Искусственный интеллект обладает огромным потенциалом для трансформации всех предприятий - IDC прогнозирует, что решения и сервисы AI окажут глобальное влияние на сумму 22,3 трлн долларов к 2030 году.
С учетом такого масштаба неудивительно, что предприятия стремятся использовать AI для повышения производительности во всех областях бизнеса. Однако им нужна комплексная стратегия, которая ускорит интеграцию AI в инфраструктуру дата-центров. С VMware Cloud Foundation Private AI Services компания Broadcom стремится помочь предприятиям раскрыть потенциал AI и повысить продуктивность при более низкой совокупной стоимости владения.
Реальный эффект: что говорят клиенты
Компании из разных отраслей уже развертывают VCF Private AI Services и получают экономию, приватность и безопасность для своих AI-нагрузок:
«Внедрив VCF Private AI Services, мы усилили возможности интеллектуальных сервисов», — говорит Тунг-Лян Чен, вице-президент Chunghwa Post. «Запуск AI в собственной инфраструктуре частного облака на базе VCF позволяет нам существенно снижать затраты и повышать эффективность автоматизированного обнаружения в реальном времени, одновременно обеспечивая бесшовную интеграцию с существующими системами».
«Анализ многолетних архивов новостей в публичном облаке обходится слишком дорого, а непредсказуемое ценообразование затрудняет планирование AI-проектов», — сказал V V Jacob, старший генеральный менеджер по системам Malayala Manorama Co Ltd. «Развернув VCF Private AI Services на существующей инфраструктуре VMware Cloud Foundation, мы сможем запускать AI-суммаризацию контента, генерацию заголовков и редакторскую помощь прямо в частном облаке. Мы считаем, что это даст нам приватность и безопасность, необходимые для защиты редакционных источников, а также предсказуемость затрат, которую обеспечивает локальная инфраструктура частного облака».
На днях был объявлен следующий выпуск VCF Private AI Services вместе с VCF 9.1. В новой версии для предприятий добавляется несколько важных функций.
Новые возможности
1. Приватность и безопасность
Broadcom помогает предприятиям создавать и развертывать приватные и безопасные AI-модели со встроенными возможностями защиты, предоставляемыми через VCF Private AI Services.
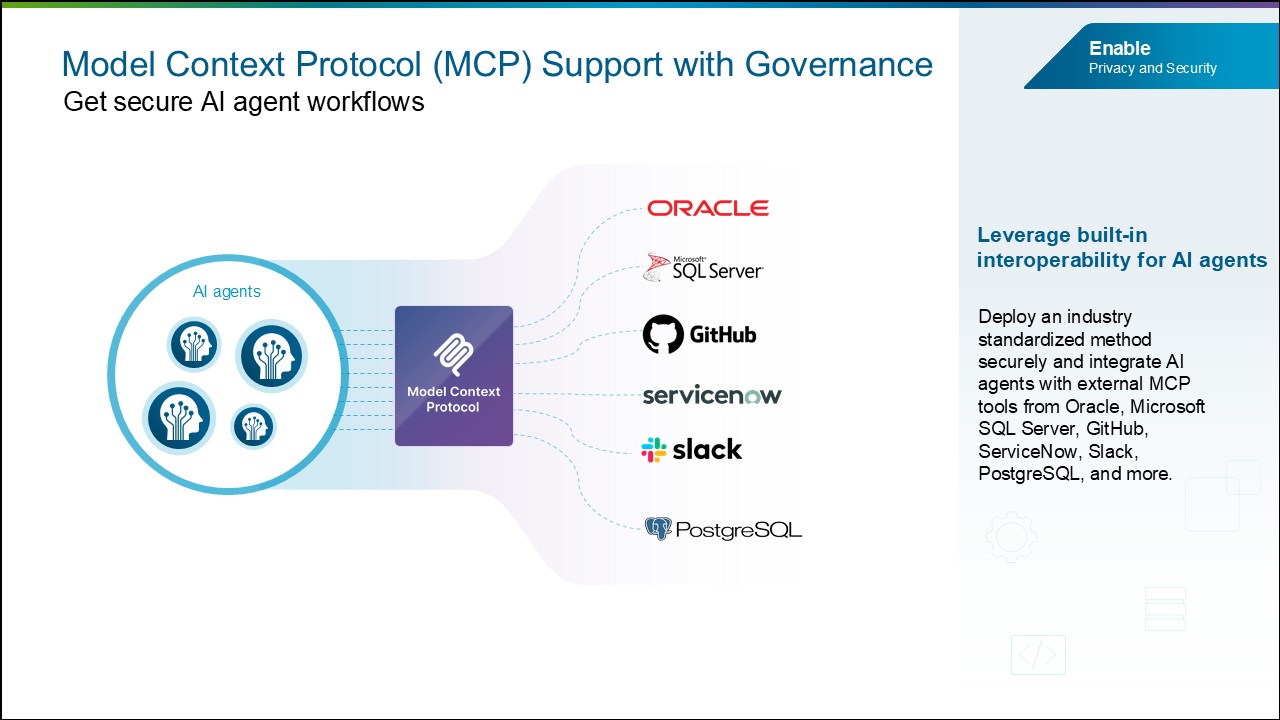
Поддержка Model Context Protocol (MCP) с управлением. Благодаря поддержке MCP предприятия получают безопасный и стандартизированный способ интегрировать AI-ассистентов с внутренними репозиториями контента и внешними MCP-инструментами от Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL и других поставщиков без разработки и сопровождения собственных коннекторов.
2. Упрощение управления инфраструктурой
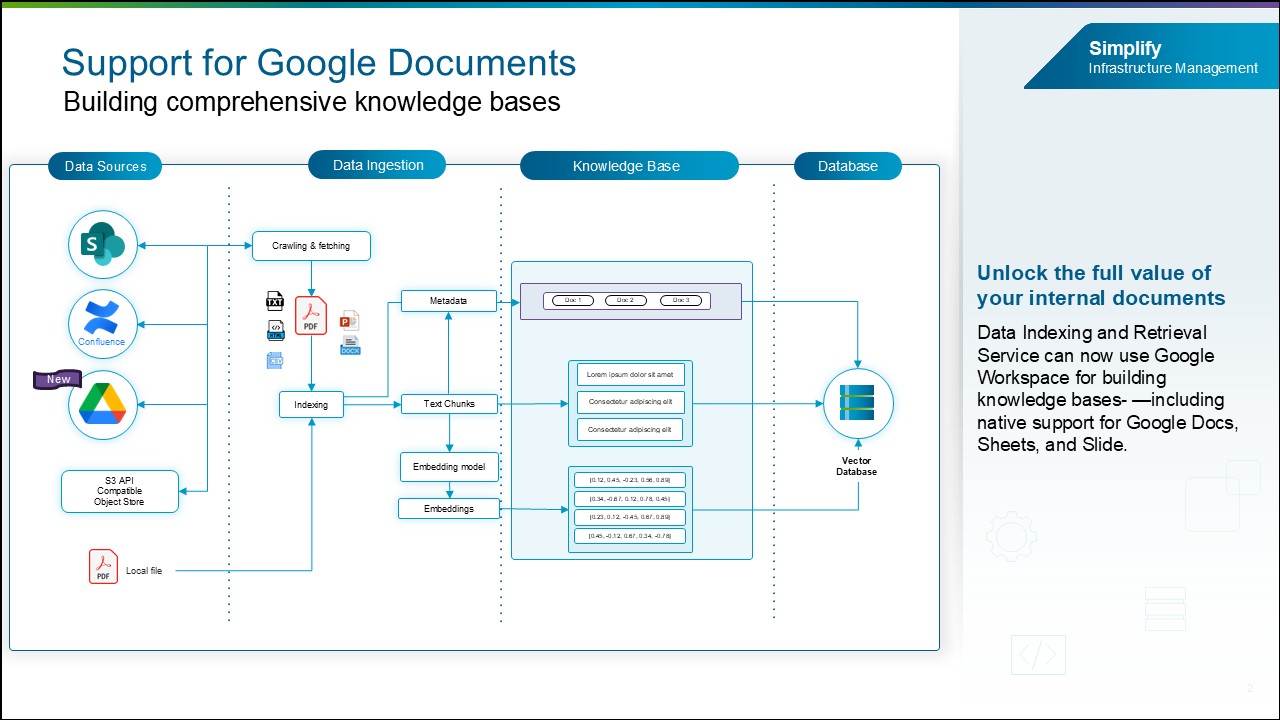
Поддержка Google Documents. VCF Private AI Services теперь предоставит полноценную поддержку Google Workspace, включая Google Docs, Sheets и Slides, без необходимости экспортировать документы в PDF и загружать их в базу знаний. В дополнение к уже существующей поддержке Microsoft Word, Microsoft PowerPoint, PDF, CSV и других форматов предприятия получают доступ к очень широкому набору типов документов и смогут добиваться качественных результатов для AI-нагрузок.
DirectPath Enablement для GPU. В этом выпуске VCF Private AI Services поддерживает DirectPath Enablement для инфраструктуры NVIDIA AI. Это обеспечит высокопроизводительный эксклюзивный доступ к GPU для одной виртуальной машины, которая сможет полностью использовать возможности GPU. С этой новой функцией предприятия смогут развертывать AI-проекты с NVIDIA GPU в режиме DirectPath.
Поддержка последнего поколения NVIDIA Blackwell GPU. VCF теперь поддерживает новейшую серию GPU NVIDIA Blackwell. В дополнение к существующей поддержке NVIDIA RTX PRO 6000 Blackwell Server Edition объявлена поддержка NVIDIA HGX B200 и NVIDIA RTX PRO 4500 Blackwell Server Edition. Поддержка этих новых GPU Blackwell на VCF определяет следующий этап корпоративного AI с беспрецедентной производительностью, эффективностью и масштабом.
Будущая поддержка. В одном из следующих выпусков VCF будет поддерживать NVIDIA HGX B300. VCF на NVIDIA HGX B300 позволит предприятиям без усилий масштабировать самые производительные AI-нагрузки и подготовить инфраструктуру к будущим требованиям.
Поддержка NVIDIA HGX Platform с Blackwell GPU и NVLink Switch. VCF теперь поддерживает NVIDIA HGX platform с Blackwell GPU и NVLink Switch. Благодаря этой возможности предприятия смогут получить преимущества крупномасштабных AI-развертываний с VCF Private AI Services и платформой NVIDIA HGX. NVIDIA HGX объединяет всю мощь инфраструктуры NVIDIA AI, включая NVIDIA GPU, NVIDIA NVLink, NVLink Switch, NVIDIA networking и полностью оптимизированные AI software stacks, чтобы обеспечивать максимальную производительность AI-приложений и ускорять получение инсайтов в каждом дата-центре.
Высокоскоростная сеть с Enhanced DirectPath I/O. VCF теперь поддерживает сетевые адаптеры NVIDIA ConnectX-7 и NVIDIA BlueField-3 с Enhanced DirectPath I/O. С этим улучшением предприятия смогут использовать такие расширенные возможности, как NVIDIA GPUDirect RDMA и GPUDirect Storage, для высокоскоростного обучения AI-моделей на нескольких хостах и передачи данных, что особенно важно для требовательных Gen AI-нагрузок.
3. Упрощение вывода моделей в эксплуатацию
Новые возможности в этой категории помогают предприятиям снижать сложность перевода моделей в production.
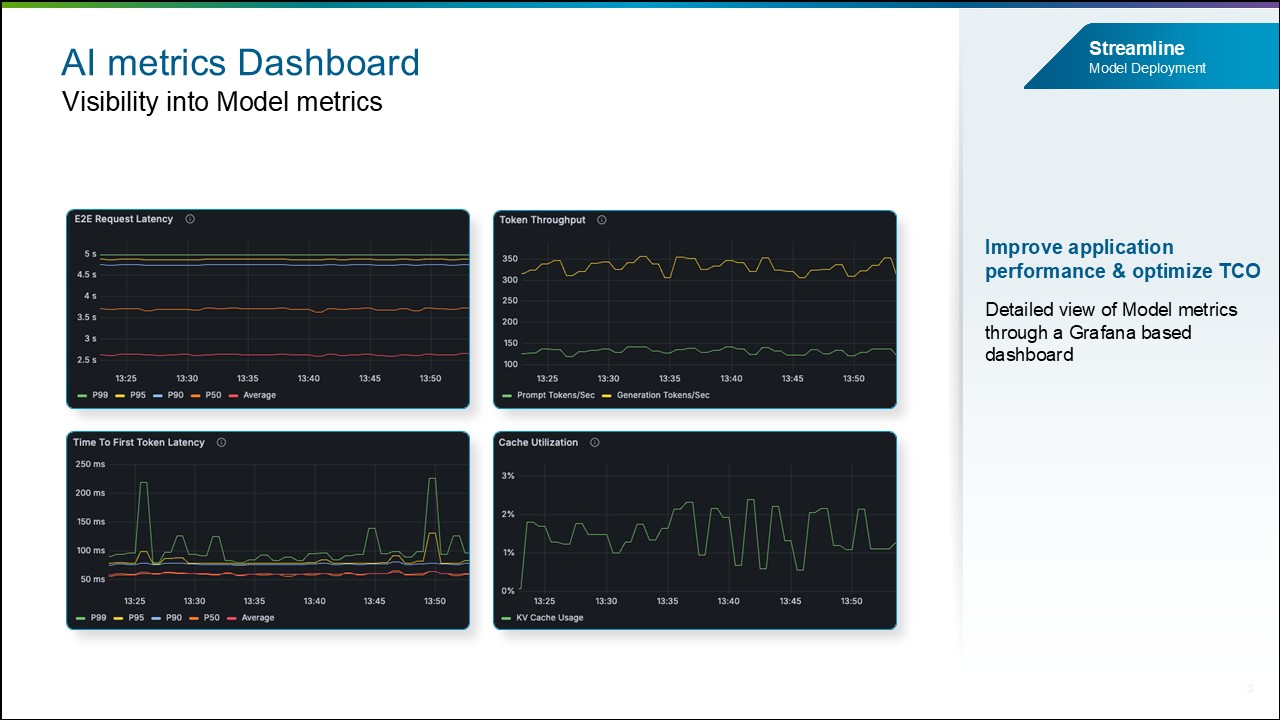
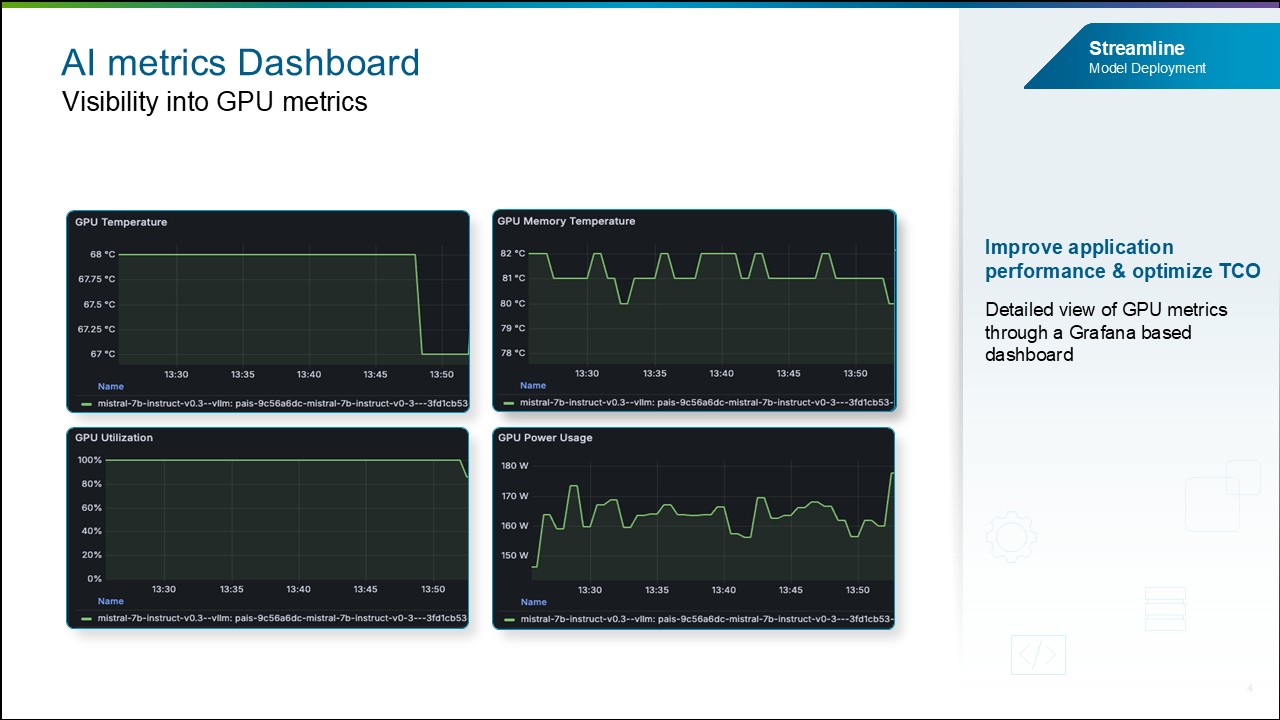
AI Metrics Observability Dashboard.
По мере масштабирования корпоративных AI-сред ограниченная видимость производительности моделей и агентов, а также факторов затрат мешает командам выявлять неэффективность, ведет к росту расходов на инфраструктуру и снижает производительность приложений. Чтобы решить эти проблемы, выпускается AI Metrics Observability Dashboard, который будет показывать важные AI-метрики.
Улучшенная видимость AI-метрик позволит специалистам по data science и MLOps выявлять узкие места, оптимизировать распределение ресурсов, повышать throughput и производительность.
Рассмотрим некоторые AI-метрики, которые будут доступны:
Метрики моделей. Эти метрики помогут предприятиям отслеживать продуктивность, скорость, задержку и другие параметры, предоставляя детальное представление о моделях. Будут доступны такие показатели, как Cache Utilization, Tokens generated per request, Token throughput, Time to first token (TFFT), End-to-end (E2E) request latency и другие.
Метрики использования GPU. Также будут доступны GPU-метрики, включая Utilization, Temperature, Power Usage, Memory Temperature, Memory Clock и другие.
Примечание: для этих AI Metrics dashboards предприятиям необходимо развернуть Grafana.
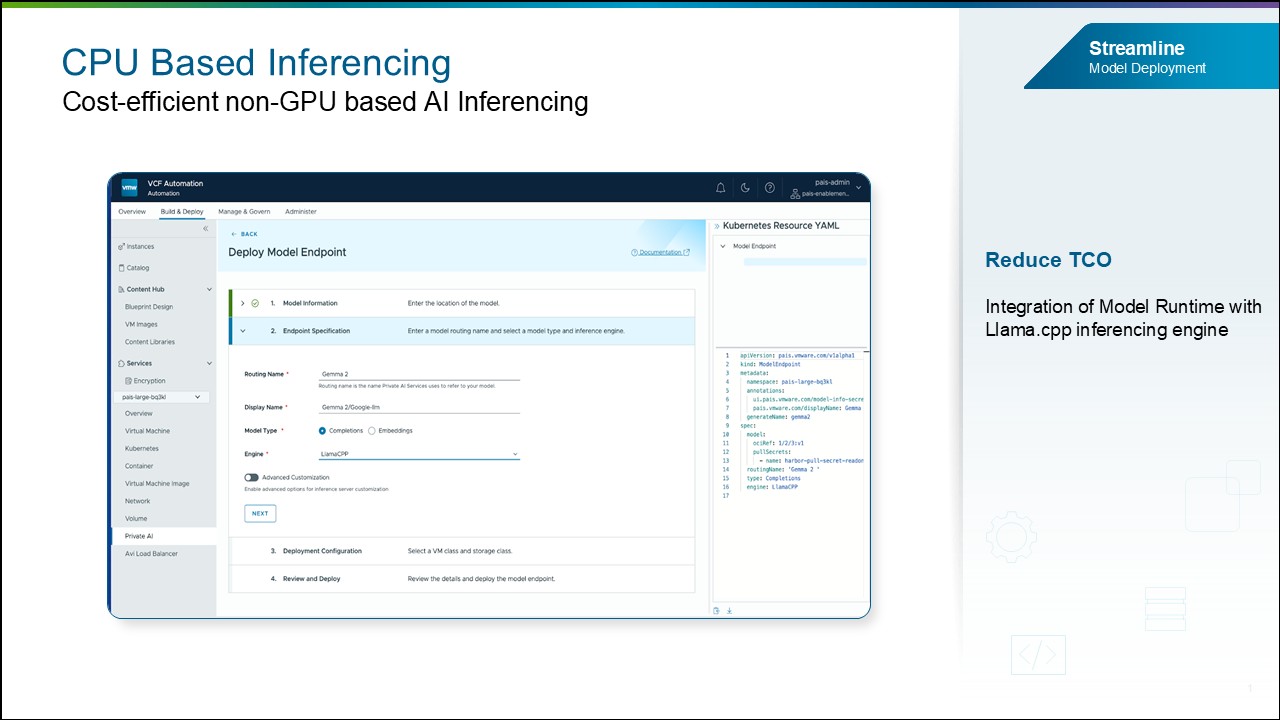
CPU-Based Inferencing. VCF Private AI Services теперь поддерживает CPU-based inferencing в дополнение к GPU-развертываниям благодаря интеграции Model Runtime с inference-движком Llama.cpp. На базе Llama.cpp, одного из ведущих open source inference-движков с широкой поддержкой сообщества, клиенты также получат доступ к большому набору моделей с day-zero-поддержкой от ведущих поставщиков, включая Google, OpenAI и других. Это улучшение снижает TCO, позволяя предприятиям развертывать менее ресурсоемкие среды для тестирования, proof-of-concept-инициатив или AI-приложений с минимальными требованиями к GPU либо без них.
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:
Конфигурация оборудования Dell PowerEdge XE9680:
Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:
Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.
Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.
Благодаря этому, у пользователей появляется ещё больше возможностей использовать подход Private AI для запуска моделей искусственного интеллекта и машинного обучения в непосредственной близости от приватных данных, как локально (on-premises), так и в облаке Azure VMware Solution.
Высокоуровневые компоненты данного решения представлены ниже:
Для получения подробных технических рекомендаций по интеграции Azure Machine Learning (AML) с VMware Cloud Foundation (VCF), пожалуйста, обратитесь к недавно опубликованной архитектуре решения.
Общие клиенты Broadcom и Microsoft признают, что гибридные решения в области искусственного интеллекта, сочетающие преимущества публичного облака и локальной (on-premises) или периферийной (edge) инфраструктуры, являются важнейшей частью их текущих и будущих архитектурных планов. Совместно с Microsoft компания Broadcom упрощает для организаций задачу обеспечения единого входа в Azure для разработчиков и специалистов по данным при планировании сервисов машинного обучения, таких как классификация данных или компьютерное зрение, и при этом дает возможность развертывать их на платформе VCF в любой точке присутствия бизнеса.
Современные задачи искусственного интеллекта (AI) и машинного обучения (ML) требуют высокопроизводительных решений при минимизации затрат на инфраструктуру, поскольку оборудование для таких нагрузок стоит дорого. Использование графических процессоров NVIDIA в сочетании с технологией NVIDIA AI Enterprise и платформой VMware Cloud Foundation (VCF) позволяет компаниям...
Компания Broadcom выпустила интересное видео, где Mark Achtemichuk и Uday Kulkurne обсуждают оптимизацию AI/ML нагрузок с использованием аппаратной платформы NVIDIA GPU и решения VMware Cloud Foundation:
Производительность и эффективность виртуализации графических процессоров (GPU) является одним из ключевых направлений для разработки решений в области искусственного интеллекта (AI) и машинного обучения (ML).
Виртуализация AI/ML задач, работающих на GPU, представляет собой вызов, так как традиционно считается, что виртуализация может значительно снижать производительность по сравнению с «чистой» конфигурацией на физическом оборудовании (bare metal). Однако VMware Cloud Foundation демонстрирует почти аналогичную производительность с минимальными потерями за счет умной виртуализации и использования технологий NVIDIA.
Рассматриваемые в данном видо графические процессоры от NVIDIA включают модели H100, A100 и L4, каждая из которых имеет уникальные характеристики для обработки AI/ML задач. Например, H100 оснащен 80 миллиардами транзисторов и способен ускорять работу трансформеров (на основе архитектуры GPT) в шесть раз. Особенностью H100 является возможность разделения GPU на несколько независимых сегментов, что позволяет обрабатывать задачи параллельно без взаимного влияния. A100 и L4 также обладают мощными возможностями для AI/ML, с небольшими различиями в спецификациях и применимости для графических задач и машинного обучения.
VMware Cloud Foundation (VCF) позволяет использовать все преимущества виртуализации, обеспечивая при этом производительность, близкую к физическому оборудованию. Одна из ключевых возможностей — это поддержка дробных виртуальных GPU (vGPU) с изоляцией, что позволяет безопасно распределять ресурсы GPU между несколькими виртуальными машинами.
Используя виртуализированные конфигурации на базе VCF и NVIDIA GPU, компании могут значительно снизить общие затраты на владение инфраструктурой (TCO). VMware Cloud Foundation позволяет консолидировать несколько виртуальных машин и задач на одном физическом хосте без существенной потери производительности. Это особенно важно в условиях современных датацентров, где необходимо максимизировать эффективность использования ресурсов.
В серии тестов было проверено, как виртуализированные GPU справляются с различными AI/ML задачами по сравнению с физическим оборудованием. Используя стандартные бенчмарки, такие как ML Commons, было показано, что виртуализированные GPU демонстрируют производительность от 95% до 104% по сравнению с bare metal конфигурациями в режиме инференса (вычисления запросов) и около 92-98% в режиме обучения. Это означает, что даже в виртуализированной среде можно добиться почти той же скорости, что и при использовании физического оборудования, а в некоторых случаях — даже превзойти её.
Основное преимущество использования VMware Cloud Foundation с NVIDIA GPU заключается в гибкости и экономии ресурсов. Виртуализированные среды позволяют разделять ресурсы GPU между множеством задач, что позволяет более эффективно использовать доступные мощности. Это особенно важно для компаний, стремящихся к оптимизации капитальных затрат на инфраструктуру и повышению эффективности использования серверных мощностей.
Тем из вас, кто интересуется технологиями машинного обучения и AI, может оказаться полезным продукт TensorFlow Management Pack For VMware Aria Operations от Эрика Слуфа, который сделан как кастомный пакет расширения для главного решения VMware по управлению всеми аспектами виртуальной инфраструктуры.
Эрик успешно подключил Raspberry Pi 5, работающий на TensorFlow, к VMware Aria Operation и решил поделиться этим. Новый конструктор пакетов управления (Management Pack Builder) от VMware превращает создание пользовательских средств управления в простую задачу. Этот интуитивно понятный инструмент, не требующий навыков программирования, позволяет расширить возможности систем мониторинга.
Конструктор пакетов управления Aria Operations - это самодостаточный инструмент, предлагающий удобный подход без программирования для импорта данных из внешних API. Этот инструмент позволяет создавать новые или улучшать существующие ресурсы VMware и сторонних разработчиков, добавляя новые данные, устанавливая связи и интегрируя события.
TensorFlow, известный своей универсальностью в области машинного обучения, особенно эффективен для проектов по обнаружению объектов, работая на платформе Raspberry Pi. Эта легкая архитектура просто интегрируется недорогим оборудованием Raspberry Pi, что делает ее идеальной для задач реального времени по обнаружению объектов. Используя камеру с TensorFlow, пользователи могут разрабатывать эффективные модели, работающие на устройстве, способные определять и категоризировать объекты в поле зрения камеры.
Raspberry Pi 5 использует Python-скрипт, предназначенный для обнаружения объектов, обрабатывая изображения с его камеры в структурированные JSON-данные. Кроме того, он работает веб-сервером, который представляет REST API для Aria Operations, позволяя собирать и статистически анализировать данные об обнаружении объектов, обработанные TensorFlow.
Файл пакета и соответствующий Python-код можно получить доступ и скачать из этого репозитория на GitHub. Руководство по настройке TensorFlow на Raspberry Pi можно найти вот тут.
Продолжаем рассказывать об интересных анонсах главного события года в мире виртуализации - конференции VMware Explore 2023. Сегодня организации стремятся использовать AI, но беспокоятся о рисках для интеллектуальной собственности, утечке данных и контроле доступа к моделям искусственного интеллекта. Эти проблемы определяют необходимость корпоративного приватного AI. О новой инициативе VMware Private AI мы детально рассказывали вот тут, а сегодня поговорим о референсной открытой архитектуре Private AI Reference Architecture for Open Source.
Архитектура VMware Private AI Reference для Open Source интегрирует инновационные технологии OSS (open source software) для предоставления открытой эталонной архитектуры создания и использования OSS-моделей на базе VMware Cloud Foundation. На конференции Explore 2023 компания VMware анонсировала сотрудничество с ведущими компаниями, которые создают ценность корпоративного AI в ИТ-инфраструктуре больших организаций на базе Open Source:
Anyscale: VMware внедряет широко используемую открытую вычислительную платформу Ray в средах VMware Cloud. Решение Ray on VMware Cloud Foundation облегчает масштабирование AI и рабочих нагрузок Python для инженеров по данным и MLOps, позволяя использовать собственные вычислительные ресурсы для ML-нагрузок, а не переходить в публичное облако.
Domino Data Lab: VMware, Domino Data Lab и NVIDIA объединились для предоставления унифицированной платформы для аналитики, Data Science и инфраструктуры, оптимизированной, проверенной и поддерживаемой для развертывания AI/ML в финансовой отрасли.
Глобальные системные интеграторы: VMware сотрудничает с ведущими интеграторами систем, такими как Wipro и HCL, чтобы помочь клиентам ощутить преимущества Private AI, создавая и предоставляя готовые решения, которые объединяют VMware Cloud с решениями экосистемы партнеров по AI.
Hugging Face: VMware сотрудничает с Hugging Face для обеспечения работы SafeCoder на виртуальных платформах, о чем было объявлено на VMware Explore. SafeCoder – это коммерческое решение-помощник по написанию кода для предприятий, включая услуги, программное обеспечение и поддержку. VMware использует SafeCoder внутри для своих процессов и публикует эталонную архитектуру с примерами кода для обеспечения максимально быстрого времени достижения ценности для клиентов при развертывании и эксплуатации SafeCoder на инфраструктуре VMware.
Intel: VMware vSphere/vSAN 8 и Tanzu оптимизированы под программный набор интеллектуальных технологий Intel для использования новых встроенных ускорителей AI на последних процессорах Intel Xeon Scalable четвертого поколения.
Кроме того, VMware объявляет о запуске новой программы VMware AI Ready (пока это доступно только для частных решений, например, в партнерстве с NVIDIA), которая предоставит ISV (независимым производителям программного обеспечения) инструменты и ресурсы, необходимые для валидации и сертификации своих продуктов на архитектуре VMware Private AI Reference. Программа будет доступна ISV, специализирующимся на ML и LLM Ops, инженерии данных, инструментах для разработчиков AI, а также встроенных AI-приложениях. Ожидается, что новая программа станет активной к концу 2023 года.
Продолжаем рассказывать об интересных анонсах главного события года в мире виртуализации - конференции VMware Explore 2023. Сегодня организации стремятся использовать AI, но беспокоятся о рисках для интеллектуальной собственности, утечке данных и контроле доступа к моделям искусственного интеллекта. Эти проблемы определяют необходимость корпоративного приватного AI.
Об этом недавно компания VMware записала интересное видео:
Рассмотрим этот важный анонс немного детальнее. Вот что приватный AI может предложить по сравнению с публичной инфраструктурой ChatGPT:
Распределенность: вычислительная мощность и модели AI будут находиться рядом с данными. Это требует инфраструктуры, поддерживающей централизованное управление.
Конфиденциальность данных: данные организации остаются в ее владении и не используются для тренировки других моделей без согласия компании.
Контроль доступа: установлены механизмы доступа и аудита для соблюдения политик компании и регуляторных правил.
Приватный AI не обязательно требует частных облаков, главное — соблюдение требований конфиденциальности и контроля.
Подход VMware Private AI
VMware специализируется на управлении рабочими нагрузками различной природы и имеет огромный опыт, полезный для имплементации успешного приватного AI. К основным преимуществам подхода VMware Private AI относятся:
Выбор: организации могут легко сменить коммерческие AI-сервисы или использовать открытые модели, адаптируясь к бизнес-требованиям.
Конфиденциальность: современные методы защиты обеспечивают конфиденциальность данных на всех этапах их обработки.
Производительность: показатели AI-задач равны или даже превышают аналоги на чистом железе, как показали отраслевые тесты.
Управление: единый подход к управлению снижает затраты и риски ошибок.
Time-to-value: AI-окружения можно быстро поднимать и выключать за считанные секунды, что повышает гибкость и скорость реакции на возникающие задачи.
Эффективность: быстрое развертывание корпоративных AI-сред и оптимизация использования ресурсов снижают общие затраты на инфраструктуру и решение задач, которые связаны с AI.
Таким образом, платформа VMware Private AI предлагает гибкий и эффективный способ внедрения корпоративного приватного AI.
VMware Private AI Foundation в партнерстве с NVIDIA
VMware сотрудничает с NVIDIA для создания универсальной платформы VMware Private AI Foundation with NVIDIA. Эта платформа поможет предприятиям настраивать большие языковые модели, создавать более безопасные модели для внутреннего использования, предлагать генеративный AI как сервис и безопасно масштабировать задачи генерации результатов. Решение основано на средах VMware Cloud Foundation и NVIDIA AI Enterprise и будет предлагать следующие преимущества:
Масштабирование уровня датацентров: множественные пути ввода-вывода для GPU позволяют масштабировать AI-загрузки на до 16 виртуальных GPU в одной виртуальной машине.
Производительное хранение: архитектура VMware vSAN Express обеспечивает оптимизированное хранение на базе хранилищ NVMe и технологии GPUDirect storage over RDMA, а также поддерживает прямую передачу данных от хранилища к GPU без участия CPU.
Образы виртуальных машин vSphere для Deep Learning: быстрое прототипирование с предустановленными фреймворками и библиотеками.
В решении будет использоваться NVIDIA NeMo, cloud-native фреймворк в составе NVIDIA AI Enterprise, который упрощает и ускоряет принятие генеративного ИИ.
Архитектура VMware для приватного AI
AI-лаборатории VMware совместно с партнерами разработали решение для AI-сервисов, обеспечивающее приватность данных, гибкость выбора ИИ-решений и интегрированную безопасность. Архитектура предлагает:
Использование лучших моделей и инструментов, адаптированных к бизнес-потребностям.
Быстрое внедрение благодаря документированной архитектуре и коду.
Интеграцию с популярными открытыми проектами, такими как ray.io, Kubeflow, PyTorch, pgvector и моделями Hugging Face.
Архитектура поддерживает коммерческие и открытые MLOps-инструменты от партнеров VMware, такие как MLOps toolkit for Kubernetes, а также различные надстройки (например, Anyscale, cnvrg.io, Domino Data Lab, NVIDIA, One Convergence, Run:ai и Weights & Biases). В состав платформы уже включен самый популярный инструмент PyTorch для генеративного AI.
Сотрудничество с AnyScale расширяет применение Ray AI для онпремизных вариантов использования. Интеграция с Hugging Face обеспечивает простоту и скорость внедрения открытых моделей.
Решение Private AI уже применяется в собственных датацентрах VMware, показывая впечатляющие результаты по стоимости, масштабу и производительности разработчиков.
Там приведены результаты тестирования производительности рабочих нагрузок обучения AI/ML на платформе виртуализации VMware vSphere с использованием нескольких графических процессоров NVIDIA A100-80GB с поддержкой технологии NVIDIA NVLink. Результаты попадают в так называемую "зону Голдилокс", что означает область хорошей производительности инфраструктуры, но с преимуществами виртуализации.
Результаты показывают, что время обучения для нескольких тестов MLPerf v3.0 Training1 увеличивается всего от 6% до 8% относительно времени тех же рабочих нагрузок на аналогичной физической системе.
Кроме того, в документе показаны результаты теста MLPerf Inference v3.0 для платформы vSphere с графическими процессорами NVIDIA H100 и A100 Tensor Core. Тесты показывают, что при использовании NVIDIA vGPU в vSphere производительность рабочей нагрузки, измеренная в запросах в секунду (QPS), составляет от 94% до 105% производительности на физической системе.
vSphere 8 и высокопроизводительная виртуализация с графическими процессорами NVIDIA и NVLink.
Партнерство между VMware и NVIDIA позволяет внедрить виртуализированные графические процессоры в vSphere благодаря программному слою NVIDIA AI Enterprise. Это дает возможность не только достигать наименьшего времени обработки для виртуализированных рабочих нагрузок машинного обучения и искусственного интеллекта, но и использовать многие преимущества vSphere, такие как клонирование, vMotion, распределенное планирование ресурсов, а также приостановка и возобновление работы виртуальных машин.
VMware, Dell и NVIDIA достигли производительности, близкой или превышающей аналогичную конфигурацию на физическом оборудовании со следующими настройками:
Dell PowerEdge R750xa с 2-мя виртуализированными графическими процессорами NVIDIA H100-PCIE-80GB
Для вывода в обеих конфигурациях требовалось всего 16 из 128 логических ядер ЦП. Оставшиеся 112 логических ядер ЦП в дата-центре могут быть использованы для других задач. Для достижения наилучшей производительности виртуальных машин во время обучения требовалось 88 логических ядер CPU из 128. Оставшиеся 40 логических ядер в дата-центре могут быть использованы для других активностей.
Производительность обучения AI/ML в vSphere 8 с NVIDIA vGPU
На картинке ниже показано сравнительное время обучения на основе тестов MLPerf v3.0 Training, с использованием vSphere 8.0.1 с NVIDIA vGPU 4x HA100-80c против конфигурации на физическом оборудовании с 4x A100-80GB GPU. Базовое значение для физического оборудования установлено как 1.00, и результат виртуализации представлен в виде относительного процента от базового значения. vSphere с NVIDIA vGPUs показывает производительность близкую к производительности на физическом оборудовании, где накладные расходы на виртуализацию составляют 6-8% при обучении с использованием BERT и RNN-T.
Таблица ниже показывает время обучения в минутах для тестов MLPerf v3.0 Training:
Результаты на физическом оборудовании были получены Dell и опубликованы в разделе закрытых тестов MLPerf v3.0 Training с ID 3.0-2050.2.
Основные моменты из документа:
VMware vSphere с NVIDIA vGPU и технологией AI работает в "зоне Голдилокс" — это область производительности для хорошей виртуализации рабочих нагрузок AI/ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPUs и программное обеспечение NVIDIA AI, показывает от 106% до 108% от главной метрики физического оборудования (100%), измеренной как время обучения для тестов MLPerf v3.0 Training.
vSphere достигла пиковой производительности, используя всего 88 логических ядер CPU из 128 доступных ядер, оставив тем самым 40 логических ядер для других задач в дата-центре.
VMware использовала NVIDIA NVLinks и гибкие группы устройств, чтобы использовать ту же аппаратную конфигурацию для обучения ML и вывода ML.
vSphere с NVIDIA AI Enterprise, используя NVIDIA vGPU и программное обеспечение NVIDIA AI, показывает от 94% до 105% производительности физического оборудования, измеренной как количество обслуживаемых запросов в секунду для тестов MLPerf Inference v3.0.
vSphere достигла максимальной производительности вывода, используя всего 16 логических ядер CPU из 128 доступных, оставив тем самым 112 логических ядер CPU для других задач в дата-центре.
vSphere сочетает в себе мощь NVIDIA vGPU и программное обеспечение NVIDIA AI с преимуществами управления дата-центром виртуализации.
Более подробно о тестировании и его результатах вы можете узнать из документа.
Многие администраторы виртуальных инфраструктур используют технологию NVIDIA vGPU, чтобы разделить физический GPU-модуль между виртуальными машинами (например, для задач машинного обучения), при этом используется профиль time-sliced vGPU (он же просто vGPU - разделение по времени использования) или MIG-vGPU (он же Multi-Instance vGPU, мы писали об этом тут). Эти два режима позволяют выбрать наиболее оптимальный профиль, исходя из особенностей инфраструктуры и получить наибольшие выгоды от технологии vGPU.
Итак, давайте рассмотрим первый вариант - сравнение vGPU и MIG vGPU при увеличении числа виртуальных машин на GPU, нагруженных задачами машинного обучения.
В этом эксперименте была запущена нагрузка Mask R-CNN с параметром batch size = 2 (training and inference), в рамках которой увеличивали число ВМ от 1 до 7, и которые разделяли A100 GPU в рамках профилей vGPU и MIG vGPU. Эта ML-нагрузка была легковесной, при этом использовались различные настройки профилей в рамках каждого тестового сценария, чтобы максимально использовать время и память модуля GPU. Результаты оказались следующими:
Как мы видим, MIG vGPU показывает лучшую производительность при росте числа ВМ, разделяющих один GPU. Из-за использования параметра batch size = 2 для Mask R-CNN, задача тренировки в каждой ВМ использует меньше вычислительных ресурсов (используется меньше ядер CUDA) и меньше памяти GPU (менее 5 ГБ, в сравнении с 40 ГБ, который имеет каждый GPU). Несмотря на то, что vGPU показывает результаты похуже, чем MIG vGPU, первый позволяет масштабировать нагрузки до 10 виртуальных машин на GPU, а MIG vGPU поддерживает на данный момент только 7.
Второй вариант теста - vGPU и MIG vGPU при масштабировании нагрузок Machine Learning.
В этом варианте исследовалась производительность ML-нагрузок при увеличении их интенсивности. Был проведен эксперимент, где также запускалась задача Mask R-CNN, которую модифицировали таким образом, чтобы она имела 3 разных степени нагрузки: lightweight, moderate и heavy. Время исполнения задачи тренировки приведено на рисунке ниже:
Когда рабочая нагрузка в каждой ВМ использует меньше процессора и памяти, время тренировки и пропускная способность MIG vGPU лучше, чем vGPU. Разница в производительности между vGPU и MIG vGPU максимальна именно для легковесной нагрузки. Для moderate-нагрузки MIG vGPU также показывает себя лучше (но немного), а вот для тяжелой - vGPU уже работает производительнее. То есть, в данном случае выбор между профилями может быть обусловлен степенью нагрузки в ваших ВМ.
Третий тест - vGPU и MIG vGPU для рабочих нагрузок с высокой интенсивность ввода-вывода (например, Network Function with Encryption).
В этом эксперименте использовалось шифрование Internet Protocol Security (IPSec), которое дает как нагрузку на процессор, так и на подсистему ввода-вывода. Тут также используется CUDA для копирования данных между CPU и GPU для освобождения ресурсов процессора. В данном тесте IPSec использовал алгоритмы HMAC-SHA1 и AES-128 в режиме CBC. Алгоритм OpenSSL AES-128 CBC был переписан в рамках тестирования в части работы CUDA. В этом сценарии vGPU отработал лучше, чем MIG vGPU:
Надо сказать, что нагрузка эта тяжелая и использует много пропускной способности памяти GPU. Для MIG vGPU эта полоса разделяется между ВМ, а вот для vGPU весь ресурс распределяется между ВМ. Это и объясняет различия в производительности для данного сценария.
Основные выводы, которые можно сделать по результатам тестирования:
Для легковесных задач машинного обучения режим MIG vGPU даст бОльшую производительность, чем vGPU, что сэкономит вам деньги на инфраструктуру AI/ML.
Для тяжелых задач, где используются большие модели и объем входных данных (а значит и меньше ВМ работают с одним GPU), разница между профилями почти незаметна.
Для тяжелых задач, вовлекающих не только вычислительные ресурсы и память, но и подсистему ввода-вывода, режим vGPU имеет преимущество перед MIG vGPU, что особенно заметно для небольшого числа ВМ.
После выхода VMware vSphere 7 Update 2 появилось много интересных статей о разного рода улучшениях, на фоне которых как-то потерялись нововведения, касающиеся работы с большими нагрузками машинного обучения на базе карт NVIDIA, которые были сделаны в обновлении платформы.
А сделано тут было 3 важных вещи:
Пакет NVIDIA AI Enterprise Suite был сертифицирован для vSphere
Появилась поддержка последних поколений GPU от NVIDIA на базе архитектуры Ampere
Добавились оптимизации в vSphere в плане коммуникации device-to-device на шине PCI, что дает преимущества в производительности для технологии NVIDIA GPUDirect RDMA
Давайте посмотрим на все это несколько подробнее:
1. NVIDIA AI Enterprise Suite сертифицирован для vSphere
Основная новость об этом находится в блоге NVIDIA. Сотрудничество двух компаний привело к тому, что комплект программного обеспечения для AI-аналитики и Data Science теперь сертифицирован для vSphere и оптимизирован для работы на этой платформе.
Оптимизации включают в себя не только средства разработки, но и развертывания и масштабирования, которые теперь удобно делать на виртуальной платформе. Все это привело к тому, что накладные расходы на виртуализацию у задач машинного обучения для карточек NVIDIA практически отсутствуют:
2. Поддержка последнего поколения NVIDIA GPU
Последнее поколение графических карт для ML-задач, Ampere Series A100 GPU от NVIDIA, имеет поддержку Multi-Instance GPU (MIG) и работает на платформе vSphere 7 Update 2.
Графический процессор NVIDIA A100 GPU, предназначенный для задач машинного обучения и самый мощный от NVIDIA на сегодняшний день в этой нише, теперь полностью поддерживается вместе с технологией MIG. Более детально об этом можно почитать вот тут. Также для этих карт поддерживается vMotion и DRS виртуальных машин.
Классический time-sliced vGPU подход подразумевает выполнение задач на всех ядрах GPU (они же streaming multiprocessors, SM), где происходит разделение задач по времени исполнения на базе алгоритмов fair-share, equal share или best effort (подробнее тут). Это не дает полной аппаратной изоляции и работает в рамках выделенной framebuffer memory конкретной виртуальной машины в соответствии с политикой.
При выборе профиля vGPU на хосте с карточкой A100 можно выбрать объем framebuffer memory (то есть памяти GPU) для виртуальной машины (это число в гигабайтах перед буквой c, в данном случае 5 ГБ):
Для режима MIG виртуальной машине выделяются определенные SM-процессоры, заданный объем framebuffer memory на самом GPU и выделяются отдельные пути коммуникации между ними (cross-bars, кэши и т.п.).
В таком режиме виртуальные машины оказываются полностью изолированы на уровне аппаратного обеспечения. Выбор профилей для MIG-режима выглядит так:
Первая цифра сразу после a100 - это число слайсов (slices), которые выделяются данной ВМ. Один слайс содержит 14 процессоров SM, которые будут использоваться только под эту нагрузку. Число доступных слайсов зависит от модели графической карты и числа ядер GPU на ней. По-сути, MIG - это настоящий параллелизм, а обычный режим работы - это все же последовательное выполнение задач из общей очереди.
Например, доступные 8 memory (framebuffers) слотов и 7 compute (slices) слотов с помощью профилей можно разбить в какой угодно комбинации по виртуальным машинам на хосте (необязательно разбивать на равные части):
3. Улучшения GPUDirect RDMA
Есть классы ML-задач, которые выходят за рамки одной графической карты, какой бы мощной она ни была - например, задачи распределенной тренировки (distributed training). В этом случае критически важной становится коммуникация между адаптерами на нескольких хостах по высокопроизводительному каналу RDMA.
Механизм прямой коммуникации через шину PCIe реализуется через Address Translation Service (ATS), который является частью стандарта PCIe и позволяет графической карточке напрямую отдавать данные в сеть, минуя CPU и память хоста, которые далее идут по высокоскоростному каналу GPUDirect RDMA. На стороне приемника все происходит полностью аналогичным образом. Это гораздо более производительно, чем стандартная схема сетевого обмена, об этом можно почитать вот тут.
Режим ATS включен по умолчанию. Для его работы карточки GPU и сетевой адаптер должны быть назначены одной ВМ. GPU должен быть в режиме Passthrough или vGPU (эта поддержка появилась только в vSphere 7 U2). Для сетевой карты должен быть настроен проброс функций SR-IOV к данной ВМ.
Более подробно обо всем этом вы можете прочитать на ресурсах VMware и NVIDIA.
На сайте проекта VMware Labs появилась еще одна утилита в сфере Machine Learning, которая может оказаться полезной некоторым Enterprise-администраторам, работающим с высокопроизводительными системами. Средство Resource-Efficient Supervised Anomaly Detection Classifier представляет собой ресурсно-эффективный классификатор для обнаружения аномалий запросов, который дополняет алгоритмы Random-Forest и XGBoost. По сравнению с упомянутыми средствами, VMware заявляет меньший объем используемой памяти и более эффективное использование CPU.
Цель данной утилиты - быстро натренировать небольшую модель таким образом, чтобы она корректно классифицировала большинство запросов. Далее, используя полученную универсальную модель, можно создавать более сложные экспертные ML-модели, натренированные на исключительные случаи.
Для работы алгоритма на Python вам потребуется наличие следующих компонентов:
CMake 3.13 или выше
numpy
pandas
sklearn
xgboost
Скачать Resource-Efficient Supervised Anomaly Detection Classifier можно по этой ссылке.
На сайте проекта VMware Labs появилась интересная штука для Data Scientist'ов - средство Federated Machine Learning on Kubernetes. Техника Federated Learning предполагает распределенную модель создания систем в области больших данных средствами машинного обучения, без необходимости расшаривать тренировочный датасет с централизованной ML-системой и другими пользователями.
Проще это понять на примере - есть такие задачи, где данные нужно обрабатывать ML-алгоритмами (например, предиктивная клавиатура Gboard от Google, которая, кстати, круче яблочной), но сами данные (набранные тексты) на центральный сервер передавать нельзя (иначе это нарушение пользовательской приватности). В этом случае распределенная система Federated Learning позволяет обрабатывать модели на оконечных устройствах. Координация тренировки моделей при этом может быть централизованная или децентрализованная. Примерами также здесь могут служить такие сферы, как кредитный скоринг, медицинские данные, страхование и многое другое, где есть большие данные и строгие правила их хранения и обработки.
Практическим воплощением принципов FL является фреймворк FATE, который поддерживается сообществом Linux Foundation. Компания VMware выпустила средство Federated Machine Learning on Kubernetes, которое позволяет быстро развернуть и управлять кластером Docker / Kubernetes, который содержит в себе компоненты FATE. В такой среде можно делать следующие вещи:
Разрабатывать и тестировать модели в Jupyter с использованием технологий Federated Machine Learning
Построить FATE-кластер с полным жизненным циклом обслуживания, в том числе на базе платформ MiniKube, Kubernetes on AWS/Google Cloud/Azure, VMware PKS и VMware Tanzu
Утилита командной строки, которая доступна в рамках данного средства, позволяет создать и развернуть весь FATE-кластер на базе уже готовой конфигурации, которую можно кастомизировать по своему усмотрению.
Для работы с Federated Machine Learning on Kubernetes можно использовать Docker 18+ / Docker-compose 1.24+, либо Kubernetes v1.15+, также вам потребуется Linux-машина для исполнения CLI-интерфейса утилиты. Загрузить данное средство можно по этой ссылке, документация доступна тут.
На сайте проекта VMware Labs появилась еще одна узкоспециализированная, но интересная штука - проект Supernova. С помощью данного интерфейса разработчики решений, использующих машинное обучение (Machine Learning), могут создавать свои проекты на базе различных открытых библиотек с поддержкой технологий аппаратного ускорения графики.
Типа таких:
Проект Supernova поддерживает все самые популярные технологии аппаратного ускорения 3D-графики:
Nvidia GPU
Intel IPU/VPU
Intel FPGA
Google (Edge) TPU
Xilinx FGPA, AMD GPU
Для работы Supernova поддерживается ОС Ubuntu или CentOS с контейнерным движком Docker. Сфера применения решения очень широка - распознавание лиц (пол, возраст, эмоции), номерных знаков автомобилей, задача классификации объектов и многое другое.
В качестве тулкитов совместно с Supernova можно использовать следующие:
OpenVINO
SynapseAI
TensorRT
Tensorflow Lite
Vitis
RoCm
Данные для тренировки нейронных сетей могут быть представлены в форматах Tensorflow, Caffe, ONNX и MxNet. Примеры работы с ними представлены в документации, которую можно скачать вместе с пакетом.
Скачать само решение Supernova можно по этой ссылке.
На прошедшей конференции VMworld 2019 было сделано немало интересных анонсов (о самых интересных из них мы рассказываем тут), один из них - это определенно технологическое превью Project Magna (год назад мы рассказывали о начале разработки этого продукта). Это облачное решение VMware, которое предназначено для постоянной непрерывной оптимизации инфраструктуры отказоустойчивых хранилищ VMware vSAN.
Magna представляет собой движок, который позволяет проводить самооптимизацию решения vSAN и его тюнинг, то есть автоматически тонко настраивать параметры кластеров хранилищ, наблюдая за их работой и постоянно анализируя метрики. Работать это будет как SaaS-продукт, который из облака будет осуществлять контроль над инфраструктурой vSAN:
Суть движка заключается в постоянной работе AI/ML-алгоритмов, которые непрерывно собирают и анализируют конфигурации и метрики хранилищ, после чего вносят корректировки, имея в виду главную цель - не ухудшить производительность. Как только алгоритм понимает, что в результате изменения настроек стало хуже, он откатывает действие назад, запоминает и анализирует эту ситуацию, дополняя свои внутренние алгоритмы оптимизаций.
В качестве ML-алгоритма используется так называемый Reinforcement Learning, который анализирует заданные вами KPI по производительности и сравнивает их с аналогичными конфигурациями для похожих нагрузок. Этот алгоритм постоянно проверяет тысячи различных сценариев конфигурации, чтобы найти оптимальный именно для вашей инфраструктуры. Само испытание производится методом проб и ошибок:
Также продукт vRealize Operations можно будет интегрировать с Project Magna таким образом, чтобы первый мог получить от последнего нужные конфигурации, а пользователь может поставить настройку селф-тюнинга, которая будет следовать заданной вами цели.
Цели (KPI) могу быть заданы в виде следующих вариантов:
Read Performance
- все настраивается для наименьших задержек на чтение (latency), увеличения пропускной способности (максимум для этого будет использоваться до 10% памяти хоста).
Write Performance - конфигурация стремится уменьшить задержки и увеличить производительность на запись (пренебрегая скоростью чтения).
Balanced - оптимизация сбалансированного режима чтения-записи, в зависимости от требований рабочей нагрузки.
Также полученные целевые KPI можно будет сравнить со средними по отрасли (эти данные будут агрегироваться от клиентов VMware). Для глубокого понимания происходящего в консоли Magna будет доступен график производительности, который в ключевых точках будет показывать, какие изменения были сделаны:
Например, на этом скриншоте мы видим, что Magna увеличила размер кэша на чтение до 50 ГБ 23 июля - и это благотворно повлияло на performance index.
Больше о решении Project Magna можно узнать из следующих сессий VMworld 2019:
HCI1620BU – Artificial Intelligence and Machine Learning for Hyperconverged Infrastructure
MLA2021BU – Realize your Self-Aware Hybrid Cloud with Machine Learning
HCI1650BU – Optimize vSAN performance using vRealize Operations and Reinforcement Learning
Доступность Project Magna ожидается в следующем году.
Эта платформа предоставляет инженерам по работе с данными следующие возможности в области Data Science в рамках виртуальной инфраструктуры:
Виртуальное окружение на основе облака VMware Cloud Foundation (VCF) и платформы Kubernetes.
На данный момент для вычислений поддерживается только CPU (но модули GPU будут поддерживаться в будущем).
Платформа построена на базе фреймворков Open Source Kubeflow и Horovod.
Также в составе идет коллекция обучающих примеров (Notebooks) и библиотек, которые помогают понять выполнение следующих задач:
Data collection and cleaning (получение данных из различных источников и описание семантики данных с использованием метаданных).
Data cleansing and transformation (приведение собранных данных в порядок и их трансформация из сырого формата в структурированный, который больше подходит для процессинга).
Model training (разработка предиктивных и оптимизационных моделей машинного обучения).
Model serving (развертывание модели для запуска в реальном окружении, где могут обслуживаться онлайн-запросы).
Для использования движка vMLP вам потребуется развернутая инфраструктура VMware Cloud Foundation 3.8.
В комплекте с платформой идет документация. Скачать весь пакет можно по этой ссылке.
Вы все, конечно же, в курсе, что графические карты уже давно используются не только для просчета графики в играх и требовательных к графике приложениях, но и для вычислительных задач. Сегодня процессоры GPGPU (General Purpose GPU) используются в ИТ-инфраструктурах High Performance Computing (HPC) для решения сложных задач, в том числе машинного обучения (Machine Learning, ML), глубокого обучения (Deep Learning, DL) и искусственного интеллекта (Artificial Intelligence, AI).
Эти задачи, зачастую, хорошо параллелятся, а архитектура GPU (по сравнению с CPU) лучше приспособлена именно для такого рода задач, так как в графических платах сейчас значительно больше вычислительных ядер:
Кроме того, архитектура CPU больше заточена на решение последовательных задач, где параметры рассчитываются друг за другом, а архитектура GPU позволяет независимо просчитывать компоненты задачи на разных процессорных кластерах, после чего сводить итоговый результат.
Вот так, если обобщить, выглядит архитектура CPU - два уровня кэша на базе каждого из ядер и общий L3-кэш для шаринга данных между ядрами:
Число ядер на CPU может достигать 32, каждое из которых работает на частоте до 3.8 ГГц в турбо-режиме.
Графическая карта имеет, как правило, только один уровень кэша на уровне вычислительных модулей, объединенных в мультипроцессоры (Streaming Multiprocessors, SM), которые, в свою очередь, объединяются в процессорные кластеры:
Также в видеокарте есть L2-кэш, который является общим для всех процессорных кластеров. Набор процессорных кластеров, имеющих собственный контроллер памяти и общую память GDDR-5 называется устройство GPU (GPU Device). Как видно, архитектура GPU имеет меньше уровней кэша (вместо транзисторов кэша на плату помещаются вычислительные блоки) и более толерантна к задержкам получения данных из памяти, что делает ее более пригодной к параллельным вычислениям, где задача локализуется на уровне отдельного вычислительного модуля.
Например, если говорить об устройствах NVIDIA, то модель Tesla V100 содержит 80 мультипроцессоров (SM), каждый из которых содержит 64 ядра, что дает в сумме 5120 ядер! Очевидно, что именно такие штуки надо использовать для задач ML/DL/AI.
Платформа VMware vSphere поддерживает технологию vGPU для реализации такого рода задач и возможности использования виртуальными машинами выделенных ВМ модулей GPU. В первую очередь, это все работает для карточек NVIDIA GRID, но и для AMD VMware также сделала поддержку, начиная с Horizon 7 (хотя и далеко не в полном объеме).
Еще одна интересная архитектура для решения подобных задач - это технология FlexDirect от компании BitFusion. Она позволяет организовать вычисления таким образом, что хосты ESXi с модулями GPU выполняют виртуальные машины, а их ВМ-компаньоны на обычных серверах ESXi исполняют непосредственно приложения. При CUDA-инструкции от клиентских ВМ передаются серверным по сети:
Обмен данными может быть организован как по TCP/IP, так и через интерфейс RDMA, который может быть организован как подключение Infiniband или RoCE (RDMA over Converged Ethernet). О результатах тестирования такого сетевого взаимодействия вы можете почитать тут.
При этом FlexDirect позволяет использовать ресурсы GPU как только одной машине, так и разделять его между несколькими. При этом администратор может выбрать, какой объем Shares выделить каждой из машин, то есть можно приоритизировать использование ресурсов GPU.
Такая архитектура позволяет разделить виртуальную инфраструктуру VMware vSphere на ярусы: кластер GPU, обсчитывающий данные, и кластер исполнения приложений пользователей, которые вводят данные в них и запускают расчеты. Это дает гибкость в обслуживании, управлении и масштабировании.
Мы много писали о рещениях NVIDIA GRID / Quadro vDWS (они используют технологии virtual GPU или vGPU), например здесь, здесь и здесь. Ранее эта технология предполагала только применение vGPU для нагрузок в виртуальных машинах, которые требовательны к графике, поэтому используют ресурсы графического адаптера в разделенном режиме.
Между тем, начиная с недавнего времени (а именно с выпуска архитектуры Pascal GPU), VMware и NVIDIA предлагают использование vGPU для задач машинного обучения (CUDA / Machine Learning / Deep Learning), которые в последнее время становятся все более актуальными, особенно для крупных компаний. С помощью этой технологии виртуальная машина с vGPU на борту может эффективно использовать библиотеки TensorFlow, Keras, Caffe, Theano, Torch и прочие.
Например, можно создать использовать профиль P40-1q vGPU для архитектуры Pascal P40 GPU, что позволит иметь до 24 виртуальных машин на одном физическом адаптере (поскольку на устройстве 24 ГБ видеопамяти).
Зачем же использовать vGPU для ML/DL-задач, ведь при исполнении тяжелой нагрузки (например, тренировка сложной нейронной сети) загружается все устройство? Дело в том, что пользователи не используют на своих машинах 100% времени на исполнение ML/DL-задач. Большинство времени они собирают данные и подготавливают их, а после исполнения задачи интерпретируют результаты и составляют отчеты. Соответственно, лишь часть времени идет большая нагрузка на GPU от одного или нескольких пользователей. В этом случае использование vGPU дает максимальный эффект.
Например, у нас есть 3 виртуальных машины, при этом тяжелая нагрузка у VM1 и VM2 пересекается только 25% времени. Нагрузка VM3 не пересекается с VM1 и VM2 во времени:
Компания VMware проводила тест для такого случая, используя виртуальные машины CentOS с профилями P40-1q vGPU, которые имели 12 vCPU, 60 ГБ памяти и 96 ГБ диска. Там запускались задачи обучения TensorFlow, включая комплексное моделирование для рекуррентной нейронной сети (recurrent neural network, RNN), а также задача распознавания рукописного текста с помощью сверточной нейронной сети (convolution neural network, CNN). Эксперимент проводился на серверах Dell PowerEdge R740 с 18-ядерным процессором Intel Xeon Gold 6140 и карточками NVIDIA Pascal P40 GPU.
Результаты для первого теста оказались таковы:
Время обучения из-за наложения окон нагрузки в среднем увеличилось на 16-23%, что в целом приемлемо для пользователей, разделяющих ресурсы на одном сервере. Для второго теста было получено что-то подобное:
Интересен тест, когда все нагрузки исполнялись в одном временном окне по следующей схеме:
Несмотря на то, что число загруженных ML/DL-нагрузкой виртуальных машин увеличилось до 24, время тренировки нейронной сети увеличилось лишь в 17 раз, то есть даже в случае полного наложения временных окон рабочих нагрузок есть некоторый позитивный эффект:
Интересны также результаты с изменением политики использования vGPU. Некоторые знают, что у планировщика vGPU есть три режима работы:
Best Effort (это исполнение задач на вычислительных ядрах по алгоритму round-robin).
Equal Share (всем дается одинаковое количество времени GPU - это позволяет избежать влияния тяжелых нагрузок на легкие машины, например).
Fixed Share (планировщик дает фиксированное время GPU на основе профиля нагрузки vGPU).
VMware поэкспериментировала с настройками Best Effort и Equal Share для тех же тестов, и вот что получилось:
С точки зрения времени исполнения задач, настройка Best Effort оказалась лучшим выбором, а вот с точки зрения использования GPU - Equal Sharing меньше грузила графический процессор:

 RSS
RSS