DVD Store — это инструментарий для тестирования баз данных с открытым исходным кодом, который активно применяется с момента своего первого релиза в 2005 году. Он поддерживает работу с СУБД SQL Server, Oracle, PostgreSQL и MySQL. DVD Store моделирует интернет-магазин, в котором пользователи авторизуются, просматривают каталог, оставляют отзывы, выставляют оценки и покупают DVD. В тесте задействуется большое число типичных возможностей реляционных БД: хранимые процедуры, индексы, внешние ключи, полнотекстовый поиск, сложные запросы с множественными join'ами и транзакции.
Изначально DVD Store разрабатывался как нагрузка, ориентированная преимущественно на CPU. Тем не менее в нём с самого начала были предусмотрены параметры, позволяющие менять этот профиль и переключаться на сценарии, в которых акцент делается на сеть, дисковую подсистему или даже память. Примеры таких профилей теперь добавлены и описаны в основном репозитории DVD Store на GitHub: https://github.com/dvdstore/ds35/tree/main/workload_profiles
VMware провела тестирование тестирование платформы VMware vSphere с помощью этого инструмента для того, чтобы понять, насколько эти профили меняют поведение нагрузки относительно стандартного CPU-ориентированного сценария. Все измерения проводились на одной виртуальной машине, развёрнутой на сервере ESX 9.0 платформы VMware Cloud Foundation (VCF). ВМ работала под управлением Windows Server 2022, в качестве СУБД использовалась SQL Server 2022. Все показатели производительности фиксировались со стороны хоста ESX с помощью утилиты esxtop (аналог linux top, но адаптированный под ESX и собирающий значительно более широкий набор метрик).
