В современных гибридных и частных облаках большое количество данных о состоянии систем поступает из самых разных источников: систем резервного копирования, хранилищ данных, SaaS-платформ и внешних сервисов. Однако интеграция этих данных в единую платформу мониторинга часто оказывается сложной задачей. Для решения этой проблемы в составе VMware Cloud Foundation был представлен инструмент Management Pack Builder (MPB), предназначенный для расширения наблюдаемости и видимости инфраструктуры. О его бета-версии мы писали еще в 2022 году, но сейчас он уже полноценно доступен в составе VCF.
Что такое Management Pack Builder
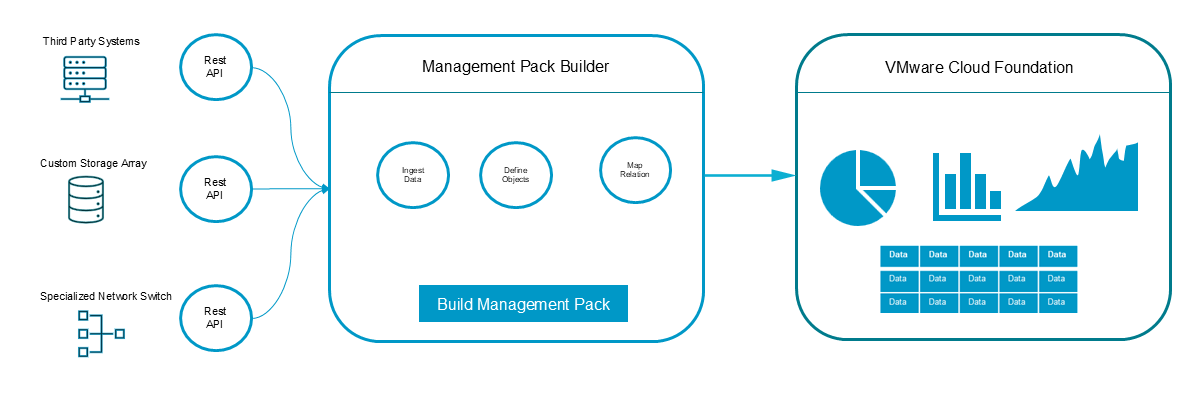
Management Pack Builder (MPB) — это функциональность VMware Cloud Foundation, представляющая собой no-code-решение для создания пакетов управления (management packs), которые позволяют импортировать данные наблюдения из внешних источников в систему мониторинга VCF Operations. MPB выполняет роль промежуточного слоя, преобразуя данные, полученные через REST API сторонних систем, в объекты, метрики, свойства и события, понятные и используемые в экосистеме VMware Cloud Foundation.
С помощью Management Pack Builder можно:
Подключаться к REST API внешних систем
Создавать собственные типы объектов мониторинга
Сопоставлять данные API с метриками и свойствами в VCF Operations
Формировать повторно используемые пакеты управления для развертывания в разных средах
Какие задачи решает Management Pack Builder
Заполнение пробелов в мониторинге
Во многих организациях используются системы, для которых не существует готовых адаптеров мониторинга VMware. MPB позволяет интегрировать такие источники данных и устранить «слепые зоны» в наблюдаемости инфраструктуры.
Упрощение интеграции сторонних решений
Традиционная разработка адаптеров требует значительных затрат времени и ресурсов. Management Pack Builder позволяет создавать интеграции без написания кода, что существенно ускоряет процесс и снижает операционные издержки.
Централизация данных наблюдаемости
MPB помогает устранить разрозненность данных, объединяя телеметрию из различных систем в единой платформе. Это упрощает корреляцию событий, ускоряет диагностику проблем и снижает среднее время восстановления сервисов.
Масштабируемость и повторное использование
Один раз созданный пакет управления может быть экспортирован и развернут в других инсталляциях VMware Cloud Foundation, обеспечивая единый подход к мониторингу в масштабах всей организации.
Работа с нестандартными API
Management Pack Builder поддерживает гибкое сопоставление данных и может использоваться даже в случаях, когда REST API внешних систем не полностью соответствует стандартным спецификациям.
Преимущества использования MPB
Использование Management Pack Builder обеспечивает следующие преимущества:
Быстрое подключение новых источников телеметрии
Единая панель мониторинга в рамках VMware Cloud Foundation
Снижение затрат на разработку и поддержку интеграций
Возможность моделирования пользовательских объектов и метрик
Простое распространение решений между средами
Типовой рабочий процесс в Management Pack Builder
Процесс создания пакета управления с помощью MPB включает следующие этапы:
Определение источника данных и необходимых конечных точек API
Проектирование объектной модели и связей между объектами
Настройка параметров сбора данных, включая аутентификацию и расписание
Сопоставление полей ответов API с метриками и свойствами
Тестирование корректности сбора и отображения данных
Экспорт и развертывание пакета управления в других средах
Пример использования: мониторинг задач резервного копирования
Предположим, что система резервного копирования предоставляет данные о заданиях через REST API, включая статус выполнения, продолжительность и объем обработанных данных. С помощью Management Pack Builder можно:
Подключиться к API системы резервного копирования
Создать новый тип объекта, представляющий задачу резервного копирования
Определить метрики, отражающие состояние и эффективность выполнения
Настроить дашборды и оповещения в VCF Operations
Использовать созданный пакет управления в других кластерах
Данный процесс на примере решения Rubrik показан в видео ниже:
В результате информация о резервном копировании становится частью единой системы наблюдаемости VMware Cloud Foundation, и вам не потребуется никаких отдельных консолей для мониторинга этого процесса.
Рекомендации по эффективному использованию MPB
Для успешного применения Management Pack Builder рекомендуется:
Начинать с минимального набора метрик и постепенно расширять модель
Использовать стабильные и уникальные идентификаторы объектов
Оптимизировать частоту опроса API, чтобы избежать избыточной нагрузки
Использовать примеры и лучшие практики, опубликованные в сообществах VMware
Роль Management Pack Builder в экосистеме VMware Cloud Foundation
VMware Cloud Foundation ориентирован на обеспечение унифицированного управления, операций и наблюдаемости в гибридных и частных облаках. Management Pack Builder дополняет эту концепцию, позволяя включать в контур мониторинга любые внешние и пользовательские системы.
Это обеспечивает целостное представление о состоянии инфраструктуры и приложений, независимо от источника данных.
Заключение
Management Pack Builder является важным инструментом для расширения возможностей наблюдаемости в VMware Cloud Foundation. Он позволяет быстро и гибко интегрировать сторонние источники телеметрии, сократить затраты на разработку адаптеров и централизовать мониторинг.
Использование MPB помогает организациям получить полную и целостную картину состояния своей инфраструктуры, повышая надежность и управляемость IT-среды.
Весной этого года вышел новый релиз бесплатной утилиты SexiGraf (Overwatch Nexus), предназначенной для мониторинга виртуальной инфраструктуры VMware vSphere. В последний раз мы писали об этом средстве в октябре прошлого года. Этот продукт был сделан энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным решениям для мониторинга серверов ESX и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Что нового
VMware vSAN Inventory — расширенная инвентаризация объектов vSAN.
PowerShell Core 7.4.6 LTS — обновление среды скриптов.
Ubuntu 22.04.5 LTS — современная версия операционной системы.
Apache 2.4.63 — обновлённый веб-сервер.
Улучшения и исправления
Возможность добавления SSH-ключа при деплое — повышает безопасность и удобство разграничения доступа.
