Это Часть 3 в серии о Storage DRS. В предыдущей части мы говорили о том как создавать и удалять SDRS Anti-Affinity правила. Чтобы закрыть тему, нам осталось редактировать/реконфигурировать существующие правила. Логично предположить, что это будет функция Set-SdrsAntiAffinityRule.
Несмотря на растущую популярность технологии VMware vSAN, большинство крупных предприятий по-прежнему частично или полностью продолжают работать с общими хранилищами (shared storage). Есть достаточно PowerCLI командлетов для конфигурирования большинства аспектов HA/DRS кластеров, однако для SDRS кластеров выбор не велик.
Интересный пост о технологии VVols появился на блогах VMware. Дескать, их часто спрашивают - почему средства балансировки нагрузки на хранилища Storage DRS не поддерживаются для томов VVols?
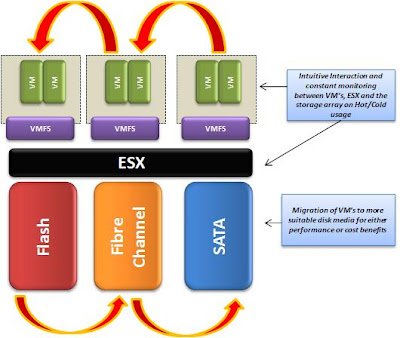
Для ответа на этот вопрос надо рассмотреть, как работает традиционная архитектура хранилищ, которая была до VVols и кластеров Virtual SAN. Обычный дисковый массив или хост можно представить набором носителей двух типов (HDD и Flash), которые дают суммарно некоторую емкость.
Например, у нас 160 ТБ на СХД, которые мы разбиваем на LUN по 8 ТБ, итого получая 20 томов VMFS. Допустим, половина емкости у нас HDD, а половина - SSD. Тогда мы создадим 2 датастор-кластера (datastore cluster), в каждом из которых будет по 10 томов VMFS:
Кластер на SSD-носителях будет хранилищем яруса Gold, а HDD - Silver. Технология Storage DRS предназначена, чтобы балансировать виртуальные машины в рамках яруса между LUN для обеспечения их равномерной загрузки, как по емкости, так и по вводу-выводу. А в случае необходимости машину можно также и перенести между ярусами (Silver->Gold) с помощью технологии Storage vMotion.
Все это вызвано сложной структурой хранилищ, которая "прячет" виртуальную машину от дискового массива, представляя ее в конечном счете как набор дисковых блоков, ничем не отличающихся таковых при подключении физических серверов.
В случае же с VVols дело обстоит совсем иначе: на все хранилище создается один Storage Container, который объединяет собой все 160 ТБ доступной емкости - и Flash, и HDD. И этот контейнер представляет собой единственный объект для хранения виртуальных машин с томами VVols:
То есть все операции по балансировке данных виртуальных машин (на уровне дисковых объектов VVols) передаются на сторону СХД, которая лучше знает, как правильно распределять данные и обеспечивать необходимый уровень обслуживания на базе политик (Storage Policies), привязанных к ярусам. Это, конечно же, требует некоторой работы со стороны производителей систем хранения, зато избавляет от забот саму VMware, которая универсализовала технологию VVols и средства работы с ней.
То есть, VVols не требует наличия Storage DRS - технологии, которая уйдет со временем на уровне отдельных аппаратных хранилищ, но будет полезной для балансировки в среде, где есть несколько СХД или кластеров хранилищ от одного или нескольких вендоров.
Duncan и Frank, известные своими изысканиями в сфере механизмов отказоустойчивости (HA) и балансировки нагрузки (DRS) в виртуальной инфраструктуре VMware vSphere, опубликовали паруинтересныхматериалов, касающихся настройки среды vCloud Director и механизма Storage DRS.
