Дункан Эппинг в своей статье ответил на этот вопрос. Он стал замечать, что этот вопрос возникает всё чаще: можно ли реплицировать или создавать снапшот виртуального модуля vSAN Stretched Cluster Witness для быстрого восстановления? Обычно люди задают его потому, что не могут соблюсти требование трёх площадок для vSAN Stretched Cluster. Поэтому, настроив какой-то механизм репликации с низким RPO, они пытаются снизить этот риск.
Возможно, этот вопрос возникает из-за недостаточного понимания того, какую роль выполняет Witness. Он обеспечивает механизм кворума, а этот механизм помогает определить, какая площадка получает доступ к данным в случае сетевого сбоя (ISL) между площадками хранения данных.
Так почему же виртуальное устройство Witness нельзя снапшотить или реплицировать? Дело в том, что для обеспечения механизма кворума Witness Appliance хранит witness-компонент для каждого объекта. Причём не для каждой площадки и не для каждой виртуальной машины, а для каждого объекта! То есть если у вас есть ВМ с несколькими VMDK, то для одной ВМ на Witness Appliance будет храниться несколько witness-объектов.
Этот witness-объект содержит метаданные и с помощью номера последовательности журнала (log sequence number) определяет, какой объект содержит самые актуальные данные. И вот здесь возникает проблема. Если вы откатите Witness Appliance к более раннему моменту времени, то witness-компоненты также откатятся назад и будут иметь другой номер последовательности журнала, чем ожидается. В результате vSAN не сможет сделать объект доступным для выжившей площадки или для той площадки, которая должна обладать кворумом.
Итак, краткий вывод: следует ли реплицировать или создавать снапшот Witness Appliance? Нет!
Компания VMware выпустила обновлённое официальное руководство vSAN Stretched Cluster Guide, предназначенное для архитекторов и администраторов, работающих с растянутыми кластерами vSAN в рамках платформы VMware Cloud Foundation (VCF) 9.0. Документ был выпущен 18 февраля 2026 года и отражает актуальные практики проектирования, развертывания и эксплуатации таких инфраструктур.
Руководство подробно описывает ключевые концепции и требования к растянутым кластерам vSAN — типу конфигурации, в которой ресурсы распределены по двум географически разнесённым сайтам с целью обеспечения максимальной отказоустойчивости и непрерывной доступности виртуальных машин.
Что нового в версии для VCF 9.0
Актуализация под VCF 9.0 и vSAN 9
Документ ориентирован на использование растянутых кластеров именно в контексте VCF 9.0, в том числе с учётом последних архитектурных изменений и интеграции с инструментами автоматизации SDDC Manager.
Расширенные рекомендации по сетевым требованиям
В руководстве обновлены требования к сети между площадками — минимальные значения пропускной способности и задержек, оптимальные настройки MTU и рекомендации по сегментации трафика.
Поддержка разных архитектур хранения
Кроме классической архитектуры vSAN (OSA), руководство учитывает и vSAN Express Storage Architecture (ESA) — более современный вариант с улучшенной производительностью и эффективностью хранения.
Процессы установки и конвертации
Обозначены пошаговые процессы установки растянутого кластера, развёртывания и конфигурации vSAN Witness Host, а также инструкция по конвертации существующего кластера vSAN в растянутую конфигурацию без прерывания работы.
Сценарии отказов и восстановление
Отдельный раздел посвящён анализу отказов, поведения кластера в стрессовых ситуациях и практикам восстановления после отказов отдельных компонентов или целых площадок.
Практическая ценность для предприятий
Растянутые кластеры vSAN в VCF 9.0 остаются одним из ключевых решений для компаний с критичными требованиями к доступности (финансовые учреждения, телеком, здравоохранение), обеспечивая непрерывность бизнес-сервисов при отказах на уровне целого дата-центра.
Новый документ vSAN Stretched Cluster Guide служит исчерпывающим справочником для ИТ-специалистов, помогая спланировать архитектуру, соблюсти требования к оборудованию и сети, правильно настроить объектные политики хранения и обеспечить корректное поведение системы в случае сбоев.
Доступность данных — ключевая компетенция корпоративных систем хранения. На протяжении десятилетий такие системы стремились обеспечить высокий уровень доступности данных при одновременном соблюдении ожиданий по производительности и эффективности использования пространства. Достичь всего этого одновременно непросто.
Кодирование с восстановлением (erasure coding) играет важную роль в хранении данных устойчивым, но при этом эффективным с точки зрения занимаемого пространства способом. Этот пост поможет лучше понять, как erasure coding реализовано в VMware vSAN, чем оно отличается от подходов, применяемых в традиционных системах хранения, и как корректно интерпретировать возможности erasure code в контексте доступности данных.
Назначение Erasure Coding
Основная ответственность любой системы хранения — вернуть запрошенный бит данных. Чтобы делать это надежно, системе хранения необходимо сохранять данные устойчивым способом. Простейшая форма устойчивости данных достигается посредством нескольких копий или «зеркал», которые позволяют поддерживать доступность при возникновении отказа в системе хранения, например при выходе из строя диска в массиве хранения или хоста в распределённой системе хранения, такой как vSAN. Одна из проблем этого подхода — высокая стоимость хранения: полные копии данных занимают много места. Одна дополнительная копия удваивает объём, две — утраивают.
Erasure codes позволяют хранить данные устойчиво, но гораздо более эффективно с точки зрения пространства, чем традиционное зеркалирование. Вместо хранения копий данные распределяются по нескольким локациям — каждая из которых может считаться точкой отказа (например, диск или хост в распределённой системе, такой как vSAN). Фрагменты данных формируют «полосу» (stripe), к которой добавляются фрагменты четности, создаваемые при записи данных. Данные четности получаются в результате математических вычислений. Если какой-либо фрагмент данных отсутствует, система может прочитать доступные части полосы и вычислить недостающий фрагмент, используя четность. Таким образом, она может либо выполнить исходный запрос чтения «на лету», либо реконструировать отсутствующие данные в новое место. Тип erasure code определяет, может ли он выдержать потерю одного, двух или более фрагментов при сохранении доступности данных.
Erasure codes обеспечивают существенную экономию пространства по сравнению с традиционным зеркальным хранением. Экономия зависит от характеристик конкретного типа erasure code — например, сколько отказов он способен выдержать и по скольким локациям распределяются данные.
Erasure codes бывают разных типов. Их обычно обозначают количеством фрагментов данных и количеством фрагментов четности. Например, обозначение 6+3 или 6,3 означает, что полоса состоит из 6 (k) фрагментов данных и 3 (m) фрагментов четности, всего 9 (n) фрагментов. Такой тип erasure code может выдержать отказ любых трёх фрагментов, сохранив доступность данных. Он обеспечивает такую устойчивость при всего лишь 50% дополнительного расхода пространства.
Но erasure codes не лишены недостатков. Операции ввода-вывода становятся более сложными: одна операция записи может преобразовываться в несколько операций чтения и записи, что называют «усилением ввода-вывода» (I/O amplification). Это может замедлять обработку в системе хранения, а также увеличивать нагрузку на CPU и требовать больше полосы пропускания. Однако при правильной реализации erasure codes могут сочетать устойчивость с высокой производительностью. Например, инновационная архитектура vSAN ESA устраняет типичные проблемы производительности erasure codes, и RAID-6 в ESA может обеспечивать такую же или даже лучшую производительность, чем RAID-1.
Хранение данных в vSAN и в традиционном массиве хранения
Прежде чем сравнивать erasure codes в vSAN и традиционных системах хранения, рассмотрим, как vSAN хранит данные по сравнению с классическим массивом.
Хранилища часто предоставляют большой пул ресурсов в виде LUN. В контексте vSphere он форматируется как datastore с VMware VMFS, где располагаются несколько виртуальных машин. Команды SCSI передаются от ВМ через хосты vSphere в систему хранения. Такой datastore на массиве охватывает большое количество устройств хранения в его корпусе, что означает не только широкую логическую границу (кластерная файловая система с множеством ВМ), но и большую физическую границу (несколько дисков). Как и многие другие файловые системы, такая кластерная ФС должна оставаться целостной, со всеми метаданными и данными, доступными в полном объёме.
vSAN использует совершенно иной подход. Вместо классической файловой системы с большой логической областью данных, распределённой по всем хостам, vSAN оперирует малой логической областью данных для каждого объекта. Примерами могут служить диски VMDK виртуальной машины, постоянный том для контейнера или файловый ресурс, предоставленный службами файлов vSAN. Именно это делает vSAN аналогичным объектному хранилищу, даже несмотря на то, что фактически это блочное хранилище с использованием SCSI-семантики или файловой семантики в случае файловых сервисов. Для дополнительной информации об объектах и компонентах vSAN см. пост «vSAN Objects and Components Revisited».
Такой подход обеспечивает vSAN целый ряд технических преимуществ по сравнению с монолитной кластерной файловой системой в традиционном массиве хранения. Erasure codes применяются к объектам независимо и более гранулярно. Это позволяет заказчикам проектировать кластеры vSAN так, как они считают нужным — будь то стандартный односайтовый кластер, кластер с доменами отказа для отказоустойчивости на уровне стоек или растянутый кластер (stretched cluster). Кроме того, такой подход позволяет vSAN масштабироваться способами, недоступными при традиционных архитектурных решениях.
Сравнение erasure coding в vSAN и традиционных системах хранения
Имея базовое понимание того, как традиционные массивы и vSAN предоставляют ресурсы хранения, рассмотрим, чем их подходы к erasure coding отличаются. В этих сравнениях предполагается наличие одновременных отказов, поскольку многие системы хранения способны справляться с единичными отказами в течение некоторого времени.
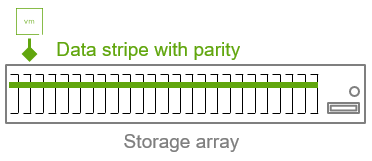
Массив хранения (Storage Array)
В данном примере традиционный массив использует erasure code конфигурации 22+3 для одного LUN (k=22, m=3, n=25).
Преимущества:
Относительно низкие накладные расходы по ёмкости. Дополнительная ёмкость, потребляемая данными четности для поддержания доступности при сбоях в доменах отказа (устройствах хранения), составляет около 14%. Такого низкого уровня удаётся достичь благодаря распределению данных по очень большому числу устройств хранения.
Относительно высокий уровень отказоустойчивости (3). Любые три устройства хранения могут выйти из строя, и том останется доступным. Но, как отмечено ниже, это только часть картины.
Компромиссы:
Относительно большой «радиус поражения». Если число отказов превысит то, на которое рассчитан массив, зона воздействия будет очень большой. В некоторых случаях может пострадать весь массив.
Защита только от отказов устройств хранения. Erasure coding в массивах защищает только от отказов самих накопителей. Массивы могут испытывать серьёзную деградацию производительности и доступности при других типах отказов, например, межсоединений (interconnects), контроллеров хранения и некорректных обновлениях прошивок. Ни один erasure code не может обеспечить доступность данных, если выйдёт из строя больше контроллеров, чем массив способен выдержать.
Относительно высокий эффект на производительность во время или после отказов. Отказы при больших значениях k и m могут требовать очень много ресурсов на восстановление и быть более подвержены высоким значениям tail latency.
Относительно большое количество потенциальных точек отказа на одну четность. Соотношение 8,33:1 отражает высокий показатель потенциальных точек отказа относительно количества битов четности, обеспечивающих доступность. Высокое соотношение указывает на более высокую хрупкость.
Последний пункт является чрезвычайно важным. Erasure codes нельзя оценивать только по заявленному уровню устойчивости (m), но необходимо учитывать сопоставление заявленной устойчивости с количеством потенциальных точек отказа, которые она прикрывает (n). Это обеспечивает более корректный подход к пониманию вероятностной надёжности системы хранения.
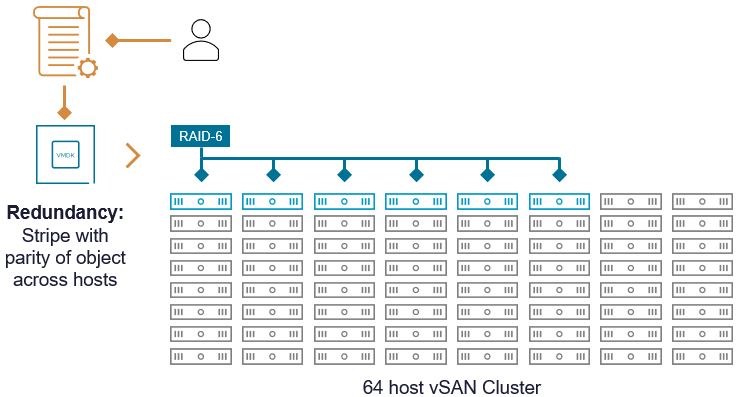
vSAN
В этом примере предположим, что у нас есть кластер vSAN из 24 хостов, и объект данных ВМ настроен на использование RAID-6 erasure code ы (k=4, m=2, n=6).
Важно отметить, что компоненты, формирующие объект vSAN при использовании RAID-6, будут содержать как фрагменты данных, так и фрагменты четности. Как описывает Христос Караманолис в статье "The Use of Erasure Coding in vSAN" (vSAN OSA, примерно 2018 год), vSAN не создаёт отдельные компоненты четности.
Преимущества:
Относительно небольшой «радиус поражения». Если кластер переживает более двух одновременных отказов хостов, это затронет лишь некоторые объекты, но не выведет из строя весь datastore.
Защита от широкого спектра типов отказов. Erasure coding в vSAN учитывает отказы отдельных устройств хранения, хостов и отказы заранее определённых доменов (например, стоек).
Относительно низкое влияние на производительность во время или после отказа. Небольшие значения k уменьшают вычислительные затраты при восстановлении.
Относительно малое число потенциальных точек отказа на единицу четности. Соотношение 3:1 указывает на малое количество возможных точек отказа по сравнению с числом битов четности, обеспечивающих доступность.
Компромиссы:
Низкая абсолютная устойчивость объекта к отказам (2). У vSAN RAID-6 (4+2) заявленная устойчивость меньше. Однако важно помнить:
граница отказа — это объект, а не весь кластер, количество потенциальных точек отказа на четность существенно ниже.
Относительно более высокие накладные расходы. Дополнительная ёмкость, потребляемая битами четности для поддержания доступности при отказе домена (хоста), составляет 50%.
Несмотря на то, что RAID-6 в vSAN защищает от 2 отказов (в отличие от 3), он остаётся чрезвычайно надёжным благодаря небольшому количеству потенциальных точек отказа: всего 6 против 25. Это обеспечивает vSAN RAID-6 (4+2) техническое преимущество перед схемой хранения массива 22+3, если сравнивать надёжность с точки зрения вероятностей отказов.
Для vSAN использование erasure code с малым значением n обеспечивает гораздо большую гибкость в построении кластеров под самые разные сценарии. Например, RAID-6 (4+2) можно использовать минимум на 6 хостах. Для erasure code 22+3 теоретически потребовалось бы не менее 25 хостов в одном кластере.
Развязка размера кластера и доступности
RAID-6 в vSAN всегда остаётся схемой 4+2, независимо от размера кластера. Когда к объекту применяется политика хранения FTT=2 с RAID-6, это означает, что объект может выдержать два одновременных отказа хостов, на которых находятся его компоненты.
Это свойство относится к состоянию объекта, а не всего кластера. Отказы на других хостах не влияют на доступность данного объекта, за исключением того, что эти хосты могут быть использованы для восстановления недостающей части полосы с помощью четности.
vSAN рассматривает такие уцелевшие хосты как кандидатов для размещения реконструируемых компонентов, чтобы вернуть объекту заданный уровень устойчивости.
Такой подход позволяет vSAN разорвать зависимость между размером кластера и уровнем доступности. В то время как многие масштабируемые системы хранения становятся более хрупкими по мере увеличения числа узлов, подход vSAN, напротив, снижает риски по мере масштабирования кластера.
Для дополнительной информации о доступности и механизмах обработки отказов в vSAN см. документ "vSAN Availability Technologies" на VMware Resource Center.
Итог
Erasure coding — это мощная технология, позволяющая хранить данные очень устойчиво и при этом эффективно использовать пространство. Но не все erasure codes одинаково полезны.
vSAN использует такие схемы erasure coding, которые обеспечивают оптимальный баланс устойчивости, гибкости и эффективности использования пространства в распределённой среде. В сочетании с дополнительными механизмами оптимизации пространства — такими как сжатие данных в vSAN и глобальная дедупликация в ESA (в составе VCF 9.0), хранилище vSAN становится ещё более производительным, ёмким и надёжным, чем когда-либо.
