Azure VMware Solution управляет глобальным парком производственных приватных облаков, каждое из которых работает в полноценной управляющей плоскости (control plane) VMware NSX и vCenter Server. Когда, например, кластер VMware NSX Manager теряет кворум, NSX может генерировать множество связанных алармов, однако наблюдаемое воздействие выглядит как одновременный каскадный сбой: обновления плоскости управления и конфигурации прекращаются, работоспособность кластера может деградировать, а некоторые симптомы Edge-узлов или транспортных узлов могут проявляться следом — при этом существующая динамическая маршрутизация Tier-0, как правило, остаётся работоспособной. Иными словами, несколько симптомов могут иметь один общий корневой сбой, который необходимо верифицировать с учётом состояния кластера, работоспособности сервисов, хранилища, состояния Compute Manager и связности транспортных узлов. Без модели, кодирующей направленные зависимости между этими уровнями, набор тревог структурно неотличим от множества независимых одновременных сбоев.
Оператор, обрабатывающий каждую тревогу независимо, продлевает инцидент, повторно проходя один и тот же путь распространения сбоя с каждым действием. В условиях производственных масштабов распространение сбоев NSX стабильно опережает ручную сортировку инцидентов. Система автономного самовосстановления приватного облака Azure VMware Solution — это архитектура управления с замкнутым контуром, созданная для устранения именно этого класса сбоев. Система коррелирует сигналы плоскости управления причинно-следственным образом с использованием динамического графа зависимостей в реальном времени, применяет полный стек политик-шлюзов перед любым автоматическим действием, захватывает ограниченное взаимное исключение перед началом выполнения и независимо верифицирует восстановление прежде, чем закрыть инцидент. В данной статье описываются архитектура системы и принятые проектные решения.
Архитектурные компоненты
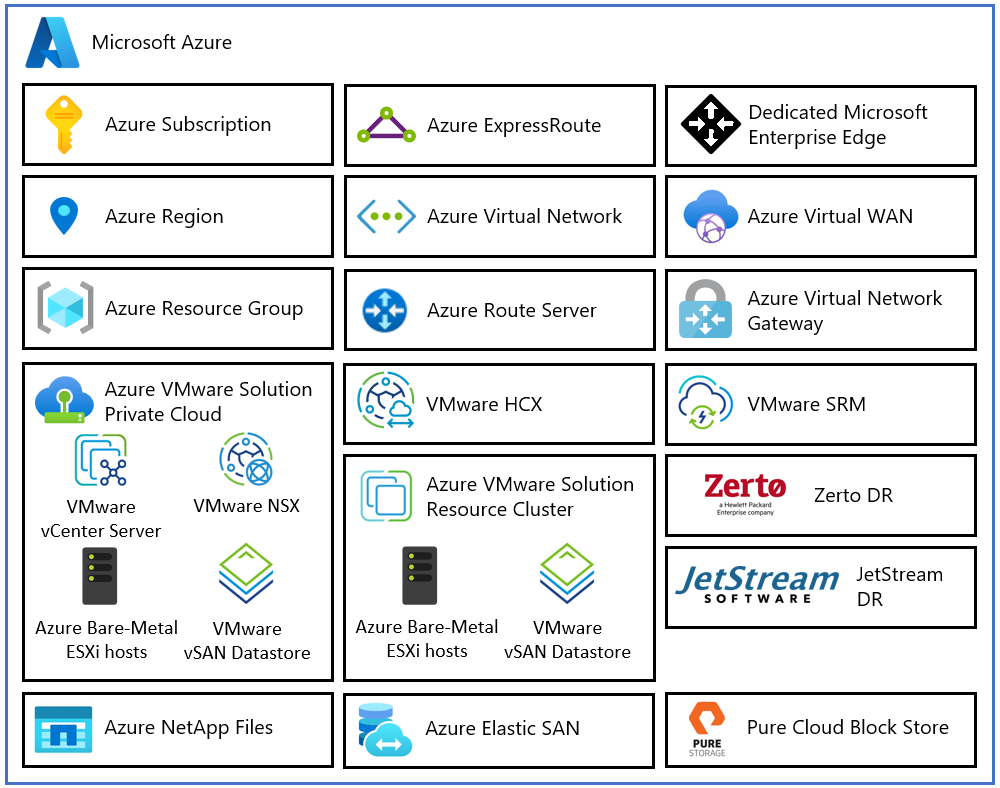
Azure VMware Solution — это VMware-валидированный сервис Azure первой стороны от Microsoft, предоставляющий приватные облака с кластерами VMware vSphere на базе выделенной bare-metal инфраструктуры Azure. Это позволяет заказчикам использовать существующие инвестиции в навыки и инструменты VMware, сосредоточившись на разработке и запуске своих VMware-нагрузок в Azure.
Каждый архитектурный компонент Azure VMware Solution выполняет следующие функции:
Azure Subscription — управление доступом, бюджетом и квотами для Azure VMware Solution.
Azure Region — физические местоположения по всему миру, объединяющие центры обработки данных в зоны доступности (AZ), а зоны доступности — в регионы.
Azure Resource Group — контейнер для группировки сервисов и ресурсов Azure в логические группы.
Azure VMware Solution Private Cloud — использует программное обеспечение VMware, включая vCenter Server, программно-определяемые сети NSX, программно-определяемое хранилище vSAN и bare-metal хосты ESXi Azure для предоставления вычислительных ресурсов, сетевых ресурсов и хранилища. Поддерживаются также Azure NetApp Files, Azure Elastic SAN и Pure Cloud Block Store.
Azure VMware Solution Resource Cluster — масштабирует приватное облако за счёт дополнительных bare-metal хостов ESXi и программного обеспечения vSAN.
VMware HCX — обеспечивает мобильность, миграцию и расширение сети.
VMware Site Recovery — обеспечивает автоматизацию аварийного восстановления и репликацию хранилища через vSphere Replication. Также поддерживаются сторонние решения DR — Zerto DR и JetStream DR.
Dedicated Microsoft Enterprise Edge (D-MSEE) — маршрутизатор, обеспечивающий связность между Azure и приватным облаком Azure VMware Solution.
Azure Virtual Network (VNet) — частная сеть для соединения сервисов и ресурсов Azure.
Azure Route Server — позволяет сетевым устройствам обмениваться динамической информацией о маршрутизации с сетями Azure.
Azure Virtual Network Gateway — кросс-облачный шлюз для подключения через IPSec VPN, ExpressRoute и VNet-to-VNet.
Azure ExpressRoute — высокоскоростные приватные подключения между центрами обработки данных Azure и локальной или колокационной инфраструктурой.
Azure Virtual WAN (vWAN) — объединяет функции сетевого взаимодействия, безопасности и маршрутизации в единую глобальную сеть.
Что обеспечивает автономное самовосстановление
Система автономного самовосстановления вводит пять гарантированных на системном уровне свойств корректности, ни одно из которых ранее не существовало как системно-принудительное поведение в пути реагирования на инциденты плоскости управления Azure VMware Solution:
Возможность
Что делает Autonomous Self-Heal
Предыдущее состояние
Ограниченное, верифицируемое время восстановления
Измеряет время от первого скоррелированного сигнала до верифицированного стабильного восстановления.
Инциденты закрывались по завершении действия, а не восстановления.
Целостность сигнала при поступлении
Нормализует события, дедуплицирует источники и подавляет флаппинг перед корреляцией.
Конвейера нормализации не существовало. Инженеры получали необработанный поток тревог.
Выполнение с политикой-шлюзом
Атомарно проверяет окна заморозки, бюджеты риска, радиус проблемы, ограничения скорости и согласования перед выполнением.
Единого атомарного стека шлюзов для ограничений и согласований не существовало.
Доказательная база инцидента с возможностью только дополнения
Сохраняет сигналы, топологию, решения, трассировку workflow и верификацию в структурированной записи.
Доказательства находились в отдельных журналах и с трудом воспроизводились.
Прогрессивная модель доверия
Поддерживает режим только-уведомления, чтобы операторы могли проверить обнаружения и предлагаемые действия перед включением.
Автоматизация была бинарной — не было механизма наблюдения за поведением системы до предоставления полномочий на выполнение.
Принципы проектирования
Автономное самовосстановление вводит семь проектных элементов в операции плоскости управления приватным облаком Azure VMware Solution:
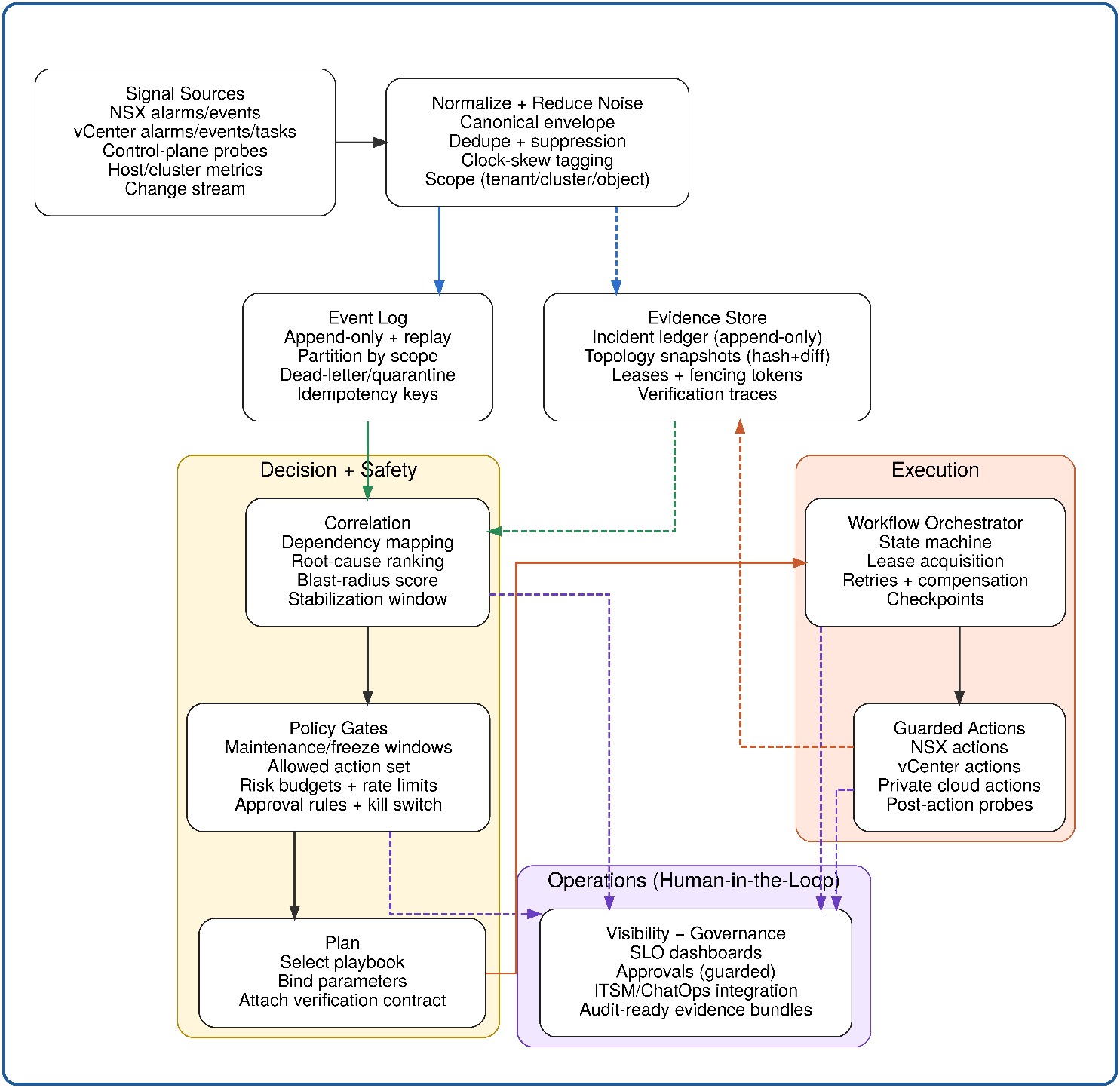
Разделение трёх плоскостей (обнаружение, принятие решений, выполнение) с изоляцией поверхностей сбоя по всему управляющему контуру.
Динамический граф зависимостей реального времени, непрерывно обновляемый из потоков событий VMware NSX и vCenter Server, заменяющий статические наборы правил, которые расходятся с реальной топологией.
Трёхвходная модель причинно-следственной корреляции (сила доказательств, временной порядок, направленность зависимости), отличающая причинно-следственные цепочки от совпадающих событий.
Вычисление радиуса проблемы перед выполнением - входной параметр шлюза, обеспечивающий пропорциональное применение политик до совершения любого действия.
Модель фазовых границ (стабилизация, выполнение, верификация), преобразующая событийные осцилляции в демпфированную петлю обратной связи с гистерезисом.
Структура контракта выполнения (триггер, объявление шлюза, спецификация шагов, контракт верификации), принудительно обеспечивающая допустимость области действия и актуальность топологии как системных ограничений.
Единый журнал с возможностью только дополнения, формирующий идентичные записи для автоматизированных и управляемых людьми путей разрешения инцидентов — для целей управления и воспроизведения после инцидента.
Для сбоев в охватываемой области результат — это ограниченное, воспроизводимое время восстановления в любое время суток без участия оператора. Для сбоев в охватываемой области, где автоматическое устранение не может быть санкционировано, результат — детерминированный пакет доказательств, заменяющий воспоминания инженера структурированной, воспроизводимой передачей дел.
Архитектура: обнаружение, принятие решений и выполнение
Автономное самовосстановление разделяет обнаружение, принятие решений и выполнение на отдельные плоскости с единственными, тестируемыми контрактами между ними. Объединение этих функций — более простой подход — разделяет поверхность сбоя между всеми тремя: ошибка в движке выполнения может повредить доказательства, от которых зависит модель корреляции; всплеск объёма тревог может лишить ресурсов оценщика шлюзов; неправильно настроенный шлюз может заблокировать нормализацию сигналов. Разделение устраняет эти режимы взаимозаражения сбоев.
Плоскость обнаружения преобразует необработанные потоки тревог VMware NSX и vCenter Server в стабильные, дискретные кандидаты на инцидент. Конвейер нормализует форматы событий из разных источников, сворачивает избыточные сигналы и применяет окно задержки для фильтрации переходных изменений состояния. Кандидаты, пересекающие границу плоскости, — это подтверждённые, стабильные единицы, единственная форма, которую модель корреляции способна корректно обработать.
Плоскость принятия решений выполняет причинно-следственную корреляцию по динамическому графу зависимостей приватного облака перед оценкой шлюза, формируя ранжированную гипотезу первопричины с оценками уверенности и вычисленной оценкой радиуса проблемы. Плоскость выдаёт ровно один из двух результатов: санкционированное шлюзом разрешение на выполнение или эскалацию с полным пакетом доказательств.
Плоскость выполнения получает токен, ограниченный минимально жизнеспособной областью сбоя, запускает версионированный идемпотентный контрольно-точечный плейбук и закрывает инцидент только после того, как независимая верификация постусловий подтверждает стабильное восстановление в течение окна стабильности. Каждый переход состояния дополняет журнал инцидента.
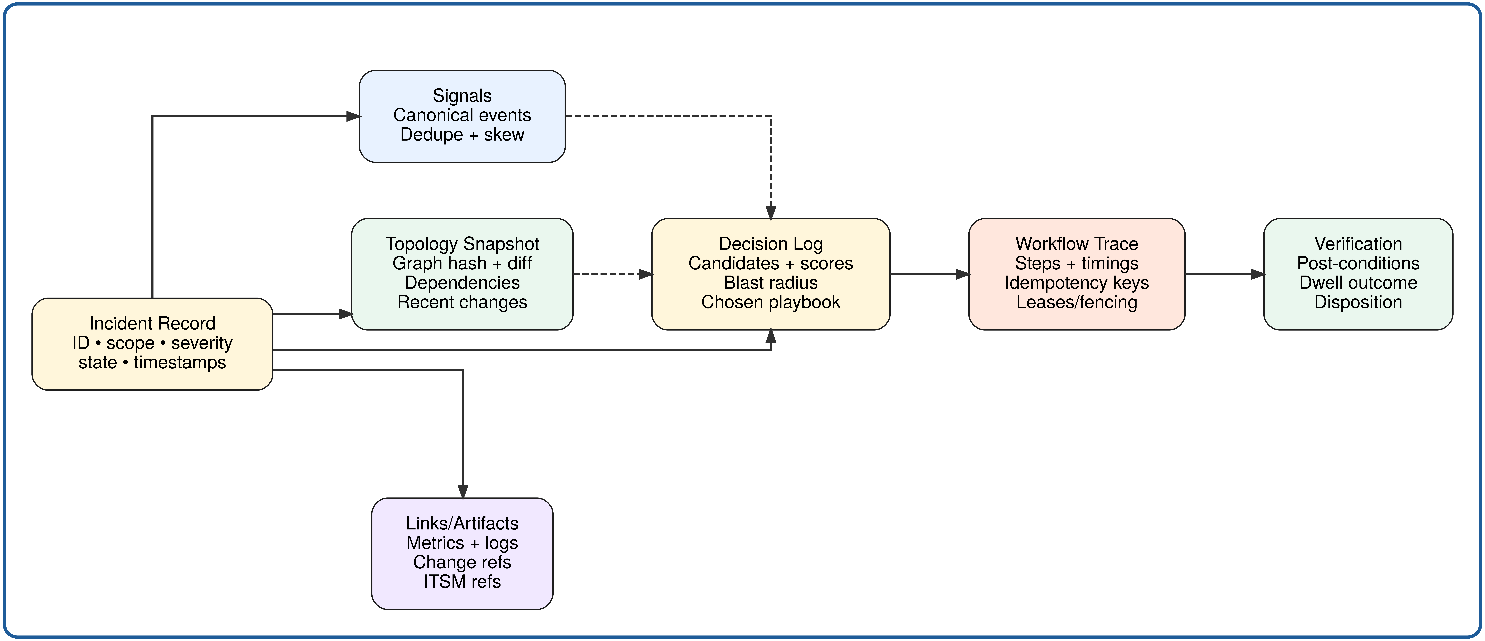
Журнал инцидентов
Автономное самовосстановление формирует структурированный журнал с возможностью только дополнения для каждого инцидента вне зависимости от пути разрешения. Последовательно фиксируются пять категорий: необработанные и нормализованные сигналы с результатами подавления; снимок топологии на момент обнаружения; полная запись решений, включая результаты корреляции, ранжирование первопричин, оценку радиуса проблемы и трассировку оценки шлюза; трассировка workflow с метаданными шагов и идентификаторами аренды; и результат верификации с результатами постусловий и диспозицией окна стабильности.
Автоматизированные и управляемые людьми пути формируют одинаковую структуру записи — это требование управляемости, а не предпочтение проектирования. Воспроизведение детерминировано: по одному и тому же журналу два рецензента реконструируют одинаковую временную шкалу инцидента.
Итог
Автономное самовосстановление обрабатывает определённое подмножество сбоев плоскости управления NSX и vCenter в приватном облаке Azure VMware Solution. Система не обрабатывает сбои плоскости данных, сбои хранилища, сбои гипервизора, аппаратные сбои или сбои плоскости управления вне смоделированного графа зависимостей. Она не запускает произвольные скрипты, не обходит управление доступом на основе ролей и не переопределяет границы изоляции тенантов. Ограниченная область является источником надёжности системы — система, пытающаяся устранять всё подряд, несёт режимы сбоя, пропорциональные её охвату.
Когда автономное самовосстановление не может предпринять действий, формируемый им пакет доказательств обеспечивает полную структурированную передачу для ответа оператора.
Независимое исследование, проведённое компанией Principled Technologies, сравнило плотность Kubernetes-подов и скорость их готовности в двух средах: VMware Cloud Foundation (VCF) 9.0 с vSphere Kubernetes Service (VKS) 3.6 и Red Hat OpenShift 4.21 на bare metal. Это нагрузочное тестирование с использованием kube-burner — инструмента, разработанного Red Hat, — наглядно демонстрирует превосходство VCF по масштабируемости и задержкам при запуске Kubernetes в корпоративной среде.
Что такое плотность подов Kubernetes
По определению CNCF, под — наименьшая единица развёртывания контейнеризованного приложения. Каждый под содержит один экземпляр приложения с одним или несколькими контейнерами, совместно использующими вычислительные ресурсы, хранилище и сеть. Плотность подов — это количество подов, которые узел способен поддерживать при сохранении стабильной работы.
Ключевые результаты
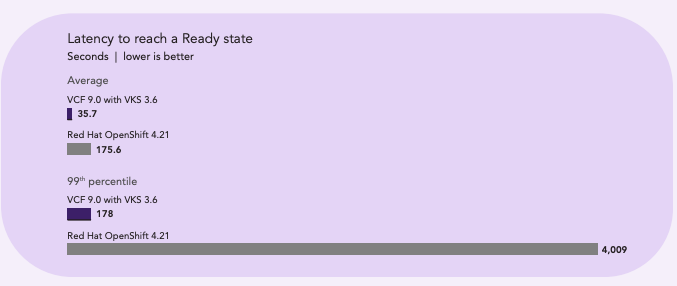
Плотность подов: vSphere Kubernetes Service (VKS) поддержал 42 000 Kubernetes-подов до достижения пределов стабильности. Red Hat OpenShift на bare metal на идентичном оборудовании смог поддержать лишь 7 400 подов. Таким образом, VCF 9.0 обеспечил в 5,6 раза больше подов на узел/хост, чем Red Hat OpenShift, при использовании инструмента kube-burner.
Скорость готовности подов: в среднем VCF 9.0 продемонстрировал задержку в 4,9 раза ниже, чем Red Hat OpenShift, при тестировании инструментом kube-burner. На уровне 99-го процентиля vSphere Kubernetes Service (VKS) оказался быстрее в 22,5 раза при одновременном поддержании почти пятикратно большего количества подов.
Методология тестирования
Оборудование: четыре сервера Dell PowerEdge R640 с идентичными процессорами, объёмом памяти и дисковой подсистемой на обеих платформах.
Инструмент тестирования:Kube-burner — открытый инструмент CNCF, разработанный преимущественно Red Hat, предназначенный для нагрузочного тестирования и оценки масштабируемости Kubernetes-кластеров.
Метод: инструмент kube-burner постепенно увеличивал количество подов в каждой среде вплоть до достижения максимальной стабильной плотности — точки, за которой дополнительные поды приводят к деградации производительности или нестабильности кластера.
Характер отказов:
Red Hat OpenShift: при превышении порогового количества подов рабочие узлы начинали переходить в состояние «Not Ready», что приводило к завершению работы подов и нестабильности кластера.
VCF 9.0: масштабирование продолжалось без нестабильности узлов; ограничением стало лишь приближение к уровням потребления памяти, влияющим на производительность.
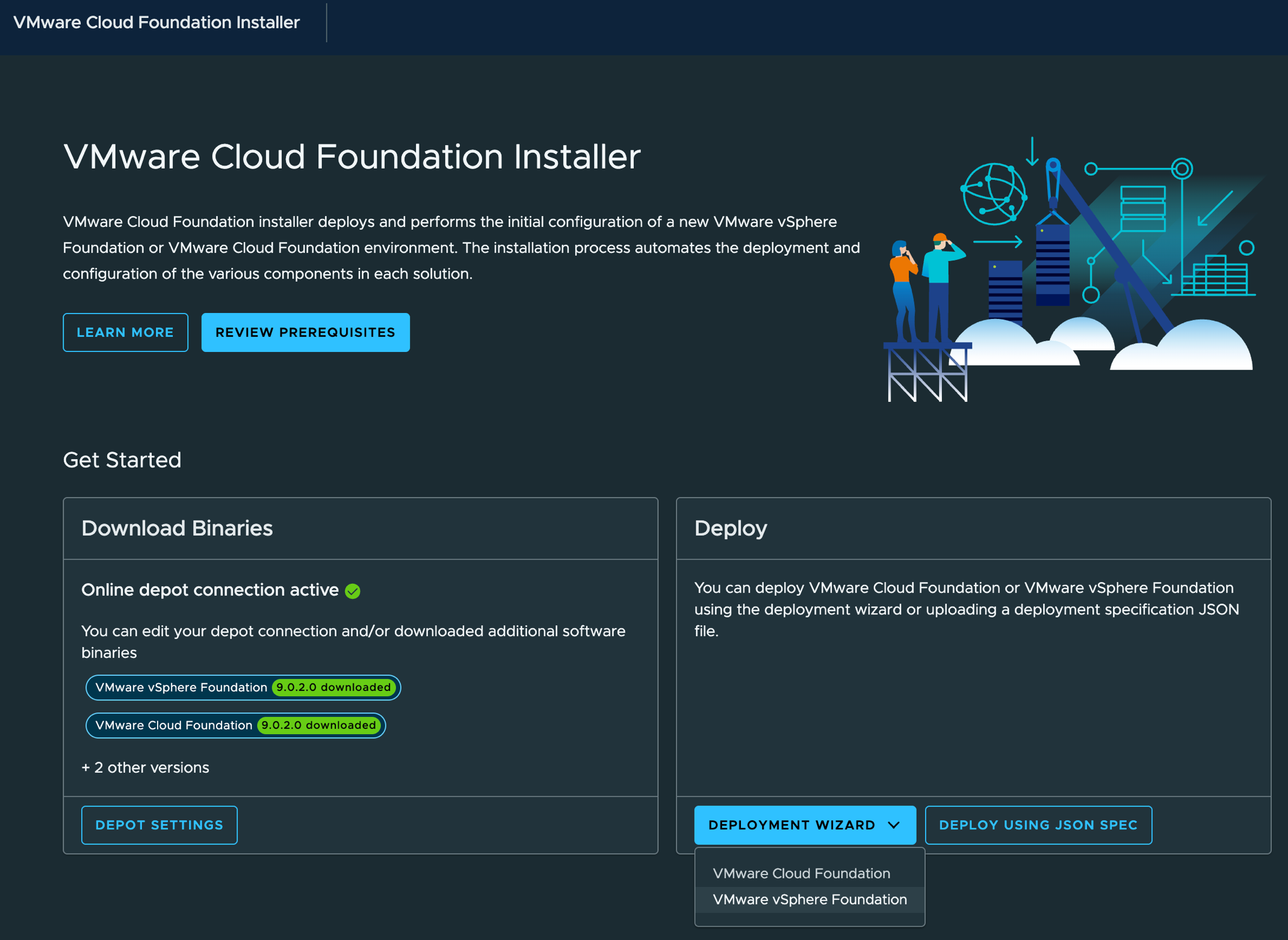
Несмотря на своё название, VCF Installer способен разворачивать как VMware Cloud Foundation (VCF), так и VMware vSphere Foundation (VVF). Многие ошибочно полагают, что установщик жёстко привязан к конкретному продукту в зависимости от имеющихся лицензий: VVF — для VVF-лицензий, VCF — для VCF-лицензий. На самом деле это не так.
VCF Installer не проверяет и не учитывает имеющиеся лицензии в момент развёртывания. Как VVF-, так и VCF-установки по умолчанию запускаются в режиме 90-дневного пробного периода. Лицензирование компонентов выполняется пользователем уже после завершения развёртывания — через VCF Operations, который обращается к Broadcom Business Service Console (BSC) для получения и применения соответствующих прав.
Гибкое развёртывание под разные сценарии
В зависимости от требований может возникнуть необходимость развернуть полный VCF-стек в основном дата-центре, а в региональном или граничном узле — только подмножество инфраструктурных компонентов. Один из типичных сценариев — развёртывание только компонентов VVF (VCF Operations, vCenter и ESX) с последующим лицензированием через VCF-права. Это полностью поддерживаемый вариант использования.
Конечно, отдельные компоненты можно развернуть вручную — через OVA VCF Operations и ISO-установщик vCenter. Однако VCF Installer предоставляет единый сквозной рабочий процесс: он разворачивает все компоненты VVF и автоматически их связывает. Весь процесс можно полностью автоматизировать, передав готовую JSON-конфигурацию.
Лицензирование через Broadcom BSC
После завершения развёртывания VCF Operations регистрируется в Broadcom Business Service Console (BSC), откуда получает и применяет соответствующие права — будь то VVF или VCF. Таким образом, выбор продукта при установке и применение лицензий — это два независимых этапа, которые не следует путать.
Отложенное развёртывание VCF Operations и VCF Automation
VCF Installer предоставляет дополнительную возможность — отложить развёртывание VCF Operations и/или VCF Automation. Это полезно, если требуется подключить их к альтернативным сетям (DVPGs или NSX-сегментам), отличным от Management Network, выбранной при начальной установке.