CPU Utilization — загрузка процессора на хосте ESX
Disk I/O per second (IOPS) — операции чтения и записи на диск со стороны хоста ESX
Mb received per second (Mb Rec/s) — мегабиты, принятые в секунду по сети
Mb sent per second (Mb Sent/s) — мегабиты, отправленные в секунду по сети
Active Memory (ActiveMem) — объём памяти, к которой недавно было обращение (активная память)
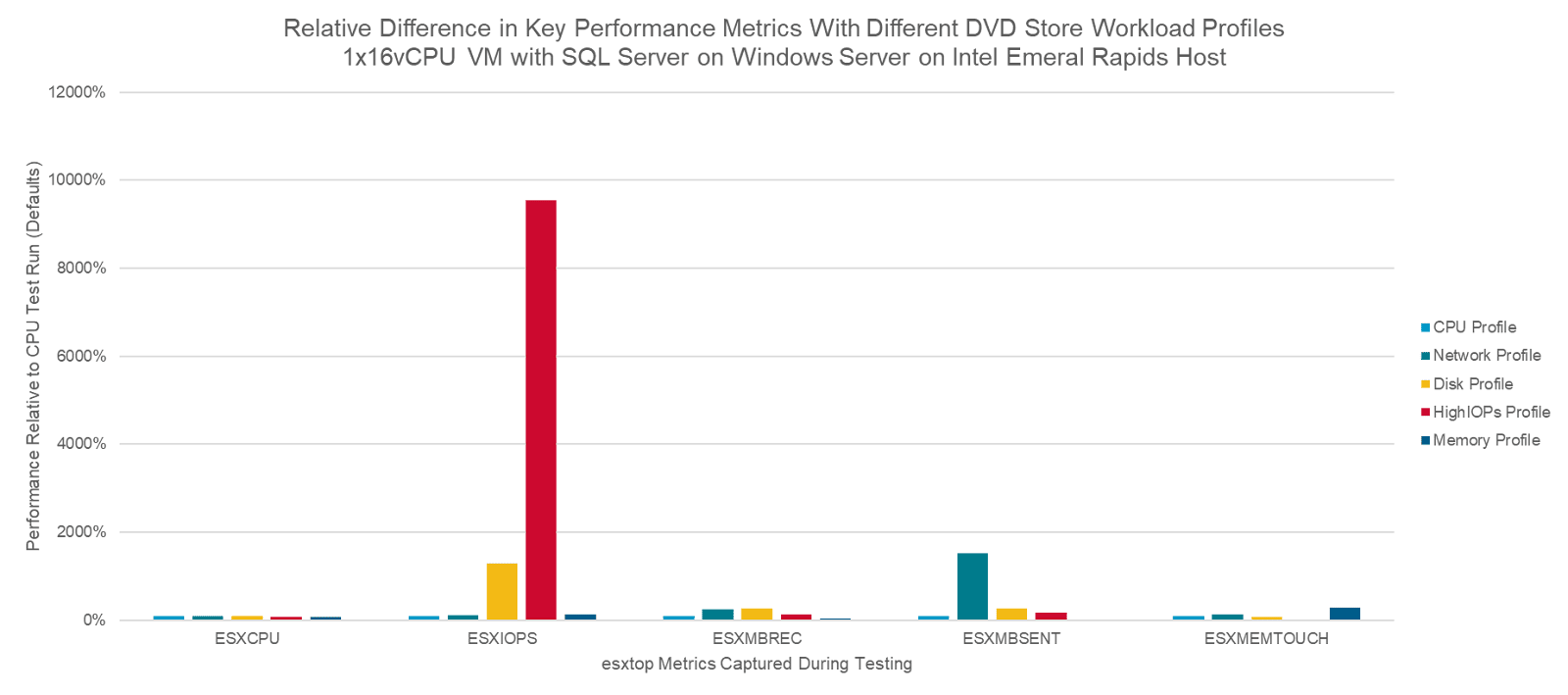
Относительное изменение ключевых метрик в разных профилях нагрузки
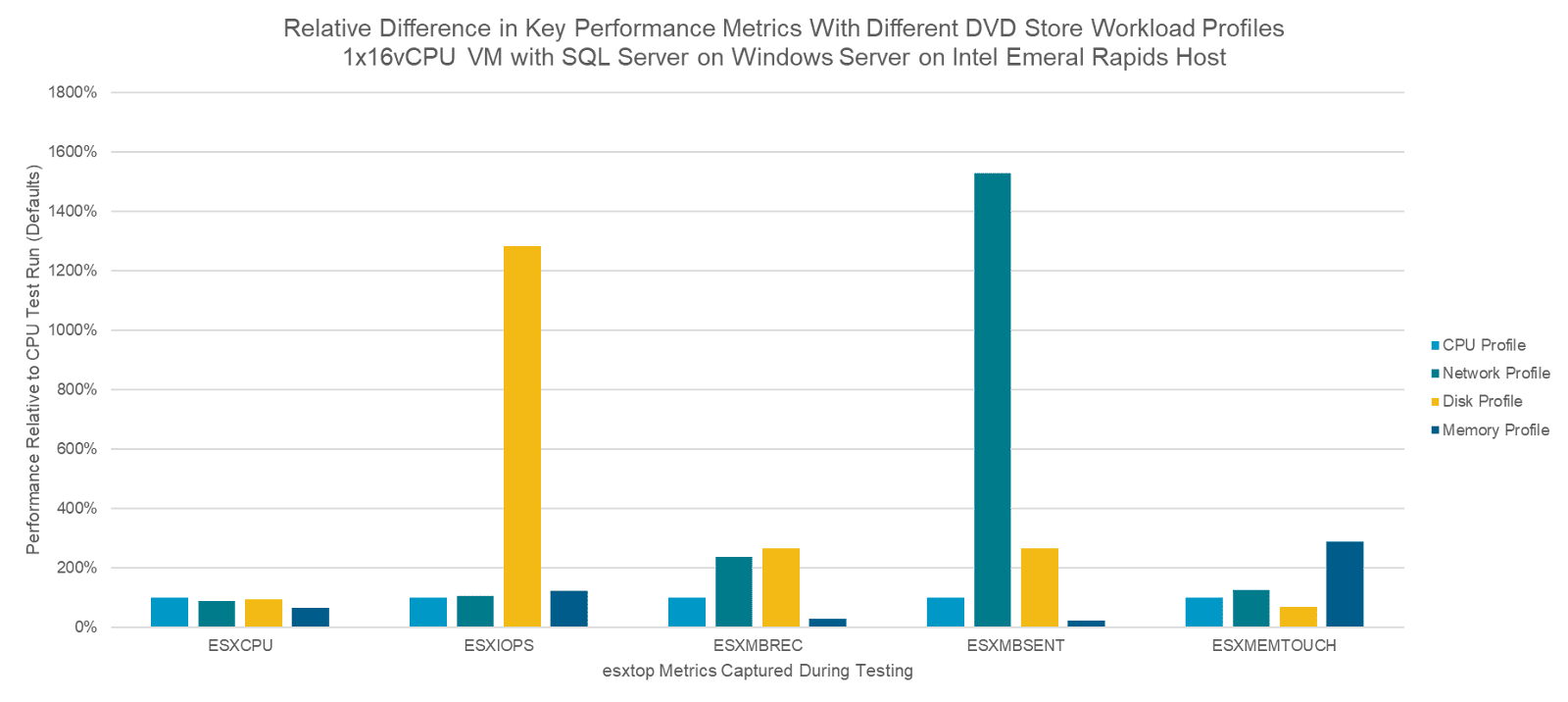
Для построения базовой линии замеры выполнялись на CPU-ориентированном профиле. Затем те же тесты были проведены с профилями, акцентированными на диск, на максимально высокий IOPS, на сеть и на память; полученные значения ключевых метрик сопоставлялись с базовыми. На графиках ниже показаны относительные различия по этим метрикам относительно базового CPU-профиля. На первом графике приведены все профили нагрузки; на втором профиль highIOPS убран, чтобы наглядно увидеть различия между остальными.
Если кратко резюмировать результаты, то в ключевой для каждого профиля метрике заметен значительный прирост:
Disk-профиль выдаёт в 13 раз больше IOPS
HighIOPS-профиль обеспечивает в 95 раз больше IOPS — это в 7 раз выше, чем у Disk-профиля
Network-профиль увеличивает количество отправленных мегабит в секунду в 15 раз
Memory-профиль вызывает в 2,9 раза большее значение активной памяти