Дункан Эппинг выпустил обзорное видео, где он отвечает на вопрос одного из читателей, который касается поведения VMware vSAN после восстановления отказавших площадок. Речь идёт о сценарии, когда производится Site Takeover и два сайта выходят из строя, а позже снова становятся доступными. Что же происходит с виртуальными машинами и их компонентами в такой ситуации?
Автор решил смоделировать следующий сценарий:
Отключить preferred-локацию и witness-узел.
Выполнить Site Takeover, чтобы виртуальная машина Photon-1 стала снова доступна после ее перезапуска, но уже только на оставшейся рабочей площадке.
После восстановления всех узлов проверить, как vSAN автоматически перераспределит компоненты виртуальной машины.
Поведение виртуальной машины после отказа
Когда preferred-локация и witness отключены, виртуальная машина Photon-1 продолжает работу благодаря механизму vSphere HA. Компоненты ВМ в этот момент существуют только на вторичном домене отказа (fault domain), то есть на той площадке, которая осталась доступной.
Автор пропускает часть сценария с перезапуском ВМ, поскольку этот процесс уже подробно освещался ранее.
Что происходит при восстановлении сайтов
После того как preferred-локация и witness возвращаются в строй, начинается полностью автоматический процесс:
vSAN анализирует политику хранения, назначенную виртуальной машине.
Поскольку политика предусматривает растяжение ВМ между двумя площадками, система автоматически начинает перераспределение компонентов.
Компоненты виртуальной машины снова создаются и на preferred-локации, и на secondary-локации.
При этом администратору не нужно предпринимать никаких действий — все операции происходят автоматически.
Важный момент: полная ресинхронизация
Дункан подчёркивает, что восстановление не является частичным, а выполняется полный ресинк данных:
Компоненты, которые находились на preferred-локации до сбоя, vSAN считает недействительными и отбрасывает.
Данные перезапущенной ВМ полностью синхронизируются с рабочей площадки (теперь это secondary FD) на вновь доступную preferred-локацию.
Это необходимо для исключения расхождений и гарантии целостности данных.
Итоги
Демонстрация показывает, что vSAN при восстановлении площадок:
Автоматически перераспределяет компоненты виртуальных машин согласно политике хранения.
Выполняет полную ресинхронизацию данных.
Не требует ручного вмешательства администратора.
Таким образом, механизм stretched-кластеров vSAN обеспечивает предсказуемое и безопасное восстановление после крупных сбоев.
Если вы уже знакомы с преимуществами локальных снапшотов для защиты данных в vSAN ESA, значит у вас есть опыт работы с одной из служб в составе объединённого виртуального модуля защиты и восстановления, являющегося частью решения ACC (Advanced Cyber Compliance).
Расширение защиты и восстановления ВМ
Давайте рассмотрим объединённую ценность защиты данных vSAN и VMware Advanced Cyber Compliance, позволяющую обеспечить надёжное, уверенное восстановление после кибератак и других катастроф. Виртуальный модуль защиты и восстановления, включённый в возможности аварийного восстановления решения Advanced Cyber Compliance, содержит три службы — все объединены в один простой в развертывании и управлении модуль (Virtual Appliance):
Служба снимков vSAN ESA
Расширенная репликация vSphere
Группы защиты и оркестрация восстановления
Сочетание этих служб модуля вместе с возможностями хранения vSAN ESA расширяет возможности для более широкой мультисайтовой защиты и восстановления ваших рабочих нагрузок в VCF.
Настройка вторичного сайта восстановления
В рамках вашей топологии развертывания VCF просто включите ещё один кластер vSAN ESA на втором сайте или в другой локации. Второй сайт подразумевает дополнительную среду vCenter в домене рабочих нагрузок VCF. Для простоты и удобства ссылки назовём эти два сайта «Site A» и «Site B» и развернём их в одном экземпляре VCF, как показано ниже.
Чтобы максимизировать ценность всех трёх упомянутых выше служб и расширить защиту данных vSAN между этими сайтами, вам потребуется лицензировать возможность оркестрации. Возможность оркестрации защиты и восстановления необходима для управления параметрами защиты данных vSAN для групп защиты, которым требуется включать функции репликации.
Имейте в виду, что расширенная репликация vSphere и возможности службы снапшотов vSAN уже включены в лицензирование VCF.
На новом вторичном сайте разверните кластер vSAN ESA для соответствующего vCenter вместе с ещё одним экземпляром объединённого виртуального модуля. Во многих случаях как модули vCenter, так и эти устройства защиты и восстановления устанавливаются в домен управления VCF.
После настройки двух сайтов процесс установления расширенной репликации vSphere между хостами ESX на каждом сайте довольно прост.
Расширение охвата политики защиты
VMware Advanced Cyber Compliance включает полностью оркестрированное аварийное восстановление между локальными сайтами VCF, и благодаря хранилищам данных vSAN ESA на этих нескольких сайтах теперь можно построить более надёжное решение по защите данных и аварийному восстановлению на уровне всего предприятия.
При наличии многосайтовой, объединённой конфигурации Advanced Cyber Compliance и vSAN ESA, группы защиты, которые вы определяете в рамках защиты данных vSAN для локального восстановления, теперь могут воспользоваться двумя дополнительными вариантами (2 и 3 пункты ниже), включающими репликацию и координацию защиты между двумя сайтами:
Локальная защита — защита с помощью снапшотов в пределах одного сайта.
Репликация — репликация данных ВМ на вторичный сайт.
Локальная защита и репликация — репликация данных ВМ между сайтами плюс локальные снапшоты и хранение удалённых снапшотов.
Давайте более подробно рассмотрим пример настройки защиты данных vSAN между двумя сайтами, которую можно использовать для аварийного восстановления, если исходный сайт станет недоступным или выйдет из строя. Для этого примера мы создадим новую группу защиты и пройдём процесс настройки политики, как показано ниже. Процесс настройки состоит всего из нескольких шагов, включая:
Задание свойств политики защиты.
Определение инвентаря защищаемых ВМ.
Настройку расписаний локальных снапшотов.
Настройку параметров репликации и хранения данных между сайтами.
Для типа защиты мы выбрали вариант «Локальная защита и репликация» (Local protection and replication). Это добавляет шаги 4 и 5 (показанные ниже) в определение политики группы защиты соответственно.
Расписания локальных снапшотов (шаг 4) определяют точки восстановления, которые будут доступны для выбранных виртуальных машин на локальном хранилище данных vSAN ESA. Каждая политика группы защиты может включать несколько расписаний, определяющих частоту создания снапшотов и период их хранения.
Примечание: это определение политики группы защиты также использует критерии выбора ВМ, основанные как на шаблонах имён (шаг 2), так и на индивидуальном выборе (шаг 3), показанных на скриншоте выше. Это обеспечивает высокую гибкость при определении состава ВМ, подлежащих защите.
Снапшоты и репликация имеют отдельные параметры конфигурации политики. Данные между сайтами Site A и Site B в данном примере будут реплицироваться независимо от локальных снапшотов, создаваемых по расписанию. Это также означает, что процесс репликации выполняется отдельно от процессов локального создания снапшотов.
С VMware Advanced Cyber Compliance для аварийного восстановления частота репликации vSphere replication — или первичная цель точки восстановления (RPO) — для каждой ВМ может быть минимальной, вплоть до 1 минуты.
При настройке параметров репликации вы также указываете хранение снапшотов на удалённом сайте, определяя глубину восстановления на вашем вторичном сайте. После завершения определения политики группы защиты в интерфейсе защиты данных vSAN вы можете увидеть различные параметры расписаний, хранения и частоты репликации, как показано на скриншоте ниже:
Примечание: группы защиты, определённые с использованием методов защиты данных vSAN, которые включают параметры репликации, будут обнаружены механизмом оркестрации защиты и восстановления и добавлены как записи групп репликации и защиты в инвентарь оркестрации, как указано в информационном блоке на скриншоте выше.
Интеграция с оркестрацией восстановления
Если переключиться на этот интерфейс, вы увидите, что наша политика "Example-Multi-Site-Protection-Group" отображается ниже — она была импортирована в инвентарь групп защиты вместе с существующими группами защиты, определёнными в пользовательском интерфейсе оркестрации защиты и восстановления.
Кроме того, любые виртуальные машины, включённые в группу защиты, определённую с использованием методов защиты данных vSAN, также отображаются в инвентаре Replications и помечаются соответствующим типом, как показано ниже:
В интерфейсе оркестрации, если вам нужно изменить группу защиты, созданную с использованием vSAN data protection, легко перейти обратно в соответствующий интерфейс управления этой группой. Контекстная ссылка для этого отображается на изображении ниже (сразу над выделенной областью Virtual Machines):
Используя совместно защиту данных vSAN и возможности аварийного восстановления VMware Advanced Cyber Compliance в вашем развертывании VCF, вы получаете улучшенную локальную защиту ВМ для оперативного восстановления, а также удалённую защиту ВМ, полезную для целей аварийного восстановления.
Поддержание доступности данных и приложений, которые эти данные создают или используют, может быть одной из самых важных задач администраторов центров обработки данных. Такие возможности, как высокая производительность или специализированные службы данных, мало что значат, если приложения и данные, которые они создают или используют, недоступны. Обеспечение доступности — это сложная тема, поскольку доступность приложений и доступность данных достигаются разными методами. Иногда требования к доступности реализуются с помощью механизмов на уровне инфраструктуры, а иногда — с использованием решений, ориентированных на приложения. Оптимальный вариант для вашей среды во многом зависит от требований и возможностей инфраструктуры.
Хотя VMware Cloud Foundation (VCF) может обеспечивать высокий уровень доступности данных и приложений простым способом, в этой статье рассматриваются различия между обеспечением высокой доступности приложений и данных с использованием технологий на уровне приложений и встроенных механизмов на уровне инфраструктуры в VCF. Мы также рассмотрим, как VMware Data Services Manager (DSM) может помочь упростить принятие подобных решений.
Учёт отказов
Защита приложений и данных требует понимания того, как выглядят типичные сбои, и что система может сделать для их компенсации. Например, сбои в физической инфраструктуре могут затрагивать:
Централизованные решения для хранения, такие как дисковые массивы
Отдельные устройства хранения в распределённых системах
Такие сбои могут затронуть данные, приложения, или и то, и другое. Сбои могут проявляться по-разному — некоторые явно, другие лишь по отсутствию отклика. Часть из них временные, другие — постоянные. Решения должны быть достаточно интеллектуальными, чтобы автоматически справляться с такими ситуациями отказа и восстановления.
Доступность и восстановление приложений и данных
Доступность приложений и их наборов данных кажется интуитивно понятной, но требует краткого пояснения.
Доступность приложения
Это состояние приложения, например базы данных или веб-приложения. Независимо от того, установлено ли оно в виртуальной машине или запущено в контейнере, приложение заранее настроено на работу с данными определённым образом. Некоторые приложения могут работать в нескольких экземплярах для повышения доступности при сбоях и использовать собственные механизмы синхронной репликации, чтобы данные сохранялись в нескольких местах. Технологии, такие как vSphere HA, могут повысить доступность приложения и его данных, перезапуская виртуальную машину на другом хосте кластера vSphere в случае сбоя.
Доступность данных
Это способность данных быть доступными для приложения или пользователей в любое время, даже при сбое. Высокодоступные данные хранятся с использованием устойчивых механизмов, обеспечивающих хранение в нескольких местах — в зависимости от возможных границ сбоя: устройства, хоста, массива хранения или целого сайта.
Надёжность данных
Хранить данные в нескольких местах недостаточно — они должны записываться синхронно и последовательно во все копии, чтобы при сбое данные из одного места совпадали с данными из другого. Корпоративные системы хранения данных реализуют принципы ACID (атомарность, согласованность, изолированность, долговечность) и протоколы, обеспечивающие надёжность данных.
Описанные выше концепции вводят два термина, которые помогают количественно определить возможности восстановления в случае сбоя:
RPO (Recovery Point Objective) — целевая точка восстановления. Показывает, с каким интервалом данные защищаются устойчивым образом. RPO=0 означает, что система всегда выполняет запись в синхронном, согласованном состоянии. Как будет отмечено далее, не все решения способны обеспечивать настоящий RPO=0.
RTO (Recovery Time Objective) — целевое время восстановления. Показывает минимальное время, необходимое для восстановления систем и/или данных до рабочего состояния. Например, RTO=10m означает, что восстановление займёт не менее 10 минут. RTO может относиться к восстановлению доступности данных или комбинации данных и приложения.
Эволюция решений для высокой доступности
Подходы к обеспечению доступности данных и приложений эволюционировали с развитием технологий и ростом требований. Некоторые приложения, такие как Microsoft SQL Server, MySQL, PostgreSQL и другие, включают собственные механизмы репликации, обеспечивающие избыточность данных и состояния приложения. Виртуализация, совместно с общим хранилищем, предоставляет простые способы обеспечения высокой доступности приложений и хранимых ими данных.
В зависимости от ваших требований может подойти один из подходов или их комбинация. Рассмотрим, как каждый из них обеспечивает высокий уровень доступности.
Высокая доступность на уровне приложений (Application-Level HA)
Этот подход основан на запуске нескольких экземпляров приложения в разных местах. Синхронное и устойчивое хранилище, а также механизмы отказоустойчивости обеспечиваются самим приложением для гарантии высокой доступности приложения и его данных.
Высокая доступность на уровне инфраструктуры (Infrastructure-Level HA)
Этот подход использует vSphere HA для перезапуска одного экземпляра приложения на другом хосте кластера. Синхронное и устойчивое хранение данных обеспечивает VMware vSAN (в контексте данного сравнения). Такая комбинация гарантирует высокую доступность приложения и его данных.
Оба подхода достигают схожих целей, но имеют определённые компромиссы. Рассмотрим два простых примера, чтобы лучше понять различия.
В приведённых примерах предполагается, что данные должны сохраняться в нескольких местах (например, на уровне сайта или зоны), чтобы обеспечить доступность при сбое площадки. Также предполагается, что приложение может работать в тех же местах. Оба варианта обеспечивают автоматический отказоустойчивый переход и RPO=0, поскольку данные записываются синхронно в несколько мест.
Высокая доступность на уровне приложений для приложений и данных
Высокая доступность на уровне приложений, как в случае MS SQL Always On Availability Groups (AG), использует два или более работающих экземпляра базы данных и дополнительное местоположение для определения кворума при различных сценариях отказа.
Этот подход полностью опирается на технологии, встроенные в само приложение, чтобы синхронно реплицировать данные в другое место и обеспечить механизм отказоустойчивого переключения состояния приложения.
Высокая доступность на уровне инфраструктуры для приложений и данных
Высокая доступность на уровне инфраструктуры использует приложение базы данных, работающее на одной виртуальной машине. vSphere HA обеспечивает автоматическое восстановление приложения, обращающегося к данным, в то время как vSAN гарантирует надёжность и доступность данных при различных типах сбоев инфраструктуры.
vSAN может выдерживать отказы отдельных устройств хранения, сетевых карт (NIC), сетевых коммутаторов, хостов и даже целых географических площадок или зон, которые определяются как «домен отказа» (fault domain).
В приведённом ниже примере кластер vSAN растянут между двумя площадками, чтобы обеспечить устойчивое хранение данных на обеих. Растянутые кластеры vSAN (vSAN Stretched Clusters) также используют третью площадку, на которой размещается небольшой виртуальный модуль — witness host appliance (хост-свидетель), помогающий определить кворум при различных возможных сценариях отказа.
Одним из самых убедительных преимуществ высокой доступности на уровне инфраструктуры является то, что в VCF она является встроенной частью платформы. vSAN интегрирован прямо в гипервизор и обеспечивает отказоустойчивость данных в соответствии с вашими требованиями, всего лишь посредством настройки простой политики хранения (storage policy). Экземпляры приложений становятся высокодоступными благодаря проверенной технологии vSphere HA, которая позволяет перезапускать виртуальные машины на любом хосте в пределах кластера vSphere. Такой подход также отлично работает, когда приложения баз данных развертываются и управляются в вашей среде VCF с помощью DSM.
Разные подходы к обеспечению согласованности данных
Хотя оба подхода могут обеспечивать цель восстановления точки (RPO), равную нулю (RPO=0), за счёт синхронной репликации, способы достижения этого различаются. Оба используют специальные протоколы, помогающие обеспечить согласованность данных, записываемых в нескольких местах — что на практике значительно сложнее, чем кажется.
