Искусственный интеллект обладает огромным потенциалом для трансформации всех предприятий - IDC прогнозирует, что решения и сервисы AI окажут глобальное влияние на сумму 22,3 трлн долларов к 2030 году.
С учетом такого масштаба неудивительно, что предприятия стремятся использовать AI для повышения производительности во всех областях бизнеса. Однако им нужна комплексная стратегия, которая ускорит интеграцию AI в инфраструктуру дата-центров. С VMware Cloud Foundation Private AI Services компания Broadcom стремится помочь предприятиям раскрыть потенциал AI и повысить продуктивность при более низкой совокупной стоимости владения.
Реальный эффект: что говорят клиенты
Компании из разных отраслей уже развертывают VCF Private AI Services и получают экономию, приватность и безопасность для своих AI-нагрузок:
«Внедрив VCF Private AI Services, мы усилили возможности интеллектуальных сервисов», — говорит Тунг-Лян Чен, вице-президент Chunghwa Post. «Запуск AI в собственной инфраструктуре частного облака на базе VCF позволяет нам существенно снижать затраты и повышать эффективность автоматизированного обнаружения в реальном времени, одновременно обеспечивая бесшовную интеграцию с существующими системами».
«Анализ многолетних архивов новостей в публичном облаке обходится слишком дорого, а непредсказуемое ценообразование затрудняет планирование AI-проектов», — сказал V V Jacob, старший генеральный менеджер по системам Malayala Manorama Co Ltd. «Развернув VCF Private AI Services на существующей инфраструктуре VMware Cloud Foundation, мы сможем запускать AI-суммаризацию контента, генерацию заголовков и редакторскую помощь прямо в частном облаке. Мы считаем, что это даст нам приватность и безопасность, необходимые для защиты редакционных источников, а также предсказуемость затрат, которую обеспечивает локальная инфраструктура частного облака».
На днях был объявлен следующий выпуск VCF Private AI Services вместе с VCF 9.1. В новой версии для предприятий добавляется несколько важных функций.
Новые возможности
1. Приватность и безопасность
Broadcom помогает предприятиям создавать и развертывать приватные и безопасные AI-модели со встроенными возможностями защиты, предоставляемыми через VCF Private AI Services.
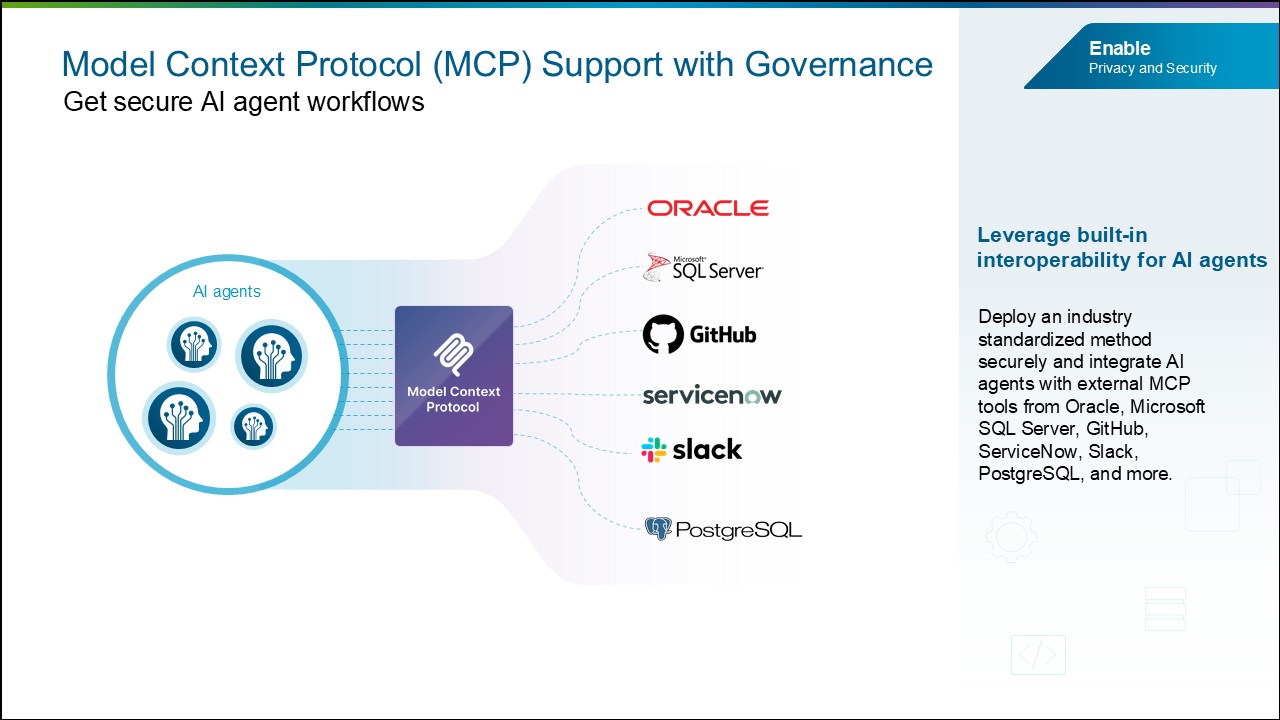
Поддержка Model Context Protocol (MCP) с управлением. Благодаря поддержке MCP предприятия получают безопасный и стандартизированный способ интегрировать AI-ассистентов с внутренними репозиториями контента и внешними MCP-инструментами от Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL и других поставщиков без разработки и сопровождения собственных коннекторов.
2. Упрощение управления инфраструктурой
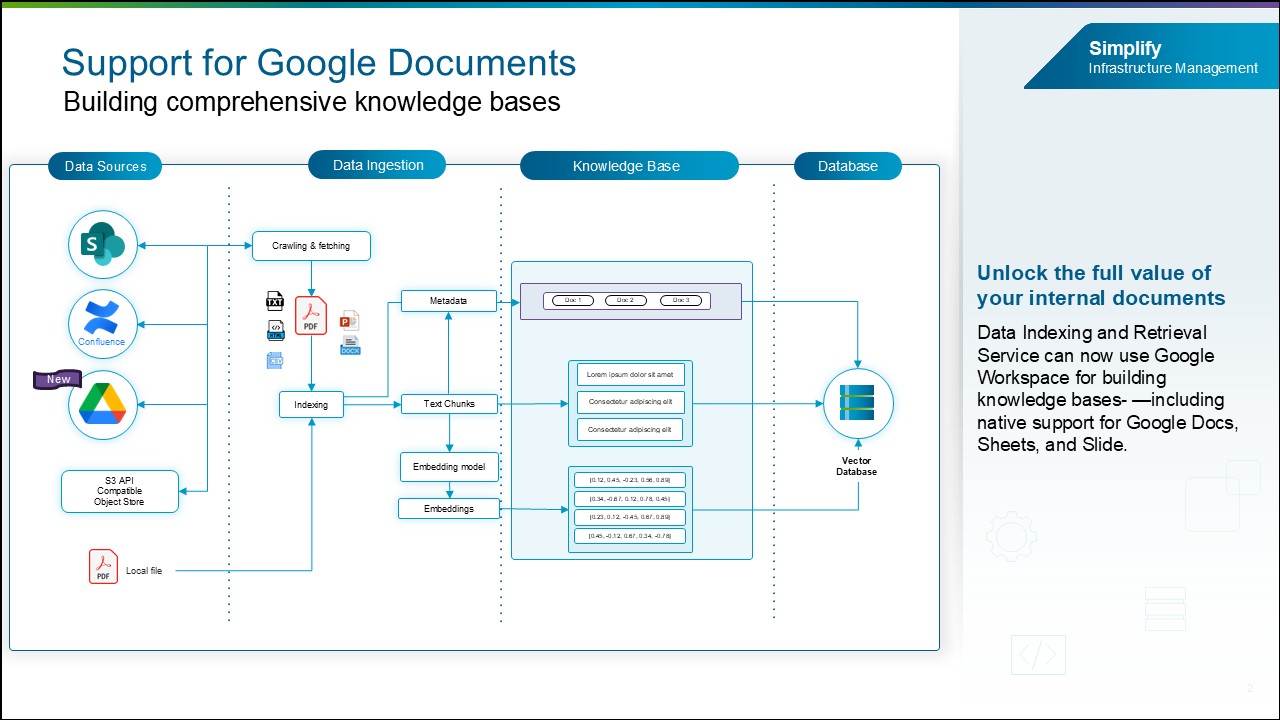
Поддержка Google Documents. VCF Private AI Services теперь предоставит полноценную поддержку Google Workspace, включая Google Docs, Sheets и Slides, без необходимости экспортировать документы в PDF и загружать их в базу знаний. В дополнение к уже существующей поддержке Microsoft Word, Microsoft PowerPoint, PDF, CSV и других форматов предприятия получают доступ к очень широкому набору типов документов и смогут добиваться качественных результатов для AI-нагрузок.
DirectPath Enablement для GPU. В этом выпуске VCF Private AI Services поддерживает DirectPath Enablement для инфраструктуры NVIDIA AI. Это обеспечит высокопроизводительный эксклюзивный доступ к GPU для одной виртуальной машины, которая сможет полностью использовать возможности GPU. С этой новой функцией предприятия смогут развертывать AI-проекты с NVIDIA GPU в режиме DirectPath.
Поддержка последнего поколения NVIDIA Blackwell GPU. VCF теперь поддерживает новейшую серию GPU NVIDIA Blackwell. В дополнение к существующей поддержке NVIDIA RTX PRO 6000 Blackwell Server Edition объявлена поддержка NVIDIA HGX B200 и NVIDIA RTX PRO 4500 Blackwell Server Edition. Поддержка этих новых GPU Blackwell на VCF определяет следующий этап корпоративного AI с беспрецедентной производительностью, эффективностью и масштабом.
Будущая поддержка. В одном из следующих выпусков VCF будет поддерживать NVIDIA HGX B300. VCF на NVIDIA HGX B300 позволит предприятиям без усилий масштабировать самые производительные AI-нагрузки и подготовить инфраструктуру к будущим требованиям.
Поддержка NVIDIA HGX Platform с Blackwell GPU и NVLink Switch. VCF теперь поддерживает NVIDIA HGX platform с Blackwell GPU и NVLink Switch. Благодаря этой возможности предприятия смогут получить преимущества крупномасштабных AI-развертываний с VCF Private AI Services и платформой NVIDIA HGX. NVIDIA HGX объединяет всю мощь инфраструктуры NVIDIA AI, включая NVIDIA GPU, NVIDIA NVLink, NVLink Switch, NVIDIA networking и полностью оптимизированные AI software stacks, чтобы обеспечивать максимальную производительность AI-приложений и ускорять получение инсайтов в каждом дата-центре.
Высокоскоростная сеть с Enhanced DirectPath I/O. VCF теперь поддерживает сетевые адаптеры NVIDIA ConnectX-7 и NVIDIA BlueField-3 с Enhanced DirectPath I/O. С этим улучшением предприятия смогут использовать такие расширенные возможности, как NVIDIA GPUDirect RDMA и GPUDirect Storage, для высокоскоростного обучения AI-моделей на нескольких хостах и передачи данных, что особенно важно для требовательных Gen AI-нагрузок.
3. Упрощение вывода моделей в эксплуатацию
Новые возможности в этой категории помогают предприятиям снижать сложность перевода моделей в production.
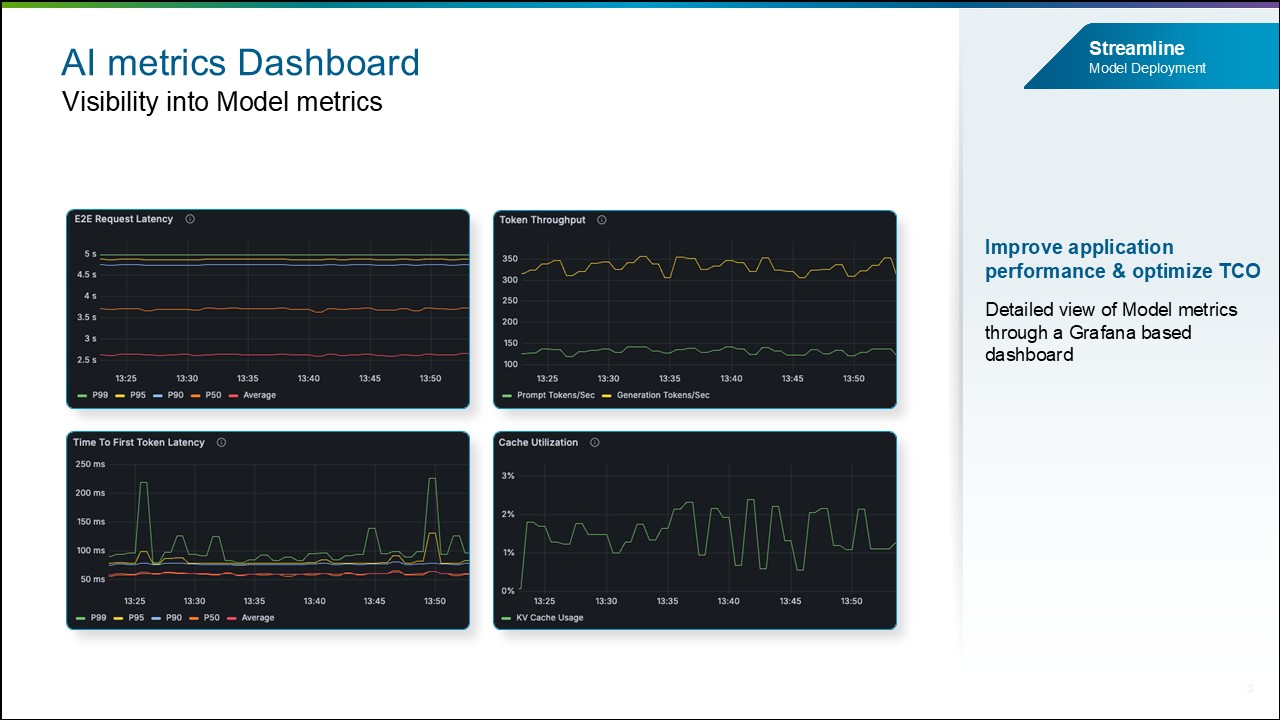
AI Metrics Observability Dashboard.
По мере масштабирования корпоративных AI-сред ограниченная видимость производительности моделей и агентов, а также факторов затрат мешает командам выявлять неэффективность, ведет к росту расходов на инфраструктуру и снижает производительность приложений. Чтобы решить эти проблемы, выпускается AI Metrics Observability Dashboard, который будет показывать важные AI-метрики.
Улучшенная видимость AI-метрик позволит специалистам по data science и MLOps выявлять узкие места, оптимизировать распределение ресурсов, повышать throughput и производительность.
Рассмотрим некоторые AI-метрики, которые будут доступны:
Метрики моделей. Эти метрики помогут предприятиям отслеживать продуктивность, скорость, задержку и другие параметры, предоставляя детальное представление о моделях. Будут доступны такие показатели, как Cache Utilization, Tokens generated per request, Token throughput, Time to first token (TFFT), End-to-end (E2E) request latency и другие.
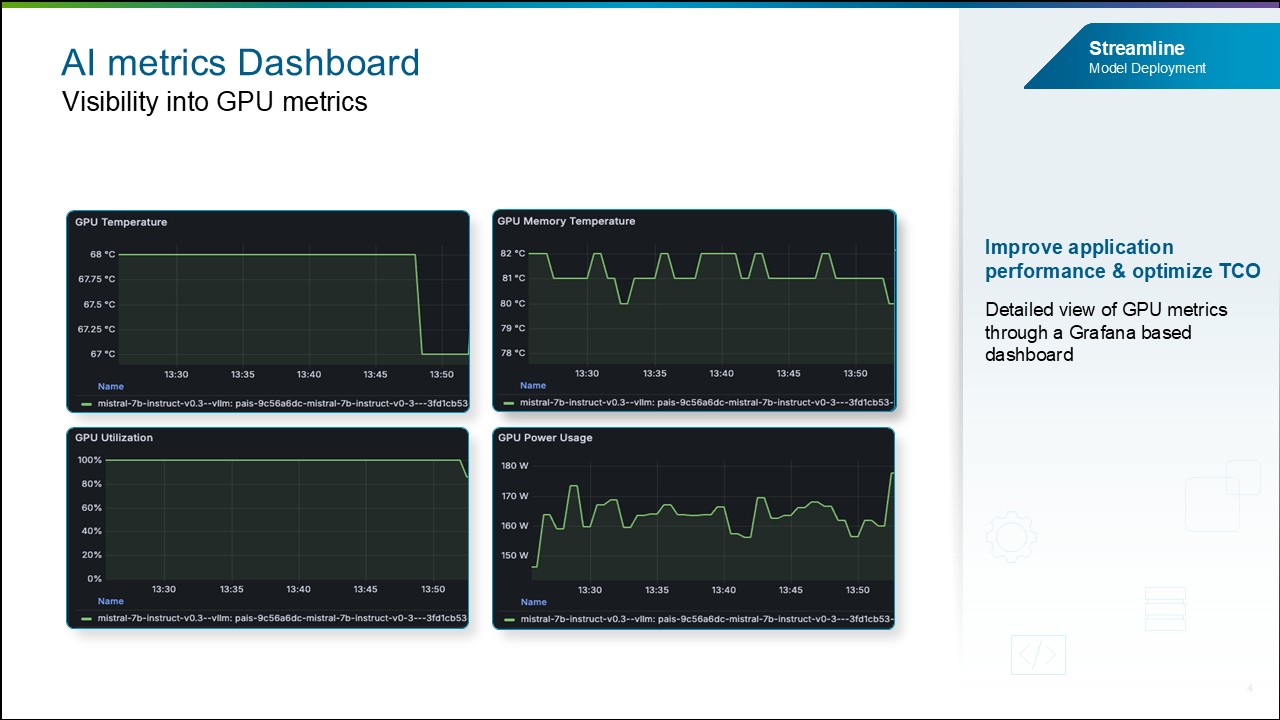
Метрики использования GPU. Также будут доступны GPU-метрики, включая Utilization, Temperature, Power Usage, Memory Temperature, Memory Clock и другие.
Примечание: для этих AI Metrics dashboards предприятиям необходимо развернуть Grafana.
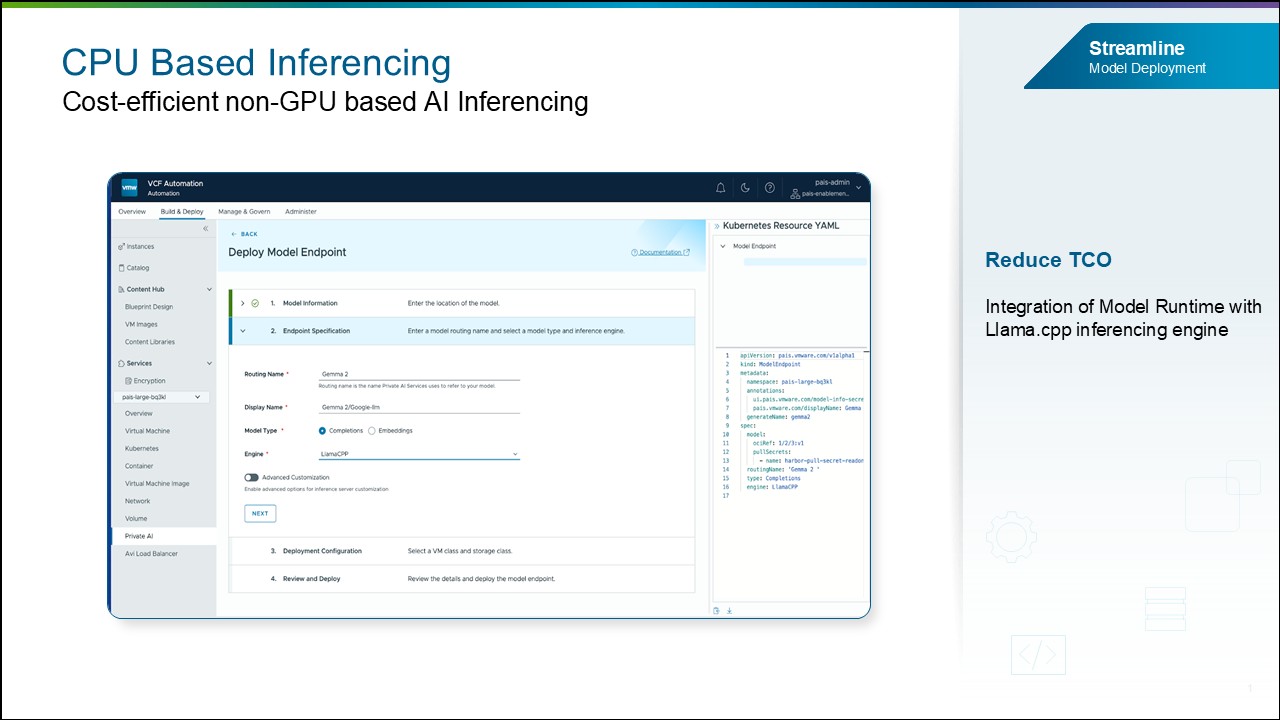
CPU-Based Inferencing. VCF Private AI Services теперь поддерживает CPU-based inferencing в дополнение к GPU-развертываниям благодаря интеграции Model Runtime с inference-движком Llama.cpp. На базе Llama.cpp, одного из ведущих open source inference-движков с широкой поддержкой сообщества, клиенты также получат доступ к большому набору моделей с day-zero-поддержкой от ведущих поставщиков, включая Google, OpenAI и других. Это улучшение снижает TCO, позволяя предприятиям развертывать менее ресурсоемкие среды для тестирования, proof-of-concept-инициатив или AI-приложений с минимальными требованиями к GPU либо без них.
Компания «Базис», работающая на российском рынке программных решений для управления динамической инфраструктурой, сообщила о выходе платформы серверной виртуализации Basis Dynamix Enterprise версии 4.5.
В новом релизе расширены возможности экосистемы за счёт более тесной интеграции с системой управления программно-определяемыми сетями Basis SDN, улучшена совместимость с отечественными системами хранения данных, а также добавлены инструменты для повышения производительности и автоматизации управления ИТ-инфраструктурой. Всего версия 4.5 включает более 90 доработок и нововведений.
Расширение поддержки отечественных систем хранения данных
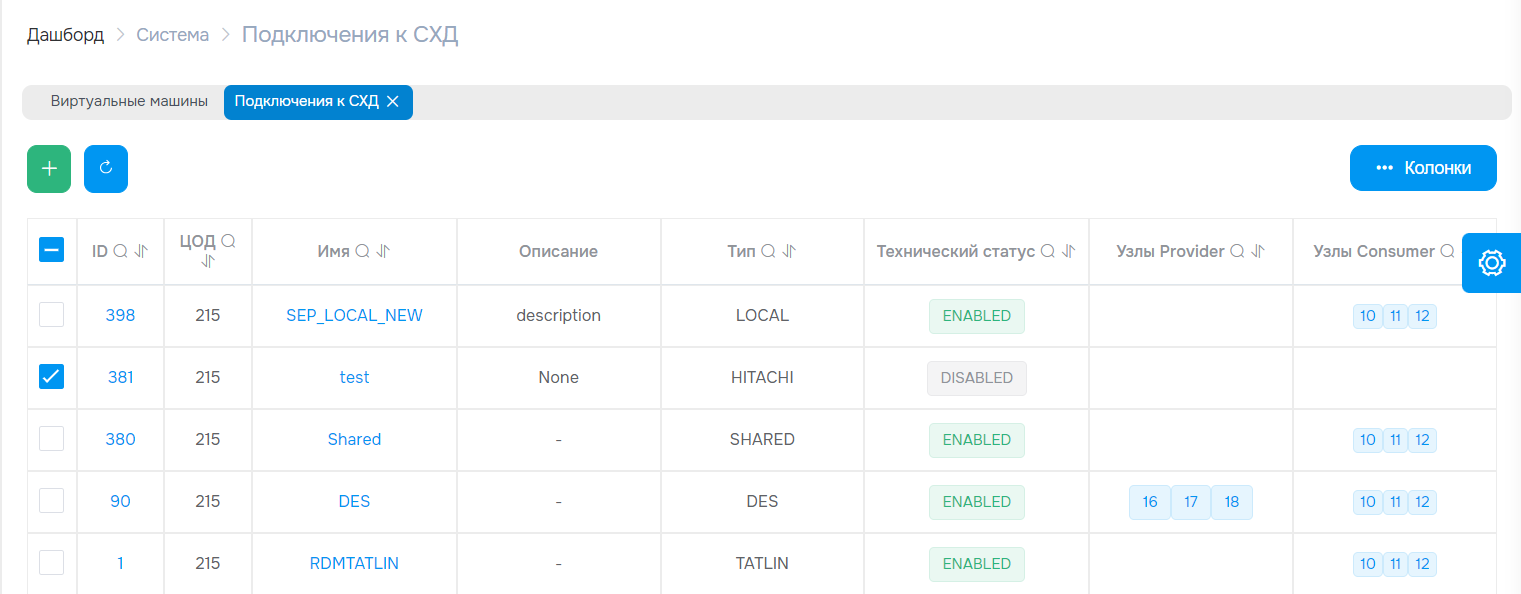
Одним из ключевых направлений развития версии 4.5.0 стало расширение поддержки российских СХД. В частности, добавлена работа с системой хранения uStor, включая полный набор операций: создание и управление дисками, работу с образами и снапшотами, а также презентацию и депрезентацию дисков вычислительным узлам.
Кроме того, реализована поддержка СХД Yadro Tatlin.Unified с версией ПО 3.2, при этом сохранена обратная совместимость с предыдущими версиями прошивки Tatlin. Это даёт заказчикам больше гибкости при выборе оборудования для построения импортонезависимой инфраструктуры и упрощает взаимодействие с ним через платформу.
Эффективное использование дискового пространства
В версии 4.5 внедрена поддержка unmap для дисков виртуальных машин. Теперь при удалении файлов внутри виртуальной машины освобождённое пространство не только помечается как свободное в гостевой системе, но и возвращается обратно в СХД. Это обеспечивает более эффективное использование дисковой ёмкости, что особенно важно при большом количестве виртуальных машин и использовании thin-provisioned дисков.
Развитие интеграции с программно-определяемыми сетями
Релиз 4.5 усиливает нативную интеграцию Basis Dynamix Enterprise с решением для программно-определяемых сетей Basis SDN и расширяет сетевые возможности платформы. Например, при создании виртуальных машин появилась возможность автоматически подключать SDN-сегменты с одновременным созданием логических портов, что сокращает объём ручной настройки и упрощает работу администраторов.
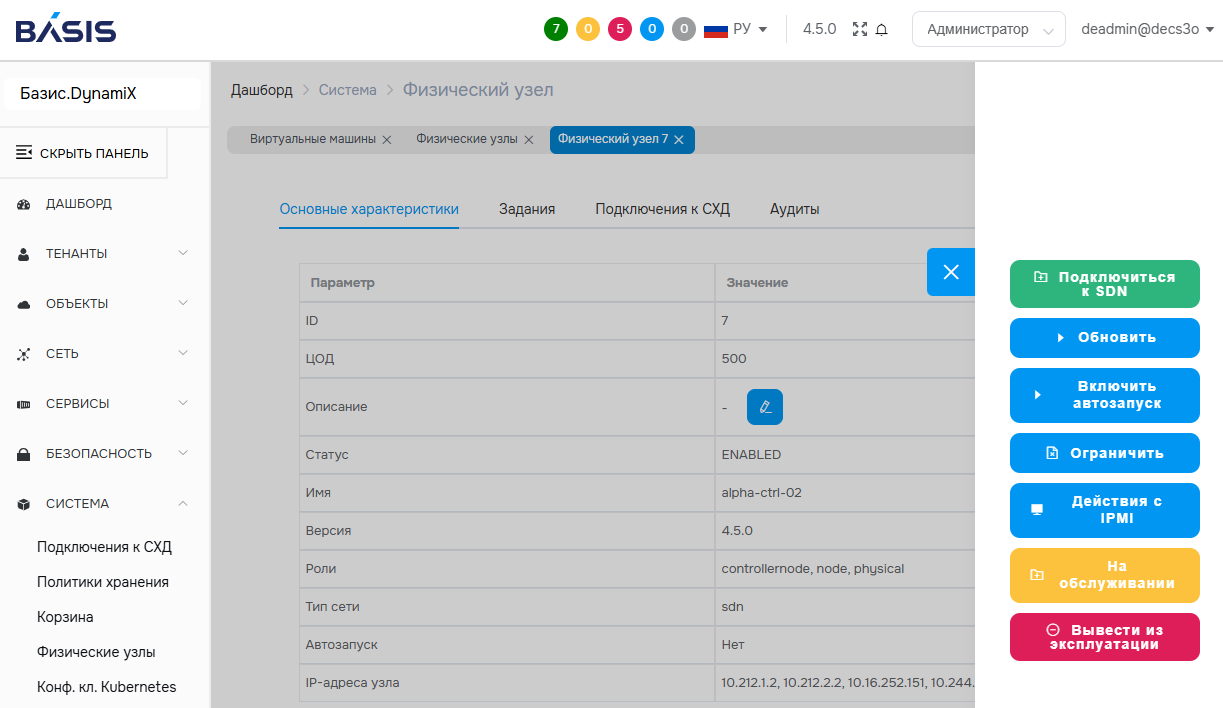
Автоматизация управления узлами
В Basis Dynamix 4.5 появился механизм автоматического перевода физического узла из состояния «На обслуживании» в статус «Работает». Соответствующая настройка доступна на странице «Физические узлы» в интерфейсе системы. При этом вместе с узлом автоматически запускаются виртуальные машины, ранее закреплённые за ним на момент перевода в режим обслуживания. Функция применима как к отдельным узлам, так и к целым зонам, что упрощает эксплуатацию крупных инфраструктур.
Другие улучшения
Помимо этого, версия 4.5.0 включает ряд дополнительных улучшений, повышающих удобство администрирования:
Механизм Watchdog, обеспечивающий автоматическое восстановление зависших виртуальных машин.
Поддержка режима Cache Write Through, повышающего производительность дисковой подсистемы.
Упрощённая начальная установка за счёт минимального конфигурационного файла.
Обновление спецификации API до версии OpenAPI 3.1.0.
Доработка модели физического узла: понятие «вычислительный узел» (stack) было упразднено, а его функциональность перенесена в сущность «физический узел» (node), что позволило упростить как модель данных, так и API платформы.
Возможность при создании виртуальной машины, даже если она разворачивается не из образа, включать дополнительные возможности гипервизора — такие как NUMA, CPU pinning и Huge Pages.
Возможность сделать виртуальную машину доступной только для чтения для всех пользователей.
При создании ВМ можно задавать маску сети для интерфейсов DPDK и VFNIC, а также настраивать MTU для транковых сетей в диапазоне от 1500 до 9216.
Можно ограничивать количество узлов, обрабатываемых одновременно, и при этом сбой на одном узле не прерывает общий процесс.
После первичной установки реализовано автоматическое обновление API-ключа для служебного пользователя.
Комментарий разработчика
«Одной из важнейших задач в рамках развития нашей флагманской платформы Basis Dynamix Enterprise является поддержание её совместимости с актуальным инфраструктурным оборудованием и ПО. Это касается в том числе и нашего собственного решения для организации программно-определяемых сетей Basis SDN, которое успешно работает в тестовых средах заказчиков и быстро развивается с учётом их пожеланий. Нашей целью является не просто поддержка отечественных систем хранения данных, инструментов резервного копирования или других решений. Мы хотим дать заказчику возможность построить на базе Basis Dynamix Enterprise полностью импортонезависимую динамическую ИТ-инфраструктуру, не ограничивая его при этом в выборе поставщиков "железа" или программных продуктов»
— Дмитрий Сорокин, технический директор компании «Базис».
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Broadcom Compatibility Guide (ранее VMware Compatibility Guide) — это ресурс, где пользователи могут проверить совместимость оборудования (нового или уже используемого) с программным обеспечением VMware. Вильям Лам написал интересную статью о доступе к BCG через программный интерфейс VMware PowerCLI.
Существует несколько различных руководств по совместимости, которые можно использовать для поиска информации, начиная от процессоров и серверов и заканчивая разнообразными устройствами ввода-вывода, такими как ускорители и видеокарты. Если у вас небольшое количество оборудования, поиск будет достаточно простым. Однако, если необходимо проверить разнообразное оборудование, веб-интерфейс может оказаться не самым быстрым и удобным вариантом.
Хорошая новость в том, что Broadcom Compatibility Guide (BCG) может легко использоваться программно, в отличие от предыдущего VMware Compatibility Guide (VCG), у которого была другая система бэкенда.
Хотя официального API с документацией, поддержкой и обратной совместимостью для BCG нет, пользователи могут взаимодействовать с BCG, используя тот же API, который применяется веб-интерфейсом BCG.
Обе функции предполагают поиск на основе комбинации идентификаторов поставщика (Vendor ID, VID), идентификатора устройства (Device ID, DID) и идентификатора поставщика подсистемы (SubSystem Vendor ID, SVID).
Примечание: BCG предоставляет разнообразные возможности поиска и фильтрации; ниже приведены лишь примеры одного из способов работы с API BCG. Если вам интересны другие методы поиска, ознакомьтесь со справочной информацией в конце документа, где описаны иные опции фильтрации и руководства по совместимости BCG.
Шаг 1 – Загрузите скрипт queryHostPCIInfo.ps1 (который Вильям также обновил, чтобы можно было легко исключить неприменимые устройства с помощью строк исключений), и запишите идентификаторы устройств (VID, DID, SVID), которые вы хотите проверить.
По умолчанию функция возвращает четыре последние поддерживаемые версии ESXi, однако вы можете изменить это, указав параметр ShowNumberOfSupportedReleases:
При проверке SSD-накопителей vSAN через BCG вы также можете указать конкретный поддерживаемый уровень vSAN (Hybrid Cache, All-Flash Cache, All-Flash Capacity или ESA), используя следующие параметры:
Если вы хотите автоматизировать работу с другими руководствами по совместимости в рамках BCG, вы можете определить формат запроса (payload), используя режим разработчика в браузере. Например, в браузере Chrome, перед выполнением поиска в конкретном руководстве по совместимости, нажмите на три точки в правом верхнем углу браузера и выберите "More Tools->Developer Tools", после чего откроется консоль разработчика Chrome. Далее вы можете использовать скриншот, чтобы разобраться, как выглядит JSON-запрос для вызова API "viewResults".
Компания VMware в марте обновила технический документ под названием «VMware vSphere 8.0 Virtual Topology - Performance Study» (ранее мы писали об этом тут). В этом исследовании рассматривается влияние использования виртуальной топологии, впервые представленной в vSphere 8.0, на производительность различных рабочих нагрузок. Виртуальная топология (Virtual Topology) упрощает назначение процессорных ресурсов виртуальной машине, предоставляя соответствующую топологию на различных уровнях, включая виртуальные сокеты, виртуальные узлы NUMA (vNUMA) и виртуальные кэши последнего уровня (last-level caches, LLC). Тестирование показало, что использование виртуальной топологии может улучшить производительность некоторых типичных приложений, работающих в виртуальных машинах vSphere 8.0, в то время как в других случаях производительность остается неизменной.
Настройка виртуальной топологии
В vSphere 8.0 при создании новой виртуальной машины с совместимостью ESXi 8.0 и выше функция виртуальной топологии включается по умолчанию. Это означает, что система автоматически настраивает оптимальное количество ядер на сокет для виртуальной машины. Ранее, до версии vSphere 8.0, конфигурация по умолчанию предусматривала одно ядро на сокет, что иногда приводило к неэффективности и требовало ручной настройки для достижения оптимальной производительности.
Влияние на производительность различных рабочих нагрузок
Базы данных: Тестирование с использованием Oracle Database на Linux и Microsoft SQL Server на Windows Server 2019 показало улучшение производительности при использовании виртуальной топологии. Например, в случае Oracle Database наблюдалось среднее увеличение показателя заказов в минуту (Orders Per Minute, OPM) на 8,9%, достигая максимума в 14%.
Инфраструктура виртуальных рабочих столов (VDI): При тестировании с использованием инструмента Login VSI не было зафиксировано значительных изменений в задержке, пропускной способности или загрузке процессора при включенной виртуальной топологии. Это связано с тем, что создаваемые Login VSI виртуальные машины имеют небольшие размеры, и виртуальная топология не оказывает значительного влияния на их производительность.
Тесты хранилищ данных: При использовании бенчмарка Iometer в Windows наблюдалось увеличение использования процессора до 21% при включенной виртуальной топологии, несмотря на незначительное повышение пропускной способности ввода-вывода (IOPS). Анализ показал, что это связано с поведением планировщика задач гостевой операционной системы и распределением прерываний.
Сетевые тесты: Тестирование с использованием Netperf в Windows показало увеличение сетевой задержки и снижение пропускной способности при включенной виртуальной топологии. Это связано с изменением схемы планирования потоков и прерываний сетевого драйвера, что приближает поведение виртуальной машины к работе на физическом оборудовании с аналогичной конфигурацией.
Рекомендации
В целом, виртуальная топология упрощает настройки виртуальных машин и обеспечивает оптимальную конфигурацию, соответствующую физическому оборудованию. В большинстве случаев это приводит к улучшению или сохранению уровня производительности приложений. Однако для некоторых микробенчмарков или специфических рабочих нагрузок может наблюдаться снижение производительности из-за особенностей гостевой операционной системы или архитектуры приложений. В таких случаях рекомендуется либо использовать предыдущую версию оборудования, либо вручную устанавливать значение «ядер на сокет» равным 1.
Для получения более подробной информации и рекомендаций по настройке виртуальной топологии в VMware vSphere 8.0 рекомендуется ознакомиться с полным текстом технического документа.
Как вы знаете, главным релизом этого года стала новая версия платформы VMware vSphere 8, где появилось множество новых возможностей и улучшений уже существующих технологий. Одной из интересных функций стала vSphere Virtual Topology.
Для виртуальных машин с Hardware version 20 теперь доступно простое конфигурирование vNUMA-топологии для виртуальных машин:
Для виртуальных машин теперь доступна информационная панелька CPU Topology с конфигурацией vNUMA:
Недавно компания VMware выпустила документ "vSphere 8.0 Virtual Topology Performance Study", где рассматриваются аспекты производительности новой технологии, которую назвали vTopology. Виртуальная топология CPU включает в себя такие техники, как virtual sockets, узлы virtual non-uniform memory access (vNUMA), а также механизм кэширования virtual last-level caches (LLC).
До vSphere 8.0 дефолтной конфигурацией виртуальных машин было одно виртуальное ядро на сокет - это в некоторых случаях создавало затыки в производительности и неэффективность использования ресурсов. Теперь же ESXi автоматически подстраивает число виртуальных ядер на сокет для заданного числа vCPU.
На картинке ниже показана высокоуровневая архитектура компонентов двухсокетной системы. Каждый сокет соединен с локальным узлом памяти (memory bank) и образует с ним NUMA-узел. Каждый сокет имеет 4 ядра (он имеет кэши L1 и L2), а ядра шарят между собой общий кэш last-level cache (LLC).
Когда создается виртуальная машина с четырьмя vCPU, в vSphere она конфигурируется на одном сокете, вместо четырех, как это было ранее:
Так это выглядит в выводе команды CoreInfo для двух рассмотренных топологий:
Слева - это старая конфигурация, где был один vCPU на сокет, а справа - 4 vCPU (виртуальных ядер ВМ) на один сокет.
В указанном документе VMware проводит различных конфигураций (от 8 до 51 vCPU на машину) для разных нагрузок с помощью бенчмарков и утилит DVD Store 3.5, Login VSI, VMmark, Iometer, Fio и Netperf в операционных системах Windows и Linux. Забегая вперед, скажем, что для нагрузок Oracle прирост производительности составил 14%, а для Microsoft SQL server - 17%.
Итак, результаты теста DVD Store для БД Oracle:
Статистики NUMA hits NUMA misses для гостевой ОС Linux:
Результаты тестов для Microsoft SQL server:
Результаты тестирования хранилищ с помощью IOmeter:
Производительность в разрезе метрики CPU cycles per I/O (CPIO):
Много лет назад мы писали о технологиях работы кэша write-through и write-back в ведущем на рынке виртуализации хранилищ решении StarWind Virtual SAN. С тех пор механика работы этих технологий была улучшена, но принципы остались теми же, как и большинство фундаментальных технологий. Сегодня мы поговорим о работе кэшей уровней L1 и L2, которые существенно улучшают быстродействие операций ввода-вывода.
При работе StarWind Virtual SAN с хранилищами используется кэш первого уровня (L1), располагающийся в оперативной памяти, а также кэш второго уровня (L2), размещенный на SSD-дисках, обеспечивающих высокое быстродействие системы.
StarWind использует традиционную оперативную память серверов (RAM) как буфер на чтение (write buffer) и L1-кэш, чтобы кэшировать операции записи, флэш-память SSD уже обслуживает кэш уровня L2. Оба кэша используют одни и те же алгоритмы - shared library, поэтому информация ниже применима, в основном, к кэшам обоих уровней. Об их отличиях мы также поговорим в статье отдельно.
При переполнении кэша нужно освободить его, используя какой-то алгоритм. StarWind применяет для этого алгоритм LRU - least recently used, то есть вытесняются данные (блоки), которые используются реже всего в последнее время.
В зависимости от степени исчерпания состояния кэша, его блоки могут находиться в одном из трех состояний: dirty, clean и empty. В самом начале блок помечается как empty - в нем нет данных, то есть блоки кэша не ассоциированы с блоками на диске. При работе кэша эти данные начинают заполняться. Блок помечается как dirty - если полезные данные были записаны в него, но еще не были записаны на диск (он не подтвердил запись данных). Блок помечается как clean, если данные из кэша были записаны на диск, либо блок кэша был записан в результате чтения в кэш блока с диска - то есть блок кэша и блок на диске содержат одинаковые данные.
Помните, что стандартный размер блока для кэша - 64 КБ.
Следующее полезное понятие - это прогрев кэша (cache warm-up). Эта концепция имплементируется на нижнем уровне в рамках сценария "in-memory" файловой системы LSFS (log-structured file system). Данные в кэш в этом случае попадают с диска, с учетом самых последних данных, записанных на диск.
Политики кэширования
Политика кэширования определяется вместе с другими параметрами кэша / устройств, когда они создаются. В StarWind Version 8 Release 5 режим работы кэша может быть изменен на лету для уже существующих устройств.
Write-back caching
Это режим, когда запись данных производится в кэш, но операция ввода-вывода (I/O) подтверждается, как запись на диск. Запись в основную память производится позже (при вытеснении или по истечению времени), группируя в одной операции несколько операций записи в соседние ячейки. Этот тип кэширования существенно ускоряет скорость записи данных на диск, однако имеет несколько меньшую надежность с точки зрения записи данных.
Если блок находится в статусе empty или clean, то запись в кэш происходит практически мгновенно, на уровне скорости записи данных в RAM или на SSD. А вот как работает кэш в разных обстоятельствах:
Если операции записи не были сделаны в dirty-кэш на протяжении некоторого времени (по умолчанию 5 секунд), то данные записываются на диск. Блок переходит в состоянии clean, но данные в нем остаются.
Если все доступные блоки кэша находятся в состоянии dirty, то данные, хранимые в самых старых блоках, форсированно скидываются на диск, а новые данные записываются в эти блоки. В этом случае производительность кэша несколько падает из-за требующихся операций записи на диск, и она сравнима со скоростью такой операции с диском.
Если происходит сбой в работе сервера или памяти (или его выключают на обслуживание), то данные в кэше write-back, помеченные как dirty, немедленно сбрасываются на диск. Если размер кэша большой (гигабайты), то эта операция может занять значительное время. Его можно оценить так: Flushing time = cache size / RAM write.
Политика кэширования write-back ускоряет производительность в следующих случаях:
Флуктуации нагрузки - кэш позволяет сгладить пики нагрузки за счет аккумуляции большого числа записей в кэше во время всплесков до момента снижения нагрузки.
Постоянная перезапись тех же самых блоков - в этом случае они постоянно перезаписываются только в кэше, а на диск сбрасываются пачки блоков по мере необходимости.
Помните, что политика write-back предпочтительна для L1-кэша и в данный момент недоступна для L2-кэша, который всегда создается в режиме write-through.
Write-through caching
Это режим, когда запись производится непосредственно в основную память и дублируется в кэш. Такой тип кэширования не ускоряет запись данных на диск (но и не замедляет), но существенно увеличивает скорость чтения данных, которые можно взять из кэша. Этот тип кэша безопасен с точки зрения надежности данных и дает однозначный выигрыш в производительности.
При использовании этого типа кэширования не будет потери данных в случае неисправности сервера и памяти. Блоки памяти кэша в этом случае всегда помечены как clean.
Рекомендации по использованию кэша
L1 Cache
Он решает следующие проблемы:
Запросы партнерского узла StarWind Virtual SAN могут приходить с небольшой задержкой и изменять порядок доступа к блокам, например, 1-2-3-4-5-6-7-8 изменится на 1-3-2-4-5-7-6-8. В этом случае L1- кэш сгладит поток последовательных запросов на запись с применением алгоритма round robin в дополнение к кэшированию. L1-кэш объединяет маленькие запросы записи в большие (write coalescing). Например, 16 запросов по 4k в кэш будут записаны на диск как единый блок 64к, что работает гораздо быстрее. Поэтому для такого кэша не нужно много памяти - от 128 МБ.
L1 также компенсирует перезапись в те же секторы диска. Самая частая перезапись - это небольшие по размеру операции. Размер кэша должен зависеть от от частоты перезаписи данных и размера working data set. Чем чаще перезапись, теперь меньше вы можете делать кэш, но если больше размер working data set, то должен быть и больше кэш. В этом случае работает формула Tcached = Tdisk * (1 – (cache size) / (working set size)). В этом случае, если у вас кэш составляет 0.1 от data working set, процессинг данных будет составлять 0.9 от времени процессинга данных на диск. Если же cache size = working data set, то средний процессинг команд будет примерно равен времени процессинга команд в памяти.
StarWind L1 cache в режимах write-back и write-through может быть использован для:
Файловых устройств StarWind HA image file на базе HDD-хранилищ в конфигурации RAID 10.
Также помните, что в большинстве случаев для дисковых массивов all-flash кэш уровня L1 вам не потребуется.
В идеале размер кэша L1 должен быть равен размеру working data set. Также размер кэша L1 влияет на время, которое вам потребуется, чтобы выключить сервер (нужно сбросить грязные блоки на диск). Также помните, что лучше не делать L1 кэш в режиме WB, чтобы не создавать ситуацию, когда большой объем данных может быть утерян.
При использовании кэша L1 в режиме write-back обязательно используйте UPS для серверов, чтобы не потерять часть данных. Время работы UPS должно позволяет сбросить содержимое грязного кэша на диск.
L2 Cache (Flash Cache)
Для обслуживания кэша L2 создается обычное устройство ImageFile device. У этого устройства нет таргета, и оно соединено с системой точно так же, как и устройство с данными (ImageFile or LSFS).
Система с кэшем L2 должна иметь больше оперативной памяти RAM для обеспечения накладных расходов. Формула тут такая: 6.5 ГБ RAM на 1 ТБ кэша L2, чтобы хранить метаданные. Более подробно о кэше L2 можно почитать в базе знаний StarWind.
StarWind L2 cache может быть использован для следующих сценариев:
HA-устройства StarWind image file на базе HDD в конфигурации RAID 10.
Устройства StarWind LSFS на базе HDD в конфигурации RAID 5, 6, 50, 60.
HA-устройства StarWind image file на all-flash хранилищах в некоторых сценариях. Более подробно об этих сценариях можно почитать в базе знаний StarWind.
В большинстве случаев, когда у вас есть L1 кэш, кэш уровня L2 вам не потребуется. Размер L2 кэша должен быть равен среднему объему уникальных данных, запрашиваемых с хранилища на регулярной основе (определяется экспериментально).
Компания VMware обновила свой гипервизор для архитектуры ARM на сайте проекта Labs - ESXi ARM Edition 1.10. В будущем этот гипервизор найдет свое применение в таких платформах, как Project Monterey. О прошлой версии ESXi для ARM 1.9 мы писали в апреле этого года.
Давайте посмотрим, что нового в ESXi ARM Edition 1.10:
Теперь поддерживается апгрейд с прошлых версий ESXi-Arm 1.x
Поддержка Arm DEN0115 (доступ к конфигурации PCIe через интерфейс firmware, протестировано на Raspberry Pi)
Поддержка L3 cache info для Ampere eMAG
Небольшие улучшения для non-cache coherent DMA
Статистики для Raspberry Pi NIC (genet)
GOS: возможность использования VNXNET3 и PVSCSI как драйверов по умолчанию в freebsd12
Поддержка чипов RK3566 SBC (например, Quartz64) - как PCIe, так и EQOS onboard NIC
Исправлены ошибки для драйвера Intel igbn NIC (повышена стабильность работы)
Возвращается нулевой код ошибки для unknown sys_reg(3, 0, 0, x, y) для виртуальных машин
Данные телеметрии - собирается статистика о системе, на которой запущен гипервизор
Вот какие данные собираются в рамках телеметрии в целях улучшения продукта:
CPU info: число ядер, NUMA, производитель и т.п.
Firmware info: вендор и версия
Platform info: вендор, продукт, UUID, список устройств
ESXi-Arm info: версия, уровень патчей, билд продукта
Скрипт /bin/telemetry выполняется при каждой загрузке и в 00:00 каждую субботу
Скачать VMware ESXi ARM Edition 1.10 можно по этой ссылке.
На сайте проекта VMware Labs появилось очередное обновление утилиты vRealize Build Tools 2.23. Напомним, что это средство позволяет разработчикам и администраторам, работая совместно, реализовывать новые сценарии и рабочие процессы vRealize Automation (vRA) и vRealize Orchestrator (vRO), используя стандартные практики DevOps.
Об одной из прошлых версий этого решения 2.20 мы писали вот тут, а теперь давайте посмотрим на нововведения двух последних версий (2.22.1 и 2.23):
Поддержка composite type values для vRO
Возможность выбора кастомных файлов для конвертации кода на базе git branch
Исправлены ошибки типа NullPointerException с аутентификацией, профилями хранилищ, файлами json и свойством formFormat
Возможность заменить свойством serverId поля учетной записи для всех типов проектов
Исправлена ошибка с исчезновением кастомного ресурса при импорте multi-tenant окружения, когда указан его ID
Исправлены ошибки экспорта при обработке алиасов
Теперь корректно обрабатываются определения интерфейсов vro-type-defs
Добавлены определения типов для плагина MQTT vRO
Удален плагин vRO hint из vRBT
Установщик удаляет ненужные файлы, которые уже импортированы
Исправлена ошибка с polyglot-cache
Скачать VMware vRealize Build Tools 2.23 можно по этой ссылке.
Многие администраторы VMware vSphere знают, что есть такой портал VMware Marketplace, где доступно более 2300 партнерских решений и продуктов для дополнения виртуальной инфраструктуры, онпремизной и облачной.
Портал VMware Marketplace позволяет сотрудникам DevOps, IT-администраторам, администраторам ИБ и прочим ИТ-специалистам получить доступ к огромному количеству решений, разбитых на категории, такие как Identity, Networking и Security, которые можно попробовать перед покупкой. Они поставляются в различных форм-факторах - виртуальные модули OVA, готовые к развертыванию контейнеры, а также менеджмент паки.
Решения от независимых поставщиков проходят программу валидации и сертификации VMware Ready и Partner Ready, для которых отображаются соответствующие бейджи на их страницах в маркетплейсе. ISV-партнеры, разрабатывающие продукты для маркетплейса, должны быть в составе экосистемы разработчиков Technology Alliance Program (TAP) компании VMware.
Только в феврале этого года на маркетплейс было добавлено 39 новых решений в различных категориях (кликайте на заголовок категории, чтобы увидеть все решения, доступные в ней):
В общем, VMware Marketplace - это отличное место для поиска нужных вам дополнений для виртуальной инфраструктуры, особенно если вы используете продукты специфических вендоров или нуждаетесь в дополнительных средствах управления и мониторинга различного оборудования или ПО.
Многие администраторы VMware vSphere в крупных компаниях рано или поздно сталкиваются с необходимостью создания кластеров из виртуальных машин, например, для использования технологии высокой доступности баз данных Oracle Real Application Clusters (RAC) или для создания систем непрерывной доступности на базе технологии VMware Fault Tolerance. При использовании кластерных решений необходимо, чтобы диски ВМ находились в режиме multi-writer, то есть позволяли...
Таги: VMware, Clustering, Backup, HA, FT, VMachines, Storage, VMDK, VMFS
Весной этого года мы рассказывали о новых возможностях продукта VMware Cloud Disaster Recovery, который позволяет производить кросс-облачное восстановление виртуальных сред. Одним из самых страшных DR-сценариев для администраторов является поражение инфраструктуры программой-вымогателем (ransomware), которая зачастую блокирует компьютеры, а данные их дисков зашифровывает.
Традиционная инфраструктура бэкапа в этом случае может оказаться малоэффективной - ведь сложно определить момент, когда произошло инфицирование компьютеров/виртуальных машин, а также трудно быстро поднять десятки и сотни систем, ну и тяжело запустить там все процедуры проверки.
Вот какие моменты важны при борьбе с массовой атакой посредством ransomware:
Возможность иметь достаточное количество копий назад во времени, чтобы выбрать точку чистой от вредоносного ПО системы.
Возможность мгновенно включить ВМ для проверки, не запуская длительный процесс восстановления. Потому что таких виртуальных машин может быть очень много.
Обеспечение сохранности и неизменности самих бэкапов - надо сделать так, чтобы зараженные машины не зашифровали сами резервные копии - ведь тогда нечего будет и восстанавливать.
Нужно регулярно убеждаться, что бэкапы не повреждены (например, вследствие какого-то бага).
Ну и все процедуры по восстановлению не должны стоить космических денег, что может разорить компанию.
В ответ на эти требования компания VMware разработала облачную файловую систему Scale-out Cloud Filesystem (SCFS), которая позволяет хранить готовые к восстановлению резервные копии ВМ, избегая больших затрат.
Делается это за счет комбинации в одном хранилище двухъярусной архитектуры - для хранения резервных копий и для исполнения нагрузок. Облако EC2 с локальными NVMe-хранилищами используется для обеспечения работы высокопроизводительных нагрузок (cache-tier), а S3-хранилища используются для больших объемов данных (capacity tier).
Это позволяет независимо масштабировать ресурсы для увеличения производительности и емкости. Часть cache-яруса используется для обработки входящих данных по резервному копированию, чтобы обеспечить баланс потока резервного копирования (backup-mode) и исполнения нагрузок. Когда нужно приступить к восстановлению (recovery-mode) ярус кэша может быть расширен, чтобы виртуальные машины запускались напрямую с этой файловой системы. То есть, такой дизайн файловой системы позволяет быстро переключаться между режимами backup-mode и recovery-mode.
Этот подход основан на Log-Structured Filesystem (LFS), файловой системы, которая была предложена еще в 1992 году одним из основателей VMware Менделем Розенблюмом. Она основывается на идее, что устройства хранения (HDD, SSD, S3) не так производительны в случайных операциях, как в последовательных, а sequential writes как раз удобно использовать для такой структуры хранения бэкапов. Идея LFS в том, чтобы сохранять данные изменений файловой системы в виде лога, а позже проводить его очистку.
Эти же техники использует VMware Cloud Disaster Recovery в облаке S3. Как видно из картинки, все входящие данные бэкапов разбиваются на большие сегменты в 10 МБ, которые последовательно записываются на хранилище как объекты S3 на высокой скорости. Данные хранятся в виде лога, то есть не перезаписывают прошлые данные. Это позволяет избежать ситуации, когда резервные копии виртуальных машин перезаписываются уже инфицированными бэкапами.
Для такой структуры необходим эффективный механизм по работе с указателями на данные, чтобы быстро позиционироваться на нужных блоках при запуске ВМ напрямую из резервной копии. Для этого VMware использует криптохэши на базе контента, которые невозможно подменить со стороны вредоносного ПО. Эти криптохэши организованы по структуре дерева (см. подробнее тут), а сами бэкапы недоступны для модификации из внешнего мира, то есть самой производственной среды.
При восстановлении сами бэкапы тоже не трогаются - создается копия объектов бэкапа и виртуальная машина сразу же запускается с использованием этих данных. Работает это практически мгновенно, причем неважно сколько машин запускается в рамках задачи.
Также в SCFS есть встроенный механизм проверки целостности резервных копий на ежедневной основе, что позволяет избежать ситуации, когда нужно восстанавливать системы, а данные повреждены.
Начать изучение платформы VMware Cloud Disaster Recovery можно с этой странички.
Многие администраторы VMware vSAN задаются вопросом - а сколько прослужат диски в кластере хранилищ? Сегодня для vSAN уже имеет смысл использовать только SSD-диски, так как их стоимость уже вполне стала приемлемой для построения All-Flash хранилищ.
Как известно, в кластере vSAN есть 2 типа дисков - Cache (кэширование данных перед записью на постоянное хранение) и Capacity (постоянное хранилище). В первом случае, конечно же, использование ресурса диска идет в разы быстрее, чем для Capacity Tier.
Florian Grehl в своем блоге провел замер использования дисков обоих ярусов в плане записанных гигабайт в сутки в тестовой лаборатории. Вы сами сможете сделать это с помощью его PowerCLI-сценария, а также визуализовав данные в Graphite.
У него получилась вот такая картина:
В день у него получилось:
300 ГБ на диски Caching tier
20 ГБ на диски Capacity tier
Надо понимать, что объем записанных данных на каждый диск зависит от числа дисков в группе, а также развернутого типа RAID и политики FTT.
Когда вы покупаете SSD-диск, гарантия на него идет как на машину: время (обычно 5 лет), либо пробег (а в случае с диском это "TBW" = Terabytes Written, то есть записанный объем в ТБ) - в зависимости от того, что наступит раньше.
Как правило, для Capacity tier ресурс TBW за 5 лет на практике выработать не получится, а вот для Caching tier неплохо бы этот параметр замерить и сопоставить с характеристиками дисков. Например, 300 ГБ в день дает 535 ТБ за 5 лет.
Ну а вот параметры TBW, например, для устройств Samsung:
Вендор
Диск
Емкость
TBW
Гарантия
Samsung
980 PRO NVMe M.2 SSD
250
150
5 лет
Samsung
980 PRO NVMe M.2 SSD
500
300
5 лет
Samsung
980 PRO NVMe M.2 SSD
1000
600
5 лет
Samsung
950 PRO NVMe M.2 SSD
256
200
5 лет
Samsung
950 PRO NVMe M.2 SSD
512
400
5 лет
Samsung
SSD 870 QVO SATA III 2.5 Inch
1000
360
3 года
Samsung
SSD 870 QVO SATA III 2.5 Inch
2000
720
3 года
Samsung
SSD 870 QVO SATA III 2.5 Inch
4000
1440
3 года
Samsung
SSD 870 QVO SATA III 2.5 Inch
8000
2880
3 года
Samsung
970 EVO Plus NVMe M.2 SSD
250
150
5 лет
Samsung
970 EVO Plus NVMe M.2 SSD
500
300
5 лет
Samsung
970 EVO Plus NVMe M.2 SSD
1000
600
5 лет
Samsung
970 EVO Plus NVMe M.2 SSD
2000
1200
5 лет
Samsung
860 QVO SATA III 2.5 Inch SSD
1000
360
3 года
Samsung
860 QVO SATA III 2.5 Inch SSD
2000
720
3 года
Samsung
860 QVO SATA III 2.5 Inch SSD
4000
1440
3 года
Samsung
970 EVO NVMe M.2 SSD
250
150
5 лет
Samsung
970 EVO NVMe M.2 SSD
500
300
5 лет
Samsung
970 EVO NVMe M.2 SSD
1000
600
5 лет
Samsung
970 EVO NVMe M.2 SSD
2000
1200
5 лет
Samsung
970 PRO NVMe M.2 SSD
512
600
5 лет
Samsung
970 PRO NVMe M.2 SSD
1000
1200
5 лет
Samsung
860 EVO SATA III 2.5 Inch SSD
250
150
5 лет
Samsung
860 EVO SATA III 2.5 Inch SSD
500
300
5 лет
Samsung
860 EVO SATA III 2.5 Inch SSD
1000
600
5 лет
Samsung
860 EVO SATA III 2.5 Inch SSD
2000
1200
5 лет
Samsung
860 EVO SATA III 2.5 Inch SSD
4000
2400
5 лет
Samsung
SSD 860 PRO SATA III 2.5 Inch
256
300
5 лет
Samsung
SSD 860 PRO SATA III 2.5 Inch
512
600
5 лет
Samsung
SSD 860 PRO SATA III 2.5 Inch
1000
1200
5 лет
Samsung
SSD 860 PRO SATA III 2.5 Inch
2000
2400
5 лет
Samsung
SSD 860 PRO SATA III 2.5 Inch
4000
4800
5 лет
Samsung
860 EVO SATA III M.2 SSD
250
150
5 лет
Samsung
860 EVO SATA III M.2 SSD
500
300
5 лет
Samsung
860 EVO SATA III M.2 SSD
1000
600
5 лет
Samsung
860 EVO SATA III M.2 SSD
2000
1200
5 лет
Intel
Intel Optane Memory 16GB
16
182.5
5 лет
Intel
Intel Optane Memory M10 16GB
16
365
5 лет
Intel
Intel Optane Memory 32GB
32
182.5
5 лет
Intel
Intel Optane Memory M10 32GB
32
365
5 лет
Intel
Intel Optane SSD 800P 58GB
58
365
5 лет
Intel
Intel Optane SSD 800P 58GB
118
365
5 лет
Intel
Intel® 545s-SSDs
256
144
5 лет
Intel
Intel® 545s-SSDs
512
288
5 лет
Intel
Intel® 545s-SSDs
256
144
5 лет
Intel
Intel® 660p-SSDs
512
100
5 лет
Intel
Intel® 660p-SSDs
1024
200
5 лет
Intel
Intel® 660p-SSDs
2048
400
5 лет
Intel
Intel® 760p-SSDs
128
72
5 лет
Intel
Intel® 760p-SSDs
256
144
5 лет
Intel
Intel® 760p-SSDs
512
288
5 лет
Intel
Intel® 760p-SSDs
1024
576
5 лет
Intel
Intel® 760p-SSDs
2048
576
5 лет
Transcend
PCIe SSD 220S
256
550
5 лет
Transcend
PCIe SSD 220S
512
1100
5 лет
Transcend
PCIe SSD 220S
1000
2200
5 лет
Transcend
PCIe SSD 220S
2000
4400
5 лет
Seagate
IronWolf 510
240
435
5 лет
Seagate
IronWolf 510
480
875
5 лет
Seagate
IronWolf 510
960
1750
5 лет
Seagate
IronWolf 510
1920
3500
5 лет
Как видно из таблицы, некоторые устройства могут прослужить вам значительно меньше 5 лет, в зависимости от интенсивности использования в вашей инфраструктуре и модели устройства.
Многие администраторы платформы VMware vSphere задаются вопросом - что произойдет, если изменить политику хранилищ (Storage Policy) в кластере vSAN для виртуальной машины? Будет ли после этого выполнена операция по перестроению дисковых объектов (Rebuild), что повлечет дополнительную нагрузку на хранилища и займет время?
Также в некоторых условиях операция Rebuild может не выполняться, но выполняется Resync - добавление новых копий данных, при котором исходные копии данных не изменяются (например, вы увеличиваете значение политики FTT, что влечет создание новых дисковых объектов).
Ответ на этот вопрос зависит от того, какую политику и на что вы меняете. Дункан Эппинг провел полезные тесты в своей лабе, чтобы выяснить, в каких случаях происходит Rebuild/Resync. После каждой операции он через интерфейс командной строки проверял, происходила ли операция ресинхронизации. Далее он свел полученные результаты в таблицу ниже, чтобы при изменении политики администраторы vSAN представляли, что произойдет дальше.
Какое-то время назад мы писали о новых возможностях недавно вышедшего обновления платформы виртуализации VMware vSphere 7 Update 1. Одним из главных улучшений стало увеличение максимальных параметров платформы, что привело к возможности организовывать кластер HA/DRS из еще большего числа хостов, а на самих хостах - исполнять виртуальные машины еще большего размера.
Данные нововведения можно проиллюстрировать следующей таблицей:
В кластере теперь может быть до 96 хостов, правда не все технологии поддерживают это число. Например, кластер VMware vSAN 7 Update 1 и топология HCI Mesh поддерживают все еще 64 хоста, а технология Native File Services в vSAN 7 U1 поддерживает только 32 хоста.
Самое большое улучшение - теперь в кластере может быть до 10 тысяч виртуальных машин, а это на 50% выше показателя vSphere седьмой версии:
Для виртуальных машин, находящихся под экстремальной нагрузкой, теперь поддерживается 768 виртуальных процессоров (vCPU) и до 24 ТБ памяти. Это больше, чем для виртуальных машин на любой из других облачных или онпремизных платформ:
К подобным нагрузкам можно отнести системы на базе SAP HANA и EPIC Cache Operational Database. Все эти ресурсы виртуальная машина может реально использовать:
Для виртуальной инфраструктуры в целом на базе одного кластера в Sphere 7 Update 1 максимальные показатели следующие: 393 216 vCPU (96 хостов по 4 096 vCPU) / 2.3 ПБ памяти (96 хостов по 24 ТБ):
Если говорить об исполнении контейнеров vSphere with Tanzu в такой инфраструктуре, то их может поместиться просто огромное количество. Согласно статистике, средний размер контейнера составляет 1 vCPU и 400 МБ памяти (например, контейнер node.js "кушает" 1/3 CPU и 384 МБ памяти). Таких контейнеров в одном кластере vSphere 7 U1 может быть запущено 393 216 штук. А контейнеров node.js можно запустить до миллиона экземпляров!
Основной фишкой первого пакета обновления седьмой версии vSphere стал, конечно же, финальный выпуск платформы VMware vSphere with VMware Tanzu, объединяющей миры виртуальных машин и контейнеризованных приложений в рамках инфраструктуры предприятия.
Вот небольшой обзор платформы VMware vSphere with Tanzu, о первых объявлениях компонентов которой мы уже писали тут и тут (а о текущей версии рассказано в блоге VMware):
Нововведения vSphere 7 U1 разбиты на 3 блока:
Инфраструктура для разработчиков (контейнеры)
Продолжение масштабирования возможностей платформы
Упрощение операций администраторов
Итак, давайте посмотрим, что нового в VMware vSphere 7 Update 1:
1. Инфраструктура для разработчиков
Здесь VMware добавила следующие важные возможности:
Служба Tanzu Kubernetes Grid (TKG) - о ней мы упоминали вот тут. Она позволяет администраторам развертывать Kubernetes-окружения и управлять их составляющими с помощью решения для кластеров Tanzu Kubernetes. Делается это теперь за минуты вместо часов. Также TKG идет в соответствии с политиками upstream Kubernetes, что позволяет сделать процесс миграции максимально бесшовным.
Bring Your Own Networking - пользователи могут выбирать, какой сетевой стек использовать для кластеров Tanzu Kubernetes. Можно использовать традиционную инфраструктуру на базе vSphere Distributed Switch (vDS) для конфигурации, мониторинга и администрирования виртуальных машин и кластеров Kubernetes. Новый Networking for Tanzu Kubernetes clusters позволяет использовать и решения VMware NSX. Также можно использовать Antrea для максимальной производительности внутренней сети для сервисов Tanzu Kubernetes Grid.
Bring Your Own Load Balancer - можно выбирать тип балансировки L4 для кластеров Tanzu Kubernetes. Первым партнером VMware стало решение HAProxy в формате виртуального модуля OVA.
Application-focused management - теперь пользователи могут применять vCenter не только для управления виртуальными машинами, но и для обслуживания, мониторинга и траблшутинга инфраструктуры контейнеров, включая приложения и неймспейсы (подход application focused management).
2. Продолжение масштабирования возможностей платформы
В этой категории нужно отметить следующие возможности:
Monster VMs - для пользователей решений SAP HANA, Epic Operational Databases, InterSystems Cache и IRIS компания VMware позволяет масштабировать виртуальные машин до 24 ТБ памяти и до 768 виртуальных процессоров (vCPU). То есть все ресурсы хоста могут быть предоставлены виртуальной машине, требующей их большое количество. Это было сделано за счет улучшения планировщика ESXi, а также логики ко-шедулинга для больших ВМ.
Cluster scale enhancements - теперь в vSphere 7 U1 кластер может содержать до 96 хостов! Это на 50% больше значения в релизе vSphere 7 (64 штуки):
3. Упрощение операций администраторов
vSphere Lifecycle Manager - теперь vLCM поддерживает и хосты vSAN, и конфигурацию сетевого стека NSX-T. В vSphere 7 Update 1 решение vLCM также мониторит соответствие образов непрерывно, что позволяет вовремя запустить процесс обновления (remediation).
vSphere Ideas - эта функциональность позволяет пользователям запросить возможности vSphere следующих версий прямо из интерфейса vSphere Client, отслеживать статус своих запросов, видеть запросы других пользователей и голосовать за них. Не факт, конечно, что к вам прислушаются, но общую обстановку по тому, что хотят администраторы, вы будете видеть.
vCenter Connect - теперь пользователи могут управлять своими виртуальными ресурсами VMware Cloud on AWS или в других облаках на базе vCenter из единого интерфейса.
Доступность для загрузки VMware vSphere 7 Update 1 ожидается в рамках или после конференции VMworld Online 2020. Следите за нашими обновлениями!
Раньше DRS был сфокусирован на выравнивании нагрузки на уровне всего кластера хостов ESXi в целом (на базе расчета стандартного отклонения по производительности), то есть бралась в расчет загрузка аппаратных ресурсов каждого из серверов ESXi, на основании которой рассчитывались рекомендации по миграциям vMotion виртуальных машин. Теперь же механизм запускается каждую минуту, а для генерации рекомендаций используется механизм VM DRS Score (он же VM Hapiness), отражающий удовлетворение потребности виртуальной машины в свободных ресурсах.
Пример 1 - хост с отклонением нагрузки от большинства
В старом DRS, работающем по принципу выравнивания нагрузки в кластере на базе анализа стандартного отклонения загруженности хостов в рамках определенного порога, могла возникнуть вот такая ситуация, когда DRS не требовалось предпринимать никаких действий по выравниванию нагрузки, хотя они, очевидно, требовались:
Новый DRS работает на базе анализа ресурсов для каждой виртуальной машины и будет перемещать их средствами vMotion, пока не достигнет максимальной доступности ресурсов для каждой ВМ. В точно таком же случае, как описано выше, это приведет в итоге к более сбалансированной ситуации:
Пример 2 - неравномерная загрузка хостов в кластере
В старом DRS был порог по дисбалансу в кластере, и если он не превышен - то механизм балансировки не запускался. Это могло приводить к образованием групп хостов с разными уровнями средней загрузки процессора и памяти:
В ситуации с новым DRS ситуация в итоге, опять-таки, получается более справедливая:
Также полезной оказывается метрика DRS Score (она же VM Hapiness), которая формируется из 10-15 главных метрик машин. Основные метрики из этого числа - Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness.
Если все машины чувствуют себя "комфортно" на всех хостах, то DRS Score оказывается максимальным:
Если подать нагрузку на пару хостов ESXi, то их средний DRS Score падает, а на дэшборде указывается число машин, для которых рассчитаны низкие уровни DRS Score:
После того, как DRS обработает эту ситуацию, нагрузка на хосты выравнивается, а значение DRS Score увеличивается:
Многие из вас знают, что в решении для организации отказоустойчивых кластеров хранилищ VMware vSAN есть функции дедупликации и сжатия данных (deduplication and compression, DD&C). С помощью этих функций можно более эффективно использовать ярус хранения данных виртуальных машин (Capacity Tier). О некоторых аспектах применения дедупликации и сжатия данных в vSAN мы рассказывали вот тут, а сегодня поговорим об их общем влиянии на производительность дисковой подсистемы.
Как знают администраторы vSAN, это решение использует двухъярусную архитектуру, создающую оптимальное соотношение цена/качество для хранилищ ВМ - на Cache Tier, собранном из дорогих SSD-дисков (быстро работающих на дисках), размещается Write Buffer и Read Cache, а на дешевых SSD/HDD-дисках - постоянные данные виртуальных машин.
Механизм DD&C работает так - если он включен, то как только из Cache Tier виртуальной машине отправляется квитанция о записи данных, то может начаться процесс дестейджинга данных на Capacity Tier, во время которого сам механизм и вступает в действие. Сначала с помощью механики дедупликации в рамках дисковой группы (deduplication domain) находятся идентичные блоки размером 4 КБ и дедуплицируются, а затем блоки сжимаются. При этом, если блок сжимается менее, чем на 50%, то целевое хранилище записывается оригинал блока в целях быстрого доступа при чтении (без декомпрессии).
Получается, что механизм DD&C - оппортунистический, то есть он работает не всегда, а по мере возможности и не гарантирует конкретных результатов по эффективности сжатия данных на целевом хранилище.
Такая модель позволяет не затрагивать процесс посылки квитанции виртуальной машине о записи данных, а также не заморачиваться с дедупликацией блоков уже на целевом хранилище в рамках пост-процессинга.
Очевидно, что дедупликация с компрессией могут влиять на производительность, так как требуют ресурсов процессора на обработку потока ввода-вывода. Давайте посмотрим, как именно.
При высоком входящем потоке операций чтения и записи vSAN старается обеспечить наименьшую задержку (latency) при прохождении команд. При этом vSAN сам решает, в какой именно момент начать процесс дестейджинга данных, поэтому буфер на запись заполняется разные моменты по-разному.
Такая двухъярусная система vSAN имеет 2 теоретических максимума:
Max burst rate - возможность Cache Tier сбрасывать обработанные пакеты данных в сторону Capacity Tier
Max steady state rate - установившаяся максимальная скорость записи данных на приемнике Capacity Tier
Реальная скорость обмена данными между ярусами лежит где-то между этими значениями. Если вы будете использовать бенчмарк HCIBench на длительном отрезке времени, то сможете практическим путем определить эти значения из соответствующих графиков замера производительности хранилища.
Если у вас идет дестейджинг данных с включенным DD&C, это потенциально может повлиять на производительность записи данных на Capacity Tier. При использовании DD&C снижается максимальная скорость записи данных на ярус постоянного хранения, так как перед этой записью должны быть выполнены операции дедупликации и сжатия.
Иными словами, кластер с включенным DD&C может давать такие же показатели качества обслуживания, как и кластер с более медленными устройствами в Capacity Tier, но с выключенным DD&C.
Логично ожидать, что при включенном DD&C буффер Write Buffer будет заполняться скорее, так как будут возникать задержки ожидания отработки DD&C. Но пока буффер полностью не заполнен - заметных просадок в производительности не будет. Очищаться также Write Buffer будет медленнее при включенном DD&C.
Также может измениться и время отсылки квитанции о записи (acknowledgment time, оно же write latency), которое увеличит latency для виртуальной машины. Это произойдет, если уже начался дестейджинг данных, а машина запрашивает ACK и ждет ответа с уровня буффера. Хотя в целом vSAN построен таким образом, чтобы как можно быстрее такой ответ дать.
Надо отметить, что vSAN не торопится сразу скинуть все данные из Write Buffer на диск. В vSAN есть интеллектуальные алгоритмы, которые позволяют делать это равномерно и вовремя, с учетом общей текущей нагрузки. Например, при частой перезаписи данных одной ячейки памяти, она обрабатывается в цепочке сначала именно на уровне буффера, а на диск уже идет финальный результат.
Если вы также используете RAID 5/6 для кластеров vSAN, то совместно с техниками DD&C могут возникнуть серьезные эффекты с влиянием на производительность. Об этих аспектах подробно рассказано вот тут - обязательно ознакомьтесь с ними (см. также комментарий к статье).
По итогу можно сделать следующие выводы из этой схемы:
Если вам хочется использовать DD&C, и вы видите, что у ВМ высокая latency - попробуйте более быстрые диски на Capacity Tier.
Используйте больше дисковых групп, так как Buffer и его пространство hot working set используется на уровне дисковой группы. Две группы на хосте нужно минимум, а лучше три.
Альтернативой DD&C могут стать устройства большой емкости - там просто все поместится).
Используйте последнюю версию vSAN - алгоритмы работы с данными все время совершенствуются.
Также помните, что RAID 5/6 также экономит место по сравнению с RAID1, что может стать альтернативой DD&C.
Ну и главный вывод он как всегда один: производительность - это всегда компромисс между требованиями рабочих нагрузок и деньгами, которые вы готовы потратить на обеспечение этих требований.
На сайте проекта VMware Labs появилась еще пара интересных обновлений.
Первое - новая версия FlowGate 1.1. Эта утилита представляет собой средство для агрегации данных из различных источников. Это middleware, которое позволяет провести агрегацию данных систем инвентаризации датацентров DCIM / CMDB и далее передать их в системы управления задачами инфраструктуры (например, vRealize Operations). Напомним, что о прошлой версии этого средства мы писали вот тут.
Что нового в обновлении FlowGate 1.1:
Переработаны адаптеры powerIQ и Nlyte - теперь они поддерживают больше метрик и свойств
Доработан Metric API
Улучшена функциональность ручного маппинга, включая поддержку PDU, коммутаторов и сенсоров
Второе - обновилось решение VMware OS Optimization Tool до версии b1160 от 2 июня 2020 года. Напомним, что о прошлой его версии мы писали вот тут.
Это средство предназначено для подготовки гостевых ОС к развертыванию и проведению тюнинга реестра в целях оптимизации производительности, а также отключения ненужных сервисов и запланированных задач.
Давайте посмотрим, что нового появилось в июньском апдейте OS Optimization Tool:
Windows Update - новая опция, которая называется Update, позволяющая заново включить функционал Windows Update, который был ранее отключен в рамках оптимизации
Полностью переработанный интерфейс, позволяющий проще изменять настройки и кастомизировать файл ответов
Добавлены команды, с помощью которых можно отключить службы App Volumes, если они установлены, перед запуском шагов стадии Finalize
Выбор опций стадии Finalize теперь сохраняется между прогонами утилиты, что позволяет не терять время на выставление настроек заново
Стандартизация опций командной строки (теперь можно использовать -optimize или -o и т.п.)
Удалены оптимизации, которые будучи не выбраны по умолчанию, могли приводить к проблемам. Например, Disable Scheduled Tasks и CacheTask
Обновлено руководство VMware Operating System Optimization Tool Guide
Скачать VMware OS Optimization Tool b1160 можно по этой ссылке.
Некоторое время назад мы писали о новых возможностях платформы виртуализации VMware vSphere 7, среди которых мы вкратце рассказывали о нововведениях механизма динамического распределения нагрузки на хосты VMware DRS. Давайте взглянем сегодня на эти новшества несколько подробнее.
Механизм DRS был полностью переписан, так как его основы закладывались достаточно давно. Раньше DRS был сфокусирован на выравнивании нагрузки на уровне всего кластера хостов ESXi в целом, то есть бралась в расчет загрузка аппаратных ресурсов каждого из серверов ESXi, на основании которой рассчитывались рекомендации по миграциям vMotion виртуальных машин:
При этом раньше DRS запускался каждые 5 минут. Теперь же этот механизм запускается каждую минуту, а для генерации рекомендаций используется механизм VM DRS Score (он же VM Hapiness). Это композитная метрика, которая формируется из 10-15 главных метрик машин. Основные метрики из этого числа - Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness. Расчеты по памяти теперь основываются на Granted Memory вместо стандартного отклонения по кластеру.
Мы уже рассказывали, что в настоящее время пользователи стараются не допускать переподписку по памяти для виртуальных машин на хостах (Memory Overcommit), поэтому вместо "Active Memory" DRS 2.0 использует параметр "Granted Memory".
VM Happiness - это основной KPI, которым руководствуется DRS 2.0 при проведении миграций (то есть главная цель всей цепочки миграций - это улучшить этот показатель). Также эту оценку можно увидеть и в интерфейсе:
Как видно из картинки, DRS Score квантуется на 5 уровней, к каждому из которых относится определенное количество ВМ в кластере. Соответственно, цель механизма балансировки нагрузки - это увеличить Cluster DRS Score как агрегированный показатель на уровне всего кластера VMware HA / DRS.
Кстати, на DRS Score влияют не только метрики, касающиеся производительности. Например, на него могут влиять и метрики по заполненности хранилищ, привязанных к хостам ESXi в кластере.
Надо понимать, что новый DRS позволяет не только выровнять нагрузку, но и защитить отдельные хосты ESXi от внезапных всплесков нагрузки, которые могут привести виртуальные машины к проседанию по производительности. Поэтому главная цель - это держать на высоком уровне Cluster DRS Score и не иметь виртуальных машин с низким VM Hapiness (0-20%):
Таким образом, фокус DRS смещается с уровня хостов ESXi на уровень рабочих нагрузок в виртуальных машинах, что гораздо ближе к требованиям реального мира с точки зрения уровня обслуживания пользователей.
Если вы нажмете на опцию View all VMs в представлении summary DRS view, то сможете получить детальную информацию о DRS Score каждой из виртуальных машин, а также другие важные метрики:
Ну и, конечно же, на улучшение общего DRS Score повлияет увеличения числа хостов ESXi в кластере и разгрузка его ресурсов.
Кстати, ниже приведен небольшой обзор работы в интерфейсе нового DRS:
Еще одной важной возможностью нового DRS является функция Assignable Hardware. Многие виртуальные машины требуют некоторые аппаратные возможности для поддержания определенного уровня производительности, например, устройств PCIe с поддержкой Dynamic DirectPath I/O или NVIDIA vGPU. В этом случае теперь DRS позволяет назначить профили с поддержкой данных функций для первоначального размещения виртуальных машин в кластере.
В видео ниже описано более подробно, как это работает:
Ну и надо отметить, что теперь появился механизм Scaleable Shares, который позволяет лучше выделять Shares в пуле ресурсов с точки зрения их балансировки. Если раньше высокий назначенный уровень Shares пула не гарантировал, что виртуальные машины этого пула получат больший объем ресурсов на практике, то теперь это может использоваться именно для честного распределения нагрузки между пулами.
Этот механизм будет очень важным для таких решений, как vSphere with Kubernetes и vSphere Pod Service, чтобы определенный ярус нагрузок мог получать необходимый уровень ресурсов. Более подробно об этом рассказано в видео ниже:
На днях пришла пара важных новостей о продуктах компании StarWind Software, которая является одним из лидеров в сфере производства программных и программно-аппаратных хранилищ для виртуальной инфраструктуры.
StarWind HCA All-Flash
Первая важная новость - это выпуск программно-аппаратного комплекса StarWind HyperConverged Appliance (HCA) All-Flash, полностью построенного на SSD-накопителях. Обновленные аппаратные конфигурации StarWind HCA, выполненные в форм-факторе 1 или 2 юнита, позволяют добиться максимальной производительности хранилищ в рамках разумной ценовой политики. Да, All-Flash постепенно становится доступен, скоро это смогут себе позволить не только большие и богатые компании.
Решение StarWind HCA - это множество возможностей по созданию высокопроизводительной и отказоустойчивой инфраструктуры хранилищ "все-в-одном" под системы виртуализации VMware vSphere и Microsoft Hyper-V. Вот основные высокоуровневые возможности платформы:
Поддержка гибридного облака: кластеризация хранилищ и active-active репликация между вашим датацентром и любым публичным облаком, таким как AWS или Azure
Функции непрерывной (Fault Tolerance) и высокой доступности (High Availability)
Безопасное резервное копирование виртуальных машин
Проактивная поддержка вашей инфраструктуры специалистами StarWind
И многое, многое другое
Сейчас спецификация на программно-аппаратные модули StarWind HCA All-Flash выглядит так:
После развертывания гиперконвергентной платформы StarWind HCA она управляется с помощью единой консоли StarWind Command Center.
Ну и самое главное - программно-аппаратные комплексы StarWind HCA All-Flash полностью на SSD-дисках продаются сегодня, по-сути, по цене гибридных хранилищ (HDD+SSD). Если хотите узнать больше - обращайтесь в StarWind за деталями на специальной странице. Посмотрите также и даташит HCA.
Давайте посмотрим, что нового появилось в StarWind Virtual SAN V8 for Hyper-V:
Ядро продукта
Добавлен мастер для настройки StarWind Log Collector. Теперь можно использовать для этого соответствующее контекстное меню сервера в Management Console. Там можно подготовить архив с логами и скачать их на машину, где запущена Management Console.
Исправлена ошибка с заголовочным файлом, который брал настройки из конфига, но не существовал на диске, что приводило с падению сервиса.
Улучшен вывод событий в файлы журнала, когда в системе происходят изменения.
Улучшена обработка ответов на команды UNMAP/TRIM от аппаратного хранилища.
Добавлена реализация процессинга заголовка и блога данных дайждестов iSCSI на процессорах с набором команд SSE4.2.
Максимальное число лог-файлов в ротации увеличено с 5 до 20.
Механизм синхронной репликации
Процедура полной синхронизации была переработана, чтобы избежать перемещения данных, которые уже есть на хранилище назначения. Делается это путем поблочного сравнения CRC и копирования только отличающихся блоков.
Исправлена ошибка падения сервиса в случае выхода в офлайн партнерского узла при большой нагрузке на HA-устройство.
Значение по умолчанию пинга партнерского узла (iScsiPingCmdSendCmdTimeoutInSec) увеличено с 1 до 3 секунд.
Исправлена ошибка с утечкой памяти для состояния, когда один из узлов был настроен с RDMA и пытался использовать iSER для соединения с партнером, который не принимал соединений iSER.
Нотификации по электронной почте
Реализована поддержка SMTP-соединений через SSL/STARTTLS.
Добавлена возможность аутентификации на SMTP.
Добавлена возможность проверки настроек SMTP путем отправки тестового сообщения.
Компоненты VTL и Cloud Replication
Список регионов для всех репликаций помещен во внешний файл JSON, который можно просто обновлять в случае изменений на стороне провайдера.
Исправлена обработка баркодов с длиной, отличающейся от дефолтной (8 символов).
Исправлена ошибка падения сервиса при загрузке tape split из большого числа частей (тысячи).
Исправлены ошибки в настройках CloudReplicator Settings.
Модуль StarWindX PowerShell
Обновился скрипт AddVirtualTape.ps1, был добавлен учет параметров, чувствительных к регистру.
Для команды Remove-Device были добавлены опциональные параметры принудительного отсоединения, сохранения сервисных данных и удаления хранимых данных на устройстве.
Добавлен метод IDevice::EnableCache для включения и отключения кэша (смотрите примеры FlashCache.ps1 и FlushCacheAll.ps1).
VTLReplicationSettings.ps1 — для назначения репликации используется число, кодирующее его тип.
Свойство "Valid" добавлено к HA channel.
Сценарий MaintenanceMode.ps1 — улучшенная обработка булевых параметров при исполнении сценария из командной строки.
Тип устройства LSFS — удален параметр AutoDefrag (он теперь всегда true).
Средство управления Management Console
Небольшие улучшения и исправления ошибок.
Скачать полнофункциональную пробную версию StarWind Virtual SAN for Hyper-V можно по этой прямой ссылке. Release Notes доступны тут.
Таги: StarWind, Update, Storage, iSCSI, HCA, Hardware, SSD, HA, DR
Свершилось. Компания Veeam Software, лидер в сфере средств для обеспечения доступности виртуальных датацентров, объявила о выпуске и доступности для загрузки новой версии пакета
Veeam Availability Suite v10, в состав которого входит решение для резервного копирования и репликации виртуальных машин Veeam Backup and Replication v10.
Таги: Veeam, Backup, Update, Replication, Availability Suire, DR
В декабре мы писали о новой версии решения VMware OS Optimization Tool, которое предназначено для подготовки гостевых ОС к развертыванию и проведению тюнинга реестра в целях оптимизации производительности, а также отключения ненужных сервисов и запланированных задач.
В январе вышла новая версия (билд b1140) этого решения. Давайте посмотрим, что в ней появилось нового:
Новая кнопка на экране результатов задач, которая позволяет сохранить страницу как HTML-файл.
Новая опция, которая упрощает задачу запуска Sysprep с использованием стандартного файла ответов. Теперь можно отредактировать файл ответов до запуска Sysprep для него.
Новая опция по автоматизации задач в рамках этапа финализации (они переехали из common options), которые запускаются как последний шаг перед тем, как Windows будет выключена, чтобы ВМ была использована в решении VMware Horizon. Она включает в себя задачи по system clean up (очистка диска, NGEN, DISM и задача Compact). Ранее эти задачи были доступны в диалоге опций командной строки. Также можно чистить лог событий, информацию о серверах KMS и отпускании IP-адреса.
Новая вкладка опций Security - она позволяет быстро выбрать наиболее частые настройки безопасности. Они относятся к Bitlocker, Firewall, Windows Defender, SmartScreen и HVCI.
Добавлен параметр командной строки -o для запуска утилиты без применения оптимизаций (например, clean up).
Изменена дефолтная настройка на "не отключать Webcache", потому что это приводило к невозможности для браузеров Edge и IE сохранять файлы.
На днях компания Intel опубликовала руководство по безопасности Security Advisory INTEL-SA-00329, в котором описаны новые обнаруженные уязвимости в CPU, названные L1D Eviction Sampling (она же "CacheOut") и Vector Register Sampling. Прежде всего, надо отметить, что обе этих уязвимости свежие, а значит исправления для них пока не выпущено.
Соответственно, VMware также не может выпустить апдейт, пока нет обновления микрокода CPU от Intel. Когда Intel сделает это, VMware сразу выпустит патч, накатив который на VMware vSphere вы избавитесь от этих потенциальных уязвимостей.
Vector Register Sampling (CVE-2020-0548). Эта уязвимость является пережитком бага, найденного в подсистеме безопасности в ноябре прошлого года. Она связана с атаками типа side-channel, о которых мы писали вот тут. В рамках данной атаки можно использовать механизм Transactional Synchronization Extensions (TSX), представленный в процессорах Cascade Lake. О прошлой подобной уязвимости можно почитать вот тут. А список подверженных уязвимости процессоров Intel можно найти тут.
L1D Eviction Sampling (CVE-2020-0549). Эта уязвимость (ее также называют CacheOut) позволяет злоумышленнику, имеющему доступ к гостевой ОС, получить доступ к данным из памяти других виртуальных машин. Более подробно об уязвимостях данного типа можно почитать на специальном веб-сайте. Также вот тут находится список уязвимых процессоров.
Следите за обновлениями VMware, патчи будут доступны сразу, как только Intel обновит микрокод процессоров. Достаточно будет просто накатить обновления vSphere - и они пофиксят уязвимости CPU.
Таги: VMware, Intel, Security, VMachines, vSphere, CPU
На сайте проекта VMware Labs обновилась очередная полезная администраторам утилита - VMware OS Optimization Tool. Она позволяет подготовить гостевые ОС к развертыванию и проводить тюнинг реестра в целях оптимизации производительности, а также отключение ненужных сервисов и запланированных задач. Напомним, что о прошлой ее версии мы писали вот тут.
Давайте посмотрим, что нового появилось в OS Optimization Tool b1110 (а нового немало!):
1. Работа с шаблонами.
Изменены 2 существующих шаблона, чтобы покрыть соответствующие серверные ОС и реализовать поддержку Windows Server 2019 отдельно.
Windows 10 1507-1803 / Server 2016
Windows 10 1809-1909 / Server 2019
Старые шаблоны Windows Server 2016 были удалены.
2. Функции System Clean Up.
Добавлены параметры очистки системы в диалог Common Options, это убирает необходимость выполнять эти операции вручную. Следующие параметры были добавлены:
Deployment Image Servicing and Management (DISM)
Native Image Generator (NGEN)
Compact (Windows 10/ Server 2016/2019)
Disk Cleanup
3. Бэкграунд/обои рабочего стола.
Новая страница Common Options для настроек фонового изображения. Также можно дать возможность пользователю поменять обои.
4. Настройки визуальных эффектов.
Добавлена третья опция, которая выключает все визуальные эффекты, кроме smooth edges и use drop shadows. Это теперь опция по умолчанию.
5. Приложения Windows Store.
Новая страница в Common Options позволяет контролировать удаление приложений Windows Store. Приложения Windows Store App и the StorePurchaseApp по умолчанию остаются.
Также можно оставить следующие приложения:
Alarms & Clock
Camera
Calculator
Paint3D
Screen Sketch
Sound Recorder
Sticky Notes
Web Extensions
6. Значения по умолчанию.
Маленькая опция в таскбаре теперь не отмечена по умолчанию. В шаблонах Windows 10/ Server теперь следующие сервисы не выбраны по умолчанию:
Application Layering Gateway Service
Block Level Backup Engine Service
BranchCache
Function Discovery Provider Host
Function Discovery Resource Publication
Internet Connection Sharing
IP Helper
Microsoft iSCSI Initiator Service
Microsoft Software Shadow Copy Provider
Secure Socket Tunneling Protocol Service
SNMP Trap
SSDP Discovery
Store Storage Service
Volume Shadow Copy Service
Windows Biometric Service
7. Несколько новых оптимизаций.
Полностью отключить Smartscreen
Отключить Content Delivery Manager
Отключить User Activity History completely
Отключить Cloud Content
Отключить Shared Experiences
Отключить Server Manager для Windows Server OS
Отключить Internet Explorer Enhanced Security для Windows Server OS (не выбрано по умолчанию)
Отключить Storage Sense service
Отключить Distributed Link Tracking Client Service
Отключить Payments и NFC/SE Manager Service
Скачать VMware OS Optimization Tool можно по этой ссылке.
В последних числах августа компания StarWind Software, выпускающая продукты для организации хранилищ под виртуализацию, выпустила обновленную версию решения для создания iSCSI-хранилищ на платформах vSphere и Hyper-V - StarWind Virtual SAN V8 build 13182. Давайте посмотрим, что нового появилось в этом продукте...
На блогах VMware появилась интересная статья о том, как работает связка кэширующего яруса (Cache tier) с ярусом хранения данных (Capacity tier) на хостах кластера VMware vSAN в контексте производительности. Многие пользователи задаются вопросом - а стоит ли ставить более быстрые устройства на хосты ESXi в Capacity tier и стоит ли увеличивать их объем? Насколько это важно для производительности?
Системы кэширования работают в датацентре на всех уровнях - это сетевые коммутаторы, процессоры серверов и видеокарт, контроллеры хранилищ и т.п. Основная цель кэширования - предоставить высокопроизводительный ярус для приема операций ввода-вывода с высокой интенсивностью и малым временем отклика (это обеспечивают дорогие устройства), после чего сбросить эти операции на постоянное устройство хранения или отправить в нужный канал (для этого используются уже более дешевые устройства).
В кластере vSAN это выглядит вот так:
Второе преимущество двухъярусной архитектуры заключается в возможности манипуляции данными не на лету (чтобы не затормаживать поток чтения-записи), а уже при их сбрасывании на Capacity tier. Например, так работают сервисы компрессии и дедупликации в VMware vSAN - эти процессы происходят уже на уровне яруса хранения, что позволяет виртуальной машине не испытывать просадок производительности на уровне яруса кэширования.
Общая производительность двухъярусной системы зависит как от производительности яруса хранения, так и параметров яруса кэширования (а именно скорость работы и его объем). Ярус кэширования позволяет в течение определенного времени принимать операции ввода-вывода с очень большой интенсивностью, превышающей возможности приема яруса хранения, но по прошествии этого времени буфер очищается, так как требуется время для сброса данных на уровень постоянного хранения.
С точки зрения производительности это можно представить так (слева система с ярусом кэширования и хранения, справа - только с ярусом хранения):
Оказывается, в реальном мире большинство профилей нагрузки выглядят именно как на картинке слева, то есть система принимает большую нагрузку пачками (burst), после чего наступает некоторый перерыв, который устройства кэширования кластера vSAN используют для сброса данных на постоянные диски (drain).
Если вы поставите более производительное устройство кэширования и большего объема, то оно сможет в течение большего времени и быстрее "впитывать" в себя пачки операций ввода-вывода, которые возникают в результате всплесков нагрузки:
Но более быстрое устройство при равном объеме будет "наполняться" быстрее при большом потоке ввода-вывода, что уменьшит время, в течение которого оно сможет обслуживать такие всплески на пиковой скорости (зато во время них не будет проблем производительности). Здесь нужно подбирать устройства кэширования именно под ваш профиль нагрузки.
С точки зрения устройств кэширования и хранения, кластер VMware vSAN представлен дисковыми группами, в каждой из которых есть как минимум одно устройство кэширования и несколько дисков хранения:
Для устройств кэширования на уровне одной дисковой группы установлен лимит в 600 ГБ. Однако это не значит, что нельзя использовать ярус большего объема. Мало того, некоторые пользователи vSAN как раз используют больший объем, так как в этом случае запись происходит во все доступные ячейки SSD (но суммарный объем буфера все равно не превышает лимит), что приводит к меньшему изнашиванию устройств в целом. Например, так происходит в кластере All-flash - там все доступная свободная емкость (но до 600 ГБ) резервируется для кэша.
Надо еще понимать, что если вы поставите очень быстрые устройства кэширования, но небольшого объема - они будут быстро заполняться на пиковой скорости, а потом брать "паузу" на сброс данных на ярус хранения. Таким образом, здесь нужен компромисс между объемом и производительностью кэша.
На базе сказанного выше можно дать следующие рекомендации по оптимизации производительности двухъярусной системы хранения в кластерах VMware vSAN:
Старайтесь использовать устройства кэширования большего объема, чтобы они могли впитывать большой поток ввода-вывода в течение большего времени. Производительность устройств уже рассматривайте во вторую очередь, только если у вас уж очень большой поток во время всплесков, который нужно обслуживать очень быстро.
Добавляйте больше дисковых групп, каждую из которых может обслуживать свое устройство кэширования. На уровне дисковой группы установлен лимит в 600 ГБ, но всего на хосте может быть до 3 ТБ буфера, поделенного на 5 дисковых групп.
Используйте более производительные устройства в ярусе хранения - так сброс данных буфера (destage rate) на них будет происходить быстрее, что приведет к более быстрой готовности оного обслуживать пиковую нагрузку.
Увеличивайте число устройств хранения в дисковой группе - это увеличит скорость дестейджинга данных на них в параллельном режиме.
Отслеживайте производительность кластера с помощью vSAN Performance Service, чтобы увидеть моменты, когда ярус кэширования захлебывается по производительности. Это позволит соотнести поведение буфера и профиля нагрузки и принять решения по сайзингу яруса кэширования и яруса хранения.
Используйте самые последнии версии VMware vSAN. Например, в vSAN 6.7 Update 3 было сделано множество программных оптимизаций производительности, особенно в плане компрессии и дедупликации данных. Всегда имеет смысл быть в курсе, что нового появилось в апдейте и накатывать его своевременно.
На конференции VMworld 2019, которая недавно прошла в Сан-Франциско, было представлено так много новых анонсов продуктов и технологий, что мы не успеваем обо всех рассказывать. Одной из самых интересных новостей стала информация про новую версию распределенного планировщика ресурсов VMware Distributed Resource Scheduler (DRS) 2.0. Об этом было рассказано в рамках сессии "Extreme Performance Series: DRS 2.0 Performance Deep Dive (HBI2880BU)", а также про это вот тут написал Дункан Эппинг.
Надо сказать, что технология DRS, позволяющая разумно назначать хосты ESXi для виртуальных машин и балансировать нагрузку за счет миграций ВМ посредством vMotion между серверами, была представлена еще в 2006 году. Работает она без кардинальных изменений и по сей день (13 лет!), а значит это очень востребованная и надежная штука. Но все надо когда-то менять, поэтому скоро появится и DRS 2.0.
Если раньше основным ресурсом датацентров были серверы, а значит DRS фокусировался на балансировке ресурсов в рамках кластера серверов ESXi, то теперь парадигма изменилась: основной элемент датацентра - это теперь виртуальная машина с приложениями, которая может перемещаться между кластерами и физическими ЦОД.
Сейчас технология DRS 2.0 находится в статусе Technical Preview, что значит, что никто не гарантирует ее присутствие именно в таком виде в будущих продуктах VMware, кроме того нет и никаких обещаний по срокам.
В целом, изменилось 3 основных момента:
Появилась новая модель затраты-преимущества (cost-benefit model)
Добавлена поддержка новых ресурсов и устройств
Все стало работать быстрее, а инфраструктура стала масштабируемее
Давайте посмотрим на самое интересное - cost-benefit model. Она вводит понятие "счастья виртуальной машины" (VM Happiness) - это композитная метрика, которая формируется из 10-15 главных метрик машин. Основные из этого числа - Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness.
VM Happiness будет основным KPI, которым будет руководствоваться DRS 2.0 при проведении миграций (то есть цель - улучшить этот показатель). Также эту оценку можно будет увидеть и в интерфейсе. Помимо этого, можно будет отслеживать этот агрегированный показатель и на уровне всего кластера VMware HA / DRS.
Второй важный момент - DRS 2.0 будет срабатывать каждую минуту, а не каждые 5 минут, как это происходит сейчас. Улучшение связано с тем, что раньше надо было снимать "снапшот кластера", чтобы вырабатывать рекомендации по перемещению виртуальных машин, а сейчас сделан простой и эффективный механизм - VM Happiness.
Отсюда вытекает еще одна полезная функциональность - возможность изменять интервал опроса счастливости виртуальных машин - для стабильных нагрузок это может быть, например, 40-60 минут, а для более непредсказуемых - 15-20 или даже 5.
Еще одна интересная фича - возможность проводить сетевую балансировку нагрузки при перемещении машин между хостами (Network Load Balancing). Да, это было доступно и раньше, что было вторичной метрикой при принятии решений о миграции посредством DRS (например, если с ресурсами CPU и памяти было все в порядке, то сетевая нагрузка не учитывалась). Теперь же это полноценный фактор при принятии самостоятельного решения для балансировки.
Вот пример выравнивания такого рода сетевой нагрузки на виртуальные машины на разных хостах:
Модель cost-benefit также включает в себя возможности Network Load Balancing и устройства PMEM. Также DRS 2.0 будет учитывать и особенности аппаратного обеспечения, например, устройства vGPU. Кстати, надо сказать, что DRS 2 будет также принимать во внимание и характер нагрузки внутри ВМ (стабильна/нестабильна), чтобы предотвратить "пинг-понг" виртуальных машин между хостами ESXi. Кстати, для обработки таких ситуаций будет использоваться подход "1 пара хостов source-destination = 1 рекомендация по миграции".
Также мы уже рассказывали, что в настоящее время пользователи стараются не допускать переподписку по памяти для виртуальных машин на хостах (memory overcommit), поэтому вместо "active memory" DRS 2.0 будет использовать параметр "granted memory".
Ну и был пересмотрен механизм пороговых значений при миграции. Теперь есть следующие уровни работы DRS для различных типов нагрузок:
Level 1 – балансировка не работает, происходит только выравнивание нагрузки в моменты, когда произошло нарушение правил DRS.
Level 2 – работает для очень стабильных нагрузок.
Level 3 – работает для стабильных нагрузок, но сфокусирован на метрике VM happiness (включено по умолчанию).
Level 4 – нагрузки со всплесками (Bursty workloads).
Level 5 – динамические (Dynamic) нагрузки с постоянными изменениями.
В среднем же, DRS 2.0 обгоняет свою первую версию на 5-10% по быстродействию, что весьма существенно при больших объемах миграций. При этом VMware понимает, что новый механизм DRS второй версии может родить новые проблемы, поэтому в любой момент можно будет вернуться к старому алгоритму балансировки с помощью расширенного параметра кластера FastLoadBalance=0.
По срокам доступности технологии DRS 2.0 информации пока нет, но, оказывается, что эта технология уже почти год работает в облаке VMware Cloud on AWS - и пока не вызывала нареканий у пользователей. Будем следить за развитием событий.
Год назад компания StarWind Software анонсировала собственный таргет и инициатор NVMe-oF для Hyper-V, с помощью которых можно организовать высокопроизводительный доступ к хранилищам на базе дисков NVMe (подключенных через шину PCI Express) из виртуальных машин. За прошедший год StarWind достаточно сильно улучшила и оптимизировала этот продукт и представила публично результаты его тестирования.
Для проведения теста в StarWind собрали стенд из 12 программно-апаратных модулей (Hyperconverged Appliances, HCA) на базе оборудования Intel, Mellanox и SuperMicro, составляющий высокопроизводительный вычислительный кластер и кластер хранилищ, где подсистема хранения реализована с помощью продукта Virtual SAN, а доступ к дискам происходит средствами инициатора NVMe-oF от StarWind. Между хостами был настроен 100 Гбит Ethernet, а диски SSD были на базе технологии NVMe (P4800X). Более подробно о конфигурации и сценарии тестирования с технологией NVMe-oF написано тут.
Аппаратная спецификация кластера выглядела так:
Platform: Supermicro SuperServer 2029UZ-TR4+
CPU: 2x Intel® Xeon® Platinum 8268 Processor 2.90 GHz. Intel® Turbo Boost ON, Intel® Hyper-Threading ON
RAM: 96GB
Boot Storage: 2x Intel® SSD D3-S4510 Series (240GB, M.2 80mm SATA 6Gb/s, 3D2, TLC)
Storage Capacity: 2x Intel® Optane™ SSD DC P4800X Series (375GB, 1/2 Height PCIe x4, 3D XPoint™). The latest available firmware installed.
RAW capacity: 9TB
Usable capacity: 8.38TB
Working set capacity: 4.08TB
Networking: 2x Mellanox ConnectX-5 MCX516A-CCAT 100GbE Dual-Port NIC
Для оптимизации потока ввода-вывода и балансировки с точки зрения CPU использовался StarWind iSCSI Accelerator, для уменьшения latency применялся StarWind Loopback Accelerator (часть решения Virtual SAN), для синхронизации данных и метаданных - StarWind iSER initiator.
Как итог, ввод-вывод оптимизировался такими технологиями, как RDMA, DMA in loopback и TCP Acceleration.
С точки зрения размещения узлов NUMA было также сделано немало оптимизаций (кликните для увеличения):
Более подробно о механике самого теста, а также программных и аппаратных компонентах и технологиях, рассказано здесь. Сначала тест проводился на чистом HCA-кластере без кэширования.
Результаты для 4К Random reads были такими - 6,709,997 IOPS при теоретически достижимом значении 13,200,000 IOPS (подробнее вот в этом видео).
Далее результаты по IOPS были следующими:
90% random reads и 10% writes = 5,139,741 IOPS
70% random reads и 30% writes = 3,434,870 IOPS
Полная табличка выглядит так:
Потом на каждом хосте Hyper-V установили еще по 2 диска Optane NVMe SSD и запустили 100% random reads, что дало еще большую пропускную способность - 108.38 GBps (это 96% от теоретической в 112.5 GBps.
Для 100% sequential 2M block writes получили 100.29 GBps.
Полные результаты с учетом добавления двух дисков:
А потом на этой же конфигурации включили Write-Back cache на уровне дисков Intel Optane NVMe SSD для каждой из ВМ и для 100% reads получили 26,834,060 IOPS.
Полная таблица результатов со включенным кэшированием выглядит так:
Да-да, 26.8 миллионов IOPS в кластере из 12 хостов - это уже реальность (10 лет назад выжимали что-то около 1-2 миллионов в подобных тестах). Это, кстати, 101.5% от теоретического максимального значения в 26.4М IOPS (12 хостов, в каждом из которых 4 диска по 550 тысяч IOPS).
Для тестов, когда хранилища были презентованы посредством технологии NVMe-oF (Linux SPDK NVMe-oF Target + StarWind NVMe-oF Initiator), было получено значение 22,239,158 IOPS для 100% reads (что составляет 84% от теоретически расчетной производительности 26,400,000 IOPS). Более подробно об этом тестировании рассказано в отдельной статье.
Полные результаты этого теста:
Все остальное можно посмотреть на этой странице компании StarWind, которая ведет учет результатов. Зал славы сейчас выглядит так :)
Мы много пишем о решении для организации отказоустойчивых хранилищ на базе хостов ESXi - платформе VMware vSAN. Сегодня мы расскажем о дисковых группах на основе вот этого поста на блогах VMware.
Архитектура vSAN включает в себя два яруса - кэш (cache tier) и пространство постоянного хранения (capacity tier). Такая структура дает возможность достичь максимальной производительности по вводу-выводу, которая абсолютно необходима в кластере хранилищ на базе хостов.
Чтобы управлять отношениями устройств кэша и дисков хранения, решение vSAN использует дисковые группы:
У дисковых групп есть следующие особенности:
Каждый хост, который дает емкость кластеру vSAN, должен содержать как минимум одну дисковую группу.
Дисковая группа содержит как минимум одно устройство для кэша и от 1 до 7 устройств хранения.
Каждый хост ESXi в кластере vSAN может иметь до 5 групп, а каждая группа - до 7 устройств хранения. То есть на хосте может быть до 35 устройств хранения, чего вполне достаточно для подавляющего большинства вариантов использования.
Неважно, используете ли вы гибридную конфигурацию (SSD и HDD диски) или All-Flash, устройство кэширования должно быть Flash-устройством.
В гибридной конфигурации устройства кэша на 70% используются как кэш на чтение (read cache) и на 30% как кэш на запись (write buffer).
В конфигурации All-Flash 100% устройства кэша выделено под write buffer.
Write buffer и capacity tier
В принципе, всем понятно, что гибридная конфигурация хостов ESXi в кластере vSAN более дешевая (HDD стоит меньше SSD), но менее производительная, чем All-Flash. Но когда-то наступит время, и все будет All-Flash (в них, кстати, еще и нет нужды организовывать кэш на чтение, так как все читается с SSD с той же скоростью). Поэтому и выделяется 100% под write buffer.
При этом если операция чтения в All-Flash хосте находит блок в кэше - то он читается именно оттуда, чтобы не искать его в capacity tier. Максимальный размер write buffer на одной дисковой группе хоста ESXi - 600 ГБ. При этом если сам диск более 600 ГБ, то его емкость будет использоваться с пользой (см. комментарий к этой статье).
Для гибридных конфигураций 70% емкости кэша выделяется под кэш на чтение, чтобы быстро получать данные с производительных SSD-устройств, при этом vSAN старается поддерживать коэффициент попадания в кэш на чтение (cache hit rate) на уровне 90%.
Write buffer (он же write-back buffer) подтверждает запись на устройство хранения еще до актуальной записи блоков на сapacity tier. Такой подход дает время и возможность организовать операции записи наиболее эффективно и записать их на сapacity tier уже пачкой и более эффективно. Это дает существенный выигрыш в производительности.
SSD-устройства бывают разных классов, в зависимости от их выносливости (среднее число операций записи до его отказа). Все понятно, что для кэширования нужно использовать устройства высоких классов (они дорогие), так как перезапись там идет постоянно, а для хранения - можно использовать недорогие SSD-диски.
Вот сравнительная таблица этих классов (колонка TBW - это terabytes written, то есть перезапись скольких ТБ они переживут):
vSAN содержит в себе несколько алгоритмов, которые учитывают, как часто write buffer сбрасывает данные на сapacity tier. Они учитывают такие параметры, как емкость устройств, их близость к кэшу по времени записи, число входящих операций ввода-вывода, очереди, использование дискового устройства и прочее.
Организация дисковых групп
При планировании хостов ESXi в кластере vSAN можно делать на нем одну или более дисковых групп. Несколько дисковых групп использовать предпочтительнее. Давайте рассмотрим пример:
Одна дисковая группа с одним кэшем и 6 устройств хранения в ней.
Две дисковых группы с двумя устройствами кэша, в каждой по 3 устройства хранения.
Если в первом случае ломается SSD-устройство кэша, то в офлайн уходит вся дисковая группа из 6 дисков, а во втором случае поломка одного девайса приведет к выходу из строя только трех дисков.
Надо понимать, что этот кейс не имеет прямого отношения к доступности данных виртуальных машин, которая определяется политикой FTT (Failures to tolerate) - о ней мы подробно рассказывали тут, а также политиками хранилищ SPBM. Между тем, размер домена отказа (failure domain) во втором случае меньше, а значит и создает меньше рисков для функционирования кластера. Также восстановление и ребилд данных на три диска займет в два раза меньше времени, чем на шесть.
Кстати, некоторые думают, что в случае отказа дисковой группы, кластер vSAN будет ждать 60 минут (настройка Object Repair Timer) до начала восстановления данных на другие диски согласно политике FTT (ребилд), но это неверно. Если вы посмотрите наш пост тут, то поймете, что 60 минут vSAN ждет в случае APD (All Paths Down - например, временное выпадение из сети), а вот в случае PDL (Physical Device Loss) восстановление данных на другие дисковые группы начнется немедленно.
С точки зрения производительности, иметь 2 дисковые группы также выгоднее, чем одну, особенно если разнести их по разным контроллерам хранилищ (storage controllers). Ну и это более гибко в обслуживании и размещении данных на физических устройствах (например, замена диска во втором примере пройдет быстрее).
Работа операций ввода-вывода (I/O)
Как уже было сказано, в гибридной конфигурации есть кэши на чтение и на запись, а в All-Flash - только на запись:
При этом хост ESXi работает так, чтобы операции чтения с дисков попадали в кэш на чтение в 90% случаев. Остальные 10% операций чтения затрагивают HDD-диски и вытаскивают блоки с них. Но и тут применяются оптимизации - например, одновременно с вытаскиванием запрошенного блока, vSAN подтягивает в кэш еще 1 МБ данных вокруг него, чтобы последовательное чтение проходило быстрее.
Для All-Flash конфигурации кэш на чтение не нужен - все данные вытаскиваются с примерно одинаковой скоростью, зато все 100% кэша используются под write buffer, что дает преимущество в скорости обработки большого входящего потока операций ввода-вывода.
Ну и напоследок отметим, что vSAN при записи на флэш-диски распределяет операции записи равномерно между ячейками независимо от размера диска. Это позволяет диску изнашиваться равномерно и иметь бОльшую наработку на отказ.

 RSS
RSS