Переход на VMware Cloud Foundation (VCF) 9 — это не просто обновление версии платформы. Он включает ребрендинг ключевых сервисов, перенос функций между компонентами, а также существенные улучшения управления жизненным циклом (Lifecycle Management). Для команд, планирующих миграцию с VCF 5.x, важно понимать, что именно изменилось: какие элементы остались прежними, какие переименованы, а какие были полностью заменены.
Об этом в общих чертах мы писали в прошлой статье, а сегодня разберём переход с VCF 5.x серии на версию VCF 9 через призму:
Сравнения ключевых компонентов
Архитектурных изменений
Обновлений управления жизненным циклом
Замены компонентов и блоков функционала
Обо всем этом рассказывается в видео ниже:
Базовая архитектура управления: что осталось неизменным
SDDC Manager — ядро VCF остаётся тем же
Один из наиболее важных выводов: SDDC Manager по-прежнему остаётся центральным движком управления VCF, и он:
Присутствует как в VCF 5, так и в VCF 9
Не меняет название (нет ребрендинга)
Остаётся основным интерфейсом управления инфраструктурой
Однако отмечается, что в VCF 9 функциональность SDDC Manager расширена и улучшена по сравнению с 5-й серией.
Это важно, потому что SDDC Manager — "точка сборки" всей архитектуры VCF: он стабильный и развивается, миграции проще планировать и стандартизировать.
Изменения бренда и унификация: Aria -> VCF Operations
Одно из наиболее заметных изменений VCF 9 — это масштабный ребрендинг линейки VMware Aria в сторону единого зонтичного бренда VCF Operations.
VMware Aria Operations -> VCF Operations
Ранее компонент VMware Aria Operations выполнял роль:
Централизованных дашбордов
Мониторинга инфраструктуры
Уведомлений и alerting
SNMP-настроек
Кастомной отчётности (например, oversizing виртуальных машин)
Capacity planning
В VCF 9 этот же компонент переименован как часть стратегии VMware по движению к унифицированной "operations-платформе" в рамках VCF. Функционально компонент выполняет те же задачи, но позиционирование стало единым для всей платформы.
Operations-экосистема: логирование и сетевые инсайты
Aria Operations for Logs -> VCF Operations for Logs
Компонент логирования в VCF 5 назывался по-разному в средах заказчиков: Aria Operations for Logs и Log Insight. По сути — это централизованный syslog-агрегатор и анализатор, собирающий логи от всех компонентов VCF. В VCF 9 Aria Operations for Logs переименован VCF Operations for Logs. Функционально это тот же концепт, сбор логов остаётся централизованным и управляется как часть единого "Operations-стека".
Aria Operations for Network Insights -> VCF Operations for Network
Сетевой компонент прошёл длинный путь переименований: vRealize Network Insight, затем Aria Operations for Networks и, наконец, в VCF 9 он называется VCF Operations for Network.
Он обеспечивает:
Централизованный мониторинг сети
Диагностику
Анализ сетевого трафика
Возможности packet capture от источника до назначения
В VCF 5 жизненным циклом (апдейты/апгрейды) занимался компонент Aria Lifecycle Management (LCM), В VCF 9 сделан важный шаг - появился компонент VCF Operations Fleet Management. Это не просто переименование - продукт получил улучшенную функциональность, управление обновлениями и версиями стало более "streamlined", то есть рациональным и оптимизированным, а также появился акцент на fleet-подход: управление инфраструктурой как "парком платформ".
Fleet Management способен управлять несколькими инстансами VCF, что становится особенно важным для крупных организаций и распределённых инфраструктур. Именно тут виден "архитектурный сдвиг": VCF 9 проектируется не только как платформа для одного частного облака, а как унифицированная экосистема для гибридных и мультиинстанс-сценариев.
Feature transition: замена Workspace ONE Access
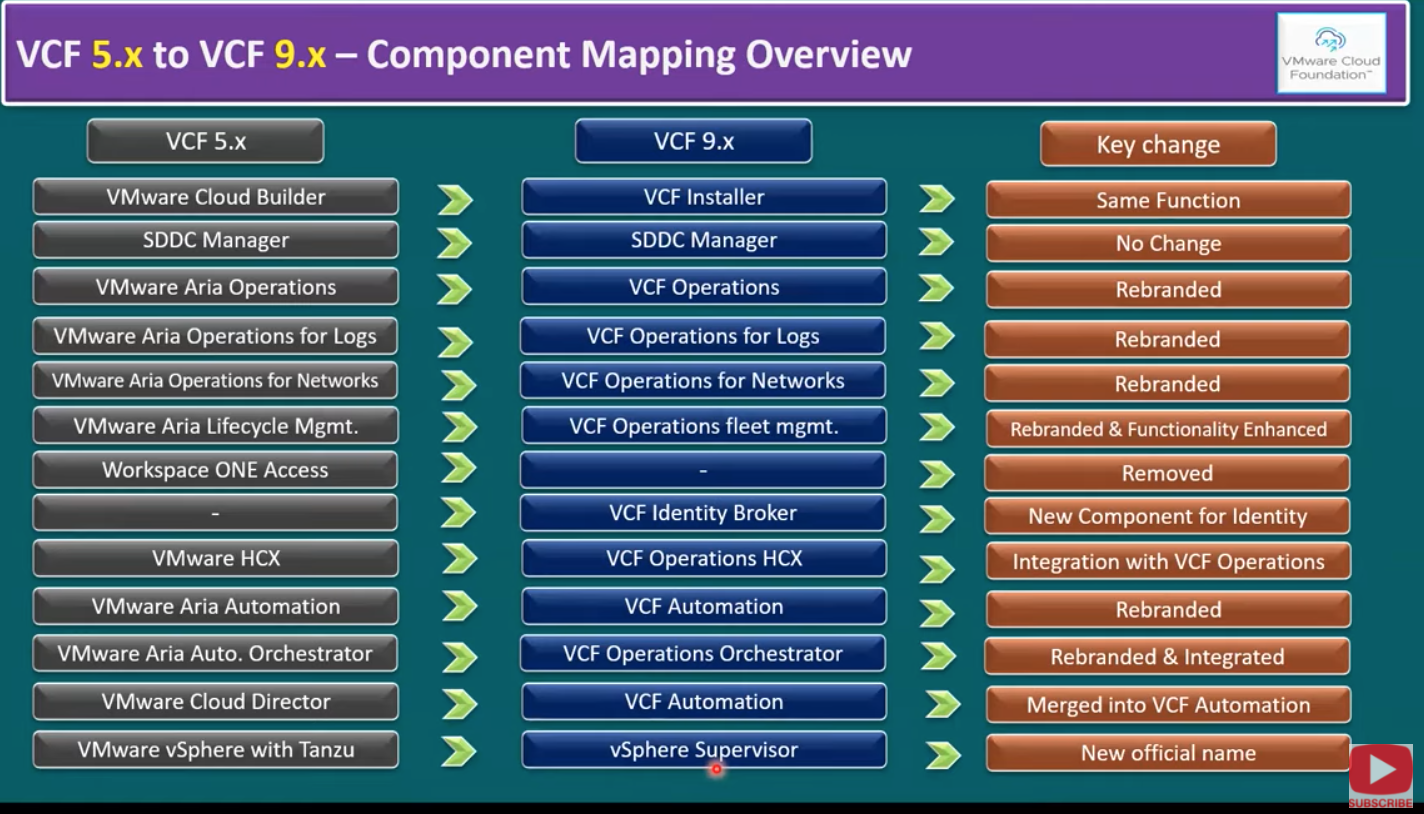
Workspace ONE Access удалён -> VCF Identity Broker
Одно из самых "жёстких" изменений — это не ребрендинг, а полная замена компонента. Workspace ONE Access полностью удалён (removed), вместо него введён новый компонент VCF Identity Broker. Это новый компонент для управления идентификацией (identity management), интеграции доступа, IAM-сценариев (identity access management), интеграции авторизации/аутентификации для экосистемы VCF.
Миграция и перемещение рабочих нагрузок: HCX теперь - часть Operations
VMware HCX -> VCF Operations HCX
HCX остаётся инструментом для пакетной миграции виртуальных машин (bulk migration) и миграций из одной локации в другую (в т.ч. удалённые площадки). Но в VCF 9 меняется позиционирование продукта: он теперь полностью интегрирован в VCF Operations и называется VCF Operations HCX. То есть HCX становится частью единого "операционного" контура VCF 9.
Автоматизация: упрощение названий и интеграция компонентов
Aria Automation -> VCF Automation
Это компонент автоматизации, отвечающий за сценарии и рабочие процессы частного облака, развертывание рабочих нагрузок и ежедневные операции. В VCF 9 это просто VCF Automation.
Orchestrator используется для end-to-end рабочих процессов и автоматизации процессов создания ВМ и операций. В VCF 9 это теперь просто VCF Operations Orchestrator. Это важно: Orchestrator закрепляется как часть "operations-логики", а не просто автономный компонент автоматизации.
VMware Cloud Director: интеграция/поглощение в VCF Automation
Теперь VMware Cloud Director имеет новое позиционирование: продукт полностью интегрирован в VCF Automation. То есть Cloud Director как самостоятельное наименование уходит на второй план, а функции “переезжают” или связываются с модулем VCF Automation.
Слой Kubernetes: vSphere with Tanzu -> vSphere Supervisor
vSphere with Tanzu переименован в vSphere Supervisor
Это важное изменение, отражающее стратегию VCF по треку modern apps. Supervisor рассматривается как компонент для приложений новой волны, перехода monolith > microservices, контейнерного слоя и инфраструктуры enterprise-grade Kubernetes.
Платформа VCF при этом описывается как:
Unified Cloud Platform
Подходит для частного облака
Интегрируется с hyperscalers (AWS, Azure, Google Cloud и т.д.)
Поддерживает enterprise Kubernetes services
Итоги: что означает переход VCF 5 -> VCF 9 для архитектуры и миграции
Переход от VCF 5.x к VCF 9 — это комбинация трёх больших тенденций:
1) Унификация бренда и операционной модели
Aria-компоненты массово становятся частью семейства VCF Operations.
2) Улучшение управления жизненным циклом
LCM эволюционирует в Fleet Management, что отражает переход к управлению группами платформ и множественными VCF-инстансами.
3) Feature transitions (замены функций и ролей компонентов)
Самое заметное — удаление Workspace ONE Access и введение VCF Identity Broker.
Cоответствие компонентов VCF 5.x и VCF 9
SDDC Manager -> SDDC Manager (улучшен)
Aria Operations -> VCF Operations
Aria Operations for Logs -> VCF Operations for Logs
Aria Operations for Network Insights -> VCF Operations for Network
Aria LCM -> VCF Operations Fleet Management
Workspace ONE Access -> VCF Identity Broker (замена продукта)
В новом видео на канале Gnan Cloud Garage подробно разобраны ключевые отличия между VMware Cloud Foundation (VCF) версии 5.2 и VCF 9.0, причем автор подчеркивает: речь идёт не о простом обновлении, а о кардинальной архитектурной переработке платформы.
VCF — это флагманская платформа частного облака от компании VMware, объединяющая вычисления, сеть, хранилище, безопасность, автоматизацию и управление жизненным циклом в едином программно-определяемом стеке. В версии 9.0 VMware делает шаг в сторону «облачного» подхода, ориентированного на масштаб, автоматизацию и гибкость.
Основные отличия VCF 5.2 и VCF 9.0
1. Модель развертывания
VCF 5.2: установка строилась вокруг SDDC Manager и требовала загрузки Cloud Builder размером около 20 ГБ. Развёртывание компонентов происходило последовательно.
VCF 9.0: представлен новый VCF Installer (~2 ГБ) и fleet-based модель. Это обеспечивает более быстрое развертывание, модульную архитектуру и гибкость с первого дня.
Результат: ускорение внедрения и переход от монолитного подхода к модульному.
2. Управление жизненным циклом (LCM)
VCF 5.2: весь LCM был сосредоточен в SDDC Manager.
VCF 9.0: управление разделено между Fleet Management Appliance и SDDC Manager.
Fleet Management отвечает за операции, автоматизацию и управление идентификацией.
SDDC Manager фокусируется на базовой инфраструктуре.
Результат: параллельные обновления, меньшее время простоя и более точный контроль.
3. Управление идентификацией
VCF 5.2: использовались Enhanced Linked Mode и vCenter Identity.
VCF 9.0: внедрены VCF Single Sign-On и VCF Identity Broker, обеспечивающие единую систему идентификации для всех компонентов.
Результат: действительно унифицированная и современная модель identity management.
4. Лицензирование
VCF 5.2: традиционные лицензии — по продуктам и ключам (vSphere, NSX, vSAN, Aria).
VCF 9.0: keyless subscription model — без ключей, с подпиской.
Результат: упрощённое соответствие требованиям, обновления и соответствие современным облачным моделям потребления.
VCF 9.0: операции встроены по умолчанию, обеспечивая fleet-wide мониторинг и compliance «из коробки».
6. Автоматизация
VCF 5.2: автоматизация была дополнительной опцией.
VCF 9.0: решение VCF Automation встроено и оптимизировано для:
AI-нагрузок
Kubernetes
виртуальных машин
Результат: платформа самообслуживания, полностью готовая для разработчиков.
7. Сеть
VCF 5.2: NSX — опциональный компонент.
VCF 9.0: NSX становится обязательным для management и workload-доменов.
Результат: единая программно-определяемая сетевая архитектура во всей среде VCF.
8. Хранилище
VCF 5.2: поддержка vSAN, NFS и Fibre Channel SAN.
VCF 9.0: акцент на vSAN ESA (Express Storage Architecture) и Original Storage Architecture, с планами по расширению поддержки внешних хранилищ.
Результат: фундамент для более современной и производительной storage-архитектуры.
9. Безопасность и соответствие требованиям
VCF 5.2: ручное управление сертификатами и патчами.
VCF 9.0: встроенные средства управления:
унифицированное управление ключами
live patching
secure-by-default подход
Результат: серьёзная модернизация безопасности и Zero Trust по умолчанию.
10. Модель обновлений
VCF 5.2: последовательные апгрейды.
VCF 9.0: параллельные обновления с учётом fleet-aware LCM.
Результат: меньше простоев и лучшая предсказуемость обслуживания.
11. Kubernetes и контейнеры
VCF 5.2: ограниченная поддержка Tanzu.
VCF 9.0: нативный Kubernetes через VCF Automation.
Результат: единая платформа для VM и Kubernetes — полноценная application platform.
12. Импорт существующих сред
VCF 5.2: импорт существующих vSphere/vCenter не поддерживался.
VCF 9.0: можно импортировать существующие окружения как management или workload-домены.
Результат: упрощённая миграция legacy-нагрузок в современное частное облако.
Итог
VCF 5.2 — это классическая платформа частного облака с опциональными возможностями, ну а VCF 9.0 — это современное, cloud-like частное и гибридное облако, ориентированное на масштабирование, автоматизацию и управление флотом инфраструктуры.
Как подчёркивает автор видео, VCF 9.0 — это не апгрейд, а полноценный редизайн, нацеленный на лучший пользовательский опыт и соответствие требованиям современных enterprise и облачных сред.
В этой части статьи мы продолжаем рассказывать об итогах 2025 года в плане серверной и настольной виртуализации на базе российских решений. Первую часть статьи можно прочитать тут.
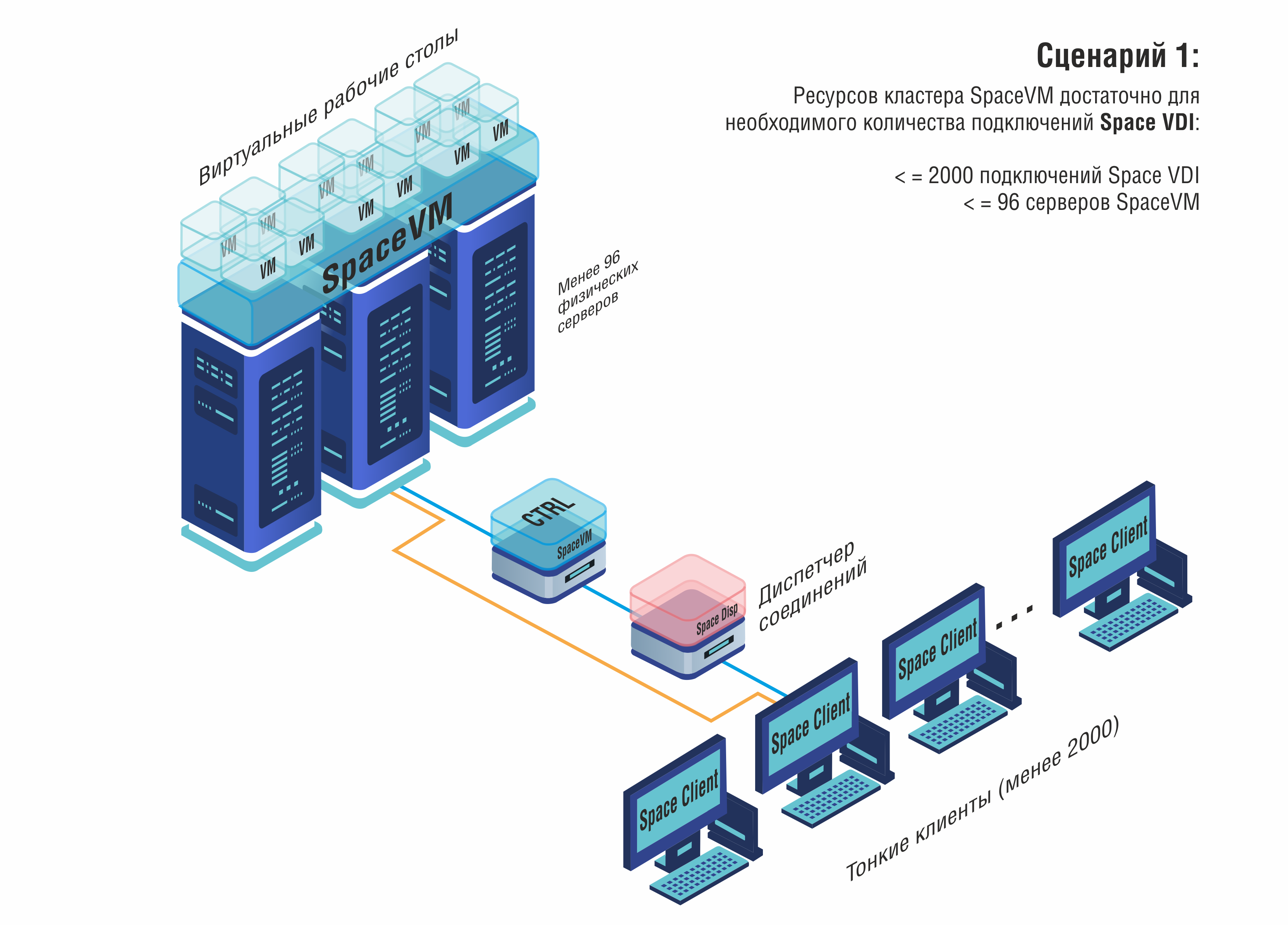
Возможности VDI (виртуализации рабочих мест)
Импортозамещение коснулось не только серверной виртуализации, но и инфраструктуры виртуальных рабочих столов (VDI). После ухода VMware Horizon (сейчас это решение Omnissa) и Citrix XenDesktop российские компании начали внедрять отечественные VDI-решения для обеспечения удалённой работы сотрудников и центрального управления рабочими станциями. К 2025 году сформировался пул новых продуктов, позволяющих развернуть полнофункциональную VDI-платформу на базе отечественных технологий.
Лидерами рынка VDI стали решения, созданные в тесной связке с платформами серверной виртуализации. Так, компания «ДАКОМ М» (бренд Space) помимо гипервизора SpaceVM предложила продукт Space VDI – систему управления виртуальными рабочими столами, интегрированную в их экосистему. Space VDI заняла 1-е место в рейтинге российских VDI-решений 2025 г., набрав 228 баллов по совокупности критериев.
Её сильные стороны – полностью собственная разработка брокера и агентов (не опирающаяся на чужие open-source) и наличие всех компонентов, аналогичных VMware Horizon: Space Dispatcher (диспетчер VDI, альтернатива Horizon Connection Server), Space Agent VDI (клиентский агент на виртуальной машине, аналог VMware Horizon Agent), Space Client для подключения с пользовательских устройств, и собственный протокол удалённых рабочих столов GLINT. Протокол GLINT разработан как замена зарубежных (RDP/PCoIP), оптимизирован для работы в российских сетях и обеспечивает сжатие/шифрование трафика. В частности, заявляется поддержка мультимедиа-ускорения и USB-перенаправления через модуль Mediapipe, который служит аналогом Citrix HDX. В результате Space VDI предоставляет высокую производительность графического интерфейса и мультимедиа, сравнимую с мировыми аналогами, при этом полностью вписывается в отечественный контур безопасности.
Вторым крупным игроком стала компания HOSTVM с продуктом HostVM VDI. Этот продукт изначально основыван на открытой платформе UDS (VirtualCable) и веб-интерфейсе на Angular, но адаптирован российским разработчиком. HostVM VDI поддерживает широкий набор протоколов – SPICE, RDP, VNC, NX, PCoIP, X2Go, HTML5 – фактически покрывая все популярные способы удалённого доступа. Такая всеядность упрощает миграцию с иностранных систем: например, если ранее использовался протокол PCoIP (как в VMware Horizon), HostVM VDI тоже его поддерживает. Решение заняло 2-е место в отраслевом рейтинге с 218 баллами, немного уступив Space VDI по глубине интеграции функций.
Своеобразный подход продемонстрировал РЕД СОФТ. Их продукт «РЕД Виртуализация» является, в первую очередь, серверной платформой (форком oVirt на KVM) для развертывания ВМ. Однако благодаря тесной интеграции с РЕД ОС и другим ПО компании, Red Виртуализация может использоваться и для VDI-сценариев. Она заняла 3-е место в рейтинге VDI-платформ. По сути, РЕД предлагает создать инфраструктуру на базе своего гипервизора и доставлять пользователям рабочие столы через стандартные протоколы (для Windows-ВМ – RDP, для Linux – SPICE или VNC). В частности, поддерживаются протоколы VNC, SPICE и RDP, что покрывает базовые потребности. Кроме того, заявлена возможность миграции виртуальных машин в РЕД Виртуализацию прямо из сред VMware vSphere и Microsoft Hyper-V, что упрощает переход на решение.
Далее, существуют специализированные отечественные VDI-продукты: ROSA VDI, Veil VDI, Termidesk и др.
ROSA VDI (разработка НТЦ ИТ РОСА) базируется на том же oVirt и ориентирована на интеграцию с российскими ОС РОСА.
Veil VDI – решение компаний «НИИ Масштаб»/Uveon – представляет собственную разработку брокера виртуальных рабочих столов; оно также попало в топ-5 рейтинга.
Termidesk – ещё одна проприетарная система, замыкающая первую шестёрку лидеров. Каждая из них предлагает конкурентоспособные функции, хотя по некоторым пунктам уступает лидерам. Например, Veil VDI и Termidesk пока набрали меньше баллов (182 и 174 соответственно) и, вероятно, имеют более узкую специализацию или меньшую базу внедрений.
Общей чертой российских VDI-платформ является ориентация на безопасность и импортозамещение. Все они зарегистрированы как отечественное ПО и могут применяться вместо VMware Horizon, Citrix или Microsoft RDS. С точки зрения пользовательского опыта, основные функции реализованы: пользователи могут подключаться к своим виртуальным рабочим столам с любых устройств (ПК, тонкие клиенты, планшеты) через удобные клиенты или даже браузер. Администраторы получают централизованную консоль для создания образов ВМ, массового обновления ПО на виртуальных рабочих столах и мониторинга активности пользователей. Многие решения интегрируются с инфраструктурой виртуализации серверов – например, Space VDI напрямую работает поверх гипервизора SpaceVM, ROSA VDI – поверх ROSA Virtualization, что упрощает установку.
Отдельно стоит отметить поддержку мультимедийных протоколов и оптимизацию трафика. Поскольку качество работы VDI сильно зависит от протокола передачи картинки, разработчики добавляют собственные улучшения. Мы уже упомянули GLINT (Space) и широкий набор протоколов в HostVM. Также используется протокол Loudplay – это отечественная разработка в области облачного гейминга, адаптированная под VDI.
Некоторые платформы (например, Space VDI, ROSA VDI, Termidesk) заявляют поддержку Loudplay наряду со SPICE/RDP, чтобы обеспечить плавную передачу видео и 3D-графики даже в сетях с высокой задержкой. Терминальные протоколы оптимизированы под российские условия: так, Termidesk применяет собственный кодек TERA для сжатия видео и звука. В результате пользователи могут комфортно работать с графическими приложениями, CAD-системами и видео в своих виртуальных десктопах.
С точки зрения масштабируемости VDI, российские решения способны обслуживать от десятков до нескольких тысяч одновременных пользователей. Лабораторные испытания показывают, что Space VDI и HostVM VDI могут управлять тысячами виртуальных рабочих столов в распределенной инфраструктуре (с добавлением необходимых серверных мощностей). Важным моментом остаётся интеграция со средствами обеспечения безопасности: многие платформы поддерживают подключение СЗИ для контроля за пользователями (DLP-системы, антивирусы на виртуальных рабочих местах) и могут работать в замкнутых контурах без доступа в интернет.
Таким образом, к концу 2025 года отечественные VDI-платформы покрывают основные потребности удалённой работы. Они позволяют централизованно развертывать и обновлять рабочие места, сохранять данные в защищённом контуре датацентра и предоставлять сотрудникам доступ к нужным приложениям из любой точки. При этом особый акцент сделан на совместимость с российским стеком (ОС, ПО, требования регуляторов) и на возможность миграции с западных систем с минимальными затратами (поддержка разных протоколов, перенос ВМ из VMware/Hyper-V). Конечно, каждой организации предстоит выбрать оптимальный продукт под свои задачи – лидеры рынка (Space VDI, HostVM, Red/ROSA) уже имеют успешные внедрения, тогда как нишевые решения могут подойти под специальные сценарии.
Кластеризация, отказоустойчивость и управление ресурсами
Функциональность, связанная с обеспечением высокой доступности (HA) и отказоустойчивости, а также удобством управления ресурсами, является критичной при сравнении платформ виртуализации. Рассмотрим, как обстоят дела с этими возможностями у российских продуктов по сравнению с VMware vSphere.
Кластеризация и высокая доступность (HA)
Почти все отечественные системы поддерживают объединение хостов в кластеры и автоматический перезапуск ВМ на доступных узлах в случае сбоя одного из серверов – аналог функции VMware HA. Например, SpaceVM имеет встроенную поддержку High Availability для кластеров: при падении хоста его виртуальные машины автоматически запускаются на других узлах кластера.
Basis Dynamix, VMmanager, Red Virtualization – все они также включают механизмы мониторинга узлов и перезапуска ВМ при отказе, что отражено в их спецификациях (наличие HA подтверждалось анкетами рейтингов). По сути, обеспечение базовой отказоустойчивости сейчас является стандартной функцией для любых платформ виртуализации. Важно отметить, что для корректной работы HA требуется резерв мощности в кластере (чтобы были свободные ресурсы для поднятия упавших нагрузок), поэтому администраторы должны планировать кластеры с некоторым запасом хостов, аналогично VMware.
Fault Tolerance (FT)
Более продвинутый режим отказоустойчивости – Fault Tolerance, при котором одна ВМ дублируется на другом хосте в режиме реального времени (две копии работают синхронно, и при сбое одной – вторая продолжает работать без прерывания сервиса). В VMware FT реализован для критичных нагрузок, но накладывает ограничения (например, количество vCPU). В российских решениях прямая аналогия FT практически не встречается. Тем не менее, некоторые разработчики заявляют поддержку подобных механизмов. В частности, Basis Dynamix Enterprise в материалах указывал наличие функции Fault Tolerance. Однако широкого распространения FT не получила – эта технология сложна в реализации, а также требовательна к каналам связи. Обычно достаточен более простой подход (HA с быстрым перезапуском, кластерные приложения на уровне ОС и т.п.). В критических сценариях (банковские системы реального времени и др.) могут быть построены решения с FT на базе метрокластеров, но это скорее штучные проекты.
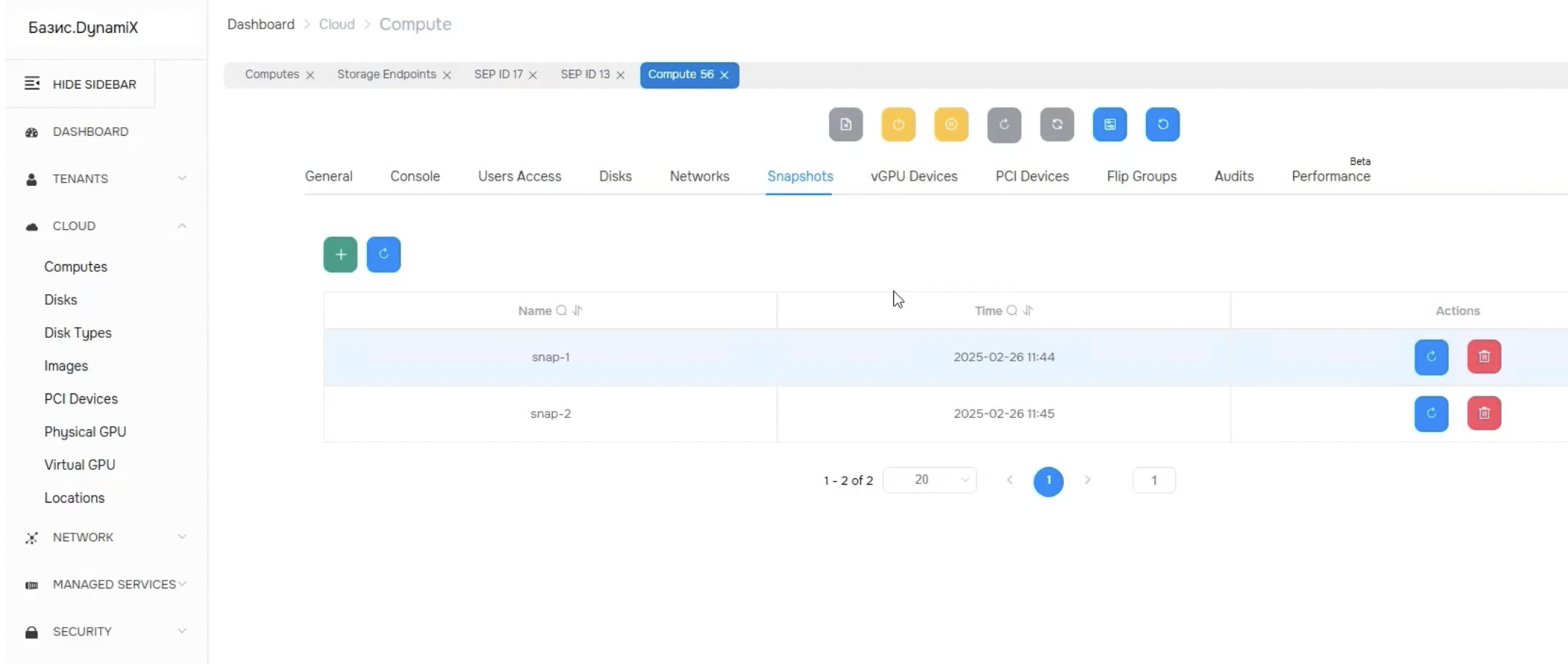
Снапшоты и резервное копирование
Снимки состояния ВМ (snapshots) – необходимая функция для безопасных изменений и откатов. Все современные платформы (zVirt, SpaceVM, Red и прочие) поддерживают создание мгновенных снапшотов ВМ в рабочем состоянии. Как правило, доступны возможности делать цепочки снимков, однако требования к хранению диктуют, что постоянно держать много снапшотов нежелательно (как и в VMware, где они влияют на производительность). Для резервного копирования обычно предлагается интеграция с внешними системами бэкапа либо встроенные средства экспорта ВМ.
Например, SpaceVM имеет встроенное резервное копирование ВМ с возможностью сохранения бэкапов на удалённое хранилище. VMmanager от ISPsystem также предоставляет модуль бэкапа. Тем не менее, организации часто используют сторонние системы резервирования – здесь важно, что у российских гипервизоров обычно открыт API для интеграции. Почти все продукты предоставляют REST API или SDK, позволяющий автоматизировать задачи бэкапа, мониторинга и пр. Отдельные вендоры (например, Basis) декларируют принцип API-first, что упрощает связку с оркестраторами резервного копирования и мониторинга.
Управление ресурсами и балансировка
Мы уже упоминали наличие аналогов DRS в некоторых платформах (автоматическое перераспределение ВМ). Кроме этого, важно, как реализовано ручное управление ресурсами: пулы CPU/памяти, приоритеты, квоты. В VMware vSphere есть ресурсные пулы и shares-приоритеты. В российских системах подобные механизмы тоже появляются. zVirt, например, позволяет объединять хосты в логические группы и задавать политику размещения ВМ, что помогает распределять нагрузку. Red Virtualization (oVirt) исторически поддерживает задание весов и ограничений на ЦП и ОЗУ для групп виртуальных машин. В Basis Dynamix управление ресурсами интегрировано с IaC-инструментами – можно через Terraform описывать необходимые ресурсы, а платформа сама их выделит.
Такое тесное сочетание с DevOps-подходами – одно из преимуществ новых продуктов: Basis и SpaceVM интегрируются с Ansible, Terraform для автоматического развертывания инфраструктуры как кода. Это позволяет компаниям гибко управлять ИТ-ресурсами и быстро масштабировать кластеры или развертывать новые ВМ по шаблонам.
Управление кластерами
Центральная консоль управления кластером – обязательный компонент. Аналог VMware vCenter в отечественных решениях присутствует везде, хотя может называться по-разному. Например, у Space – SpaceVM Controller (он же выполняет роль менеджера кластера, аналог vCenter). У zVirt – собственная веб-консоль, у Red Virtualization – знакомый интерфейс oVirt Engine, у VMmanager – веб-панель от ISPsystem. То есть любой выбранный продукт предоставляет единый интерфейс для управления всеми узлами, ВМ и ресурсами. Многие консоли русифицированы и достаточно дружелюбны. Однако по отзывам специалистов, удобство администрирования ещё требует улучшений: отмечается, что ряд операций в отечественных платформах более трудоёмкие или требуют «танцев с бубном» по сравнению с отлаженным UI VMware. Например, на Хабре приводился пример, что создание простой ВМ в некоторых системах превращается в квест с редактированием конфигурационных файлов и чтением документации, тогда как в VMware это несколько кликов мастера создания ВМ. Это как раз то направление, где нашим решениям ещё есть куда расти – UX и простота администрирования.
В плане кластеризации и отказоустойчивости можно заключить, что функционально российские платформы предоставляют почти весь минимально необходимый набор возможностей. Кластеры, миграция ВМ, HA, снапшоты, бэкап, распределенная сеть, интеграция со сториджами – всё это реализовано (см. сводную таблицу ниже). Тем не менее, зрелость реализации зачастую ниже: возможны нюансы при очень крупных масштабах, не все функции могут быть такими же «отполированными» как у VMware, а администрирование требует большей квалификации.
Платформа
Разработчик
Технологическая основа
Особенности архитектуры
Ключевые сильные стороны
Известные ограничения
Basis Dynamix
БАЗИС
Собственная разработка (KVM-совместима)
Классическая и гибридная архитектура (есть Standard и Enterprise варианты)
Высокая производительность, интеграция с Ansible/Terraform, единая экосистема (репозиторий, поддержка); востребован в госсекторе.
Мало публичной информации о тонкостях; относительно новый продукт, требует настройки под задачу.
SpaceVM
ДАКОМ M (Space)
Проприетарная (собственный стек гипервизора)
Классическая архитектура, интеграция с внешними СХД + проприетарные HCI-компоненты (FreeGRID, SDN Flow)
Максимально функциональная платформа: GPU-виртуализация (FreeGRID), своя SDN (аналог NSX), полный VDI-комплекс (Space VDI) и собственные протоколы; высокое быстродействие.