В случае MS SQL Server Always On Availability Groups согласованность достигается на уровне приложения, тогда как vSAN обеспечивает синхронную запись данных по своей сути — как часть распределённой архитектуры, изначально разработанной для обеспечения отказоустойчивости.
При репликации данных на уровне приложения такой высокий уровень доступности ограничен только этим конкретным приложением и его данными. Однако возможности на уровне приложений реализованы не одинаково. Например, MS SQL Server Always On AG могут обеспечивать RPO=0 при множестве сценариев отказа, тогда как MySQL InnoDB Cluster использует подход, при котором RPO=0 возможно только при отказе одного узла. Хотя данные при этом остаются согласованными, в некоторых сценариях отказа — например, при полном сбое кластера или незапланированной перезагрузке — могут быть потеряны последние зафиксированные транзакции. Это означает, что при определённых обстоятельствах обеспечить истинный RPO=0 невозможно.
В случае vSAN в составе VCF, высокая доступность является универсальной характеристикой, которая применяется ко всем рабочим нагрузкам, записывающим данные в хранилище vSAN datastore.
Различия во времени восстановления (RTO)
Одной из основных причин различий между возможностями RTO при доступности на уровне приложения и на уровне инфраструктуры является то, как приложение возвращается в рабочее состояние после сбоя.
Например, некоторые приложения, такие как SQL Server AG, используют лицензированные «резервные» виртуальные машины (standby VMs) в вашей инфраструктуре, чтобы обеспечить использование другого состояния приложения при отказе. Это позволяет достичь низкого RTO, но приводит к увеличению затрат из-за необходимости дополнительных лицензий и потребляемых ресурсов. Высокая доступность на уровне приложения — это специализированное решение, требующее экспертизы в конкретном приложении для достижения нужного результата. Однако DSM может значительно снизить сложность таких сценариев, поскольку автоматизирует эти процессы и снимает значительную часть административной нагрузки.
Высокая доступность на уровне инфраструктуры работает иначе. Используя механизмы виртуализации, такие как vSphere High Availability (HA), она обеспечивает перезапуск приложения в другом месте при сбое виртуальной машины. Перезапуск ВМ и самого приложения, а также процесс восстановления журналов обычно занимают больше времени, чем подход с резервной ВМ, используемый при высокой доступности на уровне приложений.
Приведённые выше значения времени восстановления являются оценочными. Фактическое время восстановления может значительно различаться в зависимости от условий среды, размера и активности экземпляра MS SQL.
Что выбрать именно вам?
Наилучший выбор зависит от ваших требований, ограничений и того, насколько решение подходит вашей организации. Например:
Требования к доступности
Возможно, ваши требования предполагают, что приложение и его данные должны быть доступны за пределами определённой границы отказа — например, уровня сайта или зоны. Это поможет определить, нужна ли вообще доступность на уровне сайта или зоны.
Требования к RTO
Если требуемое время восстановления (RTO) допускает 2–5 минут, то высокая доступность на уровне инфраструктуры — отличный вариант, поскольку она встроена в платформу и работает для всех ваших нагрузок. Если же есть несколько отдельных приложений, для которых требуется меньшее RTO, и вас не смущают дополнительные затраты и сложность, связанные с этим решением, то подход на уровне приложения может быть оправдан.
Технические ограничения
В вашей организации могут быть инициативы по упрощению инструментов и рабочих процессов, что может ограничивать возможность или желание использовать дополнительные технологии, такие как высокая доступность на уровне приложений. Обычно предпочтение отдаётся универсальным инструментам, применимым ко всем системам, а не узкоспециализированным решениям. Другие технические факторы, например задержки (latency) между сайтами или зонами, также могут сделать тот или иной подход непрактичным.
Финансовые ограничения
Возможно, на вас оказывают давление с целью сократить постоянные расходы на программное обеспечение — например, на дополнительные лицензии или более дорогие уровни лицензирования, необходимые для обеспечения высокой доступности на уровне приложений. В этом случае более выгодным решением могут оказаться уже имеющиеся технологии.
Можно также использовать комбинацию обоих подходов.
Например, на первом рисунке в начале статьи показано, как высокая доступность на уровне приложений реализуется между сайтами или зонами с помощью MS SQL Always On Availability Groups, а высокая доступность на уровне инфраструктуры обеспечивается vSAN и vSphere HA внутри каждого сайта или зоны.
Этот вариант также может быть отличным примером использования VMware Data Services Manager (DSM). Вместо запуска и управления отдельными виртуальными машинами можно использовать базы данных, развёрнутые DSM, для обеспечения доступности приложений между сайтами или зонами. Такой подход обеспечивает низкое RTO, устраняет административную сложность, связанную с репликацией на уровне приложений, и при этом позволяет vSAN обеспечивать доступность данных внутри сайтов или зон.
Современная инфраструктура не прощает простоев. Любая потеря доступности данных — это не только бизнес-риск, но и вопрос репутации. VMware vSAN, будучи ядром гиперконвергентной архитектуры VMware Cloud Foundation, всегда стремился обеспечивать высокую доступность и устойчивость хранения. Но с появлением Express Storage Architecture (ESA) подход к отказоустойчивости изменился фундаментально.
Документ vSAN Availability Technologies (часть VCF 9.0) описывает, как именно реализована устойчивость на уровне данных, сетей и устройств. Разберём, какие технологии стоят за доступностью vSAN, и почему переход к ESA меняет правила игры.
Архитектура отказоустойчивости: OSA против ESA
OSA — классика, но с ограничениями
Original Storage Architecture (OSA) — традиционный вариант vSAN, основанный на концепции дисковых групп (disk groups):
Одно кэш-устройство (SSD)
Несколько накопителей ёмкости (HDD/SSD)
Проблема в том, что выход из строя кеш-диска делает всю группу недоступной. Кроме того, классическая зеркальная защита (RAID-1) неэффективна по ёмкости: чтобы выдержать один отказ, приходится хранить копию 1:1.
ESA — новое поколение хранения
Express Storage Architecture (ESA) ломает эту модель:
Нет больше disk groups — каждый накопитель независим.
Встроен мониторинг NVMe-износа, зеркалирование метаданных и прогноз отказов устройств.
В результате ESA уменьшает "зону взрыва" при сбое и повышает эффективность хранения до 30–50 %, особенно при политике FTT=2.
Как vSAN обеспечивает доступность данных
Всё в vSAN строится вокруг объектов (диски ВМ, swap, конфигурации). Каждый объект состоит из компонентов, которые распределяются по узлам.
Доступность объекта определяется параметром FTT (Failures To Tolerate) — числом отказов, которые система выдержит без потери данных.
Например:
FTT=1 (RAID-1) — один отказ хоста или диска.
FTT=2 (RAID-6) — два отказа одновременно.
RAID-5/6 обеспечивает ту же устойчивость, но с меньшими затратами ёмкости.
Механизм кворума
Каждый компонент имеет "голос". Объект считается доступным, если более 50 % голосов доступны. Это предотвращает split-brain-ситуации, когда две части кластера считают себя активными.
В сценариях 2-Node или stretched-cluster добавляется witness-компонент — виртуальный "свидетель", решающий, какая часть кластера останется активной.
Домены отказов и географическая устойчивость
vSAN позволяет группировать узлы в домены отказов — например, по стойкам, стойкам или площадкам. Данные и компоненты одной ВМ никогда не размещаются в пределах одного домена, что исключает потерю данных при отказе стойки или сайта.
В растянутом кластере (stretched cluster) домены соответствуют сайтам, а witness appliance располагается в третьей зоне для арбитража.
Рекомендация: проектируйте кластер не по минимуму (3–4 узла), а с запасом. Например, для FTT=2 нужно минимум 6 узлов, но VMware рекомендует 7, чтобы система могла восстановить избыточность без потери устойчивости.
Поведение при сбоях: состояния компонентов
vSAN отслеживает каждое состояние компонентов:
Состояние
Описание
Active
Компонент доступен и синхронизирован
Absent
Недоступен (например, временный сбой сети)
Degraded
Компонент повреждён, требуется восстановление
Active-Stale
Компонент доступен, но содержит устаревшие данные
Reconfiguring
Идёт перестройка или изменение политики
Компоненты в состоянии Absent ждут по умолчанию 60 минут перед восстановлением — чтобы избежать лишнего трафика из-за кратковременных сбоев.
Если восстановление невозможно, создаётся новая копия на другом узле.
Сеть как основа устойчивости
vSAN — это распределённое хранилище, и его надёжность напрямую зависит от сети.
Транспорт — TCP/unicast с внутренним протоколом Reliable Datagram Transport (RDT).
Поддерживается RDMA (RoCE v2) для минимизации задержек.
Рекомендуется:
2 NIC на каждый хост;
Подключение к разным коммутаторам;
Active/Standby teaming для vSAN-трафика (предсказуемые пути).
Если часть сети теряет связность, vSAN формирует partition groups и использует кворум, чтобы определить, какая группа "основная". vSAN тесно интегрирован с vSphere HA, что обеспечивает синхронное понимание состояния сети и автоматический рестарт ВМ при отказах.
Ресинхронизация и обслуживание
Resync (восстановление)
Когда хост возвращается в строй или изменяется политика, vSAN ресинхронизирует данные для восстановления FTT-уровня. В ESA ресинхронизация стала интеллектуальной и возобновляемой (resumable) — меньше нагрузка на сеть и диски.
Maintenance Mode
При вводе хоста в обслуживание доступны три режима:
Full Data Migration — полная миграция данных (долго, безопасно).
Ensure Accessibility — минимальный перенос для сохранения доступности (дефолт).
No Data Migration — без переноса (быстро, рискованно).
ESA использует durability components, чтобы временно сохранить данные и ускорить возврат в строй.
Предиктивное обслуживание и мониторинг
VMware внедрила целый ряд механизмов прогнозирования и диагностики:
Degraded Device Handling (DDH) — анализ деградации накопителей по задержкам и ошибкам до фактического отказа.
NVMe Endurance Tracking — контроль износа NVMe с предупреждениями в vCenter.
Low-Level Metadata Resilience — зеркалирование метаданных для защиты от URE-ошибок.
Proactive Hardware Management — интеграция с OEM-телеметрией и предупреждения через Skyline Health.
Эти механизмы в ESA работают точнее и с меньшими ложными срабатываниями по сравнению с OSA.
Disaster Recovery — восстановление после катастрофы (вторая площадка, репликация, резервное копирование).
vSAN отвечает за первое. Для второго используются VMware SRM, vSphere Replication и внешние DR-решения. Однако комбинация vSAN ESA + stretched cluster уже позволяет реализовать site-level resilience без отдельного DR-инструмента.
Практические рекомендации
Используйте ESA при проектировании новых кластеров.
Современные NVMe-узлы и сети 25 GbE позволяют реализовать отказоустойчивость без потери производительности.
Проектируйте с запасом по хостам.
Один дополнительный узел обеспечит восстановление без снижения FTT-уровня.
Настройте отказоустойчивую сеть.
Два интерфейса, разные коммутаторы, Route Based on Port ID — минимальные требования для надёжного vSAN-трафика.
Следите за здоровьем устройств.
Активируйте DDH и NVMe Endurance Monitoring, используйте Skyline Health для предиктивного анализа.
Планируйте обслуживание грамотно.
Режим Ensure Accessibility — оптимальный баланс между безопасностью и скоростью.
Заключение
VMware vSAN уже давно стал стандартом для гиперконвергентных систем, но именно с Express Storage Architecture он сделал шаг от "устойчивости" к "самоисцеляемости". ESA сочетает erasure coding, предиктивную аналитику и глубокую интеграцию с платформой vSphere, обеспечивая устойчивость, производительность и эффективность хранения. Для архитекторов и инженеров это значит одно: устойчивость теперь проектируется не как надстройка, а как неотъемлемая часть самой архитектуры хранения.
Таги: VMware, vSAN, Availability, HA, DR, Storage, Whitepaper
Растянутые кластеры vSAN Stretched Clusters — это чрезвычайно популярная топология, используемая большим процентом клиентов VMware. Они зарекомендовали себя как простой и надежный способ достижения устойчивости на уровне площадки без той сложности, которая присуща метрокластерам на базе систем хранения. В версии VCF 9.0 vSAN представляет новые функции, которые повышают гибкость, доступность и упрощают операционные задачи для растянутых кластеров.
Во-первых, теперь поддерживаются растянутые вычислительные кластеры, которые могут монтировать хранилище растянутого кластера vSAN, что упрощает использование растянутых кластеров в среде vSphere.
Во-вторых, новая функция обслуживания на уровне площадки расширяет понятие "режим обслуживания" до уровня всей площадки в растянутом кластере.
И, в-третьих, функция ручного захвата управления площадкой предоставляет администратору возможность самостоятельно восстановить одну площадку в случае серьезного двойного отказа площадок в растянутом кластере.
Лучший способ растянуть кластеры vSphere между площадками
vSAN 8 Update 2 поддерживал кластеры хранения vSAN в топологии растянутого кластера, но имел определённые ограничения. Единственным типом клиентского кластера, который мог монтировать целевое хранилище, был также растянутый кластер vSAN. Любой кластер vSphere, которому требовалось монтировать хранилище, мог располагаться только на одной из двух площадок. Это означало, что для обычных кластеров vSphere можно было обеспечить устойчивость данных между двумя площадками, но нельзя было обеспечить устойчивость и высокую доступность рабочих нагрузок виртуальных машин на обеих площадках одновременно. Причина такого ограничения заключалась в том, что хосты, входящие в кластер vSphere, не имели представления о доменах отказа, как это реализовано в растянутом кластере vSAN.
vSAN в VCF 9.0 устраняет этот пробел и позволяет использовать кластер хранения vSAN, растянутый между двумя площадками, с кластером vSphere. В топологии растянутого кластера это означает, что кластер хранения vSAN может быть растянут между двумя площадками (как и ранее), и один или несколько кластеров vSphere, также растянутых между этими двумя географическими площадками, могут монтировать это хранилище (что ранее не поддерживалось). Это фактически создаёт гораздо более простой аналог «метрокластера хранения», устраняя сложность традиционных метрокластеров на базе систем хранения за счёт простой и надёжной архитектуры vSAN.
Упрощённое обслуживание площадки для растянутых кластеров vSAN
Ранее в vSAN переход в режим обслуживания происходил на уровне отдельного хоста. Для клиентов, использующих vSAN в среде растянутого кластера, не существовало простого или автоматизированного способа перевести в режим обслуживания все хосты, составляющие одну площадку. Задача обслуживания на «уровне площадки» была одной из самых частых просьб со стороны клиентов. Хотя ранее это можно было выполнить вручную, процесс включал в себя множество шагов, был подвержен ошибкам и, в зависимости от условий, мог не обеспечить требуемую согласованность данных.
В VCF 9.0 обслуживание площадки в растянутом кластере vSAN стало значительно проще.
Теперь действия, необходимые от администратора, сводятся практически к одному клику в пользовательском интерфейсе или вызову API. Этот процесс обеспечивает безопасный перевод всех хостов одной площадки в режим обслуживания при сохранении согласованности данных. Новый рабочий процесс предлагает не только надёжный способ перевода всей площадки в режим обслуживания, но и простой механизм возврата из него.
Самостоятельное восстановление при длительном отказе двух площадок
Растянутый кластер vSAN позволяет выдержать отказ любой из трёх площадок, при этом данные остаются доступными. Ранее, при одновременном отказе основной площадки с данными и площадки-свидетеля, кластер vSAN блокировал доступ к данным из-за механизма кворума. Система кворума обеспечивает согласованность данных, предотвращая сценарии разделения кластера (split-brain). В случае длительного одновременного отказа основной площадки и площадки-свидетеля, данные на оставшейся площадке становились недоступными. Чтобы восстановить доступ к этим данным, требовалось обращаться в службу поддержки (GS), и процесс восстановления вручную был трудоёмким и подверженным ошибкам.
Функция ручного захвата управления площадкой (manual site takeover) в vSAN для VCF 9.0 предоставляет возможность самостоятельного восстановления в ситуации, когда одна из площадок находится в режиме обслуживания, а затем происходит одновременный отказ двух других площадок. В этом случае площадку, находящуюся в обслуживании, можно вернуть в рабочее состояние, запустить виртуальные машины и предоставить им доступ к хранилищу.
