Frank Denneman написал отличную статью о разделении NVIDIA Multi-Instance GPU (MIG) с учетом геометрий размещения и потерянных ёмкостей ресурсов.
Архитектура инфраструктуры ИИ
Предыдущие статьи в этой серии объясняли, как работает совместное использование GPU с разделением по времени как в средах вида same-size, так и со смешанными размерами. Они показали, что такие выборы, как профили и порядок запуска рабочих нагрузок, могут напрямую влиять на использование GPU и на то, будут ли рабочие нагрузки успешно размещены. В этой части мы рассматриваем MIG и решения по проектированию, которые влияют на успешность размещения и общее использование ресурсов.
MIG использует другой подход к совместному использованию GPU. Вместо мультиплексирования вычислительных ресурсов между рабочими нагрузками MIG разделяет GPU на аппаратные экземпляры. Каждый экземпляр получает собственные выделенные вычислительные срезы (slices) и срезы памяти.
Каждый экземпляр предоставляет три основные функции: изоляцию сбоев, индивидуальное планирование и отдельное адресное пространство. Когда требуется строгая аппаратная изоляция, MIG является правильным решением, потому что рабочие нагрузки не могут мешать друг другу, а потребление ресурсов становится предсказуемым.
Многие администраторы и операторы выбирают MIG как технологию для предоставления дробных GPU без строгого требования к жёсткой изоляции. Эта статья сосредоточена на таком сценарии использования и определяет проблемы успешного размещения и использования ресурсов, включая то, как выбор профиля напрямую определяет, будет ли ёмкость GPU полностью использована или навсегда останется потерянной.
Модель ресурсов MIG
В предыдущих статьях этой серии было показано, что ёмкость GPU определяется не только объёмом свободной памяти. Ёмкость зависит от того, как ресурсы разделены и размещены. MIG добавляет ещё один уровень ограничений размещения.
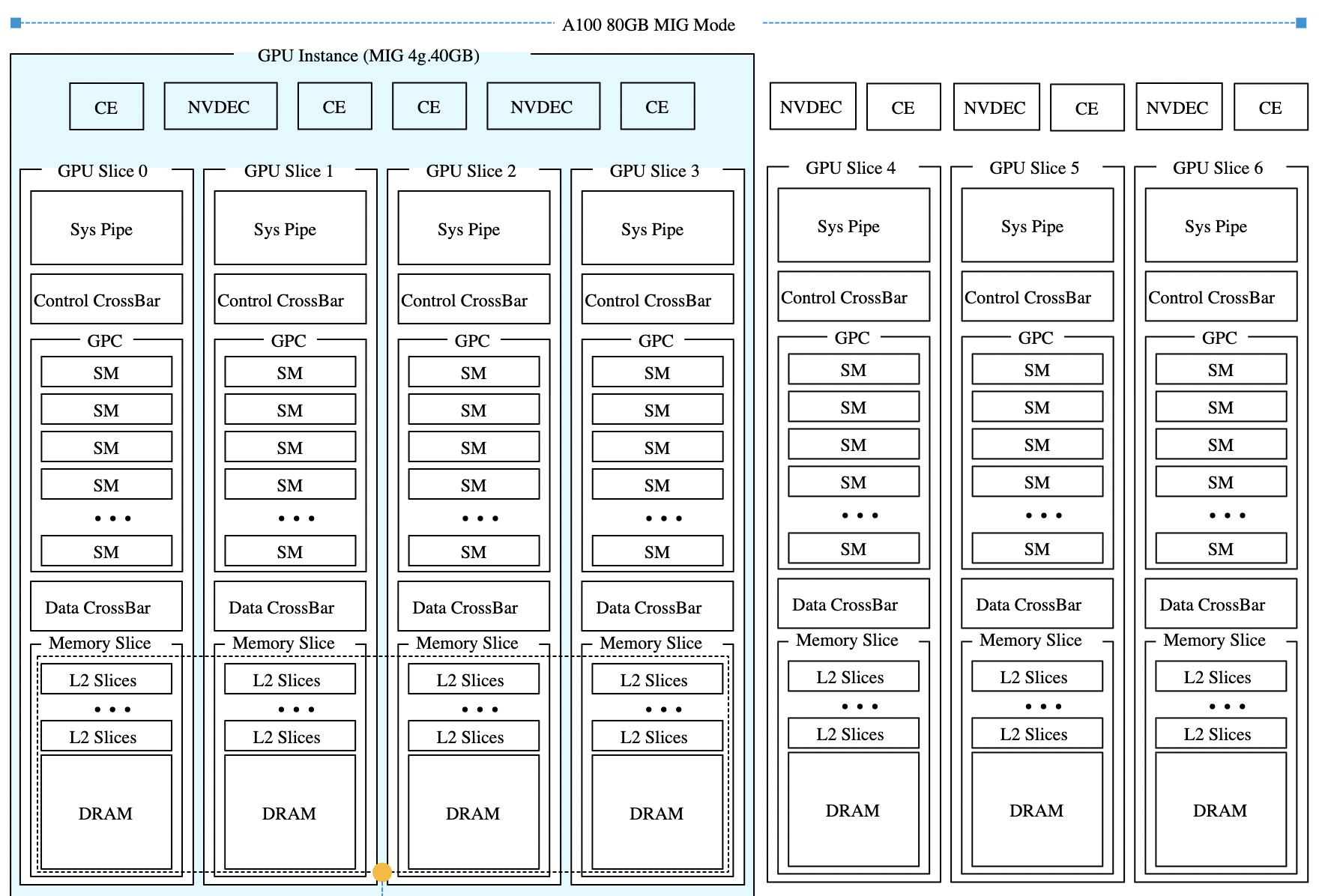
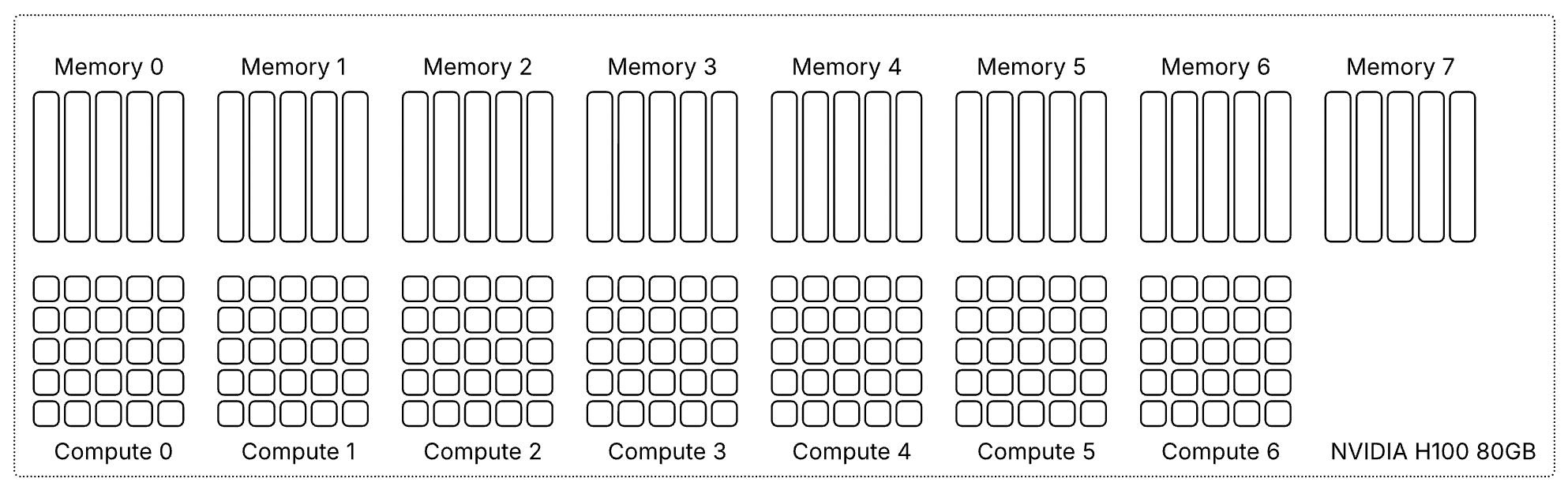
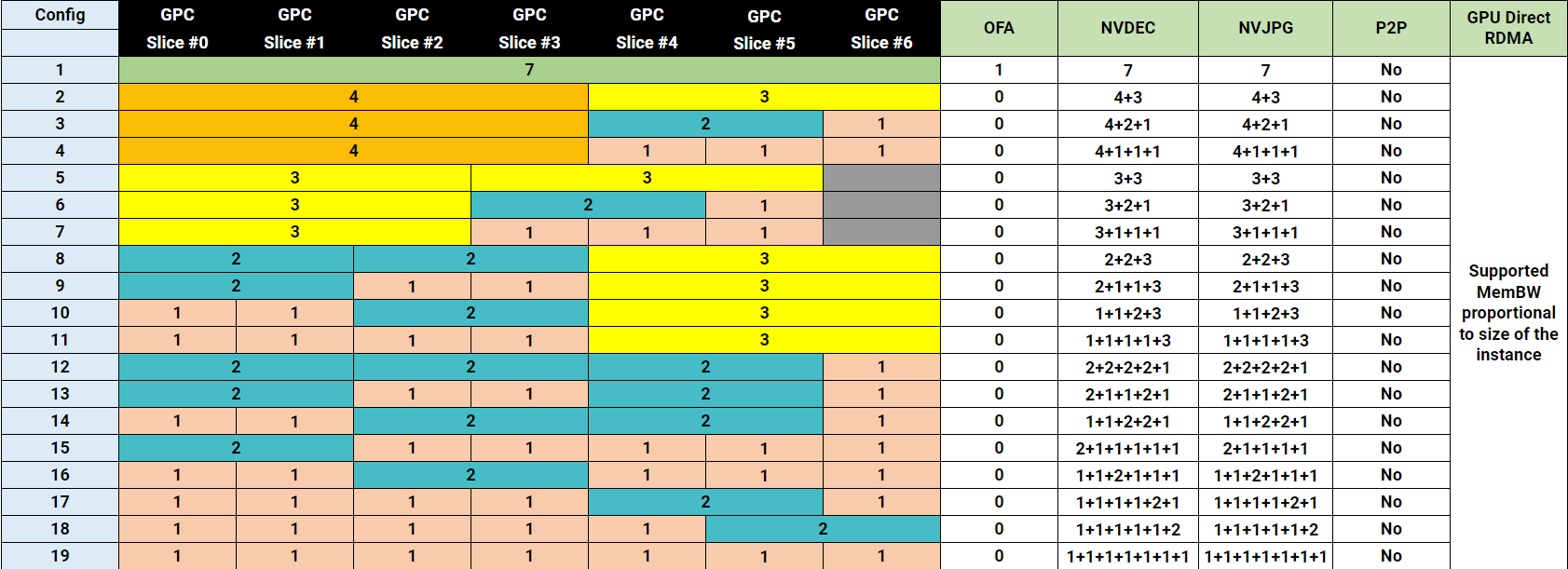
Все архитектуры GPU NVIDIA, поддерживающие MIG, включая Ampere, Hopper и Blackwell, имеют одинаковую структуру. Каждый GPU предоставляет семь вычислительных срезов и восемь срезов памяти. Профили используют оба ресурса одновременно, поэтому каждый профиль представляет собой определённую комбинацию вычислительных срезов и срезов памяти, соответствующую физической структуре GPU.