Подробное описание всех профилей нагрузки приведено в файле ds35_workload_profiles.txt в репозитории DVD Store на GitHub. Там же указаны конкретные параметры DVD Store, особенности конфигурации БД и краткие пояснения к каждому сценарию.
Недавно мы писали о полезном документе для администраторов VMware vSphere 6.5 - Performance Best Practices for VMware vSphere 6.5. Этот документ обязательно надо прочитать, там много всего полезного и интересного.
Например, там есть немного про улучшение команды esxtop, показывающей производительность хоста и виртуальных машин в различных аспектах. Теперь там добавилась метрика Power Management, где можно в реальном времени наблюдать за актуальной частотой процессора. Эта информация теперь отображается в колонке %A/MPERF.
Чтобы добавить ее, после запуска esxtop нажмите клавишу <p> и затем клавишу <f> для добавления колонки.
Вы увидите значения, некоторые из которых больше 100. Например, для процессора 2 и 4 на картинке выше значения равны 150. При этом это процессор Xeon E5-2699 v3 2.3 ГГц с функцией разгона частоты Turbo Boost до 3.6 ГГц. Значение 150 означает, что в данный момент процессор работает на частоте 2.3*1.5 = 3.45 ГГц, то есть почти на пределе.
Мы часто пишем о встроенной утилите на хосте ESXi - esxtop, которая позволяет отслеживать все основные аспекты производительности хост-серверов и виртуальных машин (процессор, память, диски и сеть). Напомним, что наши последние посты о esxtop расположены тут, тут, тут, тут, тут и тут.