Изначально эта функция будет доступна в ограниченном виде через программу Broadcom “Technical Qualification Request” (TQR), которая пришла на смену процессу “Request for Product Qualification” (RPQ) от VMware для функциональности, ещё не выпущенной в общем доступе. Для подачи TQR, пожалуйста, свяжитесь с вашим поставщиком, чтобы обратиться в отдел управления продуктом vSAN.
Растянутые кластеры vSAN — это мощное решение для сред, где требуется максимальная устойчивость данных и максимальное время доступности виртуальных машин. Упрощение задач обслуживания и улучшение сценариев восстановления значительно усиливают самый простой способ развертывания VMware Cloud Foundation в мультисайтовой конфигурации.
Таги: VMware, vSAN, Stretched, Update, DR, HA, Enterprise
VMware Cloud Foundation (VCF) — это гибридная облачная платформа, которая позволяет запускать приложения и рабочие нагрузки в частном или публичном облаке. VCF — отличный вариант для предприятий, стремящихся модернизировать свою ИТ-инфраструктуру.
Существует несколько способов переноса рабочих нагрузок в VCF. В этой заметке мы рассмотрим три различных варианта:
Решение VMware HCX
Утилита VCF Import Tool
Средство комплексной DR-защиты виртуальных сред VMware Site Recovery
Дорожная карта миграции в VCF обычно включает следующие этапы:
Оценка (Assessment): на этом этапе вы анализируете свою текущую ИТ-среду и определяете оптимальный способ миграции рабочих нагрузок в VCF.
Планирование (Planning): вы разрабатываете детальный план миграции.
Миграция (Migration): осуществляется перенос рабочих нагрузок в VCF.
Оптимизация (Optimization): в заключение, вы оптимизируете среду VCF, чтобы обеспечить стабильную и эффективную работу рабочих нагрузок.
VMware HCX (Hybrid Cloud Extension)
VMware HCX — это продукт, который позволяет переносить виртуальные машины между различными средами VMware. В том числе, он поддерживает миграцию виртуальных машин из локальных сред vSphere в облако VCF (также поддерживаются платформы Hyper-V или KVM на источнике).
HCX — отличный вариант для предприятий, которым необходимо перенести большое количество виртуальных машин с минимальным временем простоя.
VMware HCX позволяет создать единую среду между онпремизным датацентром и облачным на основе архитектуры VMware Cloud Foundation (VCF), где работают средства по обеспечению катастрофоустойчивости рабочих нагрузок VMware Live Site Recovery.
HCX предоставляет возможность миграции виртуальных машин и приложений между различными видами облаков по принципу Any2Any. С точки зрения виртуальной машины, ее ОС и приложений, HCX выступает уровнем абстракции, который представляет машине единую гибридную среду в которой находятся все локальные и облачные ресурсы (infrastructure hybridity). Это дает возможность машинам перемещаться между датацентрами, не требуя реконфигурации самих ВМ или инфраструктуры.
VMware Cloud Foundation (VCF) Import Tool
В обновлении платформы VMware Cloud Foundation 5.2 был представлен новый инструмент командной строки (CLI), называемый VCF Import Tool, который предназначен для преобразования или импорта существующих сред vSphere, которые в настоящее время не управляются менеджером SDDC, в частное облако VMware Cloud Foundation. Вы можете ознакомиться с демонстрацией работы инструмента импорта VCF в этом 6-минутном видео.
Инструмент импорта VCF позволяет клиентам ускорить переход на современное частное облако, предоставляя возможность быстро внедрить Cloud Foundation непосредственно в существующую инфраструктуру vSphere. Нет необходимости приобретать новое оборудование, проходить сложные этапы развертывания или вручную переносить рабочие нагрузки. Вы просто развертываете менеджер SDDC на существующем кластере vSphere и используете инструмент импорта для преобразования его в частное облако Cloud Foundation.
Импорт вашей существующей инфраструктуры vSphere в облако VCF происходит без сбоев, поскольку это прозрачно для работающих рабочих нагрузок. В общих чертах, процесс включает сканирование vCenter для обеспечения совместимости с VCF, а затем регистрацию сервера vCenter и его связанного инвентаря в менеджере SDDC. Зарегистрированные экземпляры сервера vCenter становятся доменами рабочих нагрузок VCF, которые можно централизованно управлять и обновлять через менеджер SDDC как часть облака VMware. После добавления в инвентарь Cloud Foundation все доступные операции менеджера SDDC становятся доступны для управления преобразованным или импортированным доменом. Это включает в себя расширение доменов путем добавления новых хостов и кластеров, а также применение обновлений программного обеспечения.
VMware Live Site Recovery
VMware Live Site Recovery (бывший VMware Site Recover, SRM) — это решение для аварийного восстановления (DR), которое также можно использовать для миграции виртуальных машин в среду VCF как часть исполнения DR-плана. Оно является частью комплексного предложения VMware Live Recovery.
Этот вариант подходит для предприятий, которым необходимо защитить свои виртуальные машины от аварийных ситуаций, таких как отключение электроэнергии или пожары, за счет исполнения планов аварийного восстановления в облако VCF.
Последняя версия документации по этому продукту находится здесь.
Документ подробно описывает, как предприятия могут использовать VMware Live Site Recovery для автоматизации и упрощения планов обеспечения непрерывности бизнеса и восстановления после катастроф (BCDR) для критически важных приложений, таких как контроллеры домена Windows Active Directory и Microsoft SQL Server.
Руководство охватывает ключевые аспекты, включая настройку репликации виртуальных машин между защищаемым и резервным сайтами, создание групп защиты и планов восстановления, а также использование встроенных сценариев для автоматизации процессов восстановления. Особое внимание уделяется тестированию планов восстановления без нарушения работы производственной среды, что позволяет организациям убедиться в надежности своих стратегий BCDR.
VMware Live Site Recovery предлагает унифицированное управление возможностями восстановления после катастроф и защиты от программ-вымогателей через облачный интерфейс, обеспечивая защиту VMware vSphere виртуальных машин путем их репликации в облачную файловую систему с возможностью быстрого восстановления при необходимости.
Это руководство является ценным ресурсом для организаций, стремящихся усилить свои стратегии защиты данных и обеспечить бесперебойную работу критически важных приложений в гибридных облачных средах.
Таги: VMware, vSphere, Live Recovery, Whitepaper, DR
Недавно компания VMware сделала важный анонс относительно компонента балансировщика нагрузки ввода-вывода Storage DRS (SDRS), который включает в себя механизм балансировки нагрузки на основе reservations для SDRS I/O и контроля ввода-вывода Storage I/O Control (SIOC). Все они будут устаревшими в будущих выпусках vSphere. Анонс был сделан в рамках релиза платформы VMware vSphere 8.0 Update 3. Об этом рассказал Дункан Эппинг.
Текущие версии ESXi 8.x и 7.x продолжат поддерживать эту функциональность. Устаревание затронет балансировку нагрузки на основе задержек (latency) для ввода-вывода и балансировку на основе reservations для ввода-вывода между хранилищами в кластере хранилищ Storage DRS. Кроме того, включение SIOC на хранилище и установка reservations и приоритетов с помощью политик хранения SPBM также будут устаревшими. Начальное размещение и балансировка нагрузки Storage DRS на основе хранилищ и настроек политик хранения SPBM для лимитов не будут затронуты.
Для Storage DRS (SDRS) это означает, что функциональность «балансировки по емкости» (capacity balancing) останется доступной, но все, что связано с производительностью, будет недоступно в следующем крупном выпуске платформы. Кроме того, обработка «шумных соседей» (noisy neighbor) через SIOC с использованием приоритетов или, например, reservations ввода-вывода также больше не будет доступна.
Некоторые из вас, возможно, уже заметили, что в интерфейсе на уровне отдельных ВМ исчезла возможность указывать лимит IOPS. Что это значит для лимитов IOPS в целом? Эта функциональность останется доступной через управление на основе политик (SPBM), как и сейчас. Таким образом, если вы задавали лимиты IOPS для каждой ВМ в vSphere 7 отдельно, после обновления до vSphere 8 вам нужно будет использовать настройку через политику SPBM. Опция задания лимитов IOPS через SPBM останется доступной. Несмотря на то, что в интерфейсе она отображается в разделе «SIOC», на самом деле эта настройка применяется через планировщик дисков на уровне каждого хоста.
На конференции Explore в Барселоне было сделано несколько объявлений и показаны элементы дорожной карты, которые не были представлены ранее в Лас-Вегасе. Так как сессии в Барселоне не записывались, Дункан Эппинг поделился функциями, о которых он говорил на Explore, и которые в настоящее время планируются для платформы VCF 9. Обратите внимание, что неизвестно, когда эти возможности станут общедоступными, и всегда существует вероятность, что они могут не выйти вообще.
Дункан сделал видео с демонстрацией обсуждаемых фич, чтобы вы могли их увидеть уже сегодня:
Для тех, кто не смотрит видео, ниже кратко описана функциональность, над которой VMware работает для VCF 9. Публичное объявление об этом пока не сделано, поэтому большого количества деталей не будет.
vSAN Automated Site Maintenance
В среде с растянутым кластером vSAN, когда вы хотите выполнить обслуживание узла, на сегодняшний день вам нужно переводить каждый хост в режим обслуживания по одному. Это не только административная/операционная нагрузка, но и увеличивает риск случайного перевода в режим обслуживания неправильных хостов. Более того, из-за последовательного подхода данные, хранящиеся на хосте 1 в сайте A, могут отличаться от данных на хосте 2 в сайте A, что создает несогласованность данных в пределах сайта.
Обычно это не является проблемой, так как система синхронизируется после завершения обслуживания, но если в это время выйдет из строя другой сайт с данными, существующий (несогласованный) набор данных не сможет быть использован для восстановления. Функция Site Maintenance не только упрощает перевод всего сайта в режим обслуживания, но и устраняет риск несогласованности данных, так как vSAN координирует процесс обслуживания и гарантирует согласованность данных в пределах сайта.
vSAN Site Takeover
Одной из функций, которой многим не хватало долгое время, была возможность сохранить работоспособность сайта в случае, если два из трех сайтов одновременно выходят из строя. Здесь на помощь приходит функция Site Takeover. Если вы оказались в ситуации, когда одновременно выходят из строя как Witness Site, так и сайт с данными, вы все равно хотите иметь возможность восстановить работу. Особенно учитывая, что на втором сайте, скорее всего, имеются здоровые объекты для каждой ВМ. Функция vSAN Site Takeover поможет в этом. Она позволит вручную (через интерфейс или скрипт) указать vSAN, что, несмотря на потерю кворума, локальный набор RAID для каждой затронутой ВМ должен быть снова доступен. После этого, конечно, vSphere HA даст хостам команду включить эти ВМ.
Блогер Дункан Эппинг записал отличное видео по теме защиты данных кластеров отказоустойчивости средствами продукта VMware vSAN Data Protection для VMware Explore в Лас-Вегасе и Барселоне. Так как ему поступали вопросы от людей по поводу защиты данных vSAN, он решил поделиться демо на YouTube и опубликовать его в своем блоге. Ранее он выпустил несколько статей о защите данных vSAN и стал замечать, что некоторые клиенты начинают тестировать эту функцию и даже использовать её в производственных средах, где это возможно. Как мы также писали ранее, решение vSAN Data Protection доступно только только в рамках архитектуры vSAN ESA, так как она использует новые возможности создания моментальных снимков (снапшотов). Также полностью новый интерфейс был представлен в средстве управления Snap Manager Appliance. Обязательно скачайте, разверните и настройте его в первую очередь.
Собственно, само демо VMware vSAN Data Protection, которое стоит посмотреть, если вы интересуетесь защитой данных в рамках виртуальной инфраструктуры VMware vSphere и vSAN:
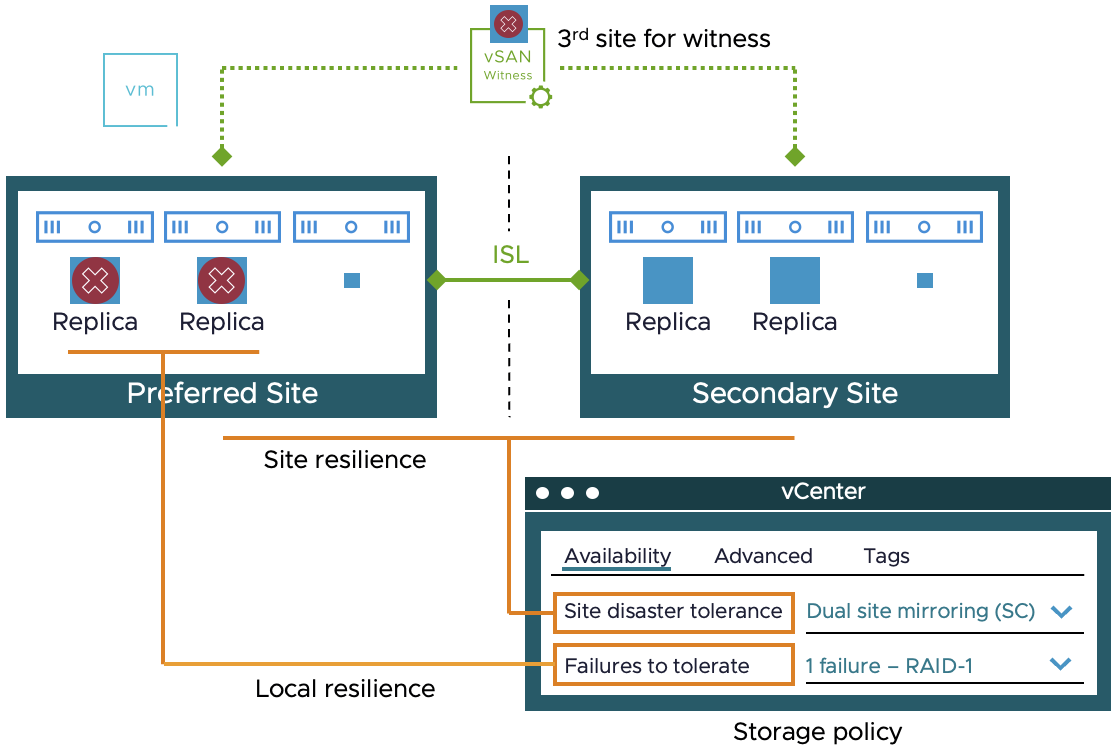
На прошлой неделе блогер Дункан Эппинг получил вопрос о vSAN Stretched Cluster, который заставил его задуматься. Человек, задавший этот вопрос, рассматривал несколько сценариев отказа, некоторые из которых Дункан уже рассматривал ранее. Вопрос, который ему задали, заключается в том, что должно произойти в следующем сценарии, показанном на диаграмме, когда разрывается связь между предпочтительным сайтом (Site A) и сайтом свидетеля (Witness):
Ответ, по крайней мере, он так думал, был прост: все виртуальные машины продолжат работать, или, иначе говоря, не будет никакого воздействия на работу vSAN. Во время теста, действительно, результат, который он зафиксировал, а также документированный в Stretched Clustering Guide и PoC Guide, был таким же: виртуальные машины продолжали работать. Однако, он обратил внимание, что когда эта ситуация происходит, и действительно связь между сайтом А и Witness теряется, свидетель почему-то больше не является частью кластера, что не то, что ожидалось. Причина, по которой он не ожидал этого, заключается в том, что если произойдет второй сбой, и, например, связь между сайтом А и сайтом B пропадет, это напрямую повлияет на все виртуальные машины. По крайней мере, так он думал.
Однако, когда был вызван этот второй сбой и отключена связь между сайтом А и сайтом В, Дункан увидел, что Witness снова появляется в кластере сразу же, а объекты свидетеля переходят из состояния «absent» в состояние «active», и, что более важно, все виртуальные машины продолжают работать. Причина, по которой это происходит, довольно проста: при запуске такой конфигурации у vSAN есть «leader» и «backup», и они каждый работают в отдельном домене отказа. И лидер, и резерв должны иметь возможность общаться с Witness для корректного функционирования. Если связь между сайтом А и Witness пропадает, то либо лидер, либо резерв больше не могут общаться со свидетелем, и свидетель исключается из кластера.
Так почему же свидетель возвращается к работе, когда вызывается второй сбой? Когда вызывается второй сбой, лидер перезапускается на сайте В (так как сайт А считается потерянным), а резерв уже работает на сайте В. Поскольку и лидер, и резерв снова могут общаться со свидетелем, свидетель возвращается к работе, и все компоненты кластера автоматически и мгновенно восстанавливаются. Это означает, что даже если связь между сайтом А и сайтом В прервана после того, как свидетель был исключен из кластера, все виртуальные машины остаются доступными, так как свидетель снова включается в работу кластера для обеспечения доступности рабочей нагрузки.