Добавлен сбор события DrsSoftRuleViolationEvent в event-коллектор — расширение мониторинга нарушений правил DRS.
Исправлено неконсистентное значение GuestId в инвентаре VM (различие между vmx и vmtools) — повышение точности данных.
Различные багфиксы — общее улучшение стабильности и надежности.
Миграция и формат поставки
SexiGraf с этой версии доступен исключительно в виде нового OVA-образа, обновления в виде патчей больше не выпускаются (за исключением экстренных случаев). Чтобы обновиться, пользователи должны:
Экспортировать данные из текущего SexiGraf-модуля.
Импортировать данные в новый OVA-модуль через функционал Export/Import.
Виртуальный модуль SexiGraf 0.99l уже доступен для загрузки и развёртывания. Установка происходит стандартным способом через OVA (например, через vSphere, OVF Tool и т.п.).
Версия поддерживает переопределение root-пароля и SSH-ключа на этапе деплоя, что упрощает настройку и повышает безопасность.
Документ Network Observability Maturity Model от компании Broadcom представляет собой руководство по достижению высокого уровня наблюдаемости (observability) сетей, что позволяет ИТ-командам эффективно управлять современными сложными сетевыми инфраструктурами.
С развитием облачных технологий, удаленной работы и зависимости от внешних провайдеров, традиционные инструменты мониторинга устарели. В документе описана модель зрелости наблюдаемости сети, которая помогает организациям эволюционировать от базового мониторинга до полностью автоматизированного и самовосстанавливающегося управления сетью.
Основные вызовы в управлении сетями
Растущая сложность – 78% компаний отмечают, что управление сетями стало значительно сложнее из-за многообразия технологий и распределенных архитектур.
Удаленная работа – 95% компаний используют гибридный режим работы, что усложняет контроль за производительностью сетей, зависящих от домашних Wi-Fi и внешних провайдеров.
Облачные технологии – 98% организаций уже используют облачную инфраструктуру, что приводит к недостатку прозрачности в управлении данными и сетевым трафиком.
Зависимость от сторонних сервисов – 65% компаний передают часть сетевого управления сторонним поставщикам, что затрудняет полное наблюдение за сетью.
Рост потребности в пропускной способности – развитие AI и других технологий увеличивает нагрузку на сети, требуя более эффективных стратегий управления трафиком.
Устаревшие инструменты – 80% компаний считают, что традиционные средства мониторинга не обеспечивают должного уровня видимости сети.
Последствия недостаточной наблюдаемости
Проблемы с диагностикой – 76% сетевых команд испытывают задержки из-за недостатка данных.
Реактивный подход – 84% компаний узнают о проблемах от пользователей, а не от систем мониторинга.
Избыточные тревоги – 41% организаций сталкиваются с ложными срабатываниями, что увеличивает время поиска неисправностей.
Сложности с наймом специалистов – 48% компаний не могут найти специалистов с нужными навыками.
Ключевые требования для построения наблюдаемости сети
Видимость внешних сред – важна мониторинговая прозрачность не только для внутренних сетей, но и для облаков и провайдеров.
Интеллектуальный анализ данных – использование алгоритмов для корреляции событий, подавления ложных тревог и прогнозирования отказов.
Активный мониторинг – симуляция сетевого трафика позволяет выявлять узкие места в режиме реального времени.
Автоматизация и интеграция – объединение разрозненных инструментов в единую систему с автоматическими рекомендациями по устранению неполадок.
Модель зрелости наблюдаемости сети
Модель зрелости состоит из пяти уровней:
Ручной уровень – разрозненные инструменты, долгие поиски неисправностей.
Традиционный уровень – базовое объединение инструментов, но с разрывами между данными.
Современный уровень – использование активного мониторинга и потоковой телеметрии.
Следующее поколение – автоматизированные решения на основе AI/ML, минимизация ложных тревог.
Самообслуживание и самовосстановление – автоматическая коррекция сетевых аномалий без вмешательства человека.
Практическая реализация модели
Для внедрения зрелой системы наблюдаемости компании должны:
Создать единую модель данных для многовендорных сетей.
Инвестировать в решения с AI-аналитикой.
Использовать активное и потоковое наблюдение за сетью.
Интегрировать мониторинг как внутренних, так и внешних сетей.
Документ Network Observability Maturity Model подчеркивает важность перехода от традиционного мониторинга к интеллектуальной наблюдаемости сети. Автоматизация, AI-аналитика и активный мониторинг позволяют существенно сократить время диагностики проблем, снизить издержки и повысить надежность сетевых сервисов. В документе даны полезные рекомендации по развитию мониторинговых систем, обеспечивающих полную прозрачность работы сети и снижение нагрузки на ИТ-отделы.
Этот дэшборд содержит пять различных разделов: один для мониторинга производительности ESXi и vCenter, другой для производительности виртуальных машин, третий для дисков, четвёртый для хранилищ, и последний для хостов и их IPMI. Дэшборд включает переменные, чтобы сделать его использование проще и подходящим для различных типов рабочих нагрузок. Индикаторы автоматически настраиваются в зависимости от выбранных вами хранилищ данных. Если у вас много хранилищ, рассмотрите возможность изменения параметра Min Width для Repeat Panel.
Здесь визуализуются все высокоуровневые параметры виртуальной инфраструктуры, такие как загрузка ресурсов кластера, заполненность хранилищ, состояние гипервизора и использование ресурсов виртуальными машинами:
2. VMware vSphere - Datastore
Этот дэшборд содержит два раздела: один для мониторинга производительности ESXi и vCenter, другой - для производительности виртуальных машин. Дашборд включает переменные, чтобы упростить его использование и сделать его подходящим для различных типов рабочих нагрузок. Индикаторы автоматически настраиваются в зависимости от выбранных вами хранилищ данных. Если у вас много хранилищ, рассмотрите возможность изменения параметра Min Width для Repeat Panel.
Здесь мы можем увидеть загрузку емкости датасторов, параметры чтения-записи, а также суммарные показатели для используемой и свободной емкости:
3. VMware vSphere - Hosts
Тут видны основные метрики с уровня хоста для каждого из серверов ESXi: конечно же, загрузка аппаратных ресурсов и сети, а также дисковые задержки (latency):
4. VMware vSphere - VMs
Здесь можно увидеть самые полезные метрики для всех виртуальных машин вашего датацентра. Здесь можно увидеть аптайм, загрузку системных ресурсов и сети, latency, счетчик CPU Ready и другое:
Ну и главное - вот эта статья. Она описывает, как настроить мониторинг VMware с помощью дэшбордов Grafana, InfluxDB и Telegraf. В ней пошагово объясняется создание стека контейнеров с использованием Docker Compose, настройка InfluxDB и Telegraf для сбора метрик VMware из vCenter, а также визуализация данных в Grafana. Там подробно рассматривается использование готовых дэшбордов для ускорения процесса настройки и предлагаются советы по устранению неполадок.
Это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Давайте посмотрим на новые возможности двух недавних релизов:
Релиз Lighthouse Point (0.99k) от 7 октября 2024
VMware Snapshot Inventory
Начиная с версии SexiGraf 0.99h, панель мониторинга «VI Offline Inventory» заменена на VMware Inventory с инвентаризацией ВМ, хостов и хранилищ данных (вскоре добавятся портгруппы и другие элементы). Эти новые панели имеют расширенные возможности фильтрации и значительно лучше подходят для крупных инфраструктур (например, с более чем 50 000 виртуальных машин). Это похоже на извлечение данных из RVtools, которое всегда отображается и актуально.
