DVD Store — это инструментарий для тестирования баз данных с открытым исходным кодом, который активно применяется с момента своего первого релиза в 2005 году. Он поддерживает работу с СУБД SQL Server, Oracle, PostgreSQL и MySQL. DVD Store моделирует интернет-магазин, в котором пользователи авторизуются, просматривают каталог, оставляют отзывы, выставляют оценки и покупают DVD. В тесте задействуется большое число типичных возможностей реляционных БД: хранимые процедуры, индексы, внешние ключи, полнотекстовый поиск, сложные запросы с множественными join'ами и транзакции.
Изначально DVD Store разрабатывался как нагрузка, ориентированная преимущественно на CPU. Тем не менее в нём с самого начала были предусмотрены параметры, позволяющие менять этот профиль и переключаться на сценарии, в которых акцент делается на сеть, дисковую подсистему или даже память. Примеры таких профилей теперь добавлены и описаны в основном репозитории DVD Store на GitHub: https://github.com/dvdstore/ds35/tree/main/workload_profiles
VMware провела тестирование тестирование платформы VMware vSphere с помощью этого инструмента для того, чтобы понять, насколько эти профили меняют поведение нагрузки относительно стандартного CPU-ориентированного сценария. Все измерения проводились на одной виртуальной машине, развёрнутой на сервере ESX 9.0 платформы VMware Cloud Foundation (VCF). ВМ работала под управлением Windows Server 2022, в качестве СУБД использовалась SQL Server 2022. Все показатели производительности фиксировались со стороны хоста ESX с помощью утилиты esxtop (аналог linux top, но адаптированный под ESX и собирающий значительно более широкий набор метрик).
CPU Utilization — загрузка процессора на хосте ESX
Disk I/O per second (IOPS) — операции чтения и записи на диск со стороны хоста ESX
Mb received per second (Mb Rec/s) — мегабиты, принятые в секунду по сети
Mb sent per second (Mb Sent/s) — мегабиты, отправленные в секунду по сети
Active Memory (ActiveMem) — объём памяти, к которой недавно было обращение (активная память)
Относительное изменение ключевых метрик в разных профилях нагрузки
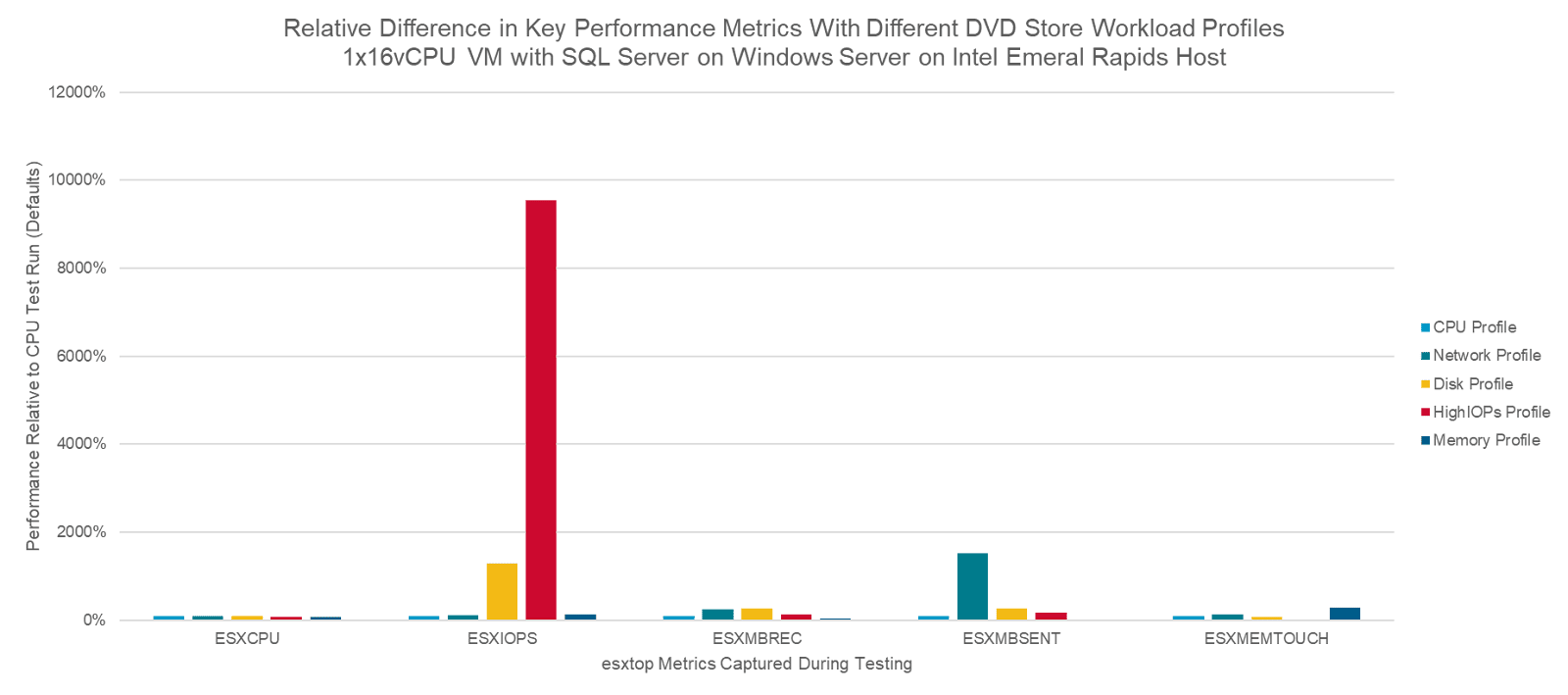
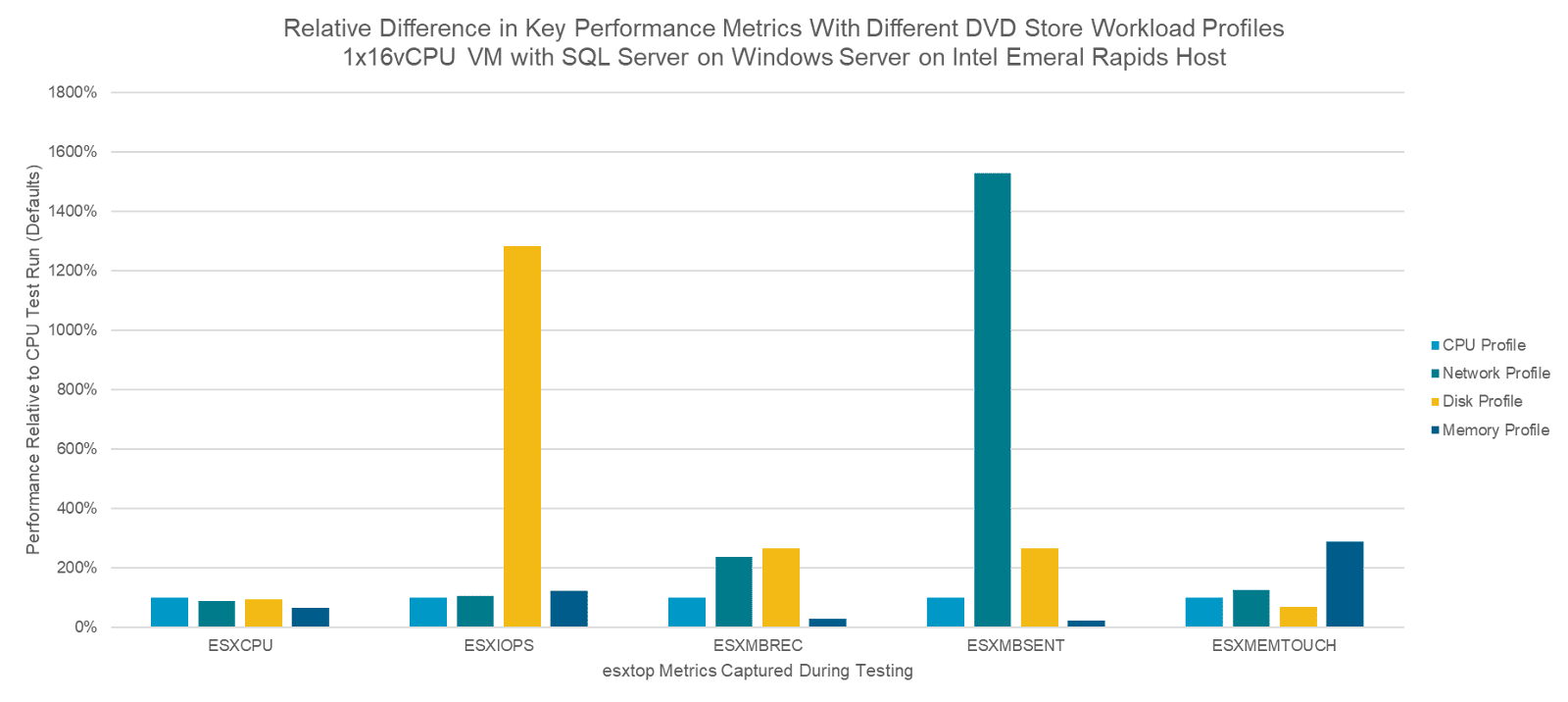
Для построения базовой линии замеры выполнялись на CPU-ориентированном профиле. Затем те же тесты были проведены с профилями, акцентированными на диск, на максимально высокий IOPS, на сеть и на память; полученные значения ключевых метрик сопоставлялись с базовыми. На графиках ниже показаны относительные различия по этим метрикам относительно базового CPU-профиля. На первом графике приведены все профили нагрузки; на втором профиль highIOPS убран, чтобы наглядно увидеть различия между остальными.
Если кратко резюмировать результаты, то в ключевой для каждого профиля метрике заметен значительный прирост:
Disk-профиль выдаёт в 13 раз больше IOPS
HighIOPS-профиль обеспечивает в 95 раз больше IOPS — это в 7 раз выше, чем у Disk-профиля
Network-профиль увеличивает количество отправленных мегабит в секунду в 15 раз
Memory-профиль вызывает в 2,9 раза большее значение активной памяти
Подробное описание всех профилей нагрузки приведено в файле ds35_workload_profiles.txt в репозитории DVD Store на GitHub. Там же указаны конкретные параметры DVD Store, особенности конфигурации БД и краткие пояснения к каждому сценарию.
Технология Advanced Memory Tiering в VMware Cloud Foundation 9 позволяет существенно расширить эффективный объём памяти хоста за счёт NVMe-накопителей — без изменения рабочих процессов и без влияния на привычные инструменты управления. Ниже собраны практические рекомендации, которые помогут правильно оценить среду, корректно настроить платформу и избежать типичных ошибок при развёртывании.
Как работает двухуровневая память
Архитектура Advanced Memory Tiering строится на двух уровнях.
Tier 0 — это DRAM: быстрая оперативная память, которая обслуживает активные страницы виртуальных машин.
Tier 1 — NVMe-накопитель, куда перемещаются холодные, редко используемые страницы. При этом память гипервизора (vmkernel) никогда не попадает в NVMe: ESX всегда работает исключительно в DRAM.
Когда виртуальная машина обращается к странице, находящейся в Tier 1, гипервизор возвращает её в DRAM — прозрачно и без участия гостевой ОС. Такая схема идеально подходит для рабочих нагрузок с выраженным разделением горячих и холодных страниц памяти.
Оценка готовности среды
Прежде чем включать Memory Tiering, необходимо проанализировать текущее потребление памяти. Ключевой показатель — активная память (active memory): объём страниц, к которым виртуальные машины реально обращаются в единицу времени. Технология оптимально работает, когда потреблённая (allocated) память превышает 50% от установленного объёма DRAM, а активная остаётся ниже этого порога.
Проверить активную память можно несколькими способами. В интерфейсе vCenter откройте VM > Monitor > Performance > Advanced, переключитесь в режим отображения памяти и выберите режим реального времени — показатель active memory доступен только в нём, поскольку относится к статистике уровня 1.
Для более широкого охвата подойдёт VCF Operations — если он уже развёрнут в инфраструктуре, он обеспечит сквозную видимость по всем хостам и кластерам. Ещё один вариант — RVTools: утилита собирает статистику памяти в реальном времени и позволяет быстро оценить картину по всей среде.
Порог активной памяти: правило 50%
Главное эксплуатационное правило Memory Tiering звучит просто: активная память должна оставаться на уровне 50% или ниже от объёма DRAM. Это гарантирует, что горячий рабочий набор данных комфортно размещается в быстрой памяти и при этом остаётся достаточный запас.
Если активная память стабильно превышает 70% от объёма DRAM, часть горячих страниц неизбежно окажется в Tier 1, и производительность виртуальных машин может заметно снизиться. В такой ситуации следует либо добавить DRAM на хост, либо перераспределить нагрузку между узлами кластера, прежде чем включать тиринг.
Настройка соотношения DRAM:NVMe
При включении Memory Tiering ESXi устанавливает соотношение DRAM к NVMe равным 1:1 по умолчанию. Это означает, что при наличии 512 ГБ DRAM хост получит дополнительные 512 ГБ ёмкости Tier 1. Параметр контролируется через расширенную настройку хоста: Mem.TierNVMePct со значением по умолчанию 100 (100% от объёма DRAM).
Рекомендуется сохранять соотношение 1:1 для большинства рабочих нагрузок — оно охватывает типичные сценарии использования. Изменять его стоит только после тщательного анализа профиля активной памяти конкретных ВМ. При выборе размера NVMe-накопителей разумно ориентироваться с запасом: более ёмкие устройства замедляют износ ячеек, дают пространство для будущего изменения соотношения и позволяют безболезненно справляться с неожиданным ростом нагрузки.
Подходящие рабочие нагрузки
Memory Tiering наиболее эффективна для рабочих нагрузок с естественным разделением горячих и холодных страниц. В их числе:
Общая серверная виртуализация — разнородный парк ВМ с умеренной и переменной активностью памяти.
VDI-среды — виртуальные рабочие столы с большим количеством ВМ, каждая из которых использует лишь часть выделенной памяти одновременно.
Среды разработки и тестирования — временные ВМ, которые редко используют всю выделенную память одновременно.
Веб-серверы и серверы приложений — нагрузки с предсказуемым рабочим набором в памяти.
Базы данных с умеренной активностью — СУБД, у которых значительная часть данных в памяти остаётся холодной
Неподходящие рабочие нагрузки
Ряд профилей виртуальных машин в настоящее время не поддерживает работу с Memory Tiering. Для таких ВМ тиринг следует отключить на уровне виртуальной машины — это принудительно размещает все её страницы в Tier 0 (DRAM).
Высокопроизводительные и latency-sensitive ВМ — приложения, требующие предсказуемых ультранизких задержек доступа к памяти
ВМ с аппаратной защитой памяти — виртуальные машины, использующие технологии шифрования AMD SEV, Intel SGX или Intel TDX
ВМ с Fault Tolerance (FT) — непрерывная синхронизация состояния несовместима с тирингом
«Монстроидальные» ВМ — машины с объёмом памяти от 1 ТБ и более 128 vCPU
ВМ с большими страницами памяти (large memory pages)
Вложенная виртуализация (nested VMs)
Если в кластере присутствуют такие нагрузки, оптимальная стратегия — выделить для них отдельные хосты и включить Memory Tiering только на оставшихся узлах кластера, либо управлять исключениями на уровне отдельных ВМ.
Интеграция с vSphere
Advanced Memory Tiering полностью интегрирована в стандартные механизмы управления vSphere — никаких специальных процедур не требуется:
vMotion — миграция ВМ между хостами работает прозрачно; оба уровня памяти учитываются при переносе.
DRS — балансировщик нагрузки осведомлён об обоих уровнях и учитывает их при принятии решений о размещении ВМ.
High Availability (HA) — при отказе хоста ВМ перезапускаются на оставшихся узлах по стандартным правилам HA.
Рекомендации по развёртыванию
Для успешного внедрения рекомендуется придерживаться следующих принципов. Во-первых, поддерживайте единую конфигурацию хостов в кластере с помощью vSphere Configuration Profiles — это исключает расхождения между узлами и упрощает масштабирование. Во-вторых, применяйте поэтапный подход: включайте тиринг последовательно, начиная с одного-двух хостов, оценивайте результаты и только потом распространяйте изменение на весь кластер. В-третьих, фиксируйте исключения: документируйте все ВМ, для которых Memory Tiering отключена на уровне виртуальной машины, чтобы не потерять контроль над конфигурацией при росте инфраструктуры.
Мониторинг после включения
После включения Memory Tiering следует регулярно отслеживать ключевые показатели:
Процент активной памяти на уровне хостов и кластера
Паттерны доступа к страницам (горячие/холодные)
Тренды утилизации памяти по кластеру в целом
Потребление памяти на уровне отдельных ВМ
Задержки чтения и записи NVMe-накопителей Tier 1
Рост задержек NVMe или увеличение активной памяти выше порога 50% DRAM — сигнал для пересмотра распределения нагрузки или конфигурации тиринга. Регулярный мониторинг позволяет выявлять изменения в профиле нагрузки на ранней стадии и реагировать проактивно.
Это заключительная часть серии статей (см. прошлые части тут, тут, тут, тут, тут и тут), посвящённых технологии Memory Tiering. В предыдущих публикациях мы рассмотрели архитектуру, проектирование, расчёт ёмкости и базовую настройку, а также другие темы. Теперь мы переходим к расширенной конфигурации. Эти параметры не являются обязательными для работы функции как таковой, но предоставляют дополнительные возможности - такие как шифрование данных и настройка соотношений памяти, но и не только.
Хотя значения по умолчанию в vSphere в составе VMware Cloud Foundation 9.0 разработаны так, чтобы «просто работать» в большинстве сред, для настоящей оптимизации требуется тонкая настройка. Независимо от того, используете ли вы виртуальные рабочие столы или базы данных, важно понимать, какие рычаги управления стоит задействовать.
Ниже описано, как освоить расширенные параметры для настройки соотношений памяти, шифрования на уровне хоста и отдельных ВМ, а также отключения технологии Memory Tiering на уровне отдельных машин.
