В этой части статей о технологии NVMe Memory Tiering (см. прошлые части тут, тут, тут и тут) мы предоставим некоторую информацию о различиях при включении Memory Tiering в разных сценариях. Хотя основной процесс остаётся тем же, есть моменты, которые могут потребовать дополнительного внимания и планирования, чтобы сэкономить время и усилия. Когда мы говорим о сценариях greenfield, мы имеем в виду совершенно новые развертывания VMware Cloud Foundation (VCF), включая новое оборудование и новую конфигурацию для всего стека. Сценарии brownfield будут охватывать настройку Memory Tiering в существующей среде VCF. Наконец, мы рассмотрим и лабораторные сценарии, поскольку встречаются неоднозначные утверждения о том, что это не поддерживается, но мы рассмотрим это в конце данной статьи.
Greenfield-развертывания
Давайте начнём с процесса конфигурации сред greenfield. Ранее мы рассказали о том, как VMware vSAN и Memory Tiering совместимы и могут сосуществовать в одном и том же кластере. Мы также обращали внимание на кое-что важное, о чём вам следует помнить во время greenfield-развертываний VCF. Начиная с VCF 9.0, включение Memory Tiering — это операция «Day 2», то есть сначала вы настраиваете VCF, а затем можете настроить Memory Tiering, но в ходе рабочего процесса развертывания VCF вы заметите, что опции для включения Memory Tiering (пока) нет, зато можно включить vSAN. То, как вы поступите с вашим NVMe-устройством, выделенным для Memory Tiering, будет определять шаги, необходимые для того, чтобы это устройство было представлено для его конфигурации.
Если все NVMe-устройства и для vSAN, и для Memory Tiering присутствуют во время развертывания VCF, есть вероятность, что vSAN может автоматически занять все накопители (включая NVMe-устройство, которое вы выделили для Memory Tiering). В этом случае вам пришлось бы удалить накопитель из vSAN после конфигурации, стереть разделы, а затем начать настройку Memory Tiering. Этот шаг был рассмотрен тут.
Другой подход — извлечь или не устанавливать устройство Memory Tiering в сервер и добавить его обратно в сервер после развертывания VCF. Таким образом вы не будете рисковать тем, что vSAN автоматически займет NVMe для Memory Tiering. Хотя это и не является серьёзным препятствием, всё равно полезно знать, что произойдёт и почему, чтобы вы могли быстро выделить ресурсы, необходимые для настройки Memory Tiering.
Brownfield-развертывания
Сценарии brownfield немного проще, так как VVF/VCF уже настроен; однако vSAN мог быть включён или ещё нет.
Если vSAN не включён, вам нужно будет отключить функцию auto-claim, пройти через конфигурацию vSAN и вручную выбрать ваши устройства (кроме NVMe-устройств для Memory Tiering). Всё выполняется в интерфейсе UI и по процедуре, которая используется уже много лет. Это гарантирует, что NVMe-устройство Memory Tiering будет доступно для настройки. Подробный процесс задокументирован в TechDocs.
Если vSAN уже включён, мы предполагаем, что NVMe-устройство для Memory Tiering только что было приобретено и готово к установке. Значит, всё, что нам нужно сделать, — добавить его в хост и убедиться, что оно корректно отображается как NVMe-устройство и что на нём нет существующих разделов. Это, вероятно, самый простой сценарий и самый распространённый.
Развертывания в тестовой среде
Теперь давайте поговорим о давно ожидаемом лабораторном сценарии. Для лаборатории типа bare metal, где сервер ESX одноуровневый и нет вложенных сред, применяются те же принципы greenfield и brownfield. Что касается вложенной (nested) виртуализации, многие говорят о том, что вложенный Memory Tiering не поддерживается. Ну, это и так, и не так.
Когда мы говорим о вложенных средах, мы имеем в виду два уровня ESX. Внешний уровень — это ESX, установленный на оборудовании (обычная настройка), а внутренний уровень ESX состоит из виртуальных машин, запускающих ESX и выступающих в роли как бы физических хостов. Memory Tiering МОЖЕТ быть включён на внутреннем уровне (вложенном), и все параметры конфигурации работают нормально. Мы делаем следующее: берём datastore и создаём виртуальный Hard Disk типа NVMe, чтобы представить его виртуальной машине, которая выступает в роли вложенного хоста. Хотя мы видим NVMe-устройство на вложенном хосте и можем настроить Memory Tiering, базовое устройство хранения состоит из устройств, формирующих выбранный datastore. Вы можете настроить Memory Tiering, и вложенные хосты смогут видеть hot и active pages, но не ожидайте какого-либо уровня производительности, учитывая, что компоненты базового хранилища построены на традиционных накопителях. Работает ли это? ДА, но только в лабораторных средах.
Тестирование в лабораторной среде очень полезно: оно помогает вам пройти шаги конфигурации и понять, как работает настройка и какие расширенные параметры можно задать. Это отличный вариант использования для подготовки (практики) к развертыванию в производственной среде или даже просто для знакомства с функцией, например, для целей сдачи сертификационного экзамена.
А как насчёт внешнего уровня? Ну, это как раз то, что не поддерживается в VCF 9.0, поскольку внешний уровень ESX не имеет видимости внутреннего уровня и не может видеть активность памяти ВМ, по сути пытаясь «прозреть» сквозь вложенный уровень до виртуальной машины (inception). Это и есть главное отличие (не вдаваясь слишком глубоко в технические детали).
Так что если вам интересно протестировать Memory Tiering, а всё, что у вас есть — это вложенная среда, вы можете настроить Memory Tiering и любые расширенные параметры. Интересно наблюдать, как несколько шагов настройки могут добавить хостам 100% дополнительной памяти.
В ранних статьях мы упоминали, что вы можете настраивать разделы NVMe с помощью команд ESXCLI, PowerCLI и даже скриптов. В более поздних публикациях мы говорили о том, что опубликуем скрипт для настройки разделов, который мы приводим ниже, но с оговоркой и прямым предупреждением: вы можете запускать скрипт на свой страх и риск, и он может не работать в вашей среде в зависимости от вашей конфигурации.
Рассматривайте этот скрипт только как пример того, как это можно автоматизировать, а не как поддерживаемое решение автоматизации. Кроме того, скрипт не стирает разделы за вас, поэтому убедитесь, что вы сделали это до запуска скрипта. Как всегда, сначала протестируйте.
Есть некоторые переменные, которые вам нужно изменить, чтобы он работал в вашей среде:
$vCenter = “ваш vCenter FQDN или IP” (строка 27)
$clusterName = “имя вашего кластера” (строка 28)
Вот и сам скрипт:
function Update-NvmeMemoryTier {
param (
[Parameter(Mandatory=$true)]
[VMware.VimAutomation.ViCore.Impl.V1.Inventory.VMHostImpl]$VMHost,
[Parameter(Mandatory=$true)]
[string]$DiskPath
)
try {
# Verify ESXCLI connection
$esxcli = Get-EsxCli -VMHost $VMHost -V2
# Note: Verify the correct ESXCLI command for NVMe memory tiering; this is a placeholder
# Replace with the actual command or API if available
$esxcli.system.tierdevice.create.Invoke(@{ nvmedevice = $DiskPath }) # Hypothetical command
Write-Output "NVMe Memory Tier created successfully on host $($VMHost.Name) with disk $DiskPath"
return $true
}
catch {
Write-Warning "Failed to create NVMe Memory Tier on host $($VMHost.Name) with disk $DiskPath. Error: $_"
return $false
}
}
# Securely prompt for credentials
$credential = Get-Credential -Message "Enter vCenter credentials"
$vCenter = "vcenter FQDN"
$clusterName = "cluster name"
try {
# Connect to vCenter
Connect-VIServer -Server $vCenter -Credential $credential -WarningAction SilentlyContinue
Write-Output "Connected to vCenter Server successfully."
# Get cluster and hosts
$cluster = Get-Cluster -Name $clusterName -ErrorAction Stop
$vmHosts = Get-VMHost -Location $cluster -ErrorAction Stop
foreach ($vmHost in $vmHosts) {
Write-Output "Fetching disks for host: $($vmHost.Name)"
$disks = @($vmHost | Get-ScsiLun -LunType disk |
Where-Object { $_.Model -like "*NVMe*" } | # Filter for NVMe disks
Select-Object CanonicalName, Vendor, Model, MultipathPolicy,
@{N='CapacityGB';E={[math]::Round($_.CapacityMB/1024,2)}} |
Sort-Object CanonicalName) # Explicit sorting
if (-not $disks) {
Write-Warning "No NVMe disks found on host $($vmHost.Name)"
continue
}
# Build disk selection table
$diskWithIndex = @()
$ctr = 1
foreach ($disk in $disks) {
$diskWithIndex += [PSCustomObject]@{
Index = $ctr
CanonicalName = $disk.CanonicalName
Vendor = $disk.Vendor
Model = $disk.Model
MultipathPolicy = $disk.MultipathPolicy
CapacityGB = $disk.CapacityGB
}
$ctr++
}
# Display disk selection table
$diskWithIndex | Format-Table -AutoSize | Out-String | Write-Output
# Get user input with validation
$maxRetries = 3
$retryCount = 0
do {
$diskChoice = Read-Host -Prompt "Select disk for NVMe Memory Tier (1 to $($disks.Count))"
if ($diskChoice -match '^\d+$' -and $diskChoice -ge 1 -and $diskChoice -le $disks.Count) {
break
}
Write-Warning "Invalid input. Enter a number between 1 and $($disks.Count)."
$retryCount++
} while ($retryCount -lt $maxRetries)
if ($retryCount -ge $maxRetries) {
Write-Warning "Maximum retries exceeded. Skipping host $($vmHost.Name)."
continue
}
# Get selected disk
$selectedDisk = $disks[$diskChoice - 1]
$devicePath = "/vmfs/devices/disks/$($selectedDisk.CanonicalName)"
# Confirm action
Write-Output "Selected disk: $($selectedDisk.CanonicalName) on host $($vmHost.Name)"
$confirm = Read-Host -Prompt "Confirm NVMe Memory Tier configuration? This may erase data (Y/N)"
if ($confirm -ne 'Y') {
Write-Output "Configuration cancelled for host $($vmHost.Name)."
continue
}
# Configure NVMe Memory Tier
$result = Update-NvmeMemoryTier -VMHost $vmHost -DiskPath $devicePath
if ($result) {
Write-Output "Successfully configured NVMe Memory Tier on host $($vmHost.Name)."
} else {
Write-Warning "Failed to configure NVMe Memory Tier on host $($vmHost.Name)."
}
}
}
catch {
Write-Warning "An error occurred: $_"
}
finally {
# Disconnect from vCenter
Disconnect-VIServer -Server $vCenter -Confirm:$false -ErrorAction SilentlyContinue
Write-Output "Disconnected from vCenter Server."
}
Доступность данных — ключевая компетенция корпоративных систем хранения. На протяжении десятилетий такие системы стремились обеспечить высокий уровень доступности данных при одновременном соблюдении ожиданий по производительности и эффективности использования пространства. Достичь всего этого одновременно непросто.
Кодирование с восстановлением (erasure coding) играет важную роль в хранении данных устойчивым, но при этом эффективным с точки зрения занимаемого пространства способом. Этот пост поможет лучше понять, как erasure coding реализовано в VMware vSAN, чем оно отличается от подходов, применяемых в традиционных системах хранения, и как корректно интерпретировать возможности erasure code в контексте доступности данных.
Назначение Erasure Coding
Основная ответственность любой системы хранения — вернуть запрошенный бит данных. Чтобы делать это надежно, системе хранения необходимо сохранять данные устойчивым способом. Простейшая форма устойчивости данных достигается посредством нескольких копий или «зеркал», которые позволяют поддерживать доступность при возникновении отказа в системе хранения, например при выходе из строя диска в массиве хранения или хоста в распределённой системе хранения, такой как vSAN. Одна из проблем этого подхода — высокая стоимость хранения: полные копии данных занимают много места. Одна дополнительная копия удваивает объём, две — утраивают.
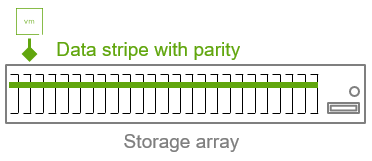
Erasure codes позволяют хранить данные устойчиво, но гораздо более эффективно с точки зрения пространства, чем традиционное зеркалирование. Вместо хранения копий данные распределяются по нескольким локациям — каждая из которых может считаться точкой отказа (например, диск или хост в распределённой системе, такой как vSAN). Фрагменты данных формируют «полосу» (stripe), к которой добавляются фрагменты четности, создаваемые при записи данных. Данные четности получаются в результате математических вычислений. Если какой-либо фрагмент данных отсутствует, система может прочитать доступные части полосы и вычислить недостающий фрагмент, используя четность. Таким образом, она может либо выполнить исходный запрос чтения «на лету», либо реконструировать отсутствующие данные в новое место. Тип erasure code определяет, может ли он выдержать потерю одного, двух или более фрагментов при сохранении доступности данных.
Erasure codes обеспечивают существенную экономию пространства по сравнению с традиционным зеркальным хранением. Экономия зависит от характеристик конкретного типа erasure code — например, сколько отказов он способен выдержать и по скольким локациям распределяются данные.
Erasure codes бывают разных типов. Их обычно обозначают количеством фрагментов данных и количеством фрагментов четности. Например, обозначение 6+3 или 6,3 означает, что полоса состоит из 6 (k) фрагментов данных и 3 (m) фрагментов четности, всего 9 (n) фрагментов. Такой тип erasure code может выдержать отказ любых трёх фрагментов, сохранив доступность данных. Он обеспечивает такую устойчивость при всего лишь 50% дополнительного расхода пространства.
Но erasure codes не лишены недостатков. Операции ввода-вывода становятся более сложными: одна операция записи может преобразовываться в несколько операций чтения и записи, что называют «усилением ввода-вывода» (I/O amplification). Это может замедлять обработку в системе хранения, а также увеличивать нагрузку на CPU и требовать больше полосы пропускания. Однако при правильной реализации erasure codes могут сочетать устойчивость с высокой производительностью. Например, инновационная архитектура vSAN ESA устраняет типичные проблемы производительности erasure codes, и RAID-6 в ESA может обеспечивать такую же или даже лучшую производительность, чем RAID-1.
Хранение данных в vSAN и в традиционном массиве хранения
Прежде чем сравнивать erasure codes в vSAN и традиционных системах хранения, рассмотрим, как vSAN хранит данные по сравнению с классическим массивом.
Хранилища часто предоставляют большой пул ресурсов в виде LUN. В контексте vSphere он форматируется как datastore с VMware VMFS, где располагаются несколько виртуальных машин. Команды SCSI передаются от ВМ через хосты vSphere в систему хранения. Такой datastore на массиве охватывает большое количество устройств хранения в его корпусе, что означает не только широкую логическую границу (кластерная файловая система с множеством ВМ), но и большую физическую границу (несколько дисков). Как и многие другие файловые системы, такая кластерная ФС должна оставаться целостной, со всеми метаданными и данными, доступными в полном объёме.
vSAN использует совершенно иной подход. Вместо классической файловой системы с большой логической областью данных, распределённой по всем хостам, vSAN оперирует малой логической областью данных для каждого объекта. Примерами могут служить диски VMDK виртуальной машины, постоянный том для контейнера или файловый ресурс, предоставленный службами файлов vSAN. Именно это делает vSAN аналогичным объектному хранилищу, даже несмотря на то, что фактически это блочное хранилище с использованием SCSI-семантики или файловой семантики в случае файловых сервисов. Для дополнительной информации об объектах и компонентах vSAN см. пост «vSAN Objects and Components Revisited».
Такой подход обеспечивает vSAN целый ряд технических преимуществ по сравнению с монолитной кластерной файловой системой в традиционном массиве хранения. Erasure codes применяются к объектам независимо и более гранулярно. Это позволяет заказчикам проектировать кластеры vSAN так, как они считают нужным — будь то стандартный односайтовый кластер, кластер с доменами отказа для отказоустойчивости на уровне стоек или растянутый кластер (stretched cluster). Кроме того, такой подход позволяет vSAN масштабироваться способами, недоступными при традиционных архитектурных решениях.
Сравнение erasure coding в vSAN и традиционных системах хранения
Имея базовое понимание того, как традиционные массивы и vSAN предоставляют ресурсы хранения, рассмотрим, чем их подходы к erasure coding отличаются. В этих сравнениях предполагается наличие одновременных отказов, поскольку многие системы хранения способны справляться с единичными отказами в течение некоторого времени.
Массив хранения (Storage Array)
В данном примере традиционный массив использует erasure code конфигурации 22+3 для одного LUN (k=22, m=3, n=25).
Преимущества:
Относительно низкие накладные расходы по ёмкости. Дополнительная ёмкость, потребляемая данными четности для поддержания доступности при сбоях в доменах отказа (устройствах хранения), составляет около 14%. Такого низкого уровня удаётся достичь благодаря распределению данных по очень большому числу устройств хранения.
Относительно высокий уровень отказоустойчивости (3). Любые три устройства хранения могут выйти из строя, и том останется доступным. Но, как отмечено ниже, это только часть картины.
Компромиссы:
Относительно большой «радиус поражения». Если число отказов превысит то, на которое рассчитан массив, зона воздействия будет очень большой. В некоторых случаях может пострадать весь массив.
Защита только от отказов устройств хранения. Erasure coding в массивах защищает только от отказов самих накопителей. Массивы могут испытывать серьёзную деградацию производительности и доступности при других типах отказов, например, межсоединений (interconnects), контроллеров хранения и некорректных обновлениях прошивок. Ни один erasure code не может обеспечить доступность данных, если выйдёт из строя больше контроллеров, чем массив способен выдержать.
Относительно высокий эффект на производительность во время или после отказов. Отказы при больших значениях k и m могут требовать очень много ресурсов на восстановление и быть более подвержены высоким значениям tail latency.
Относительно большое количество потенциальных точек отказа на одну четность. Соотношение 8,33:1 отражает высокий показатель потенциальных точек отказа относительно количества битов четности, обеспечивающих доступность. Высокое соотношение указывает на более высокую хрупкость.
Последний пункт является чрезвычайно важным. Erasure codes нельзя оценивать только по заявленному уровню устойчивости (m), но необходимо учитывать сопоставление заявленной устойчивости с количеством потенциальных точек отказа, которые она прикрывает (n). Это обеспечивает более корректный подход к пониманию вероятностной надёжности системы хранения.
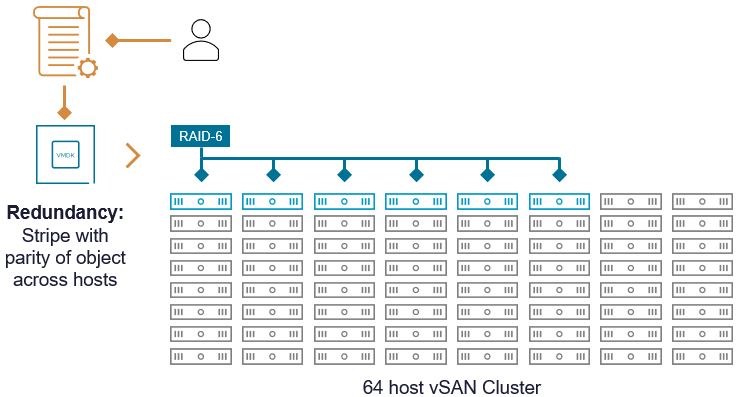
vSAN
В этом примере предположим, что у нас есть кластер vSAN из 24 хостов, и объект данных ВМ настроен на использование RAID-6 erasure code ы (k=4, m=2, n=6).
Важно отметить, что компоненты, формирующие объект vSAN при использовании RAID-6, будут содержать как фрагменты данных, так и фрагменты четности. Как описывает Христос Караманолис в статье "The Use of Erasure Coding in vSAN" (vSAN OSA, примерно 2018 год), vSAN не создаёт отдельные компоненты четности.
Преимущества:
Относительно небольшой «радиус поражения». Если кластер переживает более двух одновременных отказов хостов, это затронет лишь некоторые объекты, но не выведет из строя весь datastore.
Защита от широкого спектра типов отказов. Erasure coding в vSAN учитывает отказы отдельных устройств хранения, хостов и отказы заранее определённых доменов (например, стоек).
Относительно низкое влияние на производительность во время или после отказа. Небольшие значения k уменьшают вычислительные затраты при восстановлении.
Относительно малое число потенциальных точек отказа на единицу четности. Соотношение 3:1 указывает на малое количество возможных точек отказа по сравнению с числом битов четности, обеспечивающих доступность.
Компромиссы:
Низкая абсолютная устойчивость объекта к отказам (2). У vSAN RAID-6 (4+2) заявленная устойчивость меньше. Однако важно помнить:
граница отказа — это объект, а не весь кластер, количество потенциальных точек отказа на четность существенно ниже.
Относительно более высокие накладные расходы. Дополнительная ёмкость, потребляемая битами четности для поддержания доступности при отказе домена (хоста), составляет 50%.
Несмотря на то, что RAID-6 в vSAN защищает от 2 отказов (в отличие от 3), он остаётся чрезвычайно надёжным благодаря небольшому количеству потенциальных точек отказа: всего 6 против 25. Это обеспечивает vSAN RAID-6 (4+2) техническое преимущество перед схемой хранения массива 22+3, если сравнивать надёжность с точки зрения вероятностей отказов.
Для vSAN использование erasure code с малым значением n обеспечивает гораздо большую гибкость в построении кластеров под самые разные сценарии. Например, RAID-6 (4+2) можно использовать минимум на 6 хостах. Для erasure code 22+3 теоретически потребовалось бы не менее 25 хостов в одном кластере.
Развязка размера кластера и доступности
RAID-6 в vSAN всегда остаётся схемой 4+2, независимо от размера кластера. Когда к объекту применяется политика хранения FTT=2 с RAID-6, это означает, что объект может выдержать два одновременных отказа хостов, на которых находятся его компоненты.
Это свойство относится к состоянию объекта, а не всего кластера. Отказы на других хостах не влияют на доступность данного объекта, за исключением того, что эти хосты могут быть использованы для восстановления недостающей части полосы с помощью четности.
vSAN рассматривает такие уцелевшие хосты как кандидатов для размещения реконструируемых компонентов, чтобы вернуть объекту заданный уровень устойчивости.
Такой подход позволяет vSAN разорвать зависимость между размером кластера и уровнем доступности. В то время как многие масштабируемые системы хранения становятся более хрупкими по мере увеличения числа узлов, подход vSAN, напротив, снижает риски по мере масштабирования кластера.
Для дополнительной информации о доступности и механизмах обработки отказов в vSAN см. документ "vSAN Availability Technologies" на VMware Resource Center.
Итог
Erasure coding — это мощная технология, позволяющая хранить данные очень устойчиво и при этом эффективно использовать пространство. Но не все erasure codes одинаково полезны.
vSAN использует такие схемы erasure coding, которые обеспечивают оптимальный баланс устойчивости, гибкости и эффективности использования пространства в распределённой среде. В сочетании с дополнительными механизмами оптимизации пространства — такими как сжатие данных в vSAN и глобальная дедупликация в ESA (в составе VCF 9.0), хранилище vSAN становится ещё более производительным, ёмким и надёжным, чем когда-либо.
Поддержание доступности данных и приложений, которые эти данные создают или используют, может быть одной из самых важных задач администраторов центров обработки данных. Такие возможности, как высокая производительность или специализированные службы данных, мало что значат, если приложения и данные, которые они создают или используют, недоступны. Обеспечение доступности — это сложная тема, поскольку доступность приложений и доступность данных достигаются разными методами. Иногда требования к доступности реализуются с помощью механизмов на уровне инфраструктуры, а иногда — с использованием решений, ориентированных на приложения. Оптимальный вариант для вашей среды во многом зависит от требований и возможностей инфраструктуры.
Хотя VMware Cloud Foundation (VCF) может обеспечивать высокий уровень доступности данных и приложений простым способом, в этой статье рассматриваются различия между обеспечением высокой доступности приложений и данных с использованием технологий на уровне приложений и встроенных механизмов на уровне инфраструктуры в VCF. Мы также рассмотрим, как VMware Data Services Manager (DSM) может помочь упростить принятие подобных решений.
Учёт отказов
Защита приложений и данных требует понимания того, как выглядят типичные сбои, и что система может сделать для их компенсации. Например, сбои в физической инфраструктуре могут затрагивать:
Централизованные решения для хранения, такие как дисковые массивы
Отдельные устройства хранения в распределённых системах
Такие сбои могут затронуть данные, приложения, или и то, и другое. Сбои могут проявляться по-разному — некоторые явно, другие лишь по отсутствию отклика. Часть из них временные, другие — постоянные. Решения должны быть достаточно интеллектуальными, чтобы автоматически справляться с такими ситуациями отказа и восстановления.
Доступность и восстановление приложений и данных
Доступность приложений и их наборов данных кажется интуитивно понятной, но требует краткого пояснения.
Доступность приложения
Это состояние приложения, например базы данных или веб-приложения. Независимо от того, установлено ли оно в виртуальной машине или запущено в контейнере, приложение заранее настроено на работу с данными определённым образом. Некоторые приложения могут работать в нескольких экземплярах для повышения доступности при сбоях и использовать собственные механизмы синхронной репликации, чтобы данные сохранялись в нескольких местах. Технологии, такие как vSphere HA, могут повысить доступность приложения и его данных, перезапуская виртуальную машину на другом хосте кластера vSphere в случае сбоя.
Доступность данных
Это способность данных быть доступными для приложения или пользователей в любое время, даже при сбое. Высокодоступные данные хранятся с использованием устойчивых механизмов, обеспечивающих хранение в нескольких местах — в зависимости от возможных границ сбоя: устройства, хоста, массива хранения или целого сайта.
Надёжность данных
Хранить данные в нескольких местах недостаточно — они должны записываться синхронно и последовательно во все копии, чтобы при сбое данные из одного места совпадали с данными из другого. Корпоративные системы хранения данных реализуют принципы ACID (атомарность, согласованность, изолированность, долговечность) и протоколы, обеспечивающие надёжность данных.
Описанные выше концепции вводят два термина, которые помогают количественно определить возможности восстановления в случае сбоя:
RPO (Recovery Point Objective) — целевая точка восстановления. Показывает, с каким интервалом данные защищаются устойчивым образом. RPO=0 означает, что система всегда выполняет запись в синхронном, согласованном состоянии. Как будет отмечено далее, не все решения способны обеспечивать настоящий RPO=0.