А недавно вышло весьма полезное образовательное видео "Using esxtop to Troubleshoot Performance Problems", в котором показано на практическом примере, как именно использовать esxtop для решения проблем производительности (хотя голос и весьма уныл):
Ну и напомним, что у esxtop есть графический интерфейс - это утилита VisualEsxtop.
Вчера мы писали про режим воспроизведения, который можно использовать для утилиты esxtop, предназначенной мониторинга производительности хост-серверов VMware ESXi. А сегодня предлагаем вам скачать постер "vSphere 6 ESXTOP quick Overview for Troubleshooting", в котором приведена основная информация для начала работы с esxtop, а также базовые приемы по решению возникающих в виртуальной инфраструктуре проблем с производительностью. Также стоит заглянуть вот в эту и эту заметку на нашем сайте.
Постер можно повесить в админской или серверной, где часто приходится работать с консолью серверов ESXi:
Интересную новость мы обнаружили вот тут. Оказывается утилита esxtop может работать в режиме повтора для визуализации данных о производительности, собранных в определенный период времени (многие администраторы знают это, но далеко не все). Это позволит вам собрать данные о производительности хоста, например, ночью, а в течение рабочего дня проанализировать аномальное поведение виртуальной инфраструктуры VMware vSphere. Называется этот режим replay mode.
Для начала запустите следующую команду для сбора данных на хосте VMware ESXi:
Многие из вас знают утилиту esxtop (о которой мы часто пишем), позволяющей осуществлять мониторинг производительности сервера VMware ESXi в различных аспектах - процессорные ресурсы, хранилища и сети. Многие администраторы пользуются ей как раз для того, чтобы решать проблемы производительности.
Но оказывается, что использование esxtop само по себе может тормозить работу сервера VMware ESXi!
Это может произойти в ситуации, если у вас к ESXi смонтировано довольно много логических томов LUN, на обнаружение которых требуется более 5 секунд. Дело в том, что esxtop каждые 5 секунд повторно инициализирует объекты, с которых собирает метрики производительности. В случае с инициализацией LUN, которая занимает длительное время, запросы на инициализацию томов будут складываться в очередь. А как следствие (при большом числе томов) это будет приводить к возрастанию нагрузки на CPU и торможению - как вывода esxtop, так и к замедлению работы сервера в целом.
Выход здесь простой - надо использовать esxtop с параметром -l:
# esxtop -l
В этом случае данная утилита ограничит сбор метрик производительности только теми объектами, которые были обнаружены при первом сканировании. Соответственно, так лучше всего ее и использовать, если у вас к серверу VMware ESXi прицеплено много хранилищ.
На сайте проекта VMware Labs появилась интересная утилита ESXtopNGC Plugin, позволяющая получить функциональность консольного средства мониторинга производительности esxtop прямо в vSphere Web Client.
Возможности VMware ESXtopNGC Plugin:
Отдельные вкладки для статистик процессора, памяти, сети и дисковой подсистемы.
Гибкий вывод данных, в том числе в пакетном режиме.
Удобный и гибкий выбор необходимых счетчиков.
Полнофункциональное представление статистик с возможностью сортировки колонок, раскрытия строчек и т.п.
Настраиваемый период обновления данных.
Статистики по виртуальным машинам (VM-only stats).
Встроенные тултипы с описаниями назначений счетчиков.
Плагин ESXtopNGC на данный момент работает только с виртуальным модулем vCenter Server Appliance (vCSA) 5.5 или более поздних версий.
Для установки плагина загрузите его в одну из директорий на vCSA и выполните там команду:
Мы очень много писали о том, как с помощью утилиты esxtop можно собирать с хостов VMware ESXi данные о производительности и различные метрики (например, тут и тут). Данные, полученные с помощью этой утилиты, очень часто помогают разобраться в источнике проблем в части вычислительных ресурсов, хранилищ и сетевого взаимодействия.
В этой заметке мы поговорим немного о визуализации данных esxtop. Не так давно мы писали об утилите VisualEsxtop, которая как раз тем самым и занимается - строит графики по наборам данных. Но недавно мы наткнулись на простой способ, позволяющий с помощью Windows Perfmon сравнивать наборы данных esxtop с разных хостов ESXi.
