов искусственного интеллекта NVIDIA, в производственной среде без переписывания кода.
NVIDIA GPU Operator
Оператор NVIDIA GPU автоматизирует управление жизненным циклом программного обеспечения, необходимого для использования GPU с Kubernetes. Он обеспечивает расширенные функциональные возможности, включая повышенную производительность GPU, эффективное использование ресурсов и телеметрию. Оператор GPU позволяет организациям сосредотачиваться на создании приложений, а не на управлении инфраструктурой Kubernetes.
Поддержка ведущих производителей серверного оборудования
Платформа от VMware и NVIDIA поддерживается ведущими производителями серверного оборудования, такими как Dell, HPE и Lenovo.
Более подробно о VMware Private AI Foundation with NVIDIA можно узнать тут и тут.
На прошедшей в этом году конференции Explore 2023 компания VMware сделала множество интересных анонсов в сфере искусственного интеллекта (AI). Сейчас, когда технологии генеративного AI выходят на первый план, особенно важно организовать инфраструктуру для них - то есть подготовить программное и аппаратное обеспечение таким образом, чтобы расходовать ресурсы, необходимые для AI и ML, наиболее эффективно, так как уже сейчас в сфере Corporate AI требуются совершенно другие мощности, чтобы обслуживать эти задачи.
На конференции VMworld 2020 Online ковидного года компания VMware представила одну из самых интересных своих инициатив по сотрудничеству с вендорами оборудования - Project Monterey. Тогда была представлена технология SmartNIC/DPU, которая позволяет обеспечить высокую производительность, безопасность по модели zero-trust и простую эксплуатацию в среде VCF.
SmartNIC - это специальный сетевой адаптер (NIC) c модулем CPU на борту, который берет на себя offload основных функций управляющих сервисов (а именно, работу с хранилищами и сетями, а также управление самим хостом).
В данном решении есть три основных момента:
Поддержка перенесения сложных сетевых функций на аппаратный уровень, что увеличивает пропускную способность и уменьшает задержки (latency).
Унифицированные операции для всех приложений, включая bare-metal операционные системы.
Модель безопасности Zero-trust security - обеспечение изоляции приложений без падения производительности. Ведь если основной ESXi для исполнения рабочих нагрузок будет скомпрометирован, то управляющий DPU сможет обнаружить ее и устранить уязвимость.
В статье об аппаратных нововведениях платформы VMware vSphere 8 Update 2, представленных на конференции Explore 2023, мы писали о том, что VMware еще в vSphere 8 представила поддержку DPU, позволяя клиентам переносить инфраструктурные рабочие нагрузки с CPU на специализированный модуль DPU, тем самым повышая производительность бизнес-нагрузок. Ну а в vSphere 8 U2 клиенты, использующие серверы Lenovo или Fujitsu, теперь смогут использовать новые функции интеграции vSphere DPU и его преимущества в производительности.
Теперь в платформах vSphere 8 и NSX есть полноценная поддержка устройств SmartNIC или так называемых устройств обработки данных (DPU). Реализация DPU в vSphere называется vSphere Distributed Service Engine.
DPU (SmartNIC) — это сетевые карты с встроенным интеллектом, которые могут выполнять различные сетевые функции непосредственно на адаптере через свои собственные программируемые процессоры. В дополнение к сетевым ускорителям, такие DPU, как NVIDIA BlueField, также имеют ядра общего назначения на базе процессора Arm, которые могут запускать полноценную систему ESXi (вот для чего и пригодился гипервизор VMware ESXi Arm Edition).
С технологией DPU, службы NSX, такие как маршрутизация, коммутация, брандмауэр и мониторинг, снимаются с хост-гипервизора и переносятся на DPU. С помощью этих возможностей возможно улучшить производительность, освободить ресурсы на хосте и изолировать рабочую нагрузку и инфраструктурные домены.
Ну и несколько картинок по результатам тестирования хостов ESXi с модулями SmartNIC/DPU на борту, которые показывают, какой прирост производительности дает новая технология:
Продолжаем рассказывать об интересных анонсах главного события года в мире виртуализации - конференции VMware Explore 2023. Сегодня организации стремятся использовать AI, но беспокоятся о рисках для интеллектуальной собственности, утечке данных и контроле доступа к моделям искусственного интеллекта. Эти проблемы определяют необходимость корпоративного приватного AI.