Более сложное администрирование (богатство функций = сложность настроек).
zVirt
Orion soft
Форк oVirt (KVM) + собственный бэкенд
Классическая модель, SDN-сеть внутри (distributed vSwitch)
Богатый набор функций: микросегментация сети SDN, Storage Live Migration, авто-балансировка ресурсов (DRS-аналог), совместим с открытой экосистемой oVirt; крупнейшая инсталляционная база (21k+ хостов ожидается).
Проблемы масштабируемости на очень больших кластерах (>50 узлов); интерфейс менее удобен, чем VMware (выше порог входа).
Red Виртуализация
РЕД СОФТ
Форк oVirt (KVM)
Классическая схема, тесная интеграция с РЕД OS и ПО РЕД СОФТ
Знакомая VMware-подобная архитектура; из коробки многие функции (SAN, HA и др.); сертификация ФСТЭК РЕД ОС дает базу для безопасности; успешные кейсы миграции (Росельхозбанк, др.).
Более ограниченная экосистема поддержки (сильно завязана на продукты РЕД); обновления зависят от развития форка oVirt (нужны ресурсы на самостоятельную разработку).
vStack HCP
vStack (Россия)
FreeBSD + bhyve (HCI-платформа)
Гиперконвергентная архитектура, собственный легковесный гипервизор
Минимальные накладные расходы (2–5% CPU), масштабируемость «без ограничений» (нет фикс. лимитов на узлы/ВМ), единый веб-интерфейс; независим от Linux.
Относительно новая/экзотичная технология (FreeBSD), сообщество меньше; возможно меньше совместимых сторонних инструментов (бэкап, драйверы).
Cyber Infrastructure
Киберпротект
OpenStack + собственные улучшения (HCI)
Гиперконвергенция (Ceph-хранилище), поддержка внешних СХД
Глубокая интеграция с резервным копированием (наследие Acronis), сертификация ФСТЭК AccentOS (OpenStack), масштабируемость для облаков; работает на отечественном оборудовании.
Менее подходит для нагрузок, требующих стабильности отдельной ВМ (особенности OpenStack); сложнее в установке и сопровождении без экспертизы OpenStack.
Другие (ROSA, Numa, HostVM)
НТЦ ИТ РОСА, Нума Техн., HostVM
KVM (oVirt), Xen (xcp-ng), KVM+UDS и др.
В основном классические, частично HCI
Закрывают узкие ниши или предлагают привычный функционал для своих аудиторий (например, Xen для любителей XenServer, ROSA для Linux-инфраструктур). Часто совместимы с специфическими отечественными ОС (ROSA, ALT).
Как правило, менее функционально богаты (ниже баллы рейтингов); меньшая команда разработки = более медленное развитие.
Дорогие читатели, партнёры, коллеги-блогеры и рекламодатели!
Поздравляем вас с наступающим Новым годом и светлым праздником Рождества! Пусть эти дни станут временем перезагрузки, вдохновения и новых идей - так же, как удачно настроенная виртуальная среда даёт пространство для роста и экспериментов.
Прошедший год был насыщен изменениями: развивались продукты и облачные платформы, появлялись новые подходы к контейнеризации, безопасности и управлению виртуальной инфраструктурой, особенно в российской экосистеме. Спасибо нашим читателям — за интерес, доверие и живые обсуждения, партнёрам — за сотрудничество и совместные проекты, коллегам-блогерам — за обмен опытом и экспертизой, рекламодателям — за поддержку и веру в наш ресурс.
В новом году желаем вам стабильных систем, предсказуемой нагрузки, минимального даунтайма и максимальной отдачи от технологий. Пусть ваши проекты масштабируются легко, решения будут элегантными, а результаты — впечатляющими.
Спасибо, что вы с нами. До встречи в новом году — с новыми материалами, тестами, обзорами и идеями!
Виртуализация давно стала неотъемлемой частью корпоративной ИТ-инфраструктуры, позволяя эффективнее использовать серверное оборудование и быстро развертывать новые сервисы. До недавнего времени российский рынок практически полностью зависел от зарубежных продуктов – особенно от VMware, на долю которого приходилось до 95% внедрений. Однако после 2022 года ситуация резко изменилась: VMware покинула российский рынок, отключив аккаунты пользователей и прекратив поддержку.
Это оставило компании без обновлений, техподдержки и возможности покупки новых лицензий. Одновременно регуляторы ужесточили требования: с 1 января 2025 года значимые объекты критической информационной инфраструктуры (КИИ) обязаны использовать только отечественное ПО. В результате переход на российские системы виртуализации из опции превратился в необходимость, и за три года рынок претерпел заметную консолидацию.
По данным исследования компании «Код Безопасности», уже 78% российских организаций выбирают отечественные средства виртуализации. В реестре российского ПО на 2025 год значатся порядка 92 решений для серверной виртуализации, из которых реально «живых» около 30, а активно используемых – не более десятка. За короткий срок появились аналоги западных продуктов «большой тройки» (VMware, Microsoft Hyper-V, Citrix) и собственные разработки российских компаний. Рассмотрим новейшие российские платформы виртуализации серверов и инфраструктуры виртуальных рабочих мест (VDI) и проанализируем их архитектуру, производительность, безопасность, возможности VDI, а также функции кластеризации и управления ресурсами. Отдельно сравним их с VMware VCF/vSphere по функциональности, зрелости технологий, совместимости и поддержке – и определим, какие решения наиболее перспективны для импортозамещения VMware в корпоративных ИТ России.
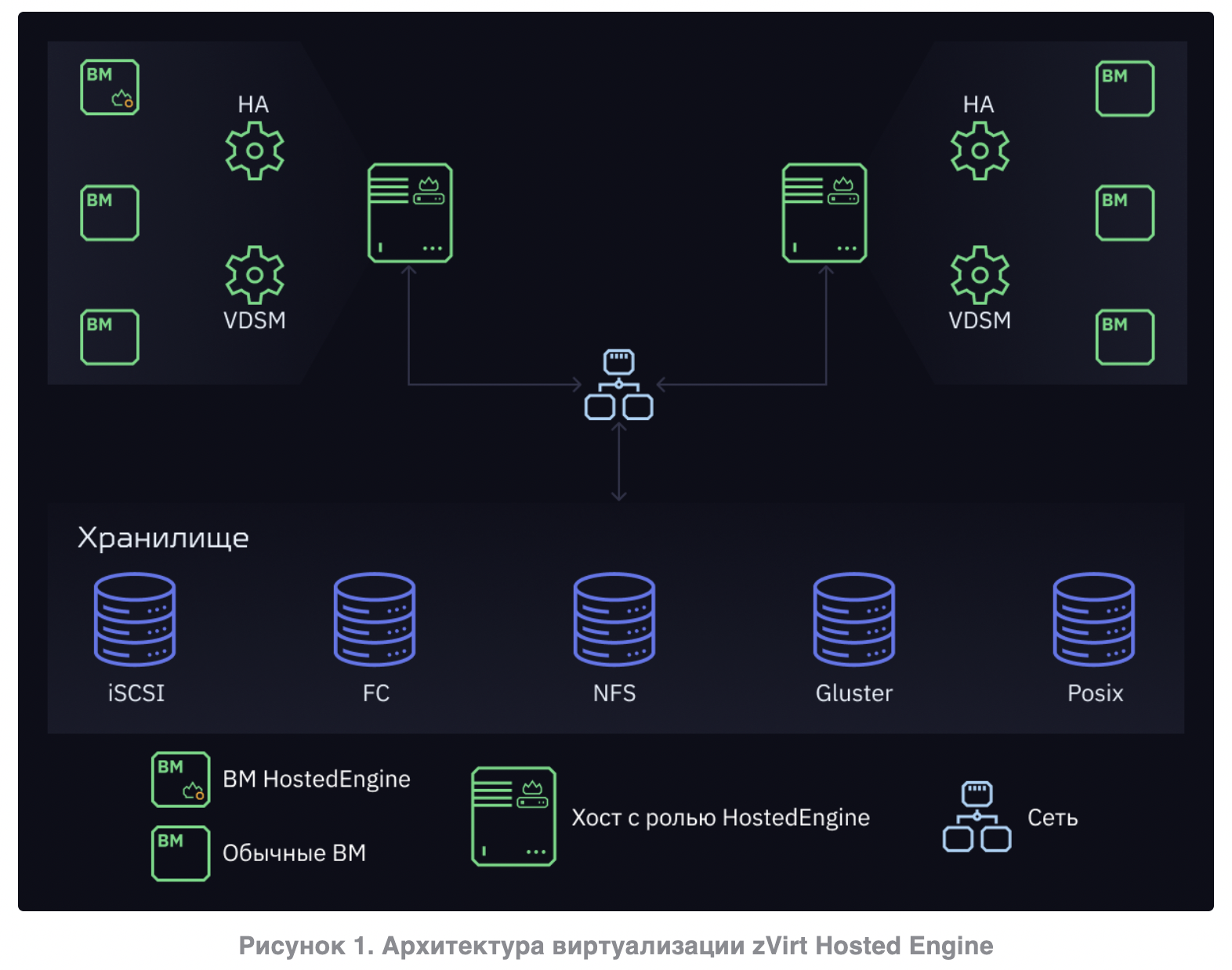
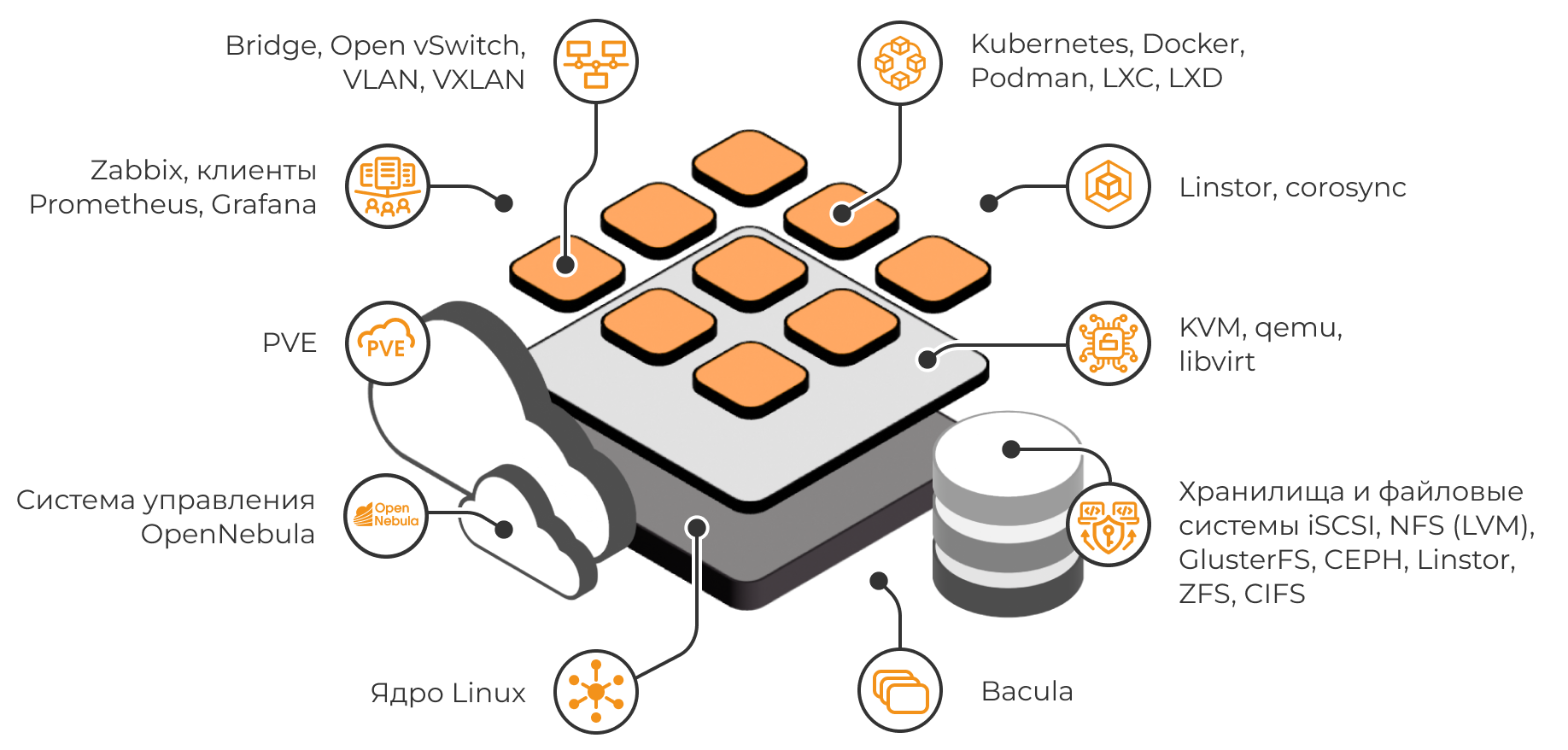
Российские платформы виртуализации 2025 года представлены широким спектром архитектурных подходов. Условно можно выделить две ключевые категории: классическая архитектура и гиперконвергентная архитектура (HCI). Также различаются технологические основы: часть решений опирается на открытый исходный код (форки oVirt, OpenStack, Proxmox и др.), тогда как другие являются проприетарными разработками.
Классическая архитектура
В классической схеме вычислительные узлы, системы хранения (СХД) и сети реализуются отдельными компонентами, объединёнными в единый кластер виртуализации. Такой подход близок к VMware vSphere и проверен десятилетиями: он даёт максимальную гибкость, позволяя подключать внешние высокопроизводительные СХД, использовать существующие сетевые инфраструктуры и масштабировать каждый слой независимо (например, наращивать хранение без изменения серверов). Для организаций с уже развернутыми дорогими СХД и развитой экспертизой администраторов этот вариант наиболее понятен.
Многие отечественные продукты поддерживают классическую модель. Например, “Ред Виртуализация” (решение компании РЕД СОФТ на базе KVM/oVirt), zVirt от Orion soft, SpaceVM (платформа компании «ДАКОМ М»), Rosa Virtualization, VMmanager от ISPsystem и Numa vServer (Xen-based) – все они ориентированы на традиционную архитектуру с интеграцией внешних хранилищ и сетей.
Архитектурно они во многом схожи с VMware (например, оVirt-платформы реализуют подключение SAN-хранилищ, динамическую балансировку ресурсов и т.п. «из коробки»). Однако есть и недостатки классического подхода: более высокая стоимость отдельных компонентов (CAPEX), требовательность к квалификации узких специалистов, сложность диагностики сбоев (не всегда очевидно, в каком слое проблема). Развёртывание классической инфраструктуры может занимать больше времени, поскольку нужно поэтапно настроить и интегрировать разнородные компоненты внутри единой платформы.
Гиперконвергентная инфраструктура (HCI)
В HCI все основные функции – вычисления, хранение, сеть – объединены на каждом узле и управляются через единую программную платформу. Локальные диски серверов объединяются программно в распределённое хранилище (часто на основе Ceph или аналогов), а сеть виртуализуется средствами самой платформы. Такой подход упрощает масштабирование: добавление нового узла сразу увеличивает и CPU/RAM, и объём хранения. Гиперконвергенция особенно хорошо подходит для распределённых площадок и филиалов, где нет штата ИТ-специалистов – достаточно поставить несколько одинаковых узлов, и система автонастроится без тонкой ручной оптимизации каждого слоя.
В России к HCI-решениям относятся, например, vStack (платформа в составе холдинга ITG на базе FreeBSD и гипервизора bhyve), «Кибер Инфраструктура» (решение компании «Киберпротект», развившей технологии Acronis), Р-платформа (российская приватная облачная платформа), Горизонт-ВС и др. – они изначально спроектированы как гиперконвергентные. Некоторые HCI-системы позволяют выходить за рамки встроенного хранения – например, Кибер Инфраструктура и Горизонт-ВС поддерживают подключение внешних блочных СХД, комбинируя подходы.
Открытый код или собственные разработки?
Многие отечественные продукты выросли из популярных open-source проектов. Например, решения на основе oVirt – это упомянутые выше zVirt, Red Виртуализация, ROSA Virtualization, HostVM и др. Их преимущество – быстрое получение базовой функциональности (live migration, подключение SAN, кластеры HA и т.д.) благодаря наследию oVirt/Red Hat. Однако после ухода Red Hat из oVirt сообщество ослабло, и российским командам пришлось форкать код и развивать его самим.
Orion soft, например, пошла по пути создания собственного бэкенда поверх ядра oVirt, сумев сохранить совместимость, но упростив и улучшив часть функций для пользователей. Другой популярный открытый проект – Proxmox VE – тоже получил российские форки (например, «Альт Виртуализация», GloVirt), что позволяет заказчикам использовать знакомый интерфейс PVE с поддержкой отечественной компанией.
Есть и решения на базе OpenStack – эта платформа хорошо масштабируется и подходит для построения частных облаков IaaS. Так, AccentOS CE – российская облачная платформа на основе OpenStack – получила сертификат ФСТЭК осенью 2025 г. Тем не менее, OpenStack-системы (например, частное облако VK Cloud) часто критикуют за избыточную сложность для задач традиционной виртуализации и проблемы стабильности отдельных ВМ под высокими нагрузками хранения. Наконец, существуют продукты на базе Xen – в частности, Numa vServer построен на открытом гипервизоре xcp-ng (форк Citrix XenServer), что даёт вариант для тех, кто привык к Xen.
Помимо форков, на рынке появились принципиально новые разработки. К ним относятся SpaceVM, Basis Dynamix, VMmanager и др., где компании создали собственные платформы управления, опираясь на комбинацию различных open-source компонентов, но реализуя уникальные возможности. Например, SpaceVM и Basis Dynamix заявляют о полном проприетарном стеке – разработчики утверждают, что не используют готовые open-source продукты внутри, а все компоненты (гипервизор, драйверы, диспетчер ресурсов) созданы самостоятельно. Такой подход требует больше усилий, но позволяет глубже интегрировать систему с отечественными ОС и средствами кибербезопасности, а также активно внедрять API-first и DevOps-интеграции. В итоге, сегодня российский рынок виртуализации предлагает решения на любой вкус – от максимально близких к VMware аналогов на базе KVM до совершенно новых платформ с оригинальной архитектурой.
Один из ключевых вопросов для корпоративных клиентов – способен ли отечественный гипервизор обеспечить производительность и масштаб, сопоставимые с vSphere. Практика показывает, что большинство российских платформ уже поддерживают необходимые уровни масштабирования: кластеры на десятки узлов, сотни и тысячи виртуальных машин, live migration и распределение нагрузки между хостами. Например, платформа SpaceVM официально поддерживает кластеры до 96 серверов, Selectel Cloud – до 2500 узлов, Red Виртуализация – до 250 хостов в одном датацентре.
Многие разработчики вообще не указывают жестких ограничений на размер кластера, утверждая, что он линеен (ISP VMmanager протестирован на 350+ узлов, 1000+ ВМ). В реальных внедрениях обычно речь идёт о десятках серверов, что этим решениям вполне по силам. Однако из опыта миграций известны и проблемы: так, эксперты отмечают, что у zVirt иногда возникают сложности при росте кластера более 50 узлов. Первые «тревожные звоночки» появлялись уже около 20 хостов, но в новых версиях горизонтальная масштабируемость доведена до 50–60 узлов, что для большинства сред достаточно. Подобные нюансы следует учитывать при проектировании – предельно возможный масштаб у разных продуктов разнится, и при планировании очень крупных инсталляций лучше привлечь вендора или интегратора для оценки нагрузок.
По производительности виртуальных машин отечественные гипервизоры стараются минимизировать накладные расходы. Так, vStack HCP заявляет о оверхеде всего 2–5% к CPU при виртуализации, то есть близкой к нативной производительности. Это достигнуто за счёт легковесного гипервизора (базирующегося на bhyve) и оптимизированного I/O стека. Большинство других решений используют проверенные гипервизоры (KVM, Xen), у которых производительность также высока. С точки зрения нагрузки на оперативную память и хранилище – многое зависит от механизмов дедупликации, компрессии и прочих оптимизаций в конкретной реализации.
Здесь можно отметить, что многие российские платформы уже внедрили современные технологии оптимизации ресурсов: поддержка NUMA для эффективной работы с многопроцессорными узлами, возможность тонкого выделения ресурсов (thin provisioning дисков, memory ballooning) и т.д. Например, по данным рейтинга Компьютерры, Basis Dynamix и SpaceVM набрали максимальные баллы по критериям вертикальной и горизонтальной масштабируемости, а также поддержки Intel VT-x/AMD-V виртуализации, NUMA и даже GPU-passthrough. То есть функционально они не уступают VMware в возможностях задействовать современное оборудование.
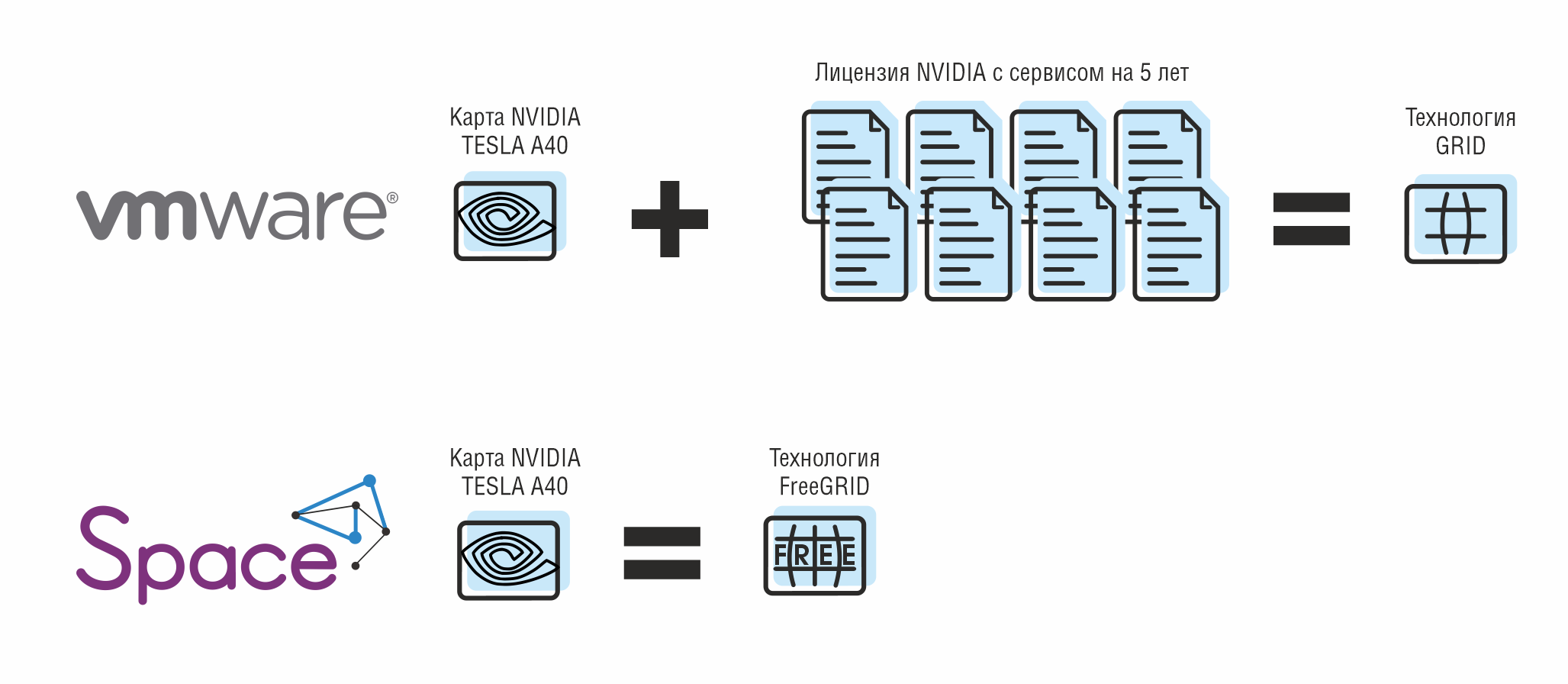
Отдельно стоит упомянуть работу с графическими нагрузками. В сфере VDI и 3D-приложений критична поддержка GPU-виртуализации. Здесь российские разработчики сделали заметный прогресс. SpaceVM изначально ориентирован на сценарии с графическими рабочими станциями: платформа поддерживает как passthrough GPU для выделения целой видеокарты ВМ, так и технологию FreeGRID – собственную разработку для виртуализации ресурсов NVIDIA-GPU без риска лицензионной блокировки.
По сути, FreeGRID выступает аналогом технологии NVIDIA vGPU (GRID), но адаптированным к ограничениям поставок – это актуально, поскольку официальные лицензии NVIDIA в России недоступны. Благодаря этому SpaceVM активно используют организации, которым нужны высокопроизводительные графические ВМ: конструкторские бюро (CAD/CAE), геоинформационные системы, видеомонтаж и др. Другие платформы также не отстают: zVirt и решения на базе oVirt умеют пробрасывать физические GPU внутрь ВМ, а HostVM и ряд VDI-платформ заявляют поддержку технологии виртуализации графических процессоров для нужд 3D-моделирования. Таким образом, в плане работы с тяжелыми графическими нагрузками отечественные продукты закрывают основные потребности.
Стоит отметить, что автоматическое распределение ресурсов и балансовка нагрузки – функции, известные в VMware как DRS (Distributed Resource Scheduler) – начинают появляться и в российских решениях. Например, zVirt реализует модуль автоматического распределения виртуальных машин по хостам, аналогичный DRS. Это значит, что платформа сама перераспределяет ВМ при изменении нагрузок, поддерживая равномерное потребление ресурсов. Кроме того, большинство продуктов поддерживают «горячую миграцию» (Live Migration) – перенос работающей ВМ между хостами без простоя, а также миграцию хранилищ на лету (Storage vMotion) – например, в zVirt есть возможность "перетаскивать" виртуальные диски между датацентрами без остановки ВМ. Эти функции критичны для обеспечения непрерывности сервисов при обслуживании оборудования или ребалансировке нагрузки.
Резюмируя, производительность российских гипервизоров уже находится на уровне, достаточном для многих корпоративных задач, а по некоторым параметрам они предлагают интересные инновации (минимальный оверхэд у vStack, поддержка GPU через FreeGRID у SpaceVM и т.п.). Тем не менее, при планировании очень нагруженных или масштабных систем следует внимательно относиться к тестированию конкретного продукта под своей нагрузкой – практика показывает, что в пилотных проектах не всегда выявляются узкие места, которые могут проявиться на продакшен-системе. Важны также оперативность вендора при оптимизации производительности и наличие у него экспертизы для помощи заказчику в тюнинге – эти аспекты мы рассмотрим в следующих статьях при сравнении опций поддержки.
Вопрос кибербезопасности и соответствия регуляторным требованиям (ФСТЭК, Закон о КИИ, ГОСТ) является определяющим для многих российских предприятий, особенно государственных и критической инфраструктуры. Отечественные решения виртуализации учитывают эти аспекты с самого начала разработки. Во-первых, практически все крупные платформы включены в Единый реестр российского ПО, что подтверждает их юридическую «отечественность» и позволяет использовать их для импортозамещения в госорганизациях. Более того, ряд продуктов прошёл добровольную сертификацию в ФСТЭК России по профильным требованиям безопасности.
Особое внимание уделяется сетевой безопасности в виртуальной среде. Одной из угроз в датацентрах является горизонтальное распространение атак между ВМ по внутренней сети. Для борьбы с этим современные платформы внедряют микросегментацию сети и распределённые виртуальные брандмауэры. Например, zVirt содержит встроенные средства SDN (Software-Defined Networking) для сегментации трафика – администратор может разделить виртуальную сеть на множество изолированных сегментов и централизованно задать политики доступа между ними. Эта функциональность, требуемая ФСТЭК для защиты виртуальных сред, реализована по умолчанию и позволяет соответствовать требованиям закона по сегментированию значимых объектов КИИ и ГосИС.
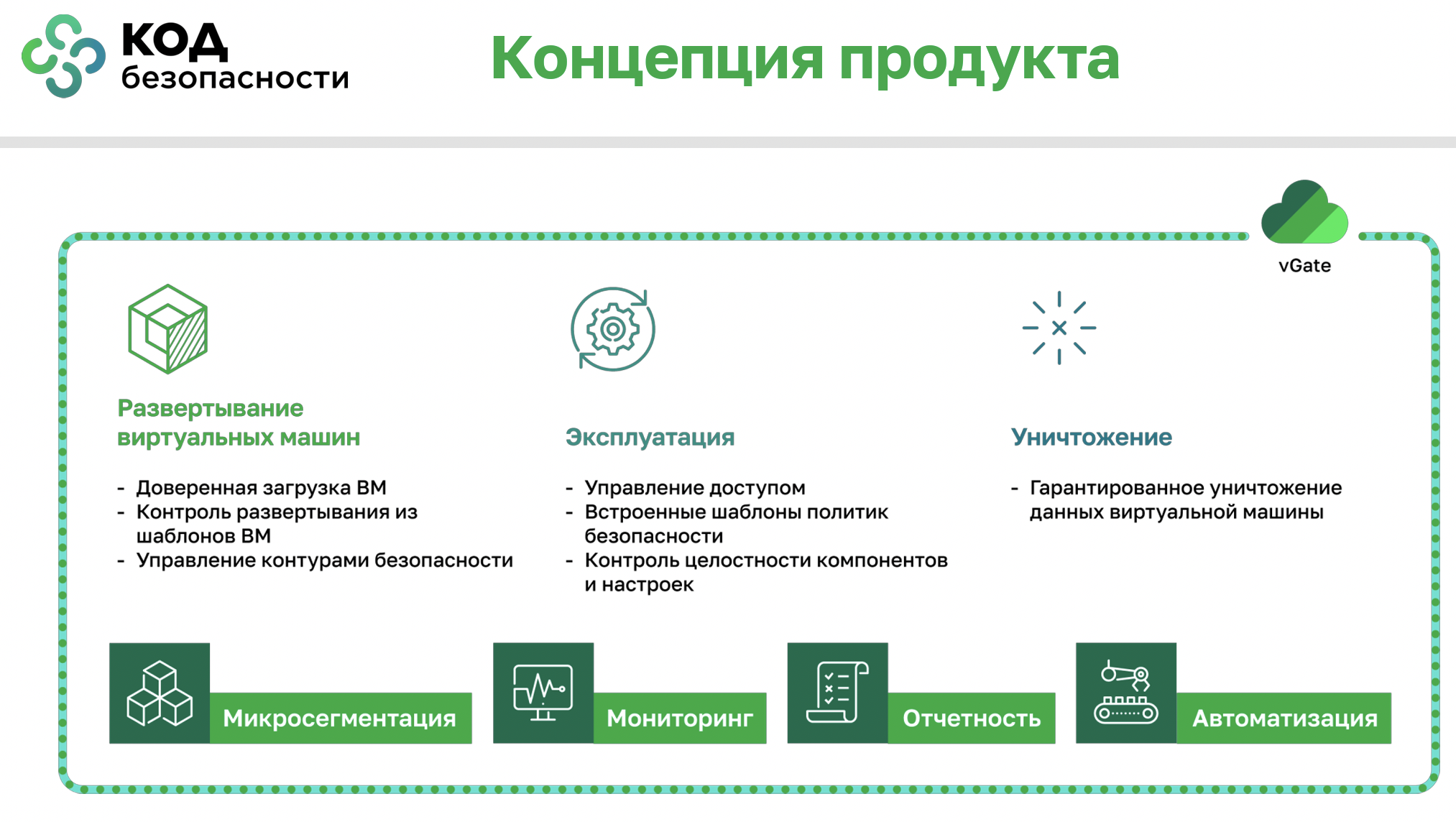
Дополнительно компания Orion soft (разработчик zVirt) рекомендует использовать совместно с гипервизором продукт vGate от компании «Код Безопасности». vGate – это межсетевой экран уровня гипервизора, который интегрируется с платформой виртуализации. Работая на уровне гипервизора, vGate перехватывает и фильтрует трафик между всеми ВМ, применяя централизованные политики безопасности. Разработчики сделали ставку на микросегментацию: каждый узел vGate хранит полный набор правил, что позволяет при миграции ВМ сразу переносить и её сетевые политики.
vGate сертифицирован ФСТЭК как межсетевой экран класса «Б» с 4-м уровнем доверия, поэтому его связка с zVirt закрывает требования регулятора для защиты виртуальных сегментов КИИ. В случае комбинированного использования, как отмечают эксперты, правила безопасности контролируются одновременно на уровне платформы (zVirt SDN) и на уровне гипервизора (vGate), дополняя друг друга. Например, если политика zVirt разрешает определённый трафик между ВМ, а политика vGate запрещает, пакет будет блокирован – то есть действует наиболее строгий из двух наборов правил. Такой «двойной заслон» повышает уверенность в защите.
Кроме сетевых экранов, встроенные механизмы безопасности практически обязательны для всех современных платформ. Российские решения включают разграничение доступа и аутентификацию корпоративного уровня: реализованы ролевые модели (RBAC), интеграция с LDAP/Active Directory для централизованного управления учетными записями, поддержка многофакторной аутентификации администраторов и журналирование действий с возможностью отправки логов на SIEM-системы. По этим пунктам разница с VMware не такая и большая – например, Basis Dynamix, SpaceVM и Red Виртуализация имеют полный набор RBAC/LDAP/2FA и получили максимально возможные оценки за безопасность в независимом рейтинге.
Дополнительно некоторые решения обеспечивают контроль целостности и доверенную загрузку (Trusted Boot) за счёт интеграции с отечественными защищёнными ОС. Например, гипервизоры могут устанавливаться поверх сертифицированных ОС (РЕД ОС, Astra Linux), что обеспечивает соответствие по требованиям НДВ (недекларированных возможностей) и использование российских криптосредств.
В контексте соответствия требованиям регуляторов важна и сертификация самих платформ виртуализации. На конец 2025 года сертифицированных по профильным требованиям ФСТЭК именно гипервизоров немного (преимущественно решения для гостевых ОС специального назначения). Однако, как отмечалось, платформы часто используют сертифицированные СЗИ «поверх» (антивирусы, СОВ, vGate и др.) для обеспечения соответствия. Кроме того, крупнейшие заказчики – госсектор, банки – проводили оценочные испытания продуктов в своих пилотных зонах. Например, при миграции в Альфа-Банке и АЛРОСА основным драйвером был закон о КИИ, и в обоих случаях итоговый выбор пал на отечественные гипервизоры (SpaceVM и zVirt соответственно) после тщательного тестирования безопасности. Таким образом, можно сказать, что российские системы виртуализации в целом готовы к работе в защищённых контурах. Они позволяют реализовать требуемую сегментацию, поддерживают российские криптоалгоритмы (при использовании соответствующих ОС и библиотек), а при правильной настройке обеспечивают изоляцию ВМ не хуже зарубежных аналогов.
Нельзя не затронуть и вопрос устойчивости к атакам и сбоям. Эксперты отмечают, что по методам защиты виртуальная инфраструктура не сильно отличается от физической – нужны регулярные обновления безопасности, сильные пароли и ограничение доступа привилегированных пользователей. Основной вектор атаки на гипервизоры в России – компрометация учётных данных администраторов, тогда как эксплойты уязвимостей встречаются гораздо реже. Это значит, что внедрение RBAC/2FA, о которых сказано выше, существенно снижает риски. Также важно строить резервное копирование на уровне приложений и данных, а не полагаться только на механизмы платформы. Как отмечают представители банковского сектора, добиться требуемого по стандартам времени восстановления (RTO) только силами гипервизора сложно – необходимо комбинировать различные уровни (репликация критичных систем, отказоустойчивые кластеры, резервные площадки). В целом же, за три года уровень зрелости безопасности российских продуктов заметно вырос: многие проблемы, ранее считавшиеся нерешаемыми, уже устранены или существуют понятные обходные пути. Производители активно учитывают требования заказчиков, внедряя наиболее востребованные функции безопасности в приоритетном порядке.