Решение VMware Cloud Foundation Instance Recovery предоставляет собой руководство по восстановлению экземпляра VMware Cloud Foundation (VCF) с нуля до полностью работоспособной среды. Процесс включает подробные инструкции по восстановлению всего экземпляра VCF, включая управляющий домен и домены рабочей нагрузки VI, где необходимо восстановить все компоненты.
Руководство предлагает пошаговые инструкции для ручного восстановления вашего экземпляра VMware Cloud Foundation, а также комплексную автоматизацию в виде модуля PowerShell, чтобы ускорить и упростить процесс ручного восстановления, используя данные из инвентаря VCF SDDC Manager для реконструкции конфигураций. Это устраняет необходимость обращаться к документации, которая может быстро устареть в условиях постоянно меняющегося и сложного программно-определяемого центра обработки данных.
Сценарии использования
Примеры сценариев, когда вам может понадобиться этот процесс:
Полный сбой площадки
Восстановление после атаки вредоносного ПО или вымогателей (Ransomware)
Катастрофическая логическая порча данных
Это особенно важно для отраслей, которые должны соблюдать нормативные требования (такие как Акт о цифровой операционной устойчивости (DORA) в Европейском Союзе).
Немного о DORA
DORA — это регламент Европейского Союза (ЕС), вступивший в силу 16 января 2023 года, который создал обязательную, всеобъемлющую систему управления рисками информационных и коммуникационных технологий (ИКТ) для финансового сектора ЕС.
DORA устанавливает технические стандарты, которые финансовые учреждения и их критически важные поставщики технологий третьих сторон должны внедрить в свои ИКТ системы до 17 января 2025 года.
Организации также должны разработать планы обеспечения непрерывности бизнеса и восстановления после аварий для различных сценариев киберрисков, таких как сбои ИКТ-услуг, природные катастрофы и кибератаки. Эти планы должны включать меры по резервному копированию и восстановлению данных, а также процессы восстановления систем.
Хотя DORA является европейским регламентом, его действия распространяются на компании, работающие в ЕС, независимо от места нахождения их штаб-квартиры. Более того, DORA является примером регламента, который станет более распространенным в других юрисдикциях в ближайшие годы.
Восстановление экземпляра VCF — это не просто на бумаге
Регламенты возлагают на предприятия, такие как финансовые учреждения и связанные с ними поставщики технологий третьих сторон, серьезные обязательства по разработке надежных планов реагирования на сбои их систем.
Организации должны будут проводить периодическое тестирование своих планов, инструментов и систем, чтобы продемонстрировать способность восстанавливать критически важную инфраструктуру в случае сбоев в своевременной и повторяемой манере.
Краткое описание решения
Решение VMware Cloud Foundation Instance Recovery использует комбинацию процессов восстановления из бэкапов, восстановления работоспособности и ребилда данных для воссоздания экземпляра VCF с точно такой же конфигурацией, даже если было утрачено основное оборудование и центр обработки данных, в котором он находился.
Основные шаги
Перестройка/ребилд хостов VMware vSphere с использованием того же или нового оборудования на основе данных, извлеченных из резервной копии инвентаря VCF SDDC Manager
Выполнение частичного развертывания VCF
Восстановление экземпляров VMware vCenter и NSX Manager, а также SDDC Manager
Реконструкция кластеров vSphere, включая их сетевые конфигурации и настройки
Восстановление NSX Edges
Восстановление рабочих нагрузок (виртуальных машин)
Восстановление настроек рабочих нагрузок (группы DRS, теги vSphere и местоположения инвентаря)
Временная шкала восстановления VMware Cloud Foundation Instance Recovery
Чтобы минимизировать время общего восстановления в VMware Cloud Foundation, задачи восстановления могут выполняться в нескольких доменах рабочих нагрузок по перекрывающемуся графику, адаптированному под требования клиентов. Временная шкала предназначена для следующего примера конфигурации:
3 домена рабочих нагрузок VI
Домен VI 1 и домен VI 2 находятся в том же домене единого входа vCenter SSO, что и домен управления. Они находятся в режиме расширенной связи (Enhanced Link Mode, ELM).
Используется только версия VMware Cloud Foundation 5.x. Домен VI 3 находится в изолированном домене единого входа vCenter (SSO).
Шаблон восстановления для домена рабочих нагрузок VI в том же домене SSO можно расширить, если к домену управления vCenter подключены дополнительные домены рабочих нагрузок VI.
Автоматизация с помощью PowerShell
Автоматизация представлена в виде модуля PowerShell под названием VMware.CloudFoundation.InstanceRecovery, являющимся комплексным набором командлетов, который упрощает рутинные процессы и уменьшает вероятность ошибок в процессе реконструкции потенциально сложного и большого программно-определяемого центра обработки данных.
Это особенно полезно в случаях, когда задачи выполняются многократно, например, для каждого хоста ESXi или для каждой восстанавливаемой виртуальной машины.
Процесс полагается на способность извлекать данные из резервной копии менеджера SDDC, которую вы собираетесь восстановить. Это означает, что автоматизация может восстановить последнюю жизнеспособную резервную копию без необходимости полагаться на актуальность ручных процессов и документации.
Пример извлечения данных конфигурации из резервной копии менеджера SDDC для использования при восстановлении:
После извлечения каждый шаг процесса использует эти данные для контроля и автоматизации реконструкции.
В лабораторных условиях полные экземпляры VCF, включая домен управления и домены рабочих нагрузок VI, были восстановлены всего за два часа. Многие задачи для дополнительных доменов рабочих нагрузок можно выполнять параллельно или в пересекающемся режиме, чтобы минимизировать общее время восстановления экземпляра.
Это уже было протестировано в лабораторной среде одним из крупнейших клиентов VCF, и они очень рады тому, что это решение предлагает им в плане соблюдения нормативных требований.
У Broadcom есть планы по дальнейшему расширению автоматизации и процессов для поддержки дополнительных топологий, конфигураций и технологий, так что следите за обновлениями!
Известный блоггер Эрика Слуф опубликовал интересное видео, посвященное обеспечению высокой доступности и восстановлению после сбоя в кластере NSX-T Management Cluster.
В этом видео Эрик демонстрирует эти концепции в действии, рассматривая различные сценарии отказов и подробно обсуждая стратегии аварийного восстановления. Вы можете получить копию оригинального файла Excalidraw и презентационные слайды в форматах PDF и PowerPoint на GitHub.
Введение
Поддержание доступности кластера управления NSX-T критически важно для обеспечения стабильности и производительности вашей виртуализованной сетевой среды. Далее будут рассмотрены стратегии обеспечения высокой доступности (HA) управляющих компонентов NSX-T, а также описан процесс восстановления при сбоях и лучшие практики для аварийного восстановления.
Обзор кластера управления NSX-T
Кластер управления NSX-T обычно состоит из трех узлов. Такая конфигурация обеспечивает избыточность и отказоустойчивость. В случае отказа одного узла кластер сохраняет кворум, и нормальная работа продолжается. Однако отказ двух узлов может нарушить работу управления, требуя оперативных действий по восстановлению.
Высокая доступность в кластере управления NSX-T
1. Поддержание кворума
Для поддержания кворума кластер управления должен иметь как минимум два из трех узлов в рабочем состоянии. Это обеспечивает доступность интерфейса NSX Manager и связанных сервисов. Если один узел выходит из строя, оставшиеся два узла могут продолжать общение и управление средой, предотвращая простой.
2. Отказы узлов и их влияние
Отказ одного узла: кластер продолжает работать нормально с двумя узлами.
Отказ двух узлов: кластер теряет кворум, интерфейс NSX Manager становится недоступным. Управление через CLI и API также будет невозможно.
Стратегии восстановления
Когда большинство узлов выходит из строя, требуются оперативные действия для восстановления кластера до функционального состояния.
1. Развертывание нового управляющего узла
Разверните новый управляющий узел как четвертый член существующего кластера.
Используйте команду CLI detach node <node-uuid> или API-метод /api/v1/cluster/<node-uuid>?action=remove_node для удаления неисправного узла из кластера.
Эту команду следует выполнять с одного из здоровых узлов.
2. Деактивация кластера (по желанию)
Выполните команду deactivate cluster на активном узле для формирования кластера из одного узла.
Добавьте новые узлы для восстановления кластера до конфигурации из трех узлов.
Лучшие практики для аварийного восстановления
1. Регулярные резервные копии
Планируйте регулярные резервные копии конфигураций NSX Manager для быстрой восстановления.
Храните резервные копии в безопасном месте и обеспечьте их доступность в случае аварийного восстановления.
2. Географическая избыточность
Развертывайте NSX Manager на нескольких площадках для обеспечения географической избыточности.
В случае отказа одной площадки другая может взять на себя операции управления с минимальными перебоями.
Проактивный мониторинг
Используйте встроенные инструменты мониторинга NSX-T и интегрируйте их с решениями сторонних производителей для постоянного мониторинга состояния кластера управления.
Раннее обнаружение проблем может предотвратить серьезные сбои и уменьшить время простоя.
Площадка аварийного восстановления
Подготовьте площадку для аварийного восстановления с резервными NSX Manager, настроенными для восстановления из резервных копий.
Такая настройка позволяет быстро восстановить и обеспечить непрерывность работы в случае отказа основной площадки.
Заключение
Обеспечение высокой доступности и аварийного восстановления вашего кластера управления NSX-T необходимо для поддержания надежной и устойчивой виртуальной сетевой среды. Следуя лучшим практикам управления узлами, развертывания географически избыточной конфигурации и регулярного создания резервных копий, вы можете минимизировать время простоя и обеспечить быстрое восстановление после сбоев.
Для более детального изучения технических деталей ознакомьтесь с следующими ресурсами:
Дункан Эппинг опубликовал интересный пост о том, как предотвратить исполнение виртуальных машин vCLS на VMware vSphere HA Failover Host. Напомним, что vSphere Clustering Service (vCLS) - это служба, которая позволяет организовать мониторинг доступности хостов кластера vSphere, без необходимости зависеть от служб vCenter. Она реализуется тремя агентскими виртуальными машинами в кластере, где 3 или более хостов, и двумя, если в кластере два хоста ESXi. Три машины нужны, чтобы обеспечивать кворум (2 против 1) в случае принятия решения о разделении кластера.
Для тех, кто не знает, сервер vSphere HA Failover Host — это хост, который используется, когда происходит сбой и vSphere HA должен перезапустить виртуальные машины. В некоторых случаях клиенты (обычно партнеры в облачных решениях) хотят предотвратить использование этих хостов для любых рабочих нагрузок, поскольку это может повлиять на стоимость использования платформы.
К сожалению, в пользовательском интерфейсе вы не можете указать, что машины vCLS не могут работать на определенных хостах, вы можете ограничить работу ВМ vCLS рядом с другими виртуальными машинами, но не хостами. Однако есть возможность указать, на каких хранилищах данных могут находиться виртуальные машины, и это может быть потенциальным способом ограничения хостов, на которых могут работать эти ВМ. Как?
Если вы создадите хранилище данных, которое недоступно назначенному Failover-хосту vSphere HA, то машины vCLS не смогут работать на этом хосте, так как хост не сможет получить доступ к датастору. Это обходной путь для решения проблемы, вы можете узнать больше о механизме размещения хранилищ данных для vCLS в этом документе. Обратите внимание, что если остальная часть кластера выйдет из строя и останется только Failover-хост, виртуальные машины vCLS не будут включены. Это означает, что механизм балансировки нагрузки VMware DRS также не будет функционировать, пока эти ВМ недоступны.
Таги: VMware, vSphere, HA, vCLS, VMachines, DRS, Blogs
Борьба с программами-вымогателями и готовность к восстановлению после катастроф продолжают оставаться в приоритете для CIO по всему миру - число атак программ-вымогателей стремительно растет, требования к соблюдению нормативов вынуждают организации внедрять меры по обеспечению аварийного восстановления инфраструктуры.
VMware предлагает предприятиям готовые возможности, чтобы удовлетворить потребности современного бизнеса за счет новых функций в решениях VMware Cloud Disaster Recovery и VMware Ransomware Recovery. VMware Ransomware Recovery for VMware Cloud Disaster Recovery предлагает уверенное восстановление от критических угроз, быстрое восстановление с помощью управляемой автоматизации и упрощенные операции восстановления. Это полностью управляемое решение Ransomware Recovery as-a-Service, которое позволяет безопасно восстанавливаться от современных программ-вымогателей через поведенческий анализ включенных рабочих нагрузок в изолированной среде восстановления (IRE) в облаке.
На днях компания VMware выпустила обновленную версию Cloud Disaster Recovery с функциями Ransomware Recovery. Давайте посмотрим, что нового стало доступно пользователям в этом феврале:
1. 15-минутное RPO с частыми снимками
Потеря доступа организации к некоторым (или всем) данным может обойтись в миллионы упущенной выручки, повреждении репутации бренда и штрафах за несоблюдение нормативных требований - и это лишь некоторые из возможных последствий. По этой причине минимизация потерь данных при восстановлении давно является ключевой задачей, особенно в крупных организациях или в сильно регулируемых отраслях. Чтобы решить эту важную проблему, VMware Cloud DR и VMware Ransomware Recovery теперь поддерживают 15-минутное RPO (требование к контрольной точке восстановления), которое предоставляет клиентам большую гибкость и выбор. Эта техника позволяет делать до 96 снимков в день и поддерживает приостановку работы приложений для обеспечения их согласованности. В сочетании с глубокой историей неизменяемых точек восстановления, сохраненных в Cloud Filesystem, это предоставляет клиентам больший выбор в частоте и политиках хранения снимков. Такая гибкость важна для достижения баланса между готовностью к восстановлению и общей стоимостью владения инфраструктурой.
2. Запуск рабочих нагрузок в облаке
В случае инцидента с программой-вымогателем защищенный сайт может оставаться недоступным в течение длительного периода; например, могут проводиться исследования правоохранительными органами, или сайт еще может быть небезопасен для восстановления, поскольку он не был восстановлен и исправлен. Начиная с сегодняшнего дня, клиенты будут иметь возможность продолжать работу с очищенными виртуальными машинами в восстановленном SDDC в облаке до тех пор, пока производственный сайт не будет полностью защищен, и угрозы не будут устранены.
3. Transit Connect для репликации, переключения на резерв и возврата к исходному сайту
Расширенная поддержка Transit Connect обеспечивает улучшенную безопасность сети для клиентов, которые не могут передавать данные по общедоступным сетям из-за требований комплаенса или просто желают минимизировать риски передачи. С этим улучшением передача данных для репликации, переключения на резерв (failover) и возврата (failback) осуществляется через защищенную частную сеть, полностью изолированную от общедоступного интернета. Трафик автоматически шифруется в состоянии покоя и в процессе передачи, а правила брандмауэра на облачном шлюзе в сочетании со списками доступа на стороне VMware Cloud DR добавляют слой безопасности.
4. Улучшенное сетевое подключение
VMware Cloud DR и VMware Ransomware Recovery теперь позволяют клиентам изолировать DR-сеть от той, что используется для тестирования и восстановления. Наличие DR-сети, полностью отделенной от сети изолированной среды восстановления (Isolated Recovery Environment, IRE), предотвращает перемещение киберугроз в SDDC-датацентр восстановления, которые могли бы заразить рабочие нагрузки, если они работают в одной и той же среде. Сегментация сети, создаваемая на уровне NSX в резервном SDDC, теперь является опцией конфигурации плана DR. VMware Cloud DR и VMware Ransomware Recovery будут использовать NSX Compute Gateway для указания отдельных сетей, что позволяет операциям DR и восстановления проводиться одновременно и безопасно в одном и том же SDDC. Это также позволяет клиентам консолидировать инфраструктуру сайта восстановления без риска заражения рабочих нагрузок.
Более подробно о новых возможностях VMware Cloud Disaster Recovery можно прочитать в Release Notes.
VMware Validated Solutions - это хорошо спроектированная и проверенная реализация, созданная и протестированная VMware для повышения бизнес-ценности клиентов VMware Cloud Foundation. Это решение для улучшения перехода от только установленного продукта к готовому к использованию. Все VMware Validated Solutions включают структурированный подход к быстрому и эффективному запуску, который включает планирование и подготовку, цели и решения проектирования, реализацию, операционное руководство и руководство по взаимодействию решений. Кроме того, многие из решений предлагают возможность развертывания большей части продуктов средствами автоматизации.