Об этом недавно компания VMware записала интересное видео:
Рассмотрим этот важный анонс немного детальнее. Вот что приватный AI может предложить по сравнению с публичной инфраструктурой ChatGPT:
Распределенность: вычислительная мощность и модели AI будут находиться рядом с данными. Это требует инфраструктуры, поддерживающей централизованное управление.
Конфиденциальность данных: данные организации остаются в ее владении и не используются для тренировки других моделей без согласия компании.
Контроль доступа: установлены механизмы доступа и аудита для соблюдения политик компании и регуляторных правил.
Приватный AI не обязательно требует частных облаков, главное — соблюдение требований конфиденциальности и контроля.
Подход VMware Private AI
VMware специализируется на управлении рабочими нагрузками различной природы и имеет огромный опыт, полезный для имплементации успешного приватного AI. К основным преимуществам подхода VMware Private AI относятся:
Выбор: организации могут легко сменить коммерческие AI-сервисы или использовать открытые модели, адаптируясь к бизнес-требованиям.
Конфиденциальность: современные методы защиты обеспечивают конфиденциальность данных на всех этапах их обработки.
Производительность: показатели AI-задач равны или даже превышают аналоги на чистом железе, как показали отраслевые тесты.
Управление: единый подход к управлению снижает затраты и риски ошибок.
Time-to-value: AI-окружения можно быстро поднимать и выключать за считанные секунды, что повышает гибкость и скорость реакции на возникающие задачи.
Эффективность: быстрое развертывание корпоративных AI-сред и оптимизация использования ресурсов снижают общие затраты на инфраструктуру и решение задач, которые связаны с AI.
Таким образом, платформа VMware Private AI предлагает гибкий и эффективный способ внедрения корпоративного приватного AI.
VMware Private AI Foundation в партнерстве с NVIDIA
VMware сотрудничает с NVIDIA для создания универсальной платформы VMware Private AI Foundation with NVIDIA. Эта платформа поможет предприятиям настраивать большие языковые модели, создавать более безопасные модели для внутреннего использования, предлагать генеративный AI как сервис и безопасно масштабировать задачи генерации результатов. Решение основано на средах VMware Cloud Foundation и NVIDIA AI Enterprise и будет предлагать следующие преимущества:
Масштабирование уровня датацентров: множественные пути ввода-вывода для GPU позволяют масштабировать AI-загрузки на до 16 виртуальных GPU в одной виртуальной машине.
Производительное хранение: архитектура VMware vSAN Express обеспечивает оптимизированное хранение на базе хранилищ NVMe и технологии GPUDirect storage over RDMA, а также поддерживает прямую передачу данных от хранилища к GPU без участия CPU.
Образы виртуальных машин vSphere для Deep Learning: быстрое прототипирование с предустановленными фреймворками и библиотеками.
В решении будет использоваться NVIDIA NeMo, cloud-native фреймворк в составе NVIDIA AI Enterprise, который упрощает и ускоряет принятие генеративного ИИ.
Архитектура VMware для приватного AI
AI-лаборатории VMware совместно с партнерами разработали решение для AI-сервисов, обеспечивающее приватность данных, гибкость выбора ИИ-решений и интегрированную безопасность. Архитектура предлагает:
Использование лучших моделей и инструментов, адаптированных к бизнес-потребностям.
Быстрое внедрение благодаря документированной архитектуре и коду.
Интеграцию с популярными открытыми проектами, такими как ray.io, Kubeflow, PyTorch, pgvector и моделями Hugging Face.
Архитектура поддерживает коммерческие и открытые MLOps-инструменты от партнеров VMware, такие как MLOps toolkit for Kubernetes, а также различные надстройки (например, Anyscale, cnvrg.io, Domino Data Lab, NVIDIA, One Convergence, Run:ai и Weights & Biases). В состав платформы уже включен самый популярный инструмент PyTorch для генеративного AI.
Сотрудничество с AnyScale расширяет применение Ray AI для онпремизных вариантов использования. Интеграция с Hugging Face обеспечивает простоту и скорость внедрения открытых моделей.
Решение Private AI уже применяется в собственных датацентрах VMware, показывая впечатляющие результаты по стоимости, масштабу и производительности разработчиков.
Там приведены результаты тестирования производительности рабочих нагрузок обучения AI/ML на платформе виртуализации VMware vSphere с использованием нескольких графических процессоров NVIDIA A100-80GB с поддержкой технологии NVIDIA NVLink. Результаты попадают в так называемую "зону Голдилокс", что означает область хорошей производительности инфраструктуры, но с преимуществами виртуализации.