Настройка соотношения DRAM:NVMe
По умолчанию при включении Memory Tiering ESX устанавливает соотношение DRAM к NVMe равным 1:1, то есть 100% дополнительной памяти за счёт NVMe. Это означает, что при наличии 512 ГБ DRAM хост получит ещё 512 ГБ NVMe-ёмкости в качестве памяти Tier 1, что в сумме даст 1 ТБ памяти.
Однако в зависимости от типа рабочих нагрузок вы можете захотеть изменить эту плотность. Например, в VDI-среде, где ключевым фактором является стоимость одного рабочего стола, может быть выгодно использовать более высокое соотношение (больше NVMe на каждый гигабайт DRAM). Напротив, для кластеров с высокими требованиями к производительности вы можете захотеть ограничить размер NVMe-яруса.
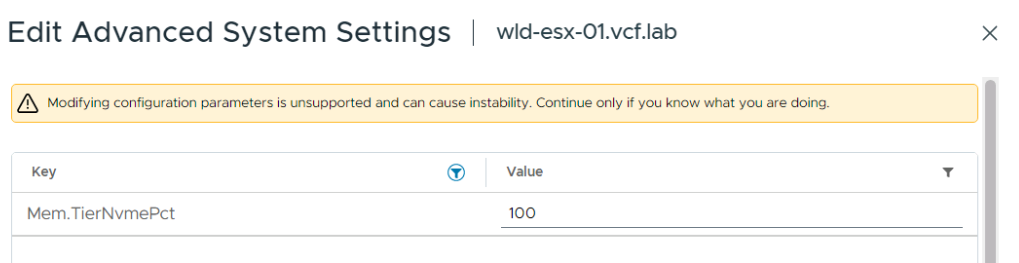
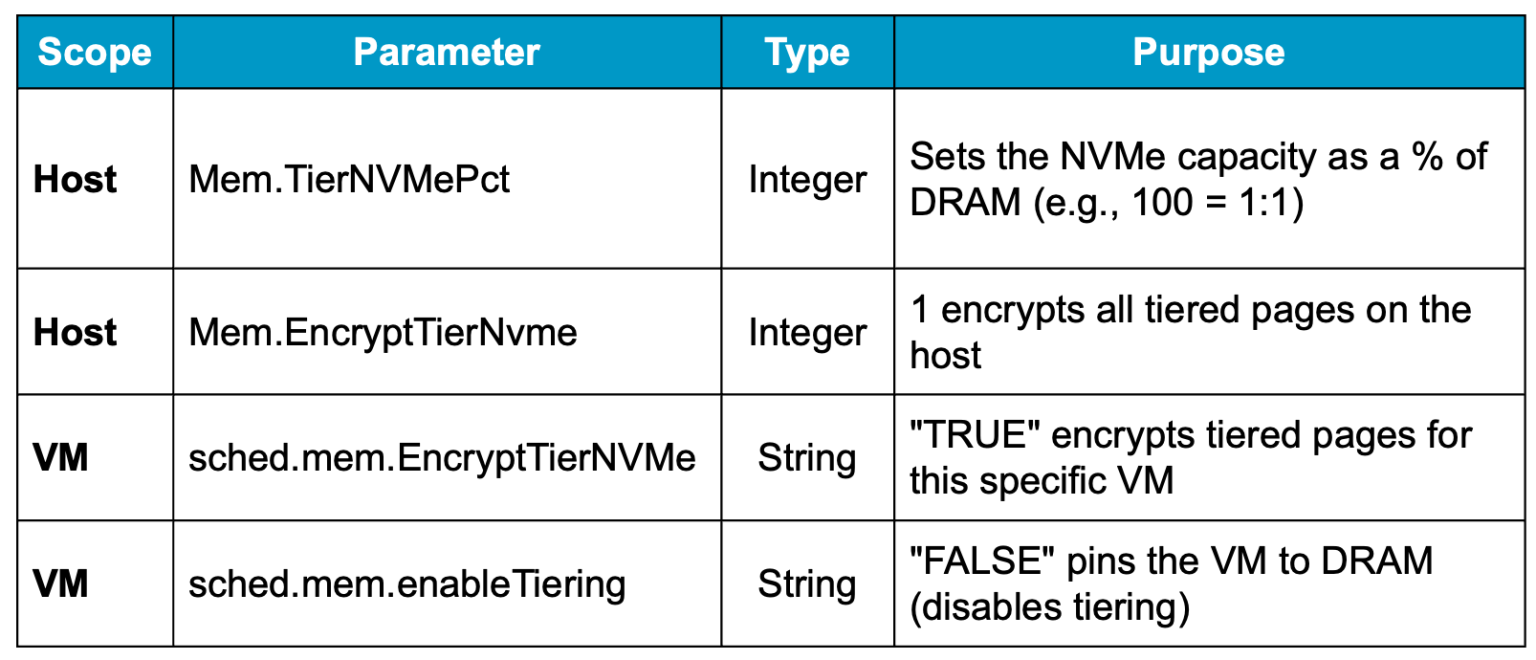
Управление этим параметром осуществляется через расширенную системную настройку хоста: Mem.TierNVMePct.
Параметр
Где настраивается: Host Advanced System Settings
Ключ: Mem.TierNVMePct
Значение: процент DRAM, используемый в качестве NVMe-яруса
Возможные значения:
100 (по умолчанию): 100% от объёма DRAM (соотношение 1:1)
200: 200% от объёма DRAM (соотношение 1:2)
50: 50% от объёма DRAM — очень консервативный вариант (соотношение 2:1)
Примечание. Рекомендации и лучшие практики предполагают сохранение соотношения по умолчанию 1:1, так как оно подходит для большинства рабочих нагрузок. Если вы решите изменить это соотношение, необходимо предварительно тщательно проанализировать свои нагрузки и убедиться, что вся активная память может быть размещена в объёме DRAM хоста. Подробнее о расчёте ёмкости Memory Tiering см. вот тут.
Защита уровня: шифрование
Одним из архитектурных различий между DRAM и NVMe является постоянство хранения данных. В то время как обычная оперативная память теряет данные (практически) мгновенно при отключении питания, NVMe является энергонезависимой. Несмотря на то что VMware выполняет очистку страниц памяти, организации с повышенными требованиями к безопасности (особенно в регулируемых отраслях) часто требуют шифрование данных «на диске» (Data-at-Rest Encryption) для любых данных, записываемых на накопители, даже если эти накопители используются как память. Более подробное описание шифрования NVMe в контексте Memory Tiering приведено вот тут.
Здесь доступны два уровня управления: защита всего NVMe-уровня хоста целиком либо выборочное шифрование данных только для определённых виртуальных машин, вместо шифрования данных всех ВМ на хосте.
Вариант A: шифрование на уровне хоста
Это «универсальный» подход. Он гарантирует, что любая страница памяти, перемещаемая из DRAM в NVMe-уровень на данном хосте, будет зашифрована с использованием алгоритма AES-XTS.
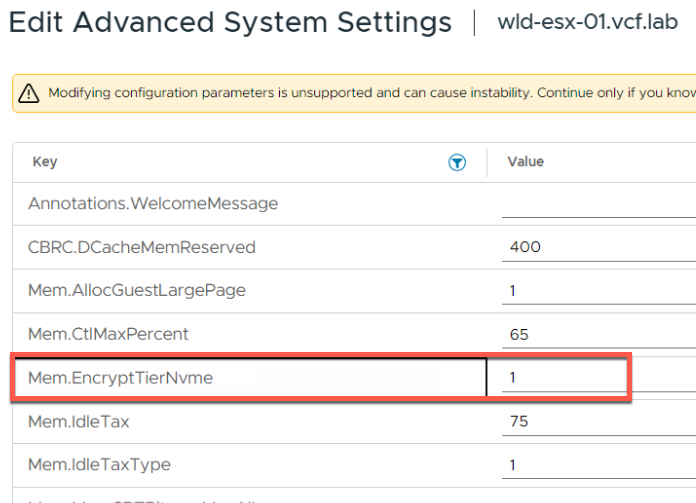
Параметр
Где настраивается:Host Advanced Configuration Parameters
Ключ: Mem.EncryptTierNvme
Значение: 1 — включено, 0 — отключено
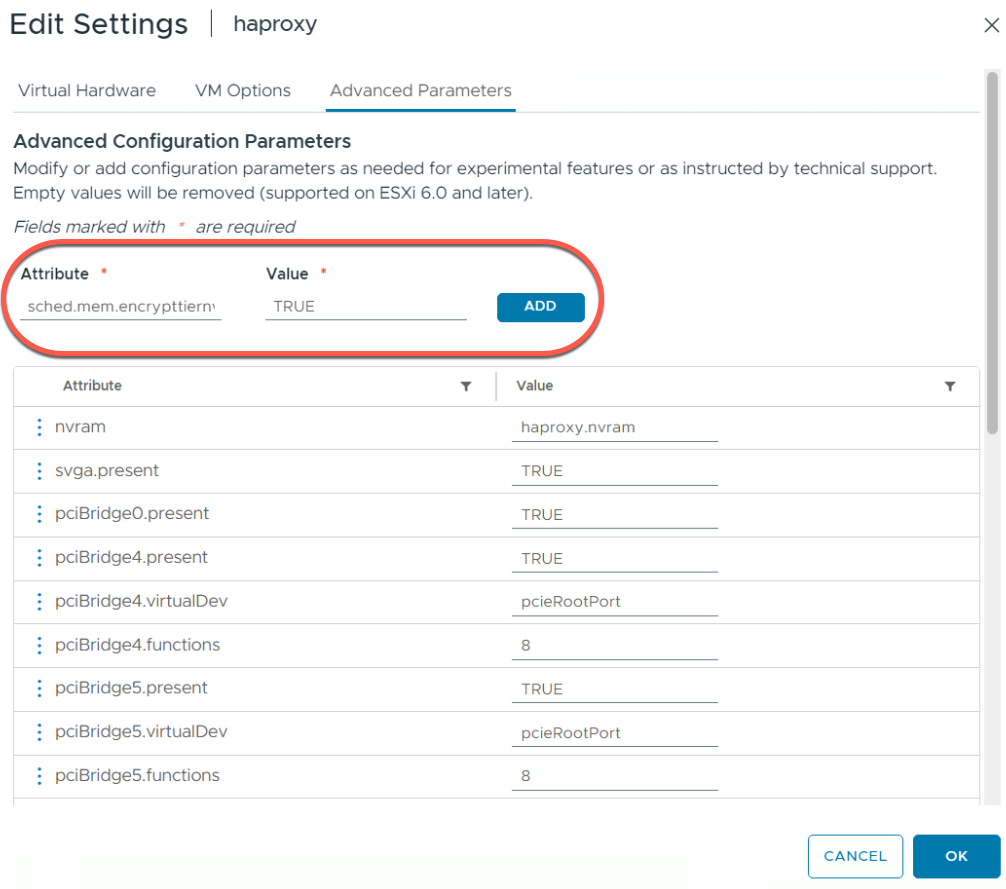
Вариант Б: шифрование на уровне виртуальной машины
Если вы хотите включить шифрование только для отдельных виртуальных машин — то есть шифровать лишь те страницы памяти, которые размещаются на NVMe, — вы можете применить эту настройку только к наиболее критичным рабочим нагрузкам (например, контроллерам домена или финансовым базам данных).
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.EncryptTierNVMe
Значение: TRUE
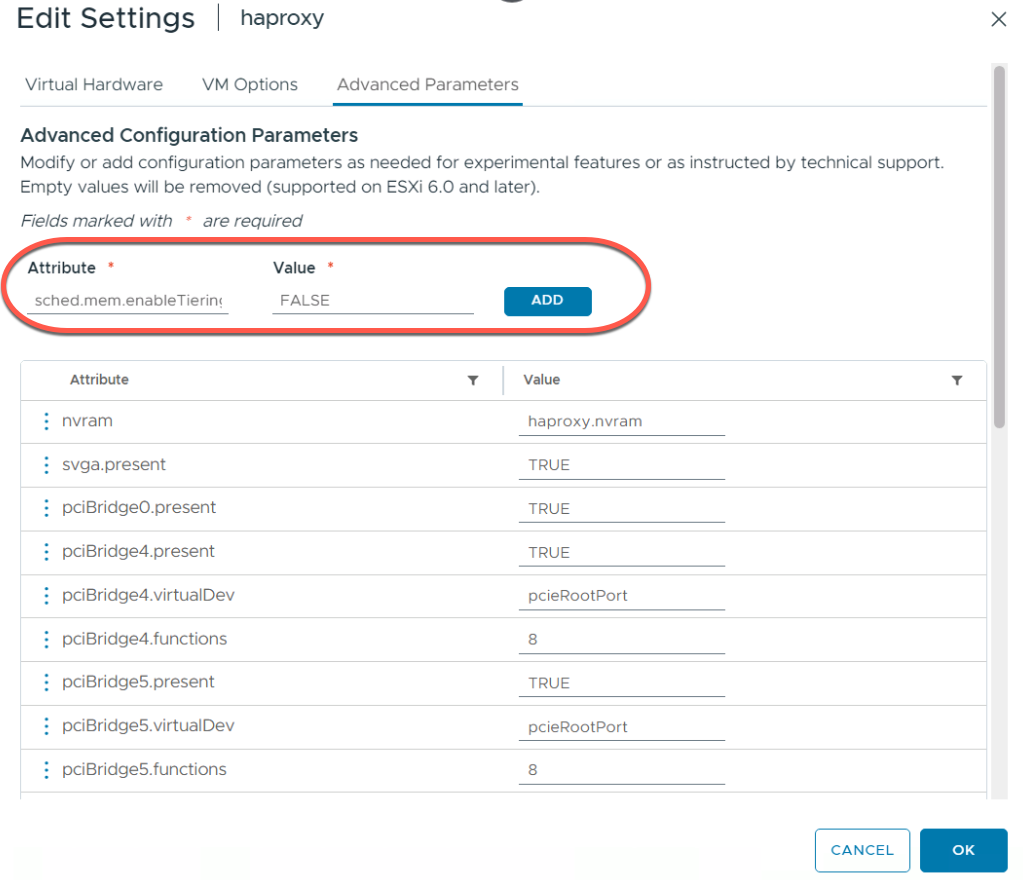
Отказ от использования: отключение Memory Tiering для критичных ВМ
Memory Tiering отлично подходит для «холодных» данных, однако «горячие» данные должны находиться в DRAM. Несмотря на то, что планировщик ESX чрезвычайно интеллектуален в вопросах размещения страниц памяти, некоторые рабочие нагрузки слишком чувствительны, чтобы допускать даже минимальные всплески задержек, связанные с использованием Memory Tiering.
Типичные сценарии использования:
SAP HANA и другие in-memory базы данных
Приложения для высокочастотной торговли (High-Frequency Trading)
Виртуальные машины безопасности
Кроме того, существуют профили виртуальных машин, которые в настоящее время не поддерживают Memory Tiering, такие как ВМ с низкой задержкой, ВМ с Fault Tolerance (FT), ВМ с большими страницами памяти (large memory pages) и др. Для таких профилей Memory Tiering необходимо отключать на уровне виртуальной машины. Это принудительно размещает страницы памяти ВМ исключительно в Tier 0 (DRAM). Полный список профилей ВМ см. в официальной документации VMware.
Параметр
Где настраивается: VM Advanced Configuration Parameters
Ключ: sched.mem.enableTiering
Значение: FALSE
Ну и в заключение - таблица расширенных параметров Memory Tiering:
Memory Tiering в VCF 9.0 представляет собой серьёзный сдвиг в подходе к плотности серверов и интеллектуальному потреблению ресурсов. Эта технология уводит нас от жёсткого «потолка по RAM» и предоставляет гибкий, экономически эффективный буфер памяти. Однако, как и в случае с любым мощным инструментом, значения по умолчанию — лишь отправная точка. Используя описанные выше параметры, вы можете настроить поведение системы в соответствии как с ограничениями бюджета, так и с требованиями SLA.
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут, тут и тут) мы поговорим о настройке этой технологии на серверах VMware ESX инфраструктуры VCF.
На протяжении всей этой серии статей мы рассматривали важные аспекты, которые следует учитывать перед настройкой Memory Tiering, такие как проектирование, подбор размеров, совместимость, избыточность, безопасность и многое другое. Теперь пришло время применить то, чему вы научились, и оптимизировать эту функцию для вашей среды, бюджета и стратегии.
Поскольку во многих статьях подробно описаны шаги настройки, этот пост будет сосредоточен на подходе высокого уровня и будет ссылаться на предыдущие посты для конкретных разделов. Всегда полагайтесь на официальную документацию Broadcom для точных шагов настройки — официальное руководство можно найти здесь, ну а основные аспекты развертывания Memory Tiering мы описывали тут.
Шаги настройки
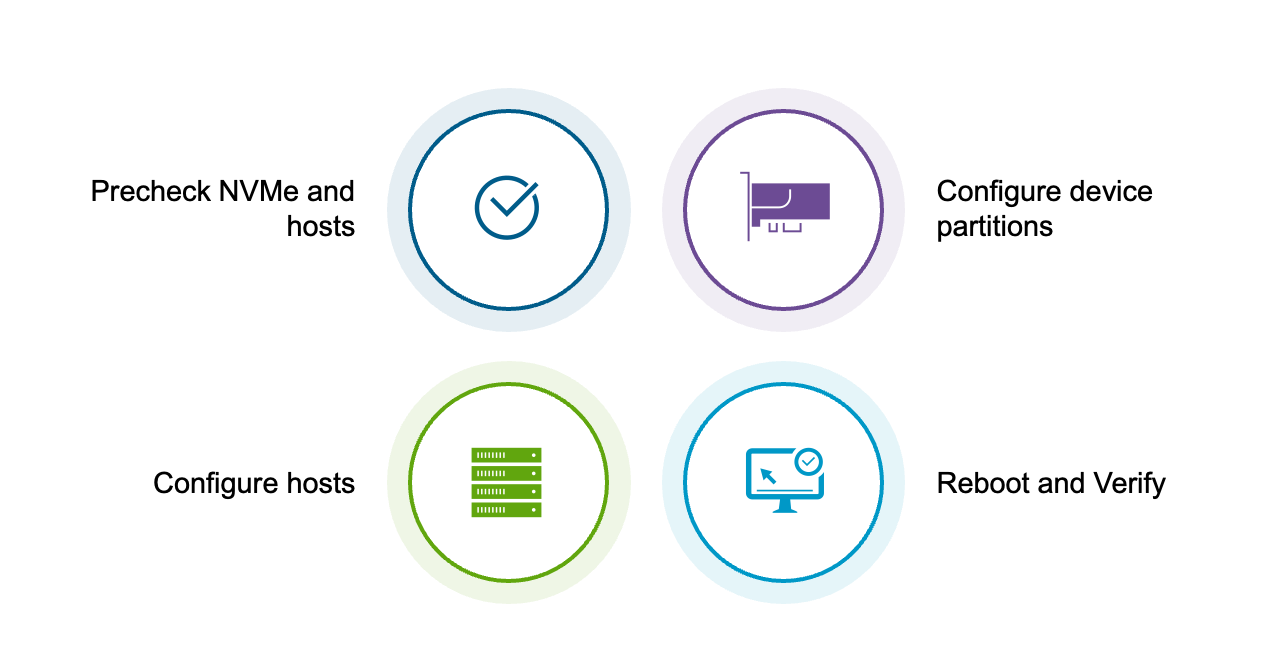
Технически для настройки Memory Tiering в вашей среде требуется всего два шага, но мы добавили задачи до и после настройки, чтобы обеспечить должную тщательность и проверить внедрение.