Часть организаций предпочитает отложить внедрение VCF Automation до того момента, когда они будут готовы перейти к современным методам доставки рабочих нагрузок через портал самообслуживания. В таком случае можно развернуть VCF-стек без VCF Automation, а позже добавить его как операцию Day-N через VCF Operations Fleet Manager.
Ключевой вывод
VCF Installer — крайне гибкий инструмент. Главное — не смешивать два разных понятия: тип развёртывания (VCF или VVF) и имеющиеся лицензионные права. Это две независимые вещи.
VCF Installer разворачивает как VCF, так и VVF вне зависимости от типа лицензий
Оба варианта запускаются с 90-дневным пробным периодом — до применения лицензий
Лицензии применяются через VCF Operations после развёртывания, через подключение к Broadcom BSC
Развёртывание VVF-компонентов с VCF-правами является полностью поддерживаемым сценарием
VCF Automation можно отложить и добавить позже как операцию Day-N
Полная автоматизация возможна через JSON-конфигурацию
Функция vSphere Configuration Profiles, впервые представленная в VMware vSphere 8.0, позволяет администраторам VMware Cloud Foundation управлять конфигурацией хостов ESX на уровне кластера. В данном материале рассматривается, чем эта функция отличается от Host Profiles, и как выполнить переход с Host Profiles на vSphere Configuration Profiles в vSphere 9.
Примечание: скриншоты и описанные шаги основаны на vSphere 9.0.2. В более ранних или более поздних версиях отдельные элементы интерфейса или формулировки могут отличаться.
О vSphere Configuration Profiles
vSphere Configuration Profiles — новая функция, впервые появившаяся в vSphere 8.0. Она является преемником Host Profiles в части управления конфигурацией хостов ESX в масштабе. Host Profiles неудобны тем, что требуют полного описания конфигурации хоста целиком. Это создаёт избыточную нагрузку на администраторов, которым, как правило, достаточно указать лишь те изменения, которые необходимо внести в конфигурацию.
vSphere Configuration Profiles, напротив, требует от администратора только определить отклонения от конфигурации по умолчанию. Это делает конфигурационный документ удобочитаемым и значительно более управляемым.
Переход с Host Profiles
Администраторы, управляющие конфигурацией хостов ESX с помощью Host Profiles в кластере, жизненный цикл которого управляется образами vSphere Lifecycle Manager, могут перевести кластеры на использование vSphere Configuration Profiles.
Примечание: использование vSphere Configuration Profiles с кластерами под управлением базовых уровней (baselines) поддерживается в vSphere 8 U3. Однако в vSphere 9 такие кластеры больше не поддерживаются, а Host Profiles считаются устаревшими, хотя и продолжают поддерживаться. Рекомендуется использовать кластеры под управлением образов vSphere Lifecycle Manager.
Перед переходом рекомендуется убедиться, что хосты ESX соответствуют текущему Host Profile. Ниже описан процесс перехода.
Управление конфигурацией на уровне кластера
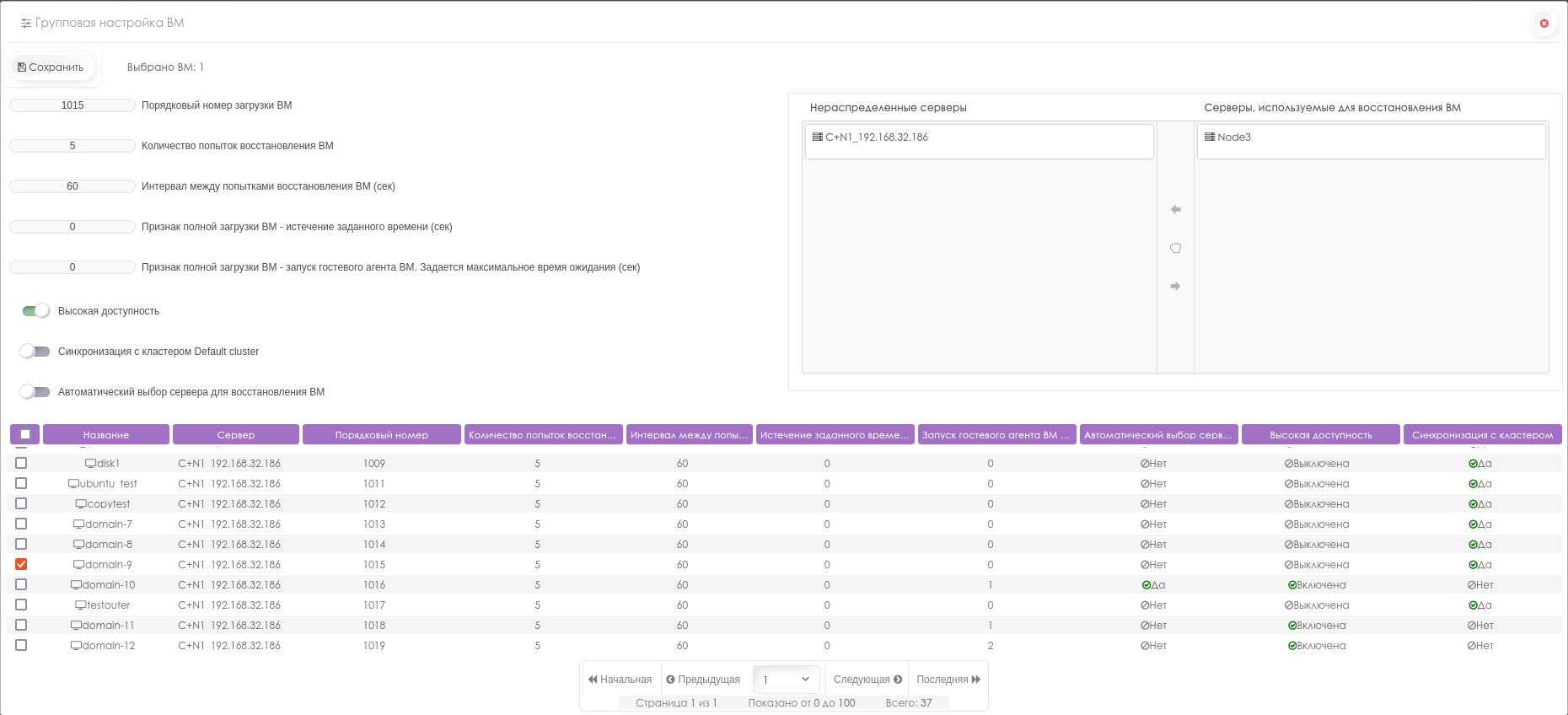
Первый шаг — включить vSphere Configuration Profiles в кластере. Для этого перейдите в Cluster > Configure > Configuration в разделе Desired State и нажмите Create Configuration. Будут запущены проверки совместимости, чтобы убедиться, что кластер может быть переведён на vSphere Configuration Profiles. На рисунке 1 показан вариант запуска vSphere Configuration Profiles в существующем кластере.
Примечание: если к кластеру прикреплён Host Profile, появится предупреждение о необходимости удалить его после завершения перехода. После перехода Host Profiles не могут быть прикреплены ни к кластеру, ни к хостам внутри него. Этот процесс можно использовать и в том случае, если Host Profiles в данный момент не применяются.
Создание конфигурации
Далее необходимо указать, каким образом конфигурация хоста ESX для vSphere Configuration Profiles должна быть импортирована. Доступны два варианта:
Импорт с эталонного хоста.
Импорт JSON-файла с желаемой конфигурацией кластера.
Поскольку выполняется переход кластера, управляемого с помощью Host Profiles, предпочтительным вариантом является IMPORT FROM REFERENCE HOST. В качестве эталонного хоста можно выбрать любой хост ESX в кластере — все хосты уже должны соответствовать используемому Host Profile.
Примечание: при импорте с эталонного хоста любые отклонения от его конфигурации будут зафиксированы как переопределения хоста. Возможно, потребуется вручную проверить конфигурацию и удалить эти переопределения, если необходима единая конфигурация для всех хостов кластера.
На рисунке 2 показаны варианты импорта. Нажмите Import.
На рисунке 3 показан выбор эталонного хоста.
После импорта нажмите Next. Процесс импорта проверяет сгенерированный документ относительно всех хостов ESX в кластере. После успешной проверки нажмите Next. На рисунке 4 показан этап проверки конфигурации.
Предварительная проверка и применение
На последнем шаге vSphere Configuration Profiles проверяет хосты ESX в кластере на соответствие желаемой конфигурации и устраняет любые отклонения, обнаруженные в ходе проверки.
Примечание: поскольку выполняется переход с кластера под управлением Host Profile, исправлений не ожидается. Ознакомьтесь с влиянием изменений конфигурации на хосты. Нажмите Finish and Apply. На рисунке 5 показан предварительный просмотр эффекта применения. Нажмите Continue.
После этого сгенерированный vSphere Configuration Profile будет установлен в качестве желаемой конфигурации кластера, а все несоответствующие хосты ESX будут приведены в соответствие. На рисунке 6 показан диалог подтверждения завершения и применения.
Функция vSphere Configuration Profiles теперь включена, и доступен просмотр заданных конфигураций. На рисунке 7 показано, что конфигурация на уровне кластера включена.
На рисунке 8 показано соответствие хостов конфигурации кластера.
На завершающем шаге необходимо отсоединить Host Profile от хостов ESX.
Итог
Управление конфигурациями ESX остаётся непростой задачей в корпоративных средах. vSphere Configuration Profiles — новая возможность, впервые представленная в vSphere 8.0, которая решает эту задачу в масштабе большой инфраструктуры.
Поскольку организации уделяют приоритетное внимание цифровой трансформации, они запускают смешанный набор приложений, используя как виртуальные машины, так и контейнеры для удовлетворения своих развивающихся инфраструктурных потребностей. Однако управление как традиционными, так и контейнерными приложениями создаёт сложность, операционную неэффективность и риски безопасности. Организациям необходима единая, упрощённая и безопасная платформа, которая соединит устаревшие и современные ИТ-среды.
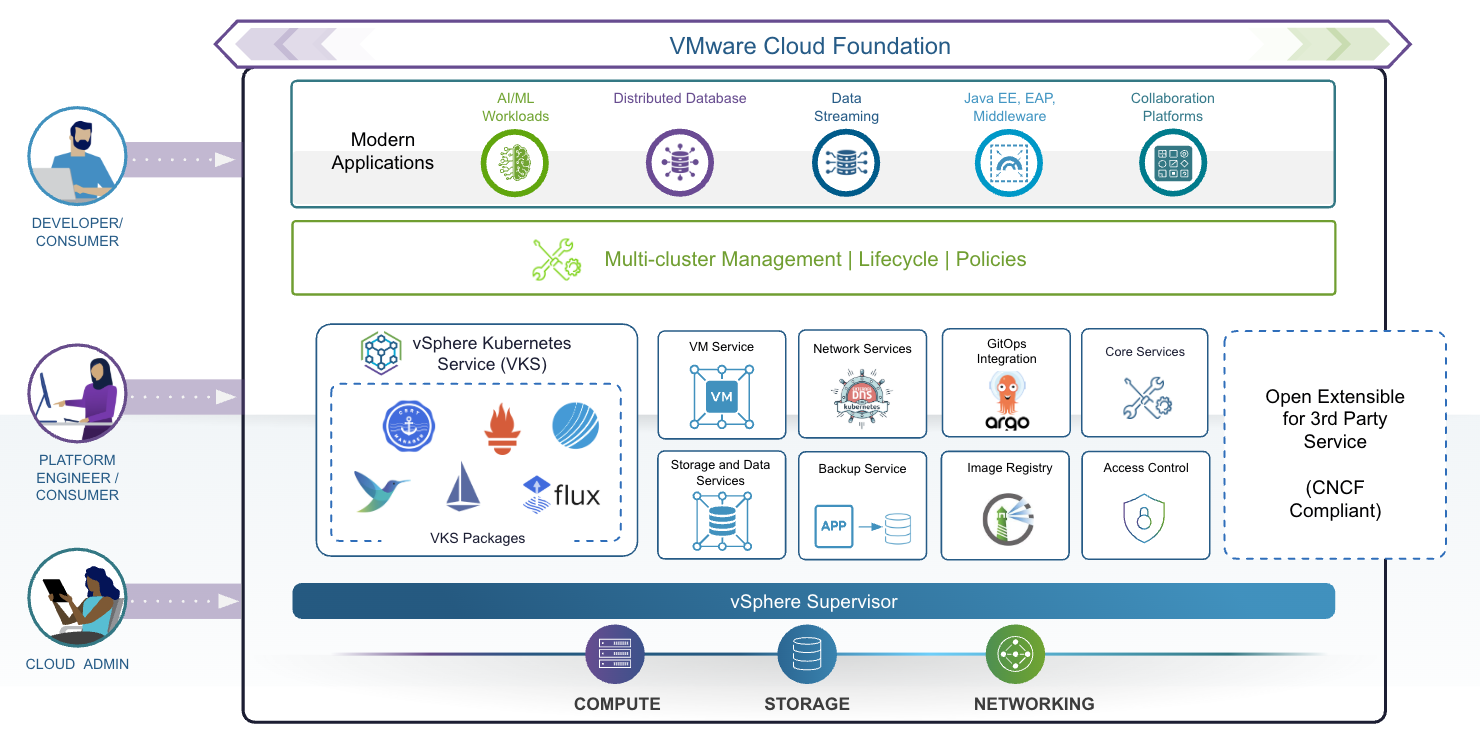
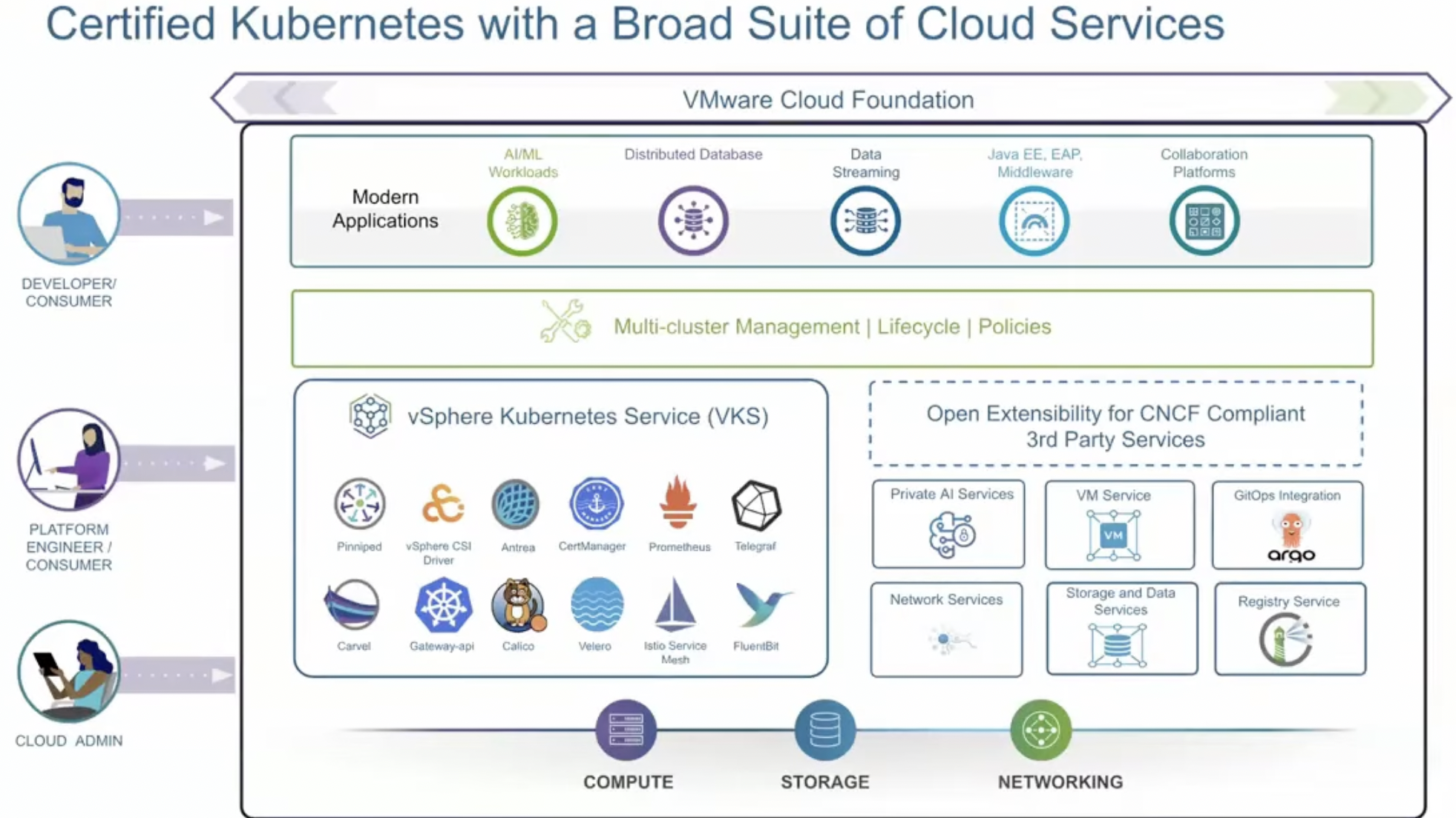
VMware Cloud Foundation (VCF) предлагает решение — VCF предоставляет единую платформу со встроенной средой выполнения Kubernetes, которая оркестрирует управление Kubernetes, позволяя предприятиям запускать современные приложения наряду с традиционными рабочими нагрузками, а также включает сертифицированный дистрибутив Kubernetes, соответствующий upstream-стандартам. С помощью vSphere Supervisor VCF предоставляет пользователям доступ к самообслуживанию для полного набора облачных сервисов «из коробки». Это работает в составе VMware vSphere Kubernetes Service (VKS), который используется для развертывания кластеров Kubernetes и включает совместимый выпуск Kubernetes, а также стандартный пакет ключевых компонентов OSS. VCF предоставляет облачным администраторам и платформенным инженерам выбор интерфейсов, включая GUI, CLI и API, что позволяет командам работать эффективно и продуктивно, вместо того чтобы тратить время на изучение новых наборов инструментов.
VMware недавно представила ключевые улучшения в работе Kubernetes на VCF 9.0. Независимо от того, модернизируете ли вы устаревшие приложения или масштабируете современные рабочие нагрузки, VCF 9.0 предлагает единую платформу для создания и эксплуатации всех ваших рабочих нагрузок в большом масштабе — безопасно и эффективно.
Единая платформа для виртуальных машин и контейнеров
VCF предоставляет единую платформу, которая поддерживает как устаревшие, так и современные рабочие нагрузки. Это позволяет организациям модернизировать все рабочие нагрузки единообразным способом с использованием последних инноваций Kubernetes.
Единый API для развёртывания и управления виртуальными машинами и контейнерами: единый API позволяет пользователям создавать, развёртывать и управлять как виртуальными машинами, так и кластерами Kubernetes. Это упрощает автоматизацию, снижает сложности интеграции и обеспечивает единые политики и средства безопасности для всех рабочих нагрузок. Благодаря единому API платформенные инженеры могут взаимодействовать с вычислительными ресурсами единообразно, устраняя необходимость в отдельных инструментах и снижая затраты на обучение.
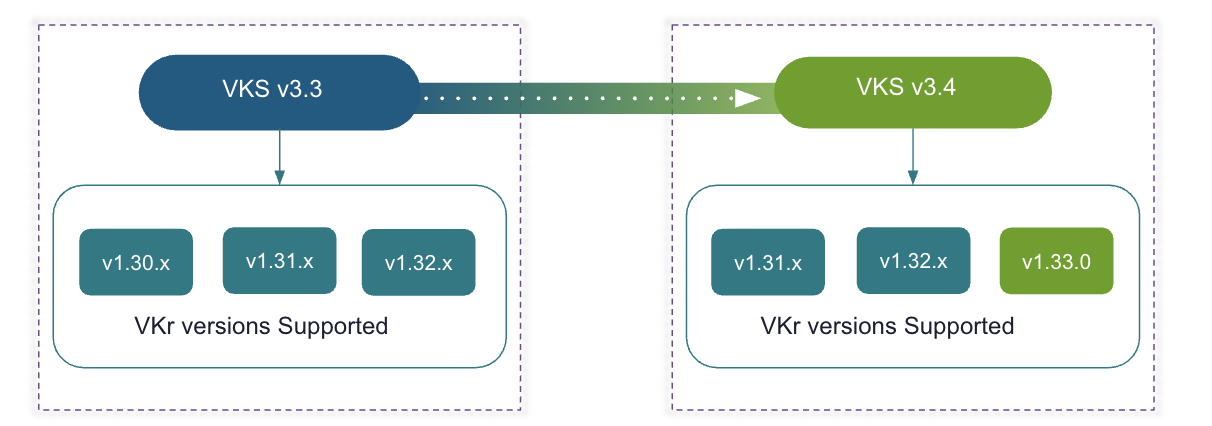
Сертифицированный релиз Kubernetes, соответствующий upstream, с независимой возможностью обновления: VCF использует полностью соответствующий upstream-дистрибутив Kubernetes, сертифицированный Cloud Native Computing Foundation (CNCF). Эта сертификация подтверждает, что реализация Kubernetes в vSphere соответствует программе Kubernetes Conformance Program, которая проверяет upstream API Kubernetes, рабочие нагрузки и инструменты экосистемы. Например, после обновления до VKS 3.4 вы сможете создавать и управлять кластерами Kubernetes с использованием последнего релиза vSphere Kubernetes 1.33, синхронизированного с последним релизом сообщества.
Поддержка N-2 версий Kubernetes для гибкого развертывания: VKS поддерживает текущий релиз Kubernetes и две предыдущие основные версии. Это означает, что VKS обеспечивает совместимость сразу с тремя версиями Kubernetes в любой момент времени, что позволяет различным корпоративным командам использовать ту версию, которая необходима их приложениям, а также иметь контроль и гибкость для обновления в собственном темпе.
Упрощённые и эффективные операции
VCF снижает операционную сложность, повышает гибкость управления и позволяет командам оптимизировать распределение ресурсов между различными средами.
Самообслуживание для доступа к облачным сервисам с управлением и контролем: благодаря модели доступа на основе ролей платформенные инженеры могут использовать возможности самообслуживания для выделения инфраструктурных ресурсов (вычислительные, хранилища и сети) и набора расширенных облачных сервисов в vSphere Supervisor, таких как VM Service, Network Services и Image Registry, по требованию, в то время как облачные администраторы сохраняют управление и контроль с помощью политик и квот ресурсов. Доступ по модели самообслуживания также поддерживает multi-tenancy с изолированными средами для разных команд и проектов.
Независимое обновление vSphere Supervisor: VMware Cloud Foundation 9.0 предоставляет облачным администраторам дополнительную гибкость, позволяя обновлять vSphere Supervisor независимо от обновления vCenter. Благодаря асинхронным обновлениям снижается операционная сложность и обеспечивается большая гибкость для ИТ-команд в поддержании актуальности сред Kubernetes при сохранении стабильности всей инфраструктуры.
Автомасштабирование кластеров Kubernetes: улучшения автомасштабирования позволяют динамически изменять количество рабочих узлов на основе метрик в реальном времени, обеспечивая как производительность, так и эффективность. Благодаря поддержке возможностей scale-down-to-zero и scale-up-from-zero кластеры могут автоматически уменьшаться до нуля рабочих узлов в периоды простоя и бесшовно масштабироваться вверх при возобновлении нагрузки. Такая масштабируемость по требованию оптимизирует использование инфраструктуры, снижает операционные затраты и обеспечивает выделение ресурсов только тогда, когда это необходимо.
Workload zones для оптимизации распределения ресурсов: VCF 9.0 вводит повышенную гибкость благодаря зонам рабочих нагрузок (workload zones), позволяя облачным администраторам определять и управлять ими независимо, чтобы лучше согласовывать инфраструктурные ресурсы с требованиями рабочих нагрузок. vSphere Namespaces поддерживают как однозонные, так и многозонные конфигурации, что упрощает удовлетворение различных требований высокой доступности и сценариев аварийного восстановления. Облачные администраторы также могут расширять инфраструктуру частного облака, добавляя специализированные зоны, например выделяя ресурсы для нагрузок с интенсивным использованием GPU, что обеспечивает больший контроль, оптимизированное использование ресурсов и повышенную гибкость для различных развертываний.
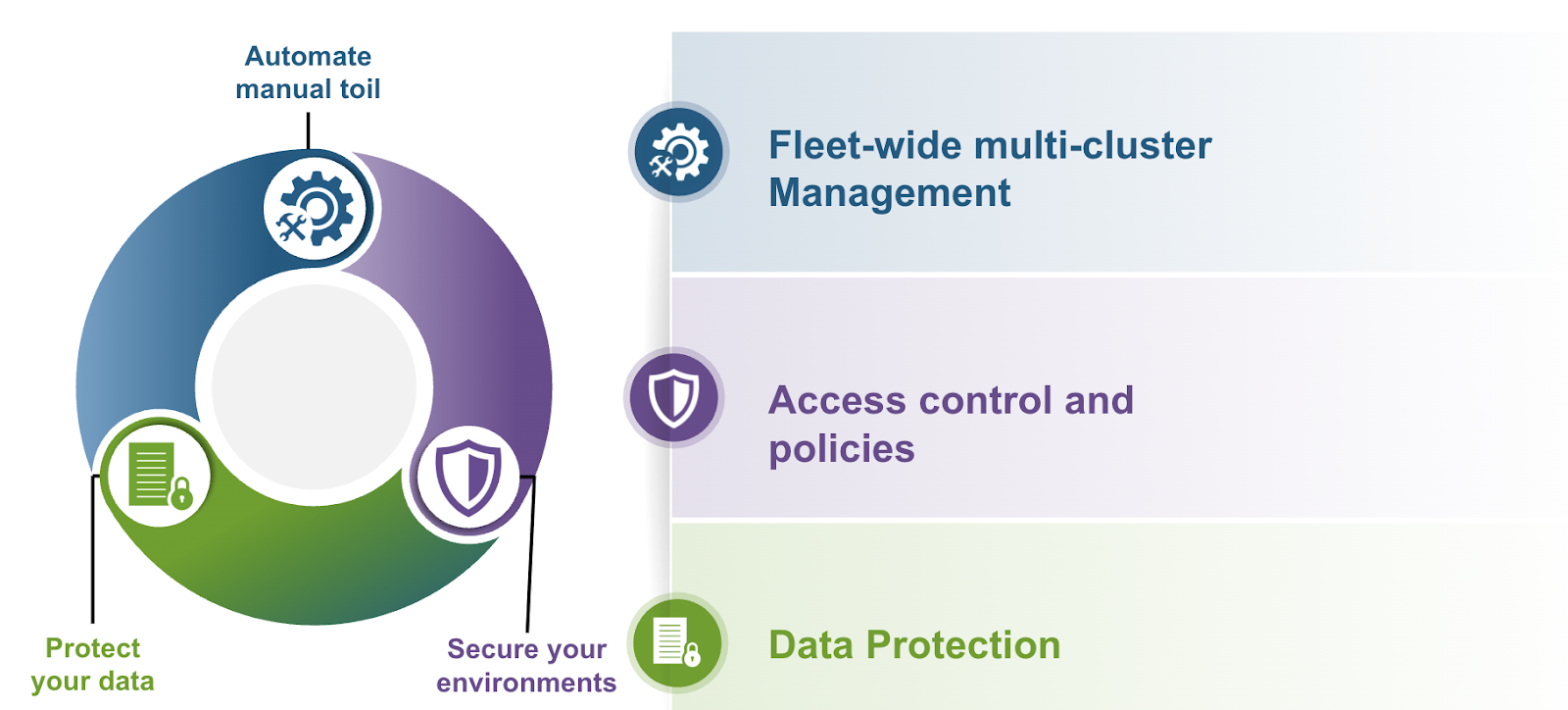
Интеграция управления кластерами VKS: управление кластерами VKS позволяет облачным администраторам эффективно управлять кластерами и группами кластеров в различных средах. Благодаря встроенным возможностям, таким как управление несколькими кластерами на уровне всей инфраструктуры (fleet-wide multicluster management) и детализированный контроль доступа, команды могут ускорить развертывание, снизить операционную сложность и обеспечить единообразную конфигурацию. Такой унифицированный подход упрощает операции Day 2 и усиливает управление и контроль всей инфраструктуры Kubernetes.
Повышенная безопасность
VCF интегрирует встроенные функции безопасности для последовательной защиты рабочих нагрузок, что позволяет организациям снижать риски и улучшать общий уровень безопасности.