В релизе v0.99k появилось представление VM Snapshot Inventory:
Улучшения "Cluster health score" для VMware vSAN 8
Вместо того чтобы бесконечно нажимать на кнопку обновления на вкладке «Resyncing Components» в WebClient, начиная с версии SexiGraf 0.99b разработчики добавили панель мониторинга vSAN Resync:
Shell In A Box
В версии SexiGraf 0.99k разработчики добавили отдельный дэшборд Shell In A Box за обратным прокси-сервером, чтобы снова сделать отладку удобной.
Прочие улучшения:
Официальная поддержка vSphere и vSAN 8.3 API, а также Veeam Backup & Replication v12
Добавлен выбор версии в панель мониторинга VMware Evo Version
Добавлена многострочная панель в панель мониторинга репозиториев Veeam
Обработка учетных записей с очень ограниченными правами
Опция использования MAC-адреса вместо Client-ID при использовании DHCP
Добавлено имя хоста гостевой ОС в инвентаризацию виртуальных машин
Релиз St. Olga (0.99j) от 12 февраля 2024
В этой версии авторы добавили официальную поддержку новых API vSphere и vSAN 8.2, а также Veeam Backup & Replication v11+.
Новые возможности:
Поддержка Veeam Backup & Replication
Автоматическое слияние метрик ВМ и ESXi между кластерами (функция DstVmMigratedEvent в VROPS)
Количество путей до HBA
PowerShell Core 7.2.17 LTS
PowerCLI 13.2.1
Grafana 8.5.9 (не 8.5.27 из-за ошибки, появившейся в v8.5.10)
Ubuntu 20.04.6 LTS
Улучшения и исправления:
Метрика IOPS для виртуальных машин
Инвентаризация VMware VBR
История инвентаризации
Панель мониторинга эволюции версий активов VMware
Исправлено пустое значение datastoreVMObservedLatency на NFS
Различные исправления ошибок
SexiGraf теперь поставляется только в виде новой OVA-аппаратной версии, больше никаких патчей (за исключением крайних случаев). Для миграции необходимо использовать функцию Export/Import, чтобы извлечь данные из вашей предыдущей версии SexiGraf и перенести их в новую.
Актуальная версия SexiGraf доступна для бесплатной загрузки на странице Quickstart.
С ростом числа сценариев использования генеративного AI, а также с существующими рабочими нагрузками AI и машинного обучения, все хотят получить больше мощностей GPU и стремятся максимально эффективно использовать те, которые у них уже есть. В настоящее время метрики использования GPU доступны только на уровне хоста в vSphere, а с помощью модуля vSphere GPU Monitoring вы теперь можете видеть их на уровне кластера. Эта информация имеет большое значение для таких задач, как планирование ёмкости, что оказывает значительное стратегическое влияние на организации, стремящиеся увеличить использование AI.
vSphere GPU Monitoring Fling предоставляет метрики GPU на уровне кластера в VMware vSphere, что позволяет максимально эффективно использовать дорогостоящее оборудование. Он совместим с vSphere версий 7 и 8. Также функционал утилиты также доступен в виде основного патча vCenter 8.0 Update 2 для тех, кто использует более новые версии платформы (то есть, Fling не требуется!). Скачайте плагин здесь и поделитесь своим мнением в разделе Threads на портале community.broadcom.com или по электронной почте vspheregpu.monitoring@broadcom.com.
Пользователям нужно провести установку плагина для объекта Datacenter, после чего они смогут видеть сводные метрики своих GPU для кластеров в этом датацентре. В представлении датацентра пользователь может нажать на «View Details», чтобы увидеть более подробную информацию о распределении и потреблении GPU, а также о типе совместного использования GPU.
Наконец, температура также является важной метрикой для отслеживания, так как долговечность и производительность GPU значительно снижаются, если они слишком долго работают при высокой температуре. Этот Fling также включает и мониторинг температуры:
В рамках функционала Configuration Profiles платформы VMware vSphere вы можете создать пользовательское определение аларма, который будет срабатывать, когда один или несколько хостов в кластере не соответствуют заданной конфигурации. Определение аларма можно создать на уровне vCenter или кластера (а также на уровнях папок и объекта datacenter). Для упрощения можно создать одно определение аларма на уровне vCenter, чтобы одно и то же определение применялось ко всем кластерам...
В начале этого года компания VMware обновила свое облачное решение для управления и мониторинга виртуальной инфраструктуры VMware Aria Operations Cloud, добавив несколько полезных новых возможностей уровня предприятия. В апреле этого года была также выпущена обновленная онпремизная версия этого продукта - VMware Aria Operations 8.12. Давайте посмотрим, что в ней появилось нового...
Наш постоянный читатель Сергей обратил внимание на то, что недавно вышла новая версия средства мониторинга ИТ-инфраструктуры Zabbix 6.2, в которой есть много всего нового и полезного для наблюдения за виртуальной инфраструктурой VMware vSphere.
Давайте посмотрим, что там интересного в плане работы с хостами vSphere:
Возможность вручную назначать шаблоны обнаруженным хостам ESXi
Создание и изменение пользовательских макросов для обнаруженных хостов ESXi
Добавление дополнительных тэгов для серверов
Также функции мониторинга были доработаны, чтобы поддерживать новые сущности и низкоуровневые правила их обнаружения.
Это позволяет отслеживать новые метрики, а именно:
Также теперь обнаружение хостов VMware vSphere может быть отфильтровано на базе их статуса включенности (например, можно добавить только работающие сейчас хосты ESXi).
Более подробно о новой версии Zabbix 6.2 можно почитать на этой странице. Скачать продукт можно тут.
На днях наш ценный читатель (и подсказыватель правильных вещей) Сергей заметил, что мы давно не упоминали об обновлениях средства SexiGraf для мониторинга виртуальной инфраструктуры VMware vSphere. В последний раз мы писали о нем осенью 2018 года вот тут (это был релиз White Forest).
Напомним, что это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
C 2018 года вышло 4 больших релиза SexiGraf, давайте рассмотрим их возможности вкратце.
Вот что появилось в релизе Traptown:
SuperStats - новые метрики уровня кластера, включающие в себя такие объекты, как hba, network, storage, power
vCenter Bad Events - возможность отслеживания "плохих" событий в инфраструктуре на уровне vCenter
Полный список всех обновлений SexiGraf и обзор новых функций можно найти на этой странице. Скачать виртуальный модуль в формате OVA можно по этой ссылке. Однако, как было отмечено, из России он не качается, поэтому перед скачиванием нужно включить VPN.
Вчера мы писали о новых возможностях январского релиза облачного решения VMware Aria Operations. Одной из них стала высокая доступность средств мониторинга приложений High Availability for Application Monitoring, которую можно рассмотреть несколько подробнее.
Многие пользователи уже применяют решение Telegraf в VMware Aria Operations, выполняющее функции мониторинга доступности приложений и зависящее от компонентов Cloud Proxies, через которые происходит сбор данных от эндпоинтов. Сам мониторинг происходит через ARC-адаптеры приложений, которые ранее не поддерживали группы коллекторов, а Cloud Proxy был единой точкой отказа для функций application monitoring. Поэтому при выходе из строя Cloud Proxy данные от эндпоинтов не могли попадать в VMware Aria Operations.