В этой статье в качестве примера используется GPU H100 с объёмом памяти 80 гигабайт. В этой конфигурации каждый срез памяти представляет десять гигабайт framebuffer-памяти. Поскольку вычислительные срезы и срезы памяти выделяются вместе, один только объём свободной памяти не определяет, может ли быть запущен новый экземпляр. Требуемые вычислительные срезы также должны быть доступны и соответствовать правильной области памяти. Таблица показывает доступные профили MIG для GPU H100-80GB:
Profile
Compute slices
Memory slices
Memory
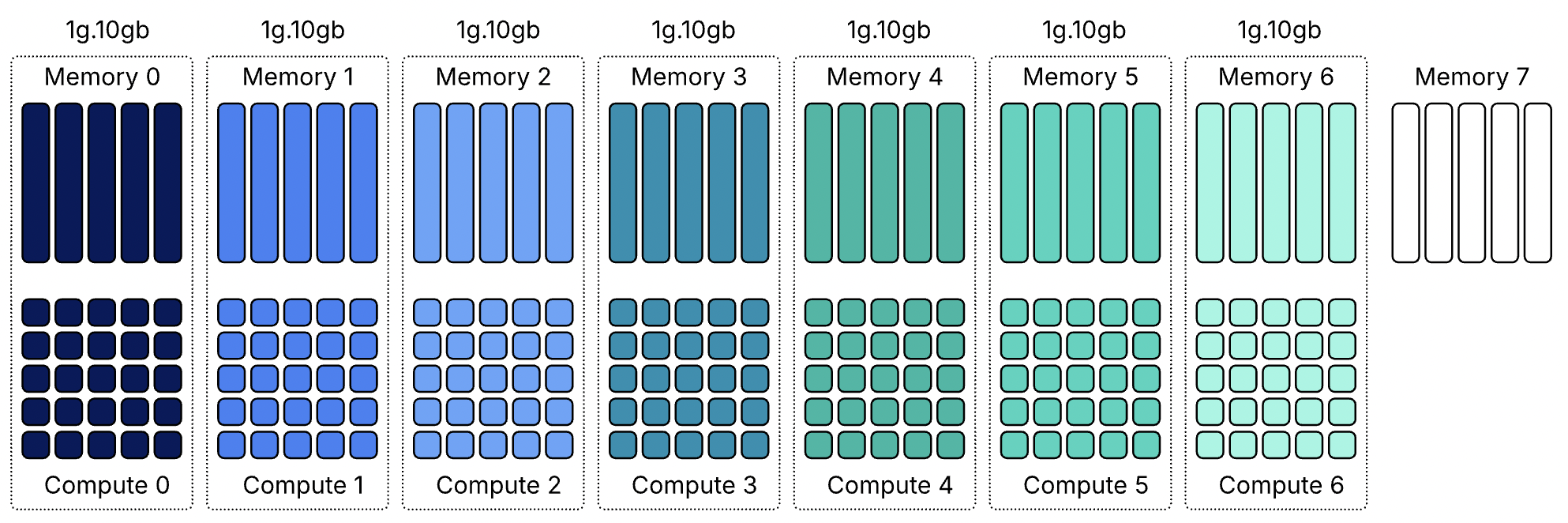
1g.10gb
1
1
10 GB
1g.20gb
1
2
20 GB
2g.20gb
2
2
20 GB
3g.40gb
3
4
40 GB
4g.40gb
4
4
40 GB
7g.80gb
7
8
80 GB
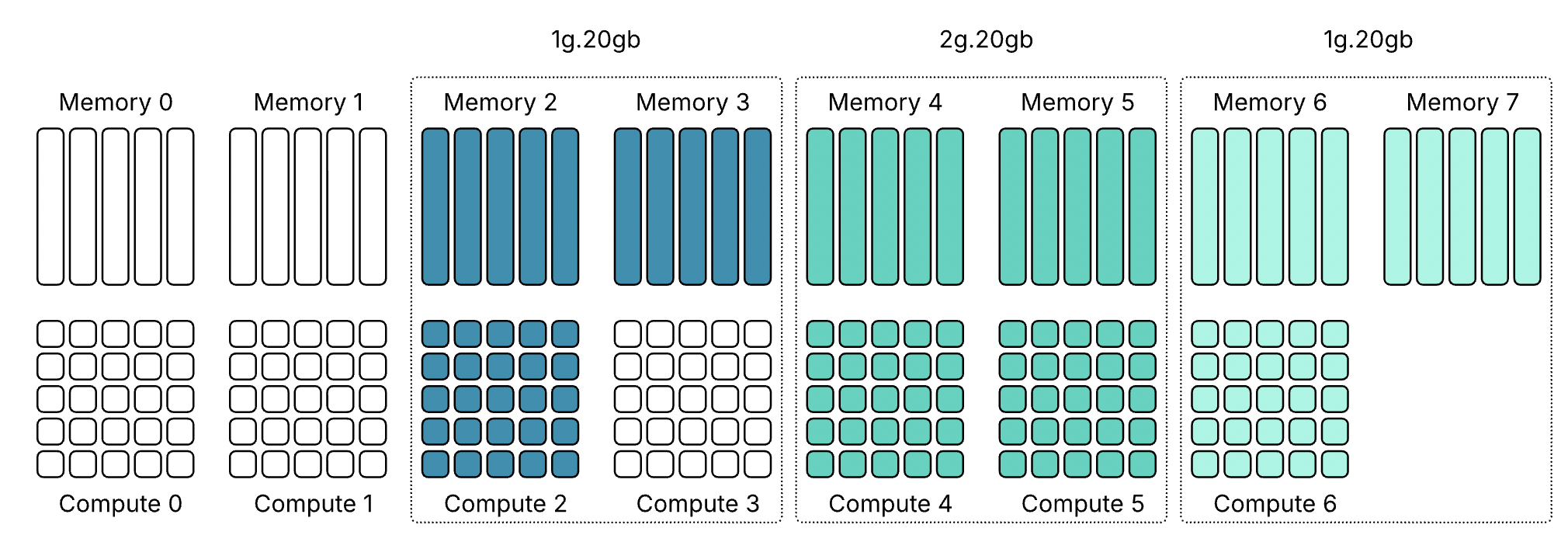
Эти профили показывают, что использование ресурсов MIG в большинстве случаев асимметрично. Некоторые профили предлагают одинаковый объём памяти, но отличаются вычислительной мощностью. Например, и 1g.20gb, и 2g.20gb предоставляют 20 GB памяти, но требуют разного количества вычислительных срезов.
То же относится и к профилям 40 GB: 3g.40gb и 4g.40gb оба используют 40 GB памяти, но требуют разные вычислительные ресурсы.
Это несоответствие между вычислениями и памятью может приводить к результатам размещения, которые на первый взгляд не очевидны.
Потерянная ёмкость
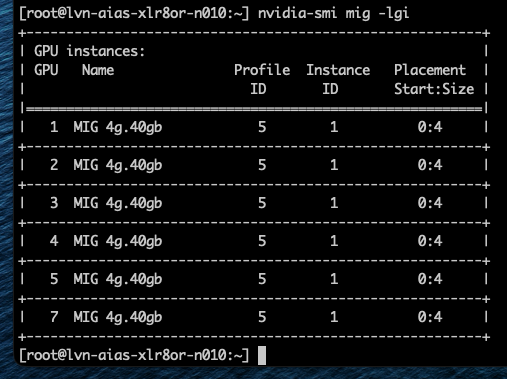
Поскольку вычислительные и срезы памяти не всегда совпадают, некоторые ресурсы GPU могут оставаться неиспользованными, даже когда устройство выглядит полностью занятым. Возьмём самый маленький профиль MIG — 1g.10gb. Этот профиль потребляет один вычислительный срез и один срез памяти. На GPU с восемьюдесятью гигабайтами можно создать семь экземпляров, потому что GPU предоставляет семь вычислительных срезов.