Встроенная высокая доступность и надежность: VCF обеспечивает встроенную высокую доступность и надежность не только для виртуальных машин, но и для современных рабочих нагрузок. Благодаря интеграции VKS, VCF гарантирует, что контейнеризированные приложения получают те же возможности корпоративного уровня по обеспечению отказоустойчивости, такие как vSphere HA. vSAN предоставляет политики постоянного хранения, адаптированные для stateful-нагрузок Kubernetes, а NSX обеспечивает сетевую доступность и безопасное соединение между кластерами. Благодаря унифицированному управлению жизненным циклом VCF поддерживает стабильное время безотказной работы и операционную устойчивость как для виртуальных машин, так и для контейнеров, работающих на надежной инфраструктуре.
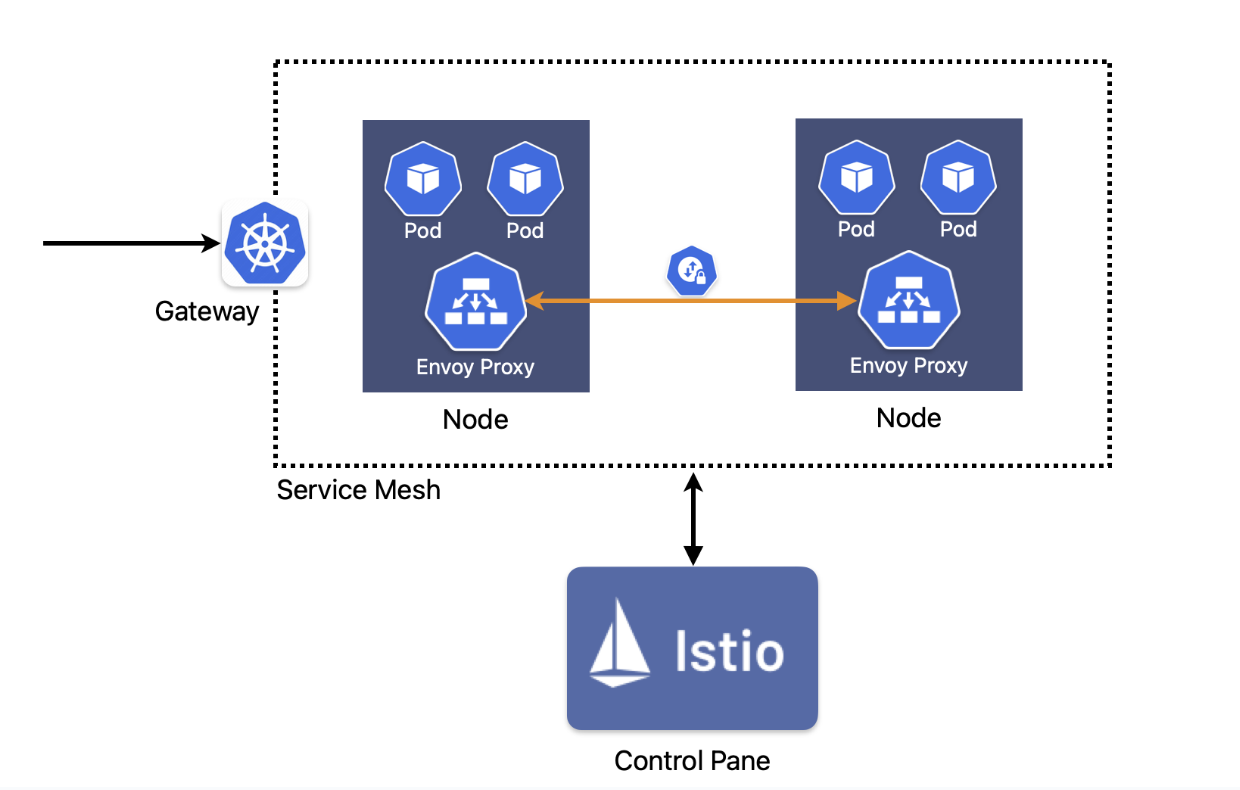
Интеграция Istio Service Mesh: предоставляет расширенные возможности, такие как обнаружение сервисов, безопасное взаимодействие сервисов друг с другом, маршрутизация трафика и балансировка нагрузки, а также применение политик через интегрированные инструменты наблюдаемости. Благодаря таким функциям, как ingress и egress шлюзы, внедрение сбоев (fault injection), ограничение скорости запросов (rate limiting) и поддержка архитектуры нулевого доверия (zero-trust), Istio Service Mesh позволяет платформенным командам управлять сложными средами микросервисов с прозрачностью, отказоустойчивостью и соответствием требованиям, одновременно упрощая операционные процессы между кластерами Kubernetes.
Режим OS FIPS для соответствия требованиям: новая опция конфигурации добавляет поддержку включения режима FIPS на уровне операционной системы, обеспечивая использование только криптографических модулей, прошедших валидацию FIPS, для соответствия строгим требованиям безопасности и комплаенса. Это улучшение даёт облачным администраторам гибкость в применении режима FIPS как для Linux, так и для Windows кластеров рабочих нагрузок, приводя среды Kubernetes в соответствие с федеральными и отраслевыми стандартами безопасности при сохранении операционного контроля над уровнем безопасности.
Расширенная поддержка: в дальнейшем VMware планирует предоставлять Extended Support для определённых версий релизов vSphere Kubernetes (VKr), делая поддержку доступной в течение 24 месяцев с момента GA. Это позволит клиентам VCF оставаться на одной минорной версии Kubernetes значительно дольше, если это необходимо. Первым релизом с расширенной поддержкой станет VKr 1.33.
Кроме этого, что еще делает VCF таким особенным для запуска контейнеризированных рабочих нагрузок? VCF делает контейнеры полноценными участниками инфраструктуры наравне с виртуальными машинами, глубоко интегрируя Kubernetes в основной стек инфраструктуры с единым управлением жизненным циклом и рассматривая контейнеризированные рабочие нагрузки с тем же операционным приоритетом, управляемостью и функциональностью, что и виртуальные машины. В VCF контейнеры запускаются внутри виртуальных машин. Такая архитектура повышает безопасность за счёт дополнительного сильного уровня изоляции между рабочими нагрузками, при этом позволяя предприятиям применять существующие инструменты безопасности, политики соответствия требованиям и контроль доступа ко всем рабочим нагрузкам.
Многие VMware-инфраструктуры сегодня находятся в переходной стадии: организации продолжают использовать
vSphere-кластеры, но постепенно переходят к модели Software-Defined Data Center и частного облака на базе VMware Cloud Foundation (VCF).
Полностью перестраивать инфраструктуру с нуля в производственной среде обычно невозможно. Там уже работают
десятки или сотни виртуальных машин, поэтому перенос на новую платформу должен происходить максимально
аккуратно. Именно для таких сценариев VMware предлагает механизм Brownfield-интеграции.
Этот подход позволяет смигрировать существующую инфраструктуру vSphere на VMware Cloud Foundation без
переустановки среды и без миграции виртуальных машин. Подробно этот процесс рассмотрел Tarsio Moraes в своем видео:
Что такое Brownfield-апгрейд
Brownfield-подход означает интеграцию уже существующей инфраструктуры в новую платформу без полного
развертывания новой среды.
В VMware-экосистеме это означает, что существующий vCenter Server,
кластеры ESX и запущенные виртуальные машины могут быть импортированы
в VCF как отдельный Workload Domain.
Таким образом инфраструктура сохраняет текущие рабочие нагрузки, но получает централизованное управление,
автоматизированное lifecycle-обновление и интеграцию сетевой платформы NSX.
Архитектура до и после интеграции
Исходная инфраструктура
Типичная среда включает vSphere 8, один или несколько кластеров ESXi,
vCenter Server и систему хранения — например vSAN или внешние датасторы.
Сетевая конфигурация обычно построена на распределенном коммутаторе Distributed Switch.
В такой архитектуре управление вычислениями, сетью и мониторингом может
осуществляться через разные инструменты.
После интеграции в VCF
После импорта инфраструктура становится частью платформы VMware Cloud Foundation.
Появляется централизованное управление через компоненты VCF, а инфраструктура
разделяется на management domain и workload domains.
Также стоит учитывать изменения в продуктовой линейке VMware:
многие функции бывшей линейки Aria теперь встроены непосредственно в VMware Cloud Foundation (как функционал модуля Operations).
Подготовка инфраструктуры
Перед запуском Brownfield-апгрейда необходимо убедиться,
что инфраструктура соответствует требованиям совместимости.
В первую очередь проверяются версии компонентов:
vSphere, vCenter Server и ESXi (теперь он снова называется ESX). Кроме того,
важно убедиться в совместимости оборудования через VMware Compatibility Guide.
Также необходимо проверить базовые инфраструктурные сервисы:
DNS, NTP, доступность сетей управления и состояние датасторов.
Особенно важно убедиться, что DNS корректно разрешает имена
хостов ESX, vCenter и будущих узлов NSX Manager.
Подготовка среды управления
Перед импортом vSphere-среды необходимо подготовить управляющие компоненты VMware Cloud Foundation.
К ним относятся VCF Fleet Management и VCF Operations.
Эти сервисы отвечают за централизованное управление инфраструктурой,
мониторинг и lifecycle-операции.
На этом этапе стоит проверить доступность management-компонентов,
валидность сертификатов и сетевую связность между сервисами управления и vCenter.
Использование VCF Import Tool
Для интеграции существующей среды используется специальный инструмент —
VCF Import Tool.
Он анализирует конфигурацию vSphere,
выполняет проверку совместимости и подготавливает инфраструктуру к импорту.
Перед запуском процесса выполняется серия pre-check проверок,
которые анализируют сеть, лицензии, сертификаты, конфигурацию кластеров
и параметры хранения.
Если обнаружены ошибки или предупреждения, их необходимо устранить
до начала импорта.
Импорт vCenter как Workload Domain
После завершения подготовительных этапов можно приступать к импорту
существующего vCenter.
В интерфейсе VCF создаётся новый workload domain,
после чего указываются параметры подключения к существующему vCenter.
После проверки параметров запускается автоматический рабочий процесс (workflow),
который выполняет регистрацию vCenter в инфраструктуре VCF.
С этого момента среда становится частью VMware Cloud Foundation.
Развертывание NSX
Следующий этап — интеграция сетевой платформы NSX.
Если NSX ранее не использовался, VMware Cloud Foundation может автоматически
развернуть NSX Manager cluster и подготовить хосты ESX.
Если NSX уже установлен в инфраструктуре,
он может быть импортирован вместе с workload domain.
Пост-апгрейд проверки
После завершения интеграции необходимо провести проверку состояния среды.
Стоит убедиться, что workload domain корректно отображается
в интерфейсе VCF, хосты ESX подключены,
датасторы доступны, а виртуальные машины работают без ошибок.
Дополнительно рекомендуется протестировать ключевые операции виртуализации:
vMotion, создание снапшота и сетевую связность между виртуальными машинами.
Итог
Brownfield-апгрейд позволяет перевести существующую инфраструктуру
vSphere 8 в модель VMware Cloud Foundation 9 без полного
перестроения среды.
Этот подход сохраняет текущие рабочие нагрузки,
централизует управление инфраструктурой
и позволяет постепенно перейти к архитектуре частного облака.
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.
vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
Требования к оборудованию и сети
Варианты развертывания кластеров
Масштабирование и отказоустойчивость
Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
General Information — общая информация о vSAN
Express Storage Architecture (ESA)
Availability — отказоустойчивость
Cloud-Native Storage
vSAN File Services
vSAN Storage Clusters (disaggregated storage)
Stretched clusters и 2-node clusters
Networking
Capacity и Space Efficiency
Operations
Performance
Security
vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.
Все ИТ-нагрузки, независимо от форм-фактора или назначения, требуют инфраструктуры. В любой момент времени на планете существует конечное количество кремниевых чипов, и распределение рабочих нагрузок, которые на них работают, постоянно меняется. Однако текущая тенденция форм-факторов нагрузок хорошо известна и может быть представлена следующим образом (точные цифры могут отличаться):
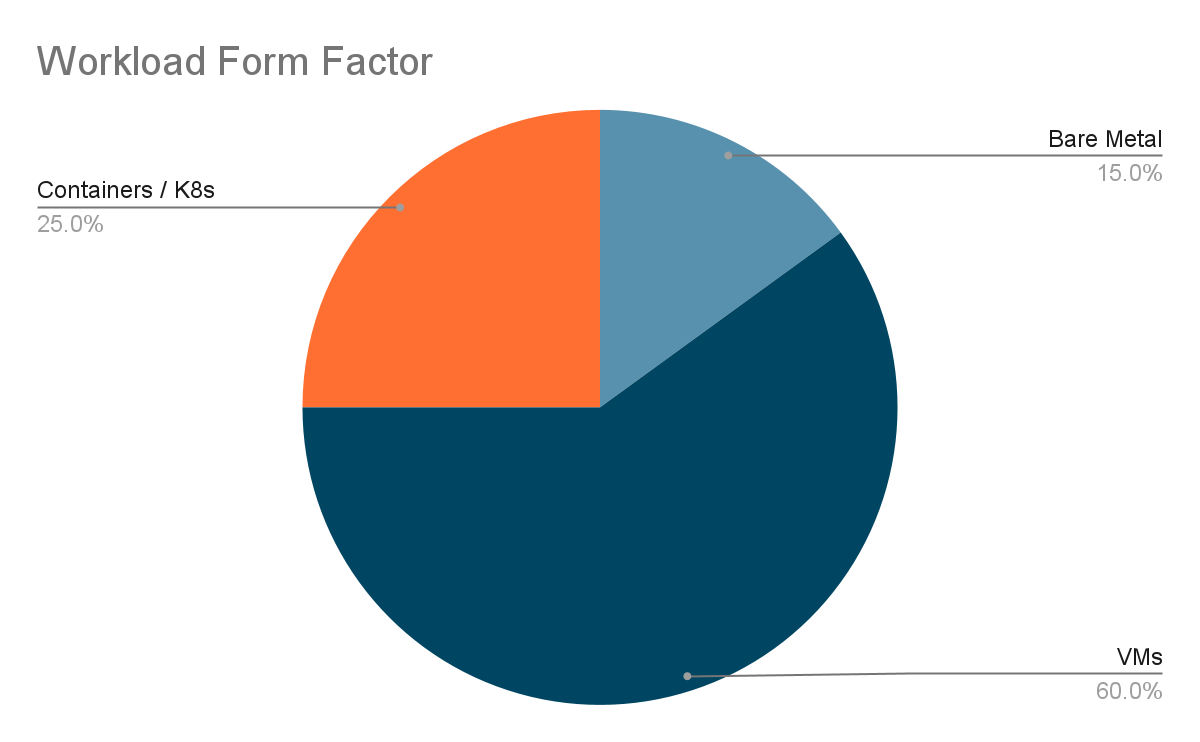
Текущее состояние (февраль 2026)
Bare Metal (прямо на «железе»): ~15%
Виртуализованные (работают в виртуальных машинах): ~60%
Контейнеры + Kubernetes: ~25%*
* До 85% контейнерных / Kubernetes-нагрузок работают поверх виртуальных машин — подробнее об этом можно прочитать в отчете IDC.
Будущее (2030+)
Bare Metal (прямо на «железе»): ~5%
Виртуализованные (работают в виртуальных машинах): ~30%
Контейнеры + Kubernetes: ~65%*
* Ожидается, что более 85% контейнерных / Kubernetes-нагрузок в 2030+ будут работать поверх виртуальных машин. Цифры основаны на данных, представленных в том же отчете IDC.
Что движет этой тенденцией?
Существует множество подтверждений этой тенденции — модернизация приложений, рост зрелости DevOps-подходов в организациях и трансформация в сторону облачных моделей. Эти процессы продолжаются практически во всех компаниях. Кроме того, ожидается резкий рост общего числа новых рабочих нагрузок из-за влияния генеративного AI. Большинство таких приложений создаются по принципам cloud-native разработки и требуют современной инфраструктуры и операционной стратегии, чтобы их можно было надежно запускать и управлять ими в производственной среде.
Никогда прежде людям не было так легко создавать новый код, который решает конкретные задачи — а новый код требует инфраструктуры: вычислительных ресурсов, сетей и хранилищ.
Подготовка инфраструктуры, установка обновлений, патчинг, усиление безопасности, оптимизация и перераспределение ресурсов становятся приоритетом для ИТ-руководителей и инженеров.
Гиперскейлеры предложили и реализовали решение этой проблемы, взяв на себя значительную часть операций жизненного цикла инфраструктуры. Однако опасения, связанные со стоимостью, соответствием требованиям и суверенитетом данных, становятся ключевыми факторами так называемого “перезапуска частного облака” (Private Cloud Reset).
Отрасль находится в точке перелома
Когда руководители оценивают потенциальных партнёров для построения стратегии частного облака, им приходится балансировать между двумя задачами: поддерживать и оптимизировать критически важные приложения и инфраструктуру, и одновременно экспериментировать и внедрять новые технологии и типы нагрузок.
Естественно, организации ищут платформы, которые предоставляют единую среду, стандартизирующую операции для рабочих нагрузок, работающих как в виртуальных машинах, так и в контейнерах. Уже десятилетиями индустрия доверяет VMware vSphere как основной платформе виртуализованной инфраструктуры для критически важных нагрузок.
Развивая vSphere и серверную виртуализацию, с появлением платформы VMware Cloud Foundation (VCF) компания Broadcom закрыла разрыв возможностей, который индустрия наблюдала между операциями в публичных облаках и традиционными ИТ-средами. При этом были сохранены преимущества локальной инфраструктуры: контроль стоимости и ресурсов, кастомизация, безопасность, приватность и соответствие требованиям.
Kubernetes как полноценная часть частного облака
В среде VCF Kubernetes является полноценным элементом современной частной облачной платформы. Решения Kubernetes, добавленные поверх инфраструктурного слоя как отдельные надстройки, неизбежно заставляют администраторов и платформенных инженеров разбираться с зависимостями и устранять проблемы абстракций инфраструктуры вместо того, чтобы сосредоточиться на задачах, создающих бизнес-ценность.
VMware vSphere Kubernetes Service (VKS) является нативной частью VCF и позволяет быстро разворачивать полностью соответствующие стандартам Kubernetes-кластеры по требованию.
VCF абстрагирует инфраструктуру и делает её доступной через API, предоставляя богатый набор cloud-native сервисов и пакетов вместе с долгосрочной корпоративной поддержкой (LTS). Все рабочие нагрузки — будь то на виртуальных машинах или в контейнерах — могут быстро разворачиваться, оптимизироваться, обновляться и мониториться с использованием одних и тех же инструментов и процессов.
Результаты
Результаты говорят сами за себя. На сегодняшний день более 90% из 10 000 крупнейших клиентов VMware приобрели VCF, включая 9 из 10 крупнейших компаний списка Fortune. Такие компании, как Audi, ING Bank, Lloyds Banking Group и Walmart, внедряют VCF и расширяют сотрудничество с Broadcom.
Собственные ИТ-команды Broadcom также внедрили эту технологию и облачную операционную модель, чтобы:
Консолидировать дата-центры и инструментарий
Повысить общую надежность систем
Ускорить выделение инфраструктуры и приложений
Снизить расходы
Что особенно важно — количество управляемых рабочих нагрузок в ИТ-инфраструктуре Broadcom увеличилось во время этой трансформации в сторону частного облака.
Что нужно современным предприятиям
Компаниям необходимо быстро развиваться, контролировать расходы и защищаться от угроз. Им нужна гибкость облака, но при этом важно использовать инструменты и навыки, на которых ИТ-команды строили свою карьеру.
Десятилетиями предприятия полагались на vSphere для работы своего бизнеса и видят будущее в единой платформе частного облака, которая способна поддерживать все типы рабочих нагрузок и обеспечивать современную модель облачного потребления и эксплуатации.
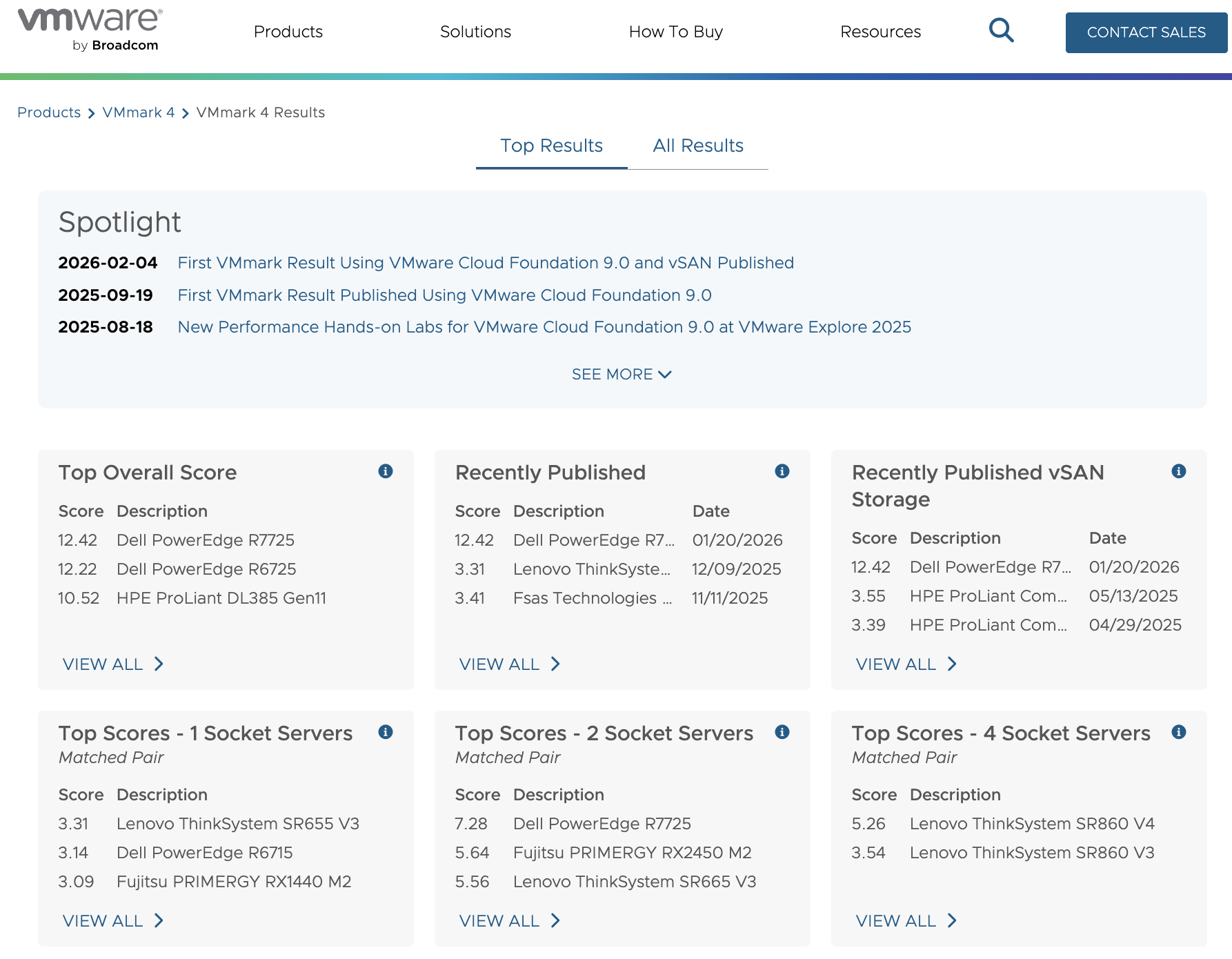
Компания VMware продолжает развитие своей платформы для частных облаков — VMware Cloud Foundation (VCF) 9.0. Недавно опубликованы первые результаты производительности с использованием бенчмарка VMmark 4, выполненные на базе VCF 9.0 с встроенным программно определяемым хранилищем VMware vSAN. Этот результат стал важной вехой для оценки возможностей платформы в реальных условиях нагрузки, демонстрируя, что VCF 9.0 способна эффективно масштабировать инфраструктуру частного облака с помощью современного оборудования и передовых технологий.
Что такое VMmark 4, и зачем он нужен
VMmark 4 — это кластерный бенчмарк VMware, предназначенный для измерения производительности и масштабируемости виртуализированных сред. В отличие от синтетических тестов, VMmark моделирует реальные корпоративные рабочие нагрузки:
базы данных
веб-серверы
почтовые системы
application-серверы
файловые сервисы
Нагрузка масштабируется в единицах tiles — каждый tile представляет собой комплекс виртуальных машин с типовым профилем предприятия. Итоговый показатель (VMmark Score) отражает способность кластера обслуживать увеличивающееся число рабочих нагрузок при сохранении SLA по производительности.
Тестовая конфигурация: ключевые компоненты
Для испытаний использовалась конфигурация, включающая новейшие аппаратные и программные компоненты:
Программное обеспечение: VMware Cloud Foundation 9.0.1.0 .
vSAN 9 ESA: программное хранилище уровня предприятия с оптимизированной архитектурой Express Storage Architecture.
NSX: сетевые сервисы и безопасность для виртуальной инфраструктуры.
Operations: мониторинг, аналитика и автоматизация облачных ресурсов.
Главная цель VCF — упростить развёртывание и управление частными облаками с уровня инфраструктуры до сервисов, при этом обеспечивая масштабируемость, производительность и возможность автоматизации.
Результат тестирования
Для объективного сравнения использовалась идентичная вычислительная платформа (AMD EPYC 9965, суммарно 1536 физических ядер кластера), но две разные подсистемы хранения:
vSAN 9.0 ESA (All-Flash, NVMe)
Классический FC SAN (Dell PowerMax 8000)
Таблица результатов:
Версия VCF
Тип хранилища
Процессор
Всего ядер
VMmark 4 Score
9.0.1.0
vSAN 9.0 ESA (All-Flash)
AMD EPYC 9965
1536
12.42 @ 15.4 tiles
9.0.0.0
FC SAN (Dell PowerMax 8000)
AMD EPYC 9965
1536
12.22 @ 14 tiles
Интерпретация результатов:
Tiles — это масштабируемые блоки нагрузки в VMmark 4. Каждый tile представляет набор типовых корпоративных рабочих нагрузок (Web, DB, Mail, Application Server и др.).
Значение 15.4 tiles означает более высокий уровень масштабирования кластера.
Итоговый показатель 12.42 — агрегированный производительный балл, учитывающий пропускную способность и latency.
Главный вывод - конфигурация с vSAN 9.0 ESA продемонстрировала:
Большее число поддерживаемых tiles (15.4 против 14 для FC)
Более высокий итоговый Score
Лучшую масштабируемость без использования внешнего SAN-массива.
Это подтверждает, что современная архитектура vSAN ESA в составе VCF 9.0 способна не только конкурировать с традиционными FC-решениями, но и превосходить их при одинаковой вычислительной базе.
Заключение
Новый VMmark 4 результат, полученный на VMware Cloud Foundation 9.0 с vSAN, подтверждает:
Высокую производительность и масштабируемость платформы.
Превосходство программно-определяемого хранения (vSAN) над традиционными SAN в современных конфигурациях.
Готовность VMware VCF 9.0 к использованию в масштабных частных облаках и корпоративных средах.
Для инженеров и архитекторов частных облаков это подтверждение того, что VCF 9.0 + vSAN — это не только удобная абстракция управления, но и мощная вычислительная платформа с высокими показателями эффективности.
По мере того как внедрение Kubernetes в корпоративной среде становится более зрелым, задачи, с которыми сталкиваются команды платформ, изменились. Развертывание кластеров больше не является основной проблемой. Настоящая работа начинается после первого дня: безопасное обновление кластеров, предсказуемая эксплуатация и поддержка нагрузок, таких как базы данных и регулируемые приложения, без хрупких скриптов или разовых исключений.
В последнем выпуске VMware vSphere Kubernetes Service (VKS) 3.6 в команде VMware сосредоточились именно на этих аспектах. Вместо того чтобы представлять длинный список несвязанных функций, этот релиз развивает платформу по нескольким ключевым операционным направлениям, которые действительно важны для платформенных инженеров и администраторов, запускающих Kubernetes в промышленной эксплуатации в крупном масштабе.
Кратко: что нового в VKS 3.6
VKS 3.6 включает улучшения в области корпоративной эксплуатации, производительности и гибкости экосистемы:
Открытая и расширяемая сетевая экосистема – поддерживаемый путь для партнерских сетевых дополнений позволяет плагинам Container Network Interface (CNI) нативно интегрироваться с VKS, оставаясь в рамках жизненного цикла и поддержки.