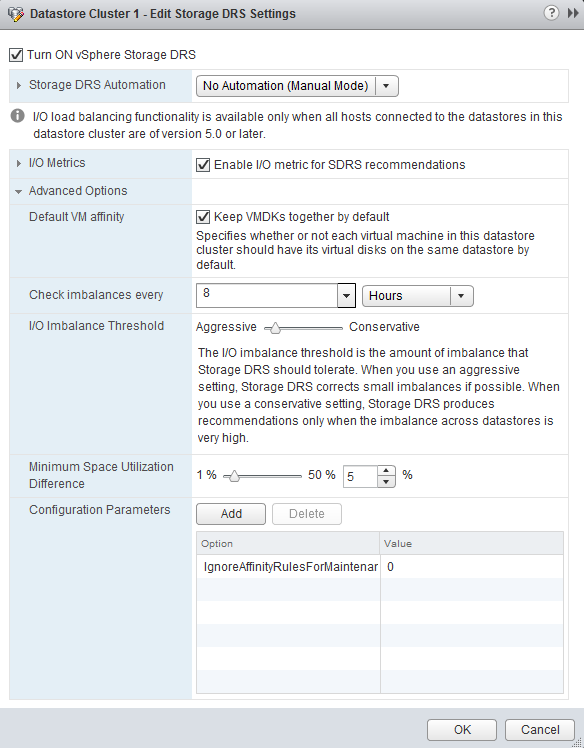
Как вы знаете, в настройках кластера хранилищ (Datastore Cluster) есть галка, которая определяет, будут ли виртуальные диски VMDK машин обязательно находиться на одном хранилище (Datastore) при миграции средствами механизма Storage DRS:
Надо отметить, что галка Keep VMDKs together by default - это не совсем простая для понимания галка. Если ее не поставить, то действовать будет обратное - диски виртуальной машины будут обязательно размещаться на разных хранилищах. Это, по заверениям блоггеров, даст больше гибкости в использовании механизма SDRS в среде vCloud Director при перемещении виртуальных машин между хранилищами, что даст больше преимуществ в динамически балансирующейся среде (особенно для "тонких" дисков). Соответственно, по умолчанию галка Keep VMDKs together by default должна быть выключена.
Не так давно мы писали про то, как работает механизм динамического выравнивания нагрузки на виртуальные хранилища VMware Storage DRS. Напомним, что он работает на базе 2-х параметров хранилищ:
Заполненность - в этом случае SDRS выравнивает виртуальные машины для равномерного заполнения хранилищ.
Производительность - при использовании этих метрик SDRS старается динамически перенести виртуальные машины с более нагруженных по параметрам ввода-вывода хранилищ на менее загруженные.
Однако бывает так, что несколько виртуальных хранилищ (Datastores) располагаются на одних и тех же RAID-группах, а значит миграция хранилищ виртуальных машин между ними ничего не даст - суммарно бэкэнд-диски системы хранения будут испытывать ту же самую нагрузку.
Например, бесполезна (с точки зрения производительности) будет миграция с Datastore1 на Datastore2:
Раньше этот факт не учитывался механизмом SDRS в vSphere 5.0, что приводило к бесполезным миграциям в автоматическом режиме. Теперь ситуация изменилась к лучшему в версии vSphere 5.1.
Как многие знают, в VMware vSphere есть механизм Storage IO Control (SIOC), который позволяет измерять мгновенную производительность хранилищ (параметр latency - задержка команд ввода-вывода) и регулировать очередь HBA-адаптеров на хостах ESXi. Так вот, одна из техник SIOC Injection позволяет производить тестирование виртуальных хранилищ на наличие корреляции производительности между ними.
Делается это следующим образом: SIOC запускает тестовую рабочую нагрузку на случайно выбранном Datastore1, измеряет latency, а потом отдельно от него запускает нагрузку на другом Datastore2 и также смотрит на latency:
Это нужно для установления базового уровня производительности для этих виртуальных хранилищ. Потом SIOC запускает нагрузку одновременно на 2 этих хранилища и смотрит, что происходит с latency:
Если оба этих хранилища физических расположены на одних и тех же дисковых устройствах (как в нашем случае), то измеряемые latency в данном случае возрастут, что говорит о взаимной корреляции данных хранилищ в плане производительности.
Узнав про этот факт, Storage DRS не будет генерировать рекомендации по перемещению виртуальных машин между хранилищами Datastore1 и Datastore2:
Однако эти рекомендации перестанут генерироваться только на базе производительности, на базе заполненности хранилищ такие рекомендации останутся.
Frank Denneman опять написал интересную статью. Оказывается у механизма VMware Storage DRS, который производит балансировку виртуальных машин по хранилищам кластера SDRS, есть механизм задания допустимого уровня over-commitment для хранилища при миграции ВМ на тонких дисках.