GPU всё ещё имеет восемь срезов памяти. После размещения семи экземпляров 10 гигабайт памяти остаются неиспользованными, или, иначе говоря, это потерянная ёмкость. Вычислительных срезов больше не осталось, поэтому ни один другой экземпляр не может быть запущен. Такое поведение легко не заметить в диаграммах размещения MIG. Эти диаграммы показывают области размещения памяти, и семь экземпляров 1g.10gb выглядят так, будто полностью заполняют GPU. На самом деле ограничивающим фактором являются вычислительные срезы, а не память.
Геометрия размещения
Профили MIG должны соответствовать определённым областям размещения памяти внутри GPU. Профили, которые используют несколько срезов памяти, требуют непрерывной области.
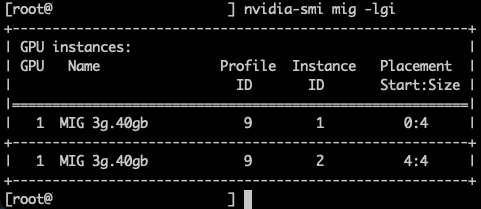
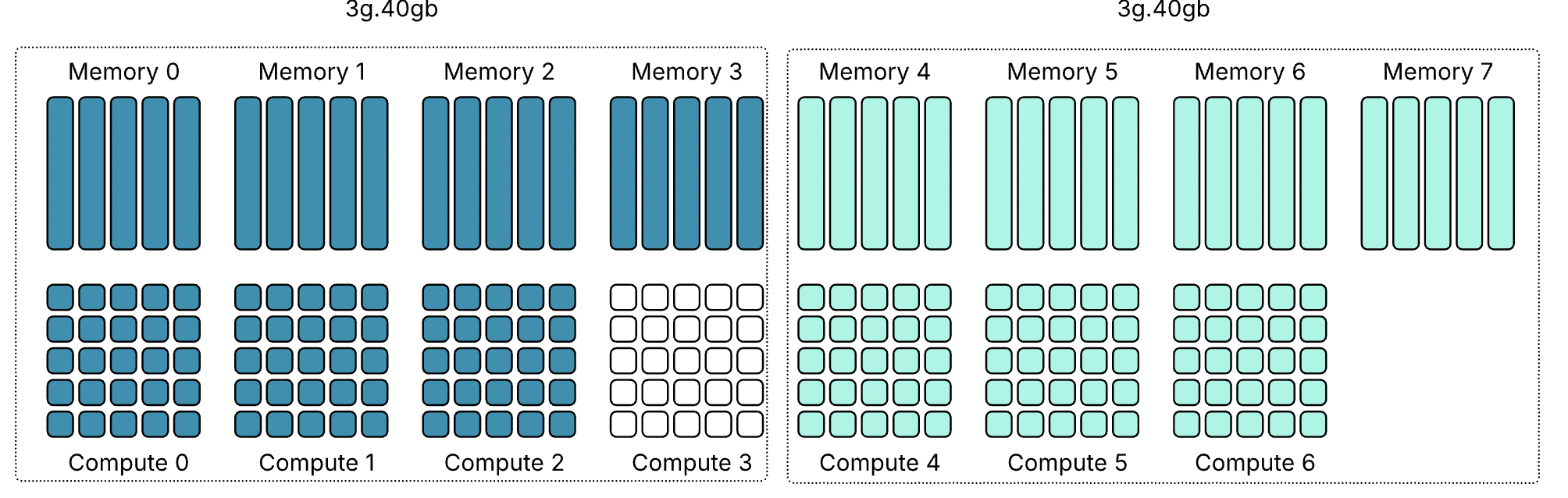
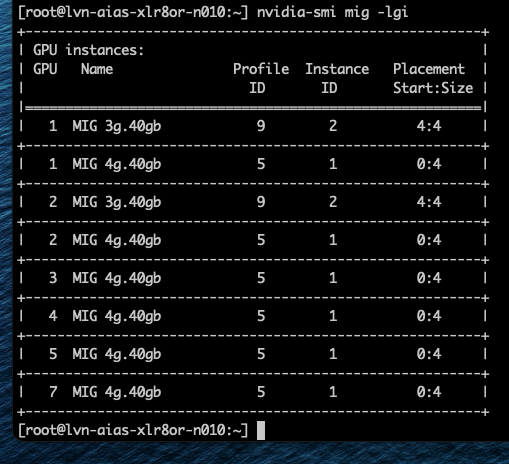
Профиль 3g.40gb потребляет четыре среза памяти. На GPU с объёмом памяти 80 гигабайт это создаёт две допустимые области размещения: срезы памяти 0–3 или 4–7. nvidia-smi — это инструмент командной строки NVIDIA, устанавливаемый вместе с драйвером. Флаг mig -lgi выводит список всех активных экземпляров MIG на хосте — list GPU instances — включая профиль, из которого был создан каждый экземпляр, и его положение в схеме памяти GPU. Вывод содержит колонку placement в формате start:size, где start — это индекс первого среза памяти, который занимает экземпляр, а size — количество срезов, которые он использует.
Экземпляр 3g.40gb с размещением 4:4 начинается с среза памяти 4 и занимает четыре среза, размещаясь во второй области. Экземпляр 4g.40gb с размещением 0:4 занимает первую область — единственную область, где может быть удовлетворено его требование к вычислительным ресурсам. Однако по мере размещения на GPU двух профилей 3g.40gb один вычислительный экземпляр оказывается потерянным.
Важно отметить — и профили 40gb хорошо это показывают — что MIG вводит две области: одну с четырьмя выровненными вычислительными и память-срезами и другую с тремя. Правила размещения MIG требуют, чтобы вычислительные и память-срезы начинались с одной позиции, но они не обязаны заканчиваться одновременно.
Хорошим примером этого является профиль 4g.40gb. Он может быть размещён только начиная с среза памяти 0 и, таким образом, напрямую выравнивается с вычислительным срезом 0. Фрэнк работал с системой Dell PowerEdge XE9680 HGX с восемью GPU H100 80 GB, семь из которых были пустыми.