Теперь же мониторинг приложений работает с помощью механизма Collector Groups, в которые объединены Cloud Proxy, поэтому при падении одного из них метрики будут передаваться в другие инстансы.
Первый шаг в интерфейсе - это создание Collector Group. Здесь были сделаны улучшения по добавлению новых групп и включению/выключению механизма высокой доступности из UI:
Здесь можно устанавливать используемый виртуальный IP, а также отмечать объекты Cloud Proxies, которые добавляются. Как только мы добавили новую группу, мы можем фильтровать по этим группам, когда они отображаются списком.
Можно группировать прокси по группам коллекторов и просматривать их в рамках групп, либо показывать все прокси без групп:
Также есть механизм по проверке конфигураций, если были внесены изменения в составе Collector Group. После того, как прокси были добавлены или удалены, становится активной опция "Retry Cloud Proxy Configuration", а также возможность активации/деактивации data persistence:
Также для использования HA нужно развертывание агента Telegraf. Старые версии агента не могут обрабатывать новые изменения, поэтому требуется повторное их развертывание с привязкой их к группам коллекторов. Поэтому при установке агента мы выбираем, будет ли агент обеспечивать функции высокой доступности, и если будет - то для какой группы с включенным HA он будет назначен:
После того, как мы задали все конфигурации, требуется время на то, чтобы развернуть агенты и создать все необходимые связи с возможностями восстановления после сбоя. В случае сбоя может потребоваться до трех холостых циклов сбора данных, чтобы сработало восстановление, и данные продолжили собираться. В большинстве случаев это происходит быстро, но если включена возможность data persistence, то можно потерять один цикл сбора метрик.
Больше подробностей об облачном решении VMware Aria Operations можно узнать на этой странице.
На днях компания VMware объявила о выпуске финальной версии решения Aria Operations for Applications (бывший продукт Tanzu Observability) для облачных провайдеров, которое позволяет их клиентам наблюдать за инфраструктурой контейнеризованных приложений на платформе Tanzu.
Решение позиционируется как платформа cloud-native observability, доступная для партнеров через портал Cloud Partner Navigator (CPN), которые участвуют в программе VMware Managed Service Providers (MSP). Aria Operations for Applications дает партнерам инструменты для команд DevOps, SecOps и SRE в части получения данных телеметрии, которые помогают планированию стратегии управления приложениями, API, базами данных, очередями сообщений для публичных, частных и гибридных облаков.
Aria Operations for Applications решает проблему мониторинга глобальной среды разнородных приложений, которые работают не только в частном датацентре, но и перемещаются между облаками. В рамках этого решения доступны функции анализа и визуализации метрик, а также отслеживания поведения приложений для распределенных приложений, контейнеров, микросервисов и бизнес-данных в датацентрах партнеров. Как только данные собраны в глобальной базе, вы можете применять запросы к ней посредством языка Wavefront Query Language, который содержит более 110 форматов запросов. Также из коробки идут дэшборды и алерты к более чем 250 приложениям:
Пользователи датацентров облачных партнеров VMware получают следующие преимущества:
Получение метрик производительности облачных сервисов с частотой до 2 миллионов датапоинтов в секунду.
Видимость Kubernetes окружений на различных уровнях, включая приложения, контейнеры, поды и узлы, пространства имен и кластеры.
Траблшутинг инфраструктуры приложений путем обнаружения аномалий и создания проактивных алертов с использованием AI и поведенческого анализа.
Использование сервиса самообслуживания для команд DevOps, которые могут исполнять широкий спектр запросов, позволяющих получать глубокие инсайты о поведении приложений в контексте изменения их кода в производственной среде.
Возможность массового мониторинга приложений с механизмом контроля доступа клиентов на базе ролевой модели для неограниченного количества аккаунтов.
Aria Operations for Applications дает разработчикам единую консоль наблюдения за инфраструктурой приложений, возможности которой регулируются со стороны сервис-провайдера за счет интеграции с решением Tanzu Mission Control.
Ну и обзорное видео о том, как это работает:
Более подробно о решении VMware Aria Operations for Applications можно узнать по этой ссылке.
На днях компания VMware объявила о выпуске пакета управления vRealize Operations Management Pack for Cloud Director Availability версии 1.2. Напомним, что он предназначен для сбора информации о задачах репликации в инстансах VMware Cloud Director Availability и предоставления относящихся к репликации свойств и метрик в решение vRealize Operations (оно теперь называется Aria Operations). Это позволяет ИТ-специалистам сервис-провайдеров получать информацию о состоянии задач репликации и потреблении ими системных ресурсов.
VMware vRealize Operations Management Pack for Cloud Director Availability 1.2 поддерживает следующие версии продуктов облачной инфраструктуры:
VMware Cloud Director Availability 4.4.x или более поздние (версии 4.2 и 4.3 НЕ поддерживаются)
VMware Cloud Director 10.1.4 – 10.4.x
VMware vRealize Operations TenantApp – 8.6.x или более поздние
VMware vRealize Operations Management Pack for VMware Cloud Director 8.6.x или более поздние
VMware vRealize Operations 8.6.x или более поздние
Теперь давайте посмотрим на новые возможности пакета:
1. Новые метрики
Теперь в VMware vRealize Operations Management Pack for Cloud Director Availability 1.2 появились метрики касательно нарушения политики RPO, а также миграций шаблонов объектов виртуальных приложений vApp.
Кроме того, на базе запросов от облачных провайдеров, теперь появился ресурс Site, для которого собираются метрики состояния системы - свободное дисковое пространство, доступность сервиса, статус соединений между компонентами, проблемы с лицензиями и сертификатами и многое другое.
Эти метрики доступы в инстансе Cloud Director Availability в разделе Provider Incoming Replications:
На базе метрик репликации и состояния системы пакет Operations Management Pack for Cloud Director Availability 1.2 предоставляет набор из 13 встроенных алертов с их определениями симптомов, размещенных на дэшборде состояния системы. Алерты покрывают большинство проблемных ситуаций, которые могут произойти со службой VMware Cloud Director Availability Cloud, а также нарушениями политик RPO и репликации в целом.
Ввиду того, что конфигурации инфраструктур облачных провайдеров очень разные, алерты не включаются автоматически в политику и находятся в деактивированном состоянии. Их нужно вручную добавлять в политику и активировать после установки Management Pack.
Дэшборд VCDA Sites Health можно найти в разделе дэшбордов All > Cloud Director Availability. Там будет показана информация о метриках статуса сайта для экземпляра VMware Cloud Director Availability. Также пользователям доступна визуализация связей между компонентами для всех репликаций, а также все алерты объектов, чтобы иметь возможность получить к ним доступ напрямую.
Не все метрики включены в дэшборд по умолчанию, но вы можете добавлять и исключать их в любой момент.
Загрузить vRealize Operations Management Pack for Cloud Director Availability 1.2 можно по этой ссылке, Release Notes доступны тут.
На сайте проекта VMware Labs появилось очередное интересное решение - утилита vRealize Automation Health Monitor. Она предназначена для мониторинга инфраструктуры vRealize Automation и получения информации о ее текущем состоянии и работоспособности.