Результаты показывают, что время обучения для нескольких тестов MLPerf v3.0 Training1 увеличивается всего от 6% до 8% относительно времени тех же рабочих нагрузок на аналогичной физической системе.
Кроме того, в документе показаны результаты теста MLPerf Inference v3.0 для платформы vSphere с графическими процессорами NVIDIA H100 и A100 Tensor Core. Тесты показывают, что при использовании NVIDIA vGPU в vSphere производительность рабочей нагрузки, измеренная в запросах в секунду (QPS), составляет от 94% до 105% производительности на физической системе.
vSphere 8 и высокопроизводительная виртуализация с графическими процессорами NVIDIA и NVLink.
Партнерство между VMware и NVIDIA позволяет внедрить виртуализированные графические процессоры в vSphere благодаря программному слою NVIDIA AI Enterprise. Это дает возможность не только достигать наименьшего времени обработки для виртуализированных рабочих нагрузок машинного обучения и искусственного интеллекта, но и использовать многие преимущества vSphere, такие как клонирование, vMotion, распределенное планирование ресурсов, а также приостановка и возобновление работы виртуальных машин.
VMware, Dell и NVIDIA достигли производительности, близкой или превышающей аналогичную конфигурацию на физическом оборудовании со следующими настройками:
Dell PowerEdge R750xa с 2-мя виртуализированными графическими процессорами NVIDIA H100-PCIE-80GB
Для вывода в обеих конфигурациях требовалось всего 16 из 128 логических ядер ЦП. Оставшиеся 112 логических ядер ЦП в дата-центре могут быть использованы для других задач. Для достижения наилучшей производительности виртуальных машин во время обучения требовалось 88 логических ядер CPU из 128. Оставшиеся 40 логических ядер в дата-центре могут быть использованы для других активностей.
Производительность обучения AI/ML в vSphere 8 с NVIDIA vGPU
На картинке ниже показано сравнительное время обучения на основе тестов MLPerf v3.0 Training, с использованием vSphere 8.0.1 с NVIDIA vGPU 4x HA100-80c против конфигурации на физическом оборудовании с 4x A100-80GB GPU. Базовое значение для физического оборудования установлено как 1.00, и результат виртуализации представлен в виде относительного процента от базового значения. vSphere с NVIDIA vGPUs показывает производительность близкую к производительности на физическом оборудовании, где накладные расходы на виртуализацию составляют 6-8% при обучении с использованием BERT и RNN-T.
Таблица ниже показывает время обучения в минутах для тестов MLPerf v3.0 Training:
Результаты на физическом оборудовании были получены Dell и опубликованы в разделе закрытых тестов MLPerf v3.0 Training с ID 3.0-2050.2.
Основные моменты из документа:
VMware vSphere с NVIDIA vGPU и технологией AI работает в "зоне Голдилокс" — это область производительности для хорошей виртуализации рабочих нагрузок AI/ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPUs и программное обеспечение NVIDIA AI, показывает от 106% до 108% от главной метрики физического оборудования (100%), измеренной как время обучения для тестов MLPerf v3.0 Training.
vSphere достигла пиковой производительности, используя всего 88 логических ядер CPU из 128 доступных ядер, оставив тем самым 40 логических ядер для других задач в дата-центре.
VMware использовала NVIDIA NVLinks и гибкие группы устройств, чтобы использовать ту же аппаратную конфигурацию для обучения ML и вывода ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPU и программное обеспечение NVIDIA AI, показывает от 94% до 105% производительности физического оборудования, измеренной как количество обслуживаемых запросов в секунду для тестов MLPerf Inference v3.0.
vSphere достигла максимальной производительности вывода, используя всего 16 логических ядер CPU из 128 доступных, оставив тем самым 112 логических ядер CPU для других задач в дата-центре.
vSphere сочетает в себе мощь NVIDIA vGPU и программное обеспечение NVIDIA AI с преимуществами управления дата-центром виртуализации.
Более подробно о тестировании и его результатах вы можете узнать из документа.
В марте компания VMware анонсировала скорую доступность первого пакета обновлений своей флагманской платформы виртуализации VMware vSphere 8.0 Update 1. Напомним, что прошлая версия VMware vSphere 8.0 была анонсирована на конференции VMware Explore 2022 в августе прошлого года.