Настройка производительности для ресурсоемких по данным и чувствительных к задержкам нагрузок – декларативные профили TuneD позволяют безопасно настраивать параметры ядра и sysctl для баз данных и высокопроизводительных приложений без неподдерживаемых изменений на хостах.
Выбор корпоративной ОС с поддержкой RHEL – узлы на базе Red Hat Enterprise Linux (RHEL), включая кластеры со смешанными операционными системами.
Kubernetes 1.35, созданный для корпоративной эксплуатации
VKS 3.6 добавляет поддержку Kubernetes версии 1.35, продолжая обязательство Broadcom по предоставлению Kubernetes с сертификацией CNCF, предназначенного для корпоративного использования. Как и в предыдущих релизах, Broadcom предоставляет расширенную поддержку на 24 месяца для каждой версии Kubernetes с перекрывающейся поддержкой версий. Это позволяет крупным организациям переводить команды на новые версии в собственном темпе, не вынуждая выполнять массовые обновления всего парка или проводить сжатые окна обслуживания.
Некоторые заметные нововведения в выпуске Kubernetes 1.35 включают:
Настраиваемая параллельность для поэтапных обновлений StatefulSet с параметром maxUnavailable – теперь платформенные команды могут одновременно выводить из работы несколько Pod’ов во время обновлений StatefulSet, контролируя уровень нарушения работы для stateful-нагрузок и сокращая время развертывания.
Улучшенная осведомленность о топологии для нагрузок – приложения могут безопасно использовать информацию о топологии узлов, повышая понимание своего расположения в инфраструктуре, что полезно для чувствительных к задержкам и ресурсоемких по данным приложений.
Модернизированные основы хранения данных – такие усовершенствования, как тома на основе OCI, делают потребление хранилища в Kubernetes более согласованным с контейнерно-ориентированными моделями поставки.
В то же время Kubernetes продолжает удалять или объявлять устаревшими некоторые функции. VKS следует срокам устаревания upstream-версии, при этом предоставляя расширенную поддержку и четкие пути миграции, давая платформенным командам время на адаптацию без внезапных сбоев. Такой баланс сохраняет соответствие upstream-версии, избегая при этом разрушительных и массовых неожиданностей.
Более плавные обновления и более безопасные операции второго дня
Именно в процессе обновлений платформы Kubernetes чаще всего испытывают наибольшую нагрузку. На практике сбои при обновлении редко вызваны самим Kubernetes, а чаще конфигурацией и интеграциями. Политики, admission webhooks, а также инструменты безопасности или управления могут непреднамеренно блокировать операции жизненного цикла.
Развивая ранее внедренные предварительные проверки PodDisruptionBudget, VKS 3.6 расширяет проверки готовности к обновлению, чтобы выявлять распространенные конфликты конфигурации до начала обновления. Вместо обнаружения блокирующих факторов в середине процесса обновления платформенные команды могут заранее выявить и устранить проблемы до окна обслуживания, снижая количество неудачных обновлений и незапланированных сбоев. Эти проверки выполняются непрерывно, выявляя риски обновления через условие SystemCheckSucceeded, а не только во время выполнения обновления.
В результате — меньше неожиданностей при обновлении, более ранние предупреждения и более надежные операции второго дня без риска непредвиденной потери данных.
Производительность и ресурсоемкие по данным нагрузки
Запуск баз данных и других stateful-платформ в Kubernetes часто требует настройки ядра и параметров узлов, выходящих за пределы стандартных значений. Во многих средах команды полагались на ручные изменения узлов или специально собранные образы для удовлетворения этих требований. В моделях управляемого Kubernetes такие изменения, как правило, должны быть выражены декларативно (например, через утвержденные механизмы конфигурации, привилегированные DaemonSet’ы или стандартизированные образы), чтобы сохраняться при обновлениях и замене узлов.
VKS 3.6 вводит поддерживаемые профили TuneD, позволяя разработчикам декларативно настраивать ядро Linux (включая параметры sysctl и sysfs) через ресурсы Kubernetes. Профили могут быть привязаны к определенным пулам узлов, обеспечивая оптимизацию под конкретные нагрузки в рамках одного кластера.
Это делает распространенные сценарии простыми и поддерживаемыми, например:
Оптимизация узлов для высокопроизводительных сетевых нагрузок
Настройка поведения памяти для баз данных и систем кэширования
Корректировка параметров ядра для нагрузок, чувствительных к задержкам
Встроенный профиль обеспечивает безопасную отправную точку конфигурации, готовую для корпоративного использования, а пользовательские профили позволяют при необходимости сделать более глубокую специализацию. Результат — согласованная, безопасная при обновлениях настройка производительности, применяемая через стандартные рабочие процессы Kubernetes, без ручной конфигурации узлов и без дрейфа конфигурации.
Безопасность, соответствие требованиям и управление
VKS 3.6 упрощает поддержку нормативных и требований безопасности без жесткой фиксации кластеров в универсальных схемах усиленной защиты. Расширенная конфигурация компонентов Kubernetes позволяет платформенным командам настраивать уровень соответствия требованиям для каждой нагрузки и среды. Команды могут применять более строгие меры там, где это требуется, ослаблять их при необходимости и постепенно развивать конфигурации вместо пересоздания кластеров для изменения политики.
В этом выпуске также упрощено управление профилями AppArmor. Администраторы теперь могут определять профили AppArmor как Custom Resources и автоматически загружать их и поддерживать синхронизацию на всех рабочих узлах кластера или в отдельных пулах узлов. Это позволяет настраивать каждый workload с требуемым профилем AppArmor без сложности конфигурации на уровне узлов.
VKS 3.6 также повышает операционную автономность. Владельцы workload-кластеров теперь могут генерировать пакеты поддержки VKS без учетных данных vCenter, устраняя необходимость повышенного инфраструктурного доступа при устранении неполадок. Это снижает трения между командами Kubernetes и инфраструктуры, сохраняя принцип наименьших привилегий.
Пользовательский опыт платформы и развитие экосистемы
Корпоративные платформы Kubernetes требуют как сильных настроек по умолчанию, так и реального выбора в экосистеме. Чрезмерная жесткость замедляет внедрение; избыточная свобода создает операционные риски. Этот релиз продвигает баланс вперед, открывая платформу для партнерских инноваций и поддерживая возможность использования собственных инструментов заказчика.
Ваша сеть — ваш выбор
Теперь доступна поддерживаемая точка интеграции для сетевых партнеров и ISV. Платформенные команды могут использовать проверенные партнерами сетевые дополнения, оставаясь в рамках стандартных процессов жизненного цикла, обновления и поддержки. Это открывает возможности для нативной интеграции сторонних сетевых и сетевых защитных решений.
Команды могут сохранить сетевой стек, которому уже доверяют, а партнеры получают стабильную и поддерживаемую основу для разработки. Это снижает трения при миграции существующих сред Kubernetes на VKS и со временем расширяет набор доступных сетевых возможностей.
Ваш фаервол — ваш выбор
VKS 3.6 вводит централизованное управление правилами сетевого экрана на уровне узлов через API для всех поддерживаемых операционных систем. Теперь платформенные команды могут открывать необходимые порты для HostPorts и сервисов NodePort через конфигурацию кластера, вместо использования привилегированных init-контейнеров или DaemonSet’ов на каждом узле.
Перенос управления файрволом с отдельных нагрузок на уровень кластера упрощает конфигурацию, повышает аудируемость и снижает риски безопасности, связанные с привилегированными компонентами. Для Linux-узлов VKS 3.6 также добавляет поддержку backend nftables для kube-proxy, обеспечивая лучшую производительность и масштабируемость по сравнению с реализацией по умолчанию на основе iptables.
Ваша ОС — ваш выбор
Red Hat Enterprise Linux (RHEL) 9 присоединяется к Photon OS 5, Ubuntu 22.04 и 24.04, а также Windows Server 2022 в качестве поддерживаемых операционных систем для узлов кластера VKS. RHEL может использоваться как для узлов control plane, так и для рабочих узлов.
Для поддержки разнообразных требований приложений в рамках одного кластера VKS продолжает позволять различным пулам узлов работать на разных операционных системах. Пулы узлов RHEL могут существовать наряду с узлами Windows, Ubuntu и Photon, обеспечивая гетерогенные кластеры и постепенную миграцию ОС со временем.
VKS 3.6 также включает улучшенные инструменты для сборки пользовательских образов узлов для всех поддерживаемых операционных систем. Image Baker предназначен для сред с ограниченной сетевой связностью, работает независимо от vCenter для снижения инфраструктурных зависимостей и поставляется как плагин CLI VMware Cloud Foundation (VCF). Broadcom продолжает предоставлять готовые образы для Photon и Ubuntu.
Kubernetes — с меньшим количеством неожиданностей
Этот релиз сосредоточен на тех аспектах Kubernetes, которые наиболее важны после первого дня. Обновления становятся более предсказуемыми, настройка производительности для ресурсоемких нагрузок упрощается, среды на базе RHEL получают четкий путь миграции, а сетевая подсистема открывается для растущей экосистемы проверенных партнеров.
В совокупности эти изменения приводят Kubernetes в соответствие с тем, как заказчики реально используют его в промышленной эксплуатации: стандартизированно, с управлением на базе политик и с интеграцией с существующими инструментами и платформами.
Для платформенных команд, работающих в масштабе, результат прост: меньше неожиданностей, ниже операционные риски и более надежная основа для дальнейшего развития.
Более подробно о VMware vSphere Kubernetes Service 3.6 можно узнать на странице продукта.
VMware недавно опубликовала обновлённый набор технических руководств, которые приводят рекомендации в соответствие с архитектурой эпохи VMware Cloud Foundation
и с новыми возможностями приложений Microsoft, включая SQL Server 2025 и Windows Server 2025.
Если вы планируете развёртывание VCF, модернизируете существующие среды, стандартизируете платформу, обновляете парк SQL Server или модернизируете инфраструктуру идентификации, мы рекомендуем ознакомиться с этими документами до того, как будет окончательно утверждён ваш следующий дизайн-воркшоп, цикл закупок или план миграции.
Руководство 1: Проектирование Microsoft SQL Server на VMware Cloud Foundation
Для многих команд решение о виртуализации SQL Server уже принято. Как говорится в руководстве: «вопрос больше не в том, виртуализировать ли SQL Server, а в том, как…». И это «как» существенно изменилось в мире VCF. Платформа стала более регламентированной, операционная модель — более стандартизированной, а поддерживающие возможности (хранилище, сеть, управление жизненным циклом, безопасность) эволюционировали с учётом развития аппаратных возможностей и операционных методик.
Обновлённое руководство предназначено для читателей, которые уже понимают как VCF, так и SQL Server. Оно ориентировано на несколько ролей: архитекторов, инженеров/администраторов и DBA.
Несколько моментов, на которые стоит обратить внимание:
Современные рекомендации по CPU и NUMA теперь учитывают и новое поведение топологии в эпоху VCF. Руководство рассматривает «новые параметры конфигурации топологии vNUMA в VMware Cloud Foundation (VCF)» и объясняет, почему это поведение важно для крупных виртуальных машин SQL Server.
Чёткая и обновлённая позиция по CPU hot plug в эпоху SQL Server 2025. В руководстве прямо указано: CPU Hot-Add больше не поддерживается в SQL Server 2025, и его не следует включать на таких виртуальных машинах.
Рекомендации по хранилищу, соответствующие направлению развития VCF. Если вы оцениваете архитектурные варианты vSAN, руководство объясняет, почему vSAN Express Storage Architecture (ESA) привлекателен для заказчиков, переходящих на более современное оборудование, и подчёркивает возможности эффективности ESA, такие как глобальная дедупликация и преимущества сжатия для нагрузок баз данных.
Пояснения по устаревающим функциям, влияющим на долгоживущие архитектуры. Если в вашей текущей архитектуре активно используются vVols, учтите, что Virtual Volumes объявлены устаревшими, начиная с VCF 9.0 и VMware vSphere Foundation 9.0 (полный отказ запланирован в будущих релизах).
Операционная реалистичность для мобильности и обслуживания. Руководство рассматривает использование multi-NIC vMotion для снижения риска зависания (stun) при миграции крупных, потребляющих много памяти виртуальных машин SQL, а также отмечает, что VCF внедряет vMotion Notifications, чтобы помочь чувствительным к задержкам и кластер-осведомлённым приложениям безопаснее обрабатывать миграции.
Если вы принимаете решения - это тот документ, который снижает объём переработок, вызванных неожиданностями. Если вы технический специалист - это тот документ, который не позволит вам унаследовать архитектуру в стиле «it depends», которая позже приведёт к простою.
Руководство 2: Проектирование Microsoft SQL Server для высокой доступности на VMware Cloud Foundation
Второе руководство сосредоточено там, где ставки особенно высоки: корректное проектирование доступности SQL Server на VCF без смешивания устаревших предположений, неподдерживаемых конфигураций или подхода «потом исправим» в кластеризации.
Оно написано для смешанной аудитории, включая DBA, администраторов VMware, архитекторов и IT-руководителей. И в нём ясно указано, что «доступность» — это не функция, которую добавляют в конце; выбранная модель защиты должна определяться бизнес-требованиями.
Несколько особенно практичных обновлений:
Реалии доступности SQL Server 2025, чётко сопоставленные с механизмами защиты. Руководство связывает уровни защиты с современными возможностями обеспечения доступности SQL Server, подчёркивает области, где SQL Server 2025 усиливает архитектуры на базе Availability Groups (AG), и отмечает, что Database Mirroring удалён в SQL Server 2025.
Рекомендации по согласованию жизненного цикла, которые действительно важны для IT-руководства. Начиная с SQL Server 2025, отмечается, что более старые версии Windows Server вышли из основной поддержки, и рекомендуется использовать Windows Server 2025 или Windows Server 2022 при наличии совместимости — прямой переход к поддерживаемым и обоснованным платформам.
Современные варианты кластеризации с общими дисками без навязывания устаревших архитектур. Руководство указывает, что в средах эпохи VCF 9 семантика общих дисков для FCI может быть реализована современными способами — подчёркивается использование Clustered VMDKs и явно обозначается движение в сторону отказа от устаревших зависимостей.
Рекомендации по DRS anti-affinity, предотвращающие «самоорганизованные» события HA. Если узлы кластера SQL работают на одном и том же хосте ESXi «потому что так решил DRS», это не высокая доступность, а отложенный инцидент. Настройте соответствующие правила DRS, чтобы узлы кластера были физически разделены.
Требования к vMotion Application Notification, изложенные подробно. Руководство описывает использование уведомлений приложений, включая требования, такие как актуальные VMware Tools и рекомендуемая настройка таймаутов — именно те детали, которые команды часто выясняют в условиях уже упавшей системы.
Рекомендации по vSAN ESA, отражающие текущие возможности. Указывается направление политик ESA и отмечается глобальная дедупликация (впервые представленная в VCF 9.0) как рекомендуемая для определённых сценариев Availability Group SQL Server в пределах одного кластера vSAN.
Это то руководство, которое вы передаёте команде, когда бизнес говорит: «нам нужна более высокая доступность», — и вы хотите, чтобы ответом стало инженерно проработанное решение.
Руководство 3: Виртуализация служб домена Active Directory на VMware Cloud Foundation
Active Directory (AD) Domain Services (DS) — одна из тех служб, о которых не думают до тех пор, пока всё не перестанет работать. Обновлённое руководство по AD DS прямо признаёт это, указывая, что многие организации справедливо рассматривают AD DS как по-настоящему критичное для бизнеса приложение, поскольку аутентификация, доступ к ресурсам и бесчисленные рабочие процессы зависят от него.
Оно также напрямую обращается к сохраняющемуся рефлексу «физического контроллера домена». Благодаря развитию Windows Server и зрелым практикам VCF, в руководстве говорится, что эти улучшения теперь позволяют организациям «безопасно виртуализировать сто процентов своей инфраструктуры AD DS».
Существенно обновлены не общие рекомендации «виртуализируйте это», а современный набор функций и механизмов защиты, которые меняют подход к проектированию и защите виртуальных контроллеров домена:
В руководстве указано, что лишь несколько усовершенствований существенно изменяют прежние рекомендации, включая Virtualization-Based Security (VBS), Secure Boot, шифрование на уровне виртуальной машины и улучшенную синхронизацию времени в гостевых ВМ — и эти изменения учтены там, где это необходимо.
Документ явно ориентирован на несколько аудиторий (архитекторов, инженеров/администраторов и руководителей/владельцев процессов), что важно для AD DS, поскольку проектирование и эксплуатация неразделимы.
Подчёркиваются операционные меры защиты при восстановлении после сбоев. Например, рекомендуется использовать приоритет перезапуска ВМ в vSphere HA, чтобы ключевые инфраструктурные службы запускались раньше после аварийного восстановления.
Подробно рассматриваются механизмы обеспечения целостности в эпоху виртуализации (например, поведение VM-Generation ID), созданные специально для устранения исторических опасений, связанных со снапшотами и откатами.
Если вы модернизируете инфраструктуру идентификации, консолидируете датацентры или строите частное облако на базе VCF с сильной позицией по безопасности, этот документ обязателен к прочтению. AD DS — это не просто ещё одна рабочая нагрузка. Это сущность, от которой зависит работа всего вашего стека.
Руководство 4: Запуск Microsoft SQL Server Failover Cluster Instance на VMware vSAN платформы VMware Cloud Foundation 9
Если ваша модель обеспечения доступности по-прежнему основана на кластеризации с общими дисками — будь то из-за ограничений приложений, операционных предпочтений или необходимости сохранить модель SQL Server FCI — это руководство является практическим дополнением «как это реально работает на VCF 9» к более общим рекомендациям по HA. Это эталонная архитектура для запуска Microsoft SQL Server Failover Cluster Instance (FCI) с использованием общих дисков на базе vSAN, валидированная как для стандартного кластера vSAN, так и для сценария растянутого кластера vSAN.
Несколько моментов, на которые стоит обратить внимание:
Нативная поддержка WSFC + общих дисков на vSAN (с подробным описанием механики). В VCF 9 «vSAN обеспечивает нативную поддержку виртуализированных Windows Server Failover Clusters (WSFC)» и «поддерживает SCSI-3 Persistent Reservations (SCSI3PR) на уровне виртуального диска» — ключевое требование для арбитража общих дисков в WSFC.
Две настройки конфигурации, от которых зависит работоспособность общих дисков. Указывается, что общие диски должны быть подключены к контроллеру с параметром SCSI Bus Sharing, установленным в Physical, и что «режим диска для всех дисков в кластере должен быть установлен в Independent – Persistent», чтобы избежать неподдерживаемой семантики снапшотов на общих дисках.
Операционные особенности растянутого кластера: задержки, размещение и кворум являются частью архитектуры. Рекомендуется «менее четырёх миллисекунд межсайтовой (round trip) задержки» для SQL-баз данных уровня tier-1 в растянутых кластерах vSAN, а также подчёркивается необходимость правил DRS VM/Host для разделения узлов WSFC по разным хостам.
Также рекомендуется использовать диск-свидетель кворума, чтобы растянутый кластер сохранял доступность witness-диска при отказе сайта без остановки службы кластера FCI.
Практический путь миграции с SAN pRDM на общие VMDK vSAN. С самого начала подчёркивается: «перед миграцией настоятельно рекомендуется создать резервную копию», и отмечается, что миграция выполняется офлайн. Описываются шаги по остановке роли кластера, выключению узлов и использованию Storage Migration для преобразования pRDM в VMDK на vSAN ± с обходным решением через PowerCLI (включая пример кода) в случае, если выбор формата диска в мастере Migrate недоступен.
Это руководство, которое вы передаёте команде, когда требование звучит как «нам нужна семантика FCI», и вы хотите получить осознанную, поддерживаемую архитектуру.
Что дальше
Если вы активно проектируете, обновляете или мигрируете инфраструктуру, рассматривайте эти руководства в контексте команд:
Команды платформы: сначала прочитайте руководство по SQL Server, чтобы согласовать значения по умолчанию вычислений/хранилища/сети с поведением SQL.
DBA и инженеры инфраструктуры: прочитайте руководство по HA до того, как зафиксируете модель кластеризации, стратегию хранения и модель обслуживания.
Команды по идентификации и безопасности: прочитайте руководство по AD DS, чтобы согласовать меры настройки, восстановления и операционные процессы с современными механизмами защиты виртуализации.
Команды, использующие (или стандартизирующие) SQL Server FCI: прочитайте руководство по FCI на vSAN, чтобы зафиксировать требования к общим дискам, позицию по политике хранения и ограничения растянутого кластера до внедрения.
Ниже приведены прямые ссылки для скачивания упомянутых документов:
Наверняка не всем из вас знаком ресурс virten.net — технический портал, посвящённый информации, новостям, руководствам и инструментам для работы с продуктами VMware и виртуализацией. Сайт предлагает полезные ресурсы как для ИТ-специалистов, так и для энтузиастов виртуализации, включая обзоры версий, документацию, таблицы сравнений и практические руководства.
Там можно найти:
Новости и статьи о продуктах VMware (релизы, обновления, сравнения версий, технические обзоры).
Полезные разделы по VMware vSphere, ESX, vCenter и другим продуктам, включая истории релизов, конфигурационные лимиты и различия между версиями.
Практические инструменты и утилиты, такие как декодеры SCSI-кодов, RSS-трекер релизов (vTracker), помощь по OVF/PowerShell, события vCenter и JSON-репозиторий полезных данных.
Давайте посмотрим, что на этом сайте есть полезного для администраторов инфраструктуры VMware Cloud Foundation.
Эта страница содержит список продуктов, выпущенных компанией VMware. vTracker автоматически обновляется, когда на сайте vmware.com становятся доступны для загрузки новые продукты (GA — общедоступный релиз). Если вы хотите получать уведомления о выходе новых продуктов VMware, подпишитесь на RSS-ленту. Вы также можете использовать экспорт в формате JSON для создания собственного инструмента. Не стесняйтесь оставлять там комментарии, если у вас есть предложения по новым функциям.
Если вы просто хотите узнать, какая версия того или иного продукта VMware сейчас актуальна, самый простой способ - это посмотреть вот эту таблицу с функцией поиска:
В этом разделе представлен полный перечень релизов флагманского гипервизора VMware ESX (ранее ESXi). Все версии, выделенные жирным шрифтом, доступны для загрузки. Все патчи указаны под своими официальными названиями релизов, датой выхода и номером билда. Обратите внимание, что гипервизор ESXi доступен начиная с версии 3.5.
Если вы столкнулись с какими-либо проблемами при работе с этим сайтом или заметили отсутствие сборок, пожалуйста, свяжитесь с автором.
Эта страница представляет собой коллекцию заранее настроенных фрагментов PowerShell-скриптов для развертывания OVF/OVA. Идея заключается в ускорении процесса развертывания, если вам необходимо устанавливать несколько виртуальных модулей, выполнять повторное развертывание из-за неверных входных данных или сохранить файл в качестве справочного примера для будущих установок.
Просто заполните подготовленные переменные так же, как вы обычно делаете это в клиенте vSphere, и запустите скрипт. Все шаблоны используют одинаковую последовательность действий и тексты подсказок из мастера развертывания. Необязательные параметры конфигурации можно закомментировать. Если у параметров есть значения по умолчанию, они уже заполнены.
Ошибки или предупреждения SCSI в логах и интерфейсе ESX отображаются с использованием 6 кодов состояния. Эта страница преобразует эти коды, полученные от хостов ESX, в понятную для человека информацию о состоянии подсистемы хранения. В системном журнале vmkernel.log на хостах ESXi версии 5.x или 6.0 вы можете увидеть записи, подобные приведённым ниже. На странице декодера вы можете ввести нужные числа в форму и получить пояснения по сообщениям SCSI:
В этой статье мы завершаем рассказывать об итогах 2025 года в сферах серверной и настольной виртуализации на базе российских решений. Сегодня мы поговорим о том, как их функционал соотносится с таковым от ведущего мирового производителя - VMware.
Первую часть статьи можно прочитать тут, вторая - доступна здесь.
Сравнение с VMware vSphere
Как же отечественные решения выглядят на фоне VMware vSphere, многолетнего эталона в сфере виртуализации? По набору функций российские платформы стремятся обеспечить полный паритет с VMware – и во многом этого уже достигли. Однако при более глубоком сравнении выявляются отличия в зрелости, экосистеме и опыте эксплуатации.
Функциональность
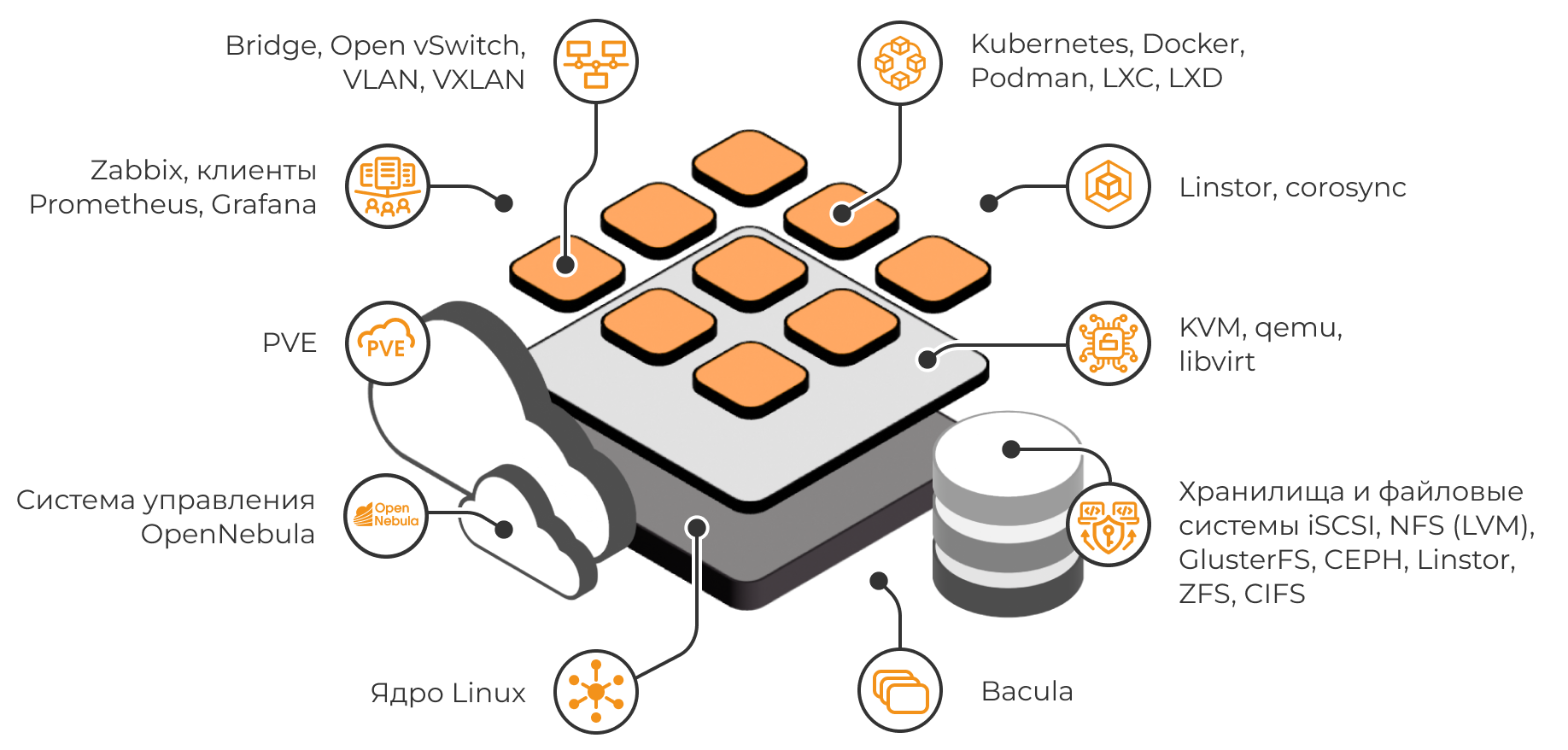
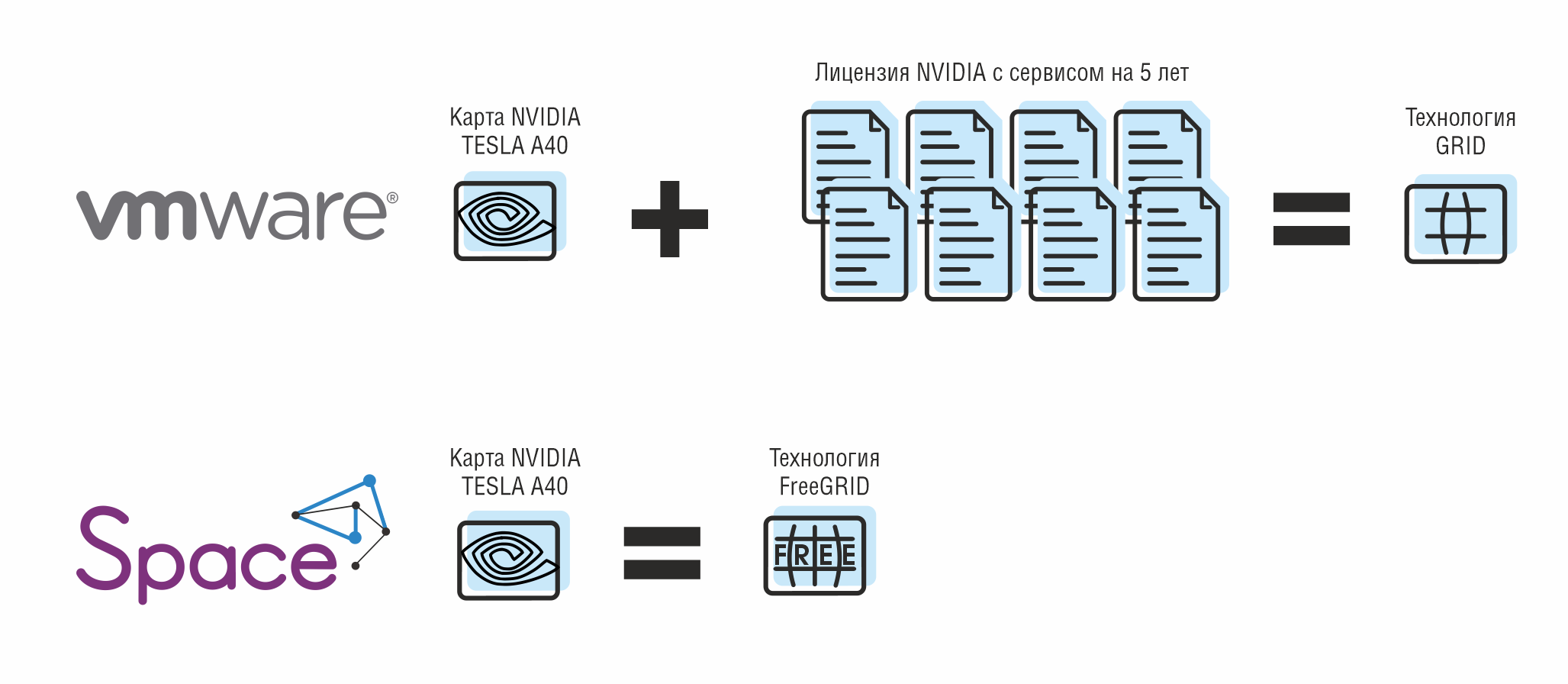
Почти все базовые возможности VMware теперь доступны и в отечественных продуктах: от управления кластерами, миграции ВМ на лету и снапшотов до сетевой виртуализации и распределения нагрузки. Многие платформы прямо ориентируются на VMware при разработке. Например, SpaceVM позиционирует свои компоненты как аналоги VMware: SDN Flow = NSX, FreeGRID = NVIDIA vGPU (для Horizon), Space Dispatcher = Horizon Connection Server. ZVirt, Red, ROSA, SpaceVM – все поддерживают VMware-совместимые форматы виртуальных дисков (VMDK/OVA) и умеют импортировать ВМ из vSphere.