Приложение построено на базе фреймворков Flask и Clarity, само оно написано на Python, и не требует базы данных. Health Monitor запускается как приложение в контейнере Docker с конфигурацией 2 CPU и 2 ГБ оперативной памяти и хранилищем 10 ГБ. Для работы утилиты вам потребуется vRealize Automation версии 8.x или более свежей.
vRealize Automation Health Monitor дает информацию в следующих разрезах:
Учетная запись root-пользователя
Потребляемое хранилище
Статус всех микро-сервисов, относящихся к vRA, таких как Catalog, Provisioning and Approval и прочее
Список доступных образов Docker с указанием потребления памяти и хранилищ
Список всех узлов Kubernetes pods
Загрузить vRA Health Monitor можно по этой ссылке. Ну и небольшое видео о продукте и его возможностях:
Это решение реализует функции мониторинга виртуальных десктопов, обнаружения аномалий и оптимизации VDI-инфраструктуры. О прошлой версии этого пакета 1.1 мы писали год назад.
Давайте посмотрим, что нового появилось в vROPs MP for Horizon 2.0:
1. Мониторинг служб и сессий Unified Access Gateway
Здесь появились следующие новые возможности:
Идентификация UAG с малой производительностью в контексте виртуальных машин и KPI сессий Horizon
Функции HTTP Health Check в рамках функциональности мониторинга доступности UAG
Просмотр производительности и доступности привязанного Connection Server
Вкладка UAG Summary дает детальную информацию, для которой теперь не требуется отдельный дэшборд
Также теперь появился новый дэшборд Unified Access Gateways:
2. Новые варианты использования для Horizon Connection Servers
Тут появились следующие нововведения:
Нахождение проблем с производительностью и доступностью серверов Connection Servers
Мониторинг доступности служб Connection Server: проверки Tomcat и HTTP Health Check
Обнаружение Connection Servers, не сбалансированных в плане сессий и вычислительных ресурсов
Вкладка Summary дает детальную информацию, для которой теперь не требуется отдельный дэшборд
Собственно, вкладка Summary выглядит так:
3. Метрики Horizon User Capacity и рекомендации по сайзингу
Они показывают рекомендации о том, стоит ли добавлять или уменьшать вычислительные ресурсы (vCPU и память):
4. Метрики Horizon VDI Pool Capacity и рекомендации по оптимизации
Для пулов виртуальных ПК мы теперь видим их емкость в разрезе различных ресурсов, а также рекомендации по изменению конфигурации пулов в целях оптимизации и баланса:
Пользователи продукта vRealize Operations Advanced / Enterprise, vRealize Suite, а также облачной подписки vRealize Cloud Universal могут включить пакет vRealize Operations Management Pack for Horizon 2.0 через vRealize Operations Marketplace.
Мы часто пишем о продукте VMware vReazlie Log Insight, который бывает в двух вариантах - облачном (Log Insight Cloud) и онпремизном. Он предназначен для аналитики лог-файлов и мониторинга инфраструктуры в облаке. Решение очень удобно для администраторов, сотрудников технической поддержки и системных инженеров, которые ищут причины проблем различного характера в виртуальной инфраструктуре и решают их...
На днях компания VMware обновила свое облачное решение VMware vRealize Log Insight Cloud. Напомним, что это решение предназначено для аналитики лог-файлов и мониторинга инфраструктуры в облаке. О прошлой версии этого продукта мы писали вот тут.
Давайте посмотрим, что появилось нового в декабрьском обновлении vRLI Cloud:
1. Расширение локаций, где доступен продукт
Теперь Log Insight Cloud можно получить в регионе Asia Pacific (Tokyo, Japan).
Таким образом, полный список доступных регионов выглядит так:
US West (Oregon)
Europe (London, Frankfurt)
Canada (Central)
Asia Pacific (Sydney, Singapore)
South America (Sao Paulo)
Asia Pacific (Tokyo, Japan)
2. Загрузка локальных логов в облако
Часто администраторы загружают лог-файлы своей онпремизной инфраструктуры в облако во время пробного периода, для этого и предусмотрели данную возможность. Можно загружать файлы в формате .log и .txt и 10 файлов одновременно (до 10 МБ каждый).
3. Интеграция с AWS Lamba и HashiCorp Vault
Новая возможность интеграции с функциями платформы AWS Lambda теперь позволяет перенаправить логи CloudWatch, CloudTrail и многих других сервисов в Log Insight Cloud. Если вам нужна дополнительная безопасность по хранению учетных данных, то можно использовать функции интеграции с защищенным хранилищем учетных данных HashiCorp Vault.
4. Новые функции аудита событий через VMware Cloud Services Content Pack 2.0
Дополнительные аудируемые события контент-пака были добавлены для того, чтобы соблюсти регуляторные требования платформы VMware Cloud Service Portal (CSP). Теперь в VMware Cloud Services Content Pack 2.0 есть следующие новые события:
Access Request Raised by Org Members
Access Request Raised by Non Org Members
Entitlement Request for Org Member Cancelled
Entitlement Request for Non Org Member Cancelled
Entitlement Request Actions
Entitlement Request Approval Actions
Violation Policies Updated
Entity Violations Count Update OAuth App
Entity Violations Count Update API Token
Advance Features Toggled
5. Поддержка SSL для Cloud Proxy
Cloud Proxy получает логи и информацию о событиях из разных источников мониторинга и отправляет эти данные в vRealize Log Insight Cloud, которые уже дальше запрашиваются и анализируются. Теперь эти логи могут пересылаться по защищенному каналу SSL.
6. Алерты об изменении статуса форвардинга логов
Теперь по почте можно получать оповещения о следующих событиях:
Log Forwarding Disabled Temporarily – перенаправление логов отключено на несколько следующих минут, ввиду обнаружения слишком большого количества ошибок на источнике.
Log Forwarding Disabled – перенаправление логов отключено постоянно из-за невозможности установить соединение.
Попробовать vRealize Log Insight Cloud в виртуальной тестовой лаборатории и запросить пробную версию в облаке VMware Cloud on AWS можно по этой ссылке.
Не так давно мы рассказывали о продукте NAKIVO Backup & Replication, который является одним из лидеров в сфере решений для резервного копирования и защиты данных виртуальной инфраструктуры, его основных возможностях и областях применения. Сегодня мы рассмотрим новые возможности версии 10.5, которая вышла недавно и доступна для загрузки.
Компания VMware обещала большие новости о своем пакете решений vRealize True Visibility и вот недавно их объявила: теперь 19 менеджмент паков для вычислительных ресурсов и хранилищ доступны для всех пользователей продукта vRealize Operations. Также произошли некоторые изменения в самом пакете vRealize True Visibility Suite, а также были выпущены новые модули vRealize True Visibility Technology Modules, лицензируемые на базе метрик.
1. Management Packs для вычислительных ресурсов и хранилищ.
Теперь пользователи vRealize Operations получают доступ к 19 пакетам vRealize True Visibility Suite, которые позволяют получить доступ к глубоким метрикам, число которых превышает 1000.
Также пользователи получают новые детализированные дэшборды и статистики в реальном времени, которые помогают решать проблемы на всех уровнях оборудования.
Вот пример дэшборда, который отображает состояние дисковых массивов от разных вендоров в едином представлении Operations:
В данном случае удобно, что массивы представлены на одном экране с соответствующими Scoreboards, которые легко сравнивать между собой.
Также на ресурсе VMware Code доступны примеры дэшбордов, которые можно использовать в своем производственном окружении.
2. Изменения в пакете vRealize True Visibility Suite.