Когда Фрэнк включил семь виртуальных машин с профилем 4g.40gb, каждая ВМ была размещена в первой области размещения (0–4) GPU H100. Последние четыре среза памяти каждого GPU всё ещё оставались свободными, но в этих областях есть только три вычислительных среза, поэтому разместить там ещё одну ВМ с профилем 4g.40gb невозможно.
Однако можно включить виртуальные машины с профилем vGPU 3g.40gb. Как показано на скриншоте, Фрэнк запустил две ВМ с этим профилем, и они были размещены на GPU 1 и 2.
Имейте в виду, что существующие экземпляры никогда не перестраиваются. То, как настроен GPU, определяет, что может быть запущено следующим. Это означает, что порядок запуска рабочих нагрузок имеет значение, поскольку он влияет на то, какие профили ещё могут быть развёрнуты, даже если кажется, что доступной памяти достаточно.
Поведение размещения
Как описано в части 4, vSphere не использует политики размещения GPU на уровне хоста, когда GPU работают в режиме MIG. Размещение следует тому же подходу, который используется в средах со смешанными размерами: сначала заполняется один GPU, прежде чем переходить к следующему, при этом сохраняется как можно больше вариантов размещения для будущих рабочих нагрузок. Это поведение значительно улучшилось в архитектуре Hopper, но Ampere иногда испытывает трудности с размещением более крупных профилей, потому что не всегда учитывает будущие размещения 4g40gb. (Reddit).
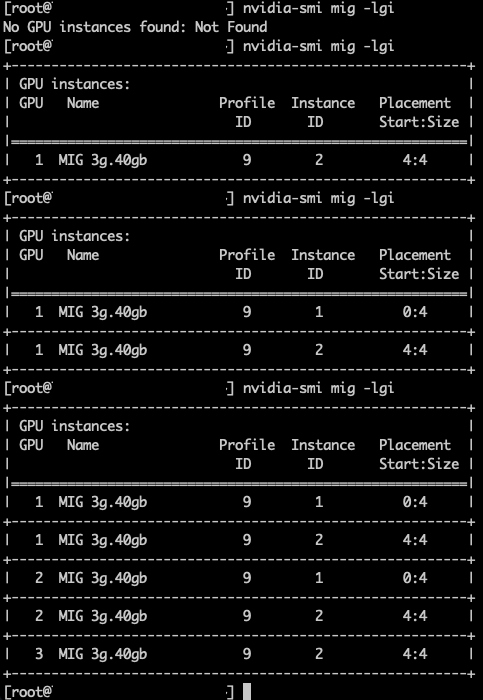
На хостах с более чем одним GPU рабочие нагрузки размещаются на одном GPU до тех пор, пока на этом устройстве больше нельзя разместить запрошенный профиль. Следующая рабочая нагрузка затем размещается на другом GPU. Та же идея применяется и внутри GPU: экземпляры размещаются так, чтобы сохранять максимально возможные непрерывные области, чтобы более крупные профили могли быть развёрнуты позже.
Хороший пример — профиль 3g.40gb. В тестовом кластере Фрэнк очистил семь GPU (кроме GPU 0, на котором выполнялась рабочая нагрузка разработчика) и запустил пять ВМ, каждая с профилем vGPU 3g.40gb. Как показано на скриншоте, первая ВМ была размещена на GPU 0 с placement id 4, оставляя место для будущего профиля 4g.40gb. Когда следующая ВМ была размещена с профилем 3g.40gb, менеджер vGPU выбрал GPU 1, оставив другие GPU открытыми для возможного размещения самого большого профиля — 7g.80gb. При каждом новом размещении менеджер vGPU сначала размещает первый профиль vGPU в позиции placement 4, прежде чем заполнять остальное пространство.
Обратите внимание, что Фрэнк зарегистрировал все эти ВМ на этом хосте, чтобы ограничить область тестирования. В реальных сценариях DRS, вместе с Assignable Hardware, распределяет ВМ между совместимыми хостами ESX в кластере на основе баланса кластера по CPU и памяти и доступности совместимых GPU.
Проектирование каталога профилей
Асимметричное потребление вычислительных срезов заставляет осознанно выбирать профили, которые будут доступны через портал самообслуживания, потому что профили, которые вы включаете, определяют, что пользователи могут запрашивать и насколько эффективно GPU будет использоваться со временем.
Профили 40 гигабайт хорошо демонстрируют этот компромисс. Один GPU может разместить два экземпляра 3g.40gb, но только один 4g.40gb, потому что второй потребовал бы восемь вычислительных срезов, тогда как GPU имеет только семь. Если вы предлагаете только 3g.40gb, один вычислительный срез всегда будет потерян на полностью загруженном GPU. Если вы предлагаете 4g.40gb вместе с более маленькими профилями, вы избегаете этих потерь, но рискуете получить ошибки размещения: профиль 4g.40gb может быть создан только в первой области памяти, поэтому если там уже есть другой экземпляр, размещение становится невозможным независимо от того, сколько памяти осталось.
Профили 20 гигабайт имеют ту же проблему, но в другой форме. Четыре экземпляра 2g.20gb не могут работать на одном GPU — снова требуется восемь вычислительных срезов, но доступно только семь. Если вы добавите профиль 1g.20gb как вариант, можно разместить четвёртую нагрузку на 20 гигабайт, но это увеличивает вероятность появления потерянной ёмкости по мере заполнения GPU экземплярами с небольшой вычислительной нагрузкой.
Не существует конфигурации, которая полностью устраняет это противоречие. Команды платформ должны решить, что важнее: предсказуемость размещения за счёт предложения меньшего количества профилей и более предсказуемого поведения или предложение полного набора профилей с принятием того, что пользователи иногда будут сталкиваться с неудачным размещением или что на некоторых GPU будет оставаться потерянная ёмкость.
Если строгая изоляция не требуется, смешанный режим, описанный в части 6 и части 7, полностью избегает этих ограничений. Четыре рабочие нагрузки по 20 гигабайт и две рабочие нагрузки по 40 гигабайт могут полностью использовать один GPU в средах со смешанными размерами, не оставляя вычислительную ёмкость потерянной.