Предварительные проверки
Плотники живут по правилу «семь раз отмерь — один раз отрежь», потому что после разреза нельзя прокрутить фарш обратно. Чтобы избежать критических ошибок при настройке, мы должны сначала убедиться, что приняли правильные архитектурные решения для нашей среды.
После того как вы приняли все эти важные решения, этап предварительных проверок включает подтверждение того, что устройства корректно отображаются на всех ESX-хостах. Вам понадобится UID каждого устройства, чтобы создать раздел, который будет использоваться Memory Tiering.
Создание разделов
Первый шаг — создание раздела для каждого NVMe-устройства. Независимо от того, разворачиваете ли вы одно устройство на хост или используете аппаратный RAID, раздел требуется на каждом логическом NVMe-устройстве.
Методы:
ESXCLI: выполните стандартную команду esxcli (подробности тут).
PowerShell: создайте скрипт для автоматизации процесса. Пример скрипта доступен тут, он может быть изменён под среду вашего кластера.
Частые вопросы
Вопрос: Могу ли я настроить разделы на двух устройствах без RAID на одном и том же хосте для обеспечения избыточности?
Ответ: Нет. Хотя VCF 9.0 позволяет без ошибок создавать разделы Memory Tiering на нескольких устройствах на хост, система не объединяет их и не зеркалирует данные.
Результат: Memory Tiering смонтирует только один диск, выбранный недетерминированным образом в процессе загрузки. Второй диск будет проигнорирован и не даст ни избыточности, ни увеличения ёмкости (см. будущую информацию об обновлении VCF 9.1 - там что-то может поменяться).
Включение Memory Tiering
Этот шаг активирует функцию Memory Tiering. Вы можете выполнить эту настройку через ESXCLI, PowerShell или интерфейс vCenter UI, применяя её к отдельным хостам или ко всему кластеру одновременно.
Вопрос: Требуется ли настраивать Memory Tiering на всех хостах в кластере VCF 9.0?
Ответ: Нет. У вас есть возможность выбрать конкретные хосты для Memory Tiering.
Хотя идеально, чтобы все хосты имели одинаковую конфигурацию, все понимают, что определённые ограничения ВМ могут потребовать исключений (см. тут).
Самый эффективный способ настроить Memory Tiering — использовать профили конфигурации vSphere. Это позволяет включить функцию сразу на всех ваших хостах, одновременно используя переопределения хостов для тех хостов, где вы не хотите включать её. Подробнее — тут.
Финальный шаг
Последний шаг прост: перезагрузите все хосты и выполните проверку. В VCF/VVF 9.0 перезагрузка является обязательной, чтобы эта функция вступила в силу.
Если вы используете профили конфигурации (Configuration Profiles), система автоматизирует поочерёдные перезагрузки (одна за другой), одновременно мигрируя ВМ, чтобы они оставались в сети. И если вам интересно, обеспечивает ли этот метод также доступность данных vSAN - ответ: да.
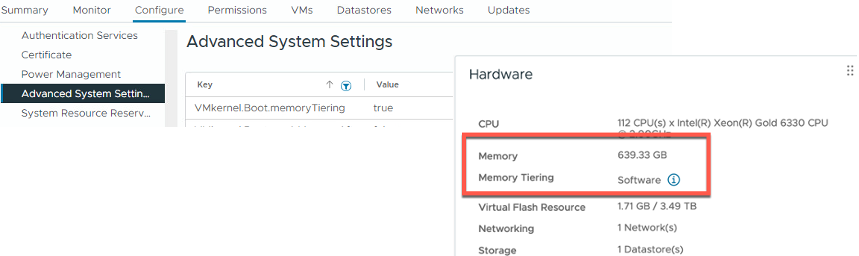
После того как все хосты снова будут онлайн, вы увидите новые элементы в интерфейсе, расположенные в разделах Advanced System Settings, на вкладке Monitor, а также Configure > Hardware > Overview > Memory.
Вы также должны увидеть, что по умолчанию объём доступной памяти увеличился в 2 раза как на уровне хоста, так и на уровне кластера. Вот это простой и недорогой способ удвоить ваш объём памяти!
В заключение: включение Memory Tiering - очень простой и понятный процесс. В качестве бонуса добавляем ссылку на актуальную лабораторную работу (Hands-on Lab), посвящённую Memory Tiering. Там вы можете выполнить настройку «от начала до конца», включая расширенные параметры, которые будут рассмотрены в следующих постах.
В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут и тут) мы предоставим некоторую информацию о различиях при включении Memory Tiering в разных сценариях. Хотя основной процесс остаётся тем же, есть моменты, которые могут потребовать дополнительного внимания и планирования, чтобы сэкономить время и усилия. Когда мы говорим о сценариях greenfield, мы имеем в виду совершенно новые развертывания VMware Cloud Foundation (VCF), включая новое оборудование и новую конфигурацию для всего стека. Сценарии brownfield будут охватывать настройку Memory Tiering в существующей среде VCF. Наконец, мы рассмотрим и лабораторные сценарии, поскольку встречаются неоднозначные утверждения о том, что это не поддерживается, но мы рассмотрим это в конце данной статьи.
Greenfield-развертывания
Давайте начнём с процесса конфигурации сред greenfield. Ранее мы рассказали о том, как VMware vSAN и Memory Tiering совместимы и могут сосуществовать в одном и том же кластере. Мы также обращали внимание на кое-что важное, о чём вам следует помнить во время greenfield-развертываний VCF. Начиная с VCF 9.0, включение Memory Tiering — это операция «Day 2», то есть сначала вы настраиваете VCF, а затем можете настроить Memory Tiering, но в ходе рабочего процесса развертывания VCF вы заметите, что опции для включения Memory Tiering (пока) нет, зато можно включить vSAN. То, как вы поступите с вашим NVMe-устройством, выделенным для Memory Tiering, будет определять шаги, необходимые для того, чтобы это устройство было представлено для его конфигурации.
Если все NVMe-устройства и для vSAN, и для Memory Tiering присутствуют во время развертывания VCF, есть вероятность, что vSAN может автоматически занять все накопители (включая NVMe-устройство, которое вы выделили для Memory Tiering). В этом случае вам пришлось бы удалить накопитель из vSAN после конфигурации, стереть разделы, а затем начать настройку Memory Tiering. Этот шаг был рассмотрен тут.
Другой подход — извлечь или не устанавливать устройство Memory Tiering в сервер и добавить его обратно в сервер после развертывания VCF. Таким образом вы не будете рисковать тем, что vSAN автоматически займет NVMe для Memory Tiering. Хотя это и не является серьёзным препятствием, всё равно полезно знать, что произойдёт и почему, чтобы вы могли быстро выделить ресурсы, необходимые для настройки Memory Tiering.
Brownfield-развертывания
Сценарии brownfield немного проще, так как VVF/VCF уже настроен; однако vSAN мог быть включён или ещё нет.
Если vSAN не включён, вам нужно будет отключить функцию auto-claim, пройти через конфигурацию vSAN и вручную выбрать ваши устройства (кроме NVMe-устройств для Memory Tiering). Всё выполняется в интерфейсе UI и по процедуре, которая используется уже много лет. Это гарантирует, что NVMe-устройство Memory Tiering будет доступно для настройки. Подробный процесс задокументирован в TechDocs.
Если vSAN уже включён, мы предполагаем, что NVMe-устройство для Memory Tiering только что было приобретено и готово к установке. Значит, всё, что нам нужно сделать, — добавить его в хост и убедиться, что оно корректно отображается как NVMe-устройство и что на нём нет существующих разделов. Это, вероятно, самый простой сценарий и самый распространённый.
Развертывания в тестовой среде
Теперь давайте поговорим о давно ожидаемом лабораторном сценарии. Для лаборатории типа bare metal, где сервер ESX одноуровневый и нет вложенных сред, применяются те же принципы greenfield и brownfield. Что касается вложенной (nested) виртуализации, многие говорят о том, что вложенный Memory Tiering не поддерживается. Ну, это и так, и не так.
Когда мы говорим о вложенных средах, мы имеем в виду два уровня ESX. Внешний уровень — это ESX, установленный на оборудовании (обычная настройка), а внутренний уровень ESX состоит из виртуальных машин, запускающих ESX и выступающих в роли как бы физических хостов. Memory Tiering МОЖЕТ быть включён на внутреннем уровне (вложенном), и все параметры конфигурации работают нормально. Мы делаем следующее: берём datastore и создаём виртуальный Hard Disk типа NVMe, чтобы представить его виртуальной машине, которая выступает в роли вложенного хоста. Хотя мы видим NVMe-устройство на вложенном хосте и можем настроить Memory Tiering, базовое устройство хранения состоит из устройств, формирующих выбранный datastore. Вы можете настроить Memory Tiering, и вложенные хосты смогут видеть hot и active pages, но не ожидайте какого-либо уровня производительности, учитывая, что компоненты базового хранилища построены на традиционных накопителях. Работает ли это? ДА, но только в лабораторных средах.
Тестирование в лабораторной среде очень полезно: оно помогает вам пройти шаги конфигурации и понять, как работает настройка и какие расширенные параметры можно задать. Это отличный вариант использования для подготовки (практики) к развертыванию в производственной среде или даже просто для знакомства с функцией, например, для целей сдачи сертификационного экзамена.
А как насчёт внешнего уровня? Ну, это как раз то, что не поддерживается в VCF 9.0, поскольку внешний уровень ESX не имеет видимости внутреннего уровня и не может видеть активность памяти ВМ, по сути пытаясь «прозреть» сквозь вложенный уровень до виртуальной машины (inception). Это и есть главное отличие (не вдаваясь слишком глубоко в технические детали).
Так что если вам интересно протестировать Memory Tiering, а всё, что у вас есть — это вложенная среда, вы можете настроить Memory Tiering и любые расширенные параметры. Интересно наблюдать, как несколько шагов настройки могут добавить хостам 100% дополнительной памяти.
В ранних статьях мы упоминали, что вы можете настраивать разделы NVMe с помощью команд ESXCLI, PowerCLI и даже скриптов. В более поздних публикациях мы говорили о том, что опубликуем скрипт для настройки разделов, который мы приводим ниже, но с оговоркой и прямым предупреждением: вы можете запускать скрипт на свой страх и риск, и он может не работать в вашей среде в зависимости от вашей конфигурации.
Рассматривайте этот скрипт только как пример того, как это можно автоматизировать, а не как поддерживаемое решение автоматизации. Кроме того, скрипт не стирает разделы за вас, поэтому убедитесь, что вы сделали это до запуска скрипта. Как всегда, сначала протестируйте.
Есть некоторые переменные, которые вам нужно изменить, чтобы он работал в вашей среде:
$vCenter = “ваш vCenter FQDN или IP” (строка 27)
$clusterName = “имя вашего кластера” (строка 28)
Вот и сам скрипт:
function Update-NvmeMemoryTier {
param (
[Parameter(Mandatory=$true)]
[VMware.VimAutomation.ViCore.Impl.V1.Inventory.VMHostImpl]$VMHost,
[Parameter(Mandatory=$true)]
[string]$DiskPath
)
try {
# Verify ESXCLI connection
$esxcli = Get-EsxCli -VMHost $VMHost -V2
# Note: Verify the correct ESXCLI command for NVMe memory tiering; this is a placeholder
# Replace with the actual command or API if available
$esxcli.system.tierdevice.create.Invoke(@{ nvmedevice = $DiskPath }) # Hypothetical command
Write-Output "NVMe Memory Tier created successfully on host $($VMHost.Name) with disk $DiskPath"
return $true
}
catch {
Write-Warning "Failed to create NVMe Memory Tier on host $($VMHost.Name) with disk $DiskPath. Error: $_"
return $false
}
}
# Securely prompt for credentials
$credential = Get-Credential -Message "Enter vCenter credentials"
$vCenter = "vcenter FQDN"
$clusterName = "cluster name"
try {
# Connect to vCenter
Connect-VIServer -Server $vCenter -Credential $credential -WarningAction SilentlyContinue
Write-Output "Connected to vCenter Server successfully."
# Get cluster and hosts
$cluster = Get-Cluster -Name $clusterName -ErrorAction Stop
$vmHosts = Get-VMHost -Location $cluster -ErrorAction Stop
foreach ($vmHost in $vmHosts) {
Write-Output "Fetching disks for host: $($vmHost.Name)"
$disks = @($vmHost | Get-ScsiLun -LunType disk |
Where-Object { $_.Model -like "*NVMe*" } | # Filter for NVMe disks
Select-Object CanonicalName, Vendor, Model, MultipathPolicy,
@{N='CapacityGB';E={[math]::Round($_.CapacityMB/1024,2)}} |
Sort-Object CanonicalName) # Explicit sorting
if (-not $disks) {
Write-Warning "No NVMe disks found on host $($vmHost.Name)"
continue
}
# Build disk selection table
$diskWithIndex = @()
$ctr = 1
foreach ($disk in $disks) {
$diskWithIndex += [PSCustomObject]@{
Index = $ctr
CanonicalName = $disk.CanonicalName
Vendor = $disk.Vendor
Model = $disk.Model
MultipathPolicy = $disk.MultipathPolicy
CapacityGB = $disk.CapacityGB
}
$ctr++
}
# Display disk selection table
$diskWithIndex | Format-Table -AutoSize | Out-String | Write-Output
# Get user input with validation
$maxRetries = 3
$retryCount = 0
do {
$diskChoice = Read-Host -Prompt "Select disk for NVMe Memory Tier (1 to $($disks.Count))"
if ($diskChoice -match '^\d+$' -and $diskChoice -ge 1 -and $diskChoice -le $disks.Count) {
break
}
Write-Warning "Invalid input. Enter a number between 1 and $($disks.Count)."
$retryCount++
} while ($retryCount -lt $maxRetries)
if ($retryCount -ge $maxRetries) {
Write-Warning "Maximum retries exceeded. Skipping host $($vmHost.Name)."
continue
}
# Get selected disk
$selectedDisk = $disks[$diskChoice - 1]
$devicePath = "/vmfs/devices/disks/$($selectedDisk.CanonicalName)"
# Confirm action
Write-Output "Selected disk: $($selectedDisk.CanonicalName) on host $($vmHost.Name)"
$confirm = Read-Host -Prompt "Confirm NVMe Memory Tier configuration? This may erase data (Y/N)"
if ($confirm -ne 'Y') {
Write-Output "Configuration cancelled for host $($vmHost.Name)."
continue
}
# Configure NVMe Memory Tier
$result = Update-NvmeMemoryTier -VMHost $vmHost -DiskPath $devicePath
if ($result) {
Write-Output "Successfully configured NVMe Memory Tier on host $($vmHost.Name)."
} else {
Write-Warning "Failed to configure NVMe Memory Tier on host $($vmHost.Name)."
}
}
}
catch {
Write-Warning "An error occurred: $_"
}
finally {
# Disconnect from vCenter
Disconnect-VIServer -Server $vCenter -Confirm:$false -ErrorAction SilentlyContinue
Write-Output "Disconnected from vCenter Server."
}
Решение VMware vSAN довольно часто всплывает в обсуждениях Memory Tiering — как из-за сходства между этими технологиями, так и из-за вопросов совместимости, поэтому давайте разберёмся подробнее.
Когда мы только начали работать с Memory Tiering, сходство между Memory Tiering и vSAN OSA было достаточно очевидным. Обе технологии используют многоуровневый подход, при котором активные данные размещаются на быстрых устройствах, а неактивные — на более дешёвых, что помогает снизить TCO и уменьшить потребность в дорогих устройствах для хранения «холодных» данных. Обе также глубоко интегрированы в vSphere и просты в реализации. Однако, помимо сходств, изначально возникала некоторая путаница относительно совместимости, интеграции и возможности одновременного использования обеих функций. Поэтому давайте попробуем ответить на эти вопросы.
Да, вы можете одновременно использовать vSAN и Memory Tiering в одних и тех же кластерах. Путаница в основном связана с идеей предоставления хранилища vSAN для Memory Tiering — а это категорически не поддерживается. Мы говорили об этом ранее, но ещё раз подчеркнем: хотя обе технологии могут использовать NVMe-устройства, это не означает, что они могут совместно использовать одни и те же ресурсы. Memory Tiering требует собственного физического или логического устройства, предназначенного исключительно для выделения памяти. Мы не хотим делить это физическое/логическое устройство с чем-либо ещё, включая vSAN или другие датасторы. Почему? Потому что в случае совместного использования мы будем конкурировать за пропускную способность, а уж точно не хотим замедлять работу памяти ради того, чтобы «не тратить впустую» NVMe-пространство. Это всё равно что сказать: "У меня бак машины наполовину пуст, поэтому я залью туда воду, чтобы не терять место".
При этом технически вы можете создать несколько разделов для лабораторной среды (на свой страх и риск), но когда речь идёт о продуктивных нагрузках, обязательно используйте выделенное физическое или логическое (HW RAID) устройство исключительно для Memory Tiering.