1. Итак, сначала нужно собрать данные с хоста ESXi в пакетном режиме в файл .csv. Например:
esxtop -b -d 10 -n 360 > esxtopresults.csv
Здесь:
-b - означает пакетный режим работы утилиты.
-d (delay) - промежуток между срезами сбора данных.
-n - число число таких срезов (сэмплов).
В данном случае будет собрано 360 сэмплов данных с промежутком в 10 секунд, то есть сбор займет 1 час.
Можно сжать результаты, чтобы экономить место на хосте, командой:
2. Загружаем данные в Windows Perfmon, выбрав источник - наш файл csv:
Визуализируем нужные счетчики:
3. Пробуем добавить еще один csv с другого хоста ESXi (с которым мы хотим сравнить данные первого хоста), но нам говорят, что так нельзя - можно такие файлы смотреть только по одному:
Не беда - сохраняем данные как бинарный файл с расширением *.blg, выбрав нужные счетчики:
Дальше просто удаляем этот файл из источников данных Perfmon, добавляем второй csv-файл и так же сохраняем его как *.blg.
Ну а дальше оба этих файла добавляем по одному - и все работает:
Добавляем сохраненные счетчики:
И данные с обоих хостов показываются на одном графике:
Мы много пишем о проекте VMware Labs, созданный для того, чтобы инженеры VMware выкладывали там свои наработки, которые не были оформлены в виде конечных продуктов компании (заметки об этом можно найти у нас по тэгу Labs).
На этот раз на VMware Labs появилась по-настоящему полезная штука - VisualEsxtop. Как можно догадаться из названия, эта утилита, написанная на Java, позволяет визуализовать данные о производительности в реальном времени, выводимые командой esxtop. Утилита кроссплатформенная и работает под Windows и Linux как .bat или .sh сценарий.
Возможности VisualEsxtop:
Соединение как с отдельным хостом ESXi, так и с vCenter Server.
Гибкий способ пакетного вывода результатов.
Загрузка результатов пакетного вывода и его "прогонка" (replay).
Возможность открыть несколько окон для отображения различных данных одновременно.
Визуализация в виде графика выбранных счетчиков производительности.
Гибкий выбор и фильтрация счетчиков.
Тултип на ячейках счетчиков, объясняющий их назначение (см. картинку).
Цветовое кодирование важных счетчиков.
Также VisualEsxtop можно заставить работать под Mac OS X - для этого почитайте вот эту статью.
Скачать VisualEsxtop можно по этой ссылке. Четырехстрочная инструкция доступна тут.
Если мы запустим утилиту esxtop, то увидим следующие столбцы (интересующее нас выделено красным):
Нас интересует 5 счетчиков, касающиеся процессоров виртуальных машин, с помощью которых мы сможем сделать выводы об их производительности. Рассмотрим их подробнее:
Счетчик %RUN
Этот счетчик отображает процент времени, в течение которого виртуальная машина исполнялась в системе. Когда этот счетчик для ВМ около нуля или принимает небольшие значение - то с производительностью процессора все в порядке (при большом его значении для idle). Однако бывает так, что он небольшой, а виртуальная машина тормозит. Это значит, что она заблокирована планировщиком ESXi или ей не выделяется процессорного времени в связи с острой нехваткой процессорных ресурсов на сервере ESXi. В этом случае надо смотреть на другие счетчики (%WAIT, %RDY и %CSTP).
Если значение данного счетчика равно <Число vCPU машины> x 100%, это значит, что в гостевой ОС виртуальной машины процессы загрузили все доступные процессорные ресурсы ее vCPU. То есть необходимо зайти внутрь ВМ и исследовать проблему.