Издания vRealize True Visibility Suite Advanced и Enterprise были немного переработаны, чтобы соответствовать ожиданиям пользователей. Теперь Management packs перемещены из категории "Connectors", а менеджмент пак ServiceNow перемещен в vRealize True Visibility Suite Advanced. Вот наглядное представление изменений:
3. Новые модули vRealize True Visibility Technology Modules
Для тех пользователей, которые хотят расширить возможности своей инфраструктуры мониторинга за счет модулей vRealize True Visibility Technology Modules, теперь есть возможности добавить их из разных категорий: Connectors, Network, Virtualization/Containers, Database и Applications. Каждый из модулей лицензируется на базе метрики, определенной для данной категории (по числу объектов, устройств, виртуальных машин и т.п.).
Вот так выглядит полная экосистема доступных модулей:
Скачать 60-дневную пробную версию vRealize True Visibility Suite можно по этой ссылке.
На сайте проекта VMware Labs очередная новая штука - vSphere Alert Center. Администраторы VMware vSphere часто настраивают алармы в vSphere Client, которые срабатывают при превышении некоторых критических порогов в виртуальной инфраструктуре. Эти алармы можно посмотреть в клиенте, но для них нельзя сделать прямые пуш-нотификации для администратора.
vSphere Alert Center работает в Windows, macOS и Linux (есть три отдельных дистрибутива). С помощью таких технологий, как Angular, Electron и vSphere.js компания VMware сделала утилиту, которая может соединяться с несколькими инстансами vCenter одновременно и показывать детальную информацию обо всех алармах.
Администратор может настроить интервал обработки алармов (по умолчанию - 5 минут), чтобы его не засыпало сообщениями.
Если какой-то из алармов требует внимания, то из приложения можно открыть vSphere Client, а исторические данные хранятся в локальном файле в зашифрованном виде.
Скачать vSphere Alert Center можно по этой ссылке.
На сайте проекта VMware Labs появилась еще одна одна мобильная версия клиента для управления большим продуктом VMware - Site Recovery Manager Mobile. Эта утилита предназначена для мониторинга состояния Protection-групп и планов восстановления в интерфейсе максимально приближенном к десктопному SRM.
Напомним, что у VMware есть мобильная версия и своего основного клиента для управления виртуальной инфраструктурой vSphere Mobile Client, а также мобильный клиент для управления решением по виртуализации и агрегации сетей NSX Mobile.
Очевидно, что мобильные версии всех этих решений сфокусированы на мониторинге - посмотреть, что случилось (или чего не случилось), а потом уже открыть ноутбук и заняться решением проблемы. VMware SRM Mobile не стал исключением, в нем администраторам доступны следующие возможности:
Мониторинг следующих сущностей:
Сводной информации о паре сайтов основной-резервный
Всех объектов protection groups / recovery plans
Объекты отображаются в отдельном представлении в виде таблиц
Объекты можно представить в виде меню drawer мобильного приложения для быстрого доступа к элементам дерева
Информация о Protection groups разделена на 3 вкладки:
Summary
Recovery Plans
Virtual Machines
Информация о планах восстановления разделена на 4 вкладки:
Summary
History
Protection Groups
Virtual Machines
Администратор получает нотификацию, если какие-либо данные невозможно загрузить
Скачать VMware
Site Recovery Manager Mobile можно по этой ссылке. Утилита пока работает только под Android версии 4.4 и выше.
На сайте проекта VMware Labs появилась новая утилита - Edge Services Observability. Она предназначена для мониторинга служб Edge Services (VMware Tunnel, Content Gateway, Secure Email Gateway, Reverse и Horizon Secure Access), которые запущены на модуле Unified Access Gateway - одном из ключевых компонентов решений VMware Horizon и Workspace ONE.
С помощью этого средства можно понять:
Производительность шлюза на основе его загрузки
Распределение трафика
Влияние правил Device Traffic Rules на производительность
Основные возможности утилиты:
Поставляется как готовый к настройке и развертыванию виртуальный модуль (Virtual Appliance) в формате OVA:
Веб-портал для управления инстансами Unified Access Gateway (UAG):
Дашборды для визуализации метрик компонентов VMware Tunnel и VMware Horizon на базе Grafana:
Возможность настройки алертов на основе различных условий, что позволяет оперативно выявлять аномалии
Скачать VMware Edge Services Observability можно по этой ссылке. Более подробная информация о продукте доступна тут.
Многие Enterprise-администраторы настраивают автоматический регулярный бэкап решения для виртуализации и агрегации сетей VMware NSX-T из консоли, что описано, например, вот тут.
Между тем, как правильно заметил автор virten.net, при неудачном завершении задачи резервного копирования администратор не получает нотификации даже в дэшборде в разделе алармов.
В случае падения задачи бэкапа информация об этом доступна только в разделе Backup & Restore настроек:
В данном примере неудачно завершился процесс резервного копирования кластера, поэтому нужно смотреть не только на статусы узлов (кстати, времена указаны в миллисекундах).
Коллега с virten.net написал сценарий на Python для Nagios, который позволит вам проверить статус последнего бэкапа кластера NSX-T, а также посмотреть возраст последней имеющейся резервной копии:
usage: check_nsxt_backup.py [-h] -n NSX_HOST [-t TCP_PORT] -u USER -p PASSWORD
[-i] [-a MAX_AGE]
# python check_nsxt_backup.py -n nsx.virten.lab -u audit -p password
NSX-T cluster backup failed
NSX-T node backup is to old (1461 minutes)
Новое решение True Visibility позволяет получить информацию обо всех компонентах виртуальной инфраструктуры, включая топологию сети, ресурсы хранилищ и серверов на физическом уровне, а также объектов приложений.
В течение ограниченного времени VMware предлагает купить новый бандл, который содержит vRealize True Visibility Suite, который дополняет обычный vRealize Suite Standard (либо отдельный продукт vRealize Operations Standard или Advanced) или vCloud Suite Standard:
В первую очередь, решение True Visibility позволит быстрее находить проблему, а также проводить root cause analysis и своевременно реагировать на события, происходящие в инфраструктуре на физическом и виртуальном уровне.
После того, как вы поставите все необходимые management packs и автоматически соберете данные о взаимосвязях и взаимодействиях в вашей инфраструктуре, вы увидите, как она выглядит на одной детализированной схеме, где видны виртуальные и физические компоненты:
Также продукт позволяет задавать политики алертинга, чтобы администраторов не забрасывало оповещениями в случае возникновения различных нештатных событий.
Бандл доступен с 1 апреля по 30 октября, потом он будет интегрирован в одно из изданий по большей цене. Пробная бесплатная версия vRealize True Visibility Suite доступна по этой ссылке.
На днях компания VMware анонсировала еще одно обновление в своей продуктовой линейке - vRealize Operations v8.4 (vROPs) и vRealize Operations Cloud, которое дополняет сделанные ранее весенние анонсы. Напомним, что это средство предназначено для комплексного управления и мониторинга виртуальной инфраструктуры в различных аспектах. О прошлой версии vRealize Operations 8.3 мы писали не так давно вот тут.
Давайте посмотрим, что нового появилось в vROPs 8.4:
1. Улучшенная поддержка служб AWS
Поддержка служб Amazon позволяет пользователям строить функциональную инфраструктуру гибридного облака, соединяющую собственную и облачную инфраструктуры. Теперь поддержка включает в себя 57 сервисов, с которыми работает vRealize Operations 8.4.