Что такое Cloud-Based Ransomware Recovery for VMware Cloud Foundation?
VMware Ransomware Recovery for VMware Cloud Disaster Recovery предлагает уверенное восстановление от критических угроз, быстрое восстановление с помощью управляемой автоматизации и упрощенные операции восстановления. Это полностью управляемое решение Ransomware Recovery as-a-Service, которое позволяет безопасно восстанавливаться от современных программ-вымогателей через поведенческий анализ включенных рабочих нагрузок в изолированной среде восстановления (IRE) в облаке. Управляемая автоматизация рабочего процесса позволяет клиентам быстро идентифицировать потенциальные точки восстановления, проверять точки восстановления с помощью живого поведенческого анализа и предотвращать повторное заражение благодаря возможностям сетевой изоляции.
Основные проблемы, с которыми сталкиваются организации при восстановлении после атак программ-вымогателей:
Определение нужной точки восстановления
Проверка найденных точек восстановления
Предотвращение повторного заражения
Минимизация потери данных
Минимизация простоя
Cloud-Based Ransomware Recovery for VMware Cloud Foundation - это хорошо спроектированное проверенное решение, которое направлено на решение этих проблем путем предоставления подробных рекомендаций по проектированию, реализации, конфигурации и эксплуатации защиты рабочих нагрузок бизнеса, работающих в экземпляре VMware Cloud Foundation, от атак программ-вымогателей, за счет подключения экземпляра к VMware Cloud на AWS с использованием сервиса VMware Cloud Disaster Recovery.
Обзор решения
Cloud-Based Ransomware Recovery для VMware Cloud Foundation подробно описывает архитектурные решения - как и где развертывать DRaaS Connectors, учитывая различные компоненты в сервисе VMware Cloud Disaster Recovery и их интеграцию в компоненты среды VMware Cloud Foundation. Это обеспечивает повторяемый процесс, который может быть использован в любой среде VMware Cloud Foundation.
На логической схеме ниже мы используем сервис VMware Cloud Disaster Recovery и активируем регион восстановления, который настраивает оркестратор и облачную файловую систему на VMware Cloud for AWS. Регион восстановления - это место, где мы разворачиваем решение SDDC для восстановления.
Из сервиса VMware Cloud Disaster Recovery мы загружаем и устанавливаем VMware DRaaS Connectors экземпляра VMware Cloud Foundation. Это позволяет сайту VMware Cloud Foundation реплицировать снимки виртуальных машин в облачную файловую систему. Количество необходимых VMware DRaaS Connectors зависит от количества виртуальных машин, которые вы хотите защитить в вашем окружении VMware Cloud Foundation.
В процессе восстановления SDDC для восстановления обеспечивает изолированную среду восстановления (IRE) в VMware Cloud for AWS, которая позволяет вам осматривать, анализировать и восстанавливать зараженные виртуальные машины перед их возвращением в производственную среду.
Операционное руководство, предоставленное в этом решении, направлено на создание основы для руководства по выполнению задач, которое включает настройку SDDC для восстановления, активацию восстановления от программ-вымогателей, создание групп защиты, планов восстановления и выполнение восстановления виртуальной машины рабочей нагрузки от программ-вымогателей.
Решение Cloud-Based Ransomware Recovery for VMware Cloud Foundation доступно уже сейчас.
Видео ниже объясняет механику голосования, используемую vSAN в случае отказа одного из сайтов и последующего отказа Witness. Адаптивное управление кворумом присваивает больше голосов выжившему сайту, чтобы обеспечить обработку последующего отказа сайта свидетеля. Путем присвоения 3 голосов компонентам на выжившем сайте по-прежнему соблюдается большинство голосов. Даже если дополнительный хост ESXi на предпочтительном сайте потерян, всё равно есть достаточно голосов для достижения большинства, поэтому виртуальные машины продолжат функционировать.
Таги: VMware, vSAN, vSphere, HA, DR, Stretched, Video
Дункан Эппинг написал интересную статью про обслуживание межсайтового соединения (ISL) растянутого кластера VMware vSAN. Обычно, если условия позволяют, можно потушить все рабочие нагрузки (ВМ) на обеих площадках, после чего можно выключить кластеры и проводить обслуживание сетевого линка между площадками. Эта процедура описана в KB 2142676.
Но что делать в случае, когда вам нужно, чтобы рабочие нагрузки на одной из площадок продолжили выполняться во время обслуживания ISL?
Этот механизм и можно использовать для обслуживания ISL-соединения. Итак, переводим все хосты кластера на сайте 1 в режим обслуживания (Maintenance Mode) или выключаем их. В этом случае в растянутом кластере голоса для компонента Witness будут пересчитаны в течение 3 минут. После этого можно выключить и сам Witness - и это не приведет к падению виртуальных машин на сайте 2.
Итак, как он это проверял. Сначала перевел все хосты сайта 1 в режим обслуживания - и все его виртуальные машины начали переезд на второй сайт.
Затем он проверил RVC-консоль (как мы писали выше) и дождался, пока за пару минут будут пересчитаны голоса. Далее он просто выключил компонент Witness, после чего он убедился, что все ВМ продолжили нормально работать на второй площадке:
После этого можно начинать обслуживание ISL-соединения и работы по улучшению межкластерного соединения.
Для верности можно выполнить команду vsan.vm_object_info в консоли RVC и проверить объекты/экземпляры виртуальных машин на предмет того, что они находятся в статусе "ACTIVE" вместо "ABSENT":
После завершения обслуживания ISL-линка, вы можете включить компонент Witness, после чего включаете обратно хосты сайта 1 и обязательно выполняете ресинхронизацию (resync). После этого механизм VMware DRS в автоматическом режиме сам сбалансирует нагрузки по площадкам, распределив их по ним с помощью vMotion.
Недавно компания VMware обновила решение Cloud Director Availability 4.7, которое предназначено для создания резервной инфраструктуры в одном из публичных облаков на основе VMware Cloud Director (так называемая услуга Disaster-Recovery-as-a-Service, DRaaS). Напомним, что о прошлой версии этого продукта мы писали вот тут.
Новый механизм репликации
До настоящего момента VMware Cloud Director Availability использовал независимые (independent) диски при репликации рабочих нагрузок в облака Cloud Director. Однако это не является их изначальным назначением, что может оказать отрицательное влияние на механику репликации в определенных случаях.
Для уменьшения действия этого фактора и дальнейшего улучшения стабильности и оперативности, а также для обеспечения возможности будущих улучшений, введена система отслеживания репликации Replication Tracking VM (RT VM). Она позволяет использовать новый способ репликации виртуальных машин, совместимый с продуктом Cloud Director Availability 4.7, который зарегистрирован в Cloud Director 10.5+.
Запущенные репликации не будут затронуты этим изменением после обновления VMware Cloud Director Availability. Существует опция для их миграции с независимых дисков на RT VM через пользовательский интерфейс VMware Cloud Director Availability.
Все новые репликации будут использовать этот новый механизм размещения.
Выбор политики хранения
VMware Cloud Director Availability 4.7 получил две новые функции, связанные с выбором политики хранения:
Выбор политики хранения для каждого диска
Переназначение политики хранения во время восстановления рабочей нагрузки
Выбор политики для каждого диска
В предыдущих версиях VMware Cloud Director Availability при выборе политики для репликации применялись одни и те же настройки для всех ее дисков. В версии 4.7 вы теперь можете указать политику для каждого диска, сохраняя при этом остальные функции, такие как исключение диска или использование Seed VM.
Эта функция доступна как для облаков Cloud Director, так и для vSphere с одним отличием - для облаков vSphere вы можете выбрать политику хранения и хранилище размещения для каждого диска.
При использовании seed VM репликация будет использовать ее настройки хранилища, и вы не сможете их указать.
Переназначение политики во время восстановления рабочей нагрузки
С учетом оптимизации затрат часто принято использовать медленное, но более дешевое хранилище для данных. Это актуально и для репликаций, где с течением времени может накапливаться большой объем данных.
Однако скорость хранилища может негативно сказаться на производительности рабочей нагрузки при ее переключении в случае сбоя. Чтобы сэкономить клиентам сложный выбор того, где именно пойти на уступки, VMware Cloud Director Availability 4.7 позволяет использовать конкретные настройки хранилища при начальной настройке репликации, а затем выбрать другие настройки при восстановлении реплик.
Эта новая функция доступна как для облаков vSphere, так и для облаков Cloud Director.
Предварительная проверка выполнения планов восстановления
При использовании планов восстановления довольно неприятно достичь определенного этапа их выполнения и обнаружить, что некоторые настройки репликации не настроены, что приводит к неудачному завершению плана. Предварительная проверка выполнения планов восстановления убирает это неудобство и уменьшает время, затрачиваемое на проверку обязательных конфигураций, необходимых Cloud Director Availability для завершения репликации или набора репликаций.
Эти проверки учитывают значительные изменения в инфраструктуре облака, проверяют настройки размещения и наличие недостающих настроек восстановления, а также доступность исходного сайта для случаев миграции.
Эта информация доступна в новой вкладке "Health", которая присутствует в каждом плане восстановления при его выборе. Там вы можете увидеть, когда была проведена последняя проверка, а также доступные действия для устранения обнаруженной проблемы.
Механизм vSphere DR и поддержка миграций Seed VM
В рамках улучшений по обеспечению равенства функций для точек назначения vSphere и Cloud Director, теперь можно выбрать начальную виртуальную машину (Seed VM) при репликации рабочих нагрузок в облака vSphere.
Улучшения для облаков VMware Cloud Director
Появилось несколько новых функций, которые решают проблемы для поставщиков облачных услуг и их клиентов, которые реплицируют рабочие нагрузки в облака назначения Cloud Director:
Передача меток безопасности NSX, связанных с реплицированной виртуальной машиной при инициировании миграции/восстановления между двумя облаками, работающими на VMware Cloud Director 10.3+.
Автовыбор политики сайзинга при cloud-to-cloud - если виртуальной машине назначена политика сайзинга на исходном сайте, и на назначенном сайте существует политика с таким же именем, она будет автоматически выбрана при настройке репликации.
Управление видимостью удаленных облачных сайтов - поставщики облачных услуг могут контролировать, какие партнерские сайты будут видны для каких организаций. Если сайт, на котором активны репликации, скрыт, они будут продолжать отображаться в пользовательском интерфейсе, но невозможно будет создавать новые репликации в/из скрытого сайта.
Управление политиками для направлений репликации - доступные средства управления расширяются еще одной новой опцией для поддержания возможного направления операций репликации для клиента облака. С ее помощью поставщики облачных услуг могут ограничить клиентов в защите рабочих нагрузок, работающих в облаке, только в направлении их собственного датацентра.
Более подробную информацию о VMware Cloud Director Availability 4.7 можно получить по этой ссылке.
Таги: VMware, vSphere, Cloud, Availability, Director, Update, DR
Распределенная архитектура vSAN всегда была естественным решением для множества топологий, таких как растянутые кластеры, 2-узловые кластеры и кластеры, использующие домены отказа (fault domains). Но что насчет vSAN Max? Давайте рассмотрим, как vSAN Max может помочь обеспечить централизованное общее хранилище для ваших кластеров vSphere, используя эти альтернативные топологии.
Гибкость распределенного объектного хранилища
Кластер vSAN HCI объединяет вычислительные ресурсы и хранилища на одних и тех же хостах, которые составляют кластер, что обеспечивает простой и мощный способ создания растянутого кластера. Просто разместите хосты vSAN в кластере на двух географических площадках вместе с виртуальным хостом Witness на третьем сайте и настройте кластер как растянутый (stretched). И вычислительные ресурсы, и хранилища распределены по площадкам в единой, согласованной манере, что обеспечивает доступность экземпляров виртуальных машин и их данных в случае частичного или полного сбоя сайта.
Хост Witness не показан ниже для ясности на всех иллюстрациях растянутых кластеров в этом посте.
Рисунок 1. Отказоустойчивость на уровне сайта для виртуальных машин в растянутом кластере vSAN HCI, охватывающем два центра обработки данных.
Данные хранятся отказоустойчиво на разных площадках, что означает наличие двух путей от вычислительных ресурсов к данным. Поскольку вычислительные ресурсы и хранилища объединяются на одних и тех же хостах, которые составляют кластер vSAN, изначально существует архитектура высокой доступности для обоих типов ресурсов и предпочтительного пути данных, что является одной из причин, по которой растянутый кластер vSAN HCI может автоматически учитывать сценарии сбоев и другие стрессовые условия.
Растянутые топологии, использующие разделенные хранилища и вычислительные ресурсы
Концептуально растянутая топология подразумевает, что данные избыточно хранятся в двух определенных доменах отказоустойчивости – обычно (но не всегда) на двух географически разнесенных площадках. Это предположение должно учитываться в такого рода среде при рассмотрении топологий.
Когда вычислительные ресурсы и хранилища отделены друг от друга, они должны понимать характеристики двух сетевых путей от вычислительных ресурсов к избыточным данным. В большинстве случаев один из сетевых путей (межсайтовая связь или ISL) будет медленнее другого. Это называется асимметричной сетевой топологией, как показано на Рисунке 2. Хотя это наиболее распространенная конфигурация для растянутого кластера, она представляет интересную задачу, потому что система должна правильно выбрать оптимальный сетевой путь вместо менее быстрого для лучшей производительности.
Рисунок 2. Асимметричные сетевые топологии для растянутых сред.
Гораздо менее распространенная симметричная сетевая топология показана на рисунке 3. Это представляет собой топологию, где пропускная способность и задержка остаются одинаковыми независимо от выбранного пути данных для выполнения запроса. Такую ситуацию можно увидеть, когда два домена отказа или "сайта", как их определяют, представляют собой просто стойки серверов, расположенные рядом друг с другом и использующие одно и то же сетевое оборудование, что обеспечивает задержку менее 1 мс между клиентским кластером и серверным кластером внутри одного домена отказа или между доменами.
Рисунок 3. Симметричные сетевые топологии для растянутых сред.
Чтобы помочь vSAN Max понять правильный сетевой путь в топологии растянутого кластера, мастер настройки vSAN Max позволит вам выбрать сетевую топологию, соответствующую вашей среде.
vSAN Max, растянутый между географическими сайтами
Кластер vSAN Max может быть настроен как кластер одного сайта или в растянутой конфигурации. vSAN Max может обеспечивать устойчивость данных на уровне сайта, зеркалируя данные между сайтами, и вторичные уровни отказоустойчивости с помощью эффективного для экономии места схемы хранения RAID-6 erasure coding в пределах каждого сайта. Это
обеспечивает высокий уровень отказоустойчивости эффективным способом и гарантирует, что восстановление данных будет выполнено локально в случае отдельного сбоя хоста в пределах сайта.
Рисунок 4 иллюстрирует растянутый кластер vSAN HCI, который подключает хранилище кластера vSAN Max, также растянутого. В этом типе асимметричной конфигурации кластер vSAN HCI и кластер vSAN Max будут поддерживать наибольшую близость сайтов обработки ввода-вывода и данных между клиентским и серверным кластерами.
Рисунок 4. Растянутый кластер vSAN Max обеспечивает устойчивое хранение данных на двух сайтах обработки данных для кластера vSAN HCI, который также является растянутым.
Поддерживаемые клиентские кластеры при использовании vSAN Max в растянутой топологии
Следующая таблица резюмирует типы клиентских кластеров, поддерживаемых при использовании кластера vSAN Max в конфигурации растянутого кластера. Предполагается, что требование к задержке в 1 мс или меньше между клиентским кластером и кластером vSAN Max выполнено, и предполагается, что все клиентские кластеры используют vSphere 8.
Тип клиентского кластера
Тип серверного кластера
Поддерживается?
Заметки
Кластер vSAN HCI (ESA) в конфигурации stretched cluster
Кластер vSAN Max или vSAN HCI (ESA) в конфигурации растянутого кластера
Да
Предоставляет высокую доступность для данных и запущенных виртуальных машин
Кластер vSAN HCI (ESA), когда он находится на одном из сайтов данных, где находится кластер vSAN Max.