RTO (Recovery Time Objective) — целевое время восстановления. Показывает минимальное время, необходимое для восстановления систем и/или данных до рабочего состояния. Например, RTO=10m означает, что восстановление займёт не менее 10 минут. RTO может относиться к восстановлению доступности данных или комбинации данных и приложения.
Эволюция решений для высокой доступности
Подходы к обеспечению доступности данных и приложений эволюционировали с развитием технологий и ростом требований. Некоторые приложения, такие как Microsoft SQL Server, MySQL, PostgreSQL и другие, включают собственные механизмы репликации, обеспечивающие избыточность данных и состояния приложения. Виртуализация, совместно с общим хранилищем, предоставляет простые способы обеспечения высокой доступности приложений и хранимых ими данных.
В зависимости от ваших требований может подойти один из подходов или их комбинация. Рассмотрим, как каждый из них обеспечивает высокий уровень доступности.
Высокая доступность на уровне приложений (Application-Level HA)
Этот подход основан на запуске нескольких экземпляров приложения в разных местах. Синхронное и устойчивое хранилище, а также механизмы отказоустойчивости обеспечиваются самим приложением для гарантии высокой доступности приложения и его данных.
Высокая доступность на уровне инфраструктуры (Infrastructure-Level HA)
Этот подход использует vSphere HA для перезапуска одного экземпляра приложения на другом хосте кластера. Синхронное и устойчивое хранение данных обеспечивает VMware vSAN (в контексте данного сравнения). Такая комбинация гарантирует высокую доступность приложения и его данных.
Оба подхода достигают схожих целей, но имеют определённые компромиссы. Рассмотрим два простых примера, чтобы лучше понять различия.
В приведённых примерах предполагается, что данные должны сохраняться в нескольких местах (например, на уровне сайта или зоны), чтобы обеспечить доступность при сбое площадки. Также предполагается, что приложение может работать в тех же местах. Оба варианта обеспечивают автоматический отказоустойчивый переход и RPO=0, поскольку данные записываются синхронно в несколько мест.
Высокая доступность на уровне приложений для приложений и данных
Высокая доступность на уровне приложений, как в случае MS SQL Always On Availability Groups (AG), использует два или более работающих экземпляра базы данных и дополнительное местоположение для определения кворума при различных сценариях отказа.
Этот подход полностью опирается на технологии, встроенные в само приложение, чтобы синхронно реплицировать данные в другое место и обеспечить механизм отказоустойчивого переключения состояния приложения.
Высокая доступность на уровне инфраструктуры для приложений и данных
Высокая доступность на уровне инфраструктуры использует приложение базы данных, работающее на одной виртуальной машине. vSphere HA обеспечивает автоматическое восстановление приложения, обращающегося к данным, в то время как vSAN гарантирует надёжность и доступность данных при различных типах сбоев инфраструктуры.
vSAN может выдерживать отказы отдельных устройств хранения, сетевых карт (NIC), сетевых коммутаторов, хостов и даже целых географических площадок или зон, которые определяются как «домен отказа» (fault domain).
В приведённом ниже примере кластер vSAN растянут между двумя площадками, чтобы обеспечить устойчивое хранение данных на обеих. Растянутые кластеры vSAN (vSAN Stretched Clusters) также используют третью площадку, на которой размещается небольшой виртуальный модуль — witness host appliance (хост-свидетель), помогающий определить кворум при различных возможных сценариях отказа.
Одним из самых убедительных преимуществ высокой доступности на уровне инфраструктуры является то, что в VCF она является встроенной частью платформы. vSAN интегрирован прямо в гипервизор и обеспечивает отказоустойчивость данных в соответствии с вашими требованиями, всего лишь посредством настройки простой политики хранения (storage policy). Экземпляры приложений становятся высокодоступными благодаря проверенной технологии vSphere HA, которая позволяет перезапускать виртуальные машины на любом хосте в пределах кластера vSphere. Такой подход также отлично работает, когда приложения баз данных развертываются и управляются в вашей среде VCF с помощью DSM.
Разные подходы к обеспечению согласованности данных
Хотя оба подхода могут обеспечивать цель восстановления точки (RPO), равную нулю (RPO=0), за счёт синхронной репликации, способы достижения этого различаются. Оба используют специальные протоколы, помогающие обеспечить согласованность данных, записываемых в нескольких местах — что на практике значительно сложнее, чем кажется.
В случае MS SQL Server Always On Availability Groups согласованность достигается на уровне приложения, тогда как vSAN обеспечивает синхронную запись данных по своей сути — как часть распределённой архитектуры, изначально разработанной для обеспечения отказоустойчивости.
При репликации данных на уровне приложения такой высокий уровень доступности ограничен только этим конкретным приложением и его данными. Однако возможности на уровне приложений реализованы не одинаково. Например, MS SQL Server Always On AG могут обеспечивать RPO=0 при множестве сценариев отказа, тогда как MySQL InnoDB Cluster использует подход, при котором RPO=0 возможно только при отказе одного узла. Хотя данные при этом остаются согласованными, в некоторых сценариях отказа — например, при полном сбое кластера или незапланированной перезагрузке — могут быть потеряны последние зафиксированные транзакции. Это означает, что при определённых обстоятельствах обеспечить истинный RPO=0 невозможно.
В случае vSAN в составе VCF, высокая доступность является универсальной характеристикой, которая применяется ко всем рабочим нагрузкам, записывающим данные в хранилище vSAN datastore.
Различия во времени восстановления (RTO)
Одной из основных причин различий между возможностями RTO при доступности на уровне приложения и на уровне инфраструктуры является то, как приложение возвращается в рабочее состояние после сбоя.
Например, некоторые приложения, такие как SQL Server AG, используют лицензированные «резервные» виртуальные машины (standby VMs) в вашей инфраструктуре, чтобы обеспечить использование другого состояния приложения при отказе. Это позволяет достичь низкого RTO, но приводит к увеличению затрат из-за необходимости дополнительных лицензий и потребляемых ресурсов. Высокая доступность на уровне приложения — это специализированное решение, требующее экспертизы в конкретном приложении для достижения нужного результата. Однако DSM может значительно снизить сложность таких сценариев, поскольку автоматизирует эти процессы и снимает значительную часть административной нагрузки.
Высокая доступность на уровне инфраструктуры работает иначе. Используя механизмы виртуализации, такие как vSphere High Availability (HA), она обеспечивает перезапуск приложения в другом месте при сбое виртуальной машины. Перезапуск ВМ и самого приложения, а также процесс восстановления журналов обычно занимают больше времени, чем подход с резервной ВМ, используемый при высокой доступности на уровне приложений.
Приведённые выше значения времени восстановления являются оценочными. Фактическое время восстановления может значительно различаться в зависимости от условий среды, размера и активности экземпляра MS SQL.
Что выбрать именно вам?
Наилучший выбор зависит от ваших требований, ограничений и того, насколько решение подходит вашей организации. Например:
Требования к доступности
Возможно, ваши требования предполагают, что приложение и его данные должны быть доступны за пределами определённой границы отказа — например, уровня сайта или зоны. Это поможет определить, нужна ли вообще доступность на уровне сайта или зоны.
Требования к RTO
Если требуемое время восстановления (RTO) допускает 2–5 минут, то высокая доступность на уровне инфраструктуры — отличный вариант, поскольку она встроена в платформу и работает для всех ваших нагрузок. Если же есть несколько отдельных приложений, для которых требуется меньшее RTO, и вас не смущают дополнительные затраты и сложность, связанные с этим решением, то подход на уровне приложения может быть оправдан.
Технические ограничения
В вашей организации могут быть инициативы по упрощению инструментов и рабочих процессов, что может ограничивать возможность или желание использовать дополнительные технологии, такие как высокая доступность на уровне приложений. Обычно предпочтение отдаётся универсальным инструментам, применимым ко всем системам, а не узкоспециализированным решениям. Другие технические факторы, например задержки (latency) между сайтами или зонами, также могут сделать тот или иной подход непрактичным.
Финансовые ограничения
Возможно, на вас оказывают давление с целью сократить постоянные расходы на программное обеспечение — например, на дополнительные лицензии или более дорогие уровни лицензирования, необходимые для обеспечения высокой доступности на уровне приложений. В этом случае более выгодным решением могут оказаться уже имеющиеся технологии.
Можно также использовать комбинацию обоих подходов.
Например, на первом рисунке в начале статьи показано, как высокая доступность на уровне приложений реализуется между сайтами или зонами с помощью MS SQL Always On Availability Groups, а высокая доступность на уровне инфраструктуры обеспечивается vSAN и vSphere HA внутри каждого сайта или зоны.
Этот вариант также может быть отличным примером использования VMware Data Services Manager (DSM). Вместо запуска и управления отдельными виртуальными машинами можно использовать базы данных, развёрнутые DSM, для обеспечения доступности приложений между сайтами или зонами. Такой подход обеспечивает низкое RTO, устраняет административную сложность, связанную с репликацией на уровне приложений, и при этом позволяет vSAN обеспечивать доступность данных внутри сайтов или зон.
Data Services Manager (DSM) 9.0 теперь доступен, и организации стремятся понять, как использование этого дополнения к VMware Cloud Foundation (VCF) может помочь им в реализации решения DBaaS в локальной среде. В этом посте будут рассмотрены убедительные преимущества DSM, адаптированные для трех различных ролей: администратора, DBA и конечного пользователя/разработчика.
Преимущества DSM для администратора виртуальной инфраструктуры
Контроль размещения и отказоустойчивости
Прежде всего, этот продукт разработан с учетом требований администратора виртуальной инфраструктуры. Цель была помочь ему контролировать «разрастание данных» и сохранять контроль над размещением баз данных и сервисов данных в инфраструктуре vSphere. Это достигается посредством конструкции DSM, называемой политикой инфраструктуры. Она определяет, какие вычислительные ресурсы, хранилище, сети и даже какая папка ВМ используются для размещения конкретной базы данных. Это не только упрощает общее управление и использование инфраструктуры, но также помогает с контролем лицензирования, прогнозированием, биллингом и т. д. Такое размещение и контроль становятся еще более детализированными с VCF 9.0, где DSM может использовать политику инфраструктуры на основе пространства имен vSphere для развертывания баз данных и сервисов данных. Администратор создает пространства имен vSphere в Supervisor. Как администратор vSphere, он устанавливает лимиты на CPU, память и хранилище в пространстве имен vSphere.
Через политику инфраструктуры администратор также может определить отказоустойчивость базы данных. В то время как DBA может выбрать, будет ли база данных автономной (один узел) или кластерной (три узла), политика инфраструктуры определит размещение кластерной базы данных с точки зрения vSphere. По умолчанию DSM разместит три виртуальные машины кластерной базы данных на разных хостах ESX в одном кластере vSphere. Однако администратор также может создать межкластерную политику инфраструктуры, которая, будучи выбранной DBA, разместит разные узлы одного и того же кластера базы данных в разных кластерах vSphere, обеспечивая еще более высокий уровень доступности.
Видимость и аналитика
Хотя DSM имеет собственный интерфейс и API, не хотелось бы, чтобы администратор «переключался» между разными интерфейсами при мониторинге баз данных и сервисов данных, развернутых DSM на vSphere. Поэтому VMware интегрировала в клиент vSphere возможность просмотра сведений о базах данных и сервисах данных. С одного взгляда администратор может увидеть список развернутых баз данных, имя экземпляра базы, тип движка (Postgres, MySQL, MS SQL) в клиенте vSphere, а также статус БД, версию, уровень оповещений, число узлов, отказоустойчивость, политику инфраструктуры, политику хранения и т. д. Администраторы могут перейти к более детализированному просмотру и увидеть соответствующее имя виртуальной машины, сведения о размещении, а также использование CPU, памяти и дисков. Хотя это само по себе полезно для администратора, это также чрезвычайно полезно для обсуждений между администраторами и DBA по всем аспектам инфраструктуры, потребляемой базой данных, когда требуется понять использование ресурсов, производительность, масштабирование и другие характеристики. Пример такого представления приведен ниже.
Интеграция с vSphere и VMware Cloud Foundation
DSM интегрируется с основными инфраструктурными продуктами vSphere. В предыдущем параграфе мы упомянули, что администратор может просматривать сведения о базах данных через клиент vSphere. Однако также имеется интеграция с Aria Automation 8.x для тех клиентов, которые хотят использовать этот уровень интеграции. DSM поставляется с пользовательским ресурсом для Aria Automation, который после установки создает элемент каталога сервисов для поддержки DBaaS. DSM 9.0 также интегрируется с VCF Automation. Администраторы могут создавать политики службы данных и назначать эти политики различным организациям для полноценного multitenant опыта DBaaS.
Аналогично осуществляется интеграция с Aria Operations, куда DSM и соответствующие базы данных могут отправлять свои метрики. За последние несколько лет была проделана работа по этим интеграциям, включая создание ряда стандартных панелей мониторинга для различных баз данных. Также в версии VCF 9.0 значительно улучшили мониторинг баз данных - теперь все метрики отправляются в VCF Operations. Более того, метрики теперь могут отправляться из DSM 9.0 в эндпоинт Prometheus для тех клиентов, которые хотят это использовать.
Наконец, в этой секции выделим еще одну интеграцию — с Aria Operations for Logs. В один шаг DSM может отправлять все журналы как из самого DSM-апплаенса, так и из всех его баз данных в единую целевую точку. Эти журналы могут отправляться на любой SYSLOG-эндпоинт.
Все вышеперечисленные точки интеграции должны быть полезны для администраторов, использующих полный стек VCF.
Поддержка
Поддержка Broadcom охватывает управление жизненным циклом движков данных, управляемых DSM, включая развертывание, обновление ОС и программного обеспечения базы данных, масштабирование и кластеризацию. Поддержка самого движка PostgreSQL или MySQL, включая, но не ограничиваясь исправлением ошибок, проблемами производительности и устранением уязвимостей, осуществляется сообществом upstream, при этом Broadcom оказывает содействие по принципу "best-effort".
Кроме того, VMware работает с сообществом с открытым исходным кодом, чтобы предоставить полноценное исправление downstream для любых ошибок, обнаруженных клиентами. Хотя VMware не может гарантировать, когда конкретное исправление будет доступно в какой-либо из баз данных с открытым исходным кодом, они могут создавать пользовательские сборки с исправлениями, которые еще не доступны в версиях open source. Это распространенная модель поддержки для продуктов с открытым исходным кодом, и многие поставщики DBaaS используют ту же модель. Это должно дать клиентам уверенность при выборе DSM для их DBaaS решения.
Преимущества DSM для DBA
Теперь сосредоточимся на DBA и тех преимуществах, которые DSM приносит этой роли.
Интуитивно понятный интерфейс для управления парком БД
DSM предоставляет DBA единую панель управления, которая позволяет легко управлять всем парком баз данных. Ниже показана страница по умолчанию для администраторов DSM с различными параметрами управления и конфигурации.
Управление жизненным циклом
Команда DSM регулярно предоставляет обновления для DSM. Это включает обновления для виртуального модуля DSM, гостевой ОС, используемой узлами базы данных, версий Kubernetes в этих узлах, а также собственно самих баз данных. Единственное, что требуется от DBA — загрузить и подготовить обновление. Как для виртуального модуля, так и для баз данных доступны окна обслуживания. Если обновление подготовлено, и наступает окно (обычно в ночь с субботы на воскресенье), обновление применяется автоматически. Никому не нужно вручную управлять жизненным циклом ОС виртуальных машин или кластера K8s — DSM делает это автоматически. Этот аспект часто упускается при сравнении DSM с другими решениями DBaaS.
Еще один важный момент — DSM теперь умеет обновлять как основные (major), так и минорные версии базы данных. Хотя при мажорный обновлениях DBA должен проявлять осторожность (например, проверить совместимость расширений), наличие такой возможности является значительным преимуществом.
Автоматизированные резервные копии и восстановление к точке во времени
Как и управление жизненным циклом, резервное копирование может быть автоматически настроено на этапе развертывания базы данных. Если эта опция включена, DSM начнет выполнять резервные копии сразу после включения базы данных. По умолчанию для Postgres раз в неделю выполняется полный бэкап. Ежедневные бэкапы выполняются каждый день, а журналы WAL отправляются каждые 5 минут или по достижении 16 МБ — что произойдет раньше. Для MySQL и MS SQL Server существуют собственные расписания по умолчанию. Благодаря такому автоматизированному расписанию резервного копирования доступны восстановления к точке во времени для всех баз данных.
Масштабирование — In / Out / Up / Down
DSM позволяет DBA легко масштабировать топологии баз данных — от автономного узла до трехузлового кластера и обратно. Также допускается вертикальное масштабирование, путем смены класса виртуальной машины, что увеличивает доступные CPU и память. И наоборот — если ресурсы остаются неиспользованными, DBA может уменьшить класс ВМ и сократить потребление ресурсов. Это особенно полезно, например, для закрытия месяца, квартала или во время “Black Friday”, когда базе данных временно требуются дополнительные ресурсы. После окончания «пика» ресурсы можно освободить.
Клонирование
DSM позволяет DBA создавать клоны базы данных, если возникает такая необходимость. Это полезно для тестовых и девелоперских сред, когда разработчики хотят запускать запросы на «живых» данных, не затрагивая продуктивную базу.
Интеграция с LDAPS
DSM поддерживает защищенный LDAP как для доступа к самому DSM, так и к базам данных. Это делает назначение прав доступа более безопасным и удобным. При развертывании базы данных DBA может выбрать интеграцию с Directory Service и затем с помощью простого оператора GRANT предоставить LDAP-пользователям доступ к базе. Кроме того, DSM поддерживает защищенный LDAP и для собственного UI, что позволяет пользователям и разработчикам (при наличии прав) самостоятельно создавать базы данных через DSM-интерфейс. Поддерживаются как ticket-based, так и self-service подходы.
Управление сертификатами
Для обеспечения защищенного доступа к базе данных необходимы сертификаты. DSM предоставляет два варианта — использовать собственные самоподписанные сертификаты DSM или загрузить пользовательские сертификаты. DBA может применить сертификаты как при создании базы, так и после ее развертывания. UI и API DSM делают процесс добавления сертификатов очень простым. С учетом современных требований безопасности — это крайне важная функция.
Аудит и оповещения
DSM предоставляет различные механизмы для оповещений, а также встроенные функции в UI. Оповещения могут отправляться по электронной почте (SMTP), а также через webhook-механизм в сторонние системы, такие как ServiceNow или Slack. Таким образом, DBA-команда никогда не пропустит важное событие.
Для целей соответствия требованиям, DSM ведет аудит событий, который DBA может быстро просмотреть. В версии DSM 9.0 журналы аудита также передаются на настроенную систему получения логов.
Высокая отказоустойчивость
Хотя это может показаться зоной ответственности администратора, именно DBA выбирает нужный уровень отказоустойчивости при создании базы. Эти параметры управляются через инфраструктурные и storage-политики. Как упоминалось ранее, кластерные базы могут быть размещены либо в одном кластере vSphere, либо распределены по разным кластерам. DBA выбирает нужный вариант, выбирая соответствующую политику.
Шифрование
Для шифрования можно использовать функцию VM Crypt, что позволяет шифровать отдельные базы данных. Это определяется в политике хранения, входящей в инфраструктурную политику. Альтернативно можно шифровать весь datastore (например, vSAN), и тогда любая база, размещенная на нем, будет автоматически зашифрована. Оба подхода поддерживаются DSM.
Отказоустойчивость и репликация
DBA может использовать репликацию для удаленной защиты базы. При наличии нескольких сред vSphere вторичный узел Postgres может быть размещен в другой среде vSphere с другим экземпляром DSM. В UI доступны элементы управления для повышения вторичного узла в первичный и наоборот. В случае потери целой среды vSphere можно выполнить восстановление баз данных в другую среду и продолжить работу.
Host-based access при развертывании
Файл pg_hba.conf в Postgres определяет, какие пользователи из каких сетей могут обращаться к базе. Через UI DSM DBA может заранее задать правила доступа при развертывании, не заходя в базу после ее создания. Это предотвращает ситуацию, когда база находится в «незащищенном» состоянии, пока эти правила не будут вручную настроены.
Расширенные параметры при развертывании
Аналогично предыдущему пункту, DBA может задать расширенные параметры при создании базы, не выполняя это как отдельный пост-шаг. Это сокращает время развертывания.
Защита от удаления
Пользователи DSM могут восстановить базу данных после ее удаления. Период хранения удаленной базы составляет 30 дней, но может быть уменьшен или увеличен при необходимости.
Преимущества DSM для конечного пользователя/разработчика
Одной из основных задач DSM является обеспечение модели самообслуживания DBaaS. Поэтому DSM предоставляет конечным пользователям и разработчикам простой механизм для запроса и доступа к базам данных. Рассмотрим эти возможности далее.
Интуитивно понятный интерфейс
Пользователи DSM получают очень простой интерфейс, позволяющий легко создавать, обновлять и удалять базы данных по мере необходимости. Они не видят настроек конфигурации и не видят базы данных других пользователей. Для тех конечных пользователей, которые предпочитают UI для развертывания баз, это интуитивно понятный и простой процесс.
Kubernetes и REST API
VMware понимает, что многие разработчики предпочитают не использовать пользовательский интерфейс. В некоторых случаях развертывание базы данных является частью более крупного CI/CD-пайплайна для тестирования. В связи с этим DSM предоставляет как API для Kubernetes, так и REST API. Это позволяет автоматизировать развертывание баз данных через DSM. API доступны на официальном сайте DSM API.
Развертывание баз DSM из удалённых K8s-кластеров
Многие разработчики уже используют Kubernetes для разработки приложений. Эти кластеры могут быть ограничены по ресурсам, например, использовать только локальное хранилище. Кроме того, SRE-команды сталкиваются с проблемой того, что разработчики создают «неконтролируемые» базы данных и сервисы данных, что приводит к конфликтам по ресурсам и вопросам соответствия. Благодаря Consumption Operator в DSM разработчики могут создавать собственные базы данных DSM на инфраструктуре vSphere и подключаться к ним из своих Kubernetes-кластеров.
Итог
Data Services Manager приносит много полезных функций в VCF. DSM предоставляет DBaaS-решение для VCF с той же поддержкой, что и сам VCF. DSM уже работает в производственной среде и в масштабах, управляемых Broadcom IT на протяжении последнего года (вся разработка Broadcom использует DBaaS через DSM на VCF). У Broadcom также есть множество крупных клиентов, реализующих аналогичные сценарии. Надеемся, этот обзор преимуществ DSM был для вас полезен, и вы рассмотрите возможность использования его в своей среде VCF.
PowerCLI уже давно зарекомендовал себя как надежный и широко используемый инструмент автоматизации в средах VMware. Он остаётся одним из наиболее предпочитаемых инструментов среди клиентов, и его популярность подтверждается цифрами — по оценкам, ежегодно происходит от 1,5 до 2 миллионов загрузок. Для тех, кто интересуется, эти данные можно проверить, посмотрев некоторые статистические показатели на PowerShell Gallery.
VMware Live Recovery (VLR) продолжает обеспечивать надёжную кибер- и информационную устойчивость для VMware Cloud Foundation 9 (VCF), предлагая унифицированную защиту и безопасное восстановление после инцидентов ИБ. Помимо возможностей кибервосстановления, VMware Live Recovery остаётся основой корпоративного оркестратора аварийного восстановления в различных топологиях на базе VCF и включает расширенную репликацию vSphere между сайтами с RPO до одной минуты для поддержки критически важных приложений. VMware Live Recovery также интегрирован с функциями защиты данных хранилища VMware vSAN ESA. Всё более глубокая интеграция между VLR и основными компонентами VCF, такими как vSAN, выделяет решение на фоне конкурентов и усиливает ценность единой платформы для клиентов.
С последним релизом VMware Cloud Foundation 9 в решение VMware Live Recovery были добавлены следующие ключевые улучшения:
VLR Appliance – упрощённое развертывание и управление сервисами
Интеграция с VMware Cloud Foundation – улучшенный доступ к данным защиты
Улучшенная интеграция Protection Group и Recovery Plan с защитой данных vSAN
Кибервосстановление – поддержка сценариев на стороне заказчика, повышение суверенитета данных
VLR Appliance – упрощённое развертывание и управление сервисами
Теперь клиенты могут управлять всеми операциями восстановления с помощью одного виртуального модуля VLR. Это обновление позволяет использовать единую, комбинированную, простую в установке и управлении виртуальную машину, упрощающую управление жизненным циклом решения для нескольких сервисов защиты.
В новом объединённом устройстве VLR консолидации подверглись следующие сервисы защиты и восстановления:
Расширенная репликация между сайтами на базе vSphere
Снапшоты на базе vSAN на заданных (исходном/целевом) сайтах vSAN ESA
Автоматизация и оркестрация Site Recovery
Этот релиз VLR Appliance доступен всем клиентам с подпиской VLR, а также владельцам бессрочных лицензий SRM с действующей поддержкой SnS или временной подпиской. Новый модуль можно установить на сервер vCenter для объединения ранее установленных компонентов, как показано ниже:
Информация по развертыванию
Виртуальный модуль VLR Appliance поставляется в двух вариантах:
Основной объединённый модуль.
Дополнительный модуль службы восстановления для расширенных сценариев оркестрации аварийного восстановления, например, при использовании общих сайтов восстановления.
Важно отметить, что новый модуль VLR будет единственным вариантом, совместимым с VCF, но при этом сохраняет обратную совместимость с более старыми версиями ESX и vCenter (8.0 U3b+, 8.0 U2d+), чтобы обеспечить корректную межсайтовую работу и совместимость при переходе клиентов на новую платформу VCF. Как всегда, рекомендуется использовать инструмент совместимости продуктов VMware перед обновлениями — в данном случае, чтобы сравнить компоненты VMware Live Site Recovery и VMware Cloud Foundation.
Расширенная репликация vSphere теперь включена в унифицированную модель развертывания VLR и обеспечивает более масштабируемую и эффективную репликацию с возможностью RPO до одной минуты.
Важно: расширенная репликация vSphere теперь является конфигурацией по умолчанию и единственно поддерживаемой для репликации между сайтами. Для сайтов, использующих старые версии vSphere Replication, перед установкой нового модуля VLR потребуется обновление до Enhanced vSphere Replication. Подробности об обновлении см. в документации. Если используется репликация на уровне СХД (array-based replication), необходимо установить SRA и array-менеджеры на новое устройство VLR и настроить их отдельно. Для дополнительной информации о выпуске этого VLR Appliance см. документацию по VMware Live Recovery Appliance.
