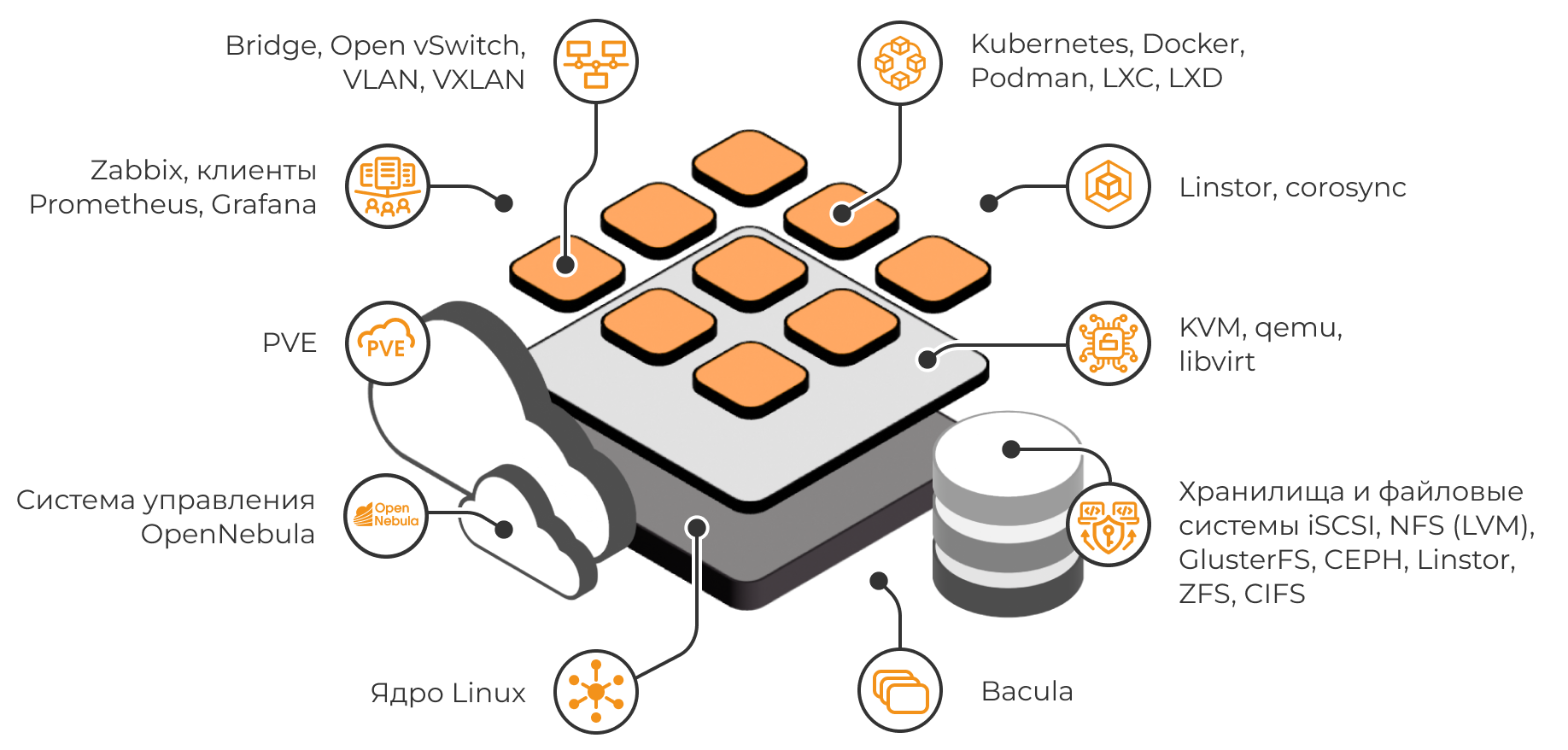
Компания «Базис», работающая на российском рынке программных решений для управления динамической инфраструктурой, сообщила о выходе платформы серверной виртуализации Basis Dynamix Enterprise версии 4.5.
В новом релизе расширены возможности экосистемы за счёт более тесной интеграции с системой управления программно-определяемыми сетями Basis SDN, улучшена совместимость с отечественными системами хранения данных, а также добавлены инструменты для повышения производительности и автоматизации управления ИТ-инфраструктурой. Всего версия 4.5 включает более 90 доработок и нововведений.
Расширение поддержки отечественных систем хранения данных
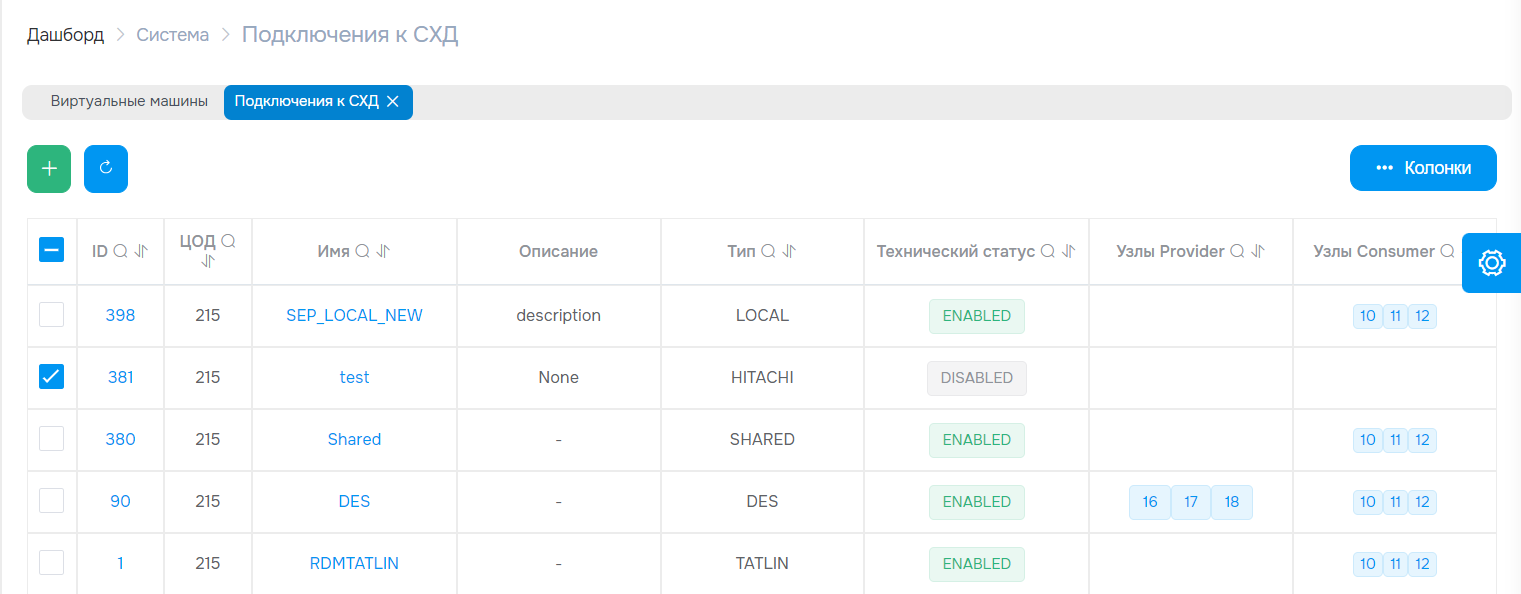
Одним из ключевых направлений развития версии 4.5.0 стало расширение поддержки российских СХД. В частности, добавлена работа с системой хранения uStor, включая полный набор операций: создание и управление дисками, работу с образами и снапшотами, а также презентацию и депрезентацию дисков вычислительным узлам.
Кроме того, реализована поддержка СХД Yadro Tatlin.Unified с версией ПО 3.2, при этом сохранена обратная совместимость с предыдущими версиями прошивки Tatlin. Это даёт заказчикам больше гибкости при выборе оборудования для построения импортонезависимой инфраструктуры и упрощает взаимодействие с ним через платформу.
Эффективное использование дискового пространства
В версии 4.5 внедрена поддержка unmap для дисков виртуальных машин. Теперь при удалении файлов внутри виртуальной машины освобождённое пространство не только помечается как свободное в гостевой системе, но и возвращается обратно в СХД. Это обеспечивает более эффективное использование дисковой ёмкости, что особенно важно при большом количестве виртуальных машин и использовании thin-provisioned дисков.
Развитие интеграции с программно-определяемыми сетями
Релиз 4.5 усиливает нативную интеграцию Basis Dynamix Enterprise с решением для программно-определяемых сетей Basis SDN и расширяет сетевые возможности платформы. Например, при создании виртуальных машин появилась возможность автоматически подключать SDN-сегменты с одновременным созданием логических портов, что сокращает объём ручной настройки и упрощает работу администраторов.
Автоматизация управления узлами
В Basis Dynamix 4.5 появился механизм автоматического перевода физического узла из состояния «На обслуживании» в статус «Работает». Соответствующая настройка доступна на странице «Физические узлы» в интерфейсе системы. При этом вместе с узлом автоматически запускаются виртуальные машины, ранее закреплённые за ним на момент перевода в режим обслуживания. Функция применима как к отдельным узлам, так и к целым зонам, что упрощает эксплуатацию крупных инфраструктур.
Другие улучшения
Помимо этого, версия 4.5.0 включает ряд дополнительных улучшений, повышающих удобство администрирования:
Механизм Watchdog, обеспечивающий автоматическое восстановление зависших виртуальных машин.
Поддержка режима Cache Write Through, повышающего производительность дисковой подсистемы.
Упрощённая начальная установка за счёт минимального конфигурационного файла.
Обновление спецификации API до версии OpenAPI 3.1.0.
Доработка модели физического узла: понятие «вычислительный узел» (stack) было упразднено, а его функциональность перенесена в сущность «физический узел» (node), что позволило упростить как модель данных, так и API платформы.
Возможность при создании виртуальной машины, даже если она разворачивается не из образа, включать дополнительные возможности гипервизора — такие как NUMA, CPU pinning и Huge Pages.
Возможность сделать виртуальную машину доступной только для чтения для всех пользователей.
При создании ВМ можно задавать маску сети для интерфейсов DPDK и VFNIC, а также настраивать MTU для транковых сетей в диапазоне от 1500 до 9216.
Можно ограничивать количество узлов, обрабатываемых одновременно, и при этом сбой на одном узле не прерывает общий процесс.
После первичной установки реализовано автоматическое обновление API-ключа для служебного пользователя.
Комментарий разработчика
«Одной из важнейших задач в рамках развития нашей флагманской платформы Basis Dynamix Enterprise является поддержание её совместимости с актуальным инфраструктурным оборудованием и ПО. Это касается в том числе и нашего собственного решения для организации программно-определяемых сетей Basis SDN, которое успешно работает в тестовых средах заказчиков и быстро развивается с учётом их пожеланий. Нашей целью является не просто поддержка отечественных систем хранения данных, инструментов резервного копирования или других решений. Мы хотим дать заказчику возможность построить на базе Basis Dynamix Enterprise полностью импортонезависимую динамическую ИТ-инфраструктуру, не ограничивая его при этом в выборе поставщиков "железа" или программных продуктов»
— Дмитрий Сорокин, технический директор компании «Базис».
Виртуализация давно стала неотъемлемой частью корпоративной ИТ-инфраструктуры, позволяя эффективнее использовать серверное оборудование и быстро развертывать новые сервисы. До недавнего времени российский рынок практически полностью зависел от зарубежных продуктов – особенно от VMware, на долю которого приходилось до 95% внедрений. Однако после 2022 года ситуация резко изменилась: VMware покинула российский рынок, отключив аккаунты пользователей и прекратив поддержку.
Это оставило компании без обновлений, техподдержки и возможности покупки новых лицензий. Одновременно регуляторы ужесточили требования: с 1 января 2025 года значимые объекты критической информационной инфраструктуры (КИИ) обязаны использовать только отечественное ПО. В результате переход на российские системы виртуализации из опции превратился в необходимость, и за три года рынок претерпел заметную консолидацию.
По данным исследования компании «Код Безопасности», уже 78% российских организаций выбирают отечественные средства виртуализации. В реестре российского ПО на 2025 год значатся порядка 92 решений для серверной виртуализации, из которых реально «живых» около 30, а активно используемых – не более десятка. За короткий срок появились аналоги западных продуктов «большой тройки» (VMware, Microsoft Hyper-V, Citrix) и собственные разработки российских компаний. Рассмотрим новейшие российские платформы виртуализации серверов и инфраструктуры виртуальных рабочих мест (VDI) и проанализируем их архитектуру, производительность, безопасность, возможности VDI, а также функции кластеризации и управления ресурсами. Отдельно сравним их с VMware VCF/vSphere по функциональности, зрелости технологий, совместимости и поддержке – и определим, какие решения наиболее перспективны для импортозамещения VMware в корпоративных ИТ России.
Российские платформы виртуализации 2025 года представлены широким спектром архитектурных подходов. Условно можно выделить две ключевые категории: классическая архитектура и гиперконвергентная архитектура (HCI). Также различаются технологические основы: часть решений опирается на открытый исходный код (форки oVirt, OpenStack, Proxmox и др.), тогда как другие являются проприетарными разработками.
Классическая архитектура
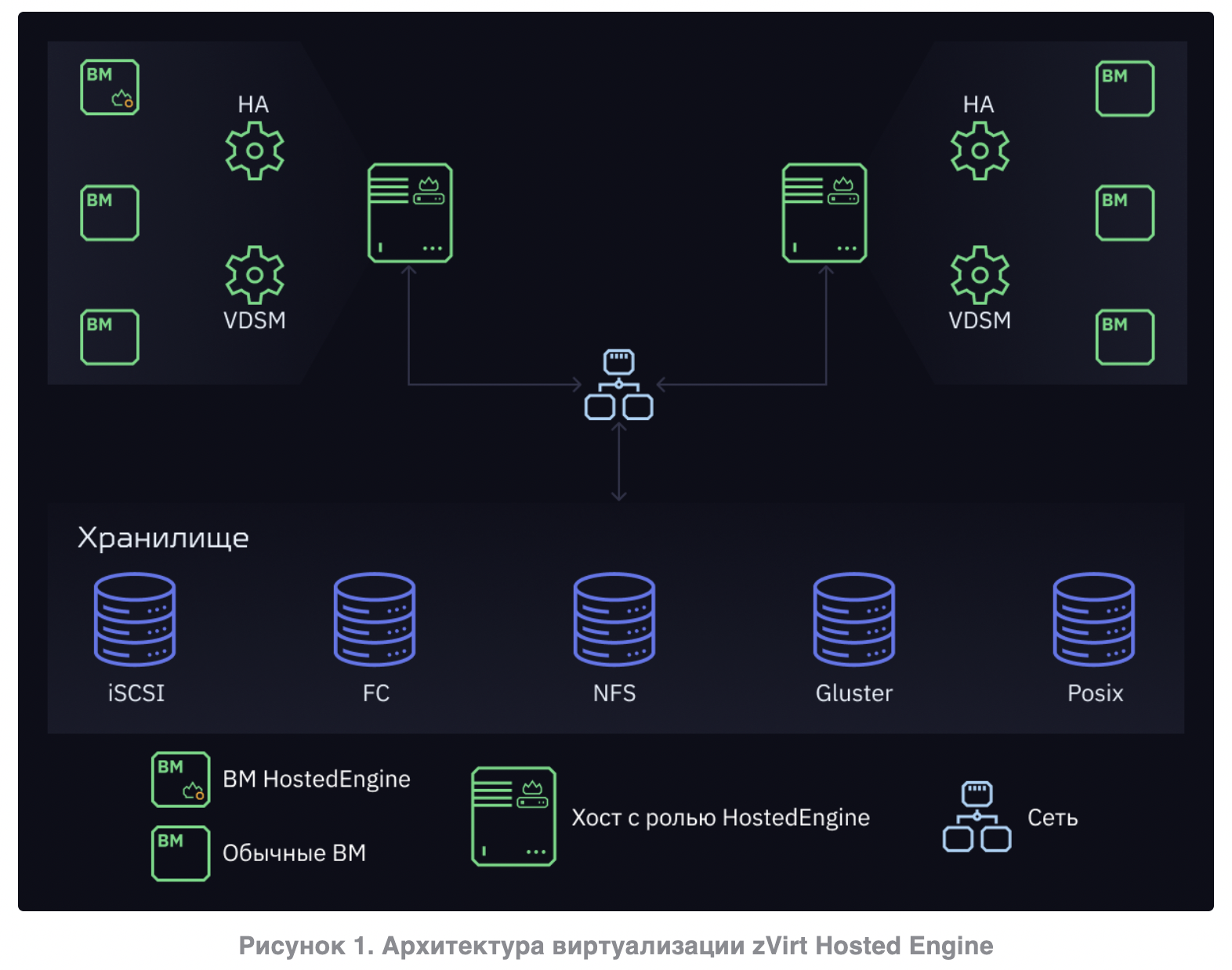
В классической схеме вычислительные узлы, системы хранения (СХД) и сети реализуются отдельными компонентами, объединёнными в единый кластер виртуализации. Такой подход близок к VMware vSphere и проверен десятилетиями: он даёт максимальную гибкость, позволяя подключать внешние высокопроизводительные СХД, использовать существующие сетевые инфраструктуры и масштабировать каждый слой независимо (например, наращивать хранение без изменения серверов). Для организаций с уже развернутыми дорогими СХД и развитой экспертизой администраторов этот вариант наиболее понятен.
Многие отечественные продукты поддерживают классическую модель. Например, “Ред Виртуализация” (решение компании РЕД СОФТ на базе KVM/oVirt), zVirt от Orion soft, SpaceVM (платформа компании «ДАКОМ М»), Rosa Virtualization, VMmanager от ISPsystem и Numa vServer (Xen-based) – все они ориентированы на традиционную архитектуру с интеграцией внешних хранилищ и сетей.
Архитектурно они во многом схожи с VMware (например, оVirt-платформы реализуют подключение SAN-хранилищ, динамическую балансировку ресурсов и т.п. «из коробки»). Однако есть и недостатки классического подхода: более высокая стоимость отдельных компонентов (CAPEX), требовательность к квалификации узких специалистов, сложность диагностики сбоев (не всегда очевидно, в каком слое проблема). Развёртывание классической инфраструктуры может занимать больше времени, поскольку нужно поэтапно настроить и интегрировать разнородные компоненты внутри единой платформы.
Гиперконвергентная инфраструктура (HCI)
В HCI все основные функции – вычисления, хранение, сеть – объединены на каждом узле и управляются через единую программную платформу. Локальные диски серверов объединяются программно в распределённое хранилище (часто на основе Ceph или аналогов), а сеть виртуализуется средствами самой платформы. Такой подход упрощает масштабирование: добавление нового узла сразу увеличивает и CPU/RAM, и объём хранения. Гиперконвергенция особенно хорошо подходит для распределённых площадок и филиалов, где нет штата ИТ-специалистов – достаточно поставить несколько одинаковых узлов, и система автонастроится без тонкой ручной оптимизации каждого слоя.
В России к HCI-решениям относятся, например, vStack (платформа в составе холдинга ITG на базе FreeBSD и гипервизора bhyve), «Кибер Инфраструктура» (решение компании «Киберпротект», развившей технологии Acronis), Р-платформа (российская приватная облачная платформа), Горизонт-ВС и др. – они изначально спроектированы как гиперконвергентные. Некоторые HCI-системы позволяют выходить за рамки встроенного хранения – например, Кибер Инфраструктура и Горизонт-ВС поддерживают подключение внешних блочных СХД, комбинируя подходы.
Открытый код или собственные разработки?
Многие отечественные продукты выросли из популярных open-source проектов. Например, решения на основе oVirt – это упомянутые выше zVirt, Red Виртуализация, ROSA Virtualization, HostVM и др. Их преимущество – быстрое получение базовой функциональности (live migration, подключение SAN, кластеры HA и т.д.) благодаря наследию oVirt/Red Hat. Однако после ухода Red Hat из oVirt сообщество ослабло, и российским командам пришлось форкать код и развивать его самим.
Orion soft, например, пошла по пути создания собственного бэкенда поверх ядра oVirt, сумев сохранить совместимость, но упростив и улучшив часть функций для пользователей. Другой популярный открытый проект – Proxmox VE – тоже получил российские форки (например, «Альт Виртуализация», GloVirt), что позволяет заказчикам использовать знакомый интерфейс PVE с поддержкой отечественной компанией.
Есть и решения на базе OpenStack – эта платформа хорошо масштабируется и подходит для построения частных облаков IaaS. Так, AccentOS CE – российская облачная платформа на основе OpenStack – получила сертификат ФСТЭК осенью 2025 г. Тем не менее, OpenStack-системы (например, частное облако VK Cloud) часто критикуют за избыточную сложность для задач традиционной виртуализации и проблемы стабильности отдельных ВМ под высокими нагрузками хранения. Наконец, существуют продукты на базе Xen – в частности, Numa vServer построен на открытом гипервизоре xcp-ng (форк Citrix XenServer), что даёт вариант для тех, кто привык к Xen.
Помимо форков, на рынке появились принципиально новые разработки. К ним относятся SpaceVM, Basis Dynamix, VMmanager и др., где компании создали собственные платформы управления, опираясь на комбинацию различных open-source компонентов, но реализуя уникальные возможности. Например, SpaceVM и Basis Dynamix заявляют о полном проприетарном стеке – разработчики утверждают, что не используют готовые open-source продукты внутри, а все компоненты (гипервизор, драйверы, диспетчер ресурсов) созданы самостоятельно. Такой подход требует больше усилий, но позволяет глубже интегрировать систему с отечественными ОС и средствами кибербезопасности, а также активно внедрять API-first и DevOps-интеграции. В итоге, сегодня российский рынок виртуализации предлагает решения на любой вкус – от максимально близких к VMware аналогов на базе KVM до совершенно новых платформ с оригинальной архитектурой.
Один из ключевых вопросов для корпоративных клиентов – способен ли отечественный гипервизор обеспечить производительность и масштаб, сопоставимые с vSphere. Практика показывает, что большинство российских платформ уже поддерживают необходимые уровни масштабирования: кластеры на десятки узлов, сотни и тысячи виртуальных машин, live migration и распределение нагрузки между хостами. Например, платформа SpaceVM официально поддерживает кластеры до 96 серверов, Selectel Cloud – до 2500 узлов, Red Виртуализация – до 250 хостов в одном датацентре.
Многие разработчики вообще не указывают жестких ограничений на размер кластера, утверждая, что он линеен (ISP VMmanager протестирован на 350+ узлов, 1000+ ВМ). В реальных внедрениях обычно речь идёт о десятках серверов, что этим решениям вполне по силам. Однако из опыта миграций известны и проблемы: так, эксперты отмечают, что у zVirt иногда возникают сложности при росте кластера более 50 узлов. Первые «тревожные звоночки» появлялись уже около 20 хостов, но в новых версиях горизонтальная масштабируемость доведена до 50–60 узлов, что для большинства сред достаточно. Подобные нюансы следует учитывать при проектировании – предельно возможный масштаб у разных продуктов разнится, и при планировании очень крупных инсталляций лучше привлечь вендора или интегратора для оценки нагрузок.
По производительности виртуальных машин отечественные гипервизоры стараются минимизировать накладные расходы. Так, vStack HCP заявляет о оверхеде всего 2–5% к CPU при виртуализации, то есть близкой к нативной производительности. Это достигнуто за счёт легковесного гипервизора (базирующегося на bhyve) и оптимизированного I/O стека. Большинство других решений используют проверенные гипервизоры (KVM, Xen), у которых производительность также высока. С точки зрения нагрузки на оперативную память и хранилище – многое зависит от механизмов дедупликации, компрессии и прочих оптимизаций в конкретной реализации.
Здесь можно отметить, что многие российские платформы уже внедрили современные технологии оптимизации ресурсов: поддержка NUMA для эффективной работы с многопроцессорными узлами, возможность тонкого выделения ресурсов (thin provisioning дисков, memory ballooning) и т.д. Например, по данным рейтинга Компьютерры, Basis Dynamix и SpaceVM набрали максимальные баллы по критериям вертикальной и горизонтальной масштабируемости, а также поддержки Intel VT-x/AMD-V виртуализации, NUMA и даже GPU-passthrough. То есть функционально они не уступают VMware в возможностях задействовать современное оборудование.
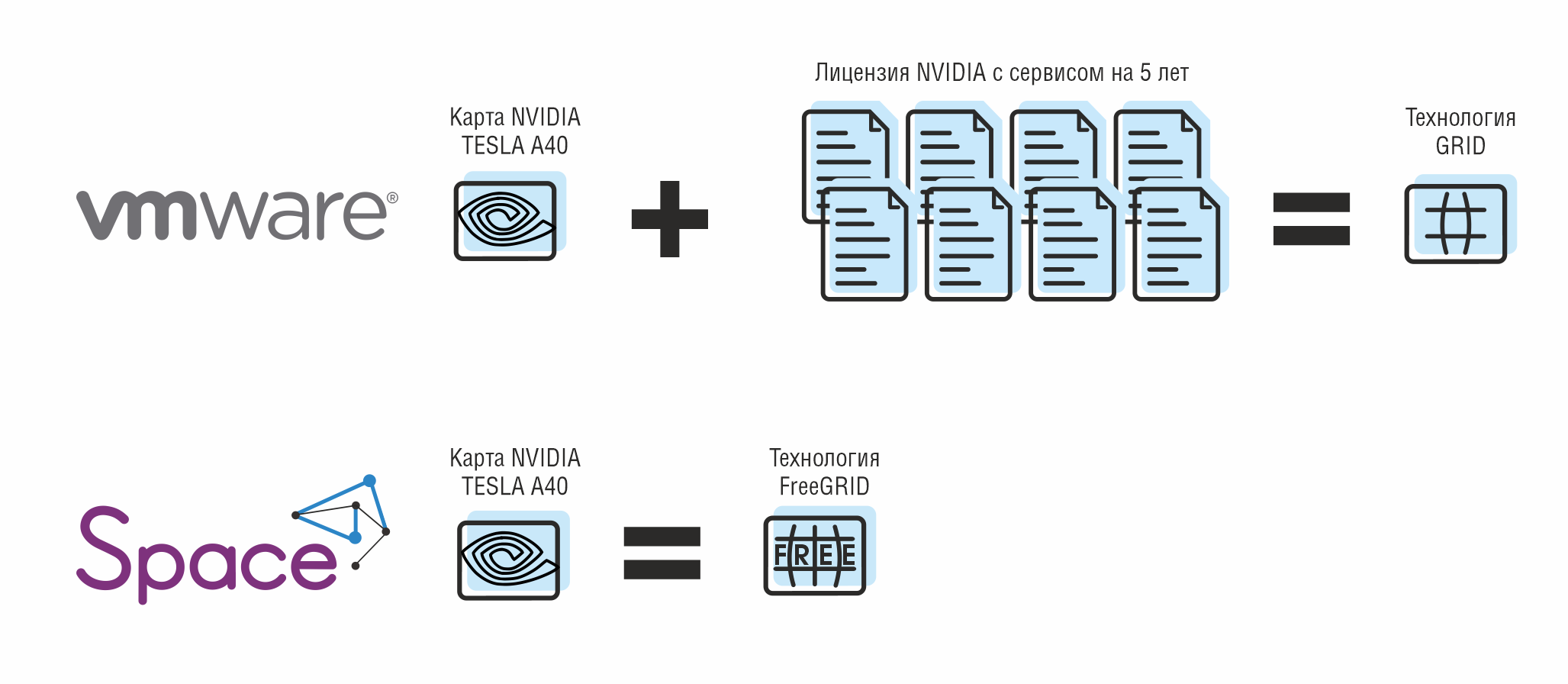
Отдельно стоит упомянуть работу с графическими нагрузками. В сфере VDI и 3D-приложений критична поддержка GPU-виртуализации. Здесь российские разработчики сделали заметный прогресс. SpaceVM изначально ориентирован на сценарии с графическими рабочими станциями: платформа поддерживает как passthrough GPU для выделения целой видеокарты ВМ, так и технологию FreeGRID – собственную разработку для виртуализации ресурсов NVIDIA-GPU без риска лицензионной блокировки.
По сути, FreeGRID выступает аналогом технологии NVIDIA vGPU (GRID), но адаптированным к ограничениям поставок – это актуально, поскольку официальные лицензии NVIDIA в России недоступны. Благодаря этому SpaceVM активно используют организации, которым нужны высокопроизводительные графические ВМ: конструкторские бюро (CAD/CAE), геоинформационные системы, видеомонтаж и др. Другие платформы также не отстают: zVirt и решения на базе oVirt умеют пробрасывать физические GPU внутрь ВМ, а HostVM и ряд VDI-платформ заявляют поддержку технологии виртуализации графических процессоров для нужд 3D-моделирования. Таким образом, в плане работы с тяжелыми графическими нагрузками отечественные продукты закрывают основные потребности.
Стоит отметить, что автоматическое распределение ресурсов и балансовка нагрузки – функции, известные в VMware как DRS (Distributed Resource Scheduler) – начинают появляться и в российских решениях. Например, zVirt реализует модуль автоматического распределения виртуальных машин по хостам, аналогичный DRS. Это значит, что платформа сама перераспределяет ВМ при изменении нагрузок, поддерживая равномерное потребление ресурсов. Кроме того, большинство продуктов поддерживают «горячую миграцию» (Live Migration) – перенос работающей ВМ между хостами без простоя, а также миграцию хранилищ на лету (Storage vMotion) – например, в zVirt есть возможность "перетаскивать" виртуальные диски между датацентрами без остановки ВМ. Эти функции критичны для обеспечения непрерывности сервисов при обслуживании оборудования или ребалансировке нагрузки.
Резюмируя, производительность российских гипервизоров уже находится на уровне, достаточном для многих корпоративных задач, а по некоторым параметрам они предлагают интересные инновации (минимальный оверхэд у vStack, поддержка GPU через FreeGRID у SpaceVM и т.п.). Тем не менее, при планировании очень нагруженных или масштабных систем следует внимательно относиться к тестированию конкретного продукта под своей нагрузкой – практика показывает, что в пилотных проектах не всегда выявляются узкие места, которые могут проявиться на продакшен-системе. Важны также оперативность вендора при оптимизации производительности и наличие у него экспертизы для помощи заказчику в тюнинге – эти аспекты мы рассмотрим в следующих статьях при сравнении опций поддержки.
Вопрос кибербезопасности и соответствия регуляторным требованиям (ФСТЭК, Закон о КИИ, ГОСТ) является определяющим для многих российских предприятий, особенно государственных и критической инфраструктуры. Отечественные решения виртуализации учитывают эти аспекты с самого начала разработки. Во-первых, практически все крупные платформы включены в Единый реестр российского ПО, что подтверждает их юридическую «отечественность» и позволяет использовать их для импортозамещения в госорганизациях. Более того, ряд продуктов прошёл добровольную сертификацию в ФСТЭК России по профильным требованиям безопасности.
Особое внимание уделяется сетевой безопасности в виртуальной среде. Одной из угроз в датацентрах является горизонтальное распространение атак между ВМ по внутренней сети. Для борьбы с этим современные платформы внедряют микросегментацию сети и распределённые виртуальные брандмауэры. Например, zVirt содержит встроенные средства SDN (Software-Defined Networking) для сегментации трафика – администратор может разделить виртуальную сеть на множество изолированных сегментов и централизованно задать политики доступа между ними. Эта функциональность, требуемая ФСТЭК для защиты виртуальных сред, реализована по умолчанию и позволяет соответствовать требованиям закона по сегментированию значимых объектов КИИ и ГосИС.
Дополнительно компания Orion soft (разработчик zVirt) рекомендует использовать совместно с гипервизором продукт vGate от компании «Код Безопасности». vGate – это межсетевой экран уровня гипервизора, который интегрируется с платформой виртуализации. Работая на уровне гипервизора, vGate перехватывает и фильтрует трафик между всеми ВМ, применяя централизованные политики безопасности. Разработчики сделали ставку на микросегментацию: каждый узел vGate хранит полный набор правил, что позволяет при миграции ВМ сразу переносить и её сетевые политики.
vGate сертифицирован ФСТЭК как межсетевой экран класса «Б» с 4-м уровнем доверия, поэтому его связка с zVirt закрывает требования регулятора для защиты виртуальных сегментов КИИ. В случае комбинированного использования, как отмечают эксперты, правила безопасности контролируются одновременно на уровне платформы (zVirt SDN) и на уровне гипервизора (vGate), дополняя друг друга. Например, если политика zVirt разрешает определённый трафик между ВМ, а политика vGate запрещает, пакет будет блокирован – то есть действует наиболее строгий из двух наборов правил. Такой «двойной заслон» повышает уверенность в защите.
Кроме сетевых экранов, встроенные механизмы безопасности практически обязательны для всех современных платформ. Российские решения включают разграничение доступа и аутентификацию корпоративного уровня: реализованы ролевые модели (RBAC), интеграция с LDAP/Active Directory для централизованного управления учетными записями, поддержка многофакторной аутентификации администраторов и журналирование действий с возможностью отправки логов на SIEM-системы. По этим пунктам разница с VMware не такая и большая – например, Basis Dynamix, SpaceVM и Red Виртуализация имеют полный набор RBAC/LDAP/2FA и получили максимально возможные оценки за безопасность в независимом рейтинге.
Дополнительно некоторые решения обеспечивают контроль целостности и доверенную загрузку (Trusted Boot) за счёт интеграции с отечественными защищёнными ОС. Например, гипервизоры могут устанавливаться поверх сертифицированных ОС (РЕД ОС, Astra Linux), что обеспечивает соответствие по требованиям НДВ (недекларированных возможностей) и использование российских криптосредств.
В контексте соответствия требованиям регуляторов важна и сертификация самих платформ виртуализации. На конец 2025 года сертифицированных по профильным требованиям ФСТЭК именно гипервизоров немного (преимущественно решения для гостевых ОС специального назначения). Однако, как отмечалось, платформы часто используют сертифицированные СЗИ «поверх» (антивирусы, СОВ, vGate и др.) для обеспечения соответствия. Кроме того, крупнейшие заказчики – госсектор, банки – проводили оценочные испытания продуктов в своих пилотных зонах. Например, при миграции в Альфа-Банке и АЛРОСА основным драйвером был закон о КИИ, и в обоих случаях итоговый выбор пал на отечественные гипервизоры (SpaceVM и zVirt соответственно) после тщательного тестирования безопасности. Таким образом, можно сказать, что российские системы виртуализации в целом готовы к работе в защищённых контурах. Они позволяют реализовать требуемую сегментацию, поддерживают российские криптоалгоритмы (при использовании соответствующих ОС и библиотек), а при правильной настройке обеспечивают изоляцию ВМ не хуже зарубежных аналогов.
Нельзя не затронуть и вопрос устойчивости к атакам и сбоям. Эксперты отмечают, что по методам защиты виртуальная инфраструктура не сильно отличается от физической – нужны регулярные обновления безопасности, сильные пароли и ограничение доступа привилегированных пользователей. Основной вектор атаки на гипервизоры в России – компрометация учётных данных администраторов, тогда как эксплойты уязвимостей встречаются гораздо реже. Это значит, что внедрение RBAC/2FA, о которых сказано выше, существенно снижает риски. Также важно строить резервное копирование на уровне приложений и данных, а не полагаться только на механизмы платформы. Как отмечают представители банковского сектора, добиться требуемого по стандартам времени восстановления (RTO) только силами гипервизора сложно – необходимо комбинировать различные уровни (репликация критичных систем, отказоустойчивые кластеры, резервные площадки). В целом же, за три года уровень зрелости безопасности российских продуктов заметно вырос: многие проблемы, ранее считавшиеся нерешаемыми, уже устранены или существуют понятные обходные пути. Производители активно учитывают требования заказчиков, внедряя наиболее востребованные функции безопасности в приоритетном порядке.
Службы VMware vSphere Kubernetes Service (VKS) версии 3.5 появились в общем доступе. Этот новый выпуск обеспечивает 24-месячную поддержку для каждой минорной версии Kubernetes, начиная с vSphere Kubernetes release (VKr) 1.34. Ранее, в июне 2025 года, VMware объявила о 24-месячной поддержке выпуска vSphere Kubernetes (VKr) 1.33. Это изменение обеспечивает командам, управляющим платформой, большую стабильность и гибкость при планировании обновлений.
VKS 3.5 также включает ряд улучшений, направленных на повышение операционной согласованности и улучшение управления жизненным циклом, включая детализированные средства конфигурации основных компонентов Kubernetes, декларативную модель управления надстройками и встроенную генерацию пакетов поддержки напрямую из интерфейса командной строки VCF CLI. Кроме того, новые защитные механизмы при обновлениях — такие как проверка PodDisruptionBudget и проверки совместимости — помогают обеспечить более безопасные и предсказуемые обновления кластеров.
В совокупности эти усовершенствования повышают надежность, операционную эффективность и качество управления Kubernetes-средами на этапе эксплуатации (Day-2) в масштабах предприятия.
Выпуск vSphere Kubernetes (VKr) 1.34
VKS 3.5 добавляет поддержку VKr 1.34. Каждая минорная версия vSphere Kubernetes теперь поддерживается в течение 24 месяцев с момента выпуска. Это снижает давление, связанное с обновлениями, стабилизирует рабочие среды и позволяет командам сосредоточиться на создании ценности, а не на постоянном планировании апгрейдов. Команды, которым нужен быстрый доступ к последним возможностям Kubernetes, могут оперативно переходить на новые версии. Те, кто предпочитает стабильную среду на длительный срок, теперь могут работать в этом режиме с уверенностью. VKS 3.5 поддерживает оба подхода к эксплуатации.
Динамическое распределение ресурсов (Dynamic Resource Allocation, DRA)
Функция DRA получила статус «стабильной» в основной ветке Kubernetes 1.34. Эта возможность позволяет администраторам централизованно классифицировать аппаратные ресурсы, такие как GPU, с помощью объекта DeviceClass. Это обеспечивает надежное и предсказуемое размещение Pod'ов на узлах с требуемым классом оборудования.
DRA повышает эффективность использования устройств, позволяя делить ресурсы между приложениями по декларативному принципу, аналогично динамическому выделению томов (Dynamic Volume Provisioning). Механизм DRA решает проблемы случайного распределения и неполного использования ресурсов. Пользователи могут выполнять точную фильтрацию, запрашивая конкретные устройства с помощью ResourceClaimsTemplates и ResourceClaims при развертывании рабочих нагрузок.
DRA также позволяет совместно использовать GPU между несколькими Pod'ами или контейнерами. Рабочие нагрузки можно настроить так, чтобы выбирать GPU-устройство с помощью Common Expression Language (CEL) и запросов ResourceSlice, что обеспечивает более эффективное использование по сравнению с count-based запросами.
Расширенные возможности конфигурации компонентов кластера Kubernetes
VKS 3.5 предоставляет гибкость для управления более чем 35 параметрами конфигурации компонентов Kubernetes, таких как kubelet, apiserver и etcd. Эти настройки позволяют командам платформ оптимизировать различные аспекты работы кластеров в соответствии с требованиями их рабочих нагрузок. Полный список доступных параметров конфигурации приведён в документации к продукту. Ниже приведён краткий обзор областей конфигурации, которые предлагает VKS 3.5:
Конфигурация
Настраиваемые компоненты
Описание
Журналирование и наблюдаемость (Logging & Observability)
Kubelet, API Server
Настройка поведения журналирования для API-сервера и kubelet, включая частоту сброса логов, формат (text/json) и уровни детализации. Управление хранением логов контейнеров с указанием максимального количества и размера файлов. Это позволяет эффективно управлять использованием диска, устранять неполадки с нужным уровнем детализации логов и интегрироваться с системами агрегирования логов с помощью структурированного JSON-журналирования.
Управление событиями (Event Management)
Kubelet
Управление генерацией событий Kubernetes с настройкой лимитов скорости создания событий (eventRecordQPS) и всплесков (eventBurst), чтобы предотвратить перегрузку API-сервера. Это позволяет контролировать частоту запросов kubelet к API-серверу, обеспечивая стабильность кластера в периоды высокой активности при сохранении видимости важных событий.
Производительность и масштабируемость (Performance & Scalability)
API Server
Управление производительностью API-сервера с помощью настройки пределов на максимальное количество одновременных изменяющих (mutating) и неизменяющих (non-mutating) запросов, а также минимальной продолжительности тайм-аута запроса. Возможность включения или отключения профилирования. Это позволяет адаптировать кластер под высоконагруженные рабочие процессы, предотвращать перегрузку API-сервера и оптимизировать отзывчивость под конкретные сценарии использования.
Конфигурации etcd
etcd
Настройка максимального размера базы данных etcd (в диапазоне 2–8 ГБ). Том создаётся с дополнительными 25 % ёмкости для учёта операций уплотнения, дефрагментации и временных всплесков использования. Это позволяет правильно подобрать объём хранилища etcd в зависимости от масштаба кластера и количества объектов, предотвращая ситуации нехватки места, которые могут перевести кластер в режим только для чтения.
Управление образами (Image Management)
Kubelet
Настройка жизненного цикла образов контейнеров, включая пороги очистки (в процентах использования диска — высокий/низкий), минимальный и максимальный возраст образов до удаления, лимиты скорости загрузки образов (registryPullQPS и registryBurst), максимальное количество параллельных загрузок и политики проверки учётных данных при загрузке. Это помогает оптимизировать использование дискового пространства узлов, контролировать потребление сетевых ресурсов, ускорять запуск Pod’ов за счёт параллельных загрузок и обеспечивать безопасность доступа к образам.
Безопасность на уровне ОС (OS-level Security)
OS
Включение защиты загрузчика GRUB паролем с использованием хэширования PBKDF2 SHA-512. Настройка обязательной повторной аутентификации при использовании sudo. Это позволяет соответствовать требованиям безопасности при загрузке системы и управлении привилегированным доступом, предотвращая несанкционированные изменения системы и обеспечивая соблюдение политик безопасности во всей инфраструктуре кластера.
Cluster API v1beta2 для улучшенного управления кластерами Kubernetes
VKS 3.5 включает Cluster API v1beta2 (CAPI v1.11.1), который вносит ряд изменений и улучшений в версии API для ресурсов по сравнению с v1beta1. Полный список улучшений можно найти в Release Notes для CAPI.
Для обеспечения плавного перехода все новые и существующие кластеры, созданные с использованием прежнего API v1beta1, будут автоматически преобразованы в API v1beta2 обновлёнными контроллерами Cluster API. В дальнейшем рекомендуется использовать API v1beta2 для управления жизненным циклом (LCM) кластеров Kubernetes.
Версия API v1beta2 является важным шагом на пути к выпуску стабильной версии v1. Основные улучшения включают:
Расширенные возможности отслеживания состояния ресурсов, обеспечивающие лучшую наблюдаемость.
Исправления на основе отзывов клиентов и инженеров с реальных внедрений.
Предотвращение сбоев обновлений из-за неверно настроенного PodDisruptionBudget
Pod Disruption Budget (PDB) — это объект Kubernetes, который помогает поддерживать доступность приложения во время плановых операций (например, обслуживания узлов, обновлений или масштабирования). Он гарантирует, что минимальное количество Pod’ов останется активным во время таких событий. Однако неправильно настроенные PDB могут блокировать обновления кластера.
VKS 3.5 вводит механизмы защиты (guardrails) для выявления ошибок конфигурации PDB, которые могут привести к зависанию обновлений или других операций жизненного цикла. Система блокирует обновление кластера, если обнаруживает, что PDB не допускает никаких прерываний.
Для повышения надёжности и успешности обновлений введено новое условие SystemChecksSucceeded в объект Cluster. Оно позволяет пользователям видеть готовность кластера к обновлению, в частности относительно конфигураций PDB.
Ключевые преимущества новой проверки:
Проактивная блокировка обновлений — система обнаруживает PDB, препятствующие выселению Pod’ов, и останавливает обновление до его начала.
Более чёткая диагностика проблем — параметр SystemChecksSucceeded устанавливается в false, если у любого PDB значение allowedDisruptions меньше или равно 0, что указывает на риск простоев.
Планирование обновлений — позволяет заранее устранить ошибки конфигурации PDB до начала обновления.
Примечание: любой PDB, не связанный с Pod’ами (например, из-за неправильного селектора), также будет иметь allowedDisruptions = 0 и, следовательно, заблокирует обновление.
Упрощённые операции: CLI, управление надстройками и инструменты поддержки
Управление надстройками (Add-On Management)
VKS 3.5 упрощает эксплуатационные операции, включая управление жизненным циклом надстроек (add-ons) и создание пакетов поддержки. Новая функция VKS Add-On Management объединяет установку, обновление и настройку стандартных пакетов, предлагая:
Единый метод для всех операций с пакетами, декларативный API и предварительные проверки совместимости.
Возможность управления стандартными пакетами VKS через Supervisor Namespace (установка, обновления, конфигурации) — доступно через VKS-M 9.0.1 или новый плагин ‘addon’ в VCF CLI.
Упрощённую установку Cluster Autoscaler с возможностью автоматического обновления при апгрейде кластера.
Управление установками и обновлениями через декларативные API (AddonInstall, AddonConfig) с помощью Argo CD или других GitOps-контроллеров. Это обеспечивает версионируемое и повторяемое развертывание надстроек с улучшенной трассируемостью и согласованностью.
Возможность настройки Addon Repository во всех кластерах VKS с помощью API AddonRepository / AddonRepositoryInstall, включая случаи с приватными регистрами.
По умолчанию встроенный репозиторий VKS Standard Package устанавливается из пакета VKS (версия v2025.10.22 для релиза VKS 3.5.0).
Во время обновлений кластеров VKS выполняет предварительные проверки совместимости надстроек и обновляет их до последних поддерживаемых версий. Если проверка не пройдена — обновление блокируется. При установке или обновлении надстроек выполняются дополнительные проверки, включая проверку на дублирование пакетов и анализ зависимостей.
Упрощённое обнаружение новых версий и метаданных совместимости для Add-on Releases.
Интегрированный сборщик пакетов поддержки (Support Bundler) в VCF CLI
VKS 3.5 включает VKS Cluster Support Bundler непосредственно в VCF CLI, что значительно упрощает процесс сбора диагностической информации о кластерах. Теперь пользователи могут собирать всю необходимую информацию с помощью команды vcf cluster support-bundle, без необходимости загружать отдельный инструмент.
Основные улучшения здесь:
Существенное уменьшение размера выходного файла.
Селективный сбор логов — только с узлов control plane, для более быстрой и точной диагностики.
Интегрированный сбор сетевых логов, что помогает анализировать сетевые проблемы и получить целостную картину состояния кластера.
С выходом VMware Cloud Foundation 9.0 произошёл переломный момент в подходе к связыванию vCenter. VCF 9 вводит принципиально новую архитектуру единого входа (Single Sign-On) для всех компонентов частного облака, устраняя необходимость в классическом ELM для объединения серверов vCenter. Фактически, в окружениях на базе VCF 9 Enhanced Linked Mode более не используется для объединения vCenter в единый домен SSO...
Diagnostics for VMware Cloud Foundation — это централизованная платформа, которая отслеживает общее состояние работы программного стека VMware Cloud Foundation (VCF). Это платформа самообслуживания, помогающая анализировать и устранять неполадки компонентов VMware Cloud Foundation, включая vCenter, ESX, vSAN, а также возможностей, таких как vSphere vMotion, снапшоты, развертывание виртуальных машин (VM provisioning), и других аспектов, включая уведомления безопасности и сертификаты. Администратор инфраструктуры может использовать диагностические данные, чтобы контролировать текущее состояние своей среды.
Диагностические результаты (Findings)
Результаты диагностики, которые ранее предоставлялись через Skyline Advisor и Skyline Health Diagnostics, теперь доступны клиентам VCF и vSphere Foundation (VVF) в рамках продукта VCF Operations. Результаты приоритизируются по:
Часто встречающимся проблемам, выявленным службой технической поддержки Broadcom.
Вопросам, поднятым в рамках анализа эскалаций (post escalation review).
В последнем релизе VCF Operations выпущено 114 новых диагностических результатов (Findings):
83 — основаны на часто встречающихся проблемах.
15 — по результатам анализа эскалаций.
14 — связаны с уязвимостями безопасности (VMSA).
2 — по запросам клиентов.
Из них:
62 результата состояния (Health Findings) — эквивалентны результатам Skyline Advisor и автоматически проверяются каждые 4 часа.
52 результата на основе логов (Log-based Findings) — эквивалентны Skyline Health Diagnostics и инициируются вручную через интерфейс конфигурации.
Эти новые находки включены в VCF Operations 9.0.1 (Release Notes). Давайте посмотрим на некоторые примеры этих результатов.
Уязвимости безопасности
В VMSA-2025-0010 описана уязвимость аутентифицированного выполнения команд в VMware vCenter Server (CVE-2025-41225) и уязвимость межсайтового скриптинга (XSS) в VMware ESXi и vCenter Server (CVE-2025-41228). Злоумышленник, обладающий привилегиями для создания или изменения тревог (alarms) и выполнения действий сценариев (script action), может воспользоваться данной уязвимостью для выполнения произвольных команд на сервере vCenter.
Злоумышленник, имеющий сетевой доступ к странице входа определённого хоста ESX или к путям URL сервера vCenter Server, может использовать эту уязвимость для кражи cookie-файлов или перенаправления пользователей на вредоносные веб-сайты. Эта уязвимость устранена в vCenter Server 8.0 Update 3e.
Анализ после эскалации (Post Escalation Review)
Техническая поддержка Broadcom внедрила процесс Post Escalation Review, в рамках которого критические обращения анализируются для предотвращения подобных инцидентов в будущем. Одним из результатов такого анализа является создание новых диагностических результатов.
Хосты ESX могут терять подключение к vCenter из-за чрезмерной скорости логирования, что приводит к потере сообщений syslog и невозможности записи сервисных логов. Часто проблема наблюдается при включении дополнительного логирования NSX, когда файл dfwpktlogs.log превышает допустимую скорость записи syslog. Однако причиной может быть и любая другая служба, создающая чрезмерный объём логов. Данный результат отображается при появлении соответствующих сообщений в vmkernel.log на хосте ESX.
На хостах ESXi 8.0.2 и 8.0.3 фиксируются предупреждения “Miss counters detected” для драйверов Mellanox с ошибкой
nmlx5_QueryNicVportContext:188 command failed: IO was aborted.
Это известная ошибка в механизме проверки состояния драйвера, при которой NIC ошибочно определяется как неисправный. Исправлено в ESX 8.0 Update 3e (драйвер nmlx5 версии 4.23.6.5).
Во время выполнения VCF Operations for Logs Query хост ESX сообщает о состоянии Permanent Device Loss (PDL). В Storage View хранилище отображается как недоступное, а адаптер сообщает об утере связи с устройством (Lost Communication). Все пути к устройству помечаются как «мертвые» (All Paths Down, APD). В результате невозможно подключиться к хосту через vSphere Client, и хост отображается как Disconnected в vCenter. Данный результат фиксируется при обнаружении соответствующих сообщений в vmkernel.log.
Главная цель команды Diagnostics — удовлетворённость клиентов. VMware стремится защитить их инфраструктуру, предоставляя результаты, основанные на опыте работы службы поддержки Broadcom, также принимаются предложения и от пользователей.
На узлах vSAN происходит PSOD (Purple Screen of Death) из-за «зависших» операций ввода-вывода после сбоя диска. Команда ввода-вывода помечается как «застрявшая», а когда она завершается, соответствующие объекты уже освобождены, что вызывает сбой. Исправлено в ESX 8.0 Update 3e.
Чтобы ознакомиться со всеми диагностическими результатами в Diagnostics for VMware Cloud Foundation, откройте Findings Catalog в разделе Diagnostics Findings интерфейса VCF Operations. Для получения актуальных обновлений подпишитесь на Diagnostics for VMware Cloud Foundation Findings KB — он обновляется при каждом выпуске нового пакета или обновлении встроенных диагностических данных.
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
PowerCLI уже давно зарекомендовал себя как надежный и широко используемый инструмент автоматизации в средах VMware. Он остаётся одним из наиболее предпочитаемых инструментов среди клиентов, и его популярность подтверждается цифрами — по оценкам, ежегодно происходит от 1,5 до 2 миллионов загрузок. Для тех, кто интересуется, эти данные можно проверить, посмотрев некоторые статистические показатели на PowerShell Gallery.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.
Как сообщалось еще в апреле, загрузки VMware Fling были перенесены в раздел бесплатных загрузок на портале поддержки Broadcom (BSP), и этот переход завершился на прошедших выходных. В дальнейшем все новые и обновленные версии VMware Flings будут публиковаться на BSP.
Чтобы получить доступ к загрузкам VMware Flings или любому другому бесплатному или предоставленному программному обеспечению Broadcom, необходимо зарегистрировать бесплатную учетную запись BSP — там допускаются и личные email-адреса (например, Gmail).
После перехода в раздел бесплатных загрузок, выберите раздел (Division) VMware и подраздел Flings:
Там вы увидите полный список бесплатных утилит для виртуальной инфраструктуры VMware vSphere / Cloud Foundation:
К сожалению, не все Flings (которые у нас можно найти по тэгу Labs) выжили, плюс не всегда актуальная версия утилиты соответствует вашей версии среды. Поискать прошлые версии этих утилит можно с помощью Wayback Machine.
В последнее время в индустрии виртуализации наблюдалась тревожная тенденция — крупнейшие игроки начали отказываться от бесплатных версий своих гипервизоров. После покупки VMware компанией Broadcom одной из первых резонансных новостей стало прекращение распространения бесплатного гипервизора VMware ESXi (ранее известного как vSphere Hypervisor). Это решение вызвало волну недовольства в сообществе, особенно среди ИТ-специалистов и малых компаний, использующих ESXi в тестовых или домашних лабораториях.
Ранее: Broadcom, завершив поглощение VMware, прекратила предоставление бесплатной версии vSphere Hypervisor. Это вызвало резкую критику и обеспокоенность среди пользователей, привыкших использовать ESXi в учебных, тестовых или малобюджетных инфраструктурах.
Теперь: В составе релиза ESXi 8.0 Update 3e появилась entry-level редакция гипервизора, которая предоставляется бесплатно, как указано в разделе "What's New" официальной документации Broadcom. Хотя точных технических ограничений этой редакции пока не раскрыто в деталях, уже ясно, что она рассчитана на начальный уровень использования и доступна без подписки.
Почему это важно?
Возвращение бесплатной версии гипервизора от Broadcom означает, что:
Независимые администраторы и энтузиасты снова могут использовать ESXi в личных или образовательных целях.
Организации с ограниченным бюджетом могут рассматривать VMware как вариант для пилотных проектов.
Broadcom, вероятно, отреагировала на давление сообщества и рынка.
Новые возможности VMware 8.0 Update 3e:
1. Поддержка протокола CDC-NCM (Communication Device Class Network Control Model) в USB-драйвере ESXi
Начиная с версии ESXi 8.0 Update 3e, USB-драйвер ESXi поддерживает протокол CDC-NCM для обеспечения совместимости с виртуальным сетевым адаптером HPE Gen12 iLO (iLO Virtual NIC) и взаимодействия с такими инструментами, как HPE Agentless Management (AMS), Integrated Smart Update Tools (iSUT), iLORest (инструмент настройки), Intelligent Provisioning, а также DPU.
2. ESXi 8.0 Update 3e добавляет поддержку технологии vSphere Quick Boot для следующих драйверов:
Intel vRAN Baseband Driver
Intel Platform Monitoring Technology Driver
Intel Data Center Graphics Driver
Драйвер серии AMD Instinct MI
Вывод
Хотя отказ от бесплатной версии ESXi вызвал разочарование и обеспокоенность, возвращение entry-level редакции в составе ESXi 8.0 Update 3e — это шаг в сторону компромисса. Broadcom, похоже, услышала голос сообщества и нашла способ вернуть гипервизор в открытый доступ, пусть и с оговорками. Теперь остаётся дождаться подробностей о лицензировании и технических возможностях этой редакции.
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Недавно было объявлено о доступности VMware vSphere Kubernetes Service (VKS) 3.3 (ранее известного как решение VMware Tanzu Kubernetes Grid (TKG) Service), а также о выпуске vSphere Kubernetes release (VKr) 1.32, ранее называвшегося Tanzu Kubernetes release. В этом выпуске представлены важные функции и улучшения, направленные на повышение безопасности, масштабируемости и управления кластерами.
Поддержка актуального релиза Kubernetes 1.32
С выпуском VKS 3.3 теперь возможно развертывание рабочих кластеров на базе VKr 1.32, основанного на последнем минорном выпуске Kubernetes 1.32. Использование последних версий Kubernetes обеспечивает безопасность, высокую производительность и совместимость с современными приложениями. vSphere Kubernetes release 1.32 обеспечивает повышение эффективности, безопасности и гибкости рабочих нагрузок.
Гибкость активации режима FIPS на уровне ОС
Данный выпуск вводит новую возможность настройки режима FIPS на уровне операционной системы, гарантируя использование только одобренных FIPS криптографических модулей. Администраторы могут самостоятельно решить, активировать ли режим FIPS для кластеров на Linux и Windows. Для активации функции необходимо настроить переменную класса кластера 'osConfiguration'. Для включения данной функции в Ubuntu-версии vSphere Kubernetes может потребоваться подписка Ubuntu Pro. Подробная информация представлена в документации.
Если ваша организация работает в регулируемой отрасли (государственные учреждения, финансы, здравоохранение и др.), соответствие стандартам FIPS необходимо для соблюдения требований безопасности и снижения рисков несоответствия.
Переход на Cluster API
Как было объявлено в документации к выпуску VKS 3.2, API TanzuKubernetesCluster будет удалён не ранее июня 2025 года. VKS 3.3 вводит упрощённый механизм миграции кластеров с TKC на Cluster API для развертывания и настройки рабочих кластеров. Переход на Cluster API обеспечивает лучшую автоматизацию и будущую совместимость. Рекомендуется заранее планировать переход на Cluster API, чтобы избежать сбоев после удаления TKC API.
Другие важные улучшения
Интеграция узлов Windows с Active Directory (поддержка gMSA) – начиная с VKS 3.3, вы можете подключать узлы Windows к локальной службе Active Directory с использованием учётных записей группового управления (Group Managed Service Accounts, gMSA) для безопасной аутентификации. Можно автоматизировать подключение узлов Windows к домену Active Directory в организационных подразделениях и добавлять их в группу безопасности, управляющую доступом к gMSA. Это упрощает интеграцию рабочих нагрузок Kubernetes на базе Windows в предприятиях, использующих Active Directory, повышая безопасность и операционную эффективность. Подробности можно найти в документации.
Автомасштабирование кластеров в обе стороны – VKS 3.3 позволяет масштабировать кластеры от нуля до любого количества рабочих узлов при использовании VKr версии 1.31.4 и новее. Ранее эта функция была недоступна со времен появления Cluster Autoscaler в vSphere 8.0 U3. Также это способствует экономии средств и оптимизации ресурсов, позволяя динамически масштабировать рабочие нагрузки до нуля в неиспользуемый период и эффективно справляться с сезонными всплесками активности.
Механизмы для упрощения обновления (Guard Rails) - обновления через несколько версий могут быть затруднены, особенно с устаревшими ресурсами. В версии VKr 1.31.1 в Antrea 2.1 некоторые CRD были объявлены устаревшими и должны быть заменены на новые версии.
Обновление до VKr 1.31.1 – перед обновлением обязательно выполнить минимальные ручные инструкции, указанные в Release Notes 1.31.1, иначе обновление может завершиться неудачно.
Обновление до VKr 1.31.4 – При обновлении до версии VKr 1.31.4 устаревшие CRD Antrea автоматически заменяются новыми версиями, поэтому ручные действия не требуются.
В VKS 3.3 встроены механизмы защиты от потенциальных ошибок при обновлении. Если рабочий кластер использует Kubernetes версии 1.30.x и обновлен до VKS 3.3, обновление до Kubernetes версии 1.31.1 заблокировано. Вместо этого рекомендуется сразу перейти на версию 1.31.4, которая не требует ручных действий. Если рабочий кластер уже на версии VKr 1.31.1, то обновление до VKS 3.3 заблокировано до предварительного обновления до VKr 1.31.4.
Заключение
vSphere Kubernetes Service 3.3 предлагает повышенную безопасность, улучшенную масштабируемость, оптимизацию расходов и усовершенствованное управление жизненным циклом кластеров для оптимизации Kubernetes-сред клиентов. О работе продукта также можно почитать вот эту полезную статью.
Недавно компания Broadcom представила защищенные адаптеры Emulex Secure Fibre Channel HBA, аппаратно шифрующие трафик между серверами и хранилищами с минимальным влиянием на производительность. Это экономичное и простое в управлении решение, которое шифрует все передаваемые данные (технология encryption data in-flight - EDIF), защищая их при перемещении между базами данных, приложениями, серверами и хранилищами...
Для тех из вас, кто пропустил релиз платформы Windows Server 2025, который состоялся 1 ноября этого года, мы сделали список новых возможностей гипервизора Hyper-V, который постепенно подтягивается к Enterprise-функционалу, но все еще остается нишевым решением. В новой ОС Hyper-V получил ряд значительных улучшений, направленных на повышение производительности, масштабируемости и гибкости виртуализации.
Итак, что нового в платформе виртуализации Hyper-V появилось с релизом Windows Server 2025:
Поддержка разделения GPU (GPU Partitioning) - теперь можно эффективно распределять вычислительные ресурсы графических процессоров между виртуальными машинами, что позволяет выполнять ресурсоемкие задачи, такие как искусственный интеллект и обработка больших данных, без необходимости выделения отдельного GPU для каждой машины. Также поддерживаются пулы GPU, позволяющие обеспечить высокую доступность виртуальных машин (HA) с использованием дискретного назначения устройств (Discrete Device Assignment, DDA) между хостами.
Живая миграция виртуальных машин с активными GPU (Live Migration) - добавлена возможность переноса виртуальных машин с задействованными GPU без прерывания их работы, что минимизирует простои при обслуживании серверов.
Увеличение максимальных ресурсов для виртуальных машин - теперь одна виртуальная машина может использовать до 240 ТБ оперативной памяти и до 2048 виртуальных процессоров, что значительно расширяет возможности для работы с большими вычислительными нагрузками.
Адаптивное управление сетевым трафиком (Adaptive Traffic Control, ATC) - введена система, которая динамически управляет трафиком между виртуальными машинами, снижая задержки и повышая пропускную способность сети.
Улучшенная поддержка виртуальных машин второго поколения (Gen 2) - в мастере создания новых виртуальных машин в Hyper-V Manager теперь по умолчанию выбирается поколение 2, что обеспечивает более высокую производительность и безопасность. Образы Azure Marketplace также работают на базе машин нового поколения.
Dynamic Processor Compatibility – позволяет использовать процессоры разных поколений и получать лучший набор функций, который поддерживается всеми из них.
Кластеры на основе сертификатов – позволяют создавать "Workgroup Clusters", которые не зависят от Active Directory (AD).
Повышенная надежность и производительность обновлений с учетом работающих в производственной среде кластеров (Cluster-aware updating).
Поддержка растянутых кластеров S2D (Storage Spaces Direct stretched cluster).
Функция Network ATC упрощает настройку сети, позволяя задавать назначение (хранение, сеть, вычисления), а Network HUD имеет функции стабилизации: может изолировать сетевой адаптер при обнаружении нестабильности или физических ошибок из-за совместного использования PCI-ресурсов.
Возможность SND multi-site обеспечивает подключение уровня L2 или L3 между физическими локациями для виртуализированных рабочих нагрузок и Kubernetes (гибридный AKS). Производительность шлюза SDN улучшена на 20-50%.
Улучшения поддержки хранилищ NVMe, с полностью переписанным слоем хранения, который обеспечивает на 90% больше IOPS на NVMe SSD. Помимо полностью переписанного хранилища, наконец, появился встроенный инициатор NVMe-oF TCP.
Улучшения Virtualization-based security (VBS) для помощи приложениям в защите их секретов за счет устранения необходимости доверять администраторам и повышения устойчивости к злонамеренным атакам.
Горячее обновление запущенного сервера (Hotpatching, требуется управление через Azure Arc) с практически мгновенным применением обновлений и без перезагрузки для физических, виртуальных и облачных серверов Windows.
Оптимизация выбора сети для живой миграции - улучшена логика определения оптимальной сети между узлами для живой миграции виртуальных машин, что ускоряет процесс и повышает его надежность.
Поддержка ARM64: Windows Server 2025 стал первой серверной операционной системой Windows с поддержкой архитектуры ARM64, расширяя возможности Hyper-V на новых аппаратных платформах.
Windows Server 2025 поддерживает множество вариантов хранения данных в корпоративной среде для таких сценариев, как запуск виртуальных машин с использованием Hyper-V. К ним относятся:
Автономный сервер с локальным хранилищем, а также NAS или SAN
Гиперконвергентная инфраструктура
Масштабируемое хранилище (scale-out storage)
Функции дедупликации и сжатия, которыми можно управлять с помощью Windows Admin Center или PowerShell. Microsoft отмечает более чем 60% сокращение объема хранения при виртуализации и резервном копировании с использованием дедупликации и сжатия. Эта технология также поддерживает работу с кластерами. Администраторы могут выбрать использование только дедупликации, только сжатия или их совместное использование, которое является конфигурацией по умолчанию. Также доступны два отдельных алгоритма сжатия, которые позволяют регулировать степень агрессивности задач сжатия.
Тонкое развертывание хранилищ (Thin Provisioning) позволяет гораздо более эффективно настраивать хранилище. Эта технология позволяет администраторам задавать размеры томов и потенциально перераспределять пространство, чтобы удовлетворять определённые требования конфигурации. Емкость может быть увеличена на лету, чтобы соответствовать изменяющимся потребностям. Благодаря более быстрому флэш-хранилищу и NVMe, тонкое развертывание теперь рекомендуется для настройки хранилища. Это позволяет выделить общее пространство, но использовать только фактически записанное место на диске.
В Windows Server 2025 теперь есть настраиваемые параметры восстановления и ресинхронизации (repair and resynchronization settings). Теперь администраторы могут точно настроить процесс восстановления, что позволяет достичь баланса между поддержанием производительности виртуальных машин и поддержанием целостности данных. Основные моменты:
Процессы восстановления и ресинхронизации могут повлиять на виртуальные машины с ограниченными ресурсами.
Используя настраиваемые параметры, администраторы могут регулировать скорость через Windows Admin Center или PowerShell.
Администраторы могут оптимизировать процесс либо для производительности виртуальных машин, либо для операции восстановления/ресинхронизации.
Windows 11 предъявляет строгие требования к аппаратному обеспечению, включая наличие устройства Trusted Platform Module (TPM) версии 2.0. Для запуска Windows 11 в виртуальной среде VMware vSphere необходимо использовать виртуальный TPM-модуль (vTPM).
В целом, установка Windows 11 ничем не отличается от установки других ОС в VMware vSphere или Workstation:
Настройка vSphere для поддержки Windows 11
Для добавления vTPM в виртуальные машины требуется настройка провайдера ключей (Key Provider). Если вы видите предупреждение, приведенное ниже, это означает, что провайдер ключей не настроен:
Microsoft Windows 11 (64-bit) requires a Virtual TPM device, which cannot be added to this virtual machine because the Sphere environment is not configured with a key provider.
На платформе vSphere в качестве провайдера ключей может быть встроенный Native Key Provider или сторонний провайдер ключей. Native Key Provider поддерживается, начиная с версии vSphere 7 Update 2. Более подробная информация о его настройке приведена тут.
Основные шаги:
1. Настройте Native Key Provider через vSphere Client, если необходимо.
2. Шифрование файлов ВМ: файлы домашней директории ВМ (память, swap, NVRAM) будут зашифрованы автоматически при использовании vTPM. Полное шифрование диска не требуется.
3. Подключение vTPM: добавьте виртуальный TPM через мастер создания ВМ (если он отсутствует) или обновите существующую ВМ.
Установка Windows 11 в виртуальной машине
Установка на vSphere 8:
1. Создайте новую виртуальную машину с совместимостью ESXi 8.0 и выше (hardware version 20).
2. Выберите Microsoft Windows 11 (64-bit) в качестве версии ОС.
3. Если отображается ошибка о необходимости настройки Key Provider, выполните настройку согласно рекомендациям выше.
4. Завершите мастер создания ВМ и установите Windows 11 как обычно.
Установка на vSphere 7:
1. Создайте новую виртуальную машину с совместимостью ESXi 6.7 U2 и выше (hardware version 15).
2. Выберите Microsoft Windows 10 (64-bit) в качестве версии ОС (Windows 11 в списке отсутствует).
3. Вручную добавьте vTPM в разделе Customize Hardware.
4. В разделе VM Options установите параметры Encrypted vMotion и Encrypted FT в значение Required (это временная мера для поддержки Windows 11).
5. Завершите мастер создания ВМ.
Помните, что для виртуальных дисков рекомендуется использовать контроллер VMware Paravirtual SCSI (PVSCSI) в целях оптимизации производительности.
Клонирование и шаблоны виртуальных машин с vTPM
Клонирование ВМ
Если вы удалите или замените устройство vTPM на виртуальной машине с Windows 11, используя функции, такие как Windows BitLocker или Windows Hello, эти функции перестанут работать, и вы можете потерять доступ к операционной системе Windows или данным, если у вас нет соответствующих вариантов восстановления.
При клонировании ВМ с vTPM с помощью vSphere Client устройство и его секреты копируются. Для соблюдения лучших практик используйте новую функцию TPM Provision Policy в vSphere 8, чтобы автоматически заменять vTPM при клонировании.
Политика TPM Provision Policy появилась в последней мажорной версии платформы - vSphere 8. Устройства vTPM могут автоматически заменяться во время операций клонирования или развёртывания. Это позволяет соблюдать лучшие практики, при которых каждая виртуальная машина содержит уникальное устройство TPM, и улучшает поддержку массового развёртывания Windows 11 в больших инсталляциях. Версия vSphere 8.0 также включает расширенную настройку vpxd.clone.tpmProvisionPolicy, которая задаёт поведение по умолчанию для клонирования, при котором устройства vTPM заменяются.
Шаблоны ВМ
1. На vSphere 8 при развёртывании из шаблона также можно настроить копирование или замену vTPM.
2. На vSphere 7 настройка vTPM выполняется вручную в процессе развёртывания из шаблона.
3. Для шаблонов в Content Library используйте формат VMTX. Формат OVF/OVA не поддерживает vTPM.
Миграция виртуальных машин Windows 11
1. Миграция ВМ с vTPM выполняется с использованием шифрования vMotion.
2. Для миграции между экземплярами vCenter требуется синхронизация Key Provider.
3. Настройте резервное копирование и восстановление Key Derivation Key (KDK) для Native Key Provider. Подробнее об этом тут:
Использование WinPE для создания шаблонов Windows 11
ВМ с vTPM не поддерживают формат OVF/OVA. Для создания шаблона можно использовать Windows Preinstallation Environment (WinPE):
1. Создайте ВМ без vTPM.
2. Сохраните её как шаблон в формате OVF/OVA.
3. После развёртывания добавьте уникальный vTPM для каждой ВМ.
Известные проблемы
1. Отсутствие опции Windows 11 при создании ВМ (KB 85665).
2. Ошибка добавления vTPM (KB 85974).
3. Проблемы с резервным копированием Native Key Provider через IP (KB 84068).
Сброс устройства TPM в Windows 11
Вы можете очистить ключи, связанные с устройством TPM, непосредственно изнутри Windows 11. Очистка TPM приведет к утрате всех созданных ключей, связанных с этим TPM, а также данных, защищённых этими ключами, таких как виртуальная смарт-карта или PIN-код для входа. При этом существующее устройство vTPM на виртуальной машине сохраняется. Убедитесь, что у вас есть резервная копия и метод восстановления любых данных, защищённых или зашифрованных с использованием TPM. Об этом написано у Microsoft вот тут.
На этот раз Дункан рассказал о работе функции Federated Storage View для платформы VMware vSAN, а также для других традиционных систем хранения данных. Это представление позволит получить визуальную информацию о емкостях и производительности хранилищ, а также наглядно отобразит конфигурацию растянутого кластера (stretched cluster).
Поскольку это визуальный инструмент, Дункан записал обзорное видео, из которого вы сможете понять, как это работает:
С момента основания VMware ее цель заключалась в том, чтобы обеспечить клиентам и партнёрам широкий выбор типов приложений и сервисов, которые они могут запускать в облачной инфраструктуре. Этот основной принцип также лежит в основе подхода к экосистеме Private AI.
Сегодня среди множества поддерживаемых коммерческих и открытых моделей и сервисов AI, клиенты теперь могут запускать Azure AI Video Indexer, поддерживаемый технологией Azure Arc, на платформе VMware Cloud Foundation на локальных серверах или в облаке Azure VMware Solution.
Клиенты и партнёры VMware просили более тесно сотрудничать с Microsoft для интеграции сервисов Azure в инфраструктуру VMware на локальных серверах. Включение Azure Video Indexer on Arc в VMware Cloud Foundation является важным первым шагом в этом направлении.
Возможности VMware Private AI и Azure Video Indexer
VMware Private AI представляет собой архитектурный подход, позволяющий предприятиям использовать потенциал генеративного AI, сохраняя при этом конфиденциальность данных, контроль и соответствие нормативным требованиям. Этот подход позволяет организациям запускать сервисы AI там, где они работают.
Azure Video Indexer — это сервис видеоаналитики в облаке и на периферии, использующий AI для извлечения полезных данных из аудио- и видеофайлов. При развертывании в виде расширения Arc на Kubernetes-кластерах он предоставляет мощные возможности видеоанализа для локальных сред.
Зачем интегрировать VMware Private AI с Azure Video Indexer on Arc?
Интеграция этих двух технологий даёт несколько важных преимуществ:
Конфиденциальность данных и контроль: обработка чувствительного видеоконтента на локальных серверах при сохранении полного контроля над данными.
Экономичность: использование существующей инфраструктуры VMware для AI-нагрузок, что потенциально снижает затраты на облако.
Улучшенное обнаружение контента: возможность поиска с автоматическим извлечением метаданных из видеоконтента.
Интеллектуальная оптимизация инфраструктуры: динамическое объединение и распределение ресурсов AI, включая вычислительные мощности, сеть и данные.
Соответствие требованиям: соблюдение регуляторных требований с размещением данных и средств их обработки в контролируемой среде.
Упрощённое управление: управление как инфраструктурой, так и AI-нагрузками через привычные инструменты VMware.
Примеры использования
Существует ряд примеров, в которых можно получить дополнительную ценность, запуская этот сервис на периферийных сайтах или внутри собственных центров обработки данных, включая такие возможности, как:
Локализация: быстро добавляйте локализацию в видеоконтент и обучающие материалы для внутренних пользователей или клиентов из разных географических регионов.
Предварительная фильтрация и локальные предсказания: снижайте нагрузку на WAN-сети, локализуя обработку AI/ML, что особенно ценно для приложений сегмента computer vision.
Медиа и развлечения: анализируйте и размечайте большие видеотеки, улучшая возможность обнаружения контента и повышая вовлечённость пользователей. Локальное развертывание обеспечивает защиту авторских прав и конфиденциальных данных.
Корпоративное обучение: крупные предприятия могут использовать эту интеграцию для автоматической индексации и анализа обучающих видеоматериалов, делая их более доступными и удобными для поиска сотрудниками, сохраняя при этом конфиденциальную информацию внутри инфраструктуры компании.
Интеграция VMware Private AI с Azure Video Indexer on Arc, работающего на кластерах Tanzu Kubernetes внутри VCF, представляет собой отличное решение для организаций, стремящихся использовать AI для анализа видео, сохраняя контроль над данными и инфраструктурой. Эта комбинация предлагает улучшенную конфиденциальность, масштабируемость и производительность, открывая новые возможности для AI-инсайтов в различных отраслях.
На конференции VMware Explore 2024, вместе с презентацией новой версии платформы VMware Cloud Foundation 9, Broadcom также объявила о планах разработки следующего поколения VMware vSphere Virtual Volumes (vVols). Следующее поколение vVols будет преследовать три основные цели: обеспечить согласованный и оптимизированный пользовательский опыт на разных платформах хранения, адаптировать vVols для современных масштабируемых задач, таких как рабочие нагрузки AI/ML и развёртывания облачных провайдеров, а также полностью интегрироваться с VMware Cloud Foundation (VCF).
vVols использует управление на основе политик хранилищ (Storage Policy-Based Management, SPBM) для оптимизации операций и минимизации потребности в специализированных навыках для работы с инфраструктурой хранения. vVols устраняет необходимость в ручном предоставлении хранилища, заменяя это описательными политиками на уровне ВМ или VMDK, которые могут быть применены или обновлены через простой рабочий процесс.
Клиенты продолжают активно внедрять VMware Cloud Foundation, и они хотят интегрировать свои существующие решения для хранения в VCF, чтобы максимизировать свою отдачу от инвестиций. Они стремятся начать путь к полностью программно-определяемому подходу к инфраструктуре, упрощая операции хранения и интегрируясь с облачными возможностями управления, встроенными в частную облачную платформу VCF. По мере того, как клиенты запускают всё больше рабочих нагрузок на массивы, поддерживающие vVols, требования к производительности, масштабу и защите данных продолжают расти, поэтому vVols должен развиваться, чтобы удовлетворять эти потребности.
Планируемые преимущества следующего поколения vVols для клиентов включают:
Полная интеграция с VMware Cloud Foundation: установка, развертывание и управление хранилищем с VCF, пригодность для использования в качестве основного и дополнительного хранилища для всех доменов рабочих нагрузок.
Прописанная модель VASA для обеспечения согласованного и оптимизированного пользовательского опыта на всех платформах хранения.
Поддержка масштабируемых сценариев использования для облаков.
Обеспечение высокой доступности и развертывания с растянутыми кластерами.
Бесшовная миграция с платформы vVols без простоев.
Масштабируемые, неизменяемые снимки (immutable snapshots) как для традиционных, так и для современных приложений.
Для получения дополнительной информации о планируемых нововведениях vSAN и vVols рекомендуем посмотреть записи вот этих сессий VMware Explore 2024:
VMware’s Vision for Storage and Data Protection in VMware Cloud Foundation [VCFB2086LV]
What’s New with vSAN and Storage Operations in VMware Cloud Foundation [VCFB2085LV]
vVols and Stretched Clusters with Pure Storage and VMware [VCFB2397LVS]
Workload Provisioning And Protection Made Easy With VMware And NetApp [VCFB2433LVS]
Недавно мы писали о новых возможностях продукта VMware NSX 4.2, который стал доступен одновременно с релизом платформы VMware Cloud Foundation 5.2. В состав этого комплексного решения также вошло и средство VMware Aria Operations 8.18 для управления и мониторинга виртуального датацентра. Напомним также, что о версии Aria Operations 8.16 мы писали вот тут.
Удаленные коллекторы
VMware Aria Operations 8.14 был последним релизом, поддерживающим удаленные коллекторы. В версиях 8.16 и позднее обновления невозможны при наличии удаленных коллекторов. Для обновления необходимо заменить все удаленные коллекторы на облачные прокси. Это изменение улучшит сбор данных и упростит управление.
Устаревание XML в REST API
В следующем крупном релизе VMware Aria Operations поддержка XML в новых API и новых функциях существующих API будет прекращена. Для обмена данными рекомендуется использовать JSON, хотя текущие API продолжат поддерживать XML.
Поддержка облачных платформ и новых интеграций
Поддержка интеграций с облачными платформами Amazon Web Services, Microsoft Azure, Oracle Cloud VMware Solution и Google Cloud Platform будет доступна только через Marketplace. Важно обновить адаптер Google Cloud Platform до версии 8.18 сразу после обновления кластера, чтобы избежать потери данных.
Улучшенная навигация и управление
Введено новое меню навигации, ориентированное на выполнение задач, и средства для управления стеком VMware Cloud Foundation, включая обновление сертификатов, контроль конфигураций и диагностику. На вкладке Overview на главной странице представлены возможности управления и мониторинга VMware Cloud Foundation.
Диагностика и мониторинг
Теперь можно получать информацию о известных проблемах, влияющих на программное обеспечение VMware, и следить за состоянием ключевых случаев использования VMware Cloud Foundation, таких как vMotion, Snapshots и Workload Provisioning. Введены новые функции для контроля и устранения отклонений конфигураций vCenter.
Единый вход и управление лицензиями
Поддержка единого входа (SSO) для VMware vSphere Foundation с возможностью импорта пользователей и групп из провайдера SSO. Управление лицензиями VMware Cloud Foundation и VMware vSphere Foundation теперь доступно в VMware Aria Operations.
Управление сертификатами
Появилось централизованное управление сертификатами для всех компонентов VMware Cloud Foundation. Также есть и возможность мониторинга и получения информации о сертификатах инфраструктуры VMware Cloud Foundation.
Улучшение пользовательского опыта и отчетности
Обновленный опыт работы с инвентарем и виджетами, поддержка просмотра объектов с предками и потомками, возможность фильтрации по возрасту объектов и определениям предупреждений. Возможность добавления до пяти панелей инструментов на главную страницу и их упорядочивания.
Снижение шума предупреждений и улучшение панели инструментов
Введение 20-секундной пиковой метрики, что позволяет получить более четкую видимость данных и уменьшить шум предупреждений. Обновленные панели инструментов, такие как панель изменений VM и панель производительности кластеров, обеспечивают лучшую видимость и взаимодействие.
Управление емкостью и стоимостью
Возможность переопределения метрик для расчета емкости и получения рекомендаций по оптимизации ресурсов. Управление затратами на лицензии VMware по ядрам, а также доступность метрик затрат для проектов и развертываний VMware Aria Automation.
Миграция Telegraf и усиление безопасности
Поддержка сохранения конфигурации плагинов Telegraf при переустановке и усиление безопасности за счет ограничения входящих сетевых подключений и предотвращения несанкционированного доступа.
Улучшения для vSAN и отчеты о соответствии
Поддержка кластера vSAN Max и улучшения виджетов для отображения информации о предках и потомках объектов. Обновления пакетов соответствия для CIS и DISA, поддержка новых версий ESXI и vSphere.
Эти новые возможности и улучшения делают VMware Aria Operations 8.18 более мощным и удобным инструментом для управления виртуальной инфраструктурой, повышая эффективность и безопасность работы с облачными и локальными ресурсами.
Подробнее обо всем этом вы можете почитать в Release Notes.
На днях компания VMware в составе Broadcom выпустила очередной пакет обновлений своей флагманской платформы виртуализации - VMware vSphere 8.0 Update 3. vSphere 8 Update 3 улучшает управление жизненным циклом, безопасность и производительность, включая поддержку двойных DPU и улучшенную настройку виртуального оборудования.
Консоль Workspace ONE UEM включает различные способы развертывания приложений Win32. Рекомендуемыми методами являются механизм развертывания программного обеспечения (Windows Desktop Software Deployment) и оркестратор для последовательной установки. Метод Product Provisioning, хотя и поддерживается, считается устаревшим для настольных ПК Windows.
Установщики Win32 имеют разные требования в зависимости от типа установки, необходимой для программного обеспечения. Они могут требовать или не требовать административного доступа и могут изменять свое поведение в зависимости от контекста установки. Для эффективного развертывания важно понимать, как работает установщик. Также вы можете самостоятельно перепаковать приложение.
Workspace ONE может устанавливать приложения в системном контексте и в контексте пользователя. Он может устанавливать пользовательские приложения от имени обычного пользователя, если соответствующие права администратора выбраны в параметрах развертывания.
Данное руководство предназначено для ИТ-специалистов и администраторов Workspace ONE в существующих производственных средах. Также будет полезен опыт управления устройствами Windows.
На настольных ПК с Microsoft Windows установщик может запускаться в системном контексте или в контексте пользователя.
Контекст установки:
Device: Команда установки выполняется как System.
User: Команда установки выполняется как User, при необходимости позволяя отображать интерфейс пользователю.
Контекст установки может влиять на поведение установщика. Некоторые установщики могут потребовать ответа на вопрос, предназначена ли установка для всех пользователей или только для текущего пользователя, и в зависимости от ответа установка будет происходить в другом месте.
Если приложение установлено пользователем, но установщик размещает бинарные файлы и ярлыки в папке для всех пользователей/Program Files, то приложение будет доступно другим пользователям. Это важно учитывать в сценарии с несколькими пользователями.
Контекст System
Системный контекст — это контекст, в котором работает операционная система, обладающая полными правами на устройстве. Он не имеет информации о пользователях, не может отображать информацию пользователю в графическом интерфейсе и не имеет доступа к HKCU.
Команда установки унаследует системные права на устройстве, что позволит ей получить доступ к ресурсам с использованием учетной записи "NT AUTHORITY\SYSTEM". Любая попытка доступа к папке или ключу реестра будет оцениваться в соответствии с этой учетной записью и списком управления доступом (ACL), установленным на объекте.
Контекст User
В пользовательском контексте команда установки запускается под учетной записью пользователя, что позволяет отображать интерфейс пользователю и получать доступ к информации и файлам пользователя. Уровень доступа к операционной системе и файлам будет зависеть от прав доступа пользователя.
Если пользователь является обычным, и приложению требуются права, превышающие его права, а административные привилегии не выбраны, установка приложения завершится неудачей из-за отказа в доступе.
В зависимости от требований установщика может потребоваться понимание того, как UAC может повлиять на развертывание приложения.
Как UAC влияет на развертывание приложений
Контроль учетных записей (User Account Control, UAC) — это функция безопасности операционной системы Microsoft Windows. Она основана на принципе, что пользователь или устройство должны иметь возможность вносить определенные изменения в конфигурацию или файлы в операционной системе без дополнительных привилегий, если это не может потенциально повлиять на стабильность или безопасность ОС. В таких случаях требуются административные права, также известные как супер-токены (super tokens).
Супер-токен необходим для изменения защищенных папок, драйверов, системных настроек и прочего. Например, изменение времени требует административных привилегий, так как это может повлиять на системы безопасности.
Защищенные папки включают следующие:
\Program Files\ с подкаталогами
\Windows\system32\
\Program Files (x86)\ с подкаталогами для 64-битных версий Microsoft Windows
Оценка необходимости административных прав
Теперь, когда мы рассмотрели, как Windows реагирует в плане доступа, наш следующий шаг — проанализировать приложение, чтобы определить, будут ли необходимы права администратора.
Как правило, приложения устанавливаются в каталог "Program Files", так как это место по умолчанию. Однако многие приложения могут быть установлены в других местах. Это верно для приложений в пользовательском контексте, которые могут потребовать установки исключительно в области пользователя (т.е. в папке пользователя).
Для установок, связанных с изменением системных настроек или установкой драйверов, требуются права администратора для внесения изменений в важные папки и настройки, так как этого потребует UAC.
Важно четко понимать действия и местоположения установщика, чтобы определить, требуются ли административные права.
Ниже представлена блок-схема, показывающая, требуются ли административные права:
Поведение установки приложений Win32 с использованием ресурсов
Единственный случай, когда установка не работает, это если пользователь является обычным пользователем, а установщику требуются административные привилегии.
Поведение установки приложений Win32 с использованием Product Provisioning
Рекомендуется развертывать приложения Win32 через ресурсы (Resources). Однако, если вы пробовали развертывать приложение через ресурсы, и это вас не устроило, в качестве альтернативного метода вы можете завершить развертывание на своих устройствах с помощью Product Provisioning.
Если вы настраиваете приложения Win32 с использованием Product Provisioning, вы можете воспользоваться следующей таблицей, чтобы понять комбинации установки и запуска манифеста и контекста команды. Вы можете выбрать установку или запуск на системном уровне, уровне пользователя или уровне учетной записи администратора. В зависимости от выбранных параметров ваша установка может различаться.
Обратитесь к таблице, чтобы понять поведение установки приложений Win32 с использованием предоставления продуктов.
Перейдите в раздел Devices > Provisioning > Components > Files/Actions и выберите Add Files/Actions, перейдите на вкладку Manifest и установите Action(s) To Perform = Install/ Run.
Предложения для параметров Retry Count, Retry Interval, Install Timeout для ваших приложений Win32
Значения параметров "Retry Count", "Retry Interval" и "Install Timeout" для приложений Win32 влияют на время, которое система затрачивает на сообщение о неудачном процессе установки. Вы можете изменить значения по умолчанию, чтобы сократить время развертывания.
Значения по умолчанию для этих параметров:
Retry Count — 3 раза
Retry Interval — 5 минут
Install Timeout — 60 минут
работают в следующей последовательности для одного неудачного процесса установки:
Через 3 часа и 15 минут система однократно сообщает о неудачной установке приложения. Затем система устанавливает следующее приложение.
Настройка параметров в зависимости от приложения
Настройте значения, соответствующие приложению.
Пример быстрой установки
Браузерное приложение устанавливается на устройство за четыре минуты. Рассмотрите возможность установки следующих значений для этого приложения:
Retry Count — 2 раза
Retry Interval — 5 минут
Install Timeout — 5 минут
Система сообщает о сбое этого приложения в течение 20 минут. Затем она устанавливает следующее приложение.
Пример медленной установки
Крупное приложение для повышения производительности устанавливается на устройство за 30 минут. Рассмотрите следующие значения для этого приложения:
Retry Count — 3 раза
Retry Interval — 5 минут
Install Timeout — 35 минут
Система может сообщить о сбое этого приложения в течение 120 минут. Затем она устанавливает следующее приложение.
Предложения для параметра Device Restart для ваших приложений Win32
Значения для перезагрузки устройства для приложений Win32 позволяют пользователю отложить перезагрузку устройства и установить крайний срок, до которого пользователь может откладывать перезагрузку. Эти значения позволяют администраторам и конечным пользователям иметь больший контроль над перезагрузками, чтобы предотвратить потерю работы пользователем.
Администраторы могут выбрать принудительную перезагрузку ПК после установки приложения или позволить пользователю отложить перезагрузку на более удобное время.
Перезагрузка устройства помогает настроить следующие параметры:
Предупредить пользователя перед перезагрузкой устройства, чтобы он мог сохранить свои файлы и закрыть приложения.
Предупредить пользователя, когда требуется перезагрузка устройства.
Позволить пользователю отложить перезагрузку устройства и перезапустить его в удобное время.
Workspace ONE Intelligent Hub отображает уведомления о перезагрузке устройства на различных этапах. Уведомление об откладывании позволяет пользователю перезагрузить или отложить перезагрузку. Workspace ONE Intelligent Hub обновляет данные о перезагрузке для откладывания или перезагрузки и показывает это уведомление в соответствии с временем, выбранным пользователем.
Следующая таблица показывает уведомления, отображаемые на различных этапах:
Во время установки приложения
Уведомляет пользователя о необходимости сохранить файлы и закрыть приложение.
После установки приложения
Отображает первое уведомление и сообщает пользователю о перезагрузке системы.
За 48 часов до крайнего срока перезагрузки
Отображает второе уведомление и предупреждает пользователя о принудительной перезагрузке.
За 15 минут до крайнего срока перезагрузки
Отображает третье уведомление и предупреждает пользователя о принудительной перезагрузке.
За 5 минут до крайнего срока перезагрузки
Отображает системные подсказки, указывающие дату и время запланированной принудительной перезагрузки.
p>22 ноября 2023 года Broadcom завершила приобретение VMware. В рамках этого приобретения Broadcom организовала подразделение End-User Computing (EUC), которое разрабатывает и поддерживает решения Workspace ONE и Horizon, как независимое бизнес-подразделение в составе Broadcom. Также в компании сообщили о намерении продать EUC сторонней организации.
26 февраля 2024 года Шанкар Иер, генеральный директор EUC, объявил, что глобальная инвестиционная компания KKR заключила окончательное соглашение о покупке подразделения EUC у Broadcom.
Точные сроки закрытия сделки будут определены в ближайшие недели, но есть несколько важных моментов, на которые следует обратить внимание:
EUC будет функционировать как независимая компания с долговременным обязательством предоставлять клиентам продукты и услуги высокого класса.
KKR поддержит EUC долгосрочными инвестициями для повышения удовлетворенности клиентов и поддержки партнеров.
И EUC, и KKR опубликовали общедоступные заявления, которые можно найти здесь: сообщение EUC и сообщение KKR.
Workspace ONE и Horizon будут продолжать предоставлять варианты развертывания для государственного сектора в облачных решениях FedRAMP
EUC и Broadcom полностью привержены поддержанию непрерывного клиентского опыта услуг FedRAMP. Отделение систем FedRAMP Workspace ONE и Horizon от границы авторизации FedRAMP VMware будет осуществляться тщательно спланированным образом. Этот процесс будет продолжаться после официальной даты закрытия сделки с KKR, но обязательства по этому процессу были формально зафиксированы в договорных документах, определяющих взаимные обязательства сторон для достижения желаемого конечного состояния.
В конечном итоге, Workspace ONE будет продолжать функционировать в рамках авторизации FedRAMP VMware до завершения действий по разделению, и EUC получит независимую авторизацию FedRAMP. Horizon будет продолжать предоставлять частные или суверенные облачные решения для соответствия требованиям, включая варианты, размещенные в FedRAMP. Главные приоритеты VMware на протяжении этого перехода - постоянное внимание к безопасности систем Workspace ONE и Horizon, непрерывное поддержание статуса авторизации FedRAMP и непрерывная операционная поддержка наших клиентов. Подробнее об этом рассказано тут.
В мае 2022 года компания Broadcom объявила о приобретении компании VMware за 61 миллиард долларов, что стало новым этапом в развитии главного вендора в сфере виртуализации. Данное поглощение стало вторым по цене за 2022 год — еще большую цену предложили только за игровой гигант Activision Blizzard, который приобрела корпорация Microsoft за $68,7 млрд. Согласно договорённости, акционеры VMware получили премию...
Недавно было объявлено о том, что Broadcom завершила процедуры по приобретению VMware и полной интеграции этого вендора в свое портфолио. В связи с этим пару дней назад Krish Prasad, занимающий позицию Senior Vice President and General Manager в подразделении VMware Cloud Foundation Division, рассказал о том, как изменится продуктовая линейка VMware. Главная новость - все станет намного проще, чего так долго ждали клиенты. А кое-что станет и в 2 раза дешевле!
Основные новые моменты тут следующие:
Впредь будут доступны только два основных стандартных предложения: vSphere Foundation и VMware Cloud Foundation (VCF).
Прекращение продажи бессрочных лицензий и продления подписки Support and Subscription (SnS).
Лицензия Bring-your-own-subscription license (BYOL), которая обеспечивает переносимость онпремизных лицензий в гибридные облака, проверенные VMware и работающие на основе VMware Cloud Foundation.
Основной версией vSphere, используемой теперь, будет "vSphere Foundation".
Новый продукт VMware vSphere Foundation предлагает более упрощенную платформу для работы с корпоративными приложениями для клиентов среднего и небольшого размера. Это решение интегрирует vSphere с решениями для интеллектуального управления операциями, обеспечивая лучшую производительность, доступность и эффективность с большей видимостью и пониманием процессов.
Другими словами, начиная с декабря этого года, клиенты vSphere получают Aria Operations (ранее известный как vRealize Operations) и Aria Operations for Logs (ранее известный как vRealize Log Insight) вместе с vSphere (в который включены vCenter и Tanzu Kubernetes Grid).
Теперь издания VMware vSphere будут выглядеть так:
Существующие клиенты VCF или будущие большие клиенты vSphere Foundation будут переходить на новый VMware Cloud Foundation, который теперь можно считать полноценным решением для управления частным и гибридным облачным стеком.
VMware Cloud Foundation — это флагманское решение гибридного облака Enterprise-уровня, позволяющее клиентам безопасно, надежно и экономно управлять критически важными и современными приложениями. Чтобы больше клиентов могли воспользоваться этим решением, стоимость подписки была уменьшена вдвое, а также были добавлены более высокие уровни поддержки, включая расширенную поддержку для первоначальной активации решения и управления жизненным циклом.
Очень важно, если вы пропустили это в разделе выше: теперь vSphere Foundation будет включать только NSX for network virtualization (overlay), без возможностей микросегментации или распределенной брандмауэрной защиты (distributed firewalling, DFW). Другими словами, клиентам, которым нужны возможности DFW NSX (дополнение к сетевому экрану VMware), сначала нужна подписка на VCF, в которую входит NSX.
Обратите внимание, что в настоящее время все новые пакеты лицензий предоставляются в "disconnected" режиме (то есть без подключения к VMware Cloud).
Решения VMware Cloud on AWS, VMware Cloud on Azure и другие будут также включаться в инфраструктуру лицензирования VCF. Продукт VMware vSAN Enterprise теперь будет лицензироваться по числу TiB (аналог терабайтов) на заданное число ядер хостов ESXi.
Информацию об аддонах для VCF вы можете увидеть в первой картинке этой статьи - они точно такие же.
За более подробной информацией о новых изданиях платформы VMware vSphere вы можете обратиться к этой статье.
Сегодня мы поговорим о новой функциональности релиза 2306 (первые две цифры - это год, а оставшиеся - месяц релиза). Давайте посмотрим, что теперь нового в Horizon 8:
1. Гранулированные привилегии RBAC для клиентов, подключенных к облаку
В версиях Horizon 8 до 2306 для доступа к службам управления и мониторинга развертываний Horizon суперадминам требовалось активировать свою SaaS-подписку через Horizon Control Plane. Теперь, начиная с Horizon 2306, появились более детализированные привилегии на основе ролевого управления доступом (RBAC), которые позволяют суперадмину предоставлять гранулированные привилегии не-суперадминам, позволяя им активировать и управлять лицензиями, а также мониторить среду Horizon. Применяя специфические привилегии для админов, эта функция исключает необходимость ролей суперадмина для рутинных задач, при этом обеспечивая более строгую безопасность и гарантируя, что значительные изменения могут вносить только авторизованные сотрудники.
2. Блокировка подключения конечного пользователя, если нет проверки сертификата
Безопасность всегда на первом месте в разработке Horizon. С этой целью мы ввели новый механизм, который может обеспечивать проверку сертификата сервера. Как только настройка сконфигурирована, когда запрос конечного пользователя к десктопу или приложению доходит до connection server, запрос будет иметь уже настроенные параметры клиента, а не настройки, сконфигурированные администратором на сервере.
Управление соединениями определяется на основе конфигурации. Теперь есть три потенциальных действия — «Применить», «Предупредить» и «Игнорировать» — которые администраторы могут использовать для обеспечения более строгих политик проверки сертификатов:
Применить (Enforce): Обязательная проверка сертификата. Если он недействителен, соединение разрывается.
Предупредить (Warn): Пользователь получает предупреждение, ему разрешено подключиться, и событие регистрируется.
Игнорировать (Ignore): Проверка сертификата выполняется, но создается только запись в журнале без уведомления пользователя.
Эта функция обеспечивает баланс между удобством использования и безопасностью, давая администраторам гибкость в определении строгости своего процесса аутентификации.
3. Фиксированный таймер для отмены учетных данных SSO, усиливающий безопасность
Клиенты могут установить фиксированный таймер для отмены учетных данных единого входа (SSO), чтобы гарантировать, что после определенного времени потребуется повторная аутентификация, что дополнительно усиливает безопасность. Администраторы могут устанавливать время сессии для конечных пользователей и гарантировать, что они проходят повторную аутентификацию при запуске новых сессий виртуальных рабочих столов или опубликованных приложений.
4. Настройка сопоставлений сертификатов из консоли
Для тех клиентов, которые используют аутентификацию на основе сертификата, такую как смарт-карты, обновление безопасности Microsoft (KB5014754) запретит слабые сопоставления сертификатов, такие как имя пользователя и электронная почта. Horizon 2306 позволяет настраивать сопоставления сертификатов из консоли Horizon. Эта функция предоставляет три варианта на выбор:
SID, который считается самым надежным и рекомендуется
Пользовательская альтернативная безопасная идентичность, такая как x509serialnumber, x509SKI.
Устаревший вариант, для клиентов, которые не применяли обновление безопасности и продолжают использовать существующие смарт-карты.
5. Режим Instant Clone Smart Provisioning по умолчанию
Теперь Instant Clone Smart Provisioning по умолчанию использует режим Mode B (ВМ создается без родительской ВМ). Режим Mode B совместим со всеми рабочими процессами, такими как vTPM и vGPU. Режим Mode A (ВМ создается с родительской ВМ) выбирается только при использовании устройства vTPM на версии хоста ESXi ранее чем 7.0 обновление 3f. Вы все равно сможете изменить режим предоставления, но делать этого не рекомендуется.
6. Улучшение с авто-отладкой для мгновенных клонов
Автоматический режим отладки позволяет администраторам сохранять внутренние шаблоны ВМ для отладки в случае ошибок при развертывании. Ранее администраторам приходилось устанавливать параметр конфигурации для золотого образа в vCenter, чтобы включить этот режим. С этой функцией администраторы могут включать режим отладки из консоли, который применяется ко всем пулам мгновенных клонов (Instant Clones) в vCenter. Когда режим включен, внутренние шаблоны ВМ сохраняются в отдельной папке в vCenter, и эти ВМ автоматически удаляются, когда этот режим выключен. Рекомендуется включить настройку "Stop Provisioning on Error", чтобы развертывание останавливалось при первой ошибке, и эту конкретную ошибку можно было идентифицировать и отладить.
7. Постоянные диски для мгновенных клонов
Horizon 2306 вновь представляет persistent-диски для выделенных (dedicated) мгновенных клонов, предназначенные для клиентов, которые все еще их используют в Horizon 7. Эта новая функция предоставляет путь миграции для клиентов, которые не могут обновиться до Horizon 8 из-за постоянных дисков. Для получения дополнительной информации о миграции прочтите документ "Руководство по миграции для перехода с Horizon 7.X на Horizon 8".
8. Распределение сессий в архитектуре Cloud Pod
Чтобы помочь архитектуре Cloud Pod Architecture (CPA) равномерно распределять сессии пользователей по ресурсам в рамках глобального назначения, релиз 2306 вводит "Политику распределения нагрузки сессий" (Session Load Distribution Policy). Эта новая настройка позволяет администраторам выбирать методику подсчета сессий для установки политики распределения нагрузки сессий на основе глобального индивидуального назначения. С ее помощью CPA будет справедливо распределять входящие запросы сессий по ресурсам на основе подсчета сессий в отношении к емкости, обеспечивая более сбалансированное распределение по доступным ресурсам. Например, если глобальный entitlement имеет два пула рабочих столов, каждый с емкостью 100 рабочих столов, сессии будут равномерно распределяться по пулам для лучшей производительности рабочих столов и приложений.
Полную информацию обо всех нововведениях и улучшениях Horizon 8 релиз 2306 можно получить из Release Notes. Скачать компоненты решения можно по этой ссылке.
В этом случае необходимо, чтобы диски ВМ находились в режиме multi-writer, то есть позволяли производить запись в файл VMDK одновременно с нескольких хостов ESXi (можно также организовать и запись от нескольких ВМ на одном хосте). Этот режим со стороны VMware поддерживается только для некоторых кластерных решений, таких как Oracle RAC, и для технологии Fault Tolerance, у которой техника vLockstep требует одновременного доступа к диску с обоих хостов ESXi.
В статье, на которую мы сослались выше, хоть и неявно, но было указано, что режим "Multi-writer" используется и для кластеров Microsoft Windows Server Failover Clustering (WSFC, ранее они назывались Microsoft Cluster Service, MSCS), однако это была неверная информация - он никогда не поддерживался для кластеров Microsoft.
Мало того, использовать режим "Multi-writer" для WSFC не только не рекомендуется, но и опасно - это может привести к потере данных. Кроме того, возможности поддержки VMware в этом случае будут очень ограничены.
Информация о поддержке "Multi-writer" и общих дисков VMDK
Использование файлов VMDK в качестве общих дисков для виртуальных машин Windows в среде vSphere возможно, но только когда файлы VMDK хранятся в кластеризованном хранилище данных с включенной поддержкой Clustered VMDK, как описано в статье Clustered VMDK support for WSFC, или ниже в этой статье.
Сначала предупреждения и предостережения - прежде чем предпринимать любые из описанных в этой статье шагов, администратору очень важно понять и принять, что VMware не гарантирует, что эти конфигурации не приведут к потере данных или их повреждению.
Итак, какие варианты предлагает VMware, если вы уже используете кластеры WSFC в режиме multi-writer:
Переконфигурирование общих дисков на основе файлов VMDK для кластеризованных виртуальных машин Windows, которые были настроены с использованием опции флага multi-writer.
Перемещение файлов VMDK в одно или несколько официально поддерживаемых хранилищ данных с поддержкой Clustered VMDK.
Представление файлов VMDK обратно виртуальным машинам таким образом, чтобы минимизировать или избежать необходимости перенастройки внутри гостевой операционной системы или на уровне приложений.
VMware настоятельно рекомендует клиентам, выполняющим эти задачи, убедиться в наличии проверенного и повторяемого плана отката в случае сбоя во время выполнения этих операций. Предполагается и ожидается, что у клиентов имеются проверенные резервные копии всех данных и информации о конфигурации всех виртуальных машин, которые будут участвовать в этом процессе переконфигурации.
Как минимум, клиенты должны выполнить (или отметить) следующее перед началом этих процедур:
Имена и расположение файлов для КАЖДОГО диска VMDK.
Номер SCSI и SCSI ID, к которому подключен КАЖДЫЙ диск. Мы должны присоединить диск к ТОМУ ЖЕ SCSI ID при повторном подключении.
В Windows - текущий владелец ресурсов диска (проверить это можно в конфигурации WSFC).
Если владение ресурсами WSFC разделено между узлами, ПЕРЕКЛЮЧИТЕ ВСЕ РЕСУРСЫ на один узел. Это упрощает процесс реконфигурации и очень полезно, чтобы избежать путаницы. Выключите все пассивные узлы ПЕРЕД выключением активного узла. После завершения настройки необходимо включить сначала активный узел, а затем остальные узлы.
Переконфигурация кластера WSFC с Multi-Writer на режим Clustered VMDK
Давайте начнем с рассмотрения нашей текущей конфигурации, посмотрим на узлы (кликабельно):
И на диски:
Протестируем WSFC путем переключения ресурсов диска - в данном случае мы выключаем активный узел и наблюдаем, как кластерные ресурсы становятся доступными на пассивном узле. Этот тест очень важен для проверки работоспособности WSFC перед внесением изменений.
Текущая конфигурация общих дисков (отображение распространенной неправильной конфигурации с включенным multi-writer, где общие диски принадлежат выключенной третьей виртуальной машине).
Вот узел WSFC Node-1 и его расшаренные диски (флаг Multi-Writer установлен в Enabled):
Многим администраторам виртуальной инфраструктуры VMware vSphere приходится документировать ее в графическом формате, формируя различные схемы и диаграммы. Для этого многие вендоры делают официальные графические ресурсы и стенсилы для Visio, чтобы эти документы выглядели в едином стиле, а между различными пользователями было взаимопонимание и один набор иконок, представляющих сущности в виртуальной среде.
Сегодня мы посмотрим, какие на данный момент есть графические ресурсы у компаний VMware и Veeam, чтобы стимулировать, так сказать, свободу творчества:) Напомним также, что мы многописалиобэтом ранее, но те ресурсы уже потеряли актуальность. Кстати, раньше было много официальных иконок, диаграм, pptx-шаблонов и прочего, но со временем это все как-то вымерло и остались только неофициальные и устаревшие ресурсы.
1. Графические ресурсы компании VMware
Самые последние иконки, стенсилы и диаграммы находятся вот в этом репозитории: https://github.com/tenthirtyam/vmware-stencils, а конкретно под Visio последние версии стенсилов находятся здесь. Отметим, что это неофициальные стенсилы, но последние из доступных.
В репозитории видно, что они не обновлялись пару лет, поэтому в 2022 их автор сделал архив с актуальными версиями начало 2022 года. Скачать его можно по этой ссылке.
Также многим будет полезно узнать о проекте draw.io, который бесплатно позволяет рисовать схемы и диаграммы средствами онлайн-утилиты с использованием стенсилов VMware, Veeam и других. Теперь этот проект переехал на diagrams.net:
Еще один полезный ресурс - Diagrams for VMware Validated Design. Тут собраны диаграммы для отрисовки дизайнов инфраструктур, которые соответствуют стандартам VMware. Он не обновлялся пару лет, но vsdx-файлы оттуда могут быть полезны. Советуем также заглянуть и сюда.
Также вот тут есть стенсилы от 2018 года, которые все еще вполне подходят для использования:
На прошлой неделе мы рассказали о новых возможностях обновленной версии платформы VMware vSphere 8 Update 1, а также новых функциях инфраструктуры хранилищ (Core Storage). Сегодня мы поговорим о новой версии vSAN 8 Update 1 - решения для организации отказоустойчивых кластеров хранилищ для виртуальных машин.
В vSAN 8 компания VMware представила архитектуру хранилища vSAN Express Storage Architecture (ESA), сделав весомый вклад в развитие гиперконвергентной инфраструктуры. В первом пакете обновлений vSAN компания VMware продолжает развивать этот продукт, позволяя клиентам использовать современные массивы, которые обеспечивают новый уровень производительности, масштабируемости, надежности и простоты использования.
Обзор основных возможностей vSAN 8 Update 1 вы также можете увидеть в видео ниже (откроется в новом окне):
В vSAN 8 Update 1 продолжают разрабатывать и улучшать обе архитектуры - vSAN OSA и vSAN ESA. Давайте посмотрим, что нового появилось в vSAN U1:
1. Масштабирование распределенных хранилищ
Обработка разделенных ресурсов вычисления и хранения в кластерах улучшена в версии vSAN 8 U1. Клиенты могут масштабироваться новыми способами, совместно используя хранилища данных vSAN с другими кластерами vSAN или только с вычислительными кластерами vSphere в рамках подхода HCI Mesh.
Управление распределенными хранилищами HCI Mesh с помощью архитектуры Express Storage
В vSAN 8 U1 архитектура Express Storage Architecture (ESA) позволяет клиентам максимизировать использование ресурсов устройств нового поколения путем предоставления общего доступа к хранилищами в нескольких нерастянутых кластерах для подхода HCI Mesh. Пользователи могут монтировать удаленные хранилища данных vSAN, расположенные в других кластерах vSAN, и использовать кластер vSAN ESA в качестве внешнего хранилища ресурсов для кластера vSphere.
Использование внешнего хранилища с помощью растянутых кластеров vSAN для OSA
В vSAN 8 U1 появилась поддержка распределенных хранилищ HCI Mesh при использовании растянутых кластеров vSAN на основе архитектуры хранения vSAN OSA. Теперь пользователи могут масштабировать хранение и вычислительные мощности независимо - в стандартных и растянутых кластерах.
Потребление емкостей хранилищ vSAN для разных экземпляров vCenter Server
vSAN 8 U1 также поддерживает распределенные хранилища в разных средах с использованием нескольких серверов vCenter при использовании традиционной архитектуры хранения (OSA).
2. Улучшение платформы
Улучшенная производительность с использованием нового адаптивного пути записи
В новом релизе представлен новый адаптивный путь записи, который позволяет рабочим нагрузкам с множеством записей и частопоследовательными записями записывать данные оптимальным способом. Улучшенная потоковая запись на ESA обеспечит увеличение пропускной способности на 25% и снижение задержки для последовательных записей. Это обновление не только повлияет на приложения с преобладающим профилем последовательной записи I/O, но и расширит разнообразие нагрузок, которые работают оптимальным образом на ESA vSAN.
Улучшенная производительность для отдельных нагрузок
Чтобы извлечь максимальную пользу из современного оборудования NVMe, в vSAN ESA 8 U1 была оптимизирована обработка I/O для каждого объекта, находящегося на хранилище данных vSAN ESA, повысив производительность на каждый VMDK на 25%. Эти улучшения производительности для отдельных объектов на ESA будут очень эффективны на критически важных виртуальных машинах, включая приложения, такие как реляционные базы данных и нагрузки OLTP.
Улучшенная надежность во время сценариев режима обслуживания.
В vSAN 8 U1 для ESA была добавлена еще одна функция, которая присутствует в vSAN OSA: поддержка RAID 5 и RAID 6 erasure coding с функциями дополнительной защиты от потери данных во время плановых операций обслуживания. Эта новая возможность гарантирует, что данные на ESA хранятся с избыточностью в случае неожиданного сбоя хоста в кластере во время режима обслуживания.
Улучшения управления датасторами
В vSAN 8 U1 администраторы смогут настраивать размер объектов пространства имен, что позволит им более просто хранить файлы ISO и библиотеки контента.
3. Упрощение управления
При использовании управления хранилищем на основе политик (SPBM), клиенты могут определять возможности хранения с помощью политик и применять их на уровне виртуальных машин. vSAN 8 U1 есть несколько новых улучшений, которые упрощают ежедневные операции администраторов, а также добавляют несколько новых возможностей, чтобы помочь глобальной команде поддержки VMware (GS) быстрее решать проблемы клиентов.
Автоматическое управление политиками для Default Storage Policies
(ESA)
В vSAN ESA 8 U1 появилась новая, необязательная кластерная политика хранения по умолчанию, которая поможет администраторам работать с кластерами ESA с оптимальной надежностью и эффективностью. В конфигурации на уровне кластера доступен новый переключатель "Auto-Policy Management". При включении этой функции кластера будет создана и назначена эффективная политика хранения по умолчанию на основе размера и типа кластера.
Skyline Health Score и исправление конфигурации
В vSAN 8 U1 модуль Skyline UX был переработан и теперь содержит новую панель управления состоянием с упрощенным видом "здоровья" каждого кластера. Новый пользовательский интерфейс поможет ответить на вопросы: "Находится ли мой кластер и обрабатываемые им нагрузки в работоспособном и здоровом состоянии?" и "Насколько серьезно это состояние? Следует ли решить эту проблему?".
С таким четким пониманием потенциальных проблем и действий для их устранения вы можете сократить среднее время до устранения проблем (mean time to resolution, MTTR).
Более высокий уровень детализации для улучшенного анализа производительности
Доступный как в Express Storage Architecture, так и в Original Storage Architecture, сервис производительности vSAN 8 U1 теперь включает мониторинг производительности почти в реальном времени, который собирает и отображает показатели производительности каждые 30 секунд.
Упрощенный сбор диагностической информации о производительности
В vSAN 8 U1 в I/O Trip Analyzer для виртуальных машин появился новый механизм планировщика. Вы можете запускать диагностику программно, что позволяет собирать больше и лучших данных, что может быть критически важно для выявления временных проблем производительности. Это улучшение идеально подходит для сред, где ВМ имеет повторяющуюся (хоть и кратковременную) проблему с производительностью.
Новая интеграция PowerCLI
В vSAN 8 U1 PowerCLI поддерживает множество новых возможностей как для архитектур ESA (Express Storage Architecture), так и OSA (Original Storage Architecture). С помощью этих интеграций клиенты ESA получат простой доступ к своему инвентарю для мониторинга и автоматизации управления своей средой и выделением ресурсов.
4. Функции Cloud Native Storage
Выделенные окружения DevOps увеличивают сложность всего центра обработки данных и увеличивают затраты. Используя существующую среду vSphere для хостинга рабочих нагрузок Kubernetes DevOps, клиенты дополнительно увеличивают ценность и ROI платформы VMware. VMware продолжает фокусироваться на потребностях разработчиков: в vSAN 8 U1 были реализованы новые улучшения производительности, простоты и гибкости для разработчиков, которые используют среду, и для администраторов, ответственных за саму платформу.
Поддержка CNS для vSAN ESA
В vSAN 8 U1 мы добавили поддержку Cloud Native Storage (CNS) для vSAN ESA. Клиенты могут получить преимущества производительности vSAN ESA для своих сред DevOps.
Поддержка DPp общих виртуальных коммутаторов
vSAN 8 U1 снижает стоимость и сложность инфраструктуры за счет того, что решения DPp (Data Persistence) теперь совместимы с VMware vSphere Distributed Switch. Клиентам нужны только лицензии vSphere+/vSAN+, чтобы использовать платформу Data Persistence — на vSAN OSA или ESA — и запускать приложения, что дает более низкую общую стоимость владения и упрощение операций.
Развертывние Thick provisioning для vSAN Direct Configuration
Наконец, в vSAN 8 U1 были доработаны кластеры, работающие в конфигурации vSAN Direct Configuration — это уникальная кластерная конфигурация, настроенная под Cloud Native Workloads. С vSAN 8 U1 постоянные тома могут быть программно выделены разработчиком как "thick" (это определяется в классе хранения).
Более подробно о новых возможностях VMware vSAN 8 Update 1 можно почитать на специальной странице.
Таги: VMware, vSAN, Update, Storage, OSA, ESA, Performance
Недавно мы писали об анонсированных новых возможностях обновленной платформы виртуализации VMware vSphere 8 Update 1, выход которой ожидается в ближайшее время. Параллельно с этим компания VMware объявила и о выпуске новой версии решения VMware vSAN 8 Update 1, предназначенного для создания высокопроизводительных отказоустойчивых хранилищ для виртуальных машин, а также об улучшениях подсистемы хранения Core Storage в обеих платформах.
Недавно компания VMware также выпустила большую техническую статью "What's New with vSphere 8 Core Storage", в которой детально рассмотрены все основные новые функции хранилищ, с которыми работают платформы vSphere и vSAN. Мы решили перевести ее с помощью ChatGPT и дальше немного поправить вручную. Давайте посмотрим, что из этого вышло :)
Итак что нового в части Core Storage платформы vSphere 8 Update 1
Одно из главных улучшений - это новая система управления сертификатами. Она упрощает возможность регистрации нескольких vCenter в одном VASA-провайдере. Это положит основу для некоторых будущих возможностей, таких как vVols vMSC. Такж есть и функции, которые касаются масштабируемости и производительности. Поскольку vVols могут масштабироваться гораздо лучше, чем традиционное хранилище, VMware улучшила подсистему хранения, чтобы тома vVols работали на больших масштабах.
1. Развертывание нескольких vCenter для VASA-провайдера без использования самоподписанных сертификатов
Новая спецификация VASA 5 была разработана для улучшения управления сертификатами vVols, что позволяет использовать самоподписанные сертификаты для многовендорных развертываний vCenter. Это решение также решает проблему управления сертификатами в случае, когда независимые развертывания vCenter, работающие с различными механизмами управления сертификатами, работают вместе. Например, один vCenter может использовать сторонний CA, а другой vCenter может использовать сертификат, подписанный VMCA. Такой тип развертывания может быть использован для общего развертывания VASA-провайдера. Эта новая возможность использует механизм Server Name Indication (SNI).
SNI - это расширение протокола Transport Layer Security (TLS), с помощью которого клиент указывает, какое имя хоста он пытается использовать в начале процесса handshake. Это позволяет серверу показывать несколько сертификатов на одном IP-адресе и TCP-порту. Следовательно, это позволяет обслуживать несколько безопасных (HTTPS) веб-сайтов (или других служб через TLS) с одним и тем же IP-адресом, не требуя, чтобы все эти сайты использовали один и тот же сертификат. Это является концептуальным эквивалентом виртуального хостинга на основе имени HTTP/1.1, но только для HTTPS. Также теперь прокси может перенаправлять трафик клиентов на правильный сервер во время хэндшейка TLS/SSL.
2. Новая спецификация vVols VASA 5.0 и некоторые детали функций
Некоторые новые функции, добавленные в vSphere 8 U1:
Изоляция контейнеров - работает по-разному для поставщиков VASA от различных производителей. Она позволяет выполнять настройку политики контроля доступа на уровне каждого vCenter, а также дает возможность перемещения контейнеров между выбранными vCenter. Это дает лучшую изоляцию на уровне контейнеров, а VASA Provider может управлять правами доступа для контейнера на уровне каждого vCenter.
Аптайм - поддержка оповещений об изменении сертификата в рамках рабочего процесса VASA 5.0, который позволяет обновлять сертификат VMCA в системах с несколькими vCenter. Недействительный или истекший сертификат вызывает простой, также возможно возникновение простоя при попытке регистрации нескольких vCenter с одним VASA Provider. В конфигурации с несколькими vCenter сертификаты теперь можно обновлять без простоя.
Улучшенная безопасность для общих сред - эта функция работает по-разному для поставщиков VASA от производителей. Все операции могут быть аутентифицированы в контексте vCenter, и каждый vCenter имеет свой список контроля доступа (ACL). Теперь нет самоподписанных сертификатов в доверенном хранилище. VASA Provider может использоваться в облачной среде, и для этого также есть доступная роль в VASA 5.0.
Обратная совместимость - сервер ESXi, который поддерживает VASA 5.0, может решать проблемы с самоподписанными сертификатами и простоями, возникающими в случае проблем. VASA 5.0 остается обратно совместимым и дает возможность контролировать обновление в соответствии с требованиями безопасности. VASA 5.0 может сосуществовать с более ранними версиями, если производитель поддерживает эту опцию.
Гетерогенная конфигурация сертификатов - работает по-разному для поставщиков VASA от производителей. Теперь используется только подписанный сертификат VMCA, дополнительный CA не требуется. Это позволяет изолировать доверенный домен vSphere. VASA 5.0 позволяет использовать разные конфигурации для каждого vCenter (например, Self-Managed 3rd Party CA Signed Certificate и VMCA managed Certificate).
Не необходимости вмешательства администратора - поддержка многократного развертывания vCenter с использованием VMCA, которая не требует от пользователя установки и управления сертификатами для VP. Служба SMS будет отвечать за предоставление сертификатов. Теперь это работает в режиме Plug and Play с автоматической предоставлением сертификатов, без вмешательства пользователя, при этом не требуется никаких ручных действий для использования VASA Provider с любым vCenter.
Комплаенс безопасности - отсутствие самоподписанных сертификатов в доверенных корневых центрах сертификации позволяет решить проблемы соответствия требованиям безопасности. Не-СА сертификаты больше не являются частью хранилища доверенных сертификатов vSphere. VASA 5.0 требует от VASA Provider использовать сертификат, подписанный СА для связи с VASA.
3. Перенос Sidecar vVols в config-vvol вместо другого объекта vVol
Sidecars vVols работали как объекты vVol, что приводило к накладным расходам на операции VASA, такие как bind/unbind. Решения, такие как First Class Disks (FCD), создают большое количество маленьких sidecars, что может ухудшить производительность vVols. Кроме того, поскольку может быть создано множество sidecars, это может учитываться в общем количестве объектов vVol, поддерживаемых на массиве хранения. Чтобы улучшить производительность и масштабируемость, теперь они обрабатываются как файлы на томе config-vvol, где могут выполняться обычные операции с файлами. Не забывайте, что в vSphere 8 был обновлен способ байндига config-vvol. В результате, с новым механизмом config-vvol уменьшается число операций и задержки, что улучшает производительность и масштабируемость.
Для этой функциональности в этом релизе есть несколько ограничений при создании ВМ. Старые виртуальные машины могут работать в новом формате на обновленных до U1 хостах, но сам новый формат не будет работать на старых ESXi. То есть новые созданные ВМ и виртуальные диски не будут поддерживаться на хостах ниже версии ESXi 8 U1.
5. Улучшения Config-vvol, поддержка VMFS6 config-vvol с SCSI vVols (вместо VMFS5)
Ранее Config-vvol, который выступает в качестве каталога для хранилища данных vVols и содержимого VM home, был ограничен размером 4 ГБ. Это не давало возможности использования папок с хранилищем данных vVols в качестве репозиториев ВМ и других объектов. Для преодоления этого ограничения Config-vvol теперь создается как тонкий объект объемом 255 ГБ. Кроме того, вместо VMFS-5 для этих объектов будет использоваться формат VMFS-6. Это позволит размещать файлы sidecar, другие файлы VM и библиотеки контента в Config-vvol.
На изображении ниже показаны Config-vvol разных размеров. Для машины Win10-5 Config-vvol использует исходный формат 4 ГБ, а ВМ Win10-vVol-8u1 использует новый формат Config-vvol объемом 255 ГБ.
6. Добавлена поддержка NVMe-TCP для vVols
В vSphere 8 была добавлена поддержка NVMe-FC для vVols. В vSphere 8 U1 также расширена поддержка NVMe-TCP, что обеспечивает совместное использование NVMeoF и vVols. См. статью vVols with NVMe - A Perfect Match | VMware.
7. Улучшения NVMeoF, PSA, HPP
Инфраструктура поддержки NVMe end-to-end:
Расширение возможностей NVMe дает возможность поддержки полного стека NVMe без какой-либо трансляции команд SCSI в NVMe на любом уровне ESXi. Еще одной важной задачей при поддержке end-to-end NVMe является возможность контроля multipath-плагинов сторонних производителей для управления массивами NVMe.
Теперь с поддержкой GOS протокол NVMe может использоваться для всего пути - от GOS до конечного таргета.
Важным аспектом реализации VMware трансляции хранилищ виртуальных машин является поддержка полной обратной совместимости. VMware реализовала такой механизм, что при любом сочетании виртуальных машин, использующих SCSI или контроллер vNVMe, и целевого устройства, являющегося SCSI или NVMe, можно транслировать путь в стеке хранения. Это дизайн, который позволяет клиентам переходить между SCSI- и NVMe-хранилищами без необходимости изменения контроллера хранилищ для виртуальной машины. Аналогично, если виртуальная машина имеет контроллер SCSI или vNVMe, он будет работать как на SCSI-, так и на NVMeoF-хранилищах.
Упрощенная диаграмма стека хранения выглядит так:
Для получения дополнительной информации о NVMeoF для vSphere, обратитесь к странице ресурсов NVMeoF.
8. Увеличение максимального количества путей для пространств имен NVMe-oF с 8 до 32
Увеличение количества путей улучшает масштабирование в окружениях с несколькими путями к пространствам имен NVMe. Это необходимо в случаях, когда хосты имеют несколько портов и модуль имеет несколько нод, а также несколько портов на одной ноде.
9. Увеличение максимального количества кластеров WSFC на один хост ESXi с 3 до 16
Это позволяет уменьшить количество лицензий Microsoft WSFC, необходимых для увеличения количества кластеров, которые могут работать на одном хосте.
Для получения дополнительной информации о работе Microsoft WSFC на vSphere можно обратиться к следующим ресурсам:
10. Улучшения VMFS - расширенная поддержка XCOPY для копирования содержимого датасторов между различными массивами
ESXi теперь поддерживает расширенные функции XCOPY, что оптимизирует копирование данных между датасторами разных массивов. Это поможет клиентам передать обработку рабочих нагрузок на сторону хранилища. Функция уже доступна в vSphere 8 U1, но по факту миграция данных между массивами должна поддерживаться на стороне хранилища.
11. Реализация NFSv3 vmkPortBinding
Данная функция позволяет привязать соединение NFS для тома к конкретному vmkernel. Это помогает обеспечить безопасность, направляя трафик NFS по выделенной подсети/VLAN, и гарантирует, что трафик NFS не будет использовать mgmt-интерфейс или другие интерфейсы vmkernel.
Предыдущие монтирования NFS не содержат этих значений, хранящихся в config store. Во время обновления, при чтении конфигурации из конфигурационного хранилища, значения vmknic и bindTovmnic, если они есть, будут считаны. Поэтому обновления с предыдущих версий не будут содержать этих значений, так как они являются необязательными.
Изменения в способе создания/удаления Swap-файлов для томов vVols помогли улучшить производительность включения/выключения, а также производительность vMotion и svMotion.
13. Улучшения Config vVol и сохранение привязки
Здесь были сделаны следующие доработки:
Уменьшено время запроса при получении информации о ВМ
Добавлено кэширование атрибутов vVol - размер, имя и прочих
Конфигурационный vVol - это место, где хранятся домашние файлы виртуальной машины (vmx, nvram, logs и т. д.) и к нему обычно обращаются только при загрузке или изменении настроек виртуальной машины.
Ранее использовалась так называемая "ленивая отмена связи" (lazy unbind), и происходил unbind конфигурационного vVol, когда он не использовался. В некоторых случаях приложения все же периодически обращались к конфигурационному vVol, что требовало новой операции привязки. Теперь эта связь сохраняется, что уменьшает задержку при доступе к домашним данным виртуальной машины.
14. Поддержка NVMeoF для vVols
vVols были основным направлением развития функциональности хранилищ VMware в последние несколько версий, и для vSphere 8.0 это не исключение. Самое большое обновление в ядре хранения vSphere 8.0 - добавление поддержки vVols в NVMeoF. Изначально поддерживается только FC, но со временем будут работать и другие протоколы, провалидированные и поддерживаемые с помощью vSphere NVMeoF. Теперь есть новая спецификация vVols и VASA/VC-фреймворка - VASA 4.0/vVols 3.0.
Причина добавления поддержки vVols в NVMeoF в том, что многие производители массивов, а также отрасль в целом, переходят на использование или, по крайней мере, добавление поддержки NVMeoF для повышения производительности и пропускной способности. Вследствие этого VMware гарантирует, что технология vVols остается поддерживаемой для последних моделей хранилищ.
Еще одним преимуществом NVMeoF vVols является настройка. При развертывании после регистрации VASA фоновая установка завершается автоматически, вам нужно только создать датастор. Виртуальные эндпоинты (vPE) и соединения управляются со стороны VASA, что упрощает настройку.
Некоторые технические детали этой реализации:
ANA Group (Асимметричный доступ к пространству имен)
С NVMeoF реализация vVols немного отличается. С традиционными SCSI vVols хранилищами контейнер является логической группировкой самих объектов vVol. С NVMeoF это варьируется в зависимости от того, как поставщик массива реализует функциональность. В общем и целом, на хранилище группа ANA является группировкой пространств имен vVol. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Пространства имен выделяются и активны только по запросу BIND к провайдеру VASA (VP). Пространства имен также добавляются в группу ANA при запросе BIND к VP. Пространство имен остается выделенным/активным до тех пор, пока последний хост не отвяжет vVol.
vPE (virtual Protocol Endpoint)
Для традиционных vVols на базе SCSI, protocol endpoint (PE) - это физический LUN или том на массиве, который отображается в появляется в разделе устройств хранения на хостах. С NVMeoF больше нет физического PE, PE теперь является логическим объектом, представлением группы ANA, в которой находятся vVols. Фактически, до тех пор, пока ВМ не запущена, vPE не существует. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Как только ВМ запущена, создается vPE, чтобы хост мог получить доступ к vVols в группе ANA. На диаграмме ниже вы можете увидеть, что vPE указывает на группу ANA на массиве.
NS (пространство имен, эквивалент LUN в NVMe)
Каждый тип vVol (Config, Swap, Data, Mem), созданный и использующийся машиной, создает NS, который находится в группе ANA. Это соотношение 1:1 между vVol и NS позволяет вендорам оборудования легко масштабировать объекты vVols. Обычно поставщики поддерживают тысячи, а иногда и сотни тысяч NS. Ограничения NS будут зависеть от модели массива.
На диаграмме вы можете увидеть, что сама виртуальная машина является NS, это будет Config vVol, а диск - это другой NS, Data vVol.
Поддержка 256 пространств имен и 2K путей с NVMe-TCP и NVMe-FC
NVMeoF продолжает набирать популярность по очевидным причинам - более высокая производительность и пропускная способность по сравнению с традиционным подключением SCSI или NFS. Многие производители хранилищ также переходят на NVMe-массивы и использование SCSI для доступа к NVMe флэш-накопителям является узким местом и потенциалом для улучшений.
Продолжая работать на этим, VMware увеличила поддерживаемое количество пространств имен и путей как для NVMe-FC, так и для TCP.
Расширение reservations для устройств NVMe
Добавлена поддержка команд reservations NVMe для использования таких решений, как WSFC. Это позволит клиентам использовать возможности кластеризованных дисков VMDK средствами Microsoft WSFC с хранилищами данных NVMeoF. Пока поддерживается только протокол FC.
Поддержка автообнаружения для NVMe Discovery Service на ESXi
Расширенная поддержка NVMe-oF в ESXi позволяет динамически обнаруживать совместимые со стандартом службы NVMe Discovery Service. ESXi использует службу mDNS/DNS-SD для получения информации, такой как IP-адрес и номер порта активных служб обнаружения NVMe-oF в сети.
Также ESXi отправляет многоадресный DNS-запрос (mDNS), запрашивая информацию от сущностей, предоставляющих службу обнаружения DNS-SD. Если такая сущность активна в сети (на которую был отправлен запрос), она отправит (одноадресный) ответ на хост с запрошенной информацией - IP-адрес и номер порта, где работает служба.
16. Улучшение очистки дискового пространства с помощью Unmap
Снижение минимальной скорости очистки до 10 МБ/с
Начиная с vSphere 6.7, была добавлена функция настройки скорости очистки (Unmap) на уровне хранилища данных. С помощью этого улучшения клиенты могут изменять скорость очистки на базе рекомендаций поставщика их массива. Более высокая скорость очистки позволяла многим пользователям быстро вернуть неиспользуемое дисковое пространство. Однако иногда даже при минимальной скорости очистки в 25 МБ/с она может быть слишком высокой и привести к проблемам при одновременной отправке команд Unmap несколькими хостами. Эти проблемы могут усугубляться при увеличении числа хостов на один датастор.
Пример возможной перегрузки: 25 МБ/с * 100 хранилищ данных * 40 хостов ~ 104 ГБ/с
Чтобы помочь клиентам в ситуациях, когда скорость очистки 25 МБ/с может приводить к проблемам, VMware снизила минимальную скорость до 10 МБ/с и сделала ее настраиваемой на уровне датасторов:
При необходимости вы также можете полностью отключить рекламацию пространства для заданного datastore.
Очередь планирования отдельных команд Unmap
Отдельная очередь планирования команд Unmap позволяет выделить высокоприоритетные операции ввода-вывода метаданных VMFS и обслуживать их из отдельных очередей планирования, чтобы избежать задержки их исполнения из-за других команд Unmap.
17. Контейнерное хранилище CNS/CSI
Теперь вы можете выбрать политику Thin provisioning (EZT, LZT) через SPBM для CNS/Tanzu.
Цель этого - добавить возможность политик SPBM для механизма создания/изменения правил политик хранения, которые используются для параметров выделения томов. Это также облегчает проверку соответствия правил выделения томов в политиках хранения для SPBM.
Операции, поддерживаемые для виртуальных дисков: создание, реконфигурация, клонирование и перемещение.
Операции, поддерживаемые для FCD: создание, обновление политики хранения, клонирование и перемещение.
18. Улучшения NFS
Инженеры VMware всегда работают над улучшением надежности доступа к хранилищам. В vSphere 8 были добавлены следующие улучшения NFS, повышающие надежность:
Повторные попытки монтирования NFS при сбое
Валидация монтирования NFS
Ну как вам работа ChatGPT с правками человека? Читабельно? Напишите в комментариях!
Иногда при работе администратора с виртуальными машинами VMware vSphere происходит ошибка при работе с дескрипторными файлами дисков VMDK, которая проявляет себя следующим образом:
Диск ВМ показывается в Datastore Browser, но иконка для него отсутствует
При включении ВМ вы получаете ошибку " File not found"
Сам файл ВМ вида <имя ВМ>-flat.vmdk есть в директории с машиной, но файла <имя ВМ>.vmdk вы не видите
Сам файл <имя ВМ>.vmdk отсутствует, либо он есть, но его содержимое повреждено
Эти симптомы могут возникать по разным причинам, но суть их одна - дескрипторный файл ВМ поврежден или отсутствует. Ситуация поправима, если у вас есть основный диск с данными - <имя ВМ>-flat.vmdk, и он сохранился в целости.
В 2012 году мы писали о том, как быть, если у вас возникла проблема с дескрипторным файлом виртуальной машины в среде VMware vSphere. В целом, с тех времен ничего особо не поменялось. Процесс этот довольно простой и описан в KB 1002511, также он детально разобран в видео ниже:
Часть 1 - восстановление основного VMDK виртуальной машины
Перед выполнением операций ниже обязательно сохраните полную копию папки виртуальной машины, и только после этого проводите все описанные ниже операции. Если у вас есть резервная копия виртуальной машины, и ее восстановление вас устраивает - то лучше сделать эту операцию вместо описанной ниже процедуры исправления дисков, так как вероятность ошибиться в ней велика.
Если вкратце, то для восстановления вам нужно выполнить следующие шаги:
1. Соединяемся с хостом VMware ESXi по SSH как root. Либо операции можно проводить непосредственно в консоли DCUI.
2. Переходим в папку с ВМ и определяем геометрию основного диска VMDK с данными <имя ВМ>-flat.vmdk
Делается это командой:
# ls -l <имя диска>-flat.vmdk
На выходе мы получим размер диска в байтах. Вывод будет выглядеть примерно так:
-rw------- 1 root root 4294967296 Oct 11 12:30 vmdisk0-flat.vmdk
3. Теперь нужно пересоздать заголовочный файл VMDK (<имя ВМ>.vmdk), чтобы он соответствовал диску с данными, используя тот же размер диска, полученный на предыдущем шаге:
# vmkfstools -c 4294967296 -a lsilogic -d thin temp.vmdk
После этого переименовываем дескрипторный VMDK-файл созданного диска в тот файл, который нам нужен для исходного диска. Затем удаляем только что созданный пустой диск данных нового диска, который уже не нужен (temp-flat.vmdk).
Если у изначальной машины диск был не растущим по мере наполнения (thin disk), то последнюю строчку, выделенную красным, можно не добавлять.
Вы также можете поменять тип адаптера ddb.adapterType = lsilogic на ddb.adapterType = pvscsi, если вы использовали паравиртуализованный SCSI-контроллер для исходной ВМ.
Консистентность виртуальной машины можно проверить командой:
vmkfstools -e filename.vmdk
Если все в порядке, то в ответе команды вы получите вот такую строчку:
Disk chain is consistent.
Если же исправить ситуацию не получилось, то будет вот такой текст:
Disk chain is not consistent : The parent virtual disk has been modified since the child was created. The content ID of the parent virtual disk does not match the corresponding parent content ID in the child (18).
После этого можно запускать виртуальную машину, добавив ее повторно в окружение vSphere Client.
Часть 2 - исправление дескрипторов файлов снапшотов ВМ (delta-файлы)
Ситуация усложняется, когда у исходной виртуальной машины были снапшоты, тогда папка с ней выглядит следующим образом (красным выделены важные для нас в дальнейших шагах файлы):
drwxr-xr-x 1 root root 1400 Aug 16 09:39 .
drwxr-xr-t 1 root root 2520 Aug 16 09:32 ..
-rw------- 1 root root 32768 Aug 17 19:11 examplevm-000002-delta.vmdk
-rw------- 1 root root 32768 Aug 17 19:11 examplevm-000002.vmdk
-rw------- 1 root root 32768 Aug 16 14:39 examplevm-000001-delta.vmdk
-rw------- 1 root root 32768 Aug 16 14:39 examplevm-000001.vmdk
-rw------- 1 root root 16106127360 Aug 16 09:32 examplevm-flat.vmdk
-rw------- 1 root root 469 Aug 16 09:32 examplevm.vmdk
-rw------- 1 root root 18396 Aug 16 14:39 examplevm-Snapshot1.vmsn
-rw------- 1 root root 18396 Aug 17 19:11 examplevm-Snapshot2.vmsn
-rw------- 1 root root 397 Aug 16 09:39 examplevm.vmsn
-rwxr-xr-x 1 root root 1626 Aug 16 09:39 examplevm.vmx
-rw------- 1 root root 259 Aug 16 09:36 examplevm.vmxf
Основной порядок действий в этой ситуации приведен в KB 1026353, здесь же мы опишем его вкратце (кстати, напомним про необходимость сделать полный бэкап всех файлов ВМ перед любыми операциями):
1. Определяем нужные нам файлы
Итак, заголовочные файлы снапшотов ВМ хранятся в так называемых файлах типа vmfsSparse, они же работают в связке с так называемым delta extent file, который непосредственно содержит данные (выше это, например, examplevm-000001-delta.vmdk).
Таким образом, опираясь на пример выше, нам интересны заголовочные файлы снапшотов examplevm-000001.vmdk и examplevm-000002.vmdk. Помните также, что диски и их снапшоты могут находиться в разных папках на разных датасторах, поэтому сначала вам нужно понять, где и что у вас хранится. Если у вас есть сомнения касательно имен нужных вам файлов, вы можете заглянуть в лог-файл vmware.log, чтобы увидеть там нужные пути к датасторам.
2. Создаем новый дескриптор снапшота
Итак, представим теперь, что файл examplevm-000001.vmdk у нас поврежден или отсутствует. Создадим новый дескриптор снапшота из исходного заголовочного файла examplevm.vmdk простым его копированием:
# cp examplevm.vmdk examplevm-000001.vmdk
3. Меняем указатели на файл с данными для снапшота
Теперь нужно открыть созданный файл в текстовом редакторе и начать его исправлять. Пусть он выглядит вот так:
# Disk DescriptorFile
version=1
encoding="UTF-8" CID=19741890
parentCID=ffffffff
createType="vmfs"
Красным мы выделили то, что будем в этом файле изменять, а синим - то, что будем удалять.
С данным файлом нужно сделать следующие манипуляции:
Строчку CID=19741890 заменяем на случайное восьмизначное значение (это идентификатор диска)
Строчку parentCID=ffffffff заменяем на parentCID=19741890 (идентификатор родительского диска, им может быть не только родительский основной диск, но и родительский снапшот, то есть его дескриптор)
Строчку createType="vmfs" заменяем на createType="vmfsSparse"
Строчку RW 31457280 VMFS "examplevm-flat.vmdk" заменяем на RW 31457280 VMFSSPARSE "examplevm-000001-delta.vmdk" (обратите внимание, что номер 31457280 остается тем же - он должен быть тем же самым для всей цепочки дочерних дисков)
4. Добавляем данные специфичные для снапшота
Теперь нам надо добавить в указатель снапшота кое-что новое:
Под строчкой createType="vmfsSparse" добавляем строчку
parentFileNameHint="examplevm.vmdk"
Ну и теперь надо убрать лишнее. Удаляем из файла следующие строчки, которые нужны только для основного родительского диска:
После этого вы можете попробовать запустить машину с дочерним снапшотом. Но перед этим также проверьте интеграцию дескриптора командой:
vmkfstools -e filename.vmdk
Ну и помните, что все эти действия по цепочке вы можете провернуть для следующих уровней дочерних снапшотов, если их диски с данными в порядке. Главное - не забывайте делать резервные копии перед любыми операциями!

 RSS
RSS