Давайте посмотрим, что нового появилось в vSphere 8.0 U1:
1. Полная поддержка vSphere Configuration Profiles
В vSphere 8.0 эта функциональность впервые появилась и работала в режиме технологического превью, а в Update 1 она полностью вышла в продакшен. Эта возможность представляет собой новое поколение инструментов для управления конфигурациями кластеров и заменяет предыдущую функцию Host Profiles. Ее особенности:
Установка желаемой конфигурации на уровне кластера в форме JSON-документа
Проверка хостов на соответствие желаемой конфигурации
При выявлении несоответствий - перенастройка хостов на заданный уровень конфигурации
В vSphere 8 Update 1 возможности Configuration Profiles поддерживают настройку распределенных коммутаторов vSphere Distributed Switch, которая не была доступна в режиме технологического превью. Однако, окружения, использующие VMware NSX, все еще не поддерживаются.
Существующие кластеры можно перевести под управление Configuration Profiles. Если для кластера есть привязанный профиль Host Profile, то вы увидите предупреждение об удалении профиля, когда кластер будет переведен в Configuration Profiles. Как только переход будет закончен, Host Profiles уже нельзя будет привязать к кластеру и хостам.
Если кластер все еще использует управление жизненным циклом на базе бейзлайнов, то сначала кластер нужно перевести в режим управления image-based:
vSphere Configuration Profiles могут быть активированы при создании нового кластера. Это требует, чтобы кластер управлялся на основе единого определения образа. После создания кластера доступна кастомизация конфигурации. Более подробно о возможностях Configuration Profiles можно почитать здесь.
2. vSphere Lifecycle Manager
для отдельных хостов
В vSphere 8 появилась возможность управлять через vSphere Lifecycle Manager отдельными хостами ESXi под управлением vCenter посредством vSphere API. В Update 1 теперь есть полная поддержка vSphere Client для этого процесса - создать образ, проверить и привести в соответствие, а также другие функции.
Все, что вы ожидаете от vSphere Lifecycle Manager для взаимодействия с кластером vSphere, вы можете делать и для отдельных хостов, включая стейджинг и функции ESXi Quick Boot.
Также вы можете определить кастомные image depots для отдельных хостов - это полезно, когда у вас есть хост, который находится на уровне edge и должен использовать depot, размещенный совместно с хостом ESXi, во избежание проблем с настройкой конфигурации при плохом соединении удаленных друг от друга хостов ESXi и vCenter.
3. Различные GPU-нагрузки хоста на базе одной видеокарты
В предыдущих версиях vSphere все рабочие нагрузки NVIDIA vGPU должны были использовать тот же самый тип профиля vGPU и размер памяти vGPU. В vSphere 8 U1 модули NVIDIA vGPU могут быть назначены для различных типов профилей. Однако, размер памяти для них должен быть, по-прежнему, одинаковым. Например, на картинке ниже мы видим 3 виртуальных машины, каждая с разным профилем (B,C и Q) и размером памяти 8 ГБ. Это позволяет более эффективно разделять ресурсы между нагрузками разных видов.
NVIDIA позволяет создавать следующие типы профилей vGPU:
Profile type A - для потоково доставляемых приложений или для решений на базе сессий
Profile type B - для VDI-приложений
Profile type C - для приложений, требовательных к вычислительным ресурсам (например, machine learning)
Profile type Q - для приложений, требовательных к графике
4. Службы Supervisor Services для vSphere Distributed Switch
В vSphere 8 Update 1, в дополнение к VM Service, службы Supervisor Services теперь доступны при использовании сетевого стека vSphere Distributed Switch.
Supervisor Services - это сертифицированные в vSphere операторы Kubernetes, которые реализуют компоненты Infrastructure-as-a-Service, тесно интегрированные со службами независимых разработчиков ПО. Вы можете установить и управлять Supervisor Services в окружении vSphere with Tanzu, чтобы сделать их доступными для использования рабочими нагрузками Kubernetes. Когда Supervisor Services установлены на Supervisors, инженеры DevOps могут использовать API для создания инстансов на Supervisors в рамках пользовательских пространств имен.
Возможность VM Service была доработана, чтобы поддерживать образы ВМ, созданные пользователями. Теперь администраторы могут собирать собственные пайплайны сборки образов с поддержкой CloudInit и vAppConfig.
Администраторы могут добавить эти новые шаблоны ВМ в Content library, чтобы они стали доступны команде DevOps. А сами DevOps создают спецификацию cloud-config, которая настроит ВМ при первой загрузке. Команда DevOps отправляет спецификацию ВМ вместе cloud-config для создания и настройки ВМ.
DevOps могут теперь получать простой доступ к виртуальным машинам, которые они развернули, с использованием kubectl.