Интеграция с VMware Cloud Foundation – лучший доступ к данным защиты
Платформа VMware Cloud Foundation поддерживает одновременную работу как традиционных виртуальных машин, так и модернизированных рабочих нагрузок. Совместимость VMware Live Recovery была обновлена, особенно в части свойств виртуальных машин для поддержки переключения (failover) и возврата (failback). Подробности о поддержке защищённых, управляемых сервисами ВМ доступны в документации.
Теперь VLR интегрирован в консоль операций VCF, что позволяет клиентам отслеживать все развертывания защиты данных VCF из единого интерфейса. Эта интеграция охватывает кибервосстановление, аварийное восстановление, репликацию vSphere, репликацию vSAN и удалённые снапшоты (remote snapshots).
Панель Data Protection & Recovery в VCF Operations для VMware Live Recovery предоставляет критически важную информацию в одном месте. Пользователи могут быстро оценить:
Сколько виртуальных машин защищено и подлежит восстановлению.
Какие ВМ в данный момент не защищены.
Ёмкость защищённого хранилища и возможности её масштабирования под нужды ИТ-инфраструктуры.
Для более глубокого анализа можно установить VLR и VR Management Packs, чтобы получить доступ к предустановленным дэшбордам. Пример дэшборда верхнего уровня:
Улучшенная интеграция групп защиты (Protection Groups) и планов восстановления (Recovery Plans) с защитой данных vSAN
Устройство VLR Appliance поддерживает службы Data Protection Snapshot Management Services для vSAN ESA и обеспечивает более глубокую интеграцию в оркестрационную платформу VMware Live Recovery. Для хранилищ на базе vSAN ESA благодаря интеграции с VLR теперь доступны три ключевые функции:
Чтобы упростить защиту виртуальных машин, конфигурации групп защиты (Protection Groups) автоматически обнаруживаются и доступны как через интерфейс vSAN Data Protection UI, так и через VMware Live Site Recovery, что существенно упрощает администрирование защиты и восстановления в масштабах всей инфраструктуры предприятия.
Кибервосстановление – поддержка локальных сценариев и повышение суверенитета данных
С этим релизом VCF и новой версией VLR клиенты могут использовать утверждённую VMware архитектуру (VMware Validated Solution), реализованную как драфт для версии 9.0, для создания локальной зоны кибервосстановления (clean room). Эта архитектура использует:
Домен рабочих нагрузок VCF как изолированную clean room.
Кластер хранения vSAN ESA как защищённое кибер-хранилище (cyber data vault).
vDefend для сетевой изоляции.
VMware Live Recovery для оркестрации процессов восстановления.
Теперь организации, которым необходимо соблюдать требования к конфиденциальности данных или территориальной принадлежности (data residency), могут обеспечивать суверенитет данных, не передавая их в публичное облако, а размещая инфраструктуру восстановления в локальной среде VCF clean room.
Общая архитектура такого сценария показана на схеме ниже:
Последний релиз VMware Cloud Foundation (VCF) и обновления VMware Live Recovery (VLR) включают важные усовершенствования, направленные на удовлетворение современных требований ИТ-организаций к защите и восстановлению данных. Чтобы узнать больше о глубокой интеграции всех средств защиты, упрощённых методах развертывания и управления, а также расширенных возможностях сценариев восстановления — ознакомьтесь с материалами по следующим ссылкам: VMware Live Recovery и документация по VLR.
Таги: VMware, Live Recovery, Update, VCF, Security, Replication
Новая версия платформы VMware Cloud Foundation 9.0, включающая компоненты виртуализации серверов и хранилищ VMware vSphere 9.0, а также виртуализации сетей VMware NSX 9, привносит не только множество улучшений, но и устраняет ряд устаревших технологий и функций. Многие возможности, присутствовавшие в предыдущих релизах ESX (ранее ESXi), vCenter и NSX, в VCF 9 объявлены устаревшими (deprecated) или полностью удалены (removed). Это сделано для упрощения архитектуры, повышения безопасности и перехода на новые подходы к архитектуре частных и публичных облаков. Ниже мы подробно рассмотрим, каких функций больше нет во vSphere 9 (в компонентах ESX и vCenter) и NSX 9, и какие альтернативы или рекомендации по миграции существуют для администраторов и архитекторов.
Почему важно знать об удалённых функциях?
Новые релизы часто сопровождаются уведомлениями об устаревании и окончании поддержки прежних возможностей. Игнорирование этих изменений может привести к проблемам при обновлении и эксплуатации. Поэтому до перехода на VCF 9 следует проанализировать, используете ли вы какие-либо из перечисленных ниже функций, и заранее спланировать отказ от них или переход на новые инструменты.
VMware vSphere 9: удалённые и устаревшие функции ESX и vCenter
В VMware vSphere 9.0 (гипервизор ESX 9.0 и сервер управления vCenter Server 9.0) прекращена поддержка ряда старых средств администрирования и внедрены новые подходы. Ниже перечислены основные функции, устаревшие (подлежащие удалению в будущих версиях) или удалённые уже в версии 9, а также рекомендации по переходу на современные альтернативы:
vSphere Auto Deploy (устарела) – сервис автоматического развертывания ESXi-хостов по сети (PXE-boot) объявлен устаревшим. В ESX 9.0 возможность Auto Deploy (в связке с Host Profiles) будет удалена в одном из следующих выпусков линейки 9.x.
Рекомендация: если вы использовали Auto Deploy для бездискового развёртывания хостов, начните планировать переход на установку ESXi на локальные диски либо использование скриптов для автоматизации установки. В дальнейшем управление конфигурацией хостов следует осуществлять через образы vLCM и vSphere Configuration Profiles, а не через загрузку по сети.
vSphere Host Profiles (устарела) – механизм профилей хоста, позволявший применять единые настройки ко многим ESXi, будет заменён новой системой конфигураций. Начиная с vCenter 9.0, функциональность Host Profiles объявлена устаревшей и будет полностью удалена в будущих версиях.
Рекомендация: вместо Host Profiles используйте vSphere Configuration Profiles, позволяющие управлять настройками на уровне кластера. Новый подход интегрирован с жизненным циклом vLCM и обеспечит более надежную и простую поддержку конфигураций.
vSphere ESX Image Builder (устарела) – инструмент для создания кастомных образов ESXi (добавления драйверов и VIB-пакетов) больше не развивается. Функциональность Image Builder фактически поглощена возможностями vSphere Lifecycle Manager (vLCM): в vSphere 9 вы можете создавать библиотеку образов ESX на уровне vCenter и собирать желаемый образ из компонентов (драйверов, надстроек от вендоров и т.д.) прямо в vCenter.
Рекомендация: для формирования образов ESXi используйте vLCM Desired State Images и новую функцию ESX Image Library в vCenter 9, которая позволит единообразно управлять образами для кластеров вместо ручной сборки ISO-файлов.
vSphere Virtual Volumes (vVols, устарела) – технология виртуальных томов хранения объявлена устаревшей с выпуском VCF 9.0 / vSphere 9.0. Поддержка vVols отныне будет осуществляться только для критических исправлений в vSphere 8.x (VCF 5.x) до конца их поддержки. В VCF/VVF 9.1 функциональность vVols планируется полностью удалить.
Рекомендация: если в вашей инфраструктуре используются хранилища на основе vVols, следует подготовиться к миграции виртуальных машин на альтернативные хранилища. Предпочтительно задействовать VMFS или vSAN, либо проверить у вашего поставщика СХД доступность поддержки vVols в VCF 9.0 (в индивидуальном порядке возможна ограниченная поддержка, по согласованию с Broadcom). В долгосрочной перспективе стратегия VMware явно смещается в сторону vSAN и NVMe, поэтому использование vVols нужно минимизировать.
vCenter Enhanced Linked Mode (устарела) – расширенный связанный режим vCenter (ELM), позволявший объединять несколько vCenter Server в единый домен SSO с общей консолью, более не используется во VCF 9. В vCenter 9.0 ELM объявлен устаревшим и будет удалён в будущих версиях. Хотя поддержка ELM сохраняется в версии 9 для возможности обновления существующих инфраструктур, сама архитектура VCF 9 переходит на иной подход: единое управление несколькими vCenter осуществляется средствами VCF Operations вместо связанного режима.
Рекомендация: при планировании VCF 9 откажитесь от развёртывания новых связанных групп vCenter. После обновления до версии 9 рассмотрите перевод существующих vCenter из ELM в раздельный режим с группированием через VCF Operations (который обеспечивает центральное управление без традиционного ELM). Функции, ранее обеспечивавшиеся ELM (единый SSO, объединённые роли, синхронизация тегов, общая точка API и пр.), теперь достигаются за счёт возможностей VCF Operations и связанных сервисов.
vSphere Clustering Service (vCLS, устарела) – встроенный сервис кластеризации, который с vSphere 7 U1 запускал небольшие служебные ВМ (vCLS VMs) для поддержки DRS и HA, в vSphere 9 более не нужен. В vCenter 9.0 сервис vCLS помечен устаревшим и подлежит удалению в будущем. Кластеры vSphere 9 могут работать без этих вспомогательных ВМ: после обновления появится возможность включить Retreat Mode и отключить развёртывание vCLS-агентов без какого-либо ущерба для функциональности DRS/HA.
Рекомендация: отключите vCLS на кластерах vSphere 9 (включив режим Retreat Mode в настройках кластера) – деактивация vCLS никак не влияет на работу DRS и HA. Внутри ESX 9 реализовано распределенное хранилище состояния кластера (embedded key-value store) непосредственно на хостах, благодаря чему кластер может сохранять и восстанавливать свою конфигурацию без внешних вспомогательных ВМ. В результате вы упростите окружение (больше никаких «мусорных» служебных ВМ) и избавитесь от связанных с ними накладных расходов.
ESX Host Cache (устарела) - в версии ESX 9.0 использование кэша на уровне хоста (SSD) в качестве кэша с обратной записью (write-back) для файлов подкачки виртуальных машин (swap) объявлено устаревшим и будет удалено в одной из будущих версий. В качестве альтернативы предлагается использовать механизм многоуровневой памяти (Memory Tiering) на базе NVMe. Memory Tiering с NVMe позволяет увеличить объём доступной оперативной памяти на хосте и интеллектуально распределять память виртуальной машины между быстрой динамической оперативной памятью (DRAM) и NVMe-накопителем на хосте.
Рекомендация: используйте функции Advanced Memory Tiering на базе NVMe-устройств в качестве второго уровня памяти. Это позволяет увеличить объём доступной памяти до 4 раз, задействуя при этом существующие слоты сервера для недорогого оборудования.
Память Intel Optane Persistent Memory (удалена) - в версии ESX 9.0 прекращена поддержка технологии Intel Optane Persistent Memory (PMEM). Для выбора альтернативных решений обратитесь к представителям вашего OEM-поставщика серверного оборудования.
Рекомендация:
в качестве альтернативы вы можете использовать функционал многоуровневой памяти (Memory Tiering), официально представленный в ESX 9.0. Эта технология позволяет добавлять локальные NVMe-устройства на хост ESX в качестве дополнительного уровня памяти. Дополнительные подробности смотрите в статье базы знаний VMware KB 326910.
Технология Storage I/O Control (SIOC) и балансировщик нагрузки Storage DRS (удалены) - в версии vCenter 9.0 прекращена поддержка балансировщика нагрузки Storage DRS (SDRS) на основе ввода-вывода (I/O Load Balancer), балансировщика SDRS на основе резервирования ввода-вывода (SDRS I/O Reservations-based load balancer), а также компонента vSphere Storage I/O Control (SIOC). Эти функции продолжают поддерживаться в текущих релизах 8.x и 7.x. Удаление указанных компонентов затрагивает балансировку нагрузки на основе задержек ввода-вывода (I/O latency-based load balancing) и балансировку на основе резервирования ввода-вывода (I/O reservations-based load balancing) между хранилищами данных (datastores), входящими в кластер хранилищ Storage DRS. Кроме того, прекращена поддержка активации функции Storage I/O Control (SIOC) на отдельном хранилище и настройки резервирования (Reservations) и долей (Shares) с помощью политик хранения SPBM Storage Policy. При этом первоначальное размещение виртуальных машин с помощью Storage DRS (initial placement), а также балансировка нагрузки на основе свободного пространства и политик SPBM Storage Policy (для лимитов) не затронуты и продолжают работать в vCenter 9.0.
Рекомендация: администраторам рекомендуется нужно перейти на балансировку нагрузки на основе свободного пространства и политик SPBM. Настройки резервирований и долей ввода-вывода (Reservations, Shares) через SPBM следует заменить альтернативными механизмами контроля производительности со стороны используемых систем хранения (например, встроенными функциями QoS). После миграции необходимо обеспечить мониторинг производительности, чтобы своевременно устранять возможные проблемы.
vSphere Lifecycle Manager Baselines (удалена) – классический режим управления патчами через базовые уровни (baselines) в vSphere 9 не поддерживается. Начиная с vCenter 9.0 полностью удалён функционал VUM/vLCM Baselines – все кластеры и хосты должны использовать только рабочий процесс управления жизненным циклом на базе образов (image-based lifecycle). При обновлении с vSphere 8 имеющиеся кластеры на baselines придётся перевести на работу с образами, прежде чем поднять их до ESX 9.
Рекомендация: перейдите от использования устаревших базовых уровней к vLCM images – желаемым образам кластера. vSphere 9 позволяет применять один образ к нескольким кластерам или хостам сразу, управлять соответствием (compliance) и обновлениями на глобальном уровне. Это упростит администрирование и устранит необходимость в ручном создании и применении множества baseline-профилей.
Integrated Windows Authentication (IWA, удалена) – в vCenter 9.0 прекращена поддержка интегрированной Windows-аутентификации (прямого добавления vCenter в домен AD). Вместо IWA следует использовать LDAP(S) или федерацию. VMware официально заявляет, что vCenter 9.0 более не поддерживает IWA, и для обеспечения безопасного доступа необходимо мигрировать учетные записи на Active Directory over LDAPS или настроить федерацию (например, через ADFS) с многофакторной аутентификацией.
Рекомендация: до обновления vCenter отключите IWA, переведите интеграцию с AD на LDAP(S), либо настройте VMware Identity Federation с MFA (эта возможность появилась начиная с vSphere 7). Это позволит сохранить доменную интеграцию vCenter в безопасном режиме после перехода на версию 9.
Локализации интерфейса (сокращены) – В vSphere 9 уменьшено число поддерживаемых языков веб-интерфейса. Если ранее vCenter поддерживал множество языковых пакетов, то в версии 9 оставлены лишь английский (US) и три локали: японский, испанский и французский. Все остальные языки (включая русский) более недоступны.
Рекомендация: администраторы, использующие интерфейс vSphere Client на других языках, должны быть готовы работать на английском либо на одной из трёх оставшихся локалей. Учебные материалы и документацию стоит ориентировать на английскую версию интерфейса, чтобы избежать недопонимания.
Общий совет по миграции для vSphere: заранее инвентаризуйте использование перечисленных функций в вашей инфраструктуре. Переход на vSphere 9 – удобный повод внедрить новые подходы: заменить Host Profiles на Configuration Profiles, перейти от VUM-бейзлайнов к образам, отказаться от ELM в пользу новых средств управления и т.д. Благодаря этому обновление пройдет более гладко, а ваша платформа будет соответствовать современным рекомендациям VMware.
Мы привели, конечно же, список только самых важных функций VMware vSphere 9, которые подверглись устареванию или удалению, для получения полной информации обратитесь к этой статье Broadcom.
VMware NSX 9: Устаревшие и неподдерживаемые функции
VMware NSX 9.0 (ранее известный как NSX-T) – компонент виртуализации сети в составе VCF 9 – также претерпел существенные изменения. Новая версия NSX ориентирована на унифицированную работу с VMware Cloud Foundation и отказывается от ряда старых возможностей, особенно связанных с гибкостью поддержки разных платформ. Вот ключевые технологии, не поддерживаемые больше в NSX 9, и как к этому адаптироваться:
Подключение физических серверов через NSX-Agent (удалено) – В NSX 9.0 больше не поддерживается развёртывание NSX bare-metal agent на физических серверах для включения их в оверлей NSX. Ранее такие агенты позволяли физическим узлам участвовать в логических сегментах NSX (оверлейных сетях). Начиная с версии 9, оверлейная взаимосвязь с физическими серверами не поддерживается – безопасность для физических серверов (DFW) остаётся, а вот L2-overlay connectivity убрана.
Рекомендация: для подключения физических нагрузок к виртуальным сетям NSX теперь следует использовать L2-мосты (bridge) на NSX Edge. VMware прямо рекомендует для новых подключений физических серверов задействовать NSX Edge bridging для обеспечения L2-связности с оверлеем, вместо установки агентов на сами серверы. То есть физические серверы подключаются в VLAN, который бриджится в логический сегмент NSX через Edge Node. Это позволяет интегрировать физическую инфраструктуру с виртуальной без установки NSX компонентов на сами серверы. Если у вас были реализованы bare-metal transport node в старых версиях NSX-T 3.x, их придётся переработать на схему с Edge-бриджами перед обновлением до NSX 9. Примечание: распределённый мост Distributed TGW, появившийся в VCF 9, также может обеспечить выход ВМ напрямую на ToR без Edge-узла, что актуально для продвинутых случаев, но базовый подход – через Edge L2 bridge.
Виртуальный коммутатор N-VDS на ESXi (удалён) – исторически NSX-T использовала собственный виртуальный коммутатор N-VDS для хостов ESXi и KVM. В NSX 9 эта технология более не применяется для ESX-хостов. Поддержка NSX N-VDS на хостах ESX удалена, начиная с NSX 4.0.0.1 (соответствует VCF 9). Теперь NSX интегрируется только с родным vSphere Distributed Switch (VDS) версии 7.0 и выше. Это означает, что все среды на ESX должны использовать конвергентный коммутатор VDS для работы NSX. N-VDS остаётся лишь в некоторых случаях: на Edge-нодах и для агентов в публичных облаках или на bare-metal Linux (где нет vSphere), но на гипервизорах ESX – больше нет.
Рекомендация: перед обновлением до NSX 9 мигрируйте все транспортные узлы ESXi с N-VDS на VDS. VMware предоставила инструменты миграции host switch (начиная с NSX 3.2) – ими следует воспользоваться, чтобы перевести существующие NSX-T 3.x host transport nodes на использование VDS. После перехода на NSX 9 вы получите более тесную интеграцию сети с vCenter и упростите управление, так как сетевые политики NSX привязываются к стандартному vSphere VDS. Учтите, что NSX 9 требует наличия vCenter для настройки сетей (фактически NSX теперь не работает автономно от vSphere), поэтому планируйте инфраструктуру исходя из этого.
Поддержка гипервизоров KVM и стороннего OpenStack (удалена) – NSX-T изначально позиционировался как мультигипервизорное решение, поддерживая кроме vSphere также KVM (Linux) и интеграцию с opensource OpenStack. Однако с выходом NSX 4.0 (и NSX 9) стратегия изменилась. NSX 9.0 больше не поддерживает гипервизоры KVM и дистрибутивы OpenStack от сторонних производителей. Поддерживается лишь VMware Integrated OpenStack (VIO) как исключение. Проще говоря, NSX сейчас нацелен исключительно на экосистему VMware.
Рекомендация: если у вас были развёрнуты политики NSX на KVM-хостах или вы использовали NSX-T совместно с не-VMware OpenStack, переход на NSX 9 невозможен без изменения архитектуры. Вам следует либо остаться на старых версиях NSX-T 3.x для таких сценариев, либо заменить сетевую виртуализацию в этих средах на альтернативные решения. В рамках же VCF 9 такая ситуация маловероятна, так как VCF подразумевает vSphere-стек. Таким образом, основное действие – убедиться, что все рабочие нагрузки NSX переведены на vSphere, либо изолировать NSX-T 3.x для специфичных нужд вне VCF. В будущем VMware будет развивать NSX как часть единой платформы, поэтому мультиплатформенные возможности урезаны в пользу оптимизации под vSphere.
NSX for vSphere (NSX-V) 6.x – не применяется – отдельно стоит упомянуть, что устаревшая платформа NSX-V (NSX 6.x для vSphere) полностью вышла из обращения и не входит в состав VCF 9. Её поддержка VMware прекращена еще в начале 2022 года, и миграция на NSX-T (NSX 4.x) стала обязательной. В VMware Cloud Foundation 4.x и выше NSX-V отсутствует, поэтому для обновления окружения старше VCF 3 потребуется заранее выполнить миграцию сетевой виртуализации на NSX-T.
Рекомендация: если вы ещё используете NSX-V в старых сегментах, необходимо развернуть параллельно NSX 4.x (NSX-T) и перенести сетевые политики и сервисы (можно с помощью утилиты Migration Coordinator, если поддерживается ваша версия). Только после перехода на NSX-T вы сможете обновиться до VCF 9. В новой архитектуре все сетевые функции будут обеспечиваться NSX 9, а NSX-V останется в прошлом.
Подводя итог по NSX: VMware NSX 9 сфокусирован на консолидации функций для частных облаков на базе vSphere. Возможности, выходящие за эти рамки (поддержка разнородных гипервизоров, агенты на физической базе и др.), были убраны ради упрощения и повышения производительности. Администраторам следует заранее учесть эти изменения: перевести сети на VDS, пересмотреть способы подключения физических серверов и убедиться, что все рабочие нагрузки, требующие NSX, работают в поддерживаемой конфигурации. Благодаря этому переход на VCF 9 будет предсказуемым, а новая среда – более унифицированной, безопасной и эффективной. Подготовившись к миграции от устаревших технологий на современные аналоги, вы сможете реализовать преимущества VMware Cloud Foundation 9.0 без длительных простоев и с минимальным риском для работы дата-центра.
Итоги
Большинство приведённых выше изменений официально перечислены в документации Product Support Notes к VMware Cloud Foundation 9.0 для vSphere и NSX. Перед обновлением настоятельно рекомендуется внимательно изучить примечания к выпуску и убедиться, что ни одна из устаревших функций, на которых зависит ваша инфраструктура, не окажется критичной после перехода. Следуя рекомендациям по переходу на новые инструменты (vLCM, Configuration Profiles, Edge Bridge и т.д.), вы обеспечите своей инфраструктуре поддерживаемость и готовность к будущим обновлениям в экосистеме VMware Cloud Foundation.
Итак, наконец-то начинаем рассказывать о новых возможностях платформы виртуализации VMware vSphere 9, которая является основой пакета решений VMware Cloud Foundation 9, о релизе которого компания Broadcom объявила несколько дней назад. Самое интересное - гипервизор теперь опять называется ESX, а не ESXi, который также стал последователем ESX в свое время :)
Управление жизненным циклом
Путь обновления vSphere
vSphere 9.0 поддерживает прямое обновление только с версии vSphere 8.0. Прямое обновление с vSphere 7.0 не поддерживается. vCenter 9.0 не поддерживает управление ESX 7.0 и более ранними версиями. Минимально поддерживаемая версия ESX, которую может обслуживать vCenter 9.0, — это ESX 8.0. Кластеры и отдельные хосты, управляемые на основе baseline-конфигураций (VMware Update Manager, VUM), не поддерживаются в vSphere 9. Кластеры и хосты должны использовать управление жизненным циклом только на основе образов.
Live Patch для большего числа компонентов ESX
Функция Live Patch теперь охватывает больше компонентов образа ESX, включая vmkernel и компоненты NSX. Это увеличивает частоту применения обновлений без перезагрузки. Компоненты NSX, теперь входящие в базовый образ ESX, можно обновлять через Live Patch без перевода хостов в режим обслуживания и без необходимости эвакуировать виртуальные машины.
Компоненты vmkernel, пользовательское пространство, vmx (исполнение виртуальных машин) и NSX теперь могут использовать Live Patch. Службы ESX (например, hostd) могут потребовать перезапуска во время применения Live Patch, что может привести к кратковременному отключению хостов ESX от vCenter. Это ожидаемое поведение и не влияет на работу запущенных виртуальных машин. vSphere Lifecycle Manager сообщает, какие службы или демоны будут перезапущены в рамках устранения уязвимостей через Live Patch. Если Live Patch применяется к среде vmx (исполнение виртуальных машин), запущенные ВМ выполнят быструю приостановку и восстановление (Fast-Suspend-Resume, FSR).
Live Patch совместим с кластерами vSAN. Однако узлы-свидетели vSAN (witness nodes) не поддерживают Live Patch и будут полностью перезагружаться при обновлении. Хосты, использующие TPM и/или DPU-устройства, в настоящее время не совместимы с Live Patch.
Создавайте кластеры по-своему с разным оборудованием
vSphere Lifecycle Manager поддерживает кластеры с оборудованием от разных производителей, а также работу с несколькими менеджерами поддержки оборудования (hardware support managers) в рамках одного кластера. vSAN также поддерживает кластеры с различным оборудованием.
Базовая версия ESX является неизменной для всех дополнительных образов и не может быть настроена. Однако надстройки от производителей (vendor addon), прошивка и компоненты в определении каждого образа могут быть настроены индивидуально для поддержки кластеров с разнородным оборудованием. Каждое дополнительное определение образа может быть связано с уникальным менеджером поддержки оборудования (HSM).
Дополнительные образы можно назначать вручную для подмножества хостов в кластере или автоматически — на основе информации из BIOS, включая значения Vendor, Model, OEM String и Family. Например, можно создать кластер, состоящий из 5 хостов Dell и 5 хостов HPE: хостам Dell можно назначить одно определение образа с надстройкой от Dell и менеджером Dell HSM, а хостам HPE — другое определение образа с надстройкой от HPE и HSM от HPE.
Масштабное управление несколькими образами
Образами vSphere Lifecycle Manager и их привязками к кластерам или хостам можно управлять на глобальном уровне — через vCenter, датацентр или папку. Одно определение образа может применяться к нескольким кластерам и/или отдельным хостам из единого централизованного интерфейса. Проверка на соответствие (Compliance), предварительная проверка (Pre-check), подготовка (Stage) и устранение (Remediation) также могут выполняться на этом же глобальном уровне.