Счетчики %WAIT и %VMWAIT
Счетчик %WAIT отображает процент времени, которое виртуальная машина ждала, пока ядро ESXi (VMkernel) выполняло какие-то операции, перед тем, как она смогла продолжить выполнение операций. Если значение этого счетчика значительно больше значений %RUN, %RDY и %CSTP, это значит, что виртуальная машина дожидается окончания какой-то операции в VMkernel, например, ввода-вывода с хранилищем. В этом случае значение счетчика %SYS, показывающего загрузку системных ресурсов хоста ESXi, будет значительно выше значения %RUN.
Когда вы видите высокое значение данного счетчика, это значит, что нужно посмотреть на производительность хранилища виртуальной машины, а также на остальные периферийные устройства виртуального "железа". Зачастую, примонтированный ISO-образ, которого больше нет на хранилище, вызывает высокое значение счетчика. Это же касается примонтированных USB-флешек и других устройств ВМ.
Не надо пугаться высокого значения %WAIT, так как оно включает в себя счетчик %IDLE, который отображает простой виртуальной машины. А вот значение счетчика %VMWAIT - уже более реальная метрика, так как не включает в себя %IDLE, но включает счетчик %SWPWT (виртуальная машина ждет, пока засвопированные таблицы будут прочитаны с диска; возможная причина - memory overcommitment). Таким образом, нужно обращать внимание на счетчик %VMWAIT. К тому же, счетчик %WAIT представляет собой сумму метрик различных сущностей процесса виртуальной машины:
Счетчик %RDY
Главный счетчик производительности процессора. Означает, что виртуальная машина (гостевая ОС) готова исполнять команды на процессоре (ready to run), но ожидает в очереди, пока процессоры сервера ESXi заняты другой задачей (например, другой ВМ). Является суммой значений %RDY для всех отдельных виртуальных процессоров ВМ (vCPU). Обращать внимание на него надо, когда он превышает пороговое значение 10%.
По сути, есть две причины, по которым данный счетчик может зашкаливать приведенное пороговое значение:
сильная нагрузка на физические процессоры из-за большого количества виртуальных машин и нагрузок в них (здесь просто надо уменьшать нагрузку)
большое количество vCPU у конкретной машины. Ведь виртуальные процессоры машин на VMware ESX работают так: если у виртуальной машины 4 vCPU, а на хосте всего 2 физических pCPU, то одна распараллеленная операция (средствами ОС) будет исполняться за в два раза дольший срок. Естественно, 4 и более vCPU для виртуальной машины может привести к существенным задержкам в гостевой ОС и высокому значению CPU Ready. Кроме того, в некоторых случаях нужен co-sheduling нескольких виртуальных vCPU (см. комментарии к статье), когда должны быть свободны столько же pCPU, это, соответственно, тоже вызывает задержки (с каждым vCPU ассоциирован pCPU). В этом случае необходимо смотреть значение счетчика %CSTP
Кроме того, значение счетчика %RDY может быть высоким при установленном значении CPU Limit в настройках виртуальной машины или пула ресурсов (в этом случае посмотрите счетчик %MLMTD, который при значении больше 0, скорее всего, говорит о достижении лимита). Также посмотрите вот этот документ VMware.
Счетчик %CSTP
Этот счетчик отображает процент времени, когда виртуальная машина готова исполнять команды, одна вынуждена ждать освобождения нескольких vCPU при использовании vSMP для одновременного исполнения операций. Например, когда на хосте ESXi много виртуальных машин с четырьмя vCPU, а на самом хосте всего 4 pCPU могут возникать такие ситуации с простоем виртуальных машин для ожидания освобождения процессоров. В этом случае надо либо перенести машины на другие хосты ESXi, либо уменьшить у них число vCPU.
В итоге мы получаем следующую формулу (она верна для одного из World ID одной виртуальной машины)
%WAIT + %RDY + %CSTP + %RUN = 100%
То есть, виртуальная машина либо простаивает и ждет сервер ESXi (%WAIT), либо готова исполнять команды, но процессор занят (%RDY), либо ожидает освобождения нескольких процессоров одновременно (%CSTP), либо, собственно, исполняется (%RUN).
