Вышла новая версия VMware Cloud Foundation 9.1, об этом вы уже знаете. В этой статье рассматриваются многие новые возможности и улучшения платформы vSphere в составе пакета VCF 9.1. Также рекомендуем ознакомиться с примечаниями к выпуску и уведомлениями о поддержке продуктов для получения важной информации.
Быстрое развёртывание патчей безопасности vCenter
Функция быстрого патчинга vCenter (vCenter Quick Patch) обеспечивает оперативное применение обновлений с минимальным, а в ряде случаев — нулевым временем простоя. Уровень простоя зависит от того, какие именно сервисы подвергаются обновлению. Механизм Quick Patch ориентирован на быстрое устранение критических уязвимостей безопасности в vCenter.
Традиционный in-place патчинг обновляет все RPM-пакеты на vCenter вне зависимости от того, изменился ли соответствующий сервис или компонент. Quick Patch затрагивает только те RPM или бинарные файлы, которые действительно изменились в составе патча. Такой подход кардинально сокращает общее окно обслуживания и снижает время простоя vCenter до менее чем 1 минуты, а в ряде случаев сводит его к нулю.
Благодаря vCenter Quick Patch критически важные обновления безопасности можно применять без прерывания рабочих процессов: развёртывание виртуальных машин и кластеров Kubernetes продолжается в штатном режиме, автоматизированные сценарии и API-вызовы не прерываются. Меньше времени уходит на планирование окон обслуживания — больше на поддержание актуальности патчей.
Помимо Quick Patch, в версии 9.1 улучшены и другие аспекты обслуживания vCenter.
Обновление vCenter с сокращённым временем простоя (Reduced Downtime Upgrade, RDU) теперь поддерживает работу с онлайн-репозиторием. Это упрощает использование метода RDU для подключённых к интернету экземпляров vCenter. Автономный метод с использованием примонтированного ISO по-прежнему доступен. Последующие патчи, обновления и апгрейды vCenter 9.1.x и более поздних версий также можно применять через RDU с онлайн-репозиторием, что значительно упрощает эксплуатацию для подключённых инсталляций.
В vCenter появился новый API, с помощью которого сторонние компоненты могут получать уведомления о планируемом или текущем техническом обслуживании. Обратный прокси Envoy будет отдавать заголовок 503 с информацией о том, что vCenter находится на обслуживании, и указанием ожидаемого времени завершения.
При выполнении мажорных апгрейдов (с 8.x до 9.1.0) или минорных обновлений (с 9.0.x до 9.1.0) методом RDU версия аппаратного обеспечения виртуальной машины vCenter автоматически повышается с версии 10 до версии 17, поскольку создаётся новая ВМ vCenter. При выполнении in-place обновления (с 9.0.x до 9.1.0) версию аппаратного обеспечения ВМ vCenter потребуется обновить вручную — эта процедура требует выключения ВМ vCenter.
Изменение ресурсов vCenter через единый API
В VCF 9.1 появился новый API, упрощающий масштабирование ресурсов vCenter. Для увеличения объёма вычислительных ресурсов и дискового пространства vCenter достаточно одного вызова API и перезагрузки.
Вызов API можно инициировать из Developer Center API Explorer в интерфейсе vCenter. API называется deployment/size и использует метод PATCH.
Упрощение обслуживания хостов ESX
Образы, создаваемые и управляемые через vSphere Lifecycle Manager, теперь включают контрольную сумму SHA256. Она позволяет проверять целостность образов при экспорте и импорте в другие экземпляры vCenter: администратор может сравнить контрольные суммы на источнике и целевом сервере. Речь идёт о контрольной сумме именно определения образа, а не VIB-файлов ESX.
В предыдущих версиях vSphere Lifecycle Manager проверял актуальность прошивок и драйверов устройств по HCL только при наличии стороннего Hardware Support Manager (HSM). Начиная с версии 9.1 вывод информации о текущих драйверах и прошивках устройств, а также их валидация по HCL выполняются для кластеров vSAN даже в отсутствие HSM. Некоторые устройства могут не сообщать данные о прошивке без соответствующего HSM. Это обеспечивает базовый уровень проверки устройств в кластере vSAN.
Подготовка кластеров vSphere с образом и конфигурацией
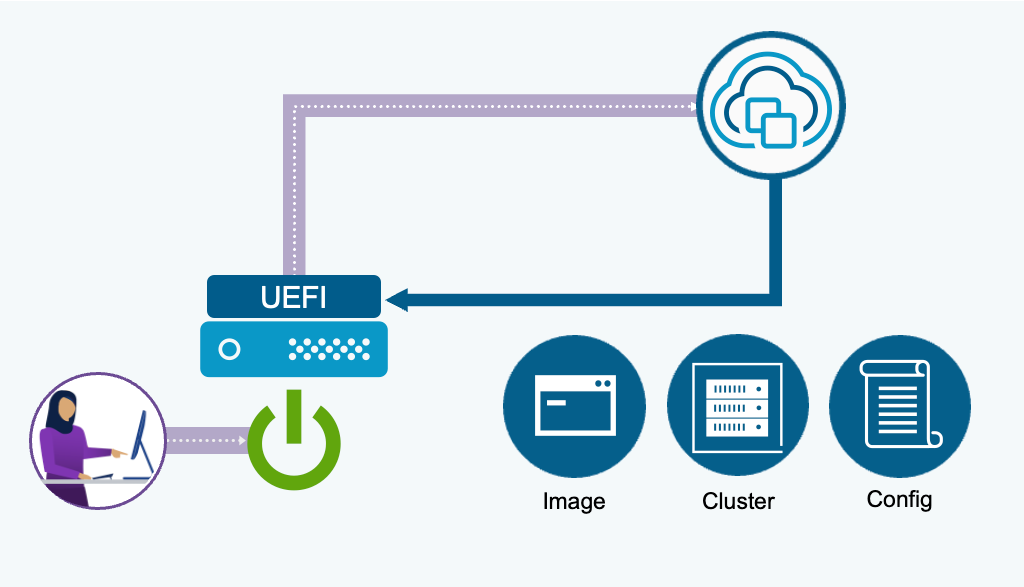
Zero Touch Provisioning (ZTP) строится на базе существующей инфраструктуры vSphere Auto-Deploy. Механизм задействует современные протоколы загрузки — UEFI HTTP/S Boot — и поддерживает актуальные серверные конфигурации, включая Secure Boot и TPM. ZTP не требует внешнего TFTP-сервера: достаточно настроить URL загрузки UEFI, указывающий на vCenter, и загрузить хост по сети. Если UEFI не поддерживает настройку статического IP для загрузки, потребуется DHCP-сервер.
Образ ESX и конфигурация определяются расположением кластера, выбранным при настройке правила развёртывания. Если для целевого кластера не настроен профиль конфигурации vSphere (VCP), хост загрузится и присоединится к кластеру с конфигурацией по умолчанию.
Быстрое и менее затратное обновление кластеров vSphere
ESX Live Patch включён по умолчанию для всех кластеров и автоматически применяется, если устанавливаемый патч поддерживает этот режим. Если патч несовместим с Live Patch, по умолчанию используется стандартный метод с переходом в режим обслуживания и перезагрузкой хоста.
Параметр можно изменить, включив принудительное применение Live Patch. В этом режиме исправление будет выполняться только через Live Patch, а для хостов, требующих режима обслуживания, процесс патчинга будет заблокирован. Настройки можно задать как на уровне кластера, так и на уровне vCenter — параметры vCenter применяются ко всем кластерам, если они не переопределены на уровне кластера.
ESX Live Patch теперь поддерживает серверы с включённым TPM. Пользователям не нужно отключать TPM или отказываться от Live Patch при использовании ESX 9.1 и более поздних версий.
Поддержка Live Patch расширена: охватывает больше компонентов vmkernel и обеспечивает более высокую производительность при патчинге ядра. Теперь механизм поддерживает дополнительные пользовательские демоны и сервисы, включая демоны vSAN, базовые демоны хранилища и соответствующие библиотеки.
Расширение интеграции с механизмом Desired State Configuration
Профили конфигурации vSphere (vSphere Configuration Profiles) обеспечивают соответствие изменений конфигурации и операций по устранению отклонений требованиям vSAN. Политики режима обслуживания vSAN и политики доступности объектов соблюдаются при исправлении кластеров vSAN. Расширенная конфигурация vSAN может применяться на уровне всего кластера.
Профили конфигурации vSphere используются для настройки memory tiering на хостах кластера. Устройства NVMe могут быть выделены для memory tiering; дополнительное устройство NVMe опционально может быть задействовано в качестве зеркального устройства для программного зеркалирования.
Профили конфигурации vSphere обеспечивают конфигурацию хостов при установке через Zero Touch Provisioning, а также поддерживают начальную настройку vSphere Distributed Switch в процессе развёртывания хоста.
Оптимизация Desired State Configuration
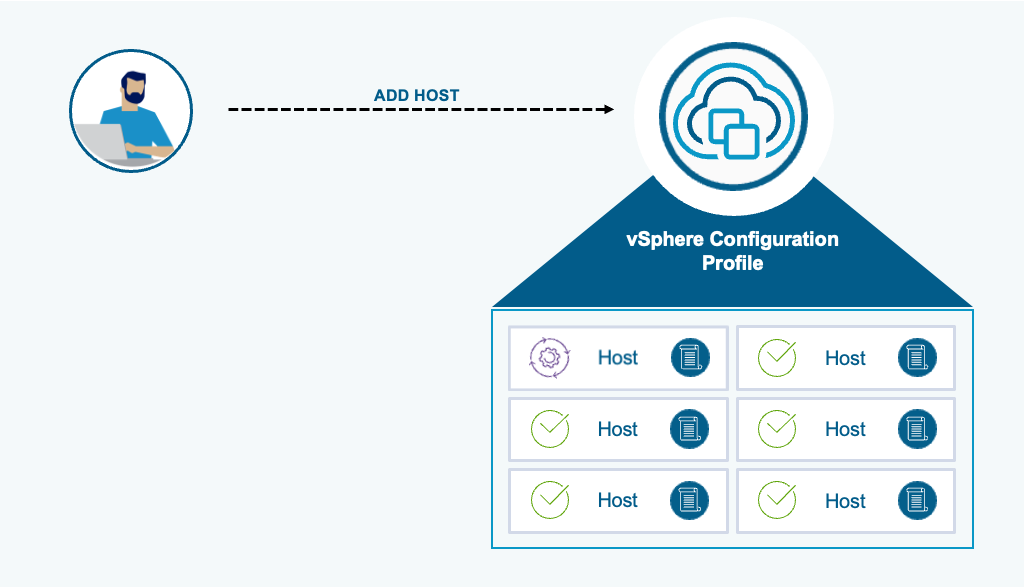
При добавлении новых хостов в кластеры с включёнными профилями конфигурации vSphere желаемая конфигурация автоматически применяется к входящему хосту. Специфичные для хоста атрибуты (например, IP-адреса) извлекаются из него автоматически и добавляются в соответствующий раздел профиля кластера.
Сертификат TLS для vCenter теперь обновляется автоматически за 5 дней до истечения срока действия. Сертификат ESX обновляется за 30 дней до истечения. Порог для ESX настраивается через расширенные параметры vCenter Server с помощью параметра vpxd.certmgmt.certs.autoRenewThreshold.
В обоих случаях автоматическое обновление выполняется для сертификатов, управляемых VMCA. Сертификаты, выданные внешними центрами сертификации, не обновляются автоматически — ответственность за их управление лежит на администраторе.
Если до истечения срока действия корневого сертификата VMCA остаётся менее 1 года, в процессе обновления vCenter автоматически обновляются корневой сертификат VMCA, а также дочерние сертификаты решений. Сертификаты TLS для vCenter и ESX в рамках этой операции не обновляются.
Масштабируемость, стабильность и производительность
В крупных и сверхкрупных развёртываниях vCenter ожидается увеличение числа операций в минуту до 25%. Это касается множества операций с виртуальными машинами и хостами, а также изменений конфигурации. Масштаб одновременных операций резервного копирования ВМ увеличен до 500–1000 в зависимости от размера vCenter. Операции резервного копирования ВМ теперь защищены от бесконтрольного потребления всех ресурсов vCenter. Передача файлов использует выделенные потоки, что исключает влияние на другие операции vCenter. Расширенные параметры vCenter для операций резервного копирования позволяют настраивать масштабируемость под конкретную среду.
Новый API мониторинга утилизации vCenter позволяет отслеживать активные подключения и сравнивать их с максимально допустимыми лимитами. Появилась возможность отслеживать количество запросов ко всем сервисам vCenter и контролировать, чтобы их интенсивность не превышала допустимых порогов.
Введены два новых оповещения — High Session Count и Increased Request Load — для сигнализации о нагрузке на один или несколько сервисов vCenter. Оповещение High Session Count срабатывает, когда число сессий приближается к лимиту (по умолчанию 3000); в сообщении указываются IP-адреса и имена пяти пользователей, создавших наибольшую нагрузку с более чем 100 сессиями каждый. При изменении состава топ-5 пользователей генерируется новое событие. В список могут попасть любые пользователи, включая сервисные аккаунты. Оповещение Increased Request Load срабатывает при достижении лимита активных запросов к конечной точке сервиса (по умолчанию 1024 для большинства конечных точек) и содержит информацию о затронутых сервисах и конечных точках.
Гибкая настройка виртуальных машин
Для поддержки миграции с VMware Cloud Director (vCD) на VMware Cloud Foundation Automation (VCFA) гостевой API настройки ОС (Guest OS Customization, GOSC) дополнен следующими возможностями, обеспечивающими паритет с функциями vCD:
Установка пароля учётной записи root в Linux
Сброс пароля учётной записи root в Linux
Сброс паролей учётных записей группы администраторов в Windows
Выполнение скриптов настройки в Windows
Теперь администраторы могут явно отключить IPv4 и настроить сеть только для IPv6 в гостевой настройке — как через интерфейс, так и через API. Это устраняет прежнее требование сохранять параллельную конфигурацию IPv4.
Появилась возможность выполнять настройку только сетевых параметров виртуальной машины — для выключенных и для работающих ВМ, что позволяет применять изменения сетевой конфигурации в реальном времени.
Сохранение производительности рабочих нагрузок во время обслуживания хоста
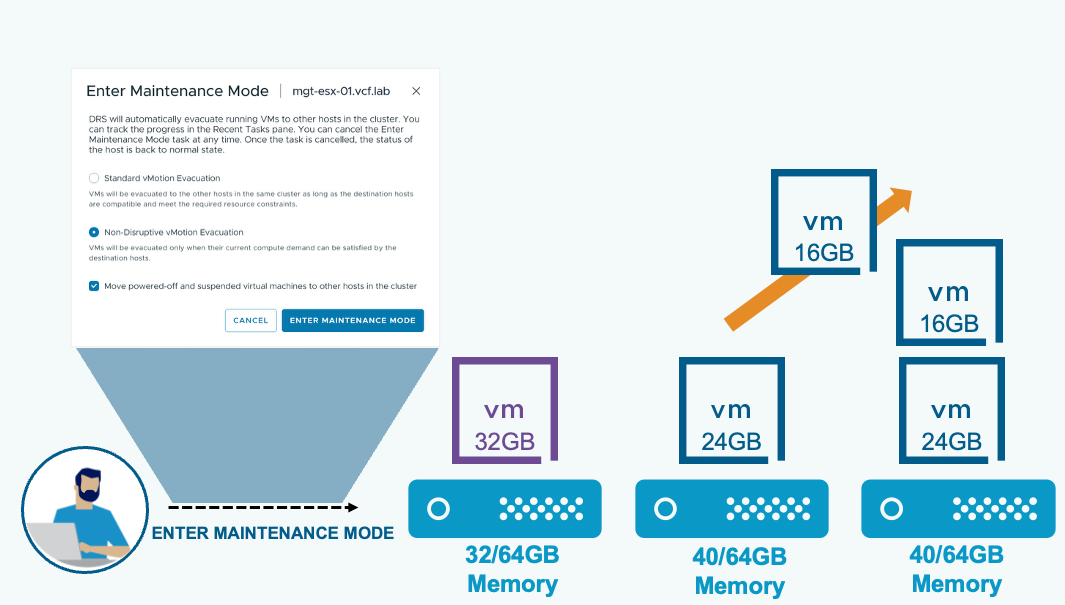
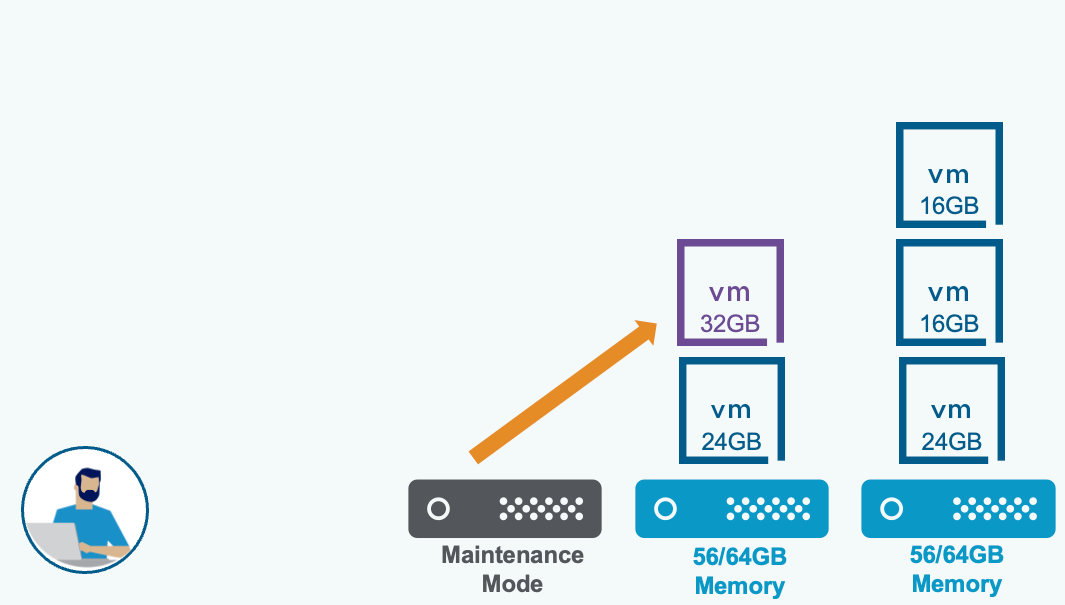
DRS-оптимизированная эвакуация через vMotion (DRS Optimized vMotion Evacuation) гарантирует, что виртуальные машины будут мигрированы с хоста только при наличии достаточной вычислительной ёмкости для их размещения без конкуренции за ресурсы. DRS может предварительно перебалансировать оставшиеся хосты, чтобы создать свободную ёмкость для эвакуируемых ВМ.
При переводе хоста в режим обслуживания для кластеров с включённым DRS доступны два варианта:
Стандартная эвакуация через vMotion: виртуальные машины переносятся на другие хосты в том же кластере при условии совместимости целевых хостов и соответствия требованиям по ресурсам.
Нон-деструктивная эвакуация через vMotion: виртуальные машины переносятся только в том случае, если их текущие вычислительные потребности могут быть удовлетворены целевыми хостами.
Примечание: термин «нон-деструктивная» применительно к новому режиму эвакуации не означает, что стандартная эвакуация как-либо вредит рабочим нагрузкам. Он лишь указывает на то, что при этом режиме эвакуация выполняется только без создания конкуренции за ресурсы на целевых хостах.
Улучшение утилизации ресурсов vMotion и снижение конкуренции
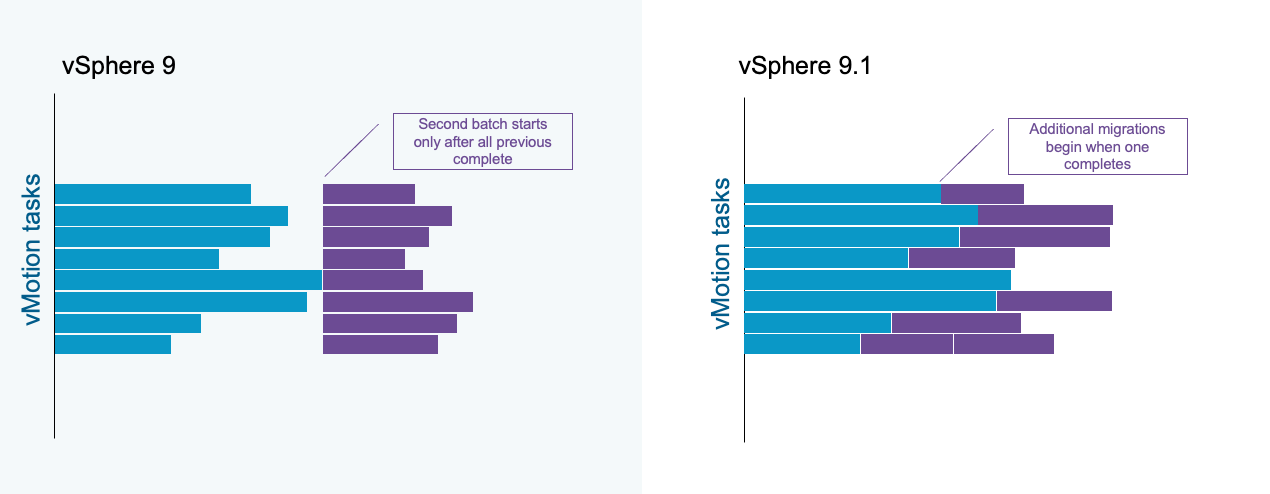
Максимальное количество одновременных задач vMotion по умолчанию равно 8. В предыдущих версиях, если 8 задач vMotion выполнялись одновременно в рамках пакетной операции, новые задачи не начинались до завершения всех предыдущих. Начиная с vSphere 9.1, как только одна задача vMotion завершается и освобождается слот, следующая задача может немедленно стартовать.
Усовершенствованная обработка задач vMotion обеспечивает более равномерное распределение нагрузки по хостам кластера. Число хостов, испытывающих пиковую одновременную нагрузку vMotion, сокращается, а сетевые ресурсы и ресурсы хранилища используются эффективнее.
Более высокая пропускная способность vMotion и сокращение времени миграции
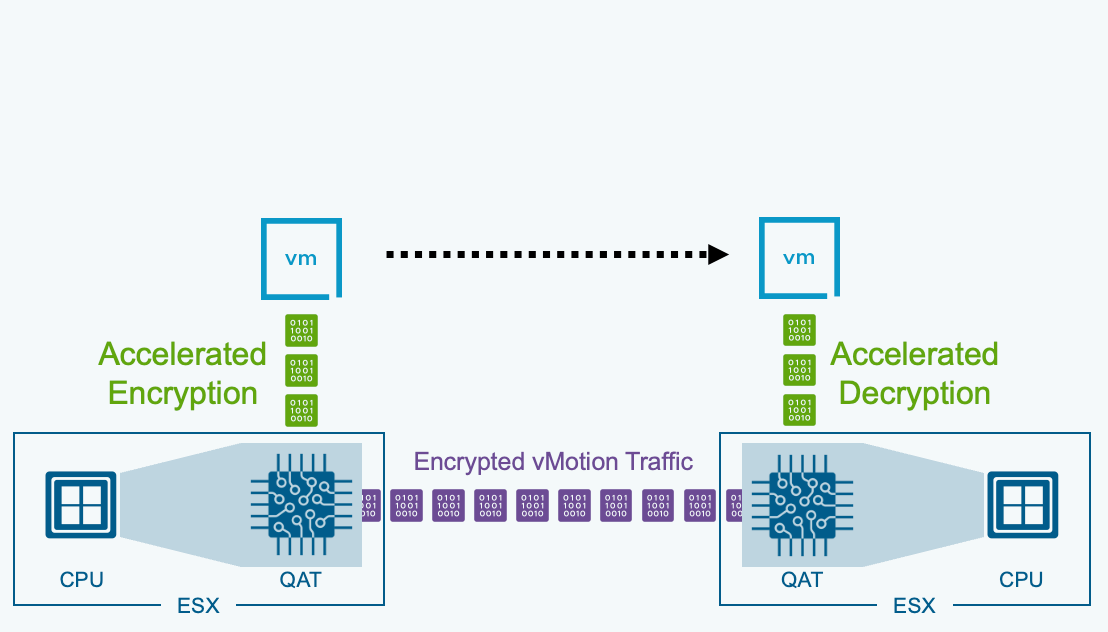
В VCF 9.1 появилась возможность разгрузки операций зашифрованного vMotion на Intel QAT (QuickAssist Technology). Это освобождает ценные ресурсы CPU и возвращает их рабочим нагрузкам.
Для максимально эффективного использования ресурсов в VCF задействована технология Intel QAT (QuickAssist Technology) для ускорения инфраструктурных операций. Перенос «тяжёлой» части задач vMotion на выделенное аппаратное обеспечение позволяет вернуть ценные ядра CPU реальным рабочим нагрузкам. Intel QAT берёт на себя шифрование данных при выполнении операций vMotion.
Оптимизированная масштабируемость и производительность для современных CPU
Планировщик Topology Aware Scheduler перешёл на событийно-ориентированный механизм встроенного обновления, что обеспечивает более согласованное и сбалансированное размещение по NUMA-узлам.
Архитектура NUMA (Non-Uniform Memory Access) используется для повышения масштабируемости и производительности серверов с несколькими процессорными сокетами. Планировщик — компонент ядра ESX, отвечающий за управление размещением виртуальных машин и балансировкой нагрузки по NUMA-узлам с целью минимизации задержек доступа к памяти и оптимального использования ресурсов CPU и памяти рабочими нагрузками.
Topology Aware Scheduler оптимизирован для нового поколения высокоплотных процессоров: улучшена модель оценки эффективности использования CPU и памяти. Существующий планировщик при принятии решений о размещении в основном учитывал конкуренцию за CPU (ready time). Topology Aware Scheduler учитывает не только конкуренцию за CPU, но и конкуренцию за кэш и пропускную способность памяти.
Для систем с асимметричной топологией NUMA, где расстояние между некоторыми парами узлов существенно больше, чем между другими, Topology Aware Scheduler может размещать смежные NUMA-клиенты одной ВМ на подмножестве узлов, расположенных ближе друг к другу.
Готовность к работе с AI-платформами различных производителей
В VCF 9.1 расширена поддержка Enhanced DirectPath I/O.
Речь идёт не просто о «проброске» оборудования, а о его виртуализации — это обеспечивает лучшую утилизацию ресурсов и возможность выполнения операций обслуживания и масштабирования без остановки AI-рабочих нагрузок. Поддержка новых аппаратных устройств в VCF 9.1 открывает доступ ко многим преимуществам виртуализации, включая stun-based операции и быстрое приостановление и возобновление работы. Среди этих преимуществ:
Storage vMotion
Снапшоты (включая снапшоты памяти)
Операции реконфигурации дисков
Горячее добавление и удаление виртуальных устройств
ESX Live Patch
ESX 9.1 расширяет свои возможности, внедряя поддержку виртуализации IOMMU для CPU AMD. Теперь администраторы могут задействовать устройства PCI passthrough на системах на базе AMD, повышая производительность и обеспечивая прямой доступ к оборудованию для виртуальных машин.
AMD vIOMMU (Virtual I/O Memory Management Unit) — аппаратно-ускоренная технология, обеспечивающая безопасный высокопроизводительный прямой доступ к памяти (DMA) для виртуальных машин за счёт прямого доступа гостевых систем к регистрам MMIO.
Flow Processing Offload (FPO) и аппаратное направление трафика (hardware steering) повышают эффективность центра обработки данных, перенося обработку сложных сетевых правил с CPU на выделенное аппаратное обеспечение. Это обеспечивает производительность на уровне линейной скорости и быструю масштабируемость виртуализированных сред, освобождая ресурсы CPU для бизнес-приложений.
Enhanced DirectPath I/O поддерживает прямую связь GPU-to-GPU через RDMA over Converged Ethernet (RoCE). Решение предназначено для организаций, выполняющих массивные AI-рабочие нагрузки или высокоскоростную обработку данных: оно обеспечивает производительность, близкую к нативной (необходимую для AI), без отказа от инструментов управления, которые упрощают эксплуатацию виртуализованных ЦОД.
GPU NVIDIA, используемые для vGPU, теперь можно настроить одновременно для тайм-слайсинга и режима MIG, что обеспечивает ещё более эффективное совместное использование ресурсов и повышение плотности.

 RSS
RSS