С ростом числа сценариев использования генеративного AI, а также с существующими рабочими нагрузками AI и машинного обучения, все хотят получить больше мощностей GPU и стремятся максимально эффективно использовать те, которые у них уже есть. В настоящее время метрики использования GPU доступны только на уровне хоста в vSphere, а с помощью модуля vSphere GPU Monitoring вы теперь можете видеть их на уровне кластера. Эта информация имеет большое значение для таких задач, как планирование ёмкости, что оказывает значительное стратегическое влияние на организации, стремящиеся увеличить использование AI.
vSphere GPU Monitoring Fling предоставляет метрики GPU на уровне кластера в VMware vSphere, что позволяет максимально эффективно использовать дорогостоящее оборудование. Он совместим с vSphere версий 7 и 8. Также функционал утилиты также доступен в виде основного патча vCenter 8.0 Update 2 для тех, кто использует более новые версии платформы (то есть, Fling не требуется!). Скачайте плагин здесь и поделитесь своим мнением в разделе Threads на портале community.broadcom.com или по электронной почте vspheregpu.monitoring@broadcom.com.
Пользователям нужно провести установку плагина для объекта Datacenter, после чего они смогут видеть сводные метрики своих GPU для кластеров в этом датацентре. В представлении датацентра пользователь может нажать на «View Details», чтобы увидеть более подробную информацию о распределении и потреблении GPU, а также о типе совместного использования GPU.
Наконец, температура также является важной метрикой для отслеживания, так как долговечность и производительность GPU значительно снижаются, если они слишком долго работают при высокой температуре. Этот Fling также включает и мониторинг температуры:
Недавно мы писали о новых возможностях пакета обновлений платформы виртуализации VMware vSphere 8 Update 3. Сегодня мы более детально рассмотрим, что нового там появилось в плане поддержки карт GPU.
Новые функции охватывают несколько областей, начиная с использования vGPU-профилей разных типов и размеров вместе и заканчивая внесением изменений в расширенные параметры DRS, которые определяют, как ВМ с поддержкой vGPU будет обрабатываться со стороны vMotion, например. Все эти улучшения направлены на упрощение жизни системных администраторов, дата-сайентистов и других пользователей, чтобы они могли использовать свои рабочие нагрузки на платформах vSphere и VCF.
Гетерогенные типы vGPU-профилей с разными размерами
В VMware vSphere мы можем назначить машине vGPU-профиль из набора заранее определенных профилей, чтобы предоставить ей определенную функциональность. Набор доступных vGPU-профилей появляется после установки NVIDIA vGPU менеджера/драйвера на уровне хоста в ESXi посредством vSphere Installation Bundle (VIB).
Эти vGPU-профили называются профилями типа C в случае, если профиль предназначен для интенсивной вычислительной работы, такой как обучение моделей машинного обучения. Существуют и несколько других типов vGPU-профилей, среди которых Q (Quadro) для графических рабочих нагрузок являются одними из самых популярных. Буквы «c» и «q» стоят в конце названия vGPU-профиля, отсюда и название этого типа.
В предыдущем обновлении vSphere 8 Update 2 мы могли назначать машине vGPU-профили, которые предоставляли поддержку различных видов функциональности, используя при этом одно и то же устройство GPU. Ограничением в этой версии vSphere было то, что они должны были быть vGPU-профилями одного и того же размера, например, те, которые заканчиваются на 8q и 8c. Здесь «8» представляет количество гигабайт памяти на самом GPU (иногда называемой framebuffer-памятью), которая назначена ВМ, использующей этот vGPU-профиль. Это значение может изменяться в зависимости от модели основного GPU.
При использовании GPU A40 или L40s мы можем иметь vGPU-профиль типа C, предназначенный для вычислительно интенсивной работы, такой как машинное обучение, и vGPU-профиль типа Q (предназначенный для графической работы), назначенные разным ВМ, которые делят один и тот же физический GPU на хосте.
Теперь в vSphere 8 Update 3 можно продолжать смешивать эти разные типы vGPU-профилей на одном физическом GPU, а также иметь vGPU-профили разного размера памяти, которые делят один и тот же GPU.
В качестве примера новой функциональности vSphere 8 Update 3: ВМ1 с vGPU-профилем l40-16c (для вычислительных нагрузок) и ВМ2 с vGPU-профилем l40-12q (для графических нагрузок) делят одно и то же устройство L40 GPU внутри хоста. Фактически, все вышеупомянутые виртуальные машины делят одно и то же физическое устройство L40 GPU.
Это позволяет лучше консолидировать рабочие нагрузки на меньшее количество GPU, когда рабочие нагрузки не потребляют весь GPU целиком. Возможность размещения гетерогенных типов и размеров vGPU-профилей на одном устройстве GPU применяется к GPU L40, L40s и A40 в частности, так как эти GPU имеют двойное назначение. То есть они могут обрабатывать как графические, так и вычислительно интенсивные задачи, в то время как GPU H100 предназначен исключительно для вычислительно интенсивных задач.
Включение настроек кластера для DRS и мобильности ВМ с vGPU
В vSphere Client версии 8.0 U3 появились новые настройки кластера, которые предоставляют более удобный метод настройки расширенных параметров для кластера DRS. Вы можете установить ограничение по времени приостановки ВМ, которое будет допускаться для машин с vGPU-профилями, которым может потребоваться больше времени, чем по умолчанию, для выполнения vMotion. Время приостановки по умолчанию для vMotion составляет 100 секунд, но этого может быть недостаточно для некоторых ВМ с большими vGPU-профилями. Дополнительное время требуется для копирования памяти GPU на целевой хост. Вы также можете узнать оценочное время приостановки для вашей конкретной ВМ с поддержкой vGPU в vSphere Client. Для получения дополнительной информации о времени приостановки, пожалуйста, ознакомьтесь с этой статьей.
В vSphere 8 Update 3 появился более удобный пользовательский интерфейс для настройки расширенных параметров для кластера DRS, связанных с vMotion виртуальных машин.
Прежде чем мы рассмотрим второй выделенный элемент на экране редактирования настроек кластера ниже, важно понять, что vGPU как механизм доступа к GPU является одной из множества техник, которые находятся в "спектре проброса устройств" (Passthrough spectrum). То есть, vGPU на самом деле является одной из форм прямого доступа. Возможно, вы считали, что подходы прямого проброса и vGPU сильно отличаются друг от друга до настоящего времени, так как они действительно разделены в vSphere Client при выборе добавления нового PCIe-устройства к ВМ. Однако, они тесно связаны друг с другом. Фактически, vGPU ранее назывался "опосредованным пробросом" (mediated passthrough). Этот спектр использования прямого доступа различными способами показан здесь.