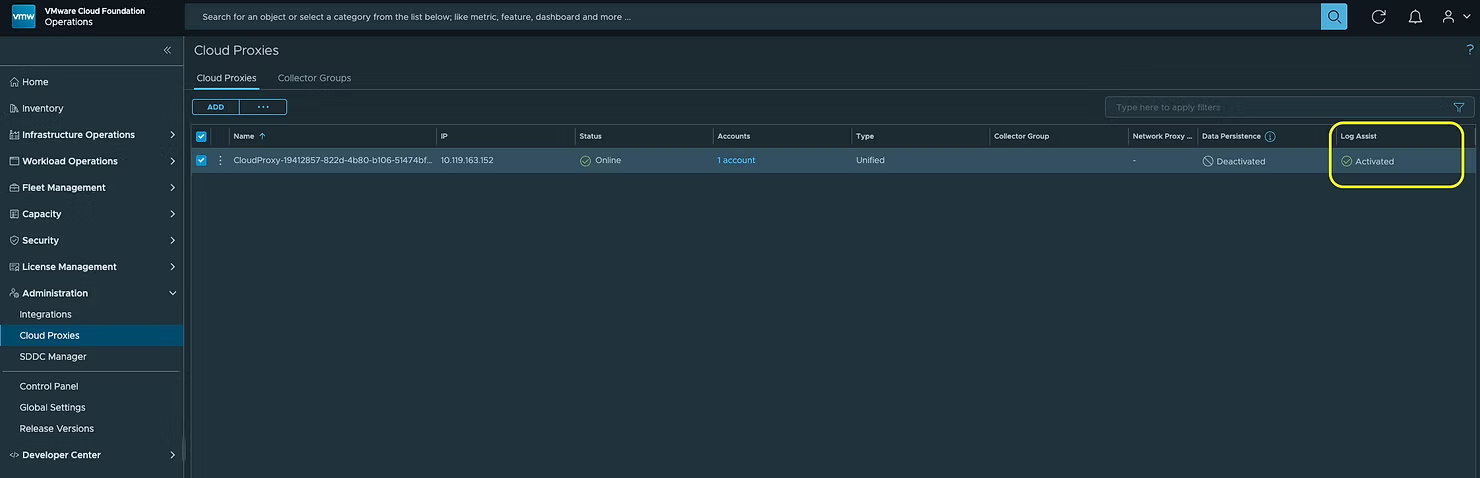
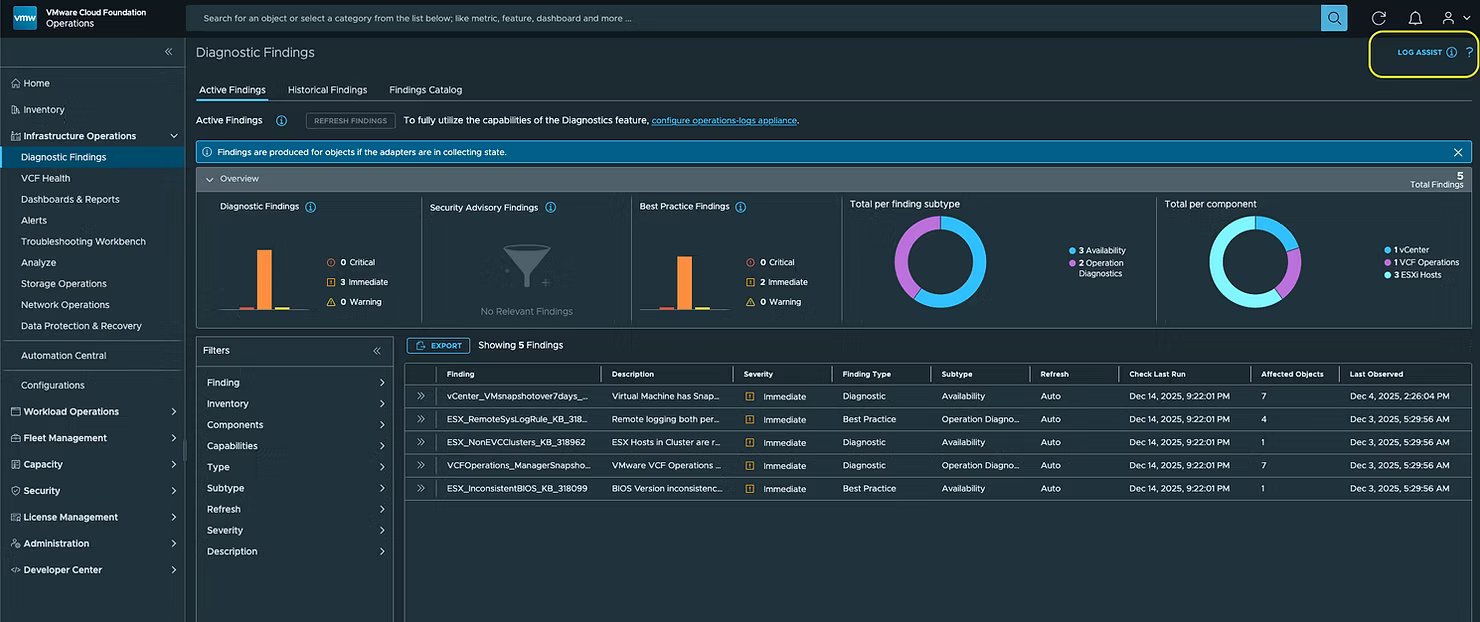
Brock Peterson написал полезную статью о том, что в новой версии VMware VCF Operations 9 была представлена функция под названием Log Assist (ранее это было частью решения Slyline), которая позволяет загружать пакеты поддержки (Support Bundles) в службу поддержки Broadcom непосредственно из VCF Operations. Вот как это работает.
Во-первых, необходимо зарегистрировать и лицензировать ваш экземпляр VCF Operations. Документацию о том, как это сделать, можно найти здесь.
Во-вторых, в вашей среде должен быть развернут Unified Cloud Proxy. Ранее автор уже рассказывал о том, как его развернуть, здесь. Обязательно убедитесь, что функция Log Assist активирована на вашем Unified Cloud Proxy.
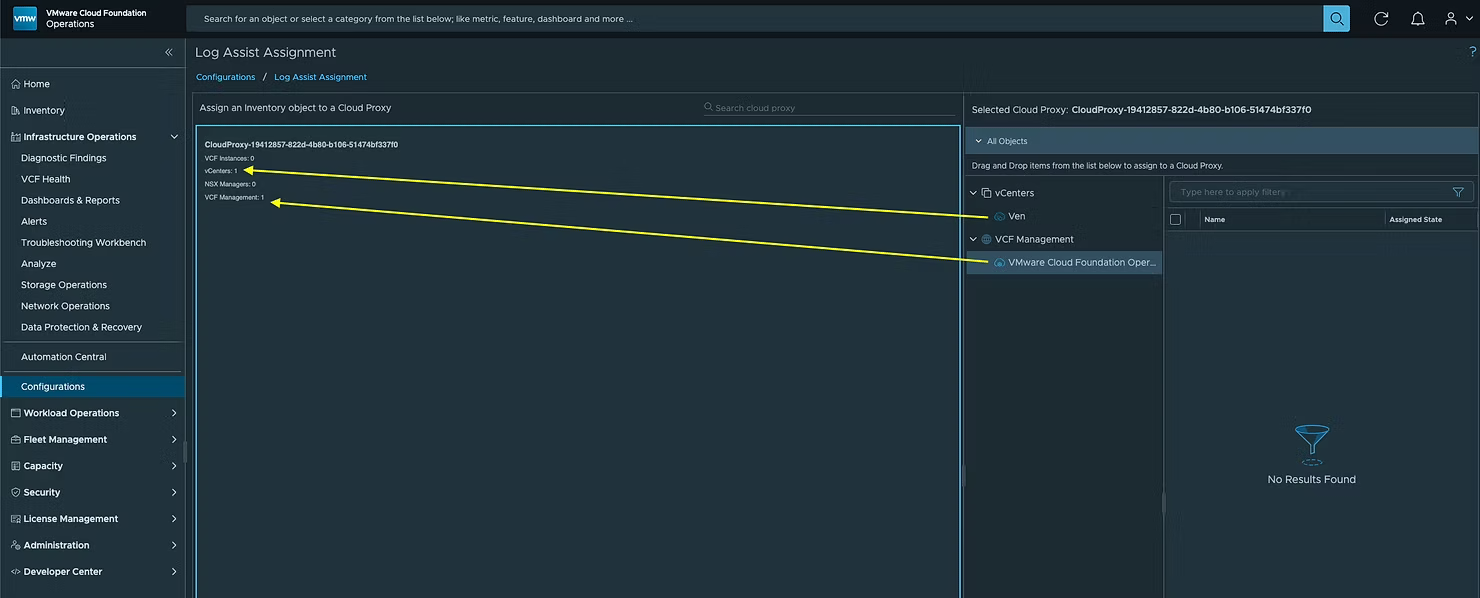
В-третьих, необходимо назначить компоненты Unified Cloud Proxy в разделе Infrastructure Operations > Configurations > Logs > Log Assist Assignment:
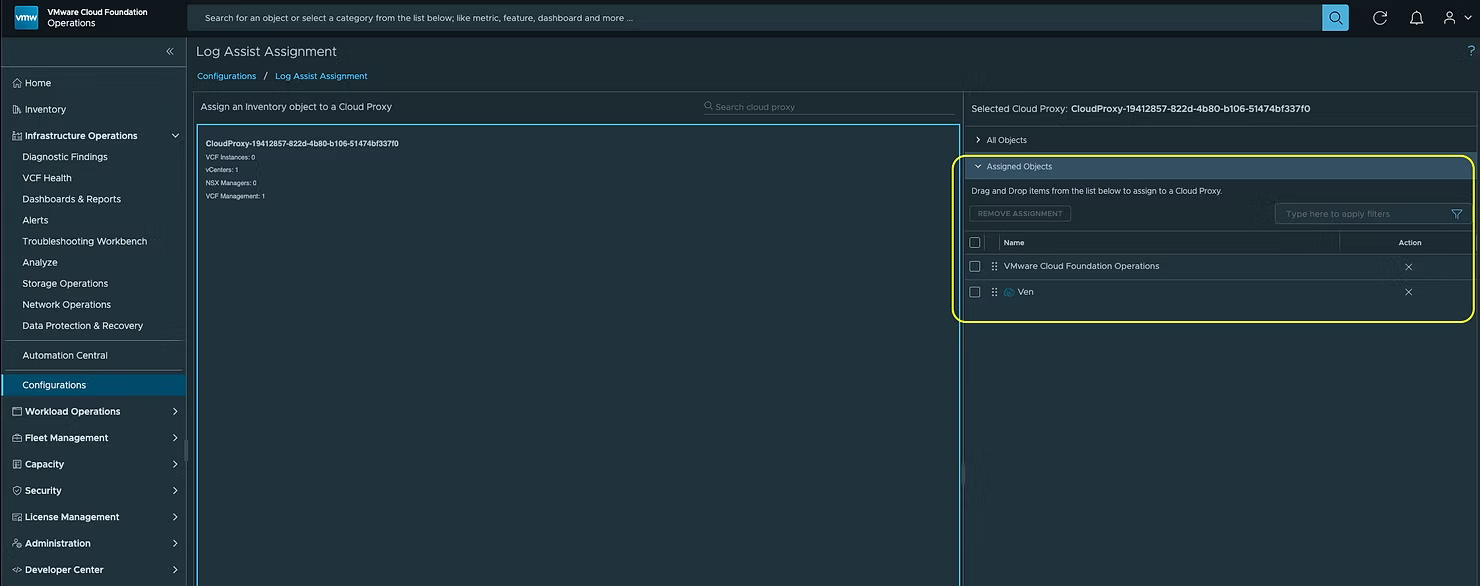
Вы можете видеть, что автор назначил свой vCenter и экземпляр VCF Operations. Перетащите компоненты с правой панели в левую:
После назначения они будут отображаться на вкладке Assigned Objects.
Теперь вы можете использовать функцию Log Assist, которая находится в разделе Infrastructure > Diagnostic Findings. Пользователи также могут найти эту функцию в разделе Administration > Control Panel > Log Assist.
Нажмите LOG ASSIST в правом верхнем углу:
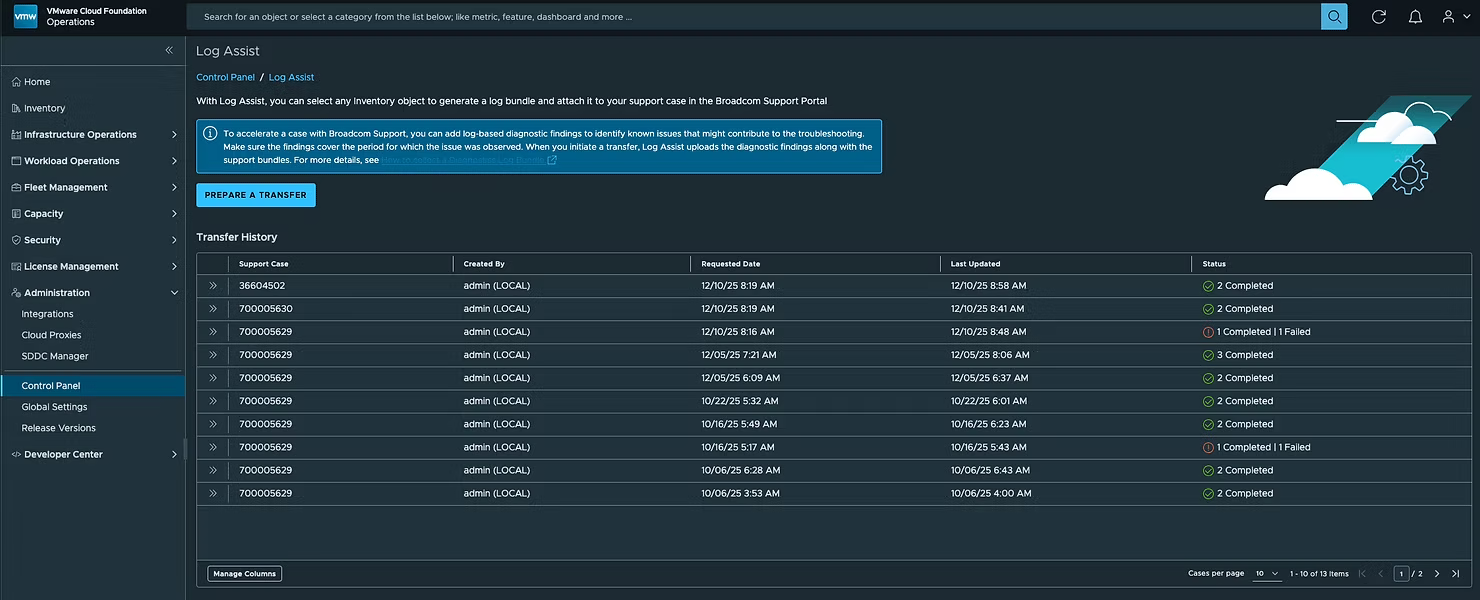
Нажмите PREPARE A TRANSFER:
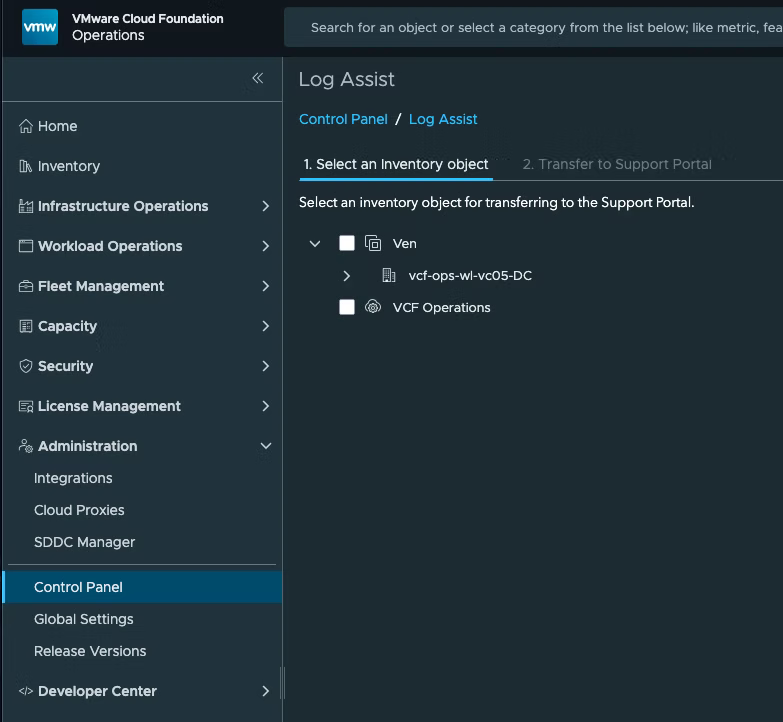
Теперь у вас есть возможность выбрать объект, для которого вы хотите собрать пакет поддержки (Support Bundle). В данном случае веберем vCenter и нажмем NEXT внизу:
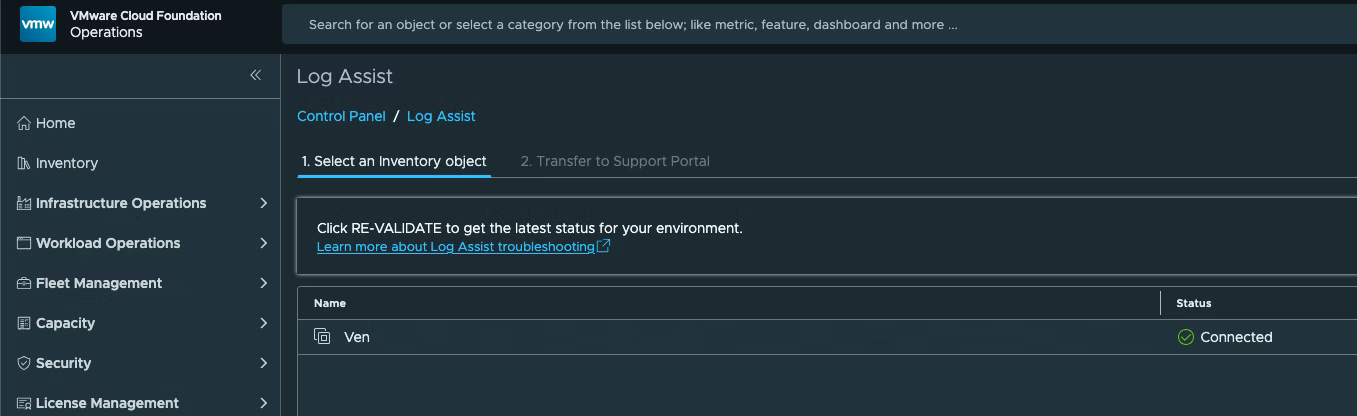
Когда статус изменится на Connected, нажмите NEXT:
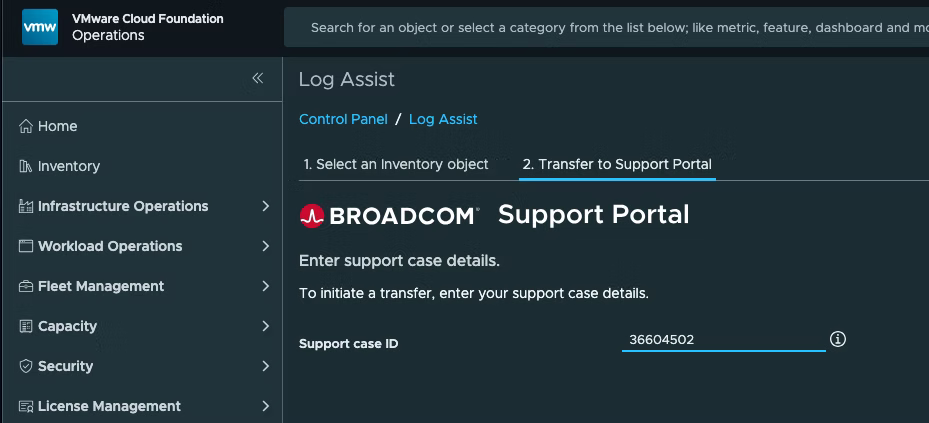
Введите идентификатор вашего обращения в службу поддержки и выберите TRANSFER:
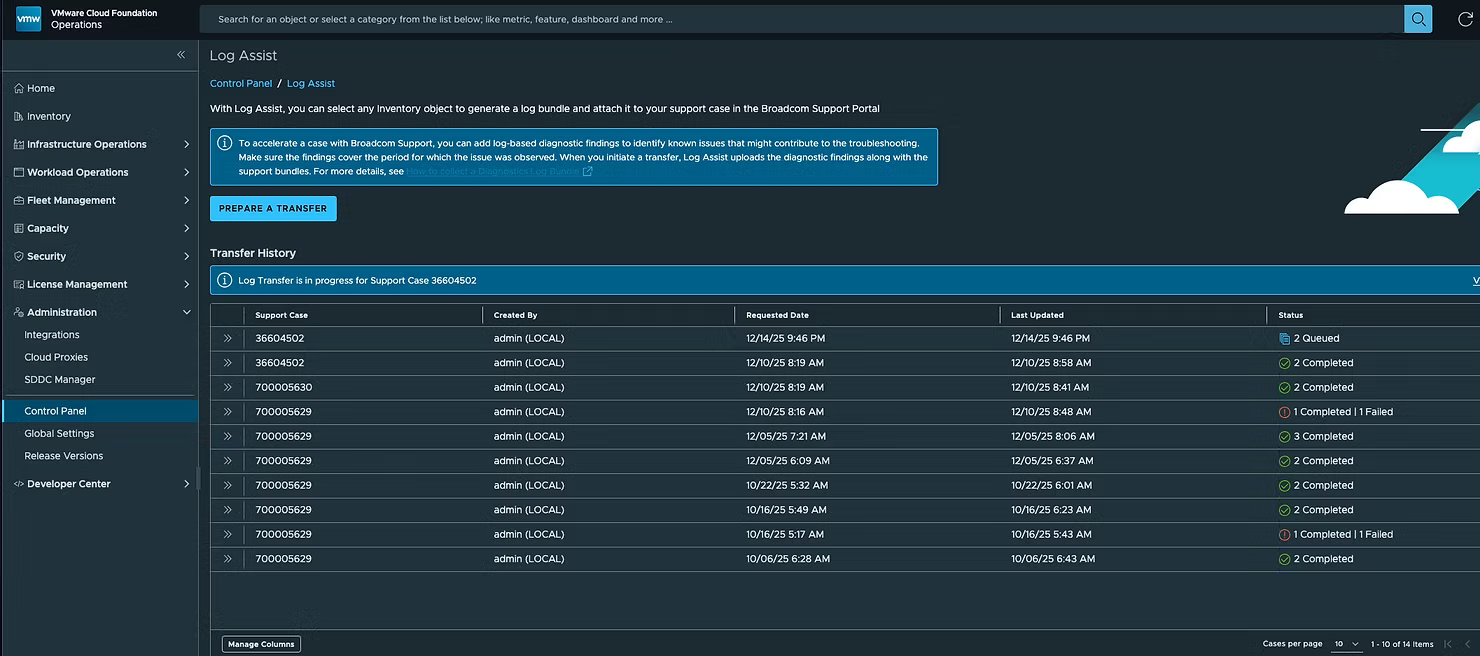
Вы увидите вашу самую последнюю отправку (Transfer) вверху списка. Нажав на двойную стрелку слева, вы сможете просмотреть детали:
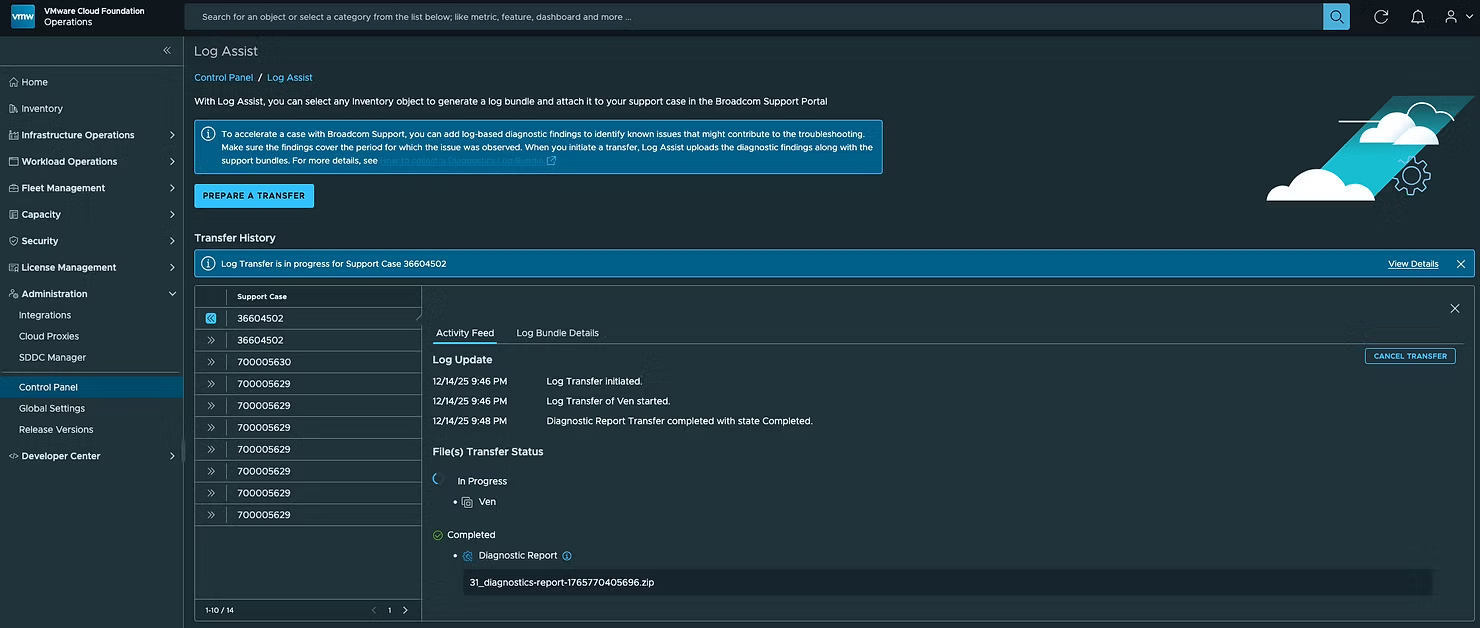
Как вы можете видеть, вместе с пакетом поддержки (Support Bundle) загружается диагностический отчет (Diagnostic Report). После завершения это будет выглядеть вот так:
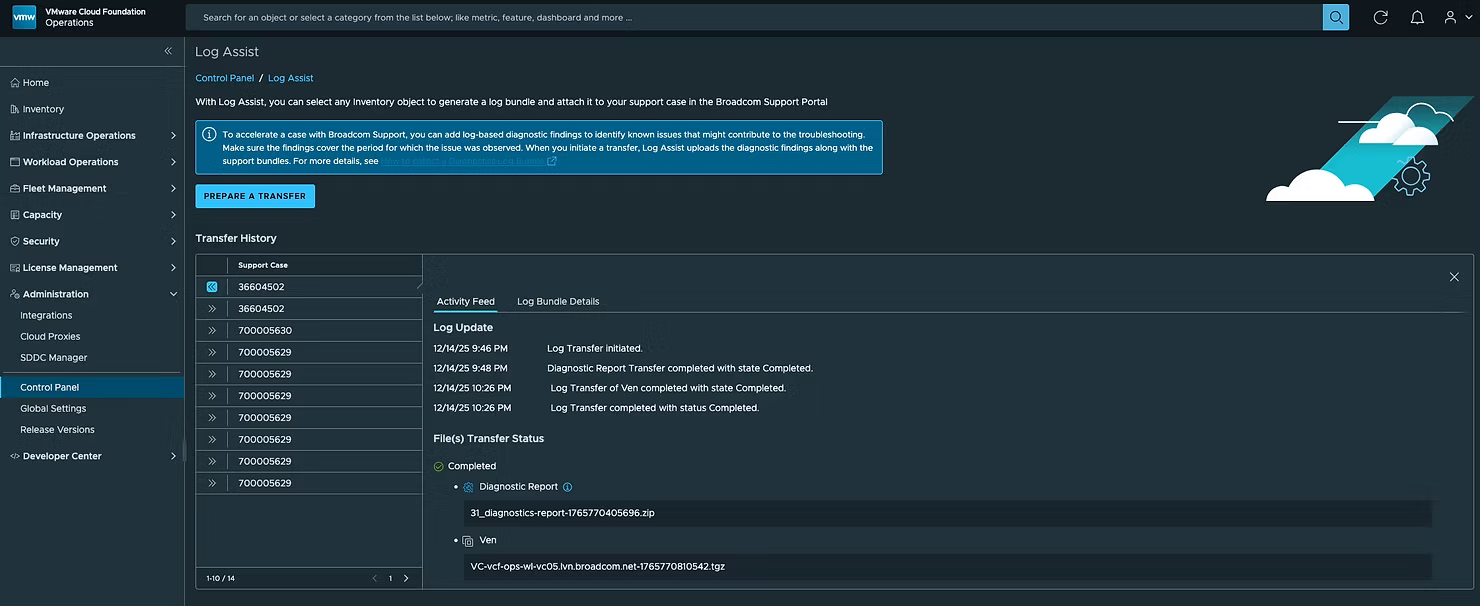
Ваш пакет журналов поддержки (Support Bundle) теперь загружен в службу поддержки Broadcom для анализа. Также существует подробная статья базы знаний (KB) по этому процессу, вы можете найти её здесь.
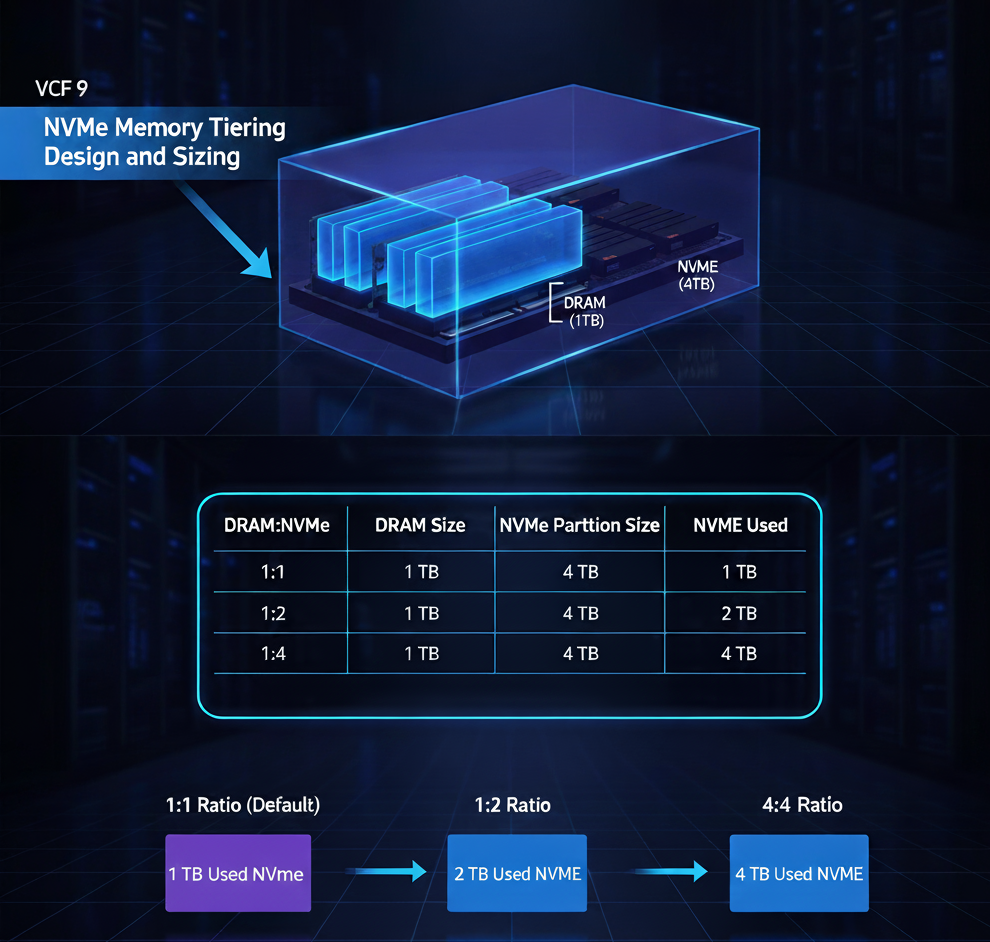
Решение VMware vSAN довольно часто всплывает в обсуждениях Memory Tiering — как из-за сходства между этими технологиями, так и из-за вопросов совместимости, поэтому давайте разберёмся подробнее.
Когда мы только начали работать с Memory Tiering, сходство между Memory Tiering и vSAN OSA было достаточно очевидным. Обе технологии используют многоуровневый подход, при котором активные данные размещаются на быстрых устройствах, а неактивные — на более дешёвых, что помогает снизить TCO и уменьшить потребность в дорогих устройствах для хранения «холодных» данных. Обе также глубоко интегрированы в vSphere и просты в реализации. Однако, помимо сходств, изначально возникала некоторая путаница относительно совместимости, интеграции и возможности одновременного использования обеих функций. Поэтому давайте попробуем ответить на эти вопросы.
Да, вы можете одновременно использовать vSAN и Memory Tiering в одних и тех же кластерах. Путаница в основном связана с идеей предоставления хранилища vSAN для Memory Tiering — а это категорически не поддерживается. Мы говорили об этом ранее, но ещё раз подчеркнем: хотя обе технологии могут использовать NVMe-устройства, это не означает, что они могут совместно использовать одни и те же ресурсы. Memory Tiering требует собственного физического или логического устройства, предназначенного исключительно для выделения памяти. Мы не хотим делить это физическое/логическое устройство с чем-либо ещё, включая vSAN или другие датасторы. Почему? Потому что в случае совместного использования мы будем конкурировать за пропускную способность, а уж точно не хотим замедлять работу памяти ради того, чтобы «не тратить впустую» NVMe-пространство. Это всё равно что сказать: "У меня бак машины наполовину пуст, поэтому я залью туда воду, чтобы не терять место".
При этом технически вы можете создать несколько разделов для лабораторной среды (на свой страх и риск), но когда речь идёт о продуктивных нагрузках, обязательно используйте выделенное физическое или логическое (HW RAID) устройство исключительно для Memory Tiering.
Подводя итог по vSAN и Memory Tiering: они МОГУТ сосуществовать, но не могут совместно использовать ресурсы (диски/датасторы). Они хорошо работают в одном кластере, но их функции не пересекаются — это независимые решения. Виртуальные машины могут одновременно использовать датастор vSAN и ресурсы Memory Tiering. Вы даже можете иметь ВМ с шифрованием vSAN и шифрованием Memory Tiering — но эти механизмы работают на разных уровнях. Несмотря на кажущееся сходство, решения функционируют независимо друг от друга и при этом отлично дополняют друг друга, обеспечивая более целостную инфраструктуру в рамках VCF.
Соображения по хранению данных
Теперь мы знаем, что нельзя использовать vSAN для предоставления хранилища для Memory Tiering, но тот же принцип применяется и к другим датасторам или решениям NAS/SAN. Для Memory Tiering требуется выделенное устройство, локально подключённое к хосту, на котором не должно быть создано никаких других разделов. Соответственно, не нужно предоставлять датастор на базе NVMe для использования в Memory Tiering.
Говоря о других вариантах хранения, также важно подчеркнуть, что мы не делим устройства между локальным хранилищем и Memory Tiering. Это означает, что одно и то же устройство не может одновременно обслуживать локальное хранилище (локальный датастор) и Memory Tiering. Однако такие устройства всё же можно использовать для Memory Tiering. Поясним.
Предположим, вы действительно хотите внедрить Memory Tiering в своей среде, но у вас нет свободных NVMe-устройств, и запрос на капитальные затраты (CapEx) на покупку новых устройств не был одобрен. В этом случае вы можете изъять NVMe-устройства из локальных датасторов или даже из vSAN и использовать их для Memory Tiering, следуя корректной процедуре:
Убедитесь, что рассматриваемое устройство входит в рекомендуемый список и имеет класс износостойкости D и класс производительности F или G (см. нашу статью тут).
Удалите NVMe-устройство из vSAN или локального датастора.
Удалите все оставшиеся разделы после использования в vSAN или локальном датасторе.
Создайте раздел для Memory Tiering.
Настройте Memory Tiering на хосте или кластере.