2. Мониторинг сервисов и процессов
С помощью агентов Telegraf решение vROPs позволяет мониторить процессы на базе имени, регулярных выражений или PID в системах Linux и Windows. Если какой-то из сервисов упадет, то администратору придет оповещение, после чего можно будет узнать детали события.
3. Планировщик операций Reclamation и Rightsizing
С помощью нового планировщика пользователи могут задавать расписание для операций Reclamation и Rightsizing, таких как удаление старых снапшотов, выключение и удаление виртуальных машин, освобождение ресурсов ВМ, либо добавление ресурсов машинам, которые испытывают проблемы с заполнением диска или производительностью.
4. Расчет затрат на VMware Cloud on AWS
Эта функция позволяет посчитать стоимость содержания виртуальных машин и кластеров VMware Cloud on AWS на базе полученных счетов. Это включает в себя также и прогнозирование затрат от освобождения ресурсов виртуальных машин. Все это можно посмотреть на одном дэшборде.
5. Улучшенные функции Cost Flow Optimization
С помощью 10 новых дэшбордов пользователи могут увидеть детальную структуру затрат на содержание виртуальной инфраструктуры, а также визуализовать их. Там же показываются такие экономические показатели, как ROI (return on investment), TCO (total cost of ownership), ежемесячная экономия затрат и многое другое.
6. VMware Cloud on AWS What-if Planning
С помощью движка планирования "что если" пользователи могут предсказать запросы будущей инфраструктуры и увидеть инсайты о предлагаемых конфигурациях для VMware Cloud on AWS. Новые возможности дают функции по отслеживанию трендов утилизации инфраструктуры, выяснению времени, которое есть до необходимого ее расширения, и влияния удаления виртуальных машин на стоимость окружения в среде VMware Cloud on AWS.
7. Поддержка Open Source Telegraf Agent
Эта возможность расширяет пути, за счет которых пользователи могут мониторить свои приложения, вытягивая метрики с любого ПО, для которого есть плагины агентов Telegraf (также можно написать и свои собственные). Кстати, мониторинг доступен не только для систем VMware, но и для физических серверов.
Релиз обновленных решений vRealize Operations v8.4 и vRealize Operations Cloud ожидается во втором квартале этого года.
В понедельник мы писали новой версии решения для автоматизации рабочих процессов VMware vRealize Orchestrator 8.3, а сегодня расскажем еще об одном обновленном продукте семейства vRealize - VMware vRealize Operations 8.3 (vROPs). Напомним, что о прошлой версии vROPs 8.2 мы подробно писали вот тут.
Давайте посмотрим, что нового появилось в апдейте vROPs 8.3, тем более, что там как и всегда - масса новых функций:
1. Cloud Management Assessment (COA)
Эта функция является логическим продолжением vSphere Optimization Assessment (VOA) в vRealize Operations. Теперь COA позволяет расширить эти возможности за пределы vSphere для следующих задач:
Подготовка к миграции на VMware Cloud on AWS
Управление решением VMware Cloud on AWS
Подготовка к миграции на VMware Cloud Foundation
Управление решением VMware Cloud on Foundation
Использование vRealize Cloud Universal
Управление публичным облаком (AWS, Azure и т.п.)
Управление решением Horizon
Для запуска этой утилиты надо нажать "+View More" на странице QuickStart и выбрать VMware vRealize Cloud Management Assessment:
Далее просто выберите нужную подкатегорию:
Дэшборды представляют облачную инфраструктуру в разных разрезах и дают массу полезной информации с объяснениями:
2. Функция Pathfinder
Pathfinder - это коллекция обучающих материалов VMware, которые представлены в виде удобных 10-15 минутных блоков (их более 100 штук).
Также движок Pathfinder напрямую интегрирован в CMA:
3. Поддержка FIPS 140-2
Operations 8.3 содержит криптографические модули, которые прошли тестирование по программе NIST FIPS 140-2 Cryptographic Module Validation Program (CMVP). Этот режим (FIPS-mode) можно выбрать только при новой установке, в процессе эксплуатации поменять его на обычный будет нельзя.
4. Метрики с циклом опроса в 20 секунд
По умолчанию метрики vROPs собираются раз в 5 минут, что обусловлено балансом между массивом хранимых и анализируемых данных и гранулярностью получения информации администратором.
Теперь же данные собираются раз в 20 секунд, а в истории хранятся средние данные раз в 5 минут, но полученные из усреднения этих 20-секундных значений. Подробнее об этом написано в KB 67792.
Иногда бывает так, что и усреднение не дает результата, так как оно сглаживает пиковые всплески, которые неплохо бы увидеть в реальном времени. Для этой цели есть механизм near real-time metric collection, который позволяют хранить точные данные за последние три дня:
Также есть и механизм 20-second peak metrics, который покажет пиковые значения для нужных метрик в 20-секундных интервалах:
5. Функции VMware Cloud on AWS
Теперь появились новые деревья для инвенторя инстансов SDDC, который реализован в объекте VMC World. Эти объекты унифицируют vCenter, vSAN и NSX-T в контексте сущностей VMC Organizations и SDDC.
Новый дэшборд VMC Configuration Maximums позволяет следить за приближением к хард и софт лимитам инфраструктуры. Для этого есть цветовое кодирование и алерты:
Новых алертов на эту тему аж 23 штуки:
Также можно создать VMC Configuration Maximum Report:
Текущие лимиты получаются через VMC API, но не все. Также можно подстроить их в разделе Administration / Configuration / Configuration Files / SolutionConfig / vmc_config_limits (подробнее в KB 81810).
6. Функции vRealize Operations Cloud
С момента последнего релиза стал доступен датацентр во Франкфурте:
vRealize Operations Cloud теперь сертифицирован по стандартам SOC 2, SOC 3 и ISO 27001/17/18.
Также появился новый дэшборд vRealize Operations Billing Usage, где показываются объекты, для которых собираются метрики в вашей инфраструктуре:
Более полный список новых возможностей вы можете найти в Release Notes. Скачать vROPs 8.3 можно по этой ссылке.
В конце августа компания VMware объявила о скором выпуске решения vRealize Operations 8.2, предназначенного для управления и мониторинга виртуальной инфраструктуры. Напомним, что о прошлой версии vROPs 8.1 мы писали вот тут.
В новой версии vROPs 8.2 появилось очень много всего нового, особенно связанного с созданием единой инфраструктуры для управления и мониторинга виртуальных машин и контейнеров из единой консоли. Давайте посмотрим на все это вкратце:
1. Функции Application-Aware Troubleshooting
В vROPs в последнее время быстро развиваются возможности для мониторинга инфраструктуры приложений в виртуальных машинах и контейнерах за счет пакетов Application Performance Management (APM) management packs. Это позволяет дополнить средства мониторинга компонентов инфраструктуры точными метриками, получаемыми от приложений.
Вот так выглядят средства обнаружения приложений и их параметров в решении vRealize Network Insight в виртуальном датацентре, которые далее передаются в vRealize Operations:
vRNI обнаруживает приложения и их взаимосвязи через анализ сетевых потоков, что отлично дополняет инфраструктурный метод обнаружения со стороны vROPs.
Еще одно важное улучшение в этой категории - опция "near real-time monitoring", что позволяет собирать данные в 15 раз чаще, что близко к режиму реального времени:
2. Улучшения поддержки Kubernetes
Главное улучшение vRealize Operations 8.2 - это возможности автоматического обнаружения гостевых кластеров Tanzu Kubernetes:
Второе важное улучшение - это интеграция с Prometheus через специальный адаптер, который используется большинством разработчиков для сбора метрик с инфраструктуры кластеров Kubernetes.