Именно поэтому в vSphere Client на выделенном участке экрана ниже используются термины «Passthrough VM» и «Passthrough Devices». Эти термины на самом деле относятся к виртуальным машинам с поддержкой vGPU – и таким образом, обсуждение касается включения DRS и vMotion для виртуальных машин с поддержкой vGPU на этом экране. vMotion не разрешен для виртуальных машин, использующих фиксированный прямой доступ, как показано на левой стороне диаграммы выше.
Новая функция интерфейса позволяет пользователю включить расширенную настройку vSphere под названием «PassthroughDrsAutomation». С включенной этой настройкой, при соблюдении правил по времени приостановки, виртуальные машины в этом кластере могут быть перемещены vMotion на другой хост по решению DRS. Для получения дополнительной информации об этих расширенных настройках DRS, пожалуйста, ознакомьтесь с этой статьей.
Доступ к медиа-движку GPU
Единый медиа-движок на GPU может использоваться виртуальной машиной, которая хостит приложение, которому требуется выполнять транскодирование (кодирование/декодирование) на GPU, а не на более медленном CPU, например, для видео-приложений.
В vSphere 8 Update 3 поддерживается новый vGPU-профиль для виртуальных машин, которым требуется доступ к медиа-движку внутри GPU. Только одна виртуальная машина может использовать этот медиа-движок. Примеры таких vGPU-профилей («me» означает media engine):
a100-1-5cme (один срез)
h100-1-10cme (два среза)
Более высокая скорость vMotion виртуальных машин с большими vGPU-профилями
Новые улучшения в vMotion позволяют нам увеличивать пропускную способность для сети vMotion со скоростью 100 Гбит/с до 60 Гбит/с для vMotion виртуальной машины, к которой подключен современный GPU (H100, L40S), что сокращает время vMotion. Это не относится к GPU A100 и A30, которые относятся к более старой архитектуре (GA100).
Новые технические документы и рекомендации по проектированию GPU с VMware Private AI Foundation with NVIDIA
Недавно были выпущены два важных публикации авторами VMware. Агустин Маланко Лейва и команда опубликовали решение VMware Validation Solution для инфраструктуры Private AI Ready Infrastructure, доступное здесь.
Этот документ предоставляет подробное руководство по настройке GPU/vGPU на VMware Cloud Foundation и многим другим факторам для организации вашей инфраструктуры для развертывания VMware Private AI.
Одним из ключевых приложений, которое будут развертывать в первую очередь в инфраструктуре VMware Private AI Foundation с NVIDIA, является генерация с дополненным извлечением или RAG. Фрэнк Деннеман и Крис МакКейн подробно рассматривают требования к безопасности и конфиденциальности и детали реализации этого в новом техническом документе под названием VMware Private AI – Privacy and Security Best Practices.
После выхода VMware vSphere 7 Update 2 появилось много интересных статей о разного рода улучшениях, на фоне которых как-то потерялись нововведения, касающиеся работы с большими нагрузками машинного обучения на базе карт NVIDIA, которые были сделаны в обновлении платформы.
А сделано тут было 3 важных вещи:
Пакет NVIDIA AI Enterprise Suite был сертифицирован для vSphere
Появилась поддержка последних поколений GPU от NVIDIA на базе архитектуры Ampere
Добавились оптимизации в vSphere в плане коммуникации device-to-device на шине PCI, что дает преимущества в производительности для технологии NVIDIA GPUDirect RDMA
Давайте посмотрим на все это несколько подробнее:
1. NVIDIA AI Enterprise Suite сертифицирован для vSphere
Основная новость об этом находится в блоге NVIDIA. Сотрудничество двух компаний привело к тому, что комплект программного обеспечения для AI-аналитики и Data Science теперь сертифицирован для vSphere и оптимизирован для работы на этой платформе.
Оптимизации включают в себя не только средства разработки, но и развертывания и масштабирования, которые теперь удобно делать на виртуальной платформе. Все это привело к тому, что накладные расходы на виртуализацию у задач машинного обучения для карточек NVIDIA практически отсутствуют:
2. Поддержка последнего поколения NVIDIA GPU
Последнее поколение графических карт для ML-задач, Ampere Series A100 GPU от NVIDIA, имеет поддержку Multi-Instance GPU (MIG) и работает на платформе vSphere 7 Update 2.
Графический процессор NVIDIA A100 GPU, предназначенный для задач машинного обучения и самый мощный от NVIDIA на сегодняшний день в этой нише, теперь полностью поддерживается вместе с технологией MIG. Более детально об этом можно почитать вот тут. Также для этих карт поддерживается vMotion и DRS виртуальных машин.
Классический time-sliced vGPU подход подразумевает выполнение задач на всех ядрах GPU (они же streaming multiprocessors, SM), где происходит разделение задач по времени исполнения на базе алгоритмов fair-share, equal share или best effort (подробнее тут). Это не дает полной аппаратной изоляции и работает в рамках выделенной framebuffer memory конкретной виртуальной машины в соответствии с политикой.
При выборе профиля vGPU на хосте с карточкой A100 можно выбрать объем framebuffer memory (то есть памяти GPU) для виртуальной машины (это число в гигабайтах перед буквой c, в данном случае 5 ГБ):
Для режима MIG виртуальной машине выделяются определенные SM-процессоры, заданный объем framebuffer memory на самом GPU и выделяются отдельные пути коммуникации между ними (cross-bars, кэши и т.п.).
В таком режиме виртуальные машины оказываются полностью изолированы на уровне аппаратного обеспечения. Выбор профилей для MIG-режима выглядит так:
Первая цифра сразу после a100 - это число слайсов (slices), которые выделяются данной ВМ. Один слайс содержит 14 процессоров SM, которые будут использоваться только под эту нагрузку. Число доступных слайсов зависит от модели графической карты и числа ядер GPU на ней. По-сути, MIG - это настоящий параллелизм, а обычный режим работы - это все же последовательное выполнение задач из общей очереди.
Например, доступные 8 memory (framebuffers) слотов и 7 compute (slices) слотов с помощью профилей можно разбить в какой угодно комбинации по виртуальным машинам на хосте (необязательно разбивать на равные части):
3. Улучшения GPUDirect RDMA
Есть классы ML-задач, которые выходят за рамки одной графической карты, какой бы мощной она ни была - например, задачи распределенной тренировки (distributed training). В этом случае критически важной становится коммуникация между адаптерами на нескольких хостах по высокопроизводительному каналу RDMA.