Как вы видите, мы можем «позаимствовать» устройства для нужд Memory Tiering, однако крайне важно убедиться, что вы можете позволить себе потерю этих устройств для прежних датасторов, а также что выбранное устройство соответствует требованиям по износостойкости, производительности и наличию «чистых» разделов. Кроме того, при необходимости обязательно защитите или перенесите данные в другое место на время использования устройств.
Это лишь один из шагов, к которому можно прибегнуть в сложной ситуации, когда необходимо получить устройства; однако если данные на этих устройствах должны сохраниться, убедитесь, что у вас есть свободное пространство в другом месте. Выполняйте эти действия на свой страх и риск.
На момент выхода VCF 9 в процессе развёртывания VCF отсутствует отдельный рабочий процесс для выделения устройств под Memory Tiering, а vSAN автоматически захватывает устройства во время развёртывания. Поэтому при развертывании VCF «с нуля» (greenfield) вам может потребоваться использовать описанную процедуру, чтобы вернуть из vSAN устройство, предназначенное для Memory Tiering. VMware работает над улучшением этого процесса и поменяет его в ближайшем будущем.
VMware Cloud Foundation (VCF) 9.0 предоставляет быстрый и простой способ развертывания частного облака. Хотя обновление с VCF 5.x спроектировано как максимально упрощённое, оно вносит обязательные изменения в методы управления и требует аккуратного, поэтапного выполнения.
Недавно Джонатан Макдональд провёл насыщенный вебинар вместе с Брентом Дугласом, где они подробно разобрали процесс обновления с VCF 5.2 до VCF 9.0. Сотни участников и шквал вопросов ясно показали, что этот переход сейчас волнует многих клиентов VMware.
Джонатан отфильтровал повторяющиеся вопросы, объединив похожие в единые, комплексные темы. Ниже представлены 10 ключевых вопросов («must-know»), заданных аудиторией, вместе с подробными ответами, которые помогут вам уверенно пройти путь к VCF 9.0.
Вопрос 1: Как VMware SDDC Manager выполняет обновления? Есть ли значительные изменения в обновлениях версии 9.0?
Было много вопросов, связанных с SDDC Manager и процессом обновлений. Существенных изменений в том, как выполняются обновления, нет. Если вы знакомы с VCF 5.2, то асинхронный механизм патчинга встроен в консоль точно так же и в версии 9.0. Это позволяет планировать обновления и патчи по необходимости. Главное отличие заключается в том, что интерфейс SDDC Manager был интегрирован в консоль VCF Operations и теперь находится в разделе управления парком (Fleet Management). Многие рабочие процессы также были перенесены, что позволило консолидировать интерфейсы.
Вопрос 2: Есть ли особенности обновления кластеров VMware vSAN Original Storage Architecture (OSA)?
vSAN OSA не «уходит» и не объявлен устаревшим в VCF 9.0. Аппаратные требования для vSAN Express Storage Architecture (ESA) существенно отличаются и могут быть несовместимы с существующим оборудованием. vSAN OSA — отличный способ продолжать эффективно использовать имеющееся оборудование без необходимости покупать новое. Для самого обновления важно проверить совместимость аппаратного обеспечения и прошивок с версией 9.0. Если они поддерживаются, обновление пройдёт так же, как и в предыдущих релизах.
Вопрос 3: Как выполняется обновление VMware NSX?
При обновлении VCF все компоненты, включая NSX, обновляются последовательно. Обычно процесс начинается с компонентов VCF Operations. После этого управление передаётся рабочим процессам SDDC Manager: сначала обновляется сам SDDC Manager, затем NSX, потом VMware vCenter и в конце — хосты VMware ESX.
Вопрос 4: Если VMware Aria Suite развернут в режиме VCF-aware в версии 5.2, нужно ли отвязывать Aria Suite перед обновлением?
Нет. Вы можете сначала обновить компоненты Aria Suite до версии, совместимой с VCF 9, а затем продолжить обновление остальных компонентов.
Вопрос 5: Можно ли обновиться с VCF 5.2 без настроенных LCM и Aria Suite?
Да. Наличие компонентов Aria Suite до обновления на VCF 9.0 не требуется. Однако в рамках обновления будут развернуты Aria Lifecycle (в версии 9.0 — VCF Fleet Management) и VCF Operations, так как они являются обязательными компонентами в 9.0.
Вопрос 6: Сколько хостов допускается в консолидированном дизайне VCF 9.0?
Для нового консолидированного дизайна рекомендуется минимум четыре хоста. При конвергенции инфраструктуры с использованием vSAN требуется минимум три ESX-хоста (четыре рекомендуются для отказоустойчивости). При использовании внешних систем хранения достаточно минимум двух хостов. Что касается максимальных значений, документированных ограничений нет, кроме ограничений VMware vSphere: 96 хостов на кластер и 2500 хостов на один vCenter. В целом рекомендуется по мере роста добавлять дополнительные домены рабочих нагрузок или кластеры для логического разделения среды с точки зрения производительности, доступности и восстановления.
Вопрос 7: Как перейти с VMware Identity Manager (vIDM) на VCF Identity Broker (VIDB) в VCF 9?
Прямого пути обновления или миграции с vIDM на VIDB не существует. Требуется «чистое» (greenfield) развертывание VIDB. Это особенно актуально, если используется VCF Automation, так как в этом случае новое развертывание VIDB является обязательным.
Вопрос 8: Нужно ли загружать дистрибутивы для VCF Operations и куда их помещать?
Это зависит от используемого сценария. В общем случае, если вы выполняете обновление и компоненты Aria ещё не установлены, потребуется загрузить и развернуть виртуальные машины VCF Operations и VCF Operations Fleet Management. После их развертывания бинарные файлы загружаются в репозиторий (depot) VCF Operations Fleet Management для установки дополнительных компонентов. Если вы конвергируете vSphere в VCF, все недостающие компоненты будут развернуты установщиком VCF, и, соответственно, должны быть загружены в него заранее.
Вопрос 9: Существует ли путь отката (rollback), если во время обновления возникла ошибка?
В целом не существует «кнопки отката» для всего VCF сразу. Лучше рассматривать каждое последовательное обновление как контрольную точку. Например, перед обновлением SDDC Manager с 5.2 до 9.0 нужно всегда делать резервную копию. Если во время обновления возникает сбой, можно откатиться к состоянию до ошибки и продолжить диагностику. То же самое относится к другим компонентам. При сбоях в обновлении NSX, vCenter или ESX-хостов нужно оценить ситуацию и либо выполнить откат, либо обратиться в поддержку, если время окна обслуживания истекает и необходимо срочно восстановить работоспособность среды. Именно поэтому тщательное планирование имеет решающее значение при любом обновлении VCF.
Вопрос 10: Существует ли путь миграции с VMware Cloud Director (VCD) на VCF Automation?
На данный момент VCD не поддерживается в VCF 9.0, и официальных путей миграции не существует. Если у вас есть вопросы по этому поводу, обратитесь к вашему Account Director.
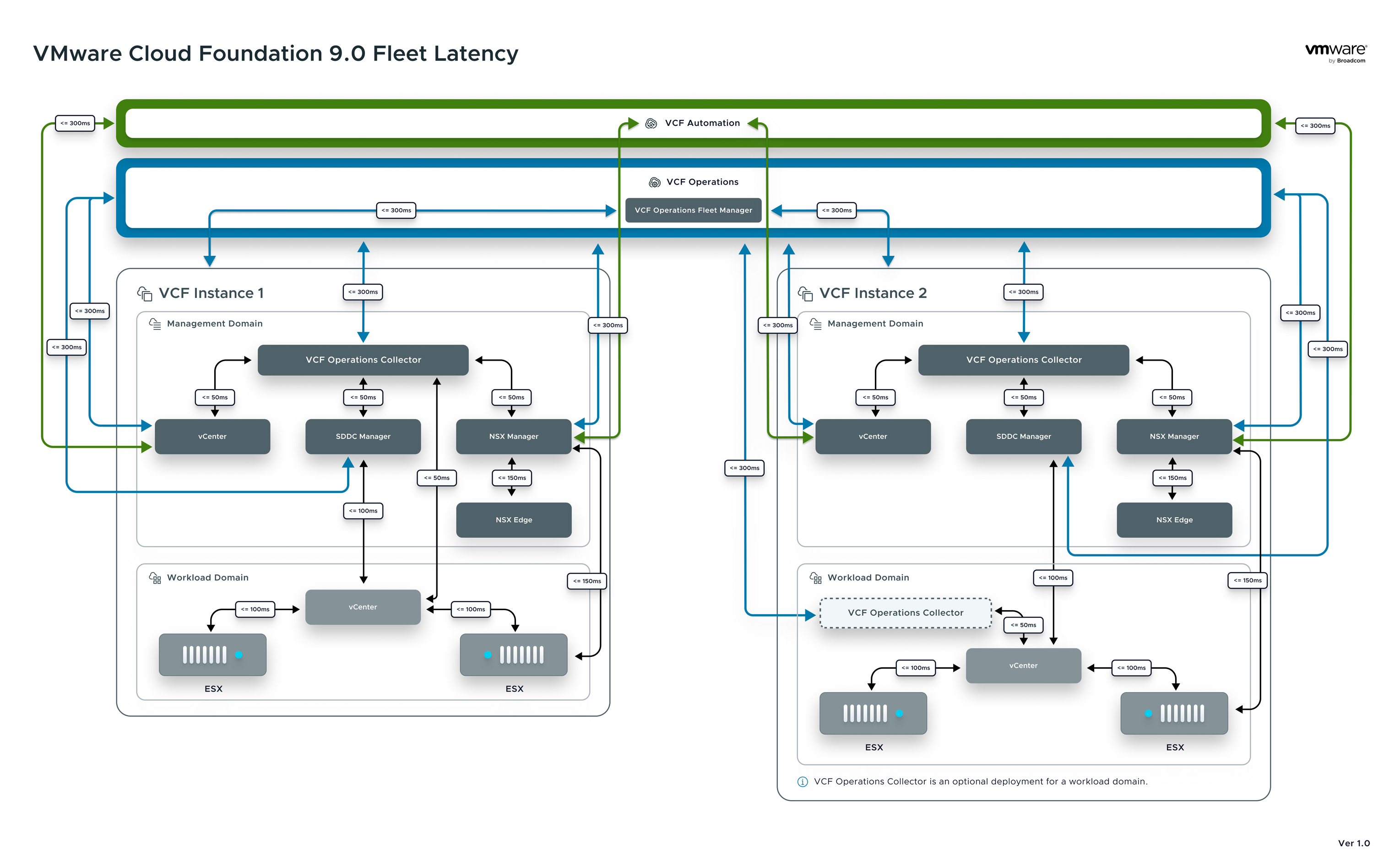
Диаграмма задержек VMware Cloud Foundation 9.0 теперь официально доступна на сайте Ports and Protocols в разделе Network Diagrams > VMware Cloud Foundation. Это официальный и авторитетный источник, который наглядно показывает сетевые взаимодействия и требования к задержкам в VCF 9.0.
Данное руководство настоятельно рекомендуется распечатать и разместить на рабочем месте каждого архитектора и администратора. Оно значительно упрощает проектирование, внедрение и сопровождение инфраструктуры, помогает быстрее выявлять узкие места, а также служит удобной шпаргалкой при обсуждении архитектурных решений, устранении неполадок и проверке соответствия требованиям. Фактически, это must-have материал для всех, кто работает с VMware Cloud Foundation в производственной среде.
Диаграмма демонстрирует, как различные элементы инфраструктуры VCF — управляющие домены, рабочие домены и центральные службы — взаимодействуют друг с другом в рамках распределённой частной облачной платформы, а также какие целевые значения Round-Trip Time (RTT) рекомендованы для стабильной и предсказуемой работы.
Что отражено на диаграмме:
VCF Fleet Components: диаграмма охватывает два отдельных экземпляра VCF (Instance 1 и Instance 2), включая их управляющие домены (Management Domain) и рабочие домены (Workload Domain), а также центральные Fleet-сервисы — VCF Operations и VCF Automation.
Целевые задержки: на диаграмме проставлены ориентировочные максимальные RTT-значения между компонентами, например между коллекторами VCF Operations и такими элементами, как vCenter, SDDC Manager, NSX Manager и ESX-хостами. Это служит практическим ориентиром для сетевых инженеров при планировании WAN- или LAN-связей между локациями.
Линии связи разной направленности: взаимодействия выполняются по разным путям и цветам, отражая направление обмена данными и зависимости между сервисами. Это помогает визуализировать, какие службы должны быть ближе друг к другу с точки зрения сети, а какие могут находиться дальше.
Практическая ценность
Такой сетевой ориентир крайне полезен архитекторам и администраторам, которые проектируют либо оптимизируют VCF-окружения в распределённых инфраструктурах. Он служит чёткой справочной картой, позволяющей:
Определить, какие связи нужно обеспечить минимально короткими с точки зрения задержки.
Согласовать проектные требования к ширине канала и RTT в разных сегментах сети.
Избежать узких мест в межкластерных коммуникациях, которые могут повлиять на производительность, управление или репликацию данных.
Диаграмма — это не просто техническая схема, а полноценный план качества сети, который должен учитываться при разворачивании VCF 9.0 на уровне предприятия.
Broadcom в сотрудничестве с Dell, Intel, NVIDIA и SuperMicro недавно продемонстрировала преимущества виртуализации, представив результаты MLPerf Inference v5.1. Платформа VMware Cloud Foundation (VCF) 9.0 показала производительность, сопоставимую с bare metal, по ключевым AI-бенчмаркам, включая Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), большие языковые модели (Llama 3.1-405B и Llama 2-70B), графовые нейронные сети (R-GAT) и компьютерное зрение (RetinaNet). Эти результаты были достигнуты как на GPU-, так и на CPU-решениях с использованием виртуализированных конфигураций NVIDIA с 8x H200 GPU, GPU 8x B200 в режиме passthrough/DirectPath I/O, а также виртуализированных двухсокетных процессоров Intel Xeon 6787P.
Для прямого сравнения соответствующих метрик смотрите официальные результаты MLCommons Inference 5.1. Этими результатами Broadcom вновь демонстрирует, что виртуализованные среды VCF обеспечивают производительность на уровне bare metal, позволяя заказчикам получать преимущества в виде повышенной гибкости, доступности и адаптивности, которые предоставляет VCF, при сохранении отличной производительности.
VMware Private AI — это архитектурный подход, который балансирует бизнес-выгоды от AI с требованиями организации к конфиденциальности и соответствию нормативам. Основанный на ведущей в отрасли платформе частного облака VMware Cloud Foundation (VCF), этот подход обеспечивает конфиденциальность и контроль данных, выбор между решениями с открытым исходным кодом и коммерческими AI-платформами, а также оптимальные затраты, производительность и соответствие требованиям.
Private AI позволяет предприятиям использовать широкий спектр AI-решений в своей среде — NVIDIA, AMD, Intel, проекты сообщества с открытым исходным кодом и независимых поставщиков программного обеспечения. С VMware Private AI компании могут развертывать решения с уверенностью, зная, что Broadcom выстроила партнерства с ведущими поставщиками AI-технологий. Broadcom добавляет мощь своих партнеров — Dell, Intel, NVIDIA и SuperMicro — в VCF, упрощая управление дата-центрами с AI-ускорением и обеспечивая эффективную разработку и выполнение приложений для ресурсоемких AI/ML-нагрузок.
В тестировании были показаны три конфигурации в VCF:
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC с NVLink-соединенными 8x B200 в режиме DirectPath I/O
Dell PowerEdge XE9680 с NVLink-соединенными 8x H200 в режиме vGPU
Конфигурация 1-node-2S-GNR_86C_ESXi_172VCPU-VM с процессорами Intel® Xeon® 6787P с 86 ядрами.
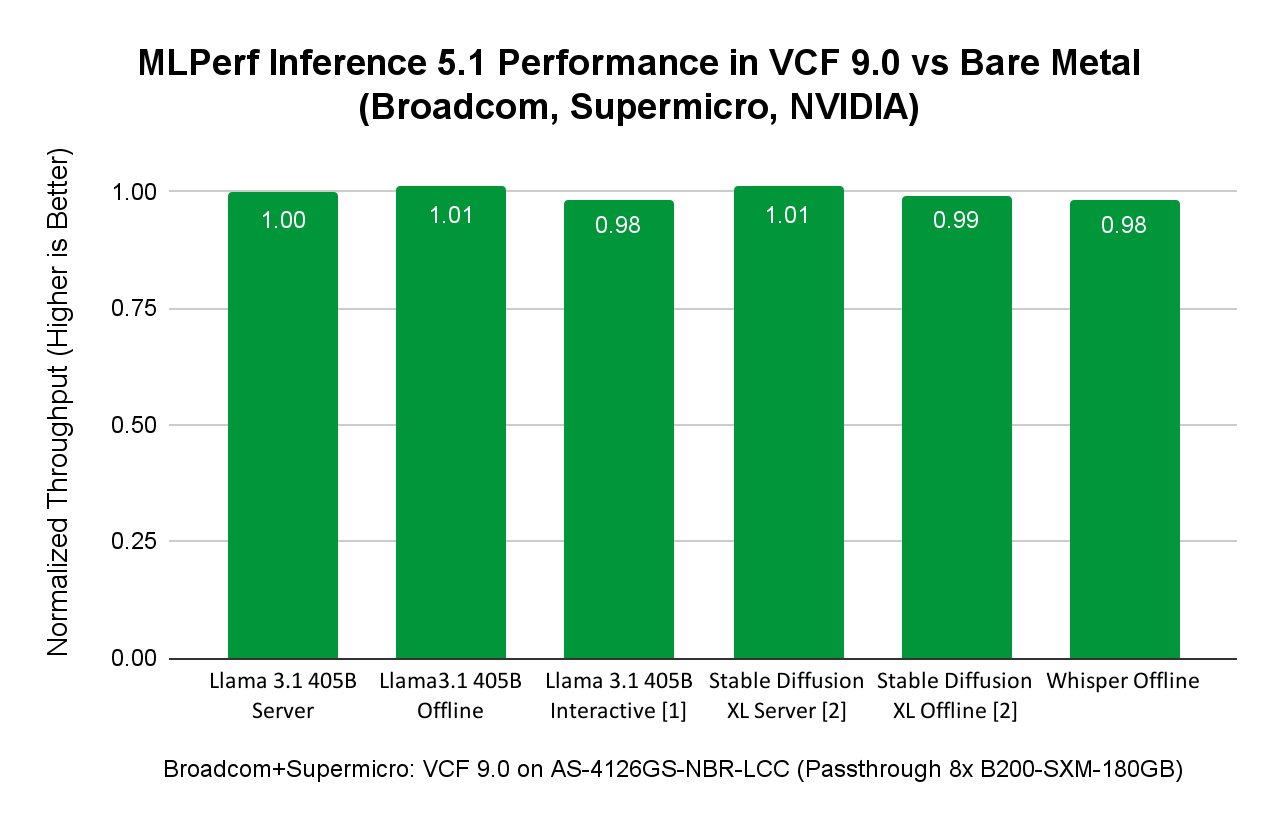
Производительность MLPerf Inference 5.1 с VCF на сервере SuperMicro с NVIDIA 8x B200
VCF поддерживает как DirectPath I/O, так и технологии NVIDIA Virtual GPU (vGPU) для использования GPU в задачах AI и других GPU-ориентированных нагрузках. Для демонстрации AI-производительности с GPU NVIDIA B200 был выбран DirectPath I/O для бенчмаркинга MLPerf Inference.
Инженеры запускали нагрузки MLPerf Inference на сервере SuperMicro SuperServer AS-4126GS-NBR-LCC с восемью GPU NVIDIA SXM B200 с 180 ГБ HBM3e при использовании VCF 9.0.0.
В таблице ниже показаны аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на bare metal и виртуализированных системах. Бенчмарки были оптимизированы с помощью NVIDIA TensorRT-LLM. TensorRT-LLM включает в себя компилятор глубокого обучения TensorRT и содержит оптимизированные ядра, этапы пред- и пост-обработки, а также примитивы меж-GPU и межузлового взаимодействия, обеспечивая выдающуюся производительность на GPU NVIDIA.
Параметр
Bare Metal
Виртуальная среда
Система
SuperMicro GPU SuperServer SYS-422GA-NBRT-LCC
SuperMicro GPU SuperServer AS-4126GS-NBR-LCC
Процессоры
2x Intel Xeon 6960P, 72 ядра
2x AMD EPYC 9965, 192 ядра
Логические процессоры
144
192 из 384 (50%) выделены виртуальной машине для инференса (при загрузке CPU менее 10%). Таким образом, 192 остаются доступными для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
GPU
8x NVIDIA B200, 180 ГБ HBM3e
DirectPath I/O, 8x NVIDIA B200, 180 ГБ HBM3e
Межсоединение ускорителей
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
18x NVIDIA NVLink 5-го поколения, суммарная пропускная способность 14,4 ТБ/с
Память
2,3 ТБ
Память хоста — 3 ТБ, 2,5 ТБ выделено виртуальной машине для инференса
Хранилище
4x NVMe SSD по 15,36 ТБ
4x NVMe SSD по 13,97 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.9 и драйвер 575.57.08
CUDA 12.8 и драйвер 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
Сравнение производительности виртуализованных и bare metal ML/AI-нагрузок на примере сервера SuperMicro SuperServer AS-4126GS-NBR-LCC:
Некоторые моменты:
Результат сценария Llama 3.1 405B в интерактивном режиме не был верифицирован Ассоциацией MLCommons. Broadcom и SuperMicro не отправляли его на проверку, поскольку это не требовалось.
Результаты Stable Diffusion XL, представленные Broadcom и SuperMicro, не могли быть напрямую сопоставлены с результатами SuperMicro на том же оборудовании, поскольку SuperMicro не отправляла результаты бенчмарка Stable Diffusion на платформе bare metal. Поэтому сравнение выполнено с другой заявкой, использующей сопоставимый хост с 8x NVIDIA B200-SXM-180GB.
Рисунок выше показывает, что AI/ML-нагрузки инференса из различных доменов — LLM (Llama 3.1 с 405 млрд параметров), Speech-to-Text (Whisper от OpenAI) и Text-to-Image (Stable Diffusion XL) — в VCF достигают производительности, сопоставимой с bare metal. При запуске AI/ML-нагрузок в VCF пользователи получают преимущества управления датацентром, предоставляемые VCF, при сохранении производительности на уровне bare metal.
Производительность MLPerf Inference 5.1 с VCF на сервере Dell с NVIDIA 8x H200
Broadcom поддерживает корпоративных заказчиков, использующих AI-инфраструктуру от различных аппаратных вендоров. В рамках раунда заявок для MLPerf Inference 5.1, VMware совместно с NVIDIA и Dell продемонстрировала VCF 9.0 как отличную платформу для AI-нагрузок, особенно для генеративного AI. Для бенчмаркинга был выбран режим vGPU, чтобы показать еще один вариант развертывания, доступный заказчикам в VCF 9.0.
Функциональность vGPU, интегрированная с VCF, предоставляет ряд преимуществ для развертывания и управления AI-инфраструктурой. Во-первых, VCF формирует группы устройств из 2, 4 или 8 GPU с использованием NVLink и NVSwitch. Эти группы могут выделяться различным виртуальным машинам, обеспечивая гибкость распределения GPU-ресурсов в соответствии с требованиями нагрузок и повышая утилизацию GPU.
Во-вторых, vGPU позволяет нескольким виртуальным машинам совместно использовать GPU-ресурсы на одном хосте. Каждой ВМ выделяется часть памяти GPU и/или вычислительных ресурсов GPU в соответствии с профилем vGPU. Это дает возможность нескольким небольшим нагрузкам совместно использовать один GPU, исходя из их требований к памяти и вычислениям, что повышает плотность консолидации, максимизирует использование ресурсов и снижает затраты на развертывание AI-инфраструктуры.
В-третьих, vGPU обеспечивает гибкое управление дата-центрами с GPU, поддерживая приостановку/возобновление работы виртуальных машин и VMware vMotion (примечание: vMotion поддерживается только в том случае, если AI-нагрузки не используют функцию Unified Virtual Memory GPU).
И наконец, vGPU позволяет различным GPU-ориентированным нагрузкам (таким как AI, графика или другие высокопроизводительные вычисления) совместно использовать одни и те же физические GPU, при этом каждая нагрузка может быть развернута в отдельной гостевой операционной системе и принадлежать разным арендаторам в мультиарендной среде.
VMware запускала нагрузки MLPerf Inference 5.1 на сервере Dell PowerEdge XE9680 с восемью GPU NVIDIA SXM H200 с 141 ГБ HBM3e при использовании VCF 9.0.0. Виртуальным машинам в тестах была выделена лишь часть ресурсов bare metal. В таблице ниже представлены аппаратные конфигурации, использованные для выполнения нагрузок MLPerf Inference 5.1 на системах bare metal и в виртуализированной среде.
Аппаратное и программное обеспечение для Dell PowerEdge XE9680:
Параметр
Bare Metal
Виртуальная среда
Система
Dell PowerEdge XE9680
Dell PowerEdge XE9680
Процессоры
Intel Xeon Platinum 8568Y+, 96 ядер
Intel Xeon Platinum 8568Y+, 96 ядер
Логические процессоры
192
Всего 192, 48 (25%) выделены виртуальной машине для инференса, 144 доступны для других ВМ/нагрузок с полной изоляцией благодаря виртуализации
Память хоста — 3 ТБ, 2 ТБ (67%) выделено виртуальной машине для инференса
Хранилище
2 ТБ SSD, 5 ТБ CIFS
2x SSD по 3,5 ТБ, 1x SSD на 7 ТБ
ОС
Ubuntu 24.04
ВМ Ubuntu 24.04 на VCF / ESXi 9.0.0.0.24755229
CUDA
CUDA 12.8 и драйвер 570.133
CUDA 12.8 и драйвер Linux 570.158.01
TensorRT
TensorRT 10.11
TensorRT 10.11
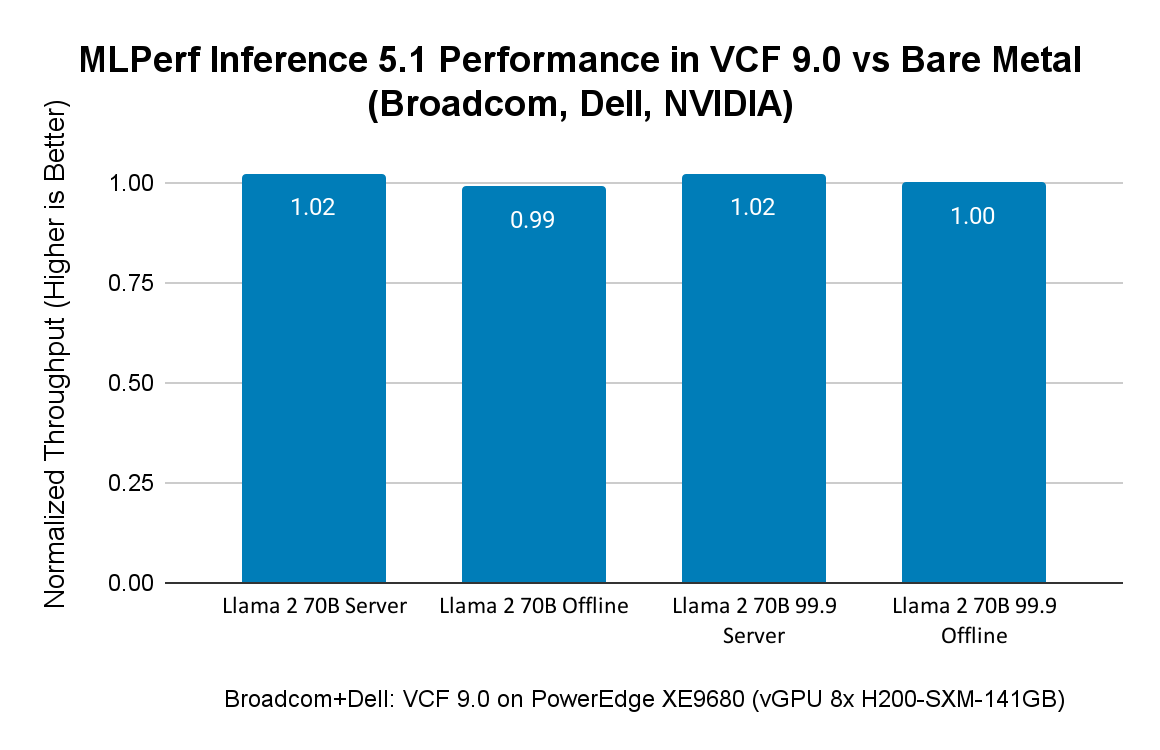
Результаты MLPerf Inference 5.1, представленные в таблице, демонстрируют высокую производительность для больших языковых моделей (Llama 3.1 405B и Llama 2 70B), а также для задач генерации изображений (SDXL — Stable Diffusion).
Результаты MLPerf Inference 5.1 при использовании 8x vGPU в VCF 9.0 на аппаратной платформе Dell PowerEdge XE9680 с 8x GPU NVIDIA H200:
Бенчмарки
Пропускная способность
Llama 3.1 405B Server (токенов/с)
277
Llama 3.1 405B Offline (токенов/с)
547
Llama 2 70B Server (токенов/с)
33 385
Llama 2 70B Offline (токенов/с)
34 301
Llama 2 70B — высокая точность — Server (токенов/с)
33 371
Llama 2 70B — высокая точность — Offline (токенов/с)
34 486
SDXL Server (сэмплов/с)
17,95
SDXL Offline (сэмплов/с)
18,64
На рисунке ниже сравниваются результаты MLPerf Inference 5.1 в VCF с результатами Dell на bare metal на том же сервере Dell PowerEdge XE9680 с GPU H200. Результаты как Broadcom, так и Dell находятся в открытом доступе на сайте MLCommons. Поскольку Dell представила только результаты для Llama 2 70B, на рисунке 2 показано сравнение производительности MLPerf Inference 5.1 в VCF 9.0 и на bare metal именно для этих нагрузок. Диаграмма демонстрирует, что разница в производительности между VCF и bare metal составляет всего 1–2%.
Сравнение производительности виртуализированных и bare metal ML/AI-нагрузок на Dell XE9680 с 8x GPU H200 SXM 141 ГБ:
Производительность MLPerf Inference 5.1 в VCF с процессорами Intel Xeon 6-го поколения
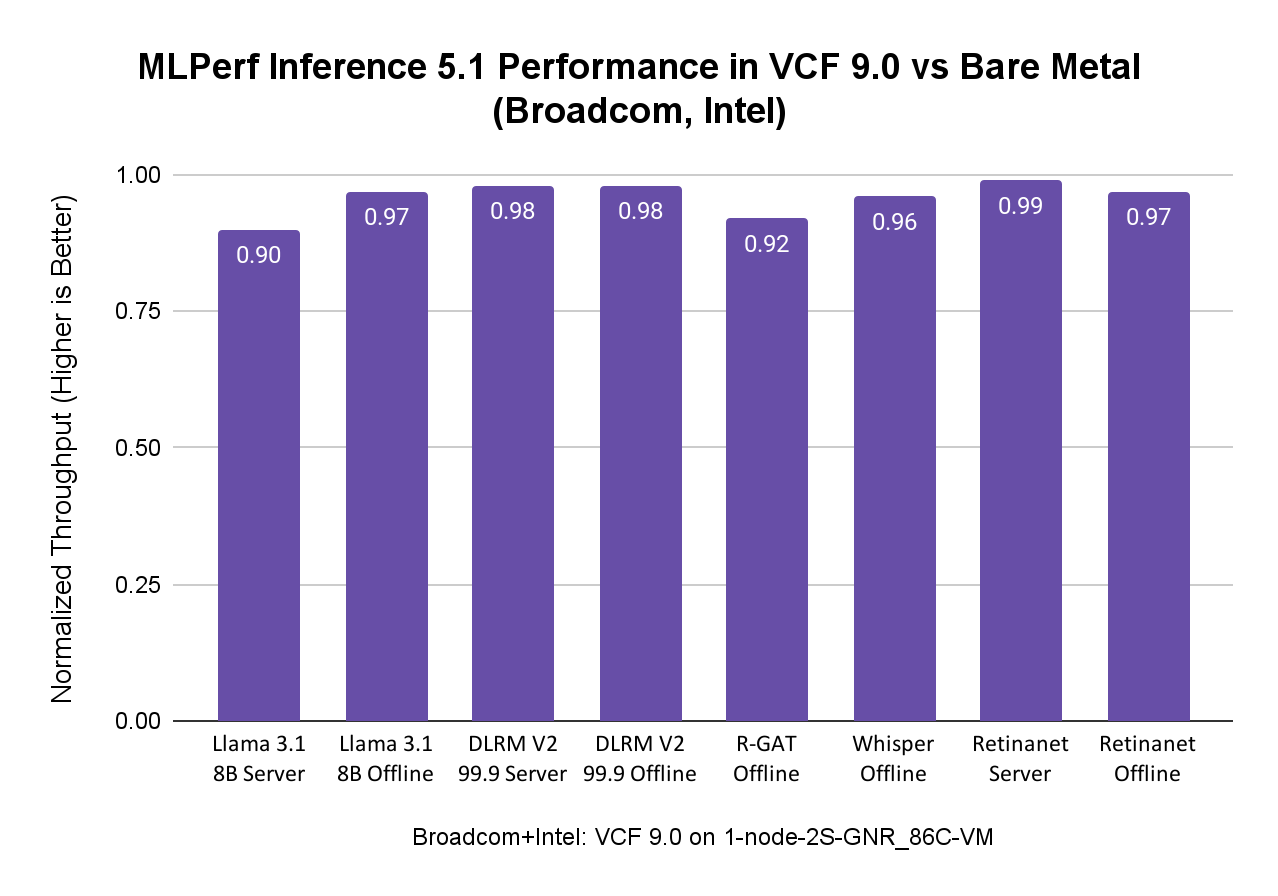
Intel и Broadcom совместно продемонстрировали возможности VCF, ориентированные на заказчиков, использующих исключительно процессоры Intel Xeon со встроенным ускорением AMX для AI-нагрузок. В тестах запускали нагрузки MLPerf Inference 5.1, включая Llama 3.1 8B, DLRM-V2, R-GAT, Whisper и RetinaNet, на системе, представленной в таблице ниже.
Аппаратное и программное обеспечение для систем Intel
AI-нагрузки, особенно модели меньшего размера, могут эффективно выполняться на процессорах Intel Xeon с ускорением AMX в среде VCF, достигая производительности, близкой к bare metal, и одновременно получая преимущества управляемости и гибкости VCF. Это делает процессоры Intel Xeon отличной отправной точкой для организаций, начинающих свой путь в области AI, поскольку они могут использовать уже имеющуюся инфраструктуру.
Результаты MLPerf Inference 5.1 при использовании процессоров Intel Xeon в VCF показывают производительность на уровне bare metal. В сценариях, где в датацентре отсутствуют ускорители, такие как GPU, или когда AI-нагрузки менее вычислительно требовательны, в зависимости от задач заказчика, AI/ML-нагрузки могут быть развернуты на процессорах Intel Xeon в VCF с преимуществами виртуализации и при сохранении производительности на уровне bare metal, как показано на рисунке ниже:
Бенчмарки MLPerf Inference
Каждый бенчмарк определяется набором данных (Dataset) и целевым уровнем качества (Quality Target). В следующей таблице приведено краткое описание бенчмарков, входящих в данную версию набора тестов (официальные правила остаются первоисточником):
В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему (SUT) в самом начале прогона. В сценарии Server LoadGen отправляет новые запросы в SUT в соответствии с распределением Пуассона. Это показано в таблице ниже.
Сценарии тестирования MLPerf Inference:
Сценарий
Генерация запросов
Длительность
Сэмплов на запрос
Ограничение по задержке
Tail latency
Метрика производительности
Server
LoadGen отправляет новые запросы в SUT согласно распределению Пуассона
270 336 запросов и 60 секунд
1
Зависит от бенчмарка
99%
Максимально поддерживаемый параметр пропускной способности Пуассона
VCF предоставляет заказчикам несколько гибких вариантов развертывания AI-инфраструктуры, поддерживает оборудование от различных вендоров и позволяет использовать разные подходы к запуску AI-нагрузок, применяющих как GPU, так и CPU для вычислений.