Существующие кластеры и хосты с управлением на основе базовых конфигураций (VUM)
Существующие кластеры и отдельные хосты, работающие на ESX 8.x и использующие управление на основе базовых конфигураций (VUM), могут по-прежнему управляться через vSphere Lifecycle Manager, но для обновления до ESX 9 их необходимо перевести на управление на основе образов. Новые кластеры и хосты не могут использовать управление на основе baseline-конфигураций, даже если они работают на ESX 8. Новые кластеры и хосты автоматически используют управление жизненным циклом на основе образов.
Больше контроля над операциями жизненного цикла кластера
При устранении проблем (remediation) в кластерах теперь доступна новая возможность — применять исправления к подмножеству хостов в виде пакета. Это дополняет уже существующие варианты — обновление всего кластера целиком или одного хоста за раз.
Гибкость при выборе хостов для обновления
Описанные возможности дают клиентам гибкость — можно выбрать, какие хосты обновлять раньше других. Другой пример использования — если в кластере много узлов и обновить все за одно окно обслуживания невозможно, клиенты могут выбирать группы хостов и обновлять их поэтапно в несколько окон обслуживания.
Больше никакой неопределённости при обновлениях и патчах
Механизм рекомендаций vSphere Lifecycle Manager учитывает версию vCenter. Версия vCenter должна быть равной или выше целевой версии ESX. Например, если vCenter работает на версии 9.1, механизм рекомендаций не предложит обновление хостов ESX до 9.2, так как это приведёт к ситуации, где хосты будут иметь более новую версию, чем vCenter — что не поддерживается. vSphere Lifecycle Manager использует матрицу совместимости продуктов Broadcom VMware (Product Interoperability Matrix), чтобы убедиться, что целевой образ ESX совместим с текущей средой и поддерживается.
Упрощённые определения образов кластера
Компоненты vSphere HA и NSX теперь встроены в базовый образ ESX. Это делает управление их жизненным циклом и обеспечением совместимости более прозрачным и надёжным. Компоненты vSphere HA и NSX автоматически обновляются вместе с установкой патчей или обновлений базового образа ESX. Это ускоряет активацию NSX на кластерах vSphere, поскольку VIB-пакеты больше не требуется отдельно загружать и устанавливать через ESX Agent Manager (EAM).
Определение и применение конфигурации NSX для кластеров vSphere с помощью vSphere Configuration Profiles
Теперь появилась интеграция NSX с кластерами, управляемыми через vSphere Configuration Profiles. Профили транспортных узлов NSX (TNP — Transport Node Profiles) применяются с использованием vSphere Configuration Profiles. vSphere Configuration Profiles позволяют применять TNP к кластеру одновременно с другими изменениями конфигурации.
Применение TNP через NSX Manager отключено для кластеров с vSphere Configuration Profiles
Для кластеров, использующих vSphere Configuration Profiles, возможность применять TNP (Transport Node Profile) через NSX Manager отключена. Чтобы применить TNP с помощью vSphere Configuration Profiles, необходимо также задать:
набор правил брандмауэра с параметром DVFilter=true
настройку Syslog с параметром remote_host_max_msg_len=4096
Снижение рисков и простоев при обновлении vCenter
Функция Reduced Downtime Update (RDU) поддерживается при использовании установщика на базе CLI. Также доступны RDU API для автоматизации. RDU поддерживает как вручную настроенные топологии vCenter HA, так и любые другие топологии vCenter. RDU является рекомендуемым способом обновления, апгрейда или установки патчей для vCenter 9.0.
Обновление vCenter с использованием RDU можно выполнять через vSphere Client, CLI или API. Интерфейс управления виртуальным устройством (VAMI) и соответствующие API для патчинга также могут использоваться для обновлений без переустановки или миграции, однако при этом потребуется значительное время простоя.
Сетевые настройки целевой виртуальной машины vCenter поддерживают автоматическую конфигурацию, упрощающую передачу данных с исходного vCenter. Эта сеть автоматически настраивается на целевой и исходной виртуальных машинах vCenter с использованием адреса из диапазона Link-Local RFC3927 169.254.0.0/16. Это означает, что не требуется указывать статический IP-адрес или использовать DHCP для временной сети.
Этап переключения (switchover) может выполняться вручную, автоматически или теперь может быть запланирован на конкретную дату и время в будущем.
Управление ресурсами
Масштабирование объема памяти с более низкой стоимостью владения благодаря Memory Tiering с использованием NVMe
Memory Tiering использует устройства NVMe на шине PCIe как второй уровень оперативной памяти, что увеличивает доступный объем памяти на хосте ESX. Memory Tiering на базе NVMe снижает общую стоимость владения (TCO) и повышает плотность размещения виртуальных машин, направляя память ВМ либо на устройства NVMe, либо на более быструю оперативную память DRAM.
Это позволяет увеличить объем доступной памяти и количество рабочих нагрузок, одновременно снижая TCO. Также повышается эффективность использования процессорных ядер и консолидация серверов, что увеличивает плотность размещения рабочих нагрузок.
Функция Memory Tiering теперь доступна в производственной среде. В vSphere 8.0 Update 3 функция Memory Tiering была представлена в режиме технологического превью. Теперь же она стала доступна в режиме GA (General Availability) с выпуском VCF 9.0. Это позволяет использовать локально установленные устройства NVMe на хостах ESX как часть многоуровневой (tiered) памяти.
Повышенное время безотказной работы для AI/ML-нагрузок
Механизм Fast-Suspend-Resume (FSR) теперь работает значительно быстрее для виртуальных машин с поддержкой vGPU. Ранее при использовании двух видеокарт NVIDIA L40 с 48 ГБ памяти каждая, операция FSR занимала около 42 секунд. Теперь — всего около 2 секунд. FSR позволяет использовать Live Patch в кластерах, обрабатывающих задачи генеративного AI (Gen AI), без прерывания работы виртуальных машин.
Передача данных vGPU с высокой пропускной способностью
Канал передачи данных vGPU разработан для перемещения больших объемов данных и построен с использованием нескольких параллельных TCP-соединений и автоматического масштабирования до максимально доступной пропускной способности канала, обеспечивая прирост скорости до 3 раз (с 10 Гбит/с до 30 Гбит/с).
Благодаря использованию концепции "zero copy" количество операций копирования данных сокращается вдвое, устраняя узкое место, связанное с копированием, и дополнительно увеличивая пропускную способность при передаче.
vMotion с предкопированием (pre-copy) — это технология передачи памяти виртуальной машины на другой хост с минимальным временем простоя. Память виртуальной машины (как "холодная", так и "горячая") копируется в несколько проходов пока ВМ ещё работает, что устраняет необходимость полного чекпойнта и передачи всей памяти во время паузы, во время которой случается простой сервисов.
Улучшения в предкопировании холодных данных могут зависеть от характера нагрузки. Например, для задачи генеративного AI с большим объёмом статических данных ожидаемое время приостановки (stun-time) будет примерно:
~1 секунда для GPU-нагрузки объёмом 24 ГБ
~2 секунды для 48 ГБ
~22 секунды для крупной 640 ГБ GPU-нагрузки
Отображение профилей vGPU в vSphere DRS
Технология vGPU позволяет распределять физический GPU между несколькими виртуальными машинами, способствуя максимальному использованию ресурсов видеокарты.
В организациях с большим числом GPU со временем создаётся множество vGPU-профилей. Однако администраторы не могут легко просматривать уже созданные vGPU, что вынуждает их вручную отслеживать профили и их распределение по GPU. Такой ручной процесс отнимает время и снижает эффективность работы администраторов.
Отслеживание использования vGPU-профилей позволяет администраторам просматривать все vGPU во всей инфраструктуре GPU через удобный интерфейс в vCenter, устраняя необходимость ручного учёта vGPU. Это существенно сокращает время, затрачиваемое администраторами на управление ресурсами.
Интеллектуальное размещение GPU-ресурсов в vSphere DRS
В предыдущих версиях распределение виртуальных машин с vGPU могло приводить к ситуации, при которой ни один из хостов не мог удовлетворить требования нового профиля vGPU. Теперь же администраторы могут резервировать ресурсы GPU для будущего использования. Это позволяет заранее выделить GPU-ресурсы, например, для задач генеративного AI, что помогает избежать проблем с производительностью при развертывании таких приложений. С появлением этой новой функции администраторы смогут резервировать пулы ресурсов под конкретные vGPU-профили заранее, улучшая планирование ресурсов и повышая производительность и операционную эффективность.
Миграция шаблонов и медиафайлов с помощью Content Library Migration
Администраторы теперь могут перемещать существующие библиотеки контента на новые хранилища данных (datastore) - OVF/OVA-шаблоны, образы и другие элементы могут быть перенесены. Элементы, хранящиеся в формате VM Template (VMTX), не переносятся в целевой каталог библиотеки контента. Шаблоны виртуальных машин (VM Templates) всегда остаются в своем назначенном хранилище, а в библиотеке контента хранятся только ссылки на них.
Во время миграции библиотека контента перейдёт в режим обслуживания, а после завершения — снова станет активной. На время миграции весь контент библиотеки (за исключением шаблонов ВМ) будет недоступен. Изменения в библиотеке будут заблокированы, синхронизация с подписными библиотеками приостановлена.
vSphere vMotion между управляющими плоскостями (Management Planes)
Служба виртуальных машин (VM Service) теперь может импортировать виртуальные машины, находящиеся за пределами Supervisor-кластера, и взять их под своё управление.
Network I/O Control (NIOC) для vMotion с использованием Unified Data Transport (UDT)
В vSphere 8 был представлен протокол Unified Data Transport (UDT) для "холодной" миграции дисков, ранее выполнявшейся с использованием NFC. UDT значительно ускоряет холодную миграцию, но вместе с повышенной эффективностью увеличивается и нагрузка на сеть предоставления ресурсов (provisioning network), которая в текущей архитектуре использует общий канал с критически важным трафиком управления.
Чтобы предотвратить деградацию трафика управления, необходимо использовать Network I/O Control (NIOC) — он позволяет гарантировать приоритет управления даже при высокой сетевой нагрузке.
vSphere Distributed Switch 9 добавляет отдельную категорию системного трафика для provisioning, что позволяет применять настройки NIOC и обеспечить баланс между производительностью и стабильностью.
Provisioning/NFC-трафик: ресурсоёмкий, но низкоприоритетный
Provisioning/NFC-трафик (включая Network File Copy) является тяжеловесным и низкоприоритетным, но при этом использует ту же категорию трафика, что и управляющий (management), который должен быть легковесным и высокоприоритетным. С учетом того, что трафик provisioning/NFC стал ещё более агрессивным с внедрением NFC SOV (Streaming Over vMotion), вопрос времени, когда критически важный трафик управления начнёт страдать.
Существует договоренность с VCF: как только NIOC для provisioning/NFC будет реализован, можно будет включать NFC SOV в развёртываниях VCF. Это ускорит внедрение NFC SOV в продуктивных средах.
Расширение поддержки Hot-Add устройств с Enhanced VM DirectPath I/O
Устройства, которые не могут быть приостановлены (non-stunnable devices), теперь поддерживают Storage vMotion (но не обычный vMotion), а также горячее добавление виртуальных устройств, таких как:
vCPU
Память (Memory)
Сетевые адаптеры (NIC)
Примеры non-stunnable устройств:
Intel DLB (Dynamic Load Balancer)
AMD MI200 GPU
Гостевые ОС и рабочие нагрузки
Виртуальное оборудование версии 22 (Virtual Hardware Version 22)
Увеличен лимит vCPU до 960 на одну виртуальную машину
Поддержка новейших моделей процессоров от AMD и Intel
vTPM теперь поддерживает спецификацию TPM 2.0, версия 1.59.
ESX 9.0 соответствует TPM 2.0 Rev 1.59.
Это повышает уровень кибербезопасности, когда вы добавляете vTPM-устройство в виртуальную машину с версией 22 виртуального железа.
Новые vAPI для настройки гостевых систем (Guest Customization)
Представлен новый интерфейс CustomizationLive API, который позволяет применять спецификацию настройки (customization spec) к виртуальной машине в работающем состоянии (без выключения). Подробности — в последней документации по vSphere Automation API для VCF 9.0. Также добавлен новый API для настройки гостевых систем, который позволяет определить, можно ли применить настройку к конкретной ВМ, ещё до её применения.
В vSphere 9 появилась защита пространств имен (namespace) и поддержка Write Zeros для виртуальных NVMe. vSphere 9 вводит поддержку:
Namespace Write Protection - позволяет горячее добавление независимых непостоянных (non-persistent) дисков в виртуальную машину без создания дополнительных delta-дисков. Эта функция особенно полезна для рабочих нагрузок, которым требуется быстрое развёртывание приложений.
Write Zeros - для виртуальных NVMe-дисков улучшает производительность, эффективность хранения данных и дает возможности управления данными для различных типов нагрузок.
Безопасность, соответствие требованиям и отказоустойчивость виртуальных машин
Одним из частых запросов в последние годы была возможность использовать собственные сертификаты Secure Boot для ВМ. Обычно виртуальные машины работают "из коробки" с коммерческими ОС, но некоторые организации используют собственные ядра Linux и внутреннюю PKI-инфраструктуру для их подписи.
Теперь появилась прямая и удобная поддержка такой конфигурации — vSphere предоставляет механизм для загрузки виртуальных машин с кастомными сертификатами Secure Boot.
Обновлён список отозванных сертификатов Secure Boot
VMware обновила стандартный список отозванных сертификатов Secure Boot, поэтому при установке Windows на виртуальную машину с новой версией виртуального оборудования может потребоваться современный установочный образ Windows от Microsoft. Это не критично, но стоит иметь в виду, если установка вдруг не загружается.
Улучшения виртуального USB
Виртуальный USB — отличная функция, но VMware внесла ряд улучшений на основе отчётов исследователей по безопасности. Это ещё один веский аргумент в пользу того, чтобы поддерживать актуальность VMware Tools и версий виртуального оборудования.
Форензик-снапшоты (Forensic Snapshots)
Обычно мы стремимся к тому, чтобы снапшот ВМ можно было запустить повторно и обеспечить согласованность при сбое (crash-consistency), то есть чтобы система выглядела как будто питание отключилось. Большинство ОС, СУБД и приложений умеют с этим справляться.
Но в случае цифровой криминалистики и реагирования на инциденты, необходимость перезапускать ВМ заново отпадает — важнее получить снимок, пригодный для анализа в специальных инструментах.
Custom EVC — лучшая совместимость между разными поколениями CPU
Теперь вы можете создавать собственный профиль EVC (Enhanced vMotion Compatibility), определяя набор CPU- и графических инструкций, общих для всех выбранных хостов. Это решение более гибкое и динамичное, чем стандартные предустановленные профили EVC.
Custom EVC позволяет:
Указать хосты и/или кластеры, для которых vCenter сам рассчитает максимально возможный общий набор инструкций
Применять полученный профиль к кластерам или отдельным ВМ
Для работы требуется vCenter 9.0 и поддержка кластеров, содержащих хосты ESX 9.0 или 8.0. Теперь доступно более эффективное использование возможностей CPU при различиях между моделями - можно полнее использовать функции процессоров, даже если модели немного отличаются. Пример: два процессора одного поколения, но разных вариантов:
CPU-1 содержит функции A, B, D, E, F
CPU-2 содержит функции B, C, D, E, F
То есть: CPU-1 поддерживает FEATURE-A, но не FEATURE-C, CPU-2 — наоборот.
Custom EVC позволяет автоматически выбрать максимальный общий набор функций, доступный на всех хостах, исключая несовместимости:
В vSphere 9 появилась новая политика вычислений: «Limit VM placement span plus one host for maintenance» («ограничить размещение ВМ числом хостов плюс один для обслуживания»).
Эта политика упрощает соблюдение лицензионных требований и контроль использования лицензий. Администраторы теперь могут создавать политики на основе тегов, которые жестко ограничивают количество хостов, на которых может запускаться группа ВМ с лицензируемым приложением.
Больше не нужно вручную закреплять ВМ за хостами или создавать отдельные кластеры/хосты. Теперь администратору нужно просто:
Знать, сколько лицензий куплено.
Знать, на скольких хостах они могут применяться.
Создать политику с указанием числа хостов, без выбора конкретных.
Применить эту политику к ВМ с нужным тегом.
vSphere сама гарантирует, что такие ВМ смогут запускаться только на разрешённом числе хостов. Всегда учитывается N+1 хост в запас для обслуживания. Ограничение динамическое — не привязано к конкретным хостам.
Полный список новых возможностей VMware vSphere 9 также приведен в Release Notes.
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Автоматизация поиска ISO-файлов в хранилищах данных VMware vCenter с помощью PowerShell
Если вам когда-либо приходилось управлять множеством ISO-файлов на нескольких хранилищах данных в среде VMware vCenter, вы знаете, насколько трудоемким и подверженным ошибкам может быть их ручной поиск. Вот тут-то и пригодится PowerShell! Используя скрипты PowerShell, можно автоматизировать процесс получения информации обо всех ISO-файлах из хранилищ данных, что позволит сэкономить время и снизить риск ошибок, связанных с человеческим фактором.
Почему именно PowerShell?
PowerShell — это мощный скриптовый язык, позволяющий системным администраторам автоматизировать задачи и эффективно управлять системами. Его интеграция с VMware PowerCLI дает возможность беспрепятственно взаимодействовать со средами VMware vSphere.
Требования:
Перед запуском скрипта убедитесь, что у вас установлен модуль VMware.PowerCLI:
Приведенный ниже скрипт подключается к серверу vCenter и выполняет поиск всех ISO-файлов во всех хранилищах данных (при необходимости вы можете изменить его для поиска других типов файлов).
2. Выполните сценарий ниже, который производит поиск всех ISO-файлов в хранилищах данных. Учтите, что выполнение может занять некоторое время в зависимости от количества хранилищ, которые необходимо просканировать, перед тем как отобразить результат.
# Get all datastores
$datastores = Get-Datastore
# Write the header once
Write-Host "Datastore | FilePath | FileName"
foreach ($datastore in $datastores) {
# Get all .iso files in the datastore
$isoFiles = Get-ChildItem -Path $datastore.DatastoreBrowserPath -Recurse -Include *.iso
foreach ($isoFile in $isoFiles) {
$isoFileDetail = @{
"Datastore" = $datastore.Name
"FilePath" = $isoFile.FullName
"FileName" = $isoFile.Name
}
# Output the file details under the header
Write-Host "$($datastore.Name) | $($isoFile.FullName) | $($isoFile.Name)"
}
}
С помощью этого сценария вы можете автоматизировать утомительную задачу управления ISO-файлами, что позволит сосредоточиться на более важных аспектах вашей среды VMware.
Ниже приведены скриншоты для справки
Ситуация:
Есть несколько ISO-файлов, расположенных в различных хранилищах данных в vCenter.
Подключаемся к vCenter с использованием командной строки, как описано выше. Теперь, имея PowerShell-скрипт, можно автоматизировать получение тех же данных/результатов. Ниже представлен вывод после выполнения указанного скрипта.
Продолжаем рассказывать о технологии ярусной памяти Memory Tiering, которая появилась в VMware vSphere 8 Update 3 (пока в статусе Tech Preview). Вильям Лам написал об интересной возможности использования одного устройства как для NVMe Tiering, так и для датасторов VMFS на платформе VMware vSphere.
На данный момент включение NVMe Tiering требует выделенного устройства NVMe. Для производственных систем это, вероятно, не проблема, так как важно избежать конкуренции за ресурсы ввода-вывода на одном устройстве NVMe. Однако для среды разработки или домашней лаборатории это может быть проблемой из-за ограниченного количества доступных NVMe-устройств.
Оказывается, можно использовать одно устройство NVMe для NVMe Tiering!
Для владельцев систем малого форм-фактора, таких как ASUS NUC, с ограниченным количеством NVMe-устройств, есть такой вариант: вы можете запустить ESXi с USB-устройства, сохранив возможность использовать локальный VMFS-датастор и NVMe Tiering. Таким образом, у вас даже останется свободный слот или два для vSAN OSA или ESA!
Важно: Это решение не поддерживается официально со стороны VMware. Используйте его на свой страх и риск.
Шаг 1 - Убедитесь, что у вас есть пустое устройство NVMe, так как нельзя использовать устройство с существующими разделами. Для идентификации и получения имени SSD-устройства используйте команду vdq -q.
Затем запустите его, как показано на скриншоте ниже:
Примечание: скрипт только генерирует необходимые команды, но вам нужно будет выполнить их вручную. Сохраните их — это избавит вас от необходимости вручную рассчитывать начальные и конечные сектора хранилища.
Пример выполнения сгенерированных команд для конкретной настройки: есть NVMe-устройство объёмом 1 ТБ (913,15 ГБ), из которого выделяется 256 ГБ для NVMe Tiering, а оставшееся пространство будет использовано для VMFS-датастора.
С помощью клиента ESXi Host Client мы можем увидеть два раздела, которые мы только что создали:
Шаг 3 – Включите функцию NVMe Tiering, если она еще не активирована, выполнив следующую команду ESXCLI:
esxcli system settings kernel set -s MemoryTiering -v TRUE
Шаг 4 – Настройте желаемый процент использования NVMe Tiering (от 25 до 400), исходя из конфигурации вашей физической оперативной памяти (DRAM), выполнив следующую команду:
esxcli system settings advanced set -o /Mem/TierNvmePct -i 400
Шаг 5 – Наконец, перезагрузите хост ESXi, чтобы настройки NVMe Tiering вступили в силу. После перезагрузки ваш хост ESXi будет поддерживать использование одного NVMe-устройства как для NVMe Tiering, так и для локального VMFS-датастора, готового для размещения виртуальных машин.
Этот дэшборд содержит пять различных разделов: один для мониторинга производительности ESXi и vCenter, другой для производительности виртуальных машин, третий для дисков, четвёртый для хранилищ, и последний для хостов и их IPMI. Дэшборд включает переменные, чтобы сделать его использование проще и подходящим для различных типов рабочих нагрузок. Индикаторы автоматически настраиваются в зависимости от выбранных вами хранилищ данных. Если у вас много хранилищ, рассмотрите возможность изменения параметра Min Width для Repeat Panel.
Здесь визуализуются все высокоуровневые параметры виртуальной инфраструктуры, такие как загрузка ресурсов кластера, заполненность хранилищ, состояние гипервизора и использование ресурсов виртуальными машинами:
2. VMware vSphere - Datastore
Этот дэшборд содержит два раздела: один для мониторинга производительности ESXi и vCenter, другой - для производительности виртуальных машин. Дашборд включает переменные, чтобы упростить его использование и сделать его подходящим для различных типов рабочих нагрузок. Индикаторы автоматически настраиваются в зависимости от выбранных вами хранилищ данных. Если у вас много хранилищ, рассмотрите возможность изменения параметра Min Width для Repeat Panel.
Здесь мы можем увидеть загрузку емкости датасторов, параметры чтения-записи, а также суммарные показатели для используемой и свободной емкости:
3. VMware vSphere - Hosts
Тут видны основные метрики с уровня хоста для каждого из серверов ESXi: конечно же, загрузка аппаратных ресурсов и сети, а также дисковые задержки (latency):
4. VMware vSphere - VMs
Здесь можно увидеть самые полезные метрики для всех виртуальных машин вашего датацентра. Здесь можно увидеть аптайм, загрузку системных ресурсов и сети, latency, счетчик CPU Ready и другое:
Ну и главное - вот эта статья. Она описывает, как настроить мониторинг VMware с помощью дэшбордов Grafana, InfluxDB и Telegraf. В ней пошагово объясняется создание стека контейнеров с использованием Docker Compose, настройка InfluxDB и Telegraf для сбора метрик VMware из vCenter, а также визуализация данных в Grafana. Там подробно рассматривается использование готовых дэшбордов для ускорения процесса настройки и предлагаются советы по устранению неполадок.
Это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Давайте посмотрим на новые возможности двух недавних релизов:
Релиз Lighthouse Point (0.99k) от 7 октября 2024
VMware Snapshot Inventory
Начиная с версии SexiGraf 0.99h, панель мониторинга «VI Offline Inventory» заменена на VMware Inventory с инвентаризацией ВМ, хостов и хранилищ данных (вскоре добавятся портгруппы и другие элементы). Эти новые панели имеют расширенные возможности фильтрации и значительно лучше подходят для крупных инфраструктур (например, с более чем 50 000 виртуальных машин). Это похоже на извлечение данных из RVtools, которое всегда отображается и актуально.
В релизе v0.99k появилось представление VM Snapshot Inventory:
Улучшения "Cluster health score" для VMware vSAN 8
Вместо того чтобы бесконечно нажимать на кнопку обновления на вкладке «Resyncing Components» в WebClient, начиная с версии SexiGraf 0.99b разработчики добавили панель мониторинга vSAN Resync:
Shell In A Box
В версии SexiGraf 0.99k разработчики добавили отдельный дэшборд Shell In A Box за обратным прокси-сервером, чтобы снова сделать отладку удобной.
Прочие улучшения:
Официальная поддержка vSphere и vSAN 8.3 API, а также Veeam Backup & Replication v12
Добавлен выбор версии в панель мониторинга VMware Evo Version
Добавлена многострочная панель в панель мониторинга репозиториев Veeam
Обработка учетных записей с очень ограниченными правами
Опция использования MAC-адреса вместо Client-ID при использовании DHCP
Добавлено имя хоста гостевой ОС в инвентаризацию виртуальных машин
Релиз St. Olga (0.99j) от 12 февраля 2024
В этой версии авторы добавили официальную поддержку новых API vSphere и vSAN 8.2, а также Veeam Backup & Replication v11+.
Новые возможности:
Поддержка Veeam Backup & Replication
Автоматическое слияние метрик ВМ и ESXi между кластерами (функция DstVmMigratedEvent в VROPS)
Количество путей до HBA
PowerShell Core 7.2.17 LTS
PowerCLI 13.2.1
Grafana 8.5.9 (не 8.5.27 из-за ошибки, появившейся в v8.5.10)
Ubuntu 20.04.6 LTS
Улучшения и исправления:
Метрика IOPS для виртуальных машин
Инвентаризация VMware VBR
История инвентаризации
Панель мониторинга эволюции версий активов VMware
Исправлено пустое значение datastoreVMObservedLatency на NFS
Различные исправления ошибок
SexiGraf теперь поставляется только в виде новой OVA-аппаратной версии, больше никаких патчей (за исключением крайних случаев). Для миграции необходимо использовать функцию Export/Import, чтобы извлечь данные из вашей предыдущей версии SexiGraf и перенести их в новую.