Механизм прямой коммуникации через шину PCIe реализуется через Address Translation Service (ATS), который является частью стандарта PCIe и позволяет графической карточке напрямую отдавать данные в сеть, минуя CPU и память хоста, которые далее идут по высокоскоростному каналу GPUDirect RDMA. На стороне приемника все происходит полностью аналогичным образом. Это гораздо более производительно, чем стандартная схема сетевого обмена, об этом можно почитать вот тут.
Режим ATS включен по умолчанию. Для его работы карточки GPU и сетевой адаптер должны быть назначены одной ВМ. GPU должен быть в режиме Passthrough или vGPU (эта поддержка появилась только в vSphere 7 U2). Для сетевой карты должен быть настроен проброс функций SR-IOV к данной ВМ.
Более подробно обо всем этом вы можете прочитать на ресурсах VMware и NVIDIA.
Многие администраторы VMware vSphere знают, что у этой платформы есть режим совместимости Enhanced vMotion Compatibility (EVC), который позволяет привести хосты с процессорами (CPU) разных моделей к единому базовому уровню по набору возможностей CPU Feature Set, чтобы обеспечить свободную миграцию vMotion между хостами ESXi. Делается это за счет маскирования некоторых наборов инструкций процессора через CPUID.
Сейчас многие приложения (например, реализующие техники Machine Learning / Deep Learning) используют ресурсы графического адаптера (GPU), поскольку их многоядерная архитектура отлично подходит для такого рода задач.
В VMware vSphere 7, вместе с соответствующей версией VM Hardware, были существенно улучшены функции работы для режима vSGA, который предназначен для совместного использования графического адаптера несколькими виртуальными машинами хоста.
Поэтому в VMware vSphere 7 Update 1 сделали еще одно полезное улучшение по этой теме - режим Enhanced vMotion Capabilities для графических процессоров GPU, который является частью EVC, настраиваемого в vSphere Client:
Графический режим VMFeatures включает в себя поддерживаемые возможности для 3D-приложений, включая библиотеки D3D 10.0/ Open Gl 3.3, D3D 10.1 / Open GL 3.3 и D3D 11.0 / Open GL 4.1. Пока приведение к базовому уровню доступно только до D3D 10.1 / OpenGL 3.3 (версии 11.0 и 4.1, соответственно, будут поддерживаться в следующих релизах).
Когда хост ESXi включается в кластер, где включена EVC for Graphics, сервер vCenter проверяет, что он поддерживает соответствующие версии библиотек. При этом можно добавлять хосты разных версий - ESXi 6.5,6.7 и 7.0, благодаря поддержке D3D 10.0 и OpenGL 3.3.
Как и для обычного EVC, пользователи могут включить EVC for Graphics на уровне отдельных ВМ. В этом случае перед тем, как включить виртуальную машину на хосте ESXi, сервер vCenter убеждается, что он поддерживает соответствующие библиотеки. Такая настройка полезна при возможной миграции виртуальной машины между датацентрами или в публичное облако.
Если у вас включена EVC for Graphics, то перед миграциями vMotion также будут проводиться нужные предпроверки по поддержке графических функций GPU со стороны видеоадаптера целевого хоста.
Недавно мы писали про интересную штуку - утилиту Machine Learning on VMware Cloud Foundation, которая предоставляет инженерам по работе с данными инструменты в области Data Science в рамках виртуальной инфраструктуры. К сожалению, она пока не поддерживает использование GPU хостов, а работает только с CPU. Но заслуживает внимание сам факт такого решения - VMware начинает плотно прорабатывать тему машинного обучения.
Еще один элемент этой концепции - выпущенный на днях документ "Learning Guide – GPUs for Machine Learning on vSphere". В нем VMware рассказывает о том, как правильно строить системы, заточенные под алгоритмы машинного обучения, на платформе VMware vSphere.
Документ позволит архитекторам ИТ-инфраструктур и командам DevOps ответить на следующие вопросы:
Зачем нужны серверы с GPU для задач machine learning (ML) на платформах high performance computing (HPC).
Как именно используется модуль GPU.
Как на платформе vSphere строить ML-системы.
Как транслировать модуль GPU в рабочую нагрузку ML в виртуальной машине.
Как наладить взаимодействие между командой data scientists и администраторов виртуальной инфраструктуры.
Задачи машинного обучения с использованием GPU можно решать тремя способами:
Эти способы реализуют соответствующие технологии:
Об остальном читайте в интереснейшем документе на 43 страницах. В конце вайтпэйпера приведена огромная коллекция полезных ссылок на документы и статьи по практическому применению задач машинного обучения в виртуальных средах.
В прошлых заметках (раз и два) мы писали о платформе VGX от NVIDIA, которая позволяет применять виртуализацию GPU со стороны сервера, чтобы реализовывать требовательные к графике нагрузки в инфраструктуре виртуальных ПК предприятия (VDI). Физически это модуль с 2,3 или 4-мя GPU и 8 или 16 ГБ памяти, который устанавливаться в сервер через стандартный разъем PCI Express (2 слота).
Платы GRID построены на основе архитектуры NVIDIA Kepler и подразумевают управление графическими ресурсами отдельных виртуальных машин средствами специального гипервизора - NVIDIA VGX Hypervisor.
Оказывается, платформа VGX уже доработана и готова к поставке компаниям корпоративного сектора под именем Virtual Graphics Server
(GRID VGX) со стороны OEM-партнеров. IBM уже начала отгрузку серверов со встроенной технологией GRID, скоро подтянутся и другие вендоры:
Серверы с GRID VGX бывают с модулями двух типов:
Графические модули GPU K1 для максимизации числа одновременных подключений пользователей к своим виртуальным ПК, в том числе со средними графическими нагрузками.
Модули GPU K2 - для обработки специфических задач в виртуальных десктопах для высокоинтенсивных графических нагрузок.
NVIDIA реализует поддержку всех трех основных вендоров платформ виртуализации (но с уклоном в сторону Citrix):
Более подробно о платформе NVIDIA GRID VGX можно почитать по этой ссылке.
Таги: NVIDIA, GPU, VMachines, VMware, Update, VGX, VDI, Citrix, Microsoft

 RSS
RSS