Подводя итог по vSAN и Memory Tiering: они МОГУТ сосуществовать, но не могут совместно использовать ресурсы (диски/датасторы). Они хорошо работают в одном кластере, но их функции не пересекаются — это независимые решения. Виртуальные машины могут одновременно использовать датастор vSAN и ресурсы Memory Tiering. Вы даже можете иметь ВМ с шифрованием vSAN и шифрованием Memory Tiering — но эти механизмы работают на разных уровнях. Несмотря на кажущееся сходство, решения функционируют независимо друг от друга и при этом отлично дополняют друг друга, обеспечивая более целостную инфраструктуру в рамках VCF.
Соображения по хранению данных
Теперь мы знаем, что нельзя использовать vSAN для предоставления хранилища для Memory Tiering, но тот же принцип применяется и к другим датасторам или решениям NAS/SAN. Для Memory Tiering требуется выделенное устройство, локально подключённое к хосту, на котором не должно быть создано никаких других разделов. Соответственно, не нужно предоставлять датастор на базе NVMe для использования в Memory Tiering.
Говоря о других вариантах хранения, также важно подчеркнуть, что мы не делим устройства между локальным хранилищем и Memory Tiering. Это означает, что одно и то же устройство не может одновременно обслуживать локальное хранилище (локальный датастор) и Memory Tiering. Однако такие устройства всё же можно использовать для Memory Tiering. Поясним.
Предположим, вы действительно хотите внедрить Memory Tiering в своей среде, но у вас нет свободных NVMe-устройств, и запрос на капитальные затраты (CapEx) на покупку новых устройств не был одобрен. В этом случае вы можете изъять NVMe-устройства из локальных датасторов или даже из vSAN и использовать их для Memory Tiering, следуя корректной процедуре:
Убедитесь, что рассматриваемое устройство входит в рекомендуемый список и имеет класс износостойкости D и класс производительности F или G (см. нашу статью тут).
Удалите NVMe-устройство из vSAN или локального датастора.
Удалите все оставшиеся разделы после использования в vSAN или локальном датасторе.
Создайте раздел для Memory Tiering.
Настройте Memory Tiering на хосте или кластере.
Как вы видите, мы можем «позаимствовать» устройства для нужд Memory Tiering, однако крайне важно убедиться, что вы можете позволить себе потерю этих устройств для прежних датасторов, а также что выбранное устройство соответствует требованиям по износостойкости, производительности и наличию «чистых» разделов. Кроме того, при необходимости обязательно защитите или перенесите данные в другое место на время использования устройств.
Это лишь один из шагов, к которому можно прибегнуть в сложной ситуации, когда необходимо получить устройства; однако если данные на этих устройствах должны сохраниться, убедитесь, что у вас есть свободное пространство в другом месте. Выполняйте эти действия на свой страх и риск.
На момент выхода VCF 9 в процессе развёртывания VCF отсутствует отдельный рабочий процесс для выделения устройств под Memory Tiering, а vSAN автоматически захватывает устройства во время развёртывания. Поэтому при развертывании VCF «с нуля» (greenfield) вам может потребоваться использовать описанную процедуру, чтобы вернуть из vSAN устройство, предназначенное для Memory Tiering. VMware работает над улучшением этого процесса и поменяет его в ближайшем будущем.
В постах ранее мы подчеркивали ценность, которую NVMe Memory Tiering приносит клиентам Broadcom, и то, как это стимулирует ее внедрение. Кто же не хочет сократить свои расходы примерно на 40% просто благодаря переходу на VMware Cloud Foundation 9? Мы также затронули предварительные требования и оборудование в части 1, а архитектуру — в Части 2; так что теперь поговорим о правильном масштабировании вашей среды, чтобы вы могли максимально эффективно использовать свои вложения и одновременно снизить затраты.
Правильное масштабирование для NVMe Memory Tiering касается главным образом оборудования, но здесь есть два возможных подхода: развёртывания greenfield и brownfield.
Начнем с brownfield — внедрения Memory Tiering на существующей инфраструктуре. Вы пришли к осознанию, что VCF 9 — действительно интегрированный продукт, и решили развернуть его, но только что узнали о Memory Tiering. Не волнуйтесь, вы всё ещё можете внедрить NVMe Memory Tiering после развертывания VCF 9. Прочитав части 1 и 2, вы узнали о важности классов производительности и выносливости NVMe, а также о требовании 50% активной памяти. Это означает, что нам нужно рассматривать NVMe-устройство как минимум такого же размера, что и DRAM, поскольку мы удвоим объём доступной памяти. То есть, если каждый хост имеет 1 ТБ DRAM, у нас также должно быть минимум 1 ТБ NVMe. Вроде бы просто. Однако мы можем взять NVMe и покрупнее — и всё равно это будет дешевле, чем покупка дополнительных DIMM. Сейчас объясним.
VMware не случайно транслирует мысль: «покупайте NVMe-устройство как минимум такого же размера, что и DRAM», поскольку по умолчанию они используют соотношение DRAM:NVMe равное 1:1 — половина памяти приходится на DRAM, а половина на NVMe. Однако существуют рабочие нагрузки, которые не слишком активны с точки зрения использования памяти — например, некоторые VDI-нагрузки. Если у вас есть рабочие нагрузки с 10% активной памяти на постоянной основе, вы можете действительно воспользоваться расширенными возможностями NVMe Memory Tiering.
Соотношение 1:1 выбрано по следующей причине: большинство нагрузок хорошо укладывается в такие пропорции. Но это отношение DRAM:NVMe является параметром расширенной конфигурации, который можно изменить — вплоть до 1:4, то есть до 400% дополнительной памяти. Поэтому для рабочих нагрузок с очень низкой активностью памяти соотношение 1:4 может максимизировать вашу выгоду. Как это влияет на стратегию масштабирования?
Отлично, что вы спросили) Поскольку DRAM:NVMe может меняться так же, как меняется активность памяти ваших рабочих нагрузок, это нужно учитывать уже на этапе закупки NVMe-устройств. Вернувшись к предыдущему примеру хоста с 1 ТБ DRAM, вы, например, решили, что 1 ТБ NVMe — разумный минимум, но при нагрузках с очень низкой активной памятью этот 1 ТБ может быть недостаточно выгодным. В таком случае NVMe на 4 ТБ позволит использовать соотношение 1:4 и увеличить объём доступной памяти на 400%. Именно поэтому так важно изучить активную память ваших рабочих нагрузок перед покупкой NVMe-устройств.
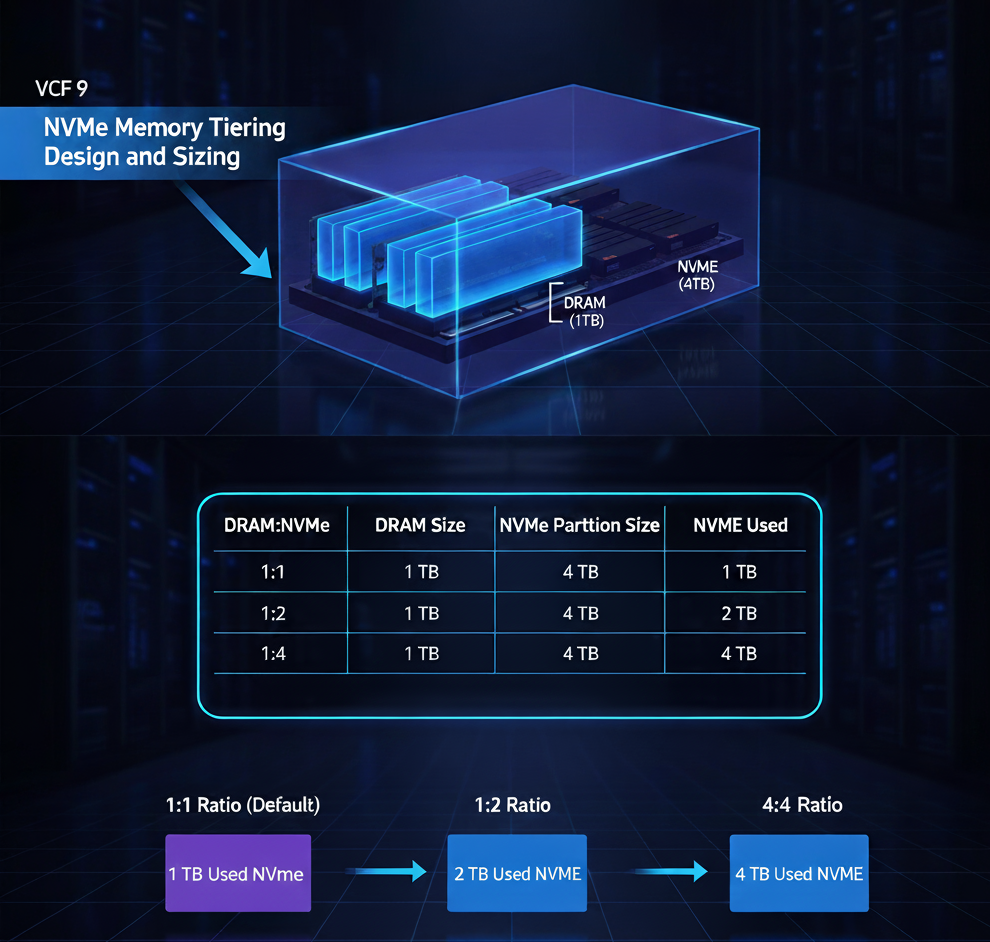
Еще один аспект, влияющий на масштабирование, — размер раздела (partition). Когда мы создаём раздел на NVMe перед настройкой NVMe Memory Tiering, мы вводим команду, но обычно не указываем размер вручную — он автоматически создаётся равным размеру диска, но максимум до 4 ТБ. Объём NVMe, который будет использоваться для Memory Tiering, — это комбинация размера раздела NVMe, объёма DRAM и заданного отношения DRAM:NVMe. Допустим, мы хотим максимизировать выгоду и «застраховать» оборудование на будущее, купив 4 ТБ SED NVMe, хотя на хосте всего 1 ТБ DRAM. После настройки вариантами по умолчанию размер раздела составит 4 ТБ (это максимальный поддерживаемый размер), но для Memory Tiering будет использован лишь 1 ТБ NVMe, поскольку используется соотношение 1:1. Если нагрузка изменится или мы поменяем соотношение на, скажем, 1:2, то размер раздела останется прежним (пересоздавать не требуется), но теперь мы будем использовать 2 ТБ NVMe вместо 1 ТБ — просто изменив коэффициент соотношения. Важно понимать, что не рекомендуется менять это соотношение без надлежащего анализа и уверенности, что активная память рабочих нагрузок вписывается в доступный объём DRAM.
DRAM:NVME
DRAM Size
NVMe Partition Size
NVMe Used
1:1
1 TB
4 TB
1 TB
1:2
1 TB
4 TB
2 TB
1:4
1 TB
4 TB
4 TB
Итак, при определении размера NVMe учитывайте максимальный поддерживаемый размер раздела (4 ТБ) и соотношения, которые можно настроить в зависимости от активной памяти ваших рабочих нагрузок. Это не только вопрос стоимости, но и вопрос масштабируемости. Имейте в виду, что даже при использовании крупных NVMe-устройств вы всё равно сэкономите значительную сумму по сравнению с использованием только DRAM.
Теперь давайте поговорим о вариантах развертывания greenfield, когда вы заранее знаете о Memory Tiering и вам нужно закупить серверы — вы можете сразу учесть эту функцию как параметр в расчете стоимости. Те же принципы, что и для brownfield-развертываний, применимы и здесь, но если вы планируете развернуть VCF, логично тщательно изучить, как NVMe Memory Tiering может существенно снизить стоимость покупки серверов. Как уже говорилось, крайне важно убедиться, что ваши рабочие нагрузки подходят для Memory Tiering (большинство подходят), но проверку провести необходимо.
После исследования вы можете принимать решения по оборудованию на основе квалификации рабочих нагрузок. Допустим, все ваши рабочие нагрузки подходят для Memory Tiering, и большинство из них используют около 30% активной памяти. В таком случае всё ещё рекомендуется придерживаться консервативного подхода и масштабировать систему с использованием стандартного соотношения DRAM:NVMe 1:1. То есть, если вам нужно 1 ТБ памяти на хост, вы можете уменьшить объем DRAM до 512 ГБ и добавить 512 ГБ NVMe — это даст вам требуемый общий объем памяти, и вы уверены (благодаря исследованию), что активная память ваших нагрузок всегда уместится в DRAM. Кроме того, количество NVMe-устройств на хост и RAID-контроллер — это отдельное решение, которое не влияет на доступный объем NVMe, поскольку в любом случае необходимо предоставить одно логическое устройство, будет ли это один независимый NVMe или 2+ устройства в RAID-конфигурации. Однако это решение влияет на стоимость и отказоустойчивость.
С другой стороны, вы можете оставить исходный объем DRAM в 1 ТБ и добавить еще 1 ТБ памяти через Memory Tiering. Это позволит использовать более плотные серверы, сократив общее количество серверов, необходимых для размещения ваших нагрузок. В этом случае экономия достигается за счет меньшего количества оборудования и компонентов, а также сокращения затрат на охлаждение и энергопотребление.
В заключение, при определении размеров необходимо учитывать все переменные: объем DRAM, размер NVMe-устройств, размер раздела и соотношение DRAM:NVMe. Помимо этих параметров, для greenfield-развертываний следует проводить более глубокий анализ — именно здесь можно добиться дополнительной экономии, покупая DRAM только для активной памяти, а не для всего пула, как мы делали годами. Говоря о факторах и планировании, стоит также учитывать совместимость Memory Tiering с vSAN — это будет рассмотрено в следующей части серии.
В первой части статей этой серии мы рассмотрели некоторые предварительные требования для NVMe Memory Tiering, такие как оценка рабочих нагрузок, процент активности памяти, ограничения профилей виртуальных машин, предварительные требования и совместимость устройств NVMe.
Кроме того, мы подчеркнули важность внедрения платформы VMware Cloud Foundation (VCF) 9, которая может обеспечить значительное сокращение затрат на память, лучшее использование CPU и более высокую консолидацию виртуальных машин. Но прежде чем полностью развернуть это решение, важно спроектировать его с учётом безопасности, отказоустойчивости и масштабируемости — именно об этом и пойдёт речь в этой статье.
Безопасность
Безопасность памяти не является особенно популярной темой среди администраторов, и это объясняется тем, что память является энергонезависимой. Однако злоумышленники могут использовать память для хранения вредоносной информации на энергонезависимых носителях, чтобы избежать обнаружения — но это уже скорее тема криминалистики. Как только питание отключается, данные в DRAM (энергозависимой памяти) исчезают в течение нескольких минут. Таким образом, с NVMe Memory Tiering мы переносим страницы из энергозависимой памяти (DRAM) на энергонезависимую (NVMe).
Чтобы устранить любые проблемы безопасности, связанные с хранением страниц памяти на устройствах NVMe, VMware разработала несколько решений, которые клиенты могут легко реализовать после первоначальной настройки.
В этом первом выпуске функции Memory Tiering шифрование уже входит в комплект и готово к использованию «из коробки». Фактически, у вас есть возможность включить шифрование на уровне виртуальной машины (для каждой ВМ) или на уровне хоста (для всех ВМ на данном хосте). По умолчанию эта опция не активирована, но её легко добавить в конфигурацию через интерфейс vCenter.
Для шифрования в NVMe Memory Tiering нам не требуется система управления ключами (KMS) или встроенный поставщик ключей (NKP). Вместо этого ключ случайным образом генерируется на уровне ядра каждым хостом с использованием шифрования AES-XTS. Это избавляет от зависимости от внешних поставщиков ключей, поскольку данные, выгруженные в NVMe, актуальны только в течение времени жизни виртуальной машины.
Случайный 256-битный ключ создаётся при включении виртуальной машины, и данные шифруются в момент их выгрузки из DRAM в NVMe, а при обратной загрузке в DRAM для чтения — расшифровываются. Во время миграции виртуальной машины (vMotion) страницы памяти сначала расшифровываются, затем передаются по зашифрованному каналу vMotion на целевой хост, где генерируется новый ключ (целевым хостом) для последующих выгрузок памяти на NVMe.
Этот процесс одинаков как для «шифрования на уровне виртуальной машины», так и для «шифрования на уровне хоста» — единственное различие заключается в том, где именно применяется конфигурация.
Отказоустойчивость
Цель отказоустойчивости — повысить надёжность, сократить время простоя и, конечно, обеспечить спокойствие администратора. В контексте памяти существует несколько методов, некоторые из которых распространены больше других. В большинстве случаев для обеспечения избыточности памяти используют модули с коррекцией ошибок (ECC) и резервные модули памяти. Однако теперь, с появлением NVMe Memory Tiering, необходимо учитывать как DRAM, так и NVMe. Мы не будем подробно останавливаться на методах избыточности для DRAM, а сосредоточимся на NVMe в контексте памяти.
В VVF/VCF 9.0 функция NVMe Memory Tiering поддерживает аппаратную конфигурацию RAID, три-режимный (tri-mode) контроллер и технологию VROC (Virtual RAID on CPU) для обеспечения отказоустойчивости холодных или неактивных страниц памяти. Что касается RAID, мы не ограничиваемся какой-то одной конфигурацией: например, RAID-1 — это хорошее и поддерживаемое решение для обеспечения отказоустойчивости NVMe, но также поддерживаются RAID-5, RAID-10 и другие схемы. Однако такие конфигурации потребуют больше NVMe-устройств и, соответственно, увеличат стоимость.
Говоря о стоимости, стоит учитывать и наличие RAID-контроллеров, если вы планируете использовать RAID для отказоустойчивости. Обеспечение резервирования для холодных страниц — это архитектурное решение, которое должно приниматься с учётом баланса между затратами и операционными издержками. Что для вас важнее — надёжность, стоимость или простота эксплуатации? Также необходимо учитывать совместимость RAID-контроллера с vSAN: vSAN ESA не поддерживает RAID-контроллеры, в то время как vSAN OSA поддерживает, но они должны использоваться раздельно.