Актуальная версия SexiGraf доступна для бесплатной загрузки на странице Quickstart.
Memory Tiering использует более дешевые устройства в качестве памяти. В Update 3 платформа vSphere использует флэш-устройства PCIe на базе NVMe в качестве второго уровня памяти, что увеличивает доступный объем памяти на хосте ESXi. Memory Tiering через NVMe оптимизирует производительность, распределяя выделение памяти виртуальных машин либо на устройства NVMe, либо на более быструю динамическую оперативную память (DRAM) на хосте. Это позволяет увеличить объем используемой памяти и повысить емкость рабочих нагрузок, одновременно снижая общую стоимость владения (TCO).
Вильям Лам написал интересный пост о выводе информации для NVMe Tiering в VMware vSphere через API. После успешного включения функции NVMe Tiering, которая была введена в vSphere 8.0 Update 3, вы можете найти полезную информацию о конфигурации NVMe Tiering, перейдя к конкретному хосту ESXi, затем выбрав "Configure" -> "Hardware" и в разделе "Memory", как показано на скриншоте ниже.
Здесь довольно много информации, поэтому давайте разберём отдельные элементы, которые полезны с точки зрения NVMe-тиринга, а также конкретные vSphere API, которые можно использовать для получения этой информации.
Memory Tiering Enabled
Поле Memory Tiering указывает, включён ли тиринг памяти на хосте ESXi, и может иметь три возможных значения: "No Tiering" (без тиринга), "Hardware Memory Tiering via Intel Optane" (аппаратный тиринг памяти с помощью технологии Intel Optane) или "Software Memory Tiering via NVMe Tiering" (программный тиринг памяти через NVMe). Мы можем получить значение этого поля, используя свойство "memoryTieringType" в vSphere API, которое имеет три перечисленных значения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Поле Tier 0 представляет общий объём физической оперативной памяти (DRAM), доступной на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "DRAM"}).Size
Tier 1 Memory
Поле Tier 1 представляет общий объём памяти, предоставляемой NVMe-тирингом, которая доступна на хосте ESXi. Мы можем получить это поле, используя свойство "memoryTierInfo" в vSphere API, которое возвращает массив результатов, содержащий значения как Tier 0, так и Tier 1.
Примечание: Можно игнорировать термин "Unmappable" — это просто другой способ обозначения памяти, отличной от DRAM.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
((Get-VMHost "esxi-01.williamlam.com").ExtensionData.Hardware.MemoryTierInfo | where {$_.Type -eq "NVMe"}).Size
Поле Total представляет общий объём памяти, доступный ESXi при объединении как DRAM, так и памяти NVMe-тиринга, который можно агрегировать, используя размеры Tier 0 и Tier 1 (в байтах).
Устройства NVMe для тиринга
Чтобы понять, какое устройство NVMe настроено для NVMe-тиринга, нужно перейти в раздел "Configure" -> "Storage" -> "Storage Devices", чтобы просмотреть список устройств. В столбце "Datastore" следует искать значение "Consumed for Memory Tiering", как показано на скриншоте ниже. Мы можем получить это поле, используя свойство "usedByMemoryTiering" при энумерации всех устройств хранения.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Отношение объёма DRAM к NVMe по умолчанию составляет 25% и настраивается с помощью следующего расширенного параметра ESXi под названием "Mem.TierNvmePct". Мы можем получить значение этого поля, используя либо vSphere API ("OptionManager"), либо через ESXCLI.
Вот небольшой фрагмент PowerCLI-кода для получения этого поля для конкретного хоста ESXi:
Вильям собрал все вышеперечисленные парметры и создал скрипт PowerCLI под названием "get-nvme-tiering-info.ps1", который предоставляет удобное резюме для всех хостов ESXi в рамках конкретного кластера Sphere (вы также можете изменить скрипт, чтобы он запрашивал конкретный хост ESXi). Это может быть полезно для быстрого получения информации о хостах, на которых NVMe-тиринг может быть настроен (или нет).
Наверняка вы слышали о недавнем обновлении программного обеспечения CrowdStrike для Microsoft Windows, которое вызвало беспрецедентный глобальный сбой по всему миру (а может даже вы были непосредственно им затронуты). Несколько дней назад ИТ-администраторы работали круглосуточно, чтобы восстановить работоспособность тысяч, если не десятков тысяч систем Windows.
Текущий рекомендуемый процесс восстановления от CrowdStrike определенно болезненный, так как он требует от пользователей перехода в безопасный режим Windows для удаления проблемного файла. Большинство организаций используют Microsoft Bitlocker, что добавляет дополнительный шаг к уже и так болезненному ручному процессу восстановления, так как теперь необходимо найти ключи восстановления перед тем, как войти в систему и применить исправление.
Вильям Лам написал об этой ситуации. В течение нескольких часов после новостей от CrowdStrike он уже увидел ряд запросов от клиентов и сотрудников на предмет наличия автоматизированных решений или скриптов, которые могли бы помочь в их восстановлении, так как требование к любой организации вручную восстанавливать системы неприемлемо из-за масштабов развертываний в большинстве предприятий. Ознакомившись с шагами по восстановлению и размышляя о том, как платформа vSphere может помочь пользователям автоматизировать то, что обычно является ручной задачей, у него возникло несколько идей, которые могут быть полезны.
Скрипты, предоставленные в этой статье, являются примерами. Пожалуйста, тестируйте и адаптируйте их в соответствии с вашей собственной средой, так как они не были протестированы официально, и их поведение может варьироваться в зависимости от среды. Используйте их на свой страх и риск.
Платформа vSphere обладает одной полезной возможностью, которая до сих пор не всем известна, позволяющей пользователям автоматизировать отправку нажатий клавиш в виртуальную машину (VM), что не требует наличия VMware Tools или даже запущенной гостевой операционной системы.
Чтобы продемонстрировать, как может выглядеть автоматизированное решение для устранения проблемы CrowdStrike, Вильям создал прототип PowerCLI-скрипта под названием crowdstrike-example-prototype-remediation-script.ps1, который зависит от функции Set-VMKeystrokes. В настройке автора работает Windows Server 2019 с включенным Bitlocker, и он "смоделировал" директорию и конфигурационный файл CrowdStrike, которые должны быть удалены в рамках процесса восстановления. Вместо загрузки в безопасный режим, что немного сложнее, автор решил просто загрузиться в установщик Windows Server 2019 и перейти в режим восстановления, что позволило ему применить тот же процесс восстановления.
Ниже представлено видео, демонстрирующее автоматизацию и шаги, происходящие между PowerCLI-скриптом и тем, что происходит в консоли виртуальной машины. Вручную никакие действия не выполнялись:
В зависимости от вашей среды и масштаба, вам может потребоваться настроить различные значения задержек, и это следует делать в тестовой или разработческой среде перед развертыванием поэтапно.
В качестве альтернативы, автор также рекомендует и немного другой подход. Один из клиентов создал кастомный WindowsPE ISO, который содержал скрипт для удаления проблемного файла CrowdStrike, и всё, что им нужно было сделать, это смонтировать ISO, изменить порядок загрузки с жесткого диска на CDROM, после чего ISO автоматически выполнил бы процесс восстановления, вместо использования безопасного режима, что является довольно умным решением.
В любом случае, вот пример фрагмента PowerCLI-кода, который реконфигурирует виртуальную машину (поддерживается, когда ВМ выключена) для монтирования нужного ISO из хранилища vSphere и обновляет порядок загрузки так, чтобы машина автоматически загружалась с ISO, а не с жесткого диска.
$vmName = "CrowdStrike-VM"
$isoPath = "[nfs-datastore-synology] ISO/en_windows_server_version_1903_x64_dvd_58ddff4b.iso"
$primaryDisk = "Hard disk 1"
$vm = Get-VM $vmName
$vmDevices = $vm.ExtensionData.Config.Hardware.Device
$cdromDevice = $vmDevices | where {$_.getType().name -eq "VirtualCdrom"}
$bootDevice = $vmDevices | where {$_.getType().name -eq "VirtualDisk" -and $_.DeviceInfo.Label -eq $primaryDisk}
# Configure Boot Order to boot from ISO and then Hard Disk
$cdromBootDevice = New-Object VMware.Vim.VirtualMachineBootOptionsBootableCdromDevice
$diskBootDevice = New-Object VMware.Vim.VirtualMachineBootOptionsBootableDiskDevice
$diskBootDevice.DeviceKey = $bootDevice.key
$bootOptions = New-Object VMware.Vim.VirtualMachineBootOptions
$bootOptions.bootOrder = @($cdromBootDevice,$diskBootDevice)
# Mount ISO from vSphere Datastore
$cdromBacking = New-Object VMware.Vim.VirtualCdromIsoBackingInfo
$cdromBacking.FileName = $isoPath
$deviceChange = New-Object VMware.Vim.VirtualDeviceConfigSpec
$deviceChange.operation = "edit"
$deviceChange.device = $cdromDevice
$deviceChange.device.Backing = $cdromBacking
$deviceChange.device.Connectable.StartConnected = $true
$deviceChange.device.Connectable.Connected = $true
$spec = New-Object VMware.Vim.VirtualMachineConfigSpec
$spec.deviceChange = @($deviceChange)
$spec.bootOptions = $bootOptions
$task = $vm.ExtensionData.ReconfigVM_Task($spec)
$task1 = Get-Task -Id ("Task-$($task.value)")
$task1 | Wait-Task | Out-Null
Чтобы подтвердить, что изменения были успешно применены, вы можете использовать интерфейс vSphere или следующий фрагмент PowerCLI-кода:
Остается только запустить виртуальную машину, а затем, после завершения восстановления, можно отменить операцию, размонтировав ISO и удалив конфигурацию порядка загрузки, чтобы вернуть исходное поведение виртуальной машины.
После неудачного развертывания VCF 5.0 у автора блога vronin.nl остался vSAN Datastore на первом хосте в кластере, что блокировало повторную попытку развертывания.
В этом состоянии vSAN Datastore не может быть удален. Если попытаться его удалить через ESXi Host Client, опция будет неактивна:
Чтобы удалить хранилище данных vSAN и разделы дисков, сначала нужно подключиться по SSH к хосту и получить Sub-Cluster Master UUID кластера:
Далее копируем этот Sub-Cluster Master UUID в следующую команду:
В ESXi Host Client будет показываться, что датастора больше нет:
Для двойной проверки выполняем следующие команды в консоли ESXi:
esxcli vsan cluster list
esxcli vsan storage list
По результатам вывода команд, на хосте не настроены кластеры или хранилища vSAN. После этого повторная попытка развертывания кластера управления VCF будет успешной.
Вчера мы писали о новых возможностях последнего пакета обновлений VMware vSphere 8.0 Update 3, а сегодня расскажем что нового появилось в плане основных функций хранилищ (Core Storage).
Каждое обновление vSphere 8 добавляет множество возможностей для повышения масштабируемости, устойчивости и производительности. В vSphere 8 Update 3 продолжили улучшать и дорабатывать технологию vVols, добавляя новые функции.
Продолжая основной инженерный фокус на vVols и NVMe-oF, VMware также обеспечивает их поддержку в VMware Cloud Foundation. Некоторые функции включают дополнительную поддержку кластеризации MS WSFC на vVols и NVMe-oF, улучшения по возврату свободного пространства (Space Reclamation), а также оптимизации для VMFS и NFS.
Ключевые улучшения
Поддержка растянутых кластеров хранилищ (Stretched Clusters) для vVols
Новая спецификация vVols VASA 6
Кластеризация VMDK для NVMe/TCP
Ограничение максимального количества хостов, выполняющих Unmap
Поддержка NFS 4.1 Port Binding и nConnect
Дополнительная поддержка CNS/CSI для vSAN
vVols
Поддержка растянутого кластера хранилища vVols на SCSI
Растянутый кластер хранения vVols (vVols-SSC) был одной из самых запрашиваемых функций для vVols в течение многих лет, особенно в Европе. В vSphere 8 U3 добавлена поддержка растянутого хранилища vVols только на SCSI (FC или iSCSI). Первоначально Pure Storage, который был партнером по дизайну этой функции, будет поддерживать vVols-SSC, но многие из партнеров VMware по хранению также активно работают над добавлением данной поддержки.
Почему это заняло так много времени?
Одна из причин, почему реализация vVols-SSC заняла столько времени, заключается в дополнительных улучшениях, необходимых для защиты компонентов виртуальных машин (VMCP). Когда используется растянутое хранилище, необходимо наличие процесса для обработки событий хранения, таких как Permanent Device Loss (PDL) или All Paths Down (APD). VMCP — это функция высокой доступности (HA) vSphere, которая обнаруживает сбои хранения виртуальных машин и обеспечивает автоматическое восстановление затронутых виртуальных машин.
Сценарии отказа и восстановления
Контейнер/datastore vVols становится недоступным. Контейнер/datastore vVols становится недоступным, если либо все пути данных (к PE), либо все пути управления (доступ к VP, предоставляющим этот контейнер) становятся недоступными, либо если все пути VASA Provider, сообщающие о растянутом контейнере, отмечают его как UNAVAILABLE (новое состояние, которое VP может сообщить для растянутых контейнеров).
PE контейнера vVols может стать недоступным. Если PE для контейнера переходит в состояние PDL, то контейнер также переходит в состояние PDL. В этот момент VMCP будет отвечать за остановку виртуальных машин на затронутых хостах и их перезапуск на других хостах, где контейнер доступен.
Контейнер или PE vVols становится доступным снова или восстанавливается подключение к VP. Контейнер вернется в доступное состояние из состояния APD, как только хотя бы один VP и один PE станут доступны снова. Контейнер вернется в доступное состояние из состояния PDL только после того, как все виртуальные машины, использующие контейнеры, будут выключены, и все клиенты, имеющие открытые файловые дескрипторы к хранилищу данных vVols, закроют их.
Поведение растянутого контейнера/хранилища данных довольно похоже на VMFS, и выход из состояния PDL требует уничтожения PE, что может произойти только после освобождения всех vVols, связанных с PE. Точно так же, как VMFS (или устройство PSA) не может выйти из состояния PDL, пока все клиенты тома VMFS (или устройства PSA) не закроют свои дескрипторы.
Требования
Хранилище SCSI (FC или iSCSI)
Макс. время отклика между хостами vSphere — 11 мс
Макс. время отклика массива хранения — 11 мс
Выделенная пропускная способность сети vSphere vMotion — 250 Мбит/с
Один vCenter (vCenter HA не поддерживается с vVols)
Контроль ввода-вывода хранения не поддерживается на datastore с включенным vVol-SSC
Дополнительная поддержка UNMAP
Начиная с vSphere 8.0 U1, config-vvol теперь создается с 255 ГБ VMFS vVol вместо 4 ГБ. Это добавило необходимость в возврате свободного пространства в config-vvol. В 8.0 U3 VMware добавила поддержку как ручного (CLI), так и автоматического UNMAP для config-vvol для SCSI и NVMe.
Это гарантирует, что при записи и удалении данных в config-vvol обеспечивается оптимизация пространства для новых записей. Начиная с vSphere 8.0 U3, также поддерживается команда Unmap для хранилищ данных NVMe-oF, а поддержка UNMAP для томов SCSI была добавлена в предыдущем релизе.
Возврат пространства в хранилищах виртуальных томов vSphere описан тут.
Кликните на картинку, чтобы посмотреть анимацию:
Поддержка кластеризации приложений на NVMe-oF vVols
В vSphere 8.0 U3 VMware расширила поддержку общих дисков MS WSFC до NVMe/TCP и NVMe/FC на основе vVols. Также добавили поддержку виртуального NVMe (vNVME) контроллера для гостевых кластерных решений, таких как MS WSFC.
Эти функции были ограничены SCSI на vVols для MS WSFC, но Oracle RAC multi-writer поддерживал как SCSI, так и NVMe-oF. В vSphere 8.0 U3 расширили поддержку общих дисков MS WSFC до vVols на базе NVMe/TCP и NVMe/FC. Также была добавлена поддержка виртуального NVMe (vNVME) контроллера виртуальной машины в качестве фронтенда для кластерных решений, таких как MS WSFC. Обратите внимание, что контроллер vNVMe в качестве фронтенда для MS WSFC в настоящее время поддерживается только с NVMe в качестве бэкенда.
Обновление отчетности по аутентификации хостов для VASA Provider
Иногда при настройке Storage Provider для vVols некоторые хосты могут не пройти аутентификацию, и это может быть сложно диагностировать. В версии 8.0 U3 VMware добавила возможность для vCenter уведомлять пользователей о сбоях аутентификации конкретных хостов с VASA провайдером и предоставили механизм для повторной аутентификации хостов в интерфейсе vCenter. Это упрощает обнаружение и решение проблем аутентификации Storage Provider.
Гранулярность хостов Storage Provider для vVols
С выходом vSphere 8 U3 была добавлена дополнительная информация о хостах для Storage Provider vVols и сертификатах. Это предоставляет клиентам и службе поддержки дополнительные детали о vVols при устранении неполадок.
NVMe-oF
Поддержка NVMe резервирования для кластерного VMDK с NVMe/TCP
В vSphere 8.0 U3 была расширена поддержка гостевой кластеризации до NVMe/TCP (первоначально поддерживалась только NVMe/FC). Это предоставляет клиентам больше возможностей при использовании NVMe-oF и желании перенести приложения для гостевой кластеризации, такие как MS WSFC и Oracle RAC, на хранилища данных NVMe-oF.
Поддержка NVMe Cross Namespace Copy
В предыдущих версиях функция VAAI, аппаратно ускоренное копирование (XCOPY), поддерживалась для SCSI, но не для NVMe-oF. Это означало, что копирование между пространствами имен NVMe использовало ресурсы хоста для передачи данных. С выпуском vSphere 8.0 U3 теперь доступна функция Cross Namespace Copy для NVMe-oF для поддерживаемых массивов. Применение здесь такое же, как и для SCSI XCOPY между логическими единицами/пространствами имен. Передачи данных, такие как копирование/клонирование дисков или виртуальных машин, теперь могут работать значительно быстрее. Эта возможность переносит функции передачи данных на массив, что, в свою очередь, снижает нагрузку на хост.
Кликните на картинку, чтобы посмотреть анимацию:
VMFS
Сокращение времени на расширение EZT дисков на VMFS
В vSphere 8.0 U3 был реализован новый API для VMFS, чтобы ускорить расширение блоков на диске VMFS, пока диск используется. Этот API может работать до 10 раз быстрее, чем существующие методы, при использовании горячего расширения диска EZT на VMFS.
Виртуальные диски на VMFS имеют тип аллокации, который определяет, как резервируется основное хранилище: Thin (тонкое), Lazy Zeroed Thick (толстое с занулением по мере обращения) или Eager Zeroed Thick (толстое с предварительным занулением). EZT обычно выбирается на VMFS для повышения производительности во время выполнения, поскольку все блоки полностью выделяются и зануляются при создании диска. Если пользователь ранее выбрал тонкое выделение диска и хотел преобразовать его в EZT, этот процесс был медленным. Новый API позволяет значительно это ускорить.
Кликните на картинку для просмотра анимации:
Ограничение количества хостов vSphere, отправляющих UNMAP на VMFS datastore
В vSphere 8.0 U2 VMware добавила возможность ограничить скорость UNMAP до 10 МБ/с с 25 МБ/с. Это предназначено для клиентов с высоким уровнем изменений или массовыми отключениями питания, чтобы помочь уменьшить влияние возврата пространства на массив.
Кликните на картинку для просмотра анимации:
По умолчанию все хосты в кластере, до 128 хостов, могут отправлять UNMAP. В версии 8.0 U3 добавлен новый параметр для расширенного возврата пространства, называемый Reclaim Max Hosts. Этот параметр может быть установлен в значение от 1 до 128 и является настройкой для каждого хранилища данных. Чтобы изменить эту настройку, используйте ESXCLI. Алгоритм работает таким образом, что после установки нового значения количество хостов, отправляющих UNMAP одновременно, ограничивается этим числом. Например, если установить максимальное значение 10, в кластере из 50 хостов только 10 будут отправлять UNMAP на хранилище данных одновременно. Если другие хосты нуждаются в возврате пространства, то, как только один из 10 завершит операцию, слот освободится для следующего хоста.
Пример использования : esxcli storage vmfs reclaim config set -l <Datastore> -n <number_of_hosts>
Вот пример изменения максимального числа хостов, отправляющих UNMAP одновременно:
PSA
Поддержка уведомлений о производительности Fabric (FPIN, ошибки связи, перегрузка)
VMware добавила поддержку Fabric Performance Impact Notification (FPIN) в vSphere 8.0 U3. С помощью FPIN слой инфраструктуры vSphere теперь может обрабатывать уведомления от SAN-коммутаторов или целевых хранилищ о падении производительности каналов SAN, чтобы использовать исправные пути к устройствам хранения. Он может уведомлять хосты о перегрузке каналов и ошибках. FPIN — это отраслевой стандарт, который предоставляет средства для уведомления устройств о проблемах с соединением.
Вы можете использовать команду esxcli storage FPIN info set -e= <true/false>, чтобы активировать или деактивировать уведомления FPIN.
Кликните на картинку, чтобы посмотреть анимацию:
NFS
Привязка порта NFS v4.1 к vmk
Эта функция добавляет возможность байндинга соединения NFS v4.1 к определенному vmknic для обеспечения изоляции пути. При использовании многопутевой конфигурации можно задать несколько vmknic. Это обеспечивает изоляцию пути и помогает повысить безопасность, направляя трафик NFS через указанную подсеть/VLAN и гарантируя, что трафик NFS не использует сеть управления или другие vmknic. Поддержка NFS v3 была добавлена еще в vSphere 8.0 U1. В настоящее время эта функция поддерживается только с использованием интерфейса esxcli и может использоваться совместно с nConnect.
Начиная с версии 8.0 U3, добавлена поддержка nConnect для хранилищ данных NFS v4.1. nConnect предоставляет несколько соединений, используя один IP-адрес в сессии, таким образом расширяя функциональность агрегации сессий для этого IP. С этой функцией многопутевая конфигурация и nConnect могут сосуществовать. Клиенты могут настроить хранилища данных с несколькими IP-адресами для одного сервера, а также с несколькими соединениями с одним IP-адресом. В настоящее время максимальное количество соединений ограничено 8, значение по умолчанию — 1. Текущие версии реализаций vSphere NFSv4.1 создают одно соединение TCP/IP от каждого хоста к каждому хранилищу данных. Возможность добавления нескольких соединений на IP может значительно увеличить производительность.
При добавлении нового хранилища данных NFSv4.1, количество соединений можно указать во время монтирования, используя команду:
Общее количество соединений, используемых для всех смонтированных хранилищ данных NFSv4.1, ограничено 256.
Для существующего хранилища данных NFSv4.1, количество соединений можно увеличить или уменьшить во время выполнения, используя следующую команду:
esxcli storage nfs41 param set -v <volume-label> -c <number_of_connections>
Это не влияет на многопутевую конфигурацию. NFSv4.1 nConnect и многопутевые соединения могут сосуществовать. Количество соединений создается для каждого из многопутевых IP.
В настоящее время CNS поддерживает только 100 файловых томов. В vSphere 8.0 U3 этот лимит увеличен до 250 томов. Это поможет масштабированию для клиентов, которым требуется больше файловых хранилищ для постоянных томов (PVs) или постоянных запросов томов (PVCs) в Kubernetes (K8s).
Поддержка файловых томов в топологии HCI Mesh в одном vCenter
Добавлена поддержка файловых томов в топологии HCI Mesh в пределах одного vCenter.
Поддержка CNS на TKGs на растянутом кластере vSAN
Появилась поддержка растянутого кластера vSAN для TKGs для обеспечения высокой доступности.
Миграция PV между несвязанными datastore в одном VC
Возможность перемещать постоянный том (PV), как присоединённый, так и отсоединённый, с одного vSAN на другой vSAN, где нет общего хоста. Примером этого может быть перемещение рабочей нагрузки Kubernetes (K8s) из кластера vSAN OSA в кластер vSAN ESA.
Поддержка CNS на vSAN Max
Появилась поддержка развертывания CSI томов для vSAN Max при использовании vSphere Container Storage Plug-in.
Многие администраторы часто добавляют новые хосты ESXi, но довольно редко обсуждается вопрос о том, как правильно выводить из эксплуатации хост VMware ESXi. Об этом интересную статью написал Stephen Wagner.
Многих может удивить, что нельзя просто выключить хост ESXi и удалить его из окружения сервера vCenter, так как необходимо выполнить ряд шагов заранее, чтобы обеспечить успешный вывод из эксплуатации (decomission). Правильное списание хоста ESXi предотвращает появление изолированных объектов в базе данных vCenter, которые иногда могут вызывать проблемы в будущем.
Итак, процесс: как списать хост ESXi
Предполагается, что вы уже перенесли все ваши виртуальные машины, шаблоны и файлы с хоста, и он не содержит данных, которые требуют резервного копирования или миграции. Если вы этого не сделали - проверьте все еще раз, на хосте могут оказаться, например, кастомные скрипты, которые вы не сохраняли в другом месте.
Вкратце процесс выглядит так:
Перевод ESXi в режим обслуживания (Maintenance Mode)
Удаление хоста из распределенного коммутатора vSphere Distributed Switch (vDS)
Отключение и размонтирование томов iSCSI LUN
Перемещение хоста из кластера в датацентр как отдельного хоста
Удаление хоста из инвентаря (Inventory)
Выполнение расширенных процедур
Вход в режим обслуживания
Мы переходим в режим обслуживания, чтобы убедиться, что на хосте не запущены виртуальные машины. Вы можете просто щелкнуть правой кнопкой мыши по хосту и войти в режим обслуживания (Enter Maintenance Mode):
Если хост ESXi входит в состав кластера VMware vSAN, то вам будут предложены опции того, что нужно сделать с данными на нем хранящимися:
Удаление хоста из окружения vSphere Distributed Switch (vDS)
Необходимо аккуратно удалить хост из любых распределенных коммутаторов vDS (VMware Distributed Switches) перед удалением хоста из сервера vCenter.
Вы можете создать стандартный vSwitch и мигрировать адаптеры vmk (VMware Kernel) с vDS на обычный vSwitch, чтобы поддерживать связь с сервером vCenter и другими сетями.
Обратите внимание, что если вы используете коммутаторы vDS для подключений iSCSI, необходимо заранее разработать план по этому поводу, либо размонтировать/отключить iSCSI LUN на vDS перед удалением хоста, либо аккуратно мигрировать адаптеры vmk на стандартный vSwitch, используя MPIO для предотвращения потери связи во время выполнения процесса.
Размонтирование и отключение iSCSI LUN
Теперь вы можете приступить к размонтированию и отключению iSCSI LUN с выбранного хоста ESXi:
Размонтируйте тома iSCSI LUN с хоста
Отключите эти iSCSI LUN
Нужно размонтировать LUN только на выводимом из эксплуатации хосте, а затем отключить LUN также только на списываемом хосте.
Перемещение хоста из кластера в датацентр как отдельного хоста
Хотя это может быть необязательным, это полезно, чтобы позволить службам кластера vSphere (HA/DRS) адаптироваться к удалению хоста, а также обработать реконфигурацию агента HA на хосте ESXi. Для этого вы можете просто переместить хост из кластера на уровень родительского дата-центра.
Удаление хоста из инвентаря
После перемещения хоста и прошествия некоторого времени, вы теперь можете приступить к его удалению из Inventory. Пока хост включен и все еще подключен к vCenter, щелкните правой кнопкой мыши по хосту и выберите «Remove from Inventory». Это позволит аккуратно удалить объекты из vCenter, а также удалить агент HA с хоста ESXi.
Повторное использование хоста
Начиная с этого момента, вы можете войти напрямую на хост ESXi с помощью локального пароля root и выключить хост. Сделать этого можно также с помощью обновленного VMware Host Client.
Некоторые пользователи, применяющие архитектуру VMware HCI Mesh для подключения емкостей удаленных кластеров в архитектуру VMware vSAN Express Storage Architecture (ESA) спрашивают - а можно ли таким образом подключить и емкости кластеров OSA (Original Storage Architecture)?
Напомним, что технология HCI Mesh появилась в VMware vSphere 7 Update 1, она позволяет смонтировать датасторы удаленного кластера vSAN (который выступает в роли "сервера" для кластеров-клиентов).
Мы уже касались этого вопроса здесь и указали на то, что это на данный момент не поддерживается. Дункан Эппинг вот тут рассказал о том, что это не только не сейчас поддерживается, но и невозможно.
Делов в том, что vSAN HCI Mesh (она же технология Datastore Sharing) использует проприетарный протокол vSAN, который называется Reliable Datagram Transport (RDT). При использовании vSAN OSA применяется другая версия протокола RDT, чем та, что используется в vSAN ESA, и в данный момент эти протоколы несовместимы. В итоге, нельзя использовать vSAN Datastore Sharing для предоставления емкости кластеров OSA в ESA или наоборот.
В будущем планируется исправить эту ситуацию, но в данный момент обходного пути нет.
Решение vSAN Max, работающее на архитектуре vSAN Express Storage - это новое предложение в семействе vSAN, которое позволяет получить модель развертывания на базе подписки для отдельных хранилищ, объединяющих петабайты информации на платформе vSphere. Используя vSAN Max в рамках отдельных или растянутых кластеров, пользователи могут масштабировать хранилище независимо от вычислительных мощностей для повышения уровня гибкости при поддержке всех своих рабочих нагрузок. Новое предложение vSAN Max лицензируется отдельно от существующих версий vSAN.
VMware vSAN Max показывает значительный прогресс в гиперконвергентной инфраструктуре (HCI) и решает проблемы хранения данных, с которыми администраторы сталкиваются в современном цифровом мире. Построенный на архитектуре хранилища Express Storage Architecture (ESA) от VMware, vSAN Max предлагает дизагрегированное HCI-решение для хранения данных в масштабах петабайт. Оно обеспечивает беспрецедентный уровень масштабируемости, гибкости и экономичности хранения для ИТ-инфраструктур.
Проблемы современных хранилищ данных
1. Масштабируемость и гибкость
Современные предприятия полагаются на разнообразные приложения, каждое из которых имеет уникальные потребности в ресурсах. Широкий спектр приложений и их разные требования к масштабированию добавляют сложности, создавая необходимость в инфраструктуре, которая была бы способна быстро расти и адаптироваться к меняющимся требованиям.
2. Управление затратами
Балансировка высокой производительности с экономией затрат крайне важна, поскольку бизнесы стремятся оптимизировать расходы на ИТ, не жертвуя качеством, особенно для критичных приложений.
3. Требования к производительности
Растущая сложность и объем рабочих нагрузок с большим объемом данных требуют гибкой инфраструктуры, способной эффективно поддерживать критичные массивные приложения.
4. Простота и эффективность
Управление изолированной ИТ-инфраструктурой может затруднить операционную эффективность, что создает необходимость в более простых решениях для управления виртуальной средой.
VMware vSAN Max: решение для современных вызовов в ИТ
VMware vSAN Max разработан для успешного преодоления этих вызовов, предлагая решение HCI с изолированными хранилищами, которое позволяет независимо масштабировать ресурсы хранения от ресурсов вычислений. Он позволяет бизнесам быстро адаптироваться к изменяющимся потребностям, гарантируя, что возможности хранения точно соответствуют спросу на эти ресурсы. Эта адаптивность поддерживает динамические рабочие нагрузки и рост, значительно улучшая гибкость и масштабируемость ИТ-инфраструктуры.
Преимущества VMware vSAN Max:
Эластичное и независимое масштабирование ресурсов хранения
vSAN Max позволяет пользователям динамически корректировать объем хранения в соответствии с изменяющимся спросом на ресурсы. Он поддерживает расширение ресурсов хранения HCI, позволяя масштабировать до более чем 8.5 петабайт в пределах кластера. Каждый узел vSAN Max может поддерживать до 360 ТБ на хост, достигая плотности хранения до 7 раз выше, чем у традиционных узлов HCI.
Снижение стоимости владения
vSAN Max предлагает снижение общей стоимости владения до 30% для критически важных приложений благодаря оптимизированной эффективности работы с ресурсами и максимальному использованию оборудования.
Исключительная производительность
Построенный на основе vSAN ESA, vSAN Max оснащен для управления огромными объемами данных и удовлетворения строгих требований к производительности и надежности. Он может обеспечивать до 3.6 миллионов операций ввода-вывода в секунду (IOPS) на кластер хранения, обеспечивая плавную работу приложений с высокими требованиями к хранилищу.
Упрощенное администрирование
vSAN Max нативно интегрируется с гипервизором VMware vSphere, предоставляя единый опыт управления через vSphere Client. Он включает отдельные разделы интерфейса пользователя для развертывания и мониторинга, тем самым уменьшая зависимость от нескольких консолей управления и упрощая административные задачи.
VMware vSAN улучшает возможности хранения VMware vSphere и VMware Cloud Foundation с введением vSAN Max как опциональной модели разделенного развертывания HCI. vSAN Max повышает эффективность управления виртуальными машинами с высокой нагрузкой на подсистему хранения в среде HCI, позволяя независимо масштабировать хранилище. Эта оптимизация использования ресурсов не только снижает затраты, но и обеспечивает уровень масштабируемости, гибкости и производительности, отвечающий требованиям современных бизнесов.
Основные технические подробности о vSAN Max рассмотрены в видео ниже:
Больше интересного о VMware vSAN Max вы можете найти по следующим ссылкам:
VMware Cloud Foundation (VCF) — это решение для частного облака от Broadcom, основанное на виртуализации вычислений, сетевых функций и хранилищ, предоставляющее клиентам возможность реализации модели облачной операционной системы на онпремизных площадках клиентов (более подробно об этом тут, тут и тут). Оно предлагает такие преимущества, как простота развертывания и управление жизненным циклом с использованием предварительно проверенного списка ПО (Bill of Materials, BOM), который тщательно тестируется на совместимость.
Хранение данных (критически важная часть частного облака) поддерживается в двух категориях: Основное (Principal) и Дополнительное (Supplemental).
Основное хранилище (Principal Storage)
Основное хранилище настраивается при создании нового домена рабочей нагрузки (Workload Domain) или кластера в консоли SDDC Manager. После создания тип основного хранилища для кластера изменить нельзя. Однако Workload Domain может включать несколько кластеров с собственными типами основного хранилища.
Основные варианты хранения данных (principal storage) включают:
vSAN
vVols
NFSv3
VMFS на FC-хранилищах
Следует отметить, что vSAN является единственно поддерживаемым типом основного хранилища для всех кластеров в управляющем домене (Management Domain). vSAN требуется для управляющего домена, поскольку он предсказуем с точки зрения производительности. vSAN предоставляет высокопроизводительное решение для хранения данных Enterprise-уровня для SDDC. Использование vSAN исключает внешние зависимости и облегчает использование средств автоматизации для инициализации управляющего домена VCF. Во время первоначальной установки VCF Cloud Builder инициализирует все основные компоненты центра обработки данных, определяемые программно - такие как vSphere, NSX и vSAN, на минимально необходимом количестве хостов. Этот процесс первоначального запуска в среднем занимает около двух часов.
Дополнительное хранилище (Supplemental storage)
Supplemental storage предоставляет дополнительную емкость кластеру и рекомендуется для данных Tier-2 или Tier-3, таких как библиотеки контента vSphere, шаблоны виртуальных машин, резервные копии, образы ISO и т. д. Дополнительное хранилище требует ручной настройки, не интегрировано и не отображается в SDDC Manager.
Начиная с версии 5.1, vSAN поддерживает как OSA (оригинальная архитектура хранения), так и ESA (экспресс архитектура хранения). vSAN ESA оптимизирован для использования с высокопроизводительными устройствами хранения нового поколения на базе NVMe, чтобы обеспечить еще более высокие уровни производительности для требовательных рабочих нагрузок, таких как OLTP и генеративный AI. Broadcom рекомендует использовать vSAN ESA в качестве основного хранилища для всех доменов рабочих нагрузок, чтобы получить все преимущества управления и обслуживания полностью программно-определенного стека.
vSAN также обновляется и патчится через LCM (Lifecycle Manager) в SDDC Manager. Обновление и патчинг хранилищ, отличных от vSAN, является ручной задачей и не входит в процедуры управления жизненным циклом, реализованные в SDDC Manager. Для обеспечения поддержки, само хранилище и его HBA необходимо проверять на соответствие VMware Compatibility Guide, когда vSAN не используется.
vSAN использует движок Storage Policy-Based Management (SPBM), который позволяет управлять политиками хранения на уровне виртуальных машин, а не на уровне всего хранилища (datastore). С помощью этого механизма вы можете управлять всеми хранилищами инфраструктуры VCF. Если у вас большая инфраструктура, то необходимо использовать программные средства автоматизации, так как вручную управлять LUN и виртуальными томами и их возможностями очень проблематично в большом масштабе.
vSAN является рекомендуемым решением для хранения данных рабочих нагрузок по вышеупомянутым причинам. Однако VMware понимает, что среды разных клиентов не идентичны, и единый для всех подход не работает. Именно поэтому VCF поддерживает разнообразие типов основного и дополнительного хранилища. Эта гибкость с другими вариантами хранения предоставляет клиентам свободу выбора и позволяет VCF удовлетворить разнообразные потребности производственных сред клиентов.
Важно понимать широкий спектр требований, таких как производительность, доступность, емкость, ожидаемый рост и инвестиции в существующую инфраструктуру. В этой связи для получения дополнительной информации о VMware Cloud Foundation и требованиях к хранилищу, пожалуйста, обратитесь к следующим ресурсам:
Есть несколько потенциальных комбинаций растянутого кластера и перечисленных возможностей, на момент релиза VMware vSAN 8.0 Update 2 поддержка возможностей выглядит следующим образом:
Датастор vSAN Stretched Cluster, расшаренный с vSAN Cluster (не stretched) –>Поддерживается
Датастор vSAN Stretched Cluster, расшаренный с Compute Only Cluster (не stretched) –>Поддерживается
Датастор vSAN Stretched Cluster, расшаренный с Compute Only Cluster (stretched, symmetric) –>Поддерживается
Датастор vSAN Stretched Cluster, расшаренный с Compute Only Cluster (stretched, asymmetric) –> Не поддерживается
В чем разница между симметричным и асимметричным растянутым кластером? На следующем изображении, взятом из конфигурации vSAN Stretched Cluster, это лучше всего объяснено:
Если вы используете растянутый кластер vSAN и растянутый Compute Only, то обычно используется Asymmetric-конфигурация, поэтому шаринг датасторов в этом случае не поддерживается.
На сайте проекта virten.net появилось отличное руководство о том, как правильно настроить USB-накопитель (обычную флэшку), подключенный к хосту VMware ESXi 8.0 в качестве датастора, откуда можно запускать виртуальные машины. Для производственной среды этого делать, само собой, не рекомендуется, а вот для тестирования различных возможностей хоста vSphere данная инструкция может оказаться очень полезной.
Итак:
Рекомендации по выбору USB-накопителя
Касательно форм-фактора или типа USB-накопителей нет никаких ограничений. Вы можете использовать маленькие флешки USB, большие жесткие диски USB 3.5" с высокой емкостью или внешние твердотельные накопители на базе USB. Из-за проблем с производительностью и надежностью, не рекомендуется использовать дешевые USB-флешки для хранилищ.
Предварительные условия
Некоторые команды требуют доступа по SSH к хосту ESXi, который можно включить из vSphere Client:
После этого вы можете зайти на хост ESXi по SSH с помощью любого клиента, например, PuTTY.
Шаг 1 - отключаем USB Passthrough
Дефолтное поведение хоста ESXi при присоединении USB-накопителя к хосту - дать возможность его проброса в виртуальную машину через механизм USB Passthrough. Поэтому нам нужно отключить этот механизм.
Есть 3 способа это сделать:
На базе устройства с помощью команды esxcli passthrough
На базе модели с использованием расширенных настроек USB quirks
Полностью отключить его для всех устройств, отключив сервис usbarbitrator
1 - Отключаем USB Passthrough на базе устройства
Этот способ основан на параметрах USB Bus и Vendor ID. Эта настройка сохраняется при перезагрузке, но учтите, что она может перестать работать в условиях, когда изменяются идентификаторы Bus ID или Device ID (например, вы воткнете флэшку в другой порт, либо будет присоединено другое устройство на время отсутствия флэшки в порту).
Итак, втыкаем USB-накопитель в хост ESXi и соединяемся с ним по SSH как root. Выводим список USB-устройств командой:
esxcli hardware usb passthrough device list
Для следующей команды вам потребуется записать параметры четырех выделенных колонок в формате Bus#:Dev#:vendorId:productId (например, 1:4:1058:1140).
Отключаем проброс для устройства:
esxcli hardware usb passthrough device disable -d 1:4:1058:1140
После этого перезагружать хост ESXi не требуется.
2 - Отключаем USB Passthrough, используя USB Quirks
Второй вариант отключает USB Passthrough для конкретной модели (сочетание идентификатора производителя и идентификатора продукта) с использованием расширенных настроек USB Quirks.
Вставьте USB-накопитель в ваш ESXi, подключитесь к хосту ESXi с использованием SSH и войдите под root. Далее просмотрите доступные USB-устройства. Первое число - это идентификатор производителя, второе число - идентификатор продукта:
lusb
Для установки USB Quirks нужно указать ID в следующем формате (см. скриншот выше): 0xDeviceID:0xVendorID (например, 0x1058:0x1140).
Отключите USB passthrough, используя следующую команду:
esxcli system settings advanced set -o /USB/quirks -s 0x1058:0x1140:0:0xffff:UQ_MSC_NO_UNCLAIM
Здесь уже нужно перезагрузить хост ESXi для применения изменений.
3 - Отключаем USB Arbitrator
Перед началом процедуры не втыкаем флэшку в сервер.
Заходим в клиент vSphere Client, идем в ESX > Configure > System > Advanced System Settings и нажимаем Edit... Далее найдем параметр USB.arbitratorAutoStartDisabled и установим его в значение 1:
После этого перезагружаем хост ESXi и уже после этого втыкаем флэшку в сервер.
То же самое можно сделать с помощью CLI-команды через SSH (после нее можно уже втыкать флэшку):
/etc/init.d/usbarbitrator stop
Также можно отключить USB Arbitrator следующей командой, которая будет применена после перезагрузки хоста:
# chkconfig usbarbitrator off
Шаг 2 - создаем VMFS Datastore на флэшке
После того, как вы отключили проброс USB, можно создавать датастор через vSphere Client, кликнув правой кнопкой на хосте ESXi и выбрав Actions > Storage > New Datastore... (в ESXi Host Client это делается в разделе Storage > New Datastore).
Если ваше устройство не отображается в мастере New Datastore, нужно сделать ресканирование хранилищ (опция Rescan Storage по правому клику) и убедиться, что устройство присутствует в списке.
Если и это не помогло, то можно попробовать создать датастор с помощью командной строки. Находим путь к устройству (Device Path в формате mpx.vmhba##). Для этого запускаем команду:
esxcli storage core device list |grep '^mpx' -A3
В выводе команды вы сможете идентифицировать устройство по его размеру:
Если у вас несколько устройств одного размера, то после подключения нужного вам устройства загляните в лог /var/log/vmkernel.log и посмотрите там наличие вот такой записи:
vmkernel: Successfully registered device "mpx.vmhba34:C0:T0:L0" from plugin "NMP" of type 0
Это и есть ваша флэшка. Теперь создаем переменную с этим устройством:
DISK="/vmfs/devices/disks/mpx.vmhba34:C0:T0:L0"
После этого создаем метку для данного устройства:
partedUtil mklabel ${DISK} gpt
Теперь с помощью утилиты partedUtil создадим раздел с идентификатором GUID=AA31E02A400F11DB9590000C2911D1B8:
После этого ваш том, созданный на флэшке, появится в списке датасторов хоста.
Для бесплатного резервного копирования виртуальных машин можно использовать скрипт ghettoVCB.
Если вы заметите, что скорость копирования на/с датастора с помощью команд cp, mv или scp очень медленная, то вы можете использовать механизм Storage vMotion или утилиту vmkfstool для копирования данных.
Например, вот так можно склонировать VMDK-диск:
vmkfstools -i <src>.vmdk <dst>.vmdk
Известные проблемы
Когда вы пытаетесь определить диск, дважды проверьте, что вы не перепутали свои накопители. Имя, отображаемое в пользовательском интерфейсе, не меняется, когда меняется идентификатор. Вот пример, где выделенный диск был перенесен на виртуальный адаптер mpx.vmhba33 как новое устройство. Отображаемое имя при этом остается старым - mpx.vmhba32.
Существующие датасторы не монтируются автоматически! То есть, если на вашей флэшке уже есть тома VMFS, то они не будут видны при ее подключении. В этом случае датастор будет offline, а в логе vmkernel.log вы увидите вот такое сообщение:
cpu0:65593)LVM: 11136: Device mpx.vmhba34:C0:T0:L0:1 detected to be a snapshot:
То есть датастор определяется как снапшот. Список снапшотов вы можете вывести командой:
# esxcli storage vmfs snapshot list 583b1a72-ade01532-55f6-f44d30649051 Volume Name: usbflash VMFS UUID: 583b1a72-ade01532-55f6-f44d30649051 Can mount: true Reason for un-mountability: Can resignature: true Reason for non-resignaturability: Unresolved Extent Count: 1
В этом случае вы можете смонтировать датастор следующей командой, используя VMFS UUID:
# esxcli storage vmfs snapshot mount -u 583b1a72-ade01532-55f6-f44d30649051
Недавно мы писали о новом релизе фреймворка для управления виртуальной инфраструктурой VMware PowerCLI 13.1. У данного средства есть очень много командлетов для автоматизации задач в различных продуктах VMware. Сегодня мы поговорим о том, как с помощью PowerCLI можно управлять задачами репликации в Site Recovery Manager (SRM) и vSphere Replication (VR). Данные операции осуществляются через REST API.
1. Подключение к серверу vSphere Replication через Connect-VrServer
Чтобы подключиться к серверу управления vSphere Replication, необходимо использовать команду Connect-VrServer. Репликация может быть настроена внутри одного сервера vCenter или между локальными и удаленными экземплярами сервера vCenter.
При настройке репликации внутри одного и того же сервера vCenter, вы можете подключиться только к локальному сайту репликации vSphere. В параметре Server укажите адрес сервера vSphere Replication. В параметрах User и Password укажите имя пользователя и пароль для экземпляра сервера vCenter, где развернут виртуальный модуль vSphere Replication.
Давайте рассмотрим объект VrServerConnection, возвращаемый командой Connect-VrServer. Он содержит свойство ConnectedPairings:
Это свойство является словарем, где хранятся все подключенные пары. Пара - это представление в API VR парных локального и удаленного сайтов. Поскольку мы только что прошли аутентификацию только на локальном сайте VR, в словаре содержится только одна запись. Это самоподключение локального vCenter.
Вы можете индексировать этот словарь по имени vCenter и получить определенный объект Pairing. Вам понадобится этот объект Pairing для вызова различных операций из API VR:
Чтобы аутентифицироваться на удаленном сервере vCenter, вы будете использовать другой набор параметров команды Connect-VrServer. Обратите внимание, что у вас должна быть настроена пара сайтов между локальным и удаленным сайтами vSphere Replication.
На этот раз для параметра LocalServer укажите уже доступный объект VrServerConnection. Для параметра RemoteServer укажите имя удаленного VC. Для параметров RemoteUser и RemotePassword укажите имя пользователя и пароль удаленного VC. Обратите внимание, что с VR мы можем настроить несколько удаленных сайтов:
Теперь, если вы проверите свойство ConnectedPairings объекта VrServerConnection, вы увидите, что в словаре появилась вторая пара, позволяющая вам вызывать операции API на удаленном сайте:
В качестве альтернативы вы можете аутентифицироваться на локальном и удаленном сайтах с помощью одного вызова Connect-VrServer:
Для начала вам нужно получить ВМ, которую вы хотите реплицировать. Используйте команду Invoke-VrGetLocalVms, для которой нужно указать параметры PairingId и VcenterId. У нас есть эти идентификаторы в объекте Pairing, который мы сохранили в переменной $remotePairing:
Вы также можете применить фильтр к этому вызову. Параметр FilterProperty указывает свойство ВМ, которое будет использоваться для поиска. В данном случае это свойство Name. Параметр Filter указывает значение свойства, которое вы ищете. Результатом этого вызова является объект VirtualMachineDrResponseList, который содержит список ВМ, соответствующих указанному фильтру. В нашем случае это будет список с одной ВМ:
Настройка HDD-дисков машин для репликации
При настройке репликации на основе хоста, вы должны указать жесткие диски ВМ, которые будут реплицированы. Для каждого реплицируемого диска вы должны указать хранилище данных на целевом vCenter. В этом примере мы будем реплицировать все жесткие диски нашей ВМ на одном целевом хранилище данных на удаленном vCenter.
Вот как получить целевое хранилище данных на удаленном vCenter, используя команду Invoke-VrGetVrCapableTargetDatastores:
Здесь для VcenterId укажите идентификатор удаленного vCenter. Укажите параметры FilterProperty и Filter, чтобы выбрать целевое хранилище данных по имени.
Жесткие диски доступны в свойстве Disks нашего объекта VirtualMachine, сохраненного в переменной $replicatedVm.
Пройдитесь по списку Disks и инициализируйте объекты ConfigureReplicationVmDisk для каждого жесткого диска. Сохраните эти конфигурации в переменной массива $replicationVmDisks:
Сначала вам нужно инициализировать объект ConfigureReplicationSpec. Помимо различных настроек репликации, мы должны указать конфигурацию репликации диска, сохраненную в переменной $replicationVmDisks, для параметра Disk. Также вам нужно указать идентификатор целевого vCenter и идентификатор реплицируемой ВМ.
Затем используйте команду Invoke-VrConfigureReplication для настройки репликации. В качестве параметров укажите PairingId и объект ConfigureReplicationSpec:
Результатом операции является объект TaskDrResponseList, который в нашем примере содержит список из одной задачи. Если хотите, вы можете указать массив объектов ConfigureReplicationSpec и реплицировать несколько ВМ одним вызовом.
Чтобы дождаться завершения задачи настройки репликации, получите задачу, пока ее свойство Status не будет равно чему-то отличному от "RUNNING":
Invoke-VrGetTaskInfo -TaskId $task.List[0].Id
В следующем разделе мы будем использовать командлеты из модуля VMware.Sdk.Srm для создания группы защиты и плана восстановления для только что созданной репликации.
3. Подключение к Site Recovery Manager с помощью Connect-SrmSdkServer
Для подключения к серверу Site Recovery Manager используйте командлет Connect-SrmSdkServer. Не используйте старый командлет Connect-SrmServer, уже доступный в модуле VMware.VimAutomation.Srm, так как он не совместим с командлетами модуля VMware.Sdk.Srm.
Site Recovery Manager поддерживает только одно соединение между локальными и удаленными сайтами SRM. Вы можете подключиться либо только к локальному сайту, либо вы можете аутентифицироваться на удаленном сайте сервера vCenter в том же вызове. Поскольку далее мы будем создавать группу защиты и план восстановления, мы выберем второй вариант. Обратите внимание, что у вас должна быть настроена пара сайтов между локальными и удаленными сайтами SRM.
Если мы посмотрим на объект SrmServerConnection, возвращенный командлетом Connect-SrmSdkServer, мы увидим, что он содержит свойство с именем ConnectedPairing. В этом случае это один объект Pairing, который представляет пару между локальным и удаленным сайтами SRM. Вам потребуется этот объект Pairing для вызова различных операций из API SRM:
4. Создание Protection Group и Recovery Plan для Host Based Replication
В этой главе мы будем использовать репликацию на основе хоста, которую мы настроили ранее. Сначала мы инициализируем HbrProtectionGroupSpec с уже реплицированной ВМ:
В этом примере мы повторно используем идентификатор ВМ, который мы сохранили в переменной $replicatedVm, поскольку он совместим между API VR и SRM. Если вам нужно получить реплицированную ВМ с помощью модуля VMware.Sdk.Srm, используйте командлет Invoke-SrmGetReplicatedVms:
Чтобы завершить этот пример, мы создадим Recovery Plan для Protection Group. Для этого сначала инициализируйте RecoveryPlanCreateSpec, требуемый командлетом Invoke-SrmCreatePlan:
После того, как вы закончили взаимодействовать с сервером SRM, закройте соединение, используя командлет Disconnect-SrmSdkServer:
Disconnect-SrmSdkServer "MySrmAddress.com"
Чтобы закрыть соединение с сервером VR, используйте командлет Disconnect-VrServer:
Disconnect-VrServer "MyVrAddress.com"
Вы можете объединить модули PowerCLI VMware.Sdk.Vr и VMware.Sdk.Srm для автоматизации всего сценария создания репликации на основе хоста и использования ее с группой защиты и планом восстановления. Если вы хотите автоматизировать репликацию на основе массива, доступную с модулем VMware.Sdk.Srm, обратитесь к статье "Array Based Replication with PowerCLI 13.1". Также вы можете ознакомиться со статьей "vSphere Replication REST API with PowerShell: Configure VM replication".
Таги: VMware, SRM, PowerCLI, Replication, Automation, DR
С 18 апреля 2023 года VMware Cloud Director 10.4.2 стал доступен сервис-провайдерам. Напомним, что о прошлом обновлении этой платформы для управления облаком на базе VMware vSphere и его клиентами мы писали вот тут.
Давайте посмотрим, что нового появилось в VCD 10.4.2:
Основная платформа
1. Виртуальный модуль доверенной загрузки (vTPM)
VMware добавила поддержку устройств виртуального модуля доверенной загрузки (vTPM), обеспечивающих дополнительный слой безопасности для гостевых операционных систем. Включив vTPM, вы можете защитить свои виртуальные машины от несанкционированного доступа, взлома и других угроз безопасности.
VMware Cloud Director позволяет использовать виртуальные машины с устройствами vTPM, которые обеспечивают повышенную безопасность гостевой операционной системы. Добавление vTPM к новой или уже существующей виртуальной машине возможно при условии выполнения определенных предварительных требований как к гостевой операционной системе виртуальной машины, так и базовой инфраструктуре vCenter Server. vTPM поддерживается в большинстве рабочих процессов VCD для виртуальных машин, vApp, шаблонов и синхронизации каталога. Более подробно об этом рассказано тут.
2. IDP Proxy for TMC Local
Это нововведение позволяет вам упростить аутентификацию пользователей для облачных сервисов, делая ее более безопасной и беспроблемной. Выступая посредником между пользователями и поставщиком идентификации, VMware Cloud Director упрощает процесс аутентификации, снижая нагрузку на провайдера идентификации. С этой возможностью вы теперь можете управлять доступом пользователей и разрешениями с большей эффективностью.
Операционные улучшения
1. Улучшенный логин для провайдеров
Последнее обновление Cloud Director позволяет вам вводить "system" в качестве названия организации при доступе к странице входа по адресу https://vcloud.example.com/. Теперь VMware Cloud Director распознает "system" как организацию и автоматически перенаправляет вас на страницу входа в портал администратора провайдера услуг.
2. Срок аренды vApp по умолчанию теперь не ограничен
В данном релизе для новых организаций-арендаторов устанавливается значение времени истечения срока аренды vApp по умолчанию "неограниченное". Благодаря этой новой настройке вы можете получить большей гибкости в управлении организациями-арендаторами, не беспокоясь о сроках истечения аренды. В предыдущих версиях значение по умолчанию составляло 7 дней до истечения срока.
3. Пакетный User Mapping
В версии 10.4.1 VMware начала процесс отказа от локальных пользователей в производственных средах. Чтобы облегчить этот переход, была введена функция массового маппинга пользователей, которая позволяет без проблем перенести любое количество пользователей с локального VCD на управление со стороны внешнего поставщика идентификации. Этот оптимизированный процесс обеспечивает плавный переход, повышая при этом безопасность и контроль над аутентификацией пользователей.
Пакетные операции пользователей реализуются в 3 основных этапа из интерфейса:
Экспорт пользователей в файл CSV
Обновление и загрузка обновленного файла CSV
Обновление пользователей
4. Улучшения NamedDisk
Теперь есть два основных сценария использования, направленных на улучшение поведения, связанного с сущностями NamedDisk. Эти сценарии использования разработаны для оптимизации производительности облачных сервисов и упрощения управления NamedDisk. Благодаря этим новым возможностям вы получите большую гибкость и контроль над виртуальными машинами, подключенными к NamedDisk.
Один из сценариев заключается в том, что теперь можно передать право владения на объекты VM или vApp, даже если к нему подключен NamedDisk.
Обратите внимание, что изменить владельца NamedDisk невозможно, пока он подключен к VM.
Второй сценарий использования касается ситуаций, когда суперпользователь удаляет пользователя, имеющего право владения на несколько сущностей VCD, включая NamedDisk. В таких случаях, если выбрана опция «передать объект», NamedDisk теперь может быть передан суперпользователю, даже если в данный момент он подключен к VM и принадлежит удаляемому пользователю.
Улучшения хранилищ
1. Политика размещения vSAN HCI Mesh
Позволяя монтировать удаленное хранилище данных к кластеру vSAN, HCI Mesh предоставляет возможность расширять кластер. Затем это удаленное хранилище данных монтируется ко всем хостам в кластере, обеспечивая эффективное использование и распределение ресурсов центра обработки данных. Такой подход предлагает оптимизированное решение для управления хранилищами данных в большом масштабе.
Платформа VCD была обновлена для предотвращения распределения виртуальных машин (ВМ) и их дисков по нескольким хранилищам данных в случаях, когда одно из хранилищ данных является удаленным хранилищем vSAN в кластере HCI Mesh vSAN, указанном в политике хранения. Интеллектуальный движок размещения виртуальных машин разработан для обеспечения целостности данных, размещая все файлы ВМ и диски либо исключительно в удаленном хранилище данных vSAN, либо в других хранилищах данных, разрешенных политикой хранения. Кроме того, есть расширенные флаги, которые позволяют использовать дополнительные условия при использовании удаленного хранилища данных vSAN.
2. Datastore Threshold
В контексте размещения различных типов объектов, таких как связанные клоны ВМ, теневые копии ВМ, полные клоны ВМ, шаблоны или диски, порогом называется минимальное количество свободного места, которое необходимо обеспечить на хранилище данных. Хранилище исключается из учета, если свободное пространство падает ниже этого порога. В последнем релизе VCD представлен более эффективный механизм для расчета порога хранилища данных (Красный или Желтый) для хранилищ данных, принадлежащих к кластеру хранения.
С внедрением этого метода расчета объекты теперь более точно распределяются по соответствующему хранилищу данных в кластере. Это достигается путем вычисления доступного свободного пространства на каждом отдельном хранилище данных, а не общего свободного пространства по всему кластеру хранилищ данных.
Скачать VMware Cloud Director 10.4.2 можно по этой ссылке, Release Notes доступны тут.
На прошлой неделе мы рассказали о новых возможностях обновленной версии платформы VMware vSphere 8 Update 1, а также новых функциях инфраструктуры хранилищ (Core Storage). Сегодня мы поговорим о новой версии vSAN 8 Update 1 - решения для организации отказоустойчивых кластеров хранилищ для виртуальных машин.
В vSAN 8 компания VMware представила архитектуру хранилища vSAN Express Storage Architecture (ESA), сделав весомый вклад в развитие гиперконвергентной инфраструктуры. В первом пакете обновлений vSAN компания VMware продолжает развивать этот продукт, позволяя клиентам использовать современные массивы, которые обеспечивают новый уровень производительности, масштабируемости, надежности и простоты использования.
Обзор основных возможностей vSAN 8 Update 1 вы также можете увидеть в видео ниже (откроется в новом окне):
В vSAN 8 Update 1 продолжают разрабатывать и улучшать обе архитектуры - vSAN OSA и vSAN ESA. Давайте посмотрим, что нового появилось в vSAN U1:
1. Масштабирование распределенных хранилищ
Обработка разделенных ресурсов вычисления и хранения в кластерах улучшена в версии vSAN 8 U1. Клиенты могут масштабироваться новыми способами, совместно используя хранилища данных vSAN с другими кластерами vSAN или только с вычислительными кластерами vSphere в рамках подхода HCI Mesh.
Управление распределенными хранилищами HCI Mesh с помощью архитектуры Express Storage
В vSAN 8 U1 архитектура Express Storage Architecture (ESA) позволяет клиентам максимизировать использование ресурсов устройств нового поколения путем предоставления общего доступа к хранилищами в нескольких нерастянутых кластерах для подхода HCI Mesh. Пользователи могут монтировать удаленные хранилища данных vSAN, расположенные в других кластерах vSAN, и использовать кластер vSAN ESA в качестве внешнего хранилища ресурсов для кластера vSphere.
Использование внешнего хранилища с помощью растянутых кластеров vSAN для OSA
В vSAN 8 U1 появилась поддержка распределенных хранилищ HCI Mesh при использовании растянутых кластеров vSAN на основе архитектуры хранения vSAN OSA. Теперь пользователи могут масштабировать хранение и вычислительные мощности независимо - в стандартных и растянутых кластерах.
Потребление емкостей хранилищ vSAN для разных экземпляров vCenter Server
vSAN 8 U1 также поддерживает распределенные хранилища в разных средах с использованием нескольких серверов vCenter при использовании традиционной архитектуры хранения (OSA).
2. Улучшение платформы
Улучшенная производительность с использованием нового адаптивного пути записи
В новом релизе представлен новый адаптивный путь записи, который позволяет рабочим нагрузкам с множеством записей и частопоследовательными записями записывать данные оптимальным способом. Улучшенная потоковая запись на ESA обеспечит увеличение пропускной способности на 25% и снижение задержки для последовательных записей. Это обновление не только повлияет на приложения с преобладающим профилем последовательной записи I/O, но и расширит разнообразие нагрузок, которые работают оптимальным образом на ESA vSAN.
Улучшенная производительность для отдельных нагрузок
Чтобы извлечь максимальную пользу из современного оборудования NVMe, в vSAN ESA 8 U1 была оптимизирована обработка I/O для каждого объекта, находящегося на хранилище данных vSAN ESA, повысив производительность на каждый VMDK на 25%. Эти улучшения производительности для отдельных объектов на ESA будут очень эффективны на критически важных виртуальных машинах, включая приложения, такие как реляционные базы данных и нагрузки OLTP.
Улучшенная надежность во время сценариев режима обслуживания.
В vSAN 8 U1 для ESA была добавлена еще одна функция, которая присутствует в vSAN OSA: поддержка RAID 5 и RAID 6 erasure coding с функциями дополнительной защиты от потери данных во время плановых операций обслуживания. Эта новая возможность гарантирует, что данные на ESA хранятся с избыточностью в случае неожиданного сбоя хоста в кластере во время режима обслуживания.
Улучшения управления датасторами
В vSAN 8 U1 администраторы смогут настраивать размер объектов пространства имен, что позволит им более просто хранить файлы ISO и библиотеки контента.
3. Упрощение управления
При использовании управления хранилищем на основе политик (SPBM), клиенты могут определять возможности хранения с помощью политик и применять их на уровне виртуальных машин. vSAN 8 U1 есть несколько новых улучшений, которые упрощают ежедневные операции администраторов, а также добавляют несколько новых возможностей, чтобы помочь глобальной команде поддержки VMware (GS) быстрее решать проблемы клиентов.
Автоматическое управление политиками для Default Storage Policies
(ESA)
В vSAN ESA 8 U1 появилась новая, необязательная кластерная политика хранения по умолчанию, которая поможет администраторам работать с кластерами ESA с оптимальной надежностью и эффективностью. В конфигурации на уровне кластера доступен новый переключатель "Auto-Policy Management". При включении этой функции кластера будет создана и назначена эффективная политика хранения по умолчанию на основе размера и типа кластера.
Skyline Health Score и исправление конфигурации
В vSAN 8 U1 модуль Skyline UX был переработан и теперь содержит новую панель управления состоянием с упрощенным видом "здоровья" каждого кластера. Новый пользовательский интерфейс поможет ответить на вопросы: "Находится ли мой кластер и обрабатываемые им нагрузки в работоспособном и здоровом состоянии?" и "Насколько серьезно это состояние? Следует ли решить эту проблему?".
С таким четким пониманием потенциальных проблем и действий для их устранения вы можете сократить среднее время до устранения проблем (mean time to resolution, MTTR).
Более высокий уровень детализации для улучшенного анализа производительности
Доступный как в Express Storage Architecture, так и в Original Storage Architecture, сервис производительности vSAN 8 U1 теперь включает мониторинг производительности почти в реальном времени, который собирает и отображает показатели производительности каждые 30 секунд.
Упрощенный сбор диагностической информации о производительности
В vSAN 8 U1 в I/O Trip Analyzer для виртуальных машин появился новый механизм планировщика. Вы можете запускать диагностику программно, что позволяет собирать больше и лучших данных, что может быть критически важно для выявления временных проблем производительности. Это улучшение идеально подходит для сред, где ВМ имеет повторяющуюся (хоть и кратковременную) проблему с производительностью.
Новая интеграция PowerCLI
В vSAN 8 U1 PowerCLI поддерживает множество новых возможностей как для архитектур ESA (Express Storage Architecture), так и OSA (Original Storage Architecture). С помощью этих интеграций клиенты ESA получат простой доступ к своему инвентарю для мониторинга и автоматизации управления своей средой и выделением ресурсов.
4. Функции Cloud Native Storage
Выделенные окружения DevOps увеличивают сложность всего центра обработки данных и увеличивают затраты. Используя существующую среду vSphere для хостинга рабочих нагрузок Kubernetes DevOps, клиенты дополнительно увеличивают ценность и ROI платформы VMware. VMware продолжает фокусироваться на потребностях разработчиков: в vSAN 8 U1 были реализованы новые улучшения производительности, простоты и гибкости для разработчиков, которые используют среду, и для администраторов, ответственных за саму платформу.
Поддержка CNS для vSAN ESA
В vSAN 8 U1 мы добавили поддержку Cloud Native Storage (CNS) для vSAN ESA. Клиенты могут получить преимущества производительности vSAN ESA для своих сред DevOps.
Поддержка DPp общих виртуальных коммутаторов
vSAN 8 U1 снижает стоимость и сложность инфраструктуры за счет того, что решения DPp (Data Persistence) теперь совместимы с VMware vSphere Distributed Switch. Клиентам нужны только лицензии vSphere+/vSAN+, чтобы использовать платформу Data Persistence — на vSAN OSA или ESA — и запускать приложения, что дает более низкую общую стоимость владения и упрощение операций.
Развертывние Thick provisioning для vSAN Direct Configuration
Наконец, в vSAN 8 U1 были доработаны кластеры, работающие в конфигурации vSAN Direct Configuration — это уникальная кластерная конфигурация, настроенная под Cloud Native Workloads. С vSAN 8 U1 постоянные тома могут быть программно выделены разработчиком как "thick" (это определяется в классе хранения).
Более подробно о новых возможностях VMware vSAN 8 Update 1 можно почитать на специальной странице.
Таги: VMware, vSAN, Update, Storage, OSA, ESA, Performance
Недавно мы писали об анонсированных новых возможностях обновленной платформы виртуализации VMware vSphere 8 Update 1, выход которой ожидается в ближайшее время. Параллельно с этим компания VMware объявила и о выпуске новой версии решения VMware vSAN 8 Update 1, предназначенного для создания высокопроизводительных отказоустойчивых хранилищ для виртуальных машин, а также об улучшениях подсистемы хранения Core Storage в обеих платформах.
Недавно компания VMware также выпустила большую техническую статью "What's New with vSphere 8 Core Storage", в которой детально рассмотрены все основные новые функции хранилищ, с которыми работают платформы vSphere и vSAN. Мы решили перевести ее с помощью ChatGPT и дальше немного поправить вручную. Давайте посмотрим, что из этого вышло :)
Итак что нового в части Core Storage платформы vSphere 8 Update 1
Одно из главных улучшений - это новая система управления сертификатами. Она упрощает возможность регистрации нескольких vCenter в одном VASA-провайдере. Это положит основу для некоторых будущих возможностей, таких как vVols vMSC. Такж есть и функции, которые касаются масштабируемости и производительности. Поскольку vVols могут масштабироваться гораздо лучше, чем традиционное хранилище, VMware улучшила подсистему хранения, чтобы тома vVols работали на больших масштабах.
1. Развертывание нескольких vCenter для VASA-провайдера без использования самоподписанных сертификатов
Новая спецификация VASA 5 была разработана для улучшения управления сертификатами vVols, что позволяет использовать самоподписанные сертификаты для многовендорных развертываний vCenter. Это решение также решает проблему управления сертификатами в случае, когда независимые развертывания vCenter, работающие с различными механизмами управления сертификатами, работают вместе. Например, один vCenter может использовать сторонний CA, а другой vCenter может использовать сертификат, подписанный VMCA. Такой тип развертывания может быть использован для общего развертывания VASA-провайдера. Эта новая возможность использует механизм Server Name Indication (SNI).
SNI - это расширение протокола Transport Layer Security (TLS), с помощью которого клиент указывает, какое имя хоста он пытается использовать в начале процесса handshake. Это позволяет серверу показывать несколько сертификатов на одном IP-адресе и TCP-порту. Следовательно, это позволяет обслуживать несколько безопасных (HTTPS) веб-сайтов (или других служб через TLS) с одним и тем же IP-адресом, не требуя, чтобы все эти сайты использовали один и тот же сертификат. Это является концептуальным эквивалентом виртуального хостинга на основе имени HTTP/1.1, но только для HTTPS. Также теперь прокси может перенаправлять трафик клиентов на правильный сервер во время хэндшейка TLS/SSL.
2. Новая спецификация vVols VASA 5.0 и некоторые детали функций
Некоторые новые функции, добавленные в vSphere 8 U1:
Изоляция контейнеров - работает по-разному для поставщиков VASA от различных производителей. Она позволяет выполнять настройку политики контроля доступа на уровне каждого vCenter, а также дает возможность перемещения контейнеров между выбранными vCenter. Это дает лучшую изоляцию на уровне контейнеров, а VASA Provider может управлять правами доступа для контейнера на уровне каждого vCenter.
Аптайм - поддержка оповещений об изменении сертификата в рамках рабочего процесса VASA 5.0, который позволяет обновлять сертификат VMCA в системах с несколькими vCenter. Недействительный или истекший сертификат вызывает простой, также возможно возникновение простоя при попытке регистрации нескольких vCenter с одним VASA Provider. В конфигурации с несколькими vCenter сертификаты теперь можно обновлять без простоя.
Улучшенная безопасность для общих сред - эта функция работает по-разному для поставщиков VASA от производителей. Все операции могут быть аутентифицированы в контексте vCenter, и каждый vCenter имеет свой список контроля доступа (ACL). Теперь нет самоподписанных сертификатов в доверенном хранилище. VASA Provider может использоваться в облачной среде, и для этого также есть доступная роль в VASA 5.0.
Обратная совместимость - сервер ESXi, который поддерживает VASA 5.0, может решать проблемы с самоподписанными сертификатами и простоями, возникающими в случае проблем. VASA 5.0 остается обратно совместимым и дает возможность контролировать обновление в соответствии с требованиями безопасности. VASA 5.0 может сосуществовать с более ранними версиями, если производитель поддерживает эту опцию.
Гетерогенная конфигурация сертификатов - работает по-разному для поставщиков VASA от производителей. Теперь используется только подписанный сертификат VMCA, дополнительный CA не требуется. Это позволяет изолировать доверенный домен vSphere. VASA 5.0 позволяет использовать разные конфигурации для каждого vCenter (например, Self-Managed 3rd Party CA Signed Certificate и VMCA managed Certificate).
Не необходимости вмешательства администратора - поддержка многократного развертывания vCenter с использованием VMCA, которая не требует от пользователя установки и управления сертификатами для VP. Служба SMS будет отвечать за предоставление сертификатов. Теперь это работает в режиме Plug and Play с автоматической предоставлением сертификатов, без вмешательства пользователя, при этом не требуется никаких ручных действий для использования VASA Provider с любым vCenter.
Комплаенс безопасности - отсутствие самоподписанных сертификатов в доверенных корневых центрах сертификации позволяет решить проблемы соответствия требованиям безопасности. Не-СА сертификаты больше не являются частью хранилища доверенных сертификатов vSphere. VASA 5.0 требует от VASA Provider использовать сертификат, подписанный СА для связи с VASA.
3. Перенос Sidecar vVols в config-vvol вместо другого объекта vVol
Sidecars vVols работали как объекты vVol, что приводило к накладным расходам на операции VASA, такие как bind/unbind. Решения, такие как First Class Disks (FCD), создают большое количество маленьких sidecars, что может ухудшить производительность vVols. Кроме того, поскольку может быть создано множество sidecars, это может учитываться в общем количестве объектов vVol, поддерживаемых на массиве хранения. Чтобы улучшить производительность и масштабируемость, теперь они обрабатываются как файлы на томе config-vvol, где могут выполняться обычные операции с файлами. Не забывайте, что в vSphere 8 был обновлен способ байндига config-vvol. В результате, с новым механизмом config-vvol уменьшается число операций и задержки, что улучшает производительность и масштабируемость.
Для этой функциональности в этом релизе есть несколько ограничений при создании ВМ. Старые виртуальные машины могут работать в новом формате на обновленных до U1 хостах, но сам новый формат не будет работать на старых ESXi. То есть новые созданные ВМ и виртуальные диски не будут поддерживаться на хостах ниже версии ESXi 8 U1.
5. Улучшения Config-vvol, поддержка VMFS6 config-vvol с SCSI vVols (вместо VMFS5)
Ранее Config-vvol, который выступает в качестве каталога для хранилища данных vVols и содержимого VM home, был ограничен размером 4 ГБ. Это не давало возможности использования папок с хранилищем данных vVols в качестве репозиториев ВМ и других объектов. Для преодоления этого ограничения Config-vvol теперь создается как тонкий объект объемом 255 ГБ. Кроме того, вместо VMFS-5 для этих объектов будет использоваться формат VMFS-6. Это позволит размещать файлы sidecar, другие файлы VM и библиотеки контента в Config-vvol.
На изображении ниже показаны Config-vvol разных размеров. Для машины Win10-5 Config-vvol использует исходный формат 4 ГБ, а ВМ Win10-vVol-8u1 использует новый формат Config-vvol объемом 255 ГБ.
6. Добавлена поддержка NVMe-TCP для vVols
В vSphere 8 была добавлена поддержка NVMe-FC для vVols. В vSphere 8 U1 также расширена поддержка NVMe-TCP, что обеспечивает совместное использование NVMeoF и vVols. См. статью vVols with NVMe - A Perfect Match | VMware.
7. Улучшения NVMeoF, PSA, HPP
Инфраструктура поддержки NVMe end-to-end:
Расширение возможностей NVMe дает возможность поддержки полного стека NVMe без какой-либо трансляции команд SCSI в NVMe на любом уровне ESXi. Еще одной важной задачей при поддержке end-to-end NVMe является возможность контроля multipath-плагинов сторонних производителей для управления массивами NVMe.
Теперь с поддержкой GOS протокол NVMe может использоваться для всего пути - от GOS до конечного таргета.
Важным аспектом реализации VMware трансляции хранилищ виртуальных машин является поддержка полной обратной совместимости. VMware реализовала такой механизм, что при любом сочетании виртуальных машин, использующих SCSI или контроллер vNVMe, и целевого устройства, являющегося SCSI или NVMe, можно транслировать путь в стеке хранения. Это дизайн, который позволяет клиентам переходить между SCSI- и NVMe-хранилищами без необходимости изменения контроллера хранилищ для виртуальной машины. Аналогично, если виртуальная машина имеет контроллер SCSI или vNVMe, он будет работать как на SCSI-, так и на NVMeoF-хранилищах.
Упрощенная диаграмма стека хранения выглядит так:
Для получения дополнительной информации о NVMeoF для vSphere, обратитесь к странице ресурсов NVMeoF.
8. Увеличение максимального количества путей для пространств имен NVMe-oF с 8 до 32
Увеличение количества путей улучшает масштабирование в окружениях с несколькими путями к пространствам имен NVMe. Это необходимо в случаях, когда хосты имеют несколько портов и модуль имеет несколько нод, а также несколько портов на одной ноде.
9. Увеличение максимального количества кластеров WSFC на один хост ESXi с 3 до 16
Это позволяет уменьшить количество лицензий Microsoft WSFC, необходимых для увеличения количества кластеров, которые могут работать на одном хосте.
Для получения дополнительной информации о работе Microsoft WSFC на vSphere можно обратиться к следующим ресурсам:
10. Улучшения VMFS - расширенная поддержка XCOPY для копирования содержимого датасторов между различными массивами
ESXi теперь поддерживает расширенные функции XCOPY, что оптимизирует копирование данных между датасторами разных массивов. Это поможет клиентам передать обработку рабочих нагрузок на сторону хранилища. Функция уже доступна в vSphere 8 U1, но по факту миграция данных между массивами должна поддерживаться на стороне хранилища.
11. Реализация NFSv3 vmkPortBinding
Данная функция позволяет привязать соединение NFS для тома к конкретному vmkernel. Это помогает обеспечить безопасность, направляя трафик NFS по выделенной подсети/VLAN, и гарантирует, что трафик NFS не будет использовать mgmt-интерфейс или другие интерфейсы vmkernel.
Предыдущие монтирования NFS не содержат этих значений, хранящихся в config store. Во время обновления, при чтении конфигурации из конфигурационного хранилища, значения vmknic и bindTovmnic, если они есть, будут считаны. Поэтому обновления с предыдущих версий не будут содержать этих значений, так как они являются необязательными.
Изменения в способе создания/удаления Swap-файлов для томов vVols помогли улучшить производительность включения/выключения, а также производительность vMotion и svMotion.
13. Улучшения Config vVol и сохранение привязки
Здесь были сделаны следующие доработки:
Уменьшено время запроса при получении информации о ВМ
Добавлено кэширование атрибутов vVol - размер, имя и прочих
Конфигурационный vVol - это место, где хранятся домашние файлы виртуальной машины (vmx, nvram, logs и т. д.) и к нему обычно обращаются только при загрузке или изменении настроек виртуальной машины.
Ранее использовалась так называемая "ленивая отмена связи" (lazy unbind), и происходил unbind конфигурационного vVol, когда он не использовался. В некоторых случаях приложения все же периодически обращались к конфигурационному vVol, что требовало новой операции привязки. Теперь эта связь сохраняется, что уменьшает задержку при доступе к домашним данным виртуальной машины.
14. Поддержка NVMeoF для vVols
vVols были основным направлением развития функциональности хранилищ VMware в последние несколько версий, и для vSphere 8.0 это не исключение. Самое большое обновление в ядре хранения vSphere 8.0 - добавление поддержки vVols в NVMeoF. Изначально поддерживается только FC, но со временем будут работать и другие протоколы, провалидированные и поддерживаемые с помощью vSphere NVMeoF. Теперь есть новая спецификация vVols и VASA/VC-фреймворка - VASA 4.0/vVols 3.0.
Причина добавления поддержки vVols в NVMeoF в том, что многие производители массивов, а также отрасль в целом, переходят на использование или, по крайней мере, добавление поддержки NVMeoF для повышения производительности и пропускной способности. Вследствие этого VMware гарантирует, что технология vVols остается поддерживаемой для последних моделей хранилищ.
Еще одним преимуществом NVMeoF vVols является настройка. При развертывании после регистрации VASA фоновая установка завершается автоматически, вам нужно только создать датастор. Виртуальные эндпоинты (vPE) и соединения управляются со стороны VASA, что упрощает настройку.
Некоторые технические детали этой реализации:
ANA Group (Асимметричный доступ к пространству имен)
С NVMeoF реализация vVols немного отличается. С традиционными SCSI vVols хранилищами контейнер является логической группировкой самих объектов vVol. С NVMeoF это варьируется в зависимости от того, как поставщик массива реализует функциональность. В общем и целом, на хранилище группа ANA является группировкой пространств имен vVol. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Пространства имен выделяются и активны только по запросу BIND к провайдеру VASA (VP). Пространства имен также добавляются в группу ANA при запросе BIND к VP. Пространство имен остается выделенным/активным до тех пор, пока последний хост не отвяжет vVol.
vPE (virtual Protocol Endpoint)
Для традиционных vVols на базе SCSI, protocol endpoint (PE) - это физический LUN или том на массиве, который отображается в появляется в разделе устройств хранения на хостах. С NVMeoF больше нет физического PE, PE теперь является логическим объектом, представлением группы ANA, в которой находятся vVols. Фактически, до тех пор, пока ВМ не запущена, vPE не существует. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Как только ВМ запущена, создается vPE, чтобы хост мог получить доступ к vVols в группе ANA. На диаграмме ниже вы можете увидеть, что vPE указывает на группу ANA на массиве.
NS (пространство имен, эквивалент LUN в NVMe)
Каждый тип vVol (Config, Swap, Data, Mem), созданный и использующийся машиной, создает NS, который находится в группе ANA. Это соотношение 1:1 между vVol и NS позволяет вендорам оборудования легко масштабировать объекты vVols. Обычно поставщики поддерживают тысячи, а иногда и сотни тысяч NS. Ограничения NS будут зависеть от модели массива.
На диаграмме вы можете увидеть, что сама виртуальная машина является NS, это будет Config vVol, а диск - это другой NS, Data vVol.
Поддержка 256 пространств имен и 2K путей с NVMe-TCP и NVMe-FC
NVMeoF продолжает набирать популярность по очевидным причинам - более высокая производительность и пропускная способность по сравнению с традиционным подключением SCSI или NFS. Многие производители хранилищ также переходят на NVMe-массивы и использование SCSI для доступа к NVMe флэш-накопителям является узким местом и потенциалом для улучшений.
Продолжая работать на этим, VMware увеличила поддерживаемое количество пространств имен и путей как для NVMe-FC, так и для TCP.
Расширение reservations для устройств NVMe
Добавлена поддержка команд reservations NVMe для использования таких решений, как WSFC. Это позволит клиентам использовать возможности кластеризованных дисков VMDK средствами Microsoft WSFC с хранилищами данных NVMeoF. Пока поддерживается только протокол FC.
Поддержка автообнаружения для NVMe Discovery Service на ESXi
Расширенная поддержка NVMe-oF в ESXi позволяет динамически обнаруживать совместимые со стандартом службы NVMe Discovery Service. ESXi использует службу mDNS/DNS-SD для получения информации, такой как IP-адрес и номер порта активных служб обнаружения NVMe-oF в сети.
Также ESXi отправляет многоадресный DNS-запрос (mDNS), запрашивая информацию от сущностей, предоставляющих службу обнаружения DNS-SD. Если такая сущность активна в сети (на которую был отправлен запрос), она отправит (одноадресный) ответ на хост с запрошенной информацией - IP-адрес и номер порта, где работает служба.
16. Улучшение очистки дискового пространства с помощью Unmap
Снижение минимальной скорости очистки до 10 МБ/с
Начиная с vSphere 6.7, была добавлена функция настройки скорости очистки (Unmap) на уровне хранилища данных. С помощью этого улучшения клиенты могут изменять скорость очистки на базе рекомендаций поставщика их массива. Более высокая скорость очистки позволяла многим пользователям быстро вернуть неиспользуемое дисковое пространство. Однако иногда даже при минимальной скорости очистки в 25 МБ/с она может быть слишком высокой и привести к проблемам при одновременной отправке команд Unmap несколькими хостами. Эти проблемы могут усугубляться при увеличении числа хостов на один датастор.
Пример возможной перегрузки: 25 МБ/с * 100 хранилищ данных * 40 хостов ~ 104 ГБ/с
Чтобы помочь клиентам в ситуациях, когда скорость очистки 25 МБ/с может приводить к проблемам, VMware снизила минимальную скорость до 10 МБ/с и сделала ее настраиваемой на уровне датасторов:
При необходимости вы также можете полностью отключить рекламацию пространства для заданного datastore.
Очередь планирования отдельных команд Unmap
Отдельная очередь планирования команд Unmap позволяет выделить высокоприоритетные операции ввода-вывода метаданных VMFS и обслуживать их из отдельных очередей планирования, чтобы избежать задержки их исполнения из-за других команд Unmap.
17. Контейнерное хранилище CNS/CSI
Теперь вы можете выбрать политику Thin provisioning (EZT, LZT) через SPBM для CNS/Tanzu.
Цель этого - добавить возможность политик SPBM для механизма создания/изменения правил политик хранения, которые используются для параметров выделения томов. Это также облегчает проверку соответствия правил выделения томов в политиках хранения для SPBM.
Операции, поддерживаемые для виртуальных дисков: создание, реконфигурация, клонирование и перемещение.
Операции, поддерживаемые для FCD: создание, обновление политики хранения, клонирование и перемещение.
18. Улучшения NFS
Инженеры VMware всегда работают над улучшением надежности доступа к хранилищам. В vSphere 8 были добавлены следующие улучшения NFS, повышающие надежность:
Повторные попытки монтирования NFS при сбое
Валидация монтирования NFS
Ну как вам работа ChatGPT с правками человека? Читабельно? Напишите в комментариях!
Многие администраторы сталкиваются с необходимостью обновления пакета VMware Tools в большом количестве виртуальных машин, работающих на серверах ESXi платформы VMware vSphere.
Общие сведения об обновлении VMware Tools
На данный момент можно использовать один из трех способов массового VMware Tools в большой инфраструктуре:
Применение средства VMware vSphere Lifecycle Manager (ранее его функционал был частью VMware Update Manager)
Написание сценариев для фреймворка VMware vSphere PowerCLI
Использование сторонних утилит для обновления тулзов
В отличие от версий аппаратной обеспечения (VM Hardware), компания VMware рекомендует всегда использовать последнюю версию пакета VMware Tools, для которого есть матрицы совместимости с различными версиями хостов ESXi. Посмотреть их можно по этой ссылке.
Например, мы видим, что VMware Tools 2016 года все еще можно использовать в ВМ на ESXi 7.0 U3. Также виртуальная машина на сервере VMware ESXi 5.5 может иметь текущую версию VMware Tools (сейчас это 12.1.5).
Напомним, что VMware Tools - это не только часть дистрибутива vSphere, но и отдельный продукт, который можно скачать с портала Customer Connect.
Есть несколько вариантов по загрузке этого пакета:
Бандл для общего репозитория Locker
(например, VMware-Tools-windows-12.1.5-20735119.zip) - он используется для создания локального или общего репозитория с нужной версией VMware Tools.
Установщик в гостевой ОС, который можно запустить в ней как исполняемый файл (VMware-tools-12.1.5-20735119-x86_64.exe.zip).
Пакеты для GuestStore
(gueststore-vmtools-12.1.5-20735119-20735876.zip) - это новая возможность, которая появилась в vSphere 7.0 U2. GuestStore сделан не для обновления VMware Tools, но может использоваться для этой цели (это тема для отдельной статьи).
Офлайн VIB-пакет с тулзами (VMware-Tools-12.1.5-core-offline-depot-ESXi-all-20735119.zip) - он используется как Baseline для обновления VMware Tools на хостах.
Исторически пакет VMware Tools, в основном, выпускался для Windows и Linux. Есть также версии этого пакета и для FreeBSD, Solaris и MacOS. Здесь есть следующие нюансы:
Начиная с версии VMware Tools 10.2.0, инсталляция на базе Perl-скриптов для FreeBSD больше не поддерживается. В этом случае также надо использовать open-vm-tools.
Последняя версия тулзов для гостевых ОС Solaris - это 10.3.10.
Как мы увидим дальше, очень важно знать, какая версия VMware Tools размещена локально на хосте ESXi после его установки. Эта версия может быть использована для проверки актуальных пакетов в виртуальных машинах. Для быстрой проверки текущей версии пакета на хосте можно использовать следующую команду:
esxcli software component get | grep VMware-VM-Tools -B 1 -A 14
Если вы хотите использовать для этого PowerCLI, то можно выполнить следующий сценарий:
Итак, рассмотрим обновление VMware Tools одним из двух способов:
Обновление VMware Tools как отдельного пакета ПО
В этом случае для нужно версии тулзов можно использовать любое средство, например Microsoft System Center, которое предназначено для массового развертывания программ. Также вы можете использовать любые скрипты и другие средства в режиме тихой установки (silent install).
Обновление VMware Tools посредством функционала vSphere
При развертывании и апгрейде хостов ESXi на них помещаются соответствующие версии VMware Tools (чтобы узнать список версий, загляните сюда). По умолчанию пакеты помещаются в папку /productLocker на хосте ESXi - это symbolic link, то есть просто указатель на настроенную папку. Чтобы узнать, какая версия VMware Tools является текущей, сервер vCenter сравнивает установленную версию тулзов в ВМ с версией, которая хранится в разделе /productLocker. Если актуальная версия в гостевой ОС меньше хранящейся на хосте, то в vSphere Client вы увидите соответствующее предупреждение:
Далее вам нужно выполнить процедуру, состоящую из двух основных шагов:
Настраиваем хост ESXi для использования определенной версии VMware Tools
Автоматизируем процесс обновления тулзов в гостевых ОС виртуальных машин
Шаг 1 - Настройка хоста ESXi для использования определенной версии VMware Tools
Надо сказать, что не рекомендуется вручную обновлять содержимое папки /productLocker, так как это не поддерживаемый официально процесс, и при апгрейде хоста вы можете получить более старую версию пакета. Также вы можете использовать конкретную версию VMware Tools для всех ВМ (например, ту, что содержит исправление конкретного бага).
Используем vSphere Lifecycle Manager для обновления VMware Tools на хостах ESXi
Это рекомендуемый способ обновления пакета VMware Tools, здесь может быть использован один из двух пакетов обновления хостов в кластере:
Если вы обновляете кластер, используя базовые уровни (baselines), вы можете создать кастомный образ, который включает желаемые версии VMware Tools, либо вы можете развернуть тулзы с использованием кастомного бейзлайна.
Давайте посмотрим на обновление с использованием метода Baseline:
Просто скачиваем VMware Tools Offline VIB bundle
Загружаем бандл на vSphere Lifecycle Manager (либо VIB-пакет может быть загружен этим продуктом автоматически)
Выполняем функцию Remediate для накатывания VMware Tools для ВМ на хостах ESXi
После успешного апдейта, локальный репозиторий VMware Tools также будет обновлен.
Несмотря на то, что хост не нужно перезагружать после обновления, он все равно должен быть помещен в режим обслуживания (maintenance mode). В противном случае, процесс обновления может выглядеть успешным, но в реальности изменений на хосте не произойдет.
Теперь посмотрим на процесс обновления VMware Tools методом Single Image:
В этом случае можно изменить только версию VMware Tools, а остальное можно оставить как есть.
Создаем общий репозиторий для нужной версии VMware Tools
Этот подход создает центральный репозиторий VMware Tools для нескольких хостов. В этом случае они не будут использовать локальный репозиторий, а на общем хранилище будет использоваться общая папка, которая станет новым репозиторием. Преимуществом данного подхода является обслуживание только одного экземпляра репозитория. Процесс создания этого репозитория описан в KB 2129825.
Как это выглядит по шагам:
1. Создаем на общем томе VMFS папку и устанавливаем для нее разрешения:
cd /vmfs/volumes/datastore
mkdir vmtools-repository-name
chmod 700 vmtools-repository-name
2. Если вы хотите использовать уже использованный репозиторий, то папку надо очистить:
3. Добавляем файлы, загруженные из Customer Connect и распакованные, в эту папку - у вас получится две подпапки, содержащие нужные файлы:
На скриншоте показан пример для VMware Tools под Windows. Если вы хотите использовать старые тулзы для Linux, то их нужно добавить в папку vmtools. Также посмотрите вот эту нашу статью о VMware Tools.
5. Если вы делаете процедуру впервые, то нужно настроить хосты ESXi для использования данной папки репозитория вместо используемой локальной папки по умолчанию. Для этого вам нужно добавить расширенную настройку UserVars.ProductLockerLocation (по умолчанию она указывает на /locker/packages/vmtoolsRepo/). Напомним, что /productLocker - это символьная ссылка, поэтому нужно использовать полный путь.
Так как мы обсуждаем массовое обновление тулзов, то имеет смысл показать здесь применение данного способа с использованием PowerCLI:
Для вывода текущей директории Locker выполняем следующий командлет:
Get-VMHost | Get-AdvancedSetting -Name "UserVars.ProductLockerLocation" | Select-Object Entity, Value
Для изменения директории выполняем такой командлет:
Будьте аккуратны при вызове второй команды, так как она меняет параметр на всех хостах, которые вы указали.
6. После этого вам нужно будет перезагрузить хост для обновления символьной ссылки /productLocker.
Шаг 2 - Автоматизация процесса обновления тулзов в гостевых ОС виртуальных машин
Теперь мы готовы автоматизировать апдейты VMware Tools в гостевой ОС. Так как мы говорим о массовом обновлении пакетов, то мы не будем обсуждать вариант с логином в гостевую ОС, монтирования ISO-образа и запуском exe-файла.
Сначала посмотрим, какие версии сейчас установлены в виртуальных машинах, с помощью PowerCLI. Запускаем следующую команду:
Это не самая удобная нотация, но она соответствует той, что мы видим на странице VM Summary на сервере vCenter. Для получения параметров этой команды используйте маппинг-файл версий.
4 способа автоматизации обновления VMware Tools в гостевой ОС:
1. Обновляем VMware Tools немедленно или ставим запланированную задачу через vCenter
Через интерфейс не всегда удобно работать с массовым обновлением, но в данном случае это можно сделать с помощью отфильтрованного списка ВМ и установки настроек по срабатыванию действий с объектами.
vSphere Lifecycle Manager имеет довольно мощный функционал в этом плане. Процесс обновления можно запланировать на базе состояния питания ВМ. Также можно задать опции предварительного создания снапшота ВМ.
Выбираем нужный кластер, идем на вкладку Updates и выбираем VMware Tools. Фильтруем нужные нам ВМ или выбираем все, далее кликаем Upgrade to match host. В следующих окнах у вас будет множество опций для создания запланированной задачи:
Вы можете не только настроить создания снапшота перед апдейтом, но и задать число часов, по истечении которых снапшот будет удален. Также в состав снапшота может входить и состояние оперативной памяти.
Также помните, что массовое удаление снапшотов в одно время может создать очень большую нагрузку на хранилище. Поэтому лучше снапшоты использовать только для самых критичных ВМ, которые должны сразу оказаться доступными в случае каких-либо проблем.
Дефолтные настройки для этих параметров вы можете установить здесь: Menu -> Lifecycle Manager -> Settings -> VMs:
2. Мгновенное обновление VMware Tools через vSphere PowerCLI
Для обновления тулзов на выбранных хостах (или всех) используется командлет Update-Tools. Он инициирует процесс обновления пакета изнутри гостевой ОС. По умолчанию Update-Tools ждет завершения обновления, после чего инициируется процесс перезагрузки ВМ. Это поведение можно изменить, используя параметры NoReboot и RunAsync.
Следующая команда начинает процесс обновления в виртуальной машине Win2019-01 в рамках задачи:
Get-VM Win2019-01 | Update-Tools –RunAsync
Чтобы посмотреть статус выполняемых задач, используйте команду Get-Task:
Так как это команда PowerShell - ее также можно добавить в запланированные задачи.
3. Обновление VMware Tools при следующей загрузке ВМ в интерфейсе vSphere Client
В рамках окна обслуживания виртуальные машины обычно можно перезагружать. Его, как раз, можно использовать и для обновления VMware Tools. Для этого надо настроить ВМ для проверки версии тулзов при загрузке. Если установленная версия меньше необходимой (по ссылке в /productLocker), то начинается процесс апдейта.
Для изменения политики обновлений, выберите нужный кластер и перейдите на вкладку Updates, где выберите VMware Tools. Там можно фильтровать список ВМ:
После того, как вы выберете машины, можно задать политику автообновления для них:
4. Обновление тулзов при следующей загрузке с использованием vSphere PowerCLI
Сначала посмотрим, текущую конфигурацию ВМ через PowerCLI:
Уделите особое внимание тому факту, какие ВМ вы поместите в переменную $VMs. При таком подходе для обновления VMware Tools вы не сможете запланировать создание предварительных снапшотов ВМ.
Иногда при работе администратора с виртуальными машинами VMware vSphere происходит ошибка при работе с дескрипторными файлами дисков VMDK, которая проявляет себя следующим образом:
Диск ВМ показывается в Datastore Browser, но иконка для него отсутствует
При включении ВМ вы получаете ошибку " File not found"
Сам файл ВМ вида <имя ВМ>-flat.vmdk есть в директории с машиной, но файла <имя ВМ>.vmdk вы не видите
Сам файл <имя ВМ>.vmdk отсутствует, либо он есть, но его содержимое повреждено
Эти симптомы могут возникать по разным причинам, но суть их одна - дескрипторный файл ВМ поврежден или отсутствует. Ситуация поправима, если у вас есть основный диск с данными - <имя ВМ>-flat.vmdk, и он сохранился в целости.
В 2012 году мы писали о том, как быть, если у вас возникла проблема с дескрипторным файлом виртуальной машины в среде VMware vSphere. В целом, с тех времен ничего особо не поменялось. Процесс этот довольно простой и описан в KB 1002511, также он детально разобран в видео ниже:
Часть 1 - восстановление основного VMDK виртуальной машины
Перед выполнением операций ниже обязательно сохраните полную копию папки виртуальной машины, и только после этого проводите все описанные ниже операции. Если у вас есть резервная копия виртуальной машины, и ее восстановление вас устраивает - то лучше сделать эту операцию вместо описанной ниже процедуры исправления дисков, так как вероятность ошибиться в ней велика.
Если вкратце, то для восстановления вам нужно выполнить следующие шаги:
1. Соединяемся с хостом VMware ESXi по SSH как root. Либо операции можно проводить непосредственно в консоли DCUI.
2. Переходим в папку с ВМ и определяем геометрию основного диска VMDK с данными <имя ВМ>-flat.vmdk
Делается это командой:
# ls -l <имя диска>-flat.vmdk
На выходе мы получим размер диска в байтах. Вывод будет выглядеть примерно так:
-rw------- 1 root root 4294967296 Oct 11 12:30 vmdisk0-flat.vmdk
3. Теперь нужно пересоздать заголовочный файл VMDK (<имя ВМ>.vmdk), чтобы он соответствовал диску с данными, используя тот же размер диска, полученный на предыдущем шаге:
# vmkfstools -c 4294967296 -a lsilogic -d thin temp.vmdk
После этого переименовываем дескрипторный VMDK-файл созданного диска в тот файл, который нам нужен для исходного диска. Затем удаляем только что созданный пустой диск данных нового диска, который уже не нужен (temp-flat.vmdk).
Если у изначальной машины диск был не растущим по мере наполнения (thin disk), то последнюю строчку, выделенную красным, можно не добавлять.
Вы также можете поменять тип адаптера ddb.adapterType = lsilogic на ddb.adapterType = pvscsi, если вы использовали паравиртуализованный SCSI-контроллер для исходной ВМ.
Консистентность виртуальной машины можно проверить командой:
vmkfstools -e filename.vmdk
Если все в порядке, то в ответе команды вы получите вот такую строчку:
Disk chain is consistent.
Если же исправить ситуацию не получилось, то будет вот такой текст:
Disk chain is not consistent : The parent virtual disk has been modified since the child was created. The content ID of the parent virtual disk does not match the corresponding parent content ID in the child (18).
После этого можно запускать виртуальную машину, добавив ее повторно в окружение vSphere Client.
Часть 2 - исправление дескрипторов файлов снапшотов ВМ (delta-файлы)
Ситуация усложняется, когда у исходной виртуальной машины были снапшоты, тогда папка с ней выглядит следующим образом (красным выделены важные для нас в дальнейших шагах файлы):
drwxr-xr-x 1 root root 1400 Aug 16 09:39 .
drwxr-xr-t 1 root root 2520 Aug 16 09:32 ..
-rw------- 1 root root 32768 Aug 17 19:11 examplevm-000002-delta.vmdk
-rw------- 1 root root 32768 Aug 17 19:11 examplevm-000002.vmdk
-rw------- 1 root root 32768 Aug 16 14:39 examplevm-000001-delta.vmdk
-rw------- 1 root root 32768 Aug 16 14:39 examplevm-000001.vmdk
-rw------- 1 root root 16106127360 Aug 16 09:32 examplevm-flat.vmdk
-rw------- 1 root root 469 Aug 16 09:32 examplevm.vmdk
-rw------- 1 root root 18396 Aug 16 14:39 examplevm-Snapshot1.vmsn
-rw------- 1 root root 18396 Aug 17 19:11 examplevm-Snapshot2.vmsn
-rw------- 1 root root 397 Aug 16 09:39 examplevm.vmsn
-rwxr-xr-x 1 root root 1626 Aug 16 09:39 examplevm.vmx
-rw------- 1 root root 259 Aug 16 09:36 examplevm.vmxf
Основной порядок действий в этой ситуации приведен в KB 1026353, здесь же мы опишем его вкратце (кстати, напомним про необходимость сделать полный бэкап всех файлов ВМ перед любыми операциями):
1. Определяем нужные нам файлы
Итак, заголовочные файлы снапшотов ВМ хранятся в так называемых файлах типа vmfsSparse, они же работают в связке с так называемым delta extent file, который непосредственно содержит данные (выше это, например, examplevm-000001-delta.vmdk).
Таким образом, опираясь на пример выше, нам интересны заголовочные файлы снапшотов examplevm-000001.vmdk и examplevm-000002.vmdk. Помните также, что диски и их снапшоты могут находиться в разных папках на разных датасторах, поэтому сначала вам нужно понять, где и что у вас хранится. Если у вас есть сомнения касательно имен нужных вам файлов, вы можете заглянуть в лог-файл vmware.log, чтобы увидеть там нужные пути к датасторам.
2. Создаем новый дескриптор снапшота
Итак, представим теперь, что файл examplevm-000001.vmdk у нас поврежден или отсутствует. Создадим новый дескриптор снапшота из исходного заголовочного файла examplevm.vmdk простым его копированием:
# cp examplevm.vmdk examplevm-000001.vmdk
3. Меняем указатели на файл с данными для снапшота
Теперь нужно открыть созданный файл в текстовом редакторе и начать его исправлять. Пусть он выглядит вот так:
# Disk DescriptorFile
version=1
encoding="UTF-8" CID=19741890
parentCID=ffffffff
createType="vmfs"
Красным мы выделили то, что будем в этом файле изменять, а синим - то, что будем удалять.
С данным файлом нужно сделать следующие манипуляции:
Строчку CID=19741890 заменяем на случайное восьмизначное значение (это идентификатор диска)
Строчку parentCID=ffffffff заменяем на parentCID=19741890 (идентификатор родительского диска, им может быть не только родительский основной диск, но и родительский снапшот, то есть его дескриптор)
Строчку createType="vmfs" заменяем на createType="vmfsSparse"
Строчку RW 31457280 VMFS "examplevm-flat.vmdk" заменяем на RW 31457280 VMFSSPARSE "examplevm-000001-delta.vmdk" (обратите внимание, что номер 31457280 остается тем же - он должен быть тем же самым для всей цепочки дочерних дисков)
4. Добавляем данные специфичные для снапшота
Теперь нам надо добавить в указатель снапшота кое-что новое:
Под строчкой createType="vmfsSparse" добавляем строчку
parentFileNameHint="examplevm.vmdk"
Ну и теперь надо убрать лишнее. Удаляем из файла следующие строчки, которые нужны только для основного родительского диска:
После этого вы можете попробовать запустить машину с дочерним снапшотом. Но перед этим также проверьте интеграцию дескриптора командой:
vmkfstools -e filename.vmdk
Ну и помните, что все эти действия по цепочке вы можете провернуть для следующих уровней дочерних снапшотов, если их диски с данными в порядке. Главное - не забывайте делать резервные копии перед любыми операциями!
На днях наш ценный читатель (и подсказыватель правильных вещей) Сергей заметил, что мы давно не упоминали об обновлениях средства SexiGraf для мониторинга виртуальной инфраструктуры VMware vSphere. В последний раз мы писали о нем осенью 2018 года вот тут (это был релиз White Forest).
Напомним, что это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
C 2018 года вышло 4 больших релиза SexiGraf, давайте рассмотрим их возможности вкратце.
Вот что появилось в релизе Traptown:
SuperStats - новые метрики уровня кластера, включающие в себя такие объекты, как hba, network, storage, power
vCenter Bad Events - возможность отслеживания "плохих" событий в инфраструктуре на уровне vCenter
Полный список всех обновлений SexiGraf и обзор новых функций можно найти на этой странице. Скачать виртуальный модуль в формате OVA можно по этой ссылке. Однако, как было отмечено, из России он не качается, поэтому перед скачиванием нужно включить VPN.

 RSS
RSS