Таги: VMware, vSphere, esxtop, ESXi, VMachines, Performance, CPU
Мы уже писали об основных приемах по решению проблем на хостах VMware ESX / ESXi с помощью утилиты esxtop, позволяющей отслеживать все аспекты производительности серверов и виртуальных машин. Через интерфейс RCLI можно удаленно получать эти же данные с помощью команды resxtop.
Сегодня мы приведем простое объяснение иерархии счетчиков esxtop, касающихся хранилищ серверов VMware vSphere. Для того, чтобы взглянуть на основные счетчики esxtop для хранилищ, нужно запустить утилиту и нажать кнопку <d> для перехода в режим отслеживания показателей конкретных виртуальных машин (кликабельно). Данные значения будут представлены в миллисекундах (ms):
Если мы посмотрим на колонки, которые выделены красным прямоугольником, то в виде иерархии их структуру можно представить следующим образом:
Распишем их назначение:
GAVG (Guest Average Latency) - общая задержка при выполнении SCSI-команд от гостевой ОС до хранилища сквозь все уровни работы машины с блоками данных. Это, само собой, самое большое значение, равное KAVG+DAVG.
KAVG (Kernel Average Latency) - это задержка, возникающая в стеке vSphere для работы с хранилищами (гипервизор, модули для работы SCSI). Это обычно небольшое значение, т.к. ESXi имеет множество оптимизаций в этих компонентах для скорейшего прохождения команд ввода-вывода сквозь них.
QAVG (Queue Average latency) - время, проведенное SCSI-командой в очереди на уровне стека работы с хранилищами, до передачи этой команды HBA-адаптеру.
DAVG (Device Average Latency) - задержка прохождения команд от HBA адаптера до физических блоков данных на дисковых устройствах.
В блоге VMware, где разобраны эти показатели, приведены параметры для типичной нагрузки по вводу-выводу (8k I/O size, 80% Random, 80% Read). Для такой нагрузки показатель Latency (GAVG) 20-30 миллисекунд и более может свидетельствовать о наличии проблем с производительностью подсистемы хранения на каком-то из подуровней.
Как мы уже отметили, показатель KAVG, в идеале, должен быть равен 0 или исчисляться сотыми долями миллисекунды. Если он стабильно находится в пределах 2-3 мс или больше - тут уже можно подозревать проблемы. В этом случае нужно проверить значение столбца QUED для ВМ - если оно достигло 1 (очередь использована), то, возможно, выставлена слишком маленькая величина очереди на HBA-адаптере, и необходимо ее увеличить.
Для просмотра очереди на HBA-адаптере нужно переключиться в представление HBA кнопкой <u>:
Ну и если у вас наблюдается большое значение DAVG, то дело, скорее всего, не в хосте ESX, а в SAN-фабрике или дисковом массиве, на уровне которых возникают большие задержки.
Компания VMware в базе знаний опубликовала интересный плакат "VMware vSphere 5 Memory Management and Monitoring diagram", раскрывающий детали работы платформы VMware vSphere 5 с оперативной памятью серверов. Плакат доступен как PDF из KB 2017642:
Основные техники оптимизации памяти хостов ESXi, объясняемые на плакате:
Есть также интересная картинка с объяснением параметров вывода esxtop, касающихся памяти (кликабельно):
Пишут, что администраторы VMware vSphere скачивают его, распечатывают в формате A2 и смотрят на него время от времени, как на новые ворота. Таги: VMware, vSphere, Memory, ESX, esxtop, VMachines, Whitepaper, Diagram
Мы уже писали о команде esxtop для серверов VMware ESX, которая позволяет отслеживать основные параметры производительности хост-сервера и его виртуальных машин. Duncan Epping недавно добавил еще несколько интересных моментов в свое руководство по работе с утилитой esxtop, некоторые из которых мы сейчас опишем.
Итак:
1. Для того, чтобы использовать пакетный режим работы esxtop (batch mode), нужно использовать ключ -b:
esxtop -b >perf.txt
Это позволит вывести результаты команды esxtop в файл perf.txt. Для задания числа хранимых итераций используйте ключ -n (например, -n 100).