Кластер vSAN Max или vSAN HCI (ESA) в конфигурации растянутого кластера
Да
Предоставляет высокую доступность для данных и запущенных виртуальных машин
Растянутый кластер vSphere между двумя сайтами с ассиметричным сетевым соединением
Кластер vSAN Max или vSAN HCI (ESA) в конфигурации растянутого кластера
Нет
Пока не поддерживается
Растянутый кластер vSphere между двумя сайтами с симметричным сетевым соединением
Кластер vSAN Max или vSAN HCI (ESA) в конфигурации растянутого кластера
Да
Поддерживается, встречается редко, так как требуется аналогичные параметры bandwidth и latency между доменами отказа, как и внутри домена
Кластеры vSphere, когда они находятся на одном из сайтов данных, там же, где и кластер vSAN Max
Кластер vSAN Max или vSAN HCI (ESA) в конфигурации растянутого кластера
Да
Предоставляет высокую доступность для данных, но НЕ для запущенных виртуальных машин
Любой клиентский кластер архитектуры vSAN OSA
vSAN Max cluster or vSAN HCI cluster (ESA) в режиме одного сайта или в конфигурации растянутого кластера
Нет
Пока не поддерживается
Как отмечено выше, когда кластер vSAN Max настроен как растянутый с использованием асимметричной сетевой топологии, кластер vSphere, подключающий хранилище данных vSAN Max и растянутый на тех же двух сайтах - в настоящее время не поддерживается. Если требуется отказоустойчивость данных и экземпляров виртуальных машин на уровне сайта, кластер vSAN HCI в качестве клиентского кластера в растянутой конфигурации может быть лучшим вариантом на данный момент. Это обеспечит высокую доступность экземпляров виртуальных машин и обслуживаемых ими данных.
При использовании в конфигурации растянутого кластера кластеры vSAN Max будут иметь те же требования к пропускной способности и задержке сети между сайтами, что и традиционные кластеры vSAN HCI того же размера. Смотрите руководство по размерам пропускной способности растянутых кластеров vSAN для получения дополнительной информации.
Рекомендация. Размер вашей межсайтовой связи (ISL) должен быть основан на требованиях вашей рабочей нагрузки. Учитывая, что кластер vSAN Max может предложить высокопроизводительное хранилище, убедитесь, что ISL может обеспечить необходимую пропускную способность и задержку для ваших рабочих нагрузок. Это означает, что ваша среда может потребовать более 10 Гбит/с пропускной способности, указанной как минимально необходимая для этого типа топологии.
vSAN Max с использованием функции доменов отказа vSAN
vSAN Max также может быть настроен с использованием функции Fault Domains, которая чаще всего используется для обеспечения отказоустойчивости на уровне стоек для больших кластеров. Функция доменов отказа стала гораздо более эффективной с ESA, и поскольку vSAN Max построен на этой архитектуре, он обеспечивает все улучшенные уровни производительности, эффективности и доступности данных, связанные с ESA.
Рисунок 5. vSAN Max обеспечивает устойчивость на уровне стоек с использованием функции доменов отказа.
Будучи настроенной правильно, функция доменов отказа обычно ограничивается большими кластерами. Это связано с тем, что, как показано на рисунке 5 выше, RAID-6 распределяет данные и четность по минимум шести доменам отказоустойчивости, и VMware рекомендует использовать по крайней мере 3 хоста на каждый домен отказа. Для достижения такой же устойчивости на уровне стоек с использованием относительно меньшего кластера можно просто разместить один (и не более одного) хоста в кластере vSAN Max на стойку, не включая функцию доменов отказа, как показано на рисунке 6. В этой конфигурации он обеспечит устойчивость на уровне стоек таким же образом.
Рисунок 6. vSAN Max обеспечивает устойчивость на уровне стоек без использования функции доменов отказа.
Такой тип стратегии изменит способ прохождения трафика vSAN через сетевое оборудование и должен быть частью вашего планирования при проектировании кластера vSAN Max.
Хотя типичная рекомендация VMware - включать опцию "Host Rebuild Reserve" для кластеров vSAN Max, обратите внимание, что эти переключатели не могут быть включены при настройке vSAN Max в растянутой топологии или при использовании функции доменов отказа vSAN.
Таги: VMware, vSAN, Max, Stretched, vSphere, HA, DR
Борьба с программами-вымогателями и готовность к восстановлению после катастроф продолжают оставаться в приоритете для CIO по всему миру - число атак программ-вымогателей стремительно растет, требования к соблюдению нормативов вынуждают организации внедрять меры по обеспечению аварийного восстановления инфраструктуры.
VMware предлагает предприятиям готовые возможности, чтобы удовлетворить потребности современного бизнеса за счет новых функций в решениях VMware Cloud DR и VMware Ransomware Recovery.
Готовность к восстановлению средствами VMware Cloud DR - быстрое переключение и восстановление, оптимизированная стоимость владения
До сегодняшнего дня, когда клиенты сталкивались со сценарием DR, у них была только одна возможность - включить восстановленные виртуальные машины в резервном датацентре DR SDDC с помощью функции Instant Power On, при этом их диски располагались в облачной файловой системе. Затем они переносились на основное хранилище в DR SDDC через Storage vMotion.
Хотя это по-прежнему рекомендуемый подход для интенсивных по вводу-выводу или крупных рабочих нагрузок, пользователи теперь могут получить преимущества улучшенной производительности восстановления с новой функцией: Run Recovered VMs on Cloud Filesystem (запуск восстановленных машин в облачной файловой системе). Подробнее об этом рассказано тут.
С этой опцией ВМ могут продолжать работать в DR SDDC, причем их диски располагаются в Cloud Filesystem, что позволяет избежать использования Storage vMotion, что сильно ускоряет переключение в случае сбоя. Машины, работающие в Cloud Filesystem, получают защиту средствами высокой доступности (HA), а также низкие значения RPO.
Ключевые преимущества функции "Запуск восстановленных ВМ на Cloud Filesystem" включают:
Быстрое переключение и улучшенная производительность после восстановления: исключение использования Storage vMotion для vSAN и запуск восстановленных ВМ с дисками, по-прежнему располагающимися в Cloud Filesystem.
Быстрое обратное восстановление: эта новая функция устраняет необходимость создания снапшотов на базе VADP в резервном SDDC при обратном восстановлении.
Оптимизация TCO: для рабочих нагрузок, ограниченных объемом хранилища, требуется меньше ресурсов облачных хостов для непосредственного запуска ВМ на Cloud Filesystem по сравнению с традиционным переключением.
Гибкость: вы можете выбрать, какие рабочие нагрузки запускать на Cloud Filesystem, а какие - переносить в резервный SDDC с помощью storage vMotion.
Более подробно о VMware Cloud DR можно почитать на этой странице.
VMware Ransomware Recovery: быстрое и эффективное восстановление от современных атак
VMware недавно представила функцию "Bulk VM Processing" для решения VMware Ransomware Recovery. С этой функцией пользователи получают преимущества автоматизированного восстановления до 50 виртуальных машин за раз, что ускоряет время восстановления и оптимизирует ИТ-ресурсы.
Обработка машин в больших объемах работает в рамках существующего руководящего рабочего процесса восстановления от программ-вымогателей (Ransomware), который охватывает идентификацию, проверку и восстановление точек восстановления. До 500 ВМ можно включить в один план восстановления от программ-вымогателей, при этом одновременная обработка возможна для 50 ВМ в одном пакете, что позволяет сразу нескольким ВМ пройти живой поведенческий анализ для выявления предупреждений безопасности, которые могут быть использованы для очистки штаммов программ-вымогателей из скомпрометированных снимков. Вместе эти интегрированные возможности обеспечивают более уверенное и быстрое восстановление работы в случае успешной атаки программы-вымогателя.
С момента введения поддержки выделенных облаков vSphere в качестве назначения репликации, VMware расширяет список доступных функций с каждым новым релизом.
VMware Cloud Director Availability 4.6 предлагает несколько заметных улучшений:
Планы восстановления
Регулирование пропускной способности (Bandwidth throttling)
Публичный API
Усовершенствования настроек процесса восстановления
Планы восстановления
Планы восстановления были частью VMware Cloud Director Availability уже некоторое время, но были доступны только для облачных мест назначения VMware Cloud Director. Теперь они стали частью набора функций vSphere DR и миграции и обеспечивают тот же интерфейс и удобство использования. План может быть создан как для миграций, так и защиты/репликации, но их смешивание не допускается.
Создавая план, вы определяете порядок миграции или переключения виртуальных машин. На каждом шаге вы можете включить одну или несколько виртуальных машин, добавить время ожидания перед началом выполнения следующего шага или запросить ручное подтверждение, которое приостановит план до его подтверждения. В качестве действий вы можете провести тестирование и затем выполнить очистку после теста, а также операции миграции/переключения.
Каждый запуск генерирует подробный отчет о выполнении, который содержит информацию о сайте, продолжительность выполнения каждого шага и общую продолжительность, а также результат операции.
Примечание: настройки восстановления всех репликаций, которые являются частью плана, должны быть заданы до его выполнения.
Регулирование пропускной способности
С этой новой функцией можно установить глобальное ограничение для входящего трафика репликации, получаемого отдельным облаком vSphere со всех партнерских сайтов. Оно не накладывает ограничений на данные рабочих нагрузок и управляющий трафик.
Лимит применяется к определенному сетевому интерфейсу виртуального модуля Tunnel и указывается в мегабитах в секунду:
Примечание: несмотря на то что внешние модули Replicator являются необязательными, для возможности управления пропускной способностью на облачном сайте должны работать только внешние репликаторы.
Публичный API
Еще одной новой функцией в VMware Cloud Director Availability 4.6 является публичный API для vSphere DR и миграции, которого не было в предыдущих релизах. Этот API позволяет вам выполнять настройку, репликацию, резервное копирование и многие другие операции.
Также произошли некоторые изменения в настройках восстановления, которые теперь проверяются вместе с настройками репликации (для датасторов) для избежания ошибок в процессе переключения/миграции из-за неправильной конфигурации. Кроме того, раздел "Network Mappings" позволяет настраивать общие сопоставления между исходными и целевыми сетями, что очень удобно при установке настроек восстановления для нескольких репликаций одновременно. Конечно, при необходимости эти сопоставления можно дополнительно настроить для каждого сетевого адаптера каждой виртуальной машины.
Каталоги VMware Cloud Director и шаблоны vApp широко используются многими организациями для оптимизации администрирования инфраструктуры виртуальных приложений vApp.
В Cloud Director Availability версии 4.3.1 компания VMware представила миграцию шаблонов vApp внутри облака или в удаленное облако Cloud Director. Это позволяет синхронизировать только конкретные элементы, а не весь каталог. Чтобы еще больше расширить возможности использования, в VMware Cloud Director Availability 4.6 теперь можно также защитить и шаблон vApp средствами репликации.
Меню консоли клиента было переработано, там добавлена новая кнопка защиты шаблона vApp:
Общий процесс репликации следует по таким же шагам, как и при миграции, но включает в себя несколько новых настроек для определения того, как будут обрабатываться изменения в исходных шаблонах vApp.
После выбора шаблона для репликации, его назначения в облаке, датацетра VDC и политики хранения, вас перенаправят на страницу настроек мастера.
Вот основные нововведения здесь:
Отслеживание исходного шаблона на предмет изменений - если включено, VMware Cloud Director Availability каждые 5 минут проверяет, не было ли каких-либо изменений в исходном шаблоне и, если они есть, настраивает новую репликацию для последней версии шаблона.
Задержка начала синхронизации - проверки на изменения будут выполняться каждые 5 минут только в течение указанного интервала. Если изменение обнаружено, VMware Cloud Director Availability приступит к выполнению операций. Обратите внимание, что они могут начаться только в течение определенного времени, но могут завершиться за его пределами этого окна.
Автоматическое поведение миграции - определяет, будет ли шаблон vApp перезаписан на месте назначения или будет добавлена новая копия в каталог, сохраняя старую версию без изменений. Для включения автоматической миграции начальная миграция должна быть выполнена вручную, и защита должна быть в состоянии восстановления после сбоя (Failed-Over recovery state).
Рабочий процесс
Рабочий процесс репликации шаблона vApp выглядит следующим образом:
Как только новая защита шаблона vApp настроена с активированными параметрами отслеживания изменений источника, Cloud Director Availability регулярно проверяет исходный шаблон каждые 5 минут. В зависимости от настройки задержки начала синхронизации, эти проверки работают круглосуточно или только в течение указанного интервала.
Когда обнаруживается изменение, VMware Cloud Director Availability автоматически создает новую репликацию с последней версией шаблона vApp и удаляет старую. Если успешно выполнена ручная миграция текущей репликации (не обязательно начальной), то каждая следующая также будет автоматически выполнена с указанными настройками (перезапись или новая копия).
Учет баллов/стоимости для сервис-провайдера
Репликации шаблона vApp учитываются как стандартные репликации vApp/VM с помощью VMware vCloud Usage Meter:
Миграции шаблона vApp как обычные миграции - 0 баллов за смигрированную ВМ.
Репликация шаблонов vApp как их защита - 10 баллов за защищенную ВМ.
Обратите внимание, что учет ведется на виртуальную машину, а не на шаблон. Это означает, что если вы защищаете шаблон vApp, состоящий из 3 ВМ, он будет потреблять 30 баллов.
Особенности процесса
Настройки восстановления можно изменить только до начала первоначальной ручной миграции. После этого они не могут быть изменены.
Настройки восстановления применяются только к автоматически созданным (будущим) репликациям, если сохраняются имена всех ВМ в шаблоне.
Настройка политики репликации "Custom SLA settings" должна быть обязательно активирована для организаций, которые будут защищать шаблоны vApp.
Недавно мы писали о новом релизе фреймворка для управления виртуальной инфраструктурой VMware PowerCLI 13.1. У данного средства есть очень много командлетов для автоматизации задач в различных продуктах VMware. Сегодня мы поговорим о том, как с помощью PowerCLI можно управлять задачами репликации в Site Recovery Manager (SRM) и vSphere Replication (VR). Данные операции осуществляются через REST API.
1. Подключение к серверу vSphere Replication через Connect-VrServer
Чтобы подключиться к серверу управления vSphere Replication, необходимо использовать команду Connect-VrServer. Репликация может быть настроена внутри одного сервера vCenter или между локальными и удаленными экземплярами сервера vCenter.
При настройке репликации внутри одного и того же сервера vCenter, вы можете подключиться только к локальному сайту репликации vSphere. В параметре Server укажите адрес сервера vSphere Replication. В параметрах User и Password укажите имя пользователя и пароль для экземпляра сервера vCenter, где развернут виртуальный модуль vSphere Replication.
Давайте рассмотрим объект VrServerConnection, возвращаемый командой Connect-VrServer. Он содержит свойство ConnectedPairings:
Это свойство является словарем, где хранятся все подключенные пары. Пара - это представление в API VR парных локального и удаленного сайтов. Поскольку мы только что прошли аутентификацию только на локальном сайте VR, в словаре содержится только одна запись. Это самоподключение локального vCenter.
Вы можете индексировать этот словарь по имени vCenter и получить определенный объект Pairing. Вам понадобится этот объект Pairing для вызова различных операций из API VR:
Чтобы аутентифицироваться на удаленном сервере vCenter, вы будете использовать другой набор параметров команды Connect-VrServer. Обратите внимание, что у вас должна быть настроена пара сайтов между локальным и удаленным сайтами vSphere Replication.
На этот раз для параметра LocalServer укажите уже доступный объект VrServerConnection. Для параметра RemoteServer укажите имя удаленного VC. Для параметров RemoteUser и RemotePassword укажите имя пользователя и пароль удаленного VC. Обратите внимание, что с VR мы можем настроить несколько удаленных сайтов:
Теперь, если вы проверите свойство ConnectedPairings объекта VrServerConnection, вы увидите, что в словаре появилась вторая пара, позволяющая вам вызывать операции API на удаленном сайте:
В качестве альтернативы вы можете аутентифицироваться на локальном и удаленном сайтах с помощью одного вызова Connect-VrServer:
Для начала вам нужно получить ВМ, которую вы хотите реплицировать. Используйте команду Invoke-VrGetLocalVms, для которой нужно указать параметры PairingId и VcenterId. У нас есть эти идентификаторы в объекте Pairing, который мы сохранили в переменной $remotePairing:
Вы также можете применить фильтр к этому вызову. Параметр FilterProperty указывает свойство ВМ, которое будет использоваться для поиска. В данном случае это свойство Name. Параметр Filter указывает значение свойства, которое вы ищете. Результатом этого вызова является объект VirtualMachineDrResponseList, который содержит список ВМ, соответствующих указанному фильтру. В нашем случае это будет список с одной ВМ:
Настройка HDD-дисков машин для репликации
При настройке репликации на основе хоста, вы должны указать жесткие диски ВМ, которые будут реплицированы. Для каждого реплицируемого диска вы должны указать хранилище данных на целевом vCenter. В этом примере мы будем реплицировать все жесткие диски нашей ВМ на одном целевом хранилище данных на удаленном vCenter.
Вот как получить целевое хранилище данных на удаленном vCenter, используя команду Invoke-VrGetVrCapableTargetDatastores:
Здесь для VcenterId укажите идентификатор удаленного vCenter. Укажите параметры FilterProperty и Filter, чтобы выбрать целевое хранилище данных по имени.
Жесткие диски доступны в свойстве Disks нашего объекта VirtualMachine, сохраненного в переменной $replicatedVm.
Пройдитесь по списку Disks и инициализируйте объекты ConfigureReplicationVmDisk для каждого жесткого диска. Сохраните эти конфигурации в переменной массива $replicationVmDisks:
Сначала вам нужно инициализировать объект ConfigureReplicationSpec. Помимо различных настроек репликации, мы должны указать конфигурацию репликации диска, сохраненную в переменной $replicationVmDisks, для параметра Disk. Также вам нужно указать идентификатор целевого vCenter и идентификатор реплицируемой ВМ.
Затем используйте команду Invoke-VrConfigureReplication для настройки репликации. В качестве параметров укажите PairingId и объект ConfigureReplicationSpec:
Результатом операции является объект TaskDrResponseList, который в нашем примере содержит список из одной задачи. Если хотите, вы можете указать массив объектов ConfigureReplicationSpec и реплицировать несколько ВМ одним вызовом.
Чтобы дождаться завершения задачи настройки репликации, получите задачу, пока ее свойство Status не будет равно чему-то отличному от "RUNNING":
Invoke-VrGetTaskInfo -TaskId $task.List[0].Id
В следующем разделе мы будем использовать командлеты из модуля VMware.Sdk.Srm для создания группы защиты и плана восстановления для только что созданной репликации.
3. Подключение к Site Recovery Manager с помощью Connect-SrmSdkServer
Для подключения к серверу Site Recovery Manager используйте командлет Connect-SrmSdkServer. Не используйте старый командлет Connect-SrmServer, уже доступный в модуле VMware.VimAutomation.Srm, так как он не совместим с командлетами модуля VMware.Sdk.Srm.
Site Recovery Manager поддерживает только одно соединение между локальными и удаленными сайтами SRM. Вы можете подключиться либо только к локальному сайту, либо вы можете аутентифицироваться на удаленном сайте сервера vCenter в том же вызове. Поскольку далее мы будем создавать группу защиты и план восстановления, мы выберем второй вариант. Обратите внимание, что у вас должна быть настроена пара сайтов между локальными и удаленными сайтами SRM.
Если мы посмотрим на объект SrmServerConnection, возвращенный командлетом Connect-SrmSdkServer, мы увидим, что он содержит свойство с именем ConnectedPairing. В этом случае это один объект Pairing, который представляет пару между локальным и удаленным сайтами SRM. Вам потребуется этот объект Pairing для вызова различных операций из API SRM:
4. Создание Protection Group и Recovery Plan для Host Based Replication
В этой главе мы будем использовать репликацию на основе хоста, которую мы настроили ранее. Сначала мы инициализируем HbrProtectionGroupSpec с уже реплицированной ВМ:
В этом примере мы повторно используем идентификатор ВМ, который мы сохранили в переменной $replicatedVm, поскольку он совместим между API VR и SRM. Если вам нужно получить реплицированную ВМ с помощью модуля VMware.Sdk.Srm, используйте командлет Invoke-SrmGetReplicatedVms:
Чтобы завершить этот пример, мы создадим Recovery Plan для Protection Group. Для этого сначала инициализируйте RecoveryPlanCreateSpec, требуемый командлетом Invoke-SrmCreatePlan:
После того, как вы закончили взаимодействовать с сервером SRM, закройте соединение, используя командлет Disconnect-SrmSdkServer:
Disconnect-SrmSdkServer "MySrmAddress.com"
Чтобы закрыть соединение с сервером VR, используйте командлет Disconnect-VrServer:
Disconnect-VrServer "MyVrAddress.com"
Вы можете объединить модули PowerCLI VMware.Sdk.Vr и VMware.Sdk.Srm для автоматизации всего сценария создания репликации на основе хоста и использования ее с группой защиты и планом восстановления. Если вы хотите автоматизировать репликацию на основе массива, доступную с модулем VMware.Sdk.Srm, обратитесь к статье "Array Based Replication with PowerCLI 13.1". Также вы можете ознакомиться со статьей "vSphere Replication REST API with PowerShell: Configure VM replication".
Таги: VMware, SRM, PowerCLI, Replication, Automation, DR
Дункан Эппинг опубликовал интересную статью, касающуюся проблем, возникающих в растянутом кластере VMware vSAN при различных сценариях отказов в нем.
В некоторых из приведенных ниже сценариев Дункан обсуждает сценарии разделения кластера. Под разделением подразумевается ситуация, когда и L3-соединение с компонентом Witness, и ISL-соединение с другим сайтом недоступны для одного из сайтов. Так, на примере приведенной выше диаграммы, если говорится, что сайт B изолирован - это означает, что сайт A все еще может общаться со свидетелем, но сайт B не может общаться ни со свидетелем, ни с сайтом A.
Во всех следующих сценариях действуют следующие условия: сайт A является предпочтительным местоположением, а сайт B - второстепенным. Что касается таблицы ниже, то первые два столбца относятся к настройке политики для виртуальной машины, как показано на скриншоте:
Третий столбец относится к местоположению, откуда виртуальная машина работает с точки зрения вычислительных ресурсов (хоста ESXi). Четвертый описывает тип сбоя, а пятый и шестой столбцы детализируют наблюдаемое в этом случае поведение.
Site Disaster Tolerance
Failures to Tolerate
VM Location
Failure
vSAN behavior
HA behavior
None Preferred
No data redundancy
Site A or B
Host failure Site A
Objects are inaccessible if failed host contained one or more components of objects
VM cannot be restarted as object is inaccessible
None Preferred
RAID-1/5/6
Site A or B
Host failure Site A
Objects are accessible as there's site local resiliency
VM does not need to be restarted, unless VM was running on failed host
None Preferred
No data redundancy / RAID-1/5/6
Site A
Full failure Site A
Objects are inaccessible as full site failed
VM cannot be restarted in Site B, as all objects reside in Site A
None Preferred
No data redundancy / RAID-1/5/6
Site B
Full failure Site B
Objects are accessible, as only Site A contains objects
VM can be restarted in Site A, as that is where all objects reside
None Preferred
No data redundancy / RAID-1/5/6
Site A
Partition Site A
Objects are accessible as all objects reside in Site A
VM does not need to be restarted
None Preferred
No data redundancy / RAID-1/5/6
Site B
Partition Site B
Objects are accessible in Site A, objects are not accessible in Site B as network is down
VM is restarted in Site A, and killed by vSAN in Site B
None Secondary
No data redundancy / RAID-1/5/6
Site B
Partition Site B
Objects are accessible in Site B
VM resides in Site B, does not need to be restarted
None Preferred
No data redundancy / RAID-1/5/6
Site A
Witness Host Failure
No impact, witness host is not used as data is not replicated
No impact
None Secondary
No data redundancy / RAID-1/5/6
Site B
Witness Host Failure
No impact, witness host is not used as data is not replicated
No impact
Site Mirroring
No data redundancy
Site A or B
Host failure Site A or B
Components on failed hosts inaccessible, read and write IO across ISL as no redundancy locally, rebuild across ISL
VM does not need to be restarted, unless VM was running on failed host
Site Mirroring
RAID-1/5/6
Site A or B
Host failure Site A or B
Components on failed hosts inaccessible, read IO locally due to RAID, rebuild locally
VM does not need to be restarted, unless VM was running on failed host
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A
Objects are inaccessible in Site A as full site failed
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Partition Site A
Objects are inaccessible in Site A as full site is partitioned and quorum is lost
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Witness Host Failure
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Full failure Site A
Objects are inaccessible in Site A as full site failed
VM does not need to be restarted as it resides in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Partition Site A
Objects are inaccessible in Site A as full site is partitioned and quorum is lost
VM does not need to be restarted as it resides in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Witness Host Failure
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Network failure between Site A and B (ISL down)
Site A binds with witness, objects in Site B becomes inaccessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Network failure between Site A and B (ISL down)
Site A binds with witness, objects in Site B becomes inaccessible
VM restarted in Site A
Site Mirroring
No data redundancy / RAID-1/5/6
Site A or Site B
Network failure between Witness and Site A/B
Witness object inaccessible, VM remains accessible
VM does not need to be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, and simultaneous Witness Host Failure
Objects are inaccessible in Site A and Site B due to quorum being lost
VM cannot be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, followed by Witness Host Failure a few minutes later
Pre vSAN 7.0 U3: Objects are inaccessible in Site A and Site B due to quorum being lost
VM cannot be restarted
Site Mirroring
No data redundancy / RAID-1/5/6
Site A
Full failure Site A, followed by Witness Host Failure a few minutes later
Post vSAN 7.0 U3: Objects are inaccessible in Site A, but accessible in Site B as votes have been recounted
VM restarted in Site B
Site Mirroring
No data redundancy / RAID-1/5/6
Site B
Full failure Site B, followed by Witness Host Failure a few minutes later
Post vSAN 7.0 U3: Objects are inaccessible in Site B, but accessible in Site A as votes have been recounted
VM restarted in Site A
Site Mirroring
No data redundancy
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, if components reside on failed host then object is inaccessible in Site B
VM cannot be restarted
Site Mirroring
No data redundancy
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, if components do not reside on failed host then object is accessible in Site B
VM restarted in Site B
Site Mirroring
RAID-1/5/6
Site A
Full failure Site A, and simultaneous host failure in Site B
Objects are inaccessible in Site A, accessible in Site B as there's site local resiliency
VM restarted in Site B
Таги: VMware, vSAN, Troubleshooting, HA, DR, Blogs
Дункан Эппинг опубликовал статью о VMware Ransomware Recovery, которая может оказаться полезной администраторам, встретившимся или готовящимся встретиться с проблемой программ-вымогателей. Об этом продукте мы также рассказывали вот тут. Приведем основные мысли этой статьи ниже.
VMware Ransomware Recovery является частью облачного решения VMware Cloud Disaster Recovery. Эту услугу можно начать использовать как службу облачного хранения, куда вы реплицируете свои рабочие нагрузки, когда вам не требуется запуска полноценного программно-определенного дата-центра. Это особенно полезно для организаций, которые могут позволить себе потратить примерно 3 часа на запуск SDDC, когда возникает необходимость восстановиться на резервную инфраструктуру (или протестировать этот процесс). Также вы можете постоянно иметь SDDC, всегда готовый к восстановлению, что значительно сократит целевое время восстановления.
VMware предоставляет возможность защиты различных сред и множества различных рабочих нагрузок, а также множества копий point-in-time (снапшотов). Но, что более важно, эта служба позволяет вам проверить вашу точку восстановления в полностью изолированной среде. Решение фактически не только изолирует рабочие нагрузки, но и предоставляет вам информацию на различных уровнях о вероятности заражения снимка. В первую очередь, в процессе восстановления показываются энтропия и скорость изменений, что дает представление о том, когда потенциально среда была заражена (или, например, был активирован вирус-вымогатель).
Кроме того, с помощью NSX и программного обеспечения Next Generation Anti-Virus от VMware можно безопасно проверить точку восстановления. Создается карантинная среда, где точка восстановления проверяется на уязвимости и угрозы, а также может быть проведен анализ рабочих нагрузок для восстановления, как показано на скриншоте ниже. Это значительно упрощает процесс восстановления и проверки, поскольку устраняет необходимость ручных операций, обычно включенных в этот процесс. Конечно, в рамках процесса восстановления используются продвинутые возможности сценариев VMware Cloud Disaster Recovery, позволяющие восстановить полный дата-центр или просто выбранную группу виртуальных машин, запустив план восстановления. В этот план восстановления включен порядок, в котором нужно включить и восстановить рабочие нагрузки, но в него также можно включить настройку IP, регистрацию DNS и многое другое.
В зависимости от результатов анализа, вы можете затем определить, что делать со снапшотом. В рамках анализа вы сможете ответить на следующие вопросы:
Данные не скомпрометированы?
Рабочие нагрузки не заражены?
Есть ли какие-либо известные уязвимости, которые мы должны сначала устранить?
Если данные скомпрометированы или среда заражена в любой форме, вы можете просто игнорировать снимок и очистить среду. Повторяйте процесс, пока не найдете точку восстановления, которая не скомпрометирована! Если есть известные уязвимости, а среда чиста, вы можете устранить их и завершить восстановление. В итоге это приведет к полному доступу к самому ценному активу вашей компании - данным.
Более подробно о решении VMware Ransomware Recovery можно почитать тут.
В конце ноября этого года компания NAKIVO выпустила бета-версию своей платформы для резервного копирования и репликации виртуальных машин Backup & Replication v10.8 Beta. Напомним, что о возможностях прошлой версии NAKIVO Backup & Replication v10.7 мы писали вот тут.
Давайте посмотрим, что нового предлагает бета-версия NAKIVO Backup & Replication v10.8:
1. Консоль сервис-провайдеров
Теперь сервис-провайдеры различного масштаба с развертываниями для нескольких клиентов могут управлять удаленными и локальными клиентами с установками NAKIVO.
До этого вы могли создавать окружения новых клиентов в рамках датацентра, а теперь можно добавить standalone-инстансы в общую инфраструктуру защиты данных как Managed Service Provider (MSP). Можно мониторить все эти окружения из единого дэшборда, что позволяет сервис-провайдерам предоставлять службы Backup-as-a-Service (BaaS) и Disaster Recovery-as-a-Service (DRaaS) для клиентов, у которых есть географически распределенные вычислительные ресурсы.
2. Поддержка VMware vSphere 8
Теперь NAKIVO Backup & Replication полностью поддерживает новые возможности платформы VMware vSphere 8, такие как digital processing units (DPU) для разгрузки основных CPU серверов и улучшение производительности онпремизных и облачных компонентов.
В прошлых релизах поддерживалось резервное копирование и репликация на хранилища Amazon S3, Wasabi Hot Cloud Storage, Azure Blob Storage и Backblaze B2 с возможностью неизменяемых бэкапов (immutability). Новая версия поддерживает гибридные окружения, которые содержат объектные хранилища S3 через API, среди которых можно выбрать из различных сервис-провайдеров, обеспечивающих их поддержку.
4. Функции прямого восстановления с ленточных носителей
Теперь с помощью решения от NAKIVO пользователи могут производить восстановление резервных копий виртуальных машин и инстансов EC2 напрямую с ленточных носителей. Такой подход обеспечивает высокую скорость восстановления и поддерживает платформы VMware vSphere, Microsoft Hyper-V, Nutanix AHV и Amazon EC2.
5. Улучшения юзабилити и средств управления
Здесь появились следующие функции:
Улучшения политики хранения бэкапов - ранее решение NAKIVO использует отдельные рабочие процессы для планирования задач резервного копирования и для настройки политики хранения резервных копий. Это позволяло вам менять политики хранения (включая схему grandfather-father-son, GFS), не затрагивая настройки задач бэкапа. Теперь же можно открыть оба вида настроек в рамках одного шага, чтобы обеспечить тонкий тюнинг и более гранулярную настройку задачи РК.
Приоритет задач РК - эта функция позволяет обеспечить высокий приоритет в очереди для задач резервного копирования наиболее критичных систем. Приоритет можно выставить от 5 (низший, ставится по умолчанию) до 1 (высший приоритет).
Слияние задач - если вы хотите изменить задачу РК, то здесь теперь доступны два возможных действия: добавить объект к уже имеющейся задаче РК и репликации, либо создать новую задачу и присоединить ее к существующей такого же типа. Второй вариант предпочтительнее, так как он позволяет не ошибиться с настройкой политик для новой системы.
Персистентный агент - при выполнении восстановления объектов ОС на уровне файлов вам нужны креды к данной виртуальной машине. Однако, в некоторых организациях политики безопасности не позволяют сообщать эти данные операторам резервного копирования. Теперь персистентный агент, настроенный однажды внутри ОС, позволяет коммуницировать с целевыми ВМ для передачи файлов из них.
Загрузить бета-версию решения NAKIVO Backup & Replication v10.8 по этой ссылке.

 RSS
RSS