То есть миграция технически осуществима без кардинальной переделки ВМ. Live Migration, HA, кластеры, резервирование – эти функции стали стандартом де-факто, и российские продукты их предоставляют. Более того, появились и некоторые новые возможности, которых нет в базовом издании vSphere: например, интеграция с Kubernetes (KubeVirt) в решении Deckhouse от Flant позволяет управлять ВМ через Kubernetes API – VMware предлагает нечто подобное (vSphere with Tanzu), но это отдельно лицензируемый модуль.
Другой пример – поддержка облачных сервисов: некоторые отечественные платформы сразу рассчитаны на гибридное облако, тогда как VMware требует vCloud Suite (сейчас это часть платформы VMware Cloud Foundation, VCF). Тем не менее, зрелость функционала различается: если у VMware каждая возможность отполирована годами использования по всему миру, то у новых продуктов возможны баги или ограничения. Эксперты отмечают, что просто сравнить чекбоксы “есть функция X” – недостаточно, важна реализация. У VMware она, как правило, образцовая, а у российского аналога – может требовать ручных доработок. Например, та же миграция ВМ в российских системах работает, но иногда возникают нюансы с live migration при специфических нагрузках (что-то, что VMware давно решила).
Производительность и масштабирование
VMware vSphere славится стабильной работой кластеров до 64 узлов (в v7 – до 96 узлов) и тысяч ВМ. В принципе, и наши решения заявляют сопоставимый масштаб, но проверены они временем меньше. Как упоминалось, некоторые продукты испытывали сложности уже на 50+ хостах. Тем не менее, для 90% типовых инсталляций (до нескольких десятков серверов) разницы в масштабируемости не будет. По производительности ВМ – разница тоже минимальна: KVM и VMware ESXi показывают близкие результаты бенчмарков. А оптимизации вроде vStack с 2% overhead вообще делают накладные расходы незаметными. GPU-виртуализация – здесь VMware имела преимущество (технология vGPU), но сейчас SpaceVM и другие сократили отставание своим FreeGRID. Зато VMware до последнего времени обеспечивала более широкую поддержку оборудования (драйверы для любых RAID, сетевых карт) – российские ОС и гипервизоры поддерживают далеко не все модели железа, особенно новейшие. Однако ситуация улучшается за счет локализации драйверов и использования стандартных интерфейсов (VirtIO, NVMe и пр.).
Совместимость и экосистема
Ключевое различие – в экосистеме смежных решений. Окружение VMware – это огромный пласт интеграций: сотни backup-продуктов, мониторингов, готовых виртуальных апплаенсов, специальных плагинов и т.д. В российской экосистеме такого разнообразия пока нет. Многие специализированные плагины и appliance, рассчитанные на VMware, не будут работать на отечественных платформах.
Например, виртуальные апплаенсы от зарубежных вендоров (сетевые экраны, балансировщики), выпускались в OVF под vSphere – их можно включить и под KVM, но официальной поддержки может не быть. Приходится либо искать аналогичный российский софт, либо убеждаться, что в open-source есть совместимый образ. Интеграция с enterprise-системами – тоже вопрос: у VMware был vCenter API, поддерживаемый многими инструментами. Отечественным гипервизорам приходится писать собственные модули интеграции. Например, не все мониторинговые системы «из коробки» знают про zVirt или SpaceVM – нужно настраивать SNMP/API вручную.
Такая же ситуация с резервным копированием: знакомые всем Veeam и Veritas пока не имеют официальных агентов под наши платформы (хотя Veeam частично работает через стандартный SSH/VIX). В итоге на текущем этапе экосистема поддержки у VMware гораздо более развита, и это объективный минус для новых продуктов. Однако постепенно вокруг популярных российских гипервизоров формируется своё сообщество: появляются модули для Zabbix, адаптеры для Veeam через скрипты, свои решения backup (например, CyberProtect для Cyber Infrastructure, модуль бэкапа в VMmanager и т.п.).
Надёжность и поддержка
VMware десятилетиями оттачивала стабильность: vSphere известна редкими «падениями» и чётким поведением в любых ситуациях. Российским платформам пока ещё не хватает шлифовки – пользователи отмечают, что полностью «скучной» работу с ними назвать нельзя. Периодически инженерам приходится разбираться с нетривиальными багами или особенностями. В пример приводят трудоёмкость настройки сетевой агрегации (линков) – то, что на VMware привычно, на некоторых отечественных системах реализовано иначе и требует дополнительных манипуляций.
При обновлении версий возможны проблемы с обратной совместимостью: участники рынка жалуются, что выход каждого нового релиза иногда «ломает» интеграции, требуя доработки скриптов и настроек. Отсюда повышенные требования к квалификации админов – нужно глубже понимать «под капотом», чем при работе с отлаженной VMware. Но есть и плюс: почти все российские вендоры предоставляют оперативную техподдержку, зачастую напрямую от команд разработчиков. В критических случаях они готовы выпустить патч под конкретного заказчика или дать обходной совет. В VMware же, особенно после перехода на Broadcom, поддержка стала менее клиентоориентированной для средних клиентов. В России же каждый клиент на вес золота, поэтому реакция, как правило, быстрая (хотя, конечно, уровень экспертизы разных команд разнится).
Стоимость и лицензирование
Ранее VMware имела понятную, хоть и недешёвую модель лицензирования (по процессорам, +опции за функции). После покупки Broadcom стоимость выросла в разы, а бессрочные лицензии отменены – только подписка. Это сделало VMware финансово тяжелее для многих. Отечественные же продукты зачастую предлагают более гибкие условия: кто-то лицензирует по ядрам, кто-то по узлам, у кого-то подписка с поддержкой. Но в целом ценовой порог для легального использования ниже, чем у VMware (тем более, что последняя официально недоступна, а «серыми» схемами пользоваться рискованно). Некоторые российские решения и вовсе доступны в рамках господдержки по льготным программам для госучреждений. Таким образом, с точки зрения совокупной стоимости владения (TCO) переход на отечественную виртуализацию может быть выгоден (но может и не быть), особенно с учётом локальной техподдержки и отсутствия валютных рисков.
Подведём коротко плюсы и минусы российских платформ относительно VMware.
Плюсы отечественных решений:
Импортонезависимость и соответствие требованиям. Полное соблюдение требований законодательства РФ для госкомпаний и КИИ (реестр ПО, совместимость с ГОСТ, сертификация ФСТЭК у компонентов).
Локальная поддержка и доработка. Возможность напрямую взаимодействовать с разработчиком, получать кастомные улучшения под свои задачи и быстро исправлять проблемы в сотрудничестве (что практически невозможно с глобальным вендором).
Интеграция с отечественной экосистемой. Совместимость с российскими ОС (Astra, РЕД, ROSA), СУБД, средствами защиты (например, vGate) – упрощает внедрение единого импортозамещённого ландшафта.
Новые технологии под свои нужды. Реализация специфичных возможностей: работа без лицензий NVIDIA (FreeGRID), поддержка гостевых Windows без обращения к зарубежным серверам активации, отсутствие жёсткого вендорлока по железу (любое x86 подходит).
Стоимость и модель владения. Более низкая цена лицензий и поддержки по сравнению с VMware (особенно после удорожания VMware); оплата в рублях, отсутствие риска отключения при санкциях.
Минусы и вызовы:
Меньшая зрелость и удобство. Интерфейсы и процессы менее отточены – администрирование требует больше времени и знаний, некоторые задачи реализованы не так элегантно, больше ручной работы.
Ограниченная экосистема. Не все привычные внешние инструменты совместимы – придется пересматривать решения для бэкапа, мониторинга, а автоматизация требует дополнительных скриптов. Нет огромного сообщества интеграторов по всему миру, как у VMware.
Риски масштабируемости и багов. На больших нагрузках или в сложных сценариях могут всплывать проблемы, которые VMware уже давно решила. Требуется тщательное пилотирование и возможно компромиссы (уменьшить размер кластера, разделить на несколько и др.).
Обучение персонала. ИТ-специалистам, годами работавшим с VMware, нужно переучиваться. Нюансы каждой платформы свои, документация не всегда идеальна, на русском языке материалов меньше, чем англоязычных по VMware.
Отсутствие некоторых enterprise-фишек. Например, у VMware есть многолетние наработки по гибридному облаку, экосистема готовых решений в VMware Marketplace. Российским аналогам предстоит путь создания таких же богатых экосистем.
Таким образом, при функциональном паритете с VMware на бумаге, в практической эксплуатации российские продукты могут требовать больше усилий и доставлять больше проблем. Но этот разрыв постепенно сокращается по мере их развития и накопления опыта внедрений.
Выводы и перспективы импортозамещения VMware
За почти четыре года, прошедшие с ухода VMware, российская индустрия виртуализации совершила огромный рывок. Из десятков появившихся решений постепенно выделился костяк наиболее зрелых и универсальных продуктов, способных заменить VMware vSphere в корпоративных ИТ-инфраструктурах. Как показывают кейсы крупных организаций (банков, промышленных предприятий, госструктур), импортозамещение виртуализации в России – задача выполнимая, хотя и сопряжена с определёнными трудностями. Подводя итоги обзора, можно назвать наиболее перспективные платформы и технологии, на которые сегодня стоит обратить внимание ИТ-директорам:
SpaceVM + Space VDI (экоcистема Space) – комплексное решение от компании «ДАКОМ M», которое отличается максимальной полнотой функционала. SpaceVM обеспечивает производительную серверную виртуализацию с собственными технологиями (SDN, FreeGRID), а Space VDI дополняет её средствами виртуализации рабочих мест. Этот тандем особенно хорош для компаний, которым нужны все компоненты "как у VMware" под одним брендом – гипервизор, диспетчеры, клиенты, протоколы. Space активно набирает популярность: 1-е место в рейтингах, успешные внедрения, награды отрасли. Можно ожидать, что он станет одним из столпов корпоративной виртуализации РФ.
Basis Dynamix – продукт компании «Базис», ставший лидером технических рейтингов. Basis привлекает госзаказчиков и большие корпорации, ценящие интегрированный подход: платформа тесно сопряжена с отечественным оборудованием, ОС и имеет собственный центр разработки. Ее козыри – высокая производительность, гибкость (поддержка и классической, и HCI-схем) и готовность к кастомизации под клиента. Basis – хороший выбор для тех, кто строит полностью отечественный программно-аппаратный комплекс, и кому нужна платформа с длительной перспективой развития в России.
zVirt (Orion soft) – одна из самых распространённых на практике платформ, обладающая богатым набором функций и сильным акцентом на безопасность. За счет происхождения от oVirt, zVirt знаком многим по архитектуре, а доработки Orion soft сделали его удобнее и безопаснее (SDN, микросегментация, интеграция с vGate). Крупнейшая инсталляционная база говорит о доверии рынка. Хотя у zVirt есть ограничения по масштабированию, для средних размеров (десятки узлов) он отлично справляется. Это надежный вариант для постепенной миграции с VMware в тех организациях, где ценят проверенные решения и требуются сертификаты ФСТЭК по безопасности.
Red Виртуализация – решение от РЕД СОФТ, важное для госсектора и компаний с экосистемой РЕД ОС. Его выбрал, к примеру, Россельхозбанк для одной из крупнейших миграций в финансовом секторе. Продукт относительно консервативный (форк известного проекта), что можно считать плюсом – меньше сюрпризов, более понятный функционал. Red Virtualization перспективна там, где нужна максимальная совместимость с отечественным ПО (ПО РЕД, СУБД РЕД и пр.) и официальная поддержка на уровне регуляторов.
vStack HCP – хотя и более нишевое решение, но весьма перспективное для тех, кому нужна простота HCI и высочайшая производительность. Отсутствие зависимости от громоздких компонентов (ни Linux, ни Windows – гипервизор на FreeBSD) дает vStack определенные преимущества в легковесности. Его стоит рассматривать в том числе для задач на периферии, в распределенных офисах, где нужна автономная работа без сложной поддержки, или для быстрорастущих облачных сервисов, где горизонтальное масштабирование – ключевой фактор.
HostVM VDI / Veil / Termidesk – в сфере VDI помимо Space VDI, внимания заслуживают и другие разработки. HostVM VDI – как универсальный брокер с множеством протоколов – может подойти интеграторам, строящим сервис VDI для разных платформ. Veil VDI и Termidesk – пока чуть менее известны на рынке, но имеют интересные технологии (например, Termidesk с собственным кодеком TERA). Для компаний, уже использующих решения этих вендоров, логично присмотреться к их VDI для совместимости.
В заключение, можно уверенно сказать: российские продукты виртуализации достигли уровня, при котором ими можно заменить VMware vSphere во многих сценариях. Да, переход потребует усилий – от тестирования до обучения персонала, – но выгоды в виде независимости от внешних факторов, соответствия требованиям законодательства и поддержки со стороны локальных вендоров зачастую перевешивают временные сложности. Российские разработчики продемонстрировали способность быстро закрыть функциональные пробелы и даже внедрить новые инновации под нужды рынка. В ближайшие годы можно ожидать дальнейшего роста качества этих продуктов: уже сейчас виртуализация перестает быть "экзотикой" и становится обыденным, надёжным инструментом в руках отечественных ИТ-специалистов. А значит, корпоративный сектор России получает реальную альтернативу VMware – собственный технологический базис для развития ИТ-инфраструктуры.
В этой части статьи мы продолжаем рассказывать об итогах 2025 года в плане серверной и настольной виртуализации на базе российских решений. Первую часть статьи можно прочитать тут.
Возможности VDI (виртуализации рабочих мест)
Импортозамещение коснулось не только серверной виртуализации, но и инфраструктуры виртуальных рабочих столов (VDI). После ухода VMware Horizon (сейчас это решение Omnissa) и Citrix XenDesktop российские компании начали внедрять отечественные VDI-решения для обеспечения удалённой работы сотрудников и центрального управления рабочими станциями. К 2025 году сформировался пул новых продуктов, позволяющих развернуть полнофункциональную VDI-платформу на базе отечественных технологий.
Лидерами рынка VDI стали решения, созданные в тесной связке с платформами серверной виртуализации. Так, компания «ДАКОМ М» (бренд Space) помимо гипервизора SpaceVM предложила продукт Space VDI – систему управления виртуальными рабочими столами, интегрированную в их экосистему. Space VDI заняла 1-е место в рейтинге российских VDI-решений 2025 г., набрав 228 баллов по совокупности критериев.
Её сильные стороны – полностью собственная разработка брокера и агентов (не опирающаяся на чужие open-source) и наличие всех компонентов, аналогичных VMware Horizon: Space Dispatcher (диспетчер VDI, альтернатива Horizon Connection Server), Space Agent VDI (клиентский агент на виртуальной машине, аналог VMware Horizon Agent), Space Client для подключения с пользовательских устройств, и собственный протокол удалённых рабочих столов GLINT. Протокол GLINT разработан как замена зарубежных (RDP/PCoIP), оптимизирован для работы в российских сетях и обеспечивает сжатие/шифрование трафика. В частности, заявляется поддержка мультимедиа-ускорения и USB-перенаправления через модуль Mediapipe, который служит аналогом Citrix HDX. В результате Space VDI предоставляет высокую производительность графического интерфейса и мультимедиа, сравнимую с мировыми аналогами, при этом полностью вписывается в отечественный контур безопасности.
Вторым крупным игроком стала компания HOSTVM с продуктом HostVM VDI. Этот продукт изначально основыван на открытой платформе UDS (VirtualCable) и веб-интерфейсе на Angular, но адаптирован российским разработчиком. HostVM VDI поддерживает широкий набор протоколов – SPICE, RDP, VNC, NX, PCoIP, X2Go, HTML5 – фактически покрывая все популярные способы удалённого доступа. Такая всеядность упрощает миграцию с иностранных систем: например, если ранее использовался протокол PCoIP (как в VMware Horizon), HostVM VDI тоже его поддерживает. Решение заняло 2-е место в отраслевом рейтинге с 218 баллами, немного уступив Space VDI по глубине интеграции функций.
Своеобразный подход продемонстрировал РЕД СОФТ. Их продукт «РЕД Виртуализация» является, в первую очередь, серверной платформой (форком oVirt на KVM) для развертывания ВМ. Однако благодаря тесной интеграции с РЕД ОС и другим ПО компании, Red Виртуализация может использоваться и для VDI-сценариев. Она заняла 3-е место в рейтинге VDI-платформ. По сути, РЕД предлагает создать инфраструктуру на базе своего гипервизора и доставлять пользователям рабочие столы через стандартные протоколы (для Windows-ВМ – RDP, для Linux – SPICE или VNC). В частности, поддерживаются протоколы VNC, SPICE и RDP, что покрывает базовые потребности. Кроме того, заявлена возможность миграции виртуальных машин в РЕД Виртуализацию прямо из сред VMware vSphere и Microsoft Hyper-V, что упрощает переход на решение.
Далее, существуют специализированные отечественные VDI-продукты: ROSA VDI, Veil VDI, Termidesk и др.
ROSA VDI (разработка НТЦ ИТ РОСА) базируется на том же oVirt и ориентирована на интеграцию с российскими ОС РОСА.
Veil VDI – решение компаний «НИИ Масштаб»/Uveon – представляет собственную разработку брокера виртуальных рабочих столов; оно также попало в топ-5 рейтинга.
Termidesk – ещё одна проприетарная система, замыкающая первую шестёрку лидеров. Каждая из них предлагает конкурентоспособные функции, хотя по некоторым пунктам уступает лидерам. Например, Veil VDI и Termidesk пока набрали меньше баллов (182 и 174 соответственно) и, вероятно, имеют более узкую специализацию или меньшую базу внедрений.
Общей чертой российских VDI-платформ является ориентация на безопасность и импортозамещение. Все они зарегистрированы как отечественное ПО и могут применяться вместо VMware Horizon, Citrix или Microsoft RDS. С точки зрения пользовательского опыта, основные функции реализованы: пользователи могут подключаться к своим виртуальным рабочим столам с любых устройств (ПК, тонкие клиенты, планшеты) через удобные клиенты или даже браузер. Администраторы получают централизованную консоль для создания образов ВМ, массового обновления ПО на виртуальных рабочих столах и мониторинга активности пользователей. Многие решения интегрируются с инфраструктурой виртуализации серверов – например, Space VDI напрямую работает поверх гипервизора SpaceVM, ROSA VDI – поверх ROSA Virtualization, что упрощает установку.
Отдельно стоит отметить поддержку мультимедийных протоколов и оптимизацию трафика. Поскольку качество работы VDI сильно зависит от протокола передачи картинки, разработчики добавляют собственные улучшения. Мы уже упомянули GLINT (Space) и широкий набор протоколов в HostVM. Также используется протокол Loudplay – это отечественная разработка в области облачного гейминга, адаптированная под VDI.
Некоторые платформы (например, Space VDI, ROSA VDI, Termidesk) заявляют поддержку Loudplay наряду со SPICE/RDP, чтобы обеспечить плавную передачу видео и 3D-графики даже в сетях с высокой задержкой. Терминальные протоколы оптимизированы под российские условия: так, Termidesk применяет собственный кодек TERA для сжатия видео и звука. В результате пользователи могут комфортно работать с графическими приложениями, CAD-системами и видео в своих виртуальных десктопах.
С точки зрения масштабируемости VDI, российские решения способны обслуживать от десятков до нескольких тысяч одновременных пользователей. Лабораторные испытания показывают, что Space VDI и HostVM VDI могут управлять тысячами виртуальных рабочих столов в распределенной инфраструктуре (с добавлением необходимых серверных мощностей). Важным моментом остаётся интеграция со средствами обеспечения безопасности: многие платформы поддерживают подключение СЗИ для контроля за пользователями (DLP-системы, антивирусы на виртуальных рабочих местах) и могут работать в замкнутых контурах без доступа в интернет.
Таким образом, к концу 2025 года отечественные VDI-платформы покрывают основные потребности удалённой работы. Они позволяют централизованно развертывать и обновлять рабочие места, сохранять данные в защищённом контуре датацентра и предоставлять сотрудникам доступ к нужным приложениям из любой точки. При этом особый акцент сделан на совместимость с российским стеком (ОС, ПО, требования регуляторов) и на возможность миграции с западных систем с минимальными затратами (поддержка разных протоколов, перенос ВМ из VMware/Hyper-V). Конечно, каждой организации предстоит выбрать оптимальный продукт под свои задачи – лидеры рынка (Space VDI, HostVM, Red/ROSA) уже имеют успешные внедрения, тогда как нишевые решения могут подойти под специальные сценарии.
Кластеризация, отказоустойчивость и управление ресурсами
Функциональность, связанная с обеспечением высокой доступности (HA) и отказоустойчивости, а также удобством управления ресурсами, является критичной при сравнении платформ виртуализации. Рассмотрим, как обстоят дела с этими возможностями у российских продуктов по сравнению с VMware vSphere.
Кластеризация и высокая доступность (HA)
Почти все отечественные системы поддерживают объединение хостов в кластеры и автоматический перезапуск ВМ на доступных узлах в случае сбоя одного из серверов – аналог функции VMware HA. Например, SpaceVM имеет встроенную поддержку High Availability для кластеров: при падении хоста его виртуальные машины автоматически запускаются на других узлах кластера.
Basis Dynamix, VMmanager, Red Virtualization – все они также включают механизмы мониторинга узлов и перезапуска ВМ при отказе, что отражено в их спецификациях (наличие HA подтверждалось анкетами рейтингов). По сути, обеспечение базовой отказоустойчивости сейчас является стандартной функцией для любых платформ виртуализации. Важно отметить, что для корректной работы HA требуется резерв мощности в кластере (чтобы были свободные ресурсы для поднятия упавших нагрузок), поэтому администраторы должны планировать кластеры с некоторым запасом хостов, аналогично VMware.
Fault Tolerance (FT)
Более продвинутый режим отказоустойчивости – Fault Tolerance, при котором одна ВМ дублируется на другом хосте в режиме реального времени (две копии работают синхронно, и при сбое одной – вторая продолжает работать без прерывания сервиса). В VMware FT реализован для критичных нагрузок, но накладывает ограничения (например, количество vCPU). В российских решениях прямая аналогия FT практически не встречается. Тем не менее, некоторые разработчики заявляют поддержку подобных механизмов. В частности, Basis Dynamix Enterprise в материалах указывал наличие функции Fault Tolerance. Однако широкого распространения FT не получила – эта технология сложна в реализации, а также требовательна к каналам связи. Обычно достаточен более простой подход (HA с быстрым перезапуском, кластерные приложения на уровне ОС и т.п.). В критических сценариях (банковские системы реального времени и др.) могут быть построены решения с FT на базе метрокластеров, но это скорее штучные проекты.
Снапшоты и резервное копирование
Снимки состояния ВМ (snapshots) – необходимая функция для безопасных изменений и откатов. Все современные платформы (zVirt, SpaceVM, Red и прочие) поддерживают создание мгновенных снапшотов ВМ в рабочем состоянии. Как правило, доступны возможности делать цепочки снимков, однако требования к хранению диктуют, что постоянно держать много снапшотов нежелательно (как и в VMware, где они влияют на производительность). Для резервного копирования обычно предлагается интеграция с внешними системами бэкапа либо встроенные средства экспорта ВМ.
Например, SpaceVM имеет встроенное резервное копирование ВМ с возможностью сохранения бэкапов на удалённое хранилище. VMmanager от ISPsystem также предоставляет модуль бэкапа. Тем не менее, организации часто используют сторонние системы резервирования – здесь важно, что у российских гипервизоров обычно открыт API для интеграции. Почти все продукты предоставляют REST API или SDK, позволяющий автоматизировать задачи бэкапа, мониторинга и пр. Отдельные вендоры (например, Basis) декларируют принцип API-first, что упрощает связку с оркестраторами резервного копирования и мониторинга.
Управление ресурсами и балансировка
Мы уже упоминали наличие аналогов DRS в некоторых платформах (автоматическое перераспределение ВМ). Кроме этого, важно, как реализовано ручное управление ресурсами: пулы CPU/памяти, приоритеты, квоты. В VMware vSphere есть ресурсные пулы и shares-приоритеты. В российских системах подобные механизмы тоже появляются. zVirt, например, позволяет объединять хосты в логические группы и задавать политику размещения ВМ, что помогает распределять нагрузку. Red Virtualization (oVirt) исторически поддерживает задание весов и ограничений на ЦП и ОЗУ для групп виртуальных машин. В Basis Dynamix управление ресурсами интегрировано с IaC-инструментами – можно через Terraform описывать необходимые ресурсы, а платформа сама их выделит.
Такое тесное сочетание с DevOps-подходами – одно из преимуществ новых продуктов: Basis и SpaceVM интегрируются с Ansible, Terraform для автоматического развертывания инфраструктуры как кода. Это позволяет компаниям гибко управлять ИТ-ресурсами и быстро масштабировать кластеры или развертывать новые ВМ по шаблонам.