При использовании GPU виртуализированные конфигурации виртуальных машин в наших бенчмарках задействуют лишь часть ресурсов CPU и памяти, при этом обеспечивая производительность MLPerf Inference 5.1 на уровне bare metal даже при пиковом использовании GPU — это одно из ключевых преимуществ виртуализации. Такой подход позволяет задействовать оставшиеся ресурсы CPU и памяти для выполнения других нагрузок с полной изоляцией, снизить стоимость AI/ML-инфраструктуры и использовать преимущества виртуализации VCF при управлении датацентрами.
Результаты бенчмарков показывают, что VCF 9.0 находится в «зоне Златовласки» для AI/ML-нагрузок, обеспечивая производительность, сопоставимую с bare metal. VCF также упрощает управление и быструю обработку нагрузок благодаря использованию vGPU, гибких NVLink-соединений между устройствами и технологий виртуализации, позволяющих применять AI/ML-инфраструктуру для графики, обучения и инференса. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой, обеспечивая совместное использование дорогостоящих аппаратных ресурсов несколькими арендаторами.
Доступность данных — ключевая компетенция корпоративных систем хранения. На протяжении десятилетий такие системы стремились обеспечить высокий уровень доступности данных при одновременном соблюдении ожиданий по производительности и эффективности использования пространства. Достичь всего этого одновременно непросто.
Кодирование с восстановлением (erasure coding) играет важную роль в хранении данных устойчивым, но при этом эффективным с точки зрения занимаемого пространства способом. Этот пост поможет лучше понять, как erasure coding реализовано в VMware vSAN, чем оно отличается от подходов, применяемых в традиционных системах хранения, и как корректно интерпретировать возможности erasure code в контексте доступности данных.
Назначение Erasure Coding
Основная ответственность любой системы хранения — вернуть запрошенный бит данных. Чтобы делать это надежно, системе хранения необходимо сохранять данные устойчивым способом. Простейшая форма устойчивости данных достигается посредством нескольких копий или «зеркал», которые позволяют поддерживать доступность при возникновении отказа в системе хранения, например при выходе из строя диска в массиве хранения или хоста в распределённой системе хранения, такой как vSAN. Одна из проблем этого подхода — высокая стоимость хранения: полные копии данных занимают много места. Одна дополнительная копия удваивает объём, две — утраивают.
Erasure codes позволяют хранить данные устойчиво, но гораздо более эффективно с точки зрения пространства, чем традиционное зеркалирование. Вместо хранения копий данные распределяются по нескольким локациям — каждая из которых может считаться точкой отказа (например, диск или хост в распределённой системе, такой как vSAN). Фрагменты данных формируют «полосу» (stripe), к которой добавляются фрагменты четности, создаваемые при записи данных. Данные четности получаются в результате математических вычислений. Если какой-либо фрагмент данных отсутствует, система может прочитать доступные части полосы и вычислить недостающий фрагмент, используя четность. Таким образом, она может либо выполнить исходный запрос чтения «на лету», либо реконструировать отсутствующие данные в новое место. Тип erasure code определяет, может ли он выдержать потерю одного, двух или более фрагментов при сохранении доступности данных.
Erasure codes обеспечивают существенную экономию пространства по сравнению с традиционным зеркальным хранением. Экономия зависит от характеристик конкретного типа erasure code — например, сколько отказов он способен выдержать и по скольким локациям распределяются данные.
Erasure codes бывают разных типов. Их обычно обозначают количеством фрагментов данных и количеством фрагментов четности. Например, обозначение 6+3 или 6,3 означает, что полоса состоит из 6 (k) фрагментов данных и 3 (m) фрагментов четности, всего 9 (n) фрагментов. Такой тип erasure code может выдержать отказ любых трёх фрагментов, сохранив доступность данных. Он обеспечивает такую устойчивость при всего лишь 50% дополнительного расхода пространства.
Но erasure codes не лишены недостатков. Операции ввода-вывода становятся более сложными: одна операция записи может преобразовываться в несколько операций чтения и записи, что называют «усилением ввода-вывода» (I/O amplification). Это может замедлять обработку в системе хранения, а также увеличивать нагрузку на CPU и требовать больше полосы пропускания. Однако при правильной реализации erasure codes могут сочетать устойчивость с высокой производительностью. Например, инновационная архитектура vSAN ESA устраняет типичные проблемы производительности erasure codes, и RAID-6 в ESA может обеспечивать такую же или даже лучшую производительность, чем RAID-1.
Хранение данных в vSAN и в традиционном массиве хранения
Прежде чем сравнивать erasure codes в vSAN и традиционных системах хранения, рассмотрим, как vSAN хранит данные по сравнению с классическим массивом.
Хранилища часто предоставляют большой пул ресурсов в виде LUN. В контексте vSphere он форматируется как datastore с VMware VMFS, где располагаются несколько виртуальных машин. Команды SCSI передаются от ВМ через хосты vSphere в систему хранения. Такой datastore на массиве охватывает большое количество устройств хранения в его корпусе, что означает не только широкую логическую границу (кластерная файловая система с множеством ВМ), но и большую физическую границу (несколько дисков). Как и многие другие файловые системы, такая кластерная ФС должна оставаться целостной, со всеми метаданными и данными, доступными в полном объёме.
vSAN использует совершенно иной подход. Вместо классической файловой системы с большой логической областью данных, распределённой по всем хостам, vSAN оперирует малой логической областью данных для каждого объекта. Примерами могут служить диски VMDK виртуальной машины, постоянный том для контейнера или файловый ресурс, предоставленный службами файлов vSAN. Именно это делает vSAN аналогичным объектному хранилищу, даже несмотря на то, что фактически это блочное хранилище с использованием SCSI-семантики или файловой семантики в случае файловых сервисов. Для дополнительной информации об объектах и компонентах vSAN см. пост «vSAN Objects and Components Revisited».
Такой подход обеспечивает vSAN целый ряд технических преимуществ по сравнению с монолитной кластерной файловой системой в традиционном массиве хранения. Erasure codes применяются к объектам независимо и более гранулярно. Это позволяет заказчикам проектировать кластеры vSAN так, как они считают нужным — будь то стандартный односайтовый кластер, кластер с доменами отказа для отказоустойчивости на уровне стоек или растянутый кластер (stretched cluster). Кроме того, такой подход позволяет vSAN масштабироваться способами, недоступными при традиционных архитектурных решениях.
Сравнение erasure coding в vSAN и традиционных системах хранения
Имея базовое понимание того, как традиционные массивы и vSAN предоставляют ресурсы хранения, рассмотрим, чем их подходы к erasure coding отличаются. В этих сравнениях предполагается наличие одновременных отказов, поскольку многие системы хранения способны справляться с единичными отказами в течение некоторого времени.
Массив хранения (Storage Array)
В данном примере традиционный массив использует erasure code конфигурации 22+3 для одного LUN (k=22, m=3, n=25).
Преимущества:
Относительно низкие накладные расходы по ёмкости. Дополнительная ёмкость, потребляемая данными четности для поддержания доступности при сбоях в доменах отказа (устройствах хранения), составляет около 14%. Такого низкого уровня удаётся достичь благодаря распределению данных по очень большому числу устройств хранения.
Относительно высокий уровень отказоустойчивости (3). Любые три устройства хранения могут выйти из строя, и том останется доступным. Но, как отмечено ниже, это только часть картины.
Компромиссы:
Относительно большой «радиус поражения». Если число отказов превысит то, на которое рассчитан массив, зона воздействия будет очень большой. В некоторых случаях может пострадать весь массив.
Защита только от отказов устройств хранения. Erasure coding в массивах защищает только от отказов самих накопителей. Массивы могут испытывать серьёзную деградацию производительности и доступности при других типах отказов, например, межсоединений (interconnects), контроллеров хранения и некорректных обновлениях прошивок. Ни один erasure code не может обеспечить доступность данных, если выйдёт из строя больше контроллеров, чем массив способен выдержать.
Относительно высокий эффект на производительность во время или после отказов. Отказы при больших значениях k и m могут требовать очень много ресурсов на восстановление и быть более подвержены высоким значениям tail latency.
Относительно большое количество потенциальных точек отказа на одну четность. Соотношение 8,33:1 отражает высокий показатель потенциальных точек отказа относительно количества битов четности, обеспечивающих доступность. Высокое соотношение указывает на более высокую хрупкость.
Последний пункт является чрезвычайно важным. Erasure codes нельзя оценивать только по заявленному уровню устойчивости (m), но необходимо учитывать сопоставление заявленной устойчивости с количеством потенциальных точек отказа, которые она прикрывает (n). Это обеспечивает более корректный подход к пониманию вероятностной надёжности системы хранения.
vSAN
В этом примере предположим, что у нас есть кластер vSAN из 24 хостов, и объект данных ВМ настроен на использование RAID-6 erasure code ы (k=4, m=2, n=6).
Важно отметить, что компоненты, формирующие объект vSAN при использовании RAID-6, будут содержать как фрагменты данных, так и фрагменты четности. Как описывает Христос Караманолис в статье "The Use of Erasure Coding in vSAN" (vSAN OSA, примерно 2018 год), vSAN не создаёт отдельные компоненты четности.
Преимущества:
Относительно небольшой «радиус поражения». Если кластер переживает более двух одновременных отказов хостов, это затронет лишь некоторые объекты, но не выведет из строя весь datastore.
Защита от широкого спектра типов отказов. Erasure coding в vSAN учитывает отказы отдельных устройств хранения, хостов и отказы заранее определённых доменов (например, стоек).
Относительно низкое влияние на производительность во время или после отказа. Небольшие значения k уменьшают вычислительные затраты при восстановлении.
Относительно малое число потенциальных точек отказа на единицу четности. Соотношение 3:1 указывает на малое количество возможных точек отказа по сравнению с числом битов четности, обеспечивающих доступность.
Компромиссы:
Низкая абсолютная устойчивость объекта к отказам (2). У vSAN RAID-6 (4+2) заявленная устойчивость меньше. Однако важно помнить:
граница отказа — это объект, а не весь кластер, количество потенциальных точек отказа на четность существенно ниже.
Относительно более высокие накладные расходы. Дополнительная ёмкость, потребляемая битами четности для поддержания доступности при отказе домена (хоста), составляет 50%.
Несмотря на то, что RAID-6 в vSAN защищает от 2 отказов (в отличие от 3), он остаётся чрезвычайно надёжным благодаря небольшому количеству потенциальных точек отказа: всего 6 против 25. Это обеспечивает vSAN RAID-6 (4+2) техническое преимущество перед схемой хранения массива 22+3, если сравнивать надёжность с точки зрения вероятностей отказов.
Для vSAN использование erasure code с малым значением n обеспечивает гораздо большую гибкость в построении кластеров под самые разные сценарии. Например, RAID-6 (4+2) можно использовать минимум на 6 хостах. Для erasure code 22+3 теоретически потребовалось бы не менее 25 хостов в одном кластере.
Развязка размера кластера и доступности
RAID-6 в vSAN всегда остаётся схемой 4+2, независимо от размера кластера. Когда к объекту применяется политика хранения FTT=2 с RAID-6, это означает, что объект может выдержать два одновременных отказа хостов, на которых находятся его компоненты.
Это свойство относится к состоянию объекта, а не всего кластера. Отказы на других хостах не влияют на доступность данного объекта, за исключением того, что эти хосты могут быть использованы для восстановления недостающей части полосы с помощью четности.
vSAN рассматривает такие уцелевшие хосты как кандидатов для размещения реконструируемых компонентов, чтобы вернуть объекту заданный уровень устойчивости.
Такой подход позволяет vSAN разорвать зависимость между размером кластера и уровнем доступности. В то время как многие масштабируемые системы хранения становятся более хрупкими по мере увеличения числа узлов, подход vSAN, напротив, снижает риски по мере масштабирования кластера.
Для дополнительной информации о доступности и механизмах обработки отказов в vSAN см. документ "vSAN Availability Technologies" на VMware Resource Center.
Итог
Erasure coding — это мощная технология, позволяющая хранить данные очень устойчиво и при этом эффективно использовать пространство. Но не все erasure codes одинаково полезны.
vSAN использует такие схемы erasure coding, которые обеспечивают оптимальный баланс устойчивости, гибкости и эффективности использования пространства в распределённой среде. В сочетании с дополнительными механизмами оптимизации пространства — такими как сжатие данных в vSAN и глобальная дедупликация в ESA (в составе VCF 9.0), хранилище vSAN становится ещё более производительным, ёмким и надёжным, чем когда-либо.
Дункан Эппинг выпустил обзорное видео, где он отвечает на вопрос одного из читателей, который касается поведения VMware vSAN после восстановления отказавших площадок. Речь идёт о сценарии, когда производится Site Takeover и два сайта выходят из строя, а позже снова становятся доступными. Что же происходит с виртуальными машинами и их компонентами в такой ситуации?
Автор решил смоделировать следующий сценарий:
Отключить preferred-локацию и witness-узел.
Выполнить Site Takeover, чтобы виртуальная машина Photon-1 стала снова доступна после ее перезапуска, но уже только на оставшейся рабочей площадке.
После восстановления всех узлов проверить, как vSAN автоматически перераспределит компоненты виртуальной машины.
Поведение виртуальной машины после отказа
Когда preferred-локация и witness отключены, виртуальная машина Photon-1 продолжает работу благодаря механизму vSphere HA. Компоненты ВМ в этот момент существуют только на вторичном домене отказа (fault domain), то есть на той площадке, которая осталась доступной.
Автор пропускает часть сценария с перезапуском ВМ, поскольку этот процесс уже подробно освещался ранее.
Что происходит при восстановлении сайтов
После того как preferred-локация и witness возвращаются в строй, начинается полностью автоматический процесс:
vSAN анализирует политику хранения, назначенную виртуальной машине.
Поскольку политика предусматривает растяжение ВМ между двумя площадками, система автоматически начинает перераспределение компонентов.
Компоненты виртуальной машины снова создаются и на preferred-локации, и на secondary-локации.
При этом администратору не нужно предпринимать никаких действий — все операции происходят автоматически.
Важный момент: полная ресинхронизация
Дункан подчёркивает, что восстановление не является частичным, а выполняется полный ресинк данных:
Компоненты, которые находились на preferred-локации до сбоя, vSAN считает недействительными и отбрасывает.
Данные перезапущенной ВМ полностью синхронизируются с рабочей площадки (теперь это secondary FD) на вновь доступную preferred-локацию.
Это необходимо для исключения расхождений и гарантии целостности данных.
Итоги
Демонстрация показывает, что vSAN при восстановлении площадок:
Автоматически перераспределяет компоненты виртуальных машин согласно политике хранения.
Выполняет полную ресинхронизацию данных.
Не требует ручного вмешательства администратора.
Таким образом, механизм stretched-кластеров vSAN обеспечивает предсказуемое и безопасное восстановление после крупных сбоев.
В Broadcom сосредоточены на том, чтобы помочь клиентам модернизировать инфраструктуру, повысить устойчивость и упростить операции — без добавления сложности для команд, которые всем этим управляют. За последние несколько месяцев было выпущено несколько обновлений, делающих облако VMware Cloud on AWS (VMC) более гибким и простым в использовании. Легко пропустить последние обновления в последних примечаниях к релизам, поэтому мы хотим рассказать о некоторых из самых свежих функций.
Последние обновления предоставляют корпоративным клиентам более экономичную устойчивость благодаря нестандартным вторичным кластерам (non-stretched secondary clusters) и улучшенным возможностям масштабирования вниз, более прозрачную операционную информацию благодаря обновлённому пользовательскому интерфейсу, улучшенный VMC Sizer, новые Host Usage API, а также продолжающиеся улучшения продукта HCX 4.11.3.
Оптимизация развертываний SDDC: улучшения для stretched-кластеров
Когда вы развертываете Software Defined Datacenter (SDDC) в VMC, вам предоставляется выбор между стандартным развертыванием и stretched-развертыванием. Стандартный кластер развертывается в одной зоне доступности AWS (AZ), тогда как stretched-кластер обеспечивает повышенную доступность, развертывая SDDC в трёх зонах доступности AWS. Две зоны используются для размещения экземпляров, а третья — для компонента vSAN Witness.
Поскольку SDDC в stretched-кластерах размещает хосты в двух зонах доступности AWS, клиентам необходимо планировать ресурсы по схеме два к одному, что может быть слишком дорого для рабочих нагрузок, которые не требуют высокой доступности. Кроме того, если stretched-кластер масштабируется более чем до шести хостов, ранее его нельзя было уменьшить обратно. Чтобы улучшить обе эти ситуации, команда VMC внедрила нестандартные вторичные кластеры (Non-Stretched Secondary Clusters) в stretched-SDDC, а также улучшенные возможности масштабирования вниз для stretched-кластеров.
Нестандартные вторичные кластеры в stretched-SDDC
Ранее все кластеры в stretched-SDDC были растянуты между двумя зонами доступности. В этом обновлении только первичный кластер должен быть stretched, в то время как вторичные кластеры теперь могут развертываться в одной зоне доступности.
В stretched-кластере хосты должны развертываться равномерно, поэтому минимальный шаг масштабирования — два хоста.
Но в нестандартном вторичном кластере можно добавлять хосты по одному, что позволяет увеличивать количество развернутых хостов только в той зоне доступности AWS, где они действительно нужны.
Некоторые ключевые преимущества:
Обеспечивает преимущества как stretched-, так и non-stretched-кластеров в одном и том же SDDC.
Позволяет расширять кластер в одной AZ по одному хосту в non-stretched-кластерах.
Снижает стоимость для рабочих нагрузок, которым не требуется доступность stretched-кластера, включая тестовые и/или девелоперские окружения, где высокая доступность не обязательна.
Поддерживает архитектуры приложений с нативной репликацией на уровне приложения — их можно развертывать в двух независимых нестандартных вторичных кластерах (Non-Stretched Secondary Clusters).
VMC поддерживает stretched-кластеры для приложений, которым требуется отказоустойчивость между AZ. Начиная с версии SDDC 1.24 v5, клиенты получают большую гибкость в том, как их кластеры развертываются и масштабируются. Non-stretched-кластеры могут быть развернуты только в одной из двух AWS AZ, в которых находятся stretched-хосты, и эта функция доступна только для SDDC версии 1.24v5 и выше. Кроме того, SLA для non-stretched-кластера отличается от SLA для stretched-кластера, так как non-stretched не предоставляет повышенную доступность.
При планировании новых развертываний SDDC рассмотрите возможность использования Stretched Cluster SDDC, чтобы получить преимущества и высокой доступности, и оптимизированного размещения рабочих нагрузок.
Улучшенные возможности масштабирования вниз (Scale-Down) для stretched-кластеров
Ранее stretched-кластеры нельзя было уменьшить ниже шести хостов (три в каждой AZ). Теперь вы можете уменьшить кластер с шести или более хостов до четырёх хостов (два в каждой AZ) или даже до двух хостов (по одному в каждой AZ), в зависимости от доступных ресурсов и других факторов. Это даёт вам больший контроль над инфраструктурой и помогает оптимизировать расходы.
Ключевые сценарии использования:
Если использование ресурсов рабочей нагрузки снижалось со временем, и теперь вам необходимо уменьшить stretched-кластер, ориентируясь на текущие потребности.
Если ранее вы увеличивали stretched-кластер до шести или более хостов в период пикового спроса, но сейчас такие мощности больше не нужны.
Если вы недавно перевели свои кластеры с i3.metal на i4i.metal или i3en.metal и больше не нуждаетесь в прежнем количестве хостов. Новые типы инстансов обеспечивают такую же или лучшую производительность с меньшим набором хостов, что позволяет экономично уменьшить кластер.
Однако перед уменьшением stretched-кластера необходимо учитывать несколько важных моментов:
Если в вашем первичном кластере используются крупные управляющие модули (large appliances), необходимо поддерживать минимум шесть хостов (три в каждой AZ).
Для кластеров с кастомной конфигурацией 8 CPU минимальный размер — четыре хоста (два в каждой AZ).
Масштабирование вниз невозможно, если кластер уже на пределе ресурсов или если уменьшение нарушило бы пользовательские политики.
Изучите текущую конфигурацию, сравните её с рекомендациями выше — и вы сможете эффективно адаптировать свой stretched-кластер под текущие потребности.
Контролируйте свои данные: новый Host Usage Report API
VMware представила новый Host Usage Report API, который обеспечивает программный доступ к данным о потреблении хостов. Теперь вы можете получать ежедневные отчёты об использовании хостов за любой период и фильтровать их по региону, типу инстанса, SKU и другим параметрам — всё через простой API.
Используйте эти данные, чтобы анализировать тенденции использования хостов, оптимизировать расходы и интегрировать метрики напрямую в существующие инструменты отчётности и дашборды. Host Usage Report API поддерживает стандартные параметры запросов, включая сортировку и фильтрацию, что даёт вам гибкость в получении именно тех данных, которые вам нужны.
Изображение выше — это пример вывода API. Вы можете автоматизировать этот процесс, чтобы передавать данные в любой аналитический инструмент по вашему выбору.
Улучшения продукта: HCX версии 4.11.3 теперь доступен для VMC
Теперь VMware HCX версии 4.11.3 доступен для VMware Cloud on AWS, и он включает важные обновления, о которых вам стоит знать.
Что нового в HCX 4.11.3?
Этот сервисный релиз содержит ключевые исправления и улучшения в областях datapath, системных обновлений и общей эксплуатационной стабильности, чтобы обеспечить более плавную работу. Полный перечень всех улучшений можно найти в официальных HCX Release Notes. Версия HCX 4.11.3 продлевает поддержку до 11 октября 2027 года, обеспечивая долгосрочную стабильность и спокойствие. VMware настоятельно рекомендует всем клиентам обновиться до версии 4.11.3 как можно скорее, так как более старые версии больше не поддерживаются.
Если вы настраиваете HCX впервые, VMware Cloud on AWS автоматически развернёт версию 4.11.3. Для существующих развертываний 4.11.3 теперь является единственной доступной версией для обновления. Нужна помощь, чтобы начать? Ознакомьтесь с инструкциями по активации HCX и по обновлению HCX в VMware Cloud on AWS.
Улучшенный интерфейс: обновлённый VMware Cloud on AWS UI
VMware Cloud on AWS теперь оснащён обновлённым пользовательским интерфейсом с более упрощённой компоновкой, более быстрой навигацией и улучшенной согласованностью на всей платформе. Новый интерфейс уже доступен по адресу https://vmc.broadcom.com.
Улучшенные рекомендации по сайзингу среды: обновления VMC Sizer и Cluster Conversion
VMware представила серьёзные улучшения в процессе конвертации кластеров VMC (VMC Cluster Conversion) в инструменте VMware Cloud Sizer. Эти обновления обеспечивают более точные рекомендации по сайзингу, большую прозрачность и улучшенный пользовательский опыт при планировании перехода с хостов i3.metal на i3en.metal или i4i.metal.
Что нового в оценках VMC Cluster Conversion?
Обновлённый алгоритм оценки в VMC Sizer теперь позволяет получить более полное представление о ваших потребностях в ресурсах перед переходом с i3.metal на более новые типы инстансов.
Рекомендация по количеству хостов в обновлённом выводе VMC Sizer формируется на основе шести ресурсных измерений, и итоговая рекомендация определяется наибольшим из них.
В отчёт включены следующие параметры:
Вычислительные ресурсы (compute)
Память (memory)
Использование хранилища (storage utilization) — с консервативным и агрессивным вариантами оценки
Политики хранения vSAN (vSAN storage policies)
NSX Edge
Другие критически важные параметры
Все эти данные объединены в ясный и практичный отчёт VMC Sizer с рекомендациями, адаптированными под ваш сценарий миграции на новые типы инстансов.
Этот результат оценки является моментальным снимком текущего использования ресурсов и не учитывает будущий рост рабочих нагрузок. При планировании конвертации кластеров следует учитывать и несколько других важных моментов:
Итоговое количество хостов и параметры сайзинга будут подтверждены уже в ходе фактической конвертации кластера.
Клиентам рекомендуется повторно выполнять оценку сайзинга после любых существенных изменений конфигурации, ресурсов или других параметров.
В ходе конвертации политики RAID не изменяются.
Предоставляемые в рамках этого процесса оценки подписки VMware служат исключительно для планирования и не являются гарантированными финальными требованиями.
Фактические потребности в подписке могут оказаться выше предварительных оценок, что может потребовать покупки дополнительных подписок после конвертации.
Возвраты средств или уменьшение объёма подписки не предусмотрены, если предварительная оценка превысит фактические потребности.
В постах ранее мы подчеркивали ценность, которую NVMe Memory Tiering приносит клиентам Broadcom, и то, как это стимулирует ее внедрение. Кто же не хочет сократить свои расходы примерно на 40% просто благодаря переходу на VMware Cloud Foundation 9? Мы также затронули предварительные требования и оборудование в части 1, а архитектуру — в Части 2; так что теперь поговорим о правильном масштабировании вашей среды, чтобы вы могли максимально эффективно использовать свои вложения и одновременно снизить затраты.
Правильное масштабирование для NVMe Memory Tiering касается главным образом оборудования, но здесь есть два возможных подхода: развёртывания greenfield и brownfield.
Начнем с brownfield — внедрения Memory Tiering на существующей инфраструктуре. Вы пришли к осознанию, что VCF 9 — действительно интегрированный продукт, и решили развернуть его, но только что узнали о Memory Tiering. Не волнуйтесь, вы всё ещё можете внедрить NVMe Memory Tiering после развертывания VCF 9. Прочитав части 1 и 2, вы узнали о важности классов производительности и выносливости NVMe, а также о требовании 50% активной памяти. Это означает, что нам нужно рассматривать NVMe-устройство как минимум такого же размера, что и DRAM, поскольку мы удвоим объём доступной памяти. То есть, если каждый хост имеет 1 ТБ DRAM, у нас также должно быть минимум 1 ТБ NVMe. Вроде бы просто. Однако мы можем взять NVMe и покрупнее — и всё равно это будет дешевле, чем покупка дополнительных DIMM. Сейчас объясним.
VMware не случайно транслирует мысль: «покупайте NVMe-устройство как минимум такого же размера, что и DRAM», поскольку по умолчанию они используют соотношение DRAM:NVMe равное 1:1 — половина памяти приходится на DRAM, а половина на NVMe. Однако существуют рабочие нагрузки, которые не слишком активны с точки зрения использования памяти — например, некоторые VDI-нагрузки. Если у вас есть рабочие нагрузки с 10% активной памяти на постоянной основе, вы можете действительно воспользоваться расширенными возможностями NVMe Memory Tiering.
Соотношение 1:1 выбрано по следующей причине: большинство нагрузок хорошо укладывается в такие пропорции. Но это отношение DRAM:NVMe является параметром расширенной конфигурации, который можно изменить — вплоть до 1:4, то есть до 400% дополнительной памяти. Поэтому для рабочих нагрузок с очень низкой активностью памяти соотношение 1:4 может максимизировать вашу выгоду. Как это влияет на стратегию масштабирования?
Отлично, что вы спросили) Поскольку DRAM:NVMe может меняться так же, как меняется активность памяти ваших рабочих нагрузок, это нужно учитывать уже на этапе закупки NVMe-устройств. Вернувшись к предыдущему примеру хоста с 1 ТБ DRAM, вы, например, решили, что 1 ТБ NVMe — разумный минимум, но при нагрузках с очень низкой активной памятью этот 1 ТБ может быть недостаточно выгодным. В таком случае NVMe на 4 ТБ позволит использовать соотношение 1:4 и увеличить объём доступной памяти на 400%. Именно поэтому так важно изучить активную память ваших рабочих нагрузок перед покупкой NVMe-устройств.
Еще один аспект, влияющий на масштабирование, — размер раздела (partition). Когда мы создаём раздел на NVMe перед настройкой NVMe Memory Tiering, мы вводим команду, но обычно не указываем размер вручную — он автоматически создаётся равным размеру диска, но максимум до 4 ТБ. Объём NVMe, который будет использоваться для Memory Tiering, — это комбинация размера раздела NVMe, объёма DRAM и заданного отношения DRAM:NVMe. Допустим, мы хотим максимизировать выгоду и «застраховать» оборудование на будущее, купив 4 ТБ SED NVMe, хотя на хосте всего 1 ТБ DRAM. После настройки вариантами по умолчанию размер раздела составит 4 ТБ (это максимальный поддерживаемый размер), но для Memory Tiering будет использован лишь 1 ТБ NVMe, поскольку используется соотношение 1:1. Если нагрузка изменится или мы поменяем соотношение на, скажем, 1:2, то размер раздела останется прежним (пересоздавать не требуется), но теперь мы будем использовать 2 ТБ NVMe вместо 1 ТБ — просто изменив коэффициент соотношения. Важно понимать, что не рекомендуется менять это соотношение без надлежащего анализа и уверенности, что активная память рабочих нагрузок вписывается в доступный объём DRAM.
DRAM:NVME
DRAM Size
NVMe Partition Size
NVMe Used
1:1
1 TB
4 TB
1 TB
1:2
1 TB
4 TB
2 TB
1:4
1 TB
4 TB
4 TB
Итак, при определении размера NVMe учитывайте максимальный поддерживаемый размер раздела (4 ТБ) и соотношения, которые можно настроить в зависимости от активной памяти ваших рабочих нагрузок. Это не только вопрос стоимости, но и вопрос масштабируемости. Имейте в виду, что даже при использовании крупных NVMe-устройств вы всё равно сэкономите значительную сумму по сравнению с использованием только DRAM.
Теперь давайте поговорим о вариантах развертывания greenfield, когда вы заранее знаете о Memory Tiering и вам нужно закупить серверы — вы можете сразу учесть эту функцию как параметр в расчете стоимости. Те же принципы, что и для brownfield-развертываний, применимы и здесь, но если вы планируете развернуть VCF, логично тщательно изучить, как NVMe Memory Tiering может существенно снизить стоимость покупки серверов. Как уже говорилось, крайне важно убедиться, что ваши рабочие нагрузки подходят для Memory Tiering (большинство подходят), но проверку провести необходимо.
После исследования вы можете принимать решения по оборудованию на основе квалификации рабочих нагрузок. Допустим, все ваши рабочие нагрузки подходят для Memory Tiering, и большинство из них используют около 30% активной памяти. В таком случае всё ещё рекомендуется придерживаться консервативного подхода и масштабировать систему с использованием стандартного соотношения DRAM:NVMe 1:1. То есть, если вам нужно 1 ТБ памяти на хост, вы можете уменьшить объем DRAM до 512 ГБ и добавить 512 ГБ NVMe — это даст вам требуемый общий объем памяти, и вы уверены (благодаря исследованию), что активная память ваших нагрузок всегда уместится в DRAM. Кроме того, количество NVMe-устройств на хост и RAID-контроллер — это отдельное решение, которое не влияет на доступный объем NVMe, поскольку в любом случае необходимо предоставить одно логическое устройство, будет ли это один независимый NVMe или 2+ устройства в RAID-конфигурации. Однако это решение влияет на стоимость и отказоустойчивость.
С другой стороны, вы можете оставить исходный объем DRAM в 1 ТБ и добавить еще 1 ТБ памяти через Memory Tiering. Это позволит использовать более плотные серверы, сократив общее количество серверов, необходимых для размещения ваших нагрузок. В этом случае экономия достигается за счет меньшего количества оборудования и компонентов, а также сокращения затрат на охлаждение и энергопотребление.
В заключение, при определении размеров необходимо учитывать все переменные: объем DRAM, размер NVMe-устройств, размер раздела и соотношение DRAM:NVMe. Помимо этих параметров, для greenfield-развертываний следует проводить более глубокий анализ — именно здесь можно добиться дополнительной экономии, покупая DRAM только для активной памяти, а не для всего пула, как мы делали годами. Говоря о факторах и планировании, стоит также учитывать совместимость Memory Tiering с vSAN — это будет рассмотрено в следующей части серии.
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
VMware повторно представила свои сертификации продвинутого уровня с выпуском трёх новых экзаменов VMware Certified Advanced Professional (VCAP) для VMware Cloud Foundation 9.0. Эти сертификации предназначены для опытных IT-специалистов, которые хотят подтвердить свою экспертизу в проектировании, построении и управлении сложными средами частного облака. Возвращение экзаменов VCAP является важной вехой для специалистов VMware, предлагая чёткий путь для карьерного роста и признания их продвинутых навыков.
Понимание сертификации VCAP
Сертификация VMware Certified Advanced Professional (VCAP) — это престижный квалификационный уровень, который означает глубокое понимание технологий VMware и способность применять эти знания в реальных сценариях. Размещённая выше уровня VMware Certified Professional (VCP), сертификация VCAP предназначена для опытных специалистов, которые уже продемонстрировали прочные базовые знания продуктов и решений VMware. Получение сертификации VCAP демонстрирует приверженность к совершенству и высокий уровень профессионализма в специализированной области технологий VMware.
Новые экзамены VCAP для VMware Cloud Foundation 9.0
С выпуском VMware Cloud Foundation 9.0 VMware представила три новых экзамена VCAP, каждый из которых сосредоточен на критически важном аспекте платформы VCF. Эти экзамены ориентированы на конкретные рабочие роли и наборы навыков, позволяя специалистам специализироваться в областях, которые соответствуют их карьерным целям.
1. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 vSphere Kubernetes Service (3V0-24.25)
Эта сертификация предназначена для специалистов, работающих с контейнеризированными рабочими нагрузками и современными приложениями. Экзамен подтверждает навыки, необходимые для развертывания, управления и обеспечения безопасности vSphere with Tanzu, что позволяет предоставлять Kubernetes-as-a-Service на платформе VCF. Кандидаты на получение этой сертификации должны иметь практический опыт работы с Kubernetes, контейнерными сетями и хранилищами.
2. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Automation (3V0-21.25)
Эта сертификация сосредоточена на возможностях автоматизации и оркестрации VMware Cloud Foundation. Экзамен оценивает способность кандидата проектировать, внедрять и управлять рабочими процессами автоматизации с помощью VMware Aria Automation (ранее vRealize Automation). Эта сертификация идеально подходит для специалистов, которые отвечают за автоматизацию предоставления инфраструктуры и сервисов приложений.
3. VMware Certified Advanced Professional - VMware Cloud Foundation 9.0 Operations (3V0-22.25)
Эта сертификация ориентирована на специалистов, отвечающих за ежедневные операции и управление средой VMware Cloud Foundation. Экзамен охватывает такие темы, как мониторинг производительности, управление ёмкостью, устранение неполадок и управление жизненным циклом. Эта сертификация хорошо подходит для системных администраторов, операторов облака и инженеров по надёжности.
Все три новых экзамена VCAP для VMware Cloud Foundation 9.0 имеют схожий формат и структуру. Экзамены проводятся под наблюдением и доступны через Pearson VUE. Они состоят из 60 вопросов и имеют длительность 135 минут. Типы вопросов разнообразны и могут включать множественный выбор, drag-and-drop и практические лабораторные симуляции, обеспечивая комплексную оценку знаний и навыков кандидата.
Заключение
Возвращение экзаменов VCAP для VMware Cloud Foundation 9.0 предоставляет ценную возможность для специалистов VMware подтвердить свои продвинутые навыки и экспертизу. Эти сертификации являются свидетельством способности работать с новейшими технологиями VMware и являются признанным эталоном качества в отрасли. Получив сертификацию VCAP, специалисты могут улучшить свои карьерные перспективы и продемонстрировать свою приверженность к тому, чтобы оставаться на переднем крае постоянно развивающегося мира облачных вычислений.
Если вы уже знакомы с преимуществами локальных снапшотов для защиты данных в vSAN ESA, значит у вас есть опыт работы с одной из служб в составе объединённого виртуального модуля защиты и восстановления, являющегося частью решения ACC (Advanced Cyber Compliance).
Расширение защиты и восстановления ВМ
Давайте рассмотрим объединённую ценность защиты данных vSAN и VMware Advanced Cyber Compliance, позволяющую обеспечить надёжное, уверенное восстановление после кибератак и других катастроф. Виртуальный модуль защиты и восстановления, включённый в возможности аварийного восстановления решения Advanced Cyber Compliance, содержит три службы — все объединены в один простой в развертывании и управлении модуль (Virtual Appliance):
Служба снимков vSAN ESA
Расширенная репликация vSphere
Группы защиты и оркестрация восстановления
Сочетание этих служб модуля вместе с возможностями хранения vSAN ESA расширяет возможности для более широкой мультисайтовой защиты и восстановления ваших рабочих нагрузок в VCF.