В этом случае создается уникальная ссылка, по которой можно получить доступ к консоли ВМ, и которая не требует настройки разрешений через vSphere Client. Веб-консоль дает по этому URL доступ пользователю к консоли машины в течение двух минут. В этом случае нужен доступ к Supervisor Control Plane по порту 443.
Веб-консоль ВМ дает возможности самостоятельной отладки и траблшутинга даже для тех ВМ, у которых может не быть доступа к сети и настроенного SSH.
7. Интегрированный плагин Skyline Health Diagnostics
Теперь развертывание и управление VMware Skyline Health Diagnostics упростилось за счет рабочего процесса, встроенного в vSphere Client, который дает возможность просто развернуть виртуальный модуль и зарегистрировать его в vCenter.
Skyline Health Diagnostics позволяет вам:
Диагностировать и исправлять различные типы отказов в инфраструктуре
Выполнять проверку состояния компонентов (health checks)
Понимать применимость VMware Security Advisories и связанных элементов
Обнаруживать проблемы, которые влияют на апдейты и апгрейды продукта
Утилита использует логи, конфигурационную информацию и другие источники для обнаружения проблем и предоставления рекомендаций в форме ссылок на статьи KB или шагов по исправлению ситуации.
8. Улучшенные метрики vSphere Green Metrics
В vSphere 8.0 появились метрики, которые отображают потребление энергии виртуальными машинами с точки зрения энергоэффективности виртуального датацентра. В vSphere 8.0 Update 1 теперь можно отслеживать их на уровне отдельных ВМ. Они берут во внимание объем ресурсов ВМ, чтобы дать пользователю более точную информацию об энергоэффективности на уровне отдельных нагрузок. Разработчики также могут получать их через API, а владельцы приложений могут получать агрегированное представление этих данных.
Метрика Static Power - это смоделированное потребление мощности простаивающих ресурсов ВМ, как если бы она был хостом bare-metal с такими же аппаратными параметрами процессора и памяти. Static Power оценивает затраты на поддержание таких хостов во включенном состоянии. Ну а Usage - это реально измеренное потребление мощности ВМ в активном режиме использования CPU и памяти, которые запрашиваются через интерфейс (IPMI - Intelligent Platform Management Interface).
9. Функция Okta Identity Federation для vCenter
vSphere 8 Update 1 поддерживает управление идентификациями и многофакторной аутентификацией в облаке, для чего на старте реализована поддержка Okta.
Использование Federated identity подразумевает, что vSphere не видит пользовательских учетных данных, что увеличивает безопасность. Это работает по аналогии со сторонними движками аутентификации в вебе, к которым пользователи уже привыкли (например, логин через Google).
10. Функции ESXi Quick Boot для защищенных систем
vSphere начала поддерживать Quick Boot еще с версии vSphere 6.7. Теперь хосты с поддержкой TPM 2.0 проходят через безопасный процесс загрузки и аттестации, что позволяет убедиться в неизменности хоста - а это надежный способ предотвратить атаки malware. Quick Boot теперь стал полноценно совместимым процессом в vSphere 8 Update 1.
11. Поддержка vSphere Fault Tolerance с устройствами vTPM
Функции непрерывной доступности VMware vSphere Fault Tolerance (FT) позволяют подхватить исполнение рабочей нагрузки на резервном хосте без простоя в случае проблем основной ВМ. Теперь эта функция поддерживает ВМ, настроенные с устройствами vTPM.
Модели Virtual TPM - это важный компонент инфраструктуры, используемый такими решениями, как Microsoft Device Guard, Credential Guard, Virtualization-Based Security, Secure Boot & OS attestation, а также многими другими. Это, зачастую, и часть регуляторных требований комплаенса.
12. Поддержка Nvidia NVSwitch
В рамках партнерства с NVIDIA, VMware продолжает расширять поддержку продуктового портфеля этого вендора.
Эта технология используется в high-performance computing (HPC) и для AI-приложений (deep learning, научное моделирование и анализ больших данных), что требует работы модулей GPU совместно в параллельном режиме. В современном серверном оборудовании различные приложения ограничены параметрами шины. Чтобы решить эту проблему, NVIDIA создала специальный коммутатор NVSwitch, который позволяет до 8 GPU взаимодействовать на максимальной скорости.
Вот нюансы технологий NVLink и NVSwitch:
NVLink - это бэкенд протокол для коммутаторов NVSwitch. NVLink создает мост для соединений точка-точка и может быть использован для линковки от 2 до 4 GPU на очень высокой скорости.