Очень удобно для сбора исторических данных производительности на хосте VMware ESX.
2. Контролируйте счетчик %SYS - он показывает загрузку системных ресурсов хоста (в процентах). Рекомендуется, чтобы он не превышал 20 для системных служб.
3. Для установки частоты обновлений результатов esxtop используйте клавишу <s>, далее задавайте интервал в секундах:
В пакетном режиме этот интервал задается ключом -d (например, -d 2).
4. Для отслеживания метрик конкретной виртуальной машины можно ограничить вывод конкретным GID. Например, чтобы посмотреть ВМ с GID 63, нажмите клавишу <l> (list) и введите этот GID:
5. Чтобы ограничить количество выводимых сущностей, используйте клавишу <#>. Например, можно сделать вывод первых 5:
И сами кнопки в режиме работающей esxtop:
c = cpu
m = memory
n = network
i = interrupts
d = disk adapter
u = disk device (включая NFS-девайсы)
v = disk VM
y = power states
V = показывать только виртуальные машины
e = раскрыть/свернуть статистики CPU для конкретного GID
k = убить процесс (только для службы техподдержки!)
l = ограничить вывод конкретным GID (см. выше)
# = ограничить число сущностей (см. выше)
2 = подсветка строчки (двигает фокус вниз)
8 = подсветка строчки (двигает фокус вверх)
4 = удалить строчку из результатов вывода
f = добавить/удалить колонки
o = изменить порядок колонок
W = сохранить сделанные изменения в файл конфигурации esxtop
? = помощь для esxtop
Компания Zenoss анонсировала доступность бесплатного средства для мониторинга серверов VMware ESX / ESXi под названием ZenPack. Мониторинг хостов происходит посредством сбора статистик производительности командой resxtop (аналог esxtop через RCLI).
Что умеет ZenPack:
Собирать метрики производительности esxtop и выводить их на графиках
Устанавливать пороговые значения для метрик и оповещать администраторов об их превышении
Хранить историю значений во времени для последующего анализа
Скачать ZenPack можно по этой ссылке, а посмотреть документацию можно по этой.
Компания VMware запустила новый сервис VMware Labs, где разработчики компании могут опубликовать различные утилиты и программы для платформ VMware, которые могут оказаться полезными при работе с инфраструктурой виртуализации. Назначение проекта Labs - публикация собственных разработок инженерами компании, которые впоследствие могут быть включены в различные продукты VMware. На данный момент утилиты для VMware vSphere доступны как Technology Previews под open source лицензиями и без каких-либо гарантий в отношении работы в производственной среде и возможности их дальнейшего полноценного выпуска.
Как вы знаете, у сервера VMware ESX есть команда esxtop для отслеживания различных метрик производительности виртуальных машин на хосте. Кроме того, есть утилита vscsiStats, позволяющая осуществлять мониторинг производительности дисковой подсистемы сервера VMware ESX.
Известный изготовитель "шпаргалок" по виртуальной инфраструктуре VMware vSphere, Forbes Guthrie, выпустил небольшое руководство по использованию команд esxtop и vscsiStats, которое можно скачать по ссылке ниже:
Интересная особенность - руководство сделано в форм-факторе кредитной карты, что позволяет, например, запихнуть такую карточку в карман недоумевающему системному администратору со словами "учи матчасть!".
Зачастую бывает необходимо понять причины, по которым та или иная виртуальная машина на сервере VMware ESX испытывает проблемы производительности (тормозит). Можно воспользоваться встроенными графиками производительности VMware vCenter (вкладка Performance), однако этого может оказаться недостаточно. В консольной ОС VMware ESX (Service Console) есть утилита esxtop, которая позволяет отслеживать все аспекты производительности сервера виртуализации, а для VMware ESXi доступна утилита resxtop, которую можно запустить с помощью VMware vSphere Management Assistant.

 RSS
RSS