Настройка вторичного сайта восстановления
В рамках вашей топологии развертывания VCF просто включите ещё один кластер vSAN ESA на втором сайте или в другой локации. Второй сайт подразумевает дополнительную среду vCenter в домене рабочих нагрузок VCF. Для простоты и удобства ссылки назовём эти два сайта «Site A» и «Site B» и развернём их в одном экземпляре VCF, как показано ниже.
Чтобы максимизировать ценность всех трёх упомянутых выше служб и расширить защиту данных vSAN между этими сайтами, вам потребуется лицензировать возможность оркестрации. Возможность оркестрации защиты и восстановления необходима для управления параметрами защиты данных vSAN для групп защиты, которым требуется включать функции репликации.
Имейте в виду, что расширенная репликация vSphere и возможности службы снапшотов vSAN уже включены в лицензирование VCF.
На новом вторичном сайте разверните кластер vSAN ESA для соответствующего vCenter вместе с ещё одним экземпляром объединённого виртуального модуля. Во многих случаях как модули vCenter, так и эти устройства защиты и восстановления устанавливаются в домен управления VCF.
После настройки двух сайтов процесс установления расширенной репликации vSphere между хостами ESX на каждом сайте довольно прост.
Расширение охвата политики защиты
VMware Advanced Cyber Compliance включает полностью оркестрированное аварийное восстановление между локальными сайтами VCF, и благодаря хранилищам данных vSAN ESA на этих нескольких сайтах теперь можно построить более надёжное решение по защите данных и аварийному восстановлению на уровне всего предприятия.
При наличии многосайтовой, объединённой конфигурации Advanced Cyber Compliance и vSAN ESA, группы защиты, которые вы определяете в рамках защиты данных vSAN для локального восстановления, теперь могут воспользоваться двумя дополнительными вариантами (2 и 3 пункты ниже), включающими репликацию и координацию защиты между двумя сайтами:
Локальная защита — защита с помощью снапшотов в пределах одного сайта.
Репликация — репликация данных ВМ на вторичный сайт.
Локальная защита и репликация — репликация данных ВМ между сайтами плюс локальные снапшоты и хранение удалённых снапшотов.
Давайте более подробно рассмотрим пример настройки защиты данных vSAN между двумя сайтами, которую можно использовать для аварийного восстановления, если исходный сайт станет недоступным или выйдет из строя. Для этого примера мы создадим новую группу защиты и пройдём процесс настройки политики, как показано ниже. Процесс настройки состоит всего из нескольких шагов, включая:
Задание свойств политики защиты.
Определение инвентаря защищаемых ВМ.
Настройку расписаний локальных снапшотов.
Настройку параметров репликации и хранения данных между сайтами.
Для типа защиты мы выбрали вариант «Локальная защита и репликация» (Local protection and replication). Это добавляет шаги 4 и 5 (показанные ниже) в определение политики группы защиты соответственно.
Расписания локальных снапшотов (шаг 4) определяют точки восстановления, которые будут доступны для выбранных виртуальных машин на локальном хранилище данных vSAN ESA. Каждая политика группы защиты может включать несколько расписаний, определяющих частоту создания снапшотов и период их хранения.
Примечание: это определение политики группы защиты также использует критерии выбора ВМ, основанные как на шаблонах имён (шаг 2), так и на индивидуальном выборе (шаг 3), показанных на скриншоте выше. Это обеспечивает высокую гибкость при определении состава ВМ, подлежащих защите.
Снапшоты и репликация имеют отдельные параметры конфигурации политики. Данные между сайтами Site A и Site B в данном примере будут реплицироваться независимо от локальных снапшотов, создаваемых по расписанию. Это также означает, что процесс репликации выполняется отдельно от процессов локального создания снапшотов.
С VMware Advanced Cyber Compliance для аварийного восстановления частота репликации vSphere replication — или первичная цель точки восстановления (RPO) — для каждой ВМ может быть минимальной, вплоть до 1 минуты.
При настройке параметров репликации вы также указываете хранение снапшотов на удалённом сайте, определяя глубину восстановления на вашем вторичном сайте. После завершения определения политики группы защиты в интерфейсе защиты данных vSAN вы можете увидеть различные параметры расписаний, хранения и частоты репликации, как показано на скриншоте ниже:
Примечание: группы защиты, определённые с использованием методов защиты данных vSAN, которые включают параметры репликации, будут обнаружены механизмом оркестрации защиты и восстановления и добавлены как записи групп репликации и защиты в инвентарь оркестрации, как указано в информационном блоке на скриншоте выше.
Интеграция с оркестрацией восстановления
Если переключиться на этот интерфейс, вы увидите, что наша политика "Example-Multi-Site-Protection-Group" отображается ниже — она была импортирована в инвентарь групп защиты вместе с существующими группами защиты, определёнными в пользовательском интерфейсе оркестрации защиты и восстановления.
Кроме того, любые виртуальные машины, включённые в группу защиты, определённую с использованием методов защиты данных vSAN, также отображаются в инвентаре Replications и помечаются соответствующим типом, как показано ниже:
В интерфейсе оркестрации, если вам нужно изменить группу защиты, созданную с использованием vSAN data protection, легко перейти обратно в соответствующий интерфейс управления этой группой. Контекстная ссылка для этого отображается на изображении ниже (сразу над выделенной областью Virtual Machines):
Используя совместно защиту данных vSAN и возможности аварийного восстановления VMware Advanced Cyber Compliance в вашем развертывании VCF, вы получаете улучшенную локальную защиту ВМ для оперативного восстановления, а также удалённую защиту ВМ, полезную для целей аварийного восстановления.
Серверная платформа виртуализации VMware Cloud Foundation (VCF 9) обеспечивает непревзойдённые преимущества для инфраструктуры виртуальных рабочих столов (VDI). Даже после выделения бизнес-группы VMware End User Computing (EUC) в состав отдельной компании Omnissa основы этого комплексного решения остаются неизменными. Однако выпуск VCF 9.0 заслуживает повторного рассмотрения этих основ, чтобы показать, насколько устойчивой остаётся платформа.
VCF 9.0 объединяет основу частного облака (vSphere, vSAN, NSX) с облачной автоматизацией (VCF Automation), интегрированным Kubernetes (VMware vSphere Kubernetes Service / VKS) и другими передовыми сервисами для VCF, такими как VMware Private AI Services и VMware Data Services Manager (DSM). Эти и многие другие инновации работают совместно с решением Omnissa Horizon VDI, обеспечивая изначально безопасный, оптимизированный и масштабируемый фундамент для самых требовательных виртуальных рабочих столов.
Запуск Horizon на VCF 9.0 позволяет клиентам воспользоваться полным набором сервисов единой платформы частного облака. VCF предоставляет домены рабочих нагрузок, оркестрированные обновления, сетевую изоляцию на основе VPC и современный API потребления. Это платформа, которая рассматривает рабочие столы как полноправные рабочие нагрузки.
Безопасность и соответствие требованиям
Безопасность — это то, где VCF сразу проявляет свои сильные стороны. Используйте межсетевой экран NSX, чтобы применить политику наименьших привилегий к Horizon Connection Server, UAG и пулу рабочих столов без направляющего трафик hairpin-маршрута через внешние файрволы. Конструкции VPC в VCF 9.0 позволяют создавать воспроизводимый сетевой периметр для каждой функции Horizon:
Edge (UAG)
Brokering (Connection Servers)
Рабочие столы
Общие сервисы
Эти меры защиты масштабируются вместе с инфраструктурой, а не усложняют её. VCF 9.0 также представляет комплекс встроенных функций безопасности и соответствия требованиям, критически важных для VDI-сред:
Централизованное управление сетевыми политиками с NSX усиливает защиту латерального трафика для чувствительных VDI-рабочих столов, соответствуя строгим регуляторным требованиям.
Микросегментация и изоляция VPC позволяют привязывать политики к объектам, а не подсетям, что повышает устойчивость в продакшене и упрощает аудит.
Неизменяемые (immutable) снапшоты, защита от вымогателей и интегрированное аварийное восстановление с vSAN ESA и VMware Live Recovery обеспечивают непрерывность бизнеса и быстрое восстановление после атак или сбоев, что критично для поддержания доступности рабочих столов и соответствия требованиям.
Для отраслей с жёсткими нормами (здравоохранение, финансы, госучреждения) сертификации безопасности VCF (TLS 1.3, FIPS 140-3, DISA STIG) позволяют рабочим средам соответствовать самым строгим стандартам.
Эффективность и оптимизация ресурсов
Благодаря дедупликации хранения, расширенным механизмам управления памятью и более высокой загрузке хостов, VCF 9.0 обеспечивает значительное снижение совокупной стоимости владения (TCO). Эффективность затрат в этом контексте — это не просто «купить меньше серверов». Речь идёт о том, чтобы преобразовать каждый ресурс — вычисления, хранение, сеть и операционные накладные расходы — в большее количество продуктивных пользователей без ущерба для их опыта.
Улучшенные коэффициенты консолидации CPU и памяти позволяют размещать больше одновременных рабочих столов на сервере, что напрямую снижает инфраструктурные расходы и упрощает масштабирование крупных развертываний.
vSAN ESA с глобальной дедупликацией может уменьшить затраты на хранение для постоянных VDI-пулов, а фоновые операции минимизируют влияние на производительность для пользователей.
Политики хранения vSAN могут назначаться для каждого пула, чтобы образы для сотрудников с типовыми задачами не вызывали то же потребление ресурсов хранения, что и пулы, насыщенные данными или графикой. Такая точность направляет IOPS туда, где они нужнее всего, и устраняет практику чрезмерного резервирования ресурсов «на всякий случай».
Благодаря функции Memory Tiering в VCF vSphere постоянно держит горячие страницы в DRAM и перемещает холодные на локальные NVMe, фактически используя локальные NVMe как вторичный уровень памяти. В недавних тестах Login Enterprise это позволило добиться стабильного двукратного увеличения плотности ВМ на хост. Эта возможность значительно повышает эффективность использования оборудования, позволяя запускать больше виртуальных рабочих столов на меньшей инфраструктуре.
Высокая производительность
VCF 9.0 предоставляет основу, которая делает производительность Horizon предсказуемой. Это начинается с вычислительных ресурсов: распределённый планировщик vSphere (DRS) помогает гарантировать, что динамичные пулы рабочих столов распределяются с учётом локальности NUMA по физическому кластеру. Это обеспечивает попадание выделенных vCPU на один NUMA-узел, уменьшая межсокетные переходы, снижая задержки и повышая общую плавность работы. Особенно критично это во время «штормов загрузки» (boot storms) и всплесков активности приложений.
Память
Память часто является узким местом в VDI. Как отмечалось ранее, Memory Tiering в VCF 9 увеличивает плотность без обычного негативного влияния на производительность или пользовательский опыт. Особенно это заметно для пулов с низкими требованиями к «горячей» памяти (например, рабочих мест сотрудников с типовыми задачами). Практический эффект в периоды пиков (утренние входы, массовые запуски приложений и т.д.) выражается в меньшем количестве зависаний и снижении задержек ввода.
Хранение
Благодаря vSAN (особенно архитектуре Express Storage Architecture на NVMe) вы получаете адаптированный под записи метод хранения и возможность использовать политики хранения на уровне пула рабочих столов, оптимизированные под конкретную задачу:
RAID-1 и повышенное количество страйпов для особо требовательных пользователей
RAID-5/6 для сотрудников с типовыми задачами
Object-space reservations для эталонных золотых образов рабочих столов, которые испытывают серьёзную нагрузку на чтение при использовании слоёв приложений
Поскольку управление реализовано полностью на базе политик, нет необходимости избыточно проектировать каждый пул под худший сценарий, но инфраструктура при этом остаётся оптимизированной для ежедневных нагрузок клонирования, развёртывания обновлений и утренних пиков входа. Итог - стабильные задержки под нагрузкой и более быстрое открытие приложений, когда все кликают одновременно.
Сеть
Сетевые сервисы NSX выполняются в ядре гипервизора, что позволяет избегать прогона через физическую инфраструктуру, что забирает ресурсы хоста и увеличивает задержки. В сочетании с сегментацией VPC пулы рабочих столов получают детерминированные маршруты с меньшим количеством переходов. Результат — меньше накладных расходов и больше пропускной способности для действительно важного трафика. Кроме того, NSX Distributed Firewall (лицензируется отдельно как часть VMware vDefend) может применять политику межсетевого экрана для east-west трафика прямо на pNIC хоста, исключая маршрутизацию через внешние устройства и уменьшая колебания задержек.
Графика
Horizon с NVIDIA vGPU на VCF позволяет выбирать vGPU-профили для каждого пула, сохраняя при этом преимущества DRS для оптимального размещения рабочих столов. Это означает, что можно консолидировать требовательных 3D-пользователей и более лёгкие графические задачи на одних и тех же физических хостах, поддерживая высокую утилизацию GPU.
Операции второго дня
Управление жизненным циклом и парком инфраструктуры в VCF — это мгновенное преимущество для администраторов, которым приходилось балансировать обслуживание и доступность пулов рабочих столов. VCF 9.0 оркестрирует задачи жизненного цикла платформы по доменам рабочих нагрузок, что позволяет выполнять обновления в узкие временные окна без длительных простоев и без оставления кластеров в смешанном состоянии. Это поддерживает эффективность DRS и согласованность политик хранения, обеспечивая доступность и производительность пулов рабочих столов. VCF выполняет поэтапные обновления всего стека, по домену, с проверками работоспособности и операционными процессами.
Автоматизация жизненного цикла частного облака упрощает патчинг, обновления и планирование ёмкости для крупных развертываний Horizon, позволяя администраторам сосредоточиться на пользовательском опыте и инновациях, а не на повторяющихся операциях. Инструменты мониторинга и устранения неполадок на уровне всей платформы ускоряют решение проблем и оптимизируют показатели пользовательского опыта, минимизируя простой и повышая продуктивность.
Сценарий использования: Developer Workbench как сервис
С VKS и дополнительным сервисом DSM организации могут подключать лёгкие сервисы на базе Kubernetes и внутренние инструменты разработки непосредственно к пулам рабочих столов разработчиков. Это превращает VDI из «удалённого рабочего стола» в управляемую платформу рабочих пространств разработчика с сервисами по запросу.
VKS — это полноценный независимый сервис с быстрым жизненным циклом и декларативными API потребления.
Инженеры платформ и команды разработки могут быстро развертывать среды разработчиков на базе VKS, значительно сокращая время настройки dev/test.
Разработчики могут самостоятельно создавать пространства имен (namespaces), VKS-кластеры и получать доступ к PostgreSQL/MySQL и другим сервисам, управляемым DSM. Всё маркируется на уровне платформы с учётом стоимости, политик и требований к суверенитету данных.
Дополнительные сценарии использования
Помимо традиционных постоянных и непостоянных рабочих столов, комбинация VCF 9.0 + Omnissa Horizon открывает ряд расширенных возможностей:
Использование растянутых или мультисайтовых архитектур для расширения VDI-сервисов между облаками VCF, поддерживая гибкое масштабирование и сценарии аварийного восстановления.
Инженеры платформ и команды разработки могут самостоятельно и быстро разворачивать среды разработчиков на базе VKS, резко сокращая время подготовки dev/test.
Интегрированные VMware Private AI Services и поддержка vGPU как сервиса позволяют организациям легко развертывать виртуальные рабочие столы с поддержкой AI.
Эта эталонная архитектура документирует проверенный, готовый к промышленной эксплуатации дизайн для запуска Omnissa Horizon 8 на VMware Cloud Foundation (VCF). Она создана, чтобы строго ответить на простой вопрос: как сегодня максимально быстро, безопасно и экономично доставлять корпоративные виртуальные рабочие столы? Эталонная архитектура подчёркивает практическую инженерную проработку, повторяемые шаблоны и измеримые результаты, формируя схему сервиса, которую организации могут уверенно применять - будь то модернизация существующей среды Horizon или создание новой платформы.
Итоги
Даже несмотря на то, что Omnissa теперь работает как независимая компания, фундаментальные требования к облачной инфраструктурной платформе для виртуальных рабочих столов остаются неизменными: согласованная сегментация и безопасность, производительность, масштабируемость, управление жизненным циклом и возможность добавлять полезные сервисы. Именно это и обеспечивает VCF 9.0 - поэтому он остаётся лучшей основой для Horizon Desktops.
Если вам важна инфраструктура виртуальных рабочих столов, которая подходит не только для сегодняшних задач, но и готова к будущему, то запуск Horizon на VCF 9.0 - идеальное решение. Он устраняет все классические проблемы - безопасность, доступность, производительность и обновления - одновременно открывая доступ к функциям следующего поколения, таким как AI, рабочие столы для разработчиков и мультисайтовое масштабирование.
В первой части статей этой серии мы рассмотрели некоторые предварительные требования для NVMe Memory Tiering, такие как оценка рабочих нагрузок, процент активности памяти, ограничения профилей виртуальных машин, предварительные требования и совместимость устройств NVMe.
Кроме того, мы подчеркнули важность внедрения платформы VMware Cloud Foundation (VCF) 9, которая может обеспечить значительное сокращение затрат на память, лучшее использование CPU и более высокую консолидацию виртуальных машин. Но прежде чем полностью развернуть это решение, важно спроектировать его с учётом безопасности, отказоустойчивости и масштабируемости — именно об этом и пойдёт речь в этой статье.
Безопасность
Безопасность памяти не является особенно популярной темой среди администраторов, и это объясняется тем, что память является энергонезависимой. Однако злоумышленники могут использовать память для хранения вредоносной информации на энергонезависимых носителях, чтобы избежать обнаружения — но это уже скорее тема криминалистики. Как только питание отключается, данные в DRAM (энергозависимой памяти) исчезают в течение нескольких минут. Таким образом, с NVMe Memory Tiering мы переносим страницы из энергозависимой памяти (DRAM) на энергонезависимую (NVMe).
Чтобы устранить любые проблемы безопасности, связанные с хранением страниц памяти на устройствах NVMe, VMware разработала несколько решений, которые клиенты могут легко реализовать после первоначальной настройки.
В этом первом выпуске функции Memory Tiering шифрование уже входит в комплект и готово к использованию «из коробки». Фактически, у вас есть возможность включить шифрование на уровне виртуальной машины (для каждой ВМ) или на уровне хоста (для всех ВМ на данном хосте). По умолчанию эта опция не активирована, но её легко добавить в конфигурацию через интерфейс vCenter.
Для шифрования в NVMe Memory Tiering нам не требуется система управления ключами (KMS) или встроенный поставщик ключей (NKP). Вместо этого ключ случайным образом генерируется на уровне ядра каждым хостом с использованием шифрования AES-XTS. Это избавляет от зависимости от внешних поставщиков ключей, поскольку данные, выгруженные в NVMe, актуальны только в течение времени жизни виртуальной машины.
Случайный 256-битный ключ создаётся при включении виртуальной машины, и данные шифруются в момент их выгрузки из DRAM в NVMe, а при обратной загрузке в DRAM для чтения — расшифровываются. Во время миграции виртуальной машины (vMotion) страницы памяти сначала расшифровываются, затем передаются по зашифрованному каналу vMotion на целевой хост, где генерируется новый ключ (целевым хостом) для последующих выгрузок памяти на NVMe.
Этот процесс одинаков как для «шифрования на уровне виртуальной машины», так и для «шифрования на уровне хоста» — единственное различие заключается в том, где именно применяется конфигурация.
Отказоустойчивость
Цель отказоустойчивости — повысить надёжность, сократить время простоя и, конечно, обеспечить спокойствие администратора. В контексте памяти существует несколько методов, некоторые из которых распространены больше других. В большинстве случаев для обеспечения избыточности памяти используют модули с коррекцией ошибок (ECC) и резервные модули памяти. Однако теперь, с появлением NVMe Memory Tiering, необходимо учитывать как DRAM, так и NVMe. Мы не будем подробно останавливаться на методах избыточности для DRAM, а сосредоточимся на NVMe в контексте памяти.
В VVF/VCF 9.0 функция NVMe Memory Tiering поддерживает аппаратную конфигурацию RAID, три-режимный (tri-mode) контроллер и технологию VROC (Virtual RAID on CPU) для обеспечения отказоустойчивости холодных или неактивных страниц памяти. Что касается RAID, мы не ограничиваемся какой-то одной конфигурацией: например, RAID-1 — это хорошее и поддерживаемое решение для обеспечения отказоустойчивости NVMe, но также поддерживаются RAID-5, RAID-10 и другие схемы. Однако такие конфигурации потребуют больше NVMe-устройств и, соответственно, увеличат стоимость.
Говоря о стоимости, стоит учитывать и наличие RAID-контроллеров, если вы планируете использовать RAID для отказоустойчивости. Обеспечение резервирования для холодных страниц — это архитектурное решение, которое должно приниматься с учётом баланса между затратами и операционными издержками. Что для вас важнее — надёжность, стоимость или простота эксплуатации? Также необходимо учитывать совместимость RAID-контроллера с vSAN: vSAN ESA не поддерживает RAID-контроллеры, в то время как vSAN OSA поддерживает, но они должны использоваться раздельно.
Преимущества RAID:
Обеспечивает избыточность для NVMe как устройства памяти
Повышает надёжность
Возможное сокращение времени простоя
Недостатки RAID:
Необходимость RAID-контроллера
Дополнительные расходы
Операционные издержки (настройка, обновление прошивок и драйверов)
Усложнение инфраструктуры
Появление новой точки отказа
Возможные проблемы совместимости с vSAN, если все накопители подключены к одной общей плате (backplane)
Как видно, у аппаратной избыточности есть как плюсы, так и минусы. Следите за обновлениями — в будущем могут появиться новые поддерживаемые методы отказоустойчивости.
Теперь предположим, что вы решили не использовать RAID-контроллер. Что произойдёт, если у вас есть один выделенный накопитель NVMe для Memory Tiering, и он выйдет из строя?
Ранее мы обсуждали, что на NVMe переносятся только «холодные» страницы памяти виртуальных машин по мере необходимости. Это означает, что страницы памяти самого хоста не находятся на NVMe, а также что на накопителе может быть как много, так и мало холодных страниц — всё зависит от нагрузки на DRAM. VMware не выгружает страницы (даже холодные), если в этом нет нужды — зачем расходовать вычислительные ресурсы?
Таким образом, если часть холодных страниц была выгружена на NVMe и накопитель вышел из строя, виртуальные машины, чьи страницы находились там, могут попасть в ситуацию высокой доступности (HA). Мы говорим "могут", потому что это произойдёт только если и когда ВМ запросит эти холодные страницы обратно из NVMe, которые теперь недоступны. Если же ВМ никогда не обратится к этим страницам, она продолжит работать без сбоев.
Иными словами, сценарий отказа зависит от активности в момент сбоя NVMe:
Если на NVMe нет холодных страниц — ничего не произойдёт.
Если есть немного холодных страниц — возможно, несколько ВМ войдут в HA-событие и перейдут на другой хост;
Если все холодные страницы хранились на NVMe — возможно, большинство ВМ окажутся в HA-режиме по мере запроса страниц.
Это не обязательно приведёт к полному отказу всех систем. Некоторые ВМ могут выйти из строя сразу, другие — позже, а третьи — вообще не пострадают. Всё зависит от их активности. Главное — хост ESX продолжит работу, а поведение виртуальных машин будет различаться в зависимости от текущих нагрузок.
Масштабируемость
Масштабируемость памяти — это, пожалуй, один из тех неожиданных факторов, который может обойтись очень дорого. Как известно, память составляет значительную часть (до 80%) общей стоимости нового сервера. В зависимости от подхода к закупке серверов, вы могли выбрать меньшие по объёму модули DIMM, установив их во все слоты — в этом случае у вас нет возможности увеличить объём памяти без полной замены всех модулей, а иногда даже самого сервера.
В также могли выбрать высокоплотные модули DIMM, оставив несколько слотов свободными для будущего роста — это позволяет масштабировать память, но тоже дорого, так как позже придётся докупать совместимые модули (если они ещё доступны). В обоих случаях масштабирование получается дорогим и медленным, особенно учитывая длительные процедуры утверждения бюджета и заказов в компаниях.
Именно здесь NVMe Memory Tiering показывает себя с лучшей стороны — снижая затраты и позволяя быстро увеличить объём памяти. В данном случае масштабирование памяти сводится к покупке хотя бы одного устройства NVMe и включению функции Memory Tiering — и вот у вас уже на 100% больше памяти для ваших хостов. Отличная выгода.
Можно даже «позаимствовать» накопитель из вашего хранилища vSAN, если есть возможность выделить его под Memory Tiering… но об этом чуть позже (делайте это с осторожностью).
В этой части важно понимать ограничения и возможности, чтобы обеспечить надёжность инвестиций в будущем. Мы уже говорили о требованиях к устройствам NVMe по показателям производительности и износостойкости, но что насчёт объёма NVMe-устройств? Об этом мы напишем в следующей части.
Компания Broadcom объявила о продвижении «открытой, расширяемой экосистемы» для VMware Cloud Foundation (VCF), с тем чтобы пользователи могли строить, подключать, защищать и расширять свои приватные облака. Цель — дать заказчикам большую свободу выбора оборудования, сетевых архитектур и софтверных компонентов при развертывании приватного облака или облачной инфраструктуры на базе VCF.
Ключевые направления:
Расширение аппаратной сертификации (OEM/ODM)
Внедрение открытых сетевых конструкций (EVPN, BGP, SONiC)
Вклад в open-source проекты (например, Kubernetes и связанные)
Усиленные партнёрства с такими игроками как Cisco Systems, Intel Corporation, OVHcloud, Supermicro Inc., SNUC.
Архитектура и аппаратная сертификация
VCF AI ReadyNodes и ODM self-certification
Одной из ключевых инициатив является расширение программы сертификации аппаратных узлов для VCF:
Появляются новые «VCF AI ReadyNodes» — предсертифицированные серверные конфигурации с CPU, GPU и другими ускорителями, пригодные для AI-обучения и вывода (inference).
В программе сертификации ReadyNode для ODM-партнёров теперь предусмотрена самосертификация (ODM Partner Self-Certification) через технологическую альянс-программу Broadcom Technology Alliance Program (TAP). Вся сертифицированная система обеспечена полной совместимостью с VCF и единым жизненным циклом управления VCF.
Поддержка edge-узлов: расширена поддержка компактных, «прочностных» (rugged) серверов для индустриальных, оборонных, розничных и удалённых площадок, что позволяет разворачивать современное приватное облако ближе к точкам генерации данных.
Технические следствия:
Возможность применять новейшие аппаратные ускорители (GPU, FPGA и др.) под VCF, с гарантией совместимости.
Упрощение цепочки выбора оборудования: благодаря self-certification ODM могут быстрее вывезти сертифицированные узлы, заказчик — выбрать из более широкого набора.
Edge-варианты означают, что приватные облака не ограничены классическими ЦОД-конфигурациями, а могут быть размещены ближе к источнику данных (IoT, фабрики, розница), что важно для задержки, пропускной способности, регулирования данных.
В совокупности это снижает TCO (Total Cost of Ownership) и ускоряет модернизацию инфраструктуры. Broadcom отмечает, что Intel, OVHcloud и др. подтверждают, что это даёт меньшее время time-to-market.
Почему это важно
Для организаций, которые строят приватные облака, часто возникает проблема «запертой» инфраструктуры: если узел не сертифицирован, риск несовместимости — обновления, жизненный цикл, поддержка. Открытая сертификация даёт больший выбор и снижает зависимость от одного производителя. При этом, с учётом AI-нагрузок и edge-инфраструктуры, требования к аппаратуре растут, и важна гарантия, что выбранный сервер будет работать под VCF без сюрпризов.
Сетевые инициативы: открытые сети и EVPN
Стратегия Broadcom в отношении сети
Broadcom объявляет стратегию объединения сетевых фабрик (network fabrics) и упрощения сетевых операций в приватном облаке через стандарты EVPN и BGP. Основные моменты:
Поддержка сетевой интероперабельности между средами приложений и сетью: применение стандарта EVPN/BGP позволяет гибче и масштабируемее организовать сетевые фабрики.
Цель — ускорить развертывание, дать мультивендорную гибкость, сохранить существующие сетевые инвестиции.
Совместимость с продуктом NSX (в составе VCF) и сторонними сетевыми решениями на уровне VPC-защиты, единой сетевой операционной модели, маршрутизации и видимости.
В рамках партнёрства с Cisco: VCF переходит к поддержке EVPN и совместимости с решением Cisco Nexus One fabric, что даёт клиентам архитектурную гибкость.
VCF Networking (NSX) поддерживает открытый NOS (network operating system) SONiC — операционную систему для сетевых коммутаторов, основанную на Linux, на многосоставном и мультивендорном оборудовании.
Технические особенности EVPN / BGP в контексте VCF
EVPN (Ethernet VPN) обеспечивает слой 2/3 виртуализации по IP/MPLS сетям, поддерживает VXLAN, MPLS-Over-EVPN и даёт нативную мультидоменную сегментацию.
BGP служит как протокол контрольной плоскости для EVPN, позволяет сетям в разных локациях или доменах обмениваться маршрутами VXLAN/EVPN.
В контексте VCF нужно, чтобы сеть поддерживала мультивендорность, работу с NSX, автоматизацию и процессы жизненного цикла. С открытым стандартом EVPN/BGP графику управления можно встроить в операции DevOps, IaC (Infrastructure as Code).
Поддержка SONiC позволяет использовать коммутаторы «commodity» с открытым NOS, снижая затраты как CAPEX, так и OPEX: модульная архитектура, контейнеризация, возможность обновлений без простоя.
Значение для заказчика
Возможность построить приватное облако, где сеть не является узким местом или «чёрным ящиком» вендора, а открытa и гибка по архитектуре.
Снижение риска vendor-lock-in: можно выбирать разное сетевое оборудование, переключаться между вендорами и сохранять совместимость.
Повышенная скорость развертывания: сертифицированные интеграции, открытые стандарты, меньше ручной настройки.
Поддержка edge-сценариев и распределённых облаков: сетевые фабрики могут распространяться по ЦОД, филиалам, edge-узлам с единым контролем и видимостью.
Вклад в открытое программное обеспечение (Open Source)
Broadcom подчёркивает свою активность как участника сообщества облачных нативных технологий. Основные пункты:
Компания является одним из пяти крупнейших долгосрочных контрибьюторов в Cloud Native Computing Foundation (CNCF) и вносит изменения/улучшения в проекты: Antrea, Cluster API, containerd, Contour, etcd, Harbor и другие.
Важная веха: решение vSphere Kubernetes Service (VKS) от VMware теперь является Certified Kubernetes AI Conformant Platform — это означает, что платформа соответствует требованиям для AI-нагрузок и встроена в стандарты Kubernetes.
Техническое значение
Совместимость с Kubernetes-экосистемой означает, что приватные облака на VCF могут использовать облачно-нативные модели: контейнеры, микро-сервисы, CI/CD, GitOps.
AI Conformant сертификация даёт уверенность, что платформа поддерживает стандартизированную среду для AI-нагрузок (модели, фреймворки, инфраструктура).
Работа с такими компонентами как containerd, etcd, Harbor облегчает создание, хранение, оркестрацию контейнеров и сбор образов, что важно для DevOps/DevSecOps практик.
Интеграция с открытым стеком упрощает автоматизацию, ускоряет выход новых функций, увеличивает портируемость и мобильность рабочих нагрузок.
Пользовательские выгоды
Организации получают возможность не просто виртуализировать нагрузки, но и расширяться в направлении «контейнеров + AI + edge».
Более лёгкий перенос рабочих нагрузок между средами, снижение необходимости в проприетарных решениях.
Возможность быстро реагировать на изменение требований бизнеса: добавление AI-сервиса, изменение инфраструктуры, использование микросервисов.
Практические сценарии применения
Приватное облако с AI-нагрузками
С сертифицированными AI ReadyNodes и поддержкой Kubernetes + AI Conformant платформой, заказчики могут:
Развернуть приватное облако для обучения моделей машинного обучения/AI (CPU + GPU + ускорители) на базе VCF.
Вывести inference-нагрузки ближе к источнику данных — например, на edge-узле в фабрике или розничном магазине.
Использовать унифицированный стек: виртуальные машины + контейнеры + Kubernetes на одной платформе.
Выполнить модернизацию инфраструктуры с меньшими затратами, за счёт сертификации и ПО с открытыми стандартами.
Развёртывание edge-инфраструктуры
С расширением поддержки edge-оптимизированных узлов:
Приватное облако может распространяться за пределы ЦОД — например, на фабрики, сеть розничных точек, удалённые площадки.
Сеть EVPN/BGP + SONiC позволяет обеспечить единое управление и видимость сетевой фабрики, даже если часть инфраструктуры находится далеко от центра.
Заказчики в индустрии, госсекторе, рознице могут использовать эту архитектуру для низкой задержки, автономной работы, гибкой интеграции в основной ЦОД или облако.
Гетерогенная инфраструктура и мультивендорные сети
Благодаря открытым стандартам и сертификации, заказчики не ограничены выбором одного поставщика оборудования или сети.
Можно комбинировать разные серверные узлы (от разных OEM/ODM), разные коммутаторы и сетевой софт, и быть уверенным в интеграции с VCF.
Это помогает снизить зависимость от единственного вендора, сделать инфраструктуру более гибкой и адаптивной к будущим изменениям.
Последствия и рекомендации
Последствия для рынка и архитектуры приватных облаков
Увеличится конкуренция среди аппаратных и сетевых поставщиков, так как сертификация и сами архитектуры становятся более открытыми.
Уменьшается риск «запирания» заказчиков в единой экосистеме производителя. Это способствует более быстрому внедрению инноваций: ускорители, AI-узлы, edge.
Открытые сети и стандарты означают повышение скорости развертывания, уменьшение сложности и затрат.
Часто частные облака превращаются в гибридные либо распределённые модели, где части инфраструктуры находятся в ЦОД, на edge, в филиалах — и такие архитектуры становятся проще благодаря инициативам Broadcom/VCF.
Что стоит учесть пользователям
При выборе инфраструктуры приватного облака важно проверять сертифицированные конфигурации VCF ReadyNodes, чтобы быть уверенным в поддержке жизненного цикла, обновлений и совместимости.
Если планируется AI-нагрузка — уделите внимание использованию AI ReadyNodes, поддержке GPU/ускорителей, сертификации.
Если сеть критична (например, распределённые локации, филиалы, edge) — рассмотрите архитектуры EVPN/BGP, совместимые с NSX и мультивендорными решениями, а также возможности SONiC.
Не забывайте об автоматизации и интеграции с облачно-нативными технологиями (Kubernetes, контейнеры, CI/CD): наличие поддержки этих технологий позволяет быстрее развивать платформу.
Оцените TCO не только с точки зрения CAPEX (серверы, оборудование) но и OPEX (обслуживание, обновления, гибкость). Использование открытых стандартов и сертифицированных решений может снизить оба.
Заключение
Объявление Broadcom о «открытой экосистеме» для VMware Cloud Foundation — это важный шаг к тому, чтобы приватные облака стали более гибкими, адаптивными и ориентированными на будущее. Сертификация аппаратуры (в том числе для AI и edge), открытые сетевые стандарты и активный вклад в open-source проекты – всё это создаёт технологическую платформу, на которой организации могут строить современные инфраструктуры.
При этом важно помнить: открытость сама по себе не решает все проблемы — требуется грамотная архитектура, планирование жизненного цикла, взаимодействие с партнёрами и понимание, как компоненты сочетаются. Тем не менее, такие инициативы создают условия для более лёгкой и менее рисковой модернизации облачной инфраструктуры.
В течение почти двух десятилетий сертификация VMware Certified Design Expert (VCDX) оставалась высшей мерой мастерства для архитекторов, работающих с решениями VMware — глобально признанным достижением экспертного уровня. Но по мере того как развитие частных облаков ускоряется и потребности нашего сообщества эволюционируют, мы не просто адаптируемся — мы совершаем революцию.