NVSwitch требует, чтобы более 4 GPU были соединены, а также использует поддержку vSphere 8U1 NVSwitch для формирования разделов из 2, 4 и 8 GPU для работы виртуальных машин.
NVLink использует архитектуру Hopper, что предполагает создания пары GPU, которые передают до 450 GB/s (то есть общая скорость до 900 GB/s).
Для сравнения архитектура Gen5 x16 может передавать на скорости до 64 GB/s, то есть NVLink и NVSwitch дают очень существенный прирост в скорости.
13. Функции VM DirectPath I/O Hot-Plug для NVMe
В прошлых релизах добавление или удаление устройств VM DirectPath IO требовало нахождения ВМ в выключенном состоянии. Теперь же в vSphere 8 Update 1 появилась поддержка горячего добавления и удаления устройств NVMe через vSphere API.
На этом пока все, в следующих статьях мы расскажем об улучшениях Core Storage в vSphere 8 Update 1.
Многие администраторы виртуальных инфраструктур используют технологию NVIDIA vGPU, чтобы разделить физический GPU-модуль между виртуальными машинами (например, для задач машинного обучения), при этом используется профиль time-sliced vGPU (он же просто vGPU - разделение по времени использования) или MIG-vGPU (он же Multi-Instance vGPU, мы писали об этом тут). Эти два режима позволяют выбрать наиболее оптимальный профиль, исходя из особенностей инфраструктуры и получить наибольшие выгоды от технологии vGPU.
Итак, давайте рассмотрим первый вариант - сравнение vGPU и MIG vGPU при увеличении числа виртуальных машин на GPU, нагруженных задачами машинного обучения.
В этом эксперименте была запущена нагрузка Mask R-CNN с параметром batch size = 2 (training and inference), в рамках которой увеличивали число ВМ от 1 до 7, и которые разделяли A100 GPU в рамках профилей vGPU и MIG vGPU. Эта ML-нагрузка была легковесной, при этом использовались различные настройки профилей в рамках каждого тестового сценария, чтобы максимально использовать время и память модуля GPU. Результаты оказались следующими:
Как мы видим, MIG vGPU показывает лучшую производительность при росте числа ВМ, разделяющих один GPU. Из-за использования параметра batch size = 2 для Mask R-CNN, задача тренировки в каждой ВМ использует меньше вычислительных ресурсов (используется меньше ядер CUDA) и меньше памяти GPU (менее 5 ГБ, в сравнении с 40 ГБ, который имеет каждый GPU). Несмотря на то, что vGPU показывает результаты похуже, чем MIG vGPU, первый позволяет масштабировать нагрузки до 10 виртуальных машин на GPU, а MIG vGPU поддерживает на данный момент только 7.
Второй вариант теста - vGPU и MIG vGPU при масштабировании нагрузок Machine Learning.
В этом варианте исследовалась производительность ML-нагрузок при увеличении их интенсивности. Был проведен эксперимент, где также запускалась задача Mask R-CNN, которую модифицировали таким образом, чтобы она имела 3 разных степени нагрузки: lightweight, moderate и heavy. Время исполнения задачи тренировки приведено на рисунке ниже:
Когда рабочая нагрузка в каждой ВМ использует меньше процессора и памяти, время тренировки и пропускная способность MIG vGPU лучше, чем vGPU. Разница в производительности между vGPU и MIG vGPU максимальна именно для легковесной нагрузки. Для moderate-нагрузки MIG vGPU также показывает себя лучше (но немного), а вот для тяжелой - vGPU уже работает производительнее. То есть, в данном случае выбор между профилями может быть обусловлен степенью нагрузки в ваших ВМ.
Третий тест - vGPU и MIG vGPU для рабочих нагрузок с высокой интенсивность ввода-вывода (например, Network Function with Encryption).
В этом эксперименте использовалось шифрование Internet Protocol Security (IPSec), которое дает как нагрузку на процессор, так и на подсистему ввода-вывода. Тут также используется CUDA для копирования данных между CPU и GPU для освобождения ресурсов процессора. В данном тесте IPSec использовал алгоритмы HMAC-SHA1 и AES-128 в режиме CBC. Алгоритм OpenSSL AES-128 CBC был переписан в рамках тестирования в части работы CUDA. В этом сценарии vGPU отработал лучше, чем MIG vGPU:
Надо сказать, что нагрузка эта тяжелая и использует много пропускной способности памяти GPU. Для MIG vGPU эта полоса разделяется между ВМ, а вот для vGPU весь ресурс распределяется между ВМ. Это и объясняет различия в производительности для данного сценария.