Помимо более глубокой интеграции с vRNI, решение vROPs 8.2 поддерживает целую экосистему интеграции с внешними системами и облачными технологиями. Это лучше всего иллюстрируется картинкой (интеграции доступны через соответствующие Management Packs):
Во-первых, был существенно упрощен рабочий процесс управления политиками, с которым теперь значительно удобнее работать в интерфейсе vROPs 8.2. Все операции доступны в контексте выбранных объектов:
Во-вторых, был существенно переработан стартовый дэшборд, на котором теперь можно более интуитивно найти действия для выполнения задач:
Идея состоит в том, чтобы разделить объекты и рабочие процессы. Также разделы теперь категоризированы по типу возникающей задачи траблшутинга (доступность, нехватка ресурсов и т.п.) и разделены на уровне провайдера услуг и пользователей сервисов (ВМ и приложения):
5. Прочие улучшения
Тут можно отметить следующие наиболее важные вещи:
Это гостевой пост нашего спонсора - компании ИТ-ГРАД, предоставляющей услуги аренды виртуальных машин VMware и сервисов Veeam из облака. Чем сложнее ИТ-инфраструктура, тем выше необходимость в ее контроле. Если за работой 2-3 серверов можно следить вручную, используя штатные средства (Windows monitoring, например, или самописные скрипты), то мониторинг сотни виртуальных машин требует автоматизированного решения. Veeam ONE – это универсальный инструмент для мониторинга и аналитики данных виртуальных, облачных и физических сред.
На сайте проекта VMware Labs обновилась утилита Horizon Reach до версии 1.1, которая позволяет проводить мониторинг и алертинг для развертываний VMware Horizon на площадках заказчиков (только в реальном времени, без исторических данных). Horizon Reach предназначен для тех окружений VMware Horizon, которые образуются в крупных компаниях на уровне площадок (Pod) в рамках концепции Cloud Pod Architecture как отдельный домен отказа (либо где площадки изолированы, но хочется иметь доступ к мониторингу в моменте из одной точки).
Это большое обновление, и в нем появилось много новых возможностей и исправлений ошибок прошлой версии (о которой мы писали осенью прошлого года вот тут).
Давайте посмотрим, что нового в Horizon Reach 1.1:
Теперь утилитой можно напрямую мониторить компоненты Unified Access Gateways, также доступны функции скачивания конфигурации и логов
Пользовательские сессии можно просматривать в рамках следующих представлений:
Pools
Farms
Unified Access Gateways
Global Entitlements
Global Application Entitlements
Алармы были полностью переработаны, чтобы поддерживать отправку нотификаций в следующие каналы:
SMTP
Slack
Сторонние средства через сценарии PowerShell
LDAP-интеграция алармов поддерживает кириллицу
Улучшенный дэшборд алармов
Обновления vCenter:
Хосты теперь видимы, и для них отслеживается производительность
Датасторы теперь видимы, показано свободное пространство
Кастеры теперь видимы, для них доступны различные представления - пулы, фермы и т.п. Также можно использовать интеграцию PowerShell и API
Профили vGPU теперь показаны в представлении пулов
Множество исправлений ошибок
Скачать VMware Horizon Reach 1.1 можно по этой ссылке.
Одновременно с анонсом новой версии платформы виртуализации VMware vSphere 7 компания VMware объявила и о скором выпуске решения vRealize Operations 8.1, предназначенного для управления и мониторинга виртуальной инфраструктуры. Напомним, что о прошлой версии vROPs 8.0 в рамках анонсов VMworld 2019 мы писали вот тут.
Давайте посмотрим, что нового появилось в vRealize Operations 8.1:
1. Операции с интегрированной инфраструктурой vSphere и Kubernetes.
vRealize Operations 8.1 позволяет обнаруживать и мониторить кластеры Kubernetes в рамках интегрированной с vSphere инфраструктуры с возможностью автодобавления объектов Supervisor Cluster, пространств имен (Namespaces), узлов (PODs) и кластеров Tanzu Kubernetes, как только вы добавите их в vCenter, используя функции Workload Management.
После этого вам станут доступны страницы Summary для мониторинга производительности, емкости, использования ресурсов и конфигурации Kubernetes на платформе vSphere 7.0. Например, функции Capacity forecasting покажут узкие места инфраструктуры на уровне узлов, а для ежедневных операций будут полезны дашборды, отчеты, представления и алерты.
2. Операции в инфраструктуре VMware Cloud on AWS.
Теперь в облаке VMware Cloud on AWS можно использовать токен VMware Cloud Service Portal для автообнаружения датацентров SDDC и настройки средств мониторинга в несколько простых шагов. Также можно будет использовать один аккаунт для управления несколькими объектами SDDC на платформе VMware Cloud on AWS, включая сервисы vCenter, vSAN и NSX, а также будет полная интеграция с биллингом VMConAWS.
В облаке можно использовать следующие дашборды:
Отслеживание использования ресурсов и производительность виртуальных машин, включая сервисы NSX Edge, Controller и vCenter Server.
Мониторинг ключевых ресурсов, включая CPU, память, диск и сеть для всей инфраструктуры и виртуальных машин.
Отслеживание трендов потребления ресурсов и прогнозирование таких метрик, как Time Remaining, Capacity Remaining и Virtual Machines Remaining.
Нахождение виртуальных машин, которые потребляют неоправданно много ресурсов и требуют реконфигурации на базе исторических данных.
Кроме этого, для сервисов VMware NSX-T будет осуществляться полная поддержка средств визуализации и мониторинга:
Ну и в релизе vROPs 8.1 есть полная интеграция функционала отслеживания затрат VMware Cloud on AWS с решением vRealize Operations в интерфейсе портала. Это позволит контролировать уже сделанные и отложенные затраты, а также детализировать их по подпискам, потреблению и датам оплат.
Также обновился механизм обследования AWS migration assessment, который теперь позволяет сохранять несколько результатов разных сценариев для дальнейшего анализа. Эти сценарии включают в себя различные варианты параметров Reserved CPU, Reserved Memory, Fault Tolerance, Raid Level и Discounts.
3. Функции мониторинга нескольких облаков (Unified Multicloud monitoring).
Теперь средства мониторинга предоставляют еще более расширенные функции, такие как поддержка Google Cloud Platform, улучшенная поддержка AWS и новый пакет Cloud Health Management pack.
Теперь в vROPS 8.1 есть следующие сервисы GCP:
Compute Engine Instance
Storage Bucket
Cloud VPN
Big Query
Kubernetes Engine
Пакет AWS Management Pack теперь поддерживает следующие объекты AWS Objects:
EFS
Elastic Beanstalk
Direct Connect Gateway
Target Group
Transit Gateway
Internet Gateway
Elastic Network Interface (ENI)
EKS Cluster
Пакет CloudHealth Management Pack был также улучшен, он включает в себя возможность передать данные о перспективах и ценообразовании GCP в vRealize Operations 8.1. Также вы сможете создавать любое число кастомных дэшбордов, комбинируя цены на различное соотношение ресурсов публичного, гибридного или частного облаков.
Как ожидается, vRealize Operations 8.1 выйдет в апреле этого года одновременно с релизом VMware vSphere 7. Мы обязательно напишем об этом.

 RSS
RSS