VMware рада объявить о развитии этой знаковой программы, расширяя её рамки за пределы традиционной роли дизайнеров виртуальной среды, чтобы приветствовать более широкий круг высококвалифицированных специалистов VMware: архитекторов, администраторов и специалистов поддержки. Чтобы отразить это расширенное видение, VMware переименовала программу в VMware Certified Distinguished Expert (VCDX).
Это не просто обновление — это стратегическое переосмысление программы VCDX, созданное специально для специалистов, стремящихся активно формировать будущее частных облаков. Это также приглашение развивать свои глубокие знания VMware, выходить за привычные рамки и прокладывать путь для нового поколения частных облачных сред, помогая формировать их будущее.
Критически важная потребность в современной облачной экспертизе
Необходимость в специализированных знаниях по современным облачным технологиям сегодня как никогда высока. Согласно отчёту Flexera 2024 State of the Cloud, 76% предприятий планируют расширять облачные сервисы через частные облака, и спрос на глубокую облачную экспертизу стремительно растёт. Тем не менее сохраняется серьёзная проблема — повсеместный дефицит облачных навыков. Аж 95% ИТ-руководителей заявили, что нехватка облачных компетенций негативно сказывается на их командах, приводя к снижению темпов инноваций и росту операционных затрат. Ещё более тревожный факт: почти треть организаций ставят под угрозу свою прибыль, не достигнув финансовых целей из-за этого критического дефицита облачных навыков.
В условиях столь стремительно меняющегося ландшафта постоянное обучение и высокоуровневая сертификация перестали быть опцией — они стали необходимостью для развития ключевых навыков, требуемых современными облачными средами. Программа VMware Certified Distinguished Expert предоставляет уникальную возможность не только преодолеть этот дефицит, но и стать тем ценнейшим специалистом, которого компании отчаянно ищут в области современных облачных технологий.
Преимущество VCDX: открывая путь к эксклюзивным возможностям
Сертификация VMware Certified Distinguished Expert — это высший уровень навыков и лидерства, необходимый для проектирования, разработки концепции и валидации самых надёжных, масштабируемых и безопасных сред VMware Cloud Foundation. Достижение этого престижного статуса предоставляет уникальную возможность использовать свои глубокие знания, активно влиять на развитие облачных сред и вести индустрию к следующему поколению облачной архитектуры.
Помимо формального признания, статус VCDX погружает вас в самую передовую часть развития решений для частных облаков, соединяя с глобальной сетью элитных технических специалистов. Представьте себе: ранний доступ к будущим бета-версиям продуктов, эксклюзивный первый взгляд на предстоящие обновления платформы VCF, позволяющие всегда оставаться впереди.
Вы также получите расширенные возможности напрямую влиять на стратегию, участвуя в ключевых форумах, таких как Product Technical Advisory Boards (PTAB) и Customer Technical Advisory Boards (CTAB). Кроме того, вы сможете усилить свою роль лидера мнений, участвуя в публичных мероприятиях, таких как собрания VMUG и конференции VMware Explore.
Быть частью глобальной сети — значит взаимодействовать с коллегами по всему миру и непосредственно влиять на направление развития продуктов VMware. Ваши востребованные, расширенные технические навыки обеспечат вам лидерские позиции в инновациях частных облаков, значительно расширив как карьерный, так и финансовый потенциал.
Ускорьте карьеру в области частных облаков
Получение сертификации VCDX выделяет вас как специалиста высшего уровня в сфере частных облаков, обладающего конкурентоспособным вознаграждением — согласно данным Glassdoor, средняя зарплата старших облачных специалистов составляет $200 000. Эта элитная квалификация прочно закрепляет вас на передовой частных облачных технологий, готовя к руководству самыми сложными инициативами VMware Cloud Foundation.
Вы не только продемонстрируете экспертное владение ключевыми ролями — Администратора, Архитектора и Специалиста поддержки, — но и утвердитесь как технический лидер-визионер. Представьте, какой вклад вы сможете внести в свою компанию, какие инновации продвинуть и какого ускорения в карьере добиться, достигнув высшего уровня экспертизы в частных облаках. Это не только укрепит ваше профессиональное развитие, но и обеспечит вам статус лидера в динамично развивающемся ландшафте частных облаков.
Ваш путь к достижению облачной экспертизы
Путь к получению статуса VCDX тщательно продуман, чтобы поднять ваш уровень лидерства и экспертизы. Для действующих и будущих специалистов по VCF путь VCDX начинается с формирования комплексной базы знаний о платформе VCF через базовую сертификацию VCP (VMware Certified Professional). Затем он углубляет экспертизу в ключевых технологиях VCF, таких как Kubernetes, с помощью продвинутых сертификаций VCAP (VMware Certified Advanced Professional). Этот строгий путь завершается защитой среди подтвержденных экспертов в рамках офлайн-сессии, подтверждающей глубокие архитектурные знания, продвинутые навыки решения проблем и непревзойдённую экспертизу, соответствующую вашей специализированной роли. Это ваш чёткий путь к элитному лидерству в области частных облаков.
Как профессионал VCDX, вы играете ключевую роль в продвижении следующего поколения облачной архитектуры. Готовы ли вы начать это невероятно перспективное путешествие? Начните путь к VMware Certified Distinguished Expert уже сегодня и определите своё место в будущем частных облаков заново.
Пожалуйста, скачайте руководствo по обучению VCF 9 для различных ролей, чтобы получить доступ к новейшим курсам с инструктором, обучению по запросу, а также ключевым ресурсам для подготовки к экзаменам. Если вы являетесь клиентом VCF Full Platform или партнером, отвечающим требованиям, посетите раздел Learning@Broadcom на Broadcom Support Portal для доступа к обучающим материалам.
Ландшафт корпоративного AI стремительно развивается, и организации сталкиваются с фундаментальными вопросами: как использовать генеративный AI, сохраняя контроль над собственными данными? Что необходимо для построения AI-инфраструктуры, которая масштабируется безопасно? Как перейти от экспериментов к рабочим AI-нагрузкам, готовым к промышленной эксплуатации?
На VMware Explore 2025 лидеры отрасли и технические эксперты напрямую рассмотрели эти критические задачи. От проектирования безопасных основ частного AI до подбора оптимальной инфраструктуры для ресурсоёмких AI-нагрузок — сессии предоставили практические инсайты, выходящие за пределы теоретических рамок и переходящие к стратегиям реальной реализации.
Будь вы инженер платформ, стремящийся внедрить AI во всей организации, специалист по безопасности, сосредоточенный на защите AI-нагрузок, или архитектор инфраструктуры, планирующий следующее AI-развёртывание, эти сессии предлагают проверенные подходы и полученные на практике уроки.
Вот ключевые AI-сессии, которые дают наиболее ясный путь вперёд для успеха при внедрении AI в корпоративной среде.
Building Secure Private AI Deep Dive [INVB1432LV]
С момента запуска VMware Private AI Foundation with NVIDIA это решение развилось и теперь предлагает надёжные сервисы, позволяющие превращать собственную интеллектуальную собственность в уникальные GenAI-приложения с использованием NVIDIA Inference Microservices (NIM), развёрнутых в архитектурах Retrieval Augmented Generation (RAG) в локальной инфраструктуре.
Присоединяйтесь к команде менеджеров продуктов VMware и NVIDIA совместно с UT Systems, чтобы узнать, как решение развивается, чтобы:
Поддерживать передовые GPU и системы HGX, разработанные специально для AI и использующие VMware Cloud Foundation (VCF)
Упростить доставку RAG-приложений с помощью: сервисов Private AI, включая среду исполнения моделей для развертывания LLM как сервиса; сервисов AI-данных, включая NVIDIA NeMo Microservices и сервис индексирования и поиска данных VMware; а также цифровых людей на VCF с использованием блупринтов NVIDIA.
Building Secure Private AI Deep Dive [INVB1432LV]
Узнайте, как безопасно создавать и масштабировать инфраструктуру Private AI с помощью VMware vDefend и VMware Private AI with NVIDIA. Эта сессия проведёт вас через процессы разработки надёжной архитектуры частного AI с встроенной защитой данных, изоляцией рабочих нагрузок и автоматическим применением политик.
Узнайте, как vDefend повышает безопасность AI-моделей с помощью сегментации и обнаружения угроз в реальном времени, а Private AI with NVIDIA предоставляет платформу для развертывания и управления AI-нагрузками с полным контролем.
Идеально подходит для архитекторов и команд безопасности: эта сессия предлагает практические инсайты для безопасного внедрения AI в среде частного облака.
Sizing AI Workloads in VMware Private AI Foundation [INVB1801LV]
По мере роста внедрения AI обеспечение оптимальной производительности и масштабируемости AI-нагрузок становится критически важным для получения точных результатов и своевременных инсайтов. В этой сессии мы разберём несколько типовых сценариев и покажем инструменты, которые помогут вам правильно рассчитать размеры ваших AI-нагрузок.
Tanzu AI Solutions Essentials: What You Need to Know to Get Up and Running [MODB1496LV]
Планируете запускать AI-нагрузки на своей платформе, но не знаете, с чего начать? Интересуетесь практической работой с AI с использованием VMware Tanzu Platform? Эта сессия предназначена для инженеров платформ, которым нужен практичный старт.
В ходе сессии рассмотриваются ключевые компоненты решений Tanzu AI — от готовности инфраструктуры до моделей развертывания, — чтобы вы могли включать, масштабировать и операционализировать AI в своих средах. Вы узнаете, как интегрировать AI-модели в новые или существующие платформы, обеспечивать управление и масштабируемость, а также предоставлять самообслуживание для команд данных и разработчиков.
Основные выводы включают архитектурные лучшие практики, ключевые шаги конфигурации и рекомендации по обеспечению быстрого и безопасного эксперимента с AI — чтобы вы были готовы поддерживать инновации с первого дня.
10 Big Benefits of Private AI That Make Your Decision Easy [CLOB1707LV]
В этой сессии мы поговорим о том, что такое Private AI, и рассмотрим 10 ключевых причин, по которым он является правильным подходом для использования генеративного AI на предприятии. Эта сессия поможет вам лучше разобраться в вопросе, принимать верные решения для своей организации и раскрыть потенциал частного AI в её масштабах.
Unlock Innovation with VMware Private AI Foundation with NVIDIA [INVB1446LV]
Узнайте, как предприятия трансформируют свои стратегии в области AI с помощью совместной платформы GenAI от Broadcom и NVIDIA — VMware Private AI Foundation with NVIDIA. В этой сессии основное внимание уделяется сервисам Private AI, включая среду выполнения моделей, индексирование и поиск данных, сервисы создания агентов и многое другое.
Real-World Lessons in Rightsizing VMware Cloud Foundation for On-Premises AI Workloads [INVB1300LV]
Нагрузки AI — особенно основанные на больших языковых моделях (LLM) — меняют то, как мы проектируем, масштабируем и эксплуатируем инфраструктуру. Речь уже не только о вычислениях и хранилищах. Размер модели, задержка при инференсе, параллельность и распределение GPU — всё это оказывает существенное влияние.
В этой сессии Фрэнк Деннеман и Йохан ван Амерсфорт делятся практическими уроками, полученными при проектировании и развертывании платформ VMware Cloud Foundation, готовых к AI, в различных средах заказчиков. Вы узнаете практические стратегии правильного подбора размеров инфраструктуры, балансировки компромиссов между резервным копированием и конвейерами MLOps, а также проектирования инфраструктуры для локальных AI-нагрузок.
Используя практический инструмент для расчёта размеров AI-инфраструктуры, они продемонстрируют, как согласовать инфраструктуру с реальными требованиями и вести предметный диалог со стейкхолдерами и поставщиками AI-решений, чтобы принимать более разумные и экономически эффективные решения по платформе.
Наблюдаемость (Observability) — это призма, через которую команды платформ получают понимание происходящего во всём ландшафте приложений. Она охватывает всё: от производительности, оповещений и устранения неполадок до развертывания и операций второго дня, таких как планирование ресурсов.
В VMware Tanzu Platform 10.3 компания Broadcom представила набор обновлений наблюдаемости в Tanzu Hub, которые углубляют видимость, ускоряют адаптацию команд и помогают сократить время решения проблем. Независимо от того, отвечаете ли вы за надежность, инженерные аспекты платформы или опыт разработчиков, новые функции позволяют автоматически получать и видеть релевантные данные, чтобы действовать быстрее и с большим доверием к своей платформе. Эти усовершенствования обеспечивают централизованный, целостный опыт наблюдаемости в Tanzu Hub.
Ключевые новые улучшения наблюдаемости в Tanzu Hub
В этом выпуске представлены усовершенствованные топологии и наложения оповещений, значительно повышающие видимость взаимосвязей инфраструктуры и зависимостей между сущностями. Теперь оверлей оповещений предоставляет более богатый контекст, включая возможность прямой связи с инфраструктурными системами или событиями в слое VCF, что упрощает процесс устранения неполадок. Контекстные оповещения автоматически сопоставляются с соответствующей сущностью, а в Tanzu Platform 10.3 эта функциональность распространяется также на сервисы и приложения. Эти оповещения будут отображаться в различных представлениях, включая Home, Alerts, Foundations, Applications, Service Instance и Topology.
Этот выпуск также предлагает новый уровень наблюдаемости и включает значительные улучшения тщательно настроенных панелей мониторинга и оповещений, основанных на ключевых показателях (KPI), а также runbook-ов для сервисов Tanzu Data Tile. Это позволяет различным командам сосредоточиться на формализации операционной экспертизы, делая её более доступной и практичной как для инженеров платформ, так и для команд разработчиков любого уровня опыта.
Ключевым аспектом этих улучшений является бесшовная интеграция runbook-ов с потоками наблюдаемости. Это означает, что оповещения и процессы их устранения больше не существуют изолированно; теперь runbook-и являются частью более широкой системы и содержат встроенные действия по следующему шагу прямо внутри оповещений, направляя инженеров через процесс диагностики и решения проблемы шаг за шагом. Runbook-и можно полностью настраивать, отображая контекстные данные, такие как соответствующие журналы ошибок во время и до возникновения оповещения, что делает рабочий процесс более плавным и сокращает время решения проблем. Такой интегрированный подход дает командам, особенно недавно присоединившимся инженерам, возможность действовать быстрее и эффективнее, снижая среднее время устранения проблем и повышая общую операционную эффективность.
Объединение метрик уровня приложений и уровня инфраструктуры в интерфейсе обеспечивает по-настоящему целостное понимание производительности системы. Этот интегрированный подход позволяет легко сопоставлять поведение приложения с состоянием базовой инфраструктуры, предоставляя детализированный обзор связанных сервисов или инфраструктурных изменений, которые могут повлиять на стабильность критически важных приложений. Объединив ранее разрозненные представления и благодаря удобной навигации Tanzu Hub, организации могут гораздо быстрее выявлять первопричины проблем, выходя за рамки поверхностных симптомов и устраняя коренные причины более эффективно.
Эти усовершенствованные представления приносят значительные бизнес-преимущества и могут быть настроены под нужды разных команд, включая инженеров платформы и команды разработчиков. Возможность создавать и управлять пользовательскими панелями мониторинга, а также гибко контролировать данные с помощью фильтров на уровне панели, позволяет командам точно адаптировать свой опыт наблюдения под свои задачи. Кроме того, настройка макетов, диаграмм и виджетов гарантирует, что критически важные данные всегда представлены в наиболее удобной и действенной форме. Это объединение направлено на покрытие большинства сценариев использования Healthwatch, обеспечивая действия на основе разрешений и расширенные возможности анализа метрик. Бесшовная миграция всех панелей Healthwatch, помеченных тегом “healthwatch”, обеспечивает преемственность и простоту поиска. В конечном итоге эти возможности приводят к снижению простоев, повышению операционной эффективности и более проактивному подходу к поддержанию оптимальной производительности приложений, напрямую влияя на удовлетворенность клиентов и непрерывность бизнеса.
Почему эти улучшения важны
Эти усовершенствования приносят значительные бизнес-преимущества, делая работу вашей платформы более эффективной, надежной и устойчивой к будущим изменениям. Наблюдаемость становится более прикладной и контекстной, обеспечивая полноценный анализ на всех уровнях стека. Вы получаете комплексное понимание не только поведения приложений, но и их прямой связи с платформой и базовой инфраструктурой. Это обеспечивает видимость на нескольких уровнях, планирование емкости и контроль соответствия требованиям. Runbook-и и встроенные рекомендации существенно снижают зависимость от индивидуального опыта и «внутренних знаний» команды, повышая эффективность операций на уровне всей организации. И наконец, по мере роста сложности сред, эти улучшения наблюдаемости масштабируются вместе с вами, обеспечивая стабильную производительность и прозрачность.
NVIDIA Run:ai ускоряет операции AI с помощью динамической оркестрации ресурсов, максимизируя использование GPU, обеспечивая комплексную поддержку жизненного цикла AI и стратегическое управление ресурсами. Объединяя ресурсы между средами и применяя продвинутую оркестрацию, NVIDIA Run:ai значительно повышает эффективность GPU и пропускную способность рабочих нагрузок.
Недавно VMware объявила, что предприятия теперь могут развертывать NVIDIA Run:ai с встроенной службой VMware vSphere Kubernetes Services (VKS) — стандартной функцией в VMware Cloud Foundation (VCF). Это поможет предприятиям достичь оптимального использования GPU с NVIDIA Run:ai, упростить развертывание Kubernetes и поддерживать как контейнеризованные нагрузки, так и виртуальные машины на VCF. Таким образом, можно запускать AI- и традиционные рабочие нагрузки на единой платформе.
Давайте посмотрим, как клиенты Broadcom теперь могут развертывать NVIDIA Run:ai на VCF, используя VMware Private AI Foundation with NVIDIA, чтобы развертывать кластеры Kubernetes для AI, максимизировать использование GPU, упростить операции и разблокировать GenAI на своих приватных данных.
NVIDIA Run:ai на VCF
Хотя многие организации по умолчанию запускают Kubernetes на выделенных серверах, такой DIY-подход часто приводит к созданию изолированных инфраструктурных островков. Это заставляет ИТ-команды вручную создавать и управлять службами, которые VCF предоставляет из коробки, лишая их глубокой интеграции, автоматизированного управления жизненным циклом и устойчивых абстракций для вычислений, хранения и сетей, необходимых для промышленного AI. Именно здесь платформа VMware Cloud Foundation обеспечивает решающее преимущество.
vSphere Kubernetes Service — лучший способ развертывания Run:ai на VCF
Наиболее эффективный и интегрированный способ развертывания NVIDIA Run:ai на VCF — использование VKS, предоставляющего готовые к корпоративному использованию кластеры Kubernetes, сертифицированные Cloud Native Computing Foundation (CNCF), полностью управляемые и автоматизированные. Затем NVIDIA Run:ai развертывается на этих кластерах VKS, создавая единую, безопасную и устойчивую платформу от аппаратного уровня до уровня приложений AI.
Ценность заключается не только в запуске Kubernetes, но и в запуске его на платформе, решающей базовые корпоративные задачи:
Снижение совокупной стоимости владения (TCO) с помощью VCF: уменьшение инфраструктурных изолятов, использование существующих инструментов и навыков без переобучения, единое управление жизненным циклом всех инфраструктурных компонентов.
Единые операции: основаны на привычных инструментах, навыках и рабочих процессах с автоматическим развертыванием кластеров и GPU-операторов, обновлениями и управлением в большом масштабе.
Запуск и управление Kubernetes для большой инфраструктуры: встроенный, сертифицированный CNCF Kubernetes runtime с полностью автоматизированным управлением жизненным циклом.
Поддержка в течение 24 месяцев для каждой минорной версии vSphere Kubernetes (VKr) - это снижает нагрузку при обновлениях, стабилизирует окружения и освобождает команды для фокусировки на ценности, а не на постоянных апгрейдах.
Лучшая конфиденциальность, безопасность и соответствие требованиям: безопасный запуск чувствительных и регулируемых AI/ML-нагрузок со встроенными средствами управления, приватности и гибкой безопасностью на уровне кластеров.
Сетевые возможности контейнеров с VCF
Сети Kubernetes на «железе» часто плоские, сложные для настройки и требующие ручного управления. В крупных централизованных кластерах обеспечение надежного соединения между приложениями с разными требованиями — сложная задача. VCF решает это с помощью Antrea, корпоративного интерфейса контейнерной сети (CNI), основанного на CNCF-проекте Antrea. Он используется по умолчанию при активации VKS и обеспечивает внутреннюю сетевую связность, реализацию политик сети Kubernetes, централизованное управление политиками и операции трассировки (traceflow) с уровня управления NSX. При необходимости можно выбрать Calico как альтернативу.
Расширенная безопасность с vDefend
Разные приложения в общем кластере требуют различных политик безопасности и контроля доступа, которые сложно реализовать последовательно и масштабируемо. Дополнение VMware vDefend для VCF расширяет возможности безопасности, позволяя применять сетевые политики Antrea и микросегментацию уровня «восток–запад» вплоть до контейнера. Это позволяет ИТ-отделам программно изолировать рабочие нагрузки AI, конвейеры данных и пространства имен арендаторов с помощью политик нулевого доверия. Эти функции необходимы для соответствия требованиям и предотвращения горизонтального перемещения в случае взлома — уровень детализации, крайне сложный для реализации на физических коммутаторах.
Высокая отказоустойчивость и автоматизация с VMware vSphere
Это не просто удобство, а основа устойчивости инфраструктуры. Сбой физического сервера, выполняющего многодневное обучение, может привести к значительным потерям времени. VCF, основанный на vSphere HA, автоматически перезапускает такие рабочие нагрузки на другом узле.
Благодаря vMotion возможно обслуживание оборудования без остановки AI-нагрузок, а Dynamic Resource Scheduler (DRS) динамически балансирует ресурсы, предотвращая перегрузки. Подобная автоматическая устойчивость отсутствует в статичных, выделенных средах.
Гибкое управление хранилищем с политиками через vSAN
AI-нагрузки требуют разнообразных типов хранения — от высокопроизводительного временного пространства для обучения до надежного объектного хранения для наборов данных. vSAN позволяет задавать эти требования (например, производительность, отказоустойчивость) индивидуально для каждой рабочей нагрузки. Это предотвращает появление новых изолированных инфраструктур и необходимость управлять несколькими хранилищами, как это часто бывает в средах на «голом железе».
Преимущества NVIDIA Run:ai
Максимизация использования GPU: динамическое выделение, дробление GPU и приоритизация задач между командами обеспечивают максимально эффективное использование мощной инфраструктуры.
Масштабируемые сервисы AI: поддержка развертывания больших языковых моделей (инференс) и других сложных AI-задач (распределённое обучение, тонкая настройка) с эффективным масштабированием ресурсов под изменяющуюся нагрузку.
Обзор архитектуры
Давайте посмотрим на высокоуровневую архитектуру решения:
VCF: базовая инфраструктура с vSphere, сетями VCF (включая VMware NSX и VMware Antrea), VMware vSAN и системой управления VCF Operations.
Кластер Kubernetes с поддержкой AI: управляемый VCF кластер VKS, обеспечивающий среду выполнения AI-нагрузок с доступом к GPU.
Панель управления NVIDIA Run:ai: доступна как услуга (SaaS) или для локального развертывания внутри кластера Kubernetes для управления рабочими нагрузками AI, планирования заданий и мониторинга.
Кластер NVIDIA Run:ai: развернут внутри Kubernetes для оркестрации GPU и выполнения рабочих нагрузок.
Рабочие нагрузки data science: контейнеризированные приложения и модели, использующие GPU-ресурсы.
Эта архитектура представляет собой полностью интегрированный программно-определяемый стек. Вместо того чтобы тратить месяцы на интеграцию разрозненных серверов, коммутаторов и систем хранения, VCF предлагает единый, эластичный и автоматизированный облачный операционный подход, готовый к использованию.
Диаграмма архитектуры
Существует два варианта установки панели управления NVIDIA Run:ai:
SaaS: панель управления размещена в облаке (см. https://run-ai-docs.nvidia.com/saas). Локальный кластер Run:ai устанавливает исходящее соединение с облачной панелью для выполнения рабочих нагрузок AI. Этот вариант требует исходящего сетевого соединения между кластером и облачным контроллером Run:ai.
Самостоятельное размещение: панель управления Run:ai устанавливается локально (см. https://run-ai-docs.nvidia.com/self-hosted) на кластере VKS, который может быть совместно используемым или выделенным только для Run:ai. Также доступен вариант с изолированной установкой (без подключения к сети).
Вот визуальное представление инфраструктурного стека:
Сценарии развертывания
Сценарий 1: Установка NVIDIA Run:ai на экземпляре VCF с включенной службой vSphere Kubernetes Service
Предварительные требования:
Среда VCF с узлами ESX, оснащёнными GPU
Кластер VKS для AI, развернутый через VCF Automation
GPU настроены как DirectPath I/O, vGPU с разделением по времени (time-sliced) или NVIDIA Multi-Instance GPU (MIG)
Если используется vGPU, NVIDIA GPU Operator автоматически устанавливается в рамках шаблона (blueprint) развертывания VCFA.
Основные шаги по настройке панели управления NVIDIA Run:ai:
Подготовьте ваш кластер VKS, назначенный для роли панели управления NVIDIA Run:ai, выполнив все необходимые предварительные условия.
Создайте секрет с токеном, полученным от NVIDIA Run:ai, для доступа к контейнерному реестру NVIDIA Run:ai.
Если используется VMware Data Services Manager, настройте базу данных Postgres для панели управления Run:ai; если нет — Run:ai будет использовать встроенную базу Postgres.
Добавьте репозиторий Helm и установите панель управления с помощью Helm.
Основные шаги по настройке кластера:
Подготовьте кластер VKS, назначенный для роли кластера, с выполнением всех предварительных условий, и запустите диагностический инструмент NVIDIA Run:ai cluster preinstall.
Установите дополнительные компоненты, такие как NVIDIA Network Operator, Knative и другие фреймворки в зависимости от ваших сценариев использования.
Войдите в веб-консоль NVIDIA Run:ai, перейдите в раздел Resources и нажмите "+New Cluster".
Следуйте инструкциям по установке и выполните команды, предоставленные для вашего кластера Kubernetes.
Преимущества:
Полный контроль над инфраструктурой
Бесшовная интеграция с экосистемой VCF
Повышенная надежность благодаря автоматизации vSphere HA, обеспечивающей защиту длительных AI-тренировок и серверов инференса от сбоев аппаратного уровня — критического риска для сред на «голом железе».
Сценарий 2: Интеграция vSphere Kubernetes Service с существующими развертываниями NVIDIA Run:ai
Почему именно vSphere Kubernetes Service:
Управляемый VMware Kubernetes упрощает операции с кластерами
Тесная интеграция со стеком VCF, включая VCF Networking и VCF Storage
Возможность выделить отдельный кластер VKS для конкретного приложения или этапа — разработка, тестирование, продакшн
Шаги:
Подключите кластер(ы) VKS к существующей панели управления NVIDIA Run:ai, установив кластер Run:ai и необходимые компоненты.
Настройте квоты GPU и политики рабочих нагрузок в пользовательском интерфейсе NVIDIA Run:ai.
Используйте возможности Run:ai, такие как автомасштабирование и разделение GPU, с полной интеграцией со стеком VCF.
Преимущества:
Простота эксплуатации
Расширенная наблюдаемость и контроль
Упрощённое управление жизненным циклом
Операционные инсайты: преимущество "Day 2" с VCF
Наблюдаемость (Observability)
В средах на «железе» наблюдаемость часто достигается с помощью разрозненного набора инструментов (Prometheus, Grafana, node exporters и др.), которые оставляют «слепые зоны» в аппаратном и сетевом уровнях. VCF, интегрированный с VCF Operations (часть VCF Fleet Management), предоставляет единую панель мониторинга для наблюдения и корреляции производительности — от физического уровня до гипервизора vSphere и кластера Kubernetes.
Теперь в системе появились специализированные панели GPU для VCF Operations, предоставляющие критически важные данные о том, как GPU и vGPU используются приложениями. Этот глубокий AI-ориентированный анализ позволяет гораздо быстрее выявлять и устранять узкие места.
Резервное копирование и восстановление (Backup & Disaster Recovery)
Velero, интегрированный с vSphere Kubernetes Service через vSphere Supervisor, служит надежным инструментом резервного копирования и восстановления для кластеров VKS и pod’ов vSphere. Он использует Velero Plugin for vSphere для создания моментальных снапшотов томов и резервного копирования метаданных напрямую из хранилища Supervisor vSphere.
Это мощная стратегия резервирования, которая может быть интегрирована в планы аварийного восстановления всей AI-платформы (включая состояние панели управления Run:ai и данные), а не только бездисковых рабочих узлов.
Итог: Bare Metal против VCF для корпоративного AI
Аспект
Kubernetes на «голом железе» (подход DIY)
Платформа VMware Cloud Foundation (VCF)
Сеть (Networking)
Плоская архитектура, высокая сложность, ручная настройка сетей.
Программно-определяемая сеть с использованием VCF Networking.
Безопасность (Security)
Трудно обеспечить защиту; политики безопасности применяются вручную.
Точная микросегментация до уровня контейнера при использовании vDefend; программные политики нулевого доверия (Zero Trust).
Высокие риски: сбой сервера может вызвать значительные простои для критических задач, таких как обучение и инференс моделей.
Автоматическая отказоустойчивость с помощью vSphere HA (перезапуск нагрузок), vMotion (обслуживание без простоя) и DRS (балансировка нагрузки).
Хранилище (Storage)
Приводит к «изолированным островам» и множеству разнородных систем хранения.
Единое, управляемое политиками хранилище через VCF Storage; предотвращает изоляцию и упрощает управление.
Резервное копирование и восстановление (Backup & DR)
Часто реализуется в последнюю очередь; чрезвычайно сложный и трудоемкий процесс.
Встроенные снимки CSI и автоматизированное резервное копирование на уровне Supervisor с помощью Velero.
Наблюдаемость (Observability)
Набор разрозненных инструментов с «слепыми зонами» в аппаратной и сетевой частях.
Единая панель наблюдения (VCF Operations) с коррелированным сквозным мониторингом — от оборудования до приложений.
Управление жизненным циклом (Lifecycle Management)
Ручное, трудоёмкое управление жизненным циклом всех компонентов.
Автоматизированное, полноуровневое управление жизненным циклом через VCF Operations.
Общая модель (Overall Model)
Заставляет ИТ-команды вручную собирать и интегрировать множество разнородных инструментов.
Единая, эластичная и автоматизированная облачная операционная модель с встроенными корпоративными сервисами.
NVIDIA Run:ai на VCF ускоряет корпоративный ИИ
Развертывание NVIDIA Run:ai на платформе VCF позволяет предприятиям создавать масштабируемые, безопасные и эффективные AI-платформы. Независимо от того, начинается ли внедрение с нуля или совершенствуются уже существующие развертывания с использованием VKS, клиенты получают гибкость, высокую производительность и корпоративные функции, на которые они могут полагаться.
VCF позволяет компаниям сосредоточиться на ускорении разработки AI и повышении отдачи от инвестиций (ROI), а не на рискованной и трудоемкой задаче построения и управления инфраструктурой. Она предоставляет автоматизированную, устойчивую и безопасную основу, необходимую для промышленных AI-нагрузок, позволяя NVIDIA Run:ai выполнять свою главную задачу — максимизировать использование GPU.
В VMware Cloud Foundation (VCF) 9.0 легко упустить из виду относительно новые функции, находящиеся прямо перед глазами. Защита данных в частном облаке в последнее время стала особенно актуальной темой, выходящей далеко за рамки обычных задач восстановления данных. Клиенты ищут практичные стратегии защиты от атак вымогателей и аварийного восстановления с помощью решений, которыми легко управлять в масштабах всей инфраструктуры.
vSAN Data Protection впервые появилась в vSAN 8 U3 как часть VMware Cloud Foundation 5.2. Наиболее часто упускаемый момент — это то, что vSAN Data Protection входит в лицензию VCF!
Почему это важно? Если вы используете vSAN ESA в своей среде VCF, у вас уже есть всё необходимое для локальной защиты рабочих нагрузок с помощью vSAN Data Protection. Это отличный способ дополнить существующие стратегии защиты или создать основу для более комплексной.
Рассмотрим кратко, что может предложить эта локальная защита и как просто и масштабируемо её внедрить.
Простая локальная защита
Как часть лицензии VCF, vSAN Data Protection позволяет использовать снапшоты именно так, как вы всегда хотели. Благодаря встроенному механизму создания снапшотов vSAN ESA, вы можете:
Легко определять группы ВМ и их расписание защиты и хранения — до 200 снапшотов на ВМ.
Создавать согласованные по сбоям снапшоты ВМ с минимальным влиянием на производительность.
Быстро восстанавливать одну или несколько ВМ прямо в vCenter Server через vSphere Client, даже если они были удалены из инвентаря.
Поскольку vSAN Data Protection работает на уровне ВМ, защита и восстановление отдельных VMDK-дисков внутри виртуальной машины пока не поддерживается.
Простое и гибкое восстановление
Причины восстановления данных могут быть разными, и vSAN Data Protection даёт администраторам платформ виртуализации возможность выполнять типовые задачи восстановления без привлечения других команд.
Например, обновление ОС виртуальной машины не удалось или произошла ошибка конфигурации — vSAN Data Protection готова обеспечить быстрое и простое восстановление. Или, допустим, виртуальная машина была случайно удалена из инвентаря. Ранее ни один тип снимков VMware не позволял восстановить снимок удалённой ВМ, но vSAN Data Protection справится и с этим.
Обратите внимание, что восстановление виртуальных машин в демонстрации выше выполняется напрямую в vSphere Client, подключённом к vCenter Server. Не нужно использовать дополнительные приложения, и поскольку процесс основан на уровне ВМ, восстановление интуитивно понятное и безопасное — без сложностей, связанных с восстановлением на основе снимков хранилища (array-based snapshots).
Для клиентов, уже внедривших vSAN Data Protection, такая простота восстановления стала одной из наиболее ценных возможностей решения.
Быстрое и гибкое клонирование
Преимущества автоматизированных снапшотов, создаваемых с помощью vSAN Data Protection, выходят далеко за рамки восстановления данных. С помощью vSAN Data Protection можно легко создавать клоны виртуальных машин из существующих снапшотов. Это чрезвычайно простой и эффективный по использованию пространства способ получить несколько ВМ для различных задач.
Клонирование из снапшотов можно использовать для разработки и тестирования программного обеспечения, а также для администрирования и тестирования приложений. Администраторы платформ виртуализации могут без труда интегрировать эту функцию в повседневные IT-операции и процессы управления жизненным циклом.
Давайте посмотрим, как выглядит такое быстрое клонирование большой базы данных в пользовательском интерфейсе.
Обратите внимание, что клонированная виртуальная машина, созданная из снапшота в vSAN Data Protection, представляет собой связанную копию (linked clone). Такой клон не может быть впоследствии защищён с помощью групп защиты и снапшотов в рамках vSAN Data Protection. Клон можно добавить в группу защиты, однако при следующем цикле защиты для этой группы появится предупреждение «Protection Group Health», указывающее, что создание снапшота для клонированной ВМ не удалось.
Ручные снапшоты таких связанных клонов можно создавать вне vSAN Data Protection (через интерфейс или с помощью VADP), что позволяет решениям резервного копирования, основанным на VADP, защищать эти клоны.
С чего начать
Так как функции защиты данных уже включены в вашу лицензию VCF, как приступить к работе? Рассмотрим краткий план.
Установка виртуального модуля для vSAN Data Protection
Для реализации описанных возможностей требуется установка виртуального модуля (Virtual Appliance) — обычно одного на каждый vCenter Server. Этот виртуальный модуль VMware Live Recovery (VLR) обеспечивает работу службы vSAN Data Protection, входящей в состав VCF, и предоставляет локальную защиту данных. Оно управляет процессом создания и координации снимков, но не участвует в передаче данных и не является единой точкой отказа.
Базовые шаги для развертывания и настройки модуля:
Загрузите виртуальный модуль для защиты данных с портала Broadcom.
Войдите в vSphere Client, подключённый к нужному vCenter Server, и разверните модуль как обычный OVF-шаблон.
Защита виртуальных машин осуществляется с помощью групп защиты (protection groups), которые определяют желаемую стратегию защиты ВМ. Вы можете управлять тем, какие ВМ будут защищены, как часто выполняется защита, а также настройками хранения снапшотов.