Основные выводы, которые можно сделать по результатам тестирования:
Для легковесных задач машинного обучения режим MIG vGPU даст бОльшую производительность, чем vGPU, что сэкономит вам деньги на инфраструктуру AI/ML.
Для тяжелых задач, где используются большие модели и объем входных данных (а значит и меньше ВМ работают с одним GPU), разница между профилями почти незаметна.
Для тяжелых задач, вовлекающих не только вычислительные ресурсы и память, но и подсистему ввода-вывода, режим vGPU имеет преимущество перед MIG vGPU, что особенно заметно для небольшого числа ВМ.
Компания VMware недавно выпустила пару интересных материалов о Project Monterey. Напомним, что продолжение развития технологии Project Pacific для контейнеров на базе виртуальной инфраструктуры, только с аппаратной точки зрения для инфраструктуры VMware Cloud Foundation (VCF).
Вендоры аппаратного обеспечения пытаются сделать высвобождение некоторых функций CPU, передав их соответствующим компонентам сервера (модуль vGPU, сетевая карта с поддержкой offload-функций и т.п.), максимально изолировав их в рамках необходимостей. Но вся эта новая аппаратная архитектура не будет хорошо работать без изменений в программной платформе.
Project Monterey - это и есть переработка архитектуры VCF таким образом, чтобы появилась родная интеграция новых аппаратных возможностей и программных компонентов. Например, новая аппаратная технология SmartNIC позволяет обеспечить высокую производительность, безопасность по модели zero-trust и простую эксплуатацию в среде VCF. За счет технологии SmartNIC инфраструктура VCF будет поддерживать операционные системы и приложения, исполняемые на "голом железе" (то есть без гипервизора).
Вот что нового в последнее время появилось о Project Monterey:
После выхода VMware vSphere 7 Update 2 появилось много интересных статей о разного рода улучшениях, на фоне которых как-то потерялись нововведения, касающиеся работы с большими нагрузками машинного обучения на базе карт NVIDIA, которые были сделаны в обновлении платформы.
А сделано тут было 3 важных вещи:
Пакет NVIDIA AI Enterprise Suite был сертифицирован для vSphere
Появилась поддержка последних поколений GPU от NVIDIA на базе архитектуры Ampere
Добавились оптимизации в vSphere в плане коммуникации device-to-device на шине PCI, что дает преимущества в производительности для технологии NVIDIA GPUDirect RDMA
Давайте посмотрим на все это несколько подробнее:
1. NVIDIA AI Enterprise Suite сертифицирован для vSphere
Основная новость об этом находится в блоге NVIDIA. Сотрудничество двух компаний привело к тому, что комплект программного обеспечения для AI-аналитики и Data Science теперь сертифицирован для vSphere и оптимизирован для работы на этой платформе.
Оптимизации включают в себя не только средства разработки, но и развертывания и масштабирования, которые теперь удобно делать на виртуальной платформе. Все это привело к тому, что накладные расходы на виртуализацию у задач машинного обучения для карточек NVIDIA практически отсутствуют:
2. Поддержка последнего поколения NVIDIA GPU
Последнее поколение графических карт для ML-задач, Ampere Series A100 GPU от NVIDIA, имеет поддержку Multi-Instance GPU (MIG) и работает на платформе vSphere 7 Update 2.
Графический процессор NVIDIA A100 GPU, предназначенный для задач машинного обучения и самый мощный от NVIDIA на сегодняшний день в этой нише, теперь полностью поддерживается вместе с технологией MIG. Более детально об этом можно почитать вот тут. Также для этих карт поддерживается vMotion и DRS виртуальных машин.
Классический time-sliced vGPU подход подразумевает выполнение задач на всех ядрах GPU (они же streaming multiprocessors, SM), где происходит разделение задач по времени исполнения на базе алгоритмов fair-share, equal share или best effort (подробнее тут). Это не дает полной аппаратной изоляции и работает в рамках выделенной framebuffer memory конкретной виртуальной машины в соответствии с политикой.
При выборе профиля vGPU на хосте с карточкой A100 можно выбрать объем framebuffer memory (то есть памяти GPU) для виртуальной машины (это число в гигабайтах перед буквой c, в данном случае 5 ГБ):
Для режима MIG виртуальной машине выделяются определенные SM-процессоры, заданный объем framebuffer memory на самом GPU и выделяются отдельные пути коммуникации между ними (cross-bars, кэши и т.п.).