Как вы знаете, у тонких VMDK-дисков (Thin Disks) виртуальных машин есть 2 параметра:
Provisioned Space - максимальный размер VMDK-файла, до которого может вырости диск виртуальной машины.
Allocated Space - текущий размер растущего VMDK-диска.
Разность этих двух парметров есть значение IdleMB, отражающее объем, на который виртуальный диск еще может вырасти. В расширенных настройках Storage DRS можно задать параметр PercentIdleMBinSpaceDemand, который определяет, сколько процентов от IdleMB механизм SDRS прибавляет к Allocated Space при выдаче и применении рекомендаций по размещению виртуальных машин на хранилищах кластера.
Рассмотрим на примере. Пусть максимальный размер диска VMDK составляет 6 ГБ при Allocated Space в 2 ГБ. Допустим мы задали PercentIdleMBinSpaceDemand = 25%. Тогда мы получим такую картину:
Таким образом, при размещении виртуальной машины на хранилище механизм Storage DRS будет считать, что ВМ занимает не 2 ГБ дискового пространства, а 2+0.25*4 = 3 ГБ. Ну и увидев такую машину на 10 ГБ-хранилище, механизм SDRS, при расчете выравнивания хранилищ по заполненности, будет считать что она занимает 3 ГБ, и свободно осталось лишь 7 ГБ.
Регулируя эту настройку можно добиться различных коэффициентов консолидации тонких VMDK-дисков машин на хранилищах. Ну и очевидно, что значение параметра PercentIdleMBinSpaceDemand равное 100% приведет к тому, что тонкие диски при размещении будут учитываться как их обычные flat-собратья.
Недавно мы уже писали о том, как работает технология балансировки нагрузки на хранилища VMware Storage DRS (там же и про Profile Driven Storage). Сегодня мы посмотрим на то, как эта технология работает совместно с различными фичами дисковых массиов, а также функциями самой VMware vSphere и других продуктов VMware.
Для начала приведем простую таблицу, из которой понятно, что поддерживается, а что нет, совместно с SDRS:
Возможность
Поддерживается или нет
Рекомендации VMware по режиму работы SDRS
Снапшоты на уровне массива (array-based snapshots)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Дедупликация на уровне массива (array-based deduplication)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование "тонких" дисков на уровне массива (array-based thin provisioning)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование функций автоматического ярусного хранения (array-based auto-tiering)
Поддерживается
Ручное применение рекомендаций (Manual Mode), только для распределения по заполненности хранилищ (auto-tiering по распределению нагрузки сам решит, что делать)
Репликация на уровне массива (array-based replication)
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология репликации на уровне хоста (VMware vSphere Replication)
Не поддерживается
-----
Снапшоты виртуальных машин (VMware vSphere Snapshots)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Использование "тонких" дисков на уровне виртуальных хранилищ (VMware vSphere Thin Provisioning)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология связанных клонов (VMware vSphere Linked Clones)
Не поддерживается
-----
"Растянутый" кластер (VMware vSphere Storage Metro Cluster)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Хосты с версией ПО, младше чем vSphere 5.0
Не поддерживается
-----
Использование совместно с продуктом VMware vSphere Site Recovery Manager
Не поддерживается
-----
Использование совместно с продуктом VMware vCloud Director
Не поддерживается
-----
Комментарии к таблице:
Снапшоты на уровне массива - они никак не влияют на работу механизма SDRS, однако рекомендуется оставить его в ручном режиме, чтобы избежать возможных проблем при одновременном создании снапшота и перемещении виртуальных дисков.
Дедупликация на уровне массива - полностью совместима со механизмом SDRS, однако рекомендуется ручной режим, так как, с точки зрения дедупликации, наиболее эффективно сначала применить рекомендации по миграции виртуальных дисков, а потом уже использовать дедупликацию (для большинства сценариев).
Использование array-based auto-tiering - очевидно, что функции анализа производительности в дисковом массиве и перемещения данных по ярусам с различными характеристиками могут вступить вступить в конфликт с алгоритмами определения нагрузки в SDRS и перемещения vmdk-дисков по хранилищам на логическом уровне. Сам Storage DRS вступает в действие после 16 часов анализа нагрузки и генерирует рекомендации каждые 8 часов, в дисковом же массиве механизм перераспределения блоков по ярусам может работать по-разному: от real-time процесса в High-end массивах, до распределения каждые 24 часа в недорогих массивах. Понятно, что массиву лучше знать, какие блоки куда перемещать с точки зрения производительности физических устройств, поэтому для SDRS рекомендуется оставить выравнивание хранилищ только по заполненности томов VMFS, с отключенной I/O Metric.
Репликация на уровне массива - полностью поддерживается со стороны SDRS, однако, в зависимости от использования метода репликации, во время применения рекомендаций SDRS виртуальные машины могут остаться в незащищенном состоянии. Поэтому рекомендуется применять эти рекомендации SDRS во время запланированного окна обслуживания хранилищ.
VMware vSphere Storage Metro Cluster - здесь нужно избегать ситуации, когда виртуальный диск vmdk машины может уехать на другой сайт по отношению к хосту ESXi, который ее исполняет (когда используется общий Datastore Cluster хранилищ). Поэтому, а еще и потому, что распределенные кластеры могут строиться на базе технологий синхронной репликации хранилищ (см. предыдущий пункт), нужно использовать ручное применение рекомендаций SDRS.
Поддержка VMware vSphere Site Recovery Manager - на данный момент SDRS не обнаруживает Datastore Groups в SRM, а SRM не отслеживает миграции SDRS по хранилищам. Соответственно, при миграции ВМ на другое хранилище не обновляются protection groups в SRM, как следствие - виртуальные машины оказываются незащищенными. Поэтому совместное использование этих продуктов не поддерживается со стороны VMware.
Поддержка томов RDM - SDRS полностью поддерживает тома RDM, однако эта поддержка совершенно ничего не дает, так как в миграциях может участвовать только vmdk pointer, то есть прокси-файл виртуального диска, который занимает мало места (нет смысла балансировать по заполненности) и не генерирует никаких I/O на хранилище, где он лежит (нет смысла балансировать по I/O). Соответственно понадобиться эта поддержка может лишь на время перевода Datastore, где лежит этот файл-указатель, в режим обслуживания.
Поддержка VMware vSphere Replication - SDRS не поддерживается в комбинации с хостовой репликацией vSphere. Это потому, что файлы *.psf, используемые для нужд репликации, не поддерживаются, а даже удаляются при миграции ВМ на другое хранилище. Вследствие этого, механизм репликации для смигрированной машины считает, что она нуждается в полной синхронизации, что вызывает ситуацию, когда репликация будет отложена, а значит существенно ухудшатся показатели RTO/RPO. Поэтому (пока) совместное использование этих функций не поддерживается.
Поддержка VMware vSphere Snapshots - SDRS полностью поддерживает спапшоты виртуальных машин. При этом, по умолчанию, все снапшоты и виртуальные диски машины при применении рекомендаций перемещаются на другое хранилище полностью (см. левую часть картинки). Если же для дисков ВМ настроено anti-affinity rule, то они разъезжаются по разным хранилищам, однако снапшоты едут вместе со своим родительским диском (см. правую часть картинки).
Использование тонких дисков VMware vSphere - полностью поддерживается SDRS, при этом учитывается реально потребляемое дисковое пространство, а не заданный в конфигурации ВМ объем виртуального диска. Также SDRS учитывает и темпы роста тонкого виртуального диска - если он в течение последующих 30 часов может заполнить хранилище до порогового значения, то такая рекомендация показана и применена не будет.
Технология Linked Clones - не поддерживается со стороны SDRS, так как этот механизм не отслеживает взаимосвязи между дисками родительской и дочерних машин, а при их перемещении между хранилищами - они будут разорваны. Это же значит, что SDRS не поддерживается совместно с продуктом VMware View.
Использование с VMware vCloud Director - пока не поддерживается из-за проблем с размещением объектов vApp в кластере хранилищ.
Хосты с версией ПО, младше чем vSphere 5.0 - если один из таких хостов поключен к тому VMFS, то для него SDRS работать не будет. Причина очевидна - хосты до ESXi 5.0 не знали о том, что будет такая функция как SDRS.
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.

 RSS
RSS








































{kind=link}