Группы защиты также позволяют указать, должны ли снапшоты быть неизменяемыми (immutable) — всё это настраивается с помощью простого флажка в интерфейсе.
Неизменяемость гарантирует, что снапшоты не могут быть каким-либо образом изменены или удалены. Эта опция обеспечивает базовую защиту от вредоносных действий и служит основой для более продвинутых механизмов киберустойчивости (cyber resilience).
Давайте посмотрим, насколько просто это реализуется в интерфейсе. Сначала рассмотрим настройку группы защиты в vSphere Client.
Группы защиты начинают выполнять заданные параметры сразу после создания первого снапшота. Это отличный пример принципа «настроил и забыл» (set it and forget it), реализованного в vSAN Data Protection, который обеспечивает простое и интуитивное восстановление одной или нескольких виртуальных машин при необходимости.
Рекомендация: если вы используете динамические шаблоны имен ВМ в группах защиты, убедитесь, что виртуальные машины, созданные из снапшотов в vSAN Data Protection, не попадают под этот шаблон. В противном случае будет сгенерировано предупреждение о состоянии группы защиты (Health Alert), указывающее, что связанный клон не может быть защищён в рамках этой группы.
Расширенные возможности в VCF 9.0
В версии VCF 9.0 vSAN Data Protection получила ряд улучшений, которые сделали её ещё более удобной и функциональной.
Единый виртуальный модуль
Независимо от того, используете ли вы только локальную защиту данных через vSAN Data Protection или расширенные возможности репликации и аварийного восстановления (DR), теперь для этого используется единый виртуальный модуль, доступный для загрузки по ссылке.
Он сокращает потребление ресурсов, упрощает управление и позволяет расширять функциональность для DR и защиты от программ-вымогателей путём простого добавления лицензионного ключа.
Защита ВМ на других кластерах vSAN
Хотя vSAN Data Protection обеспечивает простой способ локальной защиты рабочих нагрузок, новая технология, представленная в VCF 9.0, позволяет реплицировать данные на другой кластер vSAN — механизм, известный как vSAN-to-vSAN replication.
Для использования vSAN-to-vSAN репликации требуется дополнительная лицензия (add-on license). Если она отсутствует, вы по-прежнему можете использовать локальную защиту данных с помощью vSAN Data Protection. Однако эта лицензия предоставляет не только возможность удалённой репликации — она также добавляет инструменты для комплексной защиты данных и оркестрации, помогая выполнять требования по аварийному восстановлению (DR) и кибербезопасности.
Иными словами, все базовые возможности локальной защиты вы можете реализовать с помощью vSAN Data Protection. А когда придёт время расширить защиту для сценариев аварийного восстановления (DR) и восстановления после киберинцидентов (cyber recovery), это можно сделать просто — активировав дополнительные возможности с помощью add-on лицензии.
Для ответов на часто задаваемые вопросы о vSAN Data Protection см. раздел «vSAN Data Protection» в актуальной версии vSAN FAQs.
Итоги
Клиенты VCF, использующие vSAN ESA в составе VCF 5.2 или 9.0, уже обладают невероятно мощным инструментом, встроенным в их решение. vSAN Data Protection обеспечивает возможность локальной защиты рабочих нагрузок без необходимости приобретения дополнительных лицензий.
На VMware Explore 2025 в Лас-Вегасе было сделано множество анонсов, а также проведены подробные обзоры новых функций и усовершенствований, включённых в VMware Cloud Foundation (VCF) 9, включая популярную функцию NVMe Memory Tiering. Хотя эта функция доступна на уровне вычислительного компонента VCF (платформа vSphere), мы рассматриваем её в контексте всей платформы VCF, учитывая её глубокую интеграцию с другими компонентами, такими как VCF Operations, к которым мы обратимся в дальнейшем.
Memory Tiering — это новая функция, включённая в VMware Cloud Foundation, и она стала одной из основных тем обсуждения в рамках многих сессий на VMware Explore 2025. VMware заметила большой интерес и получила множество отличных вопросов от клиентов по поводу внедрения, сценариев использования и других аспектов. Эта серия статей состоит из нескольких частей, где мы постараемся ответить на наиболее частые вопросы от клиентов, партнёров и внутренних команд.
Предварительные требования и совместимость оборудования
Оценка рабочих нагрузок
Перед включением Memory Tiering крайне важно провести тщательную оценку вашей среды. Начните с анализа рабочих нагрузок в вашем датацентре, уделяя особое внимание использованию памяти. Один из ключевых показателей, на который стоит обратить внимание — активная память рабочей нагрузки.
Чтобы рабочие нагрузки подходили для Memory Tiering, общий объём активной памяти должен составлять не более 50% от ёмкости DRAM. Почему именно 50%?
По умолчанию Memory Tiering предоставляет на 100% больше памяти, то есть удваивает доступный объём. После включения функции половина памяти будет использовать DRAM (Tier 0), а другая половина — NVMe (Tier 1). Таким образом, мы стремимся, чтобы активная память умещалась в DRAM, так как именно он является самым быстрым источником памяти и обеспечивает минимальное время отклика при обращении виртуальных машин к страницам памяти. По сути, это предварительное условие, гарантирующее, что производительность при работе с активной памятью останется стабильной.
Важный момент: при оценке анализируется активность памяти приложений, а не хоста, поскольку в Memory Tiering страницы памяти ВМ переносятся (demote) на NVMe-устройство, когда становятся «холодными» или неактивными, но страницы vmkernel хоста не затрагиваются.
Как узнать объём активной памяти?
Как мы уже отметили, при использовании Memory Tiering только страницы памяти ВМ переносятся на NVMe при бездействии, тогда как системные страницы хоста остаются нетронутыми. Поэтому нам важно определить процент активности памяти рабочих нагрузок.
Это можно сделать через интерфейс vCenter в vSphere Client, перейдя в:
VM > Monitor > Performance > Advanced
Затем измените тип отображения на Memory, и вы увидите метрику Active Memory. Если она не отображается, нажмите Chart Options и выберите Active для отображения.
Обратите внимание, что метрика Active доступна только при выборе периода Real-Time, так как это показатель уровня 1 (Level 1 stat). Активная память измеряется в килобайтах (KB).
Если вы хотите собирать данные об активной памяти за более длительный период, можно сделать следующее: в vCenter Server перейдите в раздел Configure > Edit > Statistics.
Затем измените уровень статистики (Statistics Level) с Level 1 на Level 2 для нужных интервалов.
Делайте это на свой страх и риск, так как объём пространства, занимаемого базой данных, существенно увеличится. В среднем, он может вырасти раза в 3 или даже больше. Поэтому не забудьте вернуть данную настройку обратно по завершении исследования.
Также вы можете использовать другие инструменты, такие как VCF Operations или RVTools, чтобы получить информацию об активной памяти ваших рабочих нагрузок.
RVTools также собирает данные об активности памяти в режиме реального времени, поэтому убедитесь, что вы учитываете возможные пиковые значения и включаете периоды максимальной нагрузки ваших рабочих процессов.
Примечания и ограничения
Для VCF 9.0 технология Memory Tiering пока не подходит для виртуальных машин, чувствительных к задержкам (latency-sensitive VMs), включая:
Высокопроизводительные ВМ (High-performance VMs)
Защищённые ВМ, использующие SEV / SGX / TDX
ВМ с включенным механизмом непрерывной доступности Fault Tolerance
Так называемые "Monster VMs" с объёмом памяти более 1 ТБ.
В смешанных средах рекомендуется выделять отдельные хосты под Memory Tiering или отключать эту функцию на уровне отдельных ВМ. Эти ограничения могут быть сняты в будущем, поэтому стоит следить за обновлениями и расширением совместимости с различными типами нагрузок.
Программные предварительные требования
С точки зрения программного обеспечения, Memory Tiering требует новой версии vSphere, входящей в состав VCF/VVF 9.0. И vCenter, и ESX-хосты должны быть версии 9.0 или выше. Это обеспечивает готовность среды к промышленной эксплуатации, включая улучшения в области надёжности, безопасности (включая шифрование на уровне ВМ и хоста) и осведомлённости о vMotion.
Настройку Memory Tiering можно выполнить:
На уровне хоста или кластера
Через интерфейс vCenter UI
С помощью ESXCLI или PowerCLI
А также с использованием Desired State Configuration для автоматизации и последовательных перезагрузок (rolling reboots).
В VVF и VCF 9.0 необходимо создать раздел (partition) на NVMe-устройстве, который будет использоваться Memory Tiering. На данный момент эта операция выполняется через ESXCLI или PowerCLI (да, это можно автоматизировать с помощью скрипта). Для этого потребуется доступ к терминалу и включённый SSH. Позже мы подробно рассмотрим оба варианта и даже приведём готовый скрипт для автоматического создания разделов на нескольких серверах.
Совместимость NVMe
Аппаратная часть — это основа производительности Memory Tiering. Так как NVMe-накопители используются как один из уровней оперативной памяти, совместимость оборудования критически важна.
VMware рекомендует использовать накопители со следующими характеристиками:
Выносливость (Endurance): класс D или выше (больше или равно 7300 TBW) — для высокой долговечности при множественных циклах записи.
Производительность (Performance): класс F (100 000–349 999 операций записи/сек) или G (350 000+ операций записи/сек) — для эффективной работы механизма tiering.
Некоторые OEM-производители не указывают класс напрямую в спецификациях, а обозначают накопители как read-intensive (чтение) или mixed-use (смешанные нагрузки).
В таких случаях рекомендуется использовать Enterprise Mixed Drives с показателем не менее 3 DWPD (Drive Writes Per Day).
Если вы не знакомы с этим термином: DWPD отражает выносливость SSD и показывает, сколько раз в день накопитель может быть полностью перезаписан на протяжении гарантийного срока (обычно 3–5 лет) без отказов. Например, SSD объёмом 1 ТБ с 1 DWPD способен выдерживать 1 ТБ записей в день на протяжении гарантийного периода.
Чем выше DWPD, тем долговечнее накопитель — что критически важно для таких сценариев, как VMware Memory Tiering, где выполняется большое количество операций записи.
Также рекомендуется воспользоваться Broadcom Compatibility Guide, чтобы проверить, какие накопители соответствуют рекомендованным классам и как они обозначены у конкретных OEM-производителей. Этот шаг настоятельно рекомендуется, так как Memory Tiering может производить большие объёмы чтения и записи на NVMe, и накопители должны быть высокопроизводительными и надёжными.
Хотя Memory Tiering позволяет снизить совокупную стоимость владения (TCO), экономить на накопителях для этой функции категорически не рекомендуется.
Что касается форм-факторов, поддерживается широкий выбор вариантов. Вы можете использовать:
Устройства формата 2.5", если в сервере есть свободные слоты.
Вставляемые модули E3.S.
Или даже устройства формата M.2, если все 2.5" слоты уже заняты.
Наилучший подход — воспользоваться Broadcom Compatibility Guide. После выбора нужных параметров выносливости (Endurance, класс D) и производительности (Performance, класс F или G), вы сможете дополнительно указать форм-фактор и даже параметр DWPD.
Такой способ подбора поможет вам выбрать оптимальный накопитель для вашей среды и быть уверенными, что используемое оборудование полностью соответствует требованиям Memory Tiering.
Службы VMware vSphere Kubernetes Service (VKS) версии 3.5 появились в общем доступе. Этот новый выпуск обеспечивает 24-месячную поддержку для каждой минорной версии Kubernetes, начиная с vSphere Kubernetes release (VKr) 1.34. Ранее, в июне 2025 года, VMware объявила о 24-месячной поддержке выпуска vSphere Kubernetes (VKr) 1.33. Это изменение обеспечивает командам, управляющим платформой, большую стабильность и гибкость при планировании обновлений.
VKS 3.5 также включает ряд улучшений, направленных на повышение операционной согласованности и улучшение управления жизненным циклом, включая детализированные средства конфигурации основных компонентов Kubernetes, декларативную модель управления надстройками и встроенную генерацию пакетов поддержки напрямую из интерфейса командной строки VCF CLI. Кроме того, новые защитные механизмы при обновлениях — такие как проверка PodDisruptionBudget и проверки совместимости — помогают обеспечить более безопасные и предсказуемые обновления кластеров.
В совокупности эти усовершенствования повышают надежность, операционную эффективность и качество управления Kubernetes-средами на этапе эксплуатации (Day-2) в масштабах предприятия.
Выпуск vSphere Kubernetes (VKr) 1.34
VKS 3.5 добавляет поддержку VKr 1.34. Каждая минорная версия vSphere Kubernetes теперь поддерживается в течение 24 месяцев с момента выпуска. Это снижает давление, связанное с обновлениями, стабилизирует рабочие среды и позволяет командам сосредоточиться на создании ценности, а не на постоянном планировании апгрейдов. Команды, которым нужен быстрый доступ к последним возможностям Kubernetes, могут оперативно переходить на новые версии. Те, кто предпочитает стабильную среду на длительный срок, теперь могут работать в этом режиме с уверенностью. VKS 3.5 поддерживает оба подхода к эксплуатации.
Динамическое распределение ресурсов (Dynamic Resource Allocation, DRA)
Функция DRA получила статус «стабильной» в основной ветке Kubernetes 1.34. Эта возможность позволяет администраторам централизованно классифицировать аппаратные ресурсы, такие как GPU, с помощью объекта DeviceClass. Это обеспечивает надежное и предсказуемое размещение Pod'ов на узлах с требуемым классом оборудования.
DRA повышает эффективность использования устройств, позволяя делить ресурсы между приложениями по декларативному принципу, аналогично динамическому выделению томов (Dynamic Volume Provisioning). Механизм DRA решает проблемы случайного распределения и неполного использования ресурсов. Пользователи могут выполнять точную фильтрацию, запрашивая конкретные устройства с помощью ResourceClaimsTemplates и ResourceClaims при развертывании рабочих нагрузок.
DRA также позволяет совместно использовать GPU между несколькими Pod'ами или контейнерами. Рабочие нагрузки можно настроить так, чтобы выбирать GPU-устройство с помощью Common Expression Language (CEL) и запросов ResourceSlice, что обеспечивает более эффективное использование по сравнению с count-based запросами.
Расширенные возможности конфигурации компонентов кластера Kubernetes
VKS 3.5 предоставляет гибкость для управления более чем 35 параметрами конфигурации компонентов Kubernetes, таких как kubelet, apiserver и etcd. Эти настройки позволяют командам платформ оптимизировать различные аспекты работы кластеров в соответствии с требованиями их рабочих нагрузок. Полный список доступных параметров конфигурации приведён в документации к продукту. Ниже приведён краткий обзор областей конфигурации, которые предлагает VKS 3.5:
Конфигурация
Настраиваемые компоненты
Описание
Журналирование и наблюдаемость (Logging & Observability)
Kubelet, API Server
Настройка поведения журналирования для API-сервера и kubelet, включая частоту сброса логов, формат (text/json) и уровни детализации. Управление хранением логов контейнеров с указанием максимального количества и размера файлов. Это позволяет эффективно управлять использованием диска, устранять неполадки с нужным уровнем детализации логов и интегрироваться с системами агрегирования логов с помощью структурированного JSON-журналирования.
Управление событиями (Event Management)
Kubelet
Управление генерацией событий Kubernetes с настройкой лимитов скорости создания событий (eventRecordQPS) и всплесков (eventBurst), чтобы предотвратить перегрузку API-сервера. Это позволяет контролировать частоту запросов kubelet к API-серверу, обеспечивая стабильность кластера в периоды высокой активности при сохранении видимости важных событий.
Производительность и масштабируемость (Performance & Scalability)
API Server
Управление производительностью API-сервера с помощью настройки пределов на максимальное количество одновременных изменяющих (mutating) и неизменяющих (non-mutating) запросов, а также минимальной продолжительности тайм-аута запроса. Возможность включения или отключения профилирования. Это позволяет адаптировать кластер под высоконагруженные рабочие процессы, предотвращать перегрузку API-сервера и оптимизировать отзывчивость под конкретные сценарии использования.
Конфигурации etcd
etcd
Настройка максимального размера базы данных etcd (в диапазоне 2–8 ГБ). Том создаётся с дополнительными 25 % ёмкости для учёта операций уплотнения, дефрагментации и временных всплесков использования. Это позволяет правильно подобрать объём хранилища etcd в зависимости от масштаба кластера и количества объектов, предотвращая ситуации нехватки места, которые могут перевести кластер в режим только для чтения.
Управление образами (Image Management)
Kubelet
Настройка жизненного цикла образов контейнеров, включая пороги очистки (в процентах использования диска — высокий/низкий), минимальный и максимальный возраст образов до удаления, лимиты скорости загрузки образов (registryPullQPS и registryBurst), максимальное количество параллельных загрузок и политики проверки учётных данных при загрузке. Это помогает оптимизировать использование дискового пространства узлов, контролировать потребление сетевых ресурсов, ускорять запуск Pod’ов за счёт параллельных загрузок и обеспечивать безопасность доступа к образам.
Безопасность на уровне ОС (OS-level Security)
OS
Включение защиты загрузчика GRUB паролем с использованием хэширования PBKDF2 SHA-512. Настройка обязательной повторной аутентификации при использовании sudo. Это позволяет соответствовать требованиям безопасности при загрузке системы и управлении привилегированным доступом, предотвращая несанкционированные изменения системы и обеспечивая соблюдение политик безопасности во всей инфраструктуре кластера.
Cluster API v1beta2 для улучшенного управления кластерами Kubernetes
VKS 3.5 включает Cluster API v1beta2 (CAPI v1.11.1), который вносит ряд изменений и улучшений в версии API для ресурсов по сравнению с v1beta1. Полный список улучшений можно найти в Release Notes для CAPI.
Для обеспечения плавного перехода все новые и существующие кластеры, созданные с использованием прежнего API v1beta1, будут автоматически преобразованы в API v1beta2 обновлёнными контроллерами Cluster API. В дальнейшем рекомендуется использовать API v1beta2 для управления жизненным циклом (LCM) кластеров Kubernetes.
Версия API v1beta2 является важным шагом на пути к выпуску стабильной версии v1. Основные улучшения включают:
Расширенные возможности отслеживания состояния ресурсов, обеспечивающие лучшую наблюдаемость.
Исправления на основе отзывов клиентов и инженеров с реальных внедрений.
Предотвращение сбоев обновлений из-за неверно настроенного PodDisruptionBudget
Pod Disruption Budget (PDB) — это объект Kubernetes, который помогает поддерживать доступность приложения во время плановых операций (например, обслуживания узлов, обновлений или масштабирования). Он гарантирует, что минимальное количество Pod’ов останется активным во время таких событий. Однако неправильно настроенные PDB могут блокировать обновления кластера.
VKS 3.5 вводит механизмы защиты (guardrails) для выявления ошибок конфигурации PDB, которые могут привести к зависанию обновлений или других операций жизненного цикла. Система блокирует обновление кластера, если обнаруживает, что PDB не допускает никаких прерываний.
Для повышения надёжности и успешности обновлений введено новое условие SystemChecksSucceeded в объект Cluster. Оно позволяет пользователям видеть готовность кластера к обновлению, в частности относительно конфигураций PDB.
Ключевые преимущества новой проверки:
Проактивная блокировка обновлений — система обнаруживает PDB, препятствующие выселению Pod’ов, и останавливает обновление до его начала.
Более чёткая диагностика проблем — параметр SystemChecksSucceeded устанавливается в false, если у любого PDB значение allowedDisruptions меньше или равно 0, что указывает на риск простоев.
Планирование обновлений — позволяет заранее устранить ошибки конфигурации PDB до начала обновления.
Примечание: любой PDB, не связанный с Pod’ами (например, из-за неправильного селектора), также будет иметь allowedDisruptions = 0 и, следовательно, заблокирует обновление.
Упрощённые операции: CLI, управление надстройками и инструменты поддержки
Управление надстройками (Add-On Management)
VKS 3.5 упрощает эксплуатационные операции, включая управление жизненным циклом надстроек (add-ons) и создание пакетов поддержки. Новая функция VKS Add-On Management объединяет установку, обновление и настройку стандартных пакетов, предлагая:
Единый метод для всех операций с пакетами, декларативный API и предварительные проверки совместимости.
Возможность управления стандартными пакетами VKS через Supervisor Namespace (установка, обновления, конфигурации) — доступно через VKS-M 9.0.1 или новый плагин ‘addon’ в VCF CLI.
Упрощённую установку Cluster Autoscaler с возможностью автоматического обновления при апгрейде кластера.
Управление установками и обновлениями через декларативные API (AddonInstall, AddonConfig) с помощью Argo CD или других GitOps-контроллеров. Это обеспечивает версионируемое и повторяемое развертывание надстроек с улучшенной трассируемостью и согласованностью.
Возможность настройки Addon Repository во всех кластерах VKS с помощью API AddonRepository / AddonRepositoryInstall, включая случаи с приватными регистрами.
По умолчанию встроенный репозиторий VKS Standard Package устанавливается из пакета VKS (версия v2025.10.22 для релиза VKS 3.5.0).
Во время обновлений кластеров VKS выполняет предварительные проверки совместимости надстроек и обновляет их до последних поддерживаемых версий. Если проверка не пройдена — обновление блокируется. При установке или обновлении надстроек выполняются дополнительные проверки, включая проверку на дублирование пакетов и анализ зависимостей.
Упрощённое обнаружение новых версий и метаданных совместимости для Add-on Releases.
Интегрированный сборщик пакетов поддержки (Support Bundler) в VCF CLI
VKS 3.5 включает VKS Cluster Support Bundler непосредственно в VCF CLI, что значительно упрощает процесс сбора диагностической информации о кластерах. Теперь пользователи могут собирать всю необходимую информацию с помощью команды vcf cluster support-bundle, без необходимости загружать отдельный инструмент.
Основные улучшения здесь:
Существенное уменьшение размера выходного файла.
Селективный сбор логов — только с узлов control plane, для более быстрой и точной диагностики.
Интегрированный сбор сетевых логов, что помогает анализировать сетевые проблемы и получить целостную картину состояния кластера.
Поддержание доступности данных и приложений, которые эти данные создают или используют, может быть одной из самых важных задач администраторов центров обработки данных. Такие возможности, как высокая производительность или специализированные службы данных, мало что значат, если приложения и данные, которые они создают или используют, недоступны. Обеспечение доступности — это сложная тема, поскольку доступность приложений и доступность данных достигаются разными методами. Иногда требования к доступности реализуются с помощью механизмов на уровне инфраструктуры, а иногда — с использованием решений, ориентированных на приложения. Оптимальный вариант для вашей среды во многом зависит от требований и возможностей инфраструктуры.
Хотя VMware Cloud Foundation (VCF) может обеспечивать высокий уровень доступности данных и приложений простым способом, в этой статье рассматриваются различия между обеспечением высокой доступности приложений и данных с использованием технологий на уровне приложений и встроенных механизмов на уровне инфраструктуры в VCF. Мы также рассмотрим, как VMware Data Services Manager (DSM) может помочь упростить принятие подобных решений.
Учёт отказов
Защита приложений и данных требует понимания того, как выглядят типичные сбои, и что система может сделать для их компенсации. Например, сбои в физической инфраструктуре могут затрагивать:
Централизованные решения для хранения, такие как дисковые массивы
Отдельные устройства хранения в распределённых системах
Такие сбои могут затронуть данные, приложения, или и то, и другое. Сбои могут проявляться по-разному — некоторые явно, другие лишь по отсутствию отклика. Часть из них временные, другие — постоянные. Решения должны быть достаточно интеллектуальными, чтобы автоматически справляться с такими ситуациями отказа и восстановления.
Доступность и восстановление приложений и данных
Доступность приложений и их наборов данных кажется интуитивно понятной, но требует краткого пояснения.
Доступность приложения
Это состояние приложения, например базы данных или веб-приложения. Независимо от того, установлено ли оно в виртуальной машине или запущено в контейнере, приложение заранее настроено на работу с данными определённым образом. Некоторые приложения могут работать в нескольких экземплярах для повышения доступности при сбоях и использовать собственные механизмы синхронной репликации, чтобы данные сохранялись в нескольких местах. Технологии, такие как vSphere HA, могут повысить доступность приложения и его данных, перезапуская виртуальную машину на другом хосте кластера vSphere в случае сбоя.
Доступность данных
Это способность данных быть доступными для приложения или пользователей в любое время, даже при сбое. Высокодоступные данные хранятся с использованием устойчивых механизмов, обеспечивающих хранение в нескольких местах — в зависимости от возможных границ сбоя: устройства, хоста, массива хранения или целого сайта.
Надёжность данных
Хранить данные в нескольких местах недостаточно — они должны записываться синхронно и последовательно во все копии, чтобы при сбое данные из одного места совпадали с данными из другого. Корпоративные системы хранения данных реализуют принципы ACID (атомарность, согласованность, изолированность, долговечность) и протоколы, обеспечивающие надёжность данных.
Описанные выше концепции вводят два термина, которые помогают количественно определить возможности восстановления в случае сбоя:
RPO (Recovery Point Objective) — целевая точка восстановления. Показывает, с каким интервалом данные защищаются устойчивым образом. RPO=0 означает, что система всегда выполняет запись в синхронном, согласованном состоянии. Как будет отмечено далее, не все решения способны обеспечивать настоящий RPO=0.
RTO (Recovery Time Objective) — целевое время восстановления. Показывает минимальное время, необходимое для восстановления систем и/или данных до рабочего состояния. Например, RTO=10m означает, что восстановление займёт не менее 10 минут. RTO может относиться к восстановлению доступности данных или комбинации данных и приложения.
Эволюция решений для высокой доступности
Подходы к обеспечению доступности данных и приложений эволюционировали с развитием технологий и ростом требований. Некоторые приложения, такие как Microsoft SQL Server, MySQL, PostgreSQL и другие, включают собственные механизмы репликации, обеспечивающие избыточность данных и состояния приложения. Виртуализация, совместно с общим хранилищем, предоставляет простые способы обеспечения высокой доступности приложений и хранимых ими данных.
В зависимости от ваших требований может подойти один из подходов или их комбинация. Рассмотрим, как каждый из них обеспечивает высокий уровень доступности.
Высокая доступность на уровне приложений (Application-Level HA)
Этот подход основан на запуске нескольких экземпляров приложения в разных местах. Синхронное и устойчивое хранилище, а также механизмы отказоустойчивости обеспечиваются самим приложением для гарантии высокой доступности приложения и его данных.
Высокая доступность на уровне инфраструктуры (Infrastructure-Level HA)
Этот подход использует vSphere HA для перезапуска одного экземпляра приложения на другом хосте кластера. Синхронное и устойчивое хранение данных обеспечивает VMware vSAN (в контексте данного сравнения). Такая комбинация гарантирует высокую доступность приложения и его данных.
Оба подхода достигают схожих целей, но имеют определённые компромиссы. Рассмотрим два простых примера, чтобы лучше понять различия.
В приведённых примерах предполагается, что данные должны сохраняться в нескольких местах (например, на уровне сайта или зоны), чтобы обеспечить доступность при сбое площадки. Также предполагается, что приложение может работать в тех же местах. Оба варианта обеспечивают автоматический отказоустойчивый переход и RPO=0, поскольку данные записываются синхронно в несколько мест.
Высокая доступность на уровне приложений для приложений и данных
Высокая доступность на уровне приложений, как в случае MS SQL Always On Availability Groups (AG), использует два или более работающих экземпляра базы данных и дополнительное местоположение для определения кворума при различных сценариях отказа.
Этот подход полностью опирается на технологии, встроенные в само приложение, чтобы синхронно реплицировать данные в другое место и обеспечить механизм отказоустойчивого переключения состояния приложения.
Высокая доступность на уровне инфраструктуры для приложений и данных
Высокая доступность на уровне инфраструктуры использует приложение базы данных, работающее на одной виртуальной машине. vSphere HA обеспечивает автоматическое восстановление приложения, обращающегося к данным, в то время как vSAN гарантирует надёжность и доступность данных при различных типах сбоев инфраструктуры.
vSAN может выдерживать отказы отдельных устройств хранения, сетевых карт (NIC), сетевых коммутаторов, хостов и даже целых географических площадок или зон, которые определяются как «домен отказа» (fault domain).
В приведённом ниже примере кластер vSAN растянут между двумя площадками, чтобы обеспечить устойчивое хранение данных на обеих. Растянутые кластеры vSAN (vSAN Stretched Clusters) также используют третью площадку, на которой размещается небольшой виртуальный модуль — witness host appliance (хост-свидетель), помогающий определить кворум при различных возможных сценариях отказа.
Одним из самых убедительных преимуществ высокой доступности на уровне инфраструктуры является то, что в VCF она является встроенной частью платформы. vSAN интегрирован прямо в гипервизор и обеспечивает отказоустойчивость данных в соответствии с вашими требованиями, всего лишь посредством настройки простой политики хранения (storage policy). Экземпляры приложений становятся высокодоступными благодаря проверенной технологии vSphere HA, которая позволяет перезапускать виртуальные машины на любом хосте в пределах кластера vSphere. Такой подход также отлично работает, когда приложения баз данных развертываются и управляются в вашей среде VCF с помощью DSM.
Разные подходы к обеспечению согласованности данных
Хотя оба подхода могут обеспечивать цель восстановления точки (RPO), равную нулю (RPO=0), за счёт синхронной репликации, способы достижения этого различаются. Оба используют специальные протоколы, помогающие обеспечить согласованность данных, записываемых в нескольких местах — что на практике значительно сложнее, чем кажется.
В случае MS SQL Server Always On Availability Groups согласованность достигается на уровне приложения, тогда как vSAN обеспечивает синхронную запись данных по своей сути — как часть распределённой архитектуры, изначально разработанной для обеспечения отказоустойчивости.
При репликации данных на уровне приложения такой высокий уровень доступности ограничен только этим конкретным приложением и его данными. Однако возможности на уровне приложений реализованы не одинаково. Например, MS SQL Server Always On AG могут обеспечивать RPO=0 при множестве сценариев отказа, тогда как MySQL InnoDB Cluster использует подход, при котором RPO=0 возможно только при отказе одного узла. Хотя данные при этом остаются согласованными, в некоторых сценариях отказа — например, при полном сбое кластера или незапланированной перезагрузке — могут быть потеряны последние зафиксированные транзакции. Это означает, что при определённых обстоятельствах обеспечить истинный RPO=0 невозможно.
В случае vSAN в составе VCF, высокая доступность является универсальной характеристикой, которая применяется ко всем рабочим нагрузкам, записывающим данные в хранилище vSAN datastore.
Различия во времени восстановления (RTO)
Одной из основных причин различий между возможностями RTO при доступности на уровне приложения и на уровне инфраструктуры является то, как приложение возвращается в рабочее состояние после сбоя.
Например, некоторые приложения, такие как SQL Server AG, используют лицензированные «резервные» виртуальные машины (standby VMs) в вашей инфраструктуре, чтобы обеспечить использование другого состояния приложения при отказе. Это позволяет достичь низкого RTO, но приводит к увеличению затрат из-за необходимости дополнительных лицензий и потребляемых ресурсов. Высокая доступность на уровне приложения — это специализированное решение, требующее экспертизы в конкретном приложении для достижения нужного результата. Однако DSM может значительно снизить сложность таких сценариев, поскольку автоматизирует эти процессы и снимает значительную часть административной нагрузки.
Высокая доступность на уровне инфраструктуры работает иначе. Используя механизмы виртуализации, такие как vSphere High Availability (HA), она обеспечивает перезапуск приложения в другом месте при сбое виртуальной машины. Перезапуск ВМ и самого приложения, а также процесс восстановления журналов обычно занимают больше времени, чем подход с резервной ВМ, используемый при высокой доступности на уровне приложений.
Приведённые выше значения времени восстановления являются оценочными. Фактическое время восстановления может значительно различаться в зависимости от условий среды, размера и активности экземпляра MS SQL.
Что выбрать именно вам?
Наилучший выбор зависит от ваших требований, ограничений и того, насколько решение подходит вашей организации. Например:
Требования к доступности
Возможно, ваши требования предполагают, что приложение и его данные должны быть доступны за пределами определённой границы отказа — например, уровня сайта или зоны. Это поможет определить, нужна ли вообще доступность на уровне сайта или зоны.
Требования к RTO
Если требуемое время восстановления (RTO) допускает 2–5 минут, то высокая доступность на уровне инфраструктуры — отличный вариант, поскольку она встроена в платформу и работает для всех ваших нагрузок. Если же есть несколько отдельных приложений, для которых требуется меньшее RTO, и вас не смущают дополнительные затраты и сложность, связанные с этим решением, то подход на уровне приложения может быть оправдан.
Технические ограничения
В вашей организации могут быть инициативы по упрощению инструментов и рабочих процессов, что может ограничивать возможность или желание использовать дополнительные технологии, такие как высокая доступность на уровне приложений. Обычно предпочтение отдаётся универсальным инструментам, применимым ко всем системам, а не узкоспециализированным решениям. Другие технические факторы, например задержки (latency) между сайтами или зонами, также могут сделать тот или иной подход непрактичным.
Финансовые ограничения
Возможно, на вас оказывают давление с целью сократить постоянные расходы на программное обеспечение — например, на дополнительные лицензии или более дорогие уровни лицензирования, необходимые для обеспечения высокой доступности на уровне приложений. В этом случае более выгодным решением могут оказаться уже имеющиеся технологии.
Можно также использовать комбинацию обоих подходов.
Например, на первом рисунке в начале статьи показано, как высокая доступность на уровне приложений реализуется между сайтами или зонами с помощью MS SQL Always On Availability Groups, а высокая доступность на уровне инфраструктуры обеспечивается vSAN и vSphere HA внутри каждого сайта или зоны.
Этот вариант также может быть отличным примером использования VMware Data Services Manager (DSM). Вместо запуска и управления отдельными виртуальными машинами можно использовать базы данных, развёрнутые DSM, для обеспечения доступности приложений между сайтами или зонами. Такой подход обеспечивает низкое RTO, устраняет административную сложность, связанную с репликацией на уровне приложений, и при этом позволяет vSAN обеспечивать доступность данных внутри сайтов или зон.
Вильям Лам описал способ развертывания виртуального модуля OVF/OVA напрямую с сервера с Basic Authentication.
Он делал эксперименты с использованием OVFTool и доработал свой скрипт deploy_data_services_manager.sh, чтобы он ссылался на URL, где был размещён Data Services Manager (DSM) в формате OVA. В этом случае базовую аутентификацию (имя пользователя и пароль) можно включить прямым текстом в URL. Хотя это не самый безопасный способ, он позволяет удобно использовать этот метод развертывания.
p>Компания VMware опубликовала новое видео, в котором демонстрируется полный процесс обновления инфраструктуры vSphere 8.x и компонентов Aria Suite до последней версии VMware Cloud Foundation (VCF) 9.0.
В примере показано, как среда, использующая Aria Suite Lifecycle Manager и Aria Operations, переходит на новую версию платформы. Процесс начинается с обновления Aria Lifecycle Manager до версии 8.18 Patch 2 или выше. Затем с его помощью выполняется апгрейд Aria Operations до VCF Operations 9.0, что автоматически разворачивает новый компонент — VCF 9 Fleet Management Appliance.
После обновления сервисов Aria обновляется сама инфраструктура vSphere: выполняется переход на VLCM images, обновляются vCenter Server и хосты ESX до версии 9.0.
На следующем этапе используется установщик VMware Cloud Foundation, который скачивает необходимые бинарные файлы и проводит обновление среды до VCF 9.0. В ходе этого процесса выполняется консолидация существующих компонентов vCenter Server и VCF Operations в единый VCF Management Domain. Установщик также автоматически разворачивает Operations Collector, VMware NSX, настраивает SDDC Manager и при необходимости устанавливает модуль VCF Automation (его можно добавить позже через Fleet Management Appliance).
После завершения обновления выполняется повторное лицензирование среды под VCF 9.0, а также ряд действий после обновления: развёртывание VCF Logs, настройка внешнего vCenter Identity Broker, включение VCF SSO, связывание нескольких серверов vCenter и установка дополнительных модулей, включая Operations for Networks и HCX.
Видео демонстрирует комплексный процесс перехода на новую версию VMware Cloud Foundation и подчёркивает преимущества глубокой интеграции и автоматизации в экосистеме VMware.

 RSS
RSS