В таком режиме виртуальные машины оказываются полностью изолированы на уровне аппаратного обеспечения. Выбор профилей для MIG-режима выглядит так:
Первая цифра сразу после a100 - это число слайсов (slices), которые выделяются данной ВМ. Один слайс содержит 14 процессоров SM, которые будут использоваться только под эту нагрузку. Число доступных слайсов зависит от модели графической карты и числа ядер GPU на ней. По-сути, MIG - это настоящий параллелизм, а обычный режим работы - это все же последовательное выполнение задач из общей очереди.
Например, доступные 8 memory (framebuffers) слотов и 7 compute (slices) слотов с помощью профилей можно разбить в какой угодно комбинации по виртуальным машинам на хосте (необязательно разбивать на равные части):
3. Улучшения GPUDirect RDMA
Есть классы ML-задач, которые выходят за рамки одной графической карты, какой бы мощной она ни была - например, задачи распределенной тренировки (distributed training). В этом случае критически важной становится коммуникация между адаптерами на нескольких хостах по высокопроизводительному каналу RDMA.
Механизм прямой коммуникации через шину PCIe реализуется через Address Translation Service (ATS), который является частью стандарта PCIe и позволяет графической карточке напрямую отдавать данные в сеть, минуя CPU и память хоста, которые далее идут по высокоскоростному каналу GPUDirect RDMA. На стороне приемника все происходит полностью аналогичным образом. Это гораздо более производительно, чем стандартная схема сетевого обмена, об этом можно почитать вот тут.
Режим ATS включен по умолчанию. Для его работы карточки GPU и сетевой адаптер должны быть назначены одной ВМ. GPU должен быть в режиме Passthrough или vGPU (эта поддержка появилась только в vSphere 7 U2). Для сетевой карты должен быть настроен проброс функций SR-IOV к данной ВМ.
Более подробно обо всем этом вы можете прочитать на ресурсах VMware и NVIDIA.
При описании новых возможностей VMware vSphere 7 мы рассказывали о функциях платформы, появившихся в результате приобретения VMware компании Bitfusion. Эти возможности позволяют оптимизировать использование графических процессоров GPU в пуле по сети, когда vGPU может быть частично расшарен между несколькими ВМ. Это может применяться для рабочих нагрузок задач AI/ML (например, для приложений, использующих PyTorch и/или TensorFlow).
Все это позволяет организовать вычисления таким образом, что хосты ESXi с аппаратными модулями GPU выполняют виртуальные машины, а их ВМ-компаньоны на обычных серверах ESXi исполняют непосредственно приложения. При этом CUDA-инструкции от клиентских ВМ передаются серверным по сети.
Технология эта называлась FlexDirect, теперь это продукт vSphere Bitfusion:
На днях это продукт стал доступен для загрузки и использования в онпремизных инфраструктурах.
Возможность динамической привязки GPU к любой машине в датацентре, по аналогии с тем, как вы привязываете к ней хранилище.
Возможность использования ресурсов GPU как одной машине, так и разделения его между несколькими. При этом администратор может выбрать, какой объем Shares выделить каждой из машин, то есть можно приоритизировать использование ресурсов GPU между потребителями.
Возможность предоставления доступа как по TCP/IP, так и через интерфейс RDMA, который может быть организован как подключение Infiniband или RoCE (RDMA over Converged Ethernet). О результатах тестирования такого сетевого взаимодействия вы можете почитать тут.
Передача инструкций к серверным машинам и обратно на уровне CUDA-вызовов. То есть это решение не про передачу содержимого экрана как VDI, а про высокопроизводительные вычисления.
Прозрачная интеграция - с точки зрения приложений менять в инфраструктуре ничего не нужно.
Для управления инфраструктурой доставки ресурсов GPU используется продукт vSphere Bitfusion Manager, который и позволяет гибко распределять ресурсы между потребителями. Раньше он выглядел так:
Теперь же он интегрирован в vSphere Client как плагин:
Архитектура Bitfusion позволяет разделить виртуальную инфраструктуру VMware vSphere на ярусы: кластер GPU, обсчитывающий данные, и кластер исполнения приложений пользователей, которые вводят данные в них и запускают расчеты. Это дает гибкость в обслуживании, управлении и масштабировании.
С точки зрения лицензирования, решение vSphere Bitfusion доступно как аддон для издания vSphere Enterprise Plus и лицензируется точно так же - по CPU. Для других изданий vSphere, увы, этот продукт недоступен.

 RSS
RSS