Преимущества RAID:
Обеспечивает избыточность для NVMe как устройства памяти
Повышает надёжность
Возможное сокращение времени простоя
Недостатки RAID:
Необходимость RAID-контроллера
Дополнительные расходы
Операционные издержки (настройка, обновление прошивок и драйверов)
Усложнение инфраструктуры
Появление новой точки отказа
Возможные проблемы совместимости с vSAN, если все накопители подключены к одной общей плате (backplane)
Как видно, у аппаратной избыточности есть как плюсы, так и минусы. Следите за обновлениями — в будущем могут появиться новые поддерживаемые методы отказоустойчивости.
Теперь предположим, что вы решили не использовать RAID-контроллер. Что произойдёт, если у вас есть один выделенный накопитель NVMe для Memory Tiering, и он выйдет из строя?
Ранее мы обсуждали, что на NVMe переносятся только «холодные» страницы памяти виртуальных машин по мере необходимости. Это означает, что страницы памяти самого хоста не находятся на NVMe, а также что на накопителе может быть как много, так и мало холодных страниц — всё зависит от нагрузки на DRAM. VMware не выгружает страницы (даже холодные), если в этом нет нужды — зачем расходовать вычислительные ресурсы?
Таким образом, если часть холодных страниц была выгружена на NVMe и накопитель вышел из строя, виртуальные машины, чьи страницы находились там, могут попасть в ситуацию высокой доступности (HA). Мы говорим "могут", потому что это произойдёт только если и когда ВМ запросит эти холодные страницы обратно из NVMe, которые теперь недоступны. Если же ВМ никогда не обратится к этим страницам, она продолжит работать без сбоев.
Иными словами, сценарий отказа зависит от активности в момент сбоя NVMe:
Если на NVMe нет холодных страниц — ничего не произойдёт.
Если есть немного холодных страниц — возможно, несколько ВМ войдут в HA-событие и перейдут на другой хост;
Если все холодные страницы хранились на NVMe — возможно, большинство ВМ окажутся в HA-режиме по мере запроса страниц.
Это не обязательно приведёт к полному отказу всех систем. Некоторые ВМ могут выйти из строя сразу, другие — позже, а третьи — вообще не пострадают. Всё зависит от их активности. Главное — хост ESX продолжит работу, а поведение виртуальных машин будет различаться в зависимости от текущих нагрузок.
Масштабируемость
Масштабируемость памяти — это, пожалуй, один из тех неожиданных факторов, который может обойтись очень дорого. Как известно, память составляет значительную часть (до 80%) общей стоимости нового сервера. В зависимости от подхода к закупке серверов, вы могли выбрать меньшие по объёму модули DIMM, установив их во все слоты — в этом случае у вас нет возможности увеличить объём памяти без полной замены всех модулей, а иногда даже самого сервера.
В также могли выбрать высокоплотные модули DIMM, оставив несколько слотов свободными для будущего роста — это позволяет масштабировать память, но тоже дорого, так как позже придётся докупать совместимые модули (если они ещё доступны). В обоих случаях масштабирование получается дорогим и медленным, особенно учитывая длительные процедуры утверждения бюджета и заказов в компаниях.
Именно здесь NVMe Memory Tiering показывает себя с лучшей стороны — снижая затраты и позволяя быстро увеличить объём памяти. В данном случае масштабирование памяти сводится к покупке хотя бы одного устройства NVMe и включению функции Memory Tiering — и вот у вас уже на 100% больше памяти для ваших хостов. Отличная выгода.
Можно даже «позаимствовать» накопитель из вашего хранилища vSAN, если есть возможность выделить его под Memory Tiering… но об этом чуть позже (делайте это с осторожностью).
В этой части важно понимать ограничения и возможности, чтобы обеспечить надёжность инвестиций в будущем. Мы уже говорили о требованиях к устройствам NVMe по показателям производительности и износостойкости, но что насчёт объёма NVMe-устройств? Об этом мы напишем в следующей части.
Таги: VMware, NVMe, Memory, Tiering, Hardware, Security, HA
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
В числе множества новых возможностей, представленных в VMware Cloud Foundation 9.0, функция многоуровневой памяти (Memory Tiering) стала одной из ключевых в составе VMware vSphere для VCF 9.0. Как и многие другие функции vSphere, Memory Tiering с использованием NVMe снижает совокупную стоимость владения, полностью интегрируется с ESX (да, гипервизор называется снова ESX), а также с VMware vCenter. Она поддерживает гибкие варианты развертывания, предоставляя клиентам множество опций при настройке.
Memory Tiering с NVMe была представлена в составе VCF 9.0, и важно подчеркнуть её ценность для компаний, стремящихся сократить расходы, особенно при закупке оборудования, так как стоимость оперативной памяти составляет значительную часть спецификации аппаратного обеспечения (Bill of Materials, BOM). Функция, позволяющая масштабировать память за счёт использования недорогого оборудования, может существенно повлиять на распределение ИТ-бюджета и приоритетность проектов.
Memory Tiering с NVMe можно настроить через привычный вам интерфейс vCenter UI, с помощью командной строки через ESXCLI, а также через скрипты в PowerCLI. Можно использовать любую из этих опций или их комбинацию для настройки многоуровневой памяти как на уровне хоста, так и на уровне кластера.
Аппаратное обеспечение имеет значение
Перед настройкой функции Memory Tiering крайне важно обратить внимание на рекомендуемое оборудование. И это не просто совет, а настоятельная рекомендация. Поскольку в роли памяти будут использоваться устройства NVMe, важно, чтобы они были не только надёжными, но и демонстрировали высокую производительность при интенсивной нагрузке. Аналогично тому, как вы определяли рекомендуемые устройства для vSAN, здесь также есть требования: NVMe-устройства должны соответствовать классу выносливости D (не менее 7300 TBW) и классу производительности F или выше (не менее 100 000 операций записи в секунду) для использования в составе многоуровневой памяти. VMware рекомендует воспользоваться руководством по совместимости с vSAN, чтобы убедиться, что выбранные устройства соответствуют этим требованиям.
Также важно отметить, что поддерживается множество форм-факторов. Так что если в вашем сервере нет свободных слотов для 2.5-дюймовых накопителей, но есть, например, свободный слот M.2, вы вполне можете использовать его для Memory Tiering.
Создание раздела на NVMe
После того как вы тщательно выбрали рекомендованные NVMe-устройства (кстати, их можно объединить в RAID-конфигурацию для обеспечения отказоустойчивости), следующим шагом будет создание раздела для NVMe-уровня памяти. Если на выбранном устройстве уже существуют какие-либо разделы, их необходимо удалить перед конфигурацией.
Максимальный размер раздела в текущей версии составляет 4 ТБ, однако вы можете использовать и более ёмкое устройство — это позволит «циклически использовать ячейки» и потенциально продлить срок службы NVMe-накопителя. Хотя размер раздела зависит от ёмкости устройства (до 4 ТБ), фактический объём NVMe, задействованный в качестве памяти, рассчитывается на основе объёма DRAM на хосте и заданного соотношения. По умолчанию в VCF 9.0 применяется соотношение DRAM:NVMe как 1:1 — это в четыре раза больше, чем в технологическом превью на vSphere 8.0 Update 3.
Например, если у вас есть хост с 1 ТБ DRAM и NVMe-устройство на 4 ТБ, то будет создан раздел размером 4 ТБ, но использоваться в рамках Memory Tiering будет только 1 ТБ — если, конечно, вы не измените соотношение. Это соотношение настраивается пользователем, однако стоит проявить осторожность: изменение параметра может негативно повлиять на производительность и сильно зависит от характера и активности рабочих нагрузок. Подробнее об этом — далее.
В текущей версии создание раздела выполняется через командную строку ESXCLI на хосте с помощью следующей команды:
esxcli system tierdevice create -d /vmfs/devices/disks/<UID NVMe-устройства>
Пример:
Конфигурация хоста или кластера
После создания раздела tierdevice остаётся последний шаг — настроить хост или кластер. Да, вы можете гибко подойти к конфигурации: настроить один, несколько хостов или весь кластер целиком. В идеале рекомендуется настраивать кластер гомогенно; однако стоит учитывать, что некоторые типы виртуальных машин пока не поддерживаются в режиме NVMe Memory Tiering. К ним относятся:
ВМ с высокими требованиями к производительности и низкой задержке
Защищённые ВМ (SEV, SGX, TDX),
ВМ с непрерывной доступностью (FT)
"Монстр-машины" (1 ТБ памяти, 128 vCPU)
Вложенные ВМ (nested VMs).
Если в одном кластере у вас сочетаются такие ВМ с обычными рабочими нагрузками, которые могут использовать Memory Tiering, вы можете либо выделить отдельные хосты для «особых» ВМ, либо отключить Memory Tiering на уровне конкретных виртуальных машин.
Для включения Memory Tiering на хосте вы можете воспользоваться ESXCLI, PowerCLI или интерфейсом vCenter UI. В ESXCLI команда очень простая:
esxcli system settings kernel set -s MemoryTiering -v TRUE
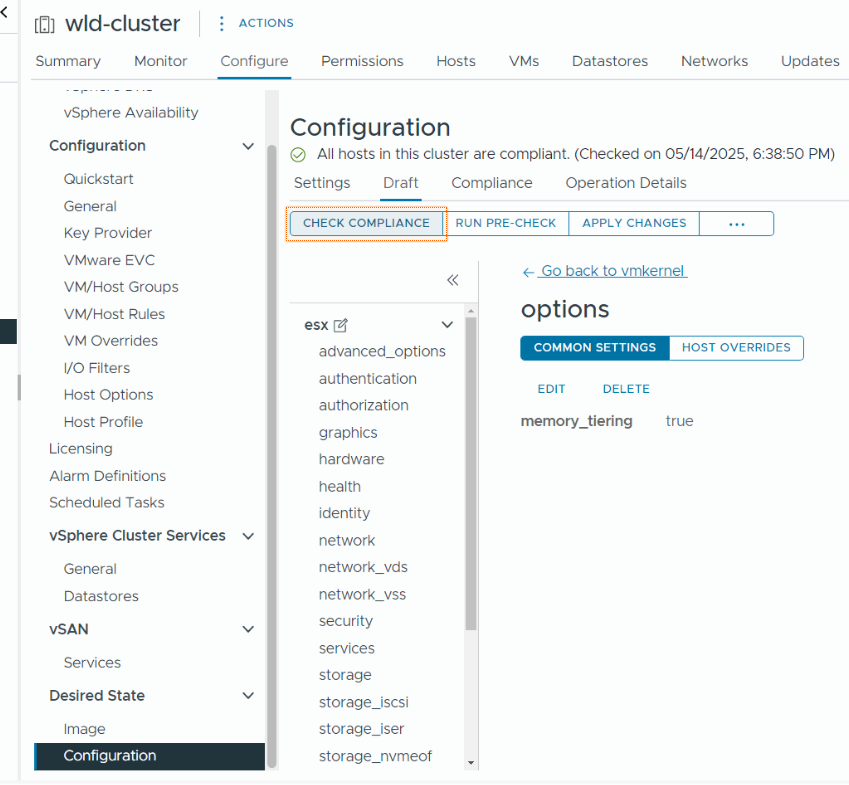
В vCenter UI это делается путём изменения параметра VMkernel.Boot.memoryTiering на значение TRUE. Обратите внимание на слово BOOT — для применения параметра хост необходимо перезагрузить. Также перед внесением изменений хост нужно перевести в режим обслуживания.
А если вы хотите настроить весь кластер? Что ж, это даже проще. Вы можете воспользоваться функцией Desired State Configuration в vCenter. Всё, что нужно — создать новый черновик с включённой настройкой memory_tiering в разделе vmkernel > options, установив её в значение true. После этого остаётся просто применить этот драфт ко всем хостам в кластере (или только к выбранным хостам).
После применения конфигурации хосты автоматически будут переведены в режим обслуживания и перезагружены поочерёдно, по мере необходимости. И всё — на этом настройка завершена. Теперь вы можете воспользоваться преимуществами:
Лучшего коэффициента консолидации ВМ
Сниженной совокупной стоимости владения
Простой масштабируемости памяти — по значительно более низкой цене
После завершения настройки вы увидите как минимум двукратное увеличение доступной памяти, а также визуальное отображение уровней памяти (memory tiers) в интерфейсе vCenter UI.
Затраты на память по-прежнему остаются одной из самых крупных статей расходов на серверную инфраструктуру, и при этом большая часть дорогой оперативной памяти (DRAM) используется неэффективно. А что, если вы могли бы удвоить плотность виртуальных машин и сократить совокупную стоимость владения до 40%?
С выходом VMware Cloud Foundation 9.0 технология Memory Tiering (многоуровневая организация памяти) делает это возможным. Команда инженеров VMware недавно представила результаты тестирования производительности, которые демонстрируют, как эта технология меняет экономику датацентров. Подробности — в новом исследовании: Memory Tiering Performance in VMware Cloud Foundation 9.0.
Ниже мы расскажем об основных результатах исследования, которые показывают, что Memory Tiering позволила увеличить плотность виртуальных машин в 2 раза при незначительном снижении производительности. Для получения полной информации о принципах работы Memory Tiering и более подробных данных о производительности, ознакомьтесь с полным текстом исследования.
Как Memory Tiering улучшает производительность датацентров и снижает затраты
В VMware Cloud Foundation 9.0 технология Memory Tiering предоставляет виртуальным машинам единое логическое адресное пространство памяти. Однако «под капотом» она управляет двумя уровнями памяти: Tier 0 (DRAM) и Tier 1 (Memory Tiering), в зависимости от активности памяти виртуальной машины. Фактически, система старается держать «горячую» (активную) память в DRAM, а «холодную» (неактивную) — на NVMe.
Со стороны виртуальной машины это выглядит как единое, увеличенное пространство памяти. В фоновом режиме гипервизор ESX динамически управляет размещением страниц памяти между двумя уровнями — DRAM и NVMe — обеспечивая при этом оптимальную производительность.
VMware провела тестирование на различных корпоративных нагрузках, чтобы подтвердить эффективность Memory Tiering. Были использованы серверы на базе процессоров Intel и AMD с различными конфигурациями DRAM. В VMware Cloud Foundation 9.0 по умолчанию используется соотношение DRAM к NVMe 1:1, и во всех тестах применялось именно оно.
Увеличение плотности ВМ в 2 раза, потеря производительности - 5-10% (MySQL, SQL)
Login Enterprise: Производительность виртуальных рабочих столов
Команда VMware использовала Login Enterprise для тестирования производительности VDI (виртуальных рабочих столов) в различных сценариях. Во всех тестах удалось удвоить количество виртуальных машин на хосте ESX при минимальном снижении производительности. Например, в конфигурации из трёх узлов vSAN:
Удвоили количество VDI-сессий, которые могли выполняться на трёхузловом кластере vSAN — с 300 (только DRAM) до 600 (с использованием Memory Tiering).
При этом не было зафиксировано потери производительности по сравнению с аналогичной конфигурацией, использующей только DRAM.
Тест VMmark 3.1, включающий несколько нагрузок, имитирующих работу корпоративных приложений, показал отличные результаты:
Конфигурация с Memory Tiering достигла 6 тайлов против 3 тайлов в конфигурации, использующей только DRAM. Это в 2 раза лучше.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering, снижение производительности составило всего 5%, несмотря на использование более медленной памяти NVMe в режиме Memory Tiering.
HammerDB и DVD Store: производительность баз данных
Производительность баз данных — один из самых ресурсоёмких тестов для любой инфраструктуры. VMware использовала HammerDB и DVD Store в качестве нагрузок для тестирования SQL Server, Oracle Database и MySQL. С помощью Memory Tiering удалось удвоить количество виртуальных машин при минимальном влиянии на производительность. Например, в тесте Oracle Database с нагрузкой DVD Store были получены следующие результаты:
На хосте ESX с Memory Tiering удалось запустить 8 виртуальных машин против 4 в конфигурации, использующей только DRAM — плотность удвоилась.
При сравнении конфигураций с 1 ТБ DRAM и с 1 ТБ Memory Tiering снижение производительности составило менее 5%.
Мониторинг Memory Tiering на хостах ESX
Для обеспечения высокой производительности при использовании Memory Tiering следует отслеживать два ключевых показателя:
Поддерживайте активную память на уровне 50% или меньше от объёма DRAM — это обеспечит оптимальную производительность.
Следите за задержкой чтения с NVMe-устройства. Наилучшая производительность достигается при задержке менее 200 микросекунд.
Преобразите экономику вашего датацентра
Memory Tiering предлагает новый подход к организации памяти:
До 40% экономии совокупной стоимости владения (TCO) за счёт снижения требований к DRAM.
Прозрачная работа — не требует изменений в приложениях или гостевых операционных системах.
До 2-кратного увеличения плотности виртуальных машин для различных типов нагрузок.
Гибкая инфраструктура, адаптирующаяся к изменяющимся требованиям рабочих нагрузок.
Memory Tiering уже доступна в VMware Cloud Foundation 9. Скачайте полное исследование производительности, чтобы подробнее ознакомиться с методологией тестирования, результатами и рекомендациями по внедрению.
Хотите попробовать Memory Tiering на практике?
Полноценный практический лабораторный курс предоставляет живую среду vSphere 9.0, где вы сможете изучить Memory Tiering и узнать, как использование NVMe-накопителей позволяет расширить и оптимизировать доступную память для хостов ESX.
Многоуровневая память (Memory Tiering) снижает затраты и повышает эффективность использования ресурсов. Эта функция была впервые представлена в виде технологического превью в vSphere 8.0 Update 3 и получила очень положительные отзывы от клиентов. Обратная связь от пользователей касалась в основном устойчивости данных, безопасности и гибкости в конфигурациях хостов и виртуальных машин. С выходом платформы VCF 9.0 все эти вопросы были решены.
Теперь многоуровневая память — это готовое к использованию в производственной среде решение, включающее поддержку DRS и vMotion, повышенную производительность, улучшенное соотношение DRAM:NVMe по умолчанию (1:1), а также множество других улучшений, направленных на повышение надёжности этой функции.
В компании Broadcom было проведено масштабное внутреннее тестирование, которое показало, что использование многоуровневой памяти позволяет сократить совокупную стоимость владения (TCO) до 40% для большинства рабочих нагрузок, а также обеспечивает рост загрузки CPU, позволяя использовать на 25–30% больше ядер под задачи. Меньше затрат — больше ресурсов. Кроме того, лучшая консолидация ВМ может означать меньше серверов или больше ВМ на каждом сервере.
Многоуровневая память обеспечивает все эти и многие другие преимущества, используя NVMe-устройства в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогих устройств, таких как NVMe. Между предварительной технической версией и готовым к промышленному использованию выпуском с VCF 9.0 существует множество важных отличий. Давайте рассмотрим эти улучшения.
Новые возможности Advanced Memory Tiering
Смешанный кластер
Многоуровневая память (Memory Tiering) может быть настроена на всех хостах в кластере, либо вы можете включить эту функцию только для части хостов. Причины для этого могут быть разными: например, вы хотите протестировать технологию на одном хосте и нескольких ВМ, возможно, только несколько хостов имеют свободные слоты для NVMe-устройств, или вам разрешили приобрести лишь ограниченное количество накопителей. Хорошая новость в том, что поддерживаются все эти и многие другие сценарии — чтобы соответствовать текущим возможностям заказчиков. Вы можете выбрать только часть хостов или активировать эту функцию на всех.
Резервирование
Резервирование всегда является приоритетом при проектировании архитектуры. Как вы знаете, не бывает серьезной производственной среды с одной единственной сетевой картой на сервер. Что касается накопителей, то обеспечить отказоустойчивость можно с помощью конфигурации RAID — именно это и было реализовано. Многоуровневая память может использовать два и более NVMe-устройств в аппаратной RAID-конфигурации для защиты от отказов устройств.
Поддержка DRS
Технология DRS (Distributed Resource Scheduler) существует уже довольно давно, это одна из функций, без которой большинство клиентов уже не могут обходиться. VMware вложила много усилий в то, чтобы сделать алгоритм Memory Tiering «умным» — чтобы он не только анализировал состояние страниц памяти, но и эффективно управлял ими в пределах кластера.
DRAM:NVMe — новое соотношение
В vSphere 8.0 U3 функция Memory Tiering была представлена как технологическое превью. Тогда использовалось соотношение 4:1, то есть на 4 части DRAM приходилась 1 часть NVMe. Это дало увеличение объёма памяти на 25%. Хотя это может показаться незначительным, при сравнении стоимости увеличения объёма памяти на 25% с использованием DRAM и NVMe становится очевидно, насколько это выгодно.
В VCF 9.0, после всех улучшений производительности, изменили соотношение по умолчанию: теперь оно 1:1 — то есть увеличение объема памяти в 2 раза по умолчанию. И это значение можно настраивать в зависимости от нагрузки и потребностей. То есть, если у вас есть хост ESX с 1 ТБ DRAM и вы включаете Memory Tiering, вы можете получить 2 ТБ доступной памяти. Для некоторых сценариев, таких как VDI, возможно соотношение до 1:4 — это позволяет вчетверо увеличить объём памяти при минимальных затратах.
Другие улучшения
В VCF 9.0 было реализовано множество других улучшений функции Memory Tiering. Общие улучшения производительности сделали решение более надёжным, гибким, отказоустойчивым и безопасным. С точки зрения безопасности добавлено шифрование: как на уровне виртуальных машин, так и на уровне хоста. Страницы памяти ВМ теперь могут быть зашифрованы индивидуально для каждой ВМ или сразу для всех машин на хосте — с помощью простой и удобной настройки.
Как начать использовать Advanced Memory Tiering
С чего начать? Как понять, подходят ли ваши рабочие нагрузки для Memory Tiering? Клиентам стоит учитывать следующие факторы при принятии решения о внедрении Memory Tiering:
Активная память
Memory Tiering особенно подходит для клиентов с высоким потреблением (выделено под ВМ более 50%) и низким уровнем активного использования памяти (фактически используемая нагрузками — менее 50% от общего объема DRAM).
Скриншот ниже показывает, как можно отслеживать активную память и объём DRAM с помощью vCenter:
NVMe-устройства
Существуют рекомендации по производительности и ресурсу для поддерживаемых накопителей — в руководстве по совместимости Broadcom (VMware) указано более 1500 одобренных моделей. NVMe-накопители, такие как E3.S, являются модульными и зачастую могут быть установлены в свободные слоты серверов, например, как в Dell PowerEdge, показанном ниже. VMware настоятельно рекомендует клиентам обращаться к руководству по совместимости Broadcom, чтобы обеспечить нужный уровень производительности своих рабочих нагрузок за счёт выбора рекомендованных устройств.
Многоуровневая память Advanced Memory Tiering снижает затраты и одновременно повышает эффективность использования ресурсов, и её будущее выглядит многообещающим. Уже ведётся работа над рядом улучшений, которые обеспечат ещё больший комфорт и дополнительные преимущества. В ближайшие месяцы будет доступно больше информации о технологии Memory Tiering.
Продолжаем рассказывать о технологии ярусной памяти Memory Tiering, которая появилась в VMware vSphere 8 Update 3 (пока в статусе Tech Preview). Вильям Лам написал об интересной возможности использования одного устройства как для NVMe Tiering, так и для датасторов VMFS на платформе VMware vSphere.
На данный момент включение NVMe Tiering требует выделенного устройства NVMe. Для производственных систем это, вероятно, не проблема, так как важно избежать конкуренции за ресурсы ввода-вывода на одном устройстве NVMe. Однако для среды разработки или домашней лаборатории это может быть проблемой из-за ограниченного количества доступных NVMe-устройств.
Оказывается, можно использовать одно устройство NVMe для NVMe Tiering!
Для владельцев систем малого форм-фактора, таких как ASUS NUC, с ограниченным количеством NVMe-устройств, есть такой вариант: вы можете запустить ESXi с USB-устройства, сохранив возможность использовать локальный VMFS-датастор и NVMe Tiering. Таким образом, у вас даже останется свободный слот или два для vSAN OSA или ESA!
Важно: Это решение не поддерживается официально со стороны VMware. Используйте его на свой страх и риск.
Шаг 1 - Убедитесь, что у вас есть пустое устройство NVMe, так как нельзя использовать устройство с существующими разделами. Для идентификации и получения имени SSD-устройства используйте команду vdq -q.
Затем запустите его, как показано на скриншоте ниже:
Примечание: скрипт только генерирует необходимые команды, но вам нужно будет выполнить их вручную. Сохраните их — это избавит вас от необходимости вручную рассчитывать начальные и конечные сектора хранилища.
Пример выполнения сгенерированных команд для конкретной настройки: есть NVMe-устройство объёмом 1 ТБ (913,15 ГБ), из которого выделяется 256 ГБ для NVMe Tiering, а оставшееся пространство будет использовано для VMFS-датастора.
С помощью клиента ESXi Host Client мы можем увидеть два раздела, которые мы только что создали:
Шаг 3 – Включите функцию NVMe Tiering, если она еще не активирована, выполнив следующую команду ESXCLI:
esxcli system settings kernel set -s MemoryTiering -v TRUE
Шаг 4 – Настройте желаемый процент использования NVMe Tiering (от 25 до 400), исходя из конфигурации вашей физической оперативной памяти (DRAM), выполнив следующую команду:
esxcli system settings advanced set -o /Mem/TierNvmePct -i 400
Шаг 5 – Наконец, перезагрузите хост ESXi, чтобы настройки NVMe Tiering вступили в силу. После перезагрузки ваш хост ESXi будет поддерживать использование одного NVMe-устройства как для NVMe Tiering, так и для локального VMFS-датастора, готового для размещения виртуальных машин.
Компания VMware недавно выпустила интересное видео в рамках серии Extreme Performance, где рассматривается, как технологии Memory Tiering могут оптимизировать серверную инфраструктуру, улучшить консолидацию серверов и снизить общую стоимость владения (TCO). Ведущие эксперты, работающие в сфере производительности платформ VMware, делятся новейшими разработками и результатами тестов, которые помогут сделать работу администраторов с серверами более эффективной.
Основные моменты видео:
Что такое Memory Tiering? Memory Tiering — это технология, реализованная в ядре ESXi, которая прозрачно для приложений и гостевых ОС разделяет память на два уровня:
Tier 1: Быстрая память DRAM.
Tier 2: Бюджетные и емкие устройства памяти, такие как NVMe SSD и CXL.
Преимущества Memory Tiering:
Увеличение доступной памяти за счет использования NVMe в качестве памяти второго уровня.
Снижение затрат на память до 50%.
Исключение таких проблем, как ballooning и случайный обмен страницами.
Реальные результаты:
Удвоение плотности виртуальных машин (VMs): на одной хост-машине можно разместить вдвое больше ВМ без заметной потери производительности (<3%).
Оптимизация работы баз данных: для SQL Server и Oracle наблюдалось почти линейное масштабирование с минимальными потерями производительности.
Стабильный пользовательский опыт (VDI): эталонный тест Login VSI показал, что даже при удвоении числа ВМ пользовательский опыт остается на высоком уровне.
Ключевые метрики и рекомендации:
Active memory: один из основных параметров для мониторинга. Оптимальный уровень — около 50% от объема Tier 1 (DRAM).
Использование NVMe: рекомендации по чтению и записи (до 200 мс latency для чтения и 500 мс для записи).
Практические примеры и кейсы:
Клиенты из финансового и медицинского секторов, такие как SS&C Cloud, уже успешно применяют Memory Tiering, чтобы уменьшить затраты на серверы и улучшить их производительность.
Советы по настройке и мониторингу:
Как отслеживать активность NVMe-устройств и состояние памяти через vCenter.
Какие показатели важны для анализа производительности.
Кому будет полезно:
Системным администраторам, DevOps-инженерам и специалистам по виртуализации.
Организациям, которые стремятся сократить затраты на ИТ-инфраструктуру и повысить плотность виртуализации.
Любителям передовых технологий, которые хотят понять, как современные подходы меняют управление памятью в дата-центрах.
Memory Tiering — это прорывная технология, которая уже сегодня позволяет добиться больших результатов в консолидации серверов. Узнайте, как её применить в вашем окружении, и станьте частью следующего поколения производительности серверов.
Таги: VMware, vSphere, Memory, Performance, NVMe, Video
Memory Tiering использует более дешевые устройства в качестве памяти. В Update 3 платформа vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Вильям Лам написал интересный пост о выводе информации для NVMe Tiering в VMware vSphere через API. После успешного включения функции NVMe Tiering, которая была введена в vSphere 8.0 Update 3, вы можете найти полезную информацию о конфигурации NVMe Tiering, перейдя к конкретному хосту ESXi, затем выбрав "Configure" -> "Hardware" и в разделе "Memory", как показано на скриншоте ниже.
Здесь довольно много информации, поэтому давайте разберём отдельные элементы, которые полезны с точки зрения NVMe-тиринга, а также конкретные vSphere API, которые можно использовать для получения этой информации.
Memory Tiering Enabled
Поле Memory Tiering указывает, включён ли тиринг памяти на хосте ESXi, и может иметь три возможных значения: "No Tiering" (без тиринга), "Hardware Memory Tiering via Intel Optane" (аппаратный тиринг памяти с помощью технологии Intel Optane) или "Software Memory Tiering via NVMe Tiering" (программный тиринг памяти через NVMe). Мы можем получить значение этого поля, используя свойство "memoryTieringType" в vSphere API, которое имеет три перечисленных значения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Поле Tier 0 представляет общий объём физической оперативной памяти (DRAM), доступной на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "DRAM"}).Size
Tier 1 Memory
Поле Tier 1 представляет общий объём памяти, предоставляемой NVMe-тирингом, которая доступна на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Примечание: Можно игнорировать термин "Unmappable" — это просто другой способ обозначения памяти, отличной от DRAM.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "NVMe"}).Size
Поле Total представляет общий объём памяти, доступный ESXi при объединении как DRAM, так и памяти NVMe-тиринга, который можно агрегировать, используя размеры Tier 0 и Tier 1 (в байтах).
Устройства NVMe для тиринга
Чтобы понять, какое устройство NVMe настроено для NVMe-тиринга, нужно перейти в раздел "Configure" -> "Storage" -> "Storage Devices", чтобы просмотреть список устройств. В столбце "Datastore" следует искать значение "Consumed for Memory Tiering", как показано на скриншоте ниже. Мы можем получить это поле, используя свойство "usedByMemoryTiering" при энумерации всех устройств хранения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Отношение объёма DRAM к NVMe по умолчанию составляет 25% и настраивается с помощью следующего расширенного параметра ESXi под названием "Mem.TierNvmePct". Мы можем получить значение этого поля, используя либо vSphere API ("OptionManager"), либо через ESXCLI.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Вильям собрал все вышеперечисленные парметры и создал скрипт PowerCLI под названием "get-nvme-tiering-info.ps1", который предоставляет удобное резюме для всех хостов ESXi в рамках конкретного кластера Sphere (вы также можете изменить скрипт, чтобы он запрашивал конкретный хост ESXi). Это может быть полезно для быстрого получения информации о хостах, на которых NVMe-тиринг может быть настроен (или нет).
vSphere Memory Tiering - это очень интересная функция, которую VMware выпустила в качестве технического превью в составе vSphere 8.0 Update 3, чтобы дать своим клиентам возможность оценить механику ранжирования памяти в их тестовых средах. Об этом мы уже немного рассказывали, а сегодня дополним.
По сути, Memory Tiering использует более дешевые устройства в качестве памяти. В vSphere 8.0 Update 3 vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Memory Tiering также решает проблемы несоответствия между ядрами процессора и объемом памяти и способствует лучшей консолидации рабочих нагрузок и виртуальных машин.
Memory Tiering настраивается на каждом ESXi в кластере, и все хосты должны работать на vSphere 8.0 U3. По умолчанию соотношение DRAM к NVMe составляет 4:1, но его можно изменить для использования большего количества ресурсов NVMe в качестве памяти.
Для изменения этого соотношения нужно зайти в Host > Manage > System > Advanced settings и поменять там настройку Mem.TierNvmePct. По умолчанию это 25, то есть NVMe занимает 25% от общей оперативной памяти хоста ESXi. Максимальное значение составляет 400, минимальное - 1.
Технические подробности настройки vSphere Memory Tiering описаны в статье базы знаний KB 95944. Там можно скачать документ "Memory Tiering over NVMe Tech Preview", где описываются все аспекты использования данной технологии:
Если же вы хотите посмотреть на работу этой штуки в действии, то можете почитать интересные посты Вильяма Лама:
Недавно Дункан Эппинг выступал с докладом на конференции VMUG в Бельгии, где была тема «Инновации в VMware от Broadcom». В ходе доклада он кратко изложил процесс и различные типы инноваций, а также то, к чему это может привести. Во время сессии он рассмотрел три проекта, а именно vSAN ESA, Distributed Services Engine и проект, над которым сейчас работают, под названием Memory Tiering.
Memory Tiering — это очень интересная концепция, которая впервые была публично представлена на конференции VMware Explore несколько лет назад как потенциальная будущая фича гипервизора. Вы можете задаться вопросом, зачем кому-то захочется ранжировать память, ведь влияние этого процесса на производительность может быть значительным. Существует несколько причин для этого, одна из которых — стоимость памяти. Еще одна проблема, с которой сталкивается индустрия, заключается в том, что емкость (и производительность) памяти не росли такими же темпами, как емкость CPU, что привело к тому, что во многих средах память стала узким местом. Иными словами, дисбаланс между процессором и памятью значительно увеличился. Именно поэтому VMware запустила проект Capitola.
Когда обсуждался проект Capitola, большинство внимания было уделено Intel Optane, и большинство интересующихся знает, что с этим случилось. Некоторые думали, что это также приведет к закрытию проекта Capitola, а также технологий ранжирования и объединения памяти. Но это совершенно не так: VMware продолжает активно работать над проектом и публично обсуждает прогресс, хотя нужно знать, где искать эту информацию. Если вы посмотрите эту сессию, станет ясно, что существует множество усилий, которые позволят клиентам ранжировать память различными способами, одним из которых, конечно, являются различные решения на базе CXL, которые скоро появятся на рынке.
Один из способов — это Memory Tiering с помощью карты ускорителя CXL, по сути, это FPGA, предназначенная исключительно для увеличения емкости памяти, аппаратной разгрузки техник ранжирования памяти и ускорения определенных функций, где память имеет ключевое значение, таких как, например, vMotion. Как упоминалось в сессии SNIA, использование карты ускорителя может привести к сокращению времени миграции на 30%. Такая карта ускорителя также открывает другие возможности, например, memory pooling, чего клиенты просили с тех пор, как в VMware создали концепцию кластера.
Также это открывает возможности совместного использования вычислительных ресурсов между хостами. Только представьте, ваша виртуальная машина может использовать емкость памяти, доступную на другом хосте, без необходимости перемещать саму виртуальную машину. Понятное дело, что это может оказать значительное влияние на производительность.
Именно здесь вступают в игру технологии VMware. На VMworld в 2021 году, когда был представлен проект Capitola, команда VMware также поделилась результатами последних тестов производительности, и было показано, что снижение производительности составило около 10% при использовании 50% оперативной памяти (DRAM) и 50% памяти Optane. Эта демонстрация показывает истинную мощь VMware vSphere, а также техник ранжирования памяти и ускорения (проект Peaberry).
В среднем снижение производительности составило около 10%, при этом примерно 40% виртуальной памяти было доступно через ускоритель Peaberry. Обратите внимание, что tiering полностью прозрачен для приложения, поэтому это работает для всех типов рабочих нагрузок. Важно понимать, что поскольку гипервизор уже отвечает за управление памятью, он знает, какие страницы являются "горячими", а какие "холодными", а это значит, что он может определить, какие страницы можно переместить на другой уровень, сохраняя при этом производительность.
В общем, ждем больше интересной информации от VMware на эту тему!
В своем финансовом отчете за второй квартал этого года компания Intel неожиданно объявила о том, что сворачивает (winding down) разработку технологии оперативной памяти Intel Optane. В свете падения квартальной выручки аж на 22% год к году, Intel просто не может поддерживать все перспективные технологии, требующие больших инвестиций в R&D.
Кстати, AMD во втором квартале этого года почти удвоила выручку (сказался еще эффект включения выручки приобретенной компании Xilinx):
Это оказалось, довольно-таки, неожиданной новостью для компании VMware, которая ориентировалась на поддержку этого типа памяти в своих продуктах, например, планируемом к выпуску решении Project Capitola. В данном продукте будет использоваться так называемая Software-Defined Memory, определяемая в облаке (неважно - публичном или онпремизном) на уровне кластеров VMware vSphere под управлением vCenter.
В Project Capitola вся доступная память серверов виртуализации в кластере агрегируется в единый пул памяти архитектуры non-uniform memory architecture (NUMA) и разбивается на ярусы (tiers), в зависимости от характеристик производительности, которые определяются категорией железа (price /performance points), предоставляющей ресурсы RAM. Все это позволяет динамически выделять память виртуальным машинам в рамках политик, созданных для соответствующих ярусов.
На рынке серверной виртуализации уже довольно давно развивается экосистема оперативной памяти различных уровней - стандартная DRAM, технология SCM (Optane и Z-SSD), модули памяти CXL, память PMEM, а также NVMe. Однако в разработке технологий по виртуализации оперативной памяти компания VMware ориентировалась, в первую очередь, именно на Intel Optane.
Память Intel Optane DC persistent memory (DCPMM она же PMEM) не такая быстрая как DRAM и имеет бОльшие задержки, но они все равно измеряются наносекундами. При этом данная память позволяет иметь ее большой объем на сервере, что существенно повышает плотность ВМ на одном хосте. В конце прошлого года мы писали о производительности этого типа памяти.
Теперь пользователи аппаратных устройств на базе Intel Optane продолжат получать стандартную поддержку Intel до окончания периода End-of-life, а также гарантию, действительную в течение 5 лет. Это касается следующих продуктовых линеек:
PMem 100 series ("Apache Pass")
PMem 200 series ("Barlow Pass")
DC P4800X SSD ("Cold Stream")
DC P5800X ("Alder Stream")
Также сообщается, что Intel продолжит развивать технологию PMem 300 series ("Crow Pass") для четвертого поколения процессоров Intel Xeon Scalable ("Sapphire Rapids").
VMware планирует продолжать поддержку памяти Intel Optane PMem в платформах vSphere 7.x и vSAN, а также будущих релизах этих продуктов. На данный момент память Optane поддерживается в трех режимах:
Обычная оперативная память (Memory mode)
App-Direct mode через механизм vPMem
Как персистентное хранилище через объекты vPMemDisk
VMware также добавила расширенные механизмы по поддержке vMMR в vSphere 7 Update 3 и добавила различные интеграции с механизмом DRS в следующей версии платформы. О технологии vMMR можно прочитать подробнее тут.
Также VMware поддерживает все предыдущие поколения технологии Intel Optane PMem, о чем можно почитать в KB 67645. Ну и VMware будет поддерживать будущее поколение Optane PMem 300, которое Intel, вроде как, не планирует сворачивать.
Ну а что касается Project Capitola, то VMware не будет поддерживать Intel Optane в этом решении, а переключится на технологии памяти стандарта CXL, который, как ожидается, получит большое распространение в отрасли. Посмотрим еще, что на эту тему еще расскажут на предстоящей конференции VMware Explore 2022.
На прошедшей онлайн-конференции VMworld 2021 компания VMware представила много новых интересных инициатив, продуктов и технологий. О некоторых из них мы уже рассказали в наших статьях:
Сегодня же мы поговорим о новом начинании VMware - Project Capitola. На рынке серверной виртуализации уже довольно давно развивается экосистема оперативной памяти различных уровней - стандартная DRAM, технология SCM (Optane и Z-SSD), модули памяти CXL, память PMEM, а также NVMe. По аналогии с сетевой инфраструктурой, где есть решение NSX для виртуализации и агрегации сетей, серверной инфраструктурой (где виртуализацией CPU занимается платформа vSphere) и инфраструктурой виртуализации хранилищ vSAN, компания VMware представила среду агрегации и виртуализации оперативной памяти - Project Capitola.
Это - так называемая Software-Defined Memory, определяемая в облаке (неважно - публичном или онпремизном) на уровне кластеров VMware vSphere под управлением vCenter:
Вся доступная память серверов виртуализации в кластере агрегируется в единый пул памяти архитектуры non-uniform memory architecture (NUMA) и разбивается на ярусы (tiers), в зависимости от характеристик производительности, которые определяются категорией железа (price /performance points), предоставляющей ресурсы RAM.
Все это позволяет динамически выделять память виртуальным машинам в рамках политик, созданных для соответствующих ярусов. Для Capitola обеспечивается поддержка большинства механизмов динамической оптимизации виртуального датацентра, таких как Distributed Resource Scheduler (DRS).
Вводить в эксплуатацию свои решения в рамках проекта Capitola компания VMware будет поэтапно: сначала появится управление памятью на уровне отдельных серверов ESXi, а потом уже на уровне кластера.
Очевидно, что такая технология требует поддержки на аппаратном уровне - и VMware уже заручилась поддержкой некоторых вендоров. В плане производителей памяти будет развиваться сотрудничество с Intel, Micron, Samsung, также будут интеграции с производителями серверов (например, Dell, HPE, Lenovo, Cisco), а также сервис-провайдерами (такими как Equinix).
Главная часть сотрудничества VMware - это взаимодействие с компанией Intel, которая предоставляет такие технологии, как Intel Optane PMem на платформах Intel Xeon.
Для получения подробностей смотрите следующие сессии с прошедшего VMworld 2021 (найти их можно тут):
[MCL2384] Big Memory – An Industry Perspective on Customer Pain Points and Potential Solutions
[MCL1453] Introducing VMware’s Project Capitola: Unbounding the "Memory Bound"
Ну а если вам хочется узнать больше о работе с памятью платформы vSphere в принципе, то есть еще и вот такие сессии:
How vSphere Will Redefine Infrastructure to Run Future Apps in the Multi-Cloud Era [MCL2500]
The Big Memory Transformation [VI2342]
Prepared for the New Memory Technology in Next Year’s Enterprise Servers? [VI2334]
Bring Intel PMem into the Mainstream with Memory Monitoring and Remediation [MCL3014S]
60 Minutes of Non-Uniform Memory Access (NUMA) 3rd Edition [MCL1853]
Chasing Down the Next Bottleneck – Accelerating Your Hybrid Cloud [MCL2857S]
Implementing HA for SAP HANA with PMem on vSphere 7.0U2 [VI2331]
5 Key Elements of an Effective Multi-Cloud Platform for Data and Analytics [MCL1594]
Будем держать вас в курсе о дальнейших анонсах инициативы Project Capitola компании VMware.
На сайте проекта VMware Labs появилось еще одно интересное средство Virtual Machine Desired State Configuration (VMDSC). Администраторам виртуальной инфраструктуры часто приходится менять параметры виртуальной машины, такие как CPU и память, чтобы проводить разного рода тюнинг и оптимизации. Для таких действий требуется перезагрузка виртуальной машины, что вызывает сложности в планировании.
Раньше подход был таким - к нужной дате/времени, согласованному с владельцами систем, происходила перезагрузка машин, которые за некоторое время уже поднимались в желаемой конфигурации (Desired State). Но это рождает довольно сложный административный процесс такого согласования.
Утилита VMDSC использует другой подход - виртуальные машины окажутся в Desired State при следующей перезагрузке гостевой ОС. Это позволяет не договариваться о простое ВМ в определенные периоды, а просто встраивать процесс реконфигурации процессора и памяти в жизненный цикл систем, когда им и так требуется перезагрузка (например, при накатывании обновлений).
Также в VMDSC встроена интеграция с vRealize Operations (vROPs), которая позволяет настраивать параметры ВМ на базе рекомендаций vROPs прямо из консоли этого решения:
Также массовую реконфигурацию ВМ можно проводить для отдельной папки, кластера или пула ресурсов.
Установка и развертывание утилиты состоит из нескольких несложных шагов:
Создаем служебный аккаунт VMDSC vCenter Service Account
Развертываем виртуальный модуль VMDSC в формате OVA
Используем Postman для настройки желаемых конфигураций ВМ (для этого нужно скачать и установить VMDSC Postman Collection)
Настроить интеграцию с vRealize Orchestrator и vRealize Operations
Для работы продукта понадобится vCenter 7 и новее, а также следующие разрешения сервисного аккаунта:
System.Read
System.View
VirtualMachine.Interact.PowerOff
VirtualMachine.Interact.PowerOn
VirtualMachine.Interact.Reset
VirtualMachine.Config.CPUCount
VirtualMachine.Config.Memory
VirtualMachine.Config.AdvancedConfig
VirtualMachine.Config.Settings
Sessions.ValidateSession
Ну и небольшое обзорное видео решения VMDSC:
Скачать Virtual Machine Desired State Configuration можно по этой ссылке.
Очередная интересная штука появилась на сайте проекта VMware Labs - утилита NUMA Observer, которая позволяет обнаружить виртуальные машины с перекрытием использования NUMA-узлов на хостах ESXi. При работе с тяжелыми нагрузками, требовательными к Latency, администраторы часто создают affinity-правила по привязке виртуальных машин к NUMA-узлам и ядрам CPU, чтобы они работали быстрее, с наименьшими задержками.
Но после сбоев и неполадок механизм VMware HA, восстанавливающий виртуальные машины на других хостах, может нарушить эту конфигурацию - там могут быть ВМ с уже привязанными NUMA-узлами, в результате чего возникнет перекрытие (overlap), которое полезно своевременно обнаружить.
С помощью NUMA Observer можно не только обнаруживать перекрытия по использованию ядер CPU и NUMA-узлов со стороны виртуальных машин, но и собирать статистики по использованию памяти дальнего узла и недостатке CPU-ресурсов (метрика CPU Ready). После анализа конфигураций и использования ресурсов, утилита генерирует алерты, которые администратор может использовать как исходные данные при настройке новой конфигурации NUMA-узлов.
Скачать NUMA Observer
можно по этой ссылке. После установки сервис доступен через веб-консоль по адресу localhost:8443. Для его работы потребуется Java 8.
На сайте проекта VMware Labs появилась новая версия утилиты Virtual Machine Compute Optimizer 3.0, о которой в последний раз мы писали летом 2019 года. С тех пор вышло несколько обновлений этого средства. Напомним, что VMCO - это PowerShell-сценарий для модуля PowerCLI VMware.VimAutomation.Core, который собирает информацию о хостах ESXi и виртуальных машинах в вашем виртуальном окружении и выдает отчет о том, правильно ли они сконфигурированы с точки зрения процессоров и памяти.
В третьей версии сценария появился рабочий процесс установки/апгрейда всех необходимых модулей - VMCO и PowerCLI. Теперь это единый сценарий, в котором есть мастер, проходящий по всем шагам установки модулей, соединения с vCenter и экспорта результатов.
Также в последних версиях была добавлена опция -simple, которая позволяет отобразить только информацию о виртуальных машинах (без серверов vCenter, кластеров и хостов ESXi), обновлена документация и исправлено много ошибок.
Скачивайте Virtual Machine Compute Optimizer 3.0 и выясняйте, правильно ли у вас настроены vCPU и Memory для виртуальных машин. Надо понимать, что VMCO анализирует вашу инфраструктуру только на базе рекомендаций для оптимальной конфигурации виртуальных машин без учета реальной нагрузки, которая исполняется внутри.
Как вы знаете, при обновлении виртуальной инфраструктуры в части хостов ESXi с помощью vSphere Lifecycle Manager (vLCM), в кластере HA/DRS хост переводится в режим обслуживания (Maintenance mode), который предполагает эвакуацию виртуальных машин на другие серверы с помощью vMotion. После обновления хоста он выводится из режима обслуживания, и виртуальные машины с помощью DRS постепенно возвращаются на него. В зависимости от характера нагрузки этот процесс может занять от нескольких минут до нескольких часов, что не всегда соответствует ожиданиям администраторов.
Второй вариант - потушить виртуальные машины, обновить ESXi, а потом включить его - тоже не подходит, так как приводит к длительным простоям сервисов виртуальных машин (нужно не только время на обновление хоста, но и время на выключение и включение ВМ, либо их небыстрый Suspend на диск).
Поэтому VMware придумала технологию Suspend-to-Memory, которая появилась в VMware vSphere 7 Update 2. Суть ее в том, что при обновлении ESXi его виртуальные машины приостанавливаются, сохраняя свое состояние (Suspend) в оперативной памяти. Очевидно, что в таком состоянии перезагружать хост нельзя, поэтому данная техника используется только совместно с ESXi Quick Boot, которая подразумевает обновление гипервизора без перезагрузки сервера.
Надо отметить, что функции Quick Boot доступны не для всех серверов. Более подробная информация по поддержке этой технологии со стороны серверных систем приведена в KB 52477, а вот ссылки на страницы вендоров серверного оборудования, где можно узнать детали поддержки этой технологии:
По умолчанию настройка кластера Cluster Remediation для виртуальных машин выставлена в значение "Do not change power state" для виртуальных машин, что подразумевает их vMotion на другие серверы, поэтому чтобы использовать Suspend to Memory, надо выставить "Suspend to memory", как на картинке выше.
При использовании такого типа обновления vLCM будет пытаться сделать Suspend виртуальных машин в память, а если этого не получится (например, недостаточно памяти), то он просто не будет переходить в режим обслуживания.
Надо сказать, что Suspend-to-Memory поддерживает vSAN и работает с такими продуктами, как vSphere Tanzu и NSX-T.
Ну и вот небольшое демо того, как это работает:
Таги: VMware, vSphere, Upgrade, Update, ESXi, VMachines, HA, DRS, Memory
Некоторое время назад мы писали о технологии Remote Direct Memory Access (RDMA) которая позволяет не использовать CPU сервера для удаленного доступа приложения к памяти другого хоста. RDMA позволяет приложению обратиться (в режиме чтение-запись) к данным памяти другого приложения на таргете, минуя CPU и операционную систему за счет использования аппаратных возможностей, которые предоставляют сетевые карты с поддержкой этой технологии - называются они Host Channel Adaptor (HCA).
Устройства HCA могут коммуницировать с памятью приложений на сервере напрямую. Грубо говоря, если в обычном режиме (TCP) коммуникация по сети происходит так:
То при наличии на обоих хостах HCA, обмен данными будет происходить вот так:
Очевидно, что такая схема не только снижает нагрузку на CPU систем, но и существенно уменьшает задержки (latency) ввиду обхода некоторых компонентов, для прохождения которых данными требуется время.
Поддержка RDMA появилась еще в VMware vSphere 6.5, когда для сетевых адаптеров PCIe с поддержкой этой технологии появилась возможность обмениваться данными памяти для виртуальных машин напрямую через RDMA API. Эта возможность получила название Paravirtual RDMA (PVRDMA).
Работает она только в окружениях, где есть хосты ESXi с сетевыми картами с соответствующей поддержкой, а также где виртуальные машины подключены к распределенному коммутатору vSphere Distributed Switch (VDS). Метод коммуникации между виртуальными машинами в таком случае выбирается по следующему сценарию:
Если две машины общаются между собой на одном ESXi, то используется техника memory copy для PVRDMA, что не требует наличия HCA-карточки на хосте, но сама коммуникация между ВМ идет напрямую.
Если машины находятся на хостах с HCA-адаптерами, которые подключены как аплинки к VDS, то коммуникация идет через PVRDMA-канал, минуя обработку на CPU хостов, что существенно повышает быстродействие.
Если в коммуникации есть хоть одна ВМ на хосте, где поддержки RDMA на уровне HCA нет, то коммуникация идет через стандартный TCP-туннель.
Начиная с VMware vSphere 7 Update 1, для PVRDMA была добавлена поддержка оконечных устройств с поддержкой RDMA (Native Endpoints), в частности хранилищ. Это позволяет передать хранилищу основной поток управляющих команд и команд доступа к данным от виртуальных машин напрямую, минуя процессоры серверов и ядро операционной системы. К сожалению для таких коммуникаций пока не поддерживается vMotion, но работа в этом направлении идет.
Чтобы у вас работала технология PVRDMA для Native Endpoints:
ESXi должен поддерживать пространство имен PVRDMA. Это значит, что аппаратная платформа должна гарантировать, что физический сетевой ресурс для виртуальной машины может быть выделен с тем же публичным идентификатором, что и был для нее на другом хосте (например, она поменяла размещение за счет vMotion или холодной миграции). Для этого обработка идентификаторов происходит на сетевых карточках, чтобы не было конфликтов в сети.
Гостевая ОС должна поддерживать RDMA namespaces
на уровне ядра (Linux kernel 5.5 и более поздние).
Виртуальная машина должна иметь версию VM Hardware 18
или более позднюю.
За счет PVRDMA для Native Endpoints виртуальные машины могут быстрее налаживать коммуникацию с хранилищами и снижать задержки в сети, что положительно сказывается на производительности как отдельных приложений и виртуальных машин, так и на работе виртуального датацентра в целом.
Напомним, что Intel Optane DC persistent memory (DCPMM) - эта память не такая быстрая как DRAM и имеет бОльшие задержки, но они все равно измеряются наносекундами. При этом данная память позволяет иметь ее большой объем на сервере, что существенно повышает плотность ВМ на одном хосте.
Модули DCPMM изготавливаются под разъем DDR4 и доступны планками по 128, 256 и 512 ГБ. В одной системе может быть до 6 ТБ памяти DCPMM. Платформа VMware vSphere 6.7 EP10 и более поздние версии поддерживают память Intel Optane persistent memory 100 series (она же Intel Optane PMem) со вторым поколением процессоров Intel Xeon Scalable в режимах App Direct и Memory.
В указанном документе рассматривается производительность данной памяти в новом режиме Balanced Profile для конфигурации BIOS, который впервые появился в процессорах Intel этой серии в целях повышения производительности. За счет данного режима производительность памяти увеличилась в 1.75 раза, как показано на картинке по результатам тестов:
В блоге VMware vSphere появилась интересная запись о том, как происходит работа с памятью в гипервизоре VMware ESXi. Приведем ее основные моменты ниже.
Работа виртуальной машины и ее приложений с памятью (RAM) идет через виртуальную память (Virtual Memory), которая транслируется в физическую память сервера (Physical Memory). Память разбита на страницы - это такие блоки, которыми виртуальная память отображается на физическую. Размер этого блока у разных систем бывает разный, но для ESXi стандартный размер страниц равен 4 КБ, а больших страниц - 2 МБ.
Для трансляции виртуальных адресов в физические используется таблица страниц (Page Table), содержащая записи PTE (Page Table Entries):
Записи PTE хранят в себе ссылки на реальные физические адреса и некоторые параметры страницы памяти (подробнее можно почитать здесь). Структуры записей PTE могут быть разного размера - это WORD (16 bits/2 bytes), DWORD (32 bits/4 bytes) и QWORD (64 bits/8 bytes). Они адресуют большие блоки адресов в физической памяти, к примеру, DWORD адресует блок адресов 4 килобайта (например, адреса от 4096 до 8191).
Память читается и передается гостевой системе и приложениям страницами по 4 КБ или 2 МБ - это позволяет читать содержимое ячеек памяти блоками, что существенно ускоряет быстродействие. Естественно, что при таком подходе есть фрагментация памяти - редко когда требуется записать целое число страниц, и часть памяти остается неиспользуемой. При увеличении размера страницы растет и их фрагментация, но увеличивается быстродействие.
Таблицы страниц (а их может быть несколько) управляются программным или аппаратным компонентом Memory Management Unit (MMU). В случае аппаратного MMU гипервизор передает функции по управлению трансляцией ему, а программный MMU реализован на уровне VMM (Virtual Machine Monitor, часть гипервизора ESXi):
Важный компонент MMU - это буфер ассоциативной трансляции (Translation Lookaside Buffer, TLB), который представляет собой кэш для MMU. TLB всегда находится как минимум в физической памяти, а для процессоров он часто реализован на уровне самого CPU, чтобы обращение к нему было максимально быстрым. Поэтому обычно время доступа к TLB на процессоре составляет около 10 наносекунд, в то время, как доступ к физической памяти составляет примерно 100 наносекунд. VMware vSphere поддерживает Hardware MMU Offload, то есть передачу функций управления памятью на сторону MMU физического процессора.
Итак, если от виртуальной машины появился запрос на доступ к виртуальному адресу 0x00004105, то этот адрес разбивается на адрес виртуальной страницы (Virtual page number - 0x0004) и смещение (Offset - 0x105 - область внутри страницы, к которой идет обращение):
Смещение напрямую передается при доступе к физической странице памяти, а вот тэг виртуальной страницы ищется в TLB. В данном случае в TLB есть запись, что соответствующий этому тэгу адрес физической страницы это 0x0007, соответственно трансляция виртуальной страницы в физическую прошла успешно. Это называется TLB Hit, то есть попадание в кэш.
Возможна и другая ситуация - при декомпозиции виртуального адреса получаемый тэг 0x0003 отсутствует в TLB. В этом случае происходит поиск страницы в физической памяти по тэгу (страницу номер 3) и уже ее адрес транслируется (0x006). Далее запись с этим тэгом добавляется в TLB (при этом старые записи из кэша вытесняются, если он заполнен):
Надо отметить, что такая операция вызывает несколько большую задержку (так как приходится искать в глобальной памяти), и такая ситуация называется TLB Miss, то есть промах TLB.
Но это не самая плохая ситуация, так как счет latency все равно идет на наносекунды. Но доступ может быть и гораздо более долгий (миллисекунды и даже секунды) в том случае, если нужная гостевой ОС страница засвопировалась на диск.
Посмотрим на пример:
Виртуальная машина обратилась к виртуальному адресу 0x00000460, для которого есть тэг 0x0000. В физической памяти для этого тэга выделена страница 0, которая означает, что искать эту страницу нужно на диске, куда страница была сброшена ввиду недостатка физической оперативной памяти.
В этом случае страница восстанавливается с диска в оперативную память (вытесняя самую старую по времени обращения страницу), ну и далее происходит трансляция адреса к этой странице. Эта ситуация называется отказ страницы (Page Fault), что приводит к задержкам в операциях приложения, поэтому иногда полезно отслеживать Page Faults отдельных процессов, чтобы понимать причину падения быстродействия при работе с памятью.
Продолжаем рассказывать (пока еще есть что!) о новых продуктах и технологиях, анонсированных на конференции VMworld 2019, которая закончилась уже почти 3 недели назад. Одна из самых интересных и перспективных технологий - это, конечно же, техника VMware Cluster Memory, которая действительно может поменять архитектуру датацентров в будущем.
Об этой технологии хорошо написал Дункан Эппинг. Как известно некоторым из вас, еще 20 лет назад скорость доступа к оперативной памяти серверов была примерно в 1000 раз выше, чем доступ к данным другого хоста по локальной сети. Шли годы, сетевой стек и оборудование улучшались - и в итоге на сегодняшний день доступ по сети всего в 10 раз медленнее, чем локальный доступ к RAM. Достигается это различными способами, в том числе технологией удалённого прямого доступа к памяти (remote direct memory access, RDMA).
Главное в этой эволюции то, что такие вещи как RDMA стали вполне доступными по цене, а значит можно обсуждать новые архитектуры на их основе. Тем более, что одной из основных проблем текущих датацентров стала трудность масштабирования инфраструктуры по памяти - ведь когда на одном из хостов не влезают виртуальные машины по RAM (например, есть машины с очень большим потреблением памяти), нужно увеличивать память и на всех остальных хостах кластера.
Поэтому VMware в рамках сессии VMworld "Big Memory with VMware Cluster Memory" рассказала о том, как можно строить кластеры с помощью так называемых "серверов памяти", которые обеспечивают работу хостов ESXi и их виртуальных машин, которым нужно дополнительное пространство памяти по требованию.
Кстати, еще есть и ограничение по объему DRAM на одном хосте - как правило, это несколькоТБ. Как мы видим на картинке выше, эту проблему можно решить созданием отдельных Memory-серверов в кластере, которые могут раздавать свою память по высокопроизводительной шине RDMA.
Технологии сетевого доступа к памяти будут развиваться, и скоро возможность использования виртуальными машинами страниц памяти с Memory-хостов будет вполне реальна:
Для этого компания VMware разработала отдельный paging-механизм, который позволяет проводить паджинацию страниц на удаленный сервер вместо локального диска, для чего будет необходим локальный кэш. При запросе страницы с удаленного сервера она сначала будет помещаться в локальный кэш для ускорения повторного использования.
Если страницы долгое время остаются невостребованными - они перемещаются обратно на Memory Server. По-сути, эта технология представляет собой оптимизацию механизма паджинации. В то же время, здесь пока существуют следующие проблемы:
Сбои, связанные с доступом к Cluster Memory
Безопасность и сохранность данных
Управление ресурсами в распределенной среде
Увеличение потребления межсерверного канала
Управление жизненным циклом страниц
Производительность механизма в целом
В рамках демо на VMworld 2019 была показана технология Cluster Memory в действии для виртуальной машины, использующей 3 ГБ такой памяти.
Конечно же, самая интересная проблема - это производительность ВМ в таких условиях. VMware сделала некоторые тесты, где были использованы различные соотношения локальной и удаленной памяти. На получившемся графике видна производительность в числе выполненных операций в минуту:
Обратите внимание, и это здесь четко видно, что Cluster Memory всегда работает быстрее, чем локальный SSD-Swap. Второй важный момент тут, что даже при 70% использовании удаленной памяти виртуальная машина, с точки зрения производительности, чувствует себя вполне хорошо.
Понятно, что технология VMware Cluster Memory еще дело будущего, но пока вы можете посмотреть интересную запись упомянутой сессии на VMworld.
Вчера мы писали об ограничениях технологии Persistent Memory в vSphere 6.7, которая еще только изучается пользователями виртуальных инфраструктур на предмет эксплуатации в производственной среде. Преимущество такой памяти - это, конечно же, ее быстродействие и энергонезависимость, что позволяет применять ее в высокопроизводительных вычислениях (High Performance Computing, HPC).
Ну а пока все это изучается, сейчас самое время для проведения всякого рода тестирований.
NVDIMM-N от компаний DELL EMC и HPE. NVDIMM-N - это такой тип устройств DIMM, который содержит модули DRAM и NANDflash на самом DIMM. Данные перемещаются между двумя этими модулями при запуске или выключении машины, а также во время внезапной потери питания (на этот случай есть батарейки на плате). На текущий момент есть модули 16 GB NVDIMM-Ns.
Intel Optane DC persistent memory (DCPMM) - эта память не такая быстрая как DRAM и имеет бОльшие задержки, но они измеряются наносекундами. Модули DCPMM изготавливаются под разъем DDR4 и доступны планками по 128, 256 и 512 ГБ. В одной системе может быть до 6 ТБ памяти DCPMM.
Для тестирования производительности такой памяти были использованы следующие конфигурации тестовой среды:
При тестировании производительности ввода-вывода были сделаны следующие заключения:
Накладные расходы на поддержку PMEM составляют менее 4%.
Конфигурация vPMEM-aware (когда приложение знает о vPMEM устройстве) может дать до 3x и более прироста пропускной способности в смешанном потоке чтения-записи в сравнении с традиционными устройствами vNVMe SSD (они использовались в качестве базового уровня).
Задержки (latency) на уровне приложений для конфигураций vPMEM составили менее 1 микросекунды.
Также тестировалась производительность баз данных Oracle, и там были сделаны такие выводы:
Улучшение на 28% в производительности приложения (количество транзакций HammerDB в минуту) с vPMEM по сравнению с vNVME SSD.
Увеличение 1.25x DB reads, 2.24x DB writes и до 16.6x в числе записей в DB log.
До 66 раз больше уменьшение задержек при выполнении операций в Oracle DB.
В MySQL тоже весьма существенное улучшение производительности:
Для PMEM-aware приложений тоже хорошие результаты:
Ну а остальные детали процесса проведения тестирования производительности устройств PMEM вы найдете в документе VMware.
В августе прошлого года мы сделали статью о новом виде памяти Persistent memory (PMEM) в VMware vSphere, которая находится на уровне между DRAM и Flash SSD с точки зрения производительности:
Надо сказать, что устройства с Persistent Memory (они же, например, девайсы с Intel Optane Memory) уже начинают рассматривать некоторые пользователи для внедрения в своей виртуальной инфраструктуре, поэтому надо помнить об их ограничениях, которые раскрыл Дункан Эппинг.
С точки зрения предоставления памяти PMEM виртуальной машине, на платформе vSphere есть 3 способа:
vPMEMDisk - vSphere представляет PMEM как обычный диск, подключенный к виртуальной машине через контроллер SCSI. В этом случае ничего не нужно менять для гостевой ОС или приложений. В таком режиме работают любые системы, включая старые ОС и приложения.
vPMEM - vSphere представляет PMEM как устройство NVDIMM для виртуальной машины. Большинство последних версий операционных систем (например, Windows Server 2016 и CentOS 7.4) поддерживают устройства NVDIMM и могут предоставлять их приложениям как блочные или байт-адресуемые устройства. Приложения могут использовать vPMEM как устройство хранения через тонкий слой файловой системы direct-access (DAX), либо замапить регион с устройства и получать к нему прямой доступ через байтовую адресацию. Такой режим может быть использован старыми или новыми приложениями, но работающими в новых версиях ОС, при этом версия Virtual Hardware должна быть не ниже 14.
vPMEM-aware - это то же самое, что и vPMEM, но только с дополнительными возможностями приложения понимать, что машина использует такое устройство, и пользоваться его преимуществами.
Если виртуальная машина использует такие устройства, то она имеет очень существенные ограничения, которые на данный момент препятствуют их использованию в производственной среде. Они приведены в документе "vSphere Resource Management Guide" на странице 47 внизу. А именно:
vSphere HA - полностью не поддерживается для машин с включенными vPMEM устройствами, вне зависимости от режима использования.
vSphere DRS - полностью не поддерживается для машин с включенными vPMEM устройствами (машины не включаются в рекомендации и не мигрируют через vMotion), вне зависимости от режима использования.
Миграция vMotion для машин с устройствами vPMEM / vPMEM-aware доступна только на хосты с устройствами PMEM.
Миграция vMotion машин с устройством vPMEMDISK возможна на хост без устройства PMEM.
Будем надеяться, что эта ситуация в будущем изменится.
Таги: VMware, vSphere, Memory, PMEM, Intel, VMachines, HA, DRS
В последней версии платформы виртуализации VMware vSphere 6.7 появилась новая возможность - поддержка Persistent Memory (PMEM). Это новый вид памяти, который покрывает разрыв между оперативной памятью (RAM) и дисковой памятью (Flash/SSD) с точки зрения быстродействия и энергонезависимости.
PMEM имеет 3 ключевые характеристики:
Параметры задержки (latency) и пропускной способности (bandwidth) как у памяти DRAM (то есть примерно в 100 быстрее, чем SSD).
Процессор может использовать стандартные байт-адресуемые инструкции для сохранения данных и их подгрузки.
Сохранение значений в памяти при перезагрузках и неожиданных падениях устройства хранения.
Таким образом, память PMEM находится в следующем положении относительно других видов памяти:
А ее характеристики соотносятся с SSD и DRAM памятью следующим образом:
Такие характеристики памяти очень подойдут для приложений, которым требуется сверхбыстродействие, при этом есть большая необходимость сохранять данные в случае сбоя. Это могут быть, например, высоконагруженные базы данных, системы тяжелой аналитики, приложения реального времени и т.п.
На данный момент vSphere 6.7 поддерживает 2 типа решений PMEM, присутствующих на рынке:
NVDIMM-N от компаний DELL EMC и HPE - это тип устройств DIMM, которые содержат как DRAM, так и модули NAND-flash на одной планке. Данные передаются между двумя модулями при загрузке, выключении или любом событии, связанном с потерей питания. Эти димы поддерживаются питанием с материнской платы на случай отказа. Сейчас обе компании HPE и DELL EMC поставлют модули 16 GB NVDIMM-N.
Модули Scalable PMEM от компании HPE (доступно, например, в серверах DL380 Gen10) - они позволяют комбинировать модули HPE SmartMemory DIMM с устройствами хранения NVMe (интерфейс Non-volatile Memory дисков SSD) и батареями, что позволяет создавать логические устройства хранения NVDIMM. Данные передаются между DIMMs и дисками NVMe. Эта технология может быть использована для создания систем с большим объемом памяти PMEM на борту.
При этом накладные затраты на использование виртуализации с устройствами PMEM не превышают 3%. Вот так выглядят примерные численные характеристики производительности памяти NVMe SSD и NVDIMM-N по сравнению с традиционными дисками:
С точки зрения предоставления памяти PMEM виртуальной машине, есть 2 способа в vSphere 6.7:
vPMEMDisk - vSphere представляет PMEM как обычный диск, подключенный к виртуальной машине через контроллер SCSI. В этом случае ничего не нужно менять для гостевой ОС или приложений. В таком режиме работают любые системы, включая старые ОС и приложения.
vPMEM - vSphere представляет PMEM как устройство NVDIMM для виртуальной машины. Большинство последних версий операционных систем (например, Windows Server 2016 и CentOS 7.4) поддерживают устройства NVDIMM и могут предоставлять их приложениям как блочные или байт-адресуемые устройства. Приложения могут использовать vPMEM как устройство хранения через тонкий слой файловой системы direct-access (DAX), либо замапить регион с устройства и получать к нему прямой доступ через байтовую адресацию. Такой режим может быть использован старыми или новыми приложениями, но работающими в новых версиях ОС, при этом версия Virtual Hardware должна быть не ниже 14.
Вот так это выглядит с точки зрения логики работы:
Если у вас хост VMware ESXi имеет на борту устройства с поддержкой PMEM, вы можете увидеть это в его свойствах в разделе Persistent Memory:
При создании новой виртуальной машины вы сможете выбрать, какое хранилище использовать для нее - стандартное или PMem:
Параметры диска на базе PMEM можно установить в разделе Customize hardware:
Также в свойствах виртуальной машины можно добавить новый жесткий диск в режиме vPMEMDisk:
Если же вы хотите добавить хранилище в режиме vPMEM, то надо указать соответствующий объем использования устройства в разделе New NVDIMM:
Надо отметить, что хранилище PMEM может быть на хосте ESXi только одно и содержит только устройства NVDIMM и виртуальные диски машин (то есть вы не сможете хранить там файлы vmx, log, iso и прочие). Для такого датастора единственное доступное действие - это просмотр статистик (при этом в vSphere Client на базе HTML5 датасторы PMEM вообще не видны). Вывести статистику по устройствам PMEM можно командой:
# esxcli storage filesystem list
Пример результатов вывода:
При включении ВМ, использующей PMEM, создается резервация этого устройства, которая сохраняется вне зависимости от состояния виртуальной машины (включена она или выключена). Резервация очищается при миграции или удалении ВМ.
Что касается миграции ВМ с устройством PMEM, то особенности этой миграции зависят от режима использования машиной устройства. Для миграции между хостами ESXi машины с PMEM включается не только vMotion, но и Storage vMotion, а на целевом хосте должно быть достаточно места для создания резервации от мигрируемой машины. При этом машину с хранилищем в режиме vPMEMDisk можно перенести на хост без устройства PMEM, а вот машину с vPMEM - уже нет.
В самом плохом случае при миграции ВМ с хранилищем NVMe SSD ее простой составит всего полсекунды:
Технологии VMware DRS и DPM (Distributed Power Management) полностью поддерживают память PMEM, при этом механизм DRS никогда не смигрирует машину, использующую PMEM на хосте, на сервер без устройства PMEM.
vPMEM-aware - это использование устройства PMEM гостевой ОС, которая умеет работать с модулем PMEM на хосте через прямой доступ к постоянной памяти устройства.
2. Бенчмарк FIO для пропускной способности (Throughput):
3. Бенчмарк HammerDB для Oracle, тестирование числа операций в секунду:
4. Тест Sysbench для базы данных MySQL, тестирование пропускной способности в транзакциях в секунду:
Еще несколько интересных графиков и тестовых кейсов вы можете найти в документе, ссылка на который приведена выше. Ну а больше технической информации о PMEM вы можете почерпнуть из этого видео:
Документация на тему использования Persistent Memory в VMware vSphere 6.7 доступна тут и тут.

 RSS
RSS