Управление кластерами
Центральная консоль управления кластером – обязательный компонент. Аналог VMware vCenter в отечественных решениях присутствует везде, хотя может называться по-разному. Например, у Space – SpaceVM Controller (он же выполняет роль менеджера кластера, аналог vCenter). У zVirt – собственная веб-консоль, у Red Virtualization – знакомый интерфейс oVirt Engine, у VMmanager – веб-панель от ISPsystem. То есть любой выбранный продукт предоставляет единый интерфейс для управления всеми узлами, ВМ и ресурсами. Многие консоли русифицированы и достаточно дружелюбны. Однако по отзывам специалистов, удобство администрирования ещё требует улучшений: отмечается, что ряд операций в отечественных платформах более трудоёмкие или требуют «танцев с бубном» по сравнению с отлаженным UI VMware. Например, на Хабре приводился пример, что создание простой ВМ в некоторых системах превращается в квест с редактированием конфигурационных файлов и чтением документации, тогда как в VMware это несколько кликов мастера создания ВМ. Это как раз то направление, где нашим решениям ещё есть куда расти – UX и простота администрирования.
В плане кластеризации и отказоустойчивости можно заключить, что функционально российские платформы предоставляют почти весь минимально необходимый набор возможностей. Кластеры, миграция ВМ, HA, снапшоты, бэкап, распределенная сеть, интеграция со сториджами – всё это реализовано (см. сводную таблицу ниже). Тем не менее, зрелость реализации зачастую ниже: возможны нюансы при очень крупных масштабах, не все функции могут быть такими же «отполированными» как у VMware, а администрирование требует большей квалификации.
Платформа
Разработчик
Технологическая основа
Особенности архитектуры
Ключевые сильные стороны
Известные ограничения
Basis Dynamix
БАЗИС
Собственная разработка (KVM-совместима)
Классическая и гибридная архитектура (есть Standard и Enterprise варианты)
Высокая производительность, интеграция с Ansible/Terraform, единая экосистема (репозиторий, поддержка); востребован в госсекторе.
Мало публичной информации о тонкостях; относительно новый продукт, требует настройки под задачу.
SpaceVM
ДАКОМ M (Space)
Проприетарная (собственный стек гипервизора)
Классическая архитектура, интеграция с внешними СХД + проприетарные HCI-компоненты (FreeGRID, SDN Flow)
Максимально функциональная платформа: GPU-виртуализация (FreeGRID), своя SDN (аналог NSX), полный VDI-комплекс (Space VDI) и собственные протоколы; высокое быстродействие.
Более сложное администрирование (богатство функций = сложность настроек).
zVirt
Orion soft
Форк oVirt (KVM) + собственный бэкенд
Классическая модель, SDN-сеть внутри (distributed vSwitch)
Богатый набор функций: микросегментация сети SDN, Storage Live Migration, авто-балансировка ресурсов (DRS-аналог), совместим с открытой экосистемой oVirt; крупнейшая инсталляционная база (21k+ хостов ожидается).
Проблемы масштабируемости на очень больших кластерах (>50 узлов); интерфейс менее удобен, чем VMware (выше порог входа).
Red Виртуализация
РЕД СОФТ
Форк oVirt (KVM)
Классическая схема, тесная интеграция с РЕД OS и ПО РЕД СОФТ
Знакомая VMware-подобная архитектура; из коробки многие функции (SAN, HA и др.); сертификация ФСТЭК РЕД ОС дает базу для безопасности; успешные кейсы миграции (Росельхозбанк, др.).
Более ограниченная экосистема поддержки (сильно завязана на продукты РЕД); обновления зависят от развития форка oVirt (нужны ресурсы на самостоятельную разработку).
vStack HCP
vStack (Россия)
FreeBSD + bhyve (HCI-платформа)
Гиперконвергентная архитектура, собственный легковесный гипервизор
Минимальные накладные расходы (2–5% CPU), масштабируемость «без ограничений» (нет фикс. лимитов на узлы/ВМ), единый веб-интерфейс; независим от Linux.
Относительно новая/экзотичная технология (FreeBSD), сообщество меньше; возможно меньше совместимых сторонних инструментов (бэкап, драйверы).
Cyber Infrastructure
Киберпротект
OpenStack + собственные улучшения (HCI)
Гиперконвергенция (Ceph-хранилище), поддержка внешних СХД
Глубокая интеграция с резервным копированием (наследие Acronis), сертификация ФСТЭК AccentOS (OpenStack), масштабируемость для облаков; работает на отечественном оборудовании.
Менее подходит для нагрузок, требующих стабильности отдельной ВМ (особенности OpenStack); сложнее в установке и сопровождении без экспертизы OpenStack.
Другие (ROSA, Numa, HostVM)
НТЦ ИТ РОСА, Нума Техн., HostVM
KVM (oVirt), Xen (xcp-ng), KVM+UDS и др.
В основном классические, частично HCI
Закрывают узкие ниши или предлагают привычный функционал для своих аудиторий (например, Xen для любителей XenServer, ROSA для Linux-инфраструктур). Часто совместимы с специфическими отечественными ОС (ROSA, ALT).
Как правило, менее функционально богаты (ниже баллы рейтингов); меньшая команда разработки = более медленное развитие.
Виртуализация давно стала неотъемлемой частью корпоративной ИТ-инфраструктуры, позволяя эффективнее использовать серверное оборудование и быстро развертывать новые сервисы. До недавнего времени российский рынок практически полностью зависел от зарубежных продуктов – особенно от VMware, на долю которого приходилось до 95% внедрений. Однако после 2022 года ситуация резко изменилась: VMware покинула российский рынок, отключив аккаунты пользователей и прекратив поддержку.
Это оставило компании без обновлений, техподдержки и возможности покупки новых лицензий. Одновременно регуляторы ужесточили требования: с 1 января 2025 года значимые объекты критической информационной инфраструктуры (КИИ) обязаны использовать только отечественное ПО. В результате переход на российские системы виртуализации из опции превратился в необходимость, и за три года рынок претерпел заметную консолидацию.
По данным исследования компании «Код Безопасности», уже 78% российских организаций выбирают отечественные средства виртуализации. В реестре российского ПО на 2025 год значатся порядка 92 решений для серверной виртуализации, из которых реально «живых» около 30, а активно используемых – не более десятка. За короткий срок появились аналоги западных продуктов «большой тройки» (VMware, Microsoft Hyper-V, Citrix) и собственные разработки российских компаний. Рассмотрим новейшие российские платформы виртуализации серверов и инфраструктуры виртуальных рабочих мест (VDI) и проанализируем их архитектуру, производительность, безопасность, возможности VDI, а также функции кластеризации и управления ресурсами. Отдельно сравним их с VMware VCF/vSphere по функциональности, зрелости технологий, совместимости и поддержке – и определим, какие решения наиболее перспективны для импортозамещения VMware в корпоративных ИТ России.
Российские платформы виртуализации 2025 года представлены широким спектром архитектурных подходов. Условно можно выделить две ключевые категории: классическая архитектура и гиперконвергентная архитектура (HCI). Также различаются технологические основы: часть решений опирается на открытый исходный код (форки oVirt, OpenStack, Proxmox и др.), тогда как другие являются проприетарными разработками.
Классическая архитектура
В классической схеме вычислительные узлы, системы хранения (СХД) и сети реализуются отдельными компонентами, объединёнными в единый кластер виртуализации. Такой подход близок к VMware vSphere и проверен десятилетиями: он даёт максимальную гибкость, позволяя подключать внешние высокопроизводительные СХД, использовать существующие сетевые инфраструктуры и масштабировать каждый слой независимо (например, наращивать хранение без изменения серверов). Для организаций с уже развернутыми дорогими СХД и развитой экспертизой администраторов этот вариант наиболее понятен.
Многие отечественные продукты поддерживают классическую модель. Например, “Ред Виртуализация” (решение компании РЕД СОФТ на базе KVM/oVirt), zVirt от Orion soft, SpaceVM (платформа компании «ДАКОМ М»), Rosa Virtualization, VMmanager от ISPsystem и Numa vServer (Xen-based) – все они ориентированы на традиционную архитектуру с интеграцией внешних хранилищ и сетей.
Архитектурно они во многом схожи с VMware (например, оVirt-платформы реализуют подключение SAN-хранилищ, динамическую балансировку ресурсов и т.п. «из коробки»). Однако есть и недостатки классического подхода: более высокая стоимость отдельных компонентов (CAPEX), требовательность к квалификации узких специалистов, сложность диагностики сбоев (не всегда очевидно, в каком слое проблема). Развёртывание классической инфраструктуры может занимать больше времени, поскольку нужно поэтапно настроить и интегрировать разнородные компоненты внутри единой платформы.
Гиперконвергентная инфраструктура (HCI)
В HCI все основные функции – вычисления, хранение, сеть – объединены на каждом узле и управляются через единую программную платформу. Локальные диски серверов объединяются программно в распределённое хранилище (часто на основе Ceph или аналогов), а сеть виртуализуется средствами самой платформы. Такой подход упрощает масштабирование: добавление нового узла сразу увеличивает и CPU/RAM, и объём хранения. Гиперконвергенция особенно хорошо подходит для распределённых площадок и филиалов, где нет штата ИТ-специалистов – достаточно поставить несколько одинаковых узлов, и система автонастроится без тонкой ручной оптимизации каждого слоя.
В России к HCI-решениям относятся, например, vStack (платформа в составе холдинга ITG на базе FreeBSD и гипервизора bhyve), «Кибер Инфраструктура» (решение компании «Киберпротект», развившей технологии Acronis), Р-платформа (российская приватная облачная платформа), Горизонт-ВС и др. – они изначально спроектированы как гиперконвергентные. Некоторые HCI-системы позволяют выходить за рамки встроенного хранения – например, Кибер Инфраструктура и Горизонт-ВС поддерживают подключение внешних блочных СХД, комбинируя подходы.
Открытый код или собственные разработки?
Многие отечественные продукты выросли из популярных open-source проектов. Например, решения на основе oVirt – это упомянутые выше zVirt, Red Виртуализация, ROSA Virtualization, HostVM и др. Их преимущество – быстрое получение базовой функциональности (live migration, подключение SAN, кластеры HA и т.д.) благодаря наследию oVirt/Red Hat. Однако после ухода Red Hat из oVirt сообщество ослабло, и российским командам пришлось форкать код и развивать его самим.
Orion soft, например, пошла по пути создания собственного бэкенда поверх ядра oVirt, сумев сохранить совместимость, но упростив и улучшив часть функций для пользователей. Другой популярный открытый проект – Proxmox VE – тоже получил российские форки (например, «Альт Виртуализация», GloVirt), что позволяет заказчикам использовать знакомый интерфейс PVE с поддержкой отечественной компанией.
Есть и решения на базе OpenStack – эта платформа хорошо масштабируется и подходит для построения частных облаков IaaS. Так, AccentOS CE – российская облачная платформа на основе OpenStack – получила сертификат ФСТЭК осенью 2025 г. Тем не менее, OpenStack-системы (например, частное облако VK Cloud) часто критикуют за избыточную сложность для задач традиционной виртуализации и проблемы стабильности отдельных ВМ под высокими нагрузками хранения. Наконец, существуют продукты на базе Xen – в частности, Numa vServer построен на открытом гипервизоре xcp-ng (форк Citrix XenServer), что даёт вариант для тех, кто привык к Xen.
Помимо форков, на рынке появились принципиально новые разработки. К ним относятся SpaceVM, Basis Dynamix, VMmanager и др., где компании создали собственные платформы управления, опираясь на комбинацию различных open-source компонентов, но реализуя уникальные возможности. Например, SpaceVM и Basis Dynamix заявляют о полном проприетарном стеке – разработчики утверждают, что не используют готовые open-source продукты внутри, а все компоненты (гипервизор, драйверы, диспетчер ресурсов) созданы самостоятельно. Такой подход требует больше усилий, но позволяет глубже интегрировать систему с отечественными ОС и средствами кибербезопасности, а также активно внедрять API-first и DevOps-интеграции. В итоге, сегодня российский рынок виртуализации предлагает решения на любой вкус – от максимально близких к VMware аналогов на базе KVM до совершенно новых платформ с оригинальной архитектурой.
Один из ключевых вопросов для корпоративных клиентов – способен ли отечественный гипервизор обеспечить производительность и масштаб, сопоставимые с vSphere. Практика показывает, что большинство российских платформ уже поддерживают необходимые уровни масштабирования: кластеры на десятки узлов, сотни и тысячи виртуальных машин, live migration и распределение нагрузки между хостами. Например, платформа SpaceVM официально поддерживает кластеры до 96 серверов, Selectel Cloud – до 2500 узлов, Red Виртуализация – до 250 хостов в одном датацентре.
Многие разработчики вообще не указывают жестких ограничений на размер кластера, утверждая, что он линеен (ISP VMmanager протестирован на 350+ узлов, 1000+ ВМ). В реальных внедрениях обычно речь идёт о десятках серверов, что этим решениям вполне по силам. Однако из опыта миграций известны и проблемы: так, эксперты отмечают, что у zVirt иногда возникают сложности при росте кластера более 50 узлов. Первые «тревожные звоночки» появлялись уже около 20 хостов, но в новых версиях горизонтальная масштабируемость доведена до 50–60 узлов, что для большинства сред достаточно. Подобные нюансы следует учитывать при проектировании – предельно возможный масштаб у разных продуктов разнится, и при планировании очень крупных инсталляций лучше привлечь вендора или интегратора для оценки нагрузок.
По производительности виртуальных машин отечественные гипервизоры стараются минимизировать накладные расходы. Так, vStack HCP заявляет о оверхеде всего 2–5% к CPU при виртуализации, то есть близкой к нативной производительности. Это достигнуто за счёт легковесного гипервизора (базирующегося на bhyve) и оптимизированного I/O стека. Большинство других решений используют проверенные гипервизоры (KVM, Xen), у которых производительность также высока. С точки зрения нагрузки на оперативную память и хранилище – многое зависит от механизмов дедупликации, компрессии и прочих оптимизаций в конкретной реализации.
Здесь можно отметить, что многие российские платформы уже внедрили современные технологии оптимизации ресурсов: поддержка NUMA для эффективной работы с многопроцессорными узлами, возможность тонкого выделения ресурсов (thin provisioning дисков, memory ballooning) и т.д. Например, по данным рейтинга Компьютерры, Basis Dynamix и SpaceVM набрали максимальные баллы по критериям вертикальной и горизонтальной масштабируемости, а также поддержки Intel VT-x/AMD-V виртуализации, NUMA и даже GPU-passthrough. То есть функционально они не уступают VMware в возможностях задействовать современное оборудование.
Отдельно стоит упомянуть работу с графическими нагрузками. В сфере VDI и 3D-приложений критична поддержка GPU-виртуализации. Здесь российские разработчики сделали заметный прогресс. SpaceVM изначально ориентирован на сценарии с графическими рабочими станциями: платформа поддерживает как passthrough GPU для выделения целой видеокарты ВМ, так и технологию FreeGRID – собственную разработку для виртуализации ресурсов NVIDIA-GPU без риска лицензионной блокировки.
По сути, FreeGRID выступает аналогом технологии NVIDIA vGPU (GRID), но адаптированным к ограничениям поставок – это актуально, поскольку официальные лицензии NVIDIA в России недоступны. Благодаря этому SpaceVM активно используют организации, которым нужны высокопроизводительные графические ВМ: конструкторские бюро (CAD/CAE), геоинформационные системы, видеомонтаж и др. Другие платформы также не отстают: zVirt и решения на базе oVirt умеют пробрасывать физические GPU внутрь ВМ, а HostVM и ряд VDI-платформ заявляют поддержку технологии виртуализации графических процессоров для нужд 3D-моделирования. Таким образом, в плане работы с тяжелыми графическими нагрузками отечественные продукты закрывают основные потребности.
Стоит отметить, что автоматическое распределение ресурсов и балансовка нагрузки – функции, известные в VMware как DRS (Distributed Resource Scheduler) – начинают появляться и в российских решениях. Например, zVirt реализует модуль автоматического распределения виртуальных машин по хостам, аналогичный DRS. Это значит, что платформа сама перераспределяет ВМ при изменении нагрузок, поддерживая равномерное потребление ресурсов. Кроме того, большинство продуктов поддерживают «горячую миграцию» (Live Migration) – перенос работающей ВМ между хостами без простоя, а также миграцию хранилищ на лету (Storage vMotion) – например, в zVirt есть возможность "перетаскивать" виртуальные диски между датацентрами без остановки ВМ. Эти функции критичны для обеспечения непрерывности сервисов при обслуживании оборудования или ребалансировке нагрузки.
Резюмируя, производительность российских гипервизоров уже находится на уровне, достаточном для многих корпоративных задач, а по некоторым параметрам они предлагают интересные инновации (минимальный оверхэд у vStack, поддержка GPU через FreeGRID у SpaceVM и т.п.). Тем не менее, при планировании очень нагруженных или масштабных систем следует внимательно относиться к тестированию конкретного продукта под своей нагрузкой – практика показывает, что в пилотных проектах не всегда выявляются узкие места, которые могут проявиться на продакшен-системе. Важны также оперативность вендора при оптимизации производительности и наличие у него экспертизы для помощи заказчику в тюнинге – эти аспекты мы рассмотрим в следующих статьях при сравнении опций поддержки.
Вопрос кибербезопасности и соответствия регуляторным требованиям (ФСТЭК, Закон о КИИ, ГОСТ) является определяющим для многих российских предприятий, особенно государственных и критической инфраструктуры. Отечественные решения виртуализации учитывают эти аспекты с самого начала разработки. Во-первых, практически все крупные платформы включены в Единый реестр российского ПО, что подтверждает их юридическую «отечественность» и позволяет использовать их для импортозамещения в госорганизациях. Более того, ряд продуктов прошёл добровольную сертификацию в ФСТЭК России по профильным требованиям безопасности.
Особое внимание уделяется сетевой безопасности в виртуальной среде. Одной из угроз в датацентрах является горизонтальное распространение атак между ВМ по внутренней сети. Для борьбы с этим современные платформы внедряют микросегментацию сети и распределённые виртуальные брандмауэры. Например, zVirt содержит встроенные средства SDN (Software-Defined Networking) для сегментации трафика – администратор может разделить виртуальную сеть на множество изолированных сегментов и централизованно задать политики доступа между ними. Эта функциональность, требуемая ФСТЭК для защиты виртуальных сред, реализована по умолчанию и позволяет соответствовать требованиям закона по сегментированию значимых объектов КИИ и ГосИС.
Дополнительно компания Orion soft (разработчик zVirt) рекомендует использовать совместно с гипервизором продукт vGate от компании «Код Безопасности». vGate – это межсетевой экран уровня гипервизора, который интегрируется с платформой виртуализации. Работая на уровне гипервизора, vGate перехватывает и фильтрует трафик между всеми ВМ, применяя централизованные политики безопасности. Разработчики сделали ставку на микросегментацию: каждый узел vGate хранит полный набор правил, что позволяет при миграции ВМ сразу переносить и её сетевые политики.
vGate сертифицирован ФСТЭК как межсетевой экран класса «Б» с 4-м уровнем доверия, поэтому его связка с zVirt закрывает требования регулятора для защиты виртуальных сегментов КИИ. В случае комбинированного использования, как отмечают эксперты, правила безопасности контролируются одновременно на уровне платформы (zVirt SDN) и на уровне гипервизора (vGate), дополняя друг друга. Например, если политика zVirt разрешает определённый трафик между ВМ, а политика vGate запрещает, пакет будет блокирован – то есть действует наиболее строгий из двух наборов правил. Такой «двойной заслон» повышает уверенность в защите.
Кроме сетевых экранов, встроенные механизмы безопасности практически обязательны для всех современных платформ. Российские решения включают разграничение доступа и аутентификацию корпоративного уровня: реализованы ролевые модели (RBAC), интеграция с LDAP/Active Directory для централизованного управления учетными записями, поддержка многофакторной аутентификации администраторов и журналирование действий с возможностью отправки логов на SIEM-системы. По этим пунктам разница с VMware не такая и большая – например, Basis Dynamix, SpaceVM и Red Виртуализация имеют полный набор RBAC/LDAP/2FA и получили максимально возможные оценки за безопасность в независимом рейтинге.
Дополнительно некоторые решения обеспечивают контроль целостности и доверенную загрузку (Trusted Boot) за счёт интеграции с отечественными защищёнными ОС. Например, гипервизоры могут устанавливаться поверх сертифицированных ОС (РЕД ОС, Astra Linux), что обеспечивает соответствие по требованиям НДВ (недекларированных возможностей) и использование российских криптосредств.
В контексте соответствия требованиям регуляторов важна и сертификация самих платформ виртуализации. На конец 2025 года сертифицированных по профильным требованиям ФСТЭК именно гипервизоров немного (преимущественно решения для гостевых ОС специального назначения). Однако, как отмечалось, платформы часто используют сертифицированные СЗИ «поверх» (антивирусы, СОВ, vGate и др.) для обеспечения соответствия. Кроме того, крупнейшие заказчики – госсектор, банки – проводили оценочные испытания продуктов в своих пилотных зонах. Например, при миграции в Альфа-Банке и АЛРОСА основным драйвером был закон о КИИ, и в обоих случаях итоговый выбор пал на отечественные гипервизоры (SpaceVM и zVirt соответственно) после тщательного тестирования безопасности. Таким образом, можно сказать, что российские системы виртуализации в целом готовы к работе в защищённых контурах. Они позволяют реализовать требуемую сегментацию, поддерживают российские криптоалгоритмы (при использовании соответствующих ОС и библиотек), а при правильной настройке обеспечивают изоляцию ВМ не хуже зарубежных аналогов.
Нельзя не затронуть и вопрос устойчивости к атакам и сбоям. Эксперты отмечают, что по методам защиты виртуальная инфраструктура не сильно отличается от физической – нужны регулярные обновления безопасности, сильные пароли и ограничение доступа привилегированных пользователей. Основной вектор атаки на гипервизоры в России – компрометация учётных данных администраторов, тогда как эксплойты уязвимостей встречаются гораздо реже. Это значит, что внедрение RBAC/2FA, о которых сказано выше, существенно снижает риски. Также важно строить резервное копирование на уровне приложений и данных, а не полагаться только на механизмы платформы. Как отмечают представители банковского сектора, добиться требуемого по стандартам времени восстановления (RTO) только силами гипервизора сложно – необходимо комбинировать различные уровни (репликация критичных систем, отказоустойчивые кластеры, резервные площадки). В целом же, за три года уровень зрелости безопасности российских продуктов заметно вырос: многие проблемы, ранее считавшиеся нерешаемыми, уже устранены или существуют понятные обходные пути. Производители активно учитывают требования заказчиков, внедряя наиболее востребованные функции безопасности в приоритетном порядке.
VMware Cloud Foundation (VCF) 9.0 предоставляет быстрый и простой способ развертывания частного облака. Хотя обновление с VCF 5.x спроектировано как максимально упрощённое, оно вносит обязательные изменения в методы управления и требует аккуратного, поэтапного выполнения.
Недавно Джонатан Макдональд провёл насыщенный вебинар вместе с Брентом Дугласом, где они подробно разобрали процесс обновления с VCF 5.2 до VCF 9.0. Сотни участников и шквал вопросов ясно показали, что этот переход сейчас волнует многих клиентов VMware.
Джонатан отфильтровал повторяющиеся вопросы, объединив похожие в единые, комплексные темы. Ниже представлены 10 ключевых вопросов («must-know»), заданных аудиторией, вместе с подробными ответами, которые помогут вам уверенно пройти путь к VCF 9.0.
Вопрос 1: Как VMware SDDC Manager выполняет обновления? Есть ли значительные изменения в обновлениях версии 9.0?
Было много вопросов, связанных с SDDC Manager и процессом обновлений. Существенных изменений в том, как выполняются обновления, нет. Если вы знакомы с VCF 5.2, то асинхронный механизм патчинга встроен в консоль точно так же и в версии 9.0. Это позволяет планировать обновления и патчи по необходимости. Главное отличие заключается в том, что интерфейс SDDC Manager был интегрирован в консоль VCF Operations и теперь находится в разделе управления парком (Fleet Management). Многие рабочие процессы также были перенесены, что позволило консолидировать интерфейсы.
Вопрос 2: Есть ли особенности обновления кластеров VMware vSAN Original Storage Architecture (OSA)?
vSAN OSA не «уходит» и не объявлен устаревшим в VCF 9.0. Аппаратные требования для vSAN Express Storage Architecture (ESA) существенно отличаются и могут быть несовместимы с существующим оборудованием. vSAN OSA — отличный способ продолжать эффективно использовать имеющееся оборудование без необходимости покупать новое. Для самого обновления важно проверить совместимость аппаратного обеспечения и прошивок с версией 9.0. Если они поддерживаются, обновление пройдёт так же, как и в предыдущих релизах.
Вопрос 3: Как выполняется обновление VMware NSX?
При обновлении VCF все компоненты, включая NSX, обновляются последовательно. Обычно процесс начинается с компонентов VCF Operations. После этого управление передаётся рабочим процессам SDDC Manager: сначала обновляется сам SDDC Manager, затем NSX, потом VMware vCenter и в конце — хосты VMware ESX.
Вопрос 4: Если VMware Aria Suite развернут в режиме VCF-aware в версии 5.2, нужно ли отвязывать Aria Suite перед обновлением?
Нет. Вы можете сначала обновить компоненты Aria Suite до версии, совместимой с VCF 9, а затем продолжить обновление остальных компонентов.
Вопрос 5: Можно ли обновиться с VCF 5.2 без настроенных LCM и Aria Suite?
Да. Наличие компонентов Aria Suite до обновления на VCF 9.0 не требуется. Однако в рамках обновления будут развернуты Aria Lifecycle (в версии 9.0 — VCF Fleet Management) и VCF Operations, так как они являются обязательными компонентами в 9.0.
Вопрос 6: Сколько хостов допускается в консолидированном дизайне VCF 9.0?
Для нового консолидированного дизайна рекомендуется минимум четыре хоста. При конвергенции инфраструктуры с использованием vSAN требуется минимум три ESX-хоста (четыре рекомендуются для отказоустойчивости). При использовании внешних систем хранения достаточно минимум двух хостов. Что касается максимальных значений, документированных ограничений нет, кроме ограничений VMware vSphere: 96 хостов на кластер и 2500 хостов на один vCenter. В целом рекомендуется по мере роста добавлять дополнительные домены рабочих нагрузок или кластеры для логического разделения среды с точки зрения производительности, доступности и восстановления.
Вопрос 7: Как перейти с VMware Identity Manager (vIDM) на VCF Identity Broker (VIDB) в VCF 9?
Прямого пути обновления или миграции с vIDM на VIDB не существует. Требуется «чистое» (greenfield) развертывание VIDB. Это особенно актуально, если используется VCF Automation, так как в этом случае новое развертывание VIDB является обязательным.
Вопрос 8: Нужно ли загружать дистрибутивы для VCF Operations и куда их помещать?
Это зависит от используемого сценария. В общем случае, если вы выполняете обновление и компоненты Aria ещё не установлены, потребуется загрузить и развернуть виртуальные машины VCF Operations и VCF Operations Fleet Management. После их развертывания бинарные файлы загружаются в репозиторий (depot) VCF Operations Fleet Management для установки дополнительных компонентов. Если вы конвергируете vSphere в VCF, все недостающие компоненты будут развернуты установщиком VCF, и, соответственно, должны быть загружены в него заранее.
Вопрос 9: Существует ли путь отката (rollback), если во время обновления возникла ошибка?
В целом не существует «кнопки отката» для всего VCF сразу. Лучше рассматривать каждое последовательное обновление как контрольную точку. Например, перед обновлением SDDC Manager с 5.2 до 9.0 нужно всегда делать резервную копию. Если во время обновления возникает сбой, можно откатиться к состоянию до ошибки и продолжить диагностику. То же самое относится к другим компонентам. При сбоях в обновлении NSX, vCenter или ESX-хостов нужно оценить ситуацию и либо выполнить откат, либо обратиться в поддержку, если время окна обслуживания истекает и необходимо срочно восстановить работоспособность среды. Именно поэтому тщательное планирование имеет решающее значение при любом обновлении VCF.
Вопрос 10: Существует ли путь миграции с VMware Cloud Director (VCD) на VCF Automation?
На данный момент VCD не поддерживается в VCF 9.0, и официальных путей миграции не существует. Если у вас есть вопросы по этому поводу, обратитесь к вашему Account Director.
VMware vCenter Converter – это классический инструмент VMware для перевода физических и виртуальных систем в формат виртуальных машин VMware. Его корни уходят к утилите VMware P2V Assistant, которая существовала в 2000-х годах для «Physical-to-Virtual» миграций. В 2007 году VMware выпустила первую версию Converter (3.0), заменив P2V Assistant...
Серверная платформа виртуализации VMware Cloud Foundation (VCF 9) обеспечивает непревзойдённые преимущества для инфраструктуры виртуальных рабочих столов (VDI). Даже после выделения бизнес-группы VMware End User Computing (EUC) в состав отдельной компании Omnissa основы этого комплексного решения остаются неизменными. Однако выпуск VCF 9.0 заслуживает повторного рассмотрения этих основ, чтобы показать, насколько устойчивой остаётся платформа.
VCF 9.0 объединяет основу частного облака (vSphere, vSAN, NSX) с облачной автоматизацией (VCF Automation), интегрированным Kubernetes (VMware vSphere Kubernetes Service / VKS) и другими передовыми сервисами для VCF, такими как VMware Private AI Services и VMware Data Services Manager (DSM). Эти и многие другие инновации работают совместно с решением Omnissa Horizon VDI, обеспечивая изначально безопасный, оптимизированный и масштабируемый фундамент для самых требовательных виртуальных рабочих столов.
Запуск Horizon на VCF 9.0 позволяет клиентам воспользоваться полным набором сервисов единой платформы частного облака. VCF предоставляет домены рабочих нагрузок, оркестрированные обновления, сетевую изоляцию на основе VPC и современный API потребления. Это платформа, которая рассматривает рабочие столы как полноправные рабочие нагрузки.
Безопасность и соответствие требованиям
Безопасность — это то, где VCF сразу проявляет свои сильные стороны. Используйте межсетевой экран NSX, чтобы применить политику наименьших привилегий к Horizon Connection Server, UAG и пулу рабочих столов без направляющего трафик hairpin-маршрута через внешние файрволы. Конструкции VPC в VCF 9.0 позволяют создавать воспроизводимый сетевой периметр для каждой функции Horizon:
Edge (UAG)
Brokering (Connection Servers)
Рабочие столы
Общие сервисы
Эти меры защиты масштабируются вместе с инфраструктурой, а не усложняют её. VCF 9.0 также представляет комплекс встроенных функций безопасности и соответствия требованиям, критически важных для VDI-сред:
Централизованное управление сетевыми политиками с NSX усиливает защиту латерального трафика для чувствительных VDI-рабочих столов, соответствуя строгим регуляторным требованиям.
Микросегментация и изоляция VPC позволяют привязывать политики к объектам, а не подсетям, что повышает устойчивость в продакшене и упрощает аудит.
Неизменяемые (immutable) снапшоты, защита от вымогателей и интегрированное аварийное восстановление с vSAN ESA и VMware Live Recovery обеспечивают непрерывность бизнеса и быстрое восстановление после атак или сбоев, что критично для поддержания доступности рабочих столов и соответствия требованиям.
Для отраслей с жёсткими нормами (здравоохранение, финансы, госучреждения) сертификации безопасности VCF (TLS 1.3, FIPS 140-3, DISA STIG) позволяют рабочим средам соответствовать самым строгим стандартам.
Эффективность и оптимизация ресурсов
Благодаря дедупликации хранения, расширенным механизмам управления памятью и более высокой загрузке хостов, VCF 9.0 обеспечивает значительное снижение совокупной стоимости владения (TCO). Эффективность затрат в этом контексте — это не просто «купить меньше серверов». Речь идёт о том, чтобы преобразовать каждый ресурс — вычисления, хранение, сеть и операционные накладные расходы — в большее количество продуктивных пользователей без ущерба для их опыта.
Улучшенные коэффициенты консолидации CPU и памяти позволяют размещать больше одновременных рабочих столов на сервере, что напрямую снижает инфраструктурные расходы и упрощает масштабирование крупных развертываний.
vSAN ESA с глобальной дедупликацией может уменьшить затраты на хранение для постоянных VDI-пулов, а фоновые операции минимизируют влияние на производительность для пользователей.
Политики хранения vSAN могут назначаться для каждого пула, чтобы образы для сотрудников с типовыми задачами не вызывали то же потребление ресурсов хранения, что и пулы, насыщенные данными или графикой. Такая точность направляет IOPS туда, где они нужнее всего, и устраняет практику чрезмерного резервирования ресурсов «на всякий случай».
Благодаря функции Memory Tiering в VCF vSphere постоянно держит горячие страницы в DRAM и перемещает холодные на локальные NVMe, фактически используя локальные NVMe как вторичный уровень памяти. В недавних тестах Login Enterprise это позволило добиться стабильного двукратного увеличения плотности ВМ на хост. Эта возможность значительно повышает эффективность использования оборудования, позволяя запускать больше виртуальных рабочих столов на меньшей инфраструктуре.
Высокая производительность
VCF 9.0 предоставляет основу, которая делает производительность Horizon предсказуемой. Это начинается с вычислительных ресурсов: распределённый планировщик vSphere (DRS) помогает гарантировать, что динамичные пулы рабочих столов распределяются с учётом локальности NUMA по физическому кластеру. Это обеспечивает попадание выделенных vCPU на один NUMA-узел, уменьшая межсокетные переходы, снижая задержки и повышая общую плавность работы. Особенно критично это во время «штормов загрузки» (boot storms) и всплесков активности приложений.
Память
Память часто является узким местом в VDI. Как отмечалось ранее, Memory Tiering в VCF 9 увеличивает плотность без обычного негативного влияния на производительность или пользовательский опыт. Особенно это заметно для пулов с низкими требованиями к «горячей» памяти (например, рабочих мест сотрудников с типовыми задачами). Практический эффект в периоды пиков (утренние входы, массовые запуски приложений и т.д.) выражается в меньшем количестве зависаний и снижении задержек ввода.
Хранение
Благодаря vSAN (особенно архитектуре Express Storage Architecture на NVMe) вы получаете адаптированный под записи метод хранения и возможность использовать политики хранения на уровне пула рабочих столов, оптимизированные под конкретную задачу:
RAID-1 и повышенное количество страйпов для особо требовательных пользователей
RAID-5/6 для сотрудников с типовыми задачами
Object-space reservations для эталонных золотых образов рабочих столов, которые испытывают серьёзную нагрузку на чтение при использовании слоёв приложений
Поскольку управление реализовано полностью на базе политик, нет необходимости избыточно проектировать каждый пул под худший сценарий, но инфраструктура при этом остаётся оптимизированной для ежедневных нагрузок клонирования, развёртывания обновлений и утренних пиков входа. Итог - стабильные задержки под нагрузкой и более быстрое открытие приложений, когда все кликают одновременно.
Сеть
Сетевые сервисы NSX выполняются в ядре гипервизора, что позволяет избегать прогона через физическую инфраструктуру, что забирает ресурсы хоста и увеличивает задержки. В сочетании с сегментацией VPC пулы рабочих столов получают детерминированные маршруты с меньшим количеством переходов. Результат — меньше накладных расходов и больше пропускной способности для действительно важного трафика. Кроме того, NSX Distributed Firewall (лицензируется отдельно как часть VMware vDefend) может применять политику межсетевого экрана для east-west трафика прямо на pNIC хоста, исключая маршрутизацию через внешние устройства и уменьшая колебания задержек.
Графика
Horizon с NVIDIA vGPU на VCF позволяет выбирать vGPU-профили для каждого пула, сохраняя при этом преимущества DRS для оптимального размещения рабочих столов. Это означает, что можно консолидировать требовательных 3D-пользователей и более лёгкие графические задачи на одних и тех же физических хостах, поддерживая высокую утилизацию GPU.
Операции второго дня
Управление жизненным циклом и парком инфраструктуры в VCF — это мгновенное преимущество для администраторов, которым приходилось балансировать обслуживание и доступность пулов рабочих столов. VCF 9.0 оркестрирует задачи жизненного цикла платформы по доменам рабочих нагрузок, что позволяет выполнять обновления в узкие временные окна без длительных простоев и без оставления кластеров в смешанном состоянии. Это поддерживает эффективность DRS и согласованность политик хранения, обеспечивая доступность и производительность пулов рабочих столов. VCF выполняет поэтапные обновления всего стека, по домену, с проверками работоспособности и операционными процессами.
Автоматизация жизненного цикла частного облака упрощает патчинг, обновления и планирование ёмкости для крупных развертываний Horizon, позволяя администраторам сосредоточиться на пользовательском опыте и инновациях, а не на повторяющихся операциях. Инструменты мониторинга и устранения неполадок на уровне всей платформы ускоряют решение проблем и оптимизируют показатели пользовательского опыта, минимизируя простой и повышая продуктивность.
Сценарий использования: Developer Workbench как сервис
С VKS и дополнительным сервисом DSM организации могут подключать лёгкие сервисы на базе Kubernetes и внутренние инструменты разработки непосредственно к пулам рабочих столов разработчиков. Это превращает VDI из «удалённого рабочего стола» в управляемую платформу рабочих пространств разработчика с сервисами по запросу.
VKS — это полноценный независимый сервис с быстрым жизненным циклом и декларативными API потребления.
Инженеры платформ и команды разработки могут быстро развертывать среды разработчиков на базе VKS, значительно сокращая время настройки dev/test.
Разработчики могут самостоятельно создавать пространства имен (namespaces), VKS-кластеры и получать доступ к PostgreSQL/MySQL и другим сервисам, управляемым DSM. Всё маркируется на уровне платформы с учётом стоимости, политик и требований к суверенитету данных.
Дополнительные сценарии использования
Помимо традиционных постоянных и непостоянных рабочих столов, комбинация VCF 9.0 + Omnissa Horizon открывает ряд расширенных возможностей:
Использование растянутых или мультисайтовых архитектур для расширения VDI-сервисов между облаками VCF, поддерживая гибкое масштабирование и сценарии аварийного восстановления.
Инженеры платформ и команды разработки могут самостоятельно и быстро разворачивать среды разработчиков на базе VKS, резко сокращая время подготовки dev/test.
Интегрированные VMware Private AI Services и поддержка vGPU как сервиса позволяют организациям легко развертывать виртуальные рабочие столы с поддержкой AI.
Эта эталонная архитектура документирует проверенный, готовый к промышленной эксплуатации дизайн для запуска Omnissa Horizon 8 на VMware Cloud Foundation (VCF). Она создана, чтобы строго ответить на простой вопрос: как сегодня максимально быстро, безопасно и экономично доставлять корпоративные виртуальные рабочие столы? Эталонная архитектура подчёркивает практическую инженерную проработку, повторяемые шаблоны и измеримые результаты, формируя схему сервиса, которую организации могут уверенно применять - будь то модернизация существующей среды Horizon или создание новой платформы.
Итоги
Даже несмотря на то, что Omnissa теперь работает как независимая компания, фундаментальные требования к облачной инфраструктурной платформе для виртуальных рабочих столов остаются неизменными: согласованная сегментация и безопасность, производительность, масштабируемость, управление жизненным циклом и возможность добавлять полезные сервисы. Именно это и обеспечивает VCF 9.0 - поэтому он остаётся лучшей основой для Horizon Desktops.
Если вам важна инфраструктура виртуальных рабочих столов, которая подходит не только для сегодняшних задач, но и готова к будущему, то запуск Horizon на VCF 9.0 - идеальное решение. Он устраняет все классические проблемы - безопасность, доступность, производительность и обновления - одновременно открывая доступ к функциям следующего поколения, таким как AI, рабочие столы для разработчиков и мультисайтовое масштабирование.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Службы VMware vSphere Kubernetes Service (VKS) версии 3.5 появились в общем доступе. Этот новый выпуск обеспечивает 24-месячную поддержку для каждой минорной версии Kubernetes, начиная с vSphere Kubernetes release (VKr) 1.34. Ранее, в июне 2025 года, VMware объявила о 24-месячной поддержке выпуска vSphere Kubernetes (VKr) 1.33. Это изменение обеспечивает командам, управляющим платформой, большую стабильность и гибкость при планировании обновлений.
VKS 3.5 также включает ряд улучшений, направленных на повышение операционной согласованности и улучшение управления жизненным циклом, включая детализированные средства конфигурации основных компонентов Kubernetes, декларативную модель управления надстройками и встроенную генерацию пакетов поддержки напрямую из интерфейса командной строки VCF CLI. Кроме того, новые защитные механизмы при обновлениях — такие как проверка PodDisruptionBudget и проверки совместимости — помогают обеспечить более безопасные и предсказуемые обновления кластеров.
В совокупности эти усовершенствования повышают надежность, операционную эффективность и качество управления Kubernetes-средами на этапе эксплуатации (Day-2) в масштабах предприятия.
Выпуск vSphere Kubernetes (VKr) 1.34
VKS 3.5 добавляет поддержку VKr 1.34. Каждая минорная версия vSphere Kubernetes теперь поддерживается в течение 24 месяцев с момента выпуска. Это снижает давление, связанное с обновлениями, стабилизирует рабочие среды и позволяет командам сосредоточиться на создании ценности, а не на постоянном планировании апгрейдов. Команды, которым нужен быстрый доступ к последним возможностям Kubernetes, могут оперативно переходить на новые версии. Те, кто предпочитает стабильную среду на длительный срок, теперь могут работать в этом режиме с уверенностью. VKS 3.5 поддерживает оба подхода к эксплуатации.
Динамическое распределение ресурсов (Dynamic Resource Allocation, DRA)
Функция DRA получила статус «стабильной» в основной ветке Kubernetes 1.34. Эта возможность позволяет администраторам централизованно классифицировать аппаратные ресурсы, такие как GPU, с помощью объекта DeviceClass. Это обеспечивает надежное и предсказуемое размещение Pod'ов на узлах с требуемым классом оборудования.
DRA повышает эффективность использования устройств, позволяя делить ресурсы между приложениями по декларативному принципу, аналогично динамическому выделению томов (Dynamic Volume Provisioning). Механизм DRA решает проблемы случайного распределения и неполного использования ресурсов. Пользователи могут выполнять точную фильтрацию, запрашивая конкретные устройства с помощью ResourceClaimsTemplates и ResourceClaims при развертывании рабочих нагрузок.
DRA также позволяет совместно использовать GPU между несколькими Pod'ами или контейнерами. Рабочие нагрузки можно настроить так, чтобы выбирать GPU-устройство с помощью Common Expression Language (CEL) и запросов ResourceSlice, что обеспечивает более эффективное использование по сравнению с count-based запросами.
Расширенные возможности конфигурации компонентов кластера Kubernetes
VKS 3.5 предоставляет гибкость для управления более чем 35 параметрами конфигурации компонентов Kubernetes, таких как kubelet, apiserver и etcd. Эти настройки позволяют командам платформ оптимизировать различные аспекты работы кластеров в соответствии с требованиями их рабочих нагрузок. Полный список доступных параметров конфигурации приведён в документации к продукту. Ниже приведён краткий обзор областей конфигурации, которые предлагает VKS 3.5:
Конфигурация
Настраиваемые компоненты
Описание
Журналирование и наблюдаемость (Logging & Observability)
Kubelet, API Server
Настройка поведения журналирования для API-сервера и kubelet, включая частоту сброса логов, формат (text/json) и уровни детализации. Управление хранением логов контейнеров с указанием максимального количества и размера файлов. Это позволяет эффективно управлять использованием диска, устранять неполадки с нужным уровнем детализации логов и интегрироваться с системами агрегирования логов с помощью структурированного JSON-журналирования.
Управление событиями (Event Management)
Kubelet
Управление генерацией событий Kubernetes с настройкой лимитов скорости создания событий (eventRecordQPS) и всплесков (eventBurst), чтобы предотвратить перегрузку API-сервера. Это позволяет контролировать частоту запросов kubelet к API-серверу, обеспечивая стабильность кластера в периоды высокой активности при сохранении видимости важных событий.
Производительность и масштабируемость (Performance & Scalability)
API Server
Управление производительностью API-сервера с помощью настройки пределов на максимальное количество одновременных изменяющих (mutating) и неизменяющих (non-mutating) запросов, а также минимальной продолжительности тайм-аута запроса. Возможность включения или отключения профилирования. Это позволяет адаптировать кластер под высоконагруженные рабочие процессы, предотвращать перегрузку API-сервера и оптимизировать отзывчивость под конкретные сценарии использования.
Конфигурации etcd
etcd
Настройка максимального размера базы данных etcd (в диапазоне 2–8 ГБ). Том создаётся с дополнительными 25 % ёмкости для учёта операций уплотнения, дефрагментации и временных всплесков использования. Это позволяет правильно подобрать объём хранилища etcd в зависимости от масштаба кластера и количества объектов, предотвращая ситуации нехватки места, которые могут перевести кластер в режим только для чтения.
Управление образами (Image Management)
Kubelet
Настройка жизненного цикла образов контейнеров, включая пороги очистки (в процентах использования диска — высокий/низкий), минимальный и максимальный возраст образов до удаления, лимиты скорости загрузки образов (registryPullQPS и registryBurst), максимальное количество параллельных загрузок и политики проверки учётных данных при загрузке. Это помогает оптимизировать использование дискового пространства узлов, контролировать потребление сетевых ресурсов, ускорять запуск Pod’ов за счёт параллельных загрузок и обеспечивать безопасность доступа к образам.
Безопасность на уровне ОС (OS-level Security)
OS
Включение защиты загрузчика GRUB паролем с использованием хэширования PBKDF2 SHA-512. Настройка обязательной повторной аутентификации при использовании sudo. Это позволяет соответствовать требованиям безопасности при загрузке системы и управлении привилегированным доступом, предотвращая несанкционированные изменения системы и обеспечивая соблюдение политик безопасности во всей инфраструктуре кластера.
Cluster API v1beta2 для улучшенного управления кластерами Kubernetes
VKS 3.5 включает Cluster API v1beta2 (CAPI v1.11.1), который вносит ряд изменений и улучшений в версии API для ресурсов по сравнению с v1beta1. Полный список улучшений можно найти в Release Notes для CAPI.
Для обеспечения плавного перехода все новые и существующие кластеры, созданные с использованием прежнего API v1beta1, будут автоматически преобразованы в API v1beta2 обновлёнными контроллерами Cluster API. В дальнейшем рекомендуется использовать API v1beta2 для управления жизненным циклом (LCM) кластеров Kubernetes.
Версия API v1beta2 является важным шагом на пути к выпуску стабильной версии v1. Основные улучшения включают:
Расширенные возможности отслеживания состояния ресурсов, обеспечивающие лучшую наблюдаемость.
Исправления на основе отзывов клиентов и инженеров с реальных внедрений.
Предотвращение сбоев обновлений из-за неверно настроенного PodDisruptionBudget
Pod Disruption Budget (PDB) — это объект Kubernetes, который помогает поддерживать доступность приложения во время плановых операций (например, обслуживания узлов, обновлений или масштабирования). Он гарантирует, что минимальное количество Pod’ов останется активным во время таких событий. Однако неправильно настроенные PDB могут блокировать обновления кластера.
VKS 3.5 вводит механизмы защиты (guardrails) для выявления ошибок конфигурации PDB, которые могут привести к зависанию обновлений или других операций жизненного цикла. Система блокирует обновление кластера, если обнаруживает, что PDB не допускает никаких прерываний.
Для повышения надёжности и успешности обновлений введено новое условие SystemChecksSucceeded в объект Cluster. Оно позволяет пользователям видеть готовность кластера к обновлению, в частности относительно конфигураций PDB.
Ключевые преимущества новой проверки:
Проактивная блокировка обновлений — система обнаруживает PDB, препятствующие выселению Pod’ов, и останавливает обновление до его начала.
Более чёткая диагностика проблем — параметр SystemChecksSucceeded устанавливается в false, если у любого PDB значение allowedDisruptions меньше или равно 0, что указывает на риск простоев.
Планирование обновлений — позволяет заранее устранить ошибки конфигурации PDB до начала обновления.
Примечание: любой PDB, не связанный с Pod’ами (например, из-за неправильного селектора), также будет иметь allowedDisruptions = 0 и, следовательно, заблокирует обновление.
Упрощённые операции: CLI, управление надстройками и инструменты поддержки
Управление надстройками (Add-On Management)
VKS 3.5 упрощает эксплуатационные операции, включая управление жизненным циклом надстроек (add-ons) и создание пакетов поддержки. Новая функция VKS Add-On Management объединяет установку, обновление и настройку стандартных пакетов, предлагая:
Единый метод для всех операций с пакетами, декларативный API и предварительные проверки совместимости.
Возможность управления стандартными пакетами VKS через Supervisor Namespace (установка, обновления, конфигурации) — доступно через VKS-M 9.0.1 или новый плагин ‘addon’ в VCF CLI.
Упрощённую установку Cluster Autoscaler с возможностью автоматического обновления при апгрейде кластера.
Управление установками и обновлениями через декларативные API (AddonInstall, AddonConfig) с помощью Argo CD или других GitOps-контроллеров. Это обеспечивает версионируемое и повторяемое развертывание надстроек с улучшенной трассируемостью и согласованностью.
Возможность настройки Addon Repository во всех кластерах VKS с помощью API AddonRepository / AddonRepositoryInstall, включая случаи с приватными регистрами.
По умолчанию встроенный репозиторий VKS Standard Package устанавливается из пакета VKS (версия v2025.10.22 для релиза VKS 3.5.0).
Во время обновлений кластеров VKS выполняет предварительные проверки совместимости надстроек и обновляет их до последних поддерживаемых версий. Если проверка не пройдена — обновление блокируется. При установке или обновлении надстроек выполняются дополнительные проверки, включая проверку на дублирование пакетов и анализ зависимостей.
Упрощённое обнаружение новых версий и метаданных совместимости для Add-on Releases.
Интегрированный сборщик пакетов поддержки (Support Bundler) в VCF CLI
VKS 3.5 включает VKS Cluster Support Bundler непосредственно в VCF CLI, что значительно упрощает процесс сбора диагностической информации о кластерах. Теперь пользователи могут собирать всю необходимую информацию с помощью команды vcf cluster support-bundle, без необходимости загружать отдельный инструмент.
Основные улучшения здесь:
Существенное уменьшение размера выходного файла.
Селективный сбор логов — только с узлов control plane, для более быстрой и точной диагностики.
Интегрированный сбор сетевых логов, что помогает анализировать сетевые проблемы и получить целостную картину состояния кластера.
Вильям Лам описал способ развертывания виртуального модуля OVF/OVA напрямую с сервера с Basic Authentication.
Он делал эксперименты с использованием OVFTool и доработал свой скрипт deploy_data_services_manager.sh, чтобы он ссылался на URL, где был размещён Data Services Manager (DSM) в формате OVA. В этом случае базовую аутентификацию (имя пользователя и пароль) можно включить прямым текстом в URL. Хотя это не самый безопасный способ, он позволяет удобно использовать этот метод развертывания.
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
Компания VMware недавно объявила о первом результате теста VMmark 4 с использованием последнего релиза платформы виртуализации VMware Cloud Foundation (VCF) 9.0. Метрики, показанные системой Lenovo, также стали первым результатом тестирования новейшей 4-сокетной системы на базе процессора Intel Xeon серии 6700 с технологией Performance-cores, который обеспечивает большее количество ядер и более высокую пропускную способность памяти. Итоговый результат доступен на странице VMmark 4 Results.
В следующей таблице приведено сравнение нового результата Lenovo с системой предыдущего поколения ThinkSystem под управлением vSphere 8.0 Update 3:
График показывает рост общего количества ядер на 43% между этими двумя результатами:
С точки зрения очков производительности, показатель VMmark 4 вырос на 49%:
Ключевые моменты:
Сочетание VCF 9.0 и нового серверного оборудования позволило запустить на 50% больше виртуальных машин / рабочих нагрузок (132) по сравнению с результатом предыдущего поколения (88 ВМ).
Процессоры Intel Xeon 6788P в Lenovo ThinkSystem SR860 V4 имеют на 43% больше ядер, чем процессоры предыдущего поколения Intel Xeon Platinum 8490H в ThinkSystem SR860 V3
Показатель VMmark на 49% выше, чем результат VMmark 4 для предыдущего поколения.
VMmark — это бесплатный инструмент тестирования, который используется партнёрами и клиентами для оценки производительности, масштабируемости и энергопотребления платформ виртуализации. Посетите страницу продукта VMmark и сообщество VMmark Community, чтобы узнать больше. Также вы можете попробовать VMmark 4 прямо сейчас через VMware Hands-on Labs Catalog, выполнив поиск по запросу «VMmark».
Недавно компания Orion soft анонсировала релизы платформы виртуализации - zVirt 4.5 и zVirt 5.0. Давайте посмотрим, что нового обещает разработчик отечественной платформы виртуализации.
zVirt 4.5: вектор на производительность и виртуализацию сетей
По словам Orion soft, релиз 4.5 сфокусирован на двух крупных направлениях:
Рост производительности (внутренние оптимизации стека),
Дальнейшее развитие сетевой виртуализации (SDN). Это не «косметика», а серия внутренних апгрейдов, которые готовят почву под 5.0. Подробный перечень фич компания не публиковала, акцент именно на эти векторы развития.
Что это означает на практике:
Ускорение «горячих» путей данных. В реальной эксплуатации это обычно выражается в уменьшении задержек операций ввода-вывода ВМ, росте пропускной способности при миграциях и репликации, а также в снижении накладных расходов управляющих сервисов. В контексте последних релизов zVirt компания уже поднимала потолок репликации и улучшала экспорт метрик/логов — версия 4.5 логично продолжает эту линию, но уже как «внутренний» апгрейд ядра платформы.
Упрочнение SDN-стека. С версии 4.0/4.2 zVirt продвигал микросегментацию и управляемые сети через UI; в 4.5 ожидаем дальнейшее выравнивание производительности и функциональности SDN под крупные инсталляции (много проектов/сетей, избыточные связи, тонкая политика East-West). Идея — дать базис для грядущей миграции сетевых конфигураций из vSphere/NSX-подобных сценариев, заявленных к 5.0.
Вывод для архитекторов: 4.5 — это «подкапотный» релиз, который не меняет ваши процессы, но подготавливает площадку: стабильнее SDN, выше пропускная способность, а значит — меньше рисков при масштабировании кластеров и при переходе на версию 5.0.
zVirt 5.0: крупные продуктовые сдвиги
Для zVirt 5.0 Orion soft публично называл ряд ключевых возможностей, которые заметно расширяют зону автоматизации и упрощают миграцию с VMware-ландшафтов:
1. Storage DRS (распределение нагрузки по хранилищам)
Идеология — объединить несколько доменов хранения в логический «кластер» и автоматически балансировать размещение/миграцию дисков/ВМ по политикам (запас по IOPS/latency/ёмкости, «горячие» тома и т. п.). Это сокращает ручные операции, снижает риск «перекоса» томов хранения (LUN) и ускоряет реакцию на всплески нагрузки. Orion soft ранее уже демонстрировал Storage DRS в линейке 4.x, ну а в 5.0 ожидается консолидация и развитие этого направления как «функции по умолчанию» для больших инсталляций.
Практический эффект:
Более предсказуемые SLA на уровне хранилища для VMs/VDIs.
Упрощение сценариев расширения емкости (add capacity -> автоматический ребаланс).
Цель — сократить TTV (time-to-value): меньше шагов, больше проверок совместимости и готовности (сети, CPU-фичи, хранилища, сертификаты), шаблоны для типовых топологий (Hosted Engine, Standalone, edge-кластера). Это критично для массовых миграций с VMware: когда десятки площадок поднимаются параллельно, выигрыш в часах на площадку умножается на десятки.
3. Управление аппаратной репликацией на СХД
Речь о DR на уровне массивов (например, YADRO TATLIN.UNIFIED, Huawei Dorado и др.) с оркестрацией из консоли zVirt. Преимущества аппаратной репликации — RPO до 0 сек при синхронных схемах и низкая нагрузка на гипервизоры/SAN. План аварийного переключения становится «кнопкой» в едином UI. В 4.x уже были интеграции и демонстрации такого подхода, а версия 5.0 укрепляет это как нативный сценарий с централизованным управлением планами DR.
Практический эффект:
Единый контрольный контур для DR (агентская и аппаратная репликации)
Меньше конфликтов за ресурсы между продуктивом и DR-задачами
Формализованные RTO/RPO для аудита
4. Terraform-провайдер
Провайдер позволяет декларативно описывать кластера, ВМ, сети/SDN-объекты, политики, хранилища — и воспроизводить их через CI/CD. Это даёт привычную для DevOps-команд «инфраструктуру как код» поверх zVirt, ускоряя создание однотипных стендов, DR-сайтов и «blue/green» сред.
Практический эффект:
Контроль версий для инфраструктуры (git-история ваших кластеров)
Воспроизводимость площадок (dev -> stage -> prod)
Быстрый откат/повторение конфигураций по слияниям (merges).
5. Миграция конфигураций с VMware vSphere на SDN zVirt
Отдельно заявлена возможность импорта сетевых конфигураций из VMware-ландшафтов в SDN-модель zVirt: перенос порт-групп, сегментации, ACL/микросегментации и прочее. Это важная часть «бесшовной» стратегии импортозамещения: раньше боль была не только «перенести ВМ», но и воссоздать сетевую политику («зашитую» в vSphere/NSX). Версия 5.0 обещает автоматизировать этот пласт работ.
Практический эффект:
Сокращение ошибок при ручном переносе сетей
Предсказуемость инфраструктуры безопасности после миграции
Ускорение cut-over окон при переездах больших ферм ВМ.
Как готовиться к zVirt 4.5/5.0 в производственной среде
Проверить лимиты и совместимость (ядра, CPU-фичи, сетевые карты, Mellanox/Intel, fabric-параметры, NUMA-profile, лимиты по миграциям/сетям/ВМ) — чтобы апгрейды прошли «в стык», без регрессий. Актуальные лимиты и best practices доступны в вики Orion soft.
Нормализовать SDN-модель: привести именование сетей/проектов к единому стандарту, сверить микросегментацию и схему ACL — это упростит будущий импорт конфигураций и policy-driven-балансировку. В версии 4.2 уже был сделан большой шаг по SDN/микросегментации.
Обновить процессы DR: если у вас есть массивы с аппаратной репликацией — инвентаризовать пары массивов, RPO/RTO, каналы межплощадочной связи; продумать, какие сервисы уйдут на аппаратную репликацию, а какие останутся на агентской (уровень гипервизора).
Заложить IaC-подход: начать описывать парки ВМ, сети, хранилища в Terraform (как минимум — черновые манифесты), чтобы к моменту выхода провайдера под 5.0 ваш репозиторий уже отражал фактическую инфраструктуру.
Более подробно о новых возможностях zVirt 4.5 и zVirt 5.0 можно почитать вот тут.
Supervisor Control Plane — это управляющий уровень встроенного Kubernetes (Supervisor Cluster) в решении VMware vSphere with Tanzu (ранее vSphere with Kubernetes). Он развёрнут как три виртуальные машины (Supervisor Control Plane VMs), которые выполняют контроль над кластером Kubernetes, включая etcd, API-сервер, контроллеры и планировщик. Важнейшие функции этих виртуальных машин:
Интеграция с инфраструктурой vSphere: Supervisor Control Plane взаимодействует с ресурсами ESX-хостов — CPU, память, сеть, хранилище — и позволяет запускать контейнеры напрямую на гипервизоре (vSphere Pods).
API-доступ: администраторы управляют кластерами через интерфейс vSphere Client и API vSphere with Tanzu, а разработчики — через kubectl.
Высокая доступность: обеспечивается трёхкомпонентной архитектурой. Если один узел выходит из строя, другие продолжают работу.
Полезный трюк — как получить SSH-пароль для Supervisor Control Plane VM
Есть простой способ получить доступ по SSH для виртуальных машин, входящих в состав Supervisor Control Plane:
Подключитесь по SSH к виртуальному модулю сервера vCenter под пользователем root.
Выполните скрипт:
/usr/lib/vmware-wcp/decryptK8Pwd.py
Скрипт выведет IP-адрес (обычно FIP, то есть "floating IP") и автоматически сгенерированный пароль. После этого вы можете подключиться по SSH к Supervisor Control Plane VM как root@<FIP> с полученным паролем.
Важно! Доступ к этим ВМ следует использовать только для диагностики и устранения проблем — любые изменения в них (особенно без одобрения от поддержки VMware) могут привести к нарушению работоспособности Supervisor-кластера, и поддержка может потребовать его полного развертывания заново.
Полезные рекомендации и предосторожения
Скрипт /usr/lib/vmware-wcp/decryptK8Pwd.py извлекает пароль из базы данных vCenter. Он удобен для быстрого доступа, особенно при отладке сетевых или других проблем с Supervisor VM.
Убедитесь, что FIP действительно доступен и корректно маршрутизируется. При сбое etcd FIP не назначится, и придётся использовать реальный IP-адрес интерфейса (например, eth0). Также при смене FIP удалите старую запись из known_hosts — сертификаты могут изменяться при «плавании» IP.
Используйте доступ только для анализа, чтения логов и выполнения команд kubectl logs/get/describe.
VMware недавно объявила о выпуске пяти новых экзаменов для профессиональной сертификации, основанных на версии 9 их платформы Cloud Foundation. Эти сертификаты представляют собой значительную эволюцию в портфеле сертификаций VMware, отражая продолжающееся новаторство компании в области технологий Cloud Foundation и виртуализации под руководством Broadcom.
Новый пакет сертификаций включает специализированные направления как для VMware Cloud Foundation (VCF), так и для VMware vSphere Foundation (VVF), охватывая ключевые роли — от администрирования и поддержки до архитектуры. Каждая сертификация предназначена для подтверждения навыков, необходимых для управления современной облачной инфраструктурой, устранения неполадок и проектирования в корпоративной среде.
Обзор нового портфеля сертификаций
Итак, появилось пять новых сертификаций уровня VMware Certified Professional (VCP):
Эти сертификации отвечают растущему спросу на квалифицированных специалистов, которые могут эффективно внедрять, администрировать, поддерживать и проектировать частные облака с использованием новейших технологий VMware. Каждый экзамен проводится в едином формате: 60 вопросов с несколькими вариантами ответов, продолжительность — 135 минут, проходной балл — 300, стоимость попытки — 250 долларов.
Подробное рассмотрение каждой сертификации
1. VMware Certified Professional - VMware vSphere Foundation Support (2V0-18.25)
Эта сертификация является важной стартовой точкой для ИТ-специалистов, стремящихся углубиться в поддержку и устранение неполадок в средах VMware vSphere Foundation (VVF). Она подтверждает владение стандартными методиками диагностики и устранения проблем, возникающих при развертывании и эксплуатации VVF. Экзамен охватывает архитектуру VVF, включая основные функции, компоненты и модели работы.
Ключевые технические области:
Операции с VCF
Администрирование vCenter Server
Управление гипервизором VMware ESX
Работа с хранилищами VMware vSAN
VMware Operations для централизованного логирования и мониторинга
Эта сертификация ценна для специалистов, переходящих от традиционной поддержки инфраструктуры к поддержке облачных виртуализированных систем. Подготовка возможна по Exam Study Guide, регистрация — через портал Broadcom.
2. VMware Certified Professional - VMware Cloud Foundation Administrator (2V0-17.25)
Эта сертификация предназначена для ИТ-специалистов, ответственных за ежедневное администрирование и управление средами VMware Cloud Foundation (VCF). Она подтверждает навыки по развертыванию, управлению и поддержке частных облаков на базе VCF. Адресована системным администраторам, облачным администраторам и специалистам по инфраструктуре, переходящим от традиционных ролей к обязанностям в области облачных технологий.
Основные темы: развертывание, администрирование, оптимизация производительности, настройка безопасности и устранение неполадок. Рекомендуемые курсы:
VMware Cloud Foundation: Build, Manage, and Secure
3. VMware Certified Professional - VMware Cloud Foundation Support (2V0-15.25)
Эта сертификация фокусируется на специалистах поддержки VMware Cloud Foundation. Она подтверждает умение диагностировать и устранять проблемы в частных облаках на базе VCF. Подходит для тех, кто переходит от традиционной поддержки инфраструктуры к ролям Cloud support или Site Reliability Engineer (SRE).
Сертификация охватывает:
Продвинутые методики диагностики
Инструменты анализа производительности
Стратегии устранения сложных инцидентов
Рекомендуемый курс: "VMware Cloud Foundation: Troubleshooting". Доступны Exam Study Guide и регистрация через портал Broadcom.
4. VMware Certified Professional - VMware Cloud Foundation Architect (2V0-13.25)
Это наиболее продвинутая сертификация уровня VCF, подтверждающая навыки архитектурного проектирования решений VMware Cloud Foundation. Она ориентирована на архитекторов инфраструктуры и консультантов, которые разрабатывают масштабируемые, отказоустойчивые и безопасные решения.
Основные темы:
Методологии проектирования
Планирование ёмкости
Высокодоступные и отказоустойчивые архитектуры
Безопасность и интеграция с существующей инфраструктурой.
Рекомендуемый курс: "VMware Cloud Foundation: Solution Architecture and Design". Подготовка — по Exam Study Guide, регистрация — через портал Broadcom.
5. VMware Certified Professional - VMware vSphere Foundation Administrator (2V0-16.25)
Эта сертификация подтверждает компетенции специалистов, администрирующих среды VMware vSphere Foundation (VVF). Она охватывает:
Развертывание и конфигурацию
Администрирование виртуальных машин
Распределение ресурсов
Мониторинг производительности
Настройку безопасности и устранение неполадок
Сертификация ориентирована на администраторов виртуальных сред. Рекомендуемый курс: "vSphere Foundation: Build, Manage and Secure".
Подготовка — через Exam Study Guide, регистрация — на портале Broadcom.
Заключение
Запуск пяти новых сертификаций отражает стремление VMware укреплять лидерство в области облачных технологий. Они позволяют ИТ-специалистам строить карьеру в направлениях поддержки, администрирования и архитектуры. В версии 9 сертификации учитывают последние возможности и лучшие практики, что особенно важно в условиях быстрого развития технологий. Каждая сертификация обеспечивает уникальный путь профессионального развития и подтверждает как технические навыки, так и стремление к постоянному обучению.
Весной этого года вышел новый релиз бесплатной утилиты SexiGraf (Overwatch Nexus), предназначенной для мониторинга виртуальной инфраструктуры VMware vSphere. В последний раз мы писали об этом средстве в октябре прошлого года. Этот продукт был сделан энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным решениям для мониторинга серверов ESX и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Что нового
VMware vSAN Inventory — расширенная инвентаризация объектов vSAN.
PowerShell Core 7.4.6 LTS — обновление среды скриптов.
Ubuntu 22.04.5 LTS — современная версия операционной системы.
Apache 2.4.63 — обновлённый веб-сервер.
Улучшения и исправления
Возможность добавления SSH-ключа при деплое — повышает безопасность и удобство разграничения доступа.
Добавлен сбор события DrsSoftRuleViolationEvent в event-коллектор — расширение мониторинга нарушений правил DRS.
Исправлено неконсистентное значение GuestId в инвентаре VM (различие между vmx и vmtools) — повышение точности данных.
Различные багфиксы — общее улучшение стабильности и надежности.
Миграция и формат поставки
SexiGraf с этой версии доступен исключительно в виде нового OVA-образа, обновления в виде патчей больше не выпускаются (за исключением экстренных случаев). Чтобы обновиться, пользователи должны:
Экспортировать данные из текущего SexiGraf-модуля.
Импортировать данные в новый OVA-модуль через функционал Export/Import.
Виртуальный модуль SexiGraf 0.99l уже доступен для загрузки и развёртывания. Установка происходит стандартным способом через OVA (например, через vSphere, OVF Tool и т.п.).
Версия поддерживает переопределение root-пароля и SSH-ключа на этапе деплоя, что упрощает настройку и повышает безопасность.
VMware vSphere 7 достигнет конца основного срока поддержки (End of General Support) 2 октября 2025 года. Если вы в настоящее время используете vSphere 7, вам необходимо перейти на vSphere 8, чтобы продолжать получать поддержку продукта, обновления безопасности и патчи. Это также подготовит вас к переходу на VCF 9, когда вы будете к этому готовы.
Существует два варианта обновления:
Вы можете напрямую обновить vSphere 7 до vSphere 8
Либо можно импортировать vSphere 7 в VMware Cloud Foundation (VCF) версии 5.2 и выполнить обновление домена рабочих нагрузок до версии 8 через VMware SDDC Manager.
Выбор подходящего пути зависит от ряда факторов, таких как готовность бизнеса, поддержка сторонних продуктов и конфигурация среды. Ниже описано, как команда VCF Professional Services подходит к каждому из этих вариантов.
Вариант 1: Обновление с использованием vSphere Lifecycle Manager
Этот вариант представляет собой традиционный способ обновления vSphere. Вы можете использовать vSphere Lifecycle Manager Images или vSphere Lifecycle Manager Baselines для выполнения задачи обновления.
Преимущества этого подхода:
Используются уже существующие операционные процессы обновления.
В большинстве случаев требуется минимальное изменение текущей среды.
Нет необходимости в дополнительных виртуальных модулях (appliances).
Недостатки этого подхода:
Вам необходимо вручную выполнять проверки совместимости и валидации между компонентами, что может занять много времени.
Каждая среда проектируется отдельно, что может привести к задержкам из-за различных архитектурных решений между экземплярами VMware vCenter.
Шаги по обновлению с использованием vSphere Lifecycle Manager
Многие организации сначала выполняют обновление на тестовой (staging) среде перед тем, как переходить к рабочей (production). Шаги, как правило, одинаковы для любых сред.
Шаг 1: Планирование, предварительная проверка и подготовка среды к обновлению.
На этом этапе необходимо вручную подтвердить, что ваша среда поддерживает новые версии. Начните с изучения Release Notes для vSphere 8 и проверьте, поддерживают ли ваши интеграции с другими продуктами VMware или сторонними приложениями vSphere 8. Также потребуется подготовка к обновлению vCenter и понимание изменений, связанных с обновлением хостов VMware ESX.
После планирования нужно загрузить необходимые бинарные файлы. Это можно сделать на сайте поддержки Broadcom.
Шаг 3: Обновление vCenter.
Обновление vCenter можно выполнить несколькими способами, в зависимости от требований пользователя. Существует три основных метода:
Обновление с сокращённым временем простоя (Reduced Downtime Upgrade) - при этом способе разворачивается вторичный виртуальный модуль, и конфигурационные данные переносятся на него. Это наиболее предпочтительный метод, поскольку он обеспечивает минимальные простои по сравнению с другими способами обновления.
Установщик vCenter (vCenter Installer) – установщик vCenter включает опцию обновления, которая позволяет обновить существующий виртуальный модуль. Этот метод может быть использован в случае, если недостаточно ресурсов для развертывания второго модуля.
Обновление через интерфейс управления виртуальным модулем (Virtual Appliance Management Interface Upgrade) – этот метод позволяет автоматически загрузить и установить бинарные файлы напрямую из интерфейса управления виртуальным модулем vCenter. Мы также можем использовать этот способ, если недостаточно ресурсов для развертывания второго модуля.
Шаг 4: Обновление хостов ESX.
После обновления vCenter можно переходить к обновлению хостов ESX. Существует несколько способов обновления хостов ESX. VMware использует два основных подхода:
vSphere Lifecycle Manager - это предпочтительный метод, так как он позволяет обновлять целые кластеры одновременно, вместо обновления каждого хоста по отдельности. Это самый простой способ выполнения обновлений.
Сценарные обновления (Scripted Upgrades) – этот метод рекомендуется, когда необходимо обновить большое количество хостов. Существует несколько способов автоматизации обновления с помощью сценариев, что позволяет адаптировать процесс под конкретные операционные процедуры и используемые языки скриптов.
Шаг 5: Обновление VMware vSAN.
После обновления хостов следующим шагом является обновление формата дисков vSAN. Этот шаг рекомендуется, но не является обязательным. Обновление vSAN позволяет воспользоваться новыми функциями.
Шаг 6: Обновление версии vSphere Distributed Switch.
Версию vSphere Distributed Switch также можно обновить. Этот шаг также является необязательным, однако рекомендуется его выполнить, чтобы получить доступ к новым возможностям.
Шаг 7: Проверка после обновления (Post-Upgrade Validation).
Этот шаг зависит от конкретной среды и может включать дополнительные обновления других компонентов для поддержки новой версии. Кроме того, вам потребуется ввести новые лицензии и выполнить все необходимые проверки.
На этом процесс обновления среды vSphere с использованием vSphere Lifecycle Manager завершается.
Вариант 2: Импорт vSphere в экземпляр VCF и обновление через SDDC Manager
Второй вариант — это импорт среды vSphere в VCF 5.2 с последующим обновлением через консоль SDDC Manager. Для этого у вас уже должен быть развернут экземпляр VCF.
Преимущества импорта vSphere в VCF и обновления через SDDC Manager:
VCF включает в себя мощный механизм проверки предварительных условий, что упрощает процесс обновления.
При импорте vSphere в VCF ваша среда проверяется, и определяются необходимые исправления, чтобы привести её в соответствие со стандартной архитектурой VCF.
Вы можете воспользоваться другими возможностями VCF, такими как встроенное управление сертификатами и паролями. Эти функции ускоряют процесс обновления, позволяя легко изменять пароли и сертификаты.
Недостатки:
Требуются дополнительные виртуальные модули. VCF представляет собой полноценный программно-определяемый датацентр, и такие компоненты, как VMware NSX, являются обязательными. Это требует выделения дополнительных ресурсов.
Как упомянуто в разделе с преимуществами, приведение среды к стандарту VCF может потребовать выполнения определённых исправлений.
Шаги по импорту vSphere в VCF и обновлению через SDDC Manager
Шаг 1: Импорт существующей среды vSphere в конфигурацию VCF.
Используйте VCF Import Tool для проверки предварительных условий и выполнения импорта в уже существующий экземпляр VCF.
Шаг 2: Обновление vSphere через SDDC Manager.
После того как в среде доступен SDDC Manager, вы можете использовать его для выполнения следующих задач:
Загрузка пакетов обновлений (Download Update Bundles) – скачайте необходимые пакеты, чтобы иметь возможность выполнить обновление.
Выполнение предварительных проверок (prechecks) – выполните проверку предварительных условий, чтобы выявить проблемы, которые могут привести к сбою обновления. Если будут обнаружены какие-либо ошибки или проблемы, их необходимо устранить перед продолжением процесса.
Обновление компонентов (Upgrade Components) – обновите все компоненты vSphere (vCenter и ESX). SDDC Manager выполнит обновление в правильной последовательности, чтобы обеспечить совместимость с перечнем компонентов (Bill of Materials) VCF 5.2.
Шаг 3: Проверка после обновления (Post-Upgrade Validation).
Этот шаг зависит от конкретной среды и может потребовать дополнительных обновлений других компонентов для поддержки новой версии. Кроме того, потребуется ввести новые лицензии и выполнить все необходимые проверки.
Как уже упоминалось, данный вариант требует наличия развернутого экземпляра VCF. Если его нет, вы можете сначала обновить хотя бы один экземпляр vCenter 7 до vSphere 8, используя Вариант 1, а затем преобразовать этот экземпляр vSphere в VCF.
VMware представила унифицированный фреймворк разработки VCF SDK 9.0 для Python и Java.
Улучшение опыта разработчиков (Developer Experience) — один из главных приоритетов в дальнейшем развитии платформы VMware Cloud Foundation (VCF). Если рассматривать автоматизацию в целом, то можно выделить две чёткие категории пользователей: администраторы и разработчики.
Администраторы в основном сосредоточены на операционной автоматизации, включая развертывание, конфигурацию и управление жизненным циклом среды VCF. Их потребности в автоматизации обычно реализуются через написание скриптов и рабочих процессов, которые управляют инфраструктурой в масштабах всей организации.
Разработчики, напротив, ориентированы на интеграцию возможностей VCF в пользовательские приложения и решения. Им необходимы API и SDK, обеспечивающие программный доступ к сервисам и данным VCF, позволяя разрабатывать собственные инструменты, сервисы и расширения. Потребности в автоматизации у этих двух групп значительно различаются и соответствуют их уникальным ролям в экосистеме VCF. Понимая эти различия, Broadcom предлагает набор интерфейсов прикладного программирования (API), средств разработки (SDK) и разнообразных инструментов автоматизации, таких как PowerCLI, Terraform и Ansible.
Оглядываясь назад, можно сказать, что VMware хорошо обслуживала сообщество администраторов, предоставляя им различные инструменты. Однако API и SDK требовали улучшения в области документации, лучшей интеграции с VCF-стеком в целом и упрощения процесса для разработчиков. До выхода VCF 9.0 разработчики использовали отдельные SDK решений, сталкиваясь с трудностями, связанными с их интеграцией — такими как совместимость, аутентификация и сложность API. С выходом VCF 9.0 VMware рада объявить о доступности Unified VCF SDK 9.0. Давайте подробнее рассмотрим, что это такое.
Unified VCF SDK
Unified VCF SDK доступен с привязками к двум языкам — Java и Python. Это объединённый SDK, который включает в себя все основные SDK решений VCF в единый, упрощённый пакет. В своей первой версии Unified VCF SDK объединяет существующие SDK и добавляет новые библиотеки для установщика VCF и менеджера SDDC.
Список компонентов VCF, включённых в первую версию Unified VCF SDK:
VMware vSphere
VMware vSAN
VMware Cloud Foundation SDDC Manager (новый)
VMware Cloud Foundation Installer (новый)
VMware vSAN Data Protection
Несмотря на то, что Unified VCF SDK поставляется как единый пакет, пользователи могут устанавливать и использовать только те библиотеки, которые необходимы для конкретных задач.
Для краткости в этом тексте Unified VCF SDK будет обозначаться как VCF SDK.
Преимущества
VCF SDK обеспечивает простой, расширяемый и единообразный опыт для разработчиков на протяжении всего жизненного цикла разработки.
Упрощённый жизненный цикл разработчика
С этим релизом были стандартизированы методы доставки и распространения, чтобы поддерживать различные сценарии развертывания:
Онлайн-установка через PyPI (Python) и Maven (Java) — для прямого доступа и лёгкой установки/обновлений.
Офлайн-установка через портал разработчиков Broadcom — идеально для сред с ограниченным доступом в интернет.
Готовность к CI/CD — интеграции через пакеты и инструкции, размещённые на GitHub, для бесшовного включения в автоматизированные пайплайны при установке и обновлении.
Улучшенная документация и онбординг
VMware переработала документацию, чтобы упростить старт:
OpenAPI-спецификация описывает API в стандартизированном машинно-читаемом формате (YAML/JSON). С выходом VCF SDK были также публикованы OpenAPI-спецификации для API-эндпоинтов. Это не просто документация — это шаг к философии API-first и ориентированности на разработчиков.
С помощью OpenAPI-спецификаций разработчики могут:
Автоматически генерировать клиентские библиотеки на предпочитаемых языках с помощью инструментов вроде Swagger Codegen, Kiota или OpenAPI Generator.
Загружать спецификации в такие инструменты, как Swagger UI, Redoc или Postman, чтобы визуально исследовать доступные эндпоинты, параметры, схемы ответов и сообщения об ошибках.
pyVmomi — это Python SDK для API управления VMware vSphere, который позволяет быстро создавать решения, интегрированные с VMware ESX и vCenter Server.
vCenter Server
Библиотека VMware vCenter Server содержит клиентские привязки для автоматизационных API VMware vCenter Server.
VMware vSAN Data Protection
Библиотека VMware vSAN Data Protection содержит клиентские привязки для управления встроенными снапшотами, хранящимися локально в кластере vSAN, восстановления ВМ после сбоев или атак вымогателей и т.д.
Библиотека VMware SDDC Manager содержит клиентские привязки к автоматизационным API для управления компонентами инфраструктуры программно-определяемого датацентра (SDDC).
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer в составе VCF SDK содержит библиотеки для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Unified VCF SDK доступен через различные каналы распространения. Это сделано для того, чтобы удовлетворить потребности разных типов сред и разработчиков — каждый может получить доступ к SDK в наиболее удобном для него месте. Ниже перечислены доступные каналы, откуда можно загрузить VCF SDK.
Портал разработчиков Broadcom
VCF Python SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-python-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами. Однако сторонние зависимости не входят в состав архива — они перечислены в файле requirements-third-party.txt, находящемся внутри vcf-python-sdk-9.0.0.0-24798170.zip.
Файлы .whl компонентов VCF SDK находятся в папках ../pypi/*, а примеры кода для компонентов расположены в директориях вида /<имя_компонента>-samples/.
PyPI
VCF SDK доступен в PyPI, что позволяет разработчикам устанавливать и обновлять модуль онлайн. Это самый быстрый способ начать работу с VCF SDK.
Чтобы установить VCF SDK, выполните следующую команду:
$ pip install vcf-sdk
Пакеты, установленные через pip, можно автоматически обновлять. Чтобы обновить VCF SDK, используйте команду:
$ pip install --upgrade vcf-sdk
Чтобы установить конкретную библиотеку из состава VCF SDK, выполните:
Модуль vCenter в составе VCF SDK предоставляет операции, связанные с контент-библиотеками, развертыванием ресурсов, тегированием, а также управлением внутренними и внешними сертификатами безопасности.
Управление виртуальной инфраструктурой (VIM)
Модуль VIM (Virtual Infrastructure Management) предоставляет операции для управления вычислительными, сетевыми и хранилищными ресурсами. Эти ресурсы включают виртуальные машины, хосты ESXi, кластеры, хранилища данных, сети и системные абстракции, такие как события, тревоги, авторизация и расширения через плагины.
SSOCLIENT
Модуль единого входа (Single Sign-On) взаимодействует с сервисом Security Token Service (STS) для выдачи SAML-токенов, необходимых для аутентификации операций с API vCenter.
VMware vSAN Data Protection (vSAN DP)
С помощью встроенных снимков, локально хранящихся в кластере vSAN, модуль защиты данных vSAN обеспечивает быстрое восстановление ВМ после сбоев или атак вымогателей. API защиты данных vSAN управляет группами защиты и обнаруживает снимки виртуальных машин.
Управление жизненным циклом виртуального хранилища (VSLM)
Модуль VSLM (Virtual Storage Lifecycle Management) предоставляет операции, связанные с First Class Disks (FCD) — виртуальными дисками, не привязанными к конкретной виртуальной машине.
Служба мониторинга хранилища (SMS)
Модуль SMS (Storage Monitoring Service) предоставляет методы для получения информации о доступной топологии хранилищ, их возможностях и текущем состоянии. API Storage Awareness (VASA) позволяет хранилищам интегрироваться с vCenter для расширенного управления. Провайдеры VASA предоставляют данные о состоянии, конфигурации и емкости физических устройств хранения. SMS устанавливает и поддерживает соединения с провайдерами VASA и извлекает из них информацию о доступности хранилищ.
Управление на основе политик хранения (SPBM)
Модуль SPBM (Storage Policy Based Management) предоставляет операции для работы с политиками хранения. Эти политики описывают требования к хранению для виртуальных машин и возможности провайдеров хранения.
vSAN
Модуль vSAN предоставляет средства конфигурации и мониторинга vSAN-кластеров хранения и связанных сервисов на хостах ESXi и экземплярах vCenter Server. Включает функции работы с виртуальными дисками, такие как монтирование, разметка, безопасное удаление и создание снимков.
Менеджер агентов ESX (EAM)
Менеджер агентов ESX (ESX Agent Manager) позволяет разработчикам расширять функциональность среды vSphere путём регистрации пользовательских программ как расширений vCenter Server. EAM действует как посредник между vCenter и такими решениями, управляя развертыванием и мониторингом агентских ВМ и установочных пакетов VIB.
SDDC Manager
Модуль SDDC Manager предоставляет операции для управления и мониторинга физической и виртуальной инфраструктуры, развернутой в рамках VMware Cloud Foundation.
Установщик VMware Cloud Foundation (VCF Installer)
Модуль VCF Installer предоставляет операции для проверки, развертывания, преобразования и мониторинга установок VCF и VVF с использованием новых или уже существующих компонентов.
Каналы распространения
Аналогично Python SDK, JAVA SDK также доступен через различные каналы распространения, что позволяет использовать его в самых разных средах.
Портал разработчиков Broadcom
VCF Java SDK доступен для загрузки на портале разработчиков Broadcom. Вы можете распаковать содержимое ZIP-архива vcf-java-sdk-9.0.0.0-24798170.zip, чтобы ознакомиться с библиотеками SDK, утилитами и примерами.
Файлы привязок SDK .jar, утилит .jar, а также BOM-файлы находятся в папке:
../maven/com/vmware/*
Maven
Артефакты VCF SDK доступны в Maven Central под groupId: com.vmware.sdk. В таблице ниже указаны данные об артефактах VCF SDK для версии 9.0.0.0.
Чтобы начать работу с VCF SDK, добавьте зависимость в файл pom.xml вашего проекта:
С выходом VCF 9.0 VMware начала публиковать журнал изменений API. В нём отражаются все изменения: новые API, обновления существующих и уведомления об устаревании. Ознакомиться с журналом изменений можно здесь.
С выпуском VMware Cloud Foundation 9.0 объединение различных библиотек в один SDK с улучшенной документацией, примерами кода и спецификацией OpenAPI — это важный шаг к простому, расширяемому и согласованному опыту для разработчиков.
Следующий шаг за вами — попробуйте Unified VCF SDK 9.0 и поделитесь с нами своими отзывами